This and its companion documents describe JBossCache's TreeCache, a tree-structured replicated transactional cache, and the TreeCacheAop, an "object-oriented" cache that is AOP-enabled subclass of TreeCache, allowing for Plain Old Java Objects (POJOs) to be inserted and replicated transactionally between nodes in a cluster. The TreeCache is configurable, i.e. aspects of the system such as replication (async, sync, or none), transaction isolation levels, eviction policy, and transactional manager are all configurable.
TreeCache can also be used independently, but TreeCacheAop requires both TreeCache and the JBossAOP standalone subsystems.
The structure of the cache is A tree with nodes. Each node has a name and zero or more children. A node can only have 1 parent; there is currently no support for graphs. A node can be reached by navigating from the root recursively through children, until the node is found. It can also be accessed by giving a fully qualified name (FQN), which consists of the concatenation of all node names from the root to this particular node.
A TreeCache can have multiple roots, allowing for a number of different trees to be present in the cache. Note that a one level tree is essentially a hashtable. Each node in the tree has a hashmap of keys and values. For a replicated cache, all keys and values have to be serializable. Serializability is not a requirement for TreeCacheAop, where reflection and AOP is used to replicate any type.
A TreeCache can be either local or replicated. Local trees exist only inside the VM in which they are created, whereas replicated trees propagate any changes to all other replicated trees in the same cluster. A cluster may span different hosts on a network or even just different JVMs on a single host.
The first version of JBossCache was a hashmap. However, the decision was taken to go with a tree structured cache because (a) it is more flexible and efficient and (b) a tree can always be reduced to a hashmap, thereby offering both possibilities. The efficiency argument was driven by concerns over replication overhead, and was that a value itself can be a rather sophisticated object, with aggregation pointing to other objects, or an object containing many fields. A small change in the object would therefore trigger the entire object (possibly the transitive closure over the object graph) to be serialized and propagated to the other nodes in the cluster. With a tree, only the modified nodes in the tree need to be serialized. This is not necessarily a concern for TreeCache, but is a vital requirement for TreeCacheAop (as we will see in the TreeCacheAop documentation).
When a change is made to the TreeCache, and that change is done in the context of a transaction, then we wait with replication until the TX commits successfully. All modifications are kept in a list associated with the transaction for the caller. When the TX commits, we replicate the changes. Otherwise, (on a rollback) we simply undo the changes and release the locks, resulting in no replication traffic. For example, if a caller makes 100 modifications and then rolls back the TX, we will not replicate anything, resulting in no network traffic.
If a caller has no TX associated with it (and isolation level is not NONE), we will replicate right after each modification, e.g. in the above case we would send 100 messages, plus an additional message for the rollback. In this sense, no transaction can be think of autocommit is on in JDBC terminology where each operation is committed automatically.
There is an API for plugging in different transaction managers: all it requires is to get the TX associated with the caller’s thread. There is a dummy TransactionManager implementation, and one for JBoss.
Finally, we use pessimistic locking of the cache by default (optimistic locking is on the todo list). As mentioned previously, we can configure the local locking policy corresponding to the JDBC style transaction isolation level, i.e., SERIALIZABLE, REPEATABLE, READ_COMMITTED, READ_UNCOMMITTED and NONE. More on the transaction isolation level will be discussed later. Note that the cluster-wide isolation level is by default read-uncommitted because we don’t acquire a cluster-wide lock on touching an object for which we don’t yet have a lock (this would result in too much overhead for messaging)[1] .
The architecture is shown above. The example shows 2 Java VMs, each has created an instance of TreeCache. These VMs can be located on the same machine, or on 2 different machines. The setup of the underlying group communication subsystem is done using JGroups (http://www.jgroups.org).
Any modification (see API below) in one cache will be replicated to the other cache[2] and vice versa. Depending on the TX settings, this will be done either after each modification or at the end of a TX (at commit time). When a new cache is created, it can optionally acquire the contents from one of the existing caches.
Here's some sample code before we dive into the API itself:
TreeCache tree = new TreeCache();
tree.setClusterName("demo-cluster");
tree.setClusterProperties("default.xml");
tree.setCacheMode(TreeCache.REPL_SYNC);
tree.createService(); // not necessary, but is same as MBean lifecycle
tree.startService(); // kick start tree cache
tree.put("/a/b/c", "name", "Ben");
tree.put("/a/b/c/d", "uid", new Integer(322649));
Integer tmp=(Integer)tree.get("/a/b/c/d", "uid");
tree.remove("/a/b");
tree.stopService();
tree.destroyService(); // not necessary, but is same as MBean lifecycle
The sample code first creates a TreeCache instance and then configures it. There is another constructor which accepts a number of configuration options. However, the TreeCache can be configured entirely from an XML file (shown later), so we don't recommend manual configuration as shown in the sample.
The cluster name, properties of the underlying JGroups stack, and cache mode (synchronous replication) are configured first (a list of configuration options is shown later). Then we start the TreeCache. If replication is enabled, this will make the TreeCache join the cluster, and (optionally) acquire initial state from an existing node.
Then we add 2 items into the cache: the first element creates a node "a" with a child node "b" that has a child node "c". (TreeCache by default creates intermediary nodes that don't exist). The key "name" is then inserted into the "/a/b/c" node, with a value of "Ben".
The other element will create just the subnode "d" of "c" because "/a/b/c" already exists. It binds the integer 322649 under key "uid".
The resulting tree looks like this:
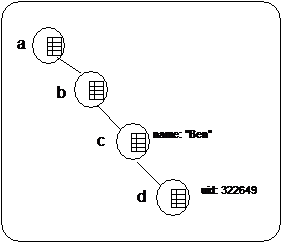
The TreeCache has 4 nodes "a", "b", "c" and "d". Nodes "/a/b/c" has values "name" associated with "Ben" in its hashmap, and node "/a/b/c/d" has values "uid" and 322649.
Each node can be retrieved by its absolute name (e.g. "/a/b/c") or by navigating from parent to children (e.g. navigate from "a" to "b", then from "b" to "c").
The next method in the example gets the value associated with key="uid" in node "/a/b/c/d", which is the integer 322649.
The remove() method then removes node "/a/b" and all subnodes recursively from the cache. In this case, nodes "/a/b/c/d", "/a/b/c" and "/a/b" will be removed, leaving only "/a".
Finally, the TreeCache is stopped. This will cause it to leave the cluster, and every node in the cluster will be notified. Note that TreeCache can be stopped and started again. When it is stopped, all contents will be deleted. And when it is restarted, if it joins a cache group, the state will be replicated initially. So potentially you can recreate the contents.
In the sample, replication was enabled, which caused the 2 put() and the 1 remove() methods to replicated their changes to all nodes in the cluster. The get() method was executed on the local cache only.
Keys into the cache can be either strings separated by slashes ('/'), e.g. "/a/b/c", or they can be fully qualified names Fqns . An Fqn is essentially a list of Objects that need to implement hashCode() and equals(). All strings are actually transformed into Fqns internally. Fqns are more efficient than strings, for example:
String n1 = "/300/322649";
Fqn n2 = new Fqn(new Object{new Integer(300), new Integer(322649)});In this example, we want to access a node that has information for employee with id=322649 in department with id=300. The string version needs 2 hashmap lookups on Strings, whereas the Fqn version needs to hashmap lookups on Integer. In a large hashtable, the hashCode() method for String may have collisions, leading to actual string comparisons. Also, clients of the cache may already have identifiers for their objects in Object form, and don't want to transform between Object and Strings, preventing unnecessary copying.
Note that the modification methods are put() and remove(). The only get method is get().
There are 2 put() methods[3] : put(Fqn node, Object key, Object key) and put(Fqn node, Hashmap values). The former takes the node name, creates it if it doesn't yet exist, and put the key and value into the node's hashmap, returning the previous value. The latter takes a hashmap of keys and values and adds them to the node's hashmap, overwriting existing keys and values. Content that is not in the new hashmap remains in the node's hashmap.
There are 3 remove() methods: remove(Fqn node, Object key), remove(Fqn node) and removeData(Fqn node). The first removes the given key from the node. The second removes the entire node and all subnodes, and the third removes all elements from the given node's hashmap.
The get methods are: get(Fqn node) and get(Fqn node, Object key). The former returns a Node[4] object, allowing for direct navigation, the latter returns the value for the given key for a node.
Also, the TreeCache has a number of getters and setters. Since the API may change at any time, we recommend the Javadoc for up-to-date information.
The TreeCache can be configured to be either local or replicated .
Local caches don't join a cluster and don't replicate changes to other nodes in a cluster. Therefore their elements don't need to be serializable[5] . On the other hand, replicated caches replicate all changes to the other TreeCaches (node) in the cluster. Replication can either happen after each modification (no transactions), or at the end of a transaction (commit time).
