Object/relational mappings can be defined in three approaches:
using Java 5 annotations (via the Java Persistence 2 annotations)
using JPA 2 XML deployment descriptors (described in chapter XXX)
using the Hibernate legacy XML files approach known as hbm.xml
Annotations are split in two categories, the logical mapping annotations (describing the object model, the association between two entities etc.) and the physical mapping annotations (describing the physical schema, tables, columns, indexes, etc). We will mix annotations from both categories in the following code examples.
JPA annotations are in the javax.persistence.* package. Hibernate specific extensions are in org.hibernate.annotations.*. You favorite IDE can auto-complete annotations and their attributes for you (even without a specific "JPA" plugin, since JPA annotations are plain Java 5 annotations).
Here is an example of mapping
package eg;
@Entity
@Table(name="cats") @Inheritance(strategy=SINGLE_TABLE)
@DiscriminatorValue("C") @DiscriminatorColumn(name="subclass", discriminatorType=CHAR)
public class Cat {
@Id @GeneratedValue
public Integer getId() { return id; }
public void setId(Integer id) { this.id = id; }
private Integer id;
public BigDecimal getWeight() { return weight; }
public void setWeight(BigDecimal weight) { this.weight = weight; }
private BigDecimal weight;
@Temporal(DATE) @NotNull @Column(updatable=false)
public Date getBirthdate() { return birthdate; }
public void setBirthdate(Date birthdate) { this.birthdate = birthdate; }
private Date birthdate;
@org.hibernate.annotations.Type(type="eg.types.ColorUserType")
@NotNull @Column(updatable=false)
public ColorType getColor() { return color; }
public void setColor(ColorType color) { this.color = color; }
private ColorType color;
@NotNull @Column(updatable=false)
public String getSex() { return sex; }
public void setSex(String sex) { this.sex = sex; }
private String sex;
@NotNull @Column(updatable=false)
public Integer getLitterId() { return litterId; }
public void setLitterId(Integer litterId) { this.litterId = litterId; }
private Integer litterId;
@ManyToOne @JoinColumn(name="mother_id", updatable=false)
public Cat getMother() { return mother; }
public void setMother(Cat mother) { this.mother = mother; }
private Cat mother;
@OneToMany(mappedBy="mother") @OrderBy("litterId")
public Set<Cat> getKittens() { return kittens; }
public void setKittens(Set<Cat> kittens) { this.kittens = kittens; }
private Set<Cat> kittens = new HashSet<Cat>();
}
@Entity @DiscriminatorValue("D")
public class DomesticCat extends Cat {
public String getName() { return name; }
public void setName(String name) { this.name = name }
private String name;
}
@Entity
public class Dog { ... }
The legacy hbm.xml approach uses an XML schema designed to be readable and hand-editable. The mapping language is Java-centric, meaning that mappings are constructed around persistent class declarations and not table declarations.
Observe que, incluso aunque muchos de los usuarios de Hibernate eligen escribir el XML a mano, existe un número de herramientas para generar el documento de mapeo, incluyendo XDoclet, Middlegen y AndroMDA.
Este es un ejemplo de mapeo:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="eg">
<class name="Cat"
table="cats"
discriminator-value="C">
<id name="id">
<generator class="native"/>
</id>
<discriminator column="subclass"
type="character"/>
<property name="weight"/>
<property name="birthdate"
type="date"
not-null="true"
update="false"/>
<property name="color"
type="eg.types.ColorUserType"
not-null="true"
update="false"/>
<property name="sex"
not-null="true"
update="false"/>
<property name="litterId"
column="litterId"
update="false"/>
<many-to-one name="mother"
column="mother_id"
update="false"/>
<set name="kittens"
inverse="true"
order-by="litter_id">
<key column="mother_id"/>
<one-to-many class="Cat"/>
</set>
<subclass name="DomesticCat"
discriminator-value="D">
<property name="name"
type="string"/>
</subclass>
</class>
<class name="Dog">
<!-- mapping for Dog could go here -->
</class>
</hibernate-mapping>
We will now discuss the concepts of the mapping documents (both annotations and XML). We will only describe, however, the document elements and attributes that are used by Hibernate at runtime. The mapping document also contains some extra optional attributes and elements that affect the database schemas exported by the schema export tool (for example, the not-null attribute).
An entity is a regular Java object (aka POJO) which will be persisted by Hibernate.
To mark an object as an entity in annotations, use the @Entity annotation.
@Entity
public class Flight implements Serializable {
Long id;
@Id
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
}
That's pretty much it, the rest is optional. There are however any options to tweak your entity mapping, let's explore them.
@Table lets you define the table the entity will be persisted into. If undefined, the table name is the unqualified class name of the entity. You can also optionally define the catalog, the schema as well as unique constraints on the table.
@Entity
@Table(name="TBL_FLIGHT",
schema="AIR_COMMAND",
uniqueConstraints=
@UniqueConstraint(
name="flight_number",
columnNames={"comp_prefix", "flight_number"} ) )
public class Flight implements Serializable {
@Column(name="comp_prefix")
public String getCompagnyPrefix() { return companyPrefix; }
@Column(name="flight_number")
public String getNumber() { return number; }
}
The constraint name is optional (generated if left undefined). The column names composing the constraint correspond to the column names as defined before the Hibernate NamingStrategy is applied.
@Entity.name lets you define the shortcut name of the entity you can used in JP-QL and HQL queries. It defaults to the unqualified class name of the class.
Hibernate goes beyond the JPA specification and provide additional configurations. Some of them are hosted on @org.hibernate.annotations.Entity:
dynamicInsert/dynamicUpdate(defaults to false): specifies thatINSERT/UPDATESQL should be generated at runtime and contain only the columns whose values are not null. Thedynamic-updateanddynamic-insertsettings are not inherited by subclasses. Although these settings can increase performance in some cases, they can actually decrease performance in others.selectBeforeUpdate(defaults to false): specifies that Hibernate should never perform an SQLUPDATEunless it is certain that an object is actually modified. Only when a transient object has been associated with a new session usingupdate(), will Hibernate perform an extra SQLSELECTto determine if anUPDATEis actually required. Use ofselect-before-updatewill usually decrease performance. It is useful to prevent a database update trigger being called unnecessarily if you reattach a graph of detached instances to aSession.polymorphisms(defaults toIMPLICIT): determines whether implicit or explicit query polymorphisms is used. Implicit polymorphisms means that instances of the class will be returned by a query that names any superclass or implemented interface or class, and that instances of any subclass of the class will be returned by a query that names the class itself. Explicit polymorphisms means that class instances will be returned only by queries that explicitly name that class. Queries that name the class will return only instances of subclasses mapped. For most purposes, the defaultpolymorphisms=IMPLICITis appropriate. Explicit polymorphisms is useful when two different classes are mapped to the same table This allows a "lightweight" class that contains a subset of the table columns.persister: specifies a customClassPersister. Thepersisterattribute lets you customize the persistence strategy used for the class. You can, for example, specify your own subclass oforg.hibernate.persister.EntityPersister, or you can even provide a completely new implementation of the interfaceorg.hibernate.persister.ClassPersisterthat implements, for example, persistence via stored procedure calls, serialization to flat files or LDAP. Seeorg.hibernate.test.CustomPersisterfor a simple example of "persistence" to aHashtable.optimisticLock(defaults toVERSION): determines the optimistic locking strategy. If you enabledynamicUpdate, you will have a choice of optimistic locking strategies:version: chequea las columnas de versión/sello de fechaall: chequea todas las columnasdirty: chequea las columnas modificadas permitiendo algunas actualizaciones concurrentesnone: no utilice bloqueo optimista
Le recomendamos mucho que utilice columnas de versión/sello de fecha para el bloqueo optimista con Hibernate. Esta estrategia optimiza el rendimiento y maneja correctamente las modificaciones realizadas a las instancias separadas, (por ejemplo, cuando se utiliza
Session.merge()).
Sugerencia
Be sure to import @javax.persistence.Entity to mark a class as an entity. It's a common mistake to import @org.hibernate.annotations.Entity by accident.
Some entities are not mutable. They cannot be updated or deleted by the application. This allows Hibernate to make some minor performance optimizations.. Use the @Immutable annotation.
You can also alter how Hibernate deals with lazy initialization for this class. On @Proxy, use lazy=false to disable lazy fetching (not recommended). You can also specify an interface to use for lazy initializing proxies (defaults to the class itself): use proxyClass on @Proxy. Hibernate will initially return proxies (Javassist or CGLIB) that implement the named interface. The persistent object will load when a method of the proxy is invoked. See "Initializing collections and proxies" below.
@BatchSize specifies a "batch size" for fetching instances of this class by identifier. Not yet loaded instances are loaded batch-size at a time (default 1).
You can specific an arbitrary SQL WHERE condition to be used when retrieving objects of this class. Use @Where for that.
In the same vein, @Check lets you define an SQL expression used to generate a multi-row check constraint for automatic schema generation.
There is no difference between a view and a base table for a Hibernate mapping. This is transparent at the database level, although some DBMS do not support views properly, especially with updates. Sometimes you want to use a view, but you cannot create one in the database (i.e. with a legacy schema). In this case, you can map an immutable and read-only entity to a given SQL subselect expression using @org.hibernate.annotations.Subselect:
@Entity
@Subselect("select item.name, max(bid.amount), count(*) "
+ "from item "
+ "join bid on bid.item_id = item.id "
+ "group by item.name")
@Synchronize( {"item", "bid"} ) //tables impacted
public class Summary {
@Id
public String getId() { return id; }
...
}
Declara las tablas con las cuales se debe sincronizar esta entidad, asegurándose de que el auto-vaciado ocurra correctamente y que las consultas frente a la entidad derivada no devuelvan datos desactualizados. El <subselect> se encuentra disponible tanto como un atributo y como un elemento anidado de mapeo.
We will now explore the same options using the hbm.xml structure. You can declare a persistent class using the class element. For example:
<class
name=" ClassName"
table=
ClassName"
table= "tableName"
discri
"tableName"
discri minator-value="discriminator_value"
mutabl
minator-value="discriminator_value"
mutabl e="true|false"
schema
e="true|false"
schema ="owner"
catalo
="owner"
catalo g="catalog"
proxy=
g="catalog"
proxy= "ProxyInterface"
dynami
"ProxyInterface"
dynami c-update="true|false"
dynami
c-update="true|false"
dynami c-insert="true|false"
select
c-insert="true|false"
select -before-update="true|false"
polymo
-before-update="true|false"
polymo rphism="implicit|explicit"
where=
rphism="implicit|explicit"
where= "arbitrary sql where condition"
persis
"arbitrary sql where condition"
persis ter="PersisterClass"
batch-
ter="PersisterClass"
batch-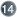 size="N"
optimi
size="N"
optimi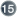 stic-lock="none|version|dirty|all"
lazy="(16)true|false"
entity(17)-name="EntityName"
check=(18)"arbitrary sql check condition"
rowid=(19)"rowid"
subsel(20)ect="SQL expression"
abstra(21)ct="true|false"
node="element-name"
/>
stic-lock="none|version|dirty|all"
lazy="(16)true|false"
entity(17)-name="EntityName"
check=(18)"arbitrary sql check condition"
rowid=(19)"rowid"
subsel(20)ect="SQL expression"
abstra(21)ct="true|false"
node="element-name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(16) |
|
(17) |
|
(18) |
|
(19) |
|
(20) |
|
(21) |
|
Es perfectamente aceptable que la clase persistente mencionada sea una interfaz. Puede declarar clases que implementan esa interfaz utilizando el elemento <subclass>. Puede persistir cualquier clase interna estática. Debe especificar el nombre de la clase utilizando la forma estándar, por ejemplo, e.g.Foo$Bar.
Here is how to do a virtual view (subselect) in XML:
<class name="Summary">
<subselect>
select item.name, max(bid.amount), count(*)
from item
join bid on bid.item_id = item.id
group by item.name
</subselect>
<synchronize table="item"/>
<synchronize table="bid"/>
<id name="name"/>
...
</class>
The <subselect> is available both as an attribute and a nested mapping element.
Mapped classes must declare the primary key column of the database table. Most classes will also have a JavaBeans-style property holding the unique identifier of an instance.
Mark the identifier property with @Id.
@Entity
public class Person {
@Id Integer getId() { ... }
...
}
In hbm.xml, use the <id> element which defines the mapping from that property to the primary key column.
<id
name="propertyName"
type="typename"
column="column_name"
unsaved-value="null|any|none|undefined|id_value"
access="field|property|ClassName">
node="element-name|@attribute-name|element/@attribute|."
<generator class="generatorClass"/>
</id>
|
|
|
|
|
|
|
|
|
|
Si se omite el atributo name, se asume que la clase no tiene propiedad identificadora.
The unsaved-value attribute is almost never needed in Hibernate3 and indeed has no corresponding element in annotations.
You can also declare the identifier as a composite identifier. This allows access to legacy data with composite keys. Its use is strongly discouraged for anything else.
You can define a composite primary key through several syntaxes:
use a component type to represent the identifier and map it as a property in the entity: you then annotated the property as
@EmbeddedId. The component type has to beSerializable.map multiple properties as
@Idproperties: the identifier type is then the entity class itself and needs to beSerializable. This approach is unfortunately not standard and only supported by Hibernate.map multiple properties as
@Idproperties and declare an external class to be the identifier type. This class, which needs to beSerializable, is declared on the entity via the@IdClassannotation. The identifier type must contain the same properties as the identifier properties of the entity: each property name must be the same, its type must be the same as well if the entity property is of a basic type, its type must be the type of the primary key of the associated entity if the entity property is an association (either a@OneToOneor a@ManyToOne).
