This page is under construction and subject to major changes
Overview
One of the objects with storage node management is to make it as easy as possible for users to determine things like,
-
When does the JVM heap need to be increased?
-
When is more disk capacity needed?
-
When should additional storage nodes be deployed to handle increasing load?
Storage nodes have several pre-defined alert definitions that are enabled out of the box. These alert definitions aim to answer these types of questions for you. Alerts can be managed from the Storage Nodes UI. We can get an aggregate view of unacknowledged alerts on the Nodes tab.
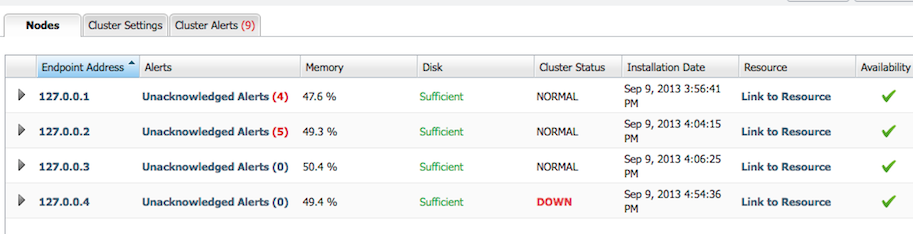
This is a screenshot of a four node cluster with some alerts that have fired. The first thing to note is that the heading of the Cluster Alerts tab shows the total number of unacknowledged alerts. Then we can see the number of alerts that have fired for each node. The Cluster Alerts tab is essentially a report similar to the Recent Alerts report, except that it is limited to storage nodes (and their child resources).
defined Alerts
This section provides a brief summary of each alert definition followed by more detailed explanations.
|
Alert Definition |
Resource Type |
|
High Heap Usage |
RHQ Storage Node --> Cassandra Server JVM --> Memory Subsystem |
|
High Disk Usage |
RHQ Storage Node --> Database Management Services --> Storage Service |
|
Snapshot Failure |
RHQ Storage Node --> Database Management Services --> Storage Service |
|
Maintenance Operation Failure |
RHQ Storage Node |
High Heap Usage
Fires an alert when the storage node JVM heap memory is high. Sustained, high memory utilization can lead to performance degradation and/or OutOfMemoryErrors. The default heap setting is 512 MB. This may be fine for small to moderate workloads, particularly those that do not include a lot of reads. For larger workloads and for those that include a larger number of reads, increasing the heap may be necessary. Alternatively, additional storage nodes can be deployed to reduce load.
Dampening is used to prevent prematurely firing alerts due to temporary spikes in heap usage.
Provide some guidelines around how much to increase the heap and what point you should consider deploying more nodes
High Disk Usage
Fires an alert when disk usage is high. Insufficient disk space can cause routine maintenance tasks like compaction to fail. Compaction is a process that merges data files for a table on disk into a single file. It is important because it frees up disk space and also improves read performance. Dampening is used to prevent prematurely firing alerts due to temporary spikes in disk usage from tasks like compaction. An alert is fired if any of the following conditions is met:
-
The size of storage node data on disk exceeds 50% of total disk space
-
The overall amount of disk space used exceeds 75% of total disk space
-
The ratio of free disk space to storage node data is less than 1.5
The first condition is fairly intuitive. It checks whether the amount of space used by the storage node relative to the total available space exceeds a threshold. If we have a 100 MB disk and the storage node accounts for 70 MB of it, then we have exceeded the 50% threshold.
The second condition checks whether the overall amount of used disk space has exceed a threshold. This is different from the first condition in that it takes into account space consumed by both storage node data as well as other data. Again suppose we have a 100 MB disk. Storage node data only accounts for 35 MB. Other data on the system accounts for 45 MB. A total of 80 MB is being used which means the 75% threshold has been surpassed.
The last condition performs a check on the overall amount of free space relative to the amount of storage node data. Maintenance tasks such as compaction and repair can cause temporary spikes in disk usage. These tasks can fail if there is an insufficient amount of free space. We have our 100 MB disk. Storage node data accounts for 35 MB. 20 MB is used by other processes. We have 45 MB of free space. which means the ratio of free space to storage data space is 1.29
Snapshot Failure
Fires an alert when the snapshot operation fails. The snapshot operation is executed during regularly scheduled maintenance to back up data files.
Maintenance Operation Failure
Fires an alert when storage node resource operations fail. Failed operations that occur during a (un)deployment is discussed in Deploying Multiple Storage Nodes.