Map<String,String> parameters = ...
Repository repository = null;
for (RepositoryFactory factory : ServiceLoader.load(RepositoryFactory.class)) {
repository = factory.getRepository(parameters);
if (repository != null) break;
}
It's important to understand the central concepts used within the JCR API. This section presents an overview of these concepts, but for a more thorough description see the JCR 2.0 specification.
Repository
A repository is a single, self-contained persistent store of information plus the software that is used to access and update that information. Each repository contains an area for system-wide information and version storage, and separate areas for its workspaces.
A repository is represented in software with the javax.jcr.Repository interface, which defines:
-
methods to authenticate and obtain a session (or connection) to the repository
-
methods to obtain the set of features supported by the repository
-
constants used to identify the various repository features
There are multiple ways that your application can obtain a Repository instance. The easiest is to simply look it up in JNDI, although this obviously only works if your application is running in an environment that has JNDI support. But another technique is to use Java's ServiceLoader to look up the javax.jcr.RepositoryFactory implementations, and use them to ask for a repository given a set of parameters; the first factory to understand the parameters will return a Repository instance:
The parameters are unique to the JCR implementation, but you can keep them outside of your codebase by simply reading them in from a properties file. For more details and other options, see the Repository and Session page.
Workspace and Sessions
Each repository is divided into separate named workspaces, and it is within these workspaces that all content is stored as a tree-structure of nodes. The top of that tree structure is the root node (named "/"), and all nodes in the tree are accessible via navigation, lookup by unique identifier, or via query result.
Accessing and updating the content within a workspace requires establishing a session obtained by authenticating with the repository. Generally speaking, sessions are intended to be short-lived, meaning that clients will create a session, use the session to read or update content, save the session's transient changes, and then close the session. However, the only way to access or update any repository content is through an authenticated session.
When using a session to read content, all of the nodes reflect the persisted state of the workspace. So as the persisted state changes, all sessions immediately see the updated content. This means that as a client uses a session, the content accessible by that session may be changing if other sessions are making changes to the content.
Sessions are also used to update content. Each session maintains the transient set of changes overlaid on top of the persisted state, and these transient changes are persisted only when the session is saved. (When using transactions, the session must still be saved, but the changes are persisted only when the transaction is committed.)
The JCR API defines the javax.jcr.Session interface to represent a session, and it's created to access and change the content of a single persistent workspace. The javax.jcr.Workspace interface to represent a persistent workspace, and contains methods that modify or copy content (including from other workspaces). Each Session object has its own distinct Workspace instance, since ensure that the session's authorizations are respected. (This is why Workspace objects are not shared.)
Let's look at a very simple example that shows the basics for obtaining a Session and Workspace:
Repository repository = ... // Create a session by logging in. There are multiple forms of 'login(...)', // but we'll use the one that just specifies the workspace name ... Session session = repository.login(workspaceName); // Obtain the session's workspace ... Workspace workspace = session.getWorkspace(); // Note how the workspace is owned by the session ... assert session == workspace.getSession(); // And we can always get back to the repository, too ... assert repository == session.getRepository(); // Work with your content ... // Eventually log out ... session.logout();
Node, children, names, and paths
The content of each workspace is organized as a tree of nodes: at the top of the tree is a single root node, and every node can contain multiple child nodes. Every node has a name and a unique identifier, and can also be identified by a path containing the names of all ancestors, from the parent to the node itself. Names are comprised of a namespace and local part, and there is a namespace registry to centralize short prefixes for each namespace.
Generally, all of the children of a single node are uniquely named, and this is considered a best-practice. However, this is not required, and it is possible (and desirable in some use cases) for a single parent node to have multiple child nodes with the same name. In these cases, the same-name siblings (SNS) are distinguished by including a 1-based SNS index in the path. The index simply identifies the order of the SNSs, so inserting, reordering, or removing children may alter the SNS index of a particular node, effectively changing the node's path.
