Node fileNode = session.getNode("/files/schemas/Customers.xsd");
Property content = fileNode.getProperty("jcr:content/jcr:data");
Node output = fileNode; // could be anywhere!
boolean success = session.sequence("XSD Sequencer", content, output);
Many repositories are used (at least in part) to manage files and other artifacts, including service definitions, policy files, images, media, documents, presentations, application components, reusable libraries, configuration files, application installations, databases schemas, management scripts, and so on. Most JCR repository implementations will store those files and maybe index them for searching.
But ModeShape does more. ModeShape sequencers can automatically unlock the structured information buried within all of those files, and this useful content derived from your files is then stored back in the repository where your client applications can search, access, and analyze it using the JCR API. Sequencing is performed in the background, so the client application does not have to wait for (or even know about) the sequencing operations.
The following diagram shows conceptually how these automatic sequencers do this.
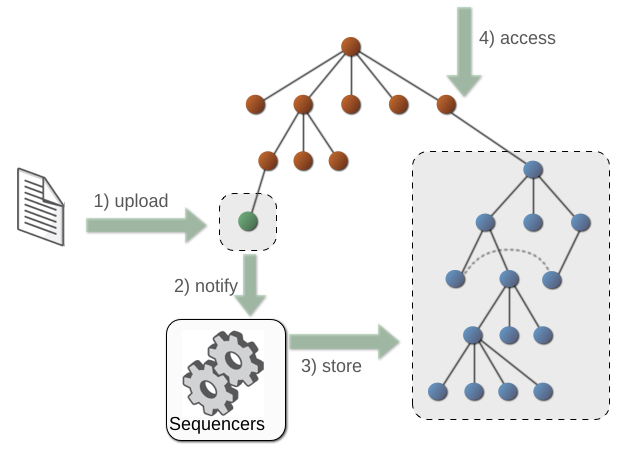
Your applications can also use a session to explicitly invoke a sequencer on a specified property. We call these manual sequencers. Any generated output is included in the session's transient state, so nothing is persisted until the application calls session.save().
Sequencers
Sequencers are just POJOs that implement a specific interface, and when they are called they simply process the supplied input, extract meaningful information, and produce an output structure of nodes that somehow represents that meaningful information. This derived information can take almost any form, and it typically varies for each sequencer. For example, ModeShape comes with an image sequencer that extracts the simple metadata from different kinds of image files (e.g., JPEG, GIF, PNG, etc.). Another example is the Compact Node Definition (CND) sequencer that processes the CND files to extract and produce a structured representation of the node type definitions, property definitions, and child node definitions contained within the file. A third example is a sequencer that works on XML Schema Documents might parse the XSD content and generate nodes that mirror the various elements, and attributes, and types defined within the schema document.
Sequencers allow a ModeShape repository to help you extract more meaning from the artifacts you already are managing, and makes it much easier for applications to find and use all that valuable information. All without your applications doing anything extra.
Each repository can be configured with any number of sequencers. Each one includes a name, the POJO class name, an optional classpath (for environments with multiple named classloaders), and any number of POJO-specific fields. Upon startup, ModeShape creates each sequencer by instantiating the POJO and setting all of the fields, then initializing the sequencer so it can register any namespaces or node type definitions.
There are two kinds of sequencers, automatic and manual.
Automatic Sequencers
An automatic sequencer has a path expression that dictates which content in the repository the sequencer is to operate upon. These path expressions are really patterns and look somewhat like simple regular expressions. When persisted content in the repository changes, ModeShape automatically looks to see which (if any) sequencers might be able to run on the changed content. If any of the sequencers do match, ModeShape automatically calls them by supplying the changed content. At that point, the sequencer then processes the supplied content and generates the output, and ModeShape then saves that generated output to the repository.
To use an automatic sequencer, simply add or change content in the repository that matches the sequencers' path expression. For example, if an XSD sequencer is configured for nodes with paths like "/files//*.xsd", then just simply upload a file into that location and save it. ModeShape will detect that the XSD sequencer should be called, and will do the rest. The generated content will magically appear in the repository.
