The process of researching an integration knowledge solution for Drools and jBPM has simply used the "droolsjbpm" group name. This name permeates GitHub accounts and Maven POMs. As scopes broadened and new projects were spun KIE, an acronym for Knowledge Is Everything, was chosen as the new group name. The KIE name is also used for the shared aspects of the system; such as the unified build, deploy and utilization.
KIE currently consists of the following subprojects:
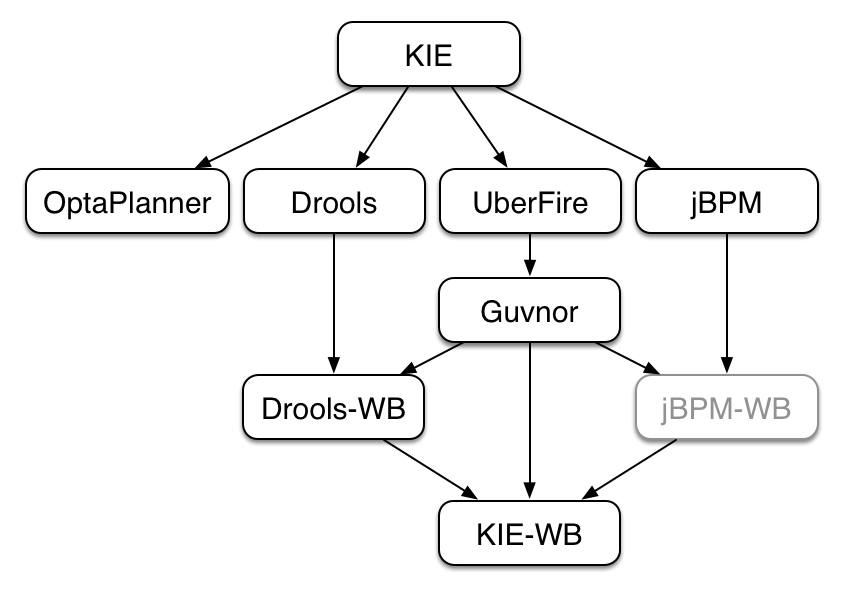
OptaPlanner, a local search and optimization tool, has been spun off from Drools Planner and is now a top level project with Drools and jBPM. This was a natural evolution as Optaplanner, while having strong Drools integration, has long been independant of Drools.
From the Polymita acquisition, along with other things, comes the powerful Dashboard Builder which provides powerful reporting capabilities. Dashboard Builder is currently a temporary name and after the 6.0 release a new name will be chosen. Dashboard Builder is completely independant of Drools and jBPM and will be used by many projects at JBoss, and hopefully outside of JBoss :)
UberFire is the new base workbench project, spun off from the ground up rewrite. UberFire provides Eclipse-like workbench capabilities, with panels and perspectives from plugins. The project is independant of Drools and jBPM and anyone can use it as a basis of building flexible and powerful workbenches. UberFire will be used for console and workbench development throughout JBoss.
It was determined that the Guvnor brand leaked too much from its intended role; such as the authoring metaphors, like Decision Tables, being considered Guvnor components instead of Drools components. This wasn't helped by the monolithic projects structure used in 5.x for Guvnor. In 6.0 Guvnor's focus has been narrowed to encapsulate the set of UberFire plugins that provide the basis for building a web based IDE. Such as Maven integration for building and deploying, management of Maven repositories and activity notifications via inboxes. Drools and jBPM build workbench distributions using Uberfire as the base and including a set of plugins, such as Guvnor, along with their own plugins for things like decision tables, guided editors, BPMN2 designer, human tasks. The Drools workbench is called Drools-WB. KIE-WB is the uber workbench that combined all the Guvnor, Drools and jBPM plugins. The jBPM-WB is ghosted out, as it doesn't actually exist, being made redundant by KIE-WB.
The different aspects, or life cycles, of working with KIE system, whether it's Drools or jBPM, can typically be broken down into the following:
Author
Authoring of knowledge using a UI metaphor, such as: DRL, BPMN2, decision table, class models.
Build
Builds the authored knowledge into deployable units.
For KIE this unit is a JAR.
Test
Test KIE knowedge before it's deployed to the application.
Deploy
Deploys the unit to a location where applications may utilize (consume) them.
KIE uses Maven style repository.
Utilize
The loading of a JAR to provide a KIE session (KieSession), for which the application can interact with.
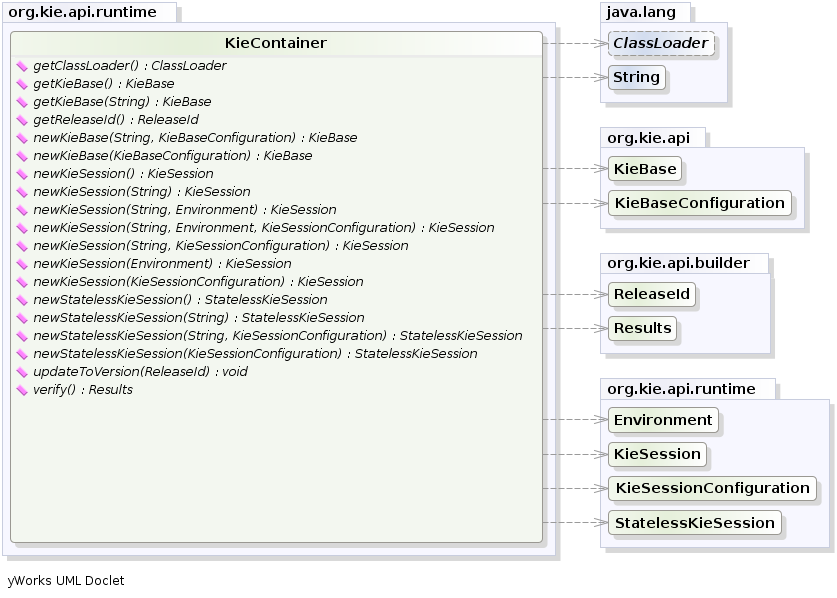
KIE exposes the JAR at runtime via a KIE container (KieContainer).
KieSessions, for the runtime's to interact with, are created from the KieContainer.
Run
System interaction with the KieSession, via API.
Work
User interaction with the KieSession, via command line or UI.
Manage
Manage any KieSession or KieContainer.
6.0 introduces a new configuration and convention approach to building knowledge bases, instead of using the programmatic builder approach in 5.x. The builder is still available to fall back on, as it's used for the tooling integration.
Building now uses Maven, and aligns with Maven practices. A KIE project or module is simply a Maven Java project or module; with an additional metadata file META-INF/kmodule.xml. The kmodule.xml file is the descriptor that selects resources to knowledge bases and configures those knowledge bases and sessions. There is also alternative XML support via Spring and OSGi BluePrints.
While standard Maven can build and package KIE resources, it will not provide validation at build time. There is a Maven plugin which is recommended to use to get build time validation. The plugin also generates many classes, making the runtime loading faster too.
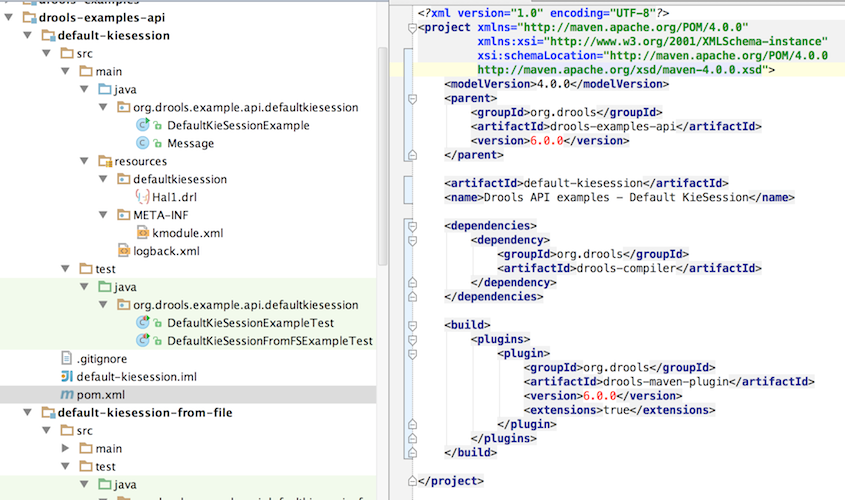
The example project layout and Maven POM descriptor is illustrated in the screenshot
KIE uses defaults to minimise the amount of configuration. With an empty kmodule.xml being the simplest configuration. There must always be a kmodule.xml file, even if empty, as it's used for discovery of the JAR and its contents.
Maven can either 'mvn install' to deploy a KieModule to the local machine, where all other applications on the local machine use it. Or it can 'mvn deploy' to push the KieModule to a remote Maven repository. Building the Application will pull in the KieModule and populate the local Maven repository in the process.
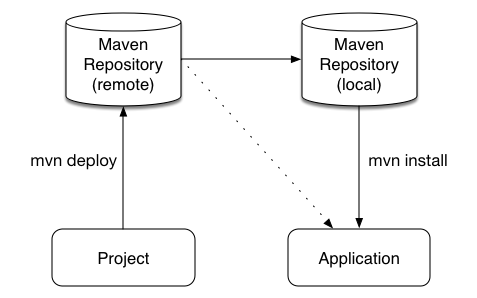
JARs can be deployed in one of two ways. Either added to the classpath, like any other JAR in a Maven dependency listing, or they can be dynamically loaded at runtime. KIE will scan the classpath to find all the JARs with a kmodule.xml in it. Each found JAR is represented by the KieModule interface. The terms classpath KieModule and dynamic KieModule are used to refer to the two loading approaches. While dynamic modules supports side by side versioning, classpath modules do not. Further once a module is on the classpath, no other version may be loaded dynamically.
Detailed references for the API are included in the next sections, the impatient can jump straight to the examples section, which is fairly self-explanatory on the different use cases.

