
Getting Started
Introduction and getting started with jBPM
1. Overview
1.1. What is jBPM?
jBPM is a flexible Business Process Management (BPM) Suite. It is light-weight, fully open-source (distributed under Apache License 2.0) and written in Java. It allows you to model, execute, and monitor business processes and cases throughout their life cycle.
A business process allows you to model your business goals by describing the steps that need to be executed to achieve those goals, and the order of those goals is depicted using a flow chart. This process greatly improves the visibility and agility of your business logic. jBPM focuses on executable business processes, which are business processes that contain enough detail so they can actually be executed on a BPM engine. Executable business processes bridge the gap between business users and developers as they are higher-level and use domain-specific concepts that are understood by business users but can also be executed directly.
Business processes need to be supported throughout their entire life cycle: authoring, deployment, process management and task lists, and dashboards and reporting.
The core of jBPM is a light-weight, extensible workflow engine written in pure Java that allows you to execute business processes using the latest BPMN 2.0 specification. It can run in any Java environment, embedded in your application or as a service.
On top of the core engine, a lot of features and tools are offered to support business processes throughout their entire life cycle:
-
Pluggable human task service based on WS-HumanTask for including tasks that need to be performed by human actors.
-
Pluggable persistence and transactions (based on JPA / JTA).
-
Case management capabilities added to the core engine to support more adaptive and flexible use cases
-
Web-based process designer to support the graphical creation and simulation of your business processes (drag and drop).
-
Web-based data modeler and form modeler to support the creation of data models and task forms
-
Web-based, customizable dashboards and reporting
-
All combined in one web-based workbench, supporting the complete BPM life cycle:
-
Modeling and deployment - author your processes, rules, data models, forms and other assets
-
Execution - execute processes, tasks, rules and events on the core runtime engine
-
Runtime Management - work on assigned task, manage process instances, etc
-
Reporting - keep track of the execution using Business Activity Monitoring capabilities
-
-
Eclipse-based developer tools to support the modeling, testing and debugging of processes
-
Remote API to process engine as a service (REST, JMS, Remote Java API)
-
Integration with Maven, Spring, OSGi, etc.
BPM creates the bridge between business analysts, developers and end users by offering process management features and tools in a way that both business users and developers like. Domain-specific nodes can be plugged into the palette, making the processes more easily understood by business users.
jBPM supports case management by offering more advanced features to support adaptive and dynamic processes that require flexibility to model complex, real-life situations that cannot easily be described using a rigid process. We bring control back to the end users by allowing them to control which parts of the process should be executed; this allows dynamic deviation from the process.
jBPM is not just an isolated process engine. Complex business logic can be modeled as a combination of business processes with business rules and complex event processing. jBPM can be combined with the Drools project to support one unified environment that integrates these paradigms where you model your business logic as a combination of processes, rules and events.
1.2. Overview
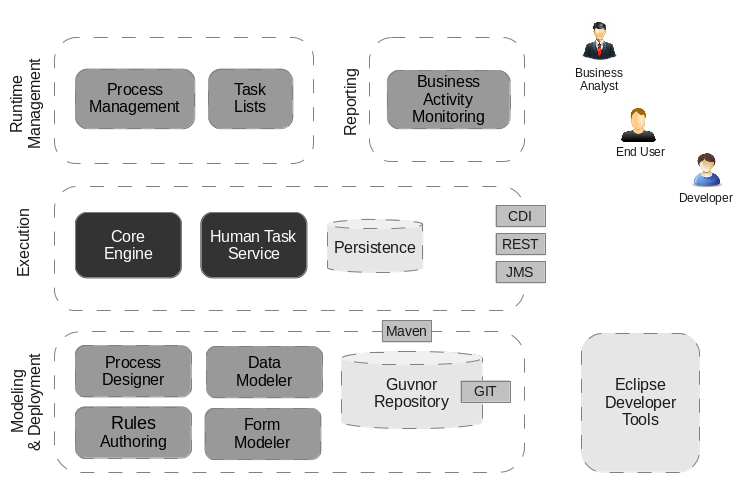
This figure gives an overview of the different components of the jBPM project.
-
The core engine is the heart of the project and allows you to execute business processes in a flexible manner. It is a pure Java component that you can choose to embed as part of your application or deploy it as a service and connect to it through the web-based UI or remote APIs.
-
An optional core service is the human task service that will take care of the human task life cycle if human actors participate in the process.
-
Another optional core service is runtime persistence; this will persist the state of all your process instances and log audit information about everything that is happening at runtime.
-
Applications can connect to the core engine through its Java API or as a set of CDI services, but also remotely through a REST and JMS API.
-
-
Web-based tools allow you to model, simulate and deploy your processes and other related artifacts (like data models, forms, rules, etc.):
-
The process designer allows business users to design and simulate business processes in a web-based environment.
-
The data modeler allows non-technical users to view, modify and create data models for use in your processes.
-
A web-based form modeler also allows you to create, generate or edit forms related to your processes (to start the process or to complete one of the user tasks).
-
Rule authoring allows you to specify different types of business rules (decision tables, guided rules, etc.) for combination with your processes.
-
All assets are stored and managed by the Guvnor repository (exposed through Git) and can be managed (versioning), built and deployed.
-
-
The web-based management console allows business users to manage their runtime (manage business processes like start new processes, inspect running instances, etc.), to manage their task list and to perform Business Activity Monitoring (BAM) and see reports.
-
The Eclipse-based developer tools are an extension to the Eclipse IDE, targeted towards developers, and allows you to create business processes using drag and drop, test and debug your processes, etc.
Each of the component is described in more detail below.
1.3. Core Engine
The core jBPM engine is the heart of the project. It’s a light-weight workflow engine that executes your business processes. It can be embedded as part of your application or deployed as a service (possibly in the cloud). Its most important features are the following:
-
Solid, stable core engine for executing your process instances.
-
Native support for the latest BPMN 2.0 specification for modeling and executing business processes.
-
Strong focus on performance and scalability.
-
Light-weight (can be deployed on almost any device that supports a simple Java Runtime Environment; does not require any web container at all).
-
(Optional) pluggable persistence with a default JPA implementation.
-
Pluggable transaction support with a default JTA implementation.
-
Implemented as a generic process engine, so it can be extended to support new node types or other process languages.
-
Listeners to get notified about various events.
-
Ability to migrate running process instances to a new version of their process definition
The core engine can also be integrated with a few other (independent) core services:
-
The human task service can be used to manage human tasks when human actors need to participate in the process. It is fully pluggable and the default implementation is based on the WS-HumanTask specification and manages the life cycle of the tasks, task lists, task forms, and some more advanced features like escalation, delegation, rule-based assignments, etc.
-
The history log can store all information about the execution of all the processes in the engine. This is necessary if you need access to historic information as runtime persistence only stores the current state of all active process instances. The history log can be used to store all current and historic states of active and completed process instances. It can be used to query for any information related to the execution of process instances, for monitoring, analysis, etc.
1.4. jBPM Workbench
The Workbench web-based application covers the complete life cycle of BPM projects starting at authoring phase, going through implementation, execution and monitoring. It combines a series web-based tools into one configurable solution to manage all assets and runtime data needed for the business solution.
It supports the following:
-
A repository service to store your business processes and related artifacts, using a Git repository, which supports versioning, remote Git access (as a file system) and access via REST.
-
A web-based user interface to manage your business processes, targeted towards business users; it also supports the visualization (and editing) of your artifacts (the web-based editors like designer, data and form modeler are integrated here), but also categorisation, build and deployment, etc..
-
Collaboration features which enable multiple actors (for example business users and developers) to work together on the same project.
1.4.1. Process Designer
The web-based jBPM Designer allows you to model your business processes in a web-based environment. It is targeted towards business users and offers a graphical editor for viewing and editing your business processes (using drag and drop), similar to the Eclipse plugin. It supports round-tripping between the Eclipse editor and the web-based designer. It also supports simulation of processes.
1.4.2. Data Modeler
Processes almost always have some kind of data to work with. The data modeler allows non-technical users to view, edit or create these data models.
Typically, a business process analyst or data analyst will capture the requirements for a process or application and turn these into a formal set of interrelated data structures. The new Data Modeler tool provides an easy, straightforward and visual aid for building both logical and physical data models, without the need for advanced development skills or explicit coding. The data modeler is transparently integrated into the workbench. Its main goals are to make data models first class citizens in the process improvement cycle and allow for full process automation through the integrated use of data structures (and the forms that will be used to interact with them).
1.4.3. Process Management
Business processes and all its related runtime information can be managed through the jBPM Workbench. It is targeted towards process administrators users and its main features include:
-
Process definitions management: view the entire list of process currently deployed into a Kie Server and its details.
-
Process instances management: the ability to start new process instances, get a filtered list of process instances, visually inspect the state of a specific process instances.
-
Human tasks management: being able to get a list of all tasks, view details such as current assignees, comments, activity logs as well as send reminders and forward tasks to different users and more.
-
Execution Errors management: allows administrators to view any execution error reported in the Kie Server instance, inspect its details including stacktrace and perform the error acknowledgement.
-
Jobs management: possibility to view currently scheduled and schedule new Jobs to run in the Kie Server instance.
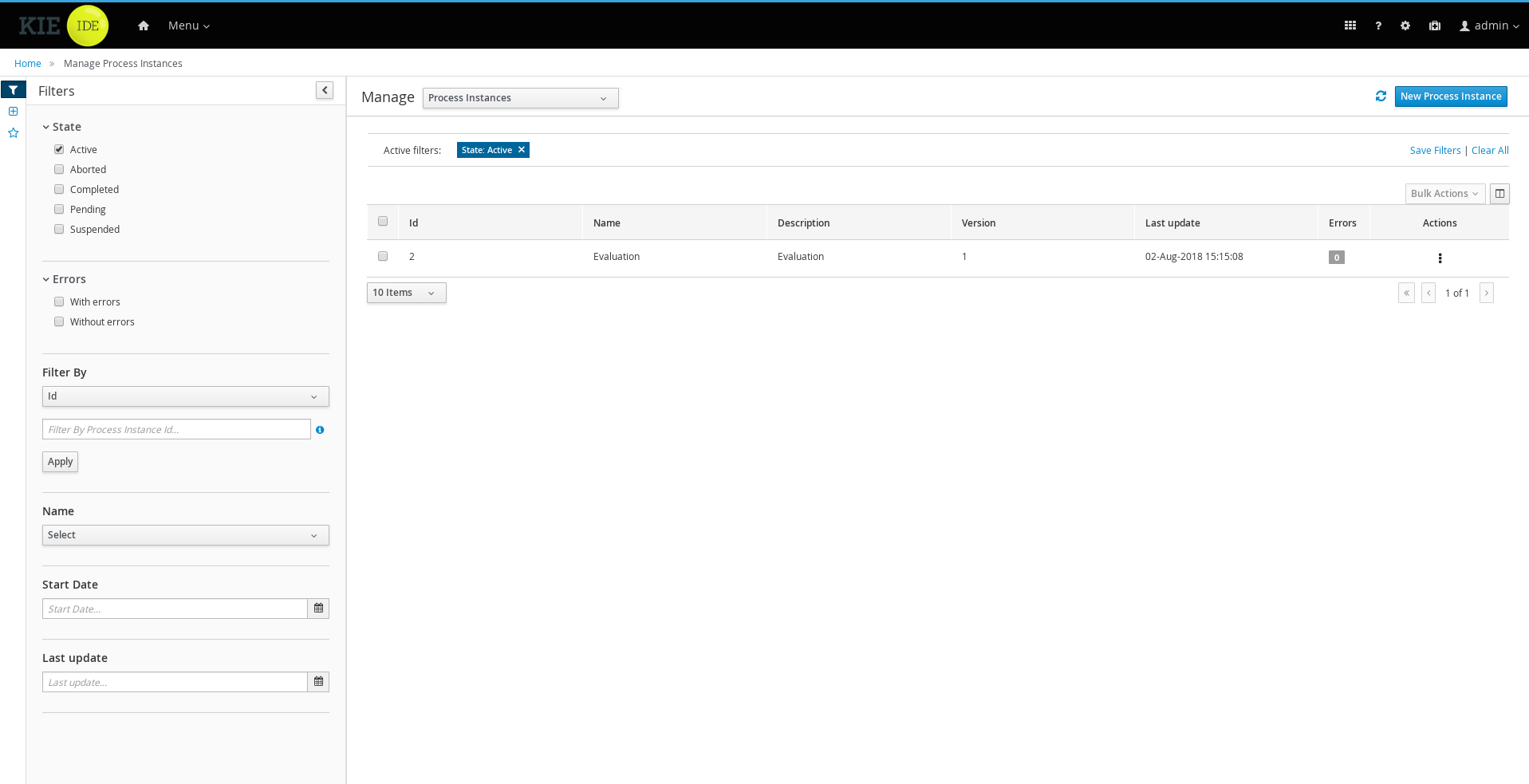
For more details around the entire management section please read the process management chapter.
1.4.4. Task Inbox
As often part of any process execution, human involvement is needed to review, approve or provide extra information. The jBPM Workbench provides a Task Inbox section where any user potentially involved with these task can manage its workload. In there, users are able to get a list of all tasks, complete tasks using customizable task forms, collaborate using comments and more.
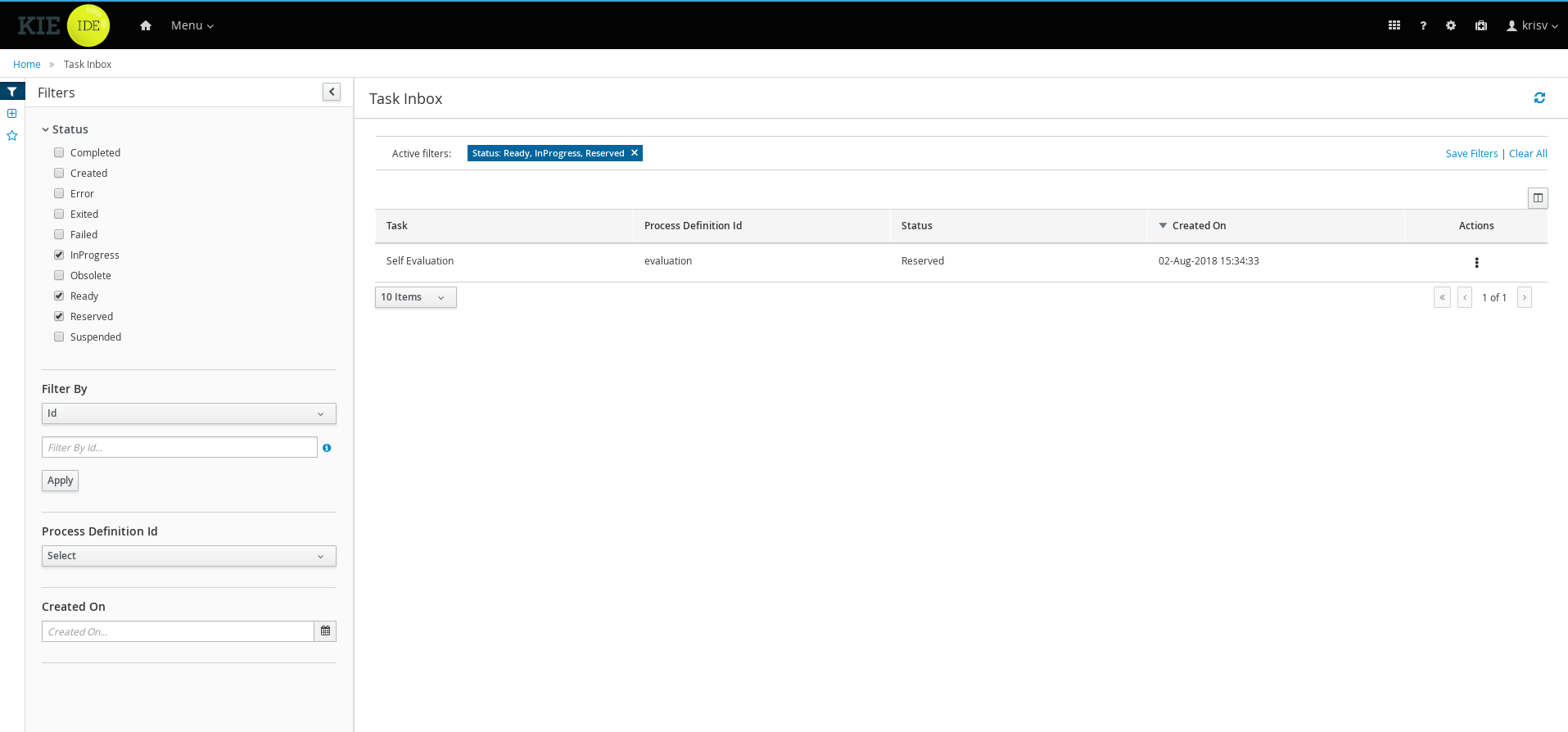
1.4.5. Business Activity Monitoring
As of version 6.0, jBPM comes with a full-featured BAM tooling which allows non-technical users to visually compose business dashboards. With this brand new module, to develop business activity monitoring and reporting solutions on top of jBPM has never been so easy!
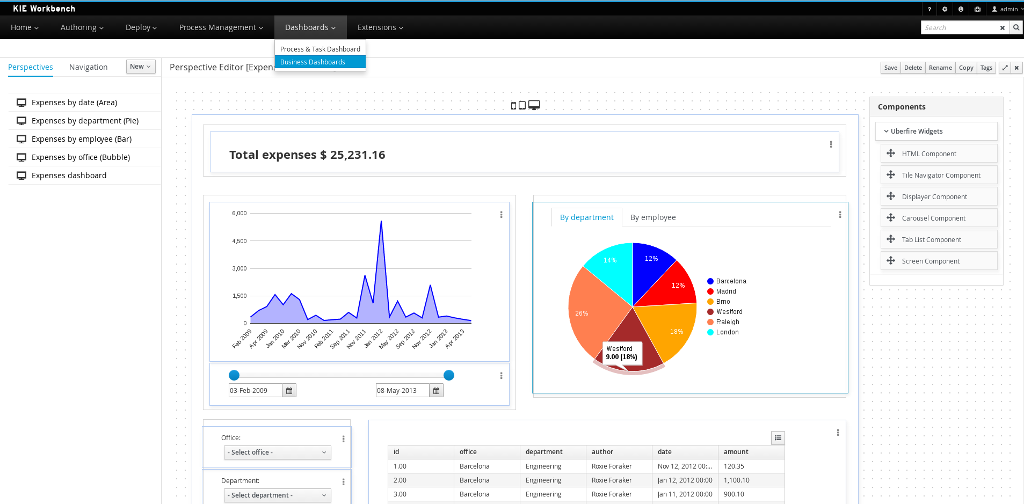
Key features:
-
Visual configuration of dashboards (Drag’n’drop).
-
Graphical representation of KPIs (Key Performance Indicators).
-
Configuration of interactive report tables.
-
Data export to Excel and CSV format.
-
Filtering and search, both in-memory or SQL based.
-
Data extraction from external systems, through different protocols.
-
Granular access control for different user profiles.
-
Look’n’feel customization tools.
-
Pluggable chart library architecture.
Target users:
-
Managers / Business owners. Consumer of dashboards and reports.
-
IT / System architects. Connectivity and data extraction.
-
Analysts / Developers. Dashboard composition & configuration.
To get further information about the new and noteworthy BAM capabilities of jBPM please read the chapter Business Activity Monitoring.
1.5. Eclipse Developer Tools
The Eclipse-based tools are a set of plugins to the Eclipse IDE and allow you to integrate your business processes in your development environment. It is targeted towards developers and has some wizards to get started, a graphical editor for creating your business processes (using drag and drop) and a lot of advanced testing and debugging capabilities.
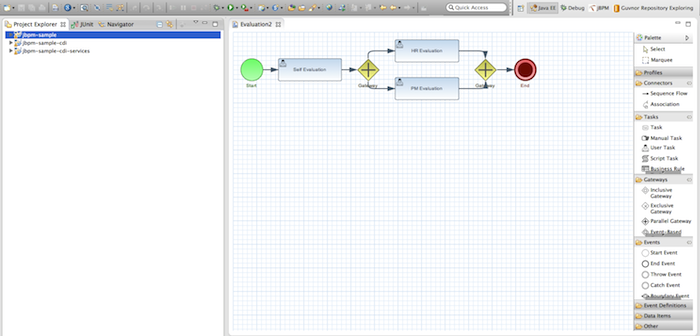
It includes the following features:
-
Wizard for creating a new jBPM project
-
A graphical editor for BPMN 2.0 processes
-
The ability to plug in your own domain-specific nodes
-
Validation
-
Runtime support (so you can select which version of jBPM you would like to use)
-
Graphical debugging to see all running process instances of a selected session, to visualize the current state of one specific process instance, etc.
2. Getting Started
We recommend taking a look at our Getting Start page as a starting point for getting a full environment up and running with all the components you need in order to design, deploy, run and monitor a process. Alternatively, you can also take a quick tutorial that will guide you through most of the components using a simple example available in the Installer Chapter. This will teach you how to download and use the installer to create a demo setup, including most of the components. It uses a simple example to guide you through the most important features. Screencasts are available to help you out as well.
If you like to read more information first, the following chapters first focus on the core engine (API, BPMN 2.0, etc.). Further chapters will then describe the other components and other more complex topics like domain-specific processes, flexible processes, etc. After reading the core chapters, you should be able to jump to other chapters that you might find interesting.
You can also start playing around with some examples that are offered in a separate download. Check out the Examples chapter to see how to start playing with these.
After reading through these chapters, you should be ready to start creating your own processes and integrate the engine with your application. These processes can be started from the installer or be started from scratch.
2.1. Downloads
Latest releases can be downloaded from jBPM.org. Just pick the artifact you want:
-
server: single zip distribution with jBPM server (including WildFly, jBPM console, jBPM case management showcase and service repository)
-
bin: all the jBPM binaries (JARs) and their transitive dependencies
-
src: the sources of the core components
-
docs: the documentation
-
examples: some jBPM examples, can be imported into Eclipse
-
installer: the jBPM Installer, downloads and installs a demo setup of jBPM
-
installer-full: full jBPM Installer, downloads and installs a demo setup of jBPM, already contains a number of dependencies prepackaged (so they don’t need to be downloaded separately)
Older releases are archived at http://downloads.jboss.org/jbpm/release/.
Alternatively, you can also use one of the many Docker images available for use at the Download section.
2.2. Community
Here are a lot of useful links part of the jBPM community:
-
jBPM Setup and jBPM Usage user forums and mailing lists
-
A JIRA bug tracking system for bugs, feature requests and roadmap
Please feel free to join us in our IRC channel at chat.freenode.net#jbpm. This is where most of the real-time discussion about the project takes place and where you can find most of the developers most of their time as well. Don’t have an IRC client installed? Simply go to http://webchat.freenode.net/, input your desired nickname, and specify #jbpm. Then click login to join the fun.
2.3. Sources
2.3.1. License
The jBPM code itself is using the Apache License v2.0.
Some other components we integrate with have their own license:
-
The new Eclipse BPMN2 plugin is Eclipse Public License (EPL) v1.0.
-
The legacy web-based designer is based on Oryx/Wapama and is MIT License
-
The Drools project is Apache License v2.0.
2.3.2. Source code
jBPM now uses git for its source code version control system. The sources of the jBPM project can be found here (including all releases starting from jBPM 5.0-CR1):
The source of some of the other components can be found here:
2.3.3. Building from source
If you’re interested in building the source code, contributing, releasing, etc. make sure to read this README.
2.4. Getting Involved
We are often asked "How do I get involved". Luckily the answer is simple, just write some code and submit it :) There are no hoops you have to jump through or secret handshakes. We have a very minimal "overhead" that we do request to allow for scalable project development. Below we provide a general overview of the tools and "workflow" we request, along with some general advice.
If you contribute some good work, don’t forget to blog about it :)
2.4.1. Sign up to jboss.org
Signing to jboss.org will give you access to the JBoss wiki, forums and JIRA. Go to https://www.jboss.org/ and click "Register".

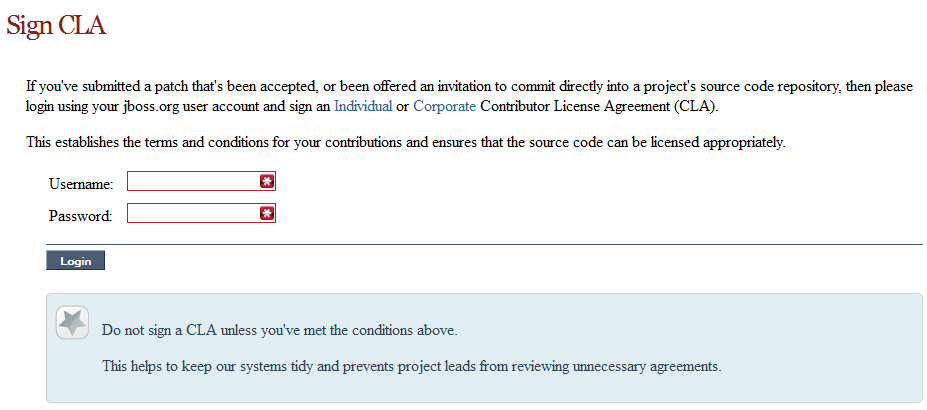
2.4.2. Sign the Contributor Agreement
The only form you need to sign is the contributor agreement, which is fully automated via the web. As the image below says "This establishes the terms and conditions for your contributions and ensures that source code can be licensed appropriately"
2.4.3. Submitting issues via JIRA
To be able to interact with the core development team you will need to use JIRA, the issue tracker. This ensures that all requests are logged and allocated to a release schedule and all discussions captured in one place. Bug reports, bug fixes, feature requests and feature submissions should all go here. General questions should be undertaken at the mailing lists.
Minor code submissions, like format or documentation fixes do not need an associated JIRA issue created.
2.4.4. Fork GitHub
With the contributor agreement signed and your requests submitted to JIRA you should now be ready to code :) Create a GitHub account and fork any of the Drools, jBPM or Guvnor repositories. The fork will create a copy in your own GitHub space which you can work on at your own pace. If you make a mistake, don’t worry blow it away and fork again. Note each GitHub repository provides you the clone (checkout) URL, GitHub will provide you URLs specific to your fork.
2.4.5. Writing Tests
When writing tests, try and keep them minimal and self contained. We prefer to keep the DRL fragments within the test, as it makes for quicker reviewing. If their are a large number of rules then using a String is not practical so then by all means place them in separate DRL files instead to be loaded from the classpath. If your tests need to use a model, please try to use those that already exist for other unit tests; such as Person, Cheese or Order. If no classes exist that have the fields you need, try and update fields of existing classes before adding a new class.
There are a vast number of tests to look over to get an idea, MiscTest is a good place to start.

2.4.6. Commit with Correct Conventions
When you commit, make sure you use the correct conventions. The commit must start with the JIRA issue id, such as DROOLS-1946. This ensures the commits are cross referenced via JIRA, so we can see all commits for a given issue in the same place. After the id the title of the issue should come next. Then use a newline, indented with a dash, to provide additional information related to this commit. Use an additional new line and dash for each separate point you wish to make. You may add additional JIRA cross references to the same commit, if it’s appropriate. In general try to avoid combining unrelated issues in the same commit.
Don’t forget to rebase your local fork from the original master and then push your commits back to your fork.

2.4.7. Submit Pull Requests
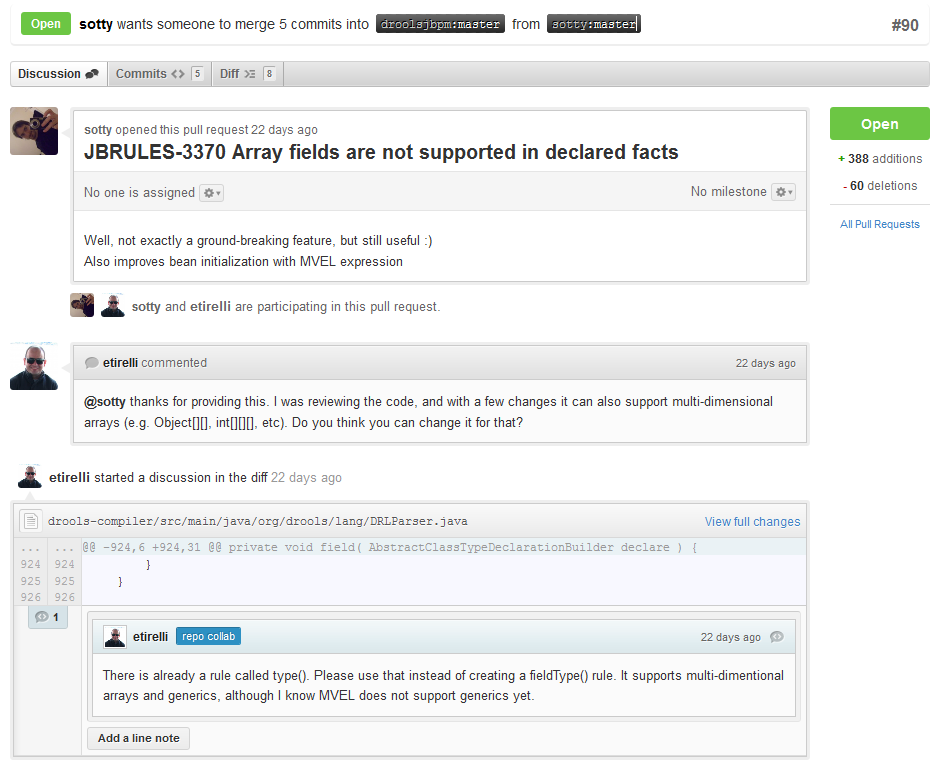
With your code rebased from original master and pushed to your personal GitHub area, you can now submit your work as a pull request. If you look at the top of the page in GitHub for your work area their will be a "Pull Request" button. Selecting this will then provide a gui to automate the submission of your pull request.
The pull request then goes into a queue for everyone to see and comment on. Below you can see a typical pull request. The pull requests allow for discussions and it shows all associated commits and the diffs for each commit. The discussions typically involve code reviews which provide helpful suggestions for improvements, and allows for us to leave inline comments on specific parts of the code. Don’t be disheartened if we don’t merge straight away, it can often take several revisions before we accept a pull request. Luckily GitHub makes it very trivial to go back to your code, do some more commits and then update your pull request to your latest and greatest.
It can take time for us to get round to responding to pull requests, so please be patient. Submitted tests that come with a fix will generally be applied quite quickly, where as just tests will often way until we get time to also submit that with a fix. Don’t forget to rebase and resubmit your request from time to time, otherwise over time it will have merge conflicts and core developers will general ignore those.
2.5. What to do if I encounter problems or have questions?
You can always contact the jBPM community for assistance.
IRC: #jbpm at chat.freenode.net
jBPM Setup Google Group - Installation, configuration, setup and administration discussions for the Workbench, Eclipse, runtime environments and general enterprise architectures.
jBPM Usage Google Group - Authoring, executing and managing processes with jBPM. Any questions regarding the use of jBPM. General API help and best practices in building BPM systems.
Visit our website for more options on how to get help.
Legacy jBPM User Forum - serves as an archive; post new questions to one of the Google Groups above
3. jBPM Installer
3.1. Prerequisites
This script assumes you have Java JDK 1.8+ (set as JAVA_HOME), and Ant 1.9+ installed. If you don’t, use the following links to download and install them:
|
To check whether Java and Ant are installed correctly, type the following commands inside a command prompt: java -version ant -version This should return information about which version of Java and Ant you are currently using. |
3.2. Downloading the Installer
First of all, you need to download the installer and unzip it on your local file system. There are two versions
-
full installer - already contains a lot of the dependencies that are necessary during the installation
-
minimal installer - contains only the installer and will download all required dependencies on the fly
In general, it is probably best to download the full installer: jBPM-7.11.0.Final-installer-full.zip
You can also download the latest build (only for the minimal installer).
3.3. Demo Setup
The easiest way to get started is to simply run the installation script to install the demo setup. The demo install will setup all the web tooling (on top of WildFly) and Eclipse tooling in a pre-configured setup. Go into the jbpm-installer folder where you unzipped the installer and (from a command prompt) run:
ant install.demoThis will:
-
Download WildFly application server
-
Configure and deploy a process execution server
-
Configure and deploy the workbench
-
Configure and deploy the case management application
-
Download Eclipse
-
Install the Drools and jBPM Eclipse plugin
-
Install the Eclipse BPMN 2.0 Modeler
Running this command could take a while (REALLY, not kidding, we are for example downloading an Eclipse installation, even if you downloaded the full installer, specifically for your operating system).
|
The script always shows which file it is downloading (you could for example check whether it is still downloading by checking the whether the size of the file in question in the jbpm-installer/lib folder is still increasing). If you want to avoid downloading specific components (because you will not be using them or you already have them installed somewhere else), check below for running only specific parts of the demo or directing the installer to an already installed component. |
Once the demo setup has finished, you can start playing with the various components by starting the demo setup:
ant start.demoThis will:
-
Start H2 database server
-
Start WildFly application server
-
Start Eclipse
Now wait until the process management console comes up:
The case management UI will be available on:
|
It could take a minute to start up the application server and web application. If the web page doesn’t show up after a while, make sure you don’t have a firewall blocking that port, or another application already using the port 8080. You can always take a look at the server log {jbpm-installer-folder}/wildfly-{version}/standalone/log/server.log |
Once everything is started, you can start playing with the Eclipse and web tooling, as explained in the following sections.
If you only want to try out the web tooling and do not wish to download and install the Eclipse tooling, you can use these alternative commands:
ant install.demo.noeclipse
ant start.demo.noeclipseSimilarly, if you only want to try out the Eclipse tooling and do not wish to download and install the web tooling, you can use these alternative commands:
ant install.demo.eclipse
ant start.demo.eclipseNow continue with the 10-minute tutorials. Once you’re done playing and you want to shut down the demo setup, you can use:
ant stop.demoIf at any point in time would like to start over with a clean demo setup - meaning all changes you did inside the web tooling and/or saved in the database will be lost, you can run the following command (after which you can run the installer again from scratch, note that this cannot be undone):
ant clean.demo3.4. 10-Minute Tutorial using the Workbench
Open up the process management console:
|
It could take a minute to start up the application server and web application. If the web page doesn’t show up after a while, make sure you don’t have a firewall blocking that port, or another application already using the port 8080. You can always take a look at the server log {jbpm-installer-folder}/wildfly-{version}/standalone/log/server.log |
Log in, using krisv / krisv as username / password.
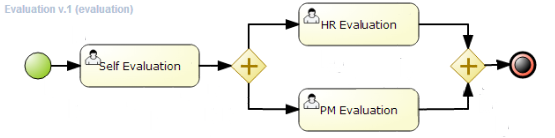
Using a prebuilt Evaluation example, the following screencast gives an overview of how to manage your process instances. It shows you:
-
How to log in to the workbench
-
How to import an existing example project and build and deploy it
-
How to start a new process instance
-
How to look up the current status of a running process instance
-
How to look up your tasks
-
How to complete a task
-
How to look at reports to monitor your process execution
The workbench supports the entire life cycle of your business processes: authoring, deployment, process management, tasks and dashboards.
-
The project authoring page allows you to look at existing repositories, where each project can contain business processes (but also business rules, data models, forms, etc.). It allows you to create your own project, or you could import an existing example to take a look at.
-
In this screencast, we start by importing the Evaluation project
-
-
The project explorer shows all available artifacts:
-
evaluation: business process describing the evaluation process as a sequence of tasks
-
evaluation-taskform: process form to start the evaluation process
-
PerformanceEvaluation-taskform: task form to perform the evaluation tasks
-
-
To make a process available for execution, you need to successfully build and deploy it first. To do so, open the selected project (in the project authoring page) and click Build & Deploy (top right corner).
-
To manage your process definitions and instances, click on the "Process Management" menu option at the top menu bar an select one of available options depending on you interest:
-
Process Definitions - lists all available process definitions
-
Process Instances - lists all active process instances (allows to show completed, aborted as well by changing filter criteria)
-
-
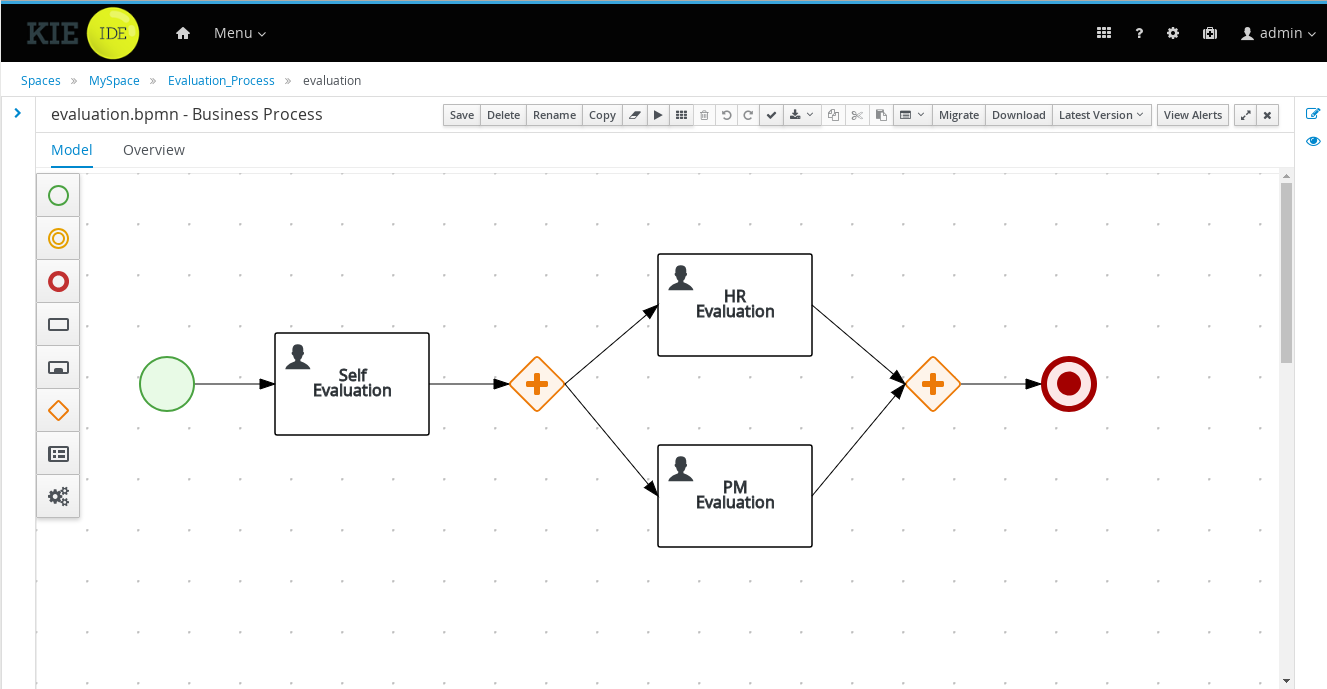
The process definitions view allows you to start a new process instance by clicking on the Start button. The process form (as defined in the project) will be shown, where you need to fill in the necessary information to start the process. In this case, you need to fill the user you want to start an evaluation for (for example use "krisv") and a reason for the request, after which you can complete the form. Some details about the process instance that was just started will be shown in the process instance details panel. From there you can access additional details:
-
Process model - to visualize current state of the process
-
Process variables - to see current values of process variables
-
Documents - documents related to the process instance
-
Logs - overview of all process events for that instance
The process instance that you just started is first requiring a self-evaluation of the user and is waiting until the user has completed this task.
-
-
To see the tasks that have been assigned to you, choose the "Tasks" menu option on the top bar. By default, it will show all active tasks, and a "Performance Evaluation" (that was created by the process instance you just started) should be availabe for you. When you click on a task, the task details will be shown, including the task form related to this task. After starting the task, you can fill in the necessary information and complete the task. After completing the task, you could check the "Process Instances" once more to check the progress of your process instance. You should be able to see that the process is now waiting for your HR manager and project manager to also perform an evaluation. You could log in as "john" / "john" and "mary" / "mary" to complete these tasks.
-
After starting and/or completing a few process instances and human tasks, you can generate a report of what has happened so far. Under "Dashboards", select "Process & Task Dashboard". This is a set of see predefined charts that allow users to spot what is going on in the system. Charts can be fully customized as well, as explained in the Business Activity Monitoring chapter.
3.5. 10-Minute Tutorial using Eclipse
The following screencast gives an overview of how to use the Eclipse tooling. It shows you:
-
How to import and execute the evaluation sample project
-
Import the evaluation project (included in the jbpm-installer)
-
Open the Evaluation.bpmn process
-
Open the com.sample.ProcessTest Java class
-
Execute the ProcessTest class to run the process
-
-
How to create a new jBPM project (including sample process and JUnit test)
You can import the evaluation project - a sample included in the jbpm-installer - by selecting "File → Import …", select "Existing Projects into Workspace" and browse to the jbpm-installer/sample/evaluation folder and click "Finish". You can open up the evaluation process and the ProcessTest class. To execute the class, right-click on it and select "Run as … - Java Application". The console should show how the process was started and how the different actors in the process completed the tasks assigned to them, to complete the process instance.
You could also create a new project using the jBPM project wizard. The sample projects contain a process and an associated Java file to start the process. Select "File - New … - Project …" and under the "jBPM" category and select "jBPM project". Select to create a project with some example files to get you started quickly and click next. Give the project a name. You can choose from a simple HelloWorld example or a slightly more advanced example using persistence and human tasks. If you select the latter and click Finish, you should see a new project containing a "sample.bpmn" process and a "com.sample.ProcessTest" JUnit test class. You can open the BPMN2 process by double-clicking it. To execute the process, right-click on ProcessTest.java and select "Run As - Java Application".
3.6. Configuration
3.6.1. Workbench Authentication
The workbench web application is using the pre-installed other security domain for authenticating and authorizing users (as specified in the WEB-INF/jboss-web.xml inside the WARs).
The application server uses by default property files based realms - Please note that this configuration is intended only for demo purposes (users, roles and passwords are stored in simple property files on the filesystem).
Authentication is configured in the standalone.xml file as follows:
<security-domain name="other" cache-type="default">
<authentication>
<login-module code="Remoting" flag="optional">
<module-option name="password-stacking" value="useFirstPass"/>
</login-module>
<login-module code="RealmDirect" flag="required">
<module-option name="password-stacking" value="useFirstPass"/>
</login-module>
<login-module code="org.kie.security.jaas.KieLoginModule" flag="optional" module="deployment.jbpm-console.war"/>
</authentication>
</security-domain><security-realm name="ApplicationRealm">
<authentication>
<local default-user="$local" allowed-users="*" skip-group-loading="true"/>
<properties path="users.properties" relative-to="jboss.server.config.dir"/>
</authentication>
<authorization>
<properties path="roles.properties" relative-to="jboss.server.config.dir"/>
</authorization>
</security-realm>These are the default users:
| Name | Password | Workbench roles | Task roles |
|---|---|---|---|
admin |
admin |
admin,analyst,kiemgmt,rest-all,kie-server |
|
krisv |
krisv |
admin,analyst,rest-all,kie-server |
|
john |
john |
analyst,kie-server |
Accounting,PM |
mary |
mary |
analyst,kie-server |
HR |
sales-rep |
sales-rep |
analyst,kie-server |
sales |
jack |
jack |
analyst,kie-server |
IT |
katy |
katy |
analyst,kie-server |
HR |
salaboy |
salaboy |
admin,analyst,rest-all,kie-server |
IT,HR,Accounting |
kieserver |
kieserver1! |
kie-server |
Authentication can be customized by using any of the following options:
-
The users and groups management screens on the workbench web application.
Navigate into the workbench web application and click on the menu Home → Admin and selecting Users.
-
The add-user script that comes by default on Wildfly/EAP.
Example for Linux platforms - run the following command and follow the script instructions:
/bin/sh $JBOSS_HOME/bin/add-user.sh
--user-properties $JBOSS_HOME/standalone/configuration/users.properties
--group-properties $JBOSS_HOME/standalone/configuration/roles.properties
--realm ApplicationRealm3.6.2. Using your own database with the jBPM installer
3.6.2.1. Introduction
jBPM uses the Java Persistence API specification (v2) to allow users to configure whatever datasource they want to use to persist runtime data. As a result, the instructions below describe how you should configure a datasource when using JPA on JBoss application server (e.g. EAP7 or Wildfly10) using a persistence.xml file and configuring your datasource and driver in your application server’s standalone.xml , similar to how you would configure any other application using JPA on the application server. The installer automates some of this (like copying the right files to the right location after installation).
By default, the jbpm-installer uses an H2 database for persisting runtime data. In this section we will:
-
modify the persistence settings for runtime persistence of process instance state
-
test the startup with our new settings!
You will need a local instance of a database, in this case we will use MySQL.
3.6.2.2. Database setup
In the MySQL database used in this quickstart, create a single user:
-
user/schema "jbpm" with password "jbpm" (which will be used to persist all entities)
If you end up using different names for your user/schemas, please make a note of where we insert "jbpm" in the configuration files.
If you want to try this quickstart with another database, a section at the end of this quickstart describes what you may need to modify.
3.6.2.3. Configuration
The following files define the persistence settings for the jbpm-installer demo:
-
jbpm-installer/db/jbpm-persistence-JPA2.xml
-
Application server configuration
-
standalone-*.xml
-
|
There are multiple standalone.xml files available (depending on whether you are using JBoss EAP or Wildfly and whether you are running the normal or full profile). The full profile is required to use the JMS component for remote integration, so will be used by default by the installer. Best practice is to update all standalone.xml files to have consistent setup but most important is to have standalone-full-wildfly-{version}.xml properly configured as this is used by default by the installer. |
Do the following:
-
Disable H2 default database and enable MySQL database in build.properties
# default is H2 # H2.version=1.3.168 # db.name=h2 # db.driver.jar.name=${db.name}.jar # db.driver.download.url=http://repo1.maven.org/maven2/com/h2database/h2/${H2.version}/h2-${H2.version}.jar #mysql db.name=mysql db.driver.module.prefix=com/mysql db.driver.jar.name=mysql-connector-java-5.1.18.jar db.driver.download.url=https://repository.jboss.org/nexus/service/local/repositories/central/content/mysql/mysql-connector-java/5.1.18/mysql-connector-java-5.1.18.jar org.kie.server.persistence.dialect=org.hibernate.dialect.MySQLDialectYou might want to update the db driver jar name and download url to whatever version of the jar matches your installation. Look to also update the dialect to what matches your installation if needed (for example change to MySQL5Dialect for MySQL 5.x specific features).
-
db/jbpm-persistence-JPA2.xml :
This is the JPA persistence file that defines the persistence settings used by jBPM for both the process engine information, the logging/BAM information and task service.
In this file, you will have to change the name of the hibernate dialect used for your database.
The original line is:
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>In the case of a MySQL database, you need to change it to:
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect"/>For those of you who decided to use another database, a list of the available hibernate dialect classes can be found here.
-
standalone-full-wildfly-{version}.xml :
Standalone.xml and standalone-full.xml are the configuration for the standalone JBoss application server. When the installer installs the demo, it copies these files to the
standalone/configurationdirectory in the JBoss server directory. Since the installer uses Wildfly by default as application server, you probably need to change standalone-full-wildfly-{version}.xml .We need to change the datasource configuration in
standalone-full.xmlso that the jBPM process engine can use our MySQL database. The original file contains (something very similar to) the following lines:<datasource jta="true" jndi-name="java:jboss/datasources/jbpmDS" pool-name="H2DS" enabled="true" use-java-context="true" use-ccm="true"> <connection-url>jdbc:h2:tcp://localhost/~/jbpm-db;MVCC=TRUE</connection-url> <driver>h2</driver> <security> <user-name>sa</user-name> </security> </datasource> <drivers> <driver name="h2" module="com.h2database.h2"> <xa-datasource-class>org.h2.jdbcx.JdbcDataSource</xa-datasource-class> </driver> </drivers>Change the lines to the following:
<datasource jta="true" jndi-name="java:jboss/datasources/jbpmDS" pool-name="MySQLDS" enabled="true" use-java-context="true" use-ccm="true"> <connection-url>jdbc:mysql://localhost:3306/jbpm</connection-url> <driver>mysql</driver> <security> <user-name>jbpm</user-name> <password>jbpm</password> </security> </datasource>and add an additional driver configuration:
<driver name="mysql" module="com.mysql"> <xa-datasource-class>com.mysql.jdbc.jdbc2.optional.MysqlXADataSource</xa-datasource-class> </driver> -
To install driver jars in JBoss application server (Wildfly, EAP, etc.), it is recommended to install the driver jar as a module. The installer already takes care of this mostly: it will copy the driver jar (you specified in the build.properties ) to the right folder inside the modules directory of your server and put a matching module.xml next to it. For MySQL, this file is called db/mysql_module.xml . Open this file and make sure that the file name of the driver jar listed there is identical the driver jar name you specified in the build.properties (including the version). Note that, even if you simply uncommented the default MySQL configuration, you will still need to add the right version here.
-
Starting the demo
We’ve modified all the necessary files at this point. Now would be a good time to make sure your database is started up as well!
The installer script copies this file into the jbpm-console WAR before the WAR is installed on the server. If you have already run the installer, it is recommended to stop the installer and clean it first using
ant stop.demoand
ant clean.demobefore continuing.
Run
ant install.demoto (re)install the wars and copy the necessary configuration files. Once you’ve done that, (re)start the demo using
ant start.demo -
Problems?
If this isn’t working for you, please try the following:
-
Please double check the files you’ve modified: I wrote this, but still made mistakes when changing files!
-
Please make sure that you don’t secretly have another (unmodified) instance of JBoss AS running.
-
If neither of those work (and you’re using MySQL), please do then let us know.
-
3.6.2.4. Using a different database
If you decide to use a different database with this demo, you need to remember the following when going through the steps above:
-
Configuring the jBPM datasource in
standalone.xml:-
After locating the
java:jboss/datasources/jbpmDSdatasource, you need to provide the following properties specific to your database:-
Change the url of your database
-
Change the user-name and password
-
Change the name of the driver (which you’ll create next)
For example:
<datasource jta="true" jndi-name="java:jboss/datasources/jbpmDS" pool-name="PostgreSQLDS" enabled="true" use-java-context="true" use-ccm="true"> <connection-url>jdbc:postgresql://localhost:5432/jbpm</connection-url> <driver>postgresql</driver> <security> <user-name>jbpm</user-name> <password>jbpm</password> </security> </datasource>
-
-
Add an additional driver configuration:
-
Change the name of the driver to match the name you specified when configuring the datasource in the previous step
-
Change the module of the driver: the database driver jar should be installed as a module (see below) and here you should reference the unique name of the module. Since the installer can take care of automatically generating this module for you (see below), this should match the
db.driver.module.prefixproperty inbuild.properties(where forward slashes are replaced by a point). In the example below, I usedorg/postgresqlasdb.driver.module.prefixwhich means that I should then useorg.postgresqlas module name for the driver. -
Fill in the correct name of the XA datasource class to use.
-
For example:
+
<driver name="postgresql" module="org.postgresql"> <xa-datasource-class>org.postgresql.xa.PGXADataSource</xa-datasource-class> </driver> -
-
You need to change the dialect in persistence.xml to the dialect for your database, for example:
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect"/> -
In order to make sure your driver will be correctly installed in the JBoss application server, there are typically multiple options, like install as a module or as a deployment. It is recommended to install the driver as a module for EAP and Wildfly.
-
Install the driver JAR as a module, which is what the install script does.
-
Otherwise, you can modify and install the downloaded JAR as a deployment. In this case you will have to copy the JAR yourself to the
standalone/deploymentsdirectory.
If you choose to install driver as JBoss module (recommended), please do the following:
-
In
build.properties, disable the default H2 driver properties# default is H2 # H2.version=1.3.168 # db.name=h2 # db.driver.jar.name=h2-${H2.version}.jar # db.driver.download.url=http://repo1.maven.org/maven2/com/h2database/h2/${H2.version}/h2-${H2.version}.jar -
Uncomment one of the other example configs (mysql or postgresql) or create your own:
#postgresql db.name=postgresql db.driver.module.prefix=org/postgresql db.driver.jar.name=postgresql-9.1-902.jdbc4.jar db.driver.download.url=https://repository.jboss.org/nexus/content/repositories/thirdparty-uploads/postgresql/postgresql/9.1-902.jdbc4/postgresql-9.1-902.jdbc4.jar-
Change the
db.nameproperty inbuild.propertiesto a name for your database. -
Change the
db.driver.module.prefixproperty to a name for the module of your driver. Note that this should match the module property when configuring the driver in standalone.xml (where forward slashes in the prefix here are replaced by a point). In the example above, I usedorg/postgresqlasdb.driver.module.prefixwhich means that I should then useorg.postgresqlas module name for the driver. -
Change the
db.driver.jar.nameproperty to the name of the jar that contains your database driver. -
Change the
db.driver.download.urlproperty to where the driver jar can be downloaded. Alternatively, you could manually download the jar yourself, and place it in thedb/driversfolder, using the same name as you specified in thedb.driver.jar.nameproperty.
-
-
Lastly, you’ll have to create the
db/${db.name}_module.xmlfile. As an example you can use db/mysql_module.xml, so just make a copy of it and:-
Change the name of the module to match the driver module name above
-
Change the name of the module resource path to the name of the
db.driver.jar.nameproperty.
-
-
For example, the top of the file would look like:
-
<module xmlns="urn:jboss:module:1.0" name="org.postgresql">
<resources>
<resource-root path="postgresql-9.1-902.jdbc4.jar"/>
</resources>
3.6.3. jBPM database schema scripts (DDL scripts)
By default the demo setup makes use of Hibernate auto DDL generation capabilities to build up the complete database schema, including all tables, sequences, etc. This might not always be welcomed (by your database administrator), and thus the installer provides DDL scripts for most popular databases.
| Database name | Location |
|---|---|
db2 |
jbpm-installer/db/ddl-scripts/db2 |
derby |
jbpm-installer/db/ddl-scripts/derby |
h2 |
jbpm-installer/db/ddl-scripts/h2 |
hsqldb |
jbpm-installer/db/ddl-scripts/hsqldb |
mysql5 |
jbpm-installer/db/ddl-scripts/mysql5 |
mysqlinnodb |
jbpm-installer/db/ddl-scripts/mysqlinnodb |
oracle |
jbpm-installer/db/ddl-scripts/oracle |
postgresql |
jbpm-installer/db/ddl-scripts/postgresql |
sqlserver |
jbpm-installer/db/ddl-scripts/sqlserver |
sqlserver2008 |
jbpm-installer/db/ddl-scripts/sqlserver2008 |
sybase |
jbpm-installer/db/ddl-scripts/sybase |
DDL scripts are provided for both jBPM and Quartz schemas although Quartz schema DDL script is only required when the timer service should be configured with Quartz database job store. See the section on timers for additional details.
This can be used to initially create the database schema, but it can also serve as the basis for any\ optimization that needs to be applied - such as indexes, etc.
|
If you use MySQL 5.7 or earlier (MariaDB 10.2.3 or earlier), you also need to run jbpm-installer/db/ddl-scripts/mysql5/mysql-jbpm-amend-auto-increment-procedure.sql This script creates a procedure for jBPM tables (ProcessInstanceInfo/WorkItemInfo/Task) to protect AUTO_INCREMENT counter. Without the procedure, ID values of those tables could be reset on MySQL/MariaDB restart (https://dev.mysql.com/doc/refman/8.0/en/innodb-auto-increment-handling.html#innodb-auto-increment-initialization). It would introduce further side effects. In addition to creating the procedure, you have to call the procedure on MySQL/MariaDB restart. For example, /etc/my.cnf Write mysql-jbpm-amend-auto-increment-call.sql |
|
If you use PostgreSQL with jBPM, you also need to run jbpm-installer/db/ddl-scripts/postgresql/postgresql-jbpm-lo-trigger-clob.sql This script creates triggers for jBPM tables to protect CLOB references of large objects. Without the triggers, vacuumlo tool (https://www.postgresql.org/docs/9.4/static/vacuumlo.html) deletes active large objects so causes an issue to jBPM. If you are already running jBPM without the triggers, you also need to run the following SQLs after applying the triggers to protect existing CLOB. |
3.6.4. jBPM installer script
jBPM installer ant script performs most of the work automatically and usually does not require additional attention but in case it does, here is a list of available targets that might be needed to perform some of the steps manually.
| Target | Description |
|---|---|
clean.db |
cleans up database used by jBPM demo (applies only to H2 database) |
clean.demo |
cleans up entire installation so new installation can be performed |
clean.demo.noeclipse |
same as clean.demo but does not remove Eclipse |
clean.eclipse |
removes Eclipse and its workspace |
clean.generated.ddl |
removes DDL scripts generated if any |
clean.jboss |
removes application server with all its deployments |
clean.jboss.repository |
removes repository content for demo setup (guvnor Maven repo, niogit, etc) |
download.db.driver |
downloads DB driver configured in build.properties |
download.ddl.dependencies |
downloads all dependencies required to run DDL script generation tool |
download.droolsjbpm.eclipse |
downloads Drools and jBPM Eclipse plugin |
download.eclipse |
downloads Eclipse distribution |
download.eclipse.gef |
downloads Eclipse GEF feature |
download.jboss |
downloads JBoss Application Server |
download.jBPM.bin |
downloads jBPM binary distribution (jBPM libs and its dependencies) |
download.jBPM.casemgmt |
downloads jBPM case management console |
download.jBPM.console |
downloads jBPM process management console |
download.kie.server |
downloads jBPM process execution server |
install.db.files |
installs DB driver as JBoss module |
install.demo |
installs complete demo environment |
install.demo.eclipse |
installs Eclipse with all jBPM plugins, no server installation |
install.demo.noeclipse |
similar to install.demo but skips Eclipse installation |
install.droolsjbpm-eclipse.into.eclipse |
installs droolsjbpm Eclipse plugin into Eclipse |
install.eclipse |
install Eclipse IDE |
install.jboss |
installs JBoss AS |
install.jBPM-casemgmt.into.jboss |
installs jBPM case management application |
install.jBPM-console.into.jboss |
installs jBPM process management console |
install.kie-server.into.jboss |
installs jBPM process execution server |
3.7. Frequently Asked Questions
Some common issues are explained below.
-
What if the installer complains it cannot download component X?
Are you connected to the Internet? Do you have a firewall turned on? Do you require a proxy? It might be possible that one of the locations we’re downloading the components from is temporarily offline. Try downloading the components manually (possibly from alternate locations) and put them in the jbpm-installer/lib folder.
-
What if the installer complains it cannot extract / unzip a certain JAR/WAR/zip?
If your download failed while downloading a component, it is possible that the installer is trying to use an incomplete file. Try deleting the component in question from the jbpm-installer/lib folder and reinstall, so it will be downloaded again.
-
What if I have been changing my installation (and it no longer works) and I want to start over again with a clean installation?
You can use
ant clean.demoto remove all the installed components, so you end up with a fresh installation again. -
I sometimes see exceptions when trying to stop or restart certain services, what should I do?
If you see errors during shutdown, are you sure the services were still running? If you see exceptions during restart, are you sure the service you started earlier was successfully shutdown? Maybe try killing the services manually if necessary.
-
Something seems to be going wrong when running Eclipse but I have no idea what. What can I do?
Always check the consoles for output like error messages or stack traces. You can also check the Eclipse Error Log for exceptions. Try adding an audit logger to your session to figure out what’s happening at runtime, or try debugging your application.
-
Something seems to be going wrong when running the a web-based application like the jbpm-console. What can I do?
You can check the server log for possible exceptions: jbpm-installer/jboss-as-{version}/standalone/log/server.log (for JBoss AS7).
For all other questions, try contacting the jBPM community as described in the Getting Started chapter.
4. Examples
4.1. Introduction
The web-based workbench by default will install two sample repositories that contain various sample projects that help you getting started. This section shows different examples that can be found in the jbpm-playground repository (also available here: https://github.com/kiegroup/jbpm-playground). All these examples are high level and business oriented.
If you want to contribute with these examples please get in touch with any member of the jBPM/Drools Team.
4.2. Importing Projects through Git
To import the Human Resources example, as well as other examples, follow these steps:
-
Logging into Workbench
-
On the command line, change into the $SERVER_HOME/bin/ directory and execute the following command:
-
for Unix environment:
./standalone.sh -
for Windows environment:
./standalone.bat
-
-
Once your server is up and running, open the following address in a web browser:
http://localhost:8080/jbpm-consoleThis opens the login page.
-
Log in to Workbench with the user credentials created during installation.
-
-
Importing Projects Through Git
-
Click .
-
Click .
-
In the New Repository dialogue, enter following information:
-
Repository Name: for example, playground.
-
Organizational Unit: select your organizational unit, for example example.
-
Git URL : enter the Git URL you want to import, for example: https://github.com/kiegroup/jbpm-playground.
-
-
Click Clone.
-
This will import a number of premade examples into your instance of jBPM Red Hat JBoss BPM Suite.
4.3. Human Resources Example
The Human Resource Example’s use case can be described as follows: A company wants to hire new developers. In this process, three departments (that is the Human resources, IT, and Accounting) are involved. These departments are represented by three users: Katy, Jack, and John respectively.
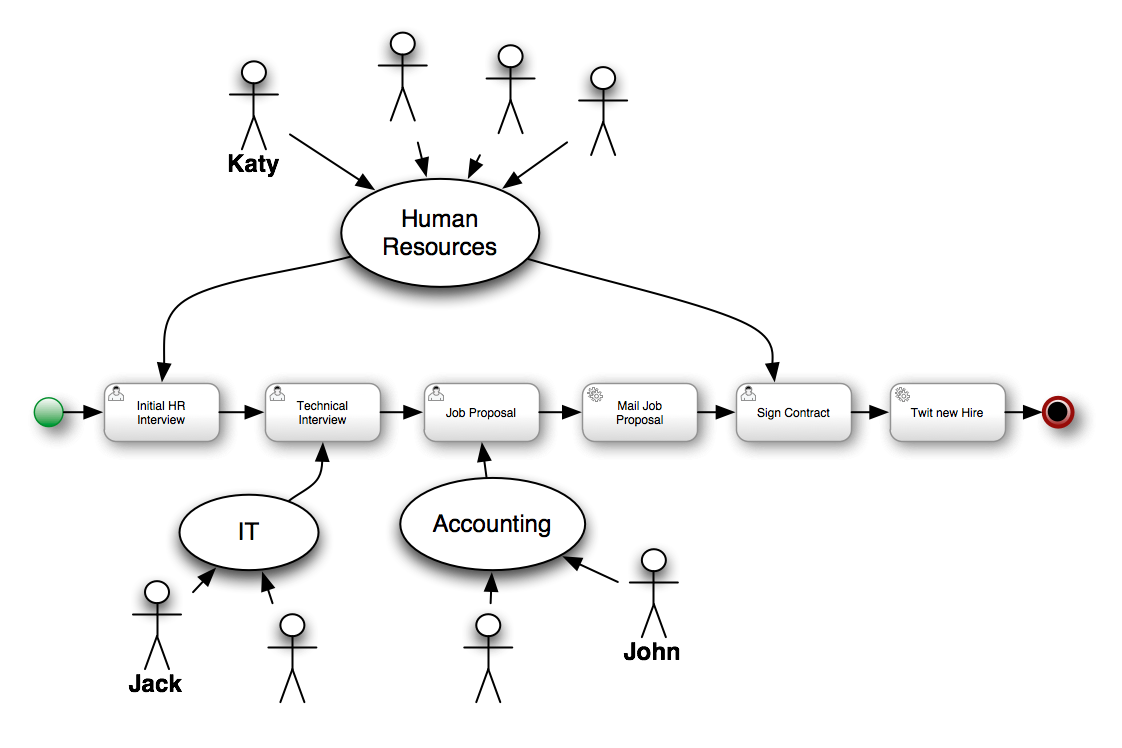
Note that only four out of the six defined activities within the business process are User Tasks. User Tasks require human interaction. The other two tasks are Service Tasks, which are automated and connected to other systems.
Each instance of the process will follow certain actions:
-
The human resources team performs the initial interview with the candidate.
-
The IT department team performs the technical interview.
-
Based on the output from the previous two steps, the accounting team creates a job proposal.
-
When the proposal has been drafted, it is automatically sent to the candidate via email.
-
If the candidate accepts the proposal, a new meeting to sign the contract is scheduled.
-
Finally, if the candidate accepts the proposal, the system posts a message about the new hire using Twitter service connector.
Note, that Jack, John, and Katy represent any employee within the company with appropriate role assigned.
4.3.1. The Kie Project: human-resources
To start exploring the project:
-
Click .
-
Click .
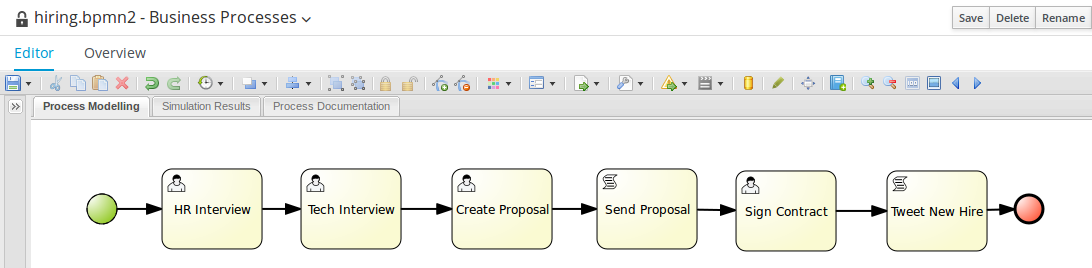
The authoring page contains the hiring.bpmn2 process and a set of forms for each human task. Click these assets to explore. Notice that different editors open for different types of assets.
4.3.2. Building the Human Resources Example
To build the Project:
-
Click .
-
Click the project name.
-
Click "Build & Deploy".
Build & Deploy creates a new JAR artifact that is deployed to the runtime environment as a new deployment unit.
After successfully building and deploying your project, you can verify its presence in the Deployments tab. Click to do so.

You can find all the deployed units in the Deployments tab. When you Build & Deploy a project from the Project Editor, it is deployed using the default configurations. That means using the Singleton Strategy, the default Kie Base and the default Kie Session.
If you want a more advanced deployment, undeploy and re-deploy your artifacts using their GAV and selecting non-default settings. Then, you will be able to set a different strategy, or use a non-default Kie Base or Kie Session.
Once your artifact that contains the process definition is deployed, the Process Definition will become available in .
4.3.3. Create a new Process Instance
To create new process instances:
Click .
Start your instance:
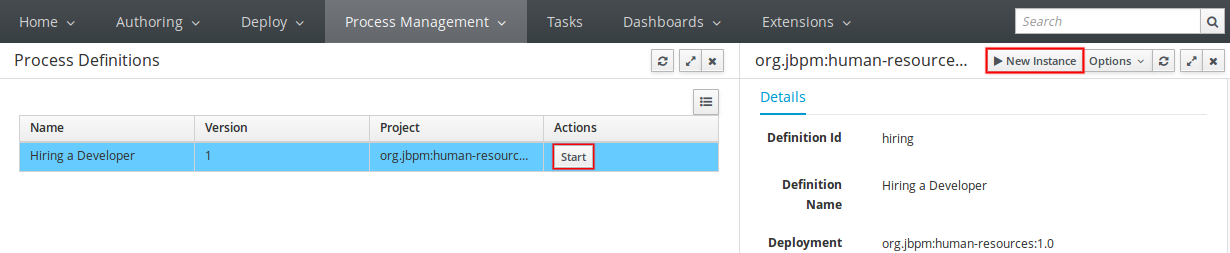
The Process Definitions tab contains all the available process definitions in the runtime environment. In order to add new process definitions, build and deploy a new project.
Most processes require additional information to create a new process instance. This is done through forms. For this project, fill in the name of the candidate that is to be interviewed.
When you click Submit , you create a new process instance. This creates the first task, that is available for the Human Resources team. To see the task, you need to logout and log in as a user with the appropriate role assigned, that is someone from the Human Resources.
When you start the process, you can interact with the human tasks. To do so, click .
Note that in order to see the tasks in the task list, you need to belong to specific user groups, for which the task is designed. For example, the HR Interview task is visible only for the members of the HR group, and the Tech Interview Task is visible only to the members of the IT group.
4.4. Examples zip
A zip file of examples can also be downloaded from the downloads page, containing various examples that can be opened in the Eclipse-based Developers Tools. Simply download and unzip the examples artefact and import into your Eclipse workspace.
5. jBPM Version Migration Guide
5.1. Deprecated in jBPM 7
| Property | Description | jBPM 7 Behavior |
|---|---|---|
|
This property is responsible for how the |
In jBPM 7, this is no longer possible: all |
5.2. Changed in jBPM 7
| Jira | Description | What to do |
|---|---|---|
Value of constant |
Update your code to reflect this change - from old value |
jBPM Core
Using the jBPM Core Engine
6. Core Engine API
6.1. Overview
This chapter introduces the API you need to load processes and execute them. For more detail on how to define the processes themselves, check out the chapter on BPMN 2.0.
To interact with the process engine (for example, to start a process), you need to set up a session. This session will be used to communicate with the process engine. A session needs to have a reference to a knowledge base, which contains a reference to all the relevant process definitions. This knowledge base is used to look up the process definitions whenever necessary. To create a session, you first need to create a knowledge base, load all the necessary process definitions (this can be from various sources, like from classpath, file system or process repository) and then instantiate a session.
Once you have set up a session, you can use it to start executing processes. Whenever a process is started, a new process instance is created (for that process definition) that maintains the state of that specific instance of the process.
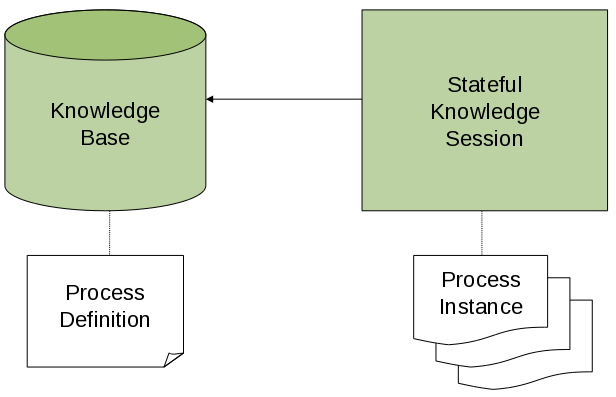
For example, imagine you are writing an application to process sales orders. You could then define one or more process definitions that define how the order should be processed. When starting up your application, you first need to create a knowledge base that contains those process definitions. You can then create a session based on this knowledge base so that, whenever a new sales order comes in, a new process instance is started for that sales order. That process instance contains the state of the process for that specific sales request.
A knowledge base can be shared across sessions and usually is only created once, at the start of the application (as creating a knowledge base can be rather heavy-weight as it involves parsing and compiling the process definitions). Knowledge bases can be dynamically changed (so you can add or remove processes at runtime).
Sessions can be created based on a knowledge base and are used to execute processes and interact with the engine. You can create as many independent session as you need and creating a session is considered relatively lightweight. How many sessions you create is up to you. In general, most simple cases start out with creating one session that is then called from various places in your application. You could decide to create multiple sessions if for example you want to have multiple independent processing units (for example, if you want all processes from one customer to be completely independent from processes for another customer, you could create an independent session for each customer) or if you need multiple sessions for scalability reasons. If you don’t know what to do, simply start by having one knowledge base that contains all your process definitions and create one session that you then use to execute all your processes.
The jBPM project has a clear separation between the API the users should be interacting with and the actual implementation classes. The public API exposes most of the features we believe "normal" users can safely use and should remain rather stable across releases. Expert users can still access internal classes but should be aware that they should know what they are doing and that the internal API might still change in the future.
As explained above, the jBPM API should thus be used to (1) create a knowledge base that contains your process definitions, and to (2) create a session to start new process instances, signal existing ones, register listeners, etc.
6.2. KieBase
The jBPM API allows you to first create a knowledge base. This knowledge base should include all your process definitions that might need to be executed by that session. To create a knowledge base, use a KieHelper to load processes from various resources (for example from the classpath or from the file system), and then create a new knowledge base from that helper. The following code snippet shows how to create a knowledge base consisting of only one process definition (using in this case a resource from the classpath).
KieHelper kieHelper = new KieHelper();
KieBase kieBase = kieHelper
.addResource(ResourceFactory.newClassPathResource("MyProcess.bpmn"))
.build();The ResourceFactory has similar methods to load files from file system, from URL, InputStream, Reader, etc.
This is considered manual creation of knowledge base and while it is simple it is not recommended for real application development but more for try outs. Following you’ll find recommended and much more powerful way of building knowledge base, knowledge session and more - RuntimeManager.
6.3. KieSession
Once you’ve loaded your knowledge base, you should create a session to interact with the engine. This session can then be used to start new processes, signal events, etc. The following code snippet shows how easy it is to create a session based on the previously created knowledge base, and to start a process (by id).
KieSession ksession = kbase.newKieSession();
ProcessInstance processInstance = ksession.startProcess("com.sample.MyProcess");6.3.1. ProcessRuntime
The ProcessRuntime interface defines all the session methods for interacting with processes, as shown below.
/**
* Start a new process instance. The process (definition) that should
* be used is referenced by the given process id.
*
* @param processId The id of the process that should be started
* @return the ProcessInstance that represents the instance of the process that was started
*/
ProcessInstance startProcess(String processId);
/**
* Start a new process instance. The process (definition) that should
* be used is referenced by the given process id. Parameters can be passed
* to the process instance (as name-value pairs), and these will be set
* as variables of the process instance.
*
* @param processId the id of the process that should be started
* @param parameters the process variables that should be set when starting the process instance
* @return the ProcessInstance that represents the instance of the process that was started
*/
ProcessInstance startProcess(String processId,
Map<String, Object> parameters);
/**
* Signals the engine that an event has occurred. The type parameter defines
* which type of event and the event parameter can contain additional information
* related to the event. All process instances that are listening to this type
* of (external) event will be notified. For performance reasons, this type of event
* signaling should only be used if one process instance should be able to notify
* other process instances. For internal event within one process instance, use the
* signalEvent method that also include the processInstanceId of the process instance
* in question.
*
* @param type the type of event
* @param event the data associated with this event
*/
void signalEvent(String type,
Object event);
/**
* Signals the process instance that an event has occurred. The type parameter defines
* which type of event and the event parameter can contain additional information
* related to the event. All node instances inside the given process instance that
* are listening to this type of (internal) event will be notified. Note that the event
* will only be processed inside the given process instance. All other process instances
* waiting for this type of event will not be notified.
*
* @param type the type of event
* @param event the data associated with this event
* @param processInstanceId the id of the process instance that should be signaled
*/
void signalEvent(String type,
Object event,
long processInstanceId);
/**
* Returns a collection of currently active process instances. Note that only process
* instances that are currently loaded and active inside the engine will be returned.
* When using persistence, it is likely not all running process instances will be loaded
* as their state will be stored persistently. It is recommended not to use this
* method to collect information about the state of your process instances but to use
* a history log for that purpose.
*
* @return a collection of process instances currently active in the session
*/
Collection<ProcessInstance> getProcessInstances();
/**
* Returns the process instance with the given id. Note that only active process instances
* will be returned. If a process instance has been completed already, this method will return
* null.
*
* @param id the id of the process instance
* @return the process instance with the given id or null if it cannot be found
*/
ProcessInstance getProcessInstance(long processInstanceId);
/**
* Aborts the process instance with the given id. If the process instance has been completed
* (or aborted), or the process instance cannot be found, this method will throw an
* IllegalArgumentException.
*
* @param id the id of the process instance
*/
void abortProcessInstance(long processInstanceId);
/**
* Returns the WorkItemManager related to this session. This can be used to
* register new WorkItemHandlers or to complete (or abort) WorkItems.
*
* @return the WorkItemManager related to this session
*/
WorkItemManager getWorkItemManager();6.3.2. Event Listeners
The session provides methods for registering and removing listeners.
A ProcessEventListener can be used to listen to process-related events, like starting or completing a process, entering and leaving a node, etc.
Below, the different methods of the ProcessEventListener class are shown.
An event object provides access to related information, like the process instance and node instance linked to the event.
You can use this API to register your own event listeners.
public interface ProcessEventListener {
void beforeProcessStarted( ProcessStartedEvent event );
void afterProcessStarted( ProcessStartedEvent event );
void beforeProcessCompleted( ProcessCompletedEvent event );
void afterProcessCompleted( ProcessCompletedEvent event );
void beforeNodeTriggered( ProcessNodeTriggeredEvent event );
void afterNodeTriggered( ProcessNodeTriggeredEvent event );
void beforeNodeLeft( ProcessNodeLeftEvent event );
void afterNodeLeft( ProcessNodeLeftEvent event );
void beforeVariableChanged(ProcessVariableChangedEvent event);
void afterVariableChanged(ProcessVariableChangedEvent event);
}A note about before and after events: these events typically act like a stack, which means that any events that occur as a direct result of the previous event, will occur between the before and the after of that event. For example, if a subsequent node is triggered as result of leaving a node, the node triggered events will occur inbetween the beforeNodeLeftEvent and the afterNodeLeftEvent of the node that is left (as the triggering of the second node is a direct result of leaving the first node). Doing that allows us to derive cause relationships between events more easily. Similarly, all node triggered and node left events that are the direct result of starting a process will occur between the beforeProcessStarted and afterProcessStarted events. In general, if you just want to be notified when a particular event occurs, you should be looking at the before events only (as they occur immediately before the event actually occurs). When only looking at the after events, one might get the impression that the events are fired in the wrong order, but because the after events are triggered as a stack (after events will only fire when all events that were triggered as a result of this event have already fired). After events should only be used if you want to make sure that all processing related to this has ended (for example, when you want to be notified when starting of a particular process instance has ended.
Also note that not all nodes always generate node triggered and/or node left events. Depending on the type of node, some nodes might only generate node left events, others might only generate node triggered events. Catching intermediate events for example are not generating triggered events (they are only generating left events, as they are not really triggered by another node, rather activated from outside). Similarly, throwing intermediate events are not generating left events (they are only generating triggered events, as they are not really left, as they have no outgoing connection).
jBPM out-of-the-box provides a listener that can be used to create an audit log (either to the console or the a file on the file system). This audit log contains all the different events that occurred at runtime so it’s easy to figure out what happened. Note that these loggers should only be used for debugging purposes. The following logger implementations are supported by default:
-
Console logger: This logger writes out all the events to the console.
-
File logger: This logger writes out all the events to a file using an XML representation. This log file might then be used in the IDE to generate a tree-based visualization of the events that occurred during execution.
-
Threaded file logger: Because a file logger writes the events to disk only when closing the logger or when the number of events in the logger reaches a predefined level, it cannot be used when debugging processes at runtime. A threaded file logger writes the events to a file after a specified time interval, making it possible to use the logger to visualize the progress in realtime, while debugging processes.
The KieServices lets you add a KieRuntimeLogger to your session, as shown below.
When creating a console logger, the knowledge session for which the logger needs to be created must be passed as an argument.
The file logger also requires the name of the log file to be created, and the threaded file logger requires the interval (in milliseconds) after which the events should be saved.
You should always close the logger at the end of your application.
import org.kie.api.KieServices;
import org.kie.api.logger.KieRuntimeLogger;
...
KieRuntimeLogger logger = KieServices.Factory.get().getLoggers().newFileLogger(ksession, "test");
// add invocations to the process engine here,
// e.g. ksession.startProcess(processId);
...
logger.close();The log file that is created by the file-based loggers contains an XML-based overview of all the events that occurred at runtime. It can be opened in Eclipse, using the Audit View in the Drools Eclipse plugin, where the events are visualized as a tree. Events that occur between the before and after event are shown as children of that event. The following screenshot shows a simple example, where a process is started, resulting in the activation of the Start node, an Action node and an End node, after which the process was completed.

6.3.3. Correlation Keys
A common requirement when working with processes is ability to assign a given process instance some sort of business identifier that can be later on referenced without knowing the actual (generated) id of the process instance. To provide such capabilities, jBPM allows to use CorrelationKey that is composed of CorrelationProperties. CorrelationKey can have either single property describing it (which is in most cases) but it can be represented as multi valued properties set.
Correlation capabilities are provided as part of interface
CorrelationAwareProcessRuntimethat exposes following methods:
/**
* Start a new process instance. The process (definition) that should
* be used is referenced by the given process id. Parameters can be passed
* to the process instance (as name-value pairs), and these will be set
* as variables of the process instance.
*
* @param processId the id of the process that should be started
* @param correlationKey custom correlation key that can be used to identify process instance
* @param parameters the process variables that should be set when starting the process instance
* @return the ProcessInstance that represents the instance of the process that was started
*/
ProcessInstance startProcess(String processId, CorrelationKey correlationKey, Map<String, Object> parameters);
/**
* Creates a new process instance (but does not yet start it). The process
* (definition) that should be used is referenced by the given process id.
* Parameters can be passed to the process instance (as name-value pairs),
* and these will be set as variables of the process instance. You should only
* use this method if you need a reference to the process instance before actually
* starting it. Otherwise, use startProcess.
*
* @param processId the id of the process that should be started
* @param correlationKey custom correlation key that can be used to identify process instance
* @param parameters the process variables that should be set when creating the process instance
* @return the ProcessInstance that represents the instance of the process that was created (but not yet started)
*/
ProcessInstance createProcessInstance(String processId, CorrelationKey correlationKey, Map<String, Object> parameters);
/**
* Returns the process instance with the given correlationKey. Note that only active process instances
* will be returned. If a process instance has been completed already, this method will return
* null.
*
* @param correlationKey the custom correlation key assigned when process instance was created
* @return the process instance with the given id or null if it cannot be found
*/
ProcessInstance getProcessInstance(CorrelationKey correlationKey);Correlation is usually used with long running processes and thus require persistence to be enabled to be able to permanently store correlation information.
6.3.4. Threads
In the following text, we will refer to two types of "multi-threading": logical and technical. Technical multi-threading is what happens when multiple threads or processes are started on a computer, for example by a Java or C program. Logical multi-threading is what we see in a BPM process after the process reaches a parallel gateway, for example. From a functional standpoint, the original process will then split into two processes that are executed in a parallel fashion.
Of course, the jBPM engine supports logical multi-threading: for example, processes that include a parallel gateway. We’ve chosen to implement logical multi-threading using one thread: a jBPM process that includes logical multi-threading will only be executed in one technical thread. The main reason for doing this is that multiple (technical) threads need to be be able to communicate state information with each other if they are working on the same process. This requirement brings with it a number of complications. While it might seem that multi-threading would bring performance benefits with it, the extra logic needed to make sure the different threads work together well means that this is not guaranteed. There is also the extra overhead incurred because we need to avoid race conditions and deadlocks.
In general, the jBPM engine executes actions in serial.
For example, when the engine encounters a script task in a process, it will synchronously execute that script and wait for it to complete before continuing execution.
Similarly, if a process encounters a parallel gateway, it will sequentially trigger each of the outgoing branches, one after the other.
This is possible since execution is almost always instantaneous, meaning that it is extremely fast and produces almost no overhead.
As a result, the user will usually not even notice this.
Similarly, action scripts in a process are also synchronously executed, and the engine will wait for them to finish before continuing the process.
For example, doing a Thread.sleep(…) as part of a script will not make the engine continue execution elsewhere but will block the engine thread during that period.
The same principle applies to service tasks.
When a service task is reached in a process, the engine will also invoke the handler of this service synchronously.
The engine will wait for the completeWorkItem(…) method to return before continuing execution.
It is important that your service handler executes your service asynchronously if its execution is not instantaneous.
An example of this would be a service task that invokes an external service. Since the delay in invoking this service remotely and waiting for the results might be too long, it might be a good idea to invoke this service asynchronously. This means that the handler will only invoke the service and will notify the engine later when the results are available. In the mean time, the process engine then continues execution of the process.
Human tasks are a typical example of a service that needs to be invoked asynchronously, as we don’t want the engine to wait until a human actor has responded to the request. The human task handler will only create a new task (on the task list of the assigned actor) when the human task node is triggered. The engine will then be able to continue execution on the rest of the process (if necessary) and the handler will notify the engine asynchronously when the user has completed the task.
6.4. RuntimeManager
6.4.1. Overview
RuntimeManager has been introduced to simplify and empower usage of knowledge API especially in context of processes. It provides configurable strategies that control actual runtime execution (how KieSessions are provided) and by default provides following:
-
Singleton - runtime manager maintains single KieSession regardless of number of processes available
-
Per Request - runtime manager delivers new KieSession for every request
-
Per Process Instance - runtime manager maintains mapping between process instance and KieSession and always provides same KieSession whenever working with given process instance
Runtime Manager is primarily responsible for managing and delivering instances of RuntimeEngine to the caller. In turn, RuntimeEngine encapsulates two the most important elements of jBPM engine:
-
KieSession
-
TaskService
Both of these components are already configured to work with each other smoothly without additional configuration from end user. No more need to register human task handler or keeping track if it’s connected to the service or not.
public interface RuntimeManager {
/**
* Returns <code>RuntimeEngine</code> instance that is fully initialized:
* <ul>
* <li>KiseSession is created or loaded depending on the strategy</li>
* <li>TaskService is initialized and attached to ksession (via listener)</li>
* <li>WorkItemHandlers are initialized and registered on ksession</li>
* <li>EventListeners (process, agenda, working memory) are initialized and added to ksession</li>
* </ul>
* @param context the concrete implementation of the context that is supported by given <code>RuntimeManager</code>
* @return instance of the <code>RuntimeEngine</code>
*/
RuntimeEngine getRuntimeEngine(Context<?> context);
/**
* Unique identifier of the <code>RuntimeManager</code>
* @return
*/
String getIdentifier();
/**
* Disposes <code>RuntimeEngine</code> and notifies all listeners about that fact.
* This method should always be used to dispose <code>RuntimeEngine</code> that is not needed
* anymore. <br/>
* ksession.dispose() shall never be used with RuntimeManager as it will break the internal
* mechanisms of the manager responsible for clear and efficient disposal.<br/>
* Dispose is not needed if <code>RuntimeEngine</code> was obtained within active JTA transaction,
* this means that when getRuntimeEngine method was invoked during active JTA transaction then dispose of
* the runtime engine will happen automatically on transaction completion.
* @param runtime
*/
void disposeRuntimeEngine(RuntimeEngine runtime);
/**
* Closes <code>RuntimeManager</code> and releases its resources. Shall always be called when
* runtime manager is not needed any more. Otherwise it will still be active and operational.
*/
void close();
}RuntimeEngine interface provides the most important methods to get access to engine components:
public interface RuntimeEngine {
/**
* Returns <code>KieSession</code> configured for this <code>RuntimeEngine</code>
* @return
*/
KieSession getKieSession();
/**
* Returns <code>TaskService</code> configured for this <code>RuntimeEngine</code>
* @return
*/
TaskService getTaskService();
}RuntimeManager will ensure that regardless of the strategy it will provide same capabilities when it comes to initialization and configuration of the RuntimeEngine. That means
-
KieSession will be loaded with same factories (either in memory or JPA based)
-
WorkItemHandlers will be registered on every KieSession (either loaded from db or newly created)
-
Event listeners (Process, Agenda, WorkingMemory) will be registered on every KieSession (either loaded from db or newly created)
-
TaskService will be configured with:
-
JTA transaction manager
-
same entity manager factory as for the KieSession
-
UserGroupCallback from environment
-
On the other hand, RuntimeManager maintains the engine disposal as well by providing dedicated methods to dispose RuntimeEngine when it’s no more needed to release any resources it might have acquired.
|
RuntimeManager’s identifier is used as "deploymentId" during runtime execution. For example, the identifier is persisted as "deploymentId" of a Task when the Task is persisted. Task’s deploymentId is used to associate the RuntimeManager when the Task is completed and its process instance is resumed. The deploymentId is also persisted as "externalId" in history log tables. If you don’t specify an identifier on RuntimeManager creation, a default value is applied (e.g. "default-per-pinstance" for PerProcessInstanceRuntimeManager). That means your application uses the same deployment in its lifecycle. If you maintain multiple RuntimeManagers in your application, you need to specify their identifiers. For example, jbpm-services (DeploymentService) maintains multiple RuntimeManagers with identifiers of kjar’s GAV. kie-workbench web application too because it depends on jbpm-services. |
6.4.2. Strategies
Singleton strategy - instructs RuntimeManager to maintain single instance of RuntimeEngine (and in turn single instance of KieSession and TaskService). Access to the RuntimeEngine is synchronized and by that thread safe although it comes with a performance penalty due to synchronization. This strategy is similar to what was available by default in jBPM version 5.x and it’s considered easiest strategy and recommended to start with.
It has following characteristics that are important to evaluate while considering it for given scenario:
-
small memory footprint - single instance of runtime engine and task service
-
simple and compact in design and usage
-
good fit for low to medium load on process engine due to synchronized access
-
due to single KieSession instance all state objects (such as facts) are directly visible to all process instances and vice versa
-
not contextual - meaning when retrieving instances of RuntimeEngine from singleton RuntimeManager Context instance is not important and usually EmptyContext.get() is used although null argument is acceptable as well
-
keeps track of id of KieSession used between RuntimeManager restarts to ensure it will use same session - this id is stored as serialized file on disc in temp location that depends on the environment can be one of following:
-
value given by jbpm.data.dir system property
-
value given by jboss.server.data.dir system property
-
value given by java.io.tmpdir system property
-
Per request strategy - instructs RuntimeManager to provide new instance of RuntimeEngine for every request. As request RuntimeManager will consider one or more invocations within single transaction. It must return same instance of RuntimeEngine within single transaction to ensure correctness of state as otherwise operation done in one call would not be visible in the other. This is sort of "stateless" strategy that provides only request scope state and once request is completed RuntimeEngine will be permanently destroyed - KieSession information will be removed from the database in case persistence was used.
It has following characteristics:
-
completely isolated process engine and task service operations for every request
-
completely stateless, storing facts makes sense only for the duration of the request
-
good fit for high load, stateless processes (no facts or timers involved that shall be preserved between requests)
-
KieSession is only available during life time of request and at the end is destroyed
-
not contextual - meaning when retrieving instances of RuntimeEngine from per request RuntimeManager Context instance is not important and usually EmptyContext.get() is used although null argument is acceptable as well
Per process instance strategy - instructs RuntimeManager to maintain a strict relationship between KieSession and ProcessInstance. That means that KieSession will be available as long as the ProcessInstance that it belongs to is active. This strategy provides the most flexible approach to use advanced capabilities of the engine like rule evaluation in isolation (for given process instance only), maximum performance and reduction of potential bottlenecks intriduced by synchronization; and at the same time reduces number of KieSessions to the actual number of process instances rather than number of requests (in contrast to per request strategy).
It has following characteristics:
-
most advanced strategy to provide isolation to given process instance only
-
maintains strict relationship between KieSession and ProcessInstance to ensure it will always deliver same KieSession for given ProcessInstance
-
merges life cycle of KieSession with ProcessInstance making both to be disposed on process instance completion (complete or abort)
-
allows to maintain data (such as facts, timers) in scope of process instance - only process instance will have access to that data
-
introduces bit of overhead due to need to look up and load KieSession for process instance
-
validates usage of KieSession so it cannot be (ab)used for other process instances, in such case an exception is thrown
-
is contextual - accepts following context instances:
-
EmptyContext or null - when starting process instance as there is no process instance id available yet
-
ProcessInstanceIdContext - used after process instance was created
-
CorrelationKeyContext - used as an alternative to ProcessInstanceIdContext to use custom (business) key instead of process instance id
-
6.4.3. Usage
Regular usage scenario for RuntimeManager is:
-
At application startup
-
build RuntimeManager and keep it for entire life time of the application, it’s thread safe and can be (or even should be) accessed concurrently
-
-
At request
-
get RuntimeEngine from RuntimeManager using proper context instance dedicated to strategy of RuntimeManager
-
get KieSession and/or TaskService from RuntimeEngine
-
perform operations on KieSession and/or TaskService such as startProcess, completeTask, etc
-
once done with processing dispose RuntimeEngine using RuntimeManager.disposeRuntimeEngine method
-
-
At application shutdown
-
close RuntimeManager
-
|
When RuntimeEngine is obtained from RuntimeManager within an active JTA transaction, then there is no need to dispose RuntimeEngine at the end, as RuntimeManager will automatically dispose the RuntimeEngine on transaction completion (regardless of the completion status commit or rollback). |
6.4.3.1. Example
Here is how you can build RuntimeManager and get RuntimeEngine (that encapsulates KieSession and TaskService) from it:
// first configure environment that will be used by RuntimeManager
RuntimeEnvironment environment = RuntimeEnvironmentBuilder.Factory.get()
.newDefaultInMemoryBuilder()
.addAsset(ResourceFactory.newClassPathResource("BPMN2-ScriptTask.bpmn2"), ResourceType.BPMN2)
.get();
// next create RuntimeManager - in this case singleton strategy is chosen
RuntimeManager manager = RuntimeManagerFactory.Factory.get().newSingletonRuntimeManager(environment);
// then get RuntimeEngine out of manager - using empty context as singleton does not keep track
// of runtime engine as there is only one
RuntimeEngine runtime = manager.getRuntimeEngine(EmptyContext.get());
// get KieSession from runtime runtimeEngine - already initialized with all handlers, listeners, etc that were configured
// on the environment
KieSession ksession = runtimeEngine.getKieSession();
// add invocations to the process engine here,
// e.g. ksession.startProcess(processId);
// and last dispose the runtime engine
manager.disposeRuntimeEngine(runtimeEngine);This example provides simplest (minimal) way of using RuntimeManager and RuntimeEngine although it provides few quite valuable information:
-
KieSession will be in memory only - by using newDefaultInMemoryBuilder
-
there will be single process available for execution - by adding it as an asset
-
TaskService will be configured and attached to KieSession via LocalHTWorkItemHandler to support user task capabilities within processes
6.4.4. Configuration
The complexity of knowing when to create, dispose, register handlers, etc is taken away from the end user and moved to the runtime manager that knows when/how to perform such operations but still allows to have a fine grained control over this process by providing comprehensive configuration of the RuntimeEnvironment.
public interface RuntimeEnvironment {
/**
* Returns <code>KieBase</code> that shall be used by the manager
* @return
*/
KieBase getKieBase();
/**
* KieSession environment that shall be used to create instances of <code>KieSession</code>
* @return
*/
Environment getEnvironment();
/**
* KieSession configuration that shall be used to create instances of <code>KieSession</code>
* @return
*/
KieSessionConfiguration getConfiguration();
/**
* Indicates if persistence shall be used for the KieSession instances
* @return
*/
boolean usePersistence();
/**
* Delivers concrete implementation of <code>RegisterableItemsFactory</code> to obtain handlers and listeners
* that shall be registered on instances of <code>KieSession</code>
* @return
*/
RegisterableItemsFactory getRegisterableItemsFactory();
/**
* Delivers concrete implementation of <code>UserGroupCallback</code> that shall be registered on instances
* of <code>TaskService</code> for managing users and groups.
* @return
*/
UserGroupCallback getUserGroupCallback();
/**
* Delivers custom class loader that shall be used by the process engine and task service instances
* @return
*/
ClassLoader getClassLoader();
/**
* Closes the environment allowing to close all depending components such as ksession factories, etc
*/
void close();6.4.4.1. Building RuntimeEnvironment
While RuntimeEnvironment interface provides mostly access to data kept as part of the environment and will be used by the RuntimeManager, users should take advantage of builder style class that provides fluent API to configure RuntimeEnvironment with predefined settings.
public interface RuntimeEnvironmentBuilder {
public RuntimeEnvironmentBuilder persistence(boolean persistenceEnabled);
public RuntimeEnvironmentBuilder entityManagerFactory(Object emf);
public RuntimeEnvironmentBuilder addAsset(Resource asset, ResourceType type);
public RuntimeEnvironmentBuilder addEnvironmentEntry(String name, Object value);
public RuntimeEnvironmentBuilder addConfiguration(String name, String value);
public RuntimeEnvironmentBuilder knowledgeBase(KieBase kbase);
public RuntimeEnvironmentBuilder userGroupCallback(UserGroupCallback callback);
public RuntimeEnvironmentBuilder registerableItemsFactory(RegisterableItemsFactory factory);
public RuntimeEnvironment get();
public RuntimeEnvironmentBuilder classLoader(ClassLoader cl);
public RuntimeEnvironmentBuilder schedulerService(Object globalScheduler);Instances of the RuntimeEnvironmentBuilder can be obtained via RuntimeEnvironmentBuilderFactory that provides preconfigured sets of builder to simplify and help users to build the environment for the RuntimeManager.
public interface RuntimeEnvironmentBuilderFactory {
/**
* Provides completely empty <code>RuntimeEnvironmentBuilder</code> instance that allows to manually
* set all required components instead of relying on any defaults.
* @return new instance of <code>RuntimeEnvironmentBuilder</code>
*/
public RuntimeEnvironmentBuilder newEmptyBuilder();
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultBuilder();
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* but it does not have persistence for process engine configured so it will only store process instances in memory
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultInMemoryBuilder();
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* This one is tailored to works smoothly with kjars as the notion of kbase and ksessions
* @param groupId group id of kjar
* @param artifactId artifact id of kjar
* @param version version number of kjar
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultBuilder(String groupId, String artifactId, String version);
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* This one is tailored to works smoothly with kjars as the notion of kbase and ksessions
* @param groupId group id of kjar
* @param artifactId artifact id of kjar
* @param version version number of kjar
* @param kbaseName name of the kbase defined in kmodule.xml stored in kjar
* @param ksessionName name of the ksession define in kmodule.xml stored in kjar
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultBuilder(String groupId, String artifactId, String version, String kbaseName, String ksessionName);
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* This one is tailored to works smoothly with kjars as the notion of kbase and ksessions
* @param releaseId <code>ReleaseId</code> that described the kjar
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultBuilder(ReleaseId releaseId);
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* This one is tailored to works smoothly with kjars as the notion of kbase and ksessions
* @param releaseId <code>ReleaseId</code> that described the kjar
* @param kbaseName name of the kbase defined in kmodule.xml stored in kjar
* @param ksessionName name of the ksession define in kmodule.xml stored in kjar
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newDefaultBuilder(ReleaseId releaseId, String kbaseName, String ksessionName);
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* It relies on KieClasspathContainer that requires to have kmodule.xml present in META-INF folder which
* defines the kjar itself.
* Expects to use default kbase and ksession from kmodule.
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newClasspathKmoduleDefaultBuilder();
/**
* Provides default configuration of <code>RuntimeEnvironmentBuilder</code> that is based on:
* <ul>
* <li>DefaultRuntimeEnvironment</li>
* </ul>
* It relies on KieClasspathContainer that requires to have kmodule.xml present in META-INF folder which
* defines the kjar itself.
* @param kbaseName name of the kbase defined in kmodule.xml
* @param ksessionName name of the ksession define in kmodule.xml
* @return new instance of <code>RuntimeEnvironmentBuilder</code> that is already preconfigured with defaults
*
* @see DefaultRuntimeEnvironment
*/
public RuntimeEnvironmentBuilder newClasspathKmoduleDefaultBuilder(String kbaseName, String ksessionName);Besides KieSession Runtime Manager provides access to TaskService too as integrated component of a RuntimeEngine that will always be configured and ready for communication between process engine and task service.
Since the default builder was used, it will already come with predefined set of elements that consists of:
-
Persistence unit name will be set to org.jbpm.persistence.jpa (for both process engine and task service)
-
Human Task handler will be automatically registered on KieSession
-
JPA based history log event listener will be automatically registered on KieSession
-
Event listener to trigger rule task evaluation (fireAllRules) will be automatically registered on KieSession
6.4.4.2. Registering handlers and listeners
To extend it with your own handlers or listeners a dedicated mechanism is provided that comes as implementation of RegisterableItemsFactory
/**
* Returns new instances of <code>WorkItemHandler</code> that will be registered on <code>RuntimeEngine</code>
* @param runtime provides <code>RuntimeEngine</code> in case handler need to make use of it internally
* @return map of handlers to be registered - in case of no handlers empty map shall be returned.
*/
Map<String, WorkItemHandler> getWorkItemHandlers(RuntimeEngine runtime);
/**
* Returns new instances of <code>ProcessEventListener</code> that will be registered on <code>RuntimeEngine</code>
* @param runtime provides <code>RuntimeEngine</code> in case listeners need to make use of it internally
* @return list of listeners to be registered - in case of no listeners empty list shall be returned.
*/
List<ProcessEventListener> getProcessEventListeners(RuntimeEngine runtime);
/**
* Returns new instances of <code>AgendaEventListener</code> that will be registered on <code>RuntimeEngine</code>
* @param runtime provides <code>RuntimeEngine</code> in case listeners need to make use of it internally
* @return list of listeners to be registered - in case of no listeners empty list shall be returned.
*/
List<AgendaEventListener> getAgendaEventListeners(RuntimeEngine runtime);
/**
* Returns new instances of <code>WorkingMemoryEventListener</code> that will be registered on <code>RuntimeEngine</code>
* @param runtime provides <code>RuntimeEngine</code> in case listeners need to make use of it internally
* @return list of listeners to be registered - in case of no listeners empty list shall be returned.
*/
List<WorkingMemoryEventListener> getWorkingMemoryEventListeners(RuntimeEngine runtime);A best practice is to just extend those that come out of the box and just add your own. Extensions are not always needed as the default implementations of RegisterableItemsFactory provides possibility to define custom handlers and listeners. Following is a list of available implementations that might be useful (they are ordered in the hierarchy of inheritance):
-
org.jbpm.runtime.manager.impl.SimpleRegisterableItemsFactory - simplest possible implementations that comes empty and is based on reflection to produce instances of handlers and listeners based on given class names
-
org.jbpm.runtime.manager.impl.DefaultRegisterableItemsFactory - extension of the Simple implementation that introduces defaults described above and still provides same capabilities as Simple implementation
-
org.jbpm.runtime.manager.impl.KModuleRegisterableItemsFactory - extension of default implementation that provides specific capabilities for kmodule and still provides same capabilities as Simple implementation
-
org.jbpm.runtime.manager.impl.cdi.InjectableRegisterableItemsFactory - extension of default implementation that is tailored for CDI environments and provides CDI style approach to finding handlers and listeners via producers
Alternatively, simple (stateless or requiring only KieSession) work item handlers might be registered in the well known way - defined as part of CustomWorkItem.conf file that shall be placed on class path. To use this approach do following:
-
create file "drools.session.conf" inside META-INF of the root of the class path, for web applications it will be WEB-INF/classes/META-INF
-
add following line to drools.session.conf file "drools.workItemHandlers = CustomWorkItemHandlers.conf"
-
create file "CustomWorkItemHandlers.conf" inside META-INF of the root of the class path, for web applications it will be WEB-INF/classes/META-INF
-
define custom work item handlers in MVEL style inside CustomWorkItemHandlers.conf
[ "Log": new org.jbpm.process.instance.impl.demo.SystemOutWorkItemHandler(), "WebService": new org.jbpm.process.workitem.webservice.WebServiceWorkItemHandler(ksession), "Rest": new org.jbpm.process.workitem.rest.RESTWorkItemHandler(), "Service Task" : new org.jbpm.process.workitem.bpmn2.ServiceTaskHandler(ksession) ]
And that’s it, now all these work item handlers will be registered for any KieSession created by that application, regardless if it uses RuntimeManager or not.
Registering handlers and listeners in CDI environment
When using RuntimeManager in CDI environment there are dedicated interfaces that can be used to provide custom WorkItemHandlers and EventListeners to the RuntimeEngine.
public interface WorkItemHandlerProducer {
/**
* Returns map of (key = work item name, value work item handler instance) of work items
* to be registered on KieSession
* <br/>
* Parameters that might be given are as follows:
* <ul>
* <li>ksession</li>
* <li>taskService</li>
* <li>runtimeManager</li>
* </ul>
*
* @param identifier - identifier of the owner - usually RuntimeManager that allows the producer to filter out
* and provide valid instances for given owner
* @param params - owner might provide some parameters, usually KieSession, TaskService, RuntimeManager instances
* @return map of work item handler instances (recommendation is to always return new instances when this method is invoked)
*/
Map<String, WorkItemHandler> getWorkItemHandlers(String identifier, Map<String, Object> params);
}Event listener producer shall be annotated with proper qualifier to indicate what type of listeners they provide, so pick one of following to indicate they type:
-
@Process - for ProcessEventListener
-
@Agenda - for AgendaEventListener
-
@WorkingMemory - for WorkingMemoryEventListener
public interface EventListenerProducer<T> {
/**
* Returns list of instances for given (T) type of listeners
* <br/>
* Parameters that might be given are as follows:
* <ul>
* <li>ksession</li>
* <li>taskService</li>
* <li>runtimeManager</li>
* </ul>
* @param identifier - identifier of the owner - usually RuntimeManager that allows the producer to filter out
* and provide valid instances for given owner
* @param params - owner might provide some parameters, usually KieSession, TaskService, RuntimeManager instances
* @return list of listener instances (recommendation is to always return new instances when this method is invoked)
*/
List<T> getEventListeners(String identifier, Map<String, Object> params);
}Implementations of these interfaces shall be packaged as bean archive (includes beans.xml inside META-INF) and placed on application classpath (e.g. WEB-INF/lib for web application). THat is enough for CDI based RuntimeManager to discover them and register on every KieSession that is created or loaded from data store.
Some parameters are provided to the producers to allow handlers/listeners to be more stateful and be able to do more advanced things with the engine - like signal of the engine or process instance in case of an error. Thus all components are provided:
-
KieSession
-
TaskService
-
RuntimeManager
|
Whenever there is a need to interact with the process engine/task service from within handler or listener, recommended approach is to use RuntimeManager and retrieve RuntimeEngine (and then KieSession and/or TaskService) from it as that will ensure proper state managed according to strategy |
In addition, some filtering can be applied based on identifier (that is given as argument to the methods) to decide if given RuntimeManager shall receive handlers/listeners or not.
6.5. Services
On top of RuntimeManager API a set of high level services has been provided from jBPM version 6.2. These services are meant to be the easiest way to embed (j)BPM capabilities into custom application. A complete set of modules are delivered as part of these services. They are partitioned into several modules to ease thier adoptions in various environments.
-
jbpm-services-api
contains only api classes and interfaces
-
jbpm-kie-services
rewritten code implementation of services api - pure java, no framework dependencies
-
jbpm-services-cdi
CDI wrapper on top of core services implementation
-
jbpm-services-ejb-api
extension to services api for ejb needs
-
jbpm-services-ejb-impl
EJB wrappers on top of core services implementation
-
jbpm-services-ejb-timer
scheduler service based on EJB TimerService to support time based operations e.g. timer events, deadlines, etc
-
jbpm-services-ejb-client
EJB remote client implementation - currently only for JBoss Service modules are grouped with its framework dependencies, so developers are free to choose which one is suitable for them and use only that.
6.5.1. Deployment Service
As the name suggest, its primary responsibility is to deploy (and undeploy) units. Deployment unit is kjar that brings in business assets (like processes, rules, forms, data model) for execution. Deployment services allow to query it to get hold of available deployment units and even their RuntimeManager instances.
|
there are some restrictions on EJB remote client to do not expose RuntimeManager as it won’t make any sense on client side (after it was serialized). |
So typical use case for this service is to provide dynamic behavior into your system so multiple kjars can be active at the same time and be executed simultaneously.
// create deployment unit by giving GAV
DeploymentUnit deploymentUnit = new KModuleDeploymentUnit(GROUP_ID, ARTIFACT_ID, VERSION);
// deploy
deploymentService.deploy(deploymentUnit);
// retrieve deployed unit
DeployedUnit deployed = deploymentService.getDeployedUnit(deploymentUnit.getIdentifier());
// get runtime manager
RuntimeManager manager = deployed.getRuntimeManager();Complete DeploymentService interface is as follows:
public interface DeploymentService {
void deploy(DeploymentUnit unit);
void undeploy(DeploymentUnit unit);
RuntimeManager getRuntimeManager(String deploymentUnitId);
DeployedUnit getDeployedUnit(String deploymentUnitId);
Collection<DeployedUnit> getDeployedUnits();
void activate(String deploymentId);
void deactivate(String deploymentId);
boolean isDeployed(String deploymentUnitId);
}6.5.2. Definition Service
Upon deployment, every process definition is scanned using definition service that parses the process and extracts valuable information out of it. These information can provide valuable input to the system to inform users about what is expected. Definition service provides information about:
-
process definition - id, name, description
-
process variables - name and type
-
reusable subprocesses used in the process (if any)
-
service tasks (domain specific activities)
-
user tasks including assignment information
-
task data input and output information
So definition service can be seen as sort of supporting service that provides quite a few information about process definition that are extracted directly from BPMN2.
String processId = "org.jbpm.writedocument";
Collection<UserTaskDefinition> processTasks =
bpmn2Service.getTasksDefinitions(deploymentUnit.getIdentifier(), processId);
Map<String, String> processData =
bpmn2Service.getProcessVariables(deploymentUnit.getIdentifier(), processId);
Map<String, String> taskInputMappings =
bpmn2Service.getTaskInputMappings(deploymentUnit.getIdentifier(), processId, "Write a Document" );While it usually is used with combination of other services (like deployment service) it can be used standalone as well to get details about process definition that do not come from kjar. This can be achieved by using buildProcessDefinition method of definition service.
public interface DefinitionService {
ProcessDefinition buildProcessDefinition(String deploymentId, String bpmn2Content,
ClassLoader classLoader, boolean cache) throws IllegalArgumentException;
ProcessDefinition getProcessDefinition(String deploymentId, String processId);
Collection<String> getReusableSubProcesses(String deploymentId, String processId);
Map<String, String> getProcessVariables(String deploymentId, String processId);
Map<String, String> getServiceTasks(String deploymentId, String processId);
Map<String, Collection<String>> getAssociatedEntities(String deploymentId, String processId);
Collection<UserTaskDefinition> getTasksDefinitions(String deploymentId, String processId);
Map<String, String> getTaskInputMappings(String deploymentId, String processId, String taskName);
Map<String, String> getTaskOutputMappings(String deploymentId, String processId, String taskName);
}6.5.3. Process Service
Process service is the one that usually is of the most interest. Once the deployment and definition service was already used to feed the system with something that can be executed. Process service provides access to execution environment that allows:
-
start new process instance
-
work with existing one - signal, get details of it, get variables, etc
-
work with work items
At the same time process service is a command executor so it allows to execute commands (essentially on ksession) to extend its capabilities.
Important to note is that process service is focused on runtime operations so use it whenever there is a need to alter (signal, change variables, etc) process instance and not for read operations like show available process instances by looping though given list and invoking getProcessInstance method. For that there is dedicated runtime data service that is described below.
An example on how to deploy and run process can be done as follows:
KModuleDeploymentUnit deploymentUnit = new KModuleDeploymentUnit(GROUP_ID, ARTIFACT_ID, VERSION);
deploymentService.deploy(deploymentUnit);
long processInstanceId = processService.startProcess(deploymentUnit.getIdentifier(), "customtask");
ProcessInstance pi = processService.getProcessInstance(processInstanceId);As you can see start process expects deploymentId as first argument. This is extremely powerful to enable service to easily work with various deployments, even with same processes but coming from different versions - kjar versions.
public interface ProcessService {
Long startProcess(String deploymentId, String processId);
Long startProcess(String deploymentId, String processId, Map<String, Object> params);
void abortProcessInstance(Long processInstanceId);
void abortProcessInstances(List<Long> processInstanceIds);
void signalProcessInstance(Long processInstanceId, String signalName, Object event);
void signalProcessInstances(List<Long> processInstanceIds, String signalName, Object event);
ProcessInstance getProcessInstance(Long processInstanceId);
void setProcessVariable(Long processInstanceId, String variableId, Object value);
void setProcessVariables(Long processInstanceId, Map<String, Object> variables);
Object getProcessInstanceVariable(Long processInstanceId, String variableName);
Map<String, Object> getProcessInstanceVariables(Long processInstanceId);
Collection<String> getAvailableSignals(Long processInstanceId);
void completeWorkItem(Long id, Map<String, Object> results);
void abortWorkItem(Long id);
WorkItem getWorkItem(Long id);
List<WorkItem> getWorkItemByProcessInstance(Long processInstanceId);
public <T> T execute(String deploymentId, Command<T> command);
public <T> T execute(String deploymentId, Context<?> context, Command<T> command);
}6.5.4. Runtime Data Service
Runtime data service as name suggests, deals with all that refers to runtime information:
-
started process instances
-
executed node instances
-
executed node instances
-
and more
Use this service as main source of information whenever building list based UI - to show process definitions, process instances, tasks for given user, etc. This service was designed to be as efficient as possible and still provide all required information.
Some examples:
-
get all process definitions
Collection definitions = runtimeDataService.getProcesses(new QueryContext()); -
get active process instances
Collection<processinstancedesc> instances = runtimeDataService.getProcessInstances(new QueryContext()); -
get active nodes for given process instance
Collection<nodeinstancedesc> instances = runtimeDataService.getProcessInstanceHistoryActive(processInstanceId, new QueryContext()); -
get tasks assigned to john
List<tasksummary> taskSummaries = runtimeDataService.getTasksAssignedAsPotentialOwner("john", new QueryFilter(0, 10));
There are two important arguments that the runtime data service operations supports:
-
QueryContext
-
QueryFilter - extension of QueryContext
These provide capabilities for efficient management result set like pagination, sorting and ordering (QueryContext). Moreover additional filtering can be applied to task queries to provide more advanced capabilities when searching for user tasks.
public interface RuntimeDataService {
// Process instance information
Collection<ProcessInstanceDesc> getProcessInstances(QueryContext queryContext);
Collection<ProcessInstanceDesc> getProcessInstances(List<Integer> states, String initiator, QueryContext queryContext);
Collection<ProcessInstanceDesc> getProcessInstancesByProcessId(List<Integer> states, String processId, String initiator, QueryContext queryContext);
Collection<ProcessInstanceDesc> getProcessInstancesByProcessName(List<Integer> states, String processName, String initiator, QueryContext queryContext);
Collection<ProcessInstanceDesc> getProcessInstancesByDeploymentId(String deploymentId, List<Integer> states, QueryContext queryContext);
ProcessInstanceDesc getProcessInstanceById(long processInstanceId);
Collection<ProcessInstanceDesc> getProcessInstancesByProcessDefinition(String processDefId, QueryContext queryContext);
Collection<ProcessInstanceDesc> getProcessInstancesByProcessDefinition(String processDefId, List<Integer> states, QueryContext queryContext);
// Node and Variable instance information
NodeInstanceDesc getNodeInstanceForWorkItem(Long workItemId);
Collection<NodeInstanceDesc> getProcessInstanceHistoryActive(long processInstanceId, QueryContext queryContext);
Collection<NodeInstanceDesc> getProcessInstanceHistoryCompleted(long processInstanceId, QueryContext queryContext);
Collection<NodeInstanceDesc> getProcessInstanceFullHistory(long processInstanceId, QueryContext queryContext);
Collection<NodeInstanceDesc> getProcessInstanceFullHistoryByType(long processInstanceId, EntryType type, QueryContext queryContext);
Collection<VariableDesc> getVariablesCurrentState(long processInstanceId);
Collection<VariableDesc> getVariableHistory(long processInstanceId, String variableId, QueryContext queryContext);
// Process information
Collection<ProcessDefinition> getProcessesByDeploymentId(String deploymentId, QueryContext queryContext);
Collection<ProcessDefinition> getProcessesByFilter(String filter, QueryContext queryContext);
Collection<ProcessDefinition> getProcesses(QueryContext queryContext);
Collection<String> getProcessIds(String deploymentId, QueryContext queryContext);
ProcessDefinition getProcessById(String processId);
ProcessDefinition getProcessesByDeploymentIdProcessId(String deploymentId, String processId);
// user task query operations
UserTaskInstanceDesc getTaskByWorkItemId(Long workItemId);
UserTaskInstanceDesc getTaskById(Long taskId);
List<TaskSummary> getTasksAssignedAsBusinessAdministrator(String userId, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsBusinessAdministratorByStatus(String userId, List<Status> statuses, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsPotentialOwner(String userId, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsPotentialOwner(String userId, List<String> groupIds, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsPotentialOwnerByStatus(String userId, List<Status> status, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsPotentialOwner(String userId, List<String> groupIds, List<Status> status, QueryFilter filter);
List<TaskSummary> getTasksAssignedAsPotentialOwnerByExpirationDateOptional(String userId, List<Status> status, Date from, QueryFilter filter);
List<TaskSummary> getTasksOwnedByExpirationDateOptional(String userId, List<Status> strStatuses, Date from, QueryFilter filter);
List<TaskSummary> getTasksOwned(String userId, QueryFilter filter);
List<TaskSummary> getTasksOwnedByStatus(String userId, List<Status> status, QueryFilter filter);
List<Long> getTasksByProcessInstanceId(Long processInstanceId);
List<TaskSummary> getTasksByStatusByProcessInstanceId(Long processInstanceId, List<Status> status, QueryFilter filter);
List<AuditTask> getAllAuditTask(String userId, QueryFilter filter);
}6.5.5. User Task Service
User task service covers complete life cycle of individual task so it can be managed from start to end. It explicitly eliminates queries from it to provide scoped execution and moves all query operations into runtime data service. Besides lifecycle operations user task service allows:
-
modification of selected properties
-
access to task variables
-
access to task attachments
-
access to task comments
On top of that user task service is a command executor as well that allows to execute custom task commands.
Complete example with start process and complete user task done by services:
long processInstanceId =
processService.startProcess(deployUnit.getIdentifier(), "org.jbpm.writedocument");
List<Long> taskIds =
runtimeDataService.getTasksByProcessInstanceId(processInstanceId);
Long taskId = taskIds.get(0);
userTaskService.start(taskId, "john");
UserTaskInstanceDesc task = runtimeDataService.getTaskById(taskId);
Map<String, Object> results = new HashMap<String, Object>();
results.put("Result", "some document data");
userTaskService.complete(taskId, "john", results);|
The most important thing when working with services is that there is no more need to create your own implementations of Process service that simply wraps runtime manager, runtime engine, ksession usage. Services make use of RuntimeManager API best practices and thus eliminate various risks when working with that API. |
6.5.6. Quartz-based Timer Service
jBPM provides a cluster-ready timer service via Quartz, allowing you to dispose or load your knowledge session at any time. In order to fire each timer appropriately, this service can be utilized to manage how long a kie session should be active.
A base Quartz configuration file in the case of a clustered environment is provided as an example below:
#============================================================================
# Configure Main Scheduler Properties
#============================================================================
org.quartz.scheduler.instanceName = jBPMClusteredScheduler
org.quartz.scheduler.instanceId = AUTO
#============================================================================
# Configure ThreadPool
#============================================================================
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 5
org.quartz.threadPool.threadPriority = 5
#============================================================================
# Configure JobStore
#============================================================================
org.quartz.jobStore.misfireThreshold = 60000
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreCMT
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.useProperties=false
org.quartz.jobStore.dataSource=managedDS
org.quartz.jobStore.nonManagedTXDataSource=nonManagedDS
org.quartz.jobStore.tablePrefix=QRTZ_
org.quartz.jobStore.isClustered=true
org.quartz.jobStore.clusterCheckinInterval = 20000
#============================================================================
# TODO: Configure Datasources
#============================================================================
#org.quartz.dataSource.managedDS.jndiURL=
#org.quartz.dataSource.nonManagedDS.jndiURL=For more information on configuring a Quartz scheduler, please see the documentation for the 1.8.5 distribution archive.
6.5.7. QueryService
QueryService provides advanced search capabilities that are based on Dashbuilder DataSets. The concept behind it is that users are given control over how to retrieve data from underlying data store. This includes complex joins with external tables such as JPA entities tables, custom systems data base tables etc.
QueryService is build around two parts:
-
Management operations
-
register query definition
-
replace query definition
-
unregister (remove) query definition
-
get query definition
-
get all registered query definitions
-
-
Runtime operations
-
query - with two flavors
-
simple based on QueryParam as filter provider
-
advanced based on QueryParamBuilder as filter provider
-
-
DashBuilder DataSets provide support for multiple data sources (CSV, SQL, elastic search, etc) while jBPM - since its backend is RDBMS based - focuses on SQL based data sets. So jBPM QueryService is a subset of DashBuilder DataSets capabilities to allow efficient queries with simple API.
Terminology
-
QueryDefinition - represents definion of the data set which consists of unique name, sql expression (the query) and source - JNDI name of the data source to use when performing queries
-
QueryParam - basic structure that represents individual query parameter - condition - that consists of: column name, operator, expected value(s)
-
QueryResultMapper - responsible for mapping raw data set data (rows and columns) into object representation
-
QueryParamBuilder - responsible for building query filters that will be applied on the query definition for given query invocation
While QueryDefinition and QueryParam is rather straight forward, QueryParamBuilder and QueryResultMapper is bit more advanced and require slightly more attention to make use of it in right way, and by that take advantage of their capabilities.
QueryResultMapper
Mapper as the name suggest, maps data taken out from data base (from data set) into object representation. Much like ORM providers such as hibernate maps tables to entities. Obviously there might be many object types that could be used for representing data set results so it’s almost impossible to provide them out of the box. Mappers are rather powerful and thus are pluggable, you can implement your own that will transform the result into whatever type you like. jBPM comes with following mappers out of the box:
-
org.jbpm.kie.services.impl.query.mapper.ProcessInstanceQueryMapper
-
registered with name - ProcessInstances
-
-
org.jbpm.kie.services.impl.query.mapper.ProcessInstanceWithVarsQueryMapper
-
registered with name - ProcessInstancesWithVariables
-
-
org.jbpm.kie.services.impl.query.mapper.ProcessInstanceWithCustomVarsQueryMapper
-
registered with name - ProcessInstancesWithCustomVariables
-
-
org.jbpm.kie.services.impl.query.mapper.UserTaskInstanceQueryMapper
-
registered with name - UserTasks
-
-
org.jbpm.kie.services.impl.query.mapper.UserTaskInstanceWithVarsQueryMapper
-
registered with name - UserTasksWithVariables
-
-
org.jbpm.kie.services.impl.query.mapper.UserTaskInstanceWithCustomVarsQueryMapper
-
registered with name - UserTasksWithCustomVariables
-
-
org.jbpm.kie.services.impl.query.mapper.TaskSummaryQueryMapper
-
registered with name - TaskSummaries
-
-
org.jbpm.kie.services.impl.query.mapper.RawListQueryMapper
-
registered with name - RawList
-
Each QueryResultMapper is registered under given name to allow simple look up by name instead of referencing its class name - especially important when using EJB remote flavor of services where we want to reduce number of dependencies and thus not relying on implementation on client side. So to be able to reference QueryResultMapper by name, NamedQueryMapper should be used which is part of jbpm-services-api. That acts as delegate (lazy delegate) as it will look up the actual mapper when the query is actually performed.
queryService.query("my query def", new NamedQueryMapper<Collection<ProcessInstanceDesc>>("ProcessInstances"), new QueryContext());QueryParamBuilder
QueryParamBuilder that provides more advanced way of building filters for our data sets. By default when using query method of QueryService that accepts zero or more QueryParam instances (as we have seen in above examples) all of these params will be joined with AND operator meaning all of them must match. But that’s not always the case so that’s why QueryParamBuilder has been introduced for users to build their on builders which will provide filters at the time the query is issued.
There is one QueryParamBuilder available out of the box and it is used to cover default QueryParams that are based on so called core functions. These core functions are SQL based conditions and includes following
-
IS_NULL
-
NOT_NULL
-
EQUALS_TO
-
NOT_EQUALS_TO
-
LIKE_TO
-
GREATER_THAN
-
GREATER_OR_EQUALS_TO
-
LOWER_THAN
-
LOWER_OR_EQUALS_TO
-
BETWEEN
-
IN
-
NOT_IN
QueryParamBuilder is simple interface that is invoked as long as its build method returns non null value before query is performed. So you can build up a complex filter options that could not be simply expressed by list of QueryParams. Here is basic implementation of QueryParamBuilder to give you a jump start to implement your own - note that it relies on DashBuilder Dataset API.
public class TestQueryParamBuilder implements QueryParamBuilder<ColumnFilter> {
private Map<String, Object> parameters;
private boolean built = false;
public TestQueryParamBuilder(Map<String, Object> parameters) {
this.parameters = parameters;
}
@Override
public ColumnFilter build() {
// return null if it was already invoked
if (built) {
return null;
}
String columnName = "processInstanceId";
ColumnFilter filter = FilterFactory.OR(
FilterFactory.greaterOrEqualsTo((Long)parameters.get("min")),
FilterFactory.lowerOrEqualsTo((Long)parameters.get("max")));
filter.setColumnId(columnName);
built = true;
return filter;
}
}Once you have query param builder implemented you simply use its instance when performing query via QueryService
queryService.query("my query def", ProcessInstanceQueryMapper.get(), new QueryContext(), paramBuilder);Typical usage scenario
First thing user needs to do is to define data set - view of the data you want to work with - so called QueryDefinition in services api.
SqlQueryDefinition query = new SqlQueryDefinition("getAllProcessInstances", "java:jboss/datasources/ExampleDS");
query.setExpression("select * from processinstancelog");This is the simplest possible query definition as it can be:
-
constructor takes
-
a unique name that identifies it on runtime
-
data source JNDI name used when performing queries on this definition - in other words source of data
-
-
expression - the most important part - is the sql statement that builds up the view to be filtered when performing queries
Once we have the sql query definition we can register it so it can be used later for actual queries.
queryService.registerQuery(query);From now on, this query definition can be used to perform actual queries (or data look ups to use terminology from data sets). Following is the basic one that collects data as is, without any filtering
Collection<ProcessInstanceDesc> instances = queryService.query("getAllProcessInstances", ProcessInstanceQueryMapper.get(), new QueryContext());Above query was very simple and used defaults from QueryContext - paging and sorting. So let’s take a look at one that changes the defaults of the paging and sorting
QueryContext ctx = new QueryContext(0, 100, "start_date", true);
Collection<ProcessInstanceDesc> instances = queryService.query("getAllProcessInstances", ProcessInstanceQueryMapper.get(), ctx);Now let’s take a look at how to do data filtering
// single filter param
Collection<ProcessInstanceDesc> instances = queryService.query("getAllProcessInstances", ProcessInstanceQueryMapper.get(), new QueryContext(), QueryParam.likeTo(COLUMN_PROCESSID, true, "org.jbpm%"));
// multiple filter params (AND)
Collection<ProcessInstanceDesc> instances = queryService.query("getAllProcessInstances", ProcessInstanceQueryMapper.get(), new QueryContext(),
QueryParam.likeTo(COLUMN_PROCESSID, true, "org.jbpm%"),
QueryParam.in(COLUMN_STATUS, 1, 3));With that end user is put in driver seat to define what data and how they should be fetched. Not being limited by JPA provider nor anything else. Moreover this promotes use of tailored queries for your environment as in most of the case there will be single data base used and thus specific features of that data base can be used to increase performance.
Further examples can be found here.
6.5.8. ProcessInstanceMigrationService
ProcessInstanceMigrationService provides administrative utility to move given process instance(s) from one deployment to another or one process definition to another. It’s main responsibility is to allow basic upgrade of process definition behind given process instance. That might include mapping of currently active nodes to other nodes in new definition.
Migration does not deal with process or task variables, they are not affected by migration. Essentially process instance migration means a change of underlying process definition process engine uses to move on with process instance.
Even though process instance migration is available it’s recommended to let active process instances finish and then start new instances with new version whenever possible. In case that approach can’t be used, migration of active process instance needs to be carefully planned before its execution as it might lead to unexpected issues.Most important to take into account is:
-
is new process definition backward compatible?
-
are there any data changes (variables that could affect process instance decisions after migration)?
-
is there need for node mapping?
Answers to these question might save a lot of headache and production problems after migration. Best is to always stick with backward compatible processes - like extending process definition rather than removing nodes. Though that’s not always possible and in some cases there is a need to remove certain nodes from process definition. In that situation, migration needs to be instructed how to map nodes that were removed in new definition in case active process instance is at the moment in such a node.
Node mapping is given as a map of node ids (UniqueIds that are set in the definition) where key is the source node id (from process definition used by process instance) to target node id (in new process definition).
| Node mapping can only be used to map same type of nodes e.g. user task to user task. |
Again, process or task variables are not affected by process instance migration at the moment.
ProcessInstanceMigrationService comes with several flavors of migrate operation:
ProcessInstanceMigrationService
----
public interface ProcessInstanceMigrationService {
/**
* Migrates given process instance that belongs to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns migration report regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceId id of the process instance to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @return returns complete migration report
*/
MigrationReport migrate(String sourceDeploymentId, Long processInstanceId, String targetDeploymentId, String targetProcessId);
/**
* Migrates given process instance (with node mapping) that belongs to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns migration report regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceId id of the process instance to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @param nodeMapping node mapping - source and target unique ids of nodes to be mapped - from process instance active nodes to new process nodes
* @return returns complete migration report
*/
MigrationReport migrate(String sourceDeploymentId, Long processInstanceId, String targetDeploymentId, String targetProcessId, Map<String, String> nodeMapping);
/**
* Migrates given process instances that belong to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns list of migration report - one per process instance, regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceIds list of process instance id to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @return returns complete migration report
*/
List<MigrationReport> migrate(String sourceDeploymentId, List<Long> processInstanceIds, String targetDeploymentId, String targetProcessId);
/**
* Migrates given process instances (with node mapping) that belong to source deployment, into target process id that belongs to target deployment.
* Following rules are enforced:
* <ul>
* <li>source deployment id must be there</li>
* <li>process instance id must point to existing and active process instance</li>
* <li>target deployment must exist</li>
* <li>target process id must exist in target deployment</li>
* </ul>
* Migration returns list of migration report - one per process instance, regardless of migration being successful or not that needs to be examined for migration outcome.
* @param sourceDeploymentId deployment that process instance to be migrated belongs to
* @param processInstanceIds list of process instance id to be migrated
* @param targetDeploymentId id of deployment that target process belongs to
* @param targetProcessId id of the process process instance should be migrated to
* @param nodeMapping node mapping - source and target unique ids of nodes to be mapped - from process instance active nodes to new process nodes
* @return returns list of migration reports one per each process instance
*/
List<MigrationReport> migrate(String sourceDeploymentId, List<Long> processInstanceIds, String targetDeploymentId, String targetProcessId, Map<String, String> nodeMapping);
}
----Migration can either be performed for single process instance or multiple process instances at the same time. Multiple process instances migration is a utility method on top of single instance, instead of calling it multiple times, users call it once and then service will take care of the migration of individual process instances.
| Multi instance migration does migrate each instance in separation (transaction) to secure that one won’t affect the other and then produces dedicated migration reports for each process instance |
6.5.8.1. Migration report
Migration is always comcluded with migration report that is per each process instance. That migration report provides following information:
-
start and end date of the migration
-
outcome of the migration - success or failure
-
complete log entry - all steps performed during migration, entry can be INFO, WARN or ERROR - in case of ERROR there will be at most one as they are causing migration to be immedietely terminated.
6.5.8.2. Example
Following is an example of how to invoke the migration
protected static final String MIGRATION_ARTIFACT_ID = "test-migration";
protected static final String MIGRATION_GROUP_ID = "org.jbpm.test";
protected static final String MIGRATION_VERSION_V1 = "1.0.0";
protected static final String MIGRATION_VERSION_V2 = "2.0.0";
// first deploy both versions
deploymentUnitV1 = new KModuleDeploymentUnit(MIGRATION_GROUP_ID, MIGRATION_ARTIFACT_ID, MIGRATION_VERSION_V1);
deploymentService.deploy(deploymentUnitV1);
// ... version 2
deploymentUnitV2 = new KModuleDeploymentUnit(MIGRATION_GROUP_ID, MIGRATION_ARTIFACT_ID, MIGRATION_VERSION_V2);
deploymentService.deploy(deploymentUnitV2);
// next start process instance in version 1
long processInstanceId = processService.startProcess(deploymentUnitV1.getIdentifier(), "processID-V1");
// and once the instance is active it can be migrated
MigrationReport report = migrationService.migrate(deploymentUnitV1.getIdentifier(), processInstanceId, deploymentUnitV2.getIdentifier(), "processID-V2");
// as last step check if the migration finished successfully
report.isSuccessful()6.5.8.3. Known limitations
-
When a new or modified task requires inputs which are not available in the migrated v2 process instance.
-
Modifying the tasks prior to the active task where the changes have an impact on the further processing.
-
Removing a human task which is currently active (can only be replaced - requires to be mapped to another human task)
-
Adding a new task parallel to the single active task (all branches in AND gateway are not activated - process will stuck)
-
Changing or removing the active recurring timer events (won’t be changed in DB)
-
Fixing or updating inputs and outputs in an active task (task data aren’t migrated)
-
Node mapping updates only the task node name and description! (other task fields won’t be mapped including the TaskName variable)
6.5.9. Working with deployments
Deployment Service provides convinient way to put business assets to an execution environment but there are cases that requires some additional management to make them available in right context.
Activation and Deactivation of deployments
Imagine situation where there are number of processes already running of given deployment and then new version of these processes comes into the runtime environment. With that administrator can decide that new instances of given process definition should be using new version only while already active instances should continue with the previous version.
To help with that deployment service has been equipped with following methods:
-
activate
allows to activate given deployment so it can be available for interaction meaning will show its process definition and allow to start new process instances of that project’s processes
-
deactivate
allows to deactivate deployment which will disable option to see or start new process instances of that project’s processes but will allow to continue working with already active process instances, e.g. signal, work with user task etc
This feature allows smooth transition between project versions whitout need of process instance migration.
Deployment synchronization
Prior to jBPM 6.2, jbpm services did not have deployment store by default. When embedded in jbpm-console/kie-wb they utilized sistem.git VFS repository to preserve deployed units across server restarts. While that works fine, it comes with some drawbacks:
-
not available for custom systems that use services
-
requires complex setup in cluster - zookeeper and helix
With version 6.2 jbpm services come with deployment synchronizer that stores available deployments into data base, including its deployment descriptor. At the same time it constantly monitors that table to keep it in sync with other installations that might be using same data source. This is especially important when running in cluster or when jbpm console runs next to custom application and both should be able to operate on the same artifacts.
By default synchronization must be configured (when runing as core services while it is automatically enabled for ejb and cdi extensions). To configure synchronization following needs to be configured:
TransactionalCommandService commandService = new TransactionalCommandService(emf);
DeploymentStore store = new DeploymentStore();
store.setCommandService(commandService);
DeploymentSynchronizer sync = new DeploymentSynchronizer();
sync.setDeploymentService(deploymentService);
sync.setDeploymentStore(store);
DeploymentSyncInvoker invoker = new DeploymentSyncInvoker(sync, 2L, 3L, TimeUnit.SECONDS);
invoker.start();
....
invoker.stop();With this, deployments will be synchronized every 3 seconds with initial delay of two seconds.
Invoking latest version of project’s processes
In case there is a need to always work with latest version of project’s process, services allow to interact with various operations using deployment id with latest keyword. Let’s go over an example to better understand the feature.
Initially deployed unit is org.jbpm:HR:1.0 which has the first version of an hiring process. After several weeks, new version is developed and deployed to the execution server - org.jbpm:HR.2.0 with version 2 of the hiring process.
To allow callers of the services to interact without being worried if they work with latest version, they can use following deployment id:
org.jbpm.HR:latestthis will alwyas find out latest available version of project that is identified by:
-
groupId: org.jbpm
-
artifactId: HR
version comparizon is based on Maven version numbers and relies on Maen based algorithm to find the latest one.
|
This is only supported when process identifier remains the same in all project versions |
Here is a complete example with deployment of multiple versions and interacting always with the latest:
KModuleDeploymentUnit deploymentUnitV1 = new KModuleDeploymentUnit("org.jbpm", "HR", "1.0");
deploymentService.deploy(deploymentUnitV1);
long processInstanceId = processService.startProcess("org.jbpm:HR:LATEST", "customtask");
ProcessInstanceDesc piDesc = runtimeDataService.getProcessInstanceById(processInstanceId);
// we have started process with project's version 1
assertEquals(deploymentUnitV1.getIdentifier(), piDesc.getDeploymentId());
// next we deploy version 1
KModuleDeploymentUnit deploymentUnitV2 = new KModuleDeploymentUnit("org.jbpm", "HR", "2.0");
deploymentService.deploy(deploymentUnitV2);
processInstanceId = processService.startProcess("org.jbpm:HR:LATEST", "customtask");
piDesc = runtimeDataService.getProcessInstanceById(processInstanceId);
// this time we have started process with project's version 2
assertEquals(deploymentUnitV2.getIdentifier(), piDesc.getDeploymentId());As illustrated this provides very powerful feature when interacting with frequently chaning environment that allows to always be up to date when it comes to use of process definitions.
|
This feature is also available in REST interface so whenever sending request with deployment id, it’s enough to replace concrete version with LATEST keyword to make use of this feature. |
6.6. Configuration
There are several control parameters available to alter engine default behavior. This allows to fine tune the execution for the environment needs and actual requirements. All of these parameters are set as JVM system properties, usually with -D when starting program e.g. application server.
| Name | Possible values | Default value | Description |
|---|---|---|---|
jbpm.ut.jndi.lookup |
String |
Alternative JNDI name to be used when there is no access to the default one (java:comp/UserTransaction). Note: Must be valid for given runtime environment. Do not use if there is no access to the default user transaction JNDI name. |
|
jbpm.enable.multi.con |
true|false |
false |
Enables multiple incoming/outgoing sequence flows support for activities |
jbpm.business.calendar.properties |
String |
/jbpm.business.calendar.properties |
Allows to provide alternative classpath location of business calendar configuration file |
jbpm.overdue.timer.delay |
Long |
2000 |
Specifies delay for overdue timers to allow proper initialization, in milliseconds |
jbpm.process.name.comparator |
String |
Allows to provide alternative comparator class to empower start process by name feature, if not set NumberVersionComparator is used |
|
jbpm.loop.level.disabled |
true|false |
true |
Allows to enable or disable loop iteration tracking, to allow advanced loop support when using XOR gateways |
org.kie.mail.session |
String |
mail/jbpmMailSession |
Allows to provide alternative JNDI name for mail session used by Task Deadlines |
jbpm.usergroup.callback.properties |
String |
/jbpm.usergroup.callback.properties |
Allows to provide alternative classpath location for user group callback implementation (LDAP, DB) |
jbpm.user.group.mapping |
String |
${jboss.server.config.dir}/roles.properties |
Allows to provide alternative location of roles.properties for JBossUserGroupCallbackImpl |
jbpm.user.info.properties |
String |
/jbpm.user.info.properties |
Allows to provide alternative classpath location of user info configuration (used by LDAPUserInfoImpl) |
org.jbpm.ht.user.separator |
String |
, |
Allows to provide alternative separator of actors and groups for user tasks, default is comma (,) |
org.quartz.properties |
String |
Allows to provide location of the quartz config file to activate quartz based timer service |
|
jbpm.data.dir |
String |
${jboss.server.data.dir} is available otherwise ${java.io.tmpdir} |
Allows to provide location where data files produced by jbpm should be stored |
org.kie.executor.pool.size |
Integer |
1 |
Allows to provide thread pool size for jbpm executor |
org.kie.executor.retry.count |
Integer |
3 |
Allows to provide number of retries attempted in case of error by jbpm executor |
org.kie.executor.interval |
Integer |
3 |
Allows to provide frequency used to check for pending jobs by jbpm executor, in seconds |
org.kie.executor.disabled |
true|false |
true |
Enables or disable jbpm executor |
org.kie.store.services.class |
String |
org.drools.persistence.jpa.KnowledgeStoreServiceImpl |
Fully qualified name of the class that implements KieStoreServices that will be responsible for bootstraping KieSession instances |
7. Processes
7.1. What is BPMN 2.0
|
"The primary goal of BPMN is to provide a notation that is readily understandable by all business users, from the business analysts that create the initial drafts of the processes, to the technical developers responsible for implementing the technology that will perform those processes, and finally, to the business people who will manage and monitor those processes." |
The Business Process Model and Notation (BPMN) 2.0 specification is an OMG specification that not only defines a standard on how to graphically represent a business process (like BPMN 1.x), but now also includes execution semantics for the elements defined, and an XML format on how to store (and share) process definitions.
jBPM6 allows you to execute processes defined using the BPMN 2.0 XML format. That means that you can use all the different jBPM6 tooling to model, execute, manage and monitor your business processes using the BPMN 2.0 format for specifying your executable business processes. Actually, the full BPMN 2.0 specification also includes details on how to represent things like choreographies and collaboration. The jBPM project however focuses on that part of the specification that can be used to specify executable processes.
Executable processes in BPMN consist of a different types of nodes being connected to each other using sequence flows. The BPMN 2.0 specification defines three main types of nodes:
-
Events: They are used to model the occurrence of a particular event. This could be a start event (that is used to indicate the start of the process), end events (that define the end of the process, or of that subflow) and intermediate events (that indicate events that might occur during the execution of the process).
-
Activities: These define the different actions that need to be performed during the execution of the process. Different types of tasks exist, depending on the type of activity you are trying to model (e.g. human task, service task, etc.) and activities could also be nested (using different types of sub-processes).
-
Gateways: Can be used to define multiple paths in the process. Depending on the type of gateway, these might indicate parallel execution, choice, etc.
jBPM6 does not implement all elements and attributes as defined in the BPMN 2.0 specification. We do however support a significant subset, including the most common node types that can be used inside executable processes. This includes (almost) all elements and attributes as defined in the "Common Executable" subclass of the BPMN 2.0 specification, extended with some additional elements and attributes we believe are valuable in that context as well. The full set of elements and attributes that are supported can be found below, but it includes elements like:
-
Flow objects
-
Events
-
Start Event (None, Conditional, Signal, Message, Timer)
-
End Event (None, Terminate, Error, Escalation, Signal, Message, Compensation)
-
Intermediate Catch Event (Signal, Timer, Conditional, Message)
-
Intermediate Throw Event (None, Signal, Escalation, Message, Compensation)
-
Non-interrupting Boundary Event (Escalation, Signal, Timer, Conditional, Message)
-
Interrupting Boundary Event (Escalation, Error, Signal, Timer, Conditional, Message, Compensation)
-
-
Activities
-
Script Task
-
Task
-
Service Task
-
User Task
-
Business Rule Task
-
Manual Task
-
Send Task
-
Receive Task
-
Reusable Sub-Process (Call Activity)
-
Embedded Sub-Process
-
Event Sub-Process
-
Ad-Hoc Sub-Process
-
Data-Object
-
-
Gateways
-
Diverging
-
Exclusive
-
Inclusive
-
Parallel
-
Event-Based
-
-
Converging
-
Exclusive
-
Inclusive
-
Parallel
-
-
-
Lanes
-
-
Data
-
Java type language
-
Process properties
-
Embedded Sub-Process properties
-
Activity properties
-
-
Connecting objects
-
Sequence flow
-
For example, consider the following "Hello World" BPMN 2.0 process, which does nothing more that writing out a "Hello World" statement when the process is started.
An executable version of this process expressed using BPMN 2.0 XML would look something like this:
<?xml version="1.0" encoding="UTF-8"?>
<definitions id="Definition"
targetNamespace="http://www.example.org/MinimalExample"
typeLanguage="http://www.java.com/javaTypes"
expressionLanguage="http://www.mvel.org/2.0"
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:xs="http://www.w3.org/2001/XMLSchema-instance"
xs:schemaLocation="http://www.omg.org/spec/BPMN/20100524/MODEL BPMN20.xsd"
xmlns:bpmndi="http://www.omg.org/spec/BPMN/20100524/DI"
xmlns:dc="http://www.omg.org/spec/DD/20100524/DC"
xmlns:di="http://www.omg.org/spec/DD/20100524/DI"
xmlns:tns="http://www.jboss.org/drools">
<process processType="Private" isExecutable="true" id="com.sample.HelloWorld" name="Hello World" >
<!-- nodes -->
<startEvent id="_1" name="StartProcess" />
<scriptTask id="_2" name="Hello" >
<script>System.out.println("Hello World");</script>
</scriptTask>
<endEvent id="_3" name="EndProcess" >
<terminateEventDefinition/>
</endEvent>
<!-- connections -->
<sequenceFlow id="_1-_2" sourceRef="_1" targetRef="_2" />
<sequenceFlow id="_2-_3" sourceRef="_2" targetRef="_3" />
</process>
<bpmndi:BPMNDiagram>
<bpmndi:BPMNPlane bpmnElement="Minimal" >
<bpmndi:BPMNShape bpmnElement="_1" >
<dc:Bounds x="15" y="91" width="48" height="48" />
</bpmndi:BPMNShape>
<bpmndi:BPMNShape bpmnElement="_2" >
<dc:Bounds x="95" y="88" width="83" height="48" />
</bpmndi:BPMNShape>
<bpmndi:BPMNShape bpmnElement="_3" >
<dc:Bounds x="258" y="86" width="48" height="48" />
</bpmndi:BPMNShape>
<bpmndi:BPMNEdge bpmnElement="_1-_2" >
<di:waypoint x="39" y="115" />
<di:waypoint x="75" y="46" />
<di:waypoint x="136" y="112" />
</bpmndi:BPMNEdge>
<bpmndi:BPMNEdge bpmnElement="_2-_3" >
<di:waypoint x="136" y="112" />
<di:waypoint x="240" y="240" />
<di:waypoint x="282" y="110" />
</bpmndi:BPMNEdge>
</bpmndi:BPMNPlane>
</bpmndi:BPMNDiagram>
</definitions>To create your own process using BPMN 2.0 format, you can
-
The jBPM Designer is an open-source web-based editor that supports the BPMN 2.0 format. We have embedded it into jbpm console for BPMN 2.0 process visualization and editing. You could use the Designer (either standalone or integrated) to create / edit BPMN 2.0 processes and then export them to BPMN 2.0 format or save them into repository and import them so they can be executed.
-
A new BPMN2 Eclipse plugin is being created to support the full BPMN2 specification.
-
You can always manually create your BPMN 2.0 process files by writing the XML directly. You can validate the syntax of your processes against the BPMN 2.0 XSD, or use the validator in the Eclipse plugin to check both syntax and completeness of your model.
-
Drools Eclipse Process editor has been deprecated in favor of BPMN2 Modeler for process modeling. It can still be used for limited number of supported elements but should be faced out as it is not being developed any more.
Create a new Process file using the Drools Eclipse plugin wizard and in the last page of the wizard, make sure you select Drools 5.1 code compatibility. This will create a new process using the BPMN 2.0 XML format. Note however that this is not exactly a BPMN 2.0 editor, as it still uses different attributes names etc. It does however save the process using valid BPMN 2.0 syntax. Also note that the editor does not support all node types and attributes that are already supported in the execution engine.
The following code fragment shows you how to load a BPMN2 process into your knowledge base …
private static KnowledgeBase createKnowledgeBase() throws Exception {
KieHelper kieHelper = new KieHelper();
KieBase kieBase = kieHelper
.addResource(ResourceFactory.newClassPathResource("sample.bpmn2"))
.build();
return kieBase;
}... and how to execute this process …
KieBase kbase = createKnowledgeBase();
KieSession ksession = kbase.newKieSession();
ksession.startProcess("com.sample.HelloWorld");For more detail, check out the chapter on the API and the basics.
7.2. Process
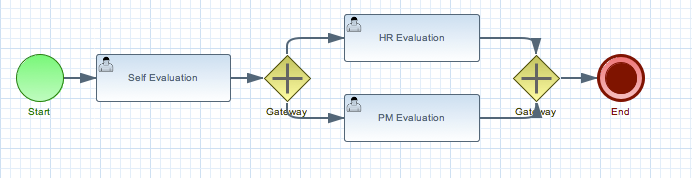
A business process is a graph that describes the order in which a series of steps need to be executed, using a flow chart. A process consists of a collection of nodes that are linked to each other using connections. Each of the nodes represents one step in the overall process while the connections specify how to transition from one node to the other. A large selection of predefined node types have been defined. This chapter describes how to define such processes and use them in your application.
7.2.1. Creating a process
Processes can be created by using one of the following three methods:
-
Using the graphical process editor such as jBPM web designer or Eclipse BPMN2 modeler
-
As an XML file, according to the XML process format as defined in the XML Schema Definition in the BPMN 2.0 specification.
-
By directly creating a process using the Process API.
7.2.1.1. Using the graphical BPMN2 Editor
The graphical BPMN2 editor is an editor that allows you to create a process by dragging and dropping different nodes on a canvas and editing the properties of these nodes. The graphical BPMN2 modeler is an Eclipse plugin hosted on eclipse.org that provides number of contributors where one of them is jBPM project. Once you have set up a jBPM project (see the installer for creating a working Eclipse environment where you can start), you can start adding processes. When in a project, launch the "New" wizard (use Ctrl+N) or right-click the directory you would like to put your process in and select "New", then "File". Give the file a name and the extension bpmn (e.g. MyProcess.bpmn). This will open up the process editor (you can safely ignore the warning that the file could not be read, this is just because the file is still empty).
First, ensure that you can see the Properties View down the bottom of the Eclipse window, as it will be necessary to fill in the different properties of the elements in your process. If you cannot see the properties view, open it using the menu "Window", then "Show View" and "Other…", and under the "General" folder select the Properties View.
The process editor consists of a palette, a canvas and an outline view. To add new elements to the canvas, select the element you would like to create in the palette and then add them to the canvas by clicking on the preferred location. For example, click on the "End Event" icon in the palette of the GUI. Clicking on an element in your process allows you to set the properties of that element. You can connect the nodes (as long as it is permitted by the different types of nodes) by using "Sequence Flow" from the palette.
You can keep adding nodes and connections to your process until it represents the business logic that you want to specify.
7.2.1.2. Defining processes using XML
It is also possible to specify processes using the underlying BPMN 2.0 XML directly. The syntax of these XML processes is defined using the BPMN 2.0 XML Schema Definition. For example, the following XML fragment shows a simple process that contains a sequence of a Start Event, a Script Task that prints "Hello World" to the console, and an End Event.
<?xml version="1.0" encoding="UTF-8"?>
<definitions id="Definition"
targetNamespace="http://www.jboss.org/drools"
typeLanguage="http://www.java.com/javaTypes"
expressionLanguage="http://www.mvel.org/2.0"
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"Rule Task
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.omg.org/spec/BPMN/20100524/MODEL BPMN20.xsd"
xmlns:g="http://www.jboss.org/drools/flow/gpd"
xmlns:bpmndi="http://www.omg.org/spec/BPMN/20100524/DI"
xmlns:dc="http://www.omg.org/spec/DD/20100524/DC"
xmlns:di="http://www.omg.org/spec/DD/20100524/DI"
xmlns:tns="http://www.jboss.org/drools">
<process processType="Private" isExecutable="true" id="com.sample.hello" name="Hello Process" >
<!-- nodes -->
<startEvent id="_1" name="Start" />
<scriptTask id="_2" name="Hello" >
<script>System.out.println("Hello World");</script>
</scriptTask>
<endEvent id="_3" name="End" >
<terminateEventDefinition/>
</endEvent>
<!-- connections -->
<sequenceFlow id="_1-_2" sourceRef="_1" targetRef="_2" />
<sequenceFlow id="_2-_3" sourceRef="_2" targetRef="_3" />
</process>
<bpmndi:BPMNDiagram>
<bpmndi:BPMNPlane bpmnElement="com.sample.hello" >
<bpmndi:BPMNShape bpmnElement="_1" >
<dc:Bounds x="16" y="16" width="48" height="48" />
</bpmndi:BPMNShape>
<bpmndi:BPMNShape bpmnElement="_2" >
<dc:Bounds x="96" y="16" width="80" height="48" />
</bpmndi:BPMNShape>
<bpmndi:BPMNShape bpmnElement="_3" >
<dc:Bounds x="208" y="16" width="48" height="48" />
</bpmndi:BPMNShape>
<bpmndi:BPMNEdge bpmnElement="_1-_2" >
<di:waypoint x="40" y="40" />
<di:waypoint x="136" y="40" />
</bpmndi:BPMNEdge>
<bpmndi:BPMNEdge bpmnElement="_2-_3" >
<di:waypoint x="136" y="40" />
<di:waypoint x="232" y="40" />
</bpmndi:BPMNEdge>
</bpmndi:BPMNPlane>
</bpmndi:BPMNDiagram>
</definitions>The process XML file consists of two parts, the top part (the "process" element) contains the definition of the different nodes and their properties, the lower part (the "BPMNDiagram" element) contains all graphical information, like the location of the nodes. The process XML consist of exactly one <process> element. This element contains parameters related to the process (its type, name, id and package name), and consists of three subsections: a header section (where process-level information like variables, globals, imports and lanes can be defined), a nodes section that defines each of the nodes in the process, and a connections section that contains the connections between all the nodes in the process. In the nodes section, there is a specific element for each node, defining the various parameters and, possibly, sub-elements for that node type.
Figure 9. The different types of BPMN2 events
|