Replication can be synchronous or asynchronous . Use of either one of the options is application dependent. Synchronous replication blocks the caller (e.g. on a put()) until the modifications have been replicated successfully to all nodes in a cluster. Asynchronous replication performs replication in the background (the put() returns immediately). TreeCache also offers a replication queue, where modifications are replicated periodically (i.e. interval-based), or when the queue size exceeds a number of elements, or a combination thereof).
Asynchronous replication is faster (no caller blocking), because synchronous replication requires acknowledgments from all nodes in a cluster that they received and applied the modification successfully (round-trip time). However, when a synchronous replication returns successfully, the caller knows for sure that all modifications have been applied at all nodes, whereas this may or may not be the case with asynchronous replication. With asynchronous replication, errors are simply written to a log.
TreeCache currently uses pessimistic locking to prevent concurrent access to the same data. Locking is not exposed directly to user. Instead, a transaction isolation level which provides different locking behavior is configurable.
Locking internally is done on a node-level, so for example when we want to access "/a/b/c", a lock will be acquired for nodes "a", "b" and "c". When the same transaction wants to access "/a/b/c/d", since we already hold locks for "a", "b" and "c", we only need to acquire a lock for "d".
Lock owners are either transactions (call comes in on a transaction) or threads (no transaction associated with incoming transaction). Regardless, a local transaction or a thread is internally transformed into an instance of GlobalTransaction, which is used as a globally unique ID for modifications across a cluster. E.g. when we run a two-phase commit protocol (see below) across the cluster, the GlobalTransaction uniquely identifies the unit of work across a cluster.
TreeCache supports transaction isolation level in the manner of the JDBC model. A user can configure per instance-wide isolation level (as those defined in java.sql.Connection), i.e., NONE, READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, and SERIALIZABLE. The mapping is summarized here.
NONE. No transaction support is needed. There is no locking at this level, e.g., users will have to manage the data integrity. Implementations use no locks.
READ_UNCOMMITTED. Data can be read anytime while write operations are exclusive. Note that this level doesn't prevent the so-called "dirty read" where data modified in Tx1 can be read in Tx2 before Tx1 commits. In other words, if you have the following sequence,
Tx1 Tx2 W Rusing this isolation level will not Tx2 read operation. Implementations typically use an exclusive lock for writes while reads don't need to acquire a lock.
READ_COMMITTED. Data can be read any time as long as there is no write. This level prevents the dirty read. But it doesn’t prevent the so-called ‘non-repeatable read’ where one thread reads the data twice can produce different results. For example, if you have the following sequence,
Tx1 Tx2 R W Rwhere the second read in Tx1 thread will produce different result.
Implementations usually use a read-write lock; reads succeed acquiring the lock when there are only reads, writes have to wait until there are no more readers holding the lock, and readers are blocked acquiring the lock until there are no more writers holding the lock. Reads typically release the read-lock when done, so that a subsequent read to the same data has to re-acquire a read-lock; this leads to nonrepeatable reads, where 2 reads of the same data might return different values. Note that, the write only applies regardless of transaction state (whether it has been committed or not).
REPEATABLE_READ. Data can be read while there is no write and vice versa. This level prevents "non-repeatable read" but it does not prevent the so-called "phantom read" where new data can be inserted into the tree from the other transaction. Implementations typically use a read-write lock.
SERIALIZABLE. Data access is synchronized with exclusive locks. Only 1 writer or reader can have the lock at any given time. Locks are released at the end of the transaction.
Locks can be read or write locks. Write locks serialize read and write access, whereas read-only locks only serialize read access. When a write lock is held, no other write or read locks can be acquired. When a read lock is held, others can acquire read locks. However, to acquire write locks, one has to wait until all read locks have been released. When scheduled concurrently, write locks always have precedence over read locks. Note that (if enabled) read locks can be upgraded to write locks.
Using read-write locks helps in the following scenario: consider a tree with entries "/a/b/n1" and "/a/b/n2". With write-locks, when Tx1 accesses "/a/b/n1", Tx2 cannot access "/a/b/n2" until Tx1 has completed and released its locks. However, with read-write locks this is possible, because Tx1 acquires read-locks for "/a/b" and a read-write lock for "/a/b/n1". Tx2 is then able to acquire read-locks for "/a/b" as well, plus a read-write lock for "/a/b/n2". This allows for more concurrency in accessing the cache.
A TreeCache can be configured to use transactions to bundle units of work, which can then be replicated as one unit. Alternatively, if transaction support is disabled, it is equivalent to setting AutoCommit to on where modifications are potentially[6] replicated after every change (if replication is enabled).
What TreeCache needs to do on every incoming call (e.g. put()) is (a) get the transaction associated with the thread and (b) register (if not already done) with the transaction manager to be notified when a transaction commits or is rolled back. In order to do this, the cache has to be configured with an instance of TransactionManagerLookup which returns a javax.transaction.TransactionManager.
There are currently 2 implementations of TransactionManagerLookup available: DummyTransactionManagerLookup and JBossTransactionManagerLookup. The former is a dummy implementation of a TransactionManager which can be used for standalone TreeCache applications (running outside an appserver). This is just for demo purposes (e.g. the standalone demo runs with this one). The latter is to be used when TreeCache is used inside JBoss, and its implementation looks like this:
public class JBossTransactionManagerLookup implements TransactionManagerLookup {
public JBossTransactionManagerLookup() {;}
public TransactionManager getTransactionManager() throws Exception {
Object tmp=new InitialContext().lookup("java:/TransactionManager");
return (TransactionManager)tmp;
}
}The implementation looks up the JBoss TransactionManager from the JNDI and returns it.
When a call comes in, the TreeCache gets the current transaction and records the modification under the transaction as key. (If there is no transaction, the modification is applied immediately and possibly replicated). So over the lifetime of the transaction all modifications will be recorded and associated with the transaction. Also, the TreeCache registers with the transaction to be notified of transaction committed or aborted when it first encounters the transaction.
When a transaction rolls back, we undo the changes in the cache and release all locks.
When the transaction commits, we initiate a two-phase commit protocol[7] : in the first phase, a PREPARE containing all modifications for the current transaction is sent to all nodes in the cluster. Each node acquires all necessary locks and applies the changes, and then sends back a success message. If a node in a cluster cannot acquire all locks, or fails otherwise, it sends back a failure message.
The coordinator of the two-phase commit protocol waits for all responses (or a timeout, whichever occurs first). If one of the nodes in the cluster responds with FAIL (or we hit the timeout), then a rollback phase is initiated: a ROLLBACK message is sent to all nodes in the cluster. On reception of the ROLLBACK message, every node undoes the changes for the given transaction, and releases all locks held for the transaction.
If all responses are OK, a COMMIT message is sent to all nodes in the cluster. On reception of a COMMIT message, each node applies the changes for the given transaction and releases all locks associated with the transaction.
When we referred to 'transaction', we actually mean a global representation of a local transaction, which uniquely identifies a transaction across a cluster.
Let's look at an example of how to use the standalone (e.g. outside an appserver) TreeCache with dummy transactions:
Properties prop = new Properties();
prop.put(Context.INITIAL_CONTEXT_FACTORY, "org.jboss.cache.transaction.DummyContextFactory");
User Transaction tx=(UserTransaction)new InitialContext(prop).lookup("UserTransaction");
TreeCache tree = new TreeCache();
PropertyConfigurator config = new PropertyConfigurator();
config.configure(tree, "META-INF/replSync-service.xml");
tree.createService(); // not necessary
tree.startService(); // kick start tree cache
try {
tx.begin();
tree.put("/classes/cs-101", "description", "the basics");
tree.put("/classes/cs-101", "teacher", "Ben");
tx.commit();
}
catch(Throwable ex) {
try { tx.rollback(); } catch(Throwable t) {}
}The first lines obtain a user transaction using the 'J2EE way' via JNDI. Note that we could also say
UserTransaction tx = new DummyUserTransaction(DummyTransactionManager.getInstance());
Then we create a new TreeCache and configure it using a PropertyConfigurator class and a configuration XML file (see below for a list of all configuration options).
Next we start the cache. Then, we start a transaction (and associate it with the current thread internally). Any methods invoked on the cache will now be collected and only applied when the transaction is committed. In the above case, we create a node "/classes/cs-101" and add 2 elements to its hashmap. Assuming that the cache is configured to use synchronous replication, on transaction commit the modifications are replicated. If there is an exception in the methods (e.g. lock acquisition failed), or in the two-phase commit protocol applying the modifications to all nodes in the cluster, the transaction is rolled back.
Eviction policy specifies the behavior of a node residing inside the cache, e.g., life time and maximum numbers allowed.
The design in the TreeCache of eviction policy framework is based on the loosely coupled observable pattern (albeit still synchronous) where the eviction policy provider will extend AbstractTreeCacheListener which implements two listeners (TreeCacheListener and ExtendedTreeCacheListener) interfaces. It's the policy provider responsibility to decide when to call back the cache "evict" operation.