Manual Sequencers
A manual sequencer is simply a sequencer that is configured without path expressions. Because no path expressions are provided, ModeShape cannot determine when/where these sequencers should be applied. Instead, manual sequencers are intended to be called by client applications.
For example, consider that a session just uploaded a file at "/files/schemas/Customers.xsd", and this node has a primary type of "nt:file". (This means the file's content is stored in the "jcr:data" property the "jcr:content" child node.) The session has not yet saved any of this information, so it is still in the session's transient state. The following code shows how an XSD sequencer configured with name "XSD Sequencer" is manually invoked to place the generated content directly under the "/files/schemas/Customers.xsd" node (and adjacent to the "jcr:content" node):
The sequence(...) method returns true if the sequencer generated output, or "false" if the sequencer couldn't use the input and instead did nothing.
Remember that when the sequence(...) does return, any generated output is only in the session's transient state and "session.save()" must be called to persist this state.
Built-in sequencers
ModeShape comes with sequencer implementations for a variety of file types:
|
Input files |
Derives |
|
A node is created for each XML element, properties are created for each XML attribute, and each declared namespace is registered in the workspace. |
|
|
A node structure that represents the structure and semantics of the XSD, including the attribute declarations, element declarations, simple type definitions, complex type definitions, import statements, include statements, attribute group declarations, annotations, other components, and even attributes with a non-schema namespace. |
|
|
WSDL 1.1 files |
A node structure that represents the WSDL file's messages, port types, bindings, services, types (including embedded XML Schemas), documentation, and extension elements (including HTTP, SOAP and MIME bindings). |
|
Extracts the files and folders contained in the archive file, representing them as nt:file and nt:folder nodes. The resulting files will be candidates for further sequencing. |
|
|
Delimited and fixed-width text files |
A simple node structure reflecting the rows of data fields. |
|
A node structure that represents the parsed data definition statements from SQL-92, Oracle, Derby, and PostgreSQL. The resulting structure is largely the same for all dialects, though some dialects have non-standard additions to their grammar that result in dialect-specific additions to the graph structure. |
|
|
Java files |
A node structure representing the Java source or class file's package structure, class declarations, class and member attribute declarations, class and member method declarations with signature (but not implementation logic), enumerations with each enumeration literal value, annotations, and JavaDoc information for all of the above. |
|
Image files |
A node containing the image metadata, including file format, image size, number of bits per pixel, number of images, comments, and physical dimensions. |
|
MP3 files |
A node that contains the metadata for the audio files, including the track's title, author, album name, year, and comment. |
Please see the Built-in sequencers section of the documentation for more detail on all of these sequencers, including how to configure them and the structure of the output they generate.
Custom sequencers
As mentioned earlier, a sequencer is actually just a plain old Java object (POJO). Creating a sequencer is pretty straightforward: create a Java class that extends a single abstract class, package it up for use, and then configure your repository to use it. We walk you through all these steps in the Custom sequencers section of the documentation.
Configuring a automatic sequencer
Each sequencer must be configured to describe the areas or types of content that the sequencer is capable of handling. This is done by specifying these patterns using path expressions that identify the nodes (or node patterns) that should be sequenced and where to store the output generated by the sequencer.
A path expression consist of two parts: a selection criteria (or an input path) and an output path:
inputPath => outputPath
Input path
The inputPath part defines an expression for the path of a node that is to be sequenced. Input paths consist of '/' separated segments, where each segment represents a pattern for a single node's name (including the same-name-sibling indexes) and '@' signifies a property name.
Let's first look at some simple examples:
|
Input Path |
Description |
|
/a/b |
Match node "b" that is a child of the top level node "a". Neither node may have any same-name-sibilings. |
|
/a/* |
Match any child node of the top level node "a". |
|
/a/*.txt |
Match any child node of the top level node "a" that also has a name ending in ".txt". |
|
/a/*.txt |
Match any child node of the top level node "a" that also has a name ending in ".txt". |
|
/a/b/@c |
Match the property "c" of node "/a/b". |
|
/a/b[2] |
The second child named "b" below the top level node "a". |
|
/a/b[2,3,4] |
The second, third or fourth child named "b" below the top level node "a". |
|
/a/b[*] |
Any (and every) child named "b" below the top level node "a". |
|
//a/b |
Any node named "b" that exists below a node named "a", regardless of where node "a" occurs. Again, neither node may have any same-name-sibilings. |
With these simple examples, you can probably discern the most important rules. First, the '*' is a wildcard character that matches any character or sequence of characters in a node's name (or index if appearing in between square brackets), and can be used in conjunction with other characters (e.g., "*.txt").