Figure 9. The different types of BPMN2 activities and gateways
|
7.2.1.3. Details: Process properties
A BPMN2 process is a flow chart where different types of nodes are linked using connections. The process itself exposes the following properties:
-
Id: The unique id of the process.
-
Name: The display name of the process.
-
Version: The version number of the process.
-
Package: The package (namespace) the process is defined in.
In addition to that following can be defined as well:
-
Variables: Variables can be defined to store data during the execution of your process. See section “[_sec.data]” for details.
-
Swimlanes: Specify the swimlanes used in this process for assigning human tasks. See chapter “[_ch.human_tasks]” for details.
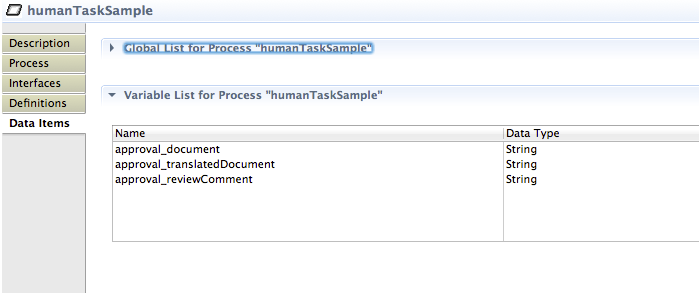
7.3. Activities
7.3.1. Script task
Represents a script that should be executed in this process.
A Script Task should have one incoming connection and one outgoing connection.
The associated action specifies what should be executed, the dialect used for coding the action (i.e., Java, JavaScript or MVEL), and the actual action code.
This code can access any variables and globals.
There is also a predefined variable kcontext that references the ProcessContext object (which can, for example, be used to access the current ProcessInstance or NodeInstance, and to get and set variables, or get access to the ksession using kcontext.getKieRuntime()). When a Script Task is reached in the process, it will execute the action and then continue with the next node.
It contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
Action: The action script associated with this action node.
Note that you can write any valid Java code inside a script node. This basically allows you to do anything inside such a script node. There are some caveats however:
-
When trying to create a higher-level business process, that should also be understood by business users, it is probably wise to avoid low-level implementation details inside the process, including inside these script tasks. A Script Task could still be used to quickly manipulate variables etc. but other concepts like a Service Task could be used to model more complex behaviour in a higher-level manner.
-
Scripts should be immediate. They are using the engine thread to execute the script. Scripts that could take some time to execute should probably be modeled as an asynchronous Service Task.
-
You should try to avoid contacting external services through a script node. Not only does this usually violate the first two caveats, it is also interacting with external services without the knowledge of the engine, which can be problematic, especially when using persistence and transactions. In general, it is probably wiser to model communication with an external service using a service task.
-
Scripts should not throw exceptions. Runtime exceptions should be caught and for example managed inside the script or transformed into signals or errors that can then be handled inside the process.
7.3.2. Service task
Represents an (abstract) unit of work that should be executed in this process. All work that is executed outside the process engine should be represented (in a declarative way) using a Service Task. Different types of services are predefined, e.g., sending an email, logging a message, etc. Users can define domain-specific services or work items, using a unique name and by defining the parameters (input) and results (output) that are associated with this type of work. Check the chapter on domain-specific processes for a detailed explanation and illustrative examples of how to define and use work items in your processes. When a Service Task is reached in the process, the associated work is executed. A Service Task should have one incoming connection and one outgoing connection.
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
Parameter mapping: Allows copying the value of process variables to parameters of the work item. Upon creation of the work item, the values will be copied.
-
Result mapping: Allows copying the value of result parameters of the work item to a process variable. Each type of work can define result parameters that will (potentially) be returned after the work item has been completed. A result mapping can be used to copy the value of the given result parameter to the given variable in this process. For example, the "FileFinder" work item returns a list of files that match the given search criteria within the result parameter
Files. This list of files can then be bound to a process variable for use within the process. Upon completion of the work item, the values will be copied. -
On-entry and on-exit actions: Actions that are executed upon entry or exit of this node, respectively.
-
Additional parameters: Each type of work item can define additional parameters that are relevant for that type of work. For example, the "Email" work item defines additional parameters such as
From,To,SubjectandBody. The user can either provide values for these parameters directly, or define a parameter mapping that will copy the value of the given variable in this process to the given parameter; if both are specified, the mapping will have precedence. Parameters of typeStringcan use#{expression}to embed a value in the string. The value will be retrieved when creating the work item, and the substitution expression will be replaced by the result of callingtoString()on the variable. The expression could simply be the name of a variable (in which case it resolves to the value of the variable), but more advanced MVEL expressions are possible as well, e.g.,\#{person.name.firstname}.
7.3.3. User task
Processes can also involve tasks that need to be executed by human actors. A User Task represents an atomic task to be executed by a human actor. It should have one incoming connection and one outgoing connection. User Tasks can be used in combination with Swimlanes to assign multiple human tasks to similar actors. Refer to the chapter on human tasks for more details. A User Task is actually nothing more than a specific type of service node (of type "Human Task"). A User Task contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
TaskName: The name of the human task.
-
Priority: An integer indicating the priority of the human task.
-
Comment: A comment associated with the human task.
-
ActorId: The actor id that is responsible for executing the human task. A list of actor id’s can be specified using a comma (',') as separator.
-
GroupId: The group id that is responsible for executing the human task. A list of group id’s can be specified using a comma (',') as separator.
-
Skippable: Specifies whether the human task can be skipped, i.e., whether the actor may decide not to execute the task.
-
Content: The data associated with this task.
-
Swimlane: The swimlane this human task node is part of. Swimlanes make it easy to assign multiple human tasks to the same actor. See the human tasks chapter for more detail on how to use swimlanes.
-
On entry and on exit actions: Action scripts that are executed upon entry and exit of this node, respectively.
-
Parameter mapping: Allows copying the value of process variables to parameters of the human task. Upon creation of the human tasks, the values will be copied.
-
Result mapping: Allows copying the value of result parameters of the human task to a process variable. Upon completion of the human task, the values will be copied. A human task has a result variable "Result" that contains the data returned by the human actor. The variable "ActorId" contains the id of the actor that actually executed the task.
A user task should define the type of task that needs to be executed (using properties like TaskName, Comment, etc.) and who needs to perform it (using either actorId or groupId). Note that if there is data related to this specific process instance that the end user needs when performing the task, this data should be passed as the content of the task. The task for example does not have access to process variables. Check out the chapter on human tasks to get more detail on how to pass data between human tasks and the process instance.
7.3.4. Reusable sub-process
Represents the invocation of another process from within this process. A sub-process node should have one incoming connection and one outgoing connection. When a Reusable Sub-Process node is reached in the process, the engine will start the process with the given id. It contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
ProcessId: The id of the process that should be executed.
-
Wait for completion (by default true): If this property is true, this sub-process node will only continue if the child process that was started has terminated its execution (completed or aborted); otherwise it will continue immediately after starting the subprocess (so it will not wait for its completion).
-
Independent (by default true): If this property is true, the child process is started as an independent process, which means that the child process will not be terminated if this parent process is completed (or this sub-process node is canceled for some other reason); otherwise the active sub-process will be canceled on termination of the parent process (or cancellation of the sub-process node). Note that you can only set independent to "false" only when "Wait for completion" is set to true.
-
On-entry and on-exit actions: Actions that are executed upon entry or exit of this node, respectively.
-
Parameter in/out mapping: A sub-process node can also define in- and out-mappings for variables. The variables given in the "in" mapping will be used as parameters (with the associated parameter name) when starting the process. The variables of the child process that are defined for the "out" mappings will be copied to the variables of this process when the child process has been completed. Note that you can use "out" mappings only when "Wait for completion" is set to true.
7.3.5. Business rule task
A Business Rule Task Represents a set of rules that need to be evaluated.
The rules are evaluated when the node is reached.
A Rule Task should have one incoming connection and one outgoing connection.
Rules are defined in separate files using the Drools rule format.
Rules can become part of a specific ruleflow group using the ruleflow-group attribute in the header of the rule.
When a Rule Task is reached in the process, the engine will start executing rules that are part of the corresponding ruleflow-group (if any). Execution will automatically continue to the next node if there are no more active rules in this ruleflow group. As a result, during the execution of a ruleflow group, new activations belonging to the currently active ruleflow group can be added to the Agenda due to changes made to the facts by the other rules. Note that the process will immediately continue with the next node if it encounters a ruleflow group where there are no active rules at that time.
If the ruleflow group was already active, the ruleflow group will remain active and execution will only continue if all active rules of the ruleflow group has been completed. It contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
RuleFlowGroup: The name of the ruleflow group that represents the set of rules of this RuleFlowGroup node.
7.3.6. Embedded sub-process
A Sub-Process is a node that can contain other nodes so that it acts as a node container. This allows not only the embedding of a part of the process within such a sub-process node, but also the definition of additional variables that are accessible for all nodes inside this container. A sub-process should have one incoming connection and one outgoing connection. It should also contain one start node that defines where to start (inside the Sub-Process) when you reach the sub-process. It should also contain one or more end events. Note that, if you use a terminating event node inside a sub-process, you are terminating just that sub-process. A sub-process ends when there are no more active nodes inside the sub-process. It contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
Variables: Additional variables can be defined to store data during the execution of this node. See section “[_sec.data]” for details.
7.3.7. Multi-instance sub-process
A Multiple Instance sub-process is a special kind of sub-process that allows you to execute the contained process segment multiple times, once for each element in a collection. A multiple instance sub-process should have one incoming connection and one outgoing connection. It waits until the embedded process fragment is completed for each of the elements in the given collection before continuing. It contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
CollectionExpression: The name of a variable that represents the collection of elements that should be iterated over. The collection variable should be an array or of type
java.util.Collection. If the collection expression evaluates to null or an empty collection, the multiple instances sub-process will be completed immediately and follow its outgoing connection. -
VariableName: The name of the variable to contain the current element from the collection. This gives nodes within the composite node access to the selected element.
-
CollectionOutput: The name of a variable that represents collection of elements that will gather all output of the multi instance sub process
-
OutputVariableName: The name of the variable to contain the currentl output from the multi instance activitiy
-
CompletionCondition: MVEL expression that will be evaluated on each instance completion to check if given multi instance activity can already be completed. In case it evaluates to true all other remaining instances within multi instance activity will be canceled.
7.4. Events
7.4.1. Start event
The start of the process. A process should have exactly one start node (none start node which does not have event definitions), which cannot have incoming connections and should have one outgoing connection. Whenever a process is started, execution will start at this node and automatically continue to the first node linked to this start event, and so on. It contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
7.4.2. End events
7.4.2.1. End event
The end of the process. A process should have one or more end events. The End Event should have one incoming connection and cannot have any outgoing connections. It contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
Terminate: An End Event can terminate the entire process or just the path. When a process instance is terminated, it means its state is set to completed and all other nodes that might still be active (on parallel paths) in this process instance are canceled. Non-terminating end events are simply end for this path (execution of this branch will end here), but other parallel paths can still continue. A process instance will automatically complete if there are no more active paths inside that process instance (for example, if a process instance reaches a non-terminating end node but there are no more active branches inside the process instance, the process instance will be completed anyway). Terminating end events are visualized using a full circle inside the event node, non-terminating event nodes are empty. Note that, if you use a terminating event node inside a sub-process, you are terminating just that sub-process and top level continues.
7.4.2.2. Throwing error event

An Error Event can be used to signal an exceptional condition in the process. It should have one incoming connection and no outgoing connections. When an Error Event is reached in the process, it will throw an error with the given name. The process will search for an appropriate error handler that is capable of handling this kind of fault. If no error handler is found, the process instance will be aborted. An Error Event contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
FaultName: The name of the fault. This name is used to search for appropriate exception handlers that are capable of handling this kind of fault.
-
FaultVariable: The name of the variable that contains the data associated with this fault. This data is also passed on to the exception handler (if one is found).
Error handlers can be specified using boundary events.
7.4.3. Intermediate events
7.4.3.1. Catching timer event
Represents a timer that can trigger one or multiple times after a given period of time. A Timer Event should have one incoming connection and one outgoing connection. The timer delay specifies how long the timer should wait before triggering the first time. When a Timer Event is reached in the process, it will start the associated timer. The timer is canceled if the timer node is canceled (e.g., by completing or aborting the enclosing process instance). Consult the section “[_sec.timers]” for more information. The Timer Event contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
Timer delay: The delay that the node should wait before triggering the first time. The expression should be of the form
[d][#h][#m][#s][[ms]]. This allows you to specify the number of days, hours, minutes, seconds and milliseconds (which is the default if you don’t specify anything). For example, the expression "1h" will wait one hour before triggering the timer. The expression could also use #{expr} to dynamically derive the delay based on some process variable. Expr in this case could be a process variable, or a more complex expression based on a process variable (e.g. myVariable.getValue()). It does support CRON like expression as well. -
Timer period: The period between two subsequent triggers. If the period is 0, the timer should only be triggered once. The expression should be of the form
[d][#h][#m][#s][[ms]]. You can specify the number of days, hours, minutes, seconds and milliseconds (which is the default if you don’t specify anything). For example, the expression "1h" will wait one hour before triggering the timer again. The expression could also use #{expr} to dynamically derive the period based on some process variable. Expr in this case could be a process variable, or a more complex expression based on a process variable (e.g. myVariable.getValue()).
Timer events could also be specified as boundary events on sub-processes and tasks that are not automatic tasks like script task that have no wait state as timer will not have a change to fire before task completion.
7.4.3.2. Catching signal event
A Signal Event can be used to respond to internal or external events during the execution of the process. A Signal Event should have one incoming connections and one outgoing connection. It specifies the type of event that is expected. Whenever that type of event is detected, the node connected to this event node will be triggered. It contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
EventType: The type of event that is expected.
-
VariableName: The name of the variable that will contain the data associated with this event (if any) when this event occurs.
A process instance can be signaled that a specific event occurred using
ksession.signalEvent(eventType, data, processInstanceId)This will trigger all (active) signal event nodes in the given process instance that are waiting for that event type. Data related to the event can be passed using the data parameter. If the event node specifies a variable name, this data will be copied to that variable when the event occurs.
It is also possible to use event nodes inside sub-processes. These event nodes will however only be active when the sub-process is active.
You can also generate a signal from inside a process instance. A script (in a script task or using on entry or on exit actions) can use
kcontext.getKieRuntime().signalEvent(eventType, data, kcontext.getProcessInstance().getId());A throwing signal event could also be used to model the signaling of an event.
7.5. Gateways
7.5.1. Diverging gateway
Allows you to create branches in your process. A Diverging Gateway should have one incoming connection and two or more outgoing connections. There are three types of gateway nodes currently supported:
-
AND or parallel means that the control flow will continue in all outgoing connections simultaneously.
-
XOR or exclusive means that exactly one of the outgoing connections will be chosen. The decision is made by evaluating the constraints that are linked to each of the outgoing connections. The constraint with the lowest priority number that evaluates to true is selected. Constraints can be specified using different dialects. Note that you should always make sure that at least one of the outgoing connections will evaluate to true at runtime (the engine will throw an exception at runtime if it cannot find at least one outgoing connection).
-
OR or inclusive means that all outgoing connections whose condition evaluates to true are selected. Conditions are similar to the exclusive gateway, except that no priorities are taken into account. Note that you should make sure that at least one of the outgoing connections will evaluate to true at runtime because the engine will throw an exception at runtime if it cannot determine an outgoing connection.
It contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
Type: The type of the split node, i.e., AND, XOR or OR (see above).
-
Constraints: The constraints linked to each of the outgoing connections (in case of an exclusive or inclusive gateway).
7.5.2. Converging gateway
Allows you to synchronize multiple branches. A Converging Gateway should have two or more incoming connections and one outgoing connection. There are three types of splits currently supported:
-
AND or parallel means that is will wait until all incoming branches are completed before continuing.
-
XOR or exclusive means that it continues as soon as one of its incoming branches has been completed. If it is triggered from more than one incoming connection, it will trigger the next node for each of those triggers.
-
OR or inclusive means that it continues as soon as all direct active paths of its incoming branches has been completed. This is complex merge behaviour that is described in BPMN2 specification but in most cases it means that OR join will wait for all active flows that started in OR split. Some advanced cases (including other gateways in between or repeatable timers) will be causing different "direct active path" calculation.
It contains the following properties:
-
Id: The id of the node (which is unique within one node container).
-
Name: The display name of the node.
-
Type: The type of the Join node, i.e. AND, OR or XOR.
7.6. Others
7.6.1. Variables
While the flow chart focuses on specifying the control flow of the process, it is usually also necessary to look at the process from a data perspective. Throughout the execution of a process, data can be retrieved, stored, passed on and used.
For storing runtime data, during the execution of the process, process variables can be used. A variable is defined by a name and a data type. This could be a basic data type, such as boolean, int, or String, or any kind of Object subclass (it must implement Serializable interface). Variables can be defined inside a variable scope. The top-level scope is the variable scope of the process itself. Subscopes can be defined using a Sub-Process. Variables that are defined in a subscope are only accessible for nodes within that scope.
Whenever a variable is accessed, the process will search for the appropriate variable scope that defines the variable. Nesting of variable scopes is allowed. A node will always search for a variable in its parent container. If the variable cannot be found, it will look in that one’s parent container, and so on, until the process instance itself is reached. If the variable cannot be found, a read access yields null, and a write access produces an error message, with the process continuing its execution.
Variables can be used in various ways:
-
Process-level variables can be set when starting a process by providing a map of parameters to the invocation of the
startProcessmethod. These parameters will be set as variables on the process scope. -
Script actions can access variables directly, simply by using the name of the variable as a local parameter in their script. For example, if the process defines a variable of type "org.jbpm.Person" in the process, a script in the process could access this directly:
// call method on the process variable "person" person.setAge(10);Changing the value of a variable in a script can be done through the knowledge context:
kcontext.setVariable(variableName, value); -
Service tasks (and reusable sub-processes) can pass the value of process variables to the outside world (or another process instance) by mapping the variable to an outgoing parameter. For example, the parameter mapping of a service task could define that the value of the process variable x should be mapped to a task parameter y right before the service is being invoked. You can also inject the value of process variable into a hard-coded parameter String using
\#{expression}. For example, the description of a human task could be defined asYou need to contact person #{person.getName()}(where person is a process variable), which will replace this expression by the actual name of the person when the service needs to be invoked. Similarly results of a service (or reusable sub-process) can also be copied back to a variable using a result mapping. -
Various other nodes can also access data. Event nodes for example can store the data associated to the event in a variable, etc. Check the properties of the different node types for more information.
-
Process variables can be accessed also from the Java code of your application. It is done by casting of
ProcessInstancetoWorkflowProcessInstance. See the following example:variable = ((WorkflowProcessInstance) processInstance).getVariable("variableName");To list all the process variables see the following code snippet:
org.jbpm.process.instance.ProcessInstance processInstance = ...; VariableScopeInstance variableScope = (VariableScopeInstance) processInstance.getContextInstance(VariableScope.VARIABLE_SCOPE); Map<String, Object> variables = variableScope.getVariables();Note that when you use persistence then you have to use a command based approach to get all process variables:
Map<String, Object> variables = ksession.execute(new GenericCommand<Map<String, Object>>() { public Map<String, Object> execute(Context context) { KieSession ksession = ((KnowledgeCommandContext) context).getStatefulKnowledgesession(); org.jbpm.process.instance.ProcessInstance processInstance = (org.jbpm.process.instance.ProcessInstance) ksession.getProcessInstance(piId); VariableScopeInstance variableScope = (VariableScopeInstance) processInstance.getContextInstance(VariableScope.VARIABLE_SCOPE); Map<String, Object> variables = variableScope.getVariables(); return variables; } });
Finally, processes (and rules) all have access to globals, i.e.
globally defined variables and data in the Knowledge Session.
Globals are directly accessible in actions just like variables.
Globals need to be defined as part of the process before they can be used.
You can for example define globals by clicking the globals button when specifying an action script in the Eclipse action property editor.
You can also set the value of a global from the outside using ksession.setGlobal(name, value) or from inside process scripts using kcontext.getKieRuntime().setGlobal(name,value);.
7.6.2. Scripts
Action scripts can be used in different ways:
-
Within a Script Task,
-
As entry or exit actions, with a number of nodes.
Actions have access to globals and the variables that are defined for the process and the predefined variable kcontext.
This variable is of type
ProcessContext and can be used for several tasks:
-
Getting the current node instance (if applicable). The node instance could be queried for data, such as its name and type. You can also cancel the current node instance.
NodeInstance node = kcontext.getNodeInstance(); String name = node.getNodeName(); -
Getting the current process instance. A process instance can be queried for data (name, id, processId, etc.), aborted or signaled an internal event.
ProcessInstance proc = kcontext.getProcessInstance(); proc.signalEvent( type, eventObject ); -
Getting or setting the value of variables.
-
Accessing the Knowledge Runtime allows you do things like starting a process, signaling (external) events, inserting data, etc.
jBPM supports multiple dialects, like Java, JavaScript and MVEL.
Java actions should be valid Java code, same for JavaScript.
MVEL actions can use the business scripting language MVEL to express the action.
MVEL accepts any valid Java code but additionally provides support for nested accesses of parameters (e.g., person.name instead of person.getName()), and many other scripting improvements.
Thus, MVEL expressions are more convenient for the business user.
For example, an action that prints out the name of the person in the "requester" variable of the process would look like this:
// Java dialect
System.out.println( person.getName() );
// JavaScript dialect
print(person.name + '\n);
// MVEL dialect
System.out.println( person.name );7.6.3. Constraints
Constraints can be used in various locations in your processes, for example in a diverging gateway. jBPM supports two types of constraints:
-
Code constraints are boolean expressions, evaluated directly whenever they are reached. We support multiple dialects for expressing these code constraints: Java, JavaScript and MVEL. All code constraints have direct access to the globals and variables defined in the process. Here is an example of a valid Java code constraint,
personbeing a variable in the process:return person.getAge() > 20;A similar example of a valid MVEL code constraint is:
return person.age > 20;And for JavaScript:
person.age > 20 -
Rule constraints are equals to normal Drools rule conditions. They use the Drools Rule Language syntax to express possibly complex constraints. These rules can, like any other rule, refer to data in the Working Memory. They can also refer to globals directly. Here is an example of a valid rule constraint:
Person( age > 20 )This tests for a person older than 20 being in the Working Memory.
Rule constraints do not have direct access to variables defined inside the process.
It is however possible to refer to the current process instance inside a rule constraint, by adding the process instance to the Working Memory and matching for the process instance in your rule constraint.
We have added special logic to make sure that a variable processInstance of type WorkflowProcessInstance will only match to the current process instance and not to other process instances in the Working Memory.
Note that you are however responsible yourself to insert the process instance into the session and, possibly, to update it, for example, using Java code or an on-entry or on-exit or explicit action in your process.
The following example of a rule constraint will search for a person with the same name as the value stored in the variable "name" of the process:
processInstance : WorkflowProcessInstance()
Person( name == ( processInstance.getVariable("name") ) )
# add more constraints here ...7.6.4. Timers
Timers wait for a predefined amount of time, before triggering, once or repeatedly. They can be used to trigger certain logic after a certain period, or to repeat some action at regular intervals.
7.6.4.1. Configure timer with delay and period
A Timer node is set up with a delay and a period. The delay specifies the amount of time to wait after node activation before triggering the timer the first time. The period defines the time between subsequent trigger activations. A period of 0 results in a one-shot timer.
The (period and delay) expression should be of the form [d][#h][#m][#s][[ms]]. You can specify the amount of days, hours, minutes, seconds and milliseconds (which is the default if you don’t specify anything). For example, the expression "1h" will wait one hour before triggering the timer (again).
7.6.4.2. Configure timer with CRON like expression
Timer events can be configured with CRON like expression when timeCycle is used as timer event definition. Important is that the language attribute of timeCycle definition must be set to cron. With that such cycle of a timer is controlled in the same way as CRON jobs. CRON like expression is supported for:
-
start event timers
-
intermediate event timers
-
boundary event timers
Following is an example of a definition of a boundary timer with CRON like expression
<bpmn2:boundaryEvent id="1" name="Send Update Timer" attachedToRef="_77A94B54-8B7C-4F8A-84EE-C1D310A343A6" cancelActivity="false">
<bpmn2:outgoing>2</bpmn2:outgoing>
<bpmn2:timerEventDefinition id="_erIyiJZ7EeSDh8PHobjSSA">
<bpmn2:timeCycle xsi:type="bpmn2:tFormalExpression" id="_erIyiZZ7EeSDh8PHobjSSA" language="cron">0/1 * * * * ?</bpmn2:timeCycle>
</bpmn2:timerEventDefinition>
</bpmn2:boundaryEvent>This timer will fire every second and will continue until activity this boundary event is attached to is active.
7.6.4.3. Configure timer ISO-8601 date format
since version 6 timers can be configured with valid ISO8601 date format that supports both one shot timers and repeatable timers. Timers can be defined as date and time representation, time duration or repeating intervals
-
Date - 2013-12-24T20:00:00.000+02:00 - fires exactly at Christmas Eve at 8PM
-
Duration - PT1S - fires once after 1 second
-
Repeatable intervals - R/PT1S - fires every second, no limit, alternatively R5/PT1S will fire 5 times every second
7.6.4.4. Configure timer with process variables
The timer service is responsible for making sure that timers get triggered at the appropriate times. Timers can also be canceled, meaning that the timer will no longer be triggered.
Timers can be used in two ways inside a process:
-
A Timer Event may be added to the process flow. Its activation starts the timer, and when it triggers, once or repeatedly, it activates the Timer node’s successor. Subsequently, the outgoing connection of a timer with a positive period is triggered multiple times. Canceling a Timer node also cancels the associated timer, after which no more triggers will occur.
-
Timers can be associated with a Sub-Process or tasks as a boundary event.
7.6.4.5. Update timer within running process instance
In some cases timer that has been already scheduled should be rescheduled to accomodate new requirements (prolong or shorten timer expiration time, change delay, period or repeat limit).
As this involves several low level steps, jBPM comes with a dedicated command to perform these operations as atomic operation to make sure all is done within same transaction.
org.jbpm.process.instance.command.UpdateTimerCommandFollowing timer events are supported to be updated:
-
boundary timer event
-
intermediate timer event
Timers can be rescheduled by providing following information to the UpdateTimerCommand
-
processInstanceId - mandatory
-
timer node name - mandatory
Next one of following three parameters set needs to be used:
-
delay
-
period and repeatLimit
-
delay, period and repeatLimit
Example on how to updated timer event:
// first start process instance and record its id
long id = kieSession.startProcess(BOUNDARY_PROCESS_NAME).getId();
//set timer delay to 3s
kieSession.execute(new UpdateTimerCommand(id, BOUNDARY_TIMER_ATTACHED_TO_NAME, 3));Important is that the update command is executed via ksession executor to ensure it’s done in transaction (when persistence is used).
7.7. Process Fluent API
While it is recommended to define processes using the graphical editor or the underlying XML (to shield yourself from internal APIs), it is also possible to define a process using the Process API directly.
The most important process model elements are defined in the packages org.jbpm.workflow.core and org.jbpm.workflow.core.node.
A "fluent API" is provided that allows you to easily construct processes in a readable manner using factories.
At the end, you can validate the process that you were constructing manually.
7.7.1. Example
This is a simple example of a basic process with a script task only:
RuleFlowProcessFactory factory =
RuleFlowProcessFactory.createProcess("org.jbpm.HelloWorld");
factory
// Header
.name("HelloWorldProcess")
.version("1.0")
.packageName("org.jbpm")
// Nodes
.startNode(1).name("Start").done()
.actionNode(2).name("Action")
.action("java", "System.out.println(\"Hello World\");").done()
.endNode(3).name("End").done()
// Connections
.connection(1, 2)
.connection(2, 3);
RuleFlowProcess process = factory.validate().getProcess();
KieServices ks = KieServices.Factory.get();
KieFileSystem kfs = ks.newKieFileSystem();
Resource resource = ks.getResources().newByteArrayResource(
XmlBPMNProcessDumper.INSTANCE.dump(process).getBytes());
resource.setSourcePath("helloworld.bpmn2");
kfs.write(resource);
ReleaseId releaseId = ks.newReleaseId("org.jbpm", "helloworld", "1.0");
kfs.generateAndWritePomXML(releaseId);
ks.newKieBuilder(kfs).buildAll();
ks.newKieContainer(releaseId).newKieSession().startProcess("org.jbpm.HelloWorld");You can see that we start by calling the static createProcess() method from the RuleFlowProcessFactory class.
This method creates a new process with the given id and returns the RuleFlowProcessFactory that can be used to create the process.
A typical process consists of three parts.
The header part comprises global elements like the name of the process, imports, variables, etc.
The nodes section contains all the different nodes that are part of the process.
The connections section finally links these nodes to each other to create a flow chart.
In this example, the header contains the name and the version of the process and the package name. After that, you can start adding nodes to the current process. If you have auto-completion you can see that you have different methods to create each of the supported node types at your disposal.
When you start adding nodes to the process, in this example by calling the startNode(), actionNode() and endNode() methods, you can see that these methods return a specific NodeFactory, that allows you to set the properties of that node.
Once you have finished configuring that specific node, the done() method returns you to the current RuleFlowProcessFactory so you can add more nodes, if necessary.
When you are finished adding nodes, you must connect them by creating connections between them.
This can be done by calling the method connection, which will link previously created nodes.
Finally, you can validate the generated process by calling the validate() method and retrieve the created RuleFlowProcess object.
7.8. Testing
Even though business processes aren’t code (we even recommend you to make them as high-level as possible and to avoid adding implementation details), they also have a life cycle like other development artefacts. And since business processes can be updated dynamically, testing them (so that you don’t break any use cases when doing a modification) is really important as well.
7.8.1. Unit testing
When unit testing your process, you test whether the process behaves as expected in specific use cases, for example test the output based on the existing input. To simplify unit testing, jBPM includes a helper class called JbpmJUnitBaseTestCase (in the jbpm-test module) that you can use to greatly simplify your JUnit testing, by offering:
-
helper methods to create a new RuntimeManager and RuntimeEngine for a given (set of) process(es)
-
you can select whether you want to use persistence or not
-
-
assert statements to check
-
the state of a process instance (active, completed, aborted)
-
which node instances are currently active
-
which nodes have been triggered (to check the path that has been followed)
-
get the value of variables
-
For example, consider the following "hello world" process containing a start event, a script task and an end event. The following JUnit test will create a new session, start the process and then verify whether the process instance completed successfully and whether these three nodes have been executed.
public class ProcessPersistenceTest extends JbpmJUnitBaseTestCase {
public ProcessPersistenceTest() {
// setup data source, enable persistence
super(true, true);
}
@Test
public void testProcess() {
// create runtime manager with single process - hello.bpmn
createRuntimeManager("hello.bpmn");
// take RuntimeManager to work with process engine
RuntimeEngine runtimeEngine = getRuntimeEngine();
// get access to KieSession instance
KieSession ksession = runtimeEngine.getKieSession();
// start process
ProcessInstance processInstance = ksession.startProcess("com.sample.bpmn.hello");
// check whether the process instance has completed successfully
assertProcessInstanceCompleted(processInstance.getId(), ksession);
// check what nodes have been triggered
assertNodeTriggered(processInstance.getId(), "StartProcess", "Hello", "EndProcess");
}
}JbpmJUnitBaseTestCase acts as base test case class that shall be used for jBPM related tests. It provides four usage areas:
-
JUnit life cycle methods
-
setUp: executed @Before and configures data source and EntityManagerFactory, cleans up Singleton’s session id
-
tearDown: executed @After and clears out history, closes EntityManagerFactory and data source, disposes RuntimeEngines and RuntimeManager
-
-
Knowledge Base and KnowledgeSession management methods
-
createRuntimeManager creates RuntimeManager for given set of assets and selected strategy
-
disposeRuntimeManager disposes RuntimeManager currently active in the scope of test
-
getRuntimeEngine creates new RuntimeEngine for given context
-
-
Assertions
-
assertProcessInstanceCompleted
-
assertProcessInstanceAborted
-
assertProcessInstanceActive
-
assertNodeActive
-
assertNodeTriggered
-
assertProcessVarExists
-
assertNodeExists
-
assertVersionEquals
-
assertProcessNameEquals
-
-
Helper methods
-
getDs - returns currently configured data source
-
getEmf - returns currently configured EntityManagerFactory
-
getTestWorkItemHandler - returns test work item handler that might be registered in addition to what is registered by default
-
clearHistory - clears history log
-
setupPoolingDataSource - sets up data source
-
JbpmJUnitBaseTestCase supports all three predefined RuntimeManager strategies as part of the unit testing. It’s enough to specify which strategy shall be used whenever creating runtime manager as part of single test:
public class ProcessHumanTaskTest extends JbpmJUnitBaseTestCase {
private static final Logger logger = LoggerFactory.getLogger(ProcessHumanTaskTest.class);
public ProcessHumanTaskTest() {
super(true, false);
}
@Test
public void testProcessProcessInstanceStrategy() {
RuntimeManager manager = createRuntimeManager(Strategy.PROCESS_INSTANCE, "manager", "humantask.bpmn");
RuntimeEngine runtimeEngine = getRuntimeEngine(ProcessInstanceIdContext.get());
KieSession ksession = runtimeEngine.getKieSession();
TaskService taskService = runtimeEngine.getTaskService();
int ksessionID = ksession.getId();
ProcessInstance processInstance = ksession.startProcess("com.sample.bpmn.hello");
assertProcessInstanceActive(processInstance.getId(), ksession);
assertNodeTriggered(processInstance.getId(), "Start", "Task 1");
manager.disposeRuntimeEngine(runtimeEngine);
runtimeEngine = getRuntimeEngine(ProcessInstanceIdContext.get(processInstance.getId()));
ksession = runtimeEngine.getKieSession();
taskService = runtimeEngine.getTaskService();
assertEquals(ksessionID, ksession.getId());
// let john execute Task 1
List<TaskSummary> list = taskService.getTasksAssignedAsPotentialOwner("john", "en-UK");
TaskSummary task = list.get(0);
logger.info("John is executing task {}", task.getName());
taskService.start(task.getId(), "john");
taskService.complete(task.getId(), "john", null);
assertNodeTriggered(processInstance.getId(), "Task 2");
// let mary execute Task 2
list = taskService.getTasksAssignedAsPotentialOwner("mary", "en-UK");
task = list.get(0);
logger.info("Mary is executing task {}", task.getName());
taskService.start(task.getId(), "mary");
taskService.complete(task.getId(), "mary", null);
assertNodeTriggered(processInstance.getId(), "End");
assertProcessInstanceCompleted(processInstance.getId(), ksession);
}
}Above is more complete example that uses PerProcessInstance runtime manager strategy and uses task service to deal with user tasks.
7.8.1.1. Testing integration with external services
Real-life business processes typically include the invocation of external services (like for example a human task service, an email server or your own domain-specific services). One of the advantages of our domain-specific process approach is that you can specify yourself how to actually execute your own domain-specific nodes, by registering a handler. And this handler can be different depending on your context, allowing you to use testing handlers for unit testing your process. When you are unit testing your business process, you can register test handlers that then verify whether specific services are requested correctly, and provide test responses for those services. For example, imagine you have an email node or a human task as part of your process. When unit testing, you don’t want to send out an actual email but rather test whether the email that is requested contains the correct information (for example the right to email, a personalized body, etc.).
A TestWorkItemHandler is provided by default that can be registered to collect all work items (a work item represents one unit of work, like for example sending one specific email or invoking one specific service and contains all the data related to that task) for a given type. This test handler can then be queried during unit testing to check whether specific work was actually requested during the execution of the process and that the data associated with the work was correct.
The following example describes how a process that sends out an email could be tested. This test case in particular will test whether an exception is raised when the email could not be sent (which is simulated by notifying the engine that the sending the email could not be completed). The test case uses a test handler that simply registers when an email was requested (and allows you to test the data related to the email like from, to, etc.). Once the engine has been notified the email could not be sent (using abortWorkItem(..)), the unit test verifies that the process handles this case successfully by logging this and generating an error, which aborts the process instance in this case.
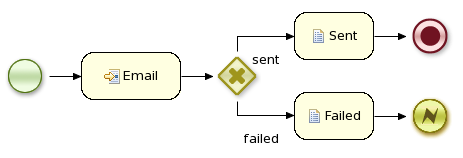
public void testProcess2() {
// create runtime manager with single process - hello.bpmn
createRuntimeManager("sample-process.bpmn");
// take RuntimeManager to work with process engine
RuntimeEngine runtimeEngine = getRuntimeEngine();
// get access to KieSession instance
KieSession ksession = runtimeEngine.getKieSession();
// register a test handler for "Email"
TestWorkItemHandler testHandler = getTestWorkItemHandler();
ksession.getWorkItemManager().registerWorkItemHandler("Email", testHandler);
// start the process
ProcessInstance processInstance = ksession.startProcess("com.sample.bpmn.hello2");
assertProcessInstanceActive(processInstance.getId(), ksession);
assertNodeTriggered(processInstance.getId(), "StartProcess", "Email");
// check whether the email has been requested
WorkItem workItem = testHandler.getWorkItem();
assertNotNull(workItem);
assertEquals("Email", workItem.getName());
assertEquals("me@mail.com", workItem.getParameter("From"));
assertEquals("you@mail.com", workItem.getParameter("To"));
// notify the engine the email has been sent
ksession.getWorkItemManager().abortWorkItem(workItem.getId());
assertProcessInstanceAborted(processInstance.getId(), ksession);
assertNodeTriggered(processInstance.getId(), "Gateway", "Failed", "Error");
}7.8.1.2. Configuring persistence
You can configure whether you want to execute the JUnit tests using persistence or not. By default, the JUnit tests will use persistence, meaning that the state of all process instances will be stored in a (in-memory H2) database (which is started by the JUnit test during setup) and a history log will be used to check assertions related to execution history. When persistence is not used, process instances will only live in memory and an in-memory logger is used for history assertions.
Persistence (and setup of data source) is controlled by the super constructor and allows following
-
default, no arg constructor - the most simple test case configuration (does NOT initialize data source and does NOT configure session persistence) - this is usually used for in memory process management, without human task interaction
-
super(boolean, boolean) - allows to explicitly configure persistence and data source. This is the most common way of bootstrapping test cases for jBPM
-
super(true, false) - to execute with in memory process management with human tasks persistence
-
super(true, true) - to execute with persistent process management with human tasks persistence
-
-
super(boolean, boolean, string) - same as super(boolean, boolean) but allows to use another persistence unit name than default (org.jbpm.persistence.jpa)
public class ProcessHumanTaskTest extends JbpmJUnitBaseTestCase {
private static final Logger logger = LoggerFactory.getLogger(ProcessHumanTaskTest.class);
public ProcessHumanTaskTest() {
// configure this tests to not use persistence for process engine but still use it for human tasks
super(true, false);
}
}8. Human Tasks
8.1. Introduction
An important aspect of business processes is human task management. While some of the work performed in a process can be executed automatically, some tasks need to be executed by human actors.
jBPM supports a special human task node inside processes for modeling this interaction with human users. This human task node allows process designers to define the properties related to the task that the human actor needs to execute, like for example the type of task, the actor(s), or the data associated with the task.
jBPM also includes a so-called human task service, a back-end service that manages the life cycle of these tasks at runtime. The jBPM implementation is based on the WS-HumanTask specification. Note however that this implementation is fully pluggable, meaning that users can integrate their own human task solution if necessary.
In order to have human actors participate in your processes, you first need to (1) include human task nodes inside your process to model the interaction with human actors, (2) integrate a task management component (like for example the WS-HumanTask based implementation provided by jBPM) and (3) have end users interact with a human task client to request their task list and claim and complete the tasks assigned to them. Each of these three elements will be discussed in more detail in the next sections.
8.2. Using User Tasks in our Processes
jBPM supports the use of human tasks inside processes using a special User Task node defined by the BPMN2 Specification(as shown in the figure above). A User Task node represents an atomic task that needs to be executed by a human actor.
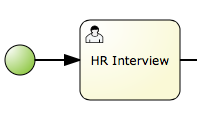
[Although jBPM has a special user task node for including human tasks inside a process, human tasks are considered the same as any other kind of external service that needs to be invoked and are therefore simply implemented as a domain-specific service. See the chapter on domain-specific processes to learn more about this.]
A User Task node contains the following core properties:
-
Actors: The actors that are responsible for executing the human task. A list of actor id’s can be specified using a comma (',') as separator.
-
Group: The group id that is responsible for executing the human task. A list of group id’s can be specified using a comma (',') as separator.
-
Name: The display name of the node.
-
TaskName: The name of the human task. This name is used to link the task to a Form. It also represent the internal name of the Task that can be used for other purposes.
-
DataInputSet: all the input variables that the task will receive to work on. Usually you will be interested in copying variables from the scope of the process to the scope of the task. (Look at the data mappings section for an example)
-
DataOutputSet: all the output variables that will be generated by the execution of the task. Here you specify all the name of the variables in the context of the task that you are interested to copy to the context of the process. (Look at the data mappings section for an example)
-
Assignments: here you specify which process variable will be linked to each Data Input and Data Output mapping. (Look at the data mappings section for an example)
You can edit these variables in the properties view (see below) when selecting the User Task node.
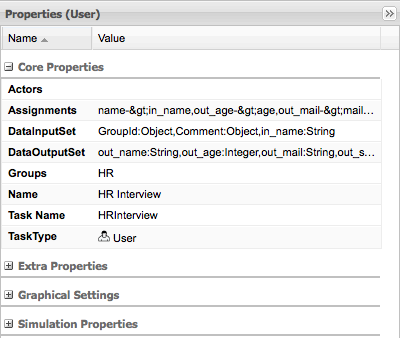
A User Task node also contains the following extra properties:
-
Comment: A comment associated with the human task. Here you can use expressions.
-
Content: The data associated with this task.
-
Priority: An integer indicating the priority of the human task.
-
Skippable: Specifies whether the human task can be skipped, i.e., whether the actor may decide not to execute the task.
-
On entry and on exit actions: Action scripts that are executed upon entry and exit of this node, respectively.
8.2.1. Swimlanes
User tasks can be used in combination with swimlanes to assign multiple human tasks to the same actor. Whenever the first task in a swimlane is created, and that task has an actorId specified, that actorId will be assigned to (all other tasks of) that swimlane as well. Note that this would override the actorId of subsequent tasks in that swimlane (if specified), so only the actorId of the first human task in a swimlane will be taken into account, all others will then take the actorId as assigned in the first one.
|
ActorId assignment will work only when there is single actor specified. Since ActorId field can contain multiple actors (john,mary,peter) auto assignment for the first task will not be performed when multiple values are found. |
Whenever a human task that is part of a swimlane is completed, the actorId of that swimlane is set to the actorId that executed that human task. This allows for example to assign a human task to a group of users, and to assign future tasks of that swimlame to the user that claimed the first task. This will also automatically change the assignment of tasks if at some point one of the tasks is reassigned to another user.
Also exists the possibility to disable the autoclaim functionality of the swimlanes. In such case, the swimlane works like a visual element to group tasks in the process diagram, but the task which belong to any swimlane won’t be assigned automatically. The Autoclaim functionality is set to true by default. If you require the property Autoclaim set to false by default, set the following runtime environment entry in your deployment descriptor on a global or a project level:
-
Name:
Autoclaim -
Value:
"false"
For example, if you want to set the entry in the XML deployment descriptor on the project level, add the following to the kie-deployment-descriptor.xml file:
<environment-entries>
..
<environment-entry>
<resolver>mvel</resolver>
<identifier>new String ("false")</identifier>
<parameters/>
<name>Autoclaim</name>
</environment-entry>
..
</environment-entries>If you are setting the runtime environment property using the API, note that the value is a String, not a Boolean type.
For further information about the deployment descriptor hierarchy, see the {URL_ADMIN_GUIDE}#sect_deployment_descriptors[Deployment Descriptors] chapter of the jBPM Administration and Configuration Guide.
8.3. Data Mappings
Human tasks typically present some data related to the task that needs to be performed to the actor that is executing the task and usually also request the actor to provide some result data related to the execution of the task. Task forms are typically used to present this data to the actor and request results.
The data that will be used by the Task needs to be specified when we define the User Task in our Process. In order to do that we need to define which data will be copied from the process context to the task context. Notice that the data is copied, so it can be modified inside the Task context but it will not affect the process variables unless we decide to copy back the value from the task to the process context.
Most of the times Forms are used to display data to the end user. Allowing them to generate/create new data that will be propagated to the process context to be used by future activities. In order to decide how the information flow from the process to a particular task and from the task to the process we need to define which pieces of information will be automatically copied by the process engine. The following sections shows how to do these mappings by configuring the DataInputSet, DataOutputSet and the Assignments properties of a User Task.
Let’s start defining the Task DataInputSet:
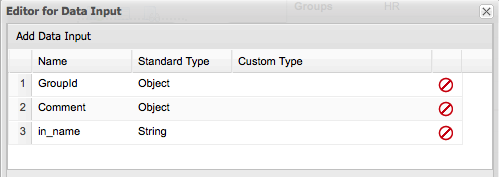
Both GroupId and Comment are automatically generated, so you don’t need to worry about that. In this case the only user defined Data Input is called: in_name. This means that the task will be receiving information from the process context and internally this variable will be called in_name. The type is also specified here.
In the Data Outputs represent the data that will be generated by the tasks. In this case we have two variables of type String called: out_name and out_mail and two Integer variables called: out_age and out_score are defined. This means that inside the task context we will need to set the value to these variables.
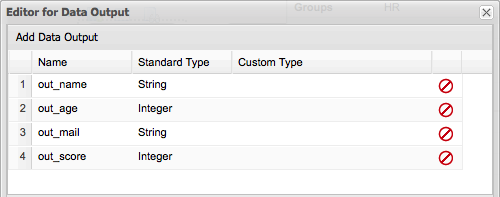
Finally all the connections with the process context needs to be done in the Data Assignments. The main idea here is to define how Data Inputs and Data Outputs will be associated with process variables.
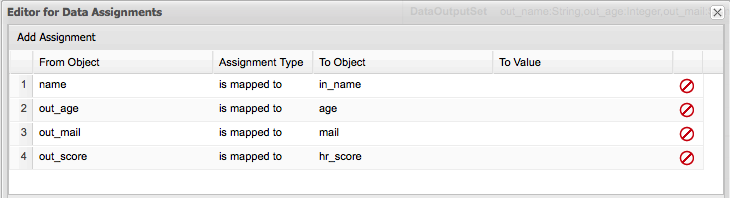
As shown in the previous screenshot, the assignments between the process variables (in this case (name, age, mail and hr_score)) and the Data Inputs and Outputs are done in the Data Assignments screen. Notice that the example uses a convention that makes it easy to know which is an internal Task variables (Data Input/Output) using the "in_" and "out_" prefix to the variable names. Using this convention you can quickly understand the Assignments screen. The first row maps the process variable called name to the data input called in_name. The second row maps the data output called out_mail to the process variable called mail, and so on.
These mappings at runtime will automatically copy the variables content from one context (process and task) to the other automatically for us.
8.4. Task Lifecycle
From the perspective of a process, when a user task node is encountered during the execution, a human task is created. The process will then only leave the user task node when the associated human task has been completed or aborted.
The human task itself usually has a complete life cycle itself as well. For details beyond what is described below, please check out the WS-HumanTask specification. The following diagram is from the WS-HumanTask specification and describes the human task life cycle.
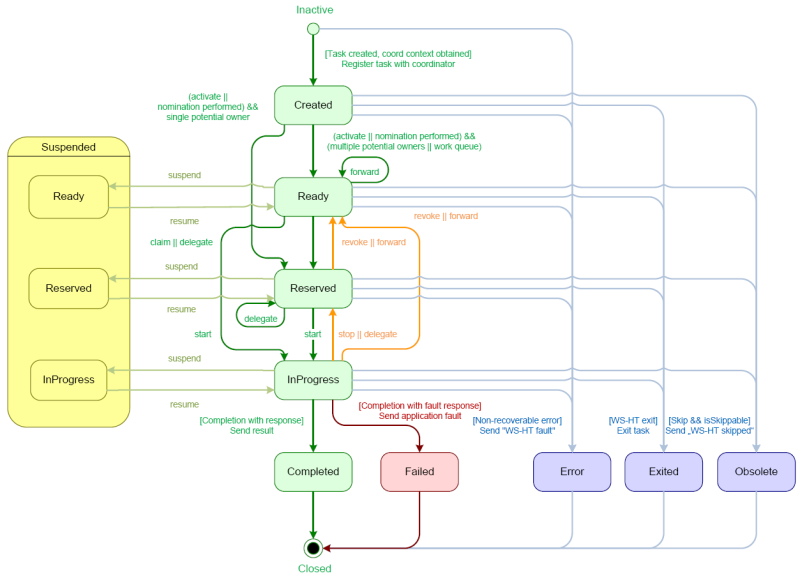
A newly created task starts in the "Created" stage. Usually, it will then automatically become "Ready", after which the task will show up on the task list of all the actors that are allowed to execute the task. The task will stay "Ready" until one of these actors claims the task, indicating that he or she will be executing it.
When a user then eventually claims the task, the status will change to "Reserved". Note that a task that only has one potential (specific) actor will automatically be assigned to that actor upon creation of the task. When the user who has claimed the task starts executing it, the task status will change from "Reserved" to "InProgress".
Lastly, once the user has performed and completed the task, the task status will change to "Completed". In this step, the user can optionally specify the result data related to the task. If the task could not be completed, the user could also indicate this by using a fault response, possibly including fault data, in which case the status would change to "Failed".
While the life cycle explained above is the normal life cycle, the specification also describes a number of other life cycle methods, including:
-
Delegating or forwarding a task, so that the task is assigned to another actor
-
Revoking a task, so that it is no longer claimed by one specific actor but is (re)available to all actors allowed to take it
-
Temporarly suspending and resuming a task
-
Stopping a task in progress
-
Skipping a task (if the task has been marked as skippable), in which case the task will not be executed
8.5. Task Permissions
Only users associated with a specific task are allowed to modify or retrieve information about the task. This allows users to create a jBPM workflow with multiple tasks and yet still be assured of both the confidentiality and integrity of the task status and information associated with a task.
Some task operations will end up throwing a org.jbpm.services.task.exception.PermissionDeniedException when used with information about an unauthorized user.
For example, when a user is trying to directly modify the task (for example, by trying to claim or complete the task), the PermissionDeniedException will be thrown if that user does not have the correct role for that operation.
Furthermore, a user will not be able to view or retrieve tasks that the user is not involved with, especially if this is via the jBPM Console or KIE Workbench applications.
User 'Administrator' and group 'Administrators' are automatically added to each Human Task.
8.5.1. Task Permissions Matrix
The permisions matrix below summarizes the actions that specific user roles are allowed to do. On the left side, possible operations are listed while user roles are listed across the top of the matrix.
The cells of the permissions matrix contain one of three possible characters, each of which indicate the user role permissions for that operation:
-
a "
+indicates that the user role CAN do the specified operation -
a “-” indicates that the user role MAY NOT do the specified operation
-
a “0” indicates that the user role MAY NOT do the specified operation, and that it is also not an operation that matches the user’s role ("not applicable")
Furthermore, the following words or abbreviations in the table header refer to the following roles:
| Word | Role | Description |
|---|---|---|
Initiator |
Task Initiator |
The user who creates the task instance |
Stakeholder |
Task Stakeholder |
The user involved in the task: this user can influence the progress of a task, by performing administrative actions on the task instance |
Potential |
Potential Owner |
The user who can claim the task before it has been claimed, or after it has been released or forward: only tasks that have the status "Ready" may be claimed; a potential owner becomes the actual owner of a task by claiming the task |
Actual |
Actual Owner |
The user who has claimed the task and will progress the task to completion or failure |
Administrator |
Business Adminstrator |
A "super user" who may modify the status or progress of a task at any point in a task’s lifecycle |
User roles are assigned to users by the definition of the task in the jBPM (BPMN2) process definition.
The following matrix describes the authorizations for all operations which modify a task:
| Operation Role | Initiator | Stakeholder | Potential | Actual | Administrator |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The matrix below describes the authorizations used when retrieving task information. In short, it says that all users which have any role with regards to the specific task, are allowed to see the task. This applies to all operations that are used to retrieve any type of information about the task.
| Operation Role | Initiator | Stakeholder | Potential | Actual | Administrator |
|---|---|---|---|---|---|
get |
|
|
|
|
|
8.6. Task Service and The Process Engine
As far as the jBPM engine is concerned, human tasks are similar to any other external service that needs to be invoked and are implemented as a domain-specific service. (For more on domain-specific services, see the chapter on them here.) Because a human task is an example of such a domain-specific service, the process itself only contains a high-level, abstract description of the human task to be executed and a work item handler that is responsible for binding this (abstract) task to a specific implementation.
Users can plug in any human task service implementation, such as the one that’s provided by jBPM, or they may register their own implementation. In the next paragraphs, we will describe the human task service implementation provided by jBPM.
The jBPM project provides a default implementation of a human task service based on the WS-HumanTask specification. If you do not need to integrate jBPM with another existing implementation of a human task service, you can use this service. The jBPM implementation manages the life cycle of the tasks (creation, claiming, completion, etc.) and stores the state of all the tasks, task lists, and other associated information. It also supports features like internationalization, calendar integration, different types of assignments, delegation, escalation and deadlines. The code for the implementation itself can be found in the jbpm-human-task module.
The jBPM task service implementation is based on the WS-HumanTask (WS-HT) specification. This specification defines (in detail) the model of the tasks, the life cycle, and many other features. It is very comprehensive and the first version can be found here.
8.7. Task Service API
The human task service exposes a Java API for managing the life cycle of tasks. This allows clients to integrate (at a low level) with the human task service. Note that end users should probably not interact with this low-level API directly, but use one of the more user-friendly task clients (see below) instead. These clients offer a graphical user interface to request task lists, claim and complete tasks, and manage tasks in general. The task clients listed below use the Java API to internally interact with the human task service. Of course, the low-level API is also available so that developers can use it in their code to interact with the human task service directly.
A task service (interface org.kie.api.task.TaskService) offers the following methods (among others) for managing the life cycle of human tasks:
...
void start( long taskId, String userId );
void stop( long taskId, String userId );
void release( long taskId, String userId );
void suspend( long taskId, String userId );
void resume( long taskId, String userId );
void skip( long taskId, String userId );
void delegate(long taskId, String userId, String targetUserId);
void complete( long taskId, String userId, Map<String, Object> results );
...If you take a look at the method signatures you will notice that almost all of these methods take the following arguments:
-
taskId: The id of the task that we are working with. This is usually extracted from the currently selected task in the user task list in the user interface.
-
userId: The id of the user that is executing the action. This is usually the id of the user that is logged in into the application.
There is also an internal interface that you should check for more methods to interact with the Task Service, this interface is internal until it gets tested. Future version of the External (public) interface can include some of the methods proposed in the InternalTaskService interface. If you want to make use of the methods provided by this interface you need to manually cast to InternalTaskService. One method that can be useful from this interface is getTaskContent():
Map<String, Object> getTaskContent( long taskId );This method saves you from doing all the boiler plate of getting the ContentMarshallerContext to unmarshall the serialized version of the task content. If you only want to use the stable/public API’s you can just copy what this method does:
Task taskById = taskQueryService.getTaskInstanceById(taskId);
Content contentById = taskContentService.getContentById(taskById.getTaskData().getDocumentContentId());
ContentMarshallerContext context = getMarshallerContext(taskById);
Object unmarshalledObject = ContentMarshallerHelper.unmarshall(contentById.getContent(), context.getEnvironment(), context.getClassloader());
if (!(unmarshalledObject instanceof Map)) {
throw new IllegalStateException(" The Task Content Needs to be a Map in order to use this method and it was: "+unmarshalledObject.getClass());
}
Map<String, Object> content = (Map<String, Object>) unmarshalledObject;
return content;Because the content of the Task can be any Object, the previous method assume that you are storing a Map of objects to work. If you are storing other than a Map you should do the correspondent checks.
8.7.1. Task event listener
Task service supports task listeners to be invoked upon various life cycle events happening on given task instance. In majority of cases task event listeners are used to intercept certain operation to perform additional logic - like storing task information in separate tables for business activity monitoring needs.
Task event listeners are pluggable and users can provide their own implementation of org.kie.api.task.TaskLifeCycleEventListener interface. There are beforeTask* and afterTask* methods that are invoked upon given event occured on a task instance.
TaskEvent (org.kie.api.task.TaskEvent) is the only argument available to the listener that provides access to:
-
Task instance that the event correspond to
-
TaskContext that provides access to services for further processing needs such as TaskPersistenceContext
In many cases implementors of task event listener need to have access to task variables (either input or output or both) to perform required operations. It can be done as described above (using various services and content marshaller helper) though that in many cases leads to code duplication in multiple listeners thus an extended support was added in 6.5 to simply use TaskContext to obtain that information.
loadTaskVariables(Task task);Method loadTaskVariables can be used to populate both input and output variables of a given task by simple and single method call. That method is "no op" in case task variables are already set on a task.
To improve performance task variables are automatically set when they are available - usually given by caller on task service:
-
when task is created it usually has input variables, these variables are then set on Task instance so there is no need to use loadTaskVariables method as only task input variables are available when task is being created - applies to beforeTaskAdded and afterTaskAdded events handling
-
when task is completed it usually has output variables, these variables are set on a task so there is no need to use loadTaskVariables method if only task output variables are required.
Other than that loadTaskVariables should be used to populate task variables.
| It’s enough to call it once (like in beforeTask) method of the listener as they will be available to both beforeTask* and afterTask* methods then. |
8.7.2. Data model of task service
Below is the data base model used by task service with all tables and their relationship illustrated.
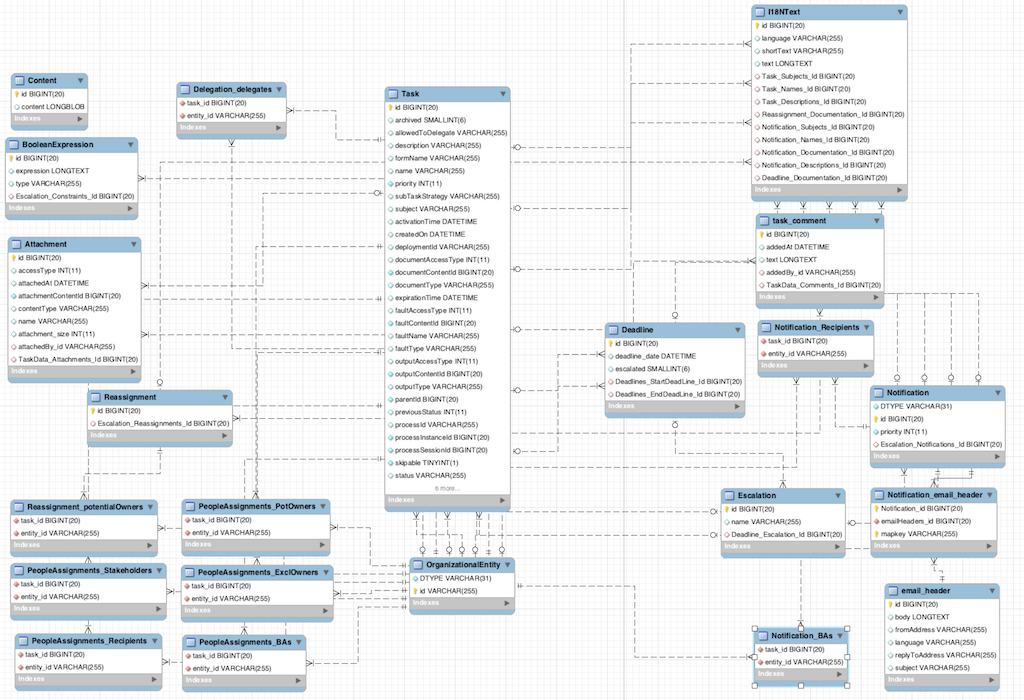
8.8. Interacting with the Task Service
In order to get access to the Task Service API it is recommended to let the Runtime Manager to make sure that everything is setup correctly. Look at the Runtime Manager section for more information. From the API perspective you should be doing something like this:
// ...
RuntimeEngine engine = runtimeManager.getRuntimeEngine(EmptyContext.get());
KieSession kieSession = engine.getKieSession();
// Start a process
kieSession.startProcess("CustomersRelationship.customers", params);
// Do Task Operations
TaskService taskService = engine.getTaskService();
List<TaskSummary> tasksAssignedAsPotentialOwner = taskService.getTasksAssignedAsPotentialOwner("mary", "en-UK");
// Claim Task
taskService.claim(taskSummary.getId(), "mary");
// Start Task
taskService.start(taskSummary.getId(), "mary");
// ...If you use this approach, there is no need to register the Task Service with the Process Engine. The Runtime Manager will do that for you automatically. If you don’t use the Runtime Manager, you will be responsible for setting the LocalHTWorkItemHandler in the session in order to get the Task Service notifying the Process Engine when a task is completed, or the Process Engine notifying that a task has been created.
In jBPM 6.x the Task Service runs locally to the Process and Rule Engine and for that reason multiple light clients can be created for different Process and Rule Engine’s instances. All the clients will be sharing the same database (backend storage for the tasks).
8.9. Experimental features
8.9.1. SubTasks
The "Subtasks" feature is an experimental feature in the task service. This feature allows one task to have sub-tasks in a parent-child relationship. The parent task can auto-complete depending on the state of its children (and the subtask strategy used).
You can use it by setting the parentId of a task, either when creating the task manually via the
task service or otherwise by setting the ParentId parameter of the task definition in the BPMN2
process definition.
9. Persistence and Transactions
9.1. Process Instance State
jBPM allows the persistent storage of certain information. This chapter describes these different types of persistence and how to configure them. An example of the information stored is the process runtime state. Storing the process runtime state is necessary in order to be able to continue execution of a process instance at any point, if something goes wrong. Also, the process definitions themselves, and the history information (logs of current and previous process states) can also be persisted.
9.1.1. Runtime State
Whenever a process is started, a process instance is created, which represents the execution of the process in that specific context. For example, when executing a process that specifies how to process a sales order, one process instance is created for each sales request. The process instance represents the current execution state in that specific context, and contains all the information related to that process instance. Note that it only contains the (minimal) runtime state that is needed to continue the execution of that process instance at some later time, but it does not include information about the history of that process instance if that information is no longer needed in the process instance.
The runtime state of an executing process can be made persistent, for example, in a database. This allows to restore the state of execution of all running processes in case of unexpected failure, or to temporarily remove running instances from memory and restore them at some later time. jBPM allows you to plug in different persistence strategies. By default, if you do not configure the process engine otherwise, process instances are not made persistent.
If you configure the engine to use persistence, it will automatically store the runtime state into the database. You do not have to trigger persistence yourself, the engine will take care of this when persistence is enabled. Whenever you invoke the engine, it will make sure that any changes are stored at the end of that invocation, at so-called safe points. Whenever something goes wrong and you restore the engine from the database, you also should not reload the process instances and trigger them manually to resume execution, as process instances will automatically resume execution if they are triggered, like for example by a timer expiring, the completion of a task that was requested by that process instance, or a signal being sent to the process instance. The engine will automatically reload process instances on demand.
The runtime persistence data should in general be considered internal, meaning that you probably should not try to access these database tables directly and especially not try to modify these directly (as changing the runtime state of process instances without the engine knowing might have unexpected side-effects). In most cases where information about the current execution state of process instances is required, the use of a history log is mostly recommended (see below). In some cases, it might still be useful to for example query the internal database tables directly, but you should only do this if you know what you are doing.
9.1.1.1. Binary Persistence
jBPM uses a binary persistence mechanism, otherwise known as marshalling, which converts the state of the process instance into a binary dataset. When you use persistence with jBPM, this mechanism is used to save or retrieve the process instance state from the database. The same mechanism is also applied to the session state and any work item states.
When the process instance state is persisted, two things happen:
-
First, the process instance information is transformed into a binary blob. For performance reasons, a custom serialization mechanism is used and not normal Java serialization.
-
This blob is then stored, alongside other metadata about this process instance. This metadata includes, among other things, the process instance id, process id, and the process start date.
Apart from the process instance state, the session itself can also store some state, such as the state of timer jobs, or the session data that any business rules would be evaluated over.
This session state is stored separately as a binary blob, along with the id of the session and some metadata.
You can always restore session state by reloading the session with the given id.
The session id can be retrieved using ksession.getId().
Note that the process instance binary datasets are usually relatively small, as they only contain the minimal execution state of the process instance. For a simple process instance, this usually contains one or a few node instances, i.e., any node that is currently executing, and any existing variable values.
As a result of jBPM using marshalling, the data model is both simple and small.

The sessioninfo entity contains the state of the (knowledge) session in which the jBPM process instance is running.
| Field | Description | Nullable |
|---|---|---|
|
The primary key. |
NOT NULL |
|
The last time that the entity was saved to the database |
|
|
The binary dataset containing the state of the session |
NOT NULL |
|
The start time of the session |
|
|
The version field that serves as its optimistic lock value |
The processinstanceinfo entity contains the state of the jBPM process instance.
| Field | Description | Nullable |
|---|---|---|
|
The primary key |
NOT NULL |
|
The last time that the entity was saved to the database |
|
|
The last time that the entity was retrieved (read) from the database |
|
|
The name (id) of the process |
|
|
This is the binary dataset containing the state of the process instance |
NOT NULL |
|
The start time of the process |
|
|
An integer representing the state of the process instance |
NOT NULL |
|
The version field that serves as its optimistic lock value |
The eventtypes entity contains information about events that a process instance will undergo or has undergone.
| Field | Description | Nullable |
|---|---|---|
|
This references the |
NOT NULL |
|
A text field related to an event that the process has undergone. |
The workiteminfo entity contains the state of a work item.
| Field | Description | Nullable |
|---|---|---|
|
The primary key |
NOT NULL |
|
The creation date of the work item |
|
|
The name of the work item |
|
|
The (primary key) id of the process: there is no foreign key constraint on this field. |
NOT NULL |
|
An integer representing the state of the work item |
NOT NULL |
|
The version field that serves as its optimistic lock value |
|
|
This is the binary dataset containing the state of the work item |
NOT NULL |
The CorrelationKeyInfo entity contains information about correlation keys assigned to given process instance - loose relationship as this table is considered optional used only when correlation capabilities are required.
| Field | Description | Nullable |
|---|---|---|
|
The primary key |
NOT NULL |
|
assigned name of the correlation key |
|
|
The id of the process instance which is assigned to this correlation key |
NOT NULL |
|
The version field that serves as its optimistic lock value |
The CorrelationPropertyInfo entity contains information about correlation properties for given correlation key that is assigned to given process instance.
| Field | Description | Nullable |
|---|---|---|
|
The primary key |
NOT NULL |
|
The name of the property |
|
|
The value of the property |
NOT NULL |
|
The version field that serves as its optimistic lock value |
|
|
Foregin key to map to correlation key |
NOT NULL |
The ContextMappingInfo entity contains information about contextual information mapped to ksession.
This is an internal part of RuntimeManager and can be considered optional when RuntimeManager is not used.
| Field | Description | Nullable |
|---|---|---|
|
The primary key |
NOT NULL |
|
Identifier of the context |
NOT NULL |
|
Identifier of the ksession mapped to this context |
NOT NULL |
|
The version field that serves as its optimistic lock value |
9.1.1.2. Safe Points
The state of a process instance is stored at so-called "safe points" during the execution of the process engine. Whenever a process instance is executing (for example when it started or continuing from a previous wait state, the engine executes the process instance until no more actions can be performed (meaning that the process instance either has completed (or was aborted), or that it has reached a wait state in all of its parallel paths). At that point, the engine has reached the next safe state, and the state of the process instance (and all other process instances that might have been affected) is stored persistently.
9.2. Audit Log
In many cases it will be useful (if not necessary) to store information about the execution of process instances, so that this information can be used afterwards. For example, sometimes we want to verify which actions have been executed for a particular process instance, or in general, we want to be able to monitor and analyze the efficiency of a particular process.
However, storing history information in the runtime database can result in the database rapidly increasing in size, not to mention the fact that monitoring and analysis queries might influence the performance of your runtime engine. This is why process execution history information can be stored separately.
This history log of execution information is created based on events that the process engine generates during execution. This is possible because the jBPM runtime engine provides a generic mechanism to listen to events. The necessary information can easily be extracted from these events and then persisted to a database. Filters can also be used to limit the scope of the logged information.
9.2.1. The jBPM Audit data model
The jbpm-audit module contains an event listener that stores process-related information in a database using JPA. The data model itself contains three entities, one for process instance information, one for node instance information, and one for (process) variable instance information.
The ProcessInstanceLog table contains the basic log information about a process instance.
| Field | Description | Nullable |
|---|---|---|
|
The primary key and id of the log entity |
NOT NULL |
|
Actual duration of this process instance since its start date |
|
|
When applicable, the end date of the process instance |
|
|
Optional external identifier used to correlate to some elements - e.g. deployment id |
|
|
Optional identifier of the user who started the process instance |
|
|
The outcome of the process instance, for instance error code in case of process instance was finished with error event |
|
|
The process instance id of the parent process instance if any |
|
|
The id of the process |
|
|
The process instance id |
NOT NULL |
|
The name of the process |
|
|
The version of the process |
|
|
The start date of the process instance |
|
|
The status of process instance that maps to process instance state |
The NodeInstanceLog table contains more information about which nodes were actually executed inside each process instance.
Whenever a node instance is entered from one of its incoming connections or is exited through one of its outgoing connections, that information is stored in this table.
| Field | Description | Nullable |
|---|---|---|
|
The primary key and id of the log entity |
NOT NULL |
|
Actual identifier of the sequence flow that led to this node instance |
|
|
The date of the event |
|
|
Optional external identifier used to correlate to some elements - e.g. deployment id |
|
|
The node id of the corresponding node in the process definition |
|
|
The node instance id |
|
|
The name of the node |
|
|
The type of the node |
|
|
The id of the process that the process instance is executing |
|
|
The process instance id |
NOT NULL |
|
The type of the event (0 = enter, 1 = exit) |
NOT NULL |
|
Optional - only for certain node types - The identifier of work item |
The VariableInstanceLog table contains information about changes in variable instances.
The default is to only generate log entries when (after) a variable changes.
It’s also possible to log entries before the variable (value) changes.
| Field | Description | Nullable |
|---|---|---|
|
The primary key and id of the log entity |
NOT NULL |
|
Optional external identifier used to correlate to some elements - e.g. deployment id |
|
|
The date of the event |
|
|
The id of the process that the process instance is executing |
|
|
The process instance id |
NOT NULL |
|
The previous value of the variable at the time that the log is made |
|
|
The value of the variable at the time that the log is made |
|
|
The variable id in the process definition |
|
|
The id of the variable instance |
The AuditTaskImpl table contains information about tasks that can be used for queries.
| Field | Description | Nullable |
|---|---|---|
|
The primary key and id of the task log entity |
|
|
Time when this task was activated |
|
|
Actual owner assigned to this task - only set when task is claimed |
|
|
User who created this task |
|
|
Date when task was created |
|
|
Deployment id this task is part of |
|
|
Description of the task |
|
|
Due date set on this task |
|
|
Name of the task |
|
|
Parent task id |
|
|
Priority of the task |
|
|
Process definition id that this task belongs to |
|
|
Process instance id that this task is associated with |
|
|
KieSession id used to create this task |
|
|
Current status of the task |
|
|
Identifier of task |
|
|
Identifier of work item assigned on process side to this task id |
The BAMTaskSummary table that collects information about tasks that is used by BAM engine to build charts and dashboards.
| Field | Description | Nullable |
|---|---|---|
|
The primary key and id of the log entity |
NOT NULL |
|
Date when task was created |
|
|
Duration since task was created |
|
|
Date when task reached end state (complete, exit, fail, skip) |
|
|
The process instance id |
|
|
Date when task was started |
|
|
Current status of the task |
|
|
Identifier of the task |
|
|
Name of the task |
|
|
User id assigned to the task |
The TaskVariableImpl table contains information about task variable instances.
| Field | Description | Nullable |
|---|---|---|
|
The primary key and id of the log entity |
NOT NULL |
|
Date when the variable was modified last time |
|
|
Name of the task |
|
|
The id of the process that the process instance is executing |
|
|
The process instance id |
|
|
Identifier of the task |
|
|
Type of the variable - either input or output of the task |
|
|
Variable value |
The TaskEvent table contains information about changes in task instances.
Operations such as claim, start, stop etc are stored here to provide time line view of events that happened to given task.
| Field | Description | Nullable |
|---|---|---|
|
The primary key and id of the log entity |
NOT NULL |
|
LDate when this event was saved |
|
|
Log event message |
|
|
The process instance id |
|
|
Identifier of the task |
|
|
Type of the event - corresponds to life cycle phases of the task |
|
|
User id assigned to the task |
9.2.2. Storing Process Events in a Database
To log process history information in a database like this, you need to register the logger on your session like this:
KieSession ksession = ...;
AbstractAuditLogger auditLogger = AuditLoggerFactory.newInstance(Type.JPA, ksession, null);
ksession.addProcessEventListener(auditLogger);
// invoke methods one your session hereTo specify the database where the information should be stored, modify the file persistence.xml file to include the audit log classes as well (ProcessInstanceLog, NodeInstanceLog and VariableInstanceLog), as shown below.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<persistence
version="2.0"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd
http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_2_0.xsd"
xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:orm="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<persistence-unit name="org.jbpm.persistence.jpa" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/jbpm-ds</jta-data-source>
<mapping-file>META-INF/JBPMorm.xml</mapping-file>
<class>org.drools.persistence.info.SessionInfo</class>
<class>org.jbpm.persistence.processinstance.ProcessInstanceInfo</class>
<class>org.drools.persistence.info.WorkItemInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationKeyInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationPropertyInfo</class>
<class>org.jbpm.runtime.manager.impl.jpa.ContextMappingInfo</class>
<class>org.jbpm.process.audit.ProcessInstanceLog</class>
<class>org.jbpm.process.audit.NodeInstanceLog</class>
<class>org.jbpm.process.audit.VariableInstanceLog</class>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.max_fetch_depth" value="3"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.transaction.jta.platform"
value="org.hibernate.service.jta.platform.internal.BitronixJtaPlatform"/>
</properties>
</persistence-unit>
</persistence>All this information can easily be queried and used in a lot of different use cases, ranging from creating a history log for one specific process instance to analyzing the performance of all instances of a specific process.
This audit log should only be considered a default implementation. We don’t know what information you need to store for analysis afterwards, and for performance reasons it is recommended to only store the relevant data. Depending on your use cases, you might define your own data model for storing the information you need, and use the process event listeners to extract that information.
9.2.3. Storing Process Events in a JMS queue for further processing
Process events are stored in the database synchronously and within the same transaction as actual process instance execution. That obviously takes some time especially in highly loaded systems and might have some impact on the database when both history log and runtime data are kept in the same database. To provide an alternative option for storing process events, a JMS based logger has been provided. It can be configured to submit messages to JMS queue instead of directly persisting them in the database. It can be configured to be transactional as well to avoid issues with inconsistent data in case of process engine transaction is rolled back.
ConnectionFactory factory = ...;
Queue queue = ...;
StatefulKnowledgeSession ksession = ...;
Map<String, Object> jmsProps = new HashMap<String, Object>();
jmsProps.put("jbpm.audit.jms.transacted", true);
jmsProps.put("jbpm.audit.jms.connection.factory", factory);
jmsProps.put("jbpm.audit.jms.queue", queue);
AbstractAuditLogger auditLogger = AuditLoggerFactory.newInstance(Type.JMS, ksession, jmsProps);
ksession.addProcessEventListener(auditLogger);
// invoke methods one your session hereThis is just one of possible ways to configure JMS audit logger, see javadocs for AuditLoggerFactory for more details.
9.2.4. Variables auditing
Process and task variables are stored in audit tables by default although there are stored in simplest possible way - by creating string representation of the variable - variable.toString(). In many cases this is enough as even for custom classes used as variables users can implement custom toString() method that produces expected "view" of the variable.
Though this might not cover all needs, especially when there is a need for efficient queries by variables (both task and process). Let’s take as an example a Person object that has following structure:
public class Person implements Serializable {
private static final long serialVersionUID = -5172443495317321032L;
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
}while at first look this seems to be sufficient as the toString() methods provide human readable format it does not make it easy to be searched by. As searching through strings like "Person [name="john", age="34"] to find people with age 34 would make data base query very inefficient.
To solve the problem variable audit has been based on VariableIndexers that are responsible for extracting relevant parts of the variable that will be stored in audit log.
/**
* Variable indexer that allows to transform variable instance into other representation (usually string)
* to be able to use it for queries.
*
* @param <V> type of the object that will represent indexed variable
*/
public interface VariableIndexer<V> {
/**
* Tests if given variable shall be indexed by this indexer
*
* NOTE: only one indexer can be used for given variable
*
* @param variable variable to be indexed
* @return true if variable should be indexed with this indexer
*/
boolean accept(Object variable);
/**
* Performs index/transform operation of the variable. Result of this operation can be
* either single value or list of values to support complex type separation.
* For example when variable is of type Person that has name, address phone indexer could
* build three entries out of it to represent individual fields:
* person = person.name
* address = person.address.street
* phone = person.phone
* that will allow more advanced queries to be used to find relevant entries.
* @param name name of the variable
* @param variable actual variable value
* @return
*/
List<V> index(String name, Object variable);
}By default (indexer that takes the toString()) will produce single audit entry for single
variable, so it’s one to one relationship. But that’s not the only option: indexers (as can be
seen in the interface) returns list of objects that are the outcome of single variable indexation.
To make our person queries more efficient we could build custom indexer that would take Person
instance and index it into separate audit entries one representing name and the other representing
age.
public class PersonTaskVariablesIndexer implements TaskVariableIndexer {
@Override
public boolean accept(Object variable) {
if (variable instanceof Person) {
return true;
}
return false;
}
@Override
public List<TaskVariable> index(String name, Object variable) {
Person person = (Person) variable;
List<TaskVariable> indexed = new ArrayList<TaskVariable>();
TaskVariableImpl personNameVar = new TaskVariableImpl();
personNameVar.setName("person.name");
personNameVar.setValue(person.getName());
indexed.add(personNameVar);
TaskVariableImpl personAgeVar = new TaskVariableImpl();
personAgeVar.setName("person.age");
personAgeVar.setValue(person.getAge()+"");
indexed.add(personAgeVar);
return indexed;
}
}That indexer will then be used to index Person class only and rest of variables will be indexed with default (toString()) indexer. Now when we want to find process instances or tasks that have person with age 34 we simple refer to it as
-
variable name: person.age
-
variable value: 34
There is not even need to use like based queries so data base can optimize the query and make it efficient even with big set of data.
Building and registering custom indexers
Indexers are supported for both process and task variables. though they are supported by different interfaces as they do produce different type of objects representing audit view of the variable. Following are the interfaces to be implemented to build custom indexers:
-
process variables:
org.kie.internal.process.ProcessVariableIndexer -
task variables:
org.kie.internal.task.api.TaskVariableIndexer
Implementation is rather simple, just two methods to be implemented
-
accept - indicates what types are handled by given indexer. Note that only one indexer can index given variable, so the first that accepts it will perform the work
-
index - actually does the work to index variables depending on custom requirements
Once the implementation is done, it should be packaged as jar file and following file needs to be included:
-
for process variables:
META-INF/services/org.kie.internal.process.ProcessVariableIndexerwith list of FQCN that represent the process variable indexers (single class name per line in that file) -
for task variables:
META-INF/services/org.kie.internal.task.api.TaskVariableIndexerwith list of FQCN that represent the task variable indexers (single class name per line in that file)
Indexers are discovered by ServiceLoader mechanism and thus the META-INF/services files need. All found indexers will be examined whenever process or task variable is about to be indexed.
Only the default (toString() based) indexer is not discovered but added explicitly as last
indexer to allow custom ones to take the precedence over it.
9.3. Transactions
The jBPM engine supports JTA transactions. It also supports local transactions only when using Spring. It does not support pure local transactions at the moment. For more information about using Spring to set up persistence, please see the Spring chapter in the Drools integration guide.
Whenever you do not provide transaction boundaries inside your application, the engine will automatically execute each method invocation on the engine in a separate transaction. If this behavior is acceptable, you don’t need to do anything else. You can, however, also specify the transaction boundaries yourself. This allows you, for example, to combine multiple commands into one transaction.
You need to register a transaction manager at the environment before using user-defined transactions. The following sample code uses the Bitronix transaction manager. Next, we use the Java Transaction API (JTA) to specify transaction boundaries, as shown below:
// create the entity manager factory
EntityManagerFactory emf = EntityManagerFactoryManager.get().getOrCreate("org.jbpm.persistence.jpa");
TransactionManager tm = TransactionManagerServices.getTransactionManager();
// setup the runtime environment
RuntimeEnvironment environment = RuntimeEnvironmentBuilder.Factory.get()
.newDefaultBuilder()
.addAsset(ResourceFactory.newClassPathResource("MyProcessDefinition.bpmn2"), ResourceType.BPMN2)
.addEnvironmentEntry(EnvironmentName.TRANSACTION_MANAGER, tm)
.get();
// get the kie session
RuntimeManager manager = RuntimeManagerFactory.Factory.get().newPerRequestRuntimeManager(environment);
RuntimeEngine runtime = manager.getRuntimeEngine(ProcessInstanceIdContext.get());
KieSession ksession = runtime.getKieSession();
// start the transaction
UserTransaction ut = InitialContext.doLookup("java:comp/UserTransaction");
ut.begin();
// perform multiple commands inside one transaction
ksession.insert( new Person( "John Doe" ) );
ksession.startProcess("MyProcess");
// commit the transaction
ut.commit();Note that, if you use Bitronix as the transaction manager, you should also add a simple jndi.properties file in you root classpath to register the Bitronix transaction manager in JNDI. If you are using the jbpm-test module, this is already included by default. If not, create a file named jndi.properties with the following content:
java.naming.factory.initial=bitronix.tm.jndi.BitronixInitialContextFactoryIf you would like to use a different JTA transaction manager, you can change the persistence.xml file to use your own transaction manager. For example, when running inside JBoss Application Server v5.x or v7.x, you can use the JBoss transaction manager. You need to change the transaction manager property in persistence.xml to:
<property name="hibernate.transaction.jta.platform" value="org.hibernate.transaction.JBossTransactionManagerLookup" />|
Using the (runtime manager) Singleton strategy with JTA transactions ( This race conditation can be avoided by explicitly synchronizing around the |
9.3.1. Container managed transactions
Special consideration need to be taken when embedding jBPM inside an application that executes in Container Managed Transaction (CMT) mode, for instance EJB beans. This especially applies to application servers that does not allow accessing UserTransaction instance from JNDI when being part of container managed transaction, e.g. WebSphere Application Server. Since default implementation of transaction manager in jBPM is based on UserTransaction to get transaction status which is used to decide if transaction should be started or not, in environments that prevent accessing UserTrancation it won’t do its job. To secure proper execution in CMT environments a dedicated transaction manager implementation is provided:
org.jbpm.persistence.jta.ContainerManagedTransactionManagerThis transaction manager expects that transaction is active and thus will always return ACTIVE when invoking getStatus method. Operations like begin, commit, rollback are no-op methods as transaction manager runs under managed transaction and can’t affect it.
|
To make sure that container is aware of any exceptions that happened during process instance execution, user needs to ensure that exceptions thrown by the engine are propagated up to the container to properly rollback transaction. |
To configure this transaction manager following must be done:
-
Insert transaction manager and persistence context manager into environment prior to creating/loading session
Environment env = EnvironmentFactory.newEnvironment(); env.set(EnvironmentName.ENTITY_MANAGER_FACTORY, emf); env.set(EnvironmentName.TRANSACTION_MANAGER, new ContainerManagedTransactionManager()); env.set(EnvironmentName.PERSISTENCE_CONTEXT_MANAGER, new JpaProcessPersistenceContextManager(env)); env.set(EnvironmentName.TASK_PERSISTENCE_CONTEXT_MANAGER, new JPATaskPersistenceContextManager(env)); -
configure JPA provider (example hibernate and WebSphere)
<property name="hibernate.transaction.factory_class" value="org.hibernate.transaction.CMTTransactionFactory"/> <property name="hibernate.transaction.jta.platform" value="org.hibernate.service.jta.platform.internal.WebSphereJtaPlatform"/>
With following configuration jBPM should run properly in CMT environment.
9.3.1.1. CMT dispose ksession command
Usually when running within container managed transaction disposing ksession directly will cause exceptions on transaction completion as there are some transaction synchronization registered by jBPM to clean up the state after invocation is finished.
To overcome this problem specialized command has been provided
org.jbpm.persistence.jta.ContainerManagedTransactionDisposeCommand which allows to simply
execute this command instead of regular ksession.dispose which will ensure that ksession will be
disposed at the transaction completion.
9.4. Configuration
By default, the engine does not save runtime data persistently. This means you can use the engine completely without persistence (so not even requiring an in memory database) if necessary, for example for performance reasons, or when you would like to manage persistence yourself. It is, however, possible to configure the engine to do use persistence by configuring it to do so. This usually requires adding the necessary dependencies, configuring a datasource and creating the engine with persistence configured.
9.4.1. Adding dependencies
You need to make sure the necessary dependencies are available in the classpath of your application if you want to user persistence. By default, persistence is based on the Java Persistence API (JPA) and can thus work with several persistence mechanisms. We are using Hibernate by default.
If you’re using the Eclipse IDE and the jBPM Eclipse plugin, you should make sure the necessary JARs are added to your jBPM runtime directory. You don’t really need to do anything (as the necessary dependencies should already be there) if you are using the jBPM runtime that is configured by default when using the jBPM installer, or if you downloaded and unzipped the jBPM runtime artifact (from the downloads) and pointed the jBPM plugin to that directory.
If you would like to manually add the necessary dependencies to your project, first of all, you need the JAR file jbpm-persistence-jpa.jar , as that contains code for saving the runtime state whenever necessary. Next, you also need various other dependencies, depending on the persistence solution and database you are using. For the default combination with Hibernate as the JPA persistence provider and using an H2 in-memory database and Bitronix for JTA-based transaction management, the following list of additional dependencies is needed:
-
jbpm-persistence-jpa (org.jbpm)
-
drools-persistence-jpa (org.drools)
-
persistence-api (javax.persistence)
-
hibernate-entitymanager (org.hibernate)
-
hibernate-annotations (org.hibernate)
-
hibernate-commons-annotations (org.hibernate)
-
hibernate-core (org.hibernate)
-
commons-collections (commons-collections)
-
dom4j (dom4j)
-
jta (javax.transaction)
-
btm (org.codehaus.btm)
-
javassist (javassist)
-
slf4j-api (org.slf4j)
-
slf4j-jdk14 (org.slf4j)
-
h2 (com.h2database)
-
jbpm-test (org.jbpm) for testing only, do not include it in the actual application
9.4.2. Manually configuring the engine to use persistence
You can use the JPAKnowledgeService to create your knowledge session.
This is slightly more complex, but gives you full access to the underlying configurations.
You can create a new knowledge session using JPAKnowledgeService based on a knowledge base, a knowledge session configuration (if necessary) and an environment.
The environment needs to contain a reference to your Entity Manager Factory.
For example:
// create the entity manager factory and register it in the environment
EntityManagerFactory emf =
Persistence.createEntityManagerFactory( "org.jbpm.persistence.jpa" );
Environment env = KnowledgeBaseFactory.newEnvironment();
env.set( EnvironmentName.ENTITY_MANAGER_FACTORY, emf );
// create a new knowledge session that uses JPA to store the runtime state
StatefulKnowledgeSession ksession = JPAKnowledgeService.newStatefulKnowledgeSession( kbase, null, env );
int sessionId = ksession.getId();
// invoke methods on your method here
ksession.startProcess( "MyProcess" );
ksession.dispose();You can also use the JPAKnowledgeService to recreate a session based on a specific session id:
// recreate the session from database using the sessionId
ksession = JPAKnowledgeService.loadStatefulKnowledgeSession(sessionId, kbase, null, env );Note that we only save the minimal state that is needed to continue execution of the process instance at some later point. This means, for example, that it does not contain information about already executed nodes if that information is no longer relevant, or that process instances that have been completed or aborted are removed from the database. If you want to search for history-related information, you should use the history log, as explained later.
You need to add a persistence configuration to your classpath to configure JPA to use Hibernate and the H2 database (or your own preference), called persistence.xml in the META-INF directory, as shown below. For more details on how to change this for your own configuration, we refer to the JPA and Hibernate documentation for more information.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<persistence
version="2.0"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd
http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_2_0.xsd"
xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:orm="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<persistence-unit name="org.jbpm.persistence.jpa" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/jbpm-ds</jta-data-source>
<mapping-file>META-INF/JBPMorm.xml</mapping-file>
<class>org.drools.persistence.info.SessionInfo</class>
<class>org.jbpm.persistence.processinstance.ProcessInstanceInfo</class>
<class>org.drools.persistence.info.WorkItemInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationKeyInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationPropertyInfo</class>
<class>org.jbpm.runtime.manager.impl.jpa.ContextMappingInfo</class>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.max_fetch_depth" value="3"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.transaction.jta.platform"
value="org.hibernate.service.jta.platform.internal.BitronixJtaPlatform"/>
</properties>
</persistence-unit>
</persistence>This configuration file refers to a data source called "jdbc/jbpm-ds". If you run your application in an application server (like for example JBoss AS), these containers typically allow you to easily set up data sources using some configuration (like for example dropping a datasource configuration file in the deploy directory). Please refer to your application server documentation to know how to do this.
For example, if you’re deploying to JBoss Application Server v5.x, you can create a datasource by dropping a configuration file in the deploy directory, for example:
<?xml version="1.0" encoding="UTF-8"?>
<datasources>
<local-tx-datasource>
<jndi-name>jdbc/jbpm-ds</jndi-name>
<connection-url>jdbc:h2:tcp://localhost/~/test</connection-url>
<driver-class>org.h2.jdbcx.JdbcDataSource</driver-class>
<user-name>sa</user-name>
<password></password>
</local-tx-datasource>
</datasources>If you are however executing in a simple Java environment, you can use the JBPMHelper class to do this for you (see below for tests only) or the following code fragment could be used to set up a data source (where we are using the H2 in-memory database in combination with Bitronix in this case).
PoolingDataSource ds = new PoolingDataSource();
ds.setUniqueName("jdbc/jbpm-ds");
ds.setClassName("bitronix.tm.resource.jdbc.lrc.LrcXADataSource");
ds.setMaxPoolSize(3);
ds.setAllowLocalTransactions(true);
ds.getDriverProperties().put("user", "sa");
ds.getDriverProperties().put("password", "sasa");
ds.getDriverProperties().put("URL", "jdbc:h2:mem:jbpm-db");
ds.getDriverProperties().put("driverClassName", "org.h2.Driver");
ds.init();9.4.3. Configuring the engine to use persistence using JBPMHelper - for tests only
You need to configure the jBPM engine to use persistence, usually simply by using the appropriate constructor when creating your session. There are various ways to create a session (as we have tried to make this as easy as possible for you and have several utility classes for you, depending for example if you are trying to write a process JUnit test).
The easiest way to do this is to use the jbpm-test module that allows you to easily create and test your processes.
The JBPMHelper class has a method to create a session, and uses a configuration file to configure this session, like whether you want to use persistence, the datasource to use, etc.
The helper class will then do all the setup and configuration for you.
To configure persistence, create a jBPM.properties file and configure the following properties (note that the example below are the default properties, using an H2 in-memory database with persistence enabled, if you are fine with all of these properties, you don’t need to add new properties file, as it will then use these properties by default):
# for creating a datasource
persistence.datasource.name=jdbc/jbpm-ds
persistence.datasource.user=sa
persistence.datasource.password=
persistence.datasource.url=jdbc:h2:tcp://localhost/~/jbpm-db
persistence.datasource.driverClassName=org.h2.Driver
# for configuring persistence of the session
persistence.enabled=true
persistence.persistenceunit.name=org.jbpm.persistence.jpa
persistence.persistenceunit.dialect=org.hibernate.dialect.H2Dialect
# for configuring the human task service
taskservice.enabled=true
taskservice.datasource.name=org.jbpm.task
taskservice.usergroupcallback=org.jbpm.services.task.identity.JBossUserGroupCallbackImpl
taskservice.usergroupmapping=classpath:/usergroups.propertiesIf you want to use persistence, you must make sure that the datasource (that you specified in the jBPM.properties
file) is initialized correctly.
This means that the database itself must be up and running, and the datasource should be registered using the correct name.
If you would like to use an H2 in-memory database (which is usually very easy to do some testing), you can use the JBPMHelper class to start up this database, using:
JBPMHelper.startH2Server();To register the datasource (this is something you always need to do, even if you’re not using H2 as your database, check below for more options on how to configure your datasource), use:
JBPMHelper.setupDataSource();Next, you can use the JBPMHelper class to create your session (after creating your knowledge base, which is identical to the case when you are not using persistence):
StatefulKnowledgeSession ksession = JBPMHelper.newStatefulKnowledgeSession(kbase);Once you have done that, you can just call methods on this ksession (like startProcess) and the engine will persist all runtime state in the created datasource.
You can also use the JBPMHelper class to recreate your session (by restoring its state from the database, by passing in the session id (that you can retrieve using ksession.getId())):
StatefulKnowledgeSession ksession = JBPMHelper.loadStatefulKnowledgeSession(kbase, sessionId);Workbench
How to use the web-based Workbench
10. Workbench (General)
10.1. Installation
10.1.1. War installation
Use the war from the workbench distribution zip that corresponds to your application server.
The differences between these war files are mainly superficial.
For example, some JARs might be excluded if the application server already supplies them.
-
eap7: tailored for Red Hat JBoss Enterprise Application Platform 7 -
tomcat8: tailored for Apache Tomcat 8Apache Tomcat requires additional configuration to correctly install the Workbench. Please consult the
README.mdin thewarfor the most up to date procedure. -
wildfly11: tailored for Wildfly 11
10.1.2. Workbench data
The workbench stores its data, by default in the directory $WORKING_DIRECTORY/.niogit, for example wildfly-11.0.0.Final/bin/.niogit, but it can be overridden with the system property-Dorg.uberfire.nio.git.dir.
|
In production, make sure to back up the workbench data directory. |
10.1.3. System properties
Here’s a list of all system properties:
-
org.appformer.m2repo.url: Location of the for the default Maven repository the workbench uses when looking for dependencies. Usually this points to the Maven repository inside the Workbench for examplehttp://localhost:8080/kie-wb/maven2. Please set this before starting up the Workbench. Default: File path to the inner m2 repository. -
org.uberfire.nio.git.dir: Location of the directory.niogit. Default: working directory -
org.uberfire.nio.git.dirname: Name of the git directory. Default:.niogit -
org.uberfire.nio.git.daemon.enabled: Enables/disables git daemon. Default:true -
org.uberfire.nio.git.daemon.host: If git daemon enabled, uses this property as local host identifier. Default:localhost -
org.uberfire.nio.git.daemon.port: If git daemon enabled, uses this property as port number. Default:9418 -
org.uberfire.nio.git.ssh.enabled: Enables/disables ssh daemon. Default:true -
org.uberfire.nio.git.ssh.host: If ssh daemon enabled, uses this property as local host identifier. Default:localhost -
org.uberfire.nio.git.ssh.port: If ssh daemon enabled, uses this property as port number. Default:8001 -
org.uberfire.nio.git.ssh.cert.dir: Location of the directory.securitywhere local certificates will be stored. Default: working directory -
org.uberfire.nio.git.ssh.passphrase: Passphrase to access your Operating Systems public keystore when cloninggitrepositories withscpstyle URLs; e.g.git@github.com:user/repository.git. -
org.uberfire.nio.git.ssh.algorithm: Algorithm used by SSH. Default:DSAIf you plan to use RSA or any algorithm other than DSA, make sure you setup properly your Application Server to use Bouncy Castle JCE library.
-
org.uberfire.metadata.index.dir: Place where Lucene.indexfolder will be stored. Default: working directory -
org.uberfire.ldap.regex.role_mapper: Regex pattern used to map LDAP principal names to application role name. Note that the variablerolemust be part of the pattern as it is substited by the application role name when matching a principal value to role name. Default: Not used. -
org.uberfire.sys.repo.monitor.disabled: Disable configuration monitor (do not disable unless you know what you’re doing). Default:false -
org.uberfire.secure.key: Secret password used by password encryption. Default:org.uberfire.admin -
org.uberfire.secure.alg: Crypto algorithm used by password encryption. Default:PBEWithMD5AndDES -
org.uberfire.domain: security-domain name used by uberfire. Default:ApplicationRealm -
org.guvnor.m2repo.dir: Place where Maven repository folder will be stored. Default: working-directory/repositories/kie -
org.guvnor.project.gav.check.disabled: Disable GAV checks. Default:false -
org.kie.demo: Enables external clone of a demo application from GitHub. -
org.kie.build.disable-project-explorer: Disable automatic build of selected Project in Project Explorer. Default:false -
org.kie.verification.disable-dtable-realtime-verification: Disables the realtime validation and verification of decision tables. Default:false -
org.kie.workbench.controller: URL for connecting with a Kie Server Controller, for example:ws://localhost:8080/kie-server-controller/websocket/controller.
Only Web Socket protocol is supported for connecting with a remote Kie Server Controller. When specifying this proporty, the Workbench will automatically disable all the features related to running the embbeded controller.
-
org.kie.workbench.controller.user: User name for connecting with a Kie Server Controller. Default:kieserver -
org.kie.workbench.controller.pwd: Password for connecting with a Kie Server Controller. Default:kieserver1! -
org.kie.workbench.controller.token: Token string for connecting with a Kie Server Controller.
Please refer to Using token based authentication for more details about how to use token based authentication.
-
kie.keystore.keyStoreURL: URL to a keystore which should be used for connecting with a remote Kie Server Controller. -
kie.keystore.keyStorePwd: Password to a keystore. -
kie.keystore.key.ctrl.alias: Alias of the key where password is stored. -
kie.keystore.key.ctrl.pwd: Password of an alias with stored password.
Please refer to Securing password using key store for more details about how to use a key store for securing your passwords.
To change one of these system properties in a WildFly or JBoss EAP cluster:
-
Edit the file
$JBOSS_HOME/domain/configuration/host.xml. -
Locate the XML elements
serverthat belong to themain-server-groupand add a system property, for example:<system-properties> <property name="org.uberfire.nio.git.dir" value="..." boot-time="false"/> ... </system-properties>
10.1.4. Trouble shooting
10.1.4.1. Loading.. does not disappear and Workbench fails to show
There have been reports that Firewalls in between the server and the browser can interfere with Server Sent Events (SSE) used by the Workbench.
The issue results in the "Loading…" spinner remaining visible and the Workbench failing to materialize.
The workaround is to disable the Workbench’s use of Server Sent Events by adding file /WEB-INF/classes/ErraiService.properties to the exploded WAR containing the value errai.bus.enable_sse_support=false.
Re-package the WAR and re-deploy.
Some Users have also reported disabling Server Sent Events does not resolve the issue. The solution found to work is to configure the JVM to use a different Entropy Gathering Device on Linux for SecureRandom. This can be configured by setting System Property java.security.egd to file:/dev/./urandom. See this Stack Overflow post for details.
Please note however this affects the JVM’s random number generation and may present other challenges where strong cryptography is required. Configure with caution.
10.1.4.2. Not able to clone KIE Workbench Git repository using ssh protocol.
Git clients using ssh to interact with the Git server that is bundled with Workbench are authenticated and authorized to perform git commands by the security API that is part of the Uberfire backend server. When using an LDAP security realm, some git clients were not being authorized as expected. This was due to the fact that for non-web clients such as Git via ssh, the principal (i.e., user or group) name assigned to a user by the application server’s user registry is the more complex DN associated to that principal by LDAP. The logic of the Uberfire backend server looked for on exact match of roles allowed with the principal name returned and therefore failed.
It is now possible to control the role-principal matching via the system property
org.uberfire.ldap.regex.role_mapperwhich takes as its value a Regex pattern to be applied when matching LDAP principal to role names. The pattern must contain the literal word variable 'role'. During authorization the variable is replaced by each of the allow application roles. If the pattern is matched the role is added to the user.
For instance, if the DN for the admin group in LDAP is
DN: cn=admin,ou=groups,dc=example,dc=comand its intended role is admin, then setting org.uberfire.ldap.regex.role_mapper with value
cn[\\ ]*=[\\ ]*rolewill find a match on role 'admin'.
10.2. Quick Start
These steps help you get started with minimum of effort.
They should not be a substitute for reading the documentation in full.
10.2.1. Importing examples
If the Workbench is empty you are shown an empty Space page. Clicking "Try Samples" button below will show the examples that are available.
Once "Try Samples" page opens, you can select one or more examples and click "Ok".
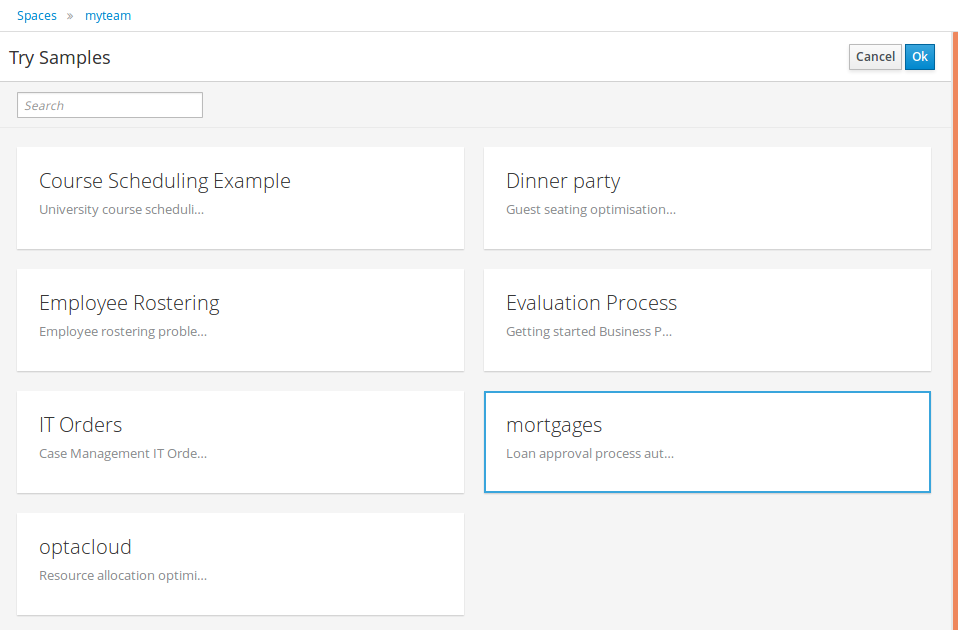
If the Workbench already contains Projects the examples can be imported with the "Try Samples" button found from the menu.
10.2.2. Add Project
Alternatively, to importing an example, a new empty project can be created from the Space page with "Add Project".
Give the Project a name and optional description.
10.2.3. Define Data Model
After a Project has been created you need to define Types to be used by your rules.
Select "Data Object" from the "Create New Asset" menu.
|
You can also use types contained in existing JARs. Please consult the full documentation for details. |
Set the name and select a package for the new type.
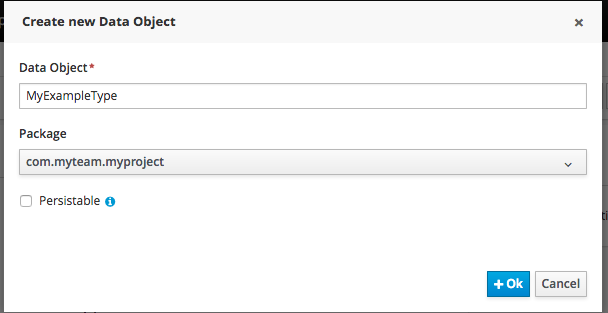
Click "+ add field" button and set a field name and type and click on "Create" to create a field for the type.
Click "Save" to update the model.
10.2.4. Define Rule
Select "DRL file" (for example) from the "Create New Asset" menu.
Enter a file name for the new rule.
|
Make sure you select the same package as the rule had. It is possible to have rules and data models in different packages, but let’s keep things simple for demo purposes. |
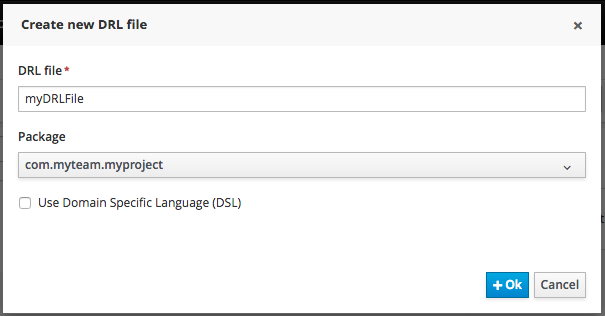
Enter a definition for the rule.
The definition process differs from asset type to asset type.
The full documentation has details about the different editors.
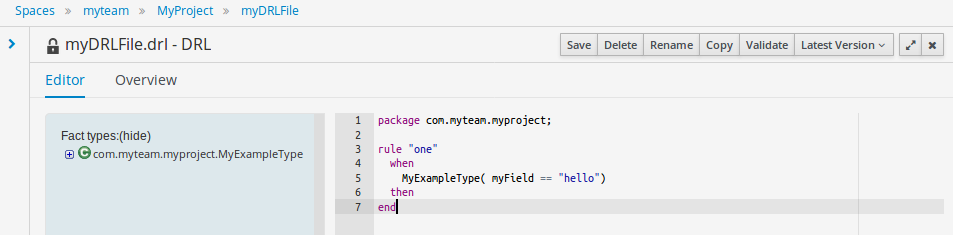
Once the rule has been defined it will need to be saved in the same way we saved the model.
10.2.5. Build and Deploy
Once rules have been defined within a project; the project can be built and deployed to the Workbench’s Maven Artifact Repository.
To build a project select the "Build & Deploy" from the Project Authoring.
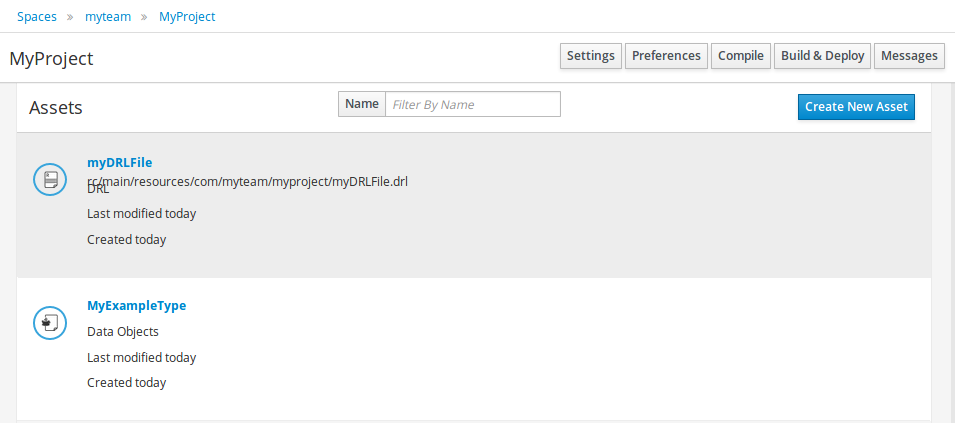
Click "Build & Deploy" to build the project and deploy it to the Workbench’s Maven Artifact Repository.
When you select Build & Deploy the workbench will deploy to any repositories defined in the Dependency Management section of the pom in your workbench project. You can edit the pom.xml file associated with your workbench project under the Repository View of the project explorer. Details on dependency management in maven can be found here : http://maven.apache.org/guides/introduction/introduction-to-dependency-mechanism.html
If there are errors during the build process they will be reported in the "Messages" panel.
Now the project has been built and deployed; it can be referenced from your own projects as any other Maven Artifact.
The full documentation contains details about integrating projects with your own applications.
10.3. Configuration
10.3.1. Basic user management
The workbench authenticates its users against the application server’s authentication and authorization (JAAS).
On JBoss EAP and WildFly, add a user with the script $JBOSS_HOME/bin/add-user.sh (or .bat):
$ ./add-user.sh
// Type: Application User
// Realm: empty (defaults to ApplicationRealm)
// Role: adminThere is no need to restart the application server.
10.3.2. Roles
The Workbench uses the following roles:
-
admin
-
analyst
-
developer
-
manager
-
user
10.3.2.1. Admin
Administrates the BPMS system.
-
Manages users
-
Manages VFS Repositories
-
Has full access to make any changes necessary
10.3.2.2. Developer
Developer can do almost everything admin can do, except clone repositories.
-
Manages rules, models, process flows, forms and dashboards
-
Manages the asset repository
-
Can create, build and deploy projects
-
Can use the JBDS connection to view processes
10.3.2.3. Analyst
Analyst is a weaker version of developer and does not have access to the asset repository or the ability to deploy projects.
10.3.2.4. Business user
Daily user of the system to take actions on business tasks that are required for the processes to continue forward. Works primarily with the task lists.
-
Does process management
-
Handles tasks and dashboards
10.3.2.5. Manager/Viewer-only User
Viewer of the system that is interested in statistics around the business processes and their performance, business indicators, and other reporting of the system and people who interact with the system.
-
Only has access to dashboards
10.4. Introduction
10.4.1. Log in and log out
Create a user with the role admin and log in with those credentials.
After successfully logging in, the account username is displayed at the top right. Click on it to review the roles of the current account.
10.4.2. Home screen
After logging in, the home screen shows. The actual content of the home screen depends on the workbench variant (Drools, jBPM, …).

