Loops can be based on transitions or on node composition. Loops can contain wait states.
To support high numbers of automatic loop executions, the Process Virtual Machine tranformed the propagation of execution from tail recursion to a while loop. This means that all the methods in the Execution class that propagate the execution like take or execute will not be executed when you call them. Instead, the method invocations will be appended to a list. The first invocation of such a method will start a loop that will execute all invocations till that list is empty. These invocations are called atomic operations.
When an Activity is used as node behaviour, it can explicitely propagate the execution with following methods:
- waitForSignal()
- take(Transition)
- end(*)
- execute(Node)
- createExecution(*)
When Activity implementations used for node behviour don't call any of the following execution propagation methods, then, after the activity is executed, the execution will just proceed.
By default proceeding will perform the first action that applies in the following list:
- If the current node has a default outgoing transition, take it.
- If the current node has a parent node, move back to the parent node.
- Otherwise, end this execution.
Process languages can overwrite the default proceed behaviour by overriding the proceed method in ExecutionImpl.
This section explains how the Process Virtual Machine boroughs the thread from the client to bring an execution from one wait state to another.
When a client invokes a method (like e.g. the signal method) on an execution, by default, the Process Virtual Machine will use that thread to progress the execution until it reached a wait state. Once the next wait state has been reached, the method returns and the client gets the thread back. This is the default way for the Process Virtual Machine to operate. Two more levels of asynchonous execution complement this default behaviour: Asynchronous continuations and the asynchronous command service.
The next process will show the basics concretely. It has three wait states and four automatic nodes.
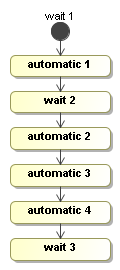
Here's how to build the process:
ProcessDefinition processDefinition = ProcessFactory.build("automatic")
.node("wait 1").initial().behaviour(new WaitState())
.transition().to("automatic 1")
.node("automatic 1").behaviour(new Display("one"))
.transition().to("wait 2")
.node("wait 2").behaviour(new WaitState())
.transition().to("automatic 2")
.node("automatic 2").behaviour(new Display("two"))
.transition().to("automatic 3")
.node("automatic 3").behaviour(new Display("three"))
.transition().to("automatic 4")
.node("automatic 4").behaviour(new Display("four"))
.transition().to("wait 3")
.node("wait 3").behaviour(new WaitState())
.done();Let's walk you through one execution of this process.
Execution execution = processDefinition.startExecution();
Starting a new execution means that the initial node is executed. So if an automatic activity would be configured as the behaviour in the initial node, the process will start executing immediatly in the startExecution. In this case however, the initial node is a wait state. So the startExecution method returns immediately and the execution will be positioned in the initial node 'wait 1'.
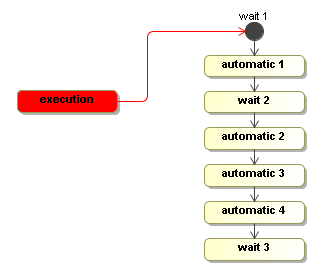
Then an external trigger is given with the signal method.
execution.signal();
As explained above when introducing the WaitState, that signal will cause the default transition to be taken. The transition will move the execution to node automatic 1 and execute it. The execute method of the Display activity in automatic 1 print a line to the console and it will not call execution.waitForSignal(). Therefore, the execution will proceed by taking the default transition out of automatic 1. The signal method is still blocking cause this action and the transitions are taken by that same thread. Then the execution arrives in wait 2 and executes the WaitState activity. That method will invoke the execution.waitForSignal(), which will cause the signal method to return. That is when the thread is given back to the client that invoked the signal method.
So when the signal method returns, the execution is positioned in wait 2.
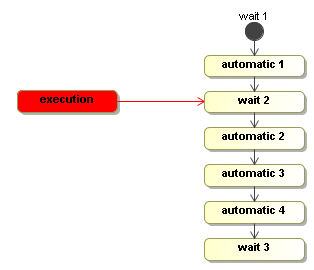
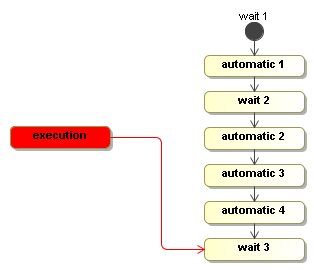
Then the execution is now waiting for an external trigger just as an object (more precisely an object graph) in memory until the next external trigger is given with the signal method.
execution.signal();
This second invocation of signal will take the execution similarly all the way to wait 3 before it returns.
To make executable processes, developers need to know exactly what the automatic activities, what the wait states are and which threads will be allocated to the process execution. For business analysts that draw the analysis process, things are a bit simpler. For the activities they draw, they usually know whether it's a human or a system that is responsible. But they typically don't not how this translates to threads and transactions.
So for the developer, the first job is to analyse what needs to be executed within the thread of control of the process and what is outside. Looking for the external triggers can be a good start to find the wait states in a process, just like verbs and nouns can be the rule of thumb in building UML class diagrams.
