Preface
Developing Object-Oriented software that deals with data from Relational Databases can be cumbersome and resource consuming. Development costs are significantly higher due to a paradigm mismatch between how data is represented in objects versus relational databases. Hibernate is an Object/Relational Mapping (ORM) solution for Java environments. ORM refers to the technique of mapping data between an object model representation to a relational data model representation. See Wikipedia for a good high-level discussion. Also, Martin Fowler’s OrmHate article takes a look at many of the mentioned mismatch problems.
Although having a strong background in SQL is not required to use Hibernate, having a basic understanding of the concepts can help you understand Hibernate more quickly and fully. An understanding of data modeling principles is especially important. Both http://www.agiledata.org/essays/dataModeling101.html and http://en.wikipedia.org/wiki/Data_modeling are good starting points for understanding these data modeling principles.
Understanding the basics of transactions and design patterns such as "Unit of Work" PoEAA or "ApplicationTransaction" are important as well. These topics will be discussed in the documentation, but a prior understanding will certainly help.
Hibernate not only takes care of the mapping from Java classes to database tables (and from Java data types to SQL data types), but also provides data query and retrieval facilities. It can significantly reduce development time otherwise spent with manual data handling in SQL and JDBC. Hibernate’s design goal is to relieve the developer from 95% of common data persistence-related programming tasks by eliminating the need for manual, hand-crafted data processing using SQL and JDBC. However, unlike many other persistence solutions, Hibernate does not hide the power of SQL from you and guarantees that your investment in relational technology and knowledge is as valid as always.
Hibernate may not be the best solution for data-centric applications that only use stored procedures to implement the business logic in the database, it is most useful with object-oriented domain models and business logic in the Java-based middle-tier. However, Hibernate can certainly help you to remove or encapsulate vendor-specific SQL code and will help with the common task of result set translation from a tabular representation to a graph of objects.
See http://hibernate.org/orm/contribute/ for information on getting involved.
|
If you are just getting started with using Hibernate you may want to start with the Hibernate Getting Started Guide available from the documentation page. It contains quick-start style tutorials as well as lots of introductory information. There is also a series of topical guides providing deep dives into various topics. |
1. Architecture
1.1. Overview

Hibernate, as an ORM solution, effectively "sits between" the Java application data access layer and the Relational Database, as can be seen in the diagram above. The Java application makes use of the Hibernate APIs to load, store, query, etc its domain data. Here we will introduce the essential Hibernate APIs. This will be a brief introduction; we will discuss these contracts in detail later.
As a JPA provider, Hibernate implements the Java Persistence API specifications and the association between JPA interfaces and Hibernate specific implementations can be visualized in the following diagram:

- SessionFactory (
org.hibernate.SessionFactory) -
A thread-safe (and immutable) representation of the mapping of the application domain model to a database. Acts as a factory for
org.hibernate.Sessioninstances. TheEntityManagerFactoryis the JPA equivalent of aSessionFactoryand basically those two converge into the sameSessionFactoryimplementation.A
SessionFactoryis very expensive to create, so, for any given database, the application should have only one associatedSessionFactory. TheSessionFactorymaintains services that Hibernate uses across allSession(s)such as second level caches, connection pools, transaction system integrations, etc. - Session (
org.hibernate.Session) -
A single-threaded, short-lived object conceptually modeling a "Unit of Work" PoEAA. In JPA nomenclature, the
Sessionis represented by anEntityManager.Behind the scenes, the Hibernate
Sessionwraps a JDBCjava.sql.Connectionand acts as a factory fororg.hibernate.Transactioninstances. It maintains a generally "repeatable read" persistence context (first level cache) of the application domain model. - Transaction (
org.hibernate.Transaction) -
A single-threaded, short-lived object used by the application to demarcate individual physical transaction boundaries.
EntityTransactionis the JPA equivalent and both act as an abstraction API to isolate the application from the underlying transaction system in use (JDBC or JTA).
2. Domain Model
The term domain model comes from the realm of data modeling. It is the model that ultimately describes the problem domain you are working in. Sometimes you will also hear the term persistent classes.
Ultimately the application domain model is the central character in an ORM.
They make up the classes you wish to map. Hibernate works best if these classes follow the Plain Old Java Object (POJO) / JavaBean programming model.
However, none of these rules are hard requirements.
Indeed, Hibernate assumes very little about the nature of your persistent objects. You can express a domain model in other ways (using trees of java.util.Map instances, for example).
Historically applications using Hibernate would have used its proprietary XML mapping file format for this purpose. With the coming of JPA, most of this information is now defined in a way that is portable across ORM/JPA providers using annotations (and/or standardized XML format). This chapter will focus on JPA mapping where possible. For Hibernate mapping features not supported by JPA we will prefer Hibernate extension annotations.
2.1. Mapping types
Hibernate understands both the Java and JDBC representations of application data.
The ability to read/write this data from/to the database is the function of a Hibernate type.
A type, in this usage, is an implementation of the org.hibernate.type.Type interface.
This Hibernate type also describes various aspects of behavior of the Java type such as how to check for equality, how to clone values, etc.
|
Usage of the word type
The Hibernate type is neither a Java type nor a SQL data type. It provides information about both of these as well as understanding marshalling between. When you encounter the term type in discussions of Hibernate, it may refer to the Java type, the JDBC type, or the Hibernate type, depending on context. |
To help understand the type categorizations, let’s look at a simple table and domain model that we wish to map.
create table Contact (
id integer not null,
first varchar(255),
last varchar(255),
middle varchar(255),
notes varchar(255),
starred boolean not null,
website varchar(255),
primary key (id)
)@Entity(name = "Contact")
public static class Contact {
@Id
private Integer id;
private Name name;
private String notes;
private URL website;
private boolean starred;
//Getters and setters are omitted for brevity
}
@Embeddable
public class Name {
private String first;
private String middle;
private String last;
// getters and setters omitted
}In the broadest sense, Hibernate categorizes types into two groups:
2.1.1. Value types
A value type is a piece of data that does not define its own lifecycle. It is, in effect, owned by an entity, which defines its lifecycle.
Looked at another way, all the state of an entity is made up entirely of value types.
These state fields or JavaBean properties are termed persistent attributes.
The persistent attributes of the Contact class are value types.
Value types are further classified into three sub-categories:
- Basic types
-
in mapping the
Contacttable, all attributes except for name would be basic types. Basic types are discussed in detail in Basic Types - Embeddable types
-
the name attribute is an example of an embeddable type, which is discussed in details in Embeddable Types
- Collection types
-
although not featured in the aforementioned example, collection types are also a distinct category among value types. Collection types are further discussed in Collections
2.1.2. Entity types
Entities, by nature of their unique identifier, exist independently of other objects whereas values do not.
Entities are domain model classes which correlate to rows in a database table, using a unique identifier.
Because of the requirement for a unique identifier, entities exist independently and define their own lifecycle.
The Contact class itself would be an example of an entity.
Mapping entities is discussed in detail in Entity.
2.2. Naming strategies
Part of the mapping of an object model to the relational database is mapping names from the object model to the corresponding database names. Hibernate looks at this as 2 stage process:
-
The first stage is determining a proper logical name from the domain model mapping. A logical name can be either explicitly specified by the user (using
@Columnor@Tablee.g.) or it can be implicitly determined by Hibernate through an ImplicitNamingStrategy contract. -
Second is the resolving of this logical name to a physical name which is defined by the PhysicalNamingStrategy contract.
|
Historical NamingStrategy contract
Historically Hibernate defined just a single Also, the NamingStrategy contract was often not flexible enough to properly apply a given naming "rule", either because the API lacked the information to decide or because the API was honestly not well defined as it grew. Due to these limitation, |
At the core, the idea behind each naming strategy is to minimize the amount of repetitive information a developer must provide for mapping a domain model.
|
JPA Compatibility
JPA defines inherent rules about implicit logical name determination. If JPA provider portability is a major concern, or if you really just like the JPA-defined implicit naming rules, be sure to stick with ImplicitNamingStrategyJpaCompliantImpl (the default) Also, JPA defines no separation between logical and physical name. Following the JPA specification, the logical name is the physical name. If JPA provider portability is important, applications should prefer not to specify a PhysicalNamingStrategy. |
2.2.1. ImplicitNamingStrategy
When an entity does not explicitly name the database table that it maps to, we need
to implicitly determine that table name. Or when a particular attribute does not explicitly name
the database column that it maps to, we need to implicitly determine that column name. There are
examples of the role of the org.hibernate.boot.model.naming.ImplicitNamingStrategy contract to
determine a logical name when the mapping did not provide an explicit name.

Hibernate defines multiple ImplicitNamingStrategy implementations out-of-the-box. Applications are also free to plug-in custom implementations.
There are multiple ways to specify the ImplicitNamingStrategy to use. First, applications can specify
the implementation using the hibernate.implicit_naming_strategy configuration setting which accepts:
-
pre-defined "short names" for the out-of-the-box implementations
default-
for
org.hibernate.boot.model.naming.ImplicitNamingStrategyJpaCompliantImpl- an alias forjpa jpa-
for
org.hibernate.boot.model.naming.ImplicitNamingStrategyJpaCompliantImpl- the JPA 2.0 compliant naming strategy legacy-hbm-
for
org.hibernate.boot.model.naming.ImplicitNamingStrategyLegacyHbmImpl- compliant with the original Hibernate NamingStrategy legacy-jpa-
for
org.hibernate.boot.model.naming.ImplicitNamingStrategyLegacyJpaImpl- compliant with the legacy NamingStrategy developed for JPA 1.0, which was unfortunately unclear in many respects regarding implicit naming rules. component-path-
for
org.hibernate.boot.model.naming.ImplicitNamingStrategyComponentPathImpl- mostly followsImplicitNamingStrategyJpaCompliantImplrules, except that it uses the full composite paths, as opposed to just the ending property part
-
reference to a Class that implements the
org.hibernate.boot.model.naming.ImplicitNamingStrategycontract -
FQN of a class that implements the
org.hibernate.boot.model.naming.ImplicitNamingStrategycontract
Secondly, applications and integrations can leverage org.hibernate.boot.MetadataBuilder#applyImplicitNamingStrategy
to specify the ImplicitNamingStrategy to use. See
Bootstrap for additional details on bootstrapping.
2.2.2. PhysicalNamingStrategy
Many organizations define rules around the naming of database objects (tables, columns, foreign-keys, etc). The idea of a PhysicalNamingStrategy is to help implement such naming rules without having to hard-code them into the mapping via explicit names.
While the purpose of an ImplicitNamingStrategy is to determine that an attribute named accountNumber maps to
a logical column name of accountNumber when not explicitly specified, the purpose of a PhysicalNamingStrategy
would be, for example, to say that the physical column name should instead be abbreviated acct_num.
|
It is true that the resolution to |
The default implementation is to simply use the logical name as the physical name. However applications and integrations can define custom implementations of this PhysicalNamingStrategy contract. Here is an example PhysicalNamingStrategy for a fictitious company named Acme Corp whose naming standards are to:
-
prefer underscore-delimited words rather than camel-casing
-
replace certain words with standard abbreviations
/*
* Hibernate, Relational Persistence for Idiomatic Java
*
* License: GNU Lesser General Public License (LGPL), version 2.1 or later.
* See the lgpl.txt file in the root directory or <http://www.gnu.org/licenses/lgpl-2.1.html>.
*/
package org.hibernate.userguide.naming;
import java.util.LinkedList;
import java.util.List;
import java.util.Locale;
import java.util.Map;
import java.util.TreeMap;
import org.hibernate.boot.model.naming.Identifier;
import org.hibernate.boot.model.naming.PhysicalNamingStrategy;
import org.hibernate.engine.jdbc.env.spi.JdbcEnvironment;
import org.apache.commons.lang3.StringUtils;
/**
* An example PhysicalNamingStrategy that implements database object naming standards
* for our fictitious company Acme Corp.
* <p/>
* In general Acme Corp prefers underscore-delimited words rather than camel casing.
* <p/>
* Additionally standards call for the replacement of certain words with abbreviations.
*
* @author Steve Ebersole
*/
public class AcmeCorpPhysicalNamingStrategy implements PhysicalNamingStrategy {
private static final Map<String,String> ABBREVIATIONS = buildAbbreviationMap();
@Override
public Identifier toPhysicalCatalogName(Identifier name, JdbcEnvironment jdbcEnvironment) {
// Acme naming standards do not apply to catalog names
return name;
}
@Override
public Identifier toPhysicalSchemaName(Identifier name, JdbcEnvironment jdbcEnvironment) {
// Acme naming standards do not apply to schema names
return null;
}
@Override
public Identifier toPhysicalTableName(Identifier name, JdbcEnvironment jdbcEnvironment) {
final List<String> parts = splitAndReplace( name.getText() );
return jdbcEnvironment.getIdentifierHelper().toIdentifier(
join( parts ),
name.isQuoted()
);
}
@Override
public Identifier toPhysicalSequenceName(Identifier name, JdbcEnvironment jdbcEnvironment) {
final LinkedList<String> parts = splitAndReplace( name.getText() );
// Acme Corp says all sequences should end with _seq
if ( !"seq".equalsIgnoreCase( parts.getLast() ) ) {
parts.add( "seq" );
}
return jdbcEnvironment.getIdentifierHelper().toIdentifier(
join( parts ),
name.isQuoted()
);
}
@Override
public Identifier toPhysicalColumnName(Identifier name, JdbcEnvironment jdbcEnvironment) {
final List<String> parts = splitAndReplace( name.getText() );
return jdbcEnvironment.getIdentifierHelper().toIdentifier(
join( parts ),
name.isQuoted()
);
}
private static Map<String, String> buildAbbreviationMap() {
TreeMap<String,String> abbreviationMap = new TreeMap<> ( String.CASE_INSENSITIVE_ORDER );
abbreviationMap.put( "account", "acct" );
abbreviationMap.put( "number", "num" );
return abbreviationMap;
}
private LinkedList<String> splitAndReplace(String name) {
LinkedList<String> result = new LinkedList<>();
for ( String part : StringUtils.splitByCharacterTypeCamelCase( name ) ) {
if ( part == null || part.trim().isEmpty() ) {
// skip null and space
continue;
}
part = applyAbbreviationReplacement( part );
result.add( part.toLowerCase( Locale.ROOT ) );
}
return result;
}
private String applyAbbreviationReplacement(String word) {
if ( ABBREVIATIONS.containsKey( word ) ) {
return ABBREVIATIONS.get( word );
}
return word;
}
private String join(List<String> parts) {
boolean firstPass = true;
String separator = "";
StringBuilder joined = new StringBuilder();
for ( String part : parts ) {
joined.append( separator ).append( part );
if ( firstPass ) {
firstPass = false;
separator = "_";
}
}
return joined.toString();
}
}There are multiple ways to specify the PhysicalNamingStrategy to use. First, applications can specify
the implementation using the hibernate.physical_naming_strategy configuration setting which accepts:
-
reference to a Class that implements the
org.hibernate.boot.model.naming.PhysicalNamingStrategycontract -
FQN of a class that implements the
org.hibernate.boot.model.naming.PhysicalNamingStrategycontract
Secondly, applications and integrations can leverage org.hibernate.boot.MetadataBuilder#applyPhysicalNamingStrategy.
See Bootstrap for additional details on bootstrapping.
2.3. Basic Types
Basic value types usually map a single database column, to a single, non-aggregated Java type. Hibernate provides a number of built-in basic types, which follow the natural mappings recommended by the JDBC specifications.
Internally Hibernate uses a registry of basic types when it needs to resolve a specific org.hibernate.type.Type.
2.3.1. Hibernate-provided BasicTypes
| Hibernate type (org.hibernate.type package) | JDBC type | Java type | BasicTypeRegistry key(s) |
|---|---|---|---|
StringType |
VARCHAR |
java.lang.String |
string, java.lang.String |
MaterializedClob |
CLOB |
java.lang.String |
materialized_clob |
TextType |
LONGVARCHAR |
java.lang.String |
text |
CharacterType |
CHAR |
char, java.lang.Character |
char, java.lang.Character |
BooleanType |
BIT |
boolean, java.lang.Boolean |
boolean, java.lang.Boolean |
NumericBooleanType |
INTEGER, 0 is false, 1 is true |
boolean, java.lang.Boolean |
numeric_boolean |
YesNoType |
CHAR, 'N'/'n' is false, 'Y'/'y' is true. The uppercase value is written to the database. |
boolean, java.lang.Boolean |
yes_no |
TrueFalseType |
CHAR, 'F'/'f' is false, 'T'/'t' is true. The uppercase value is written to the database. |
boolean, java.lang.Boolean |
true_false |
ByteType |
TINYINT |
byte, java.lang.Byte |
byte, java.lang.Byte |
ShortType |
SMALLINT |
short, java.lang.Short |
short, java.lang.Short |
IntegerTypes |
INTEGER |
int, java.lang.Integer |
int, java.lang.Integer |
LongType |
BIGINT |
long, java.lang.Long |
long, java.lang.Long |
FloatType |
FLOAT |
float, java.lang.Float |
float, java.lang.Float |
DoubleType |
DOUBLE |
double, java.lang.Double |
double, java.lang.Double |
BigIntegerType |
NUMERIC |
java.math.BigInteger |
big_integer, java.math.BigInteger |
BigDecimalType |
NUMERIC |
java.math.BigDecimal |
big_decimal, java.math.bigDecimal |
TimestampType |
TIMESTAMP |
java.sql.Timestamp |
timestamp, java.sql.Timestamp |
TimeType |
TIME |
java.sql.Time |
time, java.sql.Time |
DateType |
DATE |
java.sql.Date |
date, java.sql.Date |
CalendarType |
TIMESTAMP |
java.util.Calendar |
calendar, java.util.Calendar |
CalendarDateType |
DATE |
java.util.Calendar |
calendar_date |
CalendarTimeType |
TIME |
java.util.Calendar |
calendar_time |
CurrencyType |
java.util.Currency |
VARCHAR |
currency, java.util.Currency |
LocaleType |
VARCHAR |
java.util.Locale |
locale, java.utility.locale |
TimeZoneType |
VARCHAR, using the TimeZone ID |
java.util.TimeZone |
timezone, java.util.TimeZone |
UrlType |
VARCHAR |
java.net.URL |
url, java.net.URL |
ClassType |
VARCHAR (class FQN) |
java.lang.Class |
class, java.lang.Class |
BlobType |
BLOB |
java.sql.Blob |
blog, java.sql.Blob |
ClobType |
CLOB |
java.sql.Clob |
clob, java.sql.Clob |
BinaryType |
VARBINARY |
byte[] |
binary, byte[] |
MaterializedBlobType |
BLOB |
byte[] |
materized_blob |
ImageType |
LONGVARBINARY |
byte[] |
image |
WrapperBinaryType |
VARBINARY |
java.lang.Byte[] |
wrapper-binary, Byte[], java.lang.Byte[] |
CharArrayType |
VARCHAR |
char[] |
characters, char[] |
CharacterArrayType |
VARCHAR |
java.lang.Character[] |
wrapper-characters, Character[], java.lang.Character[] |
UUIDBinaryType |
BINARY |
java.util.UUID |
uuid-binary, java.util.UUID |
UUIDCharType |
CHAR, can also read VARCHAR |
java.util.UUID |
uuid-char |
PostgresUUIDType |
PostgreSQL UUID, through Types#OTHER, which complies to the PostgreSQL JDBC driver definition |
java.util.UUID |
pg-uuid |
SerializableType |
VARBINARY |
implementors of java.lang.Serializable |
Unlike the other value types, multiple instances of this type are registered. It is registered once under java.io.Serializable, and registered under the specific java.io.Serializable implementation class names. |
StringNVarcharType |
NVARCHAR |
java.lang.String |
nstring |
NTextType |
LONGNVARCHAR |
java.lang.String |
ntext |
NClobType |
NCLOB |
java.sql.NClob |
nclob, java.sql.NClob |
MaterializedNClobType |
NCLOB |
java.lang.String |
materialized_nclob |
PrimitiveCharacterArrayNClobType |
NCHAR |
char[] |
N/A |
CharacterNCharType |
NCHAR |
java.lang.Character |
ncharacter |
CharacterArrayNClobType |
NCLOB |
java.lang.Character[] |
N/A |
| Hibernate type (org.hibernate.type package) | JDBC type | Java type | BasicTypeRegistry key(s) |
|---|---|---|---|
DurationType |
BIGINT |
java.time.Duration |
Duration, java.time.Duration |
InstantType |
TIMESTAMP |
java.time.Instant |
Instant, java.time.Instant |
LocalDateTimeType |
TIMESTAMP |
java.time.LocalDateTime |
LocalDateTime, java.time.LocalDateTime |
LocalDateType |
DATE |
java.time.LocalDate |
LocalDate, java.time.LocalDate |
LocalTimeType |
TIME |
java.time.LocalTime |
LocalTime, java.time.LocalTime |
OffsetDateTimeType |
TIMESTAMP |
java.time.OffsetDateTime |
OffsetDateTime, java.time.OffsetDateTime |
OffsetTimeType |
TIME |
java.time.OffsetTime |
OffsetTime, java.time.OffsetTime |
OffsetTimeType |
TIMESTAMP |
java.time.ZonedDateTime |
ZonedDateTime, java.time.ZonedDateTime |
|
To use these hibernate-java8 types just add the |
These mappings are managed by a service inside Hibernate called the org.hibernate.type.BasicTypeRegistry, which essentially maintains a map of org.hibernate.type.BasicType (a org.hibernate.type.Type specialization) instances keyed by a name.
That is the purpose of the "BasicTypeRegistry key(s)" column in the previous tables.
2.3.2. The @Basic annotation
Strictly speaking, a basic type is denoted with with the javax.persistence.Basic annotation.
Generally speaking, the @Basic annotation can be ignored, as it is assumed by default.
Both of the following examples are ultimately the same.
@Basic declared explicitly@Entity(name = "Product")
public class Product {
@Id
@Basic
private Integer id;
@Basic
private String sku;
@Basic
private String name;
@Basic
private String description;
}@Basic being implicitly implied@Entity(name = "Product")
public class Product {
@Id
private Integer id;
private String sku;
private String name;
private String description;
}|
The JPA specification strictly limits the Java types that can be marked as basic to the following listing:
If provider portability is a concern, you should stick to just these basic types.
Note that JPA 2.1 did add the notion of a |
The @Basic annotation defines 2 attributes.
optional- boolean (defaults to true)-
Defines whether this attribute allows nulls. JPA defines this as "a hint", which essentially means that it effect is specifically required. As long as the type is not primitive, Hibernate takes this to mean that the underlying column should be
NULLABLE. fetch- FetchType (defaults to EAGER)-
Defines whether this attribute should be fetched eagerly or lazily. JPA says that EAGER is a requirement to the provider (Hibernate) that the value should be fetched when the owner is fetched, while LAZY is merely a hint that the value be fetched when the attribute is accessed. Hibernate ignores this setting for basic types unless you are using bytecode enhancement. See the BytecodeEnhancement for additional information on fetching and on bytecode enhancement.
2.3.3. The @Column annotation
JPA defines rules for implicitly determining the name of tables and columns. For a detailed discussion of implicit naming see Naming.
For basic type attributes, the implicit naming rule is that the column name is the same as the attribute name. If that implicit naming rule does not meet your requirements, you can explicitly tell Hibernate (and other providers) the column name to use.
@Entity(name = "Product")
public class Product {
@Id
private Integer id;
private String sku;
private String name;
@Column( name = "NOTES" )
private String description;
}Here we use @Column to explicitly map the description attribute to the NOTES column, as opposed to the implicit column name description.
The @Column annotation defines other mapping information as well. See its Javadocs for details.
2.3.4. BasicTypeRegistry
We said before that a Hibernate type is not a Java type, nor a SQL type, but that it understands both and performs the marshalling between them.
But looking at the basic type mappings from the previous examples,
how did Hibernate know to use its org.hibernate.type.StringType for mapping for java.lang.String attributes,
or its org.hibernate.type.IntegerType for mapping java.lang.Integer attributes?
The answer lies in a service inside Hibernate called the org.hibernate.type.BasicTypeRegistry, which essentially maintains a map of org.hibernate.type.BasicType (a org.hibernate.type.Type specialization) instances keyed by a name.
We will see later, in the Explicit BasicTypes section, that we can explicitly tell Hibernate which BasicType to use for a particular attribute. But first let’s explore how implicit resolution works and how applications can adjust implicit resolution.
|
A thorough discussion of the |
As an example, take a String attribute such as we saw before with Product#sku.
Since there was no explicit type mapping, Hibernate looks to the BasicTypeRegistry to find the registered mapping for java.lang.String.
This goes back to the "BasicTypeRegistry key(s)" column we saw in the tables at the start of this chapter.
As a baseline within BasicTypeRegistry, Hibernate follows the recommended mappings of JDBC for Java types.
JDBC recommends mapping Strings to VARCHAR, which is the exact mapping that StringType handles.
So that is the baseline mapping within BasicTypeRegistry for Strings.
Applications can also extend (add new BasicType registrations) or override (replace an existing BasicType registration) using one of the
MetadataBuilder#applyBasicType methods or the MetadataBuilder#applyTypes method during bootstrap.
For more details, see Custom BasicTypes section.
2.3.5. Explicit BasicTypes
Sometimes you want a particular attribute to be handled differently.
Occasionally Hibernate will implicitly pick a BasicType that you do not want (and for some reason you do not want to adjust the BasicTypeRegistry).
In these cases you must explicitly tell Hibernate the BasicType to use, via the org.hibernate.annotations.Type annotation.
@org.hibernate.annotations.Type@Entity(name = "Product")
public class Product {
@Id
private Integer id;
private String sku;
@org.hibernate.annotations.Type( type = "nstring" )
private String name;
@org.hibernate.annotations.Type( type = "materialized_nclob" )
private String description;
}This tells Hibernate to store the Strings as nationalized data. This is just for illustration purposes; for better ways to indicate nationalized character data see Mapping Nationalized Character Data section.
Additionally, the description is to be handled as a LOB. Again, for better ways to indicate LOBs see Mapping LOBs section.
The org.hibernate.annotations.Type#type attribute can name any of the following:
-
Fully qualified name of any
org.hibernate.type.Typeimplementation -
Any key registered with
BasicTypeRegistry -
The name of any known type definitions
2.3.6. Custom BasicTypes
Hibernate makes it relatively easy for developers to create their own basic type mappings type.
For example, you might want to persist properties of type java.util.BigInteger to VARCHAR columns, or support completely new types.
There are two approaches to developing a custom type:
-
implementing a
BasicTypeand registering it -
implement a
UserTypewhich doesn’t require type registration
As a means of illustrating the different approaches, let’s consider a use case where we need to support a java.util.BitSet mapping that’s stored as a VARCHAR.
Implementing a BasicType
The first approach is to directly implement the BasicType interface.
|
Because the |
First, we need to extend the AbstractSingleColumnStandardBasicType like this:
BasicType implementationpublic class BitSetType
extends AbstractSingleColumnStandardBasicType<BitSet>
implements DiscriminatorType<BitSet> {
public static final BitSetType INSTANCE = new BitSetType();
public BitSetType() {
super( VarcharTypeDescriptor.INSTANCE, BitSetTypeDescriptor.INSTANCE );
}
@Override
public BitSet stringToObject(String xml) throws Exception {
return fromString( xml );
}
@Override
public String objectToSQLString(BitSet value, Dialect dialect) throws Exception {
return toString( value );
}
@Override
public String getName() {
return "bitset";
}
}The AbstractSingleColumnStandardBasicType requires an sqlTypeDescriptor and a javaTypeDescriptor.
The sqlTypeDescriptor is VarcharTypeDescriptor.INSTANCE because the database column is a VARCHAR.
On the Java side, we need to use a BitSetTypeDescriptor instance which can be implemented like this:
AbstractTypeDescriptor implementationpublic class BitSetTypeDescriptor extends AbstractTypeDescriptor<BitSet> {
private static final String DELIMITER = ",";
public static final BitSetTypeDescriptor INSTANCE = new BitSetTypeDescriptor();
public BitSetTypeDescriptor() {
super( BitSet.class );
}
@Override
public String toString(BitSet value) {
StringBuilder builder = new StringBuilder();
for ( long token : value.toLongArray() ) {
if ( builder.length() > 0 ) {
builder.append( DELIMITER );
}
builder.append( Long.toString( token, 2 ) );
}
return builder.toString();
}
@Override
public BitSet fromString(String string) {
if ( string == null || string.isEmpty() ) {
return null;
}
String[] tokens = string.split( DELIMITER );
long[] values = new long[tokens.length];
for ( int i = 0; i < tokens.length; i++ ) {
values[i] = Long.valueOf( tokens[i], 2 );
}
return BitSet.valueOf( values );
}
@SuppressWarnings({"unchecked"})
public <X> X unwrap(BitSet value, Class<X> type, WrapperOptions options) {
if ( value == null ) {
return null;
}
if ( BitSet.class.isAssignableFrom( type ) ) {
return (X) value;
}
if ( String.class.isAssignableFrom( type ) ) {
return (X) toString( value);
}
throw unknownUnwrap( type );
}
public <X> BitSet wrap(X value, WrapperOptions options) {
if ( value == null ) {
return null;
}
if ( String.class.isInstance( value ) ) {
return fromString( (String) value );
}
if ( BitSet.class.isInstance( value ) ) {
return (BitSet) value;
}
throw unknownWrap( value.getClass() );
}
}The unwrap method is used when passing a BitSet as a PreparedStatement bind parameter, while the wrap method is used to transform the JDBC column value object (e.g. String in our case) to the actual mapping object type (e.g. BitSet in this example).
The BasicType must be registered, and this can be done at bootstrapping time:
BasicType implementationconfiguration.registerTypeContributor( (typeContributions, serviceRegistry) -> {
typeContributions.contributeType( BitSetType.INSTANCE );
} );or using the MetadataBuilder
ServiceRegistry standardRegistry =
new StandardServiceRegistryBuilder().build();
MetadataSources sources = new MetadataSources( standardRegistry );
MetadataBuilder metadataBuilder = sources.getMetadataBuilder();
metadataBuilder.applyBasicType( BitSetType.INSTANCE );With the new BitSetType being registered as bitset, the entity mapping looks like this:
BasicType mapping@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
@Type( type = "bitset" )
private BitSet bitSet;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public BitSet getBitSet() {
return bitSet;
}
public void setBitSet(BitSet bitSet) {
this.bitSet = bitSet;
}
}To validate this new BasicType implementation, we can test it as follows:
BasicTypeBitSet bitSet = BitSet.valueOf( new long[] {1, 2, 3} );
doInHibernate( this::sessionFactory, session -> {
Product product = new Product( );
product.setId( 1 );
product.setBitSet( bitSet );
session.persist( product );
} );
doInHibernate( this::sessionFactory, session -> {
Product product = session.get( Product.class, 1 );
assertEquals(bitSet, product.getBitSet());
} );When executing this unit test, Hibernate generates the following SQL statements:
BasicTypeDEBUG SQL:92 -
insert
into
Product
(bitSet, id)
values
(?, ?)
TRACE BasicBinder:65 - binding parameter [1] as [VARCHAR] - [{0, 65, 128, 129}]
TRACE BasicBinder:65 - binding parameter [2] as [INTEGER] - [1]
DEBUG SQL:92 -
select
bitsettype0_.id as id1_0_0_,
bitsettype0_.bitSet as bitSet2_0_0_
from
Product bitsettype0_
where
bitsettype0_.id=?
TRACE BasicBinder:65 - binding parameter [1] as [INTEGER] - [1]
TRACE BasicExtractor:61 - extracted value ([bitSet2_0_0_] : [VARCHAR]) - [{0, 65, 128, 129}]As you can see, the BitSetType takes care of the Java-to-SQL and SQL-to-Java type conversion.
Implementing a UserType
The second approach is to implement the UserType interface.
UserType implementationpublic class BitSetUserType implements UserType {
public static final BitSetUserType INSTANCE = new BitSetUserType();
private static final Logger log = Logger.getLogger( BitSetUserType.class );
@Override
public int[] sqlTypes() {
return new int[] {StringType.INSTANCE.sqlType()};
}
@Override
public Class returnedClass() {
return String.class;
}
@Override
public boolean equals(Object x, Object y)
throws HibernateException {
return Objects.equals( x, y );
}
@Override
public int hashCode(Object x)
throws HibernateException {
return Objects.hashCode( x );
}
@Override
public Object nullSafeGet(
ResultSet rs, String[] names, SessionImplementor session, Object owner)
throws HibernateException, SQLException {
String columnName = names[0];
String columnValue = (String) rs.getObject( columnName );
log.debugv("Result set column {0} value is {1}", columnName, columnValue);
return columnValue == null ? null :
BitSetTypeDescriptor.INSTANCE.fromString( columnValue );
}
@Override
public void nullSafeSet(
PreparedStatement st, Object value, int index, SessionImplementor session)
throws HibernateException, SQLException {
if ( value == null ) {
log.debugv("Binding null to parameter {0} ",index);
st.setNull( index, Types.VARCHAR );
}
else {
String stringValue = BitSetTypeDescriptor.INSTANCE.toString( (BitSet) value );
log.debugv("Binding {0} to parameter {1} ", stringValue, index);
st.setString( index, stringValue );
}
}
@Override
public Object deepCopy(Object value)
throws HibernateException {
return value == null ? null :
BitSet.valueOf( BitSet.class.cast( value ).toLongArray() );
}
@Override
public boolean isMutable() {
return true;
}
@Override
public Serializable disassemble(Object value)
throws HibernateException {
return (BitSet) deepCopy( value );
}
@Override
public Object assemble(Serializable cached, Object owner)
throws HibernateException {
return deepCopy( cached );
}
@Override
public Object replace(Object original, Object target, Object owner)
throws HibernateException {
return deepCopy( original );
}
}The entity mapping looks as follows:
UserType mapping@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
@Type( type = "bitset" )
private BitSet bitSet;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public BitSet getBitSet() {
return bitSet;
}
public void setBitSet(BitSet bitSet) {
this.bitSet = bitSet;
}
}In this example, the UserType is registered under the bitset name, and this is done like this:
UserType implementationconfiguration.registerTypeContributor( (typeContributions, serviceRegistry) -> {
typeContributions.contributeType( BitSetUserType.INSTANCE, "bitset");
} );or using the MetadataBuilder
ServiceRegistry standardRegistry =
new StandardServiceRegistryBuilder().build();
MetadataSources sources = new MetadataSources( standardRegistry );
MetadataBuilder metadataBuilder = sources.getMetadataBuilder();
metadataBuilder.applyBasicType( BitSetUserType.INSTANCE, "bitset" );|
Like Without registration, the |
When running the previous test case against the BitSetUserType entity mapping, Hibernate executed the following SQL statements:
BasicTypeDEBUG SQL:92 -
insert
into
Product
(bitSet, id)
values
(?, ?)
DEBUG BitSetUserType:71 - Binding 1,10,11 to parameter 1
TRACE BasicBinder:65 - binding parameter [2] as [INTEGER] - [1]
DEBUG SQL:92 -
select
bitsetuser0_.id as id1_0_0_,
bitsetuser0_.bitSet as bitSet2_0_0_
from
Product bitsetuser0_
where
bitsetuser0_.id=?
TRACE BasicBinder:65 - binding parameter [1] as [INTEGER] - [1]
DEBUG BitSetUserType:56 - Result set column bitSet2_0_0_ value is 1,10,112.3.7. Mapping enums
Hibernate supports the mapping of Java enums as basic value types in a number of different ways.
@Enumerated
The original JPA-compliant way to map enums was via the @Enumerated and @MapKeyEnumerated for map keys annotations which works on the principle that the enum values are stored according to one of 2 strategies indicated by javax.persistence.EnumType:
ORDINAL-
- stored according to the enum value’s ordinal position within the enum class, as indicated by java.lang.Enum#ordinal
STRING-
- stored according to the enum value’s name, as indicated by java.lang.Enum#name
Assuming the following enumeration:
PhoneType enumerationpublic enum PhoneType {
LAND_LINE,
MOBILE;
}In the ORDINAL example, the phone_type column is defined as an (nullable) INTEGER type and would hold:
NULL-
For null values
0-
For the
LAND_LINEenum 1-
For the
MOBILEenum
@Enumerated(ORDINAL) example@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
@Column(name = "phone_number")
private String number;
@Enumerated(EnumType.ORDINAL)
@Column(name = "phone_type")
private PhoneType type;
//Getters and setters are omitted for brevity
}When persisting this entity, Hibernate generates the following SQL statement:
@Enumerated(ORDINAL) mappingPhone phone = new Phone( );
phone.setId( 1L );
phone.setNumber( "123-456-78990" );
phone.setType( PhoneType.MOBILE );
entityManager.persist( phone );INSERT INTO Phone (phone_number, phone_type, id)
VALUES ('123-456-78990', 2, 1)In the STRING example, the phone_type column is defined as an (nullable) VARCHAR type and would hold:
NULL-
For null values
LAND_LINE-
For the
LAND_LINEenum MOBILE-
For the
MOBILEenum
@Enumerated(STRING) example@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
@Column(name = "phone_number")
private String number;
@Enumerated(EnumType.STRING)
@Column(name = "phone_type")
private PhoneType type;
//Getters and setters are omitted for brevity
}Persisting the same entity like in the @Enumerated(ORDINAL) example, Hibernate generates the following SQL statement:
@Enumerated(STRING) mappingINSERT INTO Phone (phone_number, phone_type, id)
VALUES ('123-456-78990', 'MOBILE', 1)AttributeConverter
Let’s consider the following Gender enum which stores its values using the 'M' and 'F' codes.
public enum Gender {
MALE( 'M' ),
FEMALE( 'F' );
private final char code;
Gender(char code) {
this.code = code;
}
public static Gender fromCode(char code) {
if ( code == 'M' || code == 'm' ) {
return MALE;
}
if ( code == 'F' || code == 'f' ) {
return FEMALE;
}
throw new UnsupportedOperationException(
"The code " + code + " is not supported!"
);
}
public char getCode() {
return code;
}
}You can map enums in a JPA compliant way using a JPA 2.1 AttributeConverter.
AttributeConverter example@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String name;
@Convert( converter = GenderConverter.class )
public Gender gender;
//Getters and setters are omitted for brevity
}
@Converter
public static class GenderConverter implements AttributeConverter<Gender, Character> {
public Character convertToDatabaseColumn( Gender value ) {
if ( value == null ) {
return null;
}
return value.getCode();
}
public Gender convertToEntityAttribute( Character value ) {
if ( value == null ) {
return null;
}
return Gender.fromCode( value );
}
}Here, the gender column is defined as a CHAR type and would hold:
NULL-
For null values
'M'-
For the
MALEenum 'F'-
For the
FEMALEenum
For additional details on using AttributeConverters, see JPA 2.1 AttributeConverters section.
|
JPA explicitly disallows the use of an AttributeConverter with an attribute marked as |
Custom type
You can also map enums using a Hibernate custom type mapping.
Let’s again revisit the Gender enum example, this time using a custom Type to store the more standardized 'M' and 'F' codes.
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String name;
@Type( type = "org.hibernate.userguide.mapping.basic.GenderType" )
public Gender gender;
//Getters and setters are omitted for brevity
}
public class GenderType extends AbstractSingleColumnStandardBasicType<Gender> {
public static final GenderType INSTANCE = new GenderType();
public GenderType() {
super(
CharTypeDescriptor.INSTANCE,
GenderJavaTypeDescriptor.INSTANCE
);
}
public String getName() {
return "gender";
}
@Override
protected boolean registerUnderJavaType() {
return true;
}
}
public class GenderJavaTypeDescriptor extends AbstractTypeDescriptor<Gender> {
public static final GenderJavaTypeDescriptor INSTANCE =
new GenderJavaTypeDescriptor();
protected GenderJavaTypeDescriptor() {
super( Gender.class );
}
public String toString(Gender value) {
return value == null ? null : value.name();
}
public Gender fromString(String string) {
return string == null ? null : Gender.valueOf( string );
}
public <X> X unwrap(Gender value, Class<X> type, WrapperOptions options) {
return CharacterTypeDescriptor.INSTANCE.unwrap(
value == null ? null : value.getCode(),
type,
options
);
}
public <X> Gender wrap(X value, WrapperOptions options) {
return Gender.fromCode(
CharacterTypeDescriptor.INSTANCE.wrap( value, options )
);
}
}Again, the gender column is defined as a CHAR type and would hold:
NULL-
For null values
'M'-
For the
MALEenum 'F'-
For the
FEMALEenum
For additional details on using custom types, see Custom BasicTypes section.
2.3.8. Mapping LOBs
Mapping LOBs (database Large Objects) come in 2 forms, those using the JDBC locator types and those materializing the LOB data.
JDBC LOB locators exist to allow efficient access to the LOB data. They allow the JDBC driver to stream parts of the LOB data as needed, potentially freeing up memory space. However they can be unnatural to deal with and have certain limitations. For example, a LOB locator is only portably valid during the duration of the transaction in which it was obtained.
The idea of materialized LOBs is to trade-off the potential efficiency (not all drivers handle LOB data efficiently) for a more natural programming paradigm using familiar Java types such as String or byte[], etc for these LOBs.
Materialized deals with the entire LOB contents in memory, whereas LOB locators (in theory) allow streaming parts of the LOB contents into memory as needed.
The JDBC LOB locator types include:
-
java.sql.Blob -
java.sql.Clob -
java.sql.NClob
Mapping materialized forms of these LOB values would use more familiar Java types such as String, char[], byte[], etc.
The trade off for more familiar is usually performance.
For a first look, let’s assume we have a CLOB column that we would like to map (NCLOB character LOB data will be covered in Mapping Nationalized Character Data section).
CREATE TABLE Product (
id INTEGER NOT NULL
image clob
name VARCHAR(255)
PRIMARY KEY ( id )
)Let’s first map this using the @Lob JPA annotation and the java.sql.Clob type:
CLOB mapped to java.sql.Clob@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
private Clob warranty;
//Getters and setters are omitted for brevity
}To persist such an entity, you have to create a Clob using plain JDBC:
java.sql.Clob entityString warranty = "My product warranty";
final Product product = new Product();
product.setId( 1 );
product.setName( "Mobile phone" );
session.doWork( connection -> {
product.setWarranty( connection.createClob() );
product.getWarranty().setString( 1, warranty );
} );
entityManager.persist( product );To retrieve the Clob content, you need to transform the underlying java.io.Reader:
java.sql.Clob entityProduct product = entityManager.find( Product.class, productId );
try (Reader reader = product.getWarranty().getCharacterStream()) {
assertEquals( "My product warranty", toString( reader ) );
}We could also map the CLOB in a materialized form. This way, we can either use a String or a char[].
CLOB mapped to String@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
private String warranty;
//Getters and setters are omitted for brevity
}|
How JDBC deals with However, some drivers are trickier (e.g. PostgreSQL JDBC drivers), and, in such cases, you may have to do some extra to get LOBs working. Such discussions are beyond the scope of this guide. |
We might even want the materialized data as a char array (for some crazy reason).
char[] mapping@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
private char[] warranty;
//Getters and setters are omitted for brevity
}BLOB data is mapped in a similar fashion.
CREATE TABLE Product (
id INTEGER NOT NULL ,
image blob ,
name VARCHAR(255) ,
PRIMARY KEY ( id )
)Let’s first map this using the JDBC java.sql.Blob type.
BLOB mapped to java.sql.Blob@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
private Blob image;
//Getters and setters are omitted for brevity
}To persist such an entity, you have to create a Blob using plain JDBC:
java.sql.Blob entitybyte[] image = new byte[] {1, 2, 3};
final Product product = new Product();
product.setId( 1 );
product.setName( "Mobile phone" );
session.doWork( connection -> {
product.setImage( connection.createBlob() );
product.getImage().setBytes( 1, image );
} );
entityManager.persist( product );To retrieve the Blob content, you need to transform the underlying java.io.Reader:
java.sql.Blob entityProduct product = entityManager.find( Product.class, productId );
try (InputStream inputStream = product.getImage().getBinaryStream()) {
assertArrayEquals(new byte[] {1, 2, 3}, toBytes( inputStream ) );
}We could also map the BLOB in a materialized form (e.g. byte[]).
BLOB mapped to byte[]@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
private byte[] image;
//Getters and setters are omitted for brevity
}2.3.9. Mapping Nationalized Character Data
JDBC 4 added the ability to explicitly handle nationalized character data. To this end it added specific nationalized character data types.
-
NCHAR -
NVARCHAR -
LONGNVARCHAR -
NCLOB
NVARCHAR - SQLCREATE TABLE Product (
id INTEGER NOT NULL ,
name VARCHAR(255) ,
warranty NVARCHAR(255) ,
PRIMARY KEY ( id )
)To map a specific attribute to a nationalized variant data type, Hibernate defines the @Nationalized annotation.
NVARCHAR mapping@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Nationalized
private String warranty;
//Getters and setters are omitted for brevity
}Just like with CLOB, Hibernate can also deal with NCLOB SQL data types:
NCLOB - SQLCREATE TABLE Product (
id INTEGER NOT NULL ,
name VARCHAR(255) ,
warranty nclob ,
PRIMARY KEY ( id )
)Hibernate can map the NCLOB to a java.sql.NClob
NCLOB mapped to java.sql.NClob@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
@Nationalized
// Clob also works, because NClob extends Clob.
// The database type is still NCLOB either way and handled as such.
private NClob warranty;
//Getters and setters are omitted for brevity
}To persist such an entity, you have to create a NClob using plain JDBC:
java.sql.NClob entityString warranty = "My product warranty";
final Product product = new Product();
product.setId( 1 );
product.setName( "Mobile phone" );
session.doWork( connection -> {
product.setWarranty( connection.createNClob() );
product.getWarranty().setString( 1, warranty );
} );
entityManager.persist( product );To retrieve the NClob content, you need to transform the underlying java.io.Reader:
java.sql.NClob entityProduct product = entityManager.find( Product.class, productId );
try (Reader reader = product.getWarranty().getCharacterStream()) {
assertEquals( "My product warranty", toString( reader ) );
}We could also map the NCLOB in a materialized form. This way, we can either use a String or a char[].
NCLOB mapped to String@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
@Nationalized
private String warranty;
//Getters and setters are omitted for brevity
}We might even want the materialized data as a char array.
char[] mapping@Entity(name = "Product")
public static class Product {
@Id
private Integer id;
private String name;
@Lob
@Nationalized
private char[] warranty;
//Getters and setters are omitted for brevity
}|
If you application and database are entirely nationalized you may instead want to enable nationalized character data as the default.
You can do this via the |
2.3.10. Mapping UUID Values
Hibernate also allows you to map UUID values, again in a number of ways.
|
The default UUID mapping is as binary because it represents more efficient storage.
However many applications prefer the readability of character storage.
To switch the default mapping, simply call |
2.3.11. UUID as binary
As mentioned, the default mapping for UUID attributes.
Maps the UUID to a byte[] using java.util.UUID#getMostSignificantBits and java.util.UUID#getLeastSignificantBits and stores that as BINARY data.
Chosen as the default simply because it is generally more efficient from storage perspective.
2.3.12. UUID as (var)char
Maps the UUID to a String using java.util.UUID#toString and java.util.UUID#fromString and stores that as CHAR or VARCHAR data.
2.3.13. PostgeSQL-specific UUID
|
When using one of the PostgreSQL Dialects, this becomes the default UUID mapping |
Maps the UUID using PostgreSQL’s specific UUID data type.
The PostgreSQL JDBC driver chooses to map its UUID type to the OTHER code.
Note that this can cause difficulty as the driver chooses to map many different data types to OTHER.
2.3.14. UUID as identifier
Hibernate supports using UUID values as identifiers, and they can even be generated on user’s behalf. For details, see the discussion of generators in Identifier generators.
2.3.15. Mapping Date/Time Values
Hibernate allows various Java Date/Time classes to be mapped as persistent domain model entity properties. The SQL standard defines three Date/Time types:
- DATE
-
Represents a calendar date by storing years, months and days. The JDBC equivalent is
java.sql.Date - TIME
-
Represents the time of a day and it stores hours, minutes and seconds. The JDBC equivalent is
java.sql.Time - TIMESTAMP
-
It stores both a DATE and a TIME plus nanoseconds. The JDBC equivalent is
java.sql.Timestamp
|
To avoid dependencies on the |
While the java.sql classes define a direct association to the SQL Date/Time data types,
the java.util or java.time properties need to explicitly mark the SQL type correlation with the @Temporal annotation.
This way, a java.util.Date or a java.util.Calendar cn be mapped to either an SQL DATE, TIME or TIMESTAMP type.
Considering the following entity:
java.util.Date mapped as DATE@Entity(name = "DateEvent")
public static class DateEvent {
@Id
@GeneratedValue
private Long id;
@Column(name = "`timestamp`")
@Temporal(TemporalType.DATE)
private Date timestamp;
//Getters and setters are omitted for brevity
}When persisting such entity:
java.util.Date mappingDateEvent dateEvent = new DateEvent( new Date() );
entityManager.persist( dateEvent );Hibernate generates the following INSERT statement:
INSERT INTO DateEvent ( timestamp, id )
VALUES ( '2015-12-29', 1 )Only the year, month and the day field were saved into the database.
If we change the @Temporal type to TIME:
java.util.Date mapped as TIME@Column(name = "`timestamp`")
@Temporal(TemporalType.TIME)
private Date timestamp;Hibernate will issue an INSERT statement containing the hour, minutes and seconds.
INSERT INTO DateEvent ( timestamp, id )
VALUES ( '16:51:58', 1 )When the @Temporal type is set to TIMESTAMP:
java.util.Date mapped as TIMESTAMP@Column(name = "`timestamp`")
@Temporal(TemporalType.TIMESTAMP)
private Date timestamp;Hibernate will include both the DATE, the TIME and the nanoseconds in the INSERT statement:
INSERT INTO DateEvent ( timestamp, id )
VALUES ( '2015-12-29 16:54:04.544', 1 )|
Just like the |
Mapping Java 8 Date/Time Values
Java 8 came with a new Date/Time API, offering support for instant dates, intervals, local and zoned Date/Time immutable instances, bundled in the java.time package.
Hibernate added support for the new Date/Time API in a new module, which must be included with the following Maven dependency:
hibernate-java8 Maven dependency<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-java8</artifactId>
<version>${hibernate.version}</version>
</dependency>The mapping between the standard SQL Date/Time types and the supported Java 8 Date/Time class types looks as follows;
- DATE
-
java.time.LocalDate - TIME
-
java.time.LocalTime,java.time.OffsetTime - TIMESTAMP
-
java.time.Instant,java.time.LocalDateTime,java.time.OffsetDateTimeandjava.time.ZonedDateTime
|
Because the mapping between Java 8 Date/Time classes and the SQL types is implicit, there is not need to specify the org.hibernate.AnnotationException: @Temporal should only be set on a java.util.Date or java.util.Calendar property |
2.3.16. JPA 2.1 AttributeConverters
Although Hibernate has long been offering custom types, as a JPA 2.1 provider, it also supports `AttributeConverter`s as well.
With a custom AttributeConverter, the application developer can map a given JDBC type to an entity basic type.
In the following example, the java.util.Period is going to be mapped to a VARCHAR database column.
java.util.Period custom AttributeConverter@Converter
public class PeriodStringConverter
implements AttributeConverter<Period, String> {
@Override
public String convertToDatabaseColumn(Period attribute) {
return attribute.toString();
}
@Override
public Period convertToEntityAttribute(String dbData) {
return Period.parse( dbData );
}
}To make use of this custom converter, the @Convert annotation must decorate the entity attribute.
java.util.Period AttributeConverter mapping@Entity(name = "Event")
public static class Event {
@Id
@GeneratedValue
private Long id;
@Convert(converter = PeriodStringConverter.class)
@Column(columnDefinition = "")
private Period span;
//Getters and setters are omitted for brevity
}When persisting such entity, Hibernate will do the type conversion based on the AttributeConverter logic:
AttributeConverterINSERT INTO Event ( span, id )
VALUES ( 'P1Y2M3D', 1 )2.3.17. SQL quoted identifiers
You can force Hibernate to quote an identifier in the generated SQL by enclosing the table or column name in backticks in the mapping document. While traditionally, Hibernate used backticks for escaping SQL reserved keywords, JPA uses double quotes instead.
Once the reserved keywords are escaped, Hibernate will use the correct quotation style for the SQL Dialect.
This is usually double quotes, but SQL Server uses brackets and MySQL uses backticks.
@Entity(name = "Product")
public static class Product {
@Id
private Long id;
@Column(name = "`name`")
private String name;
@Column(name = "`number`")
private String number;
//Getters and setters are omitted for brevity
}@Entity(name = "Product")
public static class Product {
@Id
private Long id;
@Column(name = "\"name\"")
private String name;
@Column(name = "\"number\"")
private String number;
//Getters and setters are omitted for brevity
}Because name and number are reserved words, the Product entity mapping uses backtricks to quote these column names.
When saving teh following Product entity, Hibernate generates the following SQL insert statement:
Product product = new Product();
product.setId( 1L );
product.setName( "Mobile phone" );
product.setNumber( "123-456-7890" );
entityManager.persist( product );INSERT INTO Product ("name", "number", id)
VALUES ('Mobile phone', '123-456-7890', 1)Global quoting
Hibernate can also quote all identifiers (e.g. table, columns) using the following configuration property:
<property
name="hibernate.globally_quoted_identifiers"
value="true"
/>This way, we don’t need to manually quote any identifier:
@Entity(name = "Product")
public static class Product {
@Id
private Long id;
private String name;
private String number;
//Getters and setters are omitted for brevity
}When persisting a Product entity, Hibernate is going to quote all identifiers as in the following example:
INSERT INTO "Product" ("name", "number", "id")
VALUES ('Mobile phone', '123-456-7890', 1)As you can see, both the table name and all the column have been quoted.
For more about quoting-related configuration properties, checkout the Mapping configurations section as well.
2.3.18. Generated properties
Generated properties are properties that have their values generated by the database.
Typically, Hibernate applications needed to refresh objects that contain any properties for which the database was generating values.
Marking properties as generated, however, lets the application delegate this responsibility to Hibernate.
When Hibernate issues an SQL INSERT or UPDATE for an entity that has defined generated properties, it immediately issues a select to retrieve the generated values.
Properties marked as generated must additionally be non-insertable and non-updateable.
Only @Version and @Basic types can be marked as generated.
never(the default)-
the given property value is not generated within the database.
insert-
the given property value is generated on insert, but is not regenerated on subsequent updates. Properties like creationTimestamp fall into this category.
always-
the property value is generated both on insert and on update.
To mark a property as generated, use The Hibernate specific @Generated annotation.
@ValueGenerationType meta-annotation
Hibernate 4.3 introduced the @ValueGenerationType meta-annotation, which is a new approach to declaring generated attributes or customizing generators.
@Generated has been retrofitted to use the @ValueGenerationType meta-annotation.
But @ValueGenerationType exposes more features than what @Generated currently supports, and,
to leverage some of those features, you’d simply wire up a new generator annotation.
As you’ll see in the following examples, the @ValueGenerationType meta-annotation is used when declaring the custom annotation used to mark the entity properties that need a specific generation strategy.
The actual generation logic must be implemented in class that implements the AnnotationValueGeneration interface.
Database-generated values
For example, let’s say we want the timestamps to be generated by calls to the standard ANSI SQL function current_timestamp (rather than triggers or DEFAULT values):
ValueGenerationType mapping for database generation@Entity(name = "Event")
public static class Event {
@Id
@GeneratedValue
private Long id;
@Column(name = "`timestamp`")
@FunctionCreationTimestamp
private Date timestamp;
public Event() {}
public Long getId() {
return id;
}
public Date getTimestamp() {
return timestamp;
}
}
@ValueGenerationType(generatedBy = FunctionCreationValueGeneration.class)
@Retention(RetentionPolicy.RUNTIME)
public @interface FunctionCreationTimestamp {}
public static class FunctionCreationValueGeneration
implements AnnotationValueGeneration<FunctionCreationTimestamp> {
@Override
public void initialize(FunctionCreationTimestamp annotation, Class<?> propertyType) {
}
/**
* Generate value on INSERT
* @return when to generate the value
*/
public GenerationTiming getGenerationTiming() {
return GenerationTiming.INSERT;
}
/**
* Returns null because the value is generated by the database.
* @return null
*/
public ValueGenerator<?> getValueGenerator() {
return null;
}
/**
* Returns true because the value is generated by the database.
* @return true
*/
public boolean referenceColumnInSql() {
return true;
}
/**
* Returns the database-generated value
* @return database-generated value
*/
public String getDatabaseGeneratedReferencedColumnValue() {
return "current_timestamp";
}
}When persisting an Event entity, Hibernate generates the following SQL statement:
INSERT INTO Event ("timestamp", id)
VALUES (current_timestamp, 1)As you can see, the current_timestamp value was used for assigning the timestamp column value.
In-memory-generated values
If the timestamp value needs to be generated in-memory, the following mapping must be used instead:
ValueGenerationType mapping for in-memory value generation@Entity(name = "Event")
public static class Event {
@Id
@GeneratedValue
private Long id;
@Column(name = "`timestamp`")
@FunctionCreationTimestamp
private Date timestamp;
public Event() {}
public Long getId() {
return id;
}
public Date getTimestamp() {
return timestamp;
}
}
@ValueGenerationType(generatedBy = FunctionCreationValueGeneration.class)
@Retention(RetentionPolicy.RUNTIME)
public @interface FunctionCreationTimestamp {}
public static class FunctionCreationValueGeneration
implements AnnotationValueGeneration<FunctionCreationTimestamp> {
@Override
public void initialize(FunctionCreationTimestamp annotation, Class<?> propertyType) {
}
/**
* Generate value on INSERT
* @return when to generate the value
*/
public GenerationTiming getGenerationTiming() {
return GenerationTiming.INSERT;
}
/**
* Returns the in-memory generated value
* @return {@code true}
*/
public ValueGenerator<?> getValueGenerator() {
return (session, owner) -> new Date( );
}
/**
* Returns false because the value is generated by the database.
* @return false
*/
public boolean referenceColumnInSql() {
return false;
}
/**
* Returns null because the value is generated in-memory.
* @return null
*/
public String getDatabaseGeneratedReferencedColumnValue() {
return null;
}
}When persisting an Event entity, Hibernate generates the following SQL statement:
INSERT INTO Event ("timestamp", id)
VALUES ('Tue Mar 01 10:58:18 EET 2016', 1)As you can see, the new Date() object value was used for assigning the timestamp column value.
2.3.19. Column transformers: read and write expressions
Hibernate allows you to customize the SQL it uses to read and write the values of columns mapped to @Basic types.
For example, if your database provides a set of data encryption functions, you can invoke them for individual columns like in the following example.
@ColumnTransformer example@Entity(name = "Employee")
public static class Employee {
@Id
private Long id;
@NaturalId
private String username;
@Column(name = "pswd")
@ColumnTransformer(
read = "decrypt( 'AES', '00', pswd )",
write = "encrypt('AES', '00', ?)"
)
private String password;
private int accessLevel;
@ManyToOne(fetch = FetchType.LAZY)
private Department department;
@ManyToMany(mappedBy = "employees")
private List<Project> projects = new ArrayList<>();
//Getters and setters omitted for brevity
}|
You can use the plural form |
If a property uses more than one column, you must use the forColumn attribute to specify which column, the expressions are targeting.
@ColumnTransformer forColumn attribute usage@Entity(name = "Savings")
public static class Savings {
@Id
private Long id;
@Type(type = "org.hibernate.userguide.mapping.basic.MonetaryAmountUserType")
@Columns(columns = {
@Column(name = "money"),
@Column(name = "currency")
})
@ColumnTransformer(
forColumn = "money",
read = "money / 100",
write = "? * 100"
)
private MonetaryAmount wallet;
//Getters and setters omitted for brevity
}Hibernate applies the custom expressions automatically whenever the property is referenced in a query. This functionality is similar to a derived-property @Formula with two differences:
-
The property is backed by one or more columns that are exported as part of automatic schema generation.
-
The property is read-write, not read-only.
The write expression, if specified, must contain exactly one '?' placeholder for the value.
@ColumnTransformer and a composite typedoInJPA( this::entityManagerFactory, entityManager -> {
Savings savings = new Savings( );
savings.setId( 1L );
savings.setWallet( new MonetaryAmount( BigDecimal.TEN, Currency.getInstance( Locale.US ) ) );
entityManager.persist( savings );
} );
doInJPA( this::entityManagerFactory, entityManager -> {
Savings savings = entityManager.find( Savings.class, 1L );
assertEquals( 10, savings.getWallet().getAmount().intValue());
} );INSERT INTO Savings (money, currency, id)
VALUES (10 * 100, 'USD', 1)
SELECT
s.id as id1_0_0_,
s.money / 100 as money2_0_0_,
s.currency as currency3_0_0_
FROM
Savings s
WHERE
s.id = 12.3.20. @Formula
Sometimes, you want the Database to do some computation for you rather than in the JVM, you might also create some kind of virtual column. You can use a SQL fragment (aka formula) instead of mapping a property into a column. This kind of property is read only (its value is calculated by your formula fragment)
|
You should be aware that the |
@Formula mapping usage@Entity(name = "Account")
public static class Account {
@Id
private Long id;
private Double credit;
private Double rate;
@Formula(value = "credit * rate")
private Double interest;
//Getters and setters omitted for brevity
}When loading the Account entity, Hibernate is going to calculate the interest property using the configured @Formula:
@Formula mappingdoInJPA( this::entityManagerFactory, entityManager -> {
Account account = new Account( );
account.setId( 1L );
account.setCredit( 5000d );
account.setRate( 1.25 / 100 );
entityManager.persist( account );
} );
doInJPA( this::entityManagerFactory, entityManager -> {
Account account = entityManager.find( Account.class, 1L );
assertEquals( Double.valueOf( 62.5d ), account.getInterest());
} );INSERT INTO Account (credit, rate, id)
VALUES (5000.0, 0.0125, 1)
SELECT
a.id as id1_0_0_,
a.credit as credit2_0_0_,
a.rate as rate3_0_0_,
a.credit * a.rate as formula0_0_
FROM
Account a
WHERE
a.id = 1|
The SQL fragment can be as complex as you want and even include subselects. |
2.3.21. @Where
Sometimes, you want to filter out entities using a custom SQL criteria.
This can be achieved using the @Where annotation, which can be applied to entities, as you can see in the following mapping.
@Where mapping usagepublic enum AccountType {
DEBIT,
CREDIT
}
@Entity(name = "Client")
public static class Client {
@Id
private Long id;
private String name;
@OneToMany(mappedBy = "client")
private List<Account> debitAccounts = new ArrayList<>( );
@OneToMany(mappedBy = "client")
private List<Account> creditAccounts = new ArrayList<>( );
//Getters and setters omitted for brevity
}
@Entity(name = "Account")
@Where( clause = "active = true" )
public static class Account {
@Id
private Long id;
@ManyToOne
private Client client;
@Column(name = "account_type")
@Enumerated(EnumType.STRING)
private AccountType type;
private Double amount;
private Double rate;
private boolean active;
//Getters and setters omitted for brevity
}If the database contains the following entities:
@Where mappingdoInJPA( this::entityManagerFactory, entityManager -> {
Client client = new Client();
client.setId( 1L );
client.setName( "John Doe" );
entityManager.persist( client );
Account account1 = new Account( );
account1.setId( 1L );
account1.setType( AccountType.CREDIT );
account1.setAmount( 5000d );
account1.setRate( 1.25 / 100 );
account1.setActive( true );
account1.setClient( client );
client.getCreditAccounts().add( account1 );
entityManager.persist( account1 );
Account account2 = new Account( );
account2.setId( 2L );
account2.setType( AccountType.DEBIT );
account2.setAmount( 0d );
account2.setRate( 1.05 / 100 );
account2.setActive( false );
account2.setClient( client );
client.getDebitAccounts().add( account2 );
entityManager.persist( account2 );
Account account3 = new Account( );
account3.setType( AccountType.DEBIT );
account3.setId( 3L );
account3.setAmount( 250d );
account3.setRate( 1.05 / 100 );
account3.setActive( true );
account3.setClient( client );
client.getDebitAccounts().add( account3 );
entityManager.persist( account3 );
} );INSERT INTO Client (name, id)
VALUES ('John Doe', 1)
INSERT INTO Account (active, amount, client_id, rate, account_type, id)
VALUES (true, 5000.0, 1, 0.0125, 'CREDIT', 1)
INSERT INTO Account (active, amount, client_id, rate, account_type, id)
VALUES (false, 0.0, 1, 0.0105, 'DEBIT', 2)
INSERT INTO Account (active, amount, client_id, rate, account_type, id)
VALUES (true, 250.0, 1, 0.0105, 'DEBIT', 3)When executing an Account entity query, Hibernate is going to filter out all records that are not active.
@WheredoInJPA( this::entityManagerFactory, entityManager -> {
List<Account> accounts = entityManager.createQuery(
"select a from Account a", Account.class)
.getResultList();
assertEquals( 2, accounts.size());
} );SELECT
a.id as id1_0_,
a.active as active2_0_,
a.amount as amount3_0_,
a.client_id as client_i6_0_,
a.rate as rate4_0_,
a.account_type as account_5_0_
FROM
Account a
WHERE ( a.active = true )2.3.22. @Filter
The @Filter annotation is another way to filter out entities or collections using a custom SQL criteria, for both entities and collections.
Unlike the @Where annotation, @Filter allows you to parameterize the filter clause at runtime.
