jBPM is based on Graph Oriented Programming (GOP). Basically, GOP specifies a simple state machine that can handle concurrent paths of execution. But in the execution algorithm specified in GOP, all state transitions are done in a single operation in the thread of the client. If you're not familiar with the execution algorithm defined in Chapter 4, Graph Oriented Programming, please read that first. By default, this performing state transitions in the thread of the client is a good approach cause it fits naturally with server side transactions. The process execution moves from one wait state to another wait state in one transaction.
But in some situations, a developer might want to fine-tune the transaction demarcation in the process definition. In jPDL, it is possible to specify that the process execution should continue asynchronously with the attribute async="true". async="true" can be specified on all node types and all action types.
Normally, a node is always executed after a token has entered the node. So the node is executed in the thread of the client. We'll explore asynchronous continuations by looking two examples. The first example is a part of a process with 3 nodes. Node 'a' is a wait state, node 'b' is an automated step and node 'c' is again a wait state. This process does not contain any asynchronous behaviour and it is represented in the picture below.
The first frame, shows the starting situation. The token points to node 'a', meaning that the path of execution is waiting for an external trigger. That trigger must be given by sending a signal to the token. When the signal arrives, the token will be passed from node 'a' over the transition to node 'b'. After the token arrived in node 'b', node 'b' is executed. Recall that node 'b' is an automated step that does not behave as a wait state (e.g. sending an email). So the second frame is a snapshot taken when node 'b' is being executed. Since node 'b' is an automated step in the process, the execute of node 'b' will include the propagation of the token over the transition to node 'c'. Node 'c' is a wait state so the third frame shows the final situation after the signal method returns.
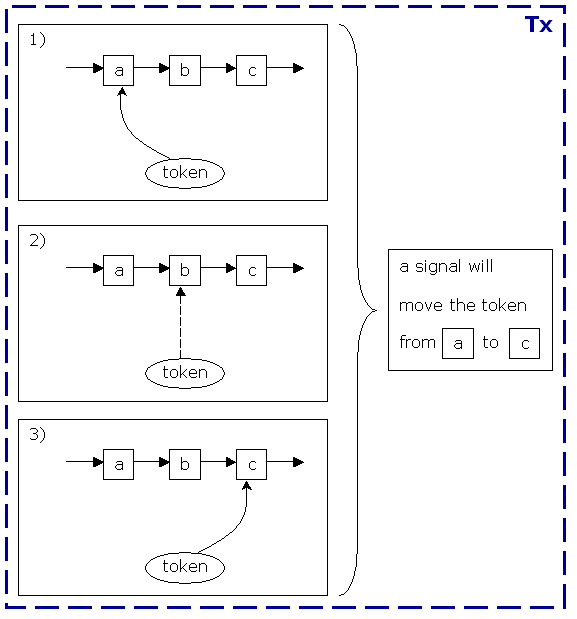
While persistence is not mandatory in jBPM, the most common scenario is that a signal is called within a transaction. Let's have a look at the updates of that transaction. First of all, the token is updated to point to node 'c'. These updates are generated by hibernate as a result of the GraphSession.saveProcessInstance on a JDBC connection. Second, in case the automated action would access and update some transactional resources, those transactional updates should be combined or part of the same transaction.
Now, we are going to look at the second example, the second example is a variant of the first example and introduces an asynchronous continuation in node 'b'. Nodes 'a' and 'c' behave the same as in the first example, namely they behave as wait states. In jPDL, a node is marked as asynchronous by setting the attribute async="true".
The result of adding async="true" to node 'b' is that the process execution will be split up into 2 parts. The first part will execute the process up to the point where node 'b' is to be executed. The second part will execute node 'b' and that execution will stop in wait state 'c'.
The transaction will hence be split up into 2 separate transactions. One transaction for each part. While it requires an external trigger (the invocation of the Token.signal method) to leave node 'a' in the first transaction, jBPM will automatically trigger and perform the second transaction.
For actions, the principle is similar. Actions that are marked with the attribute async="true" are executed outside of the thread that executes the process. If persistence is configured (it is by default), the actions will be executed in a separate transaction.