10.4.3. Workbench overview
A workbench is structured with Spaces and Projects:
10.4.3.1. Space
Spaces are useful to model departments and divisions.
A Space can hold multiple Projects.
10.4.3.2. Project
Projects are the place where assets are stored and each project belongs to a single Space.
Projects are in fact a Virtual File System based storage, that by default uses GIT as backend. Such setup allows workbench to work with multiple backends and, in the same time, take full advantage of backend specifics features like in GIT case versioning, branching and even external access.
A new Project can be created from scratch or cloned from an existing repository.
One of the biggest advantage of using GIT as backend is the ability to clone a repository from external and use your preferred tools to edit and build your assets.
|
Never clone your repositories directly from .niogit directory. |
10.4.4. Workbench user interface concepts
The Workbench is comprised of different logical entities:
-
Part
A Part is a screen or editor with which the user can interact to perform operations.
Example Parts are "Project Explorer", "Project Editor", "Guided Rule Editor" etc.
-
Page
A perspective is a logical grouping of related Panels and Parts. A perspective is usually named as page, since it is a term far more familiar to end users whereas a perspective is more developer oriented. Notice however, the Workbench supports both developer created pages and those created by end users from the page builder (aka Content Management) tooling but, generally speaking, page is used to refer both.
The user can switch between pages by clicking on one of the top-level menu items; such as "Home", "Authoring", "Deploy" etc.
10.5. Changing the layout
10.5.1. Resizing
Move the mouse pointer over the panel splitter (a grey horizontal or vertical line in between panels).
The cursor will by changing indicate it is positioned correctly over the splitter. Press and hold the left mouse button and drag the splitter to the required position; then release the left mouse button.
10.6. Authoring (General)
10.6.1. Artifact Repository
Projects often need external artifacts in their classpath in order to build, for example a domain model JARs. The artifact repository holds those artifacts.
The Artifact Repository is a full blown Maven repository. It follows the semantics of a Maven remote repository: all snapshots are timestamped. But it is often stored on the local hard drive.
By default the artifact repository is stored under $WORKING_DIRECTORY/repositories/kie, but it can be overridden with the system property-Dorg.guvnor.m2repo.dir.
There is only 1 Maven repository per installation.
The Artifact Repository screen shows a list of the artifacts in the Maven repository:

To add a new artifact to that Maven repository, either:
-
Use the upload button and select a JAR. If the JAR contains a POM file under
META-INF/maven(which every JAR build by Maven has), no further information is needed. Otherwise, a groupId, artifactId and version need be given too.
-
Using Maven,
mvn deployto that Maven repository. Refresh the list to make it show up.
|
This remote Maven repository is relatively simple. It does not support proxying, mirroring, … like Nexus or Archiva. |
10.6.2. Asset Editor
The Asset Editor is the principle component of the workbench User-Interface. It consists of two main views Editor and Overview.
-
The views
 Figure 36. The Asset Editor - Editor tab
Figure 36. The Asset Editor - Editor tab-
A : The editing area - exactly what form the editor takes depends on the Asset type. An asset can only be edited by one user at a time to avoid conflicts. When a user begins to edit an asset, a lock will automatically be acquired. This is indicated by a lock symbol appearing on the asset title bar as well as in the project explorer view (see Project Explorer for details). If a user starts editing an already locked asset a pop-up notification will appear to inform the user that the asset can’t currently be edited, as it is being worked on by another user. Changes will be prevented until the editing user saves or closes the asset, or logs out of the workbench. Session timeouts will also cause locks to be released. Every user further has the option to force a lock release, if required (see the Metadata section below).
-
B : This menu bar contains various actions for the Asset; such as Save, Rename, Copy etc. Note that saving, renaming and deleting are deactivated if the asset is locked by a different user.
-
C : Different views for asset content or asset information.
-
Editor shows the main editor for the asset
-
Overview contains the metadata and conversation views for this editor. Explained in more detail below.
-
Source shows the asset in plain DRL. Note: This tab is only visible if the asset content can be generated into DRL.
-
Data Objects contains the model available for authoring. By default only Data Objects that reside within the same package as the asset are available for authoring. Data Objects outside of this package can be imported to become available for authoring the asset.
-
 Figure 37. The Asset Editor - Data Objects tab
Figure 37. The Asset Editor - Data Objects tab -
-
Overview
-
A : General information about the asset and the asset’s description.
"Type:" The format name of the type of Asset.
"Description:" Description for the asset.
"Used in projects:" Names the projects where this rule is used.
"Last Modified:" Who made the last change and when.
"Created on:" Who created the asset and when.
-
B : Version history for the asset. Selecting a version loads the selected version into this editor.
-
C : Meta data (from the "Dublin Core" standard)
-
D : Comments regarding the development of the Asset can be recorded here.
-
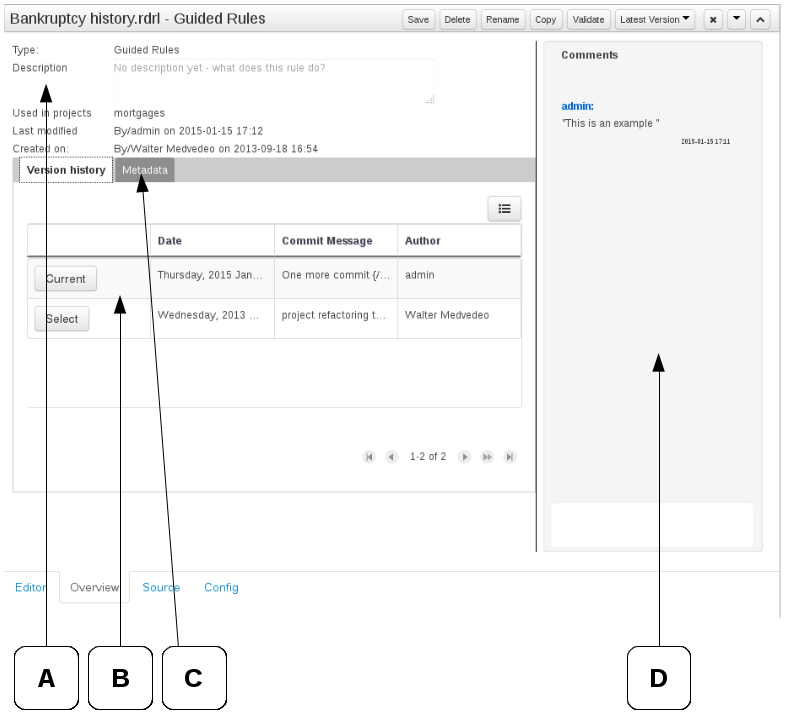
-
Metadata
-
A : Meta data:-
"Tags:" A tagging system for grouping the assets.
"Note:" A comment made when the Asset was last updated (i.e. why a change was made)
"URI:" URI to the asset inside the Git repository.
"Subject/Type/External link/Source" : Other miscellaneous meta data for the Asset.
"Lock status" : Shows the lock status of the asset and, if locked, allows to force unlocking the asset.
-
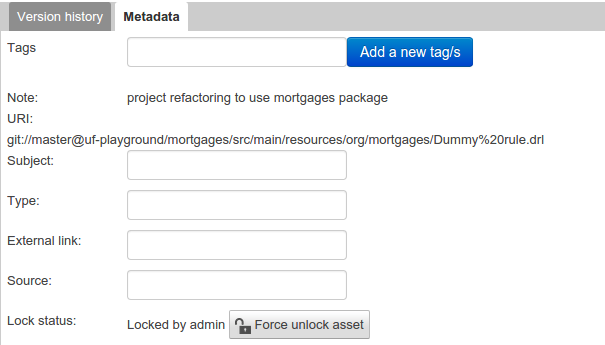
-
Locking
The Workbench supports pessimistic locking of assets. When one User starts editing an asset it is locked to change by other Users. The lock is held until a period of inactivity lapses, the Editor is closed or the application stopped and restarted. Locks can also be forcibly removed on the MetaData section of the Overview tab.
A "padlock" icon is shown in the Editor’s title bar and beside the asset in the Project Explorer when an asset is locked.
 Figure 40. The Asset Editor - Locked assets cannot be edited by other users
Figure 40. The Asset Editor - Locked assets cannot be edited by other users
10.6.3. Tags Editor
Tags allow assets to be labelled with any number of tags that you define. These tags can be used to filter assets on the Project Explorer enabling "Tag filtering".
10.6.3.1. Creating Tags
To create tags you simply have to write them on the Tags input and press the "Add new Tag/s" button. The Tag Editor allows creating tags one by one or writing more than one separated with a white space.

Once you created new Tags they will appear over the Editor allowing you to remove them by pressing on them if you want.

10.6.4. Project Explorer
The Project Explorer provides the ability to browse files inside the current Project. The Project Explorer can be accessed from the left side when an Asset Editor is open.
10.6.4.1. Initial view
If a file is currently being edited by another user, a lock symbol will be displayed in front of the file name. The symbol is blue in case the lock is owned by the currently authenticated user, otherwise black. Moving the mouse pointer over the lock symbol will display a tooltip providing the name of the user who is currently editing the file (and therefore owning the lock). To learn more about locking see Asset Editor for details.
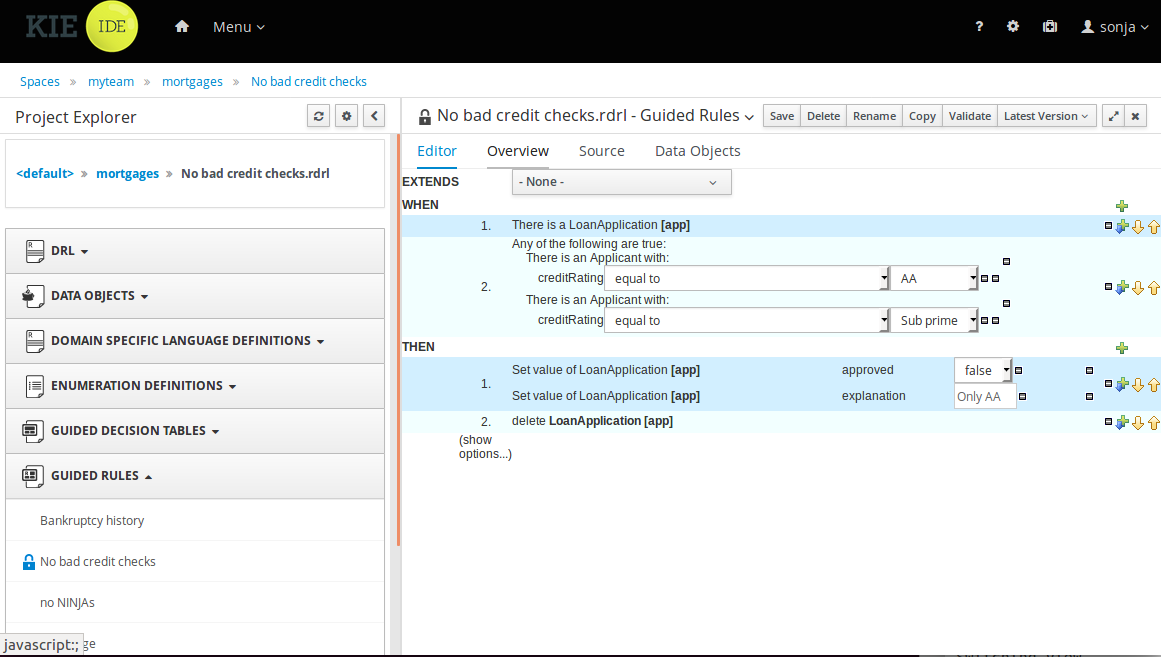
10.6.4.2. Different views
Project Explorer supports multiple views.
-
Project View
A simplified view of the underlying project structure. Certain system files are hidden from view.
-
Repository View
A complete view of the underlying project structure including all files; either user-defined or system generated.
Views can be selected by clicking on the icon within the Project Explorer, as shown below.
Both Project and Repository Views can be further refined by selecting either "Show as Folders" or "Show as Links".
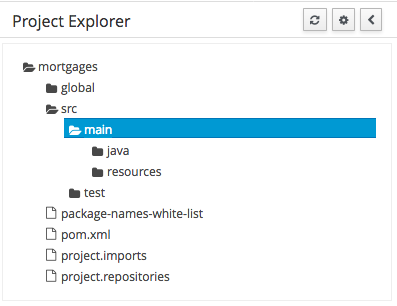

10.6.4.3. Download Project or Repository
Download Download and Download Repository make it possible to download the project or repository as a zip file.
10.6.4.4. Filtering by Tag
To make easy view the elements on packages that contain a lot of assets, is possible to enabling the Tag filter, whichs allows you to filter the assets by their tags.
To see how to add tags to an asset look at: Tags Editor



10.6.4.5. Copy, Rename, Delete and Download Actions
Copy, rename and delete actions are available on Links mode, for packages in of Project View and for files and directories in Repository View. Download action is available for directories. Download option downloads the selected the selected directory as a zip file.
-
A : Copy
-
B : Rename
-
C : Delete
-
D : Download
|
Workbench roadmap includes a refactoring and an impact analyses tools, but currenctly doesn’t have it. Until both tools are provided make sure that your changes (copy/rename/delete) on packages, files or directories doesn’t have a major impact on your project. In cases that your change had an unexcepcted impact, Workbench allows you to restore your repository using the Repository editor. |
|
Files locked by other users as well as directories that contain such files cannot be renamed or deleted until the corresponding locks are released. If that is the case the rename and delete symbols will be deactivated. To learn more about locking see Asset Editor for details. 
|
10.6.5. Project Editor
The Project Editor screen can be accessed from Project Explorer. Project Editor shows the settings for the currently active project.
Unlike most of the workbench editors, project editor edits more than one file. Showing everything that is needed for configuring the KIE project in one place.

10.6.5.1. Build & Deploy
Build & Depoy builds the current project and deploys the KJAR into the workbench internal Maven repository.
10.6.5.2. Project Settings
Project Settings edits the pom.xml file used by Maven.
Project General Settings
General settings provide tools for project name and GAV-data (Group, Artifact, Version). GAV values are used as identifiers to differentiate projects and versions of the same project.
Dependencies
The project may have any number of either internal or external dependencies. Dependency is a project that has been built and deployed to a Maven repository. Internal dependencies are projects build and deployed in the same workbench as the project. External dependencies are retrieved from repositories outside of the current workbench. Each dependency uses the GAV-values to specify the project name and version that is used by the project.
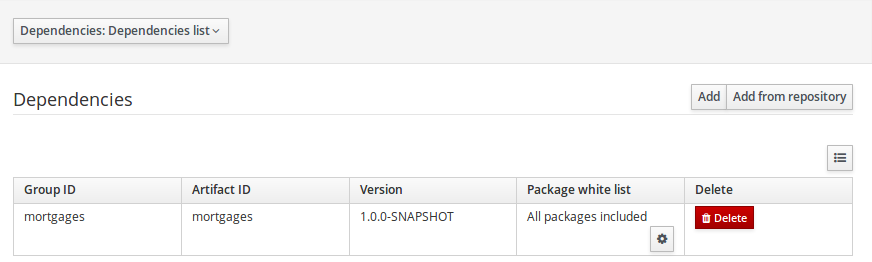
Classes and declared types in white listed packages show up as Data Objects that can be imported in assets. The full list is stored in package-name-white-list file that is stored in each project root.
Package white list has three modes:
-
All packages included: Every package defined in this jar is white listed.
-
Packages not included: None of the packages listed in this jar are white listed.
-
Some packages included: Only part of the packages in the jar are white listed.
Metadata
Metadata for the pom.xml file.
10.6.5.3. Knowledge Base Settings
Knowledge Base Settings edits the kmodule.xml file used by Drools.
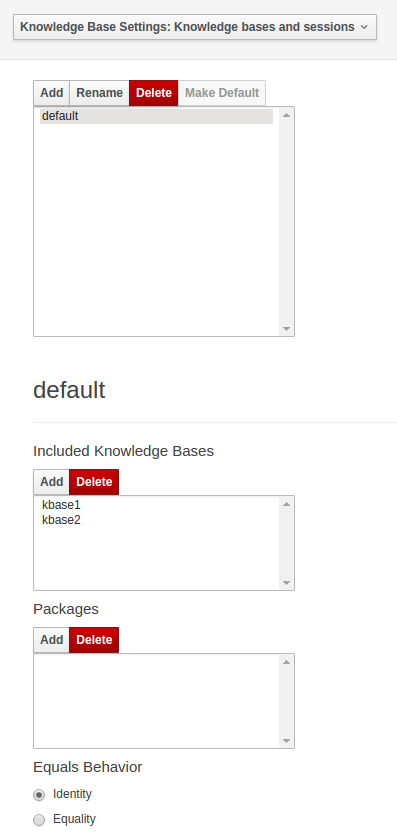
|
For more information about the Knowledge Base properties, check the Drools Expert documentation for kmodule.xml. |
Knowledge bases and sessions
Knowledge bases and sessions lists the knowledge bases and the knowledge sessions specified for the project.
Lists all the knowledge bases by name. Only one knowledge base can be set as default.
Knowledge base can include other knowledge bases. The models, rules and any other content in the included knowledge base will be visible and usable by the currently selected knowledge base.
Rules and models are stored in packages. The packages property specifies what packages are included into this knowledge base.
Equals behavior is explained in the Drools Expert part of the documentation.
Event processing mode is explained in the Drools Fusion part of the documentation.
The table lists all the knowledge sessions in the selected knowledge base. There can be only one default of each type. The types are stateless and stateful. Clicking the pen-icon opens a popup that shows more properties for the knowledge session.
Metadata
Metadata for the kmodule.xml
10.6.5.4. Imports
Settings edits the project.imports file used by the workbench editors.
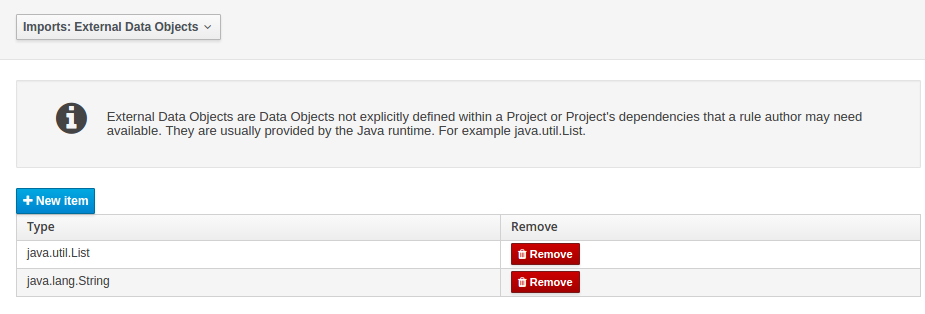
External Data Objects
Data Objects provided by the Java Runtime environment may need to be registered to be available to rule authoring where such Data Objects are not implicitly available as part of an existing Data Object defined within the Workbench or a Project dependency.
For example an Author may want to define a rule that checks for java.util.ArrayList in Working Memory.
If a domain Data Object has a field of type java.util.ArrayList there is no need create a registraton.
Metadata
Metadata for the project.imports file.
10.6.5.5. Duplicate GAV detection
When performing any of the following operations a check is now made against all Maven Repositories, resolved for the Project, for whether the Project’s GroupId, ArtifactId and Version pre-exist.
If a clash is found the operation is prevented; although this can be overridden by Users with the admin role.
|
The feature can be disabled by setting the System Property |
Resolved repositories are those discovered in:-
-
The Project’s
POMsection (or any parent<repositories>POM). -
The Project’s
POMsection.<distributionManagement> -
Maven’s global
settings.xmlconfiguration file.
Affected operations:-
-
Creation of new Managed Repositories.
-
Saving a Project defintion with the Project Editor.
-
Adding new Modules to a Managed Multi-Module Repository.
-
Saving the
pom.xmlfile. -
Build & installing a Project with the Project Editor.
-
Build & deploying a Project with the Project Editor.
-
Asset Management operations building, installing or deloying Projects.
-
RESToperations creating, installing or deploying Projects.
Users with the Admin role can override the list of Repositories checked using the "Repositories" settings in the Project Editor.

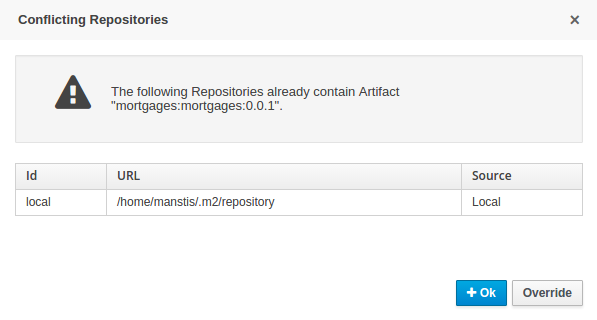
10.6.6. Validation
The Workbench provides a common and consistent service for users to understand whether files authored within the environment are valid.
10.6.6.1. Problem Panel
The Problems Panel shows real-time validation results of assets within a Project.
When a Project is selected from the Project Explorer the Problems Panel will refresh with validation results of the chosen Project.
When files are created, saved or deleted the Problems Panel content will update to show either new validation errors, or remove existing if a file was deleted.
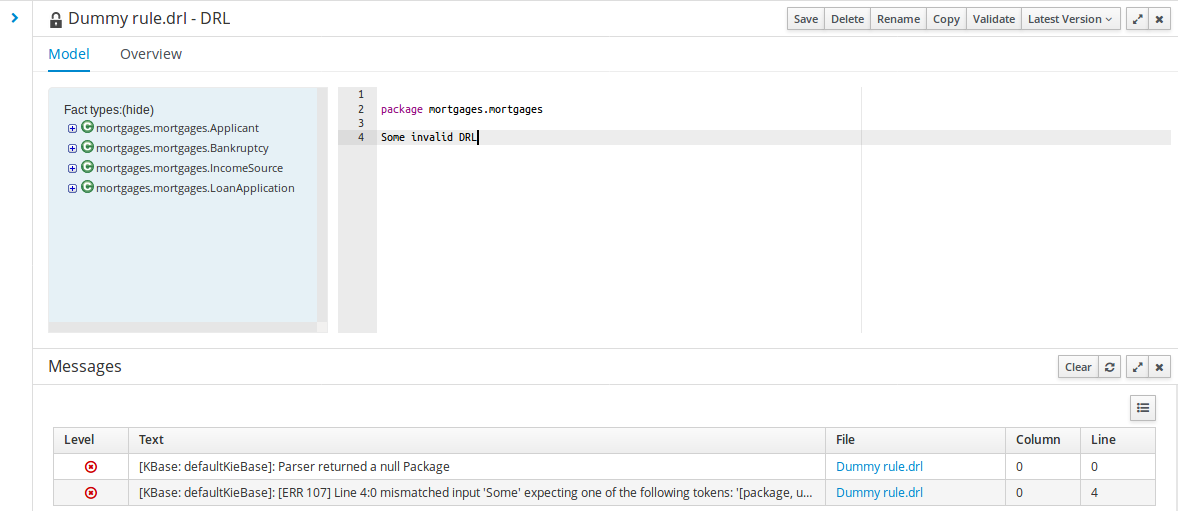
10.6.6.2. On demand validation
It is not always desirable to save a file in order to determine whether it is in a valid state.
All of the file editors provide the ability to validate the content before it is saved.
Clicking on the 'Validate' button shows validation errors, if any.
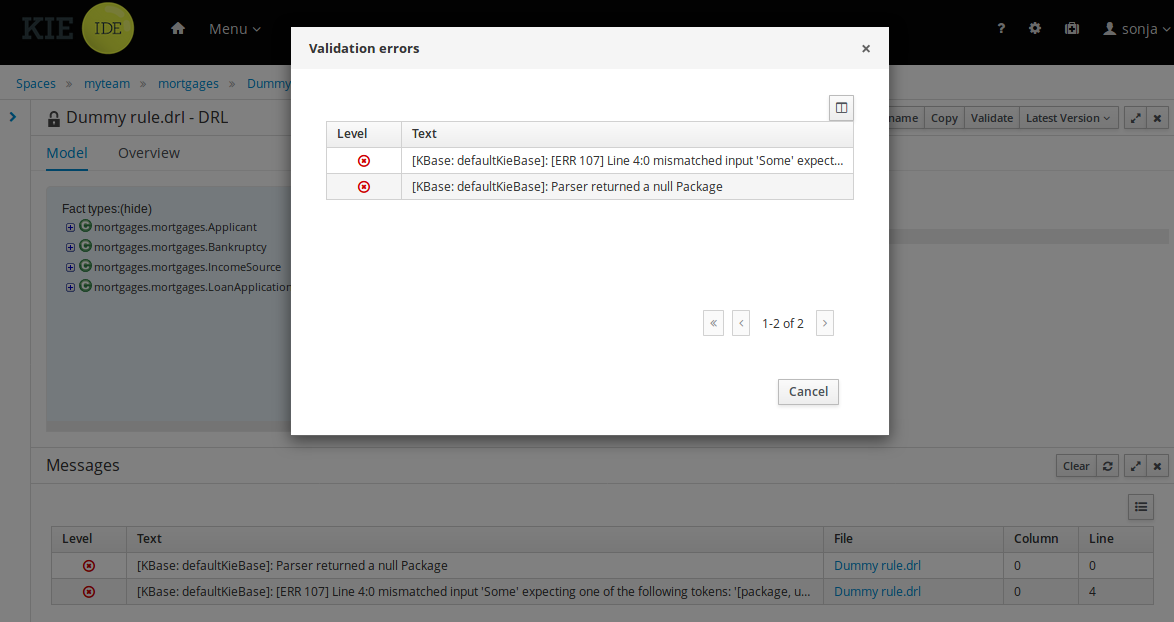
10.6.7. Data Modeller
10.6.7.1. First steps to create a data model
By default, a data model is always constrained to the context of a project. For the purpose of this tutorial, we will assume that a correctly configured project already exists and the authoring page is open.
To start the creation of a data model inside a project, take the following steps:
-
From the home panel, select the Desing page and select the given project.
 Figure 61. Go to authoring page and select a project
Figure 61. Go to authoring page and select a project -
Open the Data Modeller tool by clicking on a Data Object file, or using the "Create New Asset → Data Object" menu option. Set Data Object name to "PurchaseOrder" and click Ok.
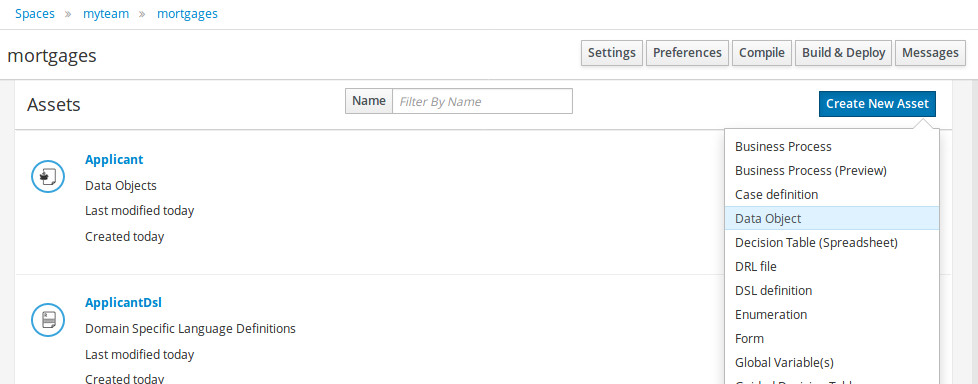 Figure 62. Click on a Data Object
Figure 62. Click on a Data Object
This will start up the Data Modeller tool, which has the following general aspect:
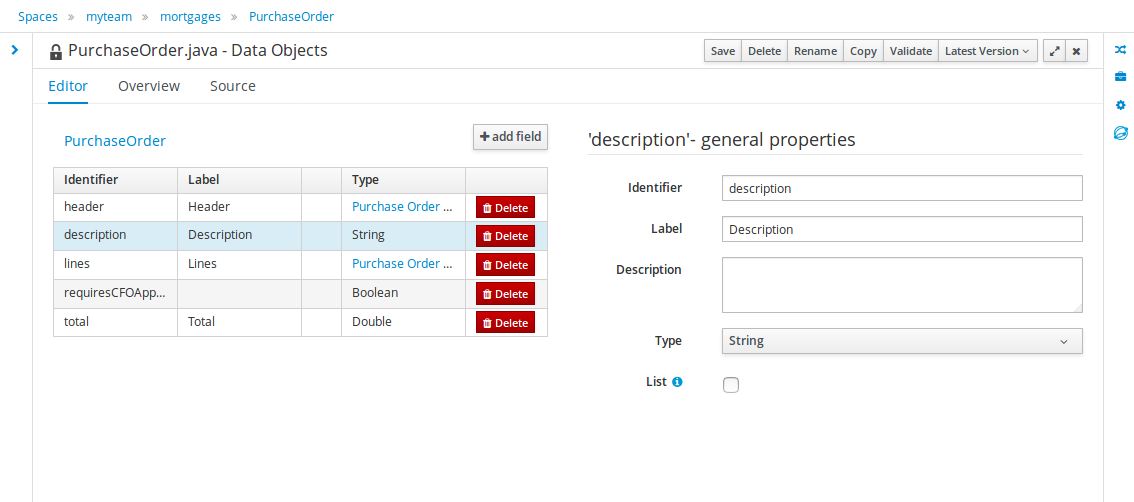
The "Editor" tab is divided into the following sections:
-
The new field section is dedicated to the creation of new fields, and is opened when the "add field" button is pressed.
 Figure 64. New field creation
Figure 64. New field creation -
The Data Object’s "field browser" section displays a list with the data object fields.
 Figure 65. The Data Object’s field browser
Figure 65. The Data Object’s field browser -
The "Data Object / Field general properties" section. This is the rightmost section of the Data Modeller editor and visualizes the "Data Object" or "Field" general properties, depending on user selection.
Data Object general properties can be selected by clicking on the Data Object Selector.
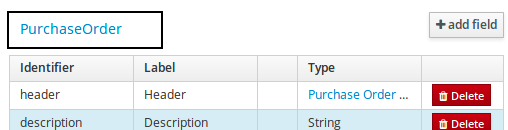 Figure 66. Data Object selector
Figure 66. Data Object selector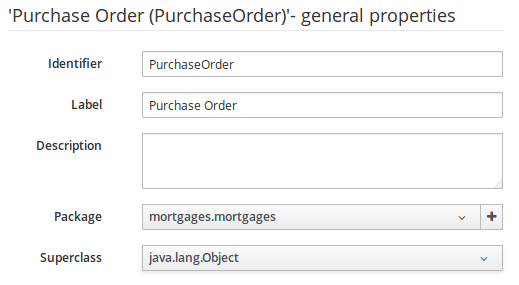 Figure 67. Data Object general properties
Figure 67. Data Object general propertiesField general properties can be selected by clicking on a field.
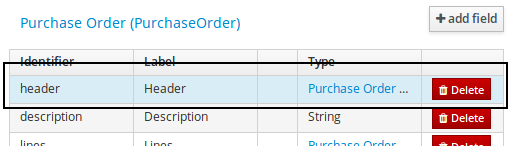
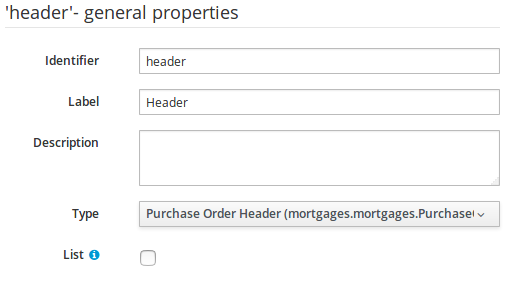
-
On workbench’s right side a new "Tool Bar" is provided that enables the selection of different context sensitive tool windows that will let the user do domain specific configurations. Currently four tool windows are provided for the following domains "Drools & jBPM", "OptaPlanner", "Persistence" and "Advanced" configurations.
 Figure 70. Data modeller Tool Bar
Figure 70. Data modeller Tool Bar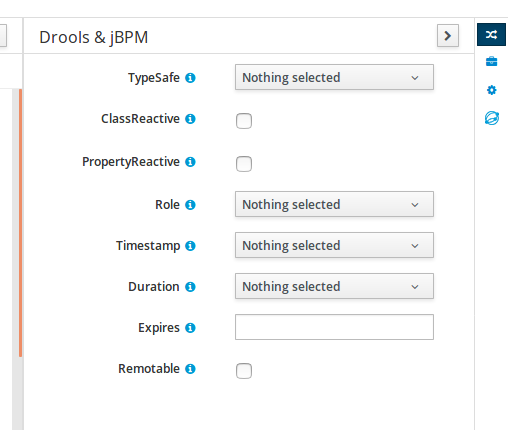 Figure 71. Drools & jBPM tool window
Figure 71. Drools & jBPM tool window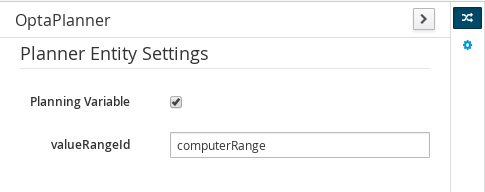 Figure 72. OptaPlanner tool window
Figure 72. OptaPlanner tool windowTo see and use the OptaPlanner tool window, the user needs to have the role
plannermgmt.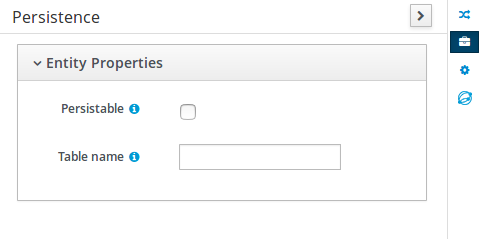 Figure 73. Persistence tool window
Figure 73. Persistence tool window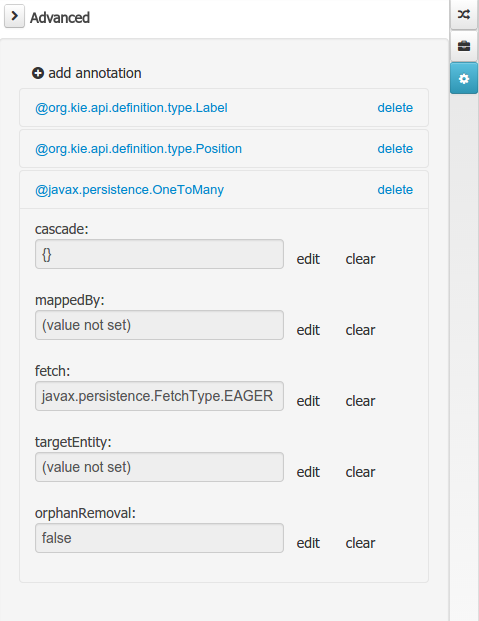 Figure 74. Advanced tool window
Figure 74. Advanced tool window
The "Source" tab shows an editor that allows the visualization and modification of the generated java code.
-
Round trip between the "Editor" and "Source" tabs is possible, and also source code preservation is provided. It means that not matter where the Java code was generated (e.g. Eclipse, Data modeller), the data modeller will only update the necessary code blocks to maintain the model updated.
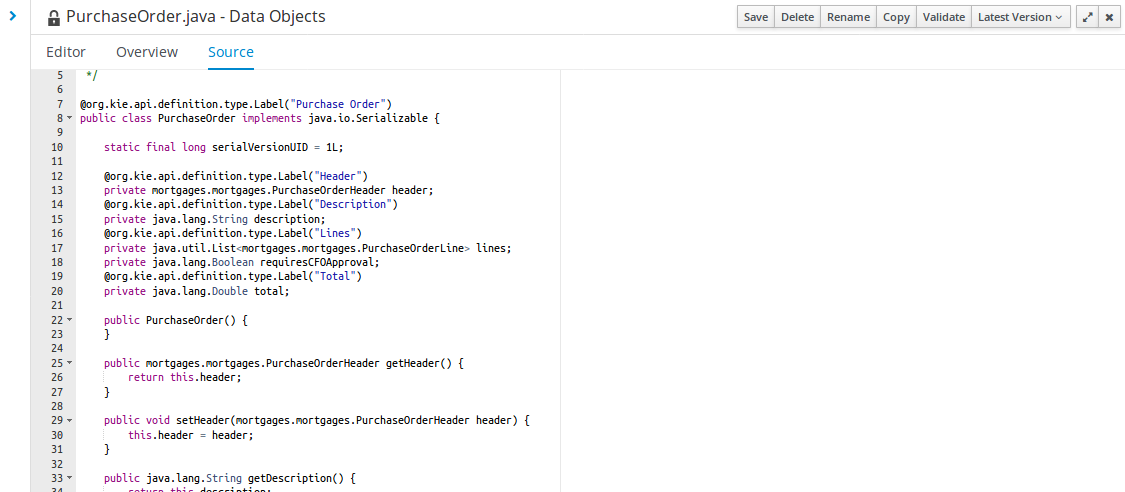 Figure 75. Source editor
Figure 75. Source editor
The "Overview" tab shows the standard metadata and version information as the other workbench editors.
10.6.7.2. Data Objects
A data model consists of data objects which are a logical representation of some real-world data. Such data objects have a fixed set of modeller (or application-owned) properties, such as its internal identifier, a label, description, package etc. Besides those, a data object also has a variable set of user-defined fields, which are an abstraction of a real-world property of the type of data that this logical data object represents.
Creating a data object can be achieved using the workbench "New Item - Data Object" menu option.
Both resource name and location are mandatory parameters. When the "Ok" button is pressed a new Java file will be created and a new editor instance will be opened for the file edition. The optional "Persistable" attribute will add by default configurations on the data object in order to make it a JPA entity. Use this option if your jBPM project needs to store data object’s information in a data base.
10.6.7.3. Properties & relationships
Once the data object has been created, it now has to be completed by adding user-defined properties to its definition. This can be achieved by pressing the "add field" button. The "New Field" dialog will be opened and the new field can be created by pressing the "Create" button. The "Create and continue" button will also add the new field to the Data Object, but won’t close the dialog. In this way multiple fields can be created avoiding the popup opening multiple times. The following fields can (or must) be filled out:
-
The field’s internal identifier (mandatory). The value of this field must be unique per data object, i.e. if the proposed identifier already exists within current data object, an error message will be displayed.
-
A label (optional): as with the data object definition, the user can define a user-friendly label for the data object field which is about to be created. This has no further implications on how fields from objects of this data object will be treated. If a label is defined, then this is how the field will be displayed throughout the data modeller tool.
-
A field type (mandatory): each data object field needs to be assigned with a type.
This type can be either of the following:
-
A 'primitive java object' type: these include most of the object equivalents of the standard Java primitive types, such as Boolean, Short, Float, etc, as well as String, Date, BigDecimal and BigInteger.
 Figure 77. Primitive object field types
Figure 77. Primitive object field types -
A 'data object' type: any user defined data object automatically becomes a candidate to be defined as a field type of another data object, thus enabling the creation of relationships between them. A data object field can be created either in 'single' or in 'multiple' form, the latter implying that the field will be defined as a collection of this type, which will be indicated by selecting "List" checkbox.
-

-
A 'primitive java' type: these include java primitive types byte, short, int, long, float, double, char and boolean.

When finished introducing the initial information for a new field, clicking the 'Create' button will add the newly created field to the end of the data object’s fields table below:
The new field will also automatically be selected in the data object’s field list, and its properties will be shown in the Field general properties editor. Additionally the field properties will be loaded in the different tool windows, in this way the field will be ready for edition in whatever selected tool window.
At any time, any field (without restrictions) can be deleted from a data object definition by clicking on the corresponding 'x' icon in the data object’s fields table.
10.6.7.4. Additional options
As stated before, both Data Objects as well as Fields require some of their initial properties to be set upon creation. Additionally there are three domains of properties that can be configured for a given Data Object. A domain is basically a set of properties related to a given business area. Current available domains are, "Drools & jJBPM", "Persistence" and the "Advanced" domain. To work on a given domain the user should select the corresponding "Tool window" (see below) on the right side toolbar. Every tool window usually provides two editors, the "Data Object" level editor and the "Field" level editor, that will be shown depending on the last selected item, the Data Object or the Field.
Drools & jBPM domain
The Drools & jBPM domain editors manages the set of Data Object or Field properties related to drools applications.
The Drools & jBPM object editor manages the object level drools properties
-
TypeSafe: this property allows to enable/disable the type safe behaviour for current type. By default all type declarations are compiled with type safety enabled. (See Drools for more information on this matter).
-
ClassReactive: this property allows to mark this type to be treated as "Class Reactive" by the Drools engine. (See Drools for more information on this matter).
-
PropertyReactive: this property allows to mark this type to be treated as "Property Reactive" by the Drools engine. (See Drools for more information on this matter).
-
Role: this property allows to configure how the Drools engine should handle instances of this type: either as regular facts or as events. By default all types are handled as a regular fact, so for the time being the only value that can be set is "Event" to declare that this type should be handled as an event. (See Drools Fusion for more information on this matter).
-
Timestamp: this property allows to configure the "timestamp" for an event, by selecting one of his attributes. If set the engine will use the timestamp from the given attribute instead of reading it from the Session Clock. If not, the engine will automatically assign a timestamp to the event. (See Drools Fusion for more information on this matter).
-
Duration: this property allows to configure the "duration" for an event, by selecting one of his attributes. If set the engine will use the duration from the given attribute instead of using the default event duration = 0. (See Drools Fusion for more information on this matter).
-
Expires: this property allows to configure the "time offset" for an event expiration. If set, this value must be a temporal interval in the form: [d][#h][#m][#s][[ms]] Where [ ] means an optional parameter and # means a numeric value. e.g.: 1d2h, means one day and two hours. (See Drools Fusion for more information on this matter).
-
Remotable: If checked this property makes the Data Object available to be used with jBPM remote services as REST, JMS and WS. (See jBPM for more information on this matter).
The Drools & jBPM object editor manages the field level drools properties
-
Equals: checking this property for a Data Object field implies that it will be taken into account, at the code generation level, for the creation of both the equals() and hashCode() methods in the generated Java class. We will explain this in more detail in the following section.
-
Position: this field requires a zero or positive integer. When set, this field will be interpreted by the Drools engine as a positional argument (see the section below and also the Drools documentation for more information on this subject).
Persistence domain
The Persistence domain editors manages the set of Data Object or Field properties related to persistence.
Persistence domain object editor manages the object level persistence properties
-
Persistable: this property allows to configure current Data Object as persistable.
-
Table name: this property allows to set a user defined database table name for current Data Object.
The persistence domain field editor manages the field level persistence properties and is divided in three sections.
A persistable Data Object should have one and only one field defined as the Data Object identifier. The identifier is typically a unique number that distinguishes a given Data Object instance from all other instances of the same class.
-
Is Identifier: marks current field as the Data Object identifier. A persistable Data Object should have one and only one field marked as identifier, and it should be a base java type, like String, Integer, Long, etc. A field that references a Data Object, or is a multiple field can not be marked as identifier. And also composite identifiers are not supported in this version. When a persistable Data Object is created an identifier field is created by default with the properly initializations, it’s strongly recommended to use this identifier.
-
Generation Strategy: the generation strategy establishes how the identifier values will be automatically generated when the Data Object instances are created and stored in a database. (e.g. by the forms associated to jBPM processes human tasks.) When the by default Identifier field is created, the generation strategy will be also automatically set and it’s strongly recommended to use this configuration.
-
Sequence Generator: the generator represents the seed for the values that will be used by the Generation Strategy. When the by default Identifier field is created the Sequence Generator will be also automatically generated and properly configured to be used by the Generation Strategy.
The column properties section enables the customization of some properties of the database column that will store the field value.
-
Column name: optional value that sets the database column name for the given field.
-
Unique: When checked the unique property establishes that current field value should be a unique key when stored in the database. (if not set the default value is false)
-
Nullable: When checked establishes that current field value can be null when stored in a database. (if not set the default value is true)
-
Insertable: When checked establishes that column will be included in SQL INSERT statements generated by the persistence provider. (if not set the default value is true)
-
Updatable: When checked establishes that the column will be included SQL UPDATE statements generated by the persistence provider. (if not set the default value is true)
When the field’s type is a Data Object type, or a list of a Data Object type a relationship type should be set in order to let the persistence provider to manage the relation. Fortunately this relation type is automatically set when such kind of fields are added to an already marked as persistable Data Object. The relationship type is set by the following popup.
-
Relationship type: sets the type of relation from one of the following options:
One to one: typically used for 1:1 relations where "A is related to one instance of B", and B exists only when A exists. e.g. PurchaseOrder → PurchaseOrderHeader (a PurchaseOrderHeader exists only if the PurchaseOrder exists)
One to many: typically used for 1:N relations where "A is related to N instances of B", and the related instances of B exists only when A exists. e.g. PurchaseOrder → PurchaseOrderLine (a PurchaseOrderLine exists only if the PurchaseOrder exists)
Many to one: typically used for 1:1 relations where "A is related to one instance of B", and B can exist even without A. e.g. PurchaseOrder → Client (a Client can exist in the database even without an associated PurchaseOrder)
Many to many: typically used for N:N relations where "A can be related to N instances of B, and B can be related to M instances of A at the same time", and both B an A instances can exits in the database independently of the related instances. e.g. Course → Student. (Course can be related to N Students, and a given Student can attend to M courses)
When a field of type "Data Object" is added to a given persistable Data Object, the "Many to One" relationship type is generated by default.
And when a field of type "list of Data Object" is added to a given persistable Data Object , the "One to Many" relationship is generated by default.
-
Cascade mode: Defines the set of cascadable operations that are propagated to the associated entity. The value cascade=ALL is equivalent to cascade={PERSIST, MERGE, REMOVE, REFRESH}. e.g. when A → B, and cascade "PERSIST or ALL" is set, if A is saved, then B will be also saved.
The by default cascade mode created by the data modeller is "ALL" and it’s strongly recommended to use this mode when Data Objects are being used by jBPM processes and forms.
-
Fetch mode: Defines how related data will be fetched from database at reading time.
EAGER: related data will be read at the same time. e.g. If A → B, when A is read from database B will be read at the same time.
LAZY: reading of related data will be delayed usually to the moment they are required. e.g. If PurchaseOrder → PurchaseOrderLine the lines reading will be postponed until a method "getLines()" is invoked on a PurchaseOrder instance.
The default fetch mode created by the data modeller is "EAGER" and it’s strongly recommended to use this mode when Data Objects are being used by jBPM processes and forms.
-
Optional: establishes if the right side member of a relationship can be null.
-
Mapped by: used for reverse relations.
Advanced domain
The advanced domain enables the configuration of whatever parameter set by the other domains as well as the adding of arbitrary parameters. As it will be shown in the code generation section every "Data Object / Field" parameter is represented by a java annotation. The advanced mode enables the configuration of this annotations.
The advanced domain editor has the same shape for both Data Object and Field.
The following operations are available
-
delete: enables the deletion of a given Data Object or Field annotation.
-
clear: clears a given annotation parameter value.
-
edit: enables the edition of a given annotation parameter value.
-
add annotation: The add annotation button will start a wizard that will let the addition of whatever java annotation available in the project dependencies.
Add annotation wizard step #1: the first step of the wizard requires the entering of a fully qualified class name of an annotation, and by pressing the "search" button the annotation definition will be loaded into the wizard. Additionally when the annotation definition is loaded, different wizard steps will be created in order to enable the completion of the different annotation parameters. Required parameters will be marked with "*".
 Figure 87. Annotation definition loaded into the wizard.
Figure 87. Annotation definition loaded into the wizard.Whenever it’s possible the wizard will provide a suitable editor for the given parameters.
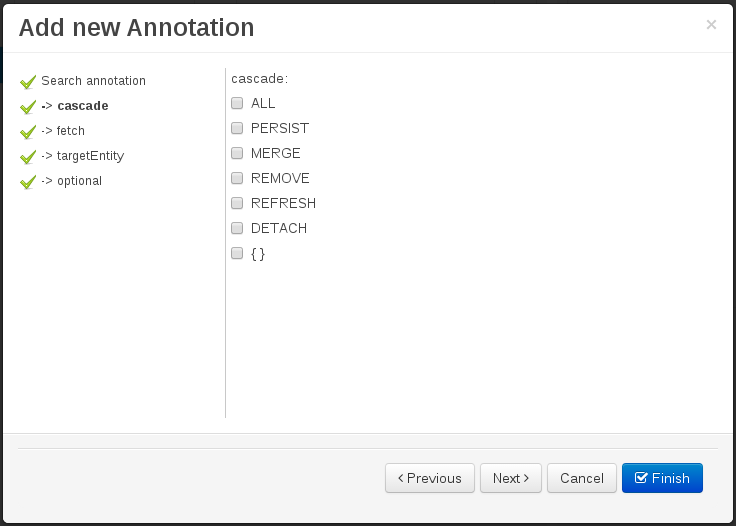 Figure 88. Automatically generated enum values editor for an Enumeration annotation parameter.
Figure 88. Automatically generated enum values editor for an Enumeration annotation parameter.A generic parameter editor will be provided when it’s not possible to calculate a customized editor
 Figure 89. Generic annotation parameter editor
Figure 89. Generic annotation parameter editorWhen all required parameters has been entered and validated, the finish button will be enabled and the wizard can be completed by adding the annotation to the given Data Object or Field.
10.6.7.5. Generate data model code.
The data model in itself is merely a visual tool that allows the user to define high-level data structures, for them to interact with the Drools Engine on the one hand, and the jBPM platform on the other. In order for this to become possible, these high-level visual structures have to be transformed into low-level artifacts that can effectively be consumed by these platforms. These artifacts are Java POJOs (Plain Old Java Objects), and they are generated every time the data model is saved, by pressing the "Save" button in the top Data Modeller Menu. Additionally when the user round trip between the "Editor" and "Source" tab, the code is auto generated to maintain the consistency with the Editor view and vice versa.

The resulting code is generated according to the following transformation rules:
-
The data object’s identifier property will become the Java class’s name. It therefore needs to be a valid Java identifier.
-
The data object’s package property becomes the Java class’s package declaration.
-
The data object’s superclass property (if present) becomes the Java class’s extension declaration.
-
The data object’s label and description properties will translate into the Java annotations "@org.kie.api.definition.type.Label" and "@org.kie.api.definition.type.Description", respectively. These annotations are merely a way of preserving the associated information, and as yet are not processed any further.
-
The data object’s role property (if present) will be translated into the "@org.kie.api.definition.type.Role" Java annotation, that IS interpreted by the application platform, in the sense that it marks this Java class as a Drools Event Fact-Type.
-
The data object’s type safe property (if present) will be translated into the "@org.kie.api.definition.type.TypeSafe Java annotation. (see Drools)
-
The data object’s class reactive property (if present) will be translated into the "@org.kie.api.definition.type.ClassReactive Java annotation. (see Drools)
-
The data object’s property reactive property (if present) will be translated into the "@org.kie.api.definition.type.PropertyReactive Java annotation. (see Drools)
-
The data object’s timestamp property (if present) will be translated into the "@org.kie.api.definition.type.Timestamp Java annotation. (see Drools)
-
The data object’s duration property (if present) will be translated into the "@org.kie.api.definition.type.Duration Java annotation. (see Drools)
-
The data object’s expires property (if present) will be translated into the "@org.kie.api.definition.type.Expires Java annotation. (see Drools)
-
The data object’s remotable property (if present) will be translated into the "@org.kie.api.remote.Remotable Java annotation. (see jBPM)
A standard Java default (or no parameter) constructor is generated, as well as a full parameter constructor, i.e. a constructor that accepts as parameters a value for each of the data object’s user-defined fields.
The data object’s user-defined fields are translated into Java class fields, each one of them with its own getter and setter method, according to the following transformation rules:
-
The data object field’s identifier will become the Java field identifier. It therefore needs to be a valid Java identifier.
-
The data object field’s type is directly translated into the Java class’s field type. In case the field was declared to be multiple (i.e. 'List'), then the generated field is of the "java.util.List" type.
-
The equals property: when it is set for a specific field, then this class property will be annotated with the "@org.kie.api.definition.type.Key" annotation, which is interpreted by the Drools Engine, and it will 'participate' in the generated equals() method, which overwrites the equals() method of the Object class. The latter implies that if the field is a 'primitive' type, the equals method will simply compares its value with the value of the corresponding field in another instance of the class. If the field is a sub-entity or a collection type, then the equals method will make a method-call to the equals method of the corresponding data object’s Java class, or of the java.util.List standard Java class, respectively.
If the equals property is checked for ANY of the data object’s user defined fields, then this also implies that in addition to the default generated constructors another constructor is generated, accepting as parameters all of the fields that were marked with Equals. Furthermore, generation of the equals() method also implies that also the Object class’s hashCode() method is overwritten, in such a manner that it will call the hashCode() methods of the corresponding Java class types (be it 'primitive' or user-defined types) for all the fields that were marked with Equals in the Data Model.
-
The position property: this field property is automatically set for all user-defined fields, starting from 0, and incrementing by 1 for each subsequent new field. However the user can freely changes the position among the fields. At code generation time this property is translated into the "@org.kie.api.definition.type.Position" annotation, which can be interpreted by the Drools Engine. Also, the established property order determines the order of the constructor parameters in the generated Java class.
As an example, the generated Java class code for the Purchase Order data object, corresponding to its definition as shown in the following figure purchase_example.jpg is visualized in the figure at the bottom of this chapter. Note that the two of the data object’s fields, namely 'header' and 'lines' were marked with Equals, and have been assigned with the positions 2 and 1, respectively).
package org.jbpm.examples.purchases;
/**
* This class was automatically generated by the data modeler tool.
*/
@org.kie.api.definition.type.Label("Purchase Order")
@org.kie.api.definition.type.TypeSafe(true)
@org.kie.api.definition.type.Role(org.kie.api.definition.type.Role.Type.EVENT)
@org.kie.api.definition.type.Expires("2d")
@org.kie.api.remote.Remotable
public class PurchaseOrder implements java.io.Serializable
{
static final long serialVersionUID = 1L;
@org.kie.api.definition.type.Label("Total")
@org.kie.api.definition.type.Position(3)
private java.lang.Double total;
@org.kie.api.definition.type.Label("Description")
@org.kie.api.definition.type.Position(0)
private java.lang.String description;
@org.kie.api.definition.type.Label("Lines")
@org.kie.api.definition.type.Position(2)
@org.kie.api.definition.type.Key
private java.util.List<org.jbpm.examples.purchases.PurchaseOrderLine> lines;
@org.kie.api.definition.type.Label("Header")
@org.kie.api.definition.type.Position(1)
@org.kie.api.definition.type.Key
private org.jbpm.examples.purchases.PurchaseOrderHeader header;
@org.kie.api.definition.type.Position(4)
private java.lang.Boolean requiresCFOApproval;
public PurchaseOrder()
{
}
public java.lang.Double getTotal()
{
return this.total;
}
public void setTotal(java.lang.Double total)
{
this.total = total;
}
public java.lang.String getDescription()
{
return this.description;
}
public void setDescription(java.lang.String description)
{
this.description = description;
}
public java.util.List<org.jbpm.examples.purchases.PurchaseOrderLine> getLines()
{
return this.lines;
}
public void setLines(java.util.List<org.jbpm.examples.purchases.PurchaseOrderLine> lines)
{
this.lines = lines;
}
public org.jbpm.examples.purchases.PurchaseOrderHeader getHeader()
{
return this.header;
}
public void setHeader(org.jbpm.examples.purchases.PurchaseOrderHeader header)
{
this.header = header;
}
public java.lang.Boolean getRequiresCFOApproval()
{
return this.requiresCFOApproval;
}
public void setRequiresCFOApproval(java.lang.Boolean requiresCFOApproval)
{
this.requiresCFOApproval = requiresCFOApproval;
}
public PurchaseOrder(java.lang.Double total, java.lang.String description,
java.util.List<org.jbpm.examples.purchases.PurchaseOrderLine> lines,
org.jbpm.examples.purchases.PurchaseOrderHeader header,
java.lang.Boolean requiresCFOApproval)
{
this.total = total;
this.description = description;
this.lines = lines;
this.header = header;
this.requiresCFOApproval = requiresCFOApproval;
}
public PurchaseOrder(java.lang.String description,
org.jbpm.examples.purchases.PurchaseOrderHeader header,
java.util.List<org.jbpm.examples.purchases.PurchaseOrderLine> lines,
java.lang.Double total, java.lang.Boolean requiresCFOApproval)
{
this.description = description;
this.header = header;
this.lines = lines;
this.total = total;
this.requiresCFOApproval = requiresCFOApproval;
}
public PurchaseOrder(
java.util.List<org.jbpm.examples.purchases.PurchaseOrderLine> lines,
org.jbpm.examples.purchases.PurchaseOrderHeader header)
{
this.lines = lines;
this.header = header;
}
@Override
public boolean equals(Object o)
{
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
org.jbpm.examples.purchases.PurchaseOrder that = (org.jbpm.examples.purchases.PurchaseOrder) o;
if (lines != null ? !lines.equals(that.lines) : that.lines != null)
return false;
if (header != null ? !header.equals(that.header) : that.header != null)
return false;
return true;
}
@Override
public int hashCode()
{
int result = 17;
result = 31 * result + (lines != null ? lines.hashCode() : 0);
result = 31 * result + (header != null ? header.hashCode() : 0);
return result;
}
}10.6.7.6. Using external models
Using an external model means the ability to use a set for already defined POJOs in current project context. In order to make those POJOs available a dependency to the given JAR should be added. Once the dependency has been added the external POJOs can be referenced from current project data model.
There are two ways to add a dependency to an external JAR file:
-
Dependency to a JAR file already installed in current local M2 repository (typically associated the the user home).
-
Dependency to a JAR file installed in current KIE Workbench/Drools Workbench "Guvnor M2 repository". (internal to the application)
Dependency to a JAR file in local M2 repository
To add a dependency to a JAR file in local M2 repository follow this steps.
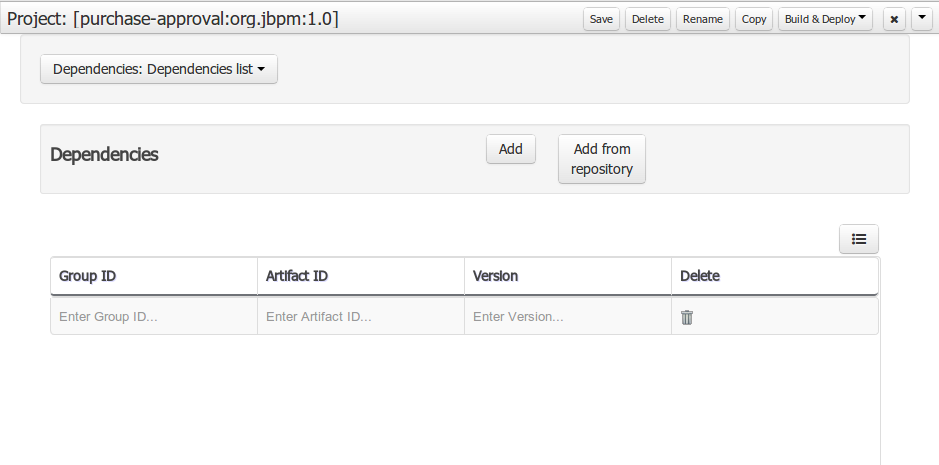
When project is saved the POJOs defined in the external file will be available.
Dependency to a JAR file in current "Guvnor M2 repository".
To add a dependency to a JAR file in current "Guvnor M2 repository" follow this steps.
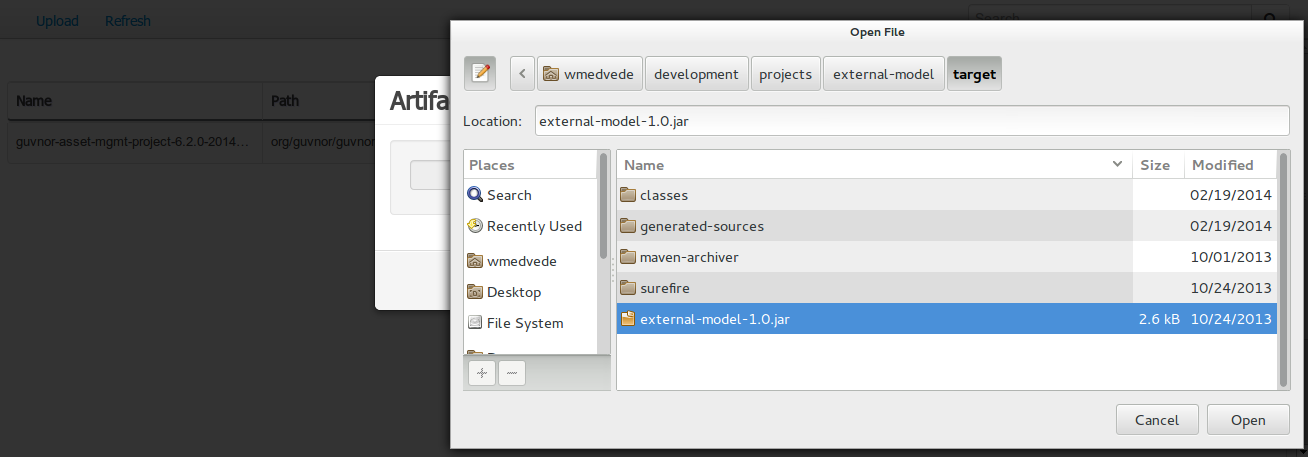
Once the file has been loaded it will be displayed in the repository files list.
If the uploaded file is not a valid Maven JAR (don’t have a pom.xml file) the system will prompt the user in order to provide a GAV for the file to be installed.
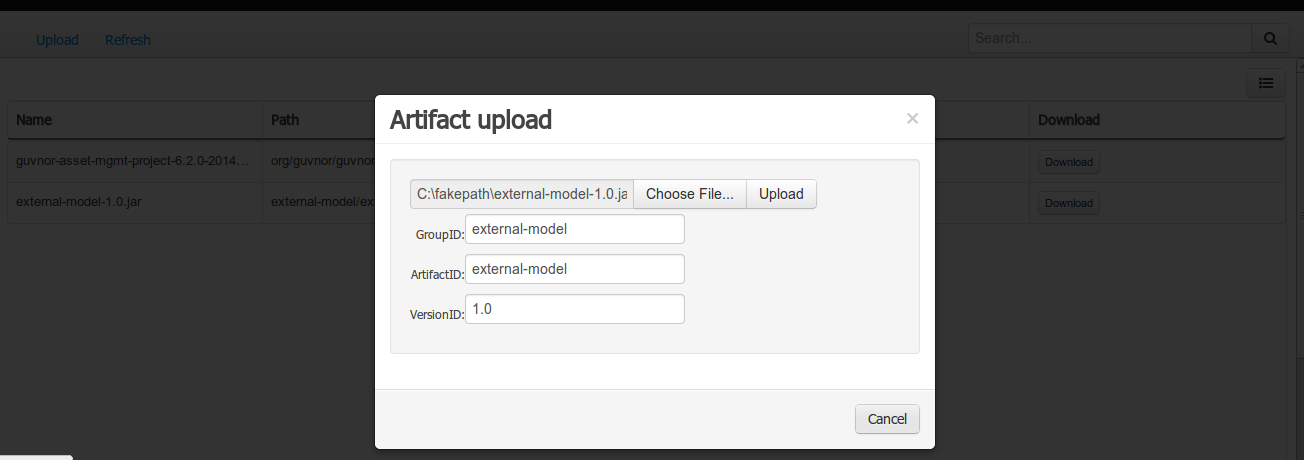
Open the project editor (see bellow) and click on the "Add from repository" button to open the JAR selector to see all the installed JAR files in current "Guvnor M2 repository". When the desired file is selected the project should be saved in order to make the new dependency available.
Using the external objects
When a dependency to an external JAR has been set, the external POJOs can be used in the context of current project data model in the following ways:
-
External POJOs can be extended by current model data objects.
-
External POJOs can be used as field types for current model data objects.
The following screenshot shows how external objects are prefixed with the string " -ext- " in order to be quickly identified.
10.6.7.7. Roundtrip and concurrency
Current version implements roundtrip and code preservation between Data modeller and Java source code. No matter where the Java code was generated (e.g. Eclipse, Data modeller), the data modeller will only create/delete/update the necessary code elements to maintain the model updated, i.e, fields, getter/setters, constructors, equals method and hashCode method. Also whatever Type or Field annotation not managed by the Data Modeler will be preserved when the Java sources are updated by the Data modeller.
Aside from code preservation, like in the other workbench editors, concurrent modification scenarios are still possible. Common scenarios are when two different users are updating the model for the same project, e.g. using the data modeller or executing a 'git push command' that modifies project sources.
From an application context’s perspective, we can basically identify two different main scenarios:
No changes have been undertaken through the application
In this scenario the application user has basically just been navigating through the data model, without making any changes to it. Meanwhile, another user modifies the data model externally.
In this case, no immediate warning is issued to the application user. However, as soon as the user tries to make any kind of change, such as add or remove data objects or properties, or change any of the existing ones, the following pop-up will be shown:

The user can choose to either:
-
Re-open the data model, thus loading any external changes, and then perform the modification he was about to undertake, or
-
Ignore any external changes, and go ahead with the modification to the model. In this case, when trying to persist these changes, another pop-up warning will be shown:
 Figure 105. Force save / re-open
Figure 105. Force save / re-openThe "Force Save" option will effectively overwrite any external changes, while "Re-open" will discard any local changes and reload the model.
"Force Save" overwrites any external changes!
Changes have been undertaken through the application
The application user has made changes to the data model. Meanwhile, another user simultaneously modifies the data model from outside the application context.
In this alternative scenario, immediately after the external user commits his changes to the asset repository (or e.g. saves the model with the data modeller in a different session), a warning is issued to the application user:
As with the previous scenario, the user can choose to either:
-
Re-open the data model, thus losing any modifications that where made through the application, or
-
Ignore any external changes, and continue working on the model.
One of the following possibilities can now occur: ** The user tries to persist the changes he made to the model by clicking the "Save" button in the data modeller top level menu. This leads to the following warning message:
+
Figure 107. Force save / re-openThe "Force Save" option will effectively overwrite any external changes, while "Re-open" will discard any local changes and reload the model.
10.6.8. Data Sets
A data set is basically a set of columns populated with some rows, a matrix of data composed of timestamps, texts and numbers. A data set can be stored in different systems: a database, an excel file, in memory or in a lot of other different systems. On the other hand, a data set definition tells the workbench modules how such data can be accessed, read and parsed.
Notice, it’s very important to make crystal clear the difference between a data set and its definition since the workbench does not take care of storing any data, it just provides an standard way to define access to those data sets regardless where the data is stored.
Let’s take for instance the data stored in a remote database. A valid data set could be, for example, an entire database table or the result of an SQL query. In both cases, the database will return a bunch of columns and rows. Now, imagine we want to get access to such data to feed some charts in a new workbench page. First thing is to create and register a data set definition in order to indicate the following:
-
where the data set is stored,
-
how can be accessed, read and parsed and
-
what columns contains and of which type.
This chapter introduces the available workbench tools for registering and handling data set definitions and how this definitions can be consumed in other workbench modules like, for instance, the Page Editor.
|
For simplicity sake we will be using the term data set to refer to the actual data set definitions as Data set and Data set definition can be considered synonyms under the data set authoring context. |
10.6.8.1. Data Set Authoring Page
Everything related to the authoring of data sets can be found under the Data Set Authoring page which is accessible from the following top level menu entry: Extensions>Data Sets, as shown in the following screenshot.
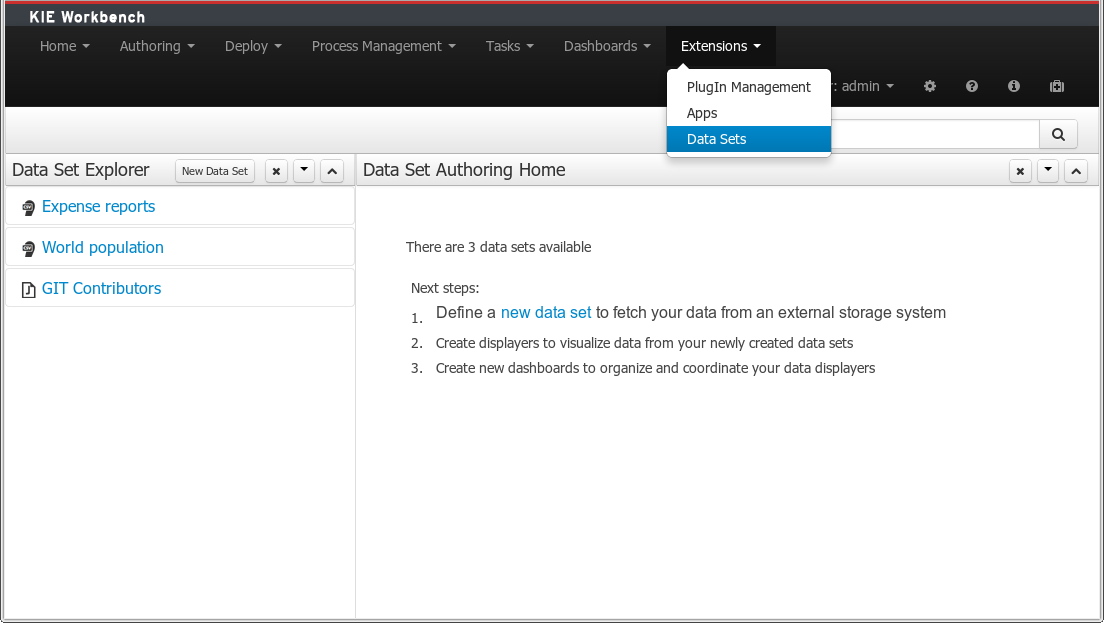
The center panel, shows a welcome screen, whilst the left panel contains the Data Set Explorer listing all the data sets available
|
This page is only intended to Administrator users, since defining data sets can be considered a low level task. |
10.6.8.2. Data Set Explorer
The Data Set Explorer list the data sets present in the system. Every time the user clicks on the data set it shows a brief summary alongside the following information:
-
(1) A button for creating a new Data set
-
(2) The list of currently available Data sets
-
(3) An icon that represents the Data set’s provider type (Bean, SQL, CSV, etc)
-
(4) Details of current cache and refresh policy status
-
(5) Details of current size on backend (unit as rows) and current size on client side (unit in bytes)
-
(6) The button for editing the Data set. Once clicked the Data set editor screen is opened on the center panel
The next sections explains how to create, edit and fine tune data set definitions.
10.6.8.3. Data Set Creation
Clicking on the New Data Set button opens a new screen from which the user is able to create a new data set definition in three steps:
-
Provider type selection
Specify the kind of the remote storage system (BEAN, SQL, CSV, ElasticSearch)
-
Provider configuration
Specify the attributes for being able to look up data from the remote system. The configuration varies depending on the data provider type selected.
-
Data set columns & filter
Live data preview, column types and initial filter configuration.
Step 1: Provider type selection
Allows the user’s specify the type of data provider of the data set being created.
This screen lists all the current available data provider types and helper popovers with descriptions. Each data provider is represented with a descriptive image:

Four types are currently supported:
-
Bean (Java class) - To generate a data set directly from Java
-
SQL - For getting data from any ANSI-SQL compliant database
-
CSV - To upload the contents of a remote or local CSV file
-
Elastic Search - To query and get documents stored on Elastic Search nodes as data sets
Once a type is selected, click on Next button to continue with the next workflow step.
Step 2: Configuration
The provider type selected in the previous step will determine which configuration settings the system asks for.

|
The UUID attribute is a read only field as it’s generated by the system. It’s only intended for usage in API calls or specific operations. |
Step 3: Data set columns and preview
After clicking on the Test button (see previous step), the system executes a data set lookup test call in order to check if the remote system is up and the data is available. If everything goes ok the user will see the following screen:
This screen shows a live data preview along with the columns the user wants to be part of the resulting data set. The user can also navigate through the data and apply some changes to the data set structure. Once finished, we can click on the Save button in order to register the new data set definition.
We can also change the configuration settings at any time just by going back to the configuration tab. We can repeat the Configuration>Test>Preview cycle as may times as needed until we consider it’s ready to be saved.
Columns
In the Columns tab area the user can select what columns are part of the resulting data set definition.
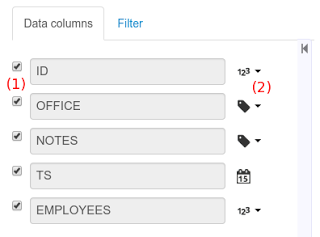
-
(1) To add or remove columns. Select only those columns you want to be part of the resulting data set
-
(2) Use the drop down image selector to change the column type
A data set may only contain columns of any of the following 4 types:
-
Label - For text values supporting group operations (similar to the SQL "group by" operator) which means you can perform data lookup calls and get one row per distinct value.
-
Text - For text values NOT supporting group operations. Typically for modeling large text columns such as abstracts, descriptions and the like.
-
Number - For numeric values. It does support aggregation functions on data lookup calls: sum, min, max, average, count, disctinct.
-
Date - For date or timestamp values. It does support time based group operations by different time intervals: minute, hour, day, month, year, …
No matter which remote system you want to retrieve data from, the resulting data set will always return a set of columns of one of the four types above. There exists, by default, a mapping between the remote system column types and the data set types. The user is able to modify the type for some columns, depending on the data provider and the column type of the remote system. The system supports the following changes to column types:
-
Label <> Text - Useful when we want to enable/disable the categorization (grouping) for the target column. For instance, imagine a database table called "document" containing a large text column called "abstract". As we do not want the system to treat such column as a "label" we might change its column type to "text". Doing so, we are optimizing the way the system handles the data set and
-
Number <> Label - Useful when we want to treat numeric columns as labels. This can be used for instance to indicate that a given numeric column is not a numeric value that can be used in aggregation functions. Despite its values are stored as numbers we want to handle the column as a "label". One example of such columns are: an item’s code, an appraisal id., …
|
BEAN data sets do not support changing column types as it’s up to the developer to decide which are the concrete types for each column. |
Filter
A data set definition may define a filter. The goal of the filter is to leave out rows the user does not consider necessary. The filter feature works on any data provider type and it lets the user to apply filter operations on any of the data set columns available.

While adding or removing filter conditions and operations, the preview table on central area is updated with live data that reflects the current filter status.
There exists two strategies for filtering data sets and it’s also important to note that choosing between the two have important implications. Imagine a dashboard with some charts feeding from a expense reports data set where such data set is built on top of an SQL table. Imagine also we only want to retrieve the expense reports from the "London" office. You may define a data set containing the filter "office=London" and then having several charts feeding from such data set. This is the recommended approach. Another option is to define a data set with no initial filter and then let the individual charts to specify their own filter. It’s up to the user to decide on the best approach.
Depending on the case it might be better to define the filter at a data set level for reusing across other modules. The decision may also have impact on the performance since a filtered cached data set will have far better performance than a lot of individual non-cached data set lookup requests. (See the next section for more information about caching data sets).
|
Notice, for SQL data sets, the user can use both the filter feature introduced or, alternatively, just add custom filter criteria to the SQL sentence. Although, the first approach is more appropriated for non technical users since they might not have the required SQL language skills. |
10.6.8.4. Data set editor
To edit an existing data set definition go the data set explorer, expand the desired data set definition and click on the Edit button. This will cause a new editor panel to be opened and placed on the center of the screen, as shown in the next screenshot:
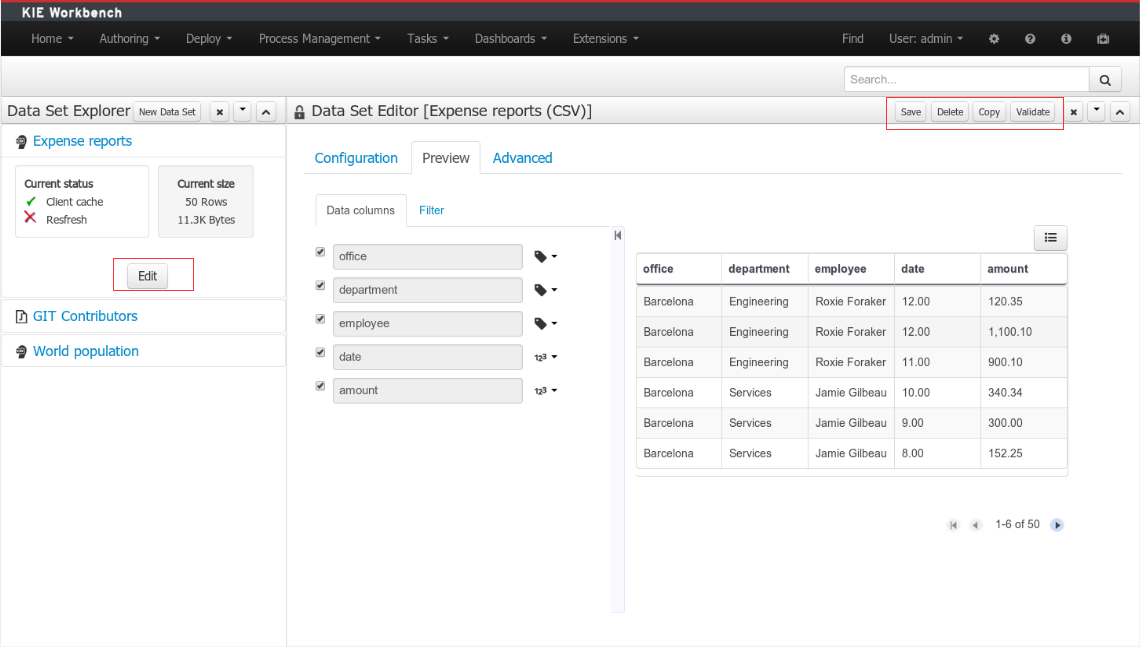

-
Save - To validate the current changes and store the data set definition.
-
Delete - To remove permanently from storage the data set definition. Any client module referencing the data set may be affected.
-
Validate - To check that all the required parameters exists and are correct, as well as to validate the data set can be retrieved with no issues.
-
Copy - To create a brand new definition as a copy of the current one.
|
Data set definitions are stored in the underlying GIT repository as JSON files. Any action performed is registered in the repository logs so it is possible to audit the change log later on. |
10.6.8.5. Advanced settings
In the Advanced settings tab area the user can specify caching and refresh settings. Those are very important for making the most of the system capabilities thus improving the performance and having better application responsive levels.
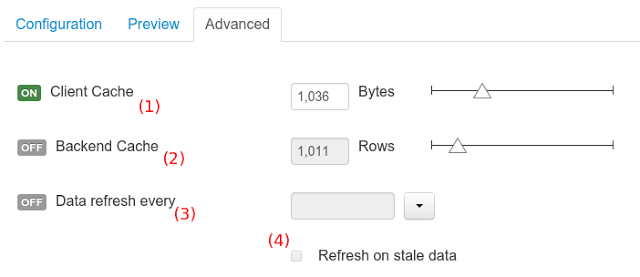
-
(1) To enable or disable the client cache and specify the maximum size (bytes).
-
(2) To enable or disable the backend cache and specify the maximum cache size (number of rows).
-
(3) To enable or disable automatic refresh for the Data set and the refresh period.
-
(4) To enable or disable the refresh on stale data setting.
Let’s dig into more details about the meaning of these settings.
10.6.8.6. Caching
The system provides caching mechanisms out-of-the-box for holding data sets and performing data operations using in-memory strategies. The use of these features brings a lot of advantages, like reducing the network traffic, remote system payload, processing times etc. On the other hand, it’s up to the user to fine tune properly the caching settings to avoid hitting performance issues.
Two cache levels are supported:
-
Client level
-
Backend level
The following diagram shows how caching is involved in any data set operation:
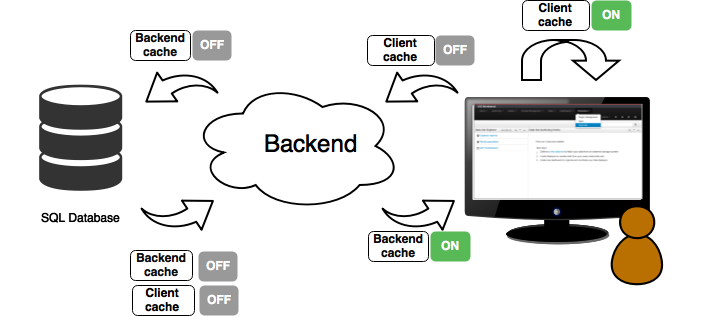
Any data look up call produces a resulting data set, so the use of the caching techniques determines where the data lookup calls are executed and where the resulting data set is located.
Client cache
If ON then the data set involved in a look up operation is pushed into the web browser so that all the components that feed from this data set do not need to perform any requests to the backend since data set operations are resolved at a client side:
-
The data set is stored in the web browser’s memory
-
The client components feed from the data set stored in the browser
-
Data set operations (grouping, aggregations, filters and sort) are processed within the web browser, by means of a Javascript data set operation engine.
If you know beforehand that your data set will remain small, you can enable the client cache. It will reduce the number of backend requests, including the requests to the storage system. On the other hand, if you consider that your data set will be quite big, disable the client cache so as to not hitting with browser issues such as slow performance or intermittent hangs.
Backend cache
Its goal is to provide a caching mechanism for data sets on backend side.
This feature allows to reduce the number of requests to the remote storage system , by holding the data set in memory and performing group, filter and sort operations using the in-memory engine.
It’s useful for data sets that do not change very often and their size can be considered acceptable to be held and processed in memory. It can be also helpful on low latency connectivity issues with the remote storage. On the other hand, if your data set is going to be updated frequently, it’s better to disable the backend cache and perform the requests to the remote storage on each look up request, so the storage system is in charge of resolving the data set lookup request.
|
BEAN and CSV data providers relies by default on the backend cache, as in both cases the data set must be always loaded into memory in order to resolve any data lookup operation using the in-memory engine. This is the reason why the backend settings are not visible in the Advanced settings tab. |
10.6.8.7. Refresh
The refresh feature allows for the invalidation of any cached data when certain conditions are meet.
-
(1) To enable or disable the refresh feature.
-
(2) To specify the refresh interval.
-
(3) To enable or disable data set invalidation when the data is outdated.
The data set refresh policy is tightly related to data set caching, detailed in previous section. This invalidation mechanism determines the cache life-cycle.
Depending on the nature of the data there exist three main use cases:
-
Source data changes predictable - Imagine a database being updated every night. In that case, the suggested configuration is to use a "refresh interval = 1 day" and disable "refresh on stale data". That way, the system will always invalidate the cached data set every day. This is the right configuration when we know in advance that the data is going to change.
-
Source data changes unpredictable - On the other hand, if we do not know whether the database is updated every day, the suggested configuration is to use a "refresh interval = 1 day" and enable "refresh on stale data". If so the system, before invalidating any data, will check for modifications. On data modifications, the system will invalidate the current stale data set so that the cache is populated with fresh data on the next data set lookup call.
-
Real time scenarios - In real time scenarios caching makes no sense as data is going to be updated constantly. In this kind of scenarios the data sent to the client has to be constantly updated, so rather than enabling the refresh settings (remember this settings affect the caching, and caching is not enabled) it’s up to the clients consuming the data set to decide when to refresh. When the client is a dashboard then it’s just a matter of modifying the refresh settings in the Displayer Editor configuration screen and set a proper refresh period, "refresh interval = 1 second" for example.
10.6.9. Data Source Management
The data source management system provides the ability of defining data sources for accessing external databases. This data sources can be later used by other workbench components like the Data Sets.
10.6.9.1. Database Drivers
To be able to communicate with the target database a data source will need a database driver to access it. This is why the system additionally provides the ability of defining database drivers for the data sources operation. A database driver is basically a JDBC compliant driver. We will see them in the next topics.
10.6.9.2. Data Source Authoring Page
Everything related to the authoring of data sources and drivers can be found under the Data Source Authoring page accessible from the following top level menu entry: Extensions>Data Sources, as shown in the following screenshot.
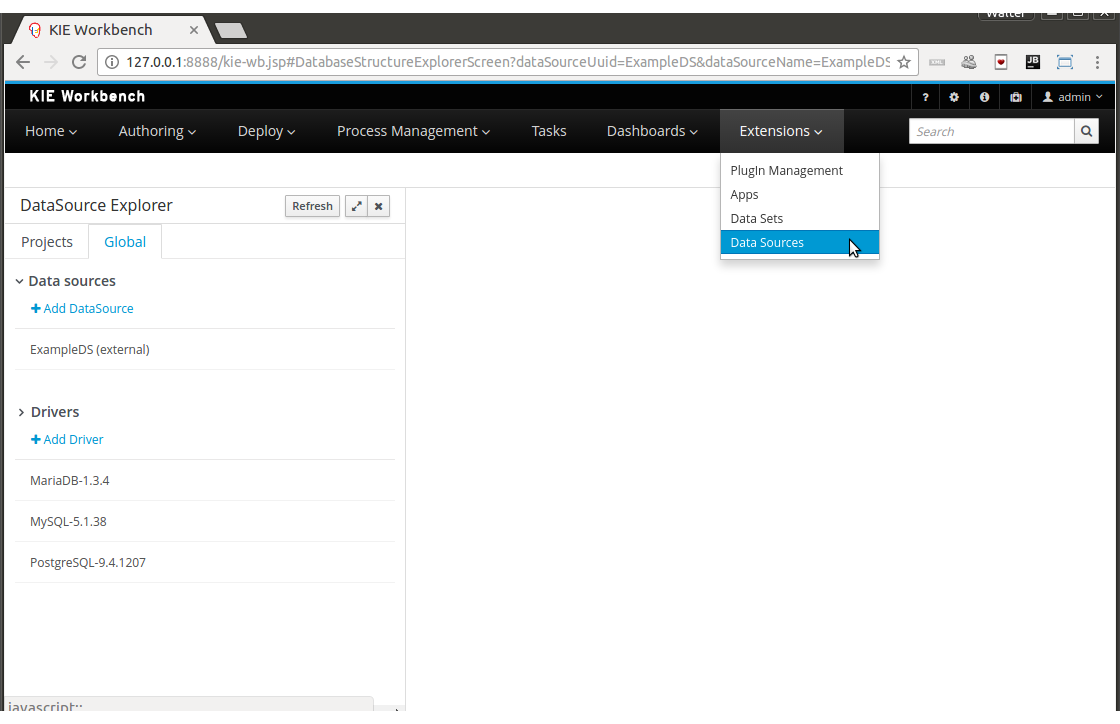
|
This page is only intended for Administrator users, since defining data sources can be considered a low level task. |
10.6.9.3. Data Source Explorer
The Data Source Explorer lists the data sources and drivers currently defined in the system, at the same time it provides the required actions for managing them.
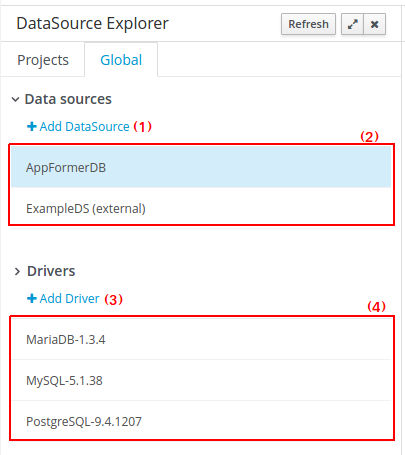
-
(1) Action link for creating a new data source
-
(2) List of currently available data sources
-
(3) Action link for creating a new driver
-
(4) List of currently available drivers
10.6.9.4. New Data Source Wizard
Clicking on the New Data Source action link opens the New Data Source Wizard:
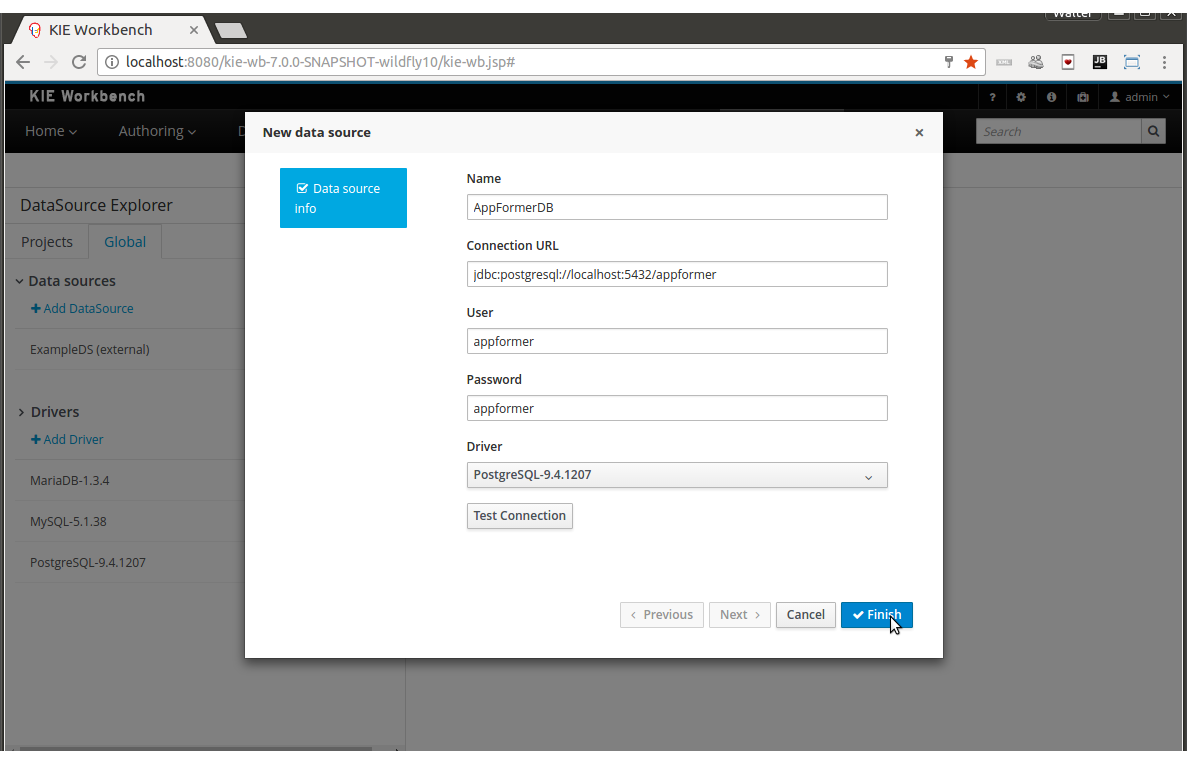
The following required parameters define a data source:
-
Name: A unique name for the data source definition.
-
Connection URL: A JDBC database connection url compliant with the selected driver type. This is an example of a connection url for a PostgreSQL database: jdbc:postgresql://localhost:5432/appformer.
-
User: A user name in the target database.
-
Password: The corresponding user password.
-
Driver: Selects the JDBC driver to be used for connecting to the target database. Note that the connection url format may vary depending on the driver, and different database vendors typically provides different drivers.
-
Test connection: Once clicked, the system will show a dialog similar to the one below showing the connection test status.
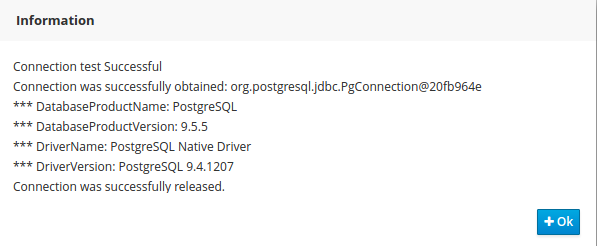
|
While not required, it’s recommended to use the test connection button to check the correctness of the data source parameters prior to finishing the data source creation. |
10.6.9.5. Data Source Editor
The Data Source Editor is opened by clicking on a data source item in the Data Source Explorer.
The following screenshot shows the Data Source Editor opened for the data source of the example above.
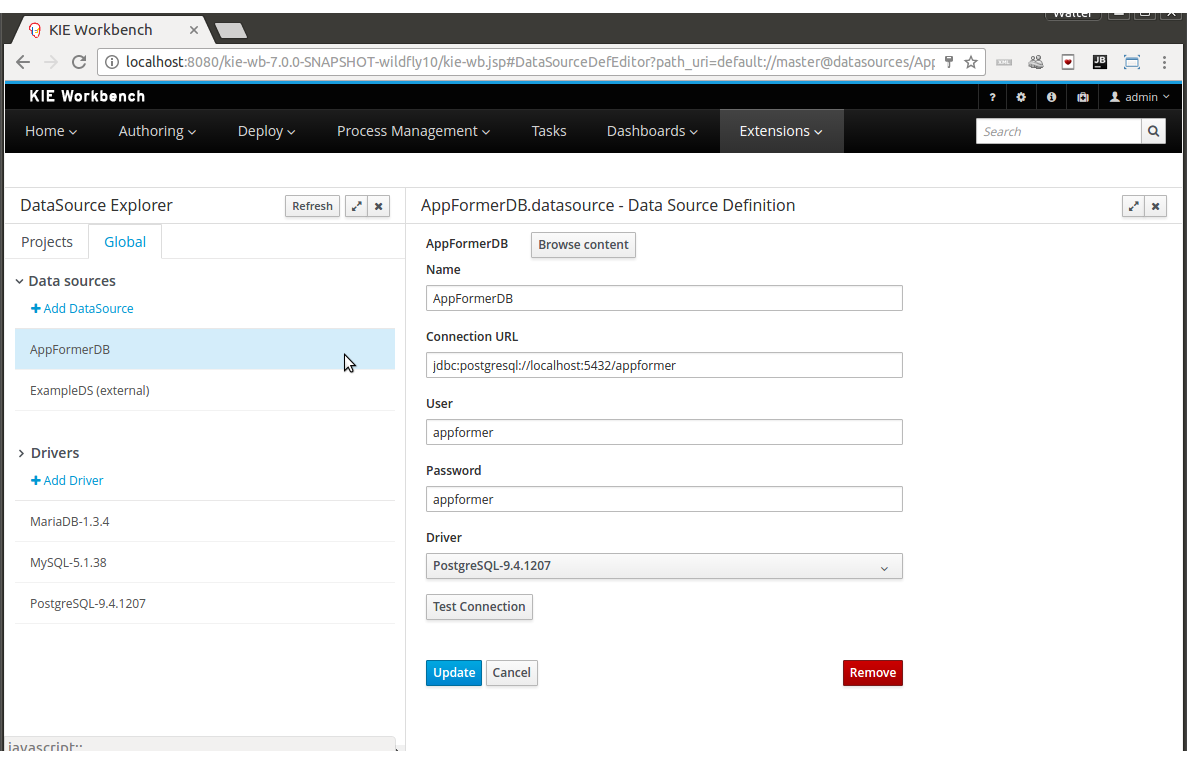
-
Main Panel: The main panel basically lets you modify the data source configuration parameters.
-
Test connection: Tests the connection.
|
It’s a recommended practice to test the connection prior saving a modified data source. |
10.6.9.6. Data Source Content Browser
The data source content browser is opened by clicking on the Browse Content button, and enables the navigation through the database structure pointed by the data source. The navigation is performed in three levels, Schemas level, Current schema level and Current table level.
-
Schemas level: lists all the database schemas accessible by current data source. Which schemas are listed depends on the database access rights granted to the user which was used in the connection configuration. Similarly for the following item.
-
Current schema level: shows all the database tables for the selected schema.
-
Current table level: shows the table content for the selected table.
The following screenshots show the information shown at each level, for a user that realized the following navigation steps. Selects the "public" schema → Selects the "country" table.
Schema Selection:
Clicking on the Open button opens the Current schema level for the selected schema.
Table Selection:
Clicking on the Open button opens the Current table level for the selected table.
Table information:
The rows for the selected table are shown at this level.
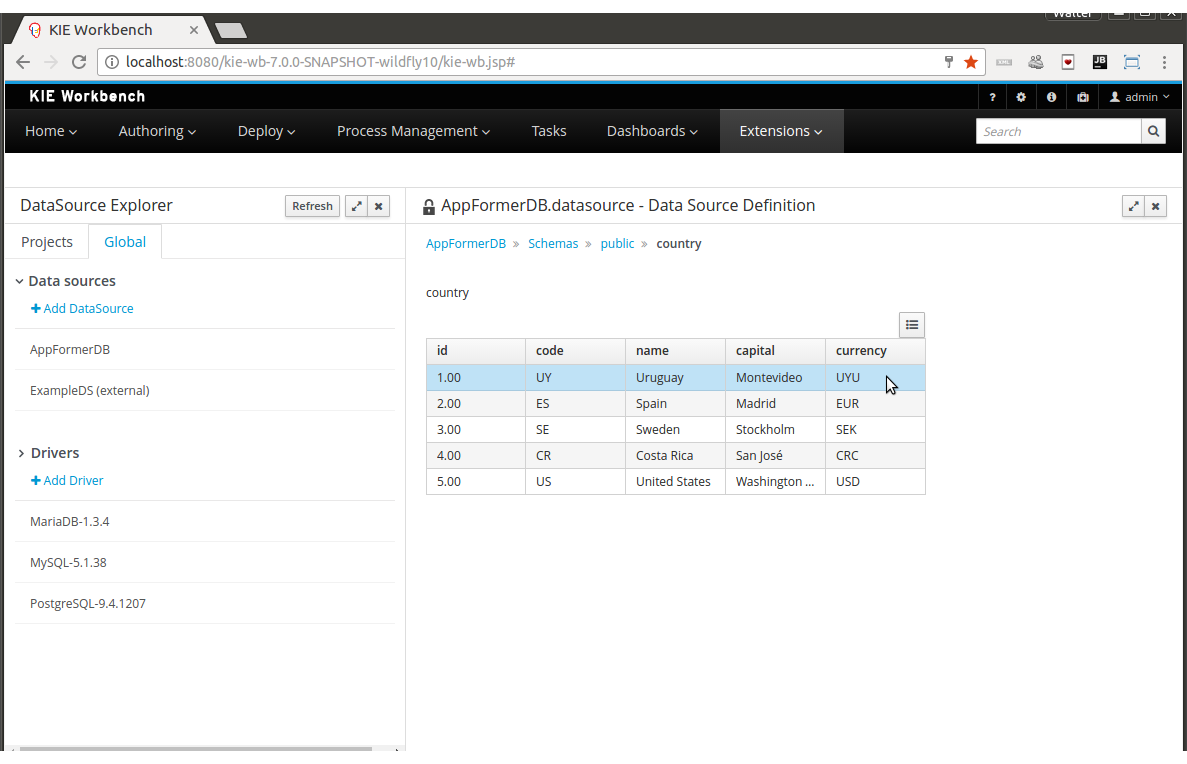
10.6.9.7. External Data Sources
External data sources are typically not defined in current workbench, instead they exist in current container and for some containers like Wildfly 11 or the JBoss EAP 7 servers they can still be listed in read only mode. In this cases only the Data Source Content Browser is enabled.
10.6.9.8. New Driver Wizard
Clicking on the New Driver action link opens the New Driver Wizard:
The following required parameters define a Driver:
-
Name: A unique name for the driver definition.
-
Driver Class Name: The java fully qualified name for the class that implements the JDBC driver contract.
-
Group Id: The maven group id for the artifact that contains the JDBC driver implementation.
-
Artifact Id: The maven artifact id for the artifact that contains the JDBC driver implementation.
-
Version: The maven version for the artifact that contains the JDBC driver implementation.
|
Some commercial database drivers (like Oracle) are not available in the maven central repository. You can use those by first uploading them via Artifact Repository page and then continue with the driver configuration as for the drivers available in the maven central repository. |
10.6.9.9. Driver Editor
The Driver Editor is opened by clicking on a driver item in the Data Source Explorer.
The following screenshot shows the Driver Editor opened for the driver of the example above.
-
Main Panel: The main panel basically lets you modify the driver configuration parameters. See New Driver Wizard.
10.6.9.10. By Default Drivers
The system is shipped with a set of by default configured drivers for the most common used open source databases. And they are aligned with the latest database versions supported by the Wildfly 11 and the JBoss EAP 7 servers.

|
The by default drivers initialization can be disabled by setting the datasource.management.disableDefaultDrivers configuration property to true. It can be set by configuring the proper value in the datasource-management.properties file, or by passing the system property -Ddatasource.management.disableDefaultDrivers=true to the JVM. For more information see Advanced Settings. |
10.6.9.11. Advanced Settings
The data source management system advanced settings can be found in the datasource-management.properties file in the WEB-INF/classes directory of the given Workbench distribution file.
The data source management system has the ability of working with two different internal implementations for the data sources and drivers. An implementation based on the Wildfly/EAP native data sources and drivers, and a container independent implementation. Wildfly/EAP Workbench distributions are configured by default for using the native Wildlfy/EAP containers implementations, and Tomcat8 distributions are configured for using the container independent implementations. This latter implementation can also be used for Wildfly/EAP containers.
The valid combinations are:
WildflyDataSourceProvider + WildflyDriverProvider
or
DBCPDataSourceProvider + DBCPDriverProvider
The datasource.management.wildfly.xxxxx properties are only suited for the WildflyXXXProviders.
10.6.9.12. Advanced Settings for Workbench Wildlfy/EAP distributions
| Property name | By default value | Description |
|---|---|---|
datasource.management.DataSourceProvider |
WildflyDataSourceProvider |
see Advanced Settings. |
datasource.management.DriverProvider |
WildflyDriverProvider |
see Advanced Settings. |
datasource.management.disableDefaultDrivers |
false |
Set to true for disabling the by default database drivers initialization. |
datasource.management.wildfly.host |
localhost |
Name or ip address used for the Wildlfy server management interface binding. |
datasource.management.wildfly.port |
9990 |
Port used for the Wildlfy server management interface binding. |
datasource.management.wildfly.admin |
Administration user for connecting to the Wildfly server running current Workbench. In general it’s not necessary to set this value but might be needed in cases when the Wildlfy management interface is bound to an address different than localhost. |
|
datasource.management.wildfly.password |
Administration user password for connecting to the Wildfly server running current Workbench. In general it’s not necessary to set this value but might be needed in cases when the Wildlfy management interface is bound to an address different than localhost. |
|
datasource.management.wildfly.realm |
ManagementRealm |
Realm for the administration user authentication. |
datasource.management.wildfly.profile |
The profile name used for starting the Wildfly domain, e.g. default, full, full-ha, etc. This value must only by set when the Workbench is running in clustering mode and the hosting Wildfly servers are configured by using domains. Do not set if the Wildlfy servers are running as standalone servers. |
|
datasource.management.wildfly.serverGroup |
The server group to which current Wildfly server instance belongs, e.g. primary-server-group, etc. This value must only by set when the Workbench is running in clustering mode and the hosting Wildfly servers are configured by using domains. Do not set if the Wildlfy servers are running as standalone servers. |
|
datasource.management.DefChangeHandler |
This value must only by set when the Workbench is running in clustering mode. If the hosting Wildfly servers are configured by using domains the following value must be used DomainModeChangeHandler and the the following value StandaloneModeChangeHandler must be used in cases when the hosting Wildlfy servers are running as standalone servers. Clustering installations that uses the DBCPXXXProviders must be configured for using the the StandaloneModeChangeHandler. |
|
The properties above can also be set by passing system properties to the JVM using the Java standard mechanism. e.g. -Ddatasource.management.wildfly.port=1234. Values configured by using this mechanism will override the values configured in the datasource-management.properties file. |
10.6.9.13. Advanced Settings for Tomcat distributions
| Property name | By default value | Description |
|---|---|---|
datasource.management.DataSourceProvider |
DBCPDataSourceProvider |
This is the only option available for Tomcat 8 distributions, see Advanced Settings. |
datasource.management.DriverProvider |
DBCPDriverProvider |
This is the only option available for Tomcat 8 distributions, see Advanced Settings. |
datasource.management.disableDefaultDrivers |
false |
Set to true for disabling the by default database drivers initialization. |
datasource.management.DefChangeHandler |
This value must only by set when the Workbench is running in clustering mode. Tomcat distributions only support the StandaloneModeChangeHandler value. |
|
The properties above can also be set by passing system properties to the JVM using the Java standard mechanism. e.g. -Ddatasource.management.wildfly.port=1234. Values configured by using this mechanism will override the values configured in the datasource-management.properties file. |
10.7. Security management
This section describes how administrator users can manage the application’s users, groups and permissions using an intuitive and friendly user interface in order to configure who can access the different resources and features available.
10.7.1. Basic concepts
10.7.1.1. Introduction to the workbench’s users, groups and roles
The workbench’s security domain defines three kind of entities: user, group and role.
The security entities are being registered in the domain by consuming some realm. The realm can be either the application server’s one (Wildfly, EAP, Tomcat) or any other of the supported types, for example, using some Keycloak remote server that performs handles the target realm.
On the other hand, it’s important to notice that each realm provides, or potentially provides, its own capabilities, semantics or structure on the security domain. These kind of differences on the security domain results on inconsistencies between different environments when moving into the workbench’s security domain. This way there exist some conventions which are important to understand - how security entities are being declared and how the platform behaves behind that complexity,
The way the workbench integrates the security entities from an external realm corresponds to:
-
User
A user, rather than attributes and some any other kind of metadata, which can be different across domains, represents the same kind entity in any of the supported security environments (Wildfly, EAP, Tomcat, Keybloak, etc), so the entity results in a user on the workbench as well
-
Role / Group
Both role and group are security entities, but rather than a user, the semantics, the behaviors or the structure in the domain is not usually common across environments. As an example consider that exist domains which do not support both, or domains were the semantics for group or role differs. As it results domain specific, the way the application behaves and figures out if an entity should be considered a group or a role, it’s by checking the application’s Role Registry. This way an entity will be considered an role in case it’s identifier is present in the application’s Role Registry, otherwise the entity will be considered as a group.
|
The Role Registry is an application’s component that provides the set of roles in the workbench’s security domain. It’s being populated by consuming the entities (role-name) declared in the security-constraints section on the application’s deployment descriptor (web.xml). See source file org.uberfire.ext.security.server.RolesRegistry. |
|
It means that depending on the concrete environment’s configuration, some entity can be as a role, on the security environment consumed by the workbench, but it results a group in the workbench’s security domain, or vice versa. It depends on the entity’s identifier by checking it it is present in the Role Registry. |
|
A User can be assigned to multiple roles and groups, but it is mandatory to have at least, a single role assignment for being considered valid in the workbench’s security domain. It does not mean, for instance, that the user is able login, or able to consume remote services, because it depends on the concrete role/s assigned and how the roles and permissions are defined the application. |
10.7.1.2. Permissions
A permission is basically something the user can do within the application. Usually, an action related to a specific resource. For instance:
-
View a page
-
Save a project
-
View a repository
-
Delete a dashboard
A permission can be granted or denied and it can be global or resource specific. For instance:
-
Global: “Create new pages”
-
Specific: “View the home page”
As you can see, a permission is a resource + action pair. In the concrete case of a page we have: read, update, delete and create as the available actions. That means that there are four possible permissions that could be granted for pages.
Permissions do not necessarily need to be tied to a resource. Sometimes it is also neccessary to protect access to specific features, like for instance "generate a sales report". That means, permissions can be used not only to protect access to resources but also to custom features within the application.
10.7.1.3. Authorization policy
The set of permissions assigned to every role and/or group is called the authorization (or security) policy. Every application contains a single security policy which is used every time the system checks a permission.
The authorization policy file is stored in a file called WEB-INF/classes/security-policy.properties under the application’s WAR structure.
| If no policy is defined then the authorization management features are disabled and the application behaves as if all the resources & features were granted by default. |
Here is an example of a security policy file:
# Role "admin"
role.admin.permission.perspective.read=true
role.admin.permission.perspective.read.Dashboard=false
# Role "user"
role.user.permission.perspective.read=false
role.user.permission.perspective.read.Home=true
role.user.permission.perspective.read.Dashboard=trueEvery entry defines a single permission which is assigned to a role/group. On application start up, the policy file is loaded and stored into memory.
10.7.1.4. Security provider
A security environment is usually provided by the use of a realm. Realms are used to restrict access to the different application’s resources. So realms contains the information about the users, groups, roles, permissions and any other related information.
In most typical scenarios the application’s security is delegated to the container’s security mechanism, which consumes a given realm at same time. It’s important to consider that there exist several realm implementations, for example Wildfly provides a realm based on the application-users.properties/application-roles.properties files, Tomcat provides a realm based on the tomcat-users.xml file, etc. So there is no single security realm to rely on, it can be different in each installation.
Due to the potential different security environments that have to be supported, the security module provides a well defined API with some default built-in security providers. A security provider is the formal name given to a concrete user and group management service implementation for a given realm.
The user & group management features available will depend on the security provider configured. If the built-in providers do not fit with the application’s security realm, it is easy to build and register your own provider.
10.7.2. Installation and setup
At the time of this writing, the application provides two pre-installed security providers:
-
Wildfly 11 / EAP 7 distribution - Both distributions use the Wildfly security provider configured for the use of the default realm files application-users.properties and application-roles.properties
-
Tomcat distribution - It uses the Tomcat security provider configured for the use of the default realm file tomcat-users.xml
Please read each provider’s documentation in order to apply the concrete settings for the target deployment environment.
On the other hand, when either using a custom security provider or using one of the availables, consider the following installation options:
-
Enable the security management feature on an existing WAR distribution
-
Setup and installation in an existing or new project
NOTE: If no security provider is installed, there will be no available user interface for managing the security realm. Once a security provider is installed and setup, the user and group management features are automatically enabled in the security management UI (see the Usage section below).
10.7.2.1. Enabling user & group management
Given an existing WAR distribution, follow these steps in order to install and enable the user & group management features:
-
Ensure the following libraries are present on WEB-INF/lib:
-
WEB-INF/lib/uberfire-security-management-api-?.jar
-
WEB-INF/lib/uberfire-security-management-backend-?.jar
-
-
Copy the the security provider library to WEB-INF/lib:
-
Eg: WEB-INF/lib/uberfire-security-management-wildfly-?.jar
-
If the provider requires additional libraries, copy them as well (read each provider’s documentation for more information).
-
-
Replace the whole content of the WEB-INF/classes/security-management.properties file, or if not present, create it. The settings present on this file depend on the concrete implementation used. Please read each provider’s documentation for more information.
-
If deploying on Wildfly or EAP, check if the WEB-INF/jboss-deployment-structure.xml requires any update (read each provider’s documentation for more information).
10.7.2.2. Disabling user & group management
The user & groups management features can be disabled, and thus no services or user interface will be available, by means of either:
-
Uninstalling the security provider from the application
When no concrete security provider is installed, the user and group management features will be disabled and no services or user interface will be displayed to the user. This is the case for instance, in Weblogic and Websphere installations as there is no a security provider implementation available at the time of this writing.
-
Removing or commenting the security management configuration file
Removing or commenting all the lines in the configuration file located at WEB-INF/classes/security-management.properties is another way to disable the user and group management features.
10.7.2.3. Upgrading an existing installation
In versions prior to 7, the only way to grant access to resources like Organizational Units, Repositories or Projects was to indicate which roles were able to access a given instance. Those roles were stored in GIT as part of the instance persistent status. The CLI was the tool used to add/remove roles:
-
remove-role-repo: remove role(s) from repository
-
add-role-org-unit: add role(s) to organizational unit
-
remove-role-org-unit: remove role(s) from organizational unit
-
add-role-project: add role(s) to project
-
remove-role-project: remove role(s) from project
As of version 7, the authorization policy is based on permissions. That means is no longer required to keep a list of roles per resource instance. What is required is to define proper permission entries into the active authorization policy using the security management UI (see the Usage section below).
The commands above are no longer required so they have been removed. Basically, what those commands did is to set what roles were able to read a specific item.
In order to guarantee backward compatibility with versions prior to 7, an automatic migration tool is bundled within the application, which converts the list of roles assigned to any organizational unit, repository or project into read permission entries of the security policy.
This tool is executed when the application start ups for the first time, during the security policy deployment. So existing customers, do not have to worry about it, as they will keep their security settings.
10.7.3. Usage
The Security Management page is available under the Home section in the top menu bar.
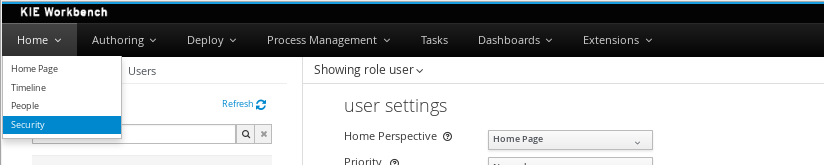
The next screenshot shows how this new page looks:
This page supports:
-
List all the roles, groups and users available
-
Create & delete users and groups
-
Edit users, assign roles or groups, and change user properties
-
Edit both roles & groups security settings, which include:
-
The home page a user will be directed to after login
-
The permissions granted or denied to the different workbench resources and features available
-
All of the above together provides a complete users and groups management subsystem as well as a permission configuration UI for protecting access to specific resources or features.
The next sections provide a deep insight into all these features.
| The user and group management related features can be entirely disabled. See the previous section Disabling user & group management. If that’s the case then both the Groups and _Users tabs will remain hidden from the user. |
10.7.3.1. User management
By selecting the Users tab in the left sidebar, the application shows all the users present by default on the application’s security realm:
-
Searching for users
In addition to listing all the users, search is also allowed:
+ When specifying the search pattern in the search box the users listed will be reduced to only those that matches the search pattern.
+
+ Search patterns depend on the concrete security provider being used by the application. Please read each provider’s documentation for more information.
-
Creating new users
By clicking on the "New user +" anchor, a form is displayed on the screen’s right.
This is a wizard like interface where the application asks for the new user name, a password as well as what roles/groups to assign.
-
Editing a user
After clicking on a user in the left sidebar, the user editor is opened on the screen’s right.
For instance, the details screen for the admin user when using the Wildfly security provider looks like the following screenshot:
Same screen but when using the Keycloak security provider looks as:
Note that when using the Keycloak provider, a new user attributes section is displayed, but it’s not present when using the Wildfly provider. This is due to the fact that the information and actions available always depend on each provider’s capabilities as explained in the Security provider capabilities section below.
Next is the type of information handled in the user’s details screen:
-
The user name
-
The user’s attributes
-
The assigned groups
-
The assigned roles
-
The permissions granted or denied
In order to update or delete an existing user, click on the Edit button present near to the username in the user editor screen:
Once the editor is in edit mode, different operations can be done (provided the security provider supports them):
For instance, to modify the set of roles and groups assigned to the user or to change the user’s password as well.
-
Permissions summary
The Permissions tab shows a summary of all the permissions assigned to this particular user. This is a very helpful view as it allows administrator users to verify if a target user has the right permission levels according to the security settings of its roles and groups.
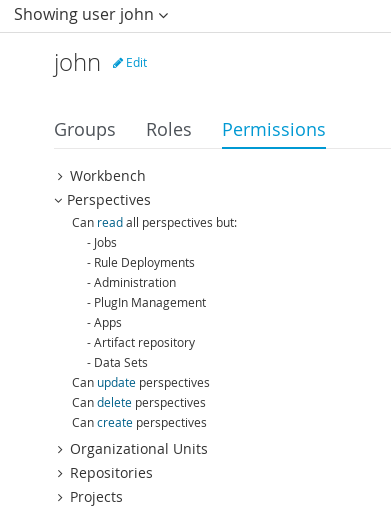
Further details about how to assign permissions to roles and groups are in the Security Settings Editor section below.
-
Updating the user’s attributes
User attributes can added or deleted using the actions available in the attributes table:
-
Updating assigned groups
From the Groups tab, a group selection popup is presented when clicking on the Add to groups button:
This popup screen allows the user to search and select or deselect the groups assigned to the user.
-
Updating assigned roles
From the Roles tab, a role selection popup is presented when clicking on Add to roles button:
This popup screen allows the user to search and select or deselect the roles assigned to the user.
-
Changing the user’s password
A change password popup screen is presented when clicking on the Change password button:
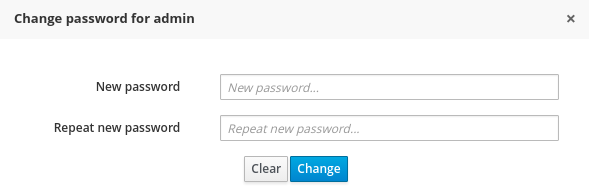
-
Deleting users
The user currently being edited can be deleted from the realm by clicking on the Delete button.
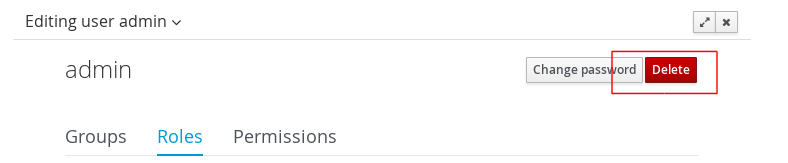
Security provider capabilities
Each security realm can provide support for different operations. For example consider the use of a Wildfly’s realm based on properties files. The contents for the applications-users.properties is like:
admin=207b6e0cc556d7084b5e2db7d822555c
salaboy=d4af256e7007fea2e581d539e05edd1b
maciej=3c8609f5e0c908a8c361ca633ed23844
kris=0bfd0f47d4817f2557c91cbab38bb92d
katy=fd37b5d0b82ce027bfad677a54fbccee
john=afda4373c6021f3f5841cd6c0a027244
jack=984ba30e11dda7b9ed86ba7b73d01481
director=6b7f87a92b62bedd0a5a94c98bd83e21
user=c5568adea472163dfc00c19c6348a665
guest=b5d048a237bfd2874b6928e1f37ee15e
kiewb=78541b7b451d8012223f29ba5141bcc2
kieserver=16c6511893651c9b4b57e0c027a96075Notice that it’s based on key-value pairs where the key is the username, and the value is the hashed value for the user’s password. So a user is just represented by a key and its username, it does not have a name nor an address or any other meta information.
On the other hand, consider the use of a realm provided by a Keycloak server. The user information is composed by more meta-data, such as the surname, address, etc, as in the following image:
So the different services and client side components from the User and Group Management API are based on capabilities. Capabilities are used to expose or restrict the available functionality provided by the different services and client side components. Examples of capabilities are:
-
Create a user
-
Update a user
-
Delete a user
-
Update user’s attributes
-
Create a group
-
Update a group
-
Assign groups to a user
-
Assign roles to a user
Each security provider must specify a set of capabilities supported. From the previous examples, it is noted that the Wildfly security provider does not support the attributes management capability - the user is only composed by the user name. On the other hand the Keycloak provider does support this capability.
The different views and user interface components rely on the capabilities supported by each provider, so if a capability is not supported by the provider in use, the UI does not provide the views for the management of that capability. As an example, consider that a concrete provider does not support deleting users - the delete user button on the user interface will be not available.
Please take a look at the concrete service provider documentation to check all the supported capabilities for each one, the default ones can be found here.
10.7.3.2. Group management
By selecting the Groups tab in the left sidebar, the application shows all the groups present by default on the application’s security realm:
-
Searching for groups
In addition to listing all the groups, search is also allowed:
+ When specifying the search pattern in the search box the groups listed will be reduced to only those that matches the search pattern.
+
+ Search patterns depend on the concrete security provider being used by the application. Please read each provider’s documentation for more information.
-
Creating new groups
By clicking on the "New group +" anchor, a new screen will be presented on the center panel to perform a new group creation.
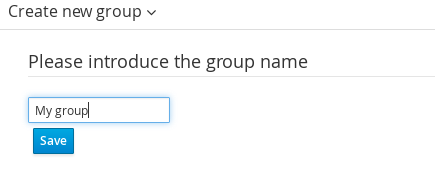
After typing a name anc clicking Save, the next step is to assign users to it:
+
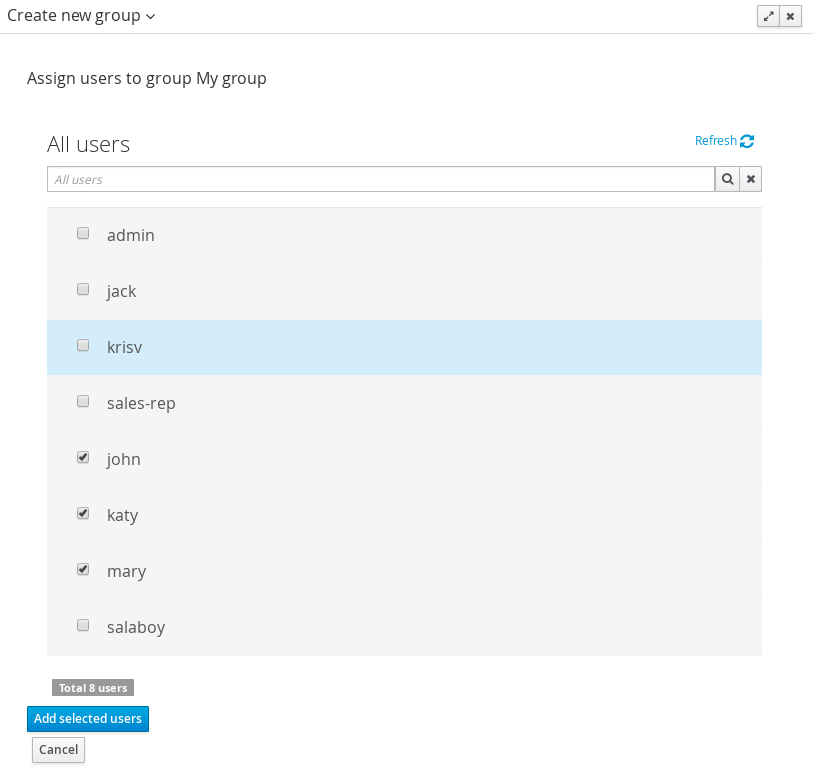
+ Clicking on the "Add selected users" button finishes the group creation.
-
Modifying a group
After clicking on a group in the left sidebar, the security settings editor for the selected group instance is opened on the screen’s right. Further details at the Security Settings Editor section.
-
Deleting groups
To delete an existing group just click on the Delete button.
10.7.3.3. Role management
By selecting the Roles tab in the left sidebar, the application shows all the application roles:
Unlike users and groups, roles can not be created nor deleted as they come from the application’s web.xml descriptor. After clicking on a role in the left sidebar, the role editor is opened on the screen’s right, which is exactly the same security settings editor used for groups. Further details at the Security Settings Editor section.
That means both role and group based permissions can be defined. The main diference between roles and group are:
-
Roles are an application defined resource. They are defined as <security-role> entries in the application’s web.xml descriptor.
-
Groups are dynamic and can be defined at runtime. The installed security provider determines where groups instances are stored.
They can be used together without any trouble. Groups are recommended though as they are a more flexible than roles.
-
Searching for roles
In addition to listing all the roles, search is also allowed:
+ When specifying the search pattern in the search box the roles listed will be reduced to only those that matches the search pattern.
+
+ Search patterns depend on the concrete security provider being used by the application. Please read each provider’s documentation for more information.
10.7.4. Security Settings Editor
This editor is used to set several security settings for both roles and groups.
+
10.7.4.1. Home page
This is the page where the user is directed after login. This makes it possible to have different home pages for different users, since users can be assigned to different roles or groups.
10.7.4.2. Priority
It is used to determine what settings (home page, permissions, …) have precedence for those users with more that one role or group assigned.
Without this setting, it won’t be possible to determine what role/group should take precedence. For instance, an administrative role has higher priority than a non-administrative one. For users with both administrative and non-administrative roles granted, administrative privileges will always win, provided the administrative role’s priority is greater than the other.
10.7.4.3. Permissions
Currently, the workbench support the following permission categories.
-
Workbench: General workbench permissions, not tied to any specific resource type.
-
Pages: If access to a page is denied then it will not be shown in any of application menus. Update, Delete and Create permissions change the behaviour of the page management plugin editor.
-
Organizational Units: Sets who can Create, Update or Delete organizational units from the Organizational Unit section at the Administration page. Sets also what organizational units are visible in the Project Explorer at the Project Authoring page.
-
Repositories: Sets who can Create, Update or Delete repositories from the Repositories section at the Administration page. Sets also what repositories are visible in the Project Explorer at the Project Authoring page.
-
Projects: In the Project Authoring page, sets who can Create, Update, Delete or Build projects from the Project Editor screen as well as what projects are visible in the Project Explorer.
For pages, organizational units, repositories and projects it is possible to define global permissions and add single instance exceptions afterwards. For instance, Read access can be granted to all the pages and deny access just to an individual page. This is called the grant all deny a few strategy.

