- 2.1. What is New and Noteworthy in Drools 6.3.0
- 2.2. New and Noteworthy in KIE Workbench 6.3.0
- 2.3. What is New and Noteworthy in Drools 6.2.0
- 2.4. New and Noteworthy in KIE Workbench 6.2.0
- 2.4.1. Download Repository or Part of the Repository as a ZIP
- 2.4.2. Project Editor permissions
- 2.4.3. Unify validation style in Guided Decision Table Wizard.
- 2.4.4. Improved Wizards
- 2.4.5. Consistent behaviour of XLS, Guided Decision Tables and Guided Templates
- 2.4.6. Improved Metadata Tab
- 2.4.7. Improved Data Objects Editor
- 2.4.8. Execution Server Management UI
- 2.4.9. Social Activities
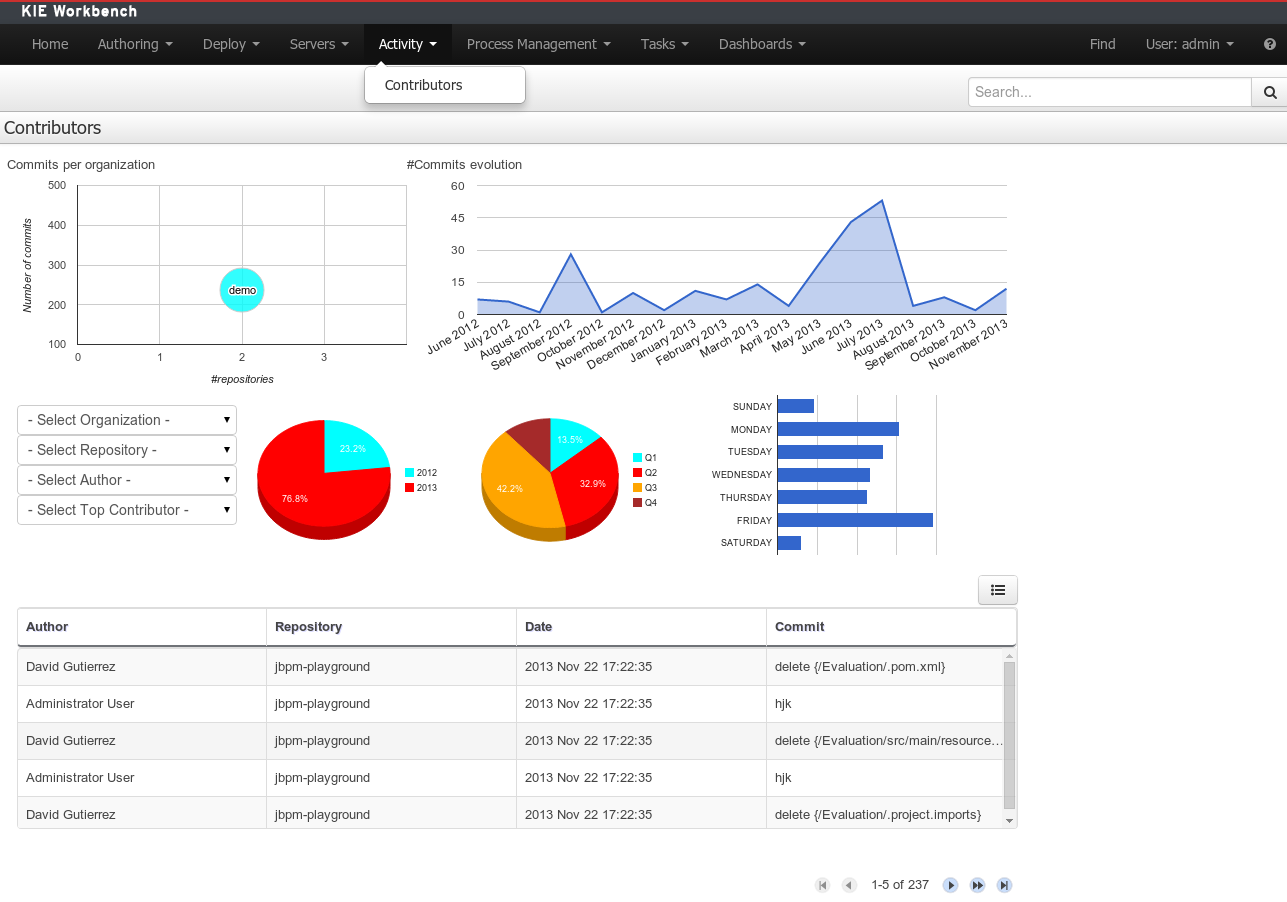
- 2.4.10. Contributors Dashboard
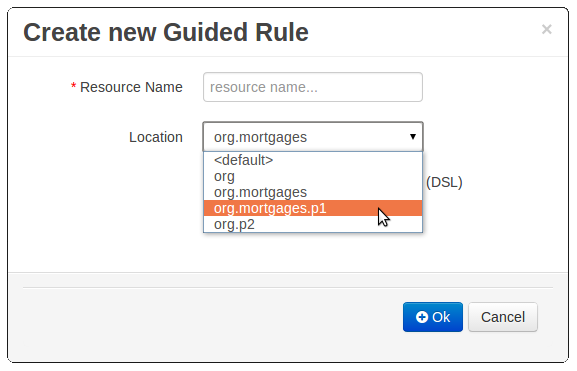
- 2.4.11. Package selector
- 2.4.12. Improved visual consistency
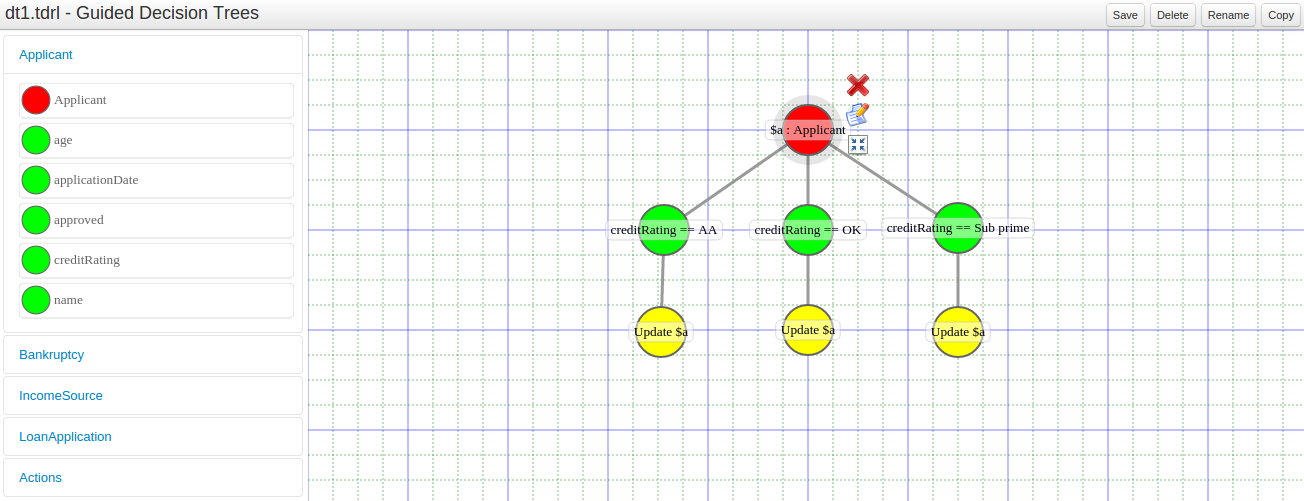
- 2.4.13. Guided Decision Tree Editor
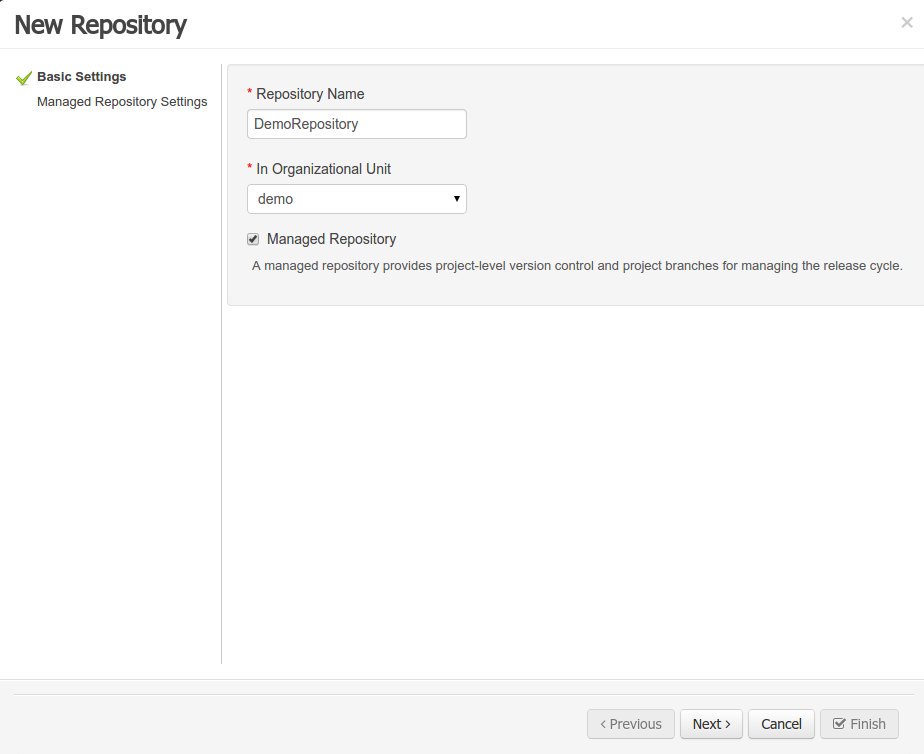
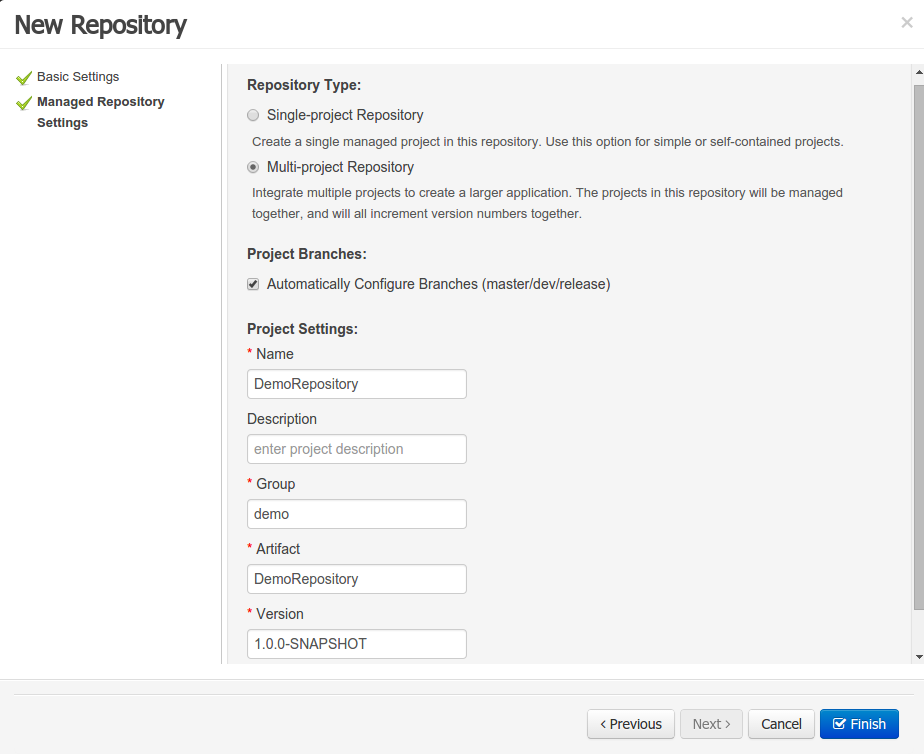
- 2.4.14. Create Repository Wizard
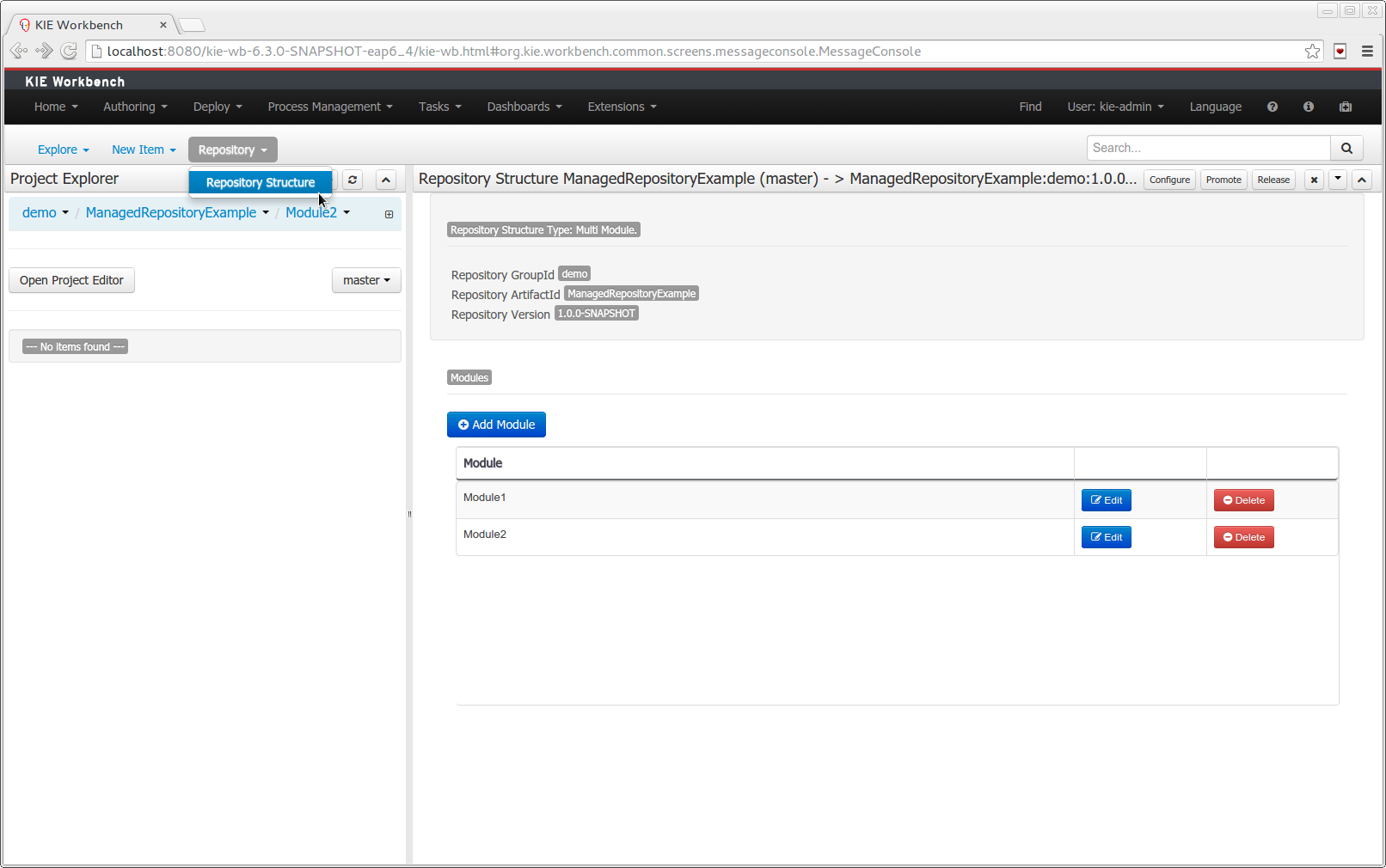
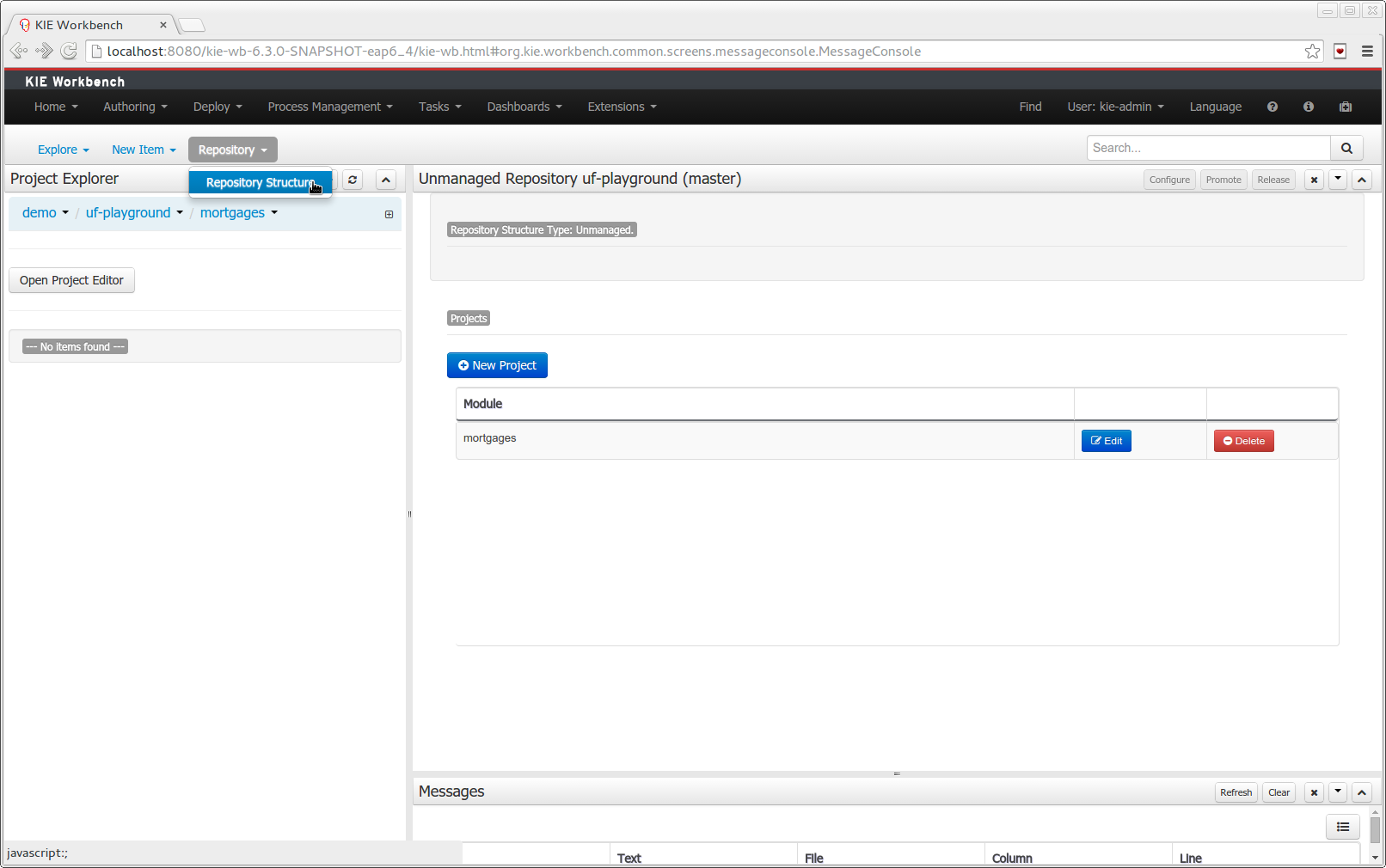
- 2.4.15. Repository Structure Screen
- 2.5. New and Noteworthy in Integration 6.2.0
- 2.6. What is New and Noteworthy in Drools 6.1.0
- 2.7. New and Noteworthy in KIE Workbench 6.1.0
- 2.8. New and Noteworthy in KIE API 6.0.0
- 2.9. What is New and Noteworthy in Drools 6.0.0
- 2.10. New and Noteworthy in KIE Workbench 6.0.0
- 2.11. New and Noteworthy in Integration 6.0.0
Decision tables used to have a Validation-button for validating the table. This is now removed and the table is validated after each cell value change. The validation and verification checks include:
- Redundancy
- Subsumption
- Conflicts
- Missing Columns
These checks are explained in detail in the workbench documentation.
