- 5.1. 映射定义(Mapping declaration)
- 5.1.1. Doctype
- 5.1.2. Hibernate-mapping
- 5.1.3. 类
- 5.1.4. id
- 5.1.5. 增强的标识符生成器
- 5.1.6. 标识符生成器的优化
- 5.1.7. composite-id
- 5.1.8. 鉴别器(discriminator)
- 5.1.9. 版本(version)(可选)
- 5.1.10. timestamp(可选)
- 5.1.11. Property
- 5.1.12. 多对一(many-to-one)
- 5.1.13. 一对一
- 5.1.14. 自然 ID(natural-id)
- 5.1.15. 组件(component)和动态组件(dynamic-component)
- 5.1.16. 属性(Properties)
- 5.1.17. 子类(subclass)
- 5.1.18. 连接的子类(joined-subclass)
- 5.1.19. 联合子类(union-subclass)
- 5.1.20. 连接(join)
- 5.1.21. Key
- 5.1.22. 字段和规则元素(column and formula elements)
- 5.1.23. 引用(import)
- 5.1.24. Any
- 5.2. Hibernate 的类型
- 5.3. 多次映射同一个类
- 5.4. SQL 中引号包围的标识符
- 5.5. 其他元数据(Metadata)
- 5.6. 数据库生成属性(Generated Properties)
- 5.7. 字段的读写表达式
- 5.8. 辅助数据库对象(Auxiliary Database Objects)
对象和关系数据库之间的映射通常是用一个 XML 文档来定义的。这个映射文档被设计为易读的,并且可以手工修改。映射语言是以 Java 为中心,这意味着映射文档是按照持久化类的定义来创建的,而非表的定义。
请注意,虽然很多 Hibernate 用户选择手写 XML 映射文档,但也有一些工具可以用来生成映射文档,包括 XDoclet、Middlegen 和 AndroMDA。
下面是一个映射的例子:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="eg">
<class name="Cat"
table="cats"
discriminator-value="C">
<id name="id">
<generator class="native"/>
</id>
<discriminator column="subclass"
type="character"/>
<property name="weight"/>
<property name="birthdate"
type="date"
not-null="true"
update="false"/>
<property name="color"
type="eg.types.ColorUserType"
not-null="true"
update="false"/>
<property name="sex"
not-null="true"
update="false"/>
<property name="litterId"
column="litterId"
update="false"/>
<many-to-one name="mother"
column="mother_id"
update="false"/>
<set name="kittens"
inverse="true"
order-by="litter_id">
<key column="mother_id"/>
<one-to-many class="Cat"/>
</set>
<subclass name="DomesticCat"
discriminator-value="D">
<property name="name"
type="string"/>
</subclass>
</class>
<class name="Dog">
<!-- mapping for Dog could go here -->
</class>
</hibernate-mapping
>
我们现在开始讨论映射文档的内容。我们只描述 Hibernate 在运行时用到的文档元素和属性。映射文档还包括一些额外的可选属性和元素,它们在使用 schema 导出工具的时候会影响导出的数据库 schema 结果(比如,not-null 属性)。
所有的 XML 映射都需要定义如上所示的 doctype。DTD 可以从上述 URL 中获取,也可以从 hibernate-x.x.x/src/org/hibernate 目录中、或 hibernate.jar 文件中找到。Hibernate 总是会首先在它的 classptah 中搜索 DTD 文件。如果你发现它是通过连接 Internet 查找 DTD 文件,就对照你的 classpath 目录检查 XML 文件里的 DTD 声明。
Hibernate 首先试图在其 classpath 中解析 DTD。这是依靠在系统中注册的 org.xml.sax.EntityResolver 的一个具体实现,SAXReader 依靠它来读取 xml 文件。这个自定义的 EntityResolver 能辨认两种不同的 systenId 命名空间:
若 resolver 遇到了一个以
http://hibernate.sourceforge.net/为开头的 systemId,它会辨认出是hibernate namespace,resolver 就试图通过加载 Hibernate 类的 classloader 来查找这些实体。若 resolver 遇到了一个使用
classpath://URL 协议的 systemId,它会辨认出这是user namespace,resolver 试图通过(1) 当前线程上下文的 classloader 和(2) 加载 Hibernate class 的 classloader 来查找这些实体。
下面是一个使用用户命名空间(user namespace)的例子:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC '-//Hibernate/Hibernate Mapping DTD 3.0//EN' 'http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd' [
<!ENTITY version "3.5.6-Final">
<!ENTITY today "September 15, 2010">
<!ENTITY types SYSTEM "classpath://your/domain/types.xml">
]>
<hibernate-mapping package="your.domain">
<class name="MyEntity">
<id name="id" type="my-custom-id-type">
...
</id>
<class>
&types;
</hibernate-mapping>
这里的 types.xml 是 your.domain 包中的一个资源,它包含了一个自定义的 typedef。
这个元素包括一些可选的属性。schema 和 catalog 属性, 指明了这个映射所连接(refer)的表所在的 schema 和/或 catalog 名称。假若指定了这个属性,表名会加上所指定的 schema 和 catalog 的名字扩展为全限定名。假若没有指定,表名就不会使用全限定名。default-cascade 指定了未明确注明 cascade 属性的 Java 属性和 集合类 Hibernate 会采取什么样的默认级联风格。auto-import 属性默认让我们在查询语言中可以使用非全限定名的类名。
<hibernate-mapping
schem a="schemaName"
catal
a="schemaName"
catal og="catalogName"
defau
og="catalogName"
defau lt-cascade="cascade_style"
defau
lt-cascade="cascade_style"
defau lt-access="field|property|ClassName"
defau
lt-access="field|property|ClassName"
defau lt-lazy="true|false"
auto-
lt-lazy="true|false"
auto- import="true|false"
packa
import="true|false"
packa ge="package.name"
/>
ge="package.name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
假若你有两个持久化类,它们的非全限定名是一样的(就是两个类的名字一样,所在的包不一样 — 译者注),你应该设置 auto-import="false"。如果你把一个“导入过”的名字同时对应两个类,Hibernate 会抛出一个异常。
注意 hibernate-mapping 元素允许你嵌套多个如上所示的 <class> 映射。但是最好的做法(也许一些工具需要的)是一个持久化类(或一个类的继承层次)对应一个映射文件,并以持久化的超类名称命名,例如:Cat.hbm.xml、Dog.hbm.xml,或者如果使用继承,Animal.hbm.xml。
你可以使用 class 元素来定义一个持久化类。例如:
<class
name="ClassName"
table="tableName"
discriminator-value="discriminator_value"
mutable="true|false"
schema="owner"
catalog="catalog"
proxy="ProxyInterface"
dynami c-update="true|false"
dynami
c-update="true|false"
dynami c-insert="true|false"
select
c-insert="true|false"
select -before-update="true|false"
polymo
