<namedCache name="cacheWithVirtualNodes">
<clustering>
<hash numVirtualNodes="10" />
</clustering>
</namedCache>
Introduction
Infinispan can be configured to be either local (standalone) or clustered. If in a cluster, the cache can be configured to replicate changes to all nodes, to invalidate changes across nodes and finally to be used in distributed mode - state changes are replicated to a small subset of nodes enough to be fault tolerant but not to many nodes to prevent scalability.
Local Mode
While Infinispan is particularly interesting in clustered mode, it also offers a very capable local mode, where it acts as a simple, in-memory data cache similar to JBoss Cache and EHCache. But why would one use a local cache rather than a map? Caches offer a lot of features over and above a simple map, including write-through and write-behind caching to persist data, eviction of entries to prevent running out of memory, and support for expirable entries. Infinispan, specifically, is built around a high-performance, read-biased data container which uses modern techniques like MVCC locking - which buys you non-blocking, thread-safe reads even when concurrent writes are taking place. Infinispan also makes heavy use of compare-and-swap and other lock-free algorithms, making it ideal for high-throughput, multi-CPU/multi-core environments. Further, Infinispan's Cache API extends the JDK's ConcurrentMap - making migration from a map to Infinispan trivial. For more details refer to Non-clustered, LOCAL mode section.
Replicated Mode
Replication is a simple clustered mode where cache instances automatically discover neighboring instances on other JVMs on the same local network, and form a cluster. Entries added to any of these cache instances will be replicated to all other cache instances in the cluster, and can be retrieved locally from any instance. This clustered mode provides a quick and easy way to share state across a cluster, however replication practically only performs well in small clusters (under 10 servers), due to the number of replication messages that need to happen - as the cluster size increases. Infinispan can be configured to use UDP multicast which mitigates this problem to some degree.
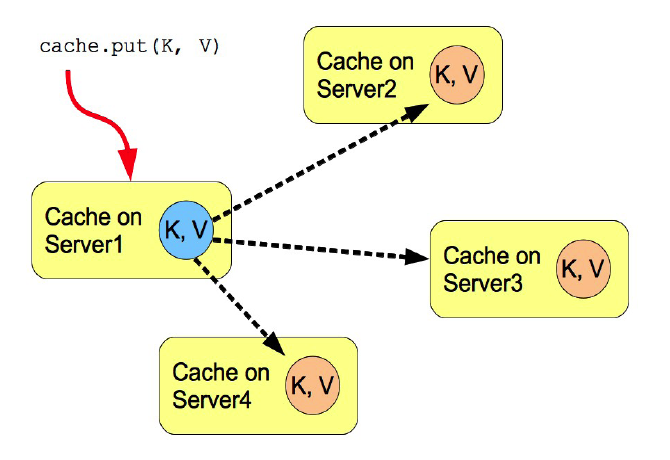
Figure 1. Replication mode
Replication can be synchronous or asynchronous. Use of either one of the options is application dependent. Synchronous replication blocks the caller (e.g. on a put() ) until the modifications have been replicated successfully to all nodes in a cluster. Asynchronous replication performs replication in the background (the put() returns immediately). Infinispan offers a replication queue, where modifications are replicated periodically (i.e. interval-based), or when the queue size exceeds a number of elements, or a combination thereof. A replication queue can therefore offer much higher performance as the actual replication is performed by a background thread.
Asynchronous replication is faster (no caller blocking), because synchronous replication requires acknowledgments from all nodes in a cluster that they received and applied the modification successfully (round-trip time). However, when a synchronous replication returns successfully, the caller knows for sure that all modifications have been applied to all cache instances, whereas this is not be the case with asynchronous replication. With asynchronous replication, errors are simply written to a log. Even when using transactions, a transaction may succeed but replication may not succeed on all cache instances.
Invalidation Mode
Invalidation is a clustered mode that does not actually share any data at all, but simply aims to remove data that may be stale from remote caches. This cache mode only makes sense if you have another, permanent store for your data such as a database and are only using Infinispan as an optimization in a read-heavy system, to prevent hitting the database every time you need some state. If a cache is configured for invalidation rather than replication, every time data is changed in a cache other caches in the cluster receive a message informing them that their data is now stale and should be evicted from memory.
