JBoss Cache can use a
CacheLoader
to back up the in-memory cache to a backend datastore.
If JBoss Cache is configured with a cache loader, then the following features are provided:
- Whenever a cache element is accessed, and that element is not in the cache (e.g. due to eviction or due to server restart), then the cache loader transparently loads the element into the cache if found in the backend store.
- Whenever an element is modified, added or removed, then that
modification is persisted in the backend store via the cache loader. If
transactions are used, all modifications created within a transaction
are persisted. To this end, the
CacheLoadertakes part in the two phase commit protocol run by the transaction manager, although it does not do so explicitly.

The interaction between JBoss Cache and a
CacheLoader
implementation is as follows. When
CacheLoaderConfiguration
(see below) is non-null, an
instance of each configured
CacheLoader
is created when the cache is created, and started when the cache is started.
CacheLoader.create()
and
CacheLoader.start()
are called when the cache is
started. Correspondingly,
stop()
and
destroy()
are called when the cache is
stopped.
Next,
setConfig()
and
setCache()
are called. The latter can be used to
store a reference to the cache, the former is used to configure this
instance of the
CacheLoader
. For example, here a database cache loader
could establish a connection to the database.
The
CacheLoader
interface has a set of methods that are called
when no transactions are used:
get()
,
put()
,
remove()
and
removeData()
: they get/set/remove the value
immediately. These methods are described as javadoc comments in the
interface.
Then there are three methods that are used with transactions:
prepare()
,
commit()
and
rollback()
. The
prepare()
method
is called when a transaction is to be committed. It has a transaction
object and a list of modfications as argument. The transaction object
can be used as a key into a hashmap of transactions, where the values
are the lists of modifications. Each modification list has a number of
Modification
elements, which represent the changes
made to a cache for a given transaction. When
prepare()
returns successfully, then the cache loader
must
be able to commit (or rollback) the
transaction successfully.
JBoss Cache takes care of calling prepare(), commit() and rollback() on the cache loaders at the right time.
The
commit()
method tells the cache loader to
commit the transaction, and the
rollback()
method
tells the cache loader to discard the changes associated with that
transaction.
See the javadocs on this interface for a detailed explanation on each method and the contract implementations would need to fulfill.
Cache loaders are configured as follows in the JBoss Cache XML
file. Note that you can define several cache loaders, in
a chain. The impact is that the cache will look at all of the cache
loaders in the order they've been configured, until it finds a valid,
non-null element of data. When performing writes, all cache loaders are
written to (except if the
ignoreModifications
element has been set to
true
for a specific cache loader. See the configuration section below for
details.
...
<!-- Cache loader config block -->
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loaders passivation="false" shared="false">
<preload>
<!-- Fqns to preload -->
<node fqn="/some/stuff"/>
</preload>
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loader class="org.jboss.cache.loader.JDBCCacheLoader" async="false" fetchPersistentState="true"
ignoreModifications="false" purgeOnStartup="false">
<properties>
cache.jdbc.driver=com.mysql.jdbc.Driver
cache.jdbc.url=jdbc:mysql://localhost:3306/jbossdb
cache.jdbc.user=root
cache.jdbc.password=
</properties>
</loader>
</loaders>
The
class
element defines the
class of the cache loader implementation. (Note that, because of a bug in
the properties editor in JBoss AS, backslashes in variables for Windows
filenames might not get expanded correctly, so replace="false" may be
necessary). Note that an implementation of cache loader has to have an empty
constructor.
The
properties
element defines a configuration
specific to the given implementation. The filesystem-based
implementation for example defines the root directory to be used,
whereas a database implementation might define the database URL, name
and password to establish a database connection. This configuration is
passed to the cache loader implementation via
CacheLoader.setConfig(Properties)
. Note that
backspaces may have to be escaped.
preload
allows us to define a list of nodes, or
even entire subtrees, that are visited by the cache on startup, in order
to preload the data associated with those nodes. The default ("/") loads
the entire data available in the backend store into the cache, which is
probably not a good idea given that the data in the backend store might
be large. As an example,
/a,
/product/catalogue
loads the subtrees
/a
and
/product/catalogue
into the cache, but nothing
else. Anything else is loaded lazily when accessed. Preloading makes
sense when one anticipates using elements under a given subtree
frequently.
