One can say that using a debugger may help to verify the execution of an application. However, in addition to the fact that a debugger decreases performance of an application, it is difficult to use it in a distributed computing environment.
This most basic form of logging involves developers manually inserting code into their applications to display small (or large) pieces of internal state information to help understand what's going on. It's a useful technique that every developer has used at least once. The problem is that it doesn't scale. Using print statements for a small program is fine, but for a large, commercial-grade piece of software there is far too much labor involved in manually adding and removing logging statements.
C programmers know, of course, that the way to conditionally add and remove code is via the C preprocessor and the #ifdef directive. Unfortunately, Java doesn't have a preprocessor. How can we make logging scale to a useful level in Java?
A simple way to provide logging in your program is to use the Java compiler's ability to evaluate boolean expressions at compile time, provided that all the arguments are known. For example, in this code, the println statements will not be executed if DEBUG not set to true.
class foo
{
public bar()
{
if(DEBUG)
{
System.out.println("Debugging enabled.");
}
}
}
A much better way, and the way that most logging is done in environments where the logged output is important, is to use a logging class.
A logging class collects all the messages in one central place and not only records them, but can also sort and filter them so that you don't have to see every message being generated. A logging class provides more information than just the message. It can automatically add information such as the time the event occurred, the thread that generated the message, and a stack trace of where the message was generated.
Some logging classes will write their output directly to the screen or a file. More advanced logging systems may instead open a socket to allow the log messages to be sent to a separate process, which is in turn responsible for passing those messages to the user or storing them. The advantage with this system is that it allows for messages from multiple sources to be aggregated in a single location and it allows for monitoring remote systems.
The format of the log being generated should be customisable. This could start from just allowing setting the Log "level" - which means that each log message is assigned a severity level and only messages of greater importance than the log level are logged - to allowing more flexible log file formatting by using some sort LogFormatter objects that do transformations on the logging information.
The logging service should be able to route logging information to different locations based on the type of the information. Examples might be printing certain messages to the console, writing to a flat file, to a number of different flat files, to a database and so on. Examples of different types information could be for example errors, access information etc.
An appropriate logging library should provide these features:
- Control over which logging statements are enabled or disabled,
- Define importance or severity for logging statement via a set of levels
- Manage output destinations,
- Manage output format.
- Manage internationalization (i18n)
- Configuration.
According to the features (described above) a logging framework should provide, we have considering the most common logging service is use.
Log4j has three main components:
- Categories
- Appenders
- Layouts
The org.log4j.Category class figures at the core of the package. Categories are named entities. In a naming scheme familiar to Java developers, a category is said to be a parent of another category if its name, followed by a dot, is a prefix of the child category name. For example, the category named com.foo is a parent of the category named com.foo.Bar. Similarly, java is a parent of java.util and an ancestor of java.util.Vector.
The root category, residing at the top of the category hierarchy, is exceptional in two ways:
- It always exists
- It cannot be retrieved by name
In the Category class, invoking the static getRoot() method retrieves the root category. The static getInstance() method instantiates all other categories. getInstance() takes the name of the desired category as a parameter. Some of the basic methods in the Category class are listed below:
package org.log4j;
public Category class {
// Creation and retrieval methods:
public static Category getRoot();
public static Category getInstance(String name);
// printing methods:
public void debug(String message);
public void info(String message);
public void warn(String message);
public void error(String message);
// generic printing method:
public void log(Priority p, String message);
}
Categories may be assigned priorities from the set defined by the org.log4j.Priority class. Five priorities are defined: FATAL, ERROR, WARN, INFO and DEBUG, listed in decreasing order of priority. New priorities may be defined by subclassing the Priority class.
- FATAL: The FATAL priority designates very severe error events that will presumably lead the application to abort.
- ERROR: The ERROR priority designates error events that might still allow the application to continue running.
- WARN: The WARN priority designates potentially harmful situations.
- INFO: The INFO priority designates informational messages that highlight the progress of the application.