-before-update="true|false"
polymo rphism="implicit|explicit"
where=
rphism="implicit|explicit"
where= "arbitrary sql where condition"
persis
"arbitrary sql where condition"
persis ter="PersisterClass"
batch-
ter="PersisterClass"
batch-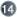 size="N"
optimi
size="N"
optimi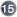 stic-lock="none|version|dirty|all"
lazy="(16)true|false"
entity(17)-name="EntityName"
check=(18)"arbitrary sql check condition"
rowid=(19)"rowid"
subsel(20)ect="SQL expression"
abstra(21)ct="true|false"
node="element-name"
/>
stic-lock="none|version|dirty|all"
lazy="(16)true|false"
entity(17)-name="EntityName"
check=(18)"arbitrary sql check condition"
rowid=(19)"rowid"
subsel(20)ect="SQL expression"
abstra(21)ct="true|false"
node="element-name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(16) |
|
(17) |
|
(18) |
|
(19) |
|
(20) |
|
(21) |
|
若指明的持久化类实际上是一个接口,这也是完全可以接受的。之后你可以用元素 <subclass> 来指定该接口的实际实现类。你可以持久化任何 static(静态的)内部类。你应该使用标准的类名格式来指定类名,比如:Foo$Bar。
不可变类,mutable="false" 不可以被应用程序更新或者删除。这允许 Hibernate 实现一些小小的性能优化。
可选的 proxy 属性允许延迟加载类的持久化实例。Hibernate 开始会返回实现了这个命名接口的 CGLIB 代理。当代理的某个方法被实际调用的时候,真实的持久化对象才会被装载。参见下面的“用于延迟装载的代理”。
Implicit(隐式)的多态是指,如果查询时给出的是任何超类、该类实现的接口或者该类的名字,都会返回这个类的实例;如果查询中给出的是子类的名字,则会返回子类的实例。Explicit(显式)的多态是指,只有在查询时给出明确的该类名字时才会返回这个类的实例; 同时只有在这个 <class> 的定义中作为 <subclass> 或者 <joined-subclass> 出现的子类,才会可能返回。在大多数情况下,默认的 polymorphism="implicit" 都是合适的。显式的多态在有两个不同的类映射到同一个表的时候很有用。(允许一个“轻量级”的类,只包含部分表字段)。
persister 属性可以让你定制这个类使用的持久化策略。你可以指定你自己实现 org.hibernate.persister.EntityPersister 的子类,你甚至可以完全从头开始编写一个 org.hibernate.persister.ClassPersister 接口的实现,比如是用储存过程调用、序列化到文件或者 LDAP 数据库来实现。参阅 org.hibernate.test.CustomPersister,这是持久化到 Hashtable 的一个简单例子。
请注意 dynamic-update 和 dynamic-insert 的设置并不会继承到子类,所以在 <subclass> 或者 <joined-subclass> 元素中可能需要再次设置。这些设置在某些情况下能够提高效率,而其他情况下则反而可能降低性能。
使用 select-before-update 通常会降低性能。如果你重新连接一个脱管(detached)对象实例 到一个 Session 中时,它可以防止数据库不必要的触发 update。这就很有用了。
如果你打开了dynamic-update,你可以选择几种乐观锁定的策略:
version(版本检查):检查 version/timestamp 字段all(全部):检查全部字段dirty(脏检查):只检察修改过的字段,允许某些并行更新none(不检查):不使用乐观锁定
我们强烈建议你在 Hibernate 中使用 version/timestamp 字段来进行乐观锁定。这个选择可以优化性能,且能够处理对脱管实例的修改(例如:在使用 Session.merge() 的时候)。
对 Hibernate 映射来说视图和表是没有区别的,这是因为它们在数据层都是透明的( 注意:一些数据库不支持视图属性,特别是更新的时候)。有时你想使用视图,但却不能在数据库中创建它(例如:在遗留的 schema 中)。这样的话,你可以映射一个不可变的(immutable)并且是 只读的实体到一个给定的 SQL 子查询表达式:
<class name="Summary">
<subselect>
select item.name, max(bid.amount), count(*)
from item
join bid on bid.item_id = item.id
group by item.name
</subselect>
<synchronize table="item"/>
<synchronize table="bid"/>
<id name="name"/>
...
</class
>
定义这个实体用到的表为同步(synchronize),确保自动刷新(auto-flush)正确执行,并且依赖原实体的查询不会返回过期数据。在属性元素和嵌套映射元素中都可使用 <subselect>。
被映射的类必须定义对应数据库表主键字段。大多数类有一个 JavaBeans 风格的属性, 为每一个实例包含唯一的标识。<id> 元素定义了该属性到数据库表主键字段的映射。
<id
name="propertyName"
type="typename"
column="column_name"
unsaved-value="null|any|none|undefined|id_value"
access="field|property|ClassName">
node="element-name|@attribute-name|element/@attribute|."
<generator class="generatorClass"/>
</id
>
|
|
|
|
|
|
|
|
|
|
如果 name 属性不存在,会认为这个类没有标识属性。
unsaved-value 属性在 Hibernate3 中几乎不再需要。
还有一个另外的 <composite-id> 定义可以访问旧式的多主键数据。我们非常不鼓励使用这种方式。
可选的 <generator> 子元素是一个 Java 类的名字,用来为该持久化类的实例生成唯一的标识。如果这个生成器实例需要某些配置值或者初始化参数,用 <param> 元素来传递。
<id name="id" type="long" column="cat_id">
<generator class="org.hibernate.id.TableHiLoGenerator">
<param name="table"
>uid_table</param>
<param name="column"
>next_hi_value_column</param>
</generator>
</id
>
所有的生成器都实现 org.hibernate.id.IdentifierGenerator 接口。这是一个非常简单的接口;某些应用程序可以选择提供他们自己特定的实现。当然,Hibernate 提供了很多内置的实现。下面是一些内置生成器的快捷名字:
increment用于为
long,short或者int类型生成 唯一标识。只有在没有其他进程往同一张表中插入数据时才能使用。在集群下不要使用。identity对 DB2,MySQL,MS SQL Server,Sybase 和 HypersonicSQL 的内置标识字段提供支持。返回的标识符是
long,short或者int类型的。sequence在 DB2,PostgreSQL,Oracle,SAP DB,McKoi 中使用序列(sequence), 而在 Interbase 中使用生成器(generator)。返回的标识符是
long,short或者int类型的。hilo使用一个高/低位算法高效的生成
long,short或者int类型的标识符。给定一个表和字段(默认分别是hibernate_unique_key和next_hi)作为高位值的来源。高/低位算法生成的标识符只在一个特定的数据库中是唯一的。seqhilo使用一个高/低位算法来高效的生成
long,short或者int类型的标识符,给定一个数据库序列(sequence)的名字。uuid用一个 128-bit 的 UUID 算法生成字符串类型的标识符,这在一个网络中是唯一的(使用了 IP 地址)。UUID 被编码为一个 32 位 16 进制数字的字符串。
guid在 MS SQL Server 和 MySQL 中使用数据库生成的 GUID 字符串。
native根据底层数据库的能力选择
identity、sequence或者hilo中的一个。assigned让应用程序在调用
save()之前为对象分配一个标识符。这是<generator>元素没有指定时的默认生成策略。select通过数据库触发器选择一些唯一主键的行并返回主键值来分配一个主键。
foreign使用另外一个相关联的对象的标识符。它通常和
<one-to-one>联合起来使用。sequence-identity一种特别的序列生成策略,它使用数据库序列来生成实际值,但将它和 JDBC3 的 getGeneratedKeys 结合在一起,使得在插入语句执行的时候就返回生成的值。目前为止只有面向 JDK 1.4 的 Oracle 10g 驱动支持这一策略。由于 Oracle 驱动程序的一个 bug,这些插入语句的注释被关闭了。