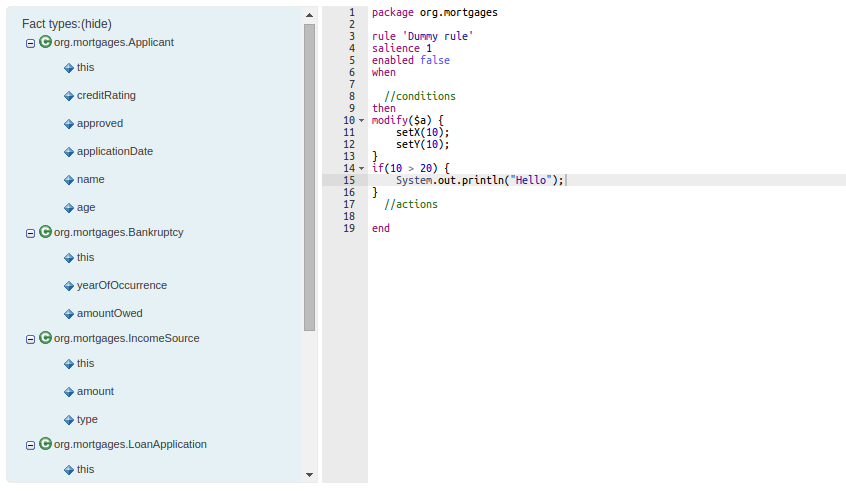
The DRL Editor has undergone a face lift; moving from a plain TextArea to using ACE Editor and a custom DRL syntax highlighter.
Warning
This feature is experimental
When the field of a fact is a collection it is possible to bind and reason over
all the items in that collection on by one using the from keyword.
Nevertheless, when it is required to browse a graph of object the extensive use of the
from conditional element may result in a verbose and cubersome syntax
like in the following example:
Example 2.1. Browsing a graph of objects with from
rule "Find all grades for Big Data exam" when
$student: Student( $plan: plan )
$exam: Exam( course == "Big Data" ) from $plan.exams
$grade: Grade() from $exam.grades
then /* RHS */ endIn this example it has been assumed to use a domain model consisting of a
Student who has a Plan of study: a Plan
can have zero or more Exams and an Exam zero or more
Grades. Note that only the root object of the graph (the Student
in this case) needs to be in the working memory in order to make this works.
By borrowing ideas from XPath, this syntax can be made more succinct, as XPath has a
compact notation for navigating through related elements while handling collections and
filtering constraints. This XPath-inspired notation has been called OOPath
since it is explictly intended to browse graph of objects. Using this notation the former
example can be rewritten as it follows:
Example 2.2. Browsing a graph of objects with OOPath
rule "Find all grades for Big Data exam" when
Student( $grade: /plan/exams{course == "Big Data"}/grades )
then /* RHS */ endFormally, the core grammar of an OOPath expression can be defined in EBNF notation in this way.
