- 5.1. Declaração de mapeamento
- 5.1.1. Doctype
- 5.1.2. Mapeamento do Hibernate
- 5.1.3. Classe
- 5.1.4. id
- 5.1.5. Aprimoração dos geradores de identificador
- 5.1.6. Otimização do Gerador de Identificação
- 5.1.7. Composição-id
- 5.1.8. Discriminador
- 5.1.9. Versão (opcional)
- 5.1.10. Timestamp (opcional)
- 5.1.11. Propriedade
- 5.1.12. Muitos-para-um
- 5.1.13. Um-para-um
- 5.1.14. Id Natural
- 5.1.15. Componente e componente dinâmico
- 5.1.16. Propriedades
- 5.1.17. Subclass
- 5.1.18. Subclasses Unidas
- 5.1.19. Subclasse de União
- 5.1.20. União
- 5.1.21. Key
- 5.1.22. Elementos coluna e fórmula
- 5.1.23. Importar
- 5.1.24. Any
- 5.2. Tipos do Hibernate
- 5.3. Mapeando uma classe mais de uma vez
- 5.4. Identificadores quotados do SQL
- 5.5. Alternativas de Metadados
- 5.6. Propriedades geradas
- 5.7. Coluna de expressöes de gravação e leitura
- 5.8. Objetos de Banco de Dados Auxiliares
O mapeamento de objeto/relacional é geralmente definido em um documento XML. O documento de mapeamento é criado para ser de leitura e editável manualmente. A linguagem do mapeamento é Java-centric, ou seja, os mapeamentos são construídos em torno de declarações de classe persistente e não de declarações de tabelas.
Note que, embora muitos usuários do Hibernate escolham gravar o XML manualmente, existem diversas ferramentas para gerar o documento de mapeamento, incluindo o XDoclet Middlegen e AndroMDA.
Vamos iniciar com um exemplo de mapeamento:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="eg">
<class name="Cat"
table="cats"
discriminator-value="C">
<id name="id">
<generator class="native"/>
</id>
<discriminator column="subclass"
type="character"/>
<property name="weight"/>
<property name="birthdate"
type="date"
not-null="true"
update="false"/>
<property name="color"
type="eg.types.ColorUserType"
not-null="true"
update="false"/>
<property name="sex"
not-null="true"
update="false"/>
<property name="litterId"
column="litterId"
update="false"/>
<many-to-one name="mother"
column="mother_id"
update="false"/>
<set name="kittens"
inverse="true"
order-by="litter_id">
<key column="mother_id"/>
<one-to-many class="Cat"/>
</set>
<subclass name="DomesticCat"
discriminator-value="D">
<property name="name"
type="string"/>
</subclass>
</class>
<class name="Dog">
<!-- mapping for Dog could go here -->
</class>
</hibernate-mapping
>
Discutiremos agora o conteúdo deste documento de mapeamento. Iremos apenas descrever os elementos do documento e funções que são utilizadas pelo Hibernate em tempo de execução. O documento de mapeamento também contém algumas funções adicionais e opcionais além de elementos que afetam os esquemas de banco de dados exportados pela ferramenta de exportação de esquemas. (Por exemplo, o atributo not-null).
Todos os mapeamentos de XML devem declarar o doctype exibido. O DTD atual pode ser encontrado na URL abaixo, no diretório hibernate-x.x.x/src/org/ hibernate ou no hibernate3.jar. O Hibernate sempre irá procurar pelo DTD inicialmente no seu classpath. Se você tentar localizar o DTD usando uma conexão de internet, compare a declaração do seu DTD com o conteúdo do seu classpath.
O Hibernate irá primeiro tentar solucionar os DTDs em seus classpath. Isto é feito, registrando uma implementação org.xml.sax.EntityResolver personalizada com o SAXReader que ele utiliza para ler os arquivos xml. Este EntityResolver personalizado, reconhece dois nomes de espaço de sistemas Id diferentes:
Um
hibernate namespaceé reconhecido quando um solucionador encontra um systema Id iniciando comhttp://hibernate.sourceforge.net/. O solucionador tenta solucionar estas entidades através do carregador de classe que carregou as classes do Hibernate.Um
user namespaceé reconhecido quando um solucionador encontra um sistema Id, utilizando um protocolo URL declasspath://. O solucionador tentará solucionar estas entidades através do carregador de classe do contexto de thread atual (1) e o carregador de classe (2) que carregou as classes do Hibernate.
Um exemplo de utilização do espaço de nome do usuário:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC '-//Hibernate/Hibernate Mapping DTD 3.0//EN' 'http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd' [
<!ENTITY version "3.5.6-Final">
<!ENTITY today "September 15, 2010">
<!ENTITY types SYSTEM "classpath://your/domain/types.xml">
]>
<hibernate-mapping package="your.domain">
<class name="MyEntity">
<id name="id" type="my-custom-id-type">
...
</id>
<class>
&types;
</hibernate-mapping>
Onde types.xml é um recurso no pacote your.domain e contém um typedef personalizado.
Este elemento possui diversos atributos opcionais. Os atributos schema e catalog especificam que tabelas referenciadas neste mapeamento pertencem ao esquema e/ou ao catálogo nomeado. Se especificados, os nomes das tabelas serão qualificados no esquema ou catálogo dado. Se não, os nomes das tabelas não serão qualificados. O atributo default-cascade especifica qual estilo de cascata será considerado pelas propriedades e coleções que não especificarem uma função cascade. A função auto-import nos deixa utilizar nomes de classes não qualificados na linguagem de consulta, por padrão.
<hibernate-mapping
schem a="schemaName"
catal
a="schemaName"
catal og="catalogName"
defau
og="catalogName"
defau lt-cascade="cascade_style"
defau
lt-cascade="cascade_style"
defau lt-access="field|property|ClassName"
defau
lt-access="field|property|ClassName"
defau lt-lazy="true|false"
auto-
lt-lazy="true|false"
auto- import="true|false"
packa
import="true|false"
packa ge="package.name"
/>
ge="package.name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Se você tem duas classes persistentes com o mesmo nome (não qualificadas), você deve ajustar auto-import="false". Caso você tentar ajustar duas classes para o mesmo nome "importado", isto resultará numa exceção.
Observe que o elemento hibernate-mapping permite que você aninhe diversos mapeamentos de <class> persistentes, como mostrado abaixo. Entretanto, é uma boa prática (e esperado por algumas ferramentas) o mapeamento de apenas uma classe persistente simples (ou uma hierarquia de classes simples) em um arquivo de mapeamento e nomeá-la após a superclasse persistente, por exemplo: Cat.hbm.xml, Dog.hbm.xml, ou se estiver usando herança, Animal.hbm.xml.
Você pode declarar uma classe persistente utilizando o elemento class. Por exemplo:
<class
name="ClassName"
table="tableName"
discriminator-value="discriminator_value"
mutable="true|false"
schema="owner"
catalog="catalog"
proxy="ProxyInterface"
dynami c-update="true|false"
dynami
c-update="true|false"
dynami c-insert="true|false"
select
c-insert="true|false"
select -before-update="true|false"
polymo
-before-update="true|false"
polymo rphism="implicit|explicit"
where=
rphism="implicit|explicit"
where= "arbitrary sql where condition"
persis
"arbitrary sql where condition"
persis ter="PersisterClass"
batch-
ter="PersisterClass"
batch-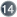 size="N"
optimi
size="N"
optimi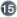 stic-lock="none|version|dirty|all"
lazy="(16)true|false"
entity(17)-name="EntityName"
check=(18)"arbitrary sql check condition"
rowid=(19)"rowid"
subsel(20)ect="SQL expression"
abstra(21)ct="true|false"
node="element-name"
/>
stic-lock="none|version|dirty|all"
lazy="(16)true|false"
entity(17)-name="EntityName"
check=(18)"arbitrary sql check condition"
rowid=(19)"rowid"
subsel(20)ect="SQL expression"
abstra(21)ct="true|false"
node="element-name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(16) |
|
(17) |
|
(18) |
|
(19) |
|
(20) |
|
(21) |
|
É perfeitamente aceitável uma classe persitente nomeada ser uma interface. Você deverá então declarar as classes implementadas desta interface utilizando o elemento <subclass>. Você pode persistir qualquer classe interna estática. Você deverá especificar o nome da classe usando a forma padrão, por exemplo: eg.Foo$Bar.
Classes imutáveis, mutable="false", não podem ser modificadas ou excluídas pela aplicação. Isso permite que o Hibernate aperfeiçoe o desempenho.
