One of the capabilities of JBoss DNA is to provide access through JCR to different kinds of repositories and storage systems. Your applications work with the JCR API, but through JBoss DNA you're able to accesses the content from where the information exists - not just a single purpose-built repository. This is fundamentally what makes JBoss DNA different.
How does JBoss DNA do this? At the heart of JBoss DNA and it's JCR implementation is a simple connector system that is designed around creating and accessing graphs. The JBoss DNA JCR implementation actually just sits on top of a single repository source, which it uses to access of the repositories content.
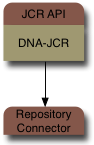
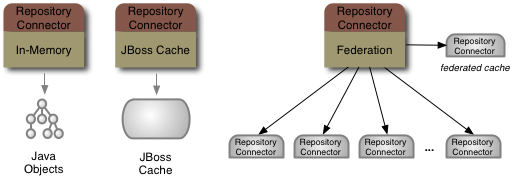
That single repository source could be an in-memory repository, a JBoss Cache instance, or a federated repository.
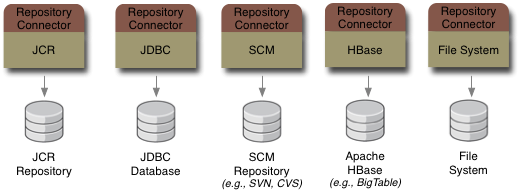
And the JBoss DNA project has plans to create other connectors, too. For instance, we're going to build a connector
to other JCR repositories. And another to a file system, so that the files and directories on an area of the file system
can be accessed through JCR. Of course, if we don't have a connector to suit your needs, you can write your own.
Note
You might be thinking that these connectors are interesting, but what do they really provide? Is it really useful to use JCR to access a relational database rather than JDBC? Or, why access the files on a file system when there are already mechanisms to do that?
Maybe putting JCR on top of a single system (like a JDBC database) isn't that interesting. What is interesting, though, is accessing the information in multiple systems as if all that information were in a single JCR repository. That's what the federated repository source is all about. The JBoss DNA connector system just makes it possible to interact with all these systems in the same way.
Think of it this way: with JBoss DNA, you can use JCR to get to the schemas of multiple relational databases and the schemas defined by DDL files in your SVN repository and the schemas defined by logical models stored on your file system.
So with this very high-level summary, let's dive a little deeper and look at how to configure and use JBoss DNA and JCR.
The JBoss DNA repository service is the component that manages the repositories
and connections to them. The service reads its configuration from a RepositorySource instance (i.e., the
"configuration repository") and automatically sets up the repositories given the RepositorySource instances
found in the configuration repository.
Note
Configuring JBoss DNA services is more manual and complex than we want. As you'll see, JBoss DNA uses dependency injection to allow a great deal of flexibility in how it can be configured and customized. But this flexibility makes it more difficult for you to use. We understand this, and will soon provide a much easier way to set up and manage JBoss DNA. Current plans are to use the JBoss Microcontainer along with a configuration repository that makes it very easy to set up and manage JBoss DNA, whether it's used in a simple application or a cluster of processes.
To set up the repository service, we need to first set up a few other objects:
An execution contexts. Execution contexts define the context (or environment) in which the service runs and in which operations against repositories are performed.
ExecutionContextinstances can be created using JAAS application contexts, meaning that they contain the information about the subject that the software represents. Execution contexts also provide access to the all of the factories and utilities used throughout the services and components, and it is through this mechanism that you can inject your own behavior. For example, if your application already had a notion of namespaces, you could create an execution context that uses your ownNamespaceRegistryimplementation (which would use the namespaces defined in your application).A repository library that manages the list of
RepositorySourceinstances. The library makes sure to inject the environments into each repository source, and it provides for each source a configurable pool of connections.A configuration repository that contains descriptions of all of the repository sources as well as any information those sources need. Because this is a regular repository, this could be a simple repository with content loaded from an XML file (as in this example). Or it could be a shared central repository with information about all of the JBoss DNA processes across your company.
With these components in place, we can then instantiate the RepositoryService and start it (using its
ServiceAdministrator). During startup, the service reads the configuration repository and loads any
defined RepositorySource instances into the repository library, using the class loader factory
(available in the ExecutionContext) to obtain.
Here's sample code that shows how to set up and start the repository service. You can see something similar
in the example application in the startRepositories() method of the org.jboss.example.dna.repository.RepositoryClient class.
// Create the execution context that we'll use for the services. If we'd want to use JAAS, we'd
// create the context by supplying LoginContext, AccessControlContext, or even Subject with
// CallbackHandlers. But this example doesn't use JAAS in this example.
ExecutionContext context = new ExecutionContext();
// Create the library for the RepositorySource instances ...
RepositoryLibrary sources = new RepositoryLibrary(context);
// Load into the source manager the repository source for the configuration repository ...
InMemoryRepositorySource configSource = new InMemoryRepositorySource();
configSource.setName("Configuration");
sources.addSource(configSource);
// Now instantiate the Repository Service ...
RepositoryService service = new RepositoryService(sources, configSource.getName(), context);
service.getAdministrator().start();
After startup completes, the repositories are ready to be used. The client application obtains the list of repositories and presents them to the user. When the user selects one, the client application starts navigating that repository starting at its root node (e.g., the "/" path). As you type a command to list the contents of the current node or to "change directories" to a different node, the client application obtains the information for the node using a simple procedure:
Get a connection to the repository.
