So where do we get started, there are so many use cases and so much functionality in a rule engine such as Drools that it becomes beguiling. Have no fear my intrepid adventurer, the complexity is layered and you can ease yourself into with simple use cases.
Stateless session, not utilising inference, forms the simplest use case. A stateless session can be called like a function passing it some data and then receiving some results back. Some common use cases for stateless sessions are, but not limited to:
Validation
Is this person eligible for a mortgage?
Calculation
Compute a mortgage premium.
Routing and Filtering
Filter incoming messages, such as emails, into folders.
Send incoming messages to a destination.
So let's start with a very simple example using a driving license application.
public class Applicant {
private String name;
private int age;
private boolean valid;
// getter and setter methods here
}
Now that we have our data model we can write our first rule. We assume that the application uses rules to refute invalid applications. As this is a simple validation use case we will add a single rule to disqualify any applicant younger than 18.
package com.company.license
rule "Is of valid age"
when
$a : Applicant( age < 18 )
then
$a.setValid( false );
endTo make the engine aware of data, so it can be processed against
the rules, we have to insert the data, much like
with a database. When
the Applicant instance is inserted into the engine it is evaluated
against the constraints of the rules, in this case just two constraints
for one rule. We say two because the type Applicant
is the first object
type constraint, and age < 18 is the second field constraint.
An object type constraint plus its zero or more field constraints is
referred to as a pattern. When an inserted instance satisfies both the
object type constraint and all the field constraints, it is said to be
matched. The $a is a binding variable which permits us to reference
the matched object in the consequence. There its properties can be
updated. The dollar character ('$') is optional, but it helps to
differentiate variable names from field names. The process of
matching patterns against the inserted data is, not surprisingly,
often referred to as pattern matching.
Let's assume that the rules are in the same folder as the classes,
so we can use the classpath resource loader to build our first
KnowledgeBase. A Knowledge Base is what we call our collection of
compiled rules, which are compiled using the KnowledgeBuilder.
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add( ResourceFactory.newClassPathResource( "licenseApplication.drl", getClass() ),
ResourceType.DRL );
if ( kbuilder.hasErrors() ) {
System.err.println( builder.getErrors().toString() );
}
kbase.addKnowledgePackages( kbuilder.getKnowledgePackages() );
The above code snippet looks on the classpath for the
licenseApplication.drl
file, using the method newClassPathResource(). The resource type
is DRL, short for "Drools Rule Language". Once the DRL file has been added
we can check the Knowledge Builder object for any errors. If there are no
errors, we can add the resulting packages to our Knowledge Base.
Now we are ready to build our session and execute against some
data:
StatelessKnowledgeSession ksession = kbase.newStatelessKnowledgeSession();
Applicant applicant = new Applicant( "Mr John Smith", 16 );
assertTrue( applicant.isValid() );
ksession.execute( applicant );
assertFalse( applicant.isValid() );
The preceding code executes the data against the rules. Since the applicant is under the age of 18, the application is marked as invalid.
So far we've only used a single instance, but what if we want to use
more than one? We can execute against any object implementing Iterable, such as
a collection. Let's add another class called Application, which has the
date of the application, and we'll also move the boolean valid field to the
Application class.
public class Applicant {
private String name;
private int age;
// getter and setter methods here
}
public class Application {
private Date dateApplied;
private boolean valid;
// getter and setter methods here
}
We can also add another rule to validate that the application was made within a period of time.
package com.company.license
rule "Is of valid age"
when
Applicant( age < 18 )
$a : Application()
then
$a.setValid( false );
end
rule "Application was made this year"
when
$a : Application( dateApplied > "01-jan-2009" )
then
$a.setValid( false );
end
Unfortunately a Java array does not implement the
Iterable
interface, so we have to use the JDK converter method
Arrays.asList(...). The code
shown below executes against an iterable list, where all collection
elements are inserted before any matched rules are fired.
StatelessKnowledgeSession ksession = kbase.newStatelessKnowledgeSession();
Applicant applicant = new Applicant( "Mr John Smith", 16 );
Application application = new Application();
assertTrue( application() );
ksession.execute( Arrays.asList( new Object[] { application, applicant } ) );
assertFalse( application() );
The two execute methods execute(Object object) and
execute(Iterable objects) are actually convenience methods for the
interface BatchExecutor's method execute(Command command).
