Under Construction
Facts
Content Subsystem
This subsystem, while offering a lot of promise is overly complex and not used by many. This is because of a couple of things:
-
in order to bring the data into this system, one has to write a lot of Java code to implement a Content Source
-
once you have a Content Source you have to organize the packages into Repositories,
-
you then have to associate individual resources with these repositories,
-
there is a conceptual disconnect between creating a resource (Inventory->Create Child) and update (Content)
-
The content may originate from content sources, maybe be manually uploaded to repos by users and also the content may originate from the resources themselves. There is no clear separation of the packages coming from these separate sources (there might not have to be, but it can become confusing to figure out where stuff comes from and where it is used).
Also the storage model is confusing to say the least:
-
A package in a concrete version and architecture is unique across repos
-
A repo is therefore merely a view on the set of all packages
-
This makes it impossible to have two "my-app.war" with different contents in RHQ
-
Only due to heroic efforts of Stefan, who replaced all the "versions" with SHA256, the above is sort of possible
-
Still, two packages with the same content but named differently are stored in the DB separately
-
Imagine this scenario:
-
Server 1 has my-app.war, the backing content is discovered and pushed to database
-
Server 2 has my-app.war, the backing content is discovered and found to be identical to the first one
-
You update the content of my-app.war on Server 1.
-
The quiz questions are: What app is deployed to Server 2? Why? Why it is not the other way round?
-
Provisioning subsystem
-
Conceptually much simpler - bundles uploaded, deployed blindly somewhere on the filesystems - paths resolved from group members
-
No notion of discovery of bundles on agents
-
No notion of providing the bundles to the RHQ server from a remote location (akin to content sources for packages)
Why do we need to bring the two together?
-
2 subsystems providing conceptually very similar thing
-
each has different advantages and disadvantages
-
we are going to need something (slightly) new for AS-Next patching
Why AS-Next patching doesn't fit either
https://community.jboss.org/wiki/SingleInstallationPatching
Patching in a nutshell
-
there can be "one-off" patches installed along side a patch
-
a newer patch discards all previous patches (the previous patch + all the one-offs)
-
patches are overlayed on top of the install, nothing gets overwritten (this is done in a similar sense to how \$PATH variable works)
-
patches are only going to be applicable using the API, no standalone tool
Content Subsystem
well, actually content would be a really nice fit for this.
Pros
-
Content being handled by the resource components directly in the AS7 plugin would have access to the API.
-
The plugin can discover installed patches
-
because installation and discovery are disjoint, we can transparently handle the "disappearance" of one-offs afer a new patch is installed
-
we can reuse all the existing infrastructure (content sources, repos, etc) to enable CSP-like delivery of patches
Cons
We don't want to invest in content subsystem anymore.
Provisioning subsystem
While bundles are the preferred way of delivering content in RHQ, they don't really fit well with AS-Next patching mainly because of two reasons:
-
The patches can be installed only through API - this means that either the user'd have to supply the credentials at each patch-bundle deployment or that we'd have to find a way of communicating between the plugin and the bundle deployer (this might just mean that more plugin properties will be passed through to the deployer - not just the base paths, but also the credentials)
-
Deployment of a new patch discards the previous one-off patches - we have a concept of upgrade and revert in bundles, but we don't model relationships between different bundles.
How to bring bundles and content closer together
The big disconnect between bundles and content is that bundles are by design ignorant of what they're deploying so that they can be used freely by the users that can script the deployment logic. On the other hand content packages are typed and can be delivered to only compatible resources. This is the fundamental difference between the two otherwise quite similar content delivery systems in RHQ.
why do we need to bring them together though? First of all, we should do something about the confusing situation we present our users with by having to deal with 2 separate content delivery subsystems, even though they serve slightly separate roles. Secondly, if bundles are our preferred way of delivering content now, we should strive for making all new content-related features be implemented using them. For AS-Next patching this will not be possible unless we enhance our bundle subsystem somehow.