A Kie Project has the structure of a normal Maven project with the only peculiarity
of including a kmodule.xml file defining in a declaratively way the KieBases
and KieSessions that can be created from it. This file has to be placed in the
resources/META-INF folder of the Maven project while all the other Kie artifacts, such as
DRL or a Excel files, must be stored in the resources folder or in any other subfolder under it.
Since meaningful defaults have been provided for all configuration aspects, the simplest kmodule.xml file can contain just an empty kmodule tag like the following:
Example 4.1. An empty kmodule.xml file
<?xml version="1.0" encoding="UTF-8"?>
<kmodule xmlns="http://www.drools.org/xsd/kmodule"/>In this way the kmodule will contain one single default KieBase. All Kie
assets stored under the resources folder, or any of its subfolders, will be compiled and added
to it. To trigger the building of these artifacts it is enough to create a
KieContainer for them.
For this simple case it is enough to create a KieContainer that reads the
files to be built from the classpath:
Example 4.2. Creating a KieContainer from the classpath
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();KieServices is the interface from where it possible to access all the Kie
building and runtime facilities:
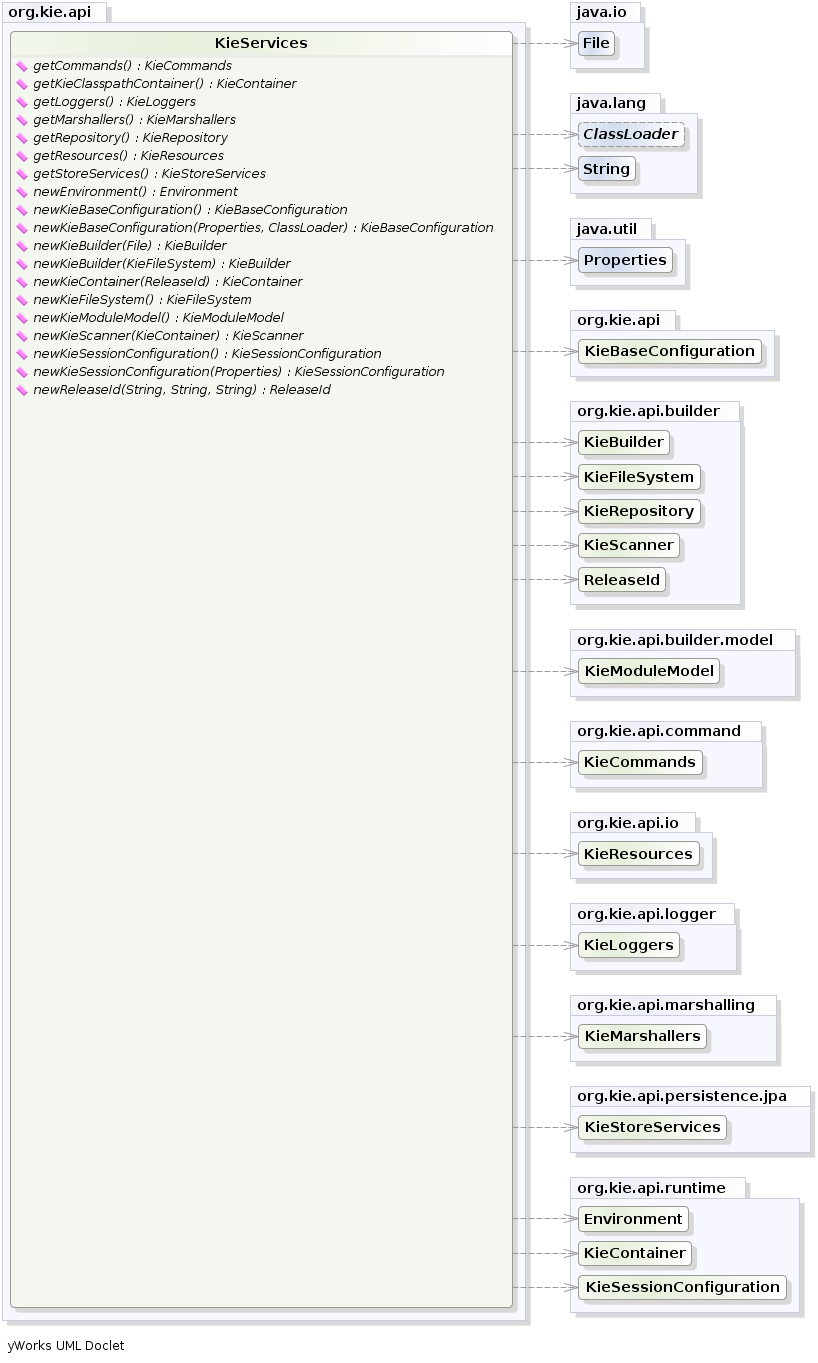
In this way all the Java sources and the Kie resources are compiled and deployed into the KieContainer which makes its contents available for use at runtime.
As explained in the former section, the kmodule.xml file is the place where it is possible
to declaratively configure the KieBase(s) and KieSession(s) that can be
created from a KIE project.
In particular a KieBase is a repository of all the application's knowledge definitions.
It will contain rules, processes, functions, and type models. The KieBase itself does not contain
data; instead, sessions are created from the KieBase into which data can be inserted and from
which process instances may be started. Creating the KieBase can be heavy, whereas session
creation is very light, so it is recommended that KieBase be cached where possible to allow
for repeated session creation. However end-users usually shouldn't worry about it, because this caching
mechanism is already automatically provided by the KieContainer.
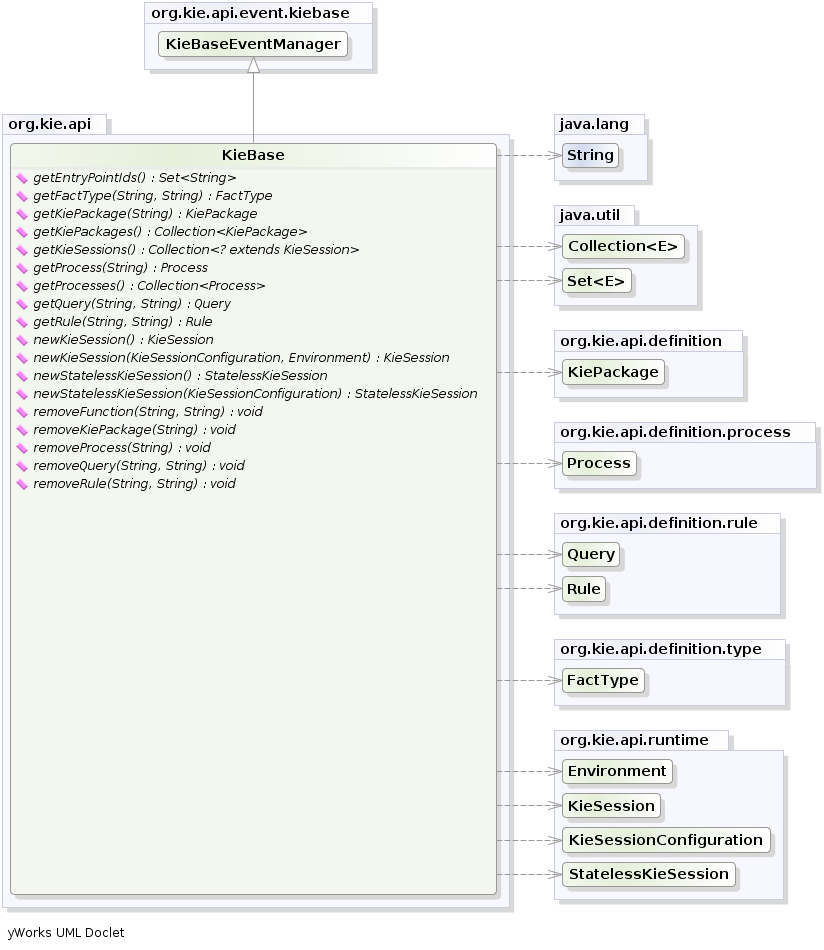
Conversely the KieSession stores and executes on the runtime data.
It is created from the KieBase or more easily can be created directly from the
KieContainer if it has been defined in the kmodule.xml file
The kmodule.xml allows to define and configure one or more KieBases and for each
KieBase all the different KieSessions that can be created from it,
as showed by the follwing example:
Example 4.3. A sample kmodule.xml file
<kmodule xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.drools.org/xsd/kmodule">
<configuration>
<property key="drools.evaluator.supersetOf" value="org.mycompany.SupersetOfEvaluatorDefinition"/>
</configuration>
<kbase name="KBase1" default="true" eventProcessingMode="cloud" equalsBehavior="equality" declarativeAgenda="enabled" packages="org.domain.pkg1">
<ksession name="KSession2_1" type="stateful" default="true"/>
<ksession name="KSession2_2" type="stateless" default="false" beliefSystem="jtms"/>
</kbase>
<kbase name="KBase2" default="false" eventProcessingMode="stream" equalsBehavior="equality" declarativeAgenda="enabled" packages="org.domain.pkg2, org.domain.pkg3" includes="KBase1">
<ksession name="KSession3_1" type="stateful" default="false" clockType="realtime">
<fileLogger file="drools.log" threaded="true" interval="10"/>
<workItemHandlers>
<workItemHandler name="name" type="org.domain.WorkItemHandler"/>
</workItemHandlers>
<listeners>
<ruleRuntimeEventListener type="org.domain.RuleRuntimeListener"/>
<agendaEventListener type="org.domain.FirstAgendaListener"/>
<agendaEventListener type="org.domain.SecondAgendaListener"/>
<processEventListener type="org.domain.ProcessListener"/>
</listeners>
</ksession>
</kbase>
</kmodule>Here the <configuration> tag contains a list of key-value pairs that are the optional properties
used to configure the KieBases building process. For instance this sample kmodule.xml file defines
an additional custom operator named supersetOf and implemented by the
org.mycompany.SupersetOfEvaluatorDefinition class.