As you can see the last case is far from obvious. It has been inherited from the dark ages of EJB 2 for backward compatibilities and we recommend you not to use it (for simplicity sake).
Let's explore all three cases using examples.
Here is a simple example of @EmbeddedId.
@Entity
class User {
@EmbeddedId
@AttributeOverride(name="firstName", column=@Column(name="fld_firstname")
UserId id;
Integer age;
}
@Embeddable
class UserId implements Serializable {
String firstName;
String lastName;
}
You can notice that the UserId class is serializable. To override the column mapping, use @AttributeOverride.
An embedded id can itself contains the primary key of an associated entity.
@Entity
class Customer {
@EmbeddedId CustomerId id;
boolean preferredCustomer;
@MapsId("userId")
@JoinColumns({
@JoinColumn(name="userfirstname_fk", referencedColumnName="firstName"),
@JoinColumn(name="userlastname_fk", referencedColumnName="lastName")
})
@OneToOne User user;
}
@Embeddable
class CustomerId implements Serializable {
UserId userId;
String customerNumber;
//implements equals and hashCode
}
@Entity
class User {
@EmbeddedId UserId id;
Integer age;
}
@Embeddable
class UserId implements Serializable {
String firstName;
String lastName;
//implements equals and hashCode
}
In the embedded id object, the association is represented as the identifier of the associated entity. But you can link its value to a regular association in the entity via the @MapsId annotation. The @MapsId value correspond to the property name of the embedded id object containing the associated entity's identifier. In the database, it means that the Customer.user and the CustomerId.userId properties share the same underlying column (user_fk in this case).
Sugerencia
The component type used as identifier must implement equals() and hashCode().
In practice, your code only sets the Customer.user property and the user id value is copied by Hibernate into the CustomerId.userId property.
Aviso
The id value can be copied as late as flush time, don't rely on it until after flush time.
While not supported in JPA, Hibernate lets you place your association directly in the embedded id component (instead of having to use the @MapsId annotation).
@Entity
class Customer {
@EmbeddedId CustomerId id;
boolean preferredCustomer;
}
@Embeddable
class CustomerId implements Serializable {
@OneToOne
@JoinColumns({
@JoinColumn(name="userfirstname_fk", referencedColumnName="firstName"),
@JoinColumn(name="userlastname_fk", referencedColumnName="lastName")
})
User user;
String customerNumber;
//implements equals and hashCode
}
@Entity
class User {
@EmbeddedId UserId id;
Integer age;
}
@Embeddable
class UserId implements Serializable {
String firstName;
String lastName;
//implements equals and hashCode
}
Let's now rewrite these examples using the hbm.xml syntax.
<composite-id
name="propertyName"
class="ClassName"
mapped="true|false"
access="field|property|ClassName"
node="element-name|.">
<key-property name="propertyName" type="typename" column="column_name"/>
<key-many-to-one name="propertyName" class="ClassName" column="column_name"/>
......
</composite-id>
First a simple example:
<class name="User">
<composite-id name="id" class="UserId">
<key-property name="firstName" column="fld_firstname"/>
<key-property name="lastName"/>
</composite-id>
</class>
Then an example showing how an association can be mapped.
<class name="Customer">
<composite-id name="id" class="CustomerId">
<key-property name="firstName" column="userfirstname_fk"/>
<key-property name="lastName" column="userfirstname_fk"/>
<key-property name="customerNumber"/>
</composite-id>
<property name="preferredCustomer"/>
<many-to-one name="user">
<column name="userfirstname_fk" updatable="false" insertable="false"/>
<column name="userlastname_fk" updatable="false" insertable="false"/>
</many-to-one>
</class>
<class name="User">
<composite-id name="id" class="UserId">
<key-property name="firstName"/>
<key-property name="lastName"/>
</composite-id>
<property name="age"/>
</class>
Notice a few things in the previous example:
the order of the properties (and column) matters. It must be the same between the association and the primary key of the associated entity
the many to one uses the same columns as the primary key and thus must be marked as read only (
insertableandupdatableto false).unlike with
@MapsId, the id value of the associated entity is not transparently copied, check theforeignid generator for more information.
The last example shows how to map association directly in the embedded id component.
<class name="Customer">
<composite-id name="id" class="CustomerId">
<key-many-to-one name="user">
<column name="userfirstname_fk"/>
<column name="userlastname_fk"/>
</key-many-to-one>
<key-property name="customerNumber"/>
</composite-id>
<property name="preferredCustomer"/>
</class>
<class name="User">
<composite-id name="id" class="UserId">
<key-property name="firstName"/>
<key-property name="lastName"/>
</composite-id>
<property name="age"/>
</class>
This is the recommended approach to map composite identifier. The following options should not be considered unless some constraint are present.
Another, arguably more natural, approach is to place @Id on multiple properties of your entity. This approach is only supported by Hibernate (not JPA compliant) but does not require an extra embeddable component.
@Entity
class Customer implements Serializable {
@Id @OneToOne
@JoinColumns({
@JoinColumn(name="userfirstname_fk", referencedColumnName="firstName"),
@JoinColumn(name="userlastname_fk", referencedColumnName="lastName")
})
User user;
@Id String customerNumber;
boolean preferredCustomer;
//implements equals and hashCode
}
@Entity
class User {
@EmbeddedId UserId id;
Integer age;
}
@Embeddable
class UserId implements Serializable {
String firstName;
String lastName;
//implements equals and hashCode
}
In this case Customer is its own identifier representation: it must implement Serializable and must implement equals() and hashCode().
In hbm.xml, the same mapping is:
<class name="Customer">
<composite-id>
<key-many-to-one name="user">
<column name="userfirstname_fk"/>
<column name="userlastname_fk"/>
</key-many-to-one>
<key-property name="customerNumber"/>
</composite-id>
<property name="preferredCustomer"/>
</class>
<class name="User">
<composite-id name="id" class="UserId">
<key-property name="firstName"/>
<key-property name="lastName"/>
</composite-id>
<property name="age"/>
</class>
@IdClass on an entity points to the class (component) representing the identifier of the class. The properties marked @Id on the entity must have their corresponding property on the @IdClass. The return type of search twin property must be either identical for basic properties or must correspond to the identifier class of the associated entity for an association.
Aviso
This approach is inherited from the EJB 2 days and we recommend against its use. But, after all it's your application and Hibernate supports it.
@Entity
@IdClass(CustomerId.class)
class Customer implements Serializable {
@Id @OneToOne
@JoinColumns({
@JoinColumn(name="userfirstname_fk", referencedColumnName="firstName"),
@JoinColumn(name="userlastname_fk", referencedColumnName="lastName")
})
User user;
@Id String customerNumber;
boolean preferredCustomer;
}
class CustomerId implements Serializable {
UserId user;
String customerNumber;
//implements equals and hashCode
}
@Entity
class User {
@EmbeddedId UserId id;
Integer age;
//implements equals and hashCode
}
@Embeddable
class UserId implements Serializable {
String firstName;
String lastName;
//implements equals and hashCode
}
Customer and CustomerId do have the same properties customerNumber as well as user. CustomerId must be Serializable and implement equals() and hashCode().
While not JPA standard, Hibernate let's you declare the vanilla associated property in the @IdClass.
@Entity
@IdClass(CustomerId.class)
class Customer implements Serializable {
@Id @OneToOne
@JoinColumns({
@JoinColumn(name="userfirstname_fk", referencedColumnName="firstName"),
@JoinColumn(name="userlastname_fk", referencedColumnName="lastName")
})
User user;
@Id String customerNumber;
boolean preferredCustomer;
}
class CustomerId implements Serializable {
@OneToOne User user;
String customerNumber;
//implements equals and hashCode
}
@Entity
class User {
@EmbeddedId UserId id;
Integer age;
//implements equals and hashCode
}
@Embeddable
class UserId implements Serializable {
String firstName;
String lastName;
}
This feature is of limited interest though as you are likely to have chosen the @IdClass approach to stay JPA compliant or you have a quite twisted mind.
Here are the equivalent on hbm.xml files:
<class name="Customer">
<composite-id class="CustomerId" mapped="true">
<key-many-to-one name="user">
<column name="userfirstname_fk"/>
<column name="userlastname_fk"/>
</key-many-to-one>
<key-property name="customerNumber"/>
</composite-id>
<property name="preferredCustomer"/>
</class>
<class name="User">
<composite-id name="id" class="UserId">
<key-property name="firstName"/>
<key-property name="lastName"/>
</composite-id>
<property name="age"/>
</class>
Hibernate can generate and populate identifier values for you automatically. This is the recommended approach over "business" or "natural" id (especially composite ids).
Hibernate offers various generation strategies, let's explore the most common ones first that happens to be standardized by JPA:
IDENTITY: supports identity columns in DB2, MySQL, MS SQL Server, Sybase and HypersonicSQL. The returned identifier is of type
long,shortorint.SEQUENCE (called
seqhiloin Hibernate): uses a hi/lo algorithm to efficiently generate identifiers of typelong,shortorint, given a named database sequence.TABLE (called
MultipleHiLoPerTableGeneratorin Hibernate) : uses a hi/lo algorithm to efficiently generate identifiers of typelong,shortorint, given a table and column as a source of hi values. The hi/lo algorithm generates identifiers that are unique only for a particular database.AUTO: selects
IDENTITY,SEQUENCEorTABLEdepending upon the capabilities of the underlying database.
Importante
We recommend all new projects to use the new enhanced identifier generators. They are deactivated by default for entities using annotations but can be activated using hibernate.id.new_generator_mappings=true. These new generators are more efficient and closer to the JPA 2 specification semantic.
However they are not backward compatible with existing Hibernate based application (if a sequence or a table is used for id generation). See XXXXXXX ??? for more information on how to activate them.
To mark an id property as generated, use the @GeneratedValue annotation. You can specify the strategy used (default to AUTO) by setting strategy.
@Entity
public class Customer {
@Id @GeneratedValue
Integer getId() { ... };
}
@Entity
public class Invoice {
@Id @GeneratedValue(strategy=GenerationType.IDENTITY)
Integer getId() { ... };
}
SEQUENCE and TABLE require additional configurations that you can set using @SequenceGenerator and @TableGenerator:
name: name of the generatortable/sequenceName: name of the table or the sequence (defaulting respectively tohibernate_sequencesandhibernate_sequence)catalog/schema:initialValue: the value from which the id is to start generatingallocationSize: the amount to increment by when allocating id numbers from the generator
In addition, the TABLE strategy also let you customize:
pkColumnName: the column name containing the entity identifiervalueColumnName: the column name containing the identifier valuepkColumnValue: the entity identifieruniqueConstraints: any potential column constraint on the table containing the ids
To link a table or sequence generator definition with an actual generated property, use the same name in both the definition name and the generator value generator as shown below.
@Id
@GeneratedValue(
strategy=GenerationType.SEQUENCE,
generator="SEQ_GEN")
@javax.persistence.SequenceGenerator(
name="SEQ_GEN",
sequenceName="my_sequence",
allocationSize=20
)
public Integer getId() { ... }
The scope of a generator definition can be the application or the class. Class-defined generators are not visible outside the class and can override application level generators. Application level generators are defined in JPA's XML deployment descriptors (see XXXXXX ???):
<table-generator name="EMP_GEN"
table="GENERATOR_TABLE"
pk-column-name="key"
value-column-name="hi"
pk-column-value="EMP"
allocation-size="20"/>
//and the annotation equivalent
@javax.persistence.TableGenerator(
name="EMP_GEN",
table="GENERATOR_TABLE",
pkColumnName = "key",
valueColumnName = "hi"
pkColumnValue="EMP",
allocationSize=20
)
<sequence-generator name="SEQ_GEN"
sequence-name="my_sequence"
allocation-size="20"/>
//and the annotation equivalent
@javax.persistence.SequenceGenerator(
name="SEQ_GEN",
sequenceName="my_sequence",
allocationSize=20
)
If a JPA XML descriptor (like META-INF/orm.xml) is used to define the generators, EMP_GEN and SEQ_GEN are application level generators.
Nota
Package level definition is not supported by the JPA specification. However, you can use the @GenericGenerator at the package level (see ???).
These are the four standard JPA generators. Hibernate goes beyond that and provide additional generators or additional options as we will see below. You can also write your own custom identifier generator by implementing org.hibernate.id.IdentifierGenerator.
To define a custom generator, use the @GenericGenerator annotation (and its plural counter part @GenericGenerators) that describes the class of the identifier generator or its short cut name (as described below) and a list of key/value parameters. When using @GenericGenerator and assigning it via @GeneratedValue.generator, the @GeneratedValue.strategy is ignored: leave it blank.
@Id @GeneratedValue(generator="system-uuid")
@GenericGenerator(name="system-uuid", strategy = "uuid")
public String getId() {
@Id @GeneratedValue(generator="trigger-generated")
@GenericGenerator(
name="trigger-generated",
strategy = "select",
parameters = @Parameter(name="key", value = "socialSecurityNumber")
)
public String getId() {
The hbm.xml approach uses the optional <generator> child element inside <id>. If any parameters are required to configure or initialize the generator instance, they are passed using the <param> element.