- DEBUG: The DEBUG priority designates fine-grained informational events that are most useful to debug an application.
To make logging requests, invoke one of the printing methods of a category instance. Those printing methods are: fatal(), error(), warn(), info(), debug(), log().
By definition, the printing method determines the priority of a logging request. For example, if c is a category instance, then the statement c.info("..") is a logging request of priority INFO.
A logging request is said to be enabled if its priority is higher than or equal to the priority of its category. Otherwise, the request is said to be disabled. A category without an assigned priority will inherit one from the hierarchy.
Log4j also allows logging requests to print to multiple output destinations called appenders in log4j speak. Currently, appenders exist for the console, files, GUI components, remote socket servers, NT Event Loggers, and remote UNIX Syslog daemons.
A category may refer to multiple appenders. Each enabled logging request for a given category will be forwarded to all the appenders in that category as well as the appenders higher in the hierarchy. In other words, appenders are inherited additively from the category hierarchy. For example, if you add a console appender to the root category, all enabled logging requests will at least print on the console. If, in addition, a file appender is added to a category, say C, then enabled logging requests for C and C's children will print on a file and on the console.
More often than not, users want to customize not only the output destination but also the output format, a feat accomplished by associating a layout with an appender. The layout formats the logging request according to the user's wishes, whereas an appender takes care of sending the formatted output to its destination.
For example, the PatternLayout with the conversion pattern %r [%t]%-5p %c - %m%n will output something like:
176 [main] INFO org.foo.Bar �Hello World.
In the output above:
- The first field equals the number of milliseconds elapsed since the start of the program
- The second field indicates the thread making the log request
- The third field represents the priority of the log statement
- The fourth field equals the name of the category associated with the log request
The text after the - indicates the statement's message.
The log4j environment can be fully configured programmatically. However, it is far more flexible to configure log4j by using configuration files. Currently, configuration files can be written in XML or in Java properties (key=value) format.
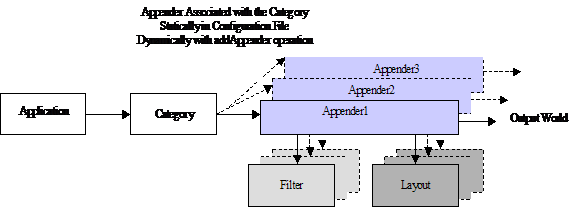
The following figure summarizes the different components when using log4j. Applications make logging calls on Category objects. The Category forwards to Appender logging requests for publication. Appender are registered with a Category with the addAppender method on the Category class. Invoking the addAppender method is made either by the Application or by Configurator objects. Log4j provides Configurators such as BasicConfigurator, which registers to the category the ConsoleAppender responsible to send logging requests to the console, or the PropertyConfigurator, which registers Appender objects based on Appender classes defined in a configuration file. Both Category and Appender may use logging Priority and (optionally) Filters to decide if they are interested in a particular logging request. An Appender can use a Layout to localize and format the message before publishing it to the output world.
The HP Logging Mechanism consists of a log handler, zero or more log writers, and one or more log channels, as illustrated in Figure below.
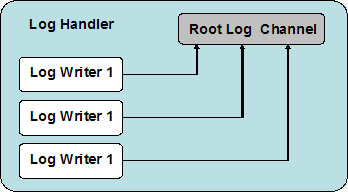
The log handler is implemented as a singleton Java Bean. It is accessible from the com.hp.mw.common.util.LogHandlerFactory which returns the single instance of com.hp.mw.common.util.LogHandler.
The following code illustrates how to obtain the LogHandler:
LogHandler handler;
handler = LogHandlerFactory.getHandler();
Log channels are virtual destinations; they receive messages and pass them to the log writers that are registered to receive them. They are not aware of the message formatting that might occur and are not aware of the logging tools that are used to view or store the messages. Log writers are registered for channels. When a log channel receives a message, and if that channel has a registered log writer(s), the message is passed along to that writer.
