RHQ 4.9
Design of the new OOB system
OOB stands for Out of Bound data – data values that are outside of some computed base band of values
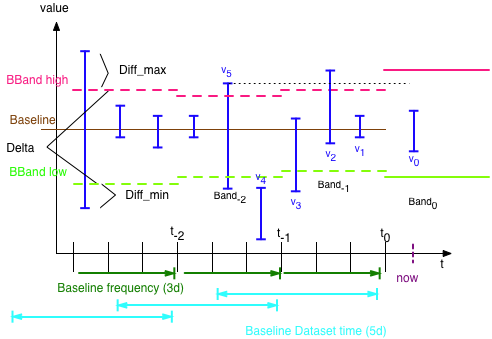
Diagram of terms
-
Data values are coming from the aggregate 1H table and thus have a min/max/avg value. Only the max and min are of interest.
-
The baseline system creates a baseline of data (basically the average) and min + max values:
-
Every baseline-frequency days the data of the last baseline dataset days is taken to compute the new values
-
A band is only valid for the min(dataset days, frequency days)
-
So the band to compare a new value,v 0, at time 'now' got created at time t 0 and is Band 0
-
-
'Incoming' Data for 'now' is always compared to the last computed band.
-
Query to find OOB values can only use the data values from t n to t n+1
-
-
OOB Factor: typically there are multiple outliers in a system, so we need to find the bad ones. Take this example
-
Baseline min =0 , Baseline max = 100, measured value =102 -> absolute outlier value is 2
-
Baseline min = 90 , Baseline max = 100, measured value = 102 -> absolute outlier value is 2
-
Here case 2 seems as bad from the absolute difference bl.max <-> value as case 1
-
In fact case 2 is worse, as the band is only 10 wide, a difference of 2 = 20% outlier factor, while in the first case the factor is only 1%
-
Query Algorithm to find OOB data
-
Query looks at data from t n to t n+1 and finds values that are higher than BBand_high of Band t n or that are lower than BBand_low.
-
For each value the weighted oob factor is computed: diff_min / delta or diff_max / delta
-
Caveat: only makes sense when delta is 'big enough' (see below)
-
-
For each oob value, a counter is increased
-
Idea is to find the values with the biggest number of oobs and the ones with the biggest factor meaning, that those outliers either create a big number of oob conditions or that there are few but strong violations.
Caveats
-
All data is floating point, meaning that there are a lot of values that differ slightly
-
Small delta values can give extremely high oob factors even if the outlier is only a little bit out of band
-
Delta should be adjusted to the total values (something like delta / BBand_high )
-
-
Data that has a count > 0 but a factor of < factor-threshold should be suppressed, as it confuses the user
-
We do not save historical baselines / bands. This means that we can not 'recompute' arbitrary past values
Computation time
Precondition: The algorithm uses data values from the 1H table.
As we do not store old baselines / bands, we can only use the
Completely dynamic
The query is run every time the user requests data
-
 needs no storage on disk
needs no storage on disk -
Results for two subsequent runs are the same if not done at the instant of 1h compression or bl recomputation
-
 Is DB intensive (especially if done often by different users)
Is DB intensive (especially if done often by different users) -
Does not allow to compute a table of recent oob issues
-
Users need to be 'protected' from bad results because of running this during baseline recomputation
-
only allows to see the number of violations of the current band that resets to zero on baseline recomputation
Once per hour (chosen solution)
Here we compute the outliers of the current band and store the results in the database
![]() we can store historical outlier data and present this for some trending analysis
we can store historical outlier data and present this for some trending analysis
Computation is done after the hourly 1h compression and after new baselines have been computed.
-
Full data
-
Always the full data from t~n~ to now is used for the computation
-
Computation is easier
-
-
New data only
-
Only use the data from the previous 1h compression run and add this to existing data for the current band
-
Less database activity as less data needs to be touched (with some luck this data is even in the db cache). If the data is not in the cache, then it is at least very close to each other on disk, as it gets written all at at around the same time (and shares the same timestamp)
-
More complex algorithm
-
Fresh results (from the last hour) can more easily be fed into Alerts
-
Storage of results
Results from the comutation are stored in a table
-
id
-
schedule_id (fk to schedule)
-
the hour it belongs to
-
oob factor
This way it would be possible to to see a history of violations (factor) and also to filter resources for which the violations get more violent ( higher in factor).
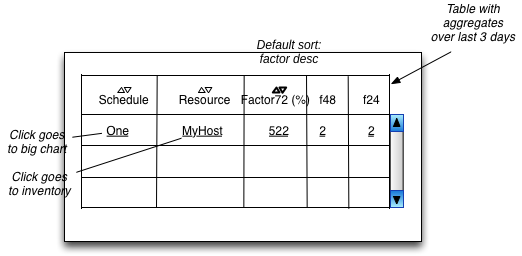
Proposed UI
The following is a proposal for the UI
Purging of OOB data
OOB Data is purged at those occasions:
-
hourly data after 3 days
-
When a Baseline is recalculated by the system, the existing, now outdated, OOB data is purged
-
When a Baseline is manually set, he existing, now outdated, OOB data is purged