Preface
Hibernate 6 is a major redesign of the world’s most popular and feature-rich ORM solution. The redesign has touched almost every subsystem of Hibernate, including the APIs, mapping annotations, and the query language. This new Hibernate is more powerful, more robust, and more typesafe.
With so many improvements, it’s very difficult to summarize the significance of this work. But the following general themes stand out. Hibernate 6:
-
finally takes advantage of the advances in relational databases over the past decade, updating the query language to support a raft of new constructs in modern dialects of SQL,
-
exhibits much more consistent behavior across different databases, greatly improving portability, and generates much higher-quality DDL from dialect-independent code,
-
improves error reporting by more scrupulous validation of queries before access to the database,
-
improves the type-safety of O/R mapping annotations, clarifies the separation of API, SPI, and internal implementation, and fixes some long-standing architectural flaws,
-
removes or deprecates legacy APIs, laying the foundation for future evolution, and
-
makes far better use of Javadoc, putting much more information at the fingertips of developers.
Hibernate 6 and Hibernate Reactive are now core components of Quarkus 3, the most exciting new environment for cloud-native development in Java, and Hibernate remains the persistence solution of choice for almost every major Java framework or server.
Unfortunately, the changes in Hibernate 6 have obsoleted much of the information about Hibernate that’s available in books, in blog posts, and on stackoverflow.
This guide is an up-to-date, high-level discussion of the current feature set and recommended usage. It does not attempt to cover every feature and should be used in conjunction with other documentation:
-
Hibernate’s extensive Javadoc,
-
the Guide to Hibernate Query Language, and
-
the Hibernate User Guide.
|
The Hibernate User Guide includes detailed discussions of most aspects of Hibernate. But with so much information to cover, readability is difficult to achieve, and so it’s most useful as a reference. Where necessary, we’ll provide links to relevant sections of the User Guide. |
1. Introduction
Hibernate is usually described as a library that makes it easy to map Java classes to relational database tables. But this formulation does no justice to the central role played by the relational data itself. So a better description might be:
Here the relational data is the focus, along with the importance of typesafety. The goal of object/relational mapping (ORM) is to eliminate fragile and untypesafe code, and make large programs easier to maintain in the long run.
ORM takes the pain out of persistence by relieving the developer of the need to hand-write tedious, repetitive, and fragile code for flattening graphs of objects to database tables and rebuilding graphs of objects from flat SQL query result sets. Even better, ORM makes it much easier to tune performance later, after the basic persistence logic has already been written.
|
A perennial question is: should I use ORM, or plain SQL? The answer is usually: use both. JPA and Hibernate were designed to work in conjunction with handwritten SQL. You see, most programs with nontrivial data access logic will benefit from the use of ORM at least somewhere. But if Hibernate is making things more difficult, for some particularly tricky piece of data access logic, the only sensible thing to do is to use something better suited to the problem! Just because you’re using Hibernate for persistence doesn’t mean you have to use it for everything. |
Developers often ask about the relationship between Hibernate and JPA, so let’s take a short detour into some history.
1.1. Hibernate and JPA
Hibernate was the inspiration behind the Java (now Jakarta) Persistence API, or JPA, and includes a complete implementation of the latest revision of this specification.
We can think of the API of Hibernate in terms of three basic elements:
-
an implementation of the JPA-defined APIs, most importantly, of the interfaces
EntityManagerFactoryandEntityManager, and of the JPA-defined O/R mapping annotations, -
a native API exposing the full set of available functionality, centered around the interfaces
SessionFactory, which extendsEntityManagerFactory, andSession, which extendsEntityManager, and -
a set of mapping annotations which augment the O/R mapping annotations defined by JPA, and which may be used with the JPA-defined interfaces, or with the native API.
Hibernate also offers a range of SPIs for frameworks and libraries which extend or integrate with Hibernate, but we’re not interested in any of that stuff here.
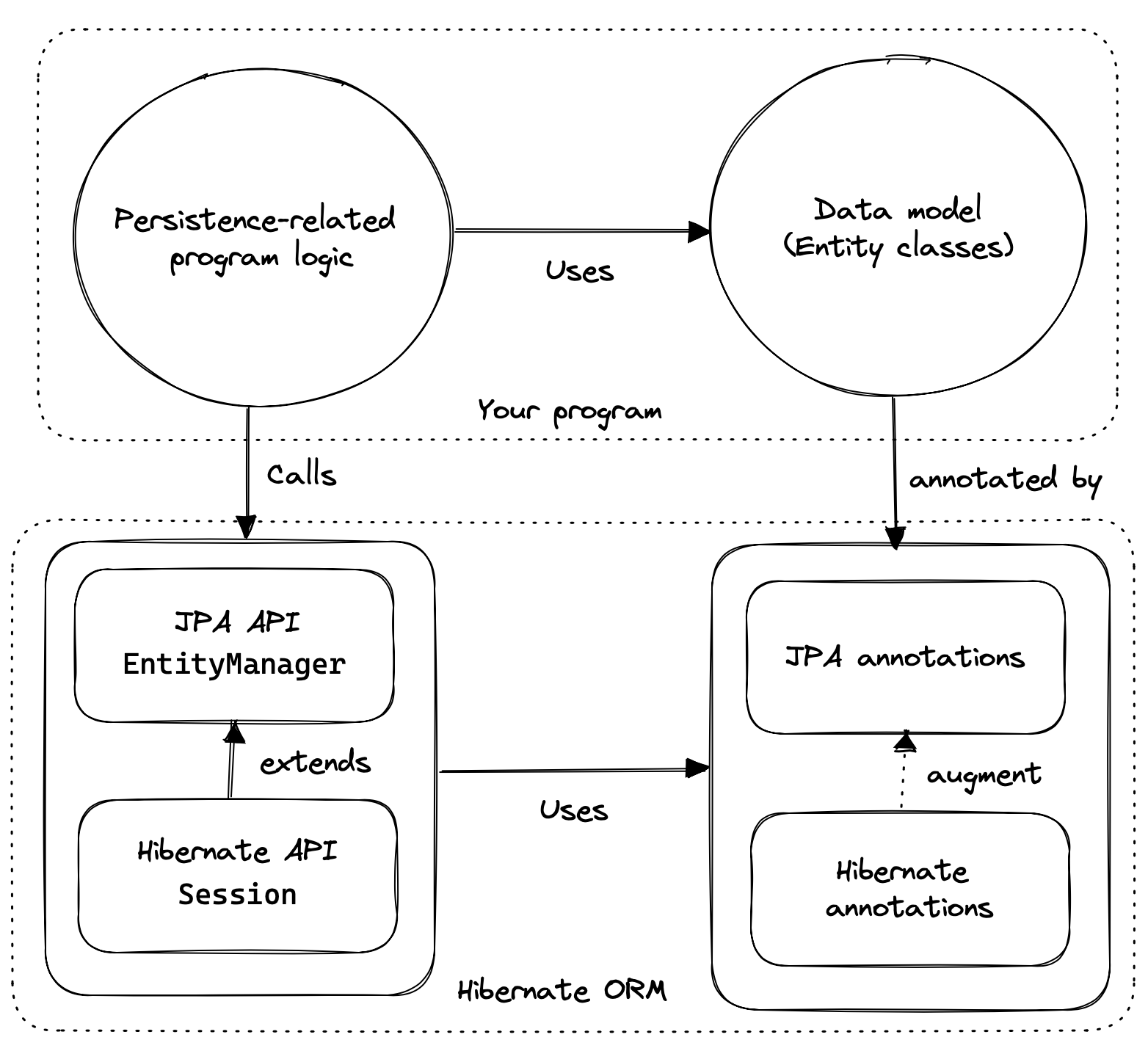
As an application developer, you must decide whether to:
-
write your program in terms of
SessionandSessionFactory, or -
maximize portability to other implementations of JPA by, wherever reasonable, writing code in terms of
EntityManagerandEntityManagerFactory, falling back to the native APIs only where necessary.
Whichever path you take, you will use the JPA-defined mapping annotations most of the time, and the Hibernate-defined annotations for more advanced mapping problems.
|
You might wonder if it’s possible to develop an application using only JPA-defined APIs, and, indeed, that’s possible in principle. JPA is a great baseline that really nails the basics of the object/relational mapping problem. But without the native APIs, and extended mapping annotations, you miss out on much of the power of Hibernate. |
Since Hibernate existed before JPA, and since JPA was modelled on Hibernate, we unfortunately have some competition and duplication in naming between the standard and native APIs. For example:
| Hibernate | JPA |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Typically, the Hibernate-native APIs offer something a little extra that’s missing in JPA, so this isn’t exactly a flaw. But it’s something to watch out for.
1.2. Writing Java code with Hibernate
If you’re completely new to Hibernate and JPA, you might already be wondering how the persistence-related code is structured.
Well, typically, our persistence-related code comes in two layers:
-
a representation of our data model in Java, which takes the form of a set of annotated entity classes, and
-
a larger number of functions which interact with Hibernate’s APIs to perform the persistence operations associated with your various transactions.
The first part, the data or "domain" model, is usually easier to write, but doing a great and very clean job of it will strongly affect your success in the second part.
Most people implement the domain model as a set of what we used to call "Plain Old Java Objects", that is, as simple Java classes with no direct dependencies on technical infrastructure, nor on application logic which deals with request processing, transaction management, communications, or interaction with the database.
|
Take your time with this code, and try to produce a Java model that’s as close as reasonable to the relational data model. Avoid using exotic or advanced mapping features when they’re not really needed.
When in the slightest doubt, map a foreign key relationship using |
The second part of the code is much trickier to get right. This code must:
-
manage transactions and sessions,
-
interact with the database via the Hibernate session,
-
fetch and prepare data needed by the UI, and
-
handle failures.
|
Responsibility for transaction and session management, and for recovery from certain kinds of failure, is best handled in some sort of framework code. |
We’re going to come back soon to the thorny question of how this persistence logic should be organized, and how it should fit into the rest of the system.
1.3. Hello, Hibernate
Before we get deeper into the weeds, we’ll quickly present a basic example program that will help you get started if you don’t already have Hibernate integrated into your project.
We begin with a simple gradle build file:
build.gradleplugins {
id 'java'
}
group = 'org.example'
version = '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
// the GOAT ORM
implementation 'org.hibernate.orm:hibernate-core:6.3.0.Final'
// Hibernate Validator
implementation 'org.hibernate.validator:hibernate-validator:8.0.0.Final'
implementation 'org.glassfish:jakarta.el:4.0.2'
// Agroal connection pool
implementation 'org.hibernate.orm:hibernate-agroal:6.3.0.Final'
implementation 'io.agroal:agroal-pool:2.1'
// logging via Log4j
implementation 'org.apache.logging.log4j:log4j-core:2.20.0'
// JPA Metamodel Generator
annotationProcessor 'org.hibernate.orm:hibernate-jpamodelgen:6.3.0.Final'
// Compile-time checking for HQL
//implementation 'org.hibernate:query-validator:2.0-SNAPSHOT'
//annotationProcessor 'org.hibernate:query-validator:2.0-SNAPSHOT'
// H2 database
runtimeOnly 'com.h2database:h2:2.1.214'
}Only the first of these dependencies is absolutely required to run Hibernate.
Next, we’ll add a logging configuration file for log4j:
log4j2.propertiesrootLogger.level = info
rootLogger.appenderRefs = console
rootLogger.appenderRef.console.ref = console
logger.hibernate.name = org.hibernate.SQL
logger.hibernate.level = info
appender.console.name = console
appender.console.type = Console
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %highlight{[%p]} %m%nNow we need some Java code. We begin with our entity class:
Book.javapackage org.hibernate.example;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import jakarta.validation.constraints.NotNull;
@Entity
class Book {
@Id
String isbn;
@NotNull
String title;
Book() {}
Book(String isbn, String title) {
this.isbn = isbn;
this.title = title;
}
}Finally, let’s see code which configures and instantiates Hibernate and asks it to persist and query the entity. Don’t worry if this makes no sense at all right now. It’s the job of this Introduction to make all this crystal clear.
Main.javapackage org.hibernate.example;
import org.hibernate.cfg.Configuration;
import static java.lang.Boolean.TRUE;
import static java.lang.System.out;
import static org.hibernate.cfg.AvailableSettings.*;
public class Main {
public static void main(String[] args) {
var sessionFactory = new Configuration()
.addAnnotatedClass(Book.class)
// use H2 in-memory database
.setProperty(URL, "jdbc:h2:mem:db1")
.setProperty(USER, "sa")
.setProperty(PASS, "")
// use Agroal connection pool
.setProperty("hibernate.agroal.maxSize", "20")
// display SQL in console
.setProperty(SHOW_SQL, TRUE.toString())
.setProperty(FORMAT_SQL, TRUE.toString())
.setProperty(HIGHLIGHT_SQL, TRUE.toString())
.buildSessionFactory();
// export the inferred database schema
sessionFactory.getSchemaManager().exportMappedObjects(true);
// persist an entity
sessionFactory.inTransaction(session -> {
session.persist(new Book("9781932394153", "Hibernate in Action"));
});
// query data using HQL
sessionFactory.inSession(session -> {
out.println(session.createSelectionQuery("select isbn||': '||title from Book").getSingleResult());
});
// query data using criteria API
sessionFactory.inSession(session -> {
var builder = sessionFactory.getCriteriaBuilder();
var query = builder.createQuery(String.class);
var book = query.from(Book.class);
query.select(builder.concat(builder.concat(book.get(Book_.isbn), builder.literal(": ")),
book.get(Book_.title)));
out.println(session.createSelectionQuery(query).getSingleResult());
});
}
}Here we’ve used Hibernate’s native APIs. We could have used JPA-standard APIs to achieve the same thing.
1.4. Hello, JPA
If we limit ourselves to the use of JPA-standard APIs, we need to use XML to configure Hibernate.
META-INF/persistence.xml<persistence xmlns="https://jakarta.ee/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://jakarta.ee/xml/ns/persistence https://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd"
version="3.0">
<persistence-unit name="example">
<class>org.hibernate.example.Book</class>
<properties>
<!-- H2 in-memory database -->
<property name="jakarta.persistence.jdbc.url"
value="jdbc:h2:mem:db1"/>
<!-- Credentials -->
<property name="jakarta.persistence.jdbc.user"
value="sa"/>
<property name="jakarta.persistence.jdbc.password"
value=""/>
<!-- Agroal connection pool -->
<property name="hibernate.agroal.maxSize"
value="20"/>
<!-- display SQL in console -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.highlight_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>Note that our build.gradle and log4j2.properties files are unchanged.
Our entity class is also unchanged from what we had before.
Unfortunately, JPA doesn’t offer an inSession() method, so we’ll have to implement session and transaction management ourselves.
We can put that logic in our own inSession() function, so that we don’t have to repeat it for every transaction.
Again, you don’t need to understand any of this code right now.
Main.java (JPA version)package org.hibernate.example;
import jakarta.persistence.EntityManager;
import jakarta.persistence.EntityManagerFactory;
import java.util.Map;
import java.util.function.Consumer;
import static jakarta.persistence.Persistence.createEntityManagerFactory;
import static java.lang.System.out;
import static org.hibernate.cfg.AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION;
import static org.hibernate.tool.schema.Action.CREATE;
public class Main {
public static void main(String[] args) {
var factory = createEntityManagerFactory("example",
// export the inferred database schema
Map.of(JAKARTA_HBM2DDL_DATABASE_ACTION, CREATE));
// persist an entity
inSession(factory, entityManager -> {
entityManager.persist(new Book("9781932394153", "Hibernate in Action"));
});
// query data using HQL
inSession(factory, entityManager -> {
out.println(entityManager.createQuery("select isbn||': '||title from Book").getSingleResult());
});
// query data using criteria API
inSession(factory, entityManager -> {
var builder = factory.getCriteriaBuilder();
var query = builder.createQuery(String.class);
var book = query.from(Book.class);
query.select(builder.concat(builder.concat(book.get(Book_.isbn), builder.literal(": ")),
book.get(Book_.title)));
out.println(entityManager.createQuery(query).getSingleResult());
});
}
// do some work in a session, performing correct transaction management
static void inSession(EntityManagerFactory factory, Consumer<EntityManager> work) {
var entityManager = factory.createEntityManager();
var transaction = entityManager.getTransaction();
try {
transaction.begin();
work.accept(entityManager);
transaction.commit();
}
catch (Exception e) {
if (transaction.isActive()) transaction.rollback();
throw e;
}
finally {
entityManager.close();
}
}
}In practice, we never access the database directly from a main() method.
So now let’s talk about how to organize persistence logic in a real system.
The rest of this chapter is not compulsory.
If you’re itching for more details about Hibernate itself, you’re quite welcome to skip straight to the next chapter, and come back later.
1.5. Organizing persistence logic
In a real program, persistence logic like the code shown above is usually interleaved with other sorts of code, including logic:
-
implementing the rules of the business domain, or
-
for interacting with the user.
Therefore, many developers quickly—even too quickly, in our opinion—reach for ways to isolate the persistence logic into some sort of separate architectural layer. We’re going to ask you to suppress this urge for now.
|
The easiest way to use Hibernate is to call the |
We prefer a bottom-up approach to organizing our code. We like to start thinking about methods and functions, not about architectural layers and container-managed objects. To illustrate the sort of approach to code organization that we advocate, let’s consider a service which queries the database using HQL or SQL.
We might start with something like this, a mix of UI and persistence logic:
@Path("/") @Produces("application/json")
public class BookResource {
@GET @Path("book/{isbn}")
public Book getBook(String isbn) {
var book = sessionFactory.fromTransaction(session -> session.find(Book.class, isbn));
return book == null ? Response.status(404).build() : book;
}
}Indeed, we might also finish with something like that—it’s quite hard to identify anything concretely wrong with the code above, and for such a simple case it seems really difficult to justify making this code more complicated by introducing additional objects.
One very nice aspect of this code, which we wish to draw your attention to, is that session and transaction management is handled by generic "framework" code, just as we already recommended above.
In this case, we’re using the fromTransaction() method, which happens to come built in to Hibernate.
But you might prefer to use something else, for example:
-
in a container environment like Jakarta EE or Quarkus, container-managed transactions and container-managed persistence contexts, or
-
something you write yourself.
The important thing is that calls like createEntityManager() and getTransaction().begin() don’t belong in regular program logic, because it’s tricky and tedious to get the error handling correct.
Let’s now consider a slightly more complicated case.
@Path("/") @Produces("application/json")
public class BookResource {
private static final RESULTS_PER_PAGE = 20;
@GET @Path("books/{titlePattern}/{page:\\d+}")
public List<Book> findBooks(String titlePattern, int page) {
var books = sessionFactory.fromTransaction(session -> {
return session.createSelectionQuery("from Book where title like ?1 order by title", Book.class)
.setParameter(1, titlePattern)
.setPage(Page.page(RESULTS_PER_PAGE, page))
.getResultList();
});
return books.isEmpty() ? Response.status(404).build() : books;
}
}This is fine, and we won’t complain if you prefer to leave the code exactly as it appears above. But there’s one thing we could perhaps improve. We love super-short methods with single responsibilities, and there looks to be an opportunity to introduce one here. Let’s hit the code with our favorite thing, the Extract Method refactoring. We obtain:
static List<Book> findBooksByTitleWithPagination(Session session,
String titlePattern, Page page) {
return session.createSelectionQuery("from Book where title like ?1 order by title", Book.class)
.setParameter(1, titlePattern)
.setPage(page)
.getResultList();
}This is an example of a query method, a function which accepts arguments to the parameters of a HQL or SQL query, and executes the query, returning its results to the caller. And that’s all it does; it doesn’t orchestrate additional program logic, and it doesn’t perform transaction or session management.
It’s even better to specify the query string using the @NamedQuery annotation, so that Hibernate can validate the query it at startup time, that is, when the SessionFactory is created, instead of when the query is first executed.
Indeed, since we included the Metamodel Generator in our Gradle build, the query can even be validated at compile time.
We need a place to put the annotation, so lets move our query method to a new class:
@CheckHQL // validate named queries at compile time
@NamedQuery(name="findBooksByTitle",
query="from Book where title like :title order by title")
class Queries {
static List<Book> findBooksByTitleWithPagination(Session session,
String titlePattern, Page page) {
return session.createNamedQuery("findBooksByTitle", Book.class)
.setParameter("title", titlePattern)
.setPage(page)
.getResultList();
}
}Notice that our query method doesn’t attempt to hide the EntityManager from its clients.
Indeed, the client code is responsible for providing the EntityManager or Session to the query method.
This is a quite distinctive feature of our whole approach.
The client code may:
-
obtain an
EntityManagerorSessionby callinginTransaction()orfromTransaction(), as we saw above, or, -
in an environment with container-managed transactions, it might obtain it via dependency injection.
Whatever the case, the code which orchestrates a unit of work usually just calls the Session or EntityManager directly, passing it along to helper methods like our query method if necessary.
@GET
@Path("books/{titlePattern}")
public List<Book> findBooks(String titlePattern) {
var books = sessionFactory.fromTransaction(session ->
Queries.findBooksByTitleWithPagination(session, titlePattern,
Page.page(RESULTS_PER_PAGE, page));
return books.isEmpty() ? Response.status(404).build() : books;
}You might be thinking that our query method looks a bit boilerplatey. That’s true, perhaps, but we’re much more concerned that it’s not very typesafe. Indeed, for many years, the lack of compile-time checking for HQL queries and code which binds arguments to query parameters was our number one source of discomfort with Hibernate.
Fortunately, there’s now a solution to both problems: as an incubating feature of Hibernate 6.3, we now offer the possibility to have the Metamodel Generator fill in the implementation of such query methods for you. This facility is the topic of a whole chapter of this introduction, so for now we’ll just leave you with one simple example.
Suppose we simplify Queries to just the following:
interface Queries {
@HQL("where title like :title order by title")
List<Book> findBooksByTitleWithPagination(String title, Page page);
}Then the Metamodel Generator automatically produces an implementation of the method annotated @HQL in a class named Queries_.
We can call it just like we called our handwritten version:
@GET
@Path("books/{titlePattern}")
public List<Book> findBooks(String titlePattern) {
var books = sessionFactory.fromTransaction(session ->
Queries_.findBooksByTitleWithPagination(session, titlePattern,
Page.page(RESULTS_PER_PAGE, page));
return books.isEmpty() ? Response.status(404).build() : books;
}In this case, the quantity of code eliminated is pretty trivial. The real value is in improved type safety. We now find out about errors in assignments of arguments to query parameters at compile time.
|
At this point, we’re certain you’re full of doubts about this idea. And quite rightly so. We would love to answer your objections right here, but that will take us much too far off track. So we ask you to file away these thoughts for now. We promise to make it make sense when we properly address this topic later. And, after that, if you still don’t like this approach, please understand that it’s completely optional. Nobody’s going to come around to your house to force it down your throat. |
Now that we have a rough picture of what our persistence logic might look like, it’s natural to ask how we should test our code.
1.6. Testing persistence logic
When we write tests for our persistence logic, we’re going to need:
-
a database, with
-
an instance of the schema mapped by our persistent entities, and
-
a set of test data, in a well-defined state at the beginning of each test.
It might seem obvious that we should test against the same database system that we’re going to use in production, and, indeed, we should certainly have at least some tests for this configuration. But on the other hand, tests which perform I/O are much slower than tests which don’t, and most databases can’t be set up to run in-process.
So, since most persistence logic written using Hibernate 6 is extremely portable between databases, it often makes good sense to test against an in-memory Java database. (H2 is the one we recommend.)
|
We do need to be careful here if our persistence code uses native SQL, or if it uses concurrency-management features like pessimistic locks. |
Whether we’re testing against our real database, or against an in-memory Java database, we’ll need to export the schema at the beginning of a test suite.
We usually do this when we create the Hibernate SessionFactory or JPA EntityManager, and so traditionally we’ve used a configuration property for this.
The JPA-standard property is jakarta.persistence.schema-generation.database.action.
For example, if we’re using Configuration to configure Hibernate, we could write:
configuration.setProperty(AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION,
Action.SPEC_ACTION_DROP_AND_CREATE);Alternatively, in Hibernate 6, we may use the new SchemaManager API to export the schema, just as we did above.
sessionFactory.getSchemaManager().exportMappedObjects(true);Since executing DDL statements is very slow on many databases, we don’t want to do this before every test. Instead, to ensure that each test begins with the test data in a well-defined state, we need to do two things before each test:
-
clean up any mess left behind by the previous test, and then
-
reinitialize the test data.
We may truncate all the tables, leaving an empty database schema, using the SchemaManager.
sessionFactory.getSchemaManager().truncateMappedObjects();After truncating tables, we might need to initialize our test data. We may specify test data in a SQL script, for example:
insert into Books (isbn, title) values ('9781932394153', 'Hibernate in Action')
insert into Books (isbn, title) values ('9781932394887', 'Java Persistence with Hibernate')
insert into Books (isbn, title) values ('9781617290459', 'Java Persistence with Hibernate, Second Edition')If we name this file import.sql, and place it in the root classpath, that’s all we need to do.
Otherwise, we need to specify the file in the configuration property jakarta.persistence.sql-load-script-source.
If we’re using Configuration to configure Hibernate, we could write:
configuration.setProperty(AvailableSettings.JAKARTA_HBM2DDL_LOAD_SCRIPT_SOURCE,
"/org/example/test-data.sql");The SQL script will be executed every time exportMappedObjects() or truncateMappedObjects() is called.
|
There’s another sort of mess a test can leave behind: cached data in the second-level cache. We recommend disabling Hibernate’s second-level cache for most sorts of testing. Alternatively, if the second-level cache is not disabled, then before each test we should call: |
Now, suppose you’ve followed our advice, and written your entities and query methods to minimize dependencies on "infrastructure", that is, on libraries other than JPA and Hibernate, on frameworks, on container-managed objects, and even on bits of your own system which are hard to instantiate from scratch. Then testing persistence logic is now straightforward!
You’ll need to:
-
bootstrap Hibernate and create a
SessionFactoryorEntityManagerFactoryand the beginning of your test suite (we’ve already seen how to do that), and -
create a new
SessionorEntityManagerinside each@Testmethod, usinginTransaction(), for example.