In order to implement an eviction policy, the provider will need to extend AbstractTreeCacheListener which implements two listeners interfaces that listen to the node events, namely,
public interface TreeCacheListener {
/**
* Called when a node is created
* @param fqn
*/
void nodeCreated(Fqn fqn);
/**
* Called when a node is removed.
* @param fqn
*/
void nodeRemoved(Fqn fqn);
/**
* Called when a node is loaded into memory via the CacheLoader. This is not the same
* as {@link #nodeCreated(Fqn)}.
*/
void nodeLoaded(Fqn fqn);
/**
* Called when a node is evicted (not the same as remove()).
* @param fqn
*/
void nodeEvicted(Fqn fqn);
/**
* Called when a node is modified, e.g., one (key, value) pair
* in the internal map storage has been modified.
* @param fqn
*/
void nodeModified(Fqn fqn);
/**
* Called when a node is visisted, i.e., get().
* @param fqn
*/
void nodeVisited(Fqn fqn);
/**
* Called when the cache is started.
* @param cache
*/
void cacheStarted(TreeCache cache);
/**
* Called when the cache is stopped.
* @param cache
*/
void cacheStopped(TreeCache cache);
void viewChange(View new_view); // might be MergeView after merging
} public interface ExtendedTreeCacheListener
{
/**
* Called when a node is about to be evicted or has been evicted from the
* in-memory cache.
* Note: Currently TreeCacheListener has {@link TreeCacheListener#nodeEvicted(Fqn)}
* which will be merged with method in release 1.3.
*
* @param fqn
* @param pre
* @see TreeCacheListener#nodeEvicted(Fqn)
*/
void nodeEvict(Fqn fqn, boolean pre);
/**
* Called when a node is about to be removed or has been removed from the
* in-memory cache.
* Note: Currently TreeCacheListener has {@link TreeCacheListener#nodeRemoved(Fqn)}
* which will be merged with this method in release 1.3.
*
* @param fqn
* @param pre
* @param isLocal
* @see TreeCacheListener#nodeRemoved(Fqn)
*/
void nodeRemove(Fqn fqn, boolean pre, boolean isLocal);
/**
* Called when a node is about to be modified or has been modified.
* Note: Currently TreeCacheListener has {@link TreeCacheListener#nodeModified(Fqn)}
* which will be merged with this method in release 1.3.
*
* @param fqn
* @param pre
* @param isLocal
* @see TreeCacheListener#nodeModified(Fqn)
*/
void nodeModify(Fqn fqn, boolean pre, boolean isLocal);
/**
* Called when a node is to be or has been activated into memory via the
* CacheLoader that was evicted earlier.
*
* @param fqn
* @param pre
*/
void nodeActivate(Fqn fqn, boolean pre);
/**
* Called when a node is to be or has been written to the backend store via the
* cache loader due to a node eviction by the eviction policy provider
*
* @param fqn
* @param pre
*/
void nodePassivate(Fqn fqn, boolean pre);
}
Note that:
The last two methods in TreeCacheListener are used during cache life cycle. Eviction policy provider can use these two to kick start the policy.
The boolean value pre in ExtendedTreeCacheListener is used to determine whether the notification should be emitted before or after the event occur. If true, the notification will be emitted before the event occurs. If false, the notification will be emitted after the event occurs.
The boolean vlaue isLocal in ExtendedTreeCacheListener is used to inform the TreeCache listeners if the event has originated from the local or remote TreeCache instance. It's solely used for replicated cache.
In addition, TreeCache has two additional APIs that relate to eviction 1) to evict a node that similar to remove, and 2) to get a node value, but both without triggering a node event,
/**
* Called by eviction policy provider. Note that eviction is done only in local mode,
* that is, it doesn't replicate the node removal.
* @param fqn Will remove everything associated with this fqn.
* @throws Exception
*/
public void evict(Fqn fqn) throws Exception;
/**
* Like <code>get</code> method but without triggering a node visit event. This is used
* to prevent refresh of the cache data in the eviction policy.
* @param fqn
* @param key
* @return
* @throws LockingException
* @throws TimeoutException
*/
public Object peek(Fqn fqn, Object key) throws LockingException, TimeoutException;Note that:
Eviction policy is only applied locally. I.e., if the mode is replicated, only the local node is evicted and it won't propagate the eviction to other participating caches. This is necessary because different caches may have different get operations that will touch the timestamp in the eviction policy algorithm. However, get operation is not replicated. Therefore, node in cache2 may get evicted even when it is accessed often in cache1! There is always the question of state synchronization. This is OK since if user in cache1 finds out a node does not exist, it should get it from the underlying database and then put it into the cache. This operation will replicate across the group and the data will then be synchronized.
When a node is evicted, it will check if it has children nodes. If it has, it will only remove the data value in the hashmap (without removing the whole node). If not, the whole node is removed.
TreeCache has implemented a LRU eviction policy, org.jboss.cache.eviction.LRUPolicy, that controls both the node lifetime and age. It has the following configuration parameters:
wakeUpIntervalSeconds. This is the interval (in seconds) to process the node events and also to perform sweeping for the size limit and age-out nodes.
Region. Region is a group of nodes where they posses the same eviction policy, e.g., same expired time. In TreeCache, region is denoted by a fqn, e.g., /company/personnel, and it is recursive. In specifying the region, the order is important. For example, if /org/jboss/test specified before /org/jboss/test/data, then any node under /org/jboss/test/data belongs to the first region rather than the second. Note also that whenever eviction policy is activated, there should be always a /_default_ region where it covers all the eviction policy not specify by the user. In addition, the region configuration is not programmable, i.e., all the polciy has to be specified via XML configuration.
maxNodes. This is the maximum number of nodes allowed in this region. 0 denotes no limit.
timeToLiveSeconds. Time to idle (in seconds) before the node is swept away. 0 denotes no limit.
maxAgeSeconds. Time an object should exist in TreeCache (in seconds) regardless of idle time before the node is swept away. 0 denotes no limit.
Please read the following section for an example.
JBossCache can use a CacheLoader to access a backend datastore. If JBossCache is configured with a CacheLoader, then the following properties are provided:
- whenever an element is accessed, and that element is not in the cache (e.g. due to eviction), then the CacheLoader transparently loads the element into the cache if found in the backend store
- whenever an element is modified, added or removed, then that modification is persisted in the backend store via the CacheLoader. If transactions are used, all modifications created within a transaction are persisted. To this end, the CacheLoader takes part in the two phase commit protocol run by the transaction manager
Currently, the CacheLoader looks similar to the TreeCache interface. In the future, it will actually implement the same interface. The goal is to be able to form hierarchical cache topologies, where one cache can delegate to another, which in turn may delegate to yet another cache.
The CacheLoader interface is defined in org.jboss.cache.loader.CacheLoader as follows (edited for brevity):
public interface CacheLoader extends Service {
/**
* Sets the configuration. Will be called before {@link #create()} and {@link #start()}
* @param props A set of properties specific to a given CacheLoader
*/
void setConfig(Properties props);
void setCache(TreeCache c);
/**
* Returns a list of children names, all names are <em>relative</em>. Returns null if the parent node is not found.
* The returned set must not be modified, e.g. use Collections.unmodifiableSet(s) to return the result
* @param fqn The FQN of the parent
* @return Set<String>. A list of children. Returns null if no children nodes are present, or the parent is
* not present
*/
Set getChildrenNames(Fqn fqn) throws Exception;
/**
* Returns the value for a given key. Returns null if the node doesn't exist, or the value is not bound
*/
Object get(Fqn name, Object key) throws Exception;
/**
* Returns all keys and values from the persistent store, given a fully qualified name
* @param name
* @return Map<Object,Object> of keys and values for the given node. Returns null if the node was not found
* @throws Exception
*/
Map get(Fqn name) throws Exception;
/**
* Checks whether the CacheLoader has a node with Fqn
* @return True if node exists, false otherwise
*/
boolean exists(Fqn name) throws Exception;
/**
* Inserts key and value into the attributes hashmap of the given node. If the node does not exist, all
* parent nodes from the root down are created automatically
*/
void put(Fqn name, Object key, Object value) throws Exception;
/**
* Inserts all elements of attributes into the attributes hashmap of the given node, overwriting existing
* attributes, but not clearing the existing hashmap before insertion (making it a union of existing and
* new attributes)
* If the node does not exist, all parent nodes from the root down are created automatically
* @param name The fully qualified name of the node
* @param attributes A Map of attributes. Can be null
*/
void put(Fqn name, Map attributes) throws Exception;
/**
* Inserts all modifications to the backend store. Overwrite whatever is already in
* the datastore.