hilo 和 seqhilo 生成器给出了两种 hi/lo 算法的实现, 这是一种很令人满意的标识符生成算法。第一种实现需要一个“特殊”的数据库表来保存下一个可用的“hi”值。 第二种实现使用一个 Oracle 风格的序列(在被支持的情况下)。
<id name="id" type="long" column="cat_id">
<generator class="hilo">
<param name="table"
>hi_value</param>
<param name="column"
>next_value</param>
<param name="max_lo"
>100</param>
</generator>
</id
>
<id name="id" type="long" column="cat_id">
<generator class="seqhilo">
<param name="sequence"
>hi_value</param>
<param name="max_lo"
>100</param>
</generator>
</id
>
可惜的是,你在为 Hibernate 自行提供 Connection 时无法使用 hilo。 当 Hibernate 使用 JTA 获取应用服务器的数据源连接时,你必须正确地配置 hibernate.transaction.manager_lookup_class。
UUID 包含:IP 地址、JVM 的启动时间(精确到 1/4 秒)、系统时间和一个计数器值(在 JVM 中唯一)。 在 Java 代码中不可能获得 MAC 地址或者内存地址,所以这已经是我们在不使用 JNI 的前提下的能做的最好实现了。
对于内部支持标识字段的数据库(DB2、MySQL、Sybase 和 MS SQL),你可以使用 identity 关键字生成。对于内部支持序列的数据库(DB2、Oracle、PostgreSQL、Interbase、McKoi 和 SAP DB),你可以使用 sequence 风格的关键字生成。这两种方式对于插入一个新的对象都需要两次 SQL 查询。例如:
<id name="id" type="long" column="person_id">
<generator class="sequence">
<param name="sequence"
>person_id_sequence</param>
</generator>
</id
>
<id name="id" type="long" column="person_id" unsaved-value="0">
<generator class="identity"/>
</id
>
对于跨平台开发,native 策略会从 identity、sequence 和 hilo 中进行选择,选择哪一个,这取决于底层数据库的支持能力。
如果你需要应用程序分配一个标示符(而非 Hibernate 来生成),你可以使用 assigned 生成器。这种特殊的生成器会使用已经分配给对象的标识符属性的标识符值。 这个生成器使用一个自然键(natural key,有商业意义的列-译注)作为主键,而不是使用一个代理键( surrogate key,没有商业意义的列-译注)。这是没有指定 <generator> 元素时的默认行为。
当选择 assigned 生成器时,除非有一个 version 或 timestamp 属性,或者你定义了 Interceptor.isUnsaved(),否则需要让 Hiberante 使用 unsaved-value="undefined",强制 Hibernatet 查询数据库来确定一个实例是瞬时的(transient) 还是脱管的(detached)。
仅仅用于遗留的 schema 中(Hibernate 不能用触发器生成 DDL)。
<id name="id" type="long" column="person_id">
<generator class="select">
<param name="key"
>socialSecurityNumber</param>
</generator>
</id
>
在上面的例子中,类定义了一个命名为 socialSecurityNumber 的具有唯一值的属性,它是一个自然键(natural key),命名为 person_id 的代理键(surrogate key)的值由触发器生成。
从 3.2.3 版本开始,有两个代表不同标识符生成概念的新的生成器。第一个概念是数据库移植性;第二个是优化。优化表示你不需对每个新标识符的请求都查询数据库。从 3.3.x 开始,这两个新的生成器都是用来取代上面所述的生成器的。然而,它们也包括在当前版本里且可以由 FQN 进行引用。
这些生成器的第一个是 org.hibernate.id.enhanced.SequenceStyleGenerator,首先,它是作为 sequence 生成器的替代物,其次,它是比 native 具有更好移植性的生成器。这是因为 native 通常在 identity 和 sequence 之间选择,它有差别很大的 semantic,在移植时会导致潜在的问题。然而,org.hibernate.id.enhanced.SequenceStyleGenerator 以不同的方式实现移植性。它根据所使用的方言的能力,在数据库表或序列之间选择以存储其增量。这和 native 的区别是基于表或序列的存储具有恰好相同的 semantic。实际上,序列就是 Hibernate 试图用基于表的生成器来模拟的。这个生成器有如下的配置参数:
sequence_name(可选 — 默认为hibernate_sequence):序列或表的名字initial_value(可选,默认为1):从序列/表里获取的初始值。按照序列创建的术语,这等同于子句 "STARTS WITH"。increment_size(可选 - 缺省为1):对序列/表的调用应该区分的值。按照序列创建的术语,这等同于子句 "INCREMENT BY"。force_table_use(可选 - 缺省为false):即使方言可能支持序列,是否也应该强制把表用作后台结构。value_column(可选 - 缺省为next_val):只和表结构相关,它是用于保存值的字段的名称。optimizer(optional - defaults tonone): See 第 5.1.6 节 “标识符生成器的优化”
新生成器的第二个是 org.hibernate.id.enhanced.TableGenerator,它的目的首先是替代 table 生成器,即使它实际上比 org.hibernate.id.MultipleHiLoPerTableGenerator 功能要强得多;其次,作为利用可插拔 optimizer 的 org.hibernate.id.MultipleHiLoPerTableGenerator 的替代品。基本上这个生成器定义了一个可以利用多个不同的键值记录存储大量不同增量值的表。这个生成器有如下的配置参数:
table_name(可选 — 默认是hibernate_sequences):所用的表的名称。value_column_name(可选 — 默认为next_val):用于存储这些值的表的字段的名字。segment_column_name(可选,默认为sequence_name):用于保存 "segment key" 的字段的名称。这是标识使用哪个增量值的值。segment_value(可选,默认为default):我们为这个生成器获取增量值的 segment 的 "segment key"。segment_value_length(可选 — 默认为255):用于 schema 生成;创建 Segment Key 字段的字段大小。initial_value(可选 — 默认是1):从表里获取的初始值。increment_size(可选 — 默认是1):对表随后的调用应该区分的值。optimizer(optional - defaults to): See 第 5.1.6 节 “标识符生成器的优化”
For identifier generators that store values in the database, it is inefficient for them to hit the database on each and every call to generate a new identifier value. Instead, you can group a bunch of them in memory and only hit the database when you have exhausted your in-memory value group. This is the role of the pluggable optimizers. Currently only the two enhanced generators (第 5.1.5 节 “增强的标识符生成器” support this operation.
none(如果没有指定 optimizer,通常这是缺省配置):这不会执行任何优化,在每次请求时都访问数据库。hilo:对从数据库获取的值应用 hi/lo 算法。用于这个 optimizer 的从数据库获取的值应该是有序的。它们表明“组编号”。increment_size将乘以内存里的值来定义组的“hi 值”。pooled:和hilo一样,这个 optimizer 试图最小化对数据库的访问。然而,我们只是简单地把“下一组”的起始值而不是把序列值和分组算法的组合存入到数据库结构里。在这里,increment_size表示数据库里的值。
<composite-id
name="propertyName"
class="ClassName"
mapped="true|false"
access="field|property|ClassName">
node="element-name|."
<key-property name="propertyName" type="typename" column="column_name"/>
<key-many-to-one name="propertyName" class="ClassName" column="column_name"/>
......
