JBoss DNA is a JCR implementation that provides access to content stored in many different kinds of systems. A JBoss DNA repository isn't yet another silo of isolated information, but rather it's a JCR view of the information you already have in your environment: files systems, databases, other repositories, services, applications, etc.
To your applications, JBoss DNA looks and behaves like a regular JCR repository. Using the standard JCR API, applications can search, navigate, version, and listen for changes in the content. But under the covers, JBoss DNA gets its content by federating multiple back-end systems (like databases, services, other repositories, etc.), allowing those systems to continue "owning" the information while ensuring the unified repository stays up-to-date and in sync.
Of course when you start providing a unified view of all this information, you start recognizing the need to store more information, including metadata about and relationships between the existing content. JBoss DNA lets you do this, too. And JBoss DNA even tries to help you discover more about the information you already have, especially the information wrapped up in the kinds of files often found in enterprise systems: service definitions, policy files, images, media, documents, presentations, application components, reusable libraries, configuration files, application installations, databases schemas, management scripts, and so on. As files are loaded into the repository, you can make JBoss DNA automatically sequence these files to extract from their content meaningful information that can be stored in the repository, where it can then be searched, accessed, and analyzed using the JCR API.
This document goes into detail about how JBoss DNA works to provide these capabilities. It also talks in detail about many of the parts within JBoss DNA - what they do, how they work, and how you can extend or customize the behavior. In particular, you'll learn about JBoss DNA connectors and sequencers, how you can use the implementations included in JBoss DNA, and how you can write your own to tailor JBoss DNA for your needs.
So whether your a developer on the project, or you're trying to learn the intricate details of how JBoss DNA works, this document hopefully serves a good reference for developers on the project.
JBoss DNA repositories can be used in a variety of applications. One of the more obvious use cases for a metadata repository is in provisioning and management, where it's critical to understand and keep track of the metadata for models, database, services, components, applications, clusters, machines, and other systems used in an enterprise. Governance takes that a step farther, by also tracking the policies and expectations against which performance of the systems described by the repository can be verified. In these cases, a repository is an excellent mechanism for managing this complex and highly-varied information.
But these large and complex use cases aren't the only way to use a JBoss DNA repository. You could use an embedded JBoss DNA repository to manage configuration information for an application, or you could use JBoss DNA just to provide a JCR interface on top of a few non-JCR systems.
The point is that JBoss DNA can be used in many different ways, ranging from the very tiny embedded repository to a large and distributed enterprise-grade repository. The choice is yours.
Before we dive into more detail about JBoss DNA and metadata repositories, it's probably useful to explain what we mean by the term "metadata." Simply put, metadata is the information you need to manage something. For example, it's the information needed to configure an operating system, or the description of the information in an LDAP tree, or the topology of your network. It's the configuration of an application server or enterprise service bus. It's the steps involved in validating an application before it can go into production. It's the description of your database schemas, or of your services, or of the messages going in and coming out of a service. JBoss DNA is designed to be a repository for all this (and more).
There are a couple of important things to understand about metadata. First, many systems manage (and frequently change) their own metadata and information. Databases, applications, file systems, source code management systems, services, content management systems, and even other repositories are just a few types of systems that do this. We can't pull the information out and duplicate it, because then we risk having multiple copies that are out-of-sync. Ideally, we could access all of this information through a homogenous API that also provides navigation, caching, versioning, search, and notification of changes. That would make our lives significantly easier.
What we want is federation. We can connect to these back-end systems to dynamically access the content and project it into a single, unified repository. We can cache it for faster access, as long as the cache can be invalidated based upon time or event. But we also need to maintain a clear picture of where all the bits come from, so users can be sure they're looking at the right information. And we need to make it as easy as possible to write new connectors, since there are a lot of systems out there that have information we want to federate.