<id name="id" type="long" column="cat_id">
<generator class="org.hibernate.id.TableHiLoGenerator">
<param name="table">uid_table</param>
<param name="column">next_hi_value_column</param>
</generator>
</id>
Todos los generadores implementan la interfaz org.hibernate.id.IdentifierGenerator. Esta es una interfaz muy simple. Algunas aplicaciones pueden decidir brindar sus propias implementaciones especializadas. Sin embargo, Hibernate provee un rango de implementaciones ya incorporadas. Los nombres de atajo para los generadores incorporados son los siguientes:
incrementgenera indentificadores de tipo
long,shortointque sólamente son únicos cuando ningún otro proceso está insertando datos en la misma tabla. No lo utilice en un clúster.identitysoporta columnas de identidad en DB2, MySQL, MS SQL Server, Sybase y HypersonicSQL. El identificador devuelto es de tipo
long,shortoint.sequenceusa una secuencia en DB2, PostgreSQL, Oracle, SAP DB, McKoi o un generador en Interbase. El identificador devuelto es de tipo
long,shortoint.hiloutiliza un algoritmo alto/bajo para generar eficientemente identificadores de tipo
long,shortoint, dada una tabla y columna como fuente de valores altos (por defectohibernate_unique_keyynext_hirespectivamente). El algoritmo alto/bajo genera identificadores que son únicos sólamente para una base de datos particular.seqhiloutiliza un algoritmo alto/bajo para generar eficientemente identificadores de tipo
long,shortoint, dada una secuencia de base de datos.uuidGenerates a 128-bit UUID based on a custom algorithm. The value generated is represented as a string of 32 hexidecimal digits. Users can also configure it to use a separator (config parameter "separator") which separates the hexidecimal digits into 8{sep}8{sep}4{sep}8{sep}4. Note specifically that this is different than the IETF RFC 4122 representation of 8-4-4-4-12. If you need RFC 4122 compliant UUIDs, consider using "uuid2" generator discussed below.
uuid2Generates a IETF RFC 4122 compliant (variant 2) 128-bit UUID. The exact "version" (the RFC term) generated depends on the pluggable "generation strategy" used (see below). Capable of generating values as
java.util.UUID,java.lang.Stringor as a byte array of length 16 (byte[16]). The "generation strategy" is defined by the interfaceorg.hibernate.id.UUIDGenerationStrategy. The generator defines 2 configuration parameters for defining which generation strategy to use:uuid_gen_strategy_classNames the UUIDGenerationStrategy class to use
uuid_gen_strategyNames the UUIDGenerationStrategy instance to use
Out of the box, comes with the following strategies:
org.hibernate.id.uuid.StandardRandomStrategy(the default) - generates "version 3" (aka, "random") UUID values via therandomUUIDmethod ofjava.util.UUIDorg.hibernate.id.uuid.CustomVersionOneStrategy- generates "version 1" UUID values, using IP address since mac address not available. If you need mac address to be used, consider leveraging one of the existing third party UUID generators which sniff out mac address and integrating it via theorg.hibernate.id.UUIDGenerationStrategycontract. Two such libraries known at time of this writing include http://johannburkard.de/software/uuid/ and http://commons.apache.org/sandbox/id/uuid.html
guidutiliza una cadena GUID generada por base de datos en MS SQL Server y MySQL.
nativeselecciona
identity,sequenceohilodependiendo de las capacidades de la base de datos subyacente.assigneddeja a la aplicación asignar un identificador al objeto antes de que se llame a
save(). Esta es la estrategia por defecto si no se especifica un elemento<generator>.selectrecupera una clave principal asignada por un disparador de base de datos seleccionando la fila por alguna clave única y recuperando el valor de la clave principal.
foreignutiliza el identificador de otro objeto asociado. Generalmente se usa en conjunto cón a una asociación de clave principal
<one-to-one>.sequence-identityuna estrategia de generación de secuencias especilizadas que utiliza una secuencia de base de datos para el valor real de la generación, pero combina esto junto con JDBC3 getGeneratedKeys para devolver el valor del identificador generado como parte de la ejecución de la declaración de inserción. Esta estrategia está soportada sólamente en los controladores 10g de Oracle destinados para JDK1.4. Los comentarios en estas declaraciones de inserción están desactivados debido a un error en los controladores de Oracle.
Los generadores hilo y seqhilo brindan dos implementaciones opcionales del algoritmo alto/bajo. La primera implementación necesita de una tabla "especial" de base de datos para tener el siguiente valor "alto" disponible. La segunda utiliza una secuencia del estilo de Oracle, donde se encuentre soportada.
<id name="id" type="long" column="cat_id">
<generator class="hilo">
<param name="table">hi_value</param>
<param name="column">next_value</param>
<param name="max_lo">100</param>
</generator>
</id>
<id name="id" type="long" column="cat_id">
<generator class="seqhilo">
<param name="sequence">hi_value</param>
<param name="max_lo">100</param>
</generator>
</id>
Desafortunadamente, no puede utilizar hilo cuando le provea su propia Connection a Hibernate. Cuando Hibernate está utilizando una fuente de datos del servidor de aplicaciones para obtener conexiones alistadas con JTA, usted tiene que configurar el hibernate.transaction.manager_lookup_class.
El UUID contiene: la dirección IP, el tiempo de iniciación de la MVJ, con una precisión de un cuarto de segundo, el tiempo de sistema y un valor de contador (único en la MVJ). No es posible obtener una dirección MAC o una dirección de memoria desde el código Java, así que esto es la mejor opción sin tener que utilizar JNI.
Para las bases de datos que soportan columnas de identidad (DB2, MySQL, Sybase, MS SQL), puede utilizar generación de claves identity. Para las bases de datos que soportan las secuencias (DB2, Oracle, PostgreSQL, Interbase, McKoi, SAP DB) puede utilizar la generación de claves del estilo sequence. Ambas estrategias requieren dos consultas SQL para insertar un nuevo objeto. Por ejemplo:
<id name="id" type="long" column="person_id">
<generator class="sequence">
<param name="sequence">person_id_sequence</param>
</generator>
</id>
<id name="id" type="long" column="person_id" unsaved-value="0">
<generator class="identity"/>
</id>
Para desarrollos a través de plataformas, la estrategia native eligirá entre las estrategias identity, sequence e hilo, dependiendo de las capacidades de la base de datos subyacente.
If you want the application to assign identifiers, as opposed to having Hibernate generate them, you can use the assigned generator. This special generator uses the identifier value already assigned to the object's identifier property. The generator is used when the primary key is a natural key instead of a surrogate key. This is the default behavior if you do not specify @GeneratedValue nor <generator> elements.
El generador assigned hace que Hibernate utilice unsaved-value="undefined". Esto fuerza a Hibernate a ir a la base de datos para determinar si una instancia es transitoria o separada, a menos de que haya una propiedad de versión o sello de fecha, o que usted defina Interceptor.isUnsaved().
Hibernate no genera DDL con disparadores. Es para los esquemas heredados sólamente.
<id name="id" type="long" column="person_id">
<generator class="select">
<param name="key">socialSecurityNumber</param>
</generator>
</id>
En el ejemplo anterior, hay una propiedad única llamada socialSecurityNumber, Esta está definida por la clase, como una clave natural y una clave sustituta llamada person_id, cuyo valor es generado por un disparador.
Finally, you can ask Hibernate to copy the identifier from another associated entity. In the Hibernate jargon, it is known as a foreign generator but the JPA mapping reads better and is encouraged.
@Entity
class MedicalHistory implements Serializable {
@Id @OneToOne
@JoinColumn(name = "person_id")
Person patient;
}
@Entity
public class Person implements Serializable {
@Id @GeneratedValue Integer id;
}
Or alternatively
@Entity
class MedicalHistory implements Serializable {
@Id Integer id;
@MapsId @OneToOne
@JoinColumn(name = "patient_id")
Person patient;
}
@Entity
class Person {
@Id @GeneratedValue Integer id;
}
In hbm.xml use the following approach:
<class name="MedicalHistory">
<id name="id">
<generator class="foreign">
<param name="property">patient</param>
</generator>
</id>
<one-to-one name="patient" class="Person" constrained="true"/>
</class>
Desde el lanzamiento 3.2.3, hay 2 nuevos generadores, los cuales representan una nueva reflexión sobre dos aspectos diferentes de la generación del identificador. El primer aspecto es qúe tan portátil es la base de datos; el segudno es la optimización. La optimización significa que no tiene que preguntarle a la base de datos por toda petición de un nuevo valor identificador. Estos dos nuevos generadores tienen el propósito de tomar el lugar de algunos de los generadores nombrados que describimos anteriormente, empezando por 3.3.x. Sin embargo, están incluídos en los lanzamientos actuales y puede ser referenciados por FQN.
El primero de estos nuevos generadores es org.hibernate.id.enhanced.SequenceStyleGenerator, el cual tiene el propósito, primero, de ser el reemplazo para el generador sequence y segundo, de ser un generador de portabilidad mejor que native. Esto se debe a que native generalmente escoge entre identity y sequence, los cuales tienen una gran diferencia semántica que puede crear problemas sutiles en las aplicaciones mirando la portabilidad. Sin embargo, org.hibernate.id.enhanced.SequenceStyleGenerator, logra la portabilidad de una manera diferente. Escoge entre una tabla o una secuencia en la base de datos para almacenar sus valores en subida, dependiendo de las capacidades del dialecto que se está utilizando. La diferencia enter esto y native es que el almacenamiento basado en tablas y secuencias tienen la misma semántica. De hecho, las secuencias son exactamente lo que Hibernate trata de emular con sus generadores basados en tablas. Este generador tiene un número de parámetros de configuración:
sequence_name(opcional, por defecto eshibernate_sequence): el nombre de la secuencia o la tabla a utilizar.initial_value(opcional, por defecto es1): el valor inicial a recuperarse de la secuencia/tabla. En términos de creación de secuencias, esto es análogo a la cláusula que usualmente se llama "STARTS WITH".increment_size(opcional - por defecto es1): el valor por el cual las llamadas subsecuentes a la secuencia/tabla deben diferir. En términos de creación de secuencias, esto es análogo a la cláusula que usualmente se llama "INCREMENT BY".force_table_use(opcional - por defecto esfalse): ¿debemos forzar el uso de una tabla como la estructura de respaldo aunque puede que el dialecto soporte la secuencia?value_column(opcional - por defecto esnext_val): solo es relevante para estructuras de tablas, es el nombre de la columna en la tabla, la cual se usa para mantener el valor.optimizer(optional - defaults tonone): See Sección 5.1.2.3.1, “Optimización del generador del identificador”
El segundo de estos nuevos generadores es org.hibernate.id.enhanced.TableGenerator, el cual tiene el propósito, primero, de reemplazar el generador table, auqnue de hecho funciona como org.hibernate.id.MultipleHiLoPerTableGenerator, y segundo, como una re-implementación de org.hibernate.id.MultipleHiLoPerTableGenerator que utiliza la noción de los optimizadores enchufables. Esencialmente, este generador define una tabla capaz de mantener un número de valores de incremento diferentes de manera simultánea usando múltiples filas tecleadas claramente. Este generador tiene un número de parámetros de configuración:
table_name(opcional - por defecto eshibernate_sequences): el nombre de la tabla a utilizar.value_column_name(opcional - por defecto esnext_val): el nombre de la columna en la tabla que se utiliza para mantener el valor.segment_column_name(opcional - por defecto essequence_name): el nombre de la columna en la tabla que se utiliza para mantener la "llave segmento". Este es el valor que identifica que valor de incremento utilizar.segment_value(opcional - por defecto esdefault): El valor "llave segmento" para el segmento desde el cual queremos sacar los valores de incremento para este generador.segment_value_length(opcional - por defecto es255): Se utiliza para la generación de esquemas; el tamaño de la columna a crear esta columna de llave de segmento.initial_value(opcional - por defecto es1): El valor inicial a recuperar de la tabla.increment_size(opcional - por defecto es1): El valor por el cual deben diferir las llamadas subsecuentes a la tabla.optimizer(optional - defaults to??): See Sección 5.1.2.3.1, “Optimización del generador del identificador”.
For identifier generators that store values in the database, it is inefficient for them to hit the database on each and every call to generate a new identifier value. Instead, you can group a bunch of them in memory and only hit the database when you have exhausted your in-memory value group. This is the role of the pluggable optimizers. Currently only the two enhanced generators (Sección 5.1.2.3, “Generadores mejorados del identificador” support this operation.
none(generalmente este el es valor predeterminado si no se especifica un optimizador): esto no realizará ninguna optimización y accederá a la base de datos para toda petición.hilo: aplica un algoritmo hi/lo a los valores recuperados de la base de datos. Se espera que los valores de la base de datos para este optimizador sean secuenciales. Los valores recuperados de la estructura de la base de datos para este optimizador indican el "número del grupo". Elincrement_sizese multiplica por ese valor en la memoria para definir un grupo "hi value".pooled: como en el caso dehilo, este optimizador trata de minimizar el número de hits a la base de datos. Sin embargo, aquí simplemente almacenamos el valor inicial para el "siguiente grupo" en la estructura de la base de datos en lugar de un valor secuencial en combinación con un algoritmo de agrupamiento en-memoria. Aquí,increment_sizeser refiere a los valores que provienen de la base de datos.
Hibernate supports the automatic generation of some of the identifier properties. Simply use the @GeneratedValue annotation on one or several id properties.
Aviso
The Hibernate team has always felt such a construct as fundamentally wrong. Try hard to fix your data model before using this feature.
@Entity
public class CustomerInventory implements Serializable {
@Id
@TableGenerator(name = "inventory",
table = "U_SEQUENCES",
pkColumnName = "S_ID",
valueColumnName = "S_NEXTNUM",
pkColumnValue = "inventory",
allocationSize = 1000)
@GeneratedValue(strategy = GenerationType.TABLE, generator = "inventory")
Integer id;
@Id @ManyToOne(cascade = CascadeType.MERGE)
Customer customer;
}
@Entity
public class Customer implements Serializable {
@Id
private int id;
}
You can also generate properties inside an @EmbeddedId class.
When using long transactions or conversations that span several database transactions, it is useful to store versioning data to ensure that if the same entity is updated by two conversations, the last to commit changes will be informed and not override the other conversation's work. It guarantees some isolation while still allowing for good scalability and works particularly well in read-often write-sometimes situations.