</composite-id
>
如果表使用联合主键,你可以映射类的多个属性为标识符属性。<composite-id> 元素接受 <key-property> 属性映射和 <key-many-to-one> 属性映射作为子元素。
<composite-id>
<key-property name="medicareNumber"/>
<key-property name="dependent"/>
</composite-id
>
你的持久化类必须覆盖 equals() 和 hashCode() 方法,来实现组合的标识符的相等判断。实现 Serializable 接口也是必须的。
不幸的是,这种组合关键字的方法意味着一个持久化类是它自己的标识。除了对象自己之外,没有什么方便的“把手”可用。你必须初始化持久化类的实例,填充它的标识符属性,再 load() 组合关键字关联的持久状态。我们把这种方法称为 embedded(嵌入式)的组合标识符,在重要的应用中不鼓励使用这种用法。
第二种方法我们称为 mapped(映射式)组合标识符(mapped composite identifier),<composite-id> 元素中列出的标识属性不但在持久化类出现,还形成一个独立的标识符类。
<composite-id class="MedicareId" mapped="true">
<key-property name="medicareNumber"/>
<key-property name="dependent"/>
</composite-id
>
在这个例子中,组合标识符类 MedicareId 和实体类都含有 medicareNumber 和 dependent 属性。标识符类必须重载 equals() 和 hashCode() 并且实现 Serializable 接口。这种方法的缺点是出现了明显的代码重复。
下面列出的属性是用来指定一个映射式组合标识符的:
mapped(可选,默认为false):指明使用一个映射式组合标识符,其包含的属性映射同时在实体类和组合标识符类中出现。class(可选,但对映射式组合标识符必须指定):作为组合标识符类使用的类名。
We will describe a third, even more convenient approach, where the composite identifier is implemented as a component class in 第 8.4 节 “组件作为联合标识符(Components as composite identifiers)”. The attributes described below apply only to this alternative approach:
name(可选,但对这种方法而言必须):包含此组件标识符的组件类型的名字(参阅第 9 章)。access(可选 — 默认为property):Hibernate 用来访问属性值的策略。class(可选 — 默认会用反射来自动判定属性类型 ):用来作为组合标识符的组件类的类名(参阅下一节)。
第三种方式,被称为 identifier component(标识符组件)是我们对几乎所有应用都推荐使用的方式。
在"一棵对象继承树对应一个表"的策略中,<discriminator> 元素是必需的,它定义了表的鉴别器字段。鉴别器字段包含标志值,用于告知持久化层应该为某个特定的行创建哪一个子类的实例。如下这些受到限制的类型可以使用:string、character、integer、byte、short、boolean、yes_no、true_false。
<discriminator
column="discriminator_column"
type="discriminator_type"
force="true|false"
insert="true|false"
formula="arbitrary sql expression"
/>
|
|
|
|
|
|
|
|
|
|
鉴别器字段的实际值是根据 <class> 和 <subclass> 元素中的 discriminator-value 属性得来的。
force 属性仅仅在这种情况下有用的:表中包含没有被映射到持久化类的附加辨别器值。这种情况不会经常遇到。
使用 formula 属性你可以定义一个 SQL 表达式,用来判断一行数据的类型。
<discriminator
formula="case when CLASS_TYPE in ('a', 'b', 'c') then 0 else 1 end"
type="integer"/>
<version> 元素是可选的,表明表中包含附带版本信息的数据。这在你准备使用 长事务(long transactions)的时候特别有用。下面是更多信息:
<version
column="version_column"
name="propertyName"
type="typename"
access="field|property|ClassName"
unsaved-value="null|negative|undefined"
generated="never|always"
insert="true|false"
node="element-name|@attribute-name|element/@attribute|."
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
版本号必须是以下类型:long、integer、short、timestamp 或者 calendar。
一个脱管(detached)实例的 version 或 timestamp 属性不能为空(null),因为 Hibernate 不管 unsaved-value 被指定为何种策略,它将任何属性为空的 version 或 timestamp 实例看作为瞬时(transient)实例。 避免 Hibernate 中的传递重附(transitive reattachment)问题的一个简单方法是 定义一个不能为空的 version 或 timestamp 属性,特别是在人们使用程序分配的标识符(assigned identifiers) 或复合主键时非常有用。
可选的 <timestamp> 元素指明了表中包含时间戳数据。这用来作为版本的替代。时间戳本质上是一种对乐观锁定的一种不是特别安全的实现。当然,有时候应用程序可能在其他方面使用时间戳。
<timestamp
column="timestamp_column"
name="propertyName"
access="field|property|ClassName"
unsaved-value="null|undefined"
source="vm|db"
generated="never|always"
node="element-name|@attribute-name|element/@attribute|."
/>
|
|
|
|
|
|
|
|
|
|
|
|
注意
注意,<timestamp> 和 <version type="timestamp"> 是等价的。并且 <timestamp source="db"> 和 <version type="dbtimestamp"> 是等价的。
<property> 元素为类定义了一个持久化的、JavaBean 风格的属性。
<property
name="propertyName"
column="column_name"
type="typename"
update="true|false"
insert="true|false"
formula="arbitrary SQL expression"
access="field|property|ClassName"
lazy="true|false"
unique="true|false"
not-null="true|false"
optimistic-lock="true|false"
generated="never|insert|always"
node="element-name|@attribute-name|element/@attribute|."
index="index_name"
unique_key="unique_key_id"
length="L"
precision="P"
scale="S"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
typename 可以是如下几种:
Hibernate 基本类型名(比如:
integer, string, character,date, timestamp, float, binary, serializable, object, blob)。一个 Java 类的名字,这个类属于一种默认基础类型(比如:
int, float,char, java.lang.String, java.util.Date, java.lang.Integer, java.sql.Clob)。一个可以序列化的 Java 类的名字。
一个自定义类型的类的名字。(比如:
com.illflow.type.MyCustomType)。
如果你没有指定类型,Hibernarte 会使用反射来得到这个名字的属性,以此来猜测正确的 Hibernate 类型。Hibernate 会按照规则 2,3,4 的顺序对属性读取器(getter方法)的返回类进行解释。然而,这还不够。 在某些情况下你仍然需要 type 属性。(比如,为了区别Hibernate.DATE 和Hibernate.TIMESTAMP,或者为了指定一个自定义类型。)
access 属性用来让你控制 Hibernate 如何在运行时访问属性。在默认情况下,Hibernate 会使用属性的 get/set 方法对(pair)。如果你指明 access="field",Hibernate 会忽略 get/set 方法对,直接使用反射来访问成员变量。你也可以指定你自己的策略,这就需要你自己实现 org.hibernate.property.PropertyAccessor 接口,再在 access 中设置你自定义策略类的名字。
衍生属性(derive propertie)是一个特别强大的特征。这些属性应该定义为只读,属性值在装载时计算生成。 你用一个 SQL 表达式生成计算的结果,它会在这个实例转载时翻译成一个 SQL 查询的 SELECT 子查询语句。
<property name="totalPrice"
formula="( SELECT SUM (li.quantity*p.price) FROM LineItem li, Product p
WHERE li.productId = p.productId
AND li.customerId = customerId
AND li.orderNumber = orderNumber )"/>
注意,你可以使用实体自己的表,而不用为这个特别的列定义别名(上面例子中的 customerId)。同时注意,如果你不喜欢使用属性, 你可以使用嵌套的 <formula> 映射元素。
通过 many-to-one 元素,可以定义一种常见的与另一个持久化类的关联。这种关系模型是多对一关联(实际上是一个对象引用-译注):这个表的一个外键引用目标表的主键字段。
<many-to-one
name="propertyName"
column="column_name"
class="ClassName"
cascade="cascade_style"
fetch="join|select"
update="true|false"
insert="true|false"
property-ref="propertyNameFromAssociatedClass"
access="field|property|ClassName"
unique="true|false"
not-null="true|false"
optimistic-lock="true|false"
lazy="proxy|no-proxy|false"
not-found="ignore|exception"
entity-name="EntityName"
formula="arbitrary SQL expression"
node="element-name|@attribute-name|element/@attribute|."
embed-xml="true|false"
index="index_name"
unique_key="unique_key_id"
foreign-key="foreign_key_name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Setting a value of the cascade attribute to any meaningful value other than none will propagate certain operations to the associated object. The meaningful values are divided into three categories. First, basic operations, which include: persist, merge, delete, save-update, evict, replicate, lock and refresh; second, special values: delete-orphan; and third, all comma-separated combinations of operation names: cascade="persist,merge,evict" or cascade="all,delete-orphan". See 第 10.11 节 “传播性持久化(transitive persistence)” for a full explanation. Note that single valued, many-to-one and one-to-one, associations do not support orphan delete.