After this 2 KieBases have been defined and it is possible to instance 2 different types of
KieSessions from the first one, while only one from the second. A list of the attributes that
can be defined on the kbase tag, together with their meaning and default values follows:
Table 4.1. kbase Attributes
| Attribute name | Default value | Admitted values | Meaning |
|---|---|---|---|
| name | none | any | The name with which retrieve this KieBase from the KieContainer. This is the only mandatory attribute. |
| includes | none | any comma separated list | A comma separated list of other KieBases contained in this kmodule. The artifacts of all these KieBases will be also included in this one. |
| packages | all | any comma separated list | By default all the Drools artifacts under the resources folder, at any level, are included into the KieBase. This attribute allows to limit the artifacts that will be compiled in this KieBase to only the ones belonging to the list of packages. |
| default | false | true, false | Defines if this KieBase is the default one for this module, so it can be created from the KieContainer without passing any name to it. There can be at most one default KieBase in each module. |
| equalsBehavior | identity | identity, equality | Defines the behavior of Drools when a new fact is inserted into the Working Memory. With identity it always create a new FactHandle unless the same object isn't already present in the Working Memory, while with equality only if the newly inserted object is not equal (according to its equal method) to an already existing fact. |
| eventProcessingMode | cloud | cloud, stream | When compiled in cloud mode the KieBase treats events as normal facts, while in stream mode allow temporal reasoning on them. |
| declarativeAgenda | disabled | disabled, enabled | Defines if the Declarative Agenda is enabled or not. |
Similarly all attributes of the ksession tag (except of course the name) have meaningful default. They are listed and described in the following table:
Table 4.2. ksession Attributes
| Attribute name | Default value | Admitted values | Meaning |
|---|---|---|---|
| name | none | any | Unique name of this KieSession. Used to fetch the KieSession from the KieContainer. This is the only mandatory attribute. |
| type | stateful | stateful, stateless | A stateful session allows to iteratively work with the Working Memory, while a stateless one is a one-off execution of a Working Memory with a provided data set. |
| default | false | true, false | Defines if this KieSession is the default one for this module, so it can be created from the KieContainer without passing any name to it. In each module there can be at most one default KieSession for each type. |
| clockType | realtime | realtime, pseudo | Defines if events timestamps are determined by the system clock or by a psuedo clock controlled by the application. This clock is specially useful for unit testing temporal rules. |
| beliefSystem | simple | simple, jtms, defeasible | Defines the type of belief system used by the KieSession. |
As outlined in the former kmodule.xml sample, it is also possible to declaratively
create on each KieSession a file (or a console) logger, one or more
WorkItemHandlers and some listeners that can be of 3 different types:
ruleRuntimeEventListener, agendaEventListener and processEventListener
Having defined a kmodule.xml like the one in the former sample, it is now possible to simply retrieve the KieBases and KieSessions from the KieContainer using their names.
Example 4.4. Retriving KieBases and KieSessions from the KieContainer
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();
KieBase kBase1 = kContainer.getKieBase("KBase1");
KieSession kieSession1 = kContainer.newKieSession("KSession2_1");
StatelessKieSession kieSession2 = kContainer.newStatelessKieSession("KSession2_2");It has to be noted that since KSession2_1 and KSession2_2 are of 2 different types
(the first is stateful, while the second is stateless) it is necessary to invoke 2 different methods on the
KieContainer according to their declared type. If the type of the KieSession
requested to the KieContainer doesn't correspond with the one declared in the
kmodule.xml file the KieContainer will throw a RuntimeException.
Also since a KieBase and a KieSession have been flagged as default
is it possible to get them from the KieContainer without passing any name.
Example 4.5. Retriving default KieBases and KieSessions from the KieContainer
KieContainer kContainer = ...
KieBase kBase1 = kContainer.getKieBase(); // returns KBase1
KieSession kieSession1 = kContainer.newKieSession(); // returns KSession2_1Since a Kie project is also a Maven project the groupId, artifactId and version declared
in the pom.xml file are used to generate a ReleaseId that uniquely identifies
this project inside your application. This allows creation of a new KieContainer from the
project by simply passing its ReleaseId to the KieServices.
Example 4.6. Creating a KieContainer of an existing project by ReleaseId
KieServices kieServices = KieServices.Factory.get();
ReleaseId releaseId = kieServices.newReleaseId( "org.acme", "myartifact", "1.0" );
KieContainer kieContainer = kieServices.newKieContainer( releaseId );
The KIE plugin for Maven ensures that artifact resources are validated and pre-compiled, it is recommended
that this is used at all times. To use the plugin simply add it to the build
section of the Maven pom.xml and activate it by using packaging kjar.
Example 4.7. Adding the KIE plugin to a Maven pom.xml and activating it
<packaging>kjar</packaging>
...
<build>
<plugins>
<plugin>
<groupId>org.kie</groupId>
<artifactId>kie-maven-plugin</artifactId>
<version>6.5.0.Final</version>
<extensions>true</extensions>
</plugin>
</plugins>
</build>
The plugin comes with support for all the Drools/jBPM knowledge resources.
However, in case you are using specific KIE annotations in your Java classes, like for example @kie.api.Position, you will
need to add compile time dependency on kie-api into your project. We recommend to use the provided scope
for all the additional KIE dependencies. That way the kjar stays as lightweight as possible, and not dependant
on any particular KIE version.
Building a KIE module without the Maven plugin will copy all the resources, as is, into the resulting JAR. When that JAR is loaded by the runtime, it will attempt to build all the resources then. If there are compilation issues it will return a null KieContainer. It also pushes the compilation overhead to the runtime. In general this is not recommended, and the Maven plugin should always be used.
It is also possible to define the KieBases and KieSessions
belonging to a KieModule programmatically instead of the declarative definition in the
kmodule.xml file. The same programmatic API also allows in explicitly adding the file containing the
Kie artifacts instead of automatically read them from the resources folder of your project.
To do that it is necessary to create a KieFileSystem, a sort of virtual file
system, and add all the resources contained in your project to it.
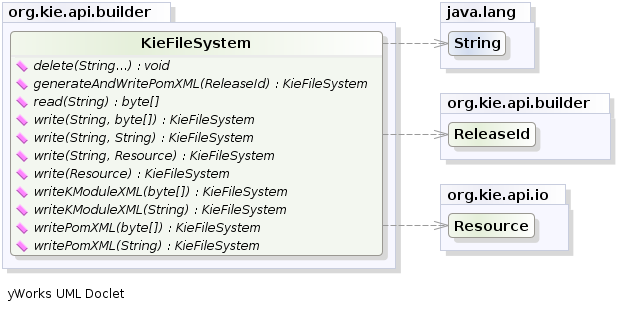
Like all other Kie core components you can obtain an instance of the KieFileSystem from
the KieServices. The kmodule.xml configuration file must be added to the filesystem. This is a
mandatory step. Kie also provides a convenient fluent API, implemented by the KieModuleModel,
to programmatically create this file.
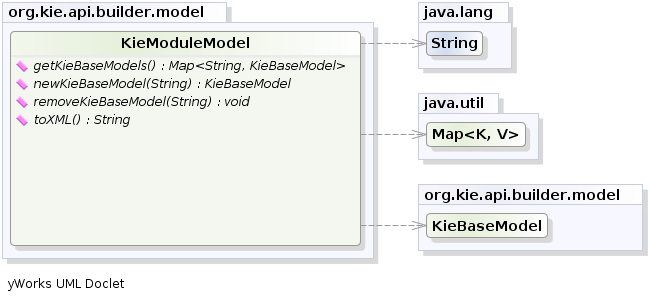
To do this in practice it is necessary to create a KieModuleModel from the
KieServices, configure it with the desired KieBases and
KieSessions, convert it in XML and add the XML to the KieFileSystem.
This process is shown by the following example:
Example 4.8. Creating a kmodule.xml programmatically and adding it to a KieFileSystem
KieServices kieServices = KieServices.Factory.get();
KieModuleModel kieModuleModel = kieServices.newKieModuleModel();
KieBaseModel kieBaseModel1 = kieModuleModel.newKieBaseModel( "KBase1 ")
.setDefault( true )
.setEqualsBehavior( EqualityBehaviorOption.EQUALITY )
.setEventProcessingMode( EventProcessingOption.STREAM );
KieSessionModel ksessionModel1 = kieBaseModel1.newKieSessionModel( "KSession1" )
.setDefault( true )
.setType( KieSessionModel.KieSessionType.STATEFUL )
.setClockType( ClockTypeOption.get("realtime") );
KieFileSystem kfs = kieServices.newKieFileSystem();
kfs.writeKModuleXML(kieModuleModel.toXML());At this point it is also necessary to add to the KieFileSystem, through its
fluent API, all others Kie artifacts composing your project. These artifacts have to be added
in the same position of a corresponding usual Maven project.
Example 4.9. Adding Kie artifacts to a KieFileSystem
KieFileSystem kfs = ...
kfs.write( "src/main/resources/KBase1/ruleSet1.drl", stringContainingAValidDRL )
.write( "src/main/resources/dtable.xls",
kieServices.getResources().newInputStreamResource( dtableFileStream ) );This example shows that it is possible to add the Kie artifacts both as plain Strings and
as Resources. In the latter case the Resources can be created by the
KieResources factory, also provided by the KieServices. The
KieResources provides many convenient factory methods to convert an InputStream,
a URL, a File, or a String representing a path of your file
system to a Resource that can be managed by the KieFileSystem.
