RHQ
The Problem with the Baseline Out of Bounds Concept
To read about the new OOB design, see Design-New OOB
The JIRA related to this is: http://jira.rhq-project.org/browse/RHQ-1071
Summary of Baselines/OOBs
Baselines are calculated periodically that consist of a min/max/average for a measurement over a period of time (on the order of days - 1 day, 3 days or 7 days typically). Baselines are normally recalculated every X days, where X is typically 1 or 3.
Once a baseline is calculated, if a measurement is collected that is more than 5% higher than the baseline max, or more than 5% lower than the baseline min, an OOB is inserted into the database (RHQ_MEASUREMENT_OOB) to indicate a collection was out of bounds from the normal values most recently seen.
A resource that has 1 or more OOBs associated with it is considered a "problem resource" because its measurements have come in out of bounds from its normal past activity.
Why OOBs Are Suboptimal
The concept of baselines is fine - they represent a known range of normal measurement values over a recent period of time.
The concept of OOBs, which sounds fine in theory, actually produces less-than-useful results in practice. Some of it is due to the way we currently implement it, and some of it is based on the semantics of the measurement in question.
To illustrate the point, I will give some examples that I have actually seen happen.
These examples are from a large environment I was running. I was running a 4-server cloud that managed over 200 agents. The data that was in the database included close to a months worth of measurement data. During this time period, the server and agents were shutdown for long periods of time (hours to days) and restarted and ran for long periods of time (again, for hours to days).
First Example
Here is the first example for annoying OOB behavior. I had shutdown all servers/agents the night before. I then completely truncated the OOB and baseline tables (to start from scratch). The next day, I started up a new server and forced it to generate new baselines (so, baselines are now new and up to date). I then started a single agent on the same box as where the server was running.
Within a few minutes (if that) I got over 100 OOBs generated. About 10 minutes later this number doubled to almost 200 OOBs.
(note that none of these OOBs were coming from perftest plugin resources - I updated the perftest plugin and fixed it so it will not generate boat loads of artificial OOBs - so all OOBs were true OOBs in true resources)
