<content name="destinationName" displayName="Friendly Destination Name" mimetypes="application/zip, text/*" allowedFileExtensions="zip,java,txt">
<configuration>
...
</configuration>
</content>
Work in Progress
AS8 Patching Without API Changes?
Yes! Implement it using the ContentFacet ! ![]() Then concentrate on bringing content into bundles as outlined below.
Then concentrate on bringing content into bundles as outlined below.
TODO
-
Incorporate the "bundle deployment may result in appearance of multiple resources" into the model. This is quite non-trivial and influences with how content-backed resources are going to behave.
-
How exactly are we going to handle the discovered packages on the resource? represent as repo-less bundles attached to the resource through a deployment? authz implications?
-
How do we represent content-backed resources in the model?
-
Propose the new server plugins for mimetype detection and migration of the existing bundle and packagetype plugins
Executive Summary
The high level end goal of this effort is to end up with a single provisioning solution for RHQ. I.e. to somehow merge or bridge the current two solutions - the bundle and content subsystems. An important milestone in this effort is to enable one or the other subsystem with the ability to handle the upocming patching ability of JBoss AS.
What is outlined below represents the arguably more complex approach but one which, IMHO, will provide us with a more consistent and future-proof design than the discussions had so far about adding new capabilities to the bundle subsystem that would mimic the capabilities already present in the content subsystem. In that case, a lot of code would have to be essentially duplicated and we would be stuck with supporting multiple versions of essentially same interfaces.
This document discusses an approach were a minimal set of changes would be applied to the existing agent-side APIs (leaving them largely backwards compatible) which enables the reuse of a large body of existing agent plugin code and modifying the server-side APIs to accomodate for removal of content subsystem while making changes to the bundle subsystem to accomodate for the most important and useful content-subsystem workflows.
This approach would kill 2 birds with one stone - it would enable AS patching as a consequence (without actually introducing hardly anything new on the agent side) and would actually solve the schizofrenic situation we deal with. This is in direct contrast with the previously discussed approach which would only enable AS patching using the bundle subsystem (by introducing new agent-side API) but would leave the overall goal untouched (or even slightly more complicated with one more API to care about).
In a nutshell, this proposal proposes 6 things:
-
Keep both the bundle and content agent APIs as much backwards compatible as possible - the changes will not affect the usual workflows, but users will have to deal with disappearance or restructuring of some parts of the model.
-
Enhance bundle subsystem to support important content workflows
-
Overhaul and conceptually simplify content storage
-
Completely remove the content-subsystem-based deployment workflows without a migration path
-
Get rid of content sources and rely on user supplied automation scripts to do much better job
-
Make content subsystem responsible only for storage of data and nothing else.
Data storage discrepancy
Apart from the fundamental difference between content and bundles, which is that content is resource-bound while bundles are filesystem location bound, another major difference that hinders the interoperability between the subsystems is the difference in their storage mechanisms.
Content subsystem is built around the idea that the deployable unit is called a PackageVersion which maps to a single (versioned) file. These files exist in a big pool on which one can create views in the form of Repos. One can also push the packages into the pool from content sources and from the resources themselves.
Bundles on the other hand have (conceptually) 2 deployable units - the bundle itself but also the individual files that the bundle consists of - these are stored as, surprisingly or not, package versions. A bundle then is stored as a repo containing files of all bundle versions it contains. Theoretically it could be possible to change and "beam down" to agents individual files of a bundle but currently there is no UI or API support for that (nor do I think it would a smart idea to allow changing a single bundle file - the whole concept of versioning the bundle would then become problematic).
Why do we need to unify?
Note
This section is unchanged from Bundles vs. Content - Proposal 1
The fundamental requirement for the two subsystems to start merging is to start unify their data storage "philosophy". As said above, content considers a package version a single deployable unit, while bundles consider a bundle (which consists of several package versions) a deployable unit. If we were able to represent a bundle as a single package version, it would bring us the advantage of keeping and reusing the existing APIs only adding new abilities to "re-purpose" them. Concretely, if a bundle version was stored as a single packageversion (not as a set of them), it would be possible have a single serverside code to handle all kinds of content (both bundles and content packages). This then could enable us to be able to re-purpose the ContentFacet on the agent as a vehicle for delivering and deploying the "typed bundles" (in another words AS patching would become so much easier - the Content APIs are well equipped for that task). Conversely, if a bundle was stored as a single package version, it would be possible to organize bundles into repos (currently there is a single bundle per repo, which causes confusion when repos are also used for content-subsystem purposes).
What are these "typed bundles" (that I already mentioned in the initial discussion of the problem) and why would we need them? This is actually a bit of a misnomer as bundles are already typed - we have Ant bundles and filetemplate bundles. By "typed bundles" I meant bundles tied to a single resource type. In the mean time we have seen this in our internal design discussions where we came up with a concept of resource-bound bundle destination that would be handled by the resource components themselves. Even during those discussions we found that that concept is very similar to CreateChildResourceFacet, namely to creating a child resource by uploading some binary data. In addition to this similarity, there is another one in the ContentFacet - the deployPackages() method.
Imagine a world, where a bundle would be a single package version (i.e. a single file). Now let's take a closer look at the above mentioned interfaces, their methods, expectations and intended usage and also how would we be able to re-purpose the ContentFacet methods to do "bundly" things:
|
BundleFacet |
CreateChildResourceFacet |
ContentFacet |
|
BundleDeployResult deployBundle(BundleDeployRequest request) |
CreateResourceReport createResource(CreateResourceReport report) |
DeployPackagesResponse deployPackages(Set<ResourcePackageDetails> packages, ContentServices contentServices) |
So what are the fundamental differences/common points here?
-
All methods deploy binary data "somewhere" (being it filesystem, API, whatever)
-
Bundle deployment may or may not result in new resources being discovered
-
Creating a child should result in exactly one new resource being discovered
-
Deploying content to a resource should result in no new resource being discovered
If we changed expectations of all the methods so that:
-
Deployment may or may not result in new resources being discovered and these are the resource keys of those "candidate" resources
The methods would become semantically identical. Note that the change to the ContentFacet and BundleFacet would even be backwards compatible (we could leave CreateChildResourceFacet return just one child and deprecate its usage for content-based resources - having 1 child being created using just configuration entries seems quite logical)!
What's even more exciting about this is that if the bundles were single package versions, we could suddenly view all the content files as potentially deployable as bundles (to compatible groups of resource types corresponding to the package types of the content). I.e. we could apply the (almost unchanged) bundle workflow on data originating from the content subsystem.
|
BundleFacet |
DeleteResourceFacet |
ContentFacet |
|
BundlePurgeResult purgeBundle(BundlePurgeRequest request) |
void deleteResource() |
RemovePackagesResponse removePackages(Set<ResourcePackageDetails> packages) |
As with the content deployment discussed above, we can modify the BundleFacet and ContentFacet to report the potential disappearance of child resources as a result of content removal at which point they become functionally equivalent.
