JBoss DNA is a repository and set of tools that make it easy to capture, version, analyze, and understand the fundamental building blocks of information. As models, service and process definitions, schemas, source code, and other artifacts are added to the repository, JBoss DNA "sequences" the makeup of these components and extracts their structure and interdependencies. The JBoss DNA web application will allow end users to access, visualize, and edit this information in the terminology and structure they are familiar with. Such domain-specific solutions can be easily created with little or no programming.
JBoss DNA supports the Java Content Repository (JCR) standard and is able to provide a single integrated view of multiple repositories, external databases, services, and applications, ensuring that JBoss DNA has access to the latest and most reliable master data. For instance, DNA could provide in a single view valuable insight into the business processes and process-level services impacted by a change to in an intermediary web server operation defined via WSDL. Similarly, a user could quickly view and navigate the dependencies between the data source models and transformation information stored within a content repository, the code base stored within a version control system, and the database schemas used by an application.
The planned architecture for JBoss DNA consists of several major components that will be built on top of standard APIs, including JCR, JDBC, JNDI and HTTP. The goal is to allow these components to be assembled as needed and add value on top of other DNA components or third-party systems that support these standard APIs. Not all of these components exist yet - at the moment we're focusing on completing our JCR-compliant implementation using our connector framework.
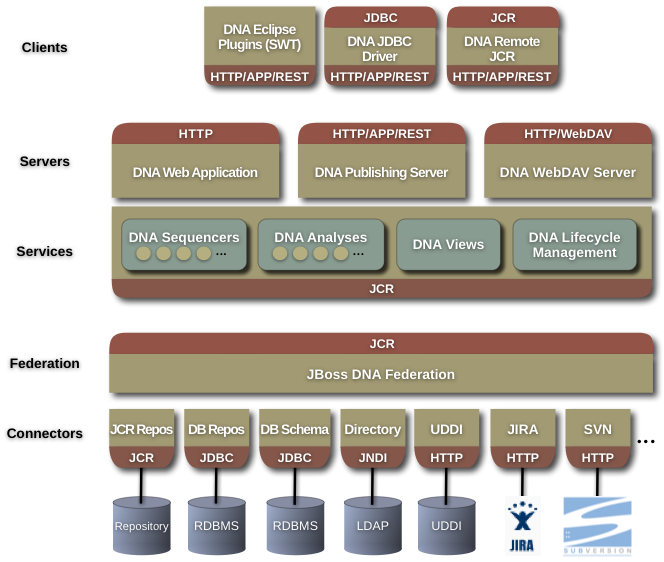
Let's go over each of these components, starting from the bottom of the diagram:
DNA Connectors are used to communicate with these external sources of information, whether there's one source (like a database) in which all of the content is stored, or information is being federated from multiple sources. The connector's job is to interact with the external source and map the source's information into the lower-level graph language used by JBoss DNA. Connectors also may optionally participate in distributed transactions by exposing an XAResource. In summary, then, the connector API isolates all of the other components from how the graph are persisted. We've built a number of connectors already, but we're always interested in adding more. Or, you could write your own, since we've designed the connector API to be as straightforward as possible.
DNA Federation is actually special repository connector that accesses information from multiple other sources via connectors, making all this information look like it is part of a single, unified graph. Because it is a connector, it can be used wherever connectors can be used. And because it uses connectors, the federation connector makes it possible to integrate a wide variety of external systems, like other JCR repositories, databases, applications, and services.
DNA JCR is an implementation of the JCR API that accesses the content from a single connector. Our implementation has come a long with in the 0.4 release, and is nearly Level 1 and Level 2 compliant. Finishing the remaining features, including search and query, are major objectives of our next release.
DNA Sequencers are pluggable components that automatically process content (typically files) that are uploaded into the repository, looking for useful structure and information in that content. When a file is uploaded to the repository, JBoss DNA automatically figures out which sequencer(s) should be run, and then runs them. Each sequencer, then, extracts the meaningful information from the file's content and places that structure in the repository. Once this information is in the repository, it can be viewed, edited, analyzed, searched, and related to other content. DNA defines a Java interface that sequencers must implement. DNA sequencers operate upon any JCR-compliant repository. We have a number of sequencers, but plan on adding more over time. Like connectors, the Sequencer API makes it very simple to write sequencers for your own file types.
