jBPM allows the persistent storage of certain information. This chapter describes these different types of persistence, and how to configure them. An example of the information stored is the process runtime state. Storing the process runtime state is necessary in order to be able to continue execution of a process instance at any point, if something goes wrong. Also, the process definitions themselves, and the history information (logs of current and previous process states already) can also be persisted.
Whenever a process is started, a process instance is created, which represents the execution of the process in that specific context. For example, when executing a process that specifies how to process a sales order, one process instance is created for each sales request. The process instance represents the current execution state in that specific context, and contains all the information related to that process instance. Note that it only contains the (minimal) runtime state that is needed to continue the execution of that process instance at some later time, but it does not include information about the history of that process instance if that information is no longer needed in the process instance.
The runtime state of an executing process can be made persistent, for example, in a database. This allows to restore the state of execution of all running processes in case of unexpected failure, or to temporarily remove running instances from memory and restore them at some later time. jBPM allows you to plug in different persistence strategies. By default, if you do not configure the process engine otherwise, process instances are not made persistent.
If you configure the engine to use persistence, it will automatically store the runtime state into the database. You do not have to trigger persistence yourself, the engine will take care of this when persistence is enabled. Whenever you invoke the engine, it will make sure that any changes are stored at the end of that invocation, at so-called safe points. Whenever something goes wrong and you restore the engine from the database, you also should not reload the process instances and trigger them manually to resume execution, as process instances will automatically resume execution if they are triggered, like for example by a timer expiring, the completion of a task that was requested by that process instance, or a signal being sent to the process instance. The engine will automatically reload process instances on demand.
The runtime persistence data should in general be considered internal, meaning that you probably should not try to access these database tables directly and especially not try to modify these directly (as changing the runtime state of process instances without the engine knowing might have unexpected side-effects). In most cases where information about the current execution state of process instances is required, the use of a history log is mostly recommended (see below). In some cases, it might still be useful to for example query the internal database tables directly, but you should only do this if you know what you are doing.
jBPM uses a binary persistence mechanism, otherwise known as marshalling, which converts the state of the process instance into a binary dataset. When you use persistence with jBPM, this mechanism is used to save or retrieve the process instance state from the database. The same mechanism is also applied to the session state and any work item states.
When the process instance state is persisted, two things happen:
- First, the process instance information is transformed into a binary blob. For performance reasons, a custom serialization mechanism is used and not normal Java serialization.
- This blob is then stored, alongside other metadata about this process instance. This metadata includes, among other things, the process instance id, process id, and the process start date.
Apart from the process instance state, the session itself can
also store some state, such as the state of timer jobs, or the session
data that any business rules would be evaluated over.
This session state is stored separately as a binary blob, along with
the id of the session and some metadata. You can always restore session
state by reloading the session with the given id. The session id can
be retrieved using ksession.getId().
Note that the process instance binary datasets are usually relatively small, as they only contain the minimal execution state of the process instance. For a simple process instance, this usually contains one or a few node instances, i.e., any node that is currently executing, and any existing variable values.
As a result of jBPM using marshalling, the data model is both simple and small:

Figure 8.1. jBPM data model
The sessioninfo entity contains the state of the
(knowledge) session in which the jBPM process instance is running.
Table 8.1. SessionInfo
| Field | Description | Nullable |
|---|---|---|
id | The primary key. | NOT NULL |
lastmodificationdate | The last time that the entity was saved to the database | |
rulesbytearray | The binary dataset containing the state of the session | NOT NULL |
startdate | The start time of the session | |
optlock | The version field that serves as its optimistic lock value |
The processinstanceinfo entity contains the state
of the jBPM process instance.
Table 8.2. ProcessInstanceInfo
| Field | Description | Nullable |
|---|---|---|
instanceid | The primary key | NOT NULL |
lastmodificationdate | The last time that the entity was saved to the database | |
lastreaddate | The last time that the entity was retrieved (read) from the database | |
processid | The name (id) of the process | |
processinstancebytearray | This is the binary dataset containing the state of the process instance | NOT NULL |
startdate | The start time of the process | |
state | An integer representing the state of the process instance | NOT NULL |
optlock | The version field that serves as its optimistic lock value |
The eventtypes entity contains information
about events that a process instance will undergo or has undergone.