* @param modifications A List<Modification> of modifications
* @throws Exception
*/
void put(List modifications) throws Exception;
/** Removes the given key and value from the attributes of the given node. No-op if node doesn't exist */
void remove(Fqn name, Object key) throws Exception;
/**
* Removes the given node. If the node is the root of a subtree, this will recursively remove all subnodes,
* depth-first
*/
void remove(Fqn name) throws Exception;
/** Removes all attributes from a given node, but doesn't delete the node itself */
void removeData(Fqn name) throws Exception;
/**
* Prepare the modifications. For example, for a DB-based CacheLoader:
* <ol>
* <li>Create a local (JDBC) transaction
* <li>Associate the local transaction with <code>tx</code> (tx is the key)
* <li>Execute the coresponding SQL statements against the DB (statements derived from modifications)
* </ol>
* For non-transactional CacheLoader (e.g. file-based), this could be a null operation
* @param tx The transaction, just used as a hashmap key
* @param modifications List<Modification>, a list of all modifications within the given transaction
* @param one_phase Persist immediately and (for example) commit the local JDBC transaction as well. When true,
* we won't get a {@link #commit(Object)} or {@link #rollback(Object)} method call later
*/
void prepare(Object tx, List modifications, boolean one_phase) throws Exception;
/**
* Commit the transaction. A DB-based CacheLoader would look up the local JDBC transaction asociated
* with <code>tx</code> and commit that transaction<br/>
* Non-transactional CacheLoaders could simply write the data that was previously saved transiently under the
* given <code>tx</code> key, to (for example) a file system (note this only holds if the previous prepare() did
* not define one_phase=true
*/
void commit(Object tx) throws Exception;
/**
* Roll the transaction back. A DB-based CacheLoader would look up the local JDBC transaction asociated
* with <code>tx</code> and roll back that transaction
*/
void rollback(Object tx);
/**
* Fetch the entire state for this cache from secondary storage (disk, DB) and return it as a byte buffer.
* This is for initialization of a new cache from a remote cache. The new cache would then call
* storeEntireState()
* todo: define binary format for exchanging state
*/
byte[] loadEntireState() throws Exception;
/** Store the given state in secondary storage. Overwrite whatever is currently in storage */
void storeEntireState(byte[] state) throws Exception;
}
The interaction between JBossCache and a CacheLoader implementation is as follows. When CacheLoaderClass (see below) is non-null, an instance of it is created when the cache is created. Since CacheLoader extends Service,
public interface Service {
void create() throws Exception;
void start() throws Exception;
void stop();
void destroy();
}
CacheLoader.create() and CacheLoader.start() are called when the cache is started. Correspondingly, stop() and destroy() are called when the cache is stopped.
Next, setConfig() and setCache() are called. The latter can be used to store a reference to the cache, the former is used to configure this instance of the CacheLoader. For example, here a database CacheLoader could establish a connection to the database.
The CacheLoader interface has a set of methods that are called when no transactions are used: get(), put(), remove() and removeData(): they get/set/remove the value immediately. These methods are described as javadoc comments in the above interface.
Then there are three methods that are used with transactions: prepare(), commit() and rollback(). The prepare() method is called when a transaction is to be committed. It has a transaction object and a list of modfications as argument. The transaction object can be used as a key into a hashmap of transactions, where the values are the lists of modifications. Each modification list has a number of Modification elements, which represent the changes made to a cache for a given transaction. When prepare() returns successfully, then the CacheLoader must be able to commit (or rollback) the transaction successfully.
The commit() method tells the CacheLoader to commit the transaction, and the rollback() method tells the CacheLoader to discard the changes associated with that transaction.
The last two methods are loadEntireState() and storeEntireState(). The first method asks the CacheLoader to get the entire state the backend store manages and return it as a byte buffer, and the second tells a CacheLoader to replace its entire state with the byte buffer argument. These methods are used for scenarios where each JBossCache node in a cluster has its own local data store, e.g. a local DB, and - when a new node starts - we have to initialize its backend store with the contents of the backend store of an existing member. See below for deails.
The CacheLoader is configured as follows in the JBossCache XML file:
<!-- ==================================================================== -->
<!-- Defines TreeCache configuration -->
<!-- ==================================================================== -->
<mbean code="org.jboss.cache.TreeCache" name="jboss.cache:service=TreeCache">
<attribute name="CacheLoaderClass">org.jboss.cache.loader.bdbje.BdbjeCacheLoader</attribute>
<!-- attribute name="CacheLoaderClass">org.jboss.cache.loader.FileCacheLoader</attribute -->
<attribute name="CacheLoaderConfig" replace="false">
location=c:\\tmp\\bdbje
</attribute>
<attribute name="CacheLoaderShared">true</attribute>
<attribute name="CacheLoaderPreload">/</attribute>
<attribute name="CacheLoaderFetchTransientState">false</attribute>
<attribute name="CacheLoaderFetchPersistentState">true</attribute>
<attribute name="CacheLoaderAsynchronous">true</attribute>
</mbean>
The CacheLoaderClass attribute defines the class of the CacheLoader implementation. (Note that, because of a bug in the properties editor in JBoss, backslashes in variables for Windows filenames might not get expanded correctly, so replace="false" may be necessary).
The currently available implementations shipped with JBossCache are:
FileCacheLoader, which is a simple filesystem-based implementation. The CacheLoaderConfig properties need to contain a "location" property, which maps to a directory, e.g. "location", "c:\\tmp".
BdbjeCacheLoader, which is a CacheLoader implementation based on the Sleepycat DB Java Edition. The CacheLoaderConfig properties need to contain a "location" property, which maps to a directory, e.g. "location", "c:\\tmp", in which the database file for Sleepycat resides.
JDBCCacheLoader, which is a CacheLoader implementation using JDBC to access any relational database. The CacheLoaderConfig properties contains a number of properties needed to connect to the database, e.g. username, password, connection URL. See the section on JDBCCacheLoader for details.
LocalDelegatingCacheLoader, which allows to load/store to/from another local (in the same VM) TreeCache.
RpcDelegatingCacheLoader, which allows to load/store to/from a remote (in a different VM) TreeCache using JGroups' RPC mechanism. The remote TreeCache delegated to is the CacheLoader's cache's coordinator (the first cache in the cluster). This CacheLoader is available since JBossCache version 1.2.1.
RmiDelegatingCacheLoader, which allows to load/store to/from a remote (in a different VM) TreeCache using the Java RMI mechanism. This CacheLoader will be available beginning with JBossCache version 1.2.2.
Note that the Sleepycat implementation is much more efficient than the filesystem-based implementation, and provides transactional guarantees, but requires a commercial license if distributed with an application (see http://www.sleepycat.com/jeforjbosscache for details). An implementation of CacheLoader has to have an empty constructor.
The CacheLoaderConfig attribute defines configuration specific to the given implementation. The filesystem-based implementation for example defines the root directory to be used, whereas a database implementation might define the database URL, name and password to establish a database connection. This configuration is passed to the CacheLoader implementation via CacheLoader.setConfig(Properties). Note that backspaces may have to be escaped.
CacheLoaderShared determines whether each JBossCache node in a cluster is to use its own CacheLoader, or a shared CacheLoader. See discussion below for details.
CacheLoaderPreload allows us to define a list of nodes, or even entire subtrees, that are visited by the cache on startup, in order to preload the data associated with those nodes. The default ("/") loads the entire data available in the backend store into the cache, which is probably not a good idea given that the data in the backend store might be potentially large. As an example, /a, /product/catalogue loads the subtrees /a and /product/catalogue into the cache, but nothing else. Anything else is loaded lazily (when accessed). Preloading makes sense when one anticipates using elements under a given subtree frequently. Note that preloading loads all nodes and associated attributes from the given node, recursively up until the root node.
CacheLoaderFetchTransientState determines whether or not to fetch the in-memory state of a cache when joining a cluster.
CacheLoaderFetchPersistentState determines whether or not to fetch the persistent state of a cache when joining a cluster. This only applies if (a) a CacheLoader has been configured and (b) CacheLoaderShared is false.
Note that an attempt to fetch the transient and/or persistent state is only made if FetchStateOnStartup is true.
CacheLoaderAsynchronous determines whether writes to the cache loader block until completed, or are run on a separate thread so writes return immediately. If this is set to true, an instance of org.jboss.cache.loader.AsyncCacheLoader is constructed with an instance of the actual cache loader to be used. The AsyncCacheLoader then delegates all requests to the underlying cache loader, using a separate thread if necessary. See the Javadocs on org.jboss.cache.loader.AsyncCacheLoader for more details. If unspecified, the CacheLoaderAsynchronous property defaults to false.
Note on using the CacheLoaderAsynchronous property: there is always the possibility of dirty reads since all writes are performed asynchronously, and it is thus impossible to guarantee when (and even if) a write succeeds. This needs to be kept in mind when setting the CacheLoaderAsynchronous property to true.
A CacheLoader can be used to enforce node passivation and activation on eviction in a TreeCache
Cache Passivation is the process of removing an object from in-memory cache and writing it to a secondary data store (i.e. file system, database) on eviction. Cache Activation is the process of restoring an object from the data store into the in-memory cache when it's needed to be used. In both cases, the configured CacheLoader will be used to read from the data store and write to the data store.
