You can create a ModeShape repository that stands alone and is self-contained, or you can create a cluster of ModeShape repositories that all work together to ensure all content is accessible to each of the repositories.
When you create a ModeShape cluster, then a client talking to any of the processes in the cluster will see exactly the same content and the same events. In fact, from a client perspective, there is no difference between talking to a repository that is clustered versus not-clustered.
ModeShape can be clustered in a variety of ways, but the biggest decision will be where ModeShape is to store all of its content. Much of this flexibility comes from the power and flexibility of Infinispan, which can use a variety of topologies:
Local
In a local mode, ModeShape is not clustered at all. This is the default, so if you don't tell both ModeShape and Infinispan to cluster, each process will happily operate without communicating or sharing any content. Updates on one process will not be visible to any of the other processes.
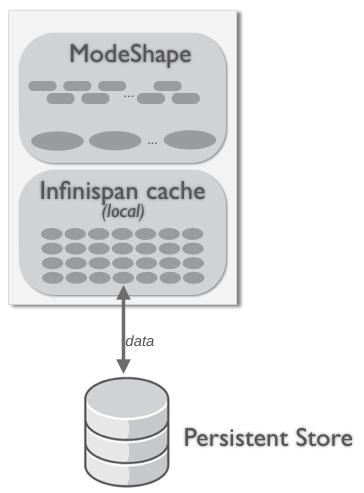
"Local
Note that in the local, non-clustered topology data must be persisted to disk or some other system. Otherwise, if the ModeShape process terminates, all data will be lost.
Replicated
The simplest clustering topology is to have each replicate all content across each member of the cluster. This means that each cluster member has its own storage for content, binaries, and indexes - nothing is shared. However, ModeShape (and Infinispan) processes in the cluster communicate to ensure that locks are acquired as necessary and that committed changes in each member are replicated to all other members of the cluster.
 Topology.png)
Replicated cluster topology with shared storage
The advantage of this topology is that each member of the cluster has a complete set of content, so all reads can be satisfied with locally-held data. Once a node is brought into memory and/or modified, then that change is immediately propagated to the other nodes in the cluster. Should that same node be needed again shortly thereafter, all processes have the latest change. This works great for small- to medium-sized repositories, even when the available memory on each process is not large enough to hold all of the nodes and binary values at one time. Additionally, because repositories share nothing (they all have their own cache, own indexes, etc.), it is simple to add or remove cluster instances.
When using a persistent store, ModeShape should be configured so that all of the members share a single persistent store. As long as that persistent store is transactional and capable of coordinating multiple concurrent operations (e.g., a relational database), then all of the data will be persisted in the store and the entire cluster can be shutdown with no data loss.
While technically possible, using multiple persistence stores - one for each cluster node - is not recommended because Infinispan transactions do not enroll the persistent store. This means that using multiple persistence stores increases the likelihood of inconsistencies. See https://issues.jboss.org/browse/MODE-2420 and https://github.com/infinispan/infinispan/wiki/Consistency-guarantees-in-Infinispan.
Because all members of a replicated cluster have copies of all of the data, it is possible to not use a persistent store. This will typically be faster, but it does mean that you must ensure that there will always be at least one (probably several) members of the cluster running at all times. And, you have to be sure that every process has enough memory to hold all of the nodes and binary values, so this is likely an option only in a limited number of use cases.
 Topology.png)
Replicated cluster topology with no storage
Either of the replicated topologies work well for repositories with fairly large amounts of content, and with relatively few members of the cluster. Typically replication is used when you want clustering for fault-tolerance purpose, to handle larger workloads of clients, or when the hardware is not terribly powerful.
Distributed
With larger cluster sizes, however, it is not as efficient for every member in the cluster to have a complete copy of all of the data. Additionally, the overhead of coordination of locks and inter-process communication starts to grow. This is when the distributed cluster topology becomes very advantageous.
In a distributed cluster, each piece of data is owned/managed by more than two members but fewer than the total size of the cluster. In other words, each bit of data is distributed across enough members so that no data will be lost if members catastrophically fail. And because of this, you can choose to not use persistent storage but to instead rely upon the multiple copies of the in-memory data, especially if the cluster is hosted in multiple data centers (or sites). In fact, a distributed cluster can have a very large number of members.
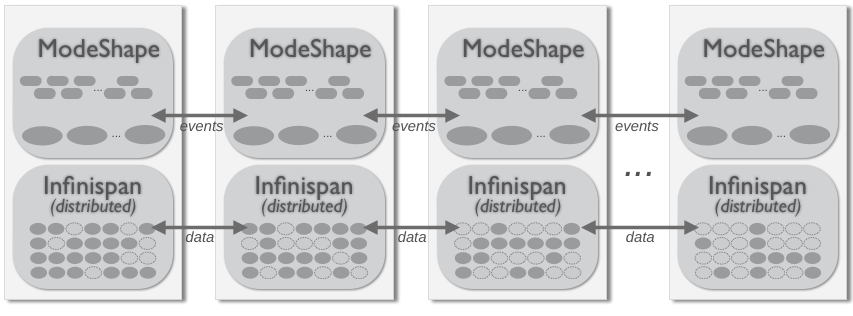
Distributed cluster topology
In this topology, you will lose data if you lose or shutdown more than n processes in the cluster, where n is the number of duplicates/copies of each node that the cluster maintains. Generally, n is chosen based upon the maximum number of processes you can lose at any one time. Remember that if you lose several, you can still bring them back up or even start additional processes, and Infinispan will reshuffle the data amongst the cluster to ensure there are again n copies of all nodes.
In this scenario, when a client requests some node or binary value, ModeShape (via Infinispan) looks to see which member owns the node and forwards the request to that node. (Each ModeShape repository instance maintains a cache of nodes, so subsequent reads of the same node will be very quick.)
Of course, you can choose to use a shared persistent store with a distributed cache:
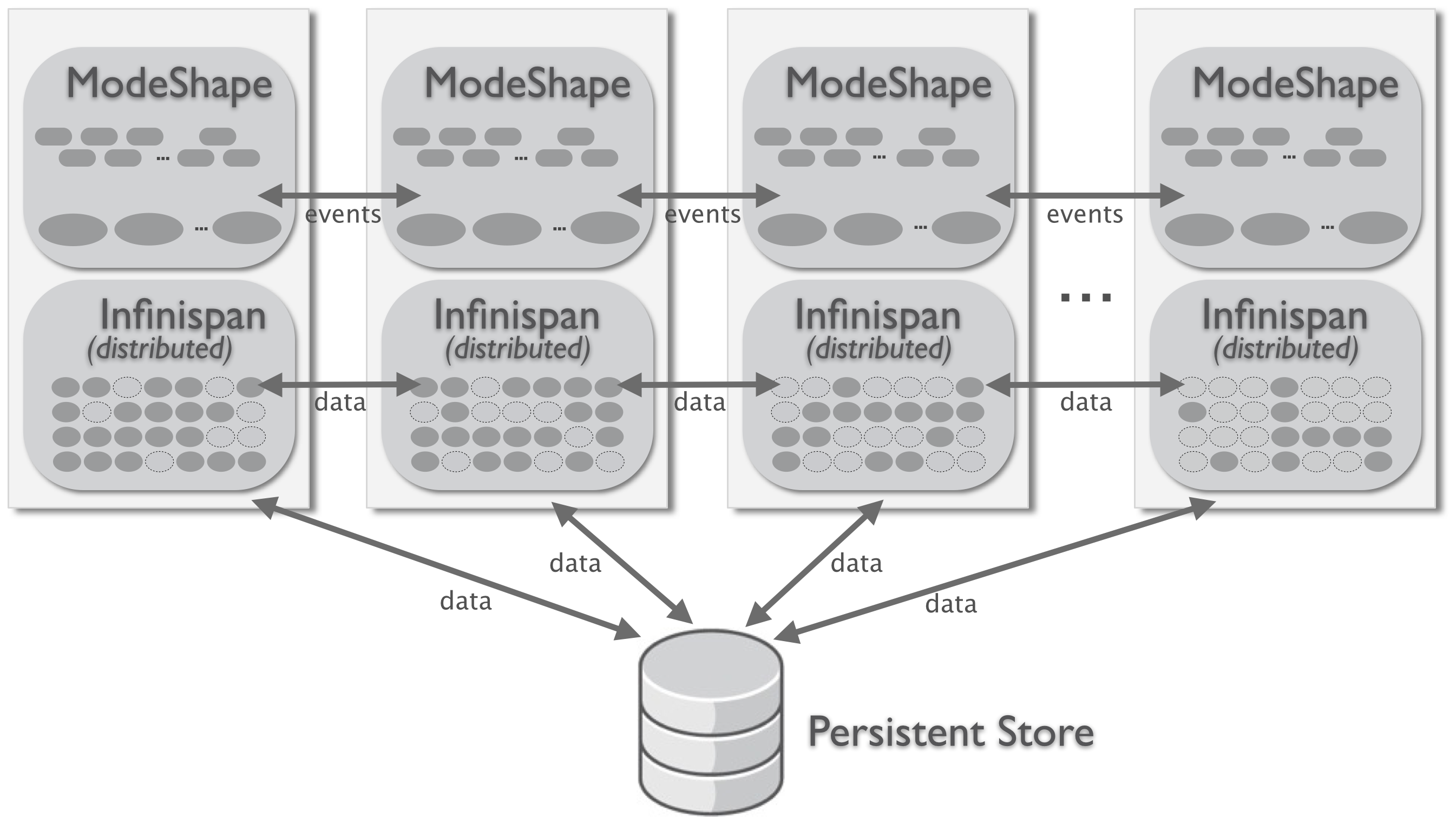
Distributed cluster topology with persistence
Here, your cluster is relying upon the shared persistent store to maintain persistence, while relying upon the distributed nature of Infinispan to maintain all of the nodes in-memory somewhere on the cluster. Often, if a process needs a node but does not have it in-memory, it can more quickly obtain that node from another process that has it in-memory than it can read it from persistent storage.
While technically possible, using multiple persistence stores - one for each cluster node - is not recommended because Infinispan transactions do not enroll the persistent store. This means that using multiple persistence stores increases the likelihood of inconsistencies. See https://issues.jboss.org/browse/MODE-2420 and https://github.com/infinispan/infinispan/wiki/Consistency-guarantees-in-Infinispan
Invalidation
Even though Infinispan supports this type of clustering, it should never be used by ModeShape. See https://github.com/infinispan/infinispan/wiki/Consistency-guarantees-in-Infinispan#2-invalidation-mode.
Using ModeShape with invalidation clustering is very similar to using replicated. The exception is that when a node is changed or added one process, a replicated cluster will send that updated or new node to all other processes in the cluster, making it very efficient should that same node be needed shortly thereafter on any of the processes in the cluster. However, some application scenarios will rarely need to access the same node again, and the replication of the changes from one process to all other processes in the cluster is really just unnecessary overhead. In these situations, invalidation mode may be much better, since changing a node on one process will simply notify the other processes to evict any cached (and now out-of-date) representation of that node from memory. Should that same node be needed on a process, it then merely just reads that representation from persistent storage.
 Topology.png)
Invalidation cluster topology with shared storage
Partition tolerance
Is not supported by ModeShape 4.
How to
Read on to learn how to to cluster an embedded repository or how to cluster a repository in Wildfly.