You can use two approaches: a dedicated version number or a timestamp.
Una propiedad de versión o de sello de fecha nunca debe ser nula para una instancia separada. Hibernate detectará cualquier instancia con una versión o sello de fecha nulo como transitoria, sin importar qué otras estrategias unsaved-value se hayan especificado. El declarar una propiedad de versión o sello de fecha nulable es una forma fácil de evitar cualquier problema con la re-unión transitiva en Hibernate. Es especialmente útil para la gente que utiliza identificadores asignados o claves compuestas.
You can add optimistic locking capability to an entity using the @Version annotation:
@Entity
public class Flight implements Serializable {
...
@Version
@Column(name="OPTLOCK")
public Integer getVersion() { ... }
}
The version property will be mapped to the OPTLOCK column, and the entity manager will use it to detect conflicting updates (preventing lost updates you might otherwise see with the last-commit-wins strategy).
The version column may be a numeric. Hibernate supports any kind of type provided that you define and implement the appropriate UserVersionType.
The application must not alter the version number set up by Hibernate in any way. To artificially increase the version number, check in Hibernate Entity Manager's reference documentation LockModeType.OPTIMISTIC_FORCE_INCREMENT or LockModeType.PESSIMISTIC_FORCE_INCREMENT.
If the version number is generated by the database (via a trigger for example), make sure to use @org.hibernate.annotations.Generated(GenerationTime.ALWAYS).
To declare a version property in hbm.xml, use:
<version
column="version_column"
name="propertyName"
type="typename"
access="field|property|ClassName"
unsaved-value="null|negative|undefined"
generated="never|always"
insert="true|false"
node="element-name|@attribute-name|element/@attribute|."
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Alternatively, you can use a timestamp. Timestamps are a less safe implementation of optimistic locking. However, sometimes an application might use the timestamps in other ways as well.
Simply mark a property of type Date or Calendar as @Version.
@Entity
public class Flight implements Serializable {
...
@Version
public Date getLastUpdate() { ... }
}
When using timestamp versioning you can tell Hibernate where to retrieve the timestamp value from - database or JVM - by optionally adding the @org.hibernate.annotations.Source annotation to the property. Possible values for the value attribute of the annotation are org.hibernate.annotations.SourceType.VM and org.hibernate.annotations.SourceType.DB. The default is SourceType.DB which is also used in case there is no @Source annotation at all.
Like in the case of version numbers, the timestamp can also be generated by the database instead of Hibernate. To do that, use @org.hibernate.annotations.Generated(GenerationTime.ALWAYS).
In hbm.xml, use the <timestamp> element:
<timestamp
column="timestamp_column"
name="propertyName"
access="field|property|ClassName"
unsaved-value="null|undefined"
source="vm|db"
generated="never|always"
node="element-name|@attribute-name|element/@attribute|."
/>
|
|
|
|
|
|
|
|
|
|
|
|
Nota
<Timestamp> es equivalente a <version type="timestamp">. Y <timestamp source="db"> es equivalente a <version type="dbtimestamp">.
You need to decide which property needs to be made persistent in a given entity. This differs slightly between the annotation driven metadata and the hbm.xml files.
In the annotations world, every non static non transient property (field or method depending on the access type) of an entity is considered persistent, unless you annotate it as @Transient. Not having an annotation for your property is equivalent to the appropriate @Basic annotation.
The @Basic annotation allows you to declare the fetching strategy for a property. If set to LAZY, specifies that this property should be fetched lazily when the instance variable is first accessed. It requires build-time bytecode instrumentation, if your classes are not instrumented, property level lazy loading is silently ignored. The default is EAGER. You can also mark a property as not optional thanks to the @Basic.optional attribute. This will ensure that the underlying column are not nullable (if possible). Note that a better approach is to use the @NotNull annotation of the Bean Validation specification.
Let's look at a few examples:
public transient int counter; //transient property
private String firstname; //persistent property
@Transient
String getLengthInMeter() { ... } //transient property
String getName() {... } // persistent property
@Basic
int getLength() { ... } // persistent property
@Basic(fetch = FetchType.LAZY)
String getDetailedComment() { ... } // persistent property
@Temporal(TemporalType.TIME)
java.util.Date getDepartureTime() { ... } // persistent property
@Enumerated(EnumType.STRING)
Starred getNote() { ... } //enum persisted as String in database
counter, a transient field, and lengthInMeter, a method annotated as @Transient, and will be ignored by the Hibernate. name, length, and firstname properties are mapped persistent and eagerly fetched (the default for simple properties). The detailedComment property value will be lazily fetched from the database once a lazy property of the entity is accessed for the first time. Usually you don't need to lazy simple properties (not to be confused with lazy association fetching). The recommended alternative is to use the projection capability of JP-QL (Java Persistence Query Language) or Criteria queries.
JPA support property mapping of all basic types supported by Hibernate (all basic Java types , their respective wrappers and serializable classes). Hibernate Annotations supports out of the box enum type mapping either into a ordinal column (saving the enum ordinal) or a string based column (saving the enum string representation): the persistence representation, defaulted to ordinal, can be overridden through the @Enumerated annotation as shown in the note property example.
In plain Java APIs, the temporal precision of time is not defined. When dealing with temporal data you might want to describe the expected precision in database. Temporal data can have DATE, TIME, or TIMESTAMP precision (ie the actual date, only the time, or both). Use the @Temporal annotation to fine tune that.
@Lob indicates that the property should be persisted in a Blob or a Clob depending on the property type: java.sql.Clob, Character[], char[] and java.lang.String will be persisted in a Clob. java.sql.Blob, Byte[], byte[] and Serializable type will be persisted in a Blob.
@Lob
public String getFullText() {
return fullText;
}
@Lob
public byte[] getFullCode() {
return fullCode;
}
If the property type implements java.io.Serializable and is not a basic type, and if the property is not annotated with @Lob, then the Hibernate serializable type is used.
You can also manually specify a type using the @org.hibernate.annotations.Type and some parameters if needed. @Type.type could be:
El nombre de un tipo básico de Hibernate:
integer, string, character, date, timestamp, float, binary, serializable, object, blob, etc.El nombre de una clase Java con un tipo básico predeterminado:
int, float, char, java.lang.String, java.util.Date, java.lang.Integer, java.sql.Clob, etc.El nombre de una clase Java serializable.
El nombre declase de un tipo personalizado:
com.illflow.type.MyCustomTypeetc.
If you do not specify a type, Hibernate will use reflection upon the named property and guess the correct Hibernate type. Hibernate will attempt to interpret the name of the return class of the property getter using, in order, rules 2, 3, and 4.
@org.hibernate.annotations.TypeDef and @org.hibernate.annotations.TypeDefs allows you to declare type definitions. These annotations can be placed at the class or package level. Note that these definitions are global for the session factory (even when defined at the class level). If the type is used on a single entity, you can place the definition on the entity itself. Otherwise, it is recommended to place the definition at the package level. In the example below, when Hibernate encounters a property of class PhoneNumer, it delegates the persistence strategy to the custom mapping type PhoneNumberType. However, properties belonging to other classes, too, can delegate their persistence strategy to PhoneNumberType, by explicitly using the @Type annotation.
Nota
Package level annotations are placed in a file named package-info.java in the appropriate package. Place your annotations before the package declaration.
@TypeDef(
name = "phoneNumber",
defaultForType = PhoneNumber.class,
typeClass = PhoneNumberType.class
)
@Entity
public class ContactDetails {
[...]
private PhoneNumber localPhoneNumber;
@Type(type="phoneNumber")
private OverseasPhoneNumber overseasPhoneNumber;
[...]
}
The following example shows the usage of the parameters attribute to customize the TypeDef.
//in org/hibernate/test/annotations/entity/package-info.java
@TypeDefs(
{
@TypeDef(
name="caster",
typeClass = CasterStringType.class,
parameters = {
@Parameter(name="cast", value="lower")
}
)
}
)
package org.hibernate.test.annotations.entity;
//in org/hibernate/test/annotations/entity/Forest.java
public class Forest {
@Type(type="caster")
public String getSmallText() {
...
}
When using composite user type, you will have to express column definitions. The @Columns has been introduced for that purpose.
@Type(type="org.hibernate.test.annotations.entity.MonetaryAmountUserType")
@Columns(columns = {
@Column(name="r_amount"),
@Column(name="r_currency")
})
public MonetaryAmount getAmount() {
return amount;
}
public class MonetaryAmount implements Serializable {
private BigDecimal amount;
private Currency currency;
...
}
By default the access type of a class hierarchy is defined by the position of the @Id or @EmbeddedId annotations. If these annotations are on a field, then only fields are considered for persistence and the state is accessed via the field. If there annotations are on a getter, then only the getters are considered for persistence and the state is accessed via the getter/setter. That works well in practice and is the recommended approach.
Nota
The placement of annotations within a class hierarchy has to be consistent (either field or on property) to be able to determine the default access type. It is recommended to stick to one single annotation placement strategy throughout your whole application.
However in some situations, you need to:
force the access type of the entity hierarchy
override the access type of a specific entity in the class hierarchy
override the access type of an embeddable type
The best use case is an embeddable class used by several entities that might not use the same access type. In this case it is better to force the access type at the embeddable class level.
To force the access type on a given class, use the @Access annotation as showed below:
@Entity
public class Order {
@Id private Long id;
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
@Embedded private Address address;
public Address getAddress() { return address; }
public void setAddress() { this.address = address; }
}
@Entity
public class User {
private Long id;
@Id public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
private Address address;
@Embedded public Address getAddress() { return address; }
public void setAddress() { this.address = address; }
}
@Embeddable
@Access(AcessType.PROPERTY)
public class Address {
private String street1;
public String getStreet1() { return street1; }
public void setStreet1() { this.street1 = street1; }
private hashCode; //not persistent
}
You can also override the access type of a single property while keeping the other properties standard.
@Entity
public class Order {
@Id private Long id;
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
@Transient private String userId;
@Transient private String orderId;
@Access(AccessType.PROPERTY)
public String getOrderNumber() { return userId + ":" + orderId; }
public void setOrderNumber() { this.userId = ...; this.orderId = ...; }
}
In this example, the default access type is FIELD except for the orderNumber property. Note that the corresponding field, if any must be marked as @Transient or transient.
@org.hibernate.annotations.AccessType
The annotation @org.hibernate.annotations.AccessType should be considered deprecated for FIELD and PROPERTY access. It is still useful however if you need to use a custom access type.
It is sometimes useful to avoid increasing the version number even if a given property is dirty (particularly collections). You can do that by annotating the property (or collection) with @OptimisticLock(excluded=true).
More formally, specifies that updates to this property do not require acquisition of the optimistic lock.
The column(s) used for a property mapping can be defined using the @Column annotation. Use it to override default values (see the JPA specification for more information on the defaults). You can use this annotation at the property level for properties that are:
not annotated at all
annotated with
@Basicannotated with
@Versionannotated with
@Lobannotated with
@Temporal
@Entity
public class Flight implements Serializable {
...
@Column(updatable = false, name = "flight_name", nullable = false, length=50)
public String getName() { ... }
The name property is mapped to the flight_name column, which is not nullable, has a length of 50 and is not updatable (making the property immutable).
This annotation can be applied to regular properties as well as @Id or @Version properties.
@Column(
name="columnName";
boolean unique() default false;
boolean nullable() default true;
boolean insertable() default true;
boolean updatable() default true;
String columnDefinition() default "";
String table() default "";
int length() default 255;
int precision() default 0; // decimal precision
int scale() default 0; // decimal scale
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Sometimes, you want the Database to do some computation for you rather than in the JVM, you might also create some kind of virtual column. You can use a SQL fragment (aka formula) instead of mapping a property into a column. This kind of property is read only (its value is calculated by your formula fragment).
@Formula("obj_length * obj_height * obj_width")
public long getObjectVolume()
The SQL fragment can be as complex as you want and even include subselects.
If a property is not annotated, the following rules apply:
If the property is of a single type, it is mapped as @Basic
Otherwise, if the type of the property is annotated as @Embeddable, it is mapped as @Embedded
Otherwise, if the type of the property is
Serializable, it is mapped as@Basicin a column holding the object in its serialized versionOtherwise, if the type of the property is
java.sql.Cloborjava.sql.Blob, it is mapped as@Lobwith the appropriateLobType
El elemento <property> declara una propiedad persistente estilo JavaBean de la clase.
<property
name="propertyName"
column="column_name"
type="typename"
update="true|false"
insert="true|false"
formula="arbitrary SQL expression"
access="field|property|ClassName"
lazy="true|false"
unique="true|false"
not-null="true|false"
optimistic-lock="true|false"
generated="never|insert|always"
node="element-name|@attribute-name|element/@attribute|."
index="index_name"
unique_key="unique_key_id"
length="L"
precision="P"
scale="S"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
escribanombre puede ser:
El nombre de un tipo básico de Hibernate:
integer, string, character, date, timestamp, float, binary, serializable, object, blob, etc.El nombre de una clase Java con un tipo básico predeterminado:
int, float, char, java.lang.String, java.util.Date, java.lang.Integer, java.sql.Clob, etc.El nombre de una clase Java serializable.
El nombre declase de un tipo personalizado:
com.illflow.type.MyCustomTypeetc.
Si no especifica un tipo, Hibernate utilizará reflección sobre la propiedad mencionada para deducir el tipo Hibernate correcto. Hibernate intentará interpretar el nombre de la clase de retorno del getter de la propiedad utilizando las reglas 2, 3 y 4 en ese mismo orden. En algunos casos necesitará el atributo type. Por ejemplo, para distinguir entre Hibernate.DATE y Hibernate.TIMESTAMP, o especificar un tipo personalizado.