一个典型的简单 many-to-one 定义例子:
<many-to-one name="product" class="Product" column="PRODUCT_ID"/>
property-ref 属性只应该用来对付遗留下来的数据库系统,可能有外键指向对方关联表的是个非主键字段(但是应该是一个惟一关键字)的情况下。这是一种十分丑陋的关系模型。比如说,假设 Product 类有一个惟一的序列号,它并不是主键。(unique 属性控制 Hibernate 通过 SchemaExport 工具进行的 DDL 生成。)
<property name="serialNumber" unique="true" type="string" column="SERIAL_NUMBER"/>
那么关于 OrderItem 的映射可能是:
<many-to-one name="product" property-ref="serialNumber" column="PRODUCT_SERIAL_NUMBER"/>
当然,我们决不鼓励这种用法。
如果被引用的唯一主键由关联实体的多个属性组成,你应该在名称为 <properties> 的元素 里面映射所有关联的属性。
假若被引用的唯一主键是组件的属性,你可以指定属性路径:
<many-to-one name="owner" property-ref="identity.ssn" column="OWNER_SSN"/>
持久化对象之间一对一的关联关系是通过 one-to-one 元素定义的。
<one-to-one
name="propertyName"
class="ClassName"
cascade="cascade_style"
constrained="true|false"
fetch="join|select"
property-ref="propertyNameFromAssociatedClass"
access="field|property|ClassName"
formula="any SQL expression"
lazy="proxy|no-proxy|false"
entity-name="EntityName"
node="element-name|@attribute-name|element/@attribute|."
embed-xml="true|false"
foreign-key="foreign_key_name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
有两种不同的一对一关联:
主键关联
惟一外键关联
主键关联不需要额外的表字段;如果两行是通过这种一对一关系相关联的,那么这两行就共享同样的主关键字值。所以如果你希望两个对象通过主键一对一关联,你必须确认它们被赋予同样的标识值。
比如说,对下面的 Employee 和 Person 进行主键一对一关联:
<one-to-one name="person" class="Person"/>
<one-to-one name="employee" class="Employee" constrained="true"/>
现在我们必须确保 PERSON 和 EMPLOYEE 中相关的字段是相等的。我们使用一个被成为 foreign 的特殊的 hibernate 标识符生成策略:
<class name="person" table="PERSON">
<id name="id" column="PERSON_ID">
<generator class="foreign">
<param name="property"
>employee</param>
</generator>
</id>
...
<one-to-one name="employee"
class="Employee"
constrained="true"/>
</class
>
一个刚刚保存的 Person 实例被赋予和该 Person 的 employee 属性所指向的 Employee 实例同样的关键字值。
另一种方式是一个外键和一个惟一关键字对应,上面的 Employee 和 Person 的例子,如果使用这种关联方式,可以表达成:
<many-to-one name="person" class="Person" column="PERSON_ID" unique="true"/>
如果在 Person 的映射加入下面几句,这种关联就是双向的:
<one-to-one name="employee" class="Employee" property-ref="person"/>
<natural-id mutable="true|false"/>
<property ... />
<many-to-one ... />
......
</natural-id
>
我们建议使用代用键(键值不具备实际意义)作为主键,我们仍然应该尝试为所有的实体采用自然的键值作为(附加——译者注)标示。自然键(natural key)是单个或组合属性,他们必须唯一且非空。如果它还是不可变的那就更理想了。在 <natural-id> 元素中列出自然键的属性。Hibernate 会帮你生成必须的唯一键值和非空约束,你的映射会更加的明显易懂(原文是 self-documenting,自我注解)。
我们强烈建议你实现 equals() 和 hashCode() 方法,来比较实体的自然键属性。
这一映射不是为了把自然键作为主键而准备的。
mutable(可选,默认为false):默认情况下,自然标识属性被假定为不可变的(常量)。
<component> 元素把子对象的一些元素与父类对应的表的一些字段映射起来。然后组件可以定义它们自己的属性、组件或者集合。参见后面的“Components”一章。
<component
name="propertyName"
class="className"
insert="true|false"
update="true|false"
access="field|property|ClassName"
lazy="true|false"
optimistic-lock="true|false"
unique="true|false"
node="element-name|."
>
<property ...../>
<many-to-one .... />
........
</component
>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
其 <property> 子标签为子类的一些属性与表字段之间建立映射。
<component> 元素允许加入一个 <parent> 子元素,在组件类内部就可以有一个指向其容器的实体的反向引用。
The <dynamic-component> element allows a Map to be mapped as a component, where the property names refer to keys of the map. See 第 8.5 节 “动态组件(Dynamic components)” for more information.
<properties> 元素允许定义一个命名的逻辑分组(grouping)包含一个类中的多个属性。这个元素最重要的用处是允许多个属性的组合作为 property-ref 的目标(target)。这也是定义多字段唯一约束的一种方便途径。例如:
<properties
name="logicalName"
insert="true|false"
update="true|false"
optimistic-lock="true|false"
unique="true|false"
>
<property ...../>
<many-to-one .... />
........
</properties
>
|
|
|
|
|
|
|
|
|
|
例如,如果我们有如下的 <properties> 映射:
<class name="Person">
<id name="personNumber"/>
...
<properties name="name"
unique="true" update="false">
<property name="firstName"/>
<property name="initial"/>
<property name="lastName"/>
</properties>
</class
>
然后,我们可能有一些遗留的数据关联,引用 Person 表的这个唯一键,而不是主键:
<many-to-one name="person"
class="Person" property-ref="name">
<column name="firstName"/>
<column name="initial"/>
<column name="lastName"/>
</many-to-one
>
我们并不推荐这样使用,除非在映射遗留数据的情况下。
最后,多态持久化需要为父类的每个子类都进行定义。对于“每一棵类继承树对应一个表”的策略来说,就需要使用 <subclass> 定义。
<subclass
name="ClassName"
discriminator-value="discriminator_value"
proxy="ProxyInterface"
lazy="true|false"
dynamic-update="true|false"
dynamic-insert="true|false"
entity-name="EntityName"
node="element-name"
extends="SuperclassName">
<property .... />
.....
</subclass
>
|
|
|
|
|
|
|
|
每个子类都应该定义它自己的持久化属性和子类。<version> 和 <id> 属性可以从根父类继承下来。在一棵继承树上的每个子类都必须定义一个唯一的 discriminator-value。如果没有指定,就会使用 Java 类的全限定名。
For information about inheritance mappings see 第 9 章 继承映射(Inheritance Mapping) .
此外,每个子类可能被映射到他自己的表中(每个子类一个表的策略)。被继承的状态通过和超类的表关联得到。我们使用 <joined-subclass> 元素。
<joined-subclass
name="ClassName"
table="tablename"
proxy="ProxyInterface"
lazy="true|false"
dynamic-update="true|false"
dynamic-insert="true|false"
schema="schema"
catalog="catalog"
extends="SuperclassName"
persister="ClassName"
subselect="SQL expression"
entity-name="EntityName"
node="element-name">
<key .... >
<property .... />
.....
