Let's start with the most basic configuration question - how do I enable Hibernate Search?
The good news is that Hibernate Search is enabled out of the box
when detected on the classpath by Hibernate Core. If, for some reason
you need to disable it, set
hibernate.search.autoregister_listeners to
false. Note that there is no performance penalty
when the listeners are enabled but no entities are annotated as
indexed.
By default, every time an object is inserted, updated or deleted through Hibernate, Hibernate Search updates the according Lucene index. It is sometimes desirable to disable that features if either your index is read-only or if index updates are done in a batch way (see Section 6.3, “Rebuilding the whole index”).
To disable event based indexing, set
hibernate.search.indexing_strategy = manual
Note
In most case, the JMS backend provides the best of both world, a lightweight event based system keeps track of all changes in the system, and the heavyweight indexing process is done by a separate process or machine.
The role of the index manager component is described in Chapter 2, Architecture. Hibernate Search provides two possible implementations for this interface to choose from.
directory-based: the default implementation which uses the LuceneDirectoryabstraction to manage index files.near-real-time: avoid flushing writes to disk at each commit. This index manager is alsoDirectorybased, but also makes uses of Lucene's NRT functionality.
To select an alternative you specify the property:
hibernate.search.[default|<indexname>].indexmanager = near-real-time
The default IndexManager implementation.
This is the one mostly referred to in this documentation. It is highly
configurable and allows you to select different settings for the reader
strategy, back ends and directory providers. Refer to Section 3.3, “Directory configuration”, Section 3.4, “Worker configuration” and Section 3.5, “Reader strategy configuration” for more details.
The NRTIndexManager is an extension of the
default IndexManager, leveraging the Lucene NRT
(Near Real Time) features for extreme low latency index writes. As a
tradeoff it requires a non-clustered and non-shared index. In other
words, it will ignore configuration settings for alternative back ends
other than lucene and will acquire exclusive write
locks on the Directory.
To achieve this low latency writes, the
IndexWriter will not flush every change to disk.
Queries will be allowed to read updated state from the unflushed index
writer buffers; the downside of this strategy is that if the application
crashes or the IndexWriter is otherwise killed
you'll have to rebuild the indexes as some updates might be lost.
Because of these downsides, and because a master node in cluster can be configured for good performance as well, the NRT configuration is only recommended for non clustered websites with a limited amount of data.
It is also possible to configure a custom
IndexManager implementation by specifying the
fully qualified class name of your custom implementation. This
implementation must have a no-argument constructor:
hibernate.search.[default|<indexname>].indexmanager = my.corp.myapp.CustomIndexManager
Tip
Your custom index manager implementation doesn't need to use the
same components as the default implementations. For example, you can
delegate to a remote indexing service which doesn't expose a
Directory interface.
As we have seen in Section 3.2, “Configuring the IndexManager” the
default index manager uses Lucene's notion of a
Directory to store the index files. The
Directory implementation can be customized and
Lucene comes bundled with a file system and an in-memory implementation.
DirectoryProvider is the Hibernate Search
abstraction around a Lucene Directory and handles
the configuration and the initialization of the underlying Lucene
resources. Table 3.1, “List of built-in DirectoryProvider” shows the list of
the directory providers available in Hibernate Search together with their
corresponding options.
To configure your DirectoryProvider you have
to understand that each indexed entity is associated to a Lucene index
(except of the case where multiple entities share the same index - Section 10.5, “Sharing indexes”). The name of the index is given by
the index property of the
@Indexed annotation. If the
index property is not specified the fully qualified
name of the indexed class will be used as name (recommended).
Knowing the index name, you can configure the directory provider and
any additional options by using the prefix
hibernate.search.<indexname>.
The name default
(hibernate.search.default) is reserved and can be
used to define properties which apply to all indexes. Example 3.2, “Configuring directory providers” shows how
hibernate.search.default.directory_provider is used
to set the default directory provider to be the filesystem one.
hibernate.search.default.indexBase sets then the
default base directory for the indexes. As a result the index for the
entity Status is created in
/usr/lucene/indexes/org.hibernate.example.Status.
The index for the Rule entity, however, is
using an in-memory directory, because the default directory provider for
this entity is overridden by the property
hibernate.search.Rules.directory_provider.
Finally the Action entity uses a custom
directory provider CustomDirectoryProvider
specified via
hibernate.search.Actions.directory_provider.
Example 3.1. Specifying the index name
package org.hibernate.example;
@Indexed
public class Status { ... }
@Indexed(index="Rules")
public class Rule { ... }
@Indexed(index="Actions")
public class Action { ... }
Example 3.2. Configuring directory providers
hibernate.search.default.directory_provider = filesystem hibernate.search.default.indexBase = /usr/lucene/indexes hibernate.search.Rules.directory_provider = ram hibernate.search.Actions.directory_provider = com.acme.hibernate.CustomDirectoryProvider
Tip
Using the described configuration scheme you can easily define common rules like the directory provider and base directory, and override those defaults later on on a per index basis.
Table 3.1. List of built-in DirectoryProvider
| Name and description | Properties |
|---|---|
ram: Memory based directory, the
directory will be uniquely identified (in the same deployment
unit) by the @Indexed.index element | none |
| filesystem: File system based directory. The directory used will be <indexBase>/< indexName > |
|
filesystem-master: File system
based directory. Like The recommended value for the refresh period is (at least) 50% higher that the time to copy the information (default 3600 seconds - 60 minutes). Note that the copy is based on an incremental copy mechanism reducing the average copy time. DirectoryProvider typically used on the master node in a JMS back end cluster. The
|
|
filesystem-slave: File system
based directory. Like The recommended value for the refresh period is (at least) 50% higher that the time to copy the information (default 3600 seconds - 60 minutes). Note that the
copy is based on an incremental copy mechanism reducing the
average copy time. If a copy is still in progress when
DirectoryProvider typically used on slave nodes using a JMS back end. The
|
|
infinispan: Infinispan based directory. Use it to store the index in a distributed grid, making index changes visible to all elements of the cluster very quickly. Also see Section 3.3.1, “Infinispan Directory configuration” for additional requirements and configuration settings. Infinispan needs a global configuration and additional dependencies; the settings defined here apply to each different index. |
|
Tip
If the built-in directory providers do not fit your needs, you can
write your own directory provider by implementing the
org.hibernate.store.DirectoryProvider interface.
In this case, pass the fully qualified class name of your provider into
the directory_provider property. You can pass any
additional properties using the prefix
hibernate.search.<indexname>.
Infinispan is a distributed, scalable, highly available data grid platform which supports autodiscovery of peer nodes. Using Infinispan and Hibernate Search in combination, it is possible to store the Lucene index in a distributed environment where index updates are quickly available on all nodes.
This section describes in greater detail how to configure Hibernate Search to use an Infinispan Lucene Directory.
When using an Infinispan Directory the index is stored in memory and shared across multiple nodes. It is considered a single directory distributed across all participating nodes. If a node updates the index, all other nodes are updated as well. Updates on one node can be immediately searched for in the whole cluster.
The default configuration replicates all data defining the index across all nodes, thus consuming a significant amount of memory. For large indexes it's suggested to enable data distribution, so that each piece of information is replicated to a subset of all cluster members.
It is also possible to offload part or most information to a
CacheStore, such as plain filesystem, Amazon S3,
Cassandra, Berkley DB or standard relational databases. You can
configure it to have a CacheStore on each node or
have a single centralized one shared by each node.
See the Infinispan documentation for all Infinispan configuration options.
To use the Infinispan directory via Maven, add the following dependencies:
Example 3.3. Maven dependencies for Hibernate Search
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search</artifactId>
<version>4.5.3.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search-infinispan</artifactId>
<version>4.5.3.Final</version>
</dependency>
For the non-maven users, add
hibernate-search-infinispan.jar,
infinispan-lucene-directory.jar and
infinispan-core.jar to your application classpath.
These last two jars are distributed by Infinispan.
Even when using an Infinispan directory it's still recommended
to use the JMS Master/Slave or JGroups backend, because in Infinispan
all nodes will share the same index and it is likely that
IndexWriters being active on different nodes
will try to acquire the lock on the same index. So instead of sending
updates directly to the index, send it to a JMS queue or JGroups
channel and have a single node apply all changes on behalf of all
other nodes.
Configuring a non-default backend is not a requirement but a performance optimization as locks are enabled to have a single node writing.
To configure a JMS slave only the backend must be replaced, the
directory provider must be set to infinispan; set
the same directory provider on the master, they will connect without
the need to setup the copy job across nodes. Using the JGroups backend
is very similar - just combine the backend configuration with the
infinispan directory provider.
The most simple configuration only requires to enable the backend:
hibernate.search.[default|<indexname>].directory_provider = infinispan
That's all what is needed to get a cluster-replicated index, but the default configuration does not enable any form of permanent persistence for the index; to enable such a feature an Infinispan configuration file should be provided.
To use Infinispan, Hibernate Search requires a
CacheManager; it can lookup and reuse an
existing CacheManager, via JNDI, or start and
manage a new one. In the latter case Hibernate Search will start and
stop it ( closing occurs when the Hibernate
SessionFactory is closed).
To use and existing CacheManager via JNDI
(optional parameter):
hibernate.search.infinispan.cachemanager_jndiname = [jndiname]
To start a new CacheManager from a
configuration file (optional parameter):
hibernate.search.infinispan.configuration_resourcename = [infinispan configuration filename]
If both parameters are defined, JNDI will have priority. If none
of these is defined, Hibernate Search will use the default Infinispan
configuration included in
hibernate-search-infinispan.jar. This configuration
should work fine in most cases but does not store the index in a
persistent cache store.
As mentioned in Table 3.1, “List of built-in DirectoryProvider”, each
index makes use of three caches, so three different caches should be
configured as shown in the
default-hibernatesearch-infinispan.xml provided in
the hibernate-search-infinispan.jar. Several
indexes can share the same caches.
It is possible to refine how Hibernate Search interacts with Lucene through the worker configuration. There exist several architectural components and possible extension points. Let's have a closer look.
First there is a Worker. An implementation of
the Worker interface is responsible for receiving
all entity changes, queuing them by context and applying them once a
context ends. The most intuitive context, especially in connection with
ORM, is the transaction. For this reason Hibernate Search will per default
use the TransactionalWorker to scope all changes
per transaction. One can, however, imagine a scenario where the context
depends for example on the number of entity changes or some other
application (lifecycle) events. For this reason the
Worker implementation is configurable as shown in
Table 3.2, “Scope configuration”.
Table 3.2. Scope configuration
| Property | Description |
| hibernate.search.worker.scope | The fully qualified class name of the
Worker implementation to use. If this
property is not set, empty or transaction the
default TransactionalWorker is
used. |
| hibernate.search.worker.* | All configuration properties prefixed with
hibernate.search.worker are passed to the
Worker during initialization. This allows adding custom, worker
specific parameters. |
Once a context ends it is time to prepare and apply the index changes. This can be done synchronously or asynchronously from within a new thread. Synchronous updates have the advantage that the index is at all times in sync with the databases. Asynchronous updates, on the other hand, can help to minimize the user response time. The drawback is potential discrepancies between database and index states. Lets look at the configuration options shown in Table 3.3, “Execution configuration”.
Note
The following options can be different on each index; in fact they
need the indexName prefix or use default to set the
default value for all indexes.
Table 3.3. Execution configuration
| Property | Description |
| hibernate.search.<indexName>.worker.execution |
|
| hibernate.search.<indexName>.worker.thread_pool.size | The backend can apply updates from the same transaction context (or batch) in parallel, using a threadpool. The default value is 1. You can experiment with larger values if you have many operations per transaction. |
| hibernate.search.<indexName>.worker.buffer_queue.max | Defines the maximal number of work queue if the thread poll is starved. Useful only for asynchronous execution. Default to infinite. If the limit is reached, the work is done by the main thread. |
So far all work is done within the same Virtual Machine (VM), no matter which execution mode. The total amount of work has not changed for the single VM. Luckily there is a better approach, namely delegation. It is possible to send the indexing work to a different server by configuring hibernate.search.default.worker.backend - see Table 3.4, “Backend configuration”. Again this option can be configured differently for each index.
Table 3.4. Backend configuration
| Property | Description |
| hibernate.search.<indexName>.worker.backend |
You can also
specify the fully qualified name of a class implementing
|
Table 3.5. JMS backend configuration
| Property | Description |
| hibernate.search.<indexName>.worker.jndi.* | Defines the JNDI properties to initiate the InitialContext (if needed). JNDI is only used by the JMS back end. |
| hibernate.search.<indexName>.worker.jms.connection_factory | Mandatory for the JMS back end. Defines the JNDI name to
lookup the JMS connection factory from
(/ConnectionFactory by default in JBoss
AS) |
| hibernate.search.<indexName>.worker.jms.queue | Mandatory for the JMS back end. Defines the JNDI name to lookup the JMS queue from. The queue will be used to post work messages. |
| hibernate.search.<indexName>.worker.jms.login | Optional for the JMS slaves. Use it when your queue requires login credentials to define your login. |
| hibernate.search.<indexName>.worker.jms.login | Optional for the JMS slaves. Use it when your queue requires login credentials to define your password. |
Warning
As you probably noticed, some of the shown properties are
correlated which means that not all combinations of property values make
sense. In fact you can end up with a non-functional configuration. This
is especially true for the case that you provide your own
implementations of some of the shown interfaces. Make sure to study the
existing code before you write your own Worker or
BackendQueueProcessor implementation.
This section describes in greater detail how to configure the Master/Slave Hibernate Search architecture.
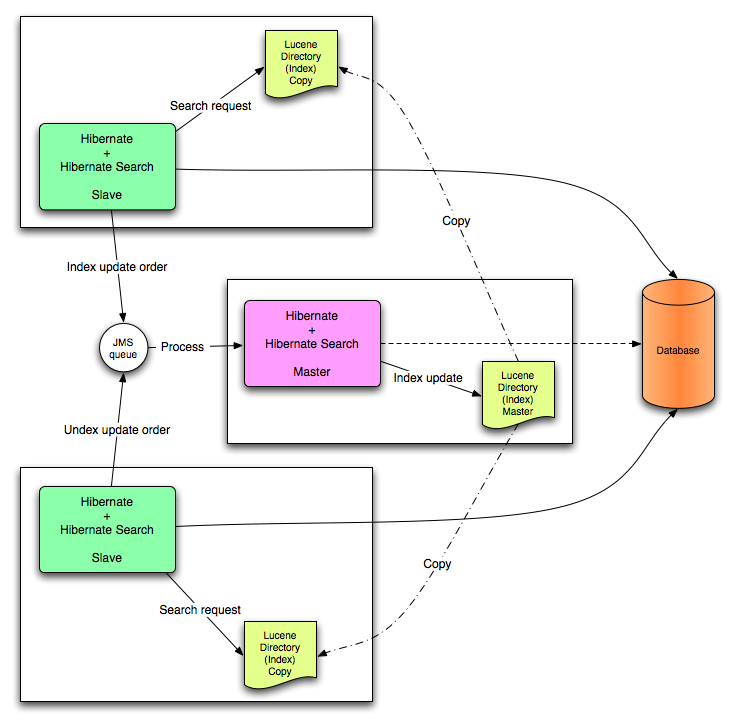
JMS back end configuration.
Every index update operation is sent to a JMS queue. Index querying operations are executed on a local index copy.
Example 3.4. JMS Slave configuration
### slave configuration ## DirectoryProvider # (remote) master location hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local copy location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = filesystem-slave ## Backend configuration hibernate.search.default.worker.backend = jms hibernate.search.default.worker.jms.connection_factory = /ConnectionFactory hibernate.search.default.worker.jms.queue = queue/hibernatesearch #optionally authentication credentials: hibernate.search.default.worker.jms.login = myname hibernate.search.default.worker.jms.password = wonttellyou #optional jndi configuration (check your JMS provider for more information) ## Optional asynchronous execution strategy # hibernate.search.default.worker.execution = async # hibernate.search.default.worker.thread_pool.size = 2 # hibernate.search.default.worker.buffer_queue.max = 50
Tip
A file system local copy is recommended for faster search results.
Every index update operation is taken from a JMS queue and executed. The master index is copied on a regular basis.
Example 3.5. JMS Master configuration
### master configuration ## DirectoryProvider # (remote) master location where information is copied to hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local master location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = filesystem-master ## Backend configuration #Backend is the default lucene one
Tip
It is recommended that the refresh period be higher than the expected copy time; if a copy operation is still being performed when the next refresh triggers, the second refresh is skipped: it's safe to set this value low even when the copy time is not known.
In addition to the Hibernate Search framework configuration, a Message Driven Bean has to be written and set up to process the index works queue through JMS.
Example 3.6. Message Driven Bean processing the indexing queue
@MessageDriven(activationConfig = {
@ActivationConfigProperty(propertyName="destinationType",
propertyValue="javax.jms.Queue"),
@ActivationConfigProperty(propertyName="destination",
propertyValue="queue/hibernatesearch"),
@ActivationConfigProperty(propertyName="DLQMaxResent", propertyValue="1")
} )
public class MDBSearchController extends AbstractJMSHibernateSearchController
implements MessageListener {
@PersistenceContext EntityManager em;
//method retrieving the appropriate session
protected Session getSession() {
return (Session) em.getDelegate();
}
//potentially close the session opened in #getSession(), not needed here
protected void cleanSessionIfNeeded(Session session)
}
}
This example inherits from the abstract JMS controller class
available in the Hibernate Search source code and implements a JavaEE
MDB. This implementation is given as an example and can be adjusted to
make use of non Java EE Message Driven Beans. For more information
about the getSession() and
cleanSessionIfNeeded(), please check
AbstractJMSHibernateSearchController's
javadoc.
This section describes how to configure the JGroups Master/Slave
back end. The master and slave roles are similar to what is illustrated
in Section 3.4.1, “JMS Master/Slave back end”, only a different backend
(hibernate.search.default.worker.backend) needs to be
set.
A specific backend can be configured to act either as a slave
using jgroupsSlave, as a master using
jgroupsMaster, or can automatically switch between
the roles as needed by using jgroups.
Note
Either you specify a single jgroupsMaster and
a set of jgroupsSlave instances, or you specify all
instances as jgroups. Never mix the two
approaches!
All backends configured to use JGroups share the same channel. The
JGroups JChannel is the main communication link
across all nodes participating in the same cluster group; since it is
convenient to have just one channel shared across all backends, the
Channel configuration properties are not defined on a per-worker section
but are defined globally. See Section 3.4.2.4, “JGroups channel configuration”.
Table Table 3.6, “JGroups backend configuration properties”
contains all configuration options which can be set independently on
each index backend. These apply to all three variants of the backend:
jgroupsSlave, jgroupsMaster,
jgroups. It is very unlikely that you need to change
any of these from their defaults.
Table 3.6. JGroups backend configuration properties
| Property | Description |
| hibernate.search.<indexName>.jgroups.block_waiting_ack | Set to either true or
false. False is more efficient but will not
wait for the operation to be delivered to the peers. Defaults to
true when the backend is synchronous, to
false when the backend is
async. |
| hibernate.search.<indexName>.jgroups.messages_timeout | The timeout of waiting for a single command to be
acknowledged and executed when
block_waiting_ack is true,
or just acknowledged otherwise. Value in milliseconds, defaults
to 20000. |
| hibernate.search.<indexName>.jgroups.delegate_backend | The master node receiving indexing operations forwards
them to a standard backend to be performed. Defaults to
lucene. See also Table 3.4, “Backend configuration” for other options, but
probably the only useful option is blackhole,
or a custom implementation, to help isolating network latency
problems. |
Every index update operation is sent through a JGroups channel
to the master node. Index querying operations are executed on a local
index copy. Enabling the JGroups worker only makes sure the index
operations are sent to the master, you still have to synchronize
configuring an appropriate directory (See
filesystem-master,
filesystem-slave or infinispan
options in Section 3.3, “Directory configuration”).
Example 3.7. JGroups Slave configuration
### slave configuration hibernate.search.default.worker.backend = jgroupsSlave
Every index update operation is taken from a JGroups channel and executed. The master index is copied on a regular basis.
Example 3.8. JGroups Master configuration
### master configuration hibernate.search.default.worker.backend = jgroupsMaster
Important
This feature is considered experimental. In particular during a re-election process there is a small window of time in which indexing requests could be lost.
In this mode the different nodes will autonomously elect a master node. When a master fails, a new node is elected automatically.
When setting this backend it is expected that all Hibernate
Search instances in the same cluster use the same backend for each
specific index: this configuration is an alternative to the static
jgroupsMaster and jgroupsSlave
approach so make sure to not mix them.
To synchronize the indexes in this configuration avoid
filesystem-master and
filesystem-slave directory providers as their
behaviour can not be switched dynamically; use the Infinispan
Directory instead, which has no need for different
configurations on each instance and allows dynamic switching of
writers; see also Section 3.3.1, “Infinispan Directory configuration”.
Example 3.9. JGroups configuration for automatic master configuration
### automatic configuration hibernate.search.default.worker.backend = jgroups
Tip
Should you use jgroups or the couple
jgroupsMaster,
jgroupsSlave?
The dynamic jgroups backend is better
suited for environments in which your master is more likely to need
to failover to a different machine, as in clouds. The static
configuration has the benefit of keeping the master at a well known
location: your architecture might take advantage of it by sending
most write requests to the known master. Also optimisation and
MassIndexer operations need to be triggered on the master
node.
Configuring the JGroups channel essentially entails specifying
the transport in terms of a network protocol stack. To configure the
JGroups transport, point the configuration property
hibernate.search.services.jgroups.configurationFile
to a JGroups configuration file; this can be either a file path or a
Java resource name.
Tip
If no property is explicitly specified it is assumed that the
JGroups default configuration file flush-udp.xml
is used. This example configuration is known to work in most
scenarios, with the notable exception of Amazon AWS; refer to the
JGroups
manual for more examples and protocol configuration
details.
The default cluster name is Hibernate Search
Cluster which can be configured as seen in Example 3.10, “JGroups cluster name configuration”.
Example 3.10. JGroups cluster name configuration
hibernate.search.services.jgroups.clusterName = My-Custom-Cluster-Id
The cluster name is what identifies a group: by changing the name you can run different clusters in the same network in isolation.
For programmatic configurations, one additional option is
available to configure the JGroups channel: to pass an existing
channel instance to Hibernate Search directly using the property
hibernate.search.services.jgroups.providedChannel,
as shown in the following example.
import org.hibernate.search.backend.impl.jgroups.JGroupsChannelProvider;
org.jgroups.JChannel channel = ...
Map<String,String> properties = new HashMap<String,String)(1);
properties.put( JGroupsChannelProvider.CHANNEL_INJECT, channel );
EntityManagerFactory emf = Persistence.createEntityManagerFactory( "userPU", properties );
The different reader strategies are described in Reader strategy. Out of the box strategies are:
shared: share index readers across several queries. This strategy is the most efficient.not-shared: create an index reader for each individual query
The default reader strategy is shared. This can
be adjusted:
hibernate.search.[default|<indexname>].reader.strategy = not-shared
Adding this property switches to the not-shared
strategy.
Or if you have a custom reader strategy:
hibernate.search.[default|<indexname>].reader.strategy = my.corp.myapp.CustomReaderProvider
where my.corp.myapp.CustomReaderProvider is
the custom strategy implementation.
Hibernate Search allows you to configure how exceptions are handled during the indexing process. If no configuration is provided then exceptions are logged to the log output by default. It is possible to explicitly declare the exception logging mechanism as seen below:
hibernate.search.error_handler = log
The default exception handling occurs for both synchronous and asynchronous indexing. Hibernate Search provides an easy mechanism to override the default error handling implementation.
In order to provide your own implementation you must implement the
ErrorHandler interface, which provides the
handle(ErrorContext context) method.
ErrorContext provides a reference to the primary
LuceneWork instance, the underlying exception and any
subsequent LuceneWork instances that could not be processed
due to the primary exception.
public interface ErrorContext {
List<LuceneWork> getFailingOperations();
LuceneWork getOperationAtFault();
Throwable getThrowable();
boolean hasErrors();
}
To register this error handler with Hibernate Search you must
declare the fully qualified classname of your
ErrorHandler implementation in the configuration
properties:
hibernate.search.error_handler = CustomerErrorHandler
Even though Hibernate Search will try to shield you as much as possible from Lucene specifics, there are several Lucene specifics which can be directly configured, either for performance reasons or for satisfying a specific usecase. The following sections discuss these configuration options.
Hibernate Search allows you to tune the Lucene indexing
performance by specifying a set of parameters which are passed through
to underlying Lucene IndexWriter such as
mergeFactor, maxMergeDocs and
maxBufferedDocs. You can specify these parameters
either as default values applying for all indexes, on a per index basis,
or even per shard.
There are several low level IndexWriter
settings which can be tuned for different use cases. These parameters
are grouped by the indexwriter keyword:
hibernate.search.[default|<indexname>].indexwriter.<parameter_name>
If no value is set for an indexwriter value in
a specific shard configuration, Hibernate Search will look at the index
section, then at the default section.
Example 3.11. Example performance option configuration
hibernate.search.Animals.2.indexwriter.max_merge_docs = 10 hibernate.search.Animals.2.indexwriter.merge_factor = 20 hibernate.search.Animals.2.indexwriter.term_index_interval = default hibernate.search.default.indexwriter.max_merge_docs = 100 hibernate.search.default.indexwriter.ram_buffer_size = 64
The configuration in Example 3.11, “Example performance option configuration” will result in
these settings applied on the second shard of the
Animal index:
max_merge_docs= 10merge_factor= 20ram_buffer_size= 64MBterm_index_interval= Lucene default
All other values will use the defaults defined in Lucene.
The default for all values is to leave them at Lucene's own
default. The values listed in Table 3.7, “List of indexing performance and behavior properties” depend for this reason on the
version of Lucene you are using. The values shown are relative to
version 2.4. For more information about Lucene
indexing performance, please refer to the Lucene documentation.
Table 3.7. List of indexing performance and behavior properties
| Property | Description | Default Value |
|---|---|---|
| hibernate.search.[default|<indexname>].exclusive_index_use |
Set to | true (improved performance, releases
locks only at shutdown) |
| hibernate.search.[default|<indexname>].max_queue_length |
Each index has a separate "pipeline" which contains the
updates to be applied to the index. When this queue is full
adding more operations to the queue becomes a blocking
operation. Configuring this setting doesn't make much sense
unless the |
1000
|
| hibernate.search.[default|<indexname>].indexwriter.max_buffered_delete_terms |
Determines the minimal number of delete terms required before the buffered in-memory delete terms are applied and flushed. If there are documents buffered in memory at the time, they are merged and a new segment is created. | Disabled (flushes by RAM usage) |
| hibernate.search.[default|<indexname>].index_flush_interval |
The interval in milliseconds between flushes of write operations
to the index storage. Ignored unless |
1000
|
| hibernate.search.[default|<indexname>].indexwriter.max_buffered_docs |
Controls the amount of documents buffered in memory during indexing. The bigger the more RAM is consumed. | Disabled (flushes by RAM usage) |
| hibernate.search.[default|<indexname>].indexwriter.max_merge_docs |
Defines the largest number of documents allowed in a segment. Smaller values perform better on frequently changing indexes, larger values provide better search performance if the index does not change often. | Unlimited (Integer.MAX_VALUE) |
| hibernate.search.[default|<indexname>].indexwriter.merge_factor |
Controls segment merge frequency and size. Determines how often segment indexes are merged when insertion occurs. With smaller values, less RAM is used while indexing, and searches on unoptimized indexes are faster, but indexing speed is slower. With larger values, more RAM is used during indexing, and while searches on unoptimized indexes are slower, indexing is faster. Thus larger values (> 10) are best for batch index creation, and smaller values (< 10) for indexes that are interactively maintained. The value must not be lower than 2. | 10 |
| hibernate.search.[default|<indexname>].indexwriter.merge_min_size |
Controls segment merge frequency and size. Segments smaller than this size (in MB) are always considered for the next segment merge operation. Setting this too large might result in expensive merge operations, even tough they are less frequent. See also
| 0 MB (actually ~1K) |
| hibernate.search.[default|<indexname>].indexwriter.merge_max_size |
Controls segment merge frequency and size. Segments larger than this size (in MB) are never merged in bigger segments. This helps reduce memory requirements and avoids some merging operations at the cost of optimal search speed. When optimizing an index this value is ignored. See also
| Unlimited |
| hibernate.search.[default|<indexname>].indexwriter.merge_max_optimize_size |
Controls segment merge frequency and size. Segments larger than this size (in MB) are not merged in
bigger segments even when optimizing the index (see
Applied to
| Unlimited |
| hibernate.search.[default|<indexname>].indexwriter.merge_calibrate_by_deletes |
Controls segment merge frequency and size. Set to Applied to
|
true
|
| hibernate.search.[default|<indexname>].indexwriter.ram_buffer_size |
Controls the amount of RAM in MB dedicated to document buffers. When used together max_buffered_docs a flush occurs for whichever event happens first. Generally for faster indexing performance it's best to flush by RAM usage instead of document count and use as large a RAM buffer as you can. | 16 MB |
| hibernate.search.[default|<indexname>].indexwriter.term_index_interval |
Expert: Set the interval between indexed terms. Large values cause less memory to be used by IndexReader, but slow random-access to terms. Small values cause more memory to be used by an IndexReader, and speed random-access to terms. See Lucene documentation for more details. | 128 |
| hibernate.search.[default|<indexname>].indexwriter.use_compound_file | The advantage of using the compound file format is that
less file descriptors are used. The disadvantage is that
indexing takes more time and temporary disk space. You can set
this parameter to false in an attempt to
improve the indexing time, but you could run out of file
descriptors if mergeFactor is also
large.Boolean parameter, use " | true |
| hibernate.search.enable_dirty_check |
Not all entity changes require an update of the Lucene index. If all of the updated entity properties (dirty properties) are not indexed Hibernate Search will skip the re-indexing work. Disable this option if you use custom
This optimization will not be applied on classes using a
Boolean parameter, use " | true |
Tip
When your architecture permits it, always keep
hibernate.search.default.exclusive_index_use=true
as it greatly improves efficiency in index writing. This is the
default since Hibernate Search version 4.
Tip
To tune the indexing speed it might be useful to time the object
loading from database in isolation from the writes to the index. To
achieve this set the blackhole as worker backend
and start your indexing routines. This backend does not disable
Hibernate Search: it will still generate the needed changesets to the
index, but will discard them instead of flushing them to the index. In
contrast to setting the
hibernate.search.indexing_strategy to
manual, using blackhole will
possibly load more data from the database. because associated entities
are re-indexed as well.
hibernate.search.[default|<indexname>].worker.backend blackhole
The recommended approach is to focus first on optimizing the object loading, and then use the timings you achieve as a baseline to tune the indexing process.
Warning
The blackhole backend is not meant to be used
in production, only as a tool to identify indexing bottlenecks.
The options merge_max_size,
merge_max_optimize_size,
merge_calibrate_by_deletes give you control on the
maximum size of the segments being created, but you need to understand
how they affect file sizes. If you need to hard limit the size,
consider that merging a segment is about adding it together with
another existing segment to form a larger one, so you might want to
set the max_size for merge operations to less than
half of your hard limit. Also segments might initially be generated
larger than your expected size at first creation time: before they are
ever merged. A segment is never created much larger than
ram_buffer_size, but the threshold is checked as an
estimate.
Example:
//to be fairly confident no files grow above 15MB, use: hibernate.search.default.indexwriter.ram_buffer_size = 10 hibernate.search.default.indexwriter.merge_max_optimize_size = 7 hibernate.search.default.indexwriter.merge_max_size = 7
Tip
When using the Infinispan Directory to cluster indexes make sure
that your segments are smaller than the chunk_size
so that you avoid fragmenting segments in the grid. Note that the
chunk_size of the Infinispan Directory is expressed
in bytes, while the index tuning options are in MB.
Lucene Directorys have default locking
strategies which work generally good enough for most cases, but it's
possible to specify for each index managed by Hibernate Search a
specific LockingFactory you want to use. This is
generally not needed but could be useful.
Some of these locking strategies require a filesystem level lock
and may be used even on RAM based indexes, this combination is valid but
in this case the indexBase configuration option
usually needed only for filesystem based
Directory instances must be specified to point to
a filesystem location where to store the lock marker files.
To select a locking factory, set the
hibernate.search.<index>.locking_strategy
option to one of simple, native,
single or none. Alternatively set
it to the fully qualified name of an implementation of
org.hibernate.search.store.LockFactoryProvider.
