Drools has a "native" rule language.
This format is very light in terms of punctuation, and supports
natural and domain specific languages via "expanders" that allow the
language to morph to your problem domain. This chapter is mostly concerted
with this native rule format. The diagrams used to present the syntax are
known as "railroad" diagrams, and they are basically flow charts for the
language terms. The
technically very keen may also refer to DRL.g which is
the Antlr3
grammar for the rule language. If you use the Rule Workbench, a lot of the
rule structure is done for you with content assistance, for example, type
"ru" and press ctrl+space, and it will build the rule structure for
you.
A rule file is typically a file with a .drl extension. In a DRL file you can have multiple rules, queries and functions, as well as some resource declarations like imports, globals and attributes that are assigned and used by your rules and queries. However, you are also able to spread your rules across multiple rule files (in that case, the extension .rule is suggested, but not required) - spreading rules across files can help with managing large numbers of rules. A DRL file is simply a text file.
The overall structure of a rule file is:
The order in which the elements are declared is not important, except for the package name that, if declared, must be the first element in the rules file. All elements are optional, so you will use only those you need. We will discuss each of them in the following sections.
For the inpatients, just as an early view, a rule has the following rough structure:
rule"name"attributeswhenLHSthenRHSend
It's really that simple. Mostly punctuation is not needed, even the double quotes for "name" are optional, as are newlines. Attributes are simple (always optional) hints to how the rule should behave. LHS is the conditional parts of the rule, which follows a certain syntax which is covered below. RHS is basically a block that allows dialect specific semantic code to be executed.
It is important to note that white space is not important, except in the case of domain specific languages, where lines are processed one by one and spaces may be significant to the domain language.
Note
(updated to Drools 5.0)
Drools 5 introduces the concept of hard and soft keywords.
Hard keywords are reserved, you cannot use any hard keyword when naming your domain objects, properties, methods, functions and other elements that are used in the rule text.
Here is the list of hard keywords that must be avoided as identifiers when writing rules:
truefalseaccumulatecollectfromnulloverthenwhen
Soft keywords are just recognized in their context, enabling you to use these words in any other place you wish. Here is a list of the soft keywords:
lock-on-activedate-effectivedate-expiresno-loopauto-focusactivation-groupagenda-groupruleflow-groupentry-pointdurationpackageimportdialectsalienceenabledattributesruleextendtemplatequerydeclarefunctionglobalevalnotinorandexistsforallactionreverseresultendinit
Of course, you can have these (hard and soft) words as part of a method name in camel case, like notSomething() or accumulateSomething() - there are no issues with that scenario.
Another improvement of the DRL language is the ability to escape hard keywords on rule text. This feature enables you to use your existing domain objects without worrying about keyword collision. To escape a word, simply enclose it in grave accents, like this:
Holiday( `when` == "july" )
The escape should be used everywehere in rule text, except within code expressions in the LHS or RHS code block. Here are examples of proper usage:
rule "validate holiday by eval"
dialect "mvel"
when
h1 : Holiday( )
eval( h1.when == "july" )
then
System.out.println(h1.name + ":" + h1.when);
end
rule "validate holiday"
dialect "mvel"
when
h1 : Holiday( `when` == "july" )
then
System.out.println(h1.name + ":" + h1.when);
end
Comments are sections of text that are ignored by the rule engine. They are stripped out when they are encountered, except inside semantic code blocks, like the RHS of a rule.
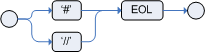
To create single line comments, you can use either '#' or '//'. The parser will ignore anything in the line after the comment symbol. Example:
rule "Testing Comments"
when
# this is a single line comment
// this is also a single line comment
eval( true ) # this is a comment in the same line of a pattern
then
// this is a comment inside a semantic code block
# this is another comment in a semantic code block
end

Multi-line comments are used to comment blocks of text, both in and outside semantic code blocks. Example:
rule "Test Multi-line Comments"
when
/* this is a multi-line comment
in the left hand side of a rule */
eval( true )
then
/* and this is a multi-line comment
in the right hand side of a rule */
end Note
(updated to Drools 5.0)
Drools 5 introduces standardized error messages. This standardization aims to help users to find and resolve problems in a easier and faster way. In this section you will learn how to identify and interpret those error messages, and you will also receive some tips on how to solve the problems associated with them.
The standardization includes the error message format and to better explain this format, let's use the following example:

1st Block: This area identifies the error code.
2nd Block: Line and column information.
3rd Block: Some text describing the problem.
4th Block: This is the first context. Usually indicates the rule, function, template or query where the error occurred. This block is not mandatory.
5th Block: Identifies the pattern where the error occurred. This block is not mandatory.
Indicates the most common errors, where the parser came to a decision point but couldn't identify an alternative. Here are some examples:
The above example generates this message:
[ERR 101] Line 4:4 no viable alternative at input 'exits' in rule one
At first glance this seems to be valid syntax, but it is not (exits != exists). Let's take a look at next example:
Example 5.3.
1: package org.drools;
2: rule
3: when
4: Object()
5: then
6: System.out.println("A RHS");
7: end
Now the above code generates this message:
[ERR 101] Line 3:2 no viable alternative at input 'WHEN'
This message means that the parser encountered the token WHEN, actually a hard keyword, but it's in the wrong place since the the rule name is missing.
The error "no viable alternative" also occurs when you make a simple lexical mistake. Here is a sample of a lexical problem:
The above code misses to close the quotes and because of this the parser generates this error message:
[ERR 101] Line 0:-1 no viable alternative at input '<eof>' in rule simple_rule in pattern Student
Note
Usually the Line and Column information are accurate, but in some cases (like unclosed quotes), the parser generates a 0:-1 position. In this case you should check whether you didn't forget to close quotes, apostrophes or parentheses.
This error indicates that the parser was looking for a particular symbol that it didn’t find at the current input position. Here are some samples:
The above example generates this message:
[ERR 102] Line 0:-1 mismatched input '<eof>' expecting ')' in rule simple_rule in pattern Bar
To fix this problem, it is necessary to complete the rule statement.
Note
Usually when you get a 0:-1 position, it means that parser reached the end of source.
The following code generates more than one error message:
Example 5.6.
1: package org.drools;
2:
3: rule "Avoid NPE on wrong syntax"
4: when
5: not( Cheese( ( type == "stilton", price == 10 ) || ( type == "brie", price == 15 ) ) from $cheeseList )
6: then
7: System.out.println("OK");
8: end
These are the errors associated with this source:
[ERR 102] Line 5:36 mismatched input ',' expecting ')' in rule "Avoid NPE on wrong syntax" in pattern Cheese
[ERR 101] Line 5:57 no viable alternative at input 'type' in rule "Avoid NPE on wrong syntax"
[ERR 102] Line 5:106 mismatched input ')' expecting 'then' in rule "Avoid NPE on wrong syntax"
Note that the second problem is related to the first. To fix it, just replace the commas (',') by AND operator ('&&').
Note
In some situations you can get more than one error message. Try to fix one by one, starting at the first one. Some error messages are generated merely as consequences of other errors.
A validating semantic predicate evaluated to false. Usually these semantic predicates are used to identify soft keywords. This sample shows exactly this situation:
Example 5.7.
1: package nesting;
2: dialect "mvel"
3:
4: import org.drools.Person
5: import org.drools.Address
6:
7: fdsfdsfds
8:
9: rule "test something"
10: when
11: p: Person( name=="Michael" )
12: then
13: p.name = "other";
14: System.out.println(p.name);
15: end
With this sample, we get this error message:
[ERR 103] Line 7:0 rule 'rule_key' failed predicate: {(validateIdentifierKey(DroolsSoftKeywords.RULE))}? in rule
The fdsfdsfds text is invalid and
the parser couldn’t identify it as the soft keyword rule.
Note
This error is very similar to 102: Mismatched input, but usually involves soft keywords.
This error is associated with the eval clause, where its
expression may not be terminated with a semicolon. Check this
example:
Due to the trailing semicolon within eval, we get this error message:
[ERR 104] Line 3:4 trailing semi-colon not allowed in rule simple_rule
This problem is simple to fix: just remove the semi-colon.
The recognizer came to a subrule in the grammar that must match an alternative at least once, but the subrule did not match anything. Simply put: the parser has entered a branch from where there is no way out. This example illustrates it:
This is the message associated to the above sample:
[ERR 105] Line 2:2 required (...)+ loop did not match anything at input 'aa' in template test_error
To fix this problem it is necessary to remove the numeric value as it is neither a valid data type which might begin a new template slot nor a possible start for any other rule file construct.
A package is a collection of rules and other related constructs, such as imports and globals. The package members are typically related to each other - perhaps HR rules, for instance. A package represents a namespace, which ideally is kept unique for a given grouping of rules. The package name itself is the namespace, and is not related to files or folders in any way.
It is possible to assemble rules from multiple rule sources, and have one top level package configuration that all the rules are kept under (when the rules are assembled). Although, it is not possible to merge into the same package resources declared under different names. A single Rulebase may, however, contain multiple packages built on it. A common structure is to have all the rules for a package in the same file as the package declaration (so that is it entirely self-contained).
The following railroad diagram shows all the components that may make
up a package. Note that a package must have a namespace and be declared
using standard Java conventions for package names; i.e., no spaces, unlike
rule names which allow spaces. In terms of the order of elements, they can
appear in any order in the rule file, with the exception of the package
statement, which must be at the top of the file. In all cases, the semicolons are
optional.
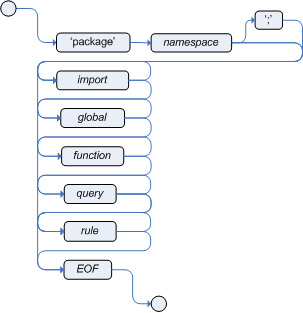
Notice that any rule atttribute (as described the section Rule Attributes) may also be written at package level, superseding the attribute's default value. The modified default may still be replaced by an attribute setting within a rule.

Import statements work like import statements in Java. You need to
specify the fully qualified paths and type names for any objects you want
to use in the rules. Drools automatically imports classes from the
Java package of the same name, and also from the package
java.lang.