Actually, some tests might require multiple sessions. But be careful not to leak a session between different tests.
|
Another important test we’ll need is one which validates our O/R mapping annotations against the actual database schema. This is again the job of the schema management tooling, either: Or: This "test" is one which many people like to run even in production, when the system starts up. |
1.7. Architecture and the persistence layer
Let’s now consider a different approach to code organization, one we treat with suspicion.
|
In this section, we’re going to give you our opinion. If you’re only interested in facts, or if you prefer not to read things that might undermine the opinion you currently hold, please feel free to skip straight to the next chapter. |
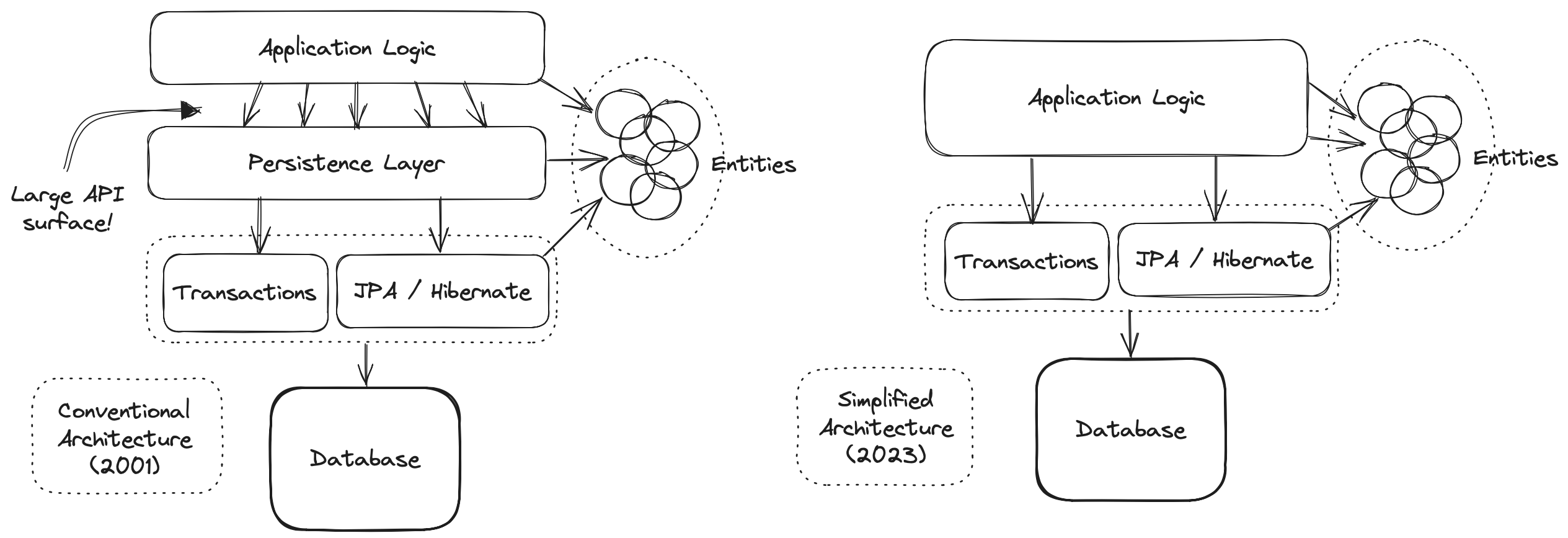
Hibernate is an architecture-agnostic library, not a framework, and therefore integrates comfortably with a wide range of Java frameworks and containers. Consistent with our place within the ecosystem, we’ve historically avoided giving out much advice on architecture. This is a practice we’re now perhaps inclined to regret, since the resulting vacuum has come to be filled with advice from people advocating architectures, design patterns, and extra frameworks which we suspect make Hibernate a bit less pleasant to use than it should be.
In particular, frameworks which wrap JPA seem to add bloat while subtracting some of the fine-grained control over data access that Hibernate works so hard to provide. These frameworks don’t expose the full feature set of Hibernate, and so the program is forced to work with a less powerful abstraction.
The stodgy, dogmatic, conventional wisdom, which we hesitate to challenge for simple fear of pricking ourselves on the erect hackles that inevitably accompany such dogma-baiting is:
Code which interacts with the database belongs in a separate persistence layer.
We lack the courage—perhaps even the conviction—to tell you categorically to not follow this recommendation. But we do ask you to consider the cost in boilerplate of any architectural layer, and whether the benefits this cost buys are really worth it in the context of your system.
To add a little background texture to this discussion, and at the risk of our Introduction degenerating into a rant at such an early stage, we’re going ask you to humor us while talk a little more about ancient history.
Ultimately, we’re not sure you need a separate persistence layer at all.
At least consider the possibility that it might be OK to call the EntityManager directly from your business logic.
We can already hear you hissing at our heresy. But before slamming shut the lid of your laptop and heading off to fetch garlic and a pitchfork, take a couple of hours to weigh what we’re proposing.
OK, so, look, if it makes you feel better, one way to view EntityManager is to think of it as a single generic "repository" that works for every entity in your system.
From this point of view, JPA is your persistence layer.
And there’s few good reasons to wrap this abstraction in a second abstraction that’s less generic.
Even where a distinct persistence layer is appropriate, DAO-style repositories aren’t the unambiguously most-correct way to factorize the equation:
-
most nontrivial queries touch multiple entities, and so it’s often quite ambiguous which repository such a query belongs to,
-
most queries are extremely specific to a particular fragment of program logic, and aren’t reused in different places across the system, and
-
the various operations of a repository rarely interact or share common internal implementation details.
Indeed, repositories, by nature, exhibit very low cohesion. A layer of repository objects might make sense if you have multiple implementations of each repository, but in practice almost nobody ever does. That’s because they’re also extremely highly coupled to their clients, with a very large API surface. And, on the contrary, a layer is only easily replaceable if it has a very narrow API.
|
Some people do indeed use mock repositories for testing, but we really struggle to see any value in this. If we don’t want to run our tests against our real database, it’s usually very easy to "mock" the database itself by running tests against an in-memory Java database like H2. This works even better in Hibernate 6 than in older versions of Hibernate, since HQL is now much more portable between platforms. |
Phew, let’s move on.
1.8. Overview
It’s now time to begin our journey toward actually understanding the code we saw earlier.
This introduction will guide you through the basic tasks involved in developing a program that uses Hibernate for persistence:
-
configuring and bootstrapping Hibernate, and obtaining an instance of
SessionFactoryorEntityManagerFactory, -
writing a domain model, that is, a set of entity classes which represent the persistent types in your program, and which map to tables of your database,
-
customizing these mappings when the model maps to a pre-existing relational schema,
-
using the
SessionorEntityManagerto perform operations which query the database and return entity instances, or which update the data held in the database, -
using the Hibernate Metamodel Generator to improve compile-time type-safety,
-
writing complex queries using the Hibernate Query Language (HQL) or native SQL, and, finally
-
tuning performance of the data access logic.
Naturally, we’ll start at the top of this list, with the least-interesting topic: configuration.
2. Configuration and bootstrap
We would love to make this section short. Unfortunately, there’s several distinct ways to configure and bootstrap Hibernate, and we’re going to have to describe at least two of them in detail.
The four basic ways to obtain an instance of Hibernate are shown in the following table:
Using the standard JPA-defined XML, and the operation |
Usually chosen when portability between JPA implementations is important. |
Using the |
When portability between JPA implementations is not important, this option is quicker, adds some flexibility and saves a typecast. |
Using the more complex APIs defined in |
Used primarily by framework integrators, this option is outside the scope of this document. |
By letting the container take care of the bootstrap process and of injecting the |
Used in a container environment like WildFly or Quarkus. |
Here we’ll focus on the first two options.
If you’re using Hibernate outside of a container environment, you’ll need to:
-
include Hibernate ORM itself, along with the appropriate JDBC driver, as dependencies of your project, and
-
configure Hibernate with information about your database, by specifying configuration properties.
2.1. Including Hibernate in your project build
First, add the following dependency to your project:
org.hibernate.orm:hibernate-core:{version}
Where {version} is the version of Hibernate you’re using.
You’ll also need to add a dependency for the JDBC driver for your database.
| Database | Driver dependency |
|---|---|
PostgreSQL or CockroachDB |
|
MySQL or TiDB |
|
MariaDB |
|
DB2 |
|
SQL Server |
|
Oracle |
|
H2 |
|
HSQLDB |
|
Where {version} is the latest version of the JDBC driver for your databse.
2.2. Optional dependencies
Optionally, you might also add any of the following additional features:
| Optional feature | Dependencies |
|---|---|
An SLF4J logging implementation |
|
A JDBC connection pool, for example, Agroal |
|
The Hibernate Metamodel Generator, especially if you’re using the JPA criteria query API |
|
The Query Validator, for compile-time checking of HQL |
|
Hibernate Validator, an implementation of Bean Validation |
|
Local second-level cache support via JCache and EHCache |
|
Local second-level cache support via JCache and Caffeine |
|
Distributed second-level cache support via Infinispan |
|
A JSON serialization library for working with JSON datatypes, for example, Jackson or Yasson |
|
|
|
Envers, for auditing historical data |
|
You might also add the Hibernate bytecode enhancer to your Gradle build if you want to use field-level lazy fetching.
2.3. Configuration using JPA XML
Sticking to the JPA-standard approach, we would provide a file named persistence.xml, which we usually place in the META-INF directory of a persistence archive, that is, of the .jar file or directory which contains our entity classes.
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence https://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd"
version="2.0">
<persistence-unit name="org.hibernate.example">
<class>org.hibernate.example.Book</class>
<class>org.hibernate.example.Author</class>
<properties>
<!-- PostgreSQL -->
<property name="jakarta.persistence.jdbc.url"
value="jdbc:postgresql://localhost/example"/>
<!-- Credentials -->
<property name="jakarta.persistence.jdbc.user"
value="gavin"/>
<property name="jakarta.persistence.jdbc.password"
value="hibernate"/>
<!-- Automatic schema export -->
<property name="jakarta.persistence.schema-generation.database.action"
value="drop-and-create"/>
<!-- SQL statement logging -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.highlight_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>The <persistence-unit> element defines a named persistence unit, that is:
-
a collection of associated entity types, along with
-
a set of default configuration settings, which may be augmented or overridden at runtime.
Each <class> element specifies the fully-qualified name of an entity class.
Each <property> element specifies a configuration property and its value.
Note that:
-
the configuration properties in the
jakarta.persistencenamespace are standard properties defined by the JPA spec, and -
properties in the
hibernatenamespace are specific to Hibernate.
We may obtain an EntityManagerFactory by calling Persistence.createEntityManagerFactory():
EntityManagerFactory entityManagerFactory =
Persistence.createEntityManagerFactory("org.hibernate.example");If necessary, we may override configuration properties specified in persistence.xml:
EntityManagerFactory entityManagerFactory =
Persistence.createEntityManagerFactory("org.hibernate.example",
Map.of(AvailableSettings.JAKARTA_JDBC_PASSWORD, password));2.4. Configuration using Hibernate API
Alternatively, the venerable class Configuration allows an instance of Hibernate to be configured in Java code.
SessionFactory sessionFactory =
new Configuration()
.addAnnotatedClass(Book.class)
.addAnnotatedClass(Author.class)
// PostgreSQL
.setProperty(AvailableSettings.JAKARTA_JDBC_URL, "jdbc:postgresql://localhost/example")
// Credentials
.setProperty(AvailableSettings.JAKARTA_JDBC_USER, user)
.setProperty(AvailableSettings.JAKARTA_JDBC_PASSWORD, password)
// Automatic schema export
.setProperty(AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION,
Action.SPEC_ACTION_DROP_AND_CREATE)
// SQL statement logging
.setProperty(AvailableSettings.SHOW_SQL, TRUE.toString())
.setProperty(AvailableSettings.FORMAT_SQL, TRUE.toString())
.setProperty(AvailableSettings.HIGHLIGHT_SQL, TRUE.toString())
// Create a new SessionFactory
.buildSessionFactory();The Configuration class has survived almost unchanged since the very earliest (pre-1.0) versions of Hibernate, and so it doesn’t look particularly modern.
On the other hand, it’s very easy to use, and exposes some options that persistence.xml doesn’t support.
2.5. Configuration using Hibernate properties file
If we’re using the Hibernate Configuration API, but we don’t want to put certain configuration properties directly in the Java code, we can specify them in a file named hibernate.properties, and place the file in the root classpath.
# PostgreSQL
jakarta.persistence.jdbc.url=jdbc:postgresql://localhost/example
# Credentials
jakarta.persistence.jdbc.user=hibernate
jakarta.persistence.jdbc.password=zAh7mY$2MNshzAQ5
# SQL statement logging
hibernate.show_sql=true
hibernate.format_sql=true
hibernate.highlight_sql=true2.6. Basic configuration settings
The class AvailableSettings enumerates all the configuration properties understood by Hibernate.
Of course, we’re not going to cover every useful configuration setting in this chapter. Instead, we’ll mention the ones you need to get started, and come back to some other important settings later, especially when we talk about performance tuning.
|
Hibernate has many—too many—switches and toggles. Please don’t go crazy messing about with these settings; most of them are rarely needed, and many only exist to provide backward compatibility with older versions of Hibernate. With rare exception, the default behavior of every one of these settings was carefully chosen to be the behavior we recommend. |
The properties you really do need to get started are these three:
| Configuration property name | Purpose |
|---|---|
|
JDBC URL of your database |
|
Your database credentials |
|
In Hibernate 6, you don’t need to specify Similarly, neither |
Pooling JDBC connections is an extremely important performance optimization. You can set the size of Hibernate’s built-in connection pool using this property:
| Configuration property name | Purpose |
|---|---|
|
The size of the built-in connection pool |
|
By default, Hibernate uses a simplistic built-in connection pool. This pool is not meant for use in production, and later, when we discuss performance, we’ll see how to select a more robust implementation. |
Alternatively, in a container environment, you’ll need at least one of these properties:
| Configuration property name | Purpose |
|---|---|
|
(Optional, defaults to |
|
JNDI name of a JTA datasource |
|
JNDI name of a non-JTA datasource |
In this case, Hibernate obtains pooled JDBC database connections from a container-managed DataSource.
2.7. Automatic schema export
You can have Hibernate infer your database schema from the mapping annotations you’ve specified in your Java code, and export the schema at initialization time by specifying one or more of the following configuration properties:
| Configuration property name | Purpose |
|---|---|
|
|
|
(Optional) If |
|
(Optional) If |
|
(Optional) The name of a SQL DDL script to be executed |
|
(Optional) The name of a SQL DML script to be executed |
This feature is extremely useful for testing.
|
The easiest way to pre-initialize a database with test or "reference" data is to place a list of SQL |
As we mentioned earlier, it can also be useful to control schema export programmatically.
|
The JPA has a more limited and less ergonomic API: |
2.8. Logging the generated SQL
To see the generated SQL as it’s sent to the database, you have two options.
One way is to set the property hibernate.show_sql to true, and Hibernate will log SQL direct to the console.
You can make the output much more readable by enabling formatting or highlighting.
These settings really help when troubleshooting the generated SQL statements.
| Configuration property name | Purpose |
|---|---|
|
If |
|
If |
|
If |
Alternatively, you can enable debug-level logging for the category org.hibernate.SQL using your preferred SLF4J logging implementation.
For example, if you’re using Log4J 2 (as above in Optional dependencies), add these lines to your log4j2.properties file:
# SQL execution
logger.hibernate.name = org.hibernate.SQL
logger.hibernate.level = debug
# JDBC parameter binding
logger.jdbc-bind.name=org.hibernate.orm.jdbc.bind
logger.jdbc-bind.level=trace
# JDBC result set extraction
logger.jdbc-extract.name=org.hibernate.orm.jdbc.extract
logger.jdbc-extract.level=traceBut with this approach we miss out on the pretty highlighting.
2.9. Minimizing repetitive mapping information
The following properties are very useful for minimizing the amount of information you’ll need to explicitly specify in @Table and @Column annotations, which we’ll discuss below in Object/relational mapping:
| Configuration property name | Purpose |
|---|---|
|
A default schema name for entities which do not explicitly declare one |
|
A default catalog name for entities which do not explicitly declare one |
|
A |
|
An |
|
Writing your own |
2.10. Nationalized character data in SQL Server
By default, SQL Server’s char and varchar types don’t accommodate Unicode data.
But a Java string may contain any Unicode character.
So, if you’re working with SQL Server, you might need to force Hibernate to use the nchar and nvarchar column types.
| Configuration property name | Purpose |
|---|---|
|
Use |
On the other hand, if only some columns store nationalized data, use the @Nationalized annotation to indicate fields of your entities which map these columns.
|
Alternatively, you can configure SQL Server to use the UTF-8 enabled collation |
3. Entities
An entity is a Java class which represents data in a relational database table. We say that the entity maps or maps to the table. Much less commonly, an entity might aggregate data from multiple tables, but we’ll get to that later.
An entity has attributes—properties or fields—which map to columns of the table. In particular, every entity must have an identifier or id, which maps to the primary key of the table. The id allows us to uniquely associate a row of the table with an instance of the Java class, at least within a given persistence context.
We’ll explore the idea of a persistence context later. For now, think of it as a one-to-one mapping between ids and entity instances.
An instance of a Java class cannot outlive the virtual machine to which it belongs.
But we may think of an entity instance having a lifecycle which transcends a particular instantiation in memory.
By providing its id to Hibernate, we may re-materialize the instance in a new persistence context, as long as the associated row is present in the database.
Therefore, the operations persist() and remove() may be thought of as demarcating the beginning and end of the lifecycle of an entity, at least with respect to persistence.
Thus, an id represents the persistent identity of an entity, an identity that outlives a particular instantiation in memory.
And this is an important difference between entity class itself and the values of its attributes—the entity has a persistent identity, and a well-defined lifecycle with respect to persistence, whereas a String or List representing one of its attribute values doesn’t.
An entity usually has associations to other entities. Typically, an association between two entities maps to a foreign key in one of the database tables. A group of mutually associated entities is often called a domain model, though data model is also a perfectly good term.
3.1. Entity classes
An entity must:
-
be a non-
finalclass, -
with a non-
privateconstructor with no parameters.
On the other hand, the entity class may be either concrete or abstract, and it may have any number of additional constructors.
|
An entity class may be a |
Every entity class must be annotated @Entity.
@Entity
class Book {
Book() {}
...
}Alternatively, the class may be identified as an entity type by providing an XML-based mapping for the class.
We won’t have much more to say about XML-based mappings in this Introduction, since it’s not our preferred way to do things.
3.2. Access types
Each entity class has a default access type, either:
-
direct field access, or
-
property access.
Hibernate automatically determines the access type from the location of attribute-level annotations. Concretely:
-
if a field is annotated
@Id, field access is used, or -
if a getter method is annotated
@Id, property access is used.
Back when Hibernate was just a baby, property access was quite popular in the Hibernate community. Today, however, field access is much more common.
|
The default access type may be specified explicitly using the |
|
Mapping annotations should be placed consistently:
It is in principle possible to mix field and property access using explicit |
An entity class like Book, which does not extend any other entity class, is called a root entity.
Every root entity must declare an identifier attribute.
3.3. Entity class inheritance
An entity class may extend another entity class.
@Entity
class AudioBook extends Book {
AudioBook() {}
...
}A subclass entity inherits every persistent attribute of every entity it extends.
A root entity may also extend another class and inherit mapped attributes from the other class.
But in this case, the class which declares the mapped attributes must be annotated @MappedSuperclass.
@MappedSuperclass
class Versioned {
...
}
@Entity
class Book extends Versioned {
...
}A root entity class must declare an attribute annotated @Id, or inherit one from a @MappedSuperclass.
A subclass entity always inherits the identifier attribute of the root entity.
It may not declare its own @Id attribute.
3.4. Identifier attributes
An identifier attribute is usually a field:
@Entity
class Book {
Book() {}
@Id
Long id;
...
}But it may be a property:
@Entity
class Book {
Book() {}
private Long id;
@Id
Long getId() { return id; }
void setId(Long id) { this.id = id; }
...
}An identifier attribute must be annotated @Id or @EmbeddedId.
Identifier values may be:
-
assigned by the application, that is, by your Java code, or
-
generated and assigned by Hibernate.
We’ll discuss the second option first.
3.5. Generated identifiers
An identifier is often system-generated, in which case it should be annotated @GeneratedValue:
@Id @GeneratedValue
Long id;|
System-generated identifiers, or surrogate keys make it easier to evolve or refactor the relational data model. If you have the freedom to define the relational schema, we recommend the use of surrogate keys. On the other hand, if, as is more common, you’re working with a pre-existing database schema, you might not have the option. |
JPA defines the following strategies for generating ids, which are enumerated by GenerationType:
| Strategy | Java type | Implementation |
|---|---|---|
|
|
A Java |
|
|
An identity or autoincrement column |
|
|
A database sequence |
|
|
A database table |
|
|
Selects |
For example, this UUID is generated in Java code:
@Id @GeneratedValue UUID id; // AUTO strategy selects UUID based on the field typeThis id maps to a SQL identity, auto_increment, or bigserial column:
@Id @GeneratedValue(strategy=IDENTITY) Long id;The @SequenceGenerator and @TableGenerator annotations allow further control over SEQUENCE and TABLE generation respectively.
Consider this sequence generator:
@SequenceGenerator(name="bookSeq", sequenceName="seq_book", initialValue = 5, allocationSize=10)Values are generated using a database sequence defined as follows:
create sequence seq_book start with 5 increment by 10Notice that Hibernate doesn’t have to go to the database every time a new identifier is needed.
Instead, a given process obtains a block of ids, of size allocationSize, and only needs to hit the database each time the block is exhausted.
Of course, the downside is that generated identifiers are not contiguous.
|
If you let Hibernate export your database schema, the sequence definition will have the right |
Any identifier attribute may now make use of the generator named bookSeq:
@Id
@GeneratedValue(strategy=SEQUENCE, generator="bookSeq") // reference to generator defined elsewhere
Long id;Actually, it’s extremely common to place the @SequenceGenerator annotation on the @Id attribute that makes use of it:
@Id
@GeneratedValue(strategy=SEQUENCE, generator="bookSeq") // reference to generator defined below
@SequenceGenerator(name="bookSeq", sequenceName="seq_book", initialValue = 5, allocationSize=10)
Long id;|
JPA id generators may be shared between entities.
A |
As you can see, JPA provides quite adequate support for the most common strategies for system-generated ids.
However, the annotations themselves are a bit more intrusive than they should be, and there’s no well-defined way to extend this framework to support custom strategies for id generation.
Nor may @GeneratedValue be used on a property not annotated @Id.
Since custom id generation is a rather common requirement, Hibernate provides a very carefully-designed framework for user-defined Generators, which we’ll discuss in User-defined generators.
3.6. Natural keys as identifiers
Not every identifier attribute maps to a (system-generated) surrogate key. Primary keys which are meaningful to the user of the system are called natural keys.
When the primary key of a table is a natural key, we don’t annotate the identifier attribute @GeneratedValue, and it’s the responsibility of the application code to assign a value to the identifier attribute.
@Entity
class Book {
@Id
String isbn;
...
}Of particular interest are natural keys which comprise more than one database column, and such natural keys are called composite keys.
3.7. Composite identifiers
If your database uses composite keys, you’ll need more than one identifier attribute. There are two ways to map composite keys in JPA:
-
using an
@IdClass, or -
using an
@EmbeddedId.
Perhaps the most immediately-natural way to represent this in an entity class is with multiple fields annotated @Id, for example:
@Entity
@IdClass(BookId.class)
class Book {
Book() {}
@Id
String isbn;
@Id
int printing;
...
}But this approach comes with a problem: what object can we use to identify a Book and pass to methods like find() which accept an identifier?
The solution is to write a separate class with fields that match the identifier attributes of the entity.
The @IdClass annotation of the Book entity identifies the id class to use for that entity:
class BookId {
String isbn;
int printing;
BookId() {}
BookId(String isbn, int printing) {
this.isbn = isbn;
this.printing = printing;
}
@Override
public boolean equals(Object other) {
if (other instanceof BookId) {
BookId bookId = (BookId) other;
return bookId.isbn.equals(isbn)
&& bookId.printing == printing;
}
else {
return false;
}
}
@Override
public int hashCode() {
return isbn.hashCode();
}
}Every id class should override equals() and hashCode().
This is not our preferred approach.
Instead, we recommend that the BookId class be declared as an @Embeddable type:
@Embeddable
class BookId {
String isbn;
int printing;
BookId() {}
BookId(String isbn, int printing) {
this.isbn = isbn;
this.printing = printing;
}
...
}We’ll learn more about Embeddable objects below.
Now the entity class may reuse this definition using @EmbeddedId, and the @IdClass annotation is no longer required:
@Entity
class Book {
Book() {}
@EmbeddedId
BookId bookId;
...
}This second approach eliminates some duplicated code.
Either way, we may now use BookId to obtain instances of Book:
Book book = session.find(Book.class, new BookId(isbn, printing));3.8. Version attributes
An entity may have an attribute which is used by Hibernate for optimistic lock checking.
A version attribute is usually of type Integer, Short, Long, LocalDateTime, OffsetDateTime, ZonedDateTime, or Instant.
@Version
LocalDateTime lastUpdated;Version attributes are automatically assigned by Hibernate when an entity is made persistent, and automatically incremented or updated each time the entity is updated.
|
If an entity doesn’t have a version number, which often happens when mapping legacy data, we can still do optimistic locking.
The |
The @Id and @Version attributes we’ve already seen are just specialized examples of basic attributes.
3.9. Natural id attributes
Even when an entity has a surrogate key, it should always be possible to write down a combination of fields which uniquely identifies an instance of the entity, from the point of view of the user of the system. This combination of fields is its natural key. Above, we considered the case where the natural key coincides with the primary key. Here, the natural key is a second unique key of the entity, distinct from its surrogate primary key.
|
If you can’t identify a natural key, it might be a sign that you need to think more carefully about some aspect of your data model. If an entity doesn’t have a meaningful unique key, then it’s impossible to say what event or object it represents in the "real world" outside your program. |
Since it’s extremely common to retrieve an entity based on its natural key, Hibernate has a way to mark the attributes of the entity which make up its natural key.
Each attribute must be annotated @NaturalId.
@Entity
class Book {
Book() {}
@Id @GeneratedValue
Long id; // the system-generated surrogate key
@NaturalId
String isbn; // belongs to the natural key
@NaturalId
int printing; // also belongs to the natural key
...
