<SEQUENCER /> <tom.TOA />
Introduction
The Total Order based protocol is a multi-master scheme (in this context, multi-master scheme means that all nodes can update all the data) as the (optimistic/pessimist) locking model implemented in Infinispan. This commit protocol relies on the concept of totally ordered delivery of messages which, informally, implies that each node which delivers a set of messages, delivers them in the same order.
This protocol comes with this advantages.
-
transactions can be committed in one phase, as they are delivered in the same order by the nodes that receive them.
-
it mitigates distributed deadlocks.
The weaknesses of this approach are the fact that its implementation relies on a single thread per node which delivers the transaction and its modification, and the slightly higher number of messages exchanged by JGroups.
Thus, this protocol delivers best performance in scenarios of high contention, in which it can benefit from the single-phase commit and the deliver thread is not the bottleneck.
Currently, the Total Order based protocol is available only in transactional caches for replicated and distributed modes.
Overview
The Total Order based commit protocol only affects how transactions are committed and it depends of the isolation level configured, more precisely the write skew check. Note that it only provides the same isolation levels as the locking model, i.e. read-committed and repeatable-read. If the write skew check is not enabled, then all the transaction are committed in one phase (independently if Infinispan is enlisted as Synchronization or XaResource). In this case, the isolation level is not violated because it is ensured during the transaction execution. Also the transactions always commit successfully because they do not need to perform any validation in prepare phase.
On other hand, when write skew check is enabled, the protocol adapts using one phase commit when it is safe. However, if Infinispan is enlisted as Synchronization, it always commit in two phases, because the Transaction Manager does not provide any information if Infinispan is the only resource enlisted or not. In XaResource enlistment, we can use one phase if the Transaction Manager request a commit in one phase (i.e. one-phase optimization, usually used when the transaction has a single XaResource registered, see XaResource.commit()) and the Infinispan cache is configured in replicated mode or in distributed mode (the last one, when the writeSkew==false). This optimization is not safe in distributed mode when writeSkew==true because each node performs the validation in different keys subset.
Commit in one phase
When the transaction ends, Infinispan sends the transaction (and its modification) in total order. This ensures all the transactions are deliver in the same order in all the involved Infinispan nodes. As a result, when a transaction is delivered, it performs a deterministic validation over the same state, leading to the same outcome (transaction commit or rollback). Also, if the transactional mode is configured with syncCommitPhase==false, the node that sent the transaction still needs to wait for the self-deliver of the transaction because it needs to know the transaction outcome. In other hand, it does not need to wait for the replies from other nodes because they will reply with the same outcome. Although, if syncCommitPhase==true, it needs to wait for the replies in order to respect the semantic of the flag.
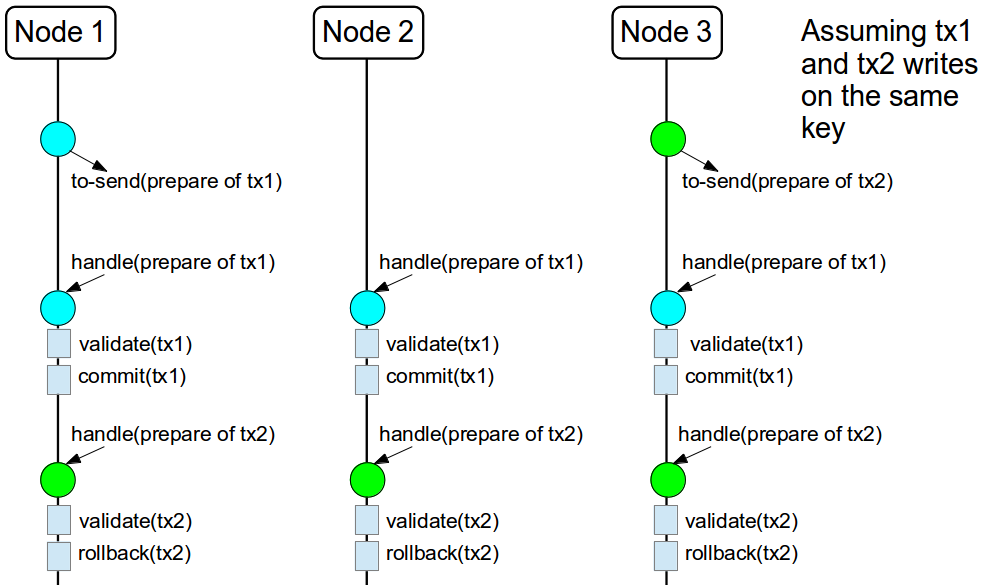
The figure above demonstrates a high level example with 3 nodes. Node1 and Node3 are running one transaction each and lets assume that both transaction writes on the same key. To make it more interesting, lets assume that both nodes tries to commit at the same time, represented by the first colored circle in the figure. The
blue
circle represents the transaction tx1 and the
green
the transaction tx2. Both nodes do a remote invocation in total order (to-send) with the transaction's modifications. At this moment, all the nodes will agree in the same deliver order, for example, tx1 followed by tx2. Then, each node delivers tx1, perform the validation and commits the modifications. The same steps are performed for tx2 but, in this case, the validation will fail and the transaction is rollback in all the involved nodes.