The opposite, deny all grant a few strategy is also supported:

| In the example above, the Update and Delete permissions are disabled as it does not makes sense to define such permissions if the user is not even able to read pages. |
10.7.5. Security Policy Storage
The security policy is stored under the workbench’s VFS. Most concrete, in a GIT repo called “security”. The ACL table is stored in a file called “security-policy.properties” under the “authz” directory. Next is an example of the entries this file contains:
role.admin.home=HomePage
role.admin.priority=0
role.admin.permission.perspective.read=true
role.admin.permission.perspective.create=true
role.admin.permission.perspective.delete=true
role.admin.permission.perspective.update=trueEvery time the ACL is modified from the security settings UI the changes are stored into the GIT repo.
Initially, when the application is deployed for the first time there is no security policy stored in GIT. However, the application might need to set-up a default policy with the different access profiles for each of the application roles.
In order to support default policies the system allows for declaring a security policy as part of the webapp’s content. This can be done just by placing a security-policy.properties file under the webapp’s resource classpath (the WEB-INF/classes directory inside the WAR archive is a valid one). On app start-up the following steps are executed:
-
Check if an active policy is already stored in GIT
-
If not, then check if a policy has been defined under the webapp’s classpath
-
If found, such policy is stored under GIT
The above is an auto-deploy mechanism which is used in the workbench to set-up its default security policy.
One slight variation of the deployment process is the ability to split the “security-policy.properties” file into small pieces so that it is possible, for example, to define one file per role. The split files must start by the “security-module-” prefix, for instance: “security-module-admin.properties”. The deployment mechanism will read and deploy both the "security-policy.properties" and all the optional “security-module-?.properties” found on the classpath.
Notice, despite using the split approach, the “security-policy.properties” must always be present as it is used as a marker file by the security subsystem in order to locate the other policy files. This split mechanism allows for a better organization of the whole security policy.
10.8. Embedding Workbench in Your Application
Apart from the individual perspectives (such as the Library or Content Management), the Workbench provides a number of editors used for designing and managing assets in different formats. Within the Workbench, each asset type has a corresponding editor.
The Workbench provides the possibility to embed the perspectives and editors in the user’s application using the standalone mode. Without actually switching to the Workbench, it is possible to display perspectives and edit various assets, such as rules, processes, or decision tables, in separate applications.
To embed a part of the Workbench in an application, the Workbench must be deployed and running on a web server or an application server. Then, in your application, include an HTML inline frame with the proper HTTP query parameters as described in the following table.
| Parameter | Values | Description |
|---|---|---|
|
none |
This parameter must be included in each URL of a perspective or an editor that will be used in the standalone mode. |
|
|
Used for specifying the perspective to be displayed. |
|
|
Displays the breadcrumbs at the top of the page that can be used for navigating to the lists of spaces and projects within the Library. This parameter can be used only if |
|
|
Specifies the path to the asset to be opened in a corresponding editor. The path must be specified in the format |
| URL | Description |
|---|---|
http://localhost:8080/business-central/kie-wb.jsp?standalone&perspective=LibraryPerspective |
Opens the Library where it is possible to select a project to be managed. |
Opens the Library with the list of projects. The |
|
Opens the editor of the specified asset. |
|
http://localhost:8080/business-central/kie-wb.jsp?standalone&perspective=ContentManagerPerspective |
Opens the Content Management perspective, where it is possible to create and manage custom pages. |
http://localhost:8080/business-central/kie-wb.jsp?standalone&perspective=MyCustomPage |
Opens the specified custom page that has been created before using the Content Management perspective. The value of the |
10.9. Execution Server Management UI
The Execution Server Management UI allows users create and modify Server Templates and Containers, it also allows users manage Remote Servers. This screen is available via Deploy → Rule Deployments menu.
|
The management UI is only available for KIE Managed Servers. |
10.9.1. Server Templates
Server templates are used to define a common configuration that can be used for multiple server, thus the name: Template.
Server Templates can be created directly from the management UI or it’s automatically create when a server connects to controller and there isn’t a template definition for that remote server. Server templates may have one or more capabilities, such capabilities can’t be modified, if you need modify the capabilities you’ll have to create a new template. Here is the list of current capabilities:
-
Rule (Drools)
-
Process (jBPM)
-
Planning (Optaplanner)
|
For Planner capability it’s mandatory to enable Rule’s capability too. |
In order to create a new Server Template you have to click at New Server Template button and follow the wizard. It’s also possible to create a container during Wizard, but for now let’s limit to just the template.
Once created you’ll get the new Template listed on the left hand side, with the new Server Template highlighted. On the right hand side you get the 2nd level navigation that lists Containers and Remote Servers that are related to selected Server Template.
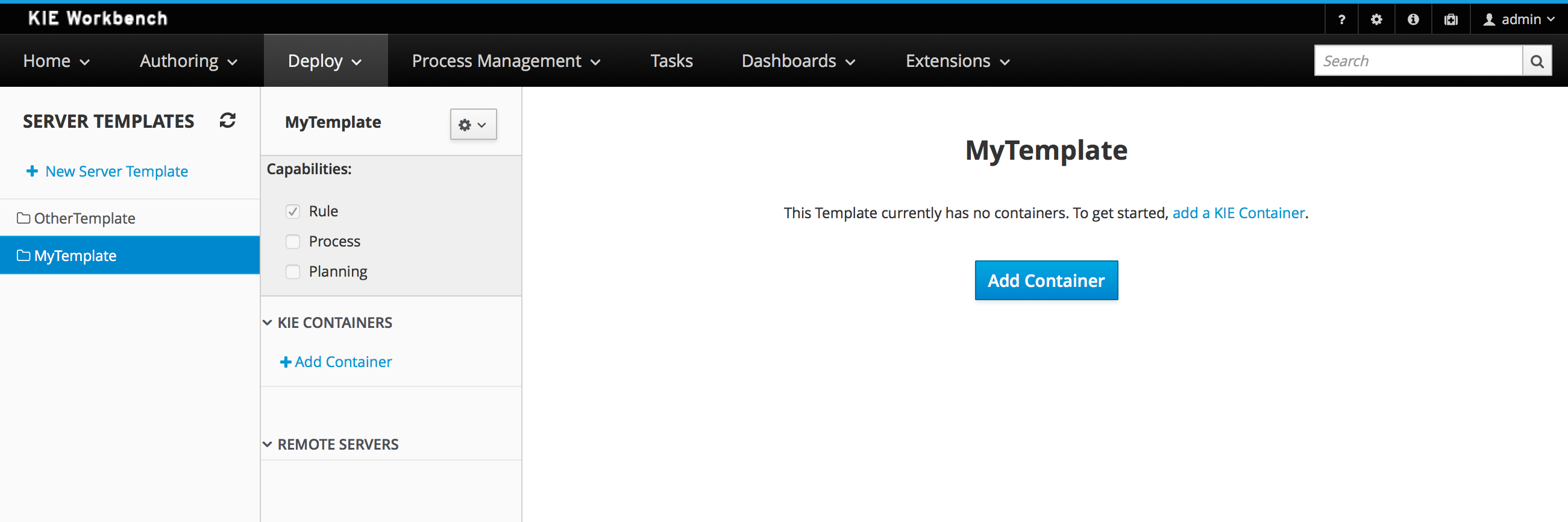
On top of the navigation is also possible to delete the current Server Template or create a copy of it.
10.9.2. Container
A Container is a KIE Container configuration of the Server Template. Click the Add Container button to create a new container for the current Server Template.
The search area can help users find an specific KJARs that they are looking for.
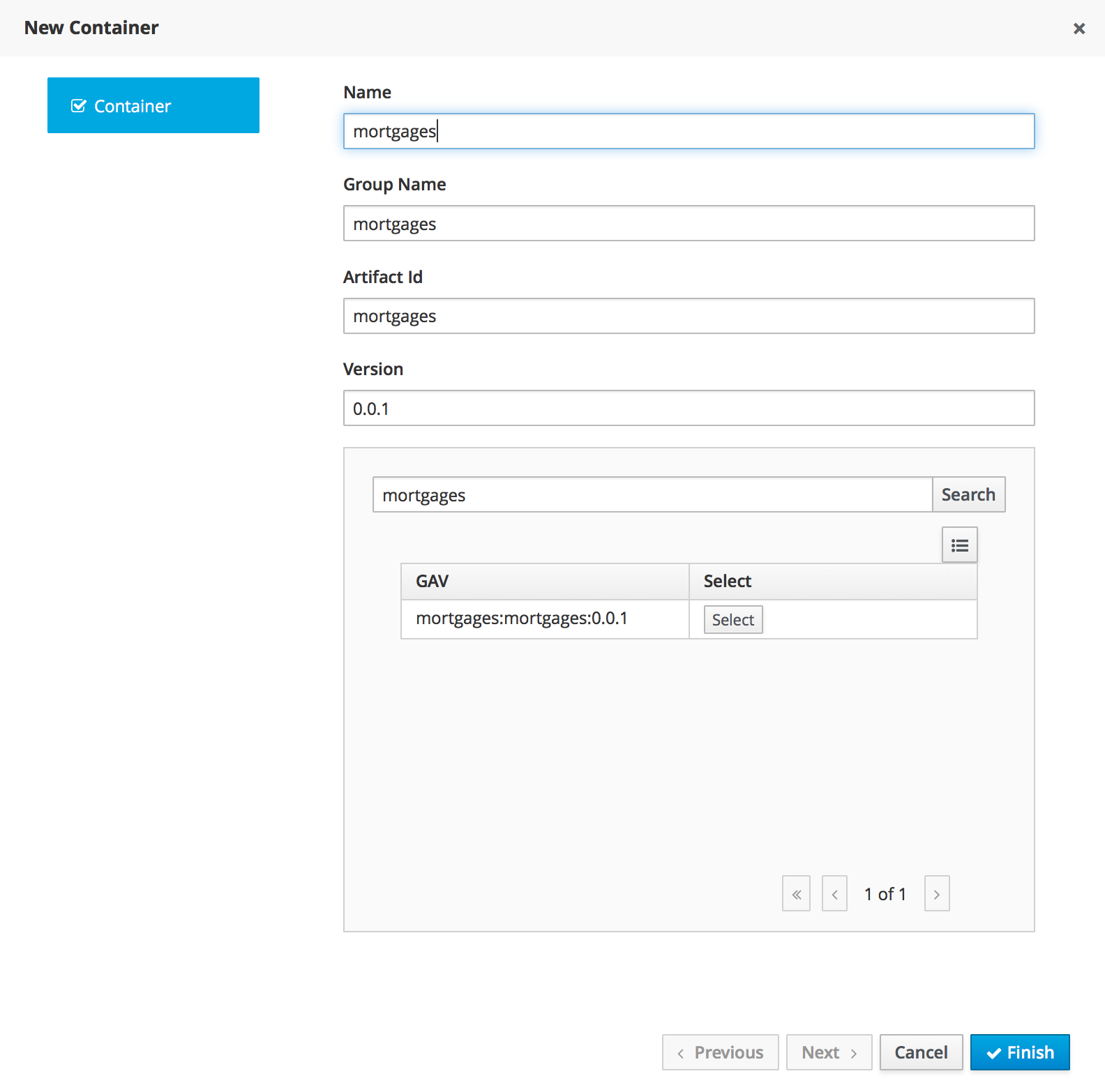
For Server Templates that have Process capabilities enabled, the Wizard has a 2nd optional step where users can configure some process related behaviors.
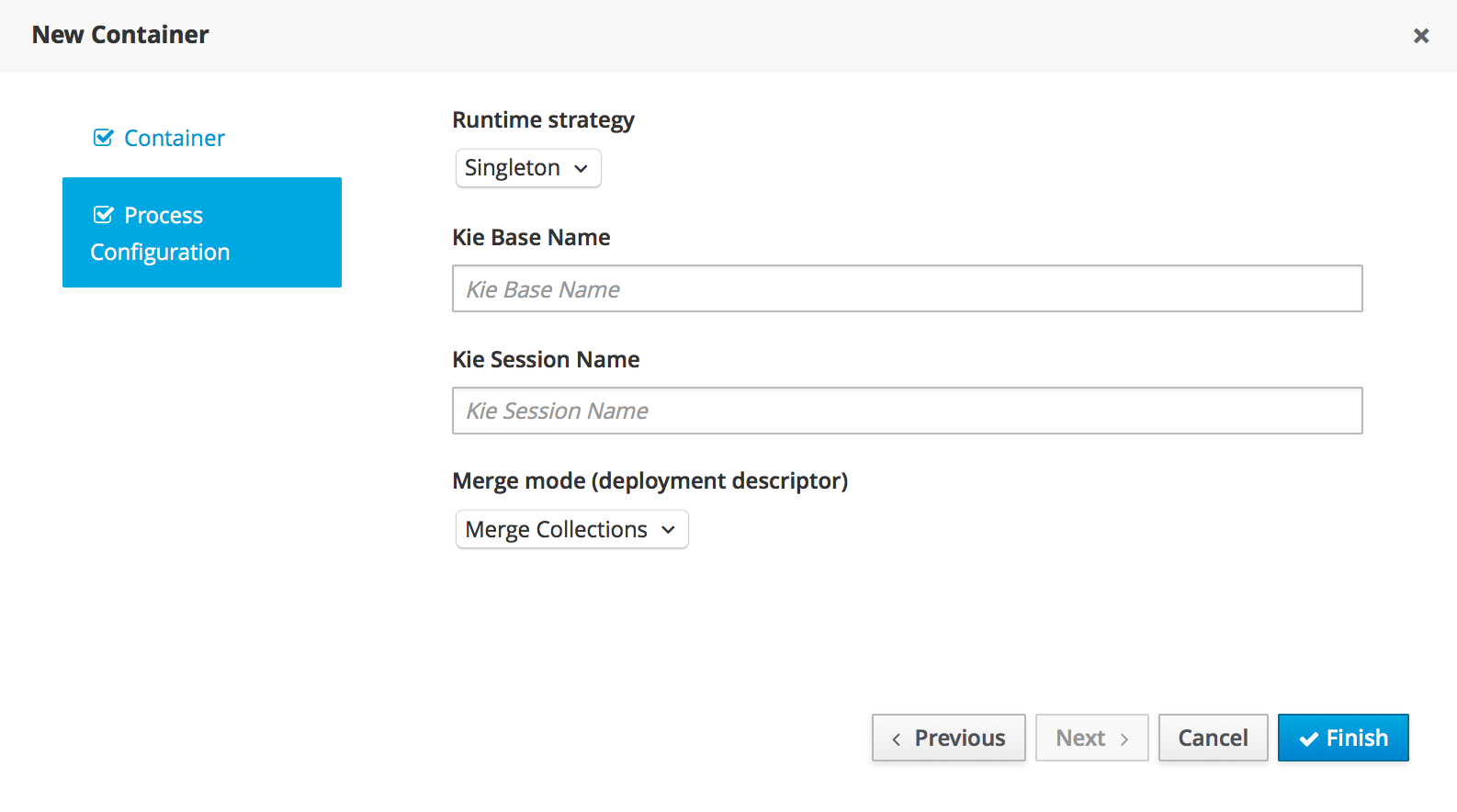
Kie Base Name determines which Kie Base of the deployed artifact will be used.
Kie Session Name determines which Kie Session of the selected Kie Base will be used.
|
Please notice that configurations on this tab takes effect only if the deployed project contains some business processeses. It is not enough if the server template has the extension for processes enabled. |
Once created the new Container will be displayed on the containers list just above the list of remote servers. Just after created a container is by default Stopped which is the only state that allows users to remove it.
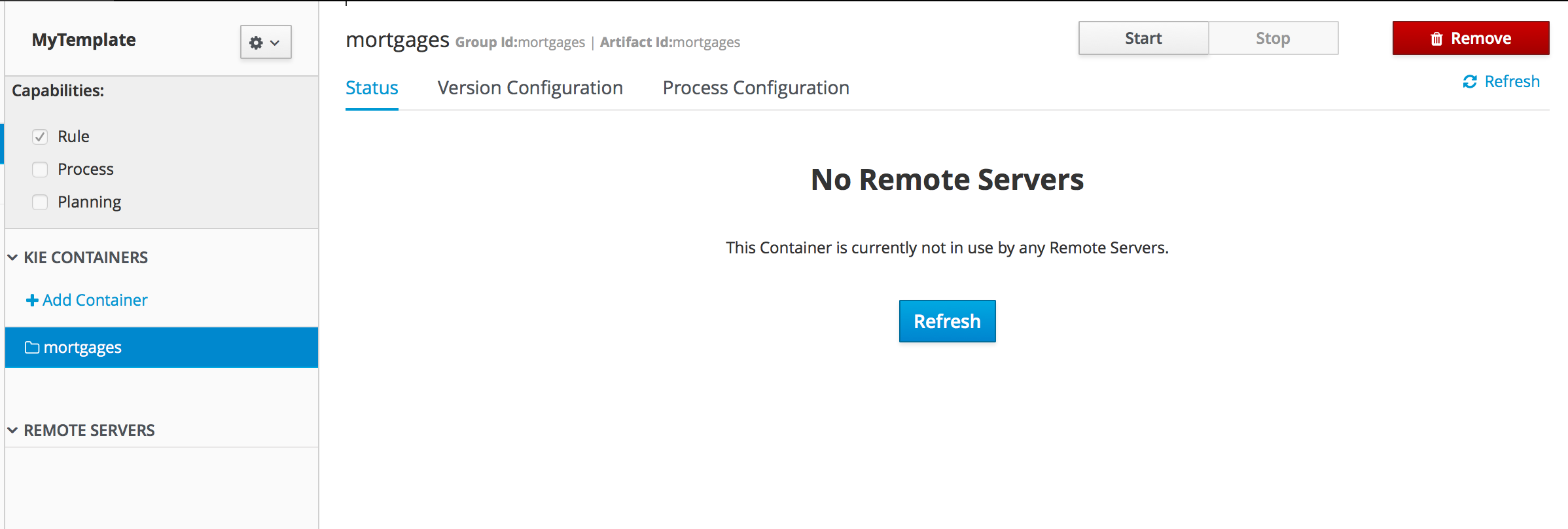
A Container has the following tabs available for management and/or configuration:
-
Status
-
Version Configuration
-
Process Configuration
Status tab lists all the Remote Servers that are running the active Container. Each Remote Server is rendered as a Card, which displays to users status and endpoint.
|
Only started Containers are deployed to remote servers. |
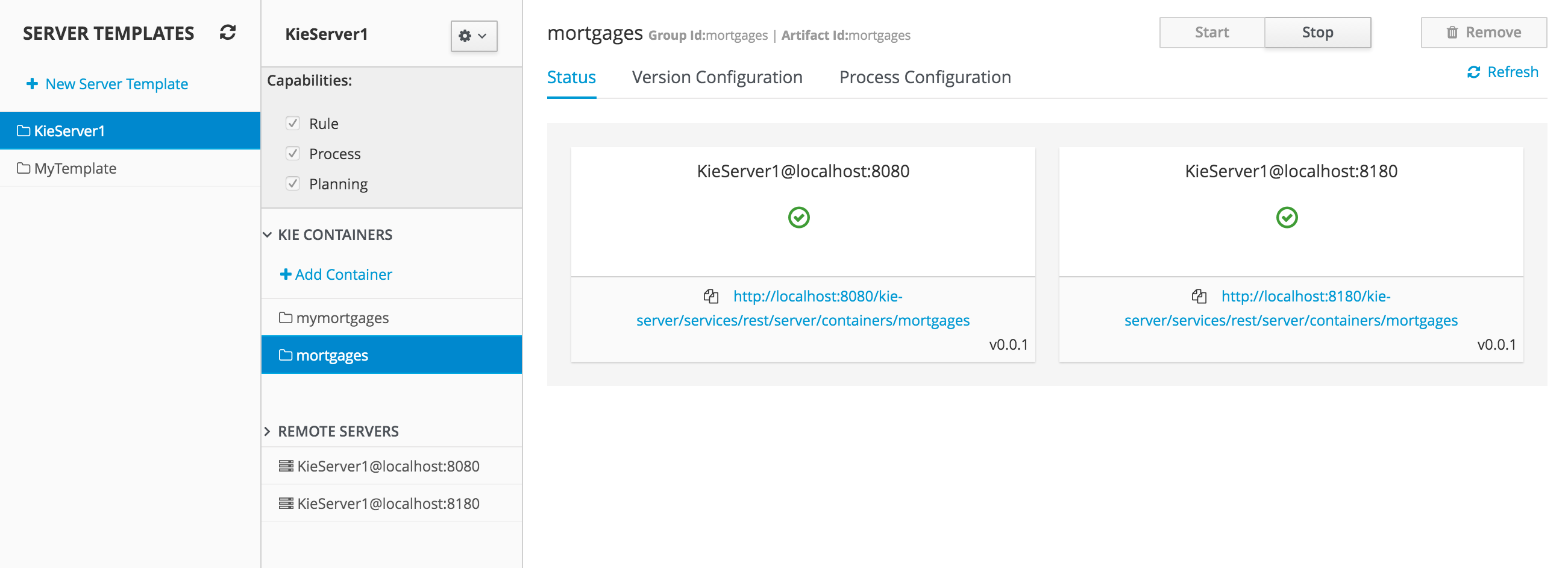
For containers that do not have process capability the Version Configuration tab allows users to change the current version of the Container. Users can upgrade manually to a specific version using the "Upgrade" button or enable/disable the Scanner. It’s also possible to execute a Scan Now operation that will scan for new versions only once.
To redeploy SNAPSHOT kjars with your latest changes all existing containers with that version must first be removed. Executing 'build and deploy' will then create a container with the latest SNAPSHOT kjar. However, this is not possible for release versions. Following maven release convensions if the GAV of a kjar is anthing but SNAPSHOT, the GAV will need to be updated to the newer release version and deployed to its own container. The new release version can also be used to upgrade an existing container as describe previously provided the container does not have process capability.
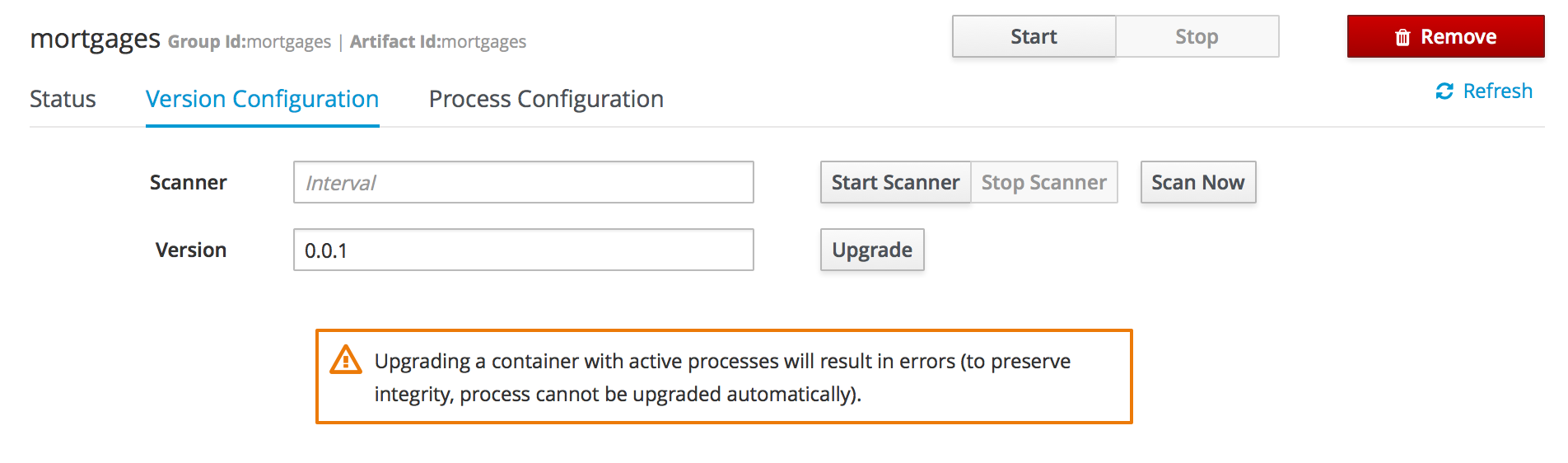
Process Configuration is the same form that is displayed during New Container Wizard for Template Servers that have Process Capability. If Template Server doesn’t have such capability, the action buttons will be disabled.
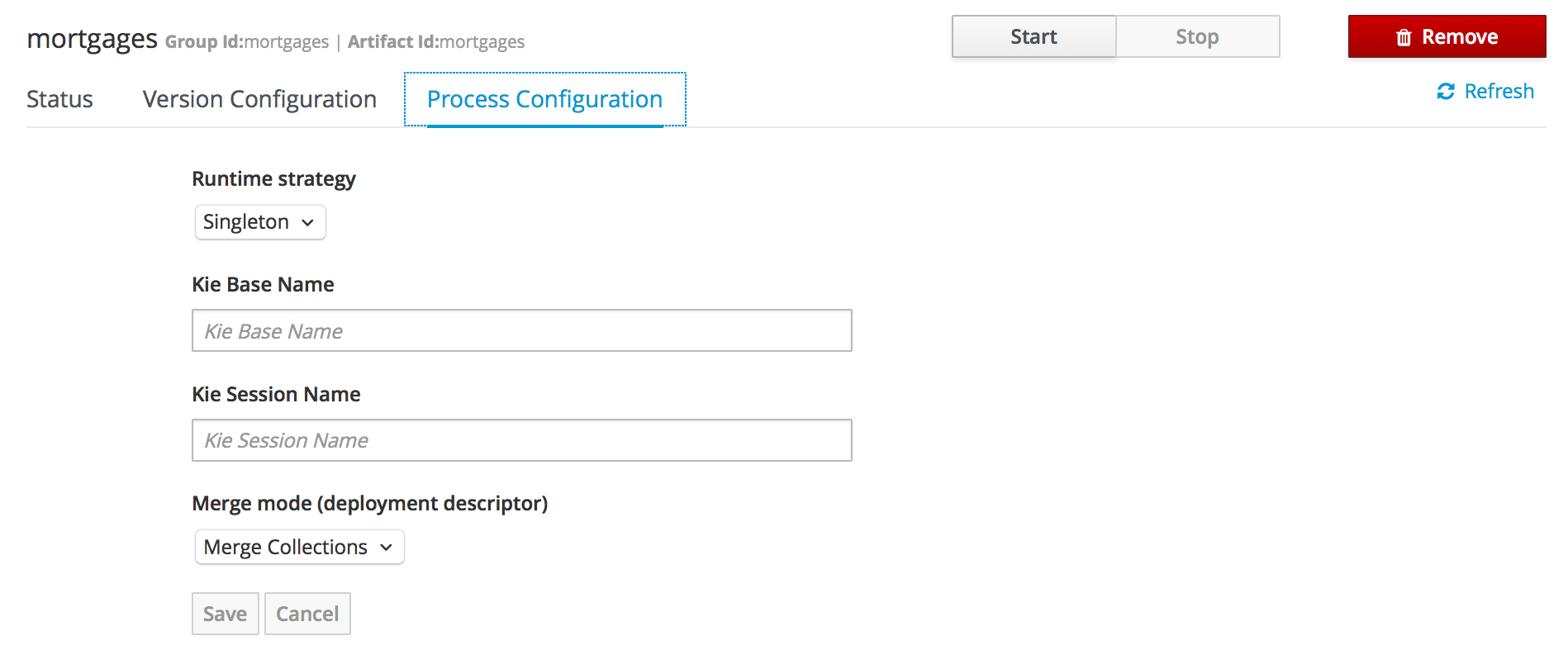
10.9.3. Remote Server
Remote Server is a Managed KIE Server instance running that has a controller configured.
|
By default Workbench comes with a Controller embedded. |
The list of Remote Servers are displayed just under the list of Containers. Once selected the screens reveals the Remote Server details and a list of cards, each card represents a running Container.
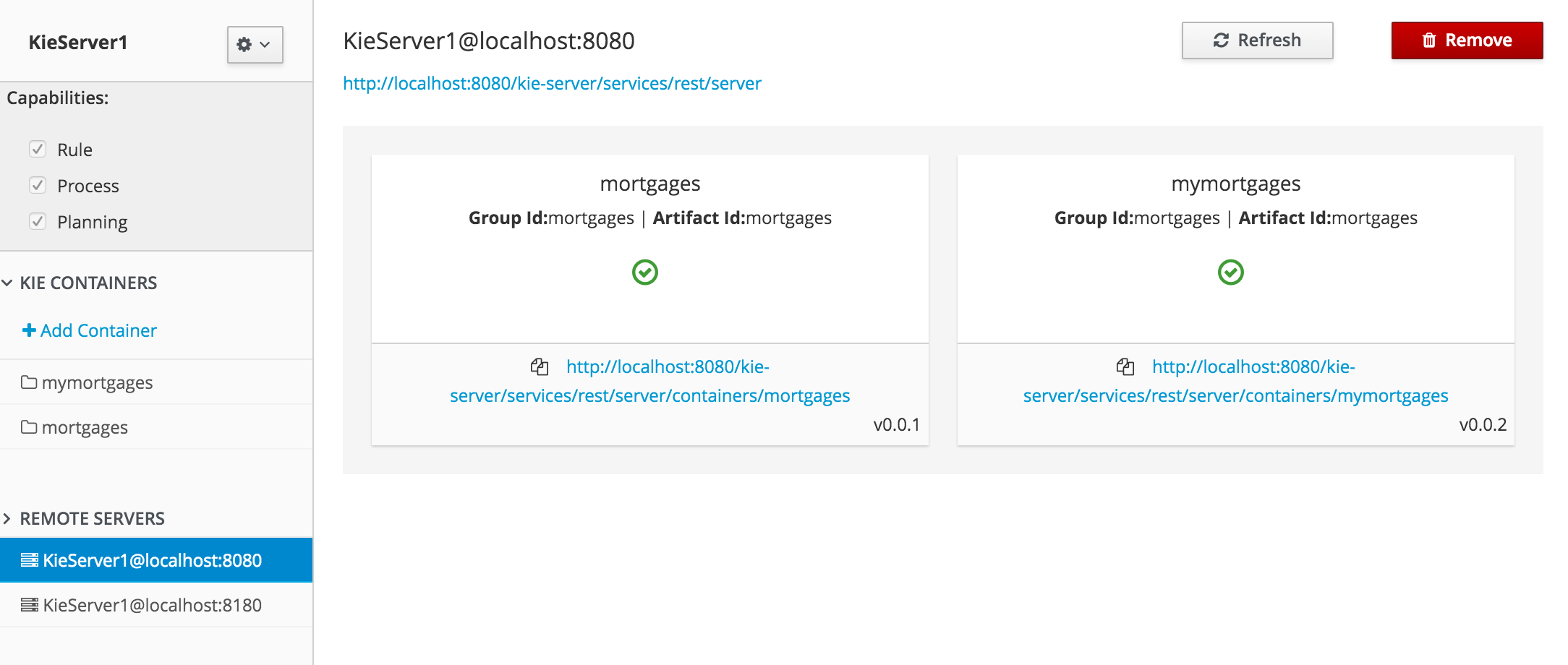
11. Workbench Integration
11.1. REST
REST API calls to Knowledge Store allow you to manage the Knowledge Store content and manipulate the static data in the repositories of the Knowledge Store. The calls are asynchronous, that is, they continue their execution as a job after a call was performed. The job ID is returned by every call to allow (after the REST API call was performed) to request the job status and verify whether the job finished successfully. Parameters of these calls are provided in the form of JSON entities.
When using Java code to interface with the REST API, the classes used in POST operations or otherwise returned by various operations can be found in the (org.uberfire:)uberfire-rest-client JAR.
All of the classes mentioned below can be found in the org.guvnor.rest.client package in that JAR.
11.1.1. Job calls
Every Knowledge Store REST call returns its job ID after it was sent. This is necessary as the calls are asynchronous and you need to be able to reference the job to check its status as it goes through its lifecycle. During its lifecycle, a job can have the following statuses:
-
ACCEPTED: the job was accepted and is being processed -
BAD_REQUEST: the request was not accepted as it contained incorrect content -
RESOURCE_NOT_EXIST: the requested resource (path) does not exist -
DUPLICATE_RESOURCE: the resource already exists -
SERVER_ERROR: an error on the server occurred -
SUCCESS: the job finished successfully -
FAIL: the job failed -
DENIED: the job was denied -
GONE: the job ID could not be foundA job can be GONE in the following cases: The job was explicitly removed The job finished and has been deleted from the status cache (the job is removed from status cache after the cache has reached its maximum capacity) ** The job never existed
The following job calls are provided:
- [GET]
/jobs/{jobID} -
Returns the job status
- [DELETE]
/jobs/{jobID} -
Removes the job: If the job is not yet being processed, this will remove the job from the job queue. However, this will not cancel or stop an ongoing job
11.1.2. Project calls
Project calls to the Knowledge Store allow you to manage Workspace projects.
The following project calls are provided:
- [GET]
/projects -
Gets information about all the projects in the Knowledge Store.
- [GET]
/spaces/{spaceName}/projects/{projectName} -
Gets information about the project.
- [POST]
/spaces/{spaceName}/projects/{projectName} -
Creates a new project in given space.
- [DELETE]
/spaces/{spaceName}/projects/{projectName} -
Removes the project from the Knowledge Store.
- [GET]
/spaces/{spaceName}/projects -
Gets information about all projects in the space
- [POST]
/spaces/{spaceName}/git/clone -
Clones a project into the space from provided git address.
- [DELETE]
/spaces/{spaceName}/projects/{projectName} -
Deletes the project from the space.
11.1.3. Space calls
Space calls to the Knowledge Store allow you to manage spaces.
The following spaces calls are provided:
- [GET]
/spaces -
Gets all spaces.
- [GET]
/spaces/{spaceName} -
Gets a single space.
- [POST]
/spaces -
Creates a space described by
SpaceJSON entity. - [DELETE]
/spaces/{spaceName} -
Deletes the space.
11.1.4. Maven calls
Maven calls to a project in the Knowledge Store allow you compile, test, install, and deploy projects.
The following maven calls are provided:
- [POST]
/spaces/{spaceName}/projects/{projectName}/maven/compile -
Compiles the project (equivalent to
mvn compile) - [POST]
/spaces/{spaceName}/projects/{projectName}/maven/test -
Tests the project (equivalent to
mvn test) - [POST]
/spaces/{spaceName}/projects/{projectName}/maven/install -
Installs the project (equivalent to
mvn install) - [POST]
/spaces/{spaceName}/projects/{projectName}/maven/deploy -
Deploys the project (equivalent to
mvn deploy)
11.1.5. REST summary
The URL templates in the table below are relative the following URL:
-
http://{server}:{port}/kie-wb/rest
11.1.6. Embedded Kie Server Controller calls
When running the Workbench with the embedded Kie Server Controller mode, a series of endpoints related to managing all aspects of Kie Server Templates, Kie Server instances and Containers are also available. See Controller REST API for more details. A Java client API is also available for interacting with these endpoints.
11.2. Keycloak SSO integration
Single Sign On (SSO) and related token exchange mechanisms are becoming the most common scenario for the authentication and authorization in different environments on the web, specially when moving into the cloud.
This section talks about the integration of Keycloak with jBPM or Drools applications in order to use all the features provided on Keycloak. Keycloak is an integrated SSO and IDM for browser applications and RESTful web services. Lean more about it in the Keycloak’s home page.
The result of the integration with Keycloak has lots of advantages such as:
-
Provide an integrated SSO and IDM environment for different clients, including jBPM and Drools workbenches
-
Social logins - use your Facebook, Google, LinkedIn, etc accounts
-
User session management
-
And much more…
Next sections cover the following integration points with Keycloak:
-
Workbench authentication through a Keycloak server
It basically consists of securing both web client and remote service clients through the Keycloak SSO. So either web interface or remote service consumers (whether a user or a service) will authenticate into trough KC.
-
Execution server authentication through a Keycloak server
Consists of securing the remote services provided by the execution server (as it does not provide web interface). Any remote service consumer (whether a user or a service) will authenticate trough KC.
-
Consuming remote services
This section describes how a third party clients can consume the remote service endpoints provided by both Workbench and Execution Server, such as the REST API or remote file system services.
-
Keycloakd and the Workbench’s security administration area
11.2.1. Scenario
Consider the following diagram as the environment for this document’s example:
Keycloak is a standalone process that provides remote authentication, authorization and administration services that can be potentially consumed by one or more jBPM applications over the network.
Consider these main steps for building this environment:
-
Install and set up a Keycloak server
-
Create and set up a Realm for this example - Configure realm’s clients, users and roles
-
Install and set up the SSO client adapter & jBPM application
Note: The resulting environment and the different configurations for this document are based on the jBPM (KIE) Workbench, but same ones can also be applied for the KIE Drools Workbench as well.
11.2.2. Install and set up a Keycloak server
Keycloak provides an extensive documentation and several articles about the installation on different environments. This section describes the minimal set up for being able to build the integrated environment for the example. Please refer to the Keycloak documentation if you need more information.
Here are the steps for a minimal Keycloak installation and set up:
-
Download latest version of Keycloak from the Downloads section. This example is based on Keycloak 1.9.0.Final
-
Unzip the downloaded distribution of Keycloak into a folder, let’s refer it as
$KC_HOME -
Run the KC server - This example is based on running both Keycloak and jBPM on same host. In order to avoid port conflicts you can use a port offset for the Keycloak’s server as:
$KC_HOME/bin/standalone.sh -Djboss.socket.binding.port-offset=100 -
Create a Keycloak’s administration 'admin' user by navigating to http://localhost:8180/auth/
The Keycloak administration console will be available at http://localhost:8180/auth/admin/.
11.2.3. Create and set up the demo realm
Security realms are used to restrict the access for the different application’s resources.
Once the Keycloak server is running next step is about creating a realm. This realm will provide the different users, roles, sessions, etc for the jBPM application/s.
Keycloak provides several examples for the realm creation and management, from the official examples to different articles with more examples.
Follow these steps in order to create the demo realm used later in this document:
-
Go to the Keycloak administration console and click on Add realm button. Give it the name demo.
-
Go to the Clients section (from the main admin console menu) and create a new client for the demo realm:
-
Client ID: kie
-
Client protocol: openid-connect
-
Acces type: confidential
-
Root URL: http://localhost:8080
-
Base URL: /kie-wb-x.y.z.Final
-
Redirect URIs: /kie-wb-x.y.z.Final/*
-
The resulting kie client settings screen:
|
As you can see in the above settings it’s being considered the value kie-wb-x.y.z.Final for the application’s context path. If your jBPM application will be deployed on a different context path, host or port, just use your concrete settings here. |
Last step for being able to use the demo realm from the jBPM workbench is create the application’s user and roles:
-
Go to the Roles section and create the roles admin, kiemgmt and rest-all
-
Go to the Users section and create the admin user. Set the password with value password in the credentials tab, unset the temporary switch.
-
In the Users section navigate to the Role Mappings tab and assign the admin, kiemgmt and rest-all roles to the admin user
At this point a Keycloak server is running on the host, set up with a minimal configuration set. Let’s move to the jBPM workbench set up.
11.2.4. Install and set up jBPM Workbench
For this tutorial let’s use a Wildfly as the application server for the jBPM workbench, as the jBPM installer does by default.
Let’s assume, after running the jBPM installer, the $JBPM_HOME as the root path for the Wildfly server where the application has been deployed.
11.2.4.1. Install the KC adapter
In order to use the Keycloak’s authentication and authorization modules from the jBPM application, the Keycloak JBoss EAP/Wildfly Adapter must be installed on our server at $JBPM_HOME. Keycloak provides multiple adapters for different containers out of the box, if you are using another container or need to use another adapter, please take a look at the Securing Applications section from the Keycloak docs. Here are the steps to install and set up the adapter for Wildfly 11/10/9:
-
Download the adapter from Keycloak Client Adapter for Wildfly 11/10/9
-
Execute the following commands on your shell:
cd $JBPM_HOME unzip keycloak-wildfly-adapter-dist-3.4.3.Final.zip // Install the KC client adapter cd $JBPM_HOME/bin ./standalone.sh -c standalone-full.xml // set up the KC client adapter. // ** Once server is up, open a new command line terminal and run: cd $JBPM_HOME/bin ./jboss-cli.sh -c --file=adapter-install.cli
11.2.4.2. Configure the KC adapter
Once installed the KC adapter into Wildfly, next step is to configure the adapter in order to specify different settings such as the location for the authentication server, the realm to use and so on.
Keycloak provides two ways of configuring the adapter:
-
Per WAR configuration
-
Via Keycloak subsystem
In this example let’s use the second option, use the Keycloak subsystem, so our WAR is free from this kind of settings. If you want to use the per WAR approach, please take a look Required Per WAR Configuration.
Edit the configuration file $JBPM_HOME/standalone/configuration/standalone-full.xml and locate the subsystem configuration section. Add the following content:
<subsystem xmlns="urn:jboss:domain:keycloak:1.1">
<secure-deployment name="kie-wb-x.y.z.Final.war">
<realm>demo</realm>
<realm-public-key>MIIBIjANBgkqhkiG9w0BAQEFAAOCA...</realm-public-key>
<auth-server-url>http://localhost:8180/auth</auth-server-url>
<ssl-required>external</ssl-required>
<resource>kie</resource>
<enable-basic-auth>true</enable-basic-auth>
<credential name="secret">925f9190-a7c1-4cfd-8a3c-004f9c73dae6</credential>
<principal-attribute>preferred_username</principal-attribute>
</secure-deployment>
</subsystem>If you have imported the example json files from this document in step 2, you can just use same configuration as above by using your concrete deployment name. Otherwise please use your values for these configurations:
-
Name for the secure deployment - Use your concrete application’s WAR file name
-
Realm - Is the realm that the applications will use, in our example, the demo realm created the previous step.
-
Realm Public Key - Provide here the public key for the demo realm. It’s not mandatory, if it’s not specified, it will be retrieved from the server. Otherwise, you can find it in the Keycloak admin console → Realm settings (for demo realm) → Keys
-
Authentication server URL - The URL for the Keycloak’s authentication server
-
Resource - The name for the client created on step 2. In our example, use the value kie.
-
Enable basic auth - For this example let’s enable Basic authentication mechanism as well, so clients can use both Token (Bearer) and Basic approaches to perform the requests.
-
Credential - Use the password value for the kie client. You can find it in the Keycloak admin console → Clients → kie → Credentials tab → Copy the value for the secret.
For this example you have to take care about using your concrete values for secure-deployment name, realm-public-key and credential password.
|
Ensure the following tag is NOT present in the Widfly/EAP profile’s configuration file (eg: standalone.xml): It’s enabled by default in some server versions. If present, it must be removed/disabled in order to allow Keycloak to properly handle the clients. |
11.2.4.3. Run the environment
At this point a Keycloak server is up and running on the host, and the KC adapter is installed and configured for the jBPM application server. You can run the application using:
$JBPM_HOME/bin/standalone.sh -c standalone-full.xmlYou can navigate into the application once the server is up at:
http://localhost:8080/kie-wb-x.y.z.Final
Use your Keycloak’s admin user credentials to login: admin/password.
11.2.5. Securing workbench remote services via Keycloak
Both jBPM and Drools workbenches provide different remote service endpoints that can be consumed by third party clients using the remote API.
In order to authenticate those services thorough Keycloak the BasicAuthSecurityFilter must be disabled, apply those modifications for the the WEB-INF/web.xml file (app deployment descriptor) from jBPM’s WAR file:
-
Remove the following filter from the deployment descriptor:
<filter> <filter-name>HTTP Basic Auth Filter</filter-name> <filter-class>org.uberfire.ext.security.server.BasicAuthSecurityFilter</filter-class> <init-param> <param-name>realmName</param-name> <param-value>KIE Workbench Realm</param-value> </init-param> </filter> <filter-mapping> <filter-name>HTTP Basic Auth Filter</filter-name> <url-pattern>/rest/*</url-pattern> <url-pattern>/maven2/*</url-pattern> <url-pattern>/ws/*</url-pattern> </filter-mapping> -
Constraint the remote services URL patterns as:
<security-constraint> <web-resource-collection> <web-resource-name>remote-services</web-resource-name> <url-pattern>/rest/*</url-pattern> <url-pattern>/maven2/*</url-pattern> <url-pattern>/ws/*</url-pattern> </web-resource-collection> <auth-constraint> <role-name>rest-all</role-name> </auth-constraint> </security-constraint>
|
The user that consumes the remote services must be member of role rest-all. As on described previous steps, the admin user in this example it’s already a member of the rest-all role. |
11.2.6. Securing workbench’s file system services via Keycloak
In order to consume other remote services such as the file system ones (e.g. remote GIT), a specific Keycloak login module must be used for the application’s security domain in the $JBPM_HOME/standalone/configuration/standalone-full.xml file. By default the workbench uses the other security domain, so the resulting configuration on the $JBPM_HOME/standalone/configuration/standalone-full.xml should be such as:
<security-domain name="other" cache-type="default">
<authentication>
<login-module code="org.keycloak.adapters.jaas.DirectAccessGrantsLoginModule" flag="required">
<!-- Parameter value can be a file system absolute path or a classpath (e.g. "classpath:/some-path/kie-git.json")-->
<module-option name="keycloak-config-file" value="$JBPM_HOME/kie-git.json"/>
</login-module>
</authentication>
</security-domain>Note that:
-
The login modules on the other security domain in the $JBPM_HOME/standalone/configuration/standalone-full.xml file must be REPLACED by the above given one.
-
Replace $JBPM_HOME/kie-git.json by the path (on file system) or the classpath (e.g. classpath:/some-path/kie-git.json) for the json configuration file used for the remote services client. Please continue reading in order to create this Keycloak client and how to obtain this json file.
At this point, remote services that use JAAS for the authentication process, such as the file system ones (e.g. GIT), are secured by Keycloak using the client specified in the above json configuration file. So let’s create this client on Keycloak and generate the required JSON file:
-
Navigate to the KC administration console and create a new client for the demo realm using kie-git as name.
-
Enable Direct Access Grants Enabled option
-
Disable Standard Flow Enabled option
-
Use a confidential access type for this client. See below image as example:
-
Go to the Installation tab in same kie-git client configuration screen and export using the Keycloak OIDC JSON type.
-
Finally copy this generated JSON file into an accessible directory on the server’s file system or add it in the application’s classpath. Use this path value as the keycloak-config-file argument for the above configuration of the org.keycloak.adapters.jaas.DirectAccessGrantsLoginModule login module.
-
More information about Keycloak JAAS Login modules can be found Keycloak JAAS plugin.
At this point, the internal Git repositories can be cloned by all users authenticated via the Keycloak server:
# Command example:
git clone ssh://admin@localhost:8001/system11.2.7. Execution server
The KIE Execution Server provides a REST API that can be consumed for any third party clients. This this section is about how to integration the KIE Execution Server with the Keycloak SSO in order to delegate the third party clients identity management to the SSO server.
Consider the above environment running, so consider having:
-
A Keycloak server running and listening on http://localhost:8180/auth
-
A realm named demo with a client named kie for the jBPM Workbench
-
A jBPM Workbench running at http://localhost:8080/kie-wb-x.y.z.Final
Follow these steps in order to add an execution server into this environment:
-
Create the client for the execution server on Keycloak
-
Install set up and the Execution server (with the KC client adapter)
11.2.7.1. Create the execution server’s client on Keycloak
As per each execution server is going to be deployed, you have to create a new client on the demo realm in Keycloak:
-
Go to the KC admin console → Clients → New client
-
Name: kie-execution-server
-
Root URL: http://localhost:8280/
-
Client protocol: openid-connect
-
Access type: confidential (or public if you want so, but not recommended for production environments)
-
Valid redirect URIs: /kie-server-x.y.z.Final/*
-
Base URL: /kie-server-x.y.z.Final
In this example the admin user already created on previous steps is the one used for the client requests. So ensure that the admin user is member of the role kie-server in order to use the execution server’s remote services. If the role does not exist, create it.
Note: This example considers that the execution server will be configured to run using a port offset of 200, so the HTTP port will be available at localhost:8280.
11.2.7.2. Install and set up the KC adapter on the execution server
At this point, a client named kie-execution-server is ready on the KC server to use from the execution server.
Let’s install, set up and deploy the execution server:
-
Install another Wildfly server to use for the execution server and the KC client adapter as well. You can follow above instructions for the Workbench or follow the securing applications guide
-
Edit the standalone-full.xml file from the Wildfly server’s configuration path and configure the KC subsystem adapter as:
<secure-deployment name="kie-server-x.y.z.Final.war"> <realm>demo</realm> <realm-public-key>MIGfMA0GCSqGSIb...</realm-public-key> <auth-server-url>http://localhost:8180/auth</auth-server-url> <ssl-required>external</ssl-required> <resource>kie-execution-server</resource> <enable-basic-auth>true</enable-basic-auth> <credential name="secret">e92ec68d-6177-4239-be05-28ef2f3460ff</credential> <principal-attribute>preferred_username</principal-attribute> </secure-deployment>
Consider your concrete environment settings if different from this example:
-
Secure deployment name → use the name of the execution server war file being deployed
-
Public key → Use the demo realm public key or leave it blank, the server will provide one if so
-
Resource → This time, instead of the kie client used in the WB configuration, use the kie-execution-server client
-
Enable basic auth → Up to you. You can enable Basic auth for third party service consumers
-
Credential → Use the secret key for the kie-execution-server client. You can find it in the Credentialstab of the KC admin console
11.2.7.3. Deploy and run the execution server
Just deploy the execution server in Wildfly using any of the available mechanisms. Run the execution server using this command:
$EXEC_SERVER_HOME/bin/standalone.sh -c standalone-full.xml -Djboss.socket.binding.port-offset=200 -Dorg.kie.server.id=<ID> -Dorg.kie.server.user=<USER> -Dorg.kie.server.pwd=<PWD> -Dorg.kie.server.location=<LOCATION_URL> -Dorg.kie.server.controller=<CONTROLLER_URL> -Dorg.kie.server.controller.user=<CONTROLLER_USER> -Dorg.kie.server.controller.pwd=<CONTOLLER_PASSWORD>Example:
$EXEC_SERVER_HOME/bin/standalone.sh -c standalone-full.xml -Djboss.socket.binding.port-offset=200 -Dorg.kie.server.id=kieserver1 -Dorg.kie.server.user=admin -Dorg.kie.server.pwd=password -Dorg.kie.server.location=http://localhost:8280/kie-server-x.y.z.Final/services/rest/server -Dorg.kie.server.controller=http://localhost:8080/kie-wb-x.y.z.Final/rest/controller -Dorg.kie.server.controller.user=admin -Dorg.kie.server.controller.pwd=password|
The users that will consume the execution server remote service endpoints must have the role kie-server assigned. So create and assign this role in the KC admin console for the users that will consume the execution server remote services. |
Once up, you can check the server status as (considered using Basic authentication for this request, see next Consuming remote services for more information):
curl http://admin:password@localhost:8280/kie-server-x.y.z.Final/services/rest/server/11.2.8. Consuming remote services
In order to use the different remote services provided by the Workbench or by an Execution Server, your client must be authenticated on the KC server and have a valid token to perform the requests.
Remember that in order to use the remote services, the authenticated user must have assigned:
-
The role rest-all for using the WB remote services
-
The role kie-server for using the Execution Server remote services
Please ensure necessary roles are created and assigned to the users that will consume the remote services on the Keycloak admin console.
You have two options to consume the different remove service endpoints:
-
Using basic authentication, if the application’s client supports it
-
Using Bearer (token) based authentication
11.2.8.1. Using basic authentication
If the KC client adapter configuration has the Basic authentication enabled, as proposed in this guide for both WB (step 3.2) and Execution Server, you can avoid the token grant/refresh calls and just call the services as the following examples.
Example for a WB remote repositories endpoint:
curl http://admin:password@localhost:8080/kie-wb-x.y.z.Final/rest/repositoriesExample to check the status for the Execution Server:
curl http://admin:password@localhost:8280/kie-server-x.y.z.Final/services/rest/server/11.2.8.2. Using token based authentication
First step is to create a new client on Keycloak that allows the third party remote service clients to obtain a token. It can be done as:
-
Go to the KC admin console and create a new client using this configuration:
-
Client id: kie-remote
-
Client protocol: openid-connect
-
Access type: public
-
Valid redirect URIs: http://localhost/
-
-
As we are going to manually obtain a token and invoke the service let’s increase the lifespan of tokens slightly. In production access tokens should have a relatively low timeout, ideally less than 5 minutes:
-
Go to the KC admin console
-
Click on your Realm Settings
-
Click on Tokens tab
-
Change the value for Access Token Lifespan to 15 minutes. That should give us plenty of time to obtain a token and invoke the service before it expires.
-
Once a public client for our remote clients has been created, you can now obtain the token by performing an HTTP request to the KC server’s tokens endpoint. Here is an example for command line:
RESULT=`curl --data "grant_type=password&client_id=kie-remote&username=admin&passwordpassword=<the_client_secret>" http://localhost:8180/auth/realms/demo/protocol/openid-connect/token`TOKEN=`echo $RESULT | sed 's/.*access_token":"//g' | sed 's/".*//g'`At this point, if you echo the $TOKEN it will output the token string obtained from the KC server, that can be now used to authorize further calls to the remote endpoints. For exmple, if you want to check the internal jBPM repositories:
curl -H "Authorization: bearer $TOKEN" http://localhost:8080/kie-wb-x.y.z.Final/rest/repositories11.2.9. Keycloak and the workbench’s security administration area
The jBPM workbench provides an administration area which provides user, group and role management features (see Security management).
By default the application’s security management system points to the application’s server realm. For instance, in case of using the packaged distribution for Wildfly, it points to the Wildfly’s ApplicationRealm (properties based). It means the entities from the realm presented in the administration area are not the ones from the Keycloak realm that the application is using. There exist the following options in order to change this default behavior:
-
Disable the user system administration
-
Use the built-in Keycloak security management provider instead of the default one
In order to customize an existing jBPM application (WAR file) for using the Keycloak security management provider please follow the next steps:
-
Add the artifact keycloak-core-x.y.z.Final.jar into WEB-INF/lib
-
Add the artifact keycloak-common-x.y.z.Final.jar into WEB-INF/lib
-
Remove the actual jar artifact for any security management provider in use from WEB-INF/lib (eg: remove WEB-INF/lib/uberfire-security-management-wdilfly-x.y.Z.jar)
-
Replace the content for WEB-INF/classes/security-management.properties by:
org.uberfire.ext.security.management.api.userManagementServices=KCAdapterUserManagementService org.uberfire.ext.security.management.keycloak.authServer=<authz_server_url> # eg: org.uberfire.ext.security.management.keycloak.authServer=http://localhost:8180/auth
-
Update the /META-INF/jboss-deployment-structure.xml in order to include/exclude the following modules:
<deployment>
<dependencies>
...
<module name="org.jboss.resteasy.resteasy-jackson-provider" services="import"/>
...
</dependencies>
<exclusions>
...
<module name="org.jboss.resteasy.resteasy-jackson2-provider"/>
...
</exclusions>
</deployment>
|
The jar artifacts required in the steps above can be either downloaded from JBoss Nexus or either build from sources. |
Once applying the above changes, the security administration area uses the access token present in the user’s session in order to authorize and manage the specific Keycloak realm data.
|
In order to be able to manage Keycloak realms remotely, please ensure the user has the realm-management client role assigned |
12. Workbench High Availability
12.1. VFS clustering
The VFS repositories (usually git repositories) stores all the assets (such as rules, decision tables, process definitions, forms, etc). If that VFS resides on each local server, then it must be kept in sync between all servers of a cluster.
Use Apache Zookeeper and Apache Helix to accomplish this. Zookeeper glues all the parts together. Helix is the cluster management component that registers all cluster details (nodes, resources and the cluster itself). Uberfire (on top of which Workbench is build) uses those 2 components to provide VFS clustering.
To create a VFS cluster:
-
Download Apache Zookeeper and Apache Helix.
-
Install both:
-
Unzip Zookeeper into a directory (
$ZOOKEEPER_HOME). -
In
$ZOOKEEPER_HOME, copyzoo_sample.conftozoo.conf -
Edit
zoo.conf. Adjust the settings if needed. Usually only these 2 properties are relevant:# the directory where the snapshot is stored. dataDir=/tmp/zookeeper # the port at which the clients will connect clientPort=2181 -
Unzip Helix into a directory (
$HELIX_HOME).
-
-
Configure the cluster in Zookeeper:
-
Go to its
bindirectory:$ cd $ZOOKEEPER_HOME/bin -
Start the Zookeeper server:
$ sudo ./zkServer.sh startIf the server fails to start, verify that the
dataDir(as specified inzoo.conf) is accessible. -
To review Zookeeper’s activities, open
zookeeper.out:$ cat $ZOOKEEPER_HOME/bin/zookeeper.out
-
-
Configure the cluster in Helix:
-
Go to its
bindirectory:$ cd $HELIX_HOME/bin -
Create the cluster:
$ ./helix-admin.sh --zkSvr localhost:2181 --addCluster kie-clusterThe
zkSvrvalue must match the used Zookeeper server. The cluster name (kie-cluster) can be changed as needed. -
Add nodes to the cluster:
# Node 1 $ ./helix-admin.sh --zkSvr localhost:2181 --addNode kie-cluster nodeOne:12345 # Node 2 $ ./helix-admin.sh --zkSvr localhost:2181 --addNode kie-cluster nodeTwo:12346 ...Usually the number of nodes a in cluster equal the number of application servers in the cluster. The node names (
nodeOne:12345, …) can be changed as needed.nodeOne:12345is the unique identifier of the node, which will be referenced later on when configuring application servers. It is not a host and port number, but instead it is used to uniquely identify the logical node. -
Add resources to the cluster:
$ ./helix-admin.sh --zkSvr localhost:2181 --addResource kie-cluster vfs-repo 1 LeaderStandby AUTO_REBALANCEThe resource name (
vfs-repo) can be changed as needed. -
Rebalance the cluster to initialize it:
$ ./helix-admin.sh --zkSvr localhost:2181 --rebalance kie-cluster vfs-repo 2 -
Start the Helix controller to manage the cluster:
$ ./run-helix-controller.sh --zkSvr localhost:2181 --cluster kie-cluster 2>&1 > /tmp/controller.log &
-
-
Configure the security domain correctly on the application server. For example on WildFly and JBoss EAP:
-
Edit the file
$JBOSS_HOME/domain/configuration/domain.xml.For simplicity sake, presume we use the default domain configuration which uses the profile
fullthat defines two server nodes as part ofmain-server-group. -
Locate the profile
fulland add a new security domain by copying the other security domain already defined there by default:<security-domain name="kie-ide" cache-type="default"> <authentication> <login-module code="Remoting" flag="optional"> <module-option name="password-stacking" value="useFirstPass"/> </login-module> <login-module code="RealmDirect" flag="required"> <module-option name="password-stacking" value="useFirstPass"/> </login-module> </authentication> </security-domain>The security-domain name is a magic value.
-
-
Configure the system properties for the cluster on the application server. For example on WildFly and JBoss EAP:
-
Edit the file
$JBOSS_HOME/domain/configuration/host.xml. -
Locate the XML elements
serverthat belong to themain-server-groupand add the necessary system property.For example for nodeOne:
<system-properties> <property name="jboss.node.name" value="nodeOne" boot-time="false"/> <property name="org.uberfire.nio.git.dir" value="/tmp/kie/nodeone" boot-time="false"/> <property name="org.uberfire.metadata.index.dir" value="/tmp/kie/nodeone" boot-time="false"/> <property name="org.uberfire.cluster.id" value="kie-cluster" boot-time="false"/> <property name="org.uberfire.cluster.zk" value="localhost:2181" boot-time="false"/> <property name="org.uberfire.cluster.local.id" value="nodeOne_12345" boot-time="false"/> <property name="org.uberfire.cluster.vfs.lock" value="vfs-repo" boot-time="false"/> <!-- If you're running both nodes on the same machine: --> <property name="org.uberfire.nio.git.daemon.port" value="9418" boot-time="false"/> </system-properties>And for nodeTwo:
<system-properties> <property name="jboss.node.name" value="nodeTwo" boot-time="false"/> <property name="org.uberfire.nio.git.dir" value="/tmp/kie/nodetwo" boot-time="false"/> <property name="org.uberfire.metadata.index.dir" value="/tmp/kie/nodetwo" boot-time="false"/> <property name="org.uberfire.cluster.id" value="kie-cluster" boot-time="false"/> <property name="org.uberfire.cluster.zk" value="localhost:2181" boot-time="false"/> <property name="org.uberfire.cluster.local.id" value="nodeTwo_12346" boot-time="false"/> <property name="org.uberfire.cluster.vfs.lock" value="vfs-repo" boot-time="false"/> <!-- If you're running both nodes on the same machine: --> <property name="org.uberfire.nio.git.daemon.port" value="9419" boot-time="false"/> </system-properties>Make sure the cluster, node and resource names match those configured in Helix.
-
12.2. jBPM clustering
In addition to the information above, jBPM clustering requires additional configuration. See this blog post to configure the database etc correctly.
13. Designer
Designer is a graphical web-based BPMN2 editor. It allows users to model and simulate executable BPMN2 processes. The main goal of Designe is to provide intuitive means to both technical and non-technical users to quickly create their executable business processes. This chapter intends to describe all feature Designer offers currently.
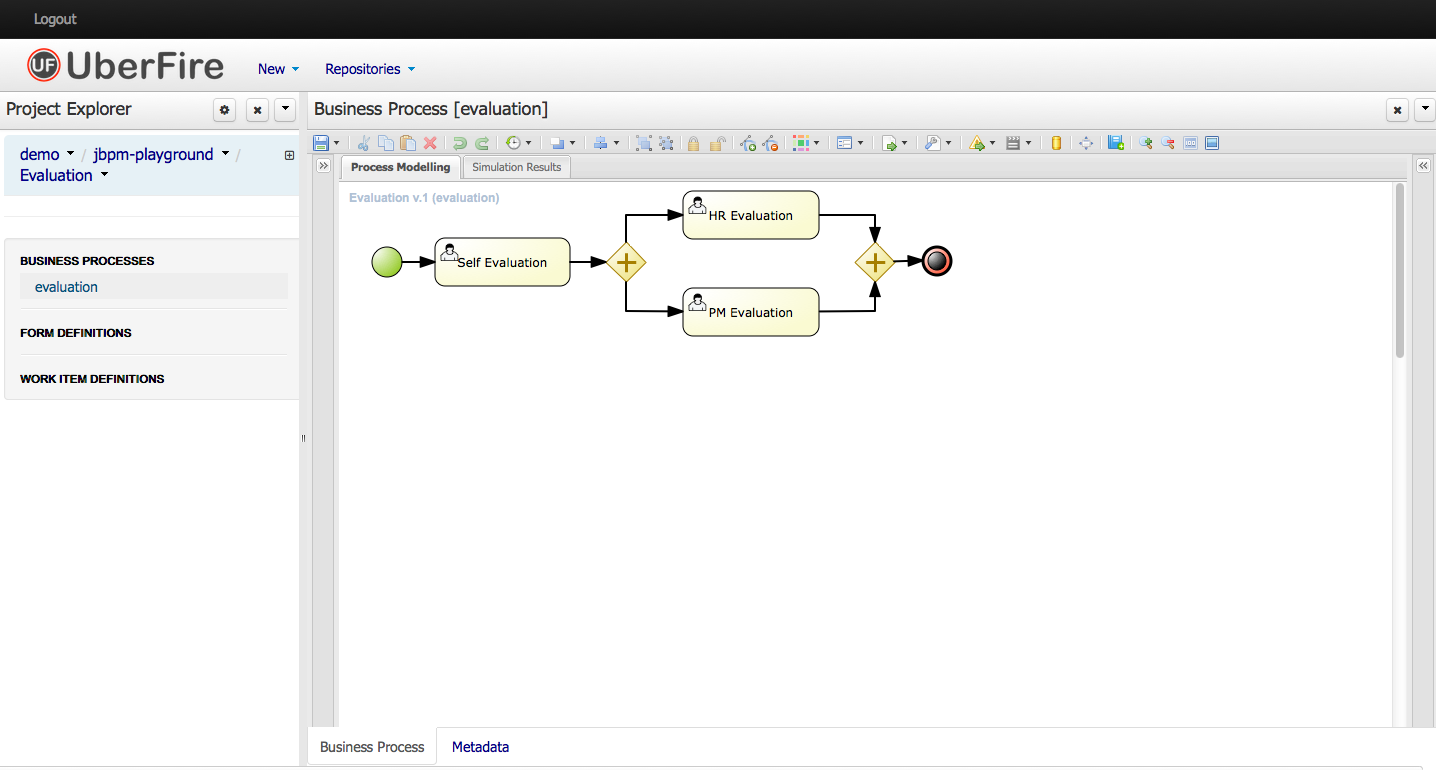
Designer targets the following business process modelling scenarios:
-
View and/or edit existing BPMN2 processes: Designer allows you to open existing BPMN2 processes (for example created using the BPMN2 Eclipse editor or any other tooling that exports BPMN2 XML).
-
Create fully executable BPMN2 processes: A user can create a new BPMN2 process in the Designer and use the editing capabilities (drag and drop and filling in properties in the properties panel) to fill in the details. This for example allows business users to create complete business processes all inside a a browser. The integration with Drools Guvnor allows for your business processes as wells as other business assets such as business rules, process forms/images, etc. to be stored and versioned inside a content repository.
-
View and/or edit Human Task forms during process modelling (using the in-line form editor or the Form Modeller).
-
Simulate your business process models. Busines Process Simulation is based on the BPSIM 1.0 specification.
Designer supports all BPMN2 elements that are also supported by jBPM as well as all jBPM-specific BPMN2 extension elements and attributes.
13.1. Designer UI Explained
Designer UI is composed of a number of sections as shown below:
-
(1) Modelling Canvas - this is your process drawing board. After dropping different shapes onto the canvas, you can move them around, connect them, etc. Clicking on a shape on the canvas allows you to set its properties in the expandable Properties Window (3) (as well as create connecting shapes and morph the shape into other shapes).
-
(2) Toolbar - the toolbar contains a vast number of functions offered by Designer (described later). These includes operations that can be performed on shapes present on the Canvas. Individual operations are disabled or enabled depending on what is selected. For example, if no shapes are selected, the Cut/Paste/Delete operations are disabled, and become enabled once you select a shape. Hovering over the icons in the Toolbar displays the description text of the operation.
-
(3) Properties Panel - this expandable section on the right side of Designer allows you to set both process and shape properties. It is divided into four sections, namely "Core properties", "Extra Properties, "Graphical Settings" and "Simulation Properties". After clicking on a shape in the Canvas, this panel is reloaded to show properties specific to that shape type. If you click on the canvas itself (not on a shape) the panel displays general process properties.
-
(4) Object Library Panel - the expandable section on the left side of Designer shows the jBPM BPMN2 (default) shape repository tree. It includes all shapes of the jBPM BPMN2 stencil set which can be used to assemble your processes. If you expand each section sub-group you can see the BPMN2 elements that can be placed onto the Designer Canvas (1) by dragging and dropping the shape onto it.
-
(5) View Tabs - currently Designer offers three tabs for Process Modelling, Simulation and Documentation. Process Modelling is the default tab. When users run process simulation, its results are presented in the Simulation tab. Process Documentation tab displays documentation generated from process definition.
-
(6) Info Tabs - there are two additional tabs at the top of Designer. The Editor tab includes the process modeling while the Overview tab displays the process metadata such as version history, creation date, last modification date etc.
13.2. Getting started with Modelling
The Object Library panel provide means for users to select and drag/drop BPMN2 shapes onto the modelling canvas. Shapes are divided into sections as shown below:
Once a shape is dropped onto the canvas users have a much faster way of continuing modelling without having to go back to the Object Library panel. This is realized through the shape morphing menu which is presented when a shape on the drawing canvas is clicked on. This menu allows users to either select a connecting shape (next shape) or morph the selected node into another node type. In addition this menu includes means to store the shape name as a dictionary item (explained later), view the specific BPMN2 code of the selected shape, as well as create/edit the task form (in the case of user tasks only).
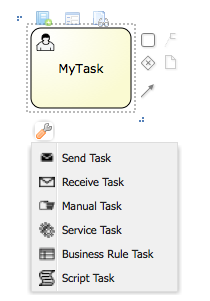
When connecting shapes Designer applies connection rules that follow the BPMN2 specification. The connection shapes presented in the morphing menu only show shapes that are allowed to be connections. Similarly same rules are applied when dropping a shape from the Object Library from the canvas and trying to connect an existing shape to it. Additional connection rules for boundary events are also available (explained later) and applied when for example moving an intermediate event node onto the edge of a task node.
Users can give names to every shape on the drawing canvas. This is done by double-clicking onto the shape as shown below.
The name of a shape can be pulled from the Process Dictionary. If terms are set up in the dictionary, auto-complete can be used for the node names:
Designer also shows five buttons on top of a clicked shape as shown below.
These include: * (1) Show in process Documentation - scrolls to the section of Process Documentation tab that corresponds to the shape clicked * (2) Add To Dictionary - allows users to add the name of the task to the Process Dictionary (explained in more details later) * (3) Edit Task Form - allows users to create/edit the Task Form. This option is only available for User Tasks * (4) Edit Data I/O - opens dialog for editting data input / output assignments for given node * (5) View Node Source - shows the BPMN2 for this particular shape only
The section should get you started with creating simple business process models by dragging/dropping BPMN2 shapes onto the drawing canvas. Next sections will dive deeper into many other aspects of Designer.
13.3. Designer Toolbar
The Designer toolbar contains many different functions which can be used during process modelling.

We will now go through each of the buttons in the Designer Toolbar and give a brief overview of what it does.
(1) Save - allows users to save, copy, rename and delete the business process model. In addition users can turn on auto-save which will automatically save the business process within a defined time interval.
(2) Cut - enabled when a portion of the model is selected.
(3) Copy - enabled when a portion of the model is selected.
(4) Paste - paste the copied portion of the model onto the drawing board.
(5) Delete - enabled when there is a portion of the model is selected and removes it.
(6, 7) Undo/Redo - undo the last performed operation on the drawing canvas.
(8) Local History - local history allows continuous storage of your business process onto your browsers internal storage. Stored version of the business process can persist internet outages or browser crashes so your work will not be lost. This feature is disabled by default and must be enabled by users. Once local history has been enabled users are able to view all previously stored snapshots of their business model, clear local history, configure the snapshot interval, or disable local history. Note that local history will only take a snapshot of your business process on the set storing interval if there were some changes done in the model. If at the end of the snapshot interval Designer detects that there were no changes since the last local history save, no new snapshot will be created.
The Local History results screen allows users to select a stored snapshot of the model, view its process image and restore it back onto their drawing board.

(9) Object positioning - allows users to position one or more nodes in the business process. Note that at last one shape must be selected first, otherwise these options are disable. Contains options "Bring to Front", "Bring to back", "Bring forward" and "Bring Backward".
(10) Alignment: enabled when a portion of the model is selected. Includes options "Align Bottom", "Align Middle", "Align Top", "Align Left", "Align Center", "Align Right" and "Align Same Size".
(11, 12) Group and Ungroup - allows grouping and ungrouping of selected shapes on the drawing board.
(13, 14) Locking and Unlocking - allows parts of the business model to be locked and unlocked. Locked parts of the model cannot be edited (visual display and properties are both locked). Locked nodes are displayed in a light blue color. This feature fosters collaboration of process modelling by allowing users to set parts of their model as "completed" and preventing any further changes to that portion. Other parts of the model can continue to be edited.
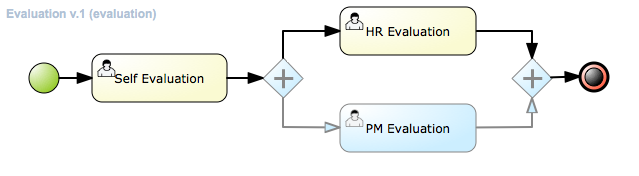
(15, 16) Add/Remove Docker - this allows users to add or remove Dockers, or edge points, to sequence flows in the model. Enabled when a sequence flow (connector) is selected. It allows users to create very customized connection points from one shape to another. Users can add and remove as many dockers as they would like on a single sequence flow.
(17) Color Themes - Colors are a big part or process modelling as they help with expressing intent as well as help allowing visually impaired users to better view the model. Designer provides two default color themes out of the box named "jBPM" and "High Contrast". The jBPM theme is the default theme used for all new business processes created. Users can switch color themes and the changes will be applied to all nodes that are currently on the model, as well as any new shapes added. Users have the ability to add new custom color themes by adding their own definitions in the Designer themes.json file. Color theme selection is persisted over browser close or possible crash/internet loss.
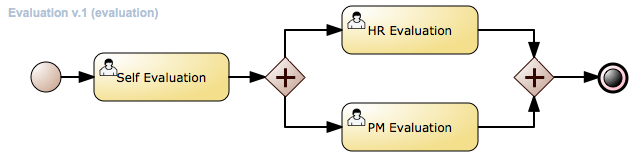
(18) Process and Task forms - here users have the ability to generate/edit process and task forms. When no user task is selected the default enabled options are "Edit Process Form" and "Generate all Forms". Generate all forms will apply the current model information such as process variables, data objects, and the user tasks data input/output parameters and associations to generate default executable input forms. Upon editing a process and task form, users have the choice between two form editors, the jBPM Form Modeler, and the Designer in-line meta editor. The Designer meta editor is targeted more to technical users as it is text based with the ability for live preview. When the user selects an user task in the model, the "Edit Task Form" and "Generate Task Form" options are enabled which allow users to edit the particular task form, or choose to apply the same generation logic to create a task form for the selected task only. Users have the ability to extend the default form generation templates in designer to create fully customized templates. Node that in the case of the Designer meta editor for forms, generating forms will overwrite existing forms for the process and user tasks. In the case of Form Modeler form generation, a merging algorithm is applied when generating.
When selecting a task, users have the ability to edit the selected tasks form via the form button shown above the user task node.
When editing forms, users are asked to choose between the Form Modeler and the Designer in-line meta editor. If the user selects Form Modeler the form is shown in a new asset tab separately from Designer. Designer meta editor is in-line and part of the Designer application.
The Designer in-line meta form editor is a powerful text-based editor with a live preview feature as well as auto-completion on process variables and user task data inputs/outputs.
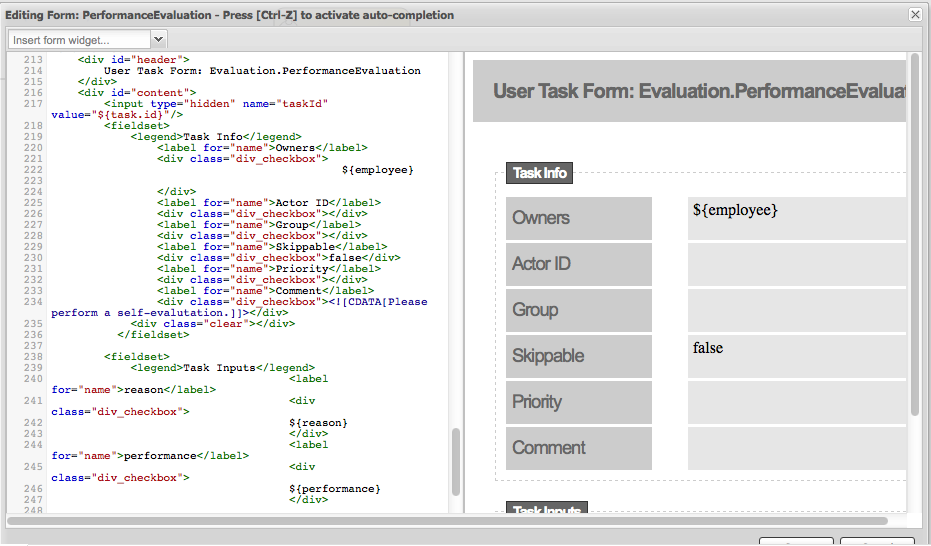
(19) Process Information Sharing - this section includes many functions that help with sharing information of your model. These include:
-
Share process image - generates a stand-alone HTML image tag which contains a Base64 encoded image source of the current model on the canvas. This link can be shared to team members or other parties and embedded in any HTML content or email that allows HTML content embedding.
-
Share process PDF - generates a stand-alone HTML object tag which contains a Base64 encoded PDF source of the current model on the canvas. This can similarly be shared and embedded in any HTML content.
-
Download process PNG - generates a PNG image of the current process on the drawing board which users can download and share.
-
Download process PDF - generates a PDF of the current process on the drawing board which can be downloaded and shared.
-
View Process Sources - displays the current process sources in various formats, namely BPMN2, JSON, SVG, and ERDF. Also has the option to download the BPMN2 sources.
(20) Extra tooling - this section allows users to import their existing BPMN2 processes into designer as well as be able to migrate their old jPDL based processes to BPMN2. For BPMN2 or JSON imports users can choose to add the import on top of the existing model on the drawing board or choose to replace the current one with the import.
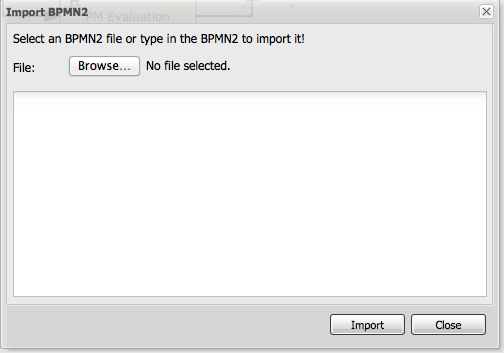
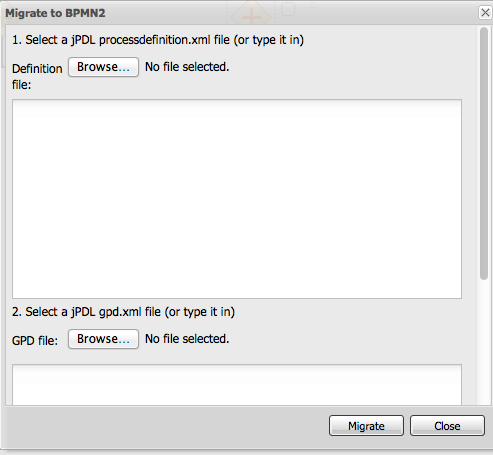
(21) Visual Validation - Designer includes over 100 validation checks and this list is growing. It allows users to view validation issues in real-time as they are modelling their business process. Users can enable visual validation, disable it, as well as view all validation issues at once. If Visual Validation is turned on, Designer with set the shape border of shapes that do not pass validation to red color. Users can then click on that particular shape to view the validation issues for that particular shape only. Alternatively "View All Issues" present a combined list of all validation errors currently found. Note that you do not have to periodically save your business process in order for validation to update. It will do so on its own short intervals during modelling. Users can extend the list of validation issues to include their own types of validation on certain elements of their business model.
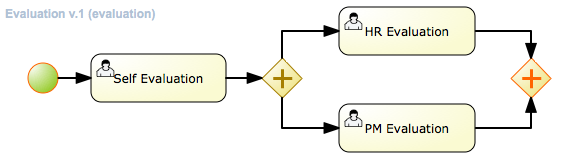
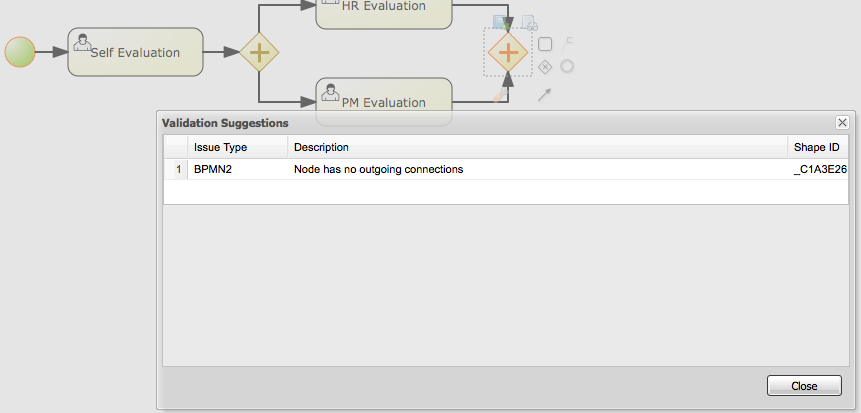
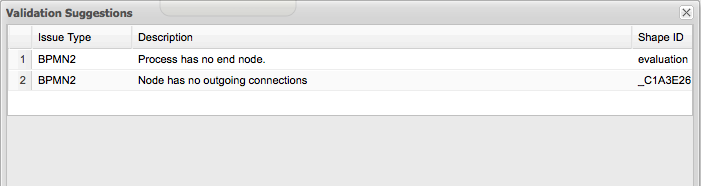
(22) Process Simulation - Business Process Simulation deals with statistical analysis of process models over time. It’s main goals include
-
Pre-execution and post-execution optimization
-
Reducing the risk of change in business processes
-
Predict business process performance
-
Foster continuous improvements of performance, quality and resource utilization of business processes
Designer includes a powerful simulation engine which is based on jBPM and Drools and a graphical user interface to view and interpret simulation results. In addition users are able to view all process paths included in their current model on the drawing board. Designer Process Simulation is based on the BPSim 1.0 specification. Details of Process Simulation capabilities in Designer are can be found in its Simulation documentation chapter. Here we just give a brief overview of all features it contains.
When selecting Process Paths, the simulation engine find all possible paths in the business model. Users can choose certain found paths and choose to display them. The chosen path is marked with given colors as shown below.
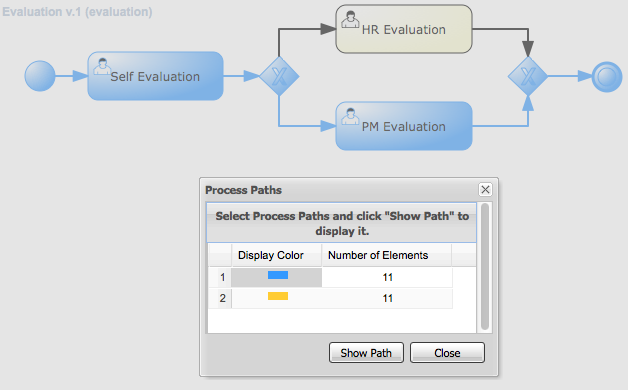
When selecting "Run Simulation", users have to enter in simulation runtime properties. These include the number of instances of this business process to simulate and the interval time and units. This interval is the time in-between consecutive simulation.
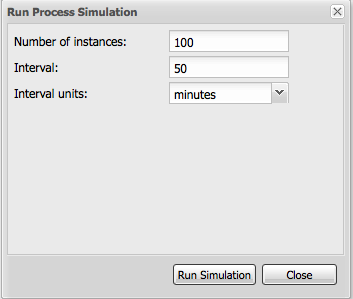
Each shape on the drawing board includes Simulation properties (properties panel) where users can set numerous simulation properties for that particular shape. More info on each of these properties can be found in the Simulation chapter of the documentation. Designer pre-sets some defaults for new processes, which allows business processes to be simulated by default without any modifications of these properties. Note however that the results of the default settings may not be optimal or targeted for the users particular needs.
Once the simulation runtime has completed, users are shown the simulation results in the "Simulation Results" tab of Designer. The results default to the process results. Users can switch to results for each particular shape in their business process to see more specific detauls. In addition, the results contain process paths simulation results for each path in the business process.
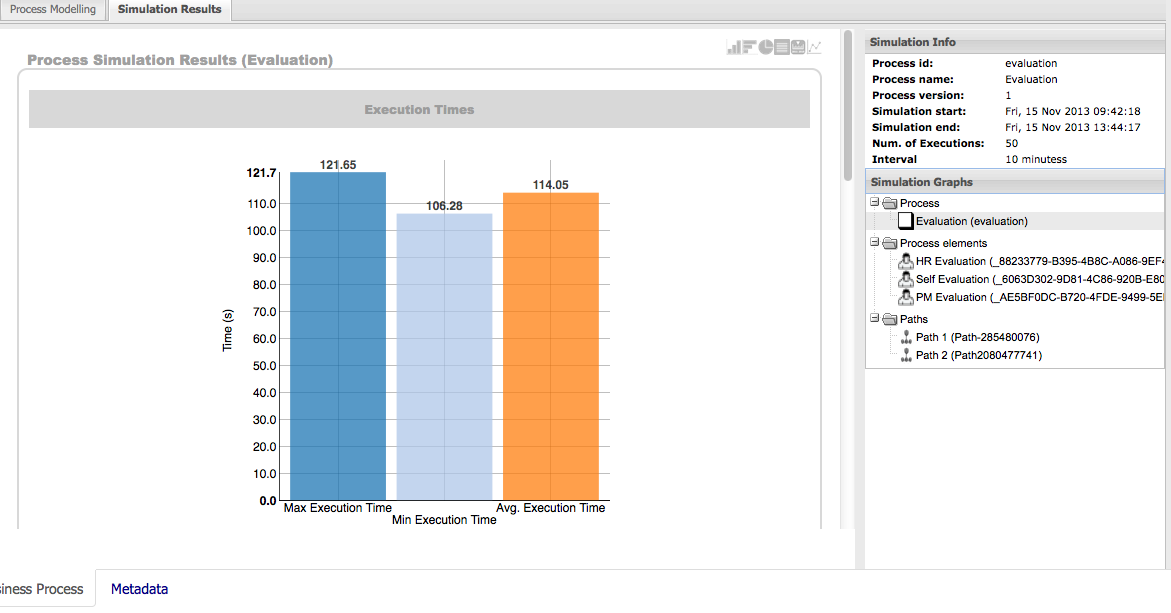
Designer simulation presents the users with many different chart types. These include:
-
Process results: Execution times, Activity instances, Total cost
-
Human Task results: Execution times, Resource Utilization, Resource Cost
-
All other nodes: Execution times
-
Process Paths: Path Execution The below image shows a number of possible chart types users can view after process simulation has completed.
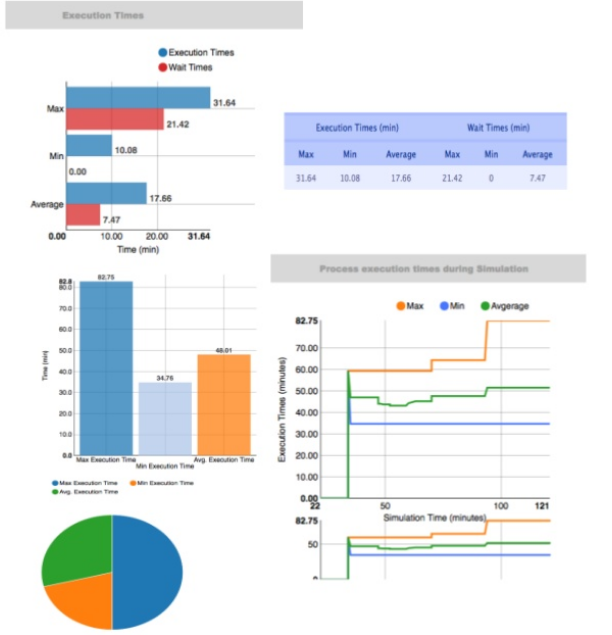
In addition to the chart results, Designer simulation also offers a full timeline display that includes all details of what happened during simulation. This timeline allows users to navigate through each event that happened during process simulation and select a particular node to display results at that particular point in time.
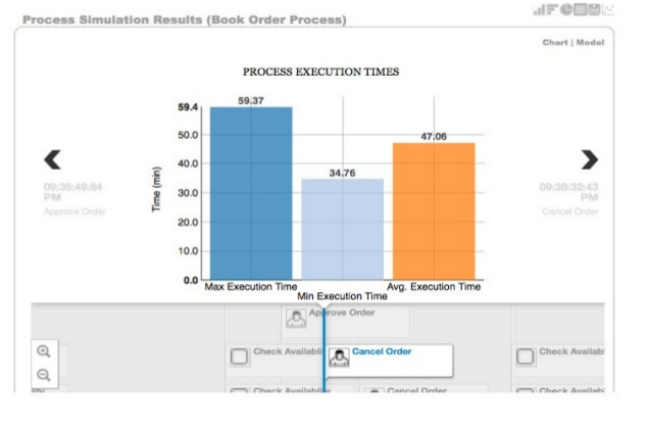
The simulation timeline can be switched to the Model view. This view displays the process model with the currently selected node in the timeline highlighted. The highlighted node displays the simulation results at that particular point in time of the simulation.
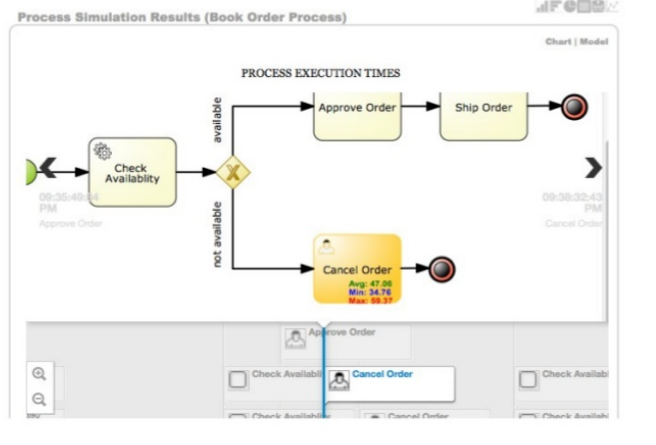
Path execution results shows a chart displaying the chosen path as well as path instance execution details.
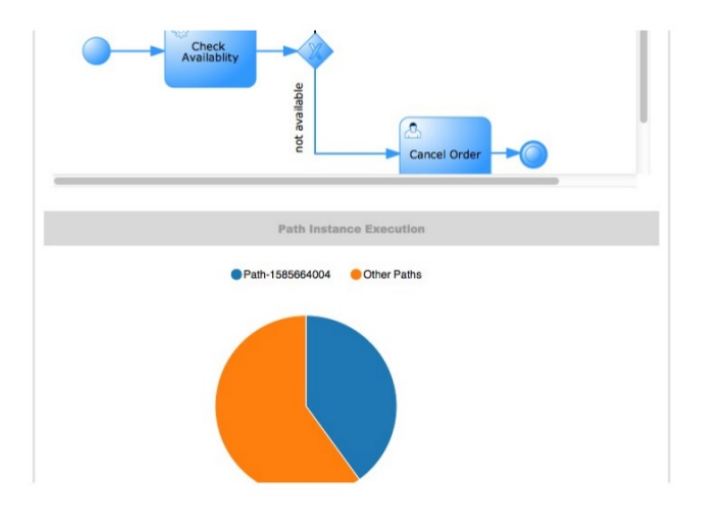
(23) Service Repository - Allows users to connect to a service repository via its URL and see the list of available services it provides. Each of the listed services can then be installed into the users project by clicking on the "wrench" icon next to each listed service. Installing a service does the following things:
-
Installs the service configuration (wid) into the users Workbench project. This can later be edited via the Workitem Definitions Editor.
-
Installs the service icon (defined in the service configuration) and if one does not exist a default one will be provided.
-
Installs the service maven dependencies into the project POM.
-
Installs the service default handler into the project Deployment Descriptor.
Users will be notified when the service is successfully installed. After the install users have to re-open the business process to be able to start using the installed services.
(24) Full screen Mode - allows users to place the drawing board of Designer into full-screen mode. This can help with better visualizing larger business processes without having to scroll. Note that this feature is possible only if your browser has full screen mode capabilities. If it does not designer will show a message stating this to the user.
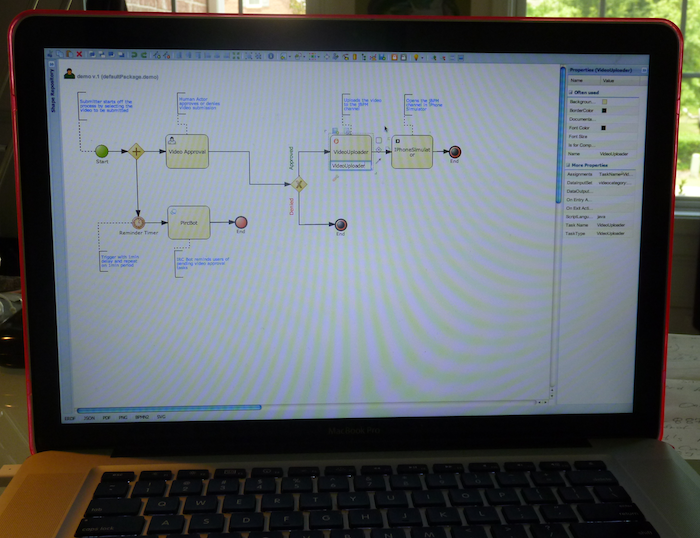
(25) Process Dictionary - Designer Dictionary Editor allows users to create their own dictionary entries or harvest from process documentation or business requirement documents. Process Dictionary entries can be used as auto-completion for shape names. This will be expanded in the future versions to allow mapping of node patters to specific dictionary entries as well. Users can add entries to the dictionary in the Dictioanry Editor or from the selected shapes directly.
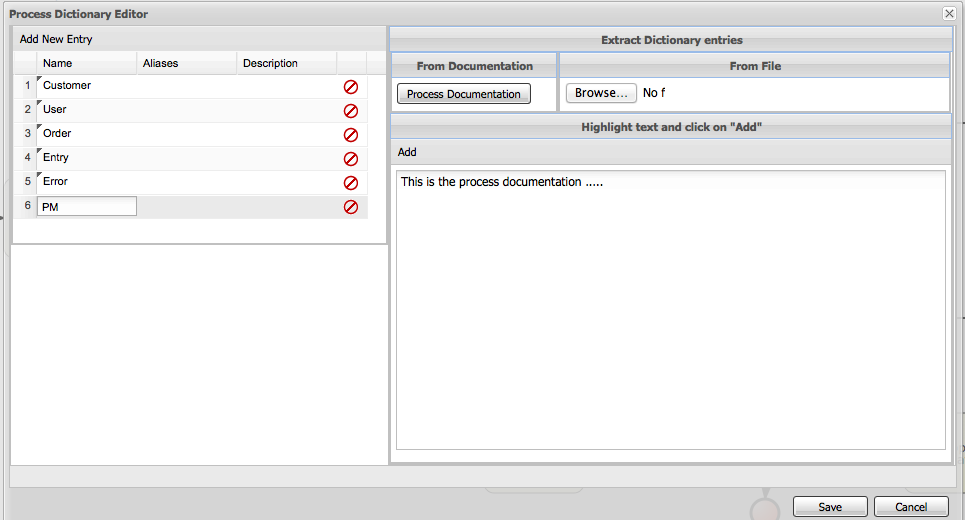
(26, 27, 28, 29) Zooming - zooming allows users to zoom in/out of the model, zoom in/out back to the original setting as well as zoom the process model on the drawing board to fit the currently dimensions of the drawing board.
13.4. Designer keyboard shortcuts overview
Designer includes a number of keyboard shortcuts you can use as an alternative to the mouse when modeling your business processes. These include some core functionalities such as copy, paste, delete, as well as utility shortcuts such as opening/closing menus and the property panel for example. Note that the Designer keyboard shortcuts may be somewhat different than the "traditional" shortcut options for similar operations you may encounter when dealing with browsers or word editors. This is done so that Designer does not replace or overwrite some of the keyboard shortcuts already used and claimed by different browsers you may use Designer in.
Below is the complete list of Designer keyboard shortcuts and their description.
| Press | To |
|---|---|
CTRL-C |
Copy one selected or multiple selected shapes from the Designer canvas. Note that copy and paste commands work across multiple opened business processes in the same browser (same tab or multiple tabs) as well as across multiple windows of the same browser type. |
CTRL-V |
Paste the copied node(s). Note that copy and paste commands work across multiple opened business processes in the same browser (same tab or multiple tabs) as well as across multiple windows of the same browser type. |
CTRL-X |
Cut one selected or multiple selected shapes from the Designer canvas. |
CTRL-Y |
Redo the last action such as a paste or node drag/resize/move/edit/cut. |
CTRL-Z |
Undo the last action such as a paste or node drag/resize/move/edit/cut/delete. |
ALT-A |
Select all shapes on the canvas. |
ALT-D |
Delete one selected or multiple selected shapes from the canvas. At least one shape must be selected. |
ALT-M |
Open/close the shape menu. |
ALT-P |
Open/close the properies panel. If a shape is selected it will open the properties for that shape. If no shape is selected the property panel for the canvas (process properties) will be opened. |
ALT-UP (up arrow) |
Move the selected shape(s) upward on the canvas. Note that all connections to the nodes being moved will be adjusted according to the move. |
ALT-DOWN (down arrow) |
Move the selected shape(s) downward on the canvas. Note that all connections to the nodes being moved will be adjusted according to the move. |
ALT-LEFT (left arrow) |
Move the selected shape(s) to the left on the canvas. Note that all connections to the nodes being moved will be adjusted according to the move. |
ALT-RIGHT (right arrow) |
Move the selected shape(s) to the right on the canvas. Note that all connections to the nodes being moved will be adjusted according to the move. |
F2 |
When a shape is selected you can use F2 to change the shapes name without having to double-click on it first. |
13.5. Designer Customization
Designer includes a number of system properties which you can use to customize its functionality. In this section we go through each one and explain what it does and how you can use it.
13.5.1. System Properties
System properties and their values can be set on appserver starup with the
-DpropertyName=propertyValuesettings. There are several system properties you can set:
| System Property | Description | Values |
|---|---|---|
designer.dev |
Enables/disables additional logging. Default is false. |
true / false |
designer.useolddataassignments |
Replaces the new Data IO editor with the old style Data Assignments editor. Default is false. |
true / false |
designer.showpdfdoc |
Enables/disables display of PDF docs link in Process Documentation tab. |
true / false |
org.jbpm.designer.perspective |
Use to pre-select a perspective in the Shape Menu. Default is "full" |
"full" / "simple" / "ruleflow" |
org.jbpm.designer.bpsimdisplay |
Enables/disables display of BPSim (simulation) options in the menu bar as well as generation of BPSim BPMN2 elements in the generated process sources. Default is true. |
true / false |
org.jbpm.designer.formstype |
Sets the type of process/task forms to be generated/edited. If not set Designer will ask users to choose the type (".form", ".frm"). By setting this property you declare to use one of these two form types and users will no longer be asked to choose. |
"form" / "frm" |
designer.preprocess |
Designer performs a number of pre-processing steps before it displays the process model. These include install of default workitem definitions, icons, etc. Allows you to completely disable these pre-processing steps. Use caution when setting this to false as it will affect Designer functioning properly within the workbench. Default is true. |
true / false |
designer.skin |
Allows users to choose between pre-defined Designer color themes. Default is "default". |
"default" / "olive" / "purple" / "slickness" |
org.jbpm.service.repository |
You can pre-install a number of custom workitems on server startup so they are available for the users in addition to the default ones Designer installs during the pre-processing steps. This property allows you to set a location to your service repository. |
location to your repository, for example http://www.myservicerepository.org/repo or file://my/service/repo |
org.jbpm.service.servicetasknames |
Comma-separated list of custom workitem names which you would like to be installed on server startup. Names have to match the "name" attribute as defined in your workitem definition and exist in the repository defined by system property org.jbpm.service.repository |
comma-separated string, for example "MyWorkitem, MyOtherWorkitem, …" |
designerdataobjects |
Can be used to enable/disable of BPMN2 Data Object nodes to be present or not in the shape menu. Default is "true". |
"true" / "false" |
org.jbpm.designer.storesvgonsave |
Designer stores the process SVG when a business process is saved during modeling. This property allows you to enable/disable this feature. Default is "true". |
"true" / "false" |
13.5.2. Development System Properties
These system properties are designed for development purposes only. It is recommended not to set/change them in production environments. Designer includes an api abstraction ontop of the workbench file repository. Via these development properties you can define an alternative repository for business process data. Again in order for Designer to play along nicely in the workbench it is recommended not set these unless in a development environment.
| System Property | Description | Values |
|---|---|---|
designer.repository.protocol |
Set the repository protocol. |
String defining the repository protocol |
designer.repository.host |
Set the repository host. |
String defining the repository host |
designer.repository.subdomain |
Set the repository subdomain |
String defining the repository subdomain if one exists |
designer.repository.usr |
In the case custom repository needs authentication this one defines the username for it. |
String defining the user name for authentication |
designer.repository.pwd |
In the case custom repository needs authentication this one defines the user password. |
String defining the user password for authentication |
14. Runtime Management
14.1. Deployments
In version 5.x processes were stored in so called packages produced by Guvnor and next downloaded by jbpm console for execution using KnowledgeAgent. Alternatively one could drop their process files (bpmn2 files) into a predefined directory that was scanned on the jbpm console start. That was it. That enforces users to always use Guvnor when dynamic deployment was needed. Although there is nothing wrong with it, actually that was recommended approach but not everytime it was desired.
Version 6, on the other hand moves away from proprietary packages in favor of, well known and mature, Apache Maven based packaging - known as knowledge archives - kjar. Processes, rules etc (aka business assets) are now part of a simple jar file built and managed by Maven. Along the business assets, java classes and other file types are stored in the jar file too. Moreover, as any other maven artifact, kjar can have defined dependencies on other artifacts including other kjars. What makes the kjar special when compared with regular jars is a single descriptor file kept inside META-INF directory of the kjar - kmodule.xml. That descriptor allows to define:
-
knowledge bases and their properties
-
knowledge sessions and their properties
-
work item handlers
-
event listeners
By default, this descriptor is empty (just kmodule root element) and is considered as marker file. Whenever a runtime component (such as jbpm console) is about to process kjar it looks up kmodule.xml to build its runtime representation. In addition to kmodule.xml a deployment descriptor (that provides fine grained control over deployment) is available (since 6.1).
14.1.1. Deployment descriptors
While kmodule is mainly targeting on knowledge base and knowledge session basic configuration, deployment descriptors are considered more technical configuration. Following are the items available for configuration via deployment descriptors:
-
persistence unit name for runtime data
-
persistence unit for audit data
-
persistence mode (JPA or NONE)
-
audit mode (JPA, JMS, NONE)
-
runtime strategy (SINGLETON, PER_REQUEST, PER_PROCESS_INSTANCE)
-
list of event listeners to be registered
-
list of task event listeners to be registered
-
list of work item handlers to be registered
-
list of globals to be registered
-
marshalling strategies to be registered (for pluggable variable persistence)
-
required roles to be granted access to resources of the kjar
-
additional configuration options of knowledge session
-
additional environment entries for knowledge session
-
list of fully qualified class names that shall be added to the classes used for serialization by remote services
-
whether or not to limit the classes from the deployment used for serialization by the remote services
Deployment descriptor is an xml file that is placed inside META-INF folder of the kjar, although it is an optional file and deployments will succeed even when such descriptor is missing.
<deployment-descriptor xsi:schemaLocation="http://www.jboss.org/jbpm deployment-descriptor.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<persistence-unit>org.jbpm.domain</persistence-unit>
<audit-persistence-unit>org.jbpm.domain</audit-persistence-unit>
<audit-mode>JPA</audit-mode>
<persistence-mode>JPA</persistence-mode>
<runtime-strategy>PER_PROCESS_INSTANCE</runtime-strategy>
<marshalling-strategies/>
<event-listeners/>
<task-event-listeners/>
<globals/>
<work-item-handlers/>
<environment-entries/>
<configurations/>
<required-roles/>
<remoteable-classes/>
<limit-serialization-classes/>
</deployment-descriptor>It provides more configuration options then the standard deployment has. Deployment descriptors are used in hierarchical way meaning they can be placed on various levels of the system and merged on runtime. jBPM supports following levels of deployment descriptors:
-
server level - this is the main and considered default deployment descriptors that apply to all deployments on given server
-
kjar level - this is dedicated deployment descriptor to given kjar
-
deploy time level - this is deployment descriptor that is given at the time of deployment
Deployment descriptors on different levels are merged on deployment time where the master is considered descriptor lower in the hierarchy and slave one that is higher in hierarchy. To give an example, when a kjar is deployed and it contains deployment descriptor kjar’s deployment descriptor is considered slave and server level descriptor is considered master. With default merge mode it will override all master entries with slave ones as long as they are not empty and combine all collections.
Since kjar can have dependencies to other kjars, and in turn that dependencies might have deployment descriptors as well, they will be placed in deployment descriptors hierarchy lower than the actual kjar that is being deployed. With that said, this is how it will look like from hierarchy point of view, starting with master (server level):
-
server level
-
dependency kjar level
-
kjar level
That in default merging mode will result in deployment descriptor where with non empty values from kjar’s deployment descriptors and merged collection from all levels.
So far all merging was done with default mode, which is MERGE_COLLECTIONS but that’s not the only mode that is available:
-
KEEP_ALL - meaning that the master wins - all configuration defined in master will be retained
-
OVERRIDE_ALL - meaning that slave wins - all configuration defined in master will be retained
-
OVERRIDE_EMPTY - meaning all non empty configuration items from slave will replace those in master, including collections
-
MERGE_COLLECTIONS - meaning all non empty configuration items from slave will replace those in master but collections will me merged (combined)
|
Deployment descriptos can be given as partial xml documents, meaning they do not need to be complete set of all configuration items, e.g. if user would like to override only the audit mode in kjar, it’s enough to have following deployment descriptor: Although it’s worth noting that when using OVERRIDE_ALL merge mode all configuration items should be specified since it will always use them and do not merge with any other deployment descriptor in the hierarchy. |
Default deployment descriptor
There is always default deployment descriptor available, even if it was not explicitly configured, when running in jbpm-console (kie-workbench) the default values are as follows:
-
persistence-unit is set to org.jbpm.domain
-
audit-persistence-unit is set to org.jbpm.domain
-
persistence-mode is set to JPA
-
audit-mode is set to JPA
-
runtime-strategy is set to SINGLETON
-
all collection based configuration items are left empty
|
Regardless of collection elements in default deployment descriptor are empty there will be some work item handlers/listeners registered that are required to support functionality of the jbpm console such as BAM listeners or human task work item handler. |
Default deployment descriptor can be altered by specifying valid URL location to an xml file that will provide fully defined deployment descriptor. By fully defined we mean that all elements should be specified as this deployment descriptor will become server level deployment descriptor.
-Dorg.kie.deployment.desc.location=file:/my/custom/location/deployment-descriptor.xmlCollection configuration items
Deployment descriptor consists of collection based items (event listeners, work item handlers, globals, etc) that usually require definition of an object that should be created on runtime. There are two types of collection based configuration items:
-
object model - that is clear definition of the object to be built or looked up in available registry
-
named object model - that is an extension to object model and allows to provide name of the object which will be used to register object
Object model consits of:
-
identifier - defines main information about the object, such as fully qualified class name, spring bean id, mvel expression
-
parameters - optional parameters that should be used while creating object instance from the model
-
resolver - identifier of the resolver that will be used to create object instances from the model - (reflection, mvel, spring)
| Configuration item | Type of collection items |
|---|---|
event-listeners |
ObjectModel |
task-event-listeners |
ObjectModel |
marshalling-strategies |
ObjectModel |
work-item-handlers |
NamedObjectModel |
globals |
NamedObjectModel |
environment-entries |
NamedObjectModel |
configurations |
NamedObjectModel |
required-roles |
String |
Depending on resolver type, creation or look up of the object will be performed. The default (and easiest) is reflection that will use both parameters and identifier (in this case is FQCN) to construct the object. Parameters in this case can be String or another object model for representing other types than String. Following is an example of an object model that will create an instance of org.jbpm.test.CustomStrategy using reflection resolver that will use constructor of that class with two String parameters. Note that String paramaters are created with different ways (using object model - first param, directly by giving String - second param).
...
<marshalling-strategy>
<resolver>reflection</resolver>
<identifier>org.jbpm.test.CustomStrategy</identifier>
<parameters>
<parameter xsi:type="objectModel">
<resolver>reflection</resolver>
<identifier>java.lang.String</identifier>
<parameters>
<parameter xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">param1</parameter>
</parameters>
</parameter>
<parameter xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">param2</parameter>
</parameters>
</marshalling-strategy>
...Same can be done by using DeploymentDescriptor fluent API:
// create instance of DeploymentDescriptor with default persistence unit name
DeploymentDescriptor descriptor = new DeploymentDescriptorImpl("org.jbpm.domain");
// get builder and modify the descriptor
descriptor.getBuilder()
.addMarshalingStrategy(new ObjectModel("org.jbpm.testCustomStrategy",
new Object[]{
new ObjectModel("java.lang.String", new Object[]{"param1"}),
"param2"}));Reflection based object model resolver is the most verbose in case there are parameters involved but there are few parameters that are available out of the box and do not need to be created, they are simply referenced by name:
-
entityManagerFactory (type of this parameter is javax.persistence.EntityManagerFactory)
-
runtimeManager (type of this parameter is org.kie.api.runtime.manager.RuntimeManager)
-
kieSession (type of this parameter is org.kie.api.KieServices)
-
taskService (type of this parameter is org.kie.api.task.TaskService)
-
executorService (type of this parameter is org.kie.internal.executor.api.ExecutorService)
So to be able to use one of these it’s enough to reference them by name and make sure that proper object type is used within your class:
...
<marshalling-strategy>
<resolver>reflection</resolver>
<identifier>org.jbpm.test.CustomStrategy</identifier>
<parameters>
<parameter xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">runtimeManager</parameter>
</parameters>
</marshalling-strategy>
...In case reflection based resolver is not enough, more advanced resolver can be used that utilizes power of MVEL language. It’s much easier in the configuration as it expects mvel expression as identifier of the object model. It will provide the out of the box parameters (listed above: runtime manager, kie session, etc) into the mvel context while evaluating expression. To define object model with mvel resolver use following xml (that will be equivalent to replection based above):
...
<marshalling-strategy>
<resolver>mvel</resolver>
<identifier>new org.jbpm.test.CustomStrategy(runtimeManager)</identifier>
</marshalling-strategy>
...Last but not least, there is Spring based resolver available as well that allows to simply look up a bean by its identifier from spring application context. This resolver is not used in jbpm console (kie-workbench) as it does not use spring but whenever jBPM is used together with Spring it might become handy when deploying kjars into the runtime. It’s very simple definition in xml, again equivalent to the other one assuming org.jbpm.test.CustomStrategy is registered in spring application context under customStrategy id.
...
<marshalling-strategy>
<resolver>spring</resolver>
<identifier>customStrategy</identifier>
</marshalling-strategy>
...Manage deployment descriptor
Deployment descriptor is created as soon as project is created. It does contins the most basic deployment descriptor that is based on the default one. Meaning all settings present in default deployment descriptor will be copied into the one placed in the project. Further changes can be done directly in the xml content (in next versions more user friendly editor will most likely be provided). It is accessible from Administration perspecitve as this is considered technical administration task rather than business related activity.
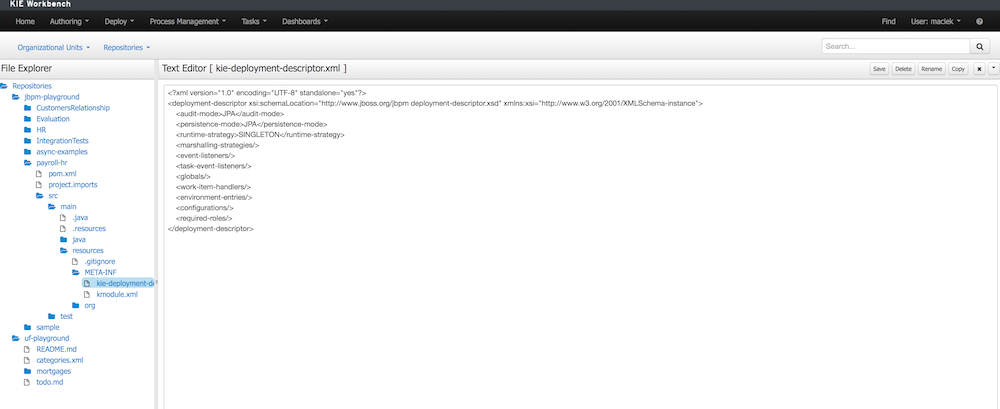
Restrict access to runtime engine
jbpm console (kie-workbench) enables configuration of access restrictions to repositories (see Security management chapter for how this can be done). This protects repositories in the authoring page based on roles membership. Deployment descriptors moves this capability to the runtime engine by ensuring that access to processes will be granted only to users that belong to groups defined in the deployment descriptor as required roles. By default when project is created (at the same time deployment descriptor is created as well) required roles are automatically filled in based on repository restrictions. These roles can be still altered by editing deployment descriptor via Administration page as presented in Manage deployment descriptor section.
Security is enforced on two levels:
-
user interface - user will see only process definitions that are available for his/her roles
-
runtime manager - each access to get RuntimeEngine out of RuntimeManager is pretected based on the role membership, in case unauthorized access it attempted SecurityException will be thrown
Required roles are defined as simple strings that should match actual roles defined in security realm. Following is a xml snippet that shows definition of required roles in deployment descriptor:
<deployment-descriptor>
...
<required-roles>
<required-role>experts</required-role>
</required-roles>
...
</deployment-descriptor>In case fine grained control is required defined roles can be prefixed with one of the following to control it on further level:
-
view:
to restrict access to be able to see given process definitions/instances on UI
-
execute:
to restrict access to be able to execute given process definitions
-
all:
applies to both view and execute restrictions and this is the default when no prefix is given.
For example to restrict access to show process from given kjar only to group 'management' but still allow them to be executed by anyone (sort of system processes) one could define it as follows:
<deployment-descriptor>
...
<required-roles>
<required-role>view:management</required-role>
</required-roles>
...
</deployment-descriptor>Classes used for serialization in the remote services
When processes make use of custom types (or in general non primitive types) and there is a use case to include remote API invocations (REST, SOAP, JMS) such types must be available to the remote services marshalling mechanism that is based on JAXB for XML type. By default all types defined in kjar will be automatically included in JAXB context and therefore will be available for remote interaction. Though there might be more classes (like from dependent model) that shall be included there too.
Upon deployment, jBPM will scan classpath of given kjar to automatically register classes that might be needed for remote interaction. This is done based on following rules:
-
all classes included in kjar project itself
-
all classes included as dependency of projects type kjar
-
classes that are annotated with @XmlRootElement (JAXB annotation) and included as regular dependency of the kjar
-
classes that are annotated with @Remotable (kie annotation) and included as regular dependency of the kjar
If that is not enough deployment descriptor allows to manually specify classes that shall be added to the JAXB context via remoteable-classes element:
<remoteable-classes>
...
<remoteable-class>org.jbpm.test.CustomClass</remoteable-class>
<remoteable-class>org.jbpm.test.AnotherCustomClass</remoteable-class>
...
</remoteable-classes>With this all classes can be added to the JAXB context to properly marshal and unmarshal data types when interacting with jBPM remotely.
Limiting classes used for serialization in the remote services
When there are classes in the kjar project or in the dependencies of the kjar project that would cause problems when used for serialization, the limit-serialization-classes property can be used to limit which classes are used for serialization.
<limit-serialization-classes>true</limit-serialization-classes>This property limits classes used for serialization to classes which fulfill both of the following "location" and "annotation" criteria:
Classes that:
-
are located in the kjar project
-
are in a direct dependency of the kjar project
-
are listed in the
remoteable-classeselement and are available on the classpath of the kjar
These classes must also be annotated with one of the following type annotations:
-
javax.xml.bind.annotation.XmlRootElement -
javax.xml.bind.annotation.XmlType -
org.kie.api.remote.Remotable
Additionally, classes will be excluded if they are any of the following: interfaces, local classes, member classes or anonymous classes.
14.2. Process Deployments
You can access to the Process Deployments List under the Deploy top level menu of the KIE Workbench
The Deployed Unit list shows all the Process Deployed Units into the platform that are already enabled to be used. Each deployment unit can contain multiple business processes and business rules. In order to have your process and rules deployed and listed in this list, you need ot Build and Deploy your KIE projects from the Authoring Page or via the Remote Endpoints. If your processes and rules are in a KIE Project listed in this list and you have correspondent the rights you should be able to see the process definitions in the Process Definitions Page.
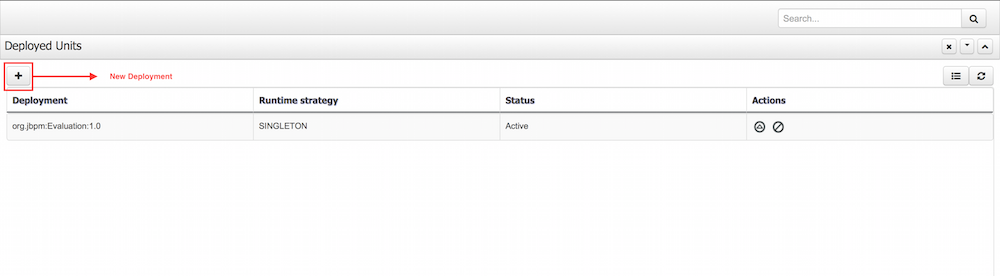
From the Authoring Page (Build and Deploy), a default deployment will be performed, for a more advanced deployments you can trigger a custom deployment with other options from this screen.
By clicking the New Deployment Unit (+) button you will be able to select a different KIE Base, KIE Session, Strategy and Merge Mode for your deployment. By default the "DEFAULT" KIE Base and KIE Sessions are used, the SINGLETON Strategy is selected and the Merge Mode is set to "Merge Collection".
15. Process Management
15.1. Management Screens Overview
Before we get into the details for the different management concepts, let’s explore the common features available in all areas. We consider this kind of view as a set of visualization parameters that modify which items can be displayed and what information should be shown.
Common features include:
-
Columns to be shown
-
Items by page
-
Sorting by column criteria
-
Restrictions over the displayed items list provided by:
-
Quick filter creation
-
Saved filters management.
-
-
General actions shared by all item list like 'Refresh'
-
Specific actions depending on each screen.
We find here different areas with different purposes: Filtering, general section configuration and specific view parameter setting in the data grid presentation:
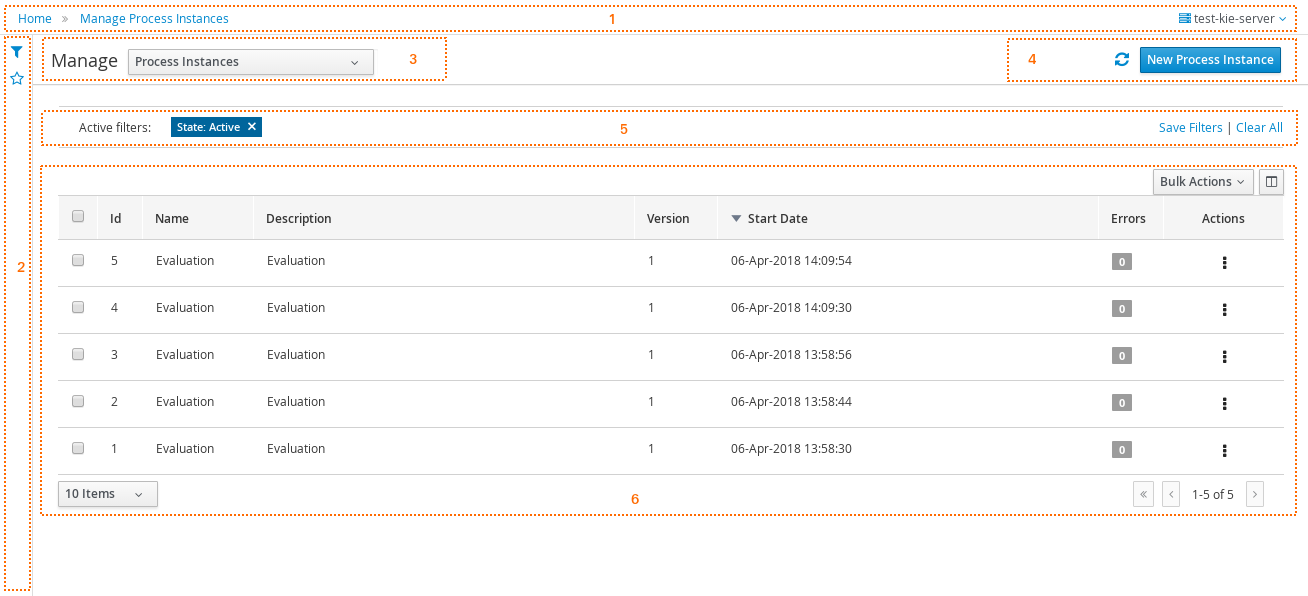
-
(1) Breadcrumb area: Contains breadcrumbs and the server template selector.
-
(2) Filters area: Contains a dock for filter creation and a dock with saved filters The docks are placed in the expandable panel on the left side of the screen. The selections made inside any of the docks are immediately reflected in the table on the right.
That panels can be expanded or collapsed using the standard workbench docks controls.
Filter dock
Contains a set of available filters to create quick filters over the left side panel list. Allows you to quickly find data related to Process Instances, Jobs, Tasks and Execution Errors.A set of pre defined filters are defined into the related views. The user is able to restrict the data by adding new active filters. This can be done by either selecting values from the dropdown list or providing values to the different attributes in the input box.
You will notice that the data is filtered as you add or remove any of the active filters.

There are different types of filters:
— Checkboxes (state and errors on the image):
Allow to select multiple values for one specific field. Any action on checkbox generate and applies that restriction on the active filter.
— Filter by:
Dropdown with the available fields to filter. Depending on the kind of field the input box have different allowed values (numeric or any text)
— Dropdown filled with specific values. (ie: in this process instances list it is filled with the available Process names)
— Date fields filter:
Once of the filter box is selected a list of date predefined filters like 'Last Hour', 'Today',.. are displayed, and also the posibility of define a custom range of dates
At the end of this dock there is the option to create a new saved 'Advanced Filter'. When the user selects it, a "New Item list" popup appears and let to introduce parameters related with the new filter like the name, the description and the filter restrictions.
If the view has to include a restriction over a specific column, then the link 'Add new' has to be selected. A drop down list with all the columns to create restrictions

Once the column is selected, depending of its type, a new dropdown list is open with the kind of restrictions available for the selected column and the necessary form to add them.

One filter can include a list of different conditions over different columns and the editor allow remove each one clicking th 'x' button near them
Once the view creation parameters are defined, the 'Ok' button launch the defined filter saving and applies that on the list.
Saved Filter dock
The 'Saved filters' dock allows manage the stored filters: It present a list with the current stored filters

-
Filters can be deleted
-
The defaults filters can be always restored as in the previous version with the 'Restore default filters' button.
-
Filters can be applied: When a user selects one filter, that is applied on the current list and the 'Active filters' displays the restrictions contained in that filter.
-
The user has the ability to modify/complete filters and save it to be reused later. The new way to save filter is selecting 'Save filters' at 'Active filters' area. A name for the new saved filter is requested and a new filter with the current restrictions is added to 'Saved filters' list.
It’s not allowed to have filters with the same name. When the user tries to save a filter with an existing name, currently an error is shown.

-
(3) Manage screen selector. The drop-down offers navigation to the all manage screens: Process Definitions, Process Instances, Tasks, Execution Errors and Jobs have been created. This selector allows the user to switch process admin screens quickly and easily.
-
(4) Toolbar area. This toolbar has been designed to contain each screen specific actions and provides different kinds of visualizations: icons for common actions like 'Refresh' that are self-explained, buttons for primary actions and it’s prepared for containing kebab with a list of available actions.
-
(5) Filter status area. Shows the currently applied filters and provides options to clear individual filters or to clear them all. The user has the ability to save the currently applied filter as a new saved filter, which becomes available in Saved filters dock (see Filters area above)
-
(6) The list table area. In this area can be done:
-
Specific view configuration like. selecting visible columns, specify the number of items by page. In this area the user can change dynamically the view editable parameters like visible columns, set the sorting column (ASC/DESC) or set the number of items to show in a page.
-
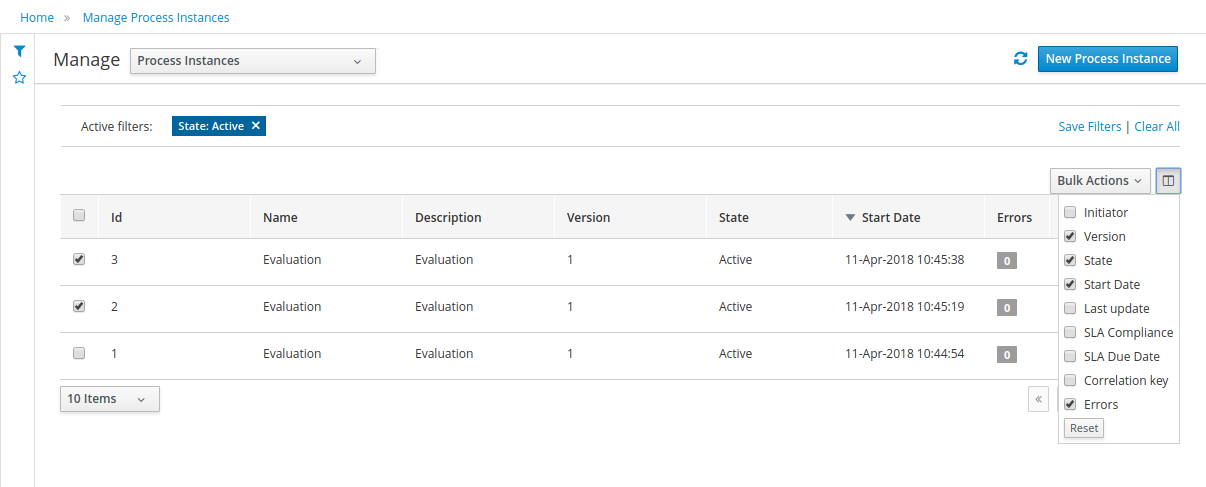
The number of items to show in a page can be configurable too, from the page size dropdown list
-
Bulk actions in some of the management screens like Process Instances, Execution errors the posibility of bulk action is provided over the selected items. In this case the available actions are 'Abort' or 'Signal'
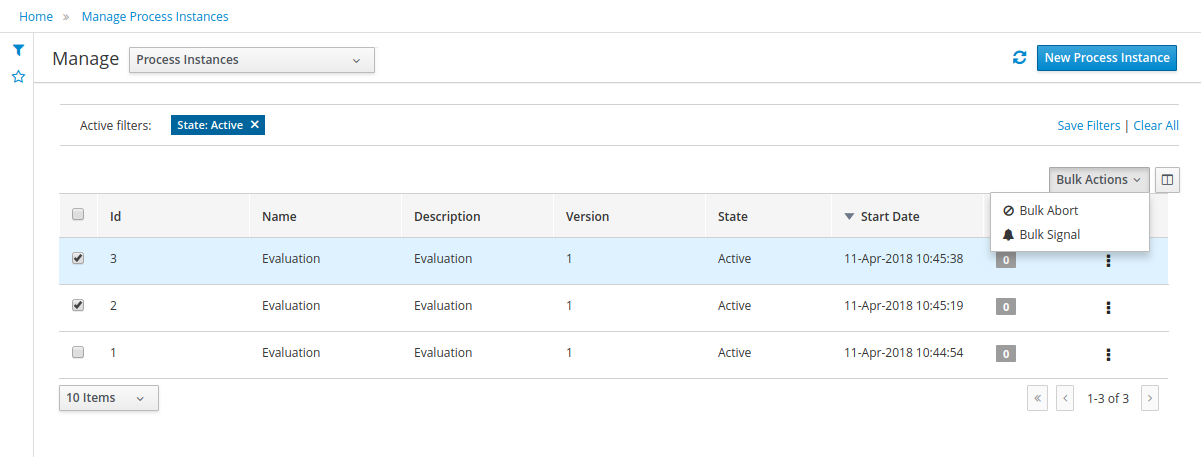
-
Perform actions on individual list item using the kebab button control. When there are more than one available actions the kebab groups the available actions. There are different areas at kebab: primary actions first and separately the navigation to other screens ones.
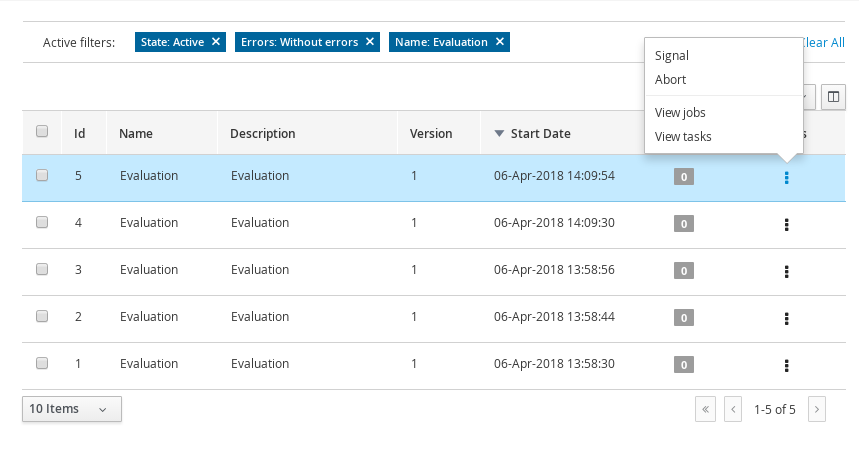
15.2. Process Management
This chapter describes the screens related with the creation and management of process definitions and process instances.
Once you have modelled, configured all the technical details and build and deployed your projects containing your business processes you should be able to see all the available process definitions in the Manage Process Definitions section. For all the process definitions listed in there you will be able to inspect the Process Definition details and start as many Process Instances as needed. The following sections describes most features available to manage process definitions and process instances from the jBPM Workbench. You can find these screens under the Manage menu: Process Definitions or Process Instances, in the jBPM Workbench.
You can find the source code related to the process definition and instances screens in the jbpm-wb-process-runtime module. Feel free to report issues, send Pull Requests and get in contact with the team via comments in github.