}Hibernate automatically generates a UNIQUE constraint on the columns mapped by the annotated fields.
|
Consider using the natural id attributes to implement |
The payoff for doing this extra work, as we will see much later, is that we can take advantage of optimized natural id lookups that make use of the second-level cache.
Note that even when you’ve identified a natural key, we still recommend the use of a generated surrogate key in foreign keys, since this makes your data model much easier to change.
3.10. Basic attributes
A basic attribute of an entity is a field or property which maps to a single column of the associated database table. The JPA specification defines a quite limited set of basic types:
| Classification | Package | Types |
|---|---|---|
Primitive types |
|
|
Primitive wrappers |
|
|
Strings |
|
|
Arbitrary-precision numeric types |
|
|
Date/time types |
|
|
Deprecated date/time types 💀 |
|
|
Deprecated JDBC date/time types 💀 |
|
|
Binary and character arrays |
|
|
UUIDs |
|
|
Enumerated types |
Any |
|
Serializable types |
Any type which implements |
|
We’re begging you to use types from the |
|
Serializing a Java object and storing its binary representation in the database is usually wrong. As we’ll soon see in Embeddable objects, Hibernate has much better ways to handle complex Java objects. |
Hibernate slightly extends this list with the following types:
| Classification | Package | Types |
|---|---|---|
Additional date/time types |
|
|
JDBC LOB types |
|
|
Java class object |
|
|
Miscellaneous types |
|
|
The @Basic annotation explicitly specifies that an attribute is basic, but it’s often not needed, since attributes are assumed basic by default.
On the other hand, if a non-primitively-typed attribute cannot be null, use of @Basic(optional=false) is highly recommended.
@Basic(optional=false) String firstName;
@Basic(optional=false) String lastName;
String middleName; // may be nullNote that primitively-typed attributes are inferred NOT NULL by default.
3.11. Enumerated types
We included Java enums on the list above.
An enumerated type is considered a sort of basic type, but since most databases don’t have a native ENUM type, JPA provides a special @Enumerated annotation to specify how the enumerated values should be represented in the database:
-
by default, an enum is stored as an integer, the value of its
ordinal()member, but -
if the attribute is annotated
@Enumerated(STRING), it will be stored as a string, the value of itsname()member.
//here, an ORDINAL encoding makes sense
@Enumerated
@Basic(optional=false)
DayOfWeek dayOfWeek;
//but usually, a STRING encoding is better
@Enumerated(EnumType.STRING)
@Basic(optional=false)
Status status;In Hibernate 6, an enum annotated @Enumerated(STRING) is mapped to:
-
a
VARCHARcolumn type with aCHECKconstraint on most databases, or -
an
ENUMcolumn type on MySQL.
Any other enum is mapped to a TINYINT column with a CHECK constraint.
|
JPA picks the wrong default here.
In most cases, storing an integer encoding of the Even considering So we prefer |
An interesting special case is PostgreSQL.
Postgres supports named ENUM types, which must be declared using a DDL CREATE TYPE statement.
Sadly, these ENUM types aren’t well-integrated with the language nor well-supported by the Postgres JDBC driver, so Hibernate doesn’t use them by default.
But if you would like to use a named enumerated type on Postgres, just annotate your enum attribute like this:
@JdbcTypeCode(SqlTypes.NAMED_ENUM)
@Basic(optional=false)
Status status;The limited set of pre-defined basic attribute types can be stretched a bit further by supplying a converter.
3.12. Converters
A JPA AttributeConverter is responsible for:
-
converting a given Java type to one of the types listed above, and/or
-
perform any other sort of pre- and post-processing you might need to perform on a basic attribute value before writing and reading it to or from the database.
Converters substantially widen the set of attribute types that can be handled by JPA.
There are two ways to apply a converter:
-
the
@Convertannotation applies anAttributeConverterto a particular entity attribute, or -
the
@Converterannotation (or, alternatively, the@ConverterRegistrationannotation) registers anAttributeConverterfor automatic application to all attributes of a given type.
For example, the following converter will be automatically applied to any attribute of type BitSet, and takes care of persisting the BitSet to a column of type varbinary:
@Converter(autoApply = true)
public static class EnumSetConverter implements AttributeConverter<EnumSet<DayOfWeek>,Integer> {
@Override
public Integer convertToDatabaseColumn(EnumSet<DayOfWeek> enumSet) {
int encoded = 0;
var values = DayOfWeek.values();
for (int i = 0; i<values.length; i++) {
if (enumSet.contains(values[i])) {
encoded |= 1<<i;
}
}
return encoded;
}
@Override
public EnumSet<DayOfWeek> convertToEntityAttribute(Integer encoded) {
var set = EnumSet.noneOf(DayOfWeek.class);
var values = DayOfWeek.values();
for (int i = 0; i<values.length; i++) {
if (((1<<i) & encoded) != 0) {
set.add(values[i]);
}
}
return set;
}
}On the other hand, if we don’t set autoapply=true, then we must explicitly apply the converter using the @Convert annotation:
@Convert(converter = BitSetConverter.class)
@Basic(optional = false)
BitSet bitset;All this is nice, but it probably won’t surprise you that Hibernate goes beyond what is required by JPA.
3.13. Compositional basic types
Hibernate considers a "basic type" to be formed by the marriage of two objects:
-
a
JavaType, which models the semantics of a certain Java class, and -
a
JdbcType, representing a SQL type which is understood by JDBC.
When mapping a basic attribute, we may explicitly specify a JavaType, a JdbcType, or both.
JavaType
An instance of org.hibernate.type.descriptor.java.JavaType represents a particular Java class.
It’s able to:
-
compare instances of the class to determine if an attribute of that class type is dirty (modified),
-
produce a useful hash code for an instance of the class,
-
coerce values to other types, and, in particular,
-
convert an instance of the class to one of several other equivalent Java representations at the request of its partner
JdbcType.
For example, IntegerJavaType knows how to convert an Integer or int value to the types Long, BigInteger, and String, among others.
We may explicitly specify a Java type using the @JavaType annotation, but for the built-in JavaTypes this is never necessary.
@JavaType(LongJavaType.class) // not needed, this is the default JavaType for long
long currentTimeMillis;For a user-written JavaType, the annotation is more useful:
@JavaType(BitSetJavaType.class)
BitSet bitSet;Alternatively, the @JavaTypeRegistration annotation may be used to register BitSetJavaType as the default JavaType for BitSet.
JdbcType
A org.hibernate.type.descriptor.jdbc.JdbcType is able to read and write a single Java type from and to JDBC.
For example, VarcharJdbcType takes care of:
-
writing Java strings to JDBC
PreparedStatements by callingsetString(), and -
reading Java strings from JDBC
ResultSets usinggetString().
By pairing LongJavaType with VarcharJdbcType in holy matrimony, we produce a basic type which maps Longs and primitive longss to the SQL type VARCHAR.
We may explicitly specify a JDBC type using the @JdbcType annotation.
@JdbcType(VarcharJdbcType.class)
long currentTimeMillis;Alternatively, we may specify a JDBC type code:
@JdbcTypeCode(Types.VARCHAR)
long currentTimeMillis;The @JdbcTypeRegistration annotation may be used to register a user-written JdbcType as the default for a given SQL type code.
AttributeConverter
If a given JavaType doesn’t know how to convert its instances to the type required by its partner JdbcType, we must help it out by providing a JPA AttributeConverter to perform the conversion.
For example, to form a basic type using LongJavaType and TimestampJdbcType, we would provide an AttributeConverter<Long,Timestamp>.
@JdbcType(TimestampJdbcType.class)
@Convert(converter = LongToTimestampConverter.class)
long currentTimeMillis;Let’s abandon our analogy right here, before we start calling this basic type a "throuple".
3.14. Embeddable objects
An embeddable object is a Java class whose state maps to multiple columns of a table, but which doesn’t have its own persistent identity.
That is, it’s a class with mapped attributes, but no @Id attribute.
An embeddable object can only be made persistent by assigning it to the attribute of an entity. Since the embeddable object does not have its own persistent identity, its lifecycle with respect to persistence is completely determined by the lifecycle of the entity to which it belongs.
An embeddable class must be annotated @Embeddable instead of @Entity.
@Embeddable
class Name {
@Basic(optional=false)
String firstName;
@Basic(optional=false)
String lastName;
String middleName;
Name() {}
Name(String firstName, String middleName, String lastName) {
this.firstName = firstName;
this.middleName = middleName;
this.lastName = lastName;
}
...
}An embeddable class must satisfy the same requirements that entity classes satisfy, with the exception that an embeddable class has no @Id attribute.
In particular, it must have a constructor with no parameters.
Alternatively, an embeddable type may be defined as a Java record type:
@Embeddable
record Name(String firstName, String middleName, String lastName) {}In this case, the requirement for a constructor with no parameters is relaxed.
|
Unfortunately, as of May 2023, Java |
We may now use our Name class (or record) as the type of an entity attribute:
@Entity
class Author {
@Id @GeneratedValue
Long id;
Name name;
...
}Embeddable types can be nested.
That is, an @Embeddable class may have an attribute whose type is itself a different @Embeddable class.
|
JPA provides an |
On the other hand a reference to an embeddable type is never polymorphic.
One @Embeddable class F may inherit a second @Embeddable class E, but an attribute of type E will always refer to an instance of that concrete class E, never to an instance of F.
Usually, embeddable types are stored in a "flattened" format. Their attributes map columns of the table of their parent entity. Later, in Mapping embeddable types to UDTs or to JSON, we’ll see a couple of different options.
An attribute of embeddable type represents a relationship between a Java object with a persistent identity, and a Java object with no persistent identity. We can think of it as a whole/part relationship. The embeddable object belongs to the entity, and can’t be shared with other entity instances. And it exits for only as long as its parent entity exists.
Next we’ll discuss a different kind of relationship: a relationship between Java objects which each have their own distinct persistent identity and persistence lifecycle.
3.15. Associations
An association is a relationship between entities.
We usually classify associations based on their multiplicity.
If E and F are both entity classes, then:
-
a one-to-one association relates at most one unique instance
Ewith at most one unique instance ofF, -
a many-to-one association relates zero or more instances of
Ewith a unique instance ofF, and -
a many-to-many association relates zero or more instances of
Ewith zero or more instance ofF.
An association between entity classes may be either:
-
unidirectional, navigable from
EtoFbut not fromFtoE, or -
bidirectional, and navigable in either direction.
In this example data model, we can see the sorts of associations which are possible:
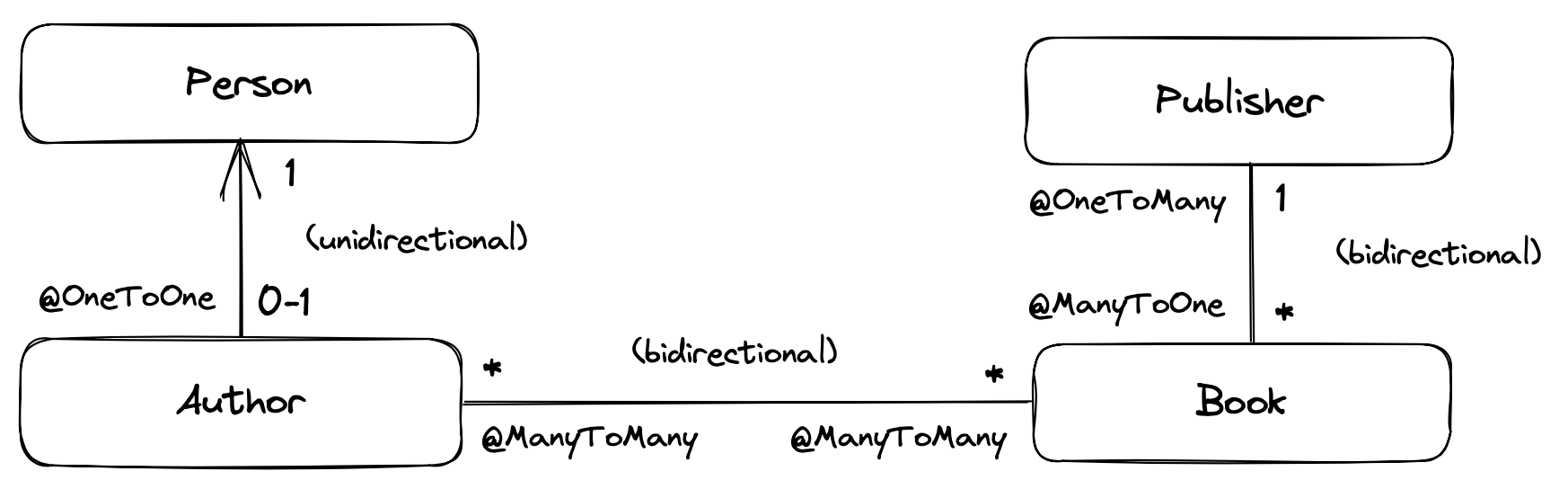
|
An astute observer of the diagram above might notice that the relationship we’ve presented as a unidirectional one-to-one association could reasonably be represented in Java using subtyping.
This is quite normal.
A one-to-one association is the usual way we implement subtyping in a fully-normalized relational model.
It’s related to the |
There are three annotations for mapping associations: @ManyToOne, @OneToMany, and @ManyToMany.
They share some common annotation members:
| Member | Interpretation | Default value |
|---|---|---|
|
Persistence operations which should cascade to the associated entity; a list of |
|
|
Whether the association is eagerly fetched or may be proxied |
|
|
The associated entity class |
Determined from the attribute type declaration |
|
For a |
|
|
For a bidirectional association, an attribute of the associated entity which maps the association |
By default, the association is assumed unidirectional |
We’ll explain the effect of these members as we consider the various types of association mapping.
Let’s begin with the most common association multiplicity.
3.16. Many-to-one
A many-to-one association is the most basic sort of association we can imagine. It maps completely naturally to a foreign key in the database. Almost all the associations in your domain model are going to be of this form.
|
Later, we’ll see how to map a many-to-one association to an association table. |
The @ManyToOne annotation marks the "to one" side of the association, so a unidirectional many-to-one association looks like this:
class Book {
@Id @GeneratedValue
Long id;
@ManyToOne(fetch=LAZY)
Publisher publisher;
...
}Here, the Book table has a foreign key column holding the identifier of the associated Publisher.
|
A very unfortunate misfeature of JPA is that |
Most of the time, we would like to be able to easily navigate our associations in both directions.
We do need a way to get the Publisher of a given Book, but we would also like to be able to obtain all the Books belonging to a given publisher.
To make this association bidirectional, we need to add a collection-valued attribute to the Publisher class, and annotate it @OneToMany.
|
Hibernate needs to proxy unfetched associations at runtime.
Therefore, the many-valued side must be declared using an interface type like |
To indicate clearly that this is a bidirectional association, and to reuse any mapping information already specified in the Book entity, we must use the mappedBy annotation member to refer back to Book.publisher.
@Entity
class Publisher {
@Id @GeneratedValue
Long id;
@OneToMany(mappedBy="publisher")
Set<Book> books;
...
}The Publisher.books field is called the unowned side of the association.
Now, we passionately hate the stringly-typed mappedBy reference to the owning side of the association.
Thankfully, the Metamodel Generator gives us a way to make it a
bit more typesafe:
@OneToMany(mappedBy=Book_.PUBLISHER) // get used to doing it this way!
Set<Book> books;We’re going to use this approach for the rest of the Introduction.
To modify a bidirectional association, we must change the owning side.
|
Changes made to the unowned side of an association are never synchronized to the database.
If we desire to change an association in the database, we must change it from the owning side.
Here, we must set In fact, it’s often necessary to change both sides of a bidirectional association.
For example, if the collection |
That said, it’s not a hard requirement to update the unowned side, at least if you’re sure you know what you’re doing.
|
In principle Hibernate does allow you to have a unidirectional one-to-many, that is, a |
Here we’ve used Set as the type of the collection, but Hibernate also allows the use of List or Collection here, with almost no difference in semantics.
In particular, the List may not contain duplicate elements, and its order will not be persistent.
@OneToMany(mappedBy=Book_.PUBLISHER)
Collection<Book> books;We’ll see how to map a collection with a persistent order much later.
3.17. One-to-one (first way)
The simplest sort of one-to-one association is almost exactly like a @ManyToOne association, except that it maps to a foreign key column with a UNIQUE constraint.
|
Later, we’ll see how to map a one-to-one association to an association table. |
A one-to-one association must be annotated @OneToOne:
@Entity
class Author {
@Id @GeneratedValue
Long id;
@OneToOne(optional=false, fetch=LAZY)
Person author;
...
}Here, the Author table has a foreign key column holding the identifier of the associated Publisher.
|
A one-to-one association often models a "type of" relationship.
In our example, an |
We can make this association bidirectional by adding a reference back to the Author in the Person entity:
@Entity
class Person {
@Id @GeneratedValue
Long id;
@OneToOne(mappedBy = Author_.PERSON)
Author author;
...
}Person.author is the unowned side, because it’s the side marked mappedBy.
This is not the only sort of one-to-one association.
3.18. One-to-one (second way)
An arguably more elegant way to represent such a relationship is to share a primary key between the two tables.
To use this approach, the Author class must be annotated like this:
@Entity
class Author {
@Id
Long id;
@OneToOne(optional=false, fetch=LAZY)
@MapsId
Person author;
...
}Notice that, compared with the previous mapping:
-
the
@Idattribute is no longer a@GeneratedValueand, -
instead, the
authorassociation is annotated@MapsId.
This lets Hibernate know that the association to Person is the source of primary key values for Author.
Here, there’s no extra foreign key column in the Author table, since the id column holds the identifier of Person.
That is, the primary key of the Author table does double duty as the foreign key referring to the Person table.
The Person class doesn’t change.
If the association is bidirectional, we annotate the unowned side @OneToOne(mappedBy = Author_.PERSON) just as before.
3.19. Many-to-many
A unidirectional many-to-many association is represented as a collection-valued attribute. It always maps to a separate association table in the database.
It tends to happen that a many-to-many association eventually turns out to be an entity in disguise.
|
Suppose we start with a nice clean many-to-many association between For example, imagine that we needed to report the percentage contribution of each author to a book.
That information naturally belongs to the association table.
We can’t easily store it as an attribute of When this happens, we need to change our Java model, usually introducing a new entity class which maps the association table directly.
In our example, we might call this entity something like We can evade the disruption occasioned by such "discoveries" by simply avoiding the use of |
A many-to-many association must be annotated @ManyToMany:
@Entity
class Book {
@Id @GeneratedValue
Long id;
@ManyToMany
Set<Author> authors;
...
}If the association is bidirectional, we add a very similar-looking attribute to Book, but this time we must specify mappedBy to indicate that this is the unowned side of the association:
@Entity
class Book {
@Id @GeneratedValue
Long id;
@ManyToMany(mappedBy=Author_.BOOKS)
Set<Author> authors;
...
}Remember, if we wish to the modify the collection we must change the owning side.
We’ve again used Sets to represent the association.
As before, we have the option to use Collection or List.
But in this case it does make a difference to the semantics of the association.
|
A many-to-many association represented as a |
3.20. Collections of basic values and embeddable objects
We’ve now seen the following kinds of entity attribute:
| Kind of entity attribute | Kind of reference | Multiplicity | Examples |
|---|---|---|---|
Single-valued attribute of basic type |
Non-entity |
At most one |
|
Single-valued attribute of embeddable type |
Non-entity |
At most one |
|
Single-valued association |
Entity |
At most one |
|
Many-valued association |
Entity |
Zero or more |
|
Scanning this taxonomy, you might ask: does Hibernate have multivalued attributes of basic or embeddable type?
Well, actually, we’ve already seen that it does, at least in two special cases.
So first, lets recall that JPA treats byte[] and char[] arrays as basic types.
Hibernate persists a byte[] or char[] array to a VARBINARY or VARCHAR column, respectively.
But in this section we’re really concerned with cases other than these two special cases.
So then, apart from byte[] and char[], does Hibernate have multivalued attributes of basic or embeddable type?
And the answer again is that it does. Indeed, there are two different ways to handle such a collection, by mapping it:
-
to a column of SQL
ARRAYtype (assuming the database has anARRAYtype), or -
to a separate table.
So we may expand our taxonomy with:
| Kind of entity attribute | Kind of reference | Multiplicity | Examples |
|---|---|---|---|
|
Non-entity |
Zero or more |
|
Collection of basic-typed elements |
Non-entity |
Zero or more |
|
Collection of embeddable elements |
Non-entity |
Zero or more |
|
There’s actually two new kinds of mapping here: @Array mappings, and @ElementCollection mappings.
|
These sorts of mappings are overused. There are situations where we think it’s appropriate to use a collection of basic-typed values in our entity class. But such situations are rare. Almost every many-valued relationship should map to a foreign key association between separate tables. And almost every table should be mapped by an entity class. The features we’re about to meet in the next two subsections are used much more often by beginners than they’re used by experts. So if you’re a beginner, you’ll save yourself same hassle by staying away from these features for now. |
We’ll talk about @Array mappings first.
3.21. Collections mapped to SQL arrays
Let’s consider a calendar event which repeats on certain days of the week.
We might represent this in our Event entity as an attribute of type DayOfWeek[] or List<DayOfWeek>.
Since the number of elements of this array or list is upper bounded by 7, this is a reasonable case for the use of an ARRAY-typed column.
It’s hard to see much value in storing this collection in a separate table.
Unfortunately, JPA doesn’t define a standard way to map SQL arrays, but here’s how we can do it in Hibernate:
@Entity
class Event {
@Id @GeneratedValue
Long id;
...
@Array(length=7)
DayOfWeek[] daysOfWeek; // stored as a SQL ARRAY type
...
}The @Array annotation is optional, but it’s important to limit the amount of storage space the database allocates to the ARRAY column.
|
Now for the gotcha: not every database has a SQL In particular, neither DB2 nor SQL Server have array-typed columns.
On these databases, Hibernate falls back to something much worse: it uses Java serialization to encode the array to a binary representation, and stores the binary stream in a |
Alternatively, we could store this array or list in a separate table.
3.22. Collections mapped to a separate table
JPA does define a standard way to map a collection to an auxiliary table: the @ElementCollection annotation.
@Entity
class Event {
@Id @GeneratedValue
Long id;
...
@ElementCollection
DayOfWeek[] daysOfWeek; // stored in a dedicated table
...
}Actually, we shouldn’t use an array here, since array types can’t be proxied, and so the JPA specification doesn’t even say they’re supported.
Instead, we should use Set, List, or Map.
@Entity
class Event {
@Id @GeneratedValue
Long id;
...
@ElementCollection
List<DayOfWeek> daysOfWeek; // stored in a dedicated table
...
}Here, each collection element is stored as a separate row of the auxiliary table. By default, this table has the following definition:
create table Event_daysOfWeek (
Event_id bigint not null,
daysOfWeek tinyint check (daysOfWeek between 0 and 6),
daysOfWeek_ORDER integer not null,
primary key (Event_id, daysOfWeek_ORDER)
)Which is fine, but it’s still a mapping we prefer to avoid.
|
The code above results in a table with three columns:
Instead of a surrogate primary key, it has a composite key comprising the foreign key of When—inevitably—we find that we need to add a fourth column to that table, our Java code must change completely. Most likely, we’ll realize that we need to add a separate entity after all. So this mapping isn’t very robust in the face of minor changes to our data model. |
There’s much more we could say about "element collections", but we won’t say it, because we don’t want to hand you the gun you’ll shoot your foot with.
3.23. Summary of annotations
Let’s pause to remember the annotations we’ve met so far.
| Annotation | Purpose | JPA-standard |
|---|---|---|
|
Declare an entity class |
✔ |
|
Declare a non-entity class with mapped attributes inherited by an entity |
✔ |
|
Declare an embeddable type |
✔ |
|
Declare the identifier class for an entity with multiple |
✔ |
| Annotation | Purpose | JPA-standard | |
|---|---|---|---|
|
Declare a basic-typed identifier attribute |
✔ |
|
|
Declare a version attribute |
✔ |
|
|
Declare a basic attribute |
Default |
✔ |
|
Declare an embeddable-typed identifier attribute |
✔ |
|
|
Declare an embeddable-typed attribute |
Inferred |
✔ |
|
Declare an |
Inferred |
✔ |
|
Declare that an attribute maps to a SQL |
Inferred |
✖ |
|
Declare that a collection is mapped to a dedicated table |
✔ |
| Annotation | Purpose | JPA-standard |
|---|---|---|
|
Register an |
✔ |
|
Apply a converter to an attribute |
✔ |
|
Explicitly specify an implementation of |
✖ |
|
Explicitly specify an implementation of |
✖ |
|
Explicitly specify a JDBC type code used to determine the |
✖ |
|
Register a |
✖ |
|
Register a |
✖ |
| Annotation | Purpose | JPA-standard |
|---|---|---|
|
Specify that an identifier is system-generated |
✔ |
|
Define an id generated backed by on a database sequence |
✔ |
|
Define an id generated backed by a database table |
✔ |
|
Declare an annotation that associates a custom |
✖ |
|
Declare an annotation that associates a custom |
✖ |
| Annotation | Purpose | JPA-standard |
|---|---|---|
|
Declare the single-valued side of a many-to-one association (the owning side) |
✔ |
|
Declare the many-valued side of a many-to-one association (the unowned side) |
✔ |
|
Declare either side of a one-to-one association |
✔ |
|
Declare either side of a one-to-one association |
✔ |
|
Declare that the owning side of a |
✔ |
Phew! That’s already a lot of annotations, and we have not even started with the annotations for O/R mapping!
3.24. equals() and hashCode()
Entity classes should override equals() and hashCode(), especially when associations are represented as sets.
People new to Hibernate or JPA are often confused by exactly which fields should be included in the hashCode().
And people with more experience often argue quite religiously that one or another approach is the only right way.
The truth is, there’s no unique right way to do it, but there are some constraints.
So please keep the following principles in mind:
-
You should not include a mutable field in the hashcode, since that would require rehashing every collection containing the entity whenever the field is mutated.
-
It’s not completely wrong to include a generated identifier (surrogate key) in the hashcode, but since the identifier is not generated until the entity instance is made persistent, you must take great care to not add it to any hashed collection before the identifier is generated. We therefore advise against including any database-generated field in the hashcode.
It’s OK to include any immutable, non-generated field in the hashcode.