Table 8.3. EventTypes
| Field | Description | Nullable |
|---|---|---|
instanceid | This references the processinstanceinfo primary
key and there is a foreign key constraint on this column. | NOT NULL |
eventTypes | A text field related to an event that the process has undergone. |
The workiteminfo entity contains the state of a work item.
Table 8.4. WorkItemInfo
| Field | Description | Nullable |
|---|---|---|
workitemid | The primary key | NOT NULL |
creationDate | The name of the work item | |
name | The name of the work item | |
processinstanceid | The (primary key) id of the process: there is no foreign key constraint on this field. | NOT NULL |
state | An integer representing the state of the work item | NOT NULL |
optlock | The version field that serves as its optimistic lock value | |
workitembytearay | This is the binary dataset containing the state of the work item | NOT NULL |
The CorrelationKeyInfo entity contains information
about correlation keys assigned to given process instance - loose relationship as this
table is considered optional used only when correlation capabilities are required.
Table 8.5. CorrelationKeyInfo
| Field | Description | Nullable |
|---|---|---|
keyid | The primary key | NOT NULL |
name | assigned name of the correlation key | |
processinstanceid | The id of the process instance which is assigned to this correlation key | NOT NULL |
optlock | The version field that serves as its optimistic lock value |
The CorrelationPropertyInfo entity contains information
about correlation properties for given correlation key that is assigned to given process instance.
Table 8.6. CorrelationPropertyInfo
| Field | Description | Nullable |
|---|---|---|
propertyid | The primary key | NOT NULL |
name | The name of the property | |
value | The value of the property | NOT NULL |
optlock | The version field that serves as its optimistic lock value | |
correlationKey-keyid | Foregin key to map to correlation key | NOT NULL |
The ContextMappingInfo entity contains information
about contextual information mapped to ksession. This is an internal part of RuntimeManager
and can be considered optional when RuntimeManager is not used.
Table 8.7. ContextMappingInfo
| Field | Description | Nullable |
|---|---|---|
mappingid | The primary key | NOT NULL |
context_id | Identifier of the context | NOT NULL |
ksession?id | Identifier of the ksession mapped to this context | NOT NULL |
optlock | The version field that serves as its optimistic lock value |
The state of a process instance is stored at so-called "safe points" during the execution of the process engine. Whenever a process instance is executing (for example when it started or continuing from a previous wait state, the engine executes the process instance until no more actions can be performed (meaning that the process instance either has completed (or was aborted), or that it has reached a wait state in all of its parallel paths). At that point, the engine has reached the next safe state, and the state of the process instance (and all other process instances that might have been affected) is stored persistently.
In many cases it will be useful (if not necessary) to store information about the execution of process instances, so that this information can be used afterwards. For example, sometimes we want to verify which actions have been executed for a particular process instance, or in general, we want to be able to monitor and analyze the efficiency of a particular process.
However, storing history information in the runtime database can result in the database rapidly increasing in size, not to mention the fact that monitoring and analysis queries might influence the performance of your runtime engine. This is why process execution history information can be stored separately.
This history log of execution information is created based on events that the process engine generates during execution. This is possible because the jBPM runtime engine provides a generic mechanism to listen to events. The necessary information can easily be extracted from these events and then persisted to a database. Filters can also be used to limit the scope of the logged information.
The jbpm-audit module contains an event listener that stores process-related information in a database using JPA. The data model itself contains three entities, one for process instance information, one for node instance information, and one for (process) variable instance information.