Let's consider a sample repository that stores information about various assets of a fictional company. This is of course just one possible repository design to showcase the capabilities and features of JCR repositories:
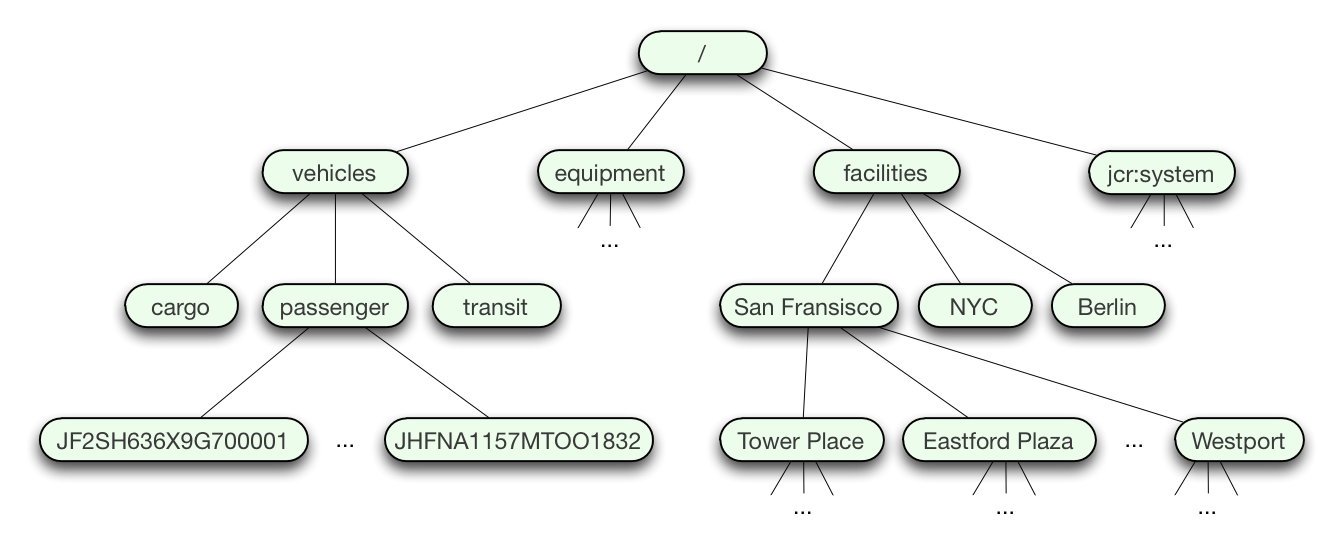
We've kept it simple: none of these nodes uses SNS indexes, since there are no two children with the same names. But even with this simple example you can see how a hierarchical structure naturally organizes the data in such a way that makes navigating to relevant data very straightforward. For example, our asset repository breaks down the assets into "vehicles", "equipment" and "facilities", and each of those is further segmented into smaller divisions. The "vehicles" assets are divided into "cargo", "passenger", and "transit" vehicles, and under each of those are all of the vehicle nodes named with their Vehicle Identification Number (VIN).
(We could have alternatively designed the repository without the "cargo", "passenger", and "transit" layer, and tracked that information as properties on the nodes. But since any given vehicle is only one of these types, including the layer has advantages.)
The "equipment" area stores information about computer assets, office equipment, etc., while the "facilities" area stores information about the buildings used or owned by our company.
So with this cursory overview of our sample repository, let's look at some code that shows just a few of the ways to navigate our repository structure:
Repository repository = ...
Session session = repository.login("assets");
Node root = session.getRootNode();
// Find a node by absolute path ...
Node nyc = session.getNode("/facilities/NYC");
// Or find a nodes by relative path ...
Node cargo = root.getNode("vehicles/cargo");
Node veh1 = cargo.getNode("JF2SH636X9G700001");
Node transit = veh1.getNode("../../transit");
// Iterate over all children ...
NodeIterator iter = cargo.getNodes(); // implements Iterator
while ( iter.hasNext() ) {
Node child = iter.nextNode();
}
// Or iterate over some children, using name patterns ...
iter = cargo.getNodes("JF*");
while ( iter.hasNext() ) {
Node child = iter.nextNode();
}
// If we know a node's identifier ...
String nodeId = veh1.getIdentifier();
// We can find it by simply looking it up ...
Node byId = session.getNodeByIdentifier(nodeId);
// And we can always get back to the session we used to get a node ...
Session sessionForNode = byId.getSession();
assert sessionForNode == session;
There are a couple of interesting things in this example:
-
You can only obtain the root node from the session (line 3). The Node object for the root should never change during the lifetime of the session, even when the properties and children of the Node object change.