With global you define global variables. They are used to make
application objects available to the rules. Typically, they are used
to provide data or services that the rules use, especially application
services used in rule consequences, and to return data from the rules,
like logs or values added in rule consequences, or for the rules to
interact with the application, doing callbacks. Globals are not
inserted into the Working Memory, and therefore a global should never be
used to establish conditions in rules except when it has a
constant immutable value. The engine cannot be notified about value
changes of globals and does not track their changes. Incorrect use
of globals in constraints may yield surprising results - surprising
in a bad way.
If multiple packages declare globals with the same identifier they must be of the same type and all of them will reference the same global value.
In order to use globals you must:
Declare your global variable in your rules file and use it in rules. Example:
global java.util.List myGlobalList; rule "Using a global" when eval( true ) then myGlobalList.add( "Hello World" ); endSet the global value on your working memory. It is a best practice to set all global values before asserting any fact to the working memory. Example:
List list = new ArrayList();
WorkingMemory wm = rulebase.newStatefulSession();
wm.setGlobal( "myGlobalList", list );
Note that these are just named instances of objects that you pass in
from your application to the working memory. This means you can pass in
any object you want: you could pass in a service locator, or perhaps a
service itself. With the new from element it is now common to pass a
Hibernate session as a global, to allow from to pull data from a named
Hibernate query.
One example may be an instance of a Email service. In your integration code that is calling the rule engine, you obtain your emailService object, and then set it in the working memory. In the DRL, you declare that you have a global of type EmailService, and give it the name "email". Then in your rule consequences, you can use things like email.sendSMS(number, message).
Globals are not designed to share data between rules and they should never be used for that purpose. Rules always reason and react to the working memory state, so if you want to pass data from rule to rule, assert the data as facts into the working memory.
It is strongly discouraged to set or change a global value from inside your rules. We recommend to you always set the value from your application using the working memory interface.
Functions are a way to put semantic code in your rule source file, as
opposed to in normal Java classes. They can't do anything more than what you
can do with helper classes. (In fact, the compiler generates the helper class
for you behind the scenes.) The main advantage of using functions in a rule
is that you can keep the logic all in one place, and you can change the
functions as needed (which can be a good or a bad thing). Functions are most
useful for invoking actions on the consequence (then) part of a rule,
especially if that particular action is used over and over again, perhaps
with only differing parameters for each rule.
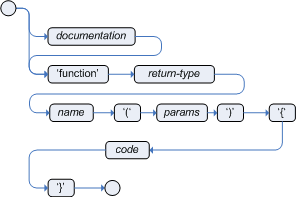
A typical function declaration looks like:
function String hello(String name) {
return "Hello "+name+"!";
}
Note that the function keyword is used, even though its not really
part of Java. Parameters to the function are defined as for a method, and
you don't have to have parameters if they are not needed. The return type
is defined just like in a regular method.
Alternatively, you could use a static method in a helper class,
e.g., Foo.hello(). Drools supports the use of
function imports, so all you would need to do is:
import function my.package.Foo.hello
Irrespective of the way the function is defined or imported, you use a function by calling it by its name, in the consequence or inside a semantic code block. Example:
rule "using a static function"
when
eval( true )
then
System.out.println( hello( "Bob" ) );
end
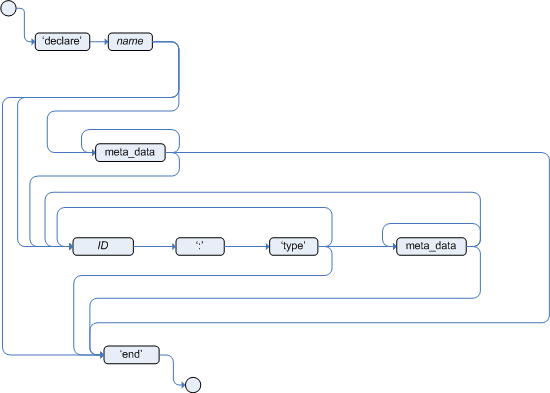
Type declarations have two main goals in the rules engine: to allow the declaration of new types, and to allow the declaration of metadata for types.
Declaring new types: Drools works out of the box with plain Java objects as facts. Sometimes, however, users may want to define the model directly to the rules engine, without worrying about creating models in a lower level language like Java. At other times, there is a domain model already built, but eventually the user wants or needs to complement this model with additional entities that are used mainly during the reasoning process.
Declaring metadata: facts may have meta information associated to them. Examples of meta information include any kind of data that is not represented by the fact attributes and is consistent among all instances of that fact type. This meta information may be queried at runtime by the engine and used in the reasoning process.
To declare a new type, all you need to do is use the keyword
declare, followed by the list of fields, and the keyword
end.
Example 5.10. Declaring a new fact type: Address
declare Address number : int streetName : String city : String end
The previous example declares a new fact type called
Address. This fact type will have three attributes:
number, streetName and city.
Each attribute has a type that can be any valid
Java type, including any other class created by the user or even other
fact types previously declared.
For instance, we may want to declare another fact type
Person:
Example 5.11. declaring a new fact type: Person
declare Person name : String dateOfBirth : java.util.Date address : Address end
As we can see on the previous example,
dateOfBirth is of type java.util.Date,
from the Java API, while address is of the previously
defined fact type Address.
You may avoid having to write the fully qualified name of a class
every time you write it by using the import clause, as previously
discussed.
Example 5.12. Avoiding the need to use fully qualified class names by using import
import java.util.Date declare Person name : String dateOfBirth : Date address : Address end
When you declare a new fact type, Drools will, at compile time, generate bytecode that implements a Java class representing the fact type. The generated Java class will be a one-to-one Java Bean mapping of the type definition. So, for the previous example, the generated Java class would be:
Example 5.13. generated Java class for the previous Person fact type declaration
public class Person implements Serializable {
private String name;
private java.util.Date dateOfBirth;
private Address address;
// getters and setters
// equals/hashCode
// toString
}
Since the generated class is a simple Java class, it can be used transparently in the rules, like any other fact.
Example 5.14. Using the declared types in rules
rule "Using a declared Type" when $p : Person( name == "Bob" ) then // Insert Mark, who is Bob's mate. Person mark = new Person(); mark.setName("Mark"); insert( mark ); end
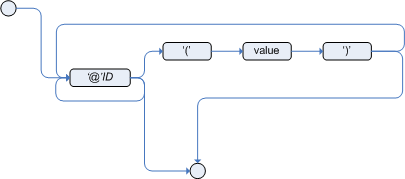
Metadata may be assigned to several different constructions in Drools: fact types, fact attributes and rules. Drools uses the at sign ('@') to introduce metadata, and it always uses the form:
@metadata_key( metadata_value )
The parenthesized metadata_value is optional.
For instance, if you want to declare a metadata attribute like
author, whose value is Bob, you
could simply write:
Drools allows the declaration of any arbitrary metadata attribute, but some will have special meaning to the engine, while others are simply available for querying at runtime. Drools allows the declaration of metadata both for fact types and for fact attributes. Any metadata that is declared before the fields of a fact type are assigned to the fact type, while metadata declared after an attribute are assigned to that particular attribute.
Example 5.16. Declaring metadata attributes for fact types and attributes
import java.util.Date declare Person @author( Bob ) @dateOfCreation( 01-Feb-2009 ) name : String @key @maxLength( 30 ) dateOfBirth : Date address : Address end
In the previous example, there are two metadata items declared for the
fact type (@author and @dateOfCreation) and two
more defined for the name attribute (@key and
@maxLength). Please note that the @key metadata
has no value, and so the parentheses and the value were omitted.
Drools allows the declaration of metadata attributes for existing types in the same way as when declaring metadata attributes for new fact types. The only difference is that there are no fields in that declaration.
For instance, if there is a class org.drools.examples.Person, and one wants to declare metadata for it, it's possible to write the following code:
Example 5.17. Declaring metadata for an existing type
import org.drools.examples.Person declare Person @author( Bob ) @dateOfCreation( 01-Feb-2009 ) end
Instead of using the import, it is also possible to reference the class by its fully qualified name, but since the class will also be referenced in the rules, it is usually shorter to add the import and use the short class name everywhere.
Example 5.18. Declaring metadata using the fully qualified class name
declare org.drools.examples.Person @author( Bob ) @dateOfCreation( 01-Feb-2009 ) end
Declared types are usually used inside rules files, while Java models are used when sharing the model between rules and applications. Although, sometimes, the application may need to access and handle facts from the declared types, especially when the application is wrapping the rules engine and providing higher level, domain specific user interfaces for rules management.
In such cases, the generated classes can be handled as usual with the Java Reflection API, but, as we know, that usually requires a lot of work for small results. Therefore, Drools provides a simplified API for the most common fact handling the application may want to do.
The first important thing to realize is that a declared fact will
belong to the package where it was declared. So, for instance, in the
example below, Person will belong to the
org.drools.examples package, and so the
fully qualified name of the generated class will be
org.drools.examples.Person.
Example 5.19. Declaring a type in the org.drools.examples package
package org.drools.examples import java.util.Date declare Person name : String dateOfBirth : Date address : Address end
Declared types, as discussed previously, are generated at knowledge base compilation time, i.e., the application will only have access to them at application run time. Therefore, these classes are not available for direct reference from the application.
Drools then provides an interface through which users can handle
declared types from the application code:
org.drools.definition.type.FactType. Through this interface, the user can
instantiate, read and write fields in the declared fact types.
Example 5.20. Handling declared fact types through the API
// get a reference to a knowledge base with a declared type:
KnowledgeBase kbase = ...
// get the declared FactType
FactType personType = kbase.getFactType( "org.drools.examples",
"Person" );
// handle the type as necessary:
// create instances:
Object bob = personType.newInstance();
// set attributes values
personType.set( bob,
"name",
"Bob" );
personType.set( bob,
"age",
42 );
// insert fact into a session
StatefulKnowledgeSession ksession = ...
ksession.insert( bob );
ksession.fireAllRules();
// read attributes
String name = personType.get( bob, "name" );
int age = personType.get( bob, "age" );
The API also includes other helpful methods, like setting all the attributes at once, reading values from a Map, or reading all attributes at once, into a Map.
Although the API is similar to Java reflection (yet much simpler to use), it does not use reflection underneath, relying on much more performant accessors implemented in generated bytecode.
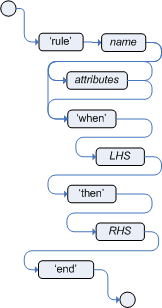
A rule specifies that when a particular set of conditions occur, specified in the Left Hand Side (LHS), then do what is specified as a list of actions in the Right Hand Side (RHS). A common question from users is "Why use when instead of if?" "When" was chosen over "if" because "if" is normally part of a procedural execution flow, where, at a specific point in time, a condition is to be checked. In contrast, "when" indicates that the condition evaluation is not tied to a specific evaluation sequence or point in time, but that it happens continually, at any time during the life time of the engine; whenever the condition is met, the actions are executed.
A rule must have a name, unique within its rule package. If you define a rule twice in the same DRL it produces an error while loading. If you add a DRL that includes a rule name already in the package, it replaces the previous rule. If a rule name is to have spaces, then it will need to be enclosd in double quotes (it is best to always use double quotes).
Attributes - described below - are optional. They are best written one per line.
The LHS of the rule follows the when keyword
(ideally on a new line), similarly the RHS follows the
then keyword (again, ideally on a newline). The rule is
terminated by the keyword end. Rules cannot be
nested.
Example 5.21. Rule Syntax Overview
rule "<name>"
<attribute>*
when
<conditional element>*
then
<action>*
endExample 5.22. A simple rule
rule "Approve if not rejected"
salience -100
agenda-group "approval"
when
not Rejection()
p : Policy(approved == false, policyState:status)
exists Driver(age > 25)
Process(status == policyState)
then
log("APPROVED: due to no objections.");
p.setApproved(true);
endRule attributes provide a declarative way to influence the behavior of the rule. Some are quite simple, while others are part of complex subsystems such as ruleflow. To get the most from Drools you should make sure you have a proper understanding of each attribute.
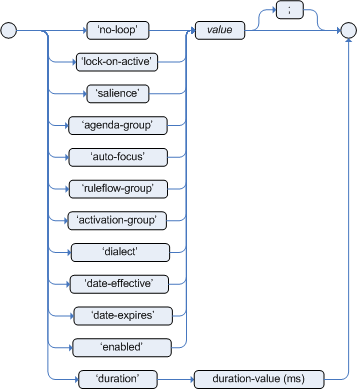
no-loopdefault value: false
type: Boolean
When the rule's consequence modifies a fact it may cause the Rule to activate again, causing recursion. Setting no-loop to true means the attempt to create the Activation for the current set of data will be ignored.
ruleflow-groupdefault value: N/A
type: String
Ruleflow is a Drools feature that lets you exercise control over the firing of rules. Rules that are assembled by the same ruleflow-group identifier fire only when their group is active.
lock-on-activedefault value: false
type: Boolean
Whenever a ruleflow-group becomes active or an agenda-group receives the focus, any rule within that group that has lock-on-active set to true will not be activated any more; irrespective of the origin of the update, the activation of a matching rule is discarded. This is a stronger version of no-loop, because the change could now be caused not only by the rule itself. It's ideal for calculation rules where you have a number of rules that modify a fact and you don't want any rule re-matching and firing again. Only when the ruleflow-group is no longer active or the agenda-group loses the focus those rules with lock-on-active set to true become eligible again for their activations to be placed onto the agenda.
saliencedefault value: 0
type: integer
Each rule has a salience attribute that can be assigned an integer number, which defaults to zero and can be negative or positive. Salience is a form of priority where rules with higher salience values are given higher priority when ordered in the Activation queue.
Drools also supports dynamic salience where you can use an expression involving bound variables.
Example 5.23. Dynamic Salience
rule "Fire in rank order 1,2,.." salience( -$rank ) when Element( $rank : rank,... ) then ... endagenda-groupdefault value: MAIN
type: String
Agenda groups allow the user to partition the Agenda providing more execution control. Only rules in the agenda group that has acquired the focus are allowed to fire.
auto-focusdefault value: false
type: Boolean
When a rule is activated where the
auto-focusvalue is true and the rule's agenda group does not have focus yet, then it is given focus, allowing the rule to potentially fire.activation-groupdefault value: N/A
type: String
Rules that belong to the same activation-group, identified by this attribute's string value, will only fire exclusively. In other words, the first rule in an activation-group to fire will cancel the other rules' activations, i.e., stop them from firing.
Note: This used to be called Xor group, but technically it's not quite an Xor. You may still hear people mention Xor group; just swap that term in your mind with activation-group.
dialectdefault value: as specified by the package
type: String
possible values: "java" or "mvel"
The dialect species the language to be used for any code expressions in the LHS or the RHS code block. Currently two dialects are available, Java and MVEL. While the dialect can be specified at the package level, this attribute allows the package definition to be overridden for a rule.
date-effectivedefault value: N/A
type: String, containing a date and time definition
A rule can only activate if the current date and time is after date-effective attribute.
date-expiresdefault value: N/A
type: String, containing a date and time definition
A rule cannot activate if the current date and time is after the date-expires attribute.
durationdefault value: no default value
type: long
The duration dictates that the rule will fire after a specified duration, if it is still true.
Rule's now suport both interval and cron based timers, which replace the now deprecated duration attribute.
Example 5.25. Sample timer attribute uses
timer ( int: <initial delay> <repeat interval>? )
timer ( int: 30s )
timer ( int: 30s 5m )
timer ( cron: <cron expression> )
timer ( cron:* 0/15 * * * ? )
Interval "int:" timers follow the JDK semantics for initial delay optionally followed by a repeat interval. Cron "cron:" timers follow standard cron expressions:
Example 5.26. A Cron Example
rule "Send SMS every 15 minutes"
timer (cron:* 0/15 * * * ?)
when
$a : Alarm( on == true )
then
channels[ "sms" ].insert( new Sms( $a.mobileNumber, "The alarm is still on" );
end
Calendars may now be used to control when rules can fire. The Calendar API is modelled on Quartz http://www.quartz-scheduler.org/ :
Example 5.27. Adapting a Quartz Calendar
Calendar weekDayCal = QuartzHelper.quartzCalendarAdapter(org.quartz.Calendar quartzCal)
Calendars are registered with the StatefulKnowledgeSession:
They can be used in conjunction with normal rules and rules including timers. The rule calendar attribute can have one or more comma calendar names.
Example 5.29. Using Calendars and Timers together
rule "weekdays are high priority"
calendars "weekday"
timer (int:0 1h)
when
Alarm()
then
send( "priority high - we have an alarm );
end
rule "weekend are low priority"
calendars "weekend"
timer (int:0 4h)
when
Alarm()
then
send( "priority low - we have an alarm );
end
The Left Hand Side (LHS) is a common name for the conditional part
of the rule. It consists of zero or more Conditional Elements. If the LHS
is left empty, it is re-written as eval(true), which means
that the rule's condition is always true. It will be activated, once, when
a new Working Memory session is created.

