jBPM provides the ability to create and use domain-specific task nodes in your business processes. This simplifies development when you're creating business processes that contain tasks dealing with other technical systems.
When using jBPM, we call these domain-specific task nodes "custom work items" or (custom) "service nodes". There are two separate aspects to creating and using custom work items:
- Adding a node with a custom work item to a process definition using the Eclipse editor or jBPM designer.
- Creating a custom work item handler that the jBPM engine will use when executing the custom work item in a running process.
With regards to a BPMN2 process, custom work items are certain types of
<task> nodes. In most cases, custom work items are <task>
nodes in a BPMN2 process definition, although they can also be used with certain other task type
nodes such as, among others, <serviceTask> or
<sendTask> nodes.
Tip
When creating custom work items, it's important to separate the data associated with the work item, from how the work item should be handled. In other words, separate the what from the how. That means that custom work items should be:
- declarative (what, not how)
- high-level (no code)
On the other hand, custom work item handlers, which are Java classes, should be:
- procedural (how, not what)
- low-level (because it's code!)
Work item handlers should almost never contain any data.
Users can thus easily define their own set of domain-specific service nodes and integrate them with the process language. For example, the next figure shows an example of a healthcare-related BPMN2 process. The process includes domain-specific service nodes for measuring blood pressure, prescribing medication, notifying care providers and following-up on the patient.
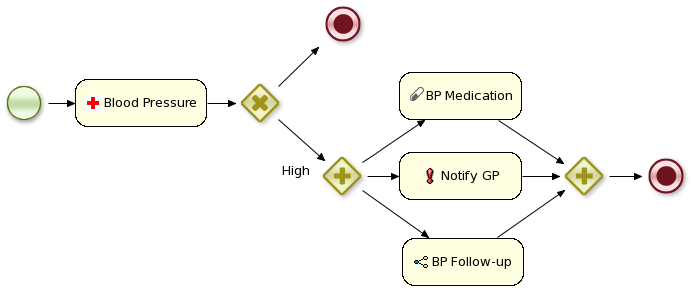
Before moving on to an example, this section explains what custom work items and custom work item handlers are.
In short, we use the term custom work item when we're describing a node
in your process that represents a domain-specific task and as such, contains extra properties and
is handled by a WorkItemHandler implementation.
Because it's a domain-specific task, that means that a custom
work item is equivalent to a <task> or <task>-type
node in BPMN2. However, a WorkItem is also Java class instance
that's used when a WorkItemHandler instance is called to complete the task or work
item.
Depending on the BPMN2 editor you're using, you can create a custom work item definition in one of two ways:
- If you're using Designer, then this means creating a MVEL based definition and adding the definition in Designer itself. A description of this can be found in the ??? section in the ??? chapter. Once this is done, a new service node will appear on the BPMN 2.0 palette.
- If you're using the Eclipse BPMN 2.0 modeler plugin (which can
be found here), then you'll can modify
the BPMN2
<task>or<task>-type element to work withWorkItemHandlerimplementations. See the ??? section in the ??? chapter.
A work item handler is a Java class used to execute (or abort) work
items. That also means that the class implements the org.kie.runtime.instance.WorkItemHandler
interface. While jBPM provides some custom WorkItemHandler instances (listed below),
a Java developer with a minimal knowledge of jBPM can easily create a new work item handler class
with its own custom business logic.
Among others, jBPM offers the following WorkItemHandler implementations:
- In the
jbpm-bpmn2module,org.jbpm.bpmn2.handlerpackage:- ReceiveTaskHandler (for use with BPMN element
<receiveTask>) - SendTaskHandler (for use with BPMN element
<sendTask>) - ServiceTaskHandler (for use with BPMN element
<serviceTask>)
- ReceiveTaskHandler (for use with BPMN element
- In the
jbpm-workitemsmodule, in various packages under theorg.jbpm.process.workitempackage:- ArchiveWorkItemHandler
There are a many more WorkItemHandler implementations present in the
jbpm-workitems module. If you're looking for specific integration logic with
Twitter, for example, we recommend you take a look at the classes made available there.