In jBPM, asynchronous continuations are realized by using an asynchronous messaging system. When the process execution arrives at a point that should be executed asynchronously, jBPM will suspend the execution, produces a command message and send it to the command executor. The command executor is a separate component that, upon receipt of a message, will resume the execution of the process where it got suspended.
jBPM can be configured to use a JMS provider or its built-in asynchronous messaging system. The built-in messaging system is quite limited in functionality, but allowes this feature to be supported on environments where JMS is unavailable.
The command executor is the component that resumes process executions asynchronously. It waits for command messages to arrive over an asynchronous messaging system and executes them. The two commands used for asynchronous continuations are ExecuteNodeCommand and ExecuteActionCommand.
These commands are produced by the process execution. During process execution, for each node that has to be executed asynchronously, an ExecuteNodeCommand (POJO) will be created in the MessageInstance. The message instance is a non-persistent extension of the ProcessInstance and it just collects all the messages that have to be sent.
The messages will be sent as part of the GraphSession.saveProcessInstance. The implementation of that method includes a context builder that acts as an aspect on the saveProcessInstance method. The actual interceptors can be configured in the jbpm.cfg.xml. One of the interceptors, SendMessagesInterceptor, is configured by default and will read the messages from the MessageInstance and send them over the configurable asynchronous messaging system.
The SendMessagesInterceptor uses the interfaces MessageServiceFactory and MessageService to send messages. This is to make the asynchronous messaging implementation configurable (also in jbpm.cfg.xml).
When using jBPM's built-in asynchronous messaging, messages will be send by persisting them to the database. This message persisting can be done in the same transaction/jdbc connection as the jBPM process updates.
The command messages will be stored in the JBPM_MESSAGE table.
The POJO command executor (org.jbpm.msg.command.CommandExecutor) will read the messages from the database table and execute them. So the typical transaction of the POJO command executor looks like this: 1) read next command message 2) execute command message 3) delete command message.
If execution of a command message fails, the transaction will be rolled back. After that, a new transaction will be started that adds the error message to the message in the database. The command executor filters out all messages that contain an exception.
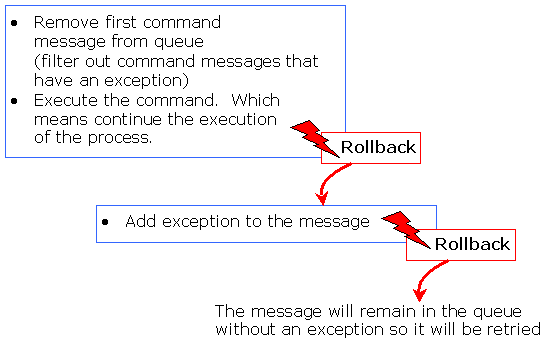
If for some reason or another, the transaction that adds the exception to the command message would fail, it is rolled back as well. In that case, the message remains in the queue without an exception so it will be retried later.
Limitation: beware that jBPM's built-in asynchronous messaging system does not support multinode locking. So you cannot just deploy the POJO command executor multiple times and have them configured to use the same database.
The asynchronous continuations feature, opens up a new world of jBPM usage scenarios. Where typically, jBPM is used for modelling business processes, it can now be used from a more technical perspective.
Imagine that you have an application with quite some asynchronous processing. That typically requires quite a bit if difficult set up to bind all the message producing and message consuming pieces of software together. With jBPM it now becomes possible to create a picture of the overall asynchronous architecture, have all your code in POJO's and add transaction demarcation in the overall process file. jBPM will now take care of binding the senders to the receivers without the need for writing all the JMS or MDB code yourself.
TODO's: add support for multiple queues. So that it becomes possible to specify a queue for each node or action that is marked as asynchronous. Also it would be great to produce message for a set of queues in a round-robin. Since all of this should be configurable for both the JMS and the built-in messaging systems, this will require some thought on how to do all this configurations. The process definitions should not have to depend on any of the 2 possible implementations.