jBPM allows the persistent storage of certain information, i.e., the process runtime state, the history information, etc.
Whenever a process is started, a process instance is created, which represents the execution of the process in that specific context. For example, when executing a process that specifies how to process a sales order, one process instance is created for each sales request. The process instance represents the current execution state in that specific context, and contains all the information related to that process instance. Note that it only contains the minimal runtime state that is needed to continue the execution of that process instance at some later time, but it does not include information about the history of that process instance if that information is no longer needed in the process instance.
The runtime state of an executing process can be made persistent, for example, in a database. This allows to restore the state of execution of all running processes in case of unexpected failure, or to temporarily remove running instances from memory and restore them at some later time. jBPM allows you to plug in different persistence strategies. By default, if you do not configure the process engine otherwise, process instances are not made persistent.
jBPM provides a binary persistence mechanism that allows you to save the state of a process instance as a binary dataset. This way, the state of all running process instances can always be stored in a persistent location. Note that these binary datasets usually are relatively small, as they only contain the minimal execution state of the process instance. For a simple process instance, this usually contains one or a few node instances, i.e., any node that is currently executing, and, possibly, some variable values.
The state of a process instance is stored at so-called "safe points" during the execution of the process engine. Whenever a process instance is executing, after its start or continuation from a wait state, the engine proceeds until no more actions can be performed. At that point, the engine has reached the next safe state, and the state of the process instance and all other process instances that might have been affected is stored persistently.
By default, the engine does not save runtime data persistently. It is, however, pretty straightforward to configure the engine to do this, by adding a configuration file and the necessary dependencies. Persistence itself is based on the Java Persistence API (JPA) and can thus work with several persistence mechanisms. We are using Hibernate by default, but feel free to employ alternatives. A H2 database is used underneath to store the data, but you might choose your own alternative for this, too.
First of all, you need to add the necessary dependencies to your
classpath. If you're using the Eclipse IDE, you can do that by adding
the jar files to your jBPM runtime directory,
or by manually adding these dependencies to your project. First of all,
you need the jar file jbpm-persistence-jpa.jar,
as that contains code for saving the runtime state whenever necessary.
Next, you also need various other dependencies, depending on the
persistence solution and database you are using. For the default
combination with Hibernate as the JPA persistence provider, the H2
database and Bitronix for JTA-based transaction management, the
following list of additional dependencies is needed:
- jbpm-persistence-jpa (org.jbpm)
- drools-persistence-jpa (org.drools)
- persistence-api (javax.persistence)
- hibernate-entitymanager (org.hibernate)
- hibernate-annotations (org.hibernate)
- hibernate-commons-annotations (org.hibernate)
- hibernate-core (org.hibernate)
- dom4j (dom4j)
- jta (javax.transaction)
- btm (org.codehaus.btm)
- javassist (javassist)
- slf4j-api (org.slf4j)
- slf4j-jdk14 (org.slf4j)
- h2 (com.h2database)
- commons-collections (commons-collections)
Next, you need to configure the jBPM engine to save the state of the
engine whenever necessary. The easiest way to do this is to use
JPAKnowledgeService to create your knowledge session, based on a
knowledge base, a knowledge session configuration (if necessary) and an
environment. The environment needs to contain a reference to your
Entity Manager Factory. For example:
// create the entity manager factory and register it in the environment
EntityManagerFactory emf =
Persistence.createEntityManagerFactory( "org.jbpm.persistence.jpa" );
Environment env = KnowledgeBaseFactory.newEnvironment();
env.set( EnvironmentName.ENTITY_MANAGER_FACTORY, emf );
// create a new knowledge session that uses JPA to store the runtime state
StatefulKnowledgeSession ksession =
JPAKnowledgeService.newStatefulKnowledgeSession( kbase, null, env );
int sessionId = ksession.getId();
// invoke methods on your method here
ksession.startProcess( "MyProcess" );
ksession.dispose();
You can also yse the JPAKnowledgeService to recreate
a session based on a specific session id:
// recreate the session from database using the sessionId
ksession = JPAKnowledgeService.loadStatefulKnowledgeSession( sessionId, kbase, null, env );
Note that we only save the minimal state that is needed to continue execution of the process instance at some later point. This means, for example, that it does not contain information about already executed nodes if that information is no longer relevant, or that process instances that have been completed or aborted are removed from the database. If you want to search for history-related information, you should use the history log, as explained later.