A função opcional proxy habilita a inicialização lazy das instâncias persistentes da classe. O Hibernate irá retornar CGLIB proxies como implementado na interface nomeada. O objeto persistente atual será carregado quando um método do proxy for invocado. Veja "Inicialização de Coleções e Proxies" abaixo.
Polimorfismo implícito significa que instâncias de uma classe serão retornadas por uma consulta que dá nome a qualquer superclasse ou interface e classe implementada, além das instâncias de qualquer subclasse da classe serão retornadas por uma consulta que nomeia a classe por si. Polimorfismo explícito significa que instâncias da classe serão retornadas apenas por consultas que explicitamente nomeiam a classe e que as consultas que nomeiam as classes irão retornar apenas instâncias de subclasses mapeadas dentro da declaração <class> como uma <subclass> ou <joined-subclass>. Para a maioria dos casos, o valor padrão polymorphism="implicit", é apropriado. Polimorfismo explicito é útil quando duas classes distintas estão mapeadas para a mesma tabela. Isso aceita uma classe "peso leve" que contém um subconjunto de colunas da tabela.
O atributo persister deixa você customizar a estratégia de persistência utilizada para a classe. Você pode, por exemplo, especificar sua própria subclasse do org.hibernate.persister.EntityPersister ou você pode criar uma implementação completamente nova da interface org.hibernate.persister.ClassPersister que implementa a persistência através de, por exemplo, chamadas a procedimentos armazenados, serialização de arquivos planos ou LDAP. Veja org.hibernate.test.CustomPersister para um exemplo simples de "persistência" para uma Hashtable.
Observe que as configurações dynamic-update e dynamic-insert não são herdadas pelas subclasses e assim podem também ser especificadas em elementos <subclass> ou <joined-subclass>. Estas configurações podem incrementar o desempenho em alguns casos, mas podem realmente diminuir o desempenho em outras.
O uso de select-before-update geralmente irá diminuir o desempenho. Ela é muito útil para prevenir que um trigger de atualização no banco de dados seja ativado desnecessariamente, se você reconectar um nó de uma instância desconectada em uma Session.
Se você ativar dynamic-update, você terá de escolher a estratégia de bloqueio otimista:
version: verifica as colunas de versão/timestampall: verifica todas as colunasdirty: verifica as colunas modificadas, permitindo algumas atualizações concorrentesnone: não utiliza o bloqueio otimista
Nós realmente recomendamos que você utilize as colunas de versão/timestamp para o bloqueio otimista com o Hibernate. Esta é a melhor estratégia em relação ao desempenho e é a única estratégia que trata corretamente as modificações efetuadas em instâncias desconectadas (por exemplo, quando Session.merge() é utilizado).
Não há diferença entre uma visão e uma tabela para o mapeamento do Hibernate, e como esperado isto é transparente no nível do banco de dados, mesmo que alguns bancos de dados não suportam visões apropriadamente, especialmente com atualizações. Algumas vezes, você quer utilizar uma visão, mas não pode criá-la no banco de dados (por exemplo, com um esquema legado). Neste caso, você pode mapear uma entidade imutável e de somente leitura, para uma dada expressão de subseleção SQL:
<class name="Summary">
<subselect>
select item.name, max(bid.amount), count(*)
from item
join bid on bid.item_id = item.id
group by item.name
</subselect>
<synchronize table="item"/>
<synchronize table="bid"/>
<id name="name"/>
...
</class
>
Declare as tabelas para sincronizar com esta entidade, garantindo que a auto-liberação ocorra corretamente, e que as consultas para esta entidade derivada não retornem dados desatualizados. O <subselect> está disponível tanto como um atributo como um elemento mapeado aninhado.
Classes mapeadas devem declarar a coluna de chave primária da tabela do banco de dados. Muitas classes irão também ter uma propriedade ao estilo Java-Beans declarando o identificador único de uma instância. O elemento <id> define o mapeamento desta propriedade para a chave primária.
<id
name="propertyName"
type="typename"
column="column_name"
unsaved-value="null|any|none|undefined|id_value"
access="field|property|ClassName">
node="element-name|@attribute-name|element/@attribute|."
<generator class="generatorClass"/>
</id
>
|
|
|
|
|
|
|
|
|
|
Se a função name não for declarada, considera-se que a classe não tem a propriedade de identificação.
A função unsaved-value não é mais necessária no Hibernate 3.
Há uma declaração alternativa <composite-id> que permite o acesso à dados legados com chaves compostas. Nós realmente desencorajamos o uso deste para qualquer outra função.
O elemento filho opcional <generator> nomeia uma classe Java usada para gerar identificadores únicos para instâncias de uma classe persistente. Se algum parâmetro é requerido para configurar ou inicializar a instância geradora, eles são passados utilizando o elemento <param>.
<id name="id" type="long" column="cat_id">
<generator class="org.hibernate.id.TableHiLoGenerator">
<param name="table"
>uid_table</param>
<param name="column"
>next_hi_value_column</param>
</generator>
</id
>
Todos os geradores implementam a interface org.hibernate.id.IdentifierGenerator. Esta é uma interface bem simples. Algumas aplicações podem prover suas próprias implementações especializadas, entretanto, o Hibernate disponibiliza um conjunto de implementações internamente. Há nomes de atalhos para estes geradores internos, conforme segue abaixo:
incrementgera identificadores dos tipos
long,shortouintque são únicos apenas quando nenhum outro processo está inserindo dados na mesma tabela. Não utilize em ambientes de cluster.identitysuporta colunas de identidade em DB2, MySQL, Servidor MS SQL, Sybase e HypersonicSQL. O identificador retornado é do tipo
long,shortouint.sequenceutiliza uma seqüência em DB2, PostgreSQL, Oracle, SAP DB, McKoi ou um gerador no Interbase. O identificador de retorno é do tipo
long,shortouint.hiloutiliza um algoritmo hi/lo para gerar de forma eficiente identificadores do tipo
long,shortouint, a partir de uma tabela e coluna fornecida (por padrãohibernate_unique_keyenext_hi) como fonte para os valores hi. O algoritmo hi/lo gera identificadores que são únicos apenas para um banco de dados específico.seqhiloutiliza um algoritmo hi/lo para gerar de forma eficiente identificadores do tipo
long,shortouint, a partir de uma seqüência de banco de dados fornecida.uuidutiliza um algorítimo UUID de 128-bits para gerar identificadores do tipo string, únicos em uma rede (o endereço IP é utilizado). O UUID é codificado como um string de dígitos hexadecimais de tamanho 32.
guidutiliza um string GUID gerado pelo banco de dados no Servidor MS SQL e MySQL.
nativeseleciona entre
identity,sequenceouhilodependendo das capacidades do banco de dados utilizado.assigneddeixa a aplicação definir um identificador para o objeto antes que o
save()seja chamado. Esta é a estratégia padrão caso nenhum elemento<generator>seja especificado.selectretorna a chave primária recuperada por um trigger do banco de dados, selecionando uma linha pela chave única e recuperando o valor da chave primária.
foreignutiliza o identificador de um outro objeto associado. Normalmente utilizado em conjunto com uma associação de chave primária do tipo
<one-to-one>.sequence-identityuma estratégia de geração de seqüência especializada que use uma seqüência de banco de dados para a geração de valor atual, mas combina isto com JDBC3 getGeneratedKeys para de fato retornar o valor do identificador gerado como parte da execução de instrução de inserção. Esta estratégia é somente conhecida para suportar drivers da Oracle 10g, focados em JDK 1.4. Note que os comentários sobre estas instruções de inserção estão desabilitados devido a um bug nos drivers da Oracle.
Os geradores hilo e seqhilo fornecem duas implementações alternativas do algoritmo hi/lo, uma solução preferencial para a geração de identificadores. A primeira implementação requer uma tabela "especial" do banco de dados para manter o próximo valor "hi" disponível. A segunda utiliza uma seqüência do estilo Oracle (quando suportado).
<id name="id" type="long" column="cat_id">
<generator class="hilo">
<param name="table"
>hi_value</param>
<param name="column"
>next_value</param>
<param name="max_lo"
>100</param>
</generator>
</id
>
<id name="id" type="long" column="cat_id">
<generator class="seqhilo">
<param name="sequence"
>hi_value</param>
<param name="max_lo"
>100</param>
</generator>
</id
>
Infelizmente, você não pode utilizar hilo quando estiver fornecendo sua própria Connection para o Hibernate. Quando o Hibernate estiver usando uma fonte de dados do servidor de aplicações para obter conexões suportadas com JTA, você precisará configurar adequadamente o hibernate.transaction.manager_lookup_class.