In general, a WorkItemHandler's .executeWorkItem(...) and
.abortWorkItem(...) methods will do the following:
- Extract information about the task being executed (or aborted) from the
WorkIteminstance - Execute the necessary business logic. This might be mean interacting with a web service, database, or other technical component.
- Inform the process engine that the work item has been completed (or aborted) by
calling one of the following two methods on the
WorkItemManagerinstance passed to the method:
WorkItemManager.completeWorkItem(long workItemId, Map<String, Object> results)
WorkItemManager.abortWorkItem(long workItemId)
In order to make sure that your custom work item handler is used for a particular process
instance, it's necessary to register the work item handler before starting the process. This makes
the engine aware of your WorkItemHandler so that the engine can use it for the proper
node. For example:
ksession.getWorkItemManager().registerWorkItemHandler("Notification",
new NotificationWorkItemHandler());
The ksession variable above is a StatefulKnowledgeSession (and
also a KieSession) instance. The example code above comes from the example that
we will go through in the next session.
Work item handler life cycle management
Work item handler is registered on kie session and then can be used whenever process engine encounters a node that should be handled by that handler. Depending on the implementation of the handler (e.g. some handler might keep state or depend on some resources such as data base connection) there might be a need to maintain life cycle of the handler. To ease the way of doing that jBPM comes with two additional interfaces that handler might implement:
org.kie.internal.runtime.Closeable - allows auto close of the handler whenever owner (work item handler manager) of it is closed or disposed. This is useful in case a handler can be quickly and frequently recreated so the engine will have it for the execution and when disposed it will dispose as well all handlers of Closeable type.
org.kie.internal.runtime.Cacheable - allows handlers to be cached and resused to avoid recreation of the objects. There might be several reasons of doing so - expensive bootstrap of the handler, dependency to external resources - socket connections, db connections, web service client. While this brings powerful feature to the work item handler management it does put additional requirement on the implementation - needs to deal with exceptions internally and recover from any failures. In case recovery cannot be performed it needs to remove itself from the cache.
Closeable interface is handled for all use cases, while Cacheable is available only when RuntimeManager is used. RuntimeManager provides caching capabilities via its CacheManager (available via InternalRuntimeManager in case self removal is required).
Tip
You can use different work item handlers for the same process depending on the
system on which it runs: by registering different work item handlers on different systems, you can
customize how a custom work item is processed on a particular system. You can also substitute mock
WorkItemHandler instances when testing.
Let's start by showing you how to include a simple work item for sending notifications. A work item is defined by a unique name and includes additional parameters that describe the work in more detail. Work items can also return information after they have been executed, specified as results.
Our notification work item could be defined using a work definition with four parameters and no results. For example:
- Name: "Notification"
- Parameters:
- From [String type]
- To [String type]
- Message [String type]
- Priority [String type]
In our example we will create a MVEL work item definition that defines a "Notification" work
item. Using MVEL is the default way to This file will be placed in the project classpath in a directory called
META-INF. The work item configuration file for this example,
MyWorkDefinitions.wid, will look like this:
import org.drools.core.process.core.datatype.impl.type.StringDataType;
[
// the Notification work item
[
"name" : "Notification",
"parameters" : [
"Message" : new StringDataType(),
"From" : new StringDataType(),
"To" : new StringDataType(),
"Priority" : new StringDataType(),
],
"displayName" : "Notification",
"icon" : "icons/notification.gif"
]
]The project directory structure could then look something like this:
project/src/main/resources/META-INF/MyWorkDefinitions.widWe also want to add a specific icon to be used in the process editor
with the work item. To add this, you will need .gif or
.png images with a pixel size of 16x16. We put them in a directory outside
of the META-INF directory, for example, here:
project/src/main/resources/icons/notification.gifThe jBPM Eclipse editor uses the configuration mechanisms supplied by Drools to register work item definition
files. That means adding a drools.workDefinitions property to the
drools.rulebase.conf file in the META-INF.
