<management-interfaces> [...] <http-interface security-realm="ManagementRealm"> <socket-binding http="management-http"/> </http-interface> <management-interfaces>
Target audience
This document is intended for people who need to setup and configure JBoss Application Server (AS) 7.
Prerequisites
You should know how to download, install and run JBoss Application Server 7. If not please consult the "Getting Started Guide".
Examples in this guide
Most of the examples in this guide are being expressed as excerpts of the XML configuration files or by using a representation of the de-typed management model.
Management clients
JBoss AS 7 offers three different approaches to configure and manage servers: A web interface, a command line client and a set of XML configuration files. No matter what approach you chose, the configuration is always synchronized across the different views and finally persisted to the XML files.
Web Management Interface
The web interface is a GWT application that uses the HTTP management API to configure a management domain or standalone server.
HTTP Management Endpoint
The HTTP API endpoint is the entry point for management clients that rely on the HTTP protocol to integrate with the management layer. It uses a JSON encoded protocol and a de-typed, RPC style API to describe and execute management operations against a managed domain or standalone server. It's used by the web console, but offers integration capabilities for a wide range of other clients too.
The HTTP API endpoint is co-located with either the domain controller or a standalone server. By default, it runs on port 9990:
(See standalone/configuration/standalone.xml or domain/configuration/host.xml)
The HTTP API Endpoint serves two different contexts. One for executing management operations and another one that allows you to access the web interface:
-
Domain API: http://<host>:9990/management
-
Web Console: http://<host>:9990/console
Accessing the web console
The web console is served through the same port as the HTTP management API. It can be accessed by pointing your browser to:
-
http://<host>:9990/console
Default URL
By default the web interface can be accessed here: http://localhost:9990/console.
Default HTTP Management Interface Security
By default JBoss AS 7.1.x is now distributed secured by default, the default security mechanism is username / password based making use of HTTP Digest for the authentication process.
The reason for securing the server by default is so that if the management interfaces are accidentally exposed on a public IP address authentication is required to connect - for this reason there is no default user in the distribution.
If you attempt to connect to the admin console before you have added a user to the server you will be presented with the following screen.
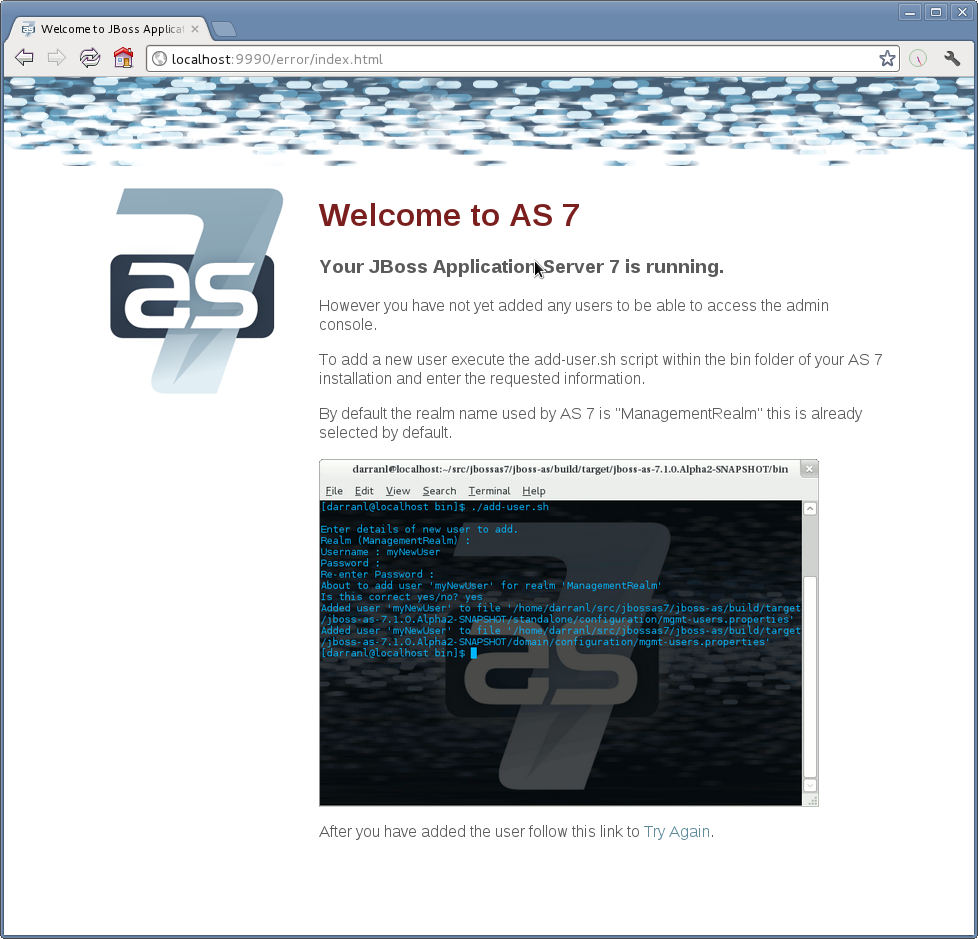
The user are stored in a properties file called mgmt-users.properties under standalone/configuration and domain/configuration depending on the running mode of the server, these files contain the users username along with a pre-prepared hash of the username along with the name of the realm and the users password.
Although the properties files do not contain the plain text passwords they should still be guarded as the pre-prepared hashes could be used to gain access to any server with the same realm if the same user has used the same password.
To manipulate the files and add users we provide a utility add-user.sh and add-user.bat to add the users and generate the hashes, to add a user you should execute the script and follow the guided process. 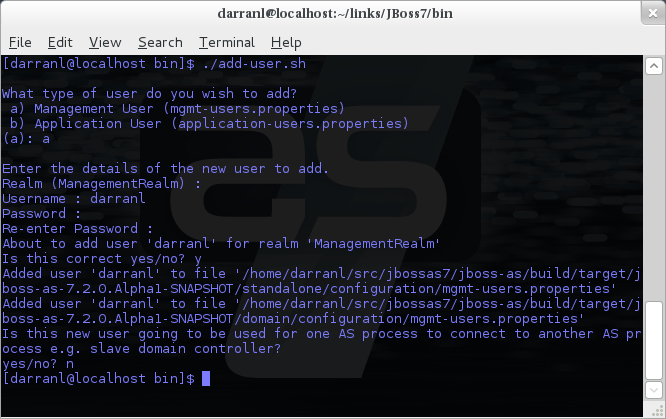
The full details of the add-user utility are described later but for the purpose of accessing the management interface you need to enter the following values: -
-
Type of user - This will be a 'Management User' to selection option a.
-
Realm - This MUST match the realm name used in the configuration so unless you have changed the configuration to use a different realm name leave this set as 'ManagementRealm'.
-
Username - The username of the user you are adding.
-
Password - The users password.
Provided the validation passes you will then be asked to confirm you want to add the user and the properties files will be updated.
For the final question, as this is a user that is going to be accessing the admin console just answer 'n' - this option will be described later for adding slave host controllers that authenticate against a master domain controller but that is a later topic.
Updates to the properties file are picked up in real time so either click 'Try Again' on the error page that was displayed in the browser or navigate to the console again and you should then be prompted to enter the username and password to connect to the server.
Command Line Interface
The Command Line Interface (CLI) is a management tool for a managed domain or standalone server. It allows a user to connect to the domain controller or a standalone server and execute management operations available through the de-typed management model.
Native Management Endpoint
The native API endpoint is the entry point for management clients that rely on the AS's native protocol to integrate with the management layer. It uses an open binary protocol and an RPC style API based on a very small number of Java types to describe and execute management operations against a managed domain or standalone server. It's used by the CLI management tool, but offers integration capabilities for a wide range of other clients too.
The native API endpoint is co-located with either the a host controller or a standalone server. To use the CLI it must be enabled. By default, it runs on port 9999:
<management-interfaces> <native-interface security-realm="ManagementRealm"> <socket-binding native="management-native"/> </native-interface> </native-interf [...] <management-interfaces>
(See standalone/configuration/standalone.xml or domain/configuration/host.xml)
Running the CLI
Depending on the operating system, the CLI is launched using jboss-cli.sh or jboss-cli.bat located in the JBoss AS 7 bin directory. For further information on the default directory structure, please consult the "Getting Started Guide"
The first thing to do after the CLI has started is to connect to a managed JBoss AS 7 instance. This is done using the command connect, e.g.
./bin/jboss-cli.sh You are disconnected at the moment. Type 'connect' to connect to the server or 'help' for the list of supported commands. [disconnected /] [disconnected /] connect Connected to domain controller at localhost:9999 [domain@localhost:9999 /] quit Closed connection to localhost:9999
localhost:9999 is the default host and port combination for the JBoss AS 7 domain controller client.
The host and the port of the server can be provided as an optional parameter, if the server is not listening on localhost:9999.
./bin/jboss-cli.sh You are disconnected at the moment. Type 'connect' to connect to the server [disconnected /] connect 192.168.0.10:9999 Connected to standalone controller at 192.168.0.1:9999
The :9999 is not required as the CLI will use port 9999 by default. The port needs to be provided if the server is listening on some other port.
To terminate the session type quit.
The jboss-cli script accepts a --connect parameter: ./jboss-cli.sh --connect
The --controller parameter can be used to specify the host and port of the server: ./jboss-cli.sh --connect --controller=192.168.0.1:9999
Help is also available:
[domain@localhost:9999 /] help Supported commands: cn (or cd) - change the current node path to the argument; connect - connect to the specified host and port; deploy - deploy an application; help (or h) - print this message; history - print or disable/enable/clear the history expansion. ls - list the contents of the node path; pwn (or pwd) - prints the current working node; quit (or q) - quit the command line interface; undeploy - undeploy an application; version - prints the version and environment information. add-jms-queue - creates a new JMS queue remove-jms-queue - removes an existing JMS queue add-jms-topic - creates a new JMS topic remove-jms-topic - removes an existing JMS topic add-jms-cf - creates a new JMS connection factory remove-jms-cf - removes an existing JMS connection factory data-source - allows to add new, modify and remove existing data sources xa-data-source - allows to add new, modify and remove existing XA data sources For a more detailed description of a specific command, execute the command with '--help' as the argument.
interactive Mode
The CLI can also be run in non-interactive mode to support scripts and other types of command line or batch processing. The --command and --commands arguments can be used to pass a command or a list of commands to execute. Additionally a --file argument is supported which enables CLI commands to be provided from a text file.
For example the following command can be used to list all the current deployments
$ ./bin/jboss-cli.sh --connect --commands=ls\ deployment sample.war osgi-bundle.jar
The output can be combined with other shell commands for further processing, for example to find out what .war files are deployed:
$ ./bin/jboss-cli.sh --connect --commands=ls\ deployment | grep war sample.war
Operation Requests
Operation requests allow for low level interaction with the management model. They are different from the high level commands (i.e. create-jms-queue) in that they allow you to read and modify the server configuration as if you were editing the XML configuration files directly. The configuration is represented as a tree of addressable resources, where each node in the tree (aka resource) offers a set of operations to execute.
An operation request basically consists of three parts: The address, an operation name and an optional set of parameters.
The formal specification for an operation request is:
[/node-type=node-name (/node-type=node-name)*] : operation-name [( [parameter-name=parameter-value (,parameter-name=parameter-value)*] )]
For example:
/profile=production/subsystem=threads/bounded-queue-thread-pool=pool1:write-core-threads (count=0, per-cpu=20)
Tab Completion
Tab-completion is supported for all commands and options, i.e. node-types and node-names, operation names and parameter names. We are also considering adding aliases that are less verbose for the user, and will translate into the corresponding operation requests in the background.
Whitespaces between the separators in the operation request strings are not significant.
Addressing resources
Operation requests might not always have the address part or the parameters. E.g.
:read-resource
which will list all the node types for the current node.
To syntactically disambiguate between the commands and operations, operations require one of the following prefixes:
To execute an operation against the current node, e.g.
cd subsystem=web :read-resource(recursive="true")
To execute an operation against a child node of the current node, e.g.
cd subsystem=web ./connector=http:read-resource
To execute an operation against the root node, e.g.
/subsystem=threads:read-resource
Available Operation Types and Descriptions
The operation types can be distinguished between common operations that exist on any node and specific operations that belong to a particular configuration resource (i.e. subsystem). The common operations are:
-
add
-
read-attribute
-
read-children-names
-
read-children-resources
-
read-children-types
-
read-operation-description
-
read-operation-names
-
read-resource
-
read-resource-description
-
remove
-
validate-address
-
write-attribute
For a list of specific operations (e.g. operations that relate to the logging subsystem) you can always query the model itself. For example, to read the operations supported by the logging subsystem resource on a standalone server:
[[standalone@localhost:9999 /] /subsystem=logging:read-operation-names
{
"outcome" => "success",
"result" => [
"add",
"change-root-log-level",
"read-attribute",
"read-children-names",
"read-children-resources",
"read-children-types",
"read-operation-description",
"read-operation-names",
"read-resource",
"read-resource-description",
"remove-root-logger",
"root-logger-assign-handler",
"root-logger-unassign-handler",
"set-root-logger",
"validate-address",
"write-attribute"
]
}
As you can see, the logging resource offers four additional operations, namely root-logger-assign-handler, root-logger-unassign-handler , set-root-logger and remove-root-logger.
Further documentation about a resource or operation can be retrieved through the description:
[standalone@localhost:9999 /] /subsystem=logging:read-operation-description(name=change-root-log-level)
{
"outcome" => "success",
"result" => {
"operation-name" => "change-root-log-level",
"description" => "Change the root logger level.",
"request-properties" => {"level" => {
"type" => STRING,
"description" => "The log level specifying which message levels will be logged by this logger.
Message levels lower than this value will be discarded.",
"required" => true
}}
}
}
Full model
To see the full model enter :read-resource(recursive=true).
Command History
Command (and operation request) history is enabled by default. The history is kept both in-memory and in a file on the disk, i.e. it is preserved between the command line sessions. The history file name is .jboss-cli-history and is automatically created in the user's home directory. When the command line interface is launched this file is read and the in-memory history is initialized with its content.
While in the command line session, you can use the arrow keys to go back and forth in the history of commands and operations.
To manipulate the history you can use history command. If executed without any arguments, it will print all the recorded commands and operations (up to the configured maximum, which defaults to 500) from the in-memory history.
history supports three optional arguments:
-
disable - will disable history expansion (but will not clear the previously recorded history);
-
enabled - will re-enable history expansion (starting from the last recorded command before the history expansion was disabled);
-
clear - will clear the in-memory history (but not the file one).
Batch Processing
The batch mode allows one to group commands and operations and execute them together as an atomic unit. If at least one of the commands or operations fails, all the other successfully executed commands and operations in the batch are rolled back.
Not all of the commands are allowed in the batch. For example, commands like cd, ls, help, etc. are not allowed in the batch since they don't translate into operation requests. Only the commands that translate into operation requests are allowed in the batch. The batch, actually, is executed as a composite operation request.
The batch mode is entered by executing command batch.
[standalone@localhost:9999 /] batch [standalone@localhost:9999 / #] /subsystem=datasources/data-source="java\:\/H2DS":enable [standalone@localhost:9999 / #] /subsystem=messaging/jms-queue="newQueue":add
You can execute a batch using the run-batch command:
[standalone@localhost:9999 / #] run-batch The batch executed successfully.
Exit the batch edit mode without losing your changes:
[standalone@localhost:9999 / #] holdback-batch [standalone@localhost:9999 /]
Then activate it later on again:
[standalone@localhost:9999 /] batch Re-activated batch #1 /subsystem=datasources/data-source=java:/H2DS:\/H2DS:enable
There are several other notable batch commands available as well (tab complete to see the list):
-
clear-batch
-
edit-batch-line (e.g. edit-batch line 3 create-jms-topic name=mytopic)
-
remove-batch-line (e.g. remove-batch-line 3)
-
move-batch-line (e.g. move-batch-line 3 1)
-
discard-batch
Default HTTP Management Interface Security
The native interface shares the same security configuration as the http interface, however we also support a local authentication mechanism which means that the CLI can authenticate against the local AS instance without prompting the user for a username and password. This mechanism only works if the user running the CLI has read access to the standalone/tmp/auth folder or domain/tmp/auth folder under the respective AS installation - if the local mechanism fails then the CLI will fallback to prompting for a username and password for a user configured as in Default HTTP Interface Security.
Establishing a CLI connection to a remote server will require a username and password by default.
Configuration Files
The XML configuration for a management domain and a standalone server can be found in the configuration subdirectory:
-
domain/configuration/domain.xml
-
domain/configuration/host.xml
-
standalone/configuration/standalone.xml
A managed domain actually ships with two different configuration types: One for the domain as a whole (domain.xml) and and another for each host that joins the domain (host.xml). A detailed explanation how to setup a domain topology can be found in the chapter "Domain Setup".
The XML configuration files act as a central, authoritative source of configuration. Any configuration changes made via the web interface or the CLI are persisted back to the XML configuration files. If a domain or standalone server is offline, the XML configuration files can be hand edited as well, and any changes will be picked up when the domain or standalone server is next started. However, users are encouraged to use the web interface or the CLI in preference to making offline edits to the configuration files. External changes made to the configuration files while processes are running will not be detected, and may be overwritten.
Core management concepts
Operating modes
JBoss Application Server 7 can be booted in two different modes. A managed domain allows you to run and manage a multi-server topology. Alternatively, you can run a standalone server instance.
Standalone Server
For many use cases, the centralized management capability available via a managed domain is not necessary. For these use cases, a JBoss Application Server 7 instance can be run as a "standalone server". A standalone server instance is an independent process, much like an JBoss Application Server 3, 4, 5, or 6 instance is. Standalone instances can be launched via the standalone.sh or standalone.bat launch scripts.
If more than one standalone instance is launched and multi-server management is desired, it is the user's responsibility to coordinate management across the servers. For example, to deploy an application across all of the standalone servers, the user would need to individually deploy the application on each server.
It is perfectly possible to launch multiple standalone server instances and have them form an HA cluster, just like it was possible with JBoss Application Server 3, 4, 5 and 6.
Managed Domain
One of the primary new features of JBoss Application Server 7 is the ability to manage multiple JBoss Application Server 7 instances from a single control point. A collection of such servers is referred to as the members of a "domain" with a single Domain Controller process acting as the central management control point. All of the JBoss Application Server 7 instances in the domain share a common management policy, with the Domain Controller acting to ensure that each server is configured according to that policy. Domains can span multiple physical (or virtual) machines, with all JBoss Application Server 7 instances on a given host under the control of a special Host Controller process. One Host Controller instance is configured to act as the central Domain Controller. The Host Controller on each host interacts with the Domain Controller to control the lifecycle of the application server instances running on its host and to assist the Domain Controller in managing them.
When you launch a JBoss Application Server 7 managed domain on a host (via the domain.sh or domain.bat launch scripts) your intent is to launch a Host Controller and usually at least one JBoss Application Server 7 instance. On one of the hosts the Host Controller should be configured to act as the Domain Controller. See Domain Setup for details.
The following is an example managed domain topology:

Host
Each "Host" box in the above diagram represents a physical or virtual host. A physical host can contain zero, one or more server instances.
Host Controller
When the domain.sh or domain.bat script is run on a host, a process known as a Host Controller is launched. The Host Controller is solely concerned with server management; it does not itself handle application server workloads. The Host Controller is responsible for starting and stopping the individual application server processes that run on its host, and interacts with the Domain Controller to help manage them.
Each Host Controller by default reads its configuration from the domain/configuration/host.xml file located in the unzipped JBoss Application Server 7 installation on its host's filesystem. The host.xml file contains configuration information that is specific to the particular host. Primarily:
-
the listing of the names of the actual JBoss Application Server 7 instances that are meant to run off of this installation.
-
configuration of how the Host Controller is to contact the Domain Controller to register itself and access the domain configuration. This may either be a configuration of how to find and contact a remote Domain Controller, or a configuration telling the Host Controller to itself act as the Domain Controller.
-
configuration of items that are specific to the local physical installation. For example, named interface definitions declared in domain.xml (see below) can be mapped to an actual machine-specific IP address in host.xml. Abstract path names in domain.xml can be mapped to actual filesystem paths in host.xml.
Domain Controller
One Host Controller instance is configured to act as the central management point for the entire domain, i.e. to be the Domain Controller. The primary responsibility of the Domain Controller is to maintain the domain's central management policy, to ensure all Host Controllers are aware of its current contents, and to assist the Host Controllers in ensuring any running application server instances are configured in accordance with this policy. This central management policy is stored by default in the domain/configuration/domain.xml file in the unzipped JBoss Application Server 7 installation on Domain Controller's host's filesystem.
A domain.xml file must be located in the domain/configuration directory of an installation that's meant to run the Domain Controller. It does not need to be present in installations that are not meant to run a Domain Controller; i.e. those whose Host Controller is configured to contact a remote Domain Controller. The presence of a domain.xml file on such a server does no harm.
The domain.xml file includes, among other things, the configuration of the various "profiles" that JBoss Application Server 7 instances in the domain can be configured to run. A profile configuration includes the detailed configuration of the various subsystems that comprise that profile (e.g. an embedded JBoss Web instance is a subsystem; a JBoss TS transaction manager is a subsystem, etc). The domain configuration also includes the definition of groups of sockets that those subsystems may open. The domain configuration also includes the definition of "server groups":
Server Group
A server group is set of server instances that will be managed and configured as one. In a managed domain each application server instance is a member of a server group. (Even if the group only has a single server, the server is still a member of a group.) It is the responsibility of the Domain Controller and the Host Controllers to ensure that all servers in a server group have a consistent configuration. They should all be configured with the same profile and they should have the same deployment content deployed.
The domain can have multiple server groups. The above diagram shows two server groups, "ServerGroupA" and "ServerGroupB". Different server groups can be configured with different profiles and deployments; for example in a domain with different tiers of servers providing different services. Different server groups can also run the same profile and have the same deployments; for example to support rolling application upgrade scenarios where a complete service outage is avoided by first upgrading the application on one server group and then upgrading a second server group.
An example server group definition is as follows:
<server-group name="main-server-group" profile="default"> <socket-binding-group ref="standard-sockets"/> <deployments> <deployment name="foo.war_v1" runtime-name="foo.war" /> <deployment name="bar.ear" runtime-name="bar.ear" /> </deployments> </server-group>
A server-group configuration includes the following required attributes:
-
name -- the name of the server group
-
profile -- the name of the profile the servers in the group should run
In addition, the following optional elements are available:
-
socket-binding-group -- specifies the name of the default socket binding group to use on servers in the group. Can be overridden on a per-server basis in host.xml. If not provided in the server-group element, it must be provided for each server in host.xml.
-
deployments -- the deployment content that should be deployed on the servers in the group.
-
system-properties -- system properties that should be set on all servers in the group
-
jvm -- default jvm settings for all servers in the group. The Host Controller will merge these settings with any provided in host.xml to derive the settings to use to launch the server's JVM. See JVM settings for further details.
Server
Each "Server" in the above diagram represents an actual application server instance. The server runs in a separate JVM process from the Host Controller. The Host Controller is responsible for launching that process. (In a managed domain the end user cannot directly launch a server process from the command line.)
The Host Controller synthesizes the server's configuration by combining elements from the domain wide configuration (from domain.xml ) and the host-specific configuration (from host.xml ).
Deciding between running standalone servers or a managed domain
Which use cases are appropriate for managed domain and which are appropriate for standalone servers? A managed domain is all about coordinated multi-server management -- with it JBoss AS 7 provides a central point through which users can manage multiple servers, with rich capabilities to keep those servers' configurations consistent and the ability to roll out configuration changes (including deployments) to the servers in a coordinated fashion.
It's important to understand that the choice between a managed domain and standalone servers is all about how your servers are managed, not what capabilities they have to service end user requests. This distinction is particularly important when it comes to high availability clusters. It's important to understand that HA functionality is orthogonal to running standalone servers or a managed domain. That is, a group of standalone servers can be configured to form an HA cluster. The domain and standalone modes determine how the servers are managed, not what capabilities they provide.
So, given all that:
-
A single server installation gains nothing from running in a managed domain, so running a standalone server is a better choice.
-
For multi-server production environments, the choice of running a managed domain versus standalone servers comes down to whether the user wants to use the centralized management capabilities a managed domain provides. Some enterprises have developed their own sophisticated multi-server management capabilities and are comfortable coordinating changes across a number of independent JBoss AS 7 instances. For these enterprises, a multi-server architecture comprised of individual standalone servers is a good option.
-
Running a standalone server is better suited for most development scenarios. Any individual server configuration that can be achieved in a managed domain can also be achieved in a standalone server, so even if the application being developed will eventually run in production on a managed domain installation, much (probably most) development can be done using a standalone server.
-
Running a managed domain mode can be helpful in some advanced development scenarios; i.e. those involving interaction between multiple JBoss AS 7 instances. Developers may find that setting up various servers as members of a domain is an efficient way to launch a multi-server cluster.
General configuration concepts
For both a managed domain or a standalone server, a number of common configuration concepts apply:
Extensions
An extension is a module that extends the core capabilities of the server. The JBoss Application Server 7 core is very simple and lightweight; most of the capabilities people associate with an application server are provided via extensions. An extension is packaged as a module in the modules folder. The user indicates that they want a particular extension to be available by including an <extension/> element naming its module in the domain.xml or standalone.xml file.
<extensions> [...] <extension module="org.jboss.as.transactions"/> <extension module="org.jboss.as.web" /> <extension module="org.jboss.as.webservices" /> <extension module="org.jboss.as.weld" /> </extensions>
Profiles and Subsystems
The most significant part of the configuration in domain.xml and standalone.xml is the configuration of one (in standalone.xml) or more (in domain.xml) "profiles". A profile is a named set of subsystem configurations. A subsystem is an added set of capabilities added to the core server by an extension (see "Extensions" above). A subsystem provides servlet handling capabilities; a subsystem provides an EJB container; a subsystem provides JTA, etc. A profile is a named list of subsystems, along with the details of each subsystem's configuration. A profile with a large number of subsystems results in a server with a large set of capabilities. A profile with a small, focused set of subsystems will have fewer capabilities but a smaller footprint.
The content of an individual profile configuration looks largely the same in domain.xml and standalone.xml. The only difference is standalone.xml is only allowed to have a single profile element (the profile the server will run), while domain.xml can have many profiles, each of which can be mapped to one or more groups of servers.
The contents of individual subsystem configurations look exactly the same between domain.xml and standalone.xml.
Paths
A logical name for a filesystem path. The domain.xml, host.xml and standalone.xml configurations all include a section where paths can be declared. Other sections of the configuration can then reference those paths by their logical name, rather than having to include the full details of the path (which may vary on different machines). For example, the logging subsystem configuration includes a reference to the "jboss.server.log.dir" path that points to the server's "log" directory.
<file relative-to="jboss.server.log.dir" path="server.log"/>
JBoss AS 7 automatically provides a number of standard paths without any need for the user to configure them in a configuration file:
-
jboss.home - the root directory of the JBoss AS distribution
-
user.home - user's home directory
-
user.dir - user's current working directory
-
java.home - java installation directory
-
jboss.server.base.dir - root directory for an individual server instance
-
jboss.server.data.dir - directory the server will use for persistent data file storage
-
jboss.server.log.dir - directory the server will use for log file storage
-
jboss.server.tmp.dir - directory the server will use for temporary file storage
-
jboss.domain.servers.dir - directory under which a host controller will create the working area for individual server instances (managed domain mode only)
Users can add their own paths or override all except the first 5 of the above by adding a <path/> element to their configuration file.
<path name="example" path="example" relative-to="jboss.server.data.dir"/>
The attributes are:
-
name -- the name of the path.
-
path -- the actual filesystem path. Treated as an absolute path, unless the 'relative-to' attribute is specified, in which case the value is treated as relative to that path.
-
relative-to -- (optional) the name of another previously named path, or of one of the standard paths provided by the system.
A <path/> element in a domain.xml need not include anything more than the name attribute; i.e. it need not include any information indicating what the actual filesystem path is:
<path name="x"/>
Such a configuration simply says, "There is a path named 'x' that other parts of the domain.xml configuration can reference. The actual filesystem location pointed to by 'x' is host-specific and will be specified in each machine's host.xml file." If this approach is used, there must be a path element in each machine's host.xml that specifies what the actual filesystem path is:
<path name="x" path="/var/x" />
A <path/> element in a standalone.xml must include the specification of the actual filesystem path.
Interfaces
A logical name for a network interface/IP address/host name to which sockets can be bound. The domain.xml, host.xml and standalone.xml configurations all include a section where interfaces can be declared. Other sections of the configuration can then reference those interfaces by their logical name, rather than having to include the full details of the interface (which may vary on different machines). An interface configuration includes the logical name of the interface as well as information specifying the criteria to use for resolving the actual physical address to use. See Interfaces and ports for further details.
An <interface/> element in a domain.xml need not include anything more than the name attribute; i.e. it need not include any information indicating what the actual IP address associated with the name is:
<interface name="internal"/>
Such a configuration simply says, "There is an interface named 'internal' that other parts of the domain.xml configuration can reference. The actual IP address pointed to by 'internal' is host-specific and will be specified in each machine's host.xml file." If this approach is used, there must be an interface element in each machine's host.xml that specifies the criteria for determining the IP address:
<interface name="internal"> <nic name="eth1"/> </interface>
An <interface/> element in a standalone.xml must include the criteria for determining the IP address.
Socket Bindings and Socket Binding Groups
A socket binding is a named configuration for a socket.
The domain.xml and standalone.xml configurations both include a section where named socket configurations can be declared. Other sections of the configuration can then reference those sockets by their logical name, rather than having to include the full details of the socket configuration (which may vary on different machines). See Interfaces and ports for full details.
System Properties
System property values can be set in a number of places in domain.xml, host.xml and standalone.xml. The values in standalone.xml are set as part of the server boot process. Values in domain.xml and host.xml are applied to servers when they are launched.
When a system property is configured in domain.xml or host.xml, the servers it ends up being applied to depends on where it is set. Setting a system property in a child element directly under the domain.xml root results in the property being set on all servers. Setting it in a <system-property/> element inside a <server-group/> element in domain.xml results in the property being set on all servers in the group. Setting it in a child element directly under the host.xml root results in the property being set on all servers controlled by that host's Host Controller. Finally, setting it in a <system-property/> element inside a <server/> element in host.xml result in the property being set on that server. The same property can be configured in multiple locations, with a value in a <server/> element taking precedence over a value specified directly under the host.xml root element, the value in a host.xml taking precedence over anything from domain.xml, and a value in a <server-group/> element taking precedence over a value specified directly under the domain.xml root element.
Management resources
When JBoss Application Server parses your configuration files at boot, or when you use one of the AS's Management Clients you are adding, removing or modifying management resources in the AS's internal management model. A JBoss AS management resource has the following characteristics:
Address
All JBoss AS management resources are organized in a tree. The path to the node in the tree for a particular resource is its address. Each segment in a resource's address is a key/value pair:
-
The key is the resource's type, in the context of its parent. So, for example, the root resource for a standalone server has children of type subsystem, interface, socket-binding, etc. The resource for the subsystem that provides the AS's webserver capability has children of type connector and virtual-server. The resource for the subsystem that provides the AS's messaging server capability has, among others, children of type jms-queue and jms-topic.
-
The value is the name of a particular resource of the given type, e.g web or messaging for subsystems or http or https for web subsystem connectors.
The full address for a resource is the ordered list of key/value pairs that lead from the root of the tree to the resource. Typical notation is to separate the elements in the address with a '/' and to separate the key and the value with an '=':
-
/subsystem=web/connector=http
-
/subsystem=messaging/jms-queue=testQueue
-
/interface=public
When using the HTTP API, a '/' is used to separate the key and the value instead of an '=':
-
http://localhost:9990/management/subsystem/web/connector/http
-
http://localhost:9990/management/subsystem/messaging/jms-queue/testQueue
-
http://localhost:9990/management/interface/public
Operations
Querying or modifying the state of a resource is done via an operation. An operation has the following characteristics:
-
A string name
-
Zero or more named parameters. Each parameter has a string name, and a value of type org.jboss.dmr.ModelNode (or, when invoked via the CLI, the text representation of a ModelNode; when invoked via the HTTP API, the JSON representation of a ModelNode.) Parameters may be optional.