O UUID contém: o endereço IP, hora de início da JVM que é com precisão de um quarto de segundo, a hora do sistema e um valor contador que é único dentro da JVM. Não é possível obter o endereço MAC ou um endereço de memória do código Java, portanto este é o melhor que pode ser feito sem utilizar JNI.
Para bancos de dados que suportam colunas de identidade (DB2, MySQL, Sybase, MS SQL), você pode utilizar uma geração de chave identity. Para bancos de dados que suportam sequencias (DB2, Oracle, PostgreSQL, Interbase, McKoi, SAP DB) você pode utilizar a geração de chaves no estilo sequence. As duas estratégias requerem duas consultas SQL para inserir um novo objeto.
<id name="id" type="long" column="person_id">
<generator class="sequence">
<param name="sequence"
>person_id_sequence</param>
</generator>
</id
>
<id name="id" type="long" column="person_id" unsaved-value="0">
<generator class="identity"/>
</id
>
Para desenvolvimento multi-plataforma, a estratégia native irá escolher entre as estratégias identity, sequence e hilo, dependendo das capacidades do banco de dados utilizado.
Se você quiser que a aplicação especifique os identificadores, em vez do Hibernate gerá-los, você deve utilizar o gerador assigned. Este gerador especial irá utilizar o valor do identificador especificado para a propriedade de identificação do objeto. Este gerador é usado quando a chave primária é a chave natural em vez de uma chave substituta. Este é o comportamento padrão se você não especificar um elemento <generator>.
A escolha do gerador assigned faz com que o Hibernate utilize unsaved-value="undefined". Isto força o Hibernate ir até o banco de dados para determinar se uma instância está transiente ou desacoplada, a não ser que haja uma versão ou uma propriedade de timestamp, ou que você definia Interceptor.isUnsaved().
O Hibernate não gera DDL com triggers, apenas para sistemas legados.
<id name="id" type="long" column="person_id">
<generator class="select">
<param name="key"
>socialSecurityNumber</param>
</generator>
</id
>
No exemplo acima, há uma única propriedade com valor nomeada socialSecurityNumber definida pela classe, uma chave natural, e uma chave substituta nomeada person_id cujo valor é gerado por um trigger.
Iniciando com a liberação 3.2.3, existem dois novos geradores que representam uma reavaliação de dois diferentes aspectos da geração identificadora. O primeiro aspecto é a portabilidade do banco de dados, o segundo é a otimização. A otimização significa que você não precisa questionar o banco de dados a cada solicitação para um novo valor de identificador. Estes dois geradores possuem por intenção substituir alguns dos geradores nomeados acima, começando em 3.3.x. No entanto, eles estão incluídos nas liberações atuais e podem ser referenciados pelo FQN.
A primeira destas novas gerações é a org.hibernate.id.enhanced.SequenceStyleGenerator que primeiramente é uma substituição para o gerador sequence e, segundo, um melhor gerador de portabilidade que o native. Isto é devido ao native normalmente escolher entre identity e sequence, que são semânticas extremamente diferentes das quais podem causar problemas súbitos em portabilidade de observação de aplicativos. No entanto, o org.hibernate.id.enhanced.SequenceStyleGenerator atinge a portabilidade numa maneira diferente. Ele escolhe entre uma tabela ou uma seqüência no banco de dados para armazenar seus valores de incrementação, dependendo nas capacidades do dialeto sendo usado. A diferença entre isto e o native é que o armazenamento baseado na tabela e seqüência possuem exatamente a mesma semântica. Na realidade, as seqüências são exatamente o que o Hibernate tenta imitar com os próprios geradores baseados na tabela. Este gerador possui um número de parâmetros de configuração:
sequence_name(opcional - valor padrãohibernate_sequence) o nome da seqüência ou tabela a ser usada.initial_value(opcional - padrão para1) O valor inicial a ser restaurado a partir da seqüência/tabela. Em termos da criação de seqüência, isto é análogo à cláusula tipicamente nomeada "STARTS WITH".increment_size(opcional - padrão para1): o valor pelo qual as chamadas para a seqüência/tabela devem diferenciar-se. Nos termos da criação da seqüência, isto é análogo à cláusula tipicamente nomeada "INCREMENT BY".force_table_use(opcional - padrão parafalse): devemos forçar o uso de uma tabela como uma estrutura de reforço, mesmo que o dialeto possa suportar a seqüência?value_column(opcional - padrão paranext_val): apenas relevante para estruturas de tabela, este é o nome da coluna onde na tabela que é usado para manter o valor.optimizer(optional - defaults tonone): See Seção 5.1.6, “Otimização do Gerador de Identificação”
O segundo destes novos geradores é o org.hibernate.id.enhanced.TableGenerator, que primeiramente é uma substituição para o gerador table, mesmo que isto funcione muito mais como um org.hibernate.id.MultipleHiLoPerTableGenerator, e segundo, como uma reimplementação do org.hibernate.id.MultipleHiLoPerTableGenerator que utiliza a noção dos otimizadores pugláveis. Basicamente, este gerador define uma tabela capacitada de manter um número de valores de incremento simultâneo pelo uso múltiplo de filas de chaves distintas. Este gerador possui um número de parâmetros de configuração.
table_name(opcional - padrão parahibernate_sequences): O nome da tabela a ser usado.value_column_name(opcional - padrão paranext_val): o nome da coluna na tabela que é usado para manter o valor.segment_column_name(opcional - padrão parasequence_name) O nome da coluna da tabela que é usado para manter a "chave de segmento". Este é o valor que identifica qual valor de incremento a ser usado.base(opcional - padrão paradefault) O valor da "chave de segmento" para o segmento pelo qual nós queremos obter os valores de incremento para este gerador.segment_value_length(opcional - padrão para255): Usado para a geração do esquema. O tamanho da coluna para criar esta coluna de chave de segmento.initial_value(opcional - valor padrão para1): O valor inicial a ser restaurado a partir da tabela.increment_size(opcional - padrão para1): O valor pelo qual as chamadas subseqüentes para a tabela devem diferir-se.optimizer(optional - defaults to): See Seção 5.1.6, “Otimização do Gerador de Identificação”
For identifier generators that store values in the database, it is inefficient for them to hit the database on each and every call to generate a new identifier value. Instead, you can group a bunch of them in memory and only hit the database when you have exhausted your in-memory value group. This is the role of the pluggable optimizers. Currently only the two enhanced generators (Seção 5.1.5, “Aprimoração dos geradores de identificador” support this operation.
none(geralmente este é o padrão, caso nenhum otimizador for especificado): isto não executará quaisquer otimizações e alcançará o banco de dados para cada e toda solicitação.hilo: aplica-se ao algoritmo em volta dos valores restaurados do banco de dados. Espera-se que os valores a partir do banco de dados para este otimizador sejam seqüenciais. Os valores restaurados a partir da estrutura do banco de dados para este otimizador indica um "número de grupo". Oincrement_sizeé multiplicado pelo valor em memória para definir um grupo "hi value".pooled: assim como o caso dohilo, este otimizador tenta minimizar o número de tentativas no banco de dados. No entanto, nós simplesmente implementamos o valor de inicialização para o "próximo grupo" na estrutura do banco de dados ao invés do valor seqüencial na combinação com um algoritmo de agrupamento em memória. Neste caso, oincrement_sizerefere-se aos valores de entrada a partir do banco de dados.
<composite-id
name="propertyName"
class="ClassName"
mapped="true|false"
access="field|property|ClassName">
node="element-name|."
<key-property name="propertyName" type="typename" column="column_name"/>
<key-many-to-one name="propertyName" class="ClassName" column="column_name"/>
......
</composite-id
>
Uma tabela com uma chave composta, pode ser mapeada com múltiplas propriedades da classe como propriedades de identificação. O elemento <composite-id> aceita o mapeamento da propriedade <key-property> e mapeamentos <key-many-to-one>como elementos filhos.
<composite-id>
<key-property name="medicareNumber"/>
<key-property name="dependent"/>
</composite-id
>
A classe persistente precisa substituir equals() e hashCode() para implementar identificadores compostos igualmente. E precisa também implementar Serializable.
Infelizmente, esta solução para um identificador composto significa que um objeto persistente é seu próprio identificador. Não há outro "handle" conveniente a não ser o próprio objeto. Você mesmo precisa instanciar uma instância de outra classe persistente e preencher suas propriedades de identificação antes que você possa dar um load() para o estado persistente associado com uma chave composta. Nós chamamos esta solução de identificador composto incorporado e não aconselhamos para aplicações sérias.