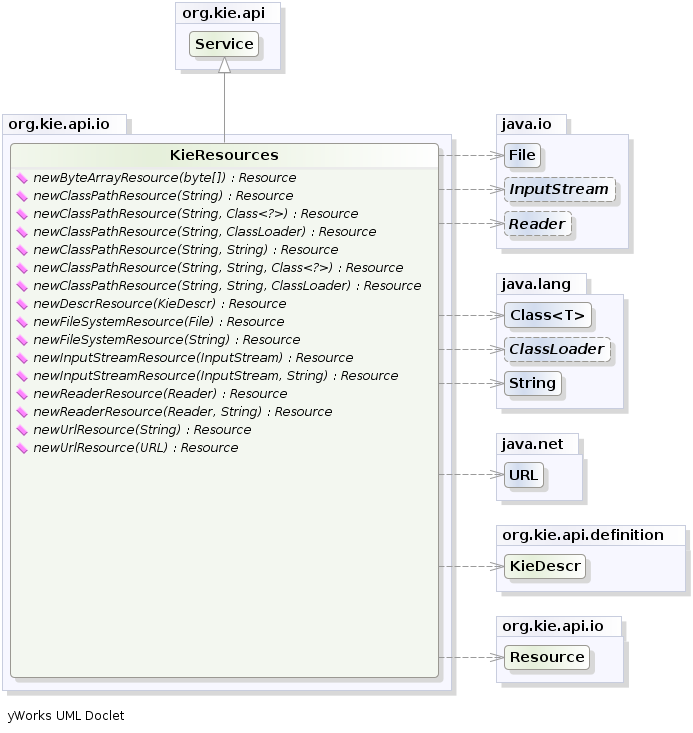
Normally the type of a Resource can be inferred from the extension of the name
used to add it to the KieFileSystem. However it also possible to not follow the Kie
conventions about file extensions and explicitly assign a specific ResourceType
to a Resource as shown below:
Example 4.10. Creating and adding a Resource with an explicit type
KieFileSystem kfs = ...
kfs.write( "src/main/resources/myDrl.txt",
kieServices.getResources().newInputStreamResource( drlStream )
.setResourceType(ResourceType.DRL) );Add all the resources to the KieFileSystem and build it by passing the KieFileSystem
to a KieBuilder
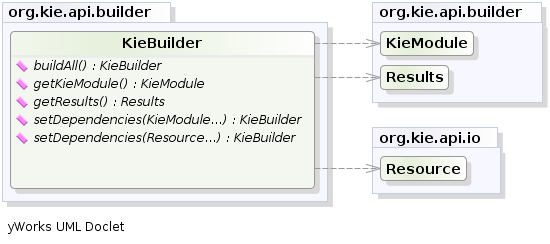
When the contents of a KieFileSystem are successfully built, the resulting KieModule
is automatically added to the KieRepository.
The KieRepository is a singleton acting as a repository for all the available KieModules.
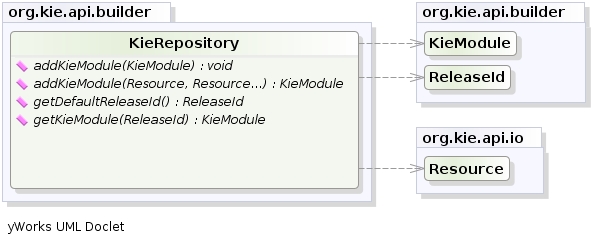
After this it is possible to create through the KieServices a new
KieContainer for that KieModule using its ReleaseId. However,
since in this case the KieFileSystem doesn't contain any pom.xml file (it is possible to
add one using the KieFileSystem.writePomXML method), Kie cannot determine the
ReleaseId of the KieModule and assign to it a default one. This
default ReleaseId can be obtained from the KieRepository and used
to identify the KieModule inside the KieRepository itself.
The following example shows this whole process.
Example 4.11. Building the contents of a KieFileSystem and creating a KieContainer
KieServices kieServices = KieServices.Factory.get();
KieFileSystem kfs = ...
kieServices.newKieBuilder( kfs ).buildAll();
KieContainer kieContainer = kieServices.newKieContainer(kieServices.getRepository().getDefaultReleaseId());At this point it is possible to get KieBases and create new KieSessions
from this KieContainer exactly in the same way as in the case of a KieContainer
created directly from the classpath.
It is a best practice to check the compilation results. The KieBuilder
reports compilation results of 3 different severities: ERROR, WARNING and INFO. An ERROR
indicates that the compilation of the project failed and in the case no KieModule is
produced and nothing is added to the KieRepository. WARNING and INFO results
can be ignored, but are available for inspection.
Example 4.12. Checking that a compilation didn't produce any error
KieBuilder kieBuilder = kieServices.newKieBuilder( kfs ).buildAll();
assertEquals( 0, kieBuilder.getResults().getMessages( Message.Level.ERROR ).size() );In some cases, it is possible to change the default severity of a type of build result. For instance, when a new rule with the same name of an existing rule is added to a package, the default behavior is to replace the old rule by the new rule and report it as an INFO. This is probably ideal for most use cases, but in some deployments the user might want to prevent the rule update and report it as an error.
Changing the default severity for a result type, configured like any other option in Drools, can be done by API calls, system properties or configuration files. As of this version, Drools supports configurable result severity for rule updates and function updates. To configure it using system properties or configuration files, the user has to use the following properties:
Example 4.13. Setting the severity using properties
// sets the severity of rule updates
drools.kbuilder.severity.duplicateRule = <INFO|WARNING|ERROR>
// sets the severity of function updates
drools.kbuilder.severity.duplicateFunction = <INFO|WARNING|ERROR>The KieBase is a repository of all the application's knowledge definitions. It will contain
rules, processes, functions, and type models. The KieBase itself does not contain data; instead,
sessions are created from the KieBase into which data can be inserted and from which process
instances may be started. The KieBase can be obtained from the KieContainer containing
the KieModule where the KieBase has been defined.
Sometimes, for instance in a OSGi environment, the KieBase needs to resolve types that are not in
the default class loader. In this case it will be necessary to create a KieBaseConfiguration with an
additional class loader and pass it to KieContainer when creating a new KieBase from
it.
Example 4.14. Creating a new KieBase with a custom ClassLoader
KieServices kieServices = KieServices.Factory.get();
KieBaseConfiguration kbaseConf = kieServices.newKieBaseConfiguration( null, MyType.class.getClassLoader() );
KieBase kbase = kieContainer.newKieBase( kbaseConf );KieSessions will be discussed in more detail in
section "Running". The KieBase creates and returns
KieSession objects, and it may optionally keep
references to those. When KieBase modifications occur
those modifications are applied against the data in the sessions. This
reference is a weak reference and it is also optional, which is controlled
by a boolean flag.
The KieScanner allows continuous monitoring of your Maven repository
to check whether a new release of a Kie project has been installed. A new release is deployed in
the KieContainer wrapping that project. The use of the KieScanner
requires kie-ci.jar to be on the classpath.

A KieScanner can be registered on a KieContainer
as in the following example.
Example 4.15. Registering and starting a KieScanner on a KieContainer
KieServices kieServices = KieServices.Factory.get();
ReleaseId releaseId = kieServices.newReleaseId( "org.acme", "myartifact", "1.0-SNAPSHOT" );
KieContainer kContainer = kieServices.newKieContainer( releaseId );
KieScanner kScanner = kieServices.newKieScanner( kContainer );
// Start the KieScanner polling the Maven repository every 10 seconds
kScanner.start( 10000L );In this example the KieScanner is configured to run with a fixed
time interval, but it is also possible to run it on demand by invoking the
scanNow() method on it. If the KieScanner finds, in the
Maven repository, an updated version of the Kie project used by that KieContainer
it automatically downloads the new version and triggers an incremental build of the new
project.
At this point, existing KieBases and KieSessions under the control of KieContainer
will get automatically upgraded with it - specifically, those KieBases obtained with getKieBase()
along with their related KieSessions, and any KieSession obtained directly with
KieContainer.newKieSession() thus referencing the default KieBase.
Additionally, from this moment on, all the new KieBases and KieSessions
created from that KieContainer will use the new project version.
Please notice however any existing KieBase which was obtained via newKieBase() before the
KieScanner upgrade, and any of its related KieSessions, will not get automatically upgraded; this is because
KieBases obtained via newKieBase() are not under the direct control of the KieContainer.
The KieScanner will only pickup changes to deployed jars if it is using a SNAPSHOT, version range,
the LATEST, or the RELEASE setting. Fixed versions will not automatically update at runtime.
Maven supports a number of mechanisms to manage versioning and dependencies within applications. Modules can be published with specific version numbers, or they can use the SNAPSHOT suffix. Dependencies can specify version ranges to consume, or take avantage of SNAPSHOT mechanism.
StackOverflow provides a very good description for this, which is reproduced below.
If you always want to use the newest version, Maven has two keywords you can use as an alternative to version ranges. You should use these options with care as you are no longer in control of the plugins/dependencies you are using.
When you depend on a plugin or a dependency, you can use the a version value of LATEST or RELEASE. LATEST refers to the latest released or snapshot version of a particular artifact, the most recently deployed artifact in a particular repository. RELEASE refers to the last non-snapshot release in the repository. In general, it is not a best practice to design software which depends on a non-specific version of an artifact. If you are developing software, you might want to use RELEASE or LATEST as a convenience so that you don't have to update version numbers when a new release of a third-party library is released. When you release software, you should always make sure that your project depends on specific versions to reduce the chances of your build or your project being affected by a software release not under your control. Use LATEST and RELEASE with caution, if at all.