Commit in two phases
The first phase is the same as described above except that the nodes will not apply the modifications after the validation, including the modifications sent in total order and the same scheme to wait for the replies. As soon as it has the confirmation that all keys are successfully validated, it give a positive response to the Transaction Manager (remember that the Transaction Manager is responsive to invoke the prepare() of the transaction). On other hand, if it receives a negative reply, it returns a negative response to the Transaction Manager. Finally, the transaction is committed or aborted in the second phase depending of the Transaction Manager.
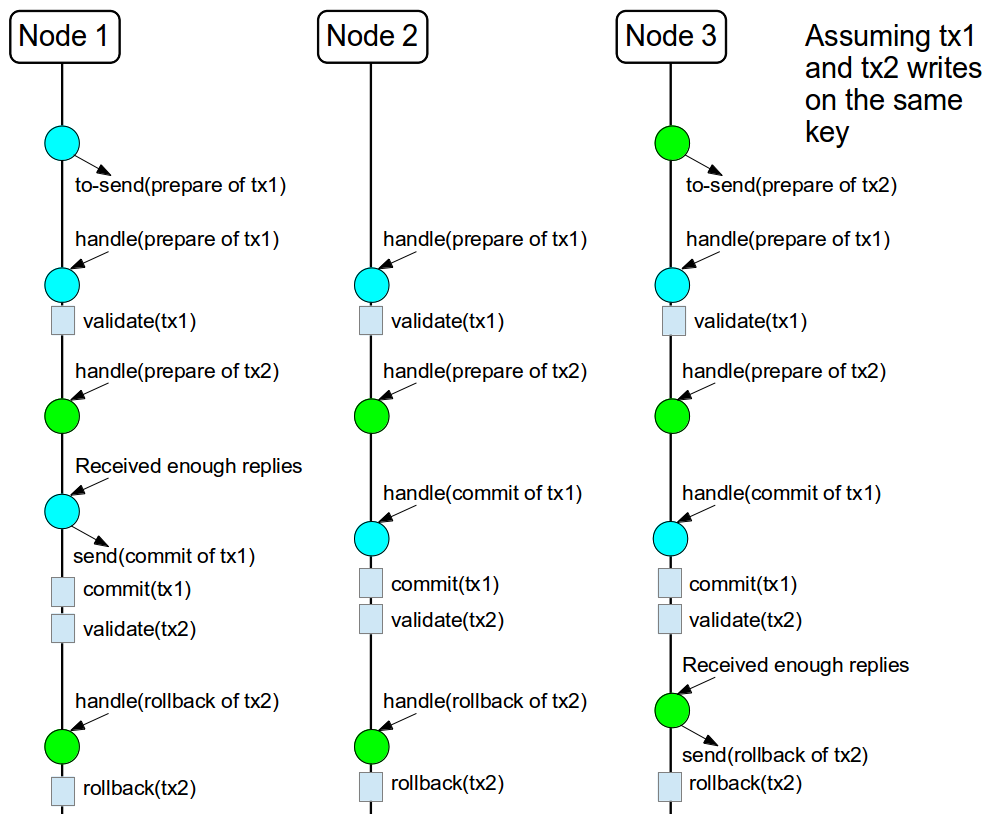
The figure above shows the scenario described in the first figure but now committing the transactions using two phases. When tx1 is deliver, it performs the validation and it replies to the Transaction Manager. Next, lets assume that tx2 is deliver before the Transaction Manager request the second phase for tx1. In this case, tx2 will be enqueued and it will be validated only when tx1 is completed. Eventually, the Transaction Manager for tx1 will request the second phase (the commit) and all the nodes are free to perform the validation of tx2.