-
A return value, which will be of type org.jboss.dmr.ModelNode (or, when invoked via the CLI, the text representation of a ModelNode; when invoked via the HTTP API, the JSON representation of a ModelNode.)
Every resource except the root resource will have an add operation and should have a remove operation ("should" because in AS 7.0 many do not.) The parameters for the add operation vary depending on the resource. The remove operation has no parameters.
There are also a number of "global" operations that apply to all resources. See Global operations for full details.
The operations a resource supports can themselves be determined by invoking an operation: the read-operation-names operation. Once the name of an operation is known, details about its parameters and return value can be determined by invoking the read-operation-description operation. For example, to learn the names of the operations exposed by the root resource for a standalone server, and then learn the full details of one of them, via the CLI one would:
[standalone@localhost:9999 /] :read-operation-names
{
"outcome" => "success",
"result" => [
"add-namespace",
"add-schema-location",
"delete-snapshot",
"full-replace-deployment",
"list-snapshots",
"read-attribute",
"read-children-names",
"read-children-resources",
"read-children-types",
"read-config-as-xml",
"read-operation-description",
"read-operation-names",
"read-resource",
"read-resource-description",
"reload",
"remove-namespace",
"remove-schema-location",
"replace-deployment",
"shutdown",
"take-snapshot",
"upload-deployment-bytes",
"upload-deployment-stream",
"upload-deployment-url",
"validate-address",
"write-attribute"
]
}
[standalone@localhost:9999 /] :read-operation-description(name=upload-deployment-url)
{
"outcome" => "success",
"result" => {
"operation-name" => "upload-deployment-url",
"description" => "Indicates that the deployment content available at the included URL should be added to the deployment content repository. Note that this operation does not indicate the content should be deployed into the runtime.",
"request-properties" => {"url" => {
"type" => STRING,
"description" => "The URL at which the deployment content is available for upload to the domain's or standalone server's deployment content repository.. Note that the URL must be accessible from the target of the operation (i.e. the Domain Controller or standalone server).",
"required" => true,
"min-length" => 1,
"nillable" => false
}},
"reply-properties" => {
"type" => BYTES,
"description" => "The hash of managed deployment content that has been uploaded to the domain's or standalone server's deployment content repository.",
"min-length" => 20,
"max-length" => 20,
"nillable" => false
}
}
}
See Descriptions below for more on how to learn about the operations a resource exposes.
Attributes
Management resources expose information about their state as attributes. Attributes have string name, and a value of type org.jboss.dmr.ModelNode (or: for the CLI, the text representation of a ModelNode; for HTTP API, the JSON representation of a ModelNode.)
Attributes can either be read-only or read-write. Reading and writing attribute values is done via the global read-attribute and write-attribute operations.
The read-attribute operation takes a single parameter "name" whose value is a the name of the attribute. For example, to read the "port" attribute of a socket-binding resource via the CLI:
[standalone@localhost:9999 /] /socket-binding-group=standard-sockets/socket-binding=https:read-attribute(name=port)
{
"outcome" => "success",
"result" => 8443
}
If an attribute is writable, the write-attribute operation is used to mutate its state. The operation takes two parameters:
-
name – the name of the attribute
-
value – the value of the attribute
For example, to read the "port" attribute of a socket-binding resource via the CLI:
[standalone@localhost:9999 /] /socket-binding-group=standard-sockets/socket-binding=https:write-attribute(name=port,value=8444)
{"outcome" => "success"}
Attributes can have one of two possible storage types:
-
CONFIGURATION – means the value of the attribute is stored in the persistent configuration; i.e. in the domain.xml, host.xml or standalone.xml file from which the resource's configuration was read.
-
RUNTIME – the attribute value is only available from a running server; the value is not stored in the persistent configuration. A metric (e.g. number of requests serviced) is a typical example of a RUNTIME attribute.
The values of all of the attributes a resource exposes can be obtained via the read-resource operation, with the "include-runtime" parameter set to "true". For example, from the CLI:
[standalone@localhost:9999 /] /subsystem=web/connector=http:read-resource(include-runtime=true)
{
"outcome" => "success",
"result" => {
"bytesReceived" => "0",
"bytesSent" => "0",
"errorCount" => "0",
"maxTime" => "0",
"processingTime" => "0",
"protocol" => "HTTP/1.1",
"requestCount" => "0",
"scheme" => "http",
"socket-binding" => "http",
"ssl" => undefined,
"virtual-server" => undefined
}
}
Omit the "include-runtime" parameter (or set it to "false") to limit output to those attributes whose values are stored in the persistent configuration:
[standalone@localhost:9999 /] /subsystem=web/connector=http:read-resource
{
"outcome" => "success",
"result" => {
"protocol" => "HTTP/1.1",
"scheme" => "http",
"socket-binding" => "http",
"ssl" => undefined,
"virtual-server" => undefined
}
}
See Descriptions below for how to learn more about the attributes a particular resource exposes.
Children
Management resources may support child resources. The types of children a resource supports (e.g. connector for the web subsystem resource) can be obtained by querying the resource's description (see Descriptions below) or by invoking the read-children-types operation. Once you know the legal child types, you can query the names of all children of a given type by using the global read-children-types operation. The operation takes a single parameter "child-type" whose value is the type. For example, a resource representing a socket binding group has children. To find the type of those children and the names of resources of that type via the CLI one could:
[standalone@localhost:9999 /] /socket-binding-group=standard-sockets:read-children-types
{
"outcome" => "success",
"result" => ["socket-binding"]
}
[standalone@localhost:9999 /] /socket-binding-group=standard-sockets:read-children-names(child-type=socket-binding)
{
"outcome" => "success",
"result" => [
"http",
"https",
"jmx-connector-registry",
"jmx-connector-server",
"jndi",
"osgi-http",
"remoting",
"txn-recovery-environment",
"txn-status-manager"
]
}
Descriptions
All resources expose metadata that describes their attributes, operations and child types. This metadata is itself obtained by invoking one or more of the global operations each resource supports. We showed examples of the read-operation-names, read-operation-description, read-children-types and read-children-names operations above.
The read-resource-description operation can be used to find the details of the attributes and child types associated with a resource. For example, using the CLI:
[standalone@localhost:9999 /] /socket-binding-group=standard-sockets:read-resource-description
{
"outcome" => "success",
"result" => {
"description" => "Contains a list of socket configurations.",
"head-comment-allowed" => true,
"tail-comment-allowed" => false,
"attributes" => {
"name" => {
"type" => STRING,
"description" => "The name of the socket binding group.",
"required" => true,
"head-comment-allowed" => false,
"tail-comment-allowed" => false,
"access-type" => "read-only",
"storage" => "configuration"
},
"default-interface" => {
"type" => STRING,
"description" => "Name of an interface that should be used as the interface for any sockets that do not explicitly declare one.",
"required" => true,
"head-comment-allowed" => false,
"tail-comment-allowed" => false,
"access-type" => "read-write",
"storage" => "configuration"
},
"port-offset" => {
"type" => INT,
"description" => "Increment to apply to the base port values defined in the socket bindings to derive the runtime values to use on this server.",
"required" => false,
"head-comment-allowed" => true,
"tail-comment-allowed" => false,
"access-type" => "read-write",
"storage" => "configuration"
}
},
"operations" => {},
"children" => {"socket-binding" => {
"description" => "The individual socket configurtions.",
"min-occurs" => 0,
"model-description" => undefined
}}
}
}
Note the "operations" => {} in the output above. If the command had included the operations parameter (i.e. /socket-binding-group=standard-sockets:read-resource-description(operations=true)) the output would have included the description of each operation supported by the resource.
See the Global operations section for details on other parameters supported by the read-resource-description operation and all the other globally available operations.
Comparison to JMX MBeans
JBoss AS management resources are conceptually quite similar to Open MBeans. They have the following primary differences:
-
JBoss AS management resources are organized in a tree structure. The order of the key value pairs in a resource's address is significant, as it defines the resource's position in the tree. The order of the key properties in a JMX ObjectName is not significant.
-
In an Open MBean attribute values, operation parameter values and operation return values must either be one of the simple JDK types (String, Boolean, Integer, etc) or implement either the javax.management.openmbean.CompositeData interface or the javax.management.openmbean.TabularData interface. JBoss AS management resource attribute values, operation parameter values and operation return values are all of type org.jboss.dmr.ModelNode.
Basic structure of the management resource trees
As noted above, management resources are organized in a tree structure. The structure of the tree depends on whether you are running a standalone server or a managed domain.
Standalone server
The structure of the managed resource tree is quite close to the structure of the standalone.xml configuration file.
-
The root resource
-
extension – extensions installed in the server
-
path – paths available on the server
-
system-property – system properties set as part of the configuration (i.e. not on the command line)
-
core-service=management – the server's core management services
-
core-service=service-container – resource for the JBoss MSC ServiceContainer that's at the heart of the AS
-
subsystem – the subsystems installed on the server. The bulk of the management model will be children of type subsystem
-
interface – interface configurations
-
socket-binding-group – the central resource for the server's socket bindings
-
socket-binding – individual socket binding configurations
-
-
deployment – available deployments on the server
-
Managed domain
In a managed domain, the structure of the managed resource tree spans the entire domain, covering both the domain wide configuration (e.g. what's in domain.xml, the host specific configuration for each host (e.g. what's in host.xml, and the resources exposed by each running application server. The Host Controller processes in a managed domain provide access to all or part of the overall resource tree. How much is available depends on whether the management client is interacting with the Host Controller that is acting as the master Domain Controller. If the Host Controller is the master Domain Controller, then the section of the tree for each host is available. If the Host Controller is a slave to a remote Domain Controller, then only the portion of the tree associated with that host is available.
-
The root resource for the entire domain. The persistent configuration associated with this resource and its children, except for those of type host, is persisted in the domain.xml file on the Domain Controller.
-
extension – extensions available in the domain
-
path – paths available on across the domain
-
system-property – system properties set as part of the configuration (i.e. not on the command line) and available across the domain
-
profile – sets of subsystem configurations that can be assigned to server groups
-
subsystem – configuration of subsystems that are part of the profile
-
-
interface – interface configurations
-
socket-binding-group – sets of socket bindings configurations that can be applied to server groups
-
socket-binding – individual socket binding configurations
-
-
deployment – deployments available for assignment to server groups
-
server-group – server group configurations
-
host – the individual Host Controllers. Each child of this type represents the root resource for a particular host. The persistent configuration associated with one of these resources or its children is persisted in the host's host.xml file.
-
path – paths available on each server on the host
-
system-property – system properties to set on each server on the host
-
core-service=management – the Host Controller's core management services
-
interface – interface configurations that apply to the Host Controller or servers on the host
-
jvm – JVM configurations that can be applied when launching servers
-
server-config – configuration describing how the Host Controller should launch a server; what server group configuration to use, and any server-specific overrides of items specified in other resources
-
server – the root resource for a running server. Resources from here and below are not directly persisted; the domain-wide and host level resources contain the persistent configuration that drives a server
-
extension – extensions installed in the server
-
path – paths available on the server
-
system-property – system properties set as part of the configuration (i.e. not on the command line)
-
core-service=management – the server's core management services
-
core-service=service-container – resource for the JBoss MSC ServiceContainer that's at the heart of the AS
-
subsystem – the subsystems installed on the server. The bulk of the management model will be children of type subsystem
-
interface – interface configurations
-
socket-binding-group – the central resource for the server's socket bindings
-
socket-binding – individual socket binding configurations
-
-
deployment – available deployments on the server
-
-
-
Management tasks
Interfaces and ports
Interface declarations
JBoss AS 7 uses named interface references throughout the configuration. A network interface is declared by specifying a logical name and a selection criteria for the physical interface:
[standalone@localhost:9999 /] :read-children-names(child-type=interface)
{
"outcome" => "success",
"result" => [
"management",
"public"
]
}
This means the server in question declares two interfaces: One is referred to as "management"; the other one "public". The "management" interface is used for all components and services that are required by the management layer (i.e. the HTTP Management Endpoint). The "public" interface binding is used for any application related network communication (i.e. Web, Messaging, etc). There is nothing special about these names; interfaces can be declared with any name. Other sections of the configuration can then reference those interfaces by their logical name, rather than having to include the full details of the interface (which, on servers in a management domain, may vary on different machines).
The domain.xml, host.xml and standalone.xml configuration files all include a section where interfaces can be declared. If we take a look at the XML declaration it reveals the selection criteria. The criteria is one of two types: either a single element indicating that the interface should be bound to a wildcard address, or a set of one or more characteristics that an interface or address must have in order to be a valid match. The selection criteria in this example are specific IP addresses for each interface:
<interfaces> <interface name="management"> <inet-address value="127.0.0.1"/> </interface> <interface name="public"> <inet-address value="127.0.0.1"/> </interface> </interfaces>
Some other examples:
<interface name="global">
<!-- Use the wildcard address -->
<any-address/>
</interface>
<interface name="ipv4-global">
<!-- Use the IPv4 wildcard address -->
<any-ipv4-address/>
</interface>
<interface name="ipv6-global">
<!-- Use the IPv6 wildcard address -->
<any-ipv6-address/>
</interface>
<interface name="external">
<nic name="eth0"/>
</interface>
<interface name="default">
<!-- Match any interface/address on the right subnet if it's
up, supports multicast and isn't point-to-point -->
<subnet-match value="192.168.0.0/16"/>
<up/>
<multicast/>
<not>
<point-to-point/>
</not>
</interface>
Socket Binding Groups
The socket configuration in JBoss AS 7 works similar to the interfaces declarations. Sockets are declared using a logical name, by which they will be referenced throughout the configuration. Socket declarations are grouped under a certain name. This allows you to easily reference a particular socket binding group when configuring server groups for instance (Managed Domain). Socket binding groups reference an interface by it's logical name:
<socket-binding-group name="standard-sockets" default-interface="public"> <socket-binding name="jndi" port="1099"/> <socket-binding name="jmx-connector-registry" port="1090"/> <socket-binding name="jmx-connector-server" port="1091"/> <socket-binding name="http" port="8080"/> <socket-binding name="https" port="8443"/> <socket-binding name="jacorb" port="3528"/> <socket-binding name="jacorb-ssl" port="3529"/> <socket-binding name="osgi-http" port="8090"/> <socket-binding name="remoting" port="4447"/> <socket-binding name="txn-recovery-environment" port="4712"/> <socket-binding name="txn-status-manager" port="4713"/> <socket-binding name="messaging" port="5445"/> <socket-binding name="messaging-throughput" port="5455"/> </socket-binding-group>
A socket binding includes the following information:
-
name -- logical name of the socket configuration that should be used elsewhere in the configuration
-
port -- base port to which a socket based on this configuration should be bound. (Note that servers can be configured to override this base value by applying an increment or decrement to all port values.)
-
interface (optional) -- logical name (see "Interfaces declarations" above) of the interface to which a socket based on this configuration should be bound. If not defined, the value of the "default-interface" attribute from the enclosing socket binding group will be used.
-
multicast-address (optional) -- if the socket will be used for multicast, the multicast address to use
-
multicast-port (optional) -- if the socket will be used for multicast, the multicast port to use
-
fixed-port (optional, defaults to false) -- if true, declares that the value of port should always be used for the socket and should not be overridden by applying an increment or decrement
IPv4 versus IPv6
JBoss AS7 supports the use of both IPv4 and IPv6 addresses. By default, AS7 is configured for use in an IPv4 network and so if you are running AS7 in an IPv4 network, no changes are required. If you need to run AS7 in an IPv6 network, the changes required are minimal and involve changing the JVM stack and address preferences, and adjusting any interface IP address values specified in the configuration (standalone.xml or domain.xml).
Stack and address preference
The system properties java.net.preferIPv4Stack and java.net.preferIPv6Addresses are used to configure the JVM for use with IPv4 or IPv6 addresses. With AS7, in order to run using IPv4 addresses, we need to specify java.net.preferIPv4Stack=true; in order to run the AS7 with IPv6 addresses, we need to specify java.net.preferIPv4Stack=false (the JVM default) and java.net.preferIPv6Addresses=true. The latter ensures that any hostname to IP address conversions always return IPv6 address variants.
These system properties are conveniently set by the JAVA_OPTS environment variable, defined in the standalone.conf (or domain.conf) file. For example, to change the IP stack preference from its default of IPv4 to IPv6, edit the standalone.conf (or domain.conf) file and change its default IPv4 setting:
if [ "x$JAVA_OPTS" = "x" ]; then JAVA_OPTS=" ... -Djava.net.preferIPv4Stack=true ..." ...
to an IPv6 suitable setting:
if [ "x$JAVA_OPTS" = "x" ]; then JAVA_OPTS=" ... -Djava.net.preferIPv4Stack=false -Djava.net.preferIPv6Addresses=true ..." ...
IP address literals
To change the IP address literals referenced in standalone.xml (or domain.xml), first visit the interface declarations and ensure that valid IPv6 addresses are being used as interface values. For example, to change the default configuration in which the loopback interface is used as the primary interface, change from the IPv4 loopback address:
<interfaces>
<interface name="management">
<inet-address value="${jboss.bind.address.management:127.0.0.1}"/>
</interface>
<interface name="public">
<inet-address value="${jboss.bind.address:127.0.0.1}"/>
</interface>
</interfaces>
to the IPv6 loopback address:
<interfaces>
<interface name="management">
<inet-address value="${jboss.bind.address.management:[::1]}"/>
</interface>
<interface name="public">
<inet-address value="${jboss.bind.address:[::1]}"/>
</interface>
</interfaces>
Note that when embedding IPv6 address literals in the substitution expression, square brackets surrounding the IP address literal are used to avoid ambiguity. This follows the convention for the use of IPv6 literals in URLs.
Over and above making such changes for the interface definitions, you should also check the rest of your configuration file and adjust IP address literals from IPv4 to IPv6 as required.
Configure Security Realms
Within JBoss AS 7 we make use of security realms to secure access to the management interfaces, these same realms are used to secure inbound access as exposed by JBoss Remoting such as remote JNDI and EJB access, the realms are also used to define an identity for the server - this identity can be used for both inbound connections to the server and outbound connections being established by the server.
General Structure
The general structure of a management realm definition is: -
<security-realm name="ManagementRealm"> <plug-ins></plug-ins> <server-identities></server-identities> <authentication></authentication> <authorization></authorization> </security-realm>
-
plug-ins - This is an optional element that is used to define modules what will be searched for security realm PlugInProviders to extend the capabilities of the security realms.
-
server-identities - An optional element to define the identity of the server as visible to the outside world, this applies to both inbound connection to a resource secured by the realm and to outbound connections also associated with the realm.
One example is the SSL identity of the server, for inbound connections this will control the identity of the server as the SSL connection is established, for outbound connections this same identity can be used where CLIENT-CERT style authentication is being performed.
A second example is where the server is establishing an outbound connection that requires username / password authentication - this element can be used to define that password.
-
authentication - This is probably the most important element that will be used within a security realm definition and mostly applies to inbound connections to the server, this element defines which backing stores will be used to provide the verification of the inbound connection.
This element is optional as there are some scenarios where it will not be required such as if a realm is being defined for an outbound connection using a username and password.
-
authorization - This is the final optional element and is used to define how roles are loaded for an authenticated identity. At the moment this is more applicable for realms used for access to EE deployments such as web applications or EJBs but this will also become relevant as we add role based authorization checks to the management model.
Enabling a Realm
After a realm has been defined it needs to be associated with an inbound or outbound connection for it to be used, the following are some examples where these associations are used within the AS7 configuration.
Inbound Connections
Management Interfaces
Either within the standalone.xml or host.xml configurations the security realms can be associated with the management interfaces as follows: -
<native-interface security-realm="ManagementRealm">...</native-interface> <http-interface security-realm="ManagementRealm">...</http-interface>
If the security-realm attribute is omitted or removed from the interface definition it means that access to that interface will be unsecured
By default we do bind these interfaces to the loopback address so that the interfaces are not accessible remotely out of the box, however do be aware that if these interfaces are then unsecured any other local user will be able to control and administer the AS7 installation.
Also do note that the security-realm attribute is defined on each interface independently, this means that you could define a different security realm for each - this may be applicable if say you want the administrators to only access over the HTTP interface and leave only local users to access the native interface.
Remoting Subsystem
The Remoting subsystem exposes a connector to allow for inbound comunications with JNDI and the EJB subsystem by default we associate the ApplicationRealm with this connection.
<subsystem xmlns="urn:jboss:domain:remoting:1.1"> <connector name="remoting-connector" socket-binding="remoting" security-realm="ApplicationRealm"/> </subsystem>
Outbound Connections
Remoting Subsystem
Outbound connections can also be defined within the Remoting subsystem, these are typically used for remote EJB invocations from one AS server to another, in this scenario the security realm is used to obtain the server identity either it's password for X.509 certificate and possibly a trust store to verify the certificate of the remote host.
Even if the referenced realm contains username and password authentication configuration the client side of the connection will NOT use this to verify the remote server.
<remote-outbound-connection name="remote-ejb-connection"
outbound-socket-binding-ref="binding-remote-ejb-connection"
username="user1"
security-realm="PasswordRealm">
The security realm is only used to obtain the password for this example, as you can see here the username is specified separately.
Slave Domain Controller
When running in domain mode slave domain controllers need to establish a connection to the native interface of the master domain controller so these also need a realm for the identity of the slave.
<domain-controller>
<remote host="${jboss.domain.master.address}" port="${jboss.domain.master.port:9999}" security-realm="ManagementRealm"/>
</domain-controller>
By default when a slave domain controller authenticates against the master domain controller it uses the name of it's host controller as it's username, if you want to override the username used for authentication a username attribute can be added to the <remote /> element.
Authentication
One of the primary functions of the security realms is to define the user stores that will be used to verify the identity of inbound connections, the actual approach taken at the transport level is based on the capabilities of these backing store definitions. The security realms are used to secure inbound connections for both the http management interface and for inbound remoting connections for both the native management interface and to access other services exposed over remoting - because of this there are some small differences between how the realm is used for each of these.
At the transport level we support the following authentication mechanisms.
|
HTTP |
Remoting (SASL) |
|
None |
Anonymous |
|
N/A |
JBoss Local User |
|
Digest |
Digest |
|
Basic |
Plain |
|
Client Cert |
Client Cert |
The most notable are the first two in this list as they need some additional explanation - the final 3 are fairly standard mechanisms.
If either the http interface, the native interface or a remoting connection are difined without a security realm reference then they are effectively unsecured, in the case of the http interface this means that no authentication will be performed on the incoming connection - for the remoting connections however we make use of SASL so require at least one authentication mechanism so make use of the anonymous mechanism to allow a user in without requiring a validated authentication process.
The next mechanism 'JBoss Local User' is specific to the remoting connections - as we ship AS 7.1 secured by default we wanted a way to allow users to connect to their own AS installation after it is started without mandating that they define a user with a password - to accomplish this we have added the 'JBoss Local User' mechanism. This mechanism makes the use of tokens exchanged on the filesystem to prove that the client is local to the AS installation and has the appropriate file permissions to read a token written by the AS to file. As this mechanism is dependent on both server and client implementation details it is only supported for the remoting connections and not the http connections - at some point we may review if we can add support for this to the http interface but we would need to explore the options available with the commony used web browsers that are used to communicate with the http interface.
The Digest mechanism is simply the HTTP Digest / SASL Digest mechanism that authenticates the user by making use of md5 hashed including nonces to avoid sending passwords in plain text over the network - this is the preferred mechanism for username / password authentication.
The HTTP Basic / SASL Plain mechanism is made available for times that Digest can not be used but effectively this means that the users password will be sent over the network in the clear unless SSL is enabled.
The final mechanism Client-Cert allows X.509 certificates to be used to verify the identity of the remote client.
One point bearing in mind is that it is possible that an association with a realm can mean that a single incoming connection has the ability to choose between one or more authentication mechanisms. As an example it is possible that an incoming remoting connection could choose between 'Client Cert', A username password mechanism or 'JBoss Local User' for authentication - this would allow say a local user to use the local mechanism, a remote user to supply their username and password whilst a remote script could make a call and authenticate using a certificate.
Authorization
The actual security realms are not involved in any authorization decisions however they can be configured to load a users roles which will subsequently be used to make authorization decisions - when references to authorization are seen in the context of security realms it is this loading of roles that is being referred to.
For the loading of roles the process is split out to occur after the authentication step so after a user has been authenticated a second step will occur to load the roles based on the username they used to authenticate with.
Out Of The Box Configuration
Before describing the complete set of configuration options available within the realms we will look at the default configuration as for most users that is going to be the starting point before customising further.
The examples here are taken from the standalone configuration however the descriptions are equally applicable to domain mode, one point worth noting is that all security realms defined in the host.xml are available to be referenced within the domain configuration for the servers running on that host controller.
Management Realm
<security-realm name="ManagementRealm">
<authentication>
<local default-user="$local"/>
<properties path="mgmt-users.properties" relative-to="jboss.server.config.dir"/>
</authentication>
</security-realm>
The realm ManagementRealm is the simplest realm within the default configuration, this realm simply enables two authentication mechanisms, the local mechanism and username/password authentication which will be using Digest authentication.
-
local
When using the local mechanism it is optional for remote clients to send a username to the server, this configuration specifies that where clients do not send a username it will be assumed that the clients username is $local - the <local /> element can also be configured to allow other usernames to be specified by remote clients however for the default configuration this is not enabled so is not supported.
-
properties
For username / password authentication the users details will be loaded from the file mgmt-users.properties which is located in {jboss.home}/standalone/configuration or {jboss.home}/domain/configuration depending on the running mode of the server.
Each user is represented on their own line and the format of each line is username=HASH where HASH is a pre-prepared hash of the users password along with their username and the name of the realm which in this case is ManagementRealm.
You do not need to worry about generating the entries within the properties file as we provide a utility add-user.sh or add-user.bat to add the users, this utility is described in more detail below.
By pre-hashing the passwords in the properties file it does mean that if the user has used the same password on different realms then the contents of the file falling into the wrong hands does not nescesarily mean all accounts are compromised. HOWEVER the contents of the files do still need to be protected as they can be used to access any server where the realm name is the same and the user has the same username and password pair.
Application Realm
<security-realm name="ApplicationRealm">
<authentication>
<local default-user="$local" allowed-users="*"/>
<properties path="application-users.properties" relative-to="jboss.server.config.dir"/>
</authentication>
<authorization>
<properties path="application-roles.properties" relative-to="jboss.server.config.dir"/>
</authorization>
</security-realm>
The realm ApplicationRealm is a slightly more complex realm as this is used for both
Authentication
The authentication configuration is very similar to the ManagementRealm in that it enabled both the local mechanism and a username/password based Digest mechanism.
-
local
The local configuration is similar to the ManagementRealm in that where the remote user does not supply a username it will be assumed that the username is $local, however in addition to this there is now an allowed-users attribute with a value of '*' - this means that the remote user can specify any username and it will be accepted over the local mechanism provided that the local verification is a success.
To restrict the usernames that can be specified by the remote user a comma separated list of usernames can be specified instead within the allowed-users attribute.
-
properties
The properties definition works in exactly the same way as the definition for ManagementRealm except now the properties file is called application-users.properties.
Authorization
The contents of the Authorization element are specific to the ApplicationRealm, in this case a properties file is used to load a users roles.
The properties file is called application-roles.properties and is located in {jboss.home}/standalone/configuration or {jboss.home}/domain/configuration depending on the running mode of the server. The format of this file is username=ROLES where ROLES is a comma separated list of the users roles.
As the loading of a users roles is a second step this is where it may be desirable to restrict which users can use the local mechanism so that some users still require username and password authentication for their roles to be loaded.
other security domain
<security-domain name="other" cache-type="default">
<authentication>
<login-module code="Remoting" flag="optional">
<module-option name="password-stacking" value="useFirstPass"/>
</login-module>
<login-module code="RealmDirect" flag="required">
<module-option name="password-stacking" value="useFirstPass"/>
</login-module>
</authentication>
</security-domain>
When applications are deployed to the application server they are associated with a security domain within the security subsystem, the other security domain is provided to work with the ApplicationRealm, this domain is defined with a pair of login modules Remoting and RealmDirect.
-
Remoting
The Remoting login module is used to check if the request currently being authenticated is a request received over a Remoting connection, if so the identity that was created during the authentication process is used and associated with the current request.
If the request did not arrive over a Remoting connection this module does nothing and allows the JAAS based login to continue to the next module.
-
RealmDirect
The RealmDirect login module makes use of a security realm to authenticate the current request if that did not occur in the Remoting login module and then use the realm to load the users roles, by default this login module assumes the realm to use is called ApplicationRealm although other names can be overridden.
The advantage of this approach is that all of the backing store configuration can be left within the realm with the security domain just delegating to the realm.
user.sh
For use with the default configuration we supply a utility add-user which can be used to manage the properties files for the default realms used to store the users and their roles.
The add-user utility can be used to manage both the users in the ManagementRealm and the users in the ApplicationRealm, changes made apply to the properties file used both for domain mode and standalone mode.
After you have installed your application server and decided if you are going to run in standalone mode or domain mode you can delete the parent folder for the mode you are not using, the add-user utility will then only be managing the properties file for the mode in use.
The add-user utility is a command line utility however it can be run in both interactive and non-interactive mode. Depending on your platform the script to run the add-user utility is either add-user.sh or add-user.bat which can be found in {jboss.home}/bin.
This guide now contains a couple of examples of this utility in use to accomplish the most common tasks.
Adding a User
Adding users to the properties files is the primary purpose of this utility.
The server caches the contents of the properties files in memory, however the server does check the modified time of the properties files on each authentication request and re-load if the time has been updated - this means all changes made by this utility are immediately applied to any running server.
A Management User
The default name of the realm for management users is ManagementRealm, when the utility prompts for the realm name just accept the default unless you have switched to a different realm.
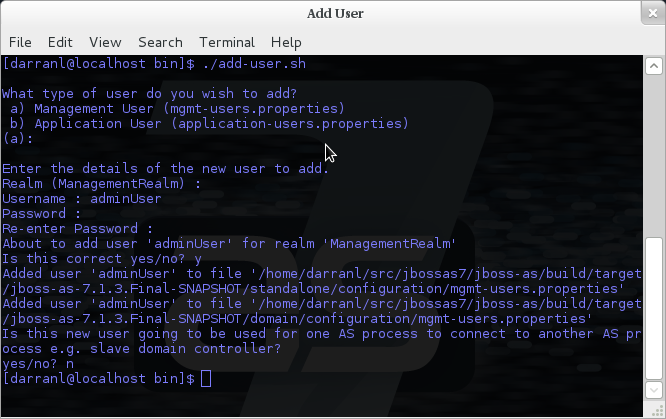
Here we have added a new Management User called adminUser, as you can see some of the questions offer default responses so you can just press enter without repeating the default value.
For now just answer n or no to the final question, adding users to be used by processes is described in more detail in the domain management chapter.
To add a user in non-interactive mode the command ./add-user.sh {username} {password} can be used.
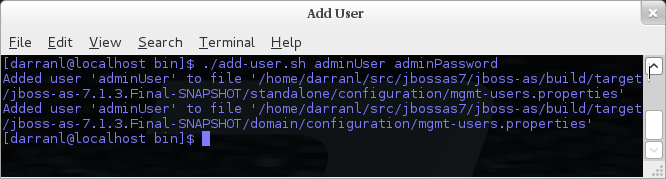
If you add users using this approach there is a risk that any other user that can view the list of running process may see the arguments including the password of the user being added, there is also the risk that the username / password combination will be cached in the history file of the shell you are currently using.
An Application User
When adding application users in addition to adding the user with their pre-hashed password it is also now possible to define the roles of the user.