Second, square brackets (i.e., '[' and ']') are used to match a node's same-name-sibiling index. You can put a single non-negative number or a comma-separated list of non-negative numbers. Use '0' to match a node that has no same-name-sibilings, or any positive number to match the specific same-name-sibling.
Third, combining two delimiters (e.g., "//") matches any sequence of nodes, regardless of what their names are or how many nodes. Often used with other patterns to identify nodes at any level matching other patterns. Three or more sequential slash characters are treated as two.
Many input paths can be created using just these simple rules. However, input paths can be more complicated. Here are some more examples:
|
Input Path |
Description |
|
/a/(b|c|d) |
Match children of the top level node "a" that are named "b", "c" or "d". None of the nodes may have same-name-sibling indexes. |
|
/a/b[c/d] |
Match node "b" child of the top level node "a", when node "b" has a child named "c", and "c" has a child named "d". Node "b" is the selected node, while nodes "c" and "d" are used as criteria but are not selected. |
|
/a(/(b|c|d|)/e)[f/g/@something] |
Match node "/a/b/e", "/a/c/e", "/a/d/e", or "/a/e" when they also have a child "f" that itself has a child "g" with property "something". None of the nodes may have same-name-sibling indexes. |
These examples show a few more advanced rules. Parentheses (i.e., '(' and ')') can be used to define a set of options for names, as shown in the first and third rules. Whatever part of the selected node's path appears between the parentheses is captured for use within the output path, similar to regular expressions. Thus, the first input path in the previous table would match node "/a/b", and "b" would be captured and could be used within the output path using "$1", where the number used in the output path identifies the parentheses. Here are some examples of what's captured by the parenthesis and available for use in the output path:
|
Input Path |
$1 |
$2 |
$3 |
|
/a/(b|c|d) |
"b" or "c" or "d" |
n/a |
n/a |
|
/a/b[c/d] |
n/a |
n/a |
n/a |
|
/a(/(b|c|d|)/e)[f/g/@something] |
"/b/e" or "/c/e" or "/d/e" or "/e" |
"b" or "c" or "d" or "" |
n/a |
Square brackets can also be used to specify criteria on a node's properties or children. Whatever appears in between the square brackets does not appear in the selected node. This distinction between the selected path and the changed path becomes important when writing custom sequencers.
Output paths
The outputPath part of a path expression defines where the content derived by the sequencer should be stored.
Typically, this points to a location in a different part of the repository, but it can actually be left off if the sequenced output is to be placed directly under the selected node. The output path can also use any of the capture groups used in the input path.
Workspaces in input and output paths
So far, we've talked about how input paths and output paths are independent of the workspace. However, there are times when it's desirable to configure sequencers to only work against content in a specific workspace. In these cases, it is possible to specify the workspace names before the path. For example:
|
Input Path |
Description |
|
:default:/a/(b|c|d) |
Match nodes in the "default" workspace within any source source that are children of the top level node "a" and named "b", "c" or "d". None of the nodes may have same-name-sibling indexes. |
|
:/a/(b|c|d) |
Match nodes in any within any source source that are children of the top level node "a" and named "b", "c" or "d". None of the nodes may have same-name-sibling indexes. (This is equivalent to the path "/a/(b|c|d)".) |
Again, the rules are pretty straightforward. You can leave off the workspace name, or you can prepend the path with "workspaceNamePattern:", where "workspaceNamePattern" is a regular-expression pattern used to match the applicable workspace names. A blank pattern implies any match, and is a shorthand notation for the ".*" regular expression. Note that the repository names may not include forward slashes (e.g., '/') or colons (e.g., ':').