The second important characteristic of the metadata is that a lot of it is represented as files, and there are a lot of different file formats. These include source code, configuration files, web pages, database schemas, XML schemas, service definitions, policies, documents, spreadsheets, presentations, images, audio files, workflow definitions, business rules, and on and on. And logically if files contain metadata, we want to add those files to our metadata repository. The problem is, all that metadata is tied up as blobs in the repository. Ideally, our repository would automatically extract from those files the content that's most useful to us, and place that content inside the repository where it can be much more easily used, searched, related, and analyzed. JBoss DNA does exactly this via a process we call sequencing, and it's an important part of a metadata repository.
The third important characteristic of metadata is that it rarely stays the same. Different consumers of the information need to see different views of it. Metadata about two similar systems is not always the same. The metadata often needs to be tagged or annotated with additional information. And the things being described often change over time, meaning the metadata has to change, too. As a result, the way in which we store and manage the metadata has to be flexible and able to adapt to our ever-changing needs, and the object model we use to interact with the repository must accommodate these needs. The graph-based nature of the JCR API provides this flexibility while also giving us the ability to constrain information when it needs to be constrained.
There are a lot of choices for how applications can store information persistently so that it can be accessed at a later time and by other processes. The challenge developers face is how to use an approach that most closely matches the needs of their application. This choice becomes more important as developers choose to focus their efforts on application-specific logic, delegating much of the responsibilities for persistence to libraries and frameworks.
Perhaps one of the easiest techniques is to simply store information in files . The Java language makes working with files relatively easy, but Java really doesn't provide many bells and whistles. So using files is an easy choice when the information is either not complicated (for example property files), or when users may need to read or change the information outside of the application (for example log files or configuration files). But using files to persist information becomes more difficult as the information becomes more complex, as the volume of it increases, or if it needs to be accessed by multiple processes. For these situations, other techniques often have more benefits.
Another technique built into the Java language is Java serialization, which is capable of persisting the state of an object graph so that it can be read back in at a later time. However, Java serialization can quickly become tricky if the classes are changed, and so it's beneficial usually when the information is persisted for a very short period of time. For example, serialization is sometimes used to send an object graph from one process to another. Using serialization for longer-term storage of information is more risky.
One of the more popular and widely-used persistence technologies is the relational database. Relational database management systems have been around for decades and are very capable. The Java Database Connectivity (JDBC) API provides a standard interface for connecting to and interacting with relational databases. However, it is a low-level API that requires a lot of code to use correctly, and it still doesn't abstract away the DBMS-specific SQL grammar. Also, working with relational data in an object-oriented language can feel somewhat unnatural, so many developers map this data to classes that fit much more cleanly into their application. The problem is that manually creating this mapping layer requires a lot of repetitive and non-trivial JDBC code.
Object-relational mapping libraries automate the creation of this mapping layer and result in far less code that is much more maintainable with performance that is often as good as (if not better than) handwritten JDBC code. The new Java Persistence API (JPA) provide a standard mechanism for defining the mappings (through annotations) and working with these entity objects. Several commercial and open-source libraries implement JPA, and some even offer additional capabilities and features that go beyond JPA. For example, Hibernate is one of the most feature-rich JPA implementations and offers object caching, statement caching, extra association mappings, and other features that help to improve performance and usefulness. Plus, Hibernate is open-source (with support offered by JBoss).
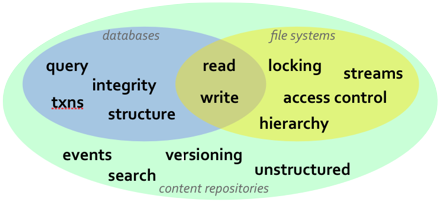
While relational databases and JPA are solutions that work well for many applications, they are more limited in cases when the information structure is highly flexible, the structure is not known a priori, or that structure is subject to frequent change and customization. In these situations, content repositories may offer a better choice for persistence. Content repositories are almost a hybrid with the storage capabilities of relational databases and the flexibility offered by other systems, such as using files. Content repositories also typically provide other capabilities as well, including versioning, indexing, search, access control, transactions, and observation. Because of this, content repositories are used by content management systems (CMS), document management systems (DMS), and other applications that manage electronic files (e.g., documents, images, multi-media, web content, etc.) and metadata associated with them (e.g., author, date, status, security information, etc.). The Content Repository for Java technology API provides a standard Java API for working with content repositories. Abbreviated "JCR", this API was developed as part of the Java Community Process under JSR-170 and is being revised under JSR-283.
The JCR API provides a number of information services that are needed by many applications, including: read and write access to information; the ability to structure information in a hierarchical and flexible manner that can adapt and evolve over time; ability to work with unstructured content; ability to (transparently) handle large strings; notifications of changes in the information; search and query; versioning of information; access control; integrity constraints; participation within distributed transactions; explicit locking of content; and of course persistence.
The roadmap for JBoss DNA is managed in the project's JIRA instance . The roadmap shows the different tasks, requirements, issues and other activities that have been targeted to each of the upcoming releases. (The roadmap report always shows the next three releases.)
By convention, the JBoss DNA project team periodically review JIRA issues that aren't targeted to a release, and then schedule them based upon current workload, severity, and the roadmap. And if we review an issue and don't know how to target it, we target it to the Future Releases bucket.
At the start of a release, the project team reviews the roadmap, identifies the goals for the release, and targets (or retargets) the issues appropriately.
JBoss DNA consists of the following modules:
dna-jcr contains JBoss DNA's implementation of the JCR API. If you're using JBoss DNA as a JCR repository, this is the top-level dependency that you'll want to use. The module defines all required dependencies, except for the repository connector(s) and any sequencer implementations needed by your configuration. As we'll see later on, using JBoss DNA as a JCR repository is easy: simply create a configuration, start JBoss DNA's JCR engine, get the JCR Repository object for your repository, and then use the JCR API. This module also uses the JCR unit tests from the reference implementation to verify the behavior of the JBoss DNA implementation.
dna-repository provides the core DNA graph engine and services for managing repository connections, sequencers, MIME type detectors, and observation. If you're using JBoss DNA repositories via our graph API rather than JCR, then this is where you'd start.
dna-cnd provides a self-contained utility for parsing CND (Compact Node Definition) files and transforming the node definitions into a graph notation compatible with JBoss DNA's JCR implementation.
dna-graph defines the Application Programming Interface (API) for JBoss DNA's low-level graph model, including a fluent-style API for working with graph content. This module also defines the APIs necessary to implement custom connectors, sequencers, and MIME type detectors.
dna-common is a small low-level library of common utilities and frameworks, including logging, progress monitoring, internationalization/localization, text translators, component management, and class loader factories.
There are several modules that provide system- and integration-level tests:
dna-integration-tests provides a home for all of the integration tests that involve more components that just unit tests. Integration tests are often more complicated, take longer, and involve testing the integration and functionality of multiple components (whereas unit tests focus on testing a single class or component and may use stubs or mock objects to isolate the code being tested from other related components).
The following modules are optional extensions that may be used selectively and as needed
(and are located in the source under the extensions/ directory):
dna-connector-infinispan is the preferred DNA repository connector for persistently storing content. Infinispan is an extremely scalable, highly available data grid platform that distributes the data across the nodes in the grid. This connector makes it possible for repository content to be stored in a very efficient, fast, highly-concurrent (essentially lock- and synchronization-free), and reliable manner, even when the content size grows to massive sizes. This connector is capable of storing any kind of content, and dictates how the content is stored on the data grid. Therefore, this connector cannot be used to access the content of existing data grids created by/for other applications.
dna-connector-jbosscache is a DNA repository connector that stores content within a JBoss Cache instance. JBoss Cache is a powerful cache implementation that can serve as a distributed cache and that can persist information. The cache instance can be found via JNDI or created and managed by the connector. This connector is capable of storing any kind of content, and dictates how the content is stored in the cache. Therefore, this connector cannot be used to access the content of existing cache instances created by/for other applications.
dna-connector-jdbc-metadata is a DNA repository connector that provides read-only access to metadata and schema information from relational databases through a JDBC connection. This connector provides an optional and configurable caching facility to prevent frequent requests to the database.
dna-connector-store-jpa is a DNA repository connector that stores content in a JDBC database, using the Java Persistence API (JPA) and the very highly-regarded and widely-used Hibernate implementation. This connector is capable of storing any kind of content, and dictates the schema in which it stores the content. Therefore, this connector cannot be used to access the data in existing created by/for other applications.
dna-connector-filesystem is a DNA repository connector that accesses the files and folders on (a part of) the local file system, providing that content in the form of
nt:fileandnt:foldernodes. This connector does support updating the file system when changes are made to thent:fileandnt:foldernodes. However, this connector does not support storing other kinds of nodes.dna-connector-svn is a DNA repository connector that accesses the content of an existing Subversion repository, providing that content in the form of
nt:fileandnt:foldernodes. This connector does support updating the SVN repository when changes are made to thent:fileandnt:foldernodes. However, this connector does not support storing other kinds of nodes.dna-sequencer-cnd is a DNA sequencer that extracts JCR node definitions from JCR Compact Node Definition (CND) files.
dna-sequencer-ddl is a DNA sequencer that extracts the structure and content from DDL files. This is still under development and includes support for the basic DDL statements in in the Oracle, PostgreSQL, Derby, and standard DDL dialects.
dna-sequencer-zip is a DNA sequencer that extracts the files (with content) and directories from ZIP archives.
dna-sequencer-xml is a DNA sequencer that extracts the structure and content from XML files.
dna-sequencer-classfile is a DNA sequencer that extracts the package, class/type, member, documentation, annotations, and other information from Java class files.
dna-sequencer-java is a DNA sequencer that extracts the package, class/type, member, documentation, annotations, and other information from Java source files.
dna-sequencer-jbpm-jpdl is a prototype DNA sequencer that extracts process definition metadata from jBPM process definition language (jPDL) files. This is still under development.
dna-sequencer-msoffice is a DNA sequencer that extracts metadata and summary information from Microsoft Office documents. For example, the sequencer extracts from a PowerPoint presentation the outline as well as thumbnails of each slide. Microsoft Word and Excel files are also supported.
dna-sequencer-images is a DNA sequencer that extracts the image metadata (e.g., size, date, etc.) from PNG, JPEG, GIF, BMP, PCS, IFF, RAS, PBM, PGM, and PPM image files.
dna-sequencer-mp3 is a DNA sequencer that extracts metadata (e.g., author, album name, etc.) from MP3 audio files.
dna-sequencer-text is a DNA sequencer that extracts data from text streams. There are separate sequencers for character-delimited sequencing and fixed width sequencing, but both treat the incoming text stream as a series of rows separated by line-terminators with each row consisting of one or more columns.
dna-search-lucene is an implementation of the SearchEngine interface that uses the Lucene library. This module is one of the few extensions that is used directly by the
dna-jcrmodule.dna-mimetype-detector-aperture is a MimeTypeDetector implementation that uses the Aperture library to determine the best MIME type given the name and contents of a file.
dna-classloader-maven is a small library that provides a ClassLoaderFactory implementation that can create ClassLoader instances capable of loading classes given a Maven Repository and a list of Maven coordinates. The Maven Repository can be managed within a JCR repository.
The following modules make up the various web application projects (and are located in the source
under the
web/
directory):
dna-web-jcr-rest provides a set of JSR-311 (JAX-RS) objects that form the basis of a RESTful server for Java Content Repositories. This project provides integration with DNA's JCR implementation (of course) but also contains a service provider interface (SPI) that can be used to integrate other JCR implementations with these RESTful services in the future. For ease of packaging, these classes are provided as a JAR that can be placed in the WEB-INF/lib of a deployed RESTful server WAR.
dna-web-jcr-rest-war wraps the RESTful services from the dna-web-jcr-rest JAR into a WAR and provides in-container integration tests. This project can be consulted as a template for how to deploy the RESTful services in a custom implementation.
dna-web-jcr-rest-client is a library that uses POJOs to access the REST web service. This module eliminates the need for applications to know how to create HTTP request URLs and payloads, and how to parse the JSON responses. It can be used to publish (upload) and unpublish (delete) files from DNA repositories.
There are also documentation modules (located in the source under the
docs/
directory):
docs-getting-started is the project with the DocBook source for the JBoss DNA Getting Started document.
docs-getting-started-examples is the project with the Java source for the example application used in the JBoss DNA Getting Started document.
docs-reference-guide is the project with the DocBook source for this document, the JBoss DNA Reference Guide document.
Another module provides some utility functionality:
dna-jpa-ddl-gen provides a standalone utility that can generate the DDL for the database schema used by the JPA connector. Because it uses Hibernate, it can generate DDL for any of the databases that the connector can use.
There is another module that runs the full suite of JCR TCK tests, and which at the moment still contains some failures.
dna-jcr-tck provides a separate testing project that executes all reference implementation's JCR TCK tests on a nightly basis to track implementation progress against the JCR 1.0 specification. This module will likely be retired when the JBoss DNA JCR implementation is complete, since
dna-jcranddna-integration-testswill be running the full suite of JCR TCK unit tests.
Finally, there is a Maven parent pom.xml file that aggregates all of the other projects, provides common
defaults for Maven plugins and dependency versions used throughout the modules, and definition of various asset files
to help build the necessary Maven artifacts during a build.
Each of these modules is a Maven project with a group ID of
org.jboss.dna
. All of these projects correspond to artifacts in the
JBoss Maven 2 Repository
.
With version 0.7, JBoss DNA introduces support for JCR query and search with a number of query languages, including the JCR XPath language (required by the 1.0 specification), the JCR-SQL2 dialect defined by the JCR 2.0 specification, and a full-text search language. This release also adds support for JCR locking and observation.
This means that JBoss DNA now implements all of the JCR Level 1 and Level 2 features, along with the optional locking and observation features. The only optional feature not implemented is versioning, and that will be coming soon. This version passes more than 95% of the JCR TCK tests, and all of the failures are because of a handful of known issues. Fortunately, most of these are either less-frequently-used features of JCR or issues that can be worked around.
This release also introduces a number of new and improved connectors. Both the file system connector and SVN connector were reworked to support reads and updates, and they both offer a preview of an optional caching system. The JPA storage connector was dramatically improved and is significantly faster, more capable, and more efficient. The new JDBC metadata connector provides read-only access to the schema information of relational databases through JDBC.
JBoss DNA 0.7 includes a number of new and improved sequencers. The new text sequencer is able to extract structured data from comma-separated or fixed-width text files. The new DDL sequencer is capable of parsing a number of DDL dialects to extract the more important DDL statements. The CND sequencer was rewritten and dramatically simplified to perform better, fix a number of known issues, and eliminate a dependency on a third-party library. There is also a new Java class file sequencer that operates on Java class files and produces output that is comparable to the Java source file sequencer, and that can be used in conjunction with the ZIP file sequencer to extract the Java metadata from JARs, WARs, and EAR files.
This release also brings numerous bug fixes and improvements, and upgrades all third-party dependencies to the latest versions available at the time of release. The build system now supports running all of the tests against a variety of databases, making it very easy to test against DBMSes that JBoss DNA doesn't directly test against. A new DDL generation utility was also introduced that produces the DDL for the database used by the JPA connector. And JCR repositories now support the use of anonymous users - this is enabled by default but can easily be changed for production purposes.