Overview
Alerting is all about recording, and providing proactive notifications about, "events" that are happening across your enterprise. An "event" could be resources going down, a particular metric value was collected, resource configuration being changed, operations being executed, or even specific conditions found by parsing log messages.
As information flows into the RHQ system, it passes through the alerts processing engine. Here, the data might be transformed, filtered, or even correlated with data from other parts of the system. Users have full control over what they want to be notified about, and RHQ keeps a full audit trail of any conditions that have triggered alerts to fire.
The alerts subsystem provides a wealth of different options for proactively being notified about potential issues in the system. As a result, it has a lot of different ways you can configure it to derive very specific and customized semantics.
Concepts
There are a few primary concepts that are required parts of alert processing.
Alert Definitions
Each resource in inventory may have zero, one or many alert definitions. An alert definition defines things such as all the conditions that should fire the alert, whether or not any dampening should take place to limit the number of fired alerts, and what notifications to send to whom if an alert is fired.
Alert Conditions
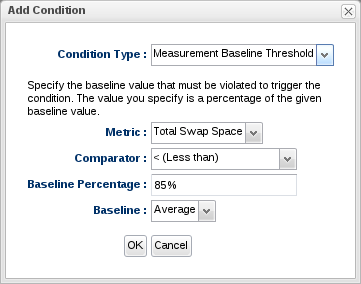
A condition simply describes some event that could fire the alert. For example, for a particular platform, we might want an alert to fire if the platform's total swap space is less than 85% of its average value.
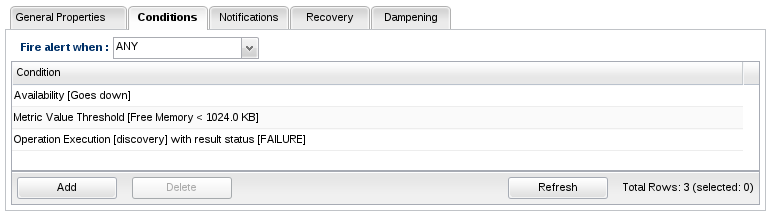
An alert definition can have multiple conditions to support the times when you only want an alert to fire if more than one condition becomes true or when you want an alert to fire if any one of a number of conditions becomes true. There's no limit to the number of conditions you can create for a single alert definition, and you can choose whether all or just one of them need to be met simultaneous in order for this definition to trigger an alert.
Notifications
When an alert definition's condition set is met, an alert is fired. When this occurs, you can optionally have one or more notifications sent. You do this by assigning alert notifications to your alert definition.
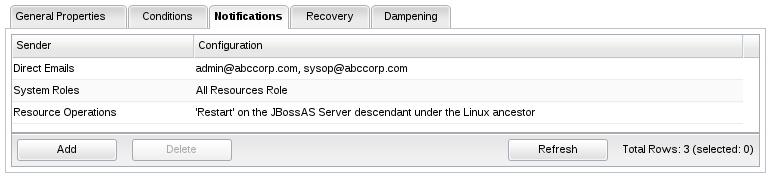
There are several types of notifications that you can assign to your alert definitions:
Direct Email Notificaton
This type of notification can send alert notification emails to any email address(es) as specified in the notification itself.
System Users Notification
This type of notification can send emails to the paritcular RHQ users specified in the notification.
System Roles Notification
This type of notification can send emails to all RHQ users that belong to a particular set of roles specified in the notification.
SNMP Trap Notification
You can send notifications as an SNMP trap.
CLI Scripts
You can have a custom CLI script executed by the server whenever the alert is fired. This can be useful if you plan to integrate RHQ with an external notification system or if you want to make complex interactions with RHQ resources.
Resource Operations
You can have a resource operation invoked by the server whenever the alert is fired (i.e. activate a backup database server when primary goes down).
Dampening
By default, each time the condition set is met an alert will fire. Dampening rules are a flexible way of changing this to suppress some of these firings. So, instead of being alerted each and every time your alert conditions are met, you have the option of suppressing some of these alert firings. In effect, dampening is a form of filtering that occurs before an alert is fired.
Below is a discussion of each of the available dampening options.
No Dampening
The default option is to have no dampening. In other words, every single time the condition set is known to be true, an alert will fire.