We therefore recommend identifying a natural key for each entity, that is, a combination of fields that uniquely identifies an instance of the entity, from the perspective of the data model of the program. The natural key should correspond to a unique constraint on the database, and to the fields which are included in equals() and hashCode().
|
In this example, the equals() and hashCode() methods agree with the @NaturalId annotation:
@Entity
class Book {
@Id @GeneratedValue
Long id;
@NaturalId
@Basic(optional=false)
String isbn;
...
@Override
public boolean equals(Object other) {
return other instanceof Book
&& ((Book) other).isbn.equals(isbn);
}
@Override
public int hashCode() {
return isbn.hashCode();
}
}That said, an implementation of equals() and hashCode() based on the generated identifier of the entity can work if you’re careful.
4. Object/relational mapping
Given a domain model—that is, a collection of entity classes decorated with all the fancy annotations we just met in the previous chapter—Hibernate will happily go away and infer a complete relational schema, and even export it to your database if you ask politely.
The resulting schema will be entirely sane and reasonable, though if you look closely, you’ll find some flaws.
For example, every VARCHAR column will have the same length, VARCHAR(255).
But the process I just described—which we call top down mapping—simply doesn’t fit the most common scenario for the use of O/R mapping. It’s only rarely that the Java classes precede the relational schema. Usually, we already have a relational schema, and we’re constructing our domain model around the schema. This is called bottom up mapping.
|
Developers often refer to a pre-existing relational database as "legacy" data. This tends to conjure images of bad old "legacy apps" written in COBOL or something. But legacy data is valuable, and learning to work with it is important. |
Especially when mapping bottom up, we often need to customize the inferred object/relational mappings. This is a somewhat tedious topic, and so we don’t want to spend too many words on it. Instead, we’ll quickly skim the most important mapping annotations.
4.1. Mapping entity inheritance hierarchies
In Entity class inheritance we saw that entity classes may exist within an inheritance hierarchy. There’s three basic strategies for mapping an entity hierarchy to relational tables. Let’s put them in a table, so we can more easily compare the points of difference between them.
| Strategy | Mapping | Polymorphic queries | Constraints | Normalization | When to use it |
|---|---|---|---|---|---|
|
Map every class in the hierarchy to the same table, and uses the value of a discriminator column to determine which concrete class each row represents. |
To retrieve instances of a given class, we only need to query the one table. |
Attributes declared by subclasses map to columns without Any association may have a |
Subclass data is denormalized. 🧐 |
Works well when subclasses declare few or no additional attributes. |
|
Map every class in the hierarchy to a separate table, but each table only maps the attributes declared by the class itself. Optionally, a discriminator column may be used. |
To retrieve instances of a given class, we must
|
Any attribute may map to a column with a Any association may have a |
The tables are normalized. 🤓 |
The best option when we care a lot about constraints and normalization. |
|
Map every concrete class in the hierarchy to a separate table, but denormalize all inherited attributes into the table. |
To retrieve instances of a given class, we must take a |
Associations targeting a superclass cannot have a corresponding Any attribute may map to a column with a |
Superclass data is denormalized. 🧐 |
Not very popular. From a certain point of view, competes with |
The three mapping strategies are enumerated by InheritanceType.
We specify an inheritance mapping strategy using the @Inheritance annotation.
For mappings with a discriminator column, we should:
-
specify the discriminator column name and type by annotating the root entity
@DiscriminatorColumn, and -
specify the values of this discriminator by annotating each entity in the hierarchy
@DiscriminatorValue.
For single table inheritance we always need a discriminator:
@Entity
@DiscriminatorColumn(discriminatorType=CHAR, name="kind")
@DiscriminatorValue('P')
class Person { ... }
@Entity
@DiscriminatorValue('A')
class Author { ... }We don’t need to explicitly specify @Inheritance(strategy=SINGLE_TABLE), since that’s the default.
For JOINED inheritance we don’t need a discriminator:
@Entity
@Inheritance(strategy=JOINED)
class Person { ... }
@Entity
class Author { ... }|
However, we can add a discriminator column if we like, and in that case the generated SQL for polymorphic queries will be slightly simpler. |
Similarly, for TABLE_PER_CLASS inheritance we have:
@Entity
@Inheritance(strategy=TABLE_PER_CLASS)
class Person { ... }
@Entity
class Author { ... }|
Hibernate doesn’t allow discriminator columns for |
Notice that in this last case, a polymorphic association like:
@ManyToOne Person person;is a bad idea, since it’s impossible to create a foreign key constraint that targets both mapped tables.
4.2. Mapping to tables
The following annotations specify exactly how elements of the domain model map to tables of the relational model:
| Annotation | Purpose |
|---|---|
|
Map an entity class to its primary table |
|
Define a secondary table for an entity class |
|
Map a many-to-many or many-to-one association to its association table |
|
Map an |
The first two annotations are used to map an entity to its primary table and, optionally, one or more secondary tables.
4.3. Mapping entities to tables
By default, an entity maps to a single table, which may be specified using @Table:
@Entity
@Table(name="People")
class Person { ... }However, the @SecondaryTable annotation allows us to spread its attributes across multiple secondary tables.
@Entity
@Table(name="Books")
@SecondaryTable(name="Editions")
class Book { ... }The @Table annotation can do more than just specify a name:
| Annotation member | Purpose |
|---|---|
|
The name of the mapped table |
|
The schema to which the table belongs |
|
The catalog to which the table belongs |
|
One or more |
|
One or more |
|
It only makes sense to explicitly specify the Otherwise, it’s a bad idea to hardcode the schema (or catalog) in a
|
The @SecondaryTable annotation is even more interesting:
| Annotation member | Purpose |
|---|---|
|
The name of the mapped table |
|
The schema to which the table belongs |
|
The catalog to which the table belongs |
|
One or more |
|
One or more |
|
One or more |
|
An |
|
Using |
4.4. Mapping associations to tables
The @JoinTable annotation specifies an association table, that is, a table holding foreign keys of both associated entities.
This annotation is usually used with @ManyToMany associations:
@Entity
class Book {
...
@ManyToMany
@JoinTable(name="BooksAuthors")
Set<Author> authors;
...
}But it’s even possible to use it to map a @ManyToOne or @OneToOne association to an association table.
@Entity
class Book {
...
@ManyToOne(fetch=LAZY)
@JoinTable(name="BookPublisher")
Publisher publisher;
...
}Here, there should be a UNIQUE constraint on one of the columns of the association table.
@Entity
class Author {
...
@OneToOne(optional=false, fetch=LAZY)
@JoinTable(name="AuthorPerson")
Person author;
...
}Here, there should be a UNIQUE constraint on both columns of the association table.
| Annotation member | Purpose |
|---|---|
|
The name of the mapped association table |
|
The schema to which the table belongs |
|
The catalog to which the table belongs |
|
One or more |
|
One or more |
|
One or more |
|
One or more |
|
An |
|
An |
To better understand these annotations, we must first discuss column mappings in general.
4.5. Mapping to columns
These annotations specify how elements of the domain model map to columns of tables in the relational model:
| Annotation | Purpose |
|---|---|
|
Map an attribute to a column |
|
Map an association to a foreign key column |
|
Map the primary key used to join a secondary table with its primary, or a subclass table in |
|
Specifies a column that should be used to maintain the order of a |
|
Specified a column that should be used to persist the keys of a |
We use the @Column annotation to map basic attributes.
4.6. Mapping basic attributes to columns
The @Column annotation is not only useful for specifying the column name.
| Annotation member | Purpose |
|---|---|
|
The name of the mapped column |
|
The name of the table to which this column belongs |
|
The length of a |
|
The decimal digits of precision of a |
|
The scale of a |
|
Whether the column has a |
|
Whether the column has a |
|
Whether the column should appear in generated SQL |
|
Whether the column should appear in generated SQL |
|
A DDL fragment that should be used to declare the column |
|
We no longer recommend the use of |
Here we see four different ways to use the @Column annotation:
@Entity
@Table(name="Books")
@SecondaryTable(name="Editions")
class Book {
@Id @GeneratedValue
@Column(name="bookId") // customize column name
Long id;
@Column(length=100, nullable=false) // declare column as VARCHAR(100) NOT NULL
String title;
@Column(length=17, unique=true, nullable=false) // declare column as VARCHAR(17) NOT NULL UNIQUE
String isbn;
@Column(table="Editions", updatable=false) // column belongs to the secondary table, and is never updated
int edition;
}We don’t use @Column to map associations.
4.7. Mapping associations to foreign key columns
The @JoinColumn annotation is used to customize a foreign key column.
| Annotation member | Purpose |
|---|---|
|
The name of the mapped foreign key column |
|
The name of the table to which this column belongs |
|
The name of the column to which the mapped foreign key column refers |
|
Whether the column has a |
|
Whether the column has a |
|
Whether the column should appear in generated SQL |
|
Whether the column should appear in generated SQL |
|
A DDL fragment that should be used to declare the column |
|
A |
A foreign key column doesn’t necessarily have to refer to the primary key of the referenced table. It’s quite acceptable for the foreign key to refer to any other unique key of the referenced entity, even to a unique key of a secondary table.
Here we see how to use @JoinColumn to define a @ManyToOne association mapping a foreign key column which refers to the @NaturalId of Book:
@Entity
@Table(name="Items")
class Item {
...
@ManyToOne(optional=false) // implies nullable=false
@JoinColumn(name = "bookIsbn", referencedColumnName = "isbn", // a reference to a non-PK column
foreignKey = @ForeignKey(name="ItemsToBooksBySsn")) // supply a name for the FK constraint
Book book;
...
}In case this is confusing:
-
bookIsbnis the name of the foreign key column in theItemstable, -
it refers to a unique key
isbnin theBookstable, and -
it has a foreign key constraint named
ItemsToBooksBySsn.
Note that the foreignKey member is completely optional and only affects DDL generation.
|
If you don’t supply an explicit name using |
For composite foreign keys we might have multiple @JoinColumn annotations:
@Entity
@Table(name="Items")
class Item {
...
@ManyToOne(optional=false)
@JoinColumn(name = "bookIsbn", referencedColumnName = "isbn")
@JoinColumn(name = "bookPrinting", referencedColumnName = "printing")
Book book;
...
}If we need to specify the @ForeignKey, this starts to get a bit messy:
@Entity
@Table(name="Items")
class Item {
...
@ManyToOne(optional=false)
@JoinColumns(value = {@JoinColumn(name = "bookIsbn", referencedColumnName = "isbn"),
@JoinColumn(name = "bookPrinting", referencedColumnName = "printing")},
foreignKey = @ForeignKey(name="ItemsToBooksBySsn"))
Book book;
...
}For associations mapped to a @JoinTable, fetching the association requires two joins, and so we must declare the @JoinColumns inside the @JoinTable annotation:
@Entity
class Book {
@Id @GeneratedValue
Long id;
@ManyToMany
@JoinTable(joinColumns=@JoinColumn(name="bookId"),
inverseJoinColumns=@joinColumn(name="authorId"),
foreignKey=@ForeignKey(name="BooksToAuthors"))
Set<Author> authors;
...
}Again, the foreignKey member is optional.
4.8. Mapping primary key joins between tables
The @PrimaryKeyJoinColumn is a special-purpose annotation for mapping:
-
the primary key column of a
@SecondaryTable—which is also a foreign key referencing the primary table, or -
the primary key column of the primary table mapped by a subclass in a
JOINEDinheritance hierarchy—which is also a foreign key referencing the primary table mapped by the root entity.
| Annotation member | Purpose |
|---|---|
|
The name of the mapped foreign key column |
|
The name of the column to which the mapped foreign key column refers |
|
A DDL fragment that should be used to declare the column |
|
A |
When mapping a subclass table primary key, we place the @PrimaryKeyJoinColumn annotation on the entity class:
@Entity
@Table(name="People")
@Inheritance(strategy=JOINED)
class Person { ... }
@Entity
@Table(name="Authors")
@PrimaryKeyJoinColumn(name="personId") // the primary key of the Authors table
class Author { ... }But to map a secondary table primary key, the @PrimaryKeyJoinColumn annotation must occur inside the @SecondaryTable annotation:
@Entity
@Table(name="Books")
@SecondaryTable(name="Editions",
pkJoinColumns = @PrimaryKeyJoinColumn(name="bookId")) // the primary key of the Editions table
class Book {
@Id @GeneratedValue
@Column(name="bookId") // the name of the primary key of the Books table
Long id;
...
}4.9. Column lengths and adaptive column types
Hibernate automatically adjusts the column type used in generated DDL based on the column length specified by the @Column annotation.
So we don’t usually need to explicitly specify that a column should be of type TEXT or CLOB—or worry about the parade of TINYTEXT, MEDIUMTEXT, TEXT, LONGTEXT types on MySQL—because Hibernate will automatically select one of those types if required to accommodate a string of the length we specify.
The constant values defined in the class Length are very helpful here:
| Constant | Value | Description |
|---|---|---|
|
255 |
The default length of a |
|
32600 |
The largest column length for a |
|
32767 |
The maximum length that can be represented using 16 bits (but this length is too large for a |
|
2147483647 |
The maximum length for a Java string |
We can use these constants in the @Column annotation:
@Column(length=LONG)
String text;
@Column(length=LONG32)
byte[] binaryData;This is usually all you need to do to make use of large object types in Hibernate.
4.10. LOBs
JPA provides a @Lob annotation which specifies that a field should be persisted as a BLOB or CLOB.
Hibernate interprets this annotation in what we think is the most reasonable way.
In Hibernate, an attribute annotated @Lob will be written to JDBC using the setClob() or setBlob() method of PreparedStatement, and will be read from JDBC using the getClob() or getBlob() method of ResultSet.
Now, the use of these JDBC methods is usually unnecessary!
JDBC drivers are perfectly capable of converting between String and CLOB or between byte[] and BLOB.
So unless you specifically need to use these JDBC LOB APIs, you don’t need the @Lob annotation.
Instead, as we just saw in Column lengths and adaptive column types, all you need is to specify a large enough column length to accommodate the data you plan to write to that column.
|
Unfortunately, the driver for PostgreSQL doesn’t allow This limitation of the Postgres driver has resulted in a whole cottage industry of bloggers and stackoverflow question-answerers recommending convoluted ways to hack the Hibernate But simply removing the Conclusion:
|
Finally, as an alternative, Hibernate lets you declare an attribute of type java.sql.Blob or java.sql.Clob.
@Entity
class Book {
...
Clob text;
Blob coverArt;
....
}The advantage is that a java.sql.Clob or java.sql.Blob can in principle index up to 263 characters or bytes, much more data than you can fit in a Java String or byte[] array (or in your computer).
To assign a value to these fields, we’ll need to use a LobHelper.
We can get one from the Session:
LobHelper helper = session.getLobHelper();
book.text = helper.createClob(text);
book.coverArt = helper.createBlob(image);In principle, the Blob and Clob objects provide efficient ways to read or stream LOB data from the server.
Book book = session.find(Book.class, bookId);
String text = book.text.getSubString(1, textLength);
InputStream bytes = book.images.getBinaryStream();Of course, the behavior here depends very much on the JDBC driver, and so we really can’t promise that this is a sensible thing to do on your database.
4.11. Mapping embeddable types to UDTs or to JSON
There’s a couple of alternative ways to represent an embeddable type on the database side.
Embeddables as UDTs
First, a really nice option, at least in the case of Java record types, and for databases which support user-defined types (UDTs), is to define a UDT which represents the record type.
Hibernate 6 makes this really easy.
Just annotate the record type, or the attribute which holds a reference to it, with the new @Struct annotation:
@Embeddable
@Struct(name="PersonName")
record Name(String firstName, String middleName, String lastName) {}@Entity
class Person {
...
Name name;
...
}This results in the following UDT:
create type PersonName as (firstName varchar(255), middleName varchar(255), lastName varchar(255))And the name column of the Author table will have the type PersonName.
Embeddables to JSON
A second option that’s available is to map the embeddable type to a JSON (or JSONB) column.
Now, this isn’t something we would exactly recommend if you’re defining a data model from scratch, but it’s at least useful for mapping pre-existing tables with JSON-typed columns.
Since embeddable types are nestable, we can map some JSON formats this way, and even query JSON properties using HQL.
|
At this time, JSON arrays are not supported! |
To map an attribute of embeddable type to JSON, we must annotate the attribute @JdbcTypeCode(SqlTypes.JSON), instead of annotating the embeddable type.
But the embeddable type Name should still be annotated @Embeddable if we want to query its attributes using HQL.
@Embeddable
record Name(String firstName, String middleName, String lastName) {}@Entity
class Person {
...
@JdbcTypeCode(SqlTypes.JSON)
Name name;
...
}We also need to add Jackson or an implementation of JSONB—for example, Yasson—to our runtime classpath. To use Jackson we could add this line to our Gradle build:
runtimeOnly 'com.fasterxml.jackson.core:jackson-databind:{jacksonVersion}'Now the name column of the Author table will have the type jsonb, and Hibernate will automatically use Jackson to serialize a Name to and from JSON format.
4.12. Summary of SQL column type mappings
So, as we’ve seen, there are quite a few annotations that affect the mapping of Java types to SQL column types in DDL. Here we summarize the ones we’ve just seen in the second half of this chapter, along with some we already mentioned in earlier chapters.
| Annotation | Interpretation |
|---|---|
|
Specify how an |
|
Use a nationalized character type: |
|
Use JDBC LOB APIs to read and write the annotated attribute |
|
Map a collection to a SQL |
|
Map an embeddable to a SQL UDT with the given name |
|
Specify how the time zone information should be persisted |
|
Use an implementation of |
In addition, there are some configuration properties which have a global affect on how basic types map to SQL column types:
| Configuration property name | Purpose |
|---|---|
|
Enable use of nationalized character types by default |
|
Specify the default SQL column type for mapping |
|
Specify the default SQL column type for mapping |
|
Specify the default SQL column type for mapping |
|
Specify the default SQL column type for mapping |
|
Specify the default strategy for storing time zone information |
|
These are global settings and thus quite clumsy. We recommend against messing with any of these settings unless you have a really good reason for it. |
There’s one more topic we would like to cover in this chapter.
4.13. Mapping to formulas
Hibernate lets us map an attribute of an entity to a SQL formula involving columns of the mapped table. Thus, the attribute is a sort of "derived" value.
| Annotation | Purpose |
|---|---|
|
Map an attribute to a SQL formula |
|
Map an association to a SQL formula |
|
Use a SQL formula as the discriminator in single table inheritance. |
For example:
@Entity
class Order {
...
@Column(name = "sub_total", scale=2, precision=8)
BigDecimal subTotal;
@Column(name = "tax", scale=4, precision=4)
BigDecimal taxRate;
@Formula("sub_total * (1.0 + tax)")
BigDecimal totalWithTax;
...
}4.14. Derived Identity
An entity has a derived identity if it inherits part of its primary key from an associated "parent" entity. We’ve already met a kind of degenerate case of derived identity when we talked about one-to-one associations with a shared primary key.
But a @ManyToOne association may also form part of a derived identity.
That is to say, there could be a foreign key column or columns included as part of the composite primary key.
There’s three different ways to represent this situation on the Java side of things:
-
using
@IdClasswithout@MapsId, -
using
@IdClasswith@MapsId, or -
using
@EmbeddedIdwith@MapsId.
Let’s suppose we have a Parent entity class defined as follows:
@Entity
class Parent {
@Id
Long parentId;
...
}The parentId field holds the primary key of the Parent table, which will also form part of the composite primary key of every Child belonging to the Parent.
First way
In the first, slightly simpler approach, we define an @IdClass to represent the primary key of Child:
class DerivedId {
Long parent;
String childId;
// constructors, equals, hashcode, etc
...
}And a Child entity class with a @ManyToOne association annotated @Id:
@Entity
@IdClass(DerivedId.class)
class Child {
@Id
String childId;
@Id @ManyToOne
@JoinColumn(name="parentId")
Parent parent;
...
}Then the primary key of the Child table comprises the columns (childId,parentId).
Second way
This is fine, but sometimes it’s nice to have a field for each element of the primary key.
We may use the @MapsId annotation we met earlier:
@Entity
@IdClass(DerivedId.class)
class Child {
@Id
Long parentId;
@Id
String childId;
@ManyToOne
@MapsId(Child_.PARENT_ID) // typesafe reference to Child.parentId
@JoinColumn(name="parentId")
Parent parent;
...
}We’re using the approach we saw previously to refer to the parentId property of Child in a typesafe way.
Note that we must place column mapping information on the association annotated @MapsId, not on the @Id field.
We must slightly modify our @IdClass so that field names align:
class DerivedId {
Long parentId;
String childId;
// constructors, equals, hashcode, etc
...
}Third way
The third alternative is to redefine our @IdClass as an @Embeddable.
We don’t actually need to change the DerivedId class, but we do need to add the annotation.
@Embeddable
class DerivedId {
Long parentId;
String childId;
// constructors, equals, hashcode, etc
...
}Then we may use @EmbeddedId in Child:
@Entity
class Child {
@EmbeddedId
DerivedId id;
@ManyToOne
@MapsId(DerivedId_.PARENT_ID) // typesafe reference to DerivedId.parentId
@JoinColumn(name="parentId")
Parent parent;
...
}The choice between @IdClass and @EmbeddedId boils down to taste.
The @EmbeddedId is perhaps a little DRYer.
4.15. Adding constraints
Database constraints are important. Even if you’re sure that your program has no bugs 🧐, it’s probably not the only program with access to the database. Constraints help ensure that different programs (and human administrators) play nicely with each other.
Hibernate adds certain constraints to generated DDL automatically: primary key constraints, foreign key constraints, and some unique constraints. But it’s common to need to:
-
add additional unique constraints,
-
add check constraints, or
-
customize the name of a foreign key constraint.
We’ve already seen how to use @ForeignKey to specify the name of a foreign key constraint.
There’s two ways to add a unique constraint to a table:
-
using
@Column(unique=true)to indicate a single-column unique key, or -
using the
@UniqueConstraintannotation to define a uniqueness constraint on a combination of columns.
@Entity
@Table(uniqueConstraints=@UniqueConstraint(columnNames={"title", "year", "publisher_id"}))
class Book { ... }This annotation looks a bit ugly perhaps, but it’s actually useful even as documentation.
The @Check annotation adds a check constraint to the table.
@Entity
@Check(name="ValidISBN", constraints="length(isbn)=13")
class Book { ... }The @Check annotation is commonly used at the field level:
@Id @Check(constraints="length(isbn)=13")
String isbn;5. Interacting with the database
To interact with the database, that is, to execute queries, or to insert, update, or delete data, we need an instance of one of the following objects:
-
a JPA
EntityManager, -
a Hibernate
Session, or -
a Hibernate
StatelessSession.
The Session interface extends EntityManager, and so the only difference between the two interfaces is that Session offers a few more operations.
|
Actually, in Hibernate, every |
An instance of Session (or of EntityManager) is a stateful session.
It mediates the interaction between your program and the database via a operations on a persistence context.
In this chapter, we’re not going to talk much about StatelessSession.
We’ll come back to this very useful API when we talk about performance.
What you need to know for now is that a stateless session doesn’t have a persistence context.
|
Still, we should let you know that some people prefer to use Stateful sessions certainly have their advantages, but they’re more difficult to reason about, and when something goes wrong, the error messages can be more difficult to understand. |
5.1. Persistence Contexts
A persistence context is a sort of cache; we sometimes call it the "first-level cache", to distinguish it from the second-level cache. For every entity instance read from the database within the scope of a persistence context, and for every new entity made persistent within the scope of the persistence context, the context holds a unique mapping from the identifier of the entity instance to the instance itself.
Thus, an entity instance may be in one of three states with respect to a given persistence context:
-
transient — never persistent, and not associated with the persistence context,
-
persistent — currently associated with the persistence context, or
-
detached — previously persistent in another session, but not currently associated with this persistence context.
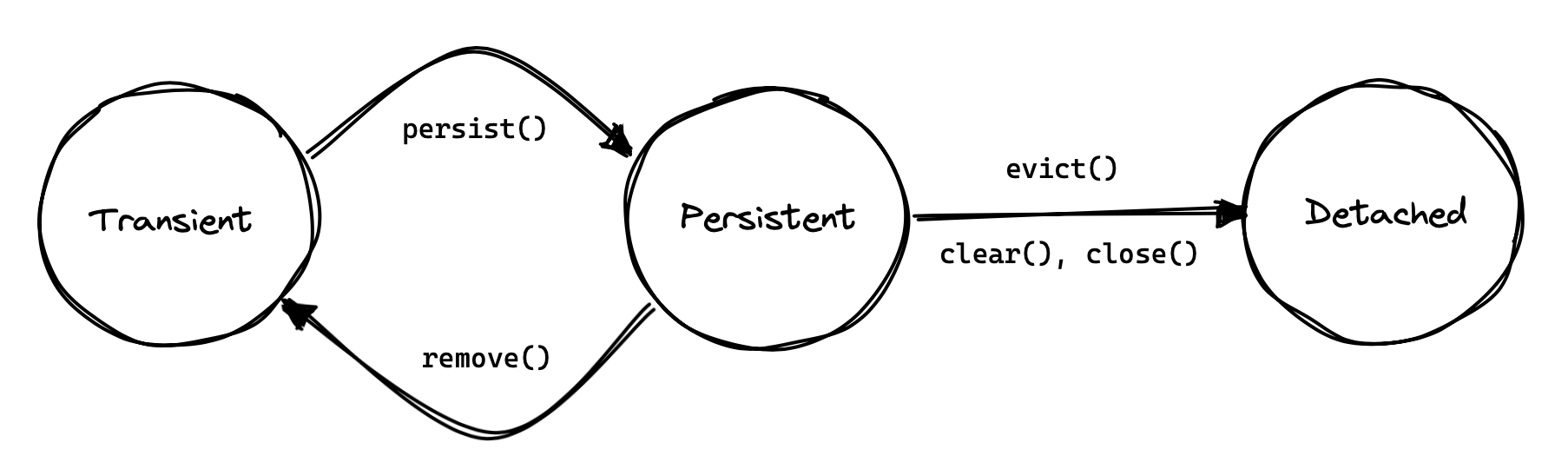
At any given moment, an instance may be associated with at most one persistence context.
The lifetime of a persistence context usually corresponds to the lifetime of a transaction, though it’s possible to have a persistence context that spans several database-level transactions that form a single logical unit of work.
|
A persistence context—that is, a If you accidentally leak a session across threads, you will suffer. |
There are several reasons we like persistence contexts.
