<service name="Datasource" class="DatasourceComponent"
discovery="org.rhq.plugins.jmx.MBeanResourceDiscoveryComponent"
createDeletePolicy="both" subCategory="Resources">
...
<resource-configuration>
<c:group name="connection" displayName="Connection Information">
<c:simple-property name="type">
<c:property-options>
<c:option value="no-tx-datasource" name="No TX Datasource"/>
<c:option value="local-tx-datasource" name="Local TX Datasource" default="true"/>
<c:option value="xa-datasource" name="XA Datasource"/>
</c:property-options>
</c:simple-property>
<c:simple-property name="jndi-name" readOnly="true" displayName="JNDI Name"
description="The JNDI name under which the DataSource wrapper will be bound."/>
<c:simple-property name="driver-class"
description="The fully qualified name of the JDBC driver or datasource class"/>
...
</c:group>
...
<c:template name="Oracle Local TX" description="Local Transaction Template for Oracle">
<c:simple-property name="type" default="local-tx-datasource"/>
<c:simple-property name="driver-class" default="oracle.jdbc.driver.OracleDriver"/>
<c:simple-property name="connection-url" default="jdbc:oracle:oci:@youroracle-tns-name"/>
<c:simple-property name="exception-sorter-class-name"
default="org.jboss.resource.adapter.jdbc.vendor.OracleExceptionSorter"/>
<c:simple-property name="check-valid-connection-sql" default="SELECT * FROM DUAL"/>
</c:template>
...
</resource-configuration>
</service>
Current Configuration
The configuration subsystem currently only supports a structured format. Today RHQ only supports structured configuration. By structured, we mean that it adheres to a schema (the RHQ plugin descriptor schema) which allows RHQ to interpret a configuration such that:
-
The UI can render arbitrary configurations
-
Changes can be applied to arbitrary configurations which are then applied to the managed resource
-
Validation can performed to determine if changes are in error before they are applied on the resource
The configuration data type is used in multiple contexts throughout RHQ, resource configuration, plugin configuration, operation parameters and results, content configuration etc. For the purposes of this document however, we are only concerned with resource configuration.
How We Make a Resource Configuration Manageable Today
Resource configuration is declared in the plugin descriptor, rhq-plugin.xml. The following example is a snippet from the JBoss AS plugin and lists part of the resource configuration for a datasource.
Thus far we have declared what actual configuration is supported. To effect changes on the resource configuration, the ResourceComponent implementation must implement the ConfigurationFacet interface which is shown below.
interface ConfigurationFacet {
Configuration loadResourceConfiguration() throws Exception;
void updateResourceConfiguration(ConfigurationUpdateReport report);
}
The two methods in ConfigurationFacet provide the read/write operations that are called by the plugin container. With the <resource-configuration> declaration and an implementation of ConfigurationFacet, we have everything in place (from the plugin side) that we need to manager a resource's configuration.
Updating a Resource Configuration
When a user (from the UI) makes a configuration change, it results in a call to ConfigurationManagerLocal.updateResourceConfiguration(Subject subject, int resourceId, Configuration newConfiguration). This method does two things - persist the update request to the audit trail and send the update request to the appropriate agent. We will look at each of these two steps in greater detail.
The update request is persisted as an instance of ResourceConfigurationUpdate. ResourceConfigurationUpdate has a status attribute which can have a value of In Progress, Success, or Failure. If a there is already an update in progress, the ResourceConfigurationUpdate is given a failure status and an exception is thrown. If no update is currently in progress, we mark the ResourceConfigurationUpdate as in progress and persist it to the database.
The second step in updateResourceConfiguration() is to send the update request to the agent. AgentClient is the RHQ agent interface that is exposed to the server. AgentClient in turn provides access to agent services, namely ConfigurationAgentService in this case. ConfigurationManagerBean (the implementation of ConfigurationManagerLocal) obtains a reference to the ConfigurationAgentService and calls ConfigurationAgentService.updateResourceConfiguration(ConfigurationUpdateRequest request). There are a few things to point out about this method call:
-
The request is sent as a ConfigurationUpdateRequest object
-
The ConfigurationUpdateRequest object contains the entire configuration, not just a series of diffs
-
The update is applied asynchronously such that when control returns back to ConfigurationManagerBean, the resource configuration update has not yet completed
ConfigurationManager is the agent service implementation of ConfigurationAgentService. ConfigurationManager is a plugin container service that forms the communication layer through which the RHQ server sends requests to plugins. ConfigurationManager looks up the ConfigurationFacet to be called, and schedules the update via a UpdateResourceConfigurationRunner object. When the update has finished, UpdateResourceConfigurationRunner calls ConfigurationServerService.completeConfigurationUpdate(ConfigurationUpdateResponse response). ConfigurationServerService resides on the RHQ server and provides an interface to the agent back into the server.