Transaction Recovery
Transaction Recovery is currently not available for Total Order based commit protocol
Total order executor service
As previous said, only one thread is delivering the transactions, which makes this thread a possible bottleneck of the system. Although, only conflicting transactions (i.e. which the write set intercepts) needs to be validated in order. For example, if a node delivers tx1(write(A)), tx2(write(A)) and tx3(write(B)), tx2 must wait until the tx1 is completed, but tx3 can be validated concurrently with tx1 and tx2. After analyzing the transaction dependencies, is possible to enqueue the transactions that conflicts to non-completed transactions and move to a executor service the transaction that can be concurrently validated.
Warning
The total order executor service needs an ExecutorService (see the Configuration section). Please make sure that the ExecutorService does not reject tasks otherwise your data becomes inconsistent.
State Transfer
For simplicity reasons, the total order based commit protocol uses a blocking version of the current state transfer. The main differences are:
-
enqueue the transaction deliver while the state transfer is in progress;
-
the state transfer control messages (CacheTopologyControlCommand) are sent in total order.
This way, it provides a synchronization between the state transfer and the transactions deliver that is the same all the nodes. Although, the transactions caught in the middle of state transfer (i.e. sent before the state transfer start and deliver after it) needs to be re-sent to find a new total order involving the new joiners.
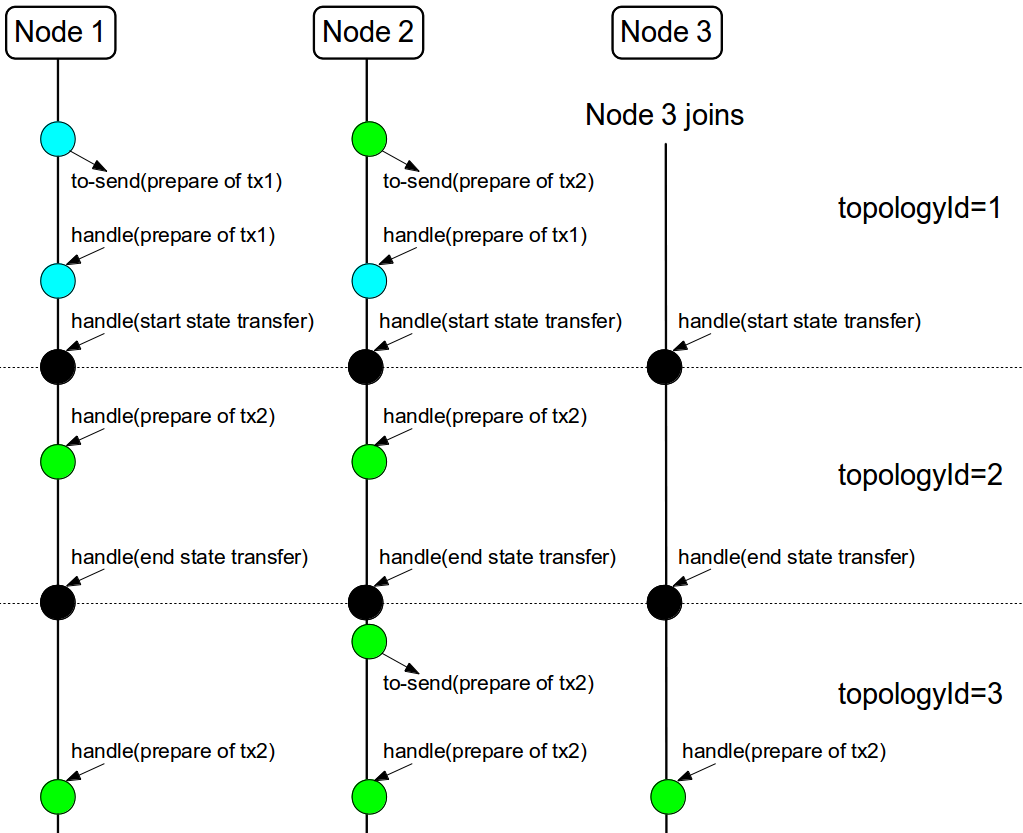
The figure above describes a node joining. In the scenario, the tx2 is sent in topologyId=1 but when it is received, it is in topologyId=2. So, the transaction is re-sent involving the new nodes.