OOPExpr = "/" OOPSegment { ( "/" | "." ) OOPSegment } ;
OOPSegment = [ID ( ":" | ":=" )] ID ["[" Number "]"] ["{" Constraints "}"];In practice an OOPath expression has the following features.
It has to start with
/.It can dereference a single property of an object with the
.operatorIt can dereference a multiple property of an object using the
/operator. If a collection is returned, it will iterate over the values in the collectionWhile traversing referenced objects it can filter away those not satisfying one or more constraints, written as predicate expressions between curly brackets like in:
Student( $grade: /plan/exams{course == "Big Data"}/grades )Items can also be accessed by their index by putting it between square brackets like in:
Student( $grade: /plan/exams[0]/grades )To adhere to Java convention OOPath indexes are 0-based, compared to XPath 1-based
At the moment Drools is not able to react to updates involving a deeply nested traversed
during the evaluation of an OOPath expression. To make these objects reactive
to changes at the moment it is necessary to make them extend the class
org.drools.core.phreak.ReactiveObject. It is planned to overcome this
limitation by implementing a mechanism that automatically instruments the classes belonging
to a specific domain model.
Having extendend that class, the domain objects can notify the engine when one of
its field has been updated by invoking the inherited method notifyModification
as in the following example:
Example 2.3. Notifying the engine that an exam has been moved to a different course
public void setCourse(String course) {
this.course = course;
notifyModification(this);
}In this way if an exam is moved to a different course, the rule is re-triggered and the list of grades matching the rule recomputed.
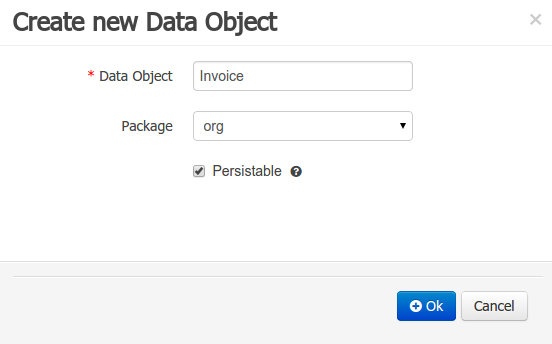
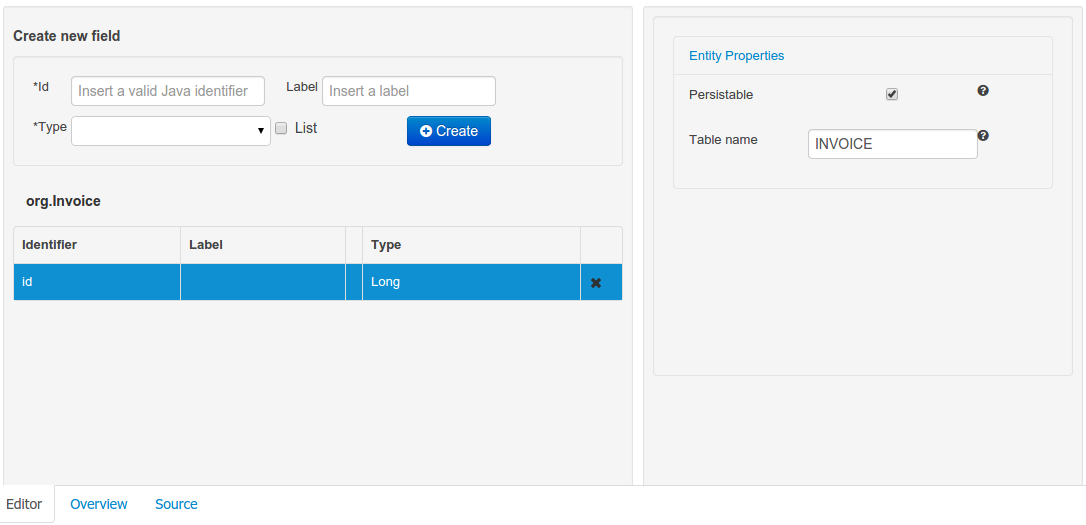
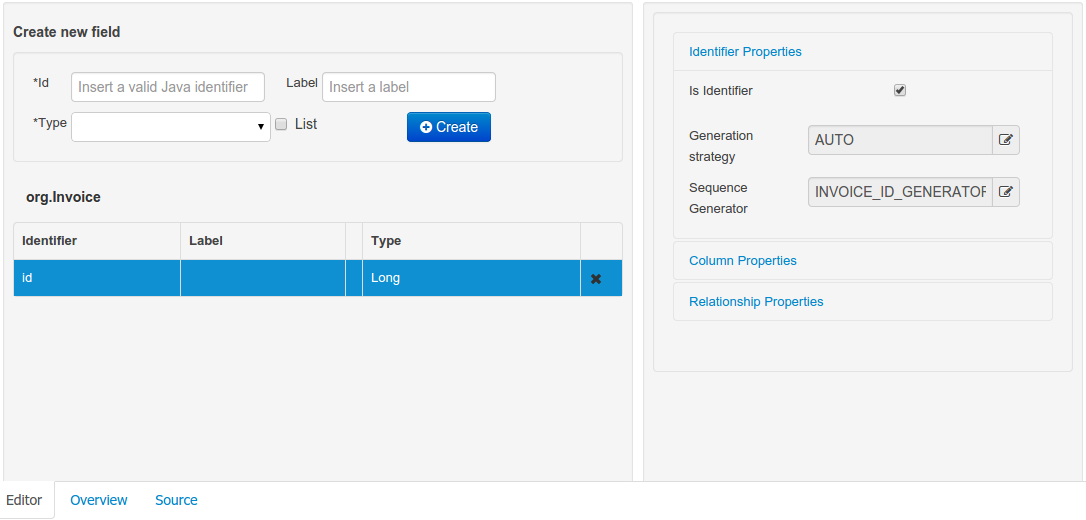
Data modeller was extended to support the generation of persistable Data Objects. The persistable Data Objects are based on the JPA specification and all the underlying metadata are automatically generated.
"The New -> Data Object" Data Objects can be marked as persistable at creation time.
JPA Domain editors for both Data Object and Field were added to manage the by default generated JPA metadata
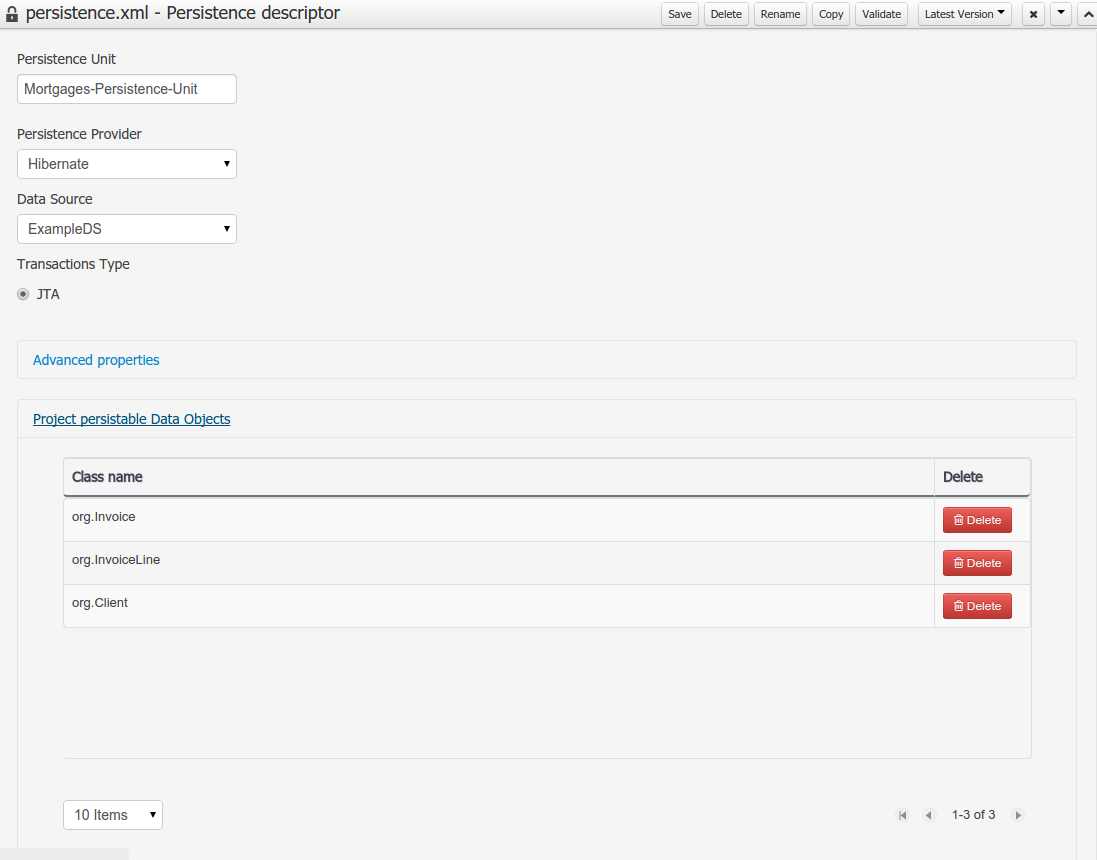
Persistence configuration screen was added to the project editor.
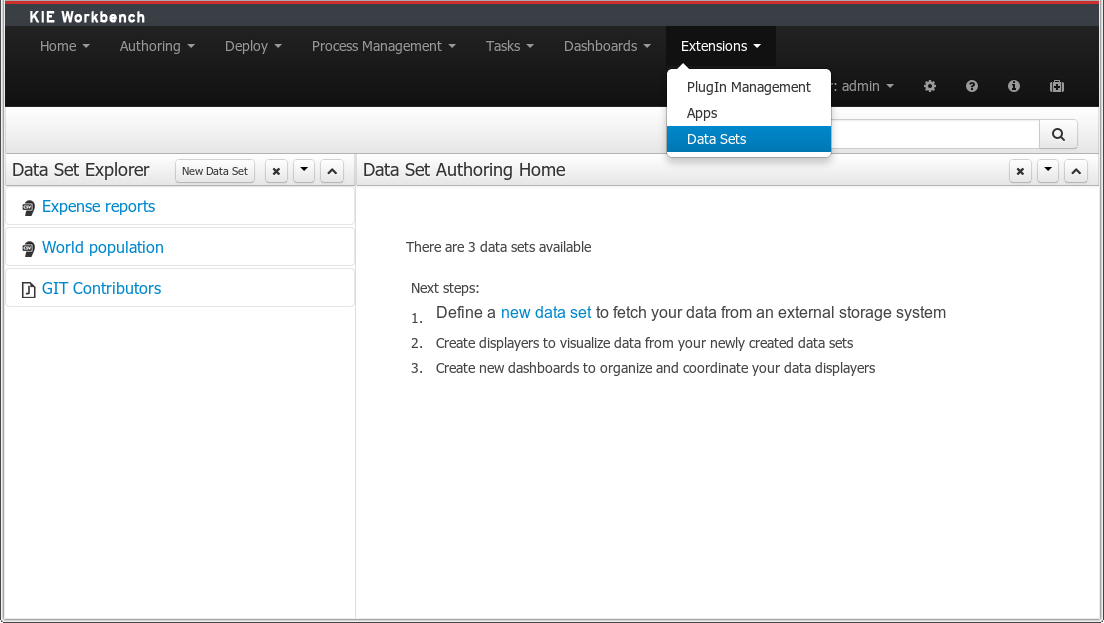
A new perspective for authoring data set definitions has been added. Data set definitions make it possible to retrieve data from external systems like databases, CSV/Excel files or even use a Java class to generate the data. Once the data is available it can be used, for instance, to create charts and dashboards from the Perspective Editor just feeding the charts from any of the data sets available.
