<resource-expr> [ <string-match-expr> ] = <value> "groupby" <resource-expr> empty <resource-expr> [ <string-match-expr> ] not empty <resource-expr> [ <string-match-expr> ] resource.id resource.name resource.version resource.type.plugin resource.type.name resource.type.category resource.availability resource.pluginConfiguration[<property-name>] resource.resourceConfiguration[<property-name>] resource.trait[<property-name>] resource.child resource.parent resource.grandParent
Overview
The dynamic search API for RHQ will focus on inventory. Its primary goal is to give users a flexible mechanism to find resources matching various different properties. The 'dynamic' part of its name comes from the fact that these properties may vary from resource to resource. For example, JBossAS resource types have a connection property called "jbossHomeDir", in which case a search for:
resource.pluginConfiguration['jbossHomeDir'] = admin
Would produce all the resources that have that specific property and whose value is 'admin'. However, a search for:
resource.pluginConfiguration['catalinaBase'] = /home*
Would produce a list of Tomcat servers rooted at your home directory since 'catalinaBase' is a property defined only by the Tomcat server resource type.
Existing Infrastructure
Terminology
-
DynaGroups - a mechanism enabling the automatic management of one or more group memberships based off of conjunctive ('and'), hierarchical search expressions; requires inventory manager permission
-
Criteria Queries - a mechanism enabling search for entities matching simple filters; also supports paging / sorting, fetching related data, fuzzy matching, conjunctive ('and') as well as disjunctive ('or') condition sets, respects authorization
API Quick Reference
class Criteria {
public void setCaseSensitive(boolean caseSensitive);
public void setFiltersOptional(boolean filtersOptional); // disjunctive
public void setStrict(boolean strict); // fuzzy-match
public void setPageControl(PageControl pageControl);
public void setPaging(int pageNumber, int pageSize);
}
class EntityCriteria extends Criteria {
public void addFilterXXX(Type value);
public void addSortXXX(PageOrdering columnOrdering);
public void fetchXXX(boolean fetchRelationship);
}
Discussion
DynaSearch is targeted at a user interface with free-form text, which is similar to what DynaGroups supports today. Sorting and paging are not a necessary part of the direct DynaSearch subsystem because the results will be displayed in a richtable, which will govern those aspects.
Criteria queries, since they were designed for exposition to remote clients, needed to be able to integrate those paging and sorting aspects directly into their interface. The criteria API can also traverse entity relationships, prefetching that data, which may be unnecessary if we are only looking to display search results in the UI. Lastly, the desire to keep the filtering mechanism simple for remote callers (invoke 'addFilterXXX' methods on the criteria object in any order) means that it would not be possible to establish a way to allow arbitrary boolean expressions of those filters.
Since the primary role of the DynaSearch framework is going to be the translation of the search expression into a JPQL fragment, it was deemed that building on top of DynaGroups (in particular the underlying expression evaluator) would be the way to go.
Syntax and Search
Enhancements
DynaSearch will improve upon what DynaGroups started by expanding the syntax to including a wider array of searchable items as well as allow them to be coupled in various ways.