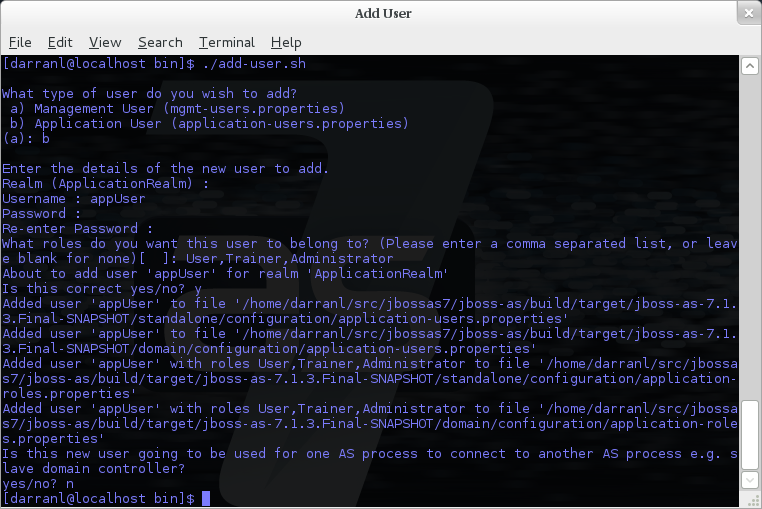
Here a new user called appUser has been added, in this case a comma separated list of roles has also been specified.
As with adding a management user just answer n or no to the final question until you know you are adding a user that will be establishing a connection from one server to another.
To add an application user non-interactively use the command ./add-user.sh -a {username} {password}.
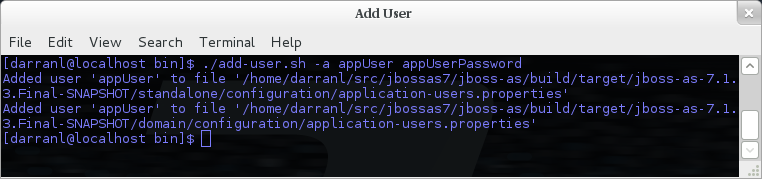
Non-interactive mode does not support defining a list of users, to associate a user with a set of roles you will need to manually edit the application-roles.properties file by hand.
Updating a User
Within the add-user utility it is also possible to update existing users, in interactive mode you will be prompted to confirm if this is your intention.
A Management User
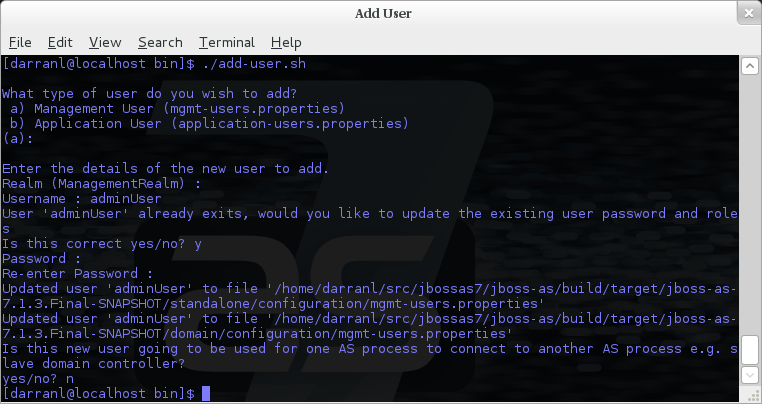
In non-interactive mode if a user already exists the update is automatic with no confirmation prompt.
An Application User

On updating a user with roles you will need to re-enter the list of roles assigned to the user.
In non-interactive mode if a user already exists the update is automatic with no confirmation prompt.
Community Contributions
There are still a few features to add to the add-user utility such as removing users or adding application users with roles in non-interactive mode, if you are interested in contributing to JBoss AS development the add-user utility is a good place to start as it is a stand alone utility, however it is a part of the AS build so you can become familiar with the AS development processes without needing to delve straight into the internals of the application server.
JMX
When configuring the security realms remote access to the servers MBeanServer needs a special mention, when running in standalone mode the following is the default configuration: -
<native-interface security-realm="ManagementRealm">...</native-interface>
<subsystem xmlns="urn:jboss:domain:jmx:1.1"> ... <remoting-connector/> </subsystem>
With this configuration remote access to JMX is provided over the native management interface, this is secured using the realm ManagementRealm, this means that any user that can connect to the native interface can also use this interface to access the MBeanServer - to disable this just remove the <remoting-connector /> element.
In domain mode it is slightly more complicates as the native interface is exposed by the host controller process however each application server is running in it's own process so by default remote access to JMX is disabled.
<subsystem xmlns="urn:jboss:domain:remoting:1.1"> <connector name="remoting-connector" socket-binding="remoting" security-realm="ApplicationRealm"/> </subsystem>
<subsystem xmlns="urn:jboss:domain:jmx:1.1"> ... <!--<remoting-connector use-management-endpoint="false"/>--> </subsystem>
To enable remote access to JMX uncomment the <remoting-connector /> element however be aware that this will make the MBeanServer accessible over the same Remoting connector used for remote JNDI and EJB access - this means that any user that can authenticate against the realm ApplicationRealm will be able to access the MBeanServer.
The following Jira issue is currently outstanding to allow access to the individual MBeanServers by proxying through the host controllers native interface AS7-4009, if this is a feature you would use please add your vote to the issue.
Detailed Configuration
This section of the documentation describes the various configuration options when defining realms, plug-ins are a slightly special case so the configuration options for plug-ins is within it's own section.
Within a security realm definition there are four optional elements <plug-ins />, <server-identities />, <authentication />, and <authorization />, as mentioned above plug-ins is defined within it's own section below so we will begin by looking at the <server-identities /> element.
<server-identities />
The server identities section of a realm definition is used to define how a server appears to the outside world, currently this element can be used to configure a password to be used when establishing a remote outbound connection and also how to load a X.509 key which can be used for both inbound and outbound SSL connections.
<ssl />
<server-identities>
<ssl protocol="...">
<keystore path="..." relative-to="..." keystore-password="..." alias="..." key-password="..." />
</ssl>
</server-identities>
-
protocol - By default this is set to TLS and in general does not need to be set.
The SSL element then contains the nested <keystore /> element, this is used to define how to load the key from the file based (JKS) keystore.
-
path (mandatory) - This is the path to the keystore, this can be an absolute path or relative to the next attribute.
-
relative-to (optional) - The name of a service representing a path the keystore is relative to.
-
keystore-password (mandatory) - The password required to open the keystore.
-
alias (optional) - The alias of the entry to use from the keystore - for a keystore with multiple entries in practice the first usable entry is used but this should not be relied on and the alias should be set to guarantee which entry is used.
-
key-password (optional) - The password to load the key entry, if omitted the keystore-password will be used instead.
If you see the error UnrecoverableKeyException: Cannot recover key the most likely cause that you need to specify a key-password and possible even an alias as well to ensure only one key is loaded.
<secret />
<server-identities> <secret value="..." /> </server-identities>
-
value (mandatory) - The password to use for outbound connections encoded as Base64, this field also supports a vault expression should stronger protection be required.
The username for the outbound connection is specified at the point the outbound connection is defined.
<authentication />
The authentication element is predominantly used to configure the authentication that is performed on an inbound connection, however there is one exception and that is if a trust store is defined - on negotiating an outbound SSL connection the trust store will be used to verify the remote server.
<authentication> <truststore /> <local /> <jaas /> <ldap /> <properties /> <users /> <plug-in /> </authentication>
An authentication definition can have zero or one <truststore />, it can also have zero or one <local /> and it can also have one of <jaas />, <ldap />, <properties />, <users />, and <plug-in /> i.e. the local mechanism and a truststore for certificate verification can be independent switched on and off and a single username / password store can be defined.
<truststore />
<authentication> <truststore path="..." relative-to="..." keystore-password="..."/> </authentication>
This element is used to define how to load a key store file that can be used as the trust store within the SSLContext we create internally, the store is then used to verify the certificates of the remote side of the connection be that inbound or outbound.
-
path (mandatory) - This is the path to the keystore, this can be an absolute path or relative to the next attribute.
-
relative-to (optional) - The name of a service representing a path the keystore is relative to.
-
keystore-password (mandatory) - The password required to open the keystore.
Although this is a definition of a trust store the attribute for the password is keystore-password, this is because the underlying file being opened is still a key store.
Due to the AS7-4698 bug in 7.1.1 use password instead of keystore-password attribute in truststore element. This bug was fixed in 7.1.2.
<local />
<authentication> <local default-user="..." allowed-users="..." /> </authentication>
This element switches on the local authentication mechanism that allows clients to the server to verify that they are local to the server, at the protocol level it is optional for the remote client to send a user name in the authentication response.
-
default-user (optional) - If the client does not pass in a username this is the assumed username, this value is also automatically added to the list of allowed-users.
-
allowed-users (optional) - This attribute is used to specify a comma separated list of users allowed to authenticate using the local mechanism, alternatively '*' can be specified to allow any username to be specified.
<jaas />
<authentication> <jaas name="..." /> </authentication>
The jaas element is used to enable username and password based authentication where the supplied username and password are verified by making use of a configured jaas domain.
-
name (mandatory) - The name of the jaas domain to use to verify the supplied username and password.
As JAAS authentication works by taking a username and password and verifying these the use of this element means that at the transport level authentication will be forced to send the password in plain text, any interception of the messages exchanged between the client and server without SSL enabled will reveal the users password.
<ldap />
<authentication>
<ldap connection="..." base-dn="..." recursive="..." user-dn="...">
<username-filter attribute="..." />
<advanced-filter filter="..." />
</ldap>
</authentication>
The ldap element is used to define how LDAP searches will be used to authenticate a user, this works by first connecting to LDAP and performing a search using the supplied user name to identity the distinguished name of the user and then a subsequent connection is made to the server using the password supplied by the user - if this second connection is a success then authentication succeeds.
Due to the verification approach used this configuration causes the authentication mechanisms selected for the protocol to cause the password to be sent from the client in plain text, the following Jira issue is to investigating proxying a Digest authentication with the LDAP server so no plain text password is needed AS7-4195.
-
connection (mandatory) - The name of the connection to use to connect to LDAP.
-
base-dn (mandatory) - The distinguished name of the context to use to begin the search from.
-
recursive (optional) - Should the filter be executed recursively? Defaults to false.
-
user-dn (optional) - After the user has been found specifies which attribute to read for the users distinguished name, defaults to 'dn'.
Within the ldap element only one of <username-filter /> or <advanced-filter /> can be specified.
<username-filter />
This element is used for a simple filter to match the username specified by the remote user against a single attribute, as an example with Active Directory the match is most likely to be against the 'sAMAccountName' attribute.
-
attribute (mandatory) - The name of the field to match the users supplied username against.
<advanced-filter />
This element is used where a more advanced filter is required, one example use of this filter is to exclude certain matches by specifying some additional criteria for the filter.
-
filter (mandatory) - The filter to execute to locate the user, this filter should contain '{0}' as a place holder for the username supplied by the user authenticating.
<properties />
<authentication> <properties path="..." relative-to="..." plain-text="..." /> </authentication>
The properties element is used to reference a properties file to load to read a users password or pre-prepared digest for the authentication process.
-
path (mandatory) - The path to the properties file, either absolute or relative to the path referenced by the relative-to attribute.
-
relative-to (optional) - The name of a path service that the defined path will be relative to.
-
plain-text (optional) - Setting to specify if the passwords are stored as plain text within the properties file, defaults to false.
By default the properties files are expected to store a pre-prepared hash of the users password in the form HEX( MD5( username ':' realm ':' password))
<users />
<authentication>
<users>
<user username="...">
<password>...</password>
</user>
</users>
</authentication>
This is a very simple store of a username and password that stores both of these within the domain model, this is only really provided for the provision of simple examples.
-
username (mandatory) - A users username.
The <password/> element is then used to define the password for the user.
<authorization />
The authorization element is used to define how a users roles can be loaded after the authentication process completes, these roles may then be used for subsequent authorization decisions based on the service being accessed. At the moment only a properties file approach or a custom plug-in are supported - support for loading roles from LDAP or from a database are planned for a subsequent release.
<authorization> <properties /> <plug-in /> </authorization>
<properties />
<authorization> <properties path="..." relative-to="..." /> </authorization>
The format of the properties file is username={ROLES} where {ROLES} is a comma separated list of the users roles.
-
path (mandatory) - The path to the properties file, either absolute or relative to the path referenced by the relative-to attribute.
-
relative-to (optional) - The name of a path service that the defined path will be relative to.
<outbound-connection />
Strictly speaking these are not a part of the security realm definition, however at the moment they are only used by security realms so the definition of outbound connection is described here.
<management>
<security-realms />
<outbound-connections>
<ldap />
</outbound-connections>
</management>
<ldap />
At the moment we only support outbound connections to ldap servers for the authentication process - this will later be expanded when we add support for database based authentication.
<outbound-connections> <ldap name="..." url="..." search-dn="..." search-credential="..." initial-context-factory="..." /> </outbound-connections>
The outbound connections are defined in this section and then referenced by name from the configuration that makes use of them.
-
name (mandatory) - The unique name used to reference this connection.
-
url (mandatory) - The URL use to establish the LDAP connection.
-
search-dn (mandatory) - The distinguished name of the user to authenticate as to perform the searches.
-
search-credential (mandatory) - The password required to connect to LDAP as the search-dn.
-
initial-context-factory (optional) - Allows overriding the initial context factory, defaults to 'com.sun.jndi.ldap.LdapCtxFactory'
Plug Ins
Within JBoss AS7 for communication with the management interfaces and for other services exposed using Remoting where username / password authentication is used the use of Digest authentication is preferred over the use of HTTP Basic or SASL Plain so that we can avoid the sending of password in the clear over the network. For validation of the digests to work on the server we either need to be able to retrieve a users plain text password or we need to be able to obtain a ready prepared hash of their password along with the username and realm.
Previously to allow the addition of custom user stores we have added an option to the realms to call out to a JAAS domain to validate a users username and password, the problem with this approach is that to call JAAS we need the remote user to send in their plain text username and password so that a JAAS LoginModule can perform the validation, this forces us down to use either the HTTP Basic authentication mechanism or the SASL Plain mechanism depending on the transport used which is undesirable as we can not longer use Digest.
To overcome this we now support plugging in custom user stores to support loading a users password, hash and roles from a custom store to allow different stores to be implemented without forcing the authentication back to plain text variant, this article describes the requirements for a plug in and shows a simple example plug-in for use with AS7.
When implementing a plug in there are two steps to the authentication process, the first step is to load the users identity and credential from the relevent store - this is then used to verify the user attempting to connect is valid. After the remote user is validated we then load the users roles in a second step. For this reason the support for plug-ins is split into the two stages, when providing a plug-in either of these two steps can be implemented but there is no requirement to implement the other side.
When implementing a plug-in the following interfaces are the bare minimum that need to be implemented so depending on if a plug-in to load a users identity or a plug-in to load a users roles is being implemented you will be implementing one of these interfaces.
Note - All classes and interfaces of the SPI to be implemented are in the 'org.jboss.as.domain.management.plugin' package which is a part of the 'org.jboss.as.domain-management' module but for simplicity for the rest of this section only the short names will be shown.
AuthenticationPlugIn
To implement an AuthenticationPlugIn the following interface needs to be implemened: -
public interface AuthenticationPlugIn<T extends Credential> {
Identity<T> loadIdentity(final String userName, final String realm) throws IOException;
}
During the authenication process this method will be called with the user name supplied by the remote user and the name of the realm they are authenticating against, this method call represents that an authentication attempt is occurring but it is the Identity instance that is returned that will be used for the actual authentication to verify the remote user.
The Identity interface is also an interface you will implement: -
public interface Identity<T extends Credential> {
String getUserName();
T getCredential();
}
Additional information can be contained within the Identity implementation although it will not currently be used, the key piece of information here is the Credential that will be returned - this needs to be one of the following: -
PasswordCredential
public final class PasswordCredential implements Credential {
public PasswordCredential(final char[] password);
public char[] getPassword();
void clear();
}
The PasswordCredential is already implemented so use this class if you have the plain text password of the remote user, by using this the secured interfaces will be able to continue using the Digest mechanism for authentication.
DigestCredential
public final class DigestCredential implements Credential {
public DigestCredential(final String hash);
public String getHash();
}
This class is also already implemented and should be returned if instead of the plain text password you already have a pre-prepared hash of the username, realm and password.
ValidatePasswordCredential
public interface ValidatePasswordCredential extends Credential {
boolean validatePassword(final char[] password);
}
This is a special Credential type to use when it is not possible to obtain either a plain text representation of the password or a pre-prepared hash - this is an interface as you will need to provide an implementation to verify a supplied password. The down side of using this type of Credential is that the authentication mechanism used at the transport level will need to drop down from Digest to either HTTP Basic or SASL Plain which will now mean that the remote client is sending their credential across the network in the clear.
If you use this type of credential be sure to force the mechanism choice to Plain as described in the configuration section below.
AuthorizationPlugIn
If you are implementing a custom mechanism to load a users roles you need to implement the AuthorizationPlugIn
public interface AuthorizationPlugIn {
String[] loadRoles(final String userName, final String realm) throws IOException;
}
As with the AuthenticationPlugIn this has a single method that takes a users userName and realm - the return type is an array of Strings with each entry representing a role the user is a member of.
PlugInConfigurationSupport
In addition to the specific interfaces above there is an additional interface that a plug-in can implement to recieve configuration information before the plug-in is used and also to recieve a Map instance that can be used to share state between the plug-in instance used for the authentication step of the call and the plug-in instance used for the authorization step.
public interface PlugInConfigurationSupport {
void init(final Map<String, String> configuration, final Map<String, Object> sharedState) throws IOException;
}
Installing and Configuring a Plug-In
The next step of this article describes the steps to implement a plug-in provider and how to make it available within AS7 and how to configure it. Example configuration and an example implementation are shown to illustrate this.
The following is an example security realm definition which will be used to illustrate this: -
<security-realm name="PlugInRealm">
<plug-ins>
<plug-in module="org.jboss.as.sample.plugin"/>
</plug-ins>
<authentication>
<plug-in name="Sample">
<properties>
<property name="darranl.password" value="dpd"/>
<property name="darranl.roles" value="Admin,Banker,User"/>
</properties>
</plug-in>
</authentication>
<authorization>
<plug-in name="Delegate" />
</authorization>
</security-realm>
Before looking closely at the packaging and configuration there is one more interface to implement and that is the PlugInProvider interface, that interface is responsible for making PlugIn instances available at runtime to handle the requests.
PlugInProvider
public interface PlugInProvider {
AuthenticationPlugIn<Credential> loadAuthenticationPlugIn(final String name);
AuthorizationPlugIn loadAuthorizationPlugIn(final String name);
}
These methods are called with the name that is supplied in the plug-in elements that are contained within the authentication and authorization elements of the configuration, based on the sample configuration above the loadAuthenticationPlugIn method will be called with a parameter of 'Sample' and the loadAuthorizationPlugIn method will be called with a parameter of 'Delegate'.
Multiple plug-in providers may be available to the application server so if a PlugInProvider implementation does not recognise a name then it should just return null and the server will continue searching the other providers. If a PlugInProvider does recognise a name but fails to instantiate the PlugIn then a RuntimeException can be thrown to indicate the failure.
As a server could have many providers registered it is recommended that a naming convention including some form of hierarchy is used e.g. use package style names to avoid conflicts.
For the example the implementation is as follows: -
public class SamplePluginProvider implements PlugInProvider {
public AuthenticationPlugIn<Credential> loadAuthenticationPlugIn(String name) {
if ("Sample".equals(name)) {
return new SampleAuthenticationPlugIn();
}
return null;
}
public AuthorizationPlugIn loadAuthorizationPlugIn(String name) {
if ("Sample".equals(name)) {
return new SampleAuthenticationPlugIn();
} else if ("Delegate".equals(name)) {
return new DelegateAuthorizationPlugIn();
}
return null;
}
}
The load methods are called for each authentication attempt but it will be an implementation detail of the provider if it decides to return a new instance of the provider each time - in this scenario as we also use configuration and shared state then new instances of the implementations make sense.
To load the provider use a ServiceLoader so within the META-INF/services folder of the jar this project adds a file called 'org.jboss.as.domain.management.plugin.PlugInProvider' - this contains a single entry which is the fully qualified class name of the PlugInProvider implementation class.
org.jboss.as.sample.SamplePluginProvider
Package as a Module
To make the PlugInProvider available to the application it is bundled as a module and added to the modules already shipped with AS7.
To add as a module we first need a module.xml: -
<?xml version="1.0" encoding="UTF-8"?>
<module xmlns="urn:jboss:module:1.1" name="org.jboss.as.sample.plugin">
<properties>
</properties>
<resources>
<resource-root path="SamplePlugIn.jar"/>
</resources>
<dependencies>
<module name="org.jboss.as.domain-management" />
</dependencies>
</module>
The interfaces being implemented are in the 'org.jboss.as.domain-management' module so a dependency on that module is defined, this module.xml is then placed in the '{jboss.home}/modules/org/jboss/as/sample/plugin/main'.
The compiled classed and META-INF/services as described above are assmbled into a jar called SamplePlugIn.jar and also placed into this folder.
Looking back at the sample configuration at the top of the realm definition the following element was added: -
<plug-ins>
<plug-in module="org.jboss.as.sample.plugin"/>
</plug-ins>
This element is used to list the modules that should be searched for plug-ins. As plug-ins are loaded during the server start up this search is a lazy search so don't expect a definition to a non existant module or to a module that does not contain a plug-in to report an error.
The AuthenticationPlugIn
The example AuthenticationPlugIn is implemented as: -
public class SampleAuthenticationPlugIn extends AbstractPlugIn {
private static final String PASSWORD_SUFFIX = ".password";
private static final String ROLES_SUFFIX = ".roles";
private Map<String, String> configuration;
public void init(Map<String, String> configuration, Map<String, Object> sharedState) throws IOException {
this.configuration = configuration;
// This will allow an AuthorizationPlugIn to delegate back to this instance.
sharedState.put(AuthorizationPlugIn.class.getName(), this);
}
public Identity loadIdentity(String userName, String realm) throws IOException {
String passwordKey = userName + PASSWORD_SUFFIX;
if (configuration.containsKey(passwordKey)) {
return new SampleIdentity(userName, configuration.get(passwordKey));
}
throw new IOException("Identity not found.");
}
public String[] loadRoles(String userName, String realm) throws IOException {
String rolesKey = userName + ROLES_SUFFIX;
if (configuration.containsKey(rolesKey)) {
String roles = configuration.get(rolesKey);
return roles.split(",");
} else {
return new String[0];
}
}
private static class SampleIdentity implements Identity {
private final String userName;
private final Credential credential;
private SampleIdentity(final String userName, final String password) {
this.userName = userName;
this.credential = new PasswordCredential(password.toCharArray());
}
public String getUserName() {
return userName;
}
public Credential getCredential() {
return credential;
}
}
}
As you can see from this implementation there is also an additional class being extended AbstractPlugIn - that is simply an abstract class that implements the AuthenticationPlugIn, AuthorizationPlugIn, and PlugInConfigurationSupport interfaces already. The properties that were defined in the configuration are passed in as a Map and importantly for this sample the plug-in adds itself to the shared state map.
The AuthorizationPlugIn
The example implementation of the authentication plug in is as follows: -
public class DelegateAuthorizationPlugIn extends AbstractPlugIn {
private AuthorizationPlugIn authorizationPlugIn;
public void init(Map<String, String> configuration, Map<String, Object> sharedState) throws IOException {
authorizationPlugIn = (AuthorizationPlugIn) sharedState.get(AuthorizationPlugIn.class.getName());
}
public String[] loadRoles(String userName, String realm) throws IOException {
return authorizationPlugIn.loadRoles(userName, realm);
}
}
This plug-in illustrates how two plug-ins can work together, by the AuthenticationPlugIn placing itself in the shared state map it is possible for the authorization plug-in to make use of it for the loadRoles implementation.
Another option to consider to achieve similar behaviour could be to provide an Identity implementation that also contains the roles and place this in the shared state map - the AuthorizationPlugIn can retrieve this and return the roles.
Forcing Plain Text Authentication
As mentioned earlier in this article if the ValidatePasswordCredential is going to be used then the authentication used at the transport level needs to be forced from Digest authentication to plain text authentication, this can be achieved by adding a mechanism attribute to the plug-in definition within the authentication element i.e.
<authentication>
<plug-in name="Sample" mechanism="PLAIN">
Example Configurations
This section of the document contains a couple of examples for the most common scenarios likely to be used with the security realms, please feel free to raise Jira issues requesting additional scenarios or if you have configured something not covered here please feel free to add your own examples - this document is editable after all ![]()
At the moment these examples are making use of the 'ManagementRealm' however the same can apply to the 'ApplicationRealm' or any custom realm you create for yourselves.
LDAP Authentication
The following example demonstrates an example configuration making use of Active Directory to verify the users username and password.
<management>
<security-realms>
<security-realm name="ManagementRealm">
<authentication>
<ldap connection="EC2" base-dn="CN=Users,DC=darranl,DC=jboss,DC=org">
<username-filter attribute="sAMAccountName" />
</ldap>
</authentication>
</security-realm>
</security-realms>
<outbound-connections>
<ldap name="EC2" url="ldap://127.0.0.1:9797" search-dn="CN=as7,CN=Users,DC=darranl,DC=jboss,DC=org" search-credential="password"/>
</outbound-connections>
...
</management>
For simplicity the <local/> configuration has been removed from this example, however there it is fine to leave that in place for local authentication to remain possible.
Enable SSL
The first step is the creation of the key, by default this is going to be used for both the native management interface and the http management interface - to create the key we can use the keyTool, the following example will create a key valid for one year.
Open a terminal window in the folder {jboss.home}/standalone/configuration and enter the following command: -
keytool -genkey -alias server -keyalg RSA -keystore server.keystore -validity 365
Enter keystore password: Re-enter new password:
In this example I choose 'keystore_password'.
What is your first and last name? [Unknown]: localhost
Of all of the questions asked this is the most important and should match the host name that will be entered into the web browser to connect to the admin console.
Answer the remaining questions as you see fit and at the end for the purpose of this example I set the key password to 'key_password'.
The following example shows how this newly created keystore will be referenced to enable SSL.
<security-realm name="ManagementRealm">
<server-identities>
<ssl>
<keystore path="server.keystore" relative-to="jboss.server.config.dir" keystore-password="keystore_password" alias="server" key-password="key_password" />
</ssl>
</server-identities>
<authentication>
...
</authentication>
</security-realm>
The contents of the <authentication /> have not been changed in this example so authentication still occurs using either the local mechanism or username/password authentication using Digest.
Add Client-Cert to SSL
To enable Client-Cert style authentication we just now need to add a <truststore /> element to the <authentication /> element referencing a trust store that has had the certificates or trusted clients imported.
<security-realm name="ManagementRealm">
<server-identities>
<ssl>
<keystore path="server.keystore" relative-to="jboss.server.config.dir" keystore-password="keystore_password" alias="server" key-password="key_password" />
</ssl>
</server-identities>
<authentication>
<truststore path="server.truststore" relative-to="jboss.server.config.dir" keystore-password="truststore_password" />
<local default-user="$local"/>
<properties path="mgmt-users.properties" relative-to="jboss.server.config.dir"/>
</authentication>
</security-realm>
In this scenario if Client-Cert authentication does not occur clients can fall back to use either the local mechanism or username/password authentication. To make Client-Cert based authentication mandatory just remove the <local /> and <properties /> elements.
JVM settings
Configuration of the JVM settings is different for a managed domain and a standalone server. In a managed domain, the domain controller components are responsible for starting and stoping server processes and hence determine the JVM settings. For a standalone server, it's the responsibility of the process that started the server (e.g. passing them as command line arguments).
Managed Domain
In a managed domain the JVM settings can be declared at different scopes: For a specific server group, for a host or for a particular server. If not declared, the settings are inherited from the parent scope. This allows you to customize or extend the JVM settings within every layer.
Let's take a look at the JVM declaration for a server group:
<server-groups>
<server-group name="main-server-group" profile="default">
<jvm name="default">
<heap size="64m" max-size="512m"/>
</jvm>
<socket-binding-group ref="standard-sockets"/>
</server-group>
<server-group name="other-server-group" profile="default">
<jvm name="default">
<heap size="64m" max-size="512m"/>
</jvm>
<socket-binding-group ref="standard-sockets"/>
</server-group>
</server-groups>
(See domain/configuration/domain.xml)
In this example the server group "main-server-group" declares a heap size of 64m and a maximum heap size of 512m. Any server that belongs to this group will inherit these settings. You can change these settings for the group as a whole, or a specific server or host:
<servers>
<server name="server-one" group="main-server-group" auto-start="true">
<jvm name="default"/>
</server>
<server name="server-two" group="main-server-group" auto-start="true">
<jvm name="default">
<heap size="64m" max-size="256m"/>
</jvm>
<socket-binding-group ref="standard-sockets" port-offset="150"/>
</server>
<server name="server-three" group="other-server-group" auto-start="false">
<socket-binding-group ref="standard-sockets" port-offset="250"/>
</server>
</servers>
(See domain/configuration/host.xml)
In this case, server-two, belongs to the main-server-group and inherits the JVM settings named default, but declares a lower maximum heap size.
[domain@localhost:9999 /] /host=local/server-config=server-two/jvm=default:read-resource
{
"outcome" => "success",
"result" => {
"heap-size" => "64m",
"max-heap-size" => "256m",
}
}
Standalone Server
For a standalone sever you have to pass in the JVM settings either as command line arguments when executing the $JBOSS_HOME/bin/standalone.sh script, or by declaring them in $JBOSS_HOME/bin/standalone.conf. (For Windows users, the script to execute is %JBOSS_HOME%/bin/standalone.bat while the JVM settings can be declared in %JBOSS_HOME%/bin/standalone.conf.bat.)
Command line parameters
To start up a JBoss AS 7 managed domain, execute the $JBOSS_HOME/bin/domain.sh script. To start up a standalone server, execute the $JBOSS_HOME/bin/standalone.sh. With no arguments, the default configuration is used. You can override the default configuration by providing arguments on the command line, or in your calling script.
System properties
The standalone and the managed domain modes each use a default configuration which expects various files and writable directories to exist in standard locations. Each of these standard locations is associated with a system property, which has a default value. To override a system property, pass its new value using the standard jvm -Dkey=value options:
$JBOSS_HOME/bin/standalone.sh -Djboss.home.dir=some/location/AS7/jboss-as \
-Djboss.server.config.dir=some/location/AS7/jboss-as/custom-standalone
This command starts up a standalone server instance using a non-standard AS home directory and a custom configuration directory. For specific information about system properties, refer to the definitions below.
Instead of passing the parameters directly, you can put them into a properties file, and pass the properties file to the script, as in the two examples below.
$JBOSS_HOME/bin/domain.sh --properties=/some/location/jboss.properties $JBOSS_HOME/bin/domain.sh -P=/some/location/jboss.properties
The syntax for passing in parameters and properties files is the same regardless of whether you are running the domain.sh, standalone.sh, or the Microsoft Windows scriptsdomain.bat or standalone.bat.