Example 5.30. Rule without a Conditional Element
rule "no CEs"
when
then
<action>*
end
# The above rule is internally rewritten as:
rule "eval(true)"
when
eval( true )
then
<action>*
endConditional elements work on one or more
patterns (which are described below). The most common
one is and, which is implicit when you have multiple
patterns in the LHS of a rule that are not connected in any way. Note that
an and cannot have a leading declaration binding like
or. This is obvious, since a declaration can only
reference a single fact, and when the and is satisfied
it matches more than one fact - so which fact would the declaration bind
to?
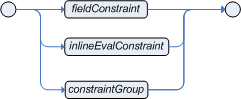
The pattern element is the most important Conditional Element. The entity relationship diagram below provides an overview of the various parts that make up the pattern's constraints and how they work together; each is then covered in more detail with railroad diagrams and examples.
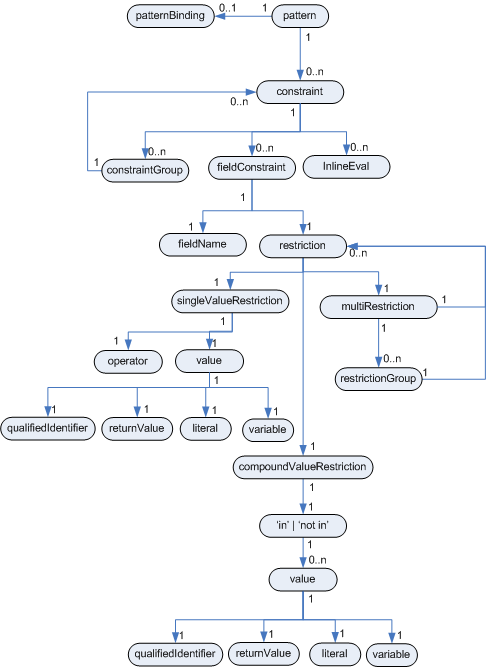
At the top of the ER diagram you can see that the pattern consists of zero or more constraints and has an optional pattern binding. The railroad diagram below shows the syntax for this.

In its simplest form, with no constraints, a pattern matches
against a fact of the given type. In the following case the type is
Cheese, which means that the pattern will match against all
Cheese objects in the Working Memory.
Notice that the type need not be the actual class of some fact object. Patterns may refer to superclasses or even interfaces, thereby potentially matching facts from many different classes.
For referring to the matched object, use a pattern binding
variable such as $c. The prefixed dollar symbol ('$') is
optional; it can be useful in complex rules where it helps to more
easily differentiate between variables and fields.
Inside of the pattern parenthesis is where all the action happens. A constraint can be either a Field Constraint, Inline Eval, or a Constraint Group. Constraints can be separated by the following symbols: ',', '&&' or '||'.
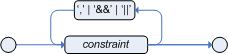

The comma character (',') is used to separate constraint groups. It has implicit and connective semantics.
Example 5.33. Constraint Group connective ','
# Cheese type is stilton and price < 10 and age is mature. Cheese( type == "stilton", price < 10, age == "mature" )
The above example has three constraint groups, each with a
single constraint:
Group 1 -
type == "stilton"requires that the type is stilton.Group 2 -
price < 10demands a price less than 10.Group 3 -
age == "mature"accepts only mature cheese.
The '&&' (and) and '||' (or) constraint connectives allow constraint groups to have multiple constraints. Example:
Example 5.34. && and || Constraint Connectives
// Cheese type is "stilton" and price < 10, and age is mature Cheese( type == "stilton" && price < 10, age == "mature" ) // Cheese type is "stilton" or price < 10, and age is mature Cheese( type == "stilton" || price < 10, age == "mature" )
The above example has two constraint groups. The first has two constraints and the second has one constraint.
The connectives are evaluated in the following order, from first to last:
&&
||
,
It is possible to change the evaluation priority by using parentheses, as in any logic or mathematical expression. Example:
Example 5.35. Using parentheses to change evaluation priority
# Cheese type is stilton and ( price is less than 20 or age is mature ). Cheese( type == "stilton" && ( price < 20 || age == "mature" ) )
In the above example, the use of parentheses evaluates the connective '||' before the connective '&&'.
Also, it is important to note that besides having the same semantics, the connectives '&&' and ',' are resolved with different priorities, and ',' cannot be embedded in a composite constraint expression.
Example 5.36. Not Equivalent connectives
// invalid as ',' cannot be embedded in an expression: Cheese( ( type == "stilton", price < 10 ) || age == "mature" ) // valid as '&&' can be embedded in an expression: Cheese( ( type == "stilton" && price < 10 ) || age == "mature")
A Field constraint specifies a restriction to be used on a named field; the field name can have an optional variable binding.

There are three types of restrictions: Single Value Restriction, Compound Value Restriction, and Multi Restriction.

A field is derived from an accessible method of the object. If your model objects follow the Java Bean pattern, then fields are exposed using "getXXX" or "isXXX" methods, where these methods take no arguments, and return something. Within patterns, fields can be accessed using the bean naming convention, so that "getType" would be accessed as "type". Drools uses the standard JDK Introspector class to do this mapping.
For example, referring to our Cheese class, the pattern
Cheese(type == "brie") applies the getType() method to
a Cheese instance. If a field name cannot be found, the compiler
will resort to using the name as a method without arguments. Thus,
the method toString() is called due to a constraint
Cheese(toString == "cheddar"). In this case, you use
the full name of the method with correct capitalization, but still
without parentheses. Do please make sure that you are accessing
methods that take no parameters, and that are in fact
accessors which don't change the state of the
object in a way that may effect the rules. Remember that the rule
engine effectively caches the results of its matching in between
invocations to make it faster.
The field constraints can take a number of values; including literal, qualifiedIdentifier (enum), variable and returnValue.
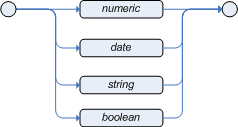


You can do checks against fields that are or may be null,
using '==' and '!=' as you would expect, and the literal
null keyword, as in Cheese(type !=
null), where the evaluator will not throw an exception and
return true if the value is null. Type coercion is always attempted
if the field and the value are of different types; exceptions will
be thrown if a bad coercion is attempted. For instance, if "ten" is
provided as a string in a numeric evaluator, an exception is thrown,
whereas "10" would coerce to a numeric 10. Coercion is always in
favor of the field type and not the value type.
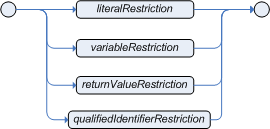
A Single Value Restriction is a binary relation, applying a binary operator to the field value and another value, which may be a literal, a variable, a parenthesized expression ("return value"), or a qualified identifier, i.e., an enum constant.

The operators '==' and '!=' are valid for all types. Other
relational operatory may be used whenever the type values are
ordered; for date fields, '<' means "before". The pair
matches and not matches is
only applicable to string fields, contains and
not contains require the field to be of some
Collection type. Coercion to the correct value for the evaluator
and the field will be attempted, as mentioned in the "Values"
section.
Matches a field against any valid Java Regular Expression. Typically that regexp is a string literal, but variables that resolve to a valid regexp are also allowed. It is important to note that, different from Java, within regular expressions written as string literals you don't need to escape '\'. Example:
The operator returns true if the string does not match the
regular expression. The same rules apply as for the
matches operator. Example:
The operator contains is used to check
whether a field that is a Collection or array contains the specified
value.
Example 5.39. Contains with Collections
CheeseCounter( cheeses contains "stilton" ) // contains with a String literal CheeseCounter( cheeses contains $var ) // contains with a variable
The operator not contains is used to
check whether a field that is a Collection or array does not
contain the specified value.
Example 5.40. Literal Constraint with Collections
CheeseCounter( cheeses not contains "cheddar" ) // not contains with a String literal CheeseCounter( cheeses not contains $var ) // not contains with a variable
Note
For backward compatibility, the
excludesoperator is supported as a synonym fornot contains.
The operator memberOf is used to check
whether a field is a member of a collection or array; that
collection must be a variable.
The operator not memberOf is used to
check whether a field is not a member of a collection or array;
that collection must be a variable.
Example 5.42. Literal Constraint with Collections
CheeseCounter( cheese not memberOf $matureCheeses )
This operator is similar to matches,
but it checks whether a word has almost the same sound (using
English pronounciation) as the given value. This is based on the
Soundex algorithm (see
http://en.wikipedia.org/wiki/Soundex).
Example 5.43. Test with soundslike
// match cheese "fubar" or "foobar" Cheese( name soundslike 'foobar' )
This operator str is used to
check whether a field that is a String starts with or ends with with a certain value. It can also be used to check
the length of the String.
Example 5.44. Test with str
$m : Message( routingValue str[startsWith] "R1" )
$m : Message( routingValue str[endsWith] "R2" )
$m : Message( routingValue str[length] 17 )
Literal restrictions are the simplest form of restrictions and evaluate a field against a specified literal, which may be numeric or a date, a string or a boolean.