DNA Analyses are similar to sequencers, except they process the graph structure rather than uploaded files. You can think of them as report generators, where they process some area of the repository and generate output. The output doesn't take the form of a document or file, but rather more graph content that is then stored in the repository, where it can be accessed and searched just like any other content. We're still figuring out how to best make analyzers easy to write and use, and have been focused on other aspects of the architecture. But we're planning on using analyzers for dependency, similarity, and statistical analyses.
DNA Maven is a classloader library compatible with Maven 2 project dependencies. This allows the creation of Java ClassLoader instances using Maven 2 style paths, and all dependencies are transitively managed and included. This exists but is still immature.
The remaining parts of the architecture haven't yet been started, but they service important purposes for a complete metadata repository system.
DNA Eclipse Plugins enable Eclipse users to access the contents of a JBoss DNA repository. This is a planned component that may be started soon.
DNA JDBC Driver provides a driver implementation, allowing JDBC-aware applications to connect to and use a JBoss DNA repository. This is a planned component on our roadmap.
DNA Remote JCR is a client-side component for accessing remote JCR repositories.
DNA Web Application is used by end users and domain experts to visualize, search, edit, change and tag the repository content. The web application uses views to define how different types of information are to be presented and edited in domain-specific ways. The goal is that this web application is easily customized and branded for inclusion into other solutions and application systems. The DNA Web Application operates upon any JCR-compliant repository, although it does rely upon the DNA analysis and templating services.
DNA Publishing Server allows content to be downloaded, uploaded, and edited using the Atom Publishing Protocol. With the DNA Publishing Server, the content of the repository can easily be created, read, edited, and deleted using the standard HTTP operations of POST, GET, PUT, and DELETE (respectively). More and more tools are being created that support working with Atom Publishing servers. The DNA Publishing Server operates upon any JCR-compliant repository.
DNA WebDAV Server allows clients such as Microsoft Windows and Apple OS X to connect to, read, and edit the content in the repository using the WebDAV standard. WebDAV is an extension of HTTP, so web browsers are able to access the content served by a WebDAV compliant server. The DNA WebDAV Server operates upon any JCR-compliant repository.
DNA Views are definitions of how types of information are to be presented in a user interface to allow for creation, reading, editing, and deletion of information. DNA view definitions consist of data stored in a JCR repository, and as such views can be easily added, changed or removed entirely by using the DNA Web Application, requiring no programming.
Continue reading the rest of this chapter for more detail about the sequencing framework available in this release, or the federation engine and connectors. Or, skip to the examples to see how to start using JBoss DNA today.
The current JBoss DNA release contains a sequencing framework that is designed to sequence data (typically files) stored in a JCR repository to automatically extract meaningful and useful information. This additional information is then saved back into the repository, where it can be accessed and used.
In other words, you can just upload various kinds of files into a JCR repository, and DNA automatically processes those files to extract meaningful structured information. For example, load DDL files into the repository, and let sequencers extract the structure and metadata for the database schema. Load Hibernate configuration files into the repository, and let sequencers extract the schema and mapping information. Load Java source into the repository, and let sequencers extract the class structure, JavaDoc, and annotations. Load a PNG, JPEG, or other image into the repository, and let sequencers extract the metadata from the image and save it in the repository. The same with XSDs, WSDL, WS policies, UML, MetaMatrix models, etc.
JBoss DNA sequencers sit on top of existing JCR repositories (including federated repositories) - they basically extract more useful information from what's already stored in the repository. And they use the existing JCR event and versioning system. Each sequencer typically processes a single kind of file format or a single kind of content.
The following sequencers are included in JBoss DNA:
Image sequencer - A sequencer that processes the binary content of an image file, extracts the metadata for the image, and then writes that image metadata to the repository. It gets the file format, image resolution, number of bits per pixel (and optionally number of images), comments and physical resolution from JPEG, GIF, BMP, PCX, PNG, IFF, RAS, PBM, PGM, PPM, and PSD files. (This sequencer may be improved in the future to also extract EXIF metadata from JPEG files; see DNA-26.)
MP3 sequencer - A sequencer that processes the contents of an MP3 audio file, extracts the metadata for the file, and then writes that image metadata to the repository. It gets the title, author, album, year, and comment. (This sequencer may be improved in the future to also extract other ID3 metadata from other audio file formats; see DNA-66.)
ZIP Archive Sequencer - Process ZIP archive files to extract (explode) the contents into the repository.
Java Source File Sequencer - Process Java source files to extract the class structure (including annotations) into the repository.
XML File Sequencer - Process XML files to extract the structure into the repository.