.
fetchPersistentState
determines whether or not
to fetch the persistent state of a cache when joining a cluster. Only
one configured cache loader may set this property to true; if more than
one cache loader does so, a configuration exception will be thrown when
starting your cache service.
async
determines whether writes to the cache
loader block until completed, or are run on a separate thread so writes
return immediately. If this is set to true, an instance of
org.jboss.cache.loader.AsyncCacheLoader
is
constructed with an instance of the actual cache loader to be used. The
AsyncCacheLoader
then delegates all requests to the
underlying cache loader, using a separate thread if necessary. See the
Javadocs on
AsyncCacheLoader
for more details. If unspecified, the
async
element
defaults to
false
.
Note on using the
async
element:
there is always the possibility of dirty reads since
all writes are performed asynchronously, and it is thus impossible to
guarantee when (and even if) a write succeeds. This needs to be kept in
mind when setting the
async
element to true.
ignoreModifications
determines whether write
methods are pushed down to the specific cache loader. Situations may
arise where transient application data should only reside in a file
based cache loader on the same server as the in-memory cache, for
example, with a further shared
JDBCCacheLoader
used by all servers in
the network. This feature allows you to write to the 'local' file cache
loader but not the shared
JDBCCacheLoader
. This property defaults to
false
, so writes are propagated to all cache loaders
configured.
purgeOnStatup
empties the specified cache loader
(if
ignoreModifications
is
false
)
when the cache loader starts up.
shared
indicates that the cache loader is shared among different cache instances, for example where all instances
in a
cluster use the same JDBC settings t talk to the same remote, shared database. Setting this to
true
prevents repeated and unnecessary writes of the same data to the cache loader by different cache instances.
Default value is
false
.
<loaders passivation="false" shared="true">
<preload>
<node fqn="/a/b/c"/>
<node fqn="/f/r/s"/>
</preload>
<!-- we can now have multiple cache loaders, which get chained -->
<loader class="org.jboss.cache.loader.JDBCCacheLoader" async="false" fetchPersistentState="false"
ignoreModifications="false" purgeOnStartup="false">
<properties>
cache.jdbc.datasource=java:/DefaultDS
</properties>
<singletonStore enabled="true" class="org.jboss.cache.loader.SingletonStoreCacheLoader">
<properties>
pushStateWhenCoordinator=true
pushStateWhenCoordinatorTimeout=20000
</properties>
</singletonStore>
</loader>
</loaders>
singletonStore
element enables modifications to be stored by only one node in the cluster,
the coordinator. Essentially, whenever any data comes in to some node
it is always replicated so as to keep the caches' in-memory states in
sync; the coordinator, though, has the sole responsibility of pushing
that state to disk. This functionality can be activated setting the
enabled
subelement to true in all nodes, but
again only the coordinator of the cluster will store the modifications
in the underlying cache loader as defined in
loader
element. You cannot define a cache loader as
shared
and with
singletonStore
enabled at the same time.
Default value for
enabled
is
false
.
Optionally, within the
singletonStore
element, you can define a
class
element that specifies the implementation class that provides the
singleton store functionality. This class must extend
org.jboss.cache.loader.AbstractDelegatingCacheLoader
, and if absent, it defaults to
org.jboss.cache.loader.SingletonStoreCacheLoader
.
The
properties
subelement defines properties that allow changing the behavior of the
class providing the singleton store functionality. By default,
pushStateWhenCoordinator
and
pushStateWhenCoordinatorTimeout
properties have been defined, but more could be added as
required by the user-defined class providing singleton store
functionality.
pushStateWhenCoordinator
allows the in-memory
state to be pushed to the cache store when a node becomes the
coordinator, as a result of the new election of coordinator due to a
cluster topology change. This can be very useful in situations where the
coordinator crashes and there's a gap in time until the new coordinator
is elected. During this time, if this property was set to
false
and the
cache was updated, these changes would never be persisted. Setting this
property to
true
would ensure that any changes during this process also
get stored in the cache loader. You would also want to set this property
to
true
if each node's cache loader is configured with a different
location. Default value is
true
.
pushStateWhenCoordinatorTimeout
is only relevant if
pushStateWhenCoordinator
is
true
in which case, sets the maximum number of milliseconds that the process
of pushing the in-memory state to the underlying cache loader should take,
reporting a
PushStateException
if exceeded. Default value is 20000.
Note on using the
singletonStore
element:
setting
up a cache loader as a singleton and using cache passivation (via
evictions) can lead to undesired effects. If a node is to be passivated
as a result of an eviction, while the cluster is in the process of
electing a new coordinator, the data will be lost. This is because no
coordinator is active at that time and therefore, none of the nodes in
the cluster will store the passivated node. A new coordinator is elected
in the cluster when either, the coordinator leaves the cluster, the
coordinator crashes or stops responding.
