There is a lot of information stored in many of different places: databases, repositories, SCM systems, registries, file systems, services, etc. The purpose of the federation engine is to allow applications to use the JCR API to access that information as if it were all stored in a single JCR repository, but to really leave the information where it is.
Why not just copy or move the information into a JCR repository? Moving it is probably pretty difficult, since most likely there are existing applications that rely upon that information being where it is. All of those applications would break or have to change. And copying the information means that we'd have to continually synchronize the changes. This not only is a lot of work, but it often creates issues with knowing which information is accurate.
The JBoss DNA allows lets us leave information where it is, yet provide access to it through the JCR API. The first benefit is that any existing applications that already use that information can keep using it. Plus, if the underlying information changes, all the client applications see the correct information. JCR clients even get the benefit of using JCR observation to be notified of the changes. And if a JBoss DNA repository is configured to allow updates, client applications can change the information in the repository and JBoss DNA will propagate those changes down to the original source.
As we've mentioned above, one of the capabilities of JBoss DNA is to provide access through JCR to different kinds of repositories and storage systems. Your applications work with the JCR API, but through JBoss DNA are able to accesses the content from where the information exists - not just a single purpose-built repository. This is fundamentally what makes JBoss DNA different.
How does JBoss DNA do this? At the heart of JBoss DNA and it's JCR implementation is a simple graph-based connector system. Essentially, the JBoss DNA JCR implementation makes use of a single repository source, from which all the content is accessed.
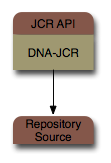
That single repository source could be an in-memory repository, a JBoss Cache instance, or a federated repository.
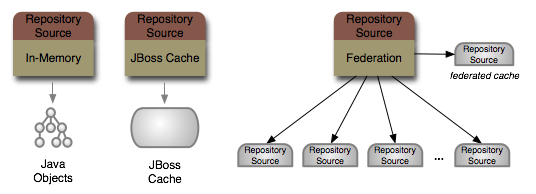
And the JBoss DNA project has plans to create other connectors, too. For instance, we're going to build a connector
to other JCR repositories. And another to a file system, so that the files and directories on an area of the file system
can be accessed through JCR. Of course, if we don't have a connector to suit your needs, you can write your own.
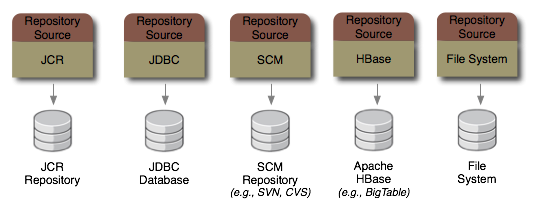
Before we go further, let's define some terminology regarding connectors.
A connector is the runnable code packaged in one or more JAR files that contains implementations of several interfaces (described below). A Java developer writes a connector to a type of source, such as a particular database management system, LDAP directory, source code management system, etc. It is then packaged into one or more JAR files (including dependent JARs) and deployed for use in applications that use JBoss DNA repositories.
The description of a particular source system is called a repository source. A connector contains a JavaBean class that implements the RepositorySource interface, with JavaBean properties for all of the connector-specific properties required to fully describe a system. Applications that use JBoss DNA create an instance that describes each external source that a repository is to access.
A repository source instance is then used to establish connections to that source. A connector provides an implementation of the RepositoryConnection interface, which defines methods for interacting with the external system. In particular, the
execute(...)method takes anExecutionContextinstance and one or moreGraphCommandobjects describing the operations that are to be executed against the graph of information the connector is exposing. Examples of commands include getting a node, moving a node, creating a node, changing a node, and deleting a node. And, if the repository source is able to participate in JTA/JTS distributed transactions, then the RepositoryConnection must implement thegetXaResource()method by returning a validjavax.transaction.xa.XAResourceobject that can be used by the transaction monitor.
As an example, consider that we want JBoss DNA to give us access through JCR to the schema information contained in a
relational databases. We first have to develop a connector that allows us to interact with relational databases using JDBC.
That connector would contain a JdbcRepositorySource Java class that implements RepositorySource,
and that has all of the various JavaBean properties for setting the name of the driver class, URL, username, password,
and other properties. (Or we might have a JavaBean property that defines the JNDI name where we can find a JDBC
DataSource instance pointing to our JDBC database.)