Also note that I only have a single agent running. 1 agent, less than 15 minutes or so generating 200 OOBs. Extrapolate that out - 1 agent in 1 hour = 800 OOBs. 100 agents in 1 hour = 80,000 OOBs. 100 agents in 1 day ~~ 2M OOBs.
Now, this was after the server and agents were down for several hours. So, the baselines included data that were several hours old and didn't include data from the newly started server and agent. Things like system memory usage, server thread count and the like are now going to be potentially very different when they were the last time the systems were running. Because of this, many metrics will have values that are no longer within the range of the baseline that was calculated based on data from days ago, hence, for every measurement collection in question, an OOB will be inserted in the DB.
Second Example
Take a look at the graph image below that shows metric "Active Thread Count":
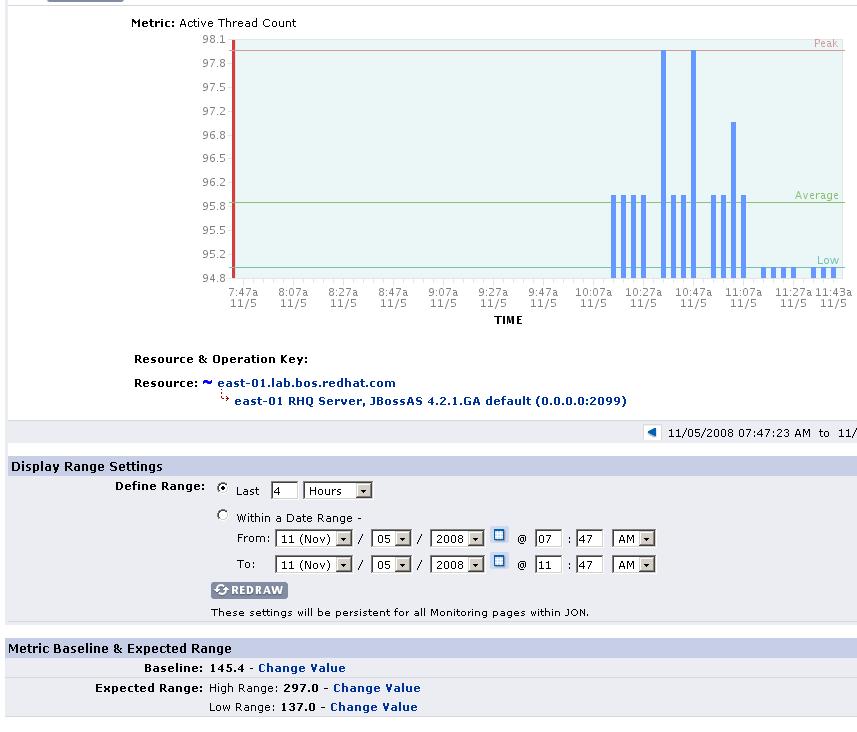
The server was shutdown as you can see for several hours earlier and then restarted. It started with a smaller number of threads than before. This metric is sending off OOBs every collection interval. Now, for the next 1 day until we recalc the baseline, I predict that every time this is collected, an OOB will be inserted because previously, the min/max was 137/297 but we are coming in at under 100 threads. So unless and until the server starts spinning up new threads (up to 130, or -5%), we are going to trigger a low OOB every time this metric is collected. Of course, as new agents start talking to this server, those threads might spin up, so this may be a bit artificial (after all, I only have 1 agent talking to this server now). However, you can assume this same kind of thing would happen with other types of measurements - that is to say, after a resource restart, measurements might come in at vastly different values than what they were before. While technically these are out of bounds from previous values, can we call these "problem resources"? Semantically, this server is not a problem resource - but because it has many OOBs associated with it, our UI would list this as a problem resource.
Third Example
Take a look at the graph image below that shows a graph for the average time it takes for the agent to send messages to the server:
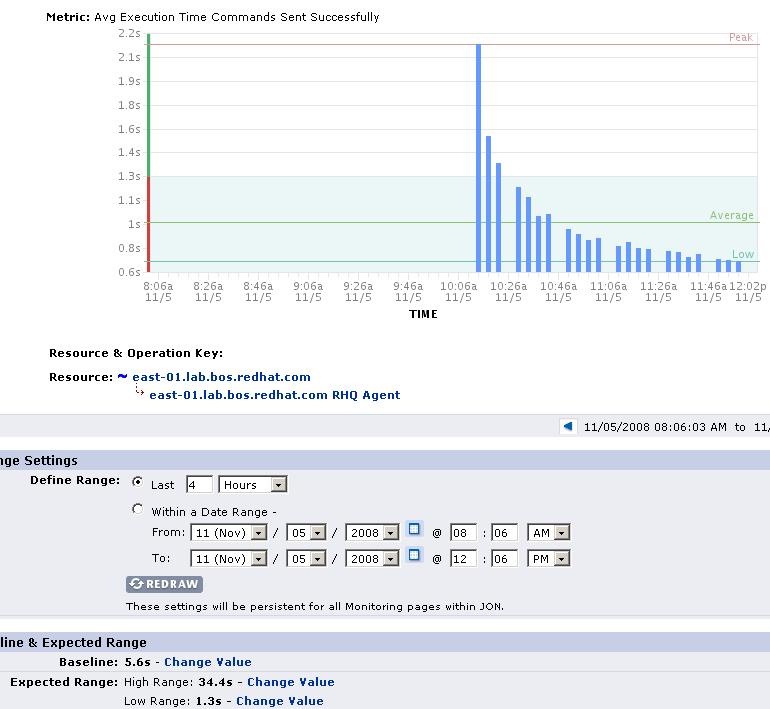
Again, the agent was restarted and the server is able to reply to the agents messages. Before, the baseline was min/max=1.3s/34.4s. But my newly started agent has stabilized and can send messages in under 1 second now (0.6s around).