Configuration
To use Total Order based commit protocol in your Infinispan cache, you need to configure a couple of thing:
-
add the total order protocols in JGroups configuration file:
Check the JGroups manual for more detail in here: JGroups Manual
-
configure the Infinispan cache as a transactional cache and set the transaction protocol to total order:
<namedCache >
<transaction
transactionMode="TRANSACTIONAL"
transactionProtocol="TOTAL_ORDER" />
</namedCache>
You can build the same configuration programmatically in the following way:
ConfigurationBuilder cb = new ConfigurationBuilder(); cb.transaction().transactionMode(TransactionMode.TRANSACTIONAL).transactionProtocol(TransactionProtocol.TOTAL_ORDER);
Optionally, you can configure the total order executor to use your own executor services. By default, it creates an executor service with coreThreads=1 and maxThreads=32. It can be configured in the following way:
<global>
<totalOrderExecutor factory="org.infinispan.executor.DefaultExecutorFactory>
<property name="coreThreads" value="1" />
<property name="maxThreads" value="32" />
</totalOrderExecutor>
</global>
or programmaticaly:
GlobalConfigurationBuilder gcb = new GlobalConfigurationBuilder();
gcb.totalOrderExectutor().factory(new DefaultExecutorFactory()).addProperty("coreThread", "1").addProperty("maxThreads", "32");
Beside the coreThreads and the maxThreads, the DefaultExecutorFactory also accepts as properties as the queueSize, keepAliveTime (in milliseconds), threadPriority, threadNamePrefix and threadNameSuffix. Note that, this parameters are used by the ExecutorService. The total order executor uses an unbouded queue. Also, when you provide an ExecutorService, make sure that it will no reject tasks, otherwise your data can became inconsistent.
Total Order protocols in JGroups.
SEQUENCER