A CommandFactory is used to create commands, so that the following is
equivalent to execute(Iterable it):
ksession.execute( CommandFactory.newInsertIterable( new Object[] { application, applicant } ) );
Batch Executor and Command Factory are particularly useful when working with multiple Commands and with output identifiers for obtaining results.
List<Command> cmds = new ArrayList<Command>();
cmds.add( CommandFactory.newInsert( new Person( "Mr John Smith" ), "mrSmith" );
cmds.add( CommandFactory.newInsert( new Person( "Mr John Doe" ), "mrDoe" );
BatchExecutionResults results = ksession.execute( CommandFactory.newBatchExecution( cmds ) );
assertEquals( new Person( "Mr John Smith" ), results.getValue( "mrSmith" ) );
CommandFactory supports many other Commands that can be used in
the BatchExecutor like StartProcess, Query, and
SetGlobal.
Stateful Sessions are longer lived and allow iterative changes over time. Some common use cases for Stateful Sessions are, but not limited to:
Monitoring
Stock market monitoring and analysis for semi-automatic buying.
Diagnostics
Fault finding, medical diagnostics
Logistics
Parcel tracking and delivery provisioning
Compliance
Validation of legality for market trades.
In contrast to a Stateless Session, the dispose()
method must be called
afterwards to ensure there are no memory leaks, as the Knowledge Base
contains references to Stateful Knowledge Sessions when they are created.
StatefulKnowledgeSession also supports the BatchExecutor
interface, like StatelessKnowledgeSession, the only difference
being that the FireAllRules command is not automatically called at the
end for a Stateful Session.
We illustrate the monitoring use case with an example for raising a
fire alarm. Using just four classes, we represent rooms in a house, each of which
has one sprinkler. If a fire starts in a room, we
represent that with a single Fire instance.
public class Room {
private String name
// getter and setter methods here
}
public classs Sprinkler {
private Room room;
private boolean on;
// getter and setter methods here
}
public class Fire {
private Room room;
// getter and setter methods here
}
public class Alarm {
}
In the previous section on Stateless Sessions the concepts of inserting and matching against data was introduced. That example assumed that only a single instance of each object type was ever inserted and thus only used literal constraints. However, a house has many rooms, so rules must express relationships between objects, such as a sprinkler being in a certain room. This is best done by using a binding variable as a constraint in a pattern. This "join" process results in what is called cross products, which are covered in the next section.
When a fire occurs an instance of the Fire class is created, for
that room, and inserted into the session. The rule uses a binding on the
room
field of the Fire object to constrain matching to the sprinkler for that room,
which is currently off. When this rule fires and the consequence is executed
the sprinkler is turned on.
rule "When there is a fire turn on the sprinkler"
when
Fire($room : room)
$sprinkler : Sprinkler( room == $room, on == false )
then
modify( $sprinkler ) { setOn( true ) };
System.out.println( "Turn on the sprinkler for room " + $room.getName() );
endWhereas the Stateless Session uses standard Java syntax to modify
a field, in the above rule we use the modify statement, which acts as a
sort of "with" statement. It may contain a series of comma separated Java
expressions, i.e., calls to setters of the object selected by the modify
statement's control
expression. This modifies the data, and makes the engine aware of those changes
so it can reason over them once more. This process is called inference, and
it's essential for the working of a Stateful Session. Stateless Sessions
typically do not use inference, so the engine does not need to be aware of
changes to data. Inference can also be turned off explicitly by using the
sequential mode.
So far we have rules that tell us when matching data exists, but
what about when it does not exist? How do we determine
that a fire has been extinguished, i.e., that there isn't a Fire
object any more? Previously the constraints have been sentences according
to Propositional Logic,
where the engine is constraining against individual intances. Drools also has
support for First Order Logic that allows you to look at sets of data.
A pattern under the keyword not matches when something does not exist.
