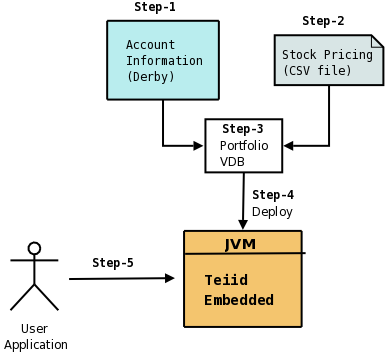
To demonstrate how Teiid Designer and Teiid Embedded work together, follow these steps to build a simple portfolio valuation virtual database. The investor's portfolio information is stored in a Derby database and "current" stock prices are stored in a delimited text file. When completed, a single query will cause Teiid Embedded to access the relational and non-relational sources, calculate the portfolio values, and return the results. Here are some of key points to consider as you build this example:
It's pretty simple to do
You're querying a text file as though it was a relational database
Imagine how much more complete this would be if you replaced the text file with a connection to a financial Web site. (Hint: You can with Teiid Embedded and a custom connector.)
Note
Derby is suggested as it is Open Source, easily obtained, and light-weight. You can substitute any other relational database, as long as you have a suitable JDBC driver. The schema file provided, and described below, is specific to Derby, but can be easily converted for use with other databases.
This example is written using "Derby" as the relational database. Download and install Derby on your machine, or if you have access to an installed instance use that. It is expected that you create a database called "accounts" in this Derby instance that is used by this example application.
Below find the corresponding schema. For the complete schema, please refer to "examples/portfolio/customer-schema.sql" file of the downloaded kit.
- -Contains the name and address of a Customer who owns portfolio account
CREATE TABLE CUSTOMER
(
SSN char(10),
FIRSTNAME varchar(64),
LASTNAME varchar(64),
ST_ADDRESS varchar(256),
APT_NUMBER varchar(32),
CITY varchar(64),
STATE varchar(32),
ZIPCODE varchar(10),
PHONE varchar(15)
);
--Contains Customer's account number and its current status
CREATE TABLE ACCOUNT
(
ACCOUNT_ID integer,
SSN char(10),
STATUS char(10),
TYPE char(10),
DATEOPENED timestamp,
DATECLOSED timestamp
);
--Contains information about stock symbol, company name etc.
CREATE TABLE PRODUCT (
ID integer,
SYMBOL varchar(16),
COMPANY_NAME varchar(256)
);
--Contains each Account's holdings of Stocks
CREATE TABLE HOLDINGS
(
TRANSACTION_ID integer,
ACCOUNT_ID integer,
PRODUCT_ID integer,
PURCHASE_DATE timestamp,
SHARES_COUNT integer
);
We need to start the Derby RDBMS and create the "accounts" database with the below schema. These commands are intended for a Linux environment. For starting the Derby instance on another platform, you will need to use commands appropariate to that platform.
Start a terminal session, and change directory to where Derby is installed and execute following commands
export DERBY_HOME=`pwd`
./bin/startNetworkServer
The above starts the Derby in network mode. Now, start another terminal and we will use Derby''s 'ij' tool (like SQL*PLus for Oracle) to create the schema, using the "customer-schema.sql" file in "examples/portfolio" directory
export DERBY_HOME=`pwd`
./bin/ij /path/to/customer-schema.sql
Make sure you did not have any issues when creating the schema as it is needed for going forward in this example. You can use 'ij' tool to verify the tables were created. As an alternative, you may use other tools like SQuirreL , or Eclipse's Data Tools plugin to connect to the Derby instance to check the schema and sample data.
In order to use a Text file as the source, we need to define two different types of files: A descriptor file and one or more data files. Conceptually, a Descriptor file defines a schema, and each data file defines data inside a table
Text Descriptor File - The Text Descriptor file defines the structure of the text file you want to use as a data source. The path to the data file, delimiter character used,and the number of header lines are attributes of the Descriptor file. A sample descriptor file is shown below.
MarketData.Price.location = /path/to/marketdata-price.txt MarketData.Price.delimiter = , MarketData.Price.headerLine = 1The table shown below details some of the available properties that can be used in a Descriptor file. For full details look in Text File Connector documentation
Table 3.1. Connection Properties
Property
Description
location
The path to the file on the local system or URL to remote file.
delimiter
The character the file uses to delimit the fields within each line in the file
headerLine
The line number in which the names of the columns are defined
skipHeaderLines
The number of top lines to skip in a text file (include one for the header).
Note that each property line starts with the "schema" information and followed by the logical "table" name and then the "property" itself. In the above sample file "MarketData" is the schema and "Price" is the table. The sample Descriptor file is for a 'single' table. You can define multiple tables in the same Descriptor file, but each "location" property for a given "table" must point to different data file.
Data File: This is the file that is identified by the "location" property in the Descriptor file. Each data file contains column information for the table. The column information is typically defined on line 1 as header line in the file, and all the following lines contain the actual rows of data. Each single line corresponds to single row. A portion of the sample file is shown below. The complete sample file is "examples/portfolio/marketdata-price.txt".
SYMBOL,PRICE IBM,83.46 RHT,11.84 BA, 44.58 ORCL,17.37
Just locate the sample data files provided or create your own data files. Make sure that the descriptor file contains the full path to the data file. Now, both our sources are ready to be used to build a VDB