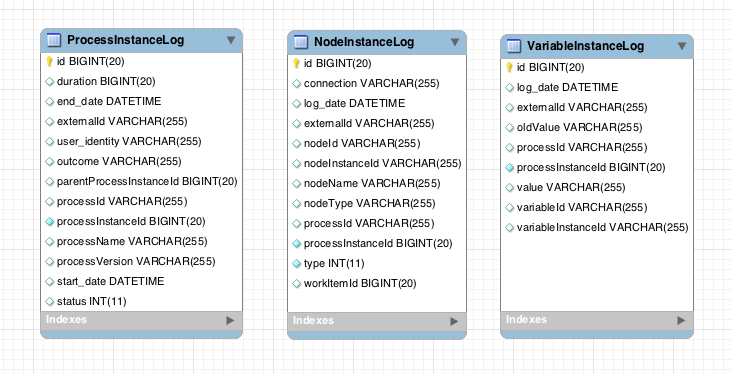
The ProcessInstanceLog table contains the basic
log information about a process instance.
Table 8.8. ProcessInstanceLog
| Field | Description | Nullable |
|---|---|---|
id | The primary key and id of the log entity | NOT NULL |
duration | Actual duration of this process instance since its start date | |
end_date | When applicable, the end date of the process instance | |
externalId | Optional external identifier used to correlate to some elements - e.g. deployment id | |
user_identity | Optional identifier of the user who started the process instance | |
outcome | The outcome of the process instance, for instance error code in case of process instance was finished with error event | |
parentProcessInstanceId | The process instance id of the parent process instance if any | |
processid | The id of the process | |
processinstanceid | The process instance id | NOT NULL |
processname | The name of the process | |
processversion | The version of the process | |
start_date | The start date of the process instance | |
status | The status of process instance that maps to process instance state |
The NodeInstanceLog table contains more information about which
nodes were actually executed inside each process instance. Whenever a node instance
is entered from one of its incoming connections or is exited through one of its outgoing
connections, that information is stored in this table.
Table 8.9. NodeInstanceLog
| Field | Description | Nullable |
|---|---|---|
id | The primary key and id of the log entity | NOT NULL |
connection | Actual identifier of the sequence flow that led to this node instance | |
log_date | The date of the event | |
externalId | Optional external identifier used to correlate to some elements - e.g. deployment id | |
nodeid | The node id of the corresponding node in the process definition | |
nodeinstanceid | The node instance id | |
nodename | The name of the node | |
nodetype | The type of the node | |
processid | The id of the process that the process instance is executing | |
processinstanceid | The process instance id | NOT NULL |
type | The type of the event (0 = enter, 1 = exit) | NOT NULL |
workItemId | Optional - only for certain node types - The identifier of work item |
The VariableInstanceLog table contains information about changes
in variable instances. The default is to only generate log entries when (after) a variable
changes. It's also possible to log entries before the variable (value) changes.
Table 8.10. VariableInstanceLog
| Field | Description | Nullable |
|---|---|---|
id | The primary key and id of the log entity | NOT NULL |
externalId | Optional external identifier used to correlate to some elements - e.g. deployment id | |
log_date | The date of the event | |
processid | The id of the process that the process instance is executing | |
processinstanceid | The process instance id | NOT NULL |
oldvalue | The previous value of the variable at the time that the log is made | |
value | The value of the variable at the time that the log is made | |
variableid | The variable id in the process definition | |
variableinstanceid | The id of the variable instance |
To log process history information in a database like this, you need to register the logger on your session like this:
EntityManagerFactory emf = ...;
StatefulKnowledgeSession ksession = ...;
AbstractAuditLogger auditLogger = AuditLoggerFactory.newJPAInstance(emf);
ksession.addProcessEventListener(auditLogger);
// invoke methods one your session here
To specify the database where the information should be stored,
modify the file persistence.xml file to include
the audit log classes as well (ProcessInstanceLog, NodeInstanceLog and
VariableInstanceLog), as shown below.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<persistence
version="2.0"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd
http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_2_0.xsd"
xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:orm="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance>
<persistence-unit name="org.jbpm.persistence.jpa" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/jbpm-ds</jta-data-source>
<mapping-file>META-INF/JBPMorm.xml</mapping-file>
<class>org.drools.persistence.info.SessionInfo</class>
<class>org.jbpm.persistence.processinstance.ProcessInstanceInfo</class>
<class>org.drools.persistence.info.WorkItemInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationKeyInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationPropertyInfo</class>
<class>org.jbpm.runtime.manager.impl.jpa.ContextMappingInfo</class>
<class>org.jbpm.process.audit.ProcessInstanceLog</class>
<class>org.jbpm.process.audit.NodeInstanceLog</class>
<class>org.jbpm.process.audit.VariableInstanceLog</class>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.max_fetch_depth" value="3"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.transaction.jta.platform"
value="org.hibernate.service.jta.platform.internal.BitronixJtaPlatform"/>
</properties>
</persistence-unit>
</persistence>
All this information can easily be queried and used in a lot of different use cases, ranging from creating a history log for one specific process instance to analyzing the performance of all instances of a specific process.