The rule given below turns the sprinkler off as soon as the fire in that
room has disappeared.
rule "When the fire is gone turn off the sprinkler"
when
$room : Room( )
$sprinkler : Sprinkler( room == $room, on == true )
not Fire( room == $room )
then
modify( $sprinkler ) { setOn( false ) };
System.out.println( "Turn off the sprinkler for room " + $room.getName() );
endWhile there is one sprinkler per room, there is just a single alarm
for the building. An Alarm object is created when a fire occurs,
but only one Alarm is needed for the entire building, no matter
how many fires occur. Previously not was introduced to match the absence of
a fact; now we use its complement exists which matches for one or more
instances of some category.
rule "Raise the alarm when we have one or more fires"
when
exists Fire()
then
insert( new Alarm() );
System.out.println( "Raise the alarm" );
endLikewise, when there are no fires we want to remove the alarm, so
the not keyword can be used again.
rule "Cancel the alarm when all the fires have gone"
when
not Fire()
$alarm : Alarm()
then
retract( $alarm );
System.out.println( "Cancel the alarm" );
end
Finally there is a general health status message that is printed when the application first starts and after the alarm is removed and all sprinklers have been turned off.
rule "Status output when things are ok"
when
not Alarm()
not Sprinkler( on === true )
then
System.out.println( "Everything is ok" );
endThe above rules should be placed in a single DRL file and saved to
some directory on the classpath and using the file name
fireAlarm.drl,
as in the Stateless Session example. We can then build a Knowledge Base,
as before, just using the new name fireAlarm.drl.
The difference is that
this time we create a Stateful Session from the Knowledge Base, whereas
before we created a Stateless Session.
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add( ResourceFactory.newClassPathResource( "fireAlarm.drl", getClass() ),
ResourceType.DRL );
if ( kbuilder.hasErrors() ) {
System.err.println( builder.getErrors().toString() );
}
kbase.addKnowledgePackages( kbuilder.getKnowledgePackages() );
StatefulKnowledgeSession ksession = kbase.newStatefulKnowledgeSession();
With the session created it is now possible to iteratvely work
with it over time. Four Room objects are created and
inserted, as well as one Sprinkler object for
each room. At this point the engine has done all of its
matching, but no rules have fired yet. Calling ksession.fireAllRules()
allows the matched rules to fire, but without a fire that will
just produce the health message.
String[] names = new String[]{"kitchen", "bedroom", "office", "livingroom"};
Map<String,Room> name2room = new HashMap<String,Room>();
for( String name: names ){
Room room = new Room( name );
name2room.put( name, room );
ksession.insert( room );
Sprinkler sprinkler = new Sprinkler( room );
ksession.insert( sprinkler );
}
ksession.fireAllRules()
> Everything is ok
We now create two fires and insert them; this time a reference is
kept for the returned FactHandle. A Fact Handle is an
internal engine reference to the inserted instance and allows instances to be
retracted or modified at a later point in time. With the fires now in
the engine, once fireAllRules() is called, the alarm is raised and the
respective sprinklers are turned on.
Fire kitchenFire = new Fire( name2room.get( "kitchen" ) );
Fire officeFire = new Fire( name2room.get( "office" ) );
FactHandle kitchenFireHandle = ksession.insert( kitchenFire );
FactHandle officeFireHandle = ksession.insert( officeFire );
ksession.fireAllRules();
> Raise the alarm > Turn on the sprinkler for room kitchen > Turn on the sprinkler for room office
After a while the fires will be put out and the Fire
instances are retracted. This results in the sprinklers being turned off, the alarm
being cancelled, and eventually the health message is printed again.
ksession.retract( kitchenFireHandle );
ksession.retract( officeFireHandle );
ksession.fireAllRules();
> Turn on the sprinkler for room office > Turn on the sprinkler for room kitchen > Cancel the alarm > Everything is ok
Everyone still with me? That wasn't so hard and already I'm hoping you can start to see the value and power of a declarative rule system.
People often confuse methods and rules, and new rule users regular ask, "How do I call a rule?" After the last section, you are now feeling like a rule expert and the answer to that is obvious, but let's summarize the differences nonetheless.
public void helloWorld(Person person) {
if ( person.getName().equals( "Chuck" ) ) {
System.out.println( "Hello Chuck" );
}
}
Methods are called directly.
Specific instances are passed.
One call results in a single execution.
rule "Hello World"
when
Person( name == "Chuck" )
then
System.out.println( "Hello Chuck" );
endRules execute by matching against any data as long it is inserted into the engine.