To model process concurrency, there is a parent-child tree structure on the execution. The idea is that the main path of execution is the root of that tree. This implies that on the level of the Process Virtual Machine, there is no differentiation between complete process instances and paths of execution within a process instance. One of the main motivations for this design is that the API actually is not made more complex then necessary for simple processes with only one single path of execution.
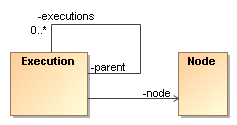
To extablish multiple concurrent paths of execution, child executions can be created. Only leaf executions can be active. Non-leave executions should be inactive. This tree structure of executions doesn't enforce a particular type of concurrency or join behaviour. It's up to the forks or and-splits and to the joins or and-merges to use the execution tree structure in any way they want to define the wanted concurrency behaviour. Here you see an example of concurrent executions.
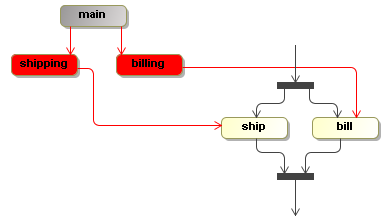
There is a billing and a shipping path of execution. In this case, the flat bar nodes represent nodes that fork and join. The execution shows a three executions. The main path of execution is inactive (represented as gray) and the billing and shipping paths of execution are active and point to the node bill and ship respectively.
It's up to the node behaviour implementations how they want to use this execution structure. Suppose that multiple tasks have to be completed before the execution is to proceed. The node behaviour can spawn a series of child executions for this. Or alternatively, the task component could support task groups that are associated to one single execution. In that case, the task component becomes responsible for synchronizing the tasks, thereby moving this responsibility outside the scope of the execution tree structure.
In all the code that is associated to a process like Activity's, Actions and Conditions, it's possible to include try-catch blocks in the method implementations to handle exceptions. But in order to build more reusable building blocks for both the delegation classes and the exception handling logic, exception handlers are added to the core process model.
An exception handler can be associated to any process element. When an exception occurs in a delegation class, a matching exception handler will be searched for. If such an exception handler is found, it will get a chance to handle the exception.
If an exception handler completes without problems, then the exception is considered handled and the execution resumes right after the delegation code that was called. For example, a transition has three actions and the second action throws an exception that is handled by an exception handler, then
Writing automatic activities that are exception handler aware is easy. The default is to proceed anyway. No method needs to be called on the execution. So if an automatic activity throws an exception that is handled by an exception handler, the execution will just proceed after that activity. It becomes a big more difficult for control flow activities. They might have to include try-finally blocks to invoke the proper methods on the execution before an exception handler gets a chance to handle the exception. For example, if an activity is a wait state and an exception occurs, then there is a risk that the thread jumps over the invocation of execution.waitForSignal(), causing the execution to proceed after the activity.
TODO: exceptionhandler.isRethrowMasked
TODO: transactional exception handlers
TODO: we never catch errors
The state of an execution is either active or locked. An active execution is either executing or waiting for an external trigger. If an execution is not in STATE_ACTIVE, then it is locked. A locked execution is read only.
When a new execution is created, it is in STATE_ACTIVE. To change the state to a locked state, use lock(String). Some STATE_* constants are provided that represent the most commonly used locked states. But the state '...' in the picture indicates that any string can be provided as the state in the lock method.
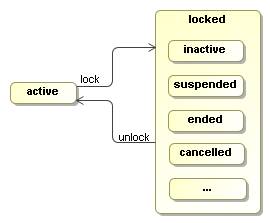
If an execution is locked, methods that change the execution will throw a PvmException and the message will reference the actual locking state. Firing events, updating variables, updating priority and adding comments are not considered to change an execution. Also creation and removal of child executions are unchecked, which means that those methods can be invoked by external API clients and node behaviour methods, even while the execution is in a locked state.
Make sure that comparisons between getState() and the STATE_* constants are done with .equals and not with '==' because if executions are loaded from persistent storage, a new string is created instead of the constants.
An execution implementation will be locked:
- When it is ended
- When it is suspended
- During asynchronous continuations
Furthermore, locking can be used by Activity implementations to make executions read only during wait states hen responsibility for the execution is transferred to an external entity such as:
- A human task
- A service invocation
- A wait state that ends when a scanner detects that a file appears
In these situations the strategy is that the external entity should get full control over the execution because it wants to control what is allowed and what not. To get that control, they lock the execution so that all interactions have to go through the external entity.
One of the main reasons to create external entities is that they can live on after the execution has already proceeded. For example, in case of a service invocation, a timer could cause the execution to take the timeout transition. When the response arrives after the timeout, the service invocation entity should make sure it doesn't signal the execution. So the service invocation can be seen as a node instance (aka activity instance) and is unique for every execution of the node.
External entities themselves are responsible for managing the execution lock. If the timers and client applications are consequent in addressing the external entities instead of the execution directly, then locking is in theory unnecessary. It's up to the node behaviour implementations whether they want to take the overhead of locking and unlocking.