El atributo access le permite controlar el cómo Hibernate accederá a la propiedad en tiempo de ejecución. Por defecto, Hibernate llamará al par de getter/setter de la propiedad. Si usted especifica access="field", Hibernate se saltará el par get/set y accederá al campo directamente utilizando reflección. Puede especificar su propia estrategia de acceso a la propiedad mencionando una clase que implemente la interfaz org.hibernate.property.PropertyAccessor.
Una funcionalidad especialmente poderosa son las propiedades derivadas. Estas propiedades son, por definición, de sólo lectura. El valor de la propiedad se computa en tiempo de carga. Usted declara la computación como una expresión SQL y ésta se traduce como una cláusula de subconsulta SELECT en la consulta SQL que carga una instancia:
<property name="totalPrice"
formula="( SELECT SUM (li.quantity*p.price) FROM LineItem li, Product p
WHERE li.productId = p.productId
AND li.customerId = customerId
AND li.orderNumber = orderNumber )"/>
Puede referenciar la tabla de las entidades sin declarar un alias o una columna particular. En el ejemplo dado sería customerId. También puede utilizar el elemento anidado de mapeo <formula> si no quiere utilizar el atributo.
Embeddable objects (or components) are objects whose properties are mapped to the same table as the owning entity's table. Components can, in turn, declare their own properties, components or collections
It is possible to declare an embedded component inside an entity and even override its column mapping. Component classes have to be annotated at the class level with the @Embeddable annotation. It is possible to override the column mapping of an embedded object for a particular entity using the @Embedded and @AttributeOverride annotation in the associated property:
@Entity
public class Person implements Serializable {
// Persistent component using defaults
Address homeAddress;
@Embedded
@AttributeOverrides( {
@AttributeOverride(name="iso2", column = @Column(name="bornIso2") ),
@AttributeOverride(name="name", column = @Column(name="bornCountryName") )
} )
Country bornIn;
...
}
@Embeddable
public class Address implements Serializable {
String city;
Country nationality; //no overriding here
}
@Embeddable
public class Country implements Serializable {
private String iso2;
@Column(name="countryName") private String name;
public String getIso2() { return iso2; }
public void setIso2(String iso2) { this.iso2 = iso2; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
...
}
An embeddable object inherits the access type of its owning entity (note that you can override that using the @Access annotation).
The Person entity has two component properties, homeAddress and bornIn. homeAddress property has not been annotated, but Hibernate will guess that it is a persistent component by looking for the @Embeddable annotation in the Address class. We also override the mapping of a column name (to bornCountryName) with the @Embedded and @AttributeOverride annotations for each mapped attribute of Country. As you can see, Country is also a nested component of Address, again using auto-detection by Hibernate and JPA defaults. Overriding columns of embedded objects of embedded objects is through dotted expressions.
@Embedded
@AttributeOverrides( {
@AttributeOverride(name="city", column = @Column(name="fld_city") ),
@AttributeOverride(name="nationality.iso2", column = @Column(name="nat_Iso2") ),
@AttributeOverride(name="nationality.name", column = @Column(name="nat_CountryName") )
//nationality columns in homeAddress are overridden
} )
Address homeAddress;
Hibernate Annotations supports something that is not explicitly supported by the JPA specification. You can annotate a embedded object with the @MappedSuperclass annotation to make the superclass properties persistent (see @MappedSuperclass for more informations).
You can also use association annotations in an embeddable object (ie @OneToOne, @ManyToOne, @OneToMany or @ManyToMany). To override the association columns you can use @AssociationOverride.
If you want to have the same embeddable object type twice in the same entity, the column name defaulting will not work as several embedded objects would share the same set of columns. In plain JPA, you need to override at least one set of columns. Hibernate, however, allows you to enhance the default naming mechanism through the NamingStrategy interface. You can write a strategy that prevent name clashing in such a situation. DefaultComponentSafeNamingStrategy is an example of this.
If a property of the embedded object points back to the owning entity, annotate it with the @Parent annotation. Hibernate will make sure this property is properly loaded with the entity reference.
In XML, use the <component> element.
<component
name="propertyName"
class="className"
insert="true|false"
update="true|false"
access="field|property|ClassName"
lazy="true|false"
optimistic-lock="true|false"
unique="true|false"
node="element-name|."
>
<property ...../>
<many-to-one .... />
........
</component>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Las etiquetas hijas <property> mapean propiedades de la clase hija a las columnas de la tabla.
El elemento <component> permite un subelemento <parent> que mapea una propiedad de la clase del componente como una referencia a la entidad contenedora.
The <dynamic-component> element allows a Map to be mapped as a component, where the property names refer to keys of the map. See Sección 9.5, “Componentes dinámicos” for more information. This feature is not supported in annotations.
Java is a language supporting polymorphism: a class can inherit from another. Several strategies are possible to persist a class hierarchy:
Single table per class hierarchy strategy: a single table hosts all the instances of a class hierarchy
Joined subclass strategy: one table per class and subclass is present and each table persist the properties specific to a given subclass. The state of the entity is then stored in its corresponding class table and all its superclasses
Table per class strategy: one table per concrete class and subclass is present and each table persist the properties of the class and its superclasses. The state of the entity is then stored entirely in the dedicated table for its class.
With this approach the properties of all the subclasses in a given mapped class hierarchy are stored in a single table.
Each subclass declares its own persistent properties and subclasses. Version and id properties are assumed to be inherited from the root class. Each subclass in a hierarchy must define a unique discriminator value. If this is not specified, the fully qualified Java class name is used.
@Entity
@Inheritance(strategy=InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(
name="planetype",
discriminatorType=DiscriminatorType.STRING
)
@DiscriminatorValue("Plane")
public class Plane { ... }
@Entity
@DiscriminatorValue("A320")
public class A320 extends Plane { ... }
In hbm.xml, for the table-per-class-hierarchy mapping strategy, the <subclass> declaration is used. For example:
<subclass
name="ClassName"
discriminator-value="discriminator_value"
proxy="ProxyInterface"
lazy="true|false"
dynamic-update="true|false"
dynamic-insert="true|false"
entity-name="EntityName"
node="element-name"
extends="SuperclassName">
<property .... />
.....
</subclass>
|
|
|
|
|
|
|
|
For information about inheritance mappings see Capítulo 10, Mapeo de herencias.
Discriminators are required for polymorphic persistence using the table-per-class-hierarchy mapping strategy. It declares a discriminator column of the table. The discriminator column contains marker values that tell the persistence layer what subclass to instantiate for a particular row. Hibernate Core supports the follwoing restricted set of types as discriminator column: string, character, integer, byte, short, boolean, yes_no, true_false.
Use the @DiscriminatorColumn to define the discriminator column as well as the discriminator type.
Nota
The enum DiscriminatorType used in javax.persitence.DiscriminatorColumn only contains the values STRING, CHAR and INTEGER which means that not all Hibernate supported types are available via the @DiscriminatorColumn annotation.
You can also use @DiscriminatorFormula to express in SQL a virtual discriminator column. This is particularly useful when the discriminator value can be extracted from one or more columns of the table. Both @DiscriminatorColumn and @DiscriminatorFormula are to be set on the root entity (once per persisted hierarchy).
@org.hibernate.annotations.DiscriminatorOptions allows to optionally specify Hibernate specific discriminator options which are not standardized in JPA. The available options are force and insert. The force attribute is useful if the table contains rows with "extra" discriminator values that are not mapped to a persistent class. This could for example occur when working with a legacy database. If force is set to true Hibernate will specify the allowed discriminator values in the SELECT query, even when retrieving all instances of the root class. The second option - insert - tells Hibernate whether or not to include the discriminator column in SQL INSERTs. Usually the column should be part of the INSERT statement, but if your discriminator column is also part of a mapped composite identifier you have to set this option to false.
Sugerencia
There is also a @org.hibernate.annotations.ForceDiscriminator annotation which is deprecated since version 3.6. Use @DiscriminatorOptions instead.
Finally, use @DiscriminatorValue on each class of the hierarchy to specify the value stored in the discriminator column for a given entity. If you do not set @DiscriminatorValue on a class, the fully qualified class name is used.
@Entity
@Inheritance(strategy=InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(
name="planetype",
discriminatorType=DiscriminatorType.STRING
)
@DiscriminatorValue("Plane")
public class Plane { ... }
@Entity
@DiscriminatorValue("A320")
public class A320 extends Plane { ... }
In hbm.xml, the <discriminator> element is used to define the discriminator column or formula:
<discriminator
column="discriminator_column"
type="discriminator_type"
force="true|false"
insert="true|false"
formula="arbitrary sql expression"
/>
|
|
|
|
|
|
|
|
|
|
Los valores reales de la columna discriminadora están especificados por el atributo discriminator-value de los elementos <class> y <subclass>.
El atributo formula le permite declarar una expresión SQL arbitraria que será utilizada para evaluar el tipo de una fila. Por ejemplo:
<discriminator
formula="case when CLASS_TYPE in ('a', 'b', 'c') then 0 else 1 end"
type="integer"/>
Each subclass can also be mapped to its own table. This is called the table-per-subclass mapping strategy. An inherited state is retrieved by joining with the table of the superclass. A discriminator column is not required for this mapping strategy. Each subclass must, however, declare a table column holding the object identifier. The primary key of this table is also a foreign key to the superclass table and described by the @PrimaryKeyJoinColumns or the <key> element.
@Entity @Table(name="CATS")
@Inheritance(strategy=InheritanceType.JOINED)
public class Cat implements Serializable {
@Id @GeneratedValue(generator="cat-uuid")
@GenericGenerator(name="cat-uuid", strategy="uuid")
String getId() { return id; }
...
}
@Entity @Table(name="DOMESTIC_CATS")
@PrimaryKeyJoinColumn(name="CAT")
public class DomesticCat extends Cat {
public String getName() { return name; }
}
Nota
The table name still defaults to the non qualified class name. Also if @PrimaryKeyJoinColumn is not set, the primary key / foreign key columns are assumed to have the same names as the primary key columns of the primary table of the superclass.
In hbm.xml, use the <joined-subclass> element. For example:
<joined-subclass
name="ClassName"
table="tablename"
proxy="ProxyInterface"
lazy="true|false"
dynamic-update="true|false"
dynamic-insert="true|false"
schema="schema"
catalog="catalog"
extends="SuperclassName"
persister="ClassName"
subselect="SQL expression"
entity-name="EntityName"
node="element-name">
<key .... >
<property .... />
.....
</joined-subclass>
|
|
|
|
|
|
|
|
Use the <key> element to declare the primary key / foreign key column. The mapping at the start of the chapter would then be re-written as:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="eg">
<class name="Cat" table="CATS">
<id name="id" column="uid" type="long">
<generator class="hilo"/>
</id>
<property name="birthdate" type="date"/>
<property name="color" not-null="true"/>
<property name="sex" not-null="true"/>
<property name="weight"/>
<many-to-one name="mate"/>
<set name="kittens">
<key column="MOTHER"/>
<one-to-many class="Cat"/>
</set>
<joined-subclass name="DomesticCat" table="DOMESTIC_CATS">
<key column="CAT"/>
<property name="name" type="string"/>
</joined-subclass>
</class>
<class name="eg.Dog">
<!-- mapping for Dog could go here -->
</class>
</hibernate-mapping>
For information about inheritance mappings see Capítulo 10, Mapeo de herencias.
A third option is to map only the concrete classes of an inheritance hierarchy to tables. This is called the table-per-concrete-class strategy. Each table defines all persistent states of the class, including the inherited state. In Hibernate, it is not necessary to explicitly map such inheritance hierarchies. You can map each class as a separate entity root. However, if you wish use polymorphic associations (e.g. an association to the superclass of your hierarchy), you need to use the union subclass mapping.
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public class Flight implements Serializable { ... }
Or in hbm.xml:
<union-subclass
name="ClassName"
table="tablename"
proxy="ProxyInterface"
lazy="true|false"
dynamic-update="true|false"
dynamic-insert="true|false"
schema="schema"
catalog="catalog"
extends="SuperclassName"
abstract="true|false"
persister="ClassName"
subselect="SQL expression"
entity-name="EntityName"
node="element-name">
<property .... />
.....
</union-subclass>
|
|
|
|
|
|
|
|
No se necesita una columna o una columna clave discriminadora para esta estrategia de mapeo.
For information about inheritance mappings see Capítulo 10, Mapeo de herencias.
This is sometimes useful to share common properties through a technical or a business superclass without including it as a regular mapped entity (ie no specific table for this entity). For that purpose you can map them as @MappedSuperclass.
@MappedSuperclass
public class BaseEntity {
@Basic
@Temporal(TemporalType.TIMESTAMP)
public Date getLastUpdate() { ... }
public String getLastUpdater() { ... }
...
}
@Entity class Order extends BaseEntity {
@Id public Integer getId() { ... }
...
}
In database, this hierarchy will be represented as an Order table having the id, lastUpdate and lastUpdater columns. The embedded superclass property mappings are copied into their entity subclasses. Remember that the embeddable superclass is not the root of the hierarchy though.
Nota
Properties from superclasses not mapped as @MappedSuperclass are ignored.
Nota
The default access type (field or methods) is used, unless you use the @Access annotation.
Nota
The same notion can be applied to @Embeddable objects to persist properties from their superclasses. You also need to use @MappedSuperclass to do that (this should not be considered as a standard EJB3 feature though)
Nota
It is allowed to mark a class as @MappedSuperclass in the middle of the mapped inheritance hierarchy.
Nota
Any class in the hierarchy non annotated with @MappedSuperclass nor @Entity will be ignored.
You can override columns defined in entity superclasses at the root entity level using the @AttributeOverride annotation.