Uma segunda solução seria chamar de identificador composto mapped quando a propriedades de identificação nomeadas dentro do elemento <composite-id> estão duplicadas tanto na classe persistente como em uma classe de identificação separada.
<composite-id class="MedicareId" mapped="true">
<key-property name="medicareNumber"/>
<key-property name="dependent"/>
</composite-id
>
No exemplo, ambas as classes de identificadores compostas, MedicareId, e a própria classe entidade possuem propriedades nomeadas medicareNumber e dependent. A classe identificadora precisa sobrepor equals() e hashCode() e implementar Serializable. A desvantagem desta solução é óbvia: duplicação de código.
As seguintes funções são utilizadas para especificar o mapeamento de um identificador composto:
mapped(opcional,falsepor padrão): Indica que um identificar composto mapeado é usado, e que as propriedades de mapeamento contidas refere-se tanto à classe entidade quanto à classe de identificação composta.class(opcional, mas requerida para um identificador composto mapeado): A classe usada como um identificador composto.
We will describe a third, even more convenient approach, where the composite identifier is implemented as a component class in Seção 8.4, “Componentes como identificadores compostos”. The attributes described below apply only to this alternative approach:
name(opcional, requerida para esta abordagem): Uma propriedade do tipo componente que armazena o identificador composto. Para maiores informações, por favor consulte o capítulo 9.access(opcional - padrão paraproperty): A estratégia que o Hiberante deve utilizar para acessar o valor da propriedade.class(opcional - valor padrão para o tipo de propriedade determinando por reflexão): A classe componente utilizada como um identificador composto. Por favor consulte a próxima seção para maiores informações.
Esta terceira abordagem, um componente identificador, é a que nós recomendamos para a maioria das aplicações.
O elemento <discriminator> é necessário para persistência polimórfica utilizando a estratégia de mapeamento de tabela-por-classe-hierárquica e declara uma coluna discriminadora da tabela. A coluna discriminadora contém valores de marcação que informam à camada de persistência qual subclasse instanciar para uma linha em específico. Um restrito conjunto de tipos que podem ser utilizados: string, character, integer, byte, short, boolean, yes_no, true_false.
<discriminator
column="discriminator_column"
type="discriminator_type"
force="true|false"
insert="true|false"
formula="arbitrary sql expression"
/>
|
|
|
|
|
|
|
|
|
|
Valores atuais de uma coluna discriminada são especificados pela função discriminator-value da <class> e elementos da <subclass>.
O atributo force é útil (apenas) em tabelas contendo linhas com valores discriminadores "extras" que não estão mapeados para uma classe persistente. Este não é geralmente o caso.
Usando o atributo formula você pode declarar uma expressão SQL arbitrária que será utilizada para avaliar o tipo de uma linha. Por exemplo:
<discriminator
formula="case when CLASS_TYPE in ('a', 'b', 'c') then 0 else 1 end"
type="integer"/>
O elemento <version> é opcional e indica que a tabela possui dados versionados. Isto é particularmente útil se você planeja utilizar transações longas. Veja abaixo maiores informações:
<version
column="version_column"
name="propertyName"
type="typename"
access="field|property|ClassName"
unsaved-value="null|negative|undefined"
generated="never|always"
insert="true|false"
node="element-name|@attribute-name|element/@attribute|."
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Números de versão podem ser dos tipos Hibernate long, integer, short, timestamp ou calendar.
A versão ou timestamp de uma propriedade nunca deve ser nula para uma instância desconectada, assim o Hibernate irá identificar qualquer instância com uma versão nula ou timestamp como transiente, não importando qual outra estratégia unsaved-value tenha sido especificada. A declaração de uma versão nula ou a propriedade timestamp é um caminho fácil para tratar problemas com reconexões transitivas no Hibernate, especialmente úteis para pessoas utilizando identificadores atribuídos ou chaves compostas.
O elemento opcional <timestamp> indica que uma tabela contém dados em timestamp. Isso tem por objetivo dar uma alternativa para versionamento. Timestamps são por natureza uma implementação menos segura do bloqueio otimista. Entretanto, algumas vezes a aplicação pode usar timestamps em outros caminhos.
<timestamp
column="timestamp_column"
name="propertyName"
access="field|property|ClassName"
unsaved-value="null|undefined"
source="vm|db"
generated="never|always"
node="element-name|@attribute-name|element/@attribute|."
/>
|
|
|
|
|
|
|
|
|
|
|
|
Nota
Observe que o <timestamp> é equivalente a <version type="timestamp">. E <timestamp source="db"> é equivalente a <version type="dbtimestamp">.
O elemento <property> declara uma propriedade de estilo JavaBean de uma classe.
<property
name="propertyName"
column="column_name"
type="typename"
update="true|false"
insert="true|false"
formula="arbitrary SQL expression"
access="field|property|ClassName"
lazy="true|false"
unique="true|false"
not-null="true|false"
optimistic-lock="true|false"
generated="never|insert|always"
node="element-name|@attribute-name|element/@attribute|."
index="index_name"
unique_key="unique_key_id"
length="L"
precision="P"
scale="S"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
typename pode ser:
O nome de um tipo básico de Hibernate:
integer, string, character, date, timestamp, float, binary, serializable, object, blob, etc.O nome da classe Java com um tipo básico padrão:
int, float, char, java.lang.String, java.util.Date, java.lang.Integer, java.sql.Clob, etc.O nome da classe Java serializável
O nome da classe de um tipo customizado:
com.illflow.type.MyCustomType, etc.
Se você não especificar um tipo, o Hibernate irá utilizar reflexão sobre a propriedade nomeada para ter uma idéia do tipo de Hibernate correto. O Hibernate tentará interpretar o nome da classe retornada, usando as regras 2, 3 e 4 nesta ordem. Em certos casos, você ainda precisará do atributo type. Por exemplo, para distinguir entre Hibernate.DATE e Hibernate.TIMESTAMP, ou para especificar um tipo customizado.
A função access permite que você controle como o Hibernate irá acessar a propriedade em tempo de execução. Por padrão, o Hibernate irá chamar os métodos get/set da propriedades. Se você especificar access="field", o Hibernate irá bipassar os metodos get/set, acessando o campo diretamente, usando reflexão. Você pode especificar sua própria estratégia para acesso da propriedade criando uma classe que implemente a interface org.hibernate.property.PropertyAccessor.
Um recurso especialmente poderoso é o de propriedades derivadas. Estas propriedades são por definição somente leitura, e o valor da propriedade é calculado em tempo de execução. Você declara este cálculo como uma expressão SQL, que traduz para cláusula SELECT de uma subconsulta da consulta SQL que carrega a instância:
<property name="totalPrice"
formula="( SELECT SUM (li.quantity*p.price) FROM LineItem li, Product p
WHERE li.productId = p.productId
AND li.customerId = customerId
AND li.orderNumber = orderNumber )"/>
Observe que você pode referenciar as entidades da própria tabela, através da não declaração de um alias para uma coluna particular. Isto seria o customerId no exemplo dado. Observe também que você pode usar o mapeamento de elemento aninhado <formula>, se você não gostar de usar o atributo.
Uma associação ordinária para outra classe persistente é declarada usando o elemento many-to-one. O modelo relacional é uma associação muitos para um: uma chave exterior de uma tabela referenciando as colunas da chave primária da tabela destino.
<many-to-one
name="propertyName"
column="column_name"
class="ClassName"
cascade="cascade_style"
fetch="join|select"
update="true|false"
insert="true|false"
property-ref="propertyNameFromAssociatedClass"
access="field|property|ClassName"
unique="true|false"
not-null="true|false"
optimistic-lock="true|false"
lazy="proxy|no-proxy|false"
not-found="ignore|exception"
entity-name="EntityName"
formula="arbitrary SQL expression"
node="element-name|@attribute-name|element/@attribute|."
embed-xml="true|false"
index="index_name"
unique_key="unique_key_id"
foreign-key="foreign_key_name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Setting a value of the cascade attribute to any meaningful value other than none will propagate certain operations to the associated object. The meaningful values are divided into three categories. First, basic operations, which include: persist, merge, delete, save-update, evict, replicate, lock and refresh; second, special values: delete-orphan; and third, all comma-separated combinations of operation names: cascade="persist,merge,evict" or cascade="all,delete-orphan". See Seção 10.11, “Persistência Transitiva” for a full explanation. Note that single valued, many-to-one and one-to-one, associations do not support orphan delete.