See the POM Syntax section of the Maven book for more details.
http://books.sonatype.com/mvnref-book/reference/pom-relationships-sect-pom-syntax.html
http://books.sonatype.com/mvnref-book/reference/pom-relationships-sect-project-dependencies.html
Here's an example illustrating the various options. In the Maven repository, com.foo:my-foo has the following metadata:
<metadata>
<groupId>com.foo</groupId>
<artifactId>my-foo</artifactId>
<version>2.0.0</version>
<versioning>
<release>1.1.1</release>
<versions>
<version>1.0</version>
<version>1.0.1</version>
<version>1.1</version>
<version>1.1.1</version>
<version>2.0.0</version>
</versions>
<lastUpdated>20090722140000</lastUpdated>
</versioning>
</metadata>If a dependency on that artifact is required, you have the following options (other version ranges can be specified of course, just showing the relevant ones here): Declare an exact version (will always resolve to 1.0.1):
<version>[1.0.1]</version>Declare an explicit version (will always resolve to 1.0.1 unless a collision occurs, when Maven will select a matching version):
<version>1.0.1</version>Declare a version range for all 1.x (will currently resolve to 1.1.1):
<version>[1.0.0,2.0.0)</version>Declare an open-ended version range (will resolve to 2.0.0):
<version>[1.0.0,)</version>Declare the version as LATEST (will resolve to 2.0.0):
<version>LATEST</version>Declare the version as RELEASE (will resolve to 1.1.1):
<version>RELEASE</version>Note that by default your own deployments will update the "latest" entry in the Maven metadata, but to update the "release" entry, you need to activate the "release-profile" from the Maven super POM. You can do this with either "-Prelease-profile" or "-DperformRelease=true"
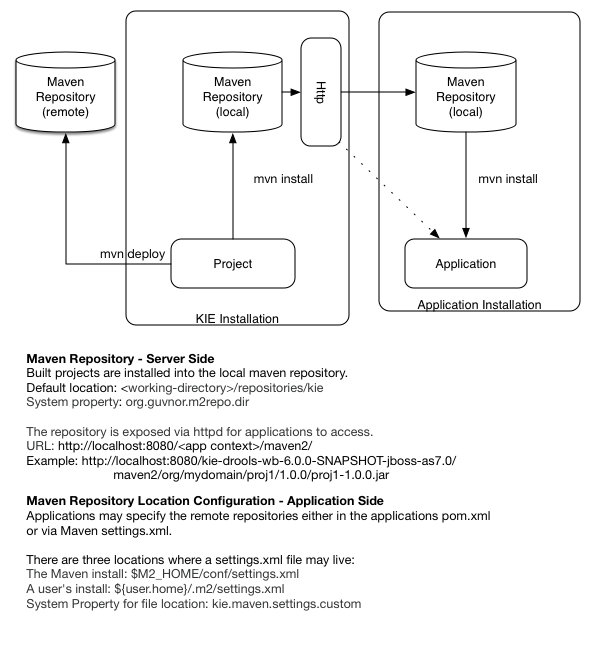
The maven settings.xml is used to configure Maven execution. Detailed instructions can be found at the Maven website:
http://maven.apache.org/settings.html
The settings.xml file can be located in 3 locations, the actual settings used is a merge of those 3 locations.
The Maven install:
$M2_HOME/conf/settings.xmlA user's install:
${user.home}/.m2/settings.xmlFolder location specified by the system property
kie.maven.settings.custom
The settings.xml is used to specify the location of remote repositories. It is important that you activate the profile that specifies the remote repository, typically this can be done using "activeByDefault":
<profiles>
<profile>
<id>profile-1</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
...
</profile>
</profiles>
Maven provides detailed documentation on using multiple remote repositories:
http://maven.apache.org/guides/mini/guide-multiple-repositories.html
The KieBase is a repository of all the
application's knowledge definitions. It will contain rules, processes,
functions, and type models. The KieBase itself does not contain
data; instead, sessions are created from the KieBase
into which data can be inserted and from which process instances may be
started. The KieBase can be obtained from the KieContainer
containing the KieModule where the KieBase has been defined.
The KieSession stores and executes on the
runtime data. It is created from the KieBase.
The KieRuntime provides methods that
are applicable to both rules and processes, such as setting globals and
registering channels. ("Exit point" is an obsolete synonym for "channel".)

Globals are named objects that are made visible to the rule engine, but in a way that is fundamentally different from the one for facts: changes in the object backing a global do not trigger reevaluation of rules. Still, globals are useful for providing static information, as an object offering services that are used in the RHS of a rule, or as a means to return objects from the rule engine. When you use a global on the LHS of a rule, make sure it is immutable, or, at least, don't expect changes to have any effect on the behavior of your rules.
A global must be declared in a rules file, and then it needs to be backed up with a Java object.
global java.util.List listWith the Knowledge Base now aware of the global identifier and
its type, it is now possible to call ksession.setGlobal()
with the global's name and an object, for any session, to associate
the object with the global. Failure to declare the global type and
identifier in DRL code will result in an exception being thrown from
this call.
List list = new ArrayList();
ksession.setGlobal("list", list); Make sure to set any global before it is used in the evaluation
of a rule. Failure to do so results in a NullPointerException.
The event package provides means to be notified of rule engine events, including rules firing, objects being asserted, etc. This allows separation of logging and auditing activities from the main part of your application (and the rules).
The KieRuntimeEventManager interface is
implemented by the KieRuntime which provides two
interfaces, RuleRuntimeEventManager and
ProcessEventManager. We will only cover the
RuleRuntimeEventManager here.
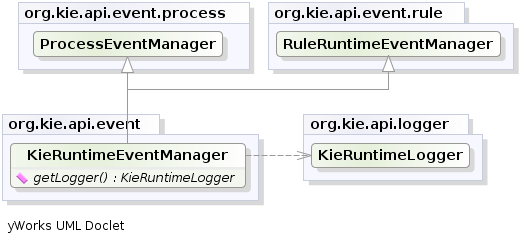
The RuleRuntimeEventManager allows for listeners to
be added and removed, so that events for the working memory and the agenda
can be listened to.

The following code snippet shows how a simple agenda listener is declared and attached to a session. It will print matches after they have fired.
Example 4.18. Adding an AgendaEventListener
ksession.addEventListener( new DefaultAgendaEventListener() {
public void afterMatchFired(AfterMatchFiredEvent event) {
super.afterMatchFired( event );
System.out.println( event );
}
});Drools also provides DebugRuleRuntimeEventListener
and DebugAgendaEventListener which implement each method with
a debug print statement. To print all Working Memory events, you add a
listener like this:
Example 4.19. Adding a DebugRuleRuntimeEventListener
ksession.addEventListener( new DebugRuleRuntimeEventListener() );All emitted events implement the KieRuntimeEvent
interface which can be used to retrieve the actual
KnowlegeRuntime the event originated from.
The events currently supported are:
MatchCreatedEvent
MatchCancelledEvent
BeforeMatchFiredEvent
AfterMatchFiredEvent
AgendaGroupPushedEvent
AgendaGroupPoppedEvent
ObjectInsertEvent
ObjectDeletedEvent
ObjectUpdatedEvent
ProcessCompletedEvent
ProcessNodeLeftEvent
ProcessNodeTriggeredEvent
ProcessStartEvent
The KieRuntimeLogger uses the comprehensive event system in Drools to create an audit log that can be used to log the execution of an application for later inspection, using tools such as the Eclipse audit viewer.
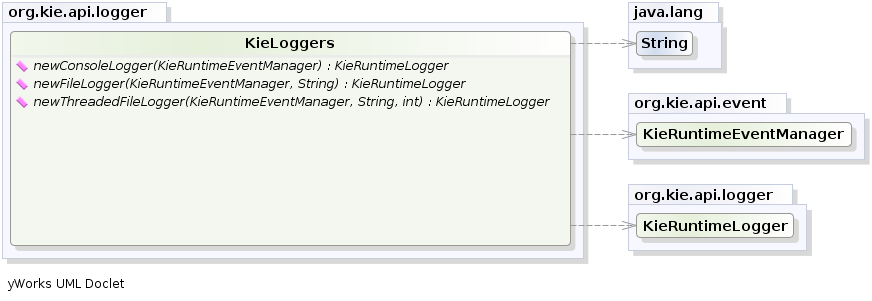
Example 4.20. FileLogger
KieRuntimeLogger logger =
KieServices.Factory.get().getLoggers().newFileLogger(ksession, "logdir/mylogfile");
...
logger.close();KIE has the concept of stateful or stateless sessions. Stateful sessions have already been covered, which use the standard KieRuntime, and can be worked with iteratively over time. Stateless is a one-off execution of a KieRuntime with a provided data set. It may return some results, with the session being disposed at the end, prohibiting further iterative interactions. You can think of stateless as treating an engine like a function call with optional return results.
The foundation for this is the CommandExecutor interface, which both the
stateful and stateless interfaces extend. This returns an
ExecutionResults:
The CommandExecutor allows for commands to be executed on those sessions, the
only difference being that the StatelessKieSession executes fireAllRules() at the
end before disposing the session. The commands can be created using the
CommandExecutor .The Javadocs provide the full list of the allowed comands
using the CommandExecutor.
setGlobal and getGlobal are two commands relevant to both Drools and jBPM.
Set Global calls setGlobal underneath. The optional boolean indicates whether the
command should return the global's value as part of the ExecutionResults. If true it uses the
same name as the global name. A String can be used instead of the boolean, if an alternative
name is desired.
Example 4.21. Set Global Command
StatelessKieSession ksession = kbase.newStatelessKieSession();
ExecutionResults bresults =
ksession.execute( CommandFactory.newSetGlobal( "stilton", new Cheese( "stilton" ), true);
Cheese stilton = bresults.getValue( "stilton" );
Allows an existing global to be returned. The second optional String argument allows for an alternative return name.
Example 4.22. Get Global Command
StatelessKieSession ksession = kbase.newStatelessKieSession();
ExecutionResults bresults =
ksession.execute( CommandFactory.getGlobal( "stilton" );
Cheese stilton = bresults.getValue( "stilton" );
All the above examples execute single commands. The BatchExecution
represents a composite command, created from a list of commands. It will iterate over the list
and execute each command in turn. This means you can insert some objects, start a process,
call fireAllRules and execute a query, all in a single execute(...) call, which
is quite powerful.
