Traits were introduced in the 5.3 release, and details on them can be found in the N&N for there. This release adds an example so that people have something simple to run, to help them understand. In the drools-examples source project open the classes and drl for the namespace "/org/drools/examples/traits". There you will find an example around classifications of students and workers.
rule "Students and Workers" no-loop when
$p : Person( $name : name,
$age : age < 25,
$weight : weight )
then
IWorker w = don( $p, IWorker.class, true );
w.setWage( 1200 );
update( w );
IStudent s = don( $p, IStudent.class, true );
s.setSchool( "SomeSchool" );
update( s );
end
rule "Working Students" salience -10 when
$s : IStudent( $school : school,
$name : name,
this isA IWorker,
$wage : fields[ "wage" ] )
then
System.out.println( $name + " : I have " + $wage + " to pay the fees at " + $school );
endA two part detailed article has been written up at a blog, which will later be improved and rolled into the main documentation. For now you can read them here.
The simulation project that was first started in 2009, http://blog.athico.com/2009/07/drools-simulation-and-test-framework.html,
has undergone an over haul and is now in a usable state. We have not yet promoted this to
knowledge-api, so it's considered unstable and will change during the beta process. For now
though, the adventurous people can take a look at the unit tests and start playing.
The Simulator runs the Simulation. The Simulation is your scenario definition. The Simulation consists of 1
to n Paths, you can think of a Path as a sort of Thread. The Path is a chronological line on which Steps are
specified at given temporal distances from the start. You don't specify a time unit for the Step, say 12:00am,
instead it is always a relative time distance from the start of the Simulation (note: in Beta2 this will be
relative time distance from the last step in the same path). Each Step contains one or more Commands, i.e. create
a StatefulKnowledgeSession or insert an object or start a process. These are the very same
commands that you would use to script a knowledge session using the batch execution, so it's re-using existing
concepts.
1.1 Simulation
1..n Paths
1..n Steps
1..n Commands
All the steps, from all paths, are added to a priority queue which is ordered by the temporal distance, and allows us to incrementally execute the engine using a time slicing approach. The simulator pops of the steps from the queue in turn. For each Step it increments the engine clock and then executes all the Step's Commands.
Here is an example Command (notice it uses the same Commands as used by the CommandExecutor):
new InsertObjectCommand( new Person( "darth", 97 ) )
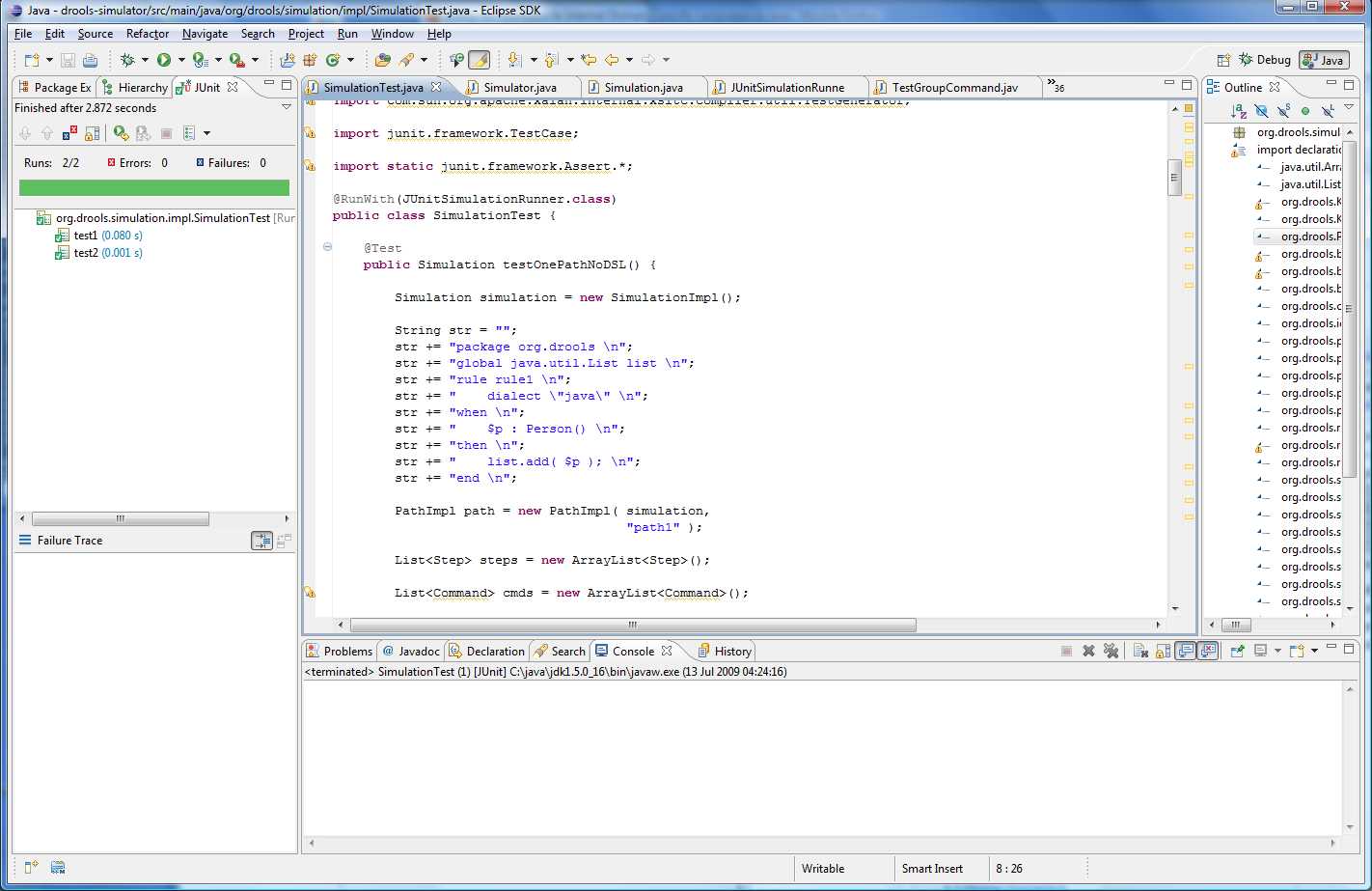
Commands can be grouped together, especially Assertion commands, via test groups. The test groups are mapped to JUnit "test methods", so as they pass or fail using a specialised JUnit Runner the Eclipse GUI is updated - as illustrated in the above image, showing two passed test groups named "test1" and "test2".
Using the JUnit integration is trivial. Just annotate the class with @RunWith(JUnitSimulationRunner.class). Then any method that is annotated with @Test and returns a Simulation instance will be invoked executing the returned Simulation instance in the Simulator. As test groups are executed the JUnit GUI is updated.
When executing any commands on a KnowledgeBuilder, KnowledgeBase or StatefulKnowledgeSession the system assumes a "register" approach. To get a feel for this look at the org.drools.simulation.impl.SimulationTest at github (path may change over time).
cmds.add( new NewKnowledgeBuilderCommand( null ) );
cmds.add( new SetVariableCommandFromLastReturn( "path1",
KnowledgeBuilder.class.getName() ) );
cmds.add( new KnowledgeBuilderAddCommand( ResourceFactory.newByteArrayResource( str.getBytes() ),
ResourceType.DRL, null ) );Notice the set command. "path1" is the context, each path has it's own variable context. All paths inherit from a "root" context. "KnowledgeBuilder.class.getName() " is the name that we are setting the return value of the last command. As mentioned before we consider the class names of those classes as registers, any further commands that attempt to operate on a knowledge builder will use what ever is assigned to that, as in the case of KnowledgeBuilderAddCommand. This allows multiple kbuilders, kbases and ksessions to exist in one context under different variable names, but only the one assigned to the register name is the one that is currently executed on.
