In version 5.x processes were stored in so called packages produced by Guvnor and next downloaded by jbpm console for execution using KnowledgeAgent. Alternatively one could drop their process files (bpmn2 files) into a predefined directory that was scanned on the jbpm console start. That was it. That enforces users to always use Guvnor when dynamic deployment was needed. Although there is nothing wrong with it, actually that was recommended approach but not everytime it was desired.
Version 6, on the other hand moves away from proprietary packages in favor of, well known and mature, Apache Maven based packaging - known as knowledge archives - kjar. Processes, rules etc (aka business assets) are now part of a simple jar file built and managed by Maven. Along the business assets, java classes and other file types are stored in the jar file too. Moreover, as any other maven artifact, kjar can have defined dependencies on other artifacts including other kjars. What makes the kjar special when compared with regular jars is a single descriptor file kept inside META-INF directory of the kjar - kmodule.xml. That descriptor allows to define:
knowledge bases and their properties
knowledge sessions and their properties
work item handlers
event listeners
By default, this descriptor is empty (just kmodule root element) and is considered as marker file. Whenever a runtime component (such as jbpm console) is about to process kjar it looks up kmodule.xml to build its runtime representation. In addition to kmodule.xml a deployment descriptor (that provides fine graind control over deployment) is available (since 6.1).
While kmodule is mainly targeting on knowledge base and knowledge session basic configuration, deployment descriptors are considered more technical configuration. Following are the items available for configuration via deployment descriptors:
persistence unit name for runtime data
persistence unit for audit data
persistence mode (JPA or NONE)
audit mode (JPA, JMS, NONE)
runtime strategy (SINGLETON, PER_REQUEST, PER_PROCESS_INSTANCE)
list of event listeners to be registered
list of task event listeners to be registered
list of work item handlers to be registered
list of globals to be registered
marshalling strategies to be registered (for pluggable variable persistence)
required roles to be granted access to resources of the kjar
additional configuration options of knowledge session
additional environment entries for knowledge session
list of fully qualified class names that shall be added to the classes used for serialization by remote services
whether or not to limit the classes from the deployment used for serialization by the remote services
Deployment descriptor is an xml file that is placed inside META-INF folder of the kjar, although it is an optional file and deployments will succeed even when such descriptor is missing.
<deployment-descriptor xsi:schemaLocation="http://www.jboss.org/jbpm deployment-descriptor.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<persistence-unit>org.jbpm.domain</persistence-unit>
<audit-persistence-unit>org.jbpm.domain</audit-persistence-unit>
<audit-mode>JPA</audit-mode>
<persistence-mode>JPA</persistence-mode>
<runtime-strategy>PER_PROCESS_INSTANCE</runtime-strategy>
<marshalling-strategies/>
<event-listeners/>
<task-event-listeners/>
<globals/>
<work-item-handlers/>
<environment-entries/>
<configurations/>
<required-roles/>
<remoteable-classes/>
<limit-serialization-classes/>
</deployment-descriptor>
It provides more configuration options then the standard deployment has. Deployment descriptors are used in hierarchical way meaning they can be placed on various levels of the system and merged on runtime. jBPM supports following levels of deployment descriptors:
server level - this is the main and considered default deployment descriptos that apply to all deployments on given server
kjar level - this is dedicated deployment descriptor to given kjar
deploy time level - this is deployment descriptor that is given at the time of deployment
Deployment descriptors on different levels are merged on deployment time where the master is considered descriptor lower in the hierarchy and slave one that is higher in hierarchy. To give an example, when a kjar is deployed and it contains deployment descriptor kjar's deployment descriptor is considered slave and server level descriptor is considered master. With default merge mode it will override all master entries with slave ones as long as they are not empty and combine all collections.
Since kjar can have dependencies to other kjars, and in turn that dependencies might have deployment descriptors as well, they will be placed in deployment descriptors hierarchy lower than the actual kjar that is being deployed. With that said, this is how it will look like from hierarchy point of view, starting with master (server level):
server level
dependency kjar level
kjar level
That in default merging mode will result in deployment descriptor where with non empty values from kjar's deployment descriptors and merged collection from all levels.