@Filter mapping usagepublic enum AccountType {
DEBIT,
CREDIT
}
@Entity(name = "Client")
public static class Client {
@Id
private Long id;
private String name;
@OneToMany(mappedBy = "client")
@Filter(name="activeAccount", condition="active = :active")
private List<Account> accounts = new ArrayList<>( );
//Getters and setters omitted for brevity
}
@Entity(name = "Account")
@FilterDef(name="activeAccount", parameters=@ParamDef( name="active", type="boolean" ) )
@Filter(name="activeAccount", condition="active = :active")
public static class Account {
@Id
private Long id;
@ManyToOne
private Client client;
@Column(name = "account_type")
@Enumerated(EnumType.STRING)
private AccountType type;
private Double amount;
private Double rate;
private boolean active;
//Getters and setters omitted for brevity
}If the database contains the following entities:
@Filter mappingdoInJPA( this::entityManagerFactory, entityManager -> {
Client client = new Client();
client.setId( 1L );
client.setName( "John Doe" );
entityManager.persist( client );
Account account1 = new Account( );
account1.setId( 1L );
account1.setType( AccountType.CREDIT );
account1.setAmount( 5000d );
account1.setRate( 1.25 / 100 );
account1.setActive( true );
account1.setClient( client );
client.getAccounts().add( account1 );
entityManager.persist( account1 );
Account account2 = new Account( );
account2.setId( 2L );
account2.setType( AccountType.DEBIT );
account2.setAmount( 0d );
account2.setRate( 1.05 / 100 );
account2.setActive( false );
account2.setClient( client );
client.getAccounts().add( account2 );
entityManager.persist( account2 );
Account account3 = new Account( );
account3.setType( AccountType.DEBIT );
account3.setId( 3L );
account3.setAmount( 250d );
account3.setRate( 1.05 / 100 );
account3.setActive( true );
account3.setClient( client );
client.getAccounts().add( account3 );
entityManager.persist( account3 );
} );INSERT INTO Client (name, id)
VALUES ('John Doe', 1)
INSERT INTO Account (active, amount, client_id, rate, account_type, id)
VALUES (true, 5000.0, 1, 0.0125, 'CREDIT', 1)
INSERT INTO Account (active, amount, client_id, rate, account_type, id)
VALUES (false, 0.0, 1, 0.0105, 'DEBIT', 2)
INSERT INTO Account (active, amount, client_id, rate, account_type, id)
VALUES (true, 250.0, 1, 0.0105, 'DEBIT', 3)By default, without explicitly enabling the filter, Hibernate is going to fetch all Account entities.
If the filter is enabled and the filter parameter value is provided,
then Hibernate is going to apply the filtering criteria to the associated Account entities.
@FilterdoInJPA( this::entityManagerFactory, entityManager -> {
List<Account> accounts = entityManager.createQuery(
"select a from Account a", Account.class)
.getResultList();
assertEquals( 3, accounts.size());
} );
doInJPA( this::entityManagerFactory, entityManager -> {
log.infof( "Activate filter [%s]", "activeAccount");
entityManager
.unwrap( Session.class )
.enableFilter( "activeAccount" )
.setParameter( "active", true);
List<Account> accounts = entityManager.createQuery(
"select a from Account a", Account.class)
.getResultList();
assertEquals( 2, accounts.size());
} );SELECT
a.id as id1_0_,
a.active as active2_0_,
a.amount as amount3_0_,
a.client_id as client_i6_0_,
a.rate as rate4_0_,
a.account_type as account_5_0_
FROM
Account a
-- Activate filter [activeAccount]
SELECT
a.id as id1_0_,
a.active as active2_0_,
a.amount as amount3_0_,
a.client_id as client_i6_0_,
a.rate as rate4_0_,
a.account_type as account_5_0_
FROM
Account a
WHERE
a.active = trueJut like with entities, collections can be filtered as well, but only if the filter is explicilty enabled on the currently running Hibernate Session.
This way, when fetching the accounts collections, Hibernate is going to apply the @Filter clause filtering criteria to the associated collection entries.
@FilterdoInJPA( this::entityManagerFactory, entityManager -> {
Client client = entityManager.find( Client.class, 1L );
assertEquals( 3, client.getAccounts().size() );
} );
doInJPA( this::entityManagerFactory, entityManager -> {
log.infof( "Activate filter [%s]", "activeAccount");
entityManager
.unwrap( Session.class )
.enableFilter( "activeAccount" )
.setParameter( "active", true);
Client client = entityManager.find( Client.class, 1L );
assertEquals( 2, client.getAccounts().size() );
} );SELECT
c.id as id1_1_0_,
c.name as name2_1_0_
FROM
Client c
WHERE
c.id = 1
SELECT
a.id as id1_0_,
a.active as active2_0_,
a.amount as amount3_0_,
a.client_id as client_i6_0_,
a.rate as rate4_0_,
a.account_type as account_5_0_
FROM
Account a
WHERE
a.client_id = 1
-- Activate filter [activeAccount]
SELECT
c.id as id1_1_0_,
c.name as name2_1_0_
FROM
Client c
WHERE
c.id = 1
SELECT
a.id as id1_0_,
a.active as active2_0_,
a.amount as amount3_0_,
a.client_id as client_i6_0_,
a.rate as rate4_0_,
a.account_type as account_5_0_
FROM
Account a
WHERE
accounts0_.active = true
and a.client_id = 1|
The main advantage of |
2.3.23. @Any mapping
There is one more type of property mapping.
The @Any mapping defines a polymorphic association to classes from multiple tables.
This type of mapping requires more than one column.
The first column contains the type of the associated entity.
The remaining columns contain the identifier.
|
It is impossible to specify a foreign key constraint for this kind of association. This is not the usual way of mapping polymorphic associations and you should use this only in special cases (e.g. audit logs, user session data, etc). |
The @Any annotation describes the column holding the metadata information.
To link the value of the metadata information and an actual entity type, the @AnyDef and @AnyDefs annotations are used.
The metaType attribute allows the application to specify a custom type that maps database column values to persistent classes that have identifier properties of the type specified by idType.
You must specify the mapping from values of the metaType to class names.
For the next examples, consider the following Property class hierarchy:
Property class hierarchypublic interface Property<T> {
String getName();
T getValue();
}
@Entity
@Table(name="integer_property")
public class IntegerProperty implements Property<Integer> {
@Id
private Long id;
@Column(name = "`name`")
private String name;
@Column(name = "`value`")
private Integer value;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
@Override
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getValue() {
return value;
}
public void setValue(Integer value) {
this.value = value;
}
}
@Entity
@Table(name="string_property")
public class StringProperty implements Property<String> {
@Id
private Long id;
@Column(name = "`name`")
private String name;
@Column(name = "`value`")
private String value;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
@Override
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}A PropertyHolder can reference any such property, and, because each Property belongs to a separate table, the @Any annotation is, therefore, required.
@Any mapping usage@Entity
@Table( name = "property_holder" )
public class PropertyHolder {
@Id
private Long id;
@Any(
metaDef = "PropertyMetaDef",
metaColumn = @Column( name = "property_type" )
)
@JoinColumn( name = "property_id" )
private Property property;
//Getters and setters are omitted for brevity
}CREATE TABLE property_holder (
id BIGINT NOT NULL,
property_type VARCHAR(255),
property_id BIGINT,
PRIMARY KEY ( id )
)As you can see, there are two columns used to reference a Property instance: property_id and property_type.
The property_id is used to match the id column of either the string_property or integer_property tables,
while the property_type is used to match the string_property or the integer_property table.
The table resolving mapping is defined by the metaDef attribute which references an @AnyMetaDef mapping.
Although the @AnyMetaDef mapping could be set right next to the @Any annotation,
it’s good practice to reuse it, therefore it makes sense to configure it on a class or package-level basis.
The package-info.java contains the @AnyMetaDef mapping:
@Any mapping usage@AnyMetaDefs(
@AnyMetaDef( name= "PropertyMetaDef", metaType = "string", idType = "long",
metaValues = {
@MetaValue(value = "S", targetEntity = StringProperty.class),
@MetaValue(value = "I", targetEntity = IntegerProperty.class)
}
)
)
package org.hibernate.userguide.mapping.basic.any;
import org.hibernate.annotations.AnyMetaDef;
import org.hibernate.annotations.AnyMetaDefs;
import org.hibernate.annotations.MetaValue;|
It is recommended to place the |
To see how the @Any annotation in action, consider the following example:
@Any mapping usagedoInHibernate( this::sessionFactory, session -> {
IntegerProperty ageProperty = new IntegerProperty();
ageProperty.setId( 1L );
ageProperty.setName( "age" );
ageProperty.setValue( 23 );
StringProperty nameProperty = new StringProperty();
nameProperty.setId( 1L );
nameProperty.setName( "name" );
nameProperty.setValue( "John Doe" );
session.persist( ageProperty );
session.persist( nameProperty );
PropertyHolder namePropertyHolder = new PropertyHolder();
namePropertyHolder.setId( 1L );
namePropertyHolder.setProperty( nameProperty );
session.persist( namePropertyHolder );
} );
doInHibernate( this::sessionFactory, session -> {
PropertyHolder propertyHolder = session.get( PropertyHolder.class, 1L );
assertEquals("name", propertyHolder.getProperty().getName());
assertEquals("John Doe", propertyHolder.getProperty().getValue());
} );INSERT INTO integer_property
( "name", "value", id )
VALUES ( 'age', 23, 1 )
INSERT INTO string_property
( "name", "value", id )
VALUES ( 'name', 'John Doe', 1 )
INSERT INTO property_holder
( property_type, property_id, id )
VALUES ( 'S', 1, 1 )
SELECT ph.id AS id1_1_0_,
ph.property_type AS property2_1_0_,
ph.property_id AS property3_1_0_
FROM property_holder ph
WHERE ph.id = 1
SELECT sp.id AS id1_2_0_,
sp."name" AS name2_2_0_,
sp."value" AS value3_2_0_
FROM string_property sp
WHERE sp.id = 1@ManyToAny mapping
The @Any mapping is useful to emulate a @ManyToOne association when there can be multiple target entities.
To emulate a @OneToMany association, the @ManyToAny annotation must be used.
In the following example, the PropertyRepository entity has a collection of Property entities.
The repository_properties link table holds the associations between PropertyRepository and Property entities.
@ManyToAny mapping usage@Entity
@Table( name = "property_repository" )
public class PropertyRepository {
@Id
private Long id;
@ManyToAny(
metaDef = "PropertyMetaDef",
metaColumn = @Column( name = "property_type" )
)
@Cascade( { org.hibernate.annotations.CascadeType.ALL })
@JoinTable(name = "repository_properties",
joinColumns = @JoinColumn(name = "repository_id"),
inverseJoinColumns = @JoinColumn(name = "property_id")
)
private List<Property<?>> properties = new ArrayList<>( );
//Getters and setters are omitted for brevity
}CREATE TABLE property_repository (
id BIGINT NOT NULL,
PRIMARY KEY ( id )
)
CREATE TABLE repository_properties (
repository_id BIGINT NOT NULL,
property_type VARCHAR(255),
property_id BIGINT NOT NULL
)To see how the @ManyToAny annotation works, consider the following example:
@Any mapping usagedoInHibernate( this::sessionFactory, session -> {
IntegerProperty ageProperty = new IntegerProperty();
ageProperty.setId( 1L );
ageProperty.setName( "age" );
ageProperty.setValue( 23 );
StringProperty nameProperty = new StringProperty();
nameProperty.setId( 1L );
nameProperty.setName( "name" );
nameProperty.setValue( "John Doe" );
session.persist( ageProperty );
session.persist( nameProperty );
PropertyRepository propertyRepository = new PropertyRepository();
propertyRepository.setId( 1L );
propertyRepository.getProperties().add( ageProperty );
propertyRepository.getProperties().add( nameProperty );
session.persist( propertyRepository );
} );
doInHibernate( this::sessionFactory, session -> {
PropertyRepository propertyRepository = session.get( PropertyRepository.class, 1L );
assertEquals(2, propertyRepository.getProperties().size());
for(Property property : propertyRepository.getProperties()) {
assertNotNull( property.getValue() );
}
} );INSERT INTO integer_property
( "name", "value", id )
VALUES ( 'age', 23, 1 )
INSERT INTO string_property
( "name", "value", id )
VALUES ( 'name', 'John Doe', 1 )
INSERT INTO property_repository ( id )
VALUES ( 1 )
INSERT INTO repository_properties
( repository_id , property_type , property_id )
VALUES
( 1 , 'I' , 1 )
INSERT INTO repository_properties
( repository_id , property_type , property_id )
VALUES
( 1 , 'S' , 1 )
SELECT pr.id AS id1_1_0_
FROM property_repository pr
WHERE pr.id = 1
SELECT ip.id AS id1_0_0_ ,
integerpro0_."name" AS name2_0_0_ ,
integerpro0_."value" AS value3_0_0_
FROM integer_property integerpro0_
WHERE integerpro0_.id = 1
SELECT sp.id AS id1_3_0_ ,
sp."name" AS name2_3_0_ ,
sp."value" AS value3_3_0_
FROM string_property sp
WHERE sp.id = 12.4. Embeddable types
Historically Hibernate called these components. JPA calls them embeddables. Either way the concept is the same: a composition of values. For example we might have a Name class that is a composition of first-name and last-name, or an Address class that is a composition of street, city, postal code, etc.
|
Usage of the word embeddable
To avoid any confusion with the annotation that marks a given embeddable type, the annotation will be further referred as Throughout this chapter and thereafter, for brevity sake, embeddable types may also be referred as embeddable. |
@Embeddable
public class Name {
private String firstName;
private String middleName;
private String lastName;
...
}@Embeddable
public class Address {
private String line1;
private String line2;
@Embedded
private ZipCode zipCode;
...
@Embeddable
public static class Zip {
private String postalCode;
private String plus4;
...
}
}An embeddable type is another form of value type, and its lifecycle is bound to a parent entity type, therefore inheriting the attribute access from its parent (for details on attribute access, see Access strategies).
Embeddable types can be made up of basic values as well as associations, with the caveat that, when used as collection elements, they cannot define collections themselves.
2.4.1. Component / Embedded
Most often, embeddable types are used to group multiple basic type mappings and reuse them across several entities.
@Entity
public class Person {
@Id
private Integer id;
@Embedded
private Name name;
...
}|
JPA defines two terms for working with an embeddable type: |
So, the embeddable type is represented by the Name class and the parent makes use of it through the person.name object composition.
create table Person (
id integer not null,
firstName VARCHAR,
middleName VARCHAR,
lastName VARCHAR,
...
)The composed values are mapped to the same table as the parent table. Composition is part of good OO data modeling (idiomatic Java). In fact, that table could also be mapped by the following entity type instead.
@Entity
public class Person {
@Id
private Integer id;
private String firstName;
private String middleName;
private String lastName;
...
}The composition form is certainly more Object-oriented, and that becomes more evident as we work with multiple embeddable types.
2.4.2. Multiple embeddable types
@Entity
public class Contact {
@Id
private Integer id;
@Embedded
private Name name;
@Embedded
private Address homeAddress;
@Embedded
private Address mailingAddress;
@Embedded
private Address workAddress;
...
}Although from an object-oriented perspective, it’s much more convenient to work with embeddable types, this example doesn’t work as-is. When the same embeddable type is included multiple times in the same parent entity type, the JPA specification demands setting the associated column names explicitly.
This requirement is due to how object properties are mapped to database columns. By default, JPA expects a database column having the same name with its associated object property. When including multiple embeddables, the implicit name-based mapping rule doesn’t work anymore because multiple object properties could end-up being mapped to the same database column.
We have a few options to handle this issue.
2.4.3. JPA’s AttributeOverride
JPA defines the @AttributeOverride annotation to handle this scenario.
@Entity
public class Contact {
@Id
private Integer id;
@Embedded
private Name name;
@Embedded
@AttributeOverrides(
@AttributeOverride(
name = "line1",
column = @Column( name = "home_address_line1" ),
),
@AttributeOverride(
name = "line2",
column = @Column( name = "home_address_line2" )
),
@AttributeOverride(
name = "zipCode.postalCode",
column = @Column( name = "home_address_postal_cd" )
),
@AttributeOverride(
name = "zipCode.plus4",
column = @Column( name = "home_address_postal_plus4" )
)
)
private Address homeAddress;
@Embedded
@AttributeOverrides(
@AttributeOverride(
name = "line1",
column = @Column( name = "mailing_address_line1" ),
),
@AttributeOverride(
name = "line2",
column = @Column( name = "mailing_address_line2" )
),
@AttributeOverride(
name = "zipCode.postalCode",
column = @Column( name = "mailing_address_postal_cd" )
),
@AttributeOverride(
name = "zipCode.plus4",
column = @Column( name = "mailing_address_postal_plus4" )
)
)
private Address mailingAddress;
@Embedded
@AttributeOverrides(
@AttributeOverride(
name = "line1",
column = @Column( name = "work_address_line1" ),
),
@AttributeOverride(
name = "line2",
column = @Column( name = "work_address_line2" )
),
@AttributeOverride(
name = "zipCode.postalCode",
column = @Column( name = "work_address_postal_cd" )
),
@AttributeOverride(
name = "zipCode.plus4",
column = @Column( name = "work_address_postal_plus4" )
)
)
private Address workAddress;
...
}This way, the mapping conflict is resolved by setting up explicit name-based property-column type mappings.
2.4.4. ImplicitNamingStrategy
|
This is a Hibernate specific feature.
Users concerned with JPA provider portability should instead prefer explicit column naming with |
Hibernate naming strategies are covered in detail in Naming. However, for the purposes of this discussion, Hibernate has the capability to interpret implicit column names in a way that is safe for use with multiple embeddable types.
MetadataSources sources = ...;
sources.addAnnotatedClass( Address.class );
sources.addAnnotatedClass( Name.class );
sources.addAnnotatedClass( Contact.class );
Metadata metadata = sources.getMetadataBuilder().applyImplicitNamingStrategy( ImplicitNamingStrategyComponentPathImpl.INSTANCE )
...
.build();create table Contact(
id integer not null,
name_firstName VARCHAR,
name_middleName VARCHAR,
name_lastName VARCHAR,
homeAddress_line1 VARCHAR,
homeAddress_line2 VARCHAR,
homeAddress_zipCode_postalCode VARCHAR,
homeAddress_zipCode_plus4 VARCHAR,
mailingAddress_line1 VARCHAR,
mailingAddress_line2 VARCHAR,
mailingAddress_zipCode_postalCode VARCHAR,
mailingAddress_zipCode_plus4 VARCHAR,
workAddress_line1 VARCHAR,
workAddress_line2 VARCHAR,
workAddress_zipCode_postalCode VARCHAR,
workAddress_zipCode_plus4 VARCHAR,
...
)Now the "path" to attributes are used in the implicit column naming. You could even develop your own to do special implicit naming.
2.4.5. Collections of embeddable types
Collections of embeddable types are specifically value collections (as embeddable types are a value type). Value collections are covered in detail in Collections of value types.
2.4.6. Embeddable types as Map key
Embeddable types can also be used as Map keys.
This topic is converted in detail in Map - key.
2.4.7. Embeddable types as identifiers
Embeddable types can also be used as entity type identifiers. This usage is covered in detail in Composite identifiers.
|
Embeddable types that are used as collection entries, map keys or entity type identifiers cannot include their own collection mappings. |
2.5. Entity types
|
Usage of the word entity
The entity type describes the mapping between the actual persistable domain model object and a database table row.
To avoid any confusion with the annotation that marks a given entity type, the annotation will be further referred as Throughout this chapter and thereafter, entity types will be simply referred as entity. |
2.5.1. POJO Models
Section 2.1 The Entity Class of the JPA 2.1 specification defines its requirements for an entity class. Applications that wish to remain portable across JPA providers should adhere to these requirements.
-
The entity class must be annotated with the
javax.persistence.Entityannotation (or be denoted as such in XML mapping) -
The entity class must have a public or protected no-argument constructor. It may define additional constructors as well.
-
The entity class must be a top-level class.
-
An enum or interface may not be designated as an entity.
-
The entity class must not be final. No methods or persistent instance variables of the entity class may be final.
-
If an entity instance is to be used remotely as a detached object, the entity class must implement the
Serializableinterface. -
Both abstract and concrete classes can be entities. Entities may extend non-entity classes as well as entity classes, and non-entity classes may extend entity classes.
-
The persistent state of an entity is represented by instance variables, which may correspond to JavaBean-style properties. An instance variable must be directly accessed only from within the methods of the entity by the entity instance itself. The state of the entity is available to clients only through the entity’s accessor methods (getter/setter methods) or other business methods.
Hibernate, however, is not as strict in its requirements. The differences from the list above include:
-
The entity class must have a no-argument constructor, which may be public, protected or package visibility. It may define additional constructors as well.
-
The entity class need not be a top-level class.
-
Technically Hibernate can persist final classes or classes with final persistent state accessor (getter/setter) methods. However, it is generally not a good idea as doing so will stop Hibernate from being able to generate proxies for lazy-loading the entity.
-
Hibernate does not restrict the application developer from exposing instance variables and reference them from outside the entity class itself. The validity of such a paradigm, however, is debatable at best.
Let’s look at each requirement in detail.
2.5.2. Prefer non-final classes
A central feature of Hibernate is the ability to load lazily certain entity instance variables (attributes) via runtime proxies. This feature depends upon the entity class being non-final or else implementing an interface that declares all the attribute getters/setters. You can still persist final classes that do not implement such an interface with Hibernate, but you will not be able to use proxies for fetching lazy associations, therefore limiting your options for performance tuning. For the very same reason, you should also avoid declaring persistent attribute getters and setters as final.
|
Starting in 5.0 Hibernate offers a more robust version of bytecode enhancement as another means for handling lazy loading. Hibernate had some bytecode re-writing capabilities prior to 5.0 but they were very rudimentary. See the BytecodeEnhancement for additional information on fetching and on bytecode enhancement. |
2.5.3. Implement a no-argument constructor
The entity class should have a no-argument constructor. Both Hibernate and JPA require this.
JPA requires that this constructor be defined as public or protected. Hibernate, for the most part, does not care about the constructor visibility, as long as the system SecurityManager allows overriding the visibility setting. That said, the constructor should be defined with at least package visibility if you wish to leverage runtime proxy generation.
2.5.4. Declare getters and setters for persistent attributes
The JPA specification requires this, otherwise the model would prevent accessing the entity persistent state fields directly from outside the entity itself.
Although Hibernate does not require it, it is recommended to follow the JavaBean conventions and define getters and setters for entity persistent attributes. Nevertheless, you can still tell Hibernate to directly access the entity fields.
Attributes (whether fields or getters/setters) need not be declared public. Hibernate can deal with attributes declared with public, protected, package or private visibility. Again, if wanting to use runtime proxy generation for lazy loading, the getter/setter should grant access to at least package visibility.
2.5.5. Provide identifier attribute(s)
|
Historically this was considered optional. However, not defining identifier attribute(s) on the entity should be considered a deprecated feature that will be removed in an upcoming release. |
The identifier attribute does not necessarily need to be mapped to the column(s) that physically define the primary key. However, it should map to column(s) that can uniquely identify each row.
|
We recommend that you declare consistently-named identifier attributes on persistent classes and that you use a nullable (i.e., non-primitive) type. |
The placement of the @Id annotation marks the persistence state access strategy.
@Id
private Integer id;Hibernate offers multiple identifier generation strategies, see the Identifier Generators chapter for more about this topic.
2.5.6. Mapping the entity
The main piece in mapping the entity is the javax.persistence.Entity annotation.
The @Entity annotation defines just one attribute name which is used to give a specific entity name for use in JPQL queries.
By default, the entity name represents the unqualified name of the entity class itself.
@Entity@Entity
public class Simple {
...
}An entity models a database table.
The identifier uniquely identifies each row in that table.
By default, the name of the table is assumed to be the same as the name of the entity.
To explicitly give the name of the table or to specify other information about the table, we would use the javax.persistence.Table annotation.
@Entity with @Table@Entity
@Table( catalog = "CRM", schema = "purchasing", name = "t_simple" )
public class Simple {
...
}2.5.7. Implementing equals() and hashCode()
|
Much of the discussion in this section deals with the relation of an entity to a Hibernate Session, whether the entity is managed, transient or detached. If you are unfamiliar with these topics, they are explained in the Persistence Context chapter. |
Whether to implement equals() and hashCode() methods in your domain model, let alone how to implement them, is a surprisingly tricky discussion when it comes to ORM.
There is really just one absolute case: a class that acts as an identifier must implement equals/hashCode based on the id value(s). Generally, this is pertinent for user-defined classes used as composite identifiers. Beyond this one very specific use case and few others we will discuss below, you may want to consider not implementing equals/hashCode altogether.
So what’s all the fuss? Normally, most Java objects provide a built-in equals() and hashCode() based on the object’s identity, so each new object will be different from all others.
This is generally what you want in ordinary Java programming.
Conceptually however this starts to break down when you start to think about the possibility of multiple instances of a class representing the same data.
This is, in fact, exactly the case when dealing with data coming from a database.
Every time we load a specific Person from the database we would naturally get a unique instance.
Hibernate, however, works hard to make sure that does not happen within a given Session.
In fact, Hibernate guarantees equivalence of persistent identity (database row) and Java identity inside a particular session scope.
So if we ask a Hibernate Session to load that specific Person multiple times we will actually get back the same instance:
Session session=...;
Person p1 = session.get( Person.class,1 );
Person p2 = session.get( Person.class,1 );
// this evaluates to true
assert p1==p2;Consider another example using a persistent java.util.Set:
Session session=...;
Club club = session.get( Club.class,1 );
Person p1 = session.get( Person.class,1 );
Person p2 = session.get( Person.class,1 );
club.getMembers().add( p1 );
club.getMembers().add( p2 );
// this evaluates to true
assert club.getMembers.size()==1;However, the semantic changes when we mix instances loaded from different Sessions:
Session session1=...;
Session session2=...;
Person p1 = session1.get( Person.class,1 );
Person p2 = session2.get( Person.class,1 );
// this evaluates to false
assert p1==p2;Session session1=...;
Session session2=...;
Club club = session1.get( Club.class,1 );
Person p1 = session1.get( Person.class,1 );
Person p2 = session2.get( Person.class,1 );
club.getMembers().add( p1 );
club.getMembers().add( p2 );
// this evaluates to ... well it depends
assert club.getMembers.size()==1;Specifically the outcome in this last example will depend on whether the Person class implemented equals/hashCode, and, if so, how.
Consider yet another case:
Session session=...;
Club club = session.get( Club.class,1 );
Person p1 = new Person(...);
Person p2 = new Person(...);
club.getMembers().add( p1 );
club.getMembers().add( p2 );
// this evaluates to ... again, it depends
assert club.getMembers.size()==1;In cases where you will be dealing with entities outside of a Session (whether they be transient or detached), especially in cases where you will be using them in Java collections, you should consider implementing equals/hashCode.
A common initial approach is to use the entity’s identifier attribute as the basis for equals/hashCode calculations:
@Entity
public class Person {
@Id
@GeneratedValue
private Integer id;
@Override
public int hashCode() {
return Objects.hash( id );
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( !( o instanceof Person ) ) {
return false;
}
Person person = (Person) o;
return Objects.equals( id, person.id );
}
}It turns out that this still breaks when adding transient instance of Person to a set as we saw in the last example:
Session session=...;
session.getTransaction().begin();
Club club = session.get( Club.class,1 );
Person p1 = new Person(...);
Person p2 = new Person(...);
club.getMembers().add( p1 );
club.getMembers().add( p2 );
session.getTransaction().commit();
// will actually resolve to false!
assert club.getMembers().contains( p1 );The issue here is a conflict between the use of generated identifier, the contract of Set` and the equals/hashCode implementations.
`Set says that the equals/hashCode value for an object should not change while the object is part of the Set.
But that is exactly what happened here because the equals/hasCode are based on the (generated) id, which was not set until the session.getTransaction().commit() call.
Note that this is just a concern when using generated identifiers.
If you are using assigned identifiers this will not be a problem, assuming the identifier value is assigned prior to adding to the Set.
Another option is to force the identifier to be generated and set prior to adding to the Set:
Session session=...;
session.getTransaction().begin();
Club club = session.get( Club.class,1 );
Person p1 = new Person(...);
Person p2 = new Person(...);
session.save( p1 );
session.save( p2 );
session.flush();
club.getMembers().add( p1 );
club.getMembers().add( p2 );
session.getTransaction().commit();
// will actually resolve to false!
assert club.getMembers().contains( p1 );But this is often not feasible.
The final approach is to use a "better" equals/hashCode implementation, making use of a natural-id or business-key.
@Entity
public class Person {
@Id
@GeneratedValue
private Integer id;
@NaturalId
private String ssn;
protected Person() {
// Constructor for ORM
}
public Person( String ssn ) {
// Constructor for app
this.ssn = ssn;
}
@Override
public int hashCode() {
return Objects.hash( ssn );
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( !( o instanceof Person ) ) {
return false;
}
Person person = (Person) o;
return Objects.equals( ssn, person.ssn );
}
}As you can see the question of equals/hashCode is not trivial, nor is there a one-size-fits-all solution.
For details on mapping the identifier, see the Identifiers chapter.
2.5.8. Mapping optimistic locking
JPA defines support for optimistic locking based on either a version (sequential numeric) or timestamp strategy.
To enable this style of optimistic locking simply add the javax.persistence.Version to the persistent attribute that defines the optimistic locking value.
According to JPA, the valid types for these attributes are limited to:
-
intorInteger -
shortorShort -
longorLong -
java.sql.Timestamp
@Entity
public class Course {
@Id
private Integer id;
@Version
private Integer version;
...
}@Entity
public class Thing {
@Id
private Integer id;
@Version
private Timestamp ts;
...
}@Entity
public class Thing2 {
@Id
private Integer id;
@Version
private Instant ts;
...
}Hibernate supports a form of optimistic locking that does not require a dedicated "version attribute".
This is intended mainly for use with modeling legacy schemas.
The idea is that you can get Hibernate to perform "version checks" using either all of the entity’s attributes, or just the attributes that have changed.
This is achieved through the use of the org.hibernate.annotations.OptimisticLocking annotation which defines a single attribute of type org.hibernate.annotations.OptimisticLockType.
There are 4 available OptimisticLockTypes:
NONE-
optimistic locking is disabled even if there is a
@Versionannotation present VERSION(the default)-
performs optimistic locking based on a
@Versionas described above ALL-
performs optimistic locking based on all fields as part of an expanded WHERE clause restriction for the UPDATE/DELETE SQL statements
DIRTY-
performs optimistic locking based on dirty fields as part of an expanded WHERE clause restriction for the UPDATE/DELETE SQL statements.
2.5.9. Access strategies
As a JPA provider, Hibernate can introspect both the entity attributes (instance fields) or the accessors (instance properties).
By default, the placement of the @Id annotation gives the default access strategy.
When placed on a field, Hibernate will assume field-based access.
Place on the identifier getter, Hibernate will use property-based access.
|
You should pay attention to Java Beans specification in regard to naming properties to avoid issues such as Property name beginning with at least two uppercase characters has odd functionality in HQL! |
Embeddable types inherit the access strategy from their parent entities.
Field-based access
@Entity
public class Simple {
@Id
private Integer id;
public Integer getId() {
return id;
}
public void setId( Integer id ) {
this.id = id;
}
}When using field-based access, adding other entity-level methods is much more flexible because Hibernate won’t consider those part of the persistence state.
To exclude a field from being part of the entity persistent state, the field must be marked with the @Transient annotation.
|
Another advantage of using field-based access is that some entity attributes can be hidden from outside the entity.
An example of such attribute is the entity |
Property-based access
@Entity
public class Simple {
private Integer id;
@Id
public Integer getId() {
return id;
}
public void setId( Integer id ) {
this.id = id;
}
}When using property-based access, Hibernate uses the accessors for both reading and writing the entity state.
Every other method that will be added to the entity (e.g. helper methods for synchronizing both ends of a bidirectional one-to-many association) will have to be marked with the @Transient annotation.
Overriding the default access strategy
The default access strategy mechanism can be overridden with the JPA @Access annotation.
In the following example, the @Version attribute is accessed by its field and not by its getter, like the rest of entity attributes.
@Entity
public class Simple {
private Integer id;
@Version
@Access( AccessType.FIELD )
private Integer version;
@Id
public Integer getId() {
return id;
}
public void setId( Integer id ) {
this.id = id;
}
}Embeddable types and access strategy
Because embeddables are managed by their owning entities, the access strategy is therefore inherited from the entity too. This applies to both simple embeddable types as well as for collection of embeddables.
The embeddable types can overrule the default implicit access strategy (inherited from the owning entity). In the following example, the embeddable uses property-based access, no matter what access strategy the owning entity is choosing:
@Embeddable
@Access(AccessType.PROPERTY)
public static class Change {
private String path;
private String diff;
public Change() {}
@Column(name = "path", nullable = false)
public String getPath() {
return path;
}
public void setPath(String path) {
this.path = path;
}
@Column(name = "diff", nullable = false)
public String getDiff() {
return diff;
}
public void setDiff(String diff) {
this.diff = diff;
}
}The owning entity can use field-based access, while the embeddable uses property-based access as it has chosen explicitly:
@Entity
public class Patch {
@Id
private Long id;
@Embedded
private Change change;
}This works also for collection of embeddable types:
@Entity
public class Patch {
@Id
private Long id;
@ElementCollection
@CollectionTable(
name="patch_change",
joinColumns=@JoinColumn(name="patch_id")
)
@OrderColumn(name = "index_id")
private List<Change> changes = new ArrayList<>();
public List<Change> getChanges() {
return changes;
}
}2.6. Identifiers
Identifiers model the primary key of an entity. They are used to uniquely identify each specific entity.
Hibernate and JPA both make the following assumptions about the corresponding database column(s):
UNIQUE-
The values must uniquely identify each row.
NOT NULL-
The values cannot be null. For composite ids, no part can be null.
IMMUTABLE-
The values, once inserted, can never be changed. This is more a general guide, than a hard-fast rule as opinions vary. JPA defines the behavior of changing the value of the identifier attribute to be undefined; Hibernate simply does not support that. In cases where the values for the PK you have chosen will be updated, Hibernate recommends mapping the mutable value as a natural id, and use a surrogate id for the PK. See Natural Ids.
|
Technically the identifier does not have to map to the column(s) physically defined as the table primary key. They just need to map to column(s) that uniquely identify each row. However this documentation will continue to use the terms identifier and primary key interchangeably. |
Every entity must define an identifier. For entity inheritance hierarchies, the identifier must be defined just on the entity that is the root of the hierarchy.
An identifier might be simple (single value) or composite (multiple values).
2.6.1. Simple identifiers
Simple identifiers map to a single basic attribute, and are denoted using the javax.persistence.Id annotation.
According to JPA only the following types should be used as identifier attribute types:
-
any Java primitive type
-
any primitive wrapper type
-
java.lang.String -
java.util.Date(TemporalType#DATE) -
java.sql.Date -
java.math.BigDecimal -
java.math.BigInteger
Any types used for identifier attributes beyond this list will not be portable.
Values for simple identifiers can be assigned, as we have seen in the examples above. The expectation for assigned identifier values is that the application assigns (sets them on the entity attribute) prior to calling save/persist.
@Entity
public class MyEntity {
@Id
public Integer id;
...
}Values for simple identifiers can be generated. To denote that an identifier attribute is generated, it is annotated with javax.persistence.GeneratedValue
@Entity
public class MyEntity {
@Id
@GeneratedValue
public Integer id;
...
}Additionally, to the type restriction list above, JPA says that if using generated identifier values (see below) only integer types (short, int, long) will be portably supported.
The expectation for generated identifier values is that Hibernate will generate the value when the save/persist occurs.
Identifier value generations strategies are discussed in detail in the Generated identifier values section.
2.6.2. Composite identifiers
Composite identifiers correspond to one or more persistent attributes. Here are the rules governing composite identifiers, as defined by the JPA specification.
-
The composite identifier must be represented by a "primary key class". The primary key class may be defined using the
javax.persistence.EmbeddedIdannotation (see Composite identifiers - aggregated (EmbeddedId)), or defined using thejavax.persistence.IdClassannotation (see Composite identifiers - non-aggregated (IdClass)). -
The primary key class must be public and must have a public no-arg constructor.
-
The primary key class must be serializable.
-
The primary key class must define equals and hashCode methods, consistent with equality for the underlying database types to which the primary key is mapped.
|
The restriction that a composite identifier has to be represented by a "primary key class" is only JPA specific. Hibernate does allow composite identifiers to be defined without a "primary key class", although that modeling technique is deprecated and therefore omitted from this discussion. |
The attributes making up the composition can be either basic, composite, ManyToOne. Note especially that collections and one-to-ones are never appropriate.
2.6.3. Composite identifiers - aggregated (EmbeddedId)
Modeling a composite identifier using an EmbeddedId simply means defining an embeddable to be a composition for the one or more attributes making up the identifier, and then exposing an attribute of that embeddable type on the entity.
@Entity
public class Login {
@EmbeddedId
private PK pk;
@Embeddable
public static class PK implements Serializable {
private String system;
private String username;
...
}
...
}As mentioned before, EmbeddedIds can even contain ManyToOne attributes.
@Entity
public class Login {
@EmbeddedId
private PK pk;
@Embeddable
public static class PK implements Serializable {
@ManyToOne
private System system;
private String username;
...
}
...
}|
Hibernate supports directly modeling the ManyToOne in the PK class, whether EmbeddedId or IdClass. However that is not portably supported by the JPA specification. In JPA terms one would use "derived identifiers"; for details, see Derived Identifiers. |
2.6.4. Composite identifiers - non-aggregated (IdClass)
Modeling a composite identifier using an IdClass differs from using an EmbeddedId in that the entity defines each individual attribute making up the composition. The IdClass simply acts as a "shadow".
@Entity
@IdClass( PK.class )
public class Login {
@Id
private String system;
@Id
private String username;
public static class PK implements Serializable {
private String system;
private String username;
...
}
...
}Non-aggregated composite identifiers can also contain ManyToOne attributes as we saw with aggregated ones (still non-portably)
@Entity
@IdClass( PK.class )
public class Login {
@Id
@ManyToOne
private System system;
@Id
private String username;
public static class PK implements Serializable {
private System system;
private String username;
...
}
...
}With non-aggregated composite identifiers, Hibernate also supports "partial" generation of the composite values.
@Entity
@IdClass( PK.class )
public class LogFile {
@Id
private String name;
@Id
private LocalDate date;
@Id
@GeneratedValue
private Integer uniqueStamp;
public static class PK implements Serializable {
private String name;
private LocalDate date;
private Integer uniqueStamp;
...
}
...
}|
This feature exists because of a highly questionable interpretation of the JPA specification made by the SpecJ committee. Hibernate does not feel that JPA defines support for this, but added the feature simply to be usable in SpecJ benchmarks. Use of this feature may or may not be portable from a JPA perspective. |
2.6.5. Composite identifiers - associations
Hibernate allows defining a composite identifier out of entity associations.
In the following example, the PersonAddress entity identifier is formed of two @ManyToOne associations.
@Entity
public class PersonAddress implements Serializable {
@Id
@ManyToOne
private Person person;
@Id
@ManyToOne()
private Address address;
public PersonAddress() {}
public PersonAddress(Person person, Address address) {
this.person = person;
this.address = address;
}
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
PersonAddress that = (PersonAddress) o;
return Objects.equals(person, that.person) &&
Objects.equals(address, that.address);
}
@Override
public int hashCode() {
return Objects.hash(person, address);
}
}
@Entity
public class Person {
@Id
@GeneratedValue
private Long id;
@NaturalId
private String registrationNumber;
public Person() {}
public Person(String registrationNumber) {
this.registrationNumber = registrationNumber;
}
public Long getId() {
return id;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(registrationNumber, person.registrationNumber);
}
@Override
public int hashCode() {
return Objects.hash(registrationNumber);
}
}
@Entity
public class Address {
@Id
@GeneratedValue
private Long id;
private String street;
private String number;
private String postalCode;
public Address() {}
public Address(String street, String number, String postalCode) {
this.street = street;
this.number = number;
this.postalCode = postalCode;
}
public Long getId() {
return id;
}
public String getStreet() {
return street;
}
public String getNumber() {
return number;
}
public String getPostalCode() {
return postalCode;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Address address = (Address) o;
return Objects.equals(street, address.street) &&
Objects.equals(number, address.number) &&
Objects.equals(postalCode, address.postalCode);
}
@Override
public int hashCode() {
return Objects.hash(street, number, postalCode);
}
}Although the mapping is much simpler than using an @EmbeddedId or an @IdClass, there’s no separation between the entity instance and the actual identifier.
To query this entity, an instance of the entity itself must be supplied to the persistence context.
PersonAddress personAddress = entityManager.find(
PersonAddress.class,
new PersonAddress( person, address )
);2.6.6. Generated identifier values
|
For discussion of generated values for non-identifier attributes, see Generated properties |
Hibernate supports identifier value generation across a number of different types. Remember that JPA portably defines identifier value generation just for integer types.
Identifier value generation is indicates using the javax.persistence.GeneratedValue annotation.
The most important piece of information here is the specified javax.persistence.GenerationType which indicates how values will be generated.
|
The discussions below assume that the application is using Hibernate’s "new generator mappings" as indicated by the |
AUTO(the default)-
Indicates that the persistence provider (Hibernate) should choose an appropriate generation strategy. See Interpreting AUTO.
IDENTITY-
Indicates that database IDENTITY columns will be used for primary key value generation. See Using IDENTITY columns.
SEQUENCE-
Indicates that database sequence should be used for obtaining primary key values. See Using sequences.
TABLE-
Indicates that a database table should be used for obtaining primary key values. See Using identifier table.
2.6.7. Interpreting AUTO
How a persistence provider interprets the AUTO generation type is left up to the provider.
The default behavior is to look at the java type of the identifier attribute.
If the identifier type is UUID, Hibernate is going to use an UUID identifier.
If the identifier type is numerical (e.g. Long, Integer), then Hibernate is going to use the IdGeneratorStrategyInterpreter to resolve the identifier generator strategy.
The IdGeneratorStrategyInterpreter has two implementations:
FallbackInterpreter-
This is the default strategy since Hibernate 5.0. For older versions, this strategy is enabled through the
hibernate.id.new_generator_mappingsconfiguration property . When using this strategy,AUTOalways resolves toSequenceStyleGenerator. If the underlying database supports sequences, then a SEQUENCE generator is used. Otherwise, a TABLE generator is going to be used instead. LegacyFallbackInterpreter-
This is a legacy mechanism that was used by Hibernate prior to version 5.0 or when the
hibernate.id.new_generator_mappingsconfiguration property is false. The legacy strategy mapsAUTOto thenativegenerator strategy which uses the Dialect#getNativeIdentifierGeneratorStrategy to resolve the actual identifier generator (e.g.identityorsequence).
2.6.8. Using sequences
For implementing database sequence-based identifier value generation Hibernate makes use of its org.hibernate.id.enhanced.SequenceStyleGenerator id generator.
It is important to note that SequenceStyleGenerator is capable of working against databases that do not support sequences by switching to a table as the underlying backing.
This gives Hibernate a huge degree of portability across databases while still maintaining consistent id generation behavior (versus say choosing between sequence and IDENTITY).
This backing storage is completely transparent to the user.
The preferred (and portable) way to configure this generator is using the JPA-defined javax.persistence.SequenceGenerator annotation.
The simplest form is to simply request sequence generation; Hibernate will use a single, implicitly-named sequence (hibernate_sequence) for all such unnamed definitions.
@Entity
public class MyEntity {
@Id
@GeneratedValue( generation = SEQUENCE )
public Integer id;
...
}Or a specifically named sequence can be requested
@Entity
public class MyEntity {
@Id
@GeneratedValue( generation = SEQUENCE, name = "my_sequence" )
public Integer id;
...
}Use javax.persistence.SequenceGenerator to specify additional configuration.
@Entity
public class MyEntity {
@Id
@GeneratedValue( generation = SEQUENCE, name = "my_sequence" )
@SequenceGenerator( name = "my_sequence", schema = "globals", allocationSize = 30 )
public Integer id;
...
}2.6.9. Using IDENTITY columns
For implementing identifier value generation based on IDENTITY columns,
Hibernate makes use of its org.hibernate.id.IdentityGenerator id generator which expects the identifier to generated by INSERT into the table.
IdentityGenerator understands 3 different ways that the INSERT-generated value might be retrieved:
-
If Hibernate believes the JDBC environment supports
java.sql.Statement#getGeneratedKeys, then that approach will be used for extracting the IDENTITY generated keys. -
Otherwise, if
Dialect#supportsInsertSelectIdentityreports true, Hibernate will use the Dialect specific INSERT+SELECT statement syntax. -
Otherwise, Hibernate will expect that the database supports some form of asking for the most recently inserted IDENTITY value via a separate SQL command as indicated by
Dialect#getIdentitySelectString
|
It is important to realize that this imposes a runtime behavior where the entity row must be physically inserted prior to the identifier value being known. This can mess up extended persistence contexts (conversations). Because of the runtime imposition/inconsistency Hibernate suggest other forms of identifier value generation be used. |
|
There is yet another important runtime impact of choosing IDENTITY generation: Hibernate will not be able to JDBC batching for inserts of the entities that use IDENTITY generation. The importance of this depends on the application specific use cases. If the application is not usually creating many new instances of a given type of entity that uses IDENTITY generation, then this is not an important impact since batching would not have been helpful anyway. |
2.6.10. Using identifier table
Hibernate achieves table-based identifier generation based on its org.hibernate.id.enhanced.TableGenerator id generator which defines a table capable of holding multiple named value segments for any number of entities.
create table hibernate_sequences(
sequence_name VARCHAR NOT NULL,
next_val INTEGER NOT NULL
)The basic idea is that a given table-generator table (hibernate_sequences for example) can hold multiple segments of identifier generation values.
@Entity
public class MyEntity {
@Id
@GeneratedValue( generation = TABLE )
public Integer id;
...
}If no table name is given Hibernate assumes an implicit name of hibernate_sequences.
Additionally, because no javax.persistence.TableGenerator#pkColumnValue is specified, Hibernate will use the default segment (sequence_name='default') from the hibernate_sequences table.
2.6.11. Using UUID generation
As mentioned above, Hibernate supports UUID identifier value generation.
This is supported through its org.hibernate.id.UUIDGenerator id generator.
UUIDGenerator supports pluggable strategies for exactly how the UUID is generated.
These strategies are defined by the org.hibernate.id.UUIDGenerationStrategy contract.
The default strategy is a version 4 (random) strategy according to IETF RFC 4122.
Hibernate does ship with an alternative strategy which is a RFC 4122 version 1 (time-based) strategy (using ip address rather than mac address).
@Entity
public class MyEntity {
@Id
@GeneratedValue
public UUID id;
...
}To specify an alternative generation strategy, we’d have to define some configuration via @GenericGenerator.
Here we choose the RFC 4122 version 1 compliant strategy named org.hibernate.id.uuid.CustomVersionOneStrategy
@Entity
public class MyEntity {
@Id
@GeneratedValue( generator = "uuid" )
@GenericGenerator(
name = "uuid",
strategy = "org.hibernate.id.UUIDGenerator",
parameters = {
@Parameter(
name = "uuid_gen_strategy_class",
value = "org.hibernate.id.uuid.CustomVersionOneStrategy"
)
}
)
public UUID id;
...
}2.6.12. Using @GenericGenerator
@GenericGenerator allows integration of any Hibernate org.hibernate.id.IdentifierGenerator implementation, including any of the specific ones discussed here and any custom ones.
2.6.13. Optimizers
Most of the Hibernate generators that separately obtain identifier values from database structures support the use of pluggable optimizers. Optimizers help manage the number of times Hibernate has to talk to the database in order to generate identifier values. For example, with no optimizer applied to a sequence-generator, every time the application asked Hibernate to generate an identifier it would need to grab the next sequence value from the database. But if we can minimize the number of times we need to communicate with the database here, the application will be able to perform better. Which is, in fact, the role of these optimizers.
- none
-
No optimization is performed. We communicate with the database each and every time an identifier value is needed from the generator.
- pooled-lo
-
The pooled-lo optimizer works on the principle that the increment-value is encoded into the database table/sequence structure. In sequence-terms this means that the sequence is defined with a greater-that-1 increment size.
For example, consider a brand new sequence defined as
create sequence m_sequence start with 1 increment by 20. This sequence essentially defines a "pool" of 20 usable id values each and every time we ask it for its next-value. The pooled-lo optimizer interprets the next-value as the low end of that pool.So when we first ask it for next-value, we’d get 1. We then assume that the valid pool would be the values from 1-20 inclusive.
The next call to the sequence would result in 21, which would define 21-40 as the valid range. And so on. The "lo" part of the name indicates that the value from the database table/sequence is interpreted as the pool lo(w) end.
- pooled
-
Just like pooled-lo, except that here the value from the table/sequence is interpreted as the high end of the value pool.
- hilo; legacy-hilo
-
Define a custom algorithm for generating pools of values based on a single value from a table or sequence.
These optimizers are not recommended for use. They are maintained (and mentioned) here simply for use by legacy applications that used these strategies previously.
Applications can also implement and use their own optimizer strategies, as defined by the org.hibernate.id.enhanced.Optimizer contract.
2.6.14. Derived Identifiers
JPA 2.0 added support for derived identifiers which allow an entity to borrow the identifier from a many-to-one or one-to-one association.
@MapsId@Entity
public class Person {
@Id
@GeneratedValue
private Long id;
@NaturalId
private String registrationNumber;
public Person() {}
public Person(String registrationNumber) {
this.registrationNumber = registrationNumber;
}
public Long getId() {
return id;
}
public String getRegistrationNumber() {
return registrationNumber;
}
}
@Entity
public class PersonDetails {
@Id
private Long id;
private String nickName;
@ManyToOne
@MapsId
private Person person;
public String getNickName() {
return nickName;
}
public void setNickName(String nickName) {
this.nickName = nickName;
}
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
}In the example above, the PersonDetails entity uses the id column for both the entity identifier and for the many-to-one association to the Person entity.
The value of the PersonDetails entity identifier is "derived" from the identifier of its parent Person entity.
The @MapsId annotation can also reference columns from an @EmbeddedId identifier as well.
The previous example can also be mapped using @PrimaryKeyJoinColumn.
@PrimaryKeyJoinColumn@Entity
public class PersonDetails {
@Id
private Long id;
private String nickName;
@ManyToOne
@PrimaryKeyJoinColumn
private Person person;
public String getNickName() {
return nickName;
}
public void setNickName(String nickName) {
this.nickName = nickName;
}
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
this.id = person.getId();
}
}|
Unlike |
2.7. Associations
Associations describe how two or more entities form a relationship based on a database joining semantics.
2.7.1. @ManyToOne
@ManyToOne is the most common association, having a direct equivalent in the relational database as well (e.g. foreign key),
and so it establishes a relationship between a child entity and a parent.
@ManyToOne association@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
public Person() {
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
@Column(name = "`number`")
private String number;
@ManyToOne
@JoinColumn(name = "person_id",
foreignKey = @ForeignKey(name = "PERSON_ID_FK")
)
private Person person;
public Phone() {
}
public Phone(String number) {
this.number = number;
}
public Long getId() {
return id;
}
public String getNumber() {
return number;
}
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
}CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
person_id BIGINT ,
PRIMARY KEY ( id )
)
ALTER TABLE Phone
ADD CONSTRAINT PERSON_ID_FK
FOREIGN KEY (person_id) REFERENCES PersonEach entity has a lifecycle of its own. Once the @ManyToOne association is set, Hibernate will set the associated database foreign key column.
@ManyToOne association lifecyclePerson person = new Person();
entityManager.persist( person );
Phone phone = new Phone( "123-456-7890" );
phone.setPerson( person );
entityManager.persist( phone );
entityManager.flush();
phone.setPerson( null );INSERT INTO Person ( id )
VALUES ( 1 )
INSERT INTO Phone ( number, person_id, id )
VALUES ( '123-456-7890', 1, 2 )
UPDATE Phone
SET number = '123-456-7890',
person_id = NULL
WHERE id = 22.7.2. @OneToMany
The @OneToMany association links a parent entity with one or more child entities.
If the @OneToMany doesn’t have a mirroring @ManyToOne association on the child side, the @OneToMany association is unidirectional.
If there is a @ManyToOne association on the child side, the @OneToMany association is bidirectional and the application developer can navigate this relationship from both ends.
Unidirectional @OneToMany
When using a unidirectional @OneToMany association, Hibernate resorts to using a link table between the two joining entities.
@OneToMany association@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
private List<Phone> phones = new ArrayList<>();
public Person() {
}
public List<Phone> getPhones() {
return phones;
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
@Column(name = "`number`")
private String number;
public Phone() {
}
public Phone(String number) {
this.number = number;
}
public Long getId() {
return id;
}
public String getNumber() {
return number;
}
}CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Person_Phone (
Person_id BIGINT NOT NULL ,
phones_id BIGINT NOT NULL
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
PRIMARY KEY ( id )
)
ALTER TABLE Person_Phone
ADD CONSTRAINT UK_9uhc5itwc9h5gcng944pcaslf
UNIQUE (phones_id)
ALTER TABLE Person_Phone
ADD CONSTRAINT FKr38us2n8g5p9rj0b494sd3391
FOREIGN KEY (phones_id) REFERENCES Phone
ALTER TABLE Person_Phone
ADD CONSTRAINT FK2ex4e4p7w1cj310kg2woisjl2
FOREIGN KEY (Person_id) REFERENCES Person|
The |
@OneToMany associationPerson person = new Person();
Phone phone1 = new Phone( "123-456-7890" );
Phone phone2 = new Phone( "321-654-0987" );
person.getPhones().add( phone1 );
person.getPhones().add( phone2 );
entityManager.persist( person );
entityManager.flush();
person.getPhones().remove( phone1 );INSERT INTO Person
( id )
VALUES ( 1 )
INSERT INTO Phone
( number, id )
VALUES ( '123 - 456 - 7890', 2 )
INSERT INTO Phone
( number, id )
VALUES ( '321 - 654 - 0987', 3 )
INSERT INTO Person_Phone
( Person_id, phones_id )
VALUES ( 1, 2 )
INSERT INTO Person_Phone
( Person_id, phones_id )
VALUES ( 1, 3 )
DELETE FROM Person_Phone
WHERE Person_id = 1
INSERT INTO Person_Phone
( Person_id, phones_id )
VALUES ( 1, 3 )
DELETE FROM Phone
WHERE id = 2When persisting the Person entity, the cascade will propagate the persist operation to the underlying Phone children as well.
Upon removing a Phone from the phones collection, the association row is deleted from the link table, and the orphanRemoval attribute will trigger a Phone removal as well.
|
The unidirectional associations are not very efficient when it comes to removing child entities. In this particular example, upon flushing the persistence context, Hibernate deletes all database child entries and reinserts the ones that are still found in the in-memory persistence context. On the other hand, a bidirectional |
Bidirectional @OneToMany
The bidirectional @OneToMany association also requires a @ManyToOne association on the child side.
Although the Domain Model exposes two sides to navigate this association, behind the scenes, the relational database has only one foreign key for this relationship.
Every bidirectional association must have one owning side only (the child side), the other one being referred to as the inverse (or the mappedBy) side.
@OneToMany association mappedBy the @ManyToOne side@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Phone> phones = new ArrayList<>();
public Person() {
}
public Person(Long id) {
this.id = id;
}
public List<Phone> getPhones() {
return phones;
}
public void addPhone(Phone phone) {
phones.add( phone );
phone.setPerson( this );
}
public void removePhone(Phone phone) {
phones.remove( phone );
phone.setPerson( null );
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
@NaturalId
@Column(name = "`number`", unique = true)
private String number;
@ManyToOne
private Person person;
public Phone() {
}
public Phone(String number) {
this.number = number;
}
public Long getId() {
return id;
}
public String getNumber() {
return number;
}
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
person_id BIGINT ,
PRIMARY KEY ( id )
)
ALTER TABLE Phone
ADD CONSTRAINT UK_l329ab0g4c1t78onljnxmbnp6
UNIQUE (number)
ALTER TABLE Phone
ADD CONSTRAINT FKmw13yfsjypiiq0i1osdkaeqpg
FOREIGN KEY (person_id) REFERENCES Person|
Whenever a bidirectional association is formed, the application developer must make sure both sides are in-sync at all times.
The |
Because the Phone class has a @NaturalId column (the phone number being unique),
the equals() and the hashCode() can make use of this property, and so the removePhone() logic is reduced to the remove() Java Collection method.
@OneToMany with an owner @ManyToOne side lifecyclePerson person = new Person();
Phone phone1 = new Phone( "123-456-7890" );
Phone phone2 = new Phone( "321-654-0987" );
person.addPhone( phone1 );
person.addPhone( phone2 );
entityManager.persist( person );
entityManager.flush();
person.removePhone( phone1 );INSERT INTO Phone
( number, person_id, id )
VALUES ( '123-456-7890', NULL, 2 )
INSERT INTO Phone
( number, person_id, id )
VALUES ( '321-654-0987', NULL, 3 )
DELETE FROM Phone
WHERE id = 2Unlike the unidirectional @OneToMany, the bidirectional association is much more efficient when managing the collection persistence state.
Every element removal only requires a single update (in which the foreign key column is set to NULL), and,
if the child entity lifecycle is bound to its owning parent so that the child cannot exist without its parent,
then we can annotate the association with the orphan-removal attribute and disassociating the child will trigger a delete statement on the actual child table row as well.
2.7.3. @OneToOne
The @OneToOne association can either be unidirectional or bidirectional.
A unidirectional association follows the relational database foreign key semantics, the client-side owning the relationship.
A bidirectional association features a mappedBy @OneToOne parent side too.
Unidirectional @OneToOne
@OneToOne@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
@Column(name = "`number`")
private String number;
@OneToOne
@JoinColumn(name = "details_id")
private PhoneDetails details;
public Phone() {
}
public Phone(String number) {
this.number = number;
}
public Long getId() {
return id;
}
public String getNumber() {
return number;
}
public PhoneDetails getDetails() {
return details;
}
public void setDetails(PhoneDetails details) {
this.details = details;
}
}
@Entity(name = "PhoneDetails")
public static class PhoneDetails {
@Id
@GeneratedValue
private Long id;
private String provider;
private String technology;
public PhoneDetails() {
}
public PhoneDetails(String provider, String technology) {
this.provider = provider;
this.technology = technology;
}
public String getProvider() {
return provider;
}
public String getTechnology() {
return technology;
}
public void setTechnology(String technology) {
this.technology = technology;
}
}CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
details_id BIGINT ,
PRIMARY KEY ( id )
)
CREATE TABLE PhoneDetails (
id BIGINT NOT NULL ,
provider VARCHAR(255) ,
technology VARCHAR(255) ,
PRIMARY KEY ( id )
)
ALTER TABLE Phone
ADD CONSTRAINT FKnoj7cj83ppfqbnvqqa5kolub7
FOREIGN KEY (details_id) REFERENCES PhoneDetailsFrom a relational database point of view, the underlying schema is identical to the unidirectional @ManyToOne association,
as the client-side controls the relationship based on the foreign key column.
But then, it’s unusual to consider the Phone as a client-side and the PhoneDetails as the parent-side because the details cannot exist without an actual phone.
A much more natural mapping would be if the Phone were the parent-side, therefore pushing the foreign key into the PhoneDetails table.
This mapping requires a bidirectional @OneToOne association as you can see in the following example:
Bidirectional @OneToOne
@OneToOne@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
@Column(name = "`number`")
private String number;
@OneToOne(mappedBy = "phone", cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.LAZY)
private PhoneDetails details;
public Phone() {
}
public Phone(String number) {
this.number = number;
}
public Long getId() {
return id;
}
public String getNumber() {
return number;
}
public PhoneDetails getDetails() {
return details;
}
public void addDetails(PhoneDetails details) {
details.setPhone( this );
this.details = details;
}
public void removeDetails() {
if ( details != null ) {
details.setPhone( null );
this.details = null;
}
}
}
@Entity(name = "PhoneDetails")
public static class PhoneDetails {
@Id
@GeneratedValue
private Long id;
private String provider;
private String technology;
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "phone_id")
private Phone phone;
public PhoneDetails() {
}
public PhoneDetails(String provider, String technology) {
this.provider = provider;
this.technology = technology;
}
public String getProvider() {
return provider;
}
public String getTechnology() {
return technology;
}
public void setTechnology(String technology) {
this.technology = technology;
}
public Phone getPhone() {
return phone;
}
public void setPhone(Phone phone) {
this.phone = phone;
}
}CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE PhoneDetails (
id BIGINT NOT NULL ,
provider VARCHAR(255) ,
technology VARCHAR(255) ,
phone_id BIGINT ,
PRIMARY KEY ( id )
)
ALTER TABLE PhoneDetails
ADD CONSTRAINT FKeotuev8ja8v0sdh29dynqj05p
FOREIGN KEY (phone_id) REFERENCES PhoneThis time, the PhoneDetails owns the association, and, like any bidirectional association, the parent-side can propagate its lifecycle to the child-side through cascading.
@OneToOne lifecyclePhone phone = new Phone( "123-456-7890" );
PhoneDetails details = new PhoneDetails( "T-Mobile", "GSM" );
phone.addDetails( details );
entityManager.persist( phone );INSERT INTO Phone ( number, id )
VALUES ( '123 - 456 - 7890', 1 )
INSERT INTO PhoneDetails ( phone_id, provider, technology, id )
VALUES ( 1, 'T - Mobile, GSM', 2 )When using a bidirectional @OneToOne association, Hibernate enforces the unique constraint upon fetching the child-side.
If there are more than one children associated with the same parent, Hibernate will throw a constraint violation exception.
Continuing the previous example, when adding another PhoneDetails, Hibernate validates the uniqueness constraint when reloading the Phone object.
@OneToOne unique constraintPhoneDetails otherDetails = new PhoneDetails( "T-Mobile", "CDMA" );
otherDetails.setPhone( phone );
entityManager.persist( otherDetails );
entityManager.flush();
entityManager.clear();
//throws javax.persistence.PersistenceException: org.hibernate.HibernateException: More than one row with the given identifier was found: 1
phone = entityManager.find( Phone.class, phone.getId() );2.7.4. @ManyToMany
The @ManyToMany association requires a link table that joins two entities.
Like the @OneToMany association, @ManyToMany can be a either unidirectional or bidirectional.
Unidirectional @ManyToMany
@ManyToMany@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
@ManyToMany(cascade = {CascadeType.PERSIST, CascadeType.MERGE})
private List<Address> addresses = new ArrayList<>();
public Person() {
}
public List<Address> getAddresses() {
return addresses;
}
}
@Entity(name = "Address")
public static class Address {
@Id
@GeneratedValue
private Long id;
private String street;
@Column(name = "`number`")
private String number;
public Address() {
}
public Address(String street, String number) {
this.street = street;
this.number = number;
}
public Long getId() {
return id;
}
public String getStreet() {
return street;
}
public String getNumber() {
return number;
}
}CREATE TABLE Address (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
street VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Person_Address (
Person_id BIGINT NOT NULL ,
addresses_id BIGINT NOT NULL
)
ALTER TABLE Person_Address
ADD CONSTRAINT FKm7j0bnabh2yr0pe99il1d066u
FOREIGN KEY (addresses_id) REFERENCES Address
ALTER TABLE Person_Address
ADD CONSTRAINT FKba7rc9qe2vh44u93u0p2auwti
FOREIGN KEY (Person_id) REFERENCES PersonJust like with unidirectional @OneToMany associations, the link table is controlled by the owning side.
When an entity is removed from the @ManyToMany collection, Hibernate simply deletes the joining record in the link table.
Unfortunately, this operation requires removing all entries associated with a given parent and recreating the ones that are listed in the current running persistent context.
@ManyToMany lifecyclePerson person1 = new Person();
Person person2 = new Person();
Address address1 = new Address( "12th Avenue", "12A" );
Address address2 = new Address( "18th Avenue", "18B" );
person1.getAddresses().add( address1 );
person1.getAddresses().add( address2 );
person2.getAddresses().add( address1 );
entityManager.persist( person1 );
entityManager.persist( person2 );
entityManager.flush();
person1.getAddresses().remove( address1 );INSERT INTO Person ( id )
VALUES ( 1 )
INSERT INTO Address ( number, street, id )
VALUES ( '12A', '12th Avenue', 2 )
INSERT INTO Address ( number, street, id )
VALUES ( '18B', '18th Avenue', 3 )
INSERT INTO Person ( id )
VALUES ( 4 )
INSERT INTO Person_Address ( Person_id, addresses_id )
VALUES ( 1, 2 )
INSERT INTO Person_Address ( Person_id, addresses_id )
VALUES ( 1, 3 )
INSERT INTO Person_Address ( Person_id, addresses_id )
VALUES ( 4, 2 )
DELETE FROM Person_Address
WHERE Person_id = 1
INSERT INTO Person_Address ( Person_id, addresses_id )
VALUES ( 1, 3 )|
For For example, if |
By simply removing the parent-side, Hibernate can safely remove the associated link records as you can see in the following example:
@ManyToMany entity removalPerson person1 = entityManager.find( Person.class, personId );
entityManager.remove( person1 );DELETE FROM Person_Address
WHERE Person_id = 1
DELETE FROM Person
WHERE id = 1Bidirectional @ManyToMany
A bidirectional @ManyToMany association has an owning and a mappedBy side.
To preserve synchronicity between both sides, it’s good practice to provide helper methods for adding or removing child entities.