Segue abaixo uma amostra de uma típica declaração many-to-one:
<many-to-one name="product" class="Product" column="PRODUCT_ID"/>
O atributo property-ref deve apenas ser usado para mapear dados legados onde uma chave exterior se refere à uma chave exclusiva da tabela associada que não seja a chave primária. Este é um modelo relacional desagradável. Por exemplo, suponha que a classe Product tenha um número seqüencial exclusivo, que não seja a chave primária. O atributo unique controla a geração de DDL do Hibernate com a ferramenta SchemaExport.
<property name="serialNumber" unique="true" type="string" column="SERIAL_NUMBER"/>
Então o mapeamento para OrderItem poderia usar:
<many-to-one name="product" property-ref="serialNumber" column="PRODUCT_SERIAL_NUMBER"/>
No entanto, isto não é recomendável.
Se a chave exclusiva referenciada engloba múltiplas propriedades da entidade associada, você deve mapear as propriedades referenciadas dentro de um elemento chamado <properties>
Se a chave exclusiva referenciada é a propriedade de um componente, você pode especificar um caminho para a propriedade:
<many-to-one name="owner" property-ref="identity.ssn" column="OWNER_SSN"/>
Uma associação um-pra-um para outra classe persistente é declarada usando um elemento one-to-one .
<one-to-one
name="propertyName"
class="ClassName"
cascade="cascade_style"
constrained="true|false"
fetch="join|select"
property-ref="propertyNameFromAssociatedClass"
access="field|property|ClassName"
formula="any SQL expression"
lazy="proxy|no-proxy|false"
entity-name="EntityName"
node="element-name|@attribute-name|element/@attribute|."
embed-xml="true|false"
foreign-key="foreign_key_name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Existem duas variedades de associações um-pra-um:
Associações de chave primária
Associações de chave exterior exclusiva
Associações de chave primária não necessitam de uma coluna extra de tabela. Se duas linhas forem relacionadas pela associação, então as duas linhas da tabela dividem o mesmo valor da chave primária. Assim, se você quiser que dois objetos sejam relacionados por uma associação de chave primária, você deve ter certeza que foram atribuídos com o mesmo valor identificador.
Para uma associação de chave primária, adicione os seguintes mapeamentos em Employee e Person, respectivamente:
<one-to-one name="person" class="Person"/>
<one-to-one name="employee" class="Employee" constrained="true"/>
Agora devemos assegurar que as chaves primárias de linhas relacionadas nas tabelas PERSON e EMPLOYEE são iguais. Nós usamos uma estratégia especial de geração de identificador do Hibernate chamada foreign:
<class name="person" table="PERSON">
<id name="id" column="PERSON_ID">
<generator class="foreign">
<param name="property"
>employee</param>
</generator>
</id>
...
<one-to-one name="employee"
class="Employee"
constrained="true"/>
</class
>
Uma nova instância de Person é atribuída com o mesmo valor da chave primária da instância de Employee referenciada com a propriedade employee daquela Person.
Alternativamente, uma chave exterior com uma restrição única, de Employee para Person, pode ser expressada como:
<many-to-one name="person" class="Person" column="PERSON_ID" unique="true"/>
Esta associação pode ser feita de forma bi-direcional adicionando o seguinte no mapeamento de Person:
<one-to-one name="employee" class="Employee" property-ref="person"/>
<natural-id mutable="true|false"/>
<property ... />
<many-to-one ... />
......
</natural-id
>
Embora recomendemos o uso das chaves substitutas como chaves primárias, você deve ainda identificar chaves naturais para todas as entidades. Uma chave natural é uma propriedade ou combinação de propriedades que é exclusiva e não nula. Mapeie as propriedades da chave natural dentro do elemento <natural-id>. O Hibernate irá gerar a chave exclusiva necessária e as restrições de anulabilidade, e seu mapeamento será apropriadamente auto documentado.
Nós recomendamos com ênfase que você implemente equals() e hashCode() para comparar as propriedades da chave natural da entidade.
Este mapeamento não pretende ser utilizado com entidades com chaves naturais primárias.
mutable(opcional, padrãofalse): Por padrão, propriedades naturais identificadoras são consideradas imutáveis (constante).
O elemento <component> mapeia propriedades de um objeto filho para colunas da tabela de uma classe pai. Os componentes podem, um após o outro, declarar suas próprias propriedades, componentes ou coleções. Veja "Components" abaixo:
<component
name="propertyName"
class="className"
insert="true|false"
update="true|false"
access="field|property|ClassName"
lazy="true|false"
optimistic-lock="true|false"
unique="true|false"
node="element-name|."
>
<property ...../>
<many-to-one .... />
........
</component
>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A tag filha <property> acrescenta a propriedade de mapeamento da classe filha para colunas de uma tabela.
O elemento <component> permite um sub-elemento <parent> mapeie uma propriedade da classe do componente como uma referencia de volta para a entidade que o contém.
The <dynamic-component> element allows a Map to be mapped as a component, where the property names refer to keys of the map. See Seção 8.5, “Componentes Dinâmicos” for more information.
O elemento <properties> permite a definição de um grupo com nome, lógico de propriedades de uma classe. A função mais importante do construtor é que ele permite que a combinação de propriedades seja o objetivo de uma property-ref. É também um modo conveninente para definir uma restrição única de múltiplas colunas. Por exemplo:
<properties
name="logicalName"
insert="true|false"
update="true|false"
optimistic-lock="true|false"
unique="true|false"
>
<property ...../>
<many-to-one .... />
........
</properties
>
|
|
|
|
|
|
|
|
|
|
Por exemplo, se temos o seguinte mapeamento de <properties>:
<class name="Person">
<id name="personNumber"/>
...
<properties name="name"
unique="true" update="false">
<property name="firstName"/>
<property name="initial"/>
<property name="lastName"/>
</properties>
</class
>
Então podemos ter uma associação de dados legados que referem a esta chave exclusiva da tabela Person, ao invés de se referirem a chave primária:
<many-to-one name="person"
class="Person" property-ref="name">
<column name="firstName"/>
<column name="initial"/>
<column name="lastName"/>
</many-to-one
>
Nós não recomendamos o uso deste tipo de coisa fora do contexto de mapeamento de dados legados.
Finalmente, a persistência polimórfica requer a declaração de cada subclasse da classe raíz de persistência. Para a estratégia de mapeamento tabela-por-hierarquia-de-classe, deve-se utilizar a declaração <subclass>. Por exemplo:
<subclass
name="ClassName"
discriminator-value="discriminator_value"
proxy="ProxyInterface"
lazy="true|false"
dynamic-update="true|false"
dynamic-insert="true|false"
entity-name="EntityName"
node="element-name"
extends="SuperclassName">
<property .... />
.....
</subclass
>
|
|
|
|
|
|
|
|
Cada subclasse deve declarar suas próprias propriedades persistentes e subclasses. As propriedades <version> e <id> são configuradas para serem herdadas da classe raíz. Cada subclasse numa hierarquia deve definir um único discriminator-value. Se nenhum for especificado, será usado o nome da classe Java completamente qualificado.
For information about inheritance mappings see Capítulo 9, Mapeamento de Herança .
Alternativamente, cada subclasse pode ser mapeada para sua própria tabela. Isto é chamado estratégia de mapeamento de tabela-por-subclasse. O estado herdado é devolvido por associação com a tabela da superclasse. Nós usamos o elemento <joined-subclass>. Por exemplo:
<joined-subclass
name="ClassName"
table="tablename"
proxy="ProxyInterface"
lazy="true|false"
dynamic-update="true|false"
dynamic-insert="true|false"
schema="schema"
catalog="catalog"
extends="SuperclassName"
persister="ClassName"
subselect="SQL expression"
entity-name="EntityName"
node="element-name">
<key .... >
<property .... />
.....
</joined-subclass
>
|
|
|
|
|
|
|
|
A coluna discriminadora não é requerida para esta estratégia de mapeamento. Cada subclasse deve declarar uma coluna de tabela com o identificador do objeto usando o elemento <key>. O mapeamento no início do capítulo poderia ser re-escrito assim:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="eg">
<class name="Cat" table="CATS">
<id name="id" column="uid" type="long">
<generator class="hilo"/>
</id>
<property name="birthdate" type="date"/>
<property name="color" not-null="true"/>
<property name="sex" not-null="true"/>
<property name="weight"/>
<many-to-one name="mate"/>
<set name="kittens">
<key column="MOTHER"/>
<one-to-many class="Cat"/>
</set>
<joined-subclass name="DomesticCat" table="DOMESTIC_CATS">
<key column="CAT"/>
<property name="name" type="string"/>
</joined-subclass>
</class>
<class name="eg.Dog">
<!-- mapping for Dog could go here -->
</class>
</hibernate-mapping
>
For information about inheritance mappings see Capítulo 9, Mapeamento de Herança .