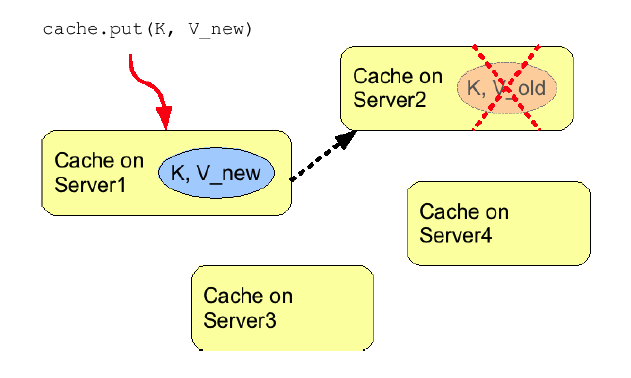
Figure 2. Invalidation mode
Invalidation, when used with a shared cache loader would cause remote caches to refer to the shared cache loader to retrieve modified data. The benefit of this is twofold: network traffic is minimized as invalidation messages are very small compared to replicating updated data, and also that other caches in the cluster look up modified data in a lazy manner, only when needed.
Invalidation messages are sent after each modification (no transactions or batches), or at the end of a transaction or batch, upon successful commit. This is usually more efficient as invalidation messages can be optimized for the transaction as a whole rather than on a per-modification basis.
Invalidation too can be synchronous or asynchronous, and just as in the case of replication, synchronous invalidation blocks until all caches in the cluster receive invalidation messages and have evicted stale data while asynchronous invalidation works in a 'fire-and-forget' mode, where invalidation messages are broadcast but doesn't block and wait for responses.
Distribution Mode
Distribution is a powerful clustering mode which allows Infinispan to scale linearly as more servers are added to the cluster. Distribution makes use of a consistent hash algorithm to determine where in a cluster entries should be stored. Hashing algorithm is configured with the number of copies each cache entry should be maintained cluster-wide. Number of copies represents the tradeoff between performance and durability of data. The more copies you maintain, the lower performance will be, but also the lower the risk of losing data due to server outages. Regardless of how many copies are maintained, distribution still scales linearly and this is key to Infinispan scalability. Another feature of the consistent hash algorithm is that it is deterministic in locating entries without resorting to multicasting requests or maintaining expensive metadata. Doing a PUT would result in at most num_copies remote calls, and doing a GET anywhere in the cluster would result in at most 1 remote call. In reality, num_copies remote calls are made even for a GET, but these are done in parallel and as soon as any one of these returns, the entry is passed back to the caller.
NOTE: This behavior is due to change in Infinispan 5.3, where just a single GET call is made. See ISPN-825.
Read consistency
Since GETs are sent to all data owners in parallel and the first returning result is used, this can lead to data inconsistency when using an asynchronous transport. If an updating thread modifies the primary data owner, but updates are only sent to backup nodes asynchronously, a concurrent read may read a stale value for a short period of time until the asynchronous replication completes.
Note that this is only if the transport is asynchronous. If using a synchronous transport this behavior is not exhibited.
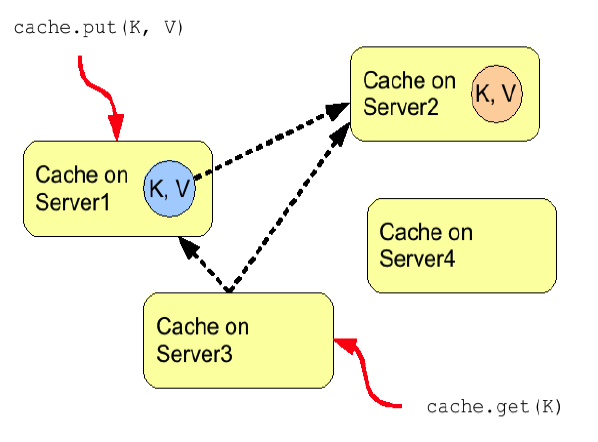
Figure 3. Distribution mode
Virtual Nodes - Improving the distribution of data
Infinispan does not attempt to evenly split the hash space between nodes – by not trying to split it evenly, it means that if a node joins or leaves the grid, there is no need to adjust the ownership of every node, just the neighbours of the joiner/leaver. This has a positive impact on network traffic. However this can mean that some nodes take on substantially larger portions of the hash space than others. This, combined with potential irregularities in the hash functions of keys, can mean the distribution of entries across the grid becomes poor. In order to address the irregularities in the hash of keys, Infinispan uses an advanced hashing function (Murmur Hash 3) by default, as well as using a bit spreader. In order to address the irregularities in the node distribution, Infinispan uses virtual nodes.