The code below show the rough outline used in SimulationTest:
Simulation simulation = new SimulationImpl();
PathImpl path = new PathImpl( simulation,
"path1" );
simulation.getPaths().put( "path1",
path );
List<Step> steps = new ArrayList<Step>();
path.setSteps( steps );
List<Command> cmds = new ArrayList<Command>();
.... add commands to step here ....
// create a step at temporal distance of 2000ms from start
steps.add( new StepImpl( path,
cmds,
2000 ) ); We know the above looks quite verbose. SimulationTest just shows our low level canonical model, the idea is that high level representations are built ontop of this. As this is a builder API we are currently focusing on two sets of fluents, compact and standard. We will also work on a spreadsheet UI for building these, and eventually a dedicated textual dsl.
The compact fluent is designed to provide the absolute minimum necessary to run against a single ksession. A good place to start is org.drools.simulation.impl.CompactFluentTest, a snippet of which is shown below. Notice we set "yoda" to "y" and can then assert on that. Currently inside of the test string it executes using mvel. The eventual goal is to build out a set of hamcrest matchers that will allow assertions against the state of the engine, such as what rules have fired and optionally with with data.
FluentCompactSimulation f = new FluentCompactSimulationImpl();
f.newStatefulKnowledgeSession()
.getKnowledgeBase()
.addKnowledgePackages( ResourceFactory.newByteArrayResource( str.getBytes() ),
ResourceType.DRL )
.end()
.newStep( 100 ) // increases the time 100ms
.insert( new Person( "yoda",
150 ) ).set( "y" )
.fireAllRules()
// show testing inside of ksession execution
.test( "y.name == 'yoda'" )
.test( "y.age == 160" );Note that the test is not executing at build time, it's building a script to be executed later. The script underneath matches what you saw in SimulationTest. Currently the way to run a simulation manually is shown below. Although you already saw in SimulationTest that JUnit will execute these automatically. We'll improve this over time.
SimulationImpl sim = (SimulationImpl) ((FluentCompactSimulationImpl) f).getSimulation();
Simulator simulator = new Simulator( sim,
new Date().getTime() );
simulator.run();The standard fluent is almost a 1 to 1 mapping to the canonical path, step and command structure in SimulationTest- just more compact. Start by looking in org.drools.simulation.impl.StandardFluentTest. This fluent allows you to run any number of paths and steps, along with a lot more control over multiple kbuilders, kbases and ksessions.
FluentStandardSimulation f = new FluentStandardSimulationImpl();
f.newPath("init")
.newStep( 0 )
// set to ROOT, as I want paths to share this
.newKnowledgeBuilder()
.add( ResourceFactory.newByteArrayResource( str.getBytes() ),
ResourceType.DRL )
.end(ContextManager.ROOT, KnowledgeBuilder.class.getName() )
.newKnowledgeBase()
.addKnowledgePackages()
.end(ContextManager.ROOT, KnowledgeBase.class.getName() )
.end()
.newPath( "path1" )
.newStep( 1000 )
.newStatefulKnowledgeSession()
.insert( new Person( "yoda", 150 ) ).set( "y" )
.fireAllRules()
.test( "y.name == 'yoda'" )
.test( "y.age == 160" )
.end()
.end()
.newPath( "path2" )
.newStep( 800 )
.newStatefulKnowledgeSession()
.insert( new Person( "darth", 70 ) ).set( "d" )
.fireAllRules()
.test( "d.name == 'darth'" )
.test( "d.age == 80" )
.end()
.end()
.endThere is still an awful lot to do, this is designed to eventually provide a unified simulation and testing environment for rules, workflow and event processing over time, and eventually also over distributed architectures.
Flesh out the api to support more commands, and also to encompass jBPM commands
Improve out of the box usability, including moving interfaces to knowledge-api and hiding "new" constructors with factory methods
Commands are already marshallable to json and xml. They should be updated to allow full round tripping from java api commands and json/xml documents.
Develop hamcrest matchers for testing state
What rule(s) fired, including optionally what data was used with the executing rule (Drools)
What rules are active for a given fact
What rules activated and de-activated for a given fact change
Process variable state (jBPM)
Wait node states (jBPM)
Design and build tabular authoring tools via spreadsheet, targeting the web with round tripping to excel.
Design and develop textual DSL for authoring - maybe part of DRL (long term task).
Multi-function accumulate now supports inline constraints. The simplified EBNF is:
lhsAccumulate := ACCUMULATE LEFT_PAREN lhsAnd (COMMA|SEMICOLON)
accumulateFunctionBinding (COMMA accumulateFunctionBinding)*
(SEMICOLON constraints)?
RIGHT_PAREN SEMICOLON?E.g.:
rule "Accumulate example"
when
accumulate( Cheese( $price : price );
$a1 : average( $price ),
$m1 : min( $price ),
$M1 : max( $price ); // a semicolon, followed by inline constraints
$a1 > 10 && $M1 <= 100, // inline constraint
$m1 == 5 // inline constraint
)
then
// do something
end
A new RuleSet property has been added called "Declare".
This provides a slot in the RuleSet definition to define declared types.
In essence the slot provides a discrete location to add type declarations where, previously, they may have been added to a Queries or Functions definition.
A working version of Wumpus World, an AI example covered in in the book "Artificial Intelligence : A Modern Approach", is now available among the other examples. A more detailed overview of Wumpus World can be found here
Support has been added for the "timer" and "calendar" attributes.
Table 4.1. New attributes
| Keyword | Initial | Value |
|---|---|---|
| TIMER | T | A timer definition. See "Timers and Calendars". |
| CALENDARS | E | A calendars definition. See "Timers and Calendars". |
KnowledgeBuilder has a new batch mode, with a fluent interface, that allows to build multiple DRLs at once as in the following example:
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.batch()
.add(ResourceFactory.newByteArrayResource(rules1.getBytes()), ResourceType.DRL)
.add(ResourceFactory.newByteArrayResource(rules2.getBytes()), ResourceType.DRL)
.add(ResourceFactory.newByteArrayResource(declarations.getBytes()), ResourceType.DRL)
.build();In this way it is no longer necessary to build the DRLs files in the right order (e.g. first the DRLs containing the type declarations and then the ones with the rules using them) and it will also be possible to have circular references among them.
Moreover the KnowledgeBuilder (regardless if you are using the batch mode or not) also allows to discard what has been added with the last DRL(s) building. This can be useful to recover from having added a wrong DRL to the KnowledgeBuilder as it follows:
kbuilder.add(ResourceFactory.newByteArrayResource(wrongDrl.getBytes()), ResourceType.DRL);
if ( kbuilder.hasErrors() ) {
kbuilder.undo();
}Currently when in a RHS you invoke update() or modify() on a given object it will trigger a revaluation of all patterns of the matching object type in the knowledge base. As some have experienced, this can be a problem that often can lead to unwanted and useless evaluations and in the worst cases to infinite recursions. The only workaround to avoid it was to split up your objects into smaller ones having a 1 to 1 relationship with the original object.