That connector would also have a JdbcRepositoryConnection Java class that implements the
RepositoryConnection interface. This class would probably wrap a JDBC database connection,
and would implement the execute(...) method such that the nodes exposed by the connector
describe the database schema of the database. For example, the connector might represent each database table
as a node wit the table's name, with properties that describe the table (e.g., the description, whether it's a
temporary table), and with child nodes that represent each of the columns, keys and constraints.
To use the connector, we need to create an instance of the JdbcRepositorySource for each database instance
that we want to access. If we have 3 MySQL databases, 9 Oracle databases, and 4 PostgreSQL databases, then we'd need
to create a total of 16 JdbcRepositorySource instances, each with the properties describing a single database instance.
Those sources are then available for use by the JBoss DNA components, including JCR.
So, we've so far learned what a repository connector is and how they're used to create RepositorySource instances. In the next section, we'll show how these source instances can be configured, managed, and their connections pooled.
The JBoss DNA RepositoryService is the component that manages the repository sources
and the connections to them. RepositorySource instances can be programmatically added to the service, but
the service can actually read its configuration from a configuration repository (which is represented by a
RepositorySource instance that's usually added programmatically to the service). The service connects to
the configuration repository and automatically sets up the repositories given the RepositorySource instances
found in the configuration repository. It also transparently maintains for each source a pool of reusable connections.
To use a repository, then, involves simply asking the RepositoryService for a RepositoryConnection
to the repository given the repository's name. If a source exists with that name, the service checks out a connection from
the pool and returns it. The resulting connection is actually a wrapper around the underlying pooled connection - when
the returned connection is closed, it returns the underlying connection to the pool.
To instantiate the RepositoryService, we need to first have a few other objects:
A ExecutionContextFactory instance, as discussed earlier.
A
RepositoryLibraryinstance that manages the list of RepositorySource instances, properly injects the execution contexts into each repository source, and provides a configurable pool of connections for each source.A configuration repository that contains descriptions of all of the repository sources as well as any information those sources need. Because this is a regular repository, this could be a simple repository with content loaded from an XML file (as in this example). Or it could be a shared central repository with information about all of the JBoss DNA processes across your company.
With these components in place, we can then instantiate the RepositoryService and start it (using its
ServiceAdministrator). During startup, the service reads the configuration repository and loads any
defined RepositorySource instances into the repository library, using the class loader factory
(available in the ExecutionContext) to obtain.
Here's sample code that shows how to set up and start the repository service. You can see something similar
in the example application in the startRepositories() method of the
org.jboss.example.dna.repository.RepositoryClient class.
// Create the factory for execution contexts, and create one ... ExecutionContextFactory contextFactory = newBasicExecutionContextFactory(); ExecutionContext context = contextFactory.create(); // Create the library for the RepositorySource instances ...RepositoryLibrarysources = newRepositoryLibrary(contextFactory); // Load into the source manager the repository source for the configuration repository ...InMemoryRepositorySourceconfigSource = newInMemoryRepositorySource(); configSource.setName("Configuration"); sources.addSource(configSource); // Now instantiate the Repository Service ...RepositoryServiceservice = newRepositoryService(sources, configSource.getName(), context); service.getAdministrator().start();
After startup completes, the repositories are ready to be used. The client application obtains the list of repositories and presents them to the user. When the user selects one, the client application starts navigating that repository starting at its root node (e.g., the "/" path). As you type a command to list the contents of the current node or to "change directories" to a different node, the client application obtains the information for the node using a simple procedure:
Get a connection to the repository.
Using the connection, find the current node and read its properties and children, putting the information into a simple Java plain old Java object (POJO).
Close the connection to the repository (in a finally block to ensure it always happens).
A number of repository connectors are already available in JBoss DNA, and are outlined in the following sections. Note that we do want to build more connectors in the upcoming releases.
The in-memory repository connector is a simple connector that creates a transient, in-memory repository. This repository is used as a very simple in-memory cache or as a standalone transient repository.
The InMemoryRepositorySource class provides a number of JavaBean properties that control its behavior:
Table 5.1. InMemoryRepositorySource properties
| Property | Description |
|---|---|
| name | The name of the repository source, which is used by the RepositoryService when obtaining a RepositoryConnection by name. |
| jndiName | Optional property that, if used, specifies the name in JNDI where an InMemoryRepository instance can be found.
This is an advanced property that is infrequently used. |
| rootNodeUuid | Optional property that, if used, defines the UUID of the root node in the in-memory repository. If not used, then a new UUID is generated. |
| retryLimit | Optional property that, if used, defines the number of times that any single operation on a RepositoryConnection to this source should be retried following a communication failure. The default value is '0'. |
| defaultCachePolicy | Optional property that, if used, defines the default for how long this information provided by this source may to be cached by other, higher-level components. The default value of null implies that this source does not define a specific duration for caching information provided by this repository source. |
The JBoss Cache repository connector allows a JBoss Cache instance to be used as a JBoss DNA (and thus JCR) repository. This provides a repository that is an effective, scalable, and distributed cache, and is often paired with other repository sources to provide a local or federated repository.
The JBossCacheSource class provides a number of JavaBean properties that control its behavior:
Table 5.2. JBossCacheSource properties
| Property | Description |
|---|---|
| name | The name of the repository source, which is used by the RepositoryService when obtaining a RepositoryConnection by name. |
| cacheFactoryJndiName | Optional property that, if used, specifies the name in JNDI where an existing JBoss Cache Factory instance can be found.
That factory would then be used if needed to create a JBoss Cache instance. If no value is provided, then the
JBoss Cache DefaultCacheFactory class is used. |
| cacheConfigurationName | Optional property that, if used, specifies the name of the configuration that is supplied to the cache factory when creating a new JBoss Cache instance. |
| cacheJndiName | Optional property that, if used, specifies the name in JNDI where an existing JBoss Cache instance can be found. This should be used if your application already has a cache that is used, or if you need to configure the cache in a special way. |
| uuidPropertyName | Optional property that, if used, defines the property that should be used to find the UUID value for each node
in the cache. "dna:uuid" is the default. |
| retryLimit | Optional property that, if used, defines the number of times that any single operation on a RepositoryConnection to this source should be retried following a communication failure. The default value is '0'. |
| defaultCachePolicy | Optional property that, if used, defines the default for how long this information provided by this source may to be cached by other, higher-level components. The default value of null implies that this source does not define a specific duration for caching information provided by this repository source. |
The federated repository source provides a unified repository consisting of information that is dynamically federated from multiple other
RepositorySource instances. This is a very powerful repository source that appears to be a single repository, when in
fact the content is stored and managed in multiple other systems. Each FederatedRepositorySource is typically configured
with the name of another RepositorySource that should be used as the local, unified cache of the federated content.
The configuration also contains the names of the other RepositorySource instances that are to be federated along with
the Projection definition describing where in the unified repository the content is to appear.
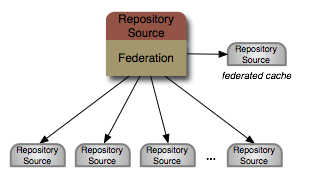
The federation connector works by effectively building up a single graph by querying each source and merging or unifying the responses. This information is cached, which improves performance, reduces the number of (potentially expensive) remote calls, reduces the load on the sources, and helps mitigate problems with source availability. As clients interact with the repository, this cache is consulted first. When the requested portion of the graph (or "subgraph") is contained completely in the cache, it is retuned immediately. However, if any part of the requested subgraph is not in the cache, each source is consulted for their contributions to that subgraph, and any results are cached.
This basic flow makes it possible for the federated repository to build up a local cache of the integrated graph (or at least the portions that are used by clients). In fact, the federated repository caches information in a manner that is similar to that of the Domain Name System (DNS). As sources are consulted for their contributions, the source also specifies whether it is the authoritative source for this information (some sources that are themselves federated may not be the information's authority), whether the information may be modified, the time-to-live (TTL) value (the time after which the cached information should be refreshed), and the expiration time (the time after which the cached information is no longer valid). In effect, the source has complete control over how the information it contributes is cached and used.
The federated repository also needs to incorporate
negative caching
, which is storage of the knowledge that something does not exist. Sources can be configured to contribute information
only below certain paths (e.g.,
/A/B/C
), and the federation engine can take advantage of this by never consulting that source for contributions to information
on other paths. However, below that path, any negative responses must also be cached (with appropriate TTL and expiry
parameters) to prevent the exclusion of that source (in case the source has information to contribute at a later time)
or the frequent checking with the source.
The federated repository uses other RepositorySources that are to be federated and a RepositorySource that is to be used as the cache of the unified contents. These are configured in another RepositorySource that is treated as a configuration repository. The name of the configuration repository is provided by JavaBean properties, and is the path to the "dna:federation" node in that configuration repository containing the information about the cache and federated sources. This graph structure is as follows (using XML elements to represent nodes and XML attributes to represent properties):
<!-- Define the federation configuration. -->
<dna:federation dna:timeToCache="100000">
<!-- Define how the content in the 'Cache' source is to map to the federated cache -->
<dna:cache>
<dna:projection jcr:name="Cache" dna:projectionRules="/ => /" />
</dna:cache>
<!-- Define how the content in the two sources maps to the federated/unified repository.
This example puts the 'Cars' and 'Aircraft' content underneath '/vehicles', but the
'Configuration' content (which is defined by this file) will appear under '/'. -->
<dna:projections>
<dna:projection jcr:name="Cars" dna:projectionRules="/Vehicles => /" />
<dna:projection jcr:name="Aircraft" dna:projectionRules="/Vehicles => /" />
<dna:projection jcr:name="Configuration" dna:projectionRules="/ => /" />
</dna:projections>
</dna:federation>
Here, the "dna" prefix denotes the "http://www.jboss.org/dna" namespace, while the
"jcr" prefix denotes the standard JCR namespace "http://www.jcp.org/jcr/1.0".
Notice that there is a cache projection and three source projections, and each projection defines
one or more projection rules that are of the form:
pathInFederatedRepository => pathInSourceRepository
So, a projection rule /Vehicles => / projects the entire contents of the source so that
it appears in the federated repository under the "/Vehicles" node.
The FederatedRepositorySource class provides a number of JavaBean properties that control its behavior:
Table 5.3. InMemoryRepositorySource properties
| Property | Description |
|---|---|
| name | The name of the repository source, which is used by the RepositoryService when obtaining a RepositoryConnection by name. |
| repositoryName | The name for the federated repository. |
| configurationSourceName | The name of the RepositorySource that should be used as the configuration repository, and in which is defined
how this federated repository is to be set up and configured.
This name is supplied to the that is provided to this instance when added to the
RepositoryLibrary. |
| configurationSourcePath | The path to the node in the configuration repository below which a "dna:federation" node exists with the graph structure describing how this federated repository is to be configured. |
| securityDomain | Optional property that, if used, specifies the name of the JAAS application context that should be used
to establish the execution context for this repository.
This should correspond to the JAAS login configuration located within the JAAS login configuration file,
and should be used only if a "username" property is defined. |
| username | Optional property that, if used, defines the name of the JAAS subject that should be used
to establish the execution context for this repository.
This should be used if a "securityDomain" property is defined. |
| password | Optional property that, if used, defines the password of the JAAS subject that should be used
to establish the execution context for this repository.
If the password is not provided but values for the "securityDomain" and "username" properties are,
then authentication will use the default JAAS callback handlers. |
| retryLimit | Optional property that, if used, defines the number of times that any single operation on a RepositoryConnection to this source should be retried following a communication failure. The default value is '0'. |
| defaultCachePolicy | Optional property that, if used, defines the default for how long this information provided by this source may to be cached by other, higher-level components. The default value of null implies that this source does not define a specific duration for caching information provided by this repository source. |
The current release of JBoss DNA comes with six sequencers. However, JBoss DNA was designed so that you can create your own connectors and to then configure JBoss DNA to use them in your own application.
Caution
At this time, we recommend consulting with the JBoss DNA project team before writing a connector. The 0.3 release will have a few changes in the connector SPI that may have a large impact on your connectors. Please contact us using any of the ways listed in the Preface.