The introduction of PHREAK as default algorithm for the Drools engine made the rules' evaluation lazy. This new Drools lazy behavior allowed a relevant performance boost but, in some very specific cases, breaks the semantic of a few Drools features.
More precisely in some circumstances it is necessary to propagate the insertion of new fact into th session immediately. For instance Drools allows a query to be executed in pull only (or passive) mode by prepending a '?' symbol to its invocation as in the following example:
Example 2.4. A passive query
query Q (Integer i)
String( this == i.toString() )
end
rule R when
$i : Integer()
?Q( $i; )
then
System.out.println( $i );
endIn this case, since the query is passive, it shouldn't react to the insertion of a String matching the join condition in the query itself. In other words this sequence of commands
KieSession ksession = ...
ksession.insert(1);
ksession.insert("1");
ksession.fireAllRules();shouldn't cause the rule R to fire because the String satisfying the query condition has been inserted after the Integer and the passive query shouldn't react to this insertion. Conversely the rule should fire if the insertion sequence is inverted because the insertion of the Integer, when the passive query can be satisfied by the presence of an already existing String, will trigger it.
Unfortunately the lazy nature of PHREAK doesn't allow the engine to make any distinction regarding the insertion sequence of the two facts, so the rule will fire in both cases. In circumstances like this it is necessary to evaluate the rule eagerly as done by the old RETEOO-based engine.
In other cases it is required that the propagation is eager, meaning that it is not immedate, but anyway has to happen before the engine/agenda starts scheduled evaluations. For instance this is necessary when a rule has the no-loop or the lock-on-active attribute and in fact when this happens this propagation mode is automatically enforced by the engine.
To cover these use cases, and in all other situations where an immediate or eager rule evaluation is required, it is possible to declaratively specify so by annotating the rule itself with @Propagation(Propagation.Type), where Propagation.Type is an enumeration with 3 possible values:
IMMEDIATE means that the propagation is performed immediately.
EAGER means that the propagation is performed lazily but eagerly evaluated before scheduled evaluations.
LAZY means that the propagation is totally lazy and this is default PHREAK behaviour
This means that the following drl:
Example 2.5. A data-driven rule using a passive query
query Q (Integer i)
String( this == i.toString() )
end
rule R @Propagation(IMMEDIATE) when
$i : Integer()
?Q( $i; )
then
System.out.println( $i );
endwill make the rule R to fire if and only if the Integer is inserted after the String, thus behaving in accordance with the semantic of the passive query.
This feature makes it possible to download a repository or a folder from the repository as a ZIP file.
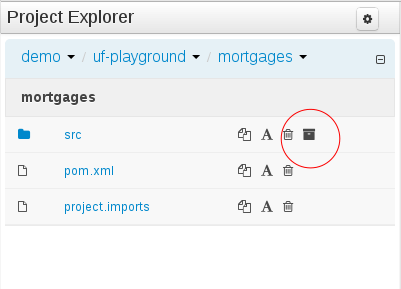
The ability to configure role-based permissions for the Project Editor have been added.
Permissions can be configured using the WEB-INF/classes/workbench-policy.properties file.
The following permissions are supported:
Save button
feature.wb_project_authoring_saveDelete button
feature.wb_project_authoring_deleteCopy button
feature.wb_project_authoring_copyRename button
feature.wb_project_authoring_renameBuild & Deploy button
feature.wb_project_authoring_buildAndDeploy
All of our new screens use GWT-Bootstrap widgets and alert users to input errors in a consistent way.
One of the most noticable differences was the Guided Decision Table Wizard that alerted errors in a way inconsistent with our use of GWT-Bootstrap.
This Wizard has been updated to use the new look and feel.
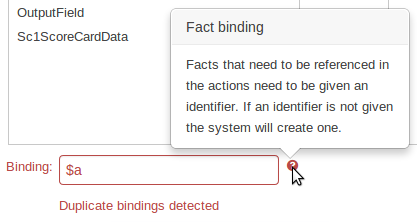
During the re-work of the Guided Decision Table's Wizard to make it's validation consistent with other areas of the application we took the opportunity to move the Wizard Framework to GWT-Bootstrap too.
The resulting appearance is much more pleasing. We hope to migrate more legacy editors to GWT-Bootstrap as time and priorities permit.
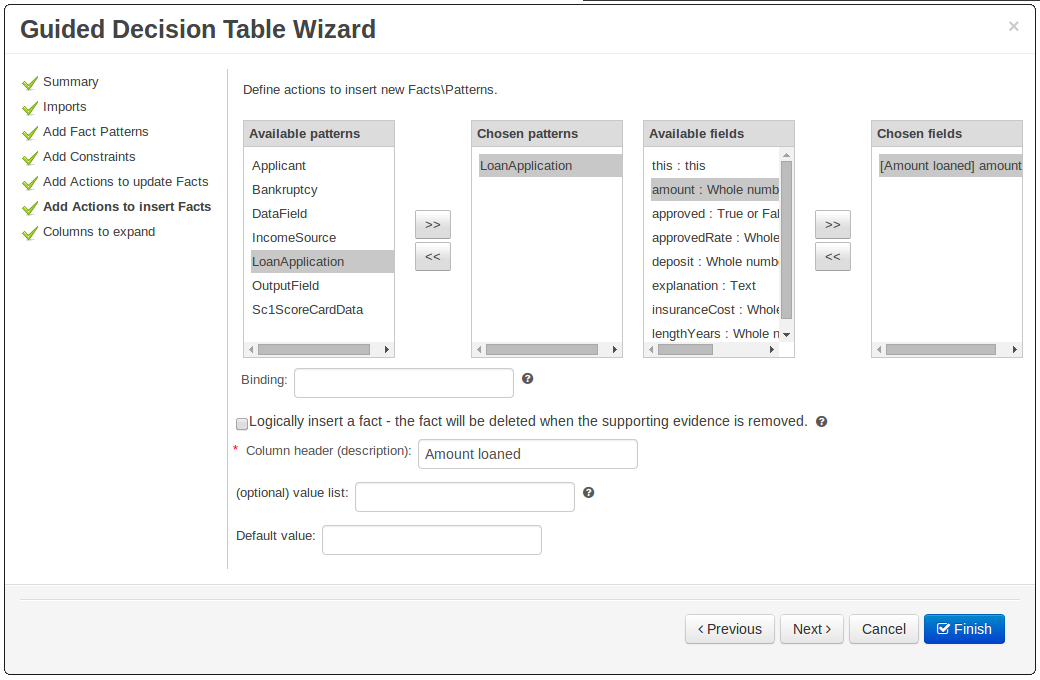
Consistency is a good thing for everybody. Users can expect different authoring metaphores to produce the same rule behaviour (and developers know when something is a bug!).
There were a few inconsistencies in the way XLS Decision Tables, Guidied Decision Tables and Guided Rule Templates generated the underlying rules for empty cells. These have been eliminated making their operation consistent.
If all constraints have null values (empty cells) the Pattern is not created.
Should you need the Pattern but no constraints; you will need to include the constraint
this != null.This operation is consistent with how XLS and Guided Decision Tables have always worked.
You can define a constraint on a String field for an empty String or white-space by delimiting it with double-quotation marks. The enclosing quotation-marks are removed from the value when generating the rules.
The use of quotation marks for other String values is not required and they can be omitted. Their use is however essential to differentiate a constraint for an empty String from an empty cell - in which case the constraint is omitted.
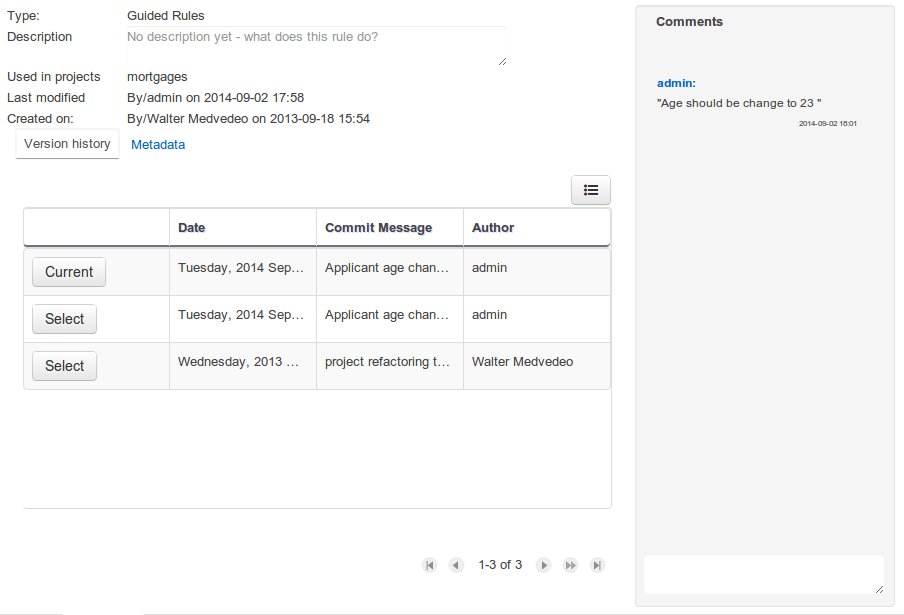
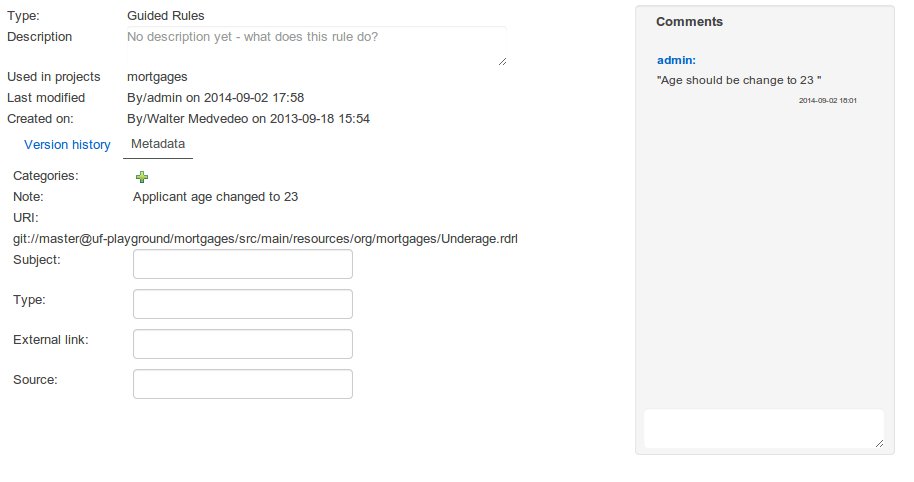
The Metadata tab provided in previous versions was redesigned to provide a better asset versioning information browsing and recovery. Now every workbench editor will provide an "Overview tab" that will enable the user to manage the following information.