ConfigurationServerService in turn calls ConfigurationManagerLocal.completeResourceConfigurationUpdate(ConfigurationUpdateResponse response). completeResourceConfiguration() takes the status (success/failure) and configuration from the response and persists them in the audit trail (i.e., in the form of a ResourceConfigurationUpdate object). If the update was a success, the configuration is assigned to the Resource.resourceConfiguration property, making the latest, known good configuration easily accessible from the Resource object.
Viewing Resource Configuration History
A user can view a resource's configuration update history, including its latest configuration. Note that the latest configuration might actually be the live configuration. First, a request for the latest configuration is made by calling ConfigurationManagerLocal.getLatestResourceConfigurationUpdate(Subject, int resourceId). This method first queries the database for the latest ResourceConfigurationUpdate know by the server. Next we call a helper method to get the live configuration. This is done by calling ConfigurationAgentService.loadResourceConfiguration(int resourceId). If the live configuration differs from the one found in the last update on the server, then we persist a ResourceConfigurationUpdate with the live configuration, effectively making it the latest, known configuration on the server. As a side effect, that configuration is also assigned to the Resource.resourceConfigration property, making the latest, known configuration easily accessible from the Resource object.
After retrieving the latest configuration, ConfigurationManagerLocal.findResourceConfigurationUpdates() is called. This method is straightforward in that it just queries the database for ResourceConfigurationUpdates.
Raw Configuration
The idea here is to support configuration management for resources for which we do not have complete understanding of the configuration model.
This should allow us to quickly support many different configuration file edits remotely without building all the context around structuring and rich validation at all times. For resources supporting only raw, the view and edit pages would simply show the raw text format. For resources supporting structured it would show only the structured format. For resources supporting both, it would show perhaps a tabbed interface allowing the user to make edits and switch between the views (switching causing the plugin to be asked to perform a live translation of formats). It is possible that some resources would allow for raw text content that is undefined by the structured format. This should be supported by typical plugins to allow for easier support of new features without breaking the entire system and would allow you to continue to perform non-destructive structured format edits that don't alter the unsupported raw contents.
Concepts
This would add a mechanism where by a user can view and edit the raw textual content of a configuration within the RHQ configuration subsystem. To allow for the best of all worlds, this system should support being a parallel to the abstract configuration model and allow the developer to support structure, raw or both configuration models.
Domain Model Changes
Here is a UML class diagram of what the Configuration entity looks like today:

All of the attributes or properties listed after the version property are all basically different views of the same underlying data structure which holds the Property objects representing the structured configuration. The next diagram includes a new RawConfiguration class.
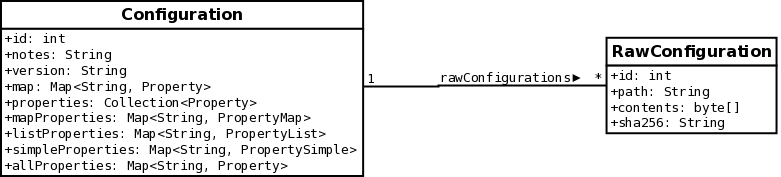
Things to note about the new RawConfiguration class added to the diagram
-
The path property corresponds to the file system path of the configuration file
-
The contents attribute is the actual file contents stored as a byte array.
-
The sha256 property is read-only and is a SHA-256 sum of the contents property.
-
There is a one-to-many association between Configuration and RawConfiguration. This provides the flexibility for supporting structured configuration, raw configuration, or both on a resource.
-
A RawConfiguration object cannot exist without having a parent Configuration object. This will be enforced with a foreign key constraint.
Potential Issues with Class/Entity Design
As has been previously noted, the Configuration class is used in a number of contexts. The rawConfigurations associations however is only applicable though to resource configurations. And to be precise, it is only application to resource types whose support raw configuration or raw and structured configuration. It is not applicable to resource type that only support structured configuration.
In all of other places where Configuration is used, we will have to put safeguards in place to ensure the correct semantics. We could address this by extending the Configuration class model as is illustrated below:

This could be implemented with a table per class hierarchy inheritance mapping strategy where we introduce a discriminator column to indicate the configuration format.
