Performance Testing
Current performance testing is done in an ad-hoc fashion meaning that servers are deployed and loaded with data to see how the system is working. There exists a perf test environment where a server is running a long time and gets data from spawned agents running the perf test plugin. While this is a good simulation of the real world, it still has the issue that it is not easy to measure effects of changes to the code base of RHQ.
The following areas need to be tested (separately):
-
Server subsystems
-
Agent server communication
-
HA failover stresstesting
-
UI load testing
-
Agents under load
Key points:
-
Performance tests will usually run for a longer period of time, so they should go into their separate Test-group so that they don't interfere with the normal development process
-
There should be a way to "pre-populate" a larger scenario as the initial resource creation takes a lot of work when writing tests
-
Emphasis should be put on running test methods in parallel in order to simulate e.g.
-
multiple agents talking to a server
-
multiple users querying the same data in the UI
-
-
In addition to the previous, some tests need to run in single thread only.
-
Writing perf tests for a subsystem before major changes allow to see the improvements after the changes and to potentially post improvement figures
-
DB agnostic: The perf tests should run on multiple database flavours
-
On developer machines to "quickly" examine changes in algorithms
-
On Hudson for (weekly) performance runs
-
population of database
There are several possible ways of doing this
-
Deploy an RHQ install and use Postgres pg_dump / pg_restore to save the state and to install it back later when testing
-
 Very fast
Very fast -
 Postgres only
Postgres only -
Setup and dump need to be re-done when data structures in RHQ change
-
Good modeling of a real-world scenario
-
-
Deploy an RHQ install and use Postgres pg_dump with manual INSERT statements
-
Fast
-
Inserts are (mostly) db independent
-
Inserts need to be re-modelled when the db structures change
-
-
Classical programatical resource setup in code
-
IDE catches Class changes and allow to refactor tests too
-
slow
-
very much manual work
-
-
Table driven setup: set up a real RHQ scenario, dump the database to a file/spread sheet, use this as input to programmatically create resources
-
Faster than manual setup
-
IDE can partially catch data structure changes
-
Database agnostic
-
Models real world scenario
-
Slower to initially get done than pg_dump / pg_restore
-
Relatively easy to set up many more resources than which are in the initial dump
-
From this comparison 4) looks like the most promising approach:
Table driven setup
Note: This has been reworked to use Entity Driven Database Setup but the principle still stays the same.
Data for agents, plugins, resource types, resources are taken from CSV files that are created from a dump of an existing setup. Then the test setup reads those files, created the appropriate resources. Within a loop additional resources of the same type can be created in order to simulate more resources e.g. in a clustered environment. 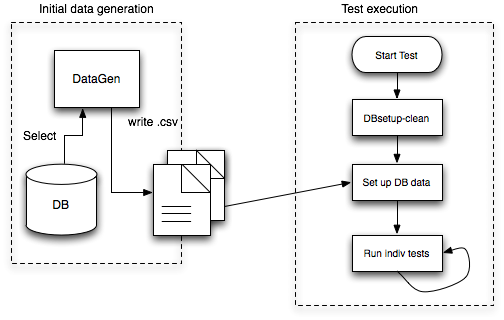
To initially get the CSV files, there is a new modules helpers/perfDataGen, that reads the tables of an existing RHQ database and creates the CSV file from those.
The test execution first does a DBsetup in a clean state and then reads the csv files to populate the database. One trick needs to be applied though, as the references to other objects are kept using foreign key ids and those are most likely to change while importing, translation tables need to be created which then keep track of the original ID and the new one, thus allowing to link the correct objects together.
If it is desired to set up more resources than from the original database dump, the "Setup DB data" step can repeat reading Agents and Resources files as the translation tables will keep track of the correct wiring. This way it is possible to create scenarios with multiple agents -- see also "Parallel Tests". Of course agent names and resource uuids need to be changed on the fly too.
Parallel Tests
TestNG which we are using allows to run tests in parallel. This way it is possible to e.g. simulate multiple agents sending measurement data or availability reports. This parallel execution can be used in multiple scenarios:
-
Server subsystem testing
-
UI testing
-
Agent server comm testing
Server subsystems
Performance testing server subsystems allows to test all subsystems that can be unit tested.
Test code can send data in parallel threads to simulate situations with multiple agents.
HA Failover stress testing
For this to take place, we need at least two servers and multiple agents. Here we could use the perf env. Agents need to be modified to switch servers every x seconds. Also agent spawning needs to be set up to ramp up spawning new agents so that for a given number of agents the test can run for a given duration of e.g. 5 minutes and then the next batch of agents (e.g. 10 at a time) are spawned until the maximum number is reached.
If more computers are available, it may make sense to set up scenarios with the help of SmartFrog, like the JBossAS performance guys are doing.
Agent server communication testing
There are already agent server comm unit tests. Performance tests can follow those and
-
Repeatedly send huge amounts of small messages
-
Have one server thread answering requests and many parallel agent threads that send messages
-
Test that by sending large messages (like e.g. bundle content) other messages are not delayed to unacceptable levels
Tests need to be equipped to fail at some given durations - e.g. "it may at most take 1s for an availability report to be acknowledged"
Agent stress testing
Agent stress testing basically consists of two parts:
-
Testing the agent-server communications as described above
-
Testing the plugin container scheduler components
For the latter one would write plugins that e.g.
-
have huge amounts of metrics that all fire at 1s intervals and see when they fall over
-
have plugins with metrics that are slow to compute metrics
UI Load testing
start one browser per thread and have them using a separate user account to do the click streams through the application. If possible, one can also set up multiple agents here, so that each simulated user gets "its agent" and can even trigger write operations like modifying schedules on resources of "its agent".
What can be (automatically) tested
TODO
-
How do CSV files and BLOBs work?
-
Probably it is not really needed to find this out. Otherwise it would be possible to store blobs just as files "-> serialize to disk" and read them back from there
-
-