@MappedSuperclass
public class FlyingObject implements Serializable {
public int getAltitude() {
return altitude;
}
@Transient
public int getMetricAltitude() {
return metricAltitude;
}
@ManyToOne
public PropulsionType getPropulsion() {
return metricAltitude;
}
...
}
@Entity
@AttributeOverride( name="altitude", column = @Column(name="fld_altitude") )
@AssociationOverride(
name="propulsion",
joinColumns = @JoinColumn(name="fld_propulsion_fk")
)
public class Plane extends FlyingObject {
...
}
The altitude property will be persisted in an fld_altitude column of table Plane and the propulsion association will be materialized in a fld_propulsion_fk foreign key column.
You can define @AttributeOverride(s) and @AssociationOverride(s) on @Entity classes, @MappedSuperclass classes and properties pointing to an @Embeddable object.
In hbm.xml, simply map the properties of the superclass in the <class> element of the entity that needs to inherit them.
While not recommended for a fresh schema, some legacy databases force your to map a single entity on several tables.
Using the @SecondaryTable or @SecondaryTables class level annotations. To express that a column is in a particular table, use the table parameter of @Column or @JoinColumn.
@Entity
@Table(name="MainCat")
@SecondaryTables({
@SecondaryTable(name="Cat1", pkJoinColumns={
@PrimaryKeyJoinColumn(name="cat_id", referencedColumnName="id")
),
@SecondaryTable(name="Cat2", uniqueConstraints={@UniqueConstraint(columnNames={"storyPart2"})})
})
public class Cat implements Serializable {
private Integer id;
private String name;
private String storyPart1;
private String storyPart2;
@Id @GeneratedValue
public Integer getId() {
return id;
}
public String getName() {
return name;
}
@Column(table="Cat1")
public String getStoryPart1() {
return storyPart1;
}
@Column(table="Cat2")
public String getStoryPart2() {
return storyPart2;
}
}
In this example, name will be in MainCat. storyPart1 will be in Cat1 and storyPart2 will be in Cat2. Cat1 will be joined to MainCat using the cat_id as a foreign key, and Cat2 using id (ie the same column name, the MainCat id column has). Plus a unique constraint on storyPart2 has been set.
There is also additional tuning accessible via the @org.hibernate.annotations.Table annotation:
fetch: If set to JOIN, the default, Hibernate will use an inner join to retrieve a secondary table defined by a class or its superclasses and an outer join for a secondary table defined by a subclass. If set toSELECTthen Hibernate will use a sequential select for a secondary table defined on a subclass, which will be issued only if a row turns out to represent an instance of the subclass. Inner joins will still be used to retrieve a secondary defined by the class and its superclasses.inverse: If true, Hibernate will not try to insert or update the properties defined by this join. Default to false.optional: If enabled (the default), Hibernate will insert a row only if the properties defined by this join are non-null and will always use an outer join to retrieve the properties.foreignKey: defines the Foreign Key name of a secondary table pointing back to the primary table.
Make sure to use the secondary table name in the appliesto property
@Entity
@Table(name="MainCat")
@SecondaryTable(name="Cat1")
@org.hibernate.annotations.Table(
appliesTo="Cat1",
fetch=FetchMode.SELECT,
optional=true)
public class Cat implements Serializable {
private Integer id;
private String name;
private String storyPart1;
private String storyPart2;
@Id @GeneratedValue
public Integer getId() {
return id;
}
public String getName() {
return name;
}
@Column(table="Cat1")
public String getStoryPart1() {
return storyPart1;
}
@Column(table="Cat2")
public String getStoryPart2() {
return storyPart2;
}
}
In hbm.xml, use the <join> element.
<join
table="tablename"
schema="owner"
catalog="catalog"
fetch="join|select"
inverse="true|false"
optional="true|false">
<key ... />
<property ... />
...
</join>
|
|
|
|
|
|
|
|
|
|
|
|
Por ejemplo, la información domiciliaria de una persona se puede mapear a una tabla separada, preservando a la vez la semántica de tipo de valor para todas las propiedades:
<class name="Person"
table="PERSON">
<id name="id" column="PERSON_ID">...</id>
<join table="ADDRESS">
<key column="ADDRESS_ID"/>
<property name="address"/>
<property name="zip"/>
<property name="country"/>
</join>
...
Con frecuencia, esta funcionalidad sólamente es útil para los modelos de datos heredados. Recomendamos menos tablas que clases y un modelo de dominio más detallado. Sin embargo, es útil para cambiar entre estrategias de mapeo de herencias en una misma jerarquía, como se explica más adelante.
To link one entity to an other, you need to map the association property as a to one association. In the relational model, you can either use a foreign key or an association table, or (a bit less common) share the same primary key value between the two entities.
To mark an association, use either @ManyToOne or @OnetoOne.
@ManyToOne and @OneToOne have a parameter named targetEntity which describes the target entity name. You usually don't need this parameter since the default value (the type of the property that stores the association) is good in almost all cases. However this is useful when you want to use interfaces as the return type instead of the regular entity.
Setting a value of the cascade attribute to any meaningful value other than nothing will propagate certain operations to the associated object. The meaningful values are divided into three categories.
basic operations, which include:
persist, merge, delete, save-update, evict, replicate, lock and refresh;special values:
delete-orphanorall;comma-separated combinations of operation names:
cascade="persist,merge,evict"orcascade="all,delete-orphan". See Sección 11.11, “Persistencia transitiva” for a full explanation. Note that single valued many-to-one associations do not support orphan delete.
By default, single point associations are eagerly fetched in JPA 2. You can mark it as lazily fetched by using @ManyToOne(fetch=FetchType.LAZY) in which case Hibernate will proxy the association and load it when the state of the associated entity is reached. You can force Hibernate not to use a proxy by using @LazyToOne(NO_PROXY). In this case, the property is fetched lazily when the instance variable is first accessed. This requires build-time bytecode instrumentation. lazy="false" specifies that the association will always be eagerly fetched.
With the default JPA options, single-ended associations are loaded with a subsequent select if set to LAZY, or a SQL JOIN is used for EAGER associations. You can however adjust the fetching strategy, ie how data is fetched by using @Fetch. FetchMode can be SELECT (a select is triggered when the association needs to be loaded) or JOIN (use a SQL JOIN to load the association while loading the owner entity). JOIN overrides any lazy attribute (an association loaded through a JOIN strategy cannot be lazy).
An ordinary association to another persistent class is declared using a
@ManyToOneif several entities can point to the the target entity@OneToOneif only a single entity can point to the the target entity
and a foreign key in one table is referencing the primary key column(s) of the target table.
@Entity
public class Flight implements Serializable {
@ManyToOne( cascade = {CascadeType.PERSIST, CascadeType.MERGE} )
@JoinColumn(name="COMP_ID")
public Company getCompany() {
return company;
}
...
}
The @JoinColumn attribute is optional, the default value(s) is the concatenation of the name of the relationship in the owner side, _ (underscore), and the name of the primary key column in the owned side. In this example company_id because the property name is company and the column id of Company is id.
@Entity
public class Flight implements Serializable {
@ManyToOne( cascade = {CascadeType.PERSIST, CascadeType.MERGE}, targetEntity=CompanyImpl.class )
@JoinColumn(name="COMP_ID")
public Company getCompany() {
return company;
}
...
}
public interface Company {
...
}
You can also map a to one association through an association table. This association table described by the @JoinTable annotation will contains a foreign key referencing back the entity table (through @JoinTable.joinColumns) and a a foreign key referencing the target entity table (through @JoinTable.inverseJoinColumns).
@Entity
public class Flight implements Serializable {
@ManyToOne( cascade = {CascadeType.PERSIST, CascadeType.MERGE} )
@JoinTable(name="Flight_Company",
joinColumns = @JoinColumn(name="FLIGHT_ID"),
inverseJoinColumns = @JoinColumn(name="COMP_ID")
)
public Company getCompany() {
return company;
}
...
}
Nota
You can use a SQL fragment to simulate a physical join column using the @JoinColumnOrFormula / @JoinColumnOrformulas annotations (just like you can use a SQL fragment to simulate a property column via the @Formula annotation).
@Entity
public class Ticket implements Serializable {
@ManyToOne
@JoinColumnOrFormula(formula="(firstname + ' ' + lastname)")
public Person getOwner() {
return person;
}
...
}
You can mark an association as mandatory by using the optional=false attribute. We recommend to use Bean Validation's @NotNull annotation as a better alternative however. As a consequence, the foreign key column(s) will be marked as not nullable (if possible).
When Hibernate cannot resolve the association because the expected associated element is not in database (wrong id on the association column), an exception is raised. This might be inconvenient for legacy and badly maintained schemas. You can ask Hibernate to ignore such elements instead of raising an exception using the @NotFound annotation.
Ejemplo 5.1. @NotFound annotation
@Entity
public class Child {
...
@ManyToOne
@NotFound(action=NotFoundAction.IGNORE)
public Parent getParent() { ... }
...
}
Sometimes you want to delegate to your database the deletion of cascade when a given entity is deleted. In this case Hibernate generates a cascade delete constraint at the database level.
Ejemplo 5.2. @OnDelete annotation
@Entity
public class Child {
...
@ManyToOne
@OnDelete(action=OnDeleteAction.CASCADE)
public Parent getParent() { ... }
...
}
Foreign key constraints, while generated by Hibernate, have a fairly unreadable name. You can override the constraint name using @ForeignKey.
Ejemplo 5.3. @ForeignKey annotation
@Entity
public class Child {
...
@ManyToOne
@ForeignKey(name="FK_PARENT")
public Parent getParent() { ... }
...
}
alter table Child add constraint FK_PARENT foreign key (parent_id) references Parent
Sometimes, you want to link one entity to an other not by the target entity primary key but by a different unique key. You can achieve that by referencing the unique key column(s) in @JoinColumn.referenceColumnName.
@Entity
class Person {
@Id Integer personNumber;
String firstName;
@Column(name="I")
String initial;
String lastName;
}
@Entity
class Home {
@ManyToOne
@JoinColumns({
@JoinColumn(name="first_name", referencedColumnName="firstName"),
@JoinColumn(name="init", referencedColumnName="I"),
@JoinColumn(name="last_name", referencedColumnName="lastName"),
})
Person owner
}
This is not encouraged however and should be reserved to legacy mappings.
In hbm.xml, mapping an association is similar. The main difference is that a @OneToOne is mapped as <many-to-one unique="true"/>, let's dive into the subject.
<many-to-one
name="propertyName"
column="column_name"
class="ClassName"
cascade="cascade_style"
fetch="join|select"
update="true|false"
insert="true|false"
property-ref="propertyNameFromAssociatedClass"
access="field|property|ClassName"
unique="true|false"
not-null="true|false"
optimistic-lock="true|false"
lazy="proxy|no-proxy|false"
not-found="ignore|exception"
entity-name="EntityName"
formula="arbitrary SQL expression"
node="element-name|@attribute-name|element/@attribute|."
embed-xml="true|false"
index="index_name"
unique_key="unique_key_id"
foreign-key="foreign_key_name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Setting a value of the cascade attribute to any meaningful value other than none will propagate certain operations to the associated object. The meaningful values are divided into three categories. First, basic operations, which include: persist, merge, delete, save-update, evict, replicate, lock and refresh; second, special values: delete-orphan; and third,all comma-separated combinations of operation names: cascade="persist,merge,evict" or cascade="all,delete-orphan". See Sección 11.11, “Persistencia transitiva” for a full explanation. Note that single valued, many-to-one and one-to-one, associations do not support orphan delete.
Este es un ejemplo de una declaración típica muchos-a-uno:
<many-to-one name="product" class="Product" column="PRODUCT_ID"/>
El atributo property-ref se debe utilizar sólamente para el mapeo de datos heredados donde una clave foránea referencia una clave única de la tabla asociada, distinta de la clave principal. Este es un modelo relacional complicado y confuso. Por ejemplo, si la clase Product tuviera un número único serial que no es la clave principal, el atributo unique controla la generación de DDL de Hibernate con la herramienta SchemaExport.
<property name="serialNumber" unique="true" type="string" column="SERIAL_NUMBER"/>
Entonces el mapeo para OrderItem puede utilizar:
<many-to-one name="product" property-ref="serialNumber" column="PRODUCT_SERIAL_NUMBER"/>
Sin embargo, esto ciertamente no se aconseja.
Si la clave única referenciada abarca múltiples propiedades de la entidad asociada, debe mapear las propiedades dentro de un elemento nombrado <properties>.
Si la clave única referenciada es propiedad de un componente, usted puede especificar una ruta de propiedad:
<many-to-one name="owner" property-ref="identity.ssn" column="OWNER_SSN"/>
The second approach is to ensure an entity and its associated entity share the same primary key. In this case the primary key column is also a foreign key and there is no extra column. These associations are always one to one.
Ejemplo 5.4. One to One association
@Entity
public class Body {
@Id
public Long getId() { return id; }
@OneToOne(cascade = CascadeType.ALL)
@MapsId
public Heart getHeart() {
return heart;
}
...
}
@Entity
public class Heart {
@Id
public Long getId() { ...}
}
Nota
Many people got confused by these primary key based one to one associations. They can only be lazily loaded if Hibernate knows that the other side of the association is always present. To indicate to Hibernate that it is the case, use @OneToOne(optional=false).
In hbm.xml, use the following mapping.
<one-to-one
name="propertyName"
class="ClassName"
cascade="cascade_style"
constrained="true|false"
fetch="join|select"
property-ref="propertyNameFromAssociatedClass"
access="field|property|ClassName"
formula="any SQL expression"
lazy="proxy|no-proxy|false"
entity-name="EntityName"
node="element-name|@attribute-name|element/@attribute|."
embed-xml="true|false"
foreign-key="foreign_key_name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Las asociaciones de claves principales no necesitan una columna extra de la tabla. Si dos filas están relacionadas por la asociación entonces las dos filas de tablas comparten el mismo valor de clave principal. Para que dos objetos estén relacionados por una asociación de clave principal, asegúrese de que se les asigne el mismo valor de identificador.