-
They help avoid data aliasing: if we modify an entity in one section of code, then other code executing within the same persistence context will see our modification.
-
They enable automatic dirty checking: after modifying an entity, we don’t need to perform any explicit operation to ask Hibernate to propagate that change back to the database. Instead, the change will be automatically synchronized with the database when the session is flushed.
-
They can improve performance by avoiding a trip to the database when a given entity instance is requested repeatedly in a given unit of work.
-
They make it possible to transparently batch together multiple database operations.
A persistence context also allows us to detect circularities when performing operations on graphs of entities. (Even in a stateless session, we need some sort of temporary cache of the entity instances we’ve visited while executing a query.)
On the other hand, stateful sessions come with some very important restrictions, since:
-
persistence contexts aren’t threadsafe, and can’t be shared across threads, and
-
a persistence context can’t be reused across unrelated transactions, since that would break the isolation and atomicity of the transactions.
Furthermore, a persistence context holds a hard references to all its entities, preventing them from being garbage collected. Thus, the session must be discarded once a unit of work is complete.
|
If you don’t completely understand the previous passage, go back and re-read it until you do.
A great deal of human suffering has resulted from users mismanaging the lifecycle of the Hibernate |
We’ll conclude by noting that whether a persistence context helps or harms the performance of a given unit of work depends greatly on the nature of the unit of work. For this reason Hibernate provides both stateful and stateless sessions.
5.2. Creating a session
Sticking with standard JPA-defined APIs, we saw how to obtain an EntityManagerFactory in Configuration using JPA XML.
It’s quite unsurprising that we may use this object to create an EntityManager:
EntityManager entityManager = entityManagerFactory.createEntityManager();When we’re finished with the EntityManager, we should explicitly clean it up:
entityManager.close();On the other hand, if we’re starting from a SessionFactory, as described in Configuration using Hibernate API, we may use:
Session session = sessionFactory.openSession();But we still need to clean up:
session.close();Outside a container environment, we’ll also have to write code to manage database transactions.
5.3. Managing transactions
Using JPA-standard APIs, the EntityTransaction interface allows us to control database transactions.
The idiom we recommend is the following:
EntityManager entityManager = entityManagerFactory.createEntityManager();
EntityTransaction tx = entityManager.getTransaction();
try {
tx.begin();
//do some work
...
tx.commit();
}
catch (Exception e) {
if (tx.isActive()) tx.rollback();
throw e;
}
finally {
entityManager.close();
}Using Hibernate’s native APIs we might write something really similar, but since this sort of code is extremely tedious, we have a much nicer option:
sessionFactory.inTransaction(session -> {
//do the work
...
});5.4. Operations on the persistence context
Of course, the main reason we need an EntityManager is to do stuff to the database.
The following important operations let us interact with the persistence context and schedule modifications to the data:
| Method name and parameters | Effect |
|---|---|
|
Make a transient object persistent and schedule a SQL |
|
Make a persistent object transient and schedule a SQL |
|
Copy the state of a given detached object to a corresponding managed persistent instance and return the persistent object |
|
Disassociate a persistent object from a session without affecting the database |
|
Empty the persistence context and detach all its entities |
|
Detect changes made to persistent objects association with the session and synchronize the database state with the state of the session by executing SQL |
Notice that persist() and remove() have no immediate effect on the database, and instead simply schedule a command for later execution.
Also notice that there’s no update() operation for a stateful session.
Modifications are automatically detected when the session is flushed.
On the other hand, except for getReference(), the following operations all result in immediate access to the database:
| Method name and parameters | Effect |
|---|---|
|
Obtain a persistent object given its type and its id |
|
Obtain a persistent object given its type and its id, requesting the given optimistic or pessimistic lock mode |
|
Obtain a reference to a persistent object given its type and its id, without actually loading its state from the database |
|
Obtain a reference to a persistent object with the same identity as the given detached instance, without actually loading its state from the database |
|
Refresh the persistent state of an object using a new SQL |
|
Refresh the persistent state of an object using a new SQL |
|
Obtain an optimistic or pessimistic lock on a persistent object |
Any of these operations might throw an exception. Now, if an exception occurs while interacting with the database, there’s no good way to resynchronize the state of the current persistence context with the state held in database tables.
Therefore, a session is considered to be unusable after any of its methods throws an exception.
|
The persistence context is fragile. If you receive an exception from Hibernate, you should immediately close and discard the current session. Open a new session if you need to, but throw the bad one away first. |
Each of the operations we’ve seen so far affects a single entity instance passed as an argument. But there’s a way to set things up so that an operation will propagate to associated entities.
5.5. Cascading persistence operations
It’s quite often the case that the lifecycle of a child entity is completely dependent on the lifecycle of some parent. This is especially common for many-to-one and one-to-one associations, though it’s very rare for many-to-many associations.
For example, it’s quite common to make an Order and all its Items persistent in the same transaction, or to delete a Project and its Filess at once.
This sort of relationship is sometimes called a whole/part-type relationship.
Cascading is a convenience which allows us to propagate one of the operations listed in Operations on the persistence context from a parent to its children.
To set up cascading, we specify the cascade member of one of the association mapping annotations, usually @OneToMany or @OneToOne.
@Entity
class Order {
...
@OneToMany(mappedby=Item_.ORDER,
// cascade persist(), remove(), and refresh() from Order to Item
cascade={PERSIST,REMOVE,REFRESH},
// also remove() orphaned Items
orphanRemoval=true)
private Set<Item> items;
...
}Orphan removal indicates that an Item should be automatically deleted if it is removed from the set of items belonging to its parent Order.
5.6. Proxies and lazy fetching
Our data model is a set of interconnected entities, and in Java our whole dataset would be represented as an enormous interconnected graph of objects. It’s possible that this graph is disconnected, but more likely it’s connected, or composed of a relatively small number of connected subgraphs.
Therefore, when we retrieve on object belonging to this graph from the database and instantiate it in memory, we simply can’t recursively retrieve and instantiate all its associated entities. Quite aside from the waste of memory on the VM side, this process would involve a huge number of round trips to the database server, or a massive multidimensional cartesian product of tables, or both. Instead, we’re forced to cut the graph somewhere.
Hibernate solves this problem using proxies and lazy fetching. A proxy is an object that masquerades as a real entity or collection, but doesn’t actually hold any state, because that state has not yet been fetched from the database. When you call a method of the proxy, Hibernate will detect the call and fetch the state from the database before allowing the invocation to proceed to the real entity object or collection.
Now for the gotchas:
-
Hibernate will only do this for an entity which is currently associated with a persistence context. Once the session ends, and the persistence context is cleaned up, the proxy is no longer fetchable, and instead its methods throw the hated
LazyInitializationException. -
A round trip to the database to fetch the state of a single entity instance is just about the least efficient way to access data. It almost inevitably leads to the infamous N+1 selects problem we’ll discuss later when we talk about how to optimize association fetching.
|
We’re getting a bit ahead of ourselves here, but let’s quickly mention the general strategy we recommend to navigate past these gotchas:
|
It’s important to know that some operations which may be performed with an unfetched proxy don’t require fetching its state from the database. First, we’re always allowed to obtain its identifier:
var pubId = entityManager.find(Book.class, bookId).getPublisher().getId(); // does not fetch publisherSecond, we may create an association to a proxy:
book.setPublisher(entityManager.getReference(Publisher.class, pubId)); // does not fetch publisherSometimes it’s useful to test whether a proxy or collection has been fetched from the database.
JPA lets us do this using the PersistenceUnitUtil:
boolean authorsFetched = entityManagerFactory.getPersistenceUnitUtil().isLoaded(book.getAuthors());Hibernate has a slightly easier way to do it:
boolean authorsFetched = Hibernate.isInitialized(book.getAuthors());But the static methods of the Hibernate class let us do a lot more, and it’s worth getting a bit familiar them.
Of particular interest are the operations which let us work with unfetched collections without fetching their state from the database. For example, consider this code:
Book book = session.find(Book.class, bookId); // fetch just the Book, leaving authors unfetched
Author authorRef = session.getReference(Author.class, authorId); // obtain an unfetched proxy
boolean isByAuthor = Hibernate.contains(book.getAuthors(), authorRef); // no fetchingThis code fragment leaves both the set book.authors and the proxy authorRef unfetched.
Finally, Hibernate.initialize() is a convenience method that force-fetches a proxy or collection:
Book book = session.find(Book.class, bookId); // fetch just the Book, leaving authors unfetched
Hibernate.initialize(book.getAuthors()); // fetch the AuthorsBut of course, this code is very inefficient, requiring two trips to the database to obtain data that could in principle be retrieved with just one query.
It’s clear from the discussion above that we need a way to request that an association be eagerly fetched using a database join, thus protecting ourselves from the infamous N+1 selects.
One way to do this is by passing an EntityGraph to find().
5.7. Entity graphs and eager fetching
When an association is mapped fetch=LAZY, it won’t, by default, be fetched when we call the find() method.
We may request that an association be fetched eagerly (immediately) by passing an EntityGraph to find().
The JPA-standard API for this is a bit unwieldy:
var graph = entityManager.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
Book book = entityManager.find(Book.class, bookId, Map.of(SpecHints.HINT_SPEC_FETCH_GRAPH, graph));This is untypesafe and unnecessarily verbose. Hibernate has a better way:
var graph = session.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
Book book = session.byId(Book.class).withFetchGraph(graph).load(bookId);This code adds a left outer join to our SQL query, fetching the associated Publisher along with the Book.
We may even attach additional nodes to our EntityGraph:
var graph = session.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
graph.addPluralSubgraph(Book_.authors).addSubgraph(Author_.person);
Book book = session.byId(Book.class).withFetchGraph(graph).load(bookId);This results in a SQL query with four left outer joins.
|
In the code examples above, The classes |
JPA specifies that any given EntityGraph may be interpreted in two different ways.
-
A fetch graph specifies exactly the associations that should be eagerly loaded. Any association not belonging to the entity graph is proxied and loaded lazily only if required.
-
A load graph specifies that the associations in the entity graph are to be fetched in addition to the associations mapped
fetch=EAGER.
You’re right, the names make no sense.
But don’t worry, if you take our advice, and map your associations fetch=LAZY, there’s no difference between a "fetch" graph and a "load" graph, so the names don’t matter.
|
JPA even specifies a way to define named entity graphs using annotations. But the annotation-based API is so verbose that it’s just not worth using. |
5.8. Flushing the session
From time to time, a flush operation is triggered, and the session synchronizes dirty state held in memory—that is, modifications to the state of entities associated with the persistence context—with persistent state held in the database. Of course, it does this by executing SQL INSERT, UPDATE, and DELETE statements.
By default, a flush is triggered:
-
when the current transaction commits, for example, when
Transaction.commit()is called, -
before execution of a query whose result would be affected by the synchronization of dirty state held in memory, or
-
when the program directly calls
flush().
|
Notice that SQL statements are not usually executed synchronously by methods of the |
This behavior can be controlled by explicitly setting the flush mode. For example, to disable flushes that occur before query execution, call:
entityManager.setFlushMode(FlushModeType.COMMIT);Hibernate allows greater control over the flush mode than JPA:
session.setHibernateFlushMode(FlushMode.MANUAL);Since flushing is a somewhat expensive operation (the session must dirty-check every entity in the persistence context), setting the flush mode to COMMIT can occasionally be a useful optimization.
Hibernate FlushMode |
JPA FlushModeType |
Interpretation |
|---|---|---|
|
Never flush automatically |
|
|
|
Flush before transaction commit |
|
|
Flush before transaction commit, and before execution of a query whose results might be affected by modifications held in memory |
|
Flush before transaction commit, and before execution of every query |
A second way to reduce the cost of flushing is to load entities in read-only mode:
-
Session.setDefaultReadOnly(false)specifies that all entities loaded by a given session should be loaded in read-only mode by default, -
SelectionQuery.setReadOnly(false)specifies that every entity returned by a given query should be loaded in read-only mode, and -
Session.setReadOnly(Object, false)specifies that a given entity already loaded by the session should be switched to read-only mode.
It’s not necessary to dirty-check an entity instance in read-only mode.
5.9. Queries
Hibernate features three complementary ways to write queries:
-
the Hibernate Query Language, an extremely powerful superset of JPQL, which abstracts most of the features of modern dialects of SQL,
-
the JPA criteria query API, along with extensions, allowing almost any HQL query to be constructed programmatically via a typesafe API, and, of course
-
for when all else fails, native SQL queries.
5.10. HQL queries
A full discussion of the query language would require almost as much text as the rest of this Introduction. Fortunately, HQL is already described in exhaustive (and exhausting) detail in A Guide to Hibernate Query Language. It doesn’t make sense to repeat that information here.
Here we want to see how to execute a query via the Session or EntityManager API.
The method we call depends on what kind of query it is:
-
selection queries return a result list, but do not modify the data, but
-
mutation queries modify data, and return the number of modified rows.
Selection queries usually start with the keyword select or from, whereas mutation queries begin with the keyword insert, update, or delete.
| Kind | Session method |
EntityManager method |
Query execution method |
|---|---|---|---|
Selection |
|
|
|
Mutation |
|
|
|
So for the Session API we would write:
List<Book> matchingBooks =
session.createSelectionQuery("from Book where title like :titleSearchPattern", Book.class)
.setParameter("titleSearchPattern", titleSearchPattern)
.getResultList();Or, if we’re sticking to the JPA-standard APIs:
List<Book> matchingBooks =
entityManager.createQuery("select b from Book b where b.title like :titleSearchPattern", Book.class)
.setParameter("titleSearchPattern", titleSearchPattern)
.getResultList();The only difference between createSelectionQuery() and createQuery() is that createSelectionQuery() throws an exception if passed an insert, delete, or update.
In the query above, :titleSearchPattern is called a named parameter.
We may also identify parameters by a number.
These are called ordinal parameters.
List<Book> matchingBooks =
session.createSelectionQuery("from Book where title like ?1", Book.class)
.setParameter(1, titleSearchPattern)
.getResultList();When a query has multiple parameters, named parameters tend to be easier to read, even if slightly more verbose.
|
Never concatenate user input with HQL and pass the concatenated string to |
If we’re expecting a query to return a single result, we can use getSingleResult().
Book book =
session.createSelectionQuery("from Book where isbn = ?1", Book.class)
.setParameter(1, isbn)
.getSingleResult();Or, if we’re expecting it to return at most one result, we can use getSingleResultOrNull().
Book bookOrNull =
session.createSelectionQuery("from Book where isbn = ?1", Book.class)
.setParameter(1, isbn)
.getSingleResultOrNull();The difference, of course, is that getSingleResult() throws an exception if there’s no matching row in the database, whereas getSingleResultOrNull() just returns null.
By default, Hibernate dirty checks entities in the persistence context before executing a query, in order to determine if the session should be flushed. If there are many entities association with the persistence context, then this can be an expensive operation.
To disable this behavior, set the flush mode to COMMIT or MANUAL:
Book bookOrNull =
session.createSelectionQuery("from Book where isbn = ?1", Book.class)
.setParameter(1, isbn)
.setHibernateFlushMode(MANUAL)
.getSingleResult();|
Setting the flush mode to |
Occasionally we need to build a query at runtime, from a set of optional conditions. For this, JPA offers an API which allows programmatic construction of a query.
5.11. Criteria queries
Imagine we’re implementing some sort of search screen, where the user of our system is offered several different ways to constrain the query result set. For example, we might let them search for books by title and/or the author name. Of course, we could construct a HQL query by string concatenation, but this is a bit fragile, so it’s quite nice to have an alternative.
First we need an object for building criteria queries.
Using the JPA-standard APIs, this would be a CriteriaBuilder, and we get it from the EntityManagerFactory:
CriteriaBuilder builder = entityManagerFactory.getCriteriaBuilder();But if we have a SessionFactory, we get something much better, a HibernateCriteriaBuilder:
HibernateCriteriaBuilder builder = sessionFactory.getCriteriaBuilder();The HibernateCriteriaBuilder extends CriteriaBuilder and adds many operations that JPQL doesn’t have.
|
If you’re using Or simply: |
We’re ready to create a criteria query.
CriteriaQuery<Book> query = builder.createQuery(Book.class);
Root<Book> book = query.from(Book.class);
Predicate where = builder.conjunction();
if (titlePattern != null) {
where = builder.and(where, builder.like(book.get(Book_.title), titlePattern));
}
if (namePattern != null) {
Join<Book,Author> author = book.join(Book_.author);
where = builder.and(where, builder.like(author.get(Author_.name), namePattern));
}
query.select(book).where(where)
.orderBy(builder.asc(book.get(Book_.title)));Here, as before, the classes Book_ and Author_ are generated by Hibernate’s JPA Metamodel Generator.
|
Notice that we didn’t bother treating |
Execution of a criteria query works almost exactly like execution of HQL.
| Kind | Session method |
EntityManager method |
Query execution method |
|---|---|---|---|
Selection |
|
|
|
Mutation |
|
|
|
For example:
List<Book> matchingBooks =
session.createSelectionQuery(query)
.getResultList();Update, insert, and delete queries work similarly:
CriteriaDelete<Book> delete = builder.createCriteriaDelete(Book.class);
Root<Book> book = delete.from(Book.class);
delete.where(builder.lt(builder.year(book.get(Book_.publicationDate)), 2000));
session.createMutationQuery(delete).executeUpdate();|
It’s even possible to transform a HQL query string to a criteria query, and modify the query programmatically before execution: |
Do you find some of the code above a bit too verbose? We do.
5.12. A more comfortable way to write criteria queries
Actually, what makes the JPA criteria API less ergonomic than it should be is the need to call all operations of the CriteriaBuilder as instance methods, instead of having them as static functions.
The reason it works this way is that each JPA provider has its own implementation of CriteriaBuilder.
Hibernate 6.3 introduces the helper class CriteriaDefinition to reduce the verbosity of criteria queries.
Our example looks like this:
CriteriaQuery<Book> query =
new CriteriaDefinition(entityManagerFactory, Book.class) {{
select(book);
if (titlePattern != null) {
restrict(like(book.get(Book_.title), titlePattern));
}
if (namePattern != null) {
var author = book.join(Book_.author);
restrict(like(author.get(Author_.name), namePattern));
}
orderBy(asc(book.get(Book_.title)));
}};When all else fails, and sometimes even before that, we’re left with the option of writing a query in SQL.
5.13. Native SQL queries
HQL is a powerful language which helps reduce the verbosity of SQL, and significantly increases portability of queries between databases. But ultimately, the true value of ORM is not in avoiding SQL, but in alleviating the pain involved in dealing with SQL result sets once we get them back to our Java program. As we said right up front, Hibernate’s generated SQL is meant to be used in conjunction with handwritten SQL, and native SQL queries are one of the facilities we provide to make that easy.
| Kind | Session method |
EntityManager method |
Query execution method |
|---|---|---|---|
Selection |
|
|
|
Mutation |
|
|
|
Stored procedure |
|
|
|
For the most simple cases, Hibernate can infer the shape of the result set:
Book book =
session.createNativeQuery("select * from Books where isbn = ?1", Book.class)
.getSingleResult();
String title =
session.createNativeQuery("select title from Books where isbn = ?1", String.class)
.getSingleResult();However, in general, there isn’t enough information in the JDBC ResultSetMetaData to infer the mapping of columns to entity objects.
So for more complicated cases, you’ll need to use the @SqlResultSetMapping annotation to define a named mapping, and pass the name to createNativeQuery(). This gets fairly messy, so we don’t want to hurt your eyes by showing you an example of it.
By default, Hibernate doesn’t flush the session before execution of a native query. That’s because the session is unaware of which modifications held in memory would affect the results of the query.
So if there are any unflushed changes to Books, this query might return stale data:
List<Book> books =
session.createNativeQuery("select * from Books")
.getResultList()There’s two ways to ensure the persistence context is flushed before this query is executed.
Either, we could simply force a flush by calling flush() or by setting the flush mode to ALWAYS:
List<Book> books =
session.createNativeQuery("select * from Books")
.setHibernateFlushMode(ALWAYS)
.getResultList()Or, alternatively, we could tell Hibernate which modified state affects the results of the query:
List<Book> books =
session.createNativeQuery("select * from Books")
.addSynchronizedEntityClass(Book.class)
.getResultList()|
You can call stored procedures using |
5.14. Limits, pagination, and ordering
If a query might return more results than we can handle at one time, we may specify:
-
a limit on the maximum number of rows returned, and,
-
optionally, an offset, the first row of an ordered result set to return.
|
The offset is used to paginate query results. |
There’s two ways to add a limit or offset to a HQL or native SQL query:
-
using the syntax of the query language itself, for example,
offset 10 rows fetch next 20 rows only, or -
using the methods
setFirstResult()andsetMaxResults()of theSelectionQueryinterface.
If the limit or offset is parameterized, the second option is simpler. For example, this:
List<Book> books =
session.createSelectionQuery("from Book where title like ?1 order by title")
.setParameter(1, titlePattern)
.setMaxResults(MAX_RESULTS)
.getResultList();is simpler than:
List<Book> books =
session.createSelectionQuery("from Book where title like ?1 order by title fetch first ?2 rows only")
.setParameter(1, titlePattern)
.setParameter(2, MAX_RESULTS)
.getResultList();Hibernate’s SelectionQuery has a slightly different way to paginate the query results:
List<Book> books =
session.createSelectionQuery("from Book where title like ?1 order by title")
.setParameter(1, titlePattern)
.setPage(Page.first(MAX_RESULTS))
.getResultList();A closely-related issue is ordering.
It’s quite common for pagination to be combined with the need to order query results by a field that’s determined at runtime.
So, as an alternative to the HQL order by clause, SelectionQuery offers the ability to specify that the query results should be ordered by one or more fields of the entity type returned by the query:
List<Book> books =
session.createSelectionQuery("from Book where title like ?1")
.setParameter(1, titlePattern)
.setOrder(List.of(Order.asc(Book._title), Order.asc(Book._isbn)))
.setMaxResults(MAX_RESULTS)
.getResultList();Unfortunately, there’s no way to do this using JPA’s TypedQuery interface.
| Method name | Purpose | JPA-standard |
|---|---|---|
|
Set a limit on the number of results returned by a query |
✔ |
|
Set an offset on the results returned by a query |
✔ |
|
Set the limit and offset by specifying a |
✖ |
|
Specify how the query results should be ordered |
✖ |
5.15. Representing projection lists
A projection list is the list of things that a query returns, that is, the list of expressions in the select clause.
Since Java has no tuple types, representing query projection lists in Java has always been a problem for JPA and Hibernate.
Traditionally, we’ve just used Object[] most of the time:
var results =
session.createSelectionQuery("select isbn, title from Book", Object[].class)
.getResultList();
for (var result : results) {
var isbn = (String) result[0];
var title = (String) result[1];
...
}This is really a bit ugly.
Java’s record types now offer an interesting alternative:
record IsbnTitle(String isbn, String title) {}
var results =
session.createSelectionQuery("select isbn, title from Book", IsbnTitle.class)
.getResultList();
for (var result : results) {
var isbn = result.isbn();
var title = result.title();
...
}Notice that we’re able to declare the record right before the line which executes the query.
Now, this is only superficially more typesafe, since the query itself is not checked statically, and so we can’t say it’s objectively better.
But perhaps you find it more aesthetically pleasing.
And if we’re going to be passing query results around the system, the use of a record type is much better.
The criteria query API offers a much more satisfying solution to the problem. Consider the following code:
var builder = sessionFactory.getCriteriaBuilder();
var query = builder.createTupleQuery();
var book = query.from(Book.class);
var bookTitle = book.get(Book_.title);
var bookIsbn = book.get(Book_.isbn);
var bookPrice = book.get(Book_.price);
query.select(builder.tuple(bookTitle, bookIsbn, bookPrice));
var resultList = session.createSelectionQuery(query).getResultList();
for (var result: resultList) {
String title = result.get(bookTitle);
String isbn = result.get(bookIsbn);
BigDecimal price = result.get(bookPrice);
...
}This code is manifestly completely typesafe, and much better than we can hope to do with HQL.
5.16. Named queries
The @NamedQuery annotation lets us define a HQL query that is compiled and checked as part of the bootstrap process.
This means we find out about errors in our queries earlier, instead of waiting until the query is actually executed.
We can place the @NamedQuery annotation on any class, even on an entity class.
@NamedQuery(name="10BooksByTitle",
query="from Book where title like :titlePattern order by title fetch first 10 rows only")
class BookQueries {}We have to make sure that the class with the @NamedQuery annotation will be scanned by Hibernate, either:
-
by adding
<class>org.hibernate.example.BookQueries</class>topersistence.xml, or -
by calling
configuration.addClass(BookQueries.class).
|
Unfortunately, JPA’s so that Hibernate knows where to find it. |
The @NamedNativeQuery annotation lets us do the same for native SQL queries.
There’s much less advantage to using @NamedNativeQuery, because there is very little that Hibernate can do to validate the correctness of a query written in the native SQL dialect of your database.
| Kind | Session method |
EntityManager method |
Query execution method |
|---|---|---|---|
Selection |
|
|
|
Mutation |
|
|
|
We execute our named query like this:
List<Book> books =
entityManager.createNamedQuery(BookQueries_.QUERY_10_BOOKS_BY_TITLE)
.setParameter("titlePattern", titlePattern)
.getResultList()Here, BookQueries_.QUERY_10_BOOKS_BY_TITLE is a constant with value "10BooksByTitle", generated by the Metamodel Generator.
Note that the code which executes the named query is not aware of whether the query was written in HQL or in native SQL, making it slightly easier to change and optimize the query later.
|
It’s nice to have our queries checked at startup time.
It’s even better to have them checked at compile time.
In Organizing persistence logic, we mentioned that the Metamodel Generator can do that for us, with the help of the But actually, Hibernate has a separate Query Validator capable of performing compile-time validation of HQL query strings that occur as arguments to |
5.17. Controlling lookup by id
We can do almost anything via HQL, criteria, or native SQL queries. But when we already know the identifier of the entity we need, a query can feel like overkill. And queries don’t make efficient use of the second level cache.
We met the find() method earlier.
It’s the most basic way to perform a lookup by id.
But as we also already saw, it can’t quite do everything.