The drools.workDefinitions property represents a list of files containing work
item definitions, separated using spaces. If you want to exclude all other
work item definitions and only use your definition, you could use the following:
drools.workDefinitions = MyWorkDefinitions.widHowever, if you only want to add the newly created node definition to the existing palette
nodes, you can define the drools.workDefinitions property as follows:
drools.workDefinitions = MyWorkDefinitions.wid WorkDefinitions.conf
We recommended that you use the extension .wid for your own definitions of
domain specific nodes. The .conf extension used with the default definition file,
WorkDefinitions.conf, for backward compatibility reasons.
We've created our work item definition and configured it, so now we can start using it in our processes. The process editor contains a separate section in the palette where the different service nodes that have been defined for the project appear.
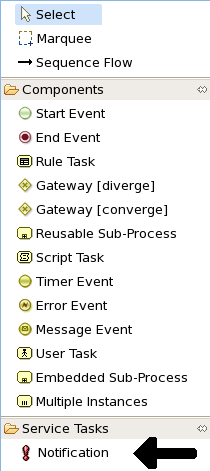
Using drag and drop, a notification node can be created inside your process. The properties can be filled in using the properties view.
Besides any custom properties, the following three properties are available for all work items:
Parameter Mapping: Allows you to map the value of a variable in the process to a parameter of the work item. This allows you to customize the work item based on the current state of the actual process instance (for example, the priority of the notification could be dependent of some process-specific information).Result Mapping: Allows you to map a result (returned once a work item has been executed) to a variable of the process. This allows you to use results in the remainder of the process.Wait for completion: By default, the process waits until the requested work item has been completed before continuing with the process. It is also possible to continue immediately after the work item has been requested (and not waiting for the results) by settingwait for completionto false.
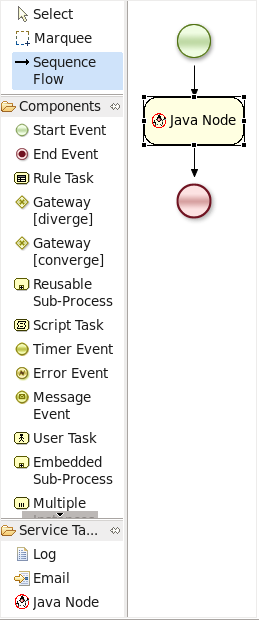
Here is an example that creates a domain specific node to execute Java, asking for
the class and method parameters. It includes a custom java.gif icon and
consists of the following files and resulting screenshot:
import org.drools.core.process.core.datatype.impl.type.StringDataType;
[
// the Java Node work item located in:
// project/src/main/resources/META-INF/JavaNodeDefinition.wid
[
"name" : "JavaNode",
"parameters" : [
"class" : new StringDataType(),
"method" : new StringDataType(),
],
"displayName" : "Java Node",
"icon" : "icons/java.gif"
]
]
// located in: project/src/main/resources/META-INF/drools.rulebase.conf
drools.workDefinitions = JavaNodeDefinition.wid WorkDefinitions.conf
// icon for java.gif located in:
// project/src/main/resources/icons/java.gif
Once we've created our Notification work item definition (see the sections
above), we can then create a custom implementation of a work item handler that
will contain the logic to send the notification.
In order to execute our Notification work items, we first create a
NotificationWorkItemHandler that implements the WorkItemHandler
interface:
package com.sample; import org.kie.api.runtime.process.WorkItem; import org.kie.api.runtime.process.WorkItemHandler; import org.kie.api.runtime.process.WorkItemManager; public class NotificationWorkItemHandler implements WorkItemHandler { public void executeWorkItem(WorkItem workItem, WorkItemManager manager) { // extract parameters String from = (String) workItem.getParameter("From"); String to = (String) workItem.getParameter("To"); String message = (String) workItem.getParameter("Message"); String priority = (String) workItem.getParameter("Priority"); // send email EmailService service = ServiceRegistry.getInstance().getEmailService(); service.sendEmail(from, to, "Notification", message); // notify manager that work item has been completed manager.completeWorkItem(workItem.getId(), null);} public void abortWorkItem(WorkItem workItem, WorkItemManager manager) { // Do nothing, notifications cannot be aborted } }
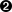
| The |
| Notifying the |
This WorkItemHandler sends a notification as an email and then
notifies the WorkItemManager that the work item has been completed.
