RHQ_CALLTIME_DEST ( id INTEGER, destination VARCHAR(4000), PRIMARY KEY (id)) RHQ_CALLTIME_DATA_VALUE ( id INTEGER, schedule_id INTEGER, call_destination_id INTEGER, PRIMARY KEY (id), FOREIGN KEY (schedule_id) REFERENCES RHQ_MEASUREMENT_SCHED (id), FOREIGN KEY (call_destination_id) REFERENCES RHQ_CALLTIME_DEST (id))
Part 1 - Transactional boundaries
I think we should add a @RequiresNew for each of the three major pieces of logic here - key insertions, checking for duplicates, data insertions.
If the check for duplicates fails, we shouldn't roll back the key insertions. It's highly likely that the keys will come across the wire in the next report, so why not let the key insertion succeed now no matter what, even if the dup checking fails for some reason.
Next, if the data insertions fail, do we really want to roll back the duplicate removal or the key insertion? The whole point of duplicate removal is to...well...remove duplicates. ; ) Duplicates are duplicates no matter what - even if some downstream logic fails. Thus, if we roll back the dups upon downstream failures, we're just going to re-remove those same dups when we receive the next report. And the same logic for the key insertions again - we might as well let it succeed because we're going to just re-insert them during the next report.
Thus, no matter which way you slice it, each part of the logic should be independent. By executing each in its own transaction, this will lessen the contention on the tables and overall cost of the insertion.
Part 2 - Refactoring table maintenance
This part of the improvement would be to relocate the deleteRedundantCallTimeDataValues method currently in CallTimeDataManager. It falls under the umbrella of a maintenance job, and so should be moved to where we run our other periodic maintenance jobs. This would allow the insertion logic to proceed even faster at the expense of the maintenance job running less frequently.
Part 3 - Schema enhancements
For every CallTimeData set we get, we try to insert destinations that haven't already been persisted - but we do this on a per schedule basis. In all likelihood, the customer will have dozens of boxes all configured the same way. That is, all boxes in app cluster XYZ will have the same destinations. Using this assumption, it should be possible to redesign the schema such that the destinations are in their own table. Then, to keep the number of required joins to a minimum I would do:
It eliminates the need for composite unique index on (schedule_id, VARCHAR(4000)) because the call destinations are no longer duplicated for each scheduleId. At the most, you would need a unique index on the single destination column of the new RHQ_CALLTIME_DEST table.
It would also further normalize the schema such that call time destinations that are the same between different resources only get a single row instead of their own rows, which reduces the overall size of this table.
Part 4 - Rewriting the insertion queries
Insertion logic should always be as simple as possible. This is what I might try:
a) The insertion logic into RHQ_CALLTIME_DEST is a matter of persisting strings that don't already exist. After we do that, we select the ids for the destinations in the report, and build a destination->id map out of them. This map will be used in the next step.
Note: this map could even be turned into app server-level cache of data. If that's the case, then we can hit the map first to see if the current report has any new destinations and by-pass the "INSERT INTO...WHERE NOT ALREADY EXISTING" logic altogether.
b) Using the map above, the insertion logic into RHQ_CALLTIME_DATA_VALUE can have its subquery removed, a subquery which would be executed for EACH row being inserted in the table referenced in the outer query.
Here, we set the call_destination_id on the data object by looking up the id in the map. Once we set all of the ids, the insertion call then becomes trivial because it doesn't depend on doing a subquery for each row of data being inserted – it does a simple insert into a single table.
This pushes some of the logic into the app server layer and out of the database.
Part 5 - Refactoring agent/server logic
If we wanted to really go wild, we could enhance the inventory synchronization mechanism to send the destination_ids down to the agents. The agent (specifically, the MeasurementManager responsible for creating the Report object) then has the responsibility of using the appropriate id for each destination it inserts into the report. If ALL destination ids are known for a given report - which is what will happen in steady state - the agent can set a special bit on the report which then allows the server to bypass the entire step #a (insertion into the destination table) as well as most of the logic in step #b (use the destination->id map to prepare each call time data value for insertion).
In other words, it would just be a straight insertion to a single table without any sub-queries. This would also dramatically reduce the contention on the RHQ_CALLTIME_DEST table because, in steady state, it would rarely be hit. However, the app server-level cache might be just as effective.
Summary & Suggestions
Each of these three groups below are mutually exclusive, meaning that any one of them can be done irrespective of the others:
-
Parts 1 & 2 are the "cheapest" in terms of man hours required to do them as well as potential for regressions
-
Part 3 is the next most expensive fix, whose major benefit will be seen by the fact that the composite index does not contain a large VARCHAR but also because the data model is further normalized thus reducing the size of the destination table considerably.