So far all merging was done with default mode, which is MERGE_COLLECTIONS but that's not the only mode that is available:
KEEP_ALL - meaning that the master wins - all configuration defined in master will be retained
OVERRIDE_ALL - meaning that slave wins - all configuration defined in master will be retained
OVERRIDE_EMPTY - meaning all non empty configuration items from slave will replace those in master, including collections
MERGE_COLLECTIONS - meaning all non empty configuration items from slave will replace those in master but collections will me merged (combined)
Tip
Deployment descriptos can be given as partial xml documents, meaning they do not need to be complete set of all configuration items, e.g. if user would like to override only the audit mode in kjar, it's enough to have following deployment descriptor:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<deployment-descriptor xsi:schemaLocation="http://www.jboss.org/jbpm deployment-descriptor.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<audit-mode>JPA</audit-mode>
</deployment-descriptor>Although it's worth noting that when using OVERRIDE_ALL merge mode all configuration items should be specified since it will always use them and do not merge with any other deployment descriptor in the hierarchy.
Default deployment descriptor
There is always default deployment descriptor available, even if it was not explicitly configured, when running in jbpm-console (kie-workbench) the default values are as follows:
persistence-unit is set to org.jbpm.domain
audit-persistence-unit is set to org.jbpm.domain
persistence-mode is set to JPA
audit-mode is set to JPA
runtime-strategy is set to SINGLETON
all collection based configuration items are left empty
Note
Regardless of collection elements in default deployment descriptor are empty there will be some work item handlers/listeners registered that are required to support functionality of the jbpm console such as BAM listeners or human task work item handler.
Default deployment descriptor can be altered by specifying valid URL location to an xml file that will provide fully defined deployment descriptor. By fully defined we mean that all elements should be specified as this deployment descriptor will become server level deployment descriptor.
-Dorg.kie.deployment.desc.location=file:/my/custom/location/deployment-descriptor.xml
Collection configuration items
Deployment descriptor consists of collection based items (event listeners, work item handlers, globals, etc) that usually require definition of an object that should be created on runtime. There are two types of collection based configuration items:
object model - that is clear definition of the object to be built or looked up in available registry
named object model - that is an extension to object model and allows to provide name of the object which will be used to register object
Object model consits of:
identifier - defines main information about the object, such as fully qualified class name, spring bean id, mvel expression
parameters - optional parameters that should be used while creating object instance from the model
resolver - identifier of the resolver that will be used to create object instances from the model - (reflection, mvel, spring)
Table 14.1. Object models
| Configuration item | Type of collection items |
|---|---|
| event-listeners | ObjectModel |
| task-event-listeners | ObjectModel |
| marshalling-strategies | ObjectModel |
| work-item-handlers | NamedObjectModel |
| globals | NamedObjectModel |
| environment-entries | NamedObjectModel |
| configurations | NamedObjectModel |
| required-roles | String |
Depending on resolver type, creation or look up of the object will be performed. The default (and easiest) is reflection that will use both parameters and identifier (in this case is FQCN) to construct the object. Parameters in this case can be String or another object model for representing other types than String. Following is an example of an object model that will create an instance of org.jbpm.test.CustomStrategy using reflection resolver that will use constructor of that class with two String parameters. Note that String paramaters are created with different ways (using object model - first param, directly by giving String - second param).
Example 14.1.
...
<marshalling-strategy>
<resolver>reflection</resolver>
<identifier>org.jbpm.test.CustomStrategy</identifier>
<parameters>
<parameter xsi:type="objectModel">
<resolver>reflection</resolver>
<identifier>java.lang.String</identifier>
<parameters>
<parameter xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">param1</parameter>
</parameters>
</parameter>
<parameter xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">param2</parameter>
</parameters>
</marshalling-strategy>
...
Same can be done by using DeploymentDescriptor fluent API:
// create instance of DeploymentDescriptor with default persistence unit name
DeploymentDescriptor descriptor = new DeploymentDescriptorImpl("org.jbpm.domain");
// get builder and modify the descriptor
descriptor.getBuilder()
.addMarshalingStrategy(new ObjectModel("org.jbpm.testCustomStrategy",
new Object[]{
new ObjectModel("java.lang.String", new Object[]{"param1"}),
"param2"}));
Reflection based object model resolver is the most verbose in case there are parameters involved but there are few parameters that are available out of the box and do not need to be created, they are simply referenced by name:
entityManagerFactory (type of this parameter is javax.persistence.EntityManagerFactory)
runtimeManager (type of this parameter is org.kie.api.runtime.manager.RuntimeManager)
kieSession (type of this parameter is org.kie.api.KieServices)
taskService (type of this parameter is org.kie.api.task.TaskService)
executorService (type of this parameter is org.kie.internal.executor.api.ExecutorService)
So to be able to use one of these it's enough to reference them by name and make sure that proper object type is used within your class:
...
<marshalling-strategy>
<resolver>reflection</resolver>
<identifier>org.jbpm.test.CustomStrategy</identifier>
<parameters>
<parameter xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">runtimeManager</parameter>
</parameters>
</marshalling-strategy>
...