The properties file is a standard Java property file containing key=value pairs:
jboss.home.dir=/some/location/AS7/jboss-as jboss.domain.config.dir=/some/location/AS7/custom-domain
Standalone
|
Property name |
Usage |
Default value |
|
java.ext.dirs |
The JDK extension directory paths |
null |
|
jboss.home.dir |
The root directory of the JBoss AS 7 installation. |
Set by standalone.sh to $JBOSS_HOME |
|
jboss.server.base.dir |
The base directory for server content. |
jboss.home.dir/standalone |
|
jboss.server.config.dir |
The base configuration directory. |
jboss.server.base.dir/configuration |
|
jboss.server.data.dir |
The directory used for persistent data file storage. |
jboss.server.base.dir/data |
|
jboss.server.log.dir |
The directory containing the server.log file. |
jboss.server.base.dir/log |
|
jboss.server.temp.dir |
The directory used for temporary file storage. |
jboss.server.base.dir/tmp |
|
jboss.server.deploy.dir |
The directory used to store deployed content |
jboss.server.data.dir/content |
Managed Domain
|
Property name |
Usage |
Default value |
|
jboss.home.dir |
The root directory of the JBoss AS 7 installation. |
Set by domain.sh to $JBOSS_HOME |
|
jboss.domain.base.dir |
The base directory for domain content. |
jboss.home.dir/domain |
|
jboss.domain.config.dir |
The base configuration directory |
jboss.domain.base.dir/configuration |
|
jboss.domain.data.dir |
The directory used for persistent data file storage. |
jboss.domain.base.dir/data |
|
jboss.domain.log.dir |
The directory containing the host-controller.log and process-controller.log files |
jboss.domain.base.dir/log |
|
jboss.domain.temp.dir |
The directory used for temporary file storage |
jboss.domain.base.dir/tmp |
|
jboss.domain.deployment.dir |
The directory used to store deployed content |
jboss.domain.base.dir/content |
|
jboss.domain.servers.dir |
The directory containing the output for the managed server instances |
jboss.domain.base.dir/servers |
Other command line parameters
The first acceptable format for command line arguments to the JBoss AS launch scripts is
--name=value
For example:
$JBOSS_HOME/bin/standalone.sh --server-config=standalone-ha.xml
If the parameter name is a single character, it is prefixed by a single '-' instead of two. Some parameters have both a long and short option.
-x=value
For example:
$JBOSS_HOME/bin/standalone.sh -P=/some/location/jboss.properties
For some command line arguments frequently used in previous major releases of JBoss AS, replacing the "=" in the above examples with a space is supported, for compatibility.
-b 192.168.100.10
If possible, use the -x=value syntax. New parameters will always support this syntax.
The sections below describe the command line parameter names that are available in standalone and domain mode.
Standalone
|
Name |
Default if absent |
Value |
|
--server-config |
jboss.server.config.dir/standalone.xml |
A relative path which is interpreted to be relative to jboss.server.config.dir. |
Managed Domain
|
Name |
Default if absent |
Value |
|
--domain-config |
jboss.domain.config.dir/domain.xml |
A relative path which is interpreted to be relative to jboss.domain.config.dir. |
|
--host-config |
jboss.domain.config.dir/host.xml |
A relative path which is interpreted to be relative to jboss.domain.config.dir. |
The following parameters take no value and are only usable on slave host controllers (i.e. hosts configured to connect to a remote domain controller.)
|
Name |
Function |
|
--backup |
Causes the slave host controller to create and maintain a local copy of the domain configuration file |
|
--cached-dc |
If the slave host controller is unable to contact the master domain controller to get its configuration at boot, boot from a local copy previously created using --backup. The slave host controller will not be able make any modifications to the domain configuration, but it will be able to launch servers. |
Common parameters
These parameters apply in both standalone or managed domain mode:
|
Name |
Function |
|
-b=<value> |
Sets system property jboss.bind.address to <value>. See Controlling the Bind Address with -b for further details. |
|
-b<name>=<value> |
Sets system property jboss.bind.address.<name> to <value> where name can vary. See Controlling the Bind Address with -b for further details. |
|
-u=<value> |
Sets system property jboss.default.multicast.address to <value>. See Controlling the Default Multicast Address with -u for further details. |
|
--version |
Prints the version of JBoss AS to standard output and exits the JVM. |
|
--help |
Prints a help message explaining the options and exits the JVM. |
Controlling the Bind Address with -b
JBoss AS binds sockets to the IP addresses and interfaces contained in the <interfaces> elements in standalone.xml, domain.xml and host.xml. (See Interfaces and Socket Bindings for further information on these elements.) The standard configurations that ship with JBoss AS includes two interface configurations:
<interfaces>
<interface name="management">
<inet-address value="${jboss.bind.address.management:127.0.0.1}"/>
</interface>
<interface name="public">
<inet-address value="${jboss.bind.address:127.0.0.1}"/>
</interface>
</interfaces>
Those configurations use the values of system properties jboss.bind.address.management and jboss.bind.address if they are set. If they are not set, 127.0.0.1 is used for each value.
As noted in Common Parameters, the AS supports the -b and -b<name> command line switches. The only function of these switches is to set system properties jboss.bind.address and jboss.bind.address.<name> respectively. However, because of the way the standard AS configuration files are set up, using the -b switches can indirectly control how the AS binds sockets.
If your interface configurations match those shown above, using this as your launch command causes all sockets associated with interface named "public" to be bound to 192.168.100.10.
$JBOSS_HOME/bin/standalone.sh -b=192.168.100.10
In the standard config files, public interfaces are those not associated with server management. Public interfaces handle normal end-user requests.
Interface names
The interface named "public" is not inherently special. It is provided as a convenience. You can name your interfaces to suit your environment.
To bind the public interfaces to all IPv4 addresses (the IPv4 wildcard address), use the following syntax:
$JBOSS_HOME/bin/standalone.sh -b=0.0.0.0
You can also bind the management interfaces, as follows:
$JBOSS_HOME/bin/standalone.sh -bmanagement=192.168.100.10
In the standard config files, management interfaces are those sockets associated with server management, such as the socket used by the CLI, the HTTP socket used by the admin console, and the JMX connector socket.
Be Careful
The -b switch only controls the interface bindings because the standard config files that ship with JBoss AS sets things up that way. If you change the <interfaces> section in your configuration to ignore the system properties controlled by -b, then setting -b in your launch command will have no effect.
For example, this perfectly valid setting for the "public" interface causes -b to have no effect on the "public" interface:
<interface name="public"> <nic name="eth0"/> </interface>
The key point is the contents of the configuration files determine the configuration. Settings like -b are not overrides of the configuration files. They only provide a shorter syntax for setting a system properties that may or may not be referenced in the configuration files. They are provided as a convenience, and you can choose to modify your configuration to ignore them.
Controlling the Default Multicast Address with -u
JBoss AS may use multicast communication for some services, particularly those involving high availability clustering. The multicast addresses and ports used are configured using the socket-binding elements in standalone.xml and domain.xml. (See Socket Bindings for further information on these elements.) The standard HA configurations that ship with JBoss AS include two socket binding configurations that use a default multicast address:
<socket-binding name="jgroups-mping" port="0" multicast-address="${jboss.default.multicast.address:230.0.0.4}" multicast-port="45700"/>
<socket-binding name="jgroups-udp" port="55200" multicast-address="${jboss.default.multicast.address:230.0.0.4}" multicast-port="45688"/>
Those configurations use the values of system property jboss.default.multicast.address if it is set. If it is not set, 230.0.0.4 is used for each value. (The configuration may include other socket bindings for multicast-based services that are not meant to use the default multicast address; e.g. a binding the mod-cluster services used to communicate on a separate address/port with Apache httpd servers.)
As noted in Common Parameters, the AS supports the -u command line switch. The only function of this switch is to set system property jboss.default.multicast.address. However, because of the way the standard AS configuration files are set up, using the -u switches can indirectly control how the AS uses multicast.
If your socket binding configurations match those shown above, using this as your launch command causes the service using those sockets configurations to be communicate over multicast address 230.0.1.2.
$JBOSS_HOME/bin/standalone.sh -u=230.0.1.2
Be Careful
As with the -b switch, the -u switch only controls the multicast address used because the standard config files that ship with JBoss AS sets things up that way. If you change the <socket-binding> sections in your configuration to ignore the system properties controlled by -u, then setting -u in your launch command will have no effect.
Subsystem configuration
The following chapters will focus on the high level management use cases that are available through the CLI and the web interface. For a detailed description of each subsystem configuration property, please consult the respective component reference.
Schema Location
The configuration schema can found in $JBOSS_HOME/docs/schema.
Data sources
Datasources are configured through the datasource subsystem. Declaring a new datasource consists of two separate steps: You would need to provide a JDBC driver and define a datasource that references the driver you installed.
JDBC Driver Installation
In a JDBC core module
For better start up server behavior, install the JDBC driver as a core module.
As a regular JAR deployment
A simple way to install a JDBC driver into the application server is to deploy it as a regular JAR deployment, the driver must be JDBC-4 compliant. A reason for this might be if you run your application server in domain mode, deployments are automatically propagated to all servers to which the deployment applies; thus distribution of the driver JAR is one less thing for you to worry about!
Any JDBC 4-compliant driver will automatically be recognized and installed into the system by name and version. A JDBC JAR is identified using the Java service provider mechanism. Such JARs will contain a text a file named META-INF/services/java.sql.Driver, which contains the name of the class(es) of the Drivers which exist in that JAR. If your JDBC driver JAR is not JDBC 4-compliant, it can be made deployable in one of a few ways.
The most straightforward solution is to simply modify the JAR and add the missing file. You can do this from your command shell by:
-
Change to, or create, an empty temporary directory.
-
Create a META-INF subdirectory.
-
Create a META-INF/services subdirectory.
-
Create a META-INF/services/java.sql.Driver file which contains one line - the fully-qualified class name of the JDBC driver.
-
Use the jar command-line tool to update the JAR like this:
jar \-uf jdbc-driver.jar META-INF/services/java.sql.Driver
For a detailed explanation how to deploy JDBC 4 compliant driver jar, please refer to the chapter "Application Deployment".
Datasource Definitions
The datasource itself is defined within the subsystem datasources:
<subsystem xmlns="urn:jboss:domain:datasources:1.0">
<datasources>
<datasource jndi-name="java:jboss/datasources/ExampleDS" pool-name="ExampleDS">
<connection-url>jdbc:h2:mem:test;DB_CLOSE_DELAY=-1</connection-url>
<driver>h2</driver>
<pool>
<min-pool-size>10</min-pool-size>
<max-pool-size>20</max-pool-size>
<prefill>true</prefill>
</pool>
<security>
<user-name>sa</user-name>
<password>sa</password>
</security>
</datasource>
<xa-datasource jndi-name="java:jboss/datasources/ExampleXADS" pool-name="ExampleXADS">
<driver>h2</driver>
<xa-datasource-property name="URL">jdbc:h2:mem:test</xa-datasource-property>
<xa-pool>
<min-pool-size>10</min-pool-size>
<max-pool-size>20</max-pool-size>
<prefill>true</prefill>
</xa-pool>
<security>
<user-name>sa</user-name>
<password>sa</password>
</security>
</xa-datasource>
<drivers>
<driver name="h2" module="com.h2database.h2">
<xa-datasource-class>org.h2.jdbcx.JdbcDataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
</subsystem>
(See standalone/configuration/standalone.xml)
As you can see the datasource references a driver by it's logical name.
You can easily query the same information through the CLI:
[standalone@localhost:9999 /] /subsystem=datasources:read-resource(recursive=true)
{
"outcome" => "success",
"result" => {
"data-source" => {"java:/H2DS" => {
"connection-url" => "jdbc:h2:mem:test;DB_CLOSE_DELAY=-1",
"jndi-name" => "java:/H2DS",
"driver-name" => "h2",
"pool-name" => "H2DS",
"use-java-context" => true,
"enabled" => true,
"jta" => true,
"pool-prefill" => true,
"pool-use-strict-min" => false,
"user-name" => "sa",
"password" => "sa",
"flush-strategy" => "FailingConnectionOnly",
"background-validation" => false,
"use-fast-fail" => false,
"validate-on-match" => false,
"use-ccm" => true
}},
"xa-data-source" => undefined,
"jdbc-driver" => {"h2" => {
"driver-name" => "h2",
"driver-module-name" => "com.h2database.h2",
"driver-xa-datasource-class-name" => "org.h2.jdbcx.JdbcDataSource"
}}
}
}
[standalone@localhost:9999 /] /subsystem=datasources:installed-drivers-list
{
"outcome" => "success",
"result" => [{
"driver-name" => "h2",
"deployment-name" => undefined,
"driver-module-name" => "com.h2database.h2",
"module-slot" => "main",
"driver-xa-datasource-class-name" => "org.h2.jdbcx.JdbcDataSource",
"driver-class-name" => "org.h2.Driver",
"driver-major-version" => 1,
"driver-minor-version" => 2,
"jdbc-compliant" => true
}]
}
Using the web console or the CLI greatly simplifies the deployment of JDBC drivers and the creation of datasources.
The CLI offers a set of commands to create and modify datasources:
[standalone@localhost:9999 /] help Supported commands: [...] data-source - allows to add new, modify and remove existing data sources xa-data-source - allows add new, modify and remove existing XA data sources For a more detailed description of a specific command, execute the command with '--help' as the argument.
Using security domains
Information can be found at https://community.jboss.org/wiki/JBossAS7SecurityDomainModel
Deployment of -ds.xml files
Starting with JBoss Application Server 7.1.0.Final you have the ability to deploy a -ds.xml file following the schema:
http://docs.jboss.org/ironjacamar/schema/datasources_1_1.xsd
It is mandatory to use a reference to an already deployed / defined <driver> entry.
This feature is primarily intended for development, and thus has a few limitations to be aware of. It can not be altered in any of the management interfaces (consle, CLI, etc). Only limited runtime information is available. Also, password vaults and security domains are not deployable, so these can not be bundled with a datasource deployment.
Component Reference
The datasource subsystem is provided by the IronJacamar project. For a detailed description of the available configuration properties, please consult the project documentation.
-
IronJacamar homepage: http://www.jboss.org/ironjacamar
-
Project Documentation: http://www.jboss.org/ironjacamar/docs
-
Schema description: http://docs.jboss.org/ironjacamar/userguide/1.0/en-US/html/deployment.html#deployingds_descriptor
Messaging
The JMS server configuration is done through the messaging subsystem. In this chapter we are going outline the frequently used configuration options. For a more detailed explanation please consult the HornetQ user guide (See "Component Reference").
Connection Factories
There are two kinds of basic JMS connection-factory:
-
In-VM connection factories can be used by a local client (i.e. one running in the same JVM as the server)
-
Netty connections factories can be used by a remote client.
There is also a pooled-connection-factory which is special in that it leverages the outbound adapter of the HornetQ JCA Resource Adapter. It is also special because:
-
It is only available to local clients, although it can be configured to point to a remote server.
-
As the name suggests, it is pooled and therefore provides superior performance to the clients which are able to use it. The pool size can be configured via the max-pool-size and min-pool-size attributes.
-
It should only be used to send (i.e. produce) messages.
-
It can be configured to use specific security credentials via the user and password attributes. This is useful if the remote server to which it is pointing is secured.
To be clear, the inbound adapter of the HornetQ JCA RA (which is for consuming messages) is only used by MDBs and is not available to other kinds of clients.
Both a connection-factory a pooled-connection-factory reference a connector declaration.
A netty-connector is associated with a socket-binding which tells the client using the connection-factory where to connect.
-
A connection-factory referencing a netty-connector is suitable to be used by a remote client to send messages to or receive messages from the server (assuming the connection-factory has an appropriately exported entry).
-
A pooled-connection-factory referencing a netty-connector is suitable to be used by a local client to send messages to a remote server granted the socket-binding references an outbound-socket-binding pointing to the remote server in question.
An in-vm-connector is associated with a server-id which tells the client using the connection-factory where to connect (since multiple HornetQ servers can run in a single JVM).
-
A connection-factory referencing an in-vm-connector is suitable to be used by a local client to either send messages to or receive messages from a local server.
-
A pooled-connection-factory referencing an in-vm-connector is suitable to be used by a local client only to send messages to a local server.
The entry declaration of a connection-factory or a pooled-connection-factory specifies the JNDI name under which the factory will be exposed. Only JNDI names bound in the "java:jboss/exported" namespace are available to remote clients. If a connection-factory has an entry bound in the "java:jboss/exported" namespace a remote client would look-up the connection-factory using the text after "java:jboss/exported". For example, the "RemoteConnectionFactory" is bound by default to "java:jboss/exported/jms/RemoteConnectionFactory" which means a remote client would look-up this connection-factory using "jms/RemoteConnectionFactory". A pooled-connection-factory should not have any entry bound in the "java:jboss/exported" namespace because a pooled-connection-factory is not suitable for remote clients.
<subsystem xmlns="urn:jboss:domain:messaging:1.0">
[...]
<connectors>
<netty-connector name="netty" socket-binding="messaging"/>
<netty-connector name="netty-throughput" socket-binding="messaging-throughput">
<param key="batch-delay" value="50"/>
</netty-connector>
<in-vm-connector name="in-vm" server-id="0"/>
</connectors>
[...]
<jms-connection-factories>
<connection-factory name="InVmConnectionFactory">
<connectors>
<connector-ref connector-name="in-vm"/>
</connectors>
<entries>
<entry name="java:/ConnectionFactory"/>
</entries>
</connection-factory>
<connection-factory name="RemoteConnectionFactory">
<connectors>
<connector-ref connector-name="netty"/>
</connectors>
<entries>
<entry name="RemoteConnectionFactory"/>
<entry name="java:jboss/exported/jms/RemoteConnectionFactory"/>
</entries>
</connection-factory>
<pooled-connection-factory name="hornetq-ra">
<transaction mode="xa"/>
<connectors>
<connector-ref connector-name="in-vm"/>
</connectors>
<entries>
<entry name="java:/JmsXA"/>
</entries>
</pooled-connection-factory>
</jms-connection-factories>
[...]
</subsystem>
(See standalone/configuration/standalone-full.xml)
JMS Queues and Topics
JMS queues and topics are sub resources of the messaging subsystem. They are defined in the jms-destinations section. One can define either a jms-queue or jms-topic. Each destination must be given a name and contain at least one entry element.
Each entry refers to a JNDI name of the queue or topic. Keep in mind that any jms-queue or jms-topic which needs to be accessed by a remote client needs to have an entry in the "java:jboss/exported" namespace. As with connection factories, if a jms-queue or jms-topic has an entry bound in the "java:jboss/exported" namespace a remote client would look it up using the text after "java:jboss/exported". For example, the following jms-queue "testQueue" is bound to "java:jboss/exported/jms/queue/test" which means a remote client would look-up this jms-queue using "jms/queue/test". A local client could look it up using "java:jboss/exported/jms/queue/test", "java:jms/queue/test", or more simply "jms/queue/test":
<subsystem xmlns="urn:jboss:domain:messaging:1.0">
[...]
<jms-destinations>
<jms-queue name="testQueue">
<entry name="jms/queue/test"/>
<entry name="java:jboss/exported/jms/queue/test"/>
</jms-queue>
<jms-topic name="testTopic">
<entry name="jms/topic/test"/>
<entry name="java:jboss/exported/jms/topic/test"/>
</jms-topic>
</jms-destinations>
</subsystem>
(See standalone/configuration/standalone-full.xml)
JMS endpoints can easily be created through the CLI:
[standalone@localhost:9999 /] jms-queue add --name=myQueue --entries=queues/myQueue
[standalone@localhost:9999 /] /subsystem=messaging/jms-queue=myQueue:read-resource
{
"outcome" => "success",
"result" => {"entries" => ["queues/myQueue"]},
"compensating-operation" => undefined
}
A number of additional commands to maintain the JMS subsystem are available as well:
[standalone@localhost:9999 /] jms-queue --help --commands add...removeTo read the description of a specific command execute'jms-queue command_name --help'.
Dead Letter & Redelivery
Some of the settings are applied against an address wild card instead of a specific messaging destination. The dead letter queue and redelivery settings belong into this group:
<subsystem xmlns="urn:jboss:domain:messaging:1.0">
[...]
<address-settings>
<address-setting match="#">
<dead-letter-address>jms.queue.DLQ</dead-letter-address>
<expiry-address>jms.queue.ExpiryQueue</expiry-address>
<redelivery-delay>0</redelivery-delay>
[...]
</address-setting>
</address-settings>
[...]
</subsystem>
(See standalone/configuration/standalone-full.xml)
Security Settings for HornetQ addresses and JMS destinations
Security constraints are matched against an address wildcard, similar to the DLQ and redelivery settings. Note: Multiple roles are separated by spaces.
<subsystem xmlns="urn:jboss:domain:messaging:1.0">
[...]
<security-settings>
<security-setting match="#">
<permission type="send" roles="guest"/>
<permission type="consume" roles="guest"/>
<permission type="createNonDurableQueue" roles="role1"/>
<permission type="deleteNonDurableQueue" roles="role1 role2"/>
</security-setting>
</security-settings>
[...]
</subsystem>
(See standalone/configuration/standalone-full.xml)
Security Domain for Users
By default, HornetQ will use the "other" JAAS security domain. This domain is used to authenticate users making connections to HornetQ and then they are authorized to perform specific functions based on their role(s) and the security-settings described above. This domain can be changed by using security-domain, e.g.:
<subsystem xmlns="urn:jboss:domain:messaging:1.0"> [...] <security-domain>mySecurityDomain</security-domain> [...] </subsystem>
Deployment of -jms.xml files
Starting with JBoss Application Server 7.1.0.Final you have the ability to deploy a -jms.xml file defining JMS destinations, e.g.:
<?xml version="1.0" encoding="UTF-8"?>
<messaging-deployment xmlns="urn:jboss:messaging-deployment:1.0">
<hornetq-server>
<jms-destinations>
<jms-queue name="sample">
<entry name="jms/queue/sample"/>
<entry name="java:jboss/exported/jms/queue/sample"/>
</jms-queue>
</jms-destinations>
</hornetq-server>
</messaging-deployment>
|
|
This feature is primarily intended for development as destinations deployed this way can not be managed with any of the provided management tools (e.g. console, CLI, etc). |
Component Reference
The messaging subsystem is provided by the HornetQ project. Fo a detailed description of the available configuration properties, please consult the project documentation.
-
HornetQ homepage: http://www.jboss.org/hornetq
-
Project Documentation: http://www.jboss.org/hornetq/docs
Web
The web subsystem configuration basically consists of three parts: The JSP Configuration, connectors and virtual servers. Advanced topics like load balancing and failover are covered on the "High Availability Guide". The default configuration does is suitable for most use cases and provides reasonable performance settings.
Required extension:
<extension module="org.jboss.as.web" />
Basic subsystem configuration example:
<subsystem xmlns="urn:jboss:domain:web:1.0" default-virtual-server="default-host"> <connector name="http" scheme="http" protocol="HTTP/1.1" socket-binding="http"/> <virtual-server name="default-host" enable-welcome-root="true"> <alias name="localhost" /> <alias name="example.com" /> </virtual-server> </subsystem>
Dependencies on other subsystems:
None
Container configuration
JSP Configuration
The "configuration" subresource covers all aspects that relate to the configuration of the servlet engine itself. For a detailed explanation of each configuration attribute, please consult the JBossWeb documentation (See "Component Reference").
[standalone@localhost:9999 /] /subsystem=web:read-resource
{
"outcome" => "success",
"result" => {
"configuration" => {
"static-resources" => {
"sendfile" => 49152,
"max-depth" => 3,
"read-only" => true,
"webdav" => false,
"listings" => false,
"disabled" => false
},
"jsp-configuration" => {
"development" => false,
"keep-generated" => true,
"recompile-on-fail" => false,
"check-interval" => 0,
"modification-test-interval" => 4,
"display-source-fragment" => true,
"error-on-use-bean-invalid-class-attribute" => false,
"java-encoding" => "UTF8",
"tag-pooling" => true,
"generate-strings-as-char-arrays" => false,
"target-vm" => "1.5",
"dump-smap" => false,
"mapped-file" => true,
"disabled" => false,
"source-vm" => "1.5",
"trim-spaces" => false,
"smap" => true
}
},
"connector" => {"http" => undefined},
"virtual-server" => {"localhost" => undefined}
}
}
(See standalone/configuration/standalone.xml)
Connector configuration
The connectors are child resources of the subsystem web. Each connector does reference a particular socket binding:
[standalone@localhost:9999 /] /subsystem=web:read-children-names(child-type=connector)
{
"outcome" => "success",
"result" => ["http"]
}
[standalone@localhost:9999 /] /subsystem=web/connector=http:read-resource(recursive=true)
{
"outcome" => "success",
"result" => {
"protocol" => "HTTP/1.1",
"scheme" => "http",
"socket-binding" => "http",
"ssl" => undefined,
"virtual-server" => undefined
}
}
Creating a new connector requires you to declare a new socket binding first:
[standalone@localhost:9999 /] /socket-binding-group=standard-sockets/socket-binding=custom:add(port=8181)
The newly created, unused socket binding can then be used to create a new connector configuration:
[standalone@localhost:9999 /] /subsystem=web/connector=test-connector:add(
socket-binding=custom, scheme=http, protocol="HTTP/1.1", enabled=true
)
Statistic information can be displayed from the connectors:
The following attributes can be queried:
|
value |
description |
|
bytesSent |
Number of byte sent by the connector |
|
bytesReceived |
Number of byte received by the connector (POST data). |
|
processingTime |
Processing time used by the connector. Im milli-seconds. |
|
errorCount |
Number of error that occurs when processing requests by the connector. |
|
maxTime |
Max time spent to process a request. |
|
requestCount |
Number of requests processed by the connector. |
For example:
[standalone@localhost:9999 /] /subsystem=web/connector=http:read-attribute(name=bytesSent, name=requestCount)
{
"outcome" => "success",
"result" => "3"
}
There are 3 different connectors available:
HTTP Connectors
This one is the default connector, it runs usually on port 8080. See above how to configure it.
HTTPS Connectors
The HTTPS connectors are child resources of the subsystem web. By default they use JSSE. Each connector does reference a particular socket binding:
[standalone@localhost:9999 /] /subsystem=web:read-children-names(child-type=connector)
{
"outcome" => "success",
"result" => [
"ajp",
"http",
"https"
]
}
[standalone@localhost:9999 /] /subsystem=web/connector=https:read-resource(recursive=true)
{
"outcome" => "success",
"result" => {
"protocol" => "HTTP/1.1",
"scheme" => "https",
"secure" => true,
"socket-binding" => "https",
"ssl" => {},
"virtual-server" => undefined
}
}
Creating a new connector may require you to declare a new socket binding first:
[standalone@localhost:9999 /] /socket-binding-group=standard-sockets/socket-binding=https:add(port=8443)
The newly created, unused socket binding can then be used to create a new connector configuration:
[standalone@localhost:9999 /] /subsystem=web/connector=test-connector:add(socket-binding=https, scheme=https, protocol="HTTP/1.1", enabled=true, ssl = {})
The default for SSL is to use Alias "tomcat" and password "changeit". It is possible to create the corresponding keystore using keytool:
keytool -genkey -alias tomcat -keyalg RSA
Of course specify a password value of "changeit".
AJP Connectors
The AJP connectors are child resources of the subsystem web. They are used with mod_jk, mod_proxy and mod_cluster of the Apache httpd front-end. Each connector does reference a particular socket binding:
[standalone@localhost:9999 /] /subsystem=web:read-children-names(child-type=connector)
{
"outcome" => "success",
"result" => [
"ajp",
"http"
]
}
[standalone@localhost:9999 /] /subsystem=web/connector=ajp:read-resource(recursive=true)
{
"outcome" => "success",
"result" => {
"protocol" => "AJP/1.3",
"scheme" => "http",
"socket-binding" => "ajp",
"ssl" => undefined,
"virtual-server" => undefined
}
}
Creating a new connector requires you to declare a new socket binding first:
[standalone@localhost:9999 /] /socket-binding-group=standard-sockets/socket-binding=ajp:add(port=8009)
The newly created, unused socket binding can then be used to create a new connector configuration:
[standalone@localhost:9999 /] /subsystem=web/connector=ajp:add(
socket-binding=ajp, protocol="AJP/1.3", enabled=true, scheme="http"
)
Native Connectors
Native connectors are high performance connectors based on Tomcat native. They are used if the native modules are installed, a lot of distributions have it included, in case you don't have it try JBoss Web Native.
At a configuration level only the SSL part needs to be configured differently because it use OpenSSL.
[standalone@localhost:9999 /] /subsystem=web/connector=https:read-resource(recursive=true)
{
"outcome" => "success",
"result" => {
"protocol" => "HTTP/1.1",
"scheme" => "https",
"secure" => true,
"socket-binding" => "https",
"ssl" => {
"certificate-file" => "/home/jfclere/CERTS/SERVER/newcert.pem",
"certificate-key-file" => "/home/jfclere/CERTS/SERVER/newkey.pem",
"password" => "xxxxxxx"
},
"virtual-server" => undefined
}
}
Virtual-Server configuration
Similar to the connectors, the virtual server declarations are child resources of the web subsystem. They will be referenced by alias names and can optionally refer to a default web application that acts serves the root web context.
[standalone@localhost:9999 /] /subsystem=web:read-children-names(child-type=virtual-server)
{
"outcome" => "success",
"result" => ["localhost"]
}
[standalone@localhost:9999 /] /subsystem=web/virtual-server=default-host:read-resource
{
"outcome" => "success",
"result" => {
"access-log" => undefined,
"alias" => ["example.com"],
"default-web-module" => undefined,
"enable-welcome-root" => true,
"rewrite" => undefined
}
}
Adding a virtual server declaration is can be done through the default :add() operation
[standalone@localhost:9999 /] /subsystem=web/virtual-server=example.com:add [standalone@localhost:9999 /] /subsystem=web/virtual-server=example.com:remove
add/remove operations exists on any node in the configuration tree.
Component Reference
The web subsystem is provided by the JBossWeb project. Fo a detailed description of the available configuration properties, please consult the JBossWeb documentation.
-
JBoss Web Configuration Reference: http://docs.jboss.org/jbossweb/7.0.x/config/index.html
-
JBossWeb homepage: http://www.jboss.org/jbossweb
-
Project Documentation: http://docs.jboss.org/jbossweb/7.0.x/
Web services
Domain management
The webservices subsystem is the subsystem that brings the services provided through JBossWS components and which deal with deployment of WS endpoints on the application server.
Structure of the webservices subsystem
Published endpoint address
JBossWS supports rewriting the of the <soap:address> element in endpoint published WSDL contracts. That's useful for controlling the server address that is advertised to clients for each endpoint.
The following elements are available and can be modified (all are optional and require server restart upon modification):
|
Name |
Type |
Description |
|
modify-wsdl-address |
boolean |
If the content of <soap:address> is a valid URL, JBossWS will not rewrite it unless modify-soap-address is true. |
|
wsdl-host |
string |
The hostname / IP address to be used for rewriting <soap:address>. |
|
wsdl-port |
int |
Set this property to explicitly define the HTTP port that will be used for rewriting the SOAP address. |
|
wsdl-secure-port |
int |
Set this property to explicitly define the HTTPS port that will be used for rewriting the SOAP address. |
Predefined endpoint configurations
JBossWS allows for defining endpoint configurations to be referenced by endpoint implementations. This allows for instance for adding a given handler to any WS endpoint that is marked with a given endpoint configuration (through @org.jboss.ws.api.annotation.EndpointConfig).
JBoss Application Server comes with a default Standard-Endpoint-Config as well as with an example of custom endpoint configuration (Recording-Endpoint-Config) including a recording handler (please reference the JBossWS documentation for details on that).
[standalone@localhost:9999 /] /subsystem=webservices:read-resource
{
"outcome" => "success",
"result" => {
"endpoint" => {},
"modify-wsdl-address" => true,
"wsdl-host" => expression "${jboss.bind.address:127.0.0.1}",
"endpoint-config" => {
"Standard-Endpoint-Config" => undefined,
"Recording-Endpoint-Config" => undefined
}
}
}
The Standard-Endpoint-Config is a special endpoint configuration that is automatically used for any endpoint which no other configuration is associated to.
Endpoint configs
Endpoint configs are defined using endpoint-config element; each endpoint config may include properties and handlers set to the endpoints associated to the config.
[standalone@localhost:9999 /] /subsystem=webservices/endpoint-config=Recording-Endpoint-Config:read-resource
{
"outcome" => "success",
"result" => {
"post-handler-chain" => undefined,
"property" => undefined,
"pre-handler-chain" => {"recording-handlers" => undefined}
}
}
A new endpoint config can be added as follows:
[standalone@localhost:9999 /] /subsystem=webservices/endpoint-config=My-Endpoint-Config:add
{
"outcome" => "success",
"response-headers" => {
"operation-requires-restart" => true,
"process-state" => "restart-required"
}
}
Handler chains
Each endpoint config may be associated both to PRE and POST handler chains. Each handler chain may include JAXWS handlers. For outbound messages, PRE handler chain handlers are meant to be executed before any handler attached to the endpoints using standard JAXWS means (e.g. using @HandlerChain), while POST handler chain handlers are executed after usual endpoint handlers. For inbound messages, the opposite applies.