Uma terceira opção é mapear apenas as classes concretas de uma hierarquia de heranças para tabelas. Isto é chamado estratégia table-per-concrete-class. Cada tabela define todos os estados persistentes da classe, incluindo estados herdados. No Hibernate, não é absolutamente necessário mapear explicitamente como hierarquia de heranças. Você pode simplesmente mapear cada classe com uma declaração <class> separada. Porém, se você deseja usar associações polimórficas (por exemplo: uma associação para a superclasse de sua hierarquia), você precisa usar o mapeamento <union-subclass>. Por exemplo:
<union-subclass
name="ClassName"
table="tablename"
proxy="ProxyInterface"
lazy="true|false"
dynamic-update="true|false"
dynamic-insert="true|false"
schema="schema"
catalog="catalog"
extends="SuperclassName"
abstract="true|false"
persister="ClassName"
subselect="SQL expression"
entity-name="EntityName"
node="element-name">
<property .... />
.....
</union-subclass
>
|
|
|
|
|
|
|
|
A coluna discriminatória não é requerida para esta estratégia de mapeamento.
For information about inheritance mappings see Capítulo 9, Mapeamento de Herança .
Usando o elemento <join>>, é possível mapear propriedades de uma classe para várias tabelas que possuem uma relação um por um. Por exemplo:
<join
table="tablename"
schema="owner"
catalog="catalog"
fetch="join|select"
inverse="true|false"
optional="true|false">
<key ... />
<property ... />
...
</join
>
|
|
|
|
|
|
|
|
|
|
|
|
Por exemplo, a informação de endereço para uma pessoa pode ser mapeada para uma tabela separada, enquanto preservando o valor da semântica de tipos para todas as propriedades:
<class name="Person"
table="PERSON">
<id name="id" column="PERSON_ID"
>...</id>
<join table="ADDRESS">
<key column="ADDRESS_ID"/>
<property name="address"/>
<property name="zip"/>
<property name="country"/>
</join>
...
Esta característica é útil apenas para modelos de dados legados. Nós recomendamos menos tabelas do que classes e um modelo de domínio fine-grained. Porém, é útil para ficar trocando entre estratégias de mapeamento de herança numa hierarquia simples, como explicaremos mais a frente.
Vimos que o elemento <key> (chave) surgiu algumas vezes até agora. Ele aparece em qualquer lugar que o elemento pai define uma junção para a nova tabela, e define a chave exterior para a tabela associada. Ele também referencia a chave primária da tabela original:
<key
column="columnname"
on-delete="noaction|cascade"
property-ref="propertyName"
not-null="true|false"
update="true|false"
unique="true|false"
/>
|
|
|
|
|
|
|
|
|
|
|
|
Nós recomendamos que para sistemas que o desempenho deletar seja importante, todas as chaves devem ser definidas on-delete="cascade". O Hibernate irá usar uma restrição a nível de banco de dados ON CASCADE DELETE, ao invés de muitas instruções DELETE. Esteja ciente que esta característica é um atalho da estratégia usual de bloqueio otimista do Hibernate para dados versionados.
As funções not-null e update são úteis quando estamos mapeando uma associação unidirecional um para muitos. Se você mapear uma associação unidirecional um para muitos para uma chave exterior não-nula, você deve declarar a coluna chave usando <key not-null="true">.
Qualquer elemento de mapeamento que aceita uma função column irá aceitar alternativamente um sub-elemento <column>. Da mesma forma, <formula> é uma alternativa para a função formula.
<column
name="column_name"
length="N"
precision="N"
scale="N"
not-null="true|false"
unique="true|false"
unique-key="multicolumn_unique_key_name"
index="index_name"
sql-type="sql_type_name"
check="SQL expression"
default="SQL expression"
read="SQL expression"
write="SQL expression"/>
<formula
>SQL expression</formula
>
A maioria das funções no column fornecem um significado de junção do DDL durante a geração automática do esquema. As funções read e write permitem que você especifique o SQL personalizado, do qual o Hibernate usará para acessar o valor da coluna. Consulte a discussão da column read and write expressions para maiores informações.
Os elementos column e formula podem até ser combinados dentro da mesma propriedade ou associação mapeando para expressar, por exemplo, condições de associações exóticas.
<many-to-one name="homeAddress" class="Address"
insert="false" update="false">
<column name="person_id" not-null="true" length="10"/>
<formula
>'MAILING'</formula>
</many-to-one
>
Vamos supor que a sua aplicação tenha duas classes persistentes com o mesmo nome, e você não quer especificar o nome qualificado do pacote nas consultas do Hibernate. As Classes deverão ser "importadas" explicitamente, de preferência contando com auto-import="true". Você pode até importar classes e interfaces que não estão explicitamente mapeadas:
<import class="java.lang.Object" rename="Universe"/>
<import
class="ClassName"
rename="ShortName"
/>
|
|
|
|
Existe mais um tipo de propriedade de mapeamento. O elemento de mapeamento <any> define uma associação polimórfica para classes de múltiplas tabelas. Este tipo de mapeamento sempre requer mais de uma coluna. A primeira coluna possui o tipo da entidade associada. A outra coluna restante possui o identificador. É impossível especificar uma restrição de chave exterior para este tipo de associação, portanto isto certamente não é visto como um caminho usual para associações (polimórficas) de mapeamento. Você deve usar este mapeamento apenas em casos muito especiais. Por exemplo: audit logs, dados de sessão do usuário, etc.
A função meta-type permite que a aplicação especifique um tipo adaptado que mapeia valores de colunas de banco de dados para classes persistentes que possuem propriedades identificadoras do tipo especificado através do id-type. Você deve especificar o mapeamento de valores do meta-type para nome de classes.
<any name="being" id-type="long" meta-type="string">
<meta-value value="TBL_ANIMAL" class="Animal"/>
<meta-value value="TBL_HUMAN" class="Human"/>
<meta-value value="TBL_ALIEN" class="Alien"/>
<column name="table_name"/>
<column name="id"/>
</any
>
<any
name="propertyName"
id-type="idtypename"
meta-type="metatypename"
cascade="cascade_style"
access="field|property|ClassName"
optimistic-lock="true|false"
>
<meta-value ... />
<meta-value ... />
.....
<column .... />
<column .... />
.....
</any
>
|
|
|
|
|
|
|
|
|
|
|
|
Os objetos de nível de linguagem Java são classificados em dois grupos, em relação ao serviço de persistência:
Uma entidade existe independentemente de qualquer outro objeto guardando referências para a entidade. Em contraste com o modelo usual de Java que um objeto não referenciado é coletado pelo coletor de lixo. Entidades devem ser explicitamente salvas ou deletadas (exceto em operações de salvamento ou deleção que possam ser executada em cascata de uma entidade pai para seus filhos). Isto é diferente do modelo ODMG de persistência do objeto por acessibilidade e se refere mais à forma como os objetos de aplicações são geralmente usados em grandes sistemas. Entidades suportam referências circulares e comuns. Eles podem ser versionados.
O estado persistente da entidade consiste de referências para outras entidades e instâncias de tipos de valor. Valores são primitivos: coleções (não o que tem dentro de uma coleção), componentes e certos objetos imutáveis. Entidades distintas, valores (em coleções e componentes particulares) são persistidos e apagados por acessibilidade. Visto que objetos de valor (e primitivos) são persistidos e apagados junto com as entidades que os contém e não podem ser versionados independentemente. Valores têm identidade não independente, assim eles não podem ser comuns para duas entidades ou coleções.
Até agora, estivemos usando o termo "classe persistente" para referir às entidades. Continuaremos a fazer isto. No entanto, nem todas as classes definidas pelo usuário com estados persistentes são entidades. Um componente é uma classe de usuário definida com valores semânticos. Uma propriedade de Java de tipo java.lang.String também tem um valor semântico. Dada esta definição, nós podemos dizer que todos os tipos (classes) fornecidos pelo JDK têm tipo de valor semântico em Java, enquanto que tipos definidos pelo usuário, podem ser mapeados com entidade ou valor de tipo semântico. Esta decisão pertence ao desenvolvedor da aplicação. Uma boa dica para uma classe de entidade em um modelo de domínio são referências comuns para uma instância simples daquela classe, enquanto a composição ou agregação geralmente se traduz para um tipo de valor.
