The previous chapter walked through the process of downloading and building the examples. This chapter will focus on the sequencer example, showing how to run the example and then walking through the code to describe what it's doing.
The sequencing example consists of a client application that sets up an in-memory JCR repository and that allows a user to upload files into that repository. The client also sets up the DNA services with two sequencers so that if any of the uploaded files are PNG, JPEG, GIF, BMP or other images, DNA will automatically extract the image's metadata (e.g., image format, physical size, pixel density, etc.) and store that in the repository. Alternatively, if the uploaded file is an MP3 audio file, DNA will extract some of the ID3 metadata (e.g., the author, title, album, year and comment) and store that in the repository.
To run the client application, go to the examples/sequencers/target/dna-example-sequencers-basic.dir/
directory and type ./run.sh. You should see the command-line client and its menus in your terminal:
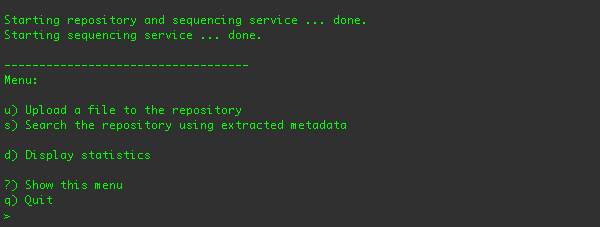
From this menu, you can upload a file into the repository, search for media in the repository, print sequencing statistics,
or quit the application.
The first step is to upload one of the example images. If you type 'u' and press return, you'll be prompted to supply the
path to the file you want to upload. Since the application is running from within the
examples/sequencers/target/dna-example-sequencers-basic.dir/ directory, you can specify any of the files
in that directory without specifying the path:
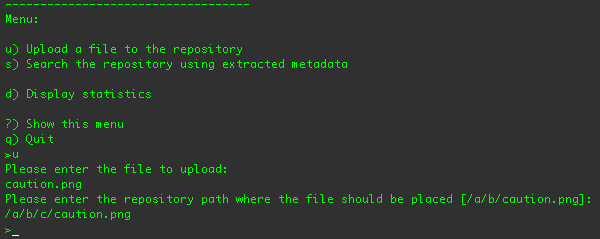
You can specify any fully-qualified or relative path. The application will notify you if it cannot find the file you
specified. The example client configures JBoss DNA to sequence MP3 audio files, Java source files, or image files with one of
the following extensions (technically, nodes that have names ending in the following):
jpg, jpeg, gif, bmp, pcx, png,
iff, ras, pbm, pgm, ppm, and psd.
Files with other extensions in the repository path will be ignored. For your convenience, the example provides several
files that will be sequenced (caution.png, caution.jpg, caution.gif, and
sample1.mp3) and one image that will not be sequenced (caution.pict). Feel free to try other files.
After you have specified the file you want to upload, the example application asks you where in the repository you'd like to
place the file. (If you want to use the suggested location, just press return.) The client application
uses the JCR API to upload the file to that location in the repository, creating any nodes (of type nt:folder)
for any directories that don't exist, and creating a node (of type nt:file) for the file. And, per the JCR specification,
the application creates a jcr:content node (of type nt:resource) under the file node.
The file contents are placed on this jcr:content node in the jcr:data property. For example, if you specify
/a/b/caution.png, the following structure will be created in the repository:
/a (nt:folder)
/b (nt:folder)
/caution.png (nt:file)
/jcr:content (nt:resource)
@jcr:data = {contents of the file}
@jcr:mimeType = {mime type of the file}
@jcr:lastModified = {now}
Other kinds of files are treated in a similar way.
When the client uploads the file using the JCR API, DNA gets notified of the changes, consults the sequencers to see whether
any of them are interested in the new or updated content, and if so runs those sequencers. The image sequencer processes image
files for metadata, and any metadata found is stored under the /images branch of the repository. The MP3 sequencer
processes MP3 audio files for metadata, and any metadata found is stored under the /mp3s
branch of the repository. And metadata about Java classes are stored under the /java area of the repository.