Rules can never be called directly.
Specific instances cannot be passed to a rule.
Depending on the matches, a rule may fire once or several times, or not at all.
Earlier the term "cross product" was mentioned, which is the result of a join. Imagine for a moment that the data from the fire alarm example were used in combination with the following rule where there ar no field constraints:
rule
when
$room : Room()
$sprinkler : Sprinkler()
then
System.out.println( "room:" + $room.getName() +
" sprinkler:" + $sprinkler.getRoom().getName() );
endIn SQL terms this would be like doing select * from Room,
Sprinkler and every row in the Room table would be joined with
every row in the Sprinkler table resulting in the following output:
room:office sprinker:office room:office sprinkler:kitchen room:office sprinkler:livingroom room:office sprinkler:bedroom room:kitchen sprinkler:office room:kitchen sprinkler:kitchen room:kitchen sprinkler:livingroom room:kitchen sprinkler:bedroom room:livingroom sprinkler:office room:livingroom sprinkler:kitchen room:livingroom sprinkler:livingroom room:livingroom sprinkler:bedroom room:bedroom sprinkler:office room:bedroom sprinkler:kitchen room:bedroom sprinkler:livingroom room:bedroom sprinkler:bedroom
These cross products can obviously become huge, and they may very well contain spurious data. The size of cross products is often the source of performance problems for new rule authors. From this it can be seen that it's always desirable to constrain the cross products, which is done with the variable constraint.
rule
when
$room : Room()
$sprinkler : Sprinkler( room == $room )
then
System.out.println( "room:" + $room.getName() +
" sprinkler:" + $sprinkler.getRoom().getName() );
endThis results in just four rows of data, with the correct Sprinkler
for each Room. In SQL (actually HQL) the corresponding query would be
select * from Room, Sprinkler where Room ==
Sprinkler.room.
room:office sprinkler:office room:kitchen sprinkler:kitchen room:livingroom sprinkler:livingroom room:bedroom sprinkler:bedroom
So far the data and the matching process has been simple and small. To mix things up a bit a new example will be explored that handles cashflow calculations over date periods. The state of the engine will be illustratively shown at key stages to help get a better understanding of what is actually going on under the hood. Three classes will be used, as shown below.
public class CashFlow {
private Date date;
private double amount;
private int type;
long accountNo;
// getter and setter methods here
}
public class Account {
private long accountNo;
private double balance;
// getter and setter methods here
}
public AccountPeriod {
private Date start;
private Date end;
// getter and setter methods here
}
By now you already know how to create Knowledge Bases and how to
instantiate facts to populate the StatefulKnowledgeSession,
so tables will be used to show the state of the inserted data, as it makes
things clearer for illustration purposes. The tables below show that a
single fact was inserted for the Account. Also inserted are a
series of debits and credits as CashFlow objects for that
account, extending over two quarters.
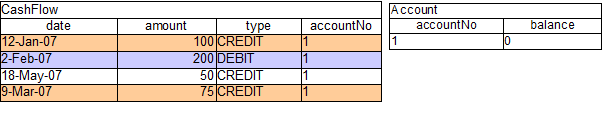
Two rules can be used to determine the debit and credit for that quarter and update the Account balance. The two rules below constrain the cashflows for an account for a given time period. Notice the "&&" which use short cut syntax to avoid repeating the field name twice.
rule "increase balance for credits"
when
ap : AccountPeriod()
acc : Account( $accountNo : accountNo )
CashFlow( type == CREDIT,
accountNo == $accountNo,
date >= ap.start && <= ap.end,
$amount : amount )
then
acc.balance += $amount;
end |
rule "decrease balance for debits"
when
ap : AccountPeriod()
acc : Account( $accountNo : accountNo )
CashFlow( type == DEBIT,
accountNo == $accountNo,
date >= ap.start && <= ap.end,
$amount : amount )
then
acc.balance -= $amount;
end |
If the AccountPeriod is set to the first quarter we
constrain the rule "increase balance for credits" to fire on two rows of
data and "decrease balance for debits" to act on one row of data.