The SEQUENCER protocol ensures total order involving all the members in the cluster. It is a sequencer-based implementation in which the sender forwards the messages to a sequencer (the current cluster coordinator), and the sequencer sends it back to the cluster on behalf of the original sender. Because it is always the same sender (whose messages are delivered in FIFO order), a global (or total) order is established.
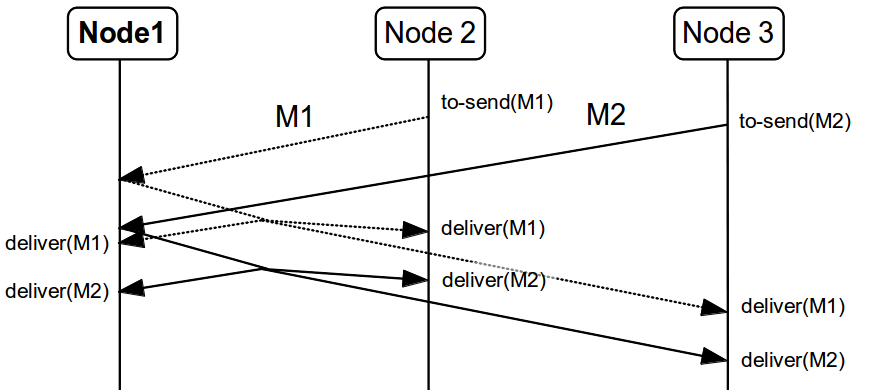
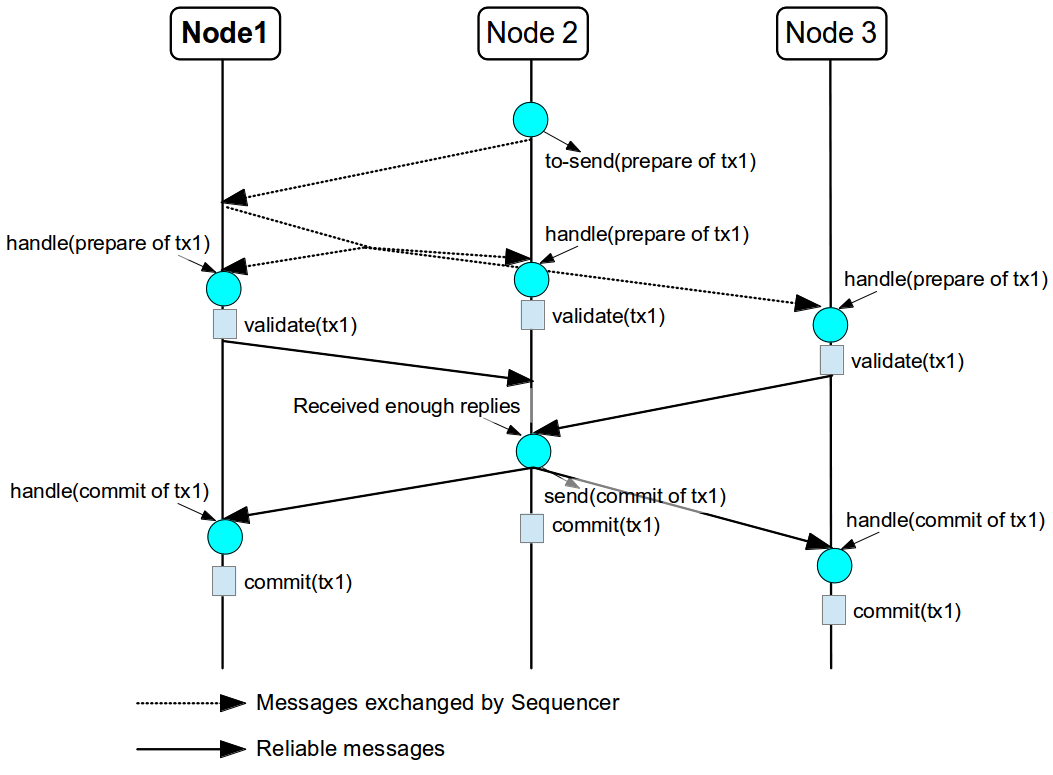
The figure above shows the the communication steps to total order broadcast two messages M1 and M2 from different senders. Below, the figure shows the communication steps needed to commit a single transaction, when two phase are used. The dotted line represents the communications steps performed by the SEQUENCER. As it is possible to see, ensure total order is not a cheap operation and it has a cost of an extra communication step comparing with the lock based implementation.
More information about the SEQUENCER in JGroups manual: SEQUENCER - JGroups Manual page
TOA - Total Order Anycast
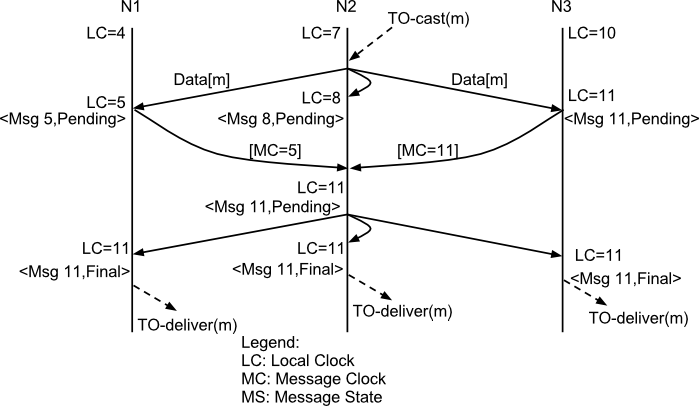
The TOA protocol is implemented based on the Skeen Algorithm. Each node has an ordered (by the message logical clock) queue with the messages and a local logical clock and it works in a centralized way. The sender sends N unicast messages with the data to all destination nodes. When the message is received, each replica increments it logical clock and it sends back the value to the sender. Meanwhile, the message is put on the queue with the value of logical clock and marked as temporary. The sender collects all values and calculates the maximum value of them. Finally it sends other N unicast message with the final value of the message. This number indicates the final order number of deliver for the message. Each replica updates it logical clock, if the value is lower than the final value received, and updates the message in the queue, re-ordered if necessary. Then the message is marked as final. The messages are delivered when it is on the top of the queue and is final. The figure below explains in a graphical way how it is done.