15.2.1. Process Definitions Management
The process definition section is composed by two main screens: the Process Definition Lists and the Process Definition Details.
15.2.1.1. Process Definition List
The process definition list shows all the available process definitions that were deployed into the platform. Look at the Deployments section for more information about how to check all the deployment units available in the platform runtime.
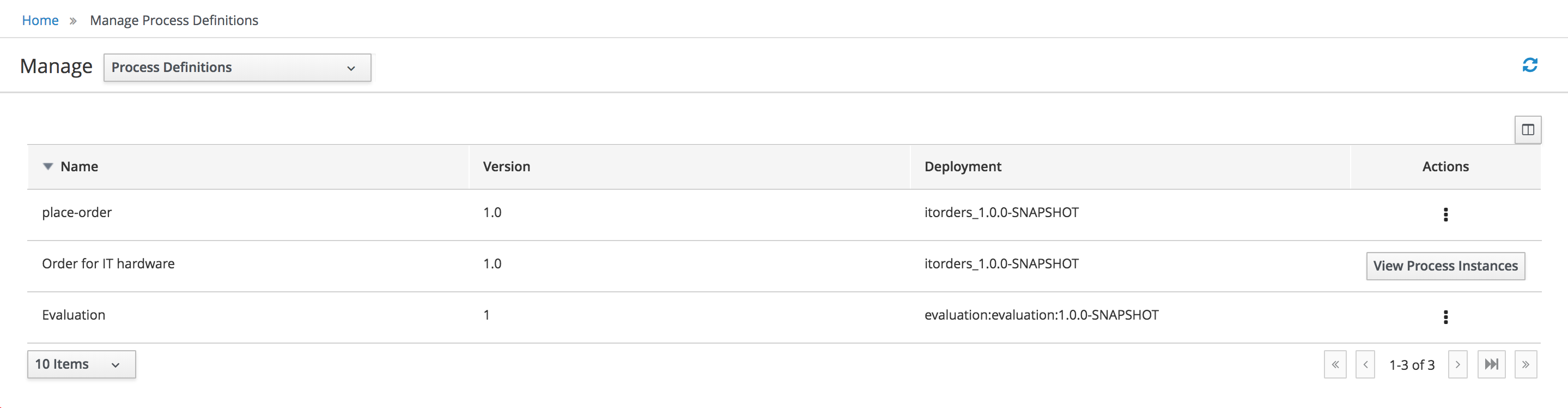
You can click in the items in the list to access the details of the process definition. You can also look at all the process instances for the selected process definition selecting 'View Process Instances' action.
15.2.1.2. Process Definition Details
The process definition details shows all the available information about the process definition. You can consider this screen as a brief about the process model. You can quickly see if there is a Sub Process associated with it, or how many users and groups are participating in the selected definition.
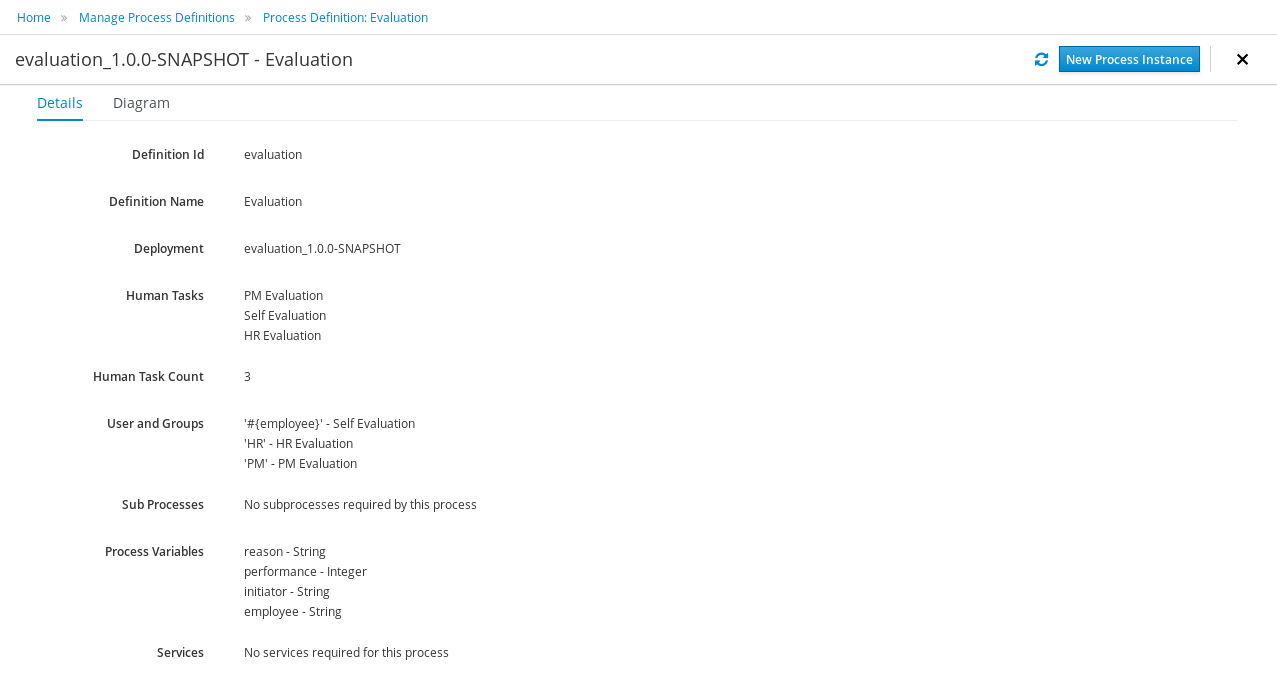
Notice that you can View the Process Model (Read Only mode) selecting 'Diagram' tab .
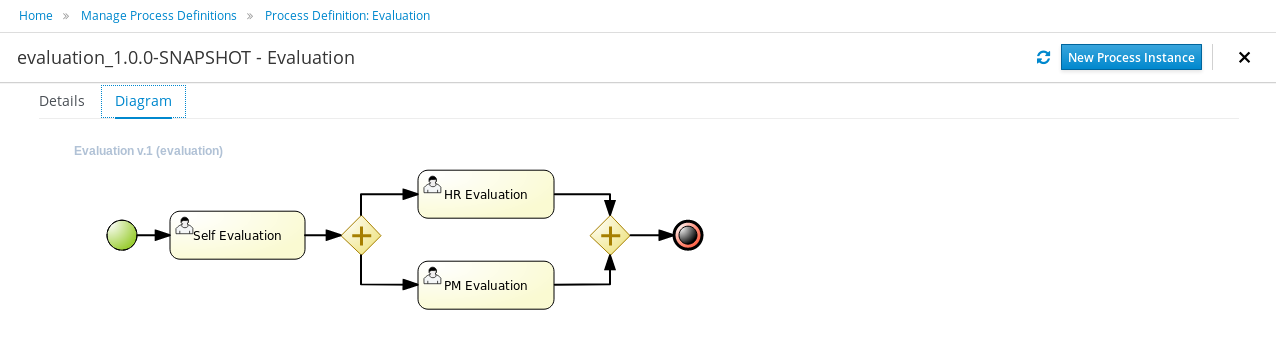
15.2.1.3. Creating new Process Instances
You can create new Process Instances from the Process Definition List (Action Column), from the Process Definition Detail view or from the Process Instance section.
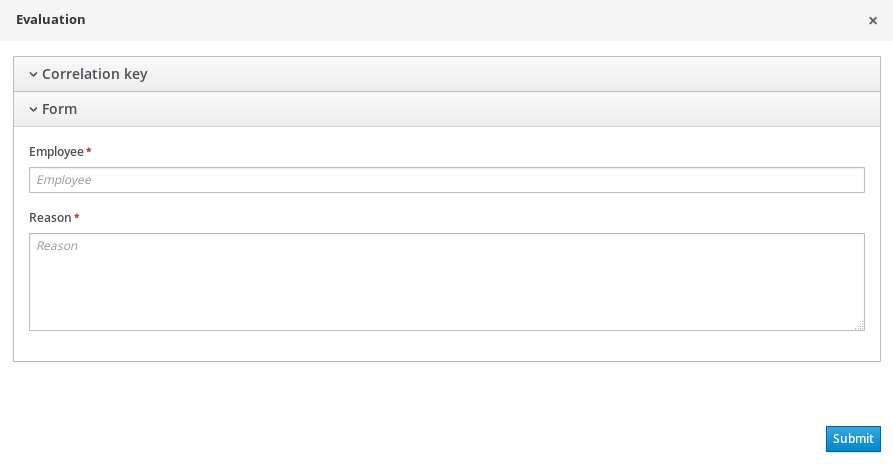
When you create a Process Instance usually a Form will be presented to introduce the information required by the process to be started. Once you complete the required information and click on the Submit button, the instance will be created and the details of the Process Instance will be displayed on top of the Process Definition Details.
15.2.2. Process Instances Management
The process instances section is composed by two main screens: the Process Instance Lists and the Process Instance Details. In this case the Process Instance Details provides several tabs with the runtime information related with the process.
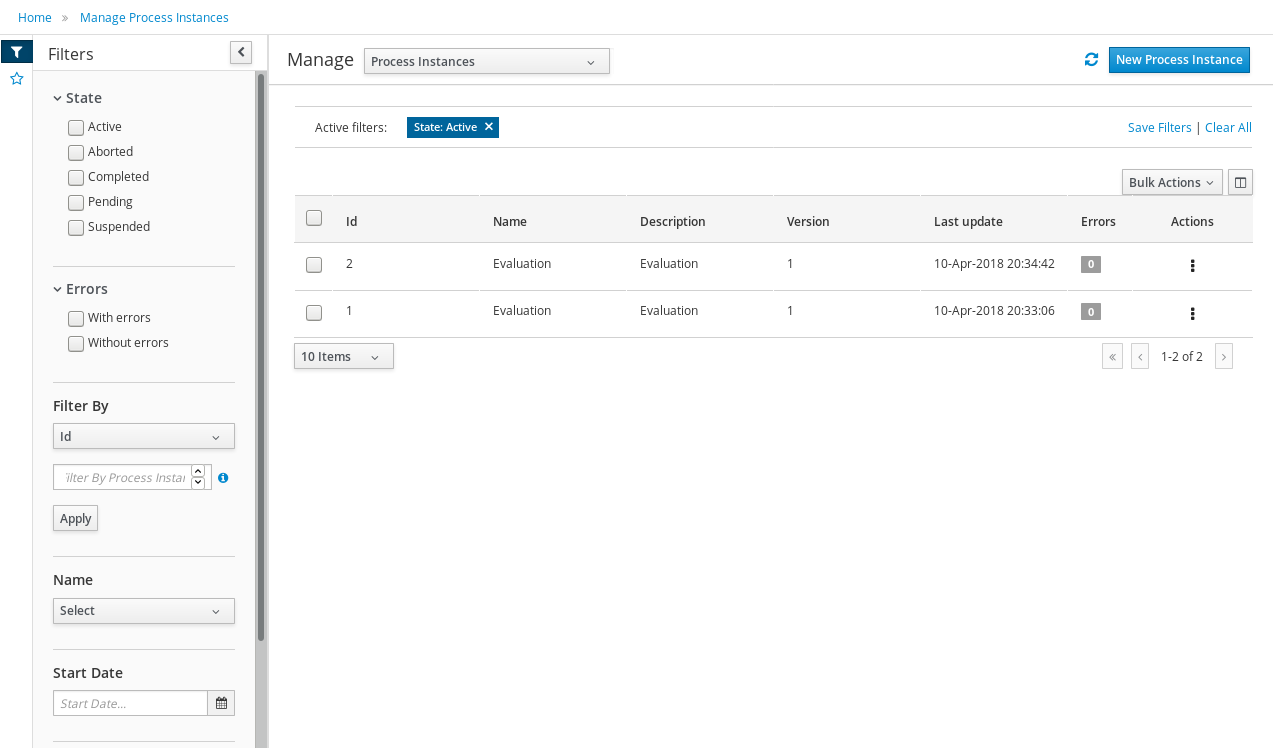
Each row inside the process instance list represent a running process instance from a particular Process Definition. Each execution is differentiated from all the others by the internal state of the information that the process is manipulating. In order to inspect this information you can click in each row to see the process instance details in full screen mode.
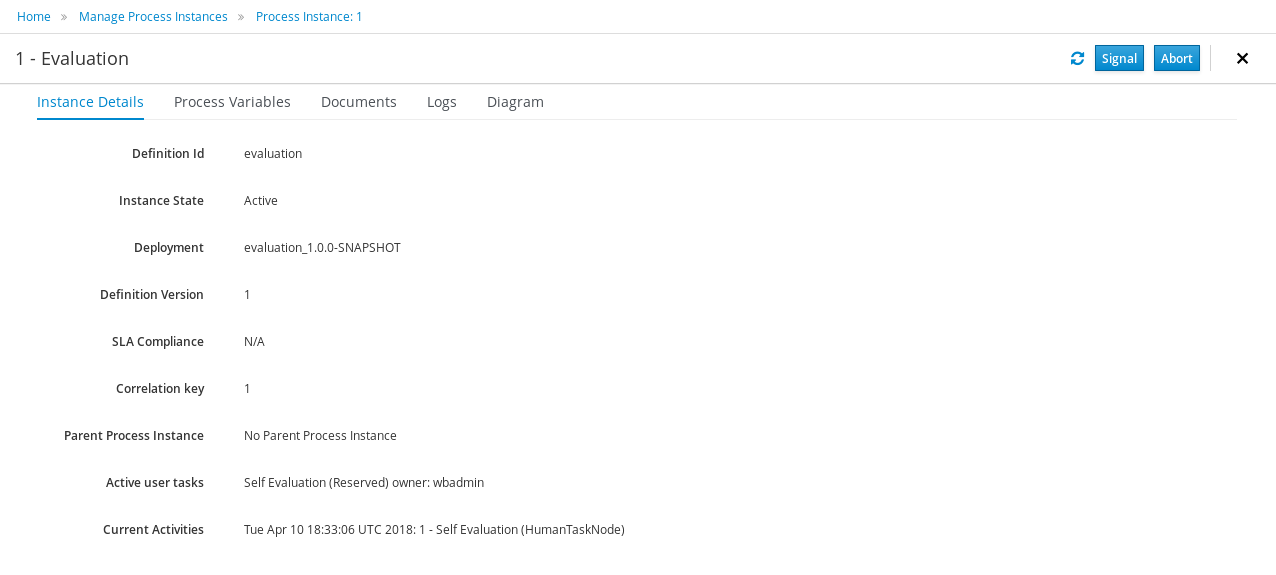
15.2.2.1. Specific actions
The user can perform the following specific action over the process instances:
-
Navigate to related tasks
-
Navigate to related jobs
-
In case there are related errors, navigate to them
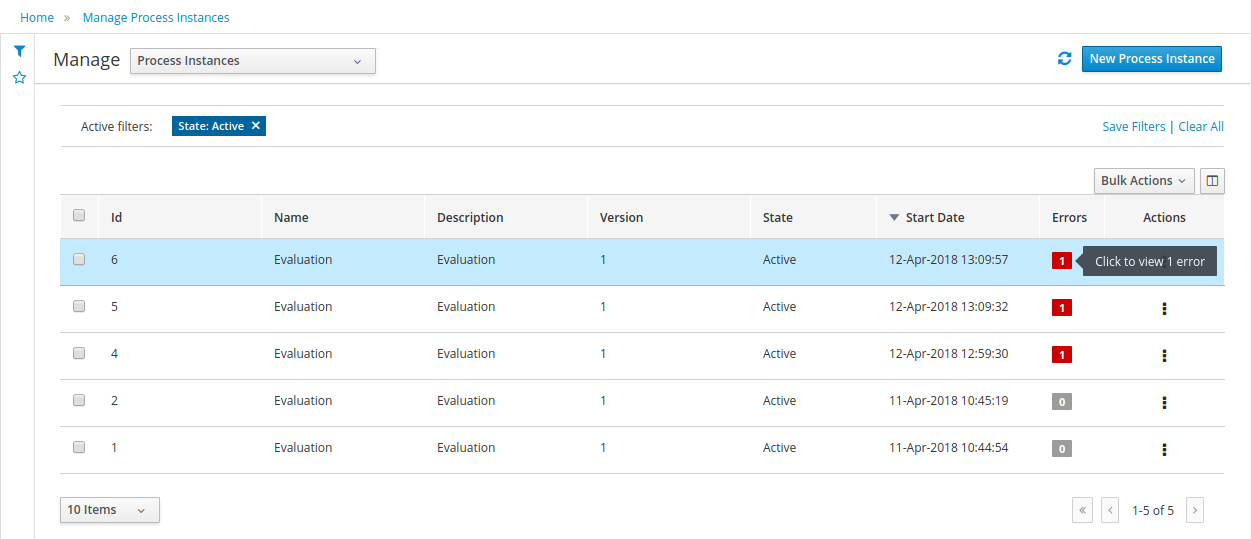
-
Abort process instance(s). This action requires a double confirmation before aborting the instance(s).
-
Signal process instance(s). When the action signaling a process instance is performed, a popup is opened asking for the signal name and signal data. (When this signal is done in a bulk action, the defined signal is used for all selected process instances.
15.2.2.2. Special filter
There is an specific restriction than makes the process instance list view to have a different behaviour. This happens when a filter over the column 'PROCESSID' is defined.
In this case, the columns available to show have been incremented with the specified process variables which have value. The user can then, view process instance variables from a specific process id, in the same grid of the process instances.
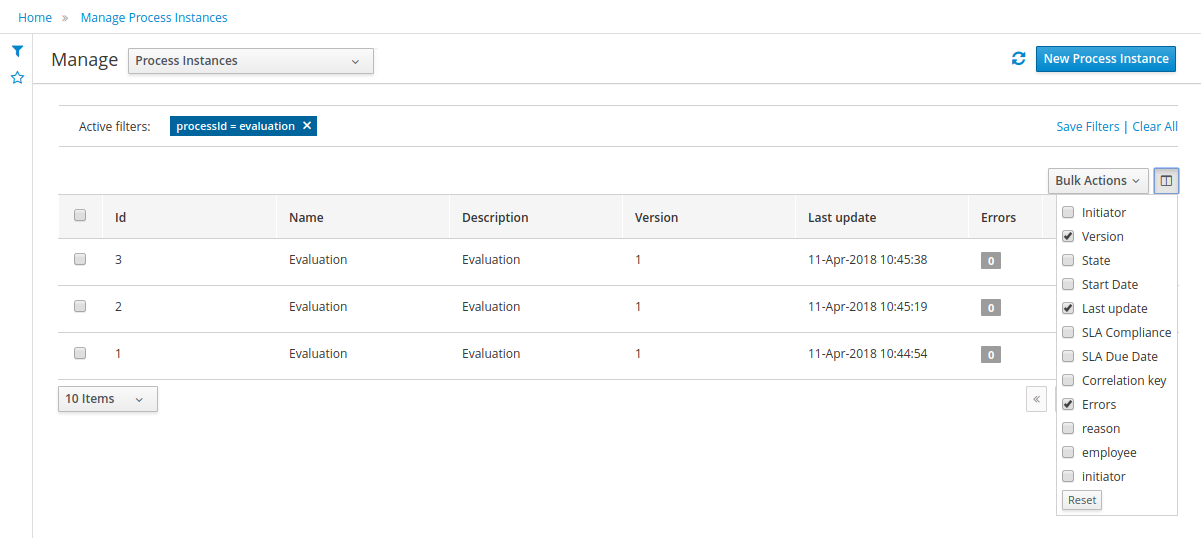
15.2.2.3. Process Instance Details
Let’s go through the different tabs to see what kind of information is provided:
As you can see the Instance Details tab gives you a quick overview about what is going on inside the process. This is by showing the current state of the instance and also the current activity that is being executed. The Process Variables tab displays all the process variables that are being manipulated by the instance with the exception of the variables that contains documents.
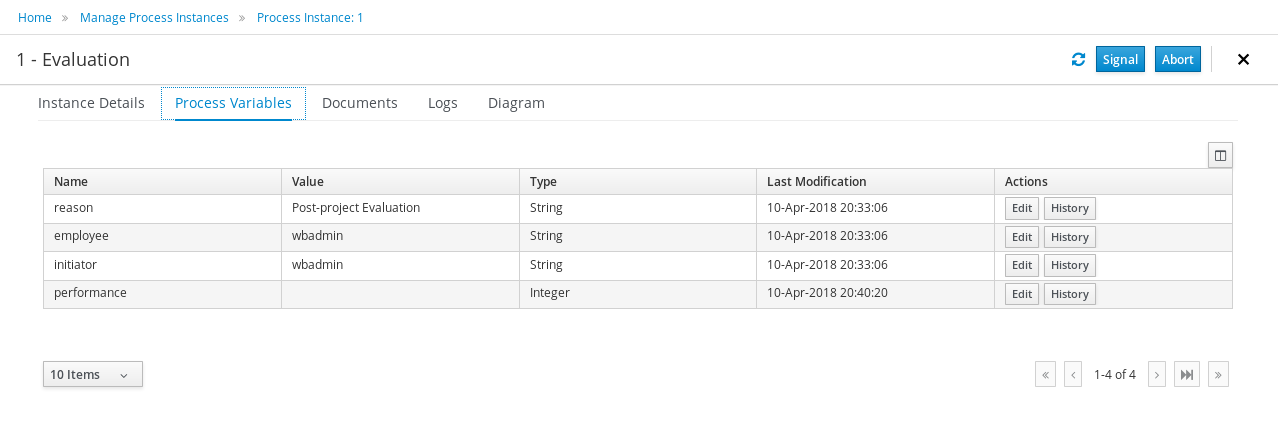
If the process contains a variable of the type: org.jbpm.Document it will be listed in the Documents tab, for easy access, download and manipulation of the attached documents. Please note that at this point you cannot attach new documents to currently running instances, but this feature will be added in future versions. See JBPM-7572.
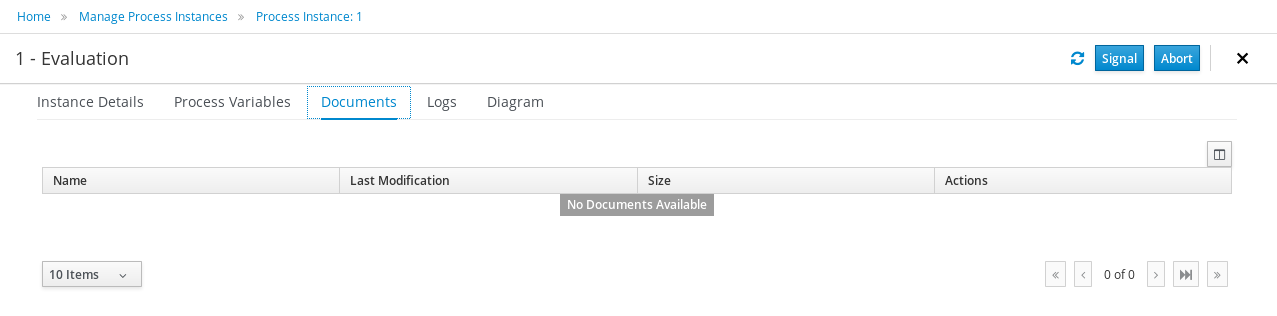
The Logs tab shows two types of logs: Business and Technical. In the Business view, only the most relevant events from a business perspective are presented. As for the Technical view, the full list of audit events concerning any node in the process instance is displayed.
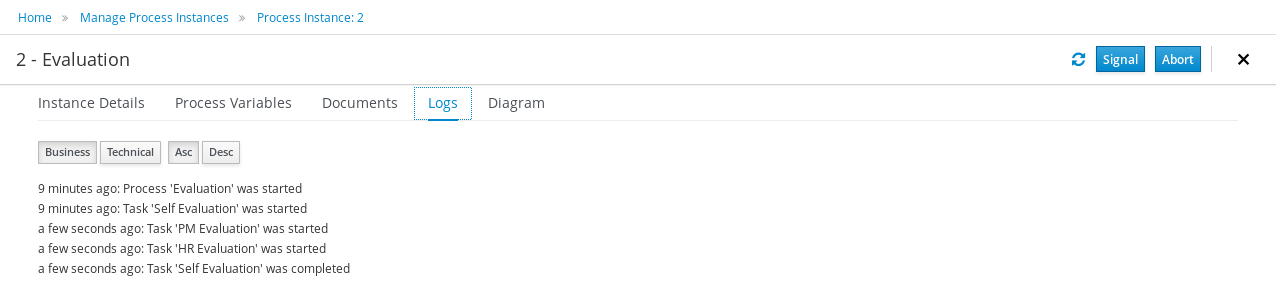
Finally, to complement the process logs you can open the Diagram tab that shows the completed activities in grey and the current activities highlighted in red.
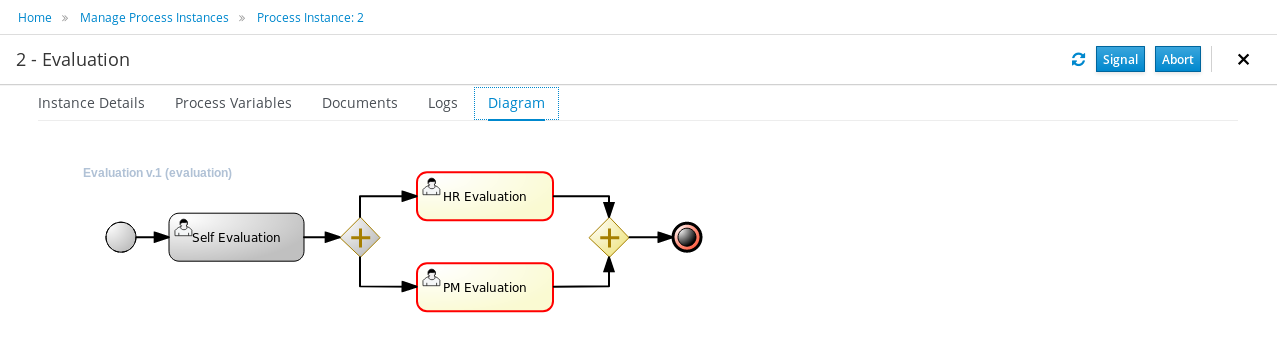
15.3. Tasks Management
This chapter introduces the Task Management screens and the its integration with the Form Modeller component to allow users to work on their assigned tasks. You can find the source code of these screens here. Feel free to report issues, send Pull Requests and get in contact with the team via comments in github. At the end of this section you will find a technical description about how to customize these views.
Designed to be used by task and business process administrators, which can manage tasks belonging to other users and see extra task management data like related execution errors.
The Task management is available in the main menu under Manage then Tasks:

In this screen the management screens selector is included to allow to navigate to the other management screens described in Process Instance List section. In this list there is a column showing the related errors, that in case there are any related execution errors allow to navigate to them.
By default, this page is only available for users with workbench roles admin and process-admin.
15.3.1. Tasks visible to the current user
The tasks which are displayed on the tasks page are determined by the current user permissions. When the user has been declared (via system property) as 'task admin user' or belongs to the tasks administrators group, this list shows all tasks. Otherwise, if the user is not declared as a business administrator, this list will show only the tasks where the user have been declared business process administrator.
By default the system associates all tasks to the user |
| Notice that the mentioned roles and group configurations are related to the KIE server’s, not the Workbench’s (in case they have separate user configurations). |
15.3.2. Task Inbox
This screen not belongs to the management group, but have been designed following the same patterns but for being used, by any user (not administrator) to track the tasks. For this reason, the management screens selector is not included.
Every user with access to the platform will have access to its personal task inbox where tasks assigned to him/her will be displayed. Each user will be able to create its own personal tasks or work on tasks that were create as a result of a business process execution.
You can access to the user Task List accessing Tasks Inbox main menu:

15.3.2.1. Tasks visible to the current user (Personal and Group Tasks)
Pending tasks for each user will be displayed in their task list screen. Notice that you will not be able to see assigned tasks from another user different from the one that is currenlty logged in.
The list will show all the tasks that match with the defined restrictions ordered by the columns presented. You can change the default ordering clicking on the column header. This view offer a more traditional BPM Task List view where you can sort the data based on different columns.
Here appears again the concept of view versus just filtering as we explained in the process instante list. The default filters have the following restrictions over the tasks to show:
-
Active: all the Active tasks that user can work on. That means Personal and Group Tasks.
-
Personal: all the personal tasks that already belong to the user.
-
Group: all the group tasks that needs to be claimed by the user in order to start working on them. It will show completed tasks as well with the exception of completed tasks that belongs to a process that is already finished. In such cases the tasks are cleaned up after the process is completed and for that reason they will not be displayed.
Specific actions in Tasks Inbox.
The user can perform the following specific action over the task:
-
Task available actions depending on it’s status: Claim, release,..
-
Navigate to related processInstance
|
The user can always restore the default filters selecting the option 'Restore default filters' on Saved filters dock |
15.3.2.2. Task Details
You can access to the Task Details by clicking in a task row. The details associated with a task can be changed, like for example the Due Date, the Priority or the task description.

The task details appear in a new region with different sections that allow view the task associated information:
Work In this tab the associated form is displayed if the task has one. In this section is where the user can interact with the process, executing the available actions in each moment.
Details Here the basic task data is accessible: priority, status, description, data related with the process instance associated.
Assignments The Task Assignments tab allows you to delegate the task to another person or group if you are not able to continue working on it.
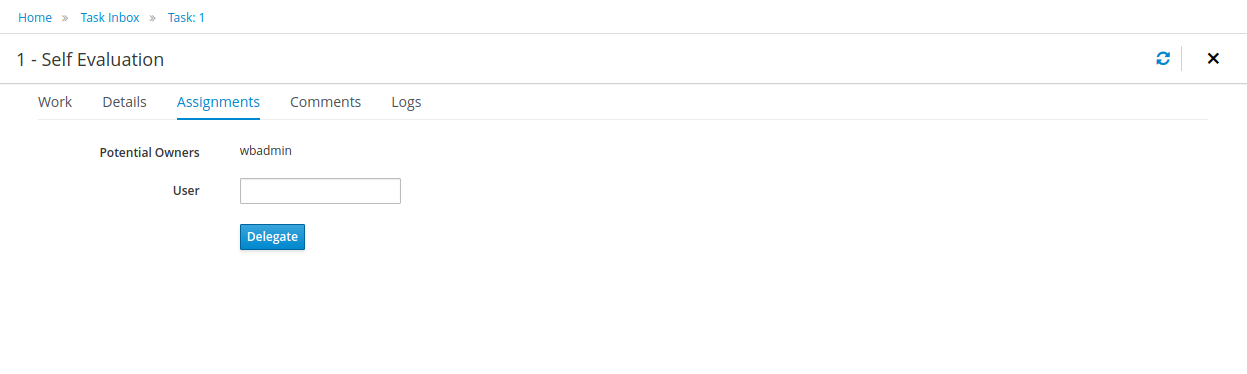
Comments You can also add while you are working on a task comments about the progress.
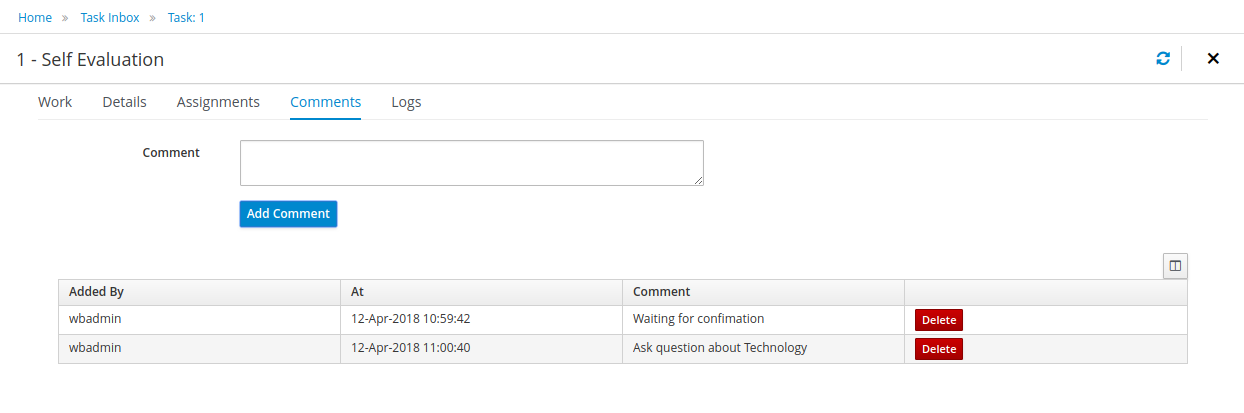
15.3.2.3. Work on a Task
Tasks can have associated a Form to store data. If tasks are part of a Business Process, usually some data needs to be collected and propagated to the business process for further usage. For that reason, tasks has to provide a way to gather and store data. Forms can be created for specific tasks using the Form Modeller. If no form is provided a dynamic form will be created based on the information that the task needs to handle.
15.3.2.4. Task Forms generated by the Form Modeller
As part of your projects you can model your forms for your human tasks, providing a rich interface for collecting data. This shows the Form Modeller canvas while designing the previously Task Form.
15.3.2.5. Available actions for a Task.
The user can perform the following specific action over the task:
-
Task available actions depending on it’s status: Claim, release,..
-
Navigate to related processInstance
-
In case there are related errors, like at the process instance list, navigate to them.
15.3.3. Special filter in Task Inbox and Tasks
As was explained in the process instance list, this screen have been designed as a Console Management list view, providing the content to the 'Filter' and 'Saved Filters' docks working over task items.
The user can create a specific filter that provides domain specific columns to be added to a task list. When the user creates a custom filter for a specific task name the task variables are enabled as columns.
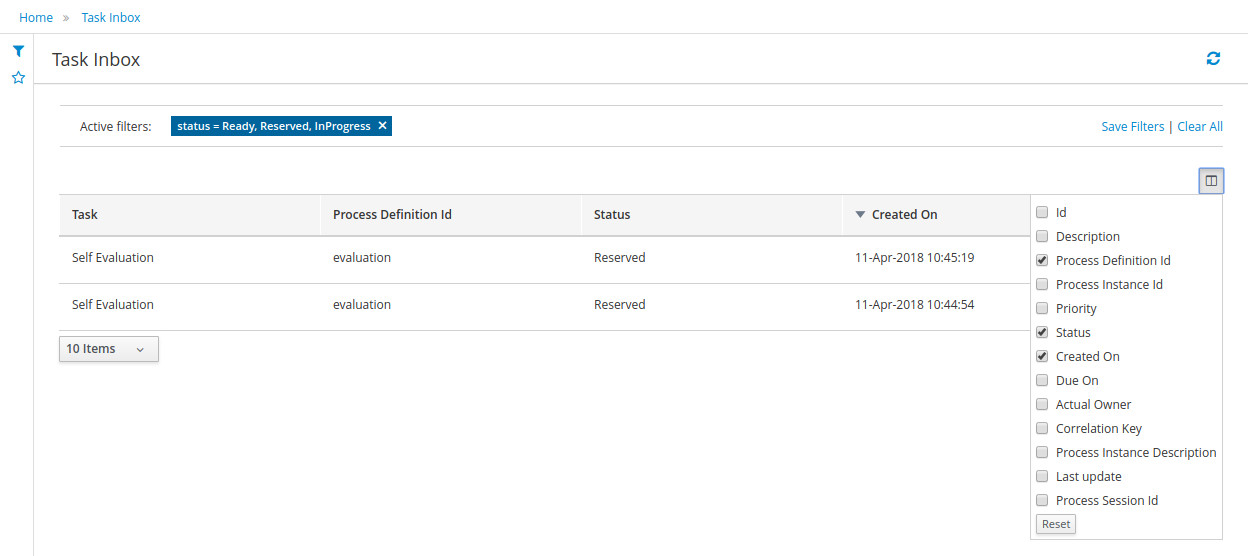
The custom filter that activates the capability to display task variables as columns is set a filter with the restriction Name="taskName".

When the filter with the restriction over a specific task name is applied, the task associated variables appear as a selectable columns, to the task list.
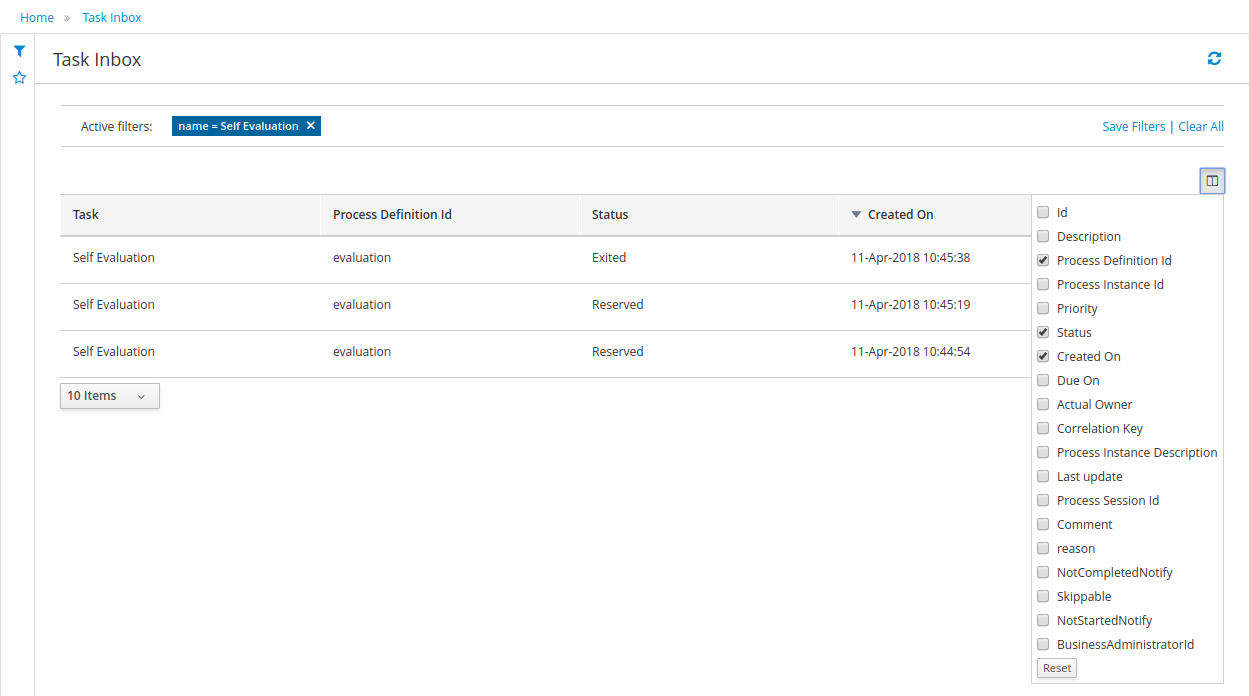
15.4. Jobs Management
The Jobs page allows you to monitor and trigger Asynchronous Jobs scheduled to the jBPM Executor Service. You can access to the Jobs option from the Manage top level menu of the jBPM Workbench.

The Jobs List shows all the Jobs that were scheduled and their status. The Filter on top of the table helps the administrator to monitor the Jobs execution and take corrective actions in case of Failure. Check the jBPM Executor section of the documentation for more information.
15.4.1. Bulk actions
The jobs list provides now a way to perform actions over multiple jobs, in a single operation. After one or more jobs are selected from the list, the bulk actions menu becomes available, with all supported actions. The available operations in this screen are 'Cancel' and 'Requeue'. If that operation is not allowed, regarding the job status, over any of the selected item, a notification is displayed and the operation is not executed on that item.
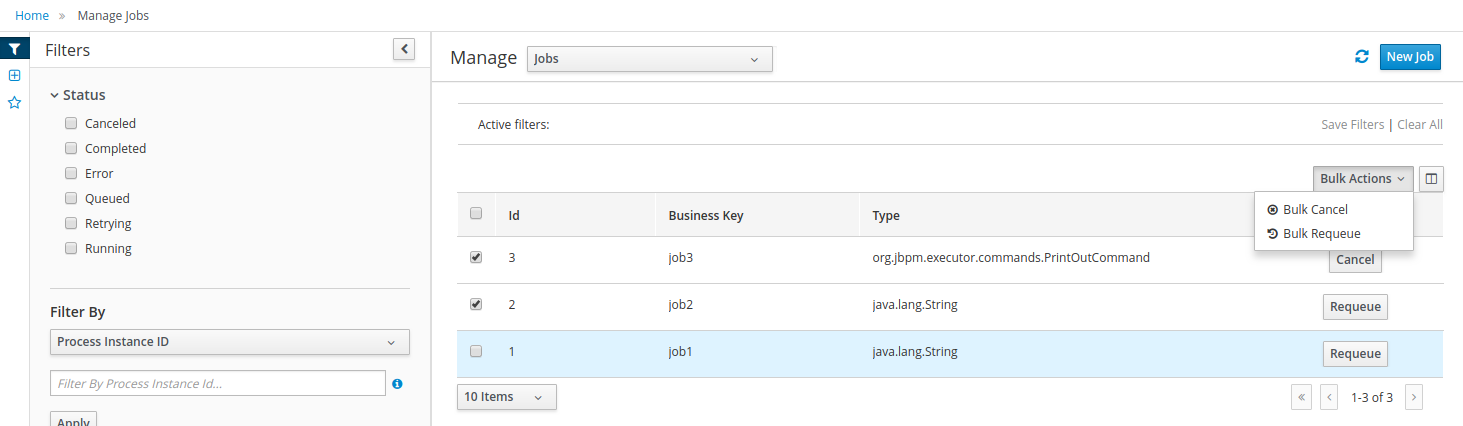
Administrators can also manually schedule new Jobs from the User Interface via the New Job option. By specifying the command class name and the parameters needed to run the command a new Job can be scheduled to run immediately or at later time. Any job created manually, will not be associated with any process instance. Notice also that the Due Date parameter allows the execution to be deferred for a later time in the future. If the Due Date is set to Run now, the jBPM Executor Service will execute the command as soon as there is an Executor Thread available. The number of retries will help the command to be executed more than once if it fails. This can help in situations when the business logic requires an external service to be called where the runtime cannot rely on that service to be available 100% of the time.
15.5. Execution Errors Management
This view allows to explore and acknowledge the generated execution error. It follows the same Console Management list view structure and behaviour, providing its own quick filters like error type, acknowledged or not, id and more.
You can access execution errors management through Execution Errors main menu:

The Execution Errors view shows the list of execution errors. The purpose of this list is to equip administrator with tools to track the errors that have happened during execution. The errors have two basic states: Acknowledged or New, which helps the administrator to keep track of new events in the system which need higher attention.
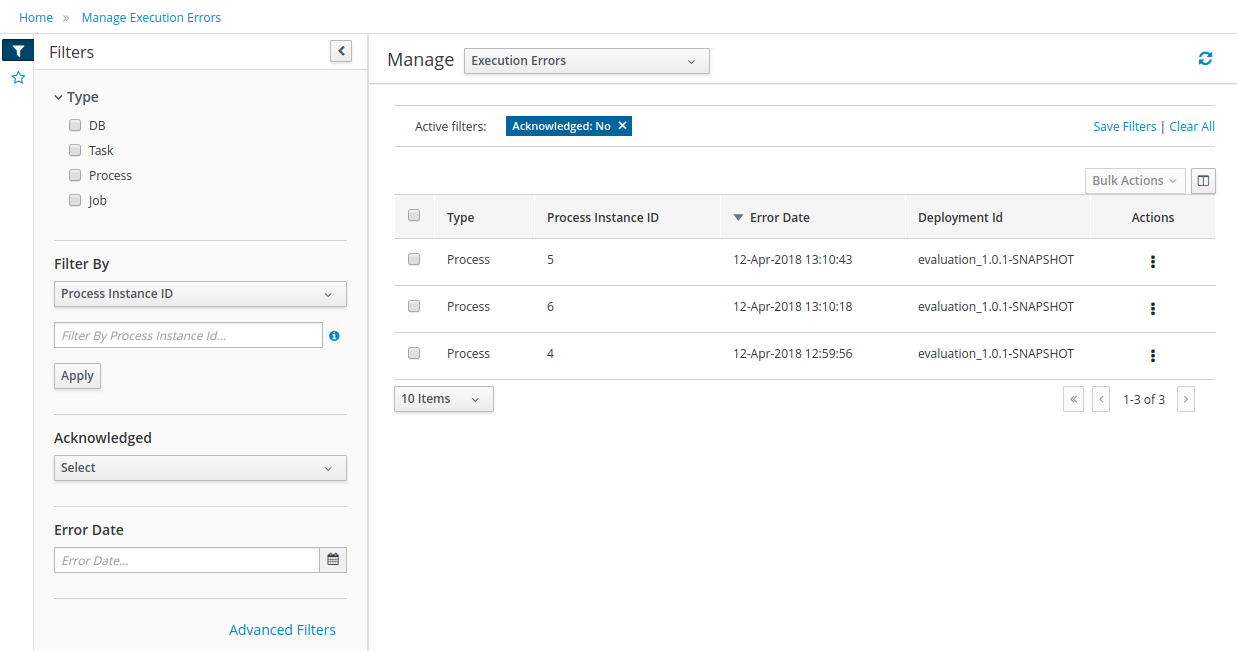
This view also provides a set of predefined saved filters: New (pending of acknowledgement), and Acknowledged.
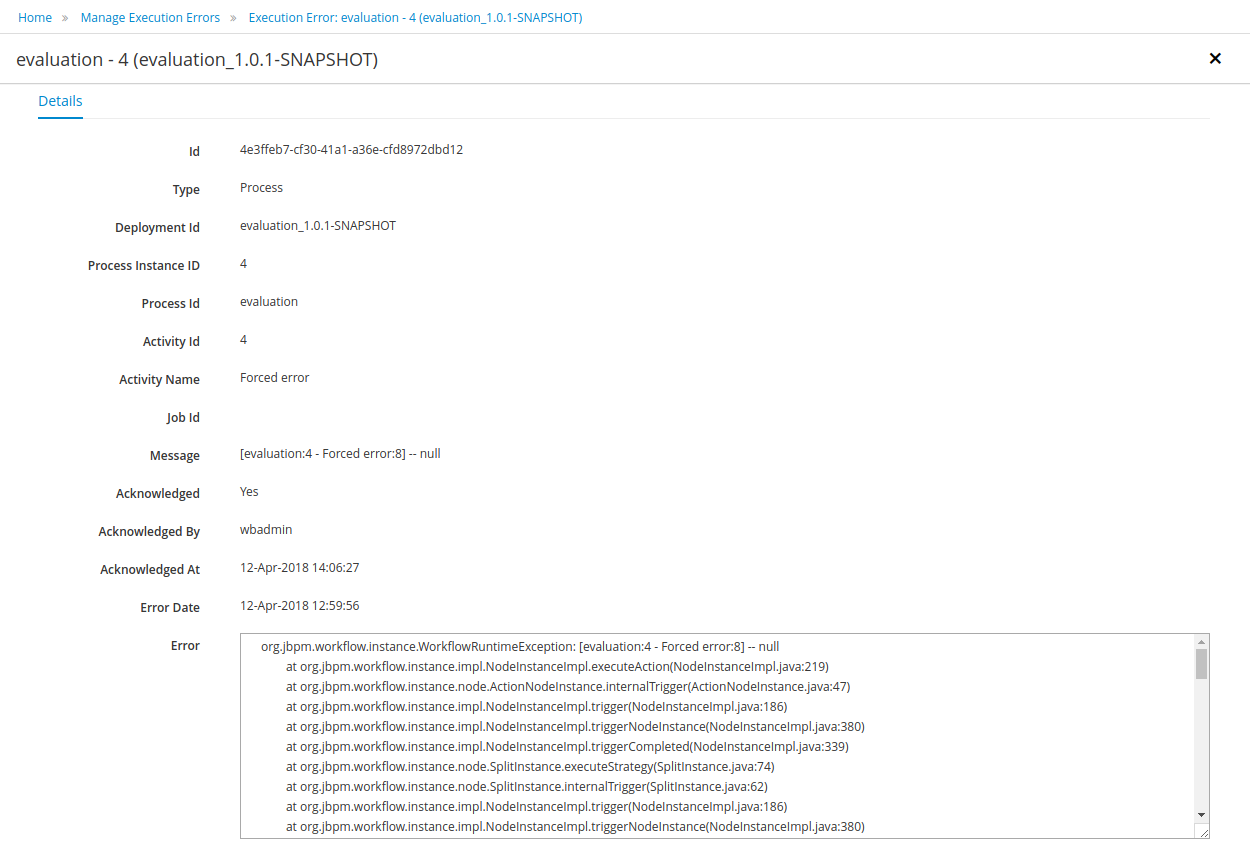
An error item have the basic data of the happened error like the error Date, the source of the error ( Job, Process, Task or Database) and also provide the error trace to help the administrator to know what happened and how to fix it.
15.5.1. Specific actions for Execution Errors.
-
Acknowledge the error it it’s not acknowledged.
-
Navigate to related processInstance, task, job depending on the error type
-
Bulk Acknowledge. You can acknowledge the unacknowledged errors by selecting the related error action. To acknowledge multiple errors at once, select all the errors you wish to acknowledge and use the 'Bulk Acknowledge' button.
16. Business Activity Monitoring
16.1. Overview
Imagine you are developing a BPM solution which mixes process with business data. Imagine also you need some forms to be used within processes in order to let the users enter data. Moreover, you’ll likely want to have some kind of dashboards to display metrics and key performance indicators in order to quickly assess how your processes are doing. So far so good.
jBPM brings you all the ingredients you need to develop end-to-end business process solutions. The jBPM’s BAM module (also known as Dashbuilder) allows for composing custom business dashboards by mixing data coming from heterogeneous sources of information. The module is now fully integrated into KIE workbench. A new specific section for dealing with reports has been added and it can be accessed either from the home page or from the menu bar, as shown in the next figure.
In the figure, within the highlighted sections, there exists two options:
-
Business Dashboards: This option is intended to give users access to a generic dashboard tooling for the composition of brand new dashboards.
-
Process & Task Reports: It opens up the Process related reports pages which contains several performance indicators related to the jBPM execution engine.
16.2. Business Dashboards
BPM solutions are not only made up with processes, rules or forms but also with data belonging to the customer business domain. Such data is handled in the forms, the rules and, of course, the dashboards that are part of the solution. Usually, dashboards feed with data coming from several sources of information, from business domain entities persisted into relational databases to data hold in legacy systems. In order to cope with this kind of scenarios a generic highly customizable dashboard tooling is needed.
It’s obviously expected that a customer building a BPM solution want to track how its processes are performing. To do so the customer need a monitoring and reporting tool. This is the main reason why the Dashbuilder project has been included as a core module of the jBPM ecosystem. Notice also that Dashbuilder, as an independent project, is not only used by jBPM but also by many other projects like, for example, JBoss Teiid a data virtualization system that allows applications to use data from multiple, heterogeneous data stores.
The Business Dashboards gives users access to a rich enviroment where it is possible to author new content as well as configuring which entries are displayed in the top menu bar.
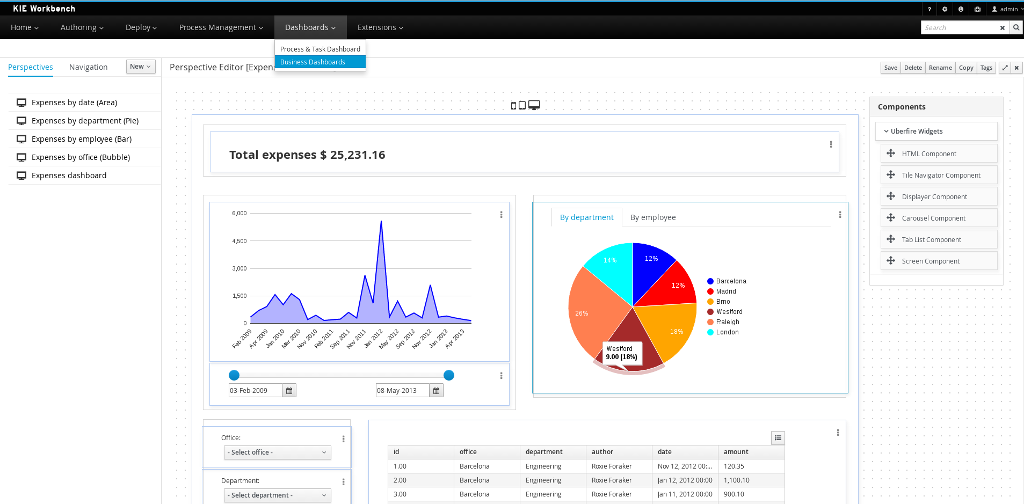
| THIS SECTION IS UNDER CONSTRUCTION |
16.3. Process & Task Reports
You can access to the reports accessing Process Reports and Task Reports main menu:

16.3.1. Process Reports
The jBPM Process Process Reports is an specific use case of a dashboard feed from data coming from a relational database via SQL queries. In this case, the database tables consumed are: processinstancelog and bamtasksummary both belonging to the jBPM engine.
Every time the jBPM runtime updates the information stored into such tables the data becomes automatically available to the dashboard indicators. The following picture shows the main screen that users get when navigating to the Process Reports.

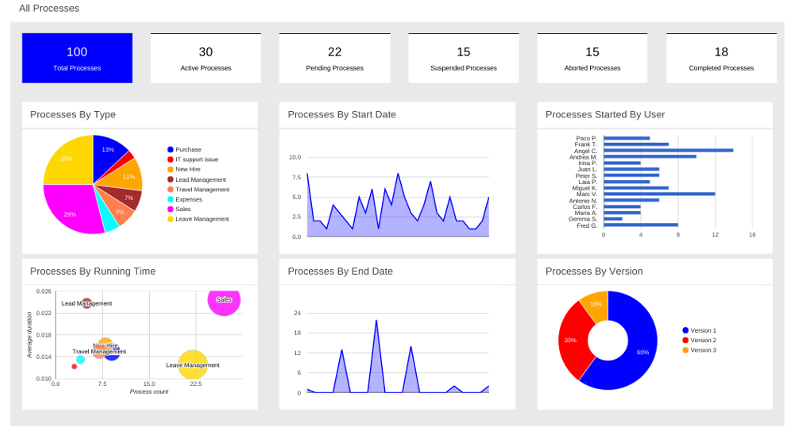
|
Notice, those are generic metrics not tied to any specific business process. Nonetheless, it’s worth to mention that it would be very easy for customers to modify, extend or adapt this generic dashboard for custom needs. A customer could take the jBPM Process Reports as the base template for building a custom dashboard which mixes data coming from the jBPM engine plus data coming from its own business domain. |
To filter through the data users can click on the charts in order to select, for instance, a given process, a given status, etc… Every time a filter is applied, all the indicators are automatically updated and synced according to the criteria set. The next picture shows, for instance, what happens when both the process Sales and the status Active are selected.

Using the built-in filter features is a good way to select the process instances the users want to look into. Additionally, at any time, no matter whether there is any active filter or not, users can also navigate to the actual list of instances the dashboard indicators are showing. The View table link at the top right side on the screen can be used to display those process instances details. Once clicked, the view is switched to the screen shown in the next picture:
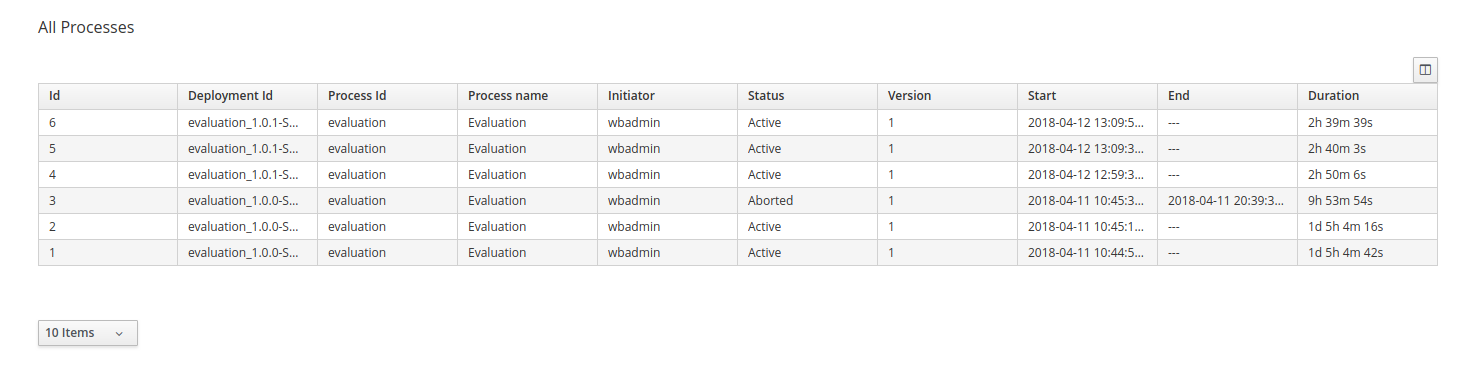
From this view, users can access to process instances details just clicking on the desired row as well.
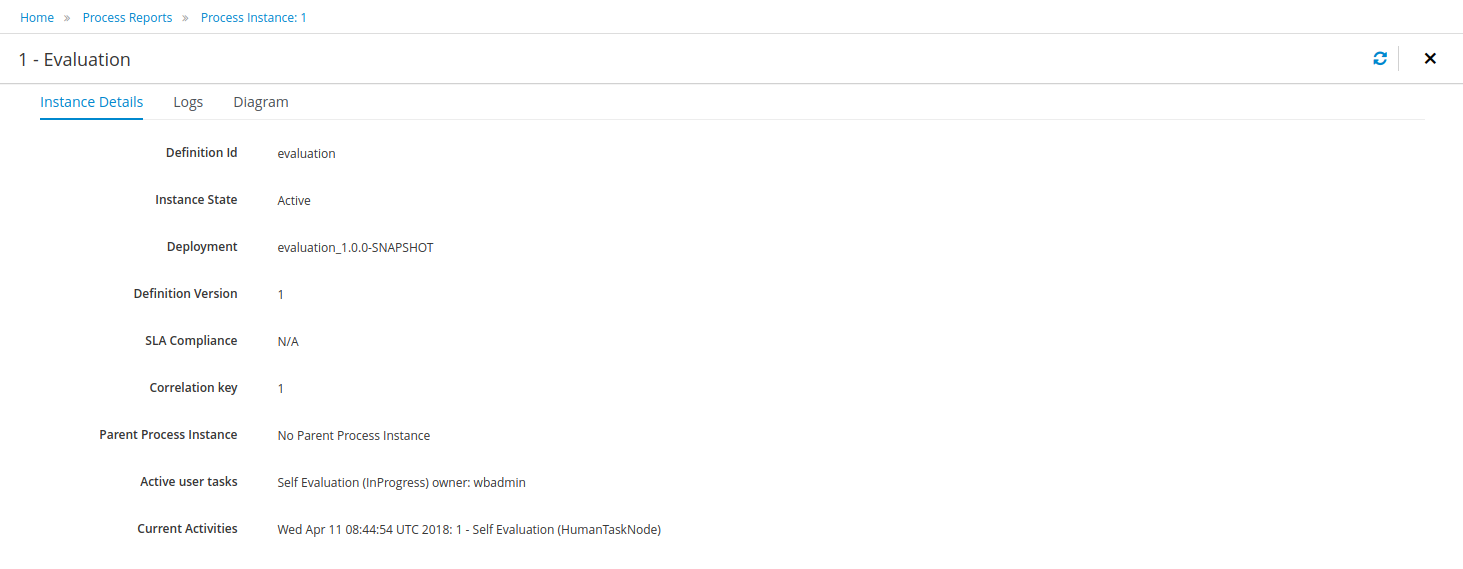
Notice this is a read only view, just for monitoring purposes. After identifying a target process instance the next step is to use the jBPM Process Instance Console in case the user needs to manage such process instance.
16.3.2. Task Reports
The task reports section only contains indicators related to tasks. It basically provides the same features introduced above for process instances (filters, show instances, get details), this time related to tasks instead of process though.
The following picture shows the Task reports header that users get when navigating to the Task Reports.

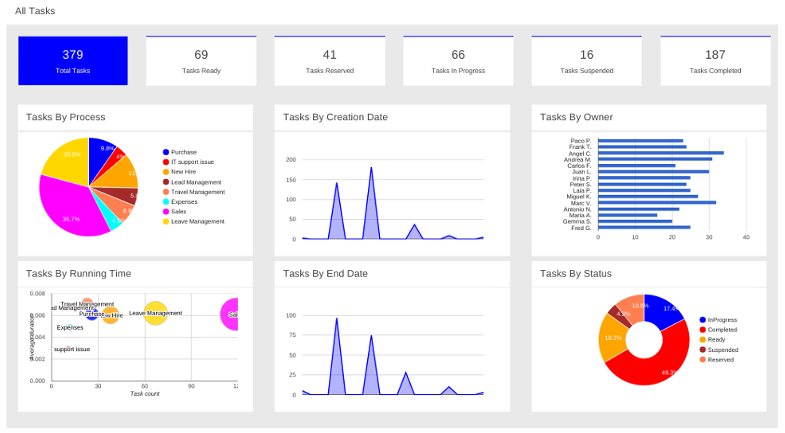
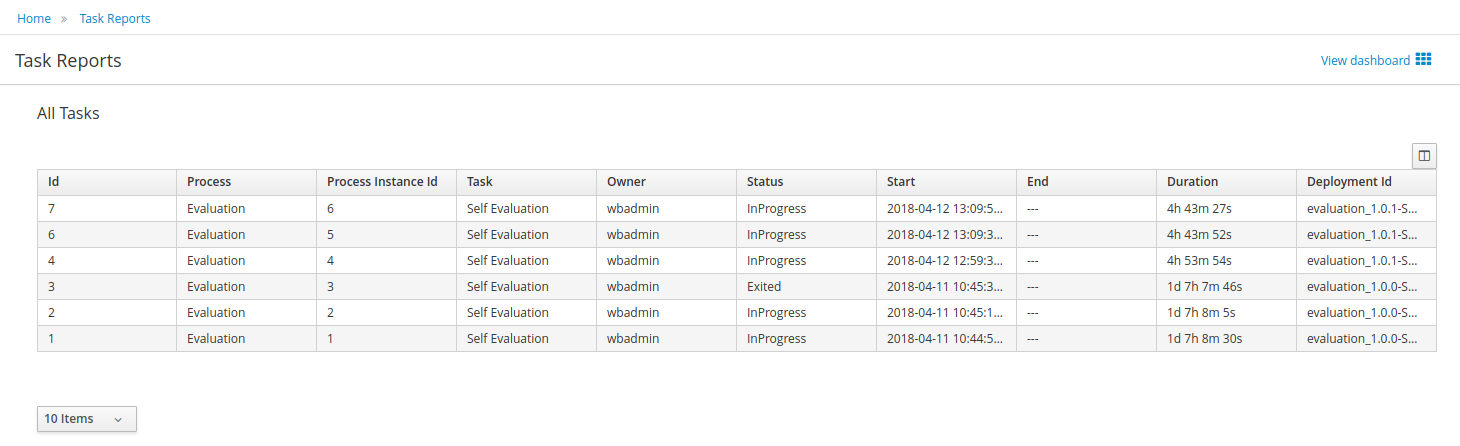
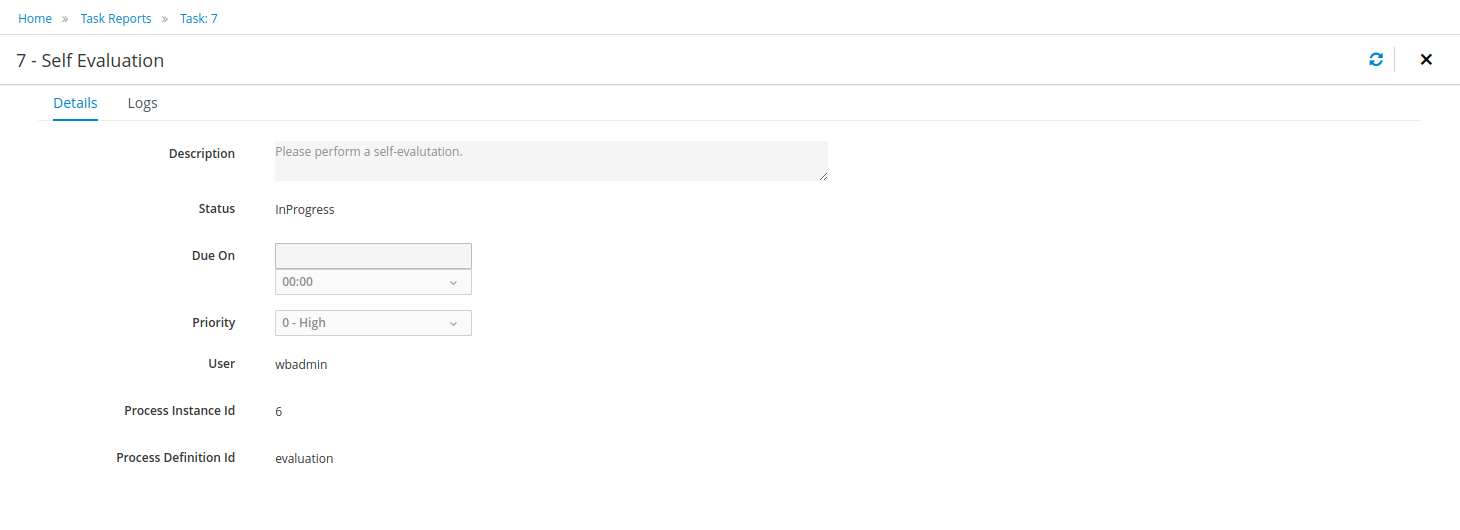
To sum up, the jBPM Process & Task Reports let users:
-
To monitor their process and tasks
-
To apply the proper filters in order quickly identify problematic instances
-
To get the required information about a given instance in order to be able to fix any unexpected issue
KIE Server
The KIE Server is a standalone execution server for rules.
17. KIE Execution Server
17.1. Overview
The Kie Server is a modular, standalone server component that can be used to instantiate and execute rules and processes. It exposes this functionality via REST, JMS and Java interfaces to client application. It also provides seamless integration with the Kie Workbench.
At its core, the Kie Server is a configurable web application packaged as a WAR file. Distributions are availables for pure web containers (like Tomcat) and for JEE 6 and JEE 7 containers.
Most capabilities on the Kie Server are configurable, and based on the concepts of extensions. Each extension can be enabled/disabled independently, allowing the user to configure the server to its need.
The current version of the Kie Server ships with two default extensions:
-
BRM: provides support for the execution of Business Rules using the Drools rules engine.
-
BPM: provides support for the execution of Business Processes using the jBPM process engine. It supports:
-
process execution
-
task execution
-
assynchronous job execution
-
Both extensions enabled by default, but can be disabled by setting the corresponding property (see configuration chapter for details).
This server was designed to have a low footprint, with minimal memory consumption, and therefore, to be easily deployable on a cloud environment. Each instance of this server can open and instantiate multiple Kie Containers which allows you to execute multiple services in parallel.
17.1.1. Glossary
-
Kie Server: execution server purely focusing on providing runtime environment for both rules and processes. These capabilities are provided by Kie Server Extensions. More capabilities can be added by further extensions (e.g. customer could add his own extensions in case of missing functionality that will then use infrastructure of the KIE Server). A Kie Server instance is a standalone Kie Server executing on a given application server/web container. A Kie Server instantiates and provides support for multiple Kie Containers.
-
Kie Server Extension: a "plugin" for the Kie Server that adds capabilities to the server. The Kie Server ships with two default kie server extensions: BRM and BPM.
-
Kie Container: an in-memory instantiation of a kjar, allowing for the instantiation and usage of its assets (domain models, processes, rules, etc). A Kie Server exposes Kie Containers through a standard API over transport protocols like REST and JMS.
-
Controller: a server-backed REST endpoint that will be responsible for managing KIE Server instances. Such end point must provide following capabilities:
-
respond to connect requests
-
sync all registered containers on the corresponding Kie Server ID
-
respond to disconnect requests
-
-
Kie Server state: currently known state of given Kie Server instance. This is a local storage (by default in file) that maintains the following information:
-
list of registered controllers
-
list of known containers
-
kie server configuration
The server state is persisted upon receival of events like: Kie Container created, Kie Container is disposed, controller accepts registration of Kie Server instance, etc.
-
-
Kie Server ID: an arbitrary assigned identifier to which configurations are assigned. At boot, each Kie Server Instance is assigned an ID, and that ID is matched to a configuration on the controller. The Kie Server Instance fetches and uses that configuration to setup itself.
17.2. Installing the KIE Server
The KIE Server is distributed as a web application archive (WAR) file. The WAR file comes in three different packagings:
-
webc - WAR for ordinary Web (Servlet) containers like Tomcat
-
ee6 - WAR for JavaEE 6 containers like JBoss EAP 6.x
-
ee7 - WAR for JavaEE 7 containers like WildFly 11.x
To install the KIE Execution Server and verify it is running, complete the following steps:
-
Deploy the WAR file into your web container.
-
Create a user with the role of
kie-serveron the container. -
Test that you can access the execution engine by navigating to the endpoint in a browser window:
http://SERVER:PORT/CONTEXT/services/rest/server/. -
When prompted for username/password, type in the username and password that you created in step 2.
-
Once authenticated, you will see an XML response in the form of engine status, similar to this:
Example 1. Sample handshaking server response<response type="SUCCESS" msg="KIE Server info"> <kie-server-info> <version>7.11.0.Final</version> </kie-server-info> </response>
17.2.1. Bootstrap switches
The Kie Server accepts a number of bootstrap switches (system properties) to configure the behaviour of the server. The following is a table of all the supported switches.
| Property | Value | Description | Required |
|---|---|---|---|
org.drools.server.ext.disabled |
boolean (default is "false") |
If true, disables the BRM support (i.e. rules support). |
No |
org.jbpm.server.ext.disabled |
boolean (default is "false") |
If true, disables the BPM support (i.e. processes support) |
No |
org.jbpm.ui.server.ext.disabled |
boolean (default is "false") |
If true, disables the BPM UI support (i.e. processes image support) |
No |
org.optaplanner.server.ext.disabled |
boolean (default is "false") |
If true, disables the BRP support (i.e. planner support) |
No |
org.kie.executor.disabled |
boolean (default is "false") |
If true, disables the BPM job executor support |
No |
org.kie.server.id |
string |
An arbitrary ID to be assigned to this server. If a remote controller is configured, this is the ID under which the server will connect to the controller to fetch the kie container configurations. |
No. If not provided, an ID is automatically generated. |
org.kie.server.user |
string (default is "kieserver") |
User name used to connect with the kieserver from the controller, required when running in managed mode |
No |
org.kie.server.pwd |
string (default is "kieserver1!") |
Password used to connect with the kieserver from the controller, required when running in managed mode |
No |
org.kie.server.controller |
comma separated list of urls |
List of urls to controller REST endpoint. E.g.:
|
Yes when using a controller |
org.kie.server.controller.user |
string (default is "kieserver") |
Username used to connect to the controller REST api |
Yes when using a controller |
org.kie.server.controller.pwd |
string (default is "kieserver1!") |
Password used to connect to the controller REST api |
Yes when using a controller |
org.kie.server.location |
URL location of kie server instance |
The URL used by the controller to call back on this server. E.g.:
|
Yes when using a controller |
org.kie.server.domain |
string |
JAAS LoginContext domain that shall be used to authenticate users when using JMS |
No |
org.kie.server.bypass.auth.user |
boolean (default is "false") |
Allows to bypass the authenticated user for task related operations e.g. queries |
No |
org.kie.server.repo |
valid file system path (default is ".") |
Location on local file system where kie server state files will be stored |
No |
org.kie.server.persistence.ds |
string |
Datasource JNDI name |
Yes when BPM support enabled |
org.kie.server.persistence.tm |
string |
Transaction manager platform for Hibernate properties set |
Yes when BPM support enabled |
org.kie.server.persistence.dialect |
string |
Hibernate dialect to be used |
Yes when BPM support enabled |
org.jbpm.ht.callback |
string |
One of supported callbacks for Task Service (default jaas) |
No |
org.jbpm.ht.custom.callback |
string |
Custom implementation of UserGroupCallback in case org.jbpm.ht.callback was set to ‘custom’ |
No |
kie.maven.settings.custom |
valid file system path |
Location of custom settings.xml for maven configuration |
No |
org.kie.executor.interval |
integer (default is 3) |
Number of time units between polls by executor |
No |
org.kie.executor.pool.size |
integer (default is 1) |
Number of threads in the pool for async work |
No |
org.kie.executor.retry.count |
integer (default is 3) |
Number of retries to handle errors |
No |
org.kie.executor.timeunit |
TimeUnit (default is "SECONDS") |
TimeUnit representing interval |
No |
org.kie.executor.disabled |
boolean (default is "false") |
Disables executor completely |
No |
kie.server.jms.queues.response |
string (default is "queue/KIE.SERVER.RESPONSE") |
JNDI name of response queue for JMS |
No |
org.kie.server.controller.connect |
long (default is 10000) |
Waiting time in milliseconds between repeated attempts to connect kie server to controller when kie server starts up |
No |
org.drools.server.filter.classes |
boolean (default is "false") |
If true, accept only classes which are annotated with @org.kie.api.remote.Remotable or @javax.xml.bind.annotation.XmlRootElement as extra JAXB classes |
No |
|
If you are running both KIE Server and KIE Workbench you must configure KIE Server to use a different Data Source to KIE Workbench using the org.kie.server.persistence.ds property. KIE Workbench uses a jBPM Executor Service that can conflict with KIE Server if they share the same Data Source. |
17.2.2. Installation details for different containers
17.2.2.1. Tomcat 7.x/8.x
-
Download and unzip the Tomcat distribution. Let’s call the root of the distribution
TOMCAT_HOME. This directory is named after the Tomcat version, so for exampleapache-tomcat-7.0.55. -
Download kie-server- -webc.war and place it into
TOMCAT_HOME/webapps. -
Configure user(s) and role(s). Make sure that file
TOMCAT_HOME/conf/tomcat-users.xmlcontains the following username and role definition. You can of course choose different username and password, just make sure that the user has rolekie-server:Example 2. Username and role definition for Tomcat<role rolename="kie-server"/> <user username="serveruser" password="my.s3cr3t.pass" roles="kie-server"/> -
Start the server by running
TOMCAT_HOME/bin/startup.[sh|bat]. You can check out the Tomcat logs inTOMCAT_HOME/logsto see if the application deployed successfully. Please read the table above for the bootstrap switches that can be used to properly configure the instance. For instance:./startup.sh -Dorg.kie.server.id=first-kie-server -Dorg.kie.server.location=http://localhost:8080/kie-server/services/rest/server -
Verify the server is running. Go to
http://SERVER:PORT/CONTEXT/services/rest/server/and type the specified username and password. You should see simple XML message with basic information about the server.
|
You can not leverage the JMS interface when running with Tomcat, or any other Web container. The Web container version of the WAR contains only the REST interface. |
17.2.2.2. WildFly 11.x
-
Download and unzip the WildFly distribution. Let’s call the root of the distribution
WILDFLY_HOME. This directory is named after the WildFly version, so for examplewildfly-11.0.0.Final. -
Download kie-server- -ee7.war and place it into
WILDFLY_HOME/standalone/deployments. -
Configure user(s) and role(s). Execute the following command
WILDFLY_HOME/bin/add-user.[sh|bat] -a -u 'kieserver' -p 'kieserver1!' -ro 'kie-server'. You can of course choose different username and password, just make sure that the user has rolekie-server. -
Start the server by running
WILDFLY_HOME/bin/standalone.[sh|bat] -c standalone-full.xml <bootstrap_switches>. You can check out the standard output or WildFly logs inWILDFLY_HOME/standalone/logsto see if the application deployed successfully. Please read the table above for the bootstrap switches that can be used to properly configure the instance. For instance:./standalone.sh --server-config=standalone-full.xml -Djboss.socket.binding.port-offset=150 -Dorg.kie.server.id=first-kie-server -Dorg.kie.server.location=http://localhost:8230/kie-server/services/rest/server -
Verify the server is running. Go to
http://SERVER:PORT/CONTEXT/services/rest/server/and type the specified username and password. You should see simple XML message with basic information about the server.
17.3. Kie Server setup
|
Server setup and registration changed significantly from versions 6.2 and before. The following applies only to version 6.3 and forward. |
17.3.1. Managed Kie Server
A managed instance is one that requires a controller to be available to properly startup the Kie Server instance.
A Controller is a component responsible for keeping and managing a Kie Server Configuration in centralized way. Each controller can manager multiple configurations at once and there can be multiple controllers in the environment. Managed KIE Servers can be configured with a list of controllers but will connect to only one at a time.
|
It’s important to mention that even though there can be multiple controllers they should be kept in sync to make sure that regardless which one of them is contacted by KIE Server instance it will provide same set of configuration. |
At startup, if a Kie Server is configured with a list of controllers, it will try succesivelly to connect to each of them until a connection is successfully stablished with one of them. If for any reason a connection can’t be stablished, the server will not start, even if there is local storage available with configuration. This happens by design in order to ensure consistency. For instance, if the Kie Server was down and the configuration has changed, this restriction guarantees that it will run with up to date configuration or not at all.
|
In order to run the Kie Server in standalone mode, without connecting to any controllers, please see "Unmanaged Kie Server". |
The configuration sets, among other things:
-
kie containers to be deployed and started
-
configuration items - currently this is a place holder for further enhancements that will allow remotely configure KIE Execution Server components - timers, persistence, etc
The Controller, besides providing configuration management, is also responsible for overall management of Kie Servers. It provides a REST api that is divided into two parts:
-
the controller itself that is exposed to interact with KIE Execution Server instances
-
an administration API that allows to remotely manage Kie Server instances:
-
add/remove servers
-
add/remove containers to/from the servers
-
start/stop containers on servers
-
The controller deals only with the Kie Server configuration or definition to put it differently. It does not handle any runtime components of KIE Execution Server instances. They are always considered remote to controller. The controller is responsible for persisting the configuration to preserve restarts of the controller itself. It should manage the synchronization as well in case multiple controllers are configured to keep all definitions up to date on all instances of the controller.
By default controller is shipped with Kie Workbench and provides a fully featured management interface (both REST api and UI). It uses underlying git repository as persistent store and thus when GIT repositories are clustered (using Apache Zookeeper and Apache Helix) it will cover the controllers synchronization as well.
The diagram above illustrates the single controller (workbench) setup with multiple Kie Server instances managed by it.
The diagram bellow illustrates the clustered setup where there are multiple instances of controller synchronized over Zookeeper.
In the above diagram we can see that the Kie Server instances are capable of connecting to any controllers, but they will connect to only one. Each instance will attempt to connect to controller as long as it can reach one. Once connection is established with one of the controllers it will skip the others.
17.3.1.1. Working with managed servers
There are two approaches that users can take when working with managed KIE Server instances:
-
Configuration first: with this approach, a user will start working with the controller (either UI or REST api) and create and configure Kie Server definitions. That consists basically of an identification for the server definition (id and name + optionally version for improved readability) and the configuration for the Kie Containers to run on the server.
-
Registration first: with this approach, the Kie Server instances are started first and auto register themselves on controller. The user then can configure the Kie Containers. This option simply skips the registration step done in the first approach and populates it with server id, name and version directly upon auto registration. There are no other differences between the two approaches.
17.3.2. Unmanaged KIE Execution Server
An unmanaged Kie Server is in turn just a standalone instance, and thus must be configured individually using REST/JMS api from the Kie Server itself. There is no controller involved. The configuration is automatically persisted by the server into a file and that is used as the internal server state, in case of restarts.
The configuration is updated during the following operations:
-
deploy Kie Container
-
undeploy Kie Container
-
start Kie Container
-
stop Kie Container
|
If the Kie Server is restarted, it will try to restablish the same state that was persisted before shutdown. That means that Kie Containers that were running, will be started, but the ones that were stopped/disposed before, will not. |
In most use cases, the Kie Server should be executed in managed mode as that provides some benefits, like a web user interface (if using the workbench as a controller) and some facilities for clustering.
17.4. Creating a Kie Container
Once your Execution Server is registered, you can start adding Kie Containers to it.
Kie Containers are self contained environments that have been provisioned to hold instances of your packaged and deployed rule instances.
-
Start by clicking the \+ icon next to the Execution Server where you want to deploy your Container. This will bring up the New Container screen.
-
If you know the Group Name, Artifact Id and Version (GAV) of your deployed package, then you can enter those details and click the Ok button to select that instance (and provide a name for the Container);
-
If you don’t know these values, you can search KIE Workbench for all packages that can be deployed. Click the Search button without entering any value in the search field (you can narrow your search by entering any term that you know exists in the package that you want to deploy).
INSERT SCREENSHOT HERE
The figure above shows that there are three deployable packages available to be used as containers on the Execution Server. Select the one that you want by clicking the Select button. This will auto-populate the GAV and you can then click the Ok button to use this deployable as the new Container.
-
Enter a name for this Container at the top and then press the Ok button.
The Container name must be unique inside each execution server and must not contain any spaces.
|
Just below the GAV row, you will see an uneditable row that shows you the URL for your Container against which you will be able to execute REST commands. |
17.5. Managing Containers
Containers within the Execution Server can be started, stopped and updated from within KIE Workbench.
17.5.1. Starting a Container
Once registered, a Container is in the 'Stopped' mode. It can be started by first selecting it and then clicking the Start button. You can also select multiple Containers and start them all at the same time.
Once the Container is in the 'Running' mode, a green arrow appears next to it. If there are any errors starting the Container(s), red icons appear next to Containers and the Execution Server that they are deployed on.
You should check the logs of both the Execution Server and the current Business Central to see what the errors are before redeploying the Containers (and possibly the Execution Server).
17.5.2. Stopping and Deleting a Container
Similar to starting a Container, select the Container(s) that you want to stop (or delete) and click the Stop button (which replaces the Start button for that Container once it has entered the 'Running' mode) or the Delete button.
17.5.3. Updating a Container
You can update deployed KieContainers without restarting the Execution Server.
This is useful in cases where the Business Rules change, creating new versions of packages to be provisioned.
You can have multiple versions of the same package provisioned and deployed, each to a different KieContainer.
To update deployments in a KieContainer dynamically, click on the icon next to the Container.
This will open up the Container Info screen.
An example of this screen is shown here:
|
INSERT SCREENSHOT HERE |
The Container Info screen is a useful tool because it not only allows you to see the endpoint for this KieContainer, but it also allows you to either manually or automatically refresh the provision if an update is available.
The update can be manual or automatic:
Manual Update: To manually update a KieContainer, enter the new Version number in the Version box and click on the Update button.
You can of course, update the Group Id or the Artifact Id , if these have changed as well.
Once updated, the Execution server updates the container and shows you the resolved GAV attributes at the bottom of the screen in the Resolved Release Id section.
Automatic Update: If you want a deployed Container to always have the latest version of your deployment without manually editing it, you will need to set the Version property to the value of LATEST and start a Scanner.
This will ensure that the deployed provision always contains the latest version.
The Scanner can be started just once on demand by clicking the Scan Now button or you can start it in the background with scans happening at a specified interval (in milliseconds).You can also set this value to LATEST when you are first creating this deployment.
The Resolved Release
Id in this case will show you the actual, latest version number.
17.6. Kie Server REST API
The Execution Server supports the following commands via the REST API.
Please note the following before using these commands:
-
The base URL for these will remain as the endpoint defined earlier (for example:
http://SERVER:PORT/CONTEXT/services/rest/server/) -
All requests require basic HTTP Authentication for the role kie-server as indicated earlier.
17.6.1. [GET] /
Returns the Execution Server information
<response type="SUCCESS" msg="KIE Server info">
<kie-server-info>
<version>6.2.0.redhat-1</version>
</kie-server-info>
</response>17.6.2. [POST] /config
Using POST HTTP method, you can execute various commands on the Execution Server. E.g: create-container, list-containers, dispose-container and call-container.
-
CreateContainerCommand
-
GetServerInfoCommand
-
ListContainersCommand
-
CallContainerCommand
-
DisposeContainerCommand
-
GetContainerInfoCommand
-
GetScannerInfoCommand
-
UpdateScannerCommand
-
UpdateReleaseIdCommand
The commands itself can be found in the org.kie.server.api.commands package.
17.6.3. [GET] /containers
Returns a list of containers that have been created on this Execution Server.
<response type="SUCCESS" msg="List of created containers">
<kie-containers>
<kie-container container-id="MyProjectContainer" status="STARTED">
<release-id>
<artifact-id>Project1</artifact-id>
<group-id>com.redhat</group-id>
<version>1.0</version>
</release-id>
<resolved-release-id>
<artifact-id>Project1</artifact-id>
<group-id>com.redhat</group-id>
<version>1.0</version>
</resolved-release-id>
</kie-container>
</kie-containers>
</response>The endpoint supports also filtering based on ReleaseId and container status. Examples:
-
/containers?groupId=org.example- returns only containers with the specified groupId -
/containers?groupId=org.example&artifactId=project1&version=1.0.0.Final- returns only containers with the specifiedReleaseId -
/containers?status=started,failed- returns containers which are either started or failed
17.6.4. [GET] /containers/{id}
Returns the status and information about a particular container.
For example, executing http://SERVER:PORT/CONTEXT/services/rest/server/containers/MyProjectContainer could return the following example container info.
<response type="SUCCESS" msg="Info for container MyProjectContainer">
<kie-container container-id="MyProjectContainer" status="STARTED">
<release-id>
<artifact-id>Project1</artifact-id>
<group-id>com.redhat</group-id>
<version>1.0</version>
</release-id>
<resolved-release-id>
<artifact-id>Project1</artifact-id>
<group-id>com.redhat</group-id>
<version>1.0</version>
</resolved-release-id>
</kie-container>
</response>17.6.5. [PUT] /containers/{id}
Allows you to create a new Container in the Execution Server.
For example, to create a Container with the id of MyRESTContainer the complete endpoint will be: http://SERVER:PORT/CONTEXT/services/rest/server/containers/MyRESTContainer.
An example of request is:
<kie-container container-id="MyRESTContainer">
<release-id>
<artifact-id>Project1</artifact-id>
<group-id>com.redhat</group-id>
<version>1.0</version>
</release-id>
</kie-container>And the response from the server, if successful, would be be:
<response type="SUCCESS" msg="Container MyRESTContainer successfully deployed with module com.redhat:Project1:1.0">
<kie-container container-id="MyProjectContainer" status="STARTED">
<release-id>
<artifact-id>Project1</artifact-id>
<group-id>com.redhat</group-id>
<version>1.0</version>
</release-id>
<resolved-release-id>
<artifact-id>Project1</artifact-id>
<group-id>com.redhat</group-id>
<version>1.0</version>
</resolved-release-id>
</kie-container>
</response>17.6.6. [DELETE] /containers/{id}
Disposes the Container specified by the id.
For example, executing http://SERVER:PORT/CONTEXT/services/rest/server/containers/MyProjectContainer using the DELETE HTTP method will return the following server response:
<response type="SUCCESS" msg="Container MyProjectContainer successfully disposed."/>17.6.7. [POST] /containers/instances/{id}
Executes operations and commands against the specified Container.
You can send commands to this Container in the body of the POST request.
For example, to fire all rules for Container with id MyRESTContainer (http://SERVER:PORT/CONTEXT/services/rest/server/containers/instances/MyRESTContainer), you would send the fire-all-rules command to it as shown below (in the body of the POST request):
<fire-all-rules/>Following is the list of supported commands:
-
AgendaGroupSetFocusCommand
-
ClearActivationGroupCommand
-
ClearAgendaCommand
-
ClearAgendaGroupCommand
-
ClearRuleFlowGroupCommand
-
DeleteCommand
-
InsertObjectCommand
-
ModifyCommand
-
GetObjectCommand
-
InsertElementsCommand
-
FireAllRulesCommand
-
QueryCommand
-
SetGlobalCommand
-
GetGlobalCommand
-
GetObjectsCommand
-
BatchExecutionCommand
These commands can be found in the org.drools.core.command.runtime package.
17.6.8. [GET] /containers/{id}/release-id
Returns the full release id for the Container specified by the id.
<response type="SUCCESS" msg="ReleaseId for container MyProjectContainer">
<release-id>
<artifact-id>Project1</artifact-id>
<group-id>com.redhat</group-id>
<version>1.0</version>
</release-id>
</response>17.6.9. [POST] /containers/{id}/release-id
Allows you to update the release id of the container deployment. Send the new complete release id to the Server.
<release-id>
<artifact-id>Project1</artifact-id>
<group-id>com.redhat</group-id>
<version>1.1</version>
</release-id>The Server will respond with a success or error message, similar to the one below:
<response type="SUCCESS" msg="Release id successfully updated.">
<release-id>
<artifact-id>Project1</artifact-id>
<group-id>com.redhat</group-id>
<version>1.0</version>
</release-id>
</response>17.6.10. [GET] /containers/{id}/scanner
Returns information about the scanner for this Container’s automatic updates.
<response type="SUCCESS" msg="Scanner info successfully retrieved">
<kie-scanner status="DISPOSED"/>
</response>17.6.11. [POST] /containers/{id}/scanner
Allows you to start or stop a scanner that controls polling for updated Container deployments.
To start the scanner, send a request similar to: http://SERVER:PORT/CONTEXT/services/rest/server/containers/{container-id}/scanner with the following POST data.
<kie-scanner status="STARTED" poll-interval="2000"/>The poll-interval attribute is in milliseconds. The response from the server will be similar to:
<response type="SUCCESS" msg="Kie scanner successfully created.">
<kie-scanner status="STARTED"/>
</response>To stop the Scanner, replace the status with DISPOSED and remove the poll-interval attribute.
17.7. OptaPlanner REST API
The Kie Server supports the following Planner REST APIs. All these APIs are also available through JMS and the Java client API. Please also note:
-
The base URL for these will remain as the endpoint defined earlier (for example
http://SERVER:PORT/CONTEXT/services/rest/server/). -
All requests require basic HTTP Authentication for the role kie-server as indicated earlier.
-
To get a specific marshalling format, add the HTTP headers
Content-Typeand optionalX-KIE-ContentTypein the HTTP request. For example:Content-Type: application/xml X-KIE-ContentType: xstream
|
|
The requests and responses in the example below assume that a Kie Container is built using the optacloud example of Planner Workbench, by calling a PUT on /services/rest/server/containers/optacloud-kiecontainer-1 with this content:
<kie-container container-id="optacloud-kiecontainer-1">
<release-id>
<group-id>opta</group-id>
<artifact-id>optacloud</artifact-id>
<version>1.0.0</version>
</release-id>
</kie-container>17.7.1. [GET] /containers
Returns the list of created containers.
<response type="SUCCESS" msg="List of created containers">
<result class="kie-containers">
<kie-container>
<container-id>optacloud-kiecontainer-1</container-id>
<release-id>
<group-id>optacloud</group-id>
<artifact-id>optacloud</artifact-id>
<version>1.0.0</version>
</release-id>
<resolved-release-id>
<group-id>optacloud</group-id>
<artifact-id>optacloud</artifact-id>
<version>1.0.0</version>
</resolved-release-id>
<status>STARTED</status>
<scanner>
<status>DISPOSED</status>
</scanner>
</kie-container>
</result>
</response>17.7.2. [PUT] /containers/{containerId}/solvers/{solverId}
Creates a new solver with the given {solverId} in the container {containerId}.
The request’s body is a marshalled SolverInstance entity that must specify the solver configuration file.
The following is an example of the request and the corresponding response.
<solver-instance>
<solver-config-file>optacloud/optacloud/cloudSolverConfig.solver.xml</solver-config-file>
</solver-instance><solver-instance>
<container-id>optacloud-kiecontainer-1</container-id>
<solver-id>solver1</solver-id>
<solver-config-file>optacloud/optacloud/cloudSolverConfig.solver.xml</solver-config-file>
<status>NOT_SOLVING</status>
<score />
</solver-instance>17.7.3. [GET] /containers/{containerId}/solvers
Returns the list of solvers created in the container.
<org.kie.server.api.model.instance.SolverInstanceList>
<solvers>
<solver-instance>
<container-id>optacloud-kiecontainer-1</container-id>
<solver-id>solver2</solver-id>
<solver-config-file>optacloud/optacloud/cloudSolverConfig2.solver.xml</solver-config-file>
<status>NOT_SOLVING</status>
<score />
</solver-instance>
<solver-instance>
<container-id>optacloud-kiecontainer-1</container-id>
<solver-id>solver1</solver-id>
<solver-config-file>optacloud/optacloud/cloudSolverConfig.solver.xml</solver-config-file>
<status>NOT_SOLVING</status>
<score />
</solver-instance>
</solvers>
</org.kie.server.api.model.instance.SolverInstanceList>17.7.4. [GET] /containers/{containerId}/solvers/{solverId}
Returns the current state of the solver {solverId} in container {containerId}.
<solver-instance>
<container-id>optacloud-kiecontainer-1</container-id>
<solver-id>solver1</solver-id>
<solver-config-file>optacloud/optacloud/cloudSolverConfig.solver.xml</solver-config-file>
<status>NOT_SOLVING</status>
<score />
</solver-instance>17.7.5. [POST] /containers/{containerId}/solvers/{solverId}/state/solving
Starts the solver {solverId} in container {containerId} if it is not executing yet.
The request’s body is a marshalled PlanningSolution to be optimized.
The following is an example to solve the OptaCloud problem with 2 computers and 6 processes. The solver runs asynchronously. Send a request to the bestsolution URL to get the best solution.
<optacloud.optacloud.CloudSolution id="1">
<computerList id="2">
<optacloud.optacloud.Computer id="3">
<cpuPower>24</cpuPower>
<memory>96</memory>
<networkBandwidth>16</networkBandwidth>
<cost>4800</cost>
</optacloud.optacloud.Computer>
<optacloud.optacloud.Computer id="4">
<cpuPower>6</cpuPower>
<memory>4</memory>
<networkBandwidth>6</networkBandwidth>
<cost>660</cost>
</optacloud.optacloud.Computer>
</computerList>
<processList id="5">
<optacloud.optacloud.Process id="6">
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>1</requiredNetworkBandwidth>
</optacloud.optacloud.Process>
<optacloud.optacloud.Process id="7">
<requiredCpuPower>3</requiredCpuPower>
<requiredMemory>6</requiredMemory>
<requiredNetworkBandwidth>1</requiredNetworkBandwidth>
</optacloud.optacloud.Process>
<optacloud.optacloud.Process id="8">
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>3</requiredNetworkBandwidth>
</optacloud.optacloud.Process>
<optacloud.optacloud.Process id="9">
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>2</requiredMemory>
<requiredNetworkBandwidth>11</requiredNetworkBandwidth>
</optacloud.optacloud.Process>
<optacloud.optacloud.Process id="10">
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>1</requiredNetworkBandwidth>
</optacloud.optacloud.Process>
<optacloud.optacloud.Process id="11">
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>5</requiredNetworkBandwidth>
</optacloud.optacloud.Process>
</processList>
</optacloud.optacloud.CloudSolution><?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
<cloudSolution>
<computerList>
<cost>4800</cost>
<cpuPower>24</cpuPower>
<memory>96</memory>
<networkBandwidth>16</networkBandwidth>
</computerList>
<computerList>
<cost>660</cost>
<cpuPower>6</cpuPower>
<memory>4</memory>
<networkBandwidth>6</networkBandwidth>
</computerList>
<processList>
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>1</requiredNetworkBandwidth>
</processList>
<processList>
<requiredCpuPower>3</requiredCpuPower>
<requiredMemory>6</requiredMemory>
<requiredNetworkBandwidth>1</requiredNetworkBandwidth>
</processList>
<processList>
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>3</requiredNetworkBandwidth>
</processList>
<processList>
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>2</requiredMemory>
<requiredNetworkBandwidth>11</requiredNetworkBandwidth>
</processList>
<processList>
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>1</requiredNetworkBandwidth>
</processList>
<processList>
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>5</requiredNetworkBandwidth>
</processList>
</cloudSolution>{
"optacloud.optacloud.CloudSolution": {
"computerList": [
{
"cpuPower": 24,
"memory": 96,
"networkBandwidth": 16,
"cost": 4800
},
{
"cpuPower": 6,
"memory": 4,
"networkBandwidth": 6,
"cost": 660
}
],
"processList": [
{
"requiredCpuPower": 1,
"requiredMemory": 1,
"requiredNetworkBandwidth": 1
},
{
"requiredCpuPower": 3,
"requiredMemory": 6,
"requiredNetworkBandwidth": 1
},
{
"requiredCpuPower": 1,
"requiredMemory": 1,
"requiredNetworkBandwidth": 3
},
{
"requiredCpuPower": 1,
"requiredMemory": 2,
"requiredNetworkBandwidth": 11
},
{
"requiredCpuPower": 1,
"requiredMemory": 1,
"requiredNetworkBandwidth": 1
},
{
"requiredCpuPower": 1,
"requiredMemory": 1,
"requiredNetworkBandwidth": 5
}
]
}
}17.7.6. [POST] /containers/{containerId}/solvers/{solverId}/state/terminating-early
Requests the solver to terminate early, if it is running. This does not delete the solver, the best solution can still be retrieved.
17.7.7. [GET] /containers/{containerId}/solvers/{solverId}/bestsolution
Returns the best solution found at the time the request is made.
If the solver has not terminated yet (so the status field is still SOLVING), it will return the best solution found up to then, but later calls can return a better solution.
<solver-instance>
<container-id>optacloud-kiecontainer-1</container-id>
<solver-id>solver1</solver-id>
<solver-config-file>optacloud/optacloud/cloudSolverConfig.solver.xml</solver-config-file>
<status>NOT_SOLVING</status>
<score scoreClass="org.optaplanner.core.api.score.buildin.hardsoft.HardSoftScore">0hard/-5460soft</score>
<best-solution class="optacloud.optacloud.CloudSolution">
<computerList>
<optacloud.optacloud.Computer>
<cpuPower>24</cpuPower>
<memory>96</memory>
<networkBandwidth>16</networkBandwidth>
<cost>4800</cost>
</optacloud.optacloud.Computer>
<optacloud.optacloud.Computer>
<cpuPower>6</cpuPower>
<memory>4</memory>
<networkBandwidth>6</networkBandwidth>
<cost>660</cost>
</optacloud.optacloud.Computer>
</computerList>
<processList>
<optacloud.optacloud.Process>
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>1</requiredNetworkBandwidth>
<computer reference="../../../computerList/optacloud.optacloud.Computer[2]"/>
</optacloud.optacloud.Process>
<optacloud.optacloud.Process>
<requiredCpuPower>3</requiredCpuPower>
<requiredMemory>6</requiredMemory>
<requiredNetworkBandwidth>1</requiredNetworkBandwidth>
<computer reference="../../../computerList/optacloud.optacloud.Computer"/>
</optacloud.optacloud.Process>
<optacloud.optacloud.Process>
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>3</requiredNetworkBandwidth>
<computer reference="../../../computerList/optacloud.optacloud.Computer"/>
</optacloud.optacloud.Process>
<optacloud.optacloud.Process>
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>2</requiredMemory>
<requiredNetworkBandwidth>11</requiredNetworkBandwidth>
<computer reference="../../../computerList/optacloud.optacloud.Computer"/>
</optacloud.optacloud.Process>
<optacloud.optacloud.Process>
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>1</requiredNetworkBandwidth>
<computer reference="../../../computerList/optacloud.optacloud.Computer"/>
</optacloud.optacloud.Process>
<optacloud.optacloud.Process>
<requiredCpuPower>1</requiredCpuPower>
<requiredMemory>1</requiredMemory>
<requiredNetworkBandwidth>5</requiredNetworkBandwidth>
<computer reference="../../../computerList/optacloud.optacloud.Computer[2]"/>
</optacloud.optacloud.Process>
</processList>
<score>0hard/-5460soft</score>
</best-solution>
</solver-instance>17.7.8. [POST] /containers/{containerId}/solvers/{solverId}/problemfactchanges
Real-time planning feature. Submits one or multiple ProblemFactChanges to update the dataset the solver currently optimizes.
17.7.9. [GET] /containers/{containerId}/solvers/{solverId}/problemfactchanges/processed
Real-time planning feature. Returns true if the solver processed all ProblemFactChanges that had been submitted. Returns false otherwise.
17.7.10. [DELETE] /containers/{containerId}/solvers/{solverId}
Disposes the solver {solverId} in container {containerId}.
If it has not terminated yet, it terminates it first.
17.8. Controller REST API
When you have Managed Kie Server setup, you need to manage Kie Servers and Containers via a Controller. Generally, it’s done by workbench UI but you may also use Controller REST API.
-
The controller base URL is provided by kie-wb war deployment, which would be the same as org.kie.server.controller property. (for example:
http://localhost:8080/kie-wb/rest/controller) -
All requests require basic HTTP Authentication for the role kie-server as indicated earlier.
17.8.1. [GET] /management/servers
Returns a list of Kie Server templates
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<server-template-list>
<server-template>
<server-id>demo</server-id>
<server-name>demo</server-name>
<container-specs>
<container-id>hr</container-id>
<container-name>hr</container-name>
<server-template-key>
<server-id>demo</server-id>
</server-template-key>
<release-id>
<artifact-id>HR</artifact-id>
<group-id>org.jbpm</group-id>
<version>1.0</version>
</release-id>
<configs>
<entry>
<key>RULE</key>
<value xsi:type="ruleConfig" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<scanner-status>STOPPED</scanner-status>
</value>
</entry>
<entry>
<key>PROCESS</key>
<value xsi:type="processConfig" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<strategy>Singleton</strategy>
<kie-base-name></kie-base-name>
<kie-session-name></kie-session-name>
<merge-mode>Merge Collections</merge-mode>
</value>
</entry>
</configs>
<status>STARTED</status>
</container-specs>
<configs/>
<server-instances>
<server-instance-id>demo@localhost:8230</server-instance-id>
<server-name>demo@localhost:8230</server-name>
<server-template-id>demo</server-template-id>
<server-url>http://localhost:8230/kie-server/services/rest/server</server-url>
</server-instances>
<capabilities>RULE</capabilities>
<capabilities>PROCESS</capabilities>
<capabilities>PLANNING</capabilities>
</server-template>
</server-template-list>17.8.2. [GET] /management/server/{id}
Returns a Kie Server template
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<server-template-details>
<server-id>product-demo</server-id>
<server-name>product-demo</server-name>
<container-specs>
<container-id>hr</container-id>
<container-name>hr</container-name>
<server-template-key>
<server-id>demo</server-id>
</server-template-key>
<release-id>
<artifact-id>HR</artifact-id>
<group-id>org.jbpm</group-id>
<version>1.0</version>
</release-id>
<configs>
<entry>
<key>RULE</key>
<value xsi:type="ruleConfig" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<scanner-status>STOPPED</scanner-status>
</value>
</entry>
<entry>
<key>PROCESS</key>
<value xsi:type="processConfig" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<strategy>Singleton</strategy>
<kie-base-name></kie-base-name>
<kie-session-name></kie-session-name>
<merge-mode>Merge Collections</merge-mode>
</value>
</entry>
</configs>
<status>STARTED</status>
</container-specs>
<configs/>
<server-instances>
<server-instance-id>demo@localhost:8230</server-instance-id>
<server-name>demo@localhost:8230</server-name>
<server-template-id>demo</server-template-id>
<server-url>http://localhost:8230/kie-server/services/rest/server</server-url>
</server-instances>
<capabilities>RULE</capabilities>
<capabilities>PROCESS</capabilities>
<capabilities>PLANNING</capabilities>
</server-template-details>17.8.3. [PUT] /management/server/{id}
Creates a new Kie Server template with the specified id
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<server-template-details>
<server-id>test-demo</server-id>
<server-name>test-demo</server-name>
<configs/>
<capabilities>RULE</capabilities>
<capabilities>PROCESS</capabilities>
<capabilities>PLANNING</capabilities>
</server-template-details>17.8.4. [DELETE] /management/server/{id}
Deletes a Kie Server template with the specified id
17.8.5. [GET] /management/server/{id}/containers
Returns all containers on given server
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<container-spec-list>
<container-spec>
<container-id>hr</container-id>
<container-name>hr</container-name>
<server-template-key>
<server-id>demo</server-id>
</server-template-key>
<release-id>
<artifact-id>HR</artifact-id>
<group-id>org.jbpm</group-id>
<version>1.0</version>
</release-id>
<configs>
<entry>
<key>RULE</key>
<value xsi:type="ruleConfig" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<scanner-status>STOPPED</scanner-status>
</value>
</entry>
<entry>
<key>PROCESS</key>
<value xsi:type="processConfig" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<strategy>Singleton</strategy>
<kie-base-name></kie-base-name>
<kie-session-name></kie-session-name>
<merge-mode>Merge Collections</merge-mode>
</value>
</entry>
</configs>
<status>STARTED</status>
</container-spec>
</container-spec-list>17.8.6. [GET] /management/server/{id}/containers/{containerId}
Returns the Container information including its release id and configuration
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<container-spec-details>
<container-id>hr</container-id>
<container-name>hr</container-name>
<server-template-key>
<server-id>demo</server-id>
</server-template-key>
<release-id>
<artifact-id>HR</artifact-id>
<group-id>org.jbpm</group-id>
<version>1.0</version>
</release-id>
<configs>
<entry>
<key>PROCESS</key>
<value xsi:type="processConfig" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<strategy>Singleton</strategy>
<kie-base-name></kie-base-name>
<kie-session-name></kie-session-name>
<merge-mode>Merge Collections</merge-mode>
</value>
</entry>
<entry>
<key>RULE</key>
<value xsi:type="ruleConfig" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<scanner-status>STOPPED</scanner-status>
</value>
</entry>
</configs>
<status>STARTED</status>
</container-spec-details>17.8.7. [PUT] /management/server/{id}/containers/{containerId}
Creates a new Container with the specified containerId and the given release id and optionally configuration
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<container-spec-details>
<container-id>hr</container-id>
<container-name>hr</container-name>
<server-template-key>
<server-id>demo</server-id>
</server-template-key>
<release-id>
<artifact-id>HR</artifact-id>
<group-id>org.jbpm</group-id>
<version>1.0</version>
</release-id>
<configs>
<entry>
<key>PROCESS</key>
<value xsi:type="processConfig" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<strategy>Singleton</strategy>
<kie-base-name></kie-base-name>
<kie-session-name></kie-session-name>
<merge-mode>Merge Collections</merge-mode>
</value>
</entry>
<entry>
<key>RULE</key>
<value xsi:type="ruleConfig" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<scanner-status>STOPPED</scanner-status>
</value>
</entry>
</configs>
<status>STARTED</status>
</container-spec-details17.8.8. [DELETE] /management/server/{id}/containers/{containerId}
Disposes a Container with the specified containerId
17.8.9. [POST] /management/server/{id}/containers/{containerId}/status/started
Starts the Container. No request body required
17.8.10. [POST] /management/server/{id}/containers/{containerId}/status/stopped
Stops the Container. No request body required
17.9. Kie Server Java Client API
The Kie Server has a great Java API to wrap REST or JMS requests to be sent to the server. In this section we will explore some of the possibilities of this API.
17.9.1. Maven Configuration
if you are a Maven user, make sure you have at least the following dependencies in the project’s pom.xml
<dependency>
<groupId>org.kie.server</groupId>
<artifactId>kie-server-client</artifactId>
<version>${kie.api.version}</version>
</dependency>
<!-- Logging -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.1.2</version>
</dependency>
<!-- Drools Commands -->
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-compiler</artifactId>
<scope>runtime</scope>
<version>${kie.api.version}</version>
</dependency>The version kie.api.version depends on the Kie Server version you are using. For jBPM 6.3, for example, you can use 6.3.1-SNAPSHOT.
17.9.2. Client Configuration
The client requires a configuration object where you set most of the server communication aspects, such as the protocol (REST and JMS) credentials and the payload format (XStream, JAXB and JSON are the supported formats at the moment). The first thing to do is create your configuration then create the KieServicesClient object, the entry point for starting the server communication.
See the source below where we use a REST client configuration:
import org.kie.server.api.marshalling.MarshallingFormat;
import org.kie.server.client.KieServicesClient;
import org.kie.server.client.KieServicesConfiguration;
import org.kie.server.client.KieServicesFactory;
public class DecisionServerTest {
private static final String URL = "http://localhost:8080/kie-server/services/rest/server";
private static final String USER = "kieserver";
private static final String PASSWORD = "kieserver1!";
private static final MarshallingFormat FORMAT = MarshallingFormat.JSON;
private KieServicesConfiguration conf;
private KieServicesClient kieServicesClient;
public void initialize() {
conf = KieServicesFactory.newRestConfiguration(URL, USER, PASSWORD);
conf.setMarshallingFormat(FORMAT);
kieServicesClient = KieServicesFactory.newKieServicesClient(conf);
}17.9.2.1. JMS interaction patterns
In version 6.5 KIE Server Client JMS integration has been enhanced with possibility to use various interaction patterns. Currently available are:
-
request reply (which is the default) - that makes the JMS integration synchronous - it blocks client until it gets the response back - not suited for JMS transactional use case
-
fire and forget - makes the integration one way only, suitable for notification like integration with kie server - makes perfect fit for transactional JMS delivery - deliver message to kie server only if transaction that ckie server client was invoked in was committed successfully
-
async with callback - allows to not block a client after sending message to kie server and receive response asynchronously - can be integrated with transactional JMS delivery
Response handlers can be either set globally - when KieServicesConfiguration is created or it can be changed on runtime on individual client instances (like RuleServiceClient, ProcessServicesClient, etc)
While 'fire and forget' and 'request reply' patterns do not require any additional configuration 'async with callback' does. And the main thing is actually the callback. KIE Server CLient comes with one out of the box - BlockingResponseCallback that provides basic support backed by blocking queue internally. Size of the queue is confgurable and thus allow receiving multiple messages, though intention of this callback is that it will only receive one message at a time - so it’s like one message (request) and then one response per client interaction.
| Kie Server Client when switching response handler is not thread safe, meaning change of the handler will affect all threads using same client instance. So in case of dynamic changes of the handler it’s recommended to use separate client instances. A good approach is to maintain set of clients that use dedicated response handler and then use these clients dependeing on which handler is required. |
Example:
client 1 will use fire and forget while client 2 will use request reply. So client 1 can be used to start processes and client 2 can be used to query for user tasks.
Users can provide their own callbacks by implementing org.kie.server.client.jms.ResponseCallback interface.
Configuration
Global JMS configuration
----
InitialContext context = ...;
Queue requestQueue = (Queue) context.lookup("jms/queue/KIE.SERVER.REQUEST"));
Queue responseQueue = (Queue) context.lookup("jms/queue/KIE.SERVER.RESPONSE");
ConnectionFactory connectionFactory = (ConnectionFactory) context.lookup("jms/RemoteConnectionFactory");
KieServicesConfiguration jmsConfiguration = KieServicesFactory.newJMSConfiguration( connectionFactory, requestQueue, responseQueue, "user", "password");
// here you set response handler globally
jmsConfiguration.setResponseHandler(new FireAndForgetResponseHandler());
----Alternatively, might be actually more common, is to set the handler on individual clients before they are used
Per client configuration
----
ProcessServiceClient processClient = client.getServicesClient(ProcessServicesClient.class);
// change response handler for processClient others are not affected
processClient.setResponseHandler(new FireAndForgetResponseHandler());
---17.9.3. Server Response
All the service responses are represented by the object org.kie.server.api.model.ServiceResponse<T> where T is the type of the payload.
It has the following attributes:
String msg: The response message;
org.kie.server.api.model.ServiceResponse.ResponseType type: the response type enum, which can be SUCCESS or FAILURE;
T result: The actual payload of the response, the requested object.
Notice that this is the same object returned if you are using REST or JMS, in another words it is agnostic to protocol.
17.9.4. Server Capabilities
Decision Server initially only supported rules execution, starting in version 6.3 it started supporting business process execution.
To know what exactly your server support, you can list the server capabilities by accessing the object org.kie.server.api.model.KieServerInfo**using the client:
public void listCapabilities() {
KieServerInfo serverInfo = kieServicesClient.getServerInfo().getResult();
System.out.print("Server capabilities:");
for(String capability: serverInfo.getCapabilities()) {
System.out.print(" " + capability);
}
System.out.println();
}If the server supports rules and process, the following should be printed when you run the code above:
Server capabilities: BRM KieServer BPM
17.9.5. Kie Containers
If you want to publish a kjar to receive requests, you must publish it in a container.
The container is represented in the client by the object org.kie.server.api.model.KieContainerResource, and a list of resources is org.kie.server.api.model.KieContainerResourceList.
Here’s an example of how to print a list of containers:
public void listContainers() {
KieContainerResourceList containersList = kieServicesClient.listContainers().getResult();
List<KieContainerResource> kieContainers = containersList.getContainers();
System.out.println("Available containers: ");
for (KieContainerResource container : kieContainers) {
System.out.println("\t" + container.getContainerId() + " (" + container.getReleaseId() + ")");
}
}It is also possible to list the containers based on specific ReleaseId (and its individual parts) or status:
public void listContainersWithFilter() {
// the following filter will match only containers with ReleaseId "org.example:contatner:1.0.0.Final" and status FAILED
KieContainerResourceFilter filter = new KieContainerResourceFilter.Builder()
.releaseId("org.example", "container", "1.0.0.Final")
.status(KieContainerStatus.FAILED)
.build();
KieContainerResourceList containersList = kieServicesClient.listContainers(filter).getResult();
List<KieContainerResource> kieContainers = containersList.getContainers();
System.out.println("Available containers: ");
for (KieContainerResource container : kieContainers) {
System.out.println("\t" + container.getContainerId() + " (" + container.getReleaseId() + ")");
}
}17.9.6. Managing Containers
You can use the client to dispose and create containers. If you dispose a containers, a ServiceResponse will be returned with Void payload(no payload) and if you create it, the KieContainerResource object itself will be returned in the response. Sample code:
public void disposeAndCreateContainer() {
System.out.println("== Disposing and creating containers ==");
List<KieContainerResource> kieContainers = kieServicesClient.listContainers().getResult().getContainers();
if (kieContainers.size() == 0) {
System.out.println("No containers available...");
return;
}
KieContainerResource container = kieContainers.get(0);
String containerId = container.getContainerId();
ServiceResponse<Void> responseDispose = kieServicesClient.disposeContainer(containerId);
if (responseDispose.getType() == ResponseType.FAILURE) {
System.out.println("Error disposing " + containerId + ". Message: ");
System.out.println(responseDispose.getMsg());
return;
}
System.out.println("Success Disposing container " + containerId);
System.out.println("Trying to recreate the container...");
ServiceResponse<KieContainerResource> createResponse = kieServicesClient.createContainer(containerId, container);
if(createResponse.getType() == ResponseType.FAILURE) {
System.out.println("Error creating " + containerId + ". Message: ");
System.out.println(responseDispose.getMsg());
return;
}
System.out.println("Container recreated with success!");
}17.9.7. Available Clients for the Decision Server
The KieServicesClient is also the entry point for others clients to perform specific operations, such as send BRMS commands and manage processes.
Currently from the KieServicesClient you can have access to the following services available in org.kie.server.client package:
-
JobServicesClient: This client allows you to schedule, cancel, requeue and get job requests;
-
ProcessServicesClient: Allows you to start, signal abort process; complete and abort work items among other capabilities;
-
QueryServicesClient: The powerful query client allows you to query process, process nodes and process variables;
-
RuleServicesClient: The simple, but powerful rules client can be used to send commands to the server to perform rules related operations(insert objects in the working memory, fire rules, get globals…);
-
UserTaskServicesClient: Finally, the user tasks clients allows you to perform all operations with an user tasks(start, claim, cancel, etc) and query tasks by certain fields(process instances id, user, etc).
For further information about these interfaces check github: https://github.com/kiegroup/droolsjbpm-integration/tree/master/kie-server-parent/kie-server-remote/kie-server-client/src/main/java/org/kie/server/client
You can have access to any of these clients using the method getServicesClient in the KieServicesClient class.
For example: RuleServicesClient rulesClient = kieServicesClient.getServicesClient(RuleServicesClient.class);
17.9.8. Sending commands to the server
To build commands to the server you must use the class org.kie.api.command.KieCommands, that can be created using org.kie.api.KieServices.get().getCommands().
The command to be send must be a BatchExecutionCommand or a single command(if a single command is sent, the server wraps it into a BatchExecutionCommand):
public void executeCommands() {
System.out.println("== Sending commands to the server ==");
RuleServicesClient rulesClient = kieServicesClient.getServicesClient(RuleServicesClient.class);
KieCommands commandsFactory = KieServices.Factory.get().getCommands();
Command<?> insert = commandsFactory.newInsert("Some String OBJ");
Command<?> fireAllRules = commandsFactory.newFireAllRules();
Command<?> batchCommand = commandsFactory.newBatchExecution(Arrays.asList(insert, fireAllRules));
ServiceResponse<String> executeResponse = rulesClient.executeCommands("hello", batchCommand);
if(executeResponse.getType() == ResponseType.SUCCESS) {
System.out.println("Commands executed with success! Response: ");
System.out.println(executeResponse.getResult());
}
else {
System.out.println("Error executing rules. Message: ");
System.out.println(executeResponse.getMsg());
}
}The result in this case is a String with the command execution result. In our case it will print the following:
== Sending commands to the server ==
Commands executed with success! Response:
{
"results" : [ ],
"facts" : [ ]
}\* You must add org.drools:drools-compiler dependency to have this part working
During creation of BatchExecutionCommand, an optional lookup argument can be specified, that determines where the comand will run. Lookup argument can be one of the following:
-
Kie Session Name defined in deployment descriptor
-
Kie Container Id
-
Kie Container Id followed by Process Instance Id (Process Instance runtime strategy have to be used on the container)
The last two options need active jBPM extension on the Kie Container.
In the third case, the usage of lookup argument looks like:
Command<?> batchCommand = commandsFactory.newBatchExecution(Arrays.asList(insert, fireAllRules), "demo-container#1");17.9.9. Listing available business processes
To list process definitions we use the QueryClient. The methods of the QueryClient usually uses pagination, which means that besides the query you are making, you must also provide the current page and the number of results per page. In the code below the query for process definitions from the given container starts on page 0 and list 1000 results, in another words, the 1000 first results.
public void listProcesses() {
System.out.println("== Listing Business Processes ==");
QueryServicesClient queryClient = kieServicesClient.getServicesClient(QueryServicesClient.class);
List<ProcessDefinition> findProcessesByContainerId = queryClient.findProcessesByContainerId("rewards", 0, 1000);
for (ProcessDefinition def : findProcessesByContainerId) {
System.out.println(def.getName() + " - " + def.getId() + " v" + def.getVersion());
}
}17.10. Securing password using key store
KIE server is using for some communication (e.g. REST api) basic authentication with passwords. From the security perspective it is not safe to store such passwords in clear text form on the disc. For this purpose a mechanism was developed to store passwords in a key store and then use it in the application.
17.10.1. Simple usecase
User wants to secure his password for communicating via REST client. He creates new keystore where he will put his password, he will setup sytem variables with the info to the keystore and KIE will automatically load the keystore and will use the password for securing the communication.
17.10.2. Implementation and business logic
Current implementation is using key store if it is defined. If not, the funcionality is falling back to old behavior using config parameters.
17.10.3. System requirements
To use a key store we need to create it first. As JKS is not supporting symetric keys we have to create JCEKS key store. Moreover, password can be stored in a key store only for Java 8 and above. For generating a key store you can use standard tool KeyTool which is part of JDK instalation.
17.10.4. Initialization of a key store
For keystore initialization we recommend to use keytool. Syntax is the following:
$ keytool -importpassword -keystore _keystore_url_ -keypass _alias_key_password_ -alias _password_alias_ -storepass _keystore_password_ -storetype JCEKS-
alias - alias name of the entry to process
-
keypass - key password
-
keystore - keystore name
-
storepass - keystore password
-
storetype - keystore type
After running this command user will be asked for entering the password which he wants to store.
17.10.5. System parameters for loading key store
-
kie.keystore.keyStoreURL - URL to a keystore which should be used
-
kie.keystore.keyStorePwd - password to a keystore
-
kie.keystore.key.server.alias - alias of the key for REST services where password is stored
-
kie.keystore.key.server.pwd - password of an alias for REST services with stored password
-
kie.keystore.key.ctrl.alias - alias of the key for default REST controller where password is stored
-
kie.keystore.key.ctrl.pwd - password of an alias for default REST controller with stored password
17.10.6. Example
-
create user and password in application server (it has to have kie-server role)
${EAP_HOME}/add-user.sh -a -e -u kieserver -p "kiePassword1!" -g kie-server
-
use key tool to create keystore with password in it
$ keytool -importpassword -keystore /home/kie/keystores/droolsServer.jceks -keypass keypwd -alias droolsKey -storepass serverpwd -storetype JCEKS
Enter the password to be stored:
Re-enter password:
$ keytool -importpassword -keystore /home/kie/keystores/droolsServer.jceks -keypass keypwd -alias restKey -storepass serverpwd -storetype JCEKS
Enter the password to be stored:
Re-enter password:-
set following system properties on application server that will let the kie server/controller to read password from keystore
<system-properties>
<property name="kie.keystore.keyStoreURL" value="droolsServer.jceks"/>
<property name="kie.keystore.keyStorePwd" value="serverpwd"/>
<property name="kie.keystore.key.server.alias" value="restKey"/>
<property name="kie.keystore.key.server.pwd" value="keypwd"/>
<property name="kie.keystore.key.ctrl.alias" value="droolsKey"/>
<property name="kie.keystore.key.ctrl.pwd" value="keypwd"/>
</system-properties>
-
start server to verify configuration
17.11. Kie Server Controller Client API
The Kie Server Controller offers a Java API to wrap REST or Web Socket requests to be sent to the server. In this section we will explore some of the capabilities of this API.
17.11.1. Maven Configuration
if you are a Maven user, you must have the following dependencies in the project’s pom.xml
<dependency>
<groupId>org.kie.server</groupId>
<artifactId>kie-server-controller-client</artifactId>
<version>${kie.api.version}</version>
</dependency>
<!-- REST Client -->
<dependency>
<groupId>org.jboss.resteasy</groupId>
<artifactId>resteasy-client</artifactId>
<version>3.0.19.Final</version>
</dependency>
<!-- Web Socket Client -->
<dependency>
<groupId>io.undertow</groupId>
<artifactId>undertow-websockets-jsr</artifactId>
<version>1.4.21.Final</version>
</dependency>
<!-- Logging -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.1.2</version>
</dependency>The version kie.api.version depends on the Kie Server Controller version you are using. For jBPM 7.6, for example, you can use 7.6.0.Final.
17.11.2. Client Configuration
The first thing to do is to create your KieServerControllerClient object, the entry point for starting the server communication,
using the provided factory methods available in KieServerControllerClientFactory where you set most of the server communication
aspects, such as the protocol (REST or Web Socket), credentials, and the payload format (currently, JAXB and JSON are the only supported
formats for the REST protocol).
See the examples below to get started:
17.11.2.1. Kie Server Controller Endpoints
-
REST: /rest/controller
-
Web Socket: /websocket/controller
import org.kie.server.controller.api.model.spec.ServerTemplateList;
import org.kie.server.controller.client.KieServerControllerClient;
import org.kie.server.controller.client.KieServerControllerClientFactory;
public class ListServerTemplatesExample {
private static final String URL = "http://localhost:8080/kie-server-controller/rest/controller";
private static final String USER = "kieserver";
private static final String PASSWORD = "kieserver1!";
public static void main(String[] args) {
KieServerControllerClient client = KieServerControllerClientFactory.newRestClient(URL,
USER,
PASSWORD);
final ServerTemplateList serverTemplateList = client.listServerTemplates();
System.out.println(String.format("Found %s server template(s) at controller url: %s",
serverTemplateList.getServerTemplates().length,
URL));
}
}import org.kie.server.controller.api.model.spec.ServerTemplateList;
import org.kie.server.controller.client.KieServerControllerClient;
import org.kie.server.controller.client.KieServerControllerClientFactory;
public class ListServerTemplatesExample {
private static final String URL = "ws://localhost:8080/kie-server-controller/websocket/controller";
private static final String USER = "kieserver";
private static final String PASSWORD = "kieserver1!";
public static void main(String[] args) {
KieServerControllerClient client = KieServerControllerClientFactory.newWebSocketClient(URL,
USER,
PASSWORD);
final ServerTemplateList serverTemplateList = client.listServerTemplates();
System.out.println(String.format("Found %s server template(s) at controller url: %s",
serverTemplateList.getServerTemplates().length,
URL));
}
}17.11.2.2. Protocol specific settings
REST
When using the REST protocol, the Kie Server Controller Client allows that you specify your own javax.ws.rs.core.Configuration.
This can be useful for fine tuning the underlying REST client API. As an example, you can tweak the connection time out according to your needs.
import java.util.concurrent.TimeUnit;
import javax.ws.rs.core.Configuration;
import org.jboss.resteasy.client.jaxrs.ResteasyClientBuilder;
import org.kie.server.api.marshalling.MarshallingFormat;
import org.kie.server.controller.api.model.spec.ServerTemplateList;
import org.kie.server.controller.client.KieServerControllerClient;
import org.kie.server.controller.client.KieServerControllerClientFactory;
public class RESTTimeoutExample {
private static final String URL = "http://localhost:8080/kie-server-controller/rest/controller";
private static final String USER = "kieserver";
private static final String PASSWORD = "kieserver1!";
public static void main(String[] args) {
final Configuration configuration =
new ResteasyClientBuilder()
.establishConnectionTimeout(10,
TimeUnit.SECONDS)
.socketTimeout(60,
TimeUnit.SECONDS)
.getConfiguration();
KieServerControllerClient client = KieServerControllerClientFactory.newRestClient(URL,
USER,
PASSWORD,
MarshallingFormat.JSON,
configuration);
final ServerTemplateList serverTemplateList = client.listServerTemplates();
System.out.println(String.format("Found %s server template(s) at controller url: %s",
serverTemplateList.getServerTemplates().length,
URL));
}
}Web Socket
When connecting via Web Socket protocol, the Kie Server Controller Client allows you to receive events notification based on changes that happen in the particular Kie Server Controller that the client API is connected to. For instance, you can receive a notification about a Kie Sever instance that got connected to the controller.
import org.kie.server.controller.api.model.events.*;
import org.kie.server.controller.api.model.spec.ServerTemplateList;
import org.kie.server.controller.client.KieServerControllerClient;
import org.kie.server.controller.client.KieServerControllerClientFactory;
import org.kie.server.controller.client.event.EventHandler;
public class WebSocketEventsExample {
private static final String URL = "ws://localhost:8080/kie-server-controller/websocket/controller";
private static final String USER = "kieserver";
private static final String PASSWORD = "kieserver1!";
public static void main(String[] args) {
KieServerControllerClient client = KieServerControllerClientFactory.newWebSocketClient(URL,
USER,
PASSWORD,
new TestEventHandler());
final ServerTemplateList serverTemplateList = client.listServerTemplates();
System.out.println(String.format("Found %s server template(s) at controller url: %s",
serverTemplateList.getServerTemplates().length,
URL));
try {
Thread.sleep(60 * 1000);
} catch (Exception e) {
e.printStackTrace();
}
}
static class TestEventHandler implements EventHandler {
@Override
public void onServerInstanceConnected(ServerInstanceConnected serverInstanceConnected) {
System.out.println("serverInstanceConnected = " + serverInstanceConnected);
}
@Override
public void onServerInstanceDeleted(ServerInstanceDeleted serverInstanceDeleted) {
System.out.println("serverInstanceDeleted = " + serverInstanceDeleted);
}
@Override
public void onServerInstanceDisconnected(ServerInstanceDisconnected serverInstanceDisconnected) {
System.out.println("serverInstanceDisconnected = " + serverInstanceDisconnected);
}
@Override
public void onServerTemplateDeleted(ServerTemplateDeleted serverTemplateDeleted) {
System.out.println("serverTemplateDeleted = " + serverTemplateDeleted);
}
@Override
public void onServerTemplateUpdated(ServerTemplateUpdated serverTemplateUpdated) {
System.out.println("serverTemplateUpdated = " + serverTemplateUpdated);
}
@Override
public void onServerInstanceUpdated(ServerInstanceUpdated serverInstanceUpdated) {
System.out.println("serverInstanceUpdated = " + serverInstanceUpdated);
}
@Override
public void onContainerSpecUpdated(ContainerSpecUpdated containerSpecUpdated) {
System.out.println("onContainerSpecUpdated = " + containerSpecUpdated);
}
}
}17.11.3. Setting up a Kie Server Controller
Below is a demonstration of additional capabilities of this API. You can follow this guide to get started with an empty Kie Server Controller instance. This example illustrates how to create a Server Template using some basic configuration as well as setting up a single container. It also shows how to start and stop the specific container and remove the newly created Server Template.
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import org.kie.server.api.model.KieContainerStatus;
import org.kie.server.api.model.KieScannerStatus;
import org.kie.server.api.model.ReleaseId;
import org.kie.server.controller.api.model.spec.*;
import org.kie.server.controller.client.KieServerControllerClient;
import org.kie.server.controller.client.KieServerControllerClientFactory;
public class WebSocketSetupControllerExample {
private static final String URL = "ws://localhost:8080/kie-server-controller/websocket/controller";
private static final String USER = "kieserver";
private static final String PASSWORD = "kieserver1!";
private static KieServerControllerClient client;
public static void main(String[] args) {
KieServerControllerClient client = KieServerControllerClientFactory.newWebSocketClient(URL,
USER,
PASSWORD);
ServerTemplate serverTemplate = createServerTemplate();
ContainerSpec container = createContainer(serverTemplate);
client.startContainer(container);
client.stopContainer(container);
client.deleteServerTemplate(serverTemplate.getId());
}
protected static ServerTemplate createServerTemplate() {
ServerTemplate serverTemplate = new ServerTemplate();
serverTemplate.setId("example-client-id");
serverTemplate.setName("example-client-name");
serverTemplate.setCapabilities(Arrays.asList(Capability.PROCESS.name(),
Capability.RULE.name(),
Capability.PLANNING.name()));
client.saveServerTemplate(serverTemplate);
return serverTemplate;
}
protected static ContainerSpec createContainer(ServerTemplate serverTemplate){
Map<Capability, ContainerConfig> containerConfigMap = new HashMap();
ProcessConfig processConfig = new ProcessConfig("PER_PROCESS_INSTANCE", "kieBase", "kieSession", "MERGE_COLLECTION");
containerConfigMap.put(Capability.PROCESS, processConfig);
RuleConfig ruleConfig = new RuleConfig(500l, KieScannerStatus.SCANNING);
containerConfigMap.put(Capability.RULE, ruleConfig);
ReleaseId releaseId = new ReleaseId("org.kie.server.testing", "stateless-session-kjar", "1.0.0-SNAPSHOT");
ContainerSpec containerSpec = new ContainerSpec("example-container-id", "example-client-name", serverTemplate, releaseId, KieContainerStatus.STOPPED, containerConfigMap);
client.saveContainerSpec(serverTemplate.getId(), containerSpec);
return containerSpec;
}
}Eclipse
How to use the Eclipse-based tooling
18. jBPM Eclipse Plugin
18.1. jBPM Eclipse Plugin
The jBPM Eclipse plugin provides developers (and very technical users) with an environment to edit and test processes, and integrate it deeply with their applications. It provides the following features (on top of the Eclipse IDE):
-
Wizards for creation of
-
a jBPM project
-
a BPMN2 process
-
-
jBPM Perspective (showing the most commonly used views in a predefined layout)
18.1.1. Installation
The jBPM installer is capable of downloading and installing an Eclipse installation, including the Drools and jBPM Eclipse plugin (with a full jBPM runtime preconfigured) and the Eclipse BPMN2 Modeler.
|
Using the jBPM installer is definitely the recommended starting point for most users. |
You can however also download and install the jBPM Eclipse Plugin manually. To do so, you need to:
-
Download Eclipse (Kepler recommended, but older versions like Indigo or Juno should also still work)
-
Start Eclipse
-
Select "Install New Software …" from the Help menu. Add the Drools and jBPM update site http://downloads.jboss.org/jbpm/release/6.0.1.Final/updatesite/. You should see the plugins as shown below. Note that you can also download and unzip the Drools and jBPM update site to your local file system and use that as local update site instead.