All of this happens asynchronously, so any DNA activity doesn't impede or slow down the client activities.
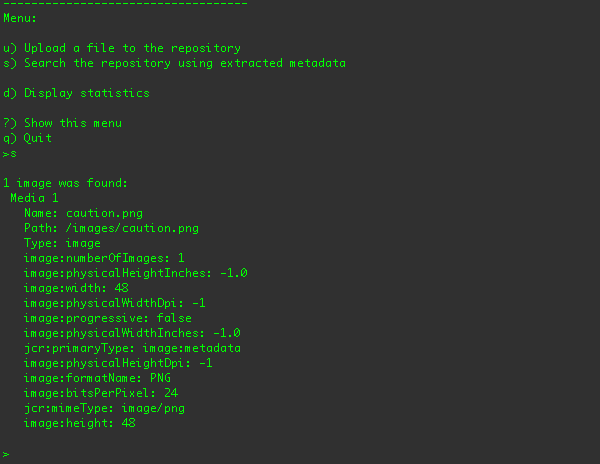
So, after the file is uploaded, you can search the repository for the image metadata using the "s" menu option:
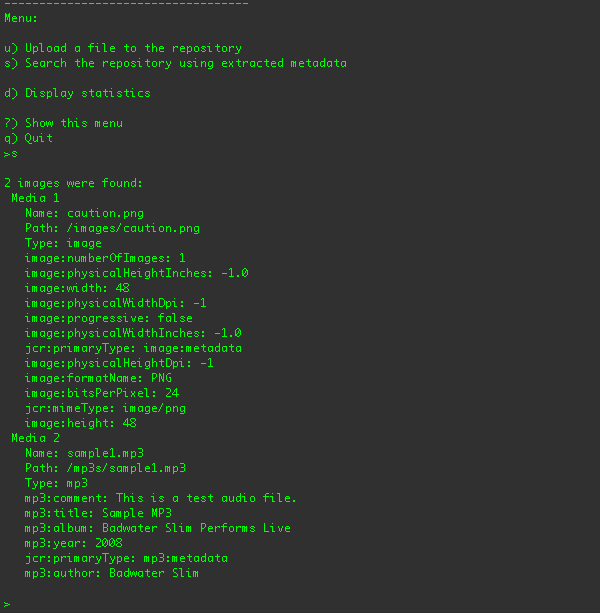
Here are the search results after the sample1.mp3 audio file has been uploaded (to the /a/b/sample1.mp3 location):
You can also display the sequencing statistics using the "d" menu option:
These stats show how many nodes were sequenced, and how many nodes were skipped because they didn't apply to the sequencer's
criteria.
Note
There will probably be more nodes skipped than sequenced, since there are more nt:folder and nt:resource
nodes than there are nt:file nodes with acceptable names.
You can repeat this process with other files. Any file that isn't an image or MP3 files (as recognized by the sequencing configurations that we'll describe later) will not be sequenced.
Recall that the example application consists of a client application that sets up an in-memory JCR repository and that allows a user to upload files into that repository. The client also sets up the DNA services with an image sequencer so that if any of the uploaded files are PNG, JPEG, GIF, BMP or other images, DNA will automatically extract the image's metadata (e.g., image format, physical size, pixel density, etc.) and store that in the repository. Or, if the client uploads MP3 audio files, the title, author, album, year, and comment are extracted from the audio file and stored in the repository.