Para una asociación de clave principal, agregue los siguientes mapeos a Employee y Person respectivamente:
<one-to-one name="person" class="Person"/>
<one-to-one name="employee" class="Employee" constrained="true"/>
Asegúrese de que las claves principales de las filas relacionadas en las tablas PERSON y EMPLOYEE sean iguales. Utilizamos una estrategia especial de generación de identificador de Hibernate denominada foreign:
<class name="person" table="PERSON">
<id name="id" column="PERSON_ID">
<generator class="foreign">
<param name="property">employee</param>
</generator>
</id>
...
<one-to-one name="employee"
class="Employee"
constrained="true"/>
</class>
A una instancia recién guardada de Person se le asigna el mismo valor de clave principal que se le asignó a la instancia Employee referida por la propiedad employee de esa Person.
Although we recommend the use of surrogate keys as primary keys, you should try to identify natural keys for all entities. A natural key is a property or combination of properties that is unique and non-null. It is also immutable. Map the properties of the natural key as @NaturalId or map them inside the <natural-id> element. Hibernate will generate the necessary unique key and nullability constraints and, as a result, your mapping will be more self-documenting.
@Entity
public class Citizen {
@Id
@GeneratedValue
private Integer id;
private String firstname;
private String lastname;
@NaturalId
@ManyToOne
private State state;
@NaturalId
private String ssn;
...
}
//and later on query
List results = s.createCriteria( Citizen.class )
.add( Restrictions.naturalId().set( "ssn", "1234" ).set( "state", ste ) )
.list();
Or in XML,
<natural-id mutable="true|false"/>
<property ... />
<many-to-one ... />
......
</natural-id>
Le recomendamos bastante que implemente equals() y hashCode() para comparar las propiedades de clave natural de la entidad.
Este mapeo no está concebido para la utilización con entidades que tienen claves principales naturales.
mutable(opcional - por defecto esfalse): Por defecto, se asume que las propiedades de identificadores naturales son inmutables (constantes).
There is one more type of property mapping. The @Any mapping defines a polymorphic association to classes from multiple tables. This type of mapping requires more than one column. The first column contains the type of the associated entity. The remaining columns contain the identifier. It is impossible to specify a foreign key constraint for this kind of association. This is not the usual way of mapping polymorphic associations and you should use this only in special cases. For example, for audit logs, user session data, etc.
The @Any annotation describes the column holding the metadata information. To link the value of the metadata information and an actual entity type, The @AnyDef and @AnyDefs annotations are used. The metaType attribute allows the application to specify a custom type that maps database column values to persistent classes that have identifier properties of the type specified by idType. You must specify the mapping from values of the metaType to class names.
@Any( metaColumn = @Column( name = "property_type" ), fetch=FetchType.EAGER )
@AnyMetaDef(
idType = "integer",
metaType = "string",
metaValues = {
@MetaValue( value = "S", targetEntity = StringProperty.class ),
@MetaValue( value = "I", targetEntity = IntegerProperty.class )
} )
@JoinColumn( name = "property_id" )
public Property getMainProperty() {
return mainProperty;
}
Note that @AnyDef can be mutualized and reused. It is recommended to place it as a package metadata in this case.
//on a package
@AnyMetaDef( name="property"
idType = "integer",
metaType = "string",
metaValues = {
@MetaValue( value = "S", targetEntity = StringProperty.class ),
@MetaValue( value = "I", targetEntity = IntegerProperty.class )
} )
package org.hibernate.test.annotations.any;
//in a class
@Any( metaDef="property", metaColumn = @Column( name = "property_type" ), fetch=FetchType.EAGER )
@JoinColumn( name = "property_id" )
public Property getMainProperty() {
return mainProperty;
}
The hbm.xml equivalent is:
<any name="being" id-type="long" meta-type="string">
<meta-value value="TBL_ANIMAL" class="Animal"/>
<meta-value value="TBL_HUMAN" class="Human"/>
<meta-value value="TBL_ALIEN" class="Alien"/>
<column name="table_name"/>
<column name="id"/>
</any>
Nota
You cannot mutualize the metadata in hbm.xml as you can in annotations.
<any
name="propertyName"
id-type="idtypename"
meta-type="metatypename"
cascade="cascade_style"
access="field|property|ClassName"
optimistic-lock="true|false"
>
<meta-value ... />
<meta-value ... />
.....
<column .... />
<column .... />
.....
</any>
|
|
|
|
|
|
|
|
|
|
|
|
El elemento <properties> permite la definición de un grupo de propiedades lógico con nombre de una clase. El uso más importante de la contrucción es que permite que una combinación de propiedades sea el objetivo de una property-ref. También es una forma práctica de definir una restricción de unicidad multicolumna. Por ejemplo:
<properties
name="logicalName"
insert="true|false"
update="true|false"
optimistic-lock="true|false"
unique="true|false"
>
<property ...../>
<many-to-one .... />
........
</properties>
|
|
|
|
|
|
|
|
|
|
Por ejemplo, si tenemos el siguiente mapeo de <properties>:
<class name="Person">
<id name="personNumber"/>
...
<properties name="name"
unique="true" update="false">
<property name="firstName"/>
<property name="initial"/>
<property name="lastName"/>
</properties>
</class>
Puede que tenga alguna asociación de datos heredados que se refiera a esta clave única de la tabla de Person, en lugar de la clave principal:
<many-to-one name="owner"
class="Person" property-ref="name">
<column name="firstName"/>
<column name="initial"/>
<column name="lastName"/>
</many-to-one>
Nota
When using annotations as a mapping strategy, such construct is not necessary as the binding between a column and its related column on the associated table is done directly
@Entity
class Person {
@Id Integer personNumber;
String firstName;
@Column(name="I")
String initial;
String lastName;
}
@Entity
class Home {
@ManyToOne
@JoinColumns({
@JoinColumn(name="first_name", referencedColumnName="firstName"),
@JoinColumn(name="init", referencedColumnName="I"),
@JoinColumn(name="last_name", referencedColumnName="lastName"),
})
Person owner
}
No recomendamos el uso de este tipo de cosas fuera del contexto del mapeo de datos heredados.
The hbm.xml structure has some specificities naturally not present when using annotations, let's describe them briefly.
Todos los mapeos XML deben declarar el tipo de documento que se muestra. El DTD en sí se puede encontrar en la URL mencionada anteriormente, en el directorio hibernate-x.x.x/src/org/hibernate , o en hibernate3.jar. Hibernate siempre buscará el DTD primero en la ruta de clase. Si el DTD realiza búsquedas utilizando una conexión de Internet, verifique que su declaración DTD frente al contenido de su ruta de clase.
Hibernate tratará primero de resolver los DTDs en su ruta de clase. La manera en que lo hace es registrando una implementación org.xml.sax.EntityResolver personalizada con el SAXReader que utiliza para leer los archivos xml. Este EntityResolver personalizado reconoce dos diferentes espacios de nombre del identificador del sistema.
a
hibernate namespaceis recognized whenever the resolver encounters a systemId starting withhttp://www.hibernate.org/dtd/. The resolver attempts to resolve these entities via the classloader which loaded the Hibernate classes.un
user namespacese reconoce cuando el resolvedor se encuentra con un identificador del sistema utilizando un protocolo URLclasspath://. El resolvedor intentará resolver estas entidades por medio de (1) el cargador de clase del contexto del hilo actual y (2) el cargador de clase, el cual cargó las clases de Hibernate.
Este es un ejemplo de la utilización de los espacios de nombre del usuario:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd" [
<!ENTITY types SYSTEM "classpath://your/domain/types.xml">
]>
<hibernate-mapping package="your.domain">
<class name="MyEntity">
<id name="id" type="my-custom-id-type">
...
</id>
<class>
&types;
</hibernate-mapping>
En donde types.xml es un recurso en el paquete your.domain y comprende un typedef personalizado.
Este elemento tiene varios atributos opcionales. Los atributos schema y catalog especifican que las tablas a las que se refiere en este mapeo pertenecen al esquema y/o catálogo mencionado(s). De especificarse, los nombres de tablas serán calificados por el nombre del esquema y del catálogo dados. De omitirse, los nombres de las tablas no serán calificados. El atributo default-cascade especifica qué estilo de cascada se debe asumir para las propiedades y colecciones que no especifican un atributo cascade. Por defecto, el atributo auto-import nos permite utilizar nombres de clase sin calificar en el lenguaje de consulta.
<hibernate-mapping
schema="schemaName"
catalog="catalogName"
default-cascade="cascade_style"
default-access="field|property|ClassName"
default-lazy="true|false"
auto-import="true|false"
package="package.name"
/>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Si tiene dos clases persistentes con el mismo nombre (sin calificar), debe establecer auto-import="false". Se presentará una excepción si usted intenta asignar dos clases al mismo nombre "importado".
El elemento hibernate-mapping le permite anidar varios mapeos <class> persistentes, como se mostró anteriormente. Sin embargo, es una buena práctica (y algunas herramientas esperan) que mapee sólamente una clase persistente, o a una sóla jerarquía de clases, en un archivo de mapeo y nombrarlo como la superclase persistente. Por ejemplo, Cat.hbm.xml, Dog.hbm.xml, o si utiliza herencia, Animal.hbm.xml.
The <key> element is featured a few times within this guide. It appears anywhere the parent mapping element defines a join to a new table that references the primary key of the original table. It also defines the foreign key in the joined table:
<key
column="columnname"
on-delete="noaction|cascade"
property-ref="propertyName"
not-null="true|false"
update="true|false"
unique="true|false"
/>
|
|
|
|
|
|
|
|
|
|
|
|
Para los sistemas en donde el rendimiento es importante, todas las claves deben ser definidas on-delete="cascade". Hibernate utiliza una restricción ON CASCADE DELETE a nivel de base de datos, en vez de muchas declaraciones DELETE individuales. Tenga en cuenta que esta funcionalidad evita la estrategia de bloqueo optimista normal de Hibernate para datos versionados.
Los atributos not-null y update son útiles al mapear una asociación uno a muchos unidireccional. Si mapea una unidireccional uno a muchos a una clave foránea no nulable, tiene que declarar la columna clave utilizando <key not-null="true">.
Si su aplicación tiene dos clases persistentes con el mismo nombre y no quiere especificar el nombre del paquete completamenta calificado en las consultas Hibernate, las clases pueden ser "importadas" explícitamente, en lugar de depender de auto-import="true". Incluso puede importar clases e interfaces que no estén mapeadas explícitamente:
<import class="java.lang.Object" rename="Universe"/>
<import
class="ClassName"
rename="ShortName"
/>
|
|
|
|
Nota
This feature is unique to hbm.xml and is not supported in annotations.
Los elementos de mapeo que acepten un atributo column aceptarán opcionalmente un subelemento <column>. De manera similar, <formula> es una alternativa al atributo formula. Por ejemplo:
<column
name="column_name"
length="N"
precision="N"
scale="N"
not-null="true|false"
unique="true|false"
unique-key="multicolumn_unique_key_name"
index="index_name"
sql-type="sql_type_name"
check="SQL expression"
default="SQL expression"
read="SQL expression"
write="SQL expression"/>
<formula>SQL expression</formula>
La mayoría de los atributos en column proporcionan una manera de personalizar el DDL durante la generación del esquema automático. Los atributos read y write le permiten especificar SQL personalizado que Hibernate utilizará para acceder el valor de la columna. Para obtener mayor información sobre esto, consulte la discusión sobre expresiones de lectura y escritura de columnas.
Los elementos column y formula incluso se pueden combinar dentro del mismo mapeo de propiedad o asociación para expresar, por ejemplo, condiciones de unión exóticas.
<many-to-one name="homeAddress" class="Address"
insert="false" update="false">
<column name="person_id" not-null="true" length="10"/>
<formula>'MAILING'</formula>
</many-to-one>
En relación con el servicio de persistencia, los objetos a nivel de lenguaje Java se clasifican en dos grupos:
Una entidad existe independientemente de cualquier otro objeto que referencie a la entidad. Compare esto con el modelo habitual de Java en donde un objeto no referenciado es recolectado como basura. Las entidades deben ser guardadas y borradas explícitamente. Sin embargo, los grabados y borrados se pueden tratar en cascada desde una entidad padre a sus hijos. Esto es diferente al modelo de persistencia de objetos por alcance (ODMG) y corresponde más a cómo se utilizan habitualmente los objetos de aplicación en sistemas grandes. Las entidades soportan referencias circulares y compartidas, que también pueden ser versionadas.
El estado persistente de una entidad consta de las referencias a otras entidades e instancias de tipo valor. Los valores son primitivos: colecciones (no lo que está dentro de la colección), componentes y ciertos objetos inmutables. A diferencia de las entidades, los valores en particular las colecciones y los componentes, son persistidos y borrados por alcance. Como los objetos valor y primitivos son persistidos y borrados junto con sus entidades contenedoras, no se pueden versionar independientemente. Los valores no tienen identidad independiente, por lo que dos entidades o colleciones no los pueden compartir.
Hasta ahora, hemos estado utilizando el término "clase persistente" para referirnos a entidades. Continuaremos haciéndolo así. Sin embargo, no todas la clases con estado persistente definidas por el usuario son entidades. Un componente es una clase definida por el usuario con semántica de valor. Una propiedad Java de tipo java.lang.String también tiene semántica de valor. Dada esta definición, podemos decir que todos los tipo (clases) provistos por el JDK tienen una semántica de tipo valor en Java, mientras que los tipos definidos por el usuario se pueden mapear con semántica de tipo valor o de entidad. La desición corre por cuenta del desarrollador de la aplicación. Una clase entidad en un modelo de dominio son las referencias compartidas a una sola instancia de esa clase, mientras que la composición o agregación usualmente se traducen a un tipo de valor.