Therefore, Hibernate has some APIs that streamline certain more complicated lookups:
| Method name | Purpose |
|---|---|
|
Lets us specify association fetching via an |
|
Lets us load a batch of ids at the same time |
Batch loading is very useful when we need to retrieve multiple instances of the same entity class by id:
var graph = session.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
List<Book> books =
session.byMultipleIds(Book.class)
.withFetchGraph(graph) // control association fetching
.withBatchSize(20) // specify an explicit batch size
.with(CacheMode.GET) // control interaction with the cache
.multiLoad(bookIds);The given list of bookIds will be broken into batches, and each batch will be fetched from the database in a single select.
If we don’t specify the batch size explicitly, a batch size will be chosen automatically.
We also have some operations for working with lookups by natural id:
| Method name | Purpose |
|---|---|
|
For an entity with just one attribute is annotated |
|
For an entity with multiple attributes are annotated |
|
Lets us load a batch of natural ids at the same time |
Here’s how we can retrieve an entity by its composite natural id:
Book book =
session.byNaturalId(Book.class)
.using(Book_.isbn, isbn)
.using(Book_.printing, printing)
.load();Notice that this code fragment is completely typesafe, again thanks to the Metamodel Generator.
5.18. Interacting directly with JDBC
From time to time we run into the need to write some code that calls JDBC directly.
Unfortunately, JPA offers no good way to do this, but the Hibernate Session does.
session.doWork(connection -> {
try (var callable = connection.prepareCall("{call myproc(?)}")) {
callable.setLong(1, argument);
callable.execute();
}
});The Connection passed to the work is the same connection being used by the session, and so any work performed using that connection occurs in the same transaction context.
If the work returns a value, use doReturningWork() instead of doWork().
|
In a container environment where transactions and database connections are managed by the container, this might not be the easiest way to obtain the JDBC connection. |
5.19. What to do when things go wrong
Object/relational mapping has been called the "Vietnam of computer science". The person who made this analogy is American, and so one supposes that he meant to imply some kind of unwinnable war. This is quite ironic, since at the very moment he made this comment, Hibernate was already on the brink of winning the war.
Today, Vietnam is a peaceful country with exploding per-capita GDP, and ORM is a solved problem. That said, Hibernate is complex, and ORM still presents many pitfalls for the inexperienced, even occasionally for the experienced. Sometimes things go wrong.
In this section we’ll quickly sketch some general strategies for avoiding "quagmires".
-
Understand SQL and the relational model. Know the capabilities of your RDBMS. Work closely with the DBA if you’re lucky enough to have one. Hibernate is not about "transparent persistence" for Java objects. It’s about making two excellent technologies work smoothly together.
-
Log the SQL executed by Hibernate. You cannot know that your persistence logic is correct until you’ve actually inspected the SQL that’s being executed. Even when everything seems to be "working", there might be a lurking N+1 selects monster.
-
Be careful when modifying bidirectional associations. In principle, you should update both ends of the association. But Hibernate doesn’t strictly enforce that, since there are some situations where such a rule would be too heavy-handed. Whatever the case, it’s up to you to maintain consistency across your model.
-
Never leak a persistence context across threads or concurrent transactions. Have a strategy or framework to guarantee this never happens.
-
When running queries that return large result sets, take care to consider the size of the session cache. Consider using a stateless session.
-
Think carefully about the semantics of the second-level cache, and how the caching policies impact transaction isolation.
-
Avoid fancy bells and whistles you don’t need. Hibernate is incredibly feature-rich, and that’s a good thing, because it serves the needs of a huge number of users, many of whom have one or two very specialized needs. But nobody has all those specialized needs. In all probability, you have none of them. Write your domain model in the simplest way that’s reasonable, using the simplest mapping strategies that make sense.
-
When something isn’t behaving as you expect, simplify. Isolate the problem. Find the absolute minimum test case which reproduces the behavior, before asking for help online. Most of the time, the mere act of isolating the problem will suggest an obvious solution.
-
Avoid frameworks and libraries that "wrap" JPA. If there’s any one criticism of Hibernate and ORM that sometimes does ring true, it’s that it takes you too far from direct control over JDBC. An additional layer just takes you even further.
-
Avoid copy/pasting code from random bloggers or stackoverflow reply guys. Many of the suggestions you’ll find online just aren’t the simplest solution, and many aren’t correct for Hibernate 6. Instead, understand what you’re doing; study the Javadoc of the APIs you’re using; read the JPA specification; follow the advice we give in this document; go direct to the Hibernate team on Zulip. (Sure, we can be a bit cantankerous at times, but we do always want you to be successful.)
-
Always consider other options. You don’t have to use Hibernate for everything.
6. Compile-time tooling
The Metamodel Generator is a standard part of JPA.
We’ve actually already seen its handiwork in the code examples earlier: it’s the author of the class Book_, which contains the static metamodel of the entity class Book.
|
We’ve already seen how to set up the annotation processor in the Gradle build we saw earlier. For more details on how to integrate the Metamodel Generator, check out the Static Metamodel Generator section in the User Guide. |
Here’s an example of the sort of code that’s generated for an entity class, as mandated by the JPA specification:
@StaticMetamodel(Book.class)
public abstract class Book_ {
/**
* @see org.example.Book#isbn
**/
public static volatile SingularAttribute<Book, String> isbn;
/**
* @see org.example.Book#text
**/
public static volatile SingularAttribute<Book, String> text;
/**
* @see org.example.Book#title
**/
public static volatile SingularAttribute<Book, String> title;
/**
* @see org.example.Book#type
**/
public static volatile SingularAttribute<Book, Type> type;
/**
* @see org.example.Book#publicationDate
**/
public static volatile SingularAttribute<Book, LocalDate> publicationDate;
/**
* @see org.example.Book#publisher
**/
public static volatile SingularAttribute<Book, Publisher> publisher;
/**
* @see org.example.Book#authors
**/
public static volatile SetAttribute<Book, Author> authors;
public static final String ISBN = "isbn";
public static final String TEXT = "text";
public static final String TITLE = "title";
public static final String TYPE = "type";
public static final String PUBLICATION_DATE = "publicationDate";
public static final String PUBLISHER = "publisher";
public static final String AUTHORS = "authors";
}For each attribute of the entity, the Book_ class has:
-
a
String-valued constant likeTITLE, and -
a typesafe reference like
titleto a metamodel object of typeAttribute.
We’ve already been using metamodel references like Book_.authors and Book.AUTHORS in the previous chapters.
So now let’s see what else the Metamodel Generator can do for us.
|
The Metamodel Generator provides statically-typed access to elements of the JPA This is very useful for writing generic code in frameworks or libraries. For example, you could use it to create your own criteria query API. |
Automatic generation of finder methods and query methods is a new feature of Hibernate’s implementation of the Metamodel Generator, and an extension to the functionality defined by the JPA specification. In this chapter, we’re going to explore these features.
|
The functionality described in the rest of this chapter depends on the use of the annotations described in Entities. The Metamodel Generator is not currently able to generate finder methods and query methods for entities declared completely in XML, and it’s not able to validate HQL which queries such entities. (On the other hand, the O/R mappings may be specified in XML, since they’re not needed by the Metamodel Generator.) |
We’re going to meet three different kinds of generated method:
-
a named query method has its signature and implementation generated directly from a
@NamedQueryannotation, -
a query method has a signature that’s explicitly declared, and a generated implementation which executes a HQL or SQL query specified via a
@HQLor@SQLannotation, and -
a finder method annotated
@Findhas a signature that’s explicitly declared, and a generated implementation inferred from the parameter list.
To whet our appetites, let’s see how this works for a @NamedQuery.
6.1. Named queries and the Metamodel Generator
The very simplest way to generate a query method is to put a @NamedQuery annotation anywhere we like, with a name beginning with the magical character #.
Let’s just stick it on the Book class:
@CheckHQL // validate the query at compile time
@NamedQuery(name = "#findByTitleAndType",
query = "select book from Book book where book.title like :titlen and book.type = :type")
@Entity
public class Book { ... }Now the Metamodel Generator adds the following method declaration to the metamodel class Book_.
/**
* Execute named query {@value #QUERY_FIND_BY_TITLE_AND_TYPE} defined by annotation of {@link Book}.
**/
public static List<Book> findByTitleAndType(@Nonnull EntityManager entityManager, String title, Type type) {
return entityManager.createNamedQuery(QUERY_FIND_BY_TITLE_AND_TYPE)
.setParameter("titlePattern", title)
.setParameter("type", type)
.getResultList();
}We can easily call this method from wherever we like, as long as we have access to an EntityManager:
List<Book> books =
Book_.findByTitleAndType(entityManager, titlePattern, Type.BOOK);Now, this is quite nice, but it’s a bit inflexible in various ways, and so this probably isn’t the best way to generate a query method.
6.2. Generated query methods
The principal problem with generating the query method straight from the @NamedQuery annotation is that it doesn’t let us explicitly specify the return type or parameter list.
In the case we just saw, the Metamodel Generator does a reasonable job of inferring the query return type and parameter types, but we’re often going to need a bit more control.
The solution is to write down the signature of the query method explicitly, as an abstract method in Java.
We’ll need a place to put this method, and since our Book entity isn’t an abstract class, we’ll just introduce a new interface for this purpose:
interface Queries {
@HQL("where title like :title and type = :type")
List<Book> findBooksByTitleAndType(String title, String type);
}Instead of @NamedQuery, which is a type-level annotation, we specify the HQL query using the new @HQL annotation, which we place directly on the query method.
This results in the following generated code in the Queries_ class:
@StaticMetamodel(Queries.class)
public abstract class Queries_ {
/**
* Execute the query {@value #FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type}.
*
* @see org.example.Queries#findBooksByTitleAndType(String,Type)
**/
public static List<Book> findBooksByTitleAndType(@Nonnull EntityManager entityManager, String title, Type type) {
return entityManager.createQuery(FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type, Book.class)
.setParameter("title", title)
.setParameter("type", type)
.getResultList();
}
static final String FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type =
"where title like :title and type = :type";
}Notice that the signature differs just slightly from the one we wrote down in the Queries interface: the Metamodel Generator has prepended a parameter accepting EntityManager to the parameter list.
If we want to explicitly specify the name and type of this parameter, we may declare it explicitly:
interface Queries {
@HQL("where title like :title and type = :type")
List<Book> findBooksByTitleAndType(StatelessSession session, String title, String type);
}The Metamodel Generator defaults to using EntityManager as the session type, but other types are allowed:
-
Session, -
StatelessSession, or -
Mutiny.Sessionfrom Hibernate Reactive.
The real value of all this is in the checks which can now be done at compile time. The Metamodel Generator verifies that the parameters of our abstract method declaration match the parameters of the HQL query, for example:
-
for a named parameter
:alice, there must be a method parameter namedalicewith exactly the same type, or -
for an ordinal parameter
?2, the second method parameter must have exactly the same type.
The query must also be syntactically legal and semantically well-typed, that is, the entities, attributes, and functions referenced in the query must actually exist and have compatible types. The Metamodel Generator determines this by inspecting the annotations of the entity classes at compile time.
|
The |
The @HQL annotation has a friend named @SQL which lets us specify a query written in native SQL instead of in HQL.
In this case there’s a lot less the Metamodel Generator can do to check that the query is legal and well-typed.
We imagine you’re wondering whether a static method is really the right thing to use here.
6.3. Generating query methods as instance methods
One thing not to like about what we’ve just seen is that we can’t transparently replace a generated static function of the Queries_ class with an improved handwritten implementation without impacting clients.
Now, if our query is only called in one place, which is quite common, this isn’t going to be a big issue, and so we’re inclined to think the static function is fine.
But if this function is called from many places, it’s probably better to promote it to an instance method of some class or interface. Fortunately, this is straightforward.
All we need to do is add an abstract getter method for the session object to our Queries interface.
(And remove the session from the method parameter list.)
We may call this method anything we like:
interface Queries {
EntityManager entityManager();
@HQL("where title like :title and type = :type")
List<Book> findBooksByTitleAndType(String title, String type);
}Here we’ve used EntityManager as the session type, but other types are allowed, as we saw above.
Now the Metamodel Generator does something a bit different:
@StaticMetamodel(Queries.class)
public class Queries_ implements Queries {
private final @Nonnull EntityManager entityManager;
public Queries_(@Nonnull EntityManager entityManager) {
this.entityManager = entityManager;
}
public @Nonnull EntityManager entityManager() {
return entityManager;
}
/**
* Execute the query {@value #FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type}.
*
* @see org.example.Queries#findBooksByTitleAndType(String,Type)
**/
@Override
public List<Book> findBooksByTitleAndType(String title, Type type) {
return entityManager.createQuery(FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type, Book.class)
.setParameter("title", title)
.setParameter("type", type)
.getResultList();
}
static final String FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type =
"where title like :title and type = :type";
}The generated class Queries_ now implements the Queries interface, and the generated query method implements our abstract method directly.
Of course, the protocol for calling the query method has to change:
Queries queries = new Queries_(entityManager);
List<Book> books = queries.findByTitleAndType(titlePattern, Type.BOOK);If we ever need to swap out the generated query method with one we write by hand, without impacting clients, all we need to do is replace the abstract method with a default method of the Queries interface.
For example:
interface Queries {
EntityManager entityManager();
// handwritten method replacing previous generated implementation
default List<Book> findBooksByTitleAndType(String title, String type) {
entityManager()
.createQuery("where title like :title and type = :type", Book.class)
.setParameter("title", title)
.setParameter("type", type)
.setFlushMode(COMMIT)
.setMaxResults(100)
.getResultList();
}
}What if we would like to inject a Queries object instead of calling its constructor directly?
|
As you recall, we don’t think these things really need to be container-managed objects. But if you want them to be—if you’re allergic to calling constructors, for some reason—then:
Thus, the generated implementation of |
Is the Queries interface starting to look a lot like a DAO-style repository object?
Well, perhaps.
You can certainly decide to use this facility to create a BookRepository if that’s what you prefer.
But unlike a repository, our Queries interface:
-
doesn’t attempt to hide the
EntityManagerfrom its clients, -
doesn’t implement or extend any framework-provided interface or abstract class, at least not unless you want to create such a framework yourself, and
-
isn’t restricted to service a particular entity class.
We can have as many or as few interfaces with query methods as we like. There’s no one-one-correspondence between these interfaces and entity types. This approach is so flexible that we don’t even really know what to call these "interfaces with query methods".
6.4. Generated finder methods
At this point, one usually begins to question whether it’s even necessary to write a query at all. Would it be possible to just infer the query from the method signature?
In some simple cases it’s indeed possible, and this is the purpose of finder methods.
A finder method is a method annotated @Find.
For example:
@Find
Book getBook(String isbn);A finder method may have multiple parameters:
@Find
List<Book> getBooksByTitle(String title, Type type);The name of the finder method is arbitrary and carries no semantics. But:
-
the return type determines the entity class to be queried, and
-
the parameters of the method must match the fields of the entity class exactly, by both name and type.
Considering our first example, Book has a persistent field String isbn, so this finder method is legal.
If there were no field named isbn in Book, or if it had a different type, this method declaration would be rejected with a meaningful error at compile time.
Similarly, the second example is legal, since Book has fields String title and Type type.
|
You might notice that our solution to this problem is very different from the approach taken by others. In DAO-style repository frameworks, you’re asked to encode the semantics of the finder method into the name of the method. This idea came to Java from Ruby, and we think it doesn’t belong here. It’s completely unnatural in Java, and by almost any measure other than counting characters it’s objectively worse than just writing the query in a string literal. At least string literals accommodate whitespace and punctuation characters. Oh and, you know, it’s pretty useful to be able to rename a finder method without changing its semantics. 🙄 |
The code generated for this finder method depends on what kind of fields match the method parameters:
|
Uses |
All |
Uses |
Other persistent fields, or a mix of field types |
Uses a criteria query |
The generated code also depends on what kind of session we have, since the capabilities of stateless sessions, and of reactive sessions, differ slightly from the capabilities of regular stateful sessions.
With EntityManager as the session type, we obtain:
/**
* Find {@link Book} by {@link Book#isbn isbn}.
*
* @see org.example.Dao#getBook(String)
**/
@Override
public Book getBook(@Nonnull String isbn) {
return entityManager.find(Book.class, isbn);
}
/**
* Find {@link Book} by {@link Book#title title} and {@link Book#type type}.
*
* @see org.example.Dao#getBooksByTitle(String,Type)
**/
@Override
public List<Book> getBooksByTitle(String title, Type type) {
var builder = entityManager.getEntityManagerFactory().getCriteriaBuilder();
var query = builder.createQuery(Book.class);
var entity = query.from(Book.class);
query.where(
title==null
? entity.get(Book_.title).isNull()
: builder.equal(entity.get(Book_.title), title),
type==null
? entity.get(Book_.type).isNull()
: builder.equal(entity.get(Book_.type), type)
);
return entityManager.createQuery(query).getResultList();
}It’s even possible to match a parameter of a finder method against a property of an associated entity or embeddable.
The natural syntax would be a parameter declaration like String publisher.name, but because that’s not legal Java, we can write it as String publisher$name, taking advantage of a legal Java identifier character that nobody ever uses for anything else:
@Find
List<Book> getBooksByPublisherName(String publisher$name);A finder method may specify fetch profiles, for example:
@Find(namedFetchProfiles=Book_.FETCH_WITH_AUTHORS)
Book getBookWithAuthors(String isbn);This lets us declare which associations of Book should be pre-fetched by annotating the Book class.
6.5. Paging and ordering
Optionally, a query method may have additional "magic" parameters which do not map to query parameters:
| Parameter type | Purpose | Example argument |
|---|---|---|
|
Specifies a page of query results |
|
|
Specifies an entity attribute to order by, if |
|
|
Specifies entity attributes to order by, if |
|
|
Specifies a column to order by, if the query returns a projection list |
|
|
Specifies columns to order by, if the query returns a projection list |
|
Thus, if we redefine our earlier query method as follows:
interface Queries {
@HQL("from Book where title like :title and type = :type")
List<Book> findBooksByTitleAndType(String title, Page page, Order<? super Book>... order);
}Then we can call it like this:
List<Book> books =
Queries_.findBooksByTitleAndType(entityManager, titlePattern, Type.BOOK,
Page.page(RESULTS_PER_PAGE, page), Order.asc(Book_.isbn));6.6. Query and finder method return types
A query method doesn’t need to return List.
It might return a single Book.
@HQL("where isbn = :isbn")
Book findBookByIsbn(String isbn);For a query with a projection list, Object[] or List<Object[]> is permitted:
@HQL("select isbn, title from Book where isbn = :isbn")
Object[] findBookAttributesByIsbn(String isbn);But when there’s just one item in the select list, the type of that item should be used:
@HQL("select title from Book where isbn = :isbn")
String getBookTitleByIsbn(String isbn);@HQL("select local datetime")
LocalDateTime getServerDateTime();A query which returns a selection list may have a query method which repackages the result as a record, as we saw in Representing projection lists.
record IsbnTitle(String isbn, String title) {}
@HQL("select isbn, title from Book")
List<IsbnTitle> listIsbnAndTitleForEachBook(Page page);A query method might even return TypedQuery or SelectionQuery:
@HQL("where title like :title")
SelectionQuery<Book> findBooksByTitle(String title);This is extremely useful at times, since it allows the client to further manipulate the query:
List<Book> books =
Queries_.findBooksByTitle(entityManager, titlePattern)
.setOrder(Order.asc(Book_.title)) // order the results
.setPage(Page.page(RESULTS_PER_PAGE, page)) // return the given page of results
.setFlushMode(FlushModeType.COMMIT) // don't flush session before query execution
.setReadOnly(true) // load the entities in read-only mode
.setCacheStoreMode(CacheStoreMode.BYPASS) // don't cache the results
.setComment("Hello world!") // add a comment to the generated SQL
.getResultList();An insert, update, or delete query must return int or void.
@HQL("delete from Book")
int deleteAllBooks();@HQL("update Book set discontinued = true where isbn = :isbn")
void discontinueBook(String isbn);On the other hand, finder methods are currently much more limited.
A finder method must return an entity type like Book, or a list of the entity type, List<Book>, for example.
|
As you might expect, for a reactive session, all query methods and finder methods must return |
6.7. An alternative approach
What if you just don’t like the ideas we’ve presented in this chapter, preferring to call the Session or EntityManager directly, but you still want compile-time validation for HQL?
Or what if you do like the ideas, but you’re working on a huge existing codebase full of code you don’t want to change?
Well, there’s a solution for you, too.
The Query Validator is a separate annotation processor that’s capable of type-checking HQL strings, not only in annotations, but even when they occur as arguments to createQuery(), createSelectionQuery(), or createMutationQuery(). It’s even able to check calls to setParameter(), with some restrictions.
The Query Validator works in javac, Gradle, Maven, and the Eclipse Java Compiler.
|
Unlike the Metamodel Generator, which is a completely bog-standard Java annotation processor based on only standard Java APIs, the Query Validator makes use of internal compiler APIs in |
7. Tuning and performance
Once you have a program up and running using Hibernate to access the database, it’s inevitable that you’ll find places where performance is disappointing or unacceptable.
Fortunately, most performance problems are relatively easy to solve with the tools that Hibernate makes available to you, as long as you keep a couple of simple principles in mind.
First and most important: the reason you’re using Hibernate is that it makes things easier. If, for a certain problem, it’s making things harder, stop using it. Solve this problem with a different tool instead.
| Just because you’re using Hibernate in your program doesn’t mean you have to use it everywhere. |
Second: there are two main potential sources of performance bottlenecks in a program that uses Hibernate:
-
too many round trips to the database, and
-
memory consumption associated with the first-level (session) cache.
So performance tuning primarily involves reducing the number of accesses to the database, and/or controlling the size of the session cache.
But before we get to those more advanced topics, we should start by tuning the connection pool.
7.1. Tuning the connection pool
The connection pool built in to Hibernate is suitable for testing, but isn’t intended for use in production. Instead, Hibernate supports a range of different connection pools, including our favorite, Agroal.
To select and configure Agroal, you’ll need to set some extra configuration properties, in addition to the settings we already saw in Basic configuration settings.
Properties with the prefix hibernate.agroal are passed through to Agroal:
# configure Agroal connection pool
hibernate.agroal.maxSize 20
hibernate.agroal.minSize 10
hibernate.agroal.acquisitionTimeout PT1s
hibernate.agroal.reapTimeout PT10sAs long as you set at least one property with the prefix hibernate.agroal, the AgroalConnectionProvider will be selected automatically.
There’s many to choose from:
| Configuration property name | Purpose |
|---|---|
|
The maximum number of connections present on the pool |
|
The minimum number of connections present on the pool |
|
The number of connections added to the pool when it is started |
|
The maximum amount of time a connection can live, after which it is removed from the pool |
|
The maximum amount of time a thread can wait for a connection, after which an exception is thrown instead |
|
The duration for eviction of idle connections |
|
The duration of time a connection can be held without causing a leak to be reported |
|
A foreground validation is executed if a connection has been idle on the pool for longer than this duration |
|
The interval between background validation checks |
|
A SQL command to be executed when a connection is created |
The following settings are common to all connection pools supported by Hibernate:
|
The default autocommit mode |
|
The default transaction isolation level |
7.2. Enabling statement batching
An easy way to improve performance of some transactions, with almost no work at all, is to turn on automatic DML statement batching. Batching only helps in cases where a program executes many inserts, updates, or deletes against the same table in a single transaction.
All we need to do is set a single property:
| Configuration property name | Purpose | Alternative |
|---|---|---|
|
Maximum batch size for SQL statement batching |
|
|
Even better than DML statement batching is the use of HQL |
7.3. Association fetching
Achieving high performance in ORM means minimizing the number of round trips to the database. This goal should be uppermost in your mind whenever you’re writing data access code with Hibernate. The most fundamental rule of thumb in ORM is:
-
explicitly specify all the data you’re going to need right at the start of a session/transaction, and fetch it immediately in one or two queries,
-
and only then start navigating associations between persistent entities.
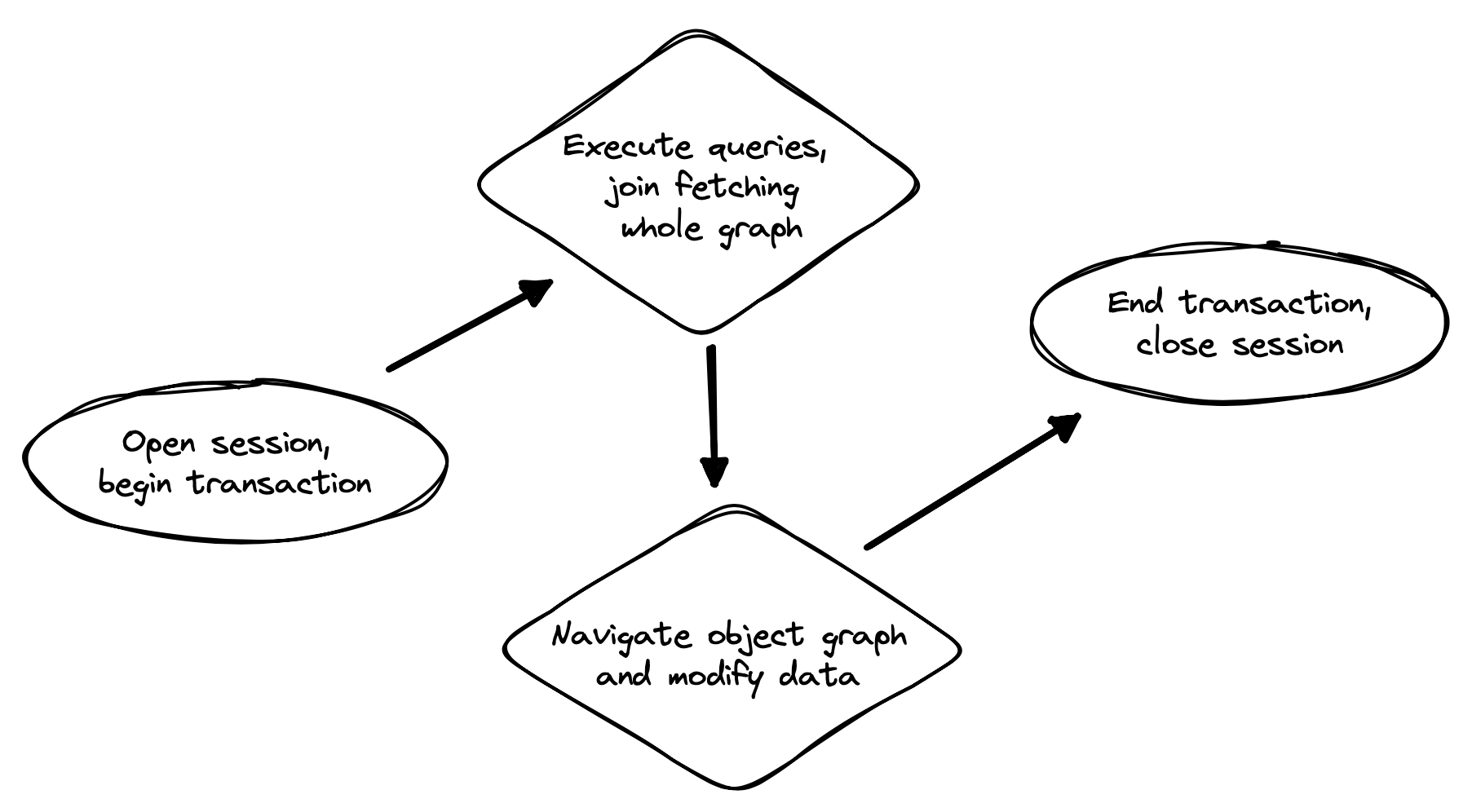
Without question, the most common cause of poorly-performing data access code in Java programs is the problem of N+1 selects. Here, a list of N rows is retrieved from the database in an initial query, and then associated instances of a related entity are fetched using N subsequent queries.
|
This isn’t a bug or limitation of Hibernate; this problem even affects typical handwritten JDBC code behind DAOs. Only you, the developer, can solve this problem, because only you know ahead of time what data you’re going to need in a given unit of work. But that’s OK. Hibernate gives you all the tools you need. |
In this section we’re going to discuss different ways to avoid such "chatty" interaction with the database.