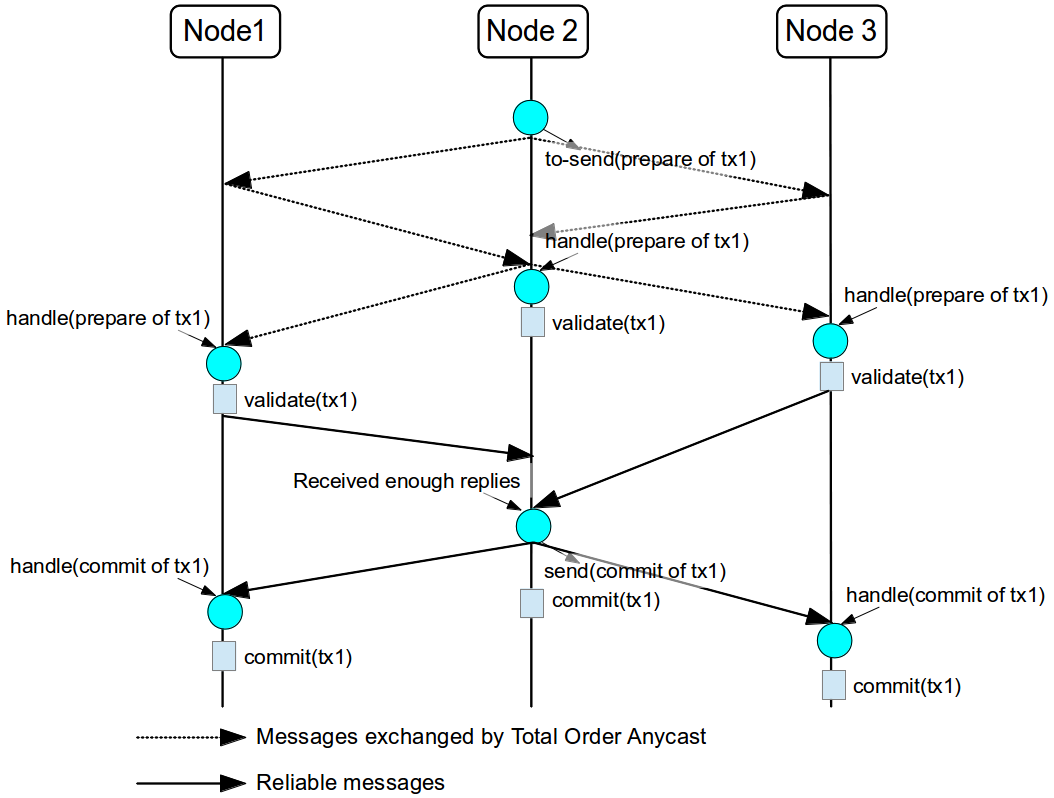
The next figure show one transaction to be committed in detail, including all the communication steps. The dotted line represents the messages exchanged by TOA and the solid lines a single unicast message. This figure shows that the total order protocol has 2 more communications steps than the lock based implementation.
More information about the Total Order Anycast in JGroups manual: TOA - JGroups Manual page
Benchmark results
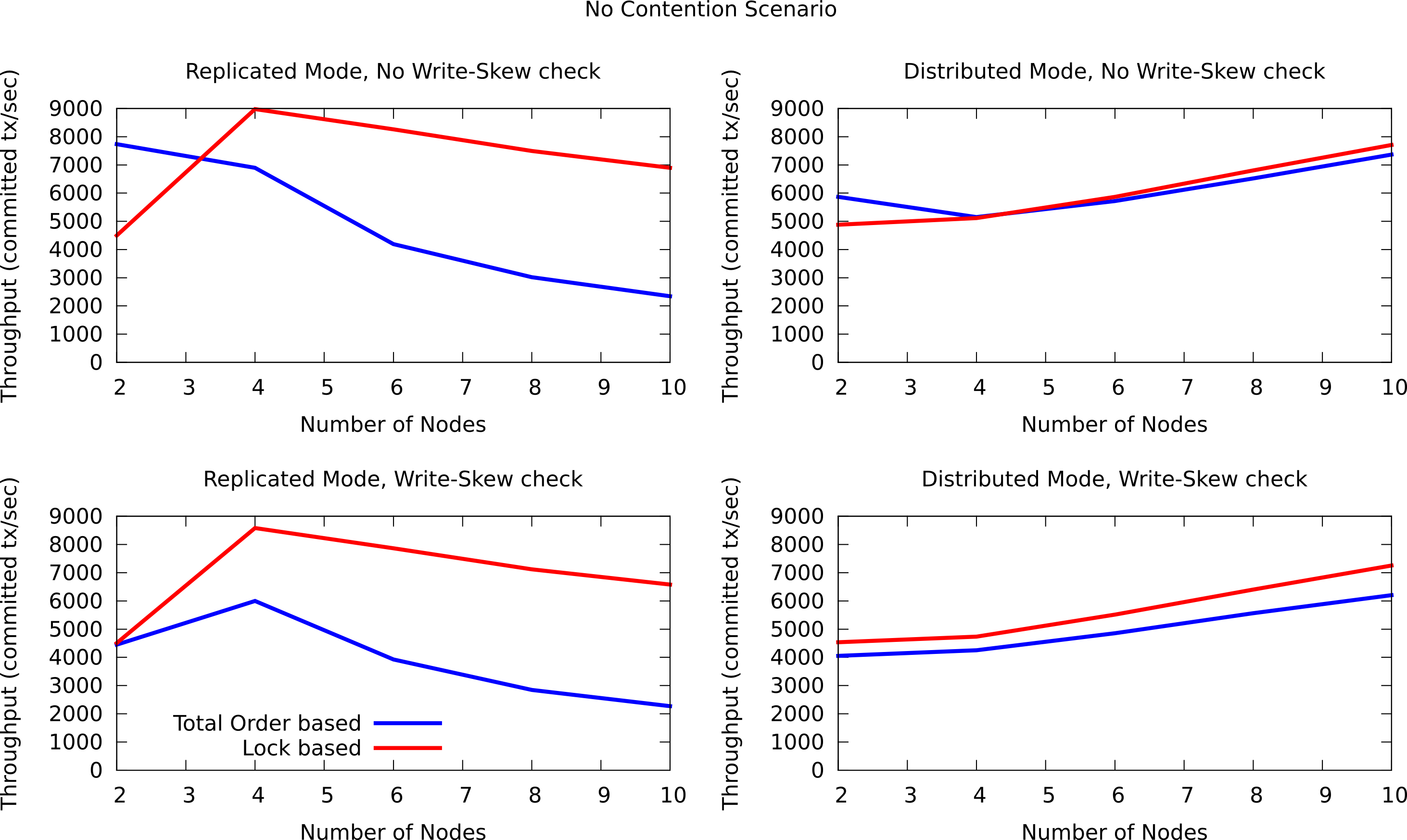
In order to compare the performance of total order with the locking model, RadarGun was used to perform a benchmark evaluation in two different scenarios: a no contention scenario and a contention scenario.
The Infinispan configuration used is:
<?xml version="1.0" encoding="UTF-8"?>
<infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:infinispan:config:5.3">
<global>
<transport clusterName="x">
<properties>
<property name="configurationFile" value="jgroups/jgroups.xml"/>
</properties>
</transport>
</global>
<default>
<transaction
transactionManagerLookupClass="org.infinispan.transaction.lookup.GenericTransactionManagerLookup"
transactionMode="TRANSACTIONAL"
transactionProtocol="TOTAL_ORDER"> <!-- transactionProtocol="DEFAULT" for the locking model -->
<recovery enabled="false"/>
</transaction>
<locking concurrencyLevel="1000" useLockStriping="false" isolationLevel="REPEATABLE_READ" writeSkewCheck="true"/> <!-- writeSkewCheck="false" for the no write skew experiments -->