This audit log should only be considered a default implementation. We don't know what information you need to store for analysis afterwards, and for performance reasons it is recommended to only store the relevant data. Depending on your use cases, you might define your own data model for storing the information you need, and use the process event listeners to extract that information.
Process events are stored in the database synchronously and within the same transaction as actual process instance execution. That obviously takes some time especially in highly loaded systems and might have some impact on the database when both history log and runtime data are kept in the same database. To provide an alternative option for storing process events, a JMS based logger has been provided. It can be configured to submit messages to JMS queue instead of directly persisting them in the database. It can be configured to be transactional as well to avoid issues with inconsistent data in case of process engine transaction is rolled back.
ConnectionFactory factory = ...;
Queue queue = ...;
StatefulKnowledgeSession ksession = ...;
Map<String, Object> jmsProps = new HashMap<String, Object>();
jmsProps.put("jbpm.audit.jms.transacted", true);
jmsProps.put("jbpm.audit.jms.connection.factory", factory);
jmsProps.put("jbpm.audit.jms.queue", queue);
AbstractAuditLogger auditLogger = AuditLoggerFactory.newInstance(Type.JMS, session, jmsProps);
ksession.addProcessEventListener(auditLogger);
// invoke methods one your session here
This is just one of possible ways to configure JMS audit logger, see javadocs for AuditLoggerFactory for more details.
The jBPM engine supports JTA transactions. It also supports local transactions only when using Spring. It does not support pure local transactions at the moment. For more information about using Spring to set up persistence, please see the Spring chapter in the Drools integration guide.
Whenever you do not provide transaction boundaries inside your application, the engine will automatically execute each method invocation on the engine in a separate transaction. If this behavior is acceptable, you don't need to do anything else. You can, however, also specify the transaction boundaries yourself. This allows you, for example, to combine multiple commands into one transaction.
You need to register a transaction manager at the environment before using user-defined transactions. The following sample code uses the Bitronix transaction manager. Next, we use the Java Transaction API (JTA) to specify transaction boundaries, as shown below:
// create the entity manager factory and register it in the environment
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "org.jbpm.persistence.jpa" );
Environment env = KnowledgeBaseFactory.newEnvironment();
env.set( EnvironmentName.ENTITY_MANAGER_FACTORY, emf );
env.set( EnvironmentName.TRANSACTION_MANAGER, TransactionManagerServices.getTransactionManager() );
// create a new knowledge session that uses JPA to store the runtime state
StatefulKnowledgeSession ksession = JPAKnowledgeService.newStatefulKnowledgeSession( kbase, null, env );
// start the transaction
UserTransaction ut = (UserTransaction) new InitialContext().lookup( "java:comp/UserTransaction" );
ut.begin();
// perform multiple commands inside one transaction
ksession.insert( new Person( "John Doe" ) );
ksession.startProcess( "MyProcess" );
// commit the transaction
ut.commit();
Note that, if you use Bitronix as the transaction manager, you should also add
a simple jndi.properties file in you root classpath to register the
Bitronix transaction manager in JNDI. If you are using the jbpm-test module, this is
already included by default. If not, create a file named jndi.properties
with the following content:
java.naming.factory.initial=bitronix.tm.jndi.BitronixInitialContextFactory
If you would like to use a different JTA transaction manager, you can change the
persistence.xml file to use your own transaction manager. For example,
when running inside JBoss Application Server v5.x or v7.x, you can use the JBoss transaction manager.