You need to add a persistence configuration to your classpath to
configures JPA to use Hibernate and the H2 database (or your preference), called
persistence.xml in the META-INF directory, as shown below.
For more details on how to change this for your own configuration, we refer to
the JPA and Hibernate documentation for more information.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<persistence
version="1.0"
xsi:schemaLocation=
"http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd
http://java.sun.com/xml/ns/persistence/orm
http://java.sun.com/xml/ns/persistence/orm_1_0.xsd"
xmlns:orm="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="org.jbpm.persistence.jpa">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/processInstanceDS</jta-data-source>
<class>org.drools.persistence.info.SessionInfo</class>
<class>org.jbpm.persistence.processinstance.ProcessInstanceInfo</class>
<class>org.drools.persistence.info.WorkItemInfo</class>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.max_fetch_depth" value="3"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.transaction.manager_lookup_class"
value="org.hibernate.transaction.BTMTransactionManagerLookup"/>
</properties>
</persistence-unit>
</persistence>
This configuration file refers to a data source called "jdbc/processInstanceDS". The following Java fragment could be used to set up this data source, where we are using the file-based H2 database.
PoolingDataSource ds = new PoolingDataSource();
ds.setUniqueName("jdbc/testDS1");
ds.setClassName("org.h2.jdbcx.JdbcDataSource");
ds.setMaxPoolSize(3);
ds.setAllowLocalTransactions(true);
ds.getDriverProperties().put("user", "sa");
ds.getDriverProperties().put("password", "sasa");
ds.getDriverProperties().put("URL", "jdbc:h2:file:/NotBackedUp/data/process-instance-db");
ds.init();
If you're deploying to an application server, you can usually create a datasource by dropping a configuration file in the deploy directory, for example:
<?xml version="1.0" encoding="UTF-8"?>
<datasources>
<local-tx-datasource>
<jndi-name>jdbc/testDS1</jndi-name>
<connection-url>jdbc:h2:file:/NotBackedUp/data/process-instance-db</connection-url>
<driver-class>org.h2.jdbcx.JdbcDataSource</driver-class>
<user-name>sa</user-name>
<password>sasa</password>
</local-tx-datasource>
</datasources>
Whenever you do not provide transaction boundaries inside your application, the engine will automatically execute each method invocation on the engine in a separate transaction. If this behavior is acceptable, you don't need to do anything else. You can, however, also specify the transaction boundaries yourself. This allows you, for example, to combine multiple commands into one transaction.
You need to register a transaction manager at the environment before using user-defined transactions. The following sample code uses the Bitronix transaction manager. Next, we use the Java Transaction API (JTA) to specify transaction boundaries, as shown below:
// create the entity manager factory and register it in the environment
EntityManagerFactory emf =
Persistence.createEntityManagerFactory( "org.jbpm.persistence.jpa" );
Environment env = KnowledgeBaseFactory.newEnvironment();
env.set( EnvironmentName.ENTITY_MANAGER_FACTORY, emf );
env.set( EnvironmentName.TRANSACTION_MANAGER,
TransactionManagerServices.getTransactionManager() );
// create a new knowledge session that uses JPA to store the runtime state
StatefulKnowledgeSession ksession =
JPAKnowledgeService.newStatefulKnowledgeSession( kbase, null, env );
// start the transaction
UserTransaction ut =
(UserTransaction) new InitialContext().lookup( "java:comp/UserTransaction" );
ut.begin();
// perform multiple commands inside one transaction
ksession.insert( new Person( "John Doe" ) );
ksession.startProcess( "MyProcess" );
// commit the transaction
ut.commit();
Process definition files are usually written in an XML format. These files can easily be stored on a file system during development. However, whenever you want to make your knowledge accessible to one or more engines in production, we recommend using a knowledge repository that (logically) centralizes your knowledge in one or more knowledge repositories.