A client may obtain a channel with a specific name as follows.
LogChannel channel;
channel = LogChannelFactory.getChannel("myapplication" );
In order to abstract the destination of a log message (e.g., console, file, database), the Logging Mechanism relies on log writers. Log writers are defined by the com.hp.mw.common.util.logging.LogWriter interface and are given messages by the channel(s) they service. They are responsible for formatting messages and outputting to the actual destination.
A log formatter is responsible for formatting a log message into a Java String. Since many log writers do not require the String representation, log formatters are not required for every log writer. As a result, the com.hp.mw.common.util.logging.LogMessageFormat interface would be used for formatting messages into Strings when applicable and necessary.
All log channels are created, initially, with a default log threshold. The threshold is the minimum severity of a log message that should be processed for that log channel. The log levels defined by the HP logging mechanisms are as follows:
Log Level Description
- LOG_LEVEL_NONE This log level should be used to turn off all messages to a channel.
- LOG_LEVEL_FLOW Flow messages indicate program flow and can be extremely frequent.
- LOG_LEVEL_DEBUG Debug messages are fairly low-level messages that provide the developer(s) with information about events occurring within the application
- LOG_LEVEL_INFO Informational messages are of higher severity than debug and should provide information that any user could understand, as opposed to debug messages, which provide code-specific information.
- LOG_LEVEL_WARNING Warning messages are typically used to report an unusual or unexpected occurrence from which recovery is possible (e.g., a missing or incorrect configuration value that has a reasonable default).
- LOG_LEVEL_ERROR Error messages are used to report an unusual or unexpected occurrence from which recovery is not possible. This does not indicate that the entire application or framework is incapable of continuing, but that the component involved might be defunct or the operation it was asked to perform is aborted.
- LOG_LEVEL_CRITICAL Critical messages are typically used to report a very unusual or unexpected occurrence. For example, a component that was functioning correctly but suddenly experiences an unrecoverable error that prevents it from continuing should emit a critical message.
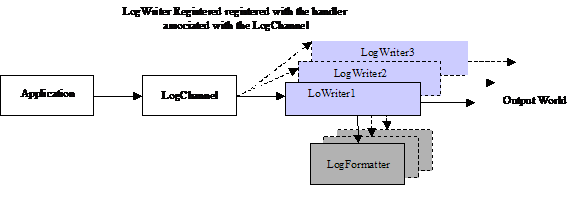
The following figure summarizes the different components when using log4j. Applications make logging calls on Channel objects. The Channel forwards to LogWriter logging requests for publication. LogWriter are registered with the handler associated to a Channel. Both LogChannel and LogWritter may use logging LogLevel to decide if they are interested in a particular logging request. A LogWriter can use a LogFormatter to format the message before publishing it to the output world.
An application is internationalized, if it can correctly handle different encodings of character data. An application is localized, if it formats and interprets data (dates, times, timezones, currencies, messages and so on) according to rules specific to the user's locale (country and language).
Internationalization (I18N) is the process of designing an application so that it can be adapted to various languages and regions without engineering changes. Localization (L10N) is the use of locale-specific language and constructs at run time.
Java Internationalization shows how to write software that is multi-lingual, using Unicode, a standard system that supports hundreds of character sets. The Java Internationalization API is a comprehensive set of APIs for creating multilingual applications. The JDK internationalization features, from its version 1.1, include:
- Classes for storing and loading language-specific objects.
- Services for formatting messages, date, times, and numbers.
- Services for comparing and collating text.
- Support for finding character, word, and sentence boundaries.
- Support for display, input, and output of Unicode characters.
Users of the Java internationalization interfaces should be familiar with the following interfaces included in the Java Developer's Kit (JDK):
- java.util.Locale Represents a specific geographical, political, or cultural region.
- java.util.ResourceBundle Containers for locale-specific objects
- java.text.MessageFormat A means to produce concatenated messages in a language-neutral way.