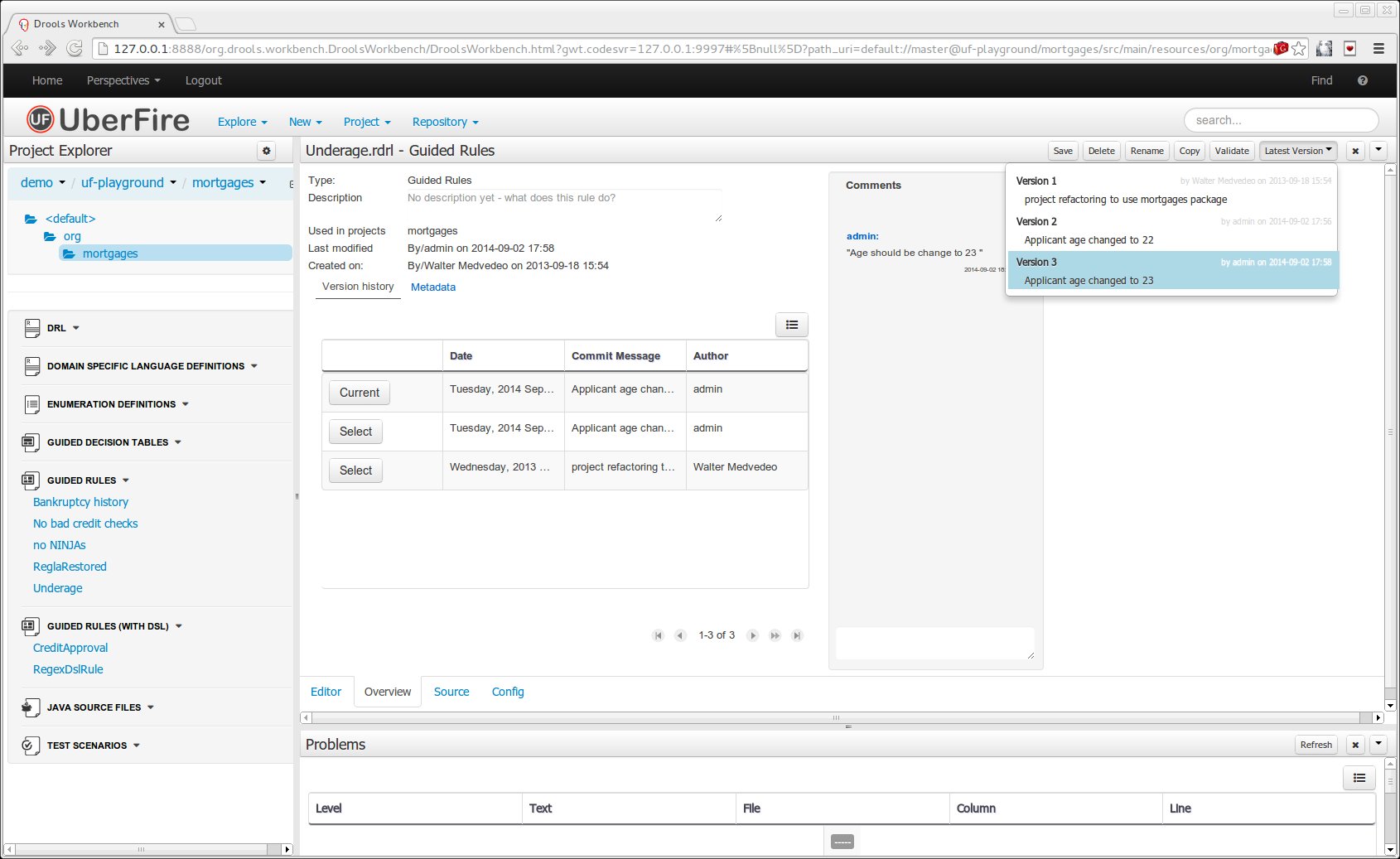
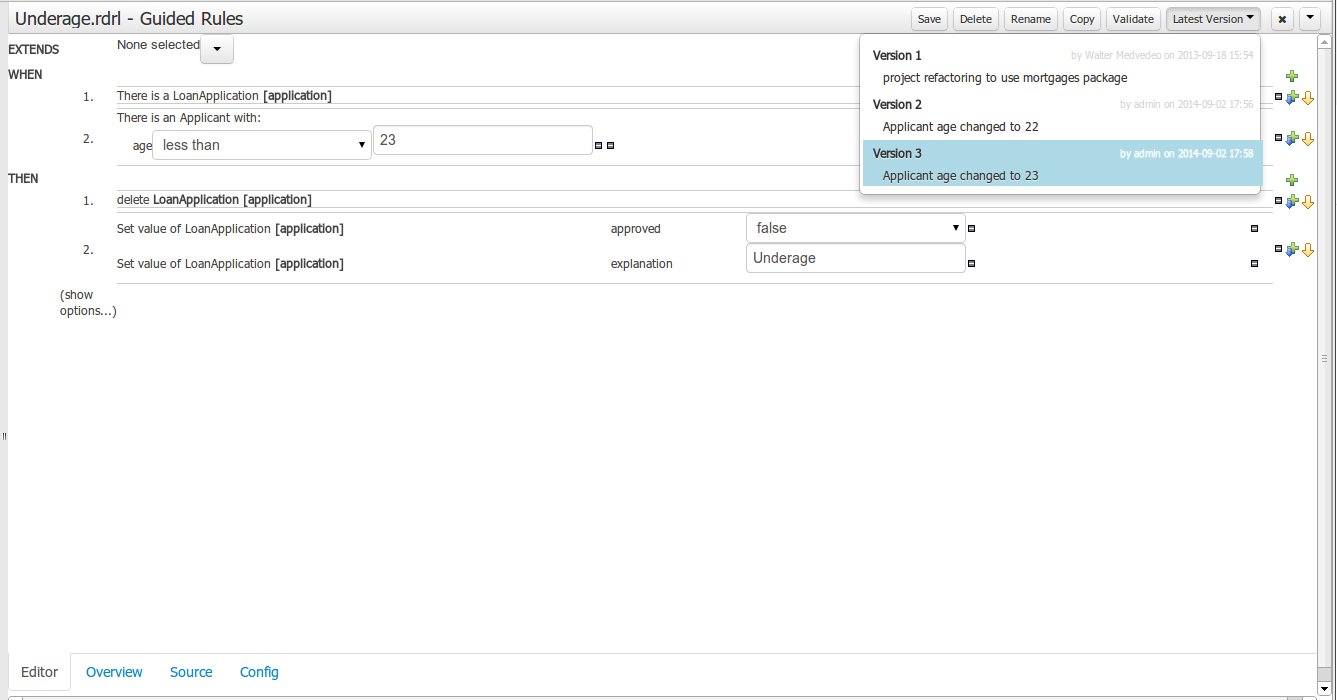
Versions history
The versions history shows a tabular view of the asset versions and provides a "Select" button that will enable the user to load a previously created version.
Metadata
The metadata section gets access to additional file attributes.
Comments area
The redesigned comments area enables much clearer discussions on a file.
Version selection dropdown
The "Version selector dropdown" located at the menu bar provides the ability to load and restore previous versions from the "Editor tab", without having to open the "Overview tab" to load the "Version history".
The Java editor was unified to the standard workbench editors functioning. It means that and now every data object is edited on his own editor window.
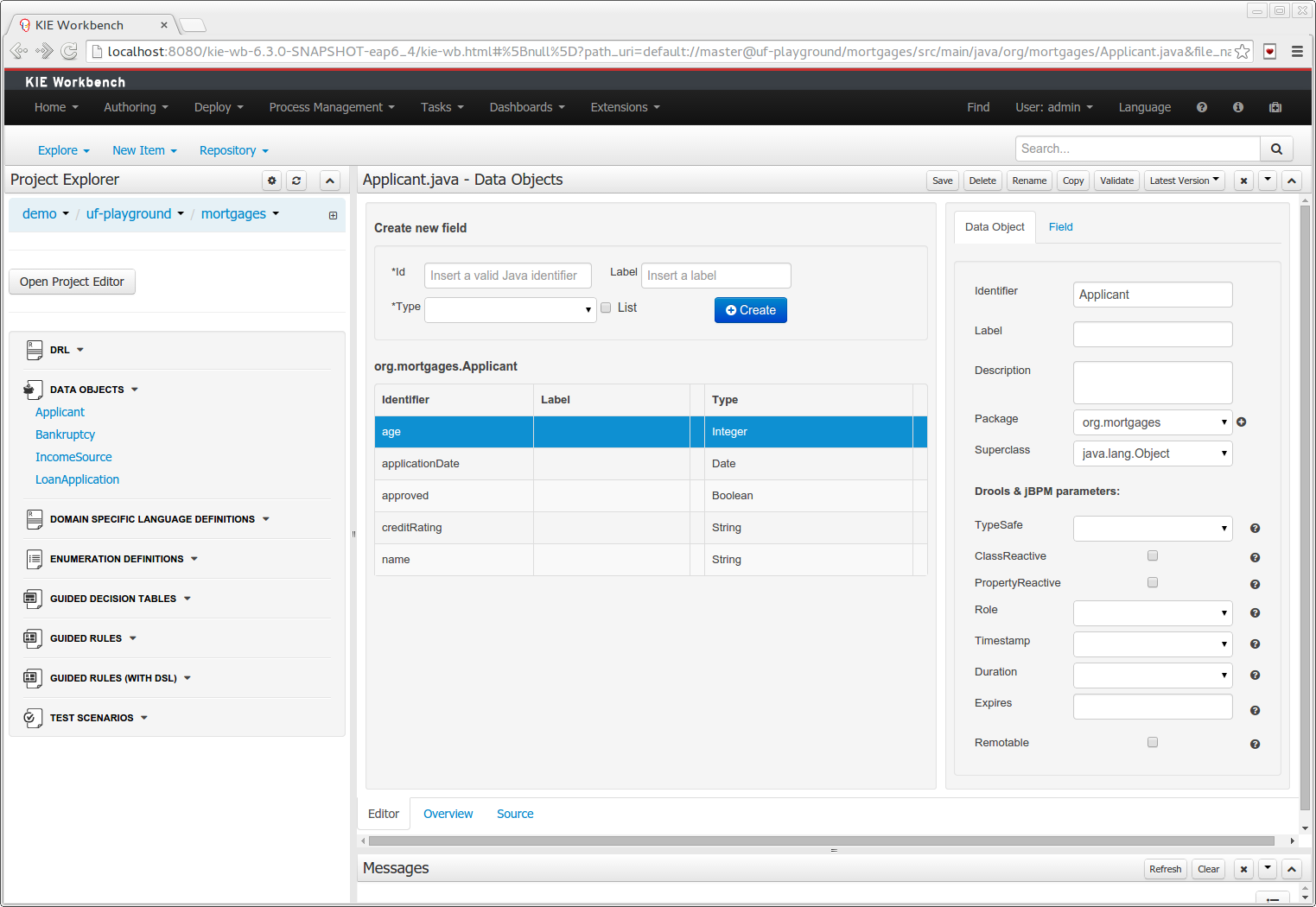
"New -> Data Object" option was added to create the data objects.
Overview tab was added for every file to manage the file metadata and have access to the file versions history.
Editable "Source Tab" tab was added. Now the Java code can be modified by administrators using the workbench.
"Editor" - "Source Tab" round trip is provided. This will let administrators to do manual changes on the generated Java code and go back to the editor tab to continue working.