The currently available implementations shipped with JBoss Cache are as follows.
JBoss Cache ships with several cache loaders that utilize the file system as a data store. They all
require
that the
<loader><properties>
configuration element
contains a
location
property, which maps to a directory to be used as a persistent store.
(e.g.,
location=/tmp/myDataStore
). Used mainly for testing and not recommended for production use.
FileCacheLoader, which is a simple filesystem-based implementation. By default, this cache loader checks for any potential character portability issues in the location or tree node names, for example invalid characters, producing warning messages. These checks can be disabled addingcheck.character.portabilityproperty to the<properties>element and setting it tofalse(e.g.,check.character.portability=false).The FileCacheLoader has some severe limitations which restrict its use in a production environment, or if used in such an environment, it should be used with due care and sufficient understanding of these limitations.
- Due to the way the FileCacheLoader represents a tree structure on disk (directories and files) traversal is inefficient for deep trees.
- Usage on shared filesystems like NFS, Windows shares, etc. should be avoided as these do not implement proper file locking and can cause data corruption.
- Usage with an isolation level of NONE can cause corrupt writes as multiple threads attempt to write to the same file.
- File systems are inherently not transactional, so when attempting to use your cache in a transactional context, failures when writing to the file (which happens during the commit phase) cannot be recovered.
As a rule of thumb, it is recommended that the FileCacheLoader not be used in a highly concurrent, transactional or stressful environment, and its use is restricted to testing.
BdbjeCacheLoader, which is a cache loader implementation based on the Oracle/Sleepycat's BerkeleyDB Java Edition .JdbmCacheLoader, which is a cache loader implementation based on the JDBM engine , a fast and free alternative to BerkeleyDB.
Note that the BerkeleyDB implementation is much more efficient than the filesystem-based implementation, and provides transactional guarantees, but requires a commercial license if distributed with an application (see http://www.oracle.com/database/berkeley-db/index.html for details).
LocalDelegatingCacheLoader, which enables loading from and storing to another local (same JVM) cache.ClusteredCacheLoader, which allows querying of other caches in the same cluster for in-memory data via the same clustering protocols used to replicate data. Writes are not 'stored' though, as replication would take care of any updates needed. You need to specify a property calledtimeout, a long value telling the cache loader how many milliseconds to wait for responses from the cluster before assuming a null value. For example,timeout = 3000would use a timeout value of 3 seconds.
JBossCache is distributed with a JDBC-based cache loader
implementation that stores/loads nodes' state into a relational database.
The implementing class is
org.jboss.cache.loader.JDBCCacheLoader
.
The current implementation uses just one table. Each row in the table represents one node and contains three columns:
- column for
Fqn(which is also a primary key column) - column for node contents (attribute/value pairs)
- column for parent
Fqn
Fqns are stored as strings. Node content is stored
as a BLOB.
WARNING:
JBoss Cache does not impose any
limitations on the types of objects used in
Fqn
but this implementation of
cache loader requires
Fqn
to contain only objects of type
java.lang.String
. Another limitation for
Fqn
is its
length. Since
Fqn
is a primary key, its default column type is
VARCHAR
which can store text values up to some
maximum length determined by the database in use.
See this wiki page for configuration tips with specific database systems.
Table and column names as well as column types are configurable with the following properties.
- cache.jdbc.table.name
- the name
of the table. Can be prepended with schema name for the given table:
{schema_name}.{table_name}. The default value is 'jbosscache'. - cache.jdbc.table.primarykey - the name of the primary key for the table. The default value is 'jbosscache_pk'.
- cache.jdbc.table.create - can be true or false. Indicates whether to create the table during startup. If true, the table is created if it doesn't already exist. The default value is true.
- cache.jdbc.table.drop - can be true or false. Indicates whether to drop the table during shutdown. The default value is true.
- cache.jdbc.fqn.column - FQN column name. The default value is 'fqn'.
- cache.jdbc.fqn.type - FQN column type. The default value is 'varchar(255)'.
- cache.jdbc.node.column - node contents column name. The default value is 'node'.
- cache.jdbc.node.type - node contents column type. The default value is 'blob'. This type must specify a valid binary data type for the database being used.
If you are using JBossCache in a managed environment (e.g., an application server) you can specify the JNDI name of the DataSource you want to use.
- cache.jdbc.datasource
- JNDI name
of the DataSource. The default value is
java:/DefaultDS.
If you are not using DataSource you have the following properties to configure database access using a JDBC driver.