Plugin Descriptor Changes
We need to add new meta data attributes that allow the resource type to declare what type of configuration it supports. Something like configurationFormat = {raw, structured, both}... Whether or not a resource supports partial validation could potentially be inferred by its implementation of this new facet interface. An example would be:
<resource-configuration configurationFormat="raw|structured|both"> </resource-configuration>
For existing plugins that will not have this new attribute declared, we will have to assume a default value of structured since that was the only one previously supported.
Plugin Model Changes
A couple different approaches have been discussed, and in the following sections we will consider each of them
Approach 1 - ConfigurationTransaltionFacet
Add a new Facet interface, ConfigurationTranslationFacet, that can support several new features.
|
Method |
Purpose |
|
translateToRaw |
Takes a structure configuration set and using the existing raw text builds a new raw text model transformed with updates |
|
translateToStructured |
Take a raw text format and translate it to the structured model |
|
updateEnumerations |
Takes a partial configuration definition and defines potential values for limited select fields |
|
validate |
Validates a partial configuration set without attempting to persist it |
These interfaces will take in Configuration objects and transform them in place updating either the raw or structured content based on the other. Except for the last two methods. They will return a new Object that will define the potential values for enumerations and do partial validation respectively.
Potential Issues
When resource configuration was a single logical type (structured only) it was easy to understand the load/update method combination. Now that we're adding more complexity (supporting both raw and structured), these methods may be too coarse-grained to keep the programming model straightforward. In order for plugin developers to implement our synchronization guarantees, they essentially need to code their methods as follows:
List<RawConfig> translateToRaw(Configuration config) {
Configuration config = loadRawResourceConfiguration();
List<RawConfiguration> results = new ArrayList<RawConfiguration>();
for (RawConfiguration nextRaw : config.getRawConfigs()) {
// merges current data from 'config' into 'nextRaw', and returns it
RawConfiguration updatedRaw = mergeRawConfiguration(config, nextRaw);
results.add(updatedRaw);
}
return results;
}
Configuration translateToStructured(List<RawConfiguration> rawConfigs) {
Configuration config = loadStructuredResourceConfiguration();
for (RawConfiguration nextRaw : rawConfigs) {
// merges current data from 'nextRaw' into 'config' in place
mergeStructuredConfiguration(nextRaw, config);
}
return config;
}
void updateResourceConfiguration(ConfigurationUpdateReport report) {
Configuration config = null;
List<RawConfiguration> rawConfigs = null;
if (report == ConfigurationUpdateReport.Type.STRUCTURED) {
config = report.getStructuredConfig();
if (rawSupported()) { // PC-level helper method
rawConfigs = translateToRaw(config);
}
} else {
rawConfigs = report.getRawConfigs();
if (structuredSupported()) { // PC-level helper method
config = translateToStructured(rawConfigs);
}
}
if (config != null) {
updateStructuredConfiguration(config);
}
if (rawConfigs != null) {
for (RawConfiguration nextRaw : rawConfigs) {
updateRawConfiguration(nextRaw);
}
}
}
If the plugin writer does not implement their methods like that, then they run the risk of returning inconsistent data. In particular, they might return one set of data from loadResourceConfiguration (which will be executed by the hourly agent-side config poller) which might be different than the returned data from one of their translateToXXX methods (executed when they make a config change server-side).
Approach 2 - ResourceConfigurationFacet
With this approach, we want to enforce some of the synchronization semantics. The plugin writer implements more fined-grained, "building block" methods. The plugin container can use those methods to implement more complex, higher-level flows (i.e., the translateXXX and updateResourceConfiguration methods).
interface ResourceConfigurationFacet {
Configuration loadStructuredConfiguration();
List<RawConfigurations> loadRawConfigurations();
void persistStructuredConfiguration(Configuration);
void persistRawConfiguration(RawConfig);
void validate(Configuration);
void validate(RawConfiguration);
void updateEnumerations(Configuration);
RawConfiguration mergeRawConfiguration(Configuration from, RawConfiguration to);
void mergeStructuredConfiguration(RawConfiguration from, Configuration to);
}
These methods form a much simpler programming model. Instead of the plugin developers having to worry about whether they are implementing complex semantics required for a perfectly sync'ed audit trail, they only have to write simpler load/persist methods...which actually mirror the original load/update model we saw in the original ConfigurationFacet definition.
The ConfigurationFacet as it exists today, will still be supported to maintain backwards compatibility; however, new plugins should implement the new ResourceConfigurationFacet. There is some complexity around determining what facet interface a plugin should implement. To address this complexity, we can take advantage of some existing plugin meta data available in the plugin descriptor that is currently unused in the server-side data model. The <plugin> element supports attribute called ampsVersion. New plugins should set this attribute to a value of 2.1 which will tell the plugin container that the new ResourceConfigurationFacet is supported.