-
Parts 4 & 5 are by far the most expensive, but should be seen as "ideal" solutions because in steady state they make the insertions dead simple. Part 4 is certainly the least risky between the two, and so should be tried first. In all likelihood, part 4 will be performant enough to make attempting part 5 moot.
I suggest that parts 1 & 2 can easily be made into a patch for any customers that might run into a performance issue with call time data, and could safely be put into trunk/master as well.
The others should be discussed and then put on a roadmap somewhere, and analysed with respect to other deliverables.
------------------
Research
Simple inserts
I did some measurement with a unit test that inserts 27976 lines of RT data from the RHQ server. Insertion ran at various sizes for the CallTimeData set transmitted to the server. After each run, the DB was cleaned.
|
BatchSize |
Curent (ms) |
RequiresNew |
ReqNew-delete |
|
50 |
1,040 |
1,16225 |
0,681 |
|
100 |
0,795 |
0,8645 |
0,45375 |
|
200 |
0,553 |
0,5465 |
0,34775 |
|
500 |
0,307 |
0,2765 |
0,2216 |
|
1000 |
0,164 |
0,1689 |
0,1624 |
|
Color |
Blue |
Green |
Orange |
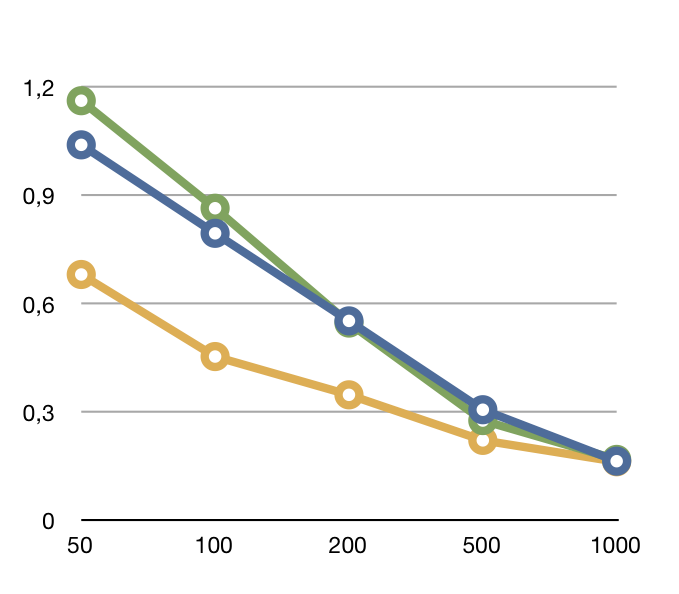
So inserting 200 items at once with the current impl is faster than inserting 50 items on the per item base - even when @RequiresNew is implemented and the deduplication is removed from the insert flow.
It also shows that the overhead to start new transactions and to call into a separate SessionBean is killing the benefit from not rolling everything back.
Insert of multiple schedules
Here data from two logfiles (RHQ ui + remoting ) is entered in parallel. Again insertion ran at different batch sizes (for the combination of the two, so data per schedule is half the batch size). After each run, the DB was cleaned
|
BatchSize |
Curent (ms) |
RequiresNew |
ReqNew-delete |
|
50 |
5,22825 |
9,351 |
2,6295 |
|
100 |
3,686 |
3,631 |
1,678 |
|
200 |
2,10175 |
2,375 |
1,013 |
|
500 |
0,93125 |
1,049 |
0,47375 |
|
1000 |
0,48275 |
0,50225 |
0,286675 |
|
Color |
Blue |
Green |
Orange |
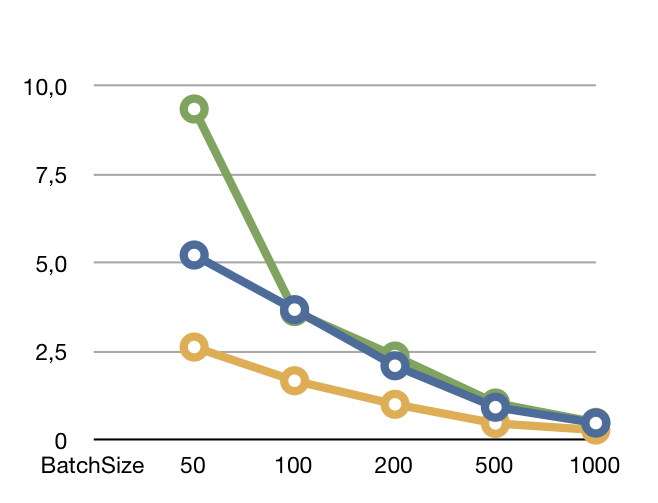
Again batch size has a big influence on performance. Just isolating the transactions brings a big overhead, that actually slows the insertions down.