<drift name="foo">
<basedir>...</basedir>
<interval>300000</interval>
<includes>
<include path="a..." pattern="a..." />
<include path="b..." pattern="b..." />
</includes>
<excludes>
<exclude path="a..." pattern="a..." />
<exclude path="b..." pattern="b..." />
</excludes>
</drift>
Plugin Changes
Generating snapshots involves copying files and comparing those files against previous versions to detect whether or not they have changed. This work is relegated to the plugin container since it is the same for any resource types that supports drift management. To support drift management resource component's will have to implement a new facet and make changes in the plugin descriptor.
Plugin Descriptor Changes
Mazz:
Under the covers, we build a Configuration object with those properties, but the plugin author should not be forced to understand the underlying configuration properties. The plugin container should create a domain object that encapsulates these config properties and provide a strongly typed API like: DriftConfigiration.getBaseDirectory() and DriftConfiguration.getIncludes() ...
jsanda: An alternartive, more concise syntax for specifying filters could be as follows,
<drift name="foo">
<basedir>...</basedir>
<interval>300000</interval>
<filters>
<include path="a..." pattern="a..." />
<include path="b..." pattern="b..." />
<exclude path="a..." pattern="a..." />
<exclude path="b..." pattern="b..." />
</filters>
</drift>
In order for a resource type to support drift management it is necessary to specify at least one <drift> element. Note that you are not required to specify any of the child elements. The preceding example illustrates the allowable child elements, though none of them are required.
Each <drift> element must have a unique name. We might for example have something like <drift name="webapps"> and <drift name="EAP server configuration"> where the former specifies drift management only for web apps whereas the latter specifies drift management for files under JBOSS_HOME/bin and JBOSS_HOME/server/default/conf (assuming we are running the default server configuration).
TODO If only one <drift> is declared, should the name attribute still be required? We could generate a default value alleviating the need to add the extra mark up.
basedir
Specifies the base or root directory from which snapshots will be taken.
Specifying the base directory in the plugin descriptor does not make a whole lot of sense the location of a resource is not know until runtime when it is discovered. But it does make sense to say you want the base directory set to the root directory of your Tomcat installation if for example you are managing drift for Tomcat servers. See the next section, Using Lazy Evaluation for more information on how to do this.
includes
Allows you to specify zero or more inclusion filters. If inclusion filters are specified, then only paths matching the filters will be included in the snapshot.
excludes
Allows you to specify zero or more exclusion filters. If exclusion filters are specified, then any paths matching the filters will be excluded in the snapshot.
interval
Allows you to specify in milliseconds how frequently drift monitoring is performed.
Generally a user should be able to enable drift monitoring for a resource without having to having to make additional configuration changes. The plugin should provide a sensible set of defaults. This can be accomplished with the properties described in this section.
Using Lazy Evaluation
You may want to specify defaults for drift configuration properties such as basedir in the plugin descriptor; however, the file system location of a resource is not known until it has been discovered. Let's consider an example to better illustrate this. Suppose we adding support for drift management of EAP 5/6 servers. This means we will add a <drift> element under JBossAS Server resource type in the plugin descriptor of the JBoss Application Server 5.x plugin. A logical default for the basedir property is the root directory of the EAP server. With lazy evaluation, you can effectively specify the root directory of the server as the value of basedir.
<drift name="Default Drift Configurtion">
<basedir>${homeDir}</basedir>
</drift>
The ${...} syntax indicates that the enclosed string is not to be treated as a literal value. It is used as a form of variable substitution. At run time during discovery the plugin container will look for a plugin configuration property of the same name, and substitute the value of that property.
The JBossAS Server type does in fact does have a plugin configuration property named homeDir (with a display name of JBoss Home Directory if you are looking at the plugin configuration in the UI as opposed to the plugin descriptor file). When a JBossAS Server resource is discovered, the discovery component initializes that property (along with several others). Let's say homeDir is initialized to a value of /var/lib/jboss-eap-5.0. That path is then substituted in for the value of the basedir drift configuration property.
