Note
Hibernate OGM defines an abstraction layer
represented by DatastoreProvider and GridDialect
to separate the OGM engine from the datastores interaction.
It has successfully abstracted various key/value stores, document stores and graph databases.
We are working on testing it on other NoSQL families.
In this chapter we will explore:
- the general architecture
- how the data is persisted in the NoSQL datastore
- how we support JP-QL queries
Let’s start with the general architecture.
Hibernate OGM is really made possible by the reuse of a few key components:
- Hibernate ORM for JPA support
- the NoSQL drivers to interact with the underlying datastore
- optionally Hibernate Search for indexing and query purposes
- optionally Infinispan’s Lucene Directory to store indexes in Infinispan itself, or in many other NoSQL using Infinispan’s write-through cachestores
- Hibernate OGM itself
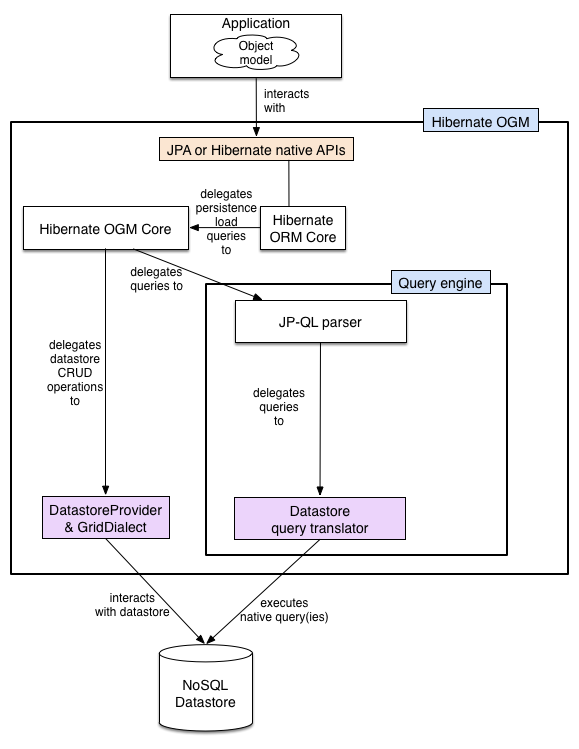
Hibernate OGM reuses as much as possible from the Hibernate ORM infrastructure.
There is no need to rewrite an entirely new JPA engine.
The Persisters and the Loaders
(two interfaces used by Hibernate ORM)
have been rewritten to persist data in the NoSQL store.
These implementations are the core of Hibernate OGM.
We will see in Section 3.2, “How is data persisted” how the data is structured.
The particularities between NoSQL stores are abstracted
by the notion of a DatastoreProvider and a GridDialect.
DatastoreProviderabstracts how to start and maintain a connection between Hibernate OGM and the datastore.GridDialectabstracts how data itself including association is persisted.
Think of them as the JDBC layer for our NoSQL stores.
Other than these, all the Create/Read/Update/Delete (CRUD) operations are implemented by the Hibernate ORM engine (object hydration and dehydration, cascading, lifecycle etc).
As of today, we have implemented the following datastore providers:
- a Map based datastore provider (for testing)
- an Infinispan based datastore provider to persist your entities in Infinispan
- a Ehcache based datastore provider to persist your entities in Ehcache
- a MongoDB based datastore provider to persist data in a MongoDB database
- a Neo4j based datastore provider to persist data in the Neo4j graph database
- a CouchDB based datastore provider to persist data in the CouchDB document store
To implement JP-QL queries, Hibernate OGM parses the JP-QL string and calls the appropriate translator functions to build a native query. If the underlying engine does not have any query support, we use Hibernate Search as an external query engine.
We will discuss the subject of querying in more details in Section 3.3, “How is data queried”.
Hibernate OGM best works in a JTA environment.
The easiest solution is to deploy it on a Java EE container.
Alternatively, you can use a standalone JTA TransactionManager.
We explain how to in Section 4.2.2, “In a standalone JTA environment”.
Let’s now see how and in which structure data is persisted in the NoSQL data store.
