- 10.1. Configuring a JGroups Channel's Protocol Stack
- 10.1.1. Common Configuration Properties
- 10.1.2. Transport Protocols
- 10.1.3. Discovery Protocols
- 10.1.4. Failure Detection Protocols
- 10.1.5. Reliable Delivery Protocols
- 10.1.6. Group Membership (GMS)
- 10.1.7. Flow Control (FC)
- 10.1.8. Fragmentation (FRAG2)
- 10.1.9. State Transfer
- 10.1.10. Distributed Garbage Collection (STABLE)
- 10.1.11. Merging (MERGE2)
- 10.2. Key JGroups Configuration Tips
- 10.3. JGroups Troubleshooting
JGroups provides the underlying group communication support for JBoss AS clusters. The way the AS's clustered services interact with JGroups was covered previously in Section 3.1, “Group Communication with JGroups”. The focus of this chapter is on the details, particularly configuration details and troubleshooting tips. This chapter is not intended to be a complete set of JGroups documentation; we recommend that users interested in in-depth JGroups knowledge also consult:
The JGroups project documentation at http://jgroups.org/ug.html
The JGroups wiki pages at jboss.org, rooted at https://www.jboss.org/community/wiki/JGroups
The first section of this chapter covers the many JGroups configuration options in considerable detail. Readers should understand that JBoss AS ships with a reasonable set of default JGroups configurations. Most applications just work out of the box with the default configurations. You only need to tweak them when you are deploying an application that has special network or performance requirements.
The JGroups framework provides services to enable peer-to-peer communications between nodes in a cluster. Communication occurs over a communication channel. The channel built up from a stack of network communication "protocols", each of which is responsible for adding a particular capability to the overall behavior of the channel. Key capabilities provided by various protocols include, among others, transport, cluster discovery, message ordering, loss-less message delivery, detection of failed peers, and cluster membership management services.
Figure 10.1, “Protocol stack in JGroups” shows a conceptual cluster with each member's channel composed of a stack of JGroups protocols.
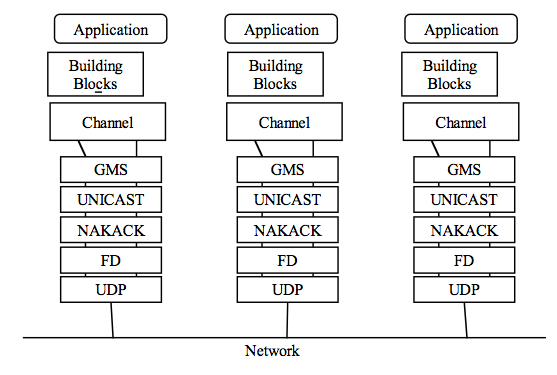
In this section of the chapter, we look into some of the most commonly used protocols, with the protocols organized by the type of behavior they add to the overall channel. For each protocol, we discuss a few key configuration attributes exposed by the protocol, but generally speaking changing configuration attributes is a matter for experts only. More important for most readers will be to get a general understanding of the purpose of the various protocols.
The JGroups configurations used in the AS appear as nested elements in
the $JBOSS_HOME/server/all/cluster/jgroups-channelfactory.sar/META-INF/jgroups-channelfactory-stacks.xml
file. This file is parsed by the ChannelFactory service, which
uses the contents to provide appropriately configured channels to the AS
clustered services that need them. See Section 3.1.1, “The Channel Factory Service”
for more on the ChannelFactory service.
Following is an example protocol stack configuration from
jgroups-channelfactory-stacks.xml:
<stack name="udp-async"
description="UDP-based stack, optimized for high performance for
asynchronous RPCs (enable_bundling=true)">
<config>
<UDP
singleton_name="udp-async"
mcast_port="${jboss.jgroups.udp_async.mcast_port:45689}"
mcast_addr="${jboss.partition.udpGroup:228.11.11.11}"
tos="8"
ucast_recv_buf_size="20000000"
ucast_send_buf_size="640000"
mcast_recv_buf_size="25000000"
mcast_send_buf_size="640000"
loopback="true"
discard_incompatible_packets="true"
enable_bundling="true"
max_bundle_size="64000"
max_bundle_timeout="30"
ip_ttl="${jgroups.udp.ip_ttl:2}"
thread_naming_pattern="cl"
timer.num_threads="12"
enable_diagnostics="${jboss.jgroups.enable_diagnostics:true}"
diagnostics_addr="${jboss.jgroups.diagnostics_addr:224.0.0.75}"
diagnostics_port="${jboss.jgroups.diagnostics_port:7500}"
thread_pool.enabled="true"
thread_pool.min_threads="8"
thread_pool.max_threads="200"
thread_pool.keep_alive_time="5000"
thread_pool.queue_enabled="true"
thread_pool.queue_max_size="1000"
thread_pool.rejection_policy="discard"
oob_thread_pool.enabled="true"
oob_thread_pool.min_threads="8"
oob_thread_pool.max_threads="200"
oob_thread_pool.keep_alive_time="1000"
oob_thread_pool.queue_enabled="false"
oob_thread_pool.rejection_policy="discard"/>
<PING timeout="2000" num_initial_members="3"/>
<MERGE2 max_interval="100000" min_interval="20000"/>
<FD_SOCK/>
<FD timeout="6000" max_tries="5" shun="true"/>
<VERIFY_SUSPECT timeout="1500"/>
<BARRIER/>
<pbcast.NAKACK use_mcast_xmit="true" gc_lag="0"
retransmit_timeout="300,600,1200,2400,4800"
discard_delivered_msgs="true"/>
<UNICAST timeout="300,600,1200,2400,3600"/>
<pbcast.STABLE stability_delay="1000" desired_avg_gossip="50000"
max_bytes="400000"/>
<VIEW_SYNC avg_send_interval="10000"/>
<pbcast.GMS print_local_addr="true" join_timeout="3000"
shun="true"
view_bundling="true"
view_ack_collection_timeout="5000"
resume_task_timeout="7500"/>
<FC max_credits="2000000" min_threshold="0.10"
ignore_synchronous_response="true"/>
<FRAG2 frag_size="60000"/>
<!-- pbcast.STREAMING_STATE_TRANSFER/ -->
<pbcast.STATE_TRANSFER/>
<pbcast.FLUSH timeout="0" start_flush_timeout="10000"/>
</config>
</stack>
All the JGroups configuration data is contained in the <config> element. This information is used to configure a JGroups Channel; the Channel is conceptually similar to a socket, and manages communication between peers in a cluster. Each element inside the <config> element defines a particular JGroups Protocol; each Protocol performs one function, and the combination of those functions is what defines the characteristics of the overall Channel. In the next several sections, we will dig into the commonly used protocols and their options and explain exactly what they mean.
The following configuration property is exposed by all of the JGroups protocols discussed below:
statswhether the protocol should gather runtime statistics on its operations that can be exposed via tools like the AS's administration console or the JGroups Probe utility. What, if any, statistics are gathered depends on the protocol. Default istrue.
Note
All of the protocols in the versions of JGroups used in JBoss AS 3.x and 4.x exposed
down_thread and up_thread attributes.
The JGroups version used in AS 5 and later no longer uses those attributes,
and a WARN message will be written to the server log if they are configured
for any protocol.
The transport protocols are responsible for actually sending messages on the network and receiving them from the network. They also manage the pools of threads that are used to deliver incoming messages up the protocol stack. JGroups supports UDP, TCP, and TUNNEL as transport protocols.
Note
The UDP, TCP, and TUNNEL protocols are
mutually exclusive. You can only have one transport protocol in each JGroups
config element
UDP is the preferred protocol for JGroups. UDP uses multicast (or,
in an unusual configuration, multiple unicasts) to send and
receive messages. If you choose UDP as the transport protocol for your cluster service, you need
to configure it in the UDP sub-element in the JGroups
config element. Here is an example.
<UDP
singleton_name="udp-async"
mcast_port="${jboss.jgroups.udp_async.mcast_port:45689}"
mcast_addr="${jboss.partition.udpGroup:228.11.11.11}"
tos="8"
ucast_recv_buf_size="20000000"
ucast_send_buf_size="640000"
mcast_recv_buf_size="25000000"
mcast_send_buf_size="640000"
loopback="true"
discard_incompatible_packets="true"
enable_bundling="true"
max_bundle_size="64000"
max_bundle_timeout="30"
ip_ttl="${jgroups.udp.ip_ttl:2}"
thread_naming_pattern="cl"
timer.num_threads="12"
enable_diagnostics="${jboss.jgroups.enable_diagnostics:true}"
diagnostics_addr="${jboss.jgroups.diagnostics_addr:224.0.0.75}"
diagnostics_port="${jboss.jgroups.diagnostics_port:7500}"
thread_pool.enabled="true"
thread_pool.min_threads="8"
thread_pool.max_threads="200"
thread_pool.keep_alive_time="5000"
thread_pool.queue_enabled="true"
thread_pool.queue_max_size="1000"
thread_pool.rejection_policy="discard"
oob_thread_pool.enabled="true"
oob_thread_pool.min_threads="8"
oob_thread_pool.max_threads="200"
oob_thread_pool.keep_alive_time="1000"
oob_thread_pool.queue_enabled="false"
oob_thread_pool.rejection_policy="discard"/>
The available attributes in the above JGroups configuration are listed discussed below. First, we discuss the attributes that are particular to the UDP transport protocol. Then we will cover those attributes shown above that are also used by the TCP and TUNNEL transport protocols.
The attributes particular to UDP are:
ip_mcast specifies whether or not to use IP multicasting. The default is
true. If set to false, for messages to the entire group UDP will send n unicast packets rather than 1 multicast packet. Either way, packets are UDP datagrams.mcast_addr specifies the multicast address (class D) for communicating with the group (i.e., the cluster). The standard protocol stack configurations in JBoss AS use the value of system property
jboss.partition.udpGroup, if set, as the value for this attribute. Using the-ucommand line switch when starting JBoss AS sets that value. See Section 10.2.2, “Isolating JGroups Channels” for how to use this configuration attribute to ensure JGroups channels are properly isolated from one another. If this attribute is omitted, the default is228.8.8.8.mcast_port specifies the port to use for multicast communication with the group. See Section 10.2.2, “Isolating JGroups Channels” for how to use this configuration attribute to ensure JGroups channels are properly isolated from one another. If this attribute is omitted, the default is
45566.mcast_send_buf_size, mcast_recv_buf_size, ucast_send_buf_size, ucast_recv_buf_size define socket receive and send buffer sizes that JGroups will request from the operating system. It is good to have a large receive buffer size, so packets are less likely to get dropped due to buffer overflow. Note, however, that the size of socket buffers is limited by OS limits, so actually obtaining the desired buffer may require OS-level configuration. See Section 10.2.3, “Improving UDP Performance by Configuring OS UDP Buffer Limits” for further details.
bind_port specifies the port to which the unicast receive socket should be bound. The default is
0; i.e. use an ephemeral port.port_range specifies the number of ports to try if the port identified by
bind_portis not available. The default is1, meaning only try to bind tobind_port.ip_ttl specifies time-to-live for IP Multicast packets. TTL is the commonly used term in multicast networking, but is actually something of a misnomer, since the value here refers to how many network hops a packet will be allowed to travel before networking equipment will drop it.
tos specifies the traffic class for sending unicast and multicast datagrams.
The attributes that are common to all transport protocols, and thus have the same meanings when used with TCP or TUNNEL, are:
singleton_name provides a unique name for this transport protocol configuration. Used by the AS
ChannelFactoryto support sharing of a transport protocol instance by different channels that use the same transport protocol configuration. See Section 3.1.2, “The JGroups Shared Transport”.bind_addr specifies the interface on which to receive and send messages. By default JGroups uses the value of system property
jgroups.bind_addr, which in turn can be easily set via the-bcommand line switch. See Section 10.2, “Key JGroups Configuration Tips” for more on binding JGroups sockets.receive_on_all_interfaces specifies whether this node should listen on all interfaces for multicasts. The default is
false. It overrides thebind_addrproperty for receiving multicasts. However,bind_addr(if set) is still used to send multicasts.send_on_all_interfaces specifies whether this node send UDP packets via all the NICs if you have a multi NIC machine. This means that the same multicast message is sent N times, so use with care.
receive_interfaces specifies a list of of interfaces on which to receive multicasts. The multicast receive socket will listen on all of these interfaces. This is a comma-separated list of IP addresses or interface names. E.g. "
192.168.5.1,eth1,127.0.0.1".send_interfaces specifies a list of of interfaces via which to send multicasts. The multicast s ender socket will send on all of these interfaces. This is a comma-separated list of IP addresses or interface names. E.g. "
192.168.5.1,eth1,127.0.0.1".This means that the same multicast message is sent N times, so use with care.enable_bundling specifies whether to enable message bundling. If
true, the tranpsort protocol would queue outgoing messages untilmax_bundle_sizebytes have accumulated, ormax_bundle_timemilliseconds have elapsed, whichever occurs first. Then the transport protocol would bundle queued messages into one large message and send it. The messages are unbundled at the receiver. The default isfalse. Message bundling can have significant performance benefits for channels that are used for high volume sending of messages where the sender does not block waiting for a response from recipients (e.g. a JBoss Cache instance configured for REPL_ASYNC.) It can add considerable latency to applications where senders need to block waiting for responses, so it is not recommended for usages like JBoss Cache REPL_SYNC.loopback specifies whether the thread sending a message to the group should itself carry the message back up the stack for delivery. (Messages sent to the group are always delivered to the sending node as well.) If
falsethe sending thread does not carry the message; rather the transport protocol waits to read the message off the network and uses one of the message delivery pool threads to deliver it. The default isfalse, however the current recommendation is to always set this totruein order to ensure the channel receives its own messages in case the network interface goes down.discard_incompatible_packets specifies whether to discard packets sent by peers using a different JGroups version. Each message in the cluster is tagged with a JGroups version. When a message from a different version of JGroups is received, it will be silently discarded if this is set to true, otherwise a warning will be logged. In no case will the message be delivered. The default is
falseenable_diagnostics specifies that the transport should open a multicast socket on address
diagnostics_addrand portdiagnostics_portto listen for diagnostic requests sent by JGroups' Probe utility.The various thread_pool attributes configure the behavior of the pool of threads JGroups uses to carry ordinary incoming messages up the stack. The various attributes end up providing the constructor arguments for an instance of
java.util.concurrent.ThreadPoolExecutorService. In the example above, the pool will have a core (i.e. minimum) size of 8 threads, and a maximum size of 200 threads. If more than 8 pool threads have been created, a thread returning from carrying a message will wait for up to 5000 ms to be assigned a new message to carry, after which it will terminate. If no threads are available to carry a message, the (separate) thread reading messages off the socket will place messages in a queue; the queue will hold up to 1000 messages. If the queue is full, the thread reading messages off the socket will discard the message.The various oob_thread_pool attributes are similar to the thread_pool attributes in that they configure a
java.util.concurrent.ThreadPoolExecutorServiceused to carry incoming messages up the protocol stack. In this case, the pool is used to carry a special type of message known as an "Out-Of-Band" message, OOB for short. OOB messages are exempt from the ordered-delivery requirements of protocols like NAKACK and UNICAST and thus can be delivered up the stack even if NAKACK or UNICAST are queueing up messages from a particular sender. OOB messages are often used internally by JGroups protocols and can be used applications as well. JBoss Cache in REPL_SYNC mode, for example, uses OOB messages for the second phase of its two-phase-commit protocol.
Alternatively, a JGroups-based cluster can also work over TCP connections. Compared with UDP,
TCP generates more network traffic when the cluster size increases. TCP
is fundamentally a unicast protocol. To send multicast messages, JGroups uses multiple TCP
unicasts. To use TCP as a transport protocol, you should define a TCP element
in the JGroups config element. Here is an example of the
TCP element.
<TCP singleton_name="tcp"
start_port="7800" end_port="7800"/>
Below are the attributes that are specific to the TCP protocol.
start_port, end_port define the range of TCP ports the server should bind to. The server socket is bound to the first available port beginning with
start_port. If no available port is found (e.g., because of other sockets already using the ports) before theend_port, the server throws an exception. If noend_portis provided orend_port < start_portthen there is no upper limit on the port range. Ifstart_port == end_port, then we force JGroups to use the given port (start fails if port is not available). The default is 7800. If set to 0, then the operating system will pick a port. Please, bear in mind that setting it to 0 will work only if we use MPING or TCPGOSSIP as discovery protocol becauseTCCPINGrequires listing the nodes and their corresponding ports.bind_port in TCP is just an alias for
start_port; if configured internally it setsstart_port.recv_buf_size, send_buf_size define receive and send buffer sizes. It is good to have a large receiver buffer size, so packets are less likely to get dropped due to buffer overflow.
conn_expire_time specifies the time (in milliseconds) after which a connection can be closed by the reaper if no traffic has been received.
reaper_interval specifies interval (in milliseconds) to run the reaper. If both values are 0, no reaping will be done. If either value is > 0, reaping will be enabled. By default, reaper_interval is 0, which means no reaper.
sock_conn_timeout specifies max time in millis for a socket creation. When doing the initial discovery, and a peer hangs, don't wait forever but go on after the timeout to ping other members. Reduces chances of *not* finding any members at all. The default is 2000.
use_send_queues specifies whether to use separate send queues for each connection. This prevents blocking on write if the peer hangs. The default is true.
external_addr specifies external IP address to broadcast to other group members (if different to local address). This is useful when you have use (Network Address Translation) NAT, e.g. a node on a private network, behind a firewall, but you can only route to it via an externally visible address, which is different from the local address it is bound to. Therefore, the node can be configured to broadcast its external address, while still able to bind to the local one. This avoids having to use the TUNNEL protocol, (and hence a requirement for a central gossip router) because nodes outside the firewall can still route to the node inside the firewall, but only on its external address. Without setting the external_addr, the node behind the firewall will broadcast its private address to the other nodes which will not be able to route to it.
skip_suspected_members specifies whether unicast messages should not be sent to suspected members. The default is true.
tcp_nodelay specifies TCP_NODELAY. TCP by default nagles messages, that is, conceptually, smaller messages are bundled into larger ones. If we want to invoke synchronous cluster method calls, then we need to disable nagling in addition to disabling message bundling (by setting
enable_bundlingto false). Nagling is disabled by settingtcp_nodelayto true. The default is false.
Note
All of the attributes common to all protocols discussed in the UDP protocol section also apply to TCP.
The TUNNEL protocol uses an external router process to send messages. The external router is a Java process running the
org.jgroups.stack.GossipRouter main class. Each node has to register with the router. All messages are sent to the router and forwarded on to their destinations. The TUNNEL approach can be used to setup communication with nodes behind firewalls. A node can establish a TCP connection to the GossipRouter through the firewall (you can use port 80). The same connection is used by the router to send messages to nodes behind the firewall as most firewalls do not permit outside hosts to initiate a TCP connection to a host inside the firewall. The TUNNEL configuration is defined in the TUNNEL element in the JGroups config element. Here is an example..
<TUNNEL singleton_name="tunnel"
router_port="12001"
router_host="192.168.5.1"/>
The available attributes in the TUNNEL element are listed below.
router_host specifies the host on which the GossipRouter is running.
router_port specifies the port on which the GossipRouter is listening.
reconnect_interval specifies the interval in ms at which TUNNEL will attempt to connect to the GossipRouter if the connection is not established. Default is
5000.
Note
All of the attributes common to all protocols discussed in the UDP protocol section also apply to TUNNEL.
When a channel on one node connects it needs to discover what other nodes have compatible channels running and which of those nodes is currently serving as the "coordinator" responsible for allowing new nodes to join the group. Discovery protocols are used to discover active nodes in the cluster and determine which is the coordinator. This information is then provided to the group membership protocol (GMS, see Section 10.1.6, “Group Membership (GMS)”) which communicates with the coordinator node's GMS to bring the newly connecting node into the group.
Discovery protocols also help merge protocols (see Section 10.1.11, “Merging (MERGE2)” to detect cluster-split situations.
Since the discovery protocols sit on top of the transport protocol, you can choose to use different discovery protocols based on your transport protocol. These are also configured as sub-elements in the JGroups config element.
PING is a discovery protocol that works by either multicasting PING requests to an IP multicast address or connecting to a gossip router. As such, PING normally sits on top of the UDP or TUNNEL transport protocols. Each node responds with a packet {C, A}, where C=coordinator's address and A=own address. After timeout milliseconds or num_initial_members replies, the joiner determines the coordinator from the responses, and sends a JOIN request to it (handled by). If nobody responds, we assume we are the first member of a group.
Here is an example PING configuration for IP multicast.
<PING timeout="2000"
num_initial_members="3"/>
Here is another example PING configuration for contacting a Gossip Router.
<PING gossip_host="localhost"
gossip_port="1234"
timeout="2000"
num_initial_members="3"/>
The available attributes in the PING element are listed below.
timeout specifies the maximum number of milliseconds to wait for any responses. The default is 3000.
num_initial_members specifies the maximum number of responses to wait for unless timeout has expired. The default is 2.
gossip_host specifies the host on which the GossipRouter is running.
gossip_port specifies the port on which the GossipRouter is listening on.
gossip_refresh specifies the interval (in milliseconds) for the lease from the GossipRouter. The default is 20000.
initial_hosts is a comma-separated list of addresses/ports (e.g.,
host1[12345],host2[23456]) which are pinged for discovery. Default isnull, meaning multicast discovery should be used. Ifinitial_hostsis specified, all possible cluster members must be listed, not just a few "well known hosts"; otherwise discovery of cluster splits by MERGE2 will not work reliably.
If both gossip_host and gossip_port are defined, the
cluster uses the GossipRouter for the initial discovery. If the initial_hosts
is specified, the cluster pings that static list of addresses for discovery. Otherwise, the
cluster uses IP multicasting for discovery.
Note
The discovery phase returns when the timeout ms have elapsed or the
num_initial_members responses have been received.
The TCPGOSSIP protocol only works with a GossipRouter. It works essentially the same way as
the PING protocol configuration with valid gossip_host and
gossip_port attributes. It works on top of both UDP and TCP transport protocols. Here is an example.
<TCPGOSSIP timeout="2000"
num_initial_members="3"
initial_hosts="192.168.5.1[12000],192.168.0.2[12000]"/>
The available attributes in the TCPGOSSIP element are listed below.
timeout specifies the maximum number of milliseconds to wait for any responses. The default is 3000.
num_initial_members specifies the maximum number of responses to wait for unless timeout has expired. The default is 2.
initial_hosts is a comma-separated list of addresses/ports (e.g.,
host1[12345],host2[23456]) of GossipRouters to register with.
The TCPPING protocol takes a set of known members and pings them for discovery. This is
essentially a static configuration. It works on top of TCP. Here is an example of the
TCPPING configuration element in the JGroups config
element.
<TCPPING timeout="2000"
num_initial_members="3"/
initial_hosts="hosta[2300],hostb[3400],hostc[4500]"
port_range="3">
The available attributes in the TCPPING element are listed below.
timeout specifies the maximum number of milliseconds to wait for any responses. The default is 3000.
num_initial_members specifies the maximum number of responses to wait for unless timeout has expired. The default is 2.
initial_hosts is a comma-separated list of addresses/ports (e.g.,
host1[12345],host2[23456]) which are pinged for discovery. All possible cluster members must be listed, not just a few "well known hosts"; otherwise discovery of cluster splits by MERGE2 will not work reliably.port_range specifies the number of consecutive ports to be probed when getting the initial membership, starting with the port specified in the initial_hosts parameter. Given the current values of port_range and initial_hosts above, the TCPPING layer will try to connect to hosta[2300], hosta[2301], hosta[2302], hostb[3400], hostb[3401], hostb[3402], hostc[4500], hostc[4501], hostc[4502]. This configuration option allows for multiple possible ports on the same host to be pinged without having to spell out all of the combinations. If in your TCP protocol configuration your
end_portis greater than yourstart_port, using a TCPPINGport_rangeequal to the difference is advised in order to ensure a node is pinged no matter which port in the allowed range it ended up bound to.
MPING uses IP multicast to discover the initial membership. Unlike the other discovery protocols, which delegate the sending and receiving of discovery messages on the network to the transport protocol, MPING handles opens its own sockets to send and receive multicast discovery messages. As a result it can be used with all transports. But, it usually is used in combination with TCP. TCP usually requires TCPPING, which has to list all possible group members explicitly, while MPING doesn't have this requirement. The typical use case for MPING is when we want TCP for regular message transport, but UDP multicasting is allowed for discovery.
<MPING timeout="2000"
num_initial_members="3"
bind_to_all_interfaces="true"
mcast_addr="228.8.8.8"
mcast_port="7500"
ip_ttl="8"/>
The available attributes in the MPING element are listed below.
timeout specifies the maximum number of milliseconds to wait for any responses. The default is 3000.
num_initial_members specifies the maximum number of responses to wait for unless timeout has expired. The default is 2..
bind_addr specifies the interface on which to send and receive multicast packets. By default JGroups uses the value of system property
jgroups.bind_addr, which in turn can be easily set via the-bcommand line switch. See Section 10.2, “Key JGroups Configuration Tips” for more on binding JGroups sockets.bind_to_all_interfaces overrides the
bind_addrand uses all interfaces in multihome nodes.mcast_addr, mcast_port, ip_ttl attributes are the same as related attributes in the UDP protocol configuration.
The failure detection protocols are used to detect failed nodes. Once a failed node is detected, a suspect verification phase can occur after which, if the node is still considered dead, the cluster updates its membership view so that further messages are not sent to the failed node and the service using JGroups is aware the node is no longer part of the cluster. The failure detection protocols are configured as sub-elements in the JGroups
config element.
FD is a failure detection protocol based on heartbeat messages. This protocol requires each node to periodically send an are-you-alive message to its neighbor. If the neighbor fails to respond, the calling node sends a SUSPECT message to the cluster. The current group coordinator can optionally double check whether the suspected node is indeed dead (see VERIFY_SUSPECT below) after which, if the node is still considered dead, it updates the cluster's membership view. Here is an example FD configuration.
<FD timeout="6000"
max_tries="5"
shun="true"/>
The available attributes in the FD element are listed below.
timeout specifies the maximum number of milliseconds to wait for the responses to the are-you-alive messages. The default is 3000.
max_tries specifies the number of missed are-you-alive messages from a node before the node is suspected. The default is 2.
shun specifies whether a failed node will be shunned, i.e. not allowed to send messages to the group without formally rejoining. A shunned node would have to re-join the cluster through the discovery process. JGroups allows applications to configure a channel such that shunning leads to automatic rejoins and state transfer. This the default behavior within JBoss Application Server.
Note
Regular traffic from a node counts as if it is a heartbeat response. So, the are-you-alive messages are only sent when there is no regular traffic to the node for some time.
FD_SOCK is a failure detection protocol based on a ring of TCP sockets created between group members. Each member in a group connects to its neighbor (last member connects to first) thus forming a ring. Member B is suspected when its neighbor A detects an abnormally closed TCP socket (presumably due to a node B crash). However, if a member B is about to leave gracefully, it lets its neighbor A know, so that it does not become suspected. The simplest FD_SOCK configuration does not take any attribute. You can just declare an empty FD_SOCK element in JGroups's config element.
<FD_SOCK/>
There available attributes in the FD_SOCK element are listed below.
bind_addr specifies the interface to which the server socket should be bound. By default JGroups uses the value of system property
jgroups.bind_addr, which in turn can be easily set via the-bcommand line switch. See Section 10.2, “Key JGroups Configuration Tips” for more on binding JGroups sockets.
This protocol verifies whether a suspected member is really dead by pinging that member once again. This verification is performed by the coordinator of the cluster. The suspected member is dropped from the cluster group if confirmed to be dead. The aim of this protocol is to minimize false suspicions. Here's an example.
<VERIFY_SUSPECT timeout="1500"/>
The available attributes in the VERIFY_SUSPECT element are listed below.
timeout specifies how long to wait for a response from the suspected member before considering it dead.
FD and FD_SOCK, each taken individually, do not provide a solid failure detection layer. Let's look at the the differences between these failure detection protocols to understand how they complement each other:
FD
An overloaded machine might be slow in sending are-you-alive responses.
A member will be suspected when suspended in a debugger/profiler.
Low timeouts lead to higher probability of false suspicions and higher network traffic.
High timeouts will not detect and remove crashed members for some time.
FD_SOCK:
Suspended in a debugger is no problem because the TCP connection is still open.
High load no problem either for the same reason.
Members will only be suspected when TCP connection breaks
So hung members will not be detected.
Also, a crashed switch will not be detected until the connection runs into the TCP timeout (between 2-20 minutes, depending on TCP/IP stack implementation).
The aim of a failure detection layer is to report promptly real failures and yet avoid false suspicions. There are two solutions:
By default, JGroups configures the FD_SOCK socket with KEEP_ALIVE, which means that TCP sends a heartbeat on socket on which no traffic has been received in 2 hours. If a host crashed (or an intermediate switch or router crashed) without closing the TCP connection properly, we would detect this after 2 hours (plus a few minutes). This is of course better than never closing the connection (if KEEP_ALIVE is off), but may not be of much help. So, the first solution would be to lower the timeout value for KEEP_ALIVE. This can only be done for the entire kernel in most operating systems, so if this is lowered to 15 minutes, this will affect all TCP sockets.
The second solution is to combine FD_SOCK and FD; the timeout in FD can be set such that it is much lower than the TCP timeout, and this can be configured individually per process. FD_SOCK will already generate a suspect message if the socket was closed abnormally. However, in the case of a crashed switch or host, FD will make sure the socket is eventually closed and the suspect message generated. Example:
<FD_SOCK/> <FD timeout="6000" max_tries="5" shun="true"/> <VERIFY_SUSPECT timeout="1500"/>
This suspects a member when the socket to the neighbor has been closed abonormally (e.g. a process crash, because the OS closes all sockets). However, if a host or switch crashes, then the sockets won't be closed, so, as a second line of defense FD will suspect the neighbor after 30 seconds. Note that with this example, if you have your system stopped in a breakpoint in the debugger, the node you're debugging will be suspected after roughly 30 seconds.
A combination of FD and FD_SOCK provides a solid failure detection layer and for this reason, such technique is used across JGroups configurations included within JBoss Application Server.
Reliable delivery protocols within the JGroups stack ensure that messages are actually delivered and delivered in the right order (FIFO) to the destination node. The basis for reliable message delivery is positive and negative delivery acknowledgments (ACK and NAK). In the ACK mode, the sender resends the message until the acknowledgment is received from the receiver. In the NAK mode, the receiver requests retransmission when it discovers a gap.
The UNICAST protocol is used for unicast messages. It uses positive acknowlegements (ACK). It is configured as a sub-element under the JGroups config element. If the JGroups stack is configured with the TCP transport protocol, UNICAST is not necessary because TCP itself guarantees FIFO delivery of unicast messages. Here is an example configuration for the UNICAST protocol:
<UNICAST timeout="300,600,1200,2400,3600"/>
There is only one configurable attribute in the UNICAST element.
timeout specifies the retransmission timeout (in milliseconds). For instance, if the timeout is "100,200,400,800", the sender resends the message if it hasn't received an ACK after 100 ms the first time, and the second time it waits for 200 ms before resending, and so on. A low value for the first timeout allows for prompt retransmission of dropped messages, but at the potential cost of unnecessary retransmissions if messages aren't actually lost, but rather ACKs just aren't received before the timeout. High values (e.g. "1000,2000,3000") can improve performance if the network has been tuned such that UDP datagram losses are infrequent. High values on lossy networks will hurt performance since later messages will not be delivered until lost messages are retransmitted.
The NAKACK protocol is used for multicast messages. It uses negative acknowlegements (NAK). Under this protocol, each
message is tagged with a sequence number. The receiver keeps track of the received sequence numbers and
delivers the messages in order. When a gap in the series of received sequence numbers is detected, the receiver
schedules a task to periodically ask the sender to retransmit the missing message. The task
is cancelled if the missing message is received. The NAKACK protocol is configured as the
pbcast.NAKACK sub-element under the JGroups config
element. Here is an example configuration.
<pbcast.NAKACK max_xmit_size="60000" use_mcast_xmit="false" retransmit_timeout="300,600,1200,2400,4800" gc_lag="0" discard_delivered_msgs="true"/>
The configurable attributes in the pbcast.NAKACK element are as follows.
retransmit_timeout specifies the series of timeouts (in milliseconds) after which retransmission is requested if a missing message has not yet been received.
use_mcast_xmit determines whether the sender should send the retransmission to the entire cluster rather than just to the node requesting it. This is useful when the sender's network layer tends to drop packets, avoiding the need to individually retransmit to each node.
max_xmit_size specifies the maximum size (in bytes) for a bundled retransmission, if multiple messages are reported missing.
discard_delivered_msgs specifies whether to discard delivered messages on the receiver nodes. By default, nodes save delivered messages so any node can retransmit a lost message in case the original sender has crashed or left the group. However, if we only ask the sender to resend their messages, we can enable this option and discard delivered messages.
gc_lag specifies the number of messages to keep in memory for retransmission even after the periodic cleanup protocol (see Section 10.1.10, “Distributed Garbage Collection (STABLE)”) indicates all peers have received the message. Default is
20.
The group membership service (GMS) protocol in the JGroups stack
maintains a list of active nodes. It handles the requests to join and
leave the cluster. It also handles the SUSPECT messages sent by failure
detection protocols. All nodes in the cluster, as well as any interested
services like JBoss Cache or HAPartition, are notified if the group membership changes. The group membership service is
configured in the pbcast.GMS sub-element under the JGroups
config element. Here is an example configuration.
<pbcast.GMS print_local_addr="true"
join_timeout="3000"
join_retry_timeout="2000"
shun="true"
view_bundling="true"/>
The configurable attributes in the pbcast.GMS element are as follows.
join_timeout specifies the maximum number of milliseconds to wait for a new node JOIN request to succeed. Retry afterwards.
join_retry_timeout specifies the number of milliseconds to wait after a failed JOIN before trying again.
print_local_addr specifies whether to dump the node's own address to the standard output when starting.
shun specifies whether a node should shun (i.e. disconnect) itself if it receives a cluster view in which it is not a member node.
disable_initial_coord specifies whether to prevent this node becoming the cluster coordinator during initial connection of the channel. This flag does not prevent a node becoming coordinator later, if the current coordinator leaves the group.
view_bundling specifies whether multiple JOIN or LEAVE requests arriving at the same time are bundled and handled together at the same time, resulting in only 1 new view incorporating all changes. This is is more efficient than handling each request separately.
The flow control (FC) protocol tries to adapt the data sending rate
to the data receipt rate among nodes. If a sender node is too fast, it
might overwhelm the receiver node and result in out-of-memory conditions
or dropped packets that have to be retransmitted. In JGroups, flow control is implemented via a
credit-based system. The sender and receiver nodes have the same number of credits (bytes) to
start with. The sender subtracts credits by the number of bytes in messages it sends. The
receiver accumulates credits for the bytes in the messages it receives. When the sender's credit
drops to a threshold, the receivers send some credit to the sender. If the sender's credit is
used up, the sender blocks until it receives credits from the receiver. The flow control protocol
is configured in the FC sub-element under the JGroups
config element. Here is an example configuration.
<FC max_credits="2000000"
min_threshold="0.10"
ignore_synchronous_response="true"/>
The configurable attributes in the FC element are as follows.
max_credits specifies the maximum number of credits (in bytes). This value should be smaller than the JVM heap size.
min_credits specifies the number of bytes the receipt of which should trigger the receiver to send more credits to the sender.
min_threshold specifies percentage of the
max_creditsthat should be used to calculatemin_credits. Setting this overrides themin_creditsattribute.ignore_synchronous_response specifies whether threads that have carried messages up to the application should be allowed to carry outgoing messages back down through FC without blocking for credits. The term "synchronous response" refers to the fact that such an outgoing message is typically a response to an incoming RPC-type message. Not allowing the threads JGroups uses to carry messages up to block in FC is useful in preventing certain deadlock scenarios, so a value of
trueis recommended.
Why is FC needed on top of TCP ? TCP has its own flow control !
The reason is group communication, where we essentially have to send group messages at the highest speed the slowest receiver can keep up with. Let's say we have a cluster {A,B,C,D}. D is slow (maybe overloaded), the rest are fast. When A sends a group message, it uses TCP connections A-A (conceptually), A-B, A-C and A-D. So let's say A sends 100 million messages to the cluster. Because TCP's flow control only applies to A-B, A-C and A-D, but not to A-{B,C,D}, where {B,C,D} is the group, it is possible that A, B and C receive the 100M, but D only received 1M messages. (By the way, this is also the reason why we need NAKACK, even though TCP does its own retransmission).
Now JGroups has to buffer all messages in memory for the case when the original sender S dies and a node asks for retransmission of a message sent by S. Because all members buffer all messages they received, they need to purge stable messages (i.e. messages seen by everyone) every now and then. (This is done purging process is managed by the STABLE protocol; see Section 10.1.10, “Distributed Garbage Collection (STABLE)”). In the above case, the slow node D will prevent the group from purging messages above 1M, so every member will buffer 99M messages ! This in most cases leads to OOM exceptions. Note that - although the sliding window protocol in TCP will cause writes to block if the window is full - we assume in the above case that this is still much faster for A-B and A-C than for A-D.
So, in summary, even with TCP we need to FC to ensure we send messages at a rate the slowest receiver (D) can handle.
So do I always need FC?
This depends on how the application uses the JGroups channel. Referring to the example above, if there was something about the application that would naturally cause A to slow down its rate of sending because D wasn't keeping up, then FC would not be needed.
A good example of such an application is one that uses JGroups to make synchronous group RPC calls. By synchronous, we mean the thread that makes the call blocks waiting for responses from all the members of the group. In that kind of application, the threads on A that are making calls would block waiting for responses from D, thus naturally slowing the overall rate of calls.
A JBoss Cache cluster configured for REPL_SYNC is a good example of an application that makes synchronous group RPC calls. If a channel is only used for a cache configured for REPL_SYNC, we recommend you remove FC from its protocol stack.
And, of course, if your cluster only consists of two nodes, including FC in a TCP-based protocol stack is unnecessary. There is no group beyond the single peer-to-peer relationship, and TCP's internal flow control will handle that just fine.
Another case where FC may not be needed is for a channel used by a JBoss Cache configured for buddy replication and a single buddy. Such a channel will in many respects act like a two node cluster, where messages are only exchanged with one other node, the buddy. (There may be other messages related to data gravitation that go to all members, but in a properly engineered buddy replication use case these should be infrequent. But if you remove FC be sure to load test your application.)
This protocol fragments messages larger than certain size. Unfragments at the receiver's side. It works for both unicast and multicast messages. It is configured in the FRAG2 sub-element under the JGroups config element. Here is an example configuration.
<FRAG2 frag_size="60000"/>
The configurable attributes in the FRAG2 element are as follows.
frag_size specifies the max frag size in bytes. Messages larger than that are fragmented. For stacks using the UDP transport, this needs to be a value less than 64KB, the maximum UDP datagram size. For TCP-based stacks it needs to be less than the value of max_credits in the FC protocol.
Note
TCP protocol already provides fragmentation but a JGroups fragmentation protocol is still needed if FC is used. The reason for this is that if you send a message larger than FC.max_credits, the FC protocol will block forever. So, frag_size within FRAG2 needs to be set to always be less than FC.max_credits.
The state transfer service requests the application state (serialized as a byte array) from an existing node (i.e., the cluster
coordinator) and transfer it to a newly joining node. It tracks the sequence of messages that
went into creating the application state, providing a valid starting point for message tracking by
reliable delivery protocols like NAKACK and UNICAST. It is configured in the
pbcast.STATE_TRANSFER sub-element under the JGroups config
element. It does not have any configurable attribute. Here is an example configuration.
<pbcast.STATE_TRANSFER/>
In a JGroups cluster, all nodes have to store all messages received for potential retransmission in case of a failure. However, if we store all messages forever, we will run out of memory. So, the distributed garbage collection service in JGroups periodically purges messages that have seen by all nodes from the memory in each node. The distributed garbage collection service is configured in the pbcast.STABLE sub-element under the JGroups config element. Here is an example configuration.
<pbcast.STABLE stability_delay="1000"
desired_avg_gossip="5000"
max_bytes="400000"/>
The configurable attributes in the pbcast.STABLE element are as follows.
desired_avg_gossip specifies intervals (in milliseconds) of garbage collection runs. Value
0disables interval-based execution of garbage collection.max_bytes specifies the maximum number of bytes received before the cluster triggers a garbage collection run. Value
0disables execution of garbage collection based on bytes received.stability_delay specifies the maximum amount (in milliseconds) of a random delay introduced before a node sends its STABILITY msg at the end of a garbage collection run. The delay gives other nodes concurrently running a STABLE task a change to send first. If used together with max_bytes, this attribute should be set to a small number.
Note
Set the max_bytes attribute when you have a high traffic
cluster.
When a network error occurs (e.g. a crashed switch), the cluster might be partitioned into several different sub-groups. JGroups has "merge" protocols that allow the coordinators in the sub-groups to communicate with each other (once the network heals) and merge back into a single group again. This service is configured in the MERGE2 sub-element under the JGroups config element. Here is an example configuration.
<MERGE2 max_interval="100000"
min_interval="20000"/>
The configurable attributes in the FC element are as follows.
max_interval specifies the maximum number of milliseconds to wait before sending out a MERGE message.
min_interval specifies the minimum number of milliseconds to wait before send out a MERGE message.
JGroups chooses a random value between min_interval and
max_interval to periodically send out the MERGE message.
Note
The application state maintained by the application using a channel is not merged by JGroups during a merge. This has to be done by the application.
Note
If MERGE2 is used in conjunction with TCPPING, the initial_hosts attribute must contain all the nodes that could potentially be merged back, in order for the merge process to work properly. Otherwise, the merge process may not detect all sub-groups, missing those comprised solely of unlisted members.
In the Transport Protocols section above, we briefly touched on how the interface to which JGroups will bind sockets is configured. Let's get into this topic in more depth:
First, it's important to understand that the value set in any bind_addr element in an XML configuration file will be ignored by JGroups if it finds that system property jgroups.bind_addr (or a deprecated earlier name for the same thing, bind.address) has been set. The system property trumps XML. If JBoss AS is started with the -b (a.k.a. --host) switch, the AS will set jgroups.bind_addr to the specified value.
Beginning with AS 4.2.0, for security reasons the AS will bind most services to localhost if -b is not set. The effect of this is that in most cases users are going to be setting -b and thus jgroups.bind_addr is going to be set and any XML setting will be ignored.
So, what are best practices for managing how JGroups binds to interfaces?
Binding JGroups to the same interface as other services. Simple, just use
-b:./run.sh -b 192.168.1.100 -c all
Binding services (e.g., JBoss Web) to one interface, but use a different one for JGroups:
./run.sh -b 10.0.0.100 -Djgroups.bind_addr=192.168.1.100 -c all
Specifically setting the system property overrides the
-bvalue. This is a common usage pattern; put client traffic on one network, with intra-cluster traffic on another.Binding services (e.g., JBoss Web) to all interfaces. This can be done like this:
./run.sh -b 0.0.0.0 -c all
However, doing this will not cause JGroups to bind to all interfaces! Instead , JGroups will bind to the machine's default interface. See the Transport Protocols section for how to tell JGroups to receive or send on all interfaces, if that is what you really want.
Binding services (e.g., JBoss Web) to all interfaces, but specify the JGroups interface:
./run.sh -b 0.0.0.0 -Djgroups.bind_addr=192.168.1.100 -c all
Again, specifically setting the system property overrides the
-bvalue.Using different interfaces for different channels:
./run.sh -b 10.0.0.100 -Djgroups.ignore.bind_addr=true -c all
This setting tells JGroups to ignore the jgroups.bind_addr system property, and instead use whatever is specfied in XML. You would need to edit the various XML configuration files to set the various bind_addr attributes to the desired interfaces.
Within JBoss AS, there are a number of services that independently create JGroups channels -- possibly multiple different JBoss Cache services (used for HttpSession replication, EJB3 SFSB replication and EJB3 entity replication), two JBoss Messaging channels, and the general purpose clustering service called HAPartition that underlies most other JBossHA services.
It is critical that these channels only communicate with their intended peers; not with the channels used by other services and not with channels for the same service opened on machines not meant to be part of the group. Nodes improperly communicating with each other is one of the most common issues users have with JBoss AS clustering.
Whom a JGroups channel will communicate with is defined by its group name and, for UDP-based channels, its multicast address and port. So isolating JGroups channels comes down to ensuring different channels use different values for the group name, the multicast address and, in some cases, the multicast port.
The issue being addressed here is the case where, in the same environment, you have multiple independent clusters running. For example, a production cluster, a staging cluster and a QA cluster. Or multiple clusters in a QA test lab or in a dev team environment. Or a large set of production machines divided into multiple clusters.
To isolate JGroups clusters from other clusters on the network, you need to:
Make sure the channels in the various clusters use different group names. This is easily to control from the command line arguments used to start JBoss; see Section 10.2.2.3, “Changing the Group Name”.
Make sure the channels in the various clusters use different multicast addresses. This is also easy to control from the command line arguments used to start JBoss; see Section 10.2.2.4, “Changing the Multicast Address”.
If you are not running on Linux, Windows, Solaris or HP-UX, you may also need to ensure that the channels in each cluster use different multicast ports. This is quite a bit more troublesome then using different group names, although it can still be controlled from the command line. See Section 10.2.2.5, “Changing the Multicast Port”. Note that using different ports should not be necessary if your servers are running on Linux, Windows, Solaris or HP-UX.
The issue being addressed here is the normal case where we have a cluster of 3 machines, each of which has, for example, an HAPartition deployed along with a JBoss Cache used for web session clustering. The HAPartition channels should not communicate with the JBoss Cache channels. Ensuring proper isolation of these channels is straightforward, and generally speaking the AS handles it for you without any special effort on your part. So most readers can skip this section.
To isolate JGroups channels for different services on the same set of AS instances from each other,
each channel must have its own group name. The configurations that ship
with JBoss AS of course ensure that this is the case. If you create a custom service
that directly uses JGroups, just make sure you use a unique group name.
If you create a custom JBoss Cache configuration, make sure you provide
a unique value in the clusterName configuration property.
In releases prior to AS 5, different channels running in the same AS also had to use unique multicast ports. With the JGroups shared transport introduced in AS 5 (see Section 3.1.2, “The JGroups Shared Transport”), it is now common for multiple channels to use the same tranpsort protocol and its sockets. This makes configuration easier, which is one of the main benefits of the shared transport. However, if you decide to create your own custom JGroups protocol stack configuration, be sure to configure its transport protocols with a multicast port that is different from the ports used in other protocol stacks.
The group name for a JGroups channel is configured via the service that
starts the channel. For all the standard clustered services, we make it easy
for you to create unique groups names by simply using the -g (a.k.a. --partition)
switch when starting JBoss:
./run.sh -g QAPartition -b 192.168.1.100 -c all
This switch sets the jboss.partition.name system property,
which is used as a component in the configuration of the group name in
all the standard clustering configuration files. For example,
<property name="clusterName">${jboss.partition.name:DefaultPartition}-SFSBCache</property>
The -u (a.k.a. --udp) command line switch may be used to control the multicast address used by the JGroups channels opened by all standard AS services.
/run.sh -u 230.1.2.3 -g QAPartition -b 192.168.1.100 -c all
This switch sets the jboss.partition.udpGroup system property,
which you can see referenced in all of the standard protocol stack configurations in JBoss AS:
<UDP mcast_addr="${jboss.partition.udpGroup:228.1.2.3}" ....Why isn't it sufficient to change the group name?
If channels with different group names share the same multicast address and port, the lower level JGroups protocols in each channel will see, process and eventually discard messages intended for the other group. This will at a minimum hurt performance and can lead to anomalous behavior.
On some operating systems (Mac OS X for example), using different
-g and -u values isn't sufficient
to isolate clusters; the channels running in the different clusters
need to use different multicast ports. Unfortunately, setting the
multicast ports is not quite as simple as -g and
-u. By default, a JBoss AS instance
running the all configuration will use up to two different instances of
the JGroups UDP transport protocol, and will thus open two
multicast sockets. You can control the ports those sockets use
by using system properties on the command line. For example,
/run.sh -u 230.1.2.3 -g QAPartition -b 192.168.1.100 -c all \\
-Djboss.jgroups.udp.mcast_port=12345 -Djboss.messaging.datachanneludpport=23456
The jboss.messaging.datachanneludpport property controls
the multicast port used by the MPING protocol in JBoss Messaging's DATA channel.
The jboss.jgroups.udp.mcast_port property controls the
multicast port used by the UDP transport protocol shared by all other clustered services.
The set of JGroups protocol stack configurations included in the
$JBOSS_HOME/server/all/cluster/jgroups-channelfactory.sar/META-INF/jgroups-channelfactory-stacks.xml
file includes a number of other example protocol stack configurations that
the standard AS distribution doesn't actually use. Those configurations also
use system properties to set any multicast ports. So, if you reconfigure some
AS service to use one of those protocol stack configurations, just use the
appropriate system property to control the port from the command line.
Why do I need to change the multicast port if I change the address?
It should be sufficient to just change the address, but unfortunately the
handling of multicast sockets is one area where the JVM fails to hide
OS behavior differences from the application. The java.net.MulticastSocket
class provides different overloaded constructors. On some operating
systems, if you use one constructor variant, there is a problem whereby
packets addressed to a particular multicast port are delivered to all
listeners on that port, regardless of the multicast address on which they are
listening. We refer to this as the "promiscuous traffic" problem.
On most operating systems that exhibit the promiscuous traffic problem
(i.e. Linux, Solaris and HP-UX) JGroups can use a different constructor
variant that avoids the problem. However, on some OSs with the
promiscuous traffic problem (e.g. Mac OS X), multicast does not work
properly if the other constructor variant is used. So, on these
operating systems the recommendation is to configure different
multicast ports for different clusters.
By default, the JGroups channels in JBoss AS use the UDP transport protocol in order to take advantage of IP multicast. However, one disadvantage of UDP is it does not come with the reliable delivery guarantees provided by TCP. The protocols discussed in Section 10.1.5, “Reliable Delivery Protocols” allow JGroups to guarantee delivery of UDP messages, but those protocols are implemented in Java, not at the OS network layer. To get peak performance from a UDP-based JGroups channel it is important to limit the need for JGroups to retransmit messages by limiting UDP datagram loss.
One of the most common causes of lost UDP datagrams is an undersized receive
buffer on the socket. The UDP protocol's mcast_recv_buf_size
and ucast_recv_buf_size configuration attributes
are used to specify the amount of receive buffer JGroups requests
from the OS, but the actual size of the buffer the OS will provide
is limited by OS-level maximums. These maximums are often very low:
Table 10.1. Default Max UDP Buffer Sizes
| Operating System | Default Max UDP Buffer (in bytes) |
|---|---|
| Linux | 131071 |
| Windows | No known limit |
| Solaris | 262144 |
| FreeBSD, Darwin | 262144 |
| AIX | 1048576 |
The command used to increase the above limits is OS-specific. The table below shows the command required to increase the maximum buffer to 25MB. In all cases root privileges are required:
Table 10.2. Commands to Change Max UDP Buffer Sizes
| Operating System | Command |
|---|---|
| Linux | sysctl -w net.core.rmem_max=26214400 |
| Solaris | ndd -set /dev/udp udp_max_buf 26214400 |
| FreeBSD, Darwin | sysctl -w kern.ipc.maxsockbuf=26214400 |
| AIX | no -o sb_max=8388608 (AIX will only allow 1MB, 4MB or 8MB). |
Make sure your machine is set up correctly for IP multicast. There are 2 test programs that can be used to detect this: McastReceiverTest and McastSenderTest. Go to the $JBOSS_HOME/server/all/lib directory and start McastReceiverTest, for example:
java -cp jgroups.jar org.jgroups.tests.McastReceiverTest -mcast_addr 224.10.10.10 -port 5555
Then in another window start McastSenderTest:
java -cp jgroups.jar org.jgroups.tests.McastSenderTest -mcast_addr 224.10.10.10 -port 5555
If you want to bind to a specific network interface card (NIC), use -bind_addr 192.168.0.2, where 192.168.0.2 is the IP address of the NIC to which you want to bind. Use this parameter in both the sender and the receiver.
You should be able to type in the McastSenderTest window and see the output in the McastReceiverTest window. If not, try to use -ttl 32 in the sender. If this still fails, consult a system administrator to help you setup IP multicast correctly, and ask the admin to make sure that multicast will work on the interface you have chosen or, if the machines have multiple interfaces, ask to be told the correct interface.
Once you know multicast is working properly on each machine in your cluster, you can repeat the above test to test the network, putting the sender on one machine and the receiver on another.
Sometimes a member is suspected by FD because a heartbeat ack has not been received for some time T (defined by timeout and max_tries). This can have multiple reasons, e.g. in a cluster of A,B,C,D; C can be suspected if (note that A pings B, B pings C, C pings D and D pings A):
B or C are running at 100% CPU for more than T seconds. So even if C sends a heartbeat ack to B, B may not be able to process it because it is at 100%
B or C are garbage collecting, same as above.
A combination of the 2 cases above
The network loses packets. This usually happens when there is a lot of traffic on the network, and the switch starts dropping packets (usually broadcasts first, then IP multicasts, TCP packets last).
B or C are processing a callback. Let's say C received a remote method call over its channel and takes T+1 seconds to process it. During this time, C will not process any other messages, including heartbeats, and therefore B will not receive the heartbeat ack and will suspect C.