</joined-subclass
>
|
|
|
|
|
|
|
|
这种映射策略不需要指定辨别标志(discriminator)字段。但是,每一个子类都必须使用 <key> 元素指定一个表字段来持有对象的标识符。本章开始的映射可以被用如下方式重写:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="eg">
<class name="Cat" table="CATS">
<id name="id" column="uid" type="long">
<generator class="hilo"/>
</id>
<property name="birthdate" type="date"/>
<property name="color" not-null="true"/>
<property name="sex" not-null="true"/>
<property name="weight"/>
<many-to-one name="mate"/>
<set name="kittens">
<key column="MOTHER"/>
<one-to-many class="Cat"/>
</set>
<joined-subclass name="DomesticCat" table="DOMESTIC_CATS">
<key column="CAT"/>
<property name="name" type="string"/>
</joined-subclass>
</class>
<class name="eg.Dog">
<!-- mapping for Dog could go here -->
</class>
</hibernate-mapping
>
For information about inheritance mappings see 第 9 章 继承映射(Inheritance Mapping) .
第三种选择是仅仅映射类继承树中具体类部分到表中(每个具体类一张表的策略)。其中,每张表定义了类的所有持久化状态,包括继承的状态。在 Hibernate 中,并不需要完全显式地映射这样的继承树。你可以简单地使用单独的 <class> 定义映射每个类。然而,如果你想使用多态关联(例如,一个对类继承树中超类的关联),你需要使用 <union-subclass> 映射。
<union-subclass
name="ClassName"
table="tablename"
proxy="ProxyInterface"
lazy="true|false"
dynamic-update="true|false"
dynamic-insert="true|false"
schema="schema"
catalog="catalog"
extends="SuperclassName"
abstract="true|false"
persister="ClassName"
subselect="SQL expression"
entity-name="EntityName"
node="element-name">
<property .... />
.....
</union-subclass
>
|
|
|
|
|
|
|
|
这种映射策略不需要指定辨别标志(discriminator)字段。
For information about inheritance mappings see 第 9 章 继承映射(Inheritance Mapping) .
使用 <join> 元素,假若在表之间存在一对一关联,可以将一个类的属性映射到多张表中。
<join
table="tablename"
schema="owner"
catalog="catalog"
fetch="join|select"
inverse="true|false"
optional="true|false">
<key ... />
<property ... />
...
</join
>
|
|
|
|
|
|
|
|
|
|
|
|
例如,一个人(person)的地址(address)信息可以被映射到单独的表中(并保留所有属性的值类型语义):
<class name="Person"
table="PERSON">
<id name="id" column="PERSON_ID"
>...</id>
<join table="ADDRESS">
<key column="ADDRESS_ID"/>
<property name="address"/>
<property name="zip"/>
<property name="country"/>
</join>
...
此特性常常对遗留数据模型有用,我们推荐表个数比类个数少,以及细粒度的领域模型。然而,在单独的继承树上切换继承映射策略是有用的,后面会解释这点。
我们目前已经见到过 <key> 元素多次了。这个元素在父映射元素定义了对新表的连接,并且在被连接表中定义了一个外键引用原表的主键的情况下经常使用。
<key
column="columnname"
on-delete="noaction|cascade"
property-ref="propertyName"
not-null="true|false"
update="true|false"
unique="true|false"
/>
|
|
|
|
|
|
|
|
|
|
|
|
对那些看重删除性能的系统,我们推荐所有的键都应该定义为 on-delete="cascade",这样 Hibernate 将使用数据库级的 ON CASCADE DELETE 约束,而不是多个 DELETE 语句。注意,这个特性会绕过 Hibernate 通常对版本数据(versioned data)采用的乐观锁策略。
not-null 和 update 属性在映射单向一对多关联的时候有用。如果你映射一个单向一对多关联到非空的(non-nullable)外键,你必须 用 <key not-null="true"> 定义此键字段。
任何接受 column 属性的映射元素都可以选择接受 <column> 子元素。同样的,formula 子元素也可以替换 <formula> 属性。
<column
name="column_name"
length="N"
precision="N"
scale="N"
not-null="true|false"
unique="true|false"
unique-key="multicolumn_unique_key_name"
index="index_name"
sql-type="sql_type_name"
check="SQL expression"
default="SQL expression"
read="SQL expression"
write="SQL expression"/>
<formula
>SQL expression</formula
>
column 上的大多数属性都提供了在自动模式生成过程中对 DDL 进行裁剪的方法。read 和 write 属性允许你指定 Hibernate 用于访问字段值的自定义的 SQL。关于更多的内容,请参考 column read and write expressions。
column 和 formula 属性甚至可以在同一个属性或关联映射中被合并来表达,例如,一些奇异的连接条件。
<many-to-one name="homeAddress" class="Address"
insert="false" update="false">
<column name="person_id" not-null="true" length="10"/>
<formula
>'MAILING'</formula>
</many-to-one
>
假设你的应用程序有两个同样名字的持久化类,但是你不想在 Hibernate 查询中使用他们的全限定名。除了依赖 auto-import="true" 以外,类也可以被显式地“import(引用)”。你甚至可以引用没有被明确映射的类和接口。
<import class="java.lang.Object" rename="Universe"/>
<import
class="ClassName"
rename="ShortName"
/>
|
|
|
|
这是属性映射的又一种类型。<any> 映射元素定义了一种从多个表到类的多态关联。这种类型的映射常常需要多于一个字段。第一个字段持有被关联实体的类型,其他的字段持有标识符。对这种类型的关联来说,不可能指定一个外键约束,所以这当然不是映射(多态)关联的通常的方式。你只应该在非常特殊的情况下使用它(比如,审计 log,用户会话数据等等)。
meta-type 属性使得应用程序能指定一个将数据库字段的值映射到持久化类的自定义类型。这个持久化类包含有用 id-type 指定的标识符属性。你必须指定从 meta-type 的值到类名的映射。
<any name="being" id-type="long" meta-type="string">
<meta-value value="TBL_ANIMAL" class="Animal"/>
<meta-value value="TBL_HUMAN" class="Human"/>
<meta-value value="TBL_ALIEN" class="Alien"/>
<column name="table_name"/>
<column name="id"/>
</any
>
<any
name="propertyName"
id-type="idtypename"
meta-type="metatypename"
cascade="cascade_style"
access="field|property|ClassName"
optimistic-lock="true|false"
>
<meta-value ... />
<meta-value ... />
.....
<column .... />
<column .... />
.....
</any
>
|
|
|
|
|
|
|
|
|
|
|
|
和持久化服务相比,Java 级别的对象分为两个组别:
实体entity 独立于任何持有实体引用的对象。与通常的 Java 模型相比,不再被引用的对象会被当作垃圾收集掉。实体必须被显式的保存和删除(除非保存和删除是从父实体向子实体引发的级联)。这和 ODMG 模型中关于对象通过可触及保持持久性有一些不同 — 比较起来更加接近应用程序对象通常在一个大系统中的使用方法。实体支持循环引用和交叉引用,它们也可以加上版本信息。
一个实体的持久状态包含指向其他实体和值类型实例的引用。值可以是原始类型,集合(不是集合中的对象),组件或者特定的不可变对象。与实体不同,值(特别是集合和组件)是通过可触及性来进行持久化和删除的。因为值对象(和原始类型数据)是随着包含他们的实体而被持久化和删除的,他们不能被独立的加上版本信息。值没有独立的标识,所以他们不能被两个实体或者集合共享。
直到现在,我们都一直使用术语“持久类”(persistent class)来代表实体。我们仍然会这么做。然而严格说来,不是所有的用户自定义的,带有持久化状态的类都是实体。组件就是用户自定义类,却是值语义的。java.lang.String 类型的 java 属性也是值语义的。给了这个定义以后,我们可以说所有 JDK 提供的类型(类)都是值类型的语义,而用于自定义类型可能被映射为实体类型或值类型语义。采用哪种类型的语义取决于开发人员。在领域模型中,寻找实体类的一个好线索是共享引用指向这个类的单一实例,而组合或聚合通常被转化为值类型。
我们会在本文档中重复碰到这两个概念。
挑战在于将 java 类型系统(和开发者定义的实体和值类型)映射到 SQL/数据库类型系统。Hibernate 提供了连接两个系统之间的桥梁:对于实体类型,我们使用 <class>,<subclass> 等等。对于值类型,我们使用 <property>,<component> 及其他,通常跟随着 type 属性。这个属性的值是Hibernate 的映射类型的名字。Hibernate 提供了许多现成的映射(标准的 JDK 值类型)。你也可以编写自己的映射类型并实现自定义的变换策略,随后我们会看到这点。
所有的 Hibernate 内建类型,除了 collections 以外,都支持空(null)语义。
内置的 basic mapping types 可以大致地分类为:
integer, long, short, float, double, character, byte, boolean, yes_no, true_false这些类型都对应 Java 的原始类型或者其封装类,来符合(特定厂商的)SQL 字段类型。
boolean, yes_no和true_false都是 Java 中boolean或者java.lang.Boolean的另外说法。string从
java.lang.String到VARCHAR(或者 Oracle 的VARCHAR2)的映射。date, time, timestamp从
java.util.Date和其子类到 SQL 类型DATE,TIME和TIMESTAMP(或等价类型)的映射。calendar, calendar_date从
java.util.Calendar到 SQL 类型TIMESTAMP和DATE(或等价类型)的映射。big_decimal, big_integer从
java.math.BigDecimal和java.math.BigInteger到NUMERIC(或者 Oracle 的NUMBER类型)的映射。locale, timezone, currency从
java.util.Locale,java.util.TimeZone和java.util.Currency到VARCHAR(或者 Oracle 的VARCHAR2类型)的映射。Locale和Currency的实例被映射为它们的 ISO 代码。TimeZone的实例被影射为它的ID。class从
java.lang.Class到VARCHAR(或者 Oracle 的VARCHAR2类型)的映射。Class被映射为它的全限定名。binary把字节数组(byte arrays)映射为对应的 SQL 二进制类型。
text把长 Java 字符串映射为 SQL 的
CLOB或者TEXT类型。serializable把可序列化的 Java 类型映射到对应的 SQL 二进制类型。你也可以为一个并非默认为基本类型的可序列化 Java 类或者接口指定 Hibernate 类型
serializable。clob, blobJDBC 类
java.sql.Clob和java.sql.Blob的映射。某些程序可能不适合使用这个类型,因为 blob 和 clob 对象可能在一个事务之外是无法重用的。(而且, 驱动程序对这种类型的支持充满着补丁和前后矛盾。)-
imm_date, imm_time, imm_timestamp, imm_calendar, imm_calendar_date, imm_serializable, imm_binary 一般来说,映射类型被假定为是可变的 Java 类型,只有对不可变 Java 类型,Hibernate 会采取特定的优化措施,应用程序会把这些对象作为不可变对象处理。比如,你不应该对作为
imm_timestamp映射的 Date 执行Date.setTime()。要改变属性的值,并且保存这一改变,应用程序必须对这一属性重新设置一个新的(不一样的)对象。
实体及其集合的唯一标识可以是除了 binary、 blob 和 clob 之外的任何基础类型。(联合标识也是允许的,后面会说到。)
在 org.hibernate.Hibernate 中,定义了基础类型对应的 Type 常量。比如,Hibernate.STRING 代表 string 类型。
开发者创建属于他们自己的值类型也是很容易的。比如说,你可能希望持久化 java.lang.BigInteger 类型的属性,持久化成为 VARCHAR 字段。Hibernate没有内置这样一种类型。自定义类型能够映射一个属性(或集合元素)到不止一个数据库表字段。比如说,你可能有这样的 Java 属性:getName()/setName(),这是 java.lang.String 类型的,对应的持久化到三个字段:FIRST_NAME,INITIAL,SURNAME。
要实现一个自定义类型,可以实现 org.hibernate.UserType 或 org.hibernate.CompositeUserType 中的任一个,并且使用类型的 Java 全限定类名来定义属性。请查看 org.hibernate.test.DoubleStringType 这个例子,看看它是怎么做的。
<property name="twoStrings" type="org.hibernate.test.DoubleStringType">
<column name="first_string"/>
<column name="second_string"/>
</property
>
注意使用 <column> 标签来把一个属性映射到多个字段的做法。
CompositeUserType,EnhancedUserType,UserCollectionType 和 UserVersionType 接口为更特殊的使用方式提供支持。
你甚至可以在一个映射文件中提供参数给一个 UserType。 为了这样做,你的 UserType 必须实现 org.hibernate.usertype.ParameterizedType 接口。为了给自定义类型提供参数,你可以在映射文件中使用 <type> 元素。
<property name="priority">
<type name="com.mycompany.usertypes.DefaultValueIntegerType">
<param name="default"
>0</param>
</type>
</property
>
现在,UserType 可以从传入的 Properties 对象中得到 default 参数的值。
如果你非常频繁地使用某一 UserType,可以为他定义一个简称。这可以通过使用 <typedef> 元素来实现。Typedefs 为一自定义类型赋予一个名称,并且如果此类型是参数化的,还可以包含一系列默认的参数值。
<typedef class="com.mycompany.usertypes.DefaultValueIntegerType" name="default_zero">
<param name="default"
>0</param>
</typedef
>
<property name="priority" type="default_zero"/>
也可以根据具体案例通过属性映射中的类型参数覆盖在 typedef 中提供的参数。
尽管 Hibernate 内建的丰富的类型和对组件的支持意味着你可能很少 需要使用自定义类型。不过,为那些在你的应用中经常出现的(非实体)类使用自定义类型也是一个好方法。例如,一个 MonetaryAmount 类使用 CompositeUserType 来映射是不错的选择,虽然他可以很容易地被映射成组件。这样做的动机之一是抽象。使用自定义类型,以后假若你改变表示金额的方法时,它可以保证映射文件不需要修改。
对特定的持久化类,映射多次是允许的。这种情形下,你必须指定 entity name 来区别不同映射实体的对象实例。(默认情况下,实体名字和类名是相同的。) Hibernate 在操作持久化对象、编写查询条件,或者把关联映射到指定实体时,允许你指定这个 entity name(实体名字)。
<class name="Contract" table="Contracts"
entity-name="CurrentContract">
...
<set name="history" inverse="true"
order-by="effectiveEndDate desc">
<key column="currentContractId"/>
<one-to-many entity-name="HistoricalContract"/>
</set>
</class>
<class name="Contract" table="ContractHistory"
entity-name="HistoricalContract">
...
<many-to-one name="currentContract"
column="currentContractId"
entity-name="CurrentContract"/>
</class
>注意这里关联是如何用 entity-name 来代替 class 的。
你可通过在映射文档中使用反向引号(`)把表名或者字段名包围起来,以强制 Hibernate 在生成的 SQL 中把标识符用引号包围起来。Hibernate 会使用相应的 SQLDialect(方言)来使用正确的引号风格(通常是双引号,但是在 SQL Server 中是括号,MySQL 中是反向引号)。
<class name="LineItem" table="`Line Item`">
<id name="id" column="`Item Id`"/><generator class="assigned"/></id>
<property name="itemNumber" column="`Item #`"/>
...