This new feature allows the pattern matching to only react to modification of properties actually constrained or bound inside of a given pattern. That will help with performance and recursion and avoid artificial object splitting. The implementation is bit mask based, so very efficient. When the engine executes a modify statement it uses a bit mask of fields being changed, the pattern will only respond if it has an overlapping bit mask. This does not work for update(), and is one of the reason why we promote modify() as it encapsulates the field changes within the statement.
By default this feature is off in order to make the behavior of the rule engine backward compatible with the former releases. When you want to activate it on a specific bean you have to annotate it with @propertyReactive. This annotation works both on drl type declarations:
declare Person
@propertyReactive
firstName : String
lastName : String
endand on Java classes:
@PropertyReactive
public static class Person {
private String firstName;
private String lastName;
}In this way, for instance, if you have a rule like the following:
rule "Every person named Mario is a male" when
$person : Person( firstName == "Mario" )
then
modify ( $person ) { setMale( true ) }
endyou won't have to add the no-loop attribute to it in order to avoid an infinite recursion because the engine recognizes that the pattern matching is done on the 'firstName' property while the RHS of the rule modifies the 'male' one. Note that this feature does not work for update(), and this is one of the reasons why we promote modify() since it encapsulates the field changes within the statement. Moreover, on Java classes, you can also annotate any method to say that its invocation actually modifies other properties. For instance in the former Person class you could have a method like:
@Modifies( { "firstName", "lastName" } )
public void setName(String name) {
String[] names = name.split("\\s");
this.firstName = names[0];
this.lastName = names[1];
}That means that if a rule has a RHS like the following:
modify($person) { setName("Mario Fusco") }it will correctly recognize that the values of both properties 'firstName' and 'lastName' could have potentially been modified and act accordingly, not missing of reevaluating the patterns constrained on them. At the moment the usage of @Modifies is not allowed on fields but only on methods. This is coherent with the most common scenario where the @Modifies will be used for methods that are not related with a class field as in the Person.setName() in the former example. Also note that @Modifies is not transitive, meaning that if another method internally invokes the Person.setName() one it won't be enough to annotate it with @Modifies( { "name" } ), but it is necessary to use @Modifies( { "firstName", "lastName" } ) even on it. Very likely @Modifies transitivity will be implemented in the next release.
For what regards nested accessors, the engine will be notified only for top level fields. In other words a pattern matching like:
Person ( address.city.name == "London )
will be reevaluated only for modification of the 'address' property of a Person object. In the same way the constraints analysis is currently strictly limited to what there is inside a pattern. Another example could help to clarify this. An LHS like the following:
$p : Person( ) Car( owner = $p.name )
will not listen on modifications of the person's name, while this one will do:
Person( $name : name ) Car( owner = $name )
To overcome this problem it is possible to annotate a pattern with @watch as it follows:
$p : Person( ) @watch ( name ) Car( owner = $p.name )
Indeed, annotating a pattern with @watch allows you to modify the inferred set of properties for which that pattern will react. Note that the properties named in the @watch annotation are actually added to the ones automatically inferred, but it is also possible to explicitly exclude one or more of them prepending their name with a ! and to make the pattern to listen for all or none of the properties of the type used in the pattern respectively with the wildcards * and !*. So, for example, you can annotate a pattern in the LHS of a rule like:
// listens for changes on both firstName (inferred) and lastName Person( firstName == $expectedFirstName ) @watch( lastName ) // listens for all the properties of the Person bean Person( firstName == $expectedFirstName ) @watch( * ) // listens for changes on lastName and explicitly exclude firstName Person( firstName == $expectedFirstName ) @watch( lastName, !firstName ) // listens for changes on all the properties except the age one Person( firstName == $expectedFirstName ) @watch( *, !age )
Since doesn't make sense to use this annotation on a pattern using a type not annotated with @PropertyReactive the rule compiler will raise a compilation error if you try to do so. Also the duplicated usage of the same property in @watch (for example like in: @watch( firstName, ! firstName ) ) will end up in a compilation error. In a next release we will make the automatic detection of the properties to be listened smarter by doing analysis even outside of the pattern.
It also possible to enable this feature by default on all the types of your model or to completely disallow it by using on option of the KnowledgeBuilderConfiguration. In particular this new PropertySpecificOption can have one of the following 3 values:
- DISABLED => the feature is turned off and all the other related annotations are just ignored - ALLOWED => this is the default behavior: types are not property reactive unless they are not annotated with @PropertySpecific - ALWAYS => all types are property reactive by default
So, for example, to have a KnowledgeBuilder generating property reactive types by default you could do:
KnowledgeBuilderConfiguration config = KnowledgeBuilderFactory.newKnowledgeBuilderConfiguration(); config.setOption(PropertySpecificOption.ALWAYS); KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder(config);
In this last case it will be possible to disable the property reactivity feature on a specific type by annotating it with @ClassReactive.
This API is experimental: future backwards incompatible changes are possible.
Using the new fluent simulation testing, you can test your rules in unit tests more easily:
@Test
public void rejectMinors() {
SimulationFluent simulationFluent = new DefaultSimulationFluent();
Driver john = new Driver("John", "Smith", new LocalDate().minusYears(10));
Car mini = new Car("MINI-01", CarType.SMALL, false, new BigDecimal("10000.00"));
PolicyRequest johnMiniPolicyRequest = new PolicyRequest(john, mini);
johnMiniPolicyRequest.addCoverageRequest(new CoverageRequest(CoverageType.COLLISION));
johnMiniPolicyRequest.addCoverageRequest(new CoverageRequest(CoverageType.COMPREHENSIVE));
simulationFluent
.newKnowledgeBuilder()
.add(ResourceFactory.newClassPathResource("org/drools/examples/carinsurance/rule/policyRequestApprovalRules.drl"),
ResourceType.DRL)
.end()
.newKnowledgeBase()
.addKnowledgePackages()
.end()
.newStatefulKnowledgeSession()
.insert(john).set("john")
.insert(mini).set("mini")
.insert(johnMiniPolicyRequest).set("johnMiniPolicyRequest")
.fireAllRules()
.test("johnMiniPolicyRequest.automaticallyRejected == true")
.test("johnMiniPolicyRequest.rejectedMessageList.size() == 1")
.end()
.runSimulation();
}
You can even test your CEP rules in unit tests without suffering from slow tests:
@Test
public void lyingAboutAge() {
SimulationFluent simulationFluent = new DefaultSimulationFluent();
Driver realJohn = new Driver("John", "Smith", new LocalDate().minusYears(10));
Car realMini = new Car("MINI-01", CarType.SMALL, false, new BigDecimal("10000.00"));
PolicyRequest realJohnMiniPolicyRequest = new PolicyRequest(realJohn, realMini);
realJohnMiniPolicyRequest.addCoverageRequest(new CoverageRequest(CoverageType.COLLISION));
realJohnMiniPolicyRequest.addCoverageRequest(new CoverageRequest(CoverageType.COMPREHENSIVE));
realJohnMiniPolicyRequest.setAutomaticallyRejected(true);
realJohnMiniPolicyRequest.addRejectedMessage("Too young.");
Driver fakeJohn = new Driver("John", "Smith", new LocalDate().minusYears(30));
Car fakeMini = new Car("MINI-01", CarType.SMALL, false, new BigDecimal("10000.00"));
PolicyRequest fakeJohnMiniPolicyRequest = new PolicyRequest(fakeJohn, fakeMini);
fakeJohnMiniPolicyRequest.addCoverageRequest(new CoverageRequest(CoverageType.COLLISION));
fakeJohnMiniPolicyRequest.addCoverageRequest(new CoverageRequest(CoverageType.COMPREHENSIVE));
fakeJohnMiniPolicyRequest.setAutomaticallyRejected(false);
simulationFluent
.newStep(0)
.newKnowledgeBuilder()
.add(ResourceFactory.newClassPathResource("org/drools/examples/carinsurance/cep/policyRequestFraudDetectionRules.drl"),
ResourceType.DRL)
.end()
.newKnowledgeBase()
.addKnowledgePackages()
.end(World.ROOT, KnowledgeBase.class.getName())
.newStatefulKnowledgeSession()
.end()
.newStep(1000)
.getStatefulKnowledgeSession()
.insert(realJohn).set("realJohn")
.insert(realMini).set("realMini")
.insert(realJohnMiniPolicyRequest).set("realJohnMiniPolicyRequest")
.fireAllRules()
.test("realJohnMiniPolicyRequest.requiresManualApproval == false")
.end()
.newStep(5000)
.getStatefulKnowledgeSession()
.insert(fakeJohn).set("fakeJohn")
.insert(fakeMini).set("fakeMini")
.insert(fakeJohnMiniPolicyRequest).set("fakeJohnMiniPolicyRequest")
.fireAllRules()
.test("fakeJohnMiniPolicyRequest.requiresManualApproval == true")
.end()
.runSimulation();
}
It is now possible to register an UnMatch listener on the Agenda in order to be notified when a given activation gets unmatched and take the appropriate compensation actions, as in the follwing example:
AgendaItem item = ( AgendaItem ) knowledgeHelper.getActivation();
final Cheese cheese = ( Cheese ) item.getTuple().getHandle().getObject();
final int oldPrice = cheese.getPrice();
cheese.setPrice( 100 );
item.setActivationUnMatchListener( new ActivationUnMatchListener() {
public void unMatch( org.drools.runtime.rule.WorkingMemory wm,
org.drools.runtime.rule.Activation activation ) {
cheese.setPrice( oldPrice );
}
} );
Note that, at the moment, this is an internal impelmentation, that will be eventually moved to a stable API in the future. This is why it is only present in our internal API and so you need to explicitly cast to AgendaItem in order to be able to use it.
The engine now supports the declaration of entry-points. This allow tools and the application to inspect, select and restrict the use of entry-points in rules.
The simplified EBNF to declare an entry-point is:
entryPointDeclaration := DECLARE ENTRY-POINT epName annotation* END epName := stringId
Example:
declare entry-point STStream
@doc("A stream of StockTicks")
end
The engine now supports the declaration of Windows. This promotes a clear separation between what are the filters applied to the window and what are the constraints applied to the result of window. It also allows easy reuse of windows among multiple rules.
Another benefit is a new implementation of the basic window support in the engine, increasing the overall performance of the rules that use sliding windows.
The simplified EBNF to declare a window is:
windowDeclaration := DECLARE WINDOW ID annotation* lhsPatternBind END
Example:
declare window Ticks
@doc("last 10 stock ticks")
StockTick( source == "NYSE" )
over window:length( 10 )
from entry-point STStream
end
Rules can then use the declared window by referencing using a FROM CE. Example:
rule "RHT ticks in the window"
when
accumulate( StockTick( symbol == "RHT" ) from window Ticks,
$cnt : count(1) )
then
// there has been $cnt RHT ticks over the last 10 ticks
end
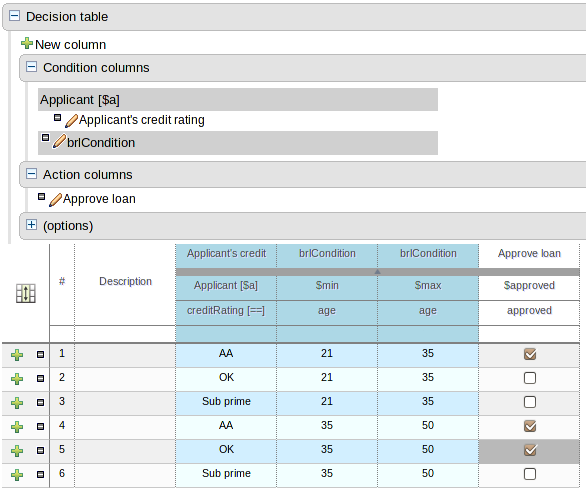
The Guided Decision Table editor and wizard now support the creation of "Limited Entry" tables.
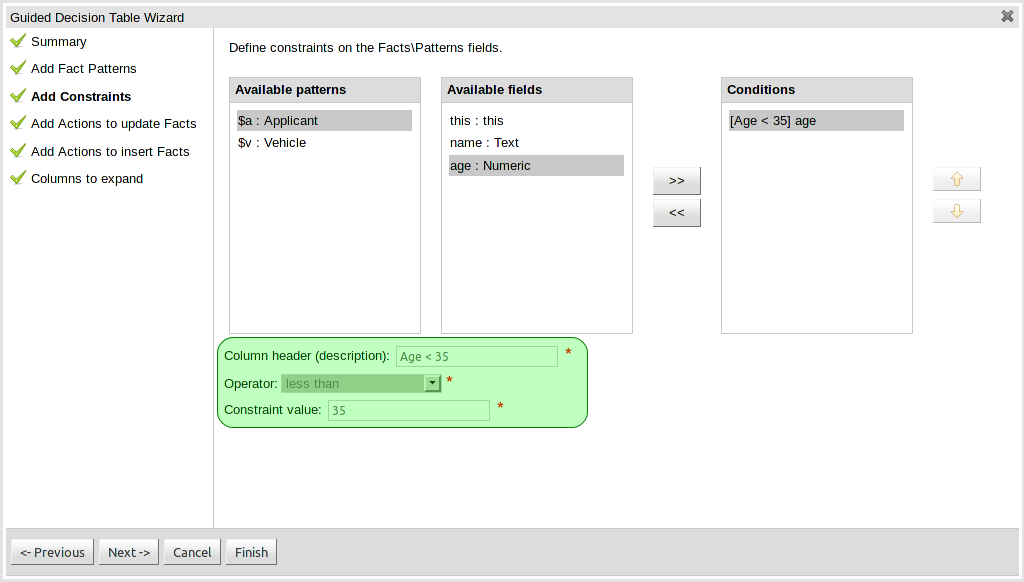
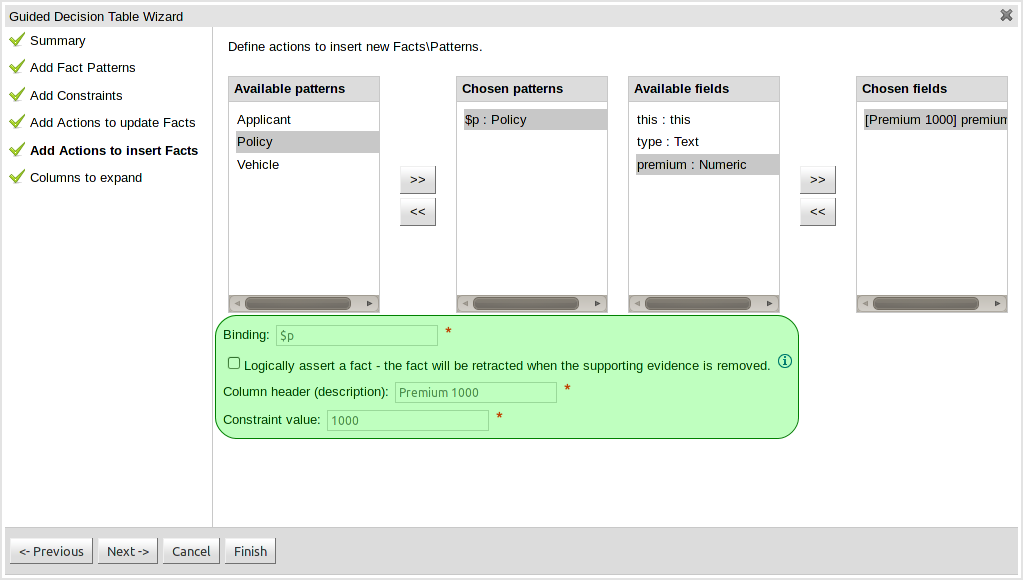
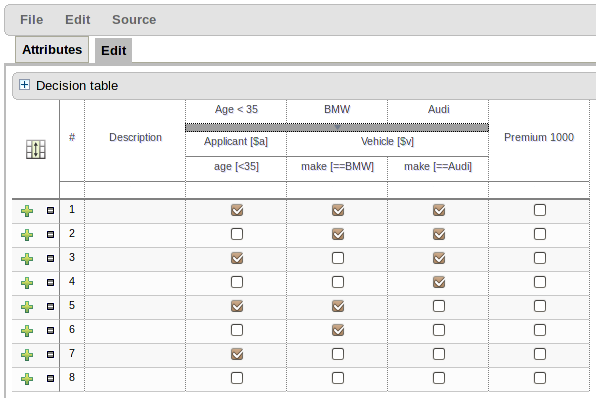
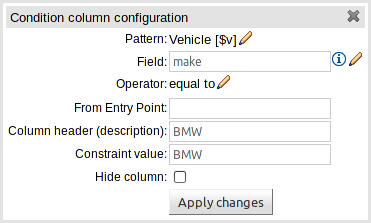

With the introduction of support for Limited Entry, the decision table format was improved to better differentiate between Condition and Action columns. Furthermore the table header was improved to show more information for Action columns.
The ability to rearrange whole patterns as well as individual conditions in the constraints section of the table has been added. This allows the table author to arrange constraints to maximise performance of the resulting rules, by placing generalised constraints before more specific. Action columns can also be re-arranged. Both patterns and columns are re-arranged by dragging and dropping.
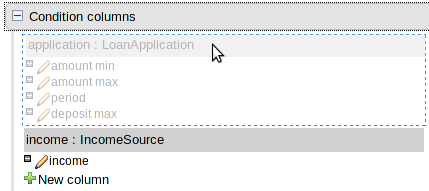
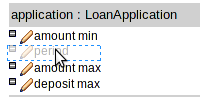
This release brings the ability to define Action columns to retract Facts.
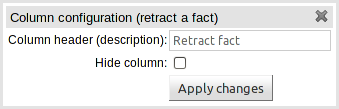
If you are authoring an Extended Entry decision table the column definition contains basic information and the fact being retracted is held in the table itself.
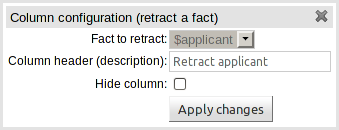
If however you are authoring a Limited Entry decision table the Fact being retracted is defined in the column definition.
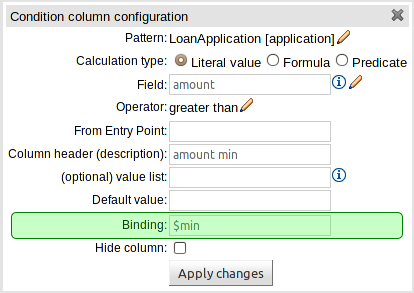
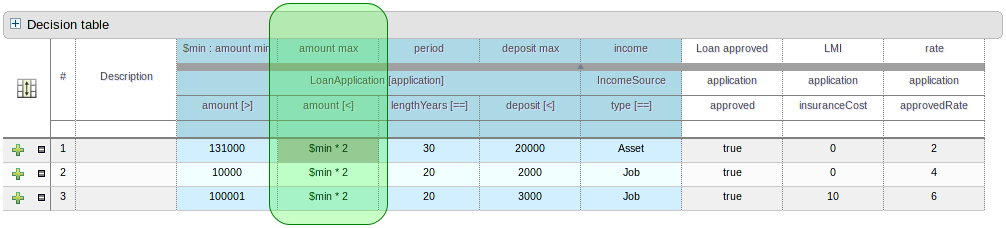
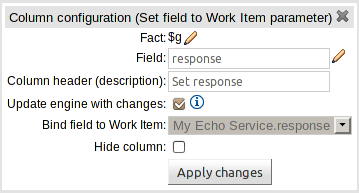
You can now bind fields in Conditions to variables. These variables can then be used in Predicate or Formula conditions, and Work Item actions.
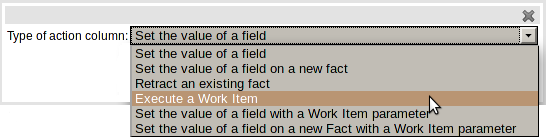
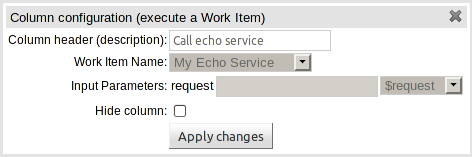
jBPM Work Items can now be used as Actions; and the corresponding Work Item Handler invoked at runtime. Work Item Handlers should be added to the runtime session as normal.
Work Item input parameters can either be defined as a literal value in the column definition or as a Fact or Fact Field binding.
New Actions have been created to perform the following functions:-
Execute a Work Item
Set the value of a field on an existing Fact to the value of a Work Item output (result) parameter.
Set the value of a field on a new Fact to the value of a Work Item output (result) parameter.
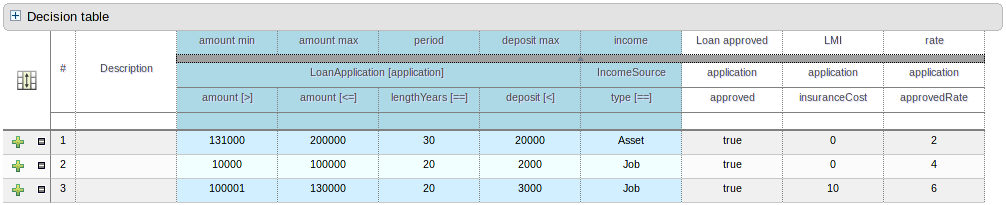
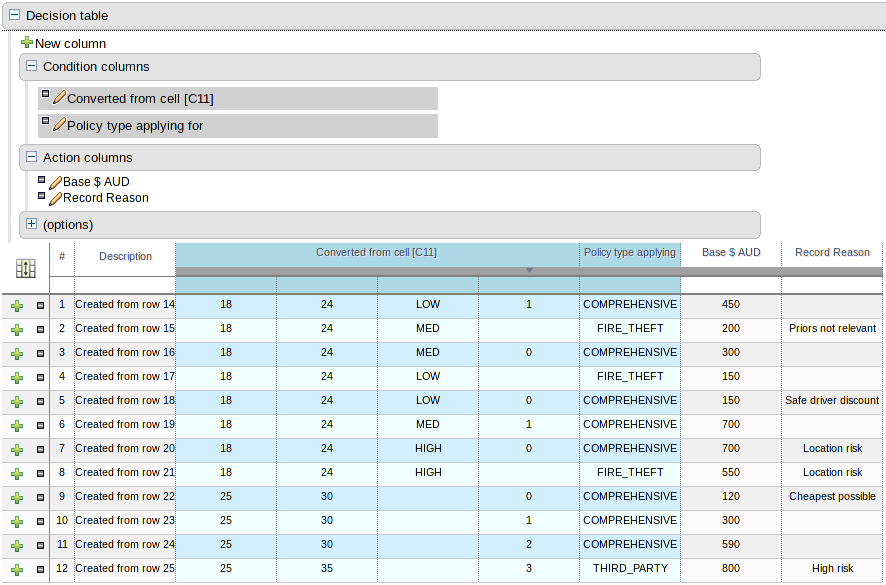
On the bottom of Web decision tables, there's now a button Analyze... which will check if there issues in your decision table, such as impossible matches and conflicting matches.
An impossible match is a row in a decision table that can never match. For example:
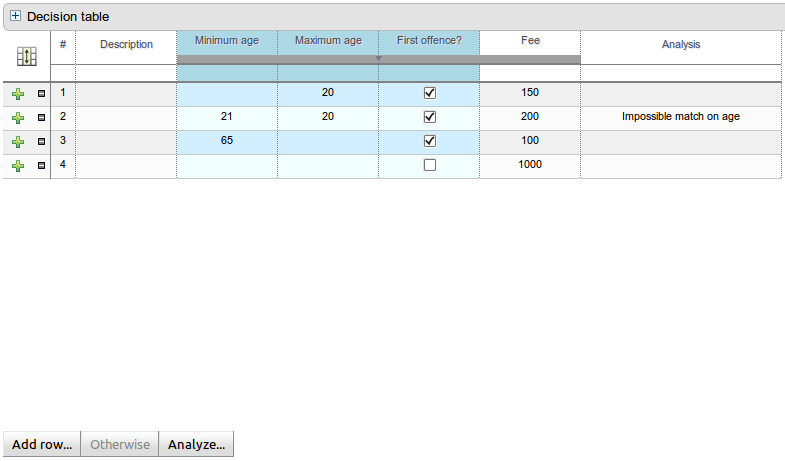
In the decision table above, row 2 is an impossible match, because there is no Person with a minimum age of 21 and a maximum age of 20.
Added support to create (PUT) and delete (DELETE) a Category with
rest/categories/{categoryName}.Removed buggy
categoryproperty fromPackage: it wasnullupon GET and ignored upon PUT.The REST resource to get the assets for a certain category has been moved from
rest/categories/{categoryName}torest/categories/{categoryName}/assets.The REST resources now properly encode and decode the URL's. Note that URL path encoding is different than URL query encoding: the former does not accept
+as encoding for space.
This does not mean that Guvnor can not be made to work in AS 6. We are just focusing on JBoss AS 7 and Tomcat.
When using Rule Templates you can now define interpolation variables in free-form DRL blocks. Template Keys are formatted as documented in Drools Expert User Guide; i.e. @{keyName}. All Template Keys in 'free-form' LHS or RHS elements are considered 'Text' (i.e. you'll get a TextBox in the Template data screen). Data-types should be correctly escaped in the 'free-form' entry. For example: System.out.println("@{key}");
All guided rule editors (BRL, Rule Templates and Decision Tables) now support relation operators for String values.
Guvnor 5.4.x requires at least Java 6 to run. The Drools and jBPM will still run on Java 5. Guvnor 5.3.x hotfixes will still run on Java 5 too.
Any custom configuration in the guvnor war in
WEB-INF/components.xml must now happen in
WEB-INF/beans.xml.
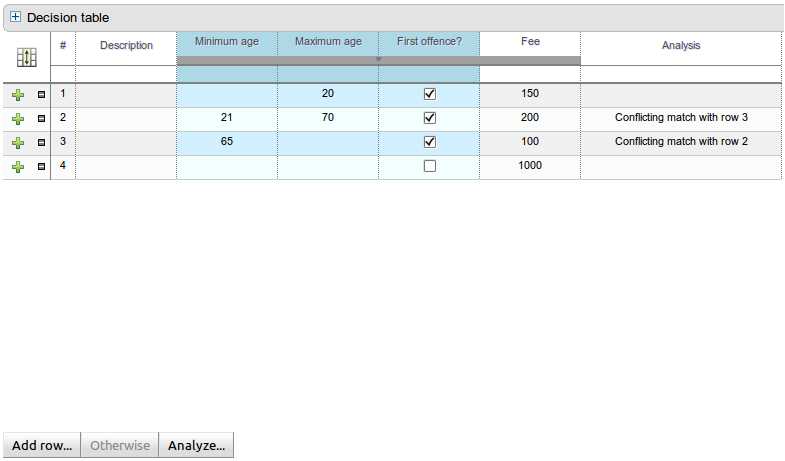
On the bottom of Web decision tables, the button Analyze... that checks for issues in your decision table, now also checks for 2 new detections:
A duplicate match are 2 rows in a decision table that can both match but have the same actions.
For example: a person between 20 and 40 has to pay a fee of 400 and a person between 30 and 50 has to pay a fee of 400 too. These 2 rows duplicate each other. If the fee would be different between them, then they would conflict each other.
A multiple values for one action match is 1 row in a decision table who's actions contradict itself. This is a common problem in limited entry tables, but rare in non-limited entry tables.
For example: a person below 40 has to pay the standard fee (400) and also has to pay the youngster fee (200). Since fee can only be set once, that's a problem.
BRL fragments can now be used for Condition and/or Action columns.

A BRL fragment is a section of a rule created using Guvnor's (BRL) Guided Rule Editor: Condition columns permit the definition of "WHEN" sections and Action columns the definition of "THEN" sections. Fields defined therein as "Template Keys" become columns in the decision table.
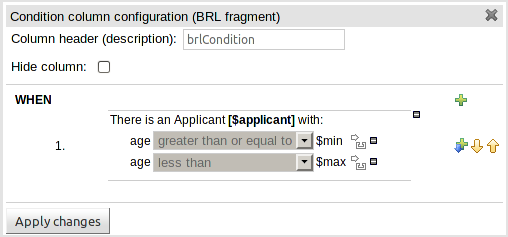
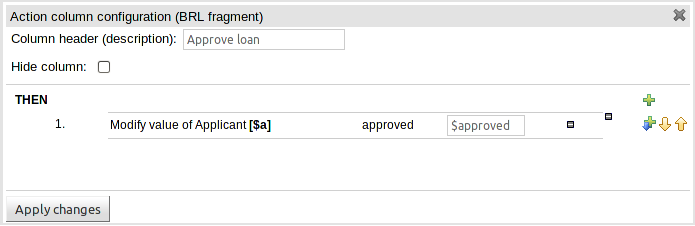
Consequently any rule that could be defined with the (BRL) Guided Rule Editor can now be defined with a decision table; including free-format DRL and DSL Sentences.
BRL fragments are fully integrated with other columns in the decision table, so that a Pattern or field defined in a regular column can be referenced in the BRL fragments and vice-versa.
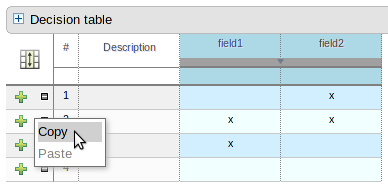
You can now copy and paste rows in both the guided Decision Table and Template Data editors.
Simply right-click a row in the tables' left hand-side selector column and choose the appropriate operation.
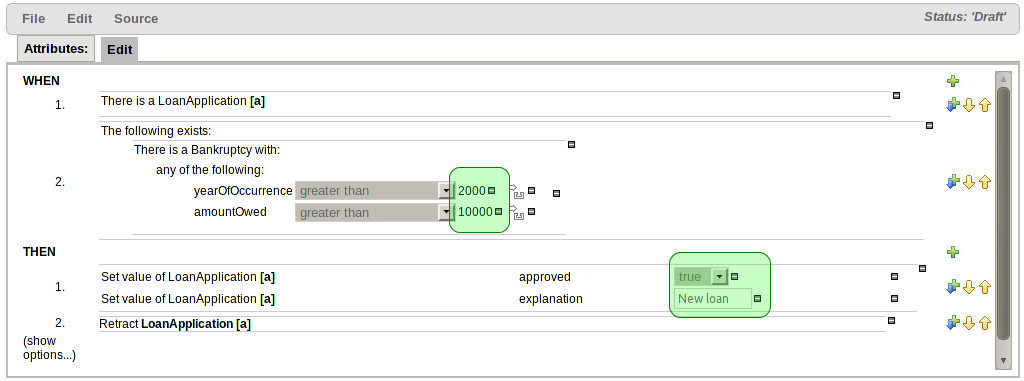
When creating new constraints or actions in the BRL guided (rule) editor it is simple to define a value as literal, or formula or expression. However, up until now, changing the value type required deletion of the whole constraint or action. This release brings the ability to remove the value definition thus enabling you to change a literal value to a formula etc without needing to delete the whole constraint or action.
A new Editor to create Change-Sets was added in Guvnor. Using this new editor you can create change-sets referencing packages, snapshots and even particular assets inside a package and expose them to external applications. For further information refer to the documentation.
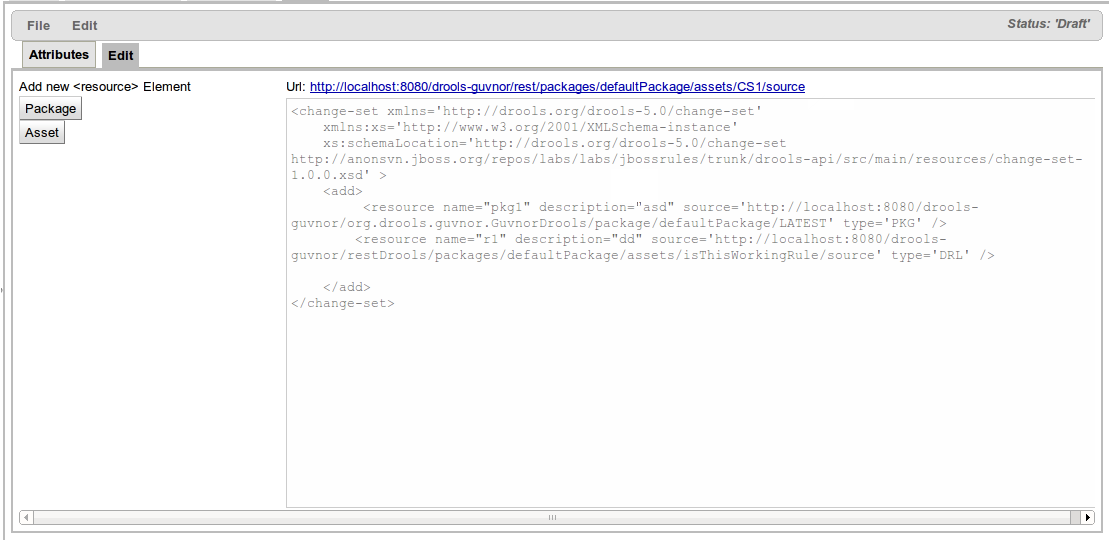
Custom Forms is a feature that exists in Guvnor since 5.1.1. It basically allows you to define external applications that will be invoked by Rule Editor when a particular field of a particular Fact Type is being used in a rule.
This feature is now also available to be used in DSL sentences. When defining a variable in a sentence you can now use this syntax for variable's definition:
{<varName>:CF:<factType.fieldName>}If you have an active Working-Set defining a Custom Form configuration for factType.fieldName, the Custom Form will be invoked by Rule Editor while setting the value of that variable.
Support has been added for the "timer" and "calendar" attributes.
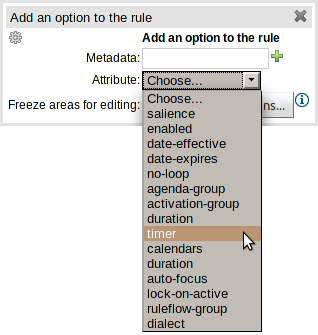
Support has been added for the "timer" and "calendar" attributes.
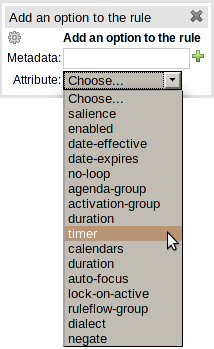
Uploading a XLS decision table results in the creation of numerous new assets, including (obviously) web-guided Decision Tables, functions, declarative types and modifications to package globals and imports etc (Queries are not converted, although supported in the XLS form, as Guvnor doesn't support them yet).
This is the first stage of "round-tripping" decision tables. We still need to add the ability to export a guided decision table back to XLS, plus we'd like to add tighter integration of updated XLS assets to their original converted cousins - so if a new version of the XLS decision table is uploaded the related assets' versions are updated (rather than creating new) upon conversion.
This is a powerful enhancement and as such your feedback is critical to ensure we implement the feature as you'd like it to operate. Check it out, feedback your opinions and help guide the future work.
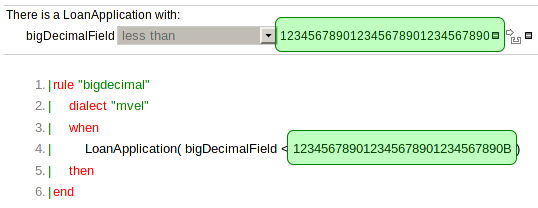
Numerical "value editors" (i.e. the text boxes for numerical values) in the BRL, Rule Template, Test Scenarios and Decision Table editors now support the types Byte, Short, Integer, Long, Double, Float, BigDecimal and BigInteger (and their primitive counterparts) correctly. The generated DRL is automatically appended with "B" or "I" type classifiers for BigDecimal and BigInteger values respectively, as provided for by Drools Expert. The Right-hand Side generates applicable DRL for BigDecimal and BigInteger values according to the rule's dialect.
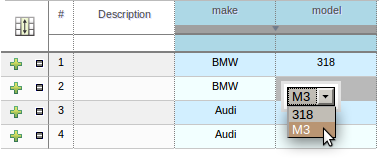
Dependent enumerations can now be used in both the Web Guided Decision Table editor and the Rule Template Data grid. Furthermore improvements were made to the operation of dependent enumerations in the BRL Guided Rule editor for sub-fields and expressions.