Before thinking about the ways we could bring these two subsystems that at the end of the day do quite similar things closer together, let's compare and contrast their functionality. First, let's take a look at a simple use case diagram:
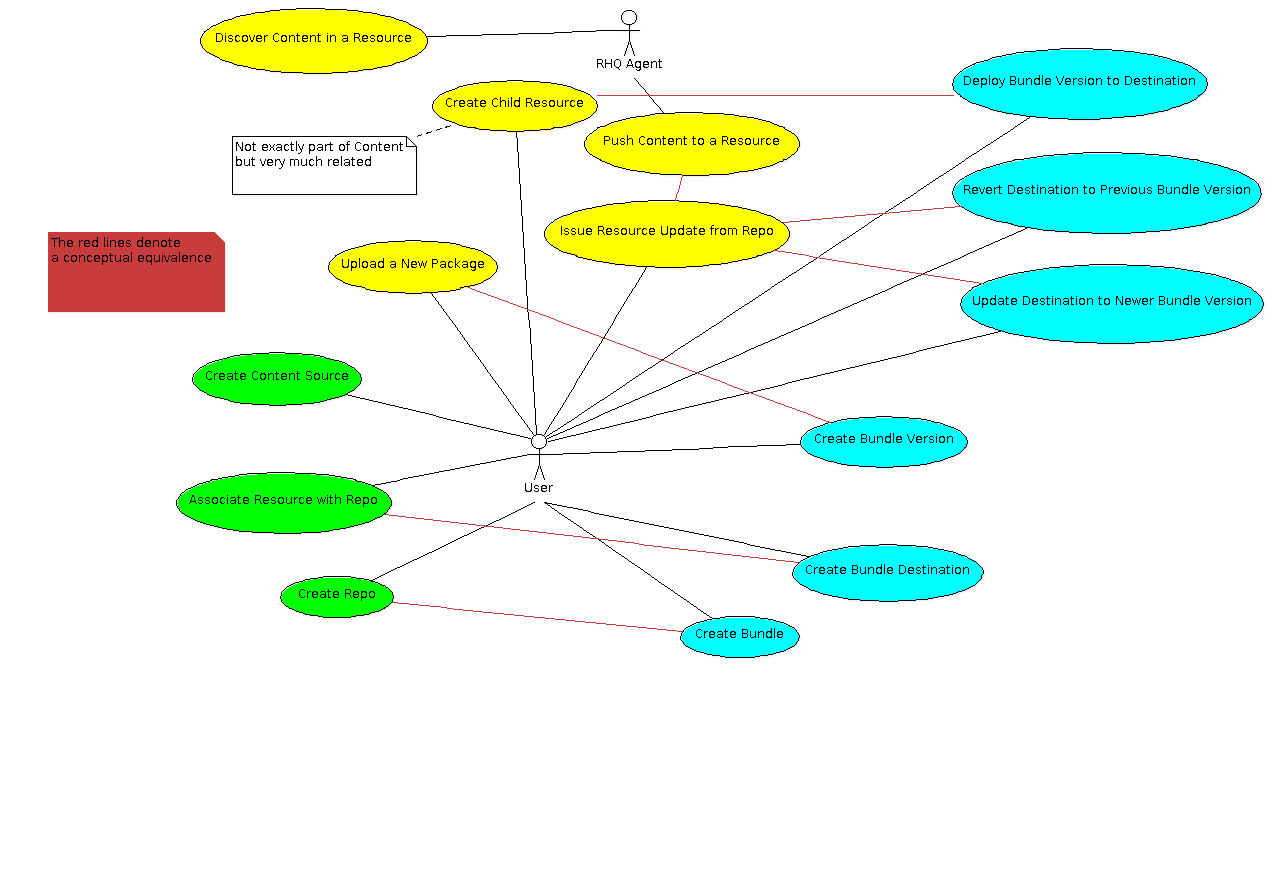
In the diagram, yellow represents the part of the content subsystem managing the actual storage and deployment of the data, the green represents the content retrieval and organization and blue represents the bundle subsystem use cases. More importantly, the red lines represent a conceptual equivalency or at least conceptual proximity of the use cases. Strikingly, the only two content use cases not matched by a bundle use case are the (agent-side) content discovery and content retrieval (using content sources or anything like that).
In contrast to the conceptual resemblance, the implementations of the two subsystems do not share much. This can be best shown by a class diagram:

In that diagram, you can see that the bundle subsystem uses content to store its data but doesn't reuse the classes for nearly identical concepts like bundle deployment and package installation (look at how similar the BundleResourceDeployment + BundleResourceDeploymentHistory is compared with InstalledPackageHistory + InstallationStep).
Closer look at the differences
Content subsystem
-
Supports retrieval of contents from remote locations (provided there exists a plugin for that)
-
Packages are typed (see PackageType in the above class diagram) - the package types are defined by agent plugins and determine what and how (by means of optional configuration) is deployable to certain resource types
-
Content can be also discovered on the managed resources
-
Content installation and discovery are not tied together - there's no expectation that deploying a piece of content will result in it being discovered at the later time.
Bundle subsystem
-
A single bundle is uploaded manually by the user at a time
-
Bundles are deployed to resource groups, not individual resources
-
The "deployers" are ignorant of what it is that is being deployed
-
A bundle is explicitly remembered as "deployed"
What do we need in Bundles for AS-Next patching
I imagine the AS patches to have a standalone agent-side bundle handler that would communicate with the AS instances using the API and would delegate all the real filesystem work to it. For this to happen though we need a couple of things:
-
Configure the bundle handler to connect to the managed resource:
-
Somehow make it possible for the handler to talk to respective resource components?
-
Make it possible to pass additional configuration properties of the resources (apart from paths) to the bundle handler?
-
-
Discover existing "bundles". This would provide a couple of things:
-
Information for the user about what is installed on a resource in the form of bundles (i.e. what patches have been applied?) - This could also be done differently, like having a trait on the resource maybe?
-
Provide the users with "discovered bundles" that they can then pick up and re-distribute to other resources (imagine picking up a war from staging server and distribute it to prod)
-
This of course requires new bundle handlers that would handle specialized recipe-less bundles (or the recipes would become something like "markers" for the type of content - essentially we'd create typed content.
-
-
Not assume a bundle deployment is predictable and final
-
I.e. do not assume that once we lay down a bundle, it is going to stay there forever (until purged) - this is needed for figuring out that one-off patches have been removed after a new patch has been installed.
-