- cache.jdbc.driver - fully qualified JDBC driver name.
- cache.jdbc.url - URL to connect to the database.
- cache.jdbc.user - user name to connect to the database.
- cache.jdbc.password - password to connect to the database.
JBoss Cache implements JDBC connection pooling when running outside of an application server standalone using the c3p0:JDBC DataSources/Resource Pools library. In order to enable it, just edit the following property:
- cache.jdbc.connection.factory - Connection factory class name. If not set, it defaults to standard non-pooled implementation. To enable c3p0 pooling, just set the connection factory class for c3p0. See example below.
You can also set any c3p0 parameters in the same cache loader properties section but don't
forget
to
start the property name with 'c3p0.'. To find a list of available properties, please check the
c3p0 documentation for the c3p0 library version distributed in
c3p0:JDBC DataSources/Resource Pools
.
Also, in order to provide quick and easy way to try out different pooling
parameters, any of these properties can be set via a System property overriding any values these
properties might have in the JBoss Cache XML configuration file, for example:
-Dc3p0.maxPoolSize=20
.
If a c3p0 property is not defined in either the configuration file or as a System property,
default
value, as indicated in the c3p0 documentation, will apply.
Below is an example of a JDBCCacheLoader using Oracle as database. The CacheLoaderConfiguration XML element contains an arbitrary set of properties which define the database-related configuration.
<loaders passivation="false" shared="false">
<preload>
<node fqn="/some/stuff"/>
</preload>
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loader class="org.jboss.cache.loader.JDBCCacheLoader" async="false" fetchPersistentState="true"
ignoreModifications="false" purgeOnStartup="false">
<properties>
cache.jdbc.table.name=jbosscache
cache.jdbc.table.create=true
cache.jdbc.table.drop=true
cache.jdbc.table.primarykey=jbosscache_pk
cache.jdbc.fqn.column=fqn
cache.jdbc.fqn.type=VARCHAR(255)
cache.jdbc.node.column=node
cache.jdbc.node.type=BLOB
cache.jdbc.parent.column=parent
cache.jdbc.driver=oracle.jdbc.OracleDriver
cache.jdbc.url=jdbc:oracle:thin:@localhost:1521:JBOSSDB
cache.jdbc.user=SCOTT
cache.jdbc.password=TIGER
</properties>
</loader>
</loaders>
As an alternative to configuring the entire JDBC connection, the name of an existing data source can be given:
<loaders passivation="false" shared="false">
<preload>
<node fqn="/some/stuff"/>
</preload>
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loader class="org.jboss.cache.loader.JDBCCacheLoader" async="false" fetchPersistentState="true"
ignoreModifications="false" purgeOnStartup="false">
<properties>
cache.jdbc.datasource=java:/DefaultDS
</properties>
</loader>
</loaders>
Cconfiguration example for a cache loader using c3p0 JDBC connection pooling:
<loaders passivation="false" shared="false">
<preload>
<node fqn="/some/stuff"/>
</preload>
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loader class="org.jboss.cache.loader.JDBCCacheLoader" async="false" fetchPersistentState="true"
ignoreModifications="false" purgeOnStartup="false">
<properties>
cache.jdbc.table.name=jbosscache
cache.jdbc.table.create=true
cache.jdbc.table.drop=true
cache.jdbc.table.primarykey=jbosscache_pk
cache.jdbc.fqn.column=fqn
cache.jdbc.fqn.type=VARCHAR(255)
cache.jdbc.node.column=node
cache.jdbc.node.type=BLOB
cache.jdbc.parent.column=parent
cache.jdbc.driver=oracle.jdbc.OracleDriver
cache.jdbc.url=jdbc:oracle:thin:@localhost:1521:JBOSSDB
cache.jdbc.user=SCOTT
cache.jdbc.password=TIGER
cache.jdbc.connection.factory=org.jboss.cache.loader.C3p0ConnectionFactory
c3p0.maxPoolSize=20
c3p0.checkoutTimeout=5000
</properties>
</loader>
</loaders>
The
S3CacheLoader
uses the
Amazon S3
(Simple Storage Solution)
for storing cache data.
Since Amazon S3 is remote network storage and has fairly high latency,
it is really best for caches that store large pieces of data, such as media
or files.
But consider this cache loader over the JDBC or
file system based cache loaders if you want remotely managed, highly reliable
storage. Or, use it for applications running on Amazon's EC2 (Elastic Compute Cloud).
If you're planning to use Amazon S3 for storage, consider using it with JBoss Cache. JBoss Cache itself provides in-memory caching for your data to minimize the amount of remote access calls, thus reducing the latency and cost of fetching your Amazon S3 data. With cache replication, you are also able to load data from your local cluster without having to remotely access it every time.
Note that Amazon S3 does not support transactions. If transactions are used in your application then there is some possibility of state inconsistency when using this cache loader. However, writes are atomic, in that if a write fails nothing is considered written and data is never corrupted.
Data is stored in keys based on the Fqn of the Node and Node data is
serialized as a java.util.Map using the
CacheSPI.getMarshaller()
instance.
Read the javadoc on how data is structured and stored.
Data is stored using Java serialization.
Be aware this means data is not readily accessible over HTTP to
non-JBoss Cache clients. Your feedback and help would be appreciated
to extend this cache loader for that purpose.
With this cache loader, single-key operations such as
Node.remove(Object)
and
Node.put(Object, Object)
are the slowest as data is stored in a single Map instance.
Use bulk operations such as
Node.replaceAll(Map)
and
Node.clearData()
for more efficiency.
Try the
cache.s3.optimize
option as well.
The S3 cache loader is provided with the default distribution but requires a library to access the service at runtime. This runtime library may be obtained through a Sourceforge Maven Repository. Include the following sections in your pom.xml file:
If you do not use Maven, you can still download the amazon-s3 library by navigating the repository or through this URL.
<repository>
<id>e-xml.sourceforge.net</id>
<url>http://e-xml.sourceforge.net/maven2/repository</url>
</repository>
...
<dependency>
<groupId>net.noderunner</groupId>
<artifactId>amazon-s3</artifactId>
<version>1.0.0.0</version>
<scope>runtime</scope>
</dependency>
At a minimum, you must configure your Amazon S3 access key and secret access key. The following configuration keys are listed in general order of utility.
cache.s3.accessKeyId- Amazon S3 Access Key, available from your account profile.cache.s3.secretAccessKey- Amazon S3 Secret Access Key, available from your account profile. As this is a password, be careful not to distribute it or include this secret key in built software.cache.s3.secure- The default isfalse: Traffic is sent unencrypted over the public Internet. Set totrueto use HTTPS. Note that unencrypted uploads and downloads use less CPU.cache.s3.bucket- Name of the bucket to store data. For different caches using the same access key, use a different bucket name. Read the S3 documentation on the definition of a bucket. The default value isjboss-cache.cache.s3.callingFormat- One ofPATH,SUBDOMAIN, orVANITY. Read the S3 documentation on the use of calling domains. The default value isSUBDOMAIN.cache.s3.optimize- The default isfalse. If true,put(Map)operations replace the data stored at an Fqn rather than attempt to fetch and merge. (This option is fairly experimental at the moment.)cache.s3.parentCache- The default istrue. Set this value tofalseif you are using multiple caches sharing the same S3 bucket, that remove parent nodes of nodes being created in other caches. (This is not a common use case.)JBoss Cache stores nodes in a tree format and automatically creates intermediate parent nodes as necessary. The S3 cache loader must also create these parent nodes as well to allow for operations such as
getChildrenNamesto work properly. Checking if all parent nodes exists for everyputoperation is fairly expensive, so by default the cache loader caches the existence of these parent nodes.cache.s3.location- This choses a primary storage location for your data to reduce loading and retrieval latency. Set toEUto store data in Europe. The default isnull, to store data in the United States.
This cache loader allows to delegate loads and stores to another instance of JBoss Cache, which could reside (a) in the same address space, (b) in a different process on the same host, or (c) in a different process on a different host.
A TcpDelegatingCacheLoader talks to a remote
org.jboss.cache.loader.tcp.TcpCacheServer
,
which can be a standalone process started on the command line, or embedded as an MBean inside
JBoss AS. The
TcpCacheServer
has a reference to another JBoss Cache instance, which
it can create itself, or which is given to it (e.g. by JBoss, using
dependency injection).
As of JBoss Cache 2.1.0, the
TcpDelegatingCacheLoader
transparently handles reconnects if the connection
to the TcpCacheServer is lost.
The TcpDelegatingCacheLoader is configured with the host and port of the remote TcpCacheServer, and
uses
this to communicate to
it. In addition, 2 new optional parameters are used to control transparent reconnecting to the
TcpCacheServer.
The
timeout
property (defaults to 5000) specifies the length of time the cache loader must continue
retrying to connect to the TcpCacheServer before giving up and throwing an exception. The
reconnectWaitTime
(defaults to 500) is how long the cache loader should wait before attempting a reconnect if it detects a
communication failure.
The last two parameters can be used to add a level of fault tolerance to the cache loader, do deal with
TcpCacheServer restarts.
The configuration looks as follows:
<loaders passivation="false" shared="false">
<preload>
<node fqn="/"/>
</preload>
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loader class="org.jboss.cache.loader.TcpDelegatingCacheLoader">
<properties>
host=myRemoteServer
port=7500
timeout=10000
reconnectWaitTime=250
</properties>
</loader>
</loaders>
This means this instance of JBoss Cache will delegate all load
and store requests to the remote TcpCacheServer running on
myRemoteServer:7500
.
A typical use case could be multiple replicated instances of JBoss Cache in the same cluster, all delegating to the same TcpCacheServer instance. The TcpCacheServer might itself delegate to a database via JDBCCacheLoader, but the point here is that - if we have 5 nodes all accessing the same dataset - they will load the data from the TcpCacheServer, which has do execute one SQL statement per unloaded data set. If the nodes went directly to the database, then we'd have the same SQL executed multiple times. So TcpCacheServer serves as a natural cache in front of the DB (assuming that a network round trip is faster than a DB access (which usually also include a network round trip)).
To alleviate single point of failure, we could configure several cache loaders. The first cache loader is a ClusteredCacheLoader, the second a TcpDelegatingCacheLoader, and the last a JDBCacheLoader, effectively defining our cost of access to a cache in increasing order.
The way cached data is written to
FileCacheLoader
and
JDBCCacheLoader
based cache stores has changed in JBoss Cache 2.0 in such way that
these cache loaders now write and read data using the same marhalling framework used to replicate data
across the network. Such change is trivial for replication purposes as it just requires the rest of the
nodes to understand this format. However, changing the format of the data in cache stores brings up a
new
problem: how do users, which have their data stored in JBoss Cache 1.x.x format, migrate their stores to
JBoss Cache 2.0 format?
With this in mind, JBoss Cache 2.0 comes with two cache loader implementations called
org.jboss.cache.loader.TransformingFileCacheLoader
and
org.jboss.cache.loader.TransformingJDBCCacheLoader
located within the optional
jbosscache-cacheloader-migration.jar file. These are one-off cache loaders that read data from the
cache store in JBoss Cache 1.x.x format and write data to cache stores in JBoss Cache 2.0 format.
The idea is for users to modify their existing cache configuration file(s) momentarily to use these
cache loaders and for them to create a small Java application that creates an instance of this cache,
recursively reads the entire cache and writes the data read back into the cache. Once the data is
transformed, users can revert back to their original cache configuration file(s). In order to help the
users
with this task, a cache loader migration example has been constructed which can be located under the
examples/cacheloader-migration
directory within the JBoss Cache distribution. This
example, called
examples.TransformStore
, is independent of the actual data stored in
the cache as it writes back whatever it was read recursively. It is highly recommended that anyone
interested in porting their data run this example first, which contains a
readme.txt
file with detailed information about the example itself, and also use it as base for their own
application.
A cache loader can be used to enforce node passivation and activation on eviction in a cache.
Cache Passivation is the process of removing an object from in-memory cache and writing it to a secondary data store (e.g., file system, database) on eviction. Cache Activation is the process of restoring an object from the data store into the in-memory cache when it's needed to be used. In both cases, the configured cache loader will be used to read from the data store and write to the data store.
When an eviction policy in effect evicts a node from the cache, if passivation is enabled, a notification that the node is being passivated will be emitted to the cache listeners and the node and its children will be stored in the cache loader store. When a user attempts to retrieve a node that was evicted earlier, the node is loaded (lazy loaded) from the cache loader store into memory. When the node and its children have been loaded, they're removed from the cache loader and a notification is emitted to the cache listeners that the node has been activated.
To enable cache passivation/activation, you can set
passivation
to true. The default is
false
.
When passivation is used, only the first cache loader configured is
used and all others are ignored.
When passivation is disabled, whenever an element is modified, added or removed, then that modification is persisted in the backend store via the cache loader. There is no direct relationship between eviction and cache loading. If you don't use eviction, what's in the persistent store is basically a copy of what's in memory. If you do use eviction, what's in the persistent store is basically a superset of what's in memory (i.e. it includes nodes that have been evicted from memory).
When passivation is enabled, there is a direct relationship between eviction and the cache loader. Writes to the persistent store via the cache loader only occur as part of the eviction process. Data is deleted from the persistent store when the application reads it back into memory. In this case, what's in memory and what's in the persistent store are two subsets of the total information set, with no intersection between the subsets.
Following is a simple example, showing what state is in RAM and in the persistent store after each step of a 6 step process:
- Insert /A
- Insert /B
- Eviction thread runs, evicts /A
- Read /A
- Eviction thread runs, evicts /B
- Remove /B
When passivation is disabled:
1) Memory: /A Disk: /A
2) Memory: /A, /B Disk: /A, /B
3) Memory: /B Disk: /A, /B
4) Memory: /A, /B Disk: /A, /B
5) Memory: /A Disk: /A, /B
6) Memory: /A Disk: /A
When passivation is enabled:
1) Memory: /A Disk:
2) Memory: /A, /B Disk:
3) Memory: /B Disk: /A
4) Memory: /A, /B Disk:
5) Memory: /A Disk: /B
6) Memory: /A Disk:
This section discusses different patterns of combining different cache loader types and configuration options to achieve specific outcomes.
This is the simplest case. We have a JBoss Cache instance, whose
cache mode is
LOCAL
, therefore no replication is going
on. The cache loader simply loads non-existing elements from the store
and stores modifications back to the store. When the cache is started,
depending on the
preload
element, certain data can
be preloaded, so that the cache is partly warmed up.
The following figure shows 2 JBoss Cache instances sharing the same backend store:
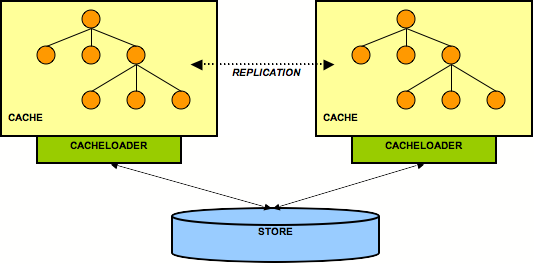
Both nodes have a cache loader that accesses a common shared
backend store. This could for example be a shared filesystem (using
the FileCacheLoader), or a shared database. Because both nodes access
the same store, they don't necessarily need state transfer on
startup.
[3]
Rather, the
FetchInMemoryState
attribute could be set to false, resulting in a 'cold' cache, that
gradually warms up as elements are accessed and loaded for the first
time. This would mean that individual caches in a cluster might have
different in-memory state at any given time (largely depending on
their preloading and eviction strategies).
When storing a value, the writer takes care of storing the change in the backend store. For example, if node1 made change C1 and node2 C2, then node1 would tell its cache loader to store C1, and node2 would tell its cache loader to store C2.
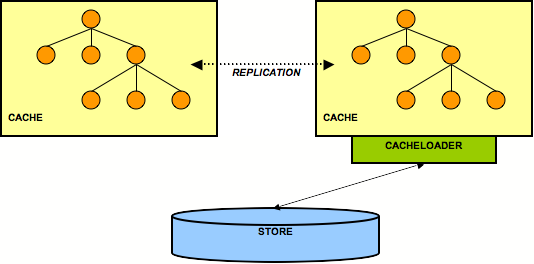
This is a similar case to the previous one, but here only one node in the cluster interacts with a backend store via its cache loader. All other nodes perform in-memory replication. The idea here is all application state is kept in memory in each node, with the existence of multiple caches making the data highly available. (This assumes that a client that needs the data is able to somehow fail over from one cache to another.) The single persistent backend store then provides a backup copy of the data in case all caches in the cluster fail or need to be restarted.
Note that here it may make sense for the cache loader to store changes asynchronously, that is not on the caller's thread, in order not to slow down the cluster by accessing (for example) a database. This is a non-issue when using asynchronous replication.
A weakness with this architecture is that the cache with access
to the cache loader becomes a single point of failure. Furthermore,
if the cluster is restarted, the cache with the cache loader must
be started first (easy to forget). A solution to the first problem
is to configure a cache loader on each node, but set the
singletonStore
configuration to
true. With this kind of setup, one but only one
node will always be writing to a persistent store. However, this
complicates the restart problem, as before restarting you need
to determine which cache was writing before the shutdown/failure
and then start that cache first.
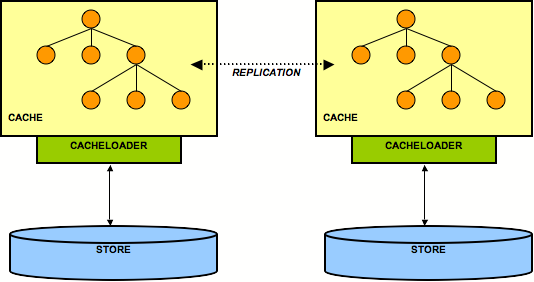
Here, each node has its own datastore. Modifications to the cache are (a) replicated across the cluster and (b) persisted using the cache loader. This means that all datastores have exactly the same state. When replicating changes synchronously and in a transaction, the two phase commit protocol takes care that all modifications are replicated and persisted in each datastore, or none is replicated and persisted (atomic updates).
Note that JBoss Cache is not an XA Resource, that means it doesn't implement recovery. When used with a transaction manager that supports recovery, this functionality is not available.
The challenge here is state transfer: when a new node starts it needs to do the following:
Tell the coordinator (oldest node in a cluster) to send it the state. This is always a full state transfer, overwriting any state that may already be present.
The coordinator then needs to wait until all in-flight transactions have completed. During this time, it will not allow for new transactions to be started.
Then the coordinator asks its cache loader for the entire state using
loadEntireState(). It then sends back that state to the new node.The new node then tells its cache loader to store that state in its store, overwriting the old state. This is the
CacheLoader.storeEntireState()methodAs an option, the transient (in-memory) state can be transferred as well during the state transfer.
The new node now has the same state in its backend store as everyone else in the cluster, and modifications received from other nodes will now be persisted using the local cache loader.
If you need to set up a hierarchy within a single JVM, you can
use the
LocalDelegatingCacheLoader
. This type of
hierarchy can currently only be set up programmatically.
Hierarchical caches could also be set up spanning more than one JVM or server, using the
TcpDelegatingCacheLoader
.
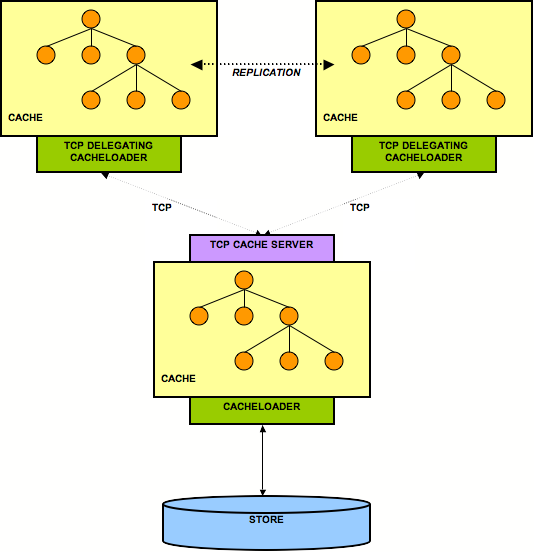
You can set up more than one cache loader in a chain. Internally, a delegating
ChainingCacheLoader
is used, with references to each
cache loader you have configured. Use cases vary depending on the type of cache loaders used in the
chain.
One example is
using a filesystem based cache loader, co-located on the same host as the JVM, used as an overflow for
memory. This ensures
data is available relatively easily and with low cost. An additional remote cache loader, such as a
TcpDelegatingCacheLoader
provides resilience between server restarts.
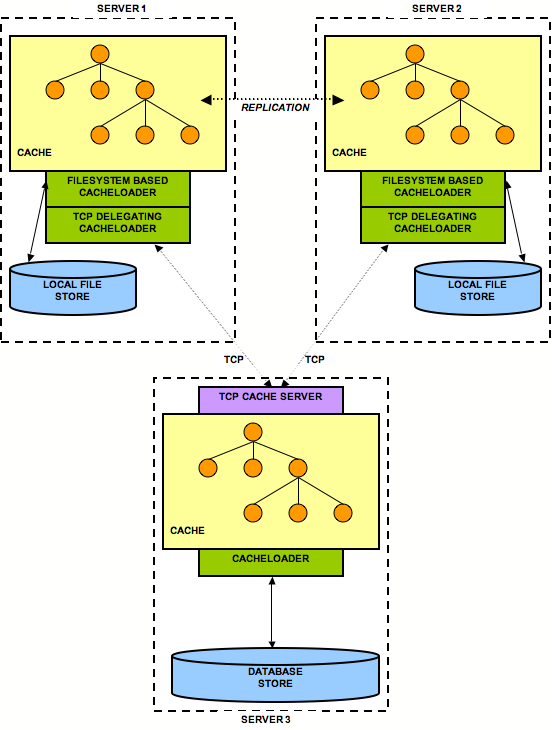
[3] Of course they can enable state transfer, if they want to have a warm or hot cache after startup.