When the eviction policy in effect calls its evict() to evict a node from the cache, if the passivation is enabled, a notification, that the node will be passivated, will be emitted to the tree cache listeners and the node and its children is stored in the cache loader store. When a user calls a get() on a node that was evicted earlier, The node is loaded (lazy loaded) from the cache loader store into the in-memory cache. Only if the node and its children have been loaded, it's removed from the cache loader then a notification is emitted to the tree cache listeners that the node is activated.
To enable cache passivation/ activation, you can set the CacheLoaderPassivation to true. The default is false. You set it either programmatically via the setter and the getter methods or via the XML cache configuration file. The XML below shows how to configure the cache passivation:
<!-- ==================================================================== -->
<!-- Defines TreeCache configuration -->
<!-- ==================================================================== -->
<mbean code="org.jboss.cache.TreeCache" name="jboss.cache:service=TreeCache">
...
<attribute name="CacheLoaderClass">org.jboss.cache.loader.FileCacheLoader</attribute>
...
<attribute name="CacheLoaderPassivation">true</attribute>
...
</mbean>
This is the simplest case. We have a JBossCache instance, whose mode is LOCAL, therefore no replication is going on. The CacheLoader simply loads non-existing elements from the store and stores modifications back to the store. When the cache is started, depending on the CacheLoaderPreload attribute, certain data can be preloaded, so that the cache is partly warmed up.
When using TreeCacheAop, this means that entire POJOs can be stored to a database or a filesystem, and when accessing fields of a POJO, they will be lazily loaded using the CacheLoader to access a backend store. This feature effectively provides simple persistency for any POJO.
The following figure shows 2 JBossCache nodes sharing the same backend store:
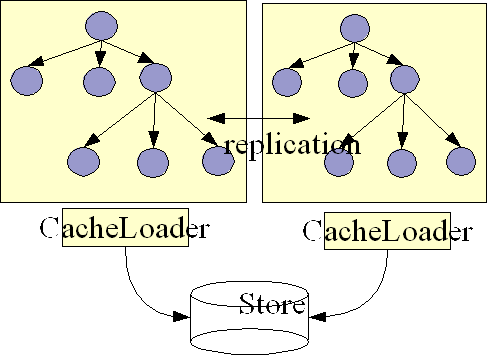
Both nodes have a CacheLoader that accesses a common shared backend store. This could for example be a shared filesystem (using the FileCacheLoader), or a shared database. Because both nodes access the same store, they don't necessarily need state transfer on startup.[8]Rather, theFetchStateOnStartup attribute could be set to false, resulting in a 'cold' cache, that gradually warms up as elements are accessed and loaded for the first time. This would mean that individual caches in a cluster might have different in-memory state at any given time (largely depending on their preloading and eviction strategies).
When storing a value, the writer takes care of storing the change in the backend store. For example, if node1 made change C1 and node2 C2, then node1 would tell its CacheLoader to store C1, and node2 would tell its CacheLoader to store C2.
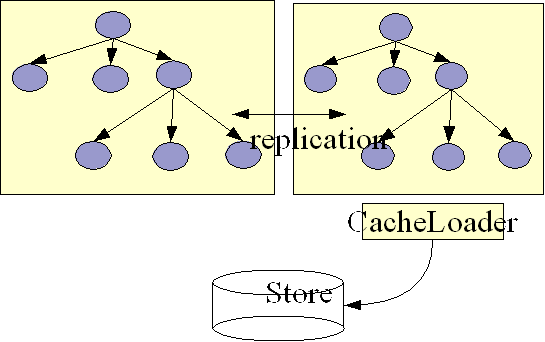
This is a similar case as the previous one, but here only one node in the cluster interacts with a backend store via its CacheLoader. All other nodes perform in-memory replication. A use case for this is HTTP session replication, where all nodes replicate sessions in-memory, and - in addition - one node saves the sessions to a persistent backend store. Note that here it may make sense for the CacheLoader to store changes asynchronously, that is not on the caller's thread, in order not to slow down the cluster by accessing (for example) a database. This is a non-issue when using asynchronous replication.
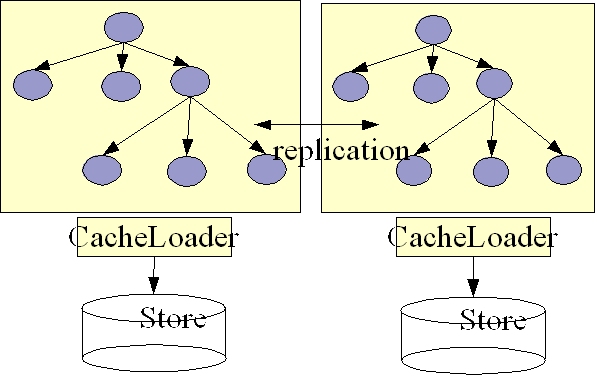
Here, each node has its own datastore. Modifications to the cache are (a) replicated across the cluster and (b) persisted using the CacheLoader. This means that all datastores have exactly the same state. When replicating changes synchronously and in a transaction, the two phase commit protocol takes care that all modifications are replicated and persisted in each datastore, or none is replicated and persisted (atomic updates).
Note that currently JBossCache is not an XAResource, that means it doesn't implement recovery. When used with a TransactionManager that supports recovery, this functionality is not available.
The challenge here is state transfer: when a new node starts it needs to do the following:
Tell the coordinator (oldest node in a cluster) to send it the state
The coordinator then needs to wait until all in-flight transactions have completed. During this time, it will not allow for new transactions to be started.
Then the coordinator asks its CacheLoader for the entire state using loadEntireState(). It then sends back that state to the new node.
The new node then tells its CacheLoader to store that state in its store, overwriting the old state. This is the CacheLoader.storeEntireState() method
As an option, the transient (in-memory) state can be transferred as well during the state transfer.
The new node now has the same state in its backend store as everyone else in the cluster, and modifications received from other nodes will now be persisted using the local CacheLoader.
If you need to set up a hierarchy within a single VM, you can use the LocalDelegatingCacheLoader. This type of hierarchy can currently only be set up programmatically. The code below shows how a first-level cache delegates to a local second-level cache:
TreeCache firstLevel, secondLevel; LocalDelegatingCacheLoader cache_loader; // create and configure firstLevel firstLevel=new TreeCache(); // create and configure secondLevel secondLevel=new TreeCache(); // create DelegatingCacheLoader cache_loader=new LocalDelegatingCacheLoader(secondLevel); // set CacheLoader in firstLevel firstLevel.setCacheLoader(cache_loader); // start secondLevel secondLevel.startService(); // start firstLevel firstLevel.startService();
If you need to set up a hierarchy across VMs but within a cluster, you can use the RpcDelegatingCacheLoader, which delegates all cache loading requests from non-coordinator caches to the cluster's coordinator cache. The coordinator cache is the first cache in the cluster to come online. Note that if the coordinator cache leaves the cluster for any reason, the second cache in the cluster to come online becomes the coordinator and so on. The XML below shows how to configure a cluster using RpcDelegatingCacheLoader:
<!-- ==================================================================== -->
<!-- Defines TreeCache configuration -->
<!-- ==================================================================== -->
<mbean code="org.jboss.cache.TreeCache" name="jboss.cache:service=TreeCache">
...
<attribute name="CacheLoaderClass">org.jboss.cache.loader.RpcDelegatingCacheLoader</attribute>
<attribute name="CacheLoaderConfig"></attribute>
<attribute name="CacheLoaderShared">false</attribute>
<attribute name="CacheLoaderPreload"></attribute>
<attribute name="CacheLoaderFetchTransientState">false</attribute>
<attribute name="CacheLoaderFetchPersistentState">false</attribute>
...
</mbean>
If you need to set up a hierarchy across VMs without any cluster membership restrictions, starting with JBossCache 1.2.2 you will be able to use the RmiDelegatingCacheLoader.
JBossCache is ditributed with the JDBC-based CacheLoader implementation that stores/loads nodes' state into relational database. The implementing class is org.jboss.cache.loader.JDBCCacheLoader.
Current implementation uses just one table. Each row in the table represents one node and contains three columns:
- column for FQN (which is also a primary key column)
- column for node's contents (attribute/value pairs)
- column for parent FQN
FQN's are stored as strings. Node's content is stored as a BLOB. WARNING: TreeCache does not impose any limitations on types of objects used in FQN. But this implementation of CacheLoader requires FQN to contain only objects of type java.lang.String. Another limitation for FQN is its length. Since FQN is a primary key, the default column type for it is VARCHAR which can store text values up to some maximum length determined by a database.
Table and column names as well as column types are configurable with the following properties.
- cache.jdbc.table.name - the name of the table. The default value is 'jbosscache'.