The concept of a Locale object, which identifies a specific cultural region, includes information about the country or region. If a class varies its behavior according to Locale, it is said to be locale-sensitive. For example, the NumberFormat class is locale-sensitive; the format of the number it returns depends on the Locale. Thus NumberFormat may return a number as 902 300 (France), or 902.300 (Germany), or 902,300 (United States). Locale objects are only identifiers.
Most operating systems allow to indicate their locale or to modify it. For instance Windows NT does this through the control panel, under the Regional Option icon. In Java, you can get the Locale object that matches the user's control-panel setting using myLocale = Locale.getDefault();. You can also create Locale objects for specific places by indicating the language and country you want, such as myLocale = new Locale("fr", "CA"); for "Canadian French."
The next example creates Locale objects for the English language in the United States and Great Britain:
bLocale = new Locale("en", "US");
cLocale = new Locale("en", "GB");
The strings you pass to the Locale constructor are two-letter language and country codes, as defined by ISO standards.
The first step in making an international Java program is to isolate all elements of your Java code that will need to change in another country. This includes user-interface text -- label text, menu items, shortcut keys, messages, and the like.
The ResourceBundle class is an abstract class that provides an easy way to organize and retrieve locale-specific strings or other resources. It stores these resources in an external file, along with a key that you use to retrieve the information. You'll create a ResourceBundle for each locale your Java program supports.
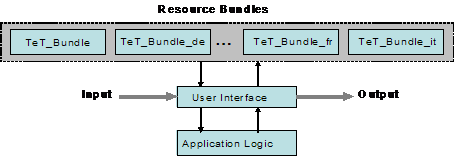
The ResourceBundle class is an abstract class in the java.util package. You can provide your own subclass of ResourceBundle or use one of the subclass implementations, as in the case of PropertyResourceBundle or ListResourceBundle.
Resource bundles inherit from the ResourceBundle class and contain localized elements that are stored external to an application. Resource bundles share a base name. The base name TeT_Bundle, to display transactional messages such as T�ransaction Commited� might be selected because of the resources it contains. Locale information further differentiates a resource bundle. For example, TeT_Bundle_it means that this resource bundle contains locale-specific transactional messages for Italian.
To select the appropriate ResourceBundle, invoke the ResourceBundle.getBundle method. The following example selects the TeT_Bundle ResourceBundle for the Locale that matches the French language, the country of Canada.
Locale currentLocale = new Locale("fr", "CA");
ResourceBundle introLabels = ResourceBundle.getBundle("TeT_Bundle", currentLocale);
Java loads your resources based on the locale argument to the getBundle method. It searches for matching files with various suffixes, based on the language, country, and any variant or dialect to try to find the best match. Java tries to find a complete match first, and then works its way down to the base filename as a last resort.
You should always supply a base resource bundle with no suffixes, so that your program will still work if the user's locale does not match any of the resource bundles you supply. The default file can contain the U.S. English strings. Then you should provide properties files for each additional language you want to support.
Basically, a resource bundle is a container for key/value pairs. The key is used to identify a locale-specific resource in a bundle. If that key is found in a particular resource bundle, its value is returned.
The jdk API defines two kinds of ResourceBundle subclasses -- the PropertyResourceBundle and ListResourceBundle.
A PropertyResourceBundle is backed by a properties file. A properties file is a plain-text file that contains translatable text. Properties files are not part of the Java source code, and they can contain values for String objects only. A simple default properties file, named hpts_Bundle.properties, for messages sent by HPTS could be.