-
Arbitrary boolean expressions including conjunctive and disjunctive operators supporting arbitrary levels of parenthetical nesting; 'AND' operator is implied between terms; 'OR' operator can use '|' or the literal word 'OR'; implicit 'AND' operator takes precedence over 'OR' operator if not explicitly grouped by parentheses
-
(a | b) (c or d), valid parenthetical expression
-
(a or b) (c | (d e)), valid two-level parenthetical expression
-
-
Each term needs to be able to control case-sensitivity individually
-
expression = value, case-insensitive comparison
-
expression == value, case-sensitive comparison
-
expression != value, negated case-insensitive comparison
-
expression !== value, negated case-sensitive comparison
-
-
Support for regex-like boundary matches, compatible with case sensitive or insensitive operators
-
expression = ^prefix, search for values beginning with the text 'prefix'
-
expression = suffix$, search for values ending in the text 'suffix'
-
expression = ^exact-match$, search for values which match the text 'exact-match' exactly
-
expression = inner, search for values which start with, end with, or contain the text 'inner'
-
-
Null searches
-
expression = null, previously implemented as "empty <expression>"
-
expression != null, previously implemented as "not empty <expression>"
-
Note: if null is used with quotes as in "expression = 'null'", it is instead interpreted as a literal string instead
-
-
-
Simplified syntax
-
"resource" token is implied, thus you say "name" instead of "resource.name"
-
All expressions reduced to a single word:
-
"type.plugin" becomes "plugin"
-
"type.name" becomes "type"
-
"type.category" becomes "category"
-
"pluginConfiguration" may become "connection"
-
"resourceConfiguration" may become "configuration"
-
-
-
Improved hierarchical control (out of scope for RHQ
-
Support for "child[x]", where x > 0
-
Support for "parent[x]", where x > 0
-
Support for "platform" (shortcut for the platform ancestor managed by the agent which is also managing the resource being searched for)
-
Group Search
As it stands today, the resource browser is the primary display for both resources and groups. Accordingly, we might want to write a second (perhaps simplified) search solution for groups. Suggested tokens would be:
-
group.name
-
group.plugin (if compatible, the plugin defining the resource type for this group)
-
group.type (if compatible, the resource type for this group)
-
group.category ('platform', 'server', 'service')
-
group.kind ('mixed' or 'compatible')
-
group.availability (UP, DOWN, perhaps support a numeric number with units, i.e. 80%)
However, similar to the resource-specific search terms, the "group" prefix should be strictly optional. Thus, if you're on the group tab and you search for "category = Platform" it will search for compatible groups containing any platform.
Resource-Group Related Search
From a resource perspective, it might be nice to search for resources that are in a group with a particular name. From a group perspective, it might be nice to search for all groups that a particular resource is in. To accomplish this, both the resource search syntax and group search syntax could be supported in both views.
From the resource view: "group.availability = DOWN" would give me all of the resources I have visibility to that are members of groups where all of their members are down.
From the group view: "resource.connection['principal'] is null" would give me all of the groups I have visibility to that contain any resources that I haven't secured with principal/credentials yet.
Tag Search
The ability to search across tags should be exposed both to resources and groups. The full, explicit syntax will be as follows:
-
resource.tag
-
group.tag
Remember, if you're searching with the resource browser the 'resource' prefix will be implied. Likewise, if you're searching within the group browser the 'group' prefix will be implied.
Relationship Search
The RHQ system will support the ability to link resources in ways that can not be expressed via the standard hierarchical resource model. For instance, when an EAR is deployed to a JBossAS server, the SLSBs (stateless session beans) get discovered as siblings of the EAR under the server, even though they have a logical dependency on the deployed EAR. In this case, two unidirectional relationship definitions would be setup between the types:
-
SLSB->"deployedUnder"->EAR
-
EAR->"deploys"->SLSB
The relationship definition that links the SLSB resource type to the EAR resource type is called "deployedUnder". It is these relationship definition names that will be searchable. The syntax will look as follows:
resource.relationship = 'deployedUnder'
You can combine this search expression with others like:
(relationship = deployedUnder) and (name ~= myapp*) and (type = EAR)
So this will find all of the resources that are 'deployedUnder' enterprise application archives prefixed with 'myapp' (case-insensitively).
Simplified Search Syntax
Some may find the search syntax provided above a bit verbose. The auto-completion (see below) mechanism should mitigate that concern a bit, but it might be possible to support an alternate format which would be a condensed subset of the full search syntax.
|
'''Syntax Variant''' |
'''Description''' |
|
deployedUnder(type=EAR, name ~= myapp*) |
Expression of relationships as auto-complete-able functions applied to a comma-delimited (conjunctive-only) search |
|
EAR:: name ~= myapp* |
Special handling for type filter, where it becomes a pseudo first class construct that needs to be suffixed with a double-colon ("::") |
|
EAR:JBossAS:: name ~= myapp* |
Similar to above, but optionally can specify type/plugin combo by separating those names with a colon (":") |
|
deployedUnder(EAR:: name ~=myapp*) |
Combination of both aforementioned syntax variants |
Note: the type filter variant might help to make the transition from those familiar with RHEV syntax smoother.
The issue with supporting syntax variants is that they increase the cost of maintenance for the query parser as well as auto-completion mechanisms. The variant, by the fact that it seeks to make the syntax more concise also makes it denser. A denser syntax will lessen the impact of auto-completion, because at each completion point the number of possible matches explodes (relative to the more verbose but much more restrictive full syntax).