The StatelessKieSession will execute fireAllRules() automatically at the end.
However the keen-eyed reader probably has already noticed the FireAllRules
command and wondered how that works with a StatelessKieSession. The FireAllRules
command is allowed, and using it will disable the automatic execution at the end; think of
using it as a sort of manual override function.
Any command, in the batch, that has an out identifier set will add its results to the
returned ExecutionResults instance. Let's look at a simple example to see how
this works. The example presented includes command from the Drools and jBPM, for the sake of
illustration. They are covered in more detail in the Drool and jBPM specific sections.
Example 4.23. BatchExecution Command
StatelessKieSession ksession = kbase.newStatelessKieSession();
List cmds = new ArrayList();
cmds.add( CommandFactory.newInsertObject( new Cheese( "stilton", 1), "stilton") );
cmds.add( CommandFactory.newStartProcess( "process cheeses" ) );
cmds.add( CommandFactory.newQuery( "cheeses" ) );
ExecutionResults bresults = ksession.execute( CommandFactory.newBatchExecution( cmds ) );
Cheese stilton = ( Cheese ) bresults.getValue( "stilton" );
QueryResults qresults = ( QueryResults ) bresults.getValue( "cheeses" );
In the above example multiple commands are executed, two of which populate the
ExecutionResults. The query command defaults to use the same identifier as the
query name, but it can also be mapped to a different identifier.
All commands support XML and jSON marshalling using XStream, as well as JAXB marshalling. This is covered in section Commands API.
The StatelessKieSession wraps the
KieSession, instead of extending it. Its main
focus is on the decision service type scenarios. It avoids the need to call
dispose(). Stateless sessions do not support iterative
insertions and the method call fireAllRules() from Java code;
the act of calling execute() is a single-shot method that
will internally instantiate a KieSession, add
all the user data and execute user commands, call
fireAllRules(), and then call dispose(). While
the main way to work with this class is via the
BatchExecution (a subinterface of Command) as
supported by the CommandExecutor interface, two convenience
methods are provided for when simple object insertion is all that's
required. The CommandExecutor and BatchExecution
are talked about in detail in their own section.
Our simple example shows a stateless session executing a given collection of Java objects using the convenience API. It will iterate the collection, inserting each element in turn.
Example 4.24. Simple StatelessKieSession execution with a Collection
StatelessKieSession ksession = kbase.newStatelessKieSession();
ksession.execute( collection );If this was done as a single Command it would be as follows:
Example 4.25. Simple StatelessKieSession execution with InsertElements Command
ksession.execute( CommandFactory.newInsertElements( collection ) ); If you wanted to insert the collection itself, and the collection's
individual elements, then
CommandFactory.newInsert(collection) would do the job.
Methods of the CommandFactory create the supported
commands, all of which can be marshalled using XStream and the
BatchExecutionHelper. BatchExecutionHelper
provides details on the XML format as well as how to use Drools Pipeline
to automate the marshalling of BatchExecution and
ExecutionResults.
StatelessKieSession supports globals, scoped in a
number of ways. We cover the non-command way first, as commands are
scoped to a specific execution call. Globals can be resolved in three
ways.
The StatelessKieSession method
getGlobals()returns a Globals instance which provides access to the session's globals. These are shared for all execution calls. Exercise caution regarding mutable globals because execution calls can be executing simultaneously in different threads.Example 4.26. Session scoped global
StatelessKieSession ksession = kbase.newStatelessKieSession(); // Set a global hbnSession, that can be used for DB interactions in the rules. ksession.setGlobal( "hbnSession", hibernateSession ); // Execute while being able to resolve the "hbnSession" identifier. ksession.execute( collection );Using a delegate is another way of global resolution. Assigning a value to a global (with
setGlobal(String, Object)) results in the value being stored in an internal collection mapping identifiers to values. Identifiers in this internal collection will have priority over any supplied delegate. Only if an identifier cannot be found in this internal collection, the delegate global (if any) will be used.The third way of resolving globals is to have execution scoped globals. Here, a
Commandto set a global is passed to theCommandExecutor.
The CommandExecutor interface also offers the ability
to export data via "out" parameters. Inserted facts, globals and query
results can all be returned.
Example 4.27. Out identifiers
// Set up a list of commands
List cmds = new ArrayList();
cmds.add( CommandFactory.newSetGlobal( "list1", new ArrayList(), true ) );
cmds.add( CommandFactory.newInsert( new Person( "jon", 102 ), "person" ) );
cmds.add( CommandFactory.newQuery( "Get People" "getPeople" );
// Execute the list
ExecutionResults results =
ksession.execute( CommandFactory.newBatchExecution( cmds ) );
// Retrieve the ArrayList
results.getValue( "list1" );
// Retrieve the inserted Person fact
results.getValue( "person" );
// Retrieve the query as a QueryResults instance.
results.getValue( "Get People" );The KieMarshallers are used to marshal and unmarshal
KieSessions.
An instance of the KieMarshallers can be retrieved from the KieServices.
A simple example is shown below:
Example 4.28. Simple Marshaller Example
// ksession is the KieSession
// kbase is the KieBase
ByteArrayOutputStream baos = new ByteArrayOutputStream();
Marshaller marshaller = KieServices.Factory.get().getMarshallers().newMarshaller( kbase );
marshaller.marshall( baos, ksession );
baos.close();
However, with marshalling, you will need more flexibility when dealing
with referenced user data. To achieve this use the
ObjectMarshallingStrategy interface. Two implementations are
provided, but users can implement their own. The two supplied strategies
are IdentityMarshallingStrategy and
SerializeMarshallingStrategy.
SerializeMarshallingStrategy is the default, as shown in the
example above, and it just calls the Serializable or
Externalizable methods on a user instance.
IdentityMarshallingStrategy creates an integer id for
each user object and stores them in a Map, while the id is written to the
stream. When unmarshalling it accesses the
IdentityMarshallingStrategy map to retrieve the instance.
This means that if you use the IdentityMarshallingStrategy,
it is stateful for the life of the Marshaller instance and will create ids
and keep references to all objects that it attempts to marshal. Below is
the code to use an Identity Marshalling Strategy.
Example 4.29. IdentityMarshallingStrategy
ByteArrayOutputStream baos = new ByteArrayOutputStream();
KieMarshallers kMarshallers = KieServices.Factory.get().getMarshallers()
ObjectMarshallingStrategy oms = kMarshallers.newIdentityMarshallingStrategy()
Marshaller marshaller =
kMarshallers.newMarshaller( kbase, new ObjectMarshallingStrategy[]{ oms } );
marshaller.marshall( baos, ksession );
baos.close();
Im most cases, a single strategy is insufficient. For added flexibility, the
ObjectMarshallingStrategyAcceptor interface can be used.
This Marshaller has a chain of strategies,
and while reading or writing a user object it iterates the
strategies asking if they accept responsibility for marshalling the user
object. One of the provided implementations is
ClassFilterAcceptor. This allows strings and wild cards to be
used to match class names. The default is "*.*", so in the above example
the Identity Marshalling Strategy is used which has a default "*.*"
acceptor.
Assuming that we want to serialize all classes except for one given package, where we will use identity lookup, we could do the following:
Example 4.30. IdentityMarshallingStrategy with Acceptor
ByteArrayOutputStream baos = new ByteArrayOutputStream();
KieMarshallers kMarshallers = KieServices.Factory.get().getMarshallers()
ObjectMarshallingStrategyAcceptor identityAcceptor =
kMarshallers.newClassFilterAcceptor( new String[] { "org.domain.pkg1.*" } );
ObjectMarshallingStrategy identityStrategy =
kMarshallers.newIdentityMarshallingStrategy( identityAcceptor );
ObjectMarshallingStrategy sms = kMarshallers.newSerializeMarshallingStrategy();
Marshaller marshaller =
kMarshallers.newMarshaller( kbase,
new ObjectMarshallingStrategy[]{ identityStrategy, sms } );
marshaller.marshall( baos, ksession );
baos.close();
Note that the acceptance checking order is in the natural order of the supplied elements.
Also note that if you are using scheduled matches (i.e. some of your rules use timers or calendars) they are marshallable only if, before you use it, you configure your KieSession to use a trackable timer job factory manager as follows:
Example 4.31. Configuring a trackable timer job factory manager
KieSessionConfiguration ksconf = KieServices.Factory.get().newKieSessionConfiguration();
ksconf.setOption(TimerJobFactoryOption.get("trackable"));
KSession ksession = kbase.newKieSession(ksconf, null);Longterm out of the box persistence with Java Persistence API (JPA) is possible with Drools. It is necessary to have some implementation of the Java Transaction API (JTA) installed. For development purposes the Bitronix Transaction Manager is suggested, as it's simple to set up and works embedded, but for production use JBoss Transactions is recommended.
Example 4.32. Simple example using transactions
KieServices kieServices = KieServices.Factory.get();
Environment env = kieServices.newEnvironment();
env.set( EnvironmentName.ENTITY_MANAGER_FACTORY,
Persistence.createEntityManagerFactory( "emf-name" ) );
env.set( EnvironmentName.TRANSACTION_MANAGER,
TransactionManagerServices.getTransactionManager() );
// KieSessionConfiguration may be null, and a default will be used
KieSession ksession =
kieServices.getStoreServices().newKieSession( kbase, null, env );
int sessionId = ksession.getId();
UserTransaction ut =
(UserTransaction) new InitialContext().lookup( "java:comp/UserTransaction" );
ut.begin();
ksession.insert( data1 );
ksession.insert( data2 );
ksession.startProcess( "process1" );
ut.commit();To use a JPA, the Environment must be set with both the
EntityManagerFactory and the TransactionManager.