-
You can get a node by absolute path directly from the Session (line 5).
-
You can find nodes relative to other nodes (including the root node) using relative paths (lines 9-11). Relative paths may contain ".." and "." segments to signify the parent or self, respectively. Thus, JCR paths are very similar to paths on a file system path.
-
You can iterate over all the children of a node (lines 14-17) that this session has authorization to see. Any child for which you don't have authorization just doesn't even appear to exist. Note that JSR-283 was designed for JRE 1.4 (pre-generics), so it defines a NodeIterator interface that extends java.util.Iterator adds type-specific methods and size information. (JSR-333 is updating this so that NodeIterator extends Iterator<Node>, though it will retain the ability to return the size for backward compatibility.)
-
You can iterate over some of the children that have names matching one or several glob patterns (line 20). In this example, the names of the nodes are VIN numbers, and we can use this knowledge and the structure of VINs to iterate over all of the passenger vehicles that were made in Japan by Fuji Heavy Industries (for Subaru). We could just as easily issued a query instead, and would likely want to if the criteria were any more complicated.
-
Every node in the workspace has a unique but opaque identifier (line 26) assigned by the implementation, and you can easily look up any node in the workspace using this ID (line 29). (Note that two different workspaces in the same repository can have nodes with the same ID. These are referred to as corresponding nodes, and this characteristic is an important factor in deciding whether to design your repository to have one or several workspaces.)
-
Every node is valid only in the context of its session, and you can always get a Node's Session object (line 32). This means that your code can pass around a Node object (assuming the Session remains open while doing so), but don't have to also pass around the Session.
One more thing about node identifiers. While all node identifiers are unique within a workspace, it is possible for multiple workspaces in the same repository to each have a node with a given identifier. Such nodes are called corresponding nodes, and this can be a primary factor in deciding whether to design your repository with a single workspace or several. For example, it's possible to clone a subgraph of nodes in one workspace into another workspace, and all these nodes will retain the same identifiers.
Properties and values
So far we've seen how the content in a repository workspace can be organized into a tree structure of nodes, but we haven't yet seen how to store any data (other than node names and parent-child relationships). In JCR, all data is stored on nodes in properties. Each property has a name and is either single-valued (meaning it always has 1 value) or multi-valued (meaning it has 0 or more values). Each value is immutable and can be any of the following types:
|
Property Type |
Java type |
|
STRING |
java.lang.String |
|
NAME |
java.lang.String |
|
PATH |
java.lang.String |
|
BOOLEAN |
java.lang.Boolean |
|
LONG |
java.lang.Long |
|
DOUBLE |
java.lang.Double |
|
DATE |
java.util.Calendar |
|
BINARY |
javax.jcr.Binary |
|
REFERENCE |
javax.jcr.Node |
|
WEAKREFERENCE |
javax.jcr.Node |
|
DECIMAL |
java.math.BigDecimal |
|
URI |
java.lang.String |
One really nice thing about values is that they have methods that will convert the value to a desired type. This means your applications don't have to keep track of the actual type of a value, but instead can simply ask for the value in the type your application wants. JCR defines conversions between most types (e.g., every value can be converted to a STRING or a BINARY representation), but some conversions don't make sense (e.g., converting a path to a date) and result in an exception.
Before we look at an example, let's talk about node types and mixin types.
Node types and mixins
The repository enforces the structure of the content by defining node types, which specify the patterns of acceptable properties and children. Some node types can allow any combination of properties and/or children, while other node types can be extremely restrictive on the names and values of properties and names and types of children. Each repository comes with a large set of predefined standard node types, but applications can define and start using custom node types at any time. The Workspace interface exposes a NodeTypeRegistry that can be used to discover the existing node types and (with proper privileges) make changes to the set of registered node types. (Note that it may not be possible to change or remove node types if they are in use by the content.)
Every node declares one primary node type and zero or more mixin node types. Primary node types are typically used to declare the core characteristics of a node, while mixin node types are used to add (i.e., "mix in") additional characteristics. A primary type must be assigned when the node is created, but may be changed at a later time. Mixin types can be added to and removed from a node at any time.