Pattern Grouping (for DynaGroups only)
This feature takes the concept of wildcard searches and applies them to pivoted (groupby) expressions. Often it is the case that resource names encode information that is specific to a particular company's topology, business tier, data center, etc. For instance, one organization might choose hostnames like 'DC001R001N001' to denote the datacenter, rack, and node information. Then, to create an expression which automatically creates one group for every datacenter, use the following syntax:
groupby substring(resource.name, 0, 5)
An alternate syntax might look like:
groupby substring(0,5) resource.name
Since simple substring functions are implemented in every major database (without requiring a vendor-specific package to be installed) we'll be able to implement the translated query in pure JPQL as follows:
select substring(res.name, 0, 5) as datacenter
from Resource res
group by datacenter
Though, due to a bug in Hibernate, the generated SQL will not properly alias the results of a projection of a string function. Thus, the following workaround JPQL will have to be used:
select substring(res.name, 0, 5)
from Resource res
group by substring(res.name, 0, 5)
Search Results
The result windows should not refresh automatically. The user interface should force the users to either press enter or click on a "search" button to activate the search. Since the search syntax fully supports auto-completion, the user should be able to type out their patterns (with assistance) without needing to constantly see the search results.
The user should have the possibility of creating a group definition directly from the search results. This would allow the user to then perform various group-related activities against that group, such as using it to setup authorization rules. If the resulting dynagroup happened to be a compatible group, the user would also gain the ability to view monitoring data, set group connection properties, execute group operations, etc.
Custom Columns
Along with saving the search conditions, we'd like to save the configuration of customized columns. These would be customizable for each saved search so that a user could combine the criteria and the necessary display columns for a given search use case. When altering the settings the user could remove existing columns, add new ones or rearrange the existing columns. These column settings would go along with the saved search if it were to be shared globally and used by others. A good example would be to allow the user to display the number of alerts on a resource in the past 24 hours for alert driven searches.
For searches that are not type specific (i.e. the search resources could return resources of all different types) the columns that could be selected would be generic to all resources. Some ideas for these are:
-
Resource Id
-
Name
-
Type
-
Description
-
Location
-
Current Availability
-
Recent Availability (up % last 24 hours)
-
Recent Alerts
-
Recent Config Changes
-
Recent Content Changes
-
Recent OOBs
-
Applicable Errata
-
Applicable Content Updates
-
Recent Operations
When the search conditions include a specific resource type conditional the search will return results that include only one type of resource. These searches can use the type metadata for that type to offer additional type specific information:
-
Current value of a specific trait
-
Current formatted value of a specific metric
-
Sparkline of metric
-
A specific configuration value
-
The installed version of a specific package
-
Complex Metric Math (think metric a - metric b or metric a / metric b)
Along with the rest of the DynaSearch functionality, saved searches should be able to ship in the box, be added by a plugin or perspective or something so we ship useful ones. The addition of column settings makes it difficult to copy-paste a useful search.
Backward Compatibility
-
All expressions will be backward compatible with the old style, to keep existing expressions working - this put burden on query processor to support a wider range of expressions but has no upgrade impact
-
Part of dbupgrade will be to inspect the 'expression' field of dynagroups, and execute sql to update the expressions to use the new syntax - this simplifies the parser, but makes the upgrade more complex
Security / Authorization
Note, the search results need to take authorization into account. As it stands today, InventoryManager permission is required to CRUD group definitions as well as recalculate dynagroups. When resource results are displayed for resource-specific searches, only the resources that are viewable by the logged in user should be shown. When group results are display for group-specific searches, only the groups that are viewable by the logged in user should be shown.
Saved Searches
The user should be able to save his searches. The user should be able to click on one of his saved searches and it will execute the search and display results. This is a convenient mechanism for users that always want to start their sessions using search to find resources, but doesn't offer the same kind of power as creating a full group from the search results.
Note, users will be able to have saved searches for both resources and groups. The list of save searches, therefore, should be populated relative to which browsing context the user is in. If the user is looking at the group browser, they should only see their list of saved group searches. Likewise, if the user is looking at the resource browser, they should only see their list of saved resource searches.
