A Cache consists of a collection of Node instances, organised in a tree structure. Each Node contains a Map which holds the data objects to be cached. It is important to note that the structure is a mathematical tree, and not a graph; each Node has one and only one parent, and the root node is denoted by the constant fully qualitied name, Fqn.ROOT .
The reason for organising nodes as such is to improve concurrent access to data and make replication and persistence more fine-grained.
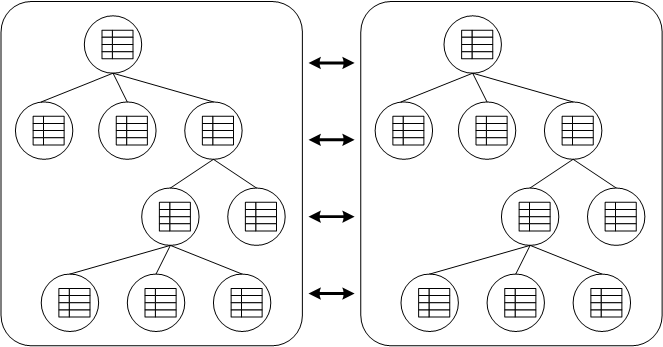
In the diagram above, each box represents a JVM. You see 2 caches in separate JVMs, replicating data to each other. These VMs can be located on the same physical machine, or on 2 different machines connected by a network link. The underlying group communication between networked nodes is done using JGroups .
Any modifications (see API chapter ) in one cache instance will be replicated to the other cache. Naturally, you can have more than 2 caches in a cluster. Depending on the transactional settings, this replication will occur either after each modification or at the end of a transaction, at commit time. When a new cache is created, it can optionally acquire the contents from one of the existing caches on startup.
In addition to Cache and Node interfaces, JBoss Cache exposes more powerful CacheSPI and NodeSPI interfaces, which offer more control over the internals of JBoss Cache. These interfaces are not intended for general use, but are designed for people who wish to extend and enhance JBoss Cache, or write custom Interceptor or CacheLoader instances.

The CacheSPI interface cannot be created, but is injected into Interceptor and CacheLoader implementations by the setCache(CacheSPI cache) methods on these interfaces. CacheSPI extends Cache so all the functionality of the basic API is made available.
Similarly, a NodeSPI interface cannot be created. Instead, one is obtained by performing operations on CacheSPI , obtained as above. For example, Cache.getRoot() : Node is overridden as CacheSPI.getRoot() : NodeSPI .
It is important to note that directly casting a Cache or Node to it's SPI counterpart is not recommended and is bad practice, since the inheritace of interfaces it is not a contract that is guaranteed to be upheld moving forward. The exposed public APIs, on the other hand, is guaranteed to be upheld.
Since the cache is essentially a collection of nodes, aspects such as clustering, persistence, eviction, etc. need to be applied to these nodes when operations are invoked on the cache as a whole or on individual nodes. To achieve this in a clean, modular and extensible manner, an interceptor chain is used. The chain is built up of a series of interceptors, each one adding an aspect or particular functionality. The chain is built when the cache is created, based on the configuration used.
It is important to note that the NodeSPI offers some methods (such as the xxxDirect() method family) that operate on a node directly without passing through the interceptor stack. Plugin authors should note that using such methods will affect the aspects of the cache that may need to be applied, such as locking, replication, etc. Basically, don't use such methods unless you really know what you're doing!
An Interceptor is an abstract class, several of which comprise an interceptor chain. It exposes an invoke() method, which must be overridden by implementing classes to add behaviour to a call before passing the call down the chain by calling super.invoke() .

JBoss Cache ships with several interceptors, representing different configuration options, some of which are:
- TxInterceptor - looks for ongoing transactions and registers with transaction managers to participate in synchronization events
- ReplicationInterceptor - replicates state across a cluster using a JGroups channel
- CacheLoaderInterceptor - loads data from a persistent store if the data requested is not available in memory
The interceptor chain configured for your cache instance can be obtained and inspected by calling CacheSPI.getInterceptorChain() , which returns an ordered List of interceptors.
Custom interceptors to add specific aspects or features can be written by extending Interceptor and overriding invoke() . The custom interceptor will need to be added to the interceptor chain by using the CacheSPI.addInterceptor() method.
Adding custom interceptors via XML is not supported at this time.
org.jboss.cache.marshall.MethodCall is a class that encapsulates a java.lang.reflection.Method and an Object[] representing the method's arguments. It is an extension of the org.jgroups.blocks.MethodCall class, that adds a mechanism for identifying known methods using magic numbers and method ids, which makes marshalling and unmarshalling more efficient and performant.
This is central to the Interceptor architecture, and is the only parameter passed in to Interceptor.invoke() .
InvocationContext holds intermediate state for the duration of a single invocation, and is set up and destroyed by the InvocationContextInterceptor which sits at the start of the chain.
InvocationContext , as its name implies, holds contextual information associated with a single cache method invocation. Contextual information includes associated javax.transaction.Transaction or org.jboss.cache.transaction.GlobalTransaction , method invocation origin ( InvocationContext.isOriginLocal() ) as well as Option overrides .
The InvocationContext can be obtained by calling Cache.getInvocationContext() .
Some aspects and functionality is shared by more than a single interceptor. Some of these have been encapsulated into managers, for use by various interceptors, and are made available by the CacheSPI interface.
This class is responsible for calls made via the JGroups channel for all RPC calls to remote caches, and encapsulates the JGroups channel used.
This class manages buddy groups and invokes group organisation remote calls to organise a cluster of caches into smaller sub-groups.
Early versions of JBoss Cache simply wrote cached data to the network by writing to an ObjectOutputStream during replication. Over various releases in the JBoss Cache 1.x.x series this approach was gradually deprecated in favour of a more mature marshalling framework. In the JBoss Cache 2.x.x series, this is the only officially supported and recommended mechanism for writing objects to datastreams.
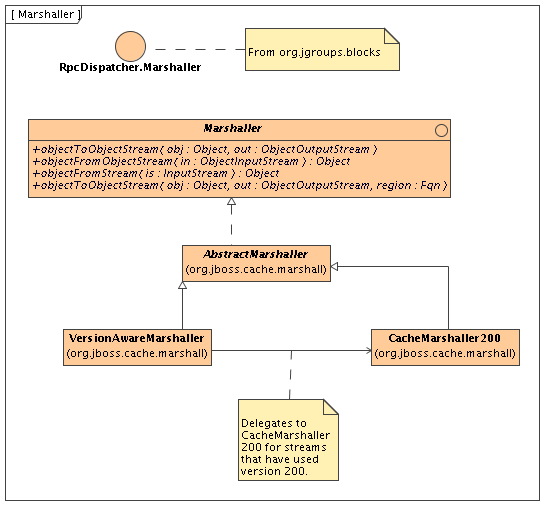
The Marshaller interface extends RpcDispatcher.Marshaller from JGroups. This interface has two main implementations - a delegating VersionAwareMarshaller and a concrete CacheMarshaller200 .
The marshaller can be obtained by calling CacheSPI.getMarshaller() , and defaults to the VersionAwareMarshaller . Users may also write their own marshallers by implementing the Marshaller interface and adding it to their configuration, by using the MarshallerClass configuration attribute.
As the name suggests, this marshaller adds a version short to the start of any stream when writing, enabling similar VersionAwareMarshaller instances to read the version short and know which specific marshaller implementation to delegate the call to. For example, CacheMarshaller200 , is the marshaller for JBoss Cache 2.0.x. JBoss Cache 2.1.x, say, may ship with CacheMarshaller210 with an improved wire protocol. Using a VersionAwareMarshaller helps achieve wire protocol compatibility between minor releases but still affords us the flexibility to tweak and improve the wire protocol between minor or micro releases.
This marshaller treats well-known objects that need marshalling - such as MethodCall , Fqn , DataVersion , and even some JDK objects such as String , List , Boolean and others as types that do not need complete class definitions. Instead, each of these well-known types are represented by a short , which is a lot more efficient.
In addition, reference counting is done to reduce duplication of writing certain objects multiple times, to help keep the streams small and efficient.
Also, if UseRegionBasedMarshalling is enabled (disabled by default) the marshaller adds region information to the stream before writing any data. This region information is in the form of a String representation of an Fqn . When unmarshalling, the RegionManager can be used to find the relevant Region , and use a region-specific ClassLoader to unmarshall the stream. This is specifically useful when used to cluster state for application servers, where each deployment has it's own ClassLoader . See the section below on regions for more information.
When used to cluster state of application servers, applications deployed in the application tend to put instances of objects specific to their application in the cache (or in an HttpSession object) which would require replication. It is common for application servers to assign separate ClassLoader instances to each application deployed, but have JBoss Cache libraries referenced by the application server's ClassLoader .
To enable us to successfully marshall and unmarshall objects from such class loaders, we use a concept called regions. A region is a portion of the cache which share a common class loader (a region also has other uses - see eviction policies ).
A region is created by using the Cache.getRegion(Fqn fqn, boolean createIfNotExists) method, and returns an implementation of the Region interface. Once a region is obtained, a class loader for the region can be set or unset, and the region can be activated/deactivated. By default, regions are active unless the InactiveOnStartup configuration attribute is set to true .