Select the JBoss jBPM Core and JBoss Drools Core plugins and click "Next >". Click "Next >" again after reviewing your selecting, accept the terms of the license agreement and click "Finish" to download and install the plugins. If you get a warning about installing software that contains unsigned content, click OK. After successful installation, Eclipse should ask you to restart, click Yes.
-
The plugin should now be installed. To check, check if you can for example see the new jBPM Project wizard: under the "File" menu, select "New Project …" and there you should be able to see "New jBPM Project" under the jBPM category.
-
Register a jBPM runtime to get started, see the section on jBPM runtimes in this chapter for more information.
Note that, when doing a manual install, you still need to manually install the Eclipse BPMN 2.0 Modeler plugin as well. Check out the chapter on the Eclipse BPMN 2.0 Modeler on how to do that.
18.1.2. jBPM Project Wizard
The aim of the new project wizard is to set up an executable sample project to start using processes immediately. This will set up a basic structure, the classpath, sample process and a test case to get you started. To create a new jBPM project, in the "File" menu select "New" and then "Project …" and under the jBPM category, select "jBPM Project". A dialog as shown below should pop up.
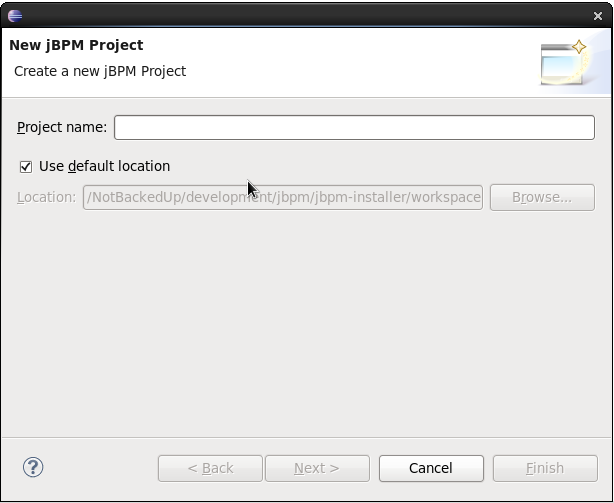
Fill in a name for your project and if necessary change the location where this project should be located (by default Eclipse will generate it inside your Eclipse workspace folder) and click "Next >".
Now you can optionally include a sample process in your project to get started. You can select to either use a simple "Hello World" process, a slightly more advanced process including human tasks and persistence or simply an empty project. You can also select to include a JUnit test class that you can use to test your process. These can serve as a starting point, and will give you something executable almost immediately, which you can then modify to your needs.
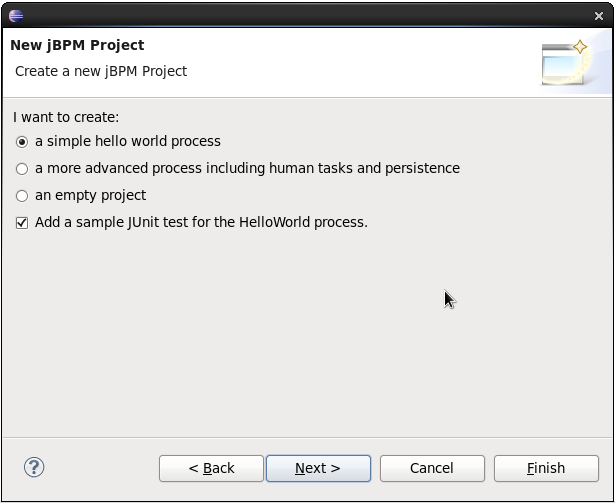
Finally, the last page in the wizard allows you select a jBPM runtime, as shown below. You can either use the default runtime (as configured for you workspace, in your workspace preferences), or you can select a specific runtime for this project. For more information about runtimes and how to create them, see the section on jBPM runtimes in this chapter.
You can also select which version of jBPM you want to generate sample code for. By default it will generate an example using the latest jBPM 6.x API, but you could also generate examples using the old jBPM 5.x API. Note that you yourself are responsible for making sure that the code you generate can be understood by the runtime (for example, if you create an example using jBPM6 API but select a jBPM5 runtime, your sample will not compile). Also note that, if you want to execute a jBPM5 example on jBPM6, you will need to have the knowledge-api JAR inside your jBPM6 runtime, as this is responsible for the backwards compatibility of the jBPM5 API in jBPM6.
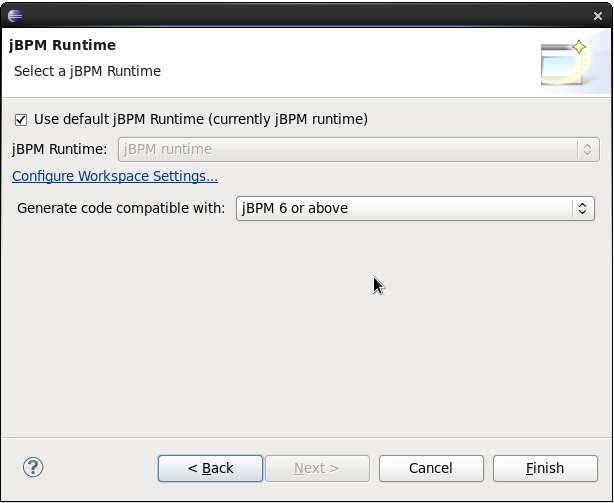
When you selected the simple 'hello world' example, the result is shown below. Feel free to experiment with the plug-in at this point.
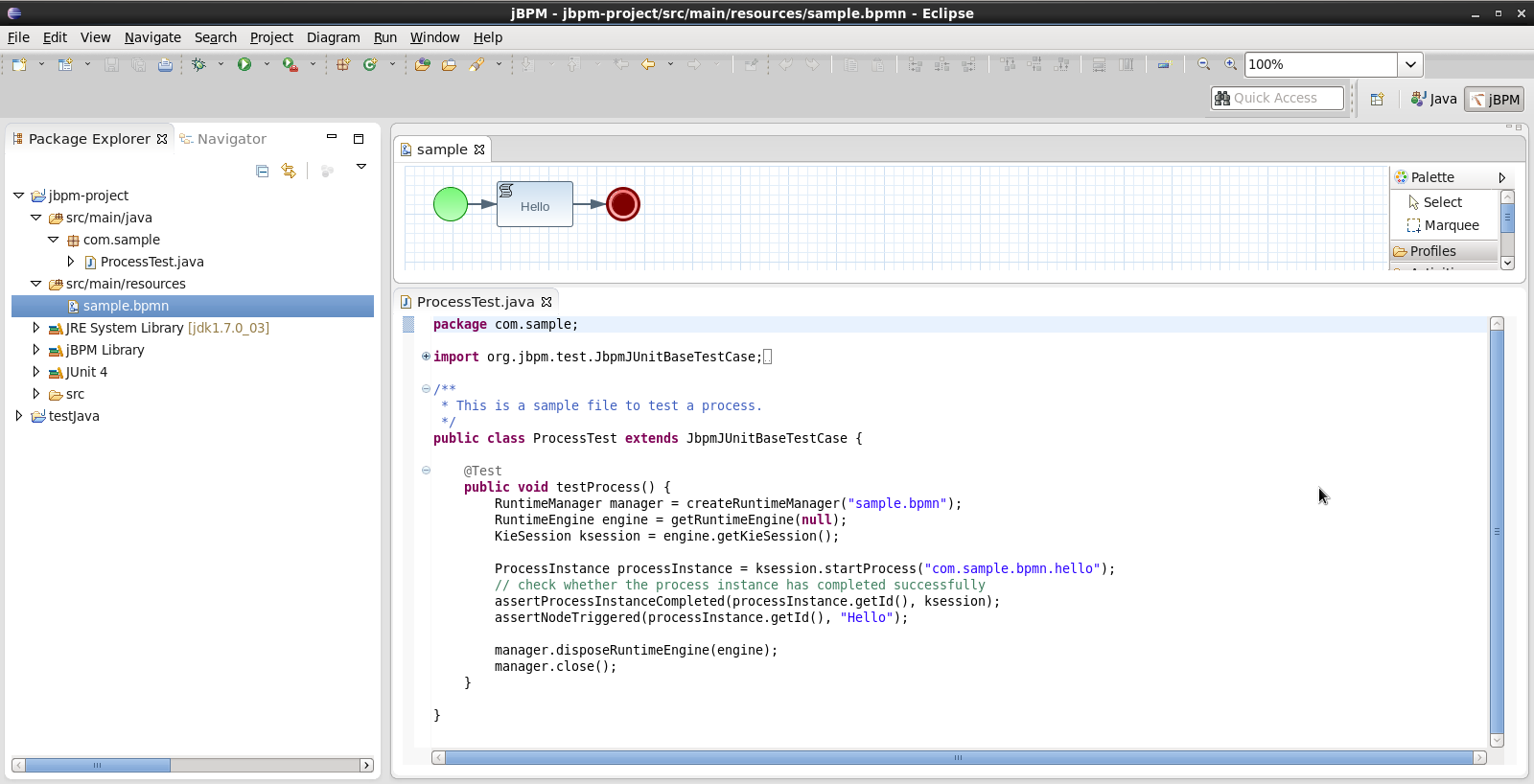
The newly created project contains an example process file (sample.bpmn) in the src/main/resources directory and an example Java file (ProcessTest.java) that can be used to test the process in a jBPM engine. You’ll find this in the folder src/main/java, in the com.sample package. All the other JARs that are necessary during execution are also added to the classpath in a custom classpath container called jBPM Library.
You can also convert an existing Java project to a jBPM project by selecting the "Convert to jBPM Project" action. Right-click the project you want to convert and under the "Configure" category (at the bottom) select "Convert to jBPM Project". This will add the jBPM Library to your project’s classpath.
18.1.3. New BPMN2 Process Wizard
You can create a new process simply as an empty text file with extension ".bpmn", or use the "New BPMN2 Process" wizard to do so. To create a new process, in the "File" menu select "New" and then "Other …" and under the jBPM category, select "BPMN2 Process" and click "Next >". In the next dialog, you should select the folder where the process should be created (for example the src/main/resources folder of your project) and a name for the process. Clicking "Finish" should create your new process (by default it should only contain one start node) and open it so you can start editing it.
18.1.4. jBPM Runtime
A jBPM runtime is a collection of JAR files that represent one specific release of the jBPM project JARs. To create a runtime, download the binary distribution of the version of jBPM you want to use and unzip on your local file system. You must then point the IDE to the release of your choice by selecting the folder where these JARs are located. If you want to create a new runtime based on the latest jBPM project JARs included in the plugin itself, you can also easily do that. You are required to specify a default jBPM runtime for your Eclipse workspace, but each individual project can override the default and select the appropriate runtime for that project specifically.
18.1.4.1. Defining a jBPM Runtime
To define one or more jBPM runtimes using the Eclipse preferences view you open up your Preferences, by selecting the "Preferences" menu item in the menu "Window". A "Preferences" dialog should show all your settings. On the left side of this dialog, under the jBPM category, select "Installed jBPM runtimes". The panel on the right should then show the currently defined jBPM runtimes. For example, if you used the jBPM Installer, it should look like the figure below.
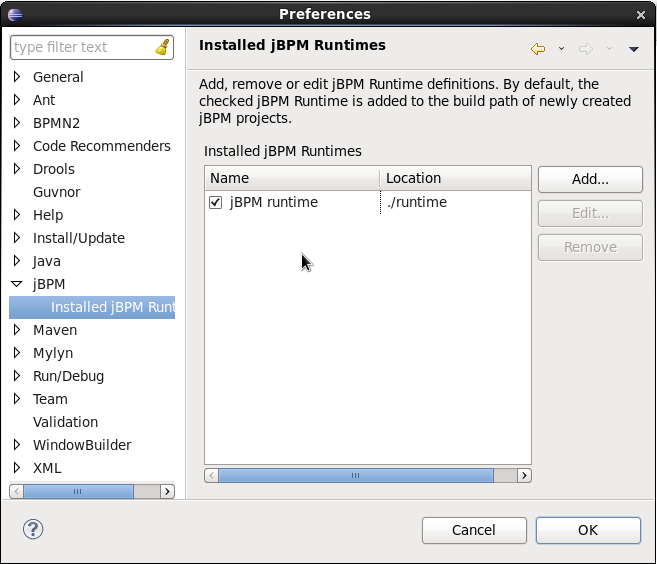
To define a new jBPM runtime, click on the "Add" button. A dialog such as the one shown below should pop up, asking for the name of your runtime and the location on your file system where it can be found.
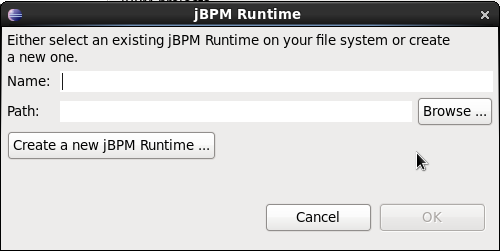
In general, you have two options:
-
If you simply want to use the default JAR files as included in the jBPM Eclipse plugin, you can create a new jBPM runtime automatically by clicking the "Create a new jBPM Runtime …" button. A file browser will show up, asking you to select the folder on your file system where you want this runtime to be created. The plugin will then automatically copy all required dependencies to the specified folder. Make sure to select a unique name for the newly created runtime and click "OK" to register this runtime.
Note that creating a jBPM runtime from the default JAR files as included in the jBPM Eclipse plugin is only recommended to get you started the first time and for very simple use cases. The runtime that is created this way only contains the minimal set of JARs, and therefore doesn’t support a significant set of features, including for example persistence. Make sure to create a full runtime (using the second approach) for real development.
-
If you want to use one specific release of the jBPM project, you should create a folder on your file system that contains all the necessary jBPM libraries and dependencies (for example by downloading the binary distribution and unzipping it on your local file system). Instead of creating a new jBPM runtime as explained above, give your runtime a unique name and click the "Browse …" button to select the location of this folder containing all the required JARs. Click "OK" to register this runtime.
After clicking the OK button, the runtime should show up in your table of installed jBPM runtimes, as shown below. Click on the checkbox in front of one of the installed runtimes to make it the default jBPM runtime. The default jBPM runtime will be used as the runtime of all your new jBPM projects (in case you didn’t select a project-specific runtime).
You can add as many jBPM runtimes as you need. Note that you will need to restart Eclipse if you changed the default runtime and you want to make sure that all the projects that are using the default runtime update their classpath accordingly.
18.1.4.2. Selecting a runtime for your jBPM project
Whenever you create a jBPM project (using the New jBPM Project wizard or by converting an existing Java project to a jBPM project), the plugin will automatically add all the required JARs to the classpath of your project.
When creating a new jBPM project, the plugin will automatically use the default Drools runtime for that project, unless you specify a project-specific one. You can do this in the final step of the New jBPM Project wizard, as shown below, by deselecting the "Use default Drools runtime" checkbox and selecting the appropriate runtime in the drop-down box. If you click the "Configure workspace settings …" link, the workspace preferences showing the currently installed jBPM runtimes will be opened, so you can add new runtimes there.
You can change the runtime of a jBPM project at any time by opening the project properties and selecting the jBPM category, as shown below. Mark the "Enable project specific settings" checkbox and select the appropriate runtime from the drop-down box. If you click the "Configure workspace settings …" link, the workspace preferences showing the currently installed jBPM runtimes will be opened, so you can add new runtimes there. If you deselect the "Enable project specific settings" checkbox, it will use the default runtime as defined in your global workspace preferences.
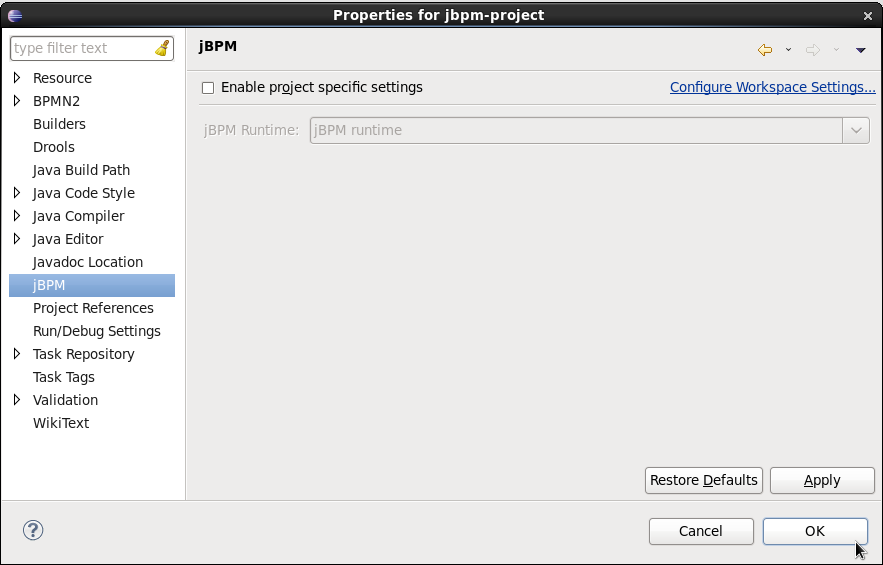
18.1.5. jBPM Maven Project Wizard
The aim of the new Maven project wizard is to set up an executable sample project to start using processes immediately (but not as normal Java project with all jBPM dependencies added using a jBPM library but by using Maven (and thus a pom.xml) to define your project’s properties and dependencies. This wizard will set up a Maven project using a pom.xml, and include a sample process and Java class to execute it. To create a new jBPM Maven project, in the "File" menu select "New" and then "Project …" and under the jBPM category, select "jBPM Project (Maven)". Give your project a name and click finish. The result should be as shown below.
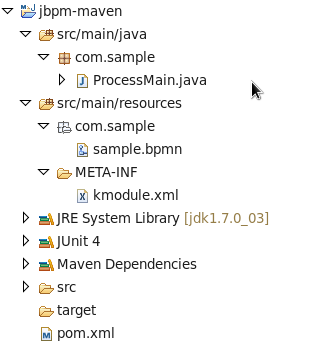
The pom.xml that is generated for your project contains the following:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.sample</groupId>
<artifactId>jbpm-example</artifactId>
<version>1.0.0-SNAPSHOT</version>
<name>jBPM :: Sample Maven Project</name>
<description>A sample jBPM Maven project</description>
<properties>
<version.org.jbpm>6.0.0.Final</version.org.jbpm>
</properties>
<repositories>
<repository>
<id>jboss-public-repository-group</id>
<name>JBoss Public Repository Group</name>
<url>http://repository.jboss.org/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
<updatePolicy>never</updatePolicy>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>daily</updatePolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.jbpm</groupId>
<artifactId>jbpm-test</artifactId>
<version>${version.org.jbpm}</version>
</dependency>
</dependencies>
</project>In the properties section, you can specify which version of jBPM you would like to use (by default it uses 6.0.0.Final). It adds the JBoss Nexus Maven repository (where all the jBPM JARs and their dependencies are located) to your project and configures the dependencies.
|
By default, only the jbpm-test JAR is specified as a dependency, as this has transitive dependencies to almost all of the core dependencies you will need. You are free to update the dependencies section however to include only the dependencies you need. |
The project also contains a sample process, under src/main/resources, in the com.sample package, and a kmodule.xml configuration file under the META-INF folder. The kmodule.xml defines which resources (processes, rules, etc.) are to be loaded as part of your project. In this case, it is defining a kbase called "kbase" that will load all the resources in the com.sample folder:
<kmodule xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="kbase" packages="com.sample"/>
</kmodule>Finally, it also contains a Java class that can be used to execute the sample process.
It will first create a kbase called "kbase" (by inspecting the kmodule.xml file and thus loading the sample.bpmn process) and then use a RuntimeManager to get access to a KieSession and TaskService.
In this case, it is used to start a process and then complete the tasks created by this process one by one.
18.1.6. Drools Eclipse plugin
The Drools Eclipse Plugin, which is bundled as part of the same Eclipse Update Site as the jBPM Eclipse Plugin, provides similar features for creating and editing business rules, and execute them using the Drools engine. This for example allows you to create and edit .drl files containing business rules. You can combine your processes and rules inside one project and execute them together on the same KieSession.
18.2. Debugging
This section describes how to debug processes using the jBPM Eclipse plugin. This means that the current state of your running processes can be inspected and visualized during the execution. Note that we currently don’t allow you to put breakpoints on the nodes within a process directly. You can however put breakpoints inside any Java code you might have (i.e. your application code that is invoking the engine or invoked by the engine, listeners, etc.) or inside rules (that could be evaluated in the context of a process). At these breakpoints, you can then inspect the internal state of all your process instances.
When debugging the application, you can use the following debug views to track the execution of the process:
-
The process instances view, showing all running process instances (and their state). When double-clicking a process instance, the process instance view visually shows the current state of that process instance at that point in time.
-
The audit view, showing the audit log (note that you should probably use a threaded file logger if you want to session to save the audit event to the file system on regular intervals, so the audit view can be update to show the latest state).
-
The global data view, showing the globals.
-
Other views related to rule execution like the working memory view (showing the contents (data) in the working memory related to rule execution), the agenda view (showing all activated rules), etc.
18.2.1. The Process Instances View
The process instances view shows the process instances currently running in the selected ksession. To be able to use the process instances view, first open the Process Instances view (Window - Show View - Other … and under the Drools category select Process Instances and Process Instance). Tip: it might be useful to drag the Process Instance view to the Outline View and slightly enlarge it, as shown in the screenshot below, so you can see both the Process Instances and Process Instance views at the same time.
Next, use a (regular) Java breakpoint to stop your application at a specific point (for example right after starting a new process instance). In the Debug perspective, select the ksession you would like to inspect, and the Process Instances view should show the process instances that are currently active inside that ksession. For example, the screenshot below shows one running process instance (with id "1"). When double-clicking a process instance, the process instance viewer will graphically show the progress of that process instance. An example where the process instance is waiting for a human actor to perform "Task 1" is shown below.
|
The process instances view shows the process instances currently active inside the selected ksession. Note that, when using persistence, process instances are not kept in memory inside the ksession, as they are stored in the database as soon as the command completes. Therefore, you will not be able to use the Process Instances view when using persistence. For example, when executing a JUnit test using the JbpmJUnitBaseTestCase, make sure to call "super(true, false);" in the constructor to create a runtime manager that is not using persistence. |
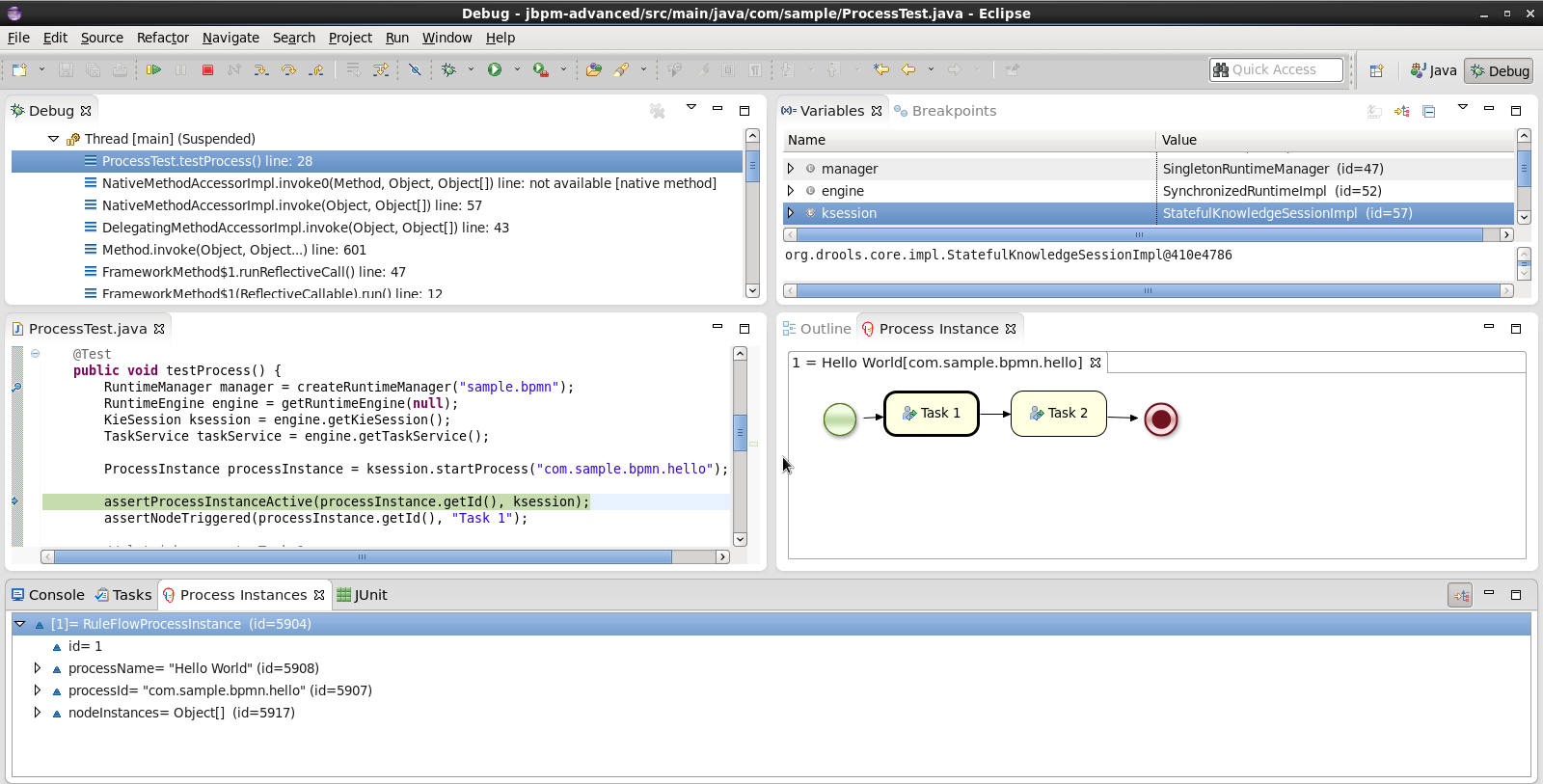
|
When you double-click a process instance in the process instances view and the process instance view complains that it cannot find the process, this means that the plugin wasn’t able to find the process definition of the selected process instance in the cache of parsed process definitions. To solve this, simply change the process definition in question and save again (so it will be parsed) or rebuild the project that contains the process definition in question. |
18.2.2. The Audit View
The audit view can be used to show the all the events inside an audit log in a tree-based manner. An audit log is an XML-based log file which contains a log of all the events that occurred while executing a specific ksession. To create a logger, use KieServices to create a new logger and attach it to a ksession. Be sure to close the logger after usage.
KieRuntimeLogger logger = KieServices.Factory.get().getLoggers()
.newThreadedFileLogger(ksession, "mylogfile", 1000);
// do something with the ksession here
logger.close();To be able to use the Audit View, first open it (Window - Show View - Other … and under the Drools category select Audit). To open up a log file in the audit view, open the selected log file in the audit view (using the "Open Log" action in the top right corner), or simply drag and drop the log file from the Package Explorer or Navigator into the audit view. A tree-based view is generated based on the data inside the audit log. An event is shown as a subnode of another event if the child event is caused by (a direct consequence of) the parent event. An example is shown below.

|
Note that the file-based logger will only save the events on close (or when a certain threshold is reached). If you want to make sure the events are saved on a regular interval (for example during debugging), make sure to use a threaded file logger, so the audit view can be update to show the latest state. When creating a threaded file logger, you can specify the interval after which events should be saved to the file (in milliseconds). |
18.3. Synchronizing with Workbench Repositories
From Eclipse, you can synchronize your local workspace with one or more repositories that are managed inside the workbench application. This enables collaboration between developers using Eclipse and users of the web-based workbench (business analysts or end users for example). Synchronization between the workbench repositories and your local version of these projects is done using Git (a popular distributed source code version control system).
When creating and executing processes inside Eclipse, you are creating them on your local file system. You can however also import an existing repository from the Workbench, apply changes and push these changes back into the Workbench repositories. We are using existing Git tools for this. Note that this section will describe how to do this using the EGit tooling (Eclipse Tooling for Git which comes by default with most versions of Eclipse), but feel free to use your preferred Git tool instead.
|
This section is not intended to explain what Git is, or how to use EGit, in detail. If you don’t have any experience with Git and/or EGit, it might be recommended to read up on them first if necessary. |
18.3.1. Importing a workbench repository
To import an existing repository from the workbench, you can use the EGit import wizard. In the File menu, select "Import …" and in the Git category, select "Projects from Git" and click "Next >". This should open a new dialog where you should select the location of the repository you would like to import. Since we are connecting to a repository that is managed by the workbench application, select "URI" and click "Next >" once more.
Use the following URI to connect to your workbench repositories:
ssh://<hostname>:8001/<repository_name>For example, if you are running the workbench application on your local host (for example by using the jbpm-installer), and you want to import the jbpm-playground repo, use the following URI:
ssh://localhost:8001/jbpm-playgroundNote that you can change the port that is used by the server to provide ssh access to the git repository if necessary, using the system property org.uberfire.nio.git.ssh.port
Fill in the URI of the repository you would like to import, as for example shown below, and click "Next >".
You will be asked to select which branch you would like to import. Select the master branch and click "Next >" again.
Finally, you need to specify where on your local file system you would like this repository to be created. Fill in the directory (you can use the Browse button to select the folder in question, and if necessary you can create a new folder there as well) and click "Next >". This will now download the repository to the folder you just selected.
You still need to import the repository you just downloaded as a project in your Eclipse workspace. Select "Import as general project" and after clicking "Next >", give it a name and click "Finish". After doing so, your workspace should now contain your repository, and you should be able to browse, open and edit the various assets inside.
18.3.2. Committing changes to the workbench
You can commit and push changes (you do locally) back to the workbench repositories. To commit changes, right-click on your repository project and select "Team → Commit …". A new dialog pops up, showing all the changes you have on your local file system. Select the files you want to commit (if you double-click them, you can get an overview of the changes you did for that file), provide an appropriate commit message and click "Commit".
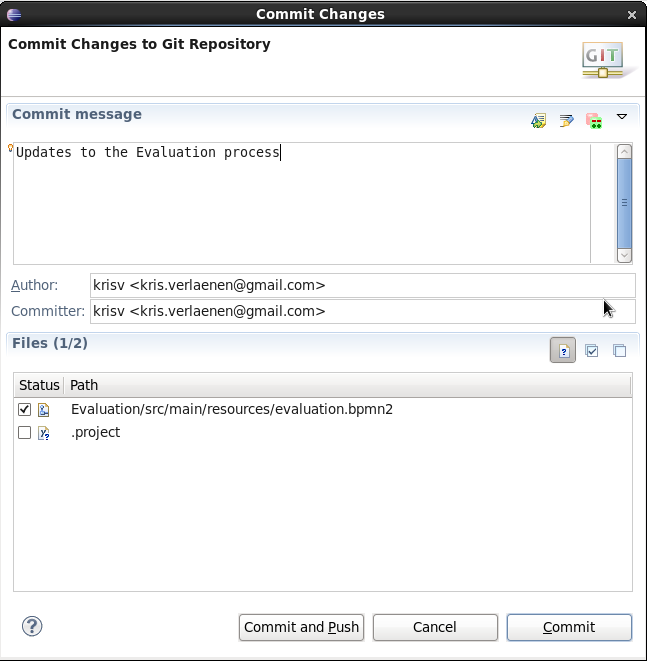
Once you’ve committed your change to your local git, you still need to push it to the workbench repository. Right-click your project again, and select "Team → Push to Upstream".
|
You are only allowed to push changes upstream if your local version includes all recent changes (otherwise you might be overriding someone else’s changes). You might be forced to update (and if necessary resolve conflicts) before you are allowed to commit any changes. |
18.3.3. Updating from to the workbench
To retrieve the latest changes from the workbench repository, right-click your repository project and select "Team → Fetch from Upstream". This will fetch all changes from the workbench repository, but not yet apply them to your local version. Now right-click your project again and select "Team → Merge …". In the dialog that pops up next, you need to select "origin/master" branch (under Remote Tracking) to indicate that you want to merge in all changes from the original repository in the workbench, and click "Merge".
|
It is possible that you have committed and/or conflicting changes in your local version, you might have to resolve these conflicts and commit the merge results before you will be able to complete the merge successfully. It is recommended to update regularly, before you start updating a file locally, to avoid merge conflicts being detected when trying to commit changes. |
18.3.4. Working on individual projects
When you import a repository, it will download all the projects that are inside that repository. It is however useful to mount one specific project as a separate Java project in Eclipse. When you do this, Eclipse will be able to interpret the information in the project pom.xml file (that you created in the workbench), download and include any dependencies you specified, compile any Java classes you have in your project (that you for example created with the data modeler), etc.
To do so, right-click on one of the projects in your repository project and select "Import …" and under the Maven category, select "Existing Maven Projects" (as shown below) and click Next.
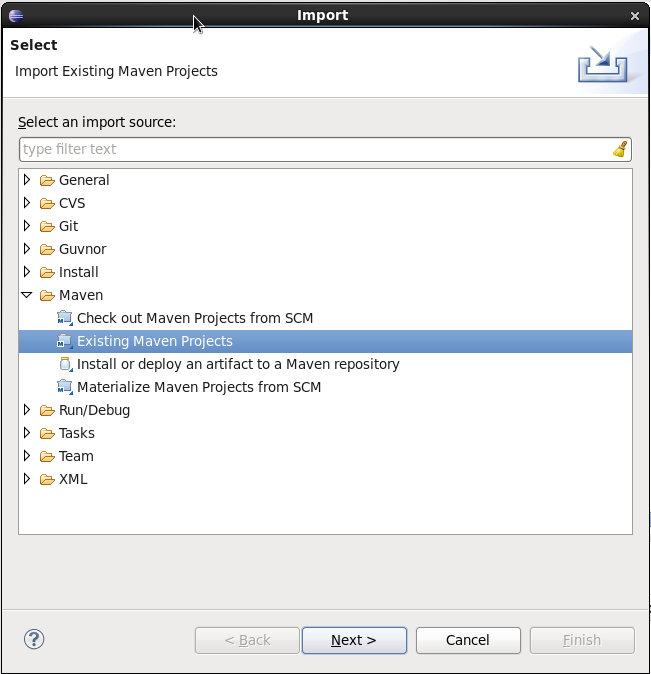
In the next page, you should see the pom.xml of the project you selected. Click Finish.
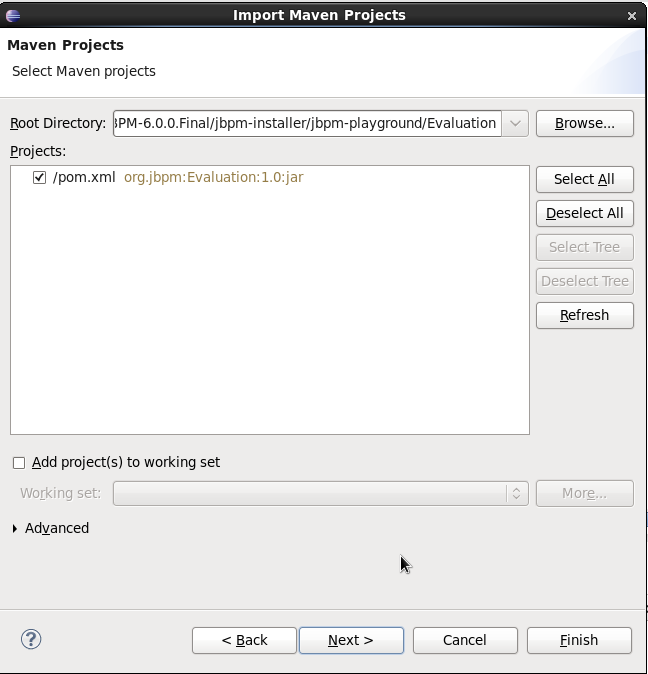
If your project requires some of the jBPM libraries to correctly compile and/or execute any Java classes in your project (for example if you have test classes in your project that start up a jBPM engine and execute some tests for your project, or if you are using the data modeler, which will add some annotations to the generated Java classes), you still need to add the jBPM libraries to the classpath of your project. To do so, simply convert your project into a jBPM project, which will add the jBPM library to your project’s classpath. Right-click your project and select "Configure → Convert to jBPM Project". Your project should now have a jBPM Library added to its classpath (it might be necessary to clean your project to pick up this change and recompile all Java classes).
19. Eclipse BPMN 2.0 Modeler
19.1. Overview
The Eclipse BPMN 2.0 Modeler allows you to specify business processes, choreographies, etc. using the BPMN 2.0 XML syntax (including BPMNDI for the graphical information). The editor itself is based on the Eclipse Graphiti framework and the Eclipse BPMN 2.0 EMF meta-model.
Features:
-
It supports almost all BPMN 2.0 process constructs and attributes (including lanes and pools, annotations and all the BPMN2 node types).
-
Added additional support for the few custom attributes that jBPM introduces using a special jBPM Target Runtime.
-
Allows you to configure which elements and attributes you want use when modeling processes (so we can limit the constructs for example to the subset currently supported by jBPM, which is a profile supported by default, or even more if you like).
The BPMN2 Modeler project is being developed at eclipse.org, sponsored by Red Hat/JBoss. Red Hat understands the benefits of developing software in the community, and therefore, the Eclipse BPMN 2.0 Modeler was developed not just for the jBPM project only, but it can be used in a much broader context and is fully spec compliant. jBPM-specific features are developed as part of a separate jBPM Target Runtime. We welcome other organizations in contributing to this modeler as well and (re)using the generic functionality and/or defining their own target runtime if necessary. Not only is this a good thing for the community, but it also leaves the path open for the jBPM suite to evolve as new features are requested by customers.
Many thanks go out to the people at Codehoop that did a great job in creating a first version of this editor.
19.2. Installation
The jBPM installer is capable of downloading and installing an Eclipse installation, including the Eclipse BPMN2 Modeler and the Drools and jBPM Eclipse plugin (with a full jBPM runtime preconfigured).
|
Using the jBPM installer is definitely the recommended starting point for most users. |
You can however also download and install the jBPM Eclipse Plugin manually. To do so, you need Eclipse 3.6.2 (Helios) or newer. To install, startup Eclipse and install the Eclipse BPMN 2.0 Modeler from the following update site (from menu Help → Install new software and then add the update site in question by clicking the Add button, filling in a name and the correct URL as shown below). It will automatically download all other dependencies as well (e.g. Graphiti etc.)
Eclipse 3.6 (Helios): http://download.eclipse.org/bpmn2-modeler/updates/helios
Eclipse 3.7 - 4.2.1 (Indigo - Juno): http://download.eclipse.org/bpmn2-modeler/updates/juno
Eclipse 4.3 (Kepler): http://download.eclipse.org/bpmn2-modeler/updates/kepler
The project is hosted at eclipse.org and open for anyone to contribute. The project home page can he found here:
Sources are available here (using Eclipse Public License v1.0):
A community forum for posting questions and exchanging ideas is also available here:
A Bugzilla bug tracking system is available for reporting new bugs, or checking the status of existing bugs, here:
19.3. Documentation
The Eclipse BPMN 2.0 Modeler documentation is available at:
It contains various screencasts but also a full user guide, describing all its features in detail:
Here are some screenshots of the editor in action.
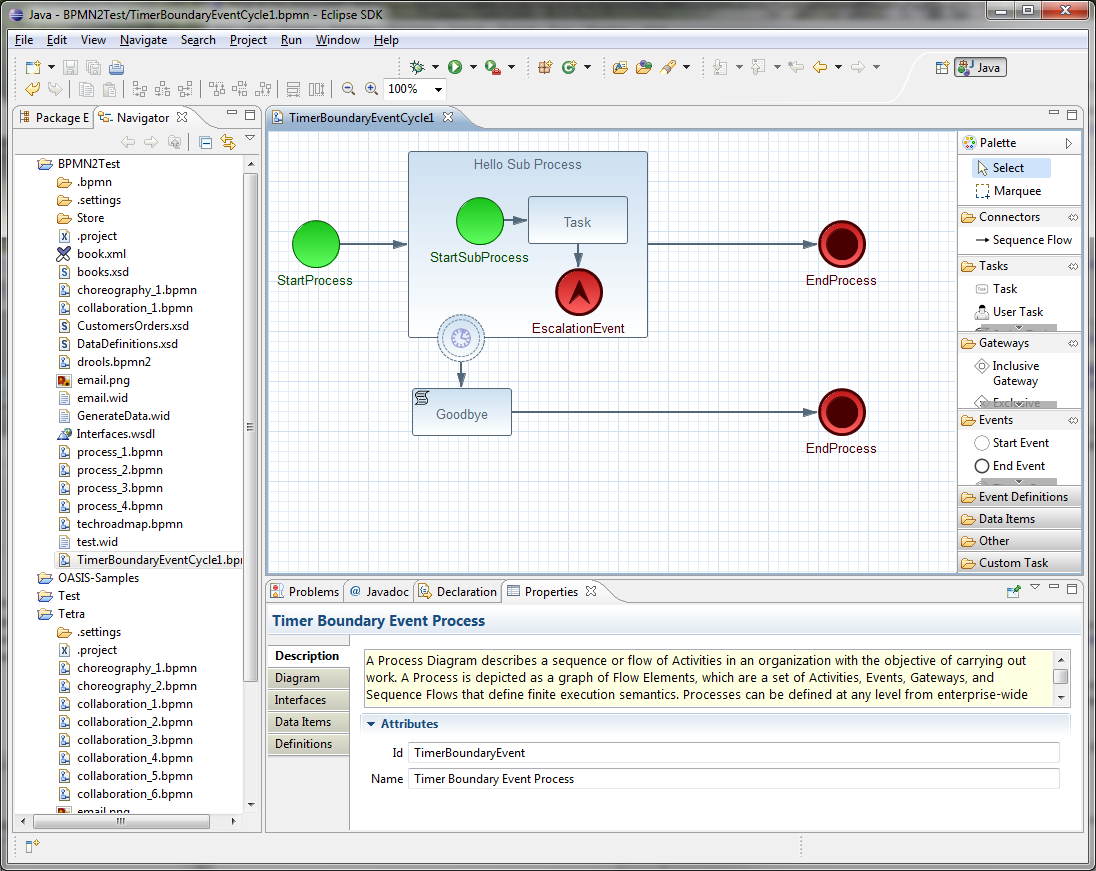
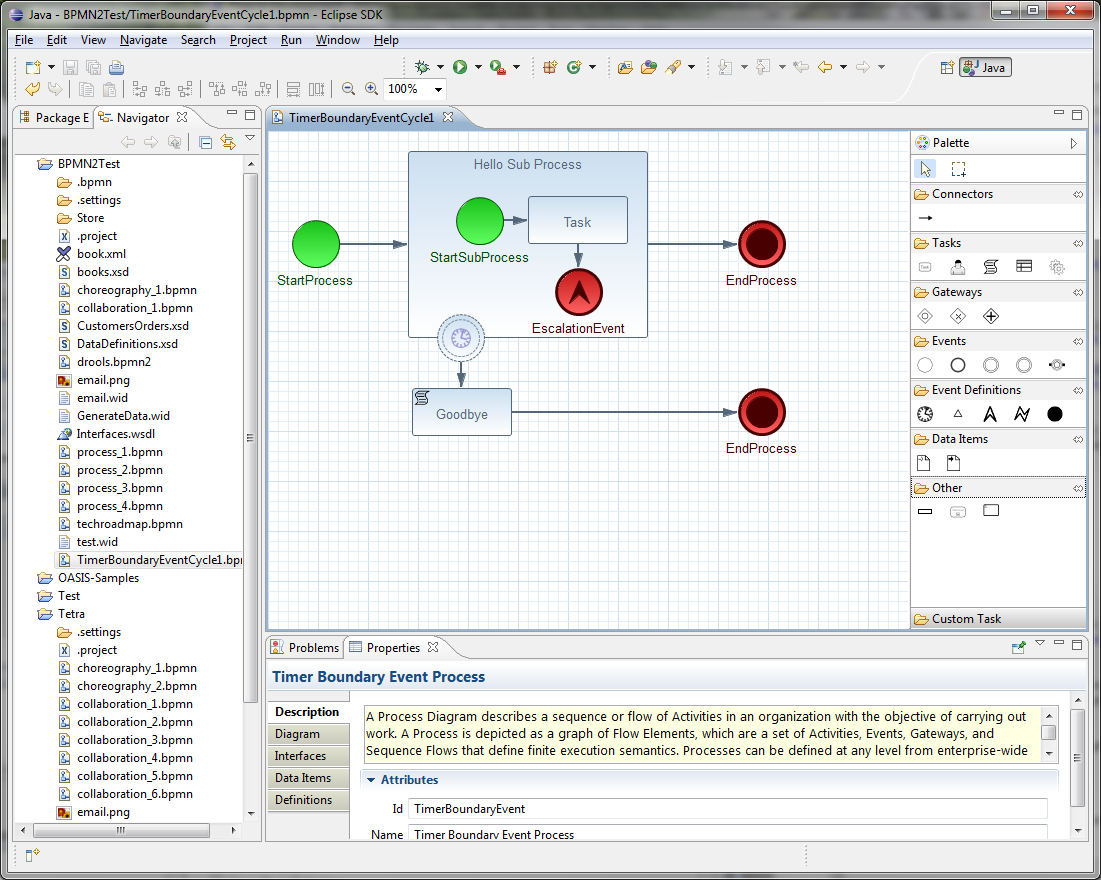
Integration
Integrating jBPM with other technologies, frameworks, etc.
20. Integration
20.1. Maven
Apache Maven is used by jBPM for two main purposes:
-
as deployment units that gets installed into runtime environment for execution
-
as dependency management tool for building systems based on jBPM - embedding jBPM into application
20.1.1. Maven artifacts as deployment units
Since version 6, jBPM provides simplified and complete deployment mechanism that is based entirely on Apache Maven artifacts. These artifacts also known as kjars are simple JAR files that include a descriptor for KIE system to produce KieBase and KieSession. Descriptor of the kjar is represented as XML file named kmodule.xml and it can be:
-
empty to apply all defaults
-
custom configuration of KieBase and KieSession
<kmodule xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.drools.org/xsd/kmodule">
</kmodule>Empty kmodule.xml that provides all defaults for the kjar:
-
single default KieBase that
-
contains all assets from all packages
-
event processing mode set to - cloud
-
equality behaviour set to - identity
-
declarative agenda is disabled
-
scope set to - ApplicationScope - valid for CDI integrations only
-
-
single default stateless KieSession that
-
is bound to above (single, default) KieBase
-
clock type is set to - real time
-
scope set to - ApplicationScope - valid for CDI integrations only
-
-
single default stateful KieSession that
-
is bound to above (single, default) KieBase
-
clock type is set to - real time
-
scope set to - ApplicationScope - valid for CDI integrations only
-
All these and more can be configured manually via kmodule.xml when defaults are not enough. The complete set of elements can be found in xsd schema of kmodule.xml.
<kmodule xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="https://www.drools.org/xsd/kmodule">
<kbase name="defaultKieBase" default="true" eventProcessingMode="cloud" equalsBehavior="identity" declarativeAgenda="disabled" scope="javax.enterprise.context.ApplicationScoped" packages="*">
<ksession name="defaultKieSession" type="stateful" default="true" clockType="realtime" scope="javax.enterprise.context.ApplicationScoped">
<workItemHandlers>
<workItemHandler name="CustomTask" type="FQCN_OF_HANDLER" />
</workItemHandlers>
<listeners>
<listener type="FQCN_OF_EVENT_LISTENER" />
</listeners>
</ksession>
<ksession name="defaultStatelessKieSession" type="stateless" default="true" clockType="realtime" scope="javax.enterprise.context.ApplicationScoped"/>
</kbase>
</kmodule>As illustrated in the listing above the kmodule.xml provides flexible way of instructing the runtime engine on what should be configured and how. The example above does not present all available options, but these are the most common when working with processes.
|
Important to note is that when using RuntimeManager, KieSession instances are created by the RuntimeManager instead of by KieContainer but kmodule.xml (or model in general) is aways used as a base of the construction process. KieBase although is always taken from KieContainer. |
Kjars are represented same way as any other Maven artifact - by Group Artifact Version which is then represented as ReleaseId in KIE API. This the the only thing required to deploy kjar into runtime environment such as KIE Workbeanch.
20.1.2. Use Maven for dependency management
When building systems that embed jBPM as workflow engine the simplest way is to configure all dependencies required by jBPM via Apache Maven. jBPM provides set of BOMs (Bill Of Material) to simplify what artifacts needs to be declared. Common way to start with integration of custom application and jBPM is to define dependency management:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<version.org.drools>6.0.0.Final</version.org.drools>
<version.org.jbpm>6.0.0.Final</version.org.jbpm>
<hibernate.version>4.2.0.Final</hibernate.version>
<hibernate.core.version>4.2.0.Final</hibernate.core.version>
<slf4j.version>1.6.4</slf4j.version>
<jboss.javaee.version>1.0.0.Final</jboss.javaee.version>
<logback.version>1.0.9</logback.version>
<h2.version>1.3.161</h2.version>
<btm.version>2.1.4</btm.version>
<junit.version>4.8.1</junit.version>
</properties>
<dependencyManagement>
<dependencies>
<!-- define drools BOM -->
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-bom</artifactId>
<type>pom</type>
<version>${version.org.drools}</version>
<scope>import</scope>
</dependency>
<!-- define drools BOM -->
<dependency>
<groupId>org.jbpm</groupId>
<artifactId>jbpm-bom</artifactId>
<type>pom</type>
<version>${version.org.jbpm}</version>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Above should be declared in top level pom.xml so all modules that need to use KIE (drools and jBPM) API can access it.
Next, module(s) that would operate on KIE API should declare following dependencies:
<dependency>
<groupId>org.jbpm</groupId>
<artifactId>jbpm-flow</artifactId>
</dependency>
<dependency>
<groupId>org.jbpm</groupId>
<artifactId>jbpm-flow-builder</artifactId>
</dependency>
<dependency>
<groupId>org.jbpm</groupId>
<artifactId>jbpm-bpmn2</artifactId>
</dependency>
<dependency>
<groupId>org.jbpm</groupId>
<artifactId>jbpm-persistence-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.jbpm</groupId>
<artifactId>jbpm-human-task-core</artifactId>
</dependency>
<dependency>
<groupId>org.jbpm</groupId>
<artifactId>jbpm-runtime-manager</artifactId>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>Above are the main runtime dependencies, regardless of where the application is deployed (application server, servlet container, standalone app). A good practice is to test the workflow components to ensure they work properly before actual deployment and thus following test dependencies should be defined:
<!-- test dependencies -->
<dependency>
<groupId>org.jbpm</groupId>
<artifactId>jbpm-shared-services</artifactId>
<classifier>btm</classifier>
<scope>test</scope>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${hibernate.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>${hibernate.core.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>${h2.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.codehaus.btm</groupId>
<artifactId>btm</artifactId>
<version>${btm.version}</version>
<scope>test</scope>
</dependency>Last but not least, define the JBoss Maven repository for artifacts resolution:
<repositories>
<repository>
<id>jboss-public-repository-group</id>
<name>JBoss Public Repository Group</name>
<url>http://repository.jboss.org/nexus/content/groups/public/</url>
<releases>
<updatePolicy>never</updatePolicy>
</releases>
<snapshots>
<updatePolicy>daily</updatePolicy>
</snapshots>
</repository>
</repositories>That should allow to configure jBPM in your application and provide access to KIE API to operate on processes, rules, events.
20.2. CDI
20.2.1. Overview
jBPM 6 comes with out of the box integration with CDI (Contexts and Dependency Injection). Although most of the API can be used in CDI world there are some dedicated modules that are designed especially for CDI containers. The most important one is jbpm-services-cdi that provides cdi wrappers on top of jbpm services, these shall be used in most of the cases were CDI is available for jBPM integration. It provides following set of services:
-
DeploymentService
-
ProcessService
-
UserTaskService
-
RuntimeDataService
-
DefinitionService
These services are first class citizens for CDI world so they are available for injection in any other CDI bean.
20.2.1.1. DeploymentService
Service responsible for deploying DeploymentUnits into runtime environment. By deploying given deployment unit becomes ready for execution and has RuntimeManager created for it.DeploymentService can next be used to retrieve:
-
RuntimeManager instance for given deployment id
-
DeployedUnit that represents complete deployment process for given deployment id
-
list of all deployed units known to the deployment service
Deployment service stores the deployed units by default in memory and thus in case of a need to restore all previously deployed units, component that uses deployment service needs to store that information itself. Common places for such a store are database, file system, repository of some sort, etc. Deployment service will fire CDI events on deployment and undeployment to allow application components to react real time to these events to be able to store deployments or remove them from the store when they are undeployed.
-
DeploymentEvent with qualifier @Deploy will be fired on deployment
-
DeploymentEvent with qualifier @Undeploy will be fired on undeployment
use CDI observer mechanism to get notification on above events. First to save deployments in the store of your choice:
public void saveDeployment(@Observes @Deploy DeploymentEvent event) {
// store deployed unit info for further needs
DeployedUnit deployedUnit = event.getDeployedUnit();
}next to remove it when it was undeployed
public void removeDeployment(@Observes @Undeploy DeploymentEvent event) {
// remove deployment with id event.getDeploymentId()
}|
Deployment service comes with deployment synchronization mechanism that allows to persist deployed units into data base (since version 6.2) that is by default enabled. See jbpm services section for more details. |
Due to the fact that there might be several implementation of DeploymentService use of qualifiers is needed to instruct CDI container which one shall be injected. jBPM comes with two out of the box:
-
@Kjar - KmoduleDeploymentService that is tailored to work with KmoduleDeploymentUnits that are small descriptor on top of a kjar - recommended to use in most of the cases
-
@Vfs - VFSDeploymentDService that allows to deploy assets directly from VFS (Virtual File System) that is provided by UberFire framework. Due to that fact VFSDeploymentService and VFSDeploymentUnit are not bundled with jbpm core modules but with jbpm-console-ng modules.
The general practice is that every implementation of DeploymentService should come with dedicated implementation of DeploymentUnit as these two provided out of the box.
20.2.1.2. FormProviderService
FormProviderService provides access to form representations usually displayed on UI for both process forms and user task forms. It is built on concept of isolated FormProviders that can provide different capabilities and be backed by different technologies. FormProvider interface describes contract for the implementations
public interface FormProvider {
int getPriority();
String render(String name, ProcessDesc process, Map<String, Object> renderContext);
String render(String name, Task task, ProcessDesc process, Map<String, Object> renderContext);
}Implementations of FormProvider interface should always define priority as this is the main driver for the FormProviderService to ask for the content of the form of a given provider. FormProviderService will collect all available providers and iterate over them asking for the form content (rendered) in their priority order. The lower the number the higher priority it gets during evaluation, e.g. provider with priority 5 will be evaluated before provider with priority 10. FormProviderService will iterate over available providers as long as one delivers the content. In the worse case scenario, simple text based forms will be returned.
jBPM comes with following FormProviders out of the box:
-
Fremarker based implementation to support jbpm version 5 process and task forms - priority 3
-
Default forms provider, considered last resort if none of the other providers deliver content this one will always provide simplest possible forms - lowest priority (1000)
-
when form modeler is used there is additional FormProvider available to deliver forms modeled in that tool - priority 2
20.2.1.3. RuntimeDataService
RuntimeDataService provides access to actual data that is availabe on runtime such as
-
available processes to be executed - with various filters
-
active process instances - with various filters
-
process instance history
-
process instance variables
-
active and completed nodes of process instance
Default implementation of RuntimeDataService is observing deployment events and index all deployed processes to expose them to the calling components. So whatever gets deployed RuntimeDataService will be aware of that.
20.2.1.4. DefinitionService
Service that provides access to process details stored as part of BPMN2 XML.
|
Before using any method that provides information, buildProcessDefinition must be invoked to populate repository with process information taken from BPMN2 content. |
BPMN2DataService provides access to following data:
-
overall description of process for given process definition
-
collection of all user tasks found in the process definition
-
information about defined inputs for user task node
-
information about defined outputs for user task node
-
ids of reusable processes (call activity) defined within given process definition
-
information about process variables defined within given process definition
-
information about all organizational entities (users and groups) included in the process definition. Depending on the actual process definition the returned values for users and groups can contain
-
actual user or group name
-
process variable that will be used to get actual user or group name on runtime e.g. #{manager}
-
20.2.1.5. Configuring CDI integration
To make use of jbpm-services-cdi in your system you’ll need to provide some beans for the out of the box services to satisfy all dependencies they have. There are several beans that depends on actual scenario
-
entity manager and entity manager factory
-
user group callback for human tasks
-
identity provider to pass authenticated user information to the services
When running in JEE environment like an JBoss Application Server following producer bean should satisfy all requirements of the jbpm-services-cdi
public class EnvironmentProducer {
@PersistenceUnit(unitName = "org.jbpm.domain")
private EntityManagerFactory emf;
@Inject
@Selectable
private UserGroupInfoProducer userGroupInfoProducer;
@Inject
@Kjar
private DeploymentService deploymentService;
@Produces
public EntityManagerFactory getEntityManagerFactory() {
return this.emf;
}
@Produces
public org.kie.api.task.UserGroupCallback produceSelectedUserGroupCalback() {
return userGroupInfoProducer.produceCallback();
}
@Produces
public UserInfo produceUserInfo() {
return userGroupInfoProducer.produceUserInfo();
}
@Produces
@Named("Logs")
public TaskLifeCycleEventListener produceTaskAuditListener() {
return new JPATaskLifeCycleEventListener(true);
}
@Produces
public DeploymentService getDeploymentService() {
return this.deploymentService;
}
@Produces
public IdentityProvider produceIdentityProvider {
return new IdentityProvider() {
// implement IdentityProvider
};
}
}Then beans.xml for the application should enable proper alternative for user group callback (that will be taken based on @Selectable qualifier)
<beans xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee https://docs.jboss.org/cdi/beans_1_0.xsd">
<alternatives>
<class>org.jbpm.kie.services.cdi.producer.JAASUserGroupInfoProducer</class>
</alternatives>
</beans>|
org.jbpm.kie.services.cdi.producer.JAASUserGroupInfoProducer is just an example here which usually is the good fit for JBoss Application Server to reuse security settings on application server regardless of what it actually is (LDAP, DB, etc). Check Human Task section for more alternatives for UserGroupCallback. |
Optionally there can be several other producers provided to deliver:
-
WorkItemHandlers
-
Process, Agenda, WorkingMemory event listeners
These components can be provided by implementing following interfaces
/**
* Allows to provide custom implementations to deliver WorkItem name and WorkItemHandler instance pairs
* for the runtime.
* <br/>
* It will be invoked by RegisterableItemsFactory implementation (especially InjectableRegisterableItemsFactory
* in CDI world) for every KieSession. Recommendation is to always produce new instances to avoid unexpected
* results.
*
*/
public interface WorkItemHandlerProducer {
/**
* Returns map of (key = work item name, value work item handler instance) of work items
* to be registered on KieSession
* <br/>
* Parameters that might be given are as follows:
* <ul>
* <li>ksession</li>
* <li>taskService</li>
* <li>runtimeManager</li>
* </ul>
*
* @param identifier - identifier of the owner - usually RuntimeManager that allows the producer to filter out
* and provide valid instances for given owner
* @param params - owner might provide some parameters, usually KieSession, TaskService, RuntimeManager instances
* @return map of work item handler instances (recommendation is to always return new instances when this method is invoked)
*/
Map<String, WorkItemHandler> getWorkItemHandlers(String identifier, Map<String, Object> params);
}and
/**
* Allows do define custom producers for know EventListeners. Intention of this is that there might be several
* implementations that might provide different listener instance based on the context they are executed in.
* <br/>
* It will be invoked by RegisterableItemsFactory implementation (especially InjectableRegisterableItemsFactory
* in CDI world) for every KieSession. Recommendation is to always produce new instances to avoid unexpected
* results.
*
* @param <T> type of the event listener - ProcessEventListener, AgendaEventListener, WorkingMemoryEventListener
*/
public interface EventListenerProducer<T> {
/**
* Returns list of instances for given (T) type of listeners
* <br/>
* Parameters that might be given are as follows:
* <ul>
* <li>ksession</li>
* <li>taskService</li>
* <li>runtimeManager</li>
* </ul>
* @param identifier - identifier of the owner - usually RuntimeManager that allows the producer to filter out
* and provide valid instances for given owner
* @param params - owner might provide some parameters, usually KieSession, TaskService, RuntimeManager instances
* @return list of listener instances (recommendation is to always return new instances when this method is invoked)
*/
List<T> getEventListeners(String identifier, Map<String, Object> params);
}Beans implementing these two interfaces will be collected on runtime and consulted when building KieSession by RuntimeManager. See RuntimeManager section for more details on this.
A complete runnable example of application built with CDI can be found here.
20.2.2. RuntimeManager as CDI bean
|
Even though RuntimeManager can be directly injected, it’s recommended to utilize jbpm services when frameworks like CDI, ejb or Spring is used. jBPM services bring in significant amount of features that encapsulate best practices when using RuntimeManager. |
RuntimeManager itself can be injected as CDI bean into any other CDI bean within the application. It has then requirement to get RungimeEnvironment properly produces to allow RuntimeManager to be correctly initialized. RuntimeManager comes with three predefined strategies and each of them gets CDI qualifier so it can be referenced:
-
@Singleton
-
@PerRequest
-
@PerProcessInstance
Producer that was defined in Configuration section should be now enhanced with producer methods to provide RuntimeEnvironment
public class EnvironmentProducer {
//add same producers as for services
@Produces
@Singleton
@PerRequest
@PerProcessInstance
public RuntimeEnvironment produceEnvironment(EntityManagerFactory emf) {
RuntimeEnvironment environment = RuntimeEnvironmentBuilder.Factory.get()
.newDefaultBuilder()
.entityManagerFactory(emf)
.userGroupCallback(getUserGroupCallback())
.registerableItemsFactory(InjectableRegisterableItemsFactory.getFactory(beanManager, null))
.addAsset(ResourceFactory.newClassPathResource("BPMN2-ScriptTask.bpmn2"), ResourceType.BPMN2)
.addAsset(ResourceFactory.newClassPathResource("BPMN2-UserTask.bpmn2"), ResourceType.BPMN2)
.get();
return environment;
}
}In this example single producer method is capable of providing RuntimeEnvironment for all strategies of RuntimeManager by specifying all qualifiers on the method level.
Once complete producer is available, RuntimeManager can be injected into application’s CDi bean
public class ProcessEngine {
@Inject
@Singleton
private RuntimeManager singletonManager;
public void startProcess() {
RuntimeEngine runtime = singletonManager.getRuntimeEngine(EmptyContext.get());
KieSession ksession = runtime.getKieSession();
ProcessInstance processInstance = ksession.startProcess("UserTask");
singletonManager.disposeRuntimeEngine(runtime);
}
}That’s all what needs to be configured to make use of CDI power with jBPM.
|
An obvious limitation of injecting directly RuntimeManager via CDI is that there might be only one RuntimeManager in the application. That in some case can be desired and that’s why there is such option. In general recommended approach is to make use of DeploymentService whenever there is a need to have many RuntimeManagers active within application. |
As an alternative to DeploymentService, RuntimeManagerFactory can be injected and then RuntimeManager instance can be created manually by the application. In such case EnvironmentProducer stays same as for DeploymentService and following is an example of simple ProcessEngine bean
public class ProcessEngine {
@Inject
private RuntimeManagerFactory managerFactory;
@Inject
private EntityManagerFactory emf;
@Inject
private BeanManager beanManager;
public void startProcess() {
RuntimeEnvironment environment = RuntimeEnvironmentBuilder.Factory.get()
.newDefaultBuilder()
.entityManagerFactory(emf)
.addAsset(ResourceFactory.newClassPathResource("BPMN2-ScriptTask.bpmn2"), ResourceType.BPMN2)
.addAsset(ResourceFactory.newClassPathResource("BPMN2-UserTask.bpmn2"), ResourceType.BPMN2)
.registerableItemsFactory(InjectableRegisterableItemsFactory.getFactory(beanManager, null))
.get();
RuntimeManager manager = managerFactory.newSingletonRuntimeManager(environment);
RuntimeEngine runtime = manager.getRuntimeEngine(EmptyContext.get());
KieSession ksession = runtime.getKieSession();
ProcessInstance processInstance = ksession.startProcess("UserTask");
manager.disposeRuntimeEngine(runtime);
manager.close();
}
}20.3. Spring
jBPM can be configured in many ways with Spring though the two most frequenlty used approaches are:
-
direct use of runtime manager API
-
use of jbpm services
While both approaches are tested and valid, which one to chose is a matter of the system functionaltiy. Before selecting one of the approache the most important question to ask is:
Will my system run multiple runtime managers at the same time?
If the asnwer to this question is no, then go ahead with direct Runtime Manager API as it will be the simplest way to use jBPM within your application. But when answer is yes, then go ahead with jbpm services as they encapsulate runtime manager API with best practices by providing dynamic runtime environment for your BPM logic - also known as execution server.
20.3.1. Direct use of Runtime Manager API
This is the standard (and the simplest) way to get up and running with jBPM in your application. You only configure it once and run as part of the application. With the RuntimeManager usage, both process engine and task service will be managed in complete synchronization, meaning there is no need from end user to deal with "plumbing" code to make these two work together.
To provide spring based way of setting up jBPM, few factory beans where added:
-
org.kie.spring.factorybeans.RuntimeEnvironmentFactoryBean
-
org.kie.spring.factorybeans.RuntimeManagerFactoryBean
-
org.kie.spring.factorybeans.TaskServiceFactoryBean
FactoryBeans provide standard way to configure Spring application spring xml though there are not custom spring xml tags equivalent for them.
20.3.1.1. RuntimeEnvironmentFactoryBean
Factory responsible for producing instances of RuntimeEnvironment that are consumed by RuntimeManager upon creation. It allows to create following types of RuntimeEnvironment (that mainly means what is configured by default):
-
DEFAULT - default (most common) configuration for RuntimeManager
-
EMPTY - completely empty environment to be manually populated
-
DEFAULT_IN_MEMORY - same as DEFAULT but without persistence of the runtime engine
-
DEFAULT_KJAR - same as DEFAULT but knowledge asset are taken from KJAR identified by releaseid or GAV
-
DEFAULT_KJAR_CL - build directly from classpath that consists kmodule.xml descriptor
Mandatory properties depends on the selected type but knowledge information must be given for all types. That means that one of the following must be provided:
-
knowledgeBase
-
assets
-
releaseId
-
groupId, artifactId, version
Next for DEFAULT, DEFAULT_KJAR, DEFAULT_KJAR_CL persistence needs to be configured:
-
entity manager factory
-
transaction manager
Transaction Manager must be Spring transaction manager as based on its presence entire persistence and transaction support is configured. Optionally EntityManager can be provided to be used instead of always creating new one from EntityManagerFactory - e.g. when using shared entity manager from Spring. All other properties are optional and are meant to override the default given by type of the environment selected.
20.3.1.2. RuntimeManagerFactoryBean
FactoryBean responsible for creation of RuntimeManager instances of given type based on provided runtimeEnvironment. Supported types:
-
SINGLETON
-
PER_REQUEST
-
PER_PROCESS_INSTANCE
where default is SINGLETON when no type is specified. Every runtime manager must be uniquely identified thus identifier is a mandatory property. All instances created by this factory are cached to be able to properly dispose them using destroy method (close()).
20.3.1.3. TaskServiceFactoryBean
Creates instance of TaskService based on given properties. Following are mandatory properties that must be provided:
-
entity manager factory
-
transaction manager
Transaction Manager must be Spring transaction manager as based on its presence entire persistence and transaction support is configured. Optionally EntityManager can be provided to be used instead of always creating new one from EntityManagerFactory - e.g. when using shared entity manager from Spring. In addition to above there are optional properties that can be set on task service instance:
-
userGroupCallback - implementation of UserGroupCallback to be used, defaults to MVELUserGroupCallbackImpl
-
userInfo - implementation of UserInfo to be used, defaults to DefaultUserInfo
-
listener - list of TaskLifeCycleEventListener that will be notified upon various operations on tasks
This factory creates single instance of task service only as it’s intended to be shared across all other beans in the system.
20.3.1.4. Sample configuration of RuntimeManager with Spring
Following section aims at giving complete spring configuration for single runtime manager wihtin spring application context.
-
Setup entity manager factory and transaction manager:
<bean id="jbpmEMF" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"> <property name="persistenceUnitName" value="org.jbpm.persistence.spring.jta"/> </bean> <bean id="btmConfig" factory-method="getConfiguration" class="bitronix.tm.TransactionManagerServices"></bean> <bean id="BitronixTransactionManager" factory-method="getTransactionManager" class="bitronix.tm.TransactionManagerServices" depends-on="btmConfig" destroy-method="shutdown" /> <bean id="jbpmTxManager" class="org.springframework.transaction.jta.JtaTransactionManager"> <property name="transactionManager" ref="BitronixTransactionManager" /> <property name="userTransaction" ref="BitronixTransactionManager" /> </bean>with this we have ready persistence configuration that gives us:
-
JTA transaction manager (backed by bitronix - for unit tests or servlet containers)
-
entity manager factory for persistence unit named org.jbpm.persistence.spring.jta
-
-
Configure resource that we are going to use - business process
<bean id="process" factory-method="newClassPathResource" class="org.kie.internal.io.ResourceFactory"> <constructor-arg> <value>jbpm/processes/sample.bpmn</value> </constructor-arg> </bean>this configures single process that will be available for execution - sample.bpmn that will be taken from class path. This is the simplest way to get your processes included when trying out jbpm.
-
Configure RuntimeEnvironment with our infrastructure (entity manager, transaction manager, resources)
<bean id="runtimeEnvironment" class="org.kie.spring.factorybeans.RuntimeEnvironmentFactoryBean"> <property name="type" value="DEFAULT"/> <property name="entityManagerFactory" ref="jbpmEMF"/> <property name="transactionManager" ref="jbpmTxManager"/> <property name="assets"> <map> <entry key-ref="process"><util:constant static-field="org.kie.api.io.ResourceType.BPMN2"/></entry> </map> </property> </bean>that gives us default runtime environment ready to be used to create instance of a RuntimeManager.
-
Create RuntimeManager with the environment we just setup
<bean id="runtimeManager" class="org.kie.spring.factorybeans.RuntimeManagerFactoryBean" destroy-method="close"> <property name="identifier" value="spring-rm"/> <property name="runtimeEnvironment" ref="runtimeEnvironment"/> </bean>with just four steps you are ready to execute your processes with Spring and jBPM 6, utilizing EntityManagerFactory and JTA transaction manager.
Complete Spring configuration files for different strategies can be found here.
This is just one configuration setup that jBPM 6 supports - JTA transaction manager and EntityManagerFactory, others are:
-
JTA and SharedEntityManager
-
Local Persistence Unit and EntityManagerFactory
-
Local Persistence Unit and SharedEntityManager
If your application is configured with Local Persistence Unit and is also utilizing AuditService for querying jBPM history related data, then it’s necessary to add org.kie.api.runtime.EnvironmentName.USE_LOCAL_TRANSACTIONS enrivonment entry to the RuntimeEnvironment, for example:
<bean id="runtimeEnvironment" class="org.kie.spring.factorybeans.RuntimeEnvironmentFactoryBean">
...
<property name="environmentEntries" ref="env" />
</bean>
...
<util:map id="env" key-type="java.lang.String" value-type="java.lang.Object">
<entry>
<key>
<util:constant
static-field="org.kie.api.runtime.EnvironmentName.USE_LOCAL_TRANSACTIONS" />
</key>
<value>true</value>
</entry>
</util:map>For more details about difference configuration options look at the example configuration files and test cases.
20.3.2. jBPM services with Spring
In case more dynamic nature is required in your Spring application then more appropriate could be to build up so called execution server based on jbpm services. jBPM services has been designed in a way to make them framework agnostic and in case framework specific addons are required they will be brought by additional module. So the code logic of the services is embedded in jbpm-kie-services. These are pure java services and by that can be easily consumed by Spring application.
Dynamic nature means that processes (And other assets like data model, rules, forms, etc) can be added and removed without restarting application.
There is almost no code involved to completely configure jBPM services in spring besides single interface that needs to be implemented - IdentityProvider that depends on your security configuration. One built with Spring Security can be like following though it might not cover all features one can have for Spring application.
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import org.kie.internal.identity.IdentityProvider;
import org.springframework.security.core.Authentication;
import org.springframework.security.core.GrantedAuthority;
import org.springframework.security.core.context.SecurityContextHolder;
public class SpringSecurityIdentityProvider implements IdentityProvider {
public String getName() {
Authentication auth = SecurityContextHolder.getContext().getAuthentication();
if (auth != null && auth.isAuthenticated()) {
return auth.getName();
}
return "system";
}
public List<String> getRoles() {
Authentication auth = SecurityContextHolder.getContext().getAuthentication();
if (auth != null && auth.isAuthenticated()) {
List<String> roles = new ArrayList<String>();
for (GrantedAuthority ga : auth.getAuthorities()) {
roles.add(ga.getAuthority());
}
return roles;
}
return Collections.emptyList();
}
public boolean hasRole(String role) {
return false;
}
}20.3.2.1. Configure jBPM services in Spring application
As usual, first thing to start with is transaction configuration:
<context:annotation-config />
<tx:annotation-driven />
<tx:jta-transaction-manager />
<bean id="transactionManager" class="org.springframework.transaction.jta.JtaTransactionManager" />Next configuration of JPA and persistence follows:
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean" depends-on="transactionManager">
<property name="persistenceXmlLocation" value="classpath:/META-INF/jbpm-persistence.xml" />
</bean>Configure security and user/group information providers
<util:properties id="roleProperties" location="classpath:/roles.properties" />
<bean id="userGroupCallback" class="org.jbpm.services.task.identity.JBossUserGroupCallbackImpl">
<constructor-arg name="userGroups" ref="roleProperties"></constructor-arg>
</bean>
<bean id="identityProvider" class="org.jbpm.spring.SpringSecurityIdentityProvider"/>Configure runtime manager factory that is Spring context aware and by that can interact with spring container in correct way and supporting services (transactional command service and task service)
<bean id="runtimeManagerFactory" class="org.kie.spring.manager.SpringRuntimeManagerFactoryImpl">
<property name="transactionManager" ref="transactionManager"/>
<property name="userGroupCallback" ref="userGroupCallback"/>
</bean>
<bean id="transactionCmdService" class="org.jbpm.shared.services.impl.TransactionalCommandService">
<constructor-arg name="emf" ref="entityManagerFactory"></constructor-arg>
</bean>
<bean id="taskService" class="org.kie.spring.factorybeans.TaskServiceFactoryBean" destroy-method="close">
<property name="entityManagerFactory" ref="entityManagerFactory"/>
<property name="transactionManager" ref="transactionManager"/>
<property name="userGroupCallback" ref="userGroupCallback"/>
<property name="listeners">
<list>
<bean class="org.jbpm.services.task.audit.JPATaskLifeCycleEventListener">
<constructor-arg value="true"/>
</bean>
</list>
</property>
</bean>Configure jBPM services as spring beans
<!-- definition service -->
<bean id="definitionService" class="org.jbpm.kie.services.impl.bpmn2.BPMN2DataServiceImpl"/>
<!-- runtime data service -->
<bean id="runtimeDataService" class="org.jbpm.kie.services.impl.RuntimeDataServiceImpl">
<property name="commandService" ref="transactionCmdService"/>
<property name="identityProvider" ref="identityProvider"/>
<property name="taskService" ref="taskService"/>
</bean>
<!-- -- deployment service -->
<bean id="deploymentService" class="org.jbpm.kie.services.impl.KModuleDeploymentService" depends-on="entityManagerFactory" init-method="onInit">
<property name="bpmn2Service" ref="definitionService"/>
<property name="emf" ref="entityManagerFactory"/>
<property name="managerFactory" ref="runtimeManagerFactory"/>
<property name="identityProvider" ref="identityProvider"/>
<property name="runtimeDataService" ref="runtimeDataService"/>
</bean>
<!-- process service -->
<bean id="processService" class="org.jbpm.kie.services.impl.ProcessServiceImpl" depends-on="deploymentService">
<property name="dataService" ref="runtimeDataService"/>
<property name="deploymentService" ref="deploymentService"/>
</bean>
<!-- user task service -->
<bean id="userTaskService" class="org.jbpm.kie.services.impl.UserTaskServiceImpl" depends-on="deploymentService">
<property name="dataService" ref="runtimeDataService"/>
<property name="deploymentService" ref="deploymentService"/>
</bean>
<!-- register runtime data service as listener on deployment service so it can receive notification about deployed and undeployed units -->
<bean id="data" class="org.springframework.beans.factory.config.MethodInvokingFactoryBean" depends-on="deploymentService">
<property name="targetObject" ref="deploymentService"></property>
<property name="targetMethod"><value>addListener</value></property>
<property name="arguments">
<list>
<ref bean="runtimeDataService"/>
</list>
</property>
</bean>And this is all is needed to build fully featured execution server with Spring and jBPM services. A complete Spring web application with this setup can be found here.
20.4. Ejb
jBPM since version 6.2 provides out of the box integration layer with Enterprise Java Beans (EJB) for both local and remote interaction.
Ejb services are brought by following modules:
-
jbpm-services-ejb-api
API module that extends jbpm-services-api with EJB specific interfaces and objects
-
jbpm-services-ejb-impl
EJB extension to core services
-
jbpm-services-ejb-timer
jBPM Scheduler Service implementation backed by EJB Timer Service
-
jbpm-services-ejb-client
EJB remote client implementation for remote interaction, provides JBoss AS support out of the box
EJB layer is based on jbpm services and thus provides almost same capabilities as the core module though there are some imiliations when it comes to remote interfaces. Main difference is for the DeploymentService that has been limited for remote ejb service to following methods:
-
deploy
-
undeploy
-
activate
-
deactivate
-
isDeployed
Main rationale behind is to avoid returning runtime objects such as RuntimeManager over EJB remote as it won’t bring any value because it will be "disconnected" state.
All other services do provide exact same set of functionality as core module.
20.4.1. Ejb services implementation
Ejb services as an extension of core services provide EJB based execution semantic and based on various EJB specific features.
-
DeploymentServiceEJBImpl
is implemented as ejb singleton with container managed concurrency and lock type set to write
-
DefinitionServiceEJBImpl
is implemented as ejb singleton with container managed concurrency with overall lock type set to read, except buildProcessDefinition method that has lock type set to write
-
ProcessServiceEJBImpl
is implemented as stateless session bean
-
RuntimeDataServiceEJBImpl
is implemented as ejb singleton with mojority of methods with lock type read, except following that are with lock type write:
-
onDeploy
-
onUnDeploy
-
onActivte
-
onDeactivate
-
-
UserTaskServiceEJBImpl
is implemented as stateless session bean
Transactions
Transaction is managed by EJB container thus there is no need to setup any sort of transaction manager or user transaction within application code.
Identity provider
Identity provider by default is backed by EJBContext and will rely on caller principal information for both name and roles. When inspecting IdentityProvider interface there are two methods related to roles:
-
getRoles
this method returns empty list due to the fact EJBContext does not provide options to fetch all roles for given user
-
hasRole
this method will delegate to context’s isCallerInRole method
This means that ejb must be secured according to JEE security practices to authentiate and authorize users so valid information will be available. In case no authentication/authorization is configured for EJB services an anonymous user is always assumed.
In addition to that, EJB services acept CDI sytly injection for IdentityProvider in case another (non ejb) security model is used. Simply create valid CDI bean that implements org.kie.internal.identity.IdentityProvider and make it available for injection with application and such implementation will take precedence over EJBContext based identity provider.
Deployment synchronization
Deployment synchronization is enabled by default and will attempt to synchronize any deployments every 3 seconds. It is implemented as ejb singleton with container managed concurrency and lock type set to write. Under the covers it utilizes EJB TimerService to schedule the synchronization jobs.
EJB Scheduler Service
jBPM uses scheduler service to deal with time based activities such as timer events, deadlines, etc. When running in EJB environment and EJB Timer Service based scheduler will be used. It will be automatically registered for all instances of RuntimeManager. When it comes to cluster support application server specific configuration might be required.
UserGroupCallback and UserInfo selection
UserGroupCallback and UserInfo might differ for various applications and thus should be sort of pluggable. With EJB we could not make it directly available for injections as they could not be injected with common type so there is another mechanism that allows to select one of provided out of the box implementation or to give a custom one. This mechanism is based on ssytem properties:
-
org.jbpm.ht.callback
specify what implementation of user group callback will be selected
-
mvel - default mostly used for testing
-
ldap - ldap backed implementation - requires additional configuration via jbpm.usergroup.callback.properties file
-
db - data base backed implementation - requires additional configuration via jbpm.usergroup.callback.properties file
-
jaas - delegates to container to fetch information about user data
-
props - simple property based callback - requires additional file that will keep all information (users and groups)
-
custom - custom implementation that requires to have additional system property set (FQCN of the implementation) - org.jbpm.ht.custom.callback
-
-
org.jbpm.ht.userinfo
specify what implementation of UserInfo shall be used, one of:
-
ldap - backed by ldap - requires configuration via jbpm-user.info.properties file
-
db - backed by data base - requires configuration via jbpm-user.info.properties file
-
props - backed by simple property file
-
custom - custom implementation that requires to have additional system property set (FQCN of the implementation) - org.jbpm.ht.custom.userinfo
-
System properties can either be added to the startup configuration of the server (jvm) which is recommended or be set programmatically before services will be used - for example with custom @Startup bean that will configure it properly for selected callback and user info.
A example application that utilizes EJB services can be found here.
20.4.2. Local interface
Local EJB services are brought via dedicated local interfaces that extends core services:
-
org.jbpm.services.ejb.api.DefinitionServiceEJBLocal
-
org.jbpm.services.ejb.api.DeploymentServiceEJBLocal
-
org.jbpm.services.ejb.api.ProcessServiceEJBLocal
-
org.jbpm.services.ejb.api.RuntimeDataServiceEJBLocal
-
org.jbpm.services.ejb.api.UserTaskServiceEJBLocal
These interfaces should be used as injection points and shall be annotated with @EJB:
@EJB
private DefinitionServiceEJBLocal bpmn2Service;
@EJB
private DeploymentServiceEJBLocal deploymentService;
@EJB
private ProcessServiceEJBLocal processService;
@EJB
private RuntimeDataServiceEJBLocal runtimeDataService;Once injected operations can be invoked on them as with core modules, there are no restrictions to their usage.
20.4.3. Remote interface
Remote EJB services are defined as dedicated remote interfaces that extends core services:
-
org.jbpm.services.ejb.api.DefinitionServiceEJBRemote
-
org.jbpm.services.ejb.api.DeploymentServiceEJBRemote
-
org.jbpm.services.ejb.api.ProcessServiceEJBRemote
-
org.jbpm.services.ejb.api.RuntimeDataServiceEJBRemote
-
org.jbpm.services.ejb.api.UserTaskServiceEJBRemote
These can be used similar way as local interfaces except for handling custom types. Custom types can be defined:
-
globally
such types are available on application classpath - included in the enterprise application
-
locally to the deployment unit
such types are declared as project (kjar) dependency and are resolved on deployment time Globally available types do not require any special handling as they will be available for EJB container when remote requests are handled - marshalling of incoming data. Though local custom types won’t be visible by default to EJB container as they are not on application classpath. Thus special handling of such types is required.
EJB services provides easy yet rather powerful mechanism to resolve the issue - it comes with two additional types:
-
org.jbpm.services.ejb.remote.api.RemoteObject
Serializable wrapper class for single value parameters
-
org.jbpm.services.ejb.remote.api.RemoteMap
Dedicated java.util.Map implementation to simplify remote invocation of service methods that accept custom object input. This map is backed by an internal map that holds already serialized content to avoid additional serialization on sending time. That removes the burden of ensuring that container will know about all custom data model classes as part of global classpath.
This implementation does not support all methods that are usually not used when sending data. It shall be considered only as a wrapper only and not actual and complete implementation of a map.
These special objects will perform eager serialization to bytes using ObjectInputStream to remove the need of serialization from the EJB client/container. Though it might be worse in case of performance it does overcome much more complecated handling of class loaders on EJB container side to allow use of custom types defined in the project.
Here is an example code needed to work with local types and remote EJB:
// start a process with custom types via remote EJB
Map<String, Object> parameters = new RemoteMap();
Person person = new org.jbpm.test.Person("john", 25, true);
parameters.put("person", person);
Long processInstanceId = processService.startProcess(deploymentUnit.getIdentifier(), "custom-data-project.work-on-custom-data", parameters);
// fetch task data and complete task with custom types via remote EJB
Map<String, Object> data = userTaskService.getTaskInputContentByTaskId(taskId);
Person fromTaskPerson = data.get("_person");
fromTaskPerson.setName("John Doe");
RemoteMap outcome = new RemoteMap();
outcome.put("person_", fromTaskPerson);
userTaskService.complete(taskId, "john", outcome);Similar way RemoteObject can be used for example to send evnet to process instance:
// send event with custom type via remote EJB
Person person = new org.jbpm.test.Person("john", 25, true);
RemoteObject myObject = new RemoteObject(person);
processService.signalProcessInstance(processInstanceId, "MySignal", myObject);These illustrates how to wrap custom data when interacting with remote EJB services. Next section will introduce how to make a connection to a remote service vai client code.
20.4.3.1. Remote EJB client
Remote client support is provided by implemetation of ClientServiceFactory interface that is facede for application server specific code:
/**
* Generic service factory used for remote look ups that are usually container specific.
*
*/
public interface ClientServiceFactory {
/**
* Returns unique name of given factory implementation
* @return
*/
String getName();
/**
* Returns remote view of given service interface from selected application
* @param application application identifier on the container
* @param serviceInterface remote service interface to be found
* @return
* @throws NamingException
*/
<T> T getService(String application, Class<T> serviceInterface) throws NamingException;
}Implementations can be dynamically registered using ServiceLoader mechanism and by default there is only one available for JBoss AS/EAP/Wildfly. Each ClientServiceFactory must provide name which will be used to register it within the client registry so it can be then easily looked up.
Here is a code used to get hold of default JBoss based remote client:
// get hold of valid client service factory
ClientServiceFactory factory = ServiceFactoryProvider.getProvider("JBoss");
// application is the name known to application server aka module name
String application = "sample-war-ejb-app";
// get given service out of the factory
DeploymentServiceEJBRemote deploymentService = factory.getService(application, DeploymentServiceEJBRemote.class);With service available all know to its interface methods are ready to be used.
When working with JBoss AS and remote client you can add following maven dependency to bring in all EJB client libraries:
<dependency>
<groupId>org.jboss.as</groupId>
<artifactId>jboss-as-ejb-client-bom</artifactId>
<version>7.2.0.Final</version> <!-- use valid version for the server you run on -->
<optional>true</optional>
<type>pom</type>
</dependency>20.5. OSGi
All core jBPM JARs (and core dependencies) are OSGi-enabled. That means that they contain MANIFEST.MF files (in the META-INF directory) that describe their dependencies etc. These manifest files are automatically generated by the build. You can plug these JARs directly into an OSGi environment.
OSGi is a dynamic module system for declarative services. So what does that mean? Each JAR in OSGi is called a bundle and has its own Classloader. Each bundle specifies the packages it exports (makes publicly available) and which packages it imports (external dependencies). OSGi will use this information to wire the classloaders of different bundles together; the key distinction is you don’t specify what bundle you depend on, or have a single monolithic classpath, instead you specify your package import and version and OSGi attempts to satisfy this from available bundles.
It also supports side by side versioning, so you can have multiple versions of a bundle installed and it’ll wire up the correct one. Further to this Bundles can register services for other bundles to use. These services need initialisation, which can cause ordering problems - how do you make sure you don’t consume a service before its registered? OSGi has a number of features to help with service composition and ordering. The two main ones are the programmatic ServiceTracker and the XML based Declarative Services. There are also other projects that help with this; Spring DM, iPOJO, Gravity.
The following jBPM JARs are OSGi-enabled:
-
jbpm-flow
-
jbpm-flow-builder
-
jbpm-bpmn2
Advanced Topics
Some more advanced topics
21. Domain Specific Processes
21.1. Introduction
jBPM provides the ability to create and use domain-specific task nodes in your business processes. This simplifies development when you’re creating business processes that contain tasks dealing with other technical systems.
When using jBPM, we call these domain-specific task nodes "custom work items" or (custom) "service nodes". There are two separate aspects to creating and using custom work items:
-
Adding a node with a custom work item to a process definition using the Eclipse editor or jBPM designer.
-
Creating a custom work item handler that the jBPM engine will use when executing the custom work item in a running process.
With regards to a BPMN2 process, custom work items are certain types of <task> nodes.
In most cases, custom work items are <task> nodes in a BPMN2 process definition, although they can also be used with certain other task type nodes such as, among others, <serviceTask> or <sendTask> nodes.
|
When creating custom work items, it’s important to separate the data associated with the work item, from how the work item should be handled. In other words, separate the what from the how. That means that custom work items should be:
On the other hand, custom work item handlers, which are Java classes, should be:
Work item handlers should almost never contain any data. |
Users can thus easily define their own set of domain-specific service nodes and integrate them with the process language. For example, the next figure shows an example of a healthcare-related BPMN2 process. The process includes domain-specific service nodes for measuring blood pressure, prescribing medication, notifying care providers and following-up on the patient.
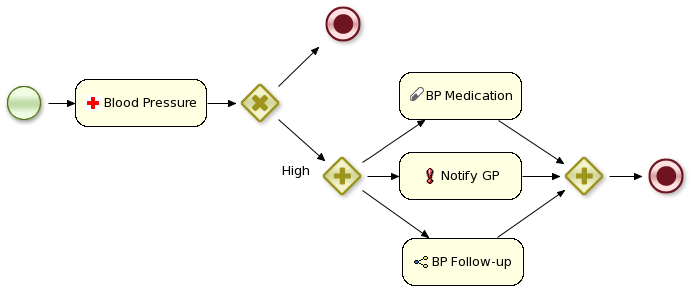
21.2. Overview
Before moving on to an example, this section explains what custom work items and custom work item handlers are.
21.2.1. Work Item Definitions
In short, we use the term custom work item when we’re describing a node in your process that represents a domain-specific task and as such, contains extra properties and is handled by a WorkItemHandler implementation.
Because it’s a domain-specific task, that means that a custom
work item is equivalent to a <task> or <task>-type node in BPMN2.
However, a WorkItem is also Java class instance that’s used when a WorkItemHandler instance is called to complete the task or work item.
Depending on the BPMN2 editor you’re using, you can create a custom work item definition in one of two ways:
-
If you’re using Designer, then this means creating a MVEL based definition and adding the definition in Designer itself. A description of this can be found in the [_sec.designer.workitems] section in the [_ch.designer] chapter. Once this is done, a new service node will appear on the BPMN 2.0 palette.
-
If you’re using the Eclipse BPMN 2.0 modeler plugin (which can be found here), then you’ll can modify the BPMN2
<task>or<task>-type element to work withWorkItemHandlerimplementations. See the [_sec.eclipse.task_nodes] section in the [_ch.eclipse_bpmn_plugin] chapter.
21.2.2. Work Item Handlers
A work item handler is a Java class used to execute (or abort) work items.
That also means that the class implements the org.kie.runtime.instance.WorkItemHandler interface.
While jBPM provides some custom WorkItemHandler instances (listed below), a Java developer with a minimal knowledge of jBPM can easily create a new work item handler class with its own custom business logic.
Among others, jBPM offers the following WorkItemHandler implementations:
-
In the jbpm-bpmn2 module,
org.jbpm.bpmn2.handlerpackage:-
ReceiveTaskHandler (for use with BPMN element
<receiveTask>) -
SendTaskHandler (for use with BPMN element
<sendTask>) -
ServiceTaskHandler (for use with BPMN element
<serviceTask>)
-
-
In the jbpm-workitems module, in various packages under the
org.jbpm.process.workitempackage:-
ArchiveWorkItemHandler There are a many more
WorkItemHandlerimplementations present in the jbpm-workitems module. If you’re looking for specific integration logic with Twitter, for example, we recommend you take a look at the classes made available there.
-
In general, a WorkItemHandler's .executeWorkItem(…) and .abortWorkItem(…) methods will do the following:
-
Extract information about the task being executed (or aborted) from the
WorkIteminstance -
Execute the necessary business logic. This might be mean interacting with a web service, database, or other technical component.
-
Inform the process engine that the work item has been completed (or aborted) by calling one of the following two methods on the
WorkItemManagerinstance passed to the method:
WorkItemManager.completeWorkItem(long workItemId, Map<String, Object> results)
WorkItemManager.abortWorkItem(long workItemId)In order to make sure that your custom work item handler is used for a particular process instance, it’s necessary to register the work item handler before starting the process.
This makes the engine aware of your WorkItemHandler so that the engine can use it for the proper node.
For example:
ksession.getWorkItemManager().registerWorkItemHandler("Notification",
new NotificationWorkItemHandler());The ksession variable above is a StatefulKnowledgeSession (and also a KieSession) instance.
The example code above comes from the example that we will go through in the next session.
Work item handler life cycle management
Work item handler is registered on kie session and then can be used whenever process engine encounters a node that should be handled by that handler. Depending on the implementation of the handler (e.g. some handler might keep state or depend on some resources such as data base connection) there might be a need to maintain life cycle of the handler. To ease the way of doing that jBPM comes with two additional interfaces that handler might implement:
-
org.kie.internal.runtime.Closeable - allows auto close of the handler whenever owner (work item handler manager) of it is closed or disposed. This is useful in case a handler can be quickly and frequently recreated so the engine will have it for the execution and when disposed it will dispose as well all handlers of Closeable type.
-
org.kie.internal.runtime.Cacheable - allows handlers to be cached and resused to avoid recreation of the objects. There might be several reasons of doing so - expensive bootstrap of the handler, dependency to external resources - socket connections, db connections, web service client. While this brings powerful feature to the work item handler management it does put additional requirement on the implementation - needs to deal with exceptions internally and recover from any failures. In case recovery cannot be performed it needs to remove itself from the cache.
Closeable interface is handled for all use cases, while Cacheable is available only when RuntimeManager is used. RuntimeManager provides caching capabilities via its CacheManager (available via InternalRuntimeManager in case self removal is required).
|
You can use different work item handlers for the same process depending on the system on which it runs: by registering different work item handlers on different systems, you can customize how a custom work item is processed on a particular system.
You can also substitute mock |
21.3. Example: Notifications
Let us start by showing you how to include a simple work item for sending notifications. A work item is defined by a unique name and includes additional parameters that describe the work in more detail. Work items can also return information after they have been executed, specified as results.
Our notification work item could be defined using a work definition with four parameters and no results. For example:
-
Name: "Notification"
-
Parameters:
-
From [String type]
-
To [String type]
-
Message [String type]
-
Priority [String type]
-
21.3.1. The Notification Work Item Definition
21.3.1.1. Creating the work item definition
In this example, let us create an MVEL work item definition that defines a "Notification" work item. Using MVEL is the default way to configure work items. This file is placed in the project classpath in a directory called META-INF. Note that, imports to the default jBPM data types (in the org.jbpm.process.core.datatype.impl.type package) are added by default and do not need to be explicitly defined. If you are using any custom defined data type, an import statement for it (using the java standard) is necessary to be added before any work item definitions begin.
The work item configuration file for this example, MyWorkDefinitions.wid, will look like this:
[
// the Notification work item
[
"name" : "Notification",
"parameters" : [
"Message" : new StringDataType(),
"From" : new StringDataType(),
"To" : new StringDataType(),
"Priority" : new StringDataType(),
],
"displayName" : "Notification",
"icon" : "icons/notification.gif"
]
]The project directory structure could then look something like this:
project/src/main/resources/META-INF/MyWorkDefinitions.widWe also want to add a specific icon to be used in the process editor with the work item. To add this, you will need .gif or .png images with a pixel size of 16x16. We put them in a directory outside of the META-INF directory, for example, here:
project/src/main/resources/icons/notification.gif21.3.1.2. Registering the work definition
The jBPM Eclipse editor uses the configuration mechanisms supplied by Drools to register work item definition files.
That means adding a drools.workDefinitions property to the drools.rulebase.conf file in the META-INF.
The drools.workDefinitions property represents a list of files containing work item definitions, separated using spaces.
If you want to exclude all other work item definitions and only use your definition, you could use the following:
drools.workDefinitions = MyWorkDefinitions.widHowever, if you only want to add the newly created node definition to the existing palette nodes, you can define the drools.workDefinitions property as follows:
drools.workDefinitions = MyWorkDefinitions.wid WorkDefinitions.confWe recommended that you use the extension +.+wid for your own definitions of domain specific nodes.
The +.+conf extension used with the default definition file, WorkDefinitions.conf, for backward compatibility reasons.
21.3.1.3. Using your new work item in your processes
We’ve created our work item definition and configured it, so now we can start using it in our processes. The process editor contains a separate section in the palette where the different service nodes that have been defined for the project appear.
Using drag and drop, a notification node can be created inside your process. The properties can be filled in using the properties view.
Besides any custom properties, the following three properties are available for all work items:
-
Parameter Mapping: Allows you to map the value of a variable in the process to a parameter of the work item. This allows you to customize the work item based on the current state of the actual process instance (for example, the priority of the notification could be dependent of some process-specific information). -
Result Mapping: Allows you to map a result (returned once a work item has been executed) to a variable of the process. This allows you to use results in the remainder of the process. -
Wait for completion: By default, the process waits until the requested work item has been completed before continuing with the process. It is also possible to continue immediately after the work item has been requested (and not waiting for the results) by settingwait for completionto false. h
Here is an example that creates a domain specific node to execute Java, asking for the class and method parameters. It includes a custom java.gif icon and consists of the following files and resulting screenshot:
[
// the Java Node work item located in:
// project/src/main/resources/META-INF/JavaNodeDefinition.wid
[
"name" : "JavaNode",
"parameters" : [
"class" : new StringDataType(),
"method" : new StringDataType(),
],
"displayName" : "Java Node",
"icon" : "icons/java.gif"
]
]// located in: project/src/main/resources/META-INF/drools.rulebase.conf
drools.workDefinitions = JavaNodeDefinition.wid WorkDefinitions.conf
// icon for java.gif located in:
// project/src/main/resources/icons/java.gif
21.3.2. The NotificationWorkItemHandler
21.3.2.1. Creating a new work item handler
Once we’ve created our Notification work item definition (see the sections above), we can then create a custom implementation of a work item handler that will contain the logic to send the notification.
In order to execute our Notification work items, we first create a NotificationWorkItemHandler that implements the WorkItemHandler interface:
package com.sample;
import org.kie.api.runtime.process.WorkItem;
import org.kie.api.runtime.process.WorkItemHandler;
import org.kie.api.runtime.process.WorkItemManager;
public class NotificationWorkItemHandler implements WorkItemHandler {
public void executeWorkItem(WorkItem workItem, WorkItemManager manager) {
// extract parameters
String from = (String) workItem.getParameter("From");
String to = (String) workItem.getParameter("To");
String message = (String) workItem.getParameter("Message");
String priority = (String) workItem.getParameter("Priority");
// send email (1)
EmailService service = ServiceRegistry.getInstance().getEmailService();
service.sendEmail(from, to, "Notification", message);
// notify manager that work item has been completed
manager.completeWorkItem(workItem.getId(), null); (2)
}
public void abortWorkItem(WorkItem workItem, WorkItemManager manager) {
// Do nothing, notifications cannot be aborted
}
}| 1 | The ServiceRegistry class is simply a made-up class that we’re using for this example. In your own WorkItemHandler implementations, the code containing your domain-specific logic would go here. |
| 2 | Notifying the WorkItemManager instance when your a work item has been completed is crucial. For many synchronous actions, like sending an email in this case, the WorkItemHandler implementation will notify the WorkItemManager in the executeWorkItem(…) method. |
This WorkItemHandler sends a notification as an email and then notifies the WorkItemManager that the work item has been completed.
Note that not all work items can be completed directly. In cases where executing a work item takes some time, execution can continue asynchronously and the work item manager can be notified later.
In these situations, it might also be possible that a work item is _aborted_before it has been completed.
The WorkItemHandler.abortWorkItem(…) method can be used to specify how to abort such work items.
|
Remember, if the |
21.3.2.2. Registering the work item handler
WorkItemHandler instances need to be registered with the WorkItemManager in order to be used.
In this case, we need to register an instance of our NotificationWorkItemHandler in order to use it with our process containing a Notification work item.
We can do that like this:
StatefulKnowledgeSession ksession = kbase.newStatefulKnowledgeSession();
ksession.getWorkItemManager().registerWorkItemHandler(
"Notification", (1)
new NotificationWorkItemHandler() (2)
);| 1 | This is the drools name of the <task> (or other task type) node. See below for an example. |
| 2 | This is the instance of our custom work item handler instance! |
If we were to look at the BPMN2 syntax for our process with the Notification process, we would see something like the following example.
Note the use of the tns:taskName attribute in the <task> node.
This is necessary for the WorkItemManager to be able to see which WorkItemHandler instance should be used with which task or work item.
<?xml version="1.0" encoding="UTF-8"?>
<definitions id="Definition"
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xs:schemaLocation="http://www.omg.org/spec/BPMN/20100524/MODEL BPMN20.xsd"
...
xmlns:tns="http://www.jboss.org/drools">
...
<process isExecutable="true" id="myCustomProcess" name="Domain-Specific Process" >
...
<task id="_5" name="Notification Task" tns:taskName="Notification" >
...|
Different work item handlers could be used depending on the context. For example, during testing or simulation, it might not be necessary to actually execute the work items. In this case specialized dummy work item handlers could be used during testing. |
21.4. Service Repository
A service repository allows easy discovery and use of existing services, as well as contributing new services to the jBPM community. It should allow public access via URL as well as allow users to locally build and update it as they see fit. The content of the service repository are domain-specific services that provide integration of your processes with different types of systems. Their implementation should work out-of-the-box or with minimal configuration to the users. Users can benefit from the service repository by having pre-tested and ready to use integration points which they do not have to implement themselves.
21.4.1. Public jBPM service repository
jBPM provides a public service repository which contains contributed reusable services:
This repository is dynamically generated from the jBPM Workitems GitHub module. It includes an user-friendly "Home Page" where you can view details about all services provied as well as download links to specific service definitions and implementation (jar). jBPM tooling as for example the jBPM Designer can be used to discover this service repository and easily install these services into the workbench for you to start using them inside business processes.
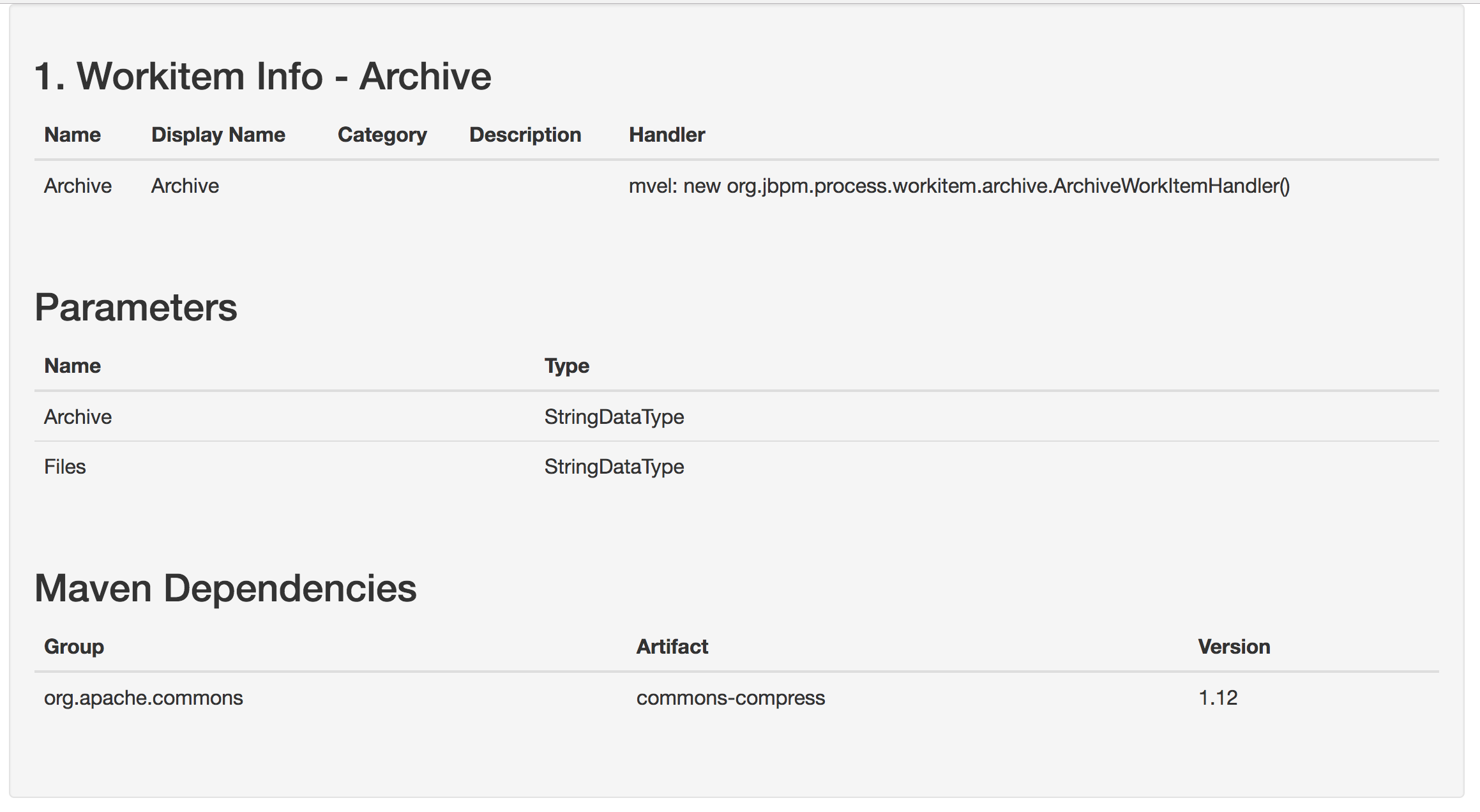
To start implementing and contributing your own service integration points please take a look at jBPM Workitems Archetype module which can get you up and running with a Maven project quickly. Otherwise feel free to contact someone from the dev team and we will be happy to help you get started.
21.4.2. Building and extending the jBPM Service Repository
You can build and extend the jBPM service repository locally. For this simply build the jBPM work items module on GitHub. The look/feel of the repository can be changed by updating the repository index file. jBPM tooling can discover your repository even if it’s not available on a public URL.
21.4.3. Using repository workitems in your processes
Within the workbench you can use jBPM Designer editor to easily start importing your services into existing processes. Inside Designer open up the workitem repository editor and type in the repository URL to connect to, for example
or if you build your repository locally it could look something like
The repository import feature then will scan the workitem repository and list its content for you to start importing:
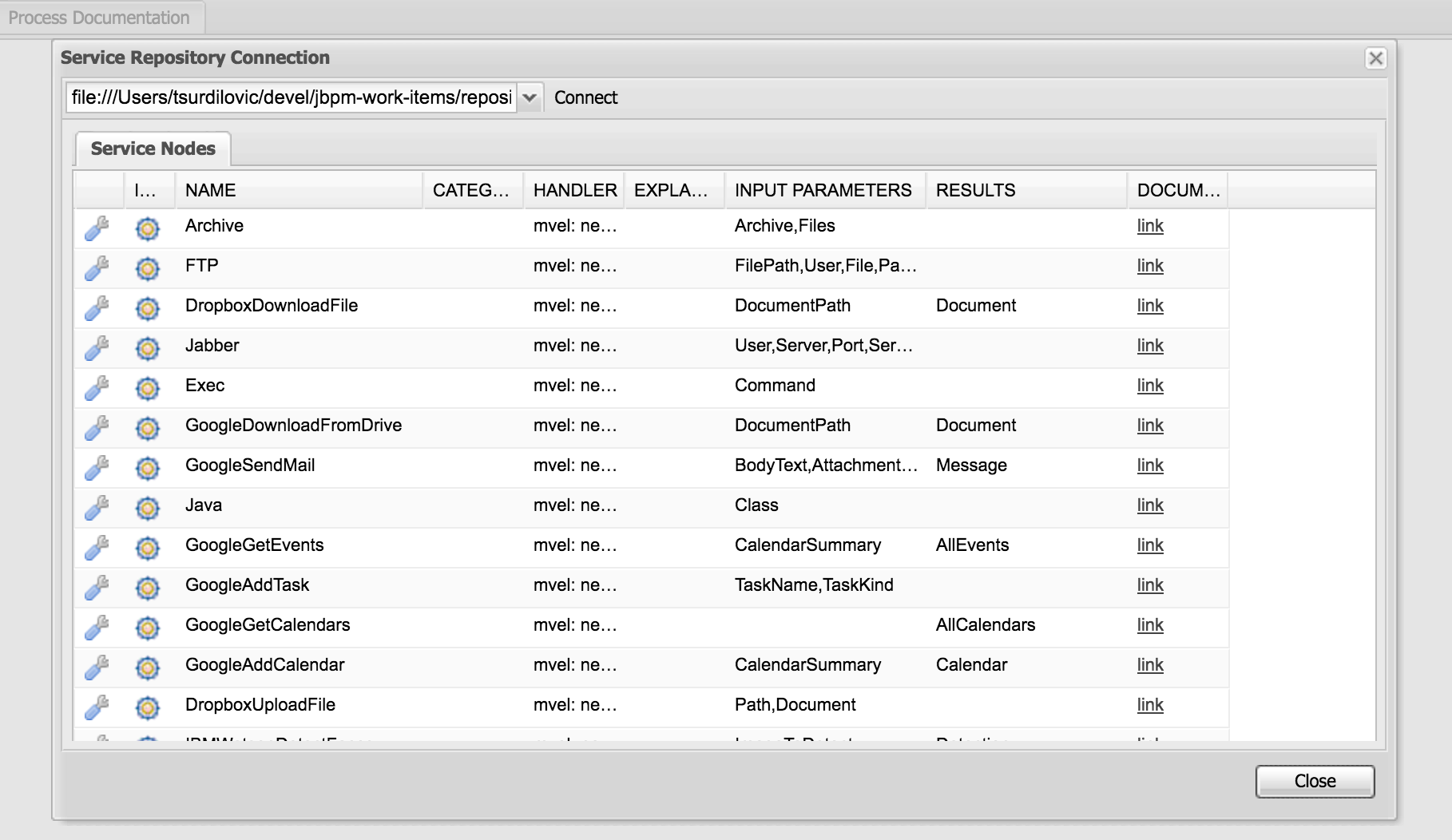
Once imported, workitems are going to be included in the Designer shapes section when new processes are created or existing are re-opened.
Another option is to tell your app server that is running the KIE workbench to automatically install specific workitems from your repository on workbench startup. This is a very nice option which saves time of having to manually import individual workitems via the repository importer. It automatically registers your workitem handler and its maven dependencies to the workbench which is very handy (same is done via the manual install using Designer).
For example let’s say you have a service repository available at http://mysite.com/myservicerepo and there you have two services, namely BuyStock and SellStock. To have these services automatically installed in the Workbench you can add the following startup parameters:
AS/bin/standalone.sh -Dorg.jbpm.service.repository=http://mysite.com/myservicerepo -Dorg.jbpm.service.servicetasknames=BuyStock,SellStockOr if you wanted just the SellStock service installed:
AS/bin/standalone.sh -Dorg.jbpm.service.repository=http://mysite.com/myservicerepo -Dorg.jbpm.service.servicetasknames=SellStockCurrently there is no install-all option available so service names must be individually specified. When creating a new or opening an existing business process then the Workbench will attempt to install the specified services from the provided repository URL. This will install the service wid configuration, the spcified icon (if there is one or if not the Workbench will provide a default one for it), the default handler will be added to the deployment descriptor of your Workbench project as well as the specified maven dependencies in the service configuration will be added to the Workbench project pom.xml file. Please note that currently there is no option to specify maven repositories via the service task configuration so they must be added via the Workbench in its POM Editor by the users.
21.4.4. Setting up your own service repository
With previous versions of the jBPM Service repository users had to manually set up their workitem configuration (.wid) files as well as provide jars and the maintain a repo configuratin file (index.conf). With the new version this is no longer the case and if you use Maven most if not all of the repository artifacts can be generated for you.
If you do have an existing custom repository already set up be rest assured that it will still work as the overall structure has not changed. In this case there are two things you will notice. One that there is no longer the need for you to maintain the index.conf file which lists all your repository workitems, and two that you now can add maven dependencies into your workitem configurations to define depends which can be pulled in at compile or runtime rather than dependencies which you had to previously provide manually.
Ok, so let’s see what are some easy ways to set up your own repository:
Create own workitem inside jBPM WorkItems module
Here you would clone the jBPM WorkItems module from GitHub and create your own modules for your services. You can follow one of the existing modules to set up your own workitem implementation. Once you have added your module to the list of modules in the main pom, then also add it to the repository Home Page setup and you are good to go. Once you build the main module all the artifacts and the repository itself will be generated for you under $moduleHome$/repository/target/repository-$version$.
This is a also a nice way to contribute your workitem impl to the community as it will be already set-up and ready to do a pull request if you so choose so.
Create own workitem with the workitem Maven Archetype
We mentioned before the jBPM Workitem Archetype module. Creating a workitem project with this archetype will provide you with full generation of all elements needed for the repository.
To get started run the following maven command (update the archetypeVersion as needed):
mvn archetype:generate -DarchetypeGroupId=org.jbpm -DarchetypeArtifactId=jbpm-workitems-archetype -DarchetypeVersion=7.5.0-SNAPSHOT -DgroupId=org.jbpm.demo.workitems -DartifactId=myworkitem -DclassPrefix=MyWorkItem -DarchetypeCatalog=local -Dversion=1.0This will create a base workitem project for you called myworkitem. If you within that workitem run
mvn clean installyou will find that the Maven build process will generate the workitem configuration, the implementation jar as well as html that contains your workitem information in the myworkitem/jbpm-workitems-myworkitem/target/jbpm-workitems-myworkitem-1.0.zip file. You can then simply extract the contents of this zip into your existing custom repository or anywhere on the file system. The zip will have the following structure (for the base project):
index.conf
MyWorkItem/
- MyWorkItem.json
- MyWorkItem.wid
- MyWorkItem.png
- index.html
- jbpm-workitems-myworkitem-1.0.jar21.4.5. Workitem Configuration (wid) from Handler Annotations
Generating the workitem configuration used to be a manual process which involved creating a workitem .wid file and having to know mvel to define your workitem input/output parameters, handler, dependencies etc. You can still manually do that but we have added a way to define your workitem configuration information in your workitem Java implementation using annotations. Here is an example of this approach
@Wid(widfile = "DropboxDownloadFileDefinitions.wid", name = "DropboxDownloadFile",
displayName = "DropboxDownloadFile",
defaultHandler = "mvel: new org.jbpm.process.workitem.dropbox.DownloadFileWorkitemHandler()",
parameters = {
@WidParameter(name = "DocumentPath")
},
results = {
@WidResult(name = "Document")
},
mavenDepends = {
@WidMavenDepends(group = "com.dropbox.core", artifact = "dropbox-core-sdk", version = "3.0.5")
})
public class DownloadFileWorkitemHandler extends AbstractLogOrThrowWorkItemHandler {
...
}Annotating your workitem handler implementation tells the jBPM Workitem Processor to use the defined information by this annotation to generate the workitem configuration from. It has a number of different properties you can use:
-
widFile: defines the name of the generated config file -
name: - unique name for your service -
displayName: - display name to be used within editors such as jBPM Designer -
parameters: - define the service data inputs given their name and type -
results: - define the service data outputs -
mavenDepends: - define a list of maven dependencies needed for your workitem to be executable at runtime. -
icon: - should refer to a file with the given file name in the same folder as the extended configuration file (so it can be downloaded by the import wizard and used in the process diagrams). Icons should be 16x16 GIF files. -
category: - defines the category this service should be placed under when browsing the repository. -
defaultHandler: - defines the default handler implementation (i.e. the Java class that implements theWorkItemHandlerinterface and can be used to execute the service). This can automatically be registered as the handler for that service when importing the service from the repository. You can also use mvel to resolve the default handler expression which has the additional benefit of being able to resolve the handlers parameters, for example:
"defaultHandler" : "mvel: new org.jbpm.process.workitem.twitter.TwitterHandler(ksession)",Some of the available named parameters you can use are:
ksession
taskService
runtimeManager
classLoader
entityManagerFactory-
documentation: - defines a documentation file that describes what the service does and how it works. This property should refer to a HTML file with the given name in the same folder as the extended configuration file (so it can be shown by the import wizard when browsing the repository). -
version: - the version (String) of the workitem implmentation
Only setup needed for the @Wid annotation is to use an already provided annotation processor, namely
org.jbpm.process.workitem.core.util.WidProcessorTo add this in your projects pom.xml, you can define in the poms <plugins> section:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<annotationProcessors>
<annotationProcessor>org.jbpm.process.workitem.core.util.WidProcessor</annotationProcessor>
</annotationProcessors>
<compilerArgs>
<arg>-AwidName=${project.artifactId}</arg>
</compilerArgs>
</configuration>
</plugin>21.4.6. Programatically interacting with the service repository
jBPM provides classes in the org.jbpm.process.workitem package which allows you to connect and retrieve your service information. For example:
Map<String, WorkDefinitionImpl> workitemsFromRepo =
WorkItemRepository.getWorkDefinitions("https://docs.jboss.org/jbpm/service-repository/7.5.0.Final");This will provide you with all services defined in the repository. You can then get more detailed information about each of services in the repository using their name as declared in the service wid file, for example we could do (for an example Workitem called "MyWorkitem"):
workitemsFromRepo.get( "MyWorkitem" ).getName();
workitemsFromRepo.get( "MyWorkitem" ).getDescription();
workitemsFromRepo.get( "MyWorkitem" ).getDefaultHandler();
workitemsFromRepo.get( "MyWorkitem" ).getMavenDependencies();
...or you could for example check if the correct version of the service you need is contained in the repository:
if( workitemsFromRepo.containsKey( "MyWorkitem" ) && workitemsFromRepo.get( "MyWorkitem" ).getVersion().equals( "1.0" )) {
// do something
}Currently all operations are read-only. There isn’t a way to update the service repository automatically.
21.4.7. Defining extended service configuration with JSON
The previous extended configuration example for the Twitter service was defined with the default mvel configuration. It is also possible to do this with JSON and the Twitter example would look like this:
[
[
"java.util.HashMap",
{
"name":"TestServiceFour",
"displayName":"Twitter",
"description":"Send a Twitter message",
"parameters":[
"java.util.HashMap",
{
"Message":["org.jbpm.process.core.datatype.impl.type.StringDataType", {}]
}
],
"eclipse:customEditor":"org.drools.eclipse.flow.common.editor.editpart.work.SampleCustomEditor",
"defaultHandler" : "org.jbpm.process.workitem.twitter.TwitterHandler",
"documentation" : "index.html",
"dependencies":[
"java.util.ArrayList", ["file:./lib/jbpm-twitter.jar", "file:./lib/twitter4j-core-2.2.2.jar"]
]
}
]
]In your service repository you can define the extended configuration of your services with mvel or JSON (or have some defined in one way and some in the other as well). Defining the extended configuration with JSON might have some benefits if being read by custom web-based clients for example but the mvel configuration option is default and currently still prefered.
22. Exception Management
22.1. Overview
This chapter will describe how to deal with unexpected behavior in your business processes using both BPMN2 and technical mechanisms.
The first section will explain Technical Exceptions: we’ll go through an example that uses both BPMN2 and WorkItemHandler implementations in order to isolate and handle exceptions caused by a technical component.
We will also explain how to modify the example to suit other use cases.
The second section will define and explain the types of (BPMN2) exceptions that can happen or be used in a business process.
22.2. Introduction
What happens to a business process when something unexpected happens during the process? Most of the time, when creating and designing a new process definition, the first step is to describe the normative or desirable behaviour. However, a process definition that only describes all of the normal tasks and their execution order is incomplete.
The next step is to think about what might go wrong when the business process is run. What would happen if any of the human or technical actors in the process do not respond in unexpected ways? Will any of the technical systems that the process interacts with return unexpected results — or not return any results at all?
Deviations from the normative or "happy" flow of a business process are called exceptions. In some cases, exceptions might not be that unusual, such as trying to debit an empty bank account. However, some processes might contain many complex situations involving exceptions, all of which must be handled correctly.
|
The rest of chapter assumes that you know how to create custom |
22.3. Technical Exceptions
22.3.1. Introduction
Technical exceptions happen when a technical component of a business process acts in an unexpected way. When using Java based systems, this often results in a literal Java Exception being thrown by the system.
Technical components used in a process can fail in a way that can not be described using BPMN2. In this case, it’s important to handle these exceptions in expected ways.
The following types of code might throw exceptions:
-
Any code that is present in the process definition itself
-
Any code that is executed during a process and is not part of jBPM
-
Any code that interacts with a technical component outside of the process engine
However, those are somewhat abstract definitions. We can narrow down the places at which an exception might be thrown. Technical exceptions can occur at the following points:
-
Code present in
<scriptTask>nodes or in the jbpm-specific<onEntry>and<onExit>elements -
Code executed in
WorkItemHandlersassociated with<task>and task-type nodes
It is much easier to ensure correct exception handling for <task> and other task-type nodes that use WorkItemHandler implementations, than for code executed directly in a <scriptTask>.
Exceptions thrown by <scriptTask> can cause the process to fail in an unrecoverable fashion.
While there are certain things that you can do to contain the damage, a process that has failed in this way can not be restarted or otherwise recovered.
This also applies for other nodes in a process definition that contain script code in the node definition, such as the <onEntry> and <onExit> elements.
When jBPM engine does throw an exception generated by the code in a <scriptTask> the exception thrown is a special Java exception called the WorkflowRuntimeException that contains information about the process.
|
Again, exceptions generated by a For this reason, it’s important to limit the scope of the code in these nodes to operations dealing with process variables.
Using a
|
22.3.2. Handling exceptions in WorkItemHandler instances
` WorkItemHandler` classes are used when your process interacts with other technical systems. For an introduction to them and how to use them in processes, please see the Domain-Specific Processes chapter.
While you can build exception handling into your own WorkItemhandler implementations, there are also two “handler decorator”
classes that you can use to wrap a WorkItemhandler implementation.
These two wrapper classes include logic that is executed when an exception is thrown during the execution (or abortion) of a work item.
| Decorator classes in the org.jbpm.bpmn2.handler package | Description |
|---|---|
|
This class wraps an existing |
|
This class reacts to all exceptions thrown by the |
While the two classes described above should cover most cases involving exception handling, a Java developer with some experience with jBPM should be able to create a WorkItemHandler that executes custom code upon an exception.
If you do decide to write a custom WorkItemHandler that includes exception handling logic, keep the following checklist in mind:
-
Are you catching all possible exceptions that you want to (and no more, or less)?
-
Are you making sure to either complete or abort the work item after an exception has been caught? If not, are there mechanisms to retry the process later? Or are incomplete process instances acceptable?
-
What other actions should be taken when an exception is caught? Do you want to simply log the exception, or is it also important to interact with other technical systems? Do you want to trigger a (BPMN2) subprocess that will handle the exception?
|
When you use the |
In the next section, we’ll describe an example that uses the SignallingTaskHandlerDecorator to signal an event subprocess when a work item handler throws an exception.
22.3.3. Examples
22.3.3.1. Example: service task handlers
We’ll go through one example in this section, and then look quickly at how you can change it to get the behavior you want.
The example involves an <error> event that’s caught by an (Error) Event SubProcess.
When an Error Event is thrown, the containing process will be interrupted. This means that after the process flow attached to the error event has executed, the following will happen:
-
process execution will stop, and no other parts of the process will execute
-
the process instance will end up in an aborted state (instead of completed)
The example we’ll go through contains an <error>, but at the end of the section, we’ll show how you can change the process to use a <signal> instead.
|
The code and BPMN2 process definition shown in the next section are available in the jbpm-examples
module.
See the |
BPMN2 configuration
Let’s look at the BPMN2 process definition first. Besides the definition of the process, the BPMN2 elements defined before the actual process definition are also important. Here’s an image of the BPMN2 process that we’ll be using in the example:
The BPMN2 process fragment below is part of the process shown above, and contains some notes on the different BPMN2 elements.
|
If you’re viewing this on a web browser, you may need to widen or narrow your browser window in order to see the "callout" or note numbers on the right hand side of the code. |
<itemDefinition id="_stringItem" structureRef="java.lang.String" /> (1)
<message id="_message" itemRef="_stringItem"/> (2)
<interface id="_serviceInterface" name="org.jbpm.examples.exceptions.service.ExceptionService">
<operation id="_serviceOperation" name="throwException">
<inMessageRef>_message</inMessageRef> (2)
</operation>
</interface>
<error id="_exception" errorCode="code" structureRef="_exceptionItem"/> (3)
<itemDefinition id="_exceptionItem" structureRef="org.kie.api.runtime.process.WorkItem"/> (4)
<message id="_exceptionMessage" itemRef="_exceptionItem"/> (4)
<interface id="_handlingServiceInterface" name="org.jbpm.examples.exceptions.service.ExceptionService">
<operation id="_handlingServiceOperation" name="handleException">
<inMessageRef>_exceptionMessage</inMessageRef> (4)
</operation>
</interface>
<process id="ProcessWithExceptionHandlingError" name="Service Process" isExecutable="true" processType="Private">
<!-- properties -->
<property id="serviceInputItem" itemSubjectRef="_stringItem"/> (1)
<property id="exceptionInputItem" itemSubjectRef="_exceptionItem"/> (4)
<!-- main process -->
<startEvent id="_1" name="Start" />
<serviceTask id="_2" name="Throw Exception" implementation="Other" operationRef="_serviceOperation">
<!-- rest of the serviceTask element and process definition... -->
<subProcess id="_X" name="Exception Handler" triggeredByEvent="true" >
<startEvent id="_X-1" name="subStart">
<dataOutput id="_X-1_Output" name="event"/>
<dataOutputAssociation>
<sourceRef>_X-1_Output</sourceRef>
<targetRef>exceptionInputItem</targetRef> (4)
</dataOutputAssociation>
<errorEventDefinition id="_X-1_ED_1" errorRef="_exception" /> (3)
</startEvent>
<!-- rest of the subprocess definition... -->
</subProcess>
</process>| 1 | This <itemDefinition> element defines a data structure that we then use in the serviceInputItem property in the process. |
| 2 | This <message> element (1rst reference) defines a message that has a String as its content (as defined by the <itemDefintion> element on line above). The <interface> element below it refers to it (2nd reference) in order to define what type of content the service (defined by the <interface>) expects. |
| 3 | This <error> element (1rst reference) defines an error for use later in the process: an Event SubProcess is defined that is triggered by this error (2nd reference). The content of the error is defined by the <itemDefintion> element defined below the <error> element. |
| 4 | This <itemDefintion> element (1rst reference) defines an item that contains a WorkItem instance. The <message> element (2nd reference) then defines a message that uses this item definition to define its content. The <interface> element below that refers to the <message> definition (3rd reference) in order to define the type of content that the service expects. |
|
When you’re using a |
SignallingTaskHandlerDecorator and WorkItemHandler configuration
Now that BPMN2 process definition is (hopefully) a little clearer, we can look at how to set up jBPM to take advantage of the above BPMN2.
In the (BPMN2) process definition above, we define two different <serviceTask> activities.
The org.jbpm.bpmn2.handler.ServiceTaskHandler class is the default task handler class used for <serviceTask> tasks.
If you don’t specify a WorkItemHandler implementation for a <serviceTask>, the ServiceTaskHandler class will be used.
In the code below, you’ll see that we actually wrap or decorate the ServiceTaskHandler class with a SignallingTaskHandlerDecorator instance.
We do this in order to define the what happens when the ServiceTaskHandler throws an exception.
In this case, the ServiceTaskHandler will throw an exception because it’s configured to call the ExceptionService.throwException method, which throws an exception.
(See the _handlingServiceInterface <interface> element in the BPMN2.)
In the code below, we also configure which (error) event is sent to the process instance by the SignallingTaskHandlerDecorator instance.
The SignallingTaskHandlerDecorator does this when an exception is thrown in a task.
In this case, since we’ve defined an <error> with the error code “code” in the BPMN2, we set the signal to Error-code.
|
When signalling the jBPM process engine with an event of some sort, you should keep in mind the rules for signalling process events.
|
import java.util.HashMap;
import java.util.Map;
import org.jbpm.bpmn2.handler.ServiceTaskHandler;
import org.jbpm.bpmn2.handler.SignallingTaskHandlerDecorator;
import org.jbpm.examples.exceptions.service.ExceptionService;
import org.kie.api.KieBase;
import org.kie.api.io.ResourceType;
import org.kie.api.runtime.KieSession;
import org.kie.api.runtime.process.ProcessInstance;
import org.kie.internal.builder.KnowledgeBuilder;
import org.kie.internal.builder.KnowledgeBuilderFactory;
import org.kie.internal.io.ResourceFactory;
public class ExceptionHandlingErrorExample {
public static final void main(String[] args) {
runExample();
}
public static ProcessInstance runExample() {
KieSession ksession = createKieSession();
String eventType = "Error-code"; (1)
SignallingTaskHandlerDecorator signallingTaskWrapper (2)
= new SignallingTaskHandlerDecorator(ServiceTaskHandler.class, eventType);
signallingTaskWrapper.setWorkItemExceptionParameterName(ExceptionService.exceptionParameterName); (3)
ksession.getWorkItemManager().registerWorkItemHandler("Service Task", signallingTaskWrapper);
Map<String, Object> params = new HashMap<String, Object>();
params.put("serviceInputItem", "Input to Original Service");
ProcessInstance processInstance = ksession.startProcess("ProcessWithExceptionHandlingError", params);
return processInstance;
}
private static KieSession createKieSession() {
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newClassPathResource("exceptions/ExceptionHandlingWithError.bpmn2"), ResourceType.BPMN2);
KieBase kbase = kbuilder.newKnowledgeBase();
return kbase.newKieSession();
}| 1 | Here we define the name of the event that will be sent to the process instance if the wrapped WorkItemHandler implementation throws an exception. The eventType string is used when instantiating the SignallingTaskHandlerDecorator class. |
| 2 | Then we construct an instance of the SignallingTaskHandlerDecorator class. In this case, we simply give it the class name of the WorkItemHandler implementation class to instantiate, but another constructor is available that we can pass an instance of a WorkItemHandler implementation to (necessary if the WorkItemHandler implementation does not have a no-argument constructor). |
| 3 | When an exception is thrown by the wrapped WorkItemHandler, the SignallingTaskHandlerDecorator saves it as a parameter in the WorkItem instance with a parameter name that we configure the SignallingTaskHandlerDecorator to give it (see the code below for the ExceptionService). |
ExceptionService setup and configuration
In the BPMN2 process definition above, a service interface is defined that references the ExceptionService class:
<interface id="_handlingServiceInterface" name="org.jbpm.examples.exceptions.service.ExceptionService">
<operation id="_handlingServiceOperation" name="handleException">In order to fill in the blanks a little bit, the code for the ExceptionService class has been included below.
In general, you can specify any Java class with the default or an other no-argument constructor and have it executed during a <serviceTask>
public class ExceptionService {
public static String exceptionParameterName = "my.exception.parameter.name";
public void handleException(WorkItem workItem) {
System.out.println( "Handling exception caused by work item '" + workItem.getName() + "' (id: " + workItem.getId() + ")");
Map<String, Object> params = workItem.getParameters();
Throwable throwable = (Throwable) params.get(exceptionParameterName);
throwable.printStackTrace();
}
public String throwException(String message) {
throw new RuntimeException("Service failed with input: " + message );
}
public static void setExceptionParameterName(String exceptionParam) {
exceptionParameterName = exceptionParam;
}
}Changing the example to use a <signal>
In the example above, the thrown Error Event interrupts the process: no other flows or activities are executed once the Error Event has been thrown.
However, when a Signal Event is processed, the process will continue after the Signal Event SubProcess (or whatever other activities that the Signal Event triggers) has been executed. Furthermore, this implies that the the process will not end up in an aborted state, unlike a process that throws an Error Event.
In the process above, we use the <error> element in order to be able to use an Error Event:
<error id="_exception" errorCode="code" structureRef="_exceptionItem"/>When we want to use a Signal Event instead, we remove that line and use a <signal> element:
<signal id="exception-signal" structureRef="_exceptionItem"/>However, we must also change all references to the _exception <error> so that they now refer to the exception-signal <signal>.
That means that the <errorEventDefintion> element in the <startEvent>,
<errorEventDefinition id="_X-1_ED_1" errorRef="_exception" />must be changed to a <signalEventDefintion> which would like like this:
<signalEventDefinition id="_X-1_ED_1" signalRef="exception-signal"/>In short, we have to make the following changes to the <startEvent> in the Event SubProcess:
-
It will now contain a
<signalEventDefintion>instead of a<errorEventDefintion> -
The
errorRefattribute in the<erroEventDefintion>is now asignalRefattribute in the<signalEventDefintion>. -
The
idattribute in thesignalRefis of course now the id of the<signal>element. Before it was id of<error>element. -
Lastly, when we signal the process in the Java code, we do not signal “`Error-code`” but simply “`exception-signal`”, the
idof the<signal>element.
22.3.3.2. Example: logging exceptions thrown by bad <scriptTask> nodes
In this section, we’ll briefly describe what’s possible when dealing with <scriptTask> nodes that throw exceptions, and then quickly go through an example (also available in the jbpm-examples
module) that illustrates this.
Introduction
If you’re reading this, then you probably already have a problem: you’re either expecting to run into this problem because there are scripts in your process definition that might throw an exception, or you’re already running a process instance with scripts that are causing a problem.
Unfortunately, if you’re running into this problem, then there is not much you can do.
The only thing that you can do is retrieve more information about exactly what’s causing the problem.
Luckily, when a <scriptTask> node causes an exception, the exception is then wrapped in a WorkflowRuntimeException.
What type of information is available? The WorkflowRuntimeException instance will contain the information outlined in the following table.
All of the fields listed are available via the normal get* methods.
| Field name | Type | Description |
|---|---|---|
|
|
The id of the |
|
|
The id of the process definition that was used to start the process (i.e.
“`ExceptionScriptTask`” in |
|
|
The value of the (BPMN2) id attribute of the node that threw the exception. |
|
|
The value of the (BPMN2) name attribute of the node that threw the exception. |
|
|
The map containing the variables in the process instance (experimental). |
|
|
The short message indicating what went wrong. |
|
|
The original exception that was thrown. |
Example: Exceptions thrown by a <scriptTask>.
The following code illustrates how to extract extra information from a process instance that throws a WorkflowRuntimeException exception instance.
import org.jbpm.workflow.instance.WorkflowRuntimeException;
import org.kie.api.KieBase;
import org.kie.api.io.ResourceType;
import org.kie.api.runtime.KieSession;
import org.kie.api.runtime.process.ProcessInstance;
import org.kie.internal.builder.KnowledgeBuilder;
import org.kie.internal.builder.KnowledgeBuilderFactory;
import org.kie.internal.io.ResourceFactory;
public class ScriptTaskExceptionExample {
public static final void main(String[] args) {
runExample();
}
public static void runExample() {
KieSession ksession = createKieSession();
Map<String, Object> params = new HashMap<String, Object>();
String varName = "var1";
params.put( varName , "valueOne" );
try {
ProcessInstance processInstance = ksession.startProcess("ExceptionScriptTask", params);
} catch( WorkflowRuntimeException wfre ) {
String msg = "An exception happened in "
+ "process instance [" + wfre.getProcessInstanceId()
+ "] of process [" + wfre.getProcessId()
+ "] in node [id: " + wfre.getNodeId()
+ ", name: " + wfre.getNodeName()
+ "] and variable " + varName + " had the value [" + wfre.getVariables().get(varName)
+ "]";
System.out.println(msg);
}
}
private static KieSession createKieSession() {
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newClassPathResource("exceptions/ScriptTaskException.bpmn2"), ResourceType.BPMN2);
KieBase kbase = kbuilder.newKnowledgeBase();
return kbase.newKieSession();
}
}22.4. Business Exceptions
Business Exceptions are exceptions that are designed and managed in the BPMN2 specification of a business process. In other words, Business Exceptions are exceptions which happen at the process or workflow level, and are not related to the technical components.
Many of the elements in BPMN2 related to Business Exceptions are related to Compensation and Business Transactions. Compensation, in particular, is complexer than many other parts of the BPMN2 specification.
Full support for compensation and business transactions is expected with the release of jBPM 6.1 or 6.2. Once that has been implemented, this section will contain more information about using those BPMN2 features with jBPM.
22.4.1. Business Exceptions elements in BPMN2
The following attempts to briefly describe Compensation and Business Transaction related elements in BPMN2. For more complete information about these elements and their uses, see the BPMN2 specification, Bruce Silver’s book BPMN Method and Style or any of the other available books about the use of BPMN2.
| BPMN2 Element types | Description |
|---|---|
Errors |
Error Events can be used to signal when a process has encountered an unexpected situation: signalling an error is often called throwing an error. Boundary Error Events in a different part of the process can then be used to catch the error and initiate a sequence of activities to handle the exception. Errors themselves can be extended with extra information that is passed from the throwing to catching event. This is done with the use of an Item Definition. |
Compensation |
Exception handling activities associated with the normal activities in a Business Transaction are triggered by Compensation Events. There are 3 types of compensation events: Intermediate (a.k.a. Boundary) (catch) events, Start (catch) events, and Intermediate or End (throw) events. Compensation Boundary (catch) events may only be attached to activities (e.g. tasks) that could cause an exception. These Boundary events are then associated (not linked!) with a Task that will be executed if the Boundary event catches a (thrown) Compensation signal. Start (catch) events are used when defining an Compensation Event SubProcess, which requires them in order to be able to catch a (thrown) Compensation signal. Compensation Intermediate and End events are used in order to throw Compensation Events. These events often follow decision nodes that determine whether the workflow executed up to that point has succeeded. If not, the path including the Intermediate or End Event is chosen in order to trigger Compensatoin for the activities that did not succeed. |
BPMN2 contains a number of constructs to model exceptions in business processes. There are several advantages to doing exception handling at the business process level (as opposed to handling it with code):
-
Transparency
-
Being able to quickly see what happens in exceptional situations means that the results and performance of a process is more easily monitored and measured.
-
It also increases how easily a process can be implemented as well as how maintainable a process definition is.
-
-
Business Logic Isolation
-
Again, the idea behind using a business process is to isolate the business logic from the technical code. This simplifies the complexity of the system and increases how quickly you can create new business processes and change existing ones.
-
Implementing exception handling at a technical level often takes more time because it’s often complexer and specific to a system.
-
22.4.2. Designing a workflow with Business Exceptions
Where are business exceptions likely to occur? There is academic research on this, but some possible examples are:
-
When an interaction with an external party or 3rd party system does not go as planned
-
When you can not fully check the the input data in your process (like a client’s address information, for example)
-
In general, if there are parts of your process that are particularly dependent on one of the following, a business exception will be a good idea:
-
Company policy or policy governing certain (in-house) procedures
-
Laws governing the business process (such as age requirements, for example)
-
23. Flexible Processes
Case management and its relation to BPM is a hot topic nowadays. There definitely seems to be a growing need amongst end users for more flexible and adaptive business processes, without ending up with overly complex solutions. Everyone seems to agree that using a process-centric approach only in many cases leads to complex solutions that are hard to maintain. The "knowledge workers" no longer want to be locked into rigid processes but wants to have the power and flexibility to regain more control over the process themselves.
The term case management is often used in that context. Without trying to give a precise definition of what it might or might not mean, as this has been a hot topic for discussion, it refers to the basic idea that many applications in the real world cannot really be described completely from start to finish (including all possible paths, deviations, exceptions, etc.). Case management takes a different approach: instead of trying to model what should happen from start to finish, let’s give the end user the flexibility to decide what should happen at runtime. In its most extreme form for example, case management doesn’t even require any process definition at all. Whenever a new case comes in, the end user can decide what to do next based on all the case data.
A typical example can be found in healthcare (clinical decision support to be more precise), where care plans can be used to describe how patients should be treated in specific circumstances, but people like general practitioners still need to have the flexibility to add additional steps and deviate from the proposed plan, as each case is unique. And there are similar examples in claim management, help desk support, etc.
So, should we just throw away our BPM system then? No! Even at its most extreme form (where we don’t model any process up front), you still need a lot of the other features a BPM system (usually) provides: there still is a clear need for audit logs, monitoring, coordinating various services, human interaction (e.g. using task forms), analysis, etc. And, more importantly, many cases are somewhere in between, or might even evolve from case management to more structured business process over time (when we for example try to extract common approaches from many cases). If we can offer flexibility as part of our processes, can’t we let the users decide how and where they would like to apply it?
Let me give you two examples that show how you can add more and more flexibility to your processes. The first example shows a care plan that shows the tasks that should be performed when a patient has high blood pressure. While a large part of the process is still well-structured, the general practitioner can decide himself which tasks should be performed as part of the sub-process. And he also has the ability to add new tasks during that period, tasks that were not defined as part of the process, or repeat tasks multiple times, etc. The process uses an ad-hoc sub-process to model this kind of flexibility, possibly augmented with rules or event processing to help in deciding which fragments to execute.
The second example actually goes a lot further than that. In this example, an internet provider could define how cases about internet connectivity problems will be handled by the internet provider. There are a number of actions the case worker can select from, but those are simply small process fragments. The case worker is responsible for selecting what to do next and can even add new tasks dynamically. As you can see, there is not process from start to finish anymore, but the user is responsible for selecting which process fragments to execute.
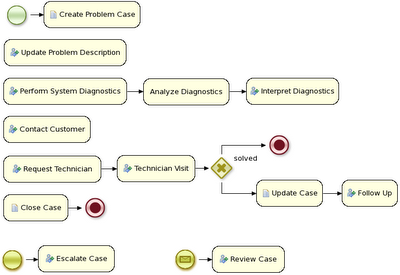
And in its most extreme form, we even allow you to create case instances without a process definition, where what needs to be performed is selected purely at runtime. This however doesn’t mean you can’t figure out anymore what 's actually happening. For example, meetings can be very ad hoc and dynamic, but we usually want a log of what was actually discussed. The following screenshot shows how our regular audit view can still be used in this case, and the end user could then for example get a lot more info about what actually happened by looking at the data associated with each of those steps. And maybe, over time, we can even automate part of that by using a semi-structured process.