Microsoft Office File Sequencer - Process Microsoft Office documents, spreadsheets, and presentation files to extract their basic structure. For example, the sequencer extracts the outline of a document, or the title and outline of a presentation.
JCR Compact Node Definition (CND) File Sequencer - Process the CND files defined by JCR, extracting the various node types with their property definitions and child node definitions.
As the community develops additional sequencers, they will also be included in JBoss DNA. Some of those that have been identified as being useful include:
Data Definition Language (DDL) Sequencer - Process various dialects of DDL, including that from Oracle, SQL Server, MySQL, PostgreSQL, and others. May need to be split up into a different sequencer for each dialect. This sequencer is being developed as part of a Google Summer of Code 2009 project. (See DNA-26 )
XML Schema Document (XSD) Sequencer - Process XSD files and extract the various elements, attributes, complex types, simple types, groups, and other information. (See DNA-32 )
Web Service Definition Language (WSDL) Sequencer - Process WSDL files and extract the services, bindings, ports, operations, parameters, and other information. (See DNA-33 )
Hibernate File Sequencer - Process Hibernate configuration (cfg.xml) and mapping (hbm.xml) files to extract the configuration and mapping information. (See DNA-61 )
XML Metadata Interchange (XMI) Sequencer - Process XMI documents that contain UML models or models using another metamodel, extracting the model structure into the repository. (See DNA-31 )
Java Archive (JAR) Sequencer - Process JAR files to extract (explode) the contents into the classes and file resources. (See DNA-64 )
Java Class File Sequencer - Process Java class files (bytecode) to extract the class structure (including annotations) into the repository. (See DNA-62 )
PDF Sequencer - Process PDF files to extract the document metadata, including table of contents. (See DNA-50 )
Maven 2 POM Sequencer - Process Maven 2 Project Object Model (POM) files to extract the project information, dependencies, plugins, and other content. (See DNA-24 )
MP3 and MP4 Sequencer - Process MP3 and MP4 audio files to extract the name of the song, artist, album, track number, and other metadata. (See DNA-30 )
The examples in this book go into more detail about how sequencers are managed and used, and Chapter 5 goes into detail about how to write custom sequencers.
There is a lot of information stored in many of different places: databases, repositories, SCM systems, registries, file systems, services, etc. The purpose of the federation engine is to allow applications to use the JCR API to access that information as if it were all stored in a single JCR repository, but to really leave the information where it is.
Why not just copy or move the information into a JCR repository? Moving it is probably pretty difficult, since most likely existing applications rely upon that information being where it is. All of those applications would break or have to change. And copying the information means that we'd have to continually synchronize the changes. This not only is a lot of work, but it often creates issues with knowing which information is accurate.
The JBoss DNA allows lets us leave the information where it is, yet provide access to that information through the JCR API. The first benefit is that any existing applications that already use that information can keep using it. Plus, if the underlying information changes, all the client applications see the correct information. JCR clients even get the benefit of using JCR observation to be notified of the changes. And if a JBoss DNA repository is configured to allow updates, client applications can change the information in the repository and JBoss DNA will propagate those changes down to the original source.
JBoss DNA uses connectors to interact with different information sources to get at the content in those systems. We already have some connectors, including:
In-Memory Connector - Uses a Map instance as a repository. This is a simple connector that works really well for small and transient graphs.
JBoss Cache Connector - Uses a JBoss Cache instance as a repository. JBoss Cache is a powerful cache capable of persisting the information and being clustered for concurrent use by multiple processes.
Federation Connector - Creates a single repository by accessing and federating the information in multiple other repository sources. This is a powerful connector that is discussed in more detail in the next section.
File System Connector - Expose the files and directories on a file system through JCR.
JDBC Storage Connector - Store and access information in a relational database through JPA. Also useful for persisting information in the federated repository not stored elsewhere.
We're working on a few other connectors:
JDBC Metadata Connector - Connect to relational databases via JDBC and expose their schema as content in a repository.
SVN Connector - Interact with Subversion software configuration management (SCM) repositories to expose the managed resources through JCR. Consider using the SVNkit (dual license) library for an API into Subversion.
And even more connectors that are planned:
JCR Repository Connector - Connect to and interact with other JCR repositories.
Maven 2 Repository Connector - Access and expose the contents of a Maven 2 repository (either on the local file system or via HTTP) through JCR.
UDDI Connector - Interact with UDDI registries to integrate their content into a repository.
CVS Connector - Interact with CVS software configuration management (SCM) repositories to expose the managed resources through JCR.