* Server inbound messages Client --> ... --> POST HANDLER --> ENDPOINT HANDLERS --> PRE HANDLERS --> Endpoint * Server outbound messages Endpoint --> PRE HANDLER --> ENDPOINT HANDLERS --> POST HANDLERS --> ... --> Client
protocol-binding attribute can be used to set the protocols which the chain needs to be triggered for.
[standalone@localhost:9999 /] /subsystem=webservices/endpoint-config=Recording-Endpoint-Config/pre-handler-chain=recording-handlers:read-resource
{
"outcome" => "success",
"result" => {
"protocol-bindings" => "##SOAP11_HTTP ##SOAP11_HTTP_MTOM ##SOAP12_HTTP ##SOAP12_HTTP_MTOM",
"handler" => {"RecordingHandler" => undefined}
},
"response-headers" => {"process-state" => "restart-required"}
}
A new handler chain can be added as follows:
[standalone@localhost:9999 /] /subsystem=webservices/endpoint-config=My-Endpoint-Config/post-handler-chain=my-handlers:add(protocol-bindings="##SOAP11_HTTP")
{
"outcome" => "success",
"response-headers" => {
"operation-requires-restart" => true,
"process-state" => "restart-required"
}
}
[standalone@localhost:9999 /] /subsystem=webservices/endpoint-config=My-Endpoint-Config/post-handler-chain=my-handlers:read-resource
{
"outcome" => "success",
"result" => {
"handler" => undefined,
"protocol-bindings" => "##SOAP11_HTTP"
},
"response-headers" => {"process-state" => "restart-required"}
}
Handlers
JAXWS handler can be added in handler chains:
[standalone@localhost:9999 /] /subsystem=webservices/endpoint-config=Recording-Endpoint-Config/pre-handler-chain=recording-handlers/handler=RecordingHandler:read-resource
{
"outcome" => "success",
"result" => {"class" => "org.jboss.ws.common.invocation.RecordingServerHandler"},
"response-headers" => {"process-state" => "restart-required"}
}
[standalone@localhost:9999 /] /subsystem=webservices/endpoint-config=My-Endpoint-Config/post-handler-chain=my-handlers/handler=foo-handler:add(class="org.jboss.ws.common.invocation.RecordingServerHandler")
{
"outcome" => "success",
"response-headers" => {
"operation-requires-restart" => true,
"process-state" => "restart-required"
}
}
Endpoint-config handler classloading
The class attribute is to be used for providing the full class name of the handler. At deploy time, an instance of that class is created for each referencing deployment; for that to succeed, either the deployment classloader or the classloader for module org.jboss.as.webservices.server.integration need to be able to load the handler class.
Runtime information
Web service endpoint are exposed through the deployments that provide endpoint implementation. Thus they can be queried as deployment resources. For further information please consult the chapter "Application Deployment". Each web service endpoint specifies a web context and a WSDL Url:
[standalone@localhost:9999 /] /deployment="*"/subsystem=webservices/endpoint="*":read-resource
{
"outcome" => "success",
"result" => [{
"address" => [
("deployment" => "jaxws-samples-handlerchain.war"),
("subsystem" => "webservices"),
("endpoint" => "jaxws-samples-handlerchain:TestService")
],
"outcome" => "success",
"result" => {
"class" => "org.jboss.test.ws.jaxws.samples.handlerchain.EndpointImpl",
"context" => "jaxws-samples-handlerchain",
"name" => "TestService",
"type" => "JAXWS_JSE",
"wsdl-url" => "http://localhost:8080/jaxws-samples-handlerchain?wsdl"
}
}]
}
Component Reference
The web service subsystem is provided by the JBossWS project. For a detailed description of the available configuration properties, please consult the project documentation.
-
JBossWS homepage: http://www.jboss.org/jbossws
-
Project Documentation: https://docs.jboss.org/author/display/JBWS
Logging
Overview
The overall server logging configuration is represented by the logging subsystem. It consists of three notable parts: handler configurations, logger and the root logger declarations (aka log categories). Each logger does reference a handler (or set of handlers). Each handler declares the log format and output:
<subsystem xmlns="urn:jboss:domain:logging:1.0">
<console-handler name="CONSOLE" autoflush="true">
<level name="DEBUG"/>
<formatter>
<pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/>
</formatter>
</console-handler>
<periodic-rotating-file-handler name="FILE" autoflush="true">
<formatter>
<pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/>
</formatter>
<file relative-to="jboss.server.log.dir" path="server.log"/>
<suffix value=".yyyy-MM-dd"/>
</periodic-rotating-file-handler>
<logger category="com.arjuna">
<level name="WARN"/>
</logger>
[...]
<root-logger>
<level name="DEBUG"/>
<handlers>
<handler name="CONSOLE"/>
<handler name="FILE"/>
</handlers>
</root-logger>
</subsystem>
Why is there a logging.properties file?
You may have noticed that there is a logging.properties file in the configuration directory. This logging configuration is used when the server boots up until the logging subsystem kicks in. If the logging subsystem is not included in your configuration, then this would act as the logging configuration for the entire server.
In the future this file may go away or be automatically generated from the logging subsystem. For most users this file should not be modified.
Note: If the logging.properties is not available during start there will be no logging until the logging subsystems kicks in, this is also the case if the configuration is damaged, the server might exit without any further message.
Default Log File Locations
Managed Domain
In a managed domain two types of log files do exist: Controller and server logs. The controller components govern the domain as whole. It's their responsibility to start/stop server instances and execute managed operations throughout the domain. Server logs contain the logging information for a particular server instance. They are co-located with the host the server is running on.
For the sake of simplicity we look at the default setup for managed domain. In this case, both the domain controller components and the servers are located on the same host:
|
Process |
Log File |
|
Host Controller |
./domain/log/host-controller/boot.log |
|
Process Controller |
./domain/log/process-controller/boot.log |
|
"Server One" |
./domain/servers/server-one/log/boot.log |
|
"Server One" |
./domain/servers/server-one/log/server.log |
|
"Server Three" |
./domain/servers/server-three/log/boot.log |
|
"Server Three" |
./domain/servers/server-three/log/server.log |
The server logs as you know it from previous JBoss AS versions are located in the servers subdirectory: I.e. ./domain/servers/server-three/log/server.log
Standalone Server
The default log files for a standalone server can be found in the log subdirectory of the distribution:
|
Process |
Log File |
|
Server |
./standalone/log/boot.log |
|
Server |
./standalone/log/server.log |
Logging Subsystem Descriptions
root-logger
Defines the root logger for this log context.
|
Attribute |
Description |
Type |
Allow Null |
Expression Allowed |
Access Type |
Restart Required |
Allowed Values |
|
level |
The log level specifying which message levels will be logged by this. Message levels lower than this value will be discarded. |
STRING |
true |
false |
read-write |
no-services |
"ALL","CONFIG","DEBUG","ERROR","FATAL","FINE","FINER","FINEST","INFO","OFF","TRACE","WARN","WARNING" |
|
filter |
Defines a simple filter type. |
OBJECT |
true |
false |
read-write |
no-services |
"all","any","accept","change-level","deny","level","level-range","match","not","replace" |
|
handlers |
The Handlers associated with this Logger. |
LIST |
true |
false |
read-write |
no-services |
Any |
logger
Defines a logger category.
|
Attribute |
Description |
Type |
Allow Null |
Expression Allowed |
Access Type |
Restart Required |
Allowed Values |
|
level |
The log level specifying which message levels will be logged by this. Message levels lower than this value will be discarded. |
STRING |
true |
false |
read-write |
no-services |
"ALL","CONFIG","DEBUG","ERROR","FATAL","FINE","FINER","FINEST","INFO","OFF","TRACE","WARN","WARNING" |
|
filter |
Defines a simple filter type. |
OBJECT |
true |
false |
read-write |
no-services |
"all","any","accept","change-level","deny","level","level-range","match","not","replace" |
|
handlers |
The Handlers associated with this Logger. |
LIST |
true |
false |
read-write |
no-services |
Any |
|
use-parent-handlers |
Specifies whether or not this logger should send its output to it's parent Logger. |
BOOLEAN |
true |
false |
read-write |
no-services |
Any |
|
category |
Specifies the category for the logger. |
STRING |
false |
false |
read-only |
|
Any |
async-handler
Defines a handler which writes to the sub-handlers in an asynchronous thread. Used for handlers which introduce a substantial amount of lag.
|
Attribute |
Description |
Type |
Allow Null |
Expression Allowed |
Access Type |
Restart Required |
Allowed Values |
|
name |
The handler's name. |
STRING |
false |
false |
read-only |
|
Any |
|
level |
The log level specifying which message levels will be logged by this. Message levels lower than this value will be discarded. |
STRING |
true |
false |
read-write |
no-services |
"ALL","CONFIG","DEBUG","ERROR","FATAL","FINE","FINER","FINEST","INFO","OFF","TRACE","WARN","WARNING" |
|
filter |
Defines a simple filter type. |
OBJECT |
true |
false |
read-write |
no-services |
"all","any","accept","change-level","deny","level","level-range","match","not","replace" |
|
formatter |
Defines a formatter. |
STRING |
true |
false |
read-write |
no-services |
Any |
|
queue-length |
The queue length to use before flushing writing |
INT |
false |
false |
read-write |
resource-services |
Any |
|
overflow-action |
Specify what action to take when the overflowing. The valid options are 'block' and 'discard' |
STRING |
false |
false |
read-write |
no-services |
"BLOCK","DISCARD" |
|
subhandlers |
The Handlers associated with this asycn handler. |
LIST |
true |
false |
read-write |
no-services |
Any |
console-handler
Defines a handler which writes to the console.
|
Attribute |
Description |
Type |
Allow Null |
Expression Allowed |
Access Type |
Restart Required |
Allowed Values |
|
name |
The handler's name. |
STRING |
false |
false |
read-only |
|
Any |
|
encoding |
The character encoding used by this Handler. |
STRING |
true |
false |
read-write |
no-services |
Any |
|
level |
The log level specifying which message levels will be logged by this. Message levels lower than this value will be discarded. |
STRING |
true |
false |
read-write |
no-services |
"ALL","CONFIG","DEBUG","ERROR","FATAL","FINE","FINER","FINEST","INFO","OFF","TRACE","WARN","WARNING" |
|
filter |
Defines a simple filter type. |
OBJECT |
true |
false |
read-write |
no-services |
"all","any","accept","change-level","deny","level","level-range","match","not","replace" |
|
formatter |
Defines a formatter. |
STRING |
true |
false |
read-write |
no-services |
Any |
|
autoflush |
Automatically flush after each write. |
BOOLEAN |
true |
false |
read-write |
no-services |
Any |
|
target |
Defines the target of the console handler. The value can either be SYSTEM_OUT or SYSTEM_ERR. |
STRING |
true |
false |
read-write |
no-services |
"System.out","System.err" |
file-handler
Defines a handler which writes to a file.
|
Attribute |
Description |
Type |
Allow Null |
Expression Allowed |
Access Type |
Restart Required |
Allowed Values |
|
name |
The handler's name. |
STRING |
false |
false |
read-only |
|
Any |
|
encoding |
The character encoding used by this Handler. |
STRING |
true |
false |
read-write |
no-services |
Any |
|
level |
The log level specifying which message levels will be logged by this. Message levels lower than this value will be discarded. |
STRING |
true |
false |
read-write |
no-services |
"ALL","CONFIG","DEBUG","ERROR","FATAL","FINE","FINER","FINEST","INFO","OFF","TRACE","WARN","WARNING" |
|
filter |
Defines a simple filter type. |
OBJECT |
true |
false |
read-write |
no-services |
"all","any","accept","change-level","deny","level","level-range","match","not","replace" |
|
formatter |
Defines a formatter. |
STRING |
true |
false |
read-write |
no-services |
Any |
|
autoflush |
Automatically flush after each write. |
BOOLEAN |
true |
false |
read-write |
no-services |
Any |
|
append |
Specify whether to append to the target file. |
BOOLEAN |
true |
false |
read-write |
resource-services |
Any |
|
file |
The file description consisting of the path and optional relative to path. |
OBJECT |
true |
false |
read-write |
no-services |
Any |
periodic-rotating-file-handler
Defines a handler which writes to a file, rotating the log after a time period derived from the given suffix string, which should be in a format understood by java.text.SimpleDateFormat.
|
Attribute |
Description |
Type |
Allow Null |
Expression Allowed |
Access Type |
Restart Required |
Allowed Values |
|
name |
The handler's name. |
STRING |
false |
false |
read-only |
|
Any |
|
encoding |
The character encoding used by this Handler. |
STRING |
true |
false |
read-write |
no-services |
Any |
|
level |
The log level specifying which message levels will be logged by this. Message levels lower than this value will be discarded. |
STRING |
true |
false |
read-write |
no-services |
"ALL","CONFIG","DEBUG","ERROR","FATAL","FINE","FINER","FINEST","INFO","OFF","TRACE","WARN","WARNING" |
|
filter |
Defines a simple filter type. |
OBJECT |
true |
false |
read-write |
no-services |
"all","any","accept","change-level","deny","level","level-range","match","not","replace" |
|
formatter |
Defines a formatter. |
STRING |
true |
false |
read-write |
no-services |
Any |
|
autoflush |
Automatically flush after each write. |
BOOLEAN |
true |
false |
read-write |
no-services |
Any |
|
append |
Specify whether to append to the target file. |
BOOLEAN |
true |
false |
read-write |
resource-services |
Any |
|
file |
The file description consisting of the path and optional relative to path. |
OBJECT |
true |
false |
read-write |
no-services |
Any |
|
suffix |
Set the suffix string. The string is in a format which can be understood by java.text.SimpleDateFormat. The period of the rotation is automatically calculated based on the suffix. |
STRING |
false |
false |
read-write |
no-services |
Any |
size-rotating-file-handler
Defines a handler which writes to a file, rotating the log after a the size of the file grows beyond a certain point and keeping a fixed number of backups.
|
Attribute |
Description |
Type |
Allow Null |
Expression Allowed |
Access Type |
Restart Required |
Allowed Values |
|
name |
The handler's name. |
STRING |
false |
false |
read-only |
|
Any |
|
encoding |
The character encoding used by this Handler. |
STRING |
true |
false |
read-write |
no-services |
Any |
|
level |
The log level specifying which message levels will be logged by this. Message levels lower than this value will be discarded. |
STRING |
true |
false |
read-write |
no-services |
"ALL","CONFIG","DEBUG","ERROR","FATAL","FINE","FINER","FINEST","INFO","OFF","TRACE","WARN","WARNING" |
|
filter |
Defines a simple filter type. |
OBJECT |
true |
false |
read-write |
no-services |
"all","any","accept","change-level","deny","level","level-range","match","not","replace" |
|
formatter |
Defines a formatter. |
STRING |
true |
false |
read-write |
no-services |
Any |
|
autoflush |
Automatically flush after each write. |
BOOLEAN |
true |
false |
read-write |
no-services |
Any |
|
append |
Specify whether to append to the target file. |
BOOLEAN |
true |
false |
read-write |
resource-services |
Any |
|
file |
The file description consisting of the path and optional relative to path. |
OBJECT |
true |
false |
read-write |
no-services |
Any |
|
rotate-size |
The size at which to rotate the log file. |
STRING |
false |
false |
read-write |
no-services |
Any |
|
max-backup-index |
The maximum number of backups to keep. |
INT |
false |
false |
read-write |
no-services |
Any |
custom-handler
Defines a custom logging handler. The custom handler must extend java.util.logging.Handler.
|
Attribute |
Description |
Type |
Allow Null |
Expression Allowed |
Access Type |
Restart Required |
Allowed Values |
|
name |
The handler's name. |
STRING |
false |
false |
read-only |
|
Any |
|
encoding |
The character encoding used by this Handler. |
STRING |
true |
false |
read-write |
no-services |
Any |
|
level |
The log level specifying which message levels will be logged by this. Message levels lower than this value will be discarded. |
STRING |
true |
false |
read-write |
no-services |
"ALL","CONFIG","DEBUG","ERROR","FATAL","FINE","FINER","FINEST","INFO","OFF","TRACE","WARN","WARNING" |
|
filter |
Defines a simple filter type. |
OBJECT |
true |
false |
read-write |
no-services |
"all","any","accept","change-level","deny","level","level-range","match","not","replace" |
|
formatter |
Defines a formatter. |
STRING |
true |
false |
read-write |
no-services |
Any |
|
class |
The logging handler class to be used. |
STRING |
false |
false |
read-only |
|
Any |
|
module |
The module that the logging handler depends on. |
STRING |
false |
false |
read-only |
|
Any |
|
properties |
Defines the properties used for the logging handler. All properties must be accessible via a setter method. |
LIST |
false |
false |
read-write |
no-services |
Any |
What is the %s and %E in the pattern-formatter's pattern?
<pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/>
%s is the message
%E is the exception if one exists
JMX
The JMX subsystem registers a service with the Remoting endpoint so that remote access to JMX can be obtained over the exposed Remoting connector.
This is switched on by default in standalone mode and accessible over port 9999 but in domain mode is switched off so needs to be enabled - in domain mode the port will be the port of the Remoting connector for the AS instance to be monitored.
To use the connector you can access it in the standard way using a service:jmx URL:
import javax.management.MBeanServerConnection;
import javax.management.remote.JMXConnector;
import javax.management.remote.JMXConnectorFactory;
import javax.management.remote.JMXServiceURL;
public class JMXExample {
public static void main(String[] args) throws Exception {
//Get a connection to the JBoss AS MBean server on localhost
String host = "localhost";
int port = 9999; // management-native port
String urlString =
System.getProperty("jmx.service.url","service:jmx:remoting-jmx://" + host + ":" + port);
JMXServiceURL serviceURL = new JMXServiceURL(urlString);
JMXConnector jmxConnector = JMXConnectorFactory.connect(serviceURL, null);
MBeanServerConnection connection = jmxConnector.getMBeanServerConnection();
//Invoke on the JBoss AS MBean server
int count = connection.getMBeanCount();
System.out.println(count);
jmxConnector.close();
}
}
You also need to set your classpath when running the above example. The following script covers Linux. If your environment is much different, paste your script when you have it working.
!/bin/bash
# specify your AS7 folder
export YOUR_AS7_HOME=~/as7
java -classpath $YOUR_AS7_HOME/bin/client/jboss-client.jar:./ JMXExample
You can also connect using jconsole.
If using jconsole use the jconsole.sh and jconsole.bat scripts included in the bin folder of the AS distribution as these set the classpath as required to connect over Remoting.
In addition to the standard JVM MBeans, the JBoss AS 7 MBean server contains the following MBeans:
|
JMX ObjectName |
Description |
|
jboss.msc:type=container,name=jboss-as |
Exposes management operations on the JBoss Modular Service Container, which is the dependency injection framework at the heart of JBoss AS 7. It is useful for debugging dependency problems, for example if you are integrating your own subsystems, as it exposes operations to dump all services and their current states |
|
jboss.naming:type=JNDIView |
Shows what is bound in JNDI |
|
jboss.modules:type=ModuleLoader,name=* |
This collection of MBeans exposes management operations on JBoss Modules classloading layer. It is useful for debugging dependency problems arising from missing module dependencies |
OSGi
OSGi functionality in JBoss AS 7 is provided through the OSGi subsystem.
The documentation of this functionality can be found at the JBoss OSGi documentation pages.
Integration with AS 7 and reference the the OSGi subsystem in the AS 7 XML configuration file can be found in the Application Server Integration section.
More information on the OSGi component in JBoss AS 7 can be found on the JBoss OSGi project pages.
Deployment Scanner
The deployment scanner is only used in standalone mode. Its job is to monitor a directory for new files and to deploy those files. It can be found in standalone.xml:
<subsystem xmlns="urn:jboss:domain:deployment-scanner:1.0">
<deployment-scanner scan-interval="5000"
relative-to="jboss.server.base.dir" path="deployments" />
</subsystem>
You can define more deployment-scanner entries to scan for deployments from more locations. The configuration showed will scan the $JBOSS_HOME/standalone/deployments directory every five seconds. The runtime model is shown below, and uses default values for attributes not specified in the xml:
[standalone@localhost:9999 /] /subsystem=deployment-scanner:read-resource(recursive=true)
{
"outcome" => "success",
"result" => {"scanner" => {"default" => {
"auto-deploy-exploded" => false,
"auto-deploy-zipped" => true,
"deployment-timeout" => 60L,
"name" => "default",
"path" => "deployments",
"relative-to" => "jboss.server.base.dir",
"scan-enabled" => true,
"scan-interval" => 5000
}}}
}
The attributes are
|
Name |
Type |
Description |
|
name |
STRING |
The name of the scanner. default is used if not specified |
|
path |
STRING |
The actual filesystem path to be scanned. Treated as an absolute path, unless the 'relative-to' attribute is specified, in which case the value is treated as relative to that path. |
|
relative-to |
STRING |
Reference to a filesystem path defined in the "paths" section of the server configuration, or one of the system properties specified on startup. In the example above jboss.server.base.dir resolves to {{$JBOSS_HOME/standalone |
|
scan-enabled |
BOOLEAN |
If true scanning is enabled |
|
scan-interval |
INT |
Periodic interval, in milliseconds, at which the repository should be scanned for changes. A value of less than 1 indicates the repository should only be scanned at initial startup. |
|
auto-deploy-zipped |
BOOLEAN |
Controls whether zipped deployment content should be automatically deployed by the scanner without requiring the user to add a .dodeploy marker file. |
|
auto-deploy-exploded |
BOOLEAN |
Controls whether exploded deployment content should be automatically deployed by the scanner without requiring the user to add a .dodeploy marker file. Setting this to 'true' is not recommended for anything but basic development scenarios, as there is no way to ensure that deployment will not occur in the middle of changes to the content. |
|
deployment-timeout |
LONG |
Timeout, in seconds, a deployment is allows to execute before being canceled. The default is 60 seconds. |
Deployment scanners can be added by modifying standalone.xml before starting up the server or they can be added and removed at runtime using the CLI
[standalone@localhost:9999 /] /subsystem=deployment-scanner/scanner=new:add(scan-interval=10000,relative-to="jboss.server.base.dir",path="other-deployments")
{"outcome" => "success"}
[standalone@localhost:9999 /] /subsystem=deployment-scanner/scanner=new:remove
{"outcome" => "success"}
You can also change the attributes at runtime, so for example to turn off scanning you can do
[standalone@localhost:9999 /] /subsystem=deployment-scanner/scanner=default:write-attribute(name="scan-enabled",value=false)
{"outcome" => "success"}
[standalone@localhost:9999 /] /subsystem=deployment-scanner:read-resource(recursive=true) {
"outcome" => "success",
"result" => {"scanner" => {"default" => {
"auto-deploy-exploded" => false,
"auto-deploy-zipped" => true,
"deployment-timeout" => 60L,
"name" => "default",
"path" => "deployments",
"relative-to" => "jboss.server.base.dir",
"scan-enabled" => false,
"scan-interval" => 5000
}}}
}
Threads subsystem
Couldn't find a page to include called: Threads Subsystem
Simple configuration subsystems
The following subsystems currently have no configuration beyond its root element in the configuration
<subsystem xmlns="urn:jboss:domain:cmp:1.0"/> <subsystem xmlns="urn:jboss:domain:configadmin:1.0"/> <subsystem xmlns="urn:jboss:domain:jaxrs:1.0"/> <subsystem xmlns="urn:jboss:domain:jdr:1.0"/> <subsystem xmlns="urn:jboss:domain:pojo:1.0"/> <subsystem xmlns="urn:jboss:domain:sar:1.0"/> <subsystem xmlns="urn:jboss:domain:weld:1.0"/>
The presence of each of these turns on a piece of functionality:
|
Name |
Description |
|
cmp |
Enables the deployment of CMP beans |
|
configadmin |
Enables the deployment and functionality of OSGI applications. |
|
JAXRS |
Enables the deployment and functionality of JAX-RS applications. This is implemented by the RestEasy project |
|
jdr |
Turns on Jboss Diagnostic Reporting subsystem |
|
pojo |
Enables deployment and functionality of MC beans |
|
sar |
Enables the deployment of .SAR archives containing MBean services, as supported by previous versions of JBoss Application Server |
|
Weld |
Enables the deployment and functionality of CDI applications |
Configuration file history
The management operations may modify the model. When this occurs the xml backing the model is written out again reflecting the latest changes. In addition a full history of the file is maintained. The history of the file goes in a separate directory under the configuration directory.
As mentioned in Command line parameters#parameters the default configuration file can be selected using a command-line parameter. For a standalone server instance the history of the active standalone.xml is kept in jboss.server.config.dir/standalone_xml_history (See Command line parameters#standalone_system_properties for more details). For a domain the active domain.xml and host.xml histories are kept in jboss.domain.config.dir/domain_xml_history and jboss.domain.config.dir/host_xml_history.
The rest of this section will only discuss the history for standalone.xml. The concepts are exactly the same for domain.xml and host.xml.
Within standalone_xml_history itself following a successful first time boot we end up with three new files:
*standalone.initial.xml - This contains the original configuration that was used the first time we successfully booted. This file will never be overwritten. You may of course delete the history directory and any files in it at any stage.
*standalone.boot.xml - This contains the original configuration that was used for the last successful boot of the server. This gets overwritten every time we boot the server successfully.
*standalone.last.xml - At this stage the contents will be identical to standalone.boot.xml. This file gets overwritten each time the server successfully writes the configuration, if there was an unexpected failure writing the configuration this file is the last known successful write.
standalone_xml_history contains a directory called current which should be empty. Now if we execute a management operation that modifies the model, for example adding a new system property using the CLI:
[standalone@localhost:9999 /] /system-property=test:add(value="test123")
{"outcome" => "success"}
What happens is:
-
The original configuration file is backed up to standalone_xml_history/current/standalone.v1.xml. The next change to the model would result in a file called standalone.v2.xml etc. The 100 most recent of these files are kept.
-
The change is applied to the original configuration file
-
The changed original configuration file is copied to standalone.last.xml
When restarting the server, any existing standalone_xml_history/current directory is moved to a new timestamped folder within the standalone_xml_history, and a new current folder is created. These timestamped folders are kept for 30 days.
Snapshots
In addition to the backups taken by the server as described above you can manually take take snapshots which will be stored in the snapshot folder under the _xml_history folder, the automatic backups described above are subject to automatic house keeping so will eventually be automatically removed, the snapshots on the other hand can be entirely managed by the administrator.
You may also take your own snapshots using the CLI:
[standalone@localhost:9999 /] :take-snapshot
{
"outcome" => "success",
"result" => {"name" => "/Users/kabir/jboss-7.0.0.CR1/standalone/configuration/standalone_xml_history/snapshot/20110630-172258657standalone.xml"}
}
You can also use the CLI to list all the snapshots
[standalone@localhost:9999 /] :list-snapshots
{
"outcome" => "success",
"result" => {
"directory" => "/Users/kabir/jboss-7.0.0.CR1/standalone/configuration/standalone_xml_history/snapshot",
"names" => [
"20110630-165714239standalone.xml",
"20110630-165821795standalone.xml",
"20110630-170113581standalone.xml",
"20110630-171411463standalone.xml",
"20110630-171908397standalone.xml",
"20110630-172258657standalone.xml"
]
}
}
To delete a particular snapshot:
[standalone@localhost:9999 /] :delete-snapshot(name="20110630-165714239standalone.xml")
{"outcome" => "success"}
and to delete all snapshots:
[standalone@localhost:9999 /] :delete-snapshot(name="all")
{"outcome" => "success"}
In domain mode executing the snapshot operations against the root node will work against the domain model. To do this for a host model you need to navigate to the host in question:
[domain@localhost:9999 /] /host=master:list-snapshots
{
"outcome" => "success",
"result" => {
"domain-results" => {"step-1" => {
"directory" => "/Users/kabir/jboss-7.0.0.CR1/domain/configuration/host_xml_history/snapshot",
"names" => [
"20110630-141129571host.xml",
"20110630-172522225host.xml"
]
}},
"server-operations" => undefined
}
}
Subsequent Starts
For subsequent server starts it may be desirable to take the state of the server back to one of the previously known states, for a number of items an abbreviated reverence to the file can be used: -
|
Abreviation |
Parameter |
Description |
|
initial |
--server-config=initial |
This will start the server using the initial configuration first used to start the server. |
|
boot |
--server-config=boot |
This will use the configuration from the last successful boot of the server. |
|
last |
--server-config=last |
This will start the server using the configuration backed up from the last successful save. |
|
v? |
--server-config=v? |
This will server the _xml_history/current folder for the configuration where ? is the number of the backup to use. |
|
???? - ????? |
--server-config=???? - ????? |
The server will be started after searching the snapshot folder for the configuration which matches this prefix. |
In addition to this the --server-config parameter can always be used to specify a configuration relative to the jboss.server.config.dir and finally if no matching configuration is found an attempt to locate the configuration as an absolute path will be made.
Starting & stopping Servers in a Managed Domain
Starting a standalone server is done through the bin/standalone.sh script. However in a managed domain server instances are managed by the domain controller and need to be started through the management layer:
First of all, get to know which servers are configured on a particular host:
[domain@localhost:9999 /] :read-children-names(child-type=host)
{
"outcome" => "success",
"result" => ["local"]
}
[domain@localhost:9999 /] /host=local:read-children-names(child-type=server-config)
{
"outcome" => "success",
"result" => [
"my-server",
"server-one",
"server-three"
]
}
Now that we know, that there are two servers configured on host "local", we can go ahead and check their status:
[domain@localhost:9999 /] /host=local/server-config=server-one:read-resource(include-runtime=true)
{
"outcome" => "success",
"result" => {
"auto-start" => true,
"group" => "main-server-group",
"interface" => undefined,
"name" => "server-one",
"path" => undefined,
"socket-binding-group" => undefined,
"socket-binding-port-offset" => undefined,
"status" => "STARTED",
"system-property" => undefined,
"jvm" => {"default" => undefined}
}
}
You can change the server state through the "start" and "stop" operations
[domain@localhost:9999 /] /host=local/server-config=server-one:stop
{
"outcome" => "success",
"result" => "STOPPING"
}
Navigating through the domain topology is much more simple when you use the web interface.
Application deployment
Managed Domain
In managed domain deployments are associated with a server group (See "Core Management Concepts"). Deployments will be provided to any server that belongs to a particular group. The domain and host controller components manage the distribution of binaries across network boundaries.
Deployment Commands
The process of distributing deployment binaries involves two steps: You need to upload the deployment to the repository from which the domain controller can distribute it's contents. In a second step you need to assign the deployment to one or more server groups:
Using the CLI you can do it one sweep:
[domain@localhost:9999 /] deploy ~/Desktop/test-application.war Either --all-server-groups or --server-groups must be specified. [domain@localhost:9999 /] deploy ~/Desktop/test-application.war --all-server-groups 'test-application.war' deployed successfully. [domain@localhost:9999 /] deploy --help [...]
After you've uploaded the binary using the "deploy" command, it will be available to the domain controller
and assigned to a server group:
[domain@localhost:9999 /] :read-children-names(child-type=deployment)
{
"outcome" => "success",
"result" => [
"mysql-connector-java-5.1.15.jar",
"test-application.war"
]
}
[domain@localhost:9999 /] /server-group=main-server-group/deployment=test-application.war:read-resource
{
"outcome" => "success",
"result" => {
"enabled" => true,
"name" => "test-application.war",
"runtime-name" => "test-application.war"
}
}
In a similar way it can be removed from the server group:
[domain@localhost:9999 /] undeploy test-application.war --all-relevant-server-groups
Successfully undeployed test-application.war.
[domain@localhost:9999 /] /server-group=main-server-group:read-children-names(child-type=deployment)
{
"outcome" => "success",
"result" => []
}
Managing deployments through the web interface provides an alternate, sometimes more simple approach.
Content Repository
Any deployment is referenced from the domain configuration file and stored co-located with the domain controller:
[...]