# Sample properties file for demonstrating PropertyResourceBundle
# Text to inform on transaction outcomes in English (by default) trans_committed = Transaction Committed trans_rolledback=Transaction Rolled Back
# �
The equivalent properties file, hpts_Bundle_fr_FR.properties, for French would be:
# Sample properties file for demonstrating PropertyResourceBundle
# Text to inform on transaction outcomes in French trans_committed = La Transaction a �t� Valid�e trans_rolledback = La Transaction a�t� Abandonn�e
# �
The following example illustrates how to use the internationalization API allowing separating the text with a language specified by the user, from the source code.
import java.util.*;
import Demo.*;
import java.io.*;
import com.arjuna.OrbCommon.*;
import com.arjuna.CosTransactions.*;
import org.omg.CosTransactions.*;
import org.omg.*;
public class TransDemoClient {
public static void main(String[] args) {
String language; String country;
if (args.length != 2) {
language = new String("en");
country = new String("US"); }
else {
language = new String(args[0]);
country = new String(args[1]); }
Locale currentLocale;
ResourceBundle messages;
currentLocale = new Locale(language, country);
trans_message = ResourceBundle.getBundle( "hpts_Bundle", currentLocale);
try {
ORBInterface.initORB(args, null);
OAInterface.initOA();
String ref = new String();
BufferedReader file = new BufferedReader(new FileReader("DemoObjReference.tmp"));
ref = file.readLine();
file.close();
org.omg.CORBA.Object obj = ORBInterface.orb().string_to_object(ref);
DemoInterface d = (DemoInterface) DemoInterfaceHelper.narrow(obj);
OTS.get_current().begin();
d.work();
OTS.get_current().commit(true);
System.out.println(tran_message.getString("trans_committed")); }
catch (Exception e) {
System.out.println(tran_message.getString("trans_rolledback")); }
}
}
In the following example the language code is fr (French) and the country code is FR (France), so the program displays the messages in French:
% java TransDemoClient fr FR La Transaction a �t� valid�e
The following ant task is provided in buildsystem.jar to automate the creation of resource bundles: com.hp.mw.buildsystem.doclet.resbundledoclet.ResourceBundleDoclet, which is a doclet for the JavaDoc tool that ships with the JDK. It produces resource bundle property files from comments placed in Java source. The comments have the following format:
/**
* @message [key] [id] [text]
* e.g., @message foo foo This is a message: {0}
*/
Where [key] is the key used to look up the corresponding message ([text]) in the resource bundle. The [id] field is typically the same as [key] but need not be: it is output with the internationalized message and is meant to be used by technical support in order to identify the [key][message] pair in a language independent manner.
It takes the following runtime options:
- -resourcebundle [filename] This pecifies the name of the resource bundle to create, only use this if the Doclet is to produce a single resource bundle.
- -basedir [directory] This specifies the base directory to generate the resource bundle property files within (MANDATORY).
- -perclass This indicates that the doclet should produce resource bundles per class. If this is not specified then a single resource bundle properties file is produced for all of the source specified.
- -ignorerepetition This indicates that the doclet should ignore key repetition and not flag an error.
- -language [language code] This indicates which language is to be used
- -locale [locale code] This indicates which locale is to be used.
- -properties This indicates that the property filename should be postfixed with the .properties postfix.
The task can be declared within ant in the following way:
<doclet name="com.hp.mw.buildsystem.doclet.resbundledoclet.ResourceBundleDoclet">
<path>
<pathelement path="${com.hp.mw.ext.depends.classpath}"/>
</path>
<param name="-basedir" value="${com.hp.mwlabs.ts.arjuna.dest}"/>
<param name="-resourcebundle" value="${com.hp.mwlabs.ts.arjuna.resourcebundle}"/>
</doclet>
Below is a sample of the internationalized messages used in the Transaction Service.
/**
* BasicAction does most of the work of an atomic action, but does not manage
* thread scoping. This is the responsibility of any derived classes.
*
* @author Mark Little (mark@arjuna.com)
* @version $Id: internationalization.xml,v 1.1 2006/03/07 17:59:23 mlittle Exp $
* @since JTS 1.0.