DeleteFacet does not fit too nicely here, because it operates from the POV of the removed resource itself, not from the POV of parent. At the same time, it does not conflict with the above changes.
|
ContentFacet |
Discussion |
|
List<DeployPackageStep> generateInstallationSteps(ResourcePackageDetails packageDetails) |
This is somewhat similar to the audit messages of bundle deployment, the biggest difference being that the content installation steps are generated ahead of the time of the actual deployment, while the bundle audit messages are only generated during the deployment itself. |
|
Set<ResourcePackageDetails> discoverDeployedPackages(PackageType type) |
This would be a new concept, not currently present in bundles - discovery of already installed bundles. The difficulty with this is that this method is meant for discoverying content "inside" a resource - i.e. a WAR resource is supposed to discover its content. This would not work with bundle subsystem because the bundle containing a WAR file should logically be deployed from the parent. On the other hand, this might not be too much of a problem - "the war file discovered its contents, let's deploy that as a bundle to the other application server" doesn't sound too illogical. |
|
InputStream retrievePackageBits(ResourcePackageDetails packageDetails) |
Used to retrieve the bits of the discovered packages. This is needed for the component-discovered content/bundles, but |
How would we unify?
One important realization that we made in previous discussions was that the ability to deliver or update individual bundle files inside bundle is a corner case left-over from previous iterations of bundle subsystem design that was actually not part of the final implementation on the agent side - agent side has no ability to request individual bundle files from the server - it only gets the whole "bundle distribution file" or nothing. On the server (and remote API) there exists the ability to upload or add new bundle files to an existing bundle.
But none of this actually prevents us from considering a bundle version to be a single package version - in another words a single file. Granted, updating the files in a bundle becomes a more complicated affair, having to download, unzip, update, rezip and upload the file to the server, but it is doable.
The benefits of considering the bundle version as a single file (aka package version) are numerous, but the main one is that we can start sending "bundles" into the agent side content APIs and there would be no misinterpretation possible. It would be just another package version with a type that would signify it is a bundle. Further, we could keep the concept of storing the "files" in repositories. This is a concept that I think we should strive to keep because it provides a) a way to organize a possibly large list of bundles and b) provides a nice parallel to resource groups in the "resource world" - we could for example hook the much requested granular authz on bundles on the repositories which would make securing access to bundles conceptually equivalent to securing access to resources. In the latter case, one assigns resource groups to roles, while in the former case one would assign repos to roles (obviously for this there needs to be a number of new permissions introduced into the system).
We made a conscious decision that we need to keep the bundle subsystem API and workflows as intact as possible. At the same time, we made no such decision for content subsystem and we also knew for some time that content subsystem is an overly complex "beast" that was quite hard to use and even harder to maintain (at least code-wise). I therefore hope that the proposal for actually removing most of the concepts and functionality of the content subsystem wouldn't be considered a blocker. The list of removed and "replaced" workflows will be discussed further down, but for now suffice it to say that content sources would go away without replacement and content-based package deployment would be replaced by bundle deployments without an ability to migrate the history and state of content-deployments from past versions of RHQ.
This proposal is not actually so much about unification of the two subsystem as it is about making the storage of content more simple and versatile while keeping the bundle deployment workflows that would use this storage model as intact as possible (note that the current version DOES NOT achieve 100% backwards compatibility there but it is incompatible in areas that are IMHO not crucial in bundle subsystem). This has 3 benefits:
-
simpler way of uploading and working with content
-
bundle workflows remain the same (almost)
-
we keep separate models for storage and for deployment (while reducing the number of deployment models to 1)
Simplifying Content Storage
We should take a look at the core use-case of content storage in RHQ. We store the content only to later deploy it somewhere. Other more minor use case is to provide a place to store content that is directly used on the server later on (like CLI alert scripts). We should make this use case as frictionless as possible.
With removal of content-based deployment, we're left with only 2 ways of deploying a content to a resource:
-
through a bundle - our objective is to actually keep the workflow intact and therefore no conceptual changes are required or wanted there.
-
through "Create Child" mechanism - by equalling bundle to a package we actually can reuse existing agent-side code and only "prepend" the usual bundle, yet simplified, workflow in front of that:
-
upload a package
-
select destination (if there is more than 1 possible for given type of package) (this will under the covers create appropriate BundleDestination object)
-
configure the deployment (this will under the covers create the appropriate BundleDeployment object)
-
Deploy
-
Note that nowhere in the above (short) descriptions of the main 2 deployment usecases a need to identify the type of the deployed "file" was mentioned. That's because bundle subsystem is smart enough to detect the type of the bundle to be deployed. Content subsystem, though, was not that smart and required the user to identify the type of the file they uploaded (let's ignore the problem of type identification in content sources here, because we're removing them anyway). To keep it simple for the user, we should strive for automatic detection of the file type by RHQ.
Another unfortunate quality of content subsystem was that the types of packages were tightly coupled with resource types. This for example meant that there was a separate "package type" for WAR files in AS4, AS5, AS7 and Tomcat. Further, these types were mutually "incompatible" and therefore one could not deploy a WAR that has been identified as "Tomcat WAR file" to AS7 even if the common sense would call for it. This of course isn't a problem in the "Create Child" workflow mentioned above - the user uploads the file with the resource type already selected and therefore only the appropriate "WAR" type is offered to him.
If we want to enable deployment of WAR files through bundle subsystem, we need to be able to determine its type before the deployment time though - before we know the resource type of the resources that the bundle will be deployed to.
One obvious solution (and one included in this proposal) is to employ the standard mime types and some mimetype detector (like (part of) Apache Tika). The most important effect this change has on the model is that a package type (which I will call just mime type from now on) is no longer tied to a resource type. Mimetypes exist on their own, the plugins no longer define them, but merely refer to them.
Let's see a simple class diagram of the new storage model.