If rollback occurs the ksession state is also rolled back, hence it is possible
to continue to use it after a rollback. To load a previously persisted
KieSession you'll need the id, as shown below:
Example 4.33. Loading a KieSession
KieSession ksession =
kieServices.getStoreServices().loadKieSession( sessionId, kbase, null, env );To enable persistence several classes must be added to your persistence.xml, as in the example below:
Example 4.34. Configuring JPA
<persistence-unit name="org.drools.persistence.jpa" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/BitronixJTADataSource</jta-data-source>
<class>org.drools.persistence.info.SessionInfo</class>
<class>org.drools.persistence.info.WorkItemInfo</class>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.max_fetch_depth" value="3"/>
<property name="hibernate.hbm2ddl.auto" value="update" />
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.transaction.manager_lookup_class"
value="org.hibernate.transaction.BTMTransactionManagerLookup" />
</properties>
</persistence-unit>
The jdbc JTA data source would have to be configured first. Bitronix provides a number of ways of doing this, and its documentation should be consulted for details. For a quick start, here is the programmatic approach:
Example 4.35. Configuring JTA DataSource
PoolingDataSource ds = new PoolingDataSource();
ds.setUniqueName( "jdbc/BitronixJTADataSource" );
ds.setClassName( "org.h2.jdbcx.JdbcDataSource" );
ds.setMaxPoolSize( 3 );
ds.setAllowLocalTransactions( true );
ds.getDriverProperties().put( "user", "sa" );
ds.getDriverProperties().put( "password", "sasa" );
ds.getDriverProperties().put( "URL", "jdbc:h2:mem:mydb" );
ds.init();
Bitronix also provides a simple embedded JNDI service, ideal for testing. To use it, add a jndi.properties file to your META-INF folder and add the following line to it:
Example 4.36. JNDI properties
java.naming.factory.initial=bitronix.tm.jndi.BitronixInitialContextFactory
The best way to learn the new build system is by example. The source project "drools-examples-api" contains a number of examples, and can be found at GitHub:
https://github.com/droolsjbpm/drools/tree/6.0.x/drools-examples-api
Each example is described below, the order starts with the simplest (most of the options are defaulted) and working its way up to more complex use cases.
The Deploy use cases shown below all involve mvn install. Remote deployment of JARs in
Maven is well covered in Maven literature. Utilize refers to the initial act of loading the
resources and providing access to the KIE runtimes. Where as Run refers to the act of
interacting with those runtimes.
Project: default-kesession.
Summary: Empty kmodule.xml KieModule on the classpath that includes all resources in a single default KieBase. The example shows the retrieval of the default KieSession from the classpath.
An empty kmodule.xml will produce a single KieBase that includes all files found under resources path, be it DRL, BPMN2, XLS etc. That single KieBase is the default and also includes a single default KieSession. Default means they can be created without knowing their names.
ks.getKieClasspathContainer() returns the KieContainer that contains the KieBases deployed onto the environment classpath. kContainer.newKieSession() creates the default KieSession. Notice that you no longer need to look up the KieBase, in order to create the KieSession. The KieSession knows which KieBase it's associated with, and use that, which in this case is the default KieBase.
Example 4.39. Utilize and Run - Java
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession();
kSession.setGlobal("out", out);
kSession.insert(new Message("Dave", "Hello, HAL. Do you read me, HAL?"));
kSession.fireAllRules();
Project: named-kiesession.
Summary: kmodule.xml that has one named KieBase and one named KieSession. The examples shows the retrieval of the named KieSession from the classpath.
kmodule.xml will produce a single named KieBase, 'kbase1' that includes all files found under resources path, be it DRL, BPMN2, XLS etc. KieSession 'ksession1' is associated with that KieBase and can be created by name.
Example 4.40. Author - kmodule.xml
<kmodule xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="kbase1">
<ksession name="ksession1"/>
</kbase>
</kmodule>ks.getKieClasspathContainer() returns the KieContainer that contains the KieBases deployed onto the environment classpath. This time the KieSession uses the name 'ksession1'. You do not need to lookup the KieBase first, as it knows which KieBase 'ksession1' is assocaited with.
Example 4.42. Utilize and Run - Java
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession("ksession1");
kSession.setGlobal("out", out);
kSession.insert(new Message("Dave", "Hello, HAL. Do you read me, HAL?"));
kSession.fireAllRules();Project: kiebase-inclusion.
Summary: 'kmodule.xml' demonstrates that one KieBase can include the resources from another KieBase, from another KieModule. In this case it inherits the named KieBase from the 'name-kiesession' example. The included KieBase can be from the current KieModule or any other KieModule that is in the pom.xml dependency list.
kmodule.xml will produce a single named KieBase, 'kbase2' that includes all files found under resources path, be it DRL, BPMN2, XLS etc. Further it will include all the resources found from the KieBase 'kbase1', due to the use of the 'includes' attribute. KieSession 'ksession2' is associated with that KieBase and can be created by name.
Example 4.43. Author - kmodule.xml
<kbase name="kbase2" includes="kbase1">
<ksession name="ksession2"/>
</kbase>This example requires that the previous example, 'named-kiesession', is built and installed to the local Maven repository first. Once installed it can be included as a dependency, using the standard Maven <dependencies> element.
Example 4.44. Author - pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.drools</groupId>
<artifactId>drools-examples-api</artifactId>
<version>6.0.0/version>
</parent>
<artifactId>kiebase-inclusion</artifactId>
<name>Drools API examples - KieBase Inclusion</name>
<dependencies>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-compiler</artifactId>
</dependency>
<dependency>
<groupId>org.drools</groupId>
<artifactId>named-kiesession</artifactId>
<version>6.0.0</version>
</dependency>
</dependencies>
</project>Once 'named-kiesession' is built and installed this example can be built and installed as normal. Again the act of installing, will force the unit tests to run, demonstrating the use case.
ks.getKieClasspathContainer() returns the KieContainer that contains the KieBases deployed onto the environment classpath. This time the KieSession uses the name 'ksession2'. You do not need to lookup the KieBase first, as it knows which KieBase 'ksession1' is assocaited with. Notice two rules fire this time, showing that KieBase 'kbase2' has included the resources from the dependency KieBase 'kbase1'.
Example 4.46. Utilize and Run - Java
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession("ksession2");
kSession.setGlobal("out", out);
kSession.insert(new Message("Dave", "Hello, HAL. Do you read me, HAL?"));
kSession.fireAllRules();
kSession.insert(new Message("Dave", "Open the pod bay doors, HAL."));
kSession.fireAllRules();Project: 'multiple-kbases.
Summary: Demonstrates that the 'kmodule.xml' can contain any number of KieBase or KieSession declarations. Introduces the 'packages' attribute to select the folders for the resources to be included in the KieBase.
kmodule.xml produces 6 different named KieBases. 'kbase1' includes all resources from the KieModule. The other KieBases include resources from other selected folders, via the 'packages' attribute. Note the use of wildcard '*', to select this package and all packages below it.
Example 4.47. Author - kmodule.xml
<kmodule xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="kbase1">
<ksession name="ksession1"/>
</kbase>
<kbase name="kbase2" packages="org.some.pkg">
<ksession name="ksession2"/>
</kbase>
<kbase name="kbase3" includes="kbase2" packages="org.some.pkg2">
<ksession name="ksession3"/>
</kbase>
<kbase name="kbase4" packages="org.some.pkg, org.other.pkg">
<ksession name="ksession4"/>
</kbase>
<kbase name="kbase5" packages="org.*">
<ksession name="ksession5"/>
</kbase>
<kbase name="kbase6" packages="org.some.*">
<ksession name="ksession6"/>
</kbase>
</kmodule>Only part of the example is included below, as there is a test method per KieSession, but each one is a repetition of the other, with different list expectations.
Example 4.49. Utilize and Run - Java
@Test
public void testSimpleKieBase() {
List<Integer> list = useKieSession("ksession1");
// no packages imported means import everything
assertEquals(4, list.size());
assertTrue( list.containsAll( asList(0, 1, 2, 3) ) );
}
//.. other tests for ksession2 to ksession6 here
private List<Integer> useKieSession(String name) {
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession(name);
List<Integer> list = new ArrayList<Integer>();
kSession.setGlobal("list", list);
kSession.insert(1);
kSession.fireAllRules();
return list;
}Project: kcontainer-from-repository
Summary: The project does not contain a kmodule.xml, nor does the pom.xml have any dependencies for other KieModules. Instead the Java code demonstrates the loading of a dynamic KieModule from a Maven repository.
The pom.xml must include kie-ci as a depdency, to ensure Maven is available at runtime. As this uses Maven under the hood you can also use the standard Maven settings.xml file.
Example 4.50. Author - pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.drools</groupId>
<artifactId>drools-examples-api</artifactId>
<version>6.0.0</version>
</parent>
<artifactId>kiecontainer-from-kierepo</artifactId>
<name>Drools API examples - KieContainer from KieRepo</name>
<dependencies>
<dependency>
<groupId>org.kie</groupId>
<artifactId>kie-ci</artifactId>
</dependency>
</dependencies>
</project>In the previous examples the classpath KieContainer used. This example creates a dynamic KieContainer as specified by the ReleaseId. The ReleaseId uses Maven conventions for group id, artifact id and version. It also obeys LATEST and SNAPSHOT for versions.
Example 4.52. Utilize and Run - Java
KieServices ks = KieServices.Factory.get();
// Install example1 in the local Maven repo before to do this
KieContainer kContainer = ks.newKieContainer(ks.newReleaseId("org.drools", "named-kiesession", "6.0.0-SNAPSHOT"));
KieSession kSession = kContainer.newKieSession("ksession1");
kSession.setGlobal("out", out);
Object msg1 = createMessage(kContainer, "Dave", "Hello, HAL. Do you read me, HAL?");
kSession.insert(msg1);
kSession.fireAllRules();Project: default-kiesession-from-file
Summary: Dynamic KieModules can also be loaded from any Resource location. The loaded KieModule provides default KieBase and KieSession definitions.