You need to change the transaction manager property in persistence.xml to:
<property name="hibernate.transaction.jta.platform" value="org.hibernate.transaction.JBossTransactionManagerLookup" />
Special consideration need to be taken when embedding jBPM inside an application that executes in Container Managed Transaction (CMT) mode, for instance EJB beans. This especially applies to application servers that does not allow accessing UserTransaction instance from JNDI when being part of container managed transaction, e.g. WebSphere Application Server. Since default implementation of transaction manager in jBPM is based on UserTransaction to get transaction status which is used to decide if transaction should be started or not, in environments that prevent accessing UserTrancation it won't do its job. To secure proper execution in CMT environments a dedicated transaction manager implementation is provided:
org.jbpm.persistence.jta.ContainerManagedTransactionManager
This transaction manager expects that transaction is active and thus will always return ACTIVE when invoking getStatus method. Operations like begin, commit, rollback are no-op methods as transaction manager runs under managed transaction and can't affect it.
Note
To make sure that container is aware of any exceptions that happened during process instance execution, user needs to ensure that exceptions thrown by the engine are propagated up to the container to properly rollback transaction.
To configure this transaction manager following must be done:
- Insert transaction manager and persistence context manager into environment prior
to creating/loading session
Environment env = EnvironmentFactory.newEnvironment(); env.set(EnvironmentName.ENTITY_MANAGER_FACTORY, emf); env.set(EnvironmentName.TRANSACTION_MANAGER, new ContainerManagedTransactionManager()); env.set(EnvironmentName.PERSISTENCE_CONTEXT_MANAGER, new JpaProcessPersistenceContextManager(env)); env.set(EnvironmentName.TASK_PERSISTENCE_CONTEXT_MANAGER, new JPATaskPersistenceContextManager(env)); - configure JPA provider (example hibernate and WebSphere)
<property name="hibernate.transaction.factory_class" value="org.hibernate.transaction.CMTTransactionFactory"/> <property name="hibernate.transaction.jta.platform" value="org.hibernate.service.jta.platform.internal.WebSphereJtaPlatform"/>
With following configuration jBPM should run properly in CMT environment.
Usually when running within container managed transaction disposing ksession directly will cause exceptions
on transaction completion as there are some transaction synchronization registered by jBPM to clean up
the state after invocation is finished. To overcome this problem specialized command has been provided
org.jbpm.persistence.jta.ContainerManagedTransactionDisposeCommand which allows to simply
execute this command instead of regular ksession.dispose which will ensure that ksession will
be disposed at the transaction completion.
By default, the engine does not save runtime data persistently. This means you can use the engine completely without persistence (so not even requiring an in memory database) if necessary, for example for performance reasons, or when you would like to manage persistence yourself. It is, however, possible to configure the engine to do use persistence by configuring it to do so. This usually requires adding the necessary dependencies, configuring a datasource and creating the engine with persistence configured.
You need to make sure the necessary dependencies are available in the classpath of your application if you want to user persistence. By default, persistence is based on the Java Persistence API (JPA) and can thus work with several persistence mechanisms. We are using Hibernate by default.
If you're using the Eclipse IDE and the jBPM Eclipse plugin, you should make sure the necessary JARs are added to your jBPM runtime directory. You don't really need to do anything (as the necessary dependencies should already be there) if you are using the jBPM runtime that is configured by default when using the jBPM installer, or if you downloaded and unzipped the jBPM runtime artifact (from the downloads) and pointed the jBPM plugin to that directory.