Literal Restrictions using the operator '==' provide for faster execution as we can index using hashing to improve performance.
All standard Java numeric primitives are supported.
The date format "dd-mmm-yyyy" is supported by default. You
can customize this by providing an alternative date format mask
as the System property named drools.dateformat. If
more control is required, use the inline-eval constraint.
Any valid Java String is allowed.
Only true or false can be used;
0 and 1 are not acceptable. A boolean field alone (as in
Cheese( smelly ) is not permitted; you must compare
this to a boolean literal.

Variables can be bound to facts and their fields and then used in subsequent Field Constraints. A bound variable is called a Declaration. Valid operators are determined by the type of the field being constrained; coercion will be attempted where possible. Bound Variable Restrictions using the operator '==' provide for very fast execution as we can use hashing to improve performance.
Example 5.50. Bound Field using the operator '=='
Person( likes : favouriteCheese ) Cheese( type == likes )
Here, likes is the variable that is bound in
its declaration to the field favouriteCheese of any
matching Person instance. It is then used to constrain the type of
Cheese in the following pattern. Any valid Java variable name can
be used, and it may be prefixed with a '$', which you will often
see used to help differentiate declarations from fields. The
example below shows a declaration for $stilton, bound
to the object matching the first pattern and used with a
contains operator. - Note the optional use of
'$'.
Example 5.51. Bound Fact using 'contains' operator
$stilton : Cheese( type == "stilton" ) Cheesery( cheeses contains $stilton )

A Return Value restriction is a parenthesized expression composed from literals, any valid Java primitive or object, previously bound variables, function calls, and operators. Functions used in a Return Value must return results that do not depend on time.
Example 5.52. Return Value Restriction
Person( girlAge : age, sex == "F" ) Person( age == ( girlAge + 2) ), sex == 'M' )
The compound value restriction is used where there is more
than one possible value to match. Currently only the
in and not in evaluators
support this. The second operand of this operator must be a
comma-separated list of values, enclosed in parentheses. Values may
be given as variables, literals, return values or qualified
identifiers. Both evaluators are actually "syntactic sugar",
internally rewritten as a list of multiple restrictions using the
operators '!=' and '=='.
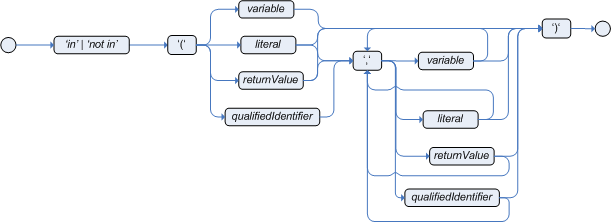
Example 5.53. Compound Restriction using "in"
Person( $cheese : favouriteCheese ) Cheese( type in ( "stilton", "cheddar", $cheese )
Multi restriction allows you to place more than one restriction on a field using the restriction connectives '&&' or '||'. Grouping via parentheses is permitted, resulting in a recursive syntax pattern.
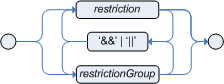

Example 5.54. Multi Restriction
// Simple multi restriction using a single &&
Person( age > 30 && < 40 )
// Complex multi restriction using groupings of multi restrictions
Person( age ( (> 30 && < 40) ||
(> 20 && < 25) ) )
// Mixing muti restrictions with constraint connectives
Person( age > 30 && < 40 || location == "london" )
An inline eval constraint can use any valid dialect expression as long as it results to a primitive boolean. The expression must be constant over time. Any previously bound variable, from the current or previous pattern, can be used; autovivification is also used to auto-create field binding variables. When an identifier is found that is not a current variable, the builder looks to see if the identifier is a field on the current object type, if it is, the field binding is auto-created as a variable of the same name. This is called autovivification of field variables inside of inline evals.
This example will find all male-female pairs where the male is 2
years older than the female; the variable age is
auto-created in the second pattern by the autovivification
process.
Example 5.55. Return Value operator
Person( girlAge : age, sex = "F" ) Person( eval( age == girlAge + 2 ), sex = 'M' )
Drools permits nested accessors in in the
field constraints using the MVEL accessor graph notation. Field
constraints involving nested accessors are actually re-written as an
MVEL dialect inline-eval. Care should be taken when using nested
accessors as the Working Memory is not aware of any of the nested
values, and does not know when they change; they should be considered
immutable while any of their parent references are inserted into the
Working Memory. If you wish to modify a nested value you should remove
the parent objects first and re-assert afterwards. If you only have a
single parent at the root of the graph, when in the MVEL dialect, you
can use the modify construct and its block setters
to write the nested accessor assignments while retracting and
inserting the the root parent object as required. Nested accessors can
be used on either side of the operator symbol.
Example 5.56. Nested Accessors
// Find a pet older than its owners first-born child $p : Person( ) Pet( owner == $p, age > $p.children[0].age )
This is internally rewriten as an MVEL inline eval:
// Find a pet older than its owners first-born child $p : Person( ) Pet( owner == $p, eval( age > $p.children[0].age ) )
Note: Nested accessors have a much greater performance cost than direct field accesses, so use them carefully.
The Conditional Element and is used to group
other Conditional Elements into a logical conjunction. The root element
of the LHS is an implicit prefix and and doesn't need
to be specified. Drools supports both prefix and and
infix and, but prefix is the preferred option as its
implicit grouping avoids confusion.

Example 5.58. implicit root prefixAnd
when
Cheese( cheeseType : type )
Person( favouriteCheese == cheeseType )Infix and is supported along with explicit
grouping with parentheses, should it be needed. The symbol '&&',
as an alternative to and, is deprecated although it
is still supported in the syntax for legacy support reasons.

Example 5.59. infixAnd
//infixAnd
Cheese( cheeseType : type ) and Person( favouriteCheese == cheeseType )
//infixAnd with grouping
( Cheese( cheeseType : type ) and
( Person( favouriteCheese == cheeseType ) or
Person( favouriteCheese == cheeseType ) )The Conditional Element or is used to group
other Conditional Elements into a logical disjunction. Drools supports
both prefix or and infix or, but
prefix is the preferred option as its implicit grouping avoids
confusion. The behavior of the Conditional Element or
is different from the connective '||' for constraints and restrictions
in field constraints. The engine actually has no understanding of the
Conditional Element or; instead, via a number of
different logic transformations, a rule with or is
rewritten as a number of subrules. This process ultimately results in a
rule that has a single or as the root node and one
subrule for each of its CEs. Each subrule can activate and fire like any
normal rule; there is no special behavior or interaction between these
subrules. - This can be most confusing to new rule authors.

Infix or is supported along with explicit
grouping with parentheses, should it be needed. The symbol '||', as an
alternative to or, is deprecated although it is still
supported in the syntax for legacy support reasons.

Example 5.61. infixOr
//infixOr
Cheese( cheeseType : type ) or Person( favouriteCheese == cheeseType )
//infixOr with grouping
( Cheese( cheeseType : type ) or
( Person( favouriteCheese == cheeseType ) and
Person( favouriteCheese == cheeseType ) )The Conditional Element or also allows for
optional pattern binding. This means that each resulting subrule will
bind its pattern to the pattern binding. Each pattern must be bound
separately, using eponymous variables:
Example 5.62. or with binding
(or pensioner : Person( sex == "f", age > 60 )
pensioner : Person( sex == "m", age > 65 ) )Since the conditional element or results in
multiple subrule generation, one for each possible logically outcome,
the example above would result in the internal generation of two rules.
These two rules work independently within the Working Memory, which
means both can match, activate and fire - there is no
shortcutting.
The best way to think of the conditional element
or is as a shortcut for generating two or more
similar rules. When you think of it that way, it's clear that for a
single rule there could be multiple activations if two or more terms of
the disjunction are true.

The CE eval is essentially a catch-all which
allows any semantic code (that returns a primitive boolean) to be
executed. This code can refer to variables that were bound in the LHS of
the rule, and functions in the rule package. Overuse of eval reduces the
declarativeness of your rules and can result in a poorly performing
engine. While eval can be used anywhere in the
patterns, the best practice is to add it as the last conditional element
in the LHS of a rule.
Evals cannot be indexed and thus are not as efficient as Field Constraints. However this makes them ideal for being used when functions return values that change over time, which is not allowed within Field Constraints.
For folks who are familiar with Drools 2.x lineage, the old Drools parameter and condition tags are equivalent to binding a variable to an appropriate type, and then using it in an eval node.
Example 5.63. eval
p1 : Parameter() p2 : Parameter() eval( p1.getList().containsKey(p2.getItem()) ) // call function isValid in the LHS eval( isValid(p1, p2) )

The CE not is first order logic's
non-existential quantifier and checks for the non-existence of something
in the Working Memory. Think of "not" as meaning "there must be none
of...".
The keyword not be followed by parentheses
around the CEs that it applies to. In the simplest case of a single
pattern (like below) you may optionally omit the parentheses.
Example 5.65. No red Busses
// Brackets are optional:
not Bus(color == "red")
// Brackets are optional:
not ( Bus(color == "red", number == 42) )
// "not" with nested infix and - two patterns,
// brackets are requires:
not ( Bus(color == "red") and
Bus(color == "blue") )
The CE exists is first order logic's
existential quantifier and checks for the existence of something in the
Working Memory. Think of "exists" as meaning "there is at least one..".
It is different from just having the pattern on its own, which is more
like saying "for each one of...". If you use exists
with a pattern, the rule will only activate at most once, regardless of
how much data there is in working memory that matches the condition
inside of the exists pattern. Since only the
existence matters, no bindings will be established.
The keyword exists must be followed by
parentheses around the CEs that it applies to. In the simplest case of a
single pattern (like below) you may omit the parentheses.
Example 5.67. At least one red Bus
exists Bus(color == "red")
// brackets are optional:
exists ( Bus(color == "red", number == 42) )
// "exists" with nested infix and,
// brackets are required:
exists ( Bus(color == "red") and
Bus(color == "blue") )
The Conditional Element forall completes the
First Order Logic support in Drools. The Conditional Element
forall evaluates to true when all facts that match
the first pattern match all the remaining patterns. Example:
rule "All English buses are red"
when
forall( $bus : Bus( type == 'english')
Bus( this == $bus, color = 'red' ) )
then
# all english buses are red
end
In the above rule, we "select" all Bus objects whose type is "english". Then, for each fact that matches this pattern we evaluate the following patterns and if they match, the forall CE will evaluate to true.
To state that all facts of a given type in the working memory must
match a set of constraints, forall can be written
with a single pattern for simplicity. Example:
Example 5.68. Single Pattern Forall
rule "All Buses are Red"
when
forall( Bus( color == 'red' ) )
then
# all asserted Bus facts are red
end
Another example shows multiple patterns inside the
forall:
Example 5.69. Multi-Pattern Forall
rule "all employees have health and dental care programs"
when
forall( $emp : Employee()
HealthCare( employee == $emp )
DentalCare( employee == $emp )
)
then
# all employees have health and dental care
end
Forall can be nested inside other CEs.
For instance, forall can be used inside a
not CE. Note that only single patterns have optional
parentheses, so that with a nested forall
parentheses must be used:
Example 5.70. Combining Forall with Not CE
rule "not all employees have health and dental care"
when
not ( forall( $emp : Employee()
HealthCare( employee == $emp )
DentalCare( employee == $emp ) )
)
then
# not all employees have health and dental care
end
As a side note, forall( p1 p2 p3...) is
equivalent to writing:
not(p1 and not(and p2 p3...))
Also, it is important to note that forall is a
scope delimiter. Therefore, it can use any
previously bound variable, but no variable bound inside it will be
available for use outside of it.