Example path expression
Let's look at an example sequencer path expression:
default://(\*.(jpg\|jpeg\|gif\|bmp\|pcx\|png)\[*])\[/jcr:content@jcr:data] => meta:/images/\$1
This matches a changed "jcr:data" property on a node named "jcr:content[1]" that is a child of a node whose name ends with ".jpg", ".jpeg", ".gif", ".bmp", ".pcx", or ".png" ( that may have any same-name-sibling index) appearing at any level in the "default" workspace. Note how the selected path capture the filename (the segment containing the file extension), including any same-name-sibling index. This filename is then used in the output path, which is where the sequenced content is placed under the "/images" node in the "meta" workspace.
So, consider a PNG image file is stored in the "default" workspace in a repository configured with an image sequencer and the aforementioned path expression, and the file is stored at "/jsmith/photos/2011/08/09/reunion.png" using the standard "nt:file" pattern. This means that an "nt:file" node named "reunion.png" is created at the designated path, and a child node named "jcr:content" will be created with primary type of "nt:resource" and a "jcr:data" binary property (at which the image file's content is store).
When the session is saved with these changes, ModeShape discovers that the
{{/jsmith/photos/2011/08/09/reunion.png/jcr:content/jcr:data}}
property satisfies the criteria of the sequencer, and calls the sequencer's execute(...) method with the selected node, input node, input property and output node of "/images" in the "meta" workspace. When the execute() method completes successfully, the session with the change in the "meta" workspace are saved and the content is immediately available to all other sessions using that workspace.

Waiting for automatic sequencing
When your application creates or uploads content that will kick off a sequencing operation, the sequencing is actually done asynchronously. If you want to be notified when the sequencing is complete, you can use ModeShape's observation feature to register a listener for the sequencing event.
The first step is to create a class that implements "javax.jcr.observation.EventListener". Normally this is pretty easy, but in our case we want to block until the listener is notified via a separate thread. An easy way to do this is to use a java.util.concurrent.CountDownLatch, and to count down the latch as soon as we get our event. (If we carefully register the listener using criteria for only the sequencing output we're interested in, we'll know we'll only receive one event.)
Here's our implementation that captures from the first event whether the sequencing was successful and the path of the output node, and then counts down the latch:
public class SequencingListener implements javax.jcr.observation.EventListener {
private final CountDownLatch latch;
private volatile String sequencedNodePath;
private volatile boolean successfulSequencing;
public SequencingListener( CountDownLatch latch ) {
this.latch = latch;
}
@Override
public void onEvent( javax.jcr.observation.EventIterator events ) {
if ( sequencedNodePath != null ) return;
try {
javax.jcr.observation.Event event = (javax.jcr.observation.Event)events.nextEvent();
this.sequencedNodePath = event.getPath();
this.successfulSequencing = event.getType() == org.modeshape.jcr.observation.Event.Sequencing.NODE_SEQUENCED;
latch.countDown();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public boolean isSequencingSuccessful() {
return this.successfulSequencing;
}
public String getSequencedNodePath() {
return sequencedNodePath;
}
}
We could then register this using the public API:
Session session = ...
ObservationManager observationManager = session.getWorkspace().getObservationManager();
String outputPath = .. // the path at or below which the output is to be placed
// Listen for sequencing completion or failure events, via the ALL type ...
int eventTypes = org.modeshape.jcr.api.observation.Event.Sequencing.ALL;
boolean isDeep = true; // if outputPath is ancestor of the sequencer output, false if identical
String[] uuids = null; // Don't care about UUIDs of nodes for sequencing events
String[] nodeTypes = null; // Don't care about node types of output nodes for sequencing events
boolean noLocal = false; // We do want events for sequencing happen locally (as well as remotely)
// Now create a listener implementation that will be called when the event is here ...
CountDownLatch latch = new CountDownLatch(1);
SequencingListener listener = new SequencingListener(latch);
observationManager.addEventListener(listener,eventTypes,outputPath,isDeep,
uuids, nodeTypes, noLocal);
// Now, block until the latch is decremented (by the listener) or when our max wait time is exceeded
latch.await(15, TimeUnit.SECONDS);
if ( listener.isSequencingSuccessful() ) {
// Grab the output produced by the sequencer ...
} else {
// Handle the failure ...
}