Since the low baseline is so small, there is a very small window that I can go under without triggering an OOB (5% is 0.13s - round it to 0.1s for sake of discussion). Baseline Min is 1.3s so unless my agent is slow enough to come in at 1.2s or slower, I will be getting OOBs. But notice what I said - the agent has to have degraded performance for it to not trigger an OOB. Once my agent is stable and can send messages fast (e.g. 0.6s) - that triggers an OOB. That is poor semantics because common sense says it should be the opposite - I shouldn't make this resource look like a "problem resource" because in this particular resource's case, falling well below the baseline min is actually a good thing. These semantics are obviously specific to this resource and this metric (i.e. other metrics that fall well below the baseline min might be cause for concern, but this is not one of those cases).
Why The OOB Concept Falls Short
The OOB design as it stands today falls short. Baselines are fine - people can see what the min/max/avg is for a particular metric over a period of time - that seems useful. But blindly triggering an event like an OOB when a measurement falls outside that range is not as useful.
Why isn't this useful? I have so many OOBs, I don't know which ones to ignore and which ones I should consider valid enough to be concerned about! And even if an OOB is valid, in some cases, I might be getting OOBs for many consecutive collection periods so its hard for me to determine if an new OOB represents a new problem, or if it represents a problem that has already been raised by a previous OOB. As with any kind of information overload, once users get flooded with OOBs like this (in which the majority will end up getting ignored), it won't be long before they simply ignore OOBs entirely.
So, while in theory OOBs sound like an interesting and useful feature, we have seen in practice that OOBs simply flood the system in such a way that they simply can't provide any useful information. When thousands to millions of OOBs occur, with the vast number of them potentially not actually representing a new problem, it is very easy for a user to conclude that trying to find a meaningful OOB is too time-consuming to be worth the trouble, and therefore OOBs to be of little-to-no value.
What Can We Make Useful?
As mentioned before, baselines are useful - they represent a normal range of values previously collected from a resource. But what we are doing today is flooding the user with OOBs that alert him to every measurement that is out of bounds from those baselines - whether or not the information is useful or semantically makes sense. We are forcing the user to scan the vast collection of OOBs and look for those that are important.
Even though OOBs (as we know them) are proving to be less useful, the concept of alerting the user when a measurement is out of bounds is still very useful - but only if the user says it is useful. In other words, let the user tell us what baselines are important to him and have the user tell us which out-of-bounds conditions is important to him. Only then should we issue an "OOB" alert.
In fact, we already have the above capability - we can alert users based on values compared to the baseline! See the screen snapshots below:
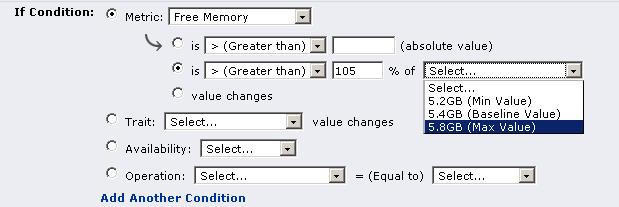
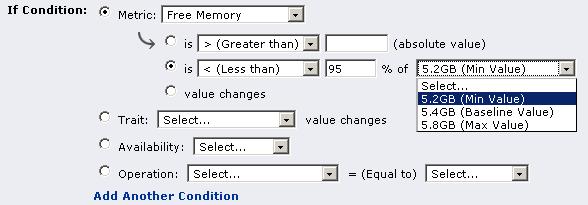
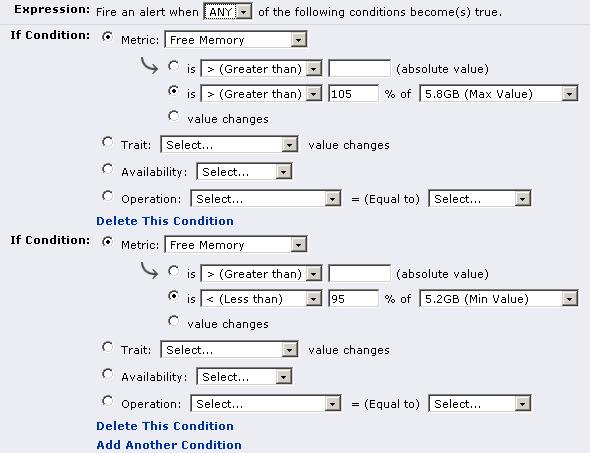
Note a couple added benefits here:
-
we can alert if a measurement only breaks one end of the baseline, ignoring the other end. So, in the agent "average time to send messages" measurement example mentioned above (where we didn't want an OOB triggered if the measurement was much lower than the baseline minimum), we can have an alert that triggers only if the baseline max threshold is broken.