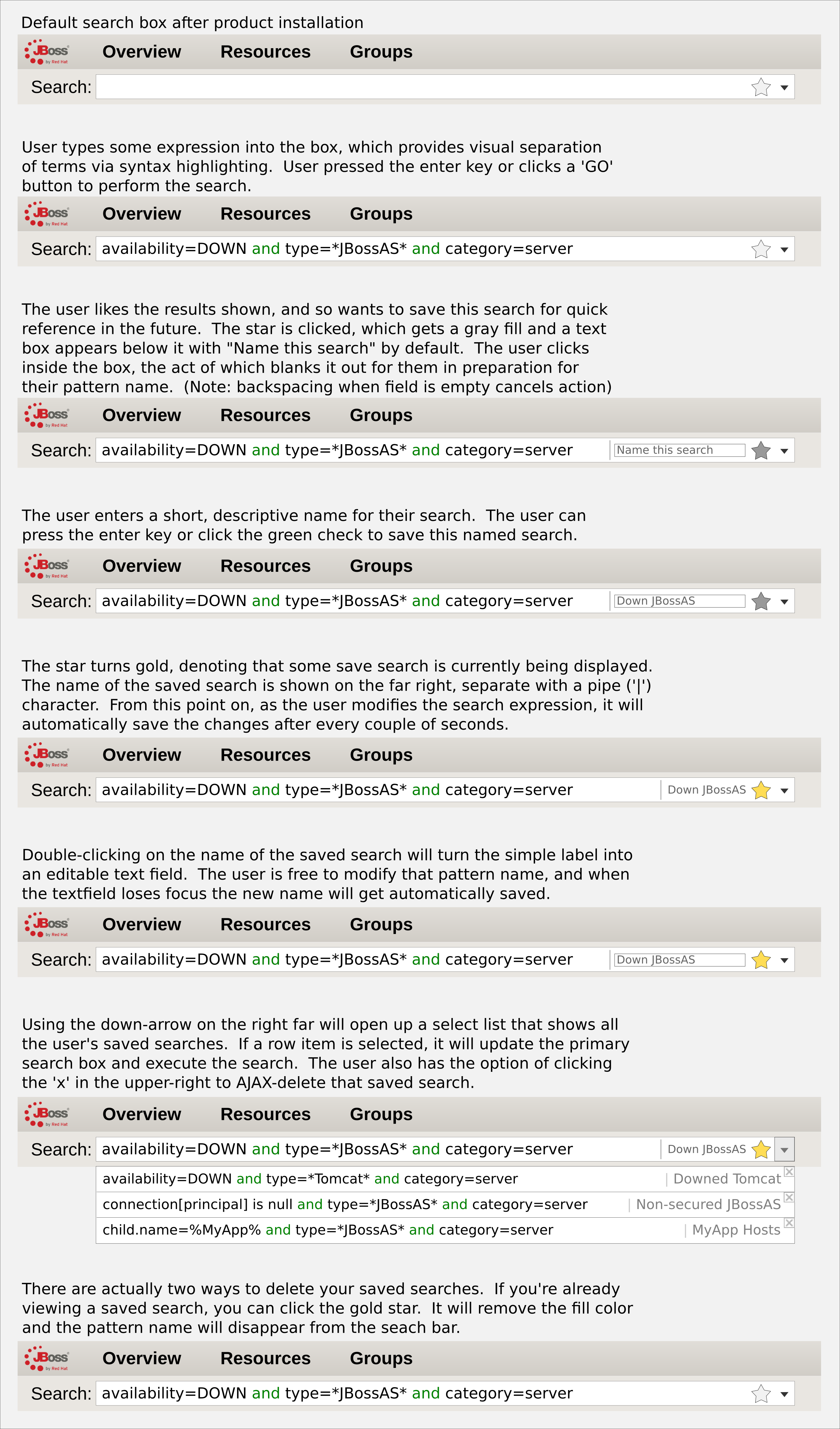
Syntax Auto-Completion
All aspects of the DynaSearch syntax will support auto-completion including 'and', 'or', parenthetical tokens, search terms, and dynamic properties. The first four categories are relatively simple because they are grammar tokens, and thus easy to deduce. The dynamic properties are a bit trickier because the list of results could be relatively long, and the screen real estate is limited. To remedy this, we can either:
-
Make the auto-completion area scrollable, thus displaying all possible matches every time no matter what, or
-
Limit the auto-completion list for property names to render ONLY after the user enters one alphabetic character following the '[' token, which will naturally limit the possible matches
Note: as of this writing there are only 1026 unique property definition names and 108 unique trait names, which is easily cacheable on the client side without a significant memory footprint concern
Another implementation concern is that the auto-completion mechanism should run completely client-side. It is anticipated that the search feature will be heavily used, and thus should not put undo load on the server by constantly round-tripping to get the list of completion candidates.
As for the parsing routine itself, it should be implemented as a finite automaton so that the algorithm can produce completion candidates in constant time. Granted, this requires remembering the parse context (where the mouse cursor is relative to the entire expression), but that's not too difficult. If the mouse cursor ever moves (due to arrow keys or a mouse click), the parse context is simply recalculated by walking the automaton from the beginning up to the selected context. By implementing auto-completion this way, it will be a big improvement from a user experience standpoint because the completion candidates will appear to re-render as quickly as the user can type (instead of a noticeable delay between when they type a character and when the area refreshes).
User Interface Modifications
-
rewrite resource browser in JSF/Facelets
-
One tab for all resources, because "category" is now a search term
-
One tab for all groups, because "kind" is now a search term
-
display list of saved searches for quick / easy reference on the page directly?
Remote / Programmatic DynaSearch
Since the DynaSearch framework is all about generating JPQL fragments, and since the criteria API is a facade that pieces together JPQL fragments, it would be possible to extend the ResourceCriteria and GroupCriteria to leverage the DynaSearch framework to allow arbitrary search expressions for these two criteria objects.
It might look something like this:
abstract class DynaSearchableCriteria extends Criteria {
...
private String expression;
...
setSearchExpression(String expression);
String getSearchExpression();
}
class Resource/GroupCriteria extends DynaSearchableCriteria {
...
}
class CriteriaQueryGenerator {
if (criteria instanceof DynaSearchableCriteria) {
// logically append...
// "WHERE id IN ( " + translateSearchToJPQL(getSearchExpression()) + " )"
// ...onto the end of the generated query
}
}
The benefit of doing it this way is that from a programmatic standpoint you get the best of both worlds. You can still use all of the features of the existing ResourceCriteria and GroupCriteria objects (including simple filters [if you so choose], paging, sorting, pre-fetching related data), but you now have the ability to search for resources much more robustly using the full capability of DynaSearch.
Advanced Features
Sorting Completion Results
-
Frequency - number of times this search was retrieved / accessed by the user, can optionally show the absolute count or a mini pie chart for frequency
-
Relevancy - saved searches that might be related to the pattern currently in the search window (not trivial!)
Syntax Highlighting
As the user types the search expression, coloring the boolean words will add clarity to the search terms by delimiting their boundaries clearly. Syntax highlighting can be seen on the accompanying UI mockup.
Value Auto-Completion
All search terms have the basic structure "<filter> <operator> <value>". Sytnax auto-completion is meant to fill in that basic structure including the known filters and operators. The values, however, are a different story. Some filters have a small set of known values, such as availability which can only be UP or DOWN. Other filters, such as the name of a resource, can be an arbitrary set of characters. Value auto-completion would be a mechanism to identify that a user is searching by one of the filtering with a known set of values, and would offer substring completion on it. For example, "EAR" would have an auto-completion result of "Enterprise Application (EAR)" if the user was filtering on "type".
Other Search Syntaxes
JIRA
http://www.atlassian.com/software/jira/docs/v3.13/querysyntax.html JIRA uses Lucene for text indexing. Most is derived from the 2.2.0 version of http://jakarta.apache.org/lucene/2_2_0/queryparsersyntax.html Lucene Query Parser Syntax.
A query is broken up into terms and operators. There are two types of terms: Single Terms and Phrases. A Single Term is a single word such as "test" or "hello". A Phrase is a group of words surrounded by double quotes such as "hello dolly". Multiple terms can be combined together with Boolean operators to form a more complex query.
-
Supports single ('?') and multiple ('*') character wildcard searches
-
Note: wildcards cannot be the first character of a search
-
Add the tilde ('~') at the end of a Single word Term to fuzzy search
-
i.e., roam~ will find terms like foam and roams
-
Add the tilde ('~') following by a number at the end of Phase to proximity search
-
i.e., "atlassian jira"~10 will find documents where 'atlassian' and 'jira' are within 10 words of each other
-
The caret ('^') symbol will boost Single word terms or Phrases to change the relevance level of document matches
-
i.e., "atlassian jira"3 querying.2
-
The defeault boost factor for all Single word terms and Phrases is 1
-
Note: although the boost factor must be positive, it can be fractional (i.e., .2)
-
Boolean operations must be all caps
-
AND, "+"
-
A required term
-
OR, "||"
-
This is the default operator is none exists between terms
-
NOT, "!", "-"
-
Note: the NOT operator cannot be used with just one term
-
Parenthetical Grouping '(' and ')' can be used to add precedence to boolean expressions
-
i.e., bugs AND (atlassian OR jira)
-
Note: '(' can not begin a search expression
-
Escaping special characters require the backslash ('\') before the character
-
Special character set: {{+ - && || ! ( ) { } [ ] ^ " ~ * ? }}
Lucene
Sytnax Reference Guide is http://jakarta.apache.org/lucene/2_2_0/queryparsersyntax.html here.
A query is broken up into terms and operators. There are two types of terms: Single Terms and Phrases. A Single Term is a single word such as "test" or "hello". A Phrase is a group of words surrounded by double quotes such as "hello dolly". Multiple terms can be combined together with Boolean operators to form a more complex query.
-
Everything from the JIRA syntax section above
-
The colon (':') separates field names from the value search
-
i.e., title:"The Right Way" AND go, since 'text' is the default text, the indicator was not required
-
Range queries allow matching documents between inclusive or exclusive boundaries
-
i.e., mod_date:[20020101 TO 20030101], inclusive search on mod_date field
-
i.e., title:{Aide TO Carmen}, search on titles between Aide and Carmen, but not including Aida and Carmen
-
Field grouping allows multiple clauses related to a single field
-
i.e., title(+return +"pink panther") to search for titles containing the word "return" and the phrase "pink panther"
-
Lucene has all of the special characters from JIRA as well as ':'
Solr
The standard http://wiki.apache.org/solr/SolrQuerySyntax Solr Query Parser syntax is a superset of the 2.4.0 version of http://lucene.apache.org/java/2_4_0/queryparsersyntax.html Lucene Query Parser Syntax. The differences are as follows:
-
Range, prefix, and wildcard queries are constant-scoring; scoring factors tf, idf, index boost, and coord are not used (Lucene 2.1 also switched to ConstantScoreRangeQuery)
-
There is no limit on the number of terms that match
-
Range queries can use wildcards for either boundary
-
i.e., field:[* TO 100] finds all field values less than or equal to 100
-
Pure negative queries, where all clauses are prohibited, are allowed
-
i.e., -inStock:false finds all field values where inStock is not false
-
Extended grammar support for http://wiki.apache.org/solr/FunctionQuery FunctionQuery
-
i.e., val:myCustomFunction(myfield)
-
Support for nested queries via bracketed delimiters
-
i.e., query:"{!dismax qf=myfield}how now brown cow"
-
http://wiki.apache.org/solr/DisMaxRequestHandler DisMaxRequestHandler
-
lightweight syntax for handling word search across several fields
-
disjunction across all words in the phrase
-
simplified subset of the Lucene QueryParser syntax, tailored for user-entered phrases without heavy syntax
Hibernate Search
This search technology is a thin integration layer on top of Lucene, where you pass the query to it and you can define the projection, result transformer/mapper, fetching rules, pagination and sorting. Its focus is integration with Lucene, not to define its own syntax variant. Below are some code examples:
// general integration
FullTextSession ftSession = Search.getFullTextSession(session);
// example 1
// all indexed entities will be searched, unless restricted
org.hibernate.search.FullTextQuery query =
ftSession.createFullTextQuery(luceneQuery, Book.class, Magazine.class, Article.class);
query.setFirstResult(15); // pagination, start from 15th
query.setMaxResults(10); // pagination, return 10 elements
org.apache.lucene.search.Sort sort = new Sort(new SortField("title"));
query.setSort(sort); // sorting
List results = query.list();
// example 2
// if type restricted to a single class, you can customize the fetch for a specific use case
Criteria criteriaQuery = ftSession.createCriteria(Book.class);
criteriaQuery.setFetchMode("authors", FetchMode.JOIN); // preload related data
org.hibernate.search.FullTextQuery query = ftSession.createFullTextQuery(luceneQuery);
query.setCriteriaQuery(criteria);
// example 3
// returning direct data, instead of entities using Lucene search
org.hibernate.search.FullTextQuery query = ftSession.createFullTextQuery(luceneQuery, Book.class);
query.setProjection("id", "summary", "body", "mainAuthor.name");
List<Object[]> results = query.list();
Object[] firstResult = (Object[]) results.get(0);
Integer id = firstResult[0];
String summary = firstResult[1];
String body = firstResult[2];
String authorName = firstResult[3];
Confluence
Marketing Summary
-
Everything in Confluence is searchable — pages, blogs, news items, comments, emails, attachments (Microsoft Word/Excel/PowerPoint documents; PDF files; HTML, XML, source and text files; ZIP files), and people
-
Confluence's 'Did you mean' feature analyses your search term and suggests an alternative spelling to give you more relevant search results
-
Narrow the search down to exactly what you are looking for — search by space, type of space (e.g. exclude all personal spaces), the type of content and/or the date it was last modified
-
Saved searches - can embed live search directly into any page
Usage
Quick Search - find all content (except mail) in all global spaces, display the results in new screen
Advanced Search - location (within a particular space), group by (content type or space), type, date
Search Fields
|
'''Content Type''' |
'''Available Field Names''' |
|
Pages |
handle, type, urlPath, title, spacekey, labelText, modified, created, userpermission, contentBody |
|
News |
(same as pages) |
|
Attachments |
handle, type, urlPath, filename, title, comment, spacekey, modified, created, userpermissin, contentBody |
|
Mails |
handle, type, urlPath, title, spacekey, messageid, inreplyto, recipients, labelText, modified, created, userpermission, contentBody |
|
Personal Info |
handle, type, urlPath, fullName, username, title, labelText, modified, created, userpermission, contentBody |
Syntax
Supports Lucene-style queries for...
|
'''Search Type''' |
'''Example''' |
|
Exact / phrase |
"chalk and cheese" |
|
AND / OR / NOT |
chalk AND cheese NOT butter |
|
Excluded Terms |
cheese -butter |
|
Parenthetical Grouping |
(cheese OR butter) AND chalk |
|
Title / Field |
title:chalk |
|
Wildcard, combined single and multiple |
*c? |
|
Proximity |
"octagon post"~1 |
|
Range |
[CONF20BACK1:adam to ben] |
|
Fuzzy, similar spelling |
octogan~ |
Red Hat Enterprise Virtualization (RHEV)
expression := resultType ':' criteria '[' sortby sortSpec ']' resultType := 'VMS' | 'Host' | 'Template' | 'Event' | 'Cluster' | 'Datacenter' | 'Storage' criteria := [objectType '.'] property operator value operator := '=' | '!=' | '>' | '<' | '>=' | '<=' value := <wildcardString> | <integer> | <enumeration> | <date> sortSpec := sortField 'asc' | sortField 'desc' sortField := <string>
|
'''resultType''' |
'''objectType''' |
'''Properties''' |
|
Datacenter |
VMs, Templates, Clusters |
Name, Status, Cluster, Description, Type, Sortby |
|
Clusters |
Datacenter, VMs, Templates |
Datacenter, Name, description, initialized, Sortby |
|
Hosts |
Clusters, Datacenter, VMs, Templates |
Name, Status, Cluster, datacenter, Hostname, CPU_Usage, Memory, Mem_Usage, committed_mem, Network_Usage, Load, swversion, CPUs, CPU_speed, CPU_type, vds_type, Active_VMS, Migrating_VMS, Sortby |
|
Storage |
Datacenter, VMs, Templates, Events |
Name, Type, size, used, Sortby |
|
Vms |
Clusters, Datacenter, Hosts, Templates, Events |
Name, Status, IP, Uptime, Domain, Hostname, os, Creation_date, CPU_Usage, Mem_Usage, Network_Usage, Memory, Apps, Pool, Loggedinuser, Cluster, tag, sortby |
|
Templates |
Clusters, Datacenter, Hosts, VMs, Events |
Type, Name, Description, Domain, Creationdate, Childcount, CPUs, Mem, os, status, datacenter, cluster, host, Sortby |
|
Events |
Hosts, VMs, Templates |
Type, Severity, Message, Time, usrname, Host, vm, template, Sortby |