Guvnor is a Drools sub-project that provides exactly that. It consists of a repository for storing different kinds of knowledge, not only process definitions but also rules, object models, etc. It allows easy retrieval of this knowledge using WebDAV or by employing a knowledge agent that automatically downloads the information from Guvnor when creating a knowledge base, and provides a web application that allows business users to view and possibly update the information in the knowledge repository. Check out the Drools Guvnor documentation for more information on how to do this.
In many cases it is useful (if not necessary) to store information about the execution of process instances, so that this information can be used afterwards, for example, to verify what actions have been executed for a particular process instance, or to monitor and analyze the efficiency of a particular process. Storing history information in the runtime database is usually not a good idea, as this would result in ever-growing runtime data, and monitoring and analysis queries might influence the performance of your runtime engine. That is why history information about the execution of process instances is stored separately.
This history log of execution information is created based on the events generated by the process engine during execution. The jBPM runtime engine provides a generic mechanism to listen to different kinds of events. The necessary information can easily be extracted from these events and made persistent, for example in a database. Filters can be used to only store the information you find relevant.
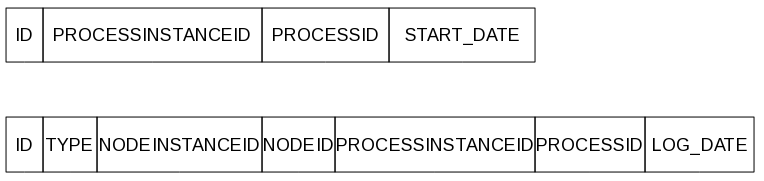
The jbpm-bam module contains an event listener that stores process-related information in a database using JPA or Hibernate directly. The database contains two tables, one for process instance information and one for node instance information (see the figure below):
- ProcessInstanceLog: This lists the process instance id, the process (definition) id, the start date and (if applicable) the end date of all process instances.
- NodeInstanceLog: This table contains more detailed information about which nodes were actually executed inside each process instance. Whenever a node instance is entered from one of its incomming connections or is exited through one of its outgoing connections, that information is stored in this table. For this, it stores the process instance id and the process id of the process instance it is being executed in, and the node instance id and the corresponding node id (in the process definition) of the node instance in question. Finally, the type of event (0 = enter, 1 = exit) and the date of the event is stored as well.
To log process history information in a database like this, you need to register the logger on your session (or working memory) like this:
StatefulKnowledgeSession ksession = ...;
JPAWorkingMemoryDbLogger logger = new JPAWorkingMemoryDbLogger(ksession);
// invoke methods one your session here
logger.dispose();
Note that this logger is like any other audit logger, which means
that you can add one or more filters by calling the method
addFilter to ensure that only relevant information is
stored in the database. Only information accepted by all your filters will
appear in the database. You should dispose the logger when it is no
longer needed.
To specify the database where the information should be stored,
modify the file persistence.xml file to include
the audit log classes as well (ProcessInstanceLog, NodeInstanceLog and
VariableInstanceLog), as shown below.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<persistence
version="1.0"
xsi:schemaLocation=
"http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd
http://java.sun.com/xml/ns/persistence/orm
http://java.sun.com/xml/ns/persistence/orm_1_0.xsd"
xmlns:orm="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="org.jbpm.persistence.jpa">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/processInstanceDS</jta-data-source>
<class>org.drools.persistence.info.SessionInfo</class>
<class>org.jbpm.persistence.processinstance.ProcessInstanceInfo</class>
<class>org.drools.persistence.info.WorkItemInfo</class>
<class>org.jbpm.process.audit.ProcessInstanceLog</class>
<class>org.jbpm.process.audit.NodeInstanceLog</class>
<class>org.jbpm.process.audit.VariableInstanceLog</class>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.max_fetch_depth" value="3"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.transaction.manager_lookup_class"
value="org.hibernate.transaction.BTMTransactionManagerLookup"/>
</properties>
</persistence-unit>
</persistence>
All this information can easily be queried and used in a lot of different use cases, ranging from creating a history log for one specific process instance to analyzing the performance of all instances of a specific process.
This audit log should only be considered a default implementation. We don't know what information you need to store for analysis afterwards, and for performance reasons it is recommended to only store the relevant data. Depending on your use cases, you might define your own data model for storing the information you need, and use the process event listeners to extract that information.