*
*
*
* @message com.arjuna.ats.arjuna.coordinator.BasicAction_1
* [com.arjuna.ats.arjuna.coordinator.BasicAction_1] - Action nesting
* error - deletion of action id {0} invoked while child actions active
* @message com.arjuna.ats.arjuna.coordinator.BasicAction_2
* [com.arjuna.ats.arjuna.coordinator.BasicAction_2] - Aborting child
* {0}
* @message com.arjuna.ats.arjuna.coordinator.BasicAction_3
* [com.arjuna.ats.arjuna.coordinator.BasicAction_3] - Destructor of
* still running action id {0} invoked - Aborting
* @message com.arjuna.ats.arjuna.coordinator.BasicAction_4
* [com.arjuna.ats.arjuna.coordinator.BasicAction_4] - The Arjuna
* licence only allows a single resource to be registered. Please apply
* for a new licence.
* @message com.arjuna.ats.arjuna.coordinator.BasicAction_5
* [com.arjuna.ats.arjuna.coordinator.BasicAction_5] - Activate of
* atomic action with id {0} and type {1} unexpectedly failed
*/
Which, when processed by the doclet, generates the following within the resource bundle:
com.arjuna.ats.arjuna.coordinator.BasicAction_1=[com.arjuna.ats.arjuna.coordinator.BasicAction_1] - Action nesting error - deletion of action id {0} invoked while child actions
active
com.arjuna.ats.arjuna.coordinator.BasicAction_2=[com.arjuna.ats.arjuna.coordinator.BasicAction_2] - Aborting child {0}
com.arjuna.ats.arjuna.coordinator.BasicAction_3=[com.arjuna.ats.arjuna.coordinator.BasicAction_3] - Destructor of still running action id {0} invoked - Aborting
com.arjuna.ats.arjuna.coordinator.BasicAction_4=[com.arjuna.ats.arjuna.coordinator.BasicAction_4] - The Arjuna licence only allows a single resource to be registered. Please apply for a new licence.
com.arjuna.ats.arjuna.coordinator.BasicAction_5=[com.arjuna.ats.arjuna.coordinator.BasicAction_5] - Activate of atomic action with id {0} and type {1} unexpectedly failed
- Logi18n A simple logging interface abstracting the various logging APIs supported by CLF and providing an internationalization layer based on resource bundles.
- LogNoi18n A simple logging interface abstracting the various logging APIs supported by CLF without internationalization support
- CommonDebugLevel The CommonDebugLevel class provides default finer debugging value to determine if finer debugging is allowed or not.
- CommonFacilityCode The CommonFacilityCode class provides default finer facilitycode value to determine if finer debugging is allowed or not.
- CommonVisibilityLevel The CommonVisibilityLevel class provides default finer visibility value to determine if finer debugging is allowed or not.
- LogFactory Factory for Log objects.
Factory for Log objects. LogFactory returns different subclasses of logger according to which logging subsystem is chosen. The log system is selected through the property com.arjuna.common.utils.logger. Supported log systems are:
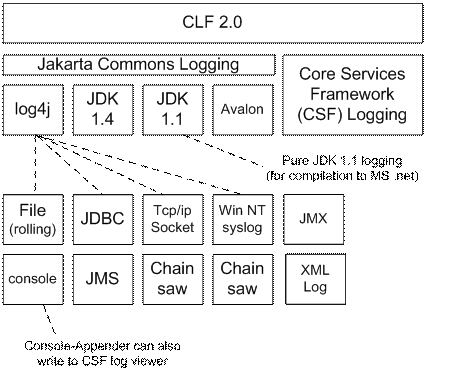
- jakarta Jakarta Commons Logging (JCL). JCL can delegate to various other logging subsystems, such as: log4j, JDK 1.4 logging, JDK 1.1 based logging (for compilation to Microsoft .net), Avalon
- dotnet .net logging. (must be JDK 1.1 compliant for compilation by the Microsoft compiler)
Note
Rather than implementing CSF and .net logging as additional loggers for JCL they have been anchored at this level to maximise code reuse and guarantee that all .net dependent code is 1.1 compliant.The underlying log system can be selected via the following property name:
- com.arjuna.common.util.logger This property selects the log subsystem to use. Note that this can only be set as a System property, e.g. as a parameter to start up the client application: java �com.arjuna.common.util.logger=log4j ....