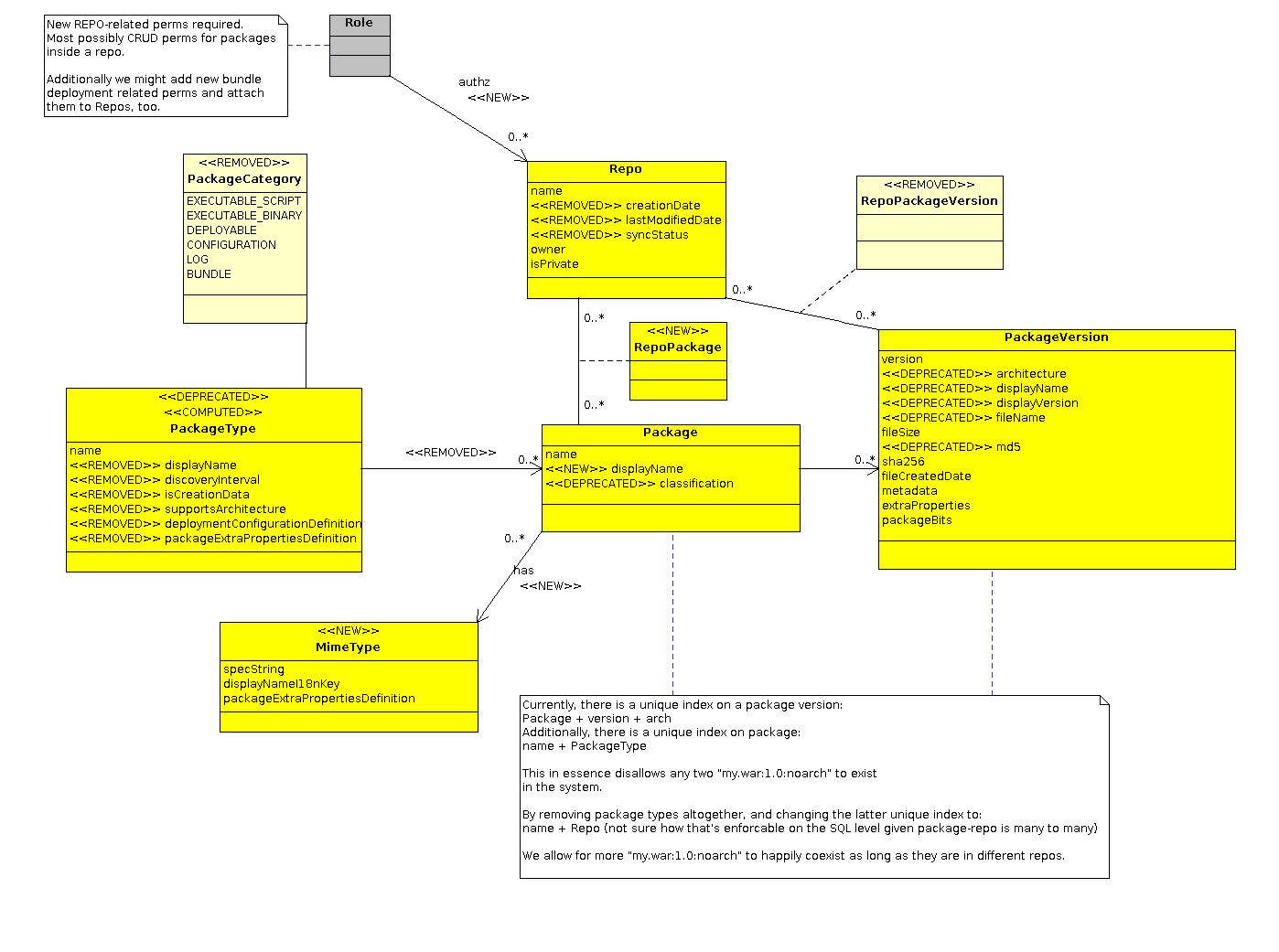
Let's ignore for a while the authz stuff (discussed below in a separate chapter) and concentrate on what changes were made to the storage itself.
PackageCategory REMOVED
As far as I could find PackageCategory had no functional use and for categorization purposes, it was more or less useless, IMHO.
PackageType DEPRECATED
NON_ENTITY computed from BundleDestinationDefinition
We need to keep package type around for the compatibility reasons. The agent side content API uses it and we want to keep that API. A striking thing about its agent-side usage is that only its name is ever used in the agent plugin code (as far as our plugins go).
Interestingly, this class should not be derived from the new MimeType, because PackageType has its origins in the plugins. Therefore it needs to be derived from something that describes the <content> tag in the new model, which is the BundleDestinationDefinition described below.
Package
IMHO, the correct way of viewing our content storage is to consider it a form of versioned "filesystem" (not hierarchical, but hey). The analogy for a file would be the Package, which can exist in a number of versions PackageVersion. The files can be stored in directories (Repos). Previous model allowed for different package versions of a single package to be present in different repositories, but I think this is unnecessarily complicated (although it made sense with content sources, where different content sources might have supplied different versions of a package into different repositories - but the key word here is "might" - I must admit I struggle to find a reason why would anyone want to keep different versions of a single "file" in different repositories - maybe security? but it is such a corner case in my mind, that it is not worth it to complicate the model with this possibility ATM).
The model therefore contains changes that make the Package a more prominent concept in the model, making it the main representation of the "file".
The fields on the Package class itself are rather few:
-
name - The name consolidates the prior use of "name" and PackageVersion.fileName, which as far as I looked through the code are always assigned the same value.
-
displayName - I can imagine someone wanting to rather see a "logical name" of a package than the actual file name. This is debatable thouhgh and this can be easily dropped.
-
classification- The javadoc for this field suggest what it "might" be used for, but it actually is never used anywhere. KISS this.
The main change comes in the two new associations Package has: -
@ManyToOne to MimeType - a package (file) has a mime type. That is an indisputable truth and is reflected in the model
 See below for discussion of mime type and its role in the new model
See below for discussion of mime type and its role in the new model -
@ManyToMany to Repo - The reason for this to be a many-to-many relationship is that if we are going to use Repos as base for authz over content and bundles then it may make sense for a package to be available in different repos, each with different authz settings. We do the same thing with resources and resource groups.
PackageVersion
Given the analogy of the versioned filesystem explained above, a package version should change so that it actually only represents a version of a file. We therefore should remove all the additional "cruft" on the class that made it both difficult to use and confusing:
-
architecture- IMHO, there's no reason for us to force the user to think about this when uploading a file to the content store. Vast majority of the content we used to produce was "noarch" anyway. I think it is reasonable to count on the users' common sense to figure out whether given file belongs on a certain "place" or not. -
displayName- a version of a file always has the same name as the file itself (while theoretically this might not be true in VCS systems, we're not one of them and I think this simple assumption suffices at least in the 90% of the cases). -
displayVersion- let's just remove this - what is really the reasonf for having version AND "displayVersion"? How do they differ? Why would we want to display different version string in the UI and different in the code? The javadoc says that it may or may not be the same as version. Again, I struggle to find a reason why it should be different. Let's KISS it. -
filename- Package being our representation of the file and packageVersion a "nameless" representation of certain version of that file, this field has no use anymore (it actually never had, IMHO, as all the plugins set the "name" and "filename" to the same value). -
md5- why do we keep 2 kinds of a hash of the file? -
sha256 - this is reasonable to keep as it helps reason about the differences between the files without having to read their contents. Additionally it might help us with a migration to a future more "clever" storage model that would store "nameless" content in a non-redundant way (like our drift subsystem).
-
fileCreatedDate - This field, while we possibly won't always have a reasonable value to assign to it, might be helpful when no version information is available on a package version. In that case it is reasonable to assume that this field will be the base for figuring out the ordering of the "versions" of such version-less file.
-
metadata - I am not sure if we want to remove this or not. It can be used to attach plugin-specific kind of information to the file.
-
extraProperties - This was used to supply additional information about the package, like parsed contents from MANIFEST.MF, etc. This information is useful to the user I guess but it should not be the responsibility of the plugins to extract this information anymore. The format of this information is going to be dependent on the mimetype of the package and the plugins are no longer responsible for determining that - mimetypes are standalone entities that the plugins merely reference. We are going to have mimetype detectors for the files and these guys should therefore be responsible for determining this kind of information on upload of the content to RHQ.
-
packageBits - the actual bits of the file in the particular version. We have to keep this, obviously, in one way or another.
MimeType
This type, while at first sight only a replacement for the PackageType, is the cornerstone of the content storage redesign. It is used for determining the type of the file, obviously, but it is also used for matching the available bundle deployers and bundle destinations (more on that below).
The fields on the entity itself are rather simple:
-
specString - the actual mime type string itself - i.e. application/zip, etc.
-
displayNameL10nKey - the key into the localization bundle to provide a language specific name for the mime type (this would only work for RHQ provided mimetypes that we could put into the GWT message bundles, unless we finally solve the problem of resource type localization - mimetypes could follow the same type of logic then).
-
packageExtraPropertiesDefinition - the format of the additional metadata that can be extracted from a file of given mimetype.
More than the fields, though, it is important to describe how the mimetype detection would work.
We have a concept of "package type" server plugins, that are governed by the PackageTypeBehavior interface. We could extend this interface (and server plugins of which there is exactly one in our codebase (and I very much doubt there is any other in the community)) to support mimetype discovery very similarly to how bundle server plugins discover the type of a bundle on upload (these guys could potentially extend this new type of server plugin, too).
The first mimetype plugin to successfully identify the type of the package would "win". If none of the plugins would identify the uploaded file, we'd use a fallback mechanism using Apache Tika, which has quite comprehensive mimetype database and robust mime-magic+file-extension detection. Alternatively we could somehow mold the bundle and mimetype plugins into Tika detectors that could be used to enhance the mimetype detection inside Tika itself.
Notes on Package Uniqueness
In the current model, as described in the introduction to the data storage discrepancy, package versions live in a big pool, to which the repos are merely views. It is impossible for there to be 2 "mywebapp.war:1.0" to exist in the database. This described in the class diagram above, but let me write down some more detail about here, too.
Currently, the model has 2 unique indices on Package and PackageVersion that implement the above restriction:
-
on Package, there's name + PackageType.id. This means that there can be no two packages with the same name of the same type in the database.
-
on PackageVersion, there's package.id + version + architecture.id. This means that a single package can have no two versions with the same version and architecture.
While I understand the reason for this is the fact that packages may come from different content sources and therefore we need some way of "merging" the imported packages to limit the redundancy/duplication of stored data and also to mimick the behavior of some linux packaging systems, I think that for the usecases present in RHQ it is just wrong to impose such a strong limitation on content that comes from the user in essentially unorganized manner (i.e. there is no external force on the webapp devs to provide consistent and robust versioning as it is on package maintainers in a packaging system).
The change that is proposed is to change the unique index on Package to:
-
name + repo.id where the repo.id can actually be null. This will allow two things:
-
In any given Repo, there is atmost 1 package with given name - a reasonable assumption following the filesystem analogy
-
There can be any number of packages with the same name without a repo assigned (this is because (both in Oracle and Postgres and according to SQL standard) NULLs are not considered equal)
-
The latter point is useful for content discovered in the plugins using the Content API (that don't end up in any repo), because it will allow for two "mywebapp.war:1.0" to coexist in the database, each coming from different resource.
Consequences in the Bundle Subsystem
While the introduction of the mimetype detection might seem innocent, it actually has quite some consequences in the bundle subsystem, too. This is not directly because of the mimetype existance but because of the fact that we need to provide a way of hooking up the bundle workflows into former content-subsystem deployment workflow. I.e. we need to be able to deploy using the Content API on the agent even if the "files" came from the bundle subsystem.
Following is the class diagram of the proposed changes which are discussed below it.
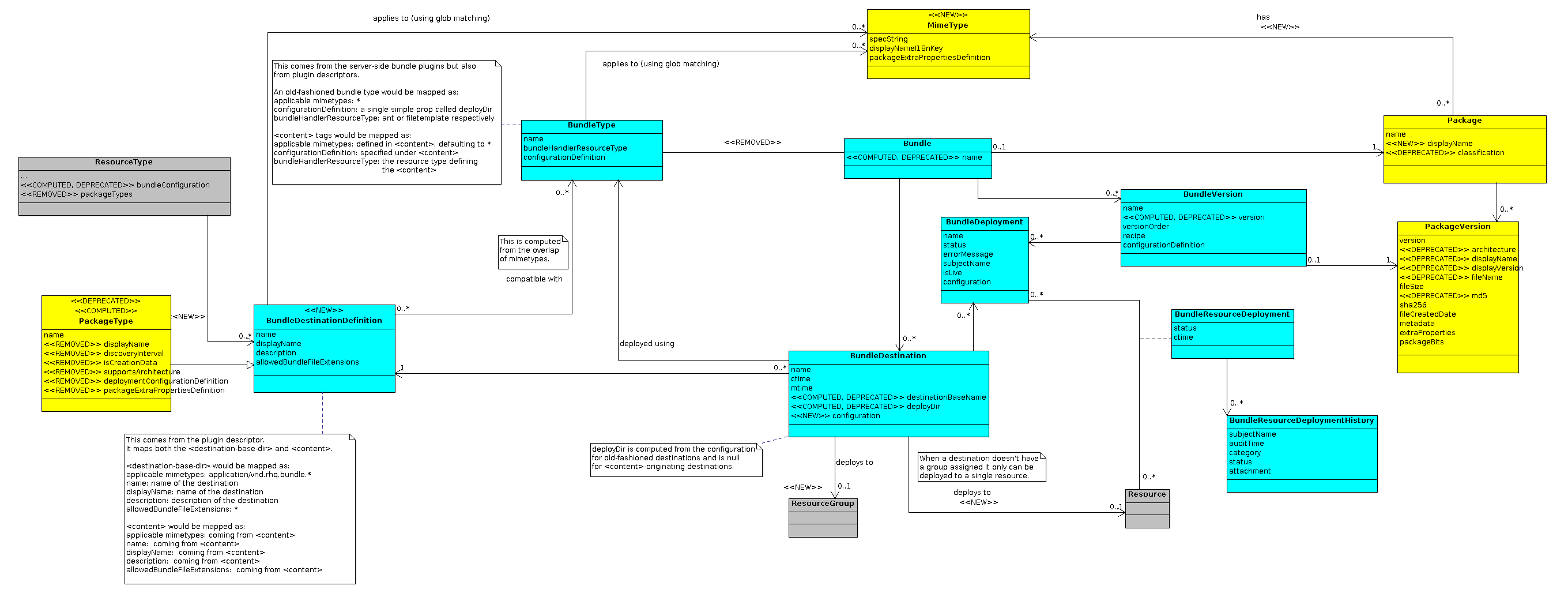
To hook up the <content> definitions (i.e. the former PackageTypes) into the bundle subsystem, the slightly non-obvious, yet powerful way of doing it is to pronounce the <content> tags new bundle destinations and at the same time derive new "bundle types" from the same definition. Understanding a <content> definition as a bundle destination has a number of consequences:
-
a bundle destination can now have an attached list of acceptable mimetypes
-
a bundle destination can now accept only files with certain file extensions
-
a bundle destination can now have a rich configuration provided with the deployment
-
a <content> cannot have the same name as <destination-base-dir>
Because the the destination-base-dir>s defined on a resource type are modeled in the domain model as a simple configuration instance with an assumed structure (ResourceType.bundleConfiguration which is then parsed as a strong type ResourceTypeBundleConfiguration), I think it makes it easiser to just introduce a new type called BundleDestinationDefinition and derive the former datastructure from it rather than try to shoehorn more stuff into the configuration object. But we may decide otherwise later on. For modelling reasons though, it definitely makes sense.
Now for the reason why we need to model the <content> definition as both the BundleDestinationDefinition and BundleType. This is actually because of the fact that the "normal" bundles define a destination without specifying the runtime configuration they need from the user, it is implied to be a deploydir, but with the <content> based destinations, the configuration is explicitly defined. This means that if we were to include the configuration definition to the BundleDestinationDefinition itself, we would be making assumptions about it: a null value would implicitly mean a configuration definition with a "deployDir" simple property. Also, in a generic sense a destination doesn't dictate the type of bundle handler - in case of ordinary bundles it doesn't - it just assumes a common configuration for them, on contrary in case of <content> bundles, the bundle handler will be equal with the resource type that defines the destination. Hence, the easiest way of resolving this duality, a <content> destination defines the allowed mimetypes and extensions on the BundleDestinationDefinition, because those definitions dont't depend on the actual bundle handler that will be responsible for deploying it, while the configuration of the deployment, i.e. the configuration of the deployer, needs to be at the BundleType.
All of this still doesn't take into account the odd outlier - the baseDir - i.e. a pointer to a value inside the resource that is understood as the root of the destination. I am actually inclined to consider this an intrinsic property of a destination definition, even if it was unused by the <content> bundles, because we don't have a good generic way of expressing such concept as a part of configuration definition (we do have option sources, but they are not a completely nice fit for this). Note that the base dir is actually not taken into account in the class diagram above yet.
Another profound change in the model is that a bundle is no longer directly associated with a bundle type. Because a mimetype can be potentially handled by multiple bundler handlers, we cannot make a choice for the bundle type until the time we create a bundle destination - at this point can we only know the resource type/resource that we are going to deploy to and using the matching of the mimetypes and possible user intervention in case multiple handlers can deploy (deploy this bundle as "patch", "library", ...), we can tie everything together. As an example, consider a WAR bundle. We don't know its "type" based only on that fact. Only once we select a group of Tomcat severs, we can say that for this destination we are going to be deploying that bundle as the bundle type with the TomcatServerComponent defined as its handler resource type.
Consequences in Content API and Plugin Descriptor
First, the plugin descriptor. With the introduction of mimetypes and the disappearance of PackageType, we need to make some changes to the plugin descriptor for it to be able to address the mimetypes.
For <destination-base-dir> there's nothing we need to change. This type of destination is meant for the generic bundle handlers that only need the destination name and deployDir underneath it.
For <content>, the following additions (as also mentioned in the class diagram above) will need to be made:
The new things in there are:
-
mimetypes - a series of mimetype spec globs, optional attribute defaulting to "*" (to provide for backwards compatibility with 3rd party plugins)
-
allowedFileExtensions - a series of file extension globs, optional attribute defaulting to '*'
-
configuration - this is actually already present in the plugin descriptor, only we are going to limit its uses to merely deployment time configuration.
Changes in the Bundle Deployment Workflow
The main change stems from the introduction of the mimetypes coupled with the late(r) detection of the bundle type to handle the deployment of a bundle.
Today, the bundle deployment is being processed like this:
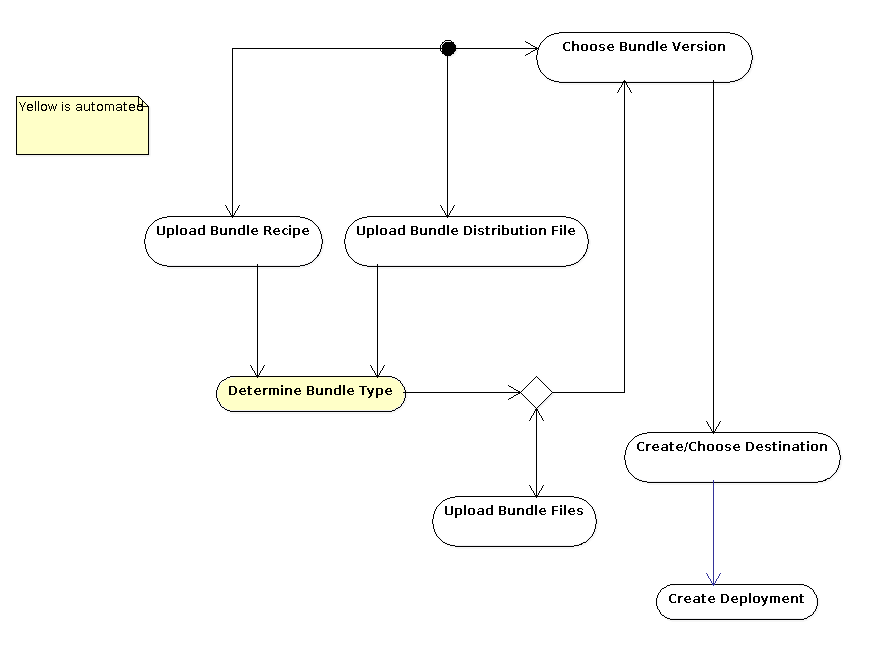
This illustrates the normal bundle workflow as driven from the UI or remote API (notice that unlike in the UI, you can upload any kind of files at any point to an existing bundle version using the remote API).
The new workflow would see the changes with the detection of the bundle type as mentioned above. Additionally we'd be deprecating uploading the bundle piecewise because we'd be storing the bundles as single package versions - updating that would require a download from the DB, unpacking, modification, repacking and uploading back into the DB (we are going to need some of that code anyway for migration purposes, but overall, I think this workflow does not offer much convenience over the "upload the bundle at once" approach).
So the new workflow would look something like this:
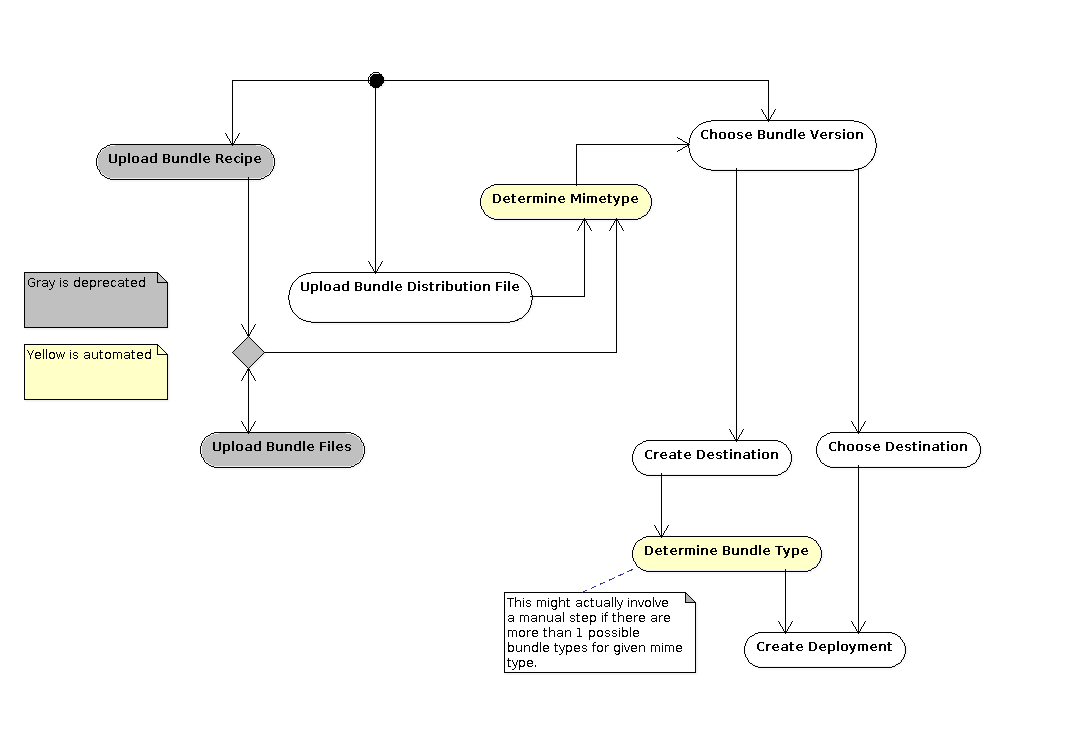
Changes in Other Deployment Workflows
The "Other" in the title would resolve to "Create Child" and "Delete Resource".
Create Child
Let's consider only content-based child creation here. Configuration based creation is obviously not affected by any of this. For this workflow, we need the ability of a bundle to deploy to a single resource. Creating a single-membered groups for this seems like an overkill so a better option might be to allow for bundle deployments to a single resource. Once we have that the "normal" bundle deployment can commence:
-
Upload a file
-
Determine the mimetype automatically
-
Match the possible destinations on the resource type automatically
-
Optionally let the user choose if more than one destination matches the mimetype
-
Deploy automatically
-
Handle the creation of the child using the CreateChildResourceFacet on the agent
You can see in the above that all the user needs to do is upload the file. Optionally s/he will need to make a choice of destination, which is reasonable. The error conditions are quite numerous, though nothing that would not have to be handled today. We might have the possibility to catch some of the errors sooner like "file already deployed" = "there exists an active deployment on the same destination of which the package version (i.e. bundle distribution file) has the same SHA", etc.
Delete Resource
Above, a change to the agent-side APIs was suggested to offer a set of affected resoures on bundle deployment (using any kind of content deploying APIs). This information would be stored in the domain model (actually, this is not yet reflected in the above class diagrams), giving us an idea what bundle deployment is responsible for what resources (the old-school bundles would not be able to provide this information most possibly, but they don't do now anyway). If a resource was deleted that we knew was backed by a bundle, we could automatically change the state of the bundle to (a new state of) out-of-sync, detailing the resource deletion as the culprit for that change in the bundle's audit.
Backwards Compatibility Consequences
There are 5 areas in the codebase that this change is going to affect:
-
domain model (as detailed above)
-
remote API (and therefore scripting APIs, too)
-
plugin API
-
server plugins
-
other server internals
While the changes in the domain model are fairly few (barring the fact that we removed a whole subsystem and basically came up with a new one for the storage), the consequences in the remote API and server plugins are important to have a very clear idea about. The same goes for the plugin API, which should see minimal to no change.
Domain Model
Removed
-
Advisory
-
consequences: the whole unused advisory "aspect" of content subsytem is going away, JSF GUI contains (never triggered) codepaths and UI for advisories
-
AdvisoryBuglist
-
AdvisoryCVE
-
AdvisoryPackage
-
RepoAdvisory
-
RepoAdvisoryPK
-
-
AdvisoryDetailsComposite
-
BundleFileCriteria
-
BREAKAGE - we won't have the ability to address individual bundle files anymore so this criteria doesn't make any sense, but it is used in the remote API!!!
-
-
ContentServiceRequest
-
REMOVE Resource.contentServiceRequets, Resource.getContentServiceRequests(), Resource.setContentServiceRequests(), Resource.addContentServiceRequest()
-
ContentRequestType
-
-
ContentSource
-
A biggie

-
many usages in ContentManager(Local|Bean) and in the JSF UI but these guys are going to get removed
-
The whole concept of content provider server plugin revolves around this entity, but that type of plugins is getting removed
-
ContentSourceSyncResults
-
ContentSourceType
-
PackageVersionContentSource
-
PackageVersionContentSourcePK
-
RepoContentSource
-
RepoContentSourcePK
-
-
ContentSyncResults
-
ContentSyncStatus
-
-
CVE
-
Distribution
-
DistributionFile
-
DistributionFilePK
-
DistributionType
-
RepoDistribution
-
RepoDistributionPK
-
-
EntitlementCertificate
-
InstalledPackageHistory
-
Used in the GWT UI, too, in portlets
-
InstalledPackageHistoryStatus
-
-
InstalledPackageCriteria
-
InstalledPackageHistoryCriteria
-
PackageCategory
-
PackageInstallationStep
-
PackageListItemComposite
-
PackageVersionContentSource
-
PackageVersionContentSourcePK
-
-
PackageVersionComposite
-
ProductVersion
-
ProductVersionPackageVersion
-
ProductVersionPackageVersionPK
-
RepoComposite
-
RepoGroup
-
RepoGroupType
-
RepoRepoGroup
-
RepoRepoGroupPK
-
-
RepoPackageVersion
-
RepoPackageVersionPK
-
-
RepoRelationship
-
RepoRelationshipType
-
RepoRepoRelationship
-
RepoRepoRelationshipPK
-
-
RepoSyncResults
-
ResourceRepo
-
ResourceRepoPK
-
-
SubscribedRepo
Kept
-
drop all the uses: drop the architecture table, no support for arch in packages, see PackageDetailsKey for more, GWT GUI consequences: child resource creation
-
deprecate methods in BundleManagerRemote that use this entity and provide identical methods without it
-
understand the role and use of the dynamic properties in the agent plugins - architecture is related to these
h6 BundleCriteria
Removed:
-
filterBundleTypeId
-
filterPackageTypeId
-
filterPackageTypeName
-
fetchPackageType
-
fetchRepo
New:
-
filterMimeType
-
filterPackageId
-
fetchPackage
Removed:
-
filterDeployDir - this is actually quite unfortunate because people might have used this. But I can't see a way of keeping it (maybe through some very wild override that would peek into the destination configuration object)
New:
-
filterBundleTypeId
-
filterBundleTypeName
-
filterMimeType
-
fetchBundleType
Removed:
-
fetchBundleFiles
-
used for servicing the content download to the agents - we're going to need this for supporting the ContentFacet
-
make this a global or per repo setting (and rename it to "StorageMode" perhaps)? - for this see the code in ContentSourceManagerBean.getPackageBitsLocalFilesystemFile
-
part of the CLI proxy of a content-backed resource - namely ResourceClientProxy.ContentBackedResource.getBackingContent()
-
make it a non-entity and compute it from the bundle deployment on the resource (of which there should be exactly one for content-backed resources)
-
also part of ContentDiscoveryReport used in the client-api - but that is a non-public server-agent communication spec so we have some freedom there. Note though that some plugin tests are using client-api to get data from the plugin container so we have to be careful and rather not break stuff unless absolutely necessary.
Added:
-
description - used by users if they need to put some more info on the package
-
repos - the set of repos the package is in
-
mimetype - the mimetype of the package
Removed:
-
packageType - replaced by mimetype
Deprecated:
-
classification - deprecate and make it an alias for description
-
as much as I wanted to replace these guys with something more intelligent (like DriftFile), I believe it is not in the scope of this first implementation to change the storage of the packages. We have enough far reaching changes and add 1 more that would have at least a very complicated migration path would be good to avoid, IMHO.
Removed:
-
filterPackageTypeId
New:
-
filterMimetype
-
used as a super class to ResourcePackageDetails. Many of the fields can be deprecated but we need the class around for not breaking back compat unnecessarily.
-
follow the deprecation/removal/addition of the fields in the PackageVersion + Package that this class mimics
-
deprecate and do not use packageTypeName and architectureName.
-
Keep only name and version. Detection of the mimetype can (and should) be done on the server.
-
make it a non-entity and deprecate everything in it. We need to keep it around because of ContentFacet.discoveryDeployedPackages(PackageType). Agent plugins only ever use the name property and so we should use just a String as a parameter to that method in the "new" ContentFacet once we define it.
Removed:
-
architecture
-
licenseName
-
licenseVersion
-
md5
-
installedPackages
-
installedPackageHistory
-
productVersionpackageVersions
-
getProductVersions()
-
addProductVersion()
-
removeProductVersion()
-
repoPackageVersions
-
getRepos()
-
addRepo()
-
removeRepo()
-
shortDescription
Deprecated:
-
longDescription - deprecate and make an alias to "description"
-
displayName - delegate to generalPackage.name, noop setter
-
displayVersion - delegate to version, noop setter
-
fileName - delegate to generalPackage.name, noop setter
New:
-
description
Kept:
-
metadata - let's make metadata the storage for recipes, too. This will enable us to keep the code in AS4 plugin intact
and at the same time port the CSP content source to script.
Removed:
-
fetchArchitecture
-
fetchInstalledPackages
-
fetchInstalledPackageHistory
-
fetchProductVersionPackageVersions
New:
-
packages
-
roles
Removed:
-
candidate
-
creationDate
-
lastModifiedTime
-
resourceRepos
-
getResources()
-
addResource()
-
removeResource()
-
-
repoAdvisories
-
repoContentSources
-
getContentSources()
-
addContentSource()
-
removeContentSource()
-
-
repoDistributions
-
repoPackageVersions
-
getPackageVersions()
-
addPackageVersion()
-
removePackageVersion()
-
-
repoRepoGroups
-
getRepoGroups()
-
addRepoGroup()
-
removeRepoGroup()
-
-
repoRepoRelationships
-
getRepoRelationships()
-
addRepoRelationship()
-
removeRepoRelationship()
-
-
syncResults
-
addSyncResult()
-
-
syncSchedule
-
syncStatus
Removed:
-
filterResourceIds
-
filterCandidate
-
filterContentSourceIds
-
fetchResourceRepos
-
fetchRepoContentSources
-
fetchRepoPackageVersions
-
fetchRepoRepoGroups
-
fetchRepoRepoRelationships
Removed:
-
contentServiceRequets
-
addContentServiceRequest()
-
installedPackageHistory
-
addInstalledPackageHistor()
-
productVersion
-
resourceRepos
-
getRepos()
-
addRepo()
-
removeRepo()
-
Removed:
-
fetchContentServiceRequests
-
fetchInstalledPackages
-
fetchInstalledPackageHistory
-
fetchResourceRepos
-
fetchProductVersion
-
deprecate and do not use packageTypeName and architectureName.
-
Keep only name and version.
Remote API
BundleManagerRemote
New:
-
BundleFile addBundleFile(Subject subject, int bundleVersionId, String name, String version, InputStream fileStream) throws Exception
-
BundleFile addBundleFileViaByteArray(Subject subject, int bundleVersionId, String name, String version, byte[] fileBytes) throws Exception
-
BundleFile addBundleFileViaURL(Subject subject, int bundleVersionId, String name, String version, String bundleFileUrl) throws Exception
-
BundleDestination createBundleDestination(Subject subject, int bundleId, String name, String description, BundleType bundleType, String destinationDefinitionName, Configuration destinationConfiguration, Integer groupId) throws Exception
-
This is for creating a destination with a specified bundle type in case there are multiple possible.
-
the destinationNameDefinition is the same thing as destBaseDirName in an already existing overloaded method but because we're going to support the <content>-based destinations, too, calling it destBaseDirName seems quite wrong.
-
destinationConfiguration is based on the BundleType.configurationDefinition - i.e. it provides the configuration needed by the given bundle handler. This corresponds to the deployDir parameter of the overloaded method, because deployDir was the implied configuration needed by all "normal" bundles.
-
bundleType can be null to signify that the implementation should try and find a single matching bundle type and check that the provided configuration matches its requirements. This is to support creation of destinations using a single method call, which would hopefully be the most common case.
-
-
List<BundleType> findDeployableBundleTypesForBundleAndDestination(Subject subject, int bundleId, String destinationDefinitionName, int groupId)
-
support for figuring out the bundle type that can be used to deploy given bundle to given destination.
-
Deprecated:
-
BundleFile addBundleFile(Subject subject, int bundleVersionId, String name, String version, Architecture architecture, InputStream fileStream) throws Exception
-
BundleFile addBundleFileViaByteArray(Subject subject, int bundleVersionId, String name, String version, Architecture architecture, byte[] fileBytes) throws Exception
-
BundleFile addBundleFileViaURL(Subject subject, int bundleVersionId, String name, String version, Architecture architecture, String bundleFileUrl) throws Exception
-
BundleDestination createBundleDestination(Subject subject, int bundleId, String name, String description, String destBaseDirName, String deployDir, Integer groupId) throws Exception
Removed:
-
PageList<BundleFile> findBundleFilesByCriteria(Subject subject, BundleFileCriteria criteria)
-
This can no longer be supported, because a bundle version is now a single package version and we can no longer "address" individual files in a bundle
-
ContentManagerRemote
New:
-
PackageVersion createPackageVersion(Subject subject, String packageName, int repoId, String version, byte[] packageBytes)
-
byte[] getPackageVersionBytes(Subject subject, int repoId, int packageVersionId)
-
just moved here from the RepoManagerRemote
-
Deprecated:
-
PackageVersion createPackageVersion(Subject subject, String packageName, int packageTypeId, String version, Integer architectureId, byte[] packageBytes)
-
packageTypeId and achitectureId are obsolete and unused
-
we should not allow for packages without a repo created through user intervention (this should be only reserved for resource-discovered stuff). We should define some behavior of this method.