The two cashflow tables above represent the matched data for the two
rules. The data is matched during the insertion stage and, as you
discovered in the previous chapter, does not fire straight away, but only
after fireAllRules() is called. Meanwhile, the rule plus its
matched data is placed on the Agenda and referred to as an Activation. The
Agenda is a table of Activations that are able to fire and have their
consequences executed, as soon as fireAllRules() is called. Activations on
the Agenda are executed in turn. Notice that the order of execution so far
is considered arbitrary.

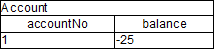
After all of the above activations are fired, the account has a balance of -25.
If the AccountPeriod is updated to the second quarter,
we have just a single matched row of data, and thus just a single
Activation on the Agenda.
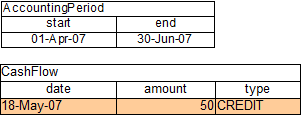
The firing of that Activation results in a balance of 25.

What if you don't want the order of Activation execution to be arbitrary? When there is one or more Activations on the Agenda they are said to be in conflict, and a conflict resolver strategy is used to determine the order of execution. At the simplest level the default strategy uses salience to determine rule priority. Each rule has a default value of 0, the higher the value the higher the priority. To illustrate this we add a rule to print the account balance, where we want this rule to be executed after all the debits and credits have been applied for all accounts. We achieve this by assigning a negative salience to this rule so that it fires after all rules with the default salience 0.
rule "Print balance for AccountPeriod"
salience -50
when
ap : AccountPeriod()
acc : Account()
then
System.out.println( acc.accountNo + " : " + acc.balance );
end
|
The table below depicts the resulting Agenda. The three debit and credit rules are shown to be in arbitrary order, while the print rule is ranked last, to execute afterwards.

Earlier we showed how rules would equate to SQL, which can often help people with an SQL background to understand rules. The two rules above can be represented with two views and a trigger for each view, as below:
select * from Account acc,
Cashflow cf,
AccountPeriod ap
where acc.accountNo == cf.accountNo and
cf.type == CREDIT and
cf.date >= ap.start and
cf.date <= ap.end
|
select * from Account acc,
Cashflow cf,
AccountPeriod ap
where acc.accountNo == cf.accountNo and
cf.type == DEBIT and
cf.date >= ap.start and
cf.date <= ap.end
|
trigger : acc.balance += cf.amount |
trigger : acc.balance -= cf.amount |
Drools also features ruleflow-group attributes which allows workflow diagrams to declaratively specify when rules are allowed to fire. The screenshot below is taken from Eclipse using the Drools plugin. It has two ruleflow-group nodes which ensures that the calculation rules are executed before the reporting rules.
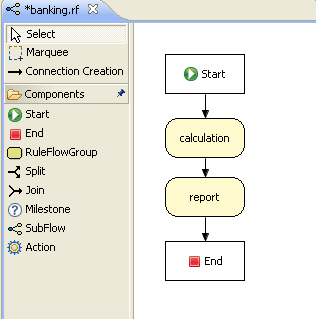
The use of the ruleflow-group attribute in a rule is shown below.
rule "increase balance for credits"
ruleflow-group "calculation"
when
ap : AccountPeriod()
acc : Account( $accountNo : accountNo )
CashFlow( type == CREDIT,
accountNo == $accountNo,
date >= ap.start && <= ap.end,
$amount : amount )
then
acc.balance += $amount;
end
|
rule "Print balance for AccountPeriod"
ruleflow-group "report"
when
ap : AccountPeriod()
acc : Account()
then
System.out.println( acc.accountNo +
" : " + acc.balance );
end
|
Inference has a bad names these days, as something not relevant to business use cases and just too complicated to be useful. It is true that contrived and complicated examples occur with inference, but that should not detract from the fact that simple and useful ones exist too. But more than this, correct use of inference can crate more agile and less error prone businesses with easier to maintain software.
So what is inference? Something is inferred when we gain knowledge of something from using previous knowledge. For example given a Person fact with an age field and a rule that provides age policy control, we can infer whether a Person is an adult or a child and act on this.
rule "Infer Adult" when $p : Person( age >= 18 ) then insert( new IsAdult( $p ) ) end
So in the above every Person who is 18 or over will have an instance of IsAdult inserted for them. This fact is special in that it is known as a relation. We can use this inferred relation in any rule:
$p : Person() IsAdult( person == $p )
So now we know what inference is, and have a basic example, how does this facilitate good rule design and maintenance?