-
We can define what percentage difference the measurement must be in order for it to be considered breaking the baseline threshold. OOBs are always +/- 5%. We can alert on any percentage that we deem appropriate for the specific metric we are alerting on.
-
We can use recovery alerts so the OOB alerts stop firing until we get back into the normal baseline range. This avoids the time when OOBs will always fire every collection period because our current measurements are in a new range that falls outside of the old range.
-
We can use dampening so we don't alert everytime an OOB is triggered.
We can set these OOB alerts on a per resource basis or across all resources of a particular type using alert templates.
So, even if we were to take out OOB functionality entirely, we still have the ability to inform the user when a value is found to be out-of-bounds - we just ask that the user define an alert to tell us when we should inform him of the OOB condition. We don't blindly log an OOB whenver the condition occurs.
If we want to keep the ability to store OOBs, I recommend we disable OOBs for all measurements, but have the user be able to turn on an "enable" flag to say, "I am interested in counting the number of times this measurement is out of bounds". Note that the user has to do this anyway if they want to be alerted when this condition occurs.
In the end, what OOBs give us that alert-on-baseline doesn't is just a count of the number of times a measurement is out of bounds. Just a number. It has no semantics whatsoever - it doesn't necessarily mean the resource is a problem resource and it doesn't necessarily mean the measurement is bad or wrong. All it simply is, is "this is the number of times a metric was seen to be out of the range of the baseline". With that in mind, I'm not sure if its worth trying to fix the OOB design - does OOB provide such a valueable feature over and above alert-on-baseline-OOB to warrant spending additional time to fix it?
What If We Removed OOB Functionality?
If we completely remove OOB calculations and storage as implemented in RHQ 1.1, our server would run much better:
-
It wouldn't have to process all of those OOB JMS messages (one message per OOB)
-
Transaction problems would alleviate due to the smaller number of JMS messages to process
-
We wouldn't have a table of 20M rows (we've seen Postgres not like large tables like this)
-
We wouldn't have to worry about purging all of those millions of rows during data purge job
(this would put less load on the database during times we run the data purge job) -
The Alert Cache would have a much smaller footprint since it no longer has to cache OOB conditions
What Can Replace Current OOB Functionality?
Remember that, in theory, the concept of an OOB sounds great. How we make this useful in the real world becomes the challenge. What can we do as a replacement to the OOB functionality we plan to rip out?
First, let's come to a conclusion as to what it is we really want when we say we like the OOB as a theoretical concept. What we want is for the system to answer a very basic question, which is:
What resources are, or have recently, emitted a measurement whose value is outside of the normal range of values it previously has emitted?
In other words, what we really want to know is which resources are behaving in a way that it hasn't before, based on recent past behavior.
This really is nothing more than a database query that compares a resource's measurements with its baselines - any measurements that are outside of the baselines will force its resource to be returned by the query.
As a corrolary, we could have this query sort the results such that those resources that are behaving the most abnormally would come first.
So, we can therefore, replace the current OOB functionality with a database query with a UI component that displays the results of that query.
What we would like future OOB features to tell us is:
-
What resources have currently emitted one or more measurements whose values fall outside of the baseline
-
Given the list of resources from above, sort them based on the largest percentage difference from its measurements to its baseline (i.e. if the baseline is 100 and a measurement came in at 110, that's a 10% difference; but if another resource had a baseline of 1000 and a measurement of 1200, that's a 20% difference and thus should appear first in the list of "OOB resources".
-
Given the list of resources from above, sort them based on how long its measurements have been OOB. If a resource only recently emitted a measurement with OOB values (say, within the last hour), it should be listed last compared to a resource that has been emitting a measurement with OOB values for the past 24 hours straight.