<deployments>
<deployment name="test-application.war"
runtime-name="test-application.war">
<content sha1="dda9881fa7811b22f1424b4c5acccb13c71202bd"/>
</deployment>
</deployments>
[...]
<server-groups>
<server-group name="main-server-group" profile="default">
[...]
<deployments>
<deployment name="test-application.war" runtime-name="test-application.war"/>
</deployments>
</server-group>
</server-groups>
[...]
(See domain/configuration/domain.xml)
The actual binaries are stored in the content subdirectory:
ls domain/content/ |---/47 |-----95cc29338b5049e238941231b36b3946952991 |---/dd |-----a9881fa7811b22f1424b4c5acccb13c71202bd
Standalone Server
Deployment on a standalone server works similar to the managed domain, just that the server-group associations don't exist.
Deployment Commands
You can rely on the same CLI command as for a managed domain to deploy an application:
[standalone@localhost:9999 /] deploy ~/Desktop/test-application.war 'test-application.war' deployed successfully. [standalone@localhost:9999 /] undeploy test-application.war Successfully undeployed test-application.war.
File System Deployments
The standalone/deployments directory in the JBoss Application Server 7 distribution is the location end users can place their deployment content (e.g. war, ear, jar, sar files) to have it automically deployed into the server runtime.
Users, particularly those running production systems, are encouraged to use the JBoss AS 7 management APIs to upload and deploy deployment content instead of relying on the deployment scanner subsystem that periodically scans this directory.
Deployment Modes
The filesystem deployment scanner in JBoss AS 7 and later works differently from previous JBoss AS releases. The scanner can operate in one of two different modes, depending on whether it will directly monitor the deployment content in order to decide to deploy (or redeploy) it.
Auto-deploy mode:
The scanner will directly monitor the deployment content, automatically deploying new content and redeploying content whose timestamp has changed. This is similiar to the behavior of previous AS releases, although there are differences:
-
A change in any file in an exploded deployment triggers redeploy. Because EE 6 applications do not require deployment descriptors,
there is no attempt to monitor deployment descriptors and only redeploy when a deployment descriptor changes. -
The scanner will place marker files in this directory as an indication of the status of its attempts to deploy or undeploy content. These are detailed below.
Manual deploy mode:
The scanner will not attempt to directly monitor the deployment content and decide if or when the end user wishes the content to be deployed. Instead, the scanner relies on a system of marker files, with the user's addition or removal of a marker file serving as a sort of command telling the scanner to deploy, undeploy or redeploy content.
Auto-deploy mode and manual deploy mode can be independently configured for zipped deployment content and exploded deployment content. This is done via the "auto-deploy" attribute on the deployment-scanner element in the standalone.xml configuration file:
<deployment-scanner scan-interval="5000" relative-to="jboss.server.base.dir" path="deployments" auto-deploy-zipped="true" auto-deploy-exploded="false"/>
By default, auto-deploy of zipped content is enabled, and auto-deploy of exploded content is disabled. Manual deploy mode is strongly recommended for exploded content, as exploded content is inherently vulnerable to the scanner trying to auto-deploy partially copied content.
Marker Files
The marker files always have the same name as the deployment content to which they relate, but with an additional file suffix appended. For example, the marker file to indicate the example.war file should be deployed is named example.war.dodeploy. Different marker file suffixes have different meanings.
The relevant marker file types are:
|
File |
Purpose |
|
.dodeploy |
Placed by the user to indicate that the given content should |
|
.skipdeploy |
Disables auto-deploy of the content for as long as the file |
|
.isdeploying |
Placed by the deployment scanner service to indicate that it |
|
.deployed |
Placed by the deployment scanner service to indicate that the |
|
.failed |
Placed by the deployment scanner service to indicate that the |
|
.isundeploying |
Placed by the deployment scanner service to indicate that it |
|
.undeployed |
Placed by the deployment scanner service to indicate that the |
|
.pending |
Placed by the deployment scanner service to indicate that it |
Basic workflows:
All examples assume variable $AS points to the root of the JBoss AS 7 distribution.
A) Add new zipped content and deploy it:
-
cp target/example.war $AS/standalone/deployments/
-
(Manual mode only) touch $AS/standalone/deployments/example.war.dodeploy
B) Add new unzipped content and deploy it:
-
cp -r target/example.war/ $AS/standalone/deployments
-
(Manual mode only) touch $AS/standalone/deployments/example.war.dodeploy
C) Undeploy currently deployed content:
-
rm $AS/standalone/deployments/example.war.deployed
D) Auto-deploy mode only: Undeploy currently deployed content:
-
rm $AS/standalone/deployments/example.war
E) Replace currently deployed zipped content with a new version and deploy it:
-
cp target/example.war/ $AS/standalone/deployments
-
(Manual mode only) touch $AS/standalone/deployments/example.war.dodeploy
F) Manual mode only: Replace currently deployed unzipped content with a new version and deploy it:
-
rm $AS/standalone/deployments/example.war.deployed
-
wait for $AS/standalone/deployments/example.war.undeployed file to appear
-
cp -r target/example.war/ $AS/standalone/deployments
-
touch $AS/standalone/deployments/example.war.dodeploy
G) Auto-deploy mode only: Replace currently deployed unzipped content with a new version and deploy it:
-
touch $AS/standalone/deployments/example.war.skipdeploy
-
cp -r target/example.war/ $AS/standalone/deployments
-
rm $AS/standalone/deployments/example.war.skipdeploy
H) Manual mode only: Live replace portions of currently deployed unzipped content without redeploying:
-
cp -r target/example.war/foo.html $AS/standalone/deployments/example.war
I) Auto-deploy mode only: Live replace portions of currently deployed unzipped content without redeploying:
-
touch $AS/standalone/deployments/example.war.skipdeploy
-
cp -r target/example.war/foo.html $AS/standalone/deployments/example.war
J) Manual or auto-deploy mode: Redeploy currently deployed content (i.e. bounce it with no content change):
-
touch $AS/standalone/deployments/example.war.dodeploy
K) Auto-deploy mode only: Redeploy currently deployed content (i.e. bounce it with no content change):
-
touch $AS/standalone/deployments/example.war
The above examples use Unix shell commands. Windows equivalents are:
cp src dest --> xcopy /y src dest
cp -r src dest --> xcopy /e /s /y src dest
rm afile --> del afile
touch afile --> echo>> afile
Note that the behavior of 'touch' and 'echo' are different but the differences are not relevant to the usages in the examples above.
Domain setup
To run a group of servers as a managed domain you need to configure both the domain controller and each host that joins the domain. The following steps focus on the network configuration for the domain and host controller components.
Domain Controller Configuration
The domain controller is the central government for a managed domain. A domain controller configuration requires two steps:
-
A host needs to be configured to act as the Domain Controller for the whole domain
-
The host must expose an addressable management interface binding for the managed hosts to communicate with it
Example IP Adresses
In this example the domain controller uses 192.168.0.101 and the host controller 192.168.0.10
Configuring a host to act as the Domain Controller is done through the domain-controller declaration in host.xml. If it includes the <local/> element, then this host will become the domain controller:
<domain-controller> <local/> </domain-controller>
(See domain/configuration/host.xml)
A host acting as the Domain Controller must expose a native (i.e. non-HTTP) management interface on an address accessible to the other hosts in the domain. Also exposing an HTTP management interface is not required, but is recommended as it allows the Administration Console to work:
<management-interfaces>
<native-interface security-realm="ManagementRealm">
<socket interface="management" port="${jboss.management.native.port:9999}"/>
</native-interface>
<http-interface security-realm="ManagementRealm">
<socket interface="management" port="${jboss.management.http.port:9990}"/>
</http-interface>
</management-interfaces>
The interface attributes above refer to a named interface declaration later in the host.xml file. This interface declaration will be used to resolve a corresponding network interface.
<interfaces>
<interface name="management">
<inet-address value="192.168.0.101"/>
</interface>
</interfaces>
(See domain/configuration/host.xml)
Please consult the chapter "Interface Configuration" for a more detailed explanation on how to configure network interfaces.
Next by default the master domain controller is configured to require authentication so a user needs to be added that can be used by the slave domain controller to connect.
Make use of the add-user utility to add a new user, for this example I am adding a new user called slave.
add-user MUST be run on the master domain controller and NOT the slave.
When you reach the final question of the interactive flow answer y or yes to indicate that the new user will be used for a process e.g.
Is this new user going to be used for one AS process to connect to another AS process e.g. slave domain controller? yes/no? y To represent the user add the following to the server-identities definition <secret value="cE3EBEkE=" />
Make a note of the XML Element output as that is going to be required within the slave configuration.
Host Controller Configuration
Once the domain controller is configured correctly you can proceed with any host that should join the domain. The host controller configuration requires three steps:
-
The logical host name (within the domain) needs to be distinct
-
The host controller needs to know the domain controller IP address
Provide a distinct, logical name for the host. In the following example we simply name it "slave":
<host xmlns="urn:jboss:domain:1.0"
name="slave">
[...]
</host>
(See domain/configuration/host.xml)
If the name attribute is not set, the default name for the host will be the value of the HOSTNAME or COMPUTERNAME environment variable, one of which will be set on most operating systems. If neither is set the name will be the value of InetAddress.getLocalHost().getHostName().
A security realm needs to be defined to hold the identity of the slave, as it is performing a specific purpose I would suggest a new realm is defined although it is possible to combine this with an existing realm.
<security-realm name="SlaveRealm">
<server-identities>
<secret value="cE3EBEkE=" />
</server-identities>
</security-realm>
The <secret /> element here is the one output from add-user previously. To create the <secret /> element yourself the value needs to be the password encoded using Base64.
Tell it how to find the domain controller so it can register itself with the domain:
<domain-controller> <remote host="192.168.0.101" port="9999" username="slave" security-realm="SlaveRealm"/> </domain-controller>
(See domain/configuration/host.xml)
The username attribute here is optional, if it is omitted then the name of the host will be used instead, in this example that was already set to name.
The name of each host needs to be unique when registering with the domain controller, however the username does not - using the username attribute allows the same account to be used by multiple hosts if this makes sense in your environment.
The <remote /> element is also associated with the security realm SlaveRealm, this is how it picks up the password from the <secret /> element.
Server groups
The domain controller defines one or more server groups and associates each of these with a profile and a socket binding group, and also :
<server-groups>
<server-group name="main-server-group" profile="default">
<jvm name="default">
<heap size="64m" max-size="512m"/>
<permgen size="128m" max-size="128m"/>
</jvm>
<socket-binding-group ref="standard-sockets"/>
</server-group>
<server-group name="other-server-group" profile="bigger">
<jvm name="default">
<heap size="64m" max-size="512m"/>
</jvm>
<socket-binding-group ref="bigger-sockets"/>
</server-group>
</server-groups>
(See domain/configuration/domain.xml)
The domain controller also defines the socket binding groups and the profiles. The socket binding groups define the default socket bindings that are used:
<socket-binding-groups>
<socket-binding-group name="standard-sockets" default-interface="public">
<socket-binding name="http" port="8080"/>
[...]
</socket-binding-group>
<socket-binding-group name="bigger-sockets" include="standard-sockets" default-interface="public">
<socket-binding name="unique-to-bigger" port="8123"/>
</socket-binding-group>
</socket-binding-groups>
(See domain/configuration/domain.xml)
In this example the bigger-sockets group includes all the socket bindings defined in the standard-sockets groups and then defines an extra socket binding of its own.
A profile is a collection of subsystems, and these subsystems are what implement the functionality people expect of an application server.
<profiles>
<profile name="default">
<subsystem xmlns="urn:jboss:domain:web:1.0">
<connector name="http" scheme="http" protocol="HTTP/1.1" socket-binding="http"/>
[...]
</subsystem>
<\!-\- The rest of the subsystems here \-->
[...]
</profile>
<profile name="bigger">
<subsystem xmlns="urn:jboss:domain:web:1.0">
<connector name="http" scheme="http" protocol="HTTP/1.1" socket-binding="http"/>
[...]
</subsystem>
<\!-\- The same subsystems as defined by 'default' here \-->
[...]
<subsystem xmlns="urn:jboss:domain:fictional-example:1.0">
<socket-to-use name="unique-to-bigger"/>
</subsystem>
</profile>
</profiles>
(See domain/configuration/domain.xml)
Here we have two profiles. The bigger profile contains all the same subsystems as the default profile (athough the parameters for the various subsystems could be different in each profile), and adds the fictional-example subsystem which references the unique-to-bigger socket binding.
Servers
The host controller defines one or more servers:
<servers>
<server name="server-one" group="main-server-group">
<\!-\- server-one inherits the default socket-group declared in the server-group \-->
<jvm name="default"/>
</server>
<server name="server-two" group="main-server-group" auto-start="true">
<socket-binding-group ref="standard-sockets" port-offset="150"/>
<jvm name="default">
<heap size="64m" max-size="256m"/>
</jvm>
</server>
<server name="server-three" group="other-server-group" auto-start="false">
<socket-binding-group ref="bigger-sockets" port-offset="250"/>
</server>
</servers>
(See domain/configuration/host.xml)
server-one and server-two both are associated with main-server-group so that means they both run the subsystems defined by the default profile, and have the socket bindings defined by the standard-sockets socket binding group. Since all the servers defined by a host will be run on the same physical host we would get port conflicts unless we used <socket-binding-group ref="standard-sockets" port-offset="150"/> for server-two. This means that server-two will use the socket bindings defined by standard-sockets but it will add 150 to each port number defined, so the value used for http will be 8230 for server-two.
server-three will not be started due to its auto-start="false". The default value if no auto-start is given is true so both server-one and server-two will be started when the host controller is started. server-three belongs to other-server-group, so if its auto-start were changed to true it would start up using the subsystems from the bigger profile, and it would use the bigger-sockets socket binding group.
JVM
The host controller contains the main jvm definitions with arguments:
<jvms>
<jvm name="default">
<heap size="64m" max-size="128m"/>
</jvm>
</jvms>
(See domain/configuration/host.xml)
From the preceeding examples we can see that we also had a jvm reference at server group level in the domain controller. The jvm's name must match one of the definitions in the host controller. The values supplied at domain controller and host controller level are combined, with the host controller taking precedence if the same parameter is given in both places.
Finally, as seen, we can also override the jvm at server level. Again, the jvm's name must match one of the definitions in the host controller. The values are combined with the ones coming in from domain controller and host controller level, this time the server definition takes precedence if the same parameter is given in all places.
Following these rules the jvm parameters to start each server would be
|
Server |
JVM parameters |
|
server-one |
-XX:PermSize=128m -XX:MaxPermSize=128m -Xms64m -Xmx128m |
|
server-two |
-XX:PermSize=128m -XX:MaxPermSize=128m -Xms64m -Xmx256m |
|
server-three |
-Xms64m -Xmx128m |
Management API reference
This section is an in depth reference to the JBoss Application Server management API. Readers are encouraged to read the Management Clients and Core management concepts sections for fundamental background information, as well as the Management tasks and Domain Setup sections for key task oriented information. This section is meant as an in depth reference to delve into some of the key details.
Global operations
The JBoss Application Server management API includes a number of operations that apply to every resource.
The read-resource operation
Reads a management resource's attribute values along with either basic or complete information about any child resources. Supports the
following parameters, none of which are required:
-
recursive – (boolean, default is false) – whether to include complete information about child resources, recursively.
-
recursive-depth – (int) – The depth to which information about child resources should be included if recursive is {{true}. If not set, the depth will be unlimited; i.e. all descendant resources will be included.
-
proxies – (boolean, default is false) – whether to include remote resources in a recursive query (i.e. host level resources from slave Host Controllers in a query of the Domain Controller; running server resources in a query of a host).
-
include-runtime – (boolean, default is false) – whether to include runtime attributes (i.e. those whose value does not come from the persistent configuration) in the response.
-
include-defaults – (boolean, default is true) – whether to include in the result default values not set by users. Many attributes have a default value that will be used in the runtime if the users have not provided an explicit value. If this parameter is false the value for such attributes in the result will be undefined. If true the result will include the default value for such parameters.
The read-attribute operation
Reads the value of an individual attribute. Takes a single, required, parameter:
-
name – (string) – the name of the attribute to read.
-
include-defaults – (boolean, default is true) – whether to include in the result default values not set by users. Many attributes have a default value that will be used in the runtime if the users have not provided an explicit value. If this parameter is false the value for such attributes in the result will be undefined. If true the result will include the default value for such parameters.
The write-attribute operation
Writes the value of an individual attribute. Takes two required parameters:
-
name – (string) – the name of the attribute to write.
-
value – (type depends on the attribute being written) – the new value.
The unset-attribute operation
Sets the value of an individual attribute to the undefined value, if such a value is allowed for the attribute. The operation will fail if the undefined value is not allowed. Takes a single required parameter:
-
name – (string) – the name of the attribute to write.
The read-resource-description operation
Returns the description of a resource's attributes, types of children and, optionally, operations. Supports the
following parameters, none of which are required:
-
recursive – (boolean, default is false) – whether to include information about child resources, recursively.
-
proxies – (boolean, default is false) – whether to include remote resources in a recursive query (i.e. host level resources from slave Host Controllers in a query of the Domain Controller; running server resources in a query of a host)
-
operations – (boolean, default is false) – whether to include descriptions of the resource's operations
-
inherited – (boolean, default is true) – if operations is true, whether to include descriptions of operations inherited from higher level resources. The global operations described in this section are themselves inherited from the root resource, so the primary effect of setting inherited to false is to exclude the descriptions of the global operations from the output.
See Description of the Management Model for details on the result of this operation.
The read-operation-names operation
Returns a list of the names of all the operations the resource supports. Takes no parameters.
The read-operation-description operation
Returns the description of an operation, along with details of its parameter types and its return value. Takes a single, required, parameter:
-
name – (string) – the name of the operation
See Description of the Management Model for details on the result of this operation.
The read-children-types operation
Returns a list of the types of child resources the resource supports. Takes no parameters.
The read-children-names operation
Returns a list of the names of all child resources of a given type. Takes a single, required, parameter:
-
child-type – (string) – the name of the type
The read-children-resources operation
Returns information about all of a resource's children that are of a given type. For each child resource, the returned information is equivalent to executing the read-resource operation on that resource. Takes the following parameters, of which only {{child-type} is required:
-
child-type – (string) – the name of the type of child resource
-
recursive – (boolean, default is false) – whether to include complete information about child resources, recursively.
-
recursive-depth – (int) – The depth to which information about child resources should be included if recursive is {{true}. If not set, the depth will be unlimited; i.e. all descendant resources will be included.
-
proxies – (boolean, default is false) – whether to include remote resources in a recursive query (i.e. host level resources from slave Host Controllers in a query of the Domain Controller; running server resources in a query of a host)
-
include-runtime – (boolean, default is false) – whether to include runtime attributes (i.e. those whose value does not come from the persistent configuration) in the response.
-
include-defaults – (boolean, default is true) – whether to include in the result default values not set by users. Many attributes have a default value that will be used in the runtime if the users have not provided an explicit value. If this parameter is false the value for such attributes in the result will be undefined. If true the result will include the default value for such parameters.
Standard Operations
Besides the global operations described above, by convention nearly every resource should expose an add operation and a remove operation. Exceptions to this convention are the root resource, and resources that do not store persistent configuration and are created dynamically at runtime (e.g. resources representing the JVM's platform mbeans or resources representing aspects of the running state of a deployment.)
The add operation
The operation that creates a new resource must be named add. The operation may take zero or more parameters; what those parameters are depends on the resource being created.
The remove operation
The operation that removes an existing resource must be named remove. The operation should take no parameters.
Detyped management and the jboss-dmr library
The management model exposed by JBoss Application Server 7 is very large and complex. There are dozens, probably hundreds of logical concepts involved – hosts, server groups, servers, subsystems, datasources, web connectors, and on and on – each of which in a classic objected oriented API design could be represented by a Java type (i.e. a Java class or interface.) However, a primary goal in the development of JBoss AS 7's native management API was to ensure that clients built to use the API had as few compile-time and run-time dependencies on JBoss-provided classes as possible, and that the API exposed by those libraries be powerful but also simple and stable. A management client running with the management libraries created for AS 7.0 should still work if used to manage an AS 7.99 domain. The management client libraries needed to be forward compatible.
It is highly unlikely that an API that consists of hundreds of Java types could be kept forward compatible. Instead, the JBoss AS 7 management API is a detyped API. A detyped API is like decaffeinated coffee – it still has a little bit of caffeine, but not enough to keep you awake at night. JBoss AS's management API still has a few Java types in it (it's impossible for a Java library to have no types!) but not enough to keep you (or us) up at night worrying that your management clients won't be forward compatible.
A detyped API works by making it possible to build up arbitrarily complex data structures using a small number of Java types. All of the parameter values and return values in the API are expressed using those few types. Ideally, most of the types are basic JDK types, like java.lang.String, java.lang.Integer, etc. In addition to the basic JDK types, JBoss AS 7's detyped management API uses a small library called jboss-dmr. The purpose of this section is to provide a basic overview of the jboss-dmr library.
Even if you don't use jboss-dmr directly (probably the case for all but a few users), some of the information in this section may be useful. When you invoke operations using the application server's Command Line Interface, the return values are just the text representation of of a jboss-dmr ModelNode. If your CLI commands require complex parameter values, you may yourself end up writing the text representation of a ModelNode. And if you use the HTTP management API, all response bodies as well as the request body for any POST will be a JSON representation of a ModelNode.
The source code for jboss-dmr is available on Github. The maven coordinates for a jboss-dmr release are org.jboss.jboss-dmr:jboss-dmr.
ModelNode and ModelType
The public API exposed by jboss-dmr is very simple: just three classes, one of which is an enum!
The primary class is org.jboss.dmr.ModelNode. A ModelNode is essentially just a wrapper around some value; the value is typically some basic JDK type. A ModelNode exposes a getType() method. This method returns a value of type org.jboss.dmr.ModelType, which is an enum of all the valid types of values. And that's 95% of the public API; a class and an enum. (We'll get to the third class, Property, below.)
Basic ModelNode manipulation
To illustrate how to work with ModelNode s, we'll use the Beanshell scripting library. We won't get into many details of beanshell here; it's a simple and intuitive tool and hopefully the following examples are as well.
We'll start by launching a beanshell interpreter, with the jboss-dmr library available on the classpath. Then we'll tell beanshell to import all the jboss-dmr classes so they are available for use:
$ java -cp bsh-2.0b4.jar:jboss-dmr-1.0.0.Final.jar bsh.Interpreter BeanShell 2.0b4 - by Pat Niemeyer (pat@pat.net) bsh % import org.jboss.dmr.*; bsh %
Next, create a ModelNode and use the beanshell print function to output what type it is:
bsh % ModelNode node = new ModelNode(); bsh % print(node.getType()); UNDEFINED
A new ModelNode has no value stored, so its type is ModelType.UNDEFINED.
Use one of the overloaded set method variants to assign a node's value:
bsh % node.set(1);
bsh % print(node.getType());
INT
bsh % node.set(true);
bsh % print(node.getType());
BOOLEAN
bsh % node.set("Hello, world");
bsh % print(node.getType());
STRING
Use one of the asXXX() methods to retrieve the value:
bsh % node.set(2);
bsh % print(node.asInt());
2
bsh % node.set("A string");
bsh % print(node.asString());
A string
ModelNode will attempt to perform type conversions when you invoke the asXXX methods:
bsh % node.set(1);
bsh % print(node.asString());
1
bsh % print(node.asBoolean());
true
bsh % node.set(0);
bsh % print(node.asBoolean());
false
bsh % node.set("true");
bsh % print(node.asBoolean());
true
Not all type conversions are possible:
bsh % node.set("A string");
bsh % print(node.asInt());
// Error: // Uncaught Exception: Method Invocation node.asInt : at Line: 20 : in file: <unknown file> : node .asInt ( )
Target exception: java.lang.NumberFormatException: For input string: "A string"
java.lang.NumberFormatException: For input string: "A string"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:48)
at java.lang.Integer.parseInt(Integer.java:449)
at java.lang.Integer.parseInt(Integer.java:499)
at org.jboss.dmr.StringModelValue.asInt(StringModelValue.java:61)
at org.jboss.dmr.ModelNode.asInt(ModelNode.java:117)
....
The ModelNode.getType() method can be used to ensure a node has an expected value type before attempting a type conversion.
One set variant takes another ModelNode as its argument. The value of the passed in node is copied, so there is no shared state between the two model nodes:
bsh % node.set("A string");
bsh % ModelNode another = new ModelNode();
bsh % another.set(node);
bsh % print(another.asString());
A string
bsh % node.set("changed");
bsh % print(node.asString());
changed
bsh % print(another.asString());
A string
A ModelNode can be cloned. Again, there is no shared state between the original node and its clone:
bsh % ModelNode clone = another.clone(); bsh % print(clone.asString()); A string bsh % another.set(42); bsh % print(another.asString()); 42 bsh % print(clone.asString()); A string
Use the protect() method to make a ModelNode immutable:
bsh % clone.protect();
bsh % clone.set("A different string");
// Error: // Uncaught Exception: Method Invocation clone.set : at Line: 15 : in file: <unknown file> : clone .set ( "A different string" )
Target exception: java.lang.UnsupportedOperationException
java.lang.UnsupportedOperationException
at org.jboss.dmr.ModelNode.checkProtect(ModelNode.java:1441)
at org.jboss.dmr.ModelNode.set(ModelNode.java:351)
....
Lists
The above examples aren't particularly interesting; if all we can do with a ModelNode is wrap a simple Java primitive, what use is that? However, a ModelNode's value can be more complex than a simple primitive, and using these more complex types we can build complex data structures. The first more complex type is ModelType.LIST.
Use the add methods to initialize a node's value as a list and add to the list:
bsh % ModelNode list = new ModelNode(); bsh % list.add(5); bsh % list.add(10); bsh % print(list.getType()); LIST
Use asInt() to find the size of the list:
bsh % print(list.asInt()); 2
Use the overloaded get method variant that takes an int param to retrieve an item. The item is returned as a ModelNode:
bsh % ModelNode child = list.get(1); bsh % print(child.asInt()); 10
Elements in a list need not all be of the same type:
bsh % list.add("A string");
bsh % print(list.get(1).getType());
INT
bsh % print(list.get(2).getType());
STRING
Here's one of the trickiest things about jboss-dmr: The get methods actually mutate state; they are not "read-only". For example, calling get with an index that does not exist yet in the list will actually create a child of type ModelType.UNDEFINED at that index (and will create UNDEFINED children for any intervening indices.)
bsh % ModelNode four = list.get(4); bsh % print(four.getType()); UNDEFINED bsh % print(list.asInt()); 6
Since the get call always returns a ModelNode and never null it is safe to manipulate the return value:
bsh % list.get(5).set(30); bsh % print(list.get(5).asInt()); 30
That's not so interesting in the above example, but later on with node of type ModelType.OBJECT we'll see how that kind of method chaining can let you build up fairly complex data structures with a minimum of code.
Use the asList() method to get a List<ModelNode> of the children:
bsh % bsh % for (ModelNode element : list.asList()) {
print(element.getType());
}
INT
INT
STRING
UNDEFINED
UNDEFINED
INT
The asString() and toString() methods provide slightly differently formatted text representations of a ModelType.LIST node:
bsh % print(list.asString());
[5,10,"A string",undefined,undefined,30]
bsh % print(list.toString());
[
5,
10,
"A string",
undefined,
undefined,
30
]
Finally, if you've previously used set to assign a node's value to some non-list type, you cannot use the add method:
bsh % node.add(5);
// Error: // Uncaught Exception: Method Invocation node.add : at Line: 18 : in file: <unknown file> : node .add ( 5 )
Target exception: java.lang.IllegalArgumentException
java.lang.IllegalArgumentException
at org.jboss.dmr.ModelValue.addChild(ModelValue.java:120)
at org.jboss.dmr.ModelNode.add(ModelNode.java:1007)
at org.jboss.dmr.ModelNode.add(ModelNode.java:761)
...
You can, however, use the setEmptyList() method to change the node's type, and then use add:
bsh % node.setEmptyList(); bsh % node.add(5); bsh % print(node.toString()); [5]
Properties
The third public class in the jboss-dmr library is org.jboss.dmr.Property. A Property is a String => ModelNode tuple.
bsh % Property prop = new Property("stuff", list);
bsh % print(prop.toString());
org.jboss.dmr.Property@79a5f739
bsh % print(prop.getName());
stuff
bsh % print(prop.getValue());
[
5,
10,
"A string",
undefined,
undefined,
30
]
The property can be passed to ModelNode.set:
bsh % node.set(prop); bsh % print(node.getType()); PROPERTY
The text format for a node of ModelType.PROPERTY is:
bsh % print(node.toString());
("stuff" => [
5,
10,
"A string",
undefined,
undefined,
30
])
Directly instantiating a Property via its constructor is not common. More typically one of the two argument ModelNode.add or ModelNode.set variants is used. The first argument is the property name:
bsh % ModelNode simpleProp = new ModelNode();
bsh % simpleProp.set("enabled", true);
bsh % print(simpleProp.toString());
("enabled" => true)
bsh % print(simpleProp.getType());
PROPERTY
bsh % ModelNode propList = new ModelNode();
bsh % propList.add("min", 1);
bsh % propList.add("max", 10);
bsh % print(propList.toString());
[
("min" => 1),
("max" => 10)
]
bsh % print(propList.getType());
LIST
bsh % print(propList.get(0).getType());
PROPERTY
The asPropertyList() method provides easy access to a List<Property>:
bsh % for (Property prop : propList.asPropertyList()) {
print(prop.getName() + " = " + prop.getValue());
}
min = 1
max = 10
ModelType.OBJECT
The most powerful and most commonly used complex value type in jboss-dmr is ModelType.OBJECT. A ModelNode whose value is ModelType.OBJECT internally maintains a Map<String, ModelNode.
Use the get method variant that takes a string argument to add an entry to the map. If no entry exists under the given name, a new entry is added with a the value being a ModelType.UNDEFINED node. The node is returned:
bsh % ModelNode range = new ModelNode();
bsh % ModelNode min = range.get("min");
bsh % print(range.toString());
{"min" => undefined}
bsh % min.set(2);
bsh % print(range.toString());
{"min" => 2}
Again it is important to remember that the get operation may mutate the state of a model node by adding a new entry. It is not a read-only operation.
Since get will never return null, a common pattern is to use method chaining to create the key/value pair:
bsh % range.get("max").set(10);
bsh % print(range.toString());
{
"min" => 2,
"max" => 10
}
A call to get passing an already existing key will of course return the same model node as was returned the first time get was called with that key:
bsh % print(min == range.get("min"));
true
Multiple parameters can be passed to get. This is a simple way to traverse a tree made up of ModelType.OBJECT nodes. Again, get may mutate the node on which it is invoked; e.g. it will actually create the tree if nodes do not exist. This next example uses a workaround to get beanshell to handle the overloaded get method that takes a variable number of arguments:
bsh % String[] varargs = { "US", "Missouri", "St. Louis" };
bsh % salesTerritories.get(varargs).set("Brian");
bsh % print(salesTerritories.toString());
{"US" => {"Missouri" => {"St. Louis" => "Brian"}}}
The normal syntax would be:
salesTerritories.get("US", "Missouri", "St. Louis").set("Brian");
The key/value pairs in the map can be accessed as a List<Property:
bsh % for (Property prop : range.asPropertyList()) {
print(prop.getName() + " = " + prop.getValue());
}
min = 2
The semantics of the backing map in a node of ModelType.OBJECT are those of a LinkedHashMap. The map remembers the order in which key/value pairs are added. This is relevant when iterating over the pairs after calling asPropertyList() and for controlling the order in which key/value pairs appear in the output from toString().