Consecutive
This dampens alerts from firing until the condition set is consecutively true for a given number of times.
This form of dampening is good to use when you have a system that spikes a lot. If you know that your CPU will often momentarily hit some high point but then should return to normal processing levels, then you can use this dampening option to ensure that you only get an alert if the CPU remains spiked for 2 or 3 consecutive measurement collections.
Setting the "Occurrences" value for this dampening rule to a high number isn't suggested because you're likely going to want to be notified sooner rather than later if one of your systems is experiencing such sustained problems. You should also keep in mind that this option only needs the condition set to be found false once and it will reset the counter, so using too high a number may effectively prevent alerts from ever being generated.

Last N Evaluations
This dampening rule is very similar to the Consecutive rule, but it's not as restrictive. This option allows for the condition set to be evaluated to false for a few times over a long span of evaluations and will still fire an alert.
This could be useful when alerting on memory usage, for example. If you want to set up an alert definition to check whether your free memory is being released periodically, you might use this dampening rule with Occurrences=5 and Evaluations=10. In this case, RHQ will look back at the last 10 evaluations of the condition set and if at least 5 of them were true, an alert would fire. You might want to set it up this way since that might indicate that your process is having trouble releasing memory back down to acceptable levels and further investigation should be performed.

Time Period
This dampening rule is nearly identical to the Last N Evaluations rule except that it is based on time instead of the number of evaluations. What this means is that an alert will fire if the condition set evaluates to true a certain number of times within a given time period.
A special note when alerting on measurement values is due here. Since metrics are collected in terms of collection intervals, the alert processing engine is thus restricted to the same concept when computing condition sets that deal with measurement values. Let's say you use this dampening rule and set the options to Occurrences=5 and Time Period=30 minutes. If the collection interval for your metric is currently scheduled for 5 minutes then a Time Period=30 minutes effectively becomes 6 collections. However, if you change your collection interval to 10 minutes, then it effectively becomes 3 collections. So if someone changes the collection interval for some metric specified in a condition, he or she may inadvertently and implicitly change how one or more alert definitions are dampened, resulting in possibly too many, too few, or no alerts firing at all.
Therefore, this time-based dampening rule can be confusing because the effects aren't always obvious. Keep this in mind when using this dampening rule in conjunction with measurement-based alert conditions.

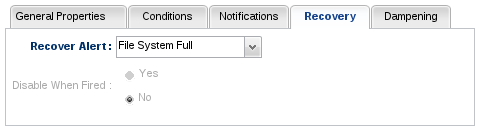
Recovery Alerts
Sometimes it is necessary to have two alert definitions work in tandem to provide a more intelligent dampening scenario. Such is the case when some alert definition's condition set becomes true where that condition set indicates some system state which can not be automatically recovered from. An alert will be fired when such a condition set is true, but you may not want this to keep firing because you know this condition set will remain true until someone intervenes and corrects the problem. In this case, we can have this first alert definition automatically disable itself when it fires once and then have a second alert definition (called a "recovery alert definition") automatically re-enable that first alert definition when the problem conditions clear up and are fixed. Thus, when this recovery alert definition fires, it will automatically re-enable the first alert definition, allowing it to fire again if it detects the error condition again.
An example is the best way to explain this feature.
Suppose an administrator has an alert definition whose condition set detects when a file system becomes full. Call this the "file system full alert definition." Whenever this alert fires, the administrator knows some human intervention will be needed in order to add new disk hardware to get more file system space. In this case, the administrator can have this file system full alert definition automatically disable itself when it fires the first time. Once someone fixes the problem by adding more disk hardware (and thus the file system is no longer full), we can have a second alert definition (the recovery alert definition) fire an alert to indicate this. When this second recovery alert definition fires, it will have been configured to re-enable that first file system full alert definition that disabled itself (as described above).
You can even add alert notifications to your recovery alert definitions in order to notify you when it fires, thus telling you when it re-enables the first alert definition.
Alert History
An alert is a form of rich auditing data which indicates all the conditions of its corresponding alert definition that were met.
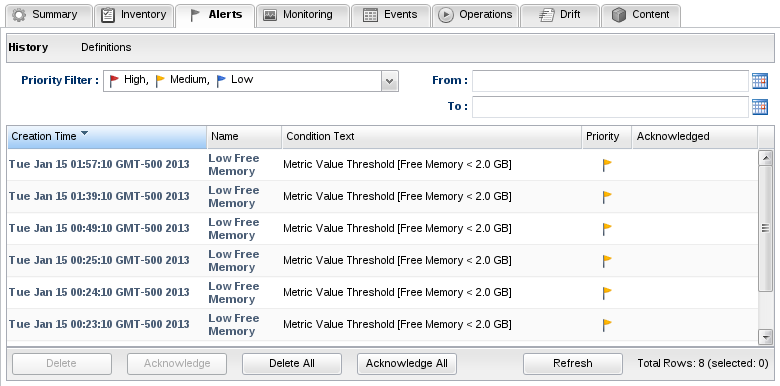
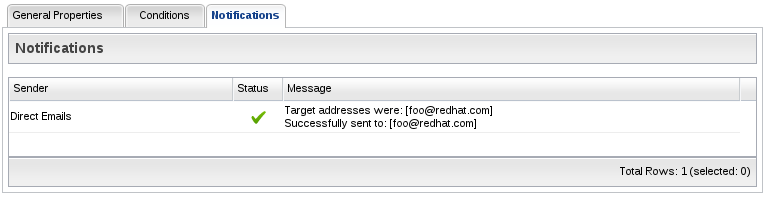
By double-clicking an alert history item, you can find details on that alert. The details of an alert will tell you specifically which conditions on the alert definition were true at the time it fired, and if you're using the notification mechanism, it will also specify which parties were notified when the alert was triggered.
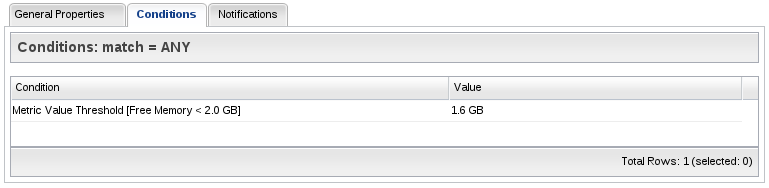
Condition Types
Alerts can fire when many different kinds of events happen in your environment. The conditions you add to your alert definition declare the events you want to look for and alert on. The following describes the different types of conditions that you can add to your alert definitions.
Availability
The Availability Change condition type can alert you when a resource transitions to a DOWN state or to an UP state. It can also be used to alert when a resource transitions away from an UP state (as is the case both when the resource goes down or when you tell RHQ to disable the resource). You can use this condition type to detect when a resource crashes or exits. This condition is also very helpful when defining a recovery alert definition - if you detect that a resource has come back up, you can use that knowledge to re-enable another alert definition.
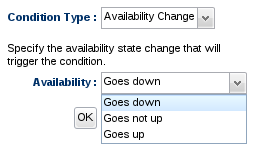
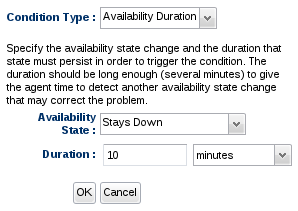
The Availability Change condition type merely alerts on the transition from state to state (that is, for example, it will only alert when a resource goes from being up to being down - but if it stays down, you will not get multiple alerts since it only went through that transition once). This may be what you want (perhaps you only want a single alert to tell you that a resource has gone down). But what if you want periodic alerts to fire to let you know a resource has gone down and has stayed down for a long period of time? This is what the Availability Duration condition type is for. You can specify the state you want to check (for example, you want to see if the resource has stayed in the DOWN state) along with the duration that that state must persist in order to fire the alert. The duration should be long enough (several minutes at least) to give the agent time to detect another availability state change that may correct the problem.
Measurement
There is a rich feature set involving measurement alerting. You are given several options dealing with alerting on incoming measurement data.
First, no matter which measurement condition type you are using, you must select a specific measurement (called a "metric") to operate on from the drop down menu:
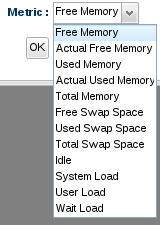
The list of metric names are derived from the type of resource you are looking at. The example you see above is from a Linux platform resource. Other resources will have a different list of metrics because different resources have different metrics that can be collected.
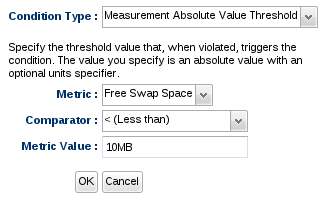
The Measurement Absolute Value Threshold condition type provides a way to look at the most recently collected measurement value and compare it against an absolute value. For example, this condition type will enable you to be alerted when your platform's Free Swap Space goes below 10 MB in size.
Due to the nature of how alert conditions are processed when measurement data comes in from the agent, you cannot have a single alert definition with multiple conditions that use the same metric along with the "ALL" conjunction (that is, the alert definition wants all the conditions for the same metric to be true for the alert to fire). For example, do not have an alert definition that says, "alert if ALL conditions are true: if metric X > 5 and if metric X < 10". Use the Measurement Value Range condition type for this functionality
The Measurement Baseline Threshold provides a more flexible comparison that can change based on your resource's recent behavior. This condition type provides a way to compare the most recently collected measurement value to a percentage of its known baseline. This alert condition option lets you choose whether you want the comparison to be made against the minimum, average, or maximum baseline value currently recorded in the system.

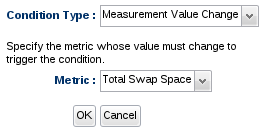
If you simply want to be told when a measurement value changed from its previous value (regardless of its actual value), use the Measurement Value Change condition type.
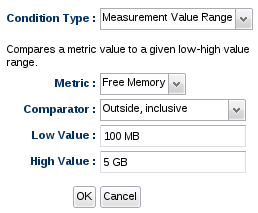
If you wish to check to see if the most recently collected measurement value falls within a specific range, or outside a specific range, use the Measurement Value Range condition type.
Traits
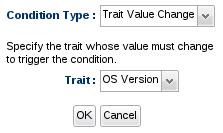
Dynamic measurement data is always numeric and tends to change very frequently. Trait data is another type of measurement data but it typically is not numeric and rarely changes. To detect a trait has changed, use the Trait Value Changed condition type. This will compare the latest value collected for that trait to its last known value.
Calltime
Some resources have a calltime metric that provides things like response time measurements (for example, the amount of time it takes for an HTTP resquest to be processed or the amount of time it takes for an EJB call to complete). There are a couple of ways you can alert on these calltime measurement data.
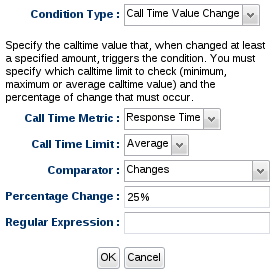
The Call Time Value Change condition type enables you to be alerted when a particular calltime value has changed by at least some specific amount. You must specify which calltime limit to check (minimum, maximum or average) and the percentage of change that must occur.
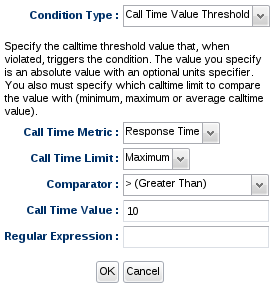
The Call Time Value Threshold condition type allows you to specify an absolute threshold value that, when violated, triggers the condition. The value you specify is an absolute value with an optional units specifier. You also must specify which calltime limit to compare the value with (minimum, maximum or average).
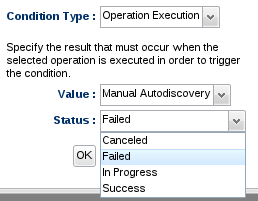
Operation
You can be alerted when an operation is executed on a particular resource using the Operation Execution condition type. This condition can fire an alert based on the status of a given operation. Below is a quick discussion of each operation state:
-
In Progress - Indicates an operation is currently running. All operations move through this state en route to being completed so you can use this to test whether an operation was invoked or not (regardless of its outcome).
-
Success - This indicates an operation completed and no errors have occurred during processing.
-
Failed - This indicates an operation completed but an error occurred during processing.
-
Canceled - This indicates an operation was canceled before completing.
Resource Configuration Change
To be alerted when a resource's configuration changes, use the Resource Configuration Change condition type.
Events (aka Logs)
To be alerted when a specific event message (such as a log message) has been seen by the resource, use the Event Detection condition type.