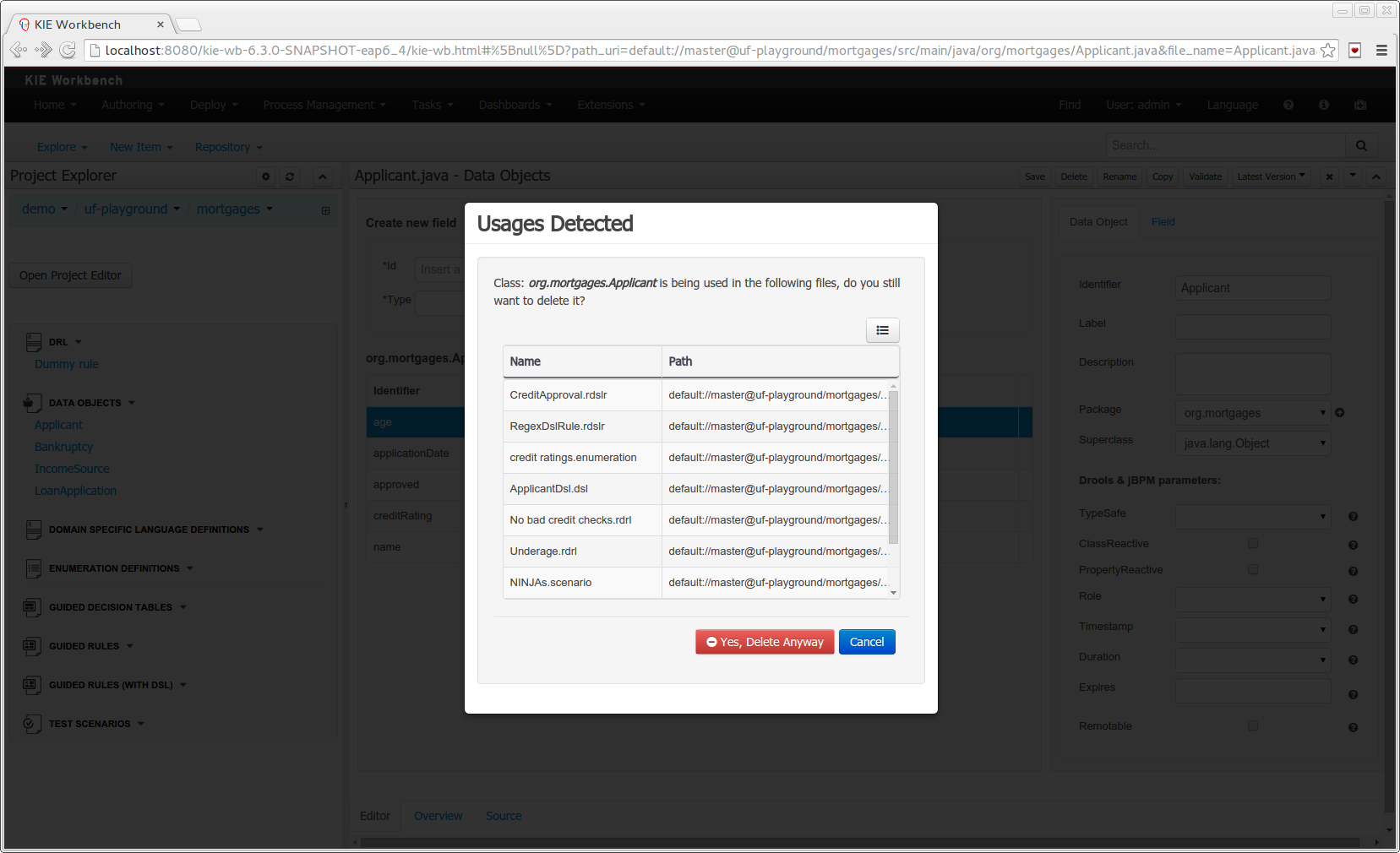
Class usages detection. Whenever a Data Object is about to be deleted or renamed, the project will be scanned for the class usages. If usages are found (e.g. in drl files, decision tables, etc.) the user will receive an alert. This will prevent the user from breaking the project build.
A new perspective called Management has been added under Servers top level menu. This perspective provides users the ability to manage multiple execution servers with multiple containers. Available features includes connect to already deployed execution servers; create new, start, stop, delete or upgrade containers.
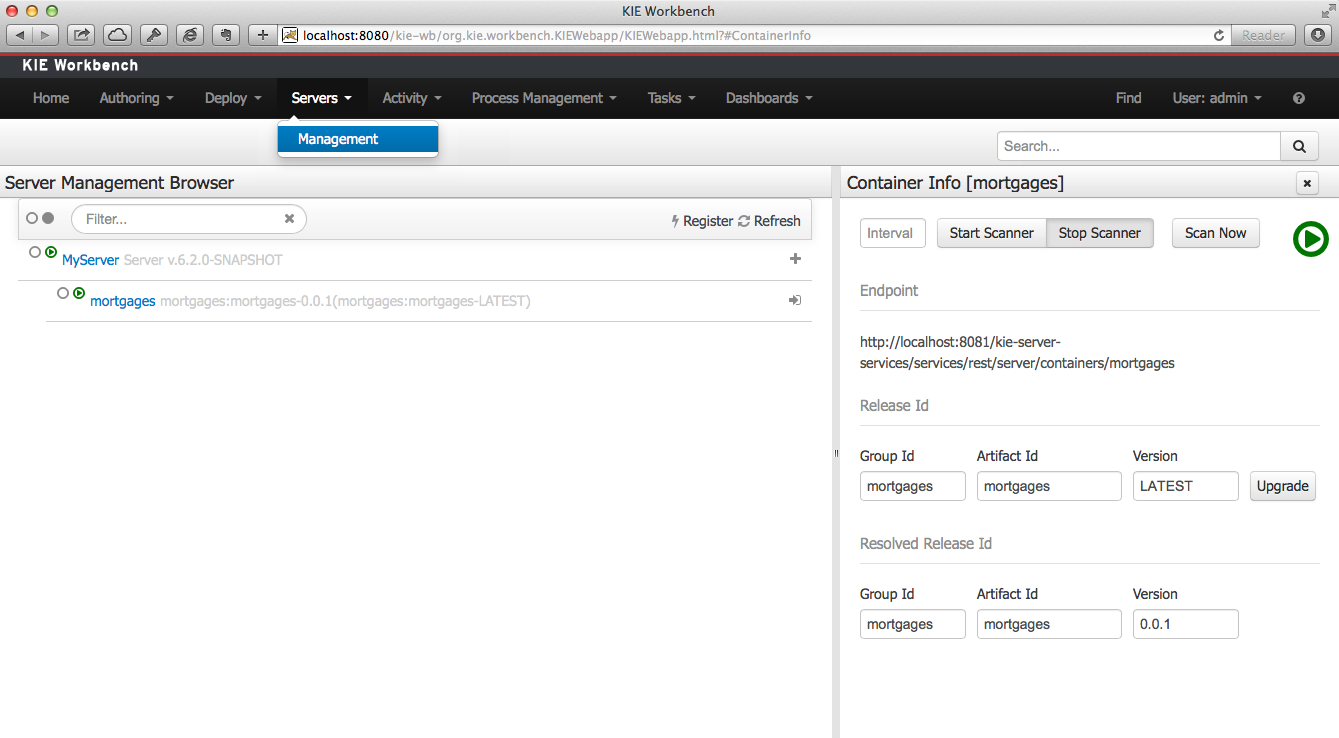
Note
Current version of Execution Server just supports rule based execution.
A brand new feature called Social Activities has been added under a new top level menu item group called Activity.
This new feature is divided in two different perspectives: Timeline Perspective and People Perspective.
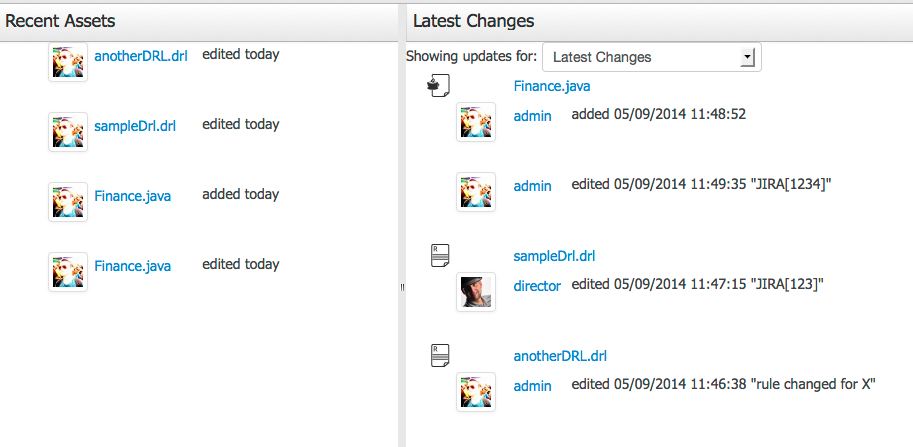
The Timeline Perspective shows on left side the recent assets created or edited by the logged user. In the main window there is the "Latest Changes" screen, showing all the recent updated assets and an option to filter the recent updates by repository.
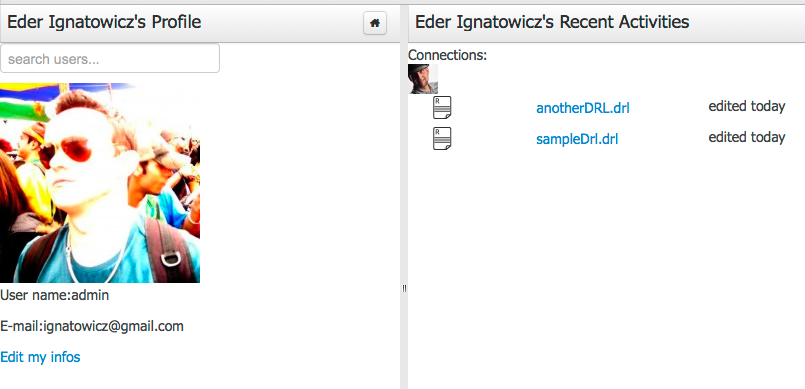
The People Perspective is the home page of an user. Showing his infos (including a gravatar picture from user e-mail), user connections (people that user follow) and user recent activities. There is also a way to edit an user info. The search suggestion can be used to navigate to a user profile, follow him and see his updates on your timeline.
A brand new perspective called Contributors has been added under a new top level menu item group called Activity. The perspective itself is a dashboard which shows several indicators about the contributions made to the managed organizations / repositories within the workbench. Every time a organization/repository is added/removed from the workbench the dashboard itself is updated accordingly.
This new perspective allows for the monitoring of the underlying activity on the managed repositories.
The location of new assets whilst authoring was driven by the context of the Project Explorer.
This has been replaced with a Package Selector in the New Resource Popup.
The location defaults to the Project Explorer context but different packages can now be more easily chosen.
All Popups have been refactored to use GWT-Bootstrap widgets.
Whilst a simple change it brings greater visual consistency to the application as a whole.
A new editor has been added to support modelling of simple decision trees.
See the applicable section within the User Guide for more information about usage.
A wizard has been created to guide the repository creation process. Now the user can decide at repository creation time if it should be a managed or unmanaged repository and configure all related parameters.
The new Repository Structure Screen will let users to manage the projects for a given repository, as well as other operations related to managed repositories like: branch creation, assets promotion and project release.
A new KIE Execution Server was created with the goal of supporting the deployment of kjars and the automatic creation of REST endpoints for remote rules execution. This initial implementation supports provisioning and execution of kjars via REST without any glue code.
A user interface was also integrated into the workbench for remote provisioning. See the workbench's New&Noteworthy for details.