If you would like to manually add the necessary dependencies to your project, first of all,
you need the JAR file jbpm-persistence-jpa.jar,
as that contains code for saving the runtime state whenever necessary.
Next, you also need various other dependencies, depending on the
persistence solution and database you are using. For the default
combination with Hibernate as the JPA persistence provider and using an H2
in-memory database and Bitronix for JTA-based transaction management, the
following list of additional dependencies is needed:
- jbpm-persistence-jpa (org.jbpm)
- drools-persistence-jpa (org.drools)
- persistence-api (javax.persistence)
- hibernate-entitymanager (org.hibernate)
- hibernate-annotations (org.hibernate)
- hibernate-commons-annotations (org.hibernate)
- hibernate-core (org.hibernate)
- commons-collections (commons-collections)
- dom4j (dom4j)
- jta (javax.transaction)
- btm (org.codehaus.btm)
- javassist (javassist)
- slf4j-api (org.slf4j)
- slf4j-jdk14 (org.slf4j)
- h2 (com.h2database)
- jbpm-test (org.jbpm) for testing only, do not include it in the actual application
You can use the JPAKnowledgeService to create your knowledge session. This
is slightly more complex, but gives you full access to the underlying configurations. You can create
a new knowledge session using JPAKnowledgeService based on a knowledge base, a
knowledge session configuration (if necessary) and an environment. The environment
needs to contain a reference to your Entity Manager Factory. For example:
// create the entity manager factory and register it in the environment
EntityManagerFactory emf =
Persistence.createEntityManagerFactory( "org.jbpm.persistence.jpa" );
Environment env = KnowledgeBaseFactory.newEnvironment();
env.set( EnvironmentName.ENTITY_MANAGER_FACTORY, emf );
// create a new knowledge session that uses JPA to store the runtime state
StatefulKnowledgeSession ksession = JPAKnowledgeService.newStatefulKnowledgeSession( kbase, null, env );
int sessionId = ksession.getId();
// invoke methods on your method here
ksession.startProcess( "MyProcess" );
ksession.dispose();
You can also use the JPAKnowledgeService to recreate
a session based on a specific session id:
// recreate the session from database using the sessionId
ksession = JPAKnowledgeService.loadStatefulKnowledgeSession(sessionId, kbase, null, env );
Note that we only save the minimal state that is needed to continue execution of the process instance at some later point. This means, for example, that it does not contain information about already executed nodes if that information is no longer relevant, or that process instances that have been completed or aborted are removed from the database. If you want to search for history-related information, you should use the history log, as explained later.
You need to add a persistence configuration to your classpath to
configure JPA to use Hibernate and the H2 database (or your own preference), called
persistence.xml in the META-INF directory, as shown below.
For more details on how to change this for your own configuration, we refer to
the JPA and Hibernate documentation for more information.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<persistence
version="2.0"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd
http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_2_0.xsd"
xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:orm="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance>
<persistence-unit name="org.jbpm.persistence.jpa" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/jbpm-ds</jta-data-source>
<mapping-file>META-INF/JBPMorm.xml</mapping-file>
<class>org.drools.persistence.info.SessionInfo</class>
<class>org.jbpm.persistence.processinstance.ProcessInstanceInfo</class>
<class>org.drools.persistence.info.WorkItemInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationKeyInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationPropertyInfo</class>
<class>org.jbpm.runtime.manager.impl.jpa.ContextMappingInfo</class>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.max_fetch_depth" value="3"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.transaction.jta.platform"
value="org.hibernate.service.jta.platform.internal.BitronixJtaPlatform"/>
</properties>
</persistence-unit>
</persistence>
This configuration file refers to a data source called "jdbc/jbpm-ds". If you run your application in an application server (like for example JBoss AS), these containers typically allow you to easily set up data sources using some configuration (like for example dropping a datasource configuration file in the deploy directory). Please refer to your application server documentation to know how to do this.