Note
Note: The properties of the underlying log system are configured in a manner specific to that log system, e.g., a log4j.properties file in the case that log4j logging is used.The allowed values for the property are:
- log4j Log4j logging (log4j classes must be available in the classpath); configuration through the log4j.properties file, which is picked up from the CLASSPATH or given through a System property: log4j.configuration
- jdk14 JDK 1.4 logging API (only supported on JVMs of version 1.4 or higher). Configuration is done through a file logging.properties in the jre/lib directory.
- simple Selects the simple JDK 1.1 compatible console-based logger provided by Jakarta Commons Logging
- jakarta Uses the default log system selection algorithm of the Jakarta Commons Logging framework
- dotnet Selects a .net logging implementation. Since a dotnet logger is not currently implemented, this is currently identical to simple. Simple is a purely JDK1.1 console-based log implementation.
- noop Disables all logging
To set log4j (default log system), provide the following System properties:
-Dcom.arjuna.common.util.logger=log4j
-Dlog4j.configuration=file://c:/Projects/common/log4j.properties
Simple use example:
import com.arjuna.common.util.logging.*;
public class Test {
static Log mylog =
LogFactory.getLog(Test.class);
public static void main(String[] args) {
String param0 = "foo";
String param1 = "bar";
// different log priorities mylog.debug("key1", new
Object[]{param0, param1});
mylog.info("key2", new Object[]{param0, param1});
mylog.warn("key3", new Object[]{param0, param1});
mylog.error("key4", new Object[]{param0, param1});
mylog.fatal("key5", new Object[]{param0, param1});
// optional throwable
Throwable throwable = new Throwable();
mylog.debug("key1", new Object[]{param0, param1}, throwable);
mylog.info("key2", new Object[]{param0, param1}, throwable);
mylog.warn("key3", new Object[]{param0, param1}, throwable);
mylog.error("key4", new Object[]{param0, param1}, throwable);
mylog.fatal("key5", new Object[]{param0, param1}, throwable);
// debug guard to avoid an expensive operation if the logger does not
// log at the given level:
if (mylog.isDebugEnabled()) {
String x = expensiveOperation(); mylog.debug("key6", new Object[]{x}); }
// ****************************************************** //
fine-grained debug extensions
mylog.debug(CommonDebugLevel.OPERATORS, CommonVisibilityLevel.VIS_PUBLIC, CommonFacilityCode.FAC_ALL, "This debug message is enabled since it matches default�+ Finer Values");
mylog.setVisibilityLevel(CommonVisibilityLevel.VIS_PACKAGE);
mylog.setDebugLevel(CommonDebugLevel.CONSTRUCT_AND_DESTRUCT);
mylog.setFacilityCode(CommonFacilityCode.FAC_ALL);
mylog.mergeDebugLevel(CommonDebugLevel.ERROR_MESSAGES);
if (mylog.debugAllowed(CommonDebugLevel.OPERATORS, CommonVisibilityLevel.VIS_PUBLIC, CommonFacilityCode.FAC_ALL)) {
mylog.debug(CommonDebugLevel.OPERATORS, CommonVisibilityLevel.VIS_PUBLIC, CommonFacilityCode.FAC_ALL, "key7", new Object[]{"foo", "bar"}, throwable); } } }
Independent of the log system chosen, it is possible to log all messages over a given severity threshold into a file. This is useful to guarantee that e.g., error and fatal level messages are not lost despite a user has not set up a log framework, such as log4j
Usage of this feature is simple and can be controlled through a set of properties. These can be provided through the Property Manager or as System properties.