First, let's consider how virtual nodes help conceptually by taking a couple of distribution examples, and armed with that knowledge, look at how Infinispan uses them.
Consider a hash space of 1000 (there are 1000 buckets into which data can be placed). If there were two nodes, it is possible you can have 1 node being used for 1 bucket, and 1 node for 999 buckets (this is the most pessimistic distribution!). If there were 200 nodes, the worst distribution of node would end up being 199 nodes responsible for one bucket each (199 buckets in total), and 1 node being responsible for 801 buckets. If there were 1000 nodes, then each node must be responsible for 1 bucket each. From this we can deduce that as the number of nodes tends to the size of the hash space, that the distribution of buckets to nodes improves.
A guiding principle of Infinispan is that it always uses an algorithm to locate a key in the hash space, never allowing the node on which the entry is stored to be specified manually. This scheme allows any node to know which nodes owns a key, without having to distribute such ownership information. This reduces the overhead of Infinispan, but more importantly improves redundancy as there is no need to replicate the ownership information in case of node failure.
With this in mind, we can see that virtual nodes are an ideal solution to the distribution of nodes problem, as it allows the location of an entry to be determined algorithmically.
Infinispan implements virtual nodes by altering the algorithm for splitting the hash space whenever a node joins or leaves the grid. Rather than allocating a block of the hashspace to the node, it allocates a number of blocks from throughout the hash space.
Often it's easier to understand the topology changes that virtual nodes introduce through diagrams.
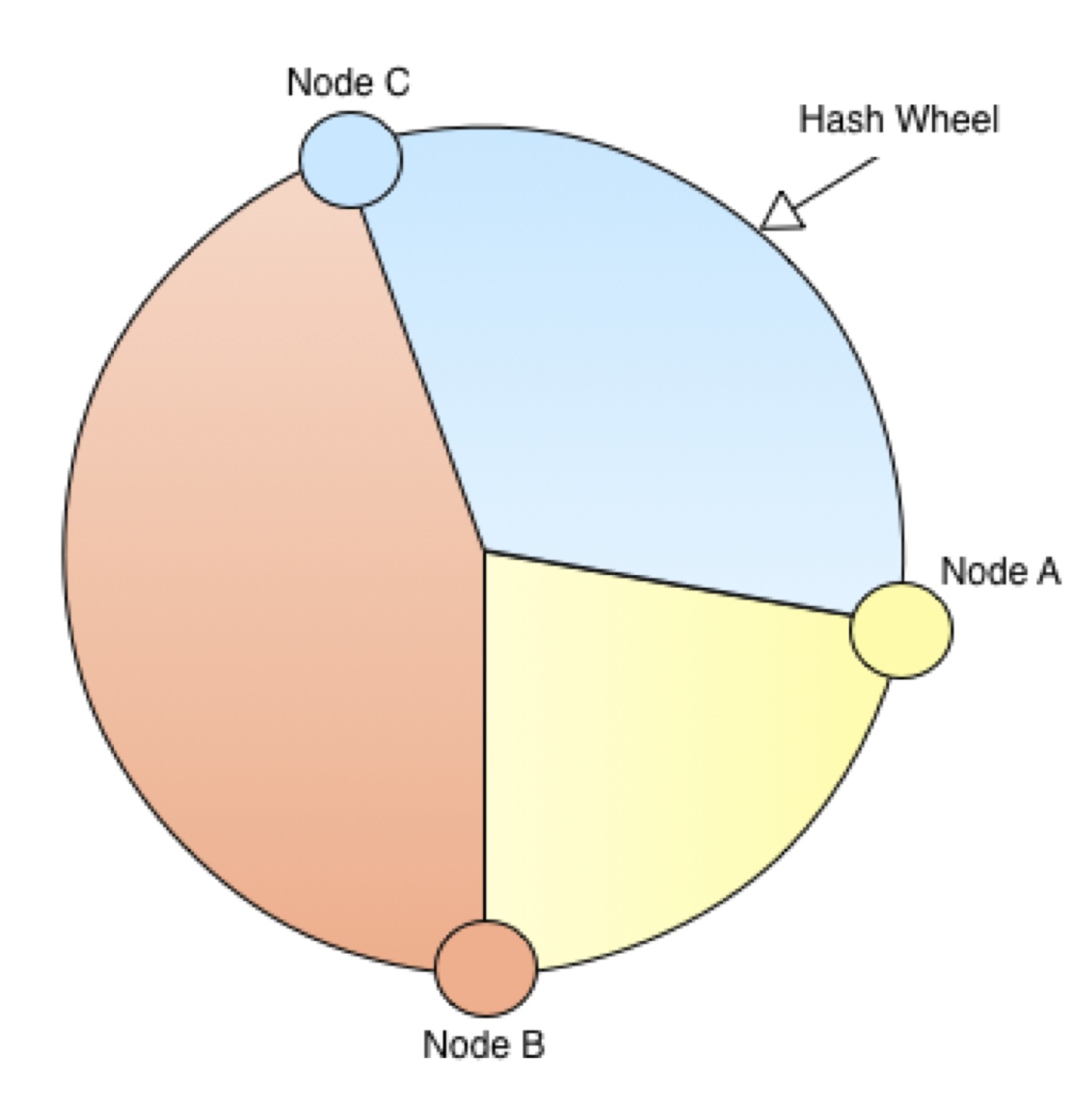
Figure: Topology Without Virtual Nodes
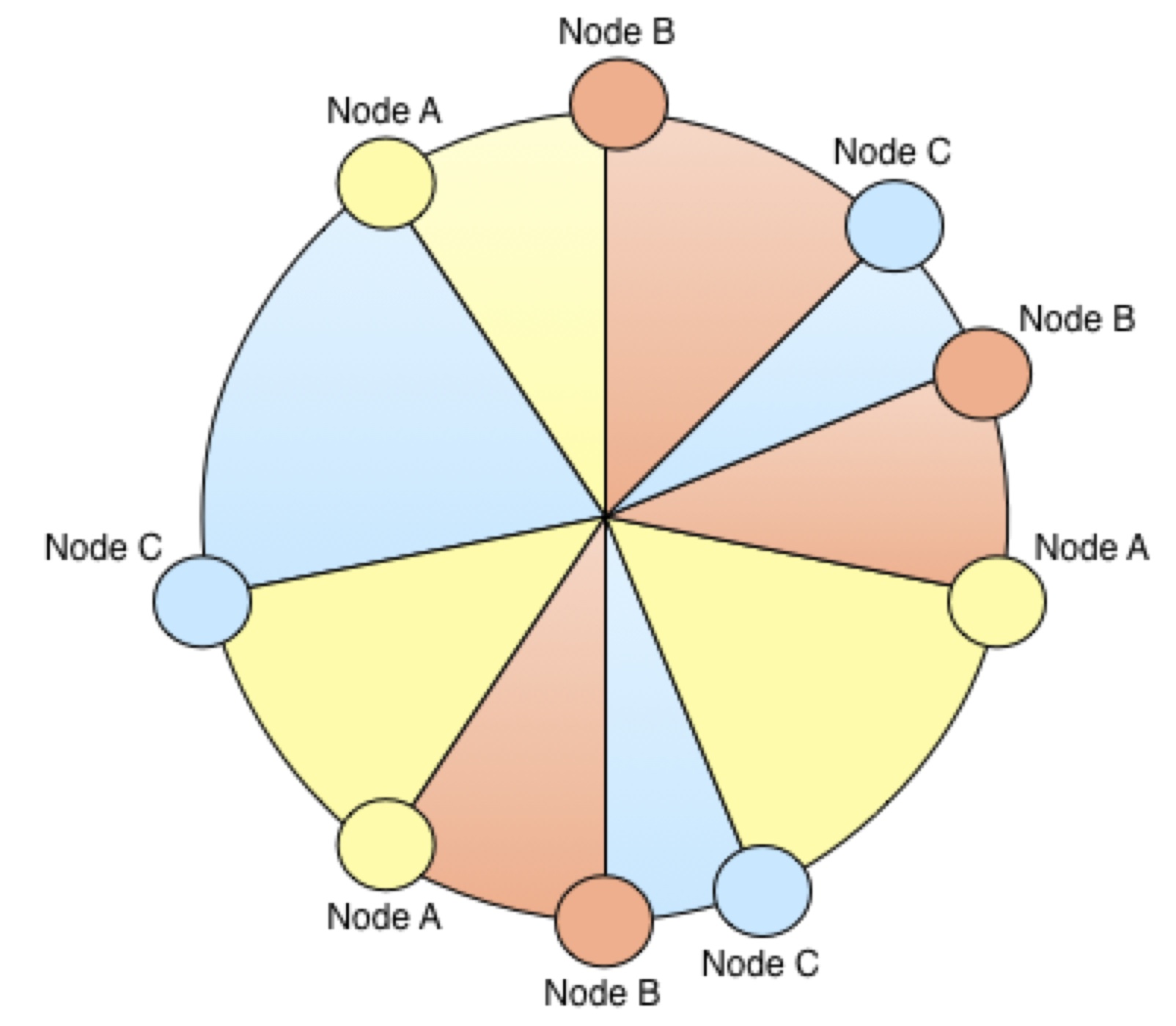
Figure: Topology With Virtual Nodes
To use virtual nodes, simply set the number of virtual nodes higher than one. For example
Alternatively, you can enable virtual nodes programmatically
new ConfigurationBuilder()
.clustering()
.hash()
.numVirtualNodes(10)
.build();
TODO Add notes on how to select number of virtual nodes.
L1 Caching
To prevent repeated remote calls when doing multiple GETs, L1 caching can be enabled. L1 caching places remotely received values in a near cache for a short period of time (configurable) so repeated lookups would not result in remote calls. In the above diagram, if L1 was enabled, a subsequent GET for the same key on Server3 would not result in any remote calls.