No kmodue.xml file exists. The project 'default-kiesession' must be built first, so that the resulting JAR, in the target folder, can be referenced as a File.
Any KieModule can be loaded from a Resource location and added to the KieRepository. Once deployed in the KieRepository it can be resolved via its ReleaseId. Note neither Maven or kie-ci are needed here. It will not set up a transitive dependency parent classloader.
Example 4.54. Utilize and Run - Java
KieServices ks = KieServices.Factory.get();
KieRepository kr = ks.getRepository();
KieModule kModule = kr.addKieModule(ks.getResources().newFileSystemResource(getFile("default-kiesession")));
KieContainer kContainer = ks.newKieContainer(kModule.getReleaseId());
KieSession kSession = kContainer.newKieSession();
kSession.setGlobal("out", out);
Object msg1 = createMessage(kContainer, "Dave", "Hello, HAL. Do you read me, HAL?");
kSession.insert(msg1);
kSession.fireAllRules();Project: named-kiesession-from-file
Summary: Dynamic KieModules can also be loaded from any Resource location. The loaded KieModule provides named KieBase and KieSession definitions.
No kmodue.xml file exists. The project 'named-kiesession' must be built first, so that the resulting JAR, in the target folder, can be referenced as a File.
Any KieModule can be loaded from a Resource location and added to the KieRepository. Once in the KieRepository it can be resolved via its ReleaseId. Note neither Maven or kie-ci are needed here. It will not setup a transitive dependency parent classloader.
Example 4.56. Utilize and Run - Java
KieServices ks = KieServices.Factory.get();
KieRepository kr = ks.getRepository();
KieModule kModule = kr.addKieModule(ks.getResources().newFileSystemResource(getFile("named-kiesession")));
KieContainer kContainer = ks.newKieContainer(kModule.getReleaseId());
KieSession kSession = kContainer.newKieSession("ksession1");
kSession.setGlobal("out", out);
Object msg1 = createMessage(kContainer, "Dave", "Hello, HAL. Do you read me, HAL?");
kSession.insert(msg1);
kSession.fireAllRules();Project: kie-module-form-multiple-files
Summary: Programmatically provide the list of dependant KieModules, without using Maven to resolve anything.
No kmodue.xml file exists. The projects 'named-kiesession' and 'kiebase-include' must be built first, so that the resulting JARs, in the target folders, can be referenced as Files.
Creates two resources. One is for the main KieModule 'exRes1' the other is for the dependency 'exRes2'. Even though kie-ci is not present and thus Maven is not available to resolve the dependencies, this shows how you can manually specify the dependent KieModules, for the vararg.
Example 4.58. Utilize and Run - Java
KieServices ks = KieServices.Factory.get();
KieRepository kr = ks.getRepository();
Resource ex1Res = ks.getResources().newFileSystemResource(getFile("kiebase-inclusion"));
Resource ex2Res = ks.getResources().newFileSystemResource(getFile("named-kiesession"));
KieModule kModule = kr.addKieModule(ex1Res, ex2Res);
KieContainer kContainer = ks.newKieContainer(kModule.getReleaseId());
KieSession kSession = kContainer.newKieSession("ksession2");
kSession.setGlobal("out", out);
Object msg1 = createMessage(kContainer, "Dave", "Hello, HAL. Do you read me, HAL?");
kSession.insert(msg1);
kSession.fireAllRules();
Object msg2 = createMessage(kContainer, "Dave", "Open the pod bay doors, HAL.");
kSession.insert(msg2);
kSession.fireAllRules();Project: kiemoduelmodel-example
Summary: Programmaticaly buid a KieModule from just a single file. The POM and models are all defaulted. This is the quickest out of the box approach, but should not be added to a Maven repository.
This programmatically builds a KieModule. It populates the model that represents the ReleaseId and kmodule.xml, and it adds the relevant resources. A pom.xml is generated from the ReleaseId.
Example 4.60. Utilize and Run - Java
KieServices ks = KieServices.Factory.get();
KieRepository kr = ks.getRepository();
KieFileSystem kfs = ks.newKieFileSystem();
kfs.write("src/main/resources/org/kie/example5/HAL5.drl", getRule());
KieBuilder kb = ks.newKieBuilder(kfs);
kb.buildAll(); // kieModule is automatically deployed to KieRepository if successfully built.
if (kb.getResults().hasMessages(Level.ERROR)) {
throw new RuntimeException("Build Errors:\n" + kb.getResults().toString());
}
KieContainer kContainer = ks.newKieContainer(kr.getDefaultReleaseId());
KieSession kSession = kContainer.newKieSession();
kSession.setGlobal("out", out);
kSession.insert(new Message("Dave", "Hello, HAL. Do you read me, HAL?"));
kSession.fireAllRules();Project: kiemoduelmodel-example
Summary: Programmaticaly build a KieModule, by creating its kmodule.xml meta model resources.
This programmatically builds a KieModule. It populates the model that represents the ReleaseId and kmodule.xml, as well as add the relevant resources. A pom.xml is generated from the ReleaseId.
Example 4.62. Utilize and Run - Java
KieServices ks = KieServices.Factory.get();
KieFileSystem kfs = ks.newKieFileSystem();
Resource ex1Res = ks.getResources().newFileSystemResource(getFile("named-kiesession"));
Resource ex2Res = ks.getResources().newFileSystemResource(getFile("kiebase-inclusion"));
ReleaseId rid = ks.newReleaseId("org.drools", "kiemodulemodel-example", "6.0.0-SNAPSHOT");
kfs.generateAndWritePomXML(rid);
KieModuleModel kModuleModel = ks.newKieModuleModel();
kModuleModel.newKieBaseModel("kiemodulemodel")
.addInclude("kiebase1")
.addInclude("kiebase2")
.newKieSessionModel("ksession6");
kfs.writeKModuleXML(kModuleModel.toXML());
kfs.write("src/main/resources/kiemodulemodel/HAL6.drl", getRule());
KieBuilder kb = ks.newKieBuilder(kfs);
kb.setDependencies(ex1Res, ex2Res);
kb.buildAll(); // kieModule is automatically deployed to KieRepository if successfully built.
if (kb.getResults().hasMessages(Level.ERROR)) {
throw new RuntimeException("Build Errors:\n" + kb.getResults().toString());
}
KieContainer kContainer = ks.newKieContainer(rid);
KieSession kSession = kContainer.newKieSession("ksession6");
kSession.setGlobal("out", out);
Object msg1 = createMessage(kContainer, "Dave", "Hello, HAL. Do you read me, HAL?");
kSession.insert(msg1);
kSession.fireAllRules();
Object msg2 = createMessage(kContainer, "Dave", "Open the pod bay doors, HAL.");
kSession.insert(msg2);
kSession.fireAllRules();
Object msg3 = createMessage(kContainer, "Dave", "What's the problem?");
kSession.insert(msg3);
kSession.fireAllRules();The KIE engine is a platform for the modelling and execution of business behavior, using a multitude of declarative abstractions and metaphores, like rules, processes, decision tables and etc.
Many times, the authoring of these metaphores is done by third party groups, be it a different group inside the same company, a group from a partner company, or even anonymous third parties on the internet.
Rules and Processes are designed to execute arbitrary code in order to do their job, but in such cases it might
be necessary to constrain what they can do. For instance, it is unlikely a rule should be allowed to create a
classloader (what could open the system to an attack) and certainly it should not be allowed to make a call to
System.exit().
The Java Platform provides a very comprehensive and well defined security framework that allows users to define policies for what a system can do. The KIE platform leverages that framework and allow application developers to define a specific policy to be applied to any execution of user provided code, be it in rules, processes, work item handlers and etc.
Rules and processes can run with very restrict permissions, but the engine itself needs to perform many complex operations in order to work. Examples are: it needs to create classloaders, read system properties, access the file system, etc.
Once a security manager is installed, though, it will apply restrictions to all the code executing in the JVM according to the defined policy. For that reason, KIE allows the user to define two different policy files: one for the engine itself and one for the assets deployed into and executed by the engine.
One easy way to setup the enviroment is to give the engine itself a very permissive policy, while providing a constrained policy for rules and processes.
Policy files follow the standard policy file syntax as described in the Java documentation. For more details, see:
http://docs.oracle.com/javase/6/docs/technotes/guides/security/PolicyFiles.html#FileSyntax
A permissive policy file for the engine can look like the following:
An example security policy for rules could be:
Example 4.64. A sample rules.policy file
grant {
permission java.util.PropertyPermission "*", "read";
permission java.lang.RuntimePermission "accessDeclaredMembers";
}Please note that depending on what the rules and processes are supposed to do, many more permissions might need to be granted, like accessing files in the filesystem, databases, etc.
In order to use these policy files, all that is necessary is to execute the application with these files as parameters to the JVM. Three parameters are required:
Table 4.3. Parameters
| Parameter | Meaning |
|---|---|
|
-Djava.security.manager | Enables the security manager |
|
-Djava.security.policy=<jvm_policy_file> | Defines the global policy file to be applied to the whole application, including the engine |
|
-Dkie.security.policy=<kie_policy_file> | Defines the policy file to be applied to rules and processes |
For instance:
java -Djava.security.manager -Djava.security.policy=global.policy -Dkie.security.policy=rules.policy
foo.bar.MyApp
Note
When executing the engine inside a container, use your container's documentation to find out how to
configure the Security Manager and how to define the global security policy. Define the kie security policy as
described above and set the kie.security.policy system property in order to configure the engine to
use it.
Note
Please note that unless a Security Manager is configured, the kie.security.policy will be
ignored.
Note
A Security Manager has a high performance impact in the JVM. Applications with strict performance requirements are strongly discouraged of using a Security Manager. An alternative is the use of other security procedures like the auditing of rules/processes before testing and deployment to prevent malicious code from being deployed to the environment.