Note that not all work items can be completed directly. In cases where executing a work item takes some time, execution can continue asynchronously and the work item manager can be notified later.
In these situations, it might also be possible that a work item is aborted
before it has been completed. The WorkItemHandler.abortWorkItem(...) method can be
used to specify how to abort such work items.
Tip
Remember, if the WorkItemManager is not notified about the completion, the
process engine will never be notified that your service node has completed.
WorkItemHandler instances need to be registered with the
WorkItemManager in order to be used. In this case, we need to register an instance of
our NotificationWorkItemHandler in order to use it with our process containing a
Notification work item. We can do that like this:
StatefulKnowledgeSession ksession = kbase.newStatefulKnowledgeSession(); ksession.getWorkItemManager().registerWorkItemHandler( "Notification",new NotificationWorkItemHandler());
| This is the drools name of the |
| This is the instance of our custom work item handler instance! |
If we were to look at the BPMN2 syntax for our process with the Notification
process, we would see something like the following example. Note the use of the
tns:taskName attribute in the <task> node. This is necessary for the
WorkItemManager to be able to see which WorkItemHandler instance should
be used with which task or work item.
<?xml version="1.0" encoding="UTF-8"?>
<definitions id="Definition"
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xs:schemaLocation="http://www.omg.org/spec/BPMN/20100524/MODEL BPMN20.xsd"
...
xmlns:tns="http://www.jboss.org/drools">
...
<process isExecutable="true" id="myCustomProcess" name="Domain-Specific Process" >
...
<task id="_5" name="Notification Task" tns:taskName="Notification" >
...
Tip
Different work item handlers could be used depending on the context. For example, during testing or simulation, it might not be necessary to actually execute the work items. In this case specialized dummy work item handlers could be used during testing.
A lot of these domain-specific services are generic, and can be reused by a lot of different users. Think for example about integration with Twitter, doing file system operations or sending email. Once such a domain-specific service has been created, you might want to make it available to other users so they can easily import and start using it.
A service repository allows you to import services by browsing the repository looking for services you might need and importing these services into your workspace. These will then automatically be added to your palette and you can start using them in your processes. You can also import additional artefacts like for example an icon, any dependencies you might need, a default handler that will be used to execute the service (although you're always free to override the default, for example for testing), etc.
To browse the repository, open the wizard to import services, point it to the right location (this could be to a directory in your file system but also a public or private URL) and select the services you would like to import. For example, in Eclipse, right-click your project that contains your processes and select "Configure ... -> Import jBPM services ...". This will open up a repository browser. In the URL field, fill in the URL of your repository (see below for the URL of the public jBPM repository that hosts some common service implementations out-of-the-box), or use the "..." button to browse to a folder on your file system. Click the Get button to retrieve the contents of that repository.
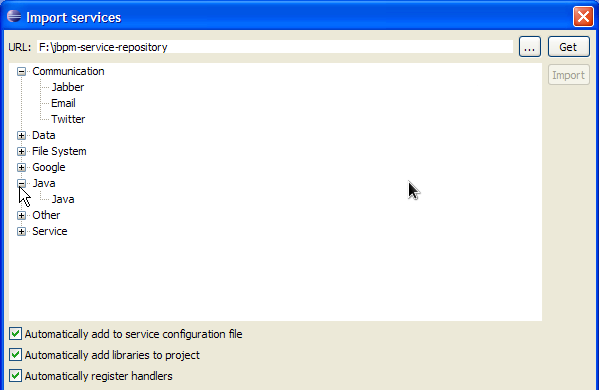
Select the service you would like to import and then click the Import button. Note that the Eclipse wizard allows you to define whether you would like to automatically configure the service (so it shows up in the palette of your processes), whether you would also like to download any dependencies that might be needed for executing the service and/or whether you would like to automatically register the default handler, so make sure to mark the right checkboxes before importing your service (if you are unsure what to do, leaving all check boxes marked is probably best).