Volveremos a revisar ambos conceptos a lo largo de este manual de referencia.
EL desafío es mapear el sistema de tipos de Java ( la definición de entidades y tipos de valor de los desarrolladores al sistema de tipos de SQL/la base de datos. El puente entre ambos sistemas lo brinda Hibernate. Para las entidades utilizamos <class>, <subclass>, etc. Para los tipos de valor utilizamos <property>, <component>, etc, usualmente con un atributo type. El valor de este atributo es el nombre de un tipo de mapeo de Hibernate. Hibernate proporciona un rango de mapeos para tipos de valores del JDK estándar. Puede escribir sus propios mapeos de tipo e implementar sus estrategias de conversión personalizadas.
Todos los tipos incorporados de Hibernate soportan la semántica de nulos, a excepción de las colecciones.
Los tipos de mapeo básicos incorporados se pueden categorizar así:
integer, long, short, float, double, character, byte, boolean, yes_no, true_falseMapeos de tipos de primitivos de Java o de clases de envoltura a los tipos de columna SQL (específica del vendedor).
boolean, yes_noytrue_falseson codificaciones alternativas abooleande Java ojava.lang.Boolean.stringUn mapeo del tipo
java.lang.StringaVARCHAR(u OracleVAARCHAR2).date, time, timestampMapeos de tipo desde
java.util.Datey sus subclases a tipos SQLDATE,TIMEyTIMESTAMP(o equivalente).calendar, calendar_dateMapeos de tipo desde
java.util.Datey tipos SQLTIMESTAMPyDATE(o equivalente).big_decimal, big_integerMapeos de tipo desde
java.math.BigDecimalyjava.math.BigIntegeraNUMERIC(oNUMBERde Oracle).locale, timezone, currencyMapeos de tipo desde
java.util.Locale,java.util.TimeZoneyjava.util.CurrencyaVARCHAR(oVARCHAR2de Oracle). Las instancias deLocaleyCurrencyson mapeadas a sus códigos ISO. Las instancias deTimeZoneson mapeadas a susID.classUn mapeo de tipo
java.lang.ClassaVARCHAR(oVARCHAR2de Oracle). UnaClasses mapeada a su nombre completamente calificado.binaryMapea arreglos de bytes a un tipo binario SQL apropiado.
textMaps long Java strings to a SQL
LONGVARCHARorTEXTtype.imageMaps long byte arrays to a SQL
LONGVARBINARY.serializableMapea tipos serializables Java a un tipo binario SQL apropiado. También puede indicar el tipo
serializablede Hibernate con el nombre de una clase o interfaz serializable Java que no sea por defecto un tipo básico.clob, blobMapeos de tipo para las clases JDBC
java.sql.Clobyjava.sql.Blob. Estos tipos pueden ser inconvenientes para algunas aplicaciones, pues el objeto blob o clob no pueden ser reusados fuera de una transacción. Además, el soporte del controlador suele ser malo e inconsistente.materialized_clobMaps long Java strings to a SQL
CLOBtype. When read, theCLOBvalue is immediately materialized into a Java string. Some drivers require theCLOBvalue to be read within a transaction. Once materialized, the Java string is available outside of the transaction.materialized_blobMaps long Java byte arrays to a SQL
BLOBtype. When read, theBLOBvalue is immediately materialized into a byte array. Some drivers require theBLOBvalue to be read within a transaction. Once materialized, the byte array is available outside of the transaction.imm_date, imm_time, imm_timestamp, imm_calendar, imm_calendar_date, imm_serializable, imm_binaryLos mapeos de tipo para lo que usualmente se considera tipos Java mutables. Aquí es donde Hibernate realiza ciertas optimizaciones apropiadas sólamente para tipos Java inmutables y la aplicación trata el objeto como inmutable. Por ejemplo, no debe llamar
Date.setTime()para una instancia mapeada comoimm_timestamp. Para cambiar el valor de la propiedad y hacer que ese cambio sea persistente, la aplicación tiene que asignar un objeto nuevo, no idéntico, a la propiedad.
Los identificadores únicos de entidades y colecciones pueden ser de cualquier tipo básico excepto binary, blob y clob. Los identificadores compuestos también están permitidos, a continuación encontrará mayor información.
Los tipos de valor básicos tienen sus constantes Type correspondientes definidas en org.hibernate.Hibernate. Por ejemplo, Hibernate.STRING representa el tipo string.
Es relativamente fácil para los desarrolladores crear sus propios tipos de valor. Por ejemplo, puede que quiera persistir propiedades del tipo java.lang.BigInteger a columnas VARCHAR. Hibernate no provee un tipo incorporado para esto. Los tipos personalizados no están limitados a mapear una propiedad o elemento de colección a una sola columna de tabla. Así, por ejemplo, podría tener una propiedad Java getName()/setName() de tipo java.lang.String que es persistida a las columnas FIRST_NAME, INITIAL, SURNAME.
Para implementar un tipo personalizado, implemente org.hibernate.UserType o org.hibernate.CompositeUserType y declare las propiedades utilizando el nombre de clase completamente calificado del tipo. Revise org.hibernate.test.DoubleStringType para ver qué clases de cosas son posibles.
<property name="twoStrings" type="org.hibernate.test.DoubleStringType">
<column name="first_string"/>
<column name="second_string"/>
</property>
Observe el uso de etiquetas <column> para mapear una propiedad a múltiples columnas.
Las interfaces CompositeUserType, EnhancedUserType, UserCollectionType, y UserVersionType brindan soporte para usos más especializados.
Incluso usted puede proporcionar parámetros a un UserType en el archivo de mapeo. Para hacer esto, su UserType tiene que implementar la interfaz org.hibernate.usertype.ParameterizedType. Para brindar parámetros a su tipo personalizado, puede utilizar el elemento <type> en sus archivos de mapeo.
<property name="priority">
<type name="com.mycompany.usertypes.DefaultValueIntegerType">
<param name="default">0</param>
</type>
</property>
Ahora el UserType puede recuperar el valor del parámetro denominado default del objeto Properties que se le pasa.
Si utiliza cierto UserType muy frecuentemente, puede ser útil el definir un nombre más corto para este. Puede hacer esto utilizando el elemento <typedef>. Los typedefs asignan un nombre a un tipo personalizado y también pueden contener una lista de valores predeterminados de parámetros si el tipo se encuentra parametrizado.
<typedef class="com.mycompany.usertypes.DefaultValueIntegerType" name="default_zero">
<param name="default">0</param>
</typedef>
<property name="priority" type="default_zero"/>
También es posible sobrescribir los parámetros provistos en un typedef sobre una base de caso por caso utilizando parámetros de tipo en el mapeo de la propiedad.
Aunque el amplio espectro de tipos incorporados y de soporte para los componentes de Hibernate significa que necesitará usar un tipo personalizado muy raramente, se considera como una buena práctica el utilizar tipos personalizados para clases no-entidades que aparezcan frecuentemente en su aplicación. Por ejemplo, una clase MonetaryAmount es una buena candidata para un CompositeUserType, incluso cuando puede ser fácilmente mapeada como un componente. Un razón para esto es la abstracción. Con un tipo personalizado, sus documentos de mapeo estarán protegidos contra posibles cambios futuros en la forma de representar valores monetarios.
Es posible proporcionar más de un mapeo para una clase persistente en particular. En este caso usted debe especificar un nombre de entidad para aclarar entre las instancias de las dos entidades mapeadas. Por defecto, el nombre de la entidad es el mismo que el nombre de la clase. Hibernate le deja especificar el nombre de entidad al trabajar con objetos persistentes, al escribir consultas, o al mapear asociaciones a la entidad mencionada.
<class name="Contract" table="Contracts"
entity-name="CurrentContract">
...
<set name="history" inverse="true"
order-by="effectiveEndDate desc">
<key column="currentContractId"/>
<one-to-many entity-name="HistoricalContract"/>
</set>
</class>
<class name="Contract" table="ContractHistory"
entity-name="HistoricalContract">
...
<many-to-one name="currentContract"
column="currentContractId"
entity-name="CurrentContract"/>
</class>Las asociaciones ahora se especifican utilizando entity-name en lugar de class.
Nota
This feature is not supported in Annotations
Puede forzar a Hibernate a que utilice comillas con un identificador en el SQL generado encerrando el nombre de tabla o de columna entre comillas sencillas en el documento de mapeo. Hibernate utilizará el estilo de comillas para el Dialect SQL. Usualmente comillas dobles, a excepción de corchetes para SQL Server y comillas sencillas para MySQL.
@Entity @Table(name="`Line Item`")
class LineItem {
@id @Column(name="`Item Id`") Integer id;
@Column(name="`Item #`") int itemNumber
}
<class name="LineItem" table="`Line Item`">
<id name="id" column="`Item Id`"/><generator class="assigned"/></id>
<property name="itemNumber" column="`Item #`"/>
...
</class>
Las propiedades generadas son propiedades cuyos valores son generados por la base de datos. Usualmente, las aplicaciones de Hibernate necesitaban refrescar los objetos que contenian cualquier propiedad para la cual la base de datos generará valores. Sin embargo, el marcar propiedades como generadas deja que la aplicación delegue esta responsabilidad a Hibernate. Cuando Hibernate emite un INSERT or UPDATE SQL para una entidad la cual ha definido propiedades generadas, inmediatamente emite un select para recuperar los valores generados.
Las propiedades marcadas como generadas tienen que ser además no insertables y no actualizables. Sólamente las versiones, sellos de fecha, y propiedades simples se pueden marcar como generadas.
never (por defecto): el valor dado de la propiedad no es generado dentro de la base de datos.
insert: el valor dado de la propiedad es generado en insert, pero no es regenerado en las actualizaciones posteriores. Las propiedades como fecha-creada (created-date) se encuentran dentro de esta categoría. Aunque las propiedades versión y sello de fecha se pueden marcar como generadas, esta opción no se encuentra disponible.
always: el valor de la propiedad es generado tanto en insert como en update.
To mark a property as generated, use @Generated.
Hibernate allows you to customize the SQL it uses to read and write the values of columns mapped to simple properties. For example, if your database provides a set of data encryption functions, you can invoke them for individual columns like this:
@Entity
class CreditCard {
@Column(name="credit_card_num")
@ColumnTransformer(
read="decrypt(credit_card_num)",
write="encrypt(?)")
public String getCreditCardNumber() { return creditCardNumber; }
public void setCreditCardNumber(String number) { this.creditCardNumber = number; }
private String creditCardNumber;
}
or in XML
<property name="creditCardNumber">
<column
name="credit_card_num"
read="decrypt(credit_card_num)"
write="encrypt(?)"/>
</property>
Nota
You can use the plural form @ColumnTransformers if more than one columns need to define either of these rules.
If a property uses more that one column, you must use the forColumn attribute to specify which column, the expressions are targeting.
@Entity
class User {
@Type(type="com.acme.type.CreditCardType")
@Columns( {
@Column(name="credit_card_num"),
@Column(name="exp_date") } )
@ColumnTransformer(
forColumn="credit_card_num",
read="decrypt(credit_card_num)",
write="encrypt(?)")
public CreditCard getCreditCard() { return creditCard; }
public void setCreditCard(CreditCard card) { this.creditCard = card; }
private CreditCard creditCard;
}
Hibernate aplica las expresiones personalizadas de manera automática cuando la propiedad se referencia en una petición. Esta funcionalidad es similar a una propiedad derivada formula con dos diferencias:
Esta propiedad está respaldada por una o más columnas que se exportan como parte de la generación automática del esquema.
La propiedad es de lectura y escritura no de sólo lectura.
Si se especifica la expresión write debe contener exactamente un parémetro de sustitución '?' para el valor.
Los objetos de bases de datos auxiliares permiten la creación - CREATE - y eliminación - DROP - de objetos de bases de datos arbitrarios. Junto con las herramientas de evolución del esquema de Hibernate, tienen la habilidad de definir de manera completa el esquema de un usuario dentro de los archivos de mapeo de Hibernate. Aunque están diseñados específicamente para crear y eliminar cosas como disparadores - triggers- o procedimientos almacenados, realmente cualquier comando SQL se puede ejecutar por medio de un método java.sql.Statement.execute() aquí es válido (por ejemplo, ALTERs, INSERTS, etc). Básicamente, hay dos modos para definir objetos de bases de datos auxiliares:
El primer modo es para numerar explícitamente los comandos CREATE y DROP en el archivo de mapeo:
<hibernate-mapping>
...
<database-object>
<create>CREATE TRIGGER my_trigger ...</create>
<drop>DROP TRIGGER my_trigger</drop>
</database-object>
</hibernate-mapping>
El segundo modo es para proporcionar una clase personalizada que construye los comandos CREATE y DROP. Esta clase personalizada tiene que implementar la interfaz org.hibernate.mapping.AuxiliaryDatabaseObject.
<hibernate-mapping>
...
<database-object>
<definition class="MyTriggerDefinition"/>
</database-object>
</hibernate-mapping>
Adicionalmente, estos objetos de la base de datos se pueden incluir de manera opcional de forma que aplique sólamente cuando se utilicen ciertos dialectos.
<hibernate-mapping>
...
<database-object>
<definition class="MyTriggerDefinition"/>
<dialect-scope name="org.hibernate.dialect.Oracle9iDialect"/>
<dialect-scope name="org.hibernate.dialect.Oracle10gDialect"/>
</database-object>
</hibernate-mapping>
Nota
This feature is not supported in Annotations