Node types can use inheritance, but it is much more common to define a few concrete node types (that might use inheritance) and many more mixins that do no use inheritance but that can be mixed and matched on nodes as needed.
The next table describes a few of the more commonly-used standard node types that are defined by the JSR-283 specification and available in all implementations:
|
Name |
Kind |
Description |
|
nt:base |
primary type |
The implicit abstract base type for all node types. |
|
nt:unstructured |
primary type |
A concrete node type that allows any single- or multi-valued properties and any children with or without same-name-siblings. This node type is frequently used as the primary node type for nodes, coupled with mixins to more accurately describe the sets of properties that are used on that node. |
|
nt:file |
primary type |
A concrete node that that represents a file uploaded to the repository, with properties describing the file's metadata and a child node used to store the content of the file. |
|
nt:folder |
primary type |
A concrete node that is often used as a container for nt:file and nt:folder nodes. |
|
nt:query |
primary type |
A concrete node type used to store a JCR query expression. |
|
nt:address |
primary type |
A concrete node type that represents the location of a JCR node or property not just within the current repository but within the set of all addressable repositories. It defines properties for the URL to the repository, the workspace, the path within the workspace, and the identifier of the node within the workspace. |
|
mix:referenceable |
mixin type |
Used on nodes that can be referenced directly by REFERENCE and WEAKREFERENCE properties. |
|
mix:created |
mixin type |
Used on a node when the repository should add properties automatically capture when the node was created and by whom. |
|
mix:lastModified |
mixin type |
Used on a node when the repository should add properties that automatically capture when the node was last modified and by whom. |
|
mix:etag |
mixin type |
Added to a node when the repository should created and automatically maintain a "jcr:etag" property containing a value that is semantically comparable to the HTTP/1.1 strong entity tag, and that changes only when a BINARY property is added, removed or changed on the node. The "jcr:etag" value can then be used by applications to quickly determine if the node has changed relative to a previously-known state. |
|
mix:versionable |
mixin type |
Added to a node to make it versionable using the JCR versioning API. |
|
mix:lockable |
mixin type |
Added to a node to make it lockable using the JCR locking API. |
|
mix:shareable |
mixin type |
Added to a node to make it able to be shared (i.e., linked) into multiple locations within the same workspace or into different workspaces. |
|
mix:title |
mixin type |
Added to a node when it should have a "jcr:title" property. |
|
mix:mimeType |
mixin type |