Let's take a government department that are responsible for issuing ID cards when children become adults, hence forth referred to as ID department. They might have a decision table that includes logic like this, which says when an adult living in london is 18 or over, issue the card:
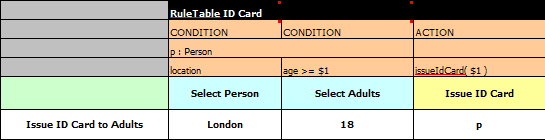
However the ID department does not set the policy on who an adult is. That's done at a central government level. If the central government where to change that age to 21 there is a change management process. Someone has to liaise with the ID department and make sure their systems are updated, in time for the law going live.
This change management process and communication between departments is not ideal for an agile environment and change become costly and error prone. Also the card department is managing more information than it needs to be aware of with its "monolothic" approach to rules management which is "leaking" information better placed else where. By this I mean that it doesn't care what explicit "age >= 18" information determines whether someone is an adult, only that they are an adult.
Instead what if we were to split (de-couple) the authoring responsibility, so the central government maintains its rules and the ID department maintains its.
So its the central governments job to determine who is an adult and if they change the law they just update their central repository with the new rules, which others use:
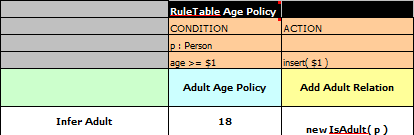
The IsAdult fact, as discussed previously, is inferred from the policy rules. It encapsulates the seemingly arbitrary piece of logic "age >= 18" and provides semantic abstractions for it's meaning. Now if anyone uses the above rules, they no longer need to be aware of explicit information that determines whether someone is an adult or not. They can just use the inferred fact:

While the example is very minimal and trivial it illustrates some important points. We started with a monolithic and leaky approach to our knowledge engineering. We create a single decision table that had all possible information in it that leaks information from central government that the ID department did not care about and did not want to manage.
We first de-coupled the knowledge process so each department was responsible for only what it needed to know. We then encapsulated this leaky knowledge using an inferred fact IsAdult. The use of the term IsAdult also gave a semantic abstraction to the previously arbitrary logic "age >= 18".
So a general rule or thumb when doing your knowledge engineering is:
Bad
Monolithic
Leaky
Good
De-couple knowledge responsibilities
Encapsulate knowledge
Provide semantic abstractions for those encapsulations
The previous example was issuing ID cards to over 18s, in this example we now issue bus passes, either a child or adult pass.
rule "Issue Child Bus Pass" when $p : Person( age < 16 ) then insert(new ChildBusPass( $p ) ); end rule "Issue Adult Bus Pass" when $p : Person( age >= 16 ) then insert(new AdultBusPass( $p ) ); end
As before the above example is considered monolithic, leaky and providing poor separation of concerns.
As before we can provide a more robust application with a separation of concerns using inference. Notice this time we don't just insert the inferred object, we use "logicalInsert":
rule "Infer Child" when
$p : Person( age < 16 )
then
logicalInsert( new IsChild( $p ) )
end
rule "Infer Adult" when
$p : Person( age >= 16 )
then
logicalInsert( new IsAdult( $p ) )
endA "logicalInsert" is part of the Drools Truth Maintenance System (TMS). Here the fact is logically inserted, this fact is dependant on the truth of the "when" clause. It means that when the rule becomes false the fact is automatically retracted. This works particularly well as the two rules are mutually exclusive. So in the above rules if the person is under 16 it inserts an IsChild fact, once the person is 16 or over the IsChild fact is automatically retracted and the IsAdult fact inserted.