<clustering mode="r"> <!-- mode="d" for distributed mode -->
<sync replTimeout="10000"/>
<stateTransfer fetchInMemoryState="false"/>
<hash numOwners="2" /> <!-- for distributed mode only -->
</clustering>
</default>
<namedCache name="testCache"/>
</infinispan>
and the benchmark configuration is:
...
<benchmark initSize="2" maxSize="${10:slaves}" increment="2">
<DestroyWrapper runOnAllSlaves="true"/>
<StartCluster staggerSlaveStartup="true" delayAfterFirstSlaveStarts="5000" delayBetweenStartingSlaves="500"/>
<ClusterValidation partialReplication="false"/>
<StressTestWarmup duration="1m" opsCountStatusLog="5000" numThreads="8" transactionSize="10"
useTransactions="true" writePercentage="50" numEntries="1000" sharedKeys="false"/>
<StressTest duration="5m" opsCountStatusLog="5000" numThreads="8" transactionSize="10"
useTransactions="true" writePercentage="50" numEntries="1000" sharedKeys="false"/>
<CsvReportGeneration targetDir="no_contention"/>
<ClearCluster/>
<StressTestWarmup duration="1m" opsCountStatusLog="5000" numThreads="8" transactionSize="10"
useTransactions="true" writePercentage="50" numEntries="1000" sharedKeys="true"/>
<StressTest duration="5m" opsCountStatusLog="5000" numThreads="8" transactionSize="10"
useTransactions="true" writePercentage="50" numEntries="1000" sharedKeys="true"/>
<CsvReportGeneration targetDir="contention"/>
</benchmark>
...