Table 3.8. List of available LockFactory implementations
| name | Class | Description |
|---|---|---|
| simple | org.apache.lucene.store.SimpleFSLockFactory | Safe implementation based on Java's File API, it marks the usage of the index by creating a marker file. If for some reason you had to kill your application, you will need to remove this file before restarting it. |
| native | org.apache.lucene.store.NativeFSLockFactory | As does This implementation has known problems on NFS, avoid it on network shares.
|
| single | org.apache.lucene.store.SingleInstanceLockFactory | This LockFactory doesn't use a file marker but is a Java object lock held in memory; therefore it's possible to use it only when you are sure the index is not going to be shared by any other process. This is the default
implementation for the |
| none | org.apache.lucene.store.NoLockFactory | All changes to this index are not coordinated by any lock; test your application carefully and make sure you know what it means. |
Configuration example:
hibernate.search.default.locking_strategy = simple hibernate.search.Animals.locking_strategy = native hibernate.search.Books.locking_strategy = org.custom.components.MyLockingFactory
The Infinispan Directory uses a custom implementation; it's still possible to override it but make sure you understand how that will work, especially with clustered indexes.
While Hibernate Search strives to offer a backwards compatible API making it easy to port your application to newer versions, it still delegates to Apache Lucene to handle the index writing and searching. This creates a dependency to the Lucene index format. The Lucene developers of course attempt to keep a stable index format, but sometimes a change in the format can not be avoided. In those cases you either have to reindex all your data or use an index upgrade tool. Sometimes Lucene is also able to read the old format so you don't need to take specific actions (besides making backup of your index).
While an index format incompatibility is a rare event, it can
happen more often that Lucene's Analyzer
implementations might slightly change its behaviour. This can lead to a
poor recall score, possibly missing many hits from the results.
Hibernate Search exposes a configuration property
hibernate.search.lucene_version which instructs the
analyzers and other Lucene classes to conform to their behaviour as
defined in an (older) specific version of Lucene. See also
org.apache.lucene.util.Version contained in the
lucene-core.jar. Depending on the specific version
of Lucene you're using you might have different options available. When
this option is not specified, Hibernate Search will instruct Lucene to
use the default version, which is usually the best option for new
projects. Still it's recommended to define the version you're using
explicitly in the configuration so that when you happen to upgrade
Lucene the analyzers will not change behaviour. You can then choose to
update this value at a later time, when you for example have the chance
to rebuild the index from scratch.
Example 3.12. Force Analyzers to be compatible with a Lucene 3.0 created index
hibernate.search.lucene_version = LUCENE_30
This option is global for the configured
SearchFactory and affects all Lucene APIs having
such a parameter, as this should be applied consistently. So if you are
also making use of Lucene bypassing Hibernate Search, make sure to apply
the same value too.
After looking at all these different configuration options, it is
time to have a look at an API which allows you to prorgammatically access
parts of the configuration. Via the metadata API you can determine the
indexed types and also how they are mapped (see Chapter 4, Mapping entities to the index structure) to the index structure. The entry point into
this API is the SearchFactory. It offers two
methods, namely getIndexedTypes() and
getIndexedTypeDescriptor(Class<?>). The
former returns a set of all indexed type, where as the latter allows to
retrieve a so called IndexedTypeDescriptorfor a
gven type. This descriptor allows you determine whether the type is
indexed at all and, if so, whether the index is for example sharded or not
(see Section 10.4, “Sharding indexes”). It also
allows you to determine the static boost of the type (see Section 4.2.1, “Static index time boosting”) as well as its dynamic boost
strategy (see Section 4.2.2, “Dynamic index time boosting”). Most importantly,
however, you get information about the indexed properties and generated
Lucene Document fields. This is exposed via
PropertyDescriptors respectively
FieldDescriptors. The easiest way to get to know
the API is to explore it via the IDE or its javadocs.
Note
All descriptor instances of the metadata API are read only. They do not allow to change any runtime configuration.
If you are deploying your application on WildFly 8, Hibernate Search is included in the application server. A benefit is that rather than including Hibernate Search jars as a dependency in your application, you can activate the module included in the server.
We provide modules for Hibernate Search, for Apache Lucene and for some useful Solr libraries. The Hibernate Search modules are:
org.hibernate.search.orm:main, for users of Hibernate Search with Hibernate. This will transitively include Hibernate ORM, Apache Lucene and Solr in your classpath, so this is all you need.
org.hibernate.search.engine:main, for projects integrating with the internal indexing engine but not using Hibernate ORM (experts only, not covered in this guide).
There are two alternative ways to get the application server to make Hibernate Search ORM module available to your deployment:
- Using the manifest
Add this entry to the MANIFEST.MF in your archive:
Dependencies: org.hibernate.search.orm services
- Using jboss-deployment-structure.xml
This is a proprietary JBoss AS descriptor, add a WEB-INF/jboss-deployment-structure.xml in your archive with content:
<jboss-deployment-structure>
<deployment>
<dependencies>
<module name="org.hibernate.search.orm" services="export" />
</dependencies>
</deployment>
</jboss-deployment-structure>
More details about modules are described in Class Loading in WildFly 8.
Tip
Modular classloading is a feature of JBoss EAP as well, but if you are using JBoss EAP, you're reading the wrong version of the user guide! JBoss EAP subscriptions include official support for Hibernate Search (as part of the WFK) and come with a different edition of this guide specifically tailored for EAP users.