The example is comprised of 5 classes and 1 interface, located in the src/main/java directory:
org/jboss/example/dna/sequencers/ConsoleInput.java
/ContentInfo.java
/JavaInfo.java
/MediaInfo.java
/SequencingClient.java
/UserInterface.java
SequencingClient is the class that contains the main application. ContentInfo is a simple class
that encapsulate metadata generated by the sequencers and accessed by this example application, and there are two subclasses:
MediaInfo encapsulates metadata about media (image and MP3) files, while JavaInfo is a subclass
encapsulating information about a Java class. The client accesses the content from the repository and represent the
information using instances of ContentInfo (and its subclasses) and then passing them to the UserInterface.
UserInterface is an interface with methods that will be called at runtime to
request data from the user. ConsoleInput is an implementation of this that creates a text user interface,
allowing the user to operate the client from the command-line. We can easily create a graphical implementation of
UserInterface at a later date. We can also create a mock implementation for testing purposes that simulates
a user entering data. This allows us to check the behavior of the client automatically using conventional JUnit test cases,
as demonstrated by the code in the src/test/java directory:
org/jboss/example/dna/sequencers/SequencingClientTest.java
/MockUserInterface.java
If we look at the SequencingClient code, there are a handful of methods that encapsulate the various activities.
Note
Some of the code samples included in this book have had some of the error handling and comments removed so that the code is more readable and concise.
The main(String[] argv) method is of course the method that is executed when the application is run. This code
creates the JBoss DNA configuration using the programmatic style.
// Create the configuration.
String repositoryId = "content";
String workspaceName = "default";
JcrConfiguration config = new JcrConfiguration();
// Set up the in-memory source where we'll upload the content and where the sequenced output will be stored ...
config.repositorySource("store")
.usingClass(InMemoryRepositorySource.class)
.setDescription("The repository for our content")
.setProperty("defaultWorkspaceName", workspaceName);
// Set up the JCR repository to use the source ...
config.repository(repositoryId)
.addNodeTypes("sequencing.cnd")
.setSource("store");
// Set up the image sequencer ...
config.sequencer("Image Sequencer")
.usingClass("org.jboss.dna.sequencer.image.ImageMetadataSequencer")
.loadedFromClasspath()
.setDescription("Sequences image files to extract the characteristics of the image")
.sequencingFrom("//(*.(jpg|jpeg|gif|bmp|pcx|png|iff|ras|pbm|pgm|ppm|psd)[*])/jcr:content[@jcr:data]")
.andOutputtingTo("/images/$1");
// Set up the MP3 sequencer ...
config.sequencer("MP3 Sequencer")
.usingClass("org.jboss.dna.sequencer.mp3.Mp3MetadataSequencer")
.loadedFromClasspath()
.setDescription("Sequences mp3 files to extract the id3 tags of the audio file")
.sequencingFrom("//(*.mp3[*])/jcr:content[@jcr:data]")
.andOutputtingTo("/mp3s/$1");
// Set up the Java source file sequencer ...
config.sequencer("Java Sequencer")
.usingClass("org.jboss.dna.sequencer.java.JavaMetadataSequencer")
.loadedFromClasspath()
.setDescription("Sequences Java files to extract the AST structure of the Java source code")
.sequencingFrom("//(*.java[*])/jcr:content[@jcr:data]")
.andOutputtingTo("/java/$1");
// Now start the client and tell it which repository and workspace to use ...
SequencingClient client = new SequencingClient(config, repositoryId, workspaceName);
client.setUserInterface(new ConsoleInput(client));
The first block of code configures the JcrConfiguration and sets up the "store" source, the "content" repository,
and three sequencers. Again, this is done via the programmatic style. An alternative would be to load the entire configuration
from a configuration file or from an existing configuration repository. (The repository example shown in the
next chapter shows how to load the configuration from a file.)
The second block simply instantiates the SequencingClient class, passing the configuration and the name of the repository
and workspace, and finally sets the user interface (which then executes its behavior, which we'll see below).
The startRepository() method builds the JcrEngine component from the configuration, starts the engine,
and obtains the JCR javax.jcr.Repository instance that the client will use. Note that the client has not yet
obtained a javax.jcr.Session instance, since this will be done each time the client needs to access content from
the repository. (This is actually a common practice according to the JCR specification, since Sessions are intended to be
very lightweight.)
public void startRepository() throws Exception {
if (this.repository == null) {
try {
// Start the DNA engine ...
this.engine = this.configuration.build();
this.engine.start();
// Now get the JCR repository instance ...
this.repository = this.engine.getRepository(repositoryName);
} catch (Exception e) {
this.repository = null;
throw e;
}
}
}
The shutdownRepository() method requests the JcrEngine instance shuts down and, since that may take
a few moments (if there are any ongoing operations or enqueued activities) awaits for it to complete the shutdown.
public void shutdownRepository() throws Exception {
if (this.repository != null) {
try {
this.engine.shutdown();
this.engine.awaitTermination(4, TimeUnit.SECONDS);
} finally {
this.repository = null;
}
}
}
None of the other methods really do anything with JBoss DNA per se. Instead, they merely work with the repository using the JCR API.
If we look at the ConsoleInput constructor, it starts the repository and a thread
for the user interface. At this point, the constructor returns, but the main application continues under the user interface thread.
When the user requests to quit, the user interface thread also shuts down the JCR repository.
public ConsoleInput( SequencerClient client ) {
try {
client.startRepository();
System.out.println(getMenu());
Thread eventThread = new Thread(new Runnable() {
private boolean quit = false;
public void run() {
try {
while (!quit) {
// Display the prompt and process the requested operation ...
}
} finally {
try {
// Terminate ...
client.shutdownRepository();
} catch (Exception err) {
System.out.println("Error shutting down sequencing service and repository: "
+ err.getLocalizedMessage());
err.printStackTrace(System.err);
}
}
}
});
eventThread.start();
} catch (Exception err) {
System.out.println("Error: " + err.getLocalizedMessage());
err.printStackTrace(System.err);
}
}
There is one more aspect of this example that is worth discussing. While the repository example in the
next chapter does show how to use JAAS, this example intentionally shows how
you might integrate a different security system into JBoss DNA. In the createSession() method,
the RepositoryClient creates a SecurityContextCredentials wrapper around a custom
SecurityContext implementation, then passes that credentials into the login(Credentials,String)
method:
protected Session createSession() throws RepositoryException {
SecurityContext securityContext = new MyCustomSecurityContext();
SecurityContextCredentials credentials = new SecurityContextCredentials(securityContext);
return this.repository.login(credentials, workspaceName);
}
where the custom SecurityContext implementation is as follows:
protected class MyCustomSecurityContext implements SecurityContext {
/**
* @see org.jboss.dna.graph.SecurityContext#getUserName()
*/
public String getUserName() {
return "Fred";
}
/**
* @see org.jboss.dna.graph.SecurityContext#hasRole(java.lang.String)
*/
public boolean hasRole( String roleName ) {
return true;
}
/**
* @see org.jboss.dna.graph.SecurityContext#logout()
*/
public void logout() {
// do something
}
}
Obviously you would want to implement this correctly. If you're using JBoss DNA in a web application, your SecurityContext
implementation would likely delegate to the HttpServletRequest.
But if you're using JAAS, then you could just pass in a javax.jcr.SimpleCredentials with the username and password,
as long as your JcrConfiguration's repository definitions are set up to use the correct JAAS login context name
(see the repository example in the next chapter). Or, you could use the approach listed
above and supply an instance of the JaasSecurityContext to the SecurityContextCredentials.
At this point, we've reviewed all of the interesting code in the example application related to JBoss DNA. However, feel free to play with the application, trying different things.
This chapter walked through running the sequencer example and looked at the example code. With the sequencer client, you could upload files into a JCR repository, while JBoss DNA automatically sequenced the image, MP3, or Java source files you uploaded, extracted the metadata from the files, and stored that metadata inside the repository.
In the next chapter we'll do the same for the repository example.