In case reflection based resolver is not enough, more advanced resolver can be used that utilizes power of MVEL language. It's much easier in the configuration as it expects mvel expression as identifier of the object model. It will provide the out of the box parameters (listed above: runtime manager, kie session, etc) into the mvel context while evaluating expression. To define object model with mvel resolver use following xml (that will be equivalent to replection based above):
...
<marshalling-strategy>
<resolver>mvel</resolver>
<identifier>new org.jbpm.test.CustomStrategy(runtimeManager)</identifier>
</marshalling-strategy>
...Last but not least, there is Spring based resolver available as well that allows to simply look up a bean by its identifier from spring application context. This resolver is not used in jbpm console (kie-workbench) as it does not use spring but whenever jBPM is used together with Spring it might become handy when deploying kjars into the runtime. It's very simple definition in xml, again equivalent to the other one assuming org.jbpm.test.CustomStrategy is registered in spring application context under customStrategy id.
...
<marshalling-strategy>
<resolver>spring</resolver>
<identifier>customStrategy</identifier>
</marshalling-strategy>
...Manage deployment descriptor
Deployment descriptor is created as soon as project is created. It does contins the most basic deployment descriptor that is based on the default one. Meaning all settings present in default deployment descriptor will be copied into the one placed in the project. Further changes can be done directly in the xml content (in next versions more user friendly editor will most likely be provided). It is accessible from Administration perspecitve as this is considered technical administration task rather than business related activity.
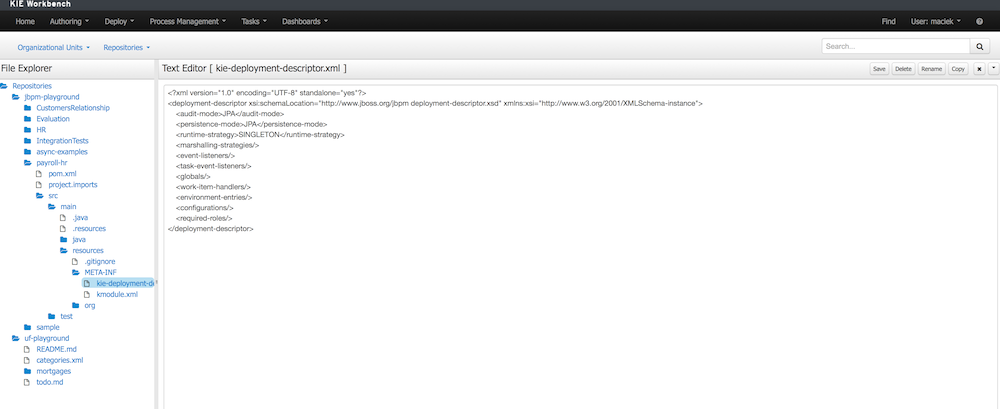
Restrict access to runtime engine
jbpm console (kie-workbench) provides access restriction to repositories that can be configured with supplementary tool called kie-config-cli. This protects repositories in the authoring perspsective based on roles membership. Deployment descriptors moves this capability to the runtime engine by ensuring that access to processes will be granted only to users that belong to groups defined in the deployment descriptor as required roles. By default when project is created (at the same time deployment descriptor is created as well) required roles are automatically filled in based on repository restrictions. These roles can be still altered by editing deployment descriptor via Administration perspective as presented in Manage deployment descriptor section.
Security is enforced on two levels:
user interface - user will see only process definitions that are available for his/her roles
runtime manager - each access to get RuntimeEngine out of RuntimeManager is pretected based on the role membership, in case unauthorized access it attempted SecurityException will be thrown
Required roles are defined as simple strings that should match actual roles defined in security realm. Following is a xml snippet that shows definition of required roles in deployment descriptor:
<deployment-descriptor>
...
<required-roles>
<required-role>experts</required-role>
</required-roles>
...
</deployment-descriptor>
In case fine grained control is required defined roles can be prefixed with one of the following to control it on further level:
view:
to restrict access to be able to see given process definitions/instances on UI
executre:
to restrict access to be able to execute given process definitions
all:
applies to both view and execute restrictions and this is the default when no prefix is given.
For example to restrict access to show process from given kjar only to group 'management' but still allow them to be executed by anyone (sort of system processes) one could define it as follows:
<deployment-descriptor>
...
<required-roles>
<required-role>view:management</required-role>
</required-roles>
...
</deployment-descriptor>
Classes used for serialization in the remote services
When processes make use of custom types (or in general non promitive types) and there is a use case to include remote api invocations (REST, SOAP, JMS) such types must be available to the remote services marshalling mechanism that is based on JAXB for XML type. By default all types defined in kjar will be automatically included in JAXB context and therefore will be avialble for remote interaction. Though there might be more classes (like from dependent model) that shall be included there too.
Upon deployment, jBPM will scan classpath of given kjar to automatically register classes that might be needed for remote interaction. This is done based on following rules:
all classes included in kjar project itself
all classes included as dependency of projects type kjar
classes that are annotated with @XmlRootElement (JAXB annotation) and included as regular dependency of the kjar
classes that are annotated with @Remotable (kie annotation) and included as regular dependency of the kjar
If that is not enough deployment descriptor allows to manually specify classes that shall be added to the JAXB context via remoteable-classes element:
<remoteable-classes>
...
<remotable-class>org.jbpm.test.CustomClass</remotable-class>
<remotable-class>org.jbpm.test.AnotherCustomClass</remotable-class>
...
</remoteable-classes>With this all classes can be added to the JAXB context to properly marshal and unmarshal data types when interacting with jBPM remotely.
Limiting classes usd for serialization in the remote services
When there are classes in the kjar project or in the dependencies of the kjar project that woudl cause problems when used for serialization, the limit-serialization-classes property can be used to limit which classes are used for serialization
<limit-serialization-classes>true</limit-serialization-classes>This property limits classes used for serialization to classes which fulfill both of the following "location" and "annotation" criteria:
Classes that:
are located in the kjar project
are in a direct dependency of the kjar project
are listed in the
remoteable-classeselement and are available on the classpath of the kjar
These classes must also be annotated with one of the following type annotations:
javax.xml.bind.annotation.XmlRootElementjavax.xml.bind.annotation.XmlTypeorg.kie.api.remote.Remotable
Additionally, classes will be excluded if they are any of the following: interfaces, local classes, member classes or anonymous classes.
You can access to the Process Deployments List under the Deploy top level menu of the KIE Workbench
The Deployed Unit list shows all the Process Deployed Units into the platform that are already enabled to be used. Each deployment unit can contain multiple business processes and business rules. In order to have your process and rules deployed and listed in this list, you need ot Build and Deploy your KIE projects from the Authoring Perspective or via the Remote Endpoints. If your processes and rules are in a KIE Project listed in this list and you have correspondent the rights you should be able to see the process definitions in the Process Definitions Perspective.
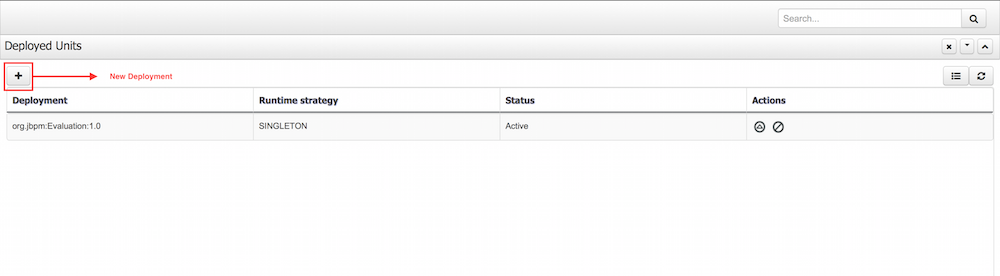
From the Authoring Perspective (Build and Deploy), a default deployment will be performed, for a more advanced deployments you can trigger a custom deployment with other options from this screen.
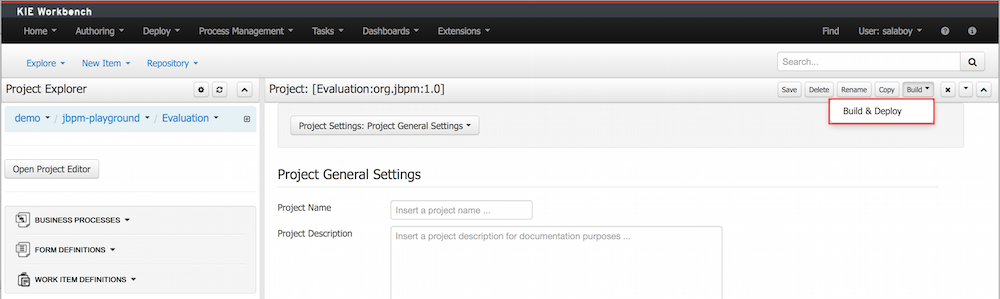
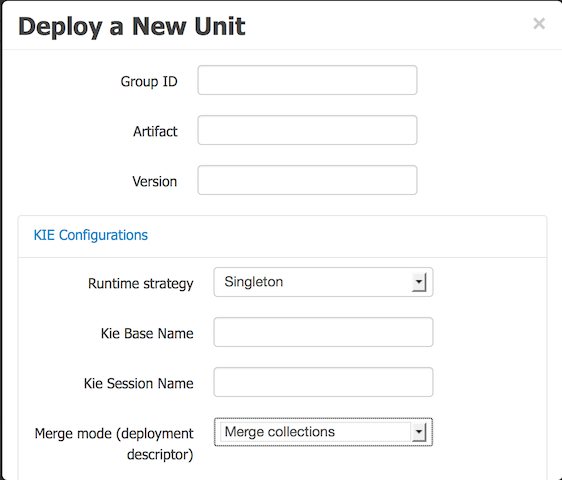
By clicking the New Deployment Unit (+) button you will be able to select a different KIE Base, KIE Session, Strategy and Merge Mode for your deployment. By default the "DEFAULT" KIE Base and KIE Sessions are used, the SINGLETON Strategy is selected and the Merge Mode is set to "Merge Collection".
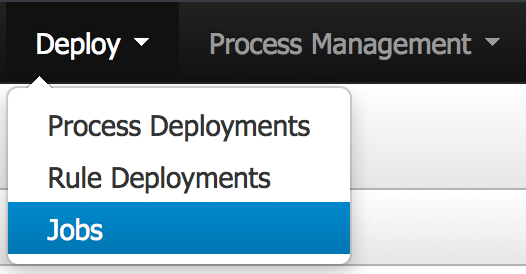
The Jobs perspective allows you to monitor and trigger Asynchronous Jobs schedulled to the jBPM Executor Service. You can access to the Jobs List from the Deploy top level menu of the KIE Workbench.
The Jobs List shows all the Jobs that were schedulled and their status. The Filter on top of the table helps the administrator to monitor the Jobs execution and take corrective actions in case of Failure. Check the jBPM Executor section of the documentation for more information.
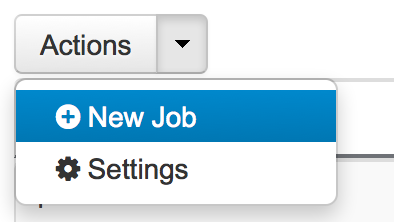
Administrators have also the option to configure the jBPM Executor Service Settings and to start and stop the service from the User Interface via the Actions -> Settings option.
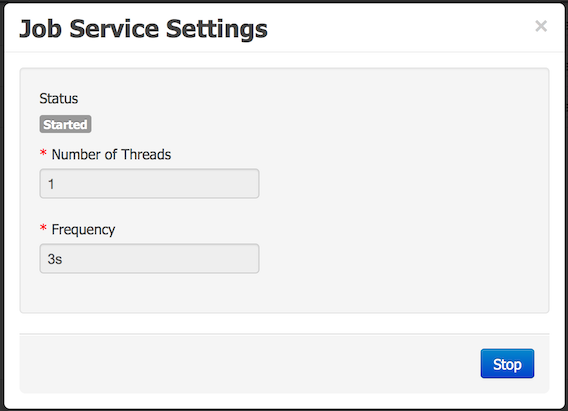
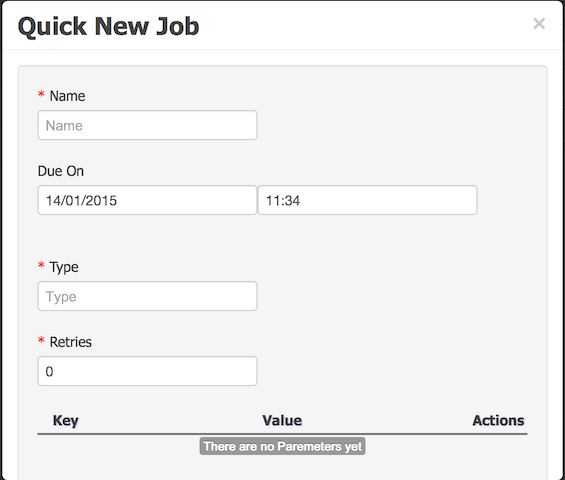
Administrators can also schedulle manually new Jobs from the User Interface via the Actions -> Settings option. By specifing the command class name and the parameters needed to run the command a new Job can be created. This manually created jobs will not be associated with any process instance. Notice also that the Due Date paramenter allows the execution to be derrefered for the future. If the Due Date is the time of schedulling the jBPM Executor Service will execute the command as soon as there is an Executor Thread available. The number of retries will help the command to be executed more than once if it fails. This can help in situations when the business logic requires an external service to be called where the runtime cannot rely on that service to be available 100% of the time.