- cache.jdbc.table.create - can be true or false. Indicates whether to create table at start phase. If true, the table is created if it does not already exist. The default value is true.
- cache.jdbc.table.drop - can be true or false. Indicates whether to drop the table at stop phase.
- cache.jdbc.fqn.column - FQN column name. The default value is 'fqn'.
- cache.jdbc.fqn.type - FQN column type. The default value is 'varchar(255)'.
- cache.jdbc.node.column - node's contents column name. The default value is 'node'.
- cache.jdbc.node.type - node's contents column type. The default value is 'blob'.
If you are using JBossCache in a managed environment (e.g. an application server) you can specify a JNDI name of the DataSource you want to use.
- cache.jdbc.datasource - JNDI name of the DataSource. The default value is 'java:/DefaultDS'.
If you are not using DataSource you have the following properties to configure database access using JDBC driver.
- cache.jdbc.driver - fully qualified JDBC driver name.
- cache.jdbc.url - URL to connect to the database.
- cache.jdbc.user - user name to connect to the database.
- cache.jdbc.password - password to connect to the database.
Below is an example of a JDBC CacheLoader using Oracle as database. The CacheLoaderConfig XML element contains an arbitrary set of properties which define the database-related configuration.
<attribute name="CacheLoaderClass">org.jboss.cache.loader.JDBCCacheLoader</attribute>
<attribute name="CacheLoaderShared">true</attribute>
<attribute name="CacheLoaderPreload">/product/catalog/us,/product/catalog/asia</attribute>
<attribute name="CacheLoaderFetchTransientState">false</attribute>
<attribute name="CacheLoaderFetchPersistentState">false</attribute>
<attribute name="CacheLoaderConfig">
cache.jdbc.table.name=jbosscache
cache.jdbc.table.create=true
cache.jdbc.table.drop=true
cache.jdbc.fqn.column=fqn
cache.jdbc.fqn.type=varchar(255)
cache.jdbc.node.column=node
cache.jdbc.node.type=blob
cache.jdbc.parent.column=parent
cache.jdbc.driver=oracle.jdbc.OracleDriver
cache.jdbc.url=jdbc:oracle:thin:@localhost:1521:JBOSSDB
cache.jdbc.user=jboss
cache.jdbc.password=sa
</attribute>
As an alternative to configuring the entire JDBC connection, the name of an existing data source can be given:
<attribute name="CacheLoaderClass">org.jboss.cache.loader.JDBCCacheLoader</attribute>
<attribute name="CacheLoaderShared">true</attribute>
<attribute name="CacheLoaderPreload">/product/catalog/us,/product/catalog/asia</attribute>
<attribute name="CacheLoaderFetchTransientState">false</attribute>
<attribute name="CacheLoaderFetchPersistentState">false</attribute>
<attribute name="CacheLoaderConfig">
cache.jdbc.datasource=java:/DefaultDS
</attribute>In order to deserialize an object replicated to it from a remote cache, a TreeCache instance needs to have access to the classloader that defines the object's class. This is simple if the TreeCache's own classloader can access the required classes, but for situations where JBossCache is used as a service supporting clients that use different classloaders, the cache can be configured to use TreeCacheMarshaller.
TreeCacheMarshaller allows application code to register a classloader that should be used to handle replication for a portion of the tree.
TreeCache exposes the following basic API for controlling the behavior of TreeCacheMarshaller:
/**
* Sets whether a {@link TreeCacheMarshaller} instance should be created
* to manage different classloaders to use for unmarshalling replicated
* objects.
* <p>
* This property must be set to true before any call to
* {@link #registerClassLoader(String, ClassLoader)} or
* {@link #activateRegion(String)}
* </p>
*/
void setUseMarshalling(boolean isTrue);
/**
* Gets whether a {@link TreeCacheMarshaller} instance should be used
* to manage different classloaders to use for unmarshalling replicated
* objects.
*/
boolean getUseMarshalling();
/**
* Registers the given classloader with TreeCacheMarshaller for
* use in unmarshalling replicated objects for the specified region.
*
* @param fqn The fqn region. This fqn and its children will use this classloader for (un)marshalling.
* @param cl The class loader to use
*
* @throws RegionNameConflictException if fqn is a descendant of
* an FQN that already has a classloader
* registered.
* @throws IllegalStateException if useMarshalling is false
*/
void registerClassLoader(String fqn, ClassLoader cl) throws RegionNameConflictException;
/**
* Instructs the TreeCacheMarshaller to no longer use a special
* classloader to unmarshal replicated objects for the specified region.
*
* @param fqn The fqn of the root node of region.
*
* @throws RegionNotFoundException if no classloader has been registered for
* fqn.
* @throws IllegalStateException if useMarshalling is false
*/
void unregisterClassLoader(String fqn) throws RegionNotFoundException;
Property UseMarshalling controls whether classloader-based marshalling should be used. This property should be set as part of normal cache configuration, typically in the cache's XML configuration file:
<attribute name="UseMarshalling">true</attribute>
Anytime after UseMarshalling is set to true, application code can call registerClassLoader to associate a classloader with the portion of the cache rooted in a particular FQN. Once registered, the classloader will be used to unmarshal any replication traffic related to the node identified by the FQN or to any of its descendants.
At this time, registerClassLoader only supports String-based FQNs.
Note that it is illegal to register a classloader for an FQN that is a descendant of an FQN for which a classloader has already been registered. For example, if classloader X is registered for FQN /a, a RegionNameConflictException will be thrown if an attempt is made to register classloader Y for FQN /a/b.
Method unregisterClassLoader is used to remove the association between a classloader and a particular cache region. Be sure to call this method when you are done using the cache with a particular classloader, or a reference to the classloader will be held, causing a memory leak!
The basic API discussed above is helpful, but in situations where applications with different classloaders are sharing a cache, the lifecycle of those applications will typically be different from that of the cache. The result of this is that it is difficult or impossible to register all required classloaders before a cache is started. For example, consider the following scenario:
- TreeCache on machine A starts.
- On A a classloader is registered under FQN /x.
- Machine B starts, so TreeCache on B starts.
- An object is put in the machine A cache under FQN /x/1.
- Replication to B fails, as the required classloader is not yet registered.
- On B a classloader is registered under FQN /x, but too late to prevent the replication error.
Furthermore, if any objects had been added to server A before server B was started, the initial transfer of state from A to B would have failed as well, as B would not be able to unmarshal the transferred objects.
To resolve this problem, if TreeCacheMarshaller is used a cache instance can be configured to ignore replication events for a portion of the tree. That portion of the tree is considered "inactive". After the needed classloader has been registered, the portion of the tree can be "activated". Activation causes the following events to occur:
- Any existing state for that portion of the tree is transferred from another node in the cluster and integrated into the local tree.
- TreeCacheMarshaller begins normal handling of replication traffic related to the portion of the tree.
In addition to the basic marshalling related API discussed above, TreeCache exposes the following API related to activating and inactivating portions of the cache:
/**
* Sets whether the entire tree is inactive upon startup, only responding
* to replication messages after {@link #activateRegion(String)} is
* called to activate one or more parts of the tree.
* <p>
* This property is only relevant if {@link #getUseMarshalling()} is
* true.
*
*/
public void setInactiveOnStartup(boolean inactiveOnStartup);
/**
* Gets whether the entire tree is inactive upon startup, only responding
* to replication messages after {@link #activateRegion(String)} is
* called to activate one or more parts of the tree.
* <p>
* This property is only relevant if {@link #getUseMarshalling()} is
* true.
*/
public boolean isInactiveOnStartup();
/**
* Causes the cache to transfer state for the subtree rooted at
* subtreeFqn and to begin accepting replication messages
* for that subtree.
* <p>
* <strong>NOTE:</strong> This method will cause the creation of a node
* in the local tree at subtreeFqn whether or not that
* node exists anywhere else in the cluster. If the node does not exist
* elsewhere, the local node will be empty. The creation of this node will
* not be replicated.
*
* @param subtreeFqn Fqn string indicating the uppermost node in the
* portion of the tree that should be activated.
*
* @throws RegionNotEmptyException if the node subtreeFqn
* exists and has either data or children
*
* @throws IllegalStateException
* if {@link #getUseMarshalling() useMarshalling} is false
*/
public void activateRegion(String subtreeFqn)
throws RegionNotEmptyException, RegionNameConflictException, CacheException;
/**
* Causes the cache to stop accepting replication events for the subtree
* rooted at subtreeFqn and evict all nodes in that subtree.
*
* @param subtreeFqn Fqn string indicating the uppermost node in the
* portion of the tree that should be activated.