Using the connection, find the current node and read its properties and children, putting the information into a simple Java plain old Java object (POJO).
Close the connection to the repository (in a finally block to ensure it always happens).
If we want to perform these steps using JCR, a JCR Session represents our connection.
So after we create a JcrRepository instance pointing to our repository library, we can
then login to obtain a JCR session:
JcrRepository jcrRepository = new JcrRepository(context, sources);
Session session = jcrRepository.login(sourceName);
Now, the above code doesn't do any authentication; it essentially trusts the caller has the appropriate privileges. Normally, your application will need to authenticate the user, so let's look at how that's done.
JBoss DNA uses the Java Authentication and Authorization Service (JAAS), making it possible to use any existing JAAS security provider. There are numerous JAAS providers, but one of the best open-source implementations is JBoss Security, which can authenticate using LDAP, certificates, the operating system, and federated single-sign-on (among others).
The JCR API defines a Credentials marker interface, an instance of which can be passed to the
Session.login(...) method. Rather than provide a concrete implementation of this interface, JBoss DNA
allows you to pass any implementation of Credentials that also has one of the following methods:
getLoginContext()that returns ajavax.security.auth.login.LoginContextinstance.getAccessControlContext()that returns ajava.security.AccessControlContextinstance.
This way, your application can obtain the JAAS LoginContext or AccessControlContext however it wants,
and then merely passes that into DNA through the JCR Credentials. No interfaces or classes specific to JBoss DNA are required.
The following code shows how this is done, using an anonymous inner class for the Credentials implementation.
CallbackHandler callbackHandler = // as needed by your app, according to JAAS
final LoginContext loginContext = new LoginContext("MyAppContextName",callbackHandler);
Credentials credentials = new Credentials() {
public LoginContext getLoginContext() { return loginContext; }
};
JcrRepository jcrRepository = new JcrRepository(context, sources);
Session session = jcrRepository.login(credentials, sourceName);
Once you have a JCR session, you can then use it to find the node of interest and access the necessary information. All of this
code will use only the JCR API - there's nothing specific to JBoss DNA's implementation. And remember, when you're finished with
the session, be sure to logout (usually in a finally block):
if (session != null) session.logout();
Like many people recommend with JCR, you can create either long-lived or short-lived JCR Sessions. The
JBoss DNA implementation of JCR was designed to efficiently do either.
In the first part of this chapter, we saw how to instantiate, configure, and start the RepositoryService.
We then saw how to use JCR to access the repository service by creating JCR Sessions, and how to log out of those
sessions when no longer needed.
In this short section we'll see how to shut down the RepositoryService and RepositoryLibrary
when you're finished with all of the repositories. It's a simple but important step, since this closes all outstanding
connections that may be sitting unused in the library's connection pools.
Shutting down these components is very straightforward: get the ServiceAdministrator on each, and call shutdown().
// Shut down the repository service ...
repositoryService.getAdministrator().shutdown();
// Shut down the manager of the RepositorySource instances, waiting until all connections are closed
sources.getAdministrator().shutdown();
sources.getAdministrator().awaitTermination(1, TimeUnit.SECONDS);
The shutdown() method attempts to close all open and unused resources (such as open and unused connections in the pool).
No more connections can be created, and any connections that are currently in use are not closed but allowed to be used and closed normally.
When the last connection is used, the service then transitions to a terminated state, which you can wait for using
the awaitTermination(int,TimeUnit) method.
If you want to shutdown the services immediately, then you could call shutdownNow(), which blocks while it attempts to immediately
close all connections - even those currently in use. So, while you generally want to use shutdown(),
it is good to be aware that this shutdownNow() method does exist.
Recall that the example repository application consists of a client application that sets up a repository service and the repositories defined in a configuration repository, allowing the user to pick a repository and interactively navigate the selected repository. Several repositories are set up, including several in-memory repositories and one federated repository that dynamically federates the content from the other repositories.
The example is comprised of 2 classes and 1 interface, located in the src/main/java directory:
org/jboss/example/dna/repositories/ConsoleInput.java
/RepositoryClient.java
/UserInterface.java
RepositoryClient is the class that contains the main application. It uses an instance of the
UserInterface interface to methods that will be called at runtime to obtain information about the
files that are imported into the in-memory repositories and the JAAS CallbackHandler implementation
that will be used by JAAS to prompt the user for authentication information. Finally, the ConsoleInput
is an implementation of this that creates a text user interface, allowing the user to operate the client from the command-line.
We can easily create a graphical implementation of UserInterface at a later date, or we can also create a mock
implementation for testing purposes that simulates a user entering data. This allows us to check the behavior of the client
automatically using conventional JUnit test cases, as demonstrated by the code in the src/test/java directory:
org/jboss/example/dna/sequencers/RepositoryClientTest.java
/RepositoryClientUsingJcrTest.java
The code we presented earlier in this chapter represent the bulk of the JBoss DNA and JCR-specific code used in the
RepositoryClient, so we won't cover it in any more detail here. Please refer to the sample client code
if you want to see more.
In this chapter we covered the different JBoss DNA components used for accessing repositories through JCR, including
repositories that federate their content from the content of other repositories. Specifically, we described how the
RepositoryService and JcrRepository can be configured and used.