Hibernate OGM tries to reuse as much as possible the relational model concepts, at least when they are practical and make sense in OGM’s case. For very good reasons, the relational model brought peace in the database landscape over 30 years ago. In particular, Hibernate OGM inherits the following traits:
- abstraction between the application object model and the persistent data model
- persist data as basic types
- keep the notion of primary key to address an entity
- keep the notion of foreign key to link two entities (not enforced)
If the application data model is too tightly coupled with your persistent data model, a few issues arise:
- any change in the application object hierarchy / composition must be reflected in the persistent data
- any change in the application object model will require a migration at the data level
- any access to the data by another application ties both applications losing flexibility
- any access to the data from another platform become somewhat more challenging
- serializing entities leads to many additional problems (see note below)
Why aren’t entities serialized in the key/value entry
There are a couple of reasons why serializing the entity directly in the datastore - key/value in particular - can lead to problems:
- When entities are pointing to other entities are you storing the whole graph? Hint: this can be quite big!
- If doing so, how do you guarantee object identity or even consistency amongst duplicated objects? It might make sense to store the same object graph from different root objects.
- What happens in case of class schema change? If you add or remove a property or include a superclass, you must migrate all entities in your datastore to avoid deserialization issues.
Entities are stored as tuples of values by Hibernate OGM.
More specifically, each entity is conceptually represented by a Map<String,Object>
where the key represents the column name (often the property name but not always)
and the value represents the column value as a basic type.
We favor basic types over complex ones to increase portability
(across platforms and across type / class schema evolution over time).
For example a URL object is stored as its String representation.
The key identifying a given entity instance is composed of:
- the table name
- the primary key column name(s)
- the primary key column value(s)

The GridDialect specific to the NoSQL datastore you target
is then responsible to convert this map into the most natural model:
- for a key/value store or a data grid, we use the logical key as the key in the grid and we store the map as the value. Note that it’s an approximation and some key/value providers will use more tailored approaches.
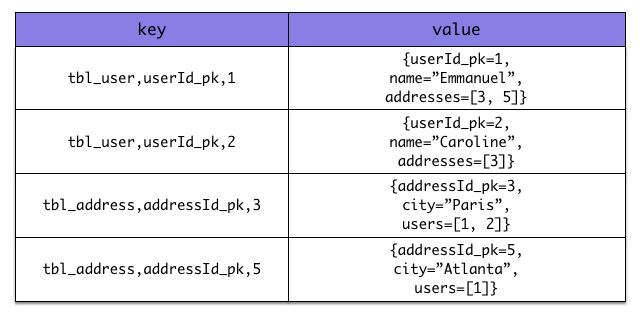
- for a document oriented store, the map is represented by a document and each entry in the map corresponds to a property in a document.
Associations are also stored as tuple as well or more specifically as a set of tuples. Hibernate OGM stores the information necessary to navigate from an entity to its associations. This is a departure from the pure relational model but it ensures that association data is reachable via key lookups based on the information contained in the entity tuple we want to navigate from. Note that this leads to some level of duplication as information has to be stored for both sides of the association.
The key in which association data are stored is composed of:
- the table name
- the column name(s) representing the foreign key to the entity we come from
- the column value(s) representing the foreign key to the entity we come from
Using this approach, we favor fast read and (slightly) slower writes.
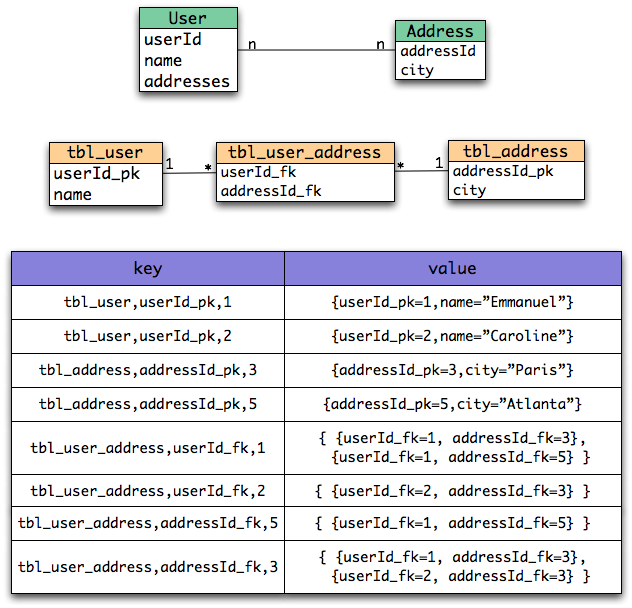
Note that this approach has benefits and drawbacks:
- it ensures that all CRUD operations are doable via key lookups
- it favors reads over writes (for associations)
- but it duplicates data
Again, there are specificities in how data is inherently stored in the specific NoSQL store. For example, in document oriented stores, the association information including the identifier to the associated entities can be stored in the entity owning the association. This is a more natural model for documents.