Since the get method will actually mutate the state of a node if the given key does not exist, ModelNode provides a couple methods to let you check whether the entry is there. The has method simply does that:
bsh % print(range.has("unit"));
false
bsh % print(range.has("min"));
true
Very often, the need is to not only know whether the key/value pair exists, but whether the value is defined (i.e. not ModelType.UNDEFINED. This kind of check is analogous to checking whether a field in a Java class has a null value. The hasDefined lets you do this:
bsh % print(range.hasDefined("unit"));
false
bsh % // Establish an undefined child 'unit';
bsh % range.get("unit");
bsh % print(range.toString());
{
"min" => 2,
"max" => 10,
"unit" => undefined
}
bsh % print(range.hasDefined("unit"));
false
bsh % range.get("unit").set("meters");
bsh % print(range.hasDefined("unit"));
true
ModelType.EXPRESSION
A value of type ModelType.EXPRESSION is stored as a string, but can later be resolved to different value. The string has a special syntax that should be familiar to those who have used the system property substitution feature in previous JBoss AS releases.
[<prefix>][${<system-property-name>[:<default-value>]}][<suffix>]*
For example:
${queue.length}
http://${host}
http://${host:localhost}:${port:8080}/index.html
Use the setExpression method to set a node's value to type expression:
bsh % ModelNode expression = new ModelNode();
bsh % expression.setExpression("${queue.length}");
bsh % print(expression.getType());
EXPRESSION
Calling asString() returns the same string that was input:
bsh % print(expression.asString());
${queue.length}
However, calling toString() tells you that this node's value is not of ModelType.STRING:
bsh % print(expression.toString());
expression "${queue.length}"
When the resolve operation is called, the string is parsed and any embedded system properties are resolved against the JVM's current system property values. A new ModelNode is returned whose value is the resolved string:
bsh % System.setProperty("queue.length", "10");
bsh % ModelNode resolved = expression.resolve();
bsh % print(resolved.asInt());
10
Note that the type of the ModelNode returned by resolve() is ModelType.STRING:
bsh % print(resolved.getType()); STRING
The resolved.asInt() call in the previous example only worked because the string "10" happens to be convertible into the int 10.
Calling resolve() has no effect on the value of the node on which the method is invoked:
bsh % resolved = expression.resolve();
bsh % print(resolved.toString());
"10"
bsh % print(expression.toString());
expression "${queue.length}"
If an expression cannot be resolved, resolve just uses the original string. The string can include more than one system property substitution:
bsh % expression.setExpression("http://${host}:${port}/index.html");
bsh % resolved = expression.resolve();
bsh % print(resolved.asString());
http://${host}:${port}/index.html
The expression can optionally include a default value, separated from the name of the system property by a colon:
bsh % expression.setExpression("http://${host:localhost}:${port:8080}/index.html");
bsh % resolved = expression.resolve();
bsh % print(resolved.asString());
http://localhost:8080/index.html
Actually including a system property substitution in the expression is not required:
bsh % expression.setExpression("no system property");
bsh % resolved = expression.resolve();
bsh % print(resolved.asString());
no system property
bsh % print(expression.toString());
expression "no system property"
The resolve method works on nodes of other types as well; it returns a copy without attempting any real resolution:
bsh % ModelNode basic = new ModelNode(); bsh % basic.set(10); bsh % resolved = basic.resolve(); bsh % print(resolved.getType()); INT bsh % resolved.set(5); bsh % print(resolved.asInt()); 5 bsh % print(basic.asInt()); 10
ModelType.TYPE
You can also pass one of the values of the ModelType enum to set:
bsh % ModelNode type = new ModelNode(); bsh % type.set(ModelType.LIST); bsh % print(type.getType()); TYPE bsh % print(type.toString()); LIST
This is useful when using a ModelNode data structure to describe another ModelNode data structure.
Full list of ModelNode types
BIG_DECIMAL
BIG_INTEGER
BOOLEAN
BYTES
DOUBLE
EXPRESSION
INT
LIST
LONG
OBJECT
PROPERTY
STRING
TYPE
UNDEFINED
Text representation of a ModelNode
JSON representation of a ModelNode
Description of the Management Model
A detailed description of the resources, attributes and operations that make up the management model provided by an individual JBoss Application Server instance or by any Domain Controller or slave Host Controller process can be queried using the read-resource-description, read-operation-names, read-operation-description and read-child-types operations described in the Global operations section. In this section we provide details on what's included in those descriptions.
Description of the JBoss Application Server Managed Resources
All portions of the management model exposed by AS 7 are addressable via an ordered list of key/value pairs. For each addressable Management Resource, the following descriptive information will be available:
-
description – String – text description of this portion of the model
-
attributes – Map of String (the attribute name) to complex structure – the configuration attributes available in this portion of the model. See below for the representation of each attribute.
-
operations – Map of String (the operation name) to complex structure – the operations that can be targetted at this address. See below for the representation of each operation.
-
children – Map of String (the type of child) to complex structure – the relationship of this portion of the model to other addressable portions of the model. See below for the representation of each child relationship.
-
head-comment-allowed – boolean – indicates whether this portion of the model can store an XML comment that would be written in the persistent form of the model (e.g. domain.xml) before the start of the XML element that represents this portion of the model. This item is optional, and if not present defaults to true. (Note: storing XML comments in the in-memory model is not currently supported. This description key is for future use.)
-
tail-comment-allowed – boolean – similar to head-comment-allowed, but indicates whether a comment just before the close of the XML element is supported. A tail comment can only be supported if the element has child elements, in which case a comment can be inserted between the final child element and the element's closing tag. This item is optional, and if not present defaults to true. (Note: storing XML comments in the in-memory model is not currently supported. This description key is for future use.)
For example:
{
"description => "A manageable resource",
"tail-comment-allowed" => false,
"attributes" => {
"foo" => {
.... details of attribute foo
}
},
"operations" => {
"start" => {
.... details of the start operation
}
},
"children" => {
"bar" => {
.... details of the relationship with children of type "bar"
}
}
}
Description of an Attribute
An attribute is a portion of the management model that is not directly addressable. Instead, it is conceptually a property of an addressable management resource. For each attribute in the model, the following descriptive information will be available:
-
description – String – text description of the attribute
-
type – org.jboss.dmr.ModelType – the type of the attribute value. One of the enum values BIG_DECIMAL, BIG_INTEGER, BOOLEAN, BYTES, DOUBLE, INT, LIST, LONG, OBJECT, PROPERTY, STRING. Most of these are self-explanatory. An OBJECT will be represented in the detyped model as a map of string keys to values of some other legal type, conceptually similar to a javax.management.openmbean.CompositeData. A PROPERTY is a single key/value pair, where the key is a string, and the value is of some other legal type.
-
value-type – ModelType or complex structure – Only present if type is LIST or OBJECT. If all elements in the LIST or all the values of the OBJECT type are of the same type, this will be one of the ModelType enums BIG_DECIMAL, BIG_INTEGER, BOOLEAN, BYTES, DOUBLE, INT, LONG, STRING. Otherwise, value-type will detail the structure of the attribute value, enumerating the value's fields and the type of their value.
-
expressions-allowed – boolean – indicates whether the value of the attribute may be of type ModelType.EXPRESSION, instead of its standard type (see type and value-type above for discussion of an attribute's standard type.) A value of ModelType.EXPRESSION contains a system-property substitution expression that the server will resolve against the server-side system property map before using the value. For example, an attribute named max-threads may have an expression value of ${example.pool.max-threads:10} instead of just 10. Default value if not present is false.
-
required – boolean – true if the attribute will always exist in a representation of its portion of the model; false if it may not (implying a null value.) If not present, true is the default.
-
storage – String – Either "configuration" or "runtime". If "configuration", the attribute's value is stored as part of the persistent configuration (e.g. in domain.xml, host.xml or standalone.xml.) If "runtime" the attribute's value is not stored in the persistent configuration; the value only exists as long as the resource is running.
-
access-type – String – One of "read-only", "read-write" or "metric". Whether an attribute value can be written, or can only read. A "metric" is a read-only attribute whose value is not stored in the persistent configuration, and whose value may change due to activity on the server. If an attribute is "read-write", the resource will expose an operation named "write-attribute" whose "name" parameter will accept this attribute's name and whose "value" parameter will accept a valid value for this attribute. That operation will be the standard means of updating this attribute's value.
-
restart-required – String – One of "no-services", "all-services", "resource-services" or "jvm". Only relevant to attributes whose access-type is read-write. Indicates whether execution of a write-attribute operation whose name parameter specifies this attribute requires a restart of services (or an entire JVM) in order for the change to take effect in the runtime . See discussion of "Applying Updates to Runtime Services" below. Default value is "no-services".
-
alternatives – List of string – Indicates an exclusive relationship between attributes. If this attribute is defined, the other attributes listed in this descriptor's value should be undefined (even if their required descriptor says true; i.e. the presence of this attribute satisfies the requirement.) Default is undefined; i.e. this does not apply to most attributes.
-
requires – List of string – Indicates that if this attribute has a value (other than undefined), the other attributes listed in this descriptor's value must also have a value, even if their required descriptor says false. This would typically be used in conjunction with alternatives. For example, attributes "a" and "b" are required, but are alternatives to each other; "c" and "d" are optional. But "b" requires "c" and "d", so if "b" is used, "c" and "d" must also be defined. Default is undefined; i.e. this does not apply to most attributes.
-
head-comment-allowed – boolean – indicates whether the model can store an XML comment that would be written in the persistent form of the model (e.g. domain.xml) before the start of the XML element that represents this attribute. This item is optional, and if not present defaults to false. (This is a different default from what is used for an entire management resource, since model attributes often map to XML attributes, which don't allow comments.) (Note: storing XML comments in the in-memory model is not currently supported. This description key is for future use.)
-
tail-comment-allowed – boolean – similar to head-comment-allowed, but indicates whether a comment just before the close of the XML element is supported. A tail comment can only be supported if the element has child elements, in which case a comment can be inserted between the final child element and the element's closing tag. This item is optional, and if not present defaults to false. (This is a different default from what is used for an entire management resource, since model attributes often map to XML attributes, which don't allow comments.) (Note: storing XML comments in the in-memory model is not currently supported. This description key is for future use.)
-
arbitrary key/value pairs that further describe the attribute value, e.g. "max" => 2. See "Arbitrary Descriptors" below.
Some examples:
"foo" => {
"description" => "The foo",
"type" => INT,
"max" => 2
}
"bar" => {
"description" => "The bar",
"type" => OBJECT,
"value-type" => {
"size" => INT,
"color" => STRING
}
}
Description of an Operation
A management resource may have operations associated with it. The description of an operation will include the following information:
-
operation-name – String – the name of the operation
-
description – String – text description of the operation
-
request-properties – Map of String to complex structure – description of the parameters of the operation. Keys are the names of the parameters, values are descriptions of the parameter value types. See below for details on the description of parameter value types.
-
reply-properties – complex structure, or empty – description of the return value of the operation, with an empty node meaning void. See below for details on the description of operation return value types.
-
restart-required – String – One of "no-services", "all-services", "resource-services" or "jvm". Indicates whether the operation makes a configuration change that requires a restart of services (or an entire JVM) in order for the change to take effect in the runtime. See discussion of "Applying Updates to Runtime Services" below. Default value is "no-services".
Description of an Operation Parameter or Return Value
-
description – String – text description of the parameter or return value
-
type – org.jboss.dmr.ModelType – the type of the parameter or return value. One of the enum values BIG_DECIMAL, BIG_INTEGER, BOOLEAN, BYTES, DOUBLE, INT, LIST, LONG, OBJECT, PROPERTY, STRING.
-
value-type – ModelType or complex structure – Only present if type is LIST or OBJECT. If all elements in the LIST or all the values of the OBJECT type are of the same type, this will be one of the ModelType enums BIG_DECIMAL, BIG_INTEGER, BOOLEAN, BYTES, DOUBLE, INT, LIST, LONG, PROPERTY, STRING. Otherwise, value-type will detail the structure of the attribute value, enumerating the value's fields and the type of their value.
-
expressions-allowed – boolean – indicates whether the value of the the parameter or return value may be of type ModelType.EXPRESSION, instead its standard type (see type and value-type above for discussion of the standard type.) A value of ModelType.EXPRESSION contains a system-property substitution expression that the server will resolve against the server-side system property map before using the value. For example, a parameter named max-threads may have an expression value of ${example.pool.max-threads:10} instead of just 10. Default value if not present is false.
-
required – boolean – Only relevant to parameters. true if the parameter must be present in the request object used to invoke the operation; false if it can omitted. If not present, true is the default.
-
nillable – boolean – true if null is a valid value. If not present, false is the default.
-
restart-required – String – One of "no-services", "all-services", "resource-services" or "jvm". Only relevant to attributes whose access-type is read-write. Indicates whether execution of a write-attribute operation whose name parameter specifies this attribute requires a restart of services (or an entire JVM) in order for the change to take effect in the runtime . See discussion of "Applying Updates to Runtime Services" below. Default value is "no-services".
-
alternatives – List of string – Indicates an exclusive relationship between parameters. If this attribute is defined, the other parameters listed in this descriptor's value should be undefined (even if their required descriptor says true; i.e. the presence of this parameter satisfies the requirement.) Default is undefined; i.e. this does not apply to most parameters.
-
requires – List of string – Indicates that if this parameter has a value (other than undefined), the other parameters listed in this descriptor's value must also have a value, even if their required descriptor says false. This would typically be used in conjunction with alternatives. For example, parameters "a" and "b" are required, but are alternatives to each other; "c" and "d" are optional. But "b" requires "c" and "d", so if "b" is used, "c" and "d" must also be defined. Default is undefined; i.e. this does not apply to most parameters.
-
arbitrary key/value pairs that further describe the attribute value, e.g. "max" =>2. See "Arbitrary Descriptors" below.
Arbitrary Descriptors
The description of an attribute, operation parameter or operation return value type can include arbitrary key/value pairs that provide extra information. Whether a particular key/value pair is present depends on the context, e.g. a pair with key "max" would probably only occur as part of the description of some numeric type.
Following are standard keys and their expected value type. If descriptor authors want to add an arbitrary key/value pair to some descriptor and the semantic matches the meaning of one of the following items, the standard key/value type must be used.
-
min – int – the minimum value of some numeric type. The absence of this item implies there is no minimum value.
-
max – int – the maximum value of some numeric type. The absence of this item implies there is no maximum value.
-
min-length – int – the minimum length of some string, list or byte[] type. The absence of this item implies a minimum length of zero.
-
max-length – int – the maximum length of some string, list or byte[]. The absence of this item implies there is no maximum value.
-
nillable – boolean – whether null or a ModelNode of type ModelType.UNDEFINED is a legal value. The absence of this item implies false; i.e. null/undefined is not a legal value.
-
allowed – List – a list of legal values. The type of the elements in the list should match the type of the attribute.
-
default – the default value for the attribute if not present in the model
-
unit - The unit of the value, if one is applicable - e.g. ns, ms, s, m, h, KB, MB, TB. See the org.jboss.as.controller.client.helpers.MeasurementUnit in the org.jboss.as:jboss-as-controller-client artifact for a listing of legal measurement units..
Some examples:
{
"operation-name" => "incrementFoo",
"description" => "Increase the value of the 'foo' attribute by the given amount",
"request-properties" => {
"increment" => {
"type" => INT,
"description" => "The amount to increment",
"required" => true
}},
"reply-properties" => {
"type" => INT,
"description" => "The new value",
}
}
{
"operation-name" => "start",
"description" => "Starts the thing",
"request-properties" => {},
"reply-properties" => {}
}
Description of Parent/Child Relationships
The address used to target an addressable portion of the model must be an ordered list of key value pairs. The effect of this requirement is the addressable portions of the model naturally form a tree structure, with parent nodes in the tree defining what the valid keys are and the children defining what the valid values are. The parent node also defines the cardinality of the relationship. The description of the parent node includes a children element that describes these relationships:
{
....
"children" => {
"connector" => {
.... description of the relationship with children of type "connector"
},
"virtual-host" => {
.... description of the relationship with children of type "virtual-host"
}
}
The description of each relationship will include the following elements:
-
description – String – text description of the relationship
-
min-occurs – int, either 0 or 1 – Minimum number of children of this type that must exist in a valid model. If not present, the default value is 0.
-
max-occurs – int – Maximum number of children of this type that may exist in a valid model. If not present, the default value is Integer.MAX_VALUE, i.e. there is no limit.
-
allowed – List of strings – legal values for children names. If not present, there is no restriction on children names.
-
model-description – either "undefined" or a complex structure – This is the full description of the child resource (its text description, attributes, operations, children) as detailed above. This may also be "undefined", i.e. a null value, if the query that asked for the parent node's description did not include the "recursive" param set to true.
Example with if the recursive flag was set to true:
{
"description" => "The connectors used to handle client connections",
"min-occurs" > 1,
"model-description" => {
"description" => "Handles client connections",
"attributes => {
... details of children as documented above
},
"operations" => {
.... details of operations as documented above
},
"children" => {
.... details of the children's children
}
}
}
If the recursive flag was false:
{
"description" => "The connectors used to handle client connections",
"min-occurs" > 1,
"model-description" => undefined
}
Applying Updates to Runtime Services
An attribute or operation description may include a "restart-required" descriptor; this section is an explanation of the meaning of that descriptor.
An operation that changes a management resource's persistent configuration usually can also also affect a runtime service associated with the resource. For example, there is a runtime service associated with any host.xml or standalone.xml <interface> element; other services in the runtime depend on that service to provide the InetAddress associated with the interface. In many cases, an update to a resource's persistent configuration can be immediately applied to the associated runtime service. The runtime service's state is updated to reflect the new value(s).
However, in many cases the runtime service's state cannot be updated without restarting the service. Restarting a service can have broad effects. A restart of a service A will trigger a restart of other services B, C and D that depend A, triggering a restart of services that depend on B, C and D, etc. Those service restarts may very well disrupt handling of end-user requests.
Because restarting a service can be disruptive to end-user request handling, the handlers for management operations will not restart any service without some form of explicit instruction from the end user indicating a service restart is desired. In a few cases, simply executing the operation is an indication the user wants services to restart (e.g. a /host=master/server-config=server-one:restart operation in a managed domain, or a /:reload operation on a standalone server.) For all other cases, if an operation (or attribute write) cannot be performed without restarting a service, the metadata describing the operation or attribute will include a "restart-required" descriptor whose value indicates what is necessary for the operation to affect the runtime:
-
no-services – Applying the operation to the runtime does not require the restart of any services. This value is the default if the restart-required descriptor is not present.
-
all-services – The operation can only immediately update the persistent configuration; applying the operation to the runtime will require a subsequent restart of all services in the affected VM. Executing the operation will put the server into a "reload-required" state. Until a restart of all services is performed the response to this operation and to any subsequent operation will include a response header "process-state" => "reload-required". For a standalone server, a restart of all services can be accomplished by executing the /:reload CLI command. For a server in a managed domain, restarting all services currently requires a full restart of the affected server VM (e.g. /host=master/server-config=server-one:restart).
-
jvm --The operation can only immediately update the persistent configuration; applying the operation to the runtime will require a full process restart (i.e. stop the JVM and launch a new JVM). Executing the operation will put the server into a "restart-required" state. Until a restart is performed the response to this operation and to any subsequent operation will include a response header "process-state" => "restart-required". For a standalone server, a full process restart requires first stopping the server via OS-level operations (Ctrl-C, kill) or via the /:shutdown CLI command, and then starting the server again from the command line. For a server in a managed domain, restarting a server requires executing the /host=<host>/server-config=<server>:restart operation.
-
resource-services – The operation can only immediately update the persistent configuration; applying the operation to the runtime will require a subsequent restart of some services associated with the resource. If the operation includes the request header "allow-resource-service-restart" => true, the handler for the operation will go ahead and restart the runtime service. Otherwise executing the operation will put the server into a "reload-required" state. (See the discussion of "all-services" above for more on the "reload-required" state.)
The native management API
A standalone JBoss Application Server process, or a managed domain Domain Controller or slave Host Controller process can be configured to listen for remote management requests using its "native management interface":
<native-interface interface="management" port="9999" security-realm="ManagementRealm"/>
(See standalone/configuration/standalone.xml or domain/configuration/host.xml)
The CLI tool that comes with the application server uses this interface, and user can develop custom clients that use it as well. In this section we'll cover the basics on how to develop such a client. We'll also cover details on the format of low-level management operation requests and responses – information that should prove useful for users of the CLI tool as well.
Native Management Client Dependencies
The native management interface uses an open protocol based on the JBoss Remoting library. JBoss Remoting is used to establish a communication channel from the client to the process being managed. Once the communication channel is established the primary traffic over the channel is management requests initiated by the client and asynchronous responses from the target process.
A custom Java-based client should have the maven artifact org.jboss.as:jboss-as-controller-client and its dependencies on the classpath. The other dependencies are:
|
Maven Artifact |
Purpose |
|
org.jboss.remoting:jboss-remoting |
Remote communication |
|
org.jboss:jboss-dmr |
|
|
org.jboss.as:jboss-as-protocol |
Wire protocol for remote JBoss AS management |
|
org.jboss.sasl:jboss-sasl |
SASL authentication |
|
org.jboss.xnio:xnio-api |
Non-blocking IO |
|
org.jboss.xnio:xnio-nio |
Non-blocking IO |
|
org.jboss.logging:jboss-logging |
Logging |
|
org.jboss.threads:jboss-threads |
Thread management |
|
org.jboss.marshalling:jboss-marshalling |
Marshalling and unmarshalling data to/from streams |
The client API is entirely within the org.jboss.as:jboss-as-controller-client artifact; the other dependencies are part of the internal implementation of org.jboss.as:jboss-as-controller-client and are not compile-time dependencies of any custom client based on it.
The management protocol is an open protocol, so a completely custom client could be developed without using these libraries (e.g. using Python or some other language.)
Working with a ModelControllerClient
The org.jboss.as.controller.client.ModelControllerClient class is the main class a custom client would use to manage a JBoss Application Server server instance or a Domain Controller or slave Host Controller.
The custom client must have maven artifact org.jboss.as:jboss-as-controller-client and its dependencies on the classpath.
Creating the ModelControllerClient
To create a management client that can connect to your target process's native management socket, simply:
ModelControllerClient client = ModelControllerClient.Factory.create(InetAddress.getByName("localhost"), 9999);
The address and port are what is configured in the target process' <management><management-interfaces><native-interface.../> element.
Typically, however, the native management interface will be secured, requiring clients to authenticate. On the client side, the custom client will need to provide the user's authentication credentials, obtained in whatever manner is appropriate for the client (e.g. from a dialog box in a GUI-based client.) Access to these credentials is provided by passing in an implementation of the javax.security.auth.callback.CallbackHandler interface. For example:
static ModelControllerClient createClient(final InetAddress host, final int port,
final String username, final char[] password, final String securityRealmName) {
final CallbackHandler callbackHandler = new CallbackHandler() {
public void handle(Callback[] callbacks) throws IOException, UnsupportedCallbackException {
for (Callback current : callbacks) {
if (current instanceof NameCallback) {
NameCallback ncb = (NameCallback) current;
ncb.setName(username);
} else if (current instanceof PasswordCallback) {
PasswordCallback pcb = (PasswordCallback) current;
pcb.setPassword(password.toCharArray());
} else if (current instanceof RealmCallback) {
RealmCallback rcb = (RealmCallback) current;
rcb.setText(rcb.getDefaultText());
} else {
throw new UnsupportedCallbackException(current);
}
}
}
};
return ModelControllerClient.Factory.create(host, port, callbackHandler);
}
One thing to note on this, is that creating the ModelController client does not tell you whether you need to authenticate or not, only when you execute an operation, like what is described below, will tell you if you need to authenticate. So, if you want your native client to be able to work in either an unauthenticated case and an authenticated case, then you need execute an operation, and catch an exception and then prompt for the credentials, and create a new ModelController client with the call back handler above. For example:
ModelControllerClient client = null;
// Try connecting to the server without authentication first
ModelControllerClient unauthenticatedClient = ModelControllerClient.Factory.create(serverHost, port);
try {
ModelNode testConnection = new ModelNode();
testConnection.get("operation").set("read-resource"); // Execute an operation to see if we need to authenticate
unauthenticatedClient.execute(testConnection);
client = unauthenticatedClient;
} catch(Exception e) {
// Failed to connect, must authenticate and get the credentials in your application specific manner
...
client = NativeClient.getInstance(serverHost, port, username, password); // NativeClient.getInstance(...) is a class that contains the above CallBackHandler
}
Creating an operation request object
Management requests are formulated using the org.jboss.dmr.ModelNode class from the jboss-dmr library. The jboss-dmr library allows the complete JBoss AS management model to be expressed using a very small number of Java types. See Detyped management and the jboss-dmr library for full details on using this library.
Let's show an example of creating an operation request object that can be used to read the resource description for the web subsystem's HTTP connector:
ModelNode op = new ModelNode();
op.get("operation").set("read-resource-description");
ModelNode address = op.get("address");
address.add("subsystem", "web");
address.add("connector", "http");
op.get("recursive").set(true);
op.get("operations").set(true);
What we've done here is created a ModelNode of type ModelType.OBJECT with the following fields:
-
operation – the name of the operation to invoke. All operation requests must include this field and its value must be a String.
-
address – the address of the resource to invoke the operation against. This field's must be of ModelType.LIST with each element in the list being a ModelType.PROPERTY. If this field is omitted the operation will target the root resource. The operation can be targeted at any address in the management model; here we are targeting it at the resource for the web subsystem's http connector.
In this case, the request includes two optional parameters:
-
recursive – true means you want the description of child resources under this resource. Default is false
-
operations – true means you want the description of operations exposed by the resource to be included. Default is false.
Different operations take different parameters, and some take no parameters at all.
See Format of a Detyped Operation Request for full details on the structure of a ModelNode that will represent an operation request.
The example above produces an operation request ModelNode equivalent to what the CLI produces internally when it parses and executes the following low-level CLI command:
[localhost:9999 /] /subsystem=web/connector=http:read-resource-description(recursive=true,operations=true)
Execute the operation and manipulate the result:
The execute method sends the operation request ModelNode to the process being managed and returns a ModelNode the contains the process' response:
ModelNode returnVal = client.execute(op);
System.out.println(returnVal.get("result").toString());
See Format of a Detyped Operation Response for general details on the structure of the "returnVal" ModelNode.
The execute operation shown above will block the calling thread until the response is received from the process being managed. ModelControllerClient also exposes and API allowing asynchronous invocation:
Future<ModelNode> future = client.executeAsync(op);
. . . // do other stuff
ModelNode returnVal = future.get();
System.out.println(returnVal.get("result").toString());
Close the ModelControllerClient
A ModelControllerClient can be reused for multiple requests. Creating a new ModelControllerClient for each request is an anti-pattern. However, when the ModelControllerClient is no longer needed, it should always be explicitly closed, allowing it to close down any connections to the process it was managing and release other resources:
client.close();
Format of a Detyped Operation Request
The basic method a user of the AS 7 programmatic management API would use is very simple:
ModelNode execute(ModelNode operation) throws IOException;
where the return value is the detyped representation of the response, and operation is the detyped representation of the operation being invoked.
The purpose of this section is to document the structure of operation.
See Format of a Detyped Operation Response for a discussion of the format of the response.
Simple Operations
A text representation of simple operation would look like this:
{
"operation" => "write-attribute",
"address" => [
("profile" => "production"),
("subsystem" => "threads"),
("bounded-queue-thread-pool" => "pool1")
],
"name" => "count",
"value" => 20
}
Java code to produce that output would be:
ModelNode op = new ModelNode();
op.get("operation").set("write-attribute");
ModelNode addr = op.get("address");
addr.add("profile", "production");
addr.add("subsystem", "threads");
addr.add("bounded-queue-thread-pool", "pool1");
op.get("name").set("count");
op.get("value").set(20);
System.out.println(op);
The order in which the outermost elements appear in the request is not relevant. The required elements are:
-
operation – String – The name of the operation being invoked.
-
address – the address of the managed resource against which the request should be executed. If not set, the address is the root resource. The address is an ordered list of key-value pairs describing where the resource resides in the overall management resource tree. Management resources are organized in a tree, so the order in which elements in the address occur is important.
The other key/value pairs are parameter names and their values. The names and values should match what is specified in the operation's description.
Parameters may have any name, except for the reserved words operation, address and operation-headers.
Operation Headers
Besides the special operation and address values discussed above, operation requests can also include special "header" values that help control how the operation executes. These headers are created under the special reserved word operation-headers:
ModelNode op = new ModelNode();
op.get("operation").set("write-attribute");
ModelNode addr = op.get("address");
addr.add("base", "domain");
addr.add("profile", "production");
addr.add("subsystem", "threads");
addr.add("bounded-queue-thread-pool", "pool1");
op.get("name").set("count");
op.get("value").set(20);
op.get("operation-headers", "rollback-on-runtime-failure").set(false);
System.out.println(op);
This produces:
{
"operation" => "write-attribute",
"address" => [
("profile" => "production"),
("subsystem" => "threads"),
("bounded-queue-thread-pool" => "pool1")
],
"name" => "count",
"value" => 20,
"operation-headers" => {
"rollback-on-runtime-failure => false
}
}
The following operation headers are supported:
-
rollback-on-runtime-failure – boolean, optional, defaults to true. Whether an operation that successfully updates the persistent configuration model should be reverted if it fails to apply to the runtime. Operations that affect the persistent configuration are applied in two stages – first to the configuration model and then to the actual running services. If there is an error applying to the configuration model the operation will be aborted with no configuration change and no change to running services will be attempted. However, operations are allowed to change the configuration model even if there is a failure to apply the change to the running services – if and only if this rollback-on-runtime-failure header is set to false. So, this header only deals with what happens if there is a problem applying an operation to the running state of a server (e.g. actually increasing the size of a runtime thread pool.)
-
rollout-plan – only relevant to requests made to a Domain Controller or Host Controller. See "Operations with a Rollout Plan" for details.
-
allow-resource-service-restart – boolean, optional, defaults to false. Whether an operation that requires restarting some runtime services in order to take effect should do so. See discussion of resource-services in the "Applying Updates to Runtime Services" section of the Description of the Management Model section for further details.
Composite Operations
The root resource for a Domain or Host Controller or an individual server will expose an operation named "composite". This operation executes a list of other operations as an atomic unit (although the atomicity requirement can be relaxed. The structure of the request for the "composite" operation has the same fundamental structure as a simple operation (i.e. operation name, address, params as key value pairs).
{
"operation" => "composite",
"address" => [],
"steps" => [
{
"operation" => "write-attribute",
"address" => [
("profile" => "production"),
("subsystem" => "threads"),
("bounded-queue-thread-pool" => "pool1")
],
"count" => "count",
"value" => 20
},
{
"operation" => "write-attribute",
"address" => [
("profile" => "production"),
("subsystem" => "threads"),
("bounded-queue-thread-pool" => "pool2")
],
"name" => "count",
"value" => 10
}
],
"operation-headers" => {
"rollback-on-runtime-failure => false
}
}
The "composite" operation takes a single parameter:
-
steps – a list, where each item in the list has the same structure as a simple operation request. In the example above each of the two steps is modifying the thread pool configuration for a different pool. There need not be any particular relationship between the steps. Note that the rollback-on-runtime-failure and rollout-plan operation headers are not supported for the individual steps in a composite operation.
The rollback-on-runtime-failure operation header discussed above has a particular meaning when applied to a composite operation, controlling whether steps that successfully execute should be reverted if other steps fail at runtime. Note that if any steps modify the persistent configuration, and any of those steps fail, all steps will be reverted. Partial/incomplete changes to the persistent configuration are not allowed.
Operations with a Rollout Plan
Operations targeted at domain or host level resources can potentially impact multiple servers. Such operations can include a "rollout plan" detailing the sequence in which the operation should be applied to servers as well as policies for detailing whether the operation should be reverted if it fails to execute successfully on some servers.
If the operation includes a rollout plan, the structure is as follows:
{
"operation" => "write-attribute",
"address" => [
("profile" => "production"),
("subsystem" => "threads"),
("bounded-queue-thread-pool" => "pool1")
],
"name" => "count",
"value" => 20,
"operation-headers" => {
"rollout-plan" => {
"in-series" => [
{
"concurrent-groups" => {
"groupA" => {
"rolling-to-servers" => true,
"max-failure-percentage" => 20
},
"groupB" => undefined
}
},
{
"server-group" => {
"groupC" => {
"rolling-to-servers" => false,
"max-failed-servers" => 1
}
}
},
{
"concurrent-groups" => {
"groupD" => {
"rolling-to-servers" => true,
"max-failure-percentage" => 20
},
"groupE" => undefined
}
}
],
"rollback-across-groups" => true
}
}
}
As you can see, the rollout plan is another structure in the operation-headers section. The root node of the structure allows two children:
-
in-series – a list – A list of activities that are to be performed in series, with each activity reaching completion before the next step is executed. Each activity involves the application of the operation to the servers in one or more server groups. See below for details on each element in the list.
-
rollback-across-groups – boolean – indicates whether the need to rollback the operation on all the servers in one server group should trigger a rollback across all the server groups. This is an optional setting, and defaults to false.
Each element in the list under the in-series node must have one or the other of the following structures:
-
concurrent-groups – a map of server group names to policies controlling how the operation should be applied to that server group. For each server group in the map, the operation may be applied concurrently. See below for details on the per-server-group policy configuration.
-
server-group – a single key/value mapping of a server group name to a policy controlling how the operation should be applied to that server group. See below for details on the policy configuration. (Note: there is no difference in plan execution between this and a "concurrent-groups" map with a single entry.)
The policy controlling how the operation is applied to the servers within a server group has the following elements, each of which is optional:
-
rolling-to-servers – boolean – If true, the operation will be applied to each server in the group in series. If false or not specified, the operation will be applied to the servers in the group concurrently.
-
max-failed-servers – int – Maximum number of servers in the group that can fail to apply the operation before it should be reverted on all servers in the group. The default value if not specified is zero; i.e. failure on any server triggers rollback across the group.
-
max-failure-percentage – int between 0 and 100 – Maximum percentage of the total number of servers in the group that can fail to apply the operation before it should be reverted on all servers in the group. The default value if not specified is zero; i.e. failure on any server triggers rollback across the group.
If both max-failed-servers and max-failure-percentage are set, max-failure-percentage takes precedence.
Looking at the (contrived) example above, application of the operation to the servers in the domain would be done in 3 phases. If the policy for any server group triggers a rollback of the operation across the server group, all other server groups will be rolled back as well. The 3 phases are:
-
Server groups groupA and groupB will have the operation applied concurrently. The operation will be applied to the servers in groupA in series, while all servers in groupB will handle the operation concurrently. If more than 20% of the servers in groupA fail to apply the operation, it will be rolled back across that group. If any servers in groupB fail to apply the operation it will be rolled back across that group.
-
Once all servers in groupA and groupB are complete, the operation will be applied to the servers in groupC. Those servers will handle the operation concurrently. If more than one server in groupC fails to apply the operation it will be rolled back across that group.
-
Once all servers in groupC are complete, server groups groupD and groupE will have the operation applied concurrently. The operation will be applied to the servers in groupD in series, while all servers in groupE will handle the operation concurrently. If more than 20% of the servers in groupD fail to apply the operation, it will be rolled back across that group. If any servers in groupE fail to apply the operation it will be rolled back across that group.
Default Rollout Plan
All operations that impact multiple servers will be executed with a rollout plan. However, actually specifying the rollout plan in the operation request is not required. If no rollout-plan operation header is specified, a default plan will be generated. The plan will have the following characteristics:
-
There will only be a single high level phase. All server groups affected by the operation will have the operation applied concurrently.
-
Within each server group, the operation will be applied to all servers concurrently.
-
Failure on any server in a server group will cause rollback across the group.
-
Failure of any server group will result in rollback of all other server groups.
Format of a Detyped Operation Response
As noted previously, the basic method a user of the AS 7 programmatic managment API would use is very simple:
ModelNode execute(ModelNode operation) throws IOException;
where the return value is the detyped representation of the response, and operation is the detyped representation of the operating being invoked.
The purpose of this section is to document the structure of the return value.
For the format of the request, see Format of a Detyped Operation Request.
Simple Responses
Simple responses are provided by the following types of operations:
-
Non-composite operations that target a single server. (See below for more on composite operations).
-
Non-composite operations that target a Domain Controller or slave Host Controller and don't require the responder to apply the operation on multiple servers and aggregate their results (e.g. a simple read of a domain configuration property.)
The response will always include a simple boolean outcome field, with one of three possible values:
-
success – the operation executed successfully
-
failed – the operation failed
-
cancelled – the execution of the operation was cancelled. (This would be an unusual outcome for a simple operation which would generally very rapidly reach a point in its execution where it couldn't be cancelled.)
The other fields in the response will depend on whether the operation was sucessful.
The response for a failed operation:
{
"outcome" => "failed",
"failure-description" => "[JBAS-12345] Some failure message"
}
A response for a successful operation will include an additional field:
-
result – the return value, or undefined for void operations or those that return null
A non-void result:
{
"outcome" => "success",
"result" => {
"name" => "Brian",
"age" => 22
}
}
A void result:
{
"outcome" => "success",
"result" => undefined
}
The response for a cancelled operation has no other fields:
{
"outcome" => "cancelled"
}
Response Headers
Besides the standard outcome, result and failure-description fields described above, the response may also include various headers that provide more information about the affect of the operation or about the overall state of the server. The headers will be child element under a field named response-headers. For example:
{
"outcome" => "success",
"result" => undefined,
"response-headers" => {
"operation-requires-reload" => true,
"process-state" => "reload-required"
}
}
A response header is typically related to whether an operation could be applied to the targeted runtime without requiring a restart of some or all services, or even of the target process itself. Please see the "Applying Updates to Runtime Services" section of the Description of the Management Model section for a discussion of the basic concepts related to what happens if an operation requires a service restart to be applied.
The current possible response headers are:
-
operation-requires-reload – boolean – indicates that the specific operation that has generated this response requires a restart of all services in the process in order to take effect in the runtime. This would typically only have a value of 'true'; the absence of the header is the same as a value of 'false.'
-
operation-requires-restart – boolean – indicates that the specific operation that has generated this response requires a full process restart in order to take effect in the runtime. This would typically only have a value of 'true'; the absence of the header is the same as a value of 'false.'
-
process-state – enumeration – Provides information about the overall state of the target process. One of the following values:
-
starting – the process is starting
-
running – the process is in a normal running state. The process-state header would typically not be seen with this value; the absence of the header is the same as a value of 'running'.
-
reload-required – some operation (not necessarily this one) has executed that requires a restart of all services in order for a configuration change to take effect in the runtime.
-
restart-required – some operation (not necessarily this one) has executed that requires a full process restart in order for a configuration change to take effect in the runtime.
-
stopping – the process is stopping
-
Basic Composite Operation Responses
A composite operation is one that incorporates more than one simple operation in a list and executes them atomically. See the "Composite Operations" section for more information.
Basic composite responses are provided by the following types of operations:
-
Composite operations that target a single server.
-
Composite operations that target a Domain Controller or a slave Host Controller and don't require the responder to apply the operation on multiple servers and aggregate their results (e.g. a list of simple reads of domain configuration properties.)
The high level format of a basic composite operation response is largely the same as that of a simple operation response, although there is an important semantic difference. For a composite operation, the meaning of the outcome flag is controlled by the value of the operation request's rollback-on-runtime-failure header field. If that field was false (default is true), the outcome flag will be success if all steps were successfully applied to the persistent configuration even if none of the composite operation's steps was successfully applied to the runtime.
What's distinctive about a composite operation response is the result field. First, even if the operation was not successful, the result field will usually be present. (It won't be present if there was some sort of immediate failure that prevented the responder from even attempting to execute the individual operations.) Second, the content of the result field will be a map. Each entry in the map will record the result of an element in the steps parameter of the composite operation request. The key for each item in the map will be the string "step-X" where "X" is the 1-based index of the step's position in the request's steps list. So each individual operation in the composite operation will have its result recorded.
The individual operation results will have the same basic format as the simple operation results described above. However, there are some differences from the simple operation case when the individual operation's outcome flag is failed. These relate to the fact that in a composite operation, individual operations can be rolled back or not even attempted.
If an individual operation was not even attempted (because the overall operation was cancelled or, more likely, a prior operation failed):
{
"outcome" => "cancelled"
}
An individual operation that failed and was rolled back:
{
"outcome" => "failed",
"failure-description" => "[JBAS-12345] Some failure message",
"rolled-back" => true
}
An individual operation that itself succeeded but was rolled back due to failure of another operation:
{
"outcome" => "failed",
"result" => {
"name" => "Brian",
"age" => 22
},
"rolled-back" => true
}
An operation that failed and was rolled back:
{
"outcome" => "failed",
"failure-description" => "[JBAS-12345] Some failure message",
"rolled-back" => true
}
Here's an example of the response for a successful 2 step composite operation:
{
"outcome" => "success",
"result" => [
{
"outcome" => "success",
"result" => {
"name" => "Brian",
"age" => 22
}
},
{
"outcome" => "success",
"result" => undefined
}
]
}
And for a failed 3 step composite operation, where the first step succeeded and the second failed, triggering cancellation of the 3rd and rollback of the others:
{
"outcome" => "failed",
"failure-description" => "[JBAS-99999] Composite operation failed; see individual operation results for details",
"result" => [
{
"outcome" => "failed",
"result" => {
"name" => "Brian",
"age" => 22
},
"rolled-back" => true
},
{
"outcome" => "failed",
"failure-description" => "[JBAS-12345] Some failure message",
"rolled-back" => true
},
{
"outcome" => "cancelled"
}
]
}
Multi-Server Responses
Multi-server responses are provided by operations that target a Domain Controller or slave Host Controller and require the responder to apply the operation on multiple servers and aggregate their results (e.g. nearly all domain or host configuration updates.)
Multi-server operations are executed in several stages.
First, the operation may need to be applied against the authoritative configuration model maintained by the Domain Controller (for domain.xml confgurations) or a Host Controller (for a host.xml configuration). If there is a failure at this stage, the operation is automatically rolled back, with a response like this:
{
"outcome" => "failed",
"domain-failure-description" => "[JBAS-33333] Failed to apply X to the domain model"
}
If the operation was addressed to the domain model, in the next stage the Domain Controller will ask each slave Host Controller to apply it to its local copy of the domain model. If any Host Controller fails to do so, the Domain Controller will tell all Host Controllers to revert the change, and it will revert the change locally as well. The response to the client will look like this:
{
"outcome" => "failed",
"host-failure-descriptions" => {
"hostA" => "[DOM-3333] Failed to apply to the domain model",
"hostB" => "[DOM-3333] Failed to apply to the domain model"
}
}
If the preceding stages succeed, the operation will be pushed to all affected servers. If the operation is successful on all servers, the response will look like this (this example operation has a void response, hence the result for each server is undefined):
{
"outcome" => "success",
"result" => undefined,
"server-groups" => {
"groupA" => {
"serverA-1" => {
"host" => "host1",
"response" => {
"outcome" => "success",
"result" => undefined
}
},
"serverA-2" => {
"host" => "host2",
"response" => {
"outcome" => "success",
"result" => undefined
}
}
},
"groupB" => {
"serverB-1" => {
"host" => "host1",
"response" => {
"outcome" => "success",
"result" => undefined
}
},
"serverB-2" => {
"host" => "host2",
"response" => {
"outcome" => "success",
"result" => undefined
}
}
}
}
}
The operation need not succeed on all servers in order to get an "outcome" => "success" result. All that is required is that it succeed on at least one server without the rollback policies in the rollout plan triggering a rollback on that server. An example response in such a situation would look like this:
{
"outcome" => "success",
"result" => undefined,
"server-groups" => {
"groupA" => {
"serverA-1" => {
"host" => "host1",
"response" => {
"outcome" => "success",
"result" => undefined
}
},
"serverA-2" => {
"host" => "host2",
"response" => {
"outcome" => "success",
"result" => undefined
}
}
},
"groupB" => {
"serverB-1" => {
"host" => "host1",
"response" => {
"outcome" => "success",
"result" => undefined,
"rolled-back" => true
}
},
"serverB-2" => {
"host" => "host2",
"response" => {
"outcome" => "success",
"result" => undefined,
"rolled-back" => true
}
},
"serverB-3" => {
"host" => "host3",
"response" => {
"outcome" => "failed",
"failure-description" => "[DOM-4556] Something didn't work right",
"rolled-back" => true
}
}
}
}
}
Finally, if the operation fails or is rolled back on all servers, an example response would look like this:
{
"outcome" => "failed",
"server-groups" => {
"groupA" => {
"serverA-1" => {
"host" => "host1",
"response" => {
"outcome" => "success",
"result" => undefined
}
},
"serverA-2" => {
"host" => "host2",
"response" => {
"outcome" => "success",
"result" => undefined
}
}
},
"groupB" => {
"serverB-1" => {
"host" => "host1",
"response" => {
"outcome" => "failed",
"result" => undefined,
"rolled-back" => true
}
},
"serverB-2" => {
"host" => "host2",
"response" => {
"outcome" => "failed",
"result" => undefined,
"rolled-back" => true
}
},
"serverB-3" => {
"host" => "host3",
"response" => {
"outcome" => "failed",
"failure-description" => "[DOM-4556] Something didn't work right",
"rolled-back" => true
}
}
}
}
}
CLI Recipes
Properties
Adding, reading and removing system property using CLI
For standalone mode:
$ ./bin/jboss-cli.sh --connect controller=IP_ADDRESS
[standalone@IP_ADDRESS:9999 /] /system-property=foo:add(value=bar)
[standalone@IP_ADDRESS:9999 /] /system-property=foo:read-resource
{
"outcome" => "success",
"result" => {"value" => "bar"}
}
[standalone@IP_ADDRESS:9999 /] /system-property=foo:remove
{"outcome" => "success"}
For domain mode the same commands are used, you can add/read/remove system properties for:
All hosts and server instances in domain
[domain@IP_ADDRESS:9999 /] /system-property=foo:add(value=bar) [domain@IP_ADDRESS:9999 /] /system-property=foo:read-resource [domain@IP_ADDRESS:9999 /] /system-property=foo:remove
Host and its server instances
[domain@IP_ADDRESS:9999 /] /host=master/system-property=foo:add(value=bar) [domain@IP_ADDRESS:9999 /] /host=master/system-property=foo:read-resource [domain@IP_ADDRESS:9999 /] /host=master/system-property=foo:remove
Just one server instance
[domain@IP_ADDRESS:9999 /] /host=master/server-config=server-one/system-property=foo:add(value=bar) [domain@IP_ADDRESS:9999 /] /host=master/server-config=server-one/system-property=foo:read-resource [domain@IP_ADDRESS:9999 /] /host=master/server-config=server-one/system-property=foo:remove
Overview of all system properties
Overview of all system properties in JBoss AS7+ including OS system properties and properties specified on command line using -D, -P or --properties arguments.
Standalone
[standalone@IP_ADDRESS:9999 /] /core-service=platform-mbean/type=runtime:read-attribute(name=system-properties)
Domain
[domain@IP_ADDRESS:9999 /] /host=master/core-service=platform-mbean/type=runtime:read-attribute(name=system-properties) [domain@IP_ADDRESS:9999 /] /host=master/server=server-one/core-service=platform-mbean/type=runtime:read-attribute(name=system-properties)
Configuration
List Subsystems
[standalone@localhost:9999 /] /:read-children-names(child-type=subsystem)
{
"outcome" => "success",
"result" => [
"configadmin",
"datasources",
"deployment-scanner",
"ee",
"ejb3",
"infinispan",
"jaxrs",
"jca",
"jdr",
"jmx",
"jpa",
"logging",
"mail",
"naming",
"osgi",
"pojo",
"remoting",
"resource-adapters",
"sar",
"security",
"threads",
"transactions",
"web",
"webservices",
"weld"
]
}
List description of available attributes and childs
Descriptions, possible attribute type and values, permission and whether expressions ( ${ ... } ) are allowed from the underlying model are shown by the read-resource-description comand.
/subsystem=datasources/data-source=ExampleDS:read-resource-description
{
"outcome" => "success",
"result" => {
"description" => "A JDBC data-source configuration",
"head-comment-allowed" => true,
"tail-comment-allowed" => true,
"attributes" => {
"connection-url" => {
"type" => STRING,
"description" => "The JDBC driver connection URL",
"expressions-allowed" => true,
"nillable" => false,
"min-length" => 1L,
"max-length" => 2147483647L,
"access-type" => "read-write",
"storage" => "configuration",
"restart-required" => "no-services"
},
"driver-class" => {
"type" => STRING,
"description" => "The fully qualified name of the JDBC driver class",
"expressions-allowed" => true,
"nillable" => true,
"min-length" => 1L,
"max-length" => 2147483647L,
"access-type" => "read-write",
"storage" => "configuration",
"restart-required" => "no-services"
},
"datasource-class" => {
"type" => STRING,
"description" => "The fully qualified name of the JDBC datasource class",
"expressions-allowed" => true,
"nillable" => true,
"min-length" => 1L,
"max-length" => 2147483647L,
"access-type" => "read-write",
"storage" => "configuration",
"restart-required" => "no-services"
},
"jndi-name" => {
"type" => STRING,
"description" => "Specifies the JNDI name for the datasource",
"expressions-allowed" => true,
"nillable" => false,
"access-type" => "read-write",
"storage" => "configuration",
"restart-required" => "no-services"
},
...
View configuration as XML for domain model or host model
Assume you have a host that is called master
[domain@localhost:9999 /] /host=master:read-config-as-xml
Just for the domain or standalone
[domain@localhost:9999 /] :read-config-as-xml
Take a snapshot of what the current domain is
[domain@localhost:9999 /] :take-snapshot()
{
"outcome" => "success",
"result" => {
"domain-results" => {"step-1" => {"name" => "/home/anil/as7/jboss-as/build/target/jboss-as-7.1.0.Alpha1-SNAPSHOT/domain/configuration/domain_xml_history/snapshot/20110908-165222603domain.xml"}},
"server-operations" => undefined
}
}
Take the latest snapshot of the host.xml for a particular host
Assume you have a host that is called master
[domain@localhost:9999 /] /host=master:take-snapshot
{
"outcome" => "success",
"result" => {
"domain-results" => {"step-1" => {"name" => "/home/anil/as7/jboss-as/build/target/jboss-as-7.1.0.Alpha1-SNAPSHOT/domain/configuration/host_xml_history/snapshot/20110908-165640215host.xml"}},
"server-operations" => undefined
}
}
How to get interface address
The attribute for interface is named "resolved-address". It's a runtime attribute so it does not show up in :read-resource by default. You have to add the "include-runtime" parameter.
./jboss-cli.sh --connect
Connected to standalone controller at localhost:9999
[standalone@localhost:9999 /] cd interface=public
[standalone@localhost:9999 interface=public] :read-resource(include-runtime=true)
{
"outcome" => "success",
"result" => {
"any" => undefined,
"any-address" => undefined,
"any-ipv4-address" => undefined,
"any-ipv6-address" => undefined,
"criteria" => [("inet-address" => expression "${jboss.bind.address:127.0.0.1}")],
"inet-address" => expression "${jboss.bind.address:127.0.0.1}",
"link-local-address" => undefined,
"loopback" => undefined,
"loopback-address" => undefined,
"multicast" => undefined,
"name" => "public",
"nic" => undefined,
"nic-match" => undefined,
"not" => undefined,
"point-to-point" => undefined,
"public-address" => undefined,
"resolved-address" => "127.0.0.1",
"site-local-address" => undefined,
"subnet-match" => undefined,
"up" => undefined,
"virtual" => undefined
}
}
[standalone@localhost:9999 interface=public] :read-attribute(name=resolved-address)
{
"outcome" => "success",
"result" => "127.0.0.1"
}
It's similar for domain, just specify path to server instance:
[domain@localhost:9999 /] /host=master/server=server-one/interface=public:read-attribute(name=resolved-address)
{
"outcome" => "success",
"result" => "127.0.0.1"
}
Remove Default Datasource and Driver
[standalone@localhost:9999 /] data-source remove --name=ExampleDS
[standalone@localhost:9999 /] /subsystem=datasources/jdbc-driver=h2:remove
{"outcome" => "success"}
Add a New JDBC Driver
standalone@localhost:9999 /] /subsystem=datasources/jdbc-driver=postgresql:add(driver-name=postgresql,driver-module-name=org.postgresql.jdbc,driver-xa-datasource-class-name=org.postgresql.xa.PGXADataSource)
{"outcome" => "success"}
Add a New Datasource
[standalone@localhost:9999 /] data-source add \ > --name=ApplicationDS \ > --driver-name=postgresql \ > --connection-url=jdbc:postgresql://localhost:5432/DemoDB \ > --jndi-name=java:jboss/jdbc/ApplicationDS \ > --user-name=demouser \ > --password=password \ > --use-ccm=false \ > --max-pool-size=25 \ > --blocking-timeout-wait-millis=5000 \ > --new-connection-sql="set datestyle = ISO, European;" [standalone@localhost:9999 /] data-source enable --name=ApplicationDS [standalone@localhost:9999 /]
Add a New XA Datasource
[standalone@localhost:9999 /] xa-data-source add \
> --name=ApplicationXADS \
> --driver-name=postgresql \
> --jndi-name=java:jboss/jdbc/ApplicationXADS \
> --user-name=demouser \
> --password=password \
> --recovery-username= demouser \
> --recovery-password = password \
> --use-ccm=false \
> --max-pool-size=25 \
> --blocking-timeout-wait-millis=5000 \
> --new-connection-sql="set datestyle = ISO, European;"
[standalone@localhost:9999 /] /subsystem=datasources/xa-data-source=ApplicationXADS/xa-datasource-properties=ServerName:add(value=localhost)
{"outcome" => "success"}
[standalone@localhost:9999 /] /subsystem=datasources/xa-data-source=ApplicationXADS/xa-datasource-properties=PortNumber:add(value=5432)
{"outcome" => "success"}
[standalone@localhost:9999 /] /subsystem=datasources/xa-data-source=ApplicationXADS/xa-datasource-properties=DatabaseName:add(value=DemoDB)
{"outcome" => "success"}
[standalone@localhost:9999 /] xa-data-source enable --name = ApplicationXADS
[standalone@localhost:9999 /]
Add a String Value into JNDI
[standalone@localhost:9999 /] /subsystem=naming/binding=java\:jboss\/param\/demoParam:add(value="Demo configuration value",binding-type=simple)
{"outcome" => "success"}
This value can then be looked up in code:
@Resource(lookup="java:jboss/param/demoParam")
private String demoParam;
Define a Security Domain Using a Database User Store, Howto Avoid a Full Server Reload Requests
This example shows usage of the operational header allow-resource-service-restart, which can be used in some cases to prevent server reload requests.
[standalone@localhost:9999 /] /subsystem=security/security-domain=DemoSecurityDomain:add
{"outcome" => "success"}
[standalone@localhost:9999 /] /subsystem=security/security-domain=DemoSecurityDomain/authentication=classic:add( \
login-modules=[ \
{ \
"code" => "Database", \
"flag" => "required", \
"module-options" => [ \
("unauthenticatedIdentity"=>"guest"), \
("dsJndiName"=>"java:jboss/jdbc/ApplicationDS"), \
("principalsQuery"=>"select password from users where username=?"), \
("rolesQuery" => "select name, 'Roles' FROM user_roles ur, roles r, user u WHERE u.username=? and u.id = ur.user_id and ur.role_id = r.id"), \
("hashAlgorithm" => "MD5"), \
("hashEncoding" => "hex") \
] \
} \
] \
) {allow-resource-service-restart=true}
{"outcome" => "success"}
Scripted Configuration
Sample CLI configuration script
demo.cli
# Demo CLI script
connect
batch
# Add postgresql JDBC driver
/subsystem=datasources/jdbc-driver=postgresql:add( \
driver-name=postgresql, \
driver-module-name=org.postgresql.jdbc, \
driver-xa-datasource-class-name=org.postgresql.xa.PGXADataSource \
)
# Add a non-XA datasource
data-source add \
--name=ApplicationDS \
--driver-name=postgresql \
--connection-url=jdbc:postgresql://localhost:5432/DemoDB \
--jndi-name=java:jboss/jdbc/ApplicationDS \
--user-name=demouser \
--password=password \
--use-ccm=false \
--max-pool-size=25 \
--blocking-timeout-wait-millis=5000 \
--new-connection-sql="set datestyle = ISO, European;"
data-source enable --name=ApplicationDS
# Add an XA datasource
xa-data-source add \
--name=ApplicationXADS \
--driver-name=postgresql \
--jndi-name=java:jboss/jdbc/ApplicationXADS \
--user-name=demouser \
--password=password \
--recovery-username= demouser \
--recovery-password = password \
--use-ccm=false \
--max-pool-size=25 \
--blocking-timeout-wait-millis=5000 \
--new-connection-sql="set datestyle = ISO, European;"
/subsystem=datasources/xa-data-source=ApplicationXADS/xa-datasource-properties=ServerName:add(value=localhost)
/subsystem=datasources/xa-data-source=ApplicationXADS/xa-datasource-properties=PortNumber:add(value=5432)
/subsystem=datasources/xa-data-source=ApplicationXADS/xa-datasource-properties=DatabaseName:add(value=DemoDB)
xa-data-source enable --name = ApplicationXADS
# Bind a string value into JNDI
/subsystem=naming/binding=java\:jboss\/param\/demoParam:add(value="Demo configuration value",binding-type=simple)
# Create a Database authentication realm
/subsystem=security/security-domain=DemoAuthRealm:add
/subsystem=security/security-domain=DemoAuthRealm/authentication=classic:add( \
login-modules=[ \
{ \
"code" => "Database", \
"flag" => "required", \
"module-options" => [ \
("unauthenticatedIdentity"=>"guest"), \
("dsJndiName"=>"java:jboss/jdbc/ApplicationDS"), \
("principalsQuery"=>"select password from users where username=?"), \
("rolesQuery" => "select name, 'Roles' FROM user_roless ur, roles r, user u WHERE u.username=? and u.id = ur.user_id and ur.role_id = r.id"), \
("hashAlgorithm" => "MD5"), \
("hashEncoding" => "hex") \
] \
} \
] \
)
# Execute and reload
run-batch
:reload
Execution of configuration script
[jboss-as-7.1.3.Final]$ bin/jboss-cli.sh --file=demo.cli
#1 /subsystem=datasources/jdbc-driver=postgresql:add( driver-name=postgresql, driver-module-name=org.postgresql.jdbc, driver-xa-datasource-class-name=org.postgresql.xa.PGXADataSource )
#2 data-source add --name=ApplicationDS --driver-name=postgresql --connection-url=jdbc:postgresql://localhost:5432/DemoDB --jndi-name=java:jboss/jdbc/ApplicationDS --user-name=demouser --password=password --use-ccm=false --max-pool-size=25 --blocking-timeout-wait-millis=5000 --new-connection-sql="set datestyle = ISO, European;"
#3 data-source enable --name=ApplicationDS
#4 xa-data-source add --name=ApplicationXADS --driver-name=postgresql --jndi-name=java:jboss/jdbc/ApplicationXADS --user-name=demouser --password=password --recovery-username= demouser --recovery-password = password --use-ccm=false --max-pool-size=25 --blocking-timeout-wait-millis=5000 --new-connection-sql="set datestyle = ISO, European;"
#5 /subsystem=datasources/xa-data-source=ApplicationXADS/xa-datasource-properties=ServerName:add(value=localhost)
#6 /subsystem=datasources/xa-data-source=ApplicationXADS/xa-datasource-properties=PortNumber:add(value=5432)
#7 /subsystem=datasources/xa-data-source=ApplicationXADS/xa-datasource-properties=DatabaseName:add(value=DemoDB)
#8 xa-data-source enable --name = ApplicationXADS
#9 /subsystem=naming/binding=java:jboss/param/demoParam:jboss\/param\/demoParam:add(value="Demo configuration value",binding-type=simple)
#10 /subsystem=security/security-domain=DemoAuthRealm:add
#11 /subsystem=security/security-domain=DemoAuthRealm/authentication=classic:add( login-modules=[ { "code" => "Database", "flag" => "required", "module-options" => [ ("unauthenticatedIdentity"=>"guest"), ("dsJndiName"=>"java:jboss/jdbc/ApplicationDS"), ("principalsQuery"=>"select password from users where username=?"), ("rolesQuery" => "select name, 'Roles' FROM user_roless ur, roles r, user u WHERE u.username=? and u.id = ur.user_id and ur.role_id = r.id"), ("hashAlgorithm" => "MD5"), ("hashEncoding" => "hex") ] } ] )
The batch executed successfully
{"outcome" => "success"}
[jboss-as-7.1.3.Final]$
Runtime
Get all configuration and runtime details from CLI
./bin/jboss-cli.sh -c command=":read-resource(include-runtime=true, recursive=true, recursive-depth=10)"
Add a log category
bin/jboss-cli.sh --connect "/subsystem=logging/logger=com.your.package.name:add(level=DEBUG)"
Toggle root logger level during runtime with out bouncing the server
In the development environment, on a running instance of JBoss, it is often desirable to turn up the level of the logs. For example, I have an application which would spit out
mega bytes of debug log statements if I had started the JBoss container with log level DEBUG. So for me, I would start the JBoss container with the default
log level (I believe the default is INFO). Then, as I am navigating the web application via the browser, I would come to a point where I would like to
turn up the verbosity of the log statements. So just before clicking on that link or button on the web page, I would open up a Terminal console and fire
up the jboss cli and modify the root-logger's log level to be DEBUG. Then, come back to the web page and click that link or button. And now, when one
views the server logs, there would be tons and tons of DEBUG statements.
In a production environment, this might be helpful when one needs more verbose logging for a short period of time. Then, when one is done collecting the log statements, one can then
switch the log level back to info. All the while the JBoss container does not need to be bounced.
1. On a freshly installed and running instance of jboss 7.1.1.Final, one would see the following when issuing a command to see the attribute
root-logger. The attribute 'root-logger' has not yet been defined.
[standalone@localhost:9999 /] /subsystem=logging/root-logger=ROOT:read-attribute(name=root-logger)
{ "outcome" => "failed",
"failure-description" => "JBAS014792: Unknown attribute root-logger",
"rolled-back" => true
}
2. Issue the command 'change-root-log-level' to modify the root logger to be of level DEBUG.
[standalone@localhost:9999 /] /subsystem=logging/root-logger=ROOT:change-root-log-level(level=DEBUG)
{"outcome" => "success"}
3. Now, when one re-issues the read-attribute command on 'root-logger', it is defined and the level is displayed.
[standalone@localhost:9999 /] /subsystem=logging/root-logger=ROOT:read-attribute(name=root-logger)
{
"outcome" => "success",
"result" => {"level" => "DEBUG"}
}
Scripting
Windows and "Press any key to continue ..." issue
AS7 scripts for Windows end with "Press any key to continue ...". This behavior is useful when script is executed by double clicking the script but not when you need to invoke several commands from custom script (e.g. 'bin/jboss-admin.bat --connect command=:shutdown').
To avoid "Press any key to continue ..." message you need to specify NOPAUSE variable. Call 'set NOPAUSE=true' in command line before running any AS7 .bat script or include it in your custom script before invoking scripts from AS7.
Statistics
Read statistics of active datasources
/subsystem=datasources/data-source=ExampleDS/statistics=pool:read-resource(include-runtime=true) /subsystem=datasources/data-source=ExampleDS/statistics=jdbc:read-resource(include-runtime=true)
or
/subsystem=datasources/data-source=ExampleDS:read-resource(include-runtime=true,recursive=true)
All JBoss AS 7 documentation
There are several guides in the JBoss Application Server 7 documentation series. This list gives an overview of each of the guides:
*Getting Started Guide - Explains how to download and start JBoss Application Server 7.
*Getting Started Developing Applications Guide - Talks you through developing your first applications on JBoss Application Server 7, and introduces you to JBoss Tools and how to deploy your applications.
*JavaEE 6 Tutorial - A Java EE 6 Tutorial.
*Admin Guide - Tells you how to configure and manage your JBoss Application Server 7 instances.
*Developer Guide - Contains concepts that you need to be aware of when developing applications for JBoss Application Server 7. Classloading is explained in depth.
*High Availability Guide - Reference guide for how to set up clustered JBoss Application Server 7 instances.
*Extending JBoss AS 7 - A guide to adding new functionality to JBoss Application Server 7.