We will update the database schema by adding the ampsVersion attribute to the RHQ_PLUGIN table. And a corresponding property will be added to the Plugin class.
Potential Issues
Data Flow Changes
There are some complexities involved with making sure that we keep the audit trail in sync at all times. In this section, we will review the existing data flow, point out some potential concerns, and finally look at some solutions that alleviate those concerns.
Original Data Flow
-
User edits a configuration and clicks save
-
A single audit trail record is persisted
-
Its current state is set to INPROGRESS
-
It gets an effectively immutable (data can technically be edited, but by convention it should be read-only) copy of the configuration data that it will push down to the agent
-
-
Server sends the request down to the agent (in a separate transaction from the persisted record)
-
Agent responds back with success or failure
-
Note: Even if the agent crashes during the update, the server-side will eventually time out/fail the request
-
This model gave us the ability to reason correctness of the audit in all known cases:
-
If the update succeeded, then the configuration data in the audit trail is what was on the box at the time up update
-
If the update failed/timed out, then the configuration data in the audit trail is what would have been on the box
Potential Issues
Let's look at some of the complexities that could arise from corner cases (depending on our chosen data flow) in the world where raw configuration exists:
-
User edits the structured configuration, but the raw side of the configuration is now "stale"
-
User clicks save
-
A single audit trail record is persisted
-
Its current state is set to INPROGRESS
-
It gets an effectively immutable copy of the structured configuration it will push down to the agent
-
It gets a "stale", mutable copy of the raw configuration, which it needs to override with the results from the agent
-
-
Server sends the request down to the agent (in a separate transaction from the persisted record)
-
Agent responds back with success or failure, as well as the current raw configuration (based on the structured input)
-
Note: If the agent crashes during the update, the job is still timed out, but now the audit trail has partially stale data
-
This model makes it difficult to reason correctness of the audit trail:
-
If the update succeeded, then the agent responds back with the updated raw which needs to be persisted
-
Failures to override the raw data with the updated values may either:
-
Keep stale data in the raw, but with a success state (violates consistency of the audit trail), or
-
Override the status and set it to failure, but we still have stale data on the raw side (again, violating audit trail consistency)
-
-
-
If the update failed, then the agent responds back with the updated raw which needs to be persisted
-
Failures to override the raw data with the updated values may either:
-
Keep stale data in the raw, with an INPROGRESS state (violates consistency of the audit trail AND forces server-side job to cleanup the job later as a timed out record)
-
Status is successfully set to failure, but the raw is still stale (yet again, violating audit trail consistency)
-
-
-
Agent crashes
-
The raw side of the model no longer has a chance to sync with the structured side...even though the server-side job will eventually come along and mark this as timed out, that audit trail entry will forever be inconsistent
-
New Data Flow
Here is a data flow that goes further to ensure consistency of the audit trail.
-
User edits the structured configuration, but the raw side is now "stale"
-
User clicks save
-
BEFORE an audit record is created, the UI thread is suspended and contacts the agent
-
Agent executes structuredToRaw passing the current state of the structured config the user just finished editing
-
Agent responses back with RawConfig which overwrites the "stale" data still in-memory from the waiting thread
-
Note: If the agent fails to respond (perhaps it crashed during that window) we immediately show that error in the UI and disallow editing the configuration for that particular resource until an admin guy brings that agent back up
-
-
Assuming a successful response from the agent, the system persists a single audit trail record with the edited structured config + sync'ed raw config – since the persistence of the audit trail record is *atomic*, then we know the commit either succeeded (and the flow continues) or failed (which sends the error message back to the UI)...in other words, at no point can there be inconsistencies in the data stored by this record
-
It current state is set to INPROGRESS
-
It gets an effectively immutable copy of the structured configuration *AND* raw configs
-
-
Server sends the structured config down to the agent (in a separate transaction from the persisted record)
-
Agent responds back with success or failed, no additional data is needed in this response - audit trail is already consistent
-
Note: Even if the agent crashes during the update, the server-side will eventually time out/fail the request
-
Using this data flow, you won't get any inconsistencies within the audit trail, and we're back to the simpler model for reasoning correctness:
-
If the update succeeded, then the structured AND raw configuration data in the audit trail is what was on the box at the time up update
-
If the update failed/timed out, then the structured AND raw configuration data in the audit trail is what would have been on the box