After importing your service, (re)open your process diagram and the new service should show up in your palette and you can start using it in your process. Note that most services also include documentation on how to use them (e.g. what the different input and output parameters are) when you select them browsing the service repository.
Click on the image below to see a screencast where we import the Twitter service in a new jBPM project and create a simple process with it that sends an actual tweet. Note that you need the necessary Twitter keys and secrets to be able to programmatically send tweets to your Twitter account. How to create these is explained here, but once you have these, you can just drop them in your project using a simple configuration file.
Figure 21.1.
We are building a public service repository that contains predefined services that people can use out-of-the-box if they want to:
http://docs.jboss.org/jbpm/v6.0/repository/
This repository contains some integrations for common services like Twitter integration or file system operations that you can import. Simply point the import wizard to this URL to start browsing the repository.
If you have an implementation of a common service that you would like to contribute to the community, do not hesitate to contact someone from the development team. We are always looking for contributions to extend our repository.
You can set up your own service repository and add your own services by creating a configuration file that contains the necessary information (this is an extended version of the normal work definition configuration file as described earlier in this chapter) and putting the necessary files (like an icon, dependencies, documentation, etc.) in the right folders.
The extended configuration file contains the normal properties (like name, parameters, results and icon), with some additional ones. For example, the following extended configuration file describes the Twitter integration service (as shown in the screencast above):
import org.drools.core.process.core.datatype.impl.type.StringDataType;
[
[
"name" : "Twitter",
"description" : "Send a Twitter message",
"parameters" : [
"Message" : new StringDataType()
],
"displayName" : "Twitter",
"eclipse:customEditor" : "org.drools.eclipse.flow.common.editor.editpart.work.SampleCustomEditor",
"icon" : "twitter.gif",
"category" : "Communication",
"defaultHandler" : "org.jbpm.process.workitem.twitter.TwitterHandler",
"documentation" : "index.html",
"dependencies" : [
"file:./lib/jbpm-twitter.jar",
"file:./lib/twitter4j-core-2.2.2.jar"
]
]
]
- The icon property should refer to a file with the given file name in the same folder as the extended configuration file (so it can be downloaded by the import wizard and used in the process diagrams). Icons should be 16x16 GIF files.
- The category property defines the category this service should be placed under when browsing the repository.
- The defaultHandler property defines the default handler implementation (i.e. the Java
class that implements the
WorkItemHandlerinterface and can be used to execute the service). This can automatically be registered as the handler for that service when importing the service from the repository. - The documentation property defines a documentation file that describes what the service does and how it works. This property should refer to a HTML file with the given name in the same folder as the extended configuration file (so it can be shown by the import wizard when browsing the repository).
- The dependencies property defines additional dependencies that are necessary to execute this service. This usually includes the handler implementation JAR, but could also include additional external dependencies. These dependencies should also be located on the repository on the given location (relative to the folder where the extended configuration file is located), so they can be downloaded by the import wizard when importing the service.
The root of your repository should also contain an index.conf file that
references all the folders that should be processed when searching for services on the repository.
Each of those folders should then contain:
- An extended configuration file with the same name as the folder (e.g.
Twitter.conf) - The icon as references in the configuration file
- The documentation as references in the configuration file
- The dependencies as references in the configuration file (for example in a lib folder)
You can create your own hierarchical structure, because if one of those folders also contains an
index.conf file, that will be used to scan additional sub-folders. Note that the
hierarchical structure of the repository is not shown when browsing the repository using the import
wizard, as the category property in the configuration file is used for that.