We can now bring back in the code to issue the passes, these two can also be logically inserted, as the TMS supports chaining of logical insertions for a cascading set of retracts.
rule "Issue Child Bus Pass" when
$p : Person( )
IsChild( person =$p )
then
logicalInsert(new ChildBusPass( $p ) );
end
rule "Issue Adult Bus Pass" when
$p : Person( age >= 16 )
IsAdult( person =$p )
then
logicalInsert(new AdultBusPass( $p ) );
endNow when the person changes from being 15 to 16, not only is the IsChild fact automatically retracted, so is the person's ChildBusPass fact. For bonus points we can combine this with the 'not' conditional element to handle notifications, in this situation a request for the returning of the pass. So when the TMS automatically retracts the ChildBusPass object, this rule triggers and sends a request to the person:
rule "Return ChildBusPass Request "when
$p : Person( )
not( ChildBusPass( person == $p ) )
then
requestChildBusPass( $p );
endSo far, the programmatic API has been used to build a Knowledge
Base. Quite often it's more desirable to do this via configuration. To
facilitate this, Drools supports the "Changeset" feature. The file
changeset.xml contains a list of resources, and it
may also point recursively to another changeset XML file. Currently there is
no XML schema for the changeset XML, but we hope to add one soon.
A few examples will be shown to give you the gist of things. A resource
approach is employed that uses a prefix to indicate the protocol. All the
protocols provided by java.net.URL, such as "file" and "http",
are supported, as well as an additional "classpath".
Currently the type attribute must always be specified for a resource, as
it is not inferred from the file name extension. Here is a simple example
that points to a http location for some rules.
<change-set xmlns='http://drools.org/drools-5.0/change-set'
xmlns:xs='http://www.w3.org/2001/XMLSchema-instance'
xs:schemaLocation='http://drools.org/drools-5.0/change-set http://anonsvn.jboss.org/repos/labs/labs/jbossrules/trunk/drools-api/src/main/resources/change-set-1.0.0.xsd' >
<add>
<resource source='http:org/domain/myrules.drl' type='DRL' />
</add>
</change-set>
To use the above XML, the code is almost identical as before, except
we change the resource type to CHANGE_SET.
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add( ResourceFactory.newClasspathResource( "myChangeSet.xml", getClass() ),
ResourceType.CHANGE_SET );
if ( kbuilder.hasErrors() ) {
System.err.println( builder.getErrors().toString() );
}
Changesets can include any number of resources, and they even support additional configuration information, which currently is only needed for decision tables. The example below is expanded to load the rules from a http URL location, and an Excel decision table from the classpath.
<change-set xmlns='http://drools.org/drools-5.0/change-set'
xmlns:xs='http://www.w3.org/2001/XMLSchema-instance'
xs:schemaLocation='http://drools.org/drools-5.0/change-set.xsd http://anonsvn.jboss.org/repos/labs/labs/jbossrules/trunk/drools-api/src/main/resources/change-set-1.0.0.xsd' >
<add>
<resource source='http:org/domain/myrules.drl' type='DRL' />
<resource source='classpath:data/IntegrationExampleTest.xls' type="DTABLE">
<decisiontable-conf input-type="XLS" worksheet-name="Tables_2" />
</resource>
</add>
</change-set>
It is also possible to specify a directory, to add the contents of that directory. It is expected that all the files are of the specified type, since type is not yet inferred from the file name extensions.
<change-set xmlns='http://drools.org/drools-5.0/change-set'
xmlns:xs='http://www.w3.org/2001/XMLSchema-instance'
xs:schemaLocation='http://drools.org/drools-5.0/change-set.xsd http://anonsvn.jboss.org/repos/labs/labs/jbossrules/trunk/drools-api/src/main/resources/change-set-1.0.0.xsd' >
<add>
<resource source='file://myfolder/' type='DRL' />
</add>
</change-set>
The Knowlege Agent provides automatic loading, caching and re-loading of resources and is configured from a properties files. The Knowledge Agent can update or rebuild this Knowlege Base as the resources it uses are changed. The strategy for this is determined by the configuration given to the factory, but it is typically pull-based using regular polling. We hope to add push-based updates and rebuilds in future versions.
KnowledgeAgent kagent = KnowledgeAgentFactory.newKnowledgeAgent( "MyAgent" );
kagent.applyChangeSet( ResourceFactory.newUrlResource( url ) );
KnowledgeBase kbase = kagent.getKnowledgeBase();
A KnowledgeAgent object will continuously scan all the
added resources, using a default polling interval of 60 seconds and, when
some last modification date is updated, it will applied the changes into the
cached Knowledge Base using the new resources. Note that the previous
KnowledgeBase reference will still exist and you'll have to
call getKnowledgeBase() to access the newly built
KnowledgeBase. If a directory is specified as part of the
change set, the entire contents of that directory will be scanned for
changes. The way modifications are applied depends on
drools.agent.newInstance property present in the
KnowledgeAgentConfiguration object passed to the agent.