Some identifiers require to store a seed in the datastore (like sequences for examples). The seed is stored in the value whose key is composed of:
- the table name
- the column name representing the segment
- the column value representing the segment
Warning
This description is how conceptually Hibernate OGM asks the datastore provider to store data. Depending on the family and even the specific datastore, the storage is optimized to be as natural as possible. In other words as you would have stored the specific structure naturally. Make sure to check the chapter dedicated to the NoSQL store you target to find the specificities.
Many NoSQL stores have no notion of schema.
Likewise, the tuple stored by Hibernate OGM is not tied to a particular schema:
the tuple is represented by a Map,
not a typed Map specific to a given entity type.
Nevertheless, JPA does describe a schema thanks to:
- the class schema
- the JPA physical annotations like
@Tableand@Column.
While tied to the application, it offers some robustness and explicit understanding when the schema is changed as the schema is right in front of the developers' eyes. This is an intermediary model between the strictly typed relational model and the totally schema-less approach pushed by some NoSQL families.
Since Hibernate OGM wants to offer all of JPA, it needs to support JP-QL queries. Hibernate OGM parses the JP-QL query string and extracts its meaning. From there, several options are available depending of the capabilities of the NoSQL store you target:
- it directly delegates the native query generation to the datastore specific query translator implementation
- it uses Hibernate Search as a query engine to execute the query
If the NoSQL datastore has some query capabilities and if the JP-QL query is simple enough to be executed by the datastore, then the JP-QL parser directly pushes the query generation to the NoSQL specific query translator. The query returns the list of matching entity columns or projections and Hibernate OGM returns managed entities.
Some NoSQL stores have poor query support, or none at all. In this case Hibernate OGM can use Hibernate Search as its indexing and query engine. Hibernate Search is able to index and query objects - entities - and run full-text queries. It uses the well known Apache Lucene to do that but adds a few interesting characteristics like clustering support and an object oriented abstraction including an object oriented query DSL. Let’s have a look at the architecture of Hibernate OGM when using Hibernate Search:
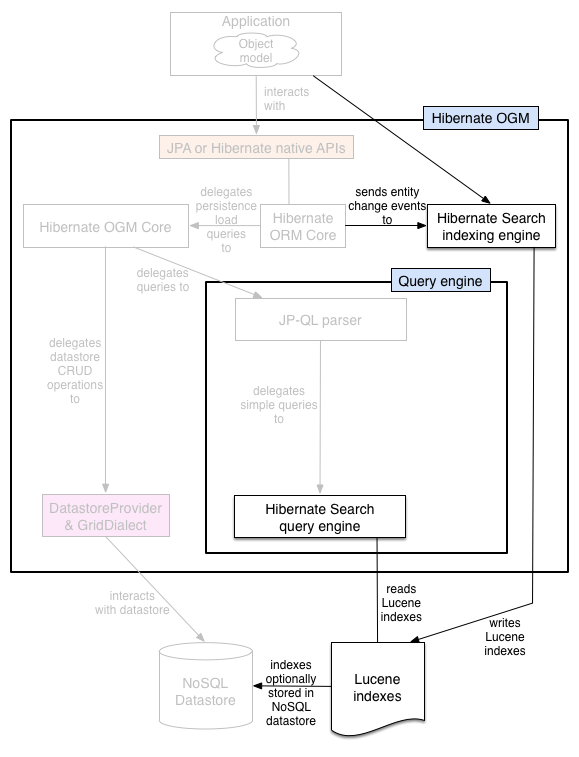
Figure 3.5. Using Hibernate Search as query engine - greyed areas are blocks already present in Hibernate OGM’s architecture
In this situation, Hibernate ORM Core pushes change events to Hibernate Search which will index entities accordingly and keep the index and the datastore in sync. The JP-QL query parser delegates the query translation to the Hibernate Search query translator and executes the query on top of the Lucene indexes. Indexes can be stored in various fashions:
- on a file system (the default in Lucene)
- in Infinispan via the Infinispan Lucene directory implementation: the index is then distributed across several servers transparently
- in NoSQL stores like Voldemort that can natively store Lucene indexes
- in NoSQL stores that can be used as overflow to Infinispan: in this case Infinispan is used as an intermediary layer to serve the index efficiently but persists the index in another NoSQL store.
Tip
You can use Hibernate Search even if you do plan to use the NoSQL datastore query capabilities. Hibernate Search offers a few interesting options:
- clusterability
- full-text queries - ie Google for your entities
- geospatial queries
- query faceting (ie dynamic categorization of the query results by price, brand etc)