@ManyToMany@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
@NaturalId
private String registrationNumber;
@ManyToMany(cascade = {CascadeType.PERSIST, CascadeType.MERGE})
private List<Address> addresses = new ArrayList<>();
public Person() {
}
public Person(String registrationNumber) {
this.registrationNumber = registrationNumber;
}
public List<Address> getAddresses() {
return addresses;
}
public void addAddress(Address address) {
addresses.add( address );
address.getOwners().add( this );
}
public void removeAddress(Address address) {
addresses.remove( address );
address.getOwners().remove( this );
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Person person = (Person) o;
return Objects.equals( registrationNumber, person.registrationNumber );
}
@Override
public int hashCode() {
return Objects.hash( registrationNumber );
}
}
@Entity(name = "Address")
public static class Address {
@Id
@GeneratedValue
private Long id;
private String street;
@Column(name = "`number`")
private String number;
private String postalCode;
@ManyToMany(mappedBy = "addresses")
private List<Person> owners = new ArrayList<>();
public Address() {
}
public Address(String street, String number, String postalCode) {
this.street = street;
this.number = number;
this.postalCode = postalCode;
}
public Long getId() {
return id;
}
public String getStreet() {
return street;
}
public String getNumber() {
return number;
}
public String getPostalCode() {
return postalCode;
}
public List<Person> getOwners() {
return owners;
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Address address = (Address) o;
return Objects.equals( street, address.street ) &&
Objects.equals( number, address.number ) &&
Objects.equals( postalCode, address.postalCode );
}
@Override
public int hashCode() {
return Objects.hash( street, number, postalCode );
}
}CREATE TABLE Address (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
postalCode VARCHAR(255) ,
street VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE Person (
id BIGINT NOT NULL ,
registrationNumber VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE Person_Address (
owners_id BIGINT NOT NULL ,
addresses_id BIGINT NOT NULL
)
ALTER TABLE Person
ADD CONSTRAINT UK_23enodonj49jm8uwec4i7y37f
UNIQUE (registrationNumber)
ALTER TABLE Person_Address
ADD CONSTRAINT FKm7j0bnabh2yr0pe99il1d066u
FOREIGN KEY (addresses_id) REFERENCES Address
ALTER TABLE Person_Address
ADD CONSTRAINT FKbn86l24gmxdv2vmekayqcsgup
FOREIGN KEY (owners_id) REFERENCES PersonWith the helper methods in place, the synchronicity management can be simplified, as you can see in the following example:
@ManyToMany lifecyclePerson person1 = new Person( "ABC-123" );
Person person2 = new Person( "DEF-456" );
Address address1 = new Address( "12th Avenue", "12A", "4005A" );
Address address2 = new Address( "18th Avenue", "18B", "4007B" );
person1.addAddress( address1 );
person1.addAddress( address2 );
person2.addAddress( address1 );
entityManager.persist( person1 );
entityManager.persist( person2 );
entityManager.flush();
person1.removeAddress( address1 );INSERT INTO Person ( registrationNumber, id )
VALUES ( 'ABC-123', 1 )
INSERT INTO Address ( number, postalCode, street, id )
VALUES ( '12A', '4005A', '12th Avenue', 2 )
INSERT INTO Address ( number, postalCode, street, id )
VALUES ( '18B', '4007B', '18th Avenue', 3 )
INSERT INTO Person ( registrationNumber, id )
VALUES ( 'DEF-456', 4 )
INSERT INTO Person_Address ( owners_id, addresses_id )
VALUES ( 1, 2 )
INSERT INTO Person_Address ( owners_id, addresses_id )
VALUES ( 1, 3 )
INSERT INTO Person_Address ( owners_id, addresses_id )
VALUES ( 4, 2 )
DELETE FROM Person_Address
WHERE owners_id = 1
INSERT INTO Person_Address ( owners_id, addresses_id )
VALUES ( 1, 3 )If a bidirectional @OneToMany association performs better when removing or changing the order of child elements,
the @ManyToMany relationship cannot benefit from such an optimization because the foreign key side is not in control.
To overcome this limitation, the link table must be directly exposed and the @ManyToMany association split into two bidirectional @OneToMany relationships.
Bidirectional many-to-many with a link entity
To most natural @ManyToMany association follows the same logic employed by the database schema,
and the link table has an associated entity which controls the relationship for both sides that need to be joined.
@Entity(name = "Person")
public static class Person implements Serializable {
@Id
@GeneratedValue
private Long id;
@NaturalId
private String registrationNumber;
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL, orphanRemoval = true)
private List<PersonAddress> addresses = new ArrayList<>();
public Person() {
}
public Person(String registrationNumber) {
this.registrationNumber = registrationNumber;
}
public Long getId() {
return id;
}
public List<PersonAddress> getAddresses() {
return addresses;
}
public void addAddress(Address address) {
PersonAddress personAddress = new PersonAddress( this, address );
addresses.add( personAddress );
address.getOwners().add( personAddress );
}
public void removeAddress(Address address) {
PersonAddress personAddress = new PersonAddress( this, address );
address.getOwners().remove( personAddress );
addresses.remove( personAddress );
personAddress.setPerson( null );
personAddress.setAddress( null );
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Person person = (Person) o;
return Objects.equals( registrationNumber, person.registrationNumber );
}
@Override
public int hashCode() {
return Objects.hash( registrationNumber );
}
}
@Entity(name = "PersonAddress")
public static class PersonAddress implements Serializable {
@Id
@ManyToOne
private Person person;
@Id
@ManyToOne
private Address address;
public PersonAddress() {
}
public PersonAddress(Person person, Address address) {
this.person = person;
this.address = address;
}
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
PersonAddress that = (PersonAddress) o;
return Objects.equals( person, that.person ) &&
Objects.equals( address, that.address );
}
@Override
public int hashCode() {
return Objects.hash( person, address );
}
}
@Entity(name = "Address")
public static class Address implements Serializable {
@Id
@GeneratedValue
private Long id;
private String street;
@Column(name = "`number`")
private String number;
private String postalCode;
@OneToMany(mappedBy = "address", cascade = CascadeType.ALL, orphanRemoval = true)
private List<PersonAddress> owners = new ArrayList<>();
public Address() {
}
public Address(String street, String number, String postalCode) {
this.street = street;
this.number = number;
this.postalCode = postalCode;
}
public Long getId() {
return id;
}
public String getStreet() {
return street;
}
public String getNumber() {
return number;
}
public String getPostalCode() {
return postalCode;
}
public List<PersonAddress> getOwners() {
return owners;
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Address address = (Address) o;
return Objects.equals( street, address.street ) &&
Objects.equals( number, address.number ) &&
Objects.equals( postalCode, address.postalCode );
}
@Override
public int hashCode() {
return Objects.hash( street, number, postalCode );
}
}CREATE TABLE Address (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
postalCode VARCHAR(255) ,
street VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE Person (
id BIGINT NOT NULL ,
registrationNumber VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE PersonAddress (
person_id BIGINT NOT NULL ,
address_id BIGINT NOT NULL ,
PRIMARY KEY ( person_id, address_id )
)
ALTER TABLE Person
ADD CONSTRAINT UK_23enodonj49jm8uwec4i7y37f
UNIQUE (registrationNumber)
ALTER TABLE PersonAddress
ADD CONSTRAINT FK8b3lru5fyej1aarjflamwghqq
FOREIGN KEY (person_id) REFERENCES Person
ALTER TABLE PersonAddress
ADD CONSTRAINT FK7p69mgialumhegyl4byrh65jk
FOREIGN KEY (address_id) REFERENCES AddressBoth the Person and the Address have a` mappedBy` @OneToMany side, while the PersonAddress owns the person and the address @ManyToOne associations.
Because this mapping is formed out of two bidirectional associations, the helper methods are even more relevant.
|
The aforementioned example uses a Hibernate specific mapping for the link entity since JPA doesn’t allow building a composite identifier out of multiple |
The entity state transitions are better managed than in the previous bidirectional @ManyToMany case.
Person person1 = new Person( "ABC-123" );
Person person2 = new Person( "DEF-456" );
Address address1 = new Address( "12th Avenue", "12A", "4005A" );
Address address2 = new Address( "18th Avenue", "18B", "4007B" );
entityManager.persist( person1 );
entityManager.persist( person2 );
entityManager.persist( address1 );
entityManager.persist( address2 );
person1.addAddress( address1 );
person1.addAddress( address2 );
person2.addAddress( address1 );
entityManager.flush();
log.info( "Removing address" );
person1.removeAddress( address1 );INSERT INTO Person ( registrationNumber, id )
VALUES ( 'ABC-123', 1 )
INSERT INTO Person ( registrationNumber, id )
VALUES ( 'DEF-456', 2 )
INSERT INTO Address ( number, postalCode, street, id )
VALUES ( '12A', '4005A', '12th Avenue', 3 )
INSERT INTO Address ( number, postalCode, street, id )
VALUES ( '18B', '4007B', '18th Avenue', 4 )
INSERT INTO PersonAddress ( person_id, address_id )
VALUES ( 1, 3 )
INSERT INTO PersonAddress ( person_id, address_id )
VALUES ( 1, 4 )
INSERT INTO PersonAddress ( person_id, address_id )
VALUES ( 2, 3 )
DELETE FROM PersonAddress
WHERE person_id = 1 AND address_id = 3There is only one delete statement executed because, this time, the association is controlled by the @ManyToOne side which only has to monitor the state of the underlying foreign key relationship to trigger the right DML statement.
2.8. Collections
Naturally Hibernate also allows to persist collections. These persistent collections can contain almost any other Hibernate type, including: basic types, custom types, components and references to other entities. In this context, the distinction between value and reference semantics is very important. An object in a collection might be handled with value semantics (its life cycle being fully depends on the collection owner), or it might be a reference to another entity with its own life cycle. In the latter case, only the link between the two objects is considered to be a state held by the collection.
The owner of the collection is always an entity, even if the collection is defined by an embeddable type. Collections form one/many-to-many associations between types so there can be:
-
value type collections
-
embeddable type collections
-
entity collections
Hibernate uses its own collection implementations which are enriched with lazy-loading, caching or state change detection semantics.
For this reason, persistent collections must be declared as an interface type.
The actual interface might be java.util.Collection, java.util.List, java.util.Set, java.util.Map, java.util.SortedSet, java.util.SortedMap or even other object types (meaning you will have to write an implementation of org.hibernate.usertype.UserCollectionType).
As the following example demonstrates, it’s important to use the interface type and not the collection implementation, as declared in the entity mapping.
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@ElementCollection
private List<String> phones = new ArrayList<>();
public List<String> getPhones() {
return phones;
}
}
Person person = entityManager.find( Person.class, 1L );
//Throws java.lang.ClassCastException: org.hibernate.collection.internal.PersistentBag cannot be cast to java.util.ArrayList
ArrayList<String> phones = (ArrayList<String>) person.getPhones();|
It is important that collections be defined using the appropriate Java Collections Framework interface rather than a specific implementation. From a theoretical perspective, this just follows good design principles. From a practical perspective, Hibernate (like other persistence providers) will use their own collection implementations which conform to the Java Collections Framework interfaces. |
The persistent collections injected by Hibernate behave like ArrayList, HashSet, TreeSet, HashMap or TreeMap, depending on the interface type.
2.8.1. Collections as a value type
Value and embeddable type collections have a similar behavior as simple value types because they are automatically persisted when referenced by a persistent object and automatically deleted when unreferenced. If a collection is passed from one persistent object to another, its elements might be moved from one table to another.
|
Two entities cannot share a reference to the same collection instance. Collection-valued properties do not support null value semantics because Hibernate does not distinguish between a null collection reference and an empty collection. |
2.8.2. Collections of value types
Collections of value type include basic and embeddable types. Collections cannot be nested, and, when used in collections, embeddable types are not allowed to define other collections.
For collections of value types, JPA 2.0 defines the @ElementCollection annotation.
The lifecycle of the value-type collection is entirely controlled by its owning entity.
Considering the previous example mapping, when clearing the phone collection, Hibernate deletes all the associated phones. When adding a new element to the value type collection, Hibernate issues a new insert statement.
person.getPhones().clear();
person.getPhones().add( "123-456-7890" );
person.getPhones().add( "456-000-1234" );DELETE FROM Person_phones WHERE Person_id = 1
INSERT INTO Person_phones ( Person_id, phones )
VALUES ( 1, '123-456-7890' )
INSERT INTO Person_phones (Person_id, phones)
VALUES ( 1, '456-000-1234' )If removing all elements or adding new ones is rather straightforward, removing a certain entry actually requires reconstructing the whole collection from scratch.
person.getPhones().remove( 0 );DELETE FROM Person_phones WHERE Person_id = 1
INSERT INTO Person_phones ( Person_id, phones )
VALUES ( 1, '456-000-1234' )Depending on the number of elements, this behavior might not be efficient, if many elements need to be deleted and reinserted back into the database table.
A workaround is to use an @OrderColumn, which, although not as efficient as when using the actual link table primary key, might improve the efficiency of the remove operations.
@ElementCollection
@OrderColumn(name = "order_id")
private List<String> phones = new ArrayList<>();
person.getPhones().remove( 0 );DELETE FROM Person_phones
WHERE Person_id = 1
AND order_id = 1
UPDATE Person_phones
SET phones = '456-000-1234'
WHERE Person_id = 1
AND order_id = 0|
The |
Embeddable type collections behave the same way as value type collections. Adding embeddables to the collection triggers the associated insert statements and removing elements from the collection will generate delete statements.
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@ElementCollection
private List<Phone> phones = new ArrayList<>();
public List<Phone> getPhones() {
return phones;
}
}
@Embeddable
public static class Phone {
private String type;
@Column(name = "`number`")
private String number;
public Phone() {
}
public Phone(String type, String number) {
this.type = type;
this.number = number;
}
public String getType() {
return type;
}
public String getNumber() {
return number;
}
}
person.getPhones().add( new Phone( "landline", "028-234-9876" ) );
person.getPhones().add( new Phone( "mobile", "072-122-9876" ) );INSERT INTO Person_phones ( Person_id, number, type )
VALUES ( 1, '028-234-9876', 'landline' )
INSERT INTO Person_phones ( Person_id, number, type )
VALUES ( 1, '072-122-9876', 'mobile' )2.8.3. Collections of entities
If value type collections can only form a one-to-many association between an owner entity and multiple basic or embeddable types, entity collections can represent both @OneToMany and @ManyToMany associations.
From a relational database perspective, associations are defined by the foreign key side (the child-side). With value type collections, only the entity can control the association (the parent-side), but for a collection of entities, both sides of the association are managed by the persistence context.
For this reason, entity collections can be devised into two main categories: unidirectional and bidirectional associations. Unidirectional associations are very similar to value type collections since only the parent side controls this relationship. Bidirectional associations are more tricky since, even if sides need to be in-sync at all times, only one side is responsible for managing the association. A bidirectional association has an owning side and an inverse (mappedBy) side.
Another way of categorizing entity collections is by the underlying collection type, and so we can have:
-
bags
-
indexed lists
-
sets
-
sorted sets
-
maps
-
sorted maps
-
arrays
In the following sections, we will go through all these collection types and discuss both unidirectional and bidirectional associations.
2.8.4. Bags
Bags are unordered lists and we can have unidirectional bags or bidirectional ones.
Unidirectional bags
The unidirectional bag is mapped using a single @OneToMany annotation on the parent side of the association.
Behind the scenes, Hibernate requires an association table to manage the parent-child relationship, as we can see in the following example:
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL)
private List<Phone> phones = new ArrayList<>();
public Person() {
}
public Person(Long id) {
this.id = id;
}
public List<Phone> getPhones() {
return phones;
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
private String type;
@Column(name = "`number`")
private String number;
public Phone() {
}
public Phone(Long id, String type, String number) {
this.id = id;
this.type = type;
this.number = number;
}
public Long getId() {
return id;
}
public String getType() {
return type;
}
public String getNumber() {
return number;
}
}CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Person_Phone (
Person_id BIGINT NOT NULL ,
phones_id BIGINT NOT NULL
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
type VARCHAR(255) ,
PRIMARY KEY ( id )
)
ALTER TABLE Person_Phone
ADD CONSTRAINT UK_9uhc5itwc9h5gcng944pcaslf
UNIQUE (phones_id)
ALTER TABLE Person_Phone
ADD CONSTRAINT FKr38us2n8g5p9rj0b494sd3391
FOREIGN KEY (phones_id) REFERENCES Phone
ALTER TABLE Person_Phone
ADD CONSTRAINT FK2ex4e4p7w1cj310kg2woisjl2
FOREIGN KEY (Person_id) REFERENCES Person|
Because both the parent and the child sides are entities, the persistence context manages each entity separately. Cascades can propagate an entity state transition from a parent entity to its children. |
By marking the parent side with the CascadeType.ALL attribute, the unidirectional association lifecycle becomes very similar to that of a value type collection.
Person person = new Person( 1L );
person.getPhones().add( new Phone( 1L, "landline", "028-234-9876" ) );
person.getPhones().add( new Phone( 2L, "mobile", "072-122-9876" ) );
entityManager.persist( person );INSERT INTO Person ( id )
VALUES ( 1 )
INSERT INTO Phone ( number, type, id )
VALUES ( '028-234-9876', 'landline', 1 )
INSERT INTO Phone ( number, type, id )
VALUES ( '072-122-9876', 'mobile', 2 )
INSERT INTO Person_Phone ( Person_id, phones_id )
VALUES ( 1, 1 )
INSERT INTO Person_Phone ( Person_id, phones_id )
VALUES ( 1, 2 )In the example above, once the parent entity is persisted, the child entities are going to be persisted as well.
|
Just like value type collections, unidirectional bags are not as efficient when it comes to modifying the collection structure (removing or reshuffling elements). Because the parent-side cannot uniquely identify each individual child, Hibernate might delete all child table rows associated with the parent entity and re-add them according to the current collection state. |
Bidirectional bags
The bidirectional bag is the most common type of entity collection.
The @ManyToOne side is the owning side of the bidirectional bag association, while the @OneToMany is the inverse side, being marked with the mappedBy attribute.
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
private List<Phone> phones = new ArrayList<>();
public Person() {
}
public Person(Long id) {
this.id = id;
}
public List<Phone> getPhones() {
return phones;
}
public void addPhone(Phone phone) {
phones.add( phone );
phone.setPerson( this );
}
public void removePhone(Phone phone) {
phones.remove( phone );
phone.setPerson( null );
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
private String type;
@Column(name = "`number`", unique = true)
@NaturalId
private String number;
@ManyToOne
private Person person;
public Phone() {
}
public Phone(Long id, String type, String number) {
this.id = id;
this.type = type;
this.number = number;
}
public Long getId() {
return id;
}
public String getType() {
return type;
}
public String getNumber() {
return number;
}
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}CREATE TABLE Person (
id BIGINT NOT NULL, PRIMARY KEY (id)
)
CREATE TABLE Phone (
id BIGINT NOT NULL,
number VARCHAR(255),
type VARCHAR(255),
person_id BIGINT,
PRIMARY KEY (id)
)
ALTER TABLE Phone
ADD CONSTRAINT UK_l329ab0g4c1t78onljnxmbnp6
UNIQUE (number)
ALTER TABLE Phone
ADD CONSTRAINT FKmw13yfsjypiiq0i1osdkaeqpg
FOREIGN KEy (person_id) REFERENCES Personperson.addPhone( new Phone( 1L, "landline", "028-234-9876" ) );
person.addPhone( new Phone( 2L, "mobile", "072-122-9876" ) );
entityManager.flush();
person.removePhone( person.getPhones().get( 0 ) );INSERT INTO Phone (number, person_id, type, id)
VALUES ( '028-234-9876', 1, 'landline', 1 )
INSERT INTO Phone (number, person_id, type, id)
VALUES ( '072-122-9876', 1, 'mobile', 2 )
UPDATE Phone
SET person_id = NULL, type = 'landline' where id = 1@OneToMany(mappedBy = "person", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Phone> phones = new ArrayList<>();DELETE FROM Phone WHERE id = 1When rerunning the previous example, the child will get removed because the parent-side propagates the removal upon disassociating the child entity reference.
2.8.5. Ordered Lists
Although they use the List interface on the Java side, bags don’t retain element order.
To preserve the collection element order, there are two possibilities:
@OrderBy-
the collection is ordered upon retrieval using a child entity property
@OrderColumn-
the collection uses a dedicated order column in the collection link table
Unidirectional ordered lists
When using the @OrderBy annotation, the mapping looks as follows:
@OrderBy list@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL)
@OrderColumn(name = "order_id")
private List<Phone> phones = new ArrayList<>();
public Person() {
}
public Person(Long id) {
this.id = id;
}
public List<Phone> getPhones() {
return phones;
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
private String type;
@Column(name = "`number`")
private String number;
public Phone() {
}
public Phone(Long id, String type, String number) {
this.id = id;
this.type = type;
this.number = number;
}
public Long getId() {
return id;
}
public String getType() {
return type;
}
public String getNumber() {
return number;
}
}The database mapping is the same as with the Unidirectional bags example, so it won’t be repeated. Upon fetching the collection, Hibernate generates the following select statement:
@OrderBy list select statementSELECT
phones0_.Person_id AS Person_i1_1_0_,
phones0_.phones_id AS phones_i2_1_0_,
unidirecti1_.id AS id1_2_1_,
unidirecti1_.number AS number2_2_1_,
unidirecti1_.type AS type3_2_1_
FROM
Person_Phone phones0_
INNER JOIN
Phone unidirecti1_ ON phones0_.phones_id=unidirecti1_.id
WHERE
phones0_.Person_id = 1
ORDER BY
unidirecti1_.numberThe child table column is used to order the list elements.
|
The If no property is specified (e.g. |
Another ordering option is to use the @OrderColumn annotation:
@OrderColumn list@OneToMany(cascade = CascadeType.ALL)
@OrderBy("number")
private List<Phone> phones = new ArrayList<>();CREATE TABLE Person_Phone (
Person_id BIGINT NOT NULL ,
phones_id BIGINT NOT NULL ,
order_id INTEGER NOT NULL ,
PRIMARY KEY ( Person_id, order_id )
)This time, the link table takes the order_id column and uses it to materialize the collection element order.
When fetching the list, the following select query is executed:
@OrderColumn list select statementselect
phones0_.Person_id as Person_i1_1_0_,
phones0_.phones_id as phones_i2_1_0_,
phones0_.order_id as order_id3_0_,
unidirecti1_.id as id1_2_1_,
unidirecti1_.number as number2_2_1_,
unidirecti1_.type as type3_2_1_
from
Person_Phone phones0_
inner join
Phone unidirecti1_
on phones0_.phones_id=unidirecti1_.id
where
phones0_.Person_id = 1With the order_id column in place, Hibernate can order the list in-memory after it’s being fetched from the database.
Bidirectional ordered lists
The mapping is similar with the Bidirectional bags example, just that the parent side is going to be annotated with either @OrderBy or @OrderColumn.
@OrderBy list@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
@OrderBy("number")
private List<Phone> phones = new ArrayList<>();Just like with the unidirectional @OrderBy list, the number column is used to order the statement on the SQL level.
When using the @OrderColumn annotation, the order_id column is going to be embedded in the child table:
@OrderColumn list@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
@OrderColumn(name = "order_id")
private List<Phone> phones = new ArrayList<>();CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
type VARCHAR(255) ,
person_id BIGINT ,
order_id INTEGER ,
PRIMARY KEY ( id )
)When fetching the collection, Hibernate will use the fetched ordered columns to sort the elements according to the @OrderColumn mapping.
2.8.6. Sets
Sets are collections that don’t allow duplicate entries and Hibernate supports both the unordered Set and the natural-ordering SortedSet.
Unidirectional sets
The unidirectional set uses a link table to hold the parent-child associations and the entity mapping looks as follows:
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL)
private Set<Phone> phones = new HashSet<>();
public Person() {
}
public Person(Long id) {
this.id = id;
}
public Set<Phone> getPhones() {
return phones;
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
private String type;
@NaturalId
@Column(name = "`number`")
private String number;
public Phone() {
}
public Phone(Long id, String type, String number) {
this.id = id;
this.type = type;
this.number = number;
}
public Long getId() {
return id;
}
public String getType() {
return type;
}
public String getNumber() {
return number;
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}The unidirectional set lifecycle is similar to that of the Unidirectional bags, so it can be omitted.
The only difference is that Set doesn’t allow duplicates, but this constraint is enforced by the Java object contract rather then the database mapping.
|
When using sets, it’s very important to supply proper equals/hashCode implementations for child entities. In the absence of a custom equals/hashCode implementation logic, Hibernate will use the default Java reference-based object equality which might render unexpected results when mixing detached and managed object instances. |
Bidirectional sets
Just like bidirectional bags, the bidirectional set doesn’t use a link table, and the child table has a foreign key referencing the parent table primary key. The lifecycle is just like with bidirectional bags except for the duplicates which are filtered out.
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
private Set<Phone> phones = new HashSet<>();
public Person() {
}
public Person(Long id) {
this.id = id;
}
public Set<Phone> getPhones() {
return phones;
}
public void addPhone(Phone phone) {
phones.add( phone );
phone.setPerson( this );
}
public void removePhone(Phone phone) {
phones.remove( phone );
phone.setPerson( null );
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
private Long id;
private String type;
@Column(name = "`number`", unique = true)
@NaturalId
private String number;
@ManyToOne
private Person person;
public Phone() {
}
public Phone(Long id, String type, String number) {
this.id = id;
this.type = type;
this.number = number;
}
public Long getId() {
return id;
}
public String getType() {
return type;
}
public String getNumber() {
return number;
}
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}2.8.7. Sorted sets
For sorted sets, the entity mapping must use the SortedSet interface instead.
According to the SortedSet contract, all elements must implement the comparable interface and therefore provide the sorting logic.
Unidirectional sorted sets
A SortedSet that relies on the natural sorting order given by the child element Comparable implementation logic must be annotated with the @SortNatural Hibernate annotation.
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL)
@SortNatural
private SortedSet<Phone> phones = new TreeSet<>();
public Person() {
}
public Person(Long id) {
this.id = id;
}
public Set<Phone> getPhones() {
return phones;
}
}
@Entity(name = "Phone")
public static class Phone implements Comparable<Phone> {
@Id
private Long id;
private String type;
@NaturalId
@Column(name = "`number`")
private String number;
public Phone() {
}
public Phone(Long id, String type, String number) {
this.id = id;
this.type = type;
this.number = number;
}
public Long getId() {
return id;
}
public String getType() {
return type;
}
public String getNumber() {
return number;
}
@Override
public int compareTo(Phone o) {
return number.compareTo( o.getNumber() );
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}The lifecycle and the database mapping are identical to the Unidirectional bags, so they are intentionally omitted.
To provide a custom sorting logic, Hibernate also provides a @SortComparator annotation:
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL)
@SortComparator(ReverseComparator.class)
private SortedSet<Phone> phones = new TreeSet<>();
public Person() {
}
public Person(Long id) {
this.id = id;
}
public Set<Phone> getPhones() {
return phones;
}
}
public static class ReverseComparator implements Comparator<Phone> {
@Override
public int compare(Phone o1, Phone o2) {
return o2.compareTo( o1 );
}
}
@Entity(name = "Phone")
public static class Phone implements Comparable<Phone> {
@Id
private Long id;
private String type;
@NaturalId
@Column(name = "`number`")
private String number;
public Phone() {
}
public Phone(Long id, String type, String number) {
this.id = id;
this.type = type;
this.number = number;
}
public Long getId() {
return id;
}
public String getType() {
return type;
}
public String getNumber() {
return number;
}
@Override
public int compareTo(Phone o) {
return number.compareTo( o.getNumber() );
}
@Override
public boolean equals(Object o) {
if ( this == o ) {
return true;
}
if ( o == null || getClass() != o.getClass() ) {
return false;
}
Phone phone = (Phone) o;
return Objects.equals( number, phone.number );
}
@Override
public int hashCode() {
return Objects.hash( number );
}
}Bidirectional sorted sets
The @SortNatural and @SortComparator work the same for bidirectional sorted sets too:
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
@SortNatural
private SortedSet<Phone> phones = new TreeSet<>();
@OneToMany(cascade = CascadeType.ALL)
@SortComparator(ReverseComparator.class)2.8.8. Maps
A java.util.Map is ternary association because it required a parent entity a map key and a value.
An entity can either be a map key or a map value, depending on the mapping.
Hibernate allows using the following map keys:
MapKeyColumn-
for value type maps, the map key is a column in the link table that defines the grouping logic
MapKey-
the map key is either the primary key or another property of the entity stored as a map entry value
MapKeyEnumerated-
the map key is an
Enumof the target child entity MapKeyTemporal-
the map key is a
Dateor aCalendarof the target child entity MapKeyJoinColumn-
the map key is an entity mapped as an association in the child entity that’s stored as a map entry key
Value type maps
A map of value type must use the @ElementCollection annotation, just like value type lists, bags or sets.
public enum PhoneType {
LAND_LINE,
MOBILE
}
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@Temporal(TemporalType.TIMESTAMP)
@ElementCollection
@CollectionTable(name = "phone_register")
@Column(name = "since")
@MapKeyJoinColumn(name = "phone_id", referencedColumnName = "id")
private Map<Phone, Date> phoneRegister = new HashMap<>();
public Person() {
}
public Person(Long id) {
this.id = id;
}
public Map<Phone, Date> getPhoneRegister() {
return phoneRegister;
}
}
@Embeddable
public static class Phone {
private PhoneType type;
@Column(name = "`number`")
private String number;
public Phone() {
}
public Phone(PhoneType type, String number) {
this.type = type;
this.number = number;
}
public PhoneType getType() {
return type;
}
public String getNumber() {
return number;
}
}CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE phone_register (
Person_id BIGINT NOT NULL ,
since TIMESTAMP ,
number VARCHAR(255) NOT NULL ,
type INTEGER NOT NULL ,
PRIMARY KEY ( Person_id, number, type )
)
ALTER TABLE phone_register
ADD CONSTRAINT FKrmcsa34hr68of2rq8qf526mlk
FOREIGN KEY (Person_id) REFERENCES PersonAdding entries to the map generates the following SQL statements:
person.getPhoneRegister().put(
new Phone( PhoneType.LAND_LINE, "028-234-9876" ), new Date()
);
person.getPhoneRegister().put(
new Phone( PhoneType.MOBILE, "072-122-9876" ), new Date()
);INSERT INTO phone_register (Person_id, number, type, since)
VALUES (1, '072-122-9876', 1, '2015-12-15 17:16:45.311')
INSERT INTO phone_register (Person_id, number, type, since)
VALUES (1, '028-234-9876', 0, '2015-12-15 17:16:45.311')Unidirectional maps
A unidirectional map exposes a parent-child association from the parent-side only.
The following example shows a unidirectional map which also uses a @MapKeyTemporal annotation.
The map key is a timestamp and it’s taken from the child entity table.
public enum PhoneType {
LAND_LINE,
MOBILE
}
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinTable(
name = "phone_register",
joinColumns = @JoinColumn(name = "phone_id"),
inverseJoinColumns = @JoinColumn(name = "person_id"))
@MapKey(name = "since")
@MapKeyTemporal(TemporalType.TIMESTAMP)
private Map<Date, Phone> phoneRegister = new HashMap<>();
public Person() {
}
public Person(Long id) {
this.id = id;
}
public Map<Date, Phone> getPhoneRegister() {
return phoneRegister;
}
public void addPhone(Phone phone) {
phoneRegister.put( phone.getSince(), phone );
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
private PhoneType type;
@Column(name = "`number`")
private String number;
private Date since;
public Phone() {
}
public Phone(PhoneType type, String number, Date since) {
this.type = type;
this.number = number;
this.since = since;
}
public PhoneType getType() {
return type;
}
public String getNumber() {
return number;
}
public Date getSince() {
return since;
}
}CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
since TIMESTAMP ,
type INTEGER ,
PRIMARY KEY ( id )
)
CREATE TABLE phone_register (
phone_id BIGINT NOT NULL ,
person_id BIGINT NOT NULL ,
PRIMARY KEY ( phone_id, person_id )
)
ALTER TABLE phone_register
ADD CONSTRAINT FKc3jajlx41lw6clbygbw8wm65w
FOREIGN KEY (person_id) REFERENCES Phone
ALTER TABLE phone_register
ADD CONSTRAINT FK6npoomh1rp660o1b55py9ndw4
FOREIGN KEY (phone_id) REFERENCES PersonBidirectional maps
Like most bidirectional associations, this relationship is owned by the child-side while the parent is the inverse side abd can propagate its own state transitions to the child entities.
In the following example, you can see that @MapKeyEnumerated was used so that the Phone enumeration becomes the map key.
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL, orphanRemoval = true)
@MapKey(name = "type")
@MapKeyEnumerated
private Map<PhoneType, Phone> phoneRegister = new HashMap<>();
public Person() {
}
public Person(Long id) {
this.id = id;
}
public Map<PhoneType, Phone> getPhoneRegister() {
return phoneRegister;
}
public void addPhone(Phone phone) {
phone.setPerson( this );
phoneRegister.put( phone.getType(), phone );
}
}
@Entity(name = "Phone")
public static class Phone {
@Id
@GeneratedValue
private Long id;
private PhoneType type;
@Column(name = "`number`")
private String number;
private Date since;
@ManyToOne
private Person person;
public Phone() {
}
public Phone(PhoneType type, String number, Date since) {
this.type = type;
this.number = number;
this.since = since;
}
public PhoneType getType() {
return type;
}
public String getNumber() {
return number;
}
public Date getSince() {
return since;
}
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
}CREATE TABLE Person (
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE Phone (
id BIGINT NOT NULL ,
number VARCHAR(255) ,
since TIMESTAMP ,
type INTEGER ,
person_id BIGINT ,
PRIMARY KEY ( id )
)
ALTER TABLE Phone
ADD CONSTRAINT FKmw13yfsjypiiq0i1osdkaeqpg
FOREIGN KEY (person_id) REFERENCES Person2.8.9. Arrays
When it comes to arrays, there is quite a difference between Java arrays and relational database array types (e.g. VARRAY, ARRAY). First, not all database systems implement the SQL-99 ARRAY type, and, for this reason, Hibernate doesn’t support native database array types. Second, Java arrays are relevant for basic types only since storing multiple embeddables or entities should always be done using the Java Collection API.
2.8.10. Arrays as binary
By default, Hibernate will choose a BINARY type, as supported by the current Dialect.
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String[] phones;
public Person() {
}
public Person(Long id) {
this.id = id;
}
public String[] getPhones() {
return phones;
}
public void setPhones(String[] phones) {
this.phones = phones;
}
}CREATE TABLE Person (
id BIGINT NOT NULL ,
phones VARBINARY(255) ,
PRIMARY KEY ( id )
)2.8.11. Collections as basic value type
Notice how all the previous examples explicitly mark the collection attribute as either ElementCollection, OneToMany or ManyToMany.
Collections not marked as such require a custom Hibernate Type and the collection elements must be stored in a single database column.
This is sometimes beneficial. Consider a use-case such as a VARCHAR column that represents a delimited list/set of Strings.
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
@Type(type = "comma_delimited_strings")
private List<String> phones = new ArrayList<>();
public List<String> getPhones() {
return phones;
}
}
public class CommaDelimitedStringsJavaTypeDescriptor extends AbstractTypeDescriptor<List> {
public static final String DELIMITER = ",";
public CommaDelimitedStringsJavaTypeDescriptor() {
super(
List.class,
new MutableMutabilityPlan<List>() {
@Override
protected List deepCopyNotNull(List value) {
return new ArrayList( value );
}
}
);
}
@Override
public String toString(List value) {
return ( (List<String>) value ).stream().collect( Collectors.joining( DELIMITER ) );
}
@Override
public List fromString(String string) {
List<String> values = new ArrayList<>();
Collections.addAll( values, string.split( DELIMITER ) );
return values;
}
@Override
public <X> X unwrap(List value, Class<X> type, WrapperOptions options) {
return (X) toString( value );
}
@Override
public <X> List wrap(X value, WrapperOptions options) {
return fromString( (String) value );
}
}
public class CommaDelimitedStringsType extends AbstractSingleColumnStandardBasicType<List> {
public CommaDelimitedStringsType() {
super(
VarcharTypeDescriptor.INSTANCE,
new CommaDelimitedStringsJavaTypeDescriptor()
);
}
@Override
public String getName() {
return "comma_delimited_strings";
}
}The developer can use the comma-delimited collection like any other collection we’ve discussed so far and Hibernate will take care of the type transformation part. The collection itself behaves like any other basic value type, as its lifecycle is bound to its owner entity.
person.phones.add( "027-123-4567" );
person.phones.add( "028-234-9876" );
session.flush();
person.getPhones().remove( 0 );INSERT INTO Person ( phones, id )
VALUES ( '027-123-4567,028-234-9876', 1 )
UPDATE Person
SET phones = '028-234-9876'
WHERE id = 1See the Hibernate Integrations Guide for more details on developing custom value type mappings.
2.9. Natural Ids
Natural ids represent domain model unique identifiers that have a meaning in the real world too. Even if a natural id does not make a good primary key (surrogate keys being usually preferred), it’s still useful to tell Hibernate about it. As we will see later, Hibernate provides a dedicated, efficient API for loading an entity by its natural id much like it offers for loading by its identifier (PK).
2.9.1. Natural Id Mapping
Natural ids are defined in terms of one or more persistent attributes.
@Entity
public class Company {
@Id
private Integer id;
@NaturalId
private String taxIdentifier;
...
}@Entity
public class PostalCarrier {
@Id
private Integer id;
@NaturalId
@Embedded
private PostalCode postalCode;
...
}
@Embeddable
public class PostalCode {
...
}@Entity
public class Course {
@Id
private Integer id;
@NaturalId
@ManyToOne
private Department department;
@NaturalId
private String code;
...
}2.9.2. Natural Id API
As stated before, Hibernate provides an API for loading entities by their associate natural id.
This is represented by the org.hibernate.NaturalIdLoadAccess contract obtained via Session#byNaturalId.
|
If the entity does not define a natural id, trying to load an entity by its natural id will throw an exception. |
Session session = ...;
Company company = session.byNaturalId( Company.class )
.using( "taxIdentifier","abc-123-xyz" )
.load();
PostalCarrier carrier = session.byNaturalId( PostalCarrier.class )
.using( "postalCode",new PostalCode(... ) )
.load();
Department department = ...;
Course course = session.byNaturalId( Course.class )
.using( "department",department )
.using( "code","101" )
.load();NaturalIdLoadAccess offers 2 distinct methods for obtaining the entity:
load()-
obtains a reference to the entity, making sure that the entity state is initialized
getReference()-
obtains a reference to the entity. The state may or may not be initialized. If the entity is already associated with the current running Session, that reference (loaded or not) is returned. If the entity is not loaded in the current Session and the entity supports proxy generation, an uninitialized proxy is generated and returned, otherwise the entity is loaded from the database and returned.
NaturalIdLoadAccess allows loading an entity by natural id and at the same time apply a pessimistic lock.
For additional details on locking, see the Locking chapter.
We will discuss the last method available on NaturalIdLoadAccess ( setSynchronizationEnabled() ) in Natural Id - Mutability and Caching.
Because the Company and PostalCarrier entities define "simple" natural ids, we can load them as follows:
Session session = ...;
Company company = session.bySimpleNaturalId( Company.class )
.load( "abc-123-xyz" );
PostalCarrier carrier = session.bySimpleNaturalId( PostalCarrier.class )
.load( new PostalCode(... ) );Here we see the use of the org.hibernate.SimpleNaturalIdLoadAccess contract, obtained via Session#bySimpleNaturalId().
`SimpleNaturalIdLoadAccess is similar to NaturalIdLoadAccess except that it does not define the using method.
Instead, because these "simple" natural ids are defined based on just one attribute we can directly pass the corresponding value of that natural id attribute directly to the load() and getReference() methods.
|
If the entity does not define a natural id, or if the natural id is not of a "simple" type, an exception will be thrown there. |
2.9.3. Natural Id - Mutability and Caching
A natural id may be mutable or immutable. By default the @NaturalId annotation marks an immutable natural id attribute.
An immutable natural id is expected to never change its value.
If the value(s) of the natural id attribute(s) change, @NaturalId(mutable=true) should be used instead.
@Entity
public class Person {
@Id
private Integer id;
@NaturalId( mutable = true )
private String ssn;
...
}Within the Session, Hibernate maintains a mapping from natural id values to entity identifiers (PK) values.
If natural ids values changed, it is possible for this mapping to become out of date until a flush occurs.
To work around this condition, Hibernate will attempt to discover any such pending changes and adjust them when the load() or getReference() methods are executed.
To be clear: this is only pertinent for mutable natural ids.
|
This discovery and adjustment have a performance impact.
If an application is certain that none of its mutable natural ids already associated with the Session have changed, it can disable that checking by calling |
Session session=...;
Person person = session.bySimpleNaturalId( Person.class ).load( "123-45-6789" );
person.setSsn( "987-65-4321" );
...
// returns null!
person = session.bySimpleNaturalId( Person.class )
.setSynchronizationEnabled( false )
.load( "987-65-4321" );
// returns correctly!
person = session.bySimpleNaturalId( Person.class )
.setSynchronizationEnabled( true )
.load( "987-65-4321" );Not only can this NaturalId-to-PK resolution be cached in the Session, but we can also have it cached in the second-level cache if second level caching is enabled.
@Entity
@NaturalIdCache
public class Company {
@Id
private Integer id;
@NaturalId
private String taxIdentifier;
...
}2.10. Dynamic Model
|
JPA only acknowledges the entity model mapping so, if you are concerned about JPA provider portability, it’s best to stick to the strict POJO model. On the other hand, Hibernate can work with both POJO entities as well as with dynamic entity models. |
2.10.1. Dynamic mapping models
Persistent entities do not necessarily have to be represented as POJO/JavaBean classes. Hibernate also supports dynamic models (using `Map`s of `Map`s at runtime). With this approach, you do not write persistent classes, only mapping files.
A given entity has just one entity mode within a given SessionFactory. This is a change from previous versions which allowed to define multiple entity modes for an entity and to select which to load. Entity modes can now be mixed within a domain model; a dynamic entity might reference a POJO entity, and vice versa.
Session s = openSession();
Transaction tx = s.beginTransaction();
// Create a customer entity
Map<String, String>david = new HashMap<>();
david.put( "name","David" );
// Create an organization entity
Map<String, String>foobar = new HashMap<>();
foobar.put( "name","Foobar Inc." );
// Link both
david.put( "organization",foobar );
// Save both
s.save( "Customer",david );
s.save( "Organization",foobar );
tx.commit();
s.close();|
The main advantage of dynamic models is quick turnaround time for prototyping without the need for entity class implementation. The main down-fall is that you lose compile-time type checking and will likely deal with many exceptions at runtime. However, as a result of the Hibernate mapping, the database schema can easily be normalized and sound, allowing to add a proper domain model implementation on top later on. It is also interesting to note that dynamic models are great for certain integration use cases as well. Envers, for example, makes extensive use of dynamic models to represent the historical data. |
2.11. Inheritance
Although relational database systems don’t provide support for inheritance, Hibernate provides several strategies to leverage this object-oriented trait onto domain model entities:
- MappedSuperclass
-
Inheritance is implemented in domain model only without reflecting it in the database schema. See MappedSuperclass.
- Single table
-
The domain model class hierarchy is materialized into a single table which contains entities belonging to different class types. See Single table.
- Joined table
-
The base class and all the subclasses have their own database tables and fetching a subclass entity requires a join with the parent table as well. See Joined table.
- Table per class
-
Each subclass has its own table containing both the subclass and the base class properties. See Table per class.
2.11.1. MappedSuperclass
In the following domain model class hierarchy, a 'DebitAccount' and a 'CreditAccount' share the same 'Account' base class.

When using MappedSuperclass, the inheritance is visible in the domain model only and each database table contains both the base class and the subclass properties.
@MappedSuperclass inheritance@MappedSuperclass
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getOwner() {
return owner;
}
public void setOwner(String owner) {
this.owner = owner;
}
public BigDecimal getBalance() {
return balance;
}
public void setBalance(BigDecimal balance) {
this.balance = balance;
}
public BigDecimal getInterestRate() {
return interestRate;
}
public void setInterestRate(BigDecimal interestRate) {
this.interestRate = interestRate;
}
}
@Entity(name = "DebitAccount")
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
public BigDecimal getOverdraftFee() {
return overdraftFee;
}
public void setOverdraftFee(BigDecimal overdraftFee) {
this.overdraftFee = overdraftFee;
}
}
@Entity(name = "CreditAccount")
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
public BigDecimal getCreditLimit() {
return creditLimit;
}
public void setCreditLimit(BigDecimal creditLimit) {
this.creditLimit = creditLimit;
}
}CREATE TABLE DebitAccount (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
overdraftFee NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)
CREATE TABLE CreditAccount (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
creditLimit NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)|
Because the |
2.11.2. Single table
The single table inheritance strategy maps all subclasses to only one database table. Each subclass declares its own persistent properties. Version and id properties are assumed to be inherited from the root class.
|
When omitting an explicit inheritance strategy (e.g. |
@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getOwner() {
return owner;
}
public void setOwner(String owner) {
this.owner = owner;
}
public BigDecimal getBalance() {
return balance;
}
public void setBalance(BigDecimal balance) {
this.balance = balance;
}
public BigDecimal getInterestRate() {
return interestRate;
}
public void setInterestRate(BigDecimal interestRate) {
this.interestRate = interestRate;
}
}
@Entity(name = "DebitAccount")
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
public BigDecimal getOverdraftFee() {
return overdraftFee;
}
public void setOverdraftFee(BigDecimal overdraftFee) {
this.overdraftFee = overdraftFee;
}
}
@Entity(name = "CreditAccount")
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
public BigDecimal getCreditLimit() {
return creditLimit;
}
public void setCreditLimit(BigDecimal creditLimit) {
this.creditLimit = creditLimit;
}
}CREATE TABLE Account (
DTYPE VARCHAR(31) NOT NULL ,
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
overdraftFee NUMERIC(19, 2) ,
creditLimit NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)Each subclass in a hierarchy must define a unique discriminator value, which is used to differentiate between rows belonging to separate subclass types.
If this is not specified, the DTYPE column is used as a discriminator, storing the associated subclass name.
DebitAccount debitAccount = new DebitAccount();
debitAccount.setId( 1L );
debitAccount.setOwner( "John Doe" );
debitAccount.setBalance( BigDecimal.valueOf( 100 ) );
debitAccount.setInterestRate( BigDecimal.valueOf( 1.5d ) );
debitAccount.setOverdraftFee( BigDecimal.valueOf( 25 ) );
CreditAccount creditAccount = new CreditAccount();
creditAccount.setId( 2L );
creditAccount.setOwner( "John Doe" );
creditAccount.setBalance( BigDecimal.valueOf( 1000 ) );
creditAccount.setInterestRate( BigDecimal.valueOf( 1.9d ) );
creditAccount.setCreditLimit( BigDecimal.valueOf( 5000 ) );
entityManager.persist( debitAccount );
entityManager.persist( creditAccount );INSERT INTO Account (balance, interestRate, owner, overdraftFee, DTYPE, id)
VALUES (100, 1.5, 'John Doe', 25, 'DebitAccount', 1)
INSERT INTO Account (balance, interestRate, owner, creditLimit, DTYPE, id)
VALUES (1000, 1.9, 'John Doe', 5000, 'CreditAccount', 2)When using polymorphic queries, only a single table is required to be scanned to fetch all associated subclass instances.
List<Account> accounts = entityManager
.createQuery( "select a from Account a" )
.getResultList();SELECT singletabl0_.id AS id2_0_ ,
singletabl0_.balance AS balance3_0_ ,
singletabl0_.interestRate AS interest4_0_ ,
singletabl0_.owner AS owner5_0_ ,
singletabl0_.overdraftFee AS overdraf6_0_ ,
singletabl0_.creditLimit AS creditLi7_0_ ,
singletabl0_.DTYPE AS DTYPE1_0_
FROM Account singletabl0_|
Among all other inheritance alternatives, the single table strategy performs the best since it requires access to one table only.
Because all subclass columns are stored in a single table, it’s not possible to use NOT NULL constraints anymore, so integrity checks must be moved either into the data access layer or enforced through |
Discriminator
The discriminator column contains marker values that tell the persistence layer what subclass to instantiate for a particular row.
Hibernate Core supports the following restricted set of types as discriminator column: String, char, int, byte, short, boolean(including yes_no, true_false).
Use the @DiscriminatorColumn to define the discriminator column as well as the discriminator type.
|
The enum
The The second option, |
|
There used to be |
Discriminator formula
Assuming a legacy database schema where the discriminator is based on inspecting a certain column,
we can take advantage of the Hibernate specific @DiscriminatorFormula annotation and map the inheritance model as follows:
@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorFormula(
"case when debitKey is not null " +
"then 'Debit' " +
"else ( " +
" case when creditKey is not null " +
" then 'Credit' " +
" else 'Unknown' " +
" end ) " +
"end "
)
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getOwner() {
return owner;
}
public void setOwner(String owner) {
this.owner = owner;
}
public BigDecimal getBalance() {
return balance;
}
public void setBalance(BigDecimal balance) {
this.balance = balance;
}
public BigDecimal getInterestRate() {
return interestRate;
}
public void setInterestRate(BigDecimal interestRate) {
this.interestRate = interestRate;
}
}
@Entity(name = "DebitAccount")
@DiscriminatorValue(value = "Debit")
public static class DebitAccount extends Account {
private String debitKey;
private BigDecimal overdraftFee;
private DebitAccount() {
}
public DebitAccount(String debitKey) {
this.debitKey = debitKey;
}
public String getDebitKey() {
return debitKey;
}
public BigDecimal getOverdraftFee() {
return overdraftFee;
}
public void setOverdraftFee(BigDecimal overdraftFee) {
this.overdraftFee = overdraftFee;
}
}
@Entity(name = "CreditAccount")
@DiscriminatorValue(value = "Credit")
public static class CreditAccount extends Account {
private String creditKey;
private BigDecimal creditLimit;
private CreditAccount() {
}
public CreditAccount(String creditKey) {
this.creditKey = creditKey;
}
public String getCreditKey() {
return creditKey;
}
public BigDecimal getCreditLimit() {
return creditLimit;
}
public void setCreditLimit(BigDecimal creditLimit) {
this.creditLimit = creditLimit;
}
}CREATE TABLE Account (
id int8 NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
debitKey VARCHAR(255) ,
overdraftFee NUMERIC(19, 2) ,
creditKey VARCHAR(255) ,
creditLimit NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)The @DiscriminatorFormula defines a custom SQL clause that can be used to identify a certain subclass type.
The @DiscriminatorValue defines the mapping between the result of the @DiscriminatorFormula and the inheritance subclass type.
Implicit discriminator values
Aside from the usual discriminator values assigned to each individual subclass type, the @DiscriminatorValue can take two additional values:
null-
If the underlying discriminator column is null, the
nulldiscriminator mapping is going to be used. not null-
If the underlying discriminator column has a not-null value that is not explicitly mapped to any entity, the
not-nulldiscriminator mapping used.
To understand how these two values work, consider the following entity mapping:
null and not-null entity mapping@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorValue( "null" )
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getOwner() {
return owner;
}
public void setOwner(String owner) {
this.owner = owner;
}
public BigDecimal getBalance() {
return balance;
}
public void setBalance(BigDecimal balance) {
this.balance = balance;
}
public BigDecimal getInterestRate() {
return interestRate;
}
public void setInterestRate(BigDecimal interestRate) {
this.interestRate = interestRate;
}
}
@Entity(name = "DebitAccount")
@DiscriminatorValue( "Debit" )
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
public BigDecimal getOverdraftFee() {
return overdraftFee;
}
public void setOverdraftFee(BigDecimal overdraftFee) {
this.overdraftFee = overdraftFee;
}
}
@Entity(name = "CreditAccount")
@DiscriminatorValue( "Credit" )
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
public BigDecimal getCreditLimit() {
return creditLimit;
}
public void setCreditLimit(BigDecimal creditLimit) {
this.creditLimit = creditLimit;
}
}
@Entity(name = "OtherAccount")
@DiscriminatorValue( "not null" )
public static class OtherAccount extends Account {
private boolean active;
public boolean isActive() {
return active;
}
public void setActive(boolean active) {
this.active = active;
}
}The Account class has a @DiscriminatorValue( "null" ) mapping, meaning that any account row which does not contain any discriminator value will be mapped to an Account base class entity.
The DebitAccount and CreditAccount entities use explicit discriminator values.
The OtherAccount entity is used as a generic account type because it maps any database row whose discriminator column is not explicitly assigned to any other entity in the current inheritance tree.
To visualize how it works, consider the following example:
null and not-null entity persistenceDebitAccount debitAccount = new DebitAccount();
debitAccount.setId( 1L );
debitAccount.setOwner( "John Doe" );
debitAccount.setBalance( BigDecimal.valueOf( 100 ) );
debitAccount.setInterestRate( BigDecimal.valueOf( 1.5d ) );
debitAccount.setOverdraftFee( BigDecimal.valueOf( 25 ) );
CreditAccount creditAccount = new CreditAccount();
creditAccount.setId( 2L );
creditAccount.setOwner( "John Doe" );
creditAccount.setBalance( BigDecimal.valueOf( 1000 ) );
creditAccount.setInterestRate( BigDecimal.valueOf( 1.9d ) );
creditAccount.setCreditLimit( BigDecimal.valueOf( 5000 ) );
Account account = new Account();
account.setId( 3L );
account.setOwner( "John Doe" );
account.setBalance( BigDecimal.valueOf( 1000 ) );
account.setInterestRate( BigDecimal.valueOf( 1.9d ) );
entityManager.persist( debitAccount );
entityManager.persist( creditAccount );
entityManager.persist( account );
entityManager.unwrap( Session.class ).doWork( connection -> {
try(Statement statement = connection.createStatement()) {
statement.executeUpdate(
"insert into Account (DTYPE, active, balance, interestRate, owner, id) " +
"values ('Other', true, 25, 0.5, 'Vlad', 4)"
);
}
} );
Map<Long, Account> accounts = entityManager.createQuery(
"select a from Account a", Account.class )
.getResultList()
.stream()
.collect( Collectors.toMap( Account::getId, Function.identity()));
assertEquals(4, accounts.size());
assertEquals( DebitAccount.class, accounts.get( 1L ).getClass() );
assertEquals( CreditAccount.class, accounts.get( 2L ).getClass() );
assertEquals( Account.class, accounts.get( 3L ).getClass() );
assertEquals( OtherAccount.class, accounts.get( 4L ).getClass() );INSERT INTO Account (balance, interestRate, owner, overdraftFee, DTYPE, id)
VALUES (100, 1.5, 'John Doe', 25, 'Debit', 1)
INSERT INTO Account (balance, interestRate, owner, overdraftFee, DTYPE, id)
VALUES (1000, 1.9, 'John Doe', 5000, 'Credit', 2)
INSERT INTO Account (balance, interestRate, owner, id)
VALUES (1000, 1.9, 'John Doe', 3)
INSERT INTO Account (DTYPE, active, balance, interestRate, owner, id)
VALUES ('Other', true, 25, 0.5, 'Vlad', 4)
SELECT a.id as id2_0_,
a.balance as balance3_0_,
a.interestRate as interest4_0_,
a.owner as owner5_0_,
a.overdraftFee as overdraf6_0_,
a.creditLimit as creditLi7_0_,
a.active as active8_0_,
a.DTYPE as DTYPE1_0_
FROM Account aAs you can see, the Account entity row has a value of NULL in the DTYPE discriminator column,
while the OtherAccount entity was saved with a DTYPE column value of other which has not explicit mapping.
2.11.3. Joined table
Each subclass can also be mapped to its own table. This is also called table-per-subclass mapping strategy. An inherited state is retrieved by joining with the table of the superclass.
A discriminator column is not required for this mapping strategy. Each subclass must, however, declare a table column holding the object identifier.
@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.JOINED)
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getOwner() {
return owner;
}
public void setOwner(String owner) {
this.owner = owner;
}
public BigDecimal getBalance() {
return balance;
}
public void setBalance(BigDecimal balance) {
this.balance = balance;
}
public BigDecimal getInterestRate() {
return interestRate;
}
public void setInterestRate(BigDecimal interestRate) {
this.interestRate = interestRate;
}
}
@Entity(name = "DebitAccount")
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
public BigDecimal getOverdraftFee() {
return overdraftFee;
}
public void setOverdraftFee(BigDecimal overdraftFee) {
this.overdraftFee = overdraftFee;
}
}
@Entity(name = "CreditAccount")
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
public BigDecimal getCreditLimit() {
return creditLimit;
}
public void setCreditLimit(BigDecimal creditLimit) {
this.creditLimit = creditLimit;
}
}CREATE TABLE Account (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE CreditAccount (
creditLimit NUMERIC(19, 2) ,
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
CREATE TABLE DebitAccount (
overdraftFee NUMERIC(19, 2) ,
id BIGINT NOT NULL ,
PRIMARY KEY ( id )
)
ALTER TABLE CreditAccount
ADD CONSTRAINT FKihw8h3j1k0w31cnyu7jcl7n7n
FOREIGN KEY (id) REFERENCES Account
ALTER TABLE DebitAccount
ADD CONSTRAINT FKia914478noepymc468kiaivqm
FOREIGN KEY (id) REFERENCES Account|
The primary key of this table is also a foreign key to the superclass table and described by the The table name still defaults to the non-qualified class name.
Also, if |
@PrimaryKeyJoinColumn@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.JOINED)
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getOwner() {
return owner;
}
public void setOwner(String owner) {
this.owner = owner;
}
public BigDecimal getBalance() {
return balance;
}
public void setBalance(BigDecimal balance) {
this.balance = balance;
}
public BigDecimal getInterestRate() {
return interestRate;
}
public void setInterestRate(BigDecimal interestRate) {
this.interestRate = interestRate;
}
}
@Entity(name = "DebitAccount")
@PrimaryKeyJoinColumn(name = "account_id")
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
public BigDecimal getOverdraftFee() {
return overdraftFee;
}
public void setOverdraftFee(BigDecimal overdraftFee) {
this.overdraftFee = overdraftFee;
}
}
@Entity(name = "CreditAccount")
@PrimaryKeyJoinColumn(name = "account_id")
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
public BigDecimal getCreditLimit() {
return creditLimit;
}
public void setCreditLimit(BigDecimal creditLimit) {
this.creditLimit = creditLimit;
}
}CREATE TABLE CreditAccount (
creditLimit NUMERIC(19, 2) ,
account_id BIGINT NOT NULL ,
PRIMARY KEY ( account_id )
)
CREATE TABLE DebitAccount (
overdraftFee NUMERIC(19, 2) ,
account_id BIGINT NOT NULL ,
PRIMARY KEY ( account_id )
)
ALTER TABLE CreditAccount
ADD CONSTRAINT FK8ulmk1wgs5x7igo370jt0q005
FOREIGN KEY (account_id) REFERENCES Account
ALTER TABLE DebitAccount
ADD CONSTRAINT FK7wjufa570onoidv4omkkru06j
FOREIGN KEY (account_id) REFERENCES AccountWhen using polymorphic queries, the base class table must be joined with all subclass tables to fetch every associated subclass instance.
List<Account> accounts = entityManager
.createQuery( "select a from Account a" )
.getResultList();SELECT jointablet0_.id AS id1_0_ ,
jointablet0_.balance AS balance2_0_ ,
jointablet0_.interestRate AS interest3_0_ ,
jointablet0_.owner AS owner4_0_ ,
jointablet0_1_.overdraftFee AS overdraf1_2_ ,
jointablet0_2_.creditLimit AS creditLi1_1_ ,
CASE WHEN jointablet0_1_.id IS NOT NULL THEN 1
WHEN jointablet0_2_.id IS NOT NULL THEN 2
WHEN jointablet0_.id IS NOT NULL THEN 0
END AS clazz_
FROM Account jointablet0_
LEFT OUTER JOIN DebitAccount jointablet0_1_ ON jointablet0_.id = jointablet0_1_.id
LEFT OUTER JOIN CreditAccount jointablet0_2_ ON jointablet0_.id = jointablet0_2_.id|
Polymorphic queries can create Cartesian Products, so caution is advised. |
2.11.4. Table per class
A third option is to map only the concrete classes of an inheritance hierarchy to tables. This is called the table-per-concrete-class strategy. Each table defines all persistent states of the class, including the inherited state.
In Hibernate, it is not necessary to explicitly map such inheritance hierarchies. You can map each class as a separate entity root. However, if you wish use polymorphic associations (e.g. an association to the superclass of your hierarchy), you need to use the union subclass mapping.
@Entity(name = "Account")
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public static class Account {
@Id
private Long id;
private String owner;
private BigDecimal balance;
private BigDecimal interestRate;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getOwner() {
return owner;
}
public void setOwner(String owner) {
this.owner = owner;
}
public BigDecimal getBalance() {
return balance;
}
public void setBalance(BigDecimal balance) {
this.balance = balance;
}
public BigDecimal getInterestRate() {
return interestRate;
}
public void setInterestRate(BigDecimal interestRate) {
this.interestRate = interestRate;
}
}
@Entity(name = "DebitAccount")
public static class DebitAccount extends Account {
private BigDecimal overdraftFee;
public BigDecimal getOverdraftFee() {
return overdraftFee;
}
public void setOverdraftFee(BigDecimal overdraftFee) {
this.overdraftFee = overdraftFee;
}
}
@Entity(name = "CreditAccount")
public static class CreditAccount extends Account {
private BigDecimal creditLimit;
public BigDecimal getCreditLimit() {
return creditLimit;
}
public void setCreditLimit(BigDecimal creditLimit) {
this.creditLimit = creditLimit;
}
}CREATE TABLE Account (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
PRIMARY KEY ( id )
)
CREATE TABLE CreditAccount (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
creditLimit NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)
CREATE TABLE DebitAccount (
id BIGINT NOT NULL ,
balance NUMERIC(19, 2) ,
interestRate NUMERIC(19, 2) ,
owner VARCHAR(255) ,
overdraftFee NUMERIC(19, 2) ,
PRIMARY KEY ( id )
)When using polymorphic queries, a UNION is required to fetch the base class table along with all subclass tables as well.
List<Account> accounts = entityManager
.createQuery( "select a from Account a" )
.getResultList();SELECT tablepercl0_.id AS id1_0_ ,
tablepercl0_.balance AS balance2_0_ ,
tablepercl0_.interestRate AS interest3_0_ ,
tablepercl0_.owner AS owner4_0_ ,
tablepercl0_.overdraftFee AS overdraf1_2_ ,
tablepercl0_.creditLimit AS creditLi1_1_ ,
tablepercl0_.clazz_ AS clazz_
FROM (
SELECT id ,
balance ,
interestRate ,
owner ,
CAST(NULL AS INT) AS overdraftFee ,
CAST(NULL AS INT) AS creditLimit ,
0 AS clazz_
FROM Account
UNION ALL
SELECT id ,
balance ,
interestRate ,
owner ,
overdraftFee ,
CAST(NULL AS INT) AS creditLimit ,
1 AS clazz_
FROM DebitAccount
UNION ALL
SELECT id ,
balance ,
interestRate ,
owner ,
CAST(NULL AS INT) AS overdraftFee ,
creditLimit ,
2 AS clazz_
FROM CreditAccount
) tablepercl0_|
Polymorphic queries require multiple UNION queries, so be aware of the performance implications of a large class hierarchy. |
3. Bootstrap
The term bootstrapping refers to initializing and starting a software component.
In Hibernate, we are specifically talking about the process of building a fully functional SessionFactory instance or EntityManagerFactory instance, for JPA.
The process is very different for each.
|
This chapter will not focus on all the possibilities of bootstrapping. Those will be covered in each specific more-relevant chapters later on. Instead, we focus here on the API calls needed to perform the bootstrapping. |
|
During the bootstrap process, you might want to customize Hibernate behavior so make sure you check the Configurations section as well. |
3.1. JPA Bootstrapping
Bootstrapping Hibernate as a JPA provider can be done in a JPA-spec compliant manner or using a proprietary bootstrapping approach. The standardized approach has some limitations in certain environments, but aside from those, it is highly recommended that you use JPA-standardized bootstrapping.
3.1.1. JPA-compliant bootstrapping
In JPA, we are ultimately interested in bootstrapping a javax.persistence.EntityManagerFactory instance.
The JPA specification defines two primary standardized bootstrap approaches depending on how the application intends to access the javax.persistence.EntityManager instances from an EntityManagerFactory.
It uses the terms EE and SE for these two approaches, but those terms are very misleading in this context. What the JPA spec calls EE bootstrapping implies the existence of a container (EE, OSGi, etc), who’ll manage and inject the persistence context on behalf of the application. What it calls SE bootstrapping is everything else. We will use the terms container-bootstrapping and application-bootstrapping in this guide.
|
If you would like additional details on accessing and using |
For compliant container-bootstrapping, the container will build an EntityManagerFactory for each persistent-unit defined in the META-INF/persistence.xml configuration file
and make that available to the application for injection via the javax.persistence.PersistenceUnit annotation or via JNDI lookup.
@PersistenceUnit
private EntityManagerFactory emf;The META-INF/persistence.xml file looks as follows:
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd"
version="2.1">
<persistence-unit name="CRM">
<description>
Persistence unit for Hibernate User Guide
</description>
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<class>org.hibernate.documentation.userguide.Document</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="org.h2.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:h2:mem:db1;DB_CLOSE_DELAY=-1;MVCC=TRUE" />
<property name="javax.persistence.jdbc.user"
value="sa" />
<property name="javax.persistence.jdbc.password"
value="" />
<property name="hibernate.show_sql"
value="true" />
<property name="hibernate.hbm2ddl.auto"
value="update" />
</properties>
</persistence-unit>
</persistence>For compliant application-bootstrapping, rather than the container building the EntityManagerFactory for the application, the application builds the EntityManagerFactory itself using the javax.persistence.Persistence bootstrap class.
The application creates an EntityManagerFactory by calling the createEntityManagerFactory method:
// Create an EMF for our CRM persistence-unit.
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "CRM" );|
If you don’t want to provide a |
3.2. Native Bootstrapping
This section discusses the process of bootstrapping a Hibernate SessionFactory.
Specifically it discusses the bootstrapping APIs as redesigned in 5.0.
For a discussion of the legacy bootstrapping API, see Legacy Bootstrapping
3.2.1. Building the ServiceRegistry
The first step in native bootstrapping is the building of a ServiceRegistry holding the services Hibernate will need during bootstrapping and at run time.
Actually, we are concerned with building 2 different ServiceRegistries.
First is the org.hibernate.boot.registry.BootstrapServiceRegistry.
The BootstrapServiceRegistry is intended to hold services that Hibernate needs at both bootstrap and run time.
This boils down to 3 services:
org.hibernate.boot.registry.classloading.spi.ClassLoaderService-
which controls how Hibernate interacts with `ClassLoader`s
org.hibernate.integrator.spi.IntegratorService-
which controls the management and discovery of
org.hibernate.integrator.spi.Integratorinstances. org.hibernate.boot.registry.selector.spi.StrategySelector-
which control how Hibernate resolves implementations of various strategy contracts. This is a very powerful service, but a full discussion of it is beyond the scope of this guide.
|
If you are ok with the default behavior of Hibernate in regards to these |
If you wish to alter how the BootstrapServiceRegistry is built, that is controlled through the org.hibernate.boot.registry.BootstrapServiceRegistryBuilder:
BootstrapServiceRegistry buildingBootstrapServiceRegistryBuilder bootstrapRegistryBuilder =
new BootstrapServiceRegistryBuilder();
// add a custom ClassLoader
bootstrapRegistryBuilder.applyClassLoader( customClassLoader );
// manually add an Integrator
bootstrapRegistryBuilder.applyIntegrator( customIntegrator );
BootstrapServiceRegistry bootstrapRegistry = bootstrapRegistryBuilder.build();|
The services of the |
The second ServiceRegistry is the org.hibernate.boot.registry.StandardServiceRegistry.
You will almost always need to configure the StandardServiceRegistry, which is done through org.hibernate.boot.registry.StandardServiceRegistryBuilder:
BootstrapServiceRegistryBuilder// An example using an implicitly built BootstrapServiceRegistry
StandardServiceRegistryBuilder standardRegistryBuilder =
new StandardServiceRegistryBuilder();
// An example using an explicitly built BootstrapServiceRegistry
BootstrapServiceRegistry bootstrapRegistry =
new BootstrapServiceRegistryBuilder().build();
StandardServiceRegistryBuilder standardRegistryBuilder =
new StandardServiceRegistryBuilder( bootstrapRegistry );A StandardServiceRegistry is also highly configurable via the StandardServiceRegistryBuilder API.
See the StandardServiceRegistryBuilder Javadocs for more details.
Some specific methods of interest:
MetadataSourcesServiceRegistry standardRegistry =
new StandardServiceRegistryBuilder().build();
MetadataSources sources = new MetadataSources( standardRegistry );
// alternatively, we can build the MetadataSources without passing
// a service registry, in which case it will build a default
// BootstrapServiceRegistry to use. But the approach shown
// above is preferred
// MetadataSources sources = new MetadataSources();
// add a class using JPA/Hibernate annotations for mapping
sources.addAnnotatedClass( MyEntity.class );
// add the name of a class using JPA/Hibernate annotations for mapping.
// differs from above in that accessing the Class is deferred which is
// important if using runtime bytecode-enhancement
sources.addAnnotatedClassName( "org.hibernate.example.Customer" );
// Read package-level metadata.
sources.addPackage( "hibernate.example" );
// Read package-level metadata.
sources.addPackage( MyEntity.class.getPackage() );
// Adds the named hbm.xml resource as a source: which performs the
// classpath lookup and parses the XML
sources.addResource( "org/hibernate/example/Order.hbm.xml" );
// Adds the named JPA orm.xml resource as a source: which performs the
// classpath lookup and parses the XML
sources.addResource( "org/hibernate/example/Product.orm.xml" );
// Read all mapping documents from a directory tree.
// Assumes that any file named *.hbm.xml is a mapping document.
sources.addDirectory( new File( ".") );
// Read mappings from a particular XML file
sources.addFile( new File( "./mapping.xml") );
// Read all mappings from a jar file.
// Assumes that any file named *.hbm.xml is a mapping document.
sources.addJar( new File( "./entities.jar") );
// Read a mapping as an application resource using the convention that a class named foo.bar.MyEntity is
// mapped by a file named foo/bar/MyEntity.hbm.xml which can be resolved as a classpath resource.
sources.addClass( MyEntity.class );3.2.2. Event Listener registration
The main use cases for an org.hibernate.integrator.spi.Integrator right now are registering event listeners and providing services (see org.hibernate.integrator.spi.ServiceContributingIntegrator).
With 5.0 we plan on expanding that to allow altering the metamodel describing the mapping between object and relational models.
public class MyIntegrator implements org.hibernate.integrator.spi.Integrator {
@Override
public void integrate(
Metadata metadata,
SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
// As you might expect, an EventListenerRegistry is the thing with which event
// listeners are registered
// It is a service so we look it up using the service registry
final EventListenerRegistry eventListenerRegistry =
serviceRegistry.getService( EventListenerRegistry.class );
// If you wish to have custom determination and handling of "duplicate" listeners,
// you would have to add an implementation of the
// org.hibernate.event.service.spi.DuplicationStrategy contract like this
eventListenerRegistry.addDuplicationStrategy( new CustomDuplicationStrategy() );
// EventListenerRegistry defines 3 ways to register listeners:
// 1) This form overrides any existing registrations with
eventListenerRegistry.setListeners( EventType.AUTO_FLUSH,
DefaultAutoFlushEventListener.class );
// 2) This form adds the specified listener(s) to the beginning of the listener chain
eventListenerRegistry.prependListeners( EventType.PERSIST,
DefaultPersistEventListener.class );
// 3) This form adds the specified listener(s) to the end of the listener chain
eventListenerRegistry.appendListeners( EventType.MERGE,
DefaultMergeEventListener.class );
}
@Override
public void disintegrate(
SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
}
}3.2.3. Building the Metadata
The second step in native bootstrapping is the building of a org.hibernate.boot.Metadata object containing the parsed representations of an application domain model and its mapping to a database.
The first thing we obviously need to build a parsed representation is the source information to be parsed (annotated classes, hbm.xml files, orm.xml files).
This is the purpose of org.hibernate.boot.MetadataSources:
MetadataSources has many other methods as well, explore its API and Javadocs for more information.
Also, all methods on MetadataSources offer fluent-style call chaining::
MetadataSources with method chainingServiceRegistry standardRegistry =
new StandardServiceRegistryBuilder().build();
MetadataSources sources = new MetadataSources( standardRegistry )
.addAnnotatedClass( MyEntity.class )
.addAnnotatedClassName( "org.hibernate.example.Customer" )
.addResource( "org/hibernate/example/Order.hbm.xml" )
.addResource( "org/hibernate/example/Product.orm.xml" );Once we have the sources of mapping information defined, we need to build the Metadata object.
If you are ok with the default behavior in building the Metadata then you can simply call the buildMetadata method of the MetadataSources.
|
Notice that a |
However, if you wish to adjust the process of building Metadata from MetadataSources,
you will need to use the MetadataBuilder as obtained via MetadataSources#getMetadataBuilder.
MetadataBuilder allows a lot of control over the Metadata building process.
See its Javadocs for full details.
MetadataBuilderServiceRegistry standardRegistry =
new StandardServiceRegistryBuilder().build();
MetadataSources sources = new MetadataSources( standardRegistry );
MetadataBuilder metadataBuilder = sources.getMetadataBuilder();
// Use the JPA-compliant implicit naming strategy
metadataBuilder.applyImplicitNamingStrategy(
ImplicitNamingStrategyJpaCompliantImpl.INSTANCE );
// specify the schema name to use for tables, etc when none is explicitly specified
metadataBuilder.applyImplicitSchemaName( "my_default_schema" );
// specify a custom Attribute Converter
metadataBuilder.applyAttributeConverter( myAttributeConverter );
Metadata metadata = metadataBuilder.build();3.2.4. Building the SessionFactory
The final step in native bootstrapping is to build the SessionFactory itself.
Much like discussed above, if you are ok with the default behavior of building a SessionFactory from a Metadata reference, you can simply call the buildSessionFactory method on the Metadata object.
However, if you would like to adjust that building process you will need to use SessionFactoryBuilder as obtained via [Metadata#getSessionFactoryBuilder. Again, see its Javadocs for more details.
StandardServiceRegistry standardRegistry = new StandardServiceRegistryBuilder()
.configure( "org/hibernate/example/hibernate.cfg.xml" )
.build();
Metadata metadata = new MetadataSources( standardRegistry )
.addAnnotatedClass( MyEntity.class )
.addAnnotatedClassName( "org.hibernate.example.Customer" )
.addResource( "org/hibernate/example/Order.hbm.xml" )
.addResource( "org/hibernate/example/Product.orm.xml" )
.getMetadataBuilder()
.applyImplicitNamingStrategy( ImplicitNamingStrategyJpaCompliantImpl.INSTANCE )
.build();
SessionFactory sessionFactory = metadata.getSessionFactoryBuilder()
.applyBeanManager( getBeanManager() )
.build();The bootstrapping API is quite flexible, but in most cases it makes the most sense to think of it as a 3 step process:
-
Build the
StandardServiceRegistry -
Build the
Metadata -
Use those 2 to build the
SessionFactory
SessionFactory via SessionFactoryBuilderStandardServiceRegistry standardRegistry = new StandardServiceRegistryBuilder()
.configure( "org/hibernate/example/hibernate.cfg.xml" )
.build();
Metadata metadata = new MetadataSources( standardRegistry )
.addAnnotatedClass( MyEntity.class )
.addAnnotatedClassName( "org.hibernate.example.Customer" )
.addResource( "org/hibernate/example/Order.hbm.xml" )
.addResource( "org/hibernate/example/Product.orm.xml" )
.getMetadataBuilder()
.applyImplicitNamingStrategy( ImplicitNamingStrategyJpaCompliantImpl.INSTANCE )
.build();
SessionFactoryBuilder sessionFactoryBuilder = metadata.getSessionFactoryBuilder();
// Supply an SessionFactory-level Interceptor
sessionFactoryBuilder.applyInterceptor( new CustomSessionFactoryInterceptor() );
// Add a custom observer
sessionFactoryBuilder.addSessionFactoryObservers( new CustomSessionFactoryObserver() );
// Apply a CDI BeanManager ( for JPA event listeners )
sessionFactoryBuilder.applyBeanManager( getBeanManager() );
SessionFactory sessionFactory = sessionFactoryBuilder.build();4. Schema generation
Hibernate allows you to generate the database from the entity mappings.
|
Although the automatic schema generation is very useful for testing and prototyping purposes, in a production environment, it’s much more flexible to manage the schema using incremental migration scripts. |
Traditionally, the process of generating schema from entity mapping has been called HBM2DDL.
To get a list of Hibernate-native and JPA-specific configuration properties consider reading the Configurations section.
Considering the following Domain Model:
@Entity(name = "Customer")
public class Customer {
@Id
private Integer id;
private String name;
@Basic( fetch = FetchType.LAZY )
private UUID accountsPayableXrefId;
@Lob
@Basic( fetch = FetchType.LAZY )
private Blob image;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public UUID getAccountsPayableXrefId() {
return accountsPayableXrefId;
}
public void setAccountsPayableXrefId(UUID accountsPayableXrefId) {
this.accountsPayableXrefId = accountsPayableXrefId;
}
public Blob getImage() {
return image;
}
public void setImage(Blob image) {
this.image = image;
}
}
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String name;
@OneToMany(mappedBy = "author")
private List<Book> books = new ArrayList<>( );
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Book> getBooks() {
return books;
}
}
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
@NaturalId
private String isbn;
@ManyToOne
private Person author;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public Person getAuthor() {
return author;
}
public void setAuthor(Person author) {
this.author = author;
}
public String getIsbn() {
return isbn;
}
public void setIsbn(String isbn) {
this.isbn = isbn;
}
}If the hibernate.hbm2ddl.auto configuration is set to create, Hibernate is going to generate the following database schema:
create table Customer (
id integer not null,
accountsPayableXrefId binary,
image blob,
name varchar(255),
primary key (id)
)
create table Book (
id bigint not null,
isbn varchar(255),
title varchar(255),
author_id bigint,
primary key (id)
)
create table Person (
id bigint not null,
name varchar(255),
primary key (id)
)
alter table Book
add constraint UK_u31e1frmjp9mxf8k8tmp990i unique (isbn)
alter table Book
add constraint FKrxrgiajod1le3gii8whx2doie
foreign key (author_id)
references Person4.1. Importing script files
To customize the schema generation process, the hibernate.hbm2ddl.import_files configuration property must be used to provide other scripts files that Hibernate can use when the SessionFactory is started.
For instance, considering the following schema-generation.sql import file:
create sequence book_sequence start with 1 increment by 1If we configure Hibernate to import the script above:
<property
name="hibernate.hbm2ddl.import_files"
value="schema-generation.sql" />Hibernate is going to execute the script file after the schema is automatically generated.
4.2. Database objects
Hibernate allows you to customize the schema generation process via the HBM database-object element.
Considering the following HBM mapping:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd" >
<hibernate-mapping>
<database-object>
<create>
CREATE OR REPLACE FUNCTION sp_count_books(
IN authorId bigint,
OUT bookCount bigint)
RETURNS bigint AS
$BODY$
BEGIN
SELECT COUNT(*) INTO bookCount
FROM book
WHERE author_id = authorId;
END;
$BODY$
LANGUAGE plpgsql;
</create>
<drop></drop>
<dialect-scope name="org.hibernate.dialect.PostgreSQL95Dialect" />
</database-object>
</hibernate-mapping>When the SessionFactory is bootstrapped, Hibernate is going to execute the database-object, therefore creating the sp_count_books funtion.
5. Persistence Contexts
Both the org.hibernate.Session API and javax.persistence.EntityManager API represent a context for dealing with persistent data.
This concept is called a persistence context.
Persistent data has a state in relation to both a persistence context and the underlying database.
transient-
the entity has just been instantiated and is not associated with a persistence context. It has no persistent representation in the database and typically no identifier value has been assigned (unless the assigned generator was used).
managed, orpersistent-
the entity has an associated identifier and is associated with a persistence context. It may or may not physically exist in the database yet.
detached-
the entity has an associated identifier, but is no longer associated with a persistence context (usually because the persistence context was closed or the instance was evicted from the context)
removed-
the entity has an associated identifier and is associated with a persistence context, however it is scheduled for removal from the database.
Much of the org.hibernate.Session and javax.persistence.EntityManager methods deal with moving entities between these states.
5.1. Accessing Hibernate APIs from JPA
JPA defines an incredibly useful method to allow applications access to the APIs of the underlying provider.
Session session = entityManager.unwrap( Session.class );
SessionImplementor sessionImplementor = entityManager.unwrap( SessionImplementor.class );
SessionFactory sessionFactory = entityManager.getEntityManagerFactory().unwrap( SessionFactory.class );5.2. Bytecode Enhancement
Hibernate "grew up" not supporting bytecode enhancement at all. At that time, Hibernate only supported proxy-based for lazy loading and always used diff-based dirty calculation. Hibernate 3.x saw the first attempts at bytecode enhancement support in Hibernate. We consider those initial attempts (up until 5.0) completely as an incubation. The support for bytecode enhancement in 5.0 onward is what we are discussing here.
5.2.1. Capabilities
Hibernate supports the enhancement of an application Java domain model for the purpose of adding various persistence-related capabilities directly into the class.
Lazy attribute loading
Think of this as partial loading support. Essentially you can tell Hibernate that only part(s) of an entity should be loaded upon fetching from the database and when the other part(s) should be loaded as well. Note that this is very much different from proxy-based idea of lazy loading which is entity-centric where the entity’s state is loaded at once as needed. With bytecode enhancement, individual attributes are loaded as needed.
@Entity
public class Customer {
@Id
private Integer id;
private String name;
@Basic( fetch = FetchType.LAZY )
private UUID accountsPayableXrefId;
@Lob
@Basic( fetch = FetchType.LAZY )
private Blob image;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public UUID getAccountsPayableXrefId() {
return accountsPayableXrefId;
}
public void setAccountsPayableXrefId(UUID accountsPayableXrefId) {
this.accountsPayableXrefId = accountsPayableXrefId;
}
public Blob getImage() {
return image;
}
public void setImage(Blob image) {
this.image = image;
}
}In the above example we have 2 lazy attributes: accountsPayableXrefId and image,
which means that accessing accountsPayableXrefId will not force the loading of image, and vice-versa.
|
As a hopefully temporary legacy hold-over, it is currently required that all lazy singular associations (many-to-one and one-to-one) also include |
In-line dirty tracking
Historically Hibernate only supported diff-based dirty calculation for determining which entities in a persistence context have changed.
This essentially means that Hibernate would keep track of the last known state of an entity in regards to the database (typically the last read or write).
Then, as part of flushing the persistence context, Hibernate would walk every entity associated with the persistence context and check its current state against that "last known database state".
This is by far the most thorough approach to dirty checking because it accounts for data-types that can change their internal state (java.util.Date is the prime example of this).
However, in a persistence context with a large number of associated entities it can also be a performance-inhibiting approach.
If your application does not need to care about "internal state changing data-type" use cases, bytecode-enhanced dirty tracking might be a worthwhile alternative to consider, especially in terms of performance. In this approach Hibernate will manipulate the bytecode of your classes to add "dirty tracking" directly to the entity, allowing the entity itself to keep track of which of its attributes have changed. During flush time, Hibernate simply asks your entity what has changed rather that having to perform the state-diff calculations.
Bidirectional association management
Hibernate strives to keep your application as close to "normal Java usage" (idiomatic Java) as possible.
Consider a domain model with a normal Person/Book bidirectional association:
@Entity(name = "Person")
public static class Person {
@Id
private Long id;
private String name;
@OneToMany(mappedBy = "author")
private List<Book> books = new ArrayList<>( );
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Book> getBooks() {
return books;
}
}
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
@NaturalId
private String isbn;
@ManyToOne
private Person author;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public Person getAuthor() {
return author;
}
public void setAuthor(Person author) {
this.author = author;
}
public String getIsbn() {
return isbn;
}
public void setIsbn(String isbn) {
this.isbn = isbn;
}
}Person person = new Person();
person.setName( "John Doe" );
Book book = new Book();
person.getBooks().add( book );
try {
book.getAuthor().getName();
}
catch (NullPointerException expected) {
// This blows up ( NPE ) in normal Java usage
}This blows up in normal Java usage. The correct normal Java usage is:
Person person = new Person();
person.setName( "John Doe" );
Book book = new Book();
person.getBooks().add( book );
book.setAuthor( person );
book.getAuthor().getName();Bytecode-enhanced bi-directional association management makes that first example work by managing the "other side" of a bi-directional association whenever one side is manipulated.
Internal performance optimizations
Additionally, we use the enhancement process to add some additional code that allows us to optimized certain performance characteristics of the persistence context. These are hard to discuss without diving into a discussion of Hibernate internals.
5.2.2. Performing enhancement
Run-time enhancement
Currently, run-time enhancement of the domain model is only supported in managed JPA environments following the JPA-defined SPI for performing class transformations.
Even then, this support is disabled by default.
To enable run-time enhancement, specify hibernate.ejb.use_class_enhancer=true as a persistent unit property.
|
Also, at the moment, only annotated classes are supported for run-time enhancement. |
Gradle plugin
Hibernate provides a Gradle plugin that is capable of providing build-time enhancement of the domain model as they are compiled as part of a Gradle build. To use the plugin a project would first need to apply it:
ext {
hibernateVersion = 'hibernate-version-you-want'
}
buildscript {
dependencies {
classpath "org.hibernate:hibernate-gradle-plugin:$hibernateVersion"
}
}
hibernate {
enhance {
// any configuration goes here
}
}The configuration that is available is exposed through a registered Gradle DSL extension:
- enableLazyInitialization
-
Whether enhancement for lazy attribute loading should be done.
- enableDirtyTracking
-
Whether enhancement for self-dirty tracking should be done.
- enableAssociationManagement
-
Whether enhancement for bi-directional association management should be done.
The default value for all 3 configuration settings is true
The enhance { } block is required in order for enhancement to occur.
Enhancement is disabled by default in preparation for additions capabilities (hbm2ddl, etc) in the plugin.
Maven plugin
Hibernate provides a Maven plugin capable of providing build-time enhancement of the domain model as they are compiled as part of a Maven build.
See the section on the Gradle plugin for details on the configuration settings. Again, the default for those 3 is true.
The Maven plugin supports one additional configuration settings: failOnError, which controls what happens in case of error. Default behavior is to fail the build, but it can be set so that only a warning is issued.
<build>
<plugins>
[...]
<plugin>
<groupId>org.hibernate.orm.tooling</groupId>
<artifactId>hibernate-enhance-maven-plugin</artifactId>
<version>$currentHibernateVersion</version>
<executions>
<execution>
<configuration>
<failOnError>true</failOnError>
<enableLazyInitialization>true</enableLazyInitialization>
<enableDirtyTracking>true</enableDirtyTracking>
<enableAssociationManagement>true</enableAssociationManagement>
</configuration>
<goals>
<goal>enhance</goal>
</goals>
</execution>
</executions>
</plugin>
[...]
</plugins>
</build>5.3. Making entities persistent
Once you’ve created a new entity instance (using the standard new operator) it is in new state.
You can make it persistent by associating it to either a org.hibernate.Session or javax.persistence.EntityManager.
Person person = new Person();
person.setId( 1L );
person.setName("John Doe");
entityManager.persist( person );Person person = new Person();
person.setId( 1L );
person.setName("John Doe");
session.save( person );org.hibernate.Session also has a method named persist which follows the exact semantic defined in the JPA specification for the persist method.
It is this org.hibernate.Session method to which the Hibernate javax.persistence.EntityManager implementation delegates.
If the DomesticCat entity type has a generated identifier, the value is associated with the instance when the save or persist is called.
If the identifier is not automatically generated, the manually assigned (usually natural) key value has to be set on the instance before the save or persist methods are called.
5.4. Deleting (removing) entities
Entities can also be deleted.
entityManager.remove( person );session.delete( person );|
Hibernate itself can handle deleting detached state.
JPA, however, disallows it.
The implication here is that the entity instance passed to the |
5.5. Obtain an entity reference without initializing its data
Sometimes referred to as lazy loading, the ability to obtain a reference to an entity without having to load its data is hugely important. The most common case being the need to create an association between an entity and another existing entity.
Book book = new Book();
book.setAuthor( entityManager.getReference( Person.class, personId ) );Book book = new Book();
book.setId( 1L );
book.setIsbn( "123-456-7890" );
entityManager.persist( book );
book.setAuthor( session.load( Person.class, personId ) );The above works on the assumption that the entity is defined to allow lazy loading, generally through use of runtime proxies. In both cases an exception will be thrown later if the given entity does not refer to actual database state when the application attempts to use the returned proxy in any way that requires access to its data.
5.6. Obtain an entity with its data initialized
It is also quite common to want to obtain an entity along with its data (e.g. like when we need to display it in the UI).
Person person = entityManager.find( Person.class, personId );Person person = session.get( Person.class, personId );byId() Hibernate APIPerson person = session.byId( Person.class ).load( personId );In both cases null is returned if no matching database row was found.
5.7. Obtain an entity by natural-id
In addition to allowing to load by identifier, Hibernate allows applications to load by declared natural identifier.
@Entity(name = "Book")
public static class Book {
@Id
private Long id;
private String title;
@NaturalId
private String isbn;
@ManyToOne
private Person author;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public Person getAuthor() {
return author;
}
public void setAuthor(Person author) {
this.author = author;
}
public String getIsbn() {
return isbn;
}
public void setIsbn(String isbn) {
this.isbn = isbn;
}
}We can also opt to fetch the entity or just retrieve a reference to it when using the natural identifier loading methods.
Book book = session.bySimpleNaturalId( Book.class ).getReference( isbn );Book book = session.byNaturalId( Book.class ).using( "isbn", isbn ).load( );Hibernate offer a consistent API for accessing persistent data by identifier or by the natural-id. Each of these defines the same two data access methods:
- getReference
-
Should be used in cases where the identifier is assumed to exist, where non-existence would be an actual error. Should never be used to test existence. That is because this method will prefer to create and return a proxy if the data is not already associated with the Session rather than hit the database. The quintessential use-case for using this method is to create foreign-key based associations.
- load
-
Will return the persistent data associated with the given identifier value or null if that identifier does not exist.
Each of these two methods define an overloading variant accepting a org.hibernate.LockOptions argument.
Locking is discussed in a separate chapter.
5.8. Modifying managed/persistent state
Entities in managed/persistent state may be manipulated by the application and any changes will be automatically detected and persisted when the persistence context is flushed. There is no need to call a particular method to make your modifications persistent.
Person person = entityManager.find( Person.class, personId );
person.setName("John Doe");
entityManager.flush();Person person = session.byId( Person.class ).load( personId );
person.setName("John Doe");
entityManager.flush();5.9. Refresh entity state
You can reload an entity instance and its collections at any time.
Person person = entityManager.find( Person.class, personId );
entityManager.createQuery( "update Person set name = UPPER(name)" ).executeUpdate();
entityManager.refresh( person );
assertEquals("JOHN DOE", person.getName() );Person person = session.byId( Person.class ).load( personId );
session.doWork( connection -> {
try(Statement statement = connection.createStatement()) {
statement.executeUpdate( "UPDATE person SET name = UPPER(name)" );
}
} );
session.refresh( person );
assertEquals("JOHN DOE", person.getName() );One case where this is useful is when it is known that the database state has changed since the data was read. Refreshing allows the current database state to be pulled into the entity instance and the persistence context.
Another case where this might be useful is when database triggers are used to initialize some of the properties of the entity.
|
Only the entity instance and its value type collections are refreshed unless you specify |
5.10. Working with detached data
Detachment is the process of working with data outside the scope of any persistence context. Data becomes detached in a number of ways. Once the persistence context is closed, all data that was associated with it becomes detached. Clearing the persistence context has the same effect. Evicting a particular entity from the persistence context makes it detached. And finally, serialization will make the deserialized form be detached (the original instance is still managed).
Detached data can still be manipulated, however the persistence context will no longer automatically know about these modification and the application will need to intervene to make the changes persistent again.
5.10.1. Reattaching detached data
Reattachment is the process of taking an incoming entity instance that is in detached state and re-associating it with the current persistence context.
|
JPA does not provide for this model. This is only available through Hibernate |
lockPerson person = session.byId( Person.class ).load( personId );
//Clear the Session so the person entity becomes detached
session.clear();
person.setName( "Mr. John Doe" );
session.lock( person, LockMode.NONE );saveOrUpdatePerson person = session.byId( Person.class ).load( personId );
//Clear the Session so the person entity becomes detached
session.clear();
person.setName( "Mr. John Doe" );
session.saveOrUpdate( person );|
The method name |
Provided the entity is detached, update and saveOrUpdate operate exactly the same.
5.10.2. Merging detached data
Merging is the process of taking an incoming entity instance that is in detached state and copying its data over onto a new managed instance.
Although not exactly per se, the following example is a good visualization of the merge operation internals.
public Person merge(Person detached) {
Person newReference = session.byId( Person.class ).load( detached.getId() );
newReference.setName( detached.getName() );
return newReference;
}Person person = entityManager.find( Person.class, personId );
//Clear the EntityManager so the person entity becomes detached
entityManager.clear();
person.setName( "Mr. John Doe" );
person = entityManager.merge( person );Person person = session.byId( Person.class ).load( personId );
//Clear the Session so the person entity becomes detached
session.clear();
person.setName( "Mr. John Doe" );
person = (Person) session.merge( person );5.11. Checking persistent state
An application can verify the state of entities and collections in relation to the persistence context.
boolean contained = entityManager.contains( person );boolean contained = session.contains( person );PersistenceUnitUtil persistenceUnitUtil = entityManager.getEntityManagerFactory().getPersistenceUnitUtil();
boolean personInitialized = persistenceUnitUtil.isLoaded( person );
boolean personBooksInitialized = persistenceUnitUtil.isLoaded( person.getBooks() );
boolean personNameInitialized = persistenceUnitUtil.isLoaded( person, "name" );boolean personInitialized = Hibernate.isInitialized( person );
boolean personBooksInitialized = Hibernate.isInitialized( person.getBooks() );
boolean personNameInitialized = Hibernate.isPropertyInitialized( person, "name" );In JPA there is an alternative means to check laziness using the following javax.persistence.PersistenceUtil pattern (which is recommended wherever possible).
PersistenceUtil persistenceUnitUtil = Persistence.getPersistenceUtil();
boolean personInitialized = persistenceUnitUtil.isLoaded( person );
boolean personBooksInitialized = persistenceUnitUtil.isLoaded( person.getBooks() );
boolean personNameInitialized = persistenceUnitUtil.isLoaded( person, "name" );5.12. Evicting entities
When the flush() method is called, the state of the entity is synchronized with the database.
If you do not want this synchronization to occur, or if you are processing a huge number of objects and need to manage memory efficiently,
the evict() method can be used to remove the object and its collections from the first-level cache.
EntityManagerfor(Person person : entityManager.createQuery("select p from Person p", Person.class)
.getResultList()) {
dtos.add(toDTO(person));
entityManager.detach( person );
}SessionSession session = entityManager.unwrap( Session.class );
for(Person person : (List<Person>) session.createQuery("select p from Person p").list()) {
dtos.add(toDTO(person));
session.evict( person );
}To detach all entities from the current persistence context, both the EntityManager and the Hibernate Session define a clear() method.
entityManager.clear();
session.clear();To verify if an entity instance is currently attached to the running persistence context, both the EntityManager and the Hibernate Session define a contains(Object entity) method.
entityManager.contains( person );
session.contains( person );6. Flushing
Flushing is the process of synchronizing the state of the persistence context with the underlying database.
The EntityManager and the Hibernate Session expose a set of methods, through which the application developer can change the persistent state of an entity.
The persistence context acts as a transactional write-behind cache, queuing any entity state change.
Like any write-behind cache, changes are first applied in-memory and synchronized with the database during flush time.
The flush operation takes every entity state change and translates it to an INSERT, UPDATE or DELETE statement.
|
Because DML statements are grouped together, Hibernate can apply batching transparently. See the Batching chapter for more information. |
The flushing strategy is given by the flushMode of the current running Hibernate Session.
Although JPA defines only two flushing strategies (AUTO and COMMIT),
Hibernate has a much broader spectrum of flush types:
- ALWAYS
-
Flushes the
Sessionbefore every query. - AUTO
-
This is the default mode and it flushes the
Sessiononly if necessary. - COMMIT
-
The
Sessiontries to delay the flush until the currentTransactionis committed, although it might flush prematurely too. - MANUAL
-
The
Sessionflushing is delegated to the application, which must callSession.flush()explicitly in order to apply the persistence context changes.
6.1. AUTO flush
By default, Hibernate uses the AUTO flush mode which triggers a flush in the following circumstances:
-
prior to committing a
Transaction -
prior to executing a JPQL/HQL query that overlaps with the queued entity actions
-
before executing any native SQL query that has no registered synchronization
6.1.1. AUTO flush on commit
In the following example, an entity is persisted and then the transaction is committed.
entityManager = entityManagerFactory().createEntityManager();
txn = entityManager.getTransaction();
txn.begin();
Person person = new Person( "John Doe" );
entityManager.persist( person );
log.info( "Entity is in persisted state" );
txn.commit();--INFO: Entity is in persisted state
INSERT INTO Person (name, id) VALUES ('John Doe', 1)Hibernate logs the message prior to inserting the entity because the flush only occurred during transaction commit.
|
This is valid for the |
6.1.2. AUTO flush on JPQL/HQL query
A flush may also be triggered when executing an entity query.
Person person = new Person( "John Doe" );
entityManager.persist( person );
entityManager.createQuery( "select p from Advertisement p" ).getResultList();
entityManager.createQuery( "select p from Person p" ).getResultList();SELECT a.id AS id1_0_ ,
a.title AS title2_0_
FROM Advertisement a
INSERT INTO Person (name, id) VALUES ('John Doe', 1)
SELECT p.id AS id1_1_ ,
p.name AS name2_1_
FROM Person pThe reason why the Advertisement entity query didn’t trigger a flush is because there’s no overlapping between the Advertisement and the Person tables:
@Entity(name = "Person")
public static class Person {
@Id
@GeneratedValue
private Long id;
private String name;
public Person() {}
public Person(String name) {
this.name = name;
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
}
@Entity(name = "Advertisement")
public static class Advertisement {
@Id
@GeneratedValue
private Long id;
private String title;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
}When querying for a Person entity, the flush is triggered prior to executing the entity query.
Person person = new Person( "John Doe" );
entityManager.persist( person );
entityManager.createQuery( "select p from Person p" ).getResultList();INSERT INTO Person (name, id) VALUES ('John Doe', 1)
SELECT p.id AS id1_1_ ,
p.name AS name2_1_
FROM Person pThis time, the flush was triggered by a JPQL query because the pending entity persist action overlaps with the query being executed.
6.1.3. AUTO flush on native SQL query
When executing a native SQL query, a flush is always triggered when using the EntityManager API.
EntityManagerassertTrue(((Number) entityManager
.createNativeQuery( "select count(*) from Person")
.getSingleResult()).intValue() == 0 );
Person person = new Person( "John Doe" );
entityManager.persist( person );
assertTrue(((Number) entityManager
.createNativeQuery( "select count(*) from Person")
.getSingleResult()).intValue() == 1 );The Session API doesn’t trigger an AUTO flush when executing a native query
SessionassertTrue(((Number) entityManager
.createNativeQuery( "select count(*) from Person")
.getSingleResult()).intValue() == 0 );
Person person = new Person( "John Doe" );
entityManager.persist( person );
Session session = entityManager.unwrap(Session.class);
assertTrue(((Number) session
.createSQLQuery( "select count(*) from Person")
.uniqueResult()).intValue() == 0 );To flush the Session, the query must use a synchronization:
Session synchronizationassertTrue(((Number) entityManager
.createNativeQuery( "select count(*) from Person")
.getSingleResult()).intValue() == 0 );
Person person = new Person( "John Doe" );
entityManager.persist( person );
Session session = entityManager.unwrap( Session.class );
assertTrue(((Number) session
.createSQLQuery( "select count(*) from Person")
.addSynchronizedEntityClass( Person.class )
.uniqueResult()).intValue() == 1 );6.2. COMMIT flush
JPA also defines a COMMIT flush mode, which is described as follows:
If
FlushModeType.COMMITis set, the effect of updates made to entities in the persistence context upon queries is unspecified.
When executing a JPQL query, the persistence context is only flushed when the current running transaction is committed.
COMMIT flushing on JPQLPerson person = new Person("John Doe");
entityManager.persist(person);
entityManager.createQuery("select p from Advertisement p")
.setFlushMode( FlushModeType.COMMIT)
.getResultList();
entityManager.createQuery("select p from Person p")
.setFlushMode( FlushModeType.COMMIT)
.getResultList();SELECT a.id AS id1_0_ ,
a.title AS title2_0_
FROM Advertisement a
SELECT p.id AS id1_1_ ,
p.name AS name2_1_
FROM Person p
INSERT INTO Person (name, id) VALUES ('John Doe', 1)Because the JPA doesn’t impose a strict rule on delaying flushing, when executing a native SQL query, the persistence context is going to be flushed.
COMMIT flushing on SQLPerson person = new Person("John Doe");
entityManager.persist(person);
assertTrue(((Number) entityManager
.createNativeQuery("select count(*) from Person")
.getSingleResult()).intValue() == 1);INSERT INTO Person (name, id) VALUES ('John Doe', 1)
SELECT COUNT(*) FROM Person6.3. ALWAYS flush
|
The |
The ALWAYS flush mode triggers a persistence context flush even when executing a native SQL query against the Session API.
COMMIT flushing on SQLPerson person = new Person("John Doe");
entityManager.persist(person);
Session session = entityManager.unwrap( Session.class);
assertTrue(((Number) session
.createSQLQuery("select count(*) from Person")
.setFlushMode( FlushMode.ALWAYS)
.uniqueResult()).intValue() == 1);INSERT INTO Person (name, id) VALUES ('John Doe', 1)
SELECT COUNT(*) FROM Person6.4. MANUAL flush
Both the EntityManager and the Hibernate Session define a flush() method that, when called, triggers a manual flush.
Hibernate also defines a MANUAL flush mode so the persistence context can only be flushed manually.
MANUAL flushingPerson person = new Person("John Doe");
entityManager.persist(person);
Session session = entityManager.unwrap( Session.class);
session.setFlushMode( FlushMode.MANUAL);
assertTrue(((Number) entityManager
.createQuery("select count(id) from Person")
.getSingleResult()).intValue() == 0);
assertTrue(((Number) session
.createSQLQuery("select count(*) from Person")
.uniqueResult()).intValue() == 0);SELECT COUNT(p.id) AS col_0_0_
FROM Person p
SELECT COUNT(*)
FROM PersonThe INSERT statement was not executed because the persistence context because there was no manual flush() call.
|
This mode is useful when using multi-request logical transactions and only the last request should flush the persistence context. |
6.5. Flush operation order
From a database perspective, a row state can be altered using either an INSERT, an UPDATE or a DELETE statement.
Because entity state changes are automatically converted to SQL statements, it’s important to know which entity actions are associated to a given SQL statement.
INSERT-
The
INSERTstatement is generated either by theEntityInsertActionorEntityIdentityInsertAction. These actions are scheduled by thepersistoperation, either explicitly or through cascading thePersistEventfrom a parent to a child entity. DELETE-
The
DELETEstatement is generated by theEntityDeleteActionorOrphanRemovalAction. UPDATE-
The
UPDATEstatement is generated byEntityUpdateActionduring flushing if the managed entity has been marked modified. The dirty checking mechanism is responsible for determining if a managed entity has been modified since it was first loaded.
Hibernate does not execute the SQL statements in the order of their associated entity state operations.
To visualize how this works, consider the following example:
Person person = entityManager.find( Person.class, 1L);
entityManager.remove(person);
Person newPerson = new Person( );
newPerson.setId( 2L );
newPerson.setName( "John Doe" );
entityManager.persist( newPerson );INSERT INTO Person (name, id)
VALUES ('John Doe', 2L)
DELETE FROM Person WHERE id = 1Even if we removed the first entity and then persist a new one, Hibernate is going to execute the DELETE statement after the INSERT.
|
The order in which SQL statements are executed is given by the |
The ActionQueue executes all operations in the following order:
-
OrphanRemovalAction -
EntityInsertActionorEntityIdentityInsertAction -
EntityUpdateAction -
CollectionRemoveAction -
CollectionUpdateAction -
CollectionRecreateAction -
EntityDeleteAction
7. Database access
7.1. ConnectionProvider
As an ORM tool, probably the single most important thing you need to tell Hibernate is how to connect to your database so that it may connect on behalf of your application.
This is ultimately the function of the org.hibernate.engine.jdbc.connections.spi.ConnectionProvider interface.
Hibernate provides some out of the box implementations of this interface.
ConnectionProvider is also an extension point so you can also use custom implementations from third parties or written yourself.
The ConnectionProvider to use is defined by the hibernate.connection.provider_class setting. See the org.hibernate.cfg.AvailableSettings#CONNECTION_PROVIDER
Generally speaking, applications should not have to configure a ConnectionProvider explicitly if using one of the Hibernate-provided implementations.
Hibernate will internally determine which ConnectionProvider to use based on the following algorithm:
-
If
hibernate.connection.provider_classis set, it takes precedence -
else if
hibernate.connection.datasourceis set → Using DataSources -
else if any setting prefixed by
hibernate.c3p0.is set → Using c3p0 -
else if any setting prefixed by
hibernate.proxool.is set → Using Proxool -
else if any setting prefixed by
hibernate.hikari.is set → Using Hikari -
else if
hibernate.connection.urlis set → Using Hibernate’s built-in (and unsupported) pooling -
else → User-provided Connections
7.2. Using DataSources
Hibernate can integrate with a javax.sql.DataSource for obtaining JDBC Connections.
Applications would tell Hibernate about the DataSource via the (required) hibernate.connection.datasource setting which can either specify a JNDI name or would reference the actual DataSource instance.
For cases where a JNDI name is given, be sure to read JNDI
|
For JPA applications, note that |
The DataSource ConnectionProvider also (optionally) accepts the hibernate.connection.username and hibernate.connection.password.
If specified, the DataSource#getConnection(String username, String password) will be used.
Otherwise, the no-arg form is used.
7.3. Using c3p0
|
To use this integration, the application must include the hibernate-c3p0 module jar (as well as its dependencies) on the classpath. |
Hibernate also provides support for applications to use c3p0 connection pooling. When using this c3p0 support, a number of additional configuration settings are recognized.
Transaction isolation of the Connections is managed by the ConnectionProvider itself. See ConnectionProvider support for transaction isolation setting.
hibernate.connection.driver_class-
The name of the JDBC Driver class to use
hibernate.connection.url-
The JDBC connection url.
- Any settings prefixed with
hibernate.connection.(other than the "special ones") -
These all have the
hibernate.connection.prefix stripped and the rest will be passed as JDBC connection properties hibernate.c3p0.min_sizeorc3p0.minPoolSize-
The minimum size of the c3p0 pool. See c3p0 minPoolSize
hibernate.c3p0.max_sizeorc3p0.maxPoolSize-
The maximum size of the c3p0 pool. See c3p0 maxPoolSize
hibernate.c3p0.timeoutorc3p0.maxIdleTime-
The Connection idle time. See c3p0 maxIdleTime
hibernate.c3p0.max_statementsorc3p0.maxStatements-
Controls the c3p0 PreparedStatement cache size (if using). See c3p0 maxStatements
hibernate.c3p0.acquire_incrementorc3p0.acquireIncrement-
Number of connections c3p0 should acquire at a time when pool is exhausted. See c3p0 acquireIncrement
hibernate.c3p0.idle_test_periodorc3p0.idleConnectionTestPeriod-
Idle time before a c3p0 pooled connection is validated. See c3p0 idleConnectionTestPeriod
hibernate.c3p0.initialPoolSize-
The initial c3p0 pool size. If not specified, default is to use the min pool size. See c3p0 initialPoolSize
- Any other settings prefixed with
hibernate.c3p0. -
Will have the
hibernate.portion stripped and be passed to c3p0. - Any other settings prefixed with
c3p0. -
Get passed to c3p0 as is. See c3p0 configuration
7.4. Using Proxool
|
To use this integration, the application must include the hibernate-proxool module jar (as well as its dependencies) on the classpath. |
Hibernate also provides support for applications to use Proxool connection pooling.
Transaction isolation of the Connections is managed by the ConnectionProvider itself. See ConnectionProvider support for transaction isolation setting.
7.5. Using existing Proxool pools
Controlled by the hibernate.proxool.existing_pool setting.
If set to true, this ConnectionProvider will use an already existing Proxool pool by alias as indicated by the hibernate.proxool.pool_alias setting.
7.6. Configuring Proxool via XML
The hibernate.proxool.xml setting names a Proxool configuration XML file to be loaded as a classpath resource and loaded by Proxool’s JAXPConfigurator.
See proxool configuration.
hibernate.proxool.pool_alias must be set to indicate which pool to use.
7.7. Configuring Proxool via Properties
The hibernate.proxool.properties setting names a Proxool configuration properties file to be loaded as a classpath resource and loaded by Proxool’s PropertyConfigurator.
See proxool configuration.
hibernate.proxool.pool_alias must be set to indicate which pool to use.
7.8. Using Hikari
|
To use this integration, the application must include the hibernate-hikari module jar (as well as its dependencies) on the classpath. |
Hibernate also provides support for applications to use Hikari connection pool.
Set all of your Hikari settings in Hibernate prefixed by hibernate.hikari. and this ConnectionProvider will pick them up and pass them along to Hikari.
Additionally, this ConnectionProvider will pick up the following Hibernate-specific properties and map them to the corresponding Hikari ones (any hibernate.hikari. prefixed ones have precedence):
hibernate.connection.driver_class-
Mapped to Hikari’s
driverClassNamesetting hibernate.connection.url-
Mapped to Hikari’s
jdbcUrlsetting hibernate.connection.username-
Mapped to Hikari’s
usernamesetting hibernate.connection.password-
Mapped to Hikari’s
passwordsetting hibernate.connection.isolation-
Mapped to Hikari’s
transactionIsolationsetting. See ConnectionProvider support for transaction isolation setting. Note that Hikari only supports JDBC standard isolation levels (apparently). hibernate.connection.autocommit-
Mapped to Hikari’s
autoCommitsetting
7.9. Using Hibernate’s built-in (and unsupported) pooling
|
The built-in connection pool is not supported supported for use. |
This section is here just for completeness.
7.10. User-provided Connections
It is possible to use Hibernate by simply passing a Connection to use to the Session when the Session is opened. This usage is discouraged and not discussed here.
7.11. ConnectionProvider support for transaction isolation setting
All of the provided ConnectionProvider implementations, other than DataSourceConnectionProvider, support consistent setting of transaction isolation for all Connections obtained from the underlying pool.
The value for hibernate.connection.isolation can be specified in one of 3 formats:
-
the integer value accepted at the JDBC level
-
the name of the
java.sql.Connectionconstant field representing the isolation you would like to use. For example,TRANSACTION_REPEATABLE_READforjava.sql.Connection#TRANSACTION_REPEATABLE_READ. Not that this is only supported for JDBC standard isolation levels, not for isolation levels specific to a particular JDBC driver. -
a short-name version of the java.sql.Connection constant field without the
TRANSACTION_prefix. For example,REPEATABLE_READforjava.sql.Connection#TRANSACTION_REPEATABLE_READ. Again, this is only supported for JDBC standard isolation levels, not for isolation levels specific to a particular JDBC driver.
7.12. Database Dialect
Although SQL is relatively standardized, each database vendor uses a subset and superset of ANSI SQL defined syntax.
This is referred to as the database’s dialect.
Hibernate handles variations across these dialects through its org.hibernate.dialect.Dialect class and the various subclasses for each database vendor.
In most cases Hibernate will be able to determine the proper Dialect to use by asking some questions of the JDBC Connection during bootstrap. For information on Hibernate’s ability to determine the proper Dialect to use (and your ability to influence that resolution), see Dialect resolution.
If for some reason it is not able to determine the proper one or you want to use a custom Dialect, you will need to set the hibernate.dialect setting.
| Dialect (short name) | Remarks |
|---|---|
Cache71 |
Support for the Caché database, version 2007.1 |
CUBRID |
Support for the CUBRID database, version 8.3. May work with later versions. |
DB2 |
Support for the DB2 database |
DB2390 |
Support for DB2 Universal Database for OS/390, also known as DB2/390. |
DB2400 |
Support for DB2 Universal Database for iSeries, also known as DB2/400. |
DerbyTenFive |
Support for the Derby database, version 10.5 |
DerbyTenSix |
Support for the Derby database, version 10.6 |
DerbyTenSeven |
Support for the Derby database, version 10.7 |
Firebird |
Support for the Firebird database |
FrontBase |
Support for the Frontbase database |
H2 |
Support for the H2 database |
HSQL |
Support for the HSQL (HyperSQL) database |
Informix |
Support for the Informix database |
Ingres |
Support for the Ingres database, version 9.2 |
Ingres9 |
Support for the Ingres database, version 9.3. May work with newer versions |
Ingres10 |
Support for the Ingres database, version 10. May work with newer versions |
Interbase |
Support for the Interbase database. |
JDataStore |
Support for the JDataStore database |
McKoi |
Support for the McKoi database |
Mimer |
Support for the Mimer database, version 9.2.1. May work with newer versions |
MySQL5 |
Support for the MySQL database, version 5.x |
MySQL5InnoDB |
Support for the MySQL database, version 5.x preferring the InnoDB storage engine when exporting tables. |
MySQL57InnoDB |
Support for the MySQL database, version 5.7 preferring the InnoDB storage engine when exporting tables. May work with newer versions |
Oracle8i |
Support for the Oracle database, version 8i |
Oracle9i |
Support for the Oracle database, version 9i |
Oracle10g |
Support for the Oracle database, version 10g |
Pointbase |
Support for the Pointbase database |
PostgresPlus |
Support for the Postgres Plus database |
PostgreSQL81 |
Support for the PostgrSQL database, version 8.1 |
PostgreSQL82 |
Support for the PostgreSQL database, version 8.2 |
PostgreSQL9 |
Support for the PostgreSQL database, version 9. May work with later versions. |
Progress |
Support for the Progress database, version 9.1C. May work with newer versions. |
SAPDB |
Support for the SAPDB/MAXDB database. |
SQLServer |
Support for the SQL Server 2000 database |
SQLServer2005 |
Support for the SQL Server 2005 database |
SQLServer2008 |
Support for the SQL Server 2008 database |
Sybase11 |
Support for the Sybase database, up to version 11.9.2 |
SybaseAnywhere |
Support for the Sybase Anywhere database |
SybaseASE15 |
Support for the Sybase Adaptive Server Enterprise database, version 15 |
SybaseASE157 |
Support for the Sybase Adaptive Server Enterprise database, version 15.7. May work with newer versions. |
Teradata |
Support for the Teradata database |
TimesTen |
Support for the TimesTen database, version 5.1. May work with newer versions |
8. Transactions and concurrency control
It is important to understand that the term transaction has many different yet related meanings in regards to persistence and Object/Relational Mapping. In most use-cases these definitions align, but that is not always the case.
-
Might refer to the physical transaction with the database.
-
Might refer to the logical notion of a transaction as related to a persistence context.
-
Might refer to the application notion of a Unit-of-Work, as defined by the archetypal pattern.
|
This documentation largely treats the physical and logic notions of a transaction as one-in-the-same. |
8.1. Physical Transactions
Hibernate uses the JDBC API for persistence. In the world of Java there are two well-defined mechanism for dealing with transactions in JDBC: JDBC itself and JTA. Hibernate supports both mechanisms for integrating with transactions and allowing applications to manage physical transactions.
Transaction handling per Session is handled by the org.hibernate.resource.transaction.TransactionCoordinator contract, which are built by the org.hibernate.resource.transaction.TransactionCoordinatorBuilder service.
TransactionCoordinatorBuilder represents a strategy for dealing with transactions whereas TransactionCoordinator represents one instance of that strategy related to a Session.
Which TransactionCoordinatorBuilder implementation to use is defined by the hibernate.transaction.coordinator_class setting.
jdbc(the default for non-JPA applications)-
Manages transactions via calls to
java.sql.Connection jta-
Manages transactions via JTA. See Java EE bootstrapping
If a JPA application does not provide a setting for hibernate.transaction.coordinator_class, Hibernate will
automatically build the proper transaction coordinator based on the transaction type for the persistence unit.
If a non-JPA application does not provide a setting for hibernate.transaction.coordinator_class, Hibernate
will use jdbc as the default. This default will cause problems if the application actually uses JTA-based transactions.
A non-JPA application that uses JTA-based transactions should explicitly set hibernate.transaction.coordinator_class=jta
or provide a custom org.hibernate.resource.transaction.TransactionCoordinatorBuilder that builds a
org.hibernate.resource.transaction.TransactionCoordinator that properly coordinates with JTA-based transactions.
|
For details on implementing a custom |
Hibernate uses JDBC connections and JTA resources directly, without adding any additional locking behavior.
Hibernate does not lock objects in memory.
The behavior defined by the isolation level of your database transactions does not change when you use Hibernate.
The Hibernate Session acts as a transaction-scoped cache providing repeatable reads for lookup by identifier and queries that result in loading entities.
|
To reduce lock contention in the database, the physical database transaction needs to be as short as possible.
Long database transactions prevent your application from scaling to a highly-concurrent load.
Do not hold a database transaction open during end-user-level work, but open it after the end-user-level work is finished.
This is concept is referred to as |
8.2. JTA configuration
Interaction with a JTA system is consolidated behind a single contract named org.hibernate.engine.transaction.jta.platform.spi.JtaPlatform which exposes access to the javax.transaction.TransactionManager
and javax.transaction.UserTransaction for that system as well as exposing the ability to register javax.transaction.Synchronization instances, check transaction status, etc.
|
Generally, |
Hibernate tries to discover the JtaPlatform it should use through the use of another service named org.hibernate.engine.transaction.jta.platform.spi.JtaPlatformResolver.
If that resolution does not work, or if you wish to provide a custom implementation you will need to specify the hibernate.transaction.jta.platform setting.
Hibernate provides many implementations of the JtaPlatform contract, all with short names:
Borland-
JtaPlatformfor the Borland Enterprise Server. Bitronix-
JtaPlatformfor Bitronix. JBossAS-
JtaPlatformfor Arjuna/JBossTransactions/Narayana when used within the JBoss/WildFly Application Server. JBossTS-
JtaPlatformfor Arjuna/JBossTransactions/Narayana when used standalone. JOnAS-
JtaPlatformfor JOTM when used within JOnAS. JOTM-
JtaPlatformfor JOTM when used standalone. JRun4-
JtaPlatformfor the JRun 4 Application Server. OC4J-
JtaPlatformfor Oracle’s OC4J container. Orion-
JtaPlatformfor the Orion Application Server. Resin-
JtaPlatformfor the Resin Application Server. SunOne-
JtaPlatformfor the SunOne Application Server. Weblogic-
JtaPlatformfor the Weblogic Application Server. WebSphere-
JtaPlatformfor older versions of the WebSphere Application Server. WebSphereExtended-
JtaPlatformfor newer versions of the WebSphere Application Server.
8.3. Hibernate Transaction API
Hibernate provides an API for helping to isolate applications from the differences in the underlying physical transaction system in use.
Based on the configured TransactionCoordinatorBuilder, Hibernate will simply do the right thing when this transaction API is used by the application.
This allows your applications and components to be more portable move around into different environments.
To use this API, you would obtain the org.hibernate.Transaction from the Session. Transaction allows for all the normal operations you’d expect: begin, commit and rollback, and it even exposes some cool methods like:
markRollbackOnly-
that works in both JTA and JDBC
getTimeoutandsetTimeout-
that again work in both JTA and JDBC
registerSynchronization-
that allows you to register JTA Synchronizations even in non-JTA environments. In fact in both JTA and JDBC environments, these
Synchronizationsare kept locally by Hibernate. In JTA environments, Hibernate will only ever register one singleSynchronizationwith theTransactionManagerto avoid ordering problems.
Additionally, it exposes a getStatus method that returns an org.hibernate.resource.transaction.spi.TransactionStatus enum.
This method checks with the underlying transaction system if needed, so care should be taken to minimize its use; it can have a big performance impact in certain JTA set ups.
Let’s take a look at using the Transaction API in the various environments.
StandardServiceRegistry serviceRegistry = new StandardServiceRegistryBuilder()
// "jdbc" is the default, but for explicitness
.applySetting( AvailableSettings.TRANSACTION_COORDINATOR_STRATEGY, "jdbc" )
.build();
Metadata metadata = new MetadataSources( serviceRegistry )
.addAnnotatedClass( Customer.class )
.getMetadataBuilder()
.build();
SessionFactory sessionFactory = metadata.getSessionFactoryBuilder()
.build();
Session session = sessionFactory.openSession();
try {
// calls Connection#setAutoCommit( false ) to
// signal start of transaction
session.getTransaction().begin();
session.createQuery( "UPDATE customer set NAME = 'Sir. '||NAME" )
.executeUpdate();
// calls Connection#commit(), if an error
// happens we attempt a rollback
session.getTransaction().commit();
}
catch ( Exception e ) {
// we may need to rollback depending on
// where the exception happened
if ( session.getTransaction().getStatus() == TransactionStatus.ACTIVE
|| session.getTransaction().getStatus() == TransactionStatus.MARKED_ROLLBACK ) {
session.getTransaction().rollback();
}
// handle the underlying error
}
finally {
session.close();
}StandardServiceRegistry serviceRegistry = new StandardServiceRegistryBuilder()
// "jdbc" is the default, but for explicitness
.applySetting( AvailableSettings.TRANSACTION_COORDINATOR_STRATEGY, "jta" )
.build();
Metadata metadata = new MetadataSources( serviceRegistry )
.addAnnotatedClass( Customer.class )
.getMetadataBuilder()
.build();
SessionFactory sessionFactory = metadata.getSessionFactoryBuilder()
.build();
// Note: depending on the JtaPlatform used and some optional settings,
// the underlying transactions here will be controlled through either
// the JTA TransactionManager or UserTransaction
Session session = sessionFactory.openSession();
try {
// Since we are in CMT, a JTA transaction would
// already have been started. This call essentially
// no-ops
session.getTransaction().begin();
Number customerCount = (Number) session.createQuery( "select count(c) from Customer c" ).uniqueResult();
// Since we did not start the transaction ( CMT ),
// we also will not end it. This call essentially
// no-ops in terms of transaction handling.
session.getTransaction().commit();
}
catch ( Exception e ) {
// again, the rollback call here would no-op (aside from
// marking the underlying CMT transaction for rollback only).
if ( session.getTransaction().getStatus() == TransactionStatus.ACTIVE
|| session.getTransaction().getStatus() == TransactionStatus.MARKED_ROLLBACK ) {
session.getTransaction().rollback();
}
// handle the underlying error
}
finally {
session.close();
}StandardServiceRegistry serviceRegistry = new StandardServiceRegistryBuilder()
// "jdbc" is the default, but for explicitness
.applySetting( AvailableSettings.TRANSACTION_COORDINATOR_STRATEGY, "jta" )
.build();
Metadata metadata = new MetadataSources( serviceRegistry )
.addAnnotatedClass( Customer.class )
.getMetadataBuilder()
.build();
SessionFactory sessionFactory = metadata.getSessionFactoryBuilder()
.build();
// Note: depending on the JtaPlatform used and some optional settings,
// the underlying transactions here will be controlled through either
// the JTA TransactionManager or UserTransaction
Session session = sessionFactory.openSession();
try {
// Assuming a JTA transaction is not already active,
// this call the TM/UT begin method. If a JTA
// transaction is already active, we remember that
// the Transaction associated with the Session did
// not "initiate" the JTA transaction and will later
// nop-op the commit and rollback calls...
session.getTransaction().begin();
session.persist( new Customer( ) );
Customer customer = (Customer) session.createQuery( "select c from Customer c" ).uniqueResult();
// calls TM/UT commit method, assuming we are initiator.
session.getTransaction().commit();
}
catch ( Exception e ) {
// we may need to rollback depending on
// where the exception happened
if ( session.getTransaction().getStatus() == TransactionStatus.ACTIVE
|| session.getTransaction().getStatus() == TransactionStatus.MARKED_ROLLBACK ) {
// calls TM/UT commit method, assuming we are initiator;
// otherwise marks the JTA transaction for rollback only
session.getTransaction().rollback();
}
// handle the underlying error
}
finally {
session.close();
}In the CMT case we really could have omitted all of the Transaction calls. But the point of the examples was to show that the Transaction API really does insulate your code from the underlying transaction mechanism. In fact, if you strip away the comments and the single configuration setting supplied at bootstrap, the code is exactly the same in all 3 examples. In other words, we could develop that code and drop it, as-is, in any of the 3 transaction environments.
The Transaction API tries hard to make the experience consistent across all environments. To that end, it generally defers to the JTA specification when there are differences (for example automatically trying rollback on a failed commit).
8.4. Contextual sessions
Most applications using Hibernate need some form of contextual session, where a given session is in effect throughout the scope of a given context.
However, across applications the definition of what constitutes a context is typically different; different contexts define different scopes to the notion of current.
Applications using Hibernate prior to version 3.0 tended to utilize either home-grown ThreadLocal-based contextual sessions, helper classes such as HibernateUtil, or utilized third-party frameworks, such as Spring or Pico, which provided proxy/interception-based contextual sessions.
Starting with version 3.0.1, Hibernate added the SessionFactory.getCurrentSession() method.
Initially, this assumed usage of JTA transactions, where the JTA transaction defined both the scope and context of a current session.
Given the maturity of the numerous stand-alone JTA TransactionManager implementations, most, if not all, applications should be using JTA transaction management, whether or not they are deployed into a J2EE container.
Based on that, the JTA-based contextual sessions are all you need to use.
However, as of version 3.1, the processing behind SessionFactory.getCurrentSession() is now pluggable.
To that end, a new extension interface, org.hibernate.context.spi.CurrentSessionContext,
and a new configuration parameter, hibernate.current_session_context_class, have been added to allow pluggability of the scope and context of defining current sessions.
See the Javadocs for the org.hibernate.context.spi.CurrentSessionContext interface for a detailed discussion of its contract.
It defines a single method, currentSession(), by which the implementation is responsible for tracking the current contextual session.
Out-of-the-box, Hibernate comes with three implementations of this interface:
org.hibernate.context.internal.JTASessionContext-
current sessions are tracked and scoped by a
JTAtransaction. The processing here is exactly the same as in the older JTA-only approach. See the Javadocs for more details.-
org.hibernate.context.internal.ThreadLocalSessionContext:current sessions are tracked by thread of execution. See the Javadocs for more details. -
org.hibernate.context.internal.ManagedSessionContext: current sessions are tracked by thread of execution. However, you are responsible to bind and unbind aSessioninstance with static methods on this class: it does not open, flush, or close aSession. See the Javadocs for details.
-
Typically, the value of this parameter would just name the implementation class to use. For the three out-of-the-box implementations, however, there are three corresponding short names: jta, thread, and managed.
The first two implementations provide a one session - one database transaction programming model.
This is also known and used as session-per-request.
The beginning and end of a Hibernate session is defined by the duration of a database transaction.
If you use programmatic transaction demarcation in plain Java SE without JTA, you are advised to use the Hibernate Transaction API to hide the underlying transaction system from your code.
If you use JTA, you can utilize the JTA interfaces to demarcate transactions.
If you execute in an EJB container that supports CMT, transaction boundaries are defined declaratively and you do not need any transaction or session demarcation operations in your code. Refer to Transactions and concurrency control for more information and code examples.
The hibernate.current_session_context_class configuration parameter defines which org.hibernate.context.spi.CurrentSessionContext implementation should be used.
For backwards compatibility, if this configuration parameter is not set but a org.hibernate.engine.transaction.jta.platform.spi.JtaPlatform is configured, Hibernate will use the org.hibernate.context.internal.JTASessionContext.
8.5. Transactional patterns (and anti-patterns)
8.6. Session-per-operation anti-pattern
This is an anti-pattern of opening and closing a Session for each database call in a single thread.
It is also an anti-pattern in terms of database transactions.
Group your database calls into a planned sequence.
In the same way, do not auto-commit after every SQL statement in your application.
Hibernate disables, or expects the application server to disable, auto-commit mode immediately.
Database transactions are never optional.
All communication with a database must be encapsulated by a transaction.
Avoid auto-commit behavior for reading data because many small transactions are unlikely to perform better than one clearly-defined unit of work, and are more difficult to maintain and extend.
|
Using auto-commit does not circumvent database transactions. Instead, when in auto-commit mode, JDBC drivers simply perform each call in an implicit transaction call. It is as if your application called commit after each and every JDBC call. |
8.7. Session-per-request pattern
This is the most common transaction pattern. The term request here relates to the concept of a system that reacts to a series of requests from a client/user. Web applications are a prime example of this type of system, though certainly not the only one. At the beginning of handling such a request, the application opens a Hibernate Session, starts a transaction, performs all data related work, ends the transaction and closes the Session. The crux of the pattern is the one-to-one relationship between the transaction and the Session.
Within this pattern there is a common technique of defining a current session to simplify the need of passing this Session around to all the application components that may need access to it.
Hibernate provides support for this technique through the getCurrentSession method of the SessionFactory.
The concept of a current session has to have a scope that defines the bounds in which the notion of current is valid.
This is the purpose of the org.hibernate.context.spi.CurrentSessionContext contract.
There are 2 reliable defining scopes:
-
First is a JTA transaction because it allows a callback hook to know when it is ending, which gives Hibernate a chance to close the
Sessionand clean up. This is represented by theorg.hibernate.context.internal.JTASessionContextimplementation of theorg.hibernate.context.spi.CurrentSessionContextcontract. Using this implementation, aSessionwill be opened the first timegetCurrentSessionis called within that transaction. -
Secondly is this application request cycle itself. This is best represented with the
org.hibernate.context.internal.ManagedSessionContextimplementation of theorg.hibernate.context.spi.CurrentSessionContextcontract. Here an external component is responsible for managing the lifecycle and scoping of a current session. At the start of such a scope,ManagedSessionContext#bind()method is called passing in theSession. At the end, itsunbind()method is called. Some common examples of such external components include:-
javax.servlet.Filterimplementation -
AOP interceptor with a pointcut on the service methods
-
A proxy/interception container
-
|
The |
8.8. Conversations
The session-per-request pattern is not the only valid way of designing units of work. Many business processes require a whole series of interactions with the user that are interleaved with database accesses. In web and enterprise applications, it is not acceptable for a database transaction to span a user interaction. Consider the following example:
The first screen of a dialog opens.
The data seen by the user is loaded in a particular Session and database transaction.
The user is free to modify the objects.
The user uses a UI element to save their work after five minutes of editing. The modifications are made persistent. The user also expects to have exclusive access to the data during the edit session.
Even though we have multiple databases access here, from the point of view of the user, this series of steps represents a single unit of work. There are many ways to implement this in your application.
A first naive implementation might keep the Session and database transaction open while the user is editing, using database-level locks to prevent other users from modifying the same data and to guarantee isolation and atomicity.
This is an anti-pattern because lock contention is a bottleneck which will prevent scalability in the future.
Several database transactions are used to implement the conversation. In this case, maintaining isolation of business processes becomes the partial responsibility of the application tier. A single conversation usually spans several database transactions. These multiple database accesses can only be atomic as a whole if only one of these database transactions (typically the last one) stores the updated data. All others only read data. A common way to receive this data is through a wizard-style dialog spanning several request/response cycles. Hibernate includes some features which make this easy to implement.
Automatic Versioning |
Hibernate can perform automatic optimistic concurrency control for you. It can automatically detect (at the end of the conversation) if a concurrent modification occurred during user think time. |
Detached Objects |
If you decide to use the session-per-request pattern, all loaded instances will be in the detached state during user think time. Hibernate allows you to reattach the objects and persist the modifications. The pattern is called session-per-request-with-detached-objects. Automatic versioning is used to isolate concurrent modifications. |
Extended |
The Hibernate |
Session-per-request-with-detached-objects and session-per-conversation each have advantages and disadvantages.
8.9. Session-per-application
The session-per-application is also considered an anti-pattern.
The Hibernate Session, like the JPA EntityManager, is not a thread-safe object and it is intended to be confined to a single thread at once.
If the Session is shared among multiple threads, there will be race conditions as well as visibility issues , so beware of this.
An exception thrown by Hibernate means you have to rollback your database transaction and close the Session immediately.
If your Session is bound to the application, you have to stop the application.
Rolling back the database transaction does not put your business objects back into the state they were at the start of the transaction.
This means that the database state and the business objects will be out of sync.
Usually, this is not a problem because exceptions are not recoverable and you will have to start over after rollback anyway.
The Session caches every object that is in a persistent state (watched and checked for dirty state by Hibernate).
If you keep it open for a long time or simply load too much data, it will grow endlessly until you get an OutOfMemoryException.
One solution is to call clear() and evict() to manage the Session cache, but you should consider a Stored Procedure if you need mass data operations.
Some solutions are shown in the Batching chapter.
Keeping a Session open for the duration of a user session also means a higher probability of stale data.
9. JNDI
Hibernate does optionally interact with JNDI on the application’s behalf. Generally, it does this when the application:
-
has asked the SessionFactory be bound to JNDI
-
has specified a DataSource to use by JNDI name
-
is using JTA transactions and the
JtaPlatformneeds to do JNDI lookups forTransactionManager,UserTransaction, etc
All of these JNDI calls route through a single service whose role is org.hibernate.engine.jndi.spi.JndiService.
The standard JndiService accepts a number of configuration settings
hibernate.jndi.class-
names the javax.naming.InitialContext implementation class to use. See
javax.naming.Context#INITIAL_CONTEXT_FACTORY hibernate.jndi.url-
names the JNDI InitialContext connection url. See
javax.naming.Context.PROVIDER_URL
Any other settings prefixed with hibernate.jndi. will be collected and passed along to the JNDI provider.
|
The standard |
10. Locking
In a relational database, locking refers to actions taken to prevent data from changing between the time it is read and the time is used.
Your locking strategy can be either optimistic or pessimistic.
- Optimistic
-
Optimistic locking assumes that multiple transactions can complete without affecting each other, and that therefore transactions can proceed without locking the data resources that they affect. Before committing, each transaction verifies that no other transaction has modified its data. If the check reveals conflicting modifications, the committing transaction rolls back.
- Pessimistic
-
Pessimistic locking assumes that concurrent transactions will conflict with each other, and requires resources to be locked after they are read and only unlocked after the application has finished using the data.
Hibernate provides mechanisms for implementing both types of locking in your applications.
10.1. Optimistic
When your application uses long transactions or conversations that span several database transactions, you can store versioning data so that if the same entity is updated by two conversations, the last to commit changes is informed of the conflict, and does not override the other conversation’s work. This approach guarantees some isolation, but scales well and works particularly well in read-often-write-sometimes situations.
Hibernate provides two different mechanisms for storing versioning information, a dedicated version number or a timestamp.
|
A version or timestamp property can never be null for a detached instance. Hibernate detects any instance with a null version or timestamp as transient, regardless of other unsaved-value strategies that you specify. Declaring a nullable version or timestamp property is an easy way to avoid problems with transitive reattachment in Hibernate, especially useful if you use assigned identifiers or composite keys. |
10.2. Dedicated version number
The version number mechanism for optimistic locking is provided through a @Version annotation.
@Version
private long version;Here, the version property is mapped to the version column, and the entity manager uses it to detect conflicting updates,
and prevent the loss of updates that would otherwise be overwritten by a last-commit-wins strategy.
The version column can be any kind of type, as long as you define and implement the appropriate UserVersionType.
Your application is forbidden from altering the version number set by Hibernate.
To artificially increase the version number, see the documentation for properties LockModeType.OPTIMISTIC_FORCE_INCREMENT or
LockModeType.PESSIMISTIC_FORCE_INCREMENT check in the Hibernate Entity Manager reference documentation.
|
If the version number is generated by the database, such as a trigger, use the annotation |
10.3. Timestamp
Timestamps are a less reliable way of optimistic locking than version numbers, but can be used by applications for other purposes as well.
Timestamping is automatically used if you the @Version annotation on a Date or Calendar property type.
@Version
private Date version;Hibernate can retrieve the timestamp value from the database or the JVM, by reading the value you specify for the @org.hibernate.annotations.Source annotation.
The value can be either org.hibernate.annotations.SourceType.DB or org.hibernate.annotations.SourceType.VM.
The default behavior is to use the database, and is also used if you don’t specify the annotation at all.
The timestamp can also be generated by the database instead of Hibernate, if you use the @org.hibernate.annotations.Generated(GenerationTime.ALWAYS) annotation.
10.4. Pessimistic
Typically, you only need to specify an isolation level for the JDBC connections and let the database handle locking issues. If you do need to obtain exclusive pessimistic locks or re-obtain locks at the start of a new transaction, Hibernate gives you the tools you need.
|
Hibernate always uses the locking mechanism of the database, and never lock objects in memory. |
10.5. LockMode and LockModeType
Long before JPA 1.0, Hibernate already defined various explicit locking strategies through its LockMode enumeration.
JPA comes with its own LockModeType enumeration which defines similar strategies as the Hibernate-native LockMode.
LockModeType |
LockMode |
Description |
|---|---|---|
|
|
The absence of a lock. All objects switch to this lock mode at the end of a Transaction. Objects associated with the session via a call to |
|
|
The entity version is checked towards the end of the currently running transaction. |
|
|
The entity version is incremented automatically even if the entity has not changed. |
|
|
The entity is locked pessimistically and its version is incremented automatically even if the entity has not changed. |
|
|
The entity is locked pessimistically using a shared lock, if the database supports such a feature. Otherwise, an explicit lock is used. |
|
|
The entity is locked using an explicit lock. |
|
|
The lock acquisition request fails fast if the row s already locked. |
|
|
The lock acquisition request skips the already locked rows. It uses a |
The explicit user request mentioned above occurs as a consequence of any of the following actions:
-
a call to
Session.load(), specifying aLockMode. -
a call to
Session.lock(). -
a call to
Query.setLockMode().
If you call Session.load() with option UPGRADE, UPGRADE_NOWAIT or UPGRADE_SKIPLOCKED,
and the requested object is not already loaded by the session, the object is loaded using SELECT … FOR UPDATE.
If you call load() for an object that is already loaded with a less restrictive lock than the one you request, Hibernate calls lock() for that object.
Session.lock() performs a version number check if the specified lock mode is READ, UPGRADE, UPGRADE_NOWAIT or UPGRADE_SKIPLOCKED.
In the case of UPGRADE, UPGRADE_NOWAIT or UPGRADE_SKIPLOCKED, the SELECT … FOR UPDATE syntax is used.
If the requested lock mode is not supported by the database, Hibernate uses an appropriate alternate mode instead of throwing an exception. This ensures that applications are portable.
10.6. JPA locking query hints
JPA 2.0 introduced two query hints:
- javax.persistence.lock.timeout
-
it gives the number of milliseconds a lock acquisition request will wait before throwing an exception
- javax.persistence.lock.scope
-
defines the scope of the lock acquisition request. The scope can either be
NORMAL(default value) orEXTENDED. TheEXTENDEDscope will cause a lock acquisition request to be passed to other owned table structured (e.g.@Inheritance(strategy=InheritanceType.JOINED),@ElementCollection)
javax.persistence.lock.timeout exampleentityManager.find(
Person.class, id, LockModeType.PESSIMISTIC_WRITE,
Collections.singletonMap( "javax.persistence.lock.timeout", 200 )
);SELECT explicitlo0_.id AS id1_0_0_,
explicitlo0_."name" AS name2_0_0_
FROM person explicitlo0_
WHERE explicitlo0_.id = 1
FOR UPDATE wait 2|
Not all JDBC database drivers support setting a timeout value for a locking request. If not supported, the Hibernate dialect ignores this query hint. |
|
The |
10.7. The buildLockRequest API
Traditionally, Hibernate offered the Session#lock() method for acquiring an optimistic or a pessimistic lock on a given entity.
Because varying the locking options was difficult when using a single LockMode parameter, Hibernate has added the Session#buildLockRequest() method API.
The following example shows how to obtain shared database lock without waiting for the lock acquisition request.
buildLockRequest examplePerson person = entityManager.find( Person.class, id );
Session session = entityManager.unwrap( Session.class );
session
.buildLockRequest( LockOptions.NONE )
.setLockMode( LockMode.PESSIMISTIC_READ )
.setTimeOut( LockOptions.NO_WAIT )
.lock( person );SELECT p.id AS id1_0_0_ ,
p.name AS name2_0_0_
FROM Person p
WHERE p.id = 1
SELECT id
FROM Person
WHERE id = 1
FOR SHARE NOWAIT10.8. Follow-on-locking
When using Oracle, the FOR UPDATE exclusive locking clause cannot be used with:
-
DISTINCT -
GROUP BY -
UNION -
inlined views (derived tables), therefore, affecting the legacy Oracle pagination mechanism as well.
For this reason, Hibernate uses secondary selects to lock the previously fetched entities.
List<Person> persons = entityManager.createQuery(
"select DISTINCT p from Person p", Person.class)
.setLockMode( LockModeType.PESSIMISTIC_WRITE )
.getResultList();SELECT DISTINCT p.id as id1_0_, p."name" as name2_0_
FROM Person p
SELECT id
FROM Person
WHERE id = 1 FOR UPDATE
SELECT id
FROM Person
WHERE id = 1 FOR UPDATE|
To avoid the N+1 query problem, a separate query can be used to apply the lock using the associated entity identifiers. |
List<Person> persons = entityManager.createQuery(
"select DISTINCT p from Person p", Person.class)
.getResultList();
entityManager.createQuery(
"select p.id from Person p where p in :persons")
.setLockMode( LockModeType.PESSIMISTIC_WRITE )
.setParameter( "persons", persons )
.getResultList();SELECT DISTINCT p.id as id1_0_, p."name" as name2_0_
FROM Person p
SELECT p.id as col_0_0_
FROM Person p
WHERE p.id IN ( 1 , 2 )
FOR UPDATEThe lock request was moved from the original query to a secondary one which takes the previously fetched entities to lock their associated database records.
11. Fetching
Fetching, essentially, is the process of grabbing data from the database and making it available to the application. Tuning how an application does fetching is one of the biggest factors in determining how an application will perform. Fetching too much data, in terms of width (values/columns) and/or depth (results/rows), adds unnecessary overhead in terms of both JDBC communication and ResultSet processing. Fetching too little data might cause additional fetching to be needed. Tuning how an application fetches data presents a great opportunity to influence the application overall performance.
11.1. The basics
The concept of fetching breaks down into two different questions.
-
When should the data be fetched? Now? Later?
-
How should the data be fetched?
|
"now" is generally termed eager or immediate. "later" is generally termed lazy or delayed. |
There are a number of scopes for defining fetching:
- static
-
Static definition of fetching strategies is done in the mappings. The statically-defined fetch strategies is used in the absence of any dynamically defined strategies
- SELECT
-
Performs a separate SQL select to load the data. This can either be EAGER (the second select is issued immediately) or LAZY (the second select is delayed until the data is needed). This is the strategy generally termed N+1.
- JOIN
-
Inherently an EAGER style of fetching. The data to be fetched is obtained through the use of an SQL outer join.
- BATCH
-
Performs a separate SQL select to load a number of related data items using an IN-restriction as part of the SQL WHERE-clause based on a batch size. Again, this can either be EAGER (the second select is issued immediately) or LAZY (the second select is delayed until the data is needed).
- SUBSELECT
-
Performs a separate SQL select to load associated data based on the SQL restriction used to load the owner. Again, this can either be EAGER (the second select is issued immediately) or LAZY (the second select is delayed until the data is needed).
- dynamic (sometimes referred to as runtime)
-
Dynamic definition is really use-case centric. There are multiple ways to define dynamic fetching:
- fetch profiles
-
defined in mappings, but can be enabled/disabled on the
Session. - HQL/JPQL
-
and both Hibernate and JPA Criteria queries have the ability to specify fetching, specific to said query.
- entity graphs
-
Starting in Hibernate 4.2 (JPA 2.1) this is also an option.
11.2. Applying fetch strategies
Let’s consider these topics as it relates to an simple domain model and a few use cases.
@Entity(name = "Department")
public static class Department {
@Id
private Long id;
@OneToMany(mappedBy = "department")
private List<Employee> employees = new ArrayList<>();
//Getters and setters omitted for brevity
}
@Entity(name = "Employee")
public static class Employee {
@Id
private Long id;
@NaturalId
private String username;
@Column(name = "pswd")
@ColumnTransformer(
read = "decrypt( 'AES', '00', pswd )",
write = "encrypt('AES', '00', ?)"
)
private String password;
private int accessLevel;
@ManyToOne(fetch = FetchType.LAZY)
private Department department;
@ManyToMany(mappedBy = "employees")
private List<Project> projects = new ArrayList<>();
//Getters and setters omitted for brevity
}
@Entity(name = "Project")
public class Project {
@Id
private Long id;
@ManyToMany
private List<Employee> employees = new ArrayList<>();
//Getters and setters omitted for brevity
}|
The Hibernate recommendation is to statically mark all associations lazy and to use dynamic fetching strategies for eagerness. This is unfortunately at odds with the JPA specification which defines that all one-to-one and many-to-one associations should be eagerly fetched by default. Hibernate, as a JPA provider, honors that default. |
11.3. No fetching
For the first use case, consider the application login process for an Employee.
Let’s assume that login only requires access to the Employee information, not Project nor Department information.
Employee employee = entityManager.createQuery(
"select e " +
"from Employee e " +
"where " +
" e.username = :username and " +
" e.password = :password",
Employee.class)
.setParameter( "username", username)
.setParameter( "password", password)
.getSingleResult();In this example, the application gets the Employee data.
However, because all associations from `Employee `are declared as LAZY (JPA defines the default for collections as LAZY) no other data is fetched.
If the login process does not need access to the Employee information specifically, another fetching optimization here would be to limit the width of the query results.
Integer accessLevel = entityManager.createQuery(
"select e.accessLevel " +
"from Employee e " +
"where " +
" e.username = :username and " +
" e.password = :password",
Integer.class)
.setParameter( "username", username)
.setParameter( "password", password)
.getSingleResult();11.4. Dynamic fetching via queries
For the second use case, consider a screen displaying the Projects for an Employee.
Certainly access to the Employee `is needed, as is the collection of `Projects for that Employee. Information about Departments, other Employees or other Projects is not needed.
Employee employee = entityManager.createQuery(
"select e " +
"from Employee e " +
"left join fetch e.projects " +
"where " +
" e.username = :username and " +
" e.password = :password",
Employee.class)
.setParameter( "username", username)
.setParameter( "password", password)
.getSingleResult();CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Employee> query = builder.createQuery( Employee.class );
Root<Employee> root = query.from( Employee.class );
root.fetch( "projects", JoinType.LEFT);
query.select(root).where(
builder.and(
builder.equal(root.get("username"), username),
builder.equal(root.get("password"), password)
)
);
Employee employee = entityManager.createQuery( query ).getSingleResult();In this example we have an Employee `and their `Projects loaded in a single query shown both as an HQL query and a JPA Criteria query.
In both cases, this resolves to exactly one database query to get all that information.
11.5. Dynamic fetching via JPA entity graph
JPA 2.1 introduced entity graphs so the application developer has more control over fetch plans.
@Entity(name = "Employee")
@NamedEntityGraph(name = "employee.projects",
attributeNodes = @NamedAttributeNode("projects")
)Employee employee = entityManager.find(
Employee.class,
userId,
Collections.singletonMap(
"javax.persistence.fetchgraph",
entityManager.getEntityGraph( "employee.projects" )
)
);|
Entity graphs are the way to override the EAGER fetching associations at runtime. With JPQL, if an EAGER association is omitted, Hibernate will issue a secondary select for every association needed to be fetched eagerly. |
11.6. Dynamic fetching via Hibernate profiles
Suppose we wanted to leverage loading by natural-id to obtain the Employee information in the "projects for and employee" use-case.
Loading by natural-id uses the statically defined fetching strategies, but does not expose a means to define load-specific fetching.
So we would leverage a fetch profile.
@Entity(name = "Employee")
@FetchProfile(
name = "employee.projects",
fetchOverrides = {
@FetchProfile.FetchOverride(
entity = Employee.class,
association = "projects",
mode = FetchMode.JOIN
)
}
)session.enableFetchProfile( "employee.projects" );
Employee employee = session.bySimpleNaturalId( Employee.class ).load( username );Here the Employee is obtained by natural-id lookup and the Employee’s Project data is fetched eagerly.
If the Employee data is resolved from cache, the Project data is resolved on its own.
However, if the Employee data is not resolved in cache, the Employee and Project data is resolved in one SQL query via join as we saw above.
12. Batching
12.1. JDBC batching
JDBC offers support for batching together SQL statements that can be represented as a single PreparedStatement. Implementation wise this generally means that drivers will send the batched operation to the server in one call, which can save on network calls to the database. Hibernate can leverage JDBC batching. The following settings control this behavior.
hibernate.jdbc.batch_size-
Controls the maximum number of statements Hibernate will batch together before asking the driver to execute the batch. Zero or a negative number disables this feature.
hibernate.jdbc.batch_versioned_data-
Some JDBC drivers return incorrect row counts when a batch is executed. If your JDBC driver falls into this category this setting should be set to
false. Otherwise, it is safe to enable this which will allow Hibernate to still batch the DML for versioned entities and still use the returned row counts for optimistic lock checks. Since 5.0, it defaults to true. Previously (versions 3.x and 4.x), it used to be false. hibernate.jdbc.batch.builder-
Names the implementation class used to manage batching capabilities. It is almost never a good idea to switch from Hibernate’s default implementation. But if you wish to, this setting would name the
org.hibernate.engine.jdbc.batch.spi.BatchBuilderimplementation to use. hibernate.order_updates-
Forces Hibernate to order SQL updates by the entity type and the primary key value of the items being updated. This allows for more batching to be used. It will also result in fewer transaction deadlocks in highly concurrent systems. Comes with a performance hit, so benchmark before and after to see if this actually helps or hurts your application.
hibernate.order_inserts-
Forces Hibernate to order inserts to allow for more batching to be used. Comes with a performance hit, so benchmark before and after to see if this actually helps or hurts your application.
12.2. Session batching
The following example shows an anti-pattern for batch inserts.
EntityManager entityManager = null;
EntityTransaction txn = null;
try {
entityManager = entityManagerFactory().createEntityManager();
txn = entityManager.getTransaction();
txn.begin();
for ( int i = 0; i < 100_000; i++ ) {
Person Person = new Person( String.format( "Person %d", i ) );
entityManager.persist( Person );
}
txn.commit();
} catch (RuntimeException e) {
if ( txn != null && txn.isActive()) txn.rollback();
throw e;
} finally {
if (entityManager != null) {
entityManager.close();
}
}There are several problems associated with this example:
-
Hibernate caches all the newly inserted
Customerinstances in the session-level c1ache, so, when the transaction ends, 100 000 entities are managed by the persistence context. If the maximum memory allocated to the JVM is rather low, this example could fails with anOutOfMemoryException. The Java 1.8 JVM allocated either 1/4 of available RAM or 1Gb, which can easily accommodate 100 000 objects on the heap. -
long-running transactions can deplete a connection pool so other transactions don’t get a chance to proceed.
-
JDBC batching is not enabled by default, so every insert statement requires a database roundtrip. To enable JDBC batching, set the
hibernate.jdbc.batch_sizeproperty to an integer between 10 and 50.
|
Hibernate disables insert batching at the JDBC level transparently if you use an identity identifier generator. |
12.2.1. Batch inserts
When you make new objects persistent, employ methods flush() and clear() to the session regularly, to control the size of the first-level cache.
SessionEntityManager entityManager = null;
EntityTransaction txn = null;
try {
entityManager = entityManagerFactory().createEntityManager();
txn = entityManager.getTransaction();
txn.begin();
int batchSize = 25;
for ( int i = 0; i < entityCount; ++i ) {
Person Person = new Person( String.format( "Person %d", i ) );
entityManager.persist( Person );
if ( i % batchSize == 0 ) {
//flush a batch of inserts and release memory
entityManager.flush();
entityManager.clear();
}
}
txn.commit();
} catch (RuntimeException e) {
if ( txn != null && txn.isActive()) txn.rollback();
throw e;
} finally {
if (entityManager != null) {
entityManager.close();
}
}12.2.2. Session scroll
When you retrieve and update data, flush() and clear() the session regularly.
In addition, use method scroll() to take advantage of server-side cursors for queries that return many rows of data.
scroll()EntityManager entityManager = null;
EntityTransaction txn = null;
ScrollableResults scrollableResults = null;
try {
entityManager = entityManagerFactory().createEntityManager();
txn = entityManager.getTransaction();
txn.begin();
int batchSize = 25;
Session session = entityManager.unwrap( Session.class );
scrollableResults = session
.createQuery( "select p from Person p" )
.setCacheMode( CacheMode.IGNORE )
.scroll( ScrollMode.FORWARD_ONLY );
int count = 0;
while ( scrollableResults.next() ) {
Person Person = (Person) scrollableResults.get( 0 );
processPerson(Person);
if ( ++count % batchSize == 0 ) {
//flush a batch of updates and release memory:
entityManager.flush();
entityManager.clear();
}
}
txn.commit();
} catch (RuntimeException e) {
if ( txn != null && txn.isActive()) txn.rollback();
throw e;
} finally {
if (scrollableResults != null) {
scrollableResults.close();
}
if (entityManager != null) {
entityManager.close();
}
}|
You should always close the |
12.2.3. StatelessSession
StatelessSession is a command-oriented API provided by Hibernate.
Use it to stream data to and from the database in the form of detached objects.
A StatelessSession has no persistence context associated with it and does not provide many of the higher-level life cycle semantics.
Some of the things not provided by a StatelessSession include:
-
a first-level cache
-
interaction with any second-level or query cache
-
transactional write-behind or automatic dirty checking
Limitations of StatelessSession:
-
Operations performed using a stateless session never cascade to associated instances.
-
Collections are ignored by a stateless session.
-
Lazy loading of associations is not supported.
-
Operations performed via a stateless session bypass Hibernate’s event model and interceptors.
-
Due to the lack of a first-level cache, Stateless sessions are vulnerable to data aliasing effects.
-
A stateless session is a lower-level abstraction that is much closer to the underlying JDBC.
StatelessSessionStatelessSession statelessSession = null;
Transaction txn = null;
ScrollableResults scrollableResults = null;
try {
SessionFactory sessionFactory = entityManagerFactory().unwrap( SessionFactory.class );
statelessSession = sessionFactory.openStatelessSession();
txn = statelessSession.getTransaction();
txn.begin();
scrollableResults = statelessSession
.createQuery( "select p from Person p" )
.scroll(ScrollMode.FORWARD_ONLY);
while ( scrollableResults.next() ) {
Person Person = (Person) scrollableResults.get( 0 );
processPerson(Person);
statelessSession.update( Person );
}
txn.commit();
} catch (RuntimeException e) {
if ( txn != null && txn.getStatus() == TransactionStatus.ACTIVE) txn.rollback();
throw e;
} finally {
if (scrollableResults != null) {
scrollableResults.close();
}
if (statelessSession != null) {
statelessSession.close();
}
}The Customer instances returned by the query are immediately detached.
They are never associated with any persistence context.
The insert(), update(), and delete() operations defined by the StatelessSession interface operate directly on database rows.
They cause the corresponding SQL operations to be executed immediately.
They have different semantics from the save(), saveOrUpdate(), and delete() operations defined by the Session interface.
12.3. Hibernate Query Language for DML
DML, or Data Manipulation Language, refers to SQL statements such as INSERT, UPDATE, and DELETE.
Hibernate provides methods for bulk SQL-style DML statement execution, in the form of Hibernate Query Language (HQL).
12.3.1. HQL/JPQL for UPDATE and DELETE
Both the Hibernate native Query Language and JPQL (Java Persistence Query Language) provide support for bulk UPDATE and DELETE.
UPDATE FROM EntityName e WHERE e.name = ?
DELETE FROM EntityName e WHERE e.name = ?|
The |
The FROM clause can only refer to a single entity, which can be aliased.
If the entity name is aliased, any property references must be qualified using that alias.
If the entity name is not aliased, then it is illegal for any property references to be qualified.
|
Joins, either implicit or explicit, are prohibited in a bulk HQL query.
You can use sub-queries in the |
UPDATE, using the Query.executeUpdate()int updatedEntities = entityManager.createQuery(
"update Person p " +
"set p.name = :newName " +
"where p.name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();UPDATE, using the Query.executeUpdate()int updatedEntities = session.createQuery(
"update Person " +
"set name = :newName " +
"where name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();In keeping with the EJB3 specification, HQL UPDATE statements, by default, do not effect the version or the timestamp property values for the affected entities.
You can use a versioned update to force Hibernate to reset the version or timestamp property values, by adding the VERSIONED keyword after the UPDATE keyword.
int updatedEntities = session.createQuery(
"update versioned Person " +
"set name = :newName " +
"where name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();|
If you use the This feature is only available in HQL since it’s not standardized by JPA. |
DELETE statementint deletedEntities = entityManager.createQuery(
"delete Person p " +
"where p.name = :name" )
.setParameter( "name", name )
.executeUpdate();DELETE statementint deletedEntities = session.createQuery(
"delete Person " +
"where name = :name" )
.setParameter( "name", name )
.executeUpdate();Method Query.executeUpdate() returns an int value, which indicates the number of entities effected by the operation.
This may or may not correlate to the number of rows effected in the database.
An JPQL/HQL bulk operation might result in multiple SQL statements being executed, such as for joined-subclass.
In the example of joined-subclass, a DELETE against one of the subclasses may actually result in deletes in the tables underlying the join, or further down the inheritance hierarchy.
12.3.2. HQL syntax for INSERT
INSERT INTO EntityName
properties_list
SELECT properties_list
FROM ...Only the INSERT INTO … SELECT … form is supported.
You cannot specify explicit values to insert.
The properties_list is analogous to the column specification in the SQL INSERT statement.
For entities involved in mapped inheritance, you can only use properties directly defined on that given class-level in the properties_list.
Superclass properties are not allowed and subclass properties are irrelevant.
In other words, INSERT statements are inherently non-polymorphic.
The SELECT statement can be any valid HQL select query, but the return types must match the types expected by the INSERT.
Hibernate verifies the return types during query compilation, instead of expecting the database to check it.
Problems might result from Hibernate types which are equivalent, rather than equal.
One such example is a mismatch between a property defined as an org.hibernate.type.DateType and a property defined as an org.hibernate.type.TimestampType,
even though the database may not make a distinction, or may be capable of handling the conversion.
If id property is not specified in the properties_list,
Hibernate generates a value automatically.
Automatic generation is only available if you use ID generators which operate on the database.
Otherwise, Hibernate throws an exception during parsing.
Available in-database generators are org.hibernate.id.SequenceGenerator and its subclasses, and objects which implement org.hibernate.id.PostInsertIdentifierGenerator.
The most notable exception is org.hibernate.id.TableHiLoGenerator, which does not expose a selectable way to get its values.
For properties mapped as either version or timestamp, the insert statement gives you two options. You can either specify the property in the properties_list, in which case its value is taken from the corresponding select expressions, or omit it from the properties_list, in which case the seed value defined by the org.hibernate.type.VersionType is used.
int insertedEntities = session.createQuery(
"insert into Partner (id, name) " +
"select p.id, p.name " +
"from Person p ")
.executeUpdate();This section is only a brief overview of HQL. For more information, see HQL.
13. Caching
At runtime, Hibernate handles moving data into and out of the second-level cache in response to the operations performed by the Session, which acts as a transaction-level cache of persistent data.
Once an entity becomes managed, that object is added to the internal cache of the current persistence context (EntityManager or Session).
The persistence context is also called the first-level cache, and it’s enabled by default.
It is possible to configure a JVM-level (SessionFactory-level) or even a cluster cache on a class-by-class and collection-by-collection basis.
|
Be aware that caches are not aware of changes made to the persistent store by other applications. They can, however, be configured to regularly expire cached data. |
13.1. Configuring second-level caching
Hibernate can integrate with various caching providers for the purpose of caching data outside the context of a particular Session.
This section defines the settings which control this behavior.
13.1.1. RegionFactory
org.hibernate.cache.spi.RegionFactory defines the integration between Hibernate and a pluggable caching provider.
hibernate.cache.region.factory_class is used to declare the provider to use.
Hibernate comes with built-in support for two popular caching libraries: Ehcache and Infinispan.
Detailed information is provided later in this chapter.
13.1.2. Caching configuration properties
Besides specific provider configuration, there are a number of configurations options on the Hibernate side of the integration that control various caching behaviors:
hibernate.cache.use_second_level_cache-
Enable or disable second level caching overall. Default is true, although the default region factory is
NoCachingRegionFactory. hibernate.cache.use_query_cache-
Enable or disable second level caching of query results. Default is false.
hibernate.cache.query_cache_factory-
Query result caching is handled by a special contract that deals with staleness-based invalidation of the results. The default implementation does not allow stale results at all. Use this for applications that would like to relax that. Names an implementation of
org.hibernate.cache.spi.QueryCacheFactory hibernate.cache.use_minimal_puts-
Optimizes second-level cache operations to minimize writes, at the cost of more frequent reads. Providers typically set this appropriately.
hibernate.cache.region_prefix-
Defines a name to be used as a prefix to all second-level cache region names.
hibernate.cache.default_cache_concurrency_strategy-
In Hibernate second-level caching, all regions can be configured differently including the concurrency strategy to use when accessing that particular region. This setting allows to define a default strategy to be used. This setting is very rarely required as the pluggable providers do specify the default strategy to use. Valid values include:
-
read-only,
-
read-write,
-
nonstrict-read-write,
-
transactional
-
hibernate.cache.use_structured_entries-
If
true, forces Hibernate to store data in the second-level cache in a more human-friendly format. Can be useful if you’d like to be able to "browse" the data directly in your cache, but does have a performance impact. hibernate.cache.auto_evict_collection_cache-
Enables or disables the automatic eviction of a bidirectional association’s collection cache entry when the association is changed just from the owning side. This is disabled by default, as it has a performance impact to track this state. However if your application does not manage both sides of bidirectional association where the collection side is cached, the alternative is to have stale data in that collection cache.
hibernate.cache.use_reference_entries-
Enable direct storage of entity references into the second level cache for read-only or immutable entities.
hibernate.cache.keys_factory-
When storing entries into second-level cache as key-value pair, the identifiers can be wrapped into tuples <entity type, tenant, identifier> to guarantee uniqueness in case that second-level cache stores all entities in single space. These tuples are then used as keys in the cache. When the second-level cache implementation (incl. its configuration) guarantees that different entity types are stored separately and multi-tenancy is not used, you can omit this wrapping to achieve better performance. Currently, this property is only supported when Infinispan is configured as the second-level cache implementation. Valid values are:
-
default(wraps identitifers in the tuple) -
simple(uses identifiers as keys without any wrapping) -
fully qualified class name that implements
org.hibernate.cache.spi.CacheKeysFactory
-
13.2. Configuring second-level cache mappings
The cache mappings can be configured via JPA annotations or XML descriptors or using the Hibernate-specific mapping files.
By default, entities are not part of the second level cache and we recommend you to stick to this setting.
However, you can override this by setting the shared-cache-mode element in your persistence.xml file
or by using the javax.persistence.sharedCache.mode property in your configuration file.
The following values are possible:
ENABLE_SELECTIVE(Default and recommended value)-
Entities are not cached unless explicitly marked as cacheable (with the
@Cacheableannotation). DISABLE_SELECTIVE-
Entities are cached unless explicitly marked as non-cacheable.
ALL-
Entities are always cached even if marked as non-cacheable.
NONE-
No entity is cached even if marked as cacheable. This option can make sense to disable second-level cache altogether.
The cache concurrency strategy used by default can be set globally via the hibernate.cache.default_cache_concurrency_strategy configuration property.
The values for this property are:
- read-only
-
If your application needs to read, but not modify, instances of a persistent class, a read-only cache is the best choice. Application can still delete entities and these changes should be reflected in second-level cache so that the cache does not provide stale entities. Implementations may use performance optimizations based on the immutability of entities.
- read-write
-
If the application needs to update data, a read-write cache might be appropriate. This strategy provides consistent access to single entity, but not a serializable transaction isolation level; e.g. when TX1 reads looks up an entity and does not find it, TX2 inserts the entity into cache and TX1 looks it up again, the new entity can be read in TX1.
- nonstrict-read-write
-
Similar to read-write strategy but there might be occasional stale reads upon concurrent access to an entity. The choice of this strategy might be appropriate if the application rarely updates the same data simultaneously and strict transaction isolation is not required. Implementations may use performance optimizations that make use of the relaxed consistency guarantee.
- transactional
-
Provides serializable transaction isolation level.
|
Rather than using a global cache concurrency strategy, it is recommended to define this setting on a per entity basis.
Use the |
The @Cache annotation define three attributes:
- usage
-
Defines the
CacheConcurrencyStrategy - region
-
Defines a cache region where entries will be stored
- include
-
If lazy properties should be included in the second level cache. The default value is
allso lazy properties are cacheable. The other possible value isnon-lazyso lazy properties are not cacheable.
13.3. Entity inheritance and second-level cache mapping
When using inheritance, the JPA @Cacheable and the Hibernate-specific @Cache annotations should be declared at the root-entity level only.
That being said, it is not possible to customize the base class @Cacheable or @Cache definition in subclasses.
Although the JPA 2.1 specification says that the @Cacheable annotation could be overwritten by a subclass:
The value of the
Cacheableannotation is inherited by subclasses; it can be overridden by specifyingCacheableon a subclass.
Hibernate requires that a given entity hierarchy share the same caching semantics.
The reasons why Hibernate requires that all entities belonging to an inheritance tree share the same caching definition can be summed as follows:
-
from a performance perspective, adding an additional check on a per entity type level would slow the bootstrap process.
-
providing different caching semantics for subclasses would violate the Liskov substitution principle.
Assuming we have a base class,
Paymentand a subclassCreditCardPayment. If thePaymentis not cacheable and theCreditCardPaymentis cached, what should happen when executing the following code snippet:Payment payment = entityManager.find(Payment.class, creditCardPaymentId); CreditCardPayment creditCardPayment = (CreditCardPayment) CreditCardPayment;In this particular case, the second level cache key is formed of the entity class name and the identifier:
keyToLoad = {org.hibernate.engine.spi.EntityKey@4712} identifier = {java.lang.Long@4716} "2" persister = {org.hibernate.persister.entity.SingleTableEntityPersister@4629} "SingleTableEntityPersister(org.hibernate.userguide.model.Payment)"Should Hibernate load the
CreditCardPaymentfrom the cache as indicated by the actual entity type, or it should not use the cache since thePaymentis not supposed to be cached?
|
Because of all these intricacies, Hibernate only considers the base class |
13.4. Entity cache
@Entity(name = "Phone")
@Cacheable
@org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
public static class Phone {
@Id
@GeneratedValue
private Long id;
private String mobile;
@ManyToOne
private Person person;
@Version
private int version;
public Phone() {}
public Phone(String mobile) {
this.mobile = mobile;
}
public Long getId() {
return id;
}
public String getMobile() {
return mobile;
}
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
}Hibernate stores cached entities in a dehydrated form, which is similar to the database representation.
Aside from the foreign key column values of the @ManyToOne or @OneToOne child-side associations,
entity relationships are not stored in the cache,
Once an entity is stored in the second-level cache, you can avoid a database hit and load the entity from the cache alone:
Person person = entityManager.find( Person.class, 1L );Person person = session.get( Person.class, 1L );The Hibernate second-level cache can also load entities by their natural id:
@Entity(name = "Person")
@Cacheable
@org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public static class Person {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
@NaturalId
@Column(name = "code", unique = true)
private String code;
public Person() {}
public Person(String name) {
this.name = name;
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}Person person = session
.byNaturalId( Person.class )
.using( "code", "unique-code")
.load();13.5. Collection cache
Hibernate can also cache collections, and the @Cache annotation must be on added to the collection property.
If the collection is made of value types (basic or embeddables mapped with @ElementCollection),
the collection is stored as such.
If the collection contains other entities (@OneToMany or @ManyToMany),
the collection cache entry will store the entity identifiers only.
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
@org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
private List<Phone> phones = new ArrayList<>( );Collections are read-through, meaning they are cached upon being accessed for the first time:
Person person = entityManager.find( Person.class, 1L );
person.getPhones().size();Subsequent collection retrievals will use the cache instead of going to the database.
|
The collection cache is not write-through so any modification will trigger a collection cache entry invalidation. On a subsequent access, the collection will be loaded from the database and re-cached. |
13.6. Query cache
Aside from caching entities and collections, Hibernate offers a query cache too. This is useful for frequently executed queries with fixed parameter values.
|
Caching of query results introduces some overhead in terms of your applications normal transactional processing.
For example, if you cache results of a query against That, coupled with the fact that most applications simply gain no benefit from caching query results, leads Hibernate to disable caching of query results by default. |
To use query caching, you will first need to enable it with the following configuration property:
<property
name="hibernate.cache.use_query_cache"
value="true" />As mentioned above, most queries do not benefit from caching or their results. So by default, individual queries are not cached even after enabling query caching. Each particular query that needs to be cached must be manually set as cacheable. This way, the query looks for existing cache results or adds the query results to the cache when being executed.
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name = :name", Person.class)
.setParameter( "name", "John Doe")
.setHint( "org.hibernate.cacheable", "true")
.getResultList();List<Person> persons = session.createQuery(
"select p " +
"from Person p " +
"where p.name = :name")
.setParameter( "name", "John Doe")
.setCacheable(true)
.list();|
The query cache does not cache the state of the actual entities in the cache; it caches only identifier values and results of value type. Just as with collection caching, the query cache should always be used in conjunction with the second-level cache for those entities expected to be cached as part of a query result cache. |
13.6.1. Query cache regions
This setting creates two new cache regions:
org.hibernate.cache.internal.StandardQueryCache-
Holding the cached query results
org.hibernate.cache.spi.UpdateTimestampsCache-
Holding timestamps of the most recent updates to queryable tables. These are used to validate the results as they are served from the query cache.
|
If you configure your underlying cache implementation to use expiration, it’s very important that the timeout of the underlying cache region for the In fact, we recommend that the |
If you require fine-grained control over query cache expiration policies, you can specify a named cache region for a particular query.
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.id > :id", Person.class)
.setParameter( "id", 0L)
.setHint( QueryHints.HINT_CACHEABLE, "true")
.setHint( QueryHints.HINT_CACHE_REGION, "query.cache.person" )
.getResultList();List<Person> persons = session.createQuery(
"select p " +
"from Person p " +
"where p.id > :id")
.setParameter( "id", 0L)
.setCacheable(true)
.setCacheRegion( "query.cache.person" )
.list();If you want to force the query cache to refresh one of its regions (disregarding any cached results it finds there), you can use custom cache modes.
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.id > :id", Person.class)
.setParameter( "id", 0L)
.setHint( QueryHints.HINT_CACHEABLE, "true")
.setHint( QueryHints.HINT_CACHE_REGION, "query.cache.person" )
.setHint( "javax.persistence.cache.storeMode", CacheStoreMode.REFRESH )
.getResultList();List<Person> persons = session.createQuery(
"select p " +
"from Person p " +
"where p.id > :id")
.setParameter( "id", 0L)
.setCacheable(true)
.setCacheRegion( "query.cache.person" )
.setCacheMode( CacheMode.REFRESH )
.list();|
When using This is particularly useful in cases where underlying data may have been updated via a separate process
and is a far more efficient alternative to bulk eviction of the region via |
13.7. Managing the cached data
Traditionally, Hibernate defined the CacheMode enumeration to describe
the ways of interactions with the cached data.
JPA split cache modes by storage (CacheStoreMode)
and retrieval (CacheRetrieveMode).
The relationship between Hibernate and JPA cache modes can be seen in the following table:
| Hibernate | JPA | Description |
|---|---|---|
|
|
Default. Reads/writes data from/into cache |
|
|
Doesn’t read from cache, but writes to the cache upon loading from the database |
|
|
Doesn’t read from cache, but writes to the cache as it reads from the database |
|
|
Read from the cache, but doesn’t write to cache |
|
|
Doesn’t read/write data from/into cache |
Setting the cache mode can be done either when loading entities directly or when executing a query.
Map<String, Object> hints = new HashMap<>( );
hints.put( "javax.persistence.cache.retrieveMode " , CacheRetrieveMode.USE );
hints.put( "javax.persistence.cache.storeMode" , CacheStoreMode.REFRESH );
Person person = entityManager.find( Person.class, 1L , hints);session.setCacheMode( CacheMode.REFRESH );
Person person = session.get( Person.class, 1L );The custom cache modes can be set for queries as well:
List<Person> persons = entityManager.createQuery(
"select p from Person p", Person.class)
.setHint( QueryHints.HINT_CACHEABLE, "true")
.setHint( "javax.persistence.cache.retrieveMode " , CacheRetrieveMode.USE )
.setHint( "javax.persistence.cache.storeMode" , CacheStoreMode.REFRESH )
.getResultList();List<Person> persons = session.createQuery(
"select p from Person p" )
.setCacheable( true )
.setCacheMode( CacheMode.REFRESH )
.list();13.7.1. Evicting cache entries
Because the second level cache is bound to the EntityManagerFactory or the SessionFactory,
cache eviction must be done through these two interfaces.
JPA only supports entity eviction through the javax.persistence.Cache interface:
entityManager.getEntityManagerFactory().getCache().evict( Person.class );Hibernate is much more flexible in this regard as it offers fine-grained control over what needs to be evicted.
The org.hibernate.Cache interface defines various evicting strategies:
-
entities (by their class or region)
-
entities stored using the natural-id (by their class or region)
-
collections (by the region, and it might take the collection owner identifier as well)
-
queries (by region)
session.getSessionFactory().getCache().evictQueryRegion( "query.cache.person" );13.8. Caching statistics
If you enable the hibernate.generate_statistics configuration property,
Hibernate will expose a number of metrics via SessionFactory.getStatistics().
Hibernate can even be configured to expose these statistics via JMX.
This way, you can get access to the Statistics class which comprises all sort of
second-level cache metrics.
Statistics statistics = session.getSessionFactory().getStatistics();
SecondLevelCacheStatistics secondLevelCacheStatistics =
statistics.getSecondLevelCacheStatistics( "query.cache.person" );
long hitCount = secondLevelCacheStatistics.getHitCount();
long missCount = secondLevelCacheStatistics.getMissCount();
double hitRatio = (double) hitCount / ( hitCount + missCount );13.9. Ehcache
|
Use of the build-in integration for Ehcache requires that the |
13.9.1. RegionFactory
The hibernate-ehcache module defines two specific region factories: EhCacheRegionFactory and SingletonEhCacheRegionFactory.
EhCacheRegionFactory
To use the EhCacheRegionFactory, you need to specify the following configuration property:
The EhCacheRegionFactory configures a net.sf.ehcache.CacheManager for each SessionFactory,
so the CacheManager is not shared among multiple SessionFactory instances in the same JVM.
SingletonEhCacheRegionFactory
To use the SingletonEhCacheRegionFactory, you need to specify the following configuration property:
SingletonEhCacheRegionFactory configuration<property
name="hibernate.cache.region.factory_class"
value="org.hibernate.cache.ehcache.SingletonEhCacheRegionFactory"/>The SingletonEhCacheRegionFactory configures a singleton net.sf.ehcache.CacheManager (see CacheManager#create()),
shared among multiple SessionFactory instances in the same JVM.
|
Ehcache documentation recommends using multiple non-singleton |
13.10. Infinispan
|
Use of the build-in integration for Infinispan requires that the |
Infinispan currently supports all cache concurrency modes, although not all combinations of configurations are compatible.
Traditionally the transactional and read-only strategy was supported on transactional invalidation caches. In version 5.0, further modes have been added:
-
non-transactional invalidation caches are supported as well with
read-writestrategy. The actual setting of cache concurrency mode (read-writevs.transactional) is not honored, the appropriate strategy is selected based on the cache configuration (non-transactional vs. transactional). -
read-writemode is supported on non-transactional distributed/replicated caches, however, eviction should not be used in this configuration. Use of eviction can lead to consistency issues. Expiration (with reasonably long max-idle times) can be used. -
nonstrict-read-writemode is supported on non-transactional distributed/replicated caches, but the eviction should be turned off as well. In addition to that, the entities must use versioning. This mode mildly relaxes the consistency - between DB commit and end of transaction commit a stale read (see example) may occur in another transaction. However this strategy uses less RPCs and can be more performant than the other ones. -
read-onlymode is supported on both transactional and non-transactional invalidation caches and non-transactional distributed/replicated caches, but use of this mode currently does not bring any performance gains.
The available combinations are summarized in table below:
| Concurrency strategy | Cache transactions | Cache mode | Eviction |
|---|---|---|---|
transactional |
transactional |
invalidation |
yes |
read-write |
non-transactional |
invalidation |
yes |
read-write |
non-transactional |
distributed/replicated |
no |
nonstrict-read-write |
non-transactional |
distributed/replicated |
no |
If your second level cache is not clustered, it is possible to use local cache instead of the clustered caches in all modes as described above.
nonstrict-read-write strategyA=0 (non-cached), B=0 (cached in 2LC)
TX1: write A = 1, write B = 1
TX1: start commit
TX1: commit A, B in DB
TX2: read A = 1 (from DB), read B = 0 (from 2LC) // breaks transactional atomicity
TX1: update A, B in 2LC
TX1: end commit
Tx3: read A = 1, B = 1 // reads after TX1 commit completes are consistent again13.10.1. RegionFactory
The hibernate-infinispan module defines two specific providers: infinispan and infinispan-jndi.
InfinispanRegionFactory
If Hibernate and Infinispan are running in a standalone environment, the InfinispanRegionFactory should be configured as follows:
InfinispanRegionFactory configuration<property
name="hibernate.cache.region.factory_class"
value="org.hibernate.cache.infinispan.InfinispanRegionFactory" />JndiInfinispanRegionFactory
If the Infinispan CacheManager is bound to JNDI, then the JndiInfinispanRegionFactory should be used as a region factory:
JndiInfinispanRegionFactory configuration<property
name="hibernate.cache.region.factory_class"
value="org.hibernate.cache.infinispan.JndiInfinispanRegionFactory" />
<property
name="hibernate.cache.infinispan.cachemanager"
value="java:CacheManager" />Infinispan in JBoss AS/WildFly
When using JPA in WildFly, region factory is automatically set upon configuring hibernate.cache.use_second_level_cache=true (by default second-level cache is not used).
For more information, please consult WildFly documentation.
13.10.2. Configuration properties
Hibernate-infinispan module comes with default configuration in infinispan-config.xml that is suited for clustered use. If there’s only single instance accessing the DB, you can use more performant infinispan-config-local.xml by setting the hibernate.cache.infinispan.cfg property. If you require further tuning of the cache, you can provide your own configuration. Caches that are not specified in the provided configuration will default to infinispan-config.xml (if the provided configuration uses clustering) or infinispan-config-local.xml. It is not possible to specify the configuration this way in WildFly.
<property
name="hibernate.cache.infinispan.cfg"
value="my-infinispan-configuration.xml" />|
If the cache is configured as transactional, InfinispanRegionFactory automatically sets transaction manager so that the TM used by Infinispan is the same as TM used by Hibernate. |
Cache configuration can differ for each type of data stored in the cache. In order to override the cache configuration template, use property hibernate.cache.infinispan.data-type.cfg where data-type can be one of:
entity-
Entities indexed by
@Idor@EmbeddedIdattribute. immutable-entity-
Entities tagged with
@Immutableannotation or set asmutable=falsein mapping file. naturalid-
Entities indexed by their
@NaturalIdattribute. collection-
All collections.
timestamps-
Mapping entity type → last modification timestamp. Used for query caching.
query-
Mapping query → query result.
pending-puts-
Auxiliary caches for regions using invalidation mode caches.
For specifying cache template for specific region, use region name instead of the data-type:
<property
name="hibernate.cache.infinispan.entities.cfg"
value="custom-entities" />
<property
name="hibernate.cache.infinispan.query.cfg"
value="custom-query-cache" />
<property
name="hibernate.cache.infinispan.com.example.MyEntity.cfg"
value="my-entities" />
<property
name="hibernate.cache.infinispan.com.example.MyEntity.someCollection.cfg"
value="my-entities-some-collection" />|
Cache configurations are used only as a template for the cache created for given region (usually each entity hierarchy or collection has its own region). It is not possible to use the same cache for different regions. |
Some options in the cache configuration can also be overridden directly through properties. These are:
hibernate.cache.infinispan.something.eviction.strategy-
Available options are
NONE,LRUandLIRS. hibernate.cache.infinispan.something.eviction.max_entries-
Maximum number of entries in the cache.
hibernate.cache.infinispan.something.expiration.lifespan-
Lifespan of entry from insert into cache (in milliseconds)
hibernate.cache.infinispan.something.expiration.max_idle-
Lifespan of entry from last read/modification (in milliseconds)
hibernate.cache.infinispan.something.eviction.wake_up_interval-
Period of thread checking expired entries.
hibernate.cache.infinispan.statistics-
Globally enables/disable Infinispan statistics collection, and their exposure via JMX.
|
Eviction settings are checked upon each cache insert, it is expiration that needs to be triggered periodically. The old property still works, but its use is deprecated. |
|
Property |
Configuring Query and Timestamps caches
Since version 5.0 it is possible to configure query caches as non-transactional. Consistency guarantees are not changed and writes to the query cache should be faster.
The query cache is configured so that queries are only cached locally . Alternatively, you can configure query caching to use replication by selecting the "replicated-query" as query cache name. However, replication for query cache only makes sense if, and only if, all of this conditions are true:
-
Performing the query is quite expensive.
-
The same query is very likely to be repeatedly executed on different cluster nodes.
-
The query is unlikely to be invalidated out of the cache
|
Hibernate must aggressively invalidate query results from the cache any time any instance of one of the entity types is modified. All cached query results referencing given entity type are invalidated, even if the change made to the specific entity instance would not have affected the query result. The timestamps cache plays here an important role - it contains last modification timestamp for each entity type. After a cached query results is loaded, its timestamp is compared to all timestamps of the entity types that are referenced in the query and if any of these is higher, the cached query result is discarded and the query is executed against DB. |
In default configuration, timestamps cache is asynchronously replicated. This means that a cached query on remote node can provide stale results for a brief time window before the remote timestamps cache is updated. However, requiring synchronous RPC would result in severe performance degradation.
Further, but possibly outdated information can be found in Infinispan documentation.
14. Interceptors and events
It is useful for the application to react to certain events that occur inside Hibernate. This allows for the implementation of generic functionality and the extension of Hibernate functionality.
14.1. Interceptors
The org.hibernate.Interceptor interface provides callbacks from the session to the application,
allowing the application to inspect and/or manipulate properties of a persistent object before it is saved, updated, deleted or loaded.
One possible use for this is to track auditing information.
The following example shows an Interceptor implementation that automatically logs when an entity is updated.
public static class LoggingInterceptor extends EmptyInterceptor {
@Override
public boolean onFlushDirty(
Object entity,
Serializable id,
Object[] currentState,
Object[] previousState,
String[] propertyNames,
Type[] types) {
LOGGER.debugv( "Entity {0}#{1} changed from {2} to {3}",
entity.getClass().getSimpleName(),
id,
Arrays.toString( previousState ),
Arrays.toString( currentState )
);
return super.onFlushDirty( entity, id, currentState,
previousState, propertyNames, types
);
}
}|
You can either implement |
An Interceptor can be either Session-scoped or SessionFactory-scoped.
A Session-scoped interceptor is specified when a session is opened.
SessionFactory sessionFactory = entityManagerFactory.unwrap( SessionFactory.class );
Session session = sessionFactory
.withOptions()
.interceptor(new LoggingInterceptor() )
.openSession();
Customer customer = session.get( Customer.class, customerId );
customer.setName( "Mr. John Doe" );
//Entity Customer#1 changed from [John Doe, 0] to [Mr. John Doe, 0]
session.flush();A SessionFactory-scoped interceptor is registered with the Configuration object prior to building the SessionFactory.
Unless a session is opened explicitly specifying the interceptor to use, the SessionFactory-scoped interceptor will be applied to all sessions opened from that SessionFactory.
SessionFactory-scoped interceptors must be thread safe.
Ensure that you do not store session-specific states since multiple sessions will use this interceptor potentially concurrently.
SessionFactory sessionFactory = new MetadataSources( new StandardServiceRegistryBuilder().build() )
.addAnnotatedClass( Customer.class )
.getMetadataBuilder()
.build()
.getSessionFactoryBuilder()
.applyInterceptor( new LoggingInterceptor() )
.build();14.2. Native Event system
If you have to react to particular events in the persistence layer, you can also use the Hibernate event architecture. The event system can be used in place of or in addition to interceptors.
Many methods of the Session interface correlate to an event type.
The full range of defined event types is declared as enum values on org.hibernate.event.spi.EventType.
When a request is made of one of these methods, the Session generates an appropriate event and passes it to the configured event listener(s) for that type.
Applications are free to implement a customization of one of the listener interfaces (i.e., the LoadEvent is processed by the registered implementation of the LoadEventListener interface), in which case their implementation would
be responsible for processing any load() requests made of the Session.
|
The listeners should be considered stateless; they are shared between requests, and should not save any state as instance variables. |
A custom listener implements the appropriate interface for the event it wants to process and/or extend one of the convenience base classes (or even the default event listeners used by Hibernate out-of-the-box as these are declared non-final for this purpose). Here is an example of a custom load event listener:
EntityManagerFactory entityManagerFactory = entityManagerFactory();
SessionFactoryImplementor sessionFactory = entityManagerFactory.unwrap( SessionFactoryImplementor.class );
sessionFactory
.getServiceRegistry()
.getService( EventListenerRegistry.class )
.prependListeners( EventType.LOAD, new SecuredLoadEntityListener() );
Customer customer = entityManager.find( Customer.class, customerId );14.3. Hibernate declarative security
Usually, declarative security in Hibernate applications is managed in a session facade layer. Hibernate allows certain actions to be authorized via JACC and JAAS. This is an optional functionality that is built on top of the event architecture.
First, you must configure the appropriate event listeners, to enable the use of JACC authorization. Again, see Event Listener Registration for the details.
Below is an example of an appropriate org.hibernate.integrator.spi.Integrator implementation for this purpose.
public static class JaccIntegrator implements ServiceContributingIntegrator {
private static final Logger log = Logger.getLogger( JaccIntegrator.class );
private static final DuplicationStrategy DUPLICATION_STRATEGY =
new DuplicationStrategy() {
@Override
public boolean areMatch(Object listener, Object original) {
return listener.getClass().equals( original.getClass() ) &&
JaccSecurityListener.class.isInstance( original );
}
@Override
public Action getAction() {
return Action.KEEP_ORIGINAL;
}
};
@Override
public void prepareServices(
StandardServiceRegistryBuilder serviceRegistryBuilder) {
boolean isSecurityEnabled = serviceRegistryBuilder
.getSettings().containsKey( AvailableSettings.JACC_ENABLED );
final JaccService jaccService = isSecurityEnabled ?
new StandardJaccServiceImpl() : new DisabledJaccServiceImpl();
serviceRegistryBuilder.addService( JaccService.class, jaccService );
}
@Override
public void integrate(
Metadata metadata,
SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
doIntegration(
serviceRegistry
.getService( ConfigurationService.class ).getSettings(),
// pass no permissions here, because atm actually injecting the
// permissions into the JaccService is handled on SessionFactoryImpl via
// the org.hibernate.boot.cfgxml.spi.CfgXmlAccessService
null,
serviceRegistry
);
}
private void doIntegration(
Map properties,
JaccPermissionDeclarations permissionDeclarations,
SessionFactoryServiceRegistry serviceRegistry) {
boolean isSecurityEnabled = properties
.containsKey( AvailableSettings.JACC_ENABLED );
if ( ! isSecurityEnabled ) {
log.debug( "Skipping JACC integration as it was not enabled" );
return;
}
final String contextId = (String) properties
.get( AvailableSettings.JACC_CONTEXT_ID );
if ( contextId == null ) {
throw new IntegrationException( "JACC context id must be specified" );
}
final JaccService jaccService = serviceRegistry
.getService( JaccService.class );
if ( jaccService == null ) {
throw new IntegrationException( "JaccService was not set up" );
}
if ( permissionDeclarations != null ) {
for ( GrantedPermission declaration : permissionDeclarations
.getPermissionDeclarations() ) {
jaccService.addPermission( declaration );
}
}
final EventListenerRegistry eventListenerRegistry =
serviceRegistry.getService( EventListenerRegistry.class );
eventListenerRegistry.addDuplicationStrategy( DUPLICATION_STRATEGY );
eventListenerRegistry.prependListeners(
EventType.PRE_DELETE, new JaccPreDeleteEventListener() );
eventListenerRegistry.prependListeners(
EventType.PRE_INSERT, new JaccPreInsertEventListener() );
eventListenerRegistry.prependListeners(
EventType.PRE_UPDATE, new JaccPreUpdateEventListener() );
eventListenerRegistry.prependListeners(
EventType.PRE_LOAD, new JaccPreLoadEventListener() );
}
@Override
public void disintegrate(SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
// nothing to do
}
}You must also decide how to configure your JACC provider. Consult your JACC provider documentation.
14.4. JPA Callbacks
JPA also defines a more limited set of callbacks through annotations.
| Type | Description |
|---|---|
@PrePersist |
Executed before the entity manager persist operation is actually executed or cascaded. This call is synchronous with the persist operation. |
@PreRemove |
Executed before the entity manager remove operation is actually executed or cascaded. This call is synchronous with the remove operation. |
@PostPersist |
Executed after the entity manager persist operation is actually executed or cascaded. This call is invoked after the database INSERT is executed. |
@PostRemove |
Executed after the entity manager remove operation is actually executed or cascaded. This call is synchronous with the remove operation. |
@PreUpdate |
Executed before the database UPDATE operation. |
@PostUpdate |
Executed after the database UPDATE operation. |
@PostLoad |
Executed after an entity has been loaded into the current persistence context or an entity has been refreshed. |
There are two available approaches defined for specifying callback handling:
-
The first approach is to annotate methods on the entity itself to receive notification of particular entity life cycle event(s).
-
The second is to use a separate entity listener class. An entity listener is a stateless class with a no-arg constructor. The callback annotations are placed on a method of this class instead of the entity class. The entity listener class is then associated with the entity using the
javax.persistence.EntityListenersannotation
@Entity
@EntityListeners( LastUpdateListener.class )
public static class Person {
@Id
private Long id;
private String name;
private Date dateOfBirth;
@Transient
private long age;
private Date lastUpdate;
public void setLastUpdate(Date lastUpdate) {
this.lastUpdate = lastUpdate;
}
/**
* Set the transient property at load time based on a calculation.
* Note that a native Hibernate formula mapping is better for this purpose.
*/
@PostLoad
public void calculateAge() {
age = ChronoUnit.YEARS.between( LocalDateTime.ofInstant(
Instant.ofEpochMilli( dateOfBirth.getTime()), ZoneOffset.UTC),
LocalDateTime.now()
);
}
}
public static class LastUpdateListener {
@PreUpdate
@PrePersist
public void setLastUpdate( Person p ) {
p.setLastUpdate( new Date() );
}
}These approaches can be mixed, meaning you can use both together.
Regardless of whether the callback method is defined on the entity or on an entity listener, it must have a void-return signature.
The name of the method is irrelevant as it is the placement of the callback annotations that makes the method a callback.
In the case of callback methods defined on the entity class, the method must additionally have a no-argument signature.
For callback methods defined on an entity listener class, the method must have a single argument signature; the type of that argument can be either java.lang.Object (to facilitate attachment to multiple entities) or the specific entity type.
A callback method can throw a RuntimeException.
If the callback method does throw a RuntimeException, then the current transaction, if any, must be rolled back.
A callback method must not invoke EntityManager or Query methods!
It is possible that multiple callback methods are defined for a particular lifecycle event. When that is the case, the defined order of execution is well defined by the JPA spec (specifically section 3.5.4):
-
Any default listeners associated with the entity are invoked first, in the order they were specified in the XML. See the
javax.persistence.ExcludeDefaultListenersannotation. -
Next, entity listener class callbacks associated with the entity hierarchy are invoked, in the order they are defined in the
EntityListeners. If multiple classes in the entity hierarchy define entity listeners, the listeners defined for a superclass are invoked before the listeners defined for its subclasses. See the `javax.persistence.ExcludeSuperclassListener`s annotation. -
Lastly, callback methods defined on the entity hierarchy are invoked. If a callback type is annotated on both an entity and one or more of its superclasses without method overriding, both would be called, the most general superclass first. An entity class is also allowed to override a callback method defined in a superclass in which case the super callback would not get invoked; the overriding method would get invoked provided it is annotated.
15. HQL and JPQL
The Hibernate Query Language (HQL) and Java Persistence Query Language (JPQL) are both object model focused query languages similar in nature to SQL. JPQL is a heavily-inspired-by subset of HQL. A JPQL query is always a valid HQL query, the reverse is not true however.
Both HQL and JPQL are non-type-safe ways to perform query operations. Criteria queries offer a type-safe approach to querying. See Criteria for more information.
15.1. Query API
15.2. Examples domain model
To better understand the further HQL and JPQL examples, it’s time to familiarize the domain model entities that are used in all the examples features in this chapter.
@NamedQueries(
@NamedQuery(
name = "get_person_by_name",
query = "select p from Person p where name = :name"
)
)
@Entity
public class Person {
@Id
@GeneratedValue
private Long id;
private String name;
private String nickName;
private String address;
@Temporal(TemporalType.TIMESTAMP )
private Date createdOn;
@OneToMany(mappedBy = "person", cascade = CascadeType.ALL)
@OrderColumn(name = "order_id")
private List<Phone> phones = new ArrayList<>();
@ElementCollection
@MapKeyEnumerated(EnumType.STRING)
private Map<AddressType, String> addresses = new HashMap<>();
@Version
private int version;
//Getters and setters are omitted for brevity
}
public enum AddressType {
HOME,
OFFICE
}
@Entity
public class Partner {
@Id
@GeneratedValue
private Long id;
private String name;
@Version
private int version;
//Getters and setters are omitted for brevity
}
@Entity
public class Phone {
@Id
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
private Person person;
@Column(name = "phone_number")
private String number;
@Enumerated(EnumType.STRING)
@Column(name = "phone_type")
private PhoneType type;
@OneToMany(mappedBy = "phone", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Call> calls = new ArrayList<>( );
@OneToMany(mappedBy = "phone")
@MapKey(name = "timestamp")
@MapKeyTemporal(TemporalType.TIMESTAMP )
private Map<Date, Call> callHistory = new HashMap<>();
@ElementCollection
private List<Date> repairTimestamps = new ArrayList<>( );
//Getters and setters are omitted for brevity
}
public enum PhoneType {
LAND_LINE,
MOBILE;
}
@Entity
@Table(name = "phone_call")
public class Call {
@Id
@GeneratedValue
private Long id;
@ManyToOne
private Phone phone;
@Column(name = "call_timestamp")
private Date timestamp;
private int duration;
//Getters and setters are omitted for brevity
}
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
public class Payment {
@Id
@GeneratedValue
private Long id;
private BigDecimal amount;
private boolean completed;
@ManyToOne
private Person person;
//Getters and setters are omitted for brevity
}
@Entity
public class CreditCardPayment extends Payment {
}
@Entity
public class WireTransferPayment extends Payment {
}15.3. JPA Query API
In JPA the query is represented by javax.persistence.Query or javax.persistence.TypedQuery as obtained from the EntityManager.
The create an inline Query or TypedQuery, you need to use the EntityManager#createQuery method.
For named queries, the EntityManager#createNamedQuery method is needed.
Query or a TypedQuery referenceQuery query = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name"
);
TypedQuery<Person> typedQuery = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name", Person.class
);Query or a TypedQuery reference for a named query@NamedQueries(
@NamedQuery(
name = "get_person_by_name",
query = "select p from Person p where name = :name"
)
)
Query query = entityManager.createNamedQuery( "get_person_by_name" );
TypedQuery<Person> typedQuery = entityManager.createNamedQuery(
"get_person_by_name", Person.class
);The Query interface can then be used to control the execution of the query.
For example, we may want to specify an execution timeout or control caching.
Query usageQuery query = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
// timeout - in milliseconds
.setHint( "javax.persistence.query.timeout", 2000 )
// flush only at commit time
.setFlushMode( FlushModeType.COMMIT );For complete details, see the Query Javadocs.
Many of the settings controlling the execution of the query are defined as hints.
JPA defines some standard hints (like timeout in the example), but most are provider specific.
Relying on provider specific hints limits your applications portability to some degree.
javax.persistence.query.timeout-
Defines the query timeout, in milliseconds.
javax.persistence.fetchgraph-
Defines a fetchgraph EntityGraph. Attributes explicitly specified as
AttributeNodesare treated asFetchType.EAGER(via join fetch or subsequent select). For details, see the EntityGraph discussions in Fetching. javax.persistence.loadgraph-
Defines a loadgraph EntityGraph. Attributes explicitly specified as AttributeNodes are treated as
FetchType.EAGER(via join fetch or subsequent select). Attributes that are not specified are treated asFetchType.LAZYorFetchType.EAGERdepending on the attribute’s definition in metadata. For details, see the EntityGraph discussions in Fetching. org.hibernate.cacheMode-
Defines the
CacheModeto use. Seeorg.hibernate.Query#setCacheMode. org.hibernate.cacheable-
Defines whether the query is cacheable. true/false. See
org.hibernate.Query#setCacheable. org.hibernate.cacheRegion-
For queries that are cacheable, defines a specific cache region to use. See
org.hibernate.Query#setCacheRegion. org.hibernate.comment-
Defines the comment to apply to the generated SQL. See
org.hibernate.Query#setComment. org.hibernate.fetchSize-
Defines the JDBC fetch-size to use. See
org.hibernate.Query#setFetchSize org.hibernate.flushMode-
Defines the Hibernate-specific
FlushModeto use. Seeorg.hibernate.Query#setFlushMode.If possible, prefer usingjavax.persistence.Query#setFlushModeinstead. org.hibernate.readOnly-
Defines that entities and collections loaded by this query should be marked as read-only. See
org.hibernate.Query#setReadOnly
The final thing that needs to happen before the query can be executed is to bind the values for any defined parameters.
JPA defines a simplified set of parameter binding methods.
Essentially it supports setting the parameter value (by name/position) and a specialized form for Calendar/Date types additionally accepting a TemporalType.
Query query = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" );
// For generic temporal field types (e.g. `java.util.Date`, `java.util.Calendar`)
// we also need to provide the associated `TemporalType`
Query query = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.createdOn > :timestamp" )
.setParameter( "timestamp", timestamp, TemporalType.DATE );JPQL-style positional parameters are declared using a question mark followed by an ordinal - ?1, ?2.
The ordinals start with 1.
Just like with named parameters, positional parameters can also appear multiple times in a query.
Query query = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like ?1" )
.setParameter( 1, "J%" );|
It’s good practice not to mix forms in a given query. |
In terms of execution, JPA Query offers 2 different methods for retrieving a result set.
-
Query#getResultList()- executes the select query and returns back the list of results. -
Query#getSingleResult()- executes the select query and returns a single result. If there were more than one result an exception is thrown.
getResultList() resultList<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" )
.getResultList();getSingleResult()Person person = (Person) entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" )
.getSingleResult();15.4. Hibernate Query API
In Hibernate, the HQL query is represented as org.hibernate.Query which is obtained from a Session.
If the HQL is a named query, Session#getNamedQuery would be used; otherwise Session#createQuery is needed.
Queryorg.hibernate.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name"
);Query reference for a named queryorg.hibernate.Query query = session.getNamedQuery( "get_person_by_name" );|
Not only was the JPQL syntax heavily inspired by HQL, but many of the JPA APIs were heavily inspired by Hibernate too.
The two |
The Query interface can then be used to control the execution of the query. For example, we may want to specify an execution timeout or control caching.
org.hibernate.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
// timeout - in seconds
.setTimeout( 2 )
// write to L2 caches, but do not read from them
.setCacheMode( CacheMode.REFRESH )
// assuming query cache was enabled for the SessionFactory
.setCacheable( true )
// add a comment to the generated SQL if enabled via the hibernate.use_sql_comments configuration property
.setComment( "+ INDEX(p idx_person_name)" );For complete details, see the Query Javadocs.
|
Query hints here are database query hints.
They are added directly to the generated SQL according to |
Flushing is covered in detail in Flushing. Locking is covered in detail in Locking. The concept of read-only state is covered in Persistence Contexts.
Hibernate also allows an application to hook into the process of building the query results via the org.hibernate.transform.ResultTransformer contract.
See its Javadocs as well as the Hibernate-provided implementations for additional details.
The last thing that needs to happen before we can execute the query is to bind the values for any parameters defined in the query. Query defines many overloaded methods for this purpose. The most generic form takes the value as well as the Hibernate Type.
org.hibernate.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%", StringType.INSTANCE );Hibernate generally understands the expected type of the parameter given its context in the query.
In the previous example since we are using the parameter in a LIKE comparison against a String-typed attribute Hibernate would automatically infer the type; so the above could be simplified.
org.hibernate.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setParameter( "name", "J%" );There are also short hand forms for binding common types such as strings, booleans, integers, etc.
org.hibernate.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name " +
" and p.createdOn > :timestamp" )
.setString( "name", "J%" )
.setTimestamp( "timestamp", timestamp );HQL-style positional parameters follow JDBC positional parameter syntax.
They are declared using ? without a following ordinal.
There is no way to relate two such positional parameters as being "the same" aside from binding the same value to each.
org.hibernate.Query query = session.createQuery(
"select p " +
"from Person p " +
"where p.name like ? " )
.setParameter( 0, "J%" );|
This form should be considered deprecated and may be removed in the near future. |
In terms of execution, Hibernate offers 4 different methods. The 2 most commonly used are
-
Query#list- executes the select query and returns back the list of results. -
Query#uniqueResult- executes the select query and returns the single result. If there were more than one result an exception is thrown.
list() resultList<Person> persons = session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setString( "name", "J%" )
.list();uniqueResult()Person person = (Person) session.createQuery(
"select p " +
"from Person p " +
"where p.name like :name" )
.setString( "name", "J%" )
.uniqueResult();|
If the unique result is used often and the attributes upon which it is based are unique, you may want to consider mapping a natural-id and using the natural-id loading API. See the Natural Ids for more information on this topic. |
Hibernate offers 2 additional, specialized methods for performing the query and handling results.
Query#scroll works in tandem with the JDBC notion of a scrollable ResultSet.
The scroll method is overloaded.
-
Then main form accepts a single argument of type
org.hibernate.ScrollModewhich indicates the type of scrolling to be used. See the Javadocs for the details on each. -
The second form takes no argument and will use the
ScrollModeindicated byDialect#defaultScrollMode.Query#scrollreturns aorg.hibernate.ScrollableResultswhich wraps the underlying JDBC (scrollable)ResultSetand provides access to the results. Since this form holds the JDBCResultSetopen, the application should indicate when it is done with theScrollableResultsby calling itsclose()method (as inherited fromjava.io.Closeableso thatScrollableResultswill work with try-with-resources blocks!). If left unclosed by the application, Hibernate will automatically close theScrollableResultswhen the current transaction completes.
|
If you plan to use |
The last is Query#iterate, which is intended for loading entities which the application feels certain will be in the second-level cache.
The idea behind iterate is that just the matching identifiers will be obtained in the SQL query.
From these the identifiers are resolved by second-level cache lookup.
If these second-level cache lookups fail, additional queries will need to be issued against the database.
|
This operation can perform significantly better for loading large numbers of entities that for certain already exist in the second-level cache. In cases where many of the entities do not exist in the second-level cache, this operation will almost definitely perform worse. |
The Iterator returned from Query#iterate is actually a specially typed Iterator: org.hibernate.engine.HibernateIterator.
It is specialized to expose a close() method (again, inherited from java.io.Closeable).
When you are done with this Iterator you should close it, either by casting to HibernateIterator or Closeable, or by calling Hibernate#close(java.util.Iterator).
15.5. Case Sensitivity
With the exception of names of Java classes and properties, queries are case-insensitive.
So SeLeCT is the same as sELEct is the same as SELECT, but org.hibernate.eg.FOO and org.hibernate.eg.Foo are different, as are foo.barSet and foo.BARSET.
|
This documentation uses lowercase keywords as convention in examples. |
15.6. Statement types
Both HQL and JPQL allow SELECT, UPDATE and DELETE statements to be performed.
HQL additionally allows INSERT statements, in a form similar to a SQL INSERT FROM SELECT.
|
Care should be taken as to when a
— Section 4.10 of the JPA 2.0 Specification
|
15.7. Select statements
The BNF for SELECT statements in HQL is:
select_statement :: =
[select_clause]
from_clause
[where_clause]
[groupby_clause]
[having_clause]
[orderby_clause]The simplest possible HQL SELECT statement is of the form:
List<Person> persons = session.createQuery(
"from Person" )
.list();|
The select statement in JPQL is exactly the same as for HQL except that JPQL requires a Even though HQL does not require the presence of a It is usually better to explicitly specify intent.
Hibernate does not actually enforce that a |
15.8. Update statements
The BNF for UPDATE statements is the same in HQL and JPQL:
update_statement ::=
update_clause [where_clause]
update_clause ::=
UPDATE entity_name [[AS] identification_variable]
SET update_item {, update_item}*
update_item ::=
[identification_variable.]{state_field | single_valued_object_field} = new_value
new_value ::=
scalar_expression | simple_entity_expression | NULLUPDATE statements, by default, do not effect the version or the timestamp attribute values for the affected entities.
However, you can force Hibernate to set the version or timestamp attribute values through the use of a versioned update.
This is achieved by adding the VERSIONED keyword after the UPDATE keyword.
|
This is a Hibernate specific feature and will not work in a portable manner. Custom version types, |
An UPDATE statement is executed using the executeUpdate() of either org.hibernate.Query or javax.persistence.Query.
The method is named for those familiar with the JDBC executeUpdate() on java.sql.PreparedStatement.
The int value returned by the executeUpdate() method indicates the number of entities effected by the operation.
This may or may not correlate to the number of rows effected in the database.
An HQL bulk operation might result in multiple actual SQL statements being executed (for joined-subclass, for example).
The returned number indicates the number of actual entities affected by the statement.
Using a JOINED inheritance hierarchy, a delete against one of the subclasses may actually result in deletes against not just the table to which that subclass is mapped, but also the "root" table and tables "in between".
int updatedEntities = entityManager.createQuery(
"update Person p " +
"set p.name = :newName " +
"where p.name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();
int updatedEntities = session.createQuery(
"update Person " +
"set name = :newName " +
"where name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();
int updatedEntities = session.createQuery(
"update versioned Person " +
"set name = :newName " +
"where name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();|
Neither |
15.9. Delete statements
The BNF for DELETE statements is the same in HQL and JPQL:
delete_statement ::=
delete_clause [where_clause]
delete_clause ::=
DELETE FROM entity_name [[AS] identification_variable]A DELETE statement is also executed using the executeUpdate() method of either org.hibernate.Query or javax.persistence.Query.
15.10. Insert statements
HQL adds the ability to define INSERT statements as well.
|
There is no JPQL equivalent to this. |
The BNF for an HQL INSERT statement is:
insert_statement ::=
insert_clause select_statement
insert_clause ::=
INSERT INTO entity_name (attribute_list)
attribute_list ::=
state_field[, state_field ]*The attribute_list is analogous to the column specification in the SQL INSERT statement.
For entities involved in mapped inheritance, only attributes directly defined on the named entity can be used in the attribute_list.
Superclass properties are not allowed and subclass properties do not make sense.
In other words, INSERT statements are inherently non-polymorphic.
select_statement can be any valid HQL select query, with the caveat that the return types must match the types expected by the insert.
Currently, this is checked during query compilation rather than allowing the check to relegate to the database.
This may cause problems between Hibernate Types which are equivalent as opposed to equal.
For example, this might cause lead to issues with mismatches between an attribute mapped as a org.hibernate.type.DateType and an attribute defined as a org.hibernate.type.TimestampType,
even though the database might not make a distinction or might be able to handle the conversion.
For the id attribute, the insert statement gives you two options.
You can either explicitly specify the id property in the attribute_list, in which case its value is taken from the corresponding select expression, or omit it from the attribute_list in which case a generated value is used.
This latter option is only available when using id generators that operate "in the database"; attempting to use this option with any "in memory" type generators will cause an exception during parsing.
For optimistic locking attributes, the insert statement again gives you two options.
You can either specify the attribute in the attribute_list in which case its value is taken from the corresponding select expressions, or omit it from the attribute_list in which case the seed value defined by the corresponding org.hibernate.type.VersionType is used.
int insertedEntities = session.createQuery(
"insert into Partner (id, name) " +
"select p.id, p.name " +
"from Person p ")
.executeUpdate();15.11. The FROM clause
The FROM clause is responsible defining the scope of object model types available to the rest of the query.
It also is responsible for defining all the "identification variables" available to the rest of the query.
15.12. Identification variables
Identification variables are often referred to as aliases.
References to object model classes in the FROM clause can be associated with an identification variable that can then be used to refer to that type throughout the rest of the query.
In most cases declaring an identification variable is optional, though it is usually good practice to declare them.
An identification variable must follow the rules for Java identifier validity.
According to JPQL, identification variables must be treated as case-insensitive. Good practice says you should use the same case throughout a query to refer to a given identification variable. In other words, JPQL says they can be case-insensitive and so Hibernate must be able to treat them as such, but this does not make it good practice.
15.13. Root entity references
A root entity reference, or what JPA calls a range variable declaration, is specifically a reference to a mapped entity type from the application.
It cannot name component/ embeddable types.
And associations, including collections, are handled in a different manner, as later discussed.
The BNF for a root entity reference is:
root_entity_reference ::=
entity_name [AS] identification_variableList<Person> persons = entityManager.createQuery(
"select p " +
"from org.hibernate.userguide.model.Person p", Person.class )
.getResultList();We see that the query is defining a root entity reference to the org.hibernate.userguide.model.Person object model type.
Additionally, it declares an alias of p to that org.hibernate.userguide.model.Person reference, which is the identification variable.
Usually, the root entity reference represents just the entity name rather than the entity class FQN (fully-qualified name).
By default, the entity name is the unqualified entity class name, here Person
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p", Person.class )
.getResultList();Multiple root entity references can also be specified, even when naming the same entity.
List<Object[]> persons = entityManager.createQuery(
"select distinct pr, ph " +
"from Person pr, Phone ph " +
"where ph.person = pr and ph is not null", Object[].class)
.getResultList();List<Person> persons = entityManager.createQuery(
"select distinct pr1 " +
"from Person pr1, Person pr2 " +
"where pr1.id <> pr2.id " +
" and pr1.address = pr2.address " +
" and pr1.createdOn < pr2.createdOn", Person.class )
.getResultList();15.14. Explicit joins
The FROM clause can also contain explicit relationship joins using the join keyword.
These joins can be either inner or left outer style joins.
List<Person> persons = entityManager.createQuery(
"select distinct pr " +
"from Person pr " +
"join pr.phones ph " +
"where ph.type = :phoneType", Person.class )
.setParameter( "phoneType", PhoneType.MOBILE )
.getResultList();
// same query but specifying join type as 'inner' explicitly
List<Person> persons = entityManager.createQuery(
"select distinct pr " +
"from Person pr " +
"inner join pr.phones ph " +
"where ph.type = :phoneType", Person.class )
.setParameter( "phoneType", PhoneType.MOBILE )
.getResultList();List<Person> persons = entityManager.createQuery(
"select distinct pr " +
"from Person pr " +
"left join pr.phones ph " +
"where ph is null " +
" or ph.type = :phoneType", Person.class )
.setParameter( "phoneType", PhoneType.LAND_LINE )
.getResultList();
// functionally the same query but using the 'left outer' phrase
List<Person> persons = entityManager.createQuery(
"select distinct pr " +
"from Person pr " +
"left outer join pr.phones ph " +
"where ph is null " +
" or ph.type = :phoneType", Person.class )
.setParameter( "phoneType", PhoneType.LAND_LINE )
.getResultList();HQL also defines a WITH clause to qualify the join conditions.
|
This is specific to HQL. JPQL defines the |
WITH clause join exampleList<Object[]> personsAndPhones = session.createQuery(
"select pr.name, ph.number " +
"from Person pr " +
"left join pr.phones ph with ph.type = :phoneType " )
.setParameter( "phoneType", PhoneType.LAND_LINE )
.list();ON clause join exampleList<Object[]> personsAndPhones = entityManager.createQuery(
"select pr.name, ph.number " +
"from Person pr " +
"left join pr.phones ph on ph.type = :phoneType " )
.setParameter( "phoneType", PhoneType.LAND_LINE )
.getResultList();|
The important distinction is that in the generated SQL the conditions of the |
The distinction in this specific example is probably not that significant.
The with clause is sometimes necessary for more complicated queries.
Explicit joins may reference association or component/embedded attributes. In the case of component/embedded attributes, the join is simply logical and does not correlate to a physical (SQL) join. For further information about collection-valued association references, see Collection member references.
An important use case for explicit joins is to define FETCH JOINS which override the laziness of the joined association.
As an example, given an entity named Person with a collection-valued association named phones, the JOIN FETCH will also load the child collection in the same SQL query:
// functionally the same query but using the 'left outer' phrase
List<Person> persons = entityManager.createQuery(
"select distinct pr " +
"from Person pr " +
"left join fetch pr.phones ", Person.class )
.getResultList();As you can see from the example, a fetch join is specified by injecting the keyword fetch after the keyword join.
In the example, we used a left outer join because we also wanted to return customers who have no orders.
Inner joins can also be fetched, but inner joins filter out the root entity. In the example, using an inner join instead would have resulted in customers without any orders being filtered out of the result.
|
Fetch joins are not valid in sub-queries. Care should be taken when fetch joining a collection-valued association which is in any way further restricted (the fetched collection will be restricted too). For this reason, it is usually considered best practice not to assign an identification variable to fetched joins except for the purpose of specifying nested fetch joins. Fetch joins should not be used in paged queries (e.g. |
15.15. Implicit joins (path expressions)
Another means of adding to the scope of object model types available to the query is through the use of implicit joins or path expressions.
List<Phone> phones = entityManager.createQuery(
"select ph " +
"from Phone ph " +
"where ph.person.address = :address ", Phone.class )
.setParameter( "address", address )
.getResultList();
// same as
List<Phone> phones = entityManager.createQuery(
"select ph " +
"from Phone ph " +
"join ph.person pr " +
"where pr.address = :address ", Phone.class )
.setParameter( "address", address)
.getResultList();An implicit join always starts from an identification variable, followed by the navigation operator ( . ),
followed by an attribute for the object model type referenced by the initial identification variable.
In the example, the initial identification variable is ph which refers to the Phone entity.
The ph.person reference then refers to the person attribute of the Phone entity.
person is an association type so we further navigate to its age attribute.
|
If the attribute represents an entity association (non-collection) or a component/embedded, that reference can be further navigated. Basic values and collection-valued associations cannot be further navigated. |
As shown in the example, implicit joins can appear outside the FROM clause.
However, they affect the FROM clause.
|
Implicit joins are always treated as inner joins. Multiple references to the same implicit join always refer to the same logical and physical (SQL) join. |
List<Phone> phones = entityManager.createQuery(
"select ph " +
"from Phone ph " +
"where ph.person.address = :address " +
" and ph.person.createdOn > :timestamp", Phone.class )
.setParameter( "address", address )
.setParameter( "timestamp", timestamp )
.getResultList();
//same as
List<Phone> phones = entityManager.createQuery(
"select ph " +
"from Phone ph " +
"inner join ph.person pr " +
"where pr.address = :address " +
" and pr.createdOn > :timestamp", Phone.class )
.setParameter( "address", address )
.setParameter( "timestamp", timestamp )
.getResultList();Just as with explicit joins, implicit joins may reference association or component/embedded attributes. For further information about collection-valued association references, see Collection member references.
In the case of component/embedded attributes, the join is simply logical and does not correlate to a physical (SQL) join. Unlike explicit joins, however, implicit joins may also reference basic state fields as long as the path expression ends there.
15.16. Collection member references
References to collection-valued associations actually refer to the values of that collection.
List<Phone> phones = entityManager.createQuery(
"select ph " +
"from Person pr " +
"join pr.phones ph " +
"join ph.calls c " +
"where pr.address = :address " +
" and c.duration > :duration", Phone.class )
.setParameter( "address", address )
.setParameter( "duration", duration )
.getResultList();
// alternate syntax
List<Phone> phones = session.createQuery(
"select pr " +
"from Person pr, " +
"in (pr.phones) ph, " +
"in (ph.calls) c " +
"where pr.address = :address " +
" and c.duration > :duration" )
.setParameter( "address", address )
.setParameter( "duration", duration )
.list();In the example, the identification variable ph actually refers to the object model type Phone, which is the type of the elements of the Person#phones association.
The example also shows the alternate syntax for specifying collection association joins using the IN syntax.
Both forms are equivalent.
Which form an application chooses to use is simply a matter of taste.
15.17. Special case - qualified path expressions
We said earlier that collection-valued associations actually refer to the values of that collection. Based on the type of collection, there are also available a set of explicit qualification expressions.
@OneToMany(mappedBy = "phone")
@MapKey(name = "timestamp")
@MapKeyTemporal(TemporalType.TIMESTAMP )
private Map<Date, Call> callHistory = new HashMap<>();
// select all the calls (the map value) for a given Phone
List<Call> calls = entityManager.createQuery(
"select ch " +
"from Phone ph " +
"join ph.callHistory ch " +
"where ph.id = :id ", Call.class )
.setParameter( "id", id )
.getResultList();
// same as above
List<Call> calls = entityManager.createQuery(
"select value(ch) " +
"from Phone ph " +
"join ph.callHistory ch " +
"where ph.id = :id ", Call.class )
.setParameter( "id", id )
.getResultList();
// select all the Call timestamps (the map key) for a given Phone
List<Date> timestamps = entityManager.createQuery(
"select key(ch) " +
"from Phone ph " +
"join ph.callHistory ch " +
"where ph.id = :id ", Date.class )
.setParameter( "id", id )
.getResultList();
// select all the Call and their timestamps (the 'Map.Entry') for a given Phone
List<Map.Entry<Date, Call>> callHistory = entityManager.createQuery(
"select entry(ch) " +
"from Phone ph " +
"join ph.callHistory ch " +
"where ph.id = :id " )
.setParameter( "id", id )
.getResultList();
// Sum all call durations for a given Phone of a specific Person
Long duration = entityManager.createQuery(
"select sum(ch.duration) " +
"from Person pr " +
"join pr.phones ph " +
"join ph.callHistory ch " +
"where ph.id = :id " +
" and index(ph) = :phoneIndex", Long.class )
.setParameter( "id", id )
.setParameter( "phoneIndex", phoneIndex )
.getSingleResult();- VALUE
-
Refers to the collection value. Same as not specifying a qualifier. Useful to explicitly show intent. Valid for any type of collection-valued reference.
- INDEX
-
According to HQL rules, this is valid for both
MapsandListswhich specify ajavax.persistence.OrderColumnannotation to refer to theMapkey or theListposition (aka theOrderColumnvalue). JPQL however, reserves this for use in theListcase and addsKEYfor theMapcase. Applications interested in JPA provider portability should be aware of this distinction. - KEY
-
Valid only for
Maps. Refers to the map’s key. If the key is itself an entity, it can be further navigated. - ENTRY
-
Only valid for
Maps. Refers to the map’s logicaljava.util.Map.Entrytuple (the combination of its key and value).ENTRYis only valid as a terminal path and it’s applicable to theSELECTclause only.
See Collection-related expressions for additional details on collection related expressions.
15.18. Polymorphism
HQL and JPQL queries are inherently polymorphic.
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p ", Payment.class )
.getResultList();This query names the Payment entity explicitly.
However, all subclasses of Payment are also available to the query.
So if the CreditCardPayment and WireTransferPayment entities extend the Payment class, all three types would be available to the entity query,
and the query would return instances of all three.
|
This can be altered by using either the The HQL query |
15.19. Expressions
Essentially expressions are references that resolve to basic or tuple values.
15.20. Identification variable
See The FROM clause.
15.21. Path expressions
Again, see The FROM clause.
15.22. Literals
String literals are enclosed in single quotes. To escape a single quote within a string literal, use double single quotes.
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like 'Joe'", Person.class)
.getResultList();
// Escaping quotes
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like 'Joe''s'", Person.class)
.getResultList();Numeric literals are allowed in a few different forms.
// simple integer literal
Person person = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.id = 1", Person.class)
.getSingleResult();
// simple integer literal, typed as a long
Person person = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.id = 1L", Person.class)
.getSingleResult();
// decimal notation
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration > 100.5", Call.class )
.getResultList();
// decimal notation, typed as a float
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration > 100.5F", Call.class )
.getResultList();
// scientific notation
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration > 1e+2", Call.class )
.getResultList();
// scientific notation, typed as a float
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration > 1e+2F", Call.class )
.getResultList();|
In the scientific notation form, the Specific typing can be achieved through the use of the same suffix approach specified by Java.
So, The boolean literals are Enums can even be referenced as literals. The fully-qualified enum class name must be used. HQL can also handle constants in the same manner, though JPQL does not define that as supported. Entity names can also be used as literal. See Entity type. Date/time literals can be specified using the JDBC escape syntax:
These Date/time literals only work if you JDBC drivers supports them. |
15.23. Arithmetic
Arithmetic operations also represent valid expressions.
// select clause date/time arithmetic operations
Long duration = entityManager.createQuery(
"select sum(ch.duration) * :multiplier " +
"from Person pr " +
"join pr.phones ph " +
"join ph.callHistory ch " +
"where ph.id = 1L ", Long.class )
.setParameter( "multiplier", 1000L )
.getSingleResult();
// select clause date/time arithmetic operations
Integer years = entityManager.createQuery(
"select year( current_date() ) - year( p.createdOn ) " +
"from Person p " +
"where p.id = 1L", Integer.class )
.getSingleResult();
// where clause arithmetic operations
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where year( current_date() ) - year( p.createdOn ) > 1", Person.class )
.getResultList();The following rules apply to the result of arithmetic operations:
-
If either of the operands is
Double/double, the result is aDouble -
else, if either of the operands is
Float/float, the result is aFloat -
else, if either operand is
BigDecimal, the result isBigDecimal -
else, if either operand is
BigInteger, the result isBigInteger(except for division, in which case the result type is not further defined) -
else, if either operand is
Long/long, the result isLong(except for division, in which case the result type is not further defined) -
else, (the assumption being that both operands are of integral type) the result is
Integer(except for division, in which case the result type is not further defined)
Date arithmetic is also supported, albeit in a more limited fashion.
This is due partially to differences in database support and partially to the lack of support for INTERVAL definition in the query language itself.
15.24. Concatenation (operation)
HQL defines a concatenation operator in addition to supporting the concatenation (CONCAT) function.
This is not defined by JPQL, so portable applications should avoid it use.
The concatenation operator is taken from the SQL concatenation operator (e.g ||).
String name = entityManager.createQuery(
"select 'Customer ' || p.name " +
"from Person p " +
"where p.id = 1", String.class )
.getSingleResult();See Scalar functions for details on the concat() function
15.25. Aggregate functions
Aggregate functions are also valid expressions in HQL and JPQL. The semantic is the same as their SQL counterpart. The supported aggregate functions are:
COUNT(including distinct/all qualifiers)-
The result type is always
Long. AVG-
The result type is always
Double. MIN-
The result type is the same as the argument type.
MAX-
The result type is the same as the argument type.
SUM-
The result type of the
SUM()function depends on the type of the values being summed. For integral values (other thanBigInteger), the result type isLong.
For floating point values (other than BigDecimal) the result type is Double.
For BigInteger values, the result type is BigInteger. For BigDecimal values, the result type is BigDecimal.
Object[] callStatistics = entityManager.createQuery(
"select " +
" count(c), " +
" sum(c.duration), " +
" min(c.duration), " +
" max(c.duration), " +
" avg(c.duration) " +
"from Call c ", Object[].class )
.getSingleResult();
Long phoneCount = entityManager.createQuery(
"select count( distinct c.phone ) " +
"from Call c ", Long.class )
.getSingleResult();
List<Object[]> callCount = entityManager.createQuery(
"select p.number, count(c) " +
"from Call c " +
"join c.phone p " +
"group by p.number", Object[].class )
.getResultList();Aggregations often appear with grouping. For information on grouping see Group by.
15.26. Scalar functions
Both HQL and JPQL define some standard functions that are available regardless of the underlying database in use. HQL can also understand additional functions defined by the Dialect as well as the application.
15.27. JPQL standardized functions
Here is the list of functions defined as supported by JPQL. Applications interested in remaining portable between JPA providers should stick to these functions.
- CONCAT
-
String concatenation function. Variable argument length of 2 or more string values to be concatenated together.
List<String> callHistory = entityManager.createQuery(
"select concat( p.number, ' : ' ,c.duration ) " +
"from Call c " +
"join c.phone p", String.class )
.getResultList();- SUBSTRING
-
Extracts a portion of a string value. The second argument denotes the starting position. The third (optional) argument denotes the length.
List<String> prefixes = entityManager.createQuery(
"select substring( p.number, 0, 2 ) " +
"from Call c " +
"join c.phone p", String.class )
.getResultList();- UPPER
-
Upper cases the specified string
List<String> names = entityManager.createQuery(
"select upper( p.name ) " +
"from Person p ", String.class )
.getResultList();- LOWER
-
Lower cases the specified string
List<String> names = entityManager.createQuery(
"select lower( p.name ) " +
"from Person p ", String.class )
.getResultList();- TRIM
-
Follows the semantics of the SQL trim function.
List<String> names = entityManager.createQuery(
"select trim( p.name ) " +
"from Person p ", String.class )
.getResultList();- LENGTH
-
Returns the length of a string.
List<Integer> lengths = entityManager.createQuery(
"select length( p.name ) " +
"from Person p ", Integer.class )
.getResultList();- LOCATE
-
Locates a string within another string. The third argument (optional) is used to denote a position from which to start looking.
List<Integer> sizes = entityManager.createQuery(
"select locate( 'John', p.name ) " +
"from Person p ", Integer.class )
.getResultList();- ABS
-
Calculates the mathematical absolute value of a numeric value.
List<Integer> abs = entityManager.createQuery(
"select abs( c.duration ) " +
"from Call c ", Integer.class )
.getResultList();- MOD
-
Calculates the remainder of dividing the first argument by the second.
List<Integer> mods = entityManager.createQuery(
"select mod( c.duration, 10 ) " +
"from Call c ", Integer.class )
.getResultList();- SQRT
-
Calculates the mathematical square root of a numeric value.
List<Double> sqrts = entityManager.createQuery(
"select sqrt( c.duration ) " +
"from Call c ", Double.class )
.getResultList();- CURRENT_DATE
-
Returns the database current date.
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.timestamp = current_date", Call.class )
.getResultList();- CURRENT_TIME
-
Returns the database current time.
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.timestamp = current_time", Call.class )
.getResultList();- CURRENT_TIMESTAMP
-
Returns the database current timestamp.
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.timestamp = current_timestamp", Call.class )
.getResultList();15.28. HQL functions
Beyond the JPQL standardized functions, HQL makes some additional functions available regardless of the underlying database in use.
- BIT_LENGTH
-
Returns the length of binary data.
List<Number> bits = entityManager.createQuery(
"select bit_length( c.duration ) " +
"from Call c ", Number.class )
.getResultList();- CAST
-
Performs a SQL cast. The cast target should name the Hibernate mapping type to use. See the data types chapter on for more information.
List<String> durations = entityManager.createQuery(
"select cast( c.duration as string ) " +
"from Call c ", String.class )
.getResultList();- EXTRACT
-
Performs a SQL extraction on datetime values. An extraction extracts parts of the datetime (the year, for example).
List<Integer> years = entityManager.createQuery(
"select extract( YEAR from c.timestamp ) " +
"from Call c ", Integer.class )
.getResultList();See the abbreviated forms below.
- YEAR
-
Abbreviated extract form for extracting the year.
List<Integer> years = entityManager.createQuery(
"select year( c.timestamp ) " +
"from Call c ", Integer.class )
.getResultList();- MONTH
-
Abbreviated extract form for extracting the month.
- DAY
-
Abbreviated extract form for extracting the day.
- HOUR
-
Abbreviated extract form for extracting the hour.
- MINUTE
-
Abbreviated extract form for extracting the minute.
- SECOND
-
Abbreviated extract form for extracting the second.
- STR
-
Abbreviated form for casting a value as character data.
List<String> timestamps = entityManager.createQuery(
"select str( c.timestamp ) " +
"from Call c ", String.class )
.getResultList();15.29. Non-standardized functions
Hibernate Dialects can register additional functions known to be available for that particular database product. These functions are also available in HQL (and JPQL, though only when using Hibernate as the JPA provider obviously). However, they would only be available when using that database Dialect. Applications that aim for database portability should avoid using functions in this category.
Application developers can also supply their own set of functions.
This would usually represent either custom SQL functions or aliases for snippets of SQL.
Such function declarations are made by using the addSqlFunction() method of org.hibernate.cfg.Configuration.
15.30. Collection-related expressions
There are a few specialized expressions for working with collection-valued associations. Generally, these are just abbreviated forms or other expressions for the sake of conciseness.
- SIZE
-
Calculate the size of a collection. Equates to a subquery!
- MAXELEMENT
-
Available for use on collections of basic type. Refers to the maximum value as determined by applying the
maxSQL aggregation. - MAXINDEX
-
Available for use on indexed collections. Refers to the maximum index (key/position) as determined by applying the
maxSQL aggregation. - MINELEMENT
-
Available for use on collections of basic type. Refers to the minimum value as determined by applying the
minSQL aggregation. - MININDEX
-
Available for use on indexed collections. Refers to the minimum index (key/position) as determined by applying the
minSQL aggregation. - ELEMENTS
-
Used to refer to the elements of a collection as a whole. Only allowed in the where clause. Often used in conjunction with
ALL,ANYorSOMErestrictions. - INDICES
-
Similar to
elementsexcept thatindicesrefers to the collections indices (keys/positions) as a whole.
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where maxelement( p.calls ) = :call", Phone.class )
.setParameter( "call", call )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where minelement( p.calls ) = :call", Phone.class )
.setParameter( "call", call )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where maxindex( p.phones ) = 0", Person.class )
.getResultList();
// the above query can be re-written with member of
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where :phone member of p.phones", Person.class )
.setParameter( "phone", phone )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where :phone = some elements ( p.phones )", Person.class )
.setParameter( "phone", phone )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where exists elements ( p.phones )", Person.class )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where current_date() > key( p.callHistory )", Phone.class )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where current_date() > all elements( p.repairTimestamps )", Phone.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where 1 in indices( p.phones )", Person.class )
.getResultList();Elements of indexed collections (arrays, lists, and maps) can be referred to by index operator.
// indexed lists
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.phones[ 0 ].type = 'LAND_LINE'", Person.class )
.getResultList();
// maps
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.addresses[ 'HOME' ] = :address", Person.class )
.setParameter( "address", address)
.getResultList();
//max index in list
List<Person> persons = entityManager.createQuery(
"select pr " +
"from Person pr " +
"where pr.phones[ maxindex(pr.phones) ].type = 'LAND_LINE'", Person.class )
.getResultList();See also Special case - qualified path expressions as there is a good deal of overlap.
15.31. Entity type
We can also refer to the type of an entity as an expression.
This is mainly useful when dealing with entity inheritance hierarchies.
The type can expressed using a TYPE function used to refer to the type of an identification variable representing an entity.
The name of the entity also serves as a way to refer to an entity type.
Additionally, the entity type can be parameterized, in which case the entity’s Java Class reference would be bound as the parameter value.
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p " +
"where type(p) = CreditCardPayment", Payment.class )
.getResultList();
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p " +
"where type(p) = :type", Payment.class )
.setParameter( "type", WireTransferPayment.class)
.getResultList();|
HQL also has a legacy form of referring to an entity type, though that legacy form is considered deprecated in favor of |
15.32. CASE expressions
Both the simple and searched forms are supported, as well as the two SQL defined abbreviated forms (NULLIF and COALESCE)
15.33. Simple CASE expressions
The simple form has the following syntax:
CASE {operand} WHEN {test_value} THEN {match_result} ELSE {miss_result} ENDList<String> nickNames = entityManager.createQuery(
"select " +
" case p.nickName " +
" when 'NA' " +
" then '<no nick name>' " +
" else p.nickName " +
" end " +
"from Person p", String.class )
.getResultList();
// same as above
List<String> nickNames = entityManager.createQuery(
"select coalesce(p.nickName, '<no nick name>') " +
"from Person p", String.class )
.getResultList();15.34. Searched CASE expressions
The searched form has the following syntax:
CASE [ WHEN {test_conditional} THEN {match_result} ]* ELSE {miss_result} ENDList<String> nickNames = entityManager.createQuery(
"select " +
" case " +
" when p.nickName is null " +
" then " +
" case " +
" when p.name is null " +
" then '<no nick name>' " +
" else p.name " +
" end" +
" else p.nickName " +
" end " +
"from Person p", String.class )
.getResultList();
// coalesce can handle this more succinctly
List<String> nickNames = entityManager.createQuery(
"select coalesce( p.nickName, p.name, '<no nick name>' ) " +
"from Person p", String.class )
.getResultList();15.35. NULLIF expressions
NULLIF is an abbreviated CASE expression that returns NULL if its operands are considered equal.
List<String> nickNames = entityManager.createQuery(
"select nullif( p.nickName, p.name ) " +
"from Person p", String.class )
.getResultList();
// equivalent CASE expression
List<String> nickNames = entityManager.createQuery(
"select " +
" case" +
" when p.nickName = p.name" +
" then null" +
" else p.nickName" +
" end " +
"from Person p", String.class )
.getResultList();15.36. COALESCE expressions
COALESCE is an abbreviated CASE expression that returns the first non-null operand.
We have seen a number of COALESCE examples above.
15.37. The SELECT clause
The SELECT clause identifies which objects and values to return as the query results.
The expressions discussed in Expressions are all valid select expressions, except where otherwise noted.
See the section Hibernate Query API for information on handling the results depending on the types of values specified in the SELECT clause.
There is a particular expression type that is only valid in the select clause. Hibernate calls this "dynamic instantiation". JPQL supports some of that feature and calls it a "constructor expression".
So rather than dealing with the Object[] (again, see Hibernate Query API) here we are wrapping the values in a type-safe java object that will be returned as the results of the query.
public class CallStatistics {
private final long count;
private final long total;
private final int min;
private final int max;
private final double abg;
public CallStatistics(long count, long total, int min, int max, double abg) {
this.count = count;
this.total = total;
this.min = min;
this.max = max;
this.abg = abg;
}
//Getters and setters omitted for brevity
}
CallStatistics callStatistics = entityManager.createQuery(
"select new org.hibernate.userguide.hql.CallStatistics(" +
" count(c), " +
" sum(c.duration), " +
" min(c.duration), " +
" max(c.duration), " +
" avg(c.duration)" +
") " +
"from Call c ", CallStatistics.class )
.getSingleResult();|
The class reference must be fully qualified and it must have a matching constructor. |
|
The class here need not be mapped. If it does represent an entity, the resulting instances are returned in the NEW state (not managed!). |
HQL supports additional "dynamic instantiation" features.
First, the query can specify to return a List rather than an Object[] for scalar results:
List<List> phoneCallDurations = entityManager.createQuery(
"select new list(" +
" p.number, " +
" c.duration " +
") " +
"from Call c " +
"join c.phone p ", List.class )
.getResultList();The results from this query will be a List<List> as opposed to a List<Object[]>
HQL also supports wrapping the scalar results in a Map.
List<Map> phoneCallTotalDurations = entityManager.createQuery(
"select new map(" +
" p.number as phoneNumber , " +
" sum(c.duration) as totalDuration, " +
" avg(c.duration) as averageDuration " +
") " +
"from Call c " +
"join c.phone p " +
"group by p.number ", Map.class )
.getResultList();The results from this query will be a List<Map<String, Object>> as opposed to a List<Object[]>.
The keys of the map are defined by the aliases given to the select expressions.
If the user doesn’t assign aliases, the key will be the index of each particular result set column (e.g. 0, 1, 2, etc).
15.38. Predicates
Predicates form the basis of the where clause, the having clause and searched case expressions.
They are expressions which resolve to a truth value, generally TRUE or FALSE, although boolean comparisons involving NULL generally resolve to UNKNOWN.
15.39. Relational comparisons
Comparisons involve one of the comparison operators: =, >, >=, <, <=, <>.
HQL also defines != as a comparison operator synonymous with <>.
The operands should be of the same type.
// numeric comparison
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration < 30 ", Call.class )
.getResultList();
// string comparison
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like 'John%' ", Person.class )
.getResultList();
// datetime comparison
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.createdOn > '1950-01-01' ", Person.class )
.getResultList();
// enum comparison
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where p.type = 'MOBILE' ", Phone.class )
.getResultList();
// boolean comparison
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p " +
"where p.completed = true ", Payment.class )
.getResultList();
// boolean comparison
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p " +
"where type(p) = WireTransferPayment ", Payment.class )
.getResultList();
// entity value comparison
List<Object[]> phonePayments = entityManager.createQuery(
"select p " +
"from Payment p, Phone ph " +
"where p.person = ph.person ", Object[].class )
.getResultList();Comparisons can also involve subquery qualifiers: ALL, ANY, SOME. SOME and ANY are synonymous.
The ALL qualifier resolves to true if the comparison is true for all of the values in the result of the subquery.
It resolves to false if the subquery result is empty.
// select all persons with all calls shorter than 50 seconds
List<Person> persons = entityManager.createQuery(
"select distinct p.person " +
"from Phone p " +
"join p.calls c " +
"where 50 > all ( " +
" select duration" +
" from Call" +
" where phone = p " +
") ", Person.class )
.getResultList();The ANY/SOME qualifier resolves to true if the comparison is true for some of (at least one of) the values in the result of the subquery.
It resolves to false if the subquery result is empty.
15.40. Nullness predicate
Check a value for nullness. Can be applied to basic attribute references, entity references and parameters. HQL additionally allows it to be applied to component/embeddable types.
// select all persons with a nickname
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.nickName is not null", Person.class )
.getResultList();
// select all persons without a nickname
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.nickName is null", Person.class )
.getResultList();15.41. Like predicate
Performs a like comparison on string values. The syntax is:
like_expression ::=
string_expression
[NOT] LIKE pattern_value
[ESCAPE escape_character]The semantics follow that of the SQL like expression.
The pattern_value is the pattern to attempt to match in the string_expression.
Just like SQL, pattern_value can use _ and % as wildcards.
The meanings are the same. The _ symbol matches any single character and % matches any number of characters.
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like 'Jo%'", Person.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name not like 'Jo%'", Person.class )
.getResultList();The optional escape 'escape character' is used to specify an escape character used to escape the special meaning of _ and % in the pattern_value.
This is useful when needing to search on patterns including either _ or %.
The syntax is formed as follows: 'like_predicate' escape 'escape_symbol'
So, if | is the escape symbol and we want to match all stored procedures prefixed with Dr_, the like criteria becomes: 'Dr|_%' escape '|':
// find any person with a name starting with "Dr_"
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name like 'Dr|_%' escape '|'", Person.class )
.getResultList();15.42. Between predicate
Analogous to the SQL BETWEEN expression,
it checks if the value is within boundaries.
All the operands should have comparable types.
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"join p.phones ph " +
"where p.id = 1L and index(ph) between 0 and 3", Person.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.createdOn between '1999-01-01' and '2001-01-02'", Person.class )
.getResultList();
List<Call> calls = entityManager.createQuery(
"select c " +
"from Call c " +
"where c.duration between 5 and 20", Call.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.name between 'H' and 'M'", Person.class )
.getResultList();15.43. In predicate
IN predicates performs a check that a particular value is in a list of values. Its syntax is:
in_expression ::=
single_valued_expression [NOT] IN single_valued_list
single_valued_list ::=
constructor_expression | (subquery) | collection_valued_input_parameter
constructor_expression ::= (expression[, expression]*)The types of the single_valued_expression and the individual values in the single_valued_list must be consistent.
JPQL limits the valid types here to string, numeric, date, time, timestamp, and enum types, and , in JPQL, single_valued_expression can only refer to:
-
"state fields", which is its term for simple attributes. Specifically this excludes association and component/embedded attributes.
-
entity type expressions. See Entity type
In HQL, single_valued_expression can refer to a far more broad set of expression types.
Single-valued association are allowed, and so are component/embedded attributes, although that feature depends on the level of support for tuple or "row value constructor syntax" in the underlying database.
Additionally, HQL does not limit the value type in any way, though application developers should be aware that different types may incur limited support based on the underlying database vendor.
This is largely the reason for the JPQL limitations.
The list of values can come from a number of different sources.
In the constructor_expression and collection_valued_input_parameter, the list of values must not be empty; it must contain at least one value.
List<Payment> payments = entityManager.createQuery(
"select p " +
"from Payment p " +
"where type(p) in ( CreditCardPayment, WireTransferPayment )", Payment.class )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where type in ( 'MOBILE', 'LAND_LINE' )", Phone.class )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select p " +
"from Phone p " +
"where type in :types", Phone.class )
.setParameter( "types", Arrays.asList( PhoneType.MOBILE, PhoneType.LAND_LINE ) )
.getResultList();
List<Phone> phones = entityManager.createQuery(
"select distinct p " +
"from Phone p " +
"where p.person.id in (" +
" select py.person.id " +
" from Payment py" +
" where py.completed = true and py.amount > 50 " +
")", Phone.class )
.getResultList();
// Not JPQL compliant!
List<Phone> phones = entityManager.createQuery(
"select distinct p " +
"from Phone p " +
"where p.person in (" +
" select py.person " +
" from Payment py" +
" where py.completed = true and py.amount > 50 " +
")", Phone.class )
.getResultList();
// Not JPQL compliant!
List<Payment> payments = entityManager.createQuery(
"select distinct p " +
"from Payment p " +
"where ( p.amount, p.completed ) in (" +
" (50, true )," +
" (100, true )," +
" (5, false )" +
")", Payment.class )
.getResultList();15.44. Exists predicate
Exists expressions test the existence of results from a subquery. The affirmative form returns true if the subquery result contains values. The negated form returns true if the subquery result is empty.
15.45. Empty collection predicate
The IS [NOT] EMPTY expression applies to collection-valued path expressions.
It checks whether the particular collection has any associated values.
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.phones is empty", Person.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where p.phones is not empty", Person.class )
.getResultList();15.46. Member-of collection predicate
The [NOT] MEMBER [OF] expression applies to collection-valued path expressions.
It checks whether a value is a member of the specified collection.
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where 'Home address' member of p.addresses", Person.class )
.getResultList();
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"where 'Home address' not member of p.addresses", Person.class )
.getResultList();15.47. NOT predicate operator
The NOT operator is used to negate the predicate that follows it.
If that following predicate is true, the NOT resolves to false.
|
If the predicate is true, NOT resolves to false. If the predicate is unknown (e.g. |
15.48. AND predicate operator
The AND operator is used to combine 2 predicate expressions.
The result of the AND expression is true if and only if both predicates resolve to true.
If either predicates resolves to unknown, the AND expression resolves to unknown as well. Otherwise, the result is false.
15.49. OR predicate operator
The OR operator is used to combine 2 predicate expressions.
The result of the OR expression is true if one predicate resolves to true.
If both predicates resolve to unknown, the OR expression resolves to unknown.
Otherwise, the result is false.
15.50. The WHERE clause
The WHERE clause of a query is made up of predicates which assert whether values in each potential row match the current filtering criteria.
Thus, the where clause restricts the results returned from a select query and limits the scope of update and delete queries.
15.51. Group by
The GROUP BY clause allows building aggregated results for various value groups. As an example, consider the following queries:
Long totalDuration = entityManager.createQuery(
"select sum( c.duration ) " +
"from Call c ", Long.class )
.getSingleResult();
List<Object[]> personTotalCallDurations = entityManager.createQuery(
"select p.name, sum( c.duration ) " +
"from Call c " +
"join c.phone ph " +
"join ph.person p " +
"group by p.name", Object[].class )
.getResultList();
//It's even possible to group by entities!
List<Object[]> personTotalCallDurations = entityManager.createQuery(
"select p, sum( c.duration ) " +
"from Call c " +
"join c.phone ph " +
"join ph.person p " +
"group by p", Object[].class )
.getResultList();The first query retrieves the complete total of all orders. The second retrieves the total for each customer, grouped by each customer.
In a grouped query, the where clause applies to the non-aggregated values (essentially it determines whether rows will make it into the aggregation).
The HAVING clause also restricts results, but it operates on the aggregated values.
In the Group by example, we retrieved Call duration totals for all persons.
If that ended up being too much data to deal with, we might want to restrict the results to focus only on customers with a summed total of more than 1000:
List<Object[]> personTotalCallDurations = entityManager.createQuery(
"select p.name, sum( c.duration ) " +
"from Call c " +
"join c.phone ph " +
"join ph.person p " +
"group by p.name " +
"having sum( c.duration ) > 1000", Object[].class )
.getResultList();The HAVING clause follows the same rules as the WHERE clause and is also made up of predicates.
HAVING is applied after the groupings and aggregations have been done, while the WHERE clause is applied before.
15.52. Order by
The results of the query can also be ordered.
The ORDER BY clause is used to specify the selected values to be used to order the result.
The types of expressions considered valid as part of the ORDER BY clause include:
-
state fields
-
component/embeddable attributes
-
scalar expressions such as arithmetic operations, functions, etc.
-
identification variable declared in the select clause for any of the previous expression types
Additionally, JPQL says that all values referenced in the ORDER BY clause must be named in the SELECT clause.
HQL does not mandate that restriction, but applications desiring database portability should be aware that not all databases support referencing values in the ORDER BY clause that are not referenced in the select clause.
Individual expressions in the order-by can be qualified with either ASC (ascending) or DESC (descending) to indicated the desired ordering direction.
Null values can be placed in front or at the end of the sorted set using NULLS FIRST or NULLS LAST clause respectively.
List<Person> persons = entityManager.createQuery(
"select p " +
"from Person p " +
"order by p.name", Person.class )
.getResultList();
List<Object[]> personTotalCallDurations = entityManager.createQuery(
"select p.name, sum( c.duration ) as total " +
"from Call c " +
"join c.phone ph " +
"join ph.person p " +
"group by p.name " +
"order by total", Object[].class )
.getResultList();16. Criteria
Criteria queries offer a type-safe alternative to HQL, JPQL and native SQL queries.
|
Hibernate offers an older, legacy This chapter will focus on the JPA APIs for declaring type-safe criteria queries. |
Criteria queries are a programmatic, type-safe way to express a query.
They are type-safe in terms of using interfaces and classes to represent various structural parts of a query such as the query itself, the select clause, or an order-by, etc.
They can also be type-safe in terms of referencing attributes as we will see in a bit.
Users of the older Hibernate org.hibernate.Criteria query API will recognize the general approach, though we believe the JPA API to be superior as it represents a clean look at the lessons learned from that API.
Criteria queries are essentially an object graph, where each part of the graph represents an increasing (as we navigate down this graph) more atomic part of query.
The first step in performing a criteria query is building this graph.
The javax.persistence.criteria.CriteriaBuilder interface is the first thing with which you need to become acquainted to begin using criteria queries.
Its role is that of a factory for all the individual pieces of the criteria.
You obtain a javax.persistence.criteria.CriteriaBuilder instance by calling the getCriteriaBuilder() method of either javax.persistence.EntityManagerFactory or javax.persistence.EntityManager.
The next step is to obtain a javax.persistence.criteria.CriteriaQuery.
This is accomplished using one of the three methods on javax.persistence.criteria.CriteriaBuilder for this purpose:
-
<T> CriteriaQuery<T> createQuery( Class<T> resultClass ) -
CriteriaQuery<Tuple> createTupleQuery() -
CriteriaQuery<Object> createQuery()
Each serves a different purpose depending on the expected type of the query results.
|
Chapter 6 Criteria API of the JPA Specification already contains a decent amount of reference material pertaining to the various parts of a criteria query. So rather than duplicate all that content here, let’s instead look at some of the more widely anticipated usages of the API. |
16.1. Typed criteria queries
The type of the criteria query (aka the <T>) indicates the expected types in the query result.
This might be an entity, an Integer, or any other object.
16.2. Selecting an entity
This is probably the most common form of query. The application wants to select entity instances.
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Person> criteria = builder.createQuery( Person.class );
Root<Person> root = criteria.from( Person.class );
criteria.select( root );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<Person> persons = entityManager.createQuery( criteria ).getResultList();The example uses createQuery() passing in the Person class reference as the results of the query will be Person objects.
|
The call to the The |
16.3. Selecting an expression
The simplest form of selecting an expression is selecting a particular attribute from an entity. But this expression might also represent an aggregation, a mathematical operation, etc.
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<String> criteria = builder.createQuery( String.class );
Root<Person> root = criteria.from( Person.class );
criteria.select( root.get( Person_.nickName ) );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<String> nickNames = entityManager.createQuery( criteria ).getResultList();In this example, the query is typed as java.lang.String because that is the anticipated type of the results (the type of the Person#nickName attribute is java.lang.String).
Because a query might contain multiple references to the Person entity, attribute references always need to be qualified.
This is accomplished by the Root#get method call.
16.4. Selecting multiple values
There are actually a few different ways to select multiple values using criteria queries. We will explore two options here, but an alternative recommended approach is to use tuples as described in Tuple criteria queries, or consider a wrapper query, see Selecting a wrapper for details.
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Object[]> criteria = builder.createQuery( Object[].class );
Root<Person> root = criteria.from( Person.class );
Path<Long> idPath = root.get( Person_.id );
Path<String> nickNamePath = root.get( Person_.nickName);
criteria.select( builder.array( idPath, nickNamePath ) );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<Object[]> idAndNickNames = entityManager.createQuery( criteria ).getResultList();Technically this is classified as a typed query, but you can see from handling the results that this is sort of misleading. Anyway, the expected result type here is an array.
The example then uses the array method of javax.persistence.criteria.CriteriaBuilder which explicitly combines individual selections into a javax.persistence.criteria.CompoundSelection.
multiselectCriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Object[]> criteria = builder.createQuery( Object[].class );
Root<Person> root = criteria.from( Person.class );
Path<Long> idPath = root.get( Person_.id );
Path<String> nickNamePath = root.get( Person_.nickName);
criteria.multiselect( idPath, nickNamePath );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<Object[]> idAndNickNames = entityManager.createQuery( criteria ).getResultList();Just as we saw in Selecting an array we have a typed criteria query returning an Object array.
Both queries are functionally equivalent.
This second example uses the multiselect() method which behaves slightly differently based on the type given when the criteria query was first built,
but, in this case, it says to select and return an Object[].
16.5. Selecting a wrapper
Another alternative to Selecting multiple values is to instead select an object that will "wrap" the multiple values. Going back to the example query there, rather than returning an array of [Person#id, Person#nickName], instead declare a class that holds these values and use that as a return object.
public class PersonWrapper {
private final Long id;
private final String nickName;
public PersonWrapper(Long id, String nickName) {
this.id = id;
this.nickName = nickName;
}
public Long getId() {
return id;
}
public String getNickName() {
return nickName;
}
}
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<PersonWrapper> criteria = builder.createQuery( PersonWrapper.class );
Root<Person> root = criteria.from( Person.class );
Path<Long> idPath = root.get( Person_.id );
Path<String> nickNamePath = root.get( Person_.nickName);
criteria.select( builder.construct( PersonWrapper.class, idPath, nickNamePath ) );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<PersonWrapper> wrappers = entityManager.createQuery( criteria ).getResultList();First, we see the simple definition of the wrapper object we will be using to wrap our result values.
Specifically, notice the constructor and its argument types.
Since we will be returning PersonWrapper objects, we use PersonWrapper as the type of our criteria query.
This example illustrates the use of the javax.persistence.criteria.CriteriaBuilder method construct which is used to build a wrapper expression.
For every row in the result we are saying we would like a PersonWrapper instantiated with the remaining arguments by the matching constructor.
This wrapper expression is then passed as the select.
16.6. Tuple criteria queries
A better approach to Selecting multiple values is to use either a wrapper (which we just saw in Selecting a wrapper) or using the javax.persistence.Tuple contract.
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Tuple> criteria = builder.createQuery( Tuple.class );
Root<Person> root = criteria.from( Person.class );
Path<Long> idPath = root.get( Person_.id );
Path<String> nickNamePath = root.get( Person_.nickName);
criteria.multiselect( idPath, nickNamePath );
criteria.where( builder.equal( root.get( Person_.name ), "John Doe" ) );
List<Tuple> tuples = entityManager.createQuery( criteria ).getResultList();
for ( Tuple tuple : tuples ) {
Long id = tuple.get( idPath );
String nickName = tuple.get( nickNamePath );
}
//or using indices
for ( Tuple tuple : tuples ) {
Long id = (Long) tuple.get( 0 );
String nickName = (String) tuple.get( 1 );
}This example illustrates accessing the query results through the javax.persistence.Tuple interface.
The example uses the explicit createTupleQuery() of javax.persistence.criteria.CriteriaBuilder.
An alternate approach is to use createQuery( Tuple.class ).
Again we see the use of the multiselect() method, just like in Selecting an array using multiselect.
The difference here is that the type of the javax.persistence.criteria.CriteriaQuery was defined as javax.persistence.Tuple so the compound selections, in this case, are interpreted to be the tuple elements.
The javax.persistence.Tuple contract provides three forms of access to the underlying elements:
- typed
-
The Selecting a tuple example illustrates this form of access in the
tuple.get( idPath )andtuple.get( nickNamePath )calls. This allows typed access to the underlying tuple values based on thejavax.persistence.TupleElementexpressions used to build the criteria. - positional
-
Allows access to the underlying tuple values based on the position. The simple Object get(int position) form is very similar to the access illustrated in Selecting an array and Selecting an array using
multiselect. The <X> X get(int position, Class<X> type form allows typed positional access, but based on the explicitly supplied type which the tuple value must be type-assignable to. - aliased
-
Allows access to the underlying tuple values based an (optionally) assigned alias. The example query did not apply an alias. An alias would be applied via the alias method on
javax.persistence.criteria.Selection. Just likepositionalaccess, there is both a typed (Object get(String alias)) and an untyped (<X> X get(String alias, Class<X> type form.
16.7. FROM clause
A CriteriaQuery object defines a query over one or more entity, embeddable, or basic abstract schema types.
The root objects of the query are entities, from which the other types are reached by navigation.
— JPA Specification, section 6.5.2 Query Roots, pg 262
|
All the individual parts of the FROM clause (roots, joins, paths) implement the |
16.8. Roots
Roots define the basis from which all joins, paths and attributes are available in the query.
A root is always an entity type. Roots are defined and added to the criteria by the overloaded from methods on javax.persistence.criteria.CriteriaQuery:
<X> Root<X> from( Class<X> );
<X> Root<X> from( EntityType<X> );CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Person> criteria = builder.createQuery( Person.class );
Root<Person> root = criteria.from( Person.class );Criteria queries may define multiple roots, the effect of which is to create a Cartesian Product between the newly added root and the others.
Here is an example defining a Cartesian Product between Person and Partner entities:
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Tuple> criteria = builder.createQuery( Tuple.class );
Root<Person> personRoot = criteria.from( Person.class );
Root<Partner> partnerRoot = criteria.from( Partner.class );
criteria.multiselect( personRoot, partnerRoot );
Predicate personRestriction = builder.and(
builder.equal( personRoot.get( Person_.address ), address ),
builder.isNotEmpty( personRoot.get( Person_.phones ) )
);
Predicate partnerRestriction = builder.and(
builder.like( partnerRoot.get( Partner_.name ), prefix ),
builder.equal( partnerRoot.get( Partner_.version ), 0 )
);
criteria.where( builder.and( personRestriction, partnerRestriction ) );
List<Tuple> tuples = entityManager.createQuery( criteria ).getResultList();16.9. Joins
Joins allow navigation from other javax.persistence.criteria.From to either association or embedded attributes.
Joins are created by the numerous overloaded join methods of the javax.persistence.criteria.From interface.
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Phone> criteria = builder.createQuery( Phone.class );
Root<Phone> root = criteria.from( Phone.class );
// Phone.person is a @ManyToOne
Join<Phone, Person> personJoin = root.join( Phone_.person );
// Person.addresses is an @ElementCollection
Join<Person, String> addressesJoin = personJoin.join( Person_.addresses );
criteria.where( builder.isNotEmpty( root.get( Phone_.calls ) ) );
List<Phone> phones = entityManager.createQuery( criteria ).getResultList();16.10. Fetches
Just like in HQL and JPQL, criteria queries can specify that associated data be fetched along with the owner.
Fetches are created by the numerous overloaded fetch methods of the javax.persistence.criteria.From interface.
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Phone> criteria = builder.createQuery( Phone.class );
Root<Phone> root = criteria.from( Phone.class );
// Phone.person is a @ManyToOne
Fetch<Phone, Person> personFetch = root.fetch( Phone_.person );
// Person.addresses is an @ElementCollection
Fetch<Person, String> addressesJoin = personFetch.fetch( Person_.addresses );
criteria.where( builder.isNotEmpty( root.get( Phone_.calls ) ) );
List<Phone> phones = entityManager.createQuery( criteria ).getResultList();|
Technically speaking, embedded attributes are always fetched with their owner.
However in order to define the fetching of Phone#addresses we needed a |
16.11. Path expressions
|
Roots, joins and fetches are themselves paths as well. |
16.12. Using parameters
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Person> criteria = builder.createQuery( Person.class );
Root<Person> root = criteria.from( Person.class );
ParameterExpression<String> nickNameParameter = builder.parameter( String.class );
criteria.where( builder.equal( root.get( Person_.nickName ), nickNameParameter ) );
TypedQuery<Person> query = entityManager.createQuery( criteria );
query.setParameter( nickNameParameter, "JD" );
List<Person> persons = query.getResultList();Use the parameter method of javax.persistence.criteria.CriteriaBuilder to obtain a parameter reference.
Then use the parameter reference to bind the parameter value to the javax.persistence.Query.
16.13. Using group by
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Tuple> criteria = builder.createQuery( Tuple.class );
Root<Person> root = criteria.from( Person.class );
criteria.groupBy(root.get("address"));
criteria.multiselect(root.get("address"), builder.count(root));
List<Tuple> tuples = entityManager.createQuery( criteria ).getResultList();
for ( Tuple tuple : tuples ) {
String name = (String) tuple.get( 0 );
Long count = (Long) tuple.get( 1 );
}17. Native SQL Queries
You may also express queries in the native SQL dialect of your database.
This is useful if you want to utilize database specific features such as window functions, Common Table Expressions (CTE) or the CONNECT BY option in Oracle.
It also provides a clean migration path from a direct SQL/JDBC based application to Hibernate/JPA.
Hibernate also allows you to specify handwritten SQL (including stored procedures) for all create, update, delete, and retrieve operations.
17.1. Creating a native query using JPA
Execution of native SQL queries is controlled via the SQLQuery interface, which is obtained by calling Session.createSQLQuery().
The following sections describe how to use this API for querying.
17.2. Scalar queries
The most basic SQL query is to get a list of scalars (column) values.
List<Object[]> persons = entityManager.createNativeQuery(
"SELECT * FROM person" )
.getResultList();List<Object[]> persons = entityManager.createNativeQuery(
"SELECT id, name FROM person" )
.getResultList();
for(Object[] person : persons) {
Number id = (Number) person[0];
String name = (String) person[1];
}List<Object[]> persons = session.createSQLQuery(
"SELECT * FROM person" )
.list();List<Object[]> persons = session.createSQLQuery(
"SELECT id, name FROM person" )
.list();
for(Object[] person : persons) {
Number id = (Number) person[0];
String name = (String) person[1];
}These will return a List of Object arrays ( Object[] ) with scalar values for each column in the PERSON table.
Hibernate will use java.sql.ResultSetMetadata to deduce the actual order and types of the returned scalar values.
To avoid the overhead of using ResultSetMetadata, or simply to be more explicit in what is returned, one can use addScalar():
List<Object[]> persons = session.createSQLQuery(
"SELECT * FROM person" )
.addScalar( "id", LongType.INSTANCE )
.addScalar( "name", StringType.INSTANCE )
.list();
for(Object[] person : persons) {
Long id = (Long) person[0];
String name = (String) person[1];
}Although it still returns an Object arrays, this query will not use the ResultSetMetadata anymore since it explicitly gets the id and name columns as respectively a BigInteger and a String from the underlying ResultSet.
This also means that only these two columns will be returned, even though the query is still using * and the ResultSet contains more than the three listed columns.
It is possible to leave out the type information for all or some of the scalars.
List<Object[]> persons = session.createSQLQuery(
"SELECT * FROM person" )
.addScalar( "id", LongType.INSTANCE )
.addScalar( "name" )
.list();
for(Object[] person : persons) {
Long id = (Long) person[0];
String name = (String) person[1];
}This is essentially the same query as before, but now ResultSetMetaData is used to determine the type of name, where as the type of id is explicitly specified.
How the java.sql.Types returned from ResultSetMetaData is mapped to Hibernate types is controlled by the Dialect.
If a specific type is not mapped, or does not result in the expected type, it is possible to customize it via calls to registerHibernateType in the Dialect.
17.3. Entity queries
The above queries were all about returning scalar values, basically returning the raw values from the ResultSet.
List<Person> persons = entityManager.createNativeQuery(
"SELECT * FROM person", Person.class )
.getResultList();List<Person> persons = session.createSQLQuery(
"SELECT * FROM person" )
.addEntity( Person.class )
.list();Assuming that Person is mapped as a class with the columns id, name, nickName, address, createdOn and version,
the following query will also return a List where each element is a Person entity.
List<Person> persons = entityManager.createNativeQuery(
"SELECT id, name, nickName, address, createdOn, version " +
"FROM person", Person.class )
.getResultList();List<Person> persons = session.createSQLQuery(
"SELECT id, name, nickName, address, createdOn, version " +
"FROM person" )
.addEntity( Person.class )
.list();17.4. Handling associations and collections
If the entity is mapped with a many-to-one or a child-side one-to-one to another entity, it is required to also return this when performing the native query,
otherwise a database specific column not found error will occur.
List<Phone> phones = entityManager.createNativeQuery(
"SELECT id, phone_number, phone_type, person_id " +
"FROM phone", Phone.class )
.getResultList();List<Phone> phones = session.createSQLQuery(
"SELECT id, phone_number, phone_type, person_id " +
"FROM phone" )
.addEntity( Phone.class )
.list();This will allow the Phone#person to function properly.
|
The additional columns will automatically be returned when using the |
It is possible to eagerly join the Phone and the Person entities to avoid the possible extra roundtrip for initializing the many-to-one association.
List<Phone> phones = entityManager.createNativeQuery(
"SELECT * " +
"FROM phone ph " +
"JOIN person pr ON ph.person_id = pr.id", Phone.class )
.getResultList();
for(Phone phone : phones) {
Person person = phone.getPerson();
}SELECT id ,
number ,
type ,
person_id
FROM phoneList<Object[]> tuples = session.createSQLQuery(
"SELECT * " +
"FROM phone ph " +
"JOIN person pr ON ph.person_id = pr.id" )
.addEntity("phone", Phone.class )
.addJoin( "pr", "phone.person")
.list();
for(Object[] tuple : tuples) {
Phone phone = (Phone) tuple[0];
Person person = (Person) tuple[1];
}SELECT id ,
number ,
type ,
person_id
FROM phone|
As seen in the associated SQL query, Hibernate manages to construct the entity hierarchy without requiring any extra database roundtrip. |
By default, when using the addJoin() method, the result set will contain both entities that are joined.
To construct the entity hierarchy, you need to use a ROOT_ENTITY or DISTINCT_ROOT_ENTITY ResultTransformer.
ResultTransformerList<Person> persons = session.createSQLQuery(
"SELECT * " +
"FROM phone ph " +
"JOIN person pr ON ph.person_id = pr.id" )
.addEntity("phone", Phone.class )
.addJoin( "pr", "phone.person")
.setResultTransformer( Criteria.ROOT_ENTITY )
.list();
for(Person person : persons) {
person.getPhones();
}|
Because of the |
Notice that you added an alias name pr to be able to specify the target property path of the join.
It is possible to do the same eager joining for collections (e.g. the Phone#calls one-to-many association).
List<Phone> phones = entityManager.createNativeQuery(
"SELECT * " +
"FROM phone ph " +
"JOIN phone_call c ON c.phone_id = ph.id", Phone.class )
.getResultList();
for(Phone phone : phones) {
List<Call> calls = phone.getCalls();
}SELECT *
FROM phone ph
JOIN call c ON c.phone_id = ph.idList<Object[]> tuples = session.createSQLQuery(
"SELECT * " +
"FROM phone ph " +
"JOIN phone_call c ON c.phone_id = ph.id" )
.addEntity("phone", Phone.class )
.addJoin( "c", "phone.calls")
.list();
for(Object[] tuple : tuples) {
Phone phone = (Phone) tuple[0];
Call call = (Call) tuple[1];
}SELECT *
FROM phone ph
JOIN call c ON c.phone_id = ph.idAt this stage you are reaching the limits of what is possible with native queries, without starting to enhance the sql queries to make them usable in Hibernate. Problems can arise when returning multiple entities of the same type or when the default alias/column names are not enough.
17.5. Returning multiple entities
Until now, the result set column names are assumed to be the same as the column names specified in the mapping document. This can be problematic for SQL queries that join multiple tables since the same column names can appear in more than one table.
Column alias injection is needed in the following query which otherwise throws NonUniqueDiscoveredSqlAliasException.
List<Object> entities = entityManager.createNativeQuery(
"SELECT * " +
"FROM person pr, partner pt " +
"WHERE pr.name = pt.name" )
.getResultList();List<Object> entities = session.createSQLQuery(
"SELECT * " +
"FROM person pr, partner pt " +
"WHERE pr.name = pt.name" )
.list();The query was intended to return all Person and Partner instances with the same name.
The query fails because there is a conflict of names since the two entities are mapped to the same column names (e.g. id, name, version).
Also, on some databases the returned column aliases will most likely be on the form pr.id, pr.name, etc.
which are not equal to the columns specified in the mappings (id and name).
The following form is not vulnerable to column name duplication:
List<Object> entities = session.createSQLQuery(
"SELECT {pr.*}, {pt.*} " +
"FROM person pr, partner pt " +
"WHERE pr.name = pt.name" )
.addEntity( "pr", Person.class)
.addEntity( "pt", Partner.class)
.list();|
There’s no such equivalent in JPA because the |
The {pr.} and {pt.} notation used above is shorthand for "all properties".
Alternatively, you can list the columns explicitly, but even in this case Hibernate injects the SQL column aliases for each property.
The placeholder for a column alias is just the property name qualified by the table alias.
17.6. Alias and property references
In most cases the above alias injection is needed. For queries relating to more complex mappings, like composite properties, inheritance discriminators, collections etc., you can use specific aliases that allow Hibernate to inject the proper aliases.
The following table shows the different ways you can use the alias injection. Please note that the alias names in the result are simply examples, each alias will have a unique and probably different name when used.
| Description | Syntax | Example |
|---|---|---|
A simple property |
|
|
A composite property |
|
|
Discriminator of an entity |
|
|
All properties of an entity |
|
|
A collection key |
|
|
The id of an collection |
|
|
The element of an collection |
|
|
property of the element in the collection |
|
|
All properties of the element in the collection |
|
|
All properties of the collection |
|
|
17.7. Returning DTOs (Data Transfer Objects)
It is possible to apply a ResultTransformer to native SQL queries, allowing it to return non-managed entities.
public class PersonSummaryDTO {
private Number id;
private String name;
public Number getId() {
return id;
}
public void setId(Number id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
List<PersonSummaryDTO> dtos = session.createSQLQuery(
"SELECT p.id as \"id\", p.name as \"name\" " +
"FROM person p")
.setResultTransformer( Transformers.aliasToBean( PersonSummaryDTO.class ) )
.list();|
There’s no such equivalent in JPA because the |
The above query will return a list of PersonSummaryDTO which has been instantiated and injected the values of id and name into its corresponding properties or fields.
17.8. Handling inheritance
Native SQL queries which query for entities that are mapped as part of an inheritance must include all properties for the base class and all its subclasses.
List<CreditCardPayment> payments = session.createSQLQuery(
"SELECT * " +
"FROM Payment p " +
"JOIN CreditCardPayment cp on cp.id = p.id" )
.addEntity( CreditCardPayment.class )
.list();|
There’s no such equivalent in JPA because the |
17.9. Parameters
Native SQL queries support positional as well as named parameters:
List<Person> persons = entityManager.createNativeQuery(
"SELECT * " +
"FROM person " +
"WHERE name like :name", Person.class )
.setParameter("name", "J%")
.getResultList();List<Person> persons = session.createSQLQuery(
"SELECT * " +
"FROM person " +
"WHERE name like :name" )
.addEntity( Person.class )
.setParameter("name", "J%")
.list();17.10. Named SQL queries
Named SQL queries can also be defined during mapping and called in exactly the same way as a named HQL query.
In this case, you do not need to call addEntity() anymore.
JPA defines the javax.persistence.NamedNativeQuery annotation for this purpose,
and the Hibernate org.hibernate.annotations.NamedNativeQuery annotation extends it and adds the following attributes:
flushMode()-
The flush mode for the query. By default, it uses the current Persistence Context flush mode.
cacheable()-
Whether the query (results) is cacheable or not. By default, queries are not cached.
cacheRegion()-
If the query results are cacheable, name the query cache region to use.
fetchSize()-
The number of rows fetched by the JDBC Driver per database trip. The default value is given by the JDBC driver.
timeout()-
The query timeout (in seconds). By default, there’s no timeout.
callable()-
Does the SQL query represent a call to a procedure/function? Default is false.
comment()-
A comment added to the SQL query for tuning the execution plan.
cacheMode()-
The cache mode used for this query. This refers to entities/collections returned by the query. The default value is
CacheModeType.NORMAL. readOnly()-
Whether the results should be read-only. By default, queries are not read-only so entities are stored in the Persistence Context.
17.10.1. Named SQL queries selecting scalar values
To fetch a single column of given table, the named query looks as follows:
NamedNativeQuery@NamedNativeQuery(
name = "find_person_name",
query =
"SELECT name " +
"FROM person "
),List<String> names = entityManager.createNamedQuery(
"find_person_name" )
.getResultList();List<String> names = session.getNamedQuery(
"find_person_name" )
.list();Selecting multiple scalar values is done like this:
NamedNativeQuery@NamedNativeQuery(
name = "find_person_name_and_nickName",
query =
"SELECT " +
" name, " +
" nickName " +
"FROM person "
),Without specifying an explicit result type, Hibernate will assume an Object array:
List<Object[]> tuples = entityManager.createNamedQuery(
"find_person_name_and_nickName" )
.getResultList();
for(Object[] tuple : tuples) {
String name = (String) tuple[0];
String nickName = (String) tuple[1];
}List<Object[]> tuples = session.getNamedQuery(
"find_person_name_and_nickName" )
.list();
for(Object[] tuple : tuples) {
String name = (String) tuple[0];
String nickName = (String) tuple[1];
}It’s possible to use a DTO to store the resulting scalar values:
public class PersonNames {
private final String name;
private final String nickName;
public PersonNames(String name, String nickName) {
this.name = name;
this.nickName = nickName;
}
public String getName() {
return name;
}
public String getNickName() {
return nickName;
}
}NamedNativeQuery with ConstructorResult@NamedNativeQuery(
name = "find_person_name_and_nickName_dto",
query =
"SELECT " +
" name, " +
" nickName " +
"FROM person ",
resultSetMapping = "name_and_nickName_dto"
),
@SqlResultSetMapping(
name = "name_and_nickName_dto",
classes = @ConstructorResult(
targetClass = PersonNames.class,
columns = {
@ColumnResult(name = "name"),
@ColumnResult(name = "nickName")
}
)
)List<PersonNames> personNames = entityManager.createNamedQuery(
"find_person_name_and_nickName_dto" )
.getResultList();List<PersonNames> personNames = session.getNamedQuery(
"find_person_name_and_nickName_dto" )
.list();17.10.2. Named SQL queries selecting entities
Considering the following named query:
NamedNativeQuery@NamedNativeQuery(
name = "find_person_by_name",
query =
"SELECT " +
" p.id AS \"id\", " +
" p.name AS \"name\", " +
" p.nickName AS \"nickName\", " +
" p.address AS \"address\", " +
" p.createdOn AS \"createdOn\", " +
" p.version AS \"version\" " +
"FROM person p " +
"WHERE p.name LIKE :name",
resultClass = Person.class
),The result set mapping declares the entities retrieved by this native query. Each field of the entity is bound to an SQL alias (or column name). All fields of the entity including the ones of subclasses and the foreign key columns of related entities have to be present in the SQL query. Field definitions are optional provided that they map to the same column name as the one declared on the class property.
Executing this named native query can be done as follows:
List<Person> persons = entityManager.createNamedQuery(
"find_person_by_name" )
.setParameter("name", "J%")
.getResultList();List<Person> persons = session.getNamedQuery(
"find_person_by_name" )
.setParameter("name", "J%")
.list();To join multiple entities, you need to use a SqlResultSetMapping for each entity the SQL query is going to fetch.
NamedNativeQuery@NamedNativeQuery(
name = "find_person_with_phones_by_name",
query =
"SELECT " +
" pr.id AS \"pr.id\", " +
" pr.name AS \"pr.name\", " +
" pr.nickName AS \"pr.nickName\", " +
" pr.address AS \"pr.address\", " +
" pr.createdOn AS \"pr.createdOn\", " +
" pr.version AS \"pr.version\", " +
" ph.id AS \"ph.id\", " +
" ph.person_id AS \"ph.person_id\", " +
" ph.phone_number AS \"ph.phone_number\", " +
" ph.type AS \"ph.type\" " +
"FROM person pr " +
"JOIN phone ph ON pr.id = ph.person_id " +
"WHERE pr.name LIKE :name",
resultSetMapping = "person_with_phones"
)
@SqlResultSetMapping(
name = "person_with_phones",
entities = {
@EntityResult(
entityClass = Person.class,
fields = {
@FieldResult( name = "id", column = "pr.id" ),
@FieldResult( name = "name", column = "pr.name" ),
@FieldResult( name = "nickName", column = "pr.nickName" ),
@FieldResult( name = "address", column = "pr.address" ),
@FieldResult( name = "createdOn", column = "pr.createdOn" ),
@FieldResult( name = "version", column = "pr.version" ),
}
),
@EntityResult(
entityClass = Phone.class,
fields = {
@FieldResult( name = "id", column = "ph.id" ),
@FieldResult( name = "person", column = "ph.person_id" ),
@FieldResult( name = "number", column = "ph.number" ),
@FieldResult( name = "type", column = "ph.type" ),
}
)
}
),List<Object[]> tuples = entityManager.createNamedQuery(
"find_person_with_phones_by_name" )
.setParameter("name", "J%")
.getResultList();
for(Object[] tuple : tuples) {
Person person = (Person) tuple[0];
Phone phone = (Phone) tuple[1];
}List<Object[]> tuples = session.getNamedQuery(
"find_person_with_phones_by_name" )
.setParameter("name", "J%")
.list();
for(Object[] tuple : tuples) {
Person person = (Person) tuple[0];
Phone phone = (Phone) tuple[1];
}Finally, if the association to a related entity involve a composite primary key, a @FieldResult element should be used for each foreign key column.
The @FieldResult name is composed of the property name for the relationship, followed by a dot ("."), followed by the name or the field or property of the primary key.
For this example, the following entities are going to be used:
@Embeddable
public class Dimensions {
private int length;
private int width;
public int getLength() {
return length;
}
public void setLength(int length) {
this.length = length;
}
public int getWidth() {
return width;
}
public void setWidth(int width) {
this.width = width;
}
}
@Embeddable
public class Identity implements Serializable {
private String firstname;
private String lastname;
public String getFirstname() {
return firstname;
}
public void setFirstname(String firstname) {
this.firstname = firstname;
}
public String getLastname() {
return lastname;
}
public void setLastname(String lastname) {
this.lastname = lastname;
}
public boolean equals(Object o) {
if ( this == o ) return true;
if ( o == null || getClass() != o.getClass() ) return false;
final Identity identity = (Identity) o;
if ( !firstname.equals( identity.firstname ) ) return false;
if ( !lastname.equals( identity.lastname ) ) return false;
return true;
}
public int hashCode() {
int result;
result = firstname.hashCode();
result = 29 * result + lastname.hashCode();
return result;
}
}
@Entity
public class Captain {
@EmbeddedId
private Identity id;
public Identity getId() {
return id;
}
public void setId(Identity id) {
this.id = id;
}
}
@Entity
@NamedNativeQueries({
@NamedNativeQuery(name = "find_all_spaceships",
query =
"SELECT " +
" name as \"name\", " +
" model, " +
" speed, " +
" lname as lastn, " +
" fname as firstn, " +
" length, " +
" width, " +
" length * width as surface, " +
" length * width * 10 as volume " +
"FROM SpaceShip",
resultSetMapping = "spaceship"
)
})
@SqlResultSetMapping(
name = "spaceship",
entities = @EntityResult(
entityClass = SpaceShip.class,
fields = {
@FieldResult(name = "name", column = "name"),
@FieldResult(name = "model", column = "model"),
@FieldResult(name = "speed", column = "speed"),
@FieldResult(name = "captain.lastname", column = "lastn"),
@FieldResult(name = "captain.firstname", column = "firstn"),
@FieldResult(name = "dimensions.length", column = "length"),
@FieldResult(name = "dimensions.width", column = "width"),
}
),
columns = {
@ColumnResult(name = "surface"),
@ColumnResult(name = "volume")
}
)
public class SpaceShip {
@Id
private String name;
private String model;
private double speed;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumns({
@JoinColumn(name = "fname", referencedColumnName = "firstname"),
@JoinColumn(name = "lname", referencedColumnName = "lastname")
})
private Captain captain;
private Dimensions dimensions;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getModel() {
return model;
}
public void setModel(String model) {
this.model = model;
}
public double getSpeed() {
return speed;
}
public void setSpeed(double speed) {
this.speed = speed;
}
public Captain getCaptain() {
return captain;
}
public void setCaptain(Captain captain) {
this.captain = captain;
}
public Dimensions getDimensions() {
return dimensions;
}
public void setDimensions(Dimensions dimensions) {
this.dimensions = dimensions;
}
}List<Object[]> tuples = entityManager.createNamedQuery(
"find_all_spaceships" )
.getResultList();
for(Object[] tuple : tuples) {
SpaceShip spaceShip = (SpaceShip) tuple[0];
Number surface = (Number) tuple[1];
Number volume = (Number) tuple[2];
}List<Object[]> tuples = session.getNamedQuery(
"find_all_spaceships" )
.list();
for(Object[] tuple : tuples) {
SpaceShip spaceShip = (SpaceShip) tuple[0];
Number surface = (Number) tuple[1];
Number volume = (Number) tuple[2];
}17.11. Using stored procedures for querying
Hibernate provides support for queries via stored procedures and functions.
A stored procedure arguments are declared using the IN parameter type, and the result can be either marked with an OUT
parameter type, a REF_CURSOR or it could just return the result like a function.
OUT parameter typestatement.executeUpdate(
"CREATE PROCEDURE sp_count_phones (" +
" IN personId INT, " +
" OUT phoneCount INT " +
") " +
"BEGIN " +
" SELECT COUNT(*) INTO phoneCount " +
" FROM phone " +
" WHERE phone.person_id = personId; " +
"END"
);To use this stored procedure, you can execute the following JPA 2.1 query:
OUT parameter type using JPAStoredProcedureQuery query = entityManager.createStoredProcedureQuery( "sp_count_phones");
query.registerStoredProcedureParameter( "personId", Long.class, ParameterMode.IN);
query.registerStoredProcedureParameter( "phoneCount", Long.class, ParameterMode.OUT);
query.setParameter("personId", 1L);
query.execute();
Long phoneCount = (Long) query.getOutputParameterValue("phoneCount");OUT parameter type using HibernateSession session = entityManager.unwrap( Session.class );
ProcedureCall call = session.createStoredProcedureCall( "sp_count_phones" );
call.registerParameter( "personId", Long.class, ParameterMode.IN ).bindValue( 1L );
call.registerParameter( "phoneCount", Long.class, ParameterMode.OUT );
Long phoneCount = (Long) call.getOutputs().getOutputParameterValue( "phoneCount" );
assertEquals( Long.valueOf( 2 ), phoneCount );If the stored procedure outputs the result directly without an OUT parameter type:
OUT parameter typestatement.executeUpdate(
"CREATE PROCEDURE sp_phones(IN personId INT) " +
"BEGIN " +
" SELECT * " +
" FROM phone " +
" WHERE person_id = personId; " +
"END"
);You can retrieve the results of the aforementioned MySQL stored procedure as follows:
OUT parameter type using JPAStoredProcedureQuery query = entityManager.createStoredProcedureQuery( "sp_phones");
query.registerStoredProcedureParameter( 1, Long.class, ParameterMode.IN);
query.setParameter(1, 1L);
List<Object[]> personComments = query.getResultList();OUT parameter type using HibernateSession session = entityManager.unwrap( Session.class );
ProcedureCall call = session.createStoredProcedureCall( "sp_phones" );
call.registerParameter( 1, Long.class, ParameterMode.IN ).bindValue( 1L );
Output output = call.getOutputs().getCurrent();
List<Object[]> personComments = ( (ResultSetOutput) output ).getResultList();For a REF_CURSOR result sets, we’ll consider the following Oracle stored procedure:
REF_CURSOR stored procedurestatement.executeUpdate(
"CREATE OR REPLACE PROCEDURE sp_person_phones ( " +
" personId IN NUMBER, " +
" personPhones OUT SYS_REFCURSOR ) " +
"AS " +
"BEGIN " +
" OPEN personPhones FOR " +
" SELECT *" +
" FROM phone " +
" WHERE person_id = personId; " +
"END;"
);|
|
This function can be called using the standard Java Persistence API:
REF_CURSOR stored procedure using JPAStoredProcedureQuery query = entityManager.createStoredProcedureQuery( "sp_person_phones" );
query.registerStoredProcedureParameter( 1, Long.class, ParameterMode.IN );
query.registerStoredProcedureParameter( 2, Class.class, ParameterMode.REF_CURSOR );
query.setParameter( 1, 1L );
query.execute();
List<Object[]> postComments = query.getResultList();REF_CURSOR stored procedure using HibernateSession session = entityManager.unwrap(Session.class);
ProcedureCall call = session.createStoredProcedureCall( "sp_person_phones");
call.registerParameter(1, Long.class, ParameterMode.IN).bindValue(1L);
call.registerParameter(2, Class.class, ParameterMode.REF_CURSOR);
Output output = call.getOutputs().getCurrent();
List<Object[]> postComments = ( (ResultSetOutput) output ).getResultList();
assertEquals(2, postComments.size());If the database defines an SQL function:
statement.executeUpdate(
"CREATE FUNCTION fn_count_phones(personId integer) " +
"RETURNS integer " +
"DETERMINISTIC " +
"READS SQL DATA " +
"BEGIN " +
" DECLARE phoneCount integer; " +
" SELECT COUNT(*) INTO phoneCount " +
" FROM phone " +
" WHERE phone.person_id = personId; " +
" RETURN phoneCount; " +
"END"
);Because the current StoredProcedureQuery implementation doesn’t yet support SQL functions,
we need to use the JDBC syntax.
|
This limitation is acknowledged and will be addressed by the HHH-10530 issue. |
final AtomicReference<Integer> phoneCount = new AtomicReference<>();
Session session = entityManager.unwrap( Session.class );
session.doWork( connection -> {
try (CallableStatement function = connection.prepareCall(
"{ ? = call fn_count_phones(?) }" )) {
function.registerOutParameter( 1, Types.INTEGER );
function.setInt( 2, 1 );
function.execute();
phoneCount.set( function.getInt( 1 ) );
}
} );|
Stored procedure queries cannot be paged with Since these servers can return multiple result sets and update counts, Hibernate will iterate the results and take the first result that is a result set as its return value, so everything else will be discarded. For SQL Server, if you can enable |
17.12. Custom SQL for create, update, and delete
Hibernate can use custom SQL for create, update, and delete operations. The SQL can be overridden at the statement level or individual column level. This section describes statement overrides. For columns, see Column transformers: read and write expressions.
The following example shows how to define custom SQL operations using annotations.
@SQLInsert, @SQLUpdate and @SQLDelete override the INSERT, UPDATE, DELETE statements of a given entity.
For the SELECT clause, a @Loader must be defined along with a @NamedNativeQuery used for loading the underlying table record.
For collections, Hibernate allows defining a custom @SQLDeleteAll which is used for removing all child records associated with a given parent entity.
To filter collections, the @Where annotation allows customizing the underlying SQL WHERE clause.
@Entity(name = "Person")
@SQLInsert(
sql = "INSERT INTO person (name, id, valid) VALUES (?, ?, true) ",
check = ResultCheckStyle.COUNT
)
@SQLUpdate(
sql = "UPDATE person SET name = ? where id = ? ")
@SQLDelete(
sql = "UPDATE person SET valid = false WHERE id = ? ")
@Loader(namedQuery = "find_valid_person")
@NamedNativeQueries({
@NamedNativeQuery(
name = "find_valid_person",
query = "SELECT id, name " +
"FROM person " +
"WHERE id = ? and valid = true",
resultClass = Person.class
)
})
public static class Person {
@Id
@GeneratedValue
private Long id;
private String name;
@ElementCollection
@SQLInsert(
sql = "INSERT INTO person_phones (person_id, phones, valid) VALUES (?, ?, true) ")
@SQLDeleteAll(
sql = "UPDATE person_phones SET valid = false WHERE person_id = ?")
@Where( clause = "valid = true" )
private List<String> phones = new ArrayList<>();
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<String> getPhones() {
return phones;
}
}In the example above, the entity is mapped so that entries are soft-deleted (the records are not removed from the database, but instead, a flag marks the row validity).
The Person entity benefits from custom INSERT, UPDATE, and DELETE statements which update the valid column accordingly.
The custom @Loader is used to retrieve only Person rows that are valid.
The same is done for the phones collection. The @SQLDeleteAll and the SQLInsert queries are used whenever the collection is modified.
|
You also call a store procedure using the custom CRUD statements; the only requirement is to set the |
To check that the execution happens correctly, Hibernate allows you to define one of those three strategies:
-
none: no check is performed; the store procedure is expected to fail upon constraint violations
-
count: use of row-count returned by the
executeUpdate()method call to check that the update was successful -
param: like count but using a
CallableStatementoutput parameter.
To define the result check style, use the check parameter.
|
The parameter order is important and is defined by the order Hibernate handles properties. You can see the expected order by enabling debug logging, so Hibernate can print out the static SQL that is used to create, update, delete etc. entities. To see the expected sequence, remember to not include your custom SQL through annotations or mapping files as that will override the Hibernate generated static sql. |
Overriding SQL statements for secondary tables is also possible using @org.hibernate.annotations.Table and the sqlInsert, sqlUpdate, sqlDelete attributes.
@Entity(name = "Person")
@Table(name = "person")
@SQLInsert(
sql = "INSERT INTO person (name, id, valid) VALUES (?, ?, true) "
)
@SQLDelete(
sql = "UPDATE person SET valid = false WHERE id = ? "
)
@SecondaryTable(name = "person_details",
pkJoinColumns = @PrimaryKeyJoinColumn(name = "person_id"))
@org.hibernate.annotations.Table(
appliesTo = "person_details",
sqlInsert = @SQLInsert(
sql = "INSERT INTO person_details (image, person_id, valid) VALUES (?, ?, true) ",
check = ResultCheckStyle.COUNT
),
sqlDelete = @SQLDelete(
sql = "UPDATE person_details SET valid = false WHERE person_id = ? "
)
)
@Loader(namedQuery = "find_valid_person")
@NamedNativeQueries({
@NamedNativeQuery(
name = "find_valid_person",
query = "select " +
" p.id, " +
" p.name, " +
" pd.image " +
"from person p " +
"left outer join person_details pd on p.id = pd.person_id " +
"where p.id = ? and p.valid = true and pd.valid = true",
resultClass = Person.class
)
})
public static class Person {
@Id
@GeneratedValue
private Long id;
private String name;
@Column(name = "image", table = "person_details")
private byte[] image;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public byte[] getImage() {
return image;
}
public void setImage(byte[] image) {
this.image = image;
}
}|
The SQL is directly executed in your database, so you can use any dialect you like. This will, however, reduce the portability of your mapping if you use database specific SQL. |
You can also use stored procedures for customizing the CRUD statements.
Assuming the following stored procedure:
statement.executeUpdate(
"CREATE OR REPLACE PROCEDURE sp_delete_person ( " +
" personId IN NUMBER ) " +
"AS " +
"BEGIN " +
" UPDATE person SET valid = 0 WHERE id = personId; " +
"END;"
);}The entity can use this stored procedure to soft-delete the entity in question:
@SQLDelete(
sql = "{ call sp_delete_person( ? ) } ",
callable = true
)|
You need to set the |
18. Spatial
18.1. Overview
Hibernate Spatial was originally developed as a generic extension to Hibernate for handling geographic data. Since 5.0, Hibernate Spatial is now part of Hibernate ORM project, and it allows you to deal with geographic data in a standardized way.
Hibernate Spatial provides a standardized, cross-database interface to geographic data storage and query functions. It supports most of the functions described by the OGC Simple Feature Specification, and the supported databases are: Oracle 10g/11g, PostgreSql/PostGIS, MySQL, Microsoft SQL Server and H2/GeoDB, yet, not all databases support all the functions defined by Hibernate Spatial.
Hibernate Spatial uses the Java Topology Suite (JTS) as its geometry model. JTS is an implementation of the OpenGIS Simple Features Implementation Specification for SQLv. 1.1 (SFS). This specification is implemented in most RDBMS with spatial data support. It is also a direct precursor to SQL/MM Part 3: Spatial (ISO/IEC 13249-3).
The SFS specification defines a set of functions on geometries. Hibernate Spatial makes a subset of these functions available in HQL and in the Criteria Query API.
18.2. Configuration
Hibernate Spatial requires some configuration prior to start using it.
18.2.1. Dependency
You need to include the hibernate-spatial dependency in your build environment.
For Maven, you need to add the following dependency:
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-spatial</artifactId>
<version>${hibernate.version}</version>
</dependency>18.2.2. Dialects
Hibernate Spatial extends the Hibernate ORM dialects so that the spatial functions of the database are made available within HQL and JPQL.
So, for instance, instead of using the PostgreSQL82Dialect, we use the Hibernate Spatial extension of that dialect which is the PostgisDialect.
<property
name="hibernate.dialect"
value="org.hibernate.spatial.dialect.postgis.PostgisDialect"
/>Not all databases support all the functions defined by Hibernate Spatial. The table below provides an overview of the functions provided by each database.
Function |
Description |
PostgresSQL |
Oracle 10g/11g |
MySQL |
SQLServer |
GeoDB (H2) |
Basic functions on Geometry |
||||||
|
SFS §2.1.1.1 |
|||||
|
SFS §2.1.1.1 |
|||||
|
SFS §2.1.1.1 |
|||||
|
SFS §2.1.1.1 |
|||||
|
SFS §2.1.1.1 |
|||||
|
SFS §2.1.1.1 |
|||||
|
SFS §2.1.1.1 |
|||||
|
SFS §2.1.1.1 |
|||||
|
SFS §2.1.1.1 |
|||||
Functions for testing Spatial Relations between geometric objects |
||||||
|
SFS §2.1.1.2 |
|||||
|
SFS §2.1.1.2 |
|||||
|
SFS §2.1.1.2 |
|||||
|
SFS §2.1.1.2 |
|||||
|
SFS §2.1.1.2 |
|||||
|
SFS §2.1.1.2 |
|||||
|
SFS §2.1.1.2 |
|||||
|
SFS §2.1.1.2 |
|||||
|
SFS §2.1.1.2 |
|||||
Functions that support Spatial Analysis |
||||||
|
SFS §2.1.1.3 |
|||||
|
SFS §2.1.1.3 |
|||||
|
SFS §2.1.1.3 |
|||||
|
SFS §2.1.1.3 |
|||||
|
SFS §2.1.1.3 (renamed from union) |
|||||
|
SFS §2.1.1.3 |
|||||
|
SFS §2.1.1.3 |
|||||
Common non-SFS functions |
||||||
|
Returns true if the geometries are within the specified distance of one another |
|||||
|
Returns a new geometry with its coordinates transformed to the SRID referenced by the integer parameter |
|||||
Spatial aggregate Functions |
||||||
|
Returns a bounding box that bounds the set of returned geometries |
- Postgis
-
For Postgis from versions 1.3 and later, the best dialect to use is
org.hibernate.spatial.dialect.postgis.PostgisDialect.This translates the HQL spatial functions to the Postgis SQL/MM-compliant functions. For older, pre v1.3 versions of Postgis, which are not SQL/MM compliant, the dialect
org.hibernate.spatial.dialect.postgis.PostgisNoSQLMMis provided.This dialect depends on the JDBC extensions in postgis.jar (see the Postgis documentation).
|
Beware of classpath problems in a Java EE containers where the JDBC drivers live in a different classpath than the Postgis JDBC extensions and/or Hibernate Spatial. For JBoss, some users found this post helpful. |
- MySQL
-
There are several dialects for MySQL:
MySQLSpatialDialect-
a spatially-extended version of Hibernate
MySQLDialect MySQLSpatialInnoDBDialect-
a spatially-extended version of Hibernate
MySQLInnoDBDialect MySQLSpatial56Dialect-
a spatially-extended version of Hibernate
MySQL5DBDialect. MySQLSpatial5InnoDBDialect-
the same as
MySQLSpatial56Dialect, but with support for the InnoDB storage engine.
|
MySQL versions before 5.6.1 had only limited support for spatial operators. Most operators only took account of the minimum bounding rectangles (MBR) of the geometries, and not the geometries themselves. This changed in version 5.6.1 were MySQL introduced These dialects may therefore produce results that differ from that of the other spatial dialects. For more information, see this page in the MySQL reference guide (esp. the section Functions That Test Spatial Relations Between Geometry Objects) |
- Oracle10g/11g
-
There is currently only one Oracle spatial dialect:
OracleSpatial10gDialectwhich extends the Hibernate dialectOracle10gDialect. This dialect has been tested on both Oracle 10g and Oracle 11g with theSDO_GEOMETRYspatial database type.This dialect is the only dialect that can be configured using these Hibernate properties:
hibernate.spatial.connection_finder-
the fully-qualified classname for the Connection finder for this Dialect (see below).
|
The
ConnectionFinder interfaceThe The default implementation will, when the passed object is not already an In may cases this strategy will suffice.
If not, you can provide your own implementation of this interface on the class path, and configure it in the |
hibernate.spatial.ogc_strict-
true to use the OGC-compliant functions on SDO_GEOMETRY (see below)
|
The Oracle Spatial dialect can be configured to run in either OGC strict or non-strict mode. In OGC strict mode, the Open Geospatial compliant functions of Oracle Spatial are used in spatial operations (they exists in Oracle 10g, but are not documented). In non-strict mode, the usual Oracle Spatial functions are used directly, and mimic the OGC semantics.The default is OGC strict mode. You can change this to non-strict mode by setting the hibernate.spatial.ogc_strict property to false. Note that changing from strict to non-strict mode changes the semantics of the spatial operation. We have attempted to implement the OGC semantics as well we could using the standard Oracle Spatial operators, but this was not possible in all cases. On the plus side, non-strict mode should be faster in most cases. |
- SQL Server
-
The dialect
SqlServer2008Dialectsupports theGEOMETRYtype in SQL Server 2008 and later.
|
The |
- GeoDB (H2)
-
The
GeoDBDialectsupports the GeoDB a spatial extension of the H2 in-memory database.
|
The dialect has been tested with GeoDB version 0.7 |
18.3. Types
Hibernate Spatial comes with the following types:
- jts_geometry
-
Handled by
org.hibernate.spatial.JTSGeometryTypeit maps a database geometry column type to acom.vividsolutions.jts.geom.Geometryentity property type. - geolatte_geometry
-
Handled by
org.hibernate.spatial.GeolatteGeometryType, it maps a database geometry column type to anorg.geolatte.geom.Geometryentity property type.
The following entity uses the jts_geometry to map the PostgreSQL geometry type to a com.vividsolutions.jts.geom.Point.
@Entity(name = "Event")
public static class Event {
@Id
private Long id;
private String name;
@Type(type = "jts_geometry")
private Point location;
//Getters and setters are omitted for brevity
}When creating such entity:
Event event = new Event();
event.setId( 1L);
event.setName( "Hibernate ORM presentation");
event.setLocation( (Point) new WKTReader().read( "POINT(10 5)"));
entityManager.persist( event );Hibernate generates the following SQL statement:
INSERT INTO
Event (location, name, id)
VALUES
('POINT (10 5)', 'Hibernate ORM presentation', 1)Hibernate Spatial defines many query functions that are available both in HQL and JPQL queries.
Event event = entityManager.createQuery(
"select e " +
"from Event e " +
"where within(e.location, :filter) = true", Event.class)
.setParameter("filter", new WKTReader().read( "POLYGON((1 1,20 1,20 20,1 20,1 1))"))
.getSingleResult();This JPQL query generates the following SQL statement:
select
e.id as id1_0_,
e.location as location2_0_,
e.name as name3_0_
from Event e
where st_within(e.location, 'POLYGON ((1 1, 20 1, 20 20, 1 20, 1 1))') = true19. Multitenancy
19.1. What is multitenancy?
The term multitenancy, in general, is applied to software development to indicate an architecture in which a single running instance of an application simultaneously serves multiple clients (tenants). This is highly common in SaaS solutions. Isolating information (data, customizations, etc.) pertaining to the various tenants is a particular challenge in these systems. This includes the data owned by each tenant stored in the database. It is this last piece, sometimes called multitenant data, on which we will focus.
19.2. Multitenant data approaches
There are three main approaches to isolating information in these multitenant systems which go hand-in-hand with different database schema definitions and JDBC setups.
|
Each approach has pros and cons as well as specific techniques and considerations. Such topics are beyond the scope of this documentation. Many resources exist which delve into these other topics, like this one which does a great job of covering these topics. |
19.2.1. Separate database
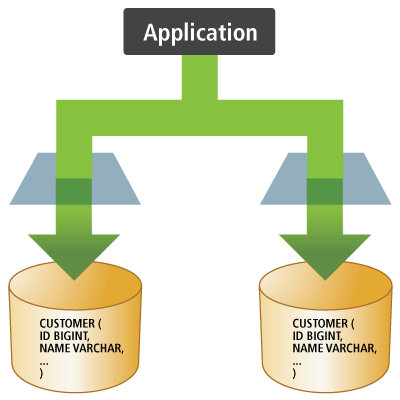
Each tenant’s data is kept in a physically separate database instance. JDBC Connections would point specifically to each database so any pooling would be per-tenant. A general application approach, here, would be to define a JDBC Connection pool per-tenant and to select the pool to use based on the tenant identifier associated with the currently logged in user.
19.2.2. Separate schema
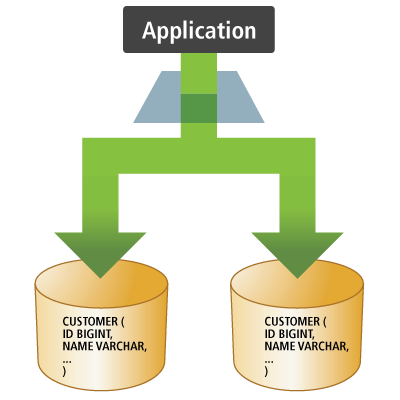
Each tenant’s data is kept in a distinct database schema on a single database instance. There are two different ways to define JDBC Connections here:
-
Connections could point specifically to each schema as we saw with the
Separate databaseapproach. This is an option provided that the driver supports naming the default schema in the connection URL or if the pooling mechanism supports naming a schema to use for its Connections. Using this approach, we would have a distinct JDBC Connection pool per-tenant where the pool to use would be selected based on the "tenant identifier" associated with the currently logged in user. -
Connections could point to the database itself (using some default schema) but the Connections would be altered using the SQL
SET SCHEMA(or similar) command. Using this approach, we would have a single JDBC Connection pool for use to service all tenants, but before using the Connection, it would be altered to reference the schema named by the "tenant identifier" associated with the currently logged in user.
19.3. Partitioned (discriminator) data
All data is kept in a single database schema. The data for each tenant is partitioned by the use of partition value or discriminator. The complexity of this discriminator might range from a simple column value to a complex SQL formula. Again, this approach would use a single Connection pool to service all tenants. However, in this approach, the application needs to alter each and every SQL statement sent to the database to reference the "tenant identifier" discriminator.
19.4. Multitenancy in Hibernate
Using Hibernate with multitenant data comes down to both an API and then integration piece(s). As usual, Hibernate strives to keep the API simple and isolated from any underlying integration complexities. The API is really just defined by passing the tenant identifier as part of opening any session.
SessionFactoryprivate void doInSession(String tenant, Consumer<Session> function) {
Session session = null;
Transaction txn = null;
try {
session = sessionFactory
.withOptions()
.tenantIdentifier( tenant )
.openSession();
txn = session.getTransaction();
txn.begin();
function.accept(session);
txn.commit();
} catch (Throwable e) {
if ( txn != null ) txn.rollback();
throw e;
} finally {
if (session != null) {
session.close();
}
}
}Additionally, when specifying the configuration, an org.hibernate.MultiTenancyStrategy should be named using the hibernate.multiTenancy setting.
Hibernate will perform validations based on the type of strategy you specify.
The strategy here correlates to the isolation approach discussed above.
- NONE
-
(the default) No multitenancy is expected. In fact, it is considered an error if a tenant identifier is specified when opening a session using this strategy.
- SCHEMA
-
Correlates to the separate schema approach. It is an error to attempt to open a session without a tenant identifier using this strategy. Additionally, a
MultiTenantConnectionProvidermust be specified. - DATABASE
-
Correlates to the separate database approach. It is an error to attempt to open a session without a tenant identifier using this strategy. Additionally, a
MultiTenantConnectionProvidermust be specified. - DISCRIMINATOR
-
Correlates to the partitioned (discriminator) approach. It is an error to attempt to open a session without a tenant identifier using this strategy. This strategy is not yet implemented and you can follow its progress via the HHH-6054 Jira issue.
19.4.1. MultiTenantConnectionProvider
When using either the DATABASE or SCHEMA approach, Hibernate needs to be able to obtain Connections in a tenant-specific manner.
That is the role of the MultiTenantConnectionProvider contract.
Application developers will need to provide an implementation of this contract.
Most of its methods are extremely self-explanatory.
The only ones which might not be are getAnyConnection and releaseAnyConnection.
It is important to note also that these methods do not accept the tenant identifier.
Hibernate uses these methods during startup to perform various configuration, mainly via the java.sql.DatabaseMetaData object.
The MultiTenantConnectionProvider to use can be specified in a number of ways:
-
Use the
hibernate.multi_tenant_connection_providersetting. It could name aMultiTenantConnectionProviderinstance, aMultiTenantConnectionProviderimplementation class reference or aMultiTenantConnectionProviderimplementation class name. -
Passed directly to the
org.hibernate.boot.registry.StandardServiceRegistryBuilder. -
If none of the above options match, but the settings do specify a
hibernate.connection.datasourcevalue, Hibernate will assume it should use the specificDataSourceBasedMultiTenantConnectionProviderImplimplementation which works on a number of pretty reasonable assumptions when running inside of an app server and using onejavax.sql.DataSourceper tenant. See its Javadocs for more details.
The following example portrays a MultiTenantConnectionProvider implementation that handles multiple ConnectionProviders.
MultiTenantConnectionProvider implementationpublic class ConfigurableMultiTenantConnectionProvider
extends AbstractMultiTenantConnectionProvider {
private final Map<String, ConnectionProvider> connectionProviderMap =
new HashMap<>( );
public ConfigurableMultiTenantConnectionProvider(
Map<String, ConnectionProvider> connectionProviderMap) {
this.connectionProviderMap.putAll( connectionProviderMap );
}
@Override
protected ConnectionProvider getAnyConnectionProvider() {
return connectionProviderMap.values().iterator().next();
}
@Override
protected ConnectionProvider selectConnectionProvider(String tenantIdentifier) {
return connectionProviderMap.get( tenantIdentifier );
}
}The ConfigurableMultiTenantConnectionProvider can be set up as follows:
MultiTenantConnectionProvider implementationprivate void init() {
registerConnectionProvider( FRONT_END_TENANT );
registerConnectionProvider( BACK_END_TENANT );
Map<String, Object> settings = new HashMap<>( );
settings.put( AvailableSettings.MULTI_TENANT, multiTenancyStrategy() );
settings.put( AvailableSettings.MULTI_TENANT_CONNECTION_PROVIDER,
new ConfigurableMultiTenantConnectionProvider( connectionProviderMap ) );
sessionFactory = sessionFactory(settings);
}
protected void registerConnectionProvider(String tenantIdentifier) {
Properties properties = properties();
properties.put( Environment.URL,
tenantUrl(properties.getProperty( Environment.URL ), tenantIdentifier) );
DriverManagerConnectionProviderImpl connectionProvider =
new DriverManagerConnectionProviderImpl();
connectionProvider.configure( properties );
connectionProviderMap.put( tenantIdentifier, connectionProvider );
}When using multitenancy, it’s possible to save an entity with the same identifier across different tenants:
MultiTenantConnectionProvider implementationdoInSession( FRONT_END_TENANT, session -> {
Person person = new Person( );
person.setId( 1L );
person.setName( "John Doe" );
session.persist( person );
} );
doInSession( BACK_END_TENANT, session -> {
Person person = new Person( );
person.setId( 1L );
person.setName( "John Doe" );
session.persist( person );
} );19.4.2. CurrentTenantIdentifierResolver
org.hibernate.context.spi.CurrentTenantIdentifierResolver is a contract for Hibernate to be able to resolve what the application considers the current tenant identifier.
The implementation to use is either passed directly to Configuration via its setCurrentTenantIdentifierResolver method.
It can also be specified via the hibernate.tenant_identifier_resolver setting.
There are two situations where CurrentTenantIdentifierResolver is used:
-
The first situation is when the application is using the
org.hibernate.context.spi.CurrentSessionContextfeature in conjunction with multitenancy. In the case of the current-session feature, Hibernate will need to open a session if it cannot find an existing one in scope. However, when a session is opened in a multitenant environment, the tenant identifier has to be specified. This is where theCurrentTenantIdentifierResolvercomes into play; Hibernate will consult the implementation you provide to determine the tenant identifier to use when opening the session. In this case, it is required that aCurrentTenantIdentifierResolveris supplied. -
The other situation is when you do not want to have to explicitly specify the tenant identifier all the time. If a
CurrentTenantIdentifierResolverhas been specified, Hibernate will use it to determine the default tenant identifier to use when opening the session.
Additionally, if the CurrentTenantIdentifierResolver implementation returns true for its validateExistingCurrentSessions method, Hibernate will make sure any existing sessions that are found in scope have a matching tenant identifier.
This capability is only pertinent when the CurrentTenantIdentifierResolver is used in current-session settings.
19.4.3. Caching
Multitenancy support in Hibernate works seamlessly with the Hibernate second level cache. The key used to cache data encodes the tenant identifier.
|
Currently, schema export will not really work with multitenancy. That may not change. The JPA expert group is in the process of defining multitenancy support for an upcoming version of the specification. |
20. OSGi
20.1. OSGi Specification and Environment
Hibernate targets the OSGi 4.3 spec or later.
It was necessary to start with 4.3, over 4.2, due to our dependency on OSGi’s BundleWiring for entity/mapping scanning.
Hibernate supports three types of configurations within OSGi.
-
Container-Managed JPA Container-Managed JPA
-
Unmanaged JPA Unmanaged JPA
-
Unmanaged Native Unmanaged Native
20.2. hibernate-osgi
Rather than embed OSGi capabilities into hibernate-core, hibernate-entitymanager, and sub-modules, hibernate-osgi was created.
It’s purposefully separated, isolating all OSGi dependencies.
It provides an OSGi-specific ClassLoader (aggregates the container’s ClassLoader with core and EntityManager ClassLoader`s),
JPA persistence provider, `SessionFactory/EntityManagerFactory bootstrapping, entities/mappings scanner, and service management.
20.3. features.xml
Apache Karaf environments tend to make heavy use of its "features" concept, where a feature is a set of order-specific bundles focused on a concise capability.
These features are typically defined in a features.xml file.
Hibernate produces and releases its own features.xml that defines a core hibernate-orm, as well as additional features for optional functionality (caching, Envers, etc.).
This is included in the binary distribution, as well as deployed to the JBoss Nexus repository (using the org.hibernate groupId and hibernate-osgi with the karaf.xml classifier).
Note that our features are versioned using the same ORM artifact versions they wrap. Also, note that the features are heavily tested against Karaf 3.0.3 as a part of our PaxExam-based integration tests. However, they’ll likely work on other versions as well.
hibernate-osgi, theoretically, supports a variety of OSGi containers, such as Equinox. In that case, please use `features.xm`l as a reference for necessary bundles to activate and their correct ordering. However, note that Karaf starts a number of bundles automatically, several of which would need to be installed manually on alternatives.
20.4. QuickStarts/Demos
All three configurations have a QuickStart/Demo available in the hibernate-demos project:
20.5. Container-Managed JPA
The Enterprise OSGi specification includes container-managed JPA.
The container is responsible for discovering persistence units in bundles and automatically creating the EntityManagerFactory (one EntityManagerFactory per PersistenceUnit).
It uses the JPA provider (hibernate-osgi) that has registered itself with the OSGi PersistenceProvider service.
20.6. Enterprise OSGi JPA Container
In order to utilize container-managed JPA, an Enterprise OSGi JPA container must be active in the runtime.
In Karaf, this means Aries JPA, which is included out-of-the-box (simply activate the jpa and transaction features).
Originally, we intended to include those dependencies within our own features.xml.
However, after guidance from the Karaf and Aries teams, it was pulled out.
This allows Hibernate OSGi to be portable and not be directly tied to Aries versions, instead having the user choose which to use.
That being said, the QuickStart/Demo projects include a sample features.xml showing which features need activated in Karaf in order to support this environment. As mentioned, use this purely as a reference!
20.7. persistence.xml
Similar to any other JPA setup, your bundle must include a persistence.xml file. This is typically located in META-INF.
20.8. DataSource
Typical Enterprise OSGi JPA usage includes a DataSource installed in the container.
Your bundle’s persistence.xml calls out the DataSource through JNDI.
For example, you could install the following H2 DataSource.
You can deploy the DataSource manually (Karaf has a deploy dir), or through a "blueprint bundle" (blueprint:file:/[PATH]/datasource-h2.xml).
<?xml version="1.0" encoding="UTF-8"?>
<!--
First install the H2 driver using:
> install -s mvn:com.h2database/h2/1.3.163
Then copy this file to the deploy folder
-->
<blueprint xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0">
<bean id="dataSource" class="org.h2.jdbcx.JdbcDataSource">
<property name="URL" value="jdbc:h2:mem:db1;DB_CLOSE_DELAY=-1;MVCC=TRUE"/>
<property name="user" value="sa"/>
<property name="password" value=""/>
</bean>
<service interface="javax.sql.DataSource" ref="dataSource">
<service-properties>
<entry key="osgi.jndi.service.name" value="jdbc/h2ds"/>
</service-properties>
</service>
</blueprint>That DataSource is then used by your persistence.xml persistence-unit. The following works in Karaf, but the names may need tweaked in alternative containers.
<jta-data-source>osgi:service/javax.sql.DataSource/(osgi.jndi.service.name=jdbc/h2ds)</jta-data-source>20.9. Bundle Package Imports
Your bundle’s manifest will need to import, at a minimum,
-
javax.persistence -
org.hibernate.proxyandjavassist.util.proxy, due to Hibernate’s ability to return proxies for lazy initialization (Javassist enhancement occurs on the entity’sClassLoaderduring runtime).
20.10. Obtaining an EntityManger
The easiest, and most supported, method of obtaining an EntityManager utilizes OSGi’s OSGI-INF/blueprint/blueprint.xml in your bundle.
The container takes the name of your persistence unit, then automatically injects an EntityManager instance into your given bean attribute.
<?xml version="1.0" encoding="UTF-8"?>
<blueprint xmlns:jpa="http://aries.apache.org/xmlns/jpa/v1.0.0"
xmlns:tx="http://aries.apache.org/xmlns/transactions/v1.0.0"
default-activation="eager"
xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0">
<!-- This gets the container-managed EntityManager and injects it into the DataPointServiceImpl bean.
Assumes DataPointServiceImpl has an "entityManager" field with a getter and setter. -->
<bean id="dpService" class="org.hibernate.osgitest.DataPointServiceImpl">
<jpa:context unitname="managed-jpa" property="entityManager"/>
<tx:transaction method="*" value="Required"/>
</bean>
<service ref="dpService" interface="org.hibernate.osgitest.DataPointService"/>
</blueprint>20.11. Unmanaged JPA
Hibernate also supports the use of JPA through hibernate-entitymanager, unmanaged by the OSGi container.
The client bundle is responsible for managing the EntityManagerFactory and `EntityManager`s.
20.12. persistence.xml
Similar to any other JPA setup, your bundle must include a persistence.xml file. This is typically located in META-INF.
20.13. Bundle Package Imports
Your bundle’s manifest will need to import, at a minimum,
-
javax.persistence
-
org.hibernate.proxyandjavassist.util.proxy, due to Hibernate’s ability to return proxies for lazy initialization (Javassist enhancement occurs on the entity’sClassLoaderduring runtime) -
JDBC driver package (example:
org.h2) -
org.osgi.framework, necessary to discover theEntityManagerFactory(described below)
20.14. Obtaining an EntityMangerFactory
hibernate-osgi registers an OSGi service, using the JPA PersistenceProvider interface name, that bootstraps and creates an EntityManagerFactory specific for OSGi environments.
|
It is VITAL that your |
EntityManagerFactorypublic class HibernateUtil {
private EntityManagerFactory emf;
public EntityManager getEntityManager() {
return getEntityManagerFactory().createEntityManager();
}
private EntityManagerFactory getEntityManagerFactory() {
if ( emf == null ) {
Bundle thisBundle = FrameworkUtil.getBundle( HibernateUtil.class );
BundleContext context = thisBundle.getBundleContext();
ServiceReference serviceReference = context.getServiceReference( PersistenceProvider.class.getName() );
PersistenceProvider persistenceProvider = ( PersistenceProvider ) context.getService( serviceReference );
emf = persistenceProvider.createEntityManagerFactory( "YourPersistenceUnitName", null );
}
return emf;
}
}20.15. Unmanaged Native
Native Hibernate use is also supported. The client bundle is responsible for managing the SessionFactory and `Session`s.
20.16. Bundle Package Imports
Your bundle’s manifest will need to import, at a minimum,
-
javax.persistence
-
org.hibernate.proxyandjavassist.util.proxy, due to Hibernate’s ability to return proxies for lazy initialization (Javassist enhancement occurs on the entity’sClassLoaderduring runtime) -
JDBC driver package (example:
org.h2) -
org.osgi.framework, necessary to discover theSessionFactory(described below) -
org.hibernate.*packages, as necessary (ex: cfg, criterion, service, etc.)
20.17. Obtaining an SessionFactory
hibernate-osgi registers an OSGi service, using the SessionFactory interface name, that bootstraps and creates a SessionFactory specific for OSGi environments.
|
It is VITAL that your |
SessionFactorypublic class HibernateUtil {
private SessionFactory sf;
public Session getSession() {
return getSessionFactory().openSession();
}
private SessionFactory getSessionFactory() {
if ( sf == null ) {
Bundle thisBundle = FrameworkUtil.getBundle( HibernateUtil.class );
BundleContext context = thisBundle.getBundleContext();
ServiceReference sr = context.getServiceReference( SessionFactory.class.getName() );
sf = ( SessionFactory ) context.getService( sr );
}
return sf;
}
}20.18. Optional Modules
The unmanaged-native demo project displays the use of optional Hibernate modules.
Each module adds additional dependency bundles that must first be activated, either manually or through an additional feature.
As of ORM 4.2, Envers is fully supported.
Support for C3P0, Proxool, EhCache, and Infinispan were added in 4.3, however none of their 3rd party libraries currently work in OSGi (lots of ClassLoader problems, etc.).
We’re tracking the issues in JIRA.
20.19. Extension Points
Multiple contracts exist to allow applications to integrate with and extend Hibernate capabilities.
Most apps utilize JDK services to provide their implementations.
hibernate-osgi supports the same extensions through OSGi services.
Implement and register them in any of the three configurations.
hibernate-osgi will discover and integrate them during EntityManagerFactory/SessionFactory bootstrapping. Supported extension points are as follows.
The specified interface should be used during service registration.
org.hibernate.integrator.spi.Integrator-
(as of 4.2)
org.hibernate.boot.registry.selector.StrategyRegistrationProvider-
(as of 4.3)
org.hibernate.boot.model.TypeContributor-
(as of 4.3)
- JTA’s
-
javax.transaction.TransactionManagerandjavax.transaction.UserTransaction(as of 4.2), however these are typically provided by the OSGi container.
The easiest way to register extension point implementations is through a blueprint.xml file.
Add OSGI-INF/blueprint/blueprint.xml to your classpath. Envers' blueprint is a great example:
<!--
~ Hibernate, Relational Persistence for Idiomatic Java
~
~ License: GNU Lesser General Public License (LGPL), version 2.1 or later.
~ See the lgpl.txt file in the root directory or <http://www.gnu.org/licenses/lgpl-2.1.html>.
-->
<blueprint default-activation="eager"
xmlns="http://www.osgi.org/xmlns/blueprint/v1.0.0">
<bean id="integrator" class="org.hibernate.envers.boot.internal.EnversIntegrator"/>
<service ref="integrator" interface="org.hibernate.integrator.spi.Integrator"/>
<bean id="typeContributor"
class="org.hibernate.envers.boot.internal.TypeContributorImpl"/>
<service ref="typeContributor" interface="org.hibernate.boot.model.TypeContributor"/>
</blueprint>Extension points can also be registered programmatically with BundleContext#registerService, typically within your BundleActivator#start.
20.20. Caveats
-
Technically, multiple persistence units are supported by Enterprise OSGi JPA and unmanaged Hibernate JPA use. However, we cannot currently support this in OSGi. In Hibernate 4, only one instance of the OSGi-specific
ClassLoaderis used per Hibernate bundle, mainly due to heavy use of static TCCL utilities. We hope to support one OSGiClassLoaderper persistence unit in Hibernate 5. -
Scanning is supported to find non-explicitly listed entities and mappings. However, they MUST be in the same bundle as your persistence unit (fairly typical anyway). Our OSGi
ClassLoaderonly considers the "requesting bundle" (hence the requirement on using services to createEntityManagerFactory/SessionFactory), rather than attempting to scan all available bundles. This is primarily for versioning considerations, collision protections, etc. -
Some containers (ex: Aries) always return true for
PersistenceUnitInfo#excludeUnlistedClasses, even if yourpersistence.xmlexplicitly hasexclude-unlisted-classesset tofalse. They claim it’s to protect JPA providers from having to implement scanning ("we handle it for you"), even though we still want to support it in many cases. The work around is to sethibernate.archive.autodetectionto, for example,hbm,class. This tells hibernate to ignore theexcludeUnlistedClassesvalue and scan for*.hbm.xmland entities regardless. -
Scanning does not currently support annotated packages on
package-info.java. -
Currently, Hibernate OSGi is primarily tested using Apache Karaf and Apache Aries JPA. Additional testing is needed with Equinox, Gemini, and other container providers.
-
Hibernate ORM has many dependencies that do not currently provide OSGi manifests. The QuickStart tutorials make heavy use of 3rd party bundles (SpringSource, ServiceMix) or the
wrap:…operator.
21. Envers
21.1. Basics
To audit changes that are performed on an entity, you only need two things:
-
the
hibernate-enversjar on the classpath, -
an
@Auditedannotation on the entity.
|
Unlike in previous versions, you no longer need to specify listeners in the Hibernate configuration file. Just putting the Envers jar on the classpath is enough because listeners will be registered automatically. |
And that’s all. You can create, modify and delete the entities as always.
If you look at the generated schema for your entities, or at the data persisted by Hibernate, you will notice that there are no changes.
However, for each audited entity, a new table is introduced - entity_table_AUD, which stores the historical data, whenever you commit a transaction.
|
Envers automatically creates audit tables if |
Instead of annotating the whole class and auditing all properties, you can annotate only some persistent properties with @Audited.
This will cause only these properties to be audited.
The audit (history) of an entity can be accessed using the AuditReader interface, which can be obtained having an open EntityManager or Session via the AuditReaderFactory.
See the Javadocs for these classes for details on the functionality offered.
21.2. Configuration
It is possible to configure various aspects of Hibernate Envers behavior, such as table names, etc.
| Property name | Default value | Description |
|---|---|---|
|
String that will be prepended to the name of an audited entity to create the name of the entity and that will hold audit information. |
|
|
|
String that will be appended to the name of an audited entity to create the name of the entity and that will hold audit information.
If you audit an entity with a table name Person, in the default setting Envers will generate a |
|
|
Name of a field in the audit entity that will hold the revision number. |
|
|
Name of a field in the audit entity that will hold the type of the revision (currently, this can be: |
|
|
Should a revision be generated when a not-owned relation field changes (this can be either a collection in a one-to-many relation, or the field using |
|
|
When true, properties to be used for optimistic locking, annotated with |
|
|
Should the entity data be stored in the revision when the entity is deleted (instead of only storing the id and all other properties as null). This is not normally needed, as the data is present in the last-but-one revision. Sometimes, however, it is easier and more efficient to access it in the last revision (then the data that the entity contained before deletion is stored twice). |
|
|
The default schema name that should be used for audit tables.
Can be overridden using the |
|
|
The default catalog name that should be used for audit tables.
Can be overridden using the |
|
|
The audit strategy that should be used when persisting audit data.
The default stores only the revision, at which an entity was modified.
An alternative, the |
|
|
The column name that will hold the end revision number in audit entities. This property is only valid if the validity audit strategy is used. |
|
|
Should the timestamp of the end revision be stored, until which the data was valid, in addition to the end revision itself.
This is useful to be able to purge old Audit records out of a relational database by using table partitioning.
Partitioning requires a column that exists within the table.
This property is only evaluated if the |
|
|
Column name of the timestamp of the end revision until which the data was valid.
Only used if the 1ValidityAuditStrategy1 is used, and |
|
|
Boolean flag that determines the strategy of revision number generation.
Default implementation of revision entity uses native identifier generator.
If current database engine does not support identity columns, users are advised to set this property to false.
In this case revision numbers are created by preconfigured |
|
|
Should entity types, that have been modified during each revision, be tracked.
The default implementation creates |
|
|
Should property modification flags be stored for all audited entities and all properties.
When set to true, for all properties an additional boolean column in the audit tables will be created, filled with information if the given property changed in the given revision.
When set to false, such column can be added to selected entities or properties using the |
|
|
The suffix for columns storing "Modified Flags". For example: a property called "age", will by default get modified flag with column name "age_MOD". |
|
|
Name of column used for storing ordinal of the change in sets of embeddable elements. |
|
|
While deleting revision entry, remove data of associated audited entities. Requires database support for cascade row removal. |
|
|
Guarantees proper validity audit strategy behavior when application reuses identifiers of deleted entities. Exactly one row with |
|
The following configuration options have been added recently and should be regarded as experimental:
|
21.3. Additional mapping annotations
The name of the audit table can be set on a per-entity basis, using the @AuditTable annotation.
It may be tedious to add this annotation to every audited entity, so if possible, it’s better to use a prefix/suffix.
If you have a mapping with secondary tables, audit tables for them will be generated in the same way (by adding the prefix and suffix).
If you wish to overwrite this behavior, you can use the @SecondaryAuditTable and @SecondaryAuditTables annotations.
If you’d like to override auditing behavior of some fields/properties inherited from @MappedSuperclass or in an embedded component,
you can apply the @AuditOverride( s ) annotation on the subtype or usage site of the component.
If you want to audit a relation mapped with @OneToMany and @JoinColumn,
please see Mapping exceptions for a description of the additional @AuditJoinTable annotation that you’ll probably want to use.
If you want to audit a relation, where the target entity is not audited (that is the case for example with dictionary-like entities, which don’t change and don’t have to be audited),
just annotate it with @Audited( targetAuditMode = RelationTargetAuditMode.NOT_AUDITED ).
Then, while reading historic versions of your entity, the relation will always point to the "current" related entity.
By default Envers throws javax.persistence.EntityNotFoundException when "current" entity does not exist in the database.
Apply @NotFound( action = NotFoundAction.IGNORE ) annotation to silence the exception and assign null value instead.
The hereby solution causes implicit eager loading of to-one relations.
If you’d like to audit properties of a superclass of an entity, which are not explicitly audited (they don’t have the @Audited annotation on any properties or on the class),
you can set the @AuditOverride( forClass = SomeEntity.class, isAudited = true/false ) annotation.
|
The |
21.4. Choosing an audit strategy
After the basic configuration, it is important to choose the audit strategy that will be used to persist and retrieve audit information. There is a trade-off between the performance of persisting and the performance of querying the audit information. Currently, there are two audit strategies.
-
The default audit strategy persists the audit data together with a start revision. For each row inserted, updated or deleted in an audited table, one or more rows are inserted in the audit tables, together with the start revision of its validity. Rows in the audit tables are never updated after insertion. Queries of audit information use subqueries to select the applicable rows in the audit tables.
These subqueries are notoriously slow and difficult to index. -
The alternative is a validity audit strategy. This strategy stores the start-revision and the end-revision of audit information. For each row inserted, updated or deleted in an audited table, one or more rows are inserted in the audit tables, together with the start revision of its validity. But at the same time the end-revision field of the previous audit rows (if available) are set to this revision. Queries on the audit information can then use 'between start and end revision' instead of subqueries as used by the default audit strategy.
The consequence of this strategy is that persisting audit information will be a bit slower because of the extra updates involved, but retrieving audit information will be a lot faster. This can be improved even further by adding extra indexes.
21.5. Revision Log
When Envers starts a new revision, it creates a new revision entity which stores information about the revision. By default, that includes just:
- revision number
-
An integral value (
int/Integerorlong/Long). Essentially the primary key of the revision - revision timestamp
-
either a
long/Longorjava.util.Datevalue representing the instant at which the revision was made. When using ajava.util.Date, instead of along/Longfor the revision timestamp, take care not to store it to a column data type which will loose precision.
Envers handles this information as an entity.
By default it uses its own internal class to act as the entity, mapped to the REVINFO table.
You can, however, supply your own approach to collecting this information which might be useful to capture additional details such as who made a change or the ip address from which the request came.
There are two things you need to make this work:
-
First, you will need to tell Envers about the entity you wish to use. Your entity must use the
@org.hibernate.envers.RevisionEntityannotation. It must define the two attributes described above annotated with@org.hibernate.envers.RevisionNumberand@org.hibernate.envers.RevisionTimestamp, respectively. You can extend fromorg.hibernate.envers.DefaultRevisionEntity, if you wish, to inherit all these required behaviors.Simply add the custom revision entity as you do your normal entities and Envers will _find it_.
It is an error for there to be multiple entities marked as @org.hibernate.envers.RevisionEntity -
Second, you need to tell Envers how to create instances of your revision entity which is handled by the
newRevision( Object revisionEntity )method of theorg.hibernate.envers.RevisionListenerinterface.You tell Envers your custom `org.hibernate.envers.RevisionListener` implementation to use by specifying it on the `@org.hibernate.envers.RevisionEntity` annotation, using the value attribute. If your `RevisionListener` class is inaccessible from `@RevisionEntity` (e.g. it exists in a different module), set `org.hibernate.envers.revision_listener` property to its fully qualified class name. Class name defined by the configuration parameter overrides revision entity's value attribute.
@RevisionEntity( MyCustomRevisionListener.class )
public class MyCustomRevisionEntity {
...
}
public class MyCustomRevisionListener implements RevisionListener {
public void newRevision( Object revisionEntity ) {
MyCustomRevisionEntity customRevisionEntity = ( MyCustomRevisionEntity ) revisionEntity;
}
}package `org.hibernate.envers.example;`
import `org.hibernate.envers.RevisionEntity;`
import `org.hibernate.envers.DefaultRevisionEntity;`
import javax.persistence.Entity;
@Entity
@RevisionEntity( ExampleListener.class )
public class ExampleRevEntity extends DefaultRevisionEntity {
private String username;
public String getUsername() { return username; }
public void setUsername( String username ) { this.username = username; }
}package `org.hibernate.envers.example;`
import `org.hibernate.envers.RevisionListener;`
import org.jboss.seam.security.Identity;
import org.jboss.seam.Component;
public class ExampleListener implements RevisionListener {
public void newRevision( Object revisionEntity ) {
ExampleRevEntity exampleRevEntity = ( ExampleRevEntity ) revisionEntity;
Identity identity =
(Identity) Component.getInstance( "org.jboss.seam.security.identity" );
exampleRevEntity.setUsername( identity.getUsername() );
}
}|
An alternative method to using the
|
21.6. Tracking entity names modified during revisions
By default entity types that have been changed in each revision are not being tracked.
This implies the necessity to query all tables storing audited data in order to retrieve changes made during specified revision.
Envers provides a simple mechanism that creates REVCHANGES table which stores entity names of modified persistent objects.
Single record encapsulates the revision identifier (foreign key to REVINFO table) and a string value.
Tracking of modified entity names can be enabled in three different ways:
-
Set
org.hibernate.envers.track_entities_changed_in_revisionparameter totrue. In this caseorg.hibernate.envers.DefaultTrackingModifiedEntitiesRevisionEntitywill be implicitly used as the revision log entity. -
Create a custom revision entity that extends
org.hibernate.envers.DefaultTrackingModifiedEntitiesRevisionEntityclass.@RevisionEntity public class ExtendedRevisionEntity extends DefaultTrackingModifiedEntitiesRevisionEntity { ... } -
Mark an appropriate field of a custom revision entity with
@org.hibernate.envers.ModifiedEntityNamesannotation. The property is required to be ofSet<String>type.@RevisionEntity public class AnnotatedTrackingRevisionEntity { ... @ElementCollection @JoinTable( name = "REVCHANGES", joinColumns = @JoinColumn( name = "REV" ) ) @Column( name = "ENTITYNAME" ) @ModifiedEntityNames private Set<String> modifiedEntityNames; ... }Users, that have chosen one of the approaches listed above, can retrieve all entities modified in a specified revision by utilizing API described in Querying for entities modified in a given revision.
Users are also allowed to implement custom mechanism of tracking modified entity types.
In this case, they shall pass their own implementation of org.hibernate.envers.EntityTrackingRevisionListener interface as the value of @org.hibernate.envers.RevisionEntity annotation.