Hibernate provides several strategies for efficiently fetching associations and avoiding N+1 selects:
-
outer join fetching—where an association is fetched using a
left outer join, -
batch fetching—where an association is fetched using a subsequent
selectwith a batch of primary keys, and -
subselect fetching—where an association is fetched using a subsequent
selectwith keys re-queried in a subselect.
Of these, you should almost always use outer join fetching. But let’s consider the alternatives first.
7.4. Batch fetching and subselect fetching
Consider the following code:
List<Book> books =
session.createSelectionQuery("from Book order by isbn", Book.class)
.getResultList();
books.forEach(book -> book.getAuthors().forEach(author -> out.println(book.title + " by " + author.name)));This code is very inefficient, resulting, by default, in the execution of N+1 select statements, where n is the number of Books.
Let’s see how we can improve on that.
SQL for batch fetching
With batch fetching enabled, Hibernate might execute the following SQL on PostgreSQL:
/* initial query for Books */
select b1_0.isbn,b1_0.price,b1_0.published,b1_0.publisher_id,b1_0.title
from Book b1_0
order by b1_0.isbn
/* first batch of associated Authors */
select a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name
from Book_Author a1_0
join Author a1_1 on a1_1.id=a1_0.authors_id
where a1_0.books_isbn = any (?)
/* second batch of associated Authors */
select a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name
from Book_Author a1_0
join Author a1_1 on a1_1.id=a1_0.authors_id
where a1_0.books_isbn = any (?)The first select statement queries and retrieves Books.
The second and third queries fetch the associated Authors in batches.
The number of batches required depends on the configured batch size.
Here, two batches were required, so two SQL statements were executed.
|
The SQL for batch fetching looks slightly different depending on the database.
Here, on PostgreSQL, Hibernate passes a batch of primary key values as a SQL |
SQL for subselect fetching
On the other hand, with subselect fetching, Hibernate would execute this SQL:
/* initial query for Books */
select b1_0.isbn,b1_0.price,b1_0.published,b1_0.publisher_id,b1_0.title
from Book b1_0
order by b1_0.isbn
/* fetch all associated Authors */
select a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name
from Book_Author a1_0
join Author a1_1 on a1_1.id=a1_0.authors_id
where a1_0.books_isbn in (select b1_0.isbn from Book b1_0)Notice that the first query is re-executed in a subselect in the second query. The execution of the subselect is likely to be relatively inexpensive, since the data should already be cached by the database. Clever, huh?
Enabling the use of batch or subselect fetching
Both batch fetching and subselect fetching are disabled by default, but we may enable one or the other globally using properties.
| Configuration property name | Property value | Alternatives |
|---|---|---|
|
A sensible batch size |
|
|
|
|
Alternatively, we can enable one or the other in a given session:
session.setFetchBatchSize(5);
session.setSubselectFetchingEnabled(true);|
We may request subselect fetching more selectively by annotating a collection or many-valued association with the Note that Later, we’ll see how we can use fetch profiles to do this even more selectively. |
That’s all there is to it. Too easy, right?
Sadly, that’s not the end of the story. While batch fetching might mitigate problems involving N+1 selects, it won’t solve them. The truly correct solution is to fetch associations using joins. Batch fetching (or subselect fetching) can only be the best solution in rare cases where outer join fetching would result in a cartesian product and a huge result set.
But batch fetching and subselect fetching have one important characteristic in common: they can be performed lazily. This is, in principle, pretty convenient. When we query data, and then navigate an object graph, lazy fetching saves us the effort of planning ahead. It turns out that this is a convenience we’re going to have to surrender.
7.5. Join fetching
Outer join fetching is usually the best way to fetch associations, and it’s what we use most of the time. Unfortunately, by its very nature, join fetching simply can’t be lazy. So to make use of join fetching, we must plan ahead. Our general advice is:
| Avoid the use of lazy fetching, which is often the source of N+1 selects. |
Now, we’re not saying that associations should be mapped for eager fetching by default! That would be a terrible idea, resulting in simple session operations that fetch almost the entire database. Therefore:
| Most associations should be mapped for lazy fetching by default. |
It sounds as if this tip is in contradiction to the previous one, but it’s not. It’s saying that you must explicitly specify eager fetching for associations precisely when and where they are needed.
If we need eager join fetching in some particular transaction, we have four different ways to specify that.
Passing a JPA |
We’ve already seen this in Entity graphs and eager fetching |
Specifying a named fetch profile |
We’ll discuss this approach later in Named fetch profiles |
Using |
See A Guide to Hibernate Query Language for details |
Using |
Same semantics as |
Typically, a query is the most convenient option. Here’s how we can ask for join fetching in HQL:
List<Book> booksWithJoinFetchedAuthors =
session.createSelectionQuery("from Book join fetch authors order by isbn")
.getResultList();And this is the same query, written using the criteria API:
var builder = sessionFactory.getCriteriaBuilder();
var query = builder.createQuery(Book.class);
var book = query.from(Book.class);
book.fetch(Book_.authors);
query.select(book);
query.orderBy(builder.asc(book.get(Book_.isbn)));
List<Book> booksWithJoinFetchedAuthors =
session.createSelectionQuery(query).getResultList();Either way, a single SQL select statement is executed:
select b1_0.isbn,a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name,b1_0.price,b1_0.published,b1_0.publisher_id,b1_0.title
from Book b1_0
join (Book_Author a1_0 join Author a1_1 on a1_1.id=a1_0.authors_id)
on b1_0.isbn=a1_0.books_isbn
order by b1_0.isbnMuch better!
Join fetching, despite its non-lazy nature, is clearly more efficient than either batch or subselect fetching, and this is the source of our recommendation to avoid the use of lazy fetching.
|
There’s one interesting case where join fetching becomes inefficient: when we fetch two many-valued associations in parallel.
Imagine we wanted to fetch both |
Of course, an alternative way to avoid many round trips to the database is to cache the data we need in the Java client. If we’re expecting to find the associated data in a local cache, we probably don’t need join fetching at all.
|
But what if we can’t be certain that all associated data will be in the cache? In that case, we might be able to reduce the cost of cache misses by enabling batch fetching. |
7.6. The second-level cache
A classic way to reduce the number of accesses to the database is to use a second-level cache, allowing data cached in memory to be shared between sessions.
By nature, a second-level cache tends to undermine the ACID properties of transaction processing in a relational database. We don’t use a distributed transaction with two-phase commit to ensure that changes to the cache and database happen atomically. So a second-level cache is often by far the easiest way to improve the performance of a system, but only at the cost of making it much more difficult to reason about concurrency. And so the cache is a potential source of bugs which are difficult to isolate and reproduce.
Therefore, by default, an entity is not eligible for storage in the second-level cache.
We must explicitly mark each entity that will be stored in the second-level cache with the @Cache annotation from org.hibernate.annotations.
But that’s still not enough. Hibernate does not itself contain an implementation of a second-level cache, so it’s necessary to configure an external cache provider.
|
Caching is disabled by default. To minimize the risk of data loss, we force you to stop and think before any entity goes into the cache. |
Hibernate segments the second-level cache into named regions, one for each:
-
mapped entity hierarchy or
-
collection role.
For example, there might be separate cache regions for Author, Book, Author.books, and Book.authors.
Each region is permitted its own policies for expiry, persistence, and replication. These policies must be configured externally to Hibernate.
The appropriate policies depend on the kind of data an entity represents. For example, a program might have different caching policies for "reference" data, for transactional data, and for data used for analytics. Ordinarily, the implementation of those policies is the responsibility of the underlying cache implementation.
7.7. Specifying which data is cached
By default, no data is eligible for storage in the second-level cache.
An entity hierarchy or collection role may be assigned a region using the @Cache annotation.
If no region name is explicitly specified, the region name is just the name of the entity class or collection role.
@Entity
@Cache(usage=NONSTRICT_READ_WRITE, region="Publishers")
class Publisher {
...
@Cache(usage=READ_WRITE, region="PublishedBooks")
@OneToMany(mappedBy=Book_.PUBLISHER)
Set<Book> books;
...
}The cache defined by a @Cache annotation is automatically utilized by Hibernate to:
-
retrieve an entity by id when
find()is called, or -
to resolve an association by id.
|
The |
The @Cache annotation always specifies a CacheConcurrencyStrategy, a policy governing access to the second-level cache by concurrent transactions.
| Concurrency policy | Interpretation | Explanation |
|---|---|---|
|
|
Indicates that the cached object is immutable, and is never updated. If an entity with this cache concurrency is updated, an exception is thrown. This is the simplest, safest, and best-performing cache concurrency strategy. It’s particularly suitable for so-called "reference" data. |
|
|
Indicates that the cached object is sometimes updated, but that it’s extremely unlikely that two transactions will attempt to update the same item of data at the same time. This strategy does not use locks. When an item is updated, the cache is invalidated both before and after completion of the updating transaction. But without locking, it’s impossible to completely rule out the possibility of a second transaction storing or retrieving stale data in or from the cache during the completion process of the first transaction. |
|
|
Indicates a non-vanishing likelihood that two concurrent transactions attempt to update the same item of data simultaneously. This strategy uses "soft" locks to prevent concurrent transactions from retrieving or storing a stale item from or in the cache during the transaction completion process. A soft lock is simply a marker entry placed in the cache while the updating transaction completes.
|
|
|
Indicates that concurrent writes are common, and the only way to maintain synchronization between the second-level cache and the database is via the use of a fully transactional cache provider. In this case, the cache and the database must cooperate via JTA or the XA protocol, and Hibernate itself takes on little responsibility for maintaining the integrity of the cache. |
Which policies make sense may also depend on the underlying second-level cache implementation.
|
JPA has a similar annotation, named
|
7.8. Caching by natural id
If our entity has a natural id, we can enable an additional cache, which holds cross-references from natural id to primary id, by annotating the entity @NaturalIdCache.
By default, the natural id cache is stored in a dedicated region of the second-level cache, separate from the cached entity data.
@Entity
@Cache(usage=READ_WRITE, region="Book")
@NaturalIdCache(region="BookIsbn")
class Book {
...
@NaturalId
String isbn;
@NaturalId
int printing;
...
}This cache is utilized when the entity is retrieved using one of the operations of Session which performs lookup by natural id.
|
Since the natural id cache doesn’t contain the actual state of the entity, it doesn’t make sense to annotate an entity |
It’s worth noticing that, unlike the primary identifier of an entity, a natural id might be mutable.
We must now consider a subtlety that often arises when we have to deal with so-called "reference data", that is, data which fits easily in memory, and doesn’t change much.
7.9. Caching and association fetching
Let’s consider again our Publisher class:
@Cache(usage=NONSTRICT_READ_WRITE, region="Publishers")
@Entity
class Publisher { ... }Data about publishers doesn’t change very often, and there aren’t so many of them. Suppose we’ve set everything up so that the publishers are almost always available in the second-level cache.
Then in this case we need to think carefully about associations of type Publisher.
@ManyToOne
Publisher publisher;There’s no need for this association to be lazily fetched, since we’re expecting it to be available in memory, so we won’t set it fetch=LAZY.
But on the other hand, if we leave it marked for eager fetching then, by default, Hibernate will often fetch it using a join.
This places completely unnecessary load on the database.
The solution is the @Fetch annotation:
@ManyToOne @Fetch(SELECT)
Publisher publisher;By annotating the association @Fetch(SELECT), we suppress join fetching, giving Hibernate a chance to find the associated Publisher in the cache.
Therefore, we arrive at this rule of thumb:
|
Many-to-one associations to "reference data", or to any other data that will almost always be available in the cache, should be mapped Other associations, as we’ve already made clear, should be |
Once we’ve marked an entity or collection as eligible for storage in the second-level cache, we still need to set up an actual cache.
7.10. Configuring the second-level cache provider
Configuring a second-level cache provider is a rather involved topic, and quite outside the scope of this document. But in case it helps, we often test Hibernate with the following configuration, which uses EHCache as the cache implementation, as above in Optional dependencies:
| Configuration property name | Property value |
|---|---|
|
|
|
|
If you’re using EHCache, you’ll also need to include an ehcache.xml file
that explicitly configures the behavior of each cache region belonging to
your entities and collections.
You’ll find more information about configuring EHCache here.
We may use any other implementation of JCache, such as Caffeine. JCache automatically selects whichever implementation it finds on the classpath. If there are multiple implementations on the classpath, we must disambiguate using:
| Configuration property name | Property value | ||||
|---|---|---|---|---|---|
|
The implementation of
|
Alternatively, to use Infinispan as the cache implementation, the following settings are required:
| Configuration property name | Property value | ||||
|---|---|---|---|---|---|
|
|
||||
|
Path to infinispan configuration file, for example:
|
Infinispan is usually used when distributed caching is required. There’s more about using Infinispan with Hibernate here.
Finally, there’s a way to globally disable the second-level cache:
| Configuration property name | Property value |
|---|---|
|
|
When hibernate.cache.region.factory_class is set, this property defaults to true.
|
This setting lets us easily disable the second-level cache completely when troubleshooting or profiling performance. |
You can find much more information about the second-level cache in the User Guide.
7.11. Caching query result sets
The caches we’ve described above are only used to optimize lookups by id or by natural id. Hibernate also has a way to cache the result sets of queries, though this is only rarely an efficient thing to do.
The query cache must be enabled explicitly:
| Configuration property name | Property value |
|---|---|
|
|
To cache the results of a query, call SelectionQuery.setCacheable(true):
session.createQuery("from Product where discontinued = false")
.setCacheable(true)
.getResultList();By default, the query result set is stored in a cache region named default-query-results-region.
Since different queries should have different caching policies, it’s common to explicitly specify a region name:
session.createQuery("from Product where discontinued = false")
.setCacheable(true)
.setCacheRegion("ProductCatalog")
.getResultList();A result set is cached together with a logical timestamp. By "logical", we mean that it doesn’t actually increase linearly with time, and in particular it’s not the system time.
When a Product is updated, Hibernate does not go through the query cache and invalidate every cached result set that’s affected by the change.
Instead, there’s a special region of the cache which holds a logical timestamp of the most-recent update to each table.
This is called the update timestamps cache, and it’s kept in the region default-update-timestamps-region.
|
It’s your responsibility to ensure that this cache region is configured with appropriate policies. In particular, update timestamps should never expire or be evicted. |
When a query result set is read from the cache, Hibernate compares its timestamp with the timestamp of each of the tables that affect the results of the query, and only returns the result set if the result set isn’t stale. If the result set is stale, Hibernate goes ahead and re-executes the query against the database and updates the cached result set.
As is generally the case with any second-level cache, the query cache can break the ACID properties of transactions.
7.12. Second-level cache management
For the most part, the second-level cache is transparent. Program logic which interacts with the Hibernate session is unaware of the cache, and is not impacted by changes to caching policies.
At worst, interaction with the cache may be controlled by specifying of an explicit CacheMode:
session.setCacheMode(CacheMode.IGNORE);Or, using JPA-standard APIs:
entityManager.setCacheRetrieveMode(CacheRetrieveMode.BYPASS);
entityManager.setCacheStoreMode(CacheStoreMode.BYPASS);The JPA-defined cache modes come in two flavors: CacheRetrieveMode and CacheStoreMode.
| Mode | Interpretation |
|---|---|
|
Read data from the cache if available |
|
Don’t read data from the cache; go direct to the database |
We might select CacheRetrieveMode.BYPASS if we’re concerned about the possibility of reading stale data from the cache.
| Mode | Interpretation |
|---|---|
|
Write data to the cache when read from the database or when modified; do not update already-cached items when reading |
|
Write data to the cache when read from the database or when modified; always update cached items when reading |
|
Don’t write data to the cache |
We should select CacheStoreMode.BYPASS if we’re querying data that doesn’t need to be cached.
|
It’s a good idea to set the |
In JPA we would use this idiom:
entityManager.setCacheStoreMode(CacheStoreMode.BYPASS);
List<Publisher> allpubs =
entityManager.createQuery("from Publisher", Publisher.class)
.getResultList();
entityManager.setCacheStoreMode(CacheStoreMode.USE);But Hibernate has a better way:
List<Publisher> allpubs =
session.createSelectionQuery("from Publisher", Publisher.class)
.setCacheStoreMode(CacheStoreMode.BYPASS)
.getResultList();A Hibernate CacheMode packages a CacheRetrieveMode with a CacheStoreMode.
Hibernate CacheMode |
Equivalent JPA modes |
|---|---|
|
|
|
|
|
|
|
|
|
|
There’s no particular reason to prefer Hibernate’s CacheMode over the JPA equivalents.
This enumeration only exists because Hibernate had cache modes long before they were added to JPA.
|
For "reference" data, that is, for data which is expected to always be found in the second-level cache, it’s a good idea to prime the cache at startup.
There’s a really easy way to do this: just execute a query immediately after obtaining the
|
Very occasionally, it’s necessary or advantageous to control the cache explicitly, for example, to evict some data that we know to be stale.
The Cache interface allows programmatic eviction of cached items.
sessionFactory.getCache().evictEntityData(Book.class, bookId);|
Second-level cache management via the |
Ordinarily, however, Hibernate automatically evicts or updates cached data after modifications, and, in addition, cached data which is unused will eventually be expired according to the configured policies.
This is quite different to what happens with the first-level cache.
7.13. Session cache management
Entity instances aren’t automatically evicted from the session cache when they’re no longer needed. Instead, they stay pinned in memory until the session they belong to is discarded by your program.
The methods detach() and clear() allow you to remove entities from the session cache, making them available for garbage collection.
Since most sessions are rather short-lived, you won’t need these operations very often.
And if you find yourself thinking you do need them in a certain situation, you should strongly consider an alternative solution: a stateless session.
7.14. Stateless sessions
An arguably-underappreciated feature of Hibernate is the StatelessSession interface, which provides a command-oriented, more bare-metal approach to interacting with the database.
You may obtain a stateless session from the SessionFactory:
StatelessSession ss = getSessionFactory().openStatelessSession();A stateless session:
-
doesn’t have a first-level cache (persistence context), nor does it interact with any second-level caches, and
-
doesn’t implement transactional write-behind or automatic dirty checking, so all operations are executed immediately when they’re explicitly called.
For a stateless session, we’re always working with detached objects. Thus, the programming model is a bit different:
| Method name and parameters | Effect |
|---|---|
|
Obtain a detached object, given its type and its id, by executing a |
|
Fetch an association of a detached object |
|
Refresh the state of a detached object by executing
a |
|
Immediately |
|
Immediately |
|
Immediately |
|
Immediately |
There’s no flush() operation, and so update() is always explicit.
|
In certain circumstances, this makes stateless sessions easier to work with, but with the caveat that a stateless session is much more vulnerable to data aliasing effects, since it’s easy to get two non-identical Java objects which both represent the same row of a database table.
|
If we use |
In particular, the absence of a persistence context means that we can safely perform bulk-processing tasks without allocating huge quantities of memory.
Use of a StatelessSession alleviates the need to call:
-
clear()ordetach()to perform first-level cache management, and -
setCacheMode()to bypass interaction with the second-level cache.
|
Stateless sessions can be useful, but for bulk operations on huge datasets, Hibernate can’t possibly compete with stored procedures! |
When using a stateless session, you should be aware of the following additional limitations:
-
persistence operations never cascade to associated instances,
-
changes to
@ManyToManyassociations and@ElementCollections cannot be made persistent, and -
operations performed via a stateless session bypass callbacks.
7.15. Optimistic and pessimistic locking
Finally, an aspect of behavior under load that we didn’t mention above is row-level data contention. When many transactions try to read and update the same data, the program might become unresponsive with lock escalation, deadlocks, and lock acquisition timeout errors.
There’s two basic approaches to data concurrency in Hibernate:
-
optimistic locking using
@Versioncolumns, and -
database-level pessimistic locking using the SQL
for updatesyntax (or equivalent).
In the Hibernate community it’s much more common to use optimistic locking, and Hibernate makes that incredibly easy.
|
Where possible, in a multiuser system, avoid holding a pessimistic lock across a user interaction. Indeed, the usual practice is to avoid having transactions that span user interactions. For multiuser systems, optimistic locking is king. |
That said, there is also a place for pessimistic locks, which can sometimes reduce the probability of transaction rollbacks.
Therefore, the find(), lock(), and refresh() methods of the reactive session accept an optional LockMode.
We can also specify a LockMode for a query.
The lock mode can be used to request a pessimistic lock, or to customize the behavior of optimistic locking:
LockMode type |
Meaning |
|---|---|
|
An optimistic lock obtained implicitly whenever
an entity is read from the database using |
|
An optimistic lock obtained when an entity is
read from the database, and verified using a
|
|
An optimistic lock obtained when an entity is
read from the database, and enforced using an
|
|
A pessimistic lock obtained implicitly whenever
an entity is written to the database using
|
|
A pessimistic |
|
A pessimistic |
|
A pessimistic lock enforced using an immediate
|
7.16. Collecting statistics
We may ask Hibernate to collect statistics about its activity by setting this configuration property:
| Configuration property name | Property value |
|---|---|
|
|
The statistics are exposed by the Statistics object:
long failedVersionChecks =
sessionFactory.getStatistics()
.getOptimisticFailureCount();
long publisherCacheMissCount =
sessionFactory.getStatistics()
.getEntityStatistics(Publisher.class.getName())
.getCacheMissCount()Hibernate’s statistics enable observability. Both Micrometer and SmallRye Metrics are capable of exposing these metrics.
7.17. Tracking down slow queries
When a poorly-performing SQL query is discovered in production, it can sometimes be hard to track down exactly where in the Java code the query originates. Hibernate offers two configuration properties that can make it easier to identify a slow query and find its source.
| Configuration property name | Purpose | Property value |
|---|---|---|
|
Log slow queries at the |
The minimum execution time, in milliseconds, which characterizes a "slow" query |
|
Prepend comments to the executed SQL |
|
When hibernate.use_sql_comments is enabled, the text of the HQL query is prepended as a comment to the generated SQL, which usually makes it easy to find the HQL in the Java code.
The comment text may be customized:
-
by calling
Query.setComment(comment)orQuery.setHint(AvailableHints.HINT_COMMENT,comment), or -
via the
@NamedQueryannotation.
|
Once you’ve identified a slow query, one of the best ways to make it faster is to actually go and talk to someone who is an expert at making queries go fast. These people are called "database administrators", and if you’re reading this document you probably aren’t one. Database administrators know lots of stuff that Java developers don’t. So if you’re lucky enough to have a DBA about, you don’t need to Dunning-Kruger your way out of a slow query. |
An expertly-defined index might be all you need to fix a slow query.
7.18. Adding indexes
The @Index annotation may be used to add an index to a table:
@Entity
@Table(indexes=@Index(columnList="title, year, publisher_id"))
class Book { ... }It’s even possible to specify an ordering for an indexed column, or that the index should be case-insensitive:
@Entity
@Table(indexes=@Index(columnList="(lower(title)), year desc, publisher_id"))
class Book { ... }This lets us create a customized index for a particular query.
Note that SQL expressions like lower(title) must be enclosed in parentheses in the columnList of the index definition.
|
It’s not clear that information about indexes belongs in annotations of Java code.
Indexes are usually maintained and modified by a database administrator, ideally by an expert in tuning the performance of one particular RDBMS.
So it might be better to keep the definition of indexes in a SQL DDL script that your DBA can easily read and modify.
Remember, we can ask Hibernate to execute a DDL script using the property |
7.19. Dealing with denormalized data
A typical relational database table in a well-normalized schema has a relatively small number of columns, and so there’s little to be gained by selectively querying columns and populating only certain fields of an entity class.
But occasionally, we hear from someone asking how to map a table with a hundred columns or more! This situation can arise when:
-
data is intentionally denormalized for performance,
-
the results of a complicated analytic query are exposed via a view, or
-
someone has done something crazy and wrong.
Let’s suppose that we’re not dealing with the last possibility. Then we would like to be able to query the monster table without returning all of its columns. At first glance, Hibernate doesn’t offer a perfect bottled solution to this problem. This first impression is misleading. Actually, Hibernate features more than one way to deal with this situation, and the real problem is deciding between the ways. We could:
-
map multiple entity classes to the same table or view, being careful about "overlaps" where a mutable column is mapped to more than one of the entities,
-
use HQL or native SQL queries returning results into record types instead of retrieving entity instances, or
-
use the bytecode enhancer and
@LazyGroupfor attribute-level lazy fetching.
Some other ORM solutions push the third option as the recommended way to handle huge tables, but this has never been the preference of the Hibernate team or Hibernate community. It’s much more typesafe to use one of the first two options.