* @throws RegionNameConflictException if subtreeFqn indicates
* a node that is part of another
* subtree that is being specially
* managed (either by activate/inactiveRegion()
* or by registerClassLoader())
* @throws CacheException if there is a problem evicting nodes
*
* @throws IllegalStateException
* if {@link #getUseMarshalling() useMarshalling} is false
*/
public void inactivateRegion(String subtreeFqn) throws RegionNameConflictException, CacheException;
Property InactiveOnStartup controls whether the entire cache should be considered inactive when the cache starts. In most use cases where region activation is needed, this property would be set to true. This property should be set as part of normal cache configuration, typically in the cache's XML configuration file:
<attribute name="InactiveOnStartup">true</attribute>
When InactiveOnStartup is set to true, no state transfer will be performed on startup, even if property FetchStateOnStartup is true.
When activateRegion() is invoked, each node in the cluster will be queried to see if it has active state for that portion of the tree. If one does, it will return the current state, which will then be integrated into the tree. Once state is transferred from one node, no other nodes will be asked for state. This process is somewhat different from the initial state transfer process that occurs at startup when property FetchStateOnStartup is set to true. During initial state transfer, only the oldest member of the cluster is queried for state. This approach is inadequate for region activation, as it is possible that the oldest member of the cluster also has the region inactivated, and thus cannot provide state. So, each node in the cluster is queried until one provides state.
Before requesting state from other nodes, activateRegion() will confirm that there is no existing data in the portion of the tree being activated. If there is any, a RegionNotEmptyException will be thrown.
It is important to understand that when a region of the tree is marked as inactive, this only means replication traffic from other cluster nodes related to that portion of the tree will be ignored. It is still technically possible for objects to be placed in the inactive portion of the tree locally (via a put call), and any such local activity will be replicated to other nodes. TreeCache will not prevent this kind of local activity on an inactive region, but, as discussed above activateRegion() will throw an exception if it discovers data in a region that is being activated.
As an example of the usage of region activation and inactivation, let's imagine a scenario where a TreeCache instance is deployed as a shared MBean service by deploying a -service.xml in the JBoss /deploy directory. One of the users of this cache could be a web application, which when started will register its classloader with the TreeCache and activate its own region of the cache.
First, the XML configuration file for the shared cache service would be configured as follows (only relevant portions are shown):
<?xml version="1.0" encoding="UTF-8" ?>
<server>
<classpath codebase="./lib" archives="jboss-cache.jar, jgroups.jar" />
<!-- ==================================================================== -->
<!-- Defines TreeCache configuration -->
<!-- ==================================================================== -->
<mbean code="org.jboss.cache.TreeCache" name="com.xyz.cache:service=SharedCache">
.......
<!-- Configure Marshalling -->
<attribute name="UseMarshalling">true</attribute>
<attribute name="InactiveOnStartup">true</attribute>
........
</mbean>
</server>
For the webapp, registering/unregistering the classloader and activating/inactivating the app's region in the cache are tasks that should be done as part of initialization and destruction of the app. So, using a ServletContextListener to manage these tasks seems logical. Following is an example listener:
package example;
import javax.management.MalformedObjectNameException;
import javax.management.ObjectName;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;
import org.jboss.cache.TreeCacheMBean;
import org.jboss.mx.util.MBeanProxyExt;
public class ActiveInactiveRegionExample implements ServletContextListener
{
private TreeCacheMBean cache;
public void contextInitialized(ServletContextEvent arg0) {
try {
findCache();
cache.registerClassLoader("/example", Thread.currentThread().getContextClassLoader());
cache.activeRegion("/example");
}
catch (Exception e) {
// ... handle exception
}
}
public void contextDestroyed(ServletContextEvent arg0) {
cache.inactivateRegion("/example");
cache.unregisterClassLoader("/example");
}
private void findCache() throws MalformedObjectNameException {
// Find the shared cache service in JMX and create a proxy to it
ObjectName cacheServiceName_ = new ObjectName("com.xyz.cache:service=SharedCache");
// Create Proxy-Object for this service
cache = (TreeCacheMBean) MBeanProxyExt.create(TreeCacheMBean.class, cacheServiceName_);
}
}
The listener makes use of the JBoss utility class MBeanProxyExt to find the TreeCache in JMX and create a proxy to it. (See the "Running and using TreeCache inside JBoss" section below for more on accessing a TreeCache). It then registers its classloader with the cache and activates its region. When the webapp is being destroyed, it inactivates its region and unregisters its classloader (thus ensuring that the classloader isn't leaked via a reference to it held by TreeCacheMarshaller).
Note the order of the method calls in the example class -- register a classloader before activating a region, and inactivate the region before unregistering the classloader.
The activateRegion()/inactivateRegion() API can be used in conjunction with a CacheLoader as well, but only if the cache loader implementation implements interface org.jboss.cache.loader.ExtendedCacheLoader. This is a subinterface of the normal CacheLoader interface. It additionally specifies the following methods needed to support the partial state transfer that occurs when a region is activated:
/**
* Fetch a portion of the state for this cache from secondary storage
* (disk, DB) and return it as a byte buffer.
* This is for activation of a portion of new cache from a remote cache.
* The new cache would then call {@link #storeState(byte[], Fqn)}.
*
* @param subtree Fqn naming the root (i.e. highest level parent) node of
* the subtree for which state is requested.
*
* @see org.jboss.cache.TreeCache#activateRegion(String)
*/
byte[] loadState(Fqn subtree) throws Exception;
/**
* Store the given portion of the cache tree's state in secondary storage.
* Overwrite whatever is currently in secondary storage.
*
* @param state the state to store
* @param subtree Fqn naming the root (i.e. highest level parent) node of
* the subtree included in state.
*/
void storeState(byte[] state, Fqn subtree) throws Exception;
/**
* Sets the {@link RegionManager} this object should use to manage
* marshalling/unmarshalling of different regions using different
* classloaders.
* <p>
* <strong>NOTE:</strong> This method is only intended to be used
* by the TreeCache instance this cache loader is
* associated with.
* </p>
*
* @param manager the region manager to use, or null.
*/
void setRegionManager(RegionManager manager);
JBossCache currently comes with two implementations of ExtendedCacheLoader, FileExtendedCacheLoader and JDBCExtendedCacheLoader. These classes extend FileCacheLoader and JDBCCacheLoader, respectively, implementing the extra methods in the extended interface.
All properties of the cache are configured via setters and can be retrieved via getters. This can be done either manually, or via the PropertyConfigurator and an XML file. A sample configuration file is shown below (stripped of comments etc):
<?xml version="1.0" encoding="UTF-8" ?>
<server>
<classpath codebase="./lib" archives="jboss-cache.jar, jgroups.jar" />
<!-- ==================================================================== -->
<!-- Defines TreeCache configuration -->
<!-- ==================================================================== -->
<mbean code="org.jboss.cache.TreeCache" name="jboss.cache:service=TreeCache">
<depends>jboss:service=Naming</depends>
<depends>jboss:service=TransactionManager</depends>
<!-- Configure the TransactionManager -->
<attribute name="TransactionManagerLookupClass">org.jboss.cache.DummyTransactionManagerLookup</attribute>
<!--
Node locking level : SERIALIZABLE
REPEATABLE_READ (default)
READ_COMMITTED
READ_UNCOMMITTED
NONE
-->
<attribute name="IsolationLevel">REPEATABLE_READ</attribute>
<!-- Valid modes are LOCAL
REPL_ASYNC
REPL_SYNC
-->
<attribute name="CacheMode">LOCAL</attribute>
<!-- Name of cluster. Needs to be the same for all clusters, in order
to find each other -->
<attribute name="ClusterName">TreeCache-Cluster</attribute>
<attribute name="ClusterConfig">
<config>
<!-- UDP: if you have a multihomed machine,
set the bind_addr attribute to the appropriate NIC IP address
-->
<!-- UDP: On Windows machines, because of the media sense feature
being broken with multicast (even after disabling media sense)
set the loopback attribute to true
-->
<UDP mcast_addr="228.1.2.3" mcast_port="45566" ip_ttl="64" ip_mcast="true"
mcast_send_buf_size="150000" mcast_recv_buf_size="80000" ucast_send_buf_size="150000"
ucast_recv_buf_size="80000" loopback="false" />
<PING timeout="2000" num_initial_members="3" up_thread="false" down_thread="false" />
<MERGE2 min_interval="10000" max_interval="20000" />
<FD shun="true" up_thread="true" down_thread="true" />
<VERIFY_SUSPECT timeout="1500" up_thread="false" down_thread="false" />
<pbcast.NAKACK gc_lag="50" max_xmit_size="8192" retransmit_timeout="600,1200,2400,4800" up_thread="false"
down_thread="false" />
<UNICAST timeout="600,1200,2400" window_size="100" min_threshold="10" down_thread="false" />
<pbcast.STABLE desired_avg_gossip="20000" up_thread="false" down_thread="false" />
<FRAG frag_size="8192" down_thread="false" up_thread="false" />
<pbcast.GMS join_timeout="5000" join_retry_timeout="2000" shun="true" print_local_addr="true" />
<pbcast.STATE_TRANSFER up_thread="false" down_thread="false" />
</config>
</attribute>
<!-- The max amount of time (in milliseconds) we wait until the
initial state (ie. the contents of the cache) are retrieved from
existing members in a clustered environment
-->
<attribute name="InitialStateRetrievalTimeout">5000</attribute>
<!-- Number of milliseconds to wait until all responses for a
synchronous call have been received.