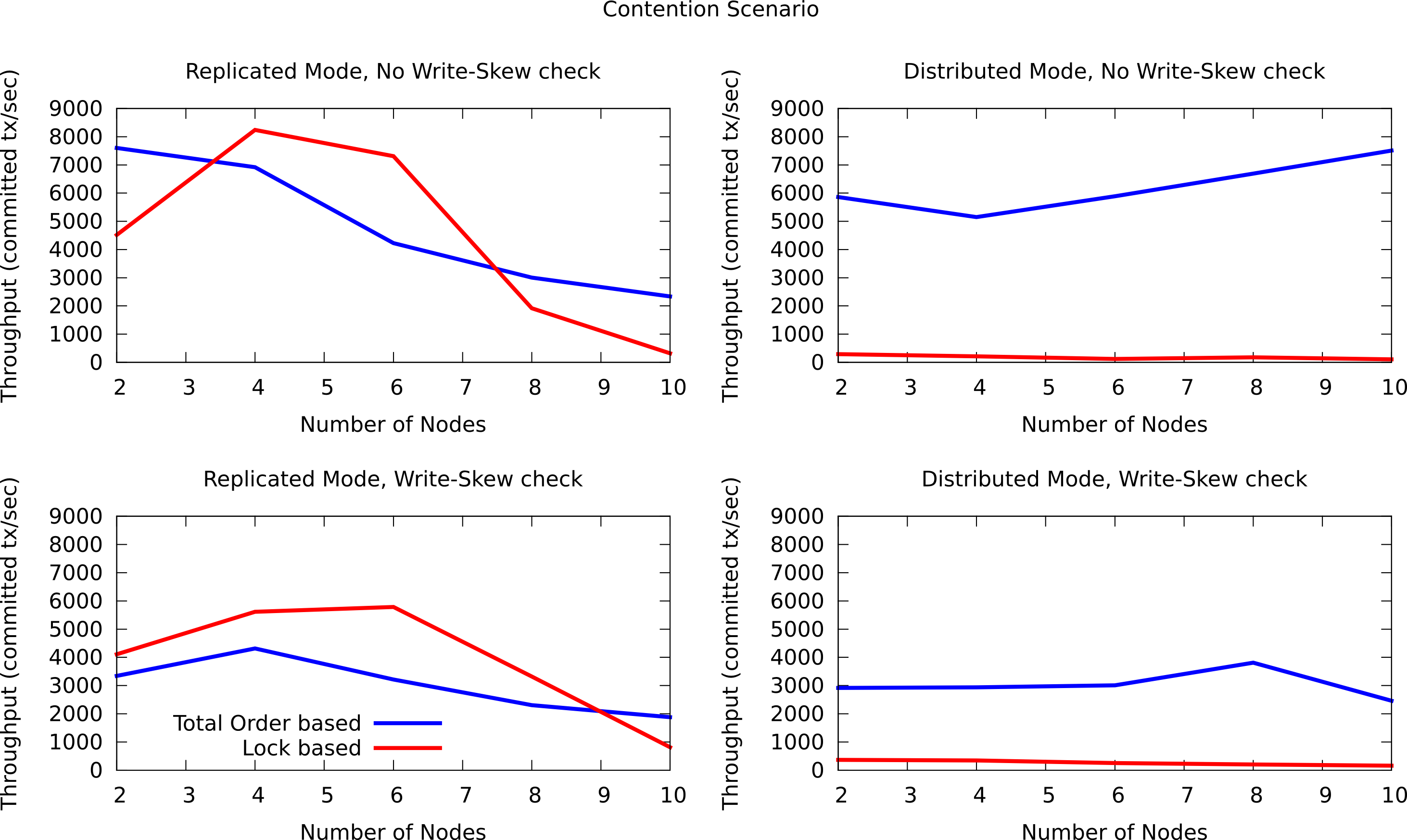
The difference between the contention and no contention is the pool of key. In the first case the pool of keys are shared among all the threads (and nodes) and in the last case each threads has it own private pool of keys.
The first group of plots shows the performance in the contented scenario:
and the next group of plots the no contended scenario: