while (e != null) {
if (e instanceof EJBTransactionRolledbackException ||
e instanceof TransactionRequiredException ||
(e instanceof ResourceException && e.getMessage().contains("ActionStatus.ABORT_ONLY"))) {
shouldRedefine = true;
break;
}
e = (Exception) e.getCause();
}
Work In Progress
This page accumulates the current thinking about the future feature of RHQ.
The usual workflow when deploying RHQ is to have a staging environment where everything is set up and tested and a production environment that has a configuration that has been "approved".
Currently we do not help the admins in keeping these two environments synced as we provide no way of exporting/importing the crucial "environment" configuration.
First of all, let's think about what aspects of the "environment", i.e. what parts of various configurations in RHQ, are candidates for exporting.
Entities to export/import
Global entities
System Settings
Apart from the "GUI Console URL", all the system settings make sense to be exported.
Users & Roles
Exporting and importing users should be no problem (is that true for LDAP?). The problem with exporting roles is their re-association with resource groups. Exporting group definitions is discussed below, but at this point I'm inclined to say that it won't be possible and thus the roles can only be exported without the role associations.
Plugins
The inventory and templates are dependent on agent plugins. The server plugins define much of the functionality of the content subsystem and alerting. It is therefore reasonable to assume that both agent and server plugins should be in sync between the environments. The configuration of the server plugins should be synced as well.
Metric Templates
We have metric per resource type. The export should be possible for one,more or all resource types. The import should offer the possibility to directly apply the templates to existing resources to cut down on the work required from the admin afterwards.
The question is if we want to export only selected templates in a resource type or if it is enough to just export all the templates of a resource type.
Alert Templates
These are very much the same as the metric templates with 1 important difference. There is a number of alert senders whose configuration is not transferable between different installations:
-
Users, Roles - the users or roles are identified by id, which are not going to be the same between installs
-
Operations - if the operation to be invoked is on a different resource
-
CLI - the package with the script as well as the user executing the script might not exist on the target install. Importing the cli notif is a possible security breach if we imported the user that it's going to be run as, because the user importing it might not have such strong privs as the one being configured to execute the script.
Content sources & repos
Content sources and repos can only be exported without the actual packages and resource subscriptions. The reason for not including packages is merely the possible size of the export. The reason for excluding the resource subscriptions is the inevitable discrepancy between the inventories of the exported and imported RHQ installation. I.e. we can only ever export "configurations" but not the actual "binding" to the inventory (this is the case for all the scenarios discussed so far).
Dyna groups
It doesn't make sense to export the "ordinary" compat and mixed groups because the inventories between the RHQ installs are going to vary and there is no way of matching the individual members of the groups. But it can make sense to export the dyna group definitions (or it might not, which is dependent on how that dyna group's expression is defined).
Resource level entities
Plugin & Resource configs
Being able to export/import plugin/resource configuration of individual resources would enable the user to easily replicate these. Being able to import a resource config to a compatible group could be useful as well. The UI should offer to exclude certain properties from import though.
Alert Defs, Metric Schedules
These could be imported to individual resource, compat group or could be imported as a new template for the resource type (i.e. "I want all my JBosses to collect metrics as this one").
Alert definitions face the same difficulties as the alert templates.
Workflow
Export
There are 3 ways the users will want to use this.
-
Looking at a particular template/user/role/content source/dynagroup/metric scheds/alert defs/plugin or resource config, it should be possible to export this particular "entity".
-
Looking at a particular list of the above, the user should be able export (a selection from) that list
-
There should be a single page, where the user would pick and choose from all the types of entities and produce a single export file.
Import
Matching
The import should offer to either redefine or merely update the existing data from the export file. Redefining means to delete all the pre-existing entities and insert the entities from the export file. Updating means to match the pre-existing entities with the ones from the export file and update them, inserting the entities from the export file without a counter-part. The "contents" of the entity is updated and not merged with the imported contents. This means that if you import a role "blah" and already have a role "blah" in your system, the role configuration is going to be that of the imported role and not a combination of what it was before + the imported.
The entities based on the plugins and their descriptors (i.e. plugins, metric templates, metric schedules) as well as users are uniquely identifiable by their name (and the names of their "parents"). The roles, dynagroups, alert templates and alert definitions have user defined names which can be used for matching.
The resource and plugin configurations are identified by the resource type they apply to.
Alert Notifications Import
As outlined in the Alert Template export description, notifications are difficult to transfer between installs. On the other hand it would be great if we could import them, otherwise alert template importing becomes much less useful.
The main difficulty here is that this problem needs to be addressed generically because of the plugin nature of the alert senders. The solution must be adoptable by any and all alert senders used. Before outlining the generic solution, let's take a detailed look at the problems we are going to face in individual alert senders:
Users Alert Sender
The user to alert is identified by ID, but the IDs are not going to match between installs. There even might not exist a "corresponding" user (matched by username for example).
Roles Alert Sender
Very much the same problem as with user alert sender. The IDs might not match or the corresponding role might not even exist in the target install.
Resource Operations Alert Sender
-
If setup to use a specific resource, the resource id won't match.
-
The operation definition id won't match
-
If setup to use relative resource, resource type ids won't match, some types might not even exist if plugins are not in sync between source and target install.
CLI Script Alert Sender
-
User id won't match
-
Package id won't match
-
Repo id won't match
If the script is going to look for any resources by their IDs (which is quite likely), it is going to fail even if all the above was successfully solved.
Security considerations
CLI Script Notification
If we imagine that the notification can be imported, which is another issue, there is a possible security issue as well if there is a difference in the effective permissions of the user that the script runs as between source and target install.
Resource & Plugin Config
The export file is going to contain the security sensitive info like JNP credentials.
Export/Import Invocation
Once all the low level technicalities are sorted out, we need to think about the ways we want to make the export/import functionality accessible to the users.
Data Format
The main question to ask is what format is the data going to be distilled to. The attractive proposition is to try and export the data in some format we already can handle, like for example CSV, which we can produce using CLI (the import is not implemented but could be using some functional programming technique like csv.forEachLine(function(data) { ResourceManager.doSomethingWith(data); });
I think it is clear that CSV alone won't cut it for the more complex data structures like alert templates, plugins or even plugin/resource configurations, or for the "bound" datastructures like content sources and repos that reference each other. We are going to have to have a special file format for these (well, XML is just fine, we just need to define the entities).
Once the entities are defined, the integration in the CLI becomes as simple as providing the entity classes and have some user friendly methods on them to construct the exports (add* methods for various exported entities, remove* methods could be used to modify the export file before importing) and providing an import method in the remote API.
Import applicability
This seems quite obvious - you export users, you import them as users. This is true for all exported entity types with 2 exceptions:
-
alert definitions & templates
-
metric schedules & templates
The alert definitions and metric schedules of an individual resource and the alert or metric templates should be interchangeable. I.e. it should be possible to import a metric template to an individual resource as well as import metric schedules of an individual resource as a metric template of a resource type.
Also, the resource level exports should be importable to:
-
individual resources
-
compat groups
UI
For "global" configs, import should be possible from one central "place" in the UI, i.e. it would seem confusing to offer to import configuration on the "Templates" page, "Users" page, "Roles" page, etc. Upon uploading the export, the import should examine it and guide the user using a wizard, offering to pick and choose what is going to be imported. The only thing that the import needs to look out for is the availability of the corresponding plugins - either in the export file or already present in the system.
Transactional behavior
Importing templates and applying them to the existing resources in the inventory is potentially a very long lasting operation. Even today the individual alert definitions are updated in their own transactions when an alert template is updated.
Performing the whole import will therefore be difficult within a single transaction because a) this transaction can update huge amounts of data across many tables and b) the current approach favors performance over the possibility of rollback or cancelling and therefore all the codepaths would have to be duplicated to perform "stuff" using two distinct transactional semantics.
Maintenance mode
For the import as well as for the dry run to be successful, the RHQ server has to be in a kind of maintenance mode. We want to prevent the users from editing of any kind of configuration that can be part of the import. The maintenance mode has to span all the RHQ servers in the HA "cluster", which slightly complicates things - instead of a simple flag, we'll have to have some kind of DB driven handshake mechanism to ensure all the servers know about the maintenance mode being requested. An interceptor on all SLSBs would check for the maintenance mode and disallow most of the update actions to occur. This is discussed in detail in the [\#Dry run|] chapter because these two concepts are intertwined.
Dry run
Even if the import ran in a single transaction, the user would possibly like to know the outcome of the import before s/he actually performs it. If the import isn't transactional, dry run is the only possibility to make sure that the user doesn't wreck the RHQ server.
Implementing this without rewriting portions of the business logic is another question though. In the dry run mode, the server will have to enter a state where everything will need to work as normal, but no changes will be made to the "state" of the server. Because the server stores all the data in the database, the dry run basically means to disallow any database modifications.
At the same time, we want the dry run mode to work as if the modifications really happened and only roll them back once the dry run finished. As mentioned above, the rollback-at-end is not possible without rewriting a bunch of existing code, because the usual pattern we use when mass-updating things is to run many small transactions instead of one uber-transaction because of the performance implications.
Dry run by rewriting the business logic
The only parts of the code that'd need to be rewritten for the dry run support would be the methods applying metric and alert templates to individual resources and that only in the case we supported automatic application of the templates during the import time. This looks promising but there's one catch. The server still needs to be in the "readonly" mode anyway, because we need to disallow concurrent modifications of the data during the import. We could do that by logging out all the users and disallowing login for the time of dry run or import, or merely by intercepting the data modifying calls and disallowing them (discussed below).
Dry run by an interceptor
In the previous point we found that even if we decided to modify the business logic to support running all the data modifications in the single transaction, we'd still need to prevent other users (connecting from other servers in the HA) from modifying the data so that we a) get reliable results from dry run or b) successfully import the config. This means we have to put all the servers in the HA to a "maintenance mode". Unfortunately, this term is already used. Currently the RHQ server can be put into a maintenance mode which means it disconnects from all the agents and disallows any new agent connections. We need slightly different behavior so instead of maintenance mode I'll use the term DRY_RUN mode.
Entering DRY_RUN mode
Because we can have more RHQ servers connecting to the single database, we need to make sure that all of the servers are aware of the fact, that the database needs to be in the dry-run mode, so that each of the servers can prevent users logged in to them from making data modifications. Because there is no direct communication between the servers, we need to have a kind of database driven "handshake" mechanism and a recurring job on each of the servers to check for the "handshake" happening.
In the diagram below, the DBStateCheckJob is the recurring job and the rest of the sequence diagram shows how a single server would ask for the dry run mode.
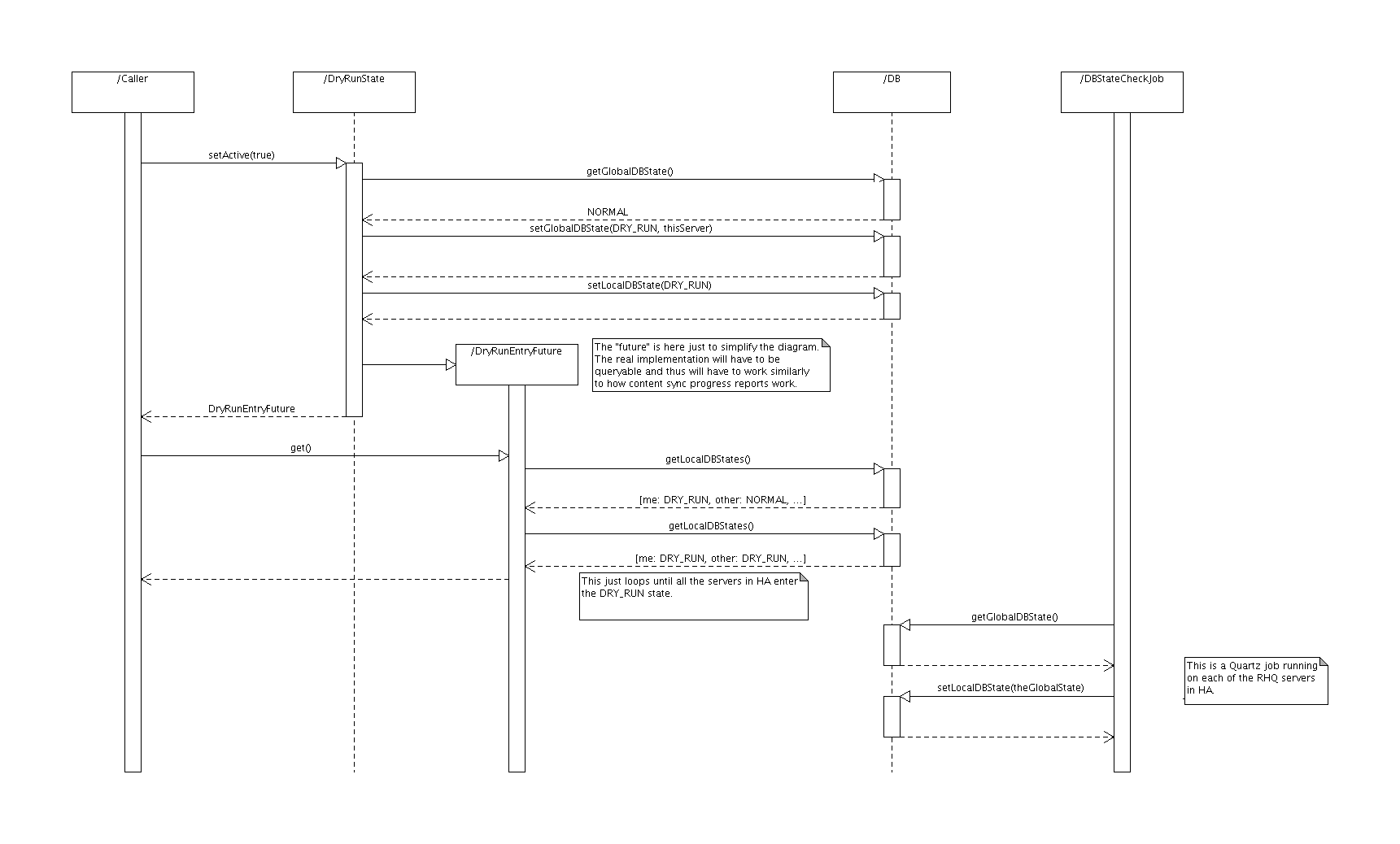
Executing import in DRY_RUN mode
When in dry run mode, no transaction is allowed to commit and therefore no data modifications are allowed. It is therefore impossible to check the correctness of relationships between the entities in the import file in any other way than performing a "manual" consistency check on that file before any modifications are even attempted at the database level. Doing this will give us confidence that, when imported, the data from the import file will not cause constraint violations in and of themselves.
The next step is to determine matches between the data already existing in the database and the entities in the import file. Because this is a read-only operation, the dry run mode doesn't influence this in any manner.
After that the actual modification attempts start to occur, as seen in the diagram below. When the dry run mode is in effect all the data modifications are attempted to catch the potential constraint violations with the existing data but all the transactions are rolled back. The import procedure will ignore the dry run exceptions but will consider all other exceptions as import failures.
Notice that the import procedure is exactly the same whether in dry run mode or in the "normal" mode, the only difference being that no "dry run" exceptions are thrown from the levels "below" the import procedure.
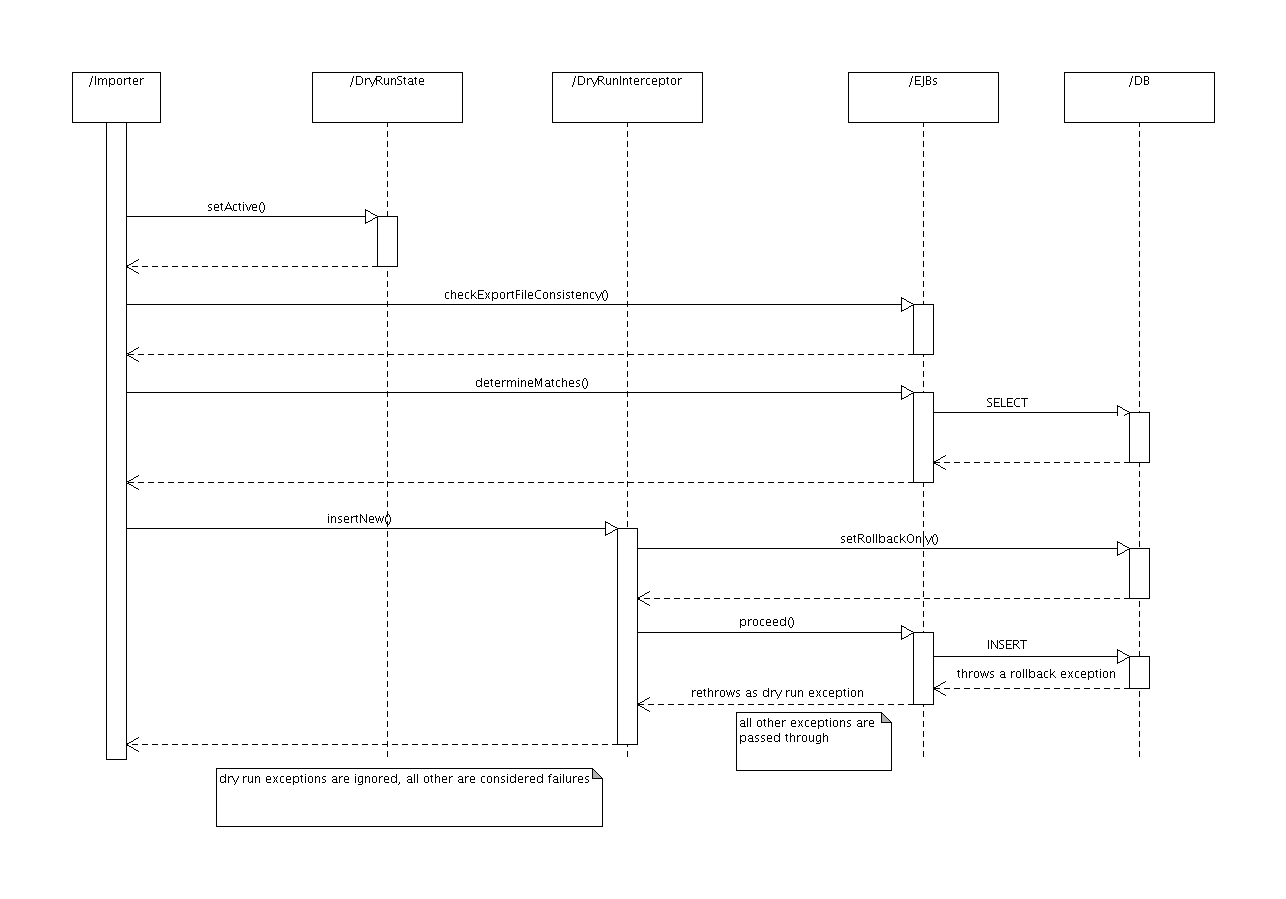
Implementing the DryRunInterceptor
So how do we implement this DryRunInterceptor? It is obviously an ordinary @AroundInvoke EJB3 interceptor but we need to answer these questions in order to implement it:
-
How to roll back all the transactions from the interceptor?
-
How to determine which methods modify data?
-
How to distinguish the exceptions caused by the "rollback-only" state of the transactions from the rest?
How to roll back all the transactions from the interceptor?
javax.ejb.SessionContext#setRollbackOnly()
How to determine which methods modify data?
The prototype implementation has very simple rules: if the invoked object's class is from org.rhq package (or below) and ends in ManagerBean and the method name "looks suspicious" (starts with "set", "create", "update", "change", "remove", "delete"), then it modifies the data. While this seems to work quite nicely in the testing because of our naming conventions, the "real" implementation would probably have to be more robust and be based on some kind of method annotation on the data-modifying methods themselves. This is of course quite error-prone approach but currently I can see no way around it.
How to distinguish the exceptions caused by the "rollback-only" state of the transactions from the rest?
Setting the transaction to rollback only mode can have non-trivial consequences and the only way to find the exceptions caused is by experimenting. So far, I have identified the following:
Open Questions
-
Is a user with only READ_CONFIG perm able find out security sensitive info from the plugin/resource configs? In another words, should we require just READ_CONFIG to be able to export or something stronger?