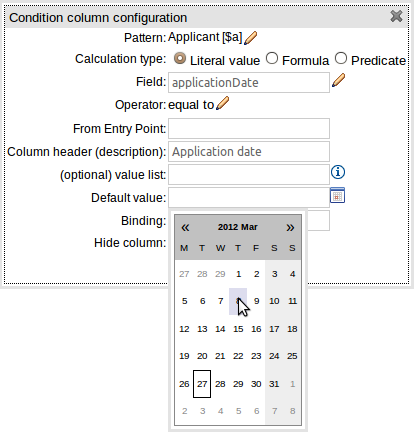
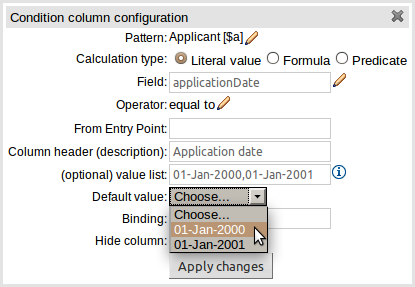
The editor to define a default value has been greatly improved:-
A default value editor is correct for the data-type of the column's Fact\.
If a "Value List" is provided, the default value needs to be one of the values in the list.
If the column represents a field with an enumeration the default value must be one of the enumeration's members.
If the column uses an operator that does not need a value (e.g. "is null") a default value cannot be provided.
If the column field is a "dependent enumeration" the default value must be one of the permitted values based upon parent enumeration default values, if any.
Default values are not required for Limited Entry tables.
A new editor to create services was added in Guvnor. Service is a special asset that enables users configure KnowledgeBases and KSessions to be executed remotely for any sort of client application (via REST or SOAP).
In order to expose those services, the editor generates automatically a war file that can be deployed on most platforms on most containers. For further information refer to the documentation.

Planner now comes with 2 build-in move factories: GenericChangeMoveFactory and
GenericSwapMoveFactory. Here's an example that uses both of them:
<localSearch>
<selector>
<selector>
<moveFactoryClass>org.drools.planner.core.move.generic.GenericChangeMoveFactory</moveFactoryClass>
</selector>
<selector>
<moveFactoryClass>org.drools.planner.core.move.generic.GenericSwapMoveFactory</moveFactoryClass>
</selector>
</selector>
...
</localSearch>It's no longer required to write your own Move and MoveFactory implementations, but you still can (and mix those in too).
The Benchmarker can now read and write the input and output files
from any format, through the ProblemIO interface. The
default is still an XStream implementation.
This is an implementation of the classic Traveling Salesman Problem: given a list of cities, find the shortest tour for a salesman that visits each city exactly once.
See this video.
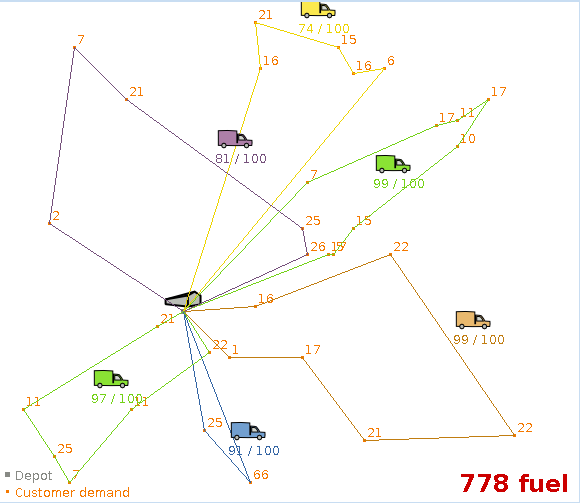
This is an implementation of capacitated vehicle routing: Using a fleet of vehicles, transport items from the depot(s) to customers at different locations. Each vehicle can service multiple locations, but it has a limited capacity for items.
In the screenshot below, there are 6 vehicles (the lines in different colors) that drop off 541 items at 33 customer locations. Each vehicle can carry 100 items.
See this video.
The employee rostering example's GUI has been reworked to show shift assignment more clearly.
See this video.
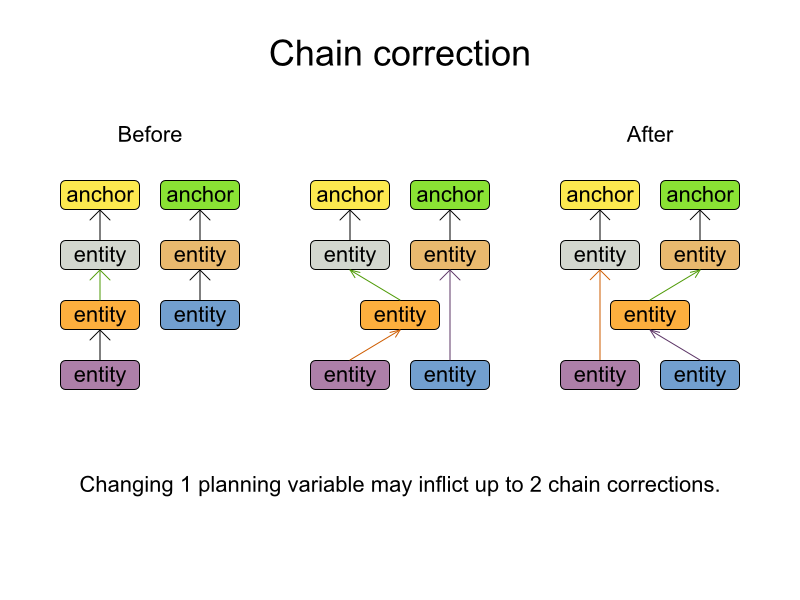
Until now, implementing TSP or Vehicle Routing like problems in Planner was hard. The new chaining support makes it easy.
You simply declare that a planning variable (previousAppearance) of this planning entity
(VrpCustomer) is chained and therefor possibly referencing another planning entity
(VrpCustomer) itself, creating a chain with that entity.
public class VrpCustomer implements VrpAppearance {
...
@PlanningVariable(chained = true)
@ValueRanges({
@ValueRange(type = ValueRangeType.FROM_SOLUTION_PROPERTY, solutionProperty = "vehicleList"),
@ValueRange(type = ValueRangeType.FROM_SOLUTION_PROPERTY, solutionProperty = "customerList",
excludeUninitializedPlanningEntity = true)})
public VrpAppearance getPreviousAppearance() {
return previousAppearance;
}
...
}
This triggers automatic chain correction:
Without any extra boilerplate code, this is compatible with:
Every optimization algorithm: including construction heuristics (first fit, first fit decreasing, ...), local search (tabu search, simulated annealing), ...
The generic build-in move factories. Note: currently there are chained alternatives for each move factory, but those will be unified with the originals soon.
Repeated planning, including real-time planning
For more information, read the Planner reference manual.
Property tabu has been renamed to planning entity tabu. Planning value tabu has been added. The generic moves support this out-of-the-box.
<acceptor>
<planningValueTabuSize>5</planningValueTabuSize>
</acceptor>
Planner can now alternatively, use a score calculation written in plain Java. Just implement this interface:
public interface SimpleScoreCalculator<Sol extends Solution> {
Score calculateScore(Sol solution);
}
See the CloudBalance example for an implementation.
In this way, Planner does not use Drools at all. This allows you to:
Use Planner, even if your company forbids any other language than Java (including DRL).
Hook Planner up to an existing score calculation system, which you don't want to migrate to DRL at this time.
Or just use Java if you prefer that over DRL.
There is 2 Java ways implemented: SimpleScoreCalculator (which is simple and slow)
and IncrementalScoreCalculator (which is fast).
The documentation now has a new chapter Quick start tutorial. It explains how to write the CloudBalance example from scratch. Read the Planner reference manual.