24. Concurrency and asynchronous execution
24.1. Concurrency
In the following text, we will refer to two types of "multi-threading": logical and technical. Technical multi-threading is what happens when multiple threads or processes are started on a computer, for example by a Java or C program. Logical multi-threading is what we see in a BPM process after the process reaches a parallel gateway, for example. From a functional standpoint, the original process will then split into two processes that are executed in a parallel fashion.
Of course, the jBPM engine supports logical multi-threading: for example, processes that include a parallel gateway. We’ve chosen to implement logical multi-threading using one thread: a jBPM process that includes logical multi-threading will only be executed in one technical thread. The main reason for doing this is that multiple (technical) threads need to be be able to communicate state information with each other if they are working on the same process. This requirement brings with it a number of complications. While it might seem that multi-threading would bring performance benefits with it, the extra logic needed to make sure the different threads work together well means that this is not guaranteed. There is also the extra overhead incurred because we need to avoid race conditions and deadlocks.
24.1.1. Engine execution
In general, the jBPM engine executes actions in serial. For example, when the engine encounters a script task in a process, it will synchronously execute that script and wait for it to complete before continuing execution. Similarly, if a process encounters a parallel gateway, it will sequentially trigger each of the outgoing branches, one after the other. This is possible since execution is almost always instantaneous, meaning that it is extremely fast and produces almost no overhead. As a result, the user will usually not even notice this. Similarly, action scripts in a process are also synchronously executed, and the engine will wait for them to finish before continuing the process. For example, doing a Thread.sleep(…) as part of a script will not make the engine continue execution elsewhere but will block the engine thread during that period.
The same principle applies to service tasks. When a service task is reached in a process, the engine will also invoke the handler of this service synchronously. The engine will wait for the completeWorkItem(…) method to return before continuing execution. It is important that your service handler executes your service asynchronously if its execution is not instantaneous.
An example of this would be a service task that invokes an external service. Since the delay in invoking this service remotely and waiting for the results might be too long, it might be a good idea to invoke this service asynchronously. This means that the handler will only invoke the service and will notify the engine later when the results are available. In the mean time, the process engine then continues execution of the process.
Human tasks are a typical example of a service that needs to be invoked asynchronously, as we don’t want the engine to wait until a human actor has responded to the request. The human task handler will only create a new task (on the task list of the assigned actor) when the human task node is triggered. The engine will then be able to continue execution on the rest of the process (if necessary) and the handler will notify the engine asynchronously when the user has completed the task.
24.1.2. Multiple knowledge sessions and persistence
The simplest way to run multiple processes is to run them all using one knowledge session. However, there are cases in which it’s necessary to run multiple processes in different knowledge sessions, even in different (technical) threads. Both are supported by jBPM.
When we add persistence (using a database, for example) to a situation in which we have multiple knowledge sessions (and processes), there is a guideline that users should be aware of. The following paragraphs explain why this guideline is important to follow.
|
Please make sure to use a database that allows row-level locks as well as table-level locks. |
For example, a user could have a situation in which there are 2 (or more) threads running, each with its own knowledge session instance. On each thread, jBPM processes are being started using the local knowledge session instance.
In this use case, a race condition exists in which both thread A and thread B will have coincidentally simultaneously finished a process. At this point, because persistence is being used, both thread A and B will be committing changes to the database. If row-level locks are not possible, then the following situation can occur:
-
Thread A has a lock on the ProcessInstanceInfo table, having just committed a change to that table.
-
Thread A wants a lock on the SessionInfo table in order to commit a change there.
-
Thread B has the opposite situation: it has a lock on the SessionInfo table, having just committed a change there.
-
Thread B wants a lock on the ProcessInstanceInfo table, even though Thread A already has a lock on it.
This is a deadlock situation which the database and application will not be able to solve. However, if row-level locks are possible (and enabled!!) in the database (and tables used), then this situation will not occur.
24.2. Asynchronous execution
24.2.1. Asynchronous handlers
How can we implement an asynchronous service handler? To start with, this depends on the technology you’re using. If you’re only using Java, you could execute the actual service in a new thread:
public class MyServiceTaskHandler implements WorkItemHandler {
public void executeWorkItem(WorkItem workItem, WorkItemManager manager) {
new Thread(new Runnable() {
public void run() {
// Do the heavy lifting here ...
}
}).start();
}
public void abortWorkItem(WorkItem workItem, WorkItemManager manager) {
}
}It’s advisable to have your handler contact a service that executes the business operation, instead of having it perform the actual work. If anything goes wrong with a business operation, it doesn’t affect your process. The loose coupling that this provides also gives you greater flexibility in reusing services and developing them.
For example, you can have your human task handler simply invoke the human task service to add a task there. To implement an asynchronous handler, you usually have to simply do an asynchronous invocation of this service. This usually depends on the technology you use to do the communication, but this might be as simple as asynchronously invoking a web service, or sending a JMS message to the external service.
24.2.2. jbpm executor
In version 6, jBPM introduces new component called jbpm executor which provides quite advanced features for asynchronous execution. It delivers generic environment for background execution of commands. Commands are nothing more than business logic encapsulated within simple interface. It does not have any process runtime related information, that means no need to complete work items, or anything of that sort. It purely focuses on the business logic to be executed. It receives data via CommandContext and returns results of the execution with ExecutionResults.
Before looking into details on jBPM support for asynchronous execution let’s look at what are the common requirements for such execution:
-
allows asynchronous execution of given piece of business logic
-
allows to retry in case of resources are temporarily unavailable e.g. external system interaction
-
allows to handle errors in case all retries have been attempted
-
provides cancellation option
-
provides history log of execution
When confronting these requirements with the "simple async handler" (executed as separate thread) you can directly notice that all of these would need to be implemented all over again by different systems. Due to that a common, generic component has been provided out of the box to simplify and empower usage.
jBPM executor operates on commands, which are essential piece of code that is going to be executed as background job.
/**
* Executor's Command are dedicated to contain purely business logic that should be executed.
* It should not have any reference to underlying process engine and should not be concerned
* with any process runtime related logic such us completing work item, sending signals, etc.
* <br/>
* Information that are taken from process will be delivered as part of data instance of
* <code>CommandContext</code>. Depending on the execution context that data can vary but
* in most of the cases following will be given:
* <ul>
* <li></li>
* <li>businessKey - usually unique identifier of the caller</li>
* <li>callbacks - FQCN of the <code>CommandCollback</code> that shall be used on command completion</li>
* </ul>
* When executed as part of the process (work item handler) additional data can be expected:
* <ul>
* <li>workItem - the actual work item that is being executed with all its parameters</li>
* <li>processInstanceId - id of the process instance that triggered this work</li>
* <li>deploymentId - if given process instance is part of an active deployment</li>
* </ul>
* Important note about implementations is that it shall always be possible to be initialized with default constructor
* as executor service is an async component so it will initialize the command on demand using reflection.
* In case there is a heavy logic on initialization it should be placed in another service implementation that
* can be looked up from within command.
*/
public interface Command {
/**
* Executed this command's logic.
* @param ctx - contextual data given by the executor service
* @return returns any results in case of successful execution
* @throws Exception in case execution failed and shall be retried if possible
*/
public ExecutionResults execute(CommandContext ctx) throws Exception;
}Looking at the interface above, there is no specific integration with the jBPM runtime engine, it’s decoupled from it to put main focus on the actual logic that shall be executed as part of that command rather to worry about integration with process engine. This design promotes reuse of already existing logic by simply wrapping it with Command implementation.
Input data is transferred from process engine to command via CommandContext. It acts purely as data transfer object and puts single requirement on the data it holds - all objects must be serializable.
/**
* Data holder for any contextual data that shall be given to the command upon execution.
* Important note that every object that is added to the data container must be serializable
* meaning it must implement <code>java.io.Seriazliable</code>
*
*/
public class CommandContext implements Serializable {
private static final long serialVersionUID = -1440017934399413860L;
private Map<String, Object> data;
public CommandContext() {
data = new HashMap<String, Object>();
}
public CommandContext(Map<String, Object> data) {
this.data = data;
}
public void setData(Map<String, Object> data) {
this.data = data;
}
public Map<String, Object> getData() {
return data;
}
public Object getData(String key) {
return data.get(key);
}
public void setData(String key, Object value) {
data.put(key, value);
}
public Set<String> keySet() {
return data.keySet();
}
@Override
public String toString() {
return "CommandContext{" + "data=" + data + '}';
}
}Next outcome is provided to process engine via ExecutionResults, which is very similar in nature to the CommandContext and acts as data transfer object.
/**
* Data holder for command's result data. Whatever command produces should be placed in
* this results so they can be later on referenced by name by the requester - e.g. process instance.
*
*/
public class ExecutionResults implements Serializable {
private static final long serialVersionUID = -1738336024526084091L;
private Map<String, Object> data = new HashMap<String, Object>();
public ExecutionResults() {
}
public void setData(Map<String, Object> data) {
this.data = data;
}
public Map<String, Object> getData() {
return data;
}
public Object getData(String key) {
return data.get(key);
}
public void setData(String key, Object value) {
data.put(key, value);
}
public Set<String> keySet() {
return data.keySet();
}
@Override
public String toString() {
return "ExecutionResults{" + "data=" + data + '}';
}
}Executor covers all requirements listed above and provides user interface as part of jbpm console and kie workbench (kie-wb) applications.
Above screenshot illustrates history view of executor’s job queue. As can be seen on it there are several options available:
-
view details of the job
-
cancel given job
-
create new job
24.2.2.1. WorkItemHandler backed with jbpm executor
jBPM (again in version 6) provides an out of the box async work item handler that is backed by the jbpm executor. So by default all features that executor delivers will be available for background execution within process instance. AsyncWorkItemHandler can be configured in two ways:
-
as generic handler that expects to get the command name as part of work item parameters
-
as specific handler for given type of work item - for example web service
Option 1 is by default configured for jbpm console and kie-wb web applications and is registered under async name in every ksession that is bootstrapped within the applications. So whenever there is a need to execute some logic asynchronously following needs to be done at modeling time (using jbpm web designer):
-
specify async as TaskName property
-
create data input called CommandClass
-
assign fully qualified class name for the CommandClass data input
Next follow regular way to complete process modeling. Note that all data inputs will be transferred to executor so they must be serializable.
Second option allows to register different instances of AsyncWorkItemHandler for different work items. Since it’s registered for dedicated work item most likely the command will be dedicated to that work item as well. If so CommandClass can be specified on registration time instead of requiring it to be set as work item parameters. To register such handlers for jbpm console or kie-wb additional class is required to inform what shall be registered. A CDI bean that implements WorkItemHandlerProducer interface needs to be provided and placed on the application classpath so CDI container will be able to find it. Then at modeling time TaskName property needs to be aligned with those used at registration time.
24.2.2.2. Configuration
jbpm executor is configurable to allow fine tuning of its environment. In general jbpm executor runs as a thread pool executor that schedules or directly executes jobs when needed. This is based on specialised executor to take into consideration job priority (important when there are many jobs to be fired at exact same time). Thread pool is backed by data base to make sure jobs will survive server restarts. When executor is initialised it will load all jobs that are awaiting execution into the thread pool executor.
Configuration of jbpm executor is done via system properties:
-
org.kie.executor.disabled = true|false - allows to completely disable executor component
-
org.kie.executor.pool.size = Integer - allows to specify thread pool size where default is 1
-
org.kie.executor.retry.count = Integer - allows to specify number of retries in case of errors while running a job
-
org.kie.executor.interval = Integer - allows to specify interval (by default in seconds) that executor will use to synchronize with data base - default is 0 seconds which means it is disabled
-
org.kie.executor.timeunit = String - allows to specify timer unit used for calculating interval, value must be a valid constant of java.util.concurrent.TimeUnit, by default it’s SECONDS.
24.2.2.3. Clustering and failover
jBPM executor will run jobs on the same server instance (jvm) that they were scheduled on. Unless that server crashes or is shutdown. In single server setup this will mean that until that server is brought up again, jobs are not going to be executed. In case of cluster, job might be executed by any cluster member if synchronisation with data base was enabled or on the same server when it was not enabled.
Whenever jBPM executor needs to run in cluster (meaning more than one instance using same data base) it’s recommended to enable synchronisation with underlying data base. That will ensure jobs from instances that failed will be processed by another cluster member.
To enable it, set org.kie.executor.interval system property to a valid interval. It’s recommended to take into account the demands of your
system, such as maximum acceptable delay for jobs to avoid too frequent synchronisations.
24.2.2.4. Reoccurring jobs
jbpm executor introduced (in verion 6.2) extension to jobs (aka commands) that allow single job to be executed multiple times. That feature is brought to the executor via additional interface that command should implement.
/**
* Marks given executor command it is reoccurring and shall be rescheduled after completion of single instance.
*
*/
public interface Reoccurring {
/**
* Returns next time to be scheduled. Date must be in future as jobs cannot be scheduled in past.
* Returns null in case it should not be scheduled any more.
* @return
*/
Date getScheduleTime();
}Reoccurring interface is very simple and enforces implementation to provide the next schedule time that the command should be executed at. It must already be valid date that is not in the past. In case no more invocation of given command should happen return value of this method should be null.
An excellent example of such command is org.jbpm.executor.commands.LogCleanupCommand that provides easy and convineint way to schedule periodic clean up of jBPM log tables on defined time intervals. See this article to see it in action and how to configure and run it.
24.2.2.5. Run jobs on same server node on which it was scheduled
By default jbpm executor is cluster ready and by that might distribute jobs across all cluster members. That might result in execution of given job on different cluster member than it was scheduled which is not always desired. To override this mechanism job can set 'Owner' as part of their data when being registered where owner is the executor instance that is scheduling the job.
CommandContext ctx = new CommandContext();
ctx.setData("some data", "data...");
ctx.setData("retries", 0);
ctx.setData("owner", ExecutorService.EXECUTOR_ID);That will ensure that only the instance that scheduled the job will be the one which will execute it. Note that it might impact the time when the job is executed especially in cases where given cluster member will be unavailable.
24.2.2.6. Assign priority to jobs
Asynchronous jobs are by default executed based on their scheduled time thus in case several jobs are scheduled to be executed at the same time there might be an issue with which one will be executed first. To override default behavior priorities can be assigned to individual jobs. Priority is given as integer from 0-9 range where 0 is the lowest priority and 9 is the highest. This can be done:
-
directly via CommandContext using priority context data object where value is a valid integer from 0-9 range
-
via data inputs of Async task where data input property name is Priority and value is a valid integer from 0-9 range
With assigned priority jBPM executor will pick the jobs based on the scheduled time and their priority. In case there is no priority assigned jBPM executor will set it to 5 as default.
jBPM executor can utilize JMS broker for notifying about job to be executed (only jobs to be executed immediately) and the priority then is also set on JMS message so the JMS broker will take this into account on delivery.
25. Release Notes
25.1. jBPM 7.11
25.1.1. New and Noteworthy in jBPM 7.11.0
The following features were added to jBPM 7.11
25.1.1.1. CMMN support in the jBPM Console
In addition to the recent support for executing CMMN 1.1 models, the jBPM Console now allows you to import, view and modify the content of .cmmn files.
When authoring a project, you will be able to import your Case Management Model and select it from the asset list for viewing or modifying using the standard XML editor.
25.1.1.2. jBPM Console Task Comments enhancements
In this release, the Task Management, Task Inbox and Task Report sections have been enhanced to display comments from completed tasks. This allows users to review any relevant mention that was added to accomplish certain task.
Task comments deletion is now restricted to the comment owner and task administrator users only.
-
Note: Task comments are available only if the deployment unit where the process lived still active and the task data still persisted. By default, the Kie Server runs a clean up job that removes any task related data from completed processes. If you wish to access the task comments once the process is completed, make sure you set the system property:
org.jbpm.task.cleanup.enabledtofalseonce starting the Kie Server instance.
25.1.1.3. Spring Boot support for KIE projects enhancements
We have further enhanced the Spring Boot support for KIE projects. Now you have the ability to use regular Spring beans for:
-
Process Event Listeners
-
Task Event Listeners
-
Case Event Listeners
-
KIE Server Event Listeners
-
Custom Workitem Handlers
In addition the following features were added:
-
Updated to the latest Narayana Spring Boot transaction manager
-
Added ability to register custom REST endpoints in KIE Server Spring Boot applications
-
Support for adding aliases when interacting with jBPM services from Spring Boot based applications
-
Support for Swagger documentation of REST api for custom Spring Boot applications
-
Replaced Jersey with the Spring Boot CXF JAX-WS Starter for serving REST endpoints. This enhancement will require a small change in your existing application.properties, namely remove existing
kieserver.restContextPath=/restand replace with
cxf.path=/rest25.1.1.4. SLA support enhancements
SLA support has been enhanced, it is now possible to define SLA (due date) on intermediate catch event nodes to track SLA on them.
25.1.1.5. Business model validation enhancement
Enhanced validation on business models for checks on empty Subprocess nodes.
25.1.1.6. Runtime engine enhancement
Updated support for broadcasting signals with expressions (e.g myevent-#{variable}). Event Subprocesses receive those correctly now.
25.2. jBPM 7.10
25.2.1. New and Noteworthy in jBPM 7.10.0
The following features were added to jBPM 7.10
25.2.1.1. jBPM Server Full Distribution Docker image
Version 7.10 introduces another way for people to get started very quickly. As an addition to the single zip distribution that we recently added on version 7.8.0.Final, you can now also use the jbpm-server-full Docker image to have a fully configured and running environment.
If you already have Docker installed on your local machine, all you need to do is run the following command:
docker run -p 8080:8080 -p 8001:8001 -d --name jbpm-server-full jboss/jbpm-server-full:latestOnce container and web applications started, you can navigate to it and login using the username wbadmin and password wbadmin
or any of the users available in the getting started document.
http://localhost:8080/jbpm-console
that’s all that is needed to get fully configured and running jBPM distribution that includes:
-
WildFly server
-
jBPM Console (aka workbench)
-
KIE Server
-
jBPM Case Management showcase
-
jBPM Service repository
Everything configured to work together smoothly and you can access them at following locations:
-
jBPM console - http://localhost:8080/jbpm-console
-
KIE Server - http://localhost:8080/kie-server/services/rest/server
-
KIE Server Swagger docs - http://localhost:8080/kie-server/docs
-
jBPM case management - http://localhost:8080/jbpm-casemgmt
-
jBPM Service repository - http://localhost:8080/repository
For mode details please read our updated Getting Started page, where you can find advanced information about using this new Docker image.
25.2.1.2. Jobs Management: Added bulk actions
The jobs list provides now a way to perform actions over multiple jobs, in a single operation. After one or more jobs are selected from the list, the bulk actions menu becomes available, with all supported actions. The available operations in this screen are 'Cancel' and 'Requeue'. If that operation is not allowed, regarding the job status, over any of the selected item, a notification is displayed and the operation is not executed on that item.
25.2.1.3. Process Instances Management: Further flexibility to access process instance related data
When retrieving process instance data, from one or more Kie Server instances, we used to enforce the rule that only data from active deployment units would be available. That is not a requirement any longer, as long as the data is persisted in the data base, it is now possible to list and display most of the information for any process instance. There is no need for the container to be running in order to list process instances in the Manage Process Instances area. Please note that the following data is not available when the deployment unit is not available:
-
Process instance diagram: As the actual image is hosted as part of the container resources, it is not possible to display the diagram.
-
Process instance variables: Only variables that changed its value during the process execution are listed.
25.2.1.4. CaseData type information is auto-imported into the process context
Prior to version 7.10 whenever referring to CaseData type a fully qualified class name has to be given. This applies to:
-
Milestone conditions
-
Stage (activation and completion) conditions
This has now been improved to allow short and direct reference to CaseData instead of org.kie.api.runtime.process.CaseData and CaseAssignment instead
of org.kie.api.runtime.process.CaseAssignment.
25.2.1.5. Stage name to trigger adhoc fragments
Initially to trigger adhoc fragments within given stage that required to use the identifier of the stage, 7.10 brings in additional option to refer to stage by name. This simplifies usability of the trigger operations and allow more human friendly approach.
25.2.1.6. Parameterized stage names
In addition to referring to stages by names, stages can now have parameterized names which will allow to distinguish them between each other in situations
when there are multiple stage instances of the same stage (definition). This makes it possible to trigger ad hoc fragments in particular stage instance when
referring to it my name and the name is unique due to use of parameters in the stage definition - Stage #{variable}
25.2.1.7. Archetypes
jBPM 7.10 introduces new maven archetypes to easily generate:
-
KJAR projects outside of workbench - allows to generate regular project and case project
-
service project - a fully featured service based on SpringBoot and equipped with business automation capabilities (kie server apis)
| Work in progress - This is an initial delivery which will be significantly improved over the coming weeks to provide comprehensive solution to build business applications with jBPM as one of the capabilities. |
Take a look at following documentation to learn more about these archetypes - kjar archetype and service archetype.
25.2.1.8. Process instance migration with timers
This is a worth noting bug fix that affects process instances with timers within subprocesses. Prior to this version such timers were simply canceled and not rescheduled after migrating process instances. This has been fixed and thus it is strongly recommended to upgrade to version 7.10 as soon as possible if you plan to migrate active process instances and there are timers within subprocesses.
25.2.1.9. JPA entities can be used as case file variables
Case file follows same approach for externalizing data storage, meaning different type of data can be stored in different systems. With 7.10 it is now possible to use JPA entities as case file variables that will be stored in separate database columns.
The only requirement is to configure the marshaller in deployment descriptor
.withJpa("org.jbpm.persistence.patient.example")and the complete registration of the marshaller is:
org.jbpm.casemgmt.impl.marshalling.CaseMarshallerFactory.builder().withDoc().withJpa("org.jbpm.persistence.patient.example").get()25.3. jBPM 7.9
25.3.1. New and Noteworthy in jBPM 7.9.0
The following features were added to jBPM 7.9
25.3.1.1. Installation of work items directly from service repository
Service repository that has been improved a lot over the last two releases received another feature - install work items into existing workbench. This then allows to have the project directly prepared for work items without a need to install it from within jBPM designer.
To read more have a look at this article.
25.3.1.2. Running the service repository on Heroku
Another feature added to the service repository was the ability to deploy the springboot repository war on Heroku.
For more information see this documentation
25.3.1.3. Service repository rest service
When using the sevice repository springboot or wildfly deployments in addition to the numerous workitems hosted users now have a rest api available to query information about these workitems.
The rest service include following end points:
/repository/rest/services
/repository/rest/services/{name}
/repository/rest/services/{name}/parameters
/repository/rest/services/{name}/results
/repository/rest/services/{name}/mavendepends
/rest/services/category/{category}
/rest/servicetriggers
/rest/servicetriggers/count
/rest/serviceactions
/rest/serviceactions/count25.3.1.4. SpringBoot jBPM auto configuration update
SpringBoot auto configuration for jBPM (and KIE Server that uses jBPM extension) has been improved to allow to use custom entities as part of the EntityManagerFactory used by the execution engine. That enables colocation of business logic and business assets.
It’s enough to provide a bean that will override entityManagerFactory bean that comes with jBPM auto configuration.
@Bean("entityManagerFactory")
public LocalContainerEntityManagerFactoryBean entityManagerFactory(JpaProperties jpaProperties, DataSource dataSource){
LocalContainerEntityManagerFactoryBean factoryBean = new LocalContainerEntityManagerFactoryBean();
factoryBean.setPersistenceUnitName(PERSISTENCE_UNIT_NAME);
factoryBean.setPersistenceXmlLocation(PERSISTENCE_XML_LOCATION);
factoryBean.setJtaDataSource(dataSource);
factoryBean.setJpaPropertyMap(jpaProperties.getProperties());
factoryBean.setPersistenceUnitPostProcessors(new PersistenceUnitPostProcessor() {
@Override
public void postProcessPersistenceUnitInfo(MutablePersistenceUnitInfo pui) {
pui.addManagedClassName("org.jbpm.springboot.samples.entities.Person");
}
});
return factoryBean;
}25.3.1.5. Performance baseline for jBPM 7
Wondering how good jBPM performs when it comes to execution? Here is a very interesting study describing base performance of jBPM execution through KIE Server.
25.3.1.6. Creation of indexes for all database tables
With the update to JPA 2.1 all jBPM entities received an update to declare index creation information. This results in a better query performance overall.
25.3.1.7. Process Designer
This release allows the user to enable/disable HiDPI via system preferences, that results on performance improvements for users with non HiDPI screens.
It also improves the performance and user experience by adding support for image strips, on both canvas and DOM side, making all icons appear instantaneously on all browsers and all components.
Also some other issues has been fixed. The most relevant ones are:
-
Fixed issues when changing between different element types, restricted the available morphing types for tasks, sub-processes and events
-
Fixed issues related to boundary events
-
Fixed issues when saving properties for the ad-hoc and multiple instance sub-process
25.4. jBPM 7.8
25.4.1. New and Noteworthy in jBPM 7.8.0
The following features were added to jBPM 7.8
25.4.1.1. CMMN 1.1 native execution
jBPM version 7.8 introduces native support for execution of CMMN 1.1 cases. It provides main constructs support and does not aim at full specification coverage. Constructs that are currently available are:
-
tasks (human task, process task, decision task, case task)
-
discretionary tasks (same as above)
-
stages
-
milestones
-
case file items
-
sentries (both entry and exit)
Not all attributes of tasks are supported - required, repeat and manual activation are currently not supported. Although most of the behaviour can still be achieved using different constructs. Sentries for individual tasks are limited to entry criteria while entry and exit are supported for stages and milestones.
Decision task by default maps to DMN decision although ruleflow group based is also possible with simplified syntax - decisionRef should be set to ruleflow-group attribute.
Event listeners are not supported as they do not bring much value for execution and instead CaseEventListener support in jBPM should be used as substitute.
jBPM does not provide any modeling capabilities for CMMN and focuses purely on execution of the model.
Even with the support of CMMN jBPM still promotes BPMN2 and the most powerful way of designing your case definition where you can take advantage of the both specifications.
25.4.1.2. Single zip distribution of jBPM
Version 7.8 introduces simplified distribution to let people start very quickly. It is a single zip distribution that requires just three steps:
| 1 | download |
| 2 | unzip |
| 3 | run |
curl https://download.jboss.org/jbpm/release/7.8.0.Final/jbpm-server-7.8.0.Final-dist.zip --output jbpm-server-distribuion.zip (1)
unzip jbpm-server-distribuion.zip -d jbpm-server (2)
jbpm-server/bin/standalone.sh (3)that’s all that is needed to get fully configured and running jBPM distribution that includes:
-
WildFly server
-
jBPM console (aka workbench)
-
KIE Server
-
jBPM case management showcase
-
jBPM Service repository
Everything configured to work together smoothly and you can access them at following locations:
-
jBPM console - http://localhost:8080/jbpm-console
-
KIE Server - http://localhost:8080/kie-server/services/rest/server
-
KIE Server Swagger docs - http://localhost:8080/kie-server/docs
-
jBPM case management - http://localhost:8080/jbpm-casemgmt
-
jBPM Service repository - http://localhost:8080/repository
In addition, this distribution simplifies switching to other databases - MySQL and PostgreSQL. As simple as just running a script from within jbpm-server/bin directory
./jboss-cli.sh --file=jbpm-mysql-config.cli (Unix / Linux)
jboss-cli.bat --file=jbpm-mysql-config.cli (Windows)To read more have a look at this article.
25.4.1.3. Pluggable Startup strategy in KIE Server
KIE server has be equipped with additional pluggable mechanism that allows to control the startup behaviour. Main use case is to allow finer control over what KIE containers are deployed and in what order. Primary usage pattern is to allow to use monitoring application (workbench) to manage processes and tasks on immutable KIE Servers. That means they are not under control of the KIE Server Controller but rather decide themselves what containers should be deployed.
There are two out of the box strategies provided:
-
ControllerBasedStartupStrategy - default startup strategy that will favour controller configuration whenever is given and thus override any local configuration. In case controller endpoint is not present it will fallback to what is known in the local server state file
-
LocalContainersStartupStrategy - strategy that will always deploy containers configured in the server state file regardless of the controller configuration although when controller endpoint is given it will connect to it.
Users can implement they own startup strategies by implementing org.kie.server.services.api.StartupStrategy interface and then packaging
it in ServiceLoader way - it needs to have services file that defines the implementation class which is then used upon startup of the
server via discovery mechanism.
To specify which startup strategy should be used a system property org.kie.server.startup.strategy should be set
to the name of the class (simple name) implementing given strategy.
Example: -Dorg.kie.server.startup.strategy=ControllerBasedStartupStrategy
25.4.1.4. Custom queries as data set editor in workbench
Custom queries are really powerful features and frequently used. jBPM 7.8 introduces a data set editor to allow use of it in workbench environment. This editor allows to build data sets that can later on be used to build pages and dashboards based on actual information retrieved from KIE servers on runtime.
These data sets are scoped to server templates and by that will only target particular subset of KIE Servers. Moreover by using KIE Server as the source of data, it removes the need to directly access databases which (especially in cloud environments) might not be desired or even possible. Additionally, these queries are executed in user context (user performing the query is actually user who is logged into workbench) which makes the results tailored to given user - important from security point of view - will only see data that is authorised to see.
To learn more have a look at this article.
25.4.1.5. Support for FEEL language as expressions for sequence flows
Drools provides support for DMN and FEEL language from the early days of version 7. jBPM added support for decision evaluation some time ago too. Now it was time to add FEEL language support for sequence flows of the process definition. Users who work with DMN can unify the language used for expressing condition logic to just single one - FEEL.
25.4.1.6. Milestone condition support for multiple instances
Milestone used in specific situation where there are multiple instances of the same milestone node active at the same time requires additional check upon match. This is to allow extra filtering of matches to find the right instance to be completed.
This advanced use case manifests itself when users model logic for multi instance activation where just simple rule is not enough.
An example of it is to have a stage that includes milestone and each of the stage deals with other types of document to be processed.
Milestone in that stage tracks progress of the document, although it should track individual documents of each stage. So an extra validation
on the milestone is required.
And for that exact scenario a MatchVariable was introduced. This is an extra parameter on milestone itself (next to condition) that specifies
name of the variable it should compare with matched items. So if the stage has a variable documentType and then the rule in milestone is as follows:
$caseData : CaseData()
$documentType : DocumentType(uploaded == true) from $caseData.getData(docName)user can set MatchVariable parameter to documentType to compare the activation item ($documentType) with documentType
variable taken from stage instance and only if this match that milestone instance will be completed.
25.4.1.7. Case instance migration
Similar as there is support for process instance migration, version 7.8 introduces case instance migration. This essentially allows to move given case instance from one definition to another - in other words migrate to another case project version. This instance migration ensures that all active process instances for given case instance are migrated at the same time, thus it’s required to provide mapping of case definition and process definitions at the time when doing migration.
Same as for process instance migration, there is optional parameter for mapping nodes from old to new version of case or process definition.
25.4.1.8. Even more improvements around service repository and work items
jBPM 7.8 continues with improvements for service repository and work items to make them as simple as possible to be build and used. It’s very powerful feature that is underused usually due to the difficult entry level… but that is now the past. The future looks much brighter than ever. Have a look at this article to see how easy it is to build your own service tasks and make use of them in your processes.
After that, read up these tips and tricks how to get even more from it.
25.4.1.9. Process Designer
One of the most important updates is that Stunner becomes the default process editor. As it’s still not fully feature complete, this new release also includes support for the jBPM process designer editor. This way there exists two editors for business processes, the Business Process, which relies on Stunner, and the Business Process (legacy) one, which relies on the legacy process editor.
It also includes new features, improvements and some bug fixings.
Features and improvements
-
Stunner becomes the default process editor (also for processes from the built-in examples)
-
Improved the overall performance, response and computation times spent by the editor’s engine
-
Fixed support for Internet Explorer 11
-
Platform integrations
-
Backend generation for the process' SVG image
-
Process SVG integration into the workbench (console)
-
Integration with the jBPM validation engine
-
Support for the Overview panel
-
Open a XML Editor in case it is not possible to open a process file in the graphical editor. This allows manual fixing of the issue in the process file.
-
Automatic deployment for service tasks (from both the default and from external repositories)
-
-
New preferences
-
Default canvas size
-
Palette close behavior
-
-
Properties panel
-
Automatic grouping for fields
-
Brand new actors field editor for User Task - it supports filtering and inline creation of new items
-
Bug fixings - most relevant
-
Fixed memory leaks after opening several processes
-
Fixed intermediate event connection cardinality rules
-
Fixed issues with control points inside containers
-
Fixed the inline editor for the element’s name
-
Make notifications more user friendly
-
Editor for tasks' data assignments is now filtering by the current project
-
Allow to see old process versions
-
Do not allow updates on view mode (old process versions)
-
Fixed issues about wrong shape locations after applying zoom
-
Fixed issues during process import that were making the editor show an error and so not be usable
-
Fixed issues when nesting containers
-
Fixed the limited command registry, that was causing the editor stop working after long time
-
Fixed issues about docking (boundary events)
25.4.2. New and Noteworthy in KIE Workbench 7.8.0
25.4.2.1. New System Property for setting the Default Maven Repository in Project pom.xml files
To make building Workbench projects outside of the Workbench easier, it is now possible to set the URL for the default Maven Repository that is added into each new Project pom.xml. It is recommended that you set this before starting you Workbench for the first time.
25.5. jBPM 7.7
25.5.1. New and Noteworthy in jBPM 7.7.0
The following features were added to jBPM 7.7
25.5.1.1. jBPM executor redesigned
up to version 7.7, jBPM executor used default mechanism based on polling. It periodically polls data base to check if there are any jobs to be executed. This does not scale too good and was main motivation to approach redesign. With version 7.7, jBPM executor is enhanced to remove polling mechanism and instead relies on specialised ScheduledThreadPoolExecutor that respects job’s priority.
This allows to have really efficient processing with less load on the data base (and less locks on data base). New mechanism does cover all possible types of jobs including retries and requeues. With additional JMS trigger (that was already present since version 6.3) this provides complete and fast asynchronous job processing solution. To read up more on this see this article and async section in the docs.
25.5.1.2. UserInfo interface allows to get user id by email
Small addition to UserInfo interface (and its default implementations) was provided to allow to find user id by email address. This is the reverse operation that was already there - get email address by user id. With this, email integration (such as completing task by email) can be easily implemented.
25.5.1.3. Service Level Agreement (SLA) tracking for processes and cases
SLA tracking has been added to jBPM to allow to easily keep track of the execution of:
-
processes
-
cases
-
individual activities of the process/case
This allows administrators to be always up to date with what is happening with running processes and be notified when SLA are violated. More can be found in SLA overview article and SLA with cases article.
25.5.1.4. Case stages activation condition
Case stages (ad hoc subprocesses) are equipped (next to completion condition) with activation condition. This means that ad hoc stage can be automatically activated when defined condition is met. Conditions should be defined as rule expressions and usually refer to case file data, although are not limited to that.
25.5.1.5. NoSQL integration
Initial integration with NoSQL (and not only that) has been introduced. This is based on additional so called Emitters that can be implemented to receive notifications when process engine executes processes. In general, this allows users to plugin their own emitters that will be responsible for sending data to externals data stores. Note that this is integration and not replacement of persistence layer of jBPM. You can read up more about it in this article and if would like to see an implementation based on Elasticsearch, take a look at this article
25.5.1.6. Process Designer (Preview)
The new version of the jBPM Process Designer (Stunner) provides lots of new features, plus some other stability and usability improvements as well.

Here is a summary of some of the most relevant new features and improvements included on this release:
-
Palette visual and structural re-design

-
Visual enhancements for shape states


-
Shape resize constraints capabilities
-
Increased the available modelling area size
-
Improved docking related capabilities (boundary shapes)
-
Enhanced the usability by doing automatic adjustment (snap) to the docking magnets while dragging the boundary shapes
-
Ability to dock boundary shapes directly when dragging from the palette
-
-
UI Exporting capabilities improved
-
Export into BPMN2
-
Export into an SVG image
-
-
Added new drop-down selector field type with filtering capabilities
-
Support for connector’s bend-points (eg: move points, add/remove points)

-
Added new connector type that renders as a regular poly-line
-
Process import/export capabilities
-
Toolbar re-design

-
Automatic migration capabilities between both process designers
-
Keyboard mappings improved (eg: arrow key)
-
Form generation capabilities
-
BPMN2
-
Support for service tasks
-
Support for event sub-process
-
Support for ad-hoc sub-process
-
Support for multiple instance sub-process
-
Support for parallel gateway
-
Shapes re-design
-
Icons re-design
-
Support for interrupting events (start events)
-
Included brand new marshaller and unmarshaller implementations, which rely on the Eclipse BPMN2 domain model, and new complete suite of unitary tests (still experimental)
-
25.5.1.7. jBPM Manage section redesign
The entire admin console screens have been re-designed focusing on:
-
Create new layout and re-styling existent elements.
-
Revise master/detail navigation
-
Review and improve quick filter creation
-
Review and improve saved filters
-
Rename top level menus
New layout
A new layout have been created as part of the admin console screens re-design. The new layout of jBPM Manage section contains the following new areas:
-
(1) Breadcrumb area: Contains breadcrumbs and the server template selector.
-
(2) Filters area: Contains the dock for filter creation and dock with saved filters
The new docks are placed in the expandable panel on the left side of the screen. The selections made inside any of the docks are immediately reflected in the table on the right.
That panels can be expanded or collapsed using the standard workbench docks controls.
-
(3) Manage screen selector.
The new drop-down offers navigation to the all manage screens: Process Definitions, Process Instances, Tasks, Execution Errors and Jobs have been created. This selector allows the user to switch process admin screens quickly and easily.
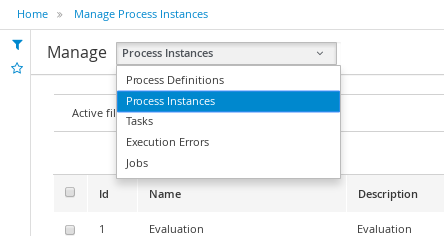
-
(4) Toolbar area.
This toolbar has been designed to contain each screen specific actions and provides different kinds of visualizations: icons for common actions like 'Refresh' that are self-explained, buttons for primary actions and it’s prepared for containing kebab with a list of actions.
-
(5) Filter status area.
As in previous version shows the currently applied filters and provides options to clear individual filters or to clear them all. The new feature introduced is the ability to save the currently applied filter as a new saved filter, which becomes available in Saved filters dock (see Filters area above)
-
(6) The list table area.
The previous table layout has been redesigned to list-like layout, matching with PatternFly guidelines. Some of the changes that have been added:
— New styles are applied to the different list elements.
— The page size selector and the pagination footer has been re-styled and placed closer to the list.
— PatternFly standards applied to list item’s actions. Perform actions on individual list items using the kebab button control. When there are more than one available actions the kebab groups the available actions. There are different areas at kebab: primary actions first and separately the navigation to other screens ones
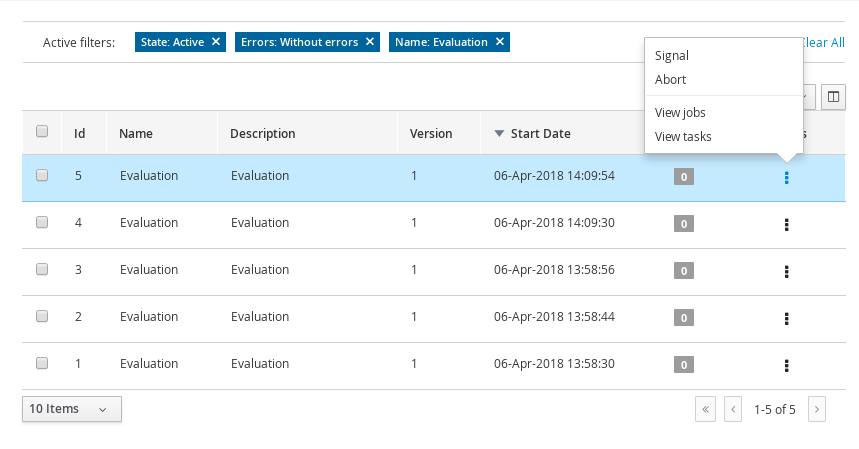
Revised master/detail navigation
The different management screens have been redesigned to change the way to open the item detail. When the user selects an item by clicking on the the list row to drill into the details, the item details are shown in full screen and the master list disappears, instead of being open in a right side panel as was in the previous versions
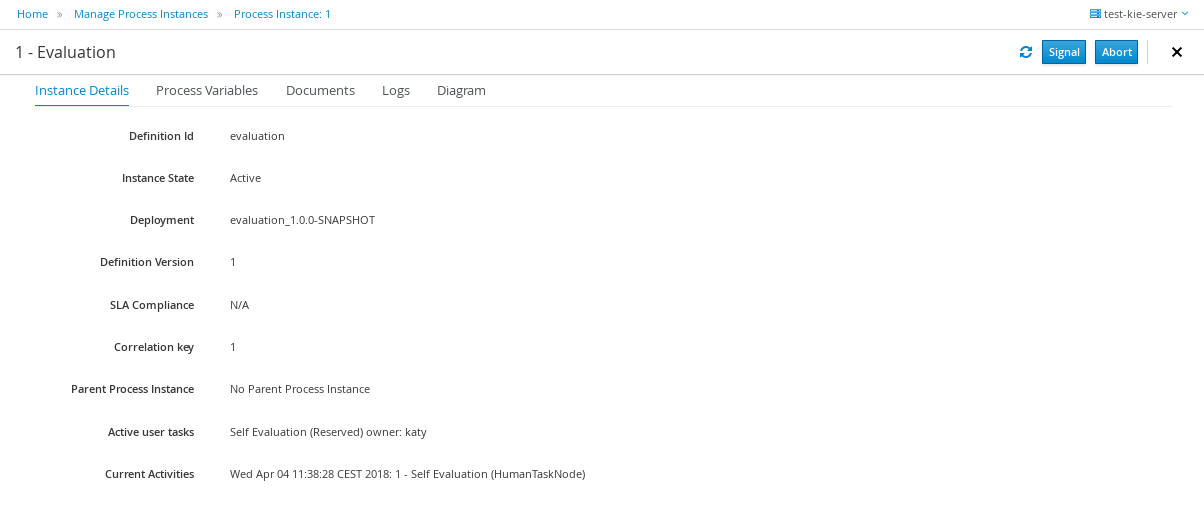
Some changes have been introduced for that purpose:
-
Migrated details views to full screen/adjust styling and breadcrumbs
-
Moved process model popup in process definition and instance to tab in details ( process definitions and process instances)
-
Moved actions to the new layout toolbar.
-
Re-styling the tabs items details to be shown in full screen mode
-
Navigate back to list view using “X” close button or breadcrumbs
Reviewed and improved quick filter creation
The quick filter bar have been placed to the dock panel and reorganized in vertical disposition.
A new type of basic filters has been introduced to allow multiple value selection. It’s using checkboxes controls to set the different values. The resulting restriction of selecting different values is retrieve the items that match with one of selected values.

This new type of filter has been applied on this following fields:
-
Process instances: State (Active, Aborted,..) and Errors (With errors, Without errors)
-
Task: Status (Completed, Created, ..)
-
Execution Errors: Type (DB, Task, Process, Job)
-
Jobs: Status (Canceled, Completed,..)
Reviewed and improved saved filters
Different changes have been done in this area:
-
Migrated filter tabs to 'Saved filters' dock, in side panel that shows the list of stored filters.
-
Moved the 'Add advanced filter' that opens the previous creation filter popup, to 'Filters' dock.
-
The 'Saved filters' dock allows manage the stored filters:
-
Filters can be deleted
-
The defaults filters can be always restored as in the previous version with the 'Restore default filters' button.
-
Filters can be applied: When a user selects one filter, that is applied on the current list and the 'Active filters' displays the restrictions contained in that filter.
-

-
The user has now the ability to modify/complete filters and save it to be reused later. The new way to save filter is selecting 'Save filters' at 'Active filters' bar. A name for the new stored filter is requested and a new filter with the current restrictions is added to 'Saved filters' list.
It’s not allowed to have filters with the same name. When the user tries to save a filter with an existing name, currently an error is shown.

Reviewed Reports section design allowing to work with master / detail
The reports screen has been separated in two sections: Task reports and Process reports.
This new screens are using the new layout, The item details are opened in full screen mode too and the breadcrumb has been added to allow the navigation and keep consistency with the other console screens.
The new layout toolbar has been filled with the action to change between dashboard and table view.
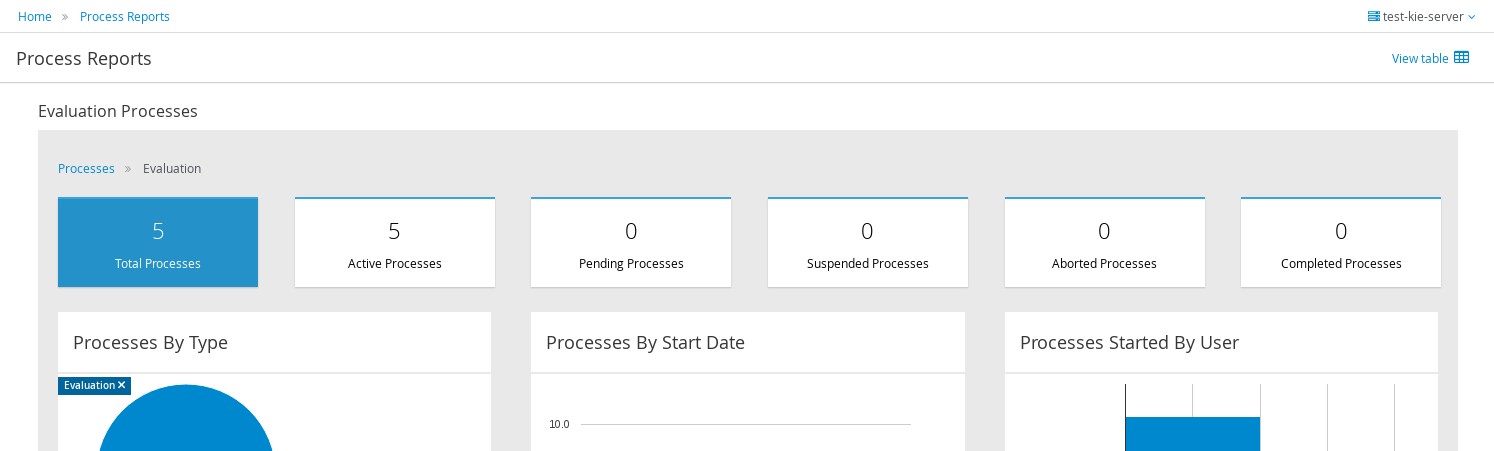

Renamed top level menus
Some naming adjustments have been done to the top level menu:
-
'Task Administration' → 'Tasks'
-
'Task List' → 'Task Inbox'
-
'Process & Task Reports' → two new options: 'Process Reports' and 'Task Reports'

25.5.1.8. Other specific changes on Admin console screens
Process Definitions
-
Navigation to process instantes has been placed at process definitions list.
-
View 'Process model' has been placed as a new tab 'Diagram' on the process definition detail.
Process Instances
-
View 'Process model' has been placed as a new tab 'Diagram' on the process definition detail.
-
Signal and abort actions are exposed as a primary actions at new layout toolbar.
Task ( previously Tasks Administration)
-
In the previous version Tasks were only displayed when the current user was part of the following system properties in Kie Server: org.jbpm.ht.admin.user (default: Administrator) or org.jbpm.ht.admin.group (default: Administrators). With the current implementation when this criteria isn’t met, this screen retrieve the list of tasks where the logged user or any of its groups have 'Business Administrator' relationship with them.
-
An error count column added to task information. Same as the error column in process instance list. Also add navigation link (View Errors).
Task details
-
Removed 'Process Context' tab. Leaving the navigation to process instance screen at task list.
-
'Process Instance Id' and 'Process Definition Id' have been placed at 'Details' tab
-
Reviewed styles on primary actions buttons
25.5.2. New and Noteworthy in KIE Workbench 7.7.0
25.5.2.1. Project Oriented Workbench
Workbench becomes Project Oriented. Meaning each project is now in a dedicated repository. Previously each project was in a folder and one repository could hold several projects. These changes merge the concepts of Project and Repository.
One project one repository approach makes the UI simpler and improves releasing or freezing a single project. Previously if a project was frozen, branched or tagged the repository was still shared with other projects, making the release control harder and more complicated.
Projects from older Workbench versions need to be migrated to the new setup. For this we offer a command line migration tool.
Project Orientated does not, at the moment, offer support for multimodule setup. This feature is planned, but not in this release. The now deprecated Asset Management features depended on multimodule support and can not be migrated to this Workbench version.
25.5.2.2. Connecting to a remote Kie Server Controller
When running a Workbench instance, there is now greater flexibility to decide how Kie Server instances will be managed. Previously, whenever a Workbench is started, it would always start an embedded Kie Server Controller. This setup is still available but now there is also an option to not start this service and instead connect to a remote Kie Server Controller. This allows a more fine grained deployment model where it’s possible to decide the best approach for a specific scenario.
To switch between these modes, a key system property is used: org.kie.workbench.controller. By default, the Workbench will continue to start the embedded service if this system property is missing. Otherwise, it will try to connect to the remote service and also ensure that none of the embedded services are started.
It is important to note that only Web Socket connection protocol is available to use when connecting to remote Kie Server Controller.
For more details regarding all possible system configs regarding user name, password, token and secured password via key store, please refer to Workbench system properties.
25.5.2.3. Content management enhancements
Properties panel
It is possible to edit the properties of the different page elements including, the page itself or any of its rows and components. Once an element is selected, either by hovering on the element and clicking on the editor’s area or selecting the element in the Properties panel dropdown, its properties are displayed in the left docked panel. See screenshot:
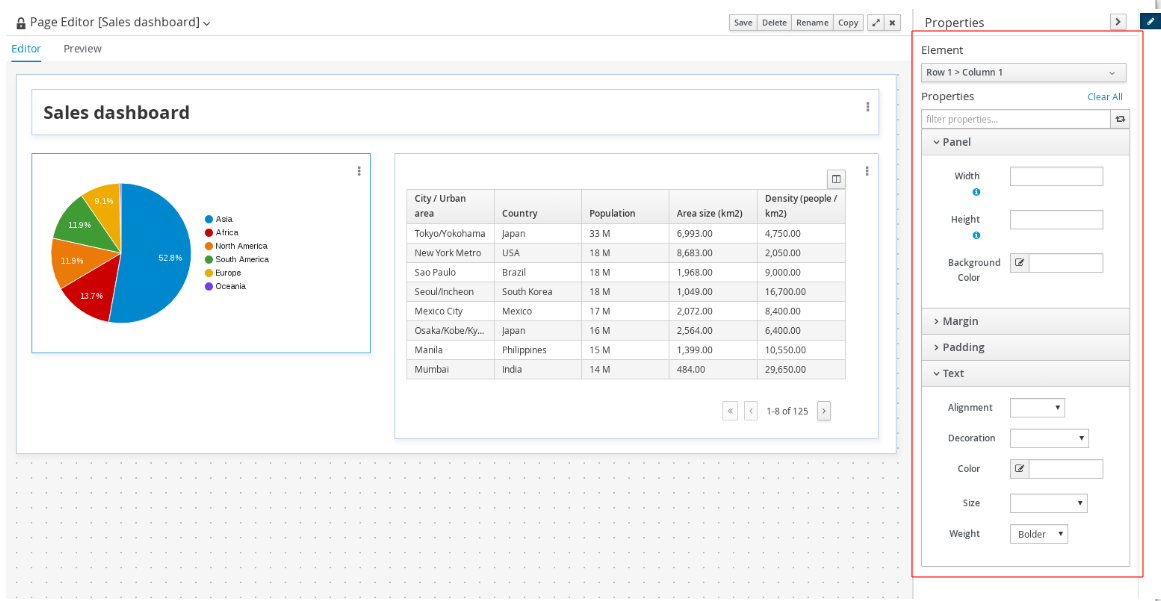
The properties available in this version are basically those related with the element style such as width, height or margins, amongst others. The properties available might differ for each type. Notice for example, the HTML component provides an extra set of properties all related with the text style.
Once a property is changed, its value is reflected in the editor’s area, both in design and preview modes.
Screen component removed
The Screen component, which was placed under the Core group in the right sidebar’s Components panel, has been removed. The reason is, this component was not suitable for production environments.
In future versions though, domain related components, such as a BPM’s task list, will be available for easy consumption by end users.
25.5.2.4. New Migration Tool
A new command line Migration tool with support for Linux and Windows has been provided to move different resources to it’s latest version. It makes possible to perform different migrations:
-
Project Migration: migrates KIE projects from the old project layout (7.4.x and previous) to the new project-oriented structure.
-
Forms Migration: migrates old jBPM Form Modeler forms into the new Forms format.

You can find more info here.
25.6. jBPM 7.6
25.6.1. New and Noteworthy in jBPM 7.6.0
The following features were added to jBPM 7.6
25.6.1.1. Process Designer (Preview)
The new version of the jBPM Process Designer (Stunner) provides stability enhancements again by introducing several bug fixings, tests and other improvements.
Most relevant features and improvements for this version are:
-
Support for multiple selection (operations with multiple elements)
-
Added cut/copy/paste capabilities
-
Support for shape size constraints
-
Improved BPMN2 support:
-
Added Start Message Event
-
Added Start Error Event
-
Added End Message Event
-
Added End Error Event
-
Added Catching Intermediate Error Event
-
Added Catching Intermediate Message Event
-
Added Throwing Intermediate Message Event
-
Improved signal management for events
-
New widget which improves the declaration for the timer event related properties
-
Added some help messages
-
25.6.1.2. Form Modeler
Old jBPM Form Modeler has been deprecated and new Form Modeler has become the default Forms Engine (a migration tool will be provided to move old forms into the new forms format). This new version improves the Forms Engine stability and provides several fixes for different bugs.
Most important features:
-
Added form synchronization on editor startup to fix possible errors caused by model changes (properties removed, type changes…)
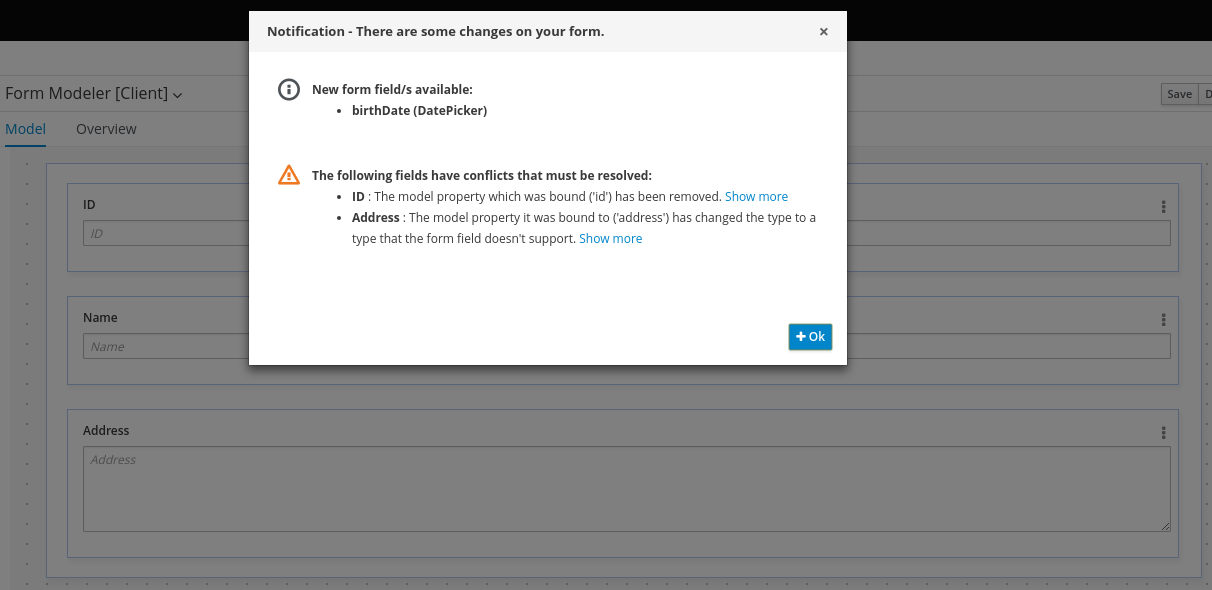
-
Added ability to show Help Messages on fields properties (supports plain text or HTML)
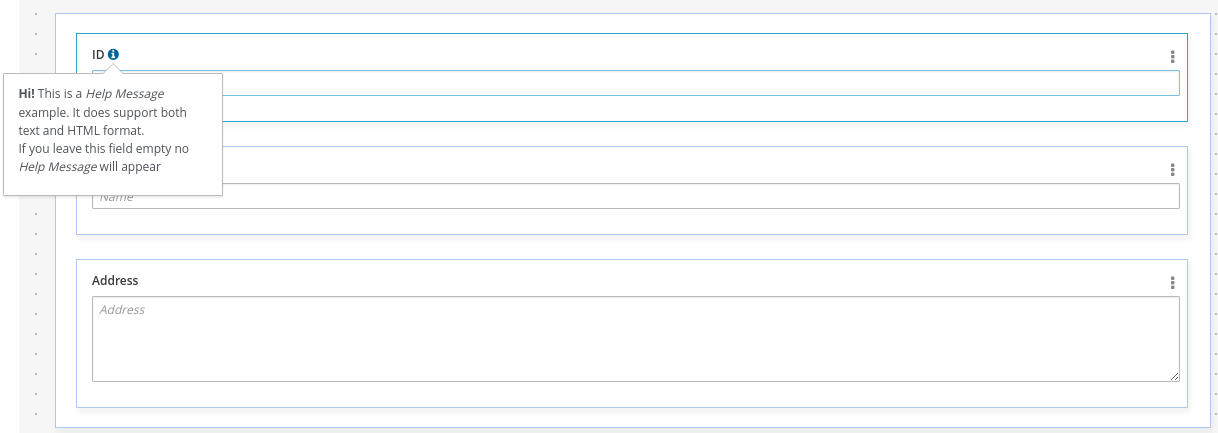
25.6.1.3. Quartz upgraded to 2.2.3
Scheduler Service based on Quartz has been upgraded to use latest version of Quartz library 2.2.3. That means when updating to 7.6.0 of jBPM and existing installation uses Quartz as scheduler service that will require upgrade before moving further. jBPM comes with upgrade script that is delivered as part of jBPM installer and is specific to data base being used by Quartz.
It is located in jBPM installer/db/upgrade-scripts/{database-name}/quartz-upgrade.sql
Procedure to be followed is:
-
stop jBPM (for example kie server)
-
upgrade Quartz data base with suitable quartz-upgrade.sql script (according to data base used)
-
upgrade jBPM (for exmaple kie server binaries)
-
start jBPM
There are no changes in the quartz.properties file as it will work exactly the same.
25.6.1.4. Support for lazy loaded variables
Pluggable variable persistence strategy has been improved to support (optionally) lazy loaded variables. That is mainly to improve performance and reduce load on external systems that store these variables. Especially valid for documents that could be of significant size and could be stored in external document management systems. To read up more on this see this article
25.6.1.5. Expose readiness and liveness checks in KIE Server
KIE Server has been equipped by default with readiness and liveness checks (REST endpoints)
-
readiness will either respond with 200 (OK) when it’s actually ready or with 503 (Service Unavailable) when it’s still booting/deploying containers/waiting for controller.
-
liveness (aka health check) will perform following:
-
check readiness
-
check for failed kie containers
-
ask each active extension to health check itself response codes for health check are same as for readiness. Meaning that any error found will result in response 503, regardless if that is failed container, failed extension or not ready yet.
-
Health check can be invoked in two modes:
-
basic - that will return status only (200 or 503)
-
report - will respond with both status and report in response body that will provide info like below (body can be XML or JSON)
Examples:
-
Readiness check
http://localhost:8080/kie-server/services/rest/server/readycheck -
Liveness check
http://localhost:8080/kie-server/services/rest/server/healthcheck -
Liveness check with report
http://localhost:8080/kie-server/services/rest/server/healthcheck?report=true
25.6.1.6. Allow to disable management api of KIE Server
Administrators can decide to disable management api of KIE Server - that is to disallow modifying server configuration once the server was started. This is especially important when running in cloud based environments where the image consists of kjars to be active and no other kjars should be deployed to it.
By setting system property org.kie.server.mgmt.api.disabled to value true KIE Server will disable management api (that changes the state of it)
and when attempted will always respond with code 400 (Bad Request). This applies both to REST api and JMS api.
25.6.1.7. Spring Boot support for KIE projects
KIE projects (jBPM, Drools and OptaPlanner) has been prepared for running in Spring Boot setup for a while now but with 7.6.0 release they are providing so called starters that can be easily used to bootstrap your projects with Spring Boot.
Following is a list of Spring Boot starters:
-
jBPM business process management - embedded engine
-
groupId: org.kie
-
artifactId: jbpm-spring-boot-starter-basic
-
-
Fully featured KIE Server (Drools, jBPM, Optaplanner)
-
groupId: org.kie
-
artifactId: kie-server-spring-boot-starter
-
-
Rules and Descisions KIE Server (Drools, DMN)
-
groupId: org.kie
-
artifactId: kie-server-spring-boot-starter-drools
-
-
Rules and Descisions, Process and Cases KIE Server (Drools, DMN, jBPM, Case mgmt)
-
groupId: org.kie
-
artifactId: kie-server-spring-boot-starter-jbpm
-
-
Planning KIE Server (Optaplanner)
-
groupId: org.kie
-
artifactId: kie-server-spring-boot-starter-optaplanner
-
Starters can also be used directly from https://start.spring.io to generate the project.
25.6.1.8. Jobs creation (Admin Console): Allow Launching the the job inmediatly or scheduling
The Job creation inferface has been modified to allow start the job inmediatly or schedule it for being executed later.
A new Date & time picker has been integrated to allow the user to select the exact moment when the job have to be executed. This option is only available when the 'Run Later' option is selected.
25.6.2. New and Noteworthy in KIE Workbench 7.6.0
25.6.2.1. Content management enhancements
A few extra changes have been introduced in the Content Management tooling (aka Page Authoring) in order to improve the user experience. The following screenshot reveals the changes introduced since the latest version.
Fluid/Page editor mode selection
The new page pop up allows for the selection of two edition modes:
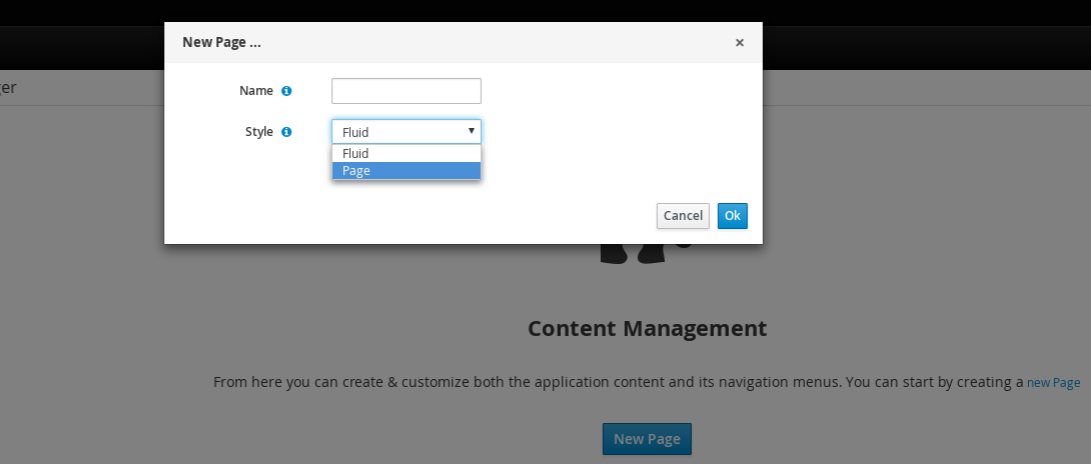
-
Fluid: it acts more as a classical web page, showing a vertical scrollbar when the page exceeds the available height.
-
Page: it was the default in previous versions. When selected, it forces the page to always fit the window’s 100% height.
Preview feature
Page authors can go back and forth from the Editor to the Preview mode as many times as needed. In the Preview mode all the editor’s controls are removed, allowing for the display of the page as it would be seen by end users once the page is published.
Use dock panels to increase the editor content area
In order to increase the available space in the editor’s central area, the page listing, the navigation configuration and the component palette panels have all been moved to the left sidebar as docked panels.
Component palette reorganization
In previous versions, there only existed one single category of components in the palette. As of version 7.6, the components are now grouped into three main categories:
-
Core: HTML and Page components
-
Navigation: Menu Bar, Tree, Tiles, Tab List, Carousel and Target Div
-
Reporting: Bar, Pie, Line, Area, Map, Bubble, Metric, Meter, Table and Filter
The goal of these changes is to make the palette more appealing as well as to ease the selection of the target component to drag.
25.7. jBPM 7.5
25.7.1. New and Noteworthy in jBPM 7.5.0
The following features were added to jBPM 7.5
25.7.1.1. Case management
jBPM 7.5 brings number of case management improvements.
Sub case support
Sub case support is provided as additional activity that can be easily drag and dropped into existing case definitions or even into regular processes to allow creating case instances from within business process.
It allows to provide all information as for regular start case plus enables users to decide what should happen after case is started. For more information take a look at this article
Case file and case comment authorization
Access to case file and case comments can be restricted to particular case roles. By default the access is open unless specified differently.
Access restrictions can be set for comment:
-
when adding a comment
-
when updating a comment
Access restrictions to case file can be set:
-
in case definition
-
when starting a case
-
when setting case file items
More detailed explanation of this feature can be found here
Case close with message
Support for close of case instance was added with optional message. That message will then show up in case instance as outcome message. It accompanies case abort and destroy operations to provide complete coverage of the possible end states of the case instance.
Case comments notifications
Case comments have been equipped with optional support for notifications, by default email notifications with template support. Whenever any of the case roles is mentioned in the comment (@onwer) email notification will be sent to user or group of users assigned to that role. See more details in this article
25.7.1.2. Document list marshalling strategy
A common requirement is to have a list of documents to be handled by business process, jBPM does provide support for physical
documents (e.g. pdf) since version 6 with custom marshalling strategy. Though it only allows to handle single document per process
variable. With version 7.5 there is a new marshalling strategy provided to allow handling list of
documents org.jbpm.document.marshalling.DocumentsMarshallingStrategy. It does rely on the DocumentMarshallingStrategy to process
individual documents so they are properly stored in document management system.
This marshalling strategy accepts only org.jbpm.document.Documents type that represents list of documents.
25.7.1.3. Update task metadata and variables in single operation
UserTaskService has been extended to provide operation to update meta data of a task and its input and output data at the same time. It allows to update following meta data of a task:
-
name
-
description
-
priority
-
expiration date
-
form name
Same feature is available via KIE Server REST and JMS api.
25.7.1.4. Quartz improvements - db job store aware of deployed kjars
Quartz scheduler service has been improved to allow to fetch jobs only for deployments (kie containers) that are currently available in the running system. This applies only to Quartz setup with data base job store and requires additional changes in quartz configuration file:
org.quartz.jobStore.driverDelegateClass=org.jbpm.process.core.timer.impl.quartz.DeploymentsAwareStdJDBCDelegate
there is another PostgreSQL delegate class (due to handling of blob data)
org.quartz.jobStore.driverDelegateClass=org.jbpm.process.core.timer.impl.quartz.DeploymentsAwarePostgreSQLDelegate
they both do the same logic to find next trigger to fire - query for triggers based on trigger group id that now is set to deploymentId of the kjar.
25.7.1.5. Move of jBPM work items into dedicated repository
As part of preparation work for revamped Service Repository, some jBPM work items have been moved to dedicated GitHub repository. This is intended to allow easier contribution from community to build up a comprehensive list of work items that users can simply import from Service repository and use in their processes.
25.7.1.6. XStream security improvements
XStream is used as one of data formats (next to JSON and XML-JAXB) used by KIE Server when interacting with runtimes. It might be exposed to certain security issues that could allow to push malicious code over the wire and affect server upon serialization process. This has been addressed by hardening security policy on XStream instances used by KIE Server marshaller. By default it allows only few selected classes from KIE projects plus classes found in kjar.
Additional classes can be added to the policy globally by system property org.kie.server.xstream.enabled.packages that accepts wildcard expressions.
25.7.1.7. KIE Server < - > KIE Controller communication security
KIE server uses either REST or WebSocket to communicate with KIE Controller. Up till now, the only way to provide password was to use system properties which had certain drawbacks from security stand point. Version 7.5 brings in support for keystore based password storage that KIE Server and KIE Controller can use on runtime to load password.
Take a look at section 'KIE Execution Server → Securing password using key store' for more details
25.7.1.8. Business rule task fire limit
Business rule task has been enhanced to limit number of fired rules to avoid situation where rules run into infinite loop and make server completely unresponsive. Fire limit is set by default to 10000 and can be configured:
-
globally (per JVM) via system property org.jbpm.rule.task.firelimit
-
per business rule task via data input named FireRuleLimit
in case fire rule limit is reached service will throw exception to indicate possible dangerous situation.
25.7.1.9. Swagger based KIE Server documentation
KIE Server documentation, that is hosted on running KIE Server has been completely rewritten based on Swagger. It provides nice looking UI plus possibility to try different endpoints directly from within the documentation.
Moreover, it does filter endpoints based on active KIE Server extensions and shows endpoints that are actually available.
It is build as KIE Server extension itself and thus can be disabled if not needed, like production environments. More on this can be found here.
25.7.1.10. Email work item with template support
Email work item (jar that provides support for emails) has been enhanced with support for html templates based on freemarker template engine. It is automatically available as soon as the jbpm-work-item-email library is on class path. It supports three system proeprties that configure it:
-
org.jbpm.email.templates.dir - mandatory property that specifies absolute directory path where templates can be found
-
org.jbpm.email.templates.watcher.enabled - (default false) optional setting to enable watcher thread for added/changed/deleted template files so they can be seen without server restart
-
org.jbpm.email.templates.watcher.interval - (default 5) optional setting for watcher thread that specifies polling interval
Templates are loaded on start up and when discovered any changes to it (in case watcher thread is configured).
To use this feature from Email work item (service node) add extra data input called Template that will be the file name of the template (without extension .html).
25.7.1.11. Updated jBPM Service Repository
jBPM Service Repository has had a complete overhaul and is now generated from the list of contributed work items. It now contains an user-friendly "Home Page" that lists all available workitems, specific workitem information, as well direct download links the workitem resources. Community contributions to the workitem repository are welcome and contributors names are showcased on the repository home page.
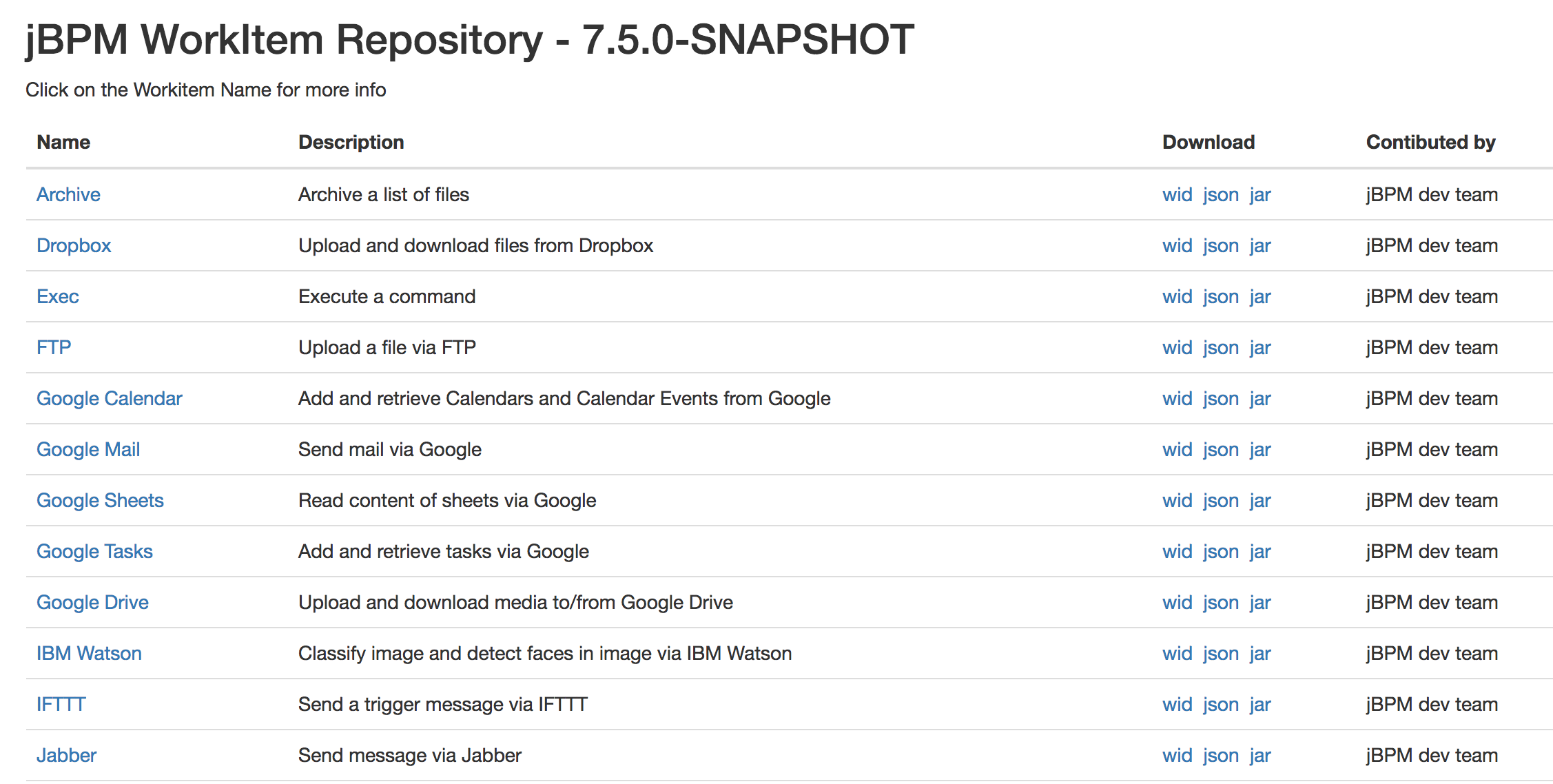
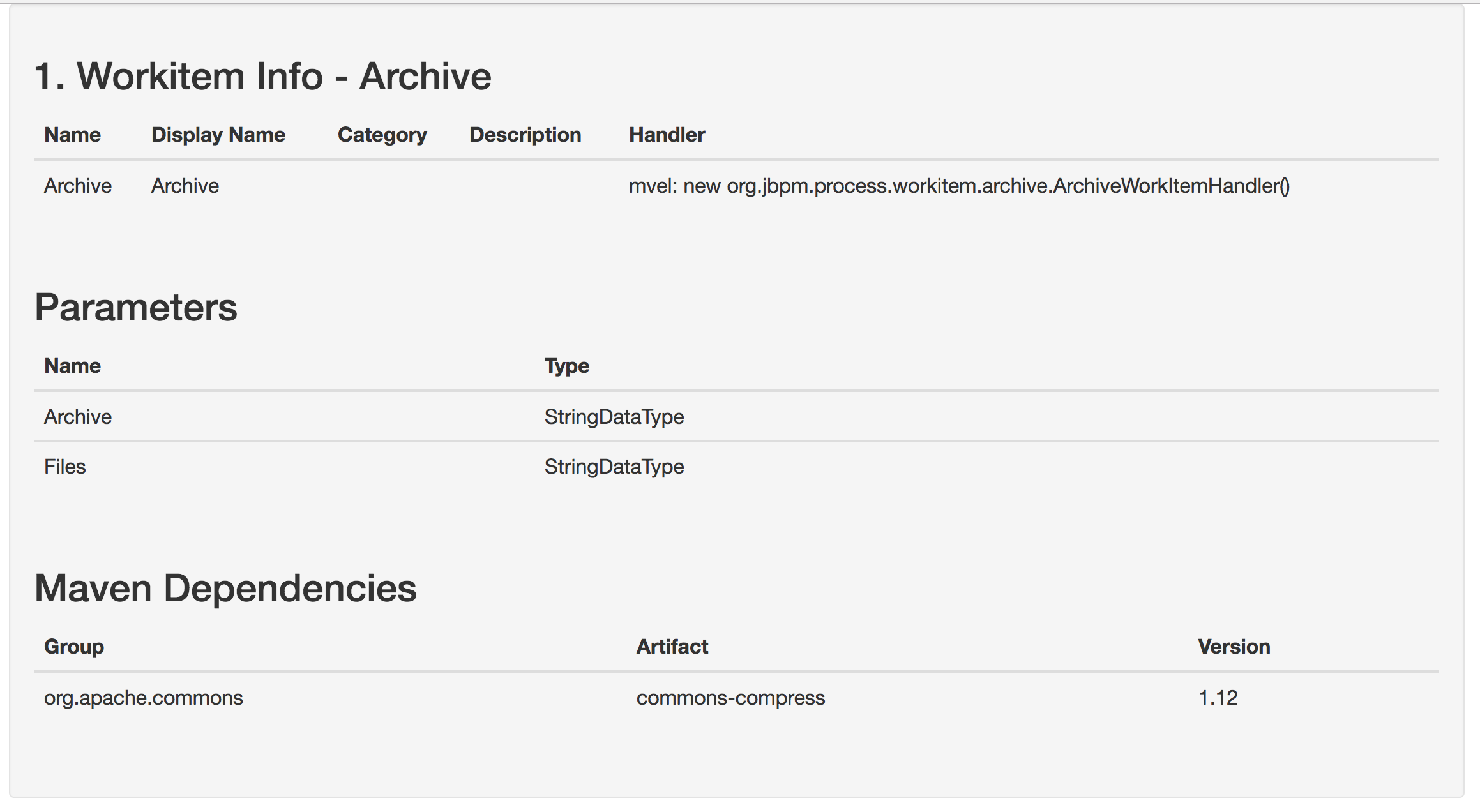
The service repository can also be generated locally by building the jBPM workitems module. The look/feel of the generated repository can be completely customized by updating the repository home page.
Need to have and maintain a repository-wide index.conf file has been removed. service repository importer available in jbpm-designer has also been updated to list all workitems available in the given repository regardless of the existence of this index.conf file.
25.7.1.12. Process Designer (Preview)
The new version of the jBPM Process Designer (Stunner) provides stability enhancements - it introduces several bug fixings, tests and usability improvements.
Most relevant added features and improvements:
-
Support for text auto-wrapping - text is being automatically wrapped to fit the shape size
-
Improved usability on connectors by making easier to achieve straight lines
-
Improved BPMN2 support:
-
Events - more common attributes being supported
-
Added Start Signal Event
-
Added Start Timer Event
-
Added End Signal Event
-
Added End Timer Event
-
Added catching intermediate signal event
-
Added throwing intermediate signal event
-
-
Re-styling BPMN2 shapes (still in progress)
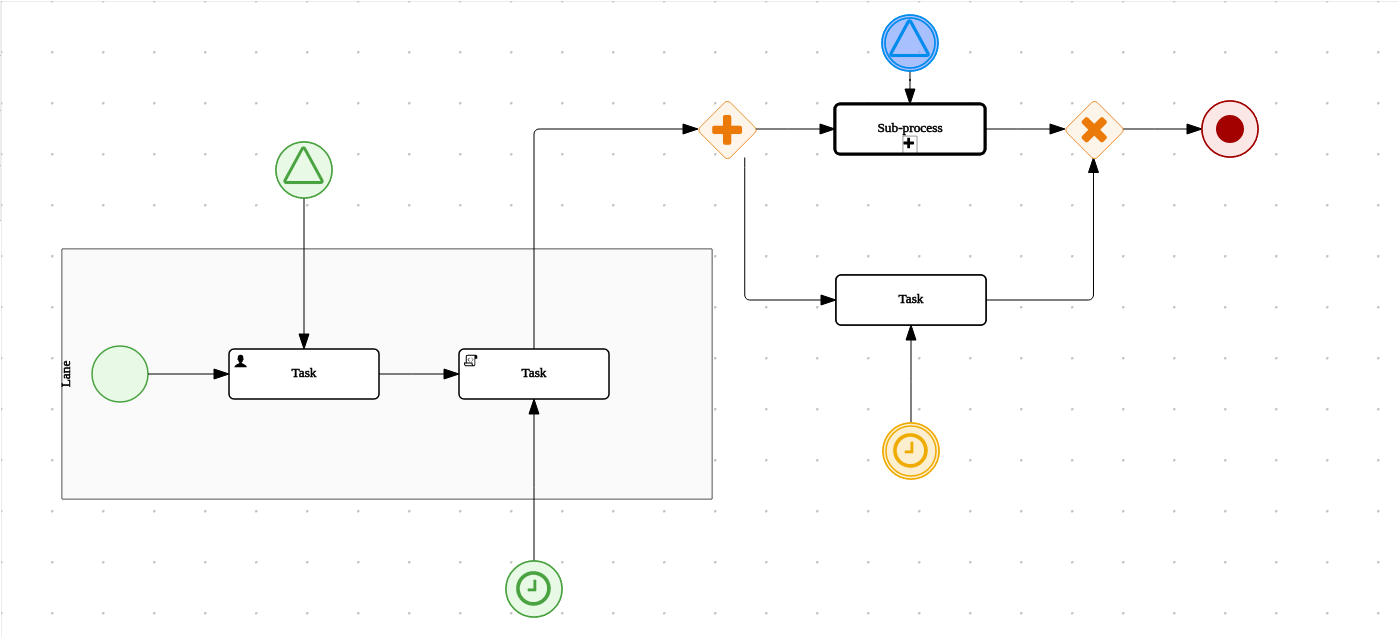
25.7.2. New and Noteworthy in KIE Workbench 7.5.0
25.7.2.1. Content management enhancements
Remarkable changes have been introduced in the Content Management (aka Dashboards) tooling in order to improve the user experience.
Perspective to page renaming
The "page" term is far more familiar to users. Notice that, "perspective" is a concept that was borrowed from the Eclipse development tool, thus it is a concept mostly used in developer circles. Page is more related to web content, easier to understand by regular people. For this reason, perspective has been renamed to page all over the tooling.
Left sidebar new look and feel
This is the most noticeable change introduced. The left sidebar has been completely rewritten in order to provide an enhanced look and feel.
The two sections Pages and Navigation have been merged into a single view. From this view users can either create new pages or change the navigation configuration.
The Navigation section lists the navigation trees. Specifically, the tree named Workbench is available by default, it can not be deleted and it contains the entries displayed in the workbench’s top mega menu. Any change applied to it will cause the mega menu to modify its entries. This is actually the mechanism users must use to extend the workbench with new pages.
Tags button disabled
The tags feature or the ability to attach a set of labels to a page during edition time has been removed. This feature in combination with the former "Apps" perspective was used to allow users to publish their dynamic pages in a categorized way. This feature is no longer needed. During the edition of a page, the Tags button, that used to appear at the editor’s top right button bar, has been removed.
As a replacement, users can leverage the existing navigation features to create new pages and attach them to the workbench’s mega menu.
25.7.2.2. Extra navigation components
The existing navigation components available in the Content Management tooling have been extended with some extra types. To date there exist the following components:
-
Tile navigator
-
Tab list
-
Carousel
The following have recently been added to the release:
Menu bar
As its name states, this component displays the entries of a navigation tree in a manu bar shape. There is no limit to the number of levels supported. When a page item is clicked, the page content is displayed in the Target div (see details below) component specified in the menu bar’s configuration.
Tree navigator
Same as the Menu bar, but the entries are displayed as a vertical tree structure.
Target div
Both the Carousel and the Tile navigator components can handle by themselves the display of the items the user clicks on. Others like Tab list, Menu bar and Tree navigator require a Target div component as its display output since they have a clear separation between the display of its entries and the content of the last item clicked.
So, every time, a Target div based navigation component is dropped into a page, a Target div component must have been dropped as well, so that the first one can link to it. The following screen shows the configuration panel that is displayed every time a target div based component is dropped into a page.
The navigation group is mandatory for all the navigation components as it indicates the navigation structure to display whereas the Target div setting is not available for non target div components like Carousel or Tile navigator.
25.7.3. New Kie Server Controller Client API
In order to facilitate the management of Kie Server Controller related tasks such as creating server templates, starting and stopping containers, etc, we developed a new Java client API available under the kie-server-controller-client Maven module. With this API, you can connect to a Kie Server Controller using either REST or Web Socket protocols. For more details, see Kie Server Controller Client API chapter.
25.7.4. Breaking changes in Kie Server 7.5.1 from 7.0
25.7.4.1. Kie Server Controller API changes
Changes to SpecManagementService interface:
-
Included new method
getContainerInfothat allows to retrieve a singleContainerSpecdefined in aServerTemplate. -
Changed methods
listContainerSpec,listServerTemplateKeys, andlistServerTemplatesreturn types from generic collection to specific domain list types (ContainerSpecList,ServerTemplateKeyList, andServerTemplateList) in order to properly serialize and deserialize the returned values using JAXB and JSON.
Changes to RuleCapabilitiesService interface:
-
startScannermethod now uses ajava.lang.Longtime instead of a primitivelongfor theintervalparameter in order to avoid JSON and JAXB serialization issues.
Changes to RuntimeManagementService interface:
-
Changed methods
getContainersandgetServerInstancesreturn types from generic collection to specific domain list types (ContainerListandServerInstanceKeyList) in order to properly serialize and deserialize the returned values using JAXB and JSON.
For more details, see JBPM-6243.
25.7.4.2. Kie Server API changes
Changes to ServiceResponse wrapper:
-
Moved
ResponseTypeenum and common methods to a new interface calledKieServiceResponse, allowing it to be extended to multiple implementations.
25.8. jBPM 7.4
25.8.1. New and Noteworthy in jBPM 7.4.0
The following features were added to jBPM 7.4
25.8.1.1. KIE Server Router enhancements
KIE Server Router received number of enhancements where majority of them were around connectivity with KIE Servers and Controller. Most of the work was to make it more reliable in case of failures of the other components
-
when controller is not available during router start a retry mechanism is in place to connect to it as soon as the controller becomes available
-
when controller is not available when there are updates to be sent to it a retry mechanism is in place
-
when KIE Server that request is sent to does not respond it is removed from the active servers and thus subsequent requests won’t target it any more, at the same time such server is put on a list to be verified if that server was only temporarily unavailable and if so will be put back on the active servers list
With these enhancements KIE Server Router is more resilient to failures and thus provides much higher level of reliability, especially important in cloud based environments.
25.8.1.2. User task update (properties and data)
Besides regular life cycle of user task, users could set task content while working on the task or change the task priority, name or description. This is all possible but requires users to do that individually. 7.4 comes with a feature that allows to update certain properties and data in one shot. Following is a list of user task properties that can be updated:
-
name
-
description
-
priority
-
expiration date
-
form name
Both user task inputs and outputs can be given to be updated. Data will be merged with existing values if any. That means if there are task inputs or outputs with same name already present on a task they will be replaced with given values.
25.8.1.3. Work Item archetype
To help users build custom service tasks (work items) jBPM 7.4 comes with Work Item Archetype that aims at generating majority of things required to build a custom service task. It does include:
-
WID file (work item definition)
-
Work Item Handler implementation class
-
WorkItem handler test class
-
maven assembly (zip) that will package everything on the build time so it can be consumed by Service Repository and thus used from within Web Designer
A detailed article can be found here
25.8.1.4. KIE Workbench enhancements
In this release, a series of bug fixes have been resolved. This list highlights some of the major fixes:
-
When selecting items in the different runtime views (Process List, Task List, Jobs, etc), selection will now be persistent across different pages. See JBPM-6374 for more details.
-
When searching for Jobs, it is now possible to filter by Due On dates in the future, see JBPM-6437 for more details.
-
Improved overall query performance for listing process instances. See JBPM-6292 for more details.
-
Consolidated process related columns name in the Task and Job search pages. See JBPM-5957 and JBPM-5955 for more details.
-
Forwarding a task via the task details page, now correctly moves the task into Ready state. See JBPM-6438 for more details.
25.8.2. New and Noteworthy in KIE Workbench 7.4.0
25.8.2.1. Guided Decision Table improvements
In addition to fixing numerous bugs the Wizard used to create and edit columns has been improved to show descriptions of the different steps required for the different column types.
25.8.2.2. Disable experimental editors
The following features are considered experimental and can be disabled using the Security/User Management administration screen:-
-
Guided Decision Tree Editor
-
Guided Score Card Editor
-
XLS Score Card Editor
-
(New) BPMN2 Process Editor
-
Deployments/Server Provisioning Perspective
These features are enabled by default.
25.9. jBPM 7.3
25.9.1. New and Noteworthy in jBPM 7.3.0
The following features were added to jBPM 7.3
25.9.1.1. KIE Workbench Monitoring Web Application
A new distribution war has been added to the project in this release. The goal for the KIE Monitoring Web Application is to be used along with Kie Server instances, managing all runtime capabilities. This includes managing containers, process instances, tasks, dashboards and more. As opposed to the standard Kie Workbench distribution, no authoring capabilities are offered,
25.9.1.2. KIE Server Maven Plugins
With version 7.3 KIE Server has been empowered with additional Maven Plugins that allow to interact with KIE Server and KIE Controller REST api directly from within a build. This enables easier integration with CI/CD pipelines when building KJars so they can be directly deployed to execution environment (both managed and unmanaged KIE Servers).
KIE Server Deploy Maven Plugin - read more
-
deploy - deploy kjar to runtime environment
-
dispose - dispose running kjar (kie container) in runtime environment
-
update - update version of running kjar (kie container) in runtime environment
KIE Server Controller Deploy Maven Plugin - read more
-
get-template - retrieves existing server templates from controller
-
create-template - creates new server templates with set of containers
-
delete-template - removes server template
-
get-containers - retrieves containers in given server template
-
get-container - retrieves given container from server template
-
create-container - create new container in given server template
-
delete-container - delete container from given server template
-
start-container - starts container in given server template
-
stop-container - stops container in given server template
-
deploy-container - creates and starts container in given server template
-
dispose-container - stops and removes container from given server template
Process Designer (Preview)
The new jBPM Process Designer (Stunner) provides stability enhancements again by introducing several bug fixings, tests and reviews.
On the other hand this release includes some new cool core features:
-
Improving user experience & usability by introducing enhancements in the connections and magnets capabilities. At this point:
-
Connections can be attached to a concrete shape magnet. Irrespective of the location of shape, the connection will target the specified magnet
-
Connections can be attached to the shape’s center magnet. In this case the connector/connections point to the shape’s border, depending on its location
-
Connections can be attached to the shape area, instead of a concrete magnet. This produces the magnet to be automatically updated depending on the shape’s location
-
Notice this information is also being persisted and stored in the BPMN diagram files
-
-
Integration for validation and error messages into the workbench’s IDE. This way users can keep track of the validations and errors produced during the modelling phase and link back to the canvas and the affected shapes in order to fixing the issues
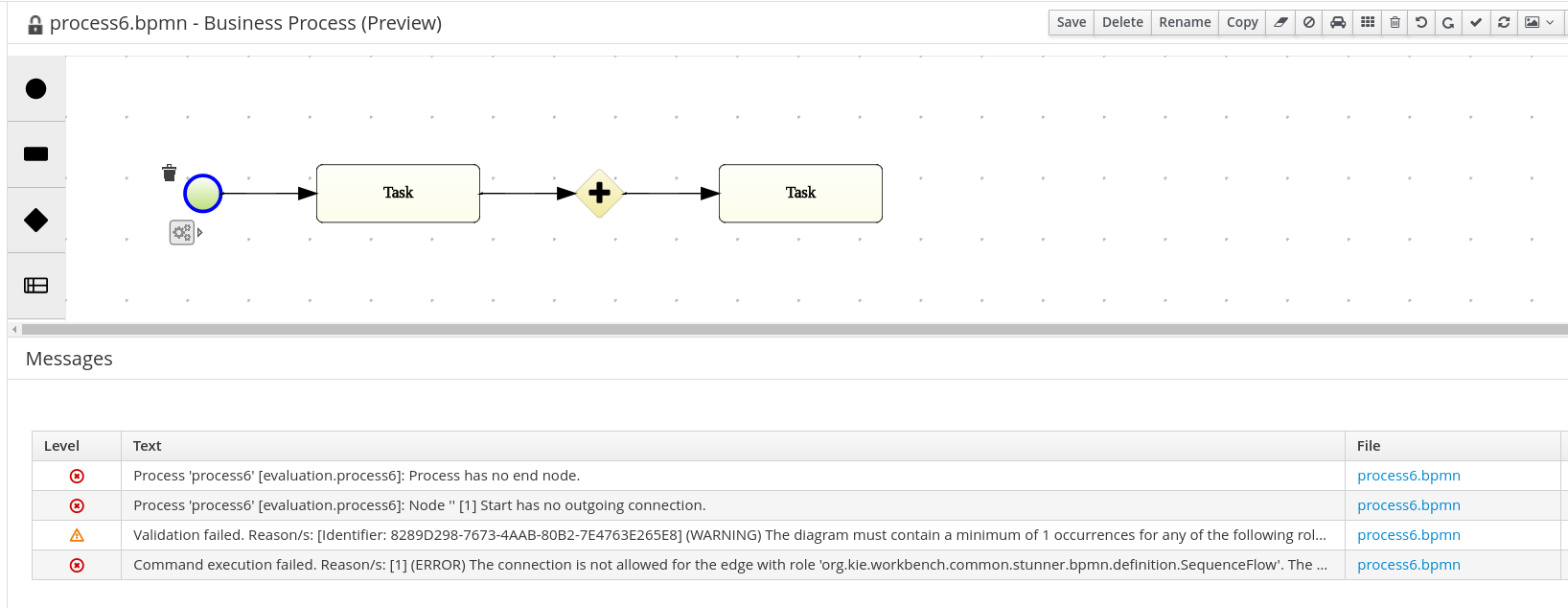
-
Toolbox re-design & usability enhancements. Many visual visual and usability improvements applied on the toolbox for this release. It now supports multiple grids, floating grids, automatic layouts and much more
25.9.2. New and Noteworthy in KIE Workbench 7.3.0
25.9.2.1. New Home and Menu Bar
The Home page, Menu bar and About popup now have a new design. Menu items are split into groups representing major functional areas.
25.9.2.2. Admin page changes
The Admin page is now accessible with the cog icon on the Menu bar and has more items. Access to the perspective artifacts, Data Sets, Data Sources and Language options have been moved there.
25.10. jBPM 7.2
25.10.1. New and Noteworthy in jBPM 7.2.0
The following features were added to jBPM 7.2
25.10.1.1. Improved validation in deployment descriptor editor
Deployment descriptor editor in workbench has been improved to validate content of entered data for
-
work item handlers
-
event listeners
-
marshalling strategies
-
globals
-
environment entries
-
configuration
Validation is performed automatically when build is invoked or manually when user clicks on Validate button
Validation mainly focuses on checking if data entered are valid based on selected types:
-
MVEL type resolver will perform compilation of the expression that was given as identifier, it can produce warning messages as it might not have access to all classes that will be available on runtime, thus it’s only warning to not block the build.
-
Reflection type resolver will verify if the identifier has valid name according to Java standard (class name)
25.10.1.2. Websocket based KIE Server communication with KIE Controller
Default communication mechanism for KIE Server to connect to KIE Controller is HTTP/REST based. This fits well in non-restricted environments where both components can freely talk to each other. Though it requires both components to know how to access and authorize itself when sending requests. That does not play well in cloud based environments or environments that utilize load balancer.
To overcome this issues, an alternative mechanism was introduced. It is based on Websocket where KIE Server is solely responsible for connection. Thus only KIE Server needs to be aware of controller and it’s authentication, while controller simply reuses already opened communication channel. More on this can be found in this article.
Process Designer (Preview)
This release includes several important bug fixes for the jBPM Process Designer (Stunner).
Here are some relevant ones:
-
Fixed conditional form fields and marshalling issues for the BPMN Script language property
-
Fixed some CSS issues of the palette
-
Use of the right title for BPMN diagrams. Add information about the file extensions and resource type description as well
-
Avoid shape interaction when right-clicking on the canvas
-
Included a few missing properties for the BPMN Embedded Subprocess
-
Removed toolbar’s refresh button. No longer need for it, it was causing confusion
-
Bug fixings for the Properties and Diagram Explorer panels, once moving between different diagrams
-
Do not show save confirm dialog only if no changes has been applied
25.11. jBPM 7.1
25.11.1. New and Noteworthy in jBPM 7.1.0
The following features were added to jBPM 7.1
25.11.1.1. Workbench
The following are the jBPM-specific enhancements made in the workbench.
Quick search filters for runtime data
To allow you to quickly find data related to Process Instances, Jobs, Tasks and Errors, a new set of pre defined filters has been introduced into the related views. These filters are always available in the "Search" tab when you first access any of the pages related to the domain mentioned above. By default, you will notice that at least one filter is defined. That is done so that only the most relevant data is shown. You’re free to restrict the data even further by adding new filters. This can be done by either selecting values from the dropdown list or proving values to the different attributes in the input box. You will notice that the data is filtered as you add or remove any of the active filters.
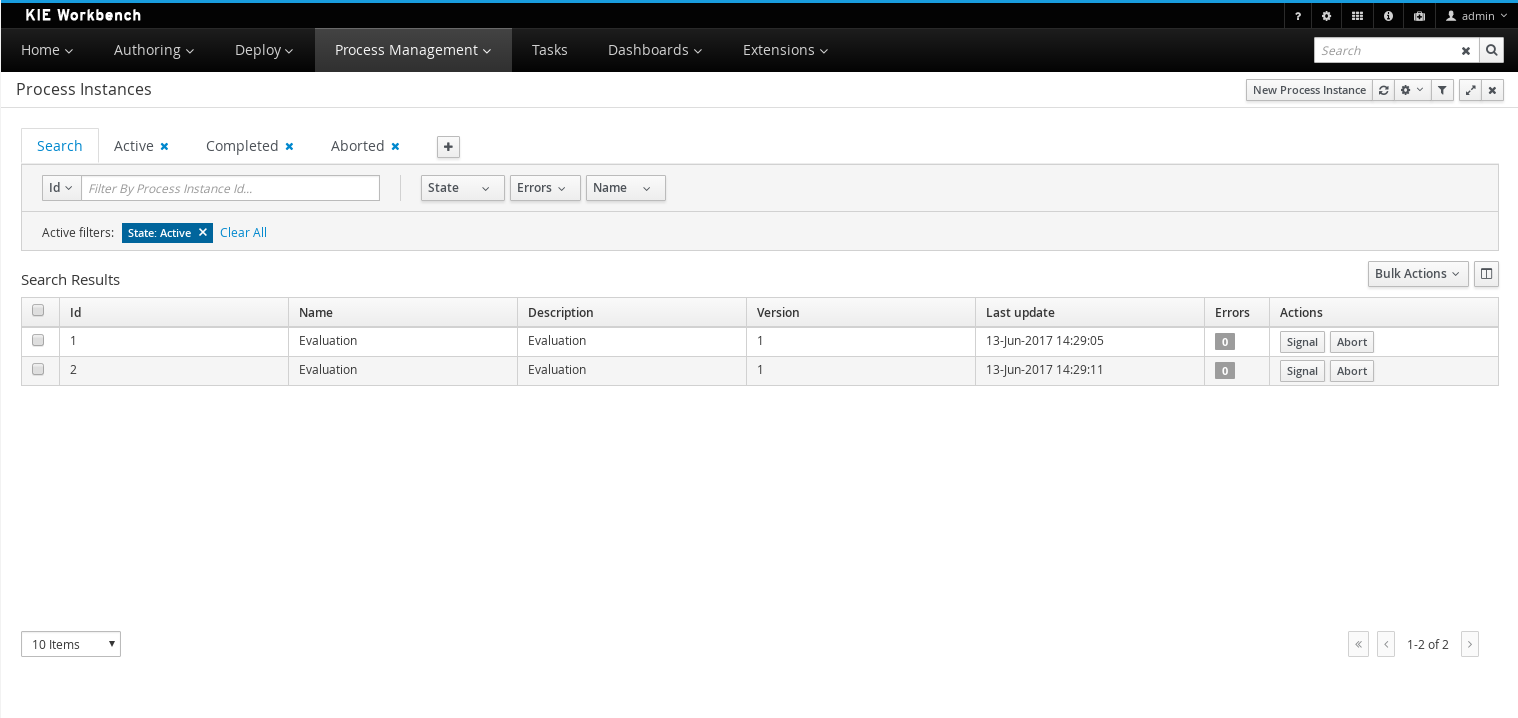
The complete list of views where quick search filters have been added include:
-
Process Instances
-
Tasks
-
Task Administration
-
Jobs
-
Execution Errors
New error handling
The system now detects and stores execution errors, such as exceptions while running a process instance or a job once the maximum retry number has been exceeded. The process instance list includes a new column that displays the number of errors per process instance which are not marked as acknowledged. When the column is clicked a popup is displayed, which will allow users to navigate to the new error perspective.
New Execution Errors View
A new view to explore and acknowledge the new generated execution error has been added.
The Execution Errors view shows a list of errors. It contains a 'Search' tab that provides quick search capabilities filtered by fields like Process Instance Id, Job Id, and Type.
This view also provides a set of predefined filters: All, New (pending of acknowledgement), and Acknowledged.
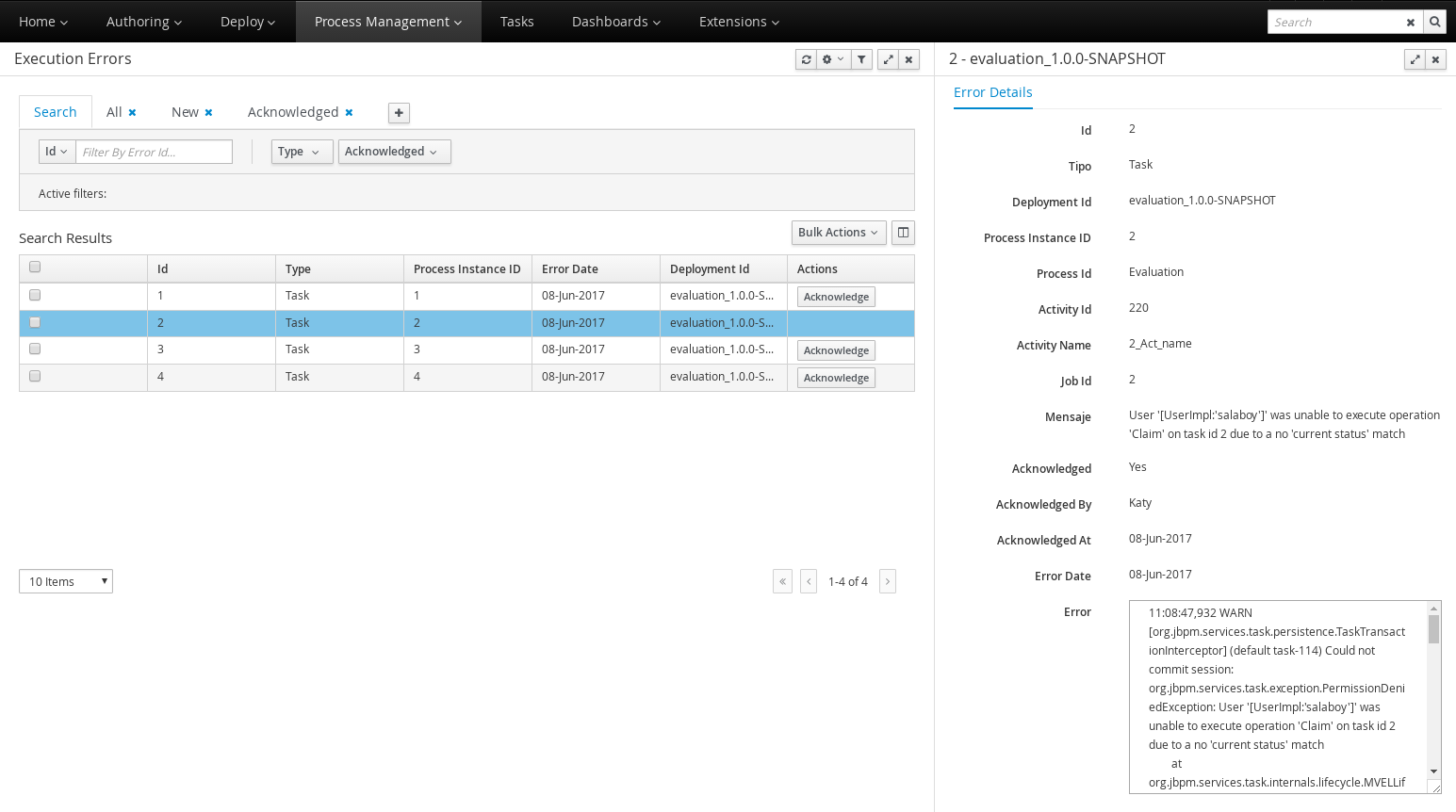
You can acknowledge the unacknowledged errors by selecting the related error action. This new view also allows acknowledgment of multiple errors. To acknowledge multiple errors at once, select all the errors you wish to acknowledge and use the 'Bulk Acknowledge' button.
Navigation between views
New actions that allow navigation between views, have been added. This actions link an origin list view that shows the action, and a destination list view prepared for filtering.
Basically this new navigation is composed by: a set of validations at the origin view to check if the action have to be displayed, a group of parameter that the action pass and a predefined filter at the destination view that uses that parameters.
The list of origin views and the new navigation allowed:
-
Process Instances: view jobs, tasks and errors
-
Tasks: view process instance
-
Task Administration: view process instance
-
Jobs : view process instance
-
Execution Errors: view job, process instance and task
Over all this new actions, there is a basic validation, checking if the user has granted privileges to access to the destination view.
New task admin perspective and actions
The former task list perspective has been divided into two:
-
Task list perspective: Aims to be used by task operators, in order to work with their assigned (or potentially assigned) tasks.
-
Task administration perspective: Designed to be used by administrators, which can manage tasks belonging to other users. This perspective is only available for users with roles
admin andprocess-admin. It is similar to the former "Admin" filter tab on the former task list perspective.
The tasks which are displayed on the task administration perspective are determined by the current user permissions. The list shows the tasks that have the current user or the current user’s group associated as business administrator. By default the system associates all tasks to the user Administrator (configured via the org.jbpm.ht.admin.user system property) and the group Administrators (configured via the org.jbpm.ht.admin.group system property), so in order to display all tasks, your admin or process-admin user needs to belong to the Administrators group.
| Notice that the mentioned roles and group configurations are related to the KIE server’s, not the Workbench’s (in case they have separate user configurations). |
In addition, the Suspend and Resume action buttons have been enabled on both perspectives. They are visible depending on the state of the associated task in regard to the current user.
Advanced Queries with ORDER BY clause
The QueryService used in executing advanced queries only supported sorting with ORDER BY clauses having the following pattern:
ORDER BY Column1, Column2, ... ASC|DESC;which limited the sorting to either ascending or descending for all columns.
The desired behavior, that of a full ORDER BY clause
ORDER BY Column1 ASC|DESC, Column2 ASC|DESC, ..., ColumnN ASC|DESC;allowing sort order per column, is now possible. Please see the documentation for examples of how to apply the new full ORDER BY clause when using the QueryService.
Process Designer (Preview)
The new jBPM Process Designer (Stunner) has enhanced stability. Several bugs and issues are identified and fixed in this release.
Following is a list of new features and relevant updates:
-
Re-design for some BPMN shapes and icons. The following picture shows an example BPMN process:
-
Palette re-design & usability enhancements
-
Improved stability, performance and design for the Diagram Explorer
-
More BPMN specification support: Inclusion of the Embedded Subprocess, including its own validations and constraints given by the BPMN specification
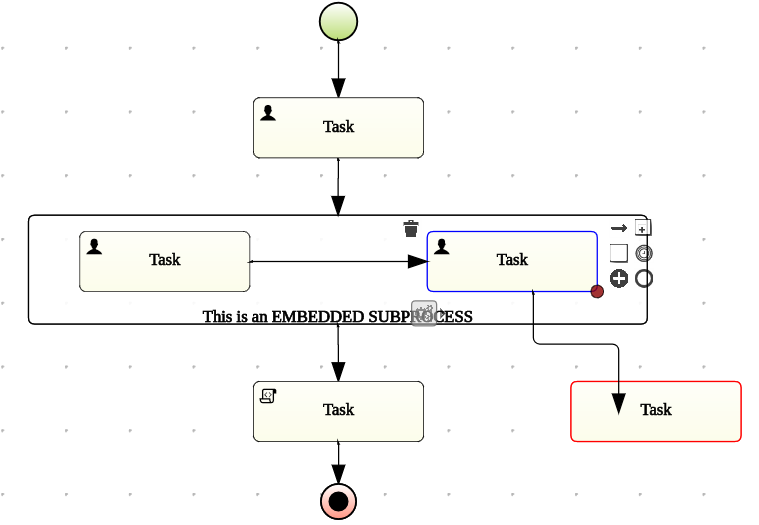
-
Improved some core features of the connector. Some examples:
-
Removing a node means removing its incoming connections as well
-
Once removing a node, if the node has single incoming and outgoing connections to another nodes, the connections are being shortcut into a single one
-
-
Improved target locations for elements created using the toolbox. The new elements are co-located with the previous ones
-
Export capabilities for the Diagram’s picture. Multiple image types (like jpg or png) and PDF formats are supported
-
Notifications and error messages displaying in much pretty and configurable workbench’s popups
25.11.2. New and Noteworthy in KIE Workbench 7.1.0
25.11.2.1. Project Metrics Dashboard
A brand new dashboard is now available for every project listed in the authoring library. After opening the project details page, a metrics card shows up on the right side of the screen.
The card shows the history of contributions (commits) made to that specific project over time. Click the View All link to access the full dashboard that shows several metrics all about the project’s contributions.
Notice that different filter controls are available for selecting the contributions made either by a concrete user or in a specific time frame.
25.11.2.2. Teams Metrics Dashboard
A brand new dashboard has also been added to the Teams page. A metrics card on the right side shows the history of all contributions (commits).
Click the View All link to access the full dashboard showing overall contributions metrics.
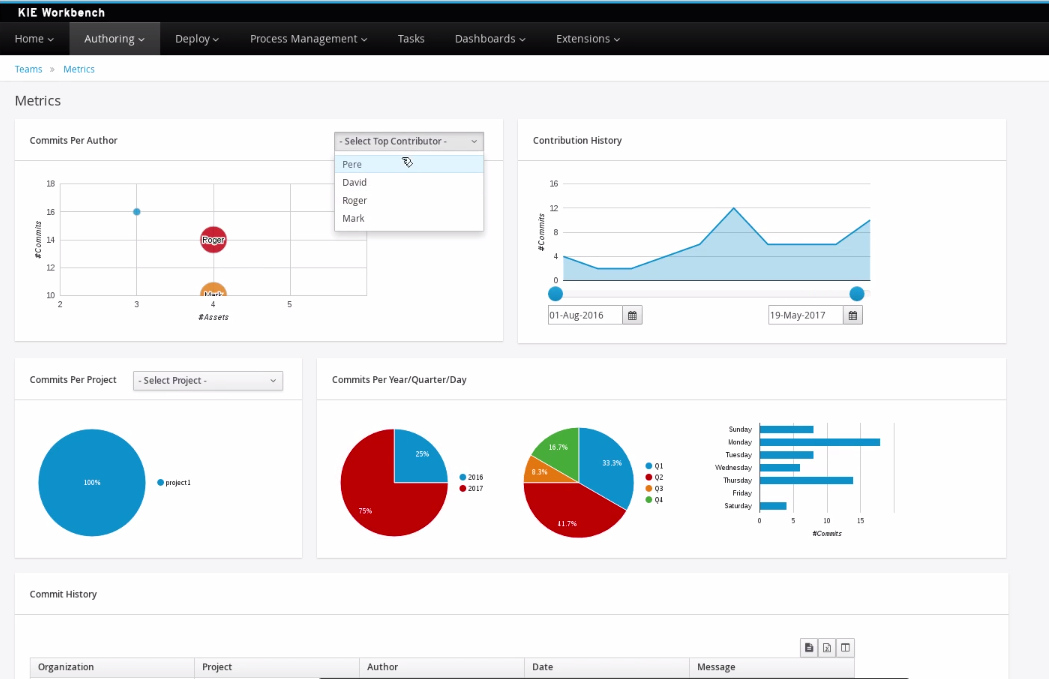
Note that different filter controls are available for selecting the contributions by different criteria:
-
by a concrete user,
-
within a specific time frame,
-
by team or,
-
by project.
This dashboard replaces the former Authoring>Contributors dashboard, which is no longer available at the top menu bar of the workbench.
25.12. jBPM 7.0
25.12.1. New and Noteworthy in jBPM 7.0.0
The following features were added to jBPM 7.0
25.12.1.1. Process engine
Case management
jBPM v7 comes with a lot of improvements to better support 'case management' use cases. These use cases are different from more traditional business processes since they (typically) require more flexibility and support more unstructured and unplanned work. Rather than following a nicely predefined plan from start to finish, actions are more ad-hoc decisions, what to do next is more based on the data associated with the case, the end user needs to be given the flexibility to decide what to do next (although recommendations are welcome), etc.
We have added a lot of features to the core engine to be able to support these 'case management' use cases better. Note that we have added these as an extension of our existing process engine (based on BPMN 2.0 specification) rather than as a separate effort, as we believe that case management is an extension of more traditional BPM, and that there is a spectrum of processes (from well-structured business processes to adaptive cases all the way to completely dynamic use cases) that we want to support with one unified solution.
As a result, the core engine has been extended to support features like:
-
Cases have a unique case identifier (which can be customised per case) and a longer life cycle (close, reopen, etc.)
-
A Case File that is responsible for collecting all data (documents, structured data, etc.) related to a case
-
Ad hoc fragments allow you to model optional paths that might be recommended to end users or automatically triggered by rules
-
Dynamic tasks can be dynamically executed in the context of a specific case instance even though it was not defined upfront in the case definition
-
Milestones and Stages to better keep track of progress
-
Case comments to be able to have discussions related to a specific case instance
-
Session per case strategy to allow reuse of the same engine (ksession) per case
Process and task administration API
A Process and task admin API has been introduced to simplify some of the more complex administrator use cases.
The process admin API allows you to:
-
get all process definition nodes
-
cancel node instance
-
retrigger node instance
-
update timer (absolute or relative)
-
list timer instances
-
trigger node
The task admin API allows you to:
-
add/remove potential owners, excluded owners and business admins
-
add/remove task inputs and outputs
-
list/create/cancel escalations and notifications
Advanced task routing
When tasks are assigned to a group of users, pluggable task assignment strategies can be used to automatically assign tasks to a suitable individual immediately (when the task is being created or later released etc.). This allows more efficient task allocation, based on basically all properties associated with the task (for example potential owners and task priority but also task data that could include information like geography, required skills, etc.). Business rules can be used to define the assignment logic, making it easy to customize this to your needs.
Other
-
Java requirement was updated to JDK 1.8
-
Business rule task was enhanced to support execution of DMN rules and to externalize rule evaluation on a remote rule decision services
-
Defining which (asynchronous) jobs to execute next based on job priority
25.12.1.2. Process Execution Server
The process execution server (also known as kie-server) has been extended to support the core engine features above (related to case management, admin APIs, etc.) and to offer a remote API for these operations. On top of that, two other important architectural changes were done.
Separate workbench from execution server
While in v6 the workbench came with an embedded execution server to execute all the process and task requests that users were performing in the web-based UI, in v7 this embedded execution server has been removed and the workbench delegates all its requests to the kie-server as well. The main advantage is that the workbench can now be used to monitor any (set of) kie-server(s). By linking the kie-server to the workbench, the process and task monitoring UIs in the workbench can now connect to this kie-server and show all relevant information. When multiple independent kie-servers are used, you can either connect to a specific one or use the smart router to aggregate information across multiple servers (see below). As a result, a few missing features that were not yet available in v6 on kie-server but only on the remote API of the workbench have also been migrated to the kie-server.
Smart router
When managing multiple independent process execution servers (for example each only having a few projects deployed, with persistence configured to a separate datasource), it might be difficult to keep track of where all these servers are and to collect information from all of these. The smart router (also known as kie-server-router) can be used as a proxy:
-
requests can be sent to the smart router, it will be able to figure out which of the known kie-server instances the request should be sent to
-
when trying to retrieve information, the smart router can collect information from different servers and aggregate that information for you
So if you have an architecture where you might end up with a lot of independent process execution servers (for example in a cloud environment), the smart router will try to hide some of this complexity for you again.
25.12.1.3. Case Management Showcase
A new (web-based) case management showcase application has been added that allows an easy and comprehensive look into the case management capabilities that were added to the core engine. This application gives a quick view at available cases (both definitions and instances) and allows you to interact with them. To make it possible to deal with any kind of case, the application is generic (so not applied to a specific domain) and:
-
Brings visibility to the technical users on case definitions and instances
-
Provides insight in where the case instance is
-
Allows to perform certain operations on a case instance
End-user focused case management applications should be domain-specific: they should be using the terminology the user is familiar with and focus on the tasks the user wants to perform. As a result, this generic showcase application should more be considered a showcase application to demonstrate some of the capabilities. However, our generic showcase application is built as a combination of various UI building blocks that each focus on a specific feature.
In this version we can find the following building blocks:
-
Case List. Allows sort and filter the case list, perform general case operations and start new cases.
-
Case Details.
-
Case Stages.
-
Case Comments.
-
Case Roles.
-
Case Milestones.
-
Case Overview. This building block, provides a generic, building block composition and exposes the general case actions like 'Complete'.
This application can be used standalone or can be automatically provisioned by workbench and accessible from within the workbench UI.
| The Case Management Showcase application launcher is only available from the workbench UI if the application has been automatically provisioned or a url has been provided via org.jbpm.casemgmt.showcase.url system property. |
25.12.1.4. Workbench
Apart from the generic improvements to the workbench (listed below in a separate section), there are also some jBPM-specific enhancements in the workbench.
Case management in the workbench
To better support case management, following enhancements were added:
-
When creating a new project, you can choose to create a case management project. This will auto-configure some additional services for you that are typically used in the context of case management.
-
Our web-based process designer has been extended with a few more properties and custom service tasks to support some of the new features related to case management.
Business Dashboards
The Business Dashboards section in the top menu bar opens up a new perspective which can be used to author brand new dashboards.
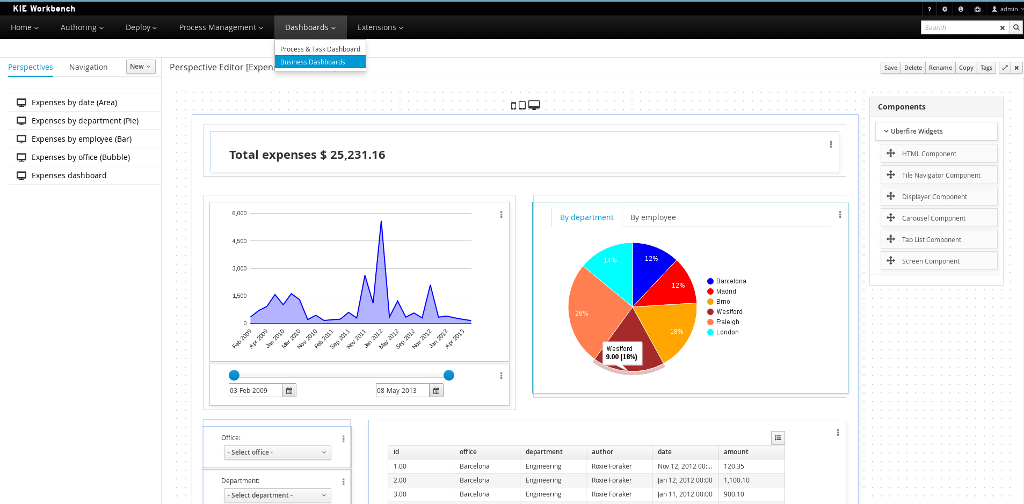
From this very new perspective, aside from creating new content, it is also possible to change the layout of the top menu bar by adding, removing or moving entries around. The menu entries are linked to existing perspectives and can be modified, thus making extremely easy to create and publish new perspectives in the top menu bar.
Altogether, it provides a rich environment which allows for both changes in the application content and its menus. A detailed introduction to the new solution can be found at the Business Dashboards section.
| Notice, the former dashboard tooling was a separated web application. The new solution has been completely rewritten from scratch and it is fully integrated in the workbench. |
New columns available on process instances, tasks and jobs
The following columns have been added to the corresponding perspectives:
-
Process instance list perspective: Last update and correlation key.
-
Task list: Last update, correlation key (of the associated process instance ID), process instance description (of the associated process instance).
-
Jobs perspective: Name of the associated process (if any), ID of the associated process instance (if any), Description of the associated process instance (if any).
These columns are sometimes optional so some of them aren’t displayed by default. In order to show them it’s necessary to select them in the column picker of the corresponding table.
Process Designer (Preview)
We are working on a completely new web-based process designer, and this release introduces a early preview (where we only support a small subset of the full feature set).
The new jBPM process designer, also known as Stunner, is an open-source software that brings to users exciting representation and authoring capabilities for business process diagrams. It is completely focused on, built and designed for end users, providing an easy yet powerful and rich modelling experience.
The following image shows an example of a BPMN2 diagram authoring screen:
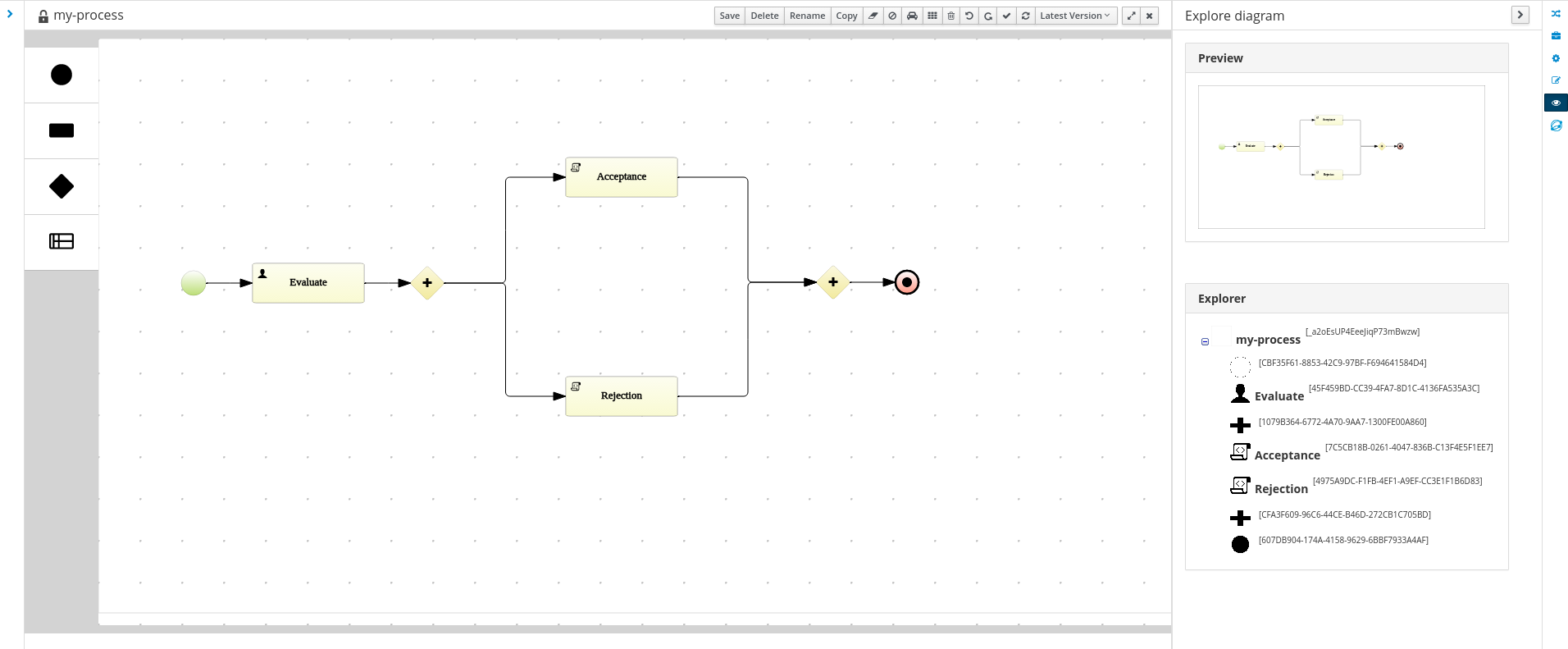
Our long-term experience along with the community and customers' feedback have allowed us to bring the most state-of-the-art modelling tool.
Built as an open-source library, it is intended for developers as well, providing useful customization and extensibility capabilities.
|
The following two process designers are included in the workbench: the already existing JBPM Designer and the Stunner, the new one. It is important to notice that the previously existing jBPM Designer is still being considered the full BPMN compliant process designer for production and regular use, meanwhile Stunner is available as a preview feature, supporting only a few BPMN elements. More amazing features are still on progress. |
|
|