Figure 2.30. Kie Server interface
@Path("/server")
public interface KieServer {
@GET
@Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
public Response getInfo();
@POST
@Consumes({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
@Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
public Response execute( CommandScript command );
@GET
@Path("containers")
@Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
public Response listContainers();
@GET
@Path("containers/{id}")
@Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
public Response getContainerInfo( @PathParam("id") String id );
@PUT
@Path("containers/{id}")
@Consumes({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
@Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
public Response createContainer( @PathParam("id") String id, KieContainerResource container );
@DELETE
@Path("containers/{id}")
@Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
public Response disposeContainer( @PathParam("id") String id );
@POST
@Path("containers/{id}")
@Consumes({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
@Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
public Response execute( @PathParam("id") String id, String cmdPayload );
@GET
@Path("containers/{id}/release-id")
@Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
public Response getReleaseId( @PathParam("id") String id);
@POST
@Path("containers/{id}/release-id")
@Consumes({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
@Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
public Response updateReleaseId( @PathParam("id") String id, ReleaseId releaseId );
@GET
@Path("containers/{id}/scanner")
@Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
public Response getScannerInfo( @PathParam("id") String id );
@POST
@Path("containers/{id}/scanner")
@Consumes({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
@Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON})
public Response updateScanner( @PathParam("id") String id, KieScannerResource resource );
}
Added support for JMX monitoring and management on KieScanner and KieContainer. To enable, set the
property kie.scanner.mbeans to enabled, for example via Java command line: -Dkie.scanner.mbeans=enabled .
KieScannerMBean will register under the name:
It exposes the following properties:
Scanner Release Id: the release ID the scanner was configured with. May include maven range versions and special keywords like LATEST, SNAPSHOT, etc.
Current Release Id: the actual release ID the artifact resolved to.
Status: STARTING, SCANNING, UPDATING, RUNNING, STOPPED, SHUTDOWN
It also exposes the following operations:
scanNow(): forces an immediate scan of the maven repository looking for artifact updates
start(): starts polling the maven repository for artifact updates based on the polling interval parameter
stop(): stops automatically polling the maven repository
Full round trip between Data modeler and Java source code is now supported. No matter where the Java code was generated (e.g. Eclipse, Data modeller), data modeler will only update the necessary code blocks to maintain the model updated.
New annotations @TypeSafe, @ClassReactive, @PropertyReactive, @Timestamp, @Duration and @Expires were added in order enrich current Drools annotations manged by the data modeler.
We have standardized the display of tabular data with a new table widget.
The new table supports the following features:
Selection of visible columns
Resizable columns
Moveable columns
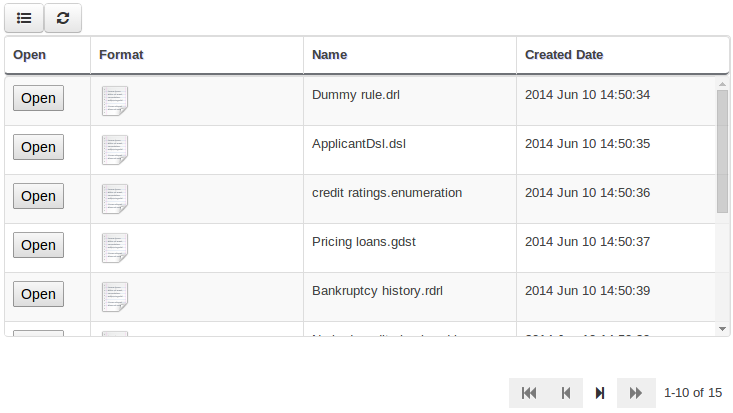
The table is used in the following scenarios:
Inbox (Incoming changes)
Inbox (Recently edited)
Inbox (Recently opened)
Project Problems summary
Artifact Repository browser
Project Editor Dependency grid
Project Editor KSession grid
Project Editor Work Item Handlers Configuration grid
Project Editor Listeners Configuration grid
Search Results grid
The Guided Rule Editor, Guided Template Editor and Guided Decision Table Editor have been
changed to generate modify(x){...}
Historically these editors supported the older update(x) syntax and hence
rules created within the Workbench would not respond correctly to
@PropertyReactive and associated annotations within a model. This has now been
rectified with the use of modify(x){...} blocks.
KIE is the new umbrella name used to group together our related projects; as the family continues to grow. KIE is also used for the generic parts of unified API; such as building, deploying and loading. This replaces the droolsjbpm and knowledge keywords that would have been used before.
One of the biggest complaints during the 5.x series was the lack of defined methodology for deployment. The mechanism used by Drools and jBPM was very flexible, but it was too flexible. A big focus for 6.0 was streamlining the build, deploy and loading (utilization) aspects of the system. Building and deploying activities are now aligned with Maven and Maven repositories. The utilization for loading rules and processess is now convention and configuration oriented, instead of programmatic, with sane defaults to minimise the configuration.
Projects can be built with Maven and installed to the local M2_REPO or remote Maven repositories. Maven is then used to declare and build the classpath of dependencies, for KIE to access.
The 'kmodule.xml' provides declarative configuration for KIE projects. Conventions and defaults are used to reduce the amount of configuration needed.
Example 2.6. Declare KieBases and KieSessions
<kmodule xmlns="http://jboss.org/kie/6.0.0/kmodule">
<kbase name="kbase1" packages="org.mypackages>
<ksession name="ksession1"/>
</kbase>
</kmodule>Example 2.7. Utilize the KieSession
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession("ksession1");
kSession.insert(new Message("Dave", "Hello, HAL. Do you read me, HAL?"));
kSession.fireAllRules();It is possible to include all the KIE artifacts belonging to a KieBase into a second KieBase. This means that the second KieBase, in addition to all the rules, function and processes directly defined into it, will also contain the ones created in the included KieBase. This inclusion can be done declaratively in the kmodule.xml file
Example 2.8. Including a KieBase into another declaratively
<kmodule xmlns="http://jboss.org/kie/6.0.0/kmodule">
<kbase name="kbase2" includes="kbase1">
<ksession name="ksession2"/>
</kbase>
</kmodule>or programmatically using the KieModuleModel.
Example 2.9. Including a KieBase into another programmatically
KieModuleModel kmodule = KieServices.Factory.get().newKieModuleModel();
KieBaseModel kieBaseModel1 = kmodule.newKieBaseModel("KBase2").addInclude("KBase1");Any Maven produced JAR with a 'kmodule.xml' in it is considered a KieModule. This can be loaded from the classpath or dynamically at runtime from a Resource location. If the kie-ci dependency is on the classpath it embeds Maven and all resolving is done automatically using Maven and can access local or remote repositories. Settings.xml is obeyed for Maven configuration.
The KieContainer provides a runtime to utilize the KieModule, versioning is built in throughout, via Maven. Kie-ci will create a classpath dynamically from all the Maven declared dependencies for the artifact being loaded. Maven LATEST, SNAPSHOT, RELEASE and version ranges are supported.
Example 2.10. Utilize and Run - Java
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.newKieContainer(
ks.newReleaseId("org.mygroup", "myartefact", "1.0") );
KieSession kSession = kContainer.newKieSession("ksession1");
kSession.insert(new Message("Dave", "Hello, HAL. Do you read me, HAL?"));
kSession.fireAllRules();KieContainers can be dynamically updated to a specific version, and resolved through Maven if KIE-CI is on the classpath. For stateful KieSessions the existing sessions are incrementally updated.
Example 2.11. Dynamically Update - Java
KieContainer kContainer.updateToVersion(
ks.newReleaseId("org.mygroup", "myartefact", "1.1") );The KieScanner is a Maven-oriented replacement of the KnowledgeAgent
present in Drools 5. It continuously monitors your Maven repository
to check if a new release of a Kie project has been installed and if so, deploys it in
the KieContainer wrapping that project. The use of the KieScanner
requires kie-ci.jar to be on the classpath.
A KieScanner can be registered on a KieContainer
as in the following example.
Example 2.12. Registering and starting a KieScanner on a KieContainer
KieServices kieServices = KieServices.Factory.get();
ReleaseId releaseId = kieServices.newReleaseId( "org.acme", "myartifact", "1.0-SNAPSHOT" );
KieContainer kContainer = kieServices.newKieContainer( releaseId );
KieScanner kScanner = kieServices.newKieScanner( kContainer );
// Start the KieScanner polling the Maven repository every 10 seconds
kScanner.start( 10000L );In this example the KieScanner is configured to run with a fixed
time interval, but it is also possible to run it on demand by invoking the
scanNow() method on it. If the KieScanner finds, in the
Maven repository, an updated version of the Kie project used by that KieContainer
it automatically downloads the new version and triggers an incremental build of the new
project. From this moment all the new KieBases and KieSessions
created from that KieContainer will use the new project version.
The CompositeClassLoader is no longer used; as it was a constant source of performance problems and bugs. Traditional hierarchical classloaders are now used. The root classloader is at the KieContext level, with one child ClassLoader per namespace. This makes it cleaner to add and remove rules, but there can now be no referencing between namespaces in DRL files; i.e. functions can only be used by the namespaces that declared them. The recommendation is to use static Java methods in your project, which is visible to all namespaces; but those cannot (like other classes on the root KieContainer ClassLoader) be dynamically updated.
The 5.x API for building and running with Drools and jBPM is still available through Maven dependency "knowledge-api-legacy5-adapter". Because the nature of deployment has significantly changed in 6.0, it was not possible to provide an adapter bridge for the KnowledgeAgent. If any other methods are missing or problematic, please open a JIRA, and we'll fix for 6.1
While a lot of new documentation has been added for working with the new KIE API, the entire documentation has not yet been brought up to date. For this reason there will be continued references to old terminologies. Apologies in advance, and thank you for your patience. We hope those in the community will work with us to get the documentation updated throughout, for 6.1
The main work done for Drools in 6.0 involves the new PREAK algorithm. This is a lazy algorithm that should enable Drools to handle a larger number of rules and facts. AngendaGroups can now help improvement performance, as rules are not evaluated until it attempts to fire them.
Sequential mode continues to be supported for PHREAK but now 'modify' is allowed. While there is no 'inference' with sequential configuration, as rules are lazily evaluated, any rule not yet evaluated will see the more recent data as a result of 'modify'. This is more inline with how people intuitively think sequential works.
The conflict resolution order has been tweaked for PHREAK, and now is ordered by salience and then rule order; based on the rule position in the file.. Prior to Drools 6.0.0, after salience, it was considered arbitrary. When KieModules and updateToVersion are used for dynamic deployment, the rule order in the file is preserved via the diff processing.
When the rule engine runs in passive mode (i.e.: using fireAllRules)
by default it doesn't fire consequences of timed rules unless fireAllRules isn't invoked again.
Now it is possible to change this default behavior by configuring the KieSession
with a TimedRuleExectionOption as shown in the following example.
Example 2.13. Configuring a KieSession to automatically execute timed rules
KieSessionConfiguration ksconf = KieServices.Factory.get().newKieSessionConfiguration();
ksconf.setOption( TimedRuleExectionOption.YES );
KSession ksession = kbase.newKieSession(ksconf, null);It is also possible to have a finer grained control on the timed rules that have to be
automatically executed. To do this it is necessary to set a FILTERED
TimedRuleExectionOption that allows to define a callback to filter those
rules, as done in the next example.
Example 2.14. Configuring a filter to choose which timed rules should be automatically executed
KieSessionConfiguration ksconf = KieServices.Factory.get().newKieSessionConfiguration();
conf.setOption( new TimedRuleExectionOption.FILTERED(new TimedRuleExecutionFilter() {
public boolean accept(Rule[] rules) {
return rules[0].getName().equals("MyRule");
}
}) );It is now possible to define both the delay and interval of an interval timer as an expression instead of a fixed value. To do that it is necessary to declare the timer as an expression one (indicated by "expr:") as in the following example:
Example 2.15. An Expression Timer Example
declare Bean
delay : String = "30s"
period : long = 60000
end
rule "Expression timer"
timer( expr: $d, $p )
when
Bean( $d : delay, $p : period )
then
endThe expressions, $d and $p in this case, can use any variable defined in the pattern matching part of the rule and can be any String that can be parsed in a time duration or any numeric value that will be internally converted in a long representing a duration expressed in milliseconds.