</class
>
XML 并不适用于所有人, 因此有其他定义 Hibernate O/R 映射元数据(metadata)的方法。
很多 Hibernate 使用者更喜欢使用 XDoclet@hibernate.tags 将映射信息直接嵌入到源代码中。我们不会在本文档中涉及这个方法,因为严格说来,这属于 XDoclet 的一部分。然而,我们包含了如下使用 XDoclet 映射的 Cat 类的例子。
package eg;
import java.util.Set;
import java.util.Date;
/**
* @hibernate.class
* table="CATS"
*/
public class Cat {
private Long id; // identifier
private Date birthdate;
private Cat mother;
private Set kittens
private Color color;
private char sex;
private float weight;
/*
* @hibernate.id
* generator-class="native"
* column="CAT_ID"
*/
public Long getId() {
return id;
}
private void setId(Long id) {
this.id=id;
}
/**
* @hibernate.many-to-one
* column="PARENT_ID"
*/
public Cat getMother() {
return mother;
}
void setMother(Cat mother) {
this.mother = mother;
}
/**
* @hibernate.property
* column="BIRTH_DATE"
*/
public Date getBirthdate() {
return birthdate;
}
void setBirthdate(Date date) {
birthdate = date;
}
/**
* @hibernate.property
* column="WEIGHT"
*/
public float getWeight() {
return weight;
}
void setWeight(float weight) {
this.weight = weight;
}
/**
* @hibernate.property
* column="COLOR"
* not-null="true"
*/
public Color getColor() {
return color;
}
void setColor(Color color) {
this.color = color;
}
/**
* @hibernate.set
* inverse="true"
* order-by="BIRTH_DATE"
* @hibernate.collection-key
* column="PARENT_ID"
* @hibernate.collection-one-to-many
*/
public Set getKittens() {
return kittens;
}
void setKittens(Set kittens) {
this.kittens = kittens;
}
// addKitten not needed by Hibernate
public void addKitten(Cat kitten) {
kittens.add(kitten);
}
/**
* @hibernate.property
* column="SEX"
* not-null="true"
* update="false"
*/
public char getSex() {
return sex;
}
void setSex(char sex) {
this.sex=sex;
}
}
参考 Hibernate 网站更多的 Xdoclet 和 Hibernate 的例子。
JDK 5.0 在语言级别引入了 XDoclet 风格的标注,并且是类型安全的,在编译期进行检查。这一机制比 XDoclet 的注解更为强大,有更好的工具和 IDE 支持。例如,IntelliJ IDEA,支持 JDK 5.0 注解的自动完成和语法高亮 。EJB 规范的新修订版 (JSR-220) 使用 JDK 5.0 的注解作为entity beans的主要元数据(metadata)机制。Hibernate 3 实现了JSR-220(the persistence API) 的 EntityManager,支持通过 Hibernate Annotations 包定义映射元数据。这个包作为单独的部分下载,支持 EJB3(JSR-220) 和 Hibernate3 的元数据。
这是一个被注解为 EJB entity bean 的 POJO 类的例子
@Entity(access = AccessType.FIELD)
public class Customer implements Serializable {
@Id;
Long id;
String firstName;
String lastName;
Date birthday;
@Transient
Integer age;
@Embedded
private Address homeAddress;
@OneToMany(cascade=CascadeType.ALL)
@JoinColumn(name="CUSTOMER_ID")
Set<Order
> orders;
// Getter/setter and business methods
}
注意
注意:对 JDK 5.0 注解(和 JSR-220)支持的工作仍然在进行中,并未完成。更多细节请参阅 Hibernate Annotations 模块。
Generated properties 指的是其值由数据库生成的属性。一般来说,如果对象有任何属性由数据库生成值,Hibernate 应用程序需要进行刷新(refresh)。但如果把属性标明为 generated,就可以转由 Hibernate 来负责这个动作。实际上。对定义了 generated properties 的实体,每当 Hibernate 执行一条 SQL INSERT 或者 UPDATE 语句,会立刻执行一条 select 来获得生成的值。
被标明为 generated 的属性还必须是 non-insertable 和 non-updateable 的。只有 versions、timestamps 和 simple properties 可以被标明为 generated。
never(默认)标明此属性值不是从数据库中生成。
insert — 标明此属性值在 insert 的时候生成,但是不会在随后的 update 时重新生成。比如说创建日期就归属于这类。注意虽然 version 和 timestamp 属性可以被标注为 generated,但是不适用这个选项。
always — 标明此属性值在 insert 和 update 时都会被生成。
Hibernate allows you to customize the SQL it uses to read and write the values of columns mapped to simple properties. For example, if your database provides a set of data encryption functions, you can invoke them for individual columns like this:
<!-- XML : generated by JHighlight v1.0 (http://jhighlight.dev.java.net) --> <span class="xml_tag_symbols"><</span><span class="xml_tag_name">property</span><span class="xml_plain"> </span><span class="xml_attribute_name">name</span><span class="xml_tag_symbols">=</span><span class="xml_attribute_value">"creditCardNumber"</span><span class="xml_tag_symbols">></span><span class="xml_plain"></span><br /> <span class="xml_plain"> </span><span class="xml_tag_symbols"><</span><span class="xml_tag_name">column</span><span class="xml_plain"> </span><br /> <span class="xml_plain"> </span><span class="xml_attribute_name">name</span><span class="xml_tag_symbols">=</span><span class="xml_attribute_value">"credit_card_num"</span><span class="xml_plain"></span><br /> <span class="xml_plain"> </span><span class="xml_attribute_name">read</span><span class="xml_tag_symbols">=</span><span class="xml_attribute_value">"decrypt(credit_card_num)"</span><span class="xml_plain"></span><br /> <span class="xml_plain"> </span><span class="xml_attribute_name">write</span><span class="xml_tag_symbols">=</span><span class="xml_attribute_value">"encrypt(?)"</span><span class="xml_tag_symbols">/></span><span class="xml_plain"></span><br /> <span class="xml_tag_symbols"></</span><span class="xml_tag_name">property</span><span class="xml_plain"></span><br /> <span class="xml_tag_symbols">></span><span class="xml_plain"></span><br />
每当属性在查询里被引用时,Hibernate 都自动应用自定义的表达式。这种功能和 derived-property formula 相似,但有两个不同的地方:
属性由一个或多个属性组成,它作为自动模式生成的一部分导出。
属性是可读写的,非只读的。
如果指定了 write 表达式,它必须只包含一个“?”占位符。
允许 CREATE 和 DROP 任意数据库对象,与 Hibernate 的 schema 交互工具组合起来,可以提供在 Hibernate 映射文件中完全定义用户 schema 的能力。虽然这是为创建和销毁 trigger(触发器)或stored procedure(存储过程)等特别设计的,实际上任何可以在 java.sql.Statement.execute() 方法中执行的 SQL 命令都可以在此使用(比如ALTER, INSERT,等等)。本质上有两种模式来定义辅助数据库对象...
第一种模式是在映射文件中显式声明 CREATE 和 DROP 命令:
<hibernate-mapping>
...
<database-object>
<create
>CREATE TRIGGER my_trigger ...</create>
<drop
>DROP TRIGGER my_trigger</drop>
</database-object>
</hibernate-mapping
>
第二种模式是提供一个类,这个类知道如何组织 CREATE 和 DROP 命令。这个特别类必须实现 org.hibernate.mapping.AuxiliaryDatabaseObject 接口。
<hibernate-mapping>
...
<database-object>
<definition class="MyTriggerDefinition"/>
</database-object>
</hibernate-mapping
>
还有,这些数据库对象可以特别指定为仅在特定的方言中才使用。
<hibernate-mapping>
...
<database-object>
<definition class="MyTriggerDefinition"/>
<dialect-scope name="org.hibernate.dialect.Oracle9iDialect"/>
<dialect-scope name="org.hibernate.dialect.Oracle10gDialect"/>
</database-object>
</hibernate-mapping
>