An important aspect of business processes is human task management. While some of the work performed in a process can be executed automatically, some tasks need to be executed by human actors.
jBPM supports a special human task node inside processes for modeling this interaction with human users. This human task node allows process designers to define the properties related to the task that the human actor needs to execute, like for example the type of task, the actor(s), or the data associated with the task.
jBPM also includes a so-called human task service, a back-end service that manages the life cycle of these tasks at runtime. The jBPM implementation is based on the WS-HumanTask specification. Note however that this implementation is fully pluggable, meaning that users can integrate their own human task solution if necessary.
In order to have human actors participate in your processes, you first need to (1) include human task nodes inside your process to model the interaction with human actors, (2) integrate a task management component (like for example the WS-HumanTask based implementation provided by jBPM) and (3) have end users interact with a human task client to request their task list and claim and complete the tasks assigned to them. Each of these three elements will be discussed in more detail in the next sections.
jBPM supports the use of human tasks inside processes using a special User Task node defined by the BPMN2 Specification(as shown in the figure above). A User Task node represents an atomic task that needs to be executed by a human actor.
[Although jBPM has a special user task node for including human tasks inside a process, human tasks are considered the same as any other kind of external service that needs to be invoked and are therefore simply implemented as a domain-specific service. See the chapter on domain-specific processes to learn more about this.]
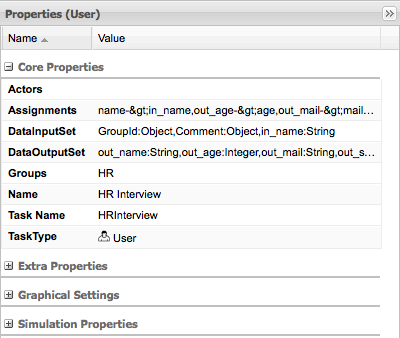
A User Task node contains the following core properties:
Actors: The actors that are responsible for executing the human task. A list of actor id's can be specified using a comma (',') as separator.
Group: The group id that is responsible for executing the human task. A list of group id's can be specified using a comma (',') as separator.
Name: The display name of the node.
TaskName: The name of the human task. This name is used to link the task to a Form. It also represent the internal name of the Task that can be used for other purposes.
DataInputSet: all the input variables that the task will receive to work on. Usually you will be interested in copying variables from the scope of the process to the scope of the task. (Look at the data mappings section for an example)
DataOutputSet: all the output variables that will be generated by the execution of the task. Here you specify all the name of the variables in the context of the task that you are interested to copy to the context of the process. (Look at the data mappings section for an example)
Assignments: here you specify which process variable will be linked to each Data Input and Data Output mapping. (Look at the data mappings section for an example)
You can edit these variables in the properties view (see below) when selecting the User Task node.
A User Task node also contains the following extra properties:
Comment: A comment associated with the human task. Here you can use expressions.
Content: The data associated with this task.
Priority: An integer indicating the priority of the human task.
Skippable: Specifies whether the human task can be skipped, i.e., whether the actor may decide not to execute the task.
On entry and on exit actions: Action scripts that are executed upon entry and exit of this node, respectively.

User tasks can be used in combination with swimlanes to assign multiple human tasks to the same actor. Whenever the first task in a swimlane is created, and that task has an actorId specified, that actorId will be assigned to (all other tasks of) that swimlane as well. Note that this would override the actorId of subsequent tasks in that swimlane (if specified), so only the actorId of the first human task in a swimlane will be taken into account, all others will then take the actorId as assigned in the first one.
Warning
ActorId assignment will work only when there is single actor specified. Since ActorId field can contain multiple actors (john,mary,peter) auto assignment for the first task will not be performed when multiple values are found.
Whenever a human task that is part of a swimlane is completed, the actorId of that swimlane is set to the actorId that executed that human task. This allows for example to assign a human task to a group of users, and to assign future tasks of that swimlame to the user that claimed the first task. This will also automatically change the assignment of tasks if at some point one of the tasks is reassigned to another user.
Human tasks typically present some data related to the task that needs to be performed to the actor that is executing the task and usually also request the actor to provide some result data related to the execution of the task. Task forms are typically used to present this data to the actor and request results.
The data that will be used by the Task needs to be specified when we define the User Task in our Process. In order to do that we need to define which data will be copied from the process context to the task context. Notice that the data is copied, so it can be modified inside the Task context but it will not affect the process variables unless we decide to copy back the value from the task to the process context.
Most of the times Forms are used to display data to the end user. Allowing them to generate/create new data that will be propagated to the process context to be used by future activities. In order to decide how the information flow from the process to a particular task and from the task to the process we need to define which pieces of information will be automatically copied by the process engine. The following sections shows how to do these mappings by configuring the DataInputSet, DataOutputSet and the Assignments properties of a User Task.
Let's start defining the Task DataInputSet:
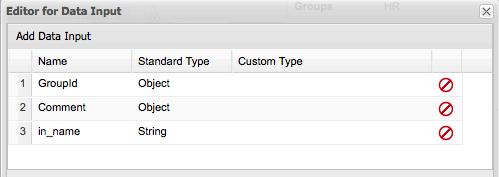
Both GroupId and Comment are automatically generated, so you don't need to worry about that. In this case the only user defined Data Input is called: in_name. This means that the task will be receiving information from the process context and internally this variable will be called in_name. The type is also specified here.
In the Data Outputs represent the data that will be generated by the tasks. In this case we have two variables of type String called: out_name and out_mail and two Integer variables called: out_age and out_score are defined. This means that inside the task context we will need to set the value to these variables.
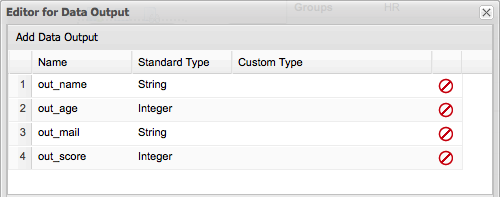
Finally all the connections with the process context needs to be done in the Data Assignments. The main idea here is to define how Data Inputs and Data Outputs will be associated with process variables.
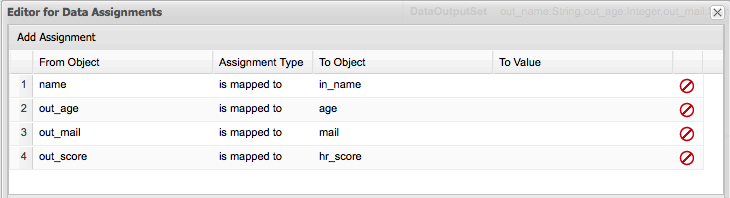
As shown in the previous screenshot, the assignments between the process variables (in this case (name, age, mail and hr_score)) and the Data Inputs and Outputs are done in the Data Assignments screen. Notice that the example uses a convention that makes it easy to know which is an internal Task variables (Data Input/Output) using the "in_" and "out_" prefix to the variable names. Using this convention you can quickly understand the Assignments screen. The first row maps the process variable called name to the data input called in_name. The second row maps the data output called out_mail to the process variable called mail, and so on.
These mappings at runtime will automatically copy the variables content from one context (process and task) to the other automatically for us.
From the perspective of a process, when a user task node is encountered during the execution, a human task is created. The process will then only leave the user task node when the associated human task has been completed or aborted.
The human task itself usually has a complete life cycle itself as well. For details beyond what is described below, please check out the WS-HumanTask specification. The following diagram is from the WS-HumanTask specification and describes the human task life cycle.
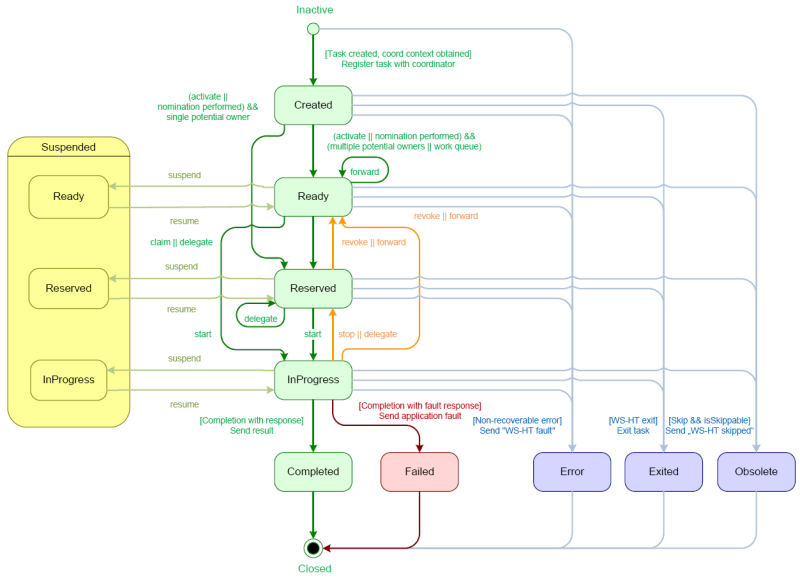
A newly created task starts in the "Created" stage. Usually, it will then automatically become "Ready", after which the task will show up on the task list of all the actors that are allowed to execute the task. The task will stay "Ready" until one of these actors claims the task, indicating that he or she will be executing it.
When a user then eventually claims the task, the status will change to "Reserved". Note that a task that only has one potential (specific) actor will automatically be assigned to that actor upon creation of the task. When the user who has claimed the task starts executing it, the task status will change from "Reserved" to "InProgress".
Lastly, once the user has performed and completed the task, the task status will change to "Completed". In this step, the user can optionally specify the result data related to the task. If the task could not be completed, the user could also indicate this by using a fault response, possibly including fault data, in which case the status would change to "Failed".
While the life cycle explained above is the normal life cycle, the specification also describes a number of other life cycle methods, including:
Delegating or forwarding a task, so that the task is assigned to another actor
Revoking a task, so that it is no longer claimed by one specific actor but is (re)available to all actors allowed to take it
Temporarly suspending and resuming a task
Stopping a task in progress
Skipping a task (if the task has been marked as skippable), in which case the task will not be executed
Only users associated with a specific task are allowed to modify or retrieve information about the task. This allows users to create a jBPM workflow with multiple tasks and yet still be assured of both the confidentiality and integrity of the task status and information associated with a task.
Some task operations will end up throwing a
org.jbpm.services.task.exception.PermissionDeniedException when used with
information about an unauthorized user. For example, when a user is trying to directly modify
the task (for example, by trying to claim or complete the task), the
PermissionDeniedException will be thrown if that user does not have the correct
role for that operation. Furthermore, a user will not be able to view or retrieve tasks that the
user is not involved with, especially if this is via the jBPM Console or KIE Workbench
applications.
User 'Administrator' and group 'Administrators' are automatically added to each Human Task.
The permisions matrix below summarizes the actions that specific user roles are allowed to do. On the left side, possible operations are listed while user roles are listed across the top of the matrix.
The cells of the permissions matrix contain one of three possible characters, each of which indicate the user role permissions for that operation:
a "
+indicates that the user role CAN do the specified operationa "
-" indicates that the user role MAY NOT do the specified operationa "
_" indicates that the user role MAY NOT do the specified operation, and that it is also not an operation that matches the user's role ("not applicable")
Furthermore, the following words or abbreviations in the table header refer to the following roles:
Table 7.1. Task roles in the permissions table
| Word | Role | Description |
|---|---|---|
|
Initiator |
Task Initiator |
The user who creates the task instance |
|
Stakeholder |
Task Stakeholder |
The user involved in the task: this user can influence the progress of a task, by performing administrative actions on the task instance |
|
Potential |
Potential Owner |
The user who can claim the task before it has been claimed, or after it has been released or forward: only tasks that have the status "Ready" may be claimed; a potential owner becomes the actual owner of a task by claiming the task |
|
Actual |
Actual Owner |
The user who has claimed the task and will progress the task to completion or failure |
|
Administrator |
Business Adminstrator |
A "super user" who may modify the status or progress of a task at any point in a task's lifecycle |
User roles are assigned to users by the definition of the task in the jBPM (BPMN2)
process definition.
Permissions Matrices. The following matrix describes the authorizations for all operations which modify a task:
Table 7.2. Main operations permissions matrix
| Operation\Role | Initiator | Stakeholder | Potential | Actual | Administrator |
|---|---|---|---|---|---|
activate | + | + | _ | _ | + |
claim | - | + | + | _ | + |
complete | - | + | _ | + | + |
delegate | + | + | + | + | + |
fail | - | + | _ | + | + |
forward | + | + | + | + | + |
nominate | + | + | + | + | + |
release | + | + | + | + | + |
remove | - | _ | _ | _ | + |
resume | + | + | + | + | + |
skip | + | + | + | + | + |
start | - | + | + | + | + |
stop | - | + | _ | + | + |
suspend | + | + | + | + | + |
The matrix below describes the authorizations used when retrieving task
information. In short, it says that all users which have any role with regards to the
specific task, are allowed to see the task. This applies to all operations that are used to
retrieve any type of information about the task.
Table 7.3. Retrieval operations permissions matrix
| Operation\Role | Initiator | Stakeholder | Potential | Actual | Administrator |
|---|---|---|---|---|---|
|
get | + | + | + | + | + |
As far as the jBPM engine is concerned, human tasks are similar to any other external service that needs to be invoked and are implemented as a domain-specific service. (For more on domain-specific services, see the chapter on them here.) Because a human task is an example of such a domain-specific service, the process itself only contains a high-level, abstract description of the human task to be executed and a work item handler that is responsible for binding this (abstract) task to a specific implementation.
Users can plug in any human task service implementation, such as the one that's provided by jBPM, or they may register their own implementation. In the next paragraphs, we will describe the human task service implementation provided by jBPM.
The jBPM project provides a default implementation of a human task service based on the WS-HumanTask specification. If you do not need to integrate jBPM with another existing implementation of a human task service, you can use this service. The jBPM implementation manages the life cycle of the tasks (creation, claiming, completion, etc.) and stores the state of all the tasks, task lists, and other associated information. It also supports features like internationalization, calendar integration, different types of assignments, delegation, escalation and deadlines. The code for the implementation itself can be found in the jbpm-human-task module.
The jBPM task service implementation is based on the WS-HumanTask (WS-HT) specification. This specification defines (in detail) the model of the tasks, the life cycle, and many other features. It is very comprehensive and the first version can be found here.
The human task service exposes a Java API for managing the life cycle of tasks. This allows clients to integrate (at a low level) with the human task service. Note that end users should probably not interact with this low-level API directly, but use one of the more user-friendly task clients (see below) instead. These clients offer a graphical user interface to request task lists, claim and complete tasks, and manage tasks in general. The task clients listed below use the Java API to internally interact with the human task service. Of course, the low-level API is also available so that developers can use it in their code to interact with the human task service directly.
A task service (interface org.kie.api.task.TaskService) offers the following methods (among others) for managing the life cycle of human tasks:
...
void start( long taskId, String userId );
void stop( long taskId, String userId );
void release( long taskId, String userId );
void suspend( long taskId, String userId );
void resume( long taskId, String userId );
void skip( long taskId, String userId );
void delegate(long taskId, String userId, String targetUserId);
void complete( long taskId, String userId, Map<String, Object> results );
...
If you take a look at the method signatures you will notice that almost all of these methods take the following arguments:
taskId: The id of the task that we are working with. This is usually extracted from the currently selected task in the user task list in the user interface.
userId: The id of the user that is executing the action. This is usually the id of the user that is logged in into the application.
There is also an internal interface that you should check for more methods to interact with the Task Service, this interface is internal until it gets tested. Future version of the External (public) interface can include some of the methods proposed in the InternalTaskService interface. If you want to make use of the methods provided by this interface you need to manually cast to InternalTaskService. One method that can be useful from this interface is getTaskContent():
Map<String, Object> getTaskContent( long taskId );
This method saves you from doing all the boiler plate of getting the ContentMarshallerContext to unmarshall the serialized version of the task content. If you only want to use the stable/public API's you can just copy what this method does:
Task taskById = taskQueryService.getTaskInstanceById(taskId);
Content contentById = taskContentService.getContentById(taskById.getTaskData().getDocumentContentId());
ContentMarshallerContext context = getMarshallerContext(taskById);
Object unmarshalledObject = ContentMarshallerHelper.unmarshall(contentById.getContent(), context.getEnvironment(), context.getClassloader());
if (!(unmarshalledObject instanceof Map)) {
throw new IllegalStateException(" The Task Content Needs to be a Map in order to use this method and it was: "+unmarshalledObject.getClass());
}
Map<String, Object> content = (Map<String, Object>) unmarshalledObject;
return content;
Because the content of the Task can be any Object, the previous method assume that you are storing a Map of objects to work. If you are storing other than a Map you should do the correspondent checks.
Task service supports task listeners to be invoked upon various life cycle events happening on given task instance. In majority of cases task event listeners are used to intercept certain operation to perform additional logic - like storing task information in separate tables for business activity monitoring needs.
Task event listeners are pluggable and users can provide their own implementation of org.kie.api.task.TaskLifeCycleEventListener interface. There are beforeTask* and afterTask* methods that are invoked upon given event occured on a task instance.
TaskEvent (org.kie.api.task.TaskEvent) is the only argument available to the listener that provides access to:
Task instance that the event correspond to
TaskContext that provides access to services for further processing needs such as TaskPersistenceContext
In many cases implementors of task event listener need to have access to task variables (either input or output or both) to perform required operations. It can be done as described above (using various services and content marshaller helper) though that in many cases leads to code duplication in multiple listeners thus an extended support was added in 6.5 to simply use TaskContext to obtain that information.
loadTaskVariables(Task task);Method loadTaskVariables can be used to populate both input and output variables of a given task by simple and single method call. That method is "no op" in case task variables are already set on a task.
To improve performance task variables are automatically set when they are available - usually given by caller on task service:
when task is created it usually has input variables, these variables are then set on Task instance so there is no need to use loadTaskVariables method as only task input variables are available when task is being created - applies to beforeTaskAdded and afterTaskAdded events handling
when task is completed it usually has output variables, these variables are set on a task so there is no need to use loadTaskVariables method if only task output variables are required.
Other than that loadTaskVariables should be used to populate task variables.
Note
It’s enough to call it once (like in beforeTask) method of the listener as they will be available to both beforeTask* and afterTask* methods then.

In order to get access to the Task Service API it is recommended to let the Runtime Manager to make sure that everything is setup correctly. Look at the Runtime Manager section for more information. From the API perspective you should be doing something like this:
...
RuntimeEngine engine = runtimeManager.getRuntimeEngine(EmptyContext.get());
KieSession kieSession = engine.getKieSession();
// Start a process
kieSession.startProcess("CustomersRelationship.customers", params);
// Do Task Operations
TaskService taskService = engine.getTaskService();
List<TaskSummary> tasksAssignedAsPotentialOwner = taskService.getTasksAssignedAsPotentialOwner("mary", "en-UK");
// Claim Task
taskService.claim(taskSummary.getId(), "mary");
// Start Task
taskService.start(taskSummary.getId(), "mary");
...
If you use this approach, there is no need to register the Task Service with the Process Engine. The Runtime Manager will do that for you automatically. If you don't use the Runtime Manager, you will be responsible for setting the LocalHTWorkItemHandler in the session in order to get the Task Service notifying the Process Engine when a task is completed, or the Process Engine notifying that a task has been created.
In jBPM 6.x the Task Service runs locally to the Process and Rule Engine and for that reason multiple light clients can be created for different Process and Rule Engine's instances. All the clients will be sharing the same database (backend storage for the tasks).