Added to a node to add properties useful for tracking the MIME type and/or encoding. |
Now that we have a cursory understanding of nodes, properties, node types, and mixins, let's continue looking at our asset repository example. The higher-level nodes aren't terribly interesting, as they are largely just containers with few properties on their own. So let's look at how vehicle information might be stored. Again, this is just an example of one possible repository design to showcase the capabilities and features of repositories.
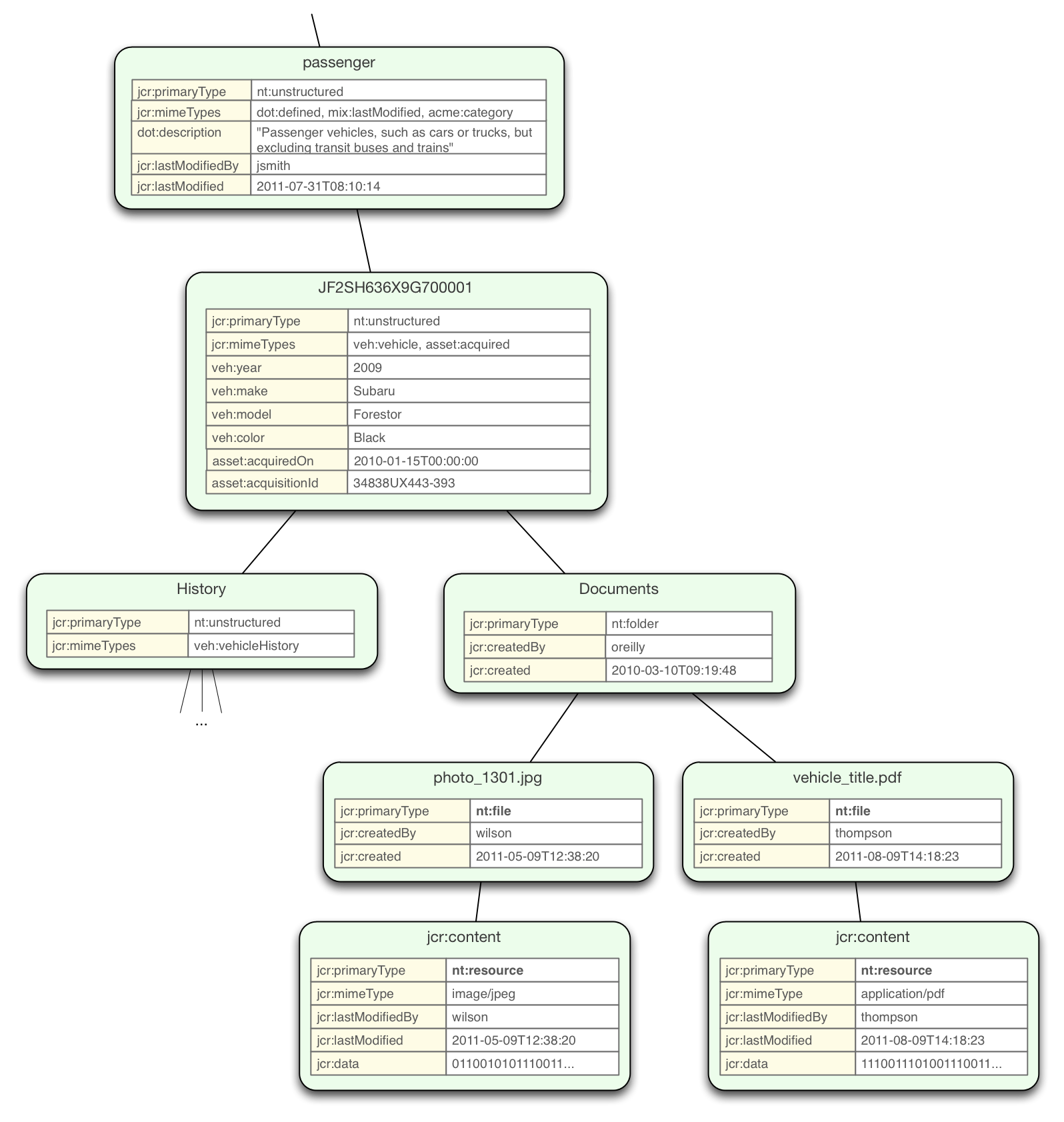
This rendering shows several of the nodes in the "/vehicles/passenger" branch and the properties on them. As we just learned, every node has a "jcr:primaryType" property that contains the name of that node's primary type. For example, the primary type of the "passenger" is "nt:unstructured", which means that it can contain any property and any child nodes (in other words, the node is not constrained by a schema). However, the "passenger" node also has three mixins: "dot:defined" is a (notional) custom node type (for our example) that represents a particular defined DOT class, a "acme:category" (notional) custom node type that is a marker (with no defined properties) signifying a category within our asset repository, and the standard "mix:lastModified" node type that enables automatic tracking of when the nod was last changed and by whom.
The "JF2SH636X9G700001" node represents a vehicle with a particular VIN, and contains a "jcr:primaryType" of "nt:unstructured" and two mixins: the "veh:vehicle" mixin is a (notional) custom node type that signifies a vehicle with several vehicle-related properties, and the "asset:acquired" mixin is a (notional) custom node type that signifies several properties related to when and how the asset was acquired. The remaining properties of the "passenger" node contain the information related to these characteristics.
The "History" node is intended to be a container for various nodes that describe important events in the ownership history of a vehicle, including the acquisition information, maintenance activities, accidents/issues, etc.
The "Documents" node is a container for documents, images, photos, and other files that are relevant to the vehicle. This particular vehicle has two such documents: a JPEG photo with EXIF metadata, and a PDF document of the vehicles title.
Events
An application can be notified of each change to the repository by registering listeners with a session. Note that each listener will only receive events until the session with which it's registered is closed. There are some common patterns for properly using listeners in long-running applications.
When registering a listener, the caller has the ability to specify the kinds of events that its interested in. Examples of filters include the types of events (e.g., created, modified, deleted), the location of nodes (e.g., by path), the identities of nodes, and even the types of nodes.