Some of the key features currently available are:
-
Visual authoring and representation capabilities for diagrams
-
Runtime server and client side processing, validation, and constraint features
-
Rich client multi-platform support
-
Rich set of client features - complex shapes, toolboxes, poly-line support, animations, layout alignment and distribution, keyboard integration and much more
-
Rich set of client components - viewer, editor and preview authoring modes, components palette, visual diagram structure , property editors, and toolbars
-
Properties rendering and authoring capabilities by extensible an form mechanism
-
Easy extensibility of data models, behaviors, validations, constraints, and shapes
-
Additional serialization formats
-
Native workbench integration
-
Built-in support for HTML5 & canvas
-
Built-in BPMN2 support
Form Modeler (Preview)
jBPM v7 includes a preview of the new Form Modeler. This new version comes with an improved Look and Feel and improvements to simplify the form creation and rendering.
Some of the new features are:
-
Form Layout based on Bootstrap Grid System
-
Drag & Drop Form Editor to simplify the form composition
-
New widget library including TextBoxes, TextAreas, DatePickers, ListBoxes, Radios, Nested Forms
-
Supports both simple Data Types (such as String, numbers, boolean) and Data Objects created using the Data Modeler
-
Ability to easily generate forms for Data Objects and Business Processes. Improved way to modify field bindings over the previous jBPM Form Modeler
-
Field validation based on Bean Validation
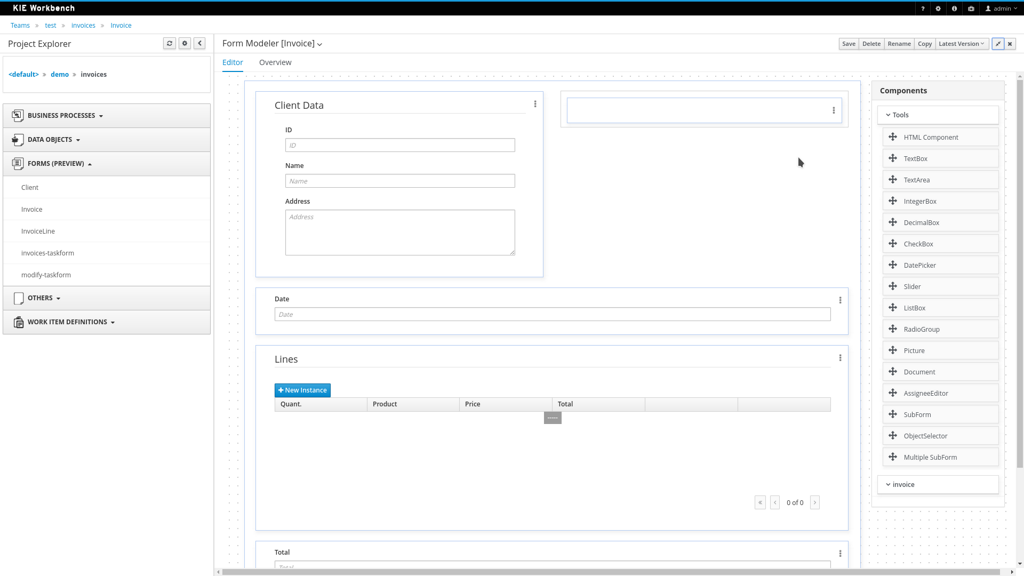
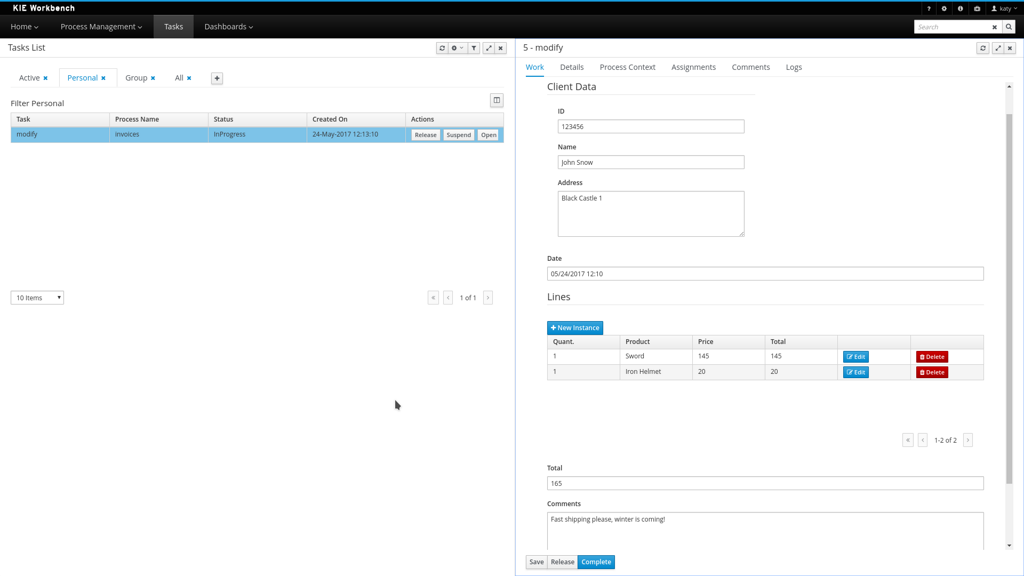
25.12.2. New and Noteworthy in KIE Workbench 7.0.0
The workbench has been updated to support Wildfly 10 and EAP7. Minimum Java requirement is JDK8.
25.12.2.1. New Authoring (Library)
Authoring now has a new design, with a better information organization. It’s now possible to manage (create, delete and edit) Teams (Organizational Units), list Projects in a Repository and the Assets in a Project. When an Asset is selected, you can see the Asset Editor and the Project Explorer.
|
The Library uses the indexing of the Workbench. It is, therefore, imperative that existing index information is deleted so that the Workbench can rebuild them with the necessary information. Index information is stored in the |
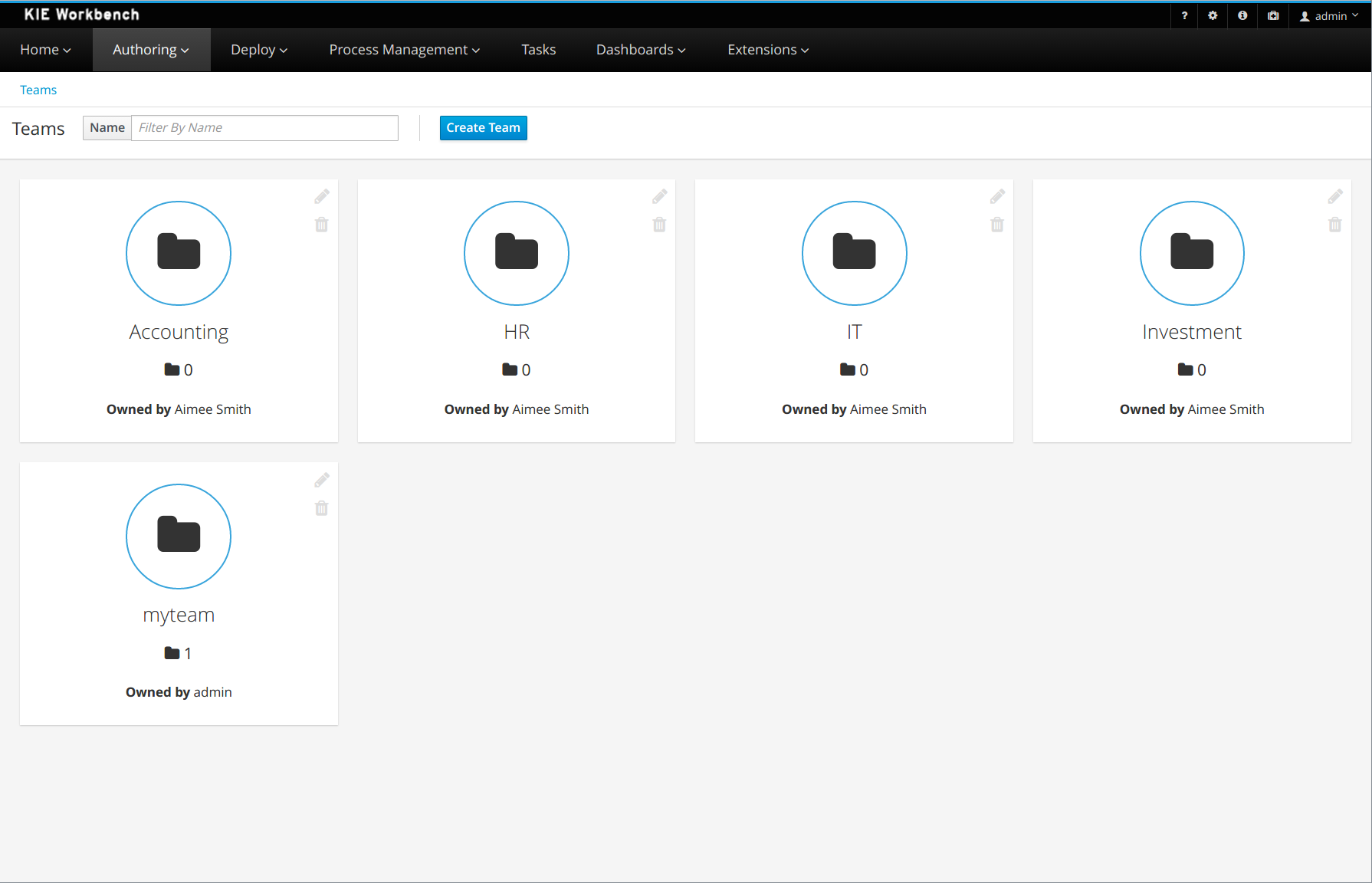
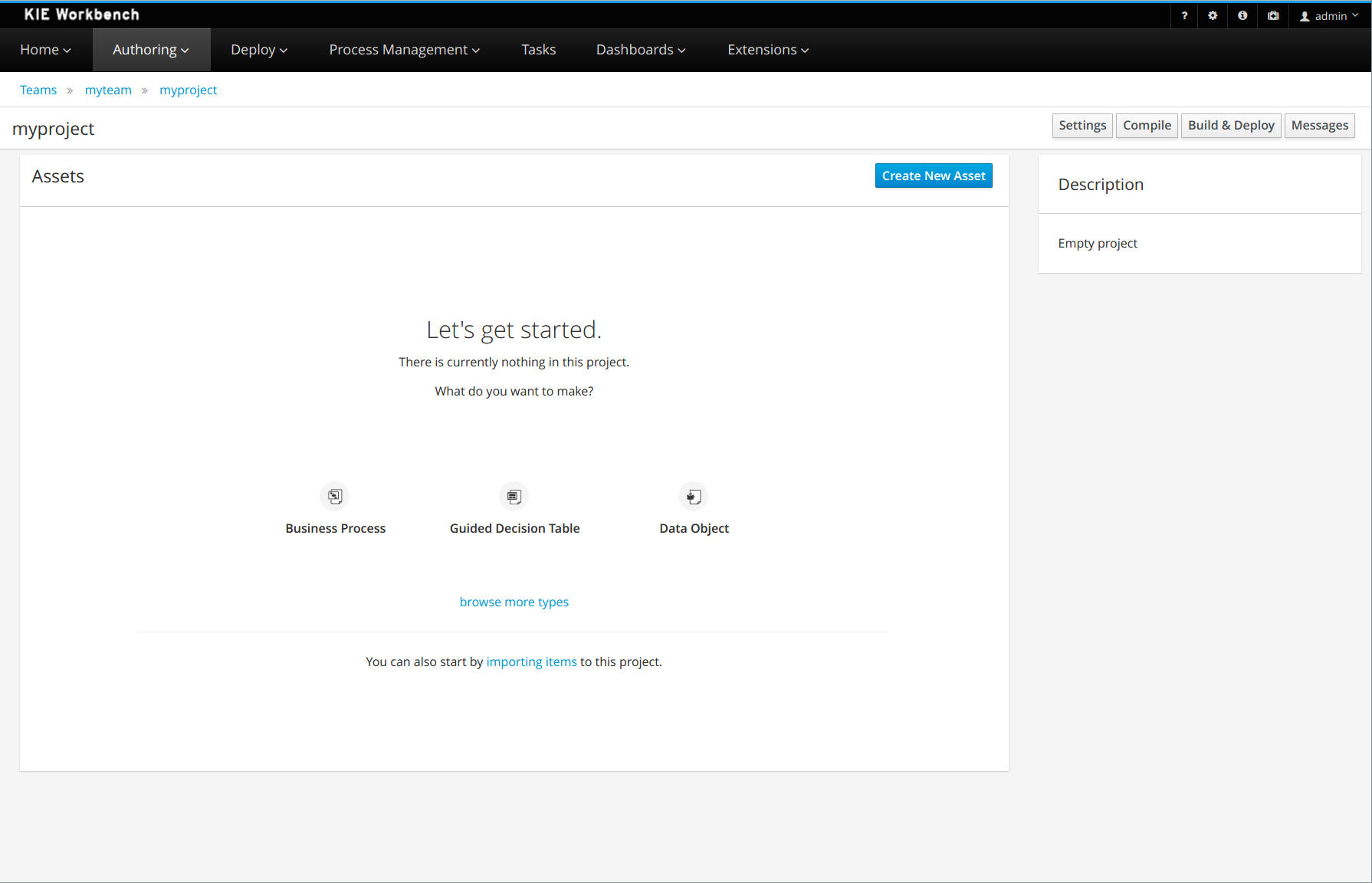
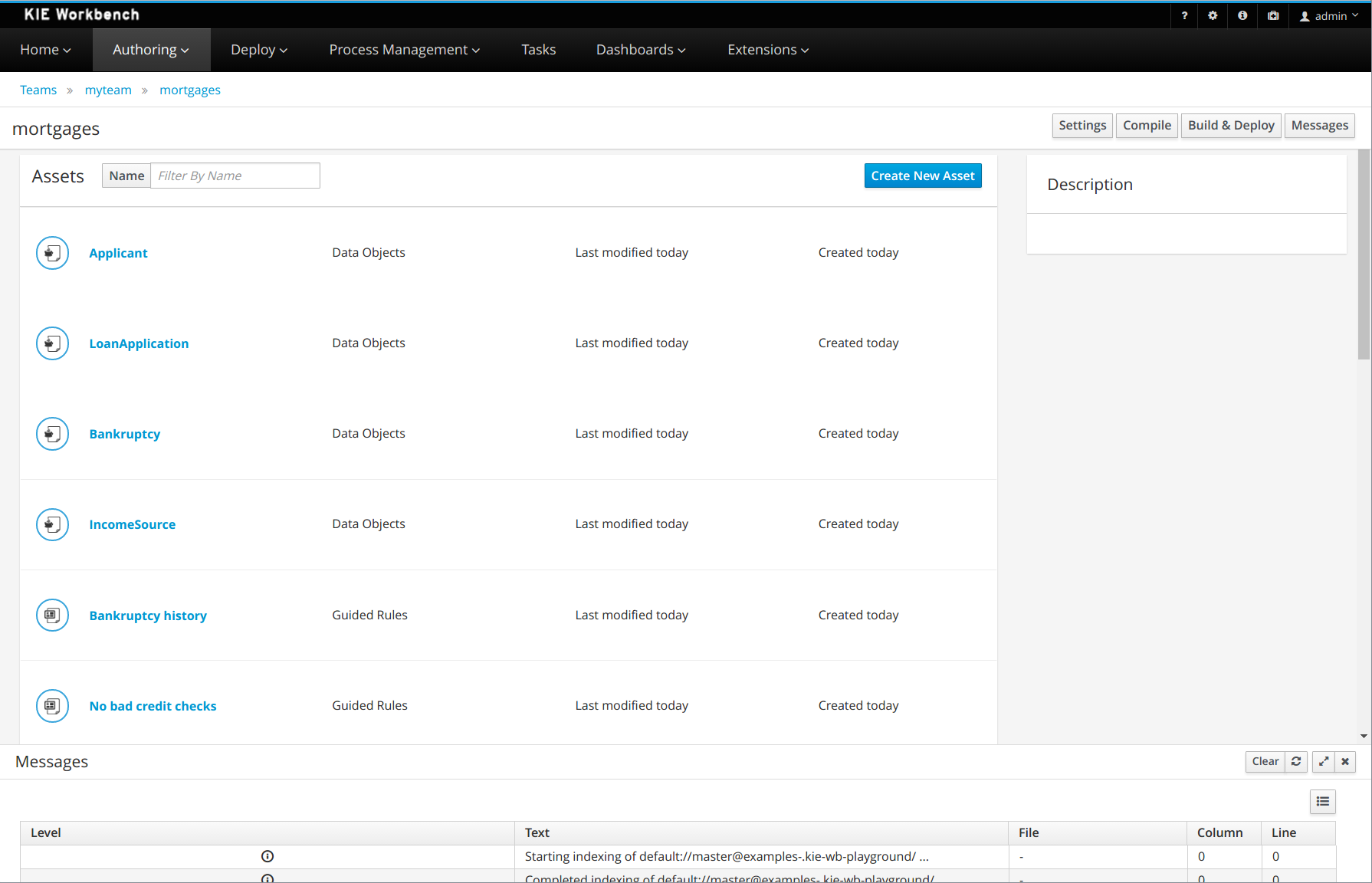
Also, you can set some preferences about your default workspace by accessing Home > Admin > Library.
25.12.2.2. Authoring - Imports of Examples
Prior to 7.x the Workbench used to install pre-defined examples at startup.
Version 7.x brings the ability to import examples from git repositories. The Authoring Perspective contains a menu item for 'Examples' clicking this launches a Wizard to guide you through the import.
The Authoring Perspective contains a menu item for 'Examples'.
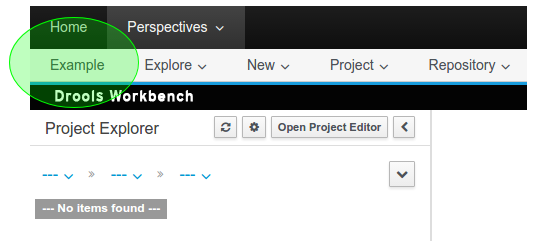
Page 1 of the Wizard allows the User to select a pre-defined examples repository, or enter their own URL.
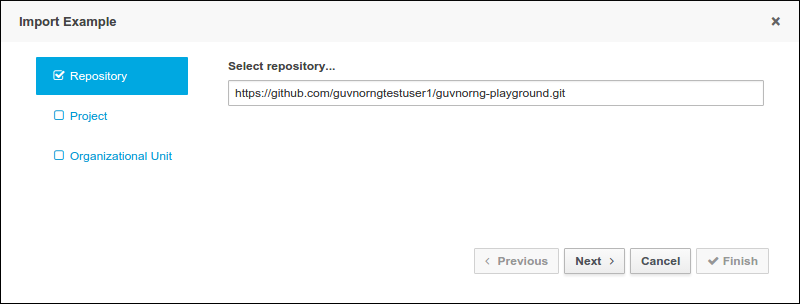
Page 2 of the Wizard lists Projects available in the source repository.
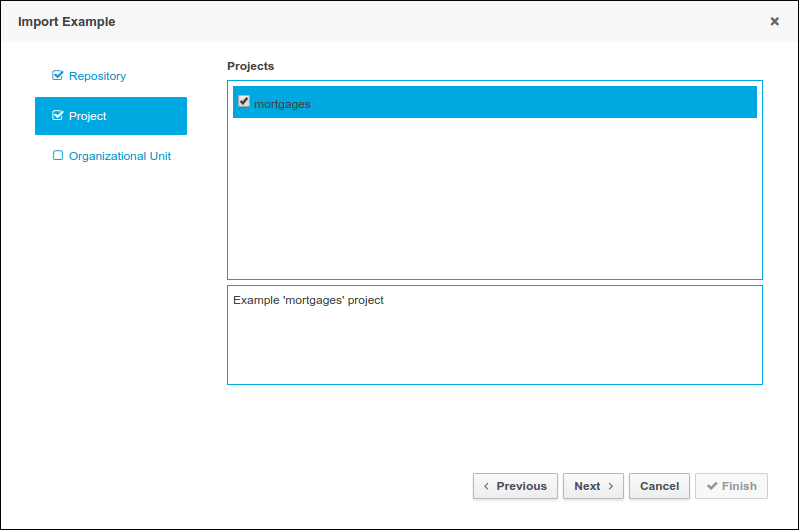
Page 3 of the Wizard allows the User to enter a target Repository name and associate it with an Organizational Unit.
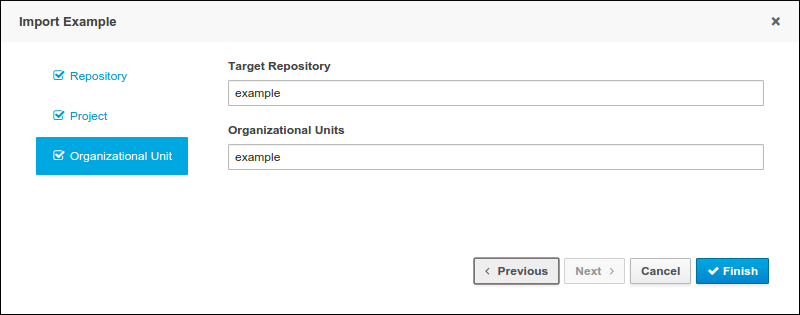
25.12.2.3. Authoring - Pop-ups improvements
All system pop-ups had their UX improved.
The "comment" field is hidden by default.

Now, the destination package can be selected when a project file is copied from any package.
25.12.2.4. Authoring - Project Editor - Reimport button
The "Reimport" button invalidates all cached dependencies, in order to handle scenarios where a specific dependency was updated without having its version modified.
25.12.2.5. Security Management
The User and Group management perspectives released in version 6.4 have been unified into a single perspective which delivers a shared view for managing both users and groups as well as the permissions granted to any of the application roles.
This very new perspective is placed under the Home section in the top menu bar.
The next screenshot shows how this new perspective looks:
A tabbed pane is shown on the left, allowing the User to select the Roles, Groups or Users tab. After clicking on a Role (or Group) a detailed screen is displayed allowing the user to configure some security settings.
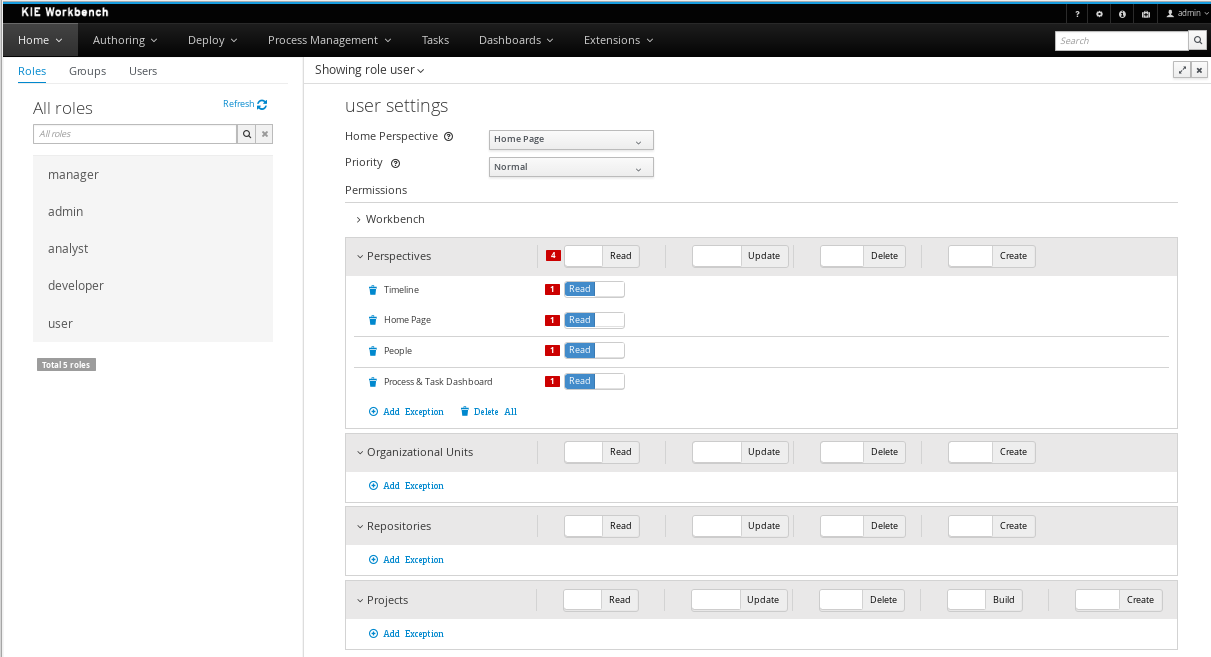
-
Home Perspective: The target perspective where the user is directed after login, which makes it possible to have different home pages per role/group.
-
Priority: Used to determine what settings (home perspective, permissions, …) have precedence for those users with more than one role or group assigned.
-
Permissions: A full ACL (Access Control List) editor for grant/deny permissions over the different resources available in the platform like Perspectives, Organizational Units, Repositories or Projects. Global permissions on top of any of those resource types can be ovewritten by means of adding individual exceptions which makes it possible to implement both the grant all deny a few or the deny all grant a few strategies.
25.12.2.6. kie-config-cli has been removed
The command-line tool kie-config-cli.[sh/bat] for managing remote repositories that was present in 6.x has been removed for the following reasons:
-
The security-related operations it provided (
add-role-repo,remove-role-repo,add-role-org-unit,remove-role-org-unit,add-role-project,remove-role-project) have been replaced by more comprehensive Security management feature. -
The operations related to managing deployments (
list-deployment,add-deployment,remove-deployment) no longer make sense, since jBPM Runtime has been removed from workbench. Deployments can still be managed programmatically using Kie Server REST API. -
The remaining operations (
create-org-unit,remove-org-unit,list-org-units,create-repo,remove-repo,list-repo,add-repo-org-unit,remove-repo-org-unit,list-project-details) are available as a part of workbench remote API
25.12.2.7. User and Project Admin Pages and Preferences
The workbench now has a new menu item: "Admin". In there, you can find some admin tools, like "Users", "Groups" and "Roles" management, and also general preferences. When a preference is changed there, it will affect all places that depend on it, but only for the logged user.
Each project also has its own admin page, with admin tools and preferences. When a preference is changed there, it will affect only that project, and only for the logged user.
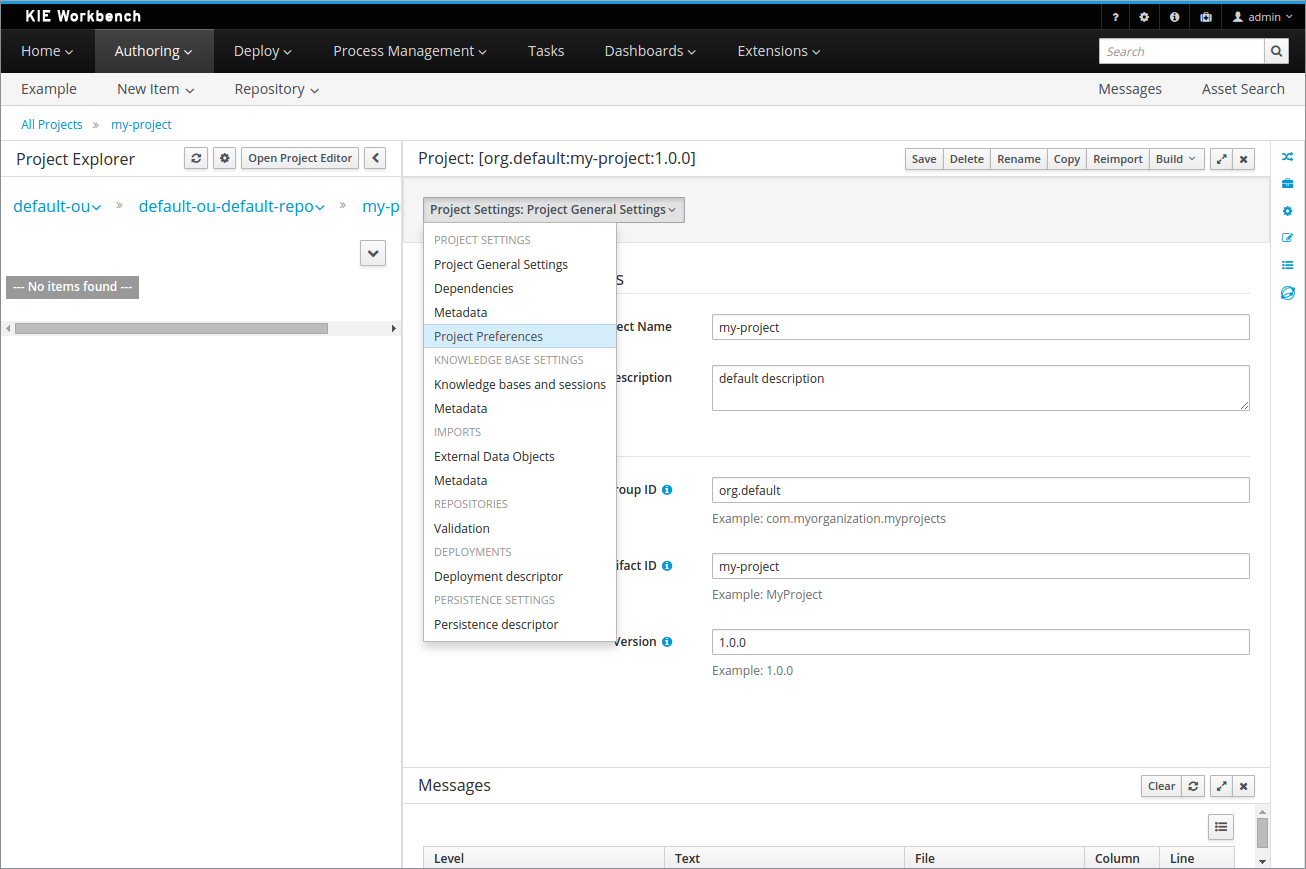
25.12.2.8. GAV conflict check and child GAV edition
It is now possible, for each user, to set the GAV conflict check flag, and also allow or block child GAV edition for all their projects, or specifically for each project.
The configuration can be found inside the admin tool "Project", in case the access is made through the "Admin" menu item. It can also be found by entering the admin tool "General", on the Project admin page.
25.12.2.9. Data Source Management
The new data source management system empowers the workbench with the ability of defining data sources and drivers for accessing external databases.
Some of the included functionalities are:
-
A new perspective for managing the data sources:
-
A new wizard for guiding the data source creation.
-
A new wizard for guiding the drivers creation.
And the ability of browsing the database information for the databases pointed to by the data sources.
-
Available schemas browsing
-
Available tables browsing
-
Table content browsing
25.12.3. Breaking changes in Kie Server 7.0 from 6.x
25.12.3.1. ServiceResponse XStream marshalling changes
| This release note applies only when directly interfacing with the Kie Server (kie-server) API, not when using the Kie Server Java Client (kie-server-client) API. |
In an effort to be more consistent with JAXB marshalling, XStream marshalling has undergone the following changes:
-
The XML ServiceResponse element’s
responseobject no longer renders with the canonical name. -
XStream now uses
typeandmsgas attributes, not child elements.
For more details, see DROOLS-1509.
25.12.3.2. Simplified Planner REST API
ServiceResponse wrapper removal
ServiceResponse wrapper has been removed from Planner service responses returned by KIE Server.
This allows an easier processing of the responses on the client side.
<solver-instance>
...
<status>SOLVING</status>
<score scoreClass="org.optaplanner.core.api.score.buildin.hardsoft.HardSoftScore">0hard/-10soft</score>
<best-solution class="curriculumcourse.curriculumcourse.CourseSchedule">
...
</best-solution>
</solver-instance>New Planner API overview
Register a solver:
Submit a solution:
Get the best solution:
Terminate a solver:
Dispose a solver:
25.13. jBPM 6.5
25.13.1. New and Noteworthy in jBPM 6.5.0
The following features were added to jBPM 6.5
25.13.1.1. Process instance migration
The jBPM services module has been extended with admin capability to allow basic process instance migration. Process instance migration allows you to upgrade an already active process instance to a newer version of the process definition (than the one it was started with). The service primary targets migration of process instance:
-
between deployments (kjars)
-
between process definitions
Optionally it allows to perform node mapping of active node instances within process instance (to accommodate for use cases where currently active nodes might have changed).
25.13.1.2. Kie Server client - fire and forget and async response handling (JMS)
Kie Server client has been enhanced to support various response handlers for JMS based integration. By default it stays as in previous version (request reply interaction pattern) but allows to select another one that might fit better for some uses cases:
-
fire and forget - essentially means there won’t be any response
-
asynchronous with callback - response to the message will be delivered asynchronously to given callback
25.13.1.3. Task variables support in TaskLifeCycleEventListener
6.5 comes with enhancement for accessing task variables (both input and output) from within task event listener. Once there is a need to get hold of task variables in the listener it’s enough to call:
@Override
public void beforeTaskStartedEvent(TaskEvent event) {
Task task = event.getTask();
event.getTaskContext().loadTaskVariables(task);
Map<String, Object> inputVariables = task.getTaskInputVariables();
Map<String, Object> outputVariables = task.getTaskOutputVariables();
}25.13.1.4. Remote API improvements for deployments
Additional operations have been added to the remote API to simplify integration: operations to get deployment information of your projects based on their group, id and/or version (GAV).
25.13.1.5. Improved automation importing service tasks in Designer
You can import custom service tasks from a service repository into Designer so they can be used in your process, like for example Twitter, FTP, etc. The workbench now automates a lot of the additional configuration as well:
-
Installs the service configuration (wid) into the users Workbench project
-
Installs the service icon (defined in the service configuration)
-
Installs the service maven dependencies into the project POM
-
Installs the service default handler into the project Deployment Descriptor
Using start up parameters, you can also register a default service repositories and even install service tasks by default for new projects. More details are available in the documentation.
25.13.1.6. Designer copy/paste
You can now also perform copy/paste operations across different processes.
25.13.1.7. Combining the workbench and kie-server
Various small improvements allow you to use the workbench together with (one or more) kie-server execution servers to manage your process instances and tasks (sharing the same underlying datasource). As a result, processes and task created on one of the execution servers can now be managed in the workbench UI as well.
The jbpm-installer is now configured out-of-the-box to have a managed kie-server deployed next to it where you can deploy your processes to as well.
25.13.1.8. Upgrades WildFly / EAP / Spring
Various components have been added / upgraded:
-
Upgraded to WildFly 10
-
Added support for EAP 7
-
Upgraded to Spring 4
The jbpm-installer now uses WildFly 10.0.0.Final as the default.
25.13.1.9. Support for enums in data modeler
The data modeler now supports selecting enums as the type when defining the parameters of a data object.
25.13.2. New and Noteworthy in KIE Workbench 6.5.0
25.13.2.1. Guided Rule Editor : Support formulae in composite field constraints
Composite field constraints now support use of formulae.
When adding constraints to a Pattern the "Multiple Field Constraint" selection ("All of (and)" and "Any of (or)") supports use of formulae in addition to expressions.
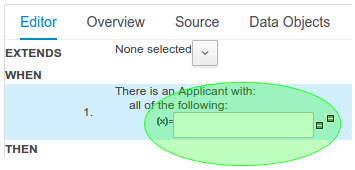
25.13.2.2. Authoring - Project Editor - Reimport button
The "Reimport" button invalidates all cached dependencies, in order to handle scenarios where a specific dependency was updated without having its version modified.
25.14. jBPM 6.4
25.14.1. New and Noteworthy in jBPM 6.4.0
The following features were added to jBPM 6.4
25.14.1.1. New jBPM Process & Task Dashboard
The jBPM Process Dashboard has been entirely rewritten in this version and now is based on a native workbench perspective instead of a separated web application. The main goal is to deliver a better user experience, thanks to a much more appealing as well as polished user interface.
This dashboard version also provides the ability to navigate from the graphical indicators to any of the related process or task instances. Now, end users can easily find out the instances that are related to a given indicator and deep into their details as well.
The resulting dashboard is more fluent, more interactive and with a better integration with the jBPM runtime.
25.14.1.2. Task variables auditing
By default process variables are stored in audit tables (VariableInstanceLog) that allows simplified access to variable values without need to load individual process instances. Moreover that provides option to search by process variables and process variable values e.g. to find process instances that have given value for given variable.
This was missing for task variables as task variables were not stored in any audit tables. This has been improved in version 6.4.0 and now task variables are stored in audit table (TaskVariableImpl) by default. It does follow the same mechanism as for process variables - variable.toString() is the value stored in table. With this services and query APIs have been enhanced to take advantage of this support and to search for tasks by their variables.
25.14.1.3. Process and task variables indexation
By default process and task variables are indexed with simplest possible mechanism - that is variable.toString() while for some object this can be sufficient, like simple types, for others it can cause significant problems when performing queries. To solve the problem process and task variables are equipped with pluggable indexation. This is realized by two interfaces that shall be implemented to provide custom indexation behavior.
-
org.kie.internal.process.ProcessVariableIndexer
-
org.kie.internal.task.api.TaskVariableIndexer
details about how to use the indexers can be found in Audit log section of the documentation
25.14.1.4. QueryService
QueryService that is an addition to jbpm services, brings in power of Dashbuilder DataSets (SQL based) to jbpm services. This allows more tailored queries that can include both jBPM tables and external tables such as external system data. With this users are in control of what data and how data are going to be queried.
Dashbuilder DataSet introduce concept of building "data base views" for part of the data that can later on be filtered to find relevant data for given invocation.
QueryService is available for all add-ons for services meanign pure java, CDI and EJB.
25.14.1.5. Pluggable Task deadlines notification listeners
One of task deadlines actions is notification which by default is implemented as email notification. Although this type of notification does not always fit the requirement. To allow custom notification to be used, jBPM 6.4 was enhanced to support pluggable notification listeners. Notification is realized as broadcast, meaning all available listeners will be invoked, although each listener can decide if it shall react to given notification or not. For instance email notification listener will only send email if it’s properly configured (with mail server etc) otherwise it will ignore the notification.
25.14.1.6. Ability to show bussiness data at task list.
The user can now create a specific filter that provides domain specific columns to be added to a task list. When the user creates a custom filter for a specific task name the task variables are enabled as columns.
The custom filter that activates the capability to display task variables as columns is set a filter with the restriction Name="taskName".
When the filter with the restriction over a specific task name is applied, the task associated variables appear as a selectable columns, to the task list.
25.14.1.7. Process Documentation.
Users are able to view and share process documentation during business process modelling. Process documentation is dynamically updated as users are working on their business process.
Users can print the documentation or view it as a png file.
Process Documentation includes the following sections:
-
Process Overview (general info, process variables, globals, and imports)
-
Process Element Details (totals, and specific element information)
-
Process Image
25.14.2. New and Noteworthy in KIE Workbench 6.4.0
25.14.2.1. New look and feel
The general look and feel in the entire workbench has been updated to adopt PatternFly. The update brings a cleaner, lightweight and more consistent user experience throughout every screen. Allowing users focus on the data and the tasks by removing all uncessary visual elements. Interactions and behaviors remain mostly unchanged, limiting the scope of this change to visual updates.
25.14.2.2. Various UI improvements
In addition to the PatternFly update described above which targeted the general look and feel, many individual components in the workbench have been improved to create a better user experience. This involved making sure the default size of modal popup windows is appropriate to fit the corresponding content, adjusting the size of text fields as well as aligning labels, and improving the resize behaviour of various components when used on smaller screens.
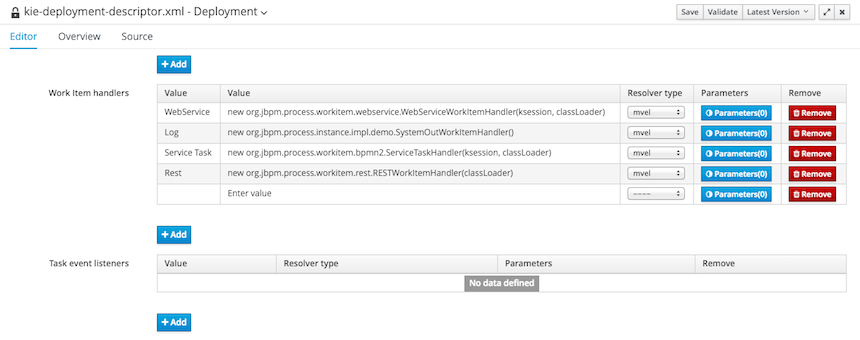
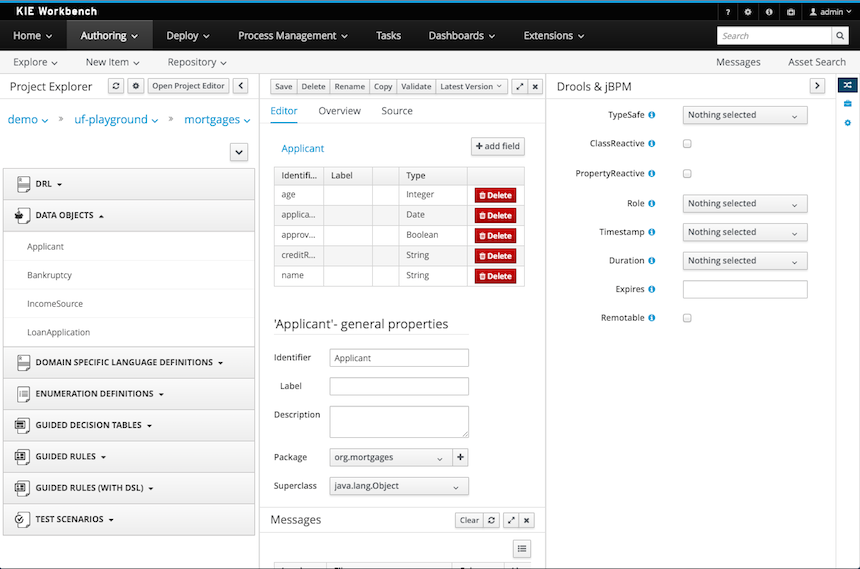
25.14.2.3. New locales
Locales ru (Russian) and zh_TW (Chineses Traditional) have now been added.
The locales now supported are:
-
Default English.
-
es(Spanish) -
fr(French) -
de(German) -
ja(Japanese) -
pt_BR(Portuguese - Brazil) -
zh_CN(Chinese - Simplified) -
zh_TW(Chinese - Traditional) -
ru(Russian)
25.14.2.4. Authoring - Imports - Consistent terminology
The Workbench used to have a section in the Project Editor for "Import Suggestions" which was really a way for Users to register classes provided by the Java Runtime environment to be available to Rule authoring. Furthermore Editors had a "Config" tab which was where Users were expected to import classes from other packages to that in which the rule resides.
Neither term was clear and both were inconsistent with each other and other aspects of the Workbench.
We have changed these terms to (hopefully) be clearer in their meaning and to be consistent with the "Data Object" term used in relation to authoring Java classes within the Workbench.
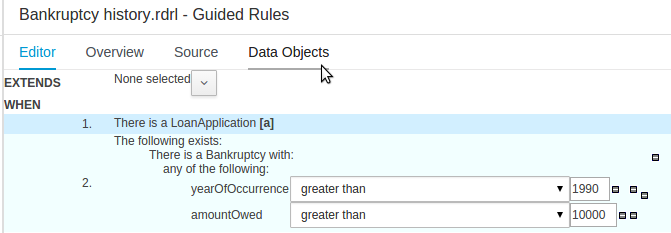
The Data Object screen lists all Data Objects in the same package as the asset and allows other Data Objects from other packages to be imported.
25.14.2.5. Disable automatic build
When navigating Projects with the Project Explorer the workbench automatically builds the selected project, displaying build messages in the Message Console.
Whilst this is beneficial it can have a detremental impact on performance of the workbench when authoring large projects.
The automatic build can now be disabled with the org.kie.build.disable-project-explorer System Property.
Set the value to true to disable.
The default value is false.
25.14.2.6. Support for SCP style git Repository URLs
When cloning git Repositories it is now possible to use SCP style URLS, for example git@github.com:user/repository.git.
If your Operating System’s public keystore is password protected the passphrase can be provided with the org.uberfire.nio.git.ssh.passphrase System Property.
25.14.2.7. Authoring - Duplicate GAV detection
When performing any of the following operations a check is now made against all Maven Repositories, resolved for the Project, for whether the Project’s GroupId, ArtifactId and Version pre-exist.
If a clash is found the operation is prevented; although this can be overridden by Users with the admin role.
|
The feature can be disabled by setting the System Property |
Resolved repositories are those discovered in:
-
The Project’s
POM<repositories>section (or any parentPOM). -
The Project’s
POM<distributionManagement>section. -
Maven’s global
settings.xmlconfiguration file.
Affected operations:
-
Creation of new Managed Repositories.
-
Saving a Project defintion with the Project Editor.
-
Adding new Modules to a Managed Multi-Module Repository.
-
Saving the
pom.xmlfile. -
Build & installing a Project with the Project Editor.
-
Build & deploying a Project with the Project Editor.
-
Asset Management operations building, installing or deloying Projects.
-
RESToperations creating, installing or deploying Projects.
Users with the Admin role can override the list of Repositories checked using the "Repositories" settings in the Project Editor.
25.14.2.8. New Execution Server Management User Interface
The KIE Execution Server Management UI has been completely redesigned to adjust to major improvements introduced recently. Besides the fact that new UI has been built from scratch and following best practices provided by PatternFly, the new interface expands previous features giving users more control of their servers.
25.14.2.9. User and group management
Provides the backend services and an intuitive and friendly user interface that allows the workbench administrators to manage the application’s users and groups.
This interface provides to the workbench administrators the ability to perform realm related operations such as create users, create groups, assign groups or roles to a given user, etc.
It comes by default with built-in implementations for the administration of Wildfly, EAP and Tomcat default realms, and it’s designed to be extensible - any third party realm management system can be easily integrated into the workbench.
25.15. jBPM 6.3
25.15.1. New and Noteworthy in jBPM 6.3.0
The following features were added to jBPM 6.3.
25.15.1.1. Process engine extensions
-
JavaScript as script language
You can now use JavaScript as dialect in scripts (script task and on-entry and on-exit scripts) and for constraints (for example on gateways). Same as with the Java and MVEL dialect, you have direct access to variables, globals and to the kcontext variable (giving you access to the ProcessContext).
For example, you can write something like:
kcontext.setVariable('surname', "tester"); var text = 'Hello '; print(text + kcontext.getVariable('name') + '\n'); try { somethingInvalid; } catch(err) { print(err + '\n'); } -
Async continuation
Async continuation simplifies usage of asynchronous processing of process activities. Simply marking process activity as async will instruct the engine to complete current processing (including committing transaction) before entering that activity. This in turn will allow more control over what is executed in sequence and improve overall managebility of process execution. Here you can read an article describing this in details.
-
Signal scopes
Version 6.3 comes with improved support for signaling process instances. Based on concepts of singals defined in BPMN2 jBPM provides additional characteristic to them - the scope. Scope defines how to propagate the signal:
-
process instance scope - signals only elements within the same process instance, other process isntances won’t be affected
-
default (ksession) scope - signals all elements that are waiting for given signal and are known to running ksession
-
project scope - signals all components within given project (that means managed by the same instance of runtime manager)
-
external scope - pluggable scope that allow to customize signal propagation - jBPM 6.3 comes with JMS based implementation which is enabled in workbench (receiving part)
More about the improved signaling can be found in this article.
-
-
Improved search capabilities when using jbpm services (RuntimeDataService) that allows
-
search by correlation key
-
search by process variable name
-
search by process variable name and value
-
-
Throw async signals
If there are several process instances from different process definitions, all of them waiting the same signal and only one of these process instances throws a RuntimeException all others not related will not move forward as well, because they are executed sequentially in the same transaction. That creates heavy dependency between unrelated process instances. Asynchronous throw event solves the problem by individually signaling each process instance in background.
25.15.1.2. Case management API
The core process engine has always contained the flexibility to model adaptive and flexible processes. These kinds of features are typically also required in the context of case management. To simplify picking up some of these more advanced features, we created a (wrapper) API that exposes some of these features in a simple API. Note that this API simply relies on other existing features / API and can easily be extended. The API and implementation is added as part of a new jbpm-case-mgmt module.
-
Process instance description
Each case can have a unique name, specific to that case.
-
Case roles
A case can keep track of who is participating by using case roles. These roles can be defined as part of the case definition (by giving them a name and (optionally) a cardinality). Case roles could also be defined dynamically (at runtime). For active case instances, specific users can be assigned to roles.
-
Ad-hoc cases
One can start a new case without even having a case definition. Whatever happens inside this case is completely determined at runtime.
-
Case file
A case can contain any kind of data, from simple key-value pairs to custom data objects or documents.
-
Ad-hoc tasks
Using the ad-hoc constructs available in BPMN2, one can model optional process fragments, where only at runtime it is decided which of these fragments should be executed (and how many times). This could be driven by end users (selecting optional fragments for execution) or automatically (for example by rules that trigger certain fragments under certain conditions, or whenever triggered by external services).
-
Dynamic tasks
It is possible to add new tasks dynamically, even if they weren’t defined upfront (in the case definition). This includes human tasks, service tasks and other processes.
-
Milestones
You can define milestones as part of the case definition (or even dynamically) and keep track of which milestones were reach for specific case instances.
25.15.1.3. Remote API
The remote REST API for accessing the workbench received the following extensions:
-
Process instance image
Through the remote REST API you can now retrieve an image that represents the status of a particular process instance, annotated on the process diagram. This will generate the same image as you could already see in the workbench by looking at the process instance diagram, i.e. active nodes will be marked with a red border and completed nodes have a gray background. This is generated based on the SVG of the process diagram, which can automatically be generated by designer whenever saving a process.
A new
SVGImageProcessorhas been used to add the necessary annotations based on the audit log data. Note that this processor (in thejbpm-process-svgmodule) could be extended to support more advanced visualizations.This feature is unfortunately not active by default! In order to activate this feature, it is necessary to follow the following steps:
-
Open the
org.kie.workbench.KIEWebapp/profiles/jbpm.xmlfile in the kie-wb war. -
Towards the top of this
jbpm.xmlfile, you’ll see the following xml element:<storesvgonsave enabled="false"/>Change the
falsevalue here totrue. -
(Re)Deploy the war
Furthermore, only process definitions that have been opened in the designer after this modification will be available via the REST operations described below. However, providing process images by default via REST (without having to turn on an option or open the process definition in designer) is on the roadmap.
-
-
2 new REST operation URLs have been made available to provide the image:
-
The following URL provides an image of the process definition:
{server}/jbpm-console/rest/runtime/{deploymentId}/process/{processDefId}/imageThe
deploymentIdURL parameter corresponds to the deployment id, while theprocessDefIdparameter corresponds to the process (definition) id. -
The following URL provides an image of the process definition, with the active nodes marked to correspond to the process instance URL parameter passed:
{server}/jbpm-console/rest/runtime/{deploymentId}/process/{processDefId}/image/{procInstId}The
deploymentIdURL parameter corresponds to the deployment id, theprocessDefIdparameter corresponds to the process (definition) id, and theprocInstIdURL parameter corresponds to the process instance id.
-
25.15.1.4. OSGi
The remote clients - kie-remote-client for accessing the workbench embedded in the workbench and kie-server-client for the separate (unified) execution server - are now also available as an OSGi feature.
25.15.1.5. jBPM Designer Data I/O Editor
jBPM Designer includes a new dialog for editing data inputs and outputs on activities in Business Processes. The dialog combines the functions of the dialogs in previous versions of jBPM Designer for editing data inputs and outputs, and for defining assignments between data inputs/outputs and process variables. The dialog allows the user to:
-
create and edit data inputs and data outputs on activities
-
define assignments from process variables or constants to data inputs, and from data outputs to process variables
The dialog is accessed by editing the Assignments property for activities which have this property, such as User Tasks, or by editing the DataInputAssociations or DataOutputAssociations property for activities which have one of these properties. The dialog is also available by clicking on a new button associated with those activities for which it is relevant:

25.15.1.6. jBPM executor
jBPM executor has been significantly enhanced in version 6.3 where the biggest improvement was to provide support for JMS based notification mechanism to improve performance for immediate job execution. Instead of always relying on poll based mechanism, in case of immediate job request the executor is notified via JMS. Though it still provides same set of capabilities:
-
retry mechanism
-
error handling
-
search capabilities to look through job requests
Retry mechanism was static in prior versions, which means that the retry happened directly with next execution cycle. That made it rather low in terms of usage as in case there was a temporary problem e.g. network issue, system not available. It has been improved as well and allows configurable retry delay to be specified on each job individually. This delay can be given as time expressions that will be calculated from current time stamp. Retry delay can be given as:
-
single time expression - 5m or 2h
-
comma separated list of time expressions that should be used for subsequent retries - 10s,10m,1h,1d
In case number of retry delays is smaller than number of retries it will use last available value from the list of retry delays. A single value means it will always be the same value.
More information about executor enhancements can be found in these two articles: Shift gears with jBPM executor and Asynchronous processing
25.15.1.7. Unified KIE Execution Server
jBPM 6.3 brings in fully featured Unified KIE Execution Server that is based on successful KIE Execution Server that was released with 6.2 and covered rules use case. In 6.3 this execution server has ben enhanced and now support for rules and process (including user tasks and asynchronous jobs). It provides lightweight mechanism for executing your business assets. Number of environments can be built with with it:
-
single execution server (similar to workbench)
-
execution server per kjar
-
execution server per domain knowledge (set of kjars)
-
and more…
It is prepared to run on almost any container where tested configuration include following:
-
JBoss EAP 6.4
-
Wildfly 8.1 and 8.2
-
Tomcat 7 and 8
-
WebSphere 8.5.5.x
-
Weblogic 12c
To get started with KIE Execution Server look at this blog series that provides KIE Execution Server introduction.
25.15.1.8. Process and Task Lists UI Improvements
The process and task lists screens are now backed up by the Dashbuilder’s DataSet APIs and data providers. This enable these runtime screens to retrieve the data in a much more efficient way and enable the users to apply more advanced filters.
The initial version for creating filters is provided with jBPM 6.3.0.Final and it will be extended and polished in future versions.
A new button to restore the default filters if needed is provided.
New filters can be created using the + button. This enable users to have custom filters. There is one filter per tab.
Users can create as many custom filters as they want. These filters will be stored in the user preferences.
The process instance list now provides domain specific columns to be added in custom filters. When the user creates a custom filter for a specific process definition the process variables are enabled as columns, to the process instance list. This feature wil be added to the task list as well in future versions.
|
Only Process Variables with values will be listed in the column picker inside the custom filter tab. |
25.15.2. New and Noteworthy in KIE Workbench 6.3.0
25.15.2.1. Real Time Validation and Verification for the Decision Tables
Decision tables used to have a Validation-button for validating the table. This is now removed and the table is validated after each cell value change. The validation and verification checks include:
-
Redundancy
-
Subsumption
-
Conflicts
-
Missing Columns
These checks are explained in detail in the workbench documentation.
25.15.2.2. Improved DRL Editor
The DRL Editor has undergone a face lift; moving from a plain TextArea to using ACE Editor and a custom DRL syntax highlighter.
25.15.2.3. Asset locking
To avoid conflicts when editing assets, a new locking mechanism has been introduced that makes sure that only one user at a time can edit an asset. When a user begins to edit an asset, a lock will automatically be acquired. This is indicated by a lock symbol appearing on the asset title bar as well as in the project explorer view. If a user starts editing an already locked asset a pop-up notification will appear to inform the user that the asset can’t currently be edited, as it is being worked on by another user. As long as the editing user holds the lock, changes by other users will be prevented. Locks will automatically be released when the editing user saves or closes the asset, or logs out of the workbench. Every user further has the option to force a lock release in the metadata tab, if required.
25.15.2.4. Data Modeller Tool Windows
Drools and jBPM configurations, Persistence (see Generation of JPA enabled Data Models) and Advanced configurations were moved into "Tool Windows". "Tool Windows" are a new concept introduced in latest Uberfire version that enables the development of context aware screens. Each "Tool Window" will contain a domain editor that will manage a set of related Data Object parameters.
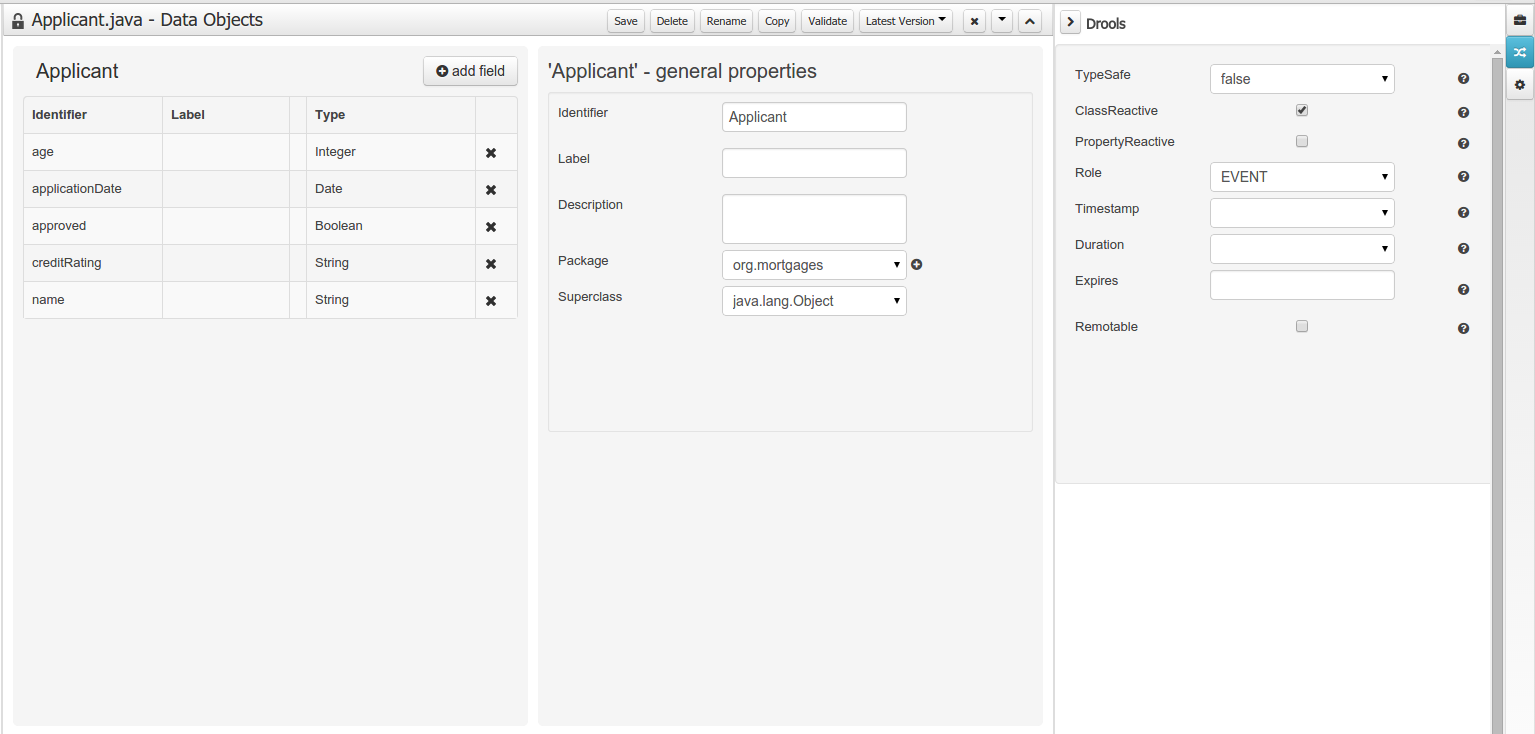
25.15.2.5. Generation of JPA enabled Data Models
Data modeller was extended to support the generation of persistable Data Objects. The persistable Data Objects are based on the JPA specification and all the underlying metadata are automatically generated.
-
"The New → Data Object" Data Objects can be marked as persistable at creation time.
 Figure 318. New Data Object
Figure 318. New Data Object -
The Persistence tool window contains the JPA Domain editors for both Data Object and Field. Each editor will manage the by default generated JPA metadata
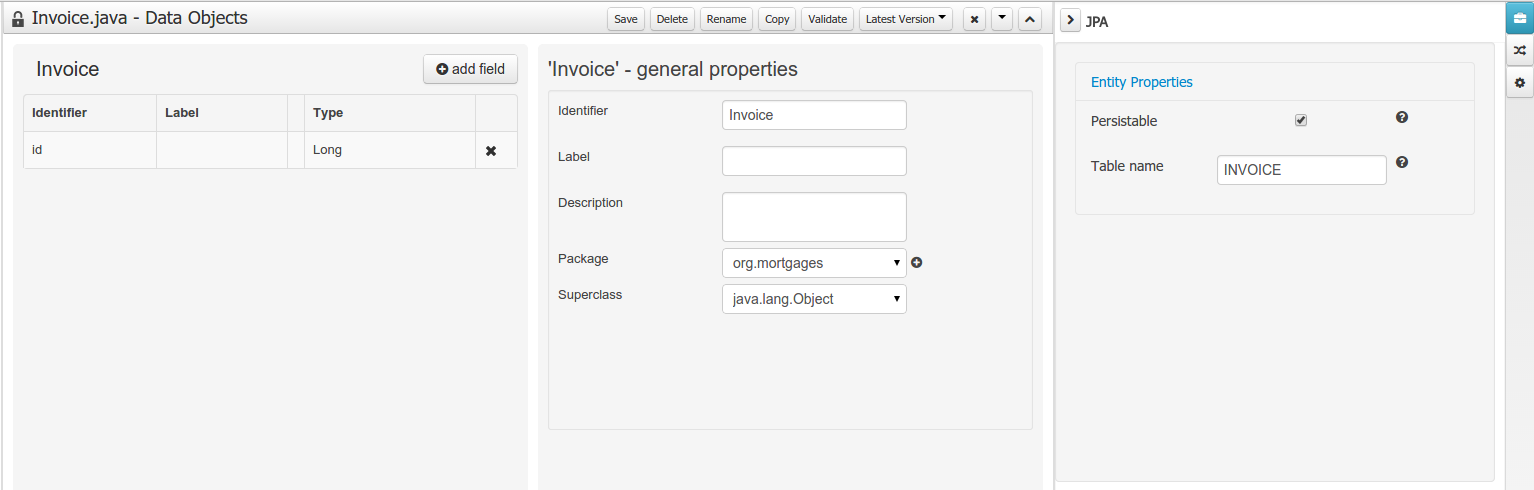 Figure 319. Data Object level JPA domain editor
Figure 319. Data Object level JPA domain editor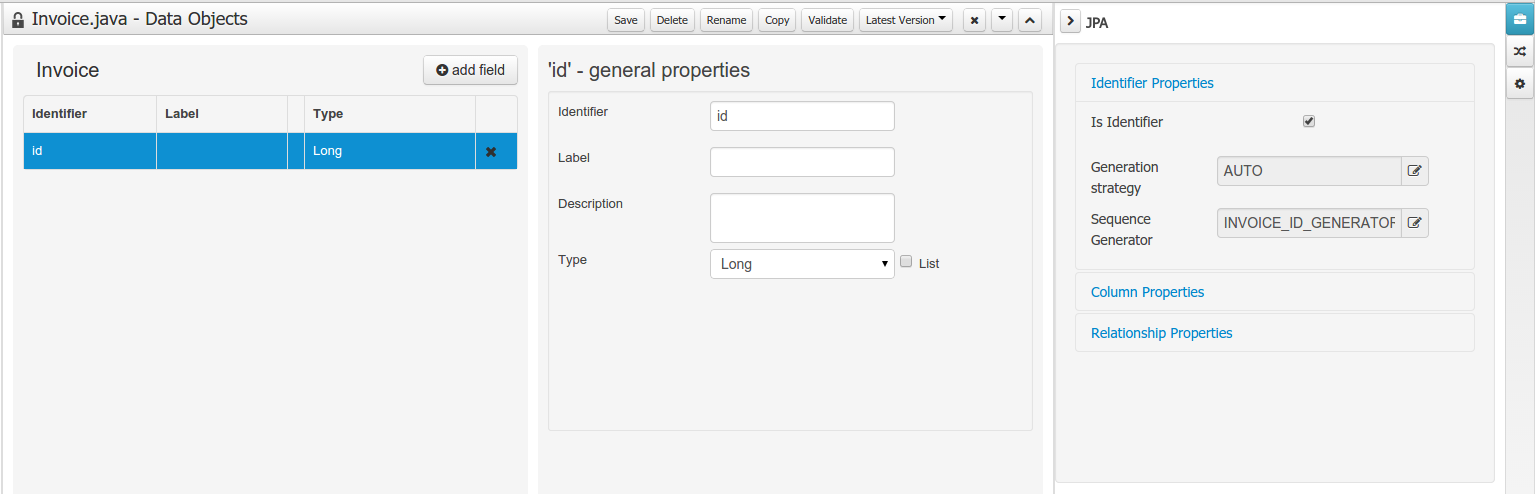 Figure 320. Field level JPA domain editor
Figure 320. Field level JPA domain editor -
Persistence configuration screen was added to the project editor.
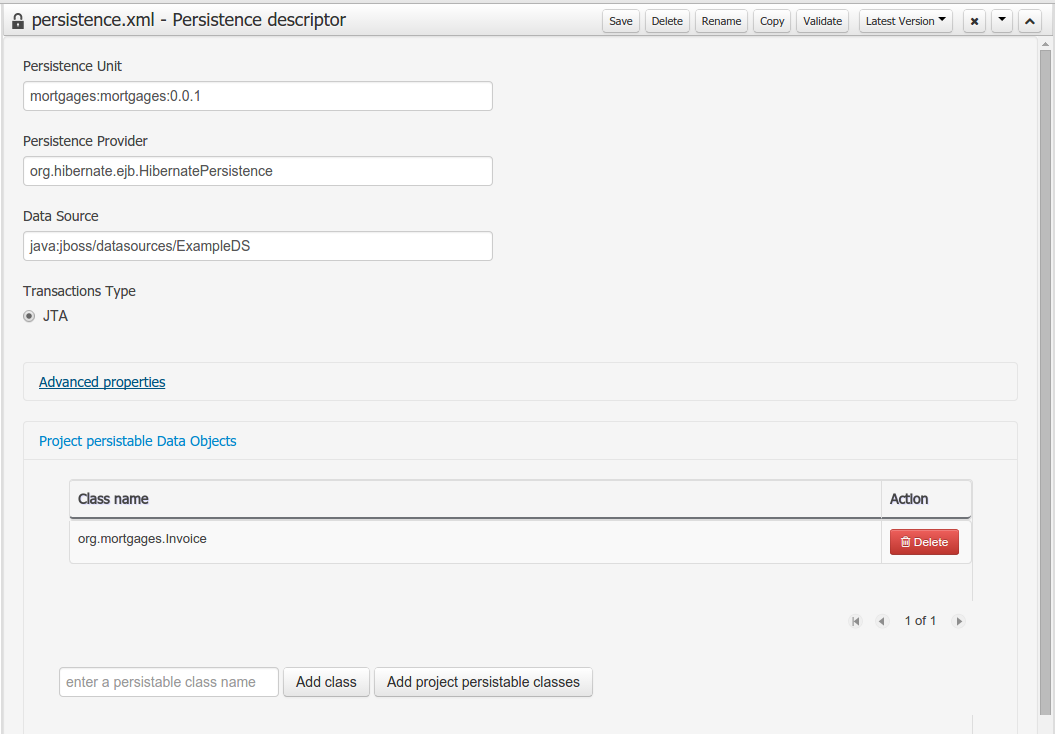 Figure 321. Persistence configuration
Figure 321. Persistence configuration
25.15.2.6. Data Set Authoring
A new perspective for authoring data set definitions has been added. Data set definitions make it possible to retrieve data from external systems like databases, CSV/Excel files or even use a Java class to generate the data. Once the data is available it can be used, for instance, to create charts and dashboards from the Perspective Editor just feeding the charts from any of the data sets available.
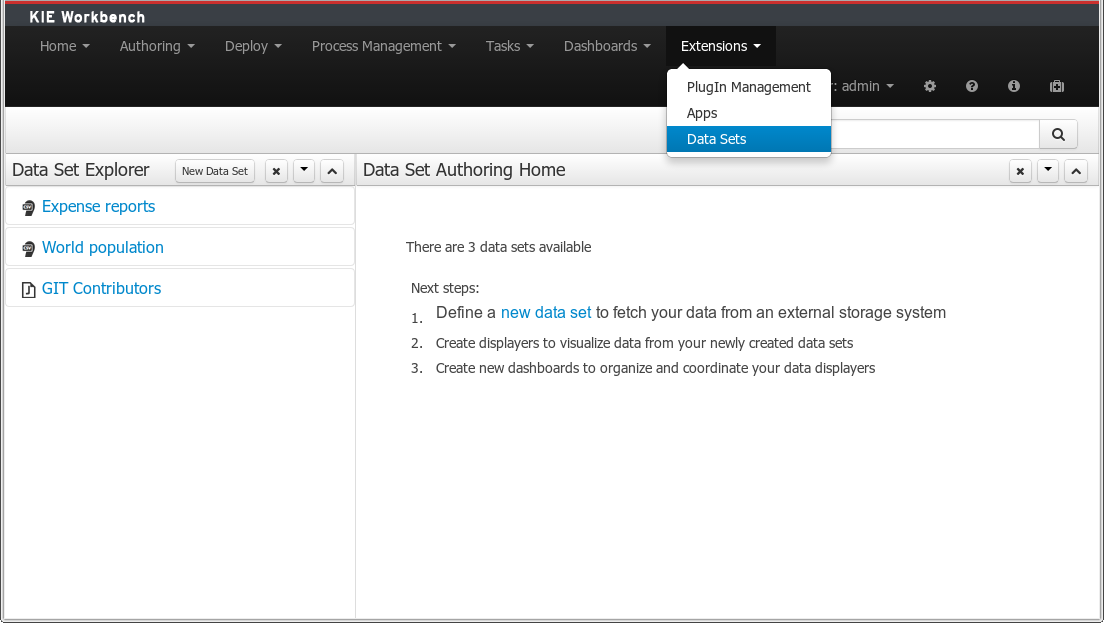
25.16. jBPM 6.2
25.16.1. New and Noteworthy in jBPM 6.2.0
The following features were added to the jBPM core on top of 6.1.
25.16.1.1. jBPM services
jBPM services modules have been significantly refactored to provide clear separation between the logic they bring and various frameworks that can be used to consume those services. With version 6.2 following modules are available:
-
jbpm-services-api - clear services api that shall be used by any client code that consumes services
-
jbpm-kie-services - core implementation of the services that do not have any framework specific code (e.g. CDI)
-
jbpm-services-cdi - CDI specific code on top of jbpm-kie-services
-
jbpm-services-ejb-api - ejb related extensions to services api - mainly to provide remote capablities for the interfaces
-
jbpm-services-ejb-impl - ejb specific code on top of jbpm-kie-services
-
jbpm-services-ejb-client - ejb client implementation to interact with services over remote ejb invocation - currently JBoss specific implementation available
-
jbpm-service-ejb-timer - ejb timer service backed by JEE timer service provided by container
jBPM services are intended to be base of execution server (regardless of what framework is used to build it up completely) so should be considered as first choice when enbedding jbpm in custom applications. With 6.2 capabilities it already provides support for most common frameworks used - CDI, EJB, Spring (should simply rely on core implementation). See this article for details and example.
25.16.1.2. Process engine extensions
-
Lazy initialization of runtime engine components by RuntimeManager to make runtime engine creation lightweight
RuntimeEngine has been enhanced to lazy initialize its components (KieSession, TaskService, AuditService) to improve overall performance of retriveing RuntimeEngine instances from RuntimeManager.
-
Life cycle management for work item handlers and event listeners
Handler and listeners can implement additional interface to be managed by runtime engine, see work item handler life cycle management for more details.
-
Deployments are now by default stored in data base (as deployment descriptors) to servive server restarts
Prior to verion 6.2 deployments that were handled by DeploymentService implementation were not persisted so they required to be handled separately - in case of kie-workbench they were stored inside system.git repo. With version 6.2 deployment service will persist that information directly into db which will make it easier in many cases including clustering as it will not require VFS clustering (Zookeeper and Helix) setup.
-
Extension to deployment descriptor to specify classes (by FQCN) that should be added to JAXB context for remote interfaces interaction
Deployment descriptor accept new set of elements
<remoteable-classes> ... <remotable-class>org.jbpm.test.CustomClass</remotable-class> ... </remoteable-classes> -
Classpath scanning for classes to be included in JAXB context for remote interfaces interaction
Classes annotated with javax.xml.bind.annotation.XmlRootElement and org.kie.api.remote.Remotable will be automatically added to JAXB context of given deployment as soon as they are defined as project dependency. At the same time all classes included in project itself are also added to deployment’s JAXB context.
-
jbpm executor has been enhanced to provide support for:
-
requeue failed jobs so they can be executed once the error that caused them to is resolved.
-
reoccuring jobs that allows single definition to be repeatedly invoked based on time intervals, e.g. daily jobs to clean up history log tables. See this article for details and example.
-
-
CRON support for intermediate and boundary timer events
-
Enhanced support for multi instance activities to support completion condition as MVEL expression
25.16.1.3. OSGi
While a number of core jars were OSGi-ready (in v5 already), a significant number of additional jars were now added to this list, including for example the human task service, the runtime managers, full persistence, etc. As a result, full core engine functionality is now available on top of OSGi. Specific extensions and tests showing it in action are available for Apache Karaf and Aries Blueprint (in the droolsjbpm-integration repository).
25.16.1.4. Camel handler
A new out-of-the-box service task has been implemented for using Apache Camel to connect a process to the outside world using some of the numerous Camel endpoint URIs. The service task allows you to for example specify how to pass data to an FTP endpoint by configuring properties such as hostname, port, username, payload, etc. for some common endpoints like (S)FTP, File, JMS, XSLT, etc. but you can use virtually any of the available endpoints by defining the URI yourself (http://camel.apache.org/uris.html).
25.16.1.5. Form Modeler improvements
Support for JavaScript code:
-
Added field property on simple fields to allow the user to add JavaScript code on the onchange event. This will allow the user to add richer functionallities on the forms.
-
Simplified the autogenerated field id’s in order to allow the user to access the inputs directly via JavaScript.
New field types:
-
Added configurable ComboBox and RadioGroup fields. This new fields types allow the user to add ComboBoxes and Radio Button groups selecting their data source from the list of the Sources registered on the application.
-
Added support to simple types Lists (java.util.List<String>, java.util.List<Integer>, java.util.List<Long>…). This fields allow the user to upload multiple basic values (strings, numbers, dates and booleans) storing them on java.util.List
25.16.2. New and Noteworthy in KIE Workbench 6.2.0
25.16.2.1. Download Repository or Part of the Repository as a ZIP
This feature makes it possible to download a repository or a folder from the repository as a ZIP file.
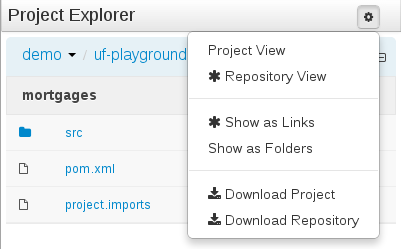

25.16.2.2. Project Editor permissions
The ability to configure role-based permissions for the Project Editor have been added.
Permissions can be configured using the WEB-INF/classes/workbench-policy.properties file.
The following permissions are supported:
-
Save button
feature.wb_project_authoring_save -
Delete button
feature.wb_project_authoring_delete -
Copy button
feature.wb_project_authoring_copy -
Rename button
feature.wb_project_authoring_rename -
Build & Deploy button
feature.wb_project_authoring_buildAndDeploy
25.16.2.3. Unify validation style in Guided Decision Table Wizard.
All of our new screens use GWT-Bootstrap widgets and alert users to input errors in a consistent way.
One of the most noticable differences was the Guided Decision Table Wizard that alerted errors in a way inconsistent with our use of GWT-Bootstrap.
This Wizard has been updated to use the new look and feel.
25.16.2.4. Improved Wizards
During the re-work of the Guided Decision Table’s Wizard to make it’s validation consistent with other areas of the application we took the opportunity to move the Wizard Framework to GWT-Bootstrap too.
The resulting appearance is much more pleasing. We hope to migrate more legacy editors to GWT-Bootstrap as time and priorities permit.
25.16.2.5. Consistent behaviour of XLS, Guided Decision Tables and Guided Templates
Consistency is a good thing for everybody. Users can expect different authoring metaphores to produce the same rule behaviour (and developers know when something is a bug!).
There were a few inconsistencies in the way XLS Decision Tables, Guidied Decision Tables and Guided Rule Templates generated the underlying rules for empty cells. These have been eliminated making their operation consistent.
-
If all constraints have null values (empty cells) the Pattern is not created.
Should you need the Pattern but no constraints; you will need to include the constraint
this != null.This operation is consistent with how XLS and Guided Decision Tables have always worked.
-
You can define a constraint on a String field for an empty String or white-space by delimiting it with double-quotation marks. The enclosing quotation-marks are removed from the value when generating the rules.
The use of quotation marks for other String values is not required and they can be omitted. Their use is however essential to differentiate a constraint for an empty String from an empty cell - in which case the constraint is omitted.
25.16.2.6. Improved Metadata Tab
The Metadata tab provided in previous versions was redesigned to provide a better asset versioning information browsing and recovery. Now every workbench editor will provide an "Overview tab" that will enable the user to manage the following information.
-
Versions history
The versions history shows a tabular view of the asset versions and provides a "Select" button that will enable the user to load a previously created version.
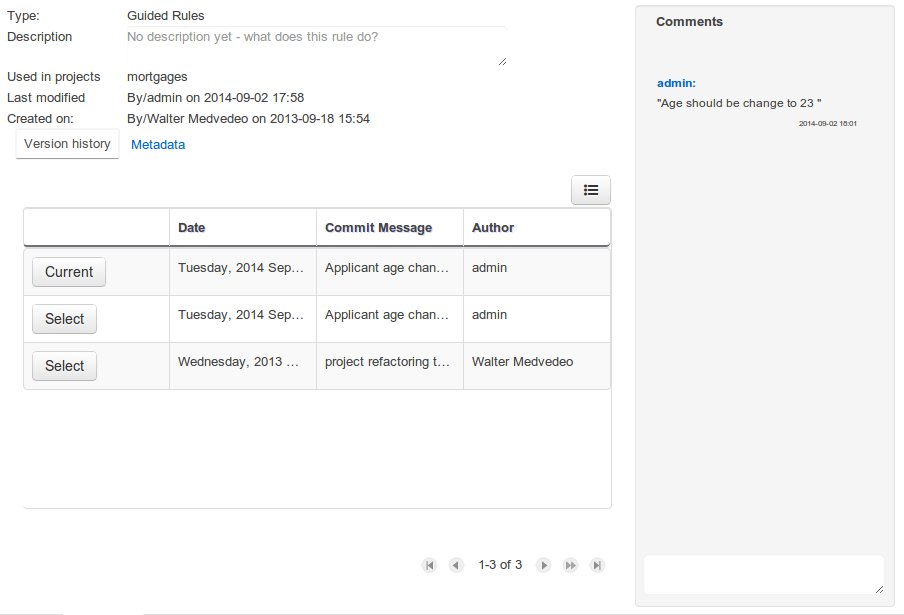 Figure 328. Versions history
Figure 328. Versions history -
Metadata
The metadata section gets access to additional file attributes.
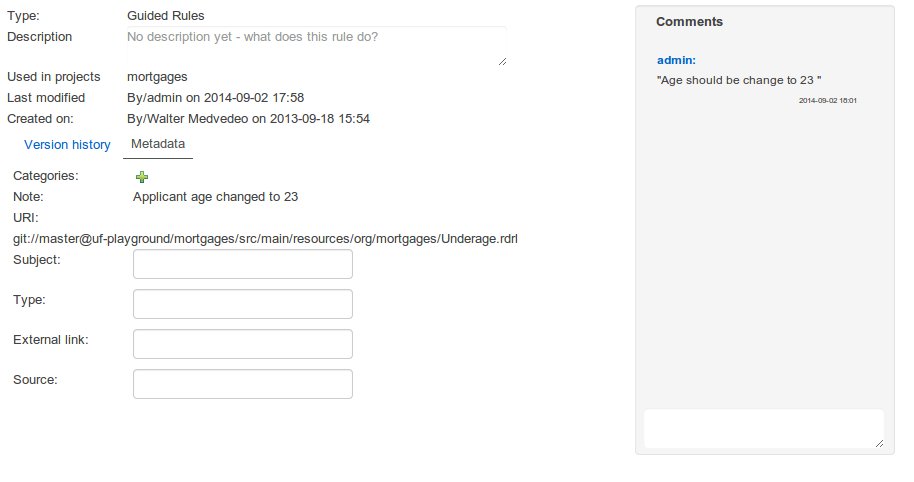 Figure 329. Metadata section
Figure 329. Metadata section -
Comments area
The redesigned comments area enables much clearer discussions on a file.
-
Version selection dropdown
The "Version selector dropdown" located at the menu bar provides the ability to load and restore previous versions from the "Editor tab", without having to open the "Overview tab" to load the "Version history".
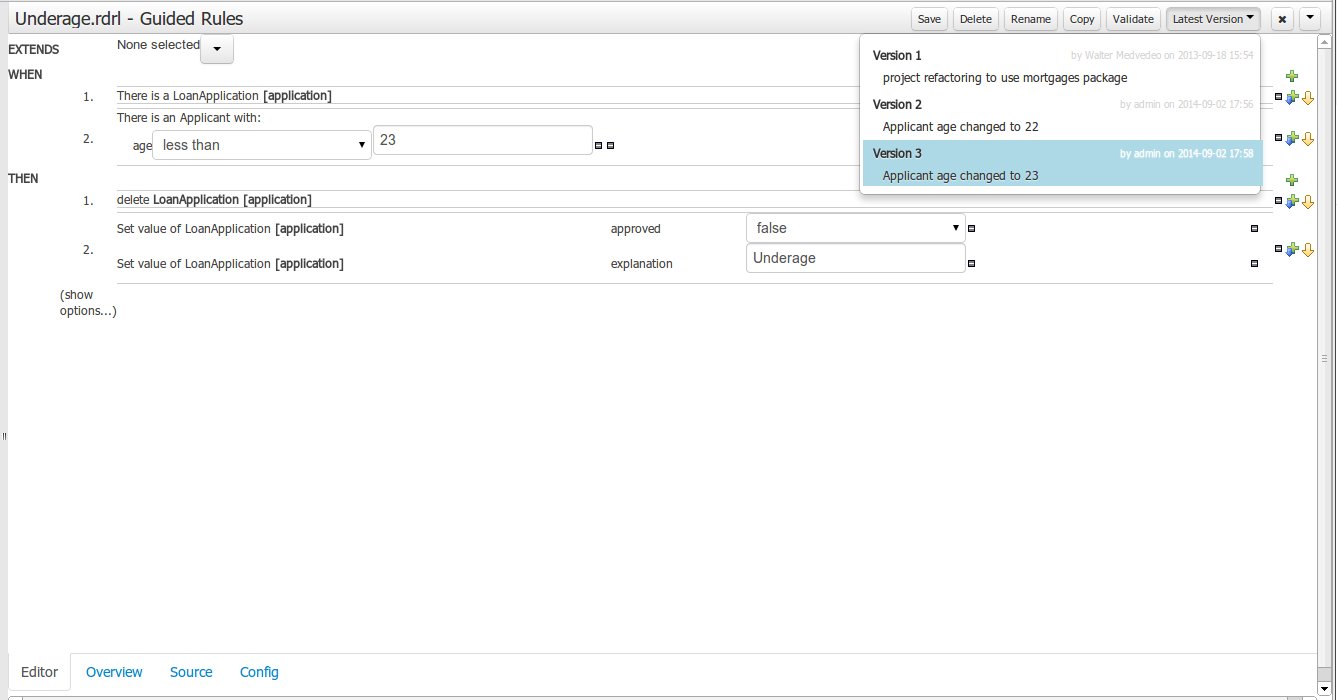 Figure 330. Version selection dropdown
Figure 330. Version selection dropdown
25.16.2.7. Improved Data Objects Editor
The Java editor was unified to the standard workbench editors functioning. It means that and now every data object is edited on his own editor window.
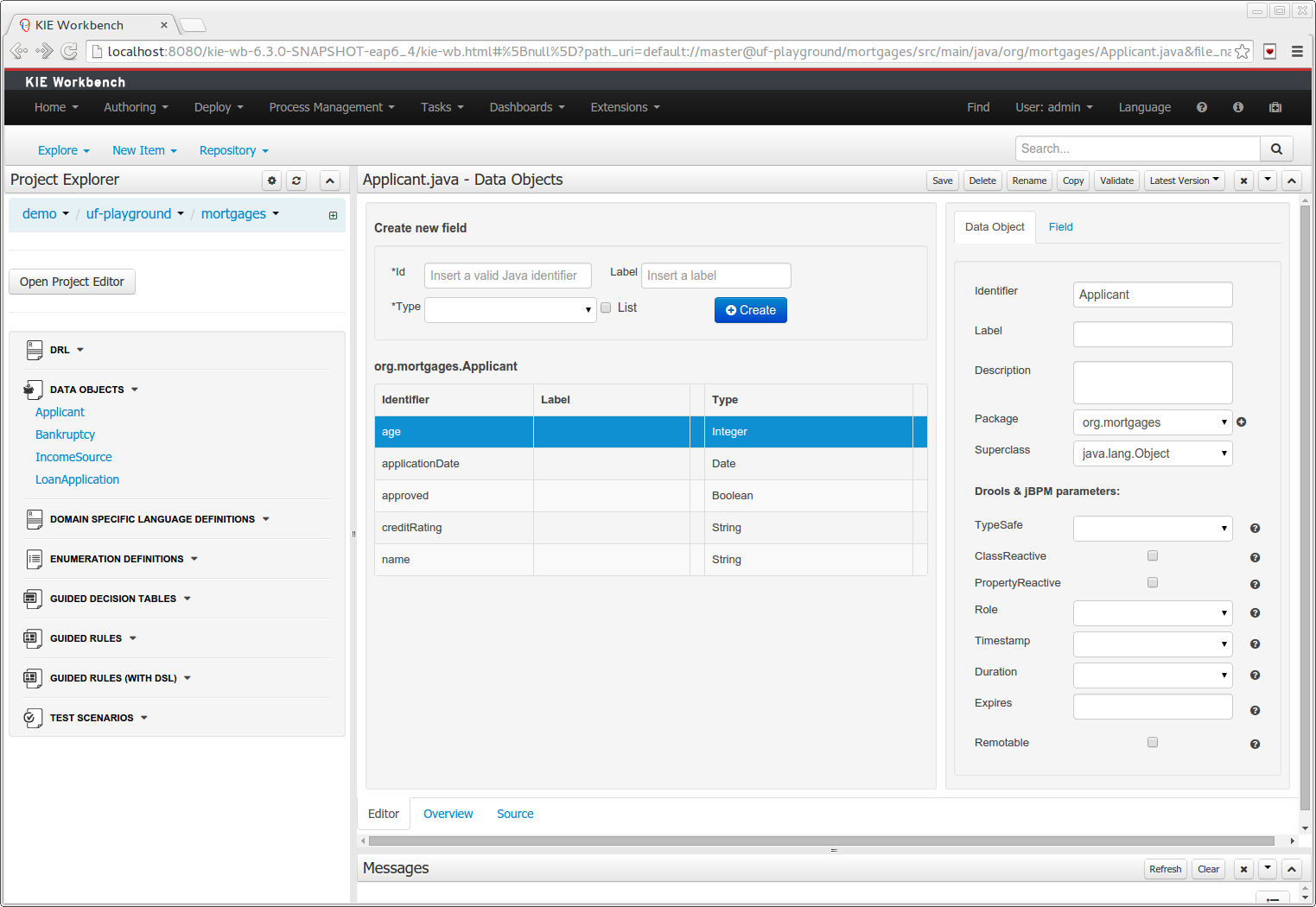
-
"New → Data Object" option was added to create the data objects.
-
Overview tab was added for every file to manage the file metadata and have access to the file versions history.
-
Editable "Source Tab" tab was added. Now the Java code can be modified by administrators using the workbench.
-
"Editor" - "Source Tab" round trip is provided. This will let administrators to do manual changes on the generated Java code and go back to the editor tab to continue working.
-
Class usages detection. Whenever a Data Object is about to be deleted or renamed, the project will be scanned for the class usages. If usages are found (e.g. in drl files, decision tables, etc.) the user will receive an alert. This will prevent the user from breaking the project build.
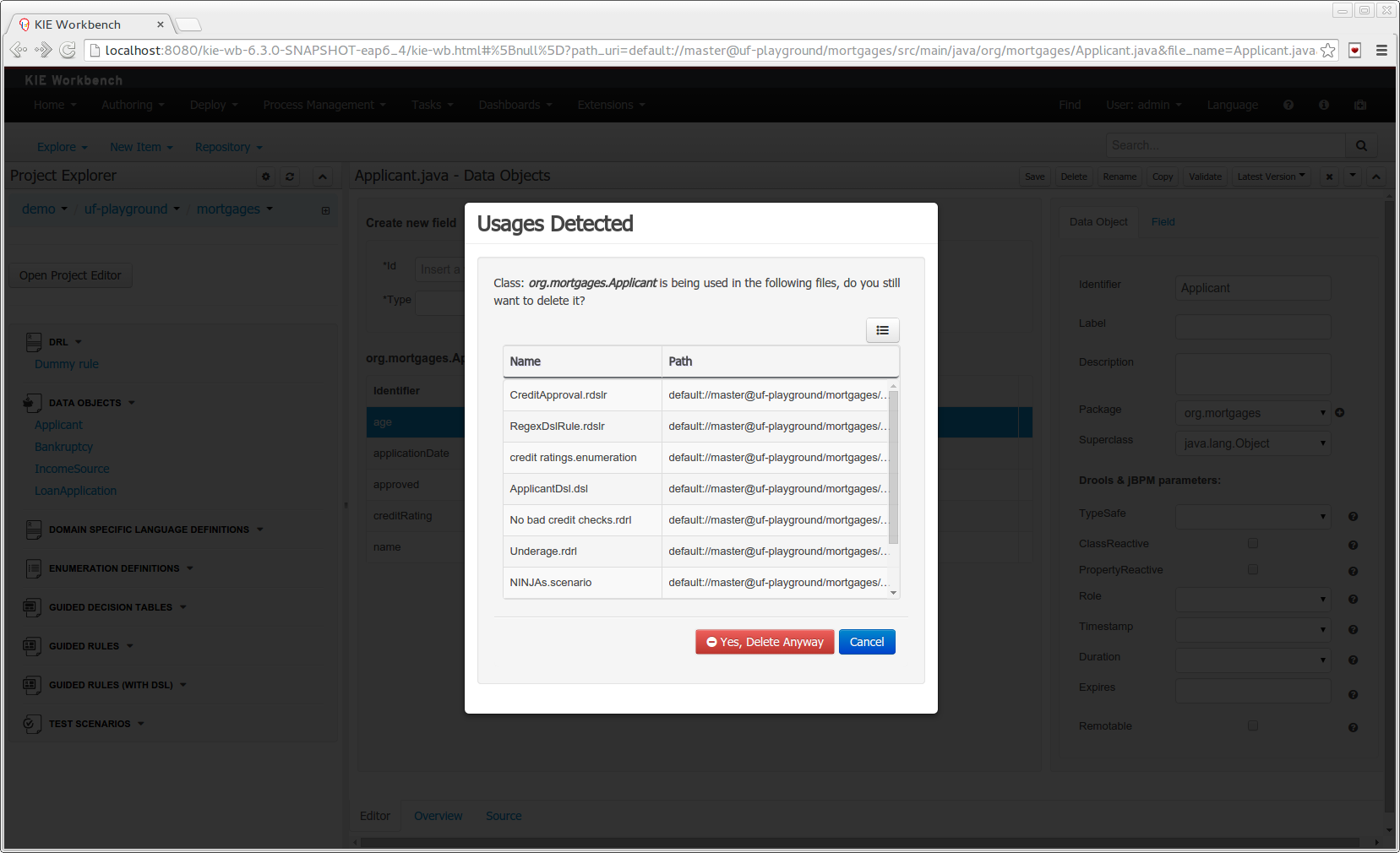 Figure 332. Usages detection
Figure 332. Usages detection
25.16.2.8. Execution Server Management UI
A new perspective called Management has been added under Servers top level menu. This perspective provides users the ability to manage multiple execution servers with multiple containers. Available features includes connect to already deployed execution servers; create new, start, stop, delete or upgrade containers.
|
Current version of Execution Server just supports rule based execution. |
25.16.2.9. Social Activities
A brand new feature called Social Activities has been added under a new top level menu item group called Activity.
This new feature is divided in two different perspectives: Timeline Perspective and People Perspective.
The Timeline Perspective shows on left side the recent assets created or edited by the logged user. In the main window there is the "Latest Changes" screen, showing all the recent updated assets and an option to filter the recent updates by repository.
The People Perspective is the home page of an user. Showing his infos (including a gravatar picture from user e-mail), user connections (people that user follow) and user recent activities. There is also a way to edit an user info. The search suggestion can be used to navigate to a user profile, follow him and see his updates on your timeline.
25.16.2.10. Contributors Dashboard
A brand new perspective called Contributors has been added under a new top level menu item group called Activity. The perspective itself is a dashboard which shows several indicators about the contributions made to the managed organizations / repositories within the workbench. Every time a organization/repository is added/removed from the workbench the dashboard itself is updated accordingly.
This new perspective allows for the monitoring of the underlying activity on the managed repositories.
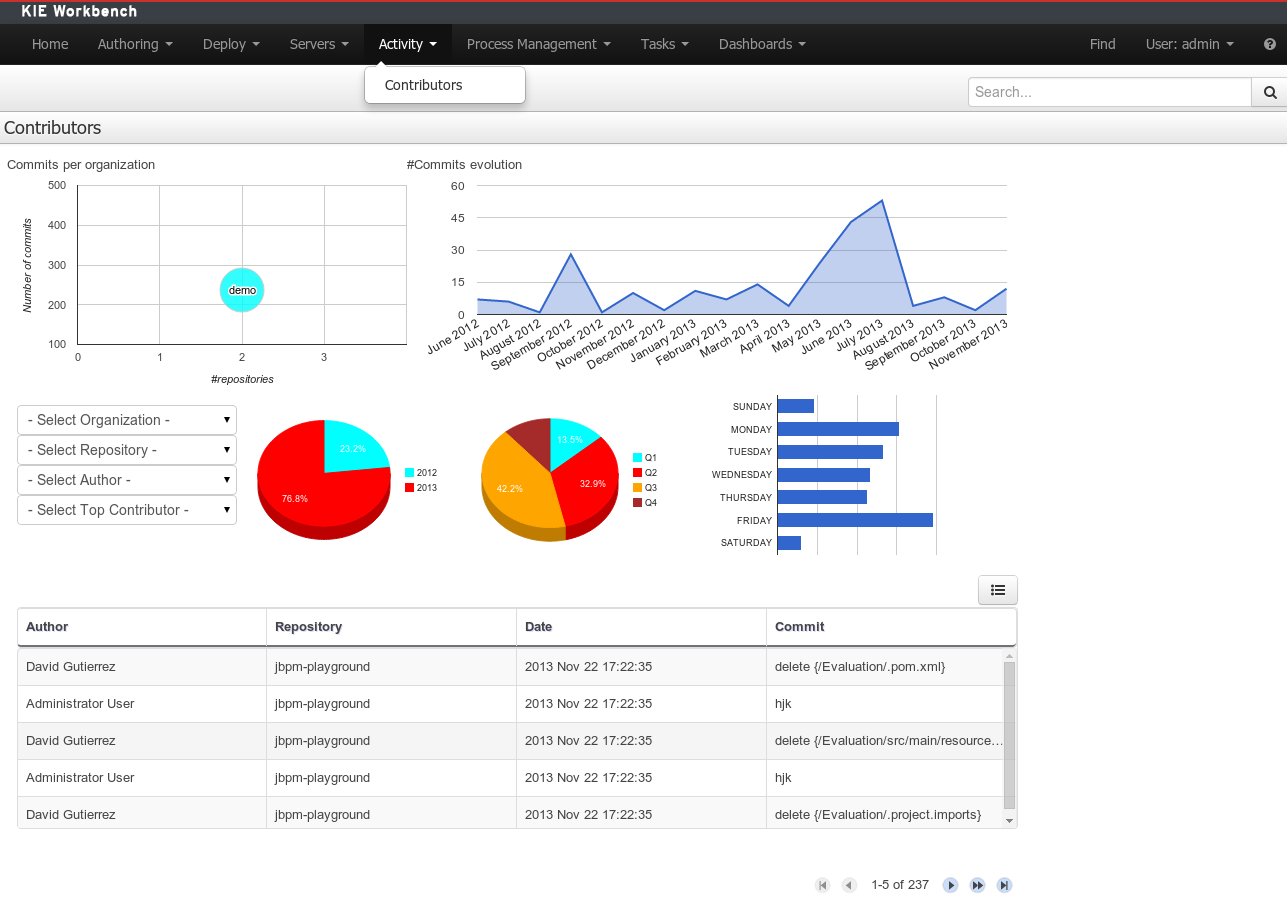
25.16.2.11. Package selector
The location of new assets whilst authoring was driven by the context of the Project Explorer.
This has been replaced with a Package Selector in the New Resource Popup.
The location defaults to the Project Explorer context but different packages can now be more easily chosen.
25.16.2.12. Improved visual consistency
All Popups have been refactored to use GWT-Bootstrap widgets.
Whilst a simple change it brings greater visual consistency to the application as a whole.
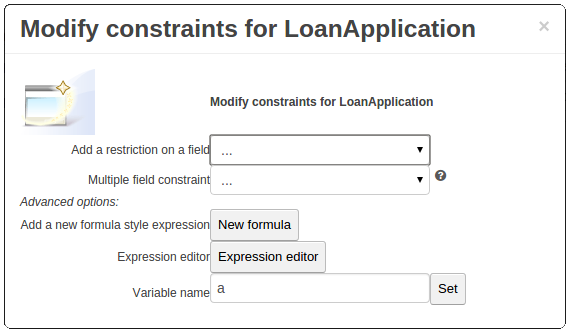
25.16.2.13. Guided Decision Tree Editor
A new editor has been added to support modelling of simple decision trees.
See the applicable section within the User Guide for more information about usage.
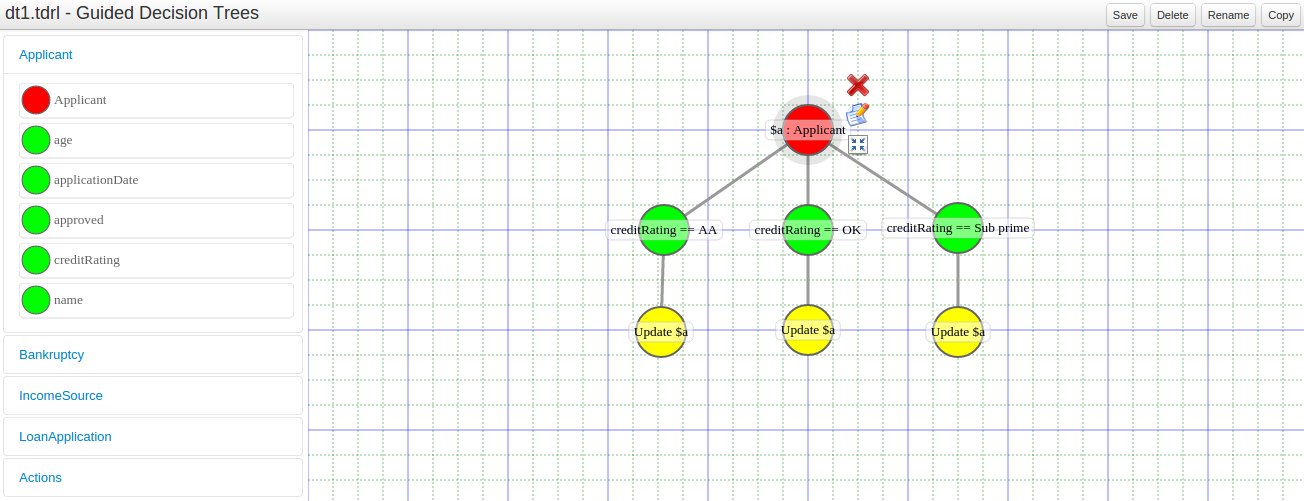
25.16.2.14. Create Repository Wizard
A wizard has been created to guide the repository creation process. Now the user can decide at repository creation time if it should be a managed or unmanaged repository and configure all related parameters.
25.16.2.15. Repository Structure Screen
The new Repository Structure Screen will let users to manage the projects for a given repository, as well as other operations related to managed repositories like: branch creation, assets promotion and project release.
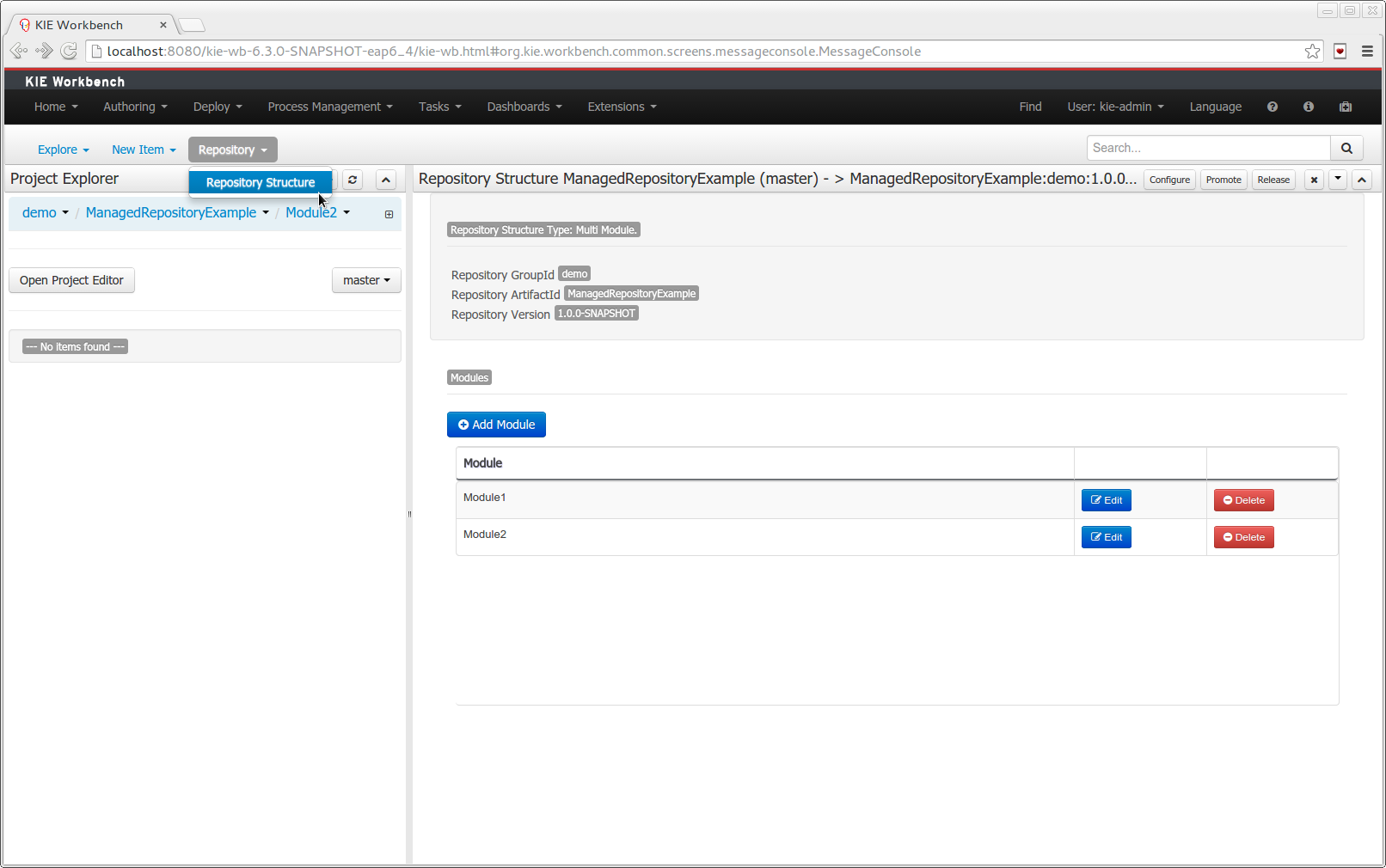
25.17. jBPM 6.1
25.17.1. New and Noteworthy in jBPM 6.1.0
jBPM 6.1 comes with a ton of smaller improvements and bug fixes (done over the last few months on top of 6.0.1.Final), and also includes some important new features, adding to the foundation delivered as part of jBPM 6.0.
25.17.1.1. Embedding forms in external applications
Now you can embed and run process/task forms that live inside the Kie-Workbench just adding a JavaScript library to your webapps. Look at the Using forms on client applications section to see the full functionality and usage examples.
25.17.1.2. Attaching documents to forms
Added new file type to manage upload documents on forms and store them on process variables. Using the Pluggable Variable Persistence you’ll be able to create your own Marshalling Strategy and store the document contents on different systems (Database, Alfresco, Google Docs…) or use the default implementation and store them in your File System.
25.17.1.3. Web Service (SOAP) interface for remote API
The execution server, that is part of the jbpm-console web tooling, now also comes with a Web Service interface (in addition to the existing REST, JMS and Java client interfaces).
25.17.1.4. Deployment descriptors
Deployment descriptors have been added as an optional, yet powerful way of configuring deployment units - kjars. Deployment descriptors allow to configure (among others)
-
persistence unit names
-
work item handlers
-
event listeners (process, agenda, task)
-
roles (for authorizarion - see section 1.5)
Deployment descriptors can be configured on various levels for enhanced flexibility to allow simple override functionality. Detailed definition of deployment descriptor can be found in section 14.1.1. Deployment descriptors
25.17.1.5. Role-based authorization at runtime for process definitions and process instances
The process definition and process instance view in the jbpm console now also take the role-based access control restrictions into account that can be defined on the project the process is defined in. You can limit the visibility of a project (or repository as a whole) by associating some roles with it that are required to be able to see the project (or repository). This can be done when creating the repository, or bu using the command line interface to connect to the execution server. The deployment descriptor (see previous section) also allows you to further customize these roles at deployment time. At runtime, the views will check if the current logged in user has one of the necessary roles to be able to see that process. If not, the user will not see this process or process instance in the process definition or process instance list respectively.
25.17.1.6. jBPM installer updates
The installer is updated to support:
-
Wildfly 8.1 as application server
-
Eclipse BPMN2 Modeler 1.0.2
-
Eclipse Kepler SR2
25.17.1.7. jBPM Spring integration
Spring integration has been improved to allow complete configuration of jBPM runtime using Spring XML. That essentially means there are number of factory beans provided as part of droolsjbpm-integration module that significanlty simplifies configuration of jBPM. Moreover it allows various configuration options such as:
-
reply on JTA and entity manager factory
-
rely on JTA and shared entity manager
-
rely on local transactions and entity manager factory
-
rely on local transactions and shared entity manager
Details about spring configuration can be found in this article.
25.17.1.8. Other
Smaller enhancements also include:
-
Task service (query) improvements, significantly speeding up queries when you have a large numbers of tasks in the database.
-
Various improvements to the asynchronous job executor so it can handle larger loads more easily and can be configured (number of parallel threads executing the jobs, retries, etc.).
-
Ability to configure task administrator groups in a UserTask (similar to how you already could configure individual task administrators).
-
Removed limitation on custom implementations of work item handler, event listeners that had to be placed on global classpath - usually in jbpm-console.war/WEB-INF/lib. With that custom classes can be added as maven dependencies into the project and will be registered on underlying components (ksession).
25.17.2. New and Noteworthy in KIE Workbench 6.1.0
25.17.2.1. Data Modeler - round trip and source code preservation
Full round trip between Data modeler and Java source code is now supported. No matter where the Java code was generated (e.g. Eclipse, Data modeller), data modeler will only update the necessary code blocks to maintain the model updated.
25.17.2.2. Data Modeler - improved annotations
New annotations @TypeSafe, @ClassReactive, @PropertyReactive, @Timestamp, @Duration and @Expires were added in order enrich current Drools annotations manged by the data modeler.
25.17.2.3. Standardization of the display of tabular data
We have standardized the display of tabular data with a new table widget.
The new table supports the following features:
-
Selection of visible columns
-
Resizable columns
-
Moveable columns
The table is used in the following scenarios:
-
Inbox (Incoming changes)
-
Inbox (Recently edited)
-
Inbox (Recently opened)
-
Project Problems summary
-
Artifact Repository browser
-
Project Editor Dependency grid
-
Project Editor KSession grid
-
Project Editor Work Item Handlers Configuration grid
-
Project Editor Listeners Configuration grid
-
Search Results grid
25.17.2.4. Generation of modify(x) {…} blocks
The Guided Rule Editor, Guided Template Editor and Guided Decision Table Editor have been changed to generate modify(x){…}
Historically these editors supported the older update(x) syntax and hence rules created within the Workbench would not respond correctly to @PropertyReactive and associated annotations within a model.
This has now been rectified with the use of modify(x){…} blocks.
25.18. jBPM 6.0
25.18.1. New and Noteworthy in KIE API 6.0.0
25.18.1.1. New KIE name
KIE is the new umbrella name used to group together our related projects; as the family continues to grow. KIE is also used for the generic parts of unified API; such as building, deploying and loading. This replaces the kiegroup and knowledge keywords that would have been used before.
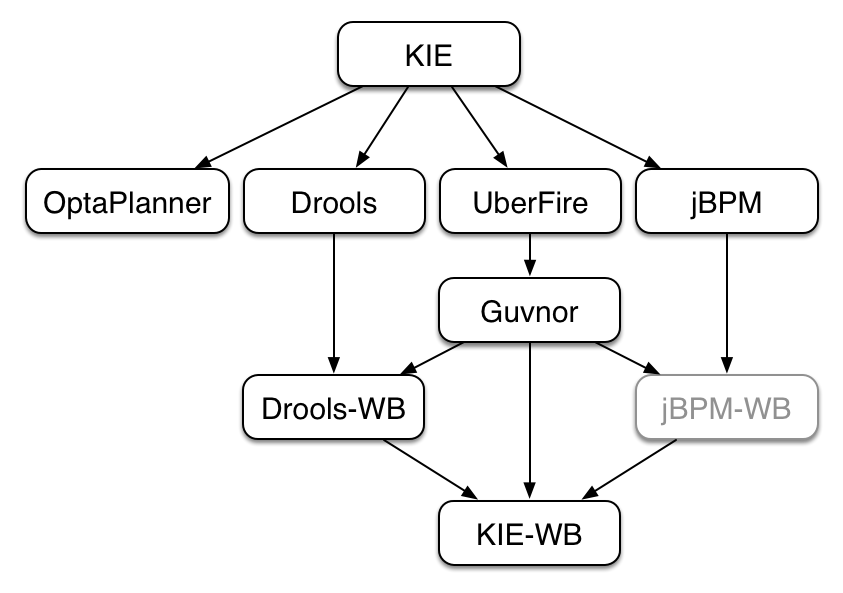
25.18.1.2. Maven aligned projects and modules and Maven Deployment
One of the biggest complaints during the 5.x series was the lack of defined methodology for deployment. The mechanism used by Drools and jBPM was very flexible, but it was too flexible. A big focus for 6.0 was streamlining the build, deploy and loading (utilization) aspects of the system. Building and deploying activities are now aligned with Maven and Maven repositories. The utilization for loading rules and processess is now convention and configuration oriented, instead of programmatic, with sane defaults to minimise the configuration.
Projects can be built with Maven and installed to the local M2_REPO or remote Maven repositories. Maven is then used to declare and build the classpath of dependencies, for KIE to access.
25.18.1.3. Configuration and convention based projects
The 'kmodule.xml' provides declarative configuration for KIE projects. Conventions and defaults are used to reduce the amount of configuration needed.
<kmodule xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="kbase1" packages="org.mypackages">
<ksession name="ksession1"/>
</kbase>
</kmodule>KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession("ksession1");
kSession.insert(new Message("Dave", "Hello, HAL. Do you read me, HAL?"));
kSession.fireAllRules();25.18.1.4. KieBase Inclusion
It is possible to include all the KIE artifacts belonging to a KieBase into a second KieBase. This means that the second KieBase, in addition to all the rules, function and processes directly defined into it, will also contain the ones created in the included KieBase. This inclusion can be done declaratively in the kmodule.xml file
<kmodule xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="kbase2" includes="kbase1">
<ksession name="ksession2"/>
</kbase>
</kmodule>or programmatically using the KieModuleModel.
KieModuleModel kmodule = KieServices.Factory.get().newKieModuleModel();
KieBaseModel kieBaseModel1 = kmodule.newKieBaseModel("KBase2").addInclude("KBase1");25.18.1.5. KieModules, KieContainer and KIE-CI
Any Maven produced JAR with a 'kmodule.xml' in it is considered a KieModule. This can be loaded from the classpath or dynamically at runtime from a Resource location. If the kie-ci dependency is on the classpath it embeds Maven and all resolving is done automatically using Maven and can access local or remote repositories. Settings.xml is obeyed for Maven configuration.
The KieContainer provides a runtime to utilize the KieModule, versioning is built in throughout, via Maven. Kie-ci will create a classpath dynamically from all the Maven declared dependencies for the artifact being loaded. Maven LATEST, SNAPSHOT, RELEASE and version ranges are supported.
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.newKieContainer(
ks.newReleaseId("org.mygroup", "myartefact", "1.0") );
KieSession kSession = kContainer.newKieSession("ksession1");
kSession.insert(new Message("Dave", "Hello, HAL. Do you read me, HAL?"));
kSession.fireAllRules();KieContainers can be dynamically updated to a specific version, and resolved through Maven if KIE-CI is on the classpath. For stateful KieSessions the existing sessions are incrementally updated.
KieContainer kContainer.updateToVersion(
ks.newReleaseId("org.mygroup", "myartefact", "1.1") );25.18.1.6. KieScanner
The KieScanner is a Maven-oriented replacement of the KnowledgeAgent present in Drools 5.
It continuously monitors your Maven repository to check if a new release of a Kie project has been installed and if so, deploys it in the KieContainer wrapping that project.
The use of the KieScanner requires kie-ci.jar to be on the classpath.
A KieScanner can be registered on a KieContainer as in the following example.
KieServices kieServices = KieServices.Factory.get();
ReleaseId releaseId = kieServices.newReleaseId( "org.acme", "myartifact", "1.0-SNAPSHOT" );
KieContainer kContainer = kieServices.newKieContainer( releaseId );
KieScanner kScanner = kieServices.newKieScanner( kContainer );
// Start the KieScanner polling the Maven repository every 10 seconds
kScanner.start( 10000L );In this example the KieScanner is configured to run with a fixed time interval, but it is also possible to run it on demand by invoking the scanNow() method on it.
If the KieScanner finds, in the Maven repository, an updated version of the Kie project used by that KieContainer it automatically downloads the new version and triggers an incremental build of the new project.
From this moment all the new KieBases and KieSessions created from that KieContainer will use the new project version.
25.18.1.7. Hierarchical ClassLoader
The CompositeClassLoader is no longer used; as it was a constant source of performance problems and bugs. Traditional hierarchical classloaders are now used. The root classloader is at the KieContext level, with one child ClassLoader per namespace. This makes it cleaner to add and remove rules, but there can now be no referencing between namespaces in DRL files; i.e. functions can only be used by the namespaces that declared them. The recommendation is to use static Java methods in your project, which is visible to all namespaces; but those cannot (like other classes on the root KieContainer ClassLoader) be dynamically updated.
25.18.1.8. Legacy API Adapter
The 5.x API for building and running with Drools and jBPM is still available through Maven dependency "knowledge-api-legacy5-adapter". Because the nature of deployment has significantly changed in 6.0, it was not possible to provide an adapter bridge for the KnowledgeAgent. If any other methods are missing or problematic, please open a JIRA, and we’ll fix for 6.1
25.18.1.9. KIE Documentation
While a lot of new documentation has been added for working with the new KIE API, the entire documentation has not yet been brought up to date. For this reason there will be continued references to old terminologies. Apologies in advance, and thank you for your patience. We hope those in the community will work with us to get the documentation updated throughout, for 6.1
25.18.2. New and Noteworthy in jBPM 6.0.0
25.18.2.1. KIE API
A new public API has been created for interacting with the core engine (shared between jBPM and Drools). This not only handles runtime operations to start processes, etc. but also instantiating sessions, registering listeners, configuration, etc.
New APIs were added in various areas, like for example the TaskService interface was moved to the public API, the new RuntimeManager was introduced and a lot of related interfaces and classes were added as well.
For backwards compatibility with v5, a knowledge-api JAR has been constructed, that implements the old v5 knowledge-api interfaces on top of the v6 engine. Make sure to include this JAR in your classpath if you want to keep using the v5 API.
25.18.2.2. jBPM Core Engine
The execution engine itself has (mostly) remained the same, although we’ve done various improvements in the following areas:
-
RuntimeManager: instantiating a ksession (and an associated task service) has been simplified significantly, by introducing a runtime manager where you can simply ask for a reference to a ksession whenever you need it. The Runtime manager is responsible for initialization, configuration and disposal of the ksession (and task service), and three predefined strategies are available:
-
Singleton: the RuntimeManager reused the same ksession for all requests (and executes the requests in sequence, one at a time)
-
Session per request: the RuntimeManager instantiates a new ksession per request that will be used for executing that request and disposed at the end. Each request will receive its own ksession and they can all be executed in parallel.
-
Session per process instance: the RuntimeManager reuses the same ksession for all requests related to one specific process instance. This might be necessary if you are storing data inside your session (for example for rule evaluations) that you need to be available later in the process as well. Note that the session is disposed after each command but stored in the database so it can be restored whenever necessary.
-
-
jBPM Services (CDI): To simplify integration of jBPM inside CDI-based applications, the jbpm-services module contains various CDI services that you can configure and use inside your application simply by injecting the necessary services (like a RuntimeManager or TaskService for example) inside your application, making integration easier than ever.
-
Timer service: a Quartz-based timer service is now available, that allows you to dispose your session at any point in time, and the timer service will be responsible for rehydrating a ksession whenever a timer should be fired. This timer service also works in a clustered environment, where multiple nodes can work together on sharing the work load but timers will only be fired once by one of the nodes.
-
Exception and compensation management: various improvements in this area allow you to use more BPMN2 constructs related to exception and compensation management in your processes, and various strategies have been extended and documented to better handle exceptions in different ways.
-
Asynchronous handlers: asynchronous execution of interaction with external services can now be implemented by reusing the asynchronous job executor.
-
Asynchronous auditing using JMS: audit logging can now also be done asynchronously by sending the events to a JMS queue rather than persisting them as part of the engine transaction.
The task service has been refactored significantly as well, and the TaskService APIs have been moved to the public kie-api. Although the TaskService interfaces themselves haven’t changed a lot, the internal implementation has been simplified. Auditing for the task-related operations (similar to the runtime engine auditing) has been added.
By default, a local task service will always be used by a ksession to perform various task-related operations (creating a task, being notified when a task is completed). Setting up a remote singleton task service and connecting multiple ksessions to this (using Mina or HornetQ) as was possible in jBPM5 is no longer possible, as it introduces more challenges that it brings advantages. Since the jBPM execution service now also provides a remote API for all task-related operations, we believe this setup is no longer necessary, and has been replaced by the use of a local task service in all use cases.
25.18.2.3. jBPM Designer
jBPM designer has been reimplemented and is fully integrated into the workbench. It now easily integrates with many of the workbench services available. In addition, the following features were added/improved on:
-
Improvement of jBPM Simulation engine and the UI. Added ability to specify simulation properties on more node type and added more results graphs such as the the Total Cost graph.
-
Many updates to the Designer Toolbar for usability purposes.
-
Visual Validation update - it now is a real-time visualization of issues done during process modeling.
-
Ability to generate task forms for specific task node.
-
Integration with the jBPM Form Modeler for both task and process forms.
-
Update to process properties - added grouping of properties into sections making it more user friendly to find properties.
-
Update to Object Library - added type specific tasks to palette (rather than having to morph to a certain type after adding a task to the canvas).
-
Save/Remove/CopyDelete feature have been added directly into Designer and integrate with the workbench services for those operations.
-
Autosave - option for users to enable auto-saving of their business process during modeling.
-
Two new default Service Tasks (REST and Web Services)
25.18.2.4. jBPM Data Modeler
A new web-based data modeler is integrated in the workbench, which allows non-technical users to create data models (to be used in your processes and rules) in a user-friendly manner. These models are saved as Java classes (with the necessary annotations) in the project and added to the kjar upon build and deploy. Check the chapter on Data Modeler in the Workbench Part for all the details.
25.18.2.5. Form Modeler
A new web-based form modeler is integrated in the workbench, which allows non-technical users to create forms (for starting processes and/or completing human task). The form modeler is a WYSIWYG editor where you can drag and drop form elements (text boxes, labels, etc.), link it to data that is expected as input or output of the form, customize properties of each element and the layout, etc. These forms are then shown when starting the process or completing a task, integrated into the appropriate runtime views. Check the chapter on Form Modeler in the Workbench Part for all the details.
25.18.2.6. jBPM Console
The jBPM console has been reimplemented and is integrated into the workbench as well. It provides similar features as jBPM5 (starting process instances, inspecting current state and variables, looking at task lists) but is now much more powerful and exposes a lot more features. Check the chapter on Process and Task Management in the Workbench Part for all the details.
25.18.2.7. BAM / Reporting
A new web-based monitoring and reporting tool has been integrated in the workbench. This displays charts, tables, etc. about the current status of your application(s). It comes with some process and task dashboards out-of-the-box (showing for example the number of running process instances, the number of tasks completed per time frame, etc.). These dashboards however can be fully customized to show the data that is relevant to you, including for example your own data sources, making domain-specific charts (for example showing your key performance indicators (KPIs) instead of generic process-related charts). Check the chapter on Business Activity Monitoring in the Workbench Part for all the details.
25.18.2.8. Workbench
A workbench application, based on the UberFire framework, now unifies all web-based editors and tools into one large, configurable web application. It has many features, including:
-
Configurable workspace where you layout your own views by dragging and dropping
-
Unified login and role-based authentication, where what features you see depends on your role (admin, analyst, developer, user, manager, etc.).
-
A new home screen that will guide you through the life cycle of your business processes (authoring, deployment, execution, tasks and reporting).
-
Git-based repository that supports versioning and collaboration.
-
New project structure where artifacts (processes, rules, etc.) are combined into kjars (we removed the custom binary packages and replaced them with a normal JAR, containing the source artifacts) when a project is built. These kjars now also include not only processes and rules, but also forms, configuration files, data models (Java classes), etc. Kjars are Maven artefacts themselves (they have a group, id and version) and exposed as a Maven repository. When creating a ksession, Maven can be used to download the necessary kjars for your project from this Maven repository.
-
Sample
playgroundrepositories are (optionally) installed when starting up the workbench the first time, to get you started quickly with some predefined examples.
Check the Workbench Part for all the details.
25.18.2.9. Remote API
The remote API has been redesigned and allows users to remotely connect to a running execution server and pass commands. The remote runtime API exposes (almost) the entire KieSession and TaskService API using REST or JMS, so commands can be sent to the remote execution server for processing and the results are returned. See the chapter on Business Activity Monitoring for all the details.
Guvnor also provides a REST API to access the various repositories, projects and artifacts inside these projects and manage and build them.
25.18.3. New and Noteworthy in KIE Workbench 6.0.0
The workbench has had a big overhaul using a new base project called UberFire. UberFire is inspired by Eclipse and provides a clean, extensible and flexible framework for the workbench. The end result is not only a richer experience for our end users, but we can now develop more rapidly with a clean component based architecture. If you like he Workbench experience you can use UberFire today to build your own web based dashboard and console efforts.
As well as the move to a UberFire the other biggest change is the move from JCR to Git; there is an utility project to help with migration. Git is the most scalable and powerful source repository bar none. JGit provides a solid OSS implementation for Git. This addresses the continued performance problems with the various JCR implementations, which would slow down once the number of files and number of versions become too high. There has been a big "low tech" drive, to remove complexity. Everything is now stored as a file, including meta data. The database is only there to provide fast indexing and search. So importing and exporting is all standard Git and external sites, like GitHub, can be used to exchange repositories.
In 5.x developers would work with their own source repository and then push JCR, via the team provider. This team provider was not full featured and not available outside Eclipse. Git enables our repository to work any existing Git tool or team provider. While not yet supported in the UI, this will be added over time, it is possible to connect to the repo and tag and branch and restore things.
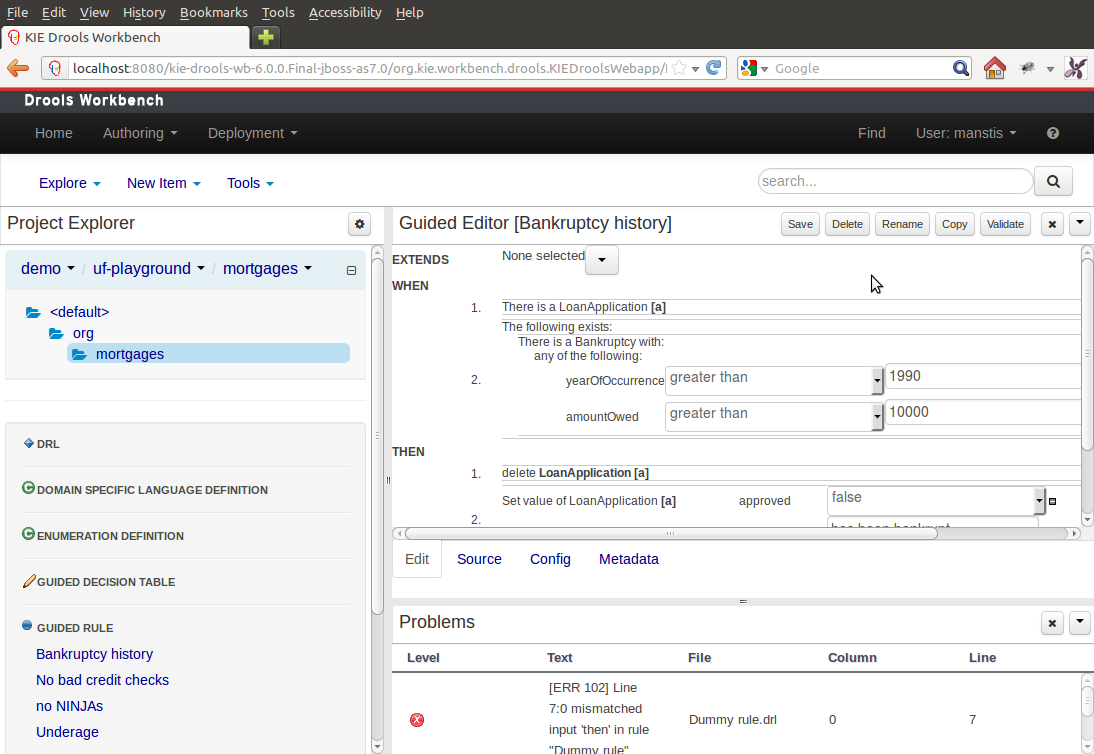
The Guvnor brand leaked too much from its intended role; such as the authoring metaphors, like Decision Tables, being considered Guvnor components instead of Drools components. This wasn’t helped by the monolithic projects structure used in 5.x for Guvnor. In 6.0 Guvnor 's focus has been narrowed to encapsulates the set of UberFire plugins that provide the basis for building a web based IDE. Such as Maven integration for building and deploying, management of Maven repositories and activity notifications via inboxes. Drools and jBPM build workbench distributions using Uberfire as the base and including a set of plugins, such as Guvnor, along with their own plugins for things like decision tables, guided editors, BPMN2 designer, human tasks.
The "Model Structure" diagram outlines the new project anatomy. The Drools workbench is called KIE-Drools-WB. KIE-WB is the uber workbench that combines all the Guvnor, Drools and jBPM plugins. The jBPM-WB is ghosted out, as it doesn’t actually exist, being made redundant by KIE-WB.
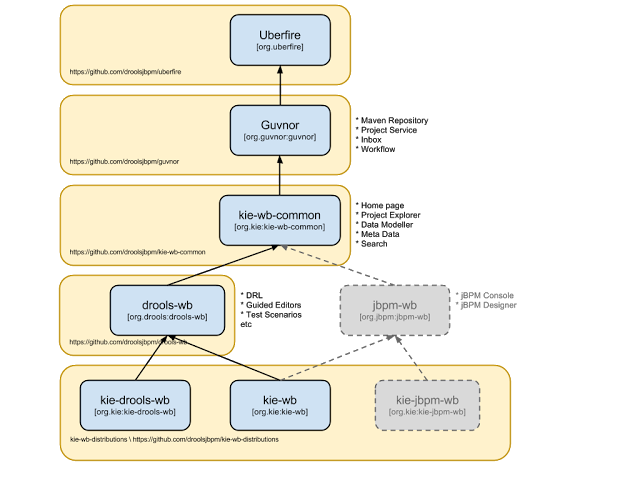
|
KIE Drools Workbench and KIE Workbench share a common set of components for generic workbench functionality such as Project navigation, Project definitions, Maven based Projects, Maven Artifact Repository. These common features are described in more detail throughout this documentation. |
The two primary distributions consist of:
-
KIE Drools Workbench
-
Drools Editors, for rules and supporting assets.
-
jBPM Designer, for Rule Flow and supporting assets.
-
-
KIE Workbench
-
Drools Editors, for rules and supporting assets.
-
jBPM Designer, for BPMN2 and supporting assets.
-
jBPM Console, runtime and Human Task support.
-
jBPM Form Builder.
-
BAM.
-
Workbench highlights:
-
New flexible Workbench environment, with perspectives and panels.
-
New packaging and build system following KIE API.
-
Maven based projects.
-
Maven Artifact Repository replaces Global Area, with full dependency support.
-
-
New Data Modeller replaces the declarative Fact Model Editor; bringing authoring of Java classes to the authoring environment. Java classes are packaged into the project and can be used within rules, processes etc and externally in your own applications.
-
Virtual File System replaces JCR with a default Git based implementation.
-
Default Git based implementation supports remote operations.
-
External modifications appear within the Workbench.
-
-
Incremental Build system showing, near real-time validation results of your project and assets.
The editors themselves are largely unchanged; however of note imports have moved from the package definition to individual editors so you need only import types used for an asset and not the package as a whole.
25.18.4. New and Noteworthy in Integration 6.0.0
25.18.4.1. CDI
@Inject
@KSession("kbase1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.0")
private KieBase kbase1v10;
@Inject
@KBase("kbase1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.1")
private KieBase kbase1v10;@Inject
@KSession("ksession1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.0")
private KieSession ksessionv10;
@Inject
@KSession("ksession1")
@KReleaseId( groupId = "jar1", rtifactId = "art1", version = "1.1")
private KieSession ksessionv11;CDI is now tightly integrated into the KIE API. It can be used to inject versioned KieSession and KieBases.
25.18.4.2. Spring
Spring has been revamped and now integrated with KIE. Spring can replace the 'kmodule.xml' with a more powerful spring version. The aim is for consistency with kmodule.xml
25.18.4.3. Aries Blueprints
Aries blueprints is now also supported, and follows the work done for spring. The aim is for consistency with spring and kmodule.xml
25.18.4.4. OSGi Ready
All modules have been refactored to avoid package splitting, which was a problem in 5.x. Testing has been moved to PAX.