7.20. Reactive programming with Hibernate
Finally, many systems which require high scalability now make use of reactive programming and reactive streams. Hibernate Reactive brings O/R mapping to the world of reactive programming. You can learn much more about Hibernate Reactive from its Reference Documentation.
|
Hibernate Reactive may be used alongside vanilla Hibernate in the same program, and can reuse the same entity classes. This means you can use the reactive programming model exactly where you need it—perhaps only in one or two places in your system. You don’t need to rewrite your whole program using reactive streams. |
8. Advanced Topics
In the last chapter of this Introduction, we turn to some topics that don’t really belong in an introduction. Here we consider some problems, and solutions, that you’re probably not going to run into immediately if you’re new to Hibernate. But we do want you to know about them, so that when the time comes, you’ll know what tool to reach for.
8.1. Filters
Filters are one of the nicest and under-usedest features of Hibernate, and we’re quite proud of them. A filter is a named, globally-defined, parameterized restriction on the data that is visible in a given session.
Examples of well-defined filters might include:
-
a filter that restricts the data visible to a given user according to row-level permissions,
-
a filter which hides data which has been soft-deleted,
-
in a versioned database, a filter that displays versions which were current at a given instant in the past, or
-
a filter that restricts to data associated with a certain geographical region.
A filter must be declared somewhere.
A package descriptor is as good a place as any for a @FilterDef:
@FilterDef(name = "ByRegion",
parameters = @ParamDef(name = "region", type = String.class))
package org.hibernate.example;This filter has one parameter. Fancier filters might in principle have multiple parameters, though we admit this must be quite rare.
|
If you add annotations to a package descriptor, and you’re using |
Typically, but not necessarily, a @FilterDef specifies a default restriction:
@FilterDef(name = "ByRegion",
parameters = @ParamDef(name = "region", type = String.class),
defaultCondition = "region = :region")
package org.hibernate.example;The restriction must contain a reference to the parameter of the filter, specified using the usual syntax for named parameters.
Any entity or collection which is affected by a filter must be annotated @Filter:
@Entity
@Filter(name = example_.BY_REGION)
class User {
@Id String username;
String region;
...
}Here, as usual, example_.BY_REGION is generated by the Metamodel Generator, and is just a constant with the value "ByRegion".
If the @Filter annotation does not explicitly specify a restriction, the default restriction given by the @FilterDef will be applied to the entity.
But an entity is free to override the default condition.
@Entity
@Filter(name = example_.FILTER_BY_REGION, condition = "name = :region")
class Region {
@Id String name;
...
}Note that the restriction specified by the condition or defaultCondition is a native SQL expression.
| Annotation | Purpose |
|---|---|
|
Defines a filter and declares its name (exactly one per filter) |
|
Specifies how a filter applies to a given entity or collection (many per filter) |
By default, a new session comes with every filter disabled.
A filter may be explicitly enabled in a given session by calling enableFilter() and assigning arguments to the parameters of the filter.
You should do this right at the start of the session.
sessionFactory.inTransaction(session -> {
session.enableFilter(example_.FILTER_BY_REGION)
.setParameter("region", "es")
.validate();
...
});Now, any queries executed within the session will have the filter restriction applied.
Collections annotated @Filter will also have their members correctly filtered.
|
On the other hand, filters are not applied to |
More than one filter may be enabled in a given session.
|
When we only need to filter rows by a static condition with no parameters, we don’t need a filter, since |
We’ve mentioned that a filter can be used to implement versioning, and to provide historical views of the data. Being such a general-purpose construct, filters provide a lot of flexibility here. But if you’re after a more focused/opinionated solution to this problem, you should definitely check out Envers.
Another closely-related problem is multi-tenancy.
8.2. Multi-tenancy
A multi-tenant database is one where the data is segregated by tenant. We don’t need to actually define what a "tenant" really represents here; all we care about at this level of abstraction is that each tenant may be distinguished by a unique identifier. And that there’s a well-defined current tenant in each session.
We may specify the current tenant when we open a session:
var session =
sessionFactory.withOptions()
.tenantIdentifier(tenantId)
.openSession();Or, when using JPA-standard APIs:
var entityManager =
entityManagerFactory.createEntityManager(Map.of(HibernateHints.HINT_TENANT_ID, tenantId));However, since we often don’t have this level of control over creation of the session, it’s more common to supply an implementation of CurrentTenantIdentifierResolver to Hibernate.
There are three common ways to implement multi-tenancy:
-
each tenant has its own database,
-
each tenant has its own schema, or
-
tenants share tables in a single schema, and rows are tagged with the tenant id.
From the point of view of Hibernate, there’s little difference between the first two options. Hibernate will need to obtain a JDBC connection with permissions on the database and schema owned by the current tenant.
Therefore, we must implement a MultiTenantConnectionProvider which takes on this responsibility:
-
from time to time, Hibernate will ask for a connection, passing the id of the current tenant, and then we must create an appropriate connection or obtain one from a pool, and return it to Hibernate, and
-
later, Hibernate will release the connection and ask us to destroy it or return it to the appropriate pool.
|
Check out |
The third option is quite different.
In this case we don’t need a MultiTenantConnectionProvider, but we will need a dedicated column holding the tenant id mapped by each of our entities.
@Entity
class Account {
@Id String id;
@TenantId String tenantId;
...
}The @TenantId annotation is used to indicate an attribute of an entity which holds the tenant id.
Within a given session, our data is automatically filtered so that only rows tagged with the tenant id of the current tenant are visible in that session.
|
Native SQL queries are not automatically filtered by tenant id; you’ll have to do that part yourself. |
To make use of multi-tenancy, we’ll usually need to set at least one of these configuration properties:
| Configuration property name | Purpose |
|---|---|
|
Specifies the |
|
Specifies the |
8.3. Using custom-written SQL
We’ve already discussed how to run queries written in SQL, but occasionally that’s not enough. Sometimes—but much less often than you might expect—we would like to customize the SQL used by Hibernate to perform basic CRUD operations for an entity or collection.
For this we can use @SQLInsert and friends:
@Entity
@SQLInsert(sql = "insert into person (name, id, valid) values (?, ?, true)", check = COUNT)
@SQLUpdate(sql = "update person set name = ? where id = ?")
@SQLDelete(sql = "update person set valid = false where id = ?")
@SQLSelect(sql = "select id, name from person where id = ? and valid = true")
public static class Person { ... }|
If the custom SQL should be executed via a |
Any SQL statement specified by one of these annotations must have exactly the number of JDBC parameters that Hibernate expects, that is, one for each column mapped by the entity, in the exact order Hibernate expects. In particular, the primary key columns must come last.
However, the @Column annotation does lend some flexibility here:
-
if a column should not be written as part of the custom
insertstatement, and has no corresponding JDBC parameter in the custom SQL, map it@Column(insertable=false), or -
if a column should not be written as part of the custom
updatestatement, and has no corresponding JDBC parameter in the custom SQL, map it@Column(updatable=false).
|
If you need custom SQL, but are targeting multiple dialects of SQL, you can use the annotations defined in It’s even possible to override the custom SQL for specific versions of a database. |
Sometimes a custom insert or update statement assigns a value to a mapped column which is calculated when the statement is executed on the database.
For example, the value might be obtained by calling a SQL function:
@SQLInsert(sql = "insert into person (name, id) values (?, gen_random_uuid())")But the entity instance which represents the row being inserted or updated won’t be automatically populated with that value.
And so our persistence context loses synchronization with the database.
In situations like this, we may use the @Generated annotation to tell Hibernate to reread the state of the entity after each insert or update.
8.4. Handling database-generated columns
Sometimes, a column value is assigned or mutated by events that happen in the database, and aren’t visible to Hibernate. For example:
-
a table might have a column value populated by a trigger,
-
a mapped column might have a default value defined in DDL, or
-
a custom SQL
insertorupdatestatement might assign a value to a mapped column, as we saw in the previous subsection.
One way to deal with this situation is to explicitly call refresh() at appropriate moments, forcing the session to reread the state of the entity.
But this is annoying.
The @Generated annotation relieves us of the burden of explicitly calling refresh().
It specifies that the value of the annotated entity attribute is generated by the database, and that the generated value should be automatically retrieved using a SQL returning clause, or separate select after it is generated.
A useful example is the following mapping:
@Entity
class Entity {
@Generated @Id
@ColumnDefault("gen_random_uuid()")
UUID id;
}The generated DDL is:
create table Entity (
id uuid default gen_random_uuid() not null,
primary key (uuid)
)So here the value of id is defined by the column default clause, by calling the PostgreSQL function gen_random_uuid().
When a column value is generated during updates, use @Generated(event=UPDATE).
When a value is generated by both inserts and updates, use @Generated(event={INSERT,UPDATE}).
|
For columns which should be generated using a SQL |
Actually, the @Generated and @GeneratedColumn annotations are defined in terms of a more generic and user-extensible framework for handling attribute values generated in Java, or by the database.
So let’s drop down a layer, and see how that works.
8.5. User-defined generators
JPA doesn’t define a standard way to extend the set of id generation strategies, but Hibernate does:
-
the
Generatorhierarchy of interfaces in the packageorg.hibernate.generatorlets you define new generators, and -
the
@IdGeneratorTypemeta-annotation from the packageorg.hibernate.annotationslets you write an annotation which associates aGeneratortype with identifier attributes.
Furthermore, the @ValueGenerationType meta-annotation lets you write an annotation which associates a Generator type with a non-@Id attribute.
|
These APIs are new in Hibernate 6, and supersede the classic |
Hibernate has a range of built-in generators which are defined in terms of this new framework.
| Annotation | Implementation | Purpose |
|---|---|---|
|
|
Generically handles database-generated values |
|
|
Handles values generated using |
|
|
Generic support for database or in-memory generation of creation or update timestamps |
|
|
A timestamp generated when an entity is first made persistent |
|
|
A timestamp generated when an entity is made persistent, and regenerated every time the entity is modified |
|
|
A more flexible generator for RFC 4122 UUIDs |
Furthermore, support for JPA’s standard id generation strategies is also defined in terms of this framework.
As an example, let’s look at how @UuidGenerator is defined:
@IdGeneratorType(org.hibernate.id.uuid.UuidGenerator.class)
@ValueGenerationType(generatedBy = org.hibernate.id.uuid.UuidGenerator.class)
@Retention(RUNTIME)
@Target({ FIELD, METHOD })
public @interface UuidGenerator { ... }@UuidGenerator is meta-annotated both @IdGeneratorType and @ValueGenerationType because it may be used to generate both ids and values of regular attributes.
Either way, this Generator class does the hard work:
public class UuidGenerator
// this generator produced values before SQL is executed
implements BeforeExecutionGenerator {
// constructors accept an instance of the @UuidGenerator
// annotation, allowing the generator to be "configured"
// called to create an id generator
public UuidGenerator(
org.hibernate.annotations.UuidGenerator config,
Member idMember,
CustomIdGeneratorCreationContext creationContext) {
this(config, idMember);
}
// called to create a generator for a regular attribute
public UuidGenerator(
org.hibernate.annotations.UuidGenerator config,
Member member,
GeneratorCreationContext creationContext) {
this(config, idMember);
}
...
@Override
public EnumSet<EventType> getEventTypes() {
// UUIDs are only assigned on insert, and never regenerated
return INSERT_ONLY;
}
@Override
public Object generate(SharedSessionContractImplementor session, Object owner, Object currentValue, EventType eventType) {
// actually generate a UUID and transform it to the required type
return valueTransformer.transform( generator.generateUuid( session ) );
}
}You can find out more about custom generators from the Javadoc for @IdGeneratorType and for org.hibernate.generator.
8.6. Naming strategies
When working with a pre-existing relational schema, it’s usual to find that the column and table naming conventions used in the schema don’t match Java’s naming conventions.
Of course, the @Table and @Column annotations let us explicitly specify a mapped table or column name.
But we would prefer to avoid scattering these annotations across our whole domain model.
Therefore, Hibernate lets us define a mapping between Java naming conventions, and the naming conventions of the relational schema. Such a mapping is called a naming strategy.
First, we need to understand how Hibernate assigns and processes names.
-
Logical naming is the process of applying naming rules to determine the logical names of objects which were not explicitly assigned names in the O/R mapping. That is, when there’s no
@Tableor@Columnannotation. -
Physical naming is the process of applying additional rules to transform a logical name into an actual "physical" name that will be used in the database. For example, the rules might include things like using standardized abbreviations, or trimming the length of identifiers.
Thus, there’s two flavors of naming strategy, with slightly different responsibilities. Hibernate comes with default implementations of these interfaces:
| Flavor | Default implementation |
|---|---|
An |
A default strategy which implements the rules defined by JPA |
A |
A trivial implementation which does no processing |
|
We happen to not much like the naming rules defined by JPA, which specify that mixed case and camel case identifiers should be concatenated using underscores.
We bet you could easily come up with a much better |
|
A popular |
Custom naming strategies may be enabled using the configuration properties we already mentioned without much explanation back in Minimizing repetitive mapping information.
| Configuration property name | Purpose |
|---|---|
|
Specifies the |
|
Specifies the |
8.7. Spatial datatypes
Hibernate Spatial augments the built-in basic types with a set of Java mappings for OGC spatial types.
-
Geolatte-geom defines a set of Java types implementing the OGC spatial types, and codecs for translating to and from database-native spatial datatypes.
-
Hibernate Spatial itself supplies integration with Hibernate.
To use Hibernate Spatial, we must add it as a dependency, as described in Optional dependencies.
Then we may immediately use Geolatte-geom and JTS types in our entities. No special annotations are needed:
import org.locationtech.jts.geom.Point;
import jakarta.persistence.*;
@Entity
class Event {
Event() {}
Event(String name, Point location) {
this.name = name;
this.location = location;
}
@Id @GeneratedValue
Long id;
String name;
Point location;
}The generated DDL uses geometry as the type of the column mapped by location:
create table Event (
id bigint not null,
location geometry,
name varchar(255),
primary key (id)
)Hibernate Spatial lets us work with spatial types just as we would with any of the built-in basic attribute types.
var geometryFactory = new GeometryFactory();
...
Point point = geometryFactory.createPoint(new Coordinate(10, 5));
session.persist(new Event("Hibernate ORM presentation", point));But what makes this powerful is that we may write some very fancy queries involving functions of spatial types:
Polygon triangle =
geometryFactory.createPolygon(
new Coordinate[] {
new Coordinate(9, 4),
new Coordinate(11, 4),
new Coordinate(11, 20),
new Coordinate(9, 4)
}
);
Point event =
session.createQuery("select location from Event where within(location, :zone) = true", Point.class)
.setParameter("zone", triangle)
.getSingleResult();Here, within() is one of the functions for testing spatial relations defined by the OpenGIS specification.
Other such functions include touches(), intersects(), distance(), boundary(), etc.
Not every spatial relation function is supported on every database.
A matrix of support for spatial relation functions may be found in the User Guide.
|
If you want to play with spatial functions on H2, run the following code first: |
8.8. Ordered and sorted collections and map keys
Java lists and maps don’t map very naturally to foreign key relationships between tables, and so we tend to avoid using them to represent associations between our entity classes.
But if you feel like you really need a collection with a fancier structure than Set, Hibernate does have options.
The first three options let us map the index of a List or key of a Map to a column, and are usually used with a @ElementCollection, or on the owning side of an association:
| Annotation | Purpose | JPA-standard |
|---|---|---|
|
Specifies the column used to maintain the order of a list |
✔ |
|
The column value for the first element of the list (zero by default) |
✖ |
|
Specifies the column used to persist the keys of a map (used when the key is of basic type) |
✔ |
|
Specifies the column used to persist the keys of a map (used when the key is an entity) |
✔ |
@ManyToMany
@OrderColumn // order of list is persistent
List<Author> authors = new ArrayList<>();@ElementCollection
@OrderColumn(name="tag_order") @ListIndexBase(1) // order column and base value
List<String> tags;@ElementCollection
@CollectionTable(name = "author_bios", // table name
joinColumns = @JoinColumn(name = "book_isbn")) // column holding foreign key of owner
@Column(name="bio") // column holding map values
@MapKeyJoinColumn(name="author_ssn") // column holding map keys
Map<Author,String> biographies;For a Map representing an unowned @OneToMany association, the column must also be mapped on the owning side, usually by an attribute of the target entity.
In this case we usually use a different annotation:
| Annotation | Purpose | JPA-standard |
|---|---|---|
|
Specifies an attribute of the target entity which acts as the key of the map |
✔ |
@OneToMany(mappedBy = Book_.PUBLISHER)
@MapKey(name = Book_.TITLE) // the key of the map is the title of the book
Map<String,Book> booksByTitle = new HashMap<>();Now, let’s introduce a little distinction:
-
an ordered collection is one with an ordering maintained in the database, and
-
a sorted collection is one which is sorted in Java code.
These annotations allow us to specify how the elements of a collection should be ordered as they are read from the database:
| Annotation | Purpose | JPA-standard |
|---|---|---|
|
Specifies a fragment of JPQL used to order the collection |
✔ |
|
Specifies a fragment of SQL used to order the collection |
✖ |
On the other hand, the following annotations specify how a collection should be sorted in memory, and are used for collections of type SortedSet or SortedMap:
| Annotation | Purpose | JPA-standard |
|---|---|---|
|
Specifies that the elements of a collection are |
✖ |
|
Specifies a |
✖ |
Under the covers, Hibernate uses a TreeSet or TreeMap to maintain the collection in sorted order.
8.9. Any mappings
An @Any mapping is a sort of polymorphic many-to-one association where the target entity types are not related by the usual entity inheritance.
The target type is distinguished using a discriminator value stored on the referring side of the relationship.
This is quite different to discriminated inheritance where the discriminator is held in the tables mapped by the referenced entity hierarchy.
For example, consider an Order entity containing Payment information, where a Payment might be a CashPayment or a CreditCardPayment:
interface Payment { ... }
@Entity
class CashPayment { ... }
@Entity
class CreditCardPayment { ... }In this example, Payment is not be declared as an entity type, and is not annotated @Entity. It might even be an interface, or at most just a mapped superclass, of CashPayment and CreditCardPayment. So in terms of the object/relational mappings, CashPayment and CreditCardPayment would not be considered to participate in the same entity inheritance hierarchy.
On the other hand, CashPayment and CreditCardPayment do have the same identifier type.
This is important.
An @Any mapping would store the discriminator value identifying the concrete type of Payment along with the state of the associated Order, instead of storing it in the table mapped by Payment.
@Entity
class Order {
...
@Any
@AnyKeyJavaClass(UUID.class) //the foreign key type
@JoinColumn(name="payment_id") // the foreign key column
@Column(name="payment_type") // the discriminator column
// map from discriminator values to target entity types
@AnyDiscriminatorValue(discriminator="CASH", entity=CashPayment.class)
@AnyDiscriminatorValue(discriminator="CREDIT", entity=CreditCardPayment.class)
Payment payment;
...
}It’s reasonable to think of the "foreign key" in an @Any mapping as a composite value made up of the foreign key and discriminator taken together. Note, however, that this composite foreign key is only conceptual and cannot be declared as a physical constraint on the relational database table.
There are a number of annotations which are useful to express this sort of complicated and unnatural mapping:
| Annotations | Purpose |
|---|---|
|
Declares that an attribute is a discriminated polymorphic association mapping |
|
Specify the Java type of the discriminator |
|
Specify the JDBC type of the discriminator |
|
Specifies how discriminator values map to entity types |
|
Specify the column or formula in which the discriminator value is stored |
|
Specify the Java type of the foreign key (that is, of the ids of the target entities) |
|
Specify the JDBC type of the foreign key |
|
Specifies the foreign key column |
Of course, @Any mappings are disfavored, except in extremely special cases, since it’s much more difficult to enforce referential integrity at the database level.
There’s also currently some limitations around querying @Any associations in HQL.
This is allowed:
from Order ord
join CashPayment cash
on id(ord.payment) = cash.id|
Polymorphic association joins for |
8.10. Selective column lists in inserts and updates
By default, Hibernate generates insert and update statements for each entity during boostrap, and reuses the same insert statement every time an instance of the entity is made persistent, and the same update statement every time an instance of the entity is modified.
This means that:
-
if an attribute is
nullwhen the entity is made persistent, its mapped column is redundantly included in the SQLinsert, and -
worse, if a certain attribute is unmodified when other attributes are changed, the column mapped by that attribute is redundantly included in the SQL
update.
Most of the time, this just isn’t an issue worth worrying about.
The cost of interacting with the database is usually dominated by the cost of a round trip, not by the number of columns in the insert or update.
But in cases where it does become important, there are two ways to be more selective about which columns are included in the SQL.
The JPA-standard way is to indicate statically which columns are eligible for inclusion via the @Column annotation.
For example, if an entity is always created with an immutable creationDate, and with no completionDate, then we would write:
@Column(updatable=false) LocalDate creationDate;
@Column(insertable=false) LocalDate completionDate;This approach works quite well in many cases, but often breaks down for entities with more than a handful of updatable columns.
An alternative solution is to ask Hibernate to generate SQL dynamically each time an insert or update is executed.
We do this by annotating the entity class.
| Annotation | Purpose |
|---|---|
Specifies that an |
|
Specifies that an |
It’s important to realize that, while @DynamicInsert has no impact on semantics, the more useful @DynamicUpdate annotation does have a subtle side effect.
|
The wrinkle is that if an entity has no version property, |
Of course, this consideration doesn’t arise for entities with a @Version attribute.
|
But there’s a solution!
Well-designed relational schemas should have constraints to ensure data integrity.
That’s true no matter what measures we take to preserve integrity in our program logic.
We may ask Hibernate to add a |
8.11. Using the bytecode enhancer
Hibernate’s bytecode enhancer enables the following features:
-
attribute-level lazy fetching for basic attributes annotated
@Basic(fetch=LAZY)and for lazy non-polymorphic associations, -
interception-based—instead of the usual snapshot-based—detection of modifications.
To use the bytecode enhancer, we must add the Hibernate plugin to our gradle build:
plugins {
id "org.hibernate.orm" version "6.3.0.Final"
}
hibernate { enhancement }Consider this field:
@Entity
class Book {
...
@Basic(optional = false, fetch = LAZY)
@Column(length = LONG32)
String fullText;
...
}The fullText field maps to a clob or text column, depending on the SQL dialect.
Since it’s expensive to retrieve the full book-length text, we’ve mapped the field fetch=LAZY, telling Hibernate not to read the field until it’s actually used.
-
Without the bytecode enhancer, this instruction is ignored, and the field is always fetched immediately, as part of the initial
selectthat retrieves theBookentity. -
With bytecode enhancement, Hibernate is able to detect access to the field, and lazy fetching is possible.
|
By default, Hibernate fetches all lazy fields of a given entity at once, in a single |
Similarly, interception lets us implement lazy fetching for non-polymorphic associations without the need for a separate proxy object. However, if an association is polymorphic, that is, if the target entity type has subclasses, then a proxy is still required.
Interception-based change detection is a nice performance optimization with a slight cost in terms of correctness.
-
Without the bytecode enhancer, Hibernate keeps a snapshot of the state of each entity after reading from or writing to the database. When the session flushes, the snapshot state is compared to the current state of the entity to determine if the entity has been modified. Maintaining these snapshots does have an impact on performance.
-
With bytecode enhancement, we may avoid this cost by intercepting writes to the field and recording these modifications as they happen.
This optimization isn’t completely transparent, however.
|
Interception-based change detection is less accurate than snapshot-based dirty checking. For example, consider this attribute: Interception is able to detect writes to the |
8.12. Named fetch profiles
We’ve already seen two different ways to override the default fetching strategy for an association:
-
JPA entity graphs, and
-
the
join fetchclause in HQL, or, equivalently, the methodFrom.fetch()in the criteria query API.
A third way is to define a named fetch profile. First, we must declare the profile, by annotating a class or package:
@FetchProfile(name = "EagerBook")
@Entity
class Book { ... }Note that even though we’ve placed this annotation on the Book entity, a fetch profile—unlike an entity graph—isn’t "rooted" at any particular entity.
We may specify association fetching strategies using the fetchOverrides member of the @FetchProfile annotation, but frankly it looks so messy that we’re embarrassed to show it to you here.
|
Similarly, a JPA entity graph may be defined using |
A better way is to annotate an association with the fetch profiles it should be fetched in:
@FetchProfile(name = "EagerBook")
@Entity
class Book {
...
@ManyToOne(fetch = LAZY)
@FetchProfileOverride(profile = Book_.PROFILE_EAGER_BOOK, mode = JOIN)
Publisher publisher;
@ManyToMany
@FetchProfileOverride(profile = Book_.PROFILE_EAGER_BOOK, mode = JOIN)
Set<Author> authors;
...
}@Entity
class Author {
...
@OneToOne
@FetchProfileOverride(profile = Book_.PROFILE_EAGER_BOOK, mode = JOIN)
Person person;
...
}Here, once again, Book_.PROFILE_EAGER_BOOK is generated by the Metamodel Generator, and is just a constant with the value "EagerBook".
For collections, we may even request subselect fetching:
@FetchProfile(name = "EagerBook")
@FetchProfile(name = "BookWithAuthorsBySubselect")
@Entity
class Book {
...
@OneToOne
@FetchProfileOverride(profile = Book_.PROFILE_EAGER_BOOK, mode = JOIN)
Person person;
@ManyToMany
@FetchProfileOverride(profile = Book_.PROFILE_EAGER_BOOK, mode = JOIN)
@FetchProfileOverride(profile = Book_.BOOK_WITH_AUTHORS_BY_SUBSELECT,
mode = SUBSELECT)
Set<Author> authors;
...
}We may define as many different fetch profiles as we like.
| Annotation | Purpose |
|---|---|
|
Declares a named fetch profile, optionally including a list of |
|
Declares a fetch strategy override as part of the |
|
Specifies the fetch strategy for the annotated association, in a given fetch profile |
A fetch profile must be explicitly enabled for a given session:
session.enableFetchProfile(Book_.PROFILE_EAGER_BOOK);
Book eagerBook = session.find(Book.class, bookId);So why or when might we prefer named fetch profiles to entity graphs? Well, it’s really hard to say. It’s nice that this feature exists, and if you love it, that’s great. But Hibernate offers alternatives that we think are more compelling most of the time.
The one and only advantage unique to fetch profiles is that they let us very selectively request subselect fetching. We can’t do that with entity graphs, and we can’t do it with HQL.
|
There’s a special built-in fetch profile named Then |
9. Credits
The full list of contributors to Hibernate ORM can be found on the GitHub repository.
The following contributors were involved in this documentation:
-
Gavin King