For polling to occur, the polling and notifier services must be started:
ResourceFactory.getResourceChangeNotifierService().start();
ResourceFactory.getResourceChangeScannerService().start();
Because Knowledge Agent could scan and process remote resources, it could ends up failing when compiling or executing rules, queries, functions, etc. that use classes outside the agent's classloader. If this is your case, you could take 2 approach: use a custom classloader for agent's kbuilder or force the agent to use the same classloader that its kbase has.
Knowledge Agent uses KnowledgeBuilder internally in order to compile managed resources. If you need to pass custom configuration to these compilers you could pass a KnowledgeBuilderConfiguration object to KnowledgeAgentFactory.newKnowledgeAgent(). This object will be used in every builder the agent creates. Using a KnowledgeBuilderConfiguration you can specify a custom classloader.
Most of the times, the classloader you wan't to use in the compilation process of remote resources is the same needed in the agent's kbase, so the rules could be executed. If you want to use this approach, you will need to setup the desired ClassLoader to the agen't kbase and use the "drools.agent.useKBaseClassLoaderForCompiling" property of KnowledgeAgentConfiguration object.
This approach lets you modify agent's kbuilder classloader in runtime by modifying the classloader the agent's kbase uses. This will serve also when not using incremental change set processing (see the section bellow). When the kbase is recreated its configuration is reused, so the classloader is maintained.
KnowledgeBaseConfiguration kbaseConfig =
KnowledgeBaseFactory.newKnowledgeBaseConfiguration(null, customClassLoader);
KnowledgeBase kbase =
KnowledgeBaseFactory.newKnowledgeBase(kbaseConfig); //kbase with custom classloader
KnowledgeAgentConfiguration aconf =
KnowledgeAgentFactory.newKnowledgeAgentConfiguration();
aconf.setProperty("drools.agent.newInstance", "false"); //incremental change set processing enabled
aconf.setProperty("drools.agent.useKBaseClassLoaderForCompiling", "true");
KnowledgeAgent kagent = KnowledgeAgentFactory.newKnowledgeAgent(
"test agent", kbase, aconf);
Knowledge Agent can process change sets in two different ways: recreating the knowledge base every time a new change set is processed or applying the change set in the cached knowledge base without destroying it. This behavior is controlled by the "newInstance" property of the KnowledgeAgentConfiguration object passed to the Agent's constructor.
When "newInstace" is set to true (the default value), the agent will destroy the cached Knowledge Base it contains and populate a new one containing the change set modifications. When "newInstance" is set to "false" change sets are applied directly to the cached Knowledge Base. The rule that were not modified in the change sets' resources are not replaced in the Knowledge Base, the modified or deleted rules are modified or deleted from the cached Knowledge Base. Functions, Queries and Definition Types are always replaced in the cached Knowledge Base whether they are modified or not.
The following code snippet creates a new Knowledge Agent with its "newInstace" property set to false
KnowledgeAgentConfiguration aconf = KnowledgeAgentFactory.newKnowledgeAgentConfiguration();
aconf.setProperty("drools.agent.newInstance", "false");
KnowledgeAgent kagent = KnowledgeAgentFactory.newKnowledgeAgent("test agent", null, aconf);
A note on remote HTTP Url Resources: if your knowledge agent is "pulling" resources from a http(s) URL, then you might rightly be concerned if that resource (remote web server) suddenly disappears. To survive a restart when a resource is no longer available remotely (eg the remote server is being restarted) then you can set a System Property: drools.resource.urlcache to a directory that has write permissions for the application: the Knowledge Agent will cache copies of the remote resources in that local directory.
For example, using the java command line: -Ddrools.resource.urlcache=/users/someone/KnowledgeCache - will keep local copies of the resources (rules, packages etc) in that directory, for the agent to use should it be restarted (when a remote resource becomes available, and is updated, it will automatically update the local cache copy).