SnapshotFacet
public interface SnapshotFacet {
DriftConfiguration getSnapshotConfiguration(Configuration pluginConfig DriftConfiguration driftConfig);
}
SnapshotFacet is implemented by the discovery component. Immediately after the plugin container invokes the discovery component's discoverResources method, it will invoke getSnapshotConfiguration for each discovered resource and for each drift configuration declared in the plugin descriptor. If two drift configurations are declared in the plugin descriptor (i.e., <drift name="foo"/> and <drift name="bar"/>), then getSnapshotConfiguration will be called twice. discoverResources returns a set of DiscoveredResourceDetails. Each DiscoveredResourceDetails object contains a plugin configuration object. That plugin configuration object is passed as the pluginConfig argument to getSnapshotConfiguration. That same plugin configuration will be used across multiple invocations of getSnapshotConfiguration.
The driftConfig argument contains properties that correspond to the child elements of <drift>. If any defaults are specified in the plugin descriptor, the corresponding properties in the driftConfig object will be initialized to those default values.
SnapshotFacet is not Required
Discovery components are not required to implement SnapshotFacet in order to enable drift management; however, you must declare at least one <drift> configuration element in the plugin descriptor to enable drift management. Implementing SnapshotFacet though provides the ultimately flexibility in defining drift configurations.
Managing Snapshots Not Associated with a Resource
We have to support creating and managing both drift configurations and snapshots independent of resources. For instance, suppose we want to perform drift management on a cluster of EAP servers. Suppose we have a golden snapshot image that we want to use as a baseline with which to compare our EAP servers. While that golden snapshot will be associated with resources, it may exist in the system before the resources are in inventory. The snapshot may also continue even after all resources with which it is associated have been removed from inventory.
Associate Snapshot with Multiple Resources
There may be times when you want to use a shared, common baseline snapshot among multiple resources. A good example of this is performing drift management on a cluster of EAP servers where you want to manage drift between those servers. In other words, you want to monitor for changes so that you know if/how those EAP servers differ.
Import Snapshot into RHQ
Server Changes
Uploading Snapshots
The server needs to provide an API for the agent to upload snapshots. Both the data and meta data files for snapshots can be very large.
Uploads Need to be Asynchronous
The API needs to provide asynchronous, non-blocking IO. Uploading the files synchronously (in the thread handling the agent request) could block the thread for an extending period of time, preventing from servicing other agent requests or UI requests. The actual upload request will be serviced by an MDB. Here are some open questions around the usage of MDBs:
-
Currently a queue is being used for passing messages since each upload request should be serviced once and only once. Should we consider instead using a topic to pass messages?
-
Are any special configuration changes needed for JMS when running RHQ in HA mode (with multiple servers)?
-
When there is only a single RHQ server, should the JVM invocation layer (IL) be used to avoid the overhead of serialization?
Uploads Should Be Streamed
Because both the data and meta data files of a snapshot can be very large, we generally want to avoid loading them into memory. This means instead of using strings or byte arrays, we want to use streams for both reading and writing snapshot files, and this includes uploading files from the agent. Here are some examples to illustrate what APIs for processing files should look like:
// This is bad! We do not want to load entire files // into memory. void uploadFile(String file); // This is also bad! We do not want to load entire // files into memory. void uploadFile(byte[] file); // This is good! Consuming the file as a stream // avoids loading the entire file into memory. void uploadFile(InputStream file);
Here are some open questions about streaming file uploads:
-
Currently the meta data and data files are being streamed separately. Could there be any performance gains by compressing them down into a single file and having then only to stream a single file?
-
Changeset snapshots could be substantially smaller than a full snapshot. Could there be advantages to batching these smaller snapshots into a single file upload?