Both interval and expression timers can have 3 optional parameters named "start", "end" and "repeat-limit". When one or more of these parameters are used the first part of the timer definition must be followed by a semicolon ';' and the parameters have to be separated by a comma ',' as in the following example:
Example 2.16. An Interval Timer with a start and an end
timer (int: 30s 10s; start=3-JAN-2010, end=5-JAN-2010)The value for start and end parameters can be a Date, a String representing a Date or a long, or more in general any Number, that will be transformed in a Java Date applying the following conversion:
new Date( ((Number) n).longValue() )Conversely the repeat-limit can be only an integer and it defines the maximum number of repetitions allowed by the timer. If both the end and the repeat-limit parameters are set the timer will stop when the first of the two will be matched.
The using of the start parameter implies the definition of a phase for the timer, where the beginning of the phase is given by the start itself plus the eventual delay. In other words in this case the timed rule will then be scheduled at times:
start + delay + n*periodfor up to repeat-limit times and no later than the end timestamp (whichever first). For instance the rule having the following interval timer
timer ( int: 30s 1m; start="3-JAN-2010" )will be scheduled at the 30th second of every minute after the midnight of the 3-JAN-2010. This also means that if for example you turn the system on at midnight of the 3-FEB-2010 it won't be scheduled immediately but will preserve the phase defined by the timer and so it will be scheduled for the first time 30 seconds after the midnight. If for some reason the system is paused (e.g. the session is serialized and then deserialized after a while) the rule will be scheduled only once to recover from missing activations (regardless of how many activations we missed) and subsequently it will be scheduled again in phase with the timer.
These two groups have been merged and now RuleFlowGroups behave the same as AgendaGroups. The get methods have been left, for deprecation reasons, but both return the same underlying data. When jBPM activates a group it now just calls setFocus. RuleFlowGroups and AgendaGroups when used together was a continued source of errors. It also aligns the codebase, towards PHREAK and the multi-core explotation that is planned in the future.
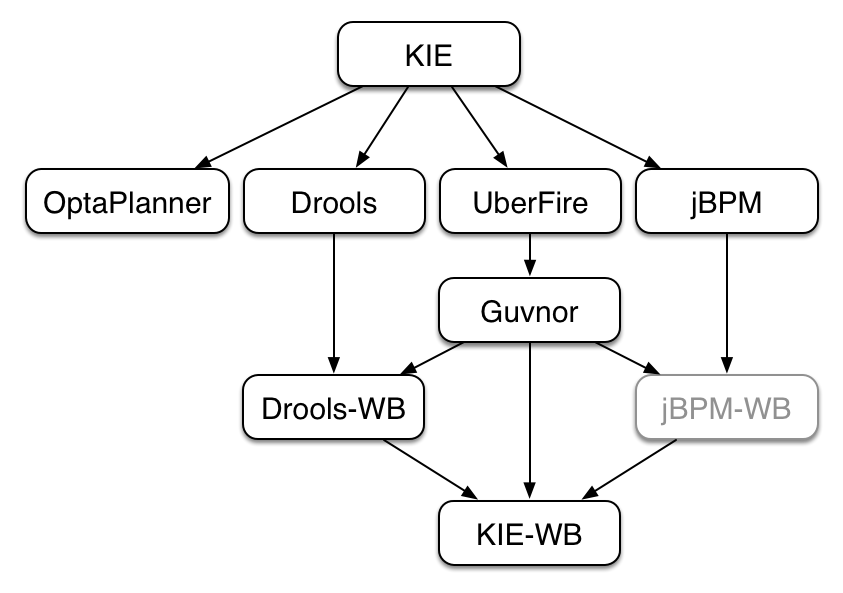
The workbench has had a big overhaul using a new base project called UberFire. UberFire is inspired by Eclipse and provides a clean, extensible and flexible framework for the workbench. The end result is not only a richer experience for our end users, but we can now develop more rapidly with a clean component based architecture. If you like he Workbench experience you can use UberFire today to build your own web based dashboard and console efforts.
As well as the move to a UberFire the other biggest change is the move from JCR to Git; there is an utility project to help with migration. Git is the most scalable and powerful source repository bar none. JGit provides a solid OSS implementation for Git. This addresses the continued performance problems with the various JCR implementations, which would slow down once the number of files and number of versions become too high. There has been a big "low tech" drive, to remove complexity. Everything is now stored as a file, including meta data. The database is only there to provide fast indexing and search. So importing and exporting is all standard Git and external sites, like GitHub, can be used to exchange repositories.
In 5.x developers would work with their own source repository and then push JCR, via the team provider. This team provider was not full featured and not available outside Eclipse. Git enables our repository to work any existing Git tool or team provider. While not yet supported in the UI, this will be added over time, it is possible to connect to the repo and tag and branch and restore things.
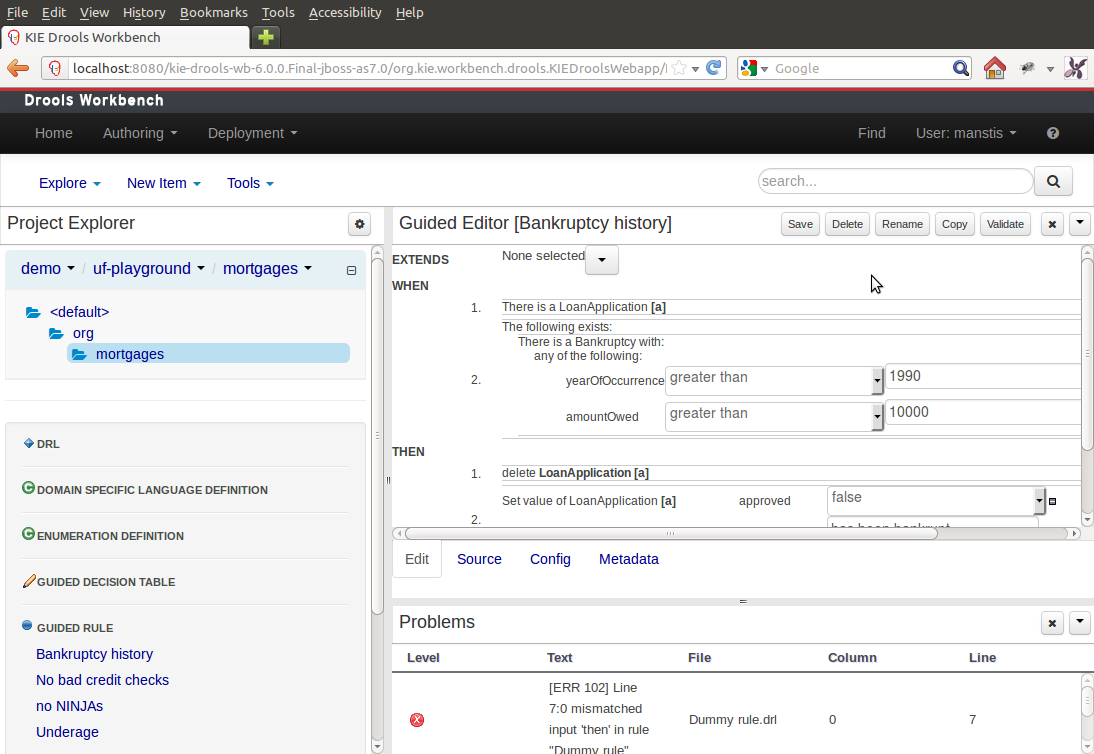
The Guvnor brand leaked too much from its intended role; such as the authoring metaphors, like Decision Tables, being considered Guvnor components instead of Drools components. This wasn't helped by the monolithic projects structure used in 5.x for Guvnor. In 6.0 Guvnor 's focus has been narrowed to encapsulates the set of UberFire plugins that provide the basis for building a web based IDE. Such as Maven integration for building and deploying, management of Maven repositories and activity notifications via inboxes. Drools and jBPM build workbench distributions using Uberfire as the base and including a set of plugins, such as Guvnor, along with their own plugins for things like decision tables, guided editors, BPMN2 designer, human tasks.
The "Model Structure" diagram outlines the new project anatomy. The Drools workbench is called KIE-Drools-WB. KIE-WB is the uber workbench that combines all the Guvnor, Drools and jBPM plugins. The jBPM-WB is ghosted out, as it doesn't actually exist, being made redundant by KIE-WB.
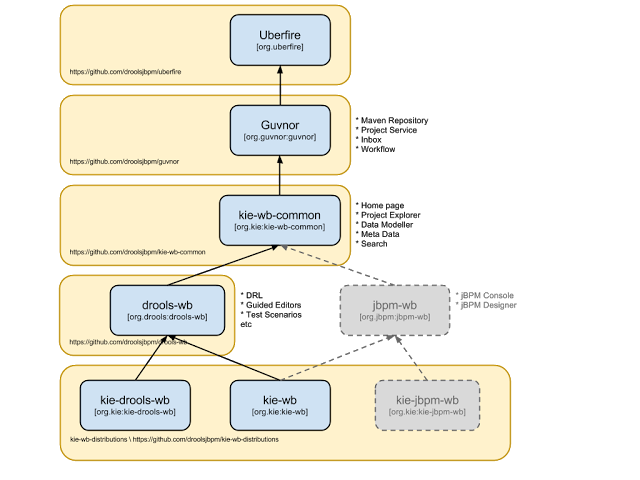
Important
KIE Drools Workbench and KIE Workbench share a common set of components for generic workbench functionality such as Project navigation, Project definitions, Maven based Projects, Maven Artifact Repository. These common features are described in more detail throughout this documentation.
The two primary distributions consist of:
KIE Drools Workbench
Drools Editors, for rules and supporting assets.
jBPM Designer, for Rule Flow and supporting assets.
KIE Workbench
Drools Editors, for rules and supporting assets.
jBPM Designer, for BPMN2 and supporting assets.
jBPM Console, runtime and Human Task support.
jBPM Form Builder.
BAM.
Workbench highlights:
New flexible Workbench environment, with perspectives and panels.
New packaging and build system following KIE API.
Maven based projects.
Maven Artifact Repository replaces Global Area, with full dependency support.
New Data Modeller replaces the declarative Fact Model Editor; bringing authoring of Java classes to the authoring environment. Java classes are packaged into the project and can be used within rules, processes etc and externally in your own applications.
Virtual File System replaces JCR with a default Git based implementation.
Default Git based implementation supports remote operations.
External modifications appear within the Workbench.
Incremental Build system showing, near real-time validation results of your project and assets.
The editors themselves are largely unchanged; however of note imports have moved from the package definition to individual editors so you need only import types used for an asset and not the package as a whole.
CDI is now tightly integrated into the KIE API. It can be used to inject versioned KieSession and KieBases.
Figure 2.35. Side by side version loading for 'jar1.KBase1' KieBase
@Inject
@KSession("kbase1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.0")
private KieBase kbase1v10;
@Inject
@KBase("kbase1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.1")
private KieBase kbase1v10;Figure 2.36. Side by side version loading for 'jar1.KBase1' KieBase
@Inject
@KSession("ksession1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.0")
private KieSession ksessionv10;
@Inject
@KSession("ksession1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.1")
private KieSession ksessionv11;Spring has been revamped and now integrated with KIE. Spring can replace the 'kmodule.xml' with a more powerful spring version. The aim is for consistency with kmodule.xml
Aries blueprints is now also supported, and follows the work done for spring. The aim is for consistency with spring and kmodule.xml