-
-
PackageVersion createPackageVersionWithDisplayVersion(Subject subject, String packageName, int packageTypeId, String version, String displayVersion, Integer architectureId, byte[] packageBytes)
-
packageTypeId, displayVersion, architectureId are unused
-
again, should we allow repo-less packages created by a user?
-
-
void deployPackagesWithNote(Subject subject, int[] resourceIds, int[] packageVersionIds, String requestNotes)
-
This method is actually wrong
It doesn't support any deployment time configuration even if required by the packages, despite its javadoc. But let's just keep it in there deprecated and add some logic to shout early if config is not provided when it should to save on server-agent chit-chat.
-
Removed:
-
void deletePackages(Subject subject, int resourceId, int[] installedPackageIds, String requestNotes)
-
we no longer support this way of interacting with content
-
use BundleManagerRemote.purgeBundleDestination instead
-
-
List<Architecture> findArchitectures(Subject subject)
-
List<PackageType> findPackageTypes(Subject subject, String resourceTypeName, String pluginName) throws ResourceTypeNotFoundException
-
package types are replaced by mimetypes
-
-
PackageType findPackageType(Subject subject, Integer resourceTypeId, String packageTypeName)
-
PackageTypeAndVersionFormatComposite findPackageTypeWithVersionFormat(Subject subject, Integer resourceTypeId, String packageTypeName)
-
PageList<InstalledPackage> findInstalledPackagesByCriteria(Subject subject, InstalledPackageCriteria criteria)
-
Use the similar BundleManagerRemote.fundBundleResourceDeploymentByCriteria()
-
-
InstalledPackage getBackingPackageForResource(Subject subject, int resourceId)
-
The concept of content-backed resources has to be thrashed out in the new model.
-
-
byte[] getPackageBytes(Subject subject, int resourceId, int installedPackageId)
-
installed package has to be replaced by something else in the model
-
RepoManagerRemote
New:
-
void addPackagesToRepo(Subject subject, int repoId, int[] packageIds)
-
boolean deletePackagesFromRepo(Subject subject, int repoId, int[] packageIds)
Deprecated:
-
byte[] getPackageVersionBytes(Subject subject, int repoId, int packageVersionId)
-
This really belongs to ContentManagerRemote
-
Removed:
-
void addPackageVersionsToRepo(Subject subject, int repoId, int[] packageVersionIds)
-
boolean deletePackageVersionsFromRepo(Subject subject, int repoId, int[] packageVersionId)
-
repo store packages not package versions
-
-
PageList<Resource> findSubscribedResources(Subject subject, int repoId, PageControl pc)
-
List<SubscribedRepo> findSubscriptions(Subject subject, int resourceId)
-
void subscribeResourceToRepos(Subject subject, int resourceId, int[] repoIds)
-
void unsubscribeResourceFromRepos(Subject subject, int resourceId, int[] repoIds)
-
int synchronizeRepos(Subject subject, int[] repoIds) throws Exception
Plugin API
Deprecated
-
ContentServices.getPackageVersionMetadata() & ContentServices.getResourceSubscriptionMD5() - these guys make use of the concept of resource subscription to a repo, which we are removing. Deprecate them and make them always return an empty list / MD5 of empty string. This makes the internal platform yum server basically defunct and we should investigate its removal or a way of making it work in another way.
Removed
-
dynamic properties - I am inclined to removing the "dynamic-property" concept from our configuration schema, because it is exclusively serverside concept that is there to support content source configurations. In the meantime we've added support for similar concept through the "option-source" attribute on a simple property that works in a much better and more extensible way, imho. In any case, the need for dynamic-property disappears with disappearance of content sources in our current code.
PackageVersionMetadataComposite
Deprecated - see above for explanation.
Server Plugins
Removed
-
ContentProvider
Other Server Internals
-
Dynamic property evaluation - what's this for? Seems like only being used in the UI?
-
org.rhq.enterprise.server.plugin.pc.content.* is being removed
-
ConentProviderSyncJob - this guy can go
-
ProductVersionManagerLocal & ProductVersionManagerBean - removed
-
Cobbler server plugin will not fit into the new way of working with content and would need a major reimplementation. Not sure it's worth it given we don't use it for anything.
Backwards Compatibility Breakage Summary
Content Subsystem Disappearance
Most of the content subsystem classes are marked as deleted. This is because they have nothing to be backed by in either database or code. The new model is too different (for a good reason) to think about some "translation layer" between the old and the new impl.
Criteria Classes
As a consequence of the changes in the entity relationships, the criteria classes needed to be changed to reflect those changes. This is rather unfortunate but unavoidable consequence of the many removals and refactorings of the model. A change in a criteria class unfortunately means that any client that uses the affected criteria search methods will have to accomodate for the change.
The affected, backwards incompatible, criteria classes are:
-
BundleFileCriteria
-
This class completely disappears
-
-
InstalledPackageCriteria
-
This class completely disappears
-
-
InstalledPackageHistoryCriteria
-
This class completely disappears
-
-
BundleCriteria
-
3 filters and 2 fetches need to be removed and 2 new filters and 1 new fetch need to be added, see above
-
-
BundleDestinationCriteria
-
filterDeployDir needs to disappear. As mentioned above, this is quite unfortunate because, this might be quite a powerful and useful filter to use on bundle destinations. Because we need to support destinations backed by full configuration objects (not just a single property called "deployDir"), it would be quite hard to come up with a filter that would fulfil the role of the current "filterDeployDir". Not to mention that such filter wouldn't probably work for bundle destinations targeting the <content> destination definitions.
-
-
BundleVersionCriteria
-
a fetch of bundle files is no longer possible, because they no longer exist as standalone entities.
-
-
PackageCriteria
-
removed the ability to filter on packageType, because a package is no longer associated with such thing.
-
-
PackageVersionCriteria
-
removed several fetches (see above) of entities no longer present in the new model.
-
-
RepoCriteria
-
remove a bunch of filters and fetches (see above) of entities and relationships no longer present in the new model. Most of these are coming from the linux distribution management attempts and thus are harmless.
-
-
ResourceCriteria
-
Remove a bunch of fetches on relationships no longer present in the new model, see above.
-
Remote API
Again, apart from the removal of all the methods implementing/supporting the obsoleted content subsystem workflows, there had to be changes that break backwards compatibility in some parts of the system. In the details above, only the removals of the methods in the remote API represents an API breakage.
Plugin API
The damage here is rather low, fortunately. See above for full details. In a nutshell we will remove 1 otherwise-unused feature of configuration used in content sources, disable the support for the internal yum server in the platform plugin and deprecate a whole bunch of fields on the classes identifying the packages (ResourcePackageDetails, PackageDetails and PackageDetailsKey).
Server Plugins
One whole type of server plugins is going to get removed (and another one possibly added). The content source plugins have no place in the new design and therefore we should remove them. We will, though, have to come up with something for pluggable mimetype detection.