Distributed Database Connector - Store and access information in a Hypertable or HBase distributed databases. Also useful for persisting information in the federated repository not stored elsewhere.
If the connectors allow the information they contribute to be updated, they must provide an
XAResource
implementation that can be used with a Java Transaction Service. Connectors that provide read-only access need not
provide an implementation.
Also, connectors talk to sources of information, and it's quite likely that the same connector is used to talk to different sources. Each source contains the configuration details (e.g., connection information, location, properties, options, etc.) for working with that particular source, as well as a reference to the connector that should be used to establish connections to the source. And of course, sources can be added or removed without having to stop and restart the federated repository.
The federation connector works by effectively building up a single graph by querying each source and merging or unifying the responses. This information is cached, which improves performance, reduces the number of (potentially expensive) remote calls, reduces the load on the sources, and helps mitigate problems with source availability. As clients interact with the repository, this cache is consulted first. When the requested portion of the graph (or "subgraph") is contained completely in the cache, it is retuned immediately. However, if any part of the requested subgraph is not in the cache, each source is consulted for their contributions to that subgraph, and any results are cached.
This basic flow makes it possible for the federated repository to build up a local cache of the integrated graph (or at least the portions that are used by clients). In fact, the federated repository caches information in a manner that is similar to that of the Domain Name System (DNS). As sources are consulted for their contributions, the source also specifies whether it is the authoritative source for this information (some sources that are themselves federated may not be the information's authority), whether the information may be modified, the time-to-live (TTL) value (the time after which the cached information should be refreshed), and the expiration time (the time after which the cached information is no longer valid). In effect, the source has complete control over how the information it contributes is cached and used.
The federated repository also needs to incorporate
negative caching
, which is storage of the knowledge that something does not exist. Sources can be configured to contribute information
only below certain paths (e.g.,
/A/B/C
), and the federation engine can take advantage of this by never consulting that source for contributions to information
on other paths. However, below that path, any negative responses must also be cached (with appropriate TTL and expiry
parameters) to prevent the exclusion of that source (in case the source has information to contribute at a later time)
or the frequent checking with the source.
The JBoss DNA federated repository will support queries against the integrated and unified graph. In some situations the query can be determined to apply to a single source, but in most situations the query must be planned (and possibly rewritten) such that it can be pushed down to all the appropriate sources. Also, the cached results must be consulted prior to returning the query results, as the results from one source might have contributions from another source.
Searching the whole federated repository is also important. This allows users to simply supply a handful of search terms, and to get results that are ranked based upon how close each result is to the search terms. (Searching is very different from querying, which involves specifying the exact semantics of what is to be searched and how the information is to be compared.) JBoss DNA will incorporate a search engine (e.g., likely to be Lucene) and will populate the engine's indexes using the federated content and the cached information. Notifications of changing information will be reflected in the indexes, but some sources may want to explicitly allow or disallow periodic crawling of their content.
The JBoss DNA federated repositories also make it possible for client applications to make changes to the unified graph within the context of distributed transactions. According to the JCR API, client applications use the Java Transaction API (JTA) to control the boundaries of their transactions. Meanwhile, the federated repository uses a distributed transaction service to coordinate the XA resources provided by the connectors.
It is quite possible that clients add properties to nodes in the unified graph, and that this information cannot be handled by the same underlying source that contributed to the node. In this case, the federated repository can be configured with a fallback source that will be used used to store this "extra" information.
It is a goal that non-XA sources (i.e., sources that use connectors without XA resources) can participate in distributed transactions through the use of compensating transactions . Because the JBoss DNA federation engine implements the JCR observation system, it is capable of recording all of the changes made to the distributed graph (and those changes sent to each updatable source). Therefore, if a non-XA source is involved in a distributed transaction that must be rolled back, any changes made to non-XA sources can be undone. (Of course, this does not make the underlying source transactional: non-transactional sources still may expose the interim changes to other clients.)
The JCR API supports observing a repository to receive notifications of additions, changes and deletions of nodes and properties. The JBoss DNA federated repository will support this API through two primary means.
When the changes are made through the federated repository, the JBoss DNA federation engine is well aware of the set of changes that have been (or are being) made to the unified graph. These events are directly propagated to listeners.
Sources have the ability to publish events, making it possible for the JBoss DNA federation engine and clients that have registered listeners to be notified of changes in the information managed by that source. These events are first processed by the federation engine and possibly altered based upon contributions from other sources. (The federation engine also uses these events to update or purge information in the cache, which may add to the event set.) The resulting (and possibly altered) event set is then sent to all client listeners.