Manage Persistence with Server Plugins
A one size fits all approach is not going to be an adequate solution for persisting snapshots. A number of things will impact the performance and reliability characteristics persistence store. Some of these things include:
-
The amount of snapshot data being stored in terms of physical storage
-
The number of snapshots and snapshot meta data being stored
-
The frequency at which agents upload snapshots to the RHQ server
-
The frequency of writes to the persistence store
The RHQ database may be a perfectly acceptable persistence store in many situations, but it may be inadequate in situations where a high write throughput to the database is needed. We already see performance limitations in this area with metrics. This is why we need a pluggable strategy. Snapshot persistence will be managed by server plugins. We can provide a default implementation that uses the RHQ database. Other plugins could be developed to utilize other persistence stores such as,
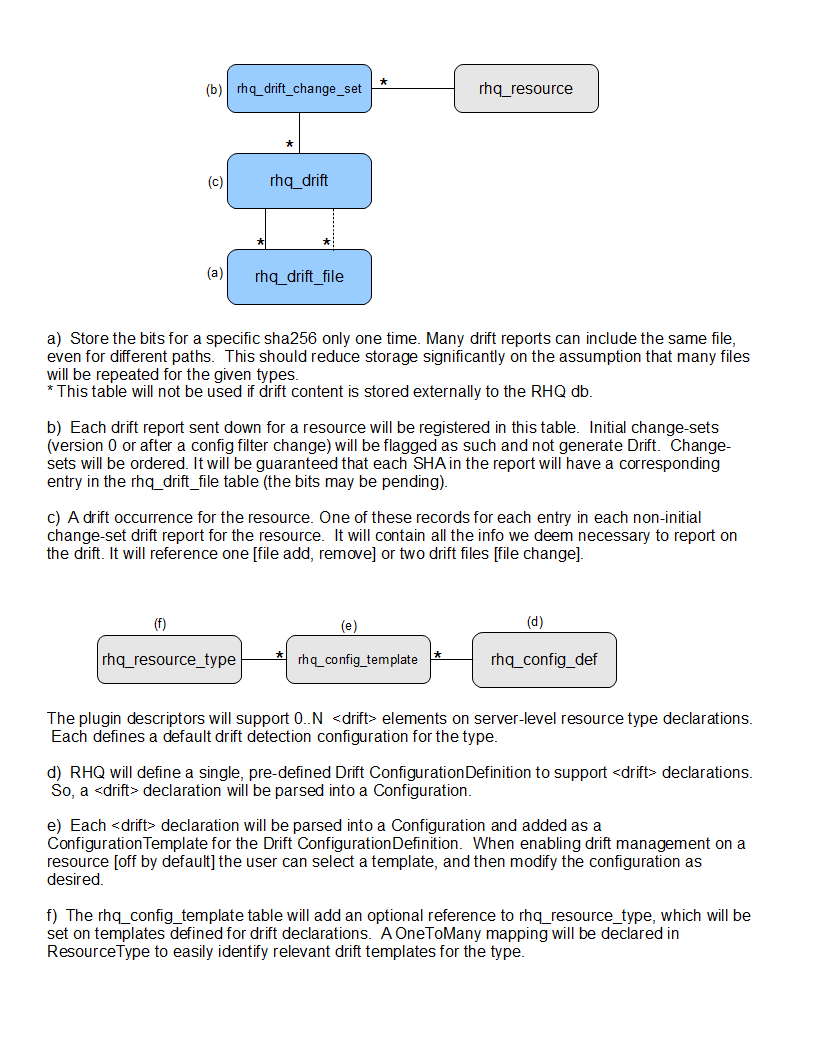
Data Model
Note that these schema changes are for a default server plugin implementation.
Data Flow
-
Add Drift Config to Resource
-
choose and tweak template (base dir, interval, filters)
-
each config for a resource has a unique name
-
-
Enable Drift Config on Resource
-
can be enabled at add time
-
-
Agent generates initial, coverage change set
-
Agent stores coverage change set file locally
-
-
Agent sends coverage change set report
-
no drift reported at this time, just notification of the files being tracked
-
server streams this zipped report and then processes (MDB used for out-of-band processing)
-
-
Server requests bits for any unknown shas in the report
-
only store one sha one time in the db
-
future - will allow for server-side upload of anticipated files
-
all requested content streamed and processed as a single zip from agent (MDB used for out-of-band processing)
-
agent gathers these lazily from the filesystem to avoid high I/O and storage for eager copy (trade-off: opens small, most likely negligible drift window)
-
-
On interval, drift detection performed on agent
-
Agent finds changes
-
Generate drift change set which consists of delta between live files on disk and latest version in coverage change set
-
Update coverage change with changes
-
-
Agent sends drift change set to server
-
one drift occurrence for each reported file in change-set (file-added, removed, changed)
-