-->
<attribute name="SyncReplTimeout">10000</attribute>
<!-- Max number of milliseconds to wait for a lock acquisition -->
<attribute name="LockAcquisitionTimeout">15000</attribute>
<!-- Name of the eviction policy class. -->
<attribute name="EvictionPolicyClass">org.jboss.cache.eviction.LRUPolicy</attribute>
<!-- Specific eviction policy configurations. This is LRU -->
<attribute name="EvictionPolicyConfig">
<config>
<attribute name="wakeUpIntervalSeconds">5</attribute>
<!-- Cache wide default -->
<region name="/_default_">
<attribute name="maxNodes">5000</attribute>
<attribute name="timeToLiveSeconds">1000</attribute>
<!-- Maximum time an object is kept in cache regardless of idle time -->
<attribute name="maxAgeSeconds">120</attribute>
</region>
<region name="/org/jboss/data">
<attribute name="maxNodes">5000</attribute>
<attribute name="timeToLiveSeconds">1000</attribute>
</region>
<region name="/org/jboss/test/data">
<attribute name="maxNodes">5</attribute>
<attribute name="timeToLiveSeconds">4</attribute>
</region>
</config>
</attribute>
<attribute name="CacheLoaderClass">org.jboss.cache.loader.bdbje.BdbjeCacheLoader</attribute>
<!-- <attribute name="CacheLoaderClass">org.jboss.cache.loader.FileCacheLoader</attribute>-->
<attribute name="CacheLoaderConfig" replace="false">
location=c:\\tmp
</attribute>
<attribute name="CacheLoaderShared">true</attribute>
<attribute name="CacheLoaderPreload">/a/b/c,/all/my/objects</attribute>
<attribute name="CacheLoaderFetchTransientState">false</attribute>
<attribute name="CacheLoaderFetchPersistentState">true</attribute>
<attribute name="CacheLoaderPassivation">true</attribute>
<attribute name="CacheLoaderAsynchronous">true</attribute>
</mbean>
</server> The PropertyConfigurator.configure() method needs to have as argument a filename that needs to be found on the classpath, and will use it to configure the TreeCache from the properties defined in it. Note that this configuration file is used to configure the TreeCache both as a standalone cache, and as an MBean if run inside the JBoss container[9] .
A list of properties is shown below:
Name | Description |
CacheLoaderClass | The fully qualified name of the CacheLoader implementation |
CacheLoaderConfig | A set of properties from which the specific CacheLoader implementation can configure itself |
CacheLoaderFetchPersistentState | {only used if FetchStateOnStartup is true) Fetches the persistent state from another node, only if CacheLoaderShared is false |
CacheLoaderFetchTransientState | (only used if FetchStateOnStartup is true) Fetches the in-memory state from another node |
CacheLoaderPreload | A list of comma-separate nodes that need to be preloaded, e.g. /aop, /productcatalogue |
CacheLoaderShared | Whether we want to shared a datastore, or whether each node wants to have its own local datastore |
CacheLoaderPassivation | Whether we want to passivate evicted nodes to a datastore (true), or use the datastore as a persistent copy of the in-memory cache (false) |
CacheLoaderAsynchronous | Whether we want writes to the cache loader to be asynchronous (true) or synchronous (false) |
CacheMode | LOCAL, REPL_SYNC or REPL_ASYNC |
ClusterName | Name of cluster. Needs to be the same for all nodes in a cluster in order to find each other |
ClusterConfig | The configuration of the underlying JGroups stack. See cluster-service.xml for an example. |
EvictionPolicyClass | The name of a class implementing EvictionPolicy. If empty, no eviction policy is enabled. |
EvictionPolicyConfig | Configuration parameter for the specified eviction policy. Note that the content is provider specific. |
FetchStateOnStartup | Whether or not to acquire the initial state from existing members. Allows for warm/hot caches (true/false). This can be further defined by CacheLoaderFetchTransientState and CacheLoaderFetchPersistentState |
InitialStateRetrievalTimeout | Time in milliseconds to wait for initial state retrieval |
InactiveOnStartup | Whether or not the entire tree is inactive upon startup, only responding to replication messages after activateRegion() is called to activate one or more parts of the tree. If true, property FetchStateOnStartup is ignored. This property should only be set to true if UseMarshalling is also true. |
IsolationLevel | Node locking level : SERIALIZABLE, REPEATABLE_READ (default), READ_COMMITTED, READ_UNCOMMITTED, and NONE. Case doesn't matter. See documentation on locking for details. |
LockAcquisitionTimeout | Time in milliseconds to wait for a lock to be acquired. If a lock cannot be acquired an exception will be thrown |
ReplQueueInterval | Time in milliseconds for elements from the replication queue to be replicated. |
SyncReplTimeout | For synchronous replication: time in milliseconds to wait until replication acks have been received from all nodes in the cluster |
ReplQueueMaxElements | Max number of elements in the replication queue until replication kicks in |
TransactionManagerLookupClass | The fully qualified name of a class implementing TransactionManagerLookup. Default is JBossTransactionManagerLookup. There is also an option of DummyTransactionManagerLookup for example. |
UseMarshalling | Whether or not a TreeCacheMarshaller should be created to manage different classloaders to use for unmarshalling replicated objects. |
UseReplQueue | For asynchronous replication: whether or not to use a replication queue (true/false). |
If TreeCache is run inside JBoss then TreeCache is deployed as an MBean. The steps below illustrate how to do this. We do not deploy as a Service Archive (SAR), but as a JAR (jboss-cache.jar in the lib dir) and an XML file defining the MBean. But of course, TreeCache could also be deployed as a SAR, or even as part of a WAR, EJB or EAR.
First, the jboss-cache.jar file has to be copied to the lib directory and JBoss has to be restarted. Then a regular TreeCache configuration file in XML format has to be copied to the /deploy directory. The XML file format is the same as discussed in Configuration.
In order to be used from a client, e.g. a servlet in the Tomcat web container inside the same JBoss container, JMX can be used:
MBeanServer server=MBeanServerLocator.locateJBoss();
TreeCacheMBean cache;
cache=(TreeCacheMBean)MBeanProxyExt.create(TreeCacheMBean.class, "jboss.cache:service=TreeCache", server);
cache.put("/a/b/c", null);The MBeanServerLocator class is a helper to find the (only) JBoss MBean server inside the current VM. The static create() method creates a dynamic proxy to the given interface and uses JMX to dynamically dispatch methods invoked against the generated interface. The name used to lookup the MBean is the same as defined in the configuration file.
If JBossCache is run inside of JBoss (as an MBean), we can bind it into JNDI using JrmpProxyFactory, just like any other MBean. Below is an example of how to do this:
<mbean
code="org.jboss.invocation.jrmp.server.JRMPProxyFactory"
name="mydomain:service=proxyFactory,type=jrmp,target=factory">
<attribute
name="InvokerName">jboss:service=invoker,type=jrmp</attribute>
<attribute
name="TargetName">jboss.cache:service=TreeCache</attribute>
<attribute name="JndiName">MyCache</attribute> <attribute
name="InvokeTargetMethod">true</attribute> <attribute
name="ExportedInterface">org.jboss.cache.TreeCacheMBean</attribute>
<attribute name="ClientInterceptors"> <iterceptors>
<interceptor>org.jboss.proxy.ClientMethodInterceptor</interceptor>
<interceptor>org.jboss.proxy.SecurityInterceptor</interceptor>
<interceptor>org.jboss.invocation.InvokerInterceptor</interceptor>
</iterceptors> </attribute>
<depends>jboss:service=invoker,type=jrmp</depends>
<depends>jboss.cache:service=TreeCache</depends>
</mbean> The InvokerName attribute needs to point to a valid JBoss invoker MBean. TargetName is the JMX name of the MBean that needs to be bound into JNDI. JndiName is the name under which the MBean will be bound, and ExportedInterface is the interface name of the MBean.
[1] We will offer a cluster-wide serializable policy once we implement optimistic locking, which will be more efficient than implementing a serializable policy over a pessimistic locking scheme.
[2] Note that you can have more than 2 caches in a cluster.
[3] Plus their equivalent helper methods taking a String as node name.
[4] This is mainly used internally, and we may decide to remove public access to the Node in a future release.
[5] However, we recommend making them serializable, enabling a user to change the cache mode at any time.
[6] Depending on whether interval-based replication is used
[7] Only with synchronous replication.
[8] Of course they can enable state transfer, if they want to have a warm or hot cache after startup.
[9] Actually, we will use an XMBean in the next release.