Queries
JCR defines a powerful query feature that applications can use to search the repository using a variety of expression languages and even a query object model that can be used to programmatically build a query. The most powerful expression language is JCR-SQL2, which is a SQL-like language for querying relational-like views defined by the properties of each node type. JCR-SQL2 has support for a variety of rich criteria (including full-text matching) and multiple kinds of joins. See the Query languages for more information about these languages, and Query language grammars for the detailed grammars of the languages supported by ModeShape.
Let's continue with our example and see how we can use the query system and the JCR-SQL2 language to find content satisfying some fairly complex criteria. First, let's imagine want to issue a simple criteria to final all Chevrolet, Toyota and Ford vehicles. We can do this with a query that selects nodes in the "veh:vehicle" table (or node type), and apply the criteria against the columns (or properties) defined by the "veh:vehicle" node type:
SELECT * FROM [veh:vehicle] AS vehicle WHERE vehicle.[veh:make] = 'Chevrolet' OR vehicle.[veh:make] = 'Toyota' OR vehicle.[veh:make] = 'Ford'
This looks very much like the SQL-99 you're probably familiar with. ModeShape even extends the JCR-SQL2 grammar to add support for "IN" clauses, so this is not standard JCR-SQL2 but works in ModeShape:
SELECT * FROM [veh:vehicle] AS vehicle
WHERE vehicle.[veh:make] IN ('Chevrolet', 'Toyota', 'Ford')
Using the JCR API, we can walk through the results and get the tuple results (like regular SQL) or get the Node object that each row represents.
Let's look at a more complicated example. Imagine that we want to find "large" images (greater than 100 pixels wide) of all Ford vehicles acquired in 2011 or later. The images will exist as files under the "Documents" child of a particular vehicle, and the vehicle has the make and acquisition information. This seems pretty straightforward, except that the criteria involves multiple nodes within a structural pattern.
One approach is to first issue a simple query to find all the FORD vehicles that match acquired in or after 2011:
SELECT * FROM [veh:vehicle] AS vehicle
JOIN [asset:acquired] AS asset ON ISSAMENODE(vehicle,asset)
WHERE vehicle.[veh:make] = 'Ford'
AND asset.[asset:acquisitionId] > CAST('2011-01-01T00:00:00' AS DATE)
but then we have to get each node in the results and for each navigate to its "Documents" folder and look for images that meet our size criteria.
Alternatively, we could issue a single (more complex) query that finds the images that satisfy all of the criteria, and with this approach we have very little programming to do. This query will need to join three "tables":
-
the "veh:vehicle" table represents all nodes that are of this particular node type, and it contains columns for the "veh:year", "veh:make", "veh:model", and "veh:color" properties defined by the "veh:vehicle" mixin. We'll apply a constraint on the "veh:make" column with the value "Ford".
-
the "asset:acquired" table represents all nodes that are of this particular node type, and it contains columns for the "asset:acquiredOn" and "asset:acquisitionId" properties defined by the "asset:acquired" mixin. We'll apply a constraint on the "asset:acquiredOn" to find all nodes acquired later than January 1, 2011 at midnight.
-
the "nt:file" table represents all of the nodes of this particular node type. We're largely interested in the path of this node.
We'll also need some join criteria:
-
that ensures that the nodes in the "veh:vehicle" table are also in the "asset:acquired" table; and
-
that the "nt:file" nodes (in the 3rd table) are below (a descendant of) the nodes in the "veh:vehicle" table
Our query then becomes:
SELECT images.[jcr:path]
FROM [veh:vehicle] AS vehicle
JOIN [asset:acquired] AS asset ON ISSAMENODE(vehicle,asset)
JOIN [nt:file] AS images ON ISDESCENDANTNODE(images,vehicle)
WHERE vehicle.[veh:make] = 'Ford'
AND asset.[asset:acquisitionId] > CAST('2011-01-01T00:00:00' AS DATE)
AND images.[jcr:mimeType] IN ('application/jpeg','application/png')
Note that this really isn't that much more complicated than our single-query, and results include a column with the path of each of our images that satisfies our constraints (or we can just look up the Node objects).
These are just some of the possibilities that the query API makes possible.