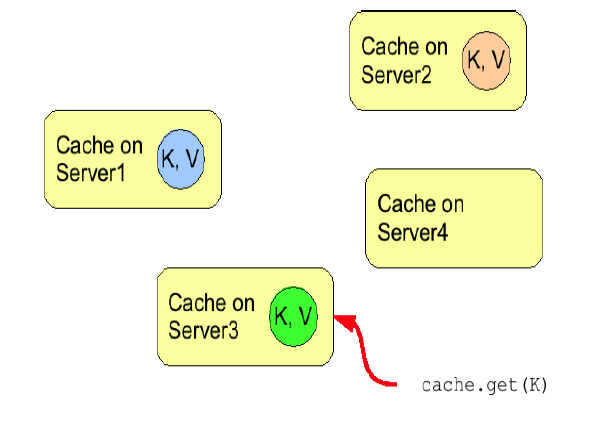
Figure 4. L1 caching
L1 caching is not free though. Enabling it comes at a cost, and this cost is that every time a key is updated, an invalidation message needs to be multicast to ensure nodes with the entry in L1 invalidates the entry. L1 caching causes the requesting node to cache the retrieved entry locally and listen for changes to the key on the wire. L1-cached entries are given an internal expiry to control memory usage. Enabling L1 will improve performance for repeated reads of non-local keys, but will increase memory consumption to some degree. It offers a nice tradeoff between the "read-mostly" performance of an invalidated data grid with the scalability of a distributed one. Is L1 caching right for you? The correct approach is to benchmark your application with and without L1 enabled and see what works best for your access pattern.
Looking for Buddy Replication? Buddy Replication - from JBoss Cache - does not exist in Infinispan. See this blog article which discusses the reasons why Buddy Replication was not implemented in Infinispan, and how the same effects can be achieved using Infinispan - <a href="http://infinispan.blogspot.com/2009/08/distribution-instead-of-buddy.html">http://infinispan.blogspot.com/2009/08/distribution-instead-of-buddy.html</a>