Iremos rever ambos os conceitos durante todo o guia de referência.
O desafio é mapear o sistema de tipo de Java e a definição do desenvolvedor de entidades e tipos de valor para o sistema de tipo SQL/banco de dados. A ponte entre ambos os sistemas é fornecida pelo Hibernate. Para entidades que usam <class>, < subclass> e assim por diante. Para tipos de valores nós usamos <property>, <component>, etc, geralmente com uma função type. O valor desta função é o nome de um tipo de mapeamento do Hibernate. O Hibernate fornece muitos mapeamentos imediatos para tipos de valores do JDK padrão. Você pode escrever os seus próprios tipos de mapeamentos e implementar sua estratégia de conversão adaptada, como você.
Todos os tipos internos do hibernate exceto coleções, suportam semânticas nulas com a exceção das coleções.
Os tipos de mapeamento básicos fazem parte da categorização do seguinte:
integer, long, short, float, double, character, byte, boolean, yes_no, true_falseTipos de mapeamentos de classes primitivas ou wrapper Java específicos (vendor-specific) para tipos de coluna SQL. Boolean,
boolean, yes_nosão todas codificações alternativas para umbooleanoujava.lang.Booleando Java.stringUm tipo de mapeamento de
java.lang.StringparaVARCHAR(ouVARCHAR2no Oracle).date, time, timestampTipos de mapeamento de
java.util.Datee suas subclasses para os tipos SQLDATE,TIMEeTIMESTAMP(ou equivalente).calendar, calendar_dateTipo de mapeamento de
java.util.Calendarpara os tipos SQLTIMESTAMPeDATE(ou equivalente).big_decimal, big_integerTipo de mapeamento de
java.math.BigDecimalandjava.math.BigIntegerparaNUMERIC(ouNUMBERno Oracle).locale, timezone, currencyTipos de mapeamentos de
java.util.Locale,java.util.TimeZoneejava.util.CurrencyparaVARCHAR(ouVARCHAR2no Oracle). Instâncias de fLocaleeCurrencysão mapeados para seus códigos ISO. Instâncias deTimeZonesão mapeados para seuID.classUm tipo de mapeamento de
java.lang.ClassparaVARCHAR(ouVARCHAR2no Oracle). UmaClassé mapeada pelo seu nome qualificado (completo).binaryMapeia matrizes de bytes para um tipo binário de SQL apropriado.
textMapeia strings de Java longos para um tipo SQL
CLOBouTEXT.serializableMapeia tipos Java serializáveis para um tipo binário SQL apropriado. Você pode também indicar o tipo
serializabledo Hibernate com o nome da classe ou interface Java serializável que não é padrão para um tipo básico.clob, blobTipos de mapeamentos para as classes JDBC
java.sql.Clobandjava.sql.Blob. Estes tipos podem ser inconvenientes para algumas aplicações, visto que o objeto blob ou clob não pode ser reusado fora de uma transação. Além disso, o suporte de driver é imcompleto e inconsistente.-
imm_date, imm_time, imm_timestamp, imm_calendar, imm_calendar_date, imm_serializable, imm_binary Mapeamento de tipos para, os geralmente considerados, tipos mutáveis de Java. Isto é onde o Hibernate faz determinadas otimizações apropriadas somente para tipos imutáveis de Java, e a aplicação trata o objeto como imutável. Por exemplo, você não deve chamar
Date.setTime()para uma instância mapeada comoimm_timestamp. Para mudar o valor da propriedade, e ter a mudança feita persistente, a aplicação deve atribuir um novo objeto (nonidentical) à propriedade.
Identificadores únicos das entidades e coleções podem ser de qualquer tipo básico exceto binary, blob ou clob. (Identificadores compostos também são permitidos. Leia abaixo para maiores informações.
Os tipos de valores básicos têm suas constantes Type correspondentes definidas em org.hibernate.Hibernate. Por exemplo, Hibernate.STRING representa o tipo string.
É relativamente fácil para desenvolvedores criarem seus próprios tipos de valores. Por exemplo, você pode querer persistir propriedades do tipo java.lang.BigInteger para colunas VARCHAR. O Hibernate não fornece um tipo correspondente para isso. Mas os tipos adaptados não são limitados a mapeamento de uma propriedade, ou elemento de coleção, a uma única coluna da tabela. Assim, por exemplo, você pode ter uma propriedade Java getName()/setName() do tipo java.lang.String que é persistido para colunas FIRST_NAME, INITIAL, SURNAME.
Para implementar um tipo personalizado, implemente org.hibernate.UserType ou org.hibernate.CompositeUserType e declare propriedades usando o nome qualificado da classe do tipo. Veja org.hibernate.test.DoubleStringType para outras funcionalidades.
<property name="twoStrings" type="org.hibernate.test.DoubleStringType">
<column name="first_string"/>
<column name="second_string"/>
</property
>
Observe o uso da tag <column> para mapear uma propriedade para colunas múltiplas.
As interfaces CompositeUserType, EnhancedUserType, UserCollectionType, e UserVersionType fornecem suporte para usos mais especializados.
Você mesmo pode fornecer parâmetros a um UserType no arquivo de mapeamento. Para isto, seu UserType deve implementar a interface org.hibernate.usertype.ParameterizedType. Para fornecer parâmetros a seu tipo personalizado, você pode usar o elemento <type> em seus arquivos de mapeamento.
<property name="priority">
<type name="com.mycompany.usertypes.DefaultValueIntegerType">
<param name="default"
>0</param>
</type>
</property
>
O UserType pode agora recuperar o valor para o parâmetro chamado padrão da Propriedade do passado a ele.
Se você usar freqüentemente um determinado UserType, pode ser útil definir um nome mais curto para ele. Você pode fazer isto usando o elemento <typedef>. Typedefs atribui um nome a um tipo personalizado, e pode também conter uma lista de valores de parâmetro padrão se o tipo for parametrizado.
<typedef class="com.mycompany.usertypes.DefaultValueIntegerType" name="default_zero">
<param name="default"
>0</param>
</typedef
>
<property name="priority" type="default_zero"/>
Também é possível substituir os parâmetros fornecidos em um tipo de definição em situações de caso a caso, utilizando tipos de parâmetros no mapeamento da propriedade.
Apesar da rica variedade, os tipos construídos do Hibernate e suporte para componentes raramente irão utilizar um tipo de padrão, no entanto, é considerado uma boa idéia, utilizar tipos customizados para classes não entidade que ocorrem com freqüência em seu aplicativo. Por exemplo, uma classe MonetaryAmount é um bom candidato para um CompositeUserType, apesar de poder ter sido mapeado facilmente como um componente. Uma motivação para isto é a abstração. Com um tipo padronizado, seus documentos de mapeamento seriam colocados à prova contra mudanças possíveis na forma de representação de valores monetários.
É possível fornecer mais de um mapeamento para uma classe persistente em específico. Neste caso, você deve especificar um nome de entidade para as instâncias das duas entidades mapeadas não se tornarem ambíguas. Por padrão, o nome da entidade é o mesmo do nome da classe. O Hibernate o deixa especificar o nome de entidade quando estiver trabalhando com objetos persistentes, quando escrever consultas, ou ao mapear associações para a entidade nomeada.
<class name="Contract" table="Contracts"
entity-name="CurrentContract">
...
<set name="history" inverse="true"
order-by="effectiveEndDate desc">
<key column="currentContractId"/>
<one-to-many entity-name="HistoricalContract"/>
</set>
</class>
<class name="Contract" table="ContractHistory"
entity-name="HistoricalContract">
...
<many-to-one name="currentContract"
column="currentContractId"
entity-name="CurrentContract"/>
</class
>Note como as associações são agora especificadas utilizando o entity-name ao invés da class.
Você poderá forçar o Hibernate a quotar um identificador no SQL gerado, anexando o nome da tabela ou coluna aos backticks no documento de mapeamento. O Hibernate usará o estilo de quotação correto para o SQL Dialect. Geralmente são quotas dúplas, mas parênteses para o Servidor SQL e backticks para MeuSQL.
<class name="LineItem" table="`Line Item`">
<id name="id" column="`Item Id`"/><generator class="assigned"/></id>
<property name="itemNumber" column="`Item #`"/>
...
</class
>
O XML não é para todos, e portanto existem algumas formas alternativas de defiinir o metadado de mapeamento no Hibernate.
Muitos usuários do Hibernate preferem encubar a informação de mapeamento diretamente no código de fonte utilizando o XDoclet @hibernate.tags. Nós não falaremos sobre esta abordagem neste documento, uma vez que é estritamente considerado parte de um XDoclet. No entanto, incluímos os seguintes exemplos da classe Cat com os mapeamentos de XDoclet:
package eg;
import java.util.Set;
import java.util.Date;
/**
* @hibernate.class
* table="CATS"
*/
public class Cat {
private Long id; // identifier
private Date birthdate;
private Cat mother;
private Set kittens
private Color color;
private char sex;
private float weight;
/*
* @hibernate.id
* generator-class="native"
* column="CAT_ID"
*/
public Long getId() {
return id;
}
private void setId(Long id) {
this.id=id;
}
/**
* @hibernate.many-to-one
* column="PARENT_ID"
*/
public Cat getMother() {
return mother;
}
void setMother(Cat mother) {
this.mother = mother;
}
/**
* @hibernate.property
* column="BIRTH_DATE"
*/
public Date getBirthdate() {
return birthdate;
}
void setBirthdate(Date date) {
birthdate = date;
}
/**
* @hibernate.property
* column="WEIGHT"
*/
public float getWeight() {
return weight;
}
void setWeight(float weight) {
this.weight = weight;
}
/**
* @hibernate.property
* column="COLOR"
* not-null="true"
*/
public Color getColor() {
return color;
}
void setColor(Color color) {
this.color = color;
}
/**
* @hibernate.set
* inverse="true"
* order-by="BIRTH_DATE"
* @hibernate.collection-key
* column="PARENT_ID"
* @hibernate.collection-one-to-many
*/
public Set getKittens() {
return kittens;
}
void setKittens(Set kittens) {
this.kittens = kittens;
}
// addKitten not needed by Hibernate
public void addKitten(Cat kitten) {
kittens.add(kitten);
}
/**
* @hibernate.property
* column="SEX"
* not-null="true"
* update="false"
*/
public char getSex() {
return sex;
}
void setSex(char sex) {
this.sex=sex;
}
}
Veja o web site do Hibernate para maiores detalhes sobre um XDoclet e Hibernate.
O JDK 5.0 introduziu as anotações estilo XDoclet em nível de linguagem, tipo seguro e checado em tempo de compilação. Este mecanismo é mais potente do que as anotações XDoclet e melhor suportado pelas ferramentas e IDEs. O IntelliJ IDEA por exemplo, suporta a auto complexão e destaque da sintaxe das anotações JDK 5.0. A nova revisão da especificação EJB (JSR-220) usa as anotações JDK 5.0 como mecanismos de metadados para beans de entidade. O Hibernate3 implementa o EntityManager do JSR-220 (o API de persistência). O suporte para mapear metadados está disponível através do pacote Anotações do Hibernate, como um download separado. Ambos os EJB3 (JSR-220) e o metadado Hibernate3 são suportados.
Este é um exemplo de uma classe POJO anotado como um bean de entidade EJB:
@Entity(access = AccessType.FIELD)
public class Customer implements Serializable {
@Id;
Long id;
String firstName;
String lastName;
Date birthday;
@Transient
Integer age;
@Embedded
private Address homeAddress;
@OneToMany(cascade=CascadeType.ALL)
@JoinColumn(name="CUSTOMER_ID")
Set<Order
> orders;
// Getter/setter and business methods
}
Nota
Note que o suporte para Anotações JDK 5.0 (e JSR-220) ainda está em construção. Consulte o módulo de Anotações do Hibernate para maiores detalhes.
Propriedades Geradas são propriedades que possuem seus valores gerados pelo banco de dados. Como sempre, os aplicativos do Hibernate precisavam renovar objetos que contenham qualquer propriedade para qual o banco de dados estivesse gerando valores. No entanto, vamos permitir que o aplicativo delegue esta responsabilidade ao Hibernate. Essencialmente, quando o Hibernate edita um SQL INSERT ou UPDATE para uma entidade que tem propriedades geradas definidas, ele edita imediatamente depois uma seleção para recuperar os valores gerados.
As propriedades marcadas como geradas devem ser não-inseríveis e não-atualizáveis. Somente versions, timestamps, e simple properties podem ser marcadas como geradas.
never (padrão) - significa que o valor de propriedade dado não é gerado dentro do banco de dados.
insert: informa que o valor de propriedade dado é gerado ao inserir, mas não é novamente gerado nas próximas atualizações. Propriedades do tipo data criada, se encaixam nesta categoria. Note que embora as propriedades version e timestamp podem ser marcadas como geradas, esta opção não está disponível.
always - informa que o valor da propriedade é gerado tanto ao inserir quanto ao atualizar.
Hibernate allows you to customize the SQL it uses to read and write the values of columns mapped to simple properties. For example, if your database provides a set of data encryption functions, you can invoke them for individual columns like this:
<!-- XML : generated by JHighlight v1.0 (http://jhighlight.dev.java.net) --> <span class="xml_tag_symbols"><</span><span class="xml_tag_name">property</span><span class="xml_plain"> </span><span class="xml_attribute_name">name</span><span class="xml_tag_symbols">=</span><span class="xml_attribute_value">"creditCardNumber"</span><span class="xml_tag_symbols">></span><span class="xml_plain"></span><br /> <span class="xml_plain"> </span><span class="xml_tag_symbols"><</span><span class="xml_tag_name">column</span><span class="xml_plain"> </span><br /> <span class="xml_plain"> </span><span class="xml_attribute_name">name</span><span class="xml_tag_symbols">=</span><span class="xml_attribute_value">"credit_card_num"</span><span class="xml_plain"></span><br /> <span class="xml_plain"> </span><span class="xml_attribute_name">read</span><span class="xml_tag_symbols">=</span><span class="xml_attribute_value">"decrypt(credit_card_num)"</span><span class="xml_plain"></span><br /> <span class="xml_plain"> </span><span class="xml_attribute_name">write</span><span class="xml_tag_symbols">=</span><span class="xml_attribute_value">"encrypt(?)"</span><span class="xml_tag_symbols">/></span><span class="xml_plain"></span><br /> <span class="xml_tag_symbols"></</span><span class="xml_tag_name">property</span><span class="xml_plain"></span><br /> <span class="xml_tag_symbols">></span><span class="xml_plain"></span><br />
O Hibernate aplica automaticamente as expressöes personalizadas a todo instante que a propriedade é referenciada numa consulta. Esta funcionalidade é parecida a uma formula de propriedade-derivada com duas diferenças:
Esta propriedade é suportada por uma ou mais colunas que são exportadas como parte da geração do esquema automático.
Esta propriedade é de gravação-leitura, e não de leitura apenas.
Caso a expressão writeseja especificada, deverá conter um '?' para o valor.
Permite o uso dos comandos CREATE e DROP para criar e remover os objetos de banco de dados arbitrários. Juntamente às ferramentas de evolução do esquema do Hibernate, eles possuem a habilidade de definir completamente um esquema de usuário dentro dos arquivos de mapeamento do Hibernate. Embora criado especificamente para criar e remover algo como trigger ou procedimento armazenado, qualquer comando SQL que pode rodar através de um método java.sql.Statement.execute() é válido. Existem dois módulos essenciais para definir objetos de banco de dados auxiliares:
O primeiro módulo é para listar explicitamente os comandos CREATE e DROP no arquivo de mapeamento:
<hibernate-mapping>
...
<database-object>
<create
>CREATE TRIGGER my_trigger ...</create>
<drop
>DROP TRIGGER my_trigger</drop>
</database-object>
</hibernate-mapping
>
O segundo módulo é para fornecer uma classe padrão que sabe como construir os comandos CREATE e DROP. Esta classe padrão deve implementar a interface org.hibernate.mapping.AuxiliaryDatabaseObject.
<hibernate-mapping>
...
<database-object>
<definition class="MyTriggerDefinition"/>
</database-object>
</hibernate-mapping
>
Além disso, estes objetos de banco de dados podem ter um escopo opcional que só será aplicado quando certos dialetos forem utilizados.
<hibernate-mapping>
...
<database-object>
<definition class="MyTriggerDefinition"/>
<dialect-scope name="org.hibernate.dialect.Oracle9iDialect"/>
<dialect-scope name="org.hibernate.dialect.Oracle10gDialect"/>
</database-object>
</hibernate-mapping
>