For example, if you're deploying to JBoss Application Server v5.x, you can create a datasource by dropping a configuration file in the deploy directory, for example:
<?xml version="1.0" encoding="UTF-8"?>
<datasources>
<local-tx-datasource>
<jndi-name>jdbc/jbpm-ds</jndi-name>
<connection-url>jdbc:h2:tcp://localhost/~/test</connection-url>
<driver-class>org.h2.jdbcx.JdbcDataSource</driver-class>
<user-name>sa</user-name>
<password></password>
</local-tx-datasource>
</datasources>
If you are however executing in a simple Java environment, you can use the
JBPMHelper class to do this for you (see below for tests only) or the following code
fragment could be used to set up a data source (where we are using the H2 in-memory
database in combination with Bitronix in this case).
PoolingDataSource ds = new PoolingDataSource();
ds.setUniqueName("jdbc/jbpm-ds");
ds.setClassName("bitronix.tm.resource.jdbc.lrc.LrcXADataSource");
ds.setMaxPoolSize(3);
ds.setAllowLocalTransactions(true);
ds.getDriverProperties().put("user", "sa");
ds.getDriverProperties().put("password", "sasa");
ds.getDriverProperties().put("URL", "jdbc:h2:mem:jbpm-db");
ds.getDriverProperties().put("driverClassName", "org.h2.Driver");
ds.init();
You need to configure the jBPM engine to use persistence, usually simply by using the appropriate constructor when creating your session. There are various ways to create a session (as we have tried to make this as easy as possible for you and have several utility classes for you, depending for example if you are trying to write a process JUnit test).
The easiest way to do this is to use the jbpm-test module that allows you to easily
create and test your processes. The JBPMHelper class has a method to create a session,
and uses a configuration file to configure this session, like whether you want to use persistence,
the datasource to use, etc. The helper class will then do all the setup and configuration
for you.
To configure persistence, create a jBPM.properties file and configure the following properties
(note that the example below are the default properties, using an H2 in-memory database with persistence
enabled, if you are fine with all of these properties, you don't need to add new properties file, as it
will then use these properties by default):
# for creating a datasource
persistence.datasource.name=jdbc/jbpm-ds
persistence.datasource.user=sa
persistence.datasource.password=
persistence.datasource.url=jdbc:h2:tcp://localhost/~/jbpm-db
persistence.datasource.driverClassName=org.h2.Driver
# for configuring persistence of the session
persistence.enabled=true
persistence.persistenceunit.name=org.jbpm.persistence.jpa
persistence.persistenceunit.dialect=org.hibernate.dialect.H2Dialect
# for configuring the human task service
taskservice.enabled=true
taskservice.datasource.name=org.jbpm.task
taskservice.usergroupcallback=org.jbpm.services.task.identity.JBossUserGroupCallbackImpl
taskservice.usergroupmapping=classpath:/usergroups.properties
If you want to use persistence, you must make sure that the datasource (that you specified
in the jBPM.properties file) is initialized correctly. This means that the database itself must
be up and running, and the datasource should be registered using the correct name. If you would like
to use an H2 in-memory database (which is usually very easy to do some testing), you can use the
JBPMHelper class to start up this database, using:
JBPMHelper.startH2Server();
To register the datasource (this is something you always need to do, even if you're not using H2 as your database, check below for more options on how to configure your datasource), use:
JBPMHelper.setupDataSource();
Next, you can use the JBPMHelper class to create your session (after creating your knowledge base,
which is identical to the case when you are not using persistence):
StatefulKnowledgeSession ksession = JBPMHelper.newStatefulKnowledgeSession(kbase);
Once you have done that, you can just call methods on this ksession (like startProcess)
and the engine will persist all runtime state in the created datasource.
You can also use the JBPMHelper class to recreate your session (by restoring its state
from the database, by passing in the session id (that you can retrieve using ksession.getId())):
StatefulKnowledgeSession ksession = JBPMHelper.loadStatefulKnowledgeSession(kbase, sessionId);