EntityTrackingRevisionListener interface exposes one method that notifies whenever audited entity instance has been added, modified or removed within current revision boundaries.
public class CustomEntityTrackingRevisionListener implements EntityTrackingRevisionListener {
@Override
public void entityChanged( Class entityClass, String entityName,
Serializable entityId, RevisionType revisionType,
Object revisionEntity ) {
String type = entityClass.getName();
( ( CustomTrackingRevisionEntity ) revisionEntity ).addModifiedEntityType( type );
}
@Override
public void newRevision( Object revisionEntity ) {
}
}@Entity
@RevisionEntity( CustomEntityTrackingRevisionListener.class )
public class CustomTrackingRevisionEntity {
@Id
@GeneratedValue
@RevisionNumber
private int customId;
@RevisionTimestamp
private long customTimestamp;
@OneToMany( mappedBy="revision", cascade={ CascadeType.PERSIST, CascadeType.REMOVE } )
private Set<ModifiedEntityTypeEntity> modifiedEntityTypes = new HashSet<ModifiedEntityTypeEntity>();
public void addModifiedEntityType( String entityClassName ) {
modifiedEntityTypes.add( new ModifiedEntityTypeEntity( this, entityClassName ) );
}
...
}@Entity
public class ModifiedEntityTypeEntity {
@Id
@GeneratedValue
private Integer id;
@ManyToOne
private CustomTrackingRevisionEntity revision;
private String entityClassName;
...
}CustomTrackingRevisionEntity revEntity =
getAuditReader().findRevision( CustomTrackingRevisionEntity.class, revisionNumber );
Set<ModifiedEntityTypeEntity> modifiedEntityTypes = revEntity.getModifiedEntityTypes();21.7. Tracking entity changes at property level
By default, the only information stored by Envers are revisions of modified entities. This approach lets user create audit queries based on historical values of entity properties. Sometimes it is useful to store additional metadata for each revision, when you are interested also in the type of changes, not only about the resulting values.
The feature described in Tracking entity names modified during revisions makes it possible to tell which entities were modified in a given revision.
The feature described here takes it one step further. "Modification Flags" enable Envers to track which properties of audited entities were modified in a given revision.
Tracking entity changes at property level can be enabled by:
-
setting
org.hibernate.envers.global_with_modified_flagconfiguration property totrue. This global switch will cause adding modification flags to be stored for all audited properties of all audited entities. -
using
@Audited( withModifiedFlag=true )on a property or on an entity.
The trade-off coming with this functionality is an increased size of audit tables and a very little, almost negligible, performance drop during audit writes. This is due to the fact that every tracked property has to have an accompanying boolean column in the schema that stores information about the property modifications. Of course it is Envers job to fill these columns accordingly - no additional work by the developer is required. Because of costs mentioned, it is recommended to enable the feature selectively, when needed with use of the granular configuration means described above.
To see how "Modified Flags" can be utilized, check out the very simple query API that uses them: Querying for revisions of entity that modified given property.
21.8. Queries
You can think of historic data as having two dimensions:
- horizontal
-
is the state of the database at a given revision. Thus, you can query for entities as they were at revision N.
- vertical
-
are the revisions, at which entities changed. Hence, you can query for revisions, in which a given entity changed.
The queries in Envers are similar to Hibernate Criteria queries, so if you are common with them, using Envers queries will be much easier.
The main limitation of the current queries implementation is that you cannot traverse relations. You can only specify constraints on the ids of the related entities, and only on the "owning" side of the relation. This however will be changed in future releases.
Please note, that queries on the audited data will be in many cases much slower than corresponding queries on "live" data, as they involve correlated subselects.
Queries are improved both in terms of speed and possibilities, when using the valid-time audit strategy, that is when storing both start and end revisions for entities. See Configuration.
21.9. Querying for entities of a class at a given revision
The entry point for this type of queries is:
AuditQuery query = getAuditReader()
.createQuery()
.forEntitiesAtRevision( MyEntity.class, revisionNumber );You can then specify constraints, which should be met by the entities returned, by adding restrictions, which can be obtained using the AuditEntity factory class.
For example, to select only entities where the "name" property is equal to "John":
query.add( AuditEntity.property( "name" ).eq( "John" ) );And to select only entities that are related to a given entity:
query.add( AuditEntity.property( "address" ).eq( relatedEntityInstance ) );
// or
query.add( AuditEntity.relatedId( "address" ).eq( relatedEntityId ) );You can limit the number of results, order them, and set aggregations and projections (except grouping) in the usual way.
When your query is complete, you can obtain the results by calling the getSingleResult() or getResultList() methods.
A full query, can look for example like this:
List personsAtAddress = getAuditReader().createQuery()
.forEntitiesAtRevision( Person.class, 12 )
.addOrder( AuditEntity.property( "surname" ).desc() )
.add( AuditEntity.relatedId( "address" ).eq( addressId ) )
.setFirstResult( 4 )
.setMaxResults( 2 )
.getResultList();21.10. Querying for revisions, at which entities of a given class changed
The entry point for this type of queries is:
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity( MyEntity.class, false, true );You can add constraints to this query in the same way as to the previous one. There are some additional possibilities:
-
using
AuditEntity.revisionNumber()you can specify constraints, projections and order on the revision number, in which the audited entity was modified -
similarly, using
AuditEntity.revisionProperty( propertyName )you can specify constraints, projections and order on a property of the revision entity, corresponding to the revision in which the audited entity was modified -
AuditEntity.revisionType()gives you access as above to the type of the revision (ADD,MOD,DEL).
Using these methods, you can order the query results by revision number, set projection or constraint the revision number to be greater or less than a specified value, etc.
For example, the following query will select the smallest revision number, at which entity of class MyEntity with id entityId has changed, after revision number 42:
Number revision = (Number) getAuditReader().createQuery()
.forRevisionsOfEntity( MyEntity.class, false, true )
.setProjection( AuditEntity.revisionNumber().min() )
.add( AuditEntity.id().eq( entityId ) )
.add( AuditEntity.revisionNumber().gt( 42 ) )
.getSingleResult();The second additional feature you can use in queries for revisions is the ability to maximize/minimize a property.
For example, if you want to select the smallest possibler revision at which the value of the actualDate for a given entity was larger then a given value:
Number revision = (Number) getAuditReader().createQuery()
.forRevisionsOfEntity( MyEntity.class, false, true) // We are only interested in the first revision
.setProjection( AuditEntity.revisionNumber().min() )
.add( AuditEntity.property( "actualDate" ).minimize()
.add( AuditEntity.property( "actualDate" ).ge( givenDate ) )
.add( AuditEntity.id().eq( givenEntityId ) )) .getSingleResult();The minimize() and maximize() methods return a criteria, to which you can add constraints, which must be met by the entities with the maximized/minimized properties.
|
|
You probably also noticed that there are two boolean parameters, passed when creating the query.
selectEntitiesOnly-
the first parameter is only valid when you don’t set an explicit projection. If true, the result of the query will be a list of entities (which changed at revisions satisfying the specified constraints). If false, the result will be a list of three element arrays:
-
the first element will be the changed entity instance.
-
the second will be an entity containing revision data (if no custom entity is used, this will be an instance of
DefaultRevisionEntity). -
the third will be the type of the revision (one of the values of the
RevisionTypeenumeration:ADD,MOD,DEL).
-
selectDeletedEntities-
the second parameter specifies if revisions, in which the entity was deleted should be included in the results. If yes, such entities will have the revision type
DELand all fields, except the id,null.
21.11. Querying for revisions of entity that modified given property
For the two types of queries described above it’s possible to use special Audit criteria called hasChanged() and hasNotChanged()
that makes use of the functionality described in Tracking entity changes at property level.
They’re best suited for vertical queries, however existing API doesn’t restrict their usage for horizontal ones.
Let’s have a look at following examples:
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity( MyEntity.class, false, true )
.add( AuditEntity.id().eq( id ) );
.add( AuditEntity.property( "actualDate" ).hasChanged() );This query will return all revisions of MyEntity with given id, where the actualDate property has been changed.
Using this query we won’t get all other revisions in which actualDate wasn’t touched.
Of course, nothing prevents user from combining hasChanged condition with some additional criteria - add method can be used here in a normal way.
AuditQuery query = getAuditReader().createQuery()
.forEntitiesAtRevision( MyEntity.class, revisionNumber )
.add( AuditEntity.property( "prop1" ).hasChanged() )
.add( AuditEntity.property( "prop2" ).hasNotChanged() );This query will return horizontal slice for MyEntity at the time revisionNumber was generated.
It will be limited to revisions that modified prop1 but not prop2.
Note that the result set will usually also contain revisions with numbers lower than the revisionNumber,
so wem cannot read this query as "Give me all MyEntities changed in revisionNumber with prop1 modified and prop2 untouched".
To get such result we have to use the forEntitiesModifiedAtRevision query:
AuditQuery query = getAuditReader().createQuery()
.forEntitiesModifiedAtRevision( MyEntity.class, revisionNumber )
.add( AuditEntity.property( "prop1" ).hasChanged() )
.add( AuditEntity.property( "prop2" ).hasNotChanged() );21.12. Querying for entities modified in a given revision
The basic query allows retrieving entity names and corresponding Java classes changed in a specified revision:
modifiedEntityTypes = getAuditReader()
.getCrossTypeRevisionChangesReader()
.findEntityTypes( revisionNumber );Other queries (also accessible from org.hibernate.envers.CrossTypeRevisionChangesReader):
List<Object> findEntities( Number )-
Returns snapshots of all audited entities changed (added, updated and removed) in a given revision. Executes
N+1SQL queries, whereNis a number of different entity classes modified within specified revision. List<Object> findEntities( Number, RevisionType )-
Returns snapshots of all audited entities changed (added, updated or removed) in a given revision filtered by modification type. Executes
N+1SQL queries, whereNis a number of different entity classes modified within specified revision. Map<RevisionType, List<Object>> findEntitiesGroupByRevisionType( Number )-
Returns a map containing lists of entity snapshots grouped by modification operation (e.g. addition, update and removal). Executes
3N+1SQL queries, whereNis a number of different entity classes modified within specified revision.
Note that methods described above can be legally used only when the default mechanism of tracking changed entity names is enabled (see Tracking entity names modified during revisions).
21.13. Conditional auditing
Envers persists audit data in reaction to various Hibernate events (e.g. post update, post insert, and so on), using a series of event listeners from the org.hibernate.envers.event.spi package.
By default, if the Envers jar is in the classpath, the event listeners are auto-registered with Hibernate.
Conditional auditing can be implemented by overriding some of the Envers event listeners. To use customized Envers event listeners, the following steps are needed:
-
Turn off automatic Envers event listeners registration by setting the
hibernate.listeners.envers.autoRegisterHibernate property tofalse. -
Create subclasses for appropriate event listeners. For example, if you want to conditionally audit entity insertions, extend the
org.hibernate.envers.event.spi.EnversPostInsertEventListenerImplclass. Place the conditional-auditing logic in the subclasses, call the super method if auditing should be performed. -
Create your own implementation of
org.hibernate.integrator.spi.Integrator, similar toorg.hibernate.envers.boot.internal.EnversIntegrator. Use your event listener classes instead of the default ones. -
For the integrator to be automatically used when Hibernate starts up, you will need to add a
META-INF/services/org.hibernate.integrator.spi.Integratorfile to your jar. The file should contain the fully qualified name of the class implementing the interface.
21.14. Understanding the Envers Schema
For each audited entity (that is, for each entity containing at least one audited field), an audit table is created.
By default, the audit table’s name is created by adding an "_AUD" suffix to the original table name,
but this can be overridden by specifying a different suffix/prefix in the configuration properties or per-entity using the @org.hibernate.envers.AuditTable annotation.
The audit table contains the following columns:
- id
-
idof the original entity (this can be more then one column in the case of composite primary keys) - revision number
-
an integer, which matches to the revision number in the revision entity table.
- revision type
-
a small integer
- audited fields
-
propertied from the original entity being audited
The primary key of the audit table is the combination of the original id of the entity and the revision number, so there can be at most one historic entry for a given entity instance at a given revision.
The current entity data is stored in the original table and in the audit table.
This is a duplication of data, however as this solution makes the query system much more powerful, and as memory is cheap, hopefully this won’t be a major drawback for the users.
A row in the audit table with entity id ID, revision N and data D means: entity with id ID has data D from revision N upwards.
Hence, if we want to find an entity at revision M, we have to search for a row in the audit table, which has the revision number smaller or equal to M, but as large as possible.
If no such row is found, or a row with a "deleted" marker is found, it means that the entity didn’t exist at that revision.
The "revision type" field can currently have three values: 0, 1 and 2, which means ADD, MOD and DEL, respectively.
A row with a revision of type DEL will only contain the id of the entity and no data (all fields NULL), as it only serves as a marker saying "this entity was deleted at that revision".
Additionally, there is a revision entity table which contains the information about the global revision.
By default the generated table is named REVINFO and contains just two columns: ID and TIMESTAMP.
A row is inserted into this table on each new revision, that is, on each commit of a transaction, which changes audited data.
The name of this table can be configured, the name of its columns as well as adding additional columns can be achieved as discussed in Revision Log.
|
While global revisions are a good way to provide correct auditing of relations, some people have pointed out that this may be a bottleneck in systems, where data is very often modified.
One viable solution is to introduce an option to have an entity "locally revisioned", that is revisions would be created for it independently.
This woulld not enable correct versioning of relations, but it would work without the |
21.15. Generating schema with Ant
If you like to generate the database schema file with the Hibernate Tools Ant task,
you’ll probably notice that the generated file doesn’t contain definitions of audit tables.
To generate the audit tables, you simply need to use org.hibernate.tool.ant.EnversHibernateToolTask, instead of the usual org.hibernate.tool.ant.HibernateToolTask.
The former class extends the latter, and only adds generation of the version entities, meaning you can use the task just as you are used to.
For example:
<target name="schemaexport" depends="build-demo"
description="Exports a generated schema to DB and file">
<taskdef name="hibernatetool"
classname="org.hibernate.tool.ant.EnversHibernateToolTask"
classpathref="build.demo.classpath"/>
<hibernatetool destdir=".">
<classpath>
<fileset refid="lib.hibernate" />
<path location="${build.demo.dir}" />
<path location="${build.main.dir}" />
</classpath>
<jpaconfiguration persistenceunit="ConsolePU" />
<hbm2ddl
drop="false"
create="true"
export="false"
outputfilename="versioning-ddl.sql"
delimiter=";"
format="true"/>
</hibernatetool>
</target>Will generate the following schema:
create table Address (
id integer generated by default as identity (start with 1),
flatNumber integer,
houseNumber integer,
streetName varchar(255),
primary key (id)
);
create table Address_AUD (
id integer not null,
REV integer not null,
flatNumber integer,
houseNumber integer,
streetName varchar(255),
REVTYPE tinyint,
primary key (id, REV)
);
create table Person (
id integer generated by default as identity (start with 1),
name varchar(255),
surname varchar(255),
address_id integer,
primary key (id)
);
create table Person_AUD (
id integer not null,
REV integer not null,
name varchar(255),
surname varchar(255),
REVTYPE tinyint,
address_id integer,
primary key (id, REV)
);
create table REVINFO (
REV integer generated by default as identity (start with 1),
REVTSTMP bigint,
primary key (REV)
);
alter table Person
add constraint FK8E488775E4C3EA63
foreign key (address_id)
references Address;21.16. Mapping exceptions
21.17. What isn’t and will not be supported
Bags are not supported because they can contain non-unique elements. Persisting, a bag of `String`s violates the relational database principle that each table is a set of tuples.
In case of bags, however (which require a join table), if there is a duplicate element, the two tuples corresponding to the elements will be the same. Hibernate allows this, however Envers (or more precisely: the database connector) will throw an exception when trying to persist two identical elements because of a unique constraint violation.
There are at least two ways out if you need bag semantics:
-
use an indexed collection, with the
@javax.persistence.OrderColumnannotation -
provide a unique id for your elements with the
@CollectionIdannotation.
21.18. What isn’t and will be supported
-
Bag style collections with a
@CollectionIdidentifier column (see HHH-3950).
21.19. @OneToMany with @JoinColumn
When a collection is mapped using these two annotations, Hibernate doesn’t generate a join table. Envers, however, has to do this so that when you read the revisions in which the related entity has changed, you don’t get false results.
To be able to name the additional join table, there is a special annotation: @AuditJoinTable, which has similar semantics to JPA @JoinTable.
One special case are relations mapped with @OneToMany with @JoinColumn on the one side, and @ManyToOne and @JoinColumn( insertable=false, updatable=false) on the many side.
Such relations are, in fact, bidirectional, but the owning side is the collection.
To properly audit such relations with Envers, you can use the @AuditMappedBy annotation.
It enables you to specify the reverse property (using the mappedBy element).
In case of indexed collections, the index column must also be mapped in the referenced entity (using @Column( insertable=false, updatable=false ), and specified using positionMappedBy.
This annotation will affect only the way Envers works.
Please note that the annotation is experimental and may change in the future.
21.20. Advanced: Audit table partitioning
21.21. Benefits of audit table partitioning
Because audit tables tend to grow indefinitely, they can quickly become really large. When the audit tables have grown to a certain limit (varying per RDBMS and/or operating system) it makes sense to start using table partitioning. SQL table partitioning offers a lot of advantages including, but certainly not limited to:
-
Improved query performance by selectively moving rows to various partitions (or even purging old rows)
-
Faster data loads, index creation, etc.
21.22. Suitable columns for audit table partitioning
Generally, SQL tables must be partitioned on a column that exists within the table. As a rule it makes sense to use either the end revision or the end revision timestamp column for partitioning of audit tables.
|
End revision information is not available for the default Therefore the following Envers configuration options are required:
Optionally, you can also override the default values using following properties:
For more information, see Configuration. |
The reason why the end revision information should be used for audit table partitioning is based on the assumption that audit tables should be partitioned on an 'increasing level of relevancy', like so:
-
A couple of partitions with audit data that is not very (or no longer) relevant. This can be stored on slow media, and perhaps even be purged eventually.
-
Some partitions for audit data that is potentially relevant.
-
One partition for audit data that is most likely to be relevant. This should be stored on the fastest media, both for reading and writing.
21.23. Audit table partitioning example
In order to determine a suitable column for the 'increasing level of relevancy', consider a simplified example of a salary registration for an unnamed agency.
Currently, the salary table contains the following rows for a certain person X:
| Year | Salary (USD) |
|---|---|
2006 |
3300 |
2007 |
3500 |
2008 |
4000 |
2009 |
4500 |
The salary for the current fiscal year (2010) is unknown. The agency requires that all changes in registered salaries for a fiscal year are recorded (i.e. an audit trail). The rationale behind this is that decisions made at a certain date are based on the registered salary at that time. And at any time it must be possible reproduce the reason why a certain decision was made at a certain date.
The following audit information is available, sorted on in order of occurrence:
| Year | Revision type | Revision timestamp | Salary (USD) | End revision timestamp |
|---|---|---|---|---|
2006 |
ADD |
2007-04-01 |
3300 |
null |
2007 |
ADD |
2008-04-01 |
35 |
2008-04-02 |
2007 |
MOD |
2008-04-02 |
3500 |
null |
2008 |
ADD |
2009-04-01 |
3700 |
2009-07-01 |
2008 |
MOD |
2009-07-01 |
4100 |
2010-02-01 |
2008 |
MOD |
2010-02-01 |
4000 |
null |
2009 |
ADD |
2010-04-01 |
4500 |
null |
21.24. Determining a suitable partitioning column
To partition this data, the 'level of relevancy' must be defined. Consider the following:
-
For fiscal year 2006 there is only one revision. It has the oldest revision timestamp of all audit rows, but should still be regarded as relevant because it’s the latest modification for this fiscal year in the salary table (its end revision timestamp is null).
Also, note that it would be very unfortunate if in 2011 there would be an update of the salary for fiscal year 2006 (which is possible in until at least 10 years after the fiscal year), and the audit information would have been moved to a slow disk (based on the age of the __revision timestamp__). Remember that, in this case, Envers will have to update the _end revision timestamp_ of the most recent audit row. . There are two revisions in the salary of fiscal year 2007 which both have nearly the same _revision timestamp_ and a different __end revision timestamp__. On first sight, it is evident that the first revision was a mistake and probably not relevant. The only relevant revision for 2007 is the one with _end revision timestamp_ null.
Based on the above, it is evident that only the end revision timestamp is suitable for audit table partitioning. The revision timestamp is not suitable.
21.25. Determining a suitable partitioning scheme
A possible partitioning scheme for the salary table would be as follows:
- end revision timestamp year = 2008
-
This partition contains audit data that is not very (or no longer) relevant.
- end revision timestamp year = 2009
-
This partition contains audit data that is potentially relevant.
- end revision timestamp year >= 2010 or null
-
This partition contains the most relevant audit data.
This partitioning scheme also covers the potential problem of the update of the end revision timestamp, which occurs if a row in the audited table is modified. Even though Envers will update the end revision timestamp of the audit row to the system date at the instant of modification, the audit row will remain in the same partition (the 'extension bucket').
And sometime in 2011, the last partition (or 'extension bucket') is split into two new partitions:
-
end revision timestamp year = 2010:: This partition contains audit data that is potentially relevant (in 2011).
-
end revision timestamp year >= 2011 or null:: This partition contains the most interesting audit data and is the new 'extension bucket'.
21.26. Envers links
-
JIRA issue tracker (when adding issues concerning Envers, be sure to select the "envers" component!)
22. Database Portability Considerations
22.1. Portability Basics
One of the selling points of Hibernate (and really Object/Relational Mapping as a whole) is the notion of database portability. This could mean an internal IT user migrating from one database vendor to another, or it could mean a framework or deployable application consuming Hibernate to simultaneously target multiple database products by their users. Regardless of the exact scenario, the basic idea is that you want Hibernate to help you run against any number of databases without changes to your code, and ideally without any changes to the mapping metadata.
22.2. Dialect
The first line of portability for Hibernate is the dialect, which is a specialization of the org.hibernate.dialect.Dialect contract.
A dialect encapsulates all the differences in how Hibernate must communicate with a particular database to accomplish some task like getting a sequence value or structuring a SELECT query.
Hibernate bundles a wide range of dialects for many of the most popular databases.
If you find that your particular database is not among them, it is not terribly difficult to write your own.
22.3. Dialect resolution
Originally, Hibernate would always require that users specify which dialect to use. In the case of users looking to simultaneously target multiple databases with their build that was problematic. Generally, this required their users to configure the Hibernate dialect or defining their own method of setting that value.
Starting with version 3.2, Hibernate introduced the notion of automatically detecting the dialect to use based on the java.sql.DatabaseMetaData obtained from a java.sql.Connection to that database.
This was much better, expect that this resolution was limited to databases Hibernate know about ahead of time and was in no way configurable or overrideable.
Starting with version 3.3, Hibernate has a fare more powerful way to automatically determine which dialect to should be used by relying on a series of delegates which implement the org.hibernate.dialect.resolver.DialectResolver which defines only a single method:
public Dialect resolveDialect(DatabaseMetaData metaData) throws JDBCConnectionExceptionThe basic contract here is that if the resolver 'understands' the given database metadata then it returns the corresponding Dialect; if not it returns null and the process continues to the next resolver.
The signature also identifies org.hibernate.exception.JDBCConnectionException as possibly being thrown.
A JDBCConnectionException here is interpreted to imply a "non transient" (aka non-recoverable) connection problem and is used to indicate an immediate stop to resolution attempts.
All other exceptions result in a warning and continuing on to the next resolver.
The cool part about these resolvers is that users can also register their own custom resolvers which will be processed ahead of the built-in Hibernate ones. This might be useful in a number of different situations:
-
it allows easy integration for auto-detection of dialects beyond those shipped with Hibernate itself
-
it allows you to specify to use a custom dialect when a particular database is recognized.
To register one or more resolvers, simply specify them (separated by commas, tabs or spaces) using the 'hibernate.dialect_resolvers' configuration setting (see the DIALECT_RESOLVERS constant on org.hibernate.cfg.Environment).
22.4. Identifier generation
When considering portability between databases, another important decision is selecting the identifier generation strategy you want to use. Originally Hibernate provided the native generator for this purpose, which was intended to select between a sequence, identity, or table strategy depending on the capability of the underlying database.
However, an insidious implication of this approach comes about when targeting some databases which support identity generation and some which do not. identity generation relies on the SQL definition of an IDENTITY (or auto-increment) column to manage the identifier value. It is what is known as a post-insert generation strategy because the insert must actually happen before we can know the identifier value.
Because Hibernate relies on this identifier value to uniquely reference entities within a persistence context,
it must then issue the insert immediately when the users requests that the entity be associated with the session (e.g. like via save() or persist()) , regardless of current transactional semantics.
|
Hibernate was changed slightly, once the implications of this were better understood, so now the insert could be delayed in cases where this is feasible. The underlying issue is that the actual semantics of the application itself changes in these cases. |
Starting with version 3.2.3, Hibernate comes with a set of enhanced identifier generators targeting portability in a much different way.
|
There are specifically 2 bundled enhancedgenerators:
|
The idea behind these generators is to port the actual semantics of the identifier value generation to the different databases.
For example, the org.hibernate.id.enhanced.SequenceStyleGenerator mimics the behavior of a sequence on databases which do not support sequences by using a table.
22.5. Database functions
|
This is an area in Hibernate in need of improvement. In terms of portability concerns, this function handling currently works pretty well in HQL, however, it is quite lacking in all other aspects. |
SQL functions can be referenced in many ways by users. However, not all databases support the same set of functions. Hibernate, provides a means of mapping a logical function name to a delegate which knows how to render that particular function, perhaps even using a totally different physical function call.
|
Technically this function registration is handled through the It is sort of implemented such that users can programmatically register functions with the |
22.6. Type mappings
TODO: document the following as well
22.6.1. BLOB/CLOB mappings
22.6.2. Boolean mappings
JPA portability
-
HQL/JPQL differences
-
naming strategies
-
basic types
-
simple id types
-
generated id types
-
composite ids and many-to-one
-
"embedded composite identifiers"
23. Configurations
23.1. Strategy configurations
Many configuration settings define pluggable strategies that Hibernate uses for various purposes. The configuration of many of these strategy type settings accept definition in various forms. The documentation of such configuration settings refer here. The types of forms available in such cases include:
- short name (if defined)
-
Certain built-in strategy implementations have a corresponding short name.
- strategy instance
-
An instance of the strategy implementation to use can be specified
- strategy Class reference
-
A
java.lang.Classreference of the strategy implementation to use - strategy Class name
-
The class name (
java.lang.String) of the strategy implementation to use
23.2. General Configuration
Property |
Example |
Purpose |
|
|
The classname of a Hibernate In most cases Hibernate can choose the correct |
|
|
Supply a custom strategy for the scoping of the current The definition of what exactly current means is controlled by the Note that for backwards compatibility, if a |
23.3. Database connection properties
Property |
Example |
Purpose |
|
|
Names the JDBC |
|
|
Names the JDBC connection URL. |
|
Names the JDBC connection user name. |
|
|
Names the JDBC connection password. |
|
|
|
Names the JDBC connection transaction isolation level. |
|
|
Names the JDBC connection autocommit mode. |
|
20 |
Maximum number of connections for the built-in Hibernate connection pool. |
|
Either a For JNDI names, ses also |
|
|
Names a prefix used to define arbitrary JDBC connection properties. These properties are passed along to the JDBC provider when creating a connection. |
|
|
|
Names the Can reference:
The term |
|
Names the JNDI |
|
|
java:global/jdbc/default |
Names the JNDI provider/connection url. |
|
Names a prefix used to define arbitrary JNDI These properties are passed along to |
|
|
|
Specifies how Hibernate should release JDBC connections. The possible values are given by the current transaction mode ( |
23.4. c3p0 properties
Property |
Example |
Purpose |
|
1 |
Minimum size of C3P0 connection pool. Refers to c3p0 |
|
5 |
Maximum size of C3P0 connection pool. Refers to c3p0 |
|
30 |
Maximum idle time for C3P0 connection pool. Refers to c3p0 |
|
5 |
Maximum size of C3P0 statement cache. Refers to c3p0 |
|
2 |
Number of connections acquired at a time when there’s no connection available in the pool. Refers to c3p0 |
|
5 |
Idle time before a C3P0 pooled connection is validated. Refers to c3p0 |
|
A setting prefix used to indicate additional c3p0 properties that need to be passed to the underlying c3p0 connection pool. |
23.5. Mapping Properties
Property |
Example |
Purpose |
Table qualifying options |
||
|
A schema name |
Qualify unqualified table names with the given schema or tablespace in generated SQL. |
|
A catalog name |
Qualifies unqualified table names with the given catalog in generated SQL. A setting to control whether to |
Identifier options |
||
|
|
Setting which indicates whether or not the new Existing applications may want to disable this (set it |
|
|
If true, generated identifier properties are reset to default values when objects are deleted. |
|
|
When a generator specified an increment-size and an optimizer was not explicitly specified, which of the pooled optimizers should be preferred? |
Quoting options |
||
|
|
Should all database identifiers be quoted. |
|
|
Specifies whether to automatically quote any names that are deemed keywords. |
Discriminator options |
||
|
|
The legacy behavior of Hibernate is to not use discriminators for joined inheritance (Hibernate does not need the discriminator). However, some JPA providers do need the discriminator for handling joined inheritance so, in the interest of portability, this capability has been added to Hibernate too. However, we want to make sure that legacy applications continue to work as well, which puts us in a bind in terms of how to handle implicit discriminator mappings. The solution is to assume that the absence of discriminator metadata means to follow the legacy behavior unless this setting is enabled. With this setting enabled, Hibernate will interpret the absence of discriminator metadata as an indication to use the JPA-defined defaults for these absent annotations. See Hibernate Jira issue HHH-6911 for additional background info. |
|
|
The legacy behavior of Hibernate is to not use discriminators for joined inheritance (Hibernate does not need the discriminator). However, some JPA providers do need the discriminator for handling joined inheritance so, in the interest of portability, this capability has been added to Hibernate too. Existing applications rely (implicitly or explicitly) on Hibernate ignoring any See Hibernate Jira issue HHH-6911 for additional background info. |
Naming strategies |
||
|
|
Used to specify the
If this property happens to be empty, the fallback is to use |
|
|
Used to specify the |
Metadata scanning options |
||
|
Pass an implementation of Accepts either:
|
|
|
Pass Accepts either:
See information on |
|
|
|
Identifies a comma-separate list of values indicating the mapping types we should auto-detect during scanning. Allowable values include:
|
|
|
Used to specify the order in which metadata sources should be processed.
Value is a delimited-list whose elements are defined by Default is |
JDBC-related options |
||
|
|
Enable nationalized character support on all string / clob based attribute ( string, char, clob, text etc ). |
|
|
Should we not use contextual LOB creation (aka based on |
Bean Validation options |
||
|
|
Specify the |
|
|
Enable nullability checking. Raises an exception if a property marked as not-null is null. Default to |
Misc options |
||
|
fully-qualified class name or an actual |
Setting to identify a |
|
|
Default |
23.6. Bytecode Enhancement Properties
Property |
Example |
Purpose |
|
|
Enable dirty tracking feature in runtime bytecode enhancement. |
|
|
Enable lazy loading feature in runtime bytecode enhancement. This way, even basic types (e.g. |
|
|
Enable association management feature in runtime bytecode enhancement which automatically synchronizes a bidirectional association when only one side is changed. |
|
|
The |
|
|
Should we use reflection optimization? The reflection optimizer implements the |
23.7. Query settings
Property |
Example |
Purpose |
|
|
The maximum number of entries including:
maintained by |
|
|
The maximum number of strong references associated with |
|
|
Defines precedence of null values in |
|
|
For entities which do not explicitly say, should we force discriminators into SQL selects? |
|
|
A comma-separated list of token substitutions to use when translating a Hibernate query to SQL. |
|
|
Chooses the HQL parser implementation. |
|
|
Map from tokens in Hibernate queries to SQL tokens, such as function or literal names. Should we strictly adhere to JPA Query Language (JPQL) syntax, or more broadly support all of Hibernate’s superset (HQL)? Setting this to |
|
|
Should named queries be checked during startup? |
|
A fully-qualified class name, an instance, or a |
Provide a custom |
|
|
Global setting for whether Values are |
|
A fully-qualified class name, an instance, or a |
Names a Can reference
|
23.8. Batching properties
Property |
Example |
Purpose |
|
5 |
Maximum JDBC batch size. A nonzero value enables batch updates. |
|
|
Forces Hibernate to order SQL inserts by the primary key value of the items being inserted. This preserves batching when using cascading. |
|
|
Forces Hibernate to order SQL updates by the primary key value of the items being updated. This preserves batching when using cascading and reduces the likelihood of transaction deadlocks in highly-concurrent systems. |
|
|
Should versioned entities be included in batching? Set this property to |
|
|
Names the Can specify either the |
|
The fully qualified name of an |
Names the |
23.8.1. Fetching properties
Property |
Example |
Purpose |
|
A value between |
Sets a maximum depth for the outer join fetch tree for single-ended associations. A single-ended association is a one-to-one or many-to-one assocation. A value of |
|
|
Default size for Hibernate Batch fetching of associations (lazily fetched associations can be fetched in batches to prevent N+1 query problems). |
|
|
A non-zero value determines the JDBC fetch size, by calling |
|
|
Enables Hibernate to use JDBC2 scrollable resultsets. This property is only relevant for user-supplied JDBC connections. Otherwise, Hibernate uses connection metadata. |
|
|
Use streams when writing or reading |
|
|
Allows Hibernate to use JDBC3 |
|
|
Enable wrapping of JDBC result sets in order to speed up column name lookups for broken JDBC drivers. |
|
|
Initialize Lazy Proxies or Collections outside a given Transactional Persistence Context. Although enabling this configuration can make In reality, you shouldn’t probably enable this setting anyway. |
23.9. Statement logging and statistics
Property |
Example |
Purpose |
SQL statement logging |
||
|
|
Write all SQL statements to the console. This is an alternative to setting the log category |
|
|
Pretty-print the SQL in the log and console. |
|
|
If true, Hibernate generates comments inside the SQL, for easier debugging. |
Statistics settings |
||
|
|
Causes Hibernate to collect statistics for performance tuning. |
|
|
A setting to control whether to |
23.10. Cache Properties
Property |
Example |
Purpose |
|
|
The fully-qualified name of the |
|
Setting used to give the name of the default |
|
|
|
Optimizes second-level cache operation to minimize writes, at the cost of more frequent reads. This is most useful for clustered caches and is enabled by default for clustered cache implementations. |
|
|
Enables the query cache. You still need to set individual queries to be cachable. |
|
|
Enable/disable the second level cache, which is enabled by default, although the default |
|
Fully-qualified classname |
A custom |
|
A string |
A prefix for second-level cache region names. |
|
|
Forces Hibernate to store data in the second-level cache in a more human-readable format. |
|
|
Enables the automatic eviction of a bi-directional association’s collection cache when an element in the |
|
|
Optimizes second-level cache operation to store immutable entities (aka "reference") which do not have associations into cache directly, this case, lots of disasseble and deep copy operations can be avoid. Default value of this property is |
|
|
Sets the associated entity class cache concurrency strategy for the designated region. Caching configuration should follow the following pattern |
|
|
Sets the associated collection cache concurrency strategy for the designated region. Caching configuration should follow the following pattern |
23.11. Transactions properties
Property |
Example |
Purpose |
|
|
Names the |
|
|
Should we prefer using the |
|
Names the |
|
|
|
A configuration value key used to indicate that it is safe to cache. |
|
|
A configuration value key used to indicate that it is safe to cache. |
|
|
Causes the session be flushed during the before completion phase of the transaction. If possible, use built-in and automatic session context management instead. |
|
|
Causes the session to be closed during the after completion phase of the transaction. If possible, use built-in and automatic session context management instead. |
|
Names the implementation of Can be
The following short names are defined for this setting:
If a JPA application does not provide a setting for If a non-JPA application does not provide a setting for |
|
|
|
A transaction can be rolled back by another thread ("tracking by thread") and not the original application. Examples of this include a JTA transaction timeout handled by a background reaper thread. The ability to handle this situation requires checking the Thread ID every time Session is called, so enabling this can certainly have a performance impact. |
23.12. Multi-tenancy settings
Property |
Example |
Purpose |
|
|
The multi-tenancy strategy in use. |
|
|
Names a |
|
Names a Can be:
|
23.13. Automatic schema generation
Property |
Example |
Purpose |
|
|
Setting to perform
|
|
|
Setting to perform
|
|
|
Setting to perform
|
|
Allows passing a specific |
|
|
Specifies the name of the database provider in cases where a Connection to the underlying database is not available (aka, mainly in generating scripts). In such cases, a value for this setting must be specified. The value of this setting is expected to match the value returned by Additionally, specifying |
|
|
Specifies the major version of the underlying database, as would be returned by This value is used to help more precisely determine how to perform schema generation tasks for the underlying database in cases where |
|
|
Specifies the minor version of the underlying database, as would be returned by This value is used to help more precisely determine how to perform schema generation tasks for the underlying database in cases where |
|
|
Specifies whether schema generation commands for schema creation are to be determine based on object/relational mapping metadata, DDL scripts, or a combination of the two.
See If no value is specified, a default is assumed as follows:
|
|
|
Specifies whether schema generation commands for schema dropping are to be determine based on object/relational mapping metadata, DDL scripts, or a combination of the two.
See If no value is specified, a default is assumed as follows:
|
|
|
Specifies the Hibernate historically also accepted |
|
|
Specifies the |
|
|
For cases where the |
|
|
For cases where the |
|
|
|
Comma-separated names of the optional files containing SQL DML statements executed during the These statements are only executed if the schema is created, meaning that |
|
JPA variant of |
|
|
Reference to the Reference may refer to an instance, a Class implementing The default value is |
|
|
|
Specifies whether to automatically create also the database schema/catalog. |
|
|
The JPA variant of |
|
A schema name |
Used to specify the |
|
|
If enabled, allows schema update and validation to support synonyms. Due to the possibility that this would return duplicate tables (especially in Oracle), this is disabled by default. |
|
|
Identifies a comma-separated list of values to specify extra table types, other than the default |
|
|
Unique columns and unique keys both use unique constraints in most dialects.
Therefore, the
|
23.14. Exception handling
Property |
Example |
Purpose |
|
Fully-qualified name of class implementing |
The |
23.15. Session events
Property |
Example |
Purpose |
|
Fully qualified class name implementing the |
|
|
|
Names a Can reference:
|
|
fully-qualified class name or class reference |
An optional Hibernate interceptor. The interceptor instance is specific to a given Session instance (and hence is not thread-safe) has to implement This property can not be combined with |
|
fully-qualified class name or class reference |
Specifies a |
|
|
Event listener list for a given event type. The list of event listeners is a comma separated fully qualified class name list. |
23.16. JMX settings
Property |
Example |
Purpose |
|
|
Enable JMX. |
|
|
Uses the platform MBeanServer as returned by |
|
The agent identifier of the associated |
|
|
The domain name of the associated |
|
|
The |
|
`org.hibernate.core |
The default object domain appended to the object name the Manageable Bean is registered with. |
23.17. JACC settings
Property |
Example |
Purpose |
|
|
Is JACC enabled? |
|
|
The property name defines the role (e.g. |
|
A String identifying the policy context whose PolicyConfiguration interface is to be returned. The value passed to this parameter must not be null. |
23.18. ClassLoaders properties
Property |
Example |
Purpose |
|
Used to define a |
|
|
Names the |
|
|
Names the |
|
|
Names the |
|
|
Names the |
23.19. Miscellaneous properties
Property |
Example |
Purpose |
|
Names any additional |
|
|
A JNDI name |
Setting used to name the Hibernate If |
|
|
Does the value defined by Defaults to |
|
By default, the persistence unit name is used, otherwise a randomly generated UUID |
Internally, Hibernate keeps track of all |
|
|
XML configuration file to use to configure Hibernate. |
|
|
If true, the persistence context will be discarded (think |
|
|
Setting that controls whether we seek out JPA static metamodel classes and populate them. Accepts three values:
|
|
|
Defines delayed access to CDI |
24. Legacy Bootstrapping
The legacy way to bootstrap a SessionFactory is via the org.hibernate.cfg.Configuration object.
Configuration represents, essentially, a single point for specifying all aspects of building the SessionFactory: everything from settings, to mappings, to strategies, etc.
I like to think of Configuration as a big pot to which we add a bunch of stuff (mappings, settings, etc) and from which we eventually get a SessionFactory.
|
There are some significant draw backs to this approach which led to its deprecation and the development of the new approach, which is discussed in Native Bootstrapping.
|
You can obtain the Configuration by instantiating it directly.
You then specify mapping metadata (XML mapping documents, annotated classes) that describe your applications object model and its mapping to a SQL database.
Configuration cfg = new Configuration()
// addResource does a classpath resource lookup
.addResource("Item.hbm.xml")
.addResource("Bid.hbm.xml")
// calls addResource using "/org/hibernate/auction/User.hbm.xml"
.addClass(`org.hibernate.auction.User.class`)
// parses Address class for mapping annotations
.addAnnotatedClass( Address.class )
// reads package-level (package-info.class) annotations in the named package
.addPackage( "org.hibernate.auction" )
.setProperty("hibernate.dialect", "org.hibernate.dialect.H2Dialect")
.setProperty("hibernate.connection.datasource", "java:comp/env/jdbc/test")
.setProperty("hibernate.order_updates", "true");There are other ways to specify Configuration information, including:
-
Place a file named hibernate.properties in a root directory of the classpath
-
Pass an instance of java.util.Properties to
Configuration#setProperties -
Via a
hibernate.cfg.xmlfile -
System properties using java
-Dproperty=value
25. Migration
Mapping Configuration methods to the corresponding methods in the new APIs..
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
26. Legacy Domain Model
hbm.xml<!--
~ Hibernate, Relational Persistence for Idiomatic Java
~
~ License: GNU Lesser General Public License (LGPL), version 2.1 or later.
~ See the lgpl.txt file in the root directory or <http://www.gnu.org/licenses/lgpl-2.1.html>.
-->
<version
column="version_column"
name="propertyName"
type="typename"
access="field|property|ClassName"
unsaved-value="null|negative|undefined"
generated="never|always"
insert="true|false"
node="element-name|@attribute-name|element/@attribute|."
/>column |
The name of the column holding the version number. Optional, defaults to the property name. |
name |
The name of a property of the persistent class. |
type |
The type of the version number. Optional, defaults to |
access |
Hibernate’s strategy for accessing the property value. Optional, defaults to |
unsaved-value |
Indicates that an instance is newly instantiated and thus unsaved.
This distinguishes it from detached instances that were saved or loaded in a previous session.
The default value, |
generated |
Indicates that the version property value is generated by the database. Optional, defaults to |
insert |
Whether or not to include the |
hbm.xml<!--
~ Hibernate, Relational Persistence for Idiomatic Java
~
~ License: GNU Lesser General Public License (LGPL), version 2.1 or later.
~ See the lgpl.txt file in the root directory or <http://www.gnu.org/licenses/lgpl-2.1.html>.
-->
<timestamp
column="timestamp_column"
name="propertyName"
access="field|property|ClassName"
unsaved-value="null|undefined"
source="vm|db"
generated="never|always"
node="element-name|@attribute-name|element/@attribute|."
/>column |
The name of the column which holds the timestamp. Optional, defaults to the property name |
name |
The name of a JavaBeans style property of Java type |
access |
The strategy Hibernate uses to access the property value. Optional, defaults to |
unsaved-value |
A version property which indicates than instance is newly instantiated, and unsaved.
This distinguishes it from detached instances that were saved or loaded in a previous session.
The default value of |
source |
Whether Hibernate retrieves the timestamp from the database or the current JVM. Database-based timestamps incur an overhead because Hibernate needs to query the database each time to determine the incremental next value. However, database-derived timestamps are safer to use in a clustered environment. Not all database dialects are known to support the retrieval of the database’s current timestamp. Others may also be unsafe for locking because of lack of precision. |
generated |
Whether the timestamp property value is generated by the database. Optional, defaults to |
27. Legacy Hibernate Criteria Queries
|
This appendix covers the legacy Hibernate New development should focus on the JPA javax.persistence.criteria.CriteriaQuery API.
Eventually, Hibernate-specific criteria features will be ported as extensions to the JPA |
Hibernate features an intuitive, extensible criteria query API.
27.1. Creating a Criteria instance
The interface org.hibernate.Criteria represents a query against a particular persistent class.
The Session is a factory for Criteria instances.
Criteria crit = sess.createCriteria(Cat.class);
crit.setMaxResults(50);
List cats = crit.list();27.2. Narrowing the result set
An individual query criterion is an instance of the interface org.hibernate.criterion.Criterion.
The class org.hibernate.criterion.Restrictions defines factory methods for obtaining certain built-in Criterion types.
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.like("name", "Fritz%") )
.add( Restrictions.between("weight", minWeight, maxWeight) )
.list();Restrictions can be grouped logically.
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.like("name", "Fritz%") )
.add( Restrictions.or(
Restrictions.eq( "age", new Integer(0) ),
Restrictions.isNull("age")
) )
.list();List cats = sess.createCriteria(Cat.class)
.add( Restrictions.in( "name", new String[] { "Fritz", "Izi", "Pk" } ) )
.add( Restrictions.disjunction()
.add( Restrictions.isNull("age") )
.add( Restrictions.eq("age", new Integer(0) ) )
.add( Restrictions.eq("age", new Integer(1) ) )
.add( Restrictions.eq("age", new Integer(2) ) )
) )
.list();There are a range of built-in criterion types (Restrictions subclasses).
One of the most useful Restrictions allows you to specify SQL directly.
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.sqlRestriction("lower({alias}.name) like lower(?)", "Fritz%", Hibernate.STRING) )
.list();The {alias} placeholder will be replaced by the row alias of the queried entity.
You can also obtain a criterion from a Property instance.
You can create a Property by calling Property.forName():
Property age = Property.forName("age");
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.disjunction()
.add( age.isNull() )
.add( age.eq( new Integer(0) ) )
.add( age.eq( new Integer(1) ) )
.add( age.eq( new Integer(2) ) )
) )
.add( Property.forName("name").in( new String[] { "Fritz", "Izi", "Pk" } ) )
.list();27.3. Ordering the results
You can order the results using org.hibernate.criterion.Order.
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.like("name", "F%")
.addOrder( Order.asc("name").nulls(NullPrecedence.LAST) )
.addOrder( Order.desc("age") )
.setMaxResults(50)
.list();List cats = sess.createCriteria(Cat.class)
.add( Property.forName("name").like("F%") )
.addOrder( Property.forName("name").asc() )
.addOrder( Property.forName("age").desc() )
.setMaxResults(50)
.list();27.4. Associations
By navigating associations using createCriteria() you can specify constraints upon related entities:
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.like("name", "F%") )
.createCriteria("kittens")
.add( Restrictions.like("name", "F%") )
.list();The second createCriteria() returns a new instance of Criteria that refers to the elements of the kittens collection.
There is also an alternate form that is useful in certain circumstances:
List cats = sess.createCriteria(Cat.class)
.createAlias("kittens", "kt")
.createAlias("mate", "mt")
.add( Restrictions.eqProperty("kt.name", "mt.name") )
.list();(createAlias() does not create a new instance of Criteria.)
The kittens collections held by the Cat instances returned by the previous two queries are not pre-filtered by the criteria.
If you want to retrieve just the kittens that match the criteria, you must use a ResultTransformer.
List cats = sess.createCriteria(Cat.class)
.createCriteria("kittens", "kt")
.add( Restrictions.eq("name", "F%") )
.setResultTransformer(Criteria.ALIAS_TO_ENTITY_MAP)
.list();
Iterator iter = cats.iterator();
while ( iter.hasNext() ) {
Map map = (Map) iter.next();
Cat cat = (Cat) map.get(Criteria.ROOT_ALIAS);
Cat kitten = (Cat) map.get("kt");
}Additionally, you may manipulate the result set using a left outer join:
List cats = session.createCriteria( Cat.class )
.createAlias("mate", "mt", Criteria.LEFT_JOIN, Restrictions.like("mt.name", "good%") )
.addOrder(Order.asc("mt.age"))
.list();This will return all of the `Cat`s with a mate whose name starts with "good" ordered by their mate’s age, and all cats who do not have a mate. This is useful when there is a need to order or limit in the database prior to returning complex/large result sets, and removes many instances where multiple queries would have to be performed and the results unioned by java in memory.
Without this feature, first all of the cats without a mate would need to be loaded in one query.
A second query would need to retrieve the cats with mates who’s name started with "good" sorted by the mates age.
Thirdly, in memory; the lists would need to be joined manually.
27.5. Dynamic association fetching
You can specify association fetching semantics at runtime using setFetchMode().
List cats = sess.createCriteria(Cat.class)
.add( Restrictions.like("name", "Fritz%") )
.setFetchMode("mate", FetchMode.EAGER)
.setFetchMode("kittens", FetchMode.EAGER)
.list();This query will fetch both mate and kittens by outer join.
27.6. Components
To add a restriction against a property of an embedded component, the component property name should be prepended to the property name when creating the Restriction.
The criteria object should be created on the owning entity, and cannot be created on the component itself.
For example, suppose the Cat has a component property fullName with sub-properties firstName and lastName:
List cats = session.createCriteria(Cat.class)
.add(Restrictions.eq("fullName.lastName", "Cattington"))
.list();Note: this does not apply when querying collections of components, for that see below Collections
27.7. Collections
When using criteria against collections, there are two distinct cases.
One is if the collection contains entities (eg. <one-to-many/> or <many-to-many/>) or components (<composite-element/> ),
and the second is if the collection contains scalar values (<element/>).
In the first case, the syntax is as given above in the section Associations where we restrict the kittens collection.
Essentially we create a Criteria object against the collection property and restrict the entity or component properties using that instance.
For querying a collection of basic values, we still create the Criteria object against the collection,
but to reference the value, we use the special property "elements".
For an indexed collection, we can also reference the index property using the special property "indices".
List cats = session.createCriteria(Cat.class)
.createCriteria("nickNames")
.add(Restrictions.eq("elements", "BadBoy"))
.list();27.8. Example queries
The class org.hibernate.criterion.Example allows you to construct a query criterion from a given instance.
Cat cat = new Cat();
cat.setSex('F');
cat.setColor(Color.BLACK);
List results = session.createCriteria(Cat.class)
.add( Example.create(cat) )
.list();Version properties, identifiers and associations are ignored. By default, null valued properties are excluded.
You can adjust how the Example is applied.
Example example = Example.create(cat)
.excludeZeroes() //exclude zero valued properties
.excludeProperty("color") //exclude the property named "color"
.ignoreCase() //perform case insensitive string comparisons
.enableLike(); //use like for string comparisons
List results = session.createCriteria(Cat.class)
.add(example)
.list();You can even use examples to place criteria upon associated objects.
List results = session.createCriteria(Cat.class)
.add( Example.create(cat) )
.createCriteria("mate")
.add( Example.create( cat.getMate() ) )
.list();27.9. Projections, aggregation and grouping
The class org.hibernate.criterion.Projections is a factory for Projection instances.
You can apply a projection to a query by calling setProjection().
List results = session.createCriteria(Cat.class)
.setProjection( Projections.rowCount() )
.add( Restrictions.eq("color", Color.BLACK) )
.list();List results = session.createCriteria(Cat.class)
.setProjection( Projections.projectionList()
.add( Projections.rowCount() )
.add( Projections.avg("weight") )
.add( Projections.max("weight") )
.add( Projections.groupProperty("color") )
)
.list();There is no explicit "group by" necessary in a criteria query.
Certain projection types are defined to be grouping projections, which also appear in the SQL group by clause.
An alias can be assigned to a projection so that the projected value can be referred to in restrictions or orderings. Here are two different ways to do this:
List results = session.createCriteria(Cat.class)
.setProjection( Projections.alias( Projections.groupProperty("color"), "colr" ) )
.addOrder( Order.asc("colr") )
.list();List results = session.createCriteria(Cat.class)
.setProjection( Projections.groupProperty("color").as("colr") )
.addOrder( Order.asc("colr") )
.list();The alias() and as() methods simply wrap a projection instance in another, aliased, instance of Projection.
As a shortcut, you can assign an alias when you add the projection to a projection list:
List results = session.createCriteria(Cat.class)
.setProjection( Projections.projectionList()
.add( Projections.rowCount(), "catCountByColor" )
.add( Projections.avg("weight"), "avgWeight" )
.add( Projections.max("weight"), "maxWeight" )
.add( Projections.groupProperty("color"), "color" )
)
.addOrder( Order.desc("catCountByColor") )
.addOrder( Order.desc("avgWeight") )
.list();List results = session.createCriteria(Domestic.class, "cat")
.createAlias("kittens", "kit")
.setProjection( Projections.projectionList()
.add( Projections.property("cat.name"), "catName" )
.add( Projections.property("kit.name"), "kitName" )
)
.addOrder( Order.asc("catName") )
.addOrder( Order.asc("kitName") )
.list();You can also use Property.forName() to express projections:
List results = session.createCriteria(Cat.class)
.setProjection( Property.forName("name") )
.add( Property.forName("color").eq(Color.BLACK) )
.list();List results = session.createCriteria(Cat.class)
.setProjection( Projections.projectionList()
.add( Projections.rowCount().as("catCountByColor") )
.add( Property.forName("weight").avg().as("avgWeight") )
.add( Property.forName("weight").max().as("maxWeight") )
.add( Property.forName("color").group().as("color" )
)
.addOrder( Order.desc("catCountByColor") )
.addOrder( Order.desc("avgWeight") )
.list();27.10. Detached queries and subqueries
The DetachedCriteria class allows you to create a query outside the scope of a session and then execute it using an arbitrary Session.
DetachedCriteria query = DetachedCriteria.forClass(Cat.class)
.add( Property.forName("sex").eq('F') );
Session session = ....;
Transaction txn = session.beginTransaction();
List results = query.getExecutableCriteria(session).setMaxResults(100).list();
txn.commit();
session.close();A DetachedCriteria can also be used to express a subquery.
Criterion instances involving subqueries can be obtained via Subqueries or Property.
DetachedCriteria avgWeight = DetachedCriteria.forClass(Cat.class)
.setProjection( Property.forName("weight").avg() );
session.createCriteria(Cat.class)
.add( Property.forName("weight").gt(avgWeight) )
.list();DetachedCriteria weights = DetachedCriteria.forClass(Cat.class)
.setProjection( Property.forName("weight") );
session.createCriteria(Cat.class)
.add( Subqueries.geAll("weight", weights) )
.list();Correlated subqueries are also possible:
DetachedCriteria avgWeightForSex = DetachedCriteria.forClass(Cat.class, "cat2")
.setProjection( Property.forName("weight").avg() )
.add( Property.forName("cat2.sex").eqProperty("cat.sex") );
session.createCriteria(Cat.class, "cat")
.add( Property.forName("weight").gt(avgWeightForSex) )
.list();Example of multi-column restriction based on a subquery:
DetachedCriteria sizeQuery = DetachedCriteria.forClass( Man.class )
.setProjection( Projections.projectionList().add( Projections.property( "weight" ) )
.add( Projections.property( "height" ) ) )
.add( Restrictions.eq( "name", "John" ) );
session.createCriteria( Woman.class )
.add( Subqueries.propertiesEq( new String[] { "weight", "height" }, sizeQuery ) )
.list();27.11. Queries by natural identifier
For most queries, including criteria queries, the query cache is not efficient because query cache invalidation occurs too frequently. However, there is a special kind of query where you can optimize the cache invalidation algorithm: lookups by a constant natural key. In some applications, this kind of query occurs frequently. The Criteria API provides special provision for this use case.
First, map the natural key of your entity using <natural-id> and enable use of the second-level cache.
<class name="User">
<cache usage="read-write"/>
<id name="id">
<generator class="increment"/>
</id>
<natural-id>
<property name="name"/>
<property name="org"/>
</natural-id>
<property name="password"/>
</class>This functionality is not intended for use with entities with mutable natural keys.
Once you have enabled the Hibernate query cache, the Restrictions.naturalId() allows you to make use of the more efficient cache algorithm.
session.createCriteria(User.class)
.add( Restrictions.naturalId()
.set("name", "gavin")
.set("org", "hb")
).setCacheable(true)
.uniqueResult();28. Legacy Hibernate Native Queries
28.1. Legacy Named SQL queries
Named SQL queries can also be defined during mapping and called in exactly the same way as a named HQL query.
In this case, you do not need to call addEntity() anymore.
<sql-query> mapping element<sql-query name = "persons">
<return alias="person" class="eg.Person"/>
SELECT person.NAME AS {person.name},
person.AGE AS {person.age},
person.SEX AS {person.sex}
FROM PERSON person
WHERE person.NAME LIKE :namePattern
</sql-query>List people = session
.getNamedQuery( "persons" )
.setString( "namePattern", namePattern )
.setMaxResults( 50 )
.list();The <return-join> element is use to join associations and the <load-collection> element is used to define queries which initialize collections.
<sql-query name = "personsWith">
<return alias="person" class="eg.Person"/>
<return-join alias="address" property="person.mailingAddress"/>
SELECT person.NAME AS {person.name},
person.AGE AS {person.age},
person.SEX AS {person.sex},
address.STREET AS {address.street},
address.CITY AS {address.city},
address.STATE AS {address.state},
address.ZIP AS {address.zip}
FROM PERSON person
JOIN ADDRESS address
ON person.ID = address.PERSON_ID AND address.TYPE='MAILING'
WHERE person.NAME LIKE :namePattern
</sql-query>A named SQL query may return a scalar value.
You must declare the column alias and Hibernate type using the <return-scalar> element:
<sql-query name = "mySqlQuery">
<return-scalar column = "name" type="string"/>
<return-scalar column = "age" type="long"/>
SELECT p.NAME AS name,
p.AGE AS age,
FROM PERSON p WHERE p.NAME LIKE 'Hiber%'
</sql-query>You can externalize the resultset mapping information in a <resultset> element which will allow you to either reuse them across several named queries or through the setResultSetMapping() API.
<resultset name = "personAddress">
<return alias="person" class="eg.Person"/>
<return-join alias="address" property="person.mailingAddress"/>
</resultset>
<sql-query name = "personsWith" resultset-ref="personAddress">
SELECT person.NAME AS {person.name},
person.AGE AS {person.age},
person.SEX AS {person.sex},
address.STREET AS {address.street},
address.CITY AS {address.city},
address.STATE AS {address.state},
address.ZIP AS {address.zip}
FROM PERSON person
JOIN ADDRESS address
ON person.ID = address.PERSON_ID AND address.TYPE='MAILING'
WHERE person.NAME LIKE :namePattern
</sql-query>You can, alternatively, use the resultset mapping information in your hbm files directly in java code.
List cats = session
.createSQLQuery( "select {cat.*}, {kitten.*} from cats cat, cats kitten where kitten.mother = cat.id" )
.setResultSetMapping("catAndKitten")
.list();28.2. Legacy return-property to explicitly specify column/alias names
You can explicitly tell Hibernate what column aliases to use with <return-property>, instead of using the {} syntax to let Hibernate inject its own aliases.
For example:
<sql-query name = "mySqlQuery">
<return alias = "person" class = "eg.Person">
<return-property name = "name" column = "myName"/>
<return-property name = "age" column = "myAge"/>
<return-property name = "sex" column = "mySex"/>
</return>
SELECT person.NAME AS myName,
person.AGE AS myAge,
person.SEX AS mySex,
FROM PERSON person WHERE person.NAME LIKE :name
</sql-query><return-property> also works with multiple columns.
This solves a limitation with the {} syntax which cannot allow fine grained control of multi-column properties.
<sql-query name = "organizationCurrentEmployments">
<return alias = "emp" class = "Employment">
<return-property name = "salary">
<return-column name = "VALUE"/>
<return-column name = "CURRENCY"/>
</return-property>
<return-property name = "endDate" column = "myEndDate"/>
</return>
SELECT EMPLOYEE AS {emp.employee}, EMPLOYER AS {emp.employer},
STARTDATE AS {emp.startDate}, ENDDATE AS {emp.endDate},
REGIONCODE as {emp.regionCode}, EID AS {emp.id}, VALUE, CURRENCY
FROM EMPLOYMENT
WHERE EMPLOYER = :id AND ENDDATE IS NULL
ORDER BY STARTDATE ASC
</sql-query>In this example <return-property> was used in combination with the {} syntax for injection.
This allows users to choose how they want to refer column and properties.
If your mapping has a discriminator you must use <return-discriminator> to specify the discriminator column.
28.3. Legacy stored procedures for querying
Hibernate provides support for queries via stored procedures and functions. Most of the following documentation is equivalent for both. The stored procedure/function must return a resultset as the first out-parameter to be able to work with Hibernate. An example of such a stored function in Oracle 9 and higher is as follows:
CREATE OR REPLACE FUNCTION selectAllEmployments
RETURN SYS_REFCURSOR
AS
st_cursor SYS_REFCURSOR;
BEGIN
OPEN st_cursor FOR
SELECT EMPLOYEE, EMPLOYER,
STARTDATE, ENDDATE,
REGIONCODE, EID, VALUE, CURRENCY
FROM EMPLOYMENT;
RETURN st_cursor;
END;To use this query in Hibernate you need to map it via a named query.
<sql-query name = "selectAllEmployees_SP" callable = "true">
<return alias="emp" class="Employment">
<return-property name = "employee" column = "EMPLOYEE"/>
<return-property name = "employer" column = "EMPLOYER"/>
<return-property name = "startDate" column = "STARTDATE"/>
<return-property name = "endDate" column = "ENDDATE"/>
<return-property name = "regionCode" column = "REGIONCODE"/>
<return-property name = "id" column = "EID"/>
<return-property name = "salary">
<return-column name = "VALUE"/>
<return-column name = "CURRENCY"/>
</return-property>
</return>
{ ? = call selectAllEmployments() }
</sql-query>Stored procedures currently only return scalars and entities.
<return-join> and <load-collection> are not supported.
28.4. Legacy rules/limitations for using stored procedures
You cannot use stored procedures with Hibernate unless you follow some procedure/function rules.
If they do not follow those rules they are not usable with Hibernate.
If you still want to use these procedures you have to execute them via session.doWork().
The rules are different for each database since database vendors have different stored procedure semantics/syntax.
Stored procedure queries cannot be paged with setFirstResult()/setMaxResults().
The recommended call form is standard SQL92: { ? = call functionName(<parameters>) } or { ? = call procedureName(<parameters>}.
Native call syntax is not supported.
For Oracle the following rules apply:
-
A function must return a result set. The first parameter of a procedure must be an
OUTthat returns a result set. This is done by using aSYS_REFCURSORtype in Oracle 9 or 10. In Oracle you need to define aREF CURSORtype. See Oracle literature for further information.
For Sybase or MS SQL server the following rules apply:
-
The procedure must return a result set. Note that since these servers can return multiple result sets and update counts, Hibernate will iterate the results and take the first result that is a result set as its return value. Everything else will be discarded.
-
If you can enable
SET NOCOUNT ONin your procedure it will probably be more efficient, but this is not a requirement.
28.5. Legacy custom SQL for create, update and delete
Hibernate can use custom SQL for create, update, and delete operations. The SQL can be overridden at the statement level or individual column level. This section describes statement overrides. For columns, see Column transformers: read and write expressions. The following example shows how to define custom SQL operations using annotations.
<class name = "Person">
<id name = "id">
<generator class = "increment"/>
</id>
<property name = "name" not-null = "true"/>
<sql-insert>INSERT INTO PERSON (NAME, ID) VALUES ( UPPER(?), ? )</sql-insert>
<sql-update>UPDATE PERSON SET NAME=UPPER(?) WHERE ID=?</sql-update>
<sql-delete>DELETE FROM PERSON WHERE ID=?</sql-delete>
</class>|
If you expect to call a store procedure, be sure to set the |
To check that the execution happens correctly, Hibernate allows you to define one of those three strategies:
-
none: no check is performed: the store procedure is expected to fail upon issues
-
count: use of rowcount to check that the update is successful
-
param: like COUNT but using an output parameter rather that the standard mechanism
To define the result check style, use the check parameter which is again available in annotations as well as in xml.
Last but not least, stored procedures are in most cases required to return the number of rows inserted, updated and deleted. Hibernate always registers the first statement parameter as a numeric output parameter for the CUD operations:
CREATE OR REPLACE FUNCTION updatePerson (uid IN NUMBER, uname IN VARCHAR2)
RETURN NUMBER IS
BEGIN
update PERSON
set
NAME = uname,
where
ID = uid;
return SQL%ROWCOUNT;
END updatePerson;28.6. Legacy custom SQL for loading
You can also declare your own SQL (or HQL) queries for entity loading. As with inserts, updates, and deletes, this can be done at the individual column level as described in For columns, see Column transformers: read and write expressions or at the statement level. Here is an example of a statement level override:
<sql-query name = "person">
<return alias = "pers" class = "Person" lock-mod e= "upgrade"/>
SELECT NAME AS {pers.name}, ID AS {pers.id}
FROM PERSON
WHERE ID=?
FOR UPDATE
</sql-query>This is just a named query declaration, as discussed earlier. You can reference this named query in a class mapping:
<class name = "Person">
<id name = "id">
<generator class = "increment"/>
</id>
<property name = "name" not-null = "true"/>
<loader query-ref = "person"/>
</class>This even works with stored procedures.
You can even define a query for collection loading:
<set name = "employments" inverse = "true">
<key/>
<one-to-many class = "Employment"/>
<loader query-ref = "employments"/>
</set><sql-query name = "employments">
<load-collection alias = "emp" role = "Person.employments"/>
SELECT {emp.*}
FROM EMPLOYMENT emp
WHERE EMPLOYER = :id
ORDER BY STARTDATE ASC, EMPLOYEE ASC
</sql-query>You can also define an entity loader that loads a collection by join fetching:
<sql-query name = "person">
<return alias = "pers" class = "Person"/>
<return-join alias = "emp" property = "pers.employments"/>
SELECT NAME AS {pers.*}, {emp.*}
FROM PERSON pers
LEFT OUTER JOIN EMPLOYMENT emp
ON pers.ID = emp.PERSON_ID
WHERE ID=?
</sql-query>29. References
-
[PoEAA] Martin Fowler. Patterns of Enterprise Application Architecture. Addison-Wesley Publishing Company. 2003.
-
[JPwH] Christian Bauer & Gavin King. Java Persistence with Hibernate. Manning Publications Co. 2007.