Table 11.1. Properties to control default file-based logging (default values are highlighted)
| Property Name | Values | Description |
|---|---|---|
| com.arjuna.common.logging.default | true/ false | Enable/disable default file-based logging |
| com.arjuna.common.util.logging.default.level | Info /error/fatal | Severity level for this log |
| com.arjuna.common.util.logging.default.showLogName | true/ false | Record the fully qualified log name |
| com.arjuna.common.util.logging.default.showShortLogName | true /false | Record an abbreviated log name |
| com.arjuna.common.util.logging.default.showDate | true /false | Record the date |
| com.arjuna.common.util.logging.default.logFile | error.log (default) | File to use for default logging. This can be an absolute filename or relative to the working directory |
| com.arjuna.common.util.logging.default.logFileAppend | true /false | Append to the log file above in case that this file already exists |
Finer-grained logging in CLF is available through a set of debug methods:
public void debug(long dl, long vl, long fl, Object message);
public void debug(long dl, long vl, long fl, Throwable throwable);
public void debug(long dl, long vl, long fl, String key, Object[] params);
public void debug(long dl, long vl, long fl, String key, Object[] params, Throwable throwable);
All of these methods take the three following parameters in addition to the log messages and possible exception:
dl - The debug finer level associated with the log message. That is, the logger object will only log if the DEBUG level is allowed and dl is either equal or greater than the debug level assigned to the logger Object. See the table below for possible values.
vl - The visibility level associated with the log message. That is, the logger object will only log if the DEBUG level is allowed and vl is either equal or greater than the visibility level assigned to the logger Object. See the table below for possible values.
fl - The facility code level associated with the log message. That is, the logger object will only log if the DEBUG level is allowed and fl is either equal or greater than the facility code level assigned to the logger Object. See the table below for possible values.
The debug message is sent to the output only if the specified debug level, visibility level, and facility code match those allowed by the logger.
Note
The first two methods above do not use i18n. i.e., the messages are directly used for log output.Possible values for debug finer level, visibility level and facility code level are declared in the classes DebugLevel, VisibilityLevel and FacilityCode respectively. This is useful for programmatically using fine-grained debugging.
Table 11.2. Possible settings for finer debug level (class DebugLevel)
| Debug Finer Level | Value | Description |
|---|---|---|
| NO_DEBUGGING | 0x0000 | No debugging |
| CONSTRUCTORS | 0x0001 | Only output for constructors |
| DESTRUCTORS | 0x0002 | Only output for finalizers |
| CONSTRUCT_AND_DESTRUCT | CONSTRUCTORS | DESTRUCTORS | |
| FUNCTIONS | 0x0010 | Only output for methods |
| OPERATORS | 0x0020 | Only output for methods such as equals, notEquals etc. |
| FUNCS_AND_OPS | FUNCTIONS | OPERATORS | |
| ALL_NON_TRIVIAL | CONSTRUCT_AND_DESTRUCT | FUNCTIONS | OPERATORS | |
| TRIVIAL_FUNCS | 0x0100 | Only output from trivial methods |
| TRIVIAL_OPERATORS | 0x0200 | Only output from trivial operators |
| ALL_TRIVIAL | TRIVIAL_FUNCS | TRIVIAL_OPERATORS | |
| ERROR_MESSAGES | 0x0400 | Only output from debugging error/warning messages |
| FULL_DEBUGGING | 0xffff | Output all debugging messages |
Table 11.3. Possible settings for visibility level (class VisibilityLevel)
| Visibility Level | Value | Description |
|---|---|---|
| VIS_NONE | 0x0000 | No visibility |
| VIS_PRIVATE | 0x0001 | Only from private methods |
| VIS_PROTECTED | 0x0002 | Only from protected methods |
| VIS_PUBLIC | 0x0004 | Only from public methods |
| VIS_PACKAGE | 0x0008 | Only from package methods |
| VIS_ALL | 0xffff | Output all visibility levels. |
Table 11.4. Possible settings for facility code level (class FacilityCode)
| Facility Code Level | Value | Description |
|---|---|---|
| FAC_NONE | 0x0000 | No facility |
| FAC_ALL | 0xffffffff | Output all facility codes |
At runtime, the fine-grained debug settings are controlled through a set of properties, listed in the table below: