<sca:service name="Goodbye" promote="GoodbyeBean/Goodbye"> <sca:interface.java interface="com.example.Goodbye"/> <sca:binding.sca sy:clustered="true"/> </sca:service>
Clustering Architecture
There are two fundamental building blocks to the clustering support in SwitchYard:
-
Shared Runtime Registry - a shared, distributed runtime registry which allows individual instances to publish and query service endpoint details.
-
Remote Communication Channels - an internal communication protocol used to allow a service client to invoke a service hosted in a remote instance.
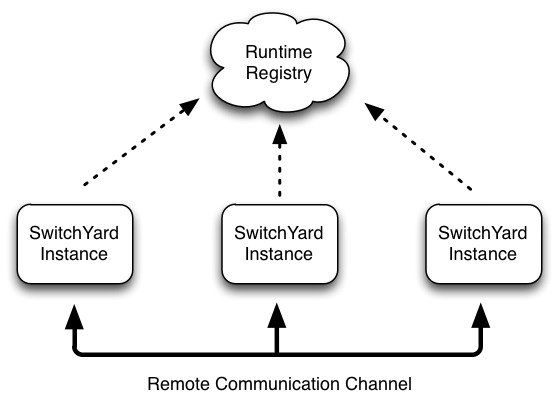
The runtime registry is backed by a replicated Infinispan cache. Each instance in a cluster points to the same replicated cache. When a node joins a cluster, it immediately has access to all remote service endpoints published in the registry. If a node leaves the cluster due to failure or shutdown, all service endpoint registrations are immediately removed for that node. The registry is not persisted, so manually clean-up and maintenance is not required. Note that the shared registry is a runtime registry and not a publication registry, which means the registry's lifecycle and state is tied to the current state of deployed services within a cluster. This is in contrast to a publication registry (e.g. UDDI), where published endpoints are independent from the runtime state of the ESB.
The communications channel is a private intra-cluster protocol used by instances to invoke a remote service. The channel is currently based on HTTP, but this may change in the future and should be considered a transparent detail of the clustering support in SwitchYard.
Configuring Clustering
Clustering support is light on configuration and should work out of the box. The only real requirements are using a shared Infinispan cache for the runtime registry and indicating which services are clustered in your application config (switchyard.xml). By default, SwitchYard uses the default cache in the "cluster" cache container which comes pre-defined in your standalone-ha.xml. Unless you have specific requirements to use a different cache or separate cache configuration, just stick with the default.
Applications take advantage of clustering by explicitly identifying which services should be clustered in the application's descriptor (switchyard.xml). You can control which services in your application will be published in the cluster's runtime registry and which references can be resolved by clustered services. To enable a service to be published in the cluster's runtime registry, promote the service in your application and add a <binding.sca> with clustering enabled to it.
Consuming services in a cluster follows the same configuration approach, but applies to references in your application. To invoke a service in a cluster, promote the reference and add an SCA binding with clustering enabled.
<sca:reference name="Goodbye" multiplicity="0..1" promote="GreetingBean/Goodbye"> <sca:interface.java interface="com.example.Goodbye"/> <sca:binding.sca sy:clustered="true" </sca:reference>
For more information on clustering using <binding.sca>, check out the SCA Binding documentation in the Developer's Guide.
Using Clustering
To create a cluster of SwitchYard instances, start two or more AS 7 instances with a shared Infinispan cache. Out-of-the-box configuration in standalone-ha.xml should be sufficient:
# start instance 1 node1> bin/standalone.sh -c standalone-ha.xml -Djboss.node.name=node1 # start instance 2 node2> bin/standalone.sh -c standalone-ha.xml -Djboss.node.name=node2 -Djboss.socket.binding.port-offset=1000
Once the instances are up, you can deploy applications independently to each instance. A homogeneous cluster would have identical applications deployed on each node. A heterogeneous cluster will have different applications and services deployed on each instance. For testing purposes, it's easiest to deploy a consumer application to one instance and a provider application to another. Thecluster demo quickstart is a great way to try kick the tires on this feature.