The Conditional Element from enables users to
specify an arbitrary source for data to be matched by LHS patterns. This
allows the engine to reason over data not in the Working Memory. The
data source could be a sub-field on a bound variable or the results of a
method call. It is a powerful construction that allows out of the box
integration with other application components and frameworks. One common
example is the integration with data retrieved on-demand from databases
using hibernate named queries.
The expression used to define the object source is any expression that follows regular MVEL syntax. Therefore, it allows you to easily use object property navigation, execute method calls and access maps and collections elements.
Here is a simple example of reasoning and binding on another pattern sub-field:
rule "validate zipcode"
when
Person( $personAddress : address )
Address( zipcode == "23920W") from $personAddress
then
# zip code is ok
end
With all the flexibility from the new expressiveness in the Drools engine you can slice and dice this problem many ways. This is the same but shows how you can use a graph notation with the 'from':
rule "validate zipcode"
when
$p : Person( )
$a : Address( zipcode == "23920W") from $p.address
then
# zip code is ok
end
Previous examples were evaluations using a single pattern. The CE
from also support object sources that return a
collection of objects. In that case, from will
iterate over all objects in the collection and try to match each of them
individually. For instance, if we want a rule that applies 10% discount
to each item in an order, we could do:
rule "apply 10% discount to all items over US$ 100,00 in an order"
when
$order : Order()
$item : OrderItem( value > 100 ) from $order.items
then
# apply discount to $item
end
The above example will cause the rule to fire once for each item whose value is greater than 100 for each given order.
You must take caution, however, when using
from, especially in conjunction with the
lock-on-active rule attribute as it may produce
unexpected results. Consider the example provided earlier, but now
slightly modified as follows:
rule "Assign people in North Carolina (NC) to sales region 1"
ruleflow-group "test"
lock-on-active true
when
$p : Person( )
$a : Address( state == "NC") from $p.address
then
modify ($p) {} #Assign person to sales region 1 in a modify block
end
rule "Apply a discount to people in the city of Raleigh"
ruleflow-group "test"
lock-on-active true
when
$p : Person( )
$a : Address( city == "Raleigh") from $p.address
then
modify ($p) {} #Apply discount to person in a modify block
end
In the above example, persons in Raleigh, NC should be assigned to sales region 1 and receive a discount; i.e., you would expect both rules to activate and fire. Instead you will find that only the second rule fires.
If you were to turn on the audit log, you would also see that when
the second rule fires, it deactivates the first rule. Since the rule
attribute lock-on-active prevents a rule from
creating new activations when a set of facts change, the first rule
fails to reactivate. Though the set of facts have not changed, the use
of from returns a new fact for all intents and
purposes each time it is evaluated.
First, it's important to review why you would use the above
pattern. You may have many rules across different rule-flow groups. When
rules modify working memory and other rules downstream of your RuleFlow
(in different rule-flow groups) need to be reevaluated, the use of
modify is critical. You don't, however, want other
rules in the same rule-flow group to place activations on one another
recursively. In this case, the no-loop attribute is
ineffective, as it would only prevent a rule from activating itself
recursively. Hence, you resort to
lock-on-active.
There are several ways to address this issue:
Avoid the use of
fromwhen you can assert all facts into working memory or use nested object references in your constraint expressions (shown below).Place the variable assigned used in the modify block as the last sentence in your condition (LHS).
Avoid the use of
lock-on-activewhen you can explicitly manage how rules within the same rule-flow group place activations on one another (explained below).
The preferred solution is to minimize use of
from when you can assert all your facts into working
memory directly. In the example above, both the Person and Address
instance can be asserted into working memory. In this case, because the
graph is fairly simple, an even easier solution is to modify your rules
as follows:
rule "Assign people in North Carolina (NC) to sales region 1"
ruleflow-group "test"
lock-on-active true
when
$p : Person(address.state == "NC" )
then
modify ($p) {} #Assign person to sales region 1 in a modify block
end
rule "Apply a discount to people in the city of Raleigh"
ruleflow-group "test"
lock-on-active true
when
$p : Person(address.city == "Raleigh" )
then
modify ($p) {} #Apply discount to person in a modify block
end
Now, you will find that both rules fire as expected. However, it
is not always possible to access nested facts as above. Consider an
example where a Person holds one or more Addresses and you wish to use
an existential quantifier to match people with at least one address that
meets certain conditions. In this case, you would have to resort to the
use of from to reason over the collection.
There are several ways to use from to achieve
this and not all of them exhibit an issue with the use of
lock-on-active. For example, the following use of
from causes both rules to fire as expected:
rule "Assign people in North Carolina (NC) to sales region 1"
ruleflow-group "test"
lock-on-active true
when
$p : Person($addresses : addresses)
exists (Address(state == "NC") from $addresses)
then
modify ($p) {} #Assign person to sales region 1 in a modify block
end
rule "Apply a discount to people in the city of Raleigh"
ruleflow-group "test"
lock-on-active true
when
$p : Person($addresses : addresses)
exists (Address(city == "Raleigh") from $addresses)
then
modify ($p) {} #Apply discount to person in a modify block
end
However, the following slightly different approach does exhibit the problem:
rule "Assign people in North Carolina (NC) to sales region 1"
ruleflow-group "test"
lock-on-active true
when
$assessment : Assessment()
$p : Person()
$addresses : List() from $p.addresses
exists (Address( state == "NC") from $addresses)
then
modify ($assessment) {} #Modify assessment in a modify block
end
rule "Apply a discount to people in the city of Raleigh"
ruleflow-group "test"
lock-on-active true
when
$assessment : Assessment()
$p : Person()
$addresses : List() from $p.addresses
exists (Address( city == "Raleigh") from $addresses)
then
modify ($assessment) {} #Modify assessment in a modify block
endIn the above example, the $addresses variable is returned from the
use of from. The example also introduces a new
object, assessment, to highlight one possible solution in this case. If
the $assessment variable assigned in the condition (LHS) is moved to the
last condition in each rule, both rules fire as expected.
Though the above examples demonstrate how to combine the use of
from with lock-on-active where no
loss of rule activations occurs, they carry the drawback of placing a
dependency on the order of conditions on the LHS. In addition, the
solutions present greater complexity for the rule author in terms of
keeping track of which conditions may create issues.
A better alternative is to assert more facts into working memory.
In this case, a person's addresses may be asserted into working memory
and the use of from would not be necessary.
There are cases, however, where asserting all data into working
memory is not practical and we need to find other solutions. Another
option is to reevaluate the need for lock-on-active.
An alternative to lock-on-active is to directly
manage how rules within the same rule-flow group activate one another by
including conditions in each rule that prevent rules from activating
each other recursively when working memory is modified. For example, in
the case above where a discount is applied to citizens of Raleigh, a
condition may be added to the rule that checks whether the discount has
already been applied. If so, the rule does not activate.
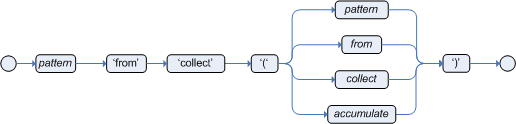
The Conditional Element collect allows rules to
reason over a collection of objects obtained from the given source or
from the working memory. In First Oder Logic terms this is the
cardinality quantifier. A simple example:
import java.util.ArrayList
rule "Raise priority if system has more than 3 pending alarms"
when
$system : System()
$alarms : ArrayList( size >= 3 )
from collect( Alarm( system == $system, status == 'pending' ) )
then
# Raise priority, because system $system has
# 3 or more alarms pending. The pending alarms
# are $alarms.
end
In the above example, the rule will look for all pending alarms in the working memory for each given system and group them in ArrayLists. If 3 or more alarms are found for a given system, the rule will fire.
The result pattern of collect can be any
concrete class that implements the java.util.Collection
interface and provides a default no-arg public constructor. This means
that you can use Java collections like ArrayList, LinkedList, HashSet,
etc., or your own class, as long as it implements the
java.util.Collection interface and provide a default no-arg
public constructor.
Both source and result patterns can be constrained as any other pattern.
Variables bound before the collect CE are in
the scope of both source and result patterns and therefore you can use
them to constrain both your source and result patterns. But note that
collect is a scope delimiter for bindings, so that
any binding made inside of it is not available for use outside of
it.
Collect accepts nested from CEs. The following
example is a valid use of "collect":
import java.util.LinkedList;
rule "Send a message to all mothers"
when
$town : Town( name == 'Paris' )
$mothers : LinkedList()
from collect( Person( gender == 'F', children > 0 )
from $town.getPeople()
)
then
# send a message to all mothers
end
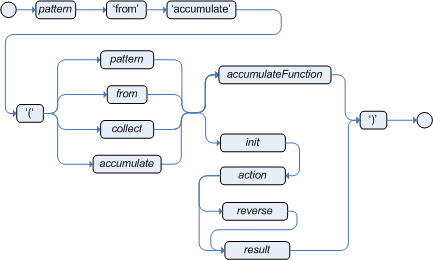
The Conditional Element accumulate is a more
flexible and powerful form of collect, the sense that
it can be used to do what collect does and also
achieve things that the CE collect is not capable of
doing. Basically, what it does is that it allows a rule to iterate over
a collection of objects, executing custom actions for each of the
elements, and at the end it returns a result object.
The general syntax of the accumulate CE
is:
<result pattern>from accumulate(<source pattern>,init(<init code>),action(<action code>),reverse(<reverse code>),result(<result expression>) )
The meaning of each of the elements is the following:
<source pattern>: the source pattern is a regular pattern that the engine will try to match against each of the source objects.
<init code>: this is a semantic block of code in the selected dialect that will be executed once for each tuple, before iterating over the source objects.
<action code>: this is a semantic block of code in the selected dialect that will be executed for each of the source objects.
<reverse code>: this is an optional semantic block of code in the selected dialect that if present will be executed for each source object that no longer matches the source pattern. The objective of this code block is to undo any calculation done in the <action code> block, so that the engine can do decremental calculation when a source object is modified or retracted, hugely improving performance of these operations.
<result expression>: this is a semantic expression in the selected dialect that is executed after all source objects are iterated.
<result pattern>: this is a regular pattern that the engine tries to match against the object returned from the <result expression>. If it matches, the
accumulateconditional element evaluates to true and the engine proceeds with the evaluation of the next CE in the rule. If it does not matches, theaccumulateCE evaluates to false and the engine stops evaluating CEs for that rule.
It is easier to understand if we look at an example:
rule "Apply 10% discount to orders over US$ 100,00"
when
$order : Order()
$total : Number( doubleValue > 100 )
from accumulate( OrderItem( order == $order, $value : value ),
init( double total = 0; ),
action( total += $value; ),
reverse( total -= $value; ),
result( total ) )
then
# apply discount to $order
end
In the above example, for each Order in the Working
Memory, the engine will execute the init code
initializing the total variable to zero. Then it will iterate over all
OrderItem objects for that order, executing the
action for each one (in the example, it will sum
the value of all items into the total variable). After iterating over
all OrderItem objects, it will return the value
corresponding to the result expression (in the
above example, the value of variable total). Finally, the
engine will try to match the result with the Number
pattern, and if the double value is greater than 100, the rule will
fire.
The example used Java as the semantic dialect, and as such, note that the usage of the semicolon as statement delimiter is mandatory in the init, action and reverse code blocks. The result is an expression and, as such, it does not admit ';'. If the user uses any other dialect, he must comply to that dialect's specific syntax.
As mentioned before, the reverse code is optional, but it is strongly recommended that the user writes it in order to benefit from the improved performance on update and retract.
The accumulate CE can be used to execute any
action on source objects. The following example instantiates and
populates a custom object:
rule "Accumulate using custom objects"
when
$person : Person( $likes : likes )
$cheesery : Cheesery( totalAmount > 100 )
from accumulate( $cheese : Cheese( type == $likes ),
init( Cheesery cheesery = new Cheesery(); ),
action( cheesery.addCheese( $cheese ); ),
reverse( cheesery.removeCheese( $cheese ); ),
result( cheesery ) );
then
// do something
endThe accumulate CE is a very powerful CE, but it gets real declarative and easy to use when using predefined functions that are known as Accumulate Functions. They work exactly like accumulate, but instead of explicitly writing custom code in every accumulate CE, the user can use predefined code for common operations.
For instance, the rule to apply discount on orders written in the previous section, could be written in the following way, using Accumulate Functions:
rule "Apply 10% discount to orders over US$ 100,00"
when
$order : Order()
$total : Number( doubleValue > 100 )
from accumulate( OrderItem( order == $order, $value : value ),
sum( $value ) )
then
# apply discount to $order
end
In the above example, sum is an Accumulate Function and will sum the $value of all OrderItems and return the result.
Drools ships with the following built-in accumulate functions:
average
min
max
count
sum
These common functions accept any expression as input. For instance, if someone wants to calculate the average profit on all items of an order, a rule could be written using the average function:
rule "Average profit"
when
$order : Order()
$profit : Number()
from accumulate( OrderItem( order == $order, $cost : cost, $price : price )
average( 1 - $cost / $price ) )
then
# average profit for $order is $profit
end
Accumulate Functions are all pluggable. That means that if
needed, custom, domain specific functions can easily be added to the
engine and rules can start to use them without any restrictions. To
implement a new Accumulate Functions all one needs to do is to create
a Java class that implements the
org.drools.base.acumulators.AccumulateFunction interface
and add a line to the configuration file or set a system property to
let the engine know about the new function. As an example of an
Accumulate Function implementation, the following is the
implementation of the average function:
/*
* Copyright 2007 JBoss Inc
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
* Created on Jun 21, 2007
*/
package org.drools.base.accumulators;
/**
* An implementation of an accumulator capable of calculating average values
*/
public class AverageAccumulateFunction implements AccumulateFunction {
protected static class AverageData {
public int count = 0;
public double total = 0;
}
/* (non-Javadoc)
* @see org.drools.base.accumulators.AccumulateFunction#createContext()
*/
public Object createContext() {
return new AverageData();
}
/* (non-Javadoc)
* @see org.drools.base.accumulators.AccumulateFunction#init(java.lang.Object)
*/
public void init(Object context) throws Exception {
AverageData data = (AverageData) context;
data.count = 0;
data.total = 0;
}
/* (non-Javadoc)
* @see org.drools.base.accumulators.AccumulateFunction#accumulate(java.lang.Object,
* java.lang.Object)
*/
public void accumulate(Object context,
Object value) {
AverageData data = (AverageData) context;
data.count++;
data.total += ((Number) value).doubleValue();
}
/* (non-Javadoc)
* @see org.drools.base.accumulators.AccumulateFunction#reverse(java.lang.Object,
* java.lang.Object)
*/
public void reverse(Object context,
Object value) throws Exception {
AverageData data = (AverageData) context;
data.count--;
data.total -= ((Number) value).doubleValue();
}
/* (non-Javadoc)
* @see org.drools.base.accumulators.AccumulateFunction#getResult(java.lang.Object)
*/
public Object getResult(Object context) throws Exception {
AverageData data = (AverageData) context;
return new Double( data.count == 0 ? 0 : data.total / data.count );
}
/* (non-Javadoc)
* @see org.drools.base.accumulators.AccumulateFunction#supportsReverse()
*/
public boolean supportsReverse() {
return true;
}
}
The code for the function is very simple, as we could expect, as all the "dirty" integration work is done by the engine. Finally, to plug the function into the engine, we added it to the configuration file:
drools.accumulate.function.average = org.drools.base.accumulators.AverageAccumulateFunction
Here, "drools.accumulate.function." is a prefix that must always be used, "average" is how the function will be used in the rule file, and "org.drools.base.accumulators.AverageAccumulateFunction" is the fully qualified name of the class that implements the function behavior.
The Right Hand Side (RHS) is a common name for the consequence or action part of the rule; this part should contain a list of actions to be executed. It is bad practice to use imperative or conditional code in the RHS of a rule; as a rule should be atomic in nature - "when this, then do this", not "when this, maybe do this". The RHS part of a rule should also be kept small, thus keeping it declarative and readable. If you find you need imperative and/or conditional code in the RHS, then maybe you should be breaking that rule down into multiple rules. The main purpose of the RHS is to insert, retractor modify working memory data. To assist with that there are a few convenience methods you can use to modify working memory; without having to first reference a working memory instance.
update(object,
handle); will tell the engine that an
object has changed (one that has been bound to something on the LHS) and
rules may need to be reconsidered.
update(object);
can also be used; here the Knowledge Helper will look up the facthandle
for you, via an identity check, for the passed object. (Note that if you
provide Property Change Listeners to your Java beans that you are
inserting into the engine, you can avoid the need to call
update() when the object changes.)
insert(new
Something()); will place a new
object of your creation into the Working Memory.
insertLogical(new
Something()); is similar to
insert, but the object will be automatically retracted when there are no
more facts to support the truth of the currently firing rule.
retract(handle);
removes an object from Working Memory.
These convenience methods are basically macros that provide short
cuts to the KnowledgeHelper instance that lets you access
your Working Memory from rules files. The predefined variable
drools of type KnowledgeHelper lets you call
several other useful methods. (Refer to the KnowledgeHelper
interface documentation for more advanced operations).
The call
drools.halt()terminates rule execution immediately. This is required for returning control to the point whence the current session was put to work withfireUntilHalt().Methods
insert(Object o),update(Object o)andretract(Object o)can be called ondroolsas well, but due to their frequent use they can be called without the object reference.drools.getWorkingMemory()returns theWorkingMemoryobject.drools.setFocus( String s)sets the focus to the specified agenda group.drools.getRule().getName(), called from a rule's RHS, returns the name of the rule.drools.getTuple()returns the Tuple that matches the currently executing rule, anddrools.getActivation()delivers the corresponding Activation. (These calls are useful for logging and debugging purposes.)
The full Knowlege Runtime API is exposed through another
predefined variable, kcontext, of type
KnowledgeContext. Its method
getKnowledgeRuntime() delivers an object of type
KnowledgeRuntime, which, in turn, provides access to a
wealth of methods, many of which are quite useful for coding RHS
logic.
The call
kcontext.getKnowledgeRuntime().halt()terminates rule execution immediately.The accessor
getAgenda()returns a reference to this session'sAgenda, which in turn provides access to the various rule groups: activation groups, agenda groups, and rule flow groups. A fairly common paradigm is the activation of some agenda group, which could be done with the lengthy call:
// give focus to the agenda group CleanUp
kcontext.getKnowledgeRuntime().getAgenda().getAgendaGroup( "CleanUp" ).setFocus();(You can achieve the same using
drools.setFocus( "CleanUp" ).)To run a query, you call
getQueryResults(String query), whereupon you may process the results, as explained in section “Query”.A set of methods dealing with event management lets you, among other things, add and remove event listeners for the Working Memory and the Agenda.
Method
getKnowledgeBase()returns theKnowledgeBaseobject, the backbone of all the Knowledge in your system, and the originator of the current session.You can manage globals with
setGlobal(...),getGlobal(...)andgetGlobals().Method
getEnvironment()returns the runtime'sEnvironmentwhich works much like what you know as your operating system's environment.
This language extension provides a structured approach to fact
updates. It combines the update operation with a number of setter calls
to change the object's fields. This is the syntax schema for the
modify statement:
modify (<fact-expression>) {<expression>[,<expression>]*}
The parenthesized <fact-expression> must yield a fact object reference. The expression list in the block should consist of setter calls for the given object, to be written without the usual object reference, which is automatically prepended by the compiler.
The example illustrates a simple fact modification.
Example 5.71. A modify statement
rule "modify stilton"
when
$stilton : Cheese(type == "stilton")
then
modify( $stilton ){
setPrice( 20 ),
setAge( "overripe" )
}
endDrools attempts to preserve numbers in their primitive or object wrapper form, so a variable bound to an int primitive when used in a code block or expression will no longer need manual unboxing; unlike Drools 3.0 where all primitives were autoboxed, requiring manual unboxing. A variable bound to an object wrapper will remain as an object; the existing JDK 1.5 and JDK 5 rules to handle auto-boxing and unboxing apply in this case. When evaluating field constraints, the system attempts to coerce one of the values into a comparable format; so a primitive is comparable to an object wrapper.
A query is a simple way to search the working memory for facts that match the stated conditions. Therefore, it contains only the structure of the LHS of a rule, so that you specify neither "when" nor "then". A query has an optional set of parameters, each of which can be optionally typed. If the type is not given, the type Object is assumed. The engine will attempt to coerce the values as needed. Query names are global to the KnowledgeBase; so do not add queries of the same name to different packages for the same RuleBase.
To return the results use
ksession.getQueryResults("name"), where "name" is the query's
name. This returns a list of query results, which allow you to retrieve the
objects that matched the query.
The first example presents a simple query for all the people over the age of 30. The second one, using parameters, combines the age limit with a location.
Example 5.72. Query People over the age of 30
query "people over the age of 30"
person : Person( age > 30 )
endExample 5.73. Query People over the age of x, and who live in y
query "people over the age of x" (int x, String y)
person : Person( age > x, location == y )
endWe iterate over the returned QueryResults using a standard "for" loop. Each element is a QueryResultsRow which we can use to access each of the columns in the tuple. These columns can be accessed by bound declaration name or index position.
Example 5.74. Query People over the age of 30
QueryResults results = ksession.getQueryResults( "people over the age of 30" );
System.out.println( "we have " + results.size() + " people over the age of 30" );
System.out.println( "These people are are over 30:" );
for ( QueryResultsRow row : results ) {
Person person = ( Person ) row.get( "person" );
System.out.println( person.getName() + "\n" );
}Domain Specific Languages (or DSLs) are a way of creating a rule language that is dedicated to your problem domain. A set of DSL definitions consists of transformations from DSL "sentences" to DRL constructs, which lets you use of all the underlying rule language and engine features. Given a DSL, you write rules in DSL rule (or DSLR) files, which will be translated into DRL files.
DSL and DSLR files are plain text files, and you can use any text editor to create and modify them. But there are also DSL and DSLR editors, both in the IDE as well as in the web based BRMS, and you can use those as well, although they may not provide you with the full DSL functionality.
DSLs can serve as a layer of separation between rule authoring (and rule authors) and the technical intricacies resulting from the modelling of domain object and the rule engine's native language and methods. If your rules need to be read and validated by domain experts (such as business analysts, for instance) who are not programmers, you should consider using a DSL; it hides implementation details and focuses on the rule logic proper. DSL sentences can also act as "templates" for conditional elements and consequence actions that are used repeatedly in your rules, possibly with minor variations. You may define DSL sentences as being mapped to these repeated phrases, with parameters providing a means for accomodating those variations.
DSLs have no impact on the rule engine at runtime, they are just a compile time feature, requiring a special parser and transformer.
The Drools DSL mechanism allows you to customise conditional expressions and consequence actions. A global substitution mechanism ("keyword") is also available.
In the preceding example, [when] indicates the scope of
the expression, i.e., whether it is valid for the LHS or the RHS of a rule. The
part after the bracketed keyword is the expression that you use in the rule;
typically a natural language expression, but it doesn't have to be. The
part to the right of the equal sign ("=") is the mapping of the expression into
the rule language. The form of this string depends on its destination, RHS or
LHS. If it is for the LHS, then it ought to be a term according to the regular
LHS syntax; if it is for the RHS then it might be a Java statement.
Whenever the DSL parser matches a line from the rule file written in the
DSL with an expression in the DSL definition, it performs three steps of
string manipulation. First, it extracts the string values appearing where the
expression contains variable names in braces (here: {colour}). Then,
the values obtained from these captures are then interpolated wherever that name,
again enclosed in braces, occurs on the right hand side of the mapping. Finally, the
interpolated string replaces whatever was matched by the entire expression
in the line of the DSL rule file.
Note that the expressions (i.e., the strings on the left hand side of the equal sign) are used as regular expressions in a pattern matching operation against a line of the DSL rule file, matching all or part of a line. This means you can use (for instance) a '?' to indicate that the preceding character is optional. One good reason to use this is to overcome variations in natural language phrases of your DSL. But, given that these expressions are regular expression patterns, this also means that all "magic" characters of Java's pattern syntax have to be escaped with a preceding backslash ('\').
It is important to note that the compiler transforms DSL rule files line by line. In the above example, all the text after "Something is " to the end of the line is captured as the replacement value for "{colour}", and this is used for interpolating the target string. This may not be exactly what you want. For instance, when you intend to merge different DSL expressions to generate a composite DRL pattern, you need to transform a DSLR line in several independent operations. The best way to achieve this is to ensure that the captures are surrounded by characteristic text - words or even single characters. As a result, the matching operation done by the parser plucks out a substring from somewhere within the line. In the example below, quotes are used as distinctive characters. Note that the characters that surround the capture are not included during interpolation, just the contents between them.
As a rule of thumb, use quotes for textual data that a rule editor
may want to enter. You can also enclose the capture with words to ensure
that the text is correctly matched. Both is illustrated by the following
example. Note that a single line such as Something is "green" and
another solid thing is now correctly expanded.
Example 5.76. Example with quotes
[when]something is "{colour}"=Something(colour=="{colour}")
[when]another {state} thing=OtherThing(state=="{state}"It is a good idea to avoid punctuation (other than quotes or apostrophes) in your DSL expressions as much as possible. The main reason is that punctuation is easy to forget for rule authors using your DSL. Another reason is that parentheses, the period and the question mark are magic characters, requiring escaping in the DSL definition.
In a DSL mapping, the braces "{" and "}" should only be used to enclose a variable definition or reference, resulting in a capture. If they should occur literally, either in the expression or within the replacement text on the right hand side, they must be escaped with a preceding backslash ("\"):
[then]do something= if (foo) \{ doSomething(); \}
Note
If braces "{" and "}" should appear in the replacement string of a DSL definition, escape them with a backslash ('\').
Example 5.77. Examples of DSL mapping entries
# This is a comment to be ignored.
[when]There is a person with name of "{name}"=Person(name=="{name}")
[when]Person is at least {age} years old and lives in "{location}"=
Person(age >= {age}, location=="{location}")
[then]Log "{message}"=System.out.println("{message}");
[when]And = andGiven the above DSL examples, the following examples show the expansion of various DSLR snippets:
Example 5.78. Examples of DSL expansions
There is a person with name of "Kitty"
==> Person(name="Kitty")
Person is at least 42 years old and lives in "Atlanta"
==> Person(age >= 42, location="Atlanta")
Log "boo"
==> System.out.println("boo");
There is a person with name of "Bob" and Person is at least 30 years old and lives in "Utah"
==> Person(name="Bob") and Person(age >= 30, location="Utah")Note
Don't forget that if you are capturing plain text from a DSL rule line and want to use it as a string literal in the expansion, you must provide the quotes on the right hand side of the mapping.
You can chain DSL expressions together on one line, as long as it is clear to the parser where one ends and the next one begins and where the text representing a parameter ends. (Otherwise you risk getting all the text until the end of the line as a parameter value.) The DSL expressions are tried, one after the other, according to their order in the DSL definition file. After any match, all remaining DSL expressions are investigated, too.
The resulting DRL text may consist of more than one line. Line ends
are in the replacement text are written as \n.
A common requirement when writing rule conditions is to be able to add an arbitrary combination of constraints to a pattern. Given that a fact type may have many fields, having to provide an individual DSL statement for each combination would be plain folly.
The DSL facility allows you to add constraints to a pattern by a simple convention: if your DSL expression starts with a hyphen (minus character, "-") it is assumed to be a field constraint and, consequently, is is added to the last pattern line preceding it.
For an example, lets take look at class Cheese,
with the following fields: type, price, age and country. We can
express some LHS condition in normal DRL like the following
Cheese(age < 5, price == 20, type=="stilton", country=="ch")
The DSL definitions given below result in three DSL phrases which may be used to create any combination of constraint involving these fields.
[when]There is a Cheese with=Cheese()
[when]- age is less than {age}=age<{age}
[when]- type is '{type}'=type=='{type}'
[when]- country equal to '{country}'=country=='{country}'You can then write rules with conditions like the following:
There is a Cheese with
- age is less than 42
- type is 'stilton'The parser will pick up a line beginning with "-" and add it as a constraint to the preceding pattern, inserting a comma when it is required. For the preceding example, the resulting DRL is:
Cheese(age<42, type=='stilton')
Combining all all numeric fields with all relational operators (according to the DSL expression "age is less than..." in the preceding example) produces an unwieldy amount of DSL entries. But you can define DSL phrases for the various operators and even a generic expression that handles any field constraint, as shown below. (Notice that the expression definition contains a regular expression in addition to the variable name.)
[when][]is less than or equal to=<= [when][]is less than=< [when][]is greater than or equal to=>= [when][]is greater than=> [when][]is equal to=== [when][]equals=== [when][]There is a Cheese with=Cheese()[when][]- {field:\w*} {operator} {value:\d*}={field} {operator} {value}
Given these DSL definitions, you can write rules with conditions such as:
There is a Cheese with - age is less than 42 - rating is greater than 50 - type equals 'stilton'
In this specific case, a phrase such as "is less than" is replaced by
<, and then the line matches the last DSL entry. This
removes the hyphen, but the final result is still added as a constraint
to the preceding pattern. After processing all of the lines, the resulting
DRL text is:
Cheese(age<42, rating > 50, type=='stilton')
Note
The order of the entries in the DSL is important if separate DSL expressions are intended to match the same line, one after the other.
A good way to get started is to write representative samples of the rules your application requires, and to test them as you develop. This will provide you with a stable framework of conditional elements and their constraints. Rules, both in DRL and in DSLR, refer to entities according to the data model representing the application data that should be subject to the reasoning process defined in rules. Notice that writing rules is generally easier if most of the data model's types are facts.
Given an initial set of rules, it should be possible to identify recurring or similar code snippets and to mark variable parts as parameters. This provides reliable leads as to what might be a handy DSL entry. Also, make sure you have a full grasp of the jargon the domain experts are using, and base your DSL phrases on this vocabulary.
You may postpone implementation decisions concerning conditions and actions during this first design phase by leaving certain conditional elements and actions in their DRL form by prefixing a line with a greater sign (">"). (This is also handy for inserting debugging statements.)
During the next development phase, you should find that the DSL configuration stabilizes pretty quickly. New rules can be written by reusing the existing DSL definitions, or by adding a parameter to an existing condition or consequence entry.
Try to keep the number of DSL entries small. Using parameters lets you apply the same DSL sentence for similar rule patterns or constraints. But do not exaggerate: authors using the DSL should still be able to identify DSL phrases by some fixed text.
A DSL file is a text file in a line-oriented format. Its entries are used for transforming a DSLR file into a file according to DRL syntax.
A line starting with "#" or "//" (with or without preceding white space) is treated as a comment. A comment line starting with "#/" is scanned for words requesting a debug option, see below.
Any line starting with an opening bracket ("[") is assumed to be the first line of a DSL entry definition.
Any other line is appended to the preceding DSL entry definition, with the line end replaced by a space.
A DSL entry consists of the following four parts:
A scope definition, written as one of the keywords "when" or "condition", "then" or "consequence", "*" and "keyword", enclosed in brackets ("[" and "]"). This indicates whether the DSL entry is valid for the condition or the consequence of a rule, or both. A scope indication of "keyword" means that the entry has global significance, i.e., it is recognized anywhere in a DSLR file.
A type definition, written as a Java class name, enclosed in brackets. This part is optional unless the the next part begins with an opening bracket. An empty pair of brackets is valid, too.
A DSL expression consists of a (Java) regular expression, with any number of embedded variable definitions, terminated by an equal sign ("="). A variable definition is enclosed in braces ("{" and "}"). It consists of a variable name and two optional attachements, separated by colons (":"). If there is one attachment, it is a regular expression for matching text that is to be assigned to the variable; if there are two attachments, the first one is a hint for the GUI editor and the second one the regular expression.
Note that all characters that are "magic" in regular expressions must be escaped with a preceding backslash ("\") if they should occur literally within the expression.
The remaining part of the line after the delimiting equal sign is the replacement text for any DSLR text matching the regular expression. It may contain variable references, i.e., a variable name enclosed in braces. Optionally, the variable name may be followed by an exclamation mark ("!") and a transformation function, see below.
Note that braces ("{" and "}") must be escaped with a preceding backslash ("\") if they should occur literally within the replacement string.
Debugging of DSL expansion can be turned on, selectively, by using a comment line starting with "#/" which may contain one or more words from the table presented below. The resulting output is written to standard output.
Table 5.1. Debug options for DSL expansion
| Word | Description |
|---|---|
| result | Prints the resulting DRL text, with line numbers. |
| steps | Prints each expansion step of condition and consequence lines. |
| keyword | Dumps the internal representation of all DSL entries with scope "keyword". |
| when | Dumps the internal representation of all DSL entries with scope "when" or "*". |
| then | Dumps the internal representation of all DSL entries with scope "then" or "*". |
| usage | Displays a usage statistic of all DSL entries. |
Below are some sample DSL definitions, with comments describing the language features they illustrate.
# Comment: DSL examples
#/ debug: display result and usage
# keyword definition: replaces "regula" by "rule"
[keyword][]regula=rule
# conditional element: "T" or "t", "a" or "an", convert matched word
[when][][Tt]here is an? {entity:\w+}=
${entity!lc}: ${entity!ucfirst} ()
# consequence statement: convert matched word, literal braces
[then][]update {entity:\w+}=modify( ${entity!lc} )\{ \}
The transformation of a DSLR file proceeds as follows:
The text is read into memory.
Each of the "keyword" entries is applied to the entire text. First, the regular expression from the keyword definition is modified by replacing white space sequences with a pattern matching any number of white space characters, and by replacing variable definitions with a capture made from the regular expression provided with the definition, or with the default (".*?"). Then, the DSLR text is searched exhaustively for occurrences of strings matching the modified regular expression. Substrings of a matching string corresponding to variable captures are extracted and replace variable references in the corresponding replacement text, and this text replaces the matching string in the DSLR text.
Sections of the DSLR text between "when" and "then", and "then" and "end", respectively, are located and processed in a uniform manner, line by line, as described below.
For a line, each DSL entry pertaining to the line's section is taken in turn, in the order it appears in the DSL file. Its regular expression part is modified: white space is replaced by a pattern matching any number of white space characters; variable definitions with a regular expression are replaced by a capture with this regular expression, its default being ".*?". If the resulting regular expression matches all or part of the line, the matched part is replaced by the suitably modified replacement text.
Modification of the replacement text is done by replacing variable references with the text corresponding to the regular expression capture. This text may be modified according to the string transformation function given in the variable reference; see below for details.
If there is a variable reference naming a variable that is not defined in the same entry, the expander substitutes a value bound to a variable of that name, provided it was defined in one of the preceding lines of the current rule.
If a DSLR line in a condition is written with a leading hyphen, the expanded result is inserted into the last line, which should contain a pattern CE, i.e., a type name followed by a pair of parentheses. if this pair is empty, the expanded line (which should contain a valid constraint) is simply inserted, otherwise a comma (",") is inserted beforehand.
If a DSLR line in a consequence is written with a leading hyphen, the expanded result is inserted into the last line, which should contain a "modify" statement, ending in a pair of braces ("{" and "}"). If this pair is empty, the expanded line (which should contain a valid method call) is simply inserted, otherwise a comma (",") is inserted beforehand.
Note
It is currently not possible to use a line with a leading hyphen to insert text into other conditional element forms (e.g., "accumulate") or it may only work for the first insertion (e.g., "eval").
All string transformation functions are described in the following table.
Table 5.2. String transformation functions
| Name | Description |
|---|---|
| uc | Converts all letters to upper case. |
| lc | Converts all letters to lower case. |
| ucfirst | Converts the first letter to upper case, and all other letters to lower case. |
| num | Extracts all digits and "-" from the string. If the last two digits in the original string are preceded by "." or ",", a decimal period is inserted in the corresponding position. |
| a?b/c | Compares the string with string a, and if they are equal, replaces it with b, otherwise with c. But c can be another triplet a, b, c, so that the entire structure is, in fact, a translation table. |
The following DSL examples show how to use string transformation functions.
# definitions for conditions
[when][]There is an? {entity}=${entity!lc}: {entity!ucfirst}()
[when][]- with an? {attr} greater than {amount}={attr} <= {amount!num}
[when][]- with a {what} {attr}={attr} {what!positive?>0/negative?%lt;0/zero?==0/ERROR}A file containing a DSL definition is customarily given the extension
.dsl. It is passed to the Knowledge Builder with
ResourceType.DSL. For a file using DSL definition, the extension
.dslr should be used. The Knowledge Builder expects
ResourceType.DSLR. The IDE, however, relies on file extensions
to correctly recognize and work with your rules file.
The DSL must be passed to the Knowledge Builder ahead of any rules file using the DSL.
KnowledgeBuilder kBuilder = new KnowledgeBuilder(); Resource dsl = ResourceFactory.newClassPathResource( dslPath, getClass() ); kBuilder.add( dsl, ResourceType.DSL ); Resource dslr = ResourceFactory.newClassPathResource( dslrPath, getClass() ); kBuilder.add( dslr, ResourceType.DSLR );
For parsing and expanding a DSLR file the DSL configuration is read and supplied to the parser. Thus, the parser can "recognize" the DSL expressions and transform them into native rule language expressions.
As an option, Drools also supports a "native" rule language as an alternative to DRL. This allows you to capture and manage your rules as XML data. Just like the non-XML DRL format, the XML format is parsed into the internal "AST" representation - as fast as possible (using a SAX parser). There is no external transformation step required. All the features are available with XML that are available to DRL.
There are several scenarios that XML is desirable. However, we recommend that it is not a default choice, as XML is not readily human readable (unless you like headaches) and can create visually bloated rules.
If you do want to edit XML by hand, use a good schema aware editor that provides nice hierarchical views of the XML, ideally visually (commercial tools like XMLSpy, Oxygen etc are good, but cost money, but then so do headache tablets).
Other scenarios where you may want to use the XML format are if you have a tool that generates rules from some input (programmatically generated rules), or perhaps interchange from another rule language, or from another tool that emits XML (using XSLT you can easily transform between XML formats). Note you can always generate normal DRL as well.
Alternatively you may be embedding Drools in a product that already uses XML for configuration, so you would like the rules to be in an XML format. You may be creating your own rule language on XML - note that you can always use the AST objects directly to create your own rule language as well (the options are many, due to the open architecture).
A full W3C standards (XMLSchema) compliant XSD is provided that describes the XML language, which will not be repeated here verbatim. A summary of the language follows.
<?xml version="1.0" encoding="UTF-8"?>
<package name="com.sample"
xmlns="http://drools.org/drools-4.0"
xmlns:xs="http://www.w3.org/2001/XMLSchema-instance"
xs:schemaLocation="http://drools.org/drools-4.0 drools-4.0.xsd">
<import name="java.util.HashMap" />
<import name="org.drools.*" />
<global identifier="x" type="com.sample.X" />
<global identifier="yada" type="com.sample.Yada" />
<function return-type="void" name="myFunc">
<parameter identifier="foo" type="Bar" />
<parameter identifier="bada" type="Bing" />
<body>
System.out.println("hello world");
</body>
</function>
<rule name="simple_rule">
<rule-attribute name="salience" value="10" />
<rule-attribute name="no-loop" value="true" />
<rule-attribute name="agenda-group" value="agenda-group" />
<rule-attribute name="activation-group" value="activation-group" />
<lhs>
<pattern identifier="foo2" object-type="Bar" >
<or-constraint-connective>
<and-constraint-connective>
<field-constraint field-name="a">
<or-restriction-connective>
<and-restriction-connective>
<literal-restriction evaluator=">" value="60" />
<literal-restriction evaluator="<" value="70" />
</and-restriction-connective>
<and-restriction-connective>
<literal-restriction evaluator="<" value="50" />
<literal-restriction evaluator=">" value="55" />
</and-restriction-connective>
</or-restriction-connective>
</field-constraint>
<field-constraint field-name="a3">
<literal-restriction evaluator="==" value="black" />
</field-constraint>
</and-constraint-connective>
<and-constraint-connective>
<field-constraint field-name="a">
<literal-restriction evaluator="==" value="40" />
</field-constraint>
<field-constraint field-name="a3">
<literal-restriction evaluator="==" value="pink" />
</field-constraint>
</and-constraint-connective>
<and-constraint-connective>
<field-constraint field-name="a">
<literal-restriction evaluator="==" value="12"/>
</field-constraint>
<field-constraint field-name="a3">
<or-restriction-connective>
<literal-restriction evaluator="==" value="yellow"/>
<literal-restriction evaluator="==" value="blue" />
</or-restriction-connective>
</field-constraint>
</and-constraint-connective>
</or-constraint-connective>
</pattern>
<not>
<pattern object-type="Person">
<field-constraint field-name="likes">
<variable-restriction evaluator="==" identifier="type"/>
</field-constraint>
</pattern>
<exists>
<pattern object-type="Person">
<field-constraint field-name="likes">
<variable-restriction evaluator="==" identifier="type"/>
</field-constraint>
</pattern>
</exists>
</not>
<or-conditional-element>
<pattern identifier="foo3" object-type="Bar" >
<field-constraint field-name="a">
<or-restriction-connective>
<literal-restriction evaluator="==" value="3" />
<literal-restriction evaluator="==" value="4" />
</or-restriction-connective>
</field-constraint>
<field-constraint field-name="a3">
<literal-restriction evaluator="==" value="hello" />
</field-constraint>
<field-constraint field-name="a4">
<literal-restriction evaluator="==" value="null" />
</field-constraint>
</pattern>
<pattern identifier="foo4" object-type="Bar" >
<field-binding field-name="a" identifier="a4" />
<field-constraint field-name="a">
<literal-restriction evaluator="!=" value="4" />
<literal-restriction evaluator="!=" value="5" />
</field-constraint>
</pattern>
</or-conditional-element>
<pattern identifier="foo5" object-type="Bar" >
<field-constraint field-name="b">
<or-restriction-connective>
<return-value-restriction evaluator="==" >a4 + 1</return-value-restriction>
<variable-restriction evaluator=">" identifier="a4" />
<qualified-identifier-restriction evaluator="==">
org.drools.Bar.BAR_ENUM_VALUE
</qualified-identifier-restriction>
</or-restriction-connective>
</field-constraint>
</pattern>
<pattern identifier="foo6" object-type="Bar" >
<field-binding field-name="a" identifier="a4" />
<field-constraint field-name="b">
<literal-restriction evaluator="==" value="6" />
</field-constraint>
</pattern>
</lhs>
<rhs>
if ( a == b ) {
assert( foo3 );
} else {
retract( foo4 );
}
System.out.println( a4 );
</rhs>
</rule>
</package>
In the preceding XML text you will see the typical XML element, the package declaration, imports, globals, functions, and the rule itself. Most of the elements are self explanatory if you have some understanding of the Drools features.
The import elements import the types you wish to
use in the rule.
The global elements define global objects that can
be referred to in the rules.
The function contains a function declaration, for
a function to be used in the rules. You have to specify a return type,
a unique name and parameters, in the body goes a snippet of code.
The rule is discussed below.
Example 5.80. Detail of rule element
<rule name="simple_rule">
<rule-attribute name="salience" value="10" />
<rule-attribute name="no-loop" value="true" />
<rule-attribute name="agenda-group" value="agenda-group" />
<rule-attribute name="activation-group" value="activation-group" />
<lhs>
<pattern identifier="cheese" object-type="Cheese">
<from>
<accumulate>
<pattern object-type="Person"></pattern>
<init>
int total = 0;
</init>
<action>
total += $cheese.getPrice();
</action>
<result>
new Integer( total ) );
</result>
</accumulate>
</from>
</pattern>
<pattern identifier="max" object-type="Number">
<from>
<accumulate>
<pattern identifier="cheese" object-type="Cheese"></pattern>
<external-function evaluator="max" expression="$price"/>
</accumulate>
</from>
</pattern>
</lhs>
<rhs>
list1.add( $cheese );
</rhs>
</rule>
In the above detail of the rule we see that the rule has LHS and RHS (conditions and consequence) sections. The RHS is simple, it is just a block of semantic code that will be executed when the rule is activated. The LHS is slightly more complicated as it contains nested elements for conditional elements, constraints and restrictions.
A key element of the LHS is the Pattern element. This allows you to specify a type (class) and perhaps bind a variable to an instance of that class. Nested under the pattern object are constraints and restrictions that have to be met. The Predicate and Return Value constraints allow Java expressions to be embedded.
That leaves the conditional elements, not, exists, and, or etc. They work like their DRL counterparts. Elements that are nested under and an "and" element are logically "anded" together. Likewise with "or" (and you can nest things further). "Exists" and "Not" work around patterns, to check for the existence or nonexistence of a fact meeting the pattern's constraints.
The Eval element allows the execution of a valid snippet of Java code - as long as it evaluates to a boolean (do not end it with a semi-colon, as it is just a fragment) - this can include calling a function. The Eval is less efficient than the columns, as the rule engine has to evaluate it each time, but it is a "catch all" feature for when you can express what you need to do with Column constraints.
The Drools 2.x legacy XML format is no longer supported by Drools XML parser
Drools comes with some utility classes to transform between formats. This works by parsing the rules from the source format into the AST, and then "dumping" out to the appropriate target format. This allows you, for example, to write rules in DRL, and when needed, export to XML if necessary at some point in the future.
The classes to look at if you need to do this are:
XmlDumper - for exporting XML. DrlDumper - for exporting DRL. DrlParser - reading DRL. XmlPackageReader - reading XML.
Using combinations of the above, you can convert between any format (including round trip). Note that DSLs will not be preserved (from DRLs that are using a DSL) - but they will be able to be converted.
Feel free to